Post Syndicated from Sofía Celi original https://blog.cloudflare.com/post-quantum-future/

“People ask me to predict the future, when all I want to do is prevent it. Better yet, build it. Predicting the future is much too easy, anyway. You look at the people around you, the street you stand on, the visible air you breathe, and predict more of the same. To hell with more. I want better.”
— Ray Bradbury, from Beyond 1984: The People Machines

The story and the path are clear: quantum computers are coming that will have the ability to break the cryptographic mechanisms we rely on to secure modern communications, but there is hope! The cryptographic community has designed new mechanisms to safeguard against this disruption. There are challenges: will the new safeguards be practical? How will the fast-evolving Internet migrate to this new reality? In other blog posts in this series, we have outlined some potential solutions to these questions: there are new algorithms for maintaining confidentiality and authentication (in a “post-quantum” manner) in the protocols we use. But will they be fast enough to deploy at scale? Will they provide the required properties and work in all protocols? Are they easy to use?
Adding post-quantum cryptography into architectures and networks is not only about being novel and looking at interesting research problems or exciting engineering challenges. It is primarily about protecting people’s communications and data because a quantum adversary can not only decrypt future traffic but, if they want to, past traffic. Quantum adversaries could also be capable of other attacks (by using quantum algorithms, for example) that we may be unaware of now, so protecting against them is, in a way, the challenge of facing the unknown. We can’t fully predict everything that will happen with the advent of quantum computers1, but we can prepare and build greater protections than the ones that currently exist. We do not see the future as apocalyptic, but as an opportunity to reflect, discover and build better.
What are the challenges, then? And related to this question: what have we learned from the past that enables us to build better in a post-quantum world?
Beyond a post-quantum TLS
As we have shown in other blog posts, the most important security and privacy properties to protect in the face of a quantum computer are confidentiality and authentication. The threat model of confidentiality is clear: quantum computers will not only be able to decrypt on-going traffic, but also any traffic that was recorded and stored prior to their arrival. The threat model for authentication is a little more complex: a quantum computer could be used to impersonate a party (by successfully mounting a monster-in-the-middle attack, for example) in a connection or conversation, and it could also be used to retroactively modify elements of the past message, like the identity of a sender (by, for example, changing the authorship of a past message to a different party). Both threat models are important to consider and pose a problem not only for future traffic but also for any traffic sent now.
In the case of using a quantum computer to impersonate a party: how can this be done? Suppose an attacker is able to use a quantum computer to compromise a user’s TLS certificate private key (which has been used to sign lots of past connections). The attacker can then forge connections and pretend that they come from the honest user (by signing with the user’s key) to another user, let’s say Bob. Bob will think the connections are coming from the honest user (as they all did in the past), when, in reality, they are now coming from the attacker.
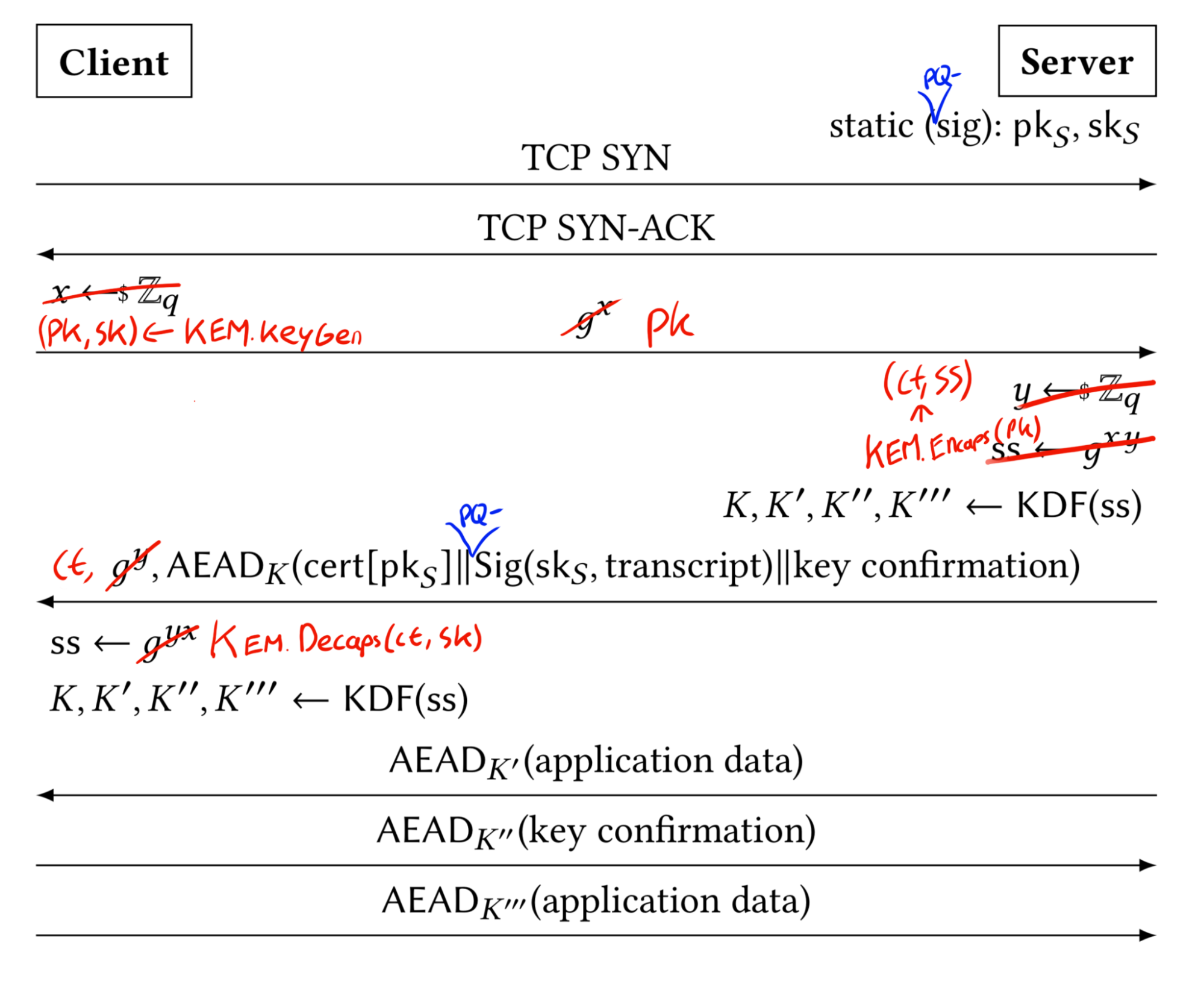
We have algorithms that protect confidentiality and authentication in the face of quantum threats. We know how to integrate them into TLS, as we have seen in this blog post, so is that it? Will our connections then be safe? We argue that we will not yet be done, and these are the future challenges we see:
- Changing the key exchange of the TLS handshake is simple; changing the authentication of TLS, in practice, is hard.
- Middleboxes and middleware in the network, such as antivirus software and corporate proxies, can be slow to upgrade, hindering the rollout of new protocols.
- TLS is not the only foundational protocol of the Internet, there are other protocols to take into account: some of them are very similar to TLS and they are easy to fix; others such as DNSSEC or QUIC are more challenging.
TLS (we will be focusing on its current version, which is 1.3) is a protocol that aims to achieve three primary security properties:
- Confidentiality: communication can be read only by the intended recipient,
- Integrity: communication cannot be changed in transit, and
- Authentication: we are assured communication comes from the peer we are talking to.
The first two properties are easy to maintain in a quantum-computer world: confidentiality is maintained by swapping the existing non-quantum-safe algorithm for a post-quantum one; integrity is maintained because the algorithms are intractable on a quantum computer. What about the last property, authentication? There are three ways to achieve authentication in a TLS handshake, depending on whether server-only or mutual authentication is required:
- By using a ‘pre-shared’ key (PSK) generated from a previous run of the TLS connection that can be used to establish a new connection (this is often called “session resumption” or “resuming” with a PSK),
- By using a Password-Authenticated Key Exchange (PAKE) for handshake authentication or post-handshake authentication (with the usage of exported authenticators, for example). This can be done by using the OPAQUE or the SPAKE protocols,
- By using public certificates that advertise parameters that are employed to assure (i.e., create a proof of) the identity of the party you are talking to (this is by far the most common method).
Securing the first authentication mechanism is easily achieved in the post-quantum sphere as a unique key is derived from the initial quantum-protected handshake. The second authentication mechanism does not pose a theoretical challenge (as public and private parameters are replaced with post-quantum counterparts) but rather faces practical limitations: certificate-based authentication involves multiple actors and it is difficult to properly synchronize this change with them, as we will see next. It is not only one public parameter and one public certificate: certificate-based authentication is achieved through the use of a certificate chain with multiple entities.
A certificate chain is a chain of trust by which different entities attest to the validity of public parameters to provide verifiability and confidence. Typically, for one party to authenticate another (for example, for a client to authenticate a server), a chain of certificates starting from a root’s Certificate Authority (CA) certificate is used, followed by at least one intermediate CA certificate, and finally by the leaf (or end-entity) certificate of the actual party. This is what you usually find in real-world connections. It is worth noting that the order of this chain (for TLS 1.3) does not require each certificate to certify the one immediately preceding it. Servers sometimes send both a current and deprecated intermediate certificate for transitional purposes, or are configured incorrectly.
What are these certificates? Why do multiple actors need to validate them? A (digital) certificate certifies the ownership of a public key by the named party of the certificate: it attests that the party owns the private counterpart of the public parameter through the use of digital signatures. A CA is the entity that issues these certificates. Browsers, operating systems or mobile devices operate CA “membership” programs where a CA must meet certain criteria to be incorporated into the trusted set. Devices accept their CA root certificates as they come “pre-installed” in a root store. Root certificates, in turn, are used to generate a number of intermediate certificates which will be, in turn, used to generate leaf certificates. This certificate chain process of generation, validation and revocation is not only a procedure that happens at a software level but rather an amalgamation of policies, rules, roles, and hardware2 and software needs. This is what is often called the Public Key Infrastructure (PKI).
All of the above goes to show that while we can change all of these parameters to post-quantum ones, it is not as simple as just modifying the TLS handshake. Certificate-based authentication involves many actors and processes, and it does not only involve one algorithm (as it happens in the key exchange phase) but typically at least six signatures: one handshake signature; two in the certificate chain; one OCSP staple and two SCTs. The last five signatures together are used to prove that the server you’re talking to is the right server for the website you’re visiting, for example. Of these five, the last three are essentially patches: the OCSP staple is used to deal with revoked certificates and the SCTs are to detect rogue CA’s. Starting with a clean slate, could we improve on the status quo with an efficient solution?
More pointedly, we can ask if indeed we still need to use this system of public attestation. The migration to post-quantum cryptography is also an opportunity to modify this system. The PKI as it exists is difficult to maintain, update, revoke, model, or compose. We have an opportunity, perhaps, to rethink this system.
Even without considering making fundamental changes to public attestation, updating the existing complex system presents both technical and management/coordination challenges:
- On the technical side: are the post-quantum signatures, which have larger sizes and bigger computation times, usable in our handshakes? We explore this idea in this experiment, but we need more information. One potential solution is to cache intermediate certificates or to use other forms of authentication beyond digital signatures (like KEMTLS).
- On the management/coordination side: how are we going to coordinate the migration of this complex system? Will there be some kind of ceremony to update algorithms? How will we deal with the situation where some systems have updated but others have not? How will we revoke past certificates?
This challenge brings into light that the migration to post-quantum cryptography is not only about the technical changes but is dependent on how the Internet works as the interconnected community that it is. Changing systems involves coordination and the collective willingness to do so.
On the other hand, post-quantum password-based authentication for TLS is still an open discussion. Most PAKE systems nowadays use Diffie-Hellman assumptions, which can be broken by a quantum computer. There are some ideas on how to transition their underlying algorithms to the post-quantum world; but these seem to be so inefficient as to render their deployment infeasible. It seems, though, that password authentication has an interesting property called “quantum annoyance”. A quantum computer can compromise the algorithm, but only one instance of the problem at the time for each guess of a password: “Essentially, the adversary must guess a password, solve a discrete logarithm based on their guess, and then check to see if they were correct”, as stated in the paper. Early quantum computers might take quite a long time to solve each guess, which means that a quantum-annoying PAKE combined with a large password space could delay quantum adversaries considerably in their goal of recovering a large number of passwords. Password-based authentication for TLS, therefore, could be safe for a longer time. But this does not mean, however, that it is not threatened by quantum adversaries.
The world of security protocols, though, does not end with TLS. There are many other security protocols (such as DNSSEC, WireGuard, SSH, QUIC, and more) that will need to transition to post-quantum cryptography. For DNSSEC, the challenge is complicated by the protocol not seeming to be able to deal with large signatures or high computation costs on verification time. According to research from SIDN Labs, it seems like only Falcon-512 and Rainbow-I-CZ can be used in DNSSEC (note that, though, there is a recent attack on Rainbow).
| Scheme | Public key size | Signature size | Speed of operations |
|---|---|---|---|
| Finalists | |||
| Dilithium2 | 1,312 | 2,420 | Very fast |
| Falcon-512 | 897 | 690 | Fast, if you have the right hardware |
| Rainbos-I-CZ | 103,648 | 66 | Fast |
| Alternate Candidates | |||
| SPHINCS+-128f | 32 | 17,088 | Slow |
| SPHINCS+-128s | 32 | 7,856 | Very slow |
| GeMSS-128 | 352,188 | 33 | Very slow |
| Picnic3 | 35 | 14,612 | Very slow |
Table 1: Signature post-quantum algorithms. The orange rows show the suitable algorithms for DNSSEC.
What are the alternatives for a post-quantum DNSSEC? Perhaps, the isogeny-based signature scheme, SQISign, might be a solution if its verification time can be improved (which currently is 42 ms as noted in the original paper when running on a 3.40GHz Intel Core i7-6700 CPU over 250 runs for verification. Still slower than P-384. Recently, it has improved to 25ms). Another solution might be the usage of MAYO, which on an Intel i5-8400H CPU at 2.5GHz, a signing operation can take 2.50 million cycles, and a verification operation can take 1.3 million cycles. There is a lot of research that needs to be done to make isogeny-based cryptography faster so it will fit the protocol’s needs (research on this area is currently ongoing —see, for example, the Isogeny School) and provide assurance of their security properties. Another alternative could be using other forms of authentication for this protocol’s case, like using hash-based signatures.
DNSSEC is just one example of a protocol where post-quantum cryptography has a long road ahead, as we need hands-on experimentation to go along with technical updates. For the other protocols, there is timely research: there are, for example, proposals for a post-quantum WireGuard and for a post-quantum SSH. More research, though, needs to be done on the practical implications of these changes over real connections.
One important thing to note here is that there will likely be an intermediate period in which security protocols provide a “hybrid” set of algorithms for transitional purposes, compliance and security. “Hybrid” means that both a pre-quantum (or classical) algorithm and a post-quantum one are used to generate the secret used to encrypt or provide authentication. The security reason for using this hybrid mode is due to safeguarding in case post-quantum algorithms are broken. There are still many unknowns here (single code point, multiple codepoints, contingency plans) that we need to consider.
The failures of cryptography in practice
The Achilles heel for cryptography is often introducing it into the real-world. Designing, implementing, and deploying cryptography is notoriously hard to get right due to flaws in security proofs, implementation bugs, and vulnerabilities3 of software and hardware. We often deploy cryptography that is found to be flawed and the cost of fixing it is immense (it involves resources, coordination, and more). We have some previous lessons to draw from it as a community, though. For TLS 1.3, we pushed for verifying implementations of the standard, and for using tools to analyze the symbolic and computational models, as seen in other blog posts. Every time we design a new algorithm, we should aim for this same level of confidence, especially for the big migration to post-quantum cryptography.
In other blog posts, we have discussed our formal verification efforts, so we will not repeat these here. Rather let’s focus on what remains to be done on the formal verification front. Verification, analysis and implementation are not yet complete and we still need to:
- Create easy-to-understand guides into what formal analysis is and how it can be used (as formal languages are unfamiliar to developers).
- Develop user-tested APIs.
- Flawless integration of a post-quantum algorithm’s API into protocols’ APIs.
- Test and analyze the boundaries between verified and unverified code.
- Verifying specifications at the standard level by, for example, integrating hacspec into IETF drafts.
Only in doing so can we prevent some of the security issues we have had in the past. Post-quantum cryptography will be a big migration and we can, if we are not careful, repeat the same issues of the past. We want a future that is better. We want to mitigate bugs and provide high assurance of the security of connections users have.
A post-quantum tunnel is born
We’ve described the challenges of post-quantum cryptography from a theoretical and practical perspective. These are problems we are working on and issues that we are analyzing. They will take time to solve. But what can you expect in the short-term? What new ideas do we have? Let’s look at where else we can put post-quantum cryptography.
Cloudflare Tunnel is a service that creates a secure, outbound-only connection between your services and Cloudflare by deploying a lightweight connector in your environment. This is the end at the server side. At the other end, at the client side, we have WARP, a ‘VPN’ for client devices that can secure and accelerate all HTTPS traffic. So, what if we add post-quantum cryptography to all our internal infrastructure, and also add it to this server and the client endpoints? We would then have a post-quantum server to client connection where any request from the WARP client to a private network (one that uses Tunnel) is secure against a quantum adversary (how to do it will be similar to what is detailed here). Why would we want to do this? First, because it is great to have a connection that is fully protected against quantum computers. Second, because we can better measure the impacts of post-quantum cryptography in this environment (and even measure them in a mobile environment). This will also mean that we can provide guidelines to clients and servers on how to migrate to post-quantum cryptography. It would also be the first available service to do so at this scale. How will all of us experience this transition? Only time will tell, but we are excited to work towards this vision.
And, furthermore, as Tunnel uses the QUIC protocol in some cases and WARP uses the WireGuard protocol, this means that we can experiment with post-quantum cryptography in protocols that are novel and have not seen much experimentation in the past.

So, what is the future in the post-quantum cryptography era? The future is better and not just the same. The future is fast and more secure. Deploying cryptography can be challenging and we have had problems with it in the past; but post-quantum cryptography is the opportunity to dream of better security, it is the path to explore, and it is the reality to make it happen.
Thank you for reading our post-quantum blog post series and expect more post-quantum content and updates from us!
If you are a student enrolled in a PhD or equivalent research program and looking for an internship for 2022, see open opportunities.
If you’re interested in contributing to projects helping Cloudflare, our engineering teams are hiring.
You can reach us with questions, comments, and research ideas at [email protected].
…..
1 And when we do predict, we often predict more of the same attacks we are accustomed to: adversaries breaking into connections, security being tampered with. Is this all that they will be capable of?
2The private part of a public key advertised in a certificate is often the target of attacks. An attacker who steals a certificate authority’s private keys is able to forge certificates, for example. Private keys are almost always stored on a hardware security module (HSM), which prevents key extraction. This is a small example of how hardware is involved in the process.
3Like constant-time failures, side-channel, and timing attacks.