Post Syndicated from Molly Clancy original https://www.backblaze.com/blog/ransomware-takeaways-from-q1-2022/

The impact of the war in Ukraine is evolving in real time, particularly when it comes to the ransomware landscape. Needless to say, it dominated the ransomware conversation throughout Q1 2022. This quarter, we’re digging into some of the consequences from the invasion and what it means for you in addition to a few broader domestic developments.
Why? Staying up to date on ransomware trends can help you prepare your security infrastructure in the short and long term to protect your valuable data. In this series, we share five key takeaways based on what we saw over the previous quarter. Here’s what we observed in Q1 2022.

1. Sanctions and International Attention May Have Depressed Some Ransomware Activity
Following the ground invasion, ransomware attacks seemed to go eerily quiet especially when government officials predicted cyberattacks could be a key tactic. That’s not to say attacks weren’t being carried out without being reported, but the radio silence was notable enough that a few media outlets wondered why.
International attention may be one reason—cybercriminals tend to be wary of the spotlight. Having the world’s eyes on a region where much cybercrime originates seems to have pushed cybercriminals into the shadows. The sanctions imposed on Russia have made it more difficult for cybercrime syndicates based in the country to receive, convert, and disperse payment from victims. The war also may have caused some chaos within ransomware syndicates and fomented fears that cyberinsurers would not pay for claims. As a result, we’ve seen a slowing of ransomware incidents in the first quarter, but that may not last.
Key Takeaway: While ransomware attacks may be down short-term, no one should be lulled into thinking the threat is gone, especially with government agencies on high alert and warnings from the highest levels that businesses should still be on guard.
2. Long-term Socioeconomic Impacts Could Trigger a New Wave of Cybercrime
As part of their ongoing analysis, cyber security consultants Coveware, illustrated how the socioeconomic precarity caused by sanctions could lead to a larger number of people turning to cybercrime as a way to support themselves. In their reporting, they analyzed the number of trained cyber security professionals who they’d expect to be out of work given Russia’s rising unemployment rate in order to estimate a pool of potential new ransomware operators. To double the number of individuals currently acting as ransomware operators, they found that only 7% of the newly unemployed workforce would have to convert to cybercrime.
They note, however, that it remains to be seen what impact a larger labor pool would have since new entrants looking for fast cash may not be as willing to put in the time and effort to carry out big game tactics that typified the first half of 2021. As such, Coveware would expect to see an increase in attacks on small to medium-sized enterprises (which already make up the largest portion of ransomware victims today) and a decline in ransom demands with new operators hoping to make paying up more attractive for victims.
Key Takeaway: If the threat materializes, new entrants to the ransomware game are likely to try to fly under the radar, which means we would expect to see a larger number of small to medium-sized businesses targeted with ransoms that won’t make headlines, but that nonetheless hurt the businesses affected.
3. One Ransomware Operator Paid the Price for Russian Allegiance; Others Declared Neutrality
In February, ransomware group Conti declared their support for Russian actions and threatened to retaliate against Western entities targeting Russian infrastructure. But Conti appears to have miscalculated the loyalty of its affiliates, many of whom are likely pro-Ukraine. The declaration backfired when one of their affiliates leaked chat logs following the announcement. Shortly after, LockBit, another prolific ransomware group, took a cue from Conti’s blunder, declaring neutrality and swearing off any attacks against Russia’s many enemies. Their reasoning? Surprisingly inclusive for an organized crime syndicate:
“Our community consists of many nationalities of the world, most of our pentesters are from the CIS including Russians and Ukrainians, but we also have Americans, Englishmen, Chinese, French, Arabs, Jews, and many others in our team… We are all simple and peaceful people, we are all Earthlings.”
As we know, the ransomware economy is a wide, interconnected network of actors with varying political allegiances. The actions of LockBit may assuage some fears that Russia would be able to weaponize the cybercrime groups that have been allowed to operate with impunity within its borders, but that’s no reason to rest easy.
Key Takeaway: LockBit’s actions and words reinforce the one thing we know for sure about cybercriminals: Despite varying political allegiances, they’re unified by money and they will come after it if it’s easy for the taking.
4. CISA Reports the Globalized Threat of Ransomware Increased in 2021
The U.S. Cybersecurity and Infrastructure Security Agency (CISA) released a statement in March summarizing the trends they saw throughout 2021. They outlined a number of tactics that we saw throughout the year as well, including:
- Targeting attacks on holidays and weekends.
- Targeting managed service providers.
- Targeting backups stored in on-premises devices and in the cloud.
Among others, these tactics pose a threat to critical infrastructure, healthcare, financial institutions, education, businesses, and nonprofits globally.
Key Takeaway: The advisory outlines 18 mitigation strategies businesses and organizations can take to protect themselves from ransomware, including some of the top strategies as we see it: protecting cloud storage by backing up to multiple locations, requiring MFA for access, and encrypting data in the cloud.
5. Russia Could Use Ransomware to Offset Sanctions
Despite our first observation that ransomware attacks slowed somewhat early in the quarter, the Financial Crimes Enforcement Network (FinCEN) issued an alert in March that Russia may employ state-sponsored actors to evade sanctions and bring in cryptocurrency by ramping up attacks. They warned financial institutions, specifically, to be vigilant against these threats to help thwart attempts by state-sponsored Russian actors to extort ransomware payments.
The warnings follow an increase in phishing and distributed denial-of-service (DDoS) attacks that have persisted throughout the year and increased toward the end of February into March as reported by Google’s Threat Analysis Group. In reports from ThreatPost covering the alert as well as Google’s observations, cybersecurity experts seemed doubtful that ransomware payouts would make much of a dent in alleviating the sanctions, and noted that opportunities to use ransomware were more likely on an individual level.
Key Takeaway: The warnings serve as a reminder that both individual actors and state-sponsored entities have ransomware tools at their disposal to use as a means to retaliate against sanctions or simply support themselves, and that the best course of action is to shore up defenses before the anticipated threats materialize.
What This All Means for You
The changing political landscape will continue to shape the ransomware economy in new and unexpected ways. Being better prepared to avoid or mitigate the effects of ransomware makes more and more sense when you can’t be sure what to expect. Ransomware protection doesn’t have to be costly or confusing. Check out our ransomware protection solutions to get started.
The post Ransomware Takeaways From Q1 2022 appeared first on Backblaze Blog | Cloud Storage & Cloud Backup.
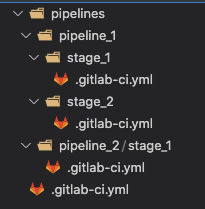
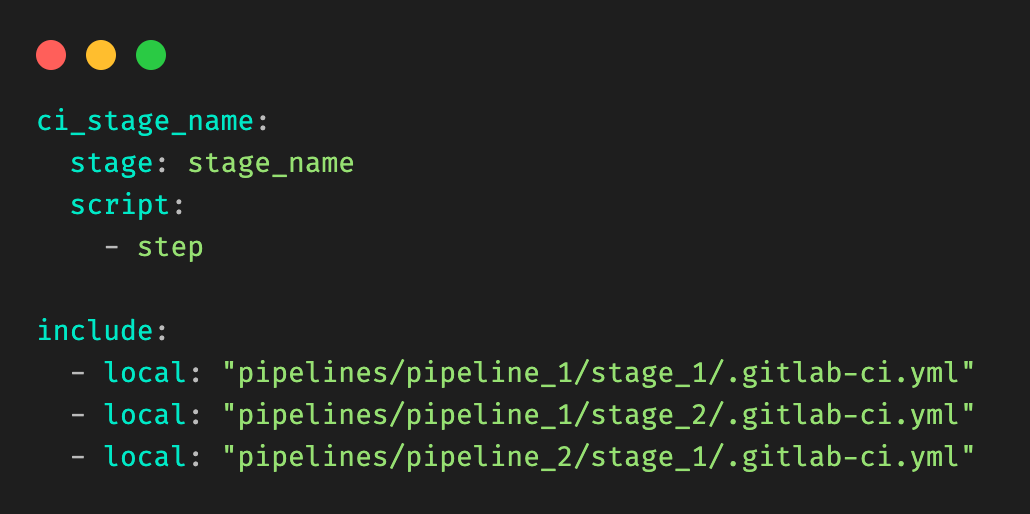

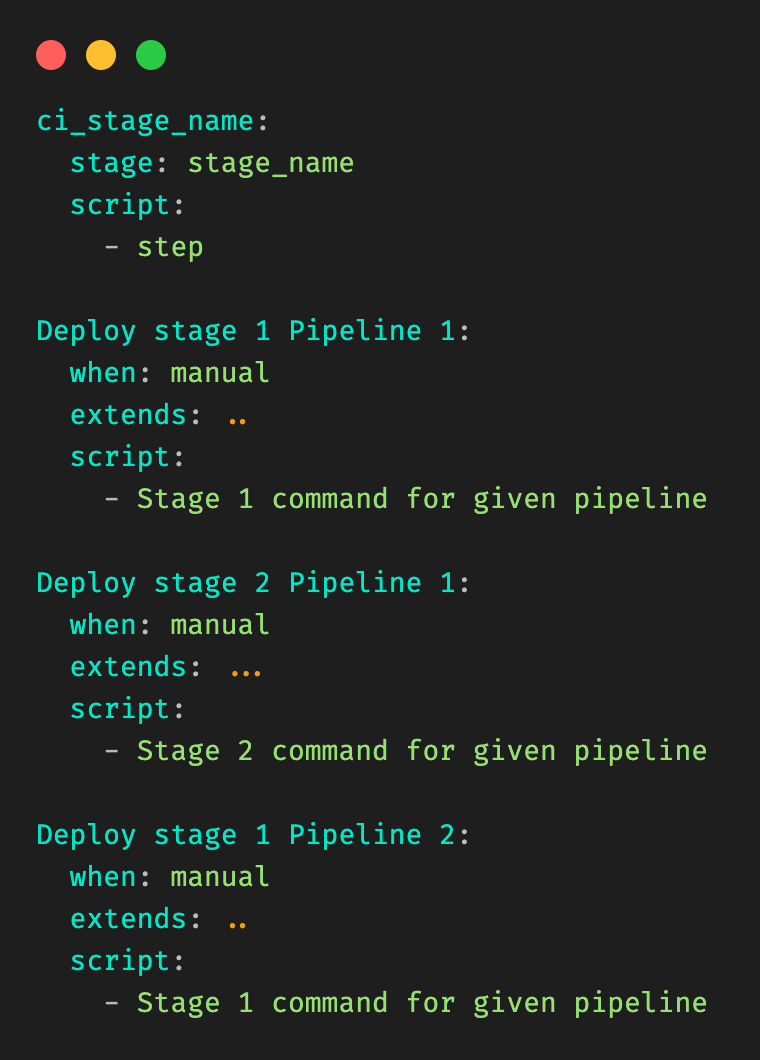
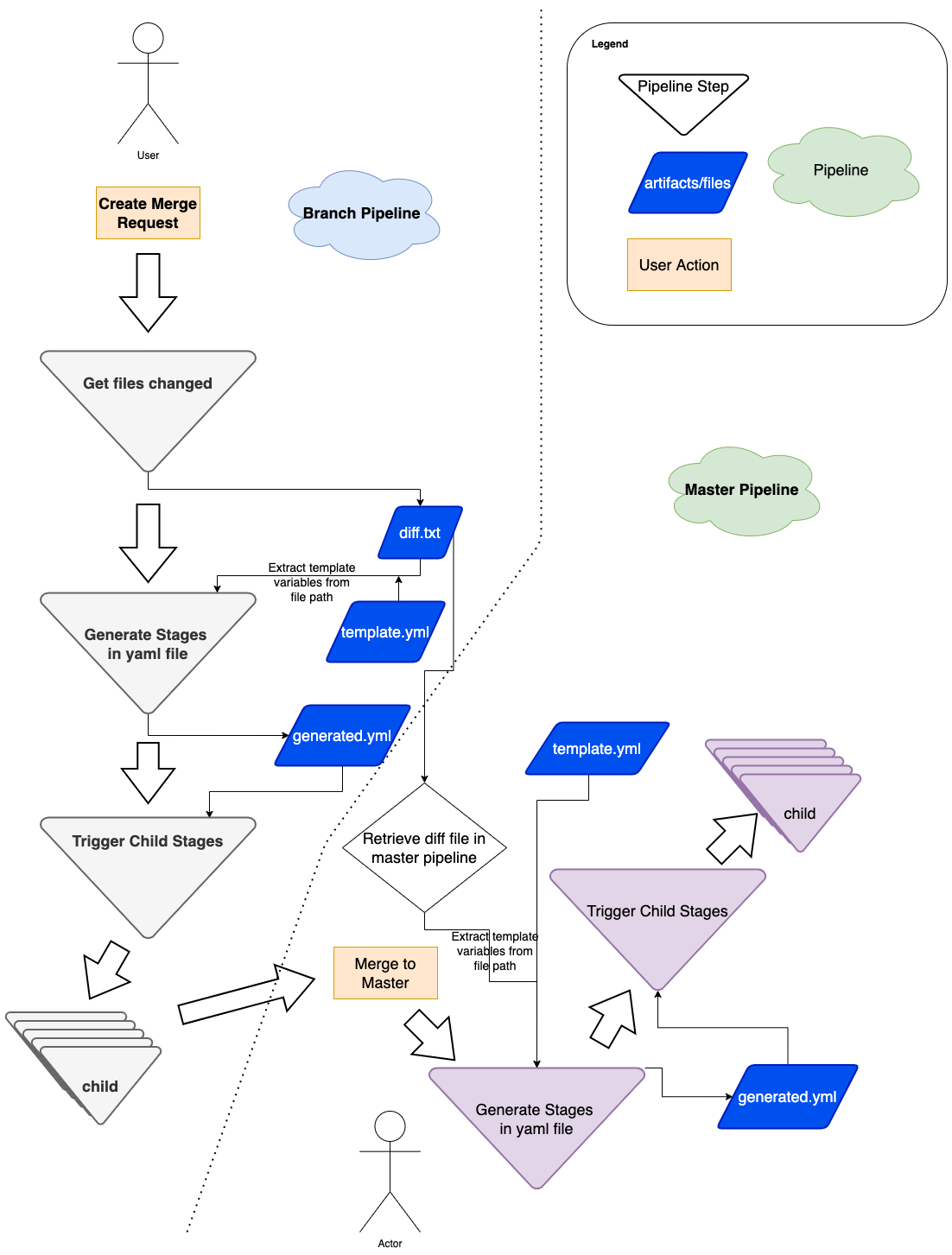




























 Ten years ago we launched
Ten years ago we launched 