Post Syndicated from Maddie Bacon original https://aws.amazon.com/blogs/security/aws-security-profile-matt-luttrell-principal-solutions-architect-for-aws-identity/

In the AWS Security Profile series, I interview some of the humans who work in Amazon Web Services Security and help keep our customers safe and secure. In this profile, I interviewed Matt Luttrell, Principal Solutions Architect for AWS Identity.
How long have you been at AWS and what do you do in your current role?
I’ve been at AWS around five years and have worked in a variety of roles from Professional Services consulting as an application architect to a solutions architect. In my current role, I work on the Identity Solutions team, which is a group of solutions architects who are embedded directly in the Identity and Control Services team. We have both internal-facing and external-facing functions. Internally, we work with product managers, drive concepts like data perimeters, and generally act as the voice of the customer to our product teams. Externally, we have conversations with customers, present at events, and so on.
How did you get started in security?
My background is in software development. I’ve always had a side interest in security and have always worked for very security-conscious companies. Early in my career, I became CISSP certified and that’s what got me kickstarted in security-specific domains and conversations. At AWS, being involved in security isn’t an optional thing. So, even before I joined the Identity Solutions team, I spent a lot of time working on identity and AWS Identity and Access Management (IAM) in particular, as well as AWS IAM Access Analyzer, while working with security-conscious customers in the financial services industry. As I got involved in that, I was able to dive deep in the security elements of AWS, but I’ve always had a background in security.
How do you explain your job to non-technical friends and family?
I typically tell them that I work in the cloud computing division at Amazon and that my job title is Solutions Architect. Naturally, the next question is, “what does a solutions architect do? I’ve never heard of that.” I explain that I work with customers to figure out how to put the building blocks together that we offer them. We offer a bunch of different services and features, and my job is to teach customers how they all work and interact with each other.
What are you currently working on that you’re excited about?
One of the things our team is working on is data perimeters. Our customers will see continued guidance on data perimeters. We’ve done a lot of work in this space—workshops and presentations at some of our big conferences, as well as blog posts and example repositories.
I’m also putting together some videos that go in depth on IAM policy evaluation and offer prescriptive guidance on writing IAM policies.
In your opinion, what’s one of the coolest things happening in identity right now?
I might be biased here, but I think there’s been a shift in the security industry at large from network-based perimeters in the traditional on-premises world to identity-based perimeters in the cloud. This is where the concept of data perimeters comes into play. Because your resources and identities are distributed, you can no longer look at your server and touch your server that’s sitting right next to you. This really puts an extra emphasis on your authentication and authorization controls, as well as the need for visibility into those controls. I think there’s a lot of innovation happening in the identity world because of this increased focus on identity perimeters. You’re hearing about concepts in this area like zero trust, data perimeters, and general identity awareness in all levels of the application and infrastructure stacks. You have services like IAM Access Analyzer to help give you that visibility into your AWS environment and what your identities are doing in terms of who can access what. I think we’ll continue to see growth in these areas because workloads are not becoming less distributed over time.
Tell me about something fun that you’ve done recently at AWS.
Roberto Migli and I presented a 400-level workshop at re:Invent 2022 on IAM policy evaluation, AWS Identity and Access Management (IAM) policy evaluation in action. This workshop introduced a new mental model for thinking about policy evaluation and walked attendees through a number of different policy evaluation scenarios. The idea behind the workshop is that we introduce a scenario and have the attendee try to figure out what the result of the evaluation would be. It spends some extra time comparing how the evaluation of resource-based policies differs from that of identity-based policies. I hope attendees walked away with a better understanding of how policy evaluations work at a deeper level and how they can write better, more secure IAM policies. We presented practical advice on how to structure different types of IAM policies and the different tradeoffs when writing a policy one way compared to another. I hope the mental model we introduced helps customers better reason about how policies will evaluate when they write them in their environment.
What is your favorite Amazon Leadership Principle and why?
This is an easy one. For me, it’s definitely Learn and Be Curious. Something I try to do is put myself in uncomfortable situations because I feel that when I’m uncomfortable, I’m learning and growing because it means I don’t know something. I find comfortable situations boring at times, so I’m always trying to dig in and learn how things work. This can sometimes be distracting, too, because there’s so much to learn and understand in the identity world.
What’s the thing you’re most proud of in your career?
There’s no particular project that I can point to and say, “this is what I’m most proud of.” I’m proud to be a part of the team I’m on now. For my team, Customer Obsession is more than just a slogan. We really advocate on behalf of the customer, listen to the voice of the customer, and push back on features that might not be the best thing for the customer. I think it’s awesome that I get to work for a company that really does advocate on behalf of the customer, and that my voice is heard when I’m trying to be that advocate. That aspect of working at AWS and with my team is what I’m most proud of.
I’m also proud of the mentoring and teaching that I get to do within AWS and within my role specifically. It’s really fulfilling to watch somebody grow and realize that career growth is not a zero-sum game—just because someone else succeeds does not mean that I have to fail.
If you had to pick an industry outside of security, what would you want to do?
I’d probably choose to be a ski instructor. I’m a big fan of skiing, but I don’t get to ski very often because of where I live. I love being out on the mountains, skiing, and teaching. I’m looking for any excuse to spend my days in the mountains.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.

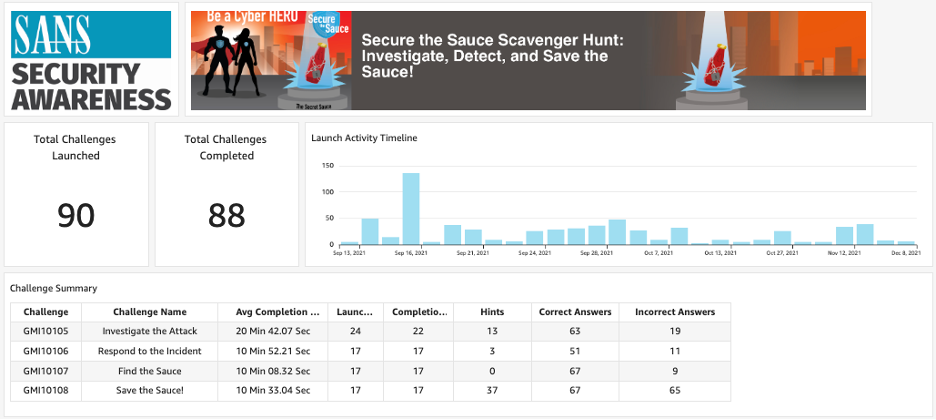
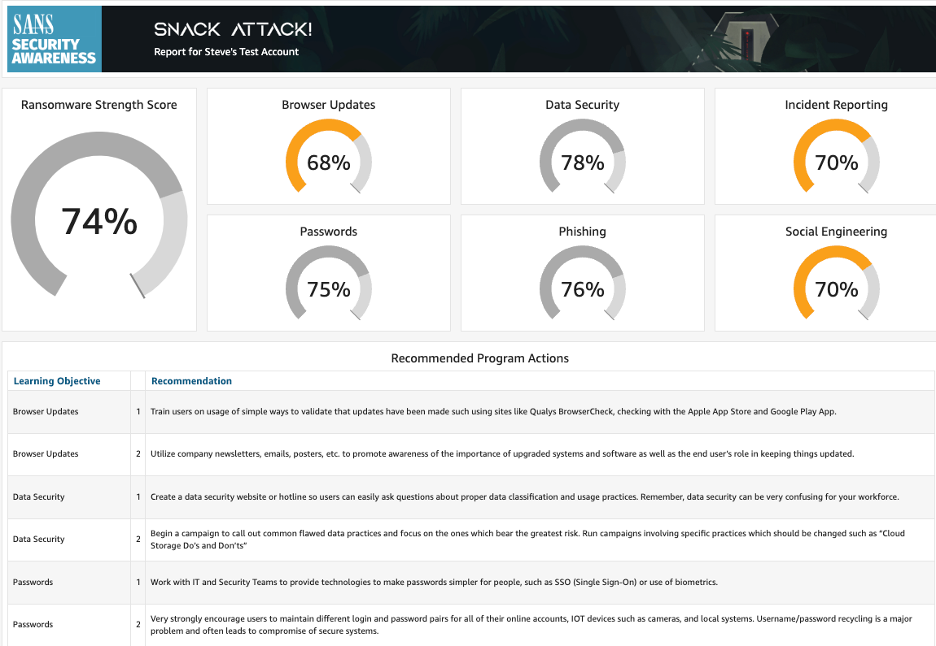
 Carl R. Marrelli is the Director of Business Development and Digital Programs at SANS Institute. Based in Charlotte, NC, he has extensive experience in cross-functional team leadership, product management, and product marketing. Previously as Head of Product at SANS, Carl led the product management team for the Online Training and Security Awareness divisions through a significant growth period. Carl’s unique perspective and innovative ideas, support SANS as the company continues its mission to empower cybersecurity practitioners around the world.
Carl R. Marrelli is the Director of Business Development and Digital Programs at SANS Institute. Based in Charlotte, NC, he has extensive experience in cross-functional team leadership, product management, and product marketing. Previously as Head of Product at SANS, Carl led the product management team for the Online Training and Security Awareness divisions through a significant growth period. Carl’s unique perspective and innovative ideas, support SANS as the company continues its mission to empower cybersecurity practitioners around the world.





 Kristin Mandia is Senior Online Community Manager for Amazon QuickSight, Amazon Web Service’s cloud-native, fully managed BI service.
Kristin Mandia is Senior Online Community Manager for Amazon QuickSight, Amazon Web Service’s cloud-native, fully managed BI service. Ian McNamara is a Program Manager and writer on the Customer Success Team for Amazon QuickSight, Amazon Web Service’s cloud-native, fully managed BI service.
Ian McNamara is a Program Manager and writer on the Customer Success Team for Amazon QuickSight, Amazon Web Service’s cloud-native, fully managed BI service.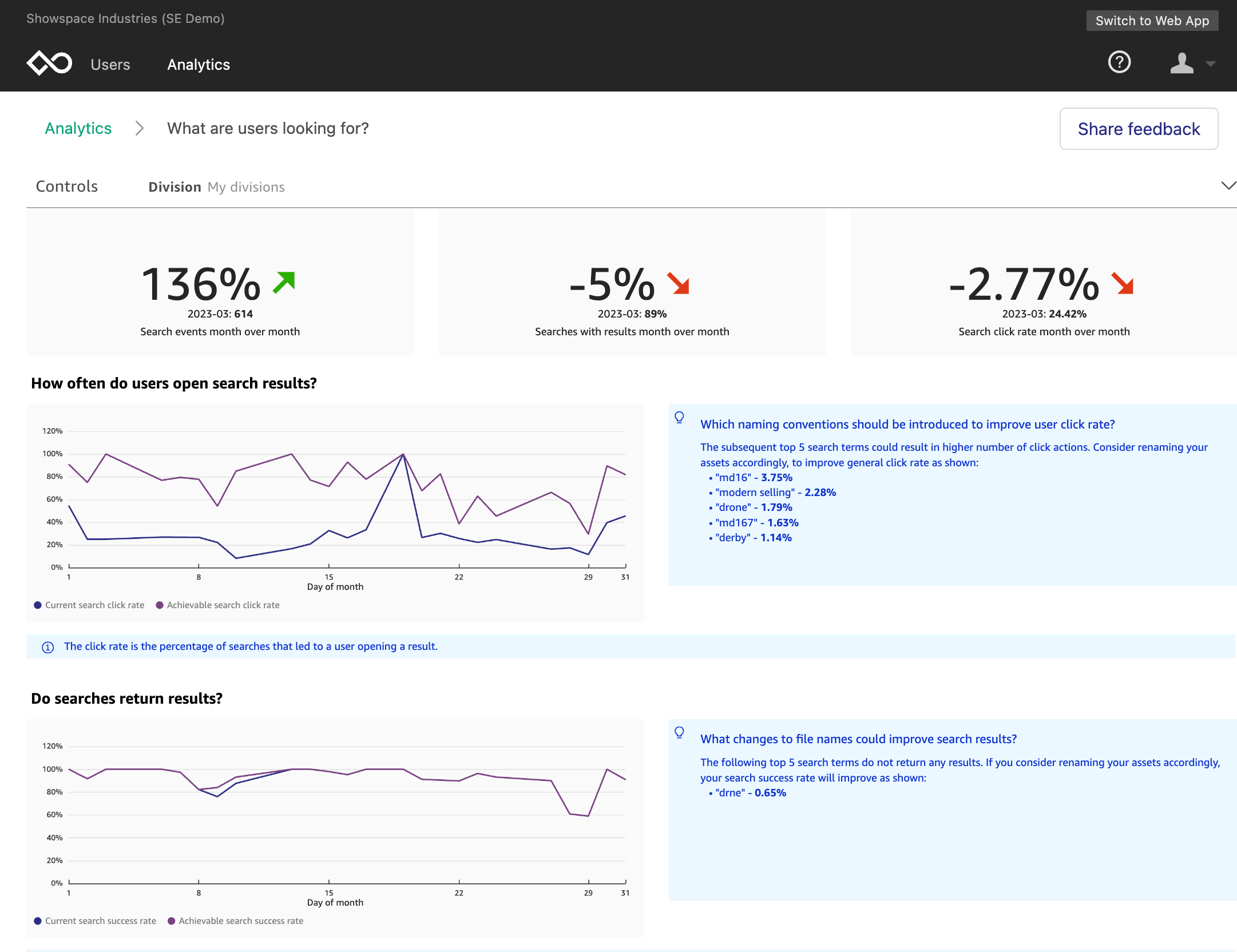
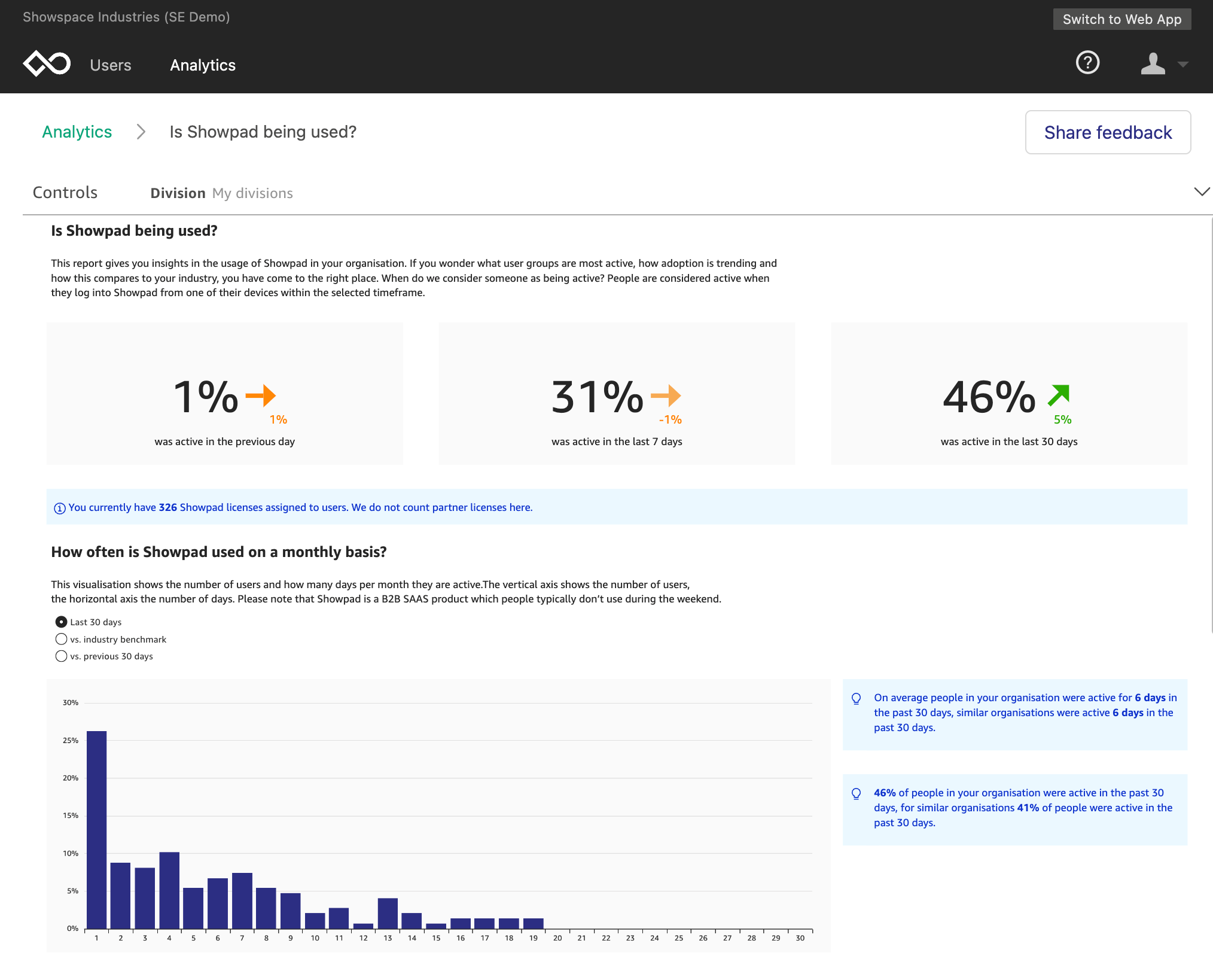
 Shruthi Panicker is a Senior Product Marketing Manager with Amazon QuickSight at AWS. As an engineer turned product marketer, Shruthi has spent over 15 years in the technology industry in various roles from software engineering, to solution architecting to product marketing. She is passionate about working at the intersection of technology and business to tell great product stories that help drive customer value.
Shruthi Panicker is a Senior Product Marketing Manager with Amazon QuickSight at AWS. As an engineer turned product marketer, Shruthi has spent over 15 years in the technology industry in various roles from software engineering, to solution architecting to product marketing. She is passionate about working at the intersection of technology and business to tell great product stories that help drive customer value.






 Lillie Atkins is a Product Manager for Amazon QuickSight, Amazon Web Service’s cloud-native, fully managed BI service.
Lillie Atkins is a Product Manager for Amazon QuickSight, Amazon Web Service’s cloud-native, fully managed BI service.








 Avinash Kolluri is a Senior Solutions Architect at AWS. He works across Amazon Alexa and Devices to architect and design modern distributed solutions. His passion is to build cost-effective and highly scalable solutions on AWS. In his spare time, he enjoys cooking fusion recipes and traveling.
Avinash Kolluri is a Senior Solutions Architect at AWS. He works across Amazon Alexa and Devices to architect and design modern distributed solutions. His passion is to build cost-effective and highly scalable solutions on AWS. In his spare time, he enjoys cooking fusion recipes and traveling. Vipul Verma is a Sr.Software Engineer at Amazon.com. He has been with Amazon since 2015,solving real-world challenges through technology that directly impact and improve the life of Amazon customers. In his spare time, he enjoys hiking.
Vipul Verma is a Sr.Software Engineer at Amazon.com. He has been with Amazon since 2015,solving real-world challenges through technology that directly impact and improve the life of Amazon customers. In his spare time, he enjoys hiking.
 Al MS is a product manager for Amazon EMR at Amazon Web Services.
Al MS is a product manager for Amazon EMR at Amazon Web Services.
 Yuzhou Sun is a software development engineer for EMR at Amazon Web Services.
Yuzhou Sun is a software development engineer for EMR at Amazon Web Services. Steve Koonce is an Engineering Manager for EMR at Amazon Web Services.
Steve Koonce is an Engineering Manager for EMR at Amazon Web Services.
 Jason Berkowitz is a Senior Product Manager with AWS Lake Formation. He comes from a background in machine learning and data lake architectures. He helps customers become data-driven.
Jason Berkowitz is a Senior Product Manager with AWS Lake Formation. He comes from a background in machine learning and data lake architectures. He helps customers become data-driven. Aarthi Srinivasan is a Senior Big Data Architect with AWS Lake Formation. She enjoys building data lake solutions for AWS customers and partners. When not on the keyboard, she explores the latest science and technology trends and spends time with her family.
Aarthi Srinivasan is a Senior Big Data Architect with AWS Lake Formation. She enjoys building data lake solutions for AWS customers and partners. When not on the keyboard, she explores the latest science and technology trends and spends time with her family.