As I often told my audiences in the early days, I wanted them to think big thoughts and dream big dreams! Looking back, I think it is safe to say that the launch of S3 empowered them to do just that, and initiated a wave of innovation that continues to this day.
Bigger, Busier, and more Cost-Effective Our customers count on Amazon S3 to provide them with reliable and highly durable object storage that scales to meet their needs, while growing more and more cost-effective over time. We’ve met those needs and many others; here are some new metrics that prove my point:
Object Storage – Amazon S3 now holds more than 200 trillion (2 x 1014) objects. That’s almost 29,000 objects for each resident of planet Earth. Counting at one object per second, it would take 6.342 million years to reach this number! According to Ethan Siegel, there are about 2 trillion galaxies in the visible Universe, so that’s 100 objects per galaxy! Shortly after the 2006 launch of S3, I was happy to announce the then-impressive metric of 800 million stored objects, so the object count has grown by a factor of 250,000 in less than 16 years.
Request Rate – Amazon S3 now averages over 100 million requests per second.
Cost Effective – Over time we have added multiple storage classes to S3 in order to optimize cost and performance for many different workloads. For example, AWS customers are making great use of Amazon S3 Intelligent Tiering (the only cloud storage class that delivers automatic storage cost savings when data access patterns change), and have saved more than $250 million in storage costs as compared to Amazon S3 Standard. When I first wrote about this storage class in 2018, I said:
In order to make it easier for you to take advantage of S3 without having to develop a deep understanding of your access patterns, we are launching a new storage class, S3 Intelligent-Tiering.
Customer Innovation As you can see from the metrics above, our customers use S3 to store and protect vast amounts of data in support of an equally vast number of use cases and applications. Here are just a few of the ways that our customers are innovating:
NASCAR – After spending 15 years collecting video, image, and audio assets representing over 70 years of motor sports history, NASCAR built a media library that encompassed over 8,600 LTO 6 tapes and a few thousand LTO 4 tapes, with a growth rate of between 1.5 PB and 2 PB per year. Over the course of 18 months they migrated all of this content (a total of 15 PB) to AWS, making use of the Amazon S3 Standard, Amazon S3 Glacier Flexible Retrieval, and Amazon S3 Glacier Deep Archive storage classes. To learn more about how they migrated this massive and invaluable archive, read Modernizing NASCAR’s multi-PB media archive at speed with AWS Storage.
Electronic Arts – This game maker’s core telemetry systems handle tens of petabytes of data, tens of thousands of tables, and over 2 billion objects. As their games became more popular and the volume of data grew, they were facing challenges around data growth, cost management, retention, and data usage. In a series of updates, they moved archival data to Amazon S3 Glacier Deep Archive, implemented tag-driven retention management, and implemented Amazon S3 Intelligent-Tiering. They have reduced their costs and made their data assets more accessible; read Electronic Arts optimizes storage costs and operations using Amazon S3 Intelligent-Tiering and S3 Glacier to learn more.
NRGene / CRISPR-IL – This team came together to build a best-in-class gene-editing prediction platform. CRISPR ( A Crack In Creation is a great introduction) is a very new and very precise way to edit genes and effect changes to an organism’s genetic makeup. The CRISPR-IL consortium is built around an iterative learning process that allows researchers to send results to a predictive engine that helps to shape the next round of experiments. As described in A gene-editing prediction engine with iterative learning cycles built on AWS, the team identified five key challenges and then used AWS to build GoGenome, a web service that performs predictions and delivers the results to users. GoGenome stores over 20 terabytes of raw sequencing data, and hundreds of millions of feature vectors, making use of Amazon S3 and other AWS storage services as the foundation of their data lake.
Designed for system administrators, engineers, developers, and architects, our sessions will bring you the latest and greatest information on security, backup, archiving, certification, and more. Join us at 9:30 AM PT on Twitch for Kevin Miller’s kickoff keynote, and stick around for the entire day to learn a lot more about how you can put Amazon S3 to use in your applications. See you there!
When the kernel first gained support for
huge pages, most of the work was left to user space. System administrators
had to set
aside memory in the special hugetlbfs filesystem for huge pages, and
programs had to explicitly map memory from there. Over time, the transparent huge pages mechanism automated the
task of using huge pages. That mechanism is not perfect, though, and some
users feel that they have better knowledge of when huge-page use makes sense
for a given process. Thus, huge pages are now coming full circle with this patch
set from Zach O’Keefe returning huge pages to user-space control.
This is a current list of where and when I am scheduled to speak:
I’m participating in an online panel discussion on “Ukraine and Russia: The Online War,” hosted by UMass Amherst, at 5:00 PM Eastern on March 31, 2022.
I’m speaking at Future Summits in Antwerp, Belgium on May 18, 2022.
I’m speaking at IT-S Now 2022 in Vienna on June 2, 2022.
I’m speaking at the 14th International Conference on Cyber Conflict, CyCon 2022, in Tallinn, Estonia on June 3, 2022.
When one mentions supply chains these days, we tend to think of microchips from China causing delays in automobile manufacturing or toilet paper disappearing from store shelves. Sure, there are some chips in the communications infrastructure, but the cyber supply chain is mostly about virtual things – the ones you can’t actually touch.
In 2018, the Cybersecurity and Infrastructure Security Agency (CISA) established the Information and Communications Technology (ICT) Supply Chain Risk Management (SCRM) Task Force as a public-private joint effort to build partnerships and enhance ICT supply chain resilience. To date, the Task Force has worked on 7 Executive Orders from the White House that underscore the importance of supply chain resilience in critical infrastructure.
Background
The ICT-SCRM Task Force is made up of members from the following sectors:
Information Technology (IT) – Over 40 IT companies, including service providers, hardware, software, and cloud have provided input.
Communications – Nearly 25 communications associations and companies are included, with representation from the wireline, wireless, broadband, and broadcast areas.
Government – More than 30 government organizations and agencies are represented on the Task Force.
These three sector groups touch nearly every facet of critical infrastructure that businesses and government require. The Task Force is dedicated to identifying threats and developing solutions to enhance resilience by reducing the attack surface of critical infrastructure. This diverse group is poised perfectly to evaluate existing practices and elevate them to new heights by enhancing existing standards and frameworks with up-to-date practical advice.
Working groups
The core of the task force is the working groups. These groups are created and disbanded as needed to address core areas of the cyber supply chain. Some of the working groups have been concentrating on areas like:
The legal risks of information sharing
Evaluating supply chain threats
Identifying criteria for building Qualified Bidder Lists and Qualified Manufacturer Lists
The impacts of the COVID-19 pandemic on supply chains
Creating a vendor supply chain risk management template
Ongoing efforts
After two years of producing some great resources and rather large reports, the ICT-SCRM Task Force recognized the need to ensure organizations of all sizes can take advantage of the group’s resources, even if they don’t have a dedicated risk management professional at their disposal. This led to the creation of both a Small and Medium Business (SMB) working group, as well as one dedicated to Product Marketing.
The SMB working group chose to review and adapt the Vendor SCRM template for use by small and medium businesses, which shows the template can be a great resource for companies and organizations of all sizes.
Out of this template, the group described three cyber supply chain scenarios that an SMB (or any size organization, really) could encounter. From that, the group further simplified the process by creating an Excel spreadsheet that provides a document that is easy for SMBs to share with their prospective vendors and partners as a tool to evaluate their cybersecurity posture. Most importantly, the document does not promote a checkbox approach to cybersecurity — it allows for partial compliance, with room provided for explanations. It also allows many of the questions to be removed if the prospective partner possesses a SOC1/2 certification, thereby eliminating duplication in questions.
What the future holds
At the time of this writing, the Product Marketing and SMB working groups are hard at work making sure everyone, including the smallest businesses, are using the ICT-SCRM Task Force Resources to their fullest potential. Additional workstreams are being developed and will be announced soon, and these will likely include expansion with international partners and additional critical-infrastructure sectors.
This week for Women’s History Month, we’re continuing to feature female authors. We’re showcasing women in the tech industry who are building, creating, and, above all, inspiring, empowering, and encouraging everyone—especially women and girls—in tech.
Companies choosing to rehost their on-premises SQL Server workloads to AWS can face challenges with setting up their disaster recovery (DR) strategy. Solutions such as Always On can be a more expensive, complex configuration across Regions. It can cause latency issues when synchronously replicating data cross-Region. Snapshots have additional overhead and may breach their stringent recovery point objective/recovery time objective (RPO/RTO) requirements.
A log shipping solution can take advantage of cross-Region replication of data using Amazon FSx for Windows File Server. It has less maintenance overhead, doesn’t introduce latency, and meets RPO/RTO requirements. A multi-Region architecture for Microsoft SQL Server is often adopted for SQL Server deployments for business continuity (disaster recovery) and improved latency (for a geographically distributed customer base).
This blog post explores SQL Server DR architecture using SQL Server failover cluster with Amazon FSx for Windows File Server for the primary site and secondary DR site. We describe how to set up a multi-Region DR using log shipping. We’ll explain the architecture patterns so you can follow along and effectively design a highly available SQL Server deployment that spans two or more AWS Regions.
Here are some advantages of using log shipping versus Always On distributed availability group DR setup.
Log shipping works with SQL Server Standard edition
It lowers total cost of ownership (TCO) as you only need one SQL Server Standard edition license at the primary/DR site
It’s straightforward to configure
There’s no need for clustering setup at the OS level
It supports all SQL Server versions. You don’t need the SQL Server version to be the same for source and destination instances.
Log shipping DR solution for SQL Server FCI with Amazon FSx
The architecture diagram in Figure 1 depicts SQL Server failover cluster instance (FCI) using Amazon FSx as storage (multiple Availability Zones) in Region 1. It uses a standalone or a similar setup on Region 2. It uses a log shipping feature for replication and DR. This will also serve as the reference architecture for our solution.
Figure 1. Log shipping DR solution for SQL Server FCI with Amazon FSx
Figure 1 shows an SQL cluster in Region 1 and standalone SQL cluster in Region 2. The primary cluster in Region 1 is initially configured with SQL Server failover cluster instance (FCI) using Amazon FSx for its shared storage. Region 2 can have a standalone Amazon EC2 server with SQL Server and Amazon Elastic Block Store (EBS) as storage. Or it can have an identical configuration to Region 1, but with different hostnames, and an SQL network name (SQLFCI02) to avoid possible collisions.
You can build the VPC peering or AWS Transit Gateway to have seamless connectivity between the two Regions for the opened ports (SQL Server, SMB for file share, and others.)
With Amazon FSx, you get a fully managed and shared file storage solution, that automatically replicates the underlying storage synchronously across multiple Availability Zones. Amazon FSx provides high availability with automatic failure detection and automatic failover if there are any hardware or storage issues. The service fully supports continuously available shares, a feature that permits SQL Server uninterrupted access to shared file data.
There is an asynchronous replication setup from Region 1 to Region 2 using the log shipping feature. In this type of configuration, Microsoft SQL Server log shipping replicates databases using transaction logs. This ensures that a physically replicated warm standby database is an exact binary replica of the primary database. This is referred to as physical replication.
Log shipping can be configured with two available modes. These are related to the state of the secondary log-shipped SQL Server database.
Standby mode. The database is available for querying. Users cannot access the database while restore is going on. But once restore is completed, users can access it in read-only mode.
Restore mode. The database is not accessible for users.
In this solution, you configure a warm standby SQL Server database on an EC2 instance designated in SQL FCI using Amazon FSx as shared storage. You can send transaction log backups asynchronously between your primary Region database and the warm standby server in the other Region. The transaction log backups are then applied to the warm standby database sequentially. When all the logs have been applied, you can perform a manual failover and point the application to the secondary Region. We recommend running the primary and secondary database instances in separate Availability Zones, and configuring a monitor instance to track all the details of log shipping.
Prerequisites
Configure two SQL Server clusters with FCI in Region 1 and Region 2, or have SQL Server cluster on Region 1 and Amazon EC2 with SQL Server with EBS on Region 2. Learn more about how to set up SQL Server FCI with Amazon FSx.
Configure VPC peering or Transit Gateway for the VPCs (where the SQL Server clusters reside).
Configure networking and security to work across the peering connection or Transit Gateway.
Verify that Amazon FSx and SQL connectivity is seamless across both Regions. For example, we should be able to connect Amazon FSx and SQL Server remotely from one Region to the other. Confirm that security group rules are in place. Learn more about FSx for Windows File Server.
SQL Server shouldn’t be running in Express edition as log shipping supports all editions except Express edition.
Give shared folders on primary and secondary Regions appropriate permissions so the network path is accessible across Regions.
The databases for log shipping must be in FULL recovery mode. Learn more about log shipping.
Walkthrough steps to set up DR for SQL Server FCI
Following are the steps required to configure SQL Server DR using SQL Server failover cluster. Amazon FSx for Windows File Server is used for the primary site and secondary DR site. We also demonstrate how to set up a multi-Region log shipping.
Make sure to configure network connectivity between your clusters. In this solution, we are using two VPCs in two separate Regions.
VPC peering is configured to enable network traffic on both VPCs.
The domain controller (AWS Managed Microsoft AD) on both VPCs are configured with conditional forwarding. This enables DNS resolution between the two VPCs.
Configure SQL FCI setup using Amazon FSx as shared storage on Region_01.
Configure SQL standalone instance on Region_02 with EBS volume as storage.
Create an Amazon FSx in the primary Region with AWS managed Active Directory, or on-premises Active Directory connected with trust relation or AD Connector.
Create a SQL Server service account with proper permissions to be able to set up transaction log settings.
Configure VPC peering between the primary and DR/secondary Region.
Join the domain to the Active Directory network for both primary and secondary servers in primary Region.
Mount Amazon FSx on primary and secondary server and allow shared permissions, so SQL Server is able to access the folder. Use Amazon FSx for storing transaction log backups and EBS for storing transaction logs on the secondary Region.
Set up log shipping from the primary server SQL Server FCI01 to the secondary SQL Server EC2SQL2 with the standby option enabled. This way the databases can be in read on the secondary SQL Server.
In case of disaster at primary Region node SQLFCI01, log shipping acts as DR solution. Following, we show the steps to bring the databases online on EC2SQL02. Once SQLFCI01 is back, Use the following steps if DR drill checks to failover. In a real disaster, follow the process from Step 3 onwards.
1. Stop all activities on SQLFCI01 databases involved in log shipping jobs on SQLFCI01 and EC2SQL02. Confirm if any process is running by using the following query:
Use master Go select * fromsysprocesses where dbid = DB_ID('DatabaseName')
2. Take full backup on SQLFCI01 as rollback option.
BACKUP DATABASE [DatabaseName] TO DISK = N'Provide Drive details' WITH COMPRESSION GO
3. Take last tail transaction log backup if we have access to SQL Server. Otherwise, check the last available transaction log stored in EC2SQL02 and restore it with RECOVERY to bring the databases online on EC2SQL02.
RESTORELOG [DatabaseName] FROM DISK = N'Provide path of last tlog' WITH FILE = 1, RECOVERY, NOUNLOAD,STATS = 10 GO
4. Redirect the application connections to EC2SQL02.
Failback methods
1. Native backup/restore or rollback strategy
Take full backup from EC2SQL02 and copy to the SQLFCI01.
RESTORE the full backup on SQLFCI01.
Reconfigure log shipping between SQLFCI01 and EC2SQL02.
2. Reverse log shipping
In case of DR drills or business continuity and disaster recovery (BCDR) activities, we can set up reverse log shipping to reduce the time taken to failover. It doesn’t require reinitializing the database with a full backup if performed carefully. It is crucial to preserve the log sequence number (LSN) chain. Perform the final log backup using the NORECOVERY option. Backing up the log with this option puts the database in a state where log backups can be restored. It ensures that the database’s LSN chain doesn’t deviate. This procedure helps reduce downtime to bring back SQLFCI01.
STOP all activities on SQLFCI01 databases involved in log shipping jobs on SQLFCI01 and EC2SQL02.
TAKE Tlog backup of SQLFCI01 with NORECOVERY option.
BACKUP LOG [DatabaseName] TO DISK = 'BackupFilePathname' WITH NORECOVERY;
RESTORE transaction log backup on EC2SQL02 with NORECOVERY.
Reconfigure log shipping and reenable the jobs back.
Reconfigure the application connections to SQLFCI01.
Conclusion
A multi-Region strategy for your mission-critical SQL Server deployments is key for business continuity and disaster recovery. This blog post shows how to achieve that using log shipping for SQL Server FCI deployment. Setting up DR using log shipping can help you save costs and meet your business requirements.
Since our founding, Cloudflare has been on a mission to take expensive, complex security solutions typically only available to the largest companies and make them easy to use and accessible to everyone. In 2011 and 2015 we did this for the web application firewall and SSL/TLS markets, simplifying the process of protecting websites from application vulnerabilities and encrypting HTTP requests down to single clicks; in 2020, during the start of the COVID-19 pandemic, we made our Zero Trust suite available to everyone; and today—in the face of heightened phishing attacks—we’re doing the same for the email security market.
Once the acquisition of Area 1 closes, as we expect early in the second quarter of 2022, we plan to give all paid self-serve plans access to their email security technology at no additional charge. Control, customization, and visibility via analytics will vary with plan level, and the highest flexibility and support levels will be available to Enterprise customers for purchase.
All self-serve users will also get access to a more feature-packed version of the Zero Trust solution we made available to everyone in 2020. Zero Trust services are incomplete without an email security solution, and CISA’s recent report makes that clearer than ever: over 90% of successful cyber attacks start with a phishing email, so we expect that over time analysts will have no choice but to include email in their definitions of secure access and zero edges.
If you’re interested in reserving your place in line, register your interest by logging into your Cloudflare account at dash.cloudflare.com, selecting your domain, clicking Email, and then “Join Waitlist” at the top of the page; we’ll reach out after the Area 1 acquisition is completed, and the integration is ready, in the order we received your request.
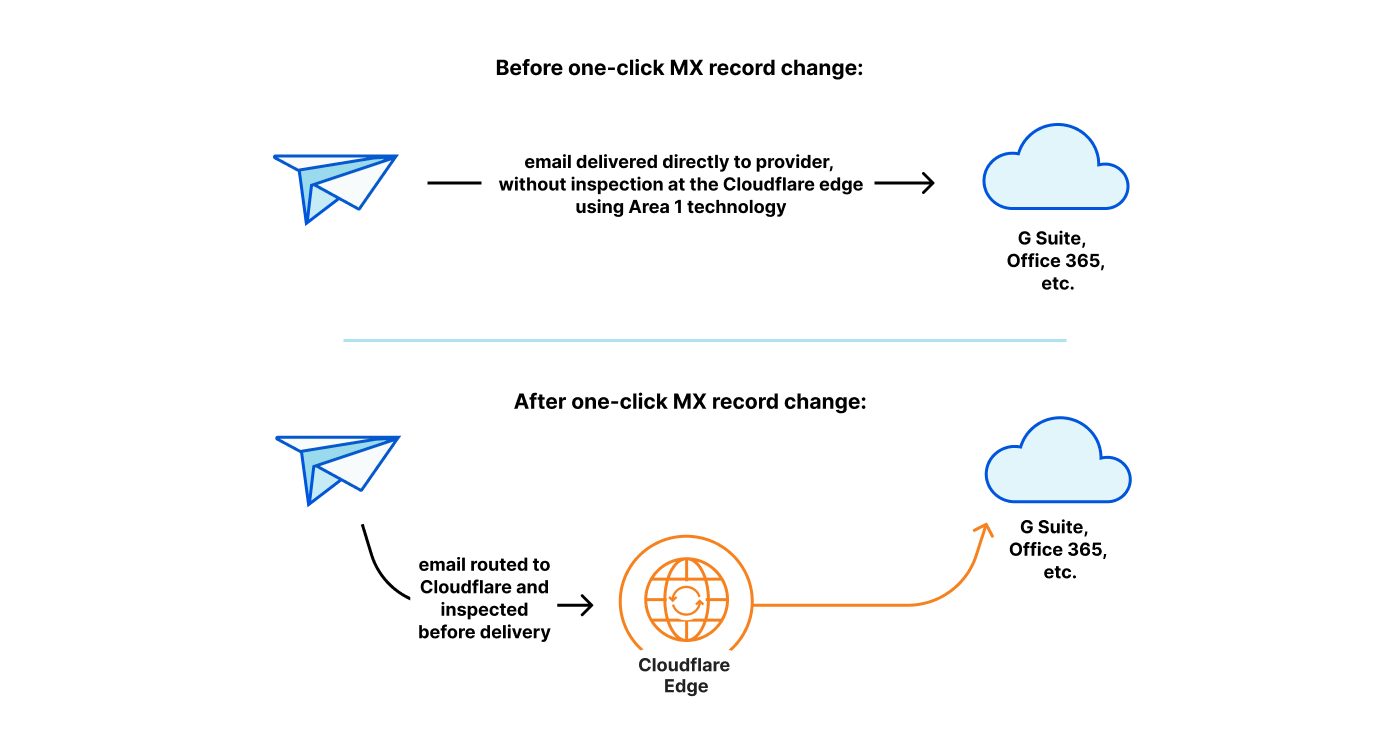
One-click deployment
If you’re already managing your authoritative DNS with Cloudflare, as nearly 100% of non-Enterprise plans are, there will just be a single click to get started. Once clicked, we’ll start returning different MX records to anyone trying to send email to your domain. This change will attract all emails destined for your domain, during which they’ll be run through Area 1’s models and potentially be quarantined or flagged. Customers of Microsoft Office 365 will also be able to take advantage of APIs for an even deeper integration and capabilities like post-delivery message redaction.
In addition to routing and filtering email, we’ll also automagically take care of your DNS email security records such as SPF, DKIM, DMARC, etc. We launched a tool to help with this last year, and soon we’ll be making it even more comprehensive and easier to use.
Integration with other Zero Trust products
As we wrote in the acquisition announcement post on this blog, we’re excited to integrate email security with other products in our Zero Trust suite. For customers of Gateway and Remote Browser Isolation (RBI), we’ll automatically route potentially suspicious domains and links through these protective layers. Our built-in data loss prevention (DLP) technology will also be wired into Area 1’s technology in deployments where visibility into outbound email is available.
Improving threat intelligence with new data sources
In addition to integrating directly with Zero Trust products, we’re excited about connecting threat data sources from Area 1 into existing Cloudflare products and vice versa. For example, phishing infrastructure identified during Area 1’s Internet-wide scans will be displayed within the recently launched Cloudflare Security Center, and 1.1.1.1’s trillions of queries per month will help Area 1 identify new domains that may be threats. Domains that are newly registered, or registered with slight variations of legitimate domains, are often warning signs of an upcoming phishing attack.
Getting started
Cloudflare has been a happy customer of Area 1’s technology for years, and we’re excited to open it up to all of our customers as soon as possible. If you’re excited as we are about being able to use this in your Pro or Business plan, reserve your place in line today within the Email tab for your domain. Or if you’re an Enterprise customer and want to get started immediately, fill out this form or contact your Customer Success Manager.
Cloudflare blocks a lot of diverse security threats, with some of the more interesting attacks targeting the “long tail” of the millions of Internet properties we protect. The data we glean from these attacks trains our machine learning models and improves the efficacy of our network and application security products, but historically hasn’t been available to query directly. This week, we’re changing that.
All customers will soon be granted access to our new threat investigations portal, Investigate, in the Cloudflare Security Center (first launched in December 2021). Additionally, we’ll be annotating threats across our analytics platform with this intelligence to streamline security workflows and tighten feedback loops.
What sorts of data might you want to look up here? Let’s say you’re seeing an IP address in your logs and want to learn which hostnames have pointed to it via DNS, or you’re seeing a cluster of attacks come from an autonomous system (AS) you’re not familiar with. Or maybe you want to investigate a domain name to see how it’s been categorized from a threat perspective. Simply enter any of those items into the omni search box, and we’ll tell you everything we know.
IPs and hostnames will be available to query this week, followed by AS details to give you insight into the networks that communicate with your Cloudflare accounts. Next month as we move to general availability we’ll add data types and properties. Integrations with partners will allow you to use your existing license keys to see all your threat data in a single, unified interface. We also plan to show how both your infrastructure and corporate employees are interacting with any objects you look up, e.g., you can see how many times an IP triggers a WAF or API Shield rule, or how many times your employees attempted to resolve a domain that’s known to serve malware.
Annotations in the dashboard: actionable intelligence in context
Looking up threat data on an ad hoc basis is great, but it’s better when that data is annotated directly in logs and analytics. Starting this week, we will begin rolling out intelligence that is available in Investigate in the dashboard where it is relevant to your workflow. We’re starting with the web application firewall analytics for your websites that are behind Cloudflare.
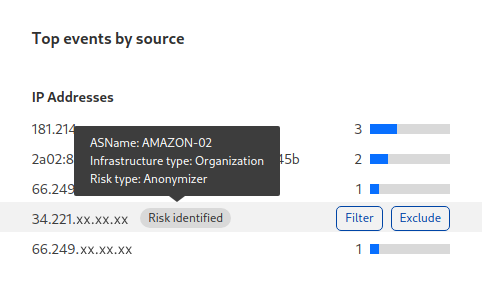
Say you are investigating a security alert for a large number of requests that are blocked by a web application firewall rule. You might see that the alert was caused by an IP address probing your website for commonly exploited software vulnerabilities. If the IP in question were a cloud IP or flagged as an anonymizer, contextual intelligence will show that information directly on the analytics page.
This context can help you see patterns. Are attacks coming from anonymizers or the Tor network? Are they coming from cloud virtual machines? An IP is just an IP. But seeing a credential stuffing attack coming from anonymizers is a pattern that enables a proactive response, “Is my bot management configuration up-to-date?”
Cloudflare’s network vantage point and how this informs our data
The scale at which each product suite operates at Cloudflare is staggering. At peak, Cloudflare handles 44 million HTTP requests a second, from more than 250 cities in over 100 countries. The Cloudflare network responds to over 1.2 trillion DNS queries per day, and it has 121 Tbps of network capacity to serve traffic and mitigate denial of service attacks across all products. But on top of this immense scale, Cloudflare’s architecture enables refining raw data and combining intelligence from all of our products to paint a holistic picture of the security landscape.
We are able to take signals refined from the raw data generated by each product and combine them with signals from other products and capabilities to enhance our network and threat data capabilities. It is a common paradigm for security products to be built to have positive flywheel effects among users of the products. If one customer sees a new piece of malware, an endpoint protection vendor can deploy an update that will detect and block this malware for all their other customers. If a botnet attacks one customer, this provides information that can be used to find the signature of that botnet and protect other customers. If a device participates in a DDoS (Distributed Denial of Service) attack, that information can be used to make the network able to faster detect and mitigate future DDoS attacks. Cloudflare’s breadth of product offerings means that the flywheel effect benefits to users accumulate not just between users, but between products as well.
Let’s look at some examples:
DNS resolution and certificate transparency
First, Cloudflare operates 1.1.1.1, one of the largest recursive DNS resolvers in the world. We operate it in a privacy-forward manner, so here at Cloudflare we do not know who or what IP performed a query, nor are we able to correlate queries together to distinct anonymous users. However, through the requests the resolver handles, Cloudflare sees newly registered and newly seen domains. Additionally, Cloudflare has one of the most advanced SSL/TLS encryption products on the market, and as part of that is a member organization helping to maintain the Certificate Transparency logs. These are public logs of every TLS certificate issued by a root certificate authority that is trusted by web browsers. Between these two products, Cloudflare has an unmatched view of what domains are out there on the Internet and when they become active. We use this information not only to populate our new and newly seen domains categories for our Gateway product, but we feed these domains into machine learning models that label suspicious or potentially malicious domains early in their lifecycle.
Email security
As another example, with the acquisition of Area 1, Cloudflare will bring a new set of mutually-reinforcing capabilities into its product offering. All the signals we can generate for a domain from our 1.1.1.1 resolver will become available to help identify malicious email, and Area 1’s years of expertise in identifying malicious email will be able to feed back into Cloudflare’s Gateway product and 1.1.1.1 for Families DNS resolver. In the past, data integrations like this would have been performed by IT or security teams. Instead, data will be able to flow seamlessly between the points on your organization’s attack surface, mutually reinforcing the quality of the analysis and classification. The entire Cloudflare Zero Trust toolkit, including request logging, blocking, and remote browser isolation will be available to handle potentially malicious links delivered via email, using the same policies already in place for other security risks.
Over the last few years, Cloudflare has integrated the use of machine learning in many of our product offerings, but today we’ve launched a new tool that puts the data and signals that power our network security into our customer’s hands as well. Whether responding to security incidents, threat hunting, or proactively setting security policies to protect for your organization, you, human, can now be part of the Cloudflare network as well. Cloudflare’s unique position in the network means that your insights can be fed back into the network to protect not just your organization across all Cloudflare products it uses, but also can participate in mutual insight and defense among all Cloudflare customers.
Looking forward
Cloudflare can cover your organization’s whole attack surface: defending websites, protecting devices and SaaS applications with Cloudflare Zero Trust, your locations and offices with Magic Transit, and your email communications. Security Center is here to make sure you have all the information you need to understand the cyber security risks present today, and to help you defend your organization using Cloudflare.
“What is the wiper malware that I hear about on the news, and how do I protect my company from it?” We hear your questions, and we’re going to give you answers. Not just raw information, but what is relevant to you and how you use the Internet. We have big plans for Security Center. A file scanning portal will provide you with information about JavaScript files seen by Page Shield, executable files scanned by Gateway, and the ability to upload and scan files. Indicators of Compromise like IP addresses and domains will link to information about the relevant threat actors, when known, giving you more information about the techniques and tactics you are faced with, and information about how Cloudflare products can be used to defend against them. CVE search will let you find information on software vulnerabilities, along with the same easy-to-understand Cloudflare perspective you are used to reading on this blog to help decode the jargon and technical language. With today’s release, we’re just getting started.
Building a great customer experience is at the heart of any business. Building resilient products is half the battle — teams also need observability into their applications and services that are running across their stack.
Cloudflare provides analytics and logs for our products in order to give our customers visibility to extract insights. Many of our customers use Cloudflare along with other applications and network services and want to be able to correlate data through all of their systems.
Understanding normal traffic patterns, causes of latency and errors can be used to improve performance and ultimately the customer experience. For example, for websites behind Cloudflare, analyzing application logs and origin server logs along with Cloudflare’s HTTP request logs give our customers an end-to-end visibility about the journey of a request.
We’re excited to have partnered with New Relic to create a direct integration that provides this visibility. The direct integration with our logging product, Logpush, means customers no longer need to pay for middleware to get their Cloudflare data into New Relic. The result is a faster log delivery and fewer costs for our mutual customers!
We’ve invited the New Relic team to dig into how New Relic One can be used to provide insights into Cloudflare.
New Relic Log Management
New Relic provides an open, extensible, cloud-based observability platform that gives visibility into your entire stack. Logs, metrics, events, and traces are automatically correlated to help our customers improve user experience, accelerate time to market, and reduce MTTR.
Deploying log management in context and at scale has never been faster, easier, or more attainable. With New Relic One, you can collect, search, and correlate logs and other telemetry data from applications, infrastructure, network devices, and more for faster troubleshooting and investigation.
New Relic correlates events from your applications, infrastructure, serverless environments, along with mobile errors, traces and spans to your logs — so you find exactly what you need with less toil. All your logs are only a click away, so there’s no need to dig through logs in a separate etool to manually correlate them with errors and traces.
See how engineers have used logs in New Relic to better serve their customers in the short video below.
A quickstart for Cloudflare Logpush and New Relic
To help you get the most of the new Logpush integration with New Relic, we’ve created the Cloudflare Logpush quickstart for New Relic. The Cloudflare quickstart will enable you to monitor and analyze web traffic metrics on a single pre-built dashboard, integrating with New Relic’s database to provide an at-a-glance overview of the most important logs and metrics from your websites and applications.
Getting started is simple:
First, ensure that you have enabled pushing logs directly into New Relic by following the documentation “Enable Logpush to New Relic”.
You’ll also need a New Relic account. If you don’t have one yet, get a free-forever account here.
Next, visit the Cloudflare quickstart in New Relic, click “Install quickstart”, and follow the guided click-through.
For full instructions to set up the integration and quickstart, read the New Relic blog post.
As a result, you’ll get a rich ready-made dashboard with key metrics about your Cloudflare logs!
Correlating Cloudflare logs across your stack in New Relic One is powerful for monitoring and debugging in order to keep services safe and reliable. Cloudflare customers get access to logs as part of the Enterprise account, if you aren’t using Cloudflare Enterprise, contact us. If you’re not already a New Relic user, sign up for New Relic to get a free account which includes this new experience and all of our product capabilities.
It’s just gone midnight, and you’ve just been notified that there is a malicious IP hitting your servers. You need to triage the situation; find the who, what, where, when, why as fast and in as much detail as possible.
Based on what you find out, your next steps could fall anywhere between classifying the alert as a false positive, to escalating the situation and alerting on-call staff from around your organization with a middle of the night wake up.
For anyone that’s gone through a similar situation, you’re aware that the security tools you have on hand can make the situation infinitely easier. It’s invaluable to have one platform that provides complete visibility of all the endpoints, systems and operations that are running at your company.
Cloudflare protects customers’ applications through application services: DNS, CDN and WAF to name a few. We also have products that protect corporate applications, like our Zero Trust offerings Access and Gateway. Each of these products generates logs that provide customers visibility into what’s happening in their environments. Many of our customers use Cloudflare’s services along with other network or application services, such as endpoint management, containerized systems and their own servers.
We’re excited to announce that Cloudflare customers are now able to push their logs directly to IBM Security QRadar SIEM. This direct integration leads to cost savings and faster log delivery for Cloudflare and QRadar SIEM customers because there is no intermediary cloud storage required.
Cloudflare has invited our partner from the IBM QRadar SIEM team to speak to the capabilities this unlocks for our mutual customers.
IBM QRadar SIEM
QRadar SIEM provides security teams centralized visibility and insights across users, endpoints, clouds, applications, and networks – helping you detect, investigate, and respond to threats enterprise wide. QRadar SIEM helps security teams work quickly and efficiently by turning thousands to millions of events into a manageable number of prioritized alerts and accelerating investigations with automated, AI-driven enrichment and root cause analysis. With QRadar SIEM, increase the productivity of your team, address critical use cases, and mature your security operation.
Cloudflare’s reverse proxy and enterprise security products are a key part of customer’s environments. Security analysis can gain visibility about logs from these products along with data from tools that span their network to build out detections and response workflows.
IBM and Cloudflare have partnered together for years to provide a single pane of glass view for our customers. This new enhanced integration means that QRadar SIEM customers can ingest Cloudflare logs directly from Cloudflare’s Logpush product. QRadar SIEM also continues to support customers who are leveraging existing integration via S3 storage.
At Cloudflare, we pride ourselves in giving every customer the ability to provision a TLS certificate for their Internet application — for free. Today, we are responsible for managing the certificate lifecycle for almost 45 million certificates from issuance to deployment to renewal. As we build out the most resilient, robust platform, we want it to be “future-proof” and resilient against events we can’t predict.
Events that cause us to re-issue certificates for our customers, like key compromises, vulnerabilities, and mass revocations require immediate action. Otherwise, customers can be left insecure or offline. When one of these events happens, we want to be ready to mitigate impact immediately. But how?
By having a backup certificate ready to deploy — wrapped with a different private key and issued from a different Certificate Authority than the primary certificate that we serve.
Events that lead to certificate re-issuance
Cloudflare re-issues certificates every day — we call this a certificate renewal. Because certificates come with an expiration date, when Cloudflare sees that a certificate is expiring soon, we initiate a new certificate renewal order. This way, by the time the certificate expires, we already have an updated certificate deployed and ready to use for TLS termination.
Unfortunately, not all certificate renewals are initiated by the expiration date. Sometimes, unforeseeable events like key compromises can lead to certificate renewals. This is because a new key needs to be issued, and therefore a corresponding certificate does as well.
Key Compromises
A key compromise is when an unauthorized person or system obtains the private key that is used to encrypt and decrypt secret information — security personnel’s worst nightmare. Key compromises can be the result of a vulnerability, such as Heartbleed, where a bug in a system can cause the private key to be leaked. They can also be the result of malicious actions, such as a rogue employee accessing unauthorized information. In the event of a key compromise, it’s crucial that (1) new private keys are immediately issued, (2) new certificates are deployed, and (3) the old certificates are revoked.
The Heartbleed Vulnerability
In 2014, the Heartbleed vulnerability was exposed. It allowed attackers to extract the TLS certificate private key for any server that was running the affected version of OpenSSL, a popular encryption library. We patched the bug and then as a precaution, quickly reissued private keys and TLS certificates belonging to all of our customers, even though none of our keys were leaked. Cloudflare’s ability to act quickly protected our customers’ data from being exposed.
Heartbleed was a wake-up call. At the time, Cloudflare’s scale was a magnitude smaller. A similar vulnerability at today’s scale would take us weeks, not hours to re-issue all of our customers certificates.
Now, with backup certificates, we don’t need to worry about initiating a mass re-issuance in a small time frame. Instead, customers will already have a certificate that we’ll be able to instantly deploy. Not just that, but the backup certificate will also be wrapped with a different key than the primary certificate, preventing it from being impacted by a key compromise.
Key compromises are one of the main reasons certificates need to be re-issued at scale. But other events can prompt re-issuance as well, including mass revocations by Certificate Authorities.
Mass Revocations from CAs
Today, the Certificate Authority/Browser Forum (CA/B Forum) is the governing body that sets the rules and standards for certificates. One of the Baseline Requirements set by the CA/B Forum states that Certificate Authorities are required to revoke certificates whose keys are at risk of being compromised within 24 hours. For less immediate issues, such as certificate misuse or violation of a CA’s Certificate Policy, certificates need to be revoked within five days. In both scenarios, certificates will be revoked by the CA in a short timeframe and immediate re-issuance of certificates is required.
While mass revocations aren’t commonly initiated by CAs, there have been a few occurrences throughout the last few years. Recently, Let’s Encrypt had to revoke roughly 2.7 million certificates when they found a non-compliance in their implementation of a DCV challenge. In this case, Cloudflare customers were unaffected.
Another time, one of the Certificate Authorities that we use found that they were renewing certificates based on validation tokens that did not comply with the CA/B Forum standards. This caused them to invoke a mass revocation, impacting about five thousand Cloudflare-managed domains. We worked with our customers and the CA to issue new certificates before the revocation, resulting in minimal impact.
We understand that mistakes happen, and we have been lucky enough that as these issues have come up, our engineering teams were able to mitigate quickly so that no customers were impacted. But that’s not enough: our systems need to be future-proof so that a revocation of 45 million certificates will have no impact on our customers. With backup certificates, we’ll be ready for a mass re-issuance, no matter the scale.
To be resilient against mass revocations initiated by our CAs, we are going to issue every backup certificate from a different CA than the primary certificate. This will add a layer of protection if one of our CAs will have to invoke a mass revocation — something that when initiated, is a ticking time bomb.
Challenges when Renewing Certificates
Scale: With great power, comes great responsibility
When the Heartbleed vulnerability was exposed, we had to re-issue about 100,000 certificates. At the time, this wasn’t a challenge for Cloudflare. Now, we are responsible for tens of millions of certificates. Even if our systems are able to handle this scale, we rely on our Certificate Authority partners to be able to handle it as well. In the case of an emergency, we don’t want to rely on systems that we do not control. That’s why it’s important for us to issue the certificates ahead of time, so that during a disaster, all we need to worry about is getting the backup certificates deployed.
Manual intervention for completing DCV
Another challenge that comes with re-issuing certificates is Domain Control Validation (DCV). DCV is a check used to validate the ownership of a domain before a Certificate Authority can issue a certificate for it. When customers onboard to Cloudflare, they can either delegate Cloudflare to be their DNS provider, or they can choose to use Cloudflare as a proxy while maintaining their current DNS provider.
When Cloudflare acts as the DNS provider for a domain, we can add Domain Control Validation (DCV) records on our customer’s behalf. This makes the certificate issuance and renewal process much simpler.
Domains that don’t use Cloudflare as their DNS provider — we call them partial zones — have to rely on other methods for completing DCV. When those domains proxy their traffic through us, we can complete HTTP DCV on their behalf, serving the HTTP DCV token from our Edge. However, customers that want their certificate issued before proxying their traffic need to manually complete DCV. In an event where Cloudflare has to re-issue thousands or millions of certificates, but cannot complete DCV on behalf of the customer, manual intervention will be required. While completing DCV is not an arduous task, it’s not something that we should rely on our customers to do in an emergency, when they have a small time frame, with high risk involved.
This is where backup certificates come into play. From now on, every certificate issuance will fire two orders: one for a certificate from the primary CA and one for the backup certificate. When we can complete the DCV on behalf of the customer, we will do so for both CAs.
Today, we’re only issuing backup certificates for domains that use Cloudflare as an Authoritative DNS provider. In the future, we’ll order backup certificates for partial zones. That means that for backup certificates for which we are unable to complete DCV, we will give customers the corresponding DCV records to get the certificate issued.
Backup Certificates Deployment Plan
We are happy to announce that Cloudflare has started deploying backup certificates on Universal Certificate orders for Free customers that use Cloudflare as an Authoritative DNS provider. We have been slowly ramping up the number of backup certificate orders and in the next few weeks, we expect every new Universal certificate pack order initiated on a Free, Pro, or Biz account to include a backup certificate, wrapped with a different key and issued from a different CA than the primary certificate.
At the end of April we will start issuing backup certificates for our Enterprise customers. If you’re an Enterprise customer and have any questions about backup certificates, please reach out to your Account Team.
Next Up: Backup Certificates for All
Today, Universal certificates make up 72% of the certificates in our pipeline. But we want full coverage! That’s why our team will continue building out our backup certificates pipeline to support Advanced Certificates and SSL for SaaS certificates. In the future, we will also issue backup certificates for certificates that our customers upload themselves, so they can have a backup they can rely on.
In addition, we will continue to improve our pipeline to make the deployment of backup certificates instantaneous — leaving our customers secure and online in an emergency.
At Cloudflare, our mission is to help build a better Internet. With backup certificates, we’re helping build a secure, reliable Internet that’s ready for any disaster. Interested in helping us out? We’re hiring.
The transparency organization Distributed Denial of Secrets has released 800GB of data from Roskomnadzor, the Russian government censorship organization.
Specifically, Distributed Denial of Secrets says the data comes from the Roskomnadzor of the Republic of Bashkortostan. The Republic of Bashkortostan is in the west of the country.
[…]
The data is split into two main categories: a series of over 360,000 files totalling in at 526.9GB and which date up to as recently as March 5, and then two databases that are 290.6GB in size, according to Distributed Denial of Secrets’ website.
Много ми се искаше да пиша за ония, дето четиридесетте лева, които били за лакомите украинци, а всъщност ще отидат при българските хотелиери, им тежат. Още повече исках да се…
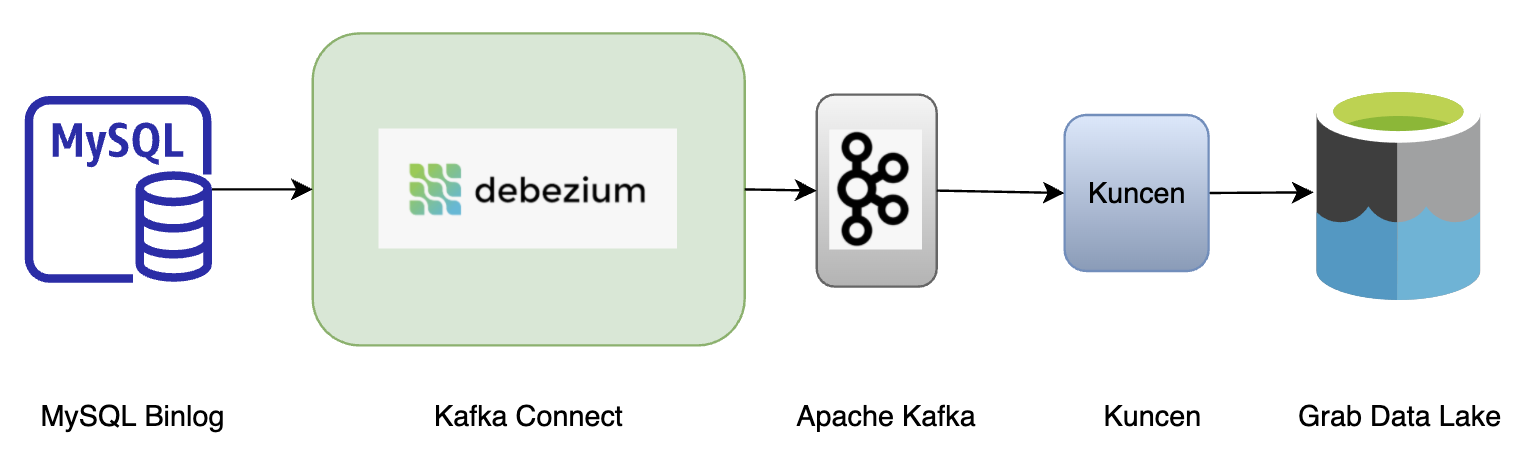
Typically, modern applications use various database engines for their service needs; within Grab, these would be MySQL, Aurora and DynamoDB. Lately, the Caspian team has observed an increasing need to consume real-time data for many service teams. These real-time changes in database records help to support online and offline business decisions for hundreds of teams.
Because of that, we have invested time into synchronising data from MySQL, Aurora and Dynamodb to the message queue, i.e. Kafka. In this blog, we share how real-time data ingestion has helped since it was launched.
Introduction
Over the last few years, service teams had to write all transactional data twice: once into Kafka and once into the database. This helped to solve the inter-service communication challenges and obtain audit trail logs. However, if the transactions fail, data integrity becomes a prominent issue. Moreover, it is a daunting task for developers to maintain the schema of data written into Kafka.
With real-time ingestion, there is a notably better schema evolution and guaranteed data consistency; service teams no longer need to write data twice.
You might be wondering, why don’t we have a single transaction that spans the services’ databases and Kafka, to make data consistent? This would not work as Kafka does not support being enlisted in distributed transactions. In some situations, we might end up having new data persisting into the services’ databases, but not having the corresponding message sent to Kafka topics.
Instead of registering or modifying the mapped table schema in Golang writer into Kafka beforehand, service teams tend to avoid such schema maintenance tasks entirely. In such cases, real-time ingestion can be adopted where data exchange among the heterogeneous databases or replication between source and replica nodes is required.
While reviewing the key challenges around real-time data ingestion, we realised that there were many potential user requirements to include. To build a standardised solution, we identified several points that we felt were high priority:
Make transactional data readily available in real time to drive business decisions at scale.
Capture audit trails of any given database.
Get rid of the burst read on databases caused by SQL-based query ingestion.
To empower Grabbers with real-time data to drive their business decisions, we decided to take a scalable event-driven approach, which is being facilitated with a bunch of internal products, and designed a solution for real-time ingestion.
Anatomy of architecture
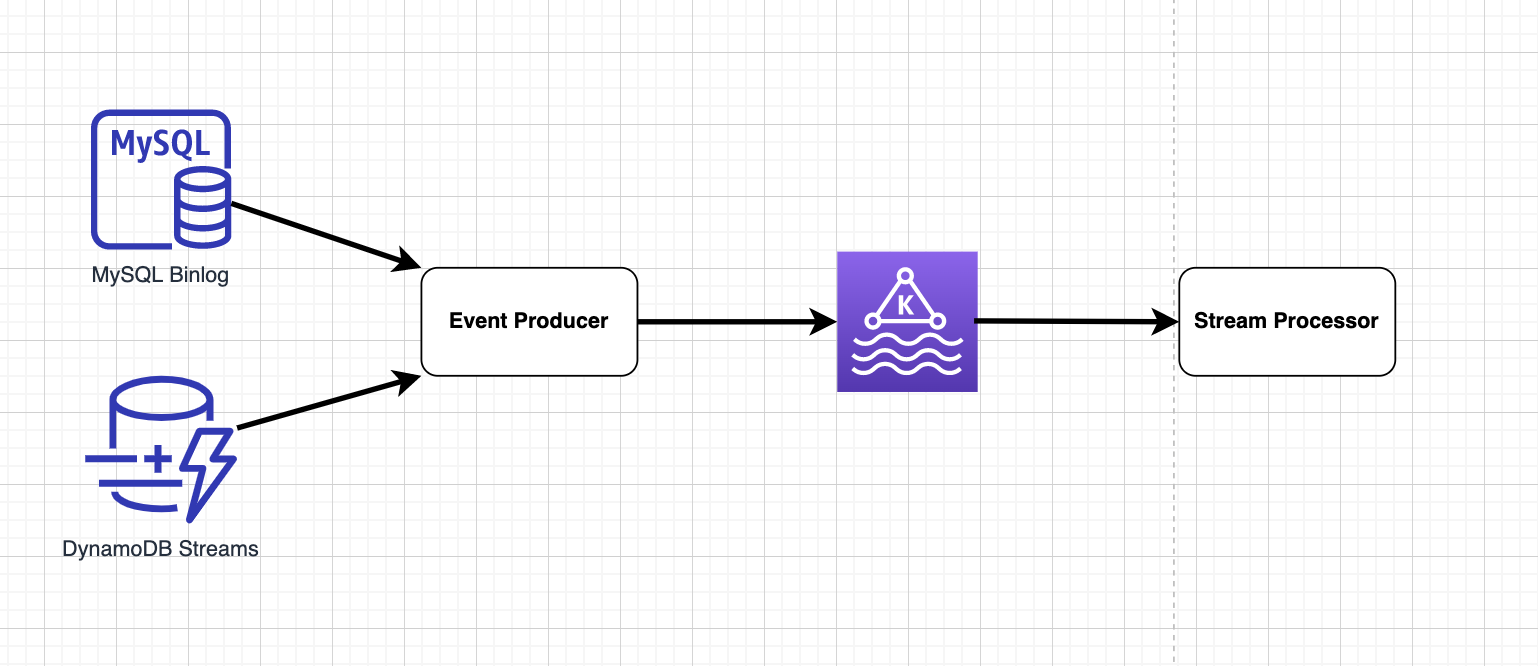
The solution for real-time ingestion has several key components:
Stream data storage
Event producer
Message queue
Stream processor
Figure 1. Real time ingestion architecture
Stream storage
Stream storage acts as a repository that stores the data transactions in order with exactly-once guarantee. However, the level of order in stream storage differs with regards to different databases.
For MySQL or Aurora, transaction data is stored in binlog files in sequence and rotated, thus ensuring global order. Data with global order assures that all MySQL records are ordered and reflects the real life situation. For example, when transaction logs are replayed or consumed by downstream consumers, consumer A’s Grab food order at 12:01:44 pm will always appear before consumer B’s order at 12:01:45 pm.
However, this does not necessarily hold true for DynamoDB stream storage as DynamoDB streams are partitioned. Audit trails of a given record show that they go into the same partition in the same order, ensuring consistent partitioned order. Thus when replay happens, consumer B’s order might appear before consumer A’s.
Moreover, there are multiple formats to choose from for both MySQL binlog and DynamoDB stream records. We eventually set ROW for binlog formats and NEW_AND_OLD_IMAGES for DynamoDB stream records. This depicts the detailed information before and after modifying any given table record. The binlog and DynamoDB stream main fields are tabulated in Figures 2 and 3 respectively.
Figure 2. Binlog record schema
Figure 3. DynamoDB stream record schema
Event producer
Event producers take in binlog messages or stream records and output to the message queue. We evaluated several technologies for the different database engines.
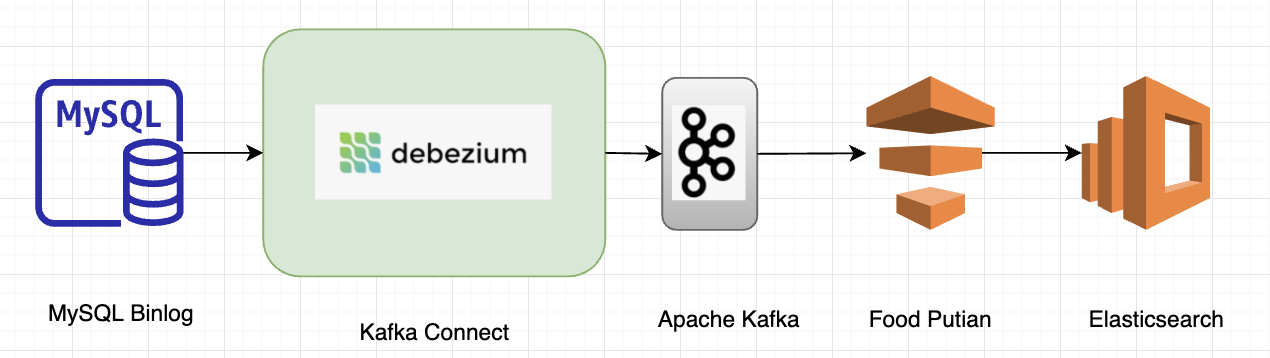
For MySQL or Aurora, three solutions were evaluated: Debezium, Maxwell, and Canal. We chose to onboard Debezium as it is deeply integrated with the Kafka Connect framework. Also, we see the potential of extending solutions among other external systems whenever moving large collections of data in and out of the Kafka cluster.
One such example is the open source project that attempts to build a custom DynamoDB connector extending the Kafka Connect (KC) framework. It self manages checkpointing via an additional DynamoDB table and can be deployed on KC smoothly.
However, the DynamoDB connector fails to exploit the fundamental nature of storage DynamoDB streams: dynamic partitioning and auto-scaling based on the traffic. Instead, it spawns only a single thread task to process all shards of a given DynamoDB table. As a result, downstream services suffer from data latency the most when write traffic surges.
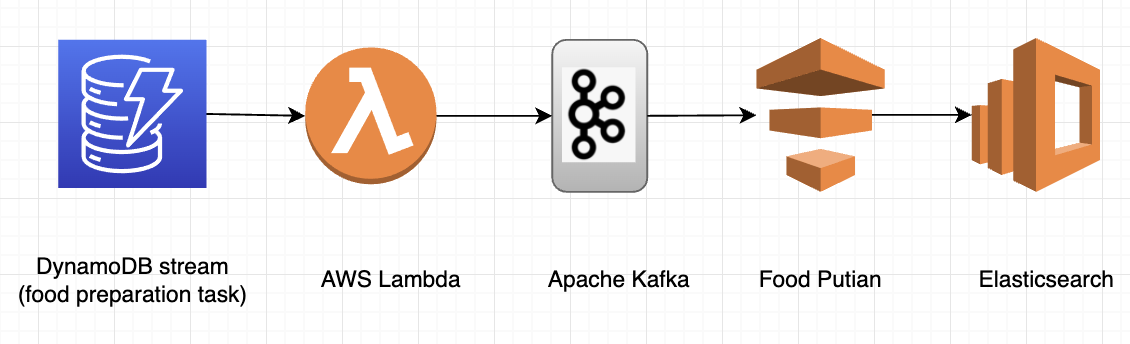
In light of this, the lambda function becomes the most suitable candidate as the event producer. Not only does the concurrency of lambda functions scale in and out based on actual traffic, but the trigger frequency is also adjustable at your discretion.
Kafka
This is the distributed data store optimised for ingesting and processing data in real time. It is widely adopted due to its high scalability, fault-tolerance, and parallelism. The messages in Kafka are abstracted and encoded into Protobuf.
Stream processor
The stream processor consumes messages in Kafka and writes into S3 every minute. There are a number of options readily available in the market; Spark and Flink are the most common choices. Within Grab, we deploy a Golang library to deal with the traffic.
Use cases
Now that we’ve covered how real-time data ingestion is done in Grab, let’s look at some of the situations that could benefit from real-time data ingestion.
1. Data pipelines
We have thousands of pipelines running hourly in Grab. Some tables have significant growth and generate workload beyond what a SQL-based query can handle. An hourly data pipeline would incur a read spike on the production database shared among various services, draining CPU and memory resources. This deteriorates other services’ performance and could even block them from reading. With real-time ingestion, the query from data pipelines would be incremental and span over a period of time.
Another scenario where we switch to real-time ingestion is when a missing index is detected on the table. To speed up the query, SQL-based query ingestion requires indexing on columns such as created_at, updated_at and id. Without indexing, SQL based query ingestion would either result in high CPU and memory usage, or fail entirely.
Although adding indexes for these columns would resolve this issue, it comes with a cost, i.e. a copy of the indexed column and primary key is created on disk and the index is kept in memory. Creating and maintaining an index on a huge table is much costlier than for small tables. With performance consideration in mind, it is not recommended to add indexes to an existing huge table.
Instead, real-time ingestion overshadows SQL-based ingestion. We can spawn a new connector, archiver (Coban team’s Golang library that dumps data from Kafka at minutes-level frequency) and compaction job to bubble up the table record from binlog to the destination table in the Grab data lake.
Figure 4. Using real-time ingestion for data pipelines
2. Drive business decisions
A key use case of enabling real-time ingestion is driving business decisions at scale without even touching the source services. Saga pattern is commonly adopted in the microservice world. Each service has its own database, splitting an overarching database transaction into a series of multiple database transactions. Communication is established among services via message queue i.e. Kafka.
In an earlier tech blog published by the Grab Search team, we talked about how real-time ingestion with Debezium optimised and boosted search capabilities. Each MySQL table is mapped to a Kafka topic and one or multiple topics build up a search index within Elasticsearch.
With this new approach, there is no data loss, i.e. changes via MySQL command line tool or other DB management tools can be captured. Schema evolution is also naturally supported; the new schema defined within a MySQL table is inherited and stored in Kafka. No producer code change is required to make the schema consistent with that in MySQL. Moreover, the database read has been reduced by 90 percent including the efforts of the Data Synchronisation Platform.
Figure 5. Grab Search team use case
The GrabFood team exemplifies mostly similar advantages in the DynamoDB area. The only differences compared to MySQL are that the frequency of the lambda functions is adjustable and parallelism is auto-scaled based on the traffic. By auto-scaling, we mean that more lambda functions will be auto-deployed to cater to a sudden spike in traffic, or destroyed as the traffic falls.
Figure 6. Grab Food team use case
3. Database replication
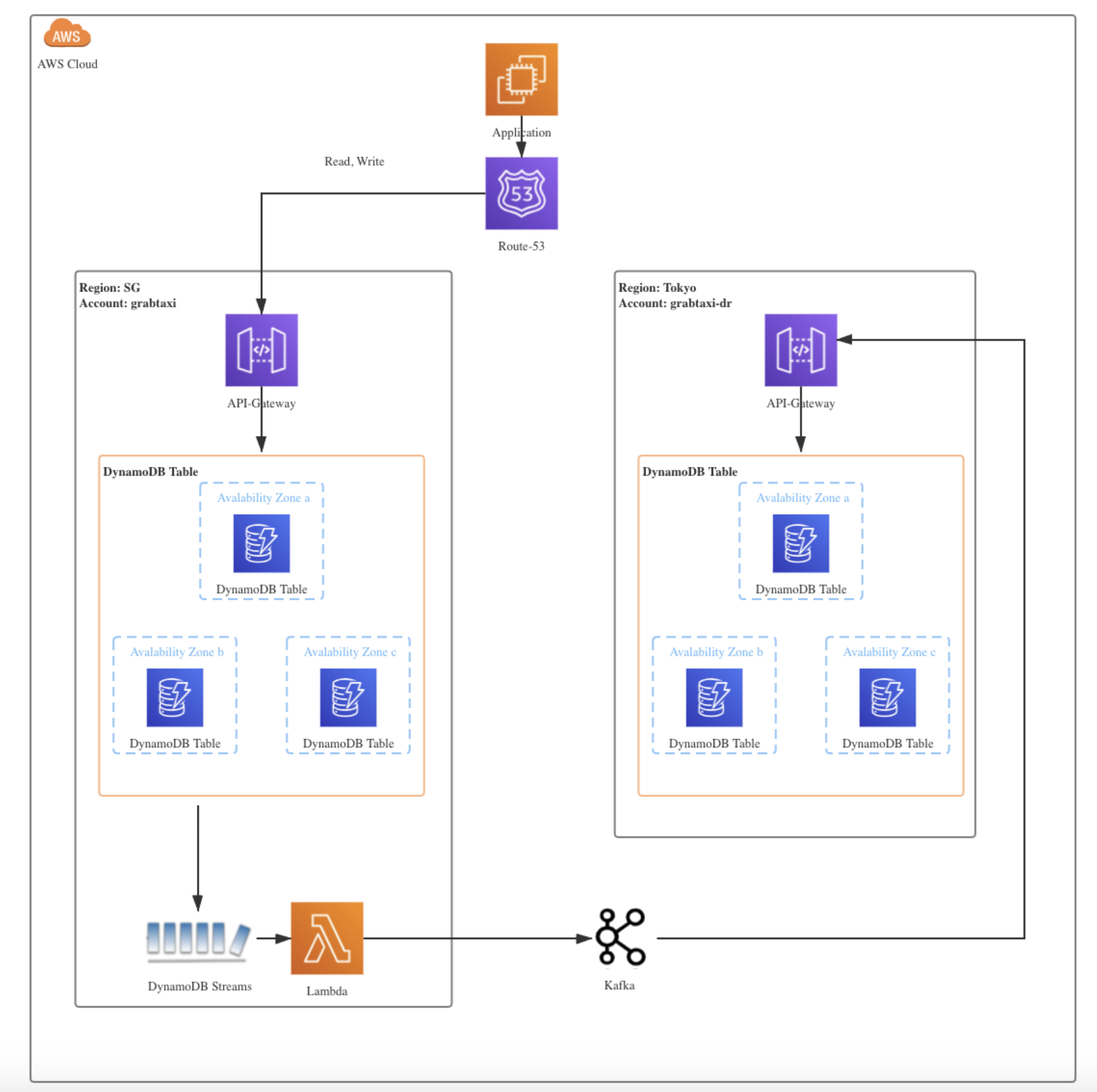
Another use case we did not originally have in mind is incremental data replication for disaster recovery. Within Grab, we enable DynamoDB streams for tier 0 and critical DynamoDB tables. Any insert, delete, modify operations would be propagated to the disaster recovery table in another availability zone.
When migrating or replicating databases, we use the strangler fig pattern, which offers an incremental, reliable process for migrating databases. This is a method whereby a new system slowly grows on top of an old system and is gradually adopted until the old system is “strangled” and can simply be removed. Figure 7 depicts how DynamoDB streams drive real-time synchronisation between tables in different regions.
Figure 7. Data replication among DynamoDB tables across different regions in DBOps team
4. Deliver audit trails
Reasons for maintaining data audit trails are manifold in Grab: regulatory requirements might mandate businesses to keep complete historical information of a consumer or to apply machine learning techniques to detect fraudulent transactions made by consumers. Figure 8 demonstrates how we deliver audit trails in Grab.
Figure 8. Deliver audit trails in Grab
Summary
Real time ingestion is playing a pivotal role in Grab’s ecosystem. It:
boosts data pipelines with less read pressure imposed on databases shared among various services;
empowers real-time business decisions with assured resource efficiency;
provides data replication among tables residing in various regions; and
delivers audit trails that either keep complete history or help unearth fraudulent operations.
Since this project launched, we have made crucial enhancements to facilitate daily operations with several in-house products that are used for data onboarding, quality checking, maintaining freshness, etc.
We will continuously improve our platform to provide users with a seamless experience in data ingestion, starting with unifying our internal tools. Apart from providing a unified platform, we will also contribute more ideas to the ingestion, extending it to Azure and GCP, supporting multi-catalogue and offering multi-tenancy.
In our next blog, we will drill down to other interesting features of real-time ingestion, such as how ordering is achieved in different cases and custom partitioning in real-time ingestion. Stay tuned!
Join us
Grab is a leading superapp in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across over 400 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
Last week was somewhat messy, mostly because of embargoed patches
we had pending with another variation of spectre attacks. And
while the patches were mostly fine, we had the usual “because it
was hidden, all our normal testing automation didn’t see it
either”.
And once the automation sees things, it tests all the insane
combinations that people don’t tend to actually use or test in any
normal case, and so there was a (small) flurry of fixes for the
fixes.
None of this was really surprising, but I naïvely thought I’d be
able to do the final release this weekend anyway.
And honestly, I considered it. I don’t think we really have any
pending issues that would hold up a release, but on the other hand
we also really don’t have any reason _not_ to give it another week
with all the proper automated testing. So that’s what I’m doing,
and as a result we have an -rc8 release today instead of doing a
final 5.17.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.
 We launched Amazon Simple Storage Service (Amazon S3) sixteen years ago today!
We launched Amazon Simple Storage Service (Amazon S3) sixteen years ago today! After spending 15 years collecting video, image, and audio assets representing over 70 years of motor sports history, NASCAR built a media library that encompassed over 8,600 LTO 6 tapes and a few thousand LTO 4 tapes, with a growth rate of between 1.5 PB and 2 PB per year. Over the course of 18 months they migrated all of this content (a total of 15 PB) to AWS, making use of the Amazon S3 Standard, Amazon S3 Glacier Flexible Retrieval, and Amazon S3 Glacier Deep Archive storage classes. To learn more about how they migrated this massive and invaluable archive, read Modernizing NASCAR’s multi-PB media archive at speed with AWS Storage.
After spending 15 years collecting video, image, and audio assets representing over 70 years of motor sports history, NASCAR built a media library that encompassed over 8,600 LTO 6 tapes and a few thousand LTO 4 tapes, with a growth rate of between 1.5 PB and 2 PB per year. Over the course of 18 months they migrated all of this content (a total of 15 PB) to AWS, making use of the Amazon S3 Standard, Amazon S3 Glacier Flexible Retrieval, and Amazon S3 Glacier Deep Archive storage classes. To learn more about how they migrated this massive and invaluable archive, read Modernizing NASCAR’s multi-PB media archive at speed with AWS Storage. This game maker’s core telemetry systems handle tens of petabytes of data, tens of thousands of tables, and over 2 billion objects. As their games became more popular and the volume of data grew, they were facing challenges around data growth, cost management, retention, and data usage. In a series of updates, they moved archival data to Amazon S3 Glacier Deep Archive, implemented tag-driven retention management, and implemented Amazon S3 Intelligent-Tiering. They have reduced their costs and made their data assets more accessible; read
This game maker’s core telemetry systems handle tens of petabytes of data, tens of thousands of tables, and over 2 billion objects. As their games became more popular and the volume of data grew, they were facing challenges around data growth, cost management, retention, and data usage. In a series of updates, they moved archival data to Amazon S3 Glacier Deep Archive, implemented tag-driven retention management, and implemented Amazon S3 Intelligent-Tiering. They have reduced their costs and made their data assets more accessible; read This team came together to build a best-in-class gene-editing prediction platform. CRISPR (
This team came together to build a best-in-class gene-editing prediction platform. CRISPR (