Post Syndicated from Sébastien Stormacq original https://aws.amazon.com/blogs/aws/getting-started-with-new-amazon-rds-for-db2/
I am pleased to announce that IBM and AWS have come together to offer Amazon Relational Database Service (Amazon RDS) for Db2, a fully managed Db2 database engine running on AWS infrastructure.
IBM Db2 is an enterprise-grade relational database management system (RDBMS) developed by IBM. It offers a comprehensive set of features, including strong data processing capabilities, robust security mechanisms, scalability, and support for diverse data types. Db2 is a well-established choice among organizations for effectively managing data in various applications and handling data-intensive workloads due to its reliability and performance. Db2 has its roots in the pioneering work around data storage and structured query language (SQL) IBM has done since the 1970s. It has been commercially available since 1983, initially just for mainframes, and was later ported to Linux, Unix, and Windows platforms (LUW). Today, Db2 powers thousands of business-critical applications in all verticals.
With Amazon RDS for Db2, you can now create a Db2 database with just a few clicks in the AWS Management Console, one command to type with the AWS Command Line Interface (AWS CLI), or a few lines of code with the AWS SDKs. AWS takes care of the infrastructure heavy lifting, freeing your time for higher-level tasks such as schema and query optimizations for your applications.
If you are new to Amazon RDS or coming from an on-premises Db2 background, let me quickly recap the benefits of Amazon RDS.
- Amazon RDS offers the same Db2 database as the one you use on-premises today. Your existing applications will reconnect to RDS for Db2 without changing their code.
- The database runs on a fully managed infrastructure. You don’t have to provision servers, install the packages, install patches, or maintain the infrastructure in an operational state.
- The database is also fully managed. We take care of the installation, minor version upgrades, daily backup, scaling, and high availability.
- The infrastructure can scale up and down as required. You can simply stop and then restart the database to change the underlying hardware and meet changing performance requirements or benefit from last-generation hardware.
- Amazon RDS offers a choice of storage types designed to deliver fast, predictable, and consistent I/O performance. For new or unpredictable workloads, you can configure the system to automatically scale your storage.
- Amazon RDS automatically takes care of your backups, and you can restore them to a new database with just a few clicks.
- Amazon RDS helps to deploy highly available architectures. Amazon RDS synchronously replicates data to a standby database in a different Availability Zone (an Availability Zone is a group of distinct data centers). When a failure is detected with a Multi-AZ deployment, Amazon RDS automatically fails over to the standby instance and routes requests without changing the database endpoint DNS name. This switch happens with minimal downtime and zero data loss.
- Amazon RDS is built on the secure infrastructure of AWS. It encrypts data in transit using TLS and at rest using keys managed with AWS Key Management Service (AWS KMS). This helps you deploy workloads that are compliant with your company or industry regulations, such as FedRAMP, GDPR, HIPAA, PCI, and SOC.
- Third-party auditors assess the security and compliance of Amazon RDS as part of multiple AWS compliance programs and you can verify the full list of Amazon RDS compliance validations.
You can migrate your existing on-premises Db2 database to Amazon RDS using native Db2 tools, such as restore and import, or AWS Database Migration Service (AWS DMS). AWS DMS allows you to migrate databases in a single operation or continuously, while your applications continue to update the data on the source database, until you decide on the cut off.
Amazon RDS supports multiple tools for monitoring your database instances, including Amazon RDS Enhanced Monitoring and Amazon CloudWatch, or you can continue to use the IBM Data Management Console or IBM DSMtop.
Let’s see how it works
I always like to get my hands on a new service to learn how it works. Let’s create a Db2 database and connect to it using the standard tool provided by IBM. I assume most of you reading this post come from an IBM Db2 background and don’t know much about Amazon RDS.
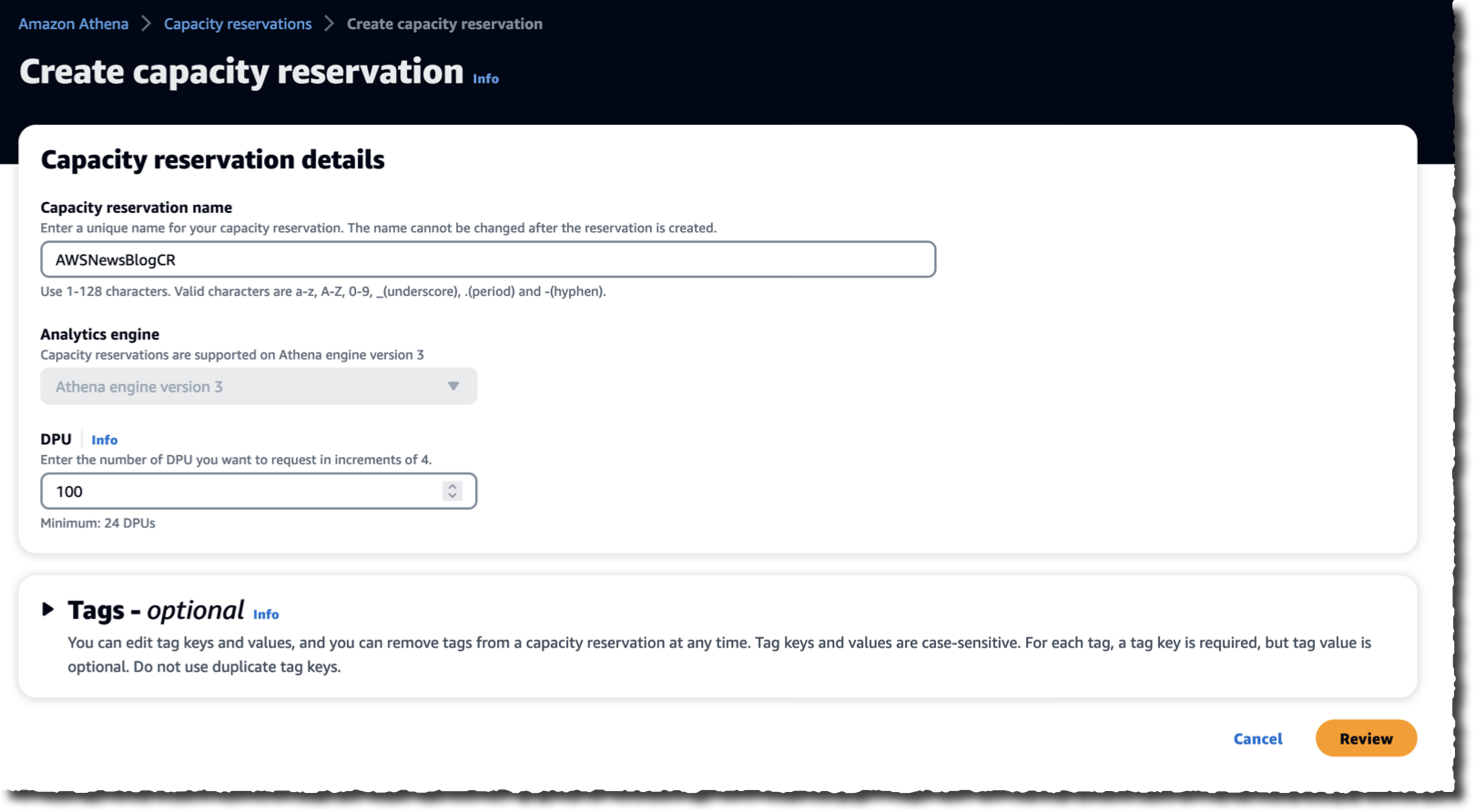
First, I create a Db2 database. To do this, I navigate to the Amazon RDS page of the AWS Management Console and select Create database. For this demo, I’ll accept most of the default values. I’ll show you, however, all the sections and will comment on the important configuration points you have to think about.
I select Db2 from among the multiple database engines Amazon RDS offers.
 I scroll down the page and select IBM Db2 Standard and Engine Version 11.5.9. Amazon RDS patches the database instances automatically if you so desire. You can learn more about Amazon RDS database maintenance here.
I scroll down the page and select IBM Db2 Standard and Engine Version 11.5.9. Amazon RDS patches the database instances automatically if you so desire. You can learn more about Amazon RDS database maintenance here.
I select Production. Amazon RDS will deploy a default configuration tuned for high availability and fast, consistent performance.


Under Settings, I give a name to my RDS instance (this is not the Db2 catalog name!), and I select the master username and password.
Under Instance configuration, I choose the type of node to run my database. This will define the hardware characteristics of the virtual server: the number of vCPUs, quantity of memory, and so on. Depending on the requirements of your application, you can allocate instances offering up to 32 vCPUs and 128 GiB of RAM for IBM Db2 Standard instances. When you select IBM Db2 Advanced instances, you can allocate instances offering up to 128 vCPUs and 1 TiB of RAM. This parameter has a direct impact on the price.


Under Storage, I choose the type of Amazon Elastic Block Store (Amazon EBS) volumes, their size, and their IOPS and throughput. For this demo, I accept the values proposed by default. This is also a set of parameters that directly impact the price.

Under Connectivity, I select the VPC (in AWS terms, a VPC is a private network) where the database will be deployed. Under Public access, I select No to make sure the database instance is only accessible from my private network. I can’t think of a (good) use case where you want to select Yes for this option.
This is also where you select the VPC security group. A security group is a network filter that defines what IP addresses or networks can access your database instance and on what TCP port. Be sure to select or create a security group with TCP 50000 open to allow applications to connect to your Db2 database.

I leave all other options with their default value. It is important to open the Additional configuration section at the very bottom of the page. This is where you can give an Initial database name. If you don’t name your Db2 database here, your only option will be to restore an existing Db2 database backup on that instance.
This section also contains the parameters for the Amazon RDS automatic backup. You can choose a time window and how long we will retain the backups.
I accept all the defaults and select Create database.

After a few minutes, you can see your database is available.
I select the DNS name of the database instance Endpoint, and I connect to a Linux machine running in the same network. After installing the Db2 client package that I downloaded from the IBM website, I type the following commands to connect to the database. There is nothing specific to Amazon RDS here.
db2 catalog TCPIP node blognode remote awsnewsblog-demo.abcdef.us-east-2.rds-preview.amazonaws.com server 50000
db2 catalog database NEWSBLOG as blogdb2 at node blognode authentication server_encrypt
db2 connect to blogdb2 user admin using MySuperPassword
Once connected, I download a sample dataset and script from the popular Db2Tutorial website. I run the scripts against the database I just created.
wget https://www.db2tutorial.com/wp-content/uploads/2019/06/books.zip
unzip books.zip
db2 -stvf ./create.sql
db2 -stvf ./data.sql
db2 "select count(*) author_count from authors"

As you can see, there is nothing specific to Amazon RDS when it comes to connecting and using the database. I use standard Db2 tools and scripts.
One more thing
Amazon RDS for Db2 requires you to bring your own Db2 license. You must enter your IBM customer ID and site number before starting a Db2 instance.
To do so, create a custom DB parameter group and attach it to your database instance at launch time. A DB parameter group acts as a container for engine configuration values that are applied to one or more DB instances. In a Db2 parameter group, there are two parameters specific to IBM Db2 licenses: your IBM Customer Number (rds.ibm_customer_id) and your IBM site number (rds.ibm_site_id).

If you do not know your site number, reach out to your IBM sales organization for a copy of a recent Proof-of-Entitlement (PoE), invoice, or sales order. All these documents should include your site number.
Pricing and availability
Amazon RDS for Db2 is available in all AWS Regions except China and GovCloud.
Amazon RDS pricing is on demand, and there are no upfront costs or subscriptions. You only pay by the hour when the database is running, plus the GB per month of database storage provisioned and backup storage you use and the number of IOPS you provision. The Amazon RDS for Db2 pricing page has the details of pricing per Region. As I mentioned earlier, Amazon RDS for Db2 requires you to bring your own Db2 license.
If you already know Amazon RDS, you’ll be delighted to have a new database engine available for your application developers. If you’re coming from an on-premises world, you will love the simplicity and automation that Amazon RDS offers.
You can learn many more details on the Amazon RDS for Db2 documentation page. Now go and deploy your first database with Amazon RDS for Db2 today!
























 .
.


























 available.
available.






















 AWS Global Summits – Check your calendars and sign up for the AWS Summit close to where you live or work:
AWS Global Summits – Check your calendars and sign up for the AWS Summit close to where you live or work: