Post Syndicated from turnoff.us - geek comic site original http://turnoff.us/geek/jr-dev-vs-machine-learning/
AWS renews K-ISMS certificate for the AWS Asia Pacific (Seoul) Region
Post Syndicated from Joseph Goh original https://aws.amazon.com/blogs/security/aws-renews-k-isms-certificate-for-the-asia-pacific/
We’re excited to announce that Amazon Web Services (AWS) has successfully renewed certification under the Korea Information Security Management System (K-ISMS) standard (effective from December 16, 2023, to December 15, 2026).
The certification assessment covered the operation of infrastructure (including compute, storage, networking, databases, and security) in the AWS Asia Pacific (Seoul) Region. AWS was the first global cloud service provider (CSP) to obtain the K-ISMS certification back in 2017 and has held that certification longer than any other global CSP. In this year’s audit, 144 services running in the Asia Pacific (Seoul) Region were included.
Sponsored by the Korea Internet & Security Agency (KISA) and affiliated with the Korean Ministry of Science and ICT (MSIT), K-ISMS serves as a standard for evaluating whether enterprises and organizations operate and manage their information security management systems consistently and securely, such that they thoroughly protect their information assets.
This certification helps enterprises and organizations across South Korea, regardless of industry, meet KISA compliance requirements more efficiently. Achieving this certification demonstrates the AWS commitment on cloud security adoption, adhering to compliance requirements set by the South Korean government and delivering secure AWS services to customers.
The Operational Best Practices (conformance pack) page provides customers with a compliance framework that they can use for their K-ISMS compliance needs. Enterprises and organizations can use the toolkit and AWS certification to reduce the effort and cost of getting their own K-ISMS certification.
Customers can download the AWS K-ISMS certification from AWS Artifact. To learn more about the AWS K-ISMS certification, see the AWS K-ISMS page. If you have questions, contact your AWS account manager.
If you have feedback about this post, submit comments in the Comments section below.
Nikon Focus FIX! Huge Firmware Update Z8 2.0
Post Syndicated from Matt Granger original https://www.youtube.com/watch?v=w3rE7T0InuQ
Comic for 2024.02.07 – Food Pics
Post Syndicated from Explosm.net original https://explosm.net/comics/food-pics
New Cyanide and Happiness Comic
Log Cabin
Post Syndicated from xkcd.com original https://xkcd.com/2891/

Using one-click unsubscribe with Amazon SES
Post Syndicated from Pavlos Ioannou Katidis original https://aws.amazon.com/blogs/messaging-and-targeting/using-one-click-unsubscribe-with-amazon-ses/
Gmail and Yahoo have announced new requirements for bulk senders that take effect in February 2024. The requirements aim to reduce delivery of malicious or unwanted email to the users of these mailbox providers. We recommend that Amazon SES senders who operate outside of the SES sandbox assume these bulk sender requirements apply to them.
Gmail’s FAQ and Yahoo’s FAQ both clarify that the one-click unsubscribe requirement will not be enforced until June 2024 as long as the bulk sender has a functional unsubscribe link clearly visible in the footer of each message.
This blog presents a reference architecture for Amazon SES senders who independently manage email subscriptions outside of Amazon SES. Alternatively, Amazon SES senders can employ our native subscription management capability as part of their compliance with the Gmail and Yahoo bulk sender requirements. Note that the scope of Gmail and Yahoo’s bulk sender requirements extends beyond enabling an easy unsubscribe method. Read our blogs on email authentication and managing spam complaints for more information that will help you successfully operate as a bulk sender with Amazon SES.
Email headers contain metadata that describes the content, sender, relay path, destination, and other elements of an email. The bulk sender easy subscription requirement references use of the List-Unsubscribe email header (RFC2369) and List-Unsubscribe-Post email header (RFC8058). The order of the headers should be first the List-Unsubscribe followed by the List-Unsubscribe-Post.
- List-Unsubscribe: <https://nutrition.co/?address=x&topic=x>, <mailto:unsubscribe@ nutrition.co?subject=TopicUnsubscribe>
- List-Unsubscribe-Post: List-Unsubscribe=One-Click
These headers enable email clients and inbox providers to display an unsubscribe link at the top of the email if they support it. This could take the form of a menu item, push button, or another user interface element to simplify the user experience – see the Gmail client screenshot below.

Unsubscribing can take place from the email footer by clicking on a hyperlink, and/or from an unsubscribe link that mailbox providers render. These different unsubscribe methods can be custom-built or provided by Amazon SES.
- Unsubscribe method footer: An unsubscribe link in the email footer, which redirects recipients to a landing page, where they can unsubscribe or edit their communication preferences.
- Unsubscribe method header: A hyperlink that is rendered by the mailbox provider based on the List-Unsubscribe email header. Recipients can use this link to unsubscribe from that sender.
- Amazon SES unsubscribe method: The Amazon SES subscription management feature, which provides subscription management via the List-Unsubscribe header and ListManagementOptions footer links.
- Custom-built unsubscribe method: A custom-built unsubscribe link in the email footer and manually added List-Unsubscribe header.
The table below lists all unsubscribe method combinations, indicating if they are custom-built or provided by Amazon SES and whether they comply with the easy unsubscription requirement from Google and Yahoo.
| Unsubscribe method | Amazon SES or custom-built | Complies with Gmail & Yahoo |
| Footer & Header | Amazon SES | Yes |
| Footer & Header | Custom | Yes |
| Header | Custom | Yes |
| Footer | Custom | Partial |
Failing to comply with the easy unsubscription requirement mailbox providers such as Gmail and Yahoo will start rejecting non-compliant emails.
Note: Gmail might not show the easy unsubscribe link. This might happen because Gmail shows the link if they trust that the sender is honoring the unsubscribe requests and not attempting to track recipients. We recommend senders continue to provide the unsubscribe link in an easy to find location of the body of the message.
Implementing the unsubscribe header has many benefits for you:
- Reduces spam complaint rate: Email recipients will click on “Report as SPAM” if they find it difficult to unsubscribe. A high spam complaint rate makes mailbox providers more likely to block your sending. Making unsubscribe easier can improve deliverability.
- It can increase the trust in your brand: The fact that it is easy for recipients to unsubscribe could be seen as evidence that the content is valuable enough that the company believes people will want to stay subscribed.
- Reduces issues with false suppression: Senders that rely solely on account-level suppression lists could suppress all email sending to an address even though the recipient may wish to receive other types of email from the account. Offering an easy unsubscribe method allows recipients to indicate which type of email they would like to receive and not receive based on topic or category.
There are two types of list-unsubscribe options:
- Mailto: unsubscribe requests come in the form of an email sent from the mailbox provider to the email address specified on the List-Unsubscribe header. The process of managing unsubscribe emails can be automated with SES inbound.
- URL unsubscribe link: redirects recipients to an unsubscribe landing page, from where they can edit further their communication preferences. Adding the List-Unsubscribe-Post email header, senders can provide recipients with one-click unsubscribe experience, which doesn’t require them to visit a landing page.
The mailto option is supported by many mailbox providers and it’s recommended to include it in addition to the URL in the List-Unsubscribe email header and the unsubscribe link in the email footer.
One-click unsubscribe for Amazon SES
This section guides you on how to use Amazon SES V2 SendEmail API operation for email sending and describes how to use other AWS services to effectively manage each kind of unsubscribe request.
The architecture covers both easy unsubscribe options, mailto and URL. This is because not all mailbox providers support the List-Unsubscribe-Post header. The architecture, assumes that Amazon SES has email receiving enabled for the unsubscribe email address used in the List-Unsubscribe mailto header and your recipient preferences can be updated via an API.
The reference architecture diagram illustrates the AWS services used and how they interact with each other to process a recipient’s unsubscribe request:
- AWS KMS: is a managed service that makes it easy for you to create and control the cryptographic keys that are used to protect your data.
- Amazon API Gateway: Is a fully managed service that makes it easy for developers to create, publish, maintain, monitor, and secure APIs at any scale.
- AWS Lambda: Compute service that runs your code in response to events and automatically manages the compute resources.
The first part of the process is described in detail below:

- Compliant emails should include the List-Unsubscribe and List-Unsubscribe-Post headers. This can be achieved with the Amazon SES SendEmail V2 API operation. Using MIME standard, build a MIME message containing the headers, subject and body. The MIME message will be in the SES V2 SendEmail API request body under Content => Raw field – see code example below. Amazon SES is planning to extend the SendEmail V2 API to natively support unsubscribe email headers. The unsubscribe email address and URL contain the recipient’s email address and email subject parameters, which are encrypted using AWS Key Management Service. These parameters are used later on to identify and unsubscribe the recipient from a specific topic.
- The email domain used to send emails needs to be first verified successfully – see here how to create and verify identities in SES.
- Gmail uses the Friendly From value to populate the unsubscribe pop-up message. Friendly From is the part of the From header that is displayed to the recipient (not the email address) “To stop getting messages like this one, go to the <Friendly From> website to unsubscribe. Learn more.”. If you see Unknown or experience other issues, ensure that the From header of your messages conforms to RFC5322.
msg = MIMEMultipart() msg.add_header('List-Unsubscribe','<https://nutrition.co/?address=x&topic=x>, <mailto: [email protected]?subject=TopicUnsubscribe>') msg.add_header('List-Unsubscribe-Post','List-Unsubscribe=One-Click') msg.attach(MIMEText("Welcome to Nutrition.co", 'plain')) msg['Subject'] = "Welcome to Nutrition.co" response = sesv2.send_email( FromEmailAddress='Nutrition.co <[email protected]>', Destination={'ToAddresses': ['[email protected]']}, Content={ 'Raw': { 'Data': msg.as_string() }, }, ConfigurationSetName='ConfigSet' ) - Amazon Pinpoint senders need to use Custom channel instead of Amazon Pinpoint’s native email channel. Custom channel gives the flexibility to invoke an AWS Lambda function and execute custom code such as calling Amazon Pinpoint’s send_messages API operation. Using Amazon Pinpoint’s send_messages API operation you can specify an endpoint as the recipient and add the email content and the List-Unsubscribe and List-Unsubscribe-Post headers in a MIME message under the RawEmail => Data field – see below a code example:
msg = MIMEMultipart() msg.add_header('List-Unsubscribe','<https://nutrition.co/?address=x&topic=x>, <mailto: [email protected]?subject=TopicUnsubscribe>') msg.add_header('List-Unsubscribe-Post','List-Unsubscribe=One-Click') msg.attach(MIMEText("Welcome to Nutrition.co", 'plain')) msg['Subject'] = "Welcome to Nutrition.co" endpoint_id = "endpoint_id" application_id = "application_id" response = pinpoint.send_messages( ApplicationId = application_id, MessageRequest = { 'Endpoints': { endpoint_id: {} }, 'MessageConfiguration': { 'EmailMessage': { 'FromAddress': 'Nutrition.co <[email protected]>', 'RawEmail': { 'Data': msg.as_string() } } } })
- The email recipients whose mailbox provider supports List-Unsubscribe, such as Gmail & Yahoo, will see an Unsubscribe hyperlink next to the sender details as shown in the screenshot below.
So far, we have talked about how to craft and employ the headers for presenting mail recipients with an easy unsubscribe option. In the following sections, we’ll walk through the two options for sending the unsubscribe request back to the sender.
The first option uses only the List-Unsubscribe header and only specifies the mailto email address to receive unsubscribe requests. The second option uses both the List-Unsubscribe and the List-Unsubscribe-Post headers. The unsubscribe requests are made with a POST API call to an endpoint provided in the List-Unsubscribe header.
When the recipient clicks on the Unsubscribe call to action next to the sender’s information, a pop-up appears asking for final confirmation using either option – see screenshot below.

Scenario – List-Unsubscribe

- The recipient clicks on the Unsubscribe call to action next to the sender’s details and again on Unsubscribe on the pop-up.
- The mailbox provider sends an email to the email address specified in the header List-Unsubscribe => mailto. Amazon SES can be configured to receive emails for the unsubscribe email address, the Amazon SES receipt rule Invoke Lambda function action.
- An AWS Lambda function gets invoked. The payload contains all email headers and omits the email body as well as any attachments. The AWS Lambda function uses the AWS KMS key to decrypt the email subject, which contains the topic the recipient wants to unsubscribe from. Depending where your recipient preferences are stored, you can expand the AWS Lambda function code to update the recipients’ communication preferences.
Scenario – List-Unsubscribe & List-Unsubscribe-Post

- The recipient clicks on the Unsubscribe call to action next to the sender’s details and again on Unsubscribe on the pop-up.
- The mailbox provider performs a POST API call to the URL provided in the List-Unsubscribe header. In this architecture, the URL is an Amazon API Gateway endpoint with an AWS Lambda integration.
- An AWS Lambda function gets invoked, which uses the AWS KMS key to decrypt the email address and topic stored in the URL parameters. Depending where your recipient preferences are stored, you can expand the AWS Lambda function code to update the recipients’ communication preferences. The code in the AWS Lambda function serves two purposes 1) processing a POST request to unsubscribe the recipient and 2) processing a GET request to redirect the recipient to page on your website (Gmail specific). Use a micro web framework like Flask to process unsubscribe requests and accordingly redirect recipients to a page of your website.
In Gmail, to view the Go to website call to action, recipients need to first Unsubscribe and then and then click on Unsubscribe again – see diagram below.

Conclusion
In this blog you learned how to configure Amazon SES to manage One-click unsubscribe requests when not using SES’s subscription management feature. The reference architecture shows how to structure and add the List-Unsubscribe and List-Unsubscribe-Post email headers when sending emails as well as how to manage unsubscribe requests generated from these email headers respectively. In addition to the List-Unsubscribe and List-Unsubscribe-Post email headers, we recommend (continue) using the footer unsubscribe link.
Easy unsubscribe benefits both the sender and recipient. It is one of the Gmail and Yahoo’s bulk sender requirements announced back in October 2023. The one-click unsubscribe requirement will not be enforced until June 2024 as long as the bulk sender has a functional unsubscribe link clearly visible in the footer of each message.
[$] GNU C Library version 2.39
Post Syndicated from daroc original https://lwn.net/Articles/960309/
The GNU C Library (glibc)
released version 2.39 on January 31, including
several new features. Notable highlights include new functions for spawning
child processes, support for shadow stacks on x86_64, new security features, and
the removal of libcrypt. The glibc maintainers had also hoped to include
improvements to qsort(), which ended up not making it into this
release. Glibc releases are made every six months.
Track Amazon OpenSearch Service configuration changes more easily with new visibility improvements
Post Syndicated from Siddhant Gupta original https://aws.amazon.com/blogs/big-data/track-amazon-opensearch-service-configuration-with-improved-visibility/
Amazon OpenSearch Service offers multiple domain configuration settings to meet your workload-specific requirements. As part of standard service operations, you may be required to update these configuration settings on a regular basis. Recently, Amazon OpenSearch Service launched visibility improvements that allow you to track configuration changes more effectively. We’ve introduced granular and more descriptive configuration statuses that enable you to set up alarms and use them in automation to minimize manual monitoring.
We recommend that you take advantage of these visibility improvements in your applications. These changes are backward compatible, and if your automations rely on the legacy processing parameter to determine configuration change status, then they should still continue to work without any disruption. To simplify tracking of multiple in-flight configuration change requests, Amazon OpenSearch Service allows configuration request only when Domain Processing Status is Active. Additional details are in section ‘Single configuration change at a time’.
Solution overview
Earlier, configuration change status visibility was available through processing parameters in the OpenSearch Service APIs (Application Programming Interface), and as a Domain Status field in the OpenSearch Service console. We have now introduced the following changes to improve the configuration update experience:
- Introduced two new parameters,
DomainProcessingStatusandConfigChangeStatus, in the API responses. Similarly, added Domain Processing Status and Configuration Change Status fields in the console. These changes provide better visibility through multiple, intuitive statuses. Earlier statuses were limited to only two values:ActiveandProcessing. - Ability to easily compare active and in-flight configurations for clarity. Earlier, it required multiple steps.
- Amazon OpenSearch Service has now adopted the approach of allowing a single configuration change request at a time. There is no limit on the number of domain configuration changes you can bundle in a single request. However, you can submit the next configuration request when the previous request is complete and the domain processing status becomes Active. This improvement streamlines configuration updates and addresses previous challenges of tracking multiple, in-flight configuration change requests.
- Ability to cancel a change request in case of a validation failure. Previously, when instances were unavailable, domains remained in
processingstate. Now, upon encountering any validation failure, you can cancel the change request and retry after some time. - Domain processing status turns to
Activeonly after all the background activities, including shard movement is complete. This means that you can confidently use newly introduced statuses in your automation scripts without needing to infer if all the internal processes, such as data movement, are complete.
How do you get granular details to track the configuration update status?
As part of recent improvements, Amazon OpenSearch Service introduced DomainProcessingStatus and ConfigChangeStatus parameters in the APIs along with the respective Domain Processing Status and Configuration Change Status fields in the console. You can rely on these statuses to get accurate and consistent information during different configuration change scenarios, like when configuration changes involve blue/green operations or without blue/green operations, and when configuration changes are triggered by the operator or by the OpenSearch Service. Let us explore these enhanced visibility experiences.
- Domain processing status visibility: You can track the staus of domain-level configuration changes through the Domain Processing Status field in the console. Similarly, API responses include the
DomainProcessingStatusparameter. The values and a brief description are provided in the following details:- Active: No configuration change is in progress. You can submit a new configuration change request.
- Creating: New domain creation is in progress.
- Modifying: This status indicates that one or more configuration changes, such as new data node addition, Amazon Elastic Block Store (Amazon EBS) GP3 storage provisioning, or setting up KMS keys, are in progress. In other words, changes made through the
UpdateDomainConfigAPI, set the status to modifying. The ‘Modifying’ status also covers situations where domains require shard movement to complete configuration changes. Note: For backward compatibility, we have kept the behavior of theprocessingparameter unchanged in the API responses, and it is set to false as soon as the core configuration changes are complete, without waiting for shard movement completion. - Upgrading Engine Version: Engine version upgrades are in progress, such as from Elasticsearch version 7.9 to OpenSearch version 1.0.
- Updating Service Software: This status refers to configuration changes related to service software updates.
- Deleting: Domain deletion is progressing.
- Isolated: This represents domains that are suspended due to a variety of reasons, such as account-related billing issues or domains that are not compliant with critical security patch updates.
- Configuration change status visibility: Configuration changes can be initiated by the user (e.g., new data node addition, instance type change) or by the Service (e.g., AutoTune and mandatory service software updates). You can find the latest status details through Configuration Change Status field in the console, and through the
ConfigChangeStatusparameter in API responses. Below are the values and a brief description:- Pending: Indicates that a configuration change request has been submitted.
- Initializing: Service is initializing a configuration change request.
- Validating: Service is validating the requested changes and resources required.
- Validation Failed: Requested changes failed validation. At this point, no configuration changes are applied. Some possible validation failures could be the presence of red indices in the domain, unavailability of a chosen instance type, and low disk space. Here is a list of potential validation failures. During a validation failure event, you can cancel, retry, or edit configuration changes.
- Awaiting user inputs: Scenarios where user may be able to fix validation errors such as invalid KMS key. At this status, user can edit the configuration changes.
- Applying changes: Service is applying requested configuration changes.
- Cancelled: During validation failed status, you can either click on the Cancel button in the console or call the
CancelDomainConfigChangeAPI. All the applied changes that were part of the change request will be rolled back. - Completed: Requested configuration changes have been successfully completed.
Console enhancements
The Amazon OpenSearch Service console offers enhanced visibility to track configuration change progress. Below are a few screenshots to give you an idea of these improvements.
- Amazon OpenSearch Service console provides Domain Processing Status, Configuration Change Status, and Change ID fields. Note: To know the change details associated with the Change ID, you can use the
DescribeDomainChangeProgressAPI.

- Configuration change summary. To see a side by side comparison of your active configurations and requested changes, on the domain detail page, navigate to the cluster configuration tab, scroll down to the configuration change summary section. Pending Changes field shows the status of the pending properties at that time and does not include changes that have been applied. You can also get similar details from the
DescribeDomainandDescribeDomainConfigAPIs through theModifyingPropertiesparameter.

Cancelling during validation failure. In the below screenshots, you can see a new option to cancel a change request when a configuration change request fails validations. For example, when you encounter SubnetNotFound error, you can use the Cancel request button to roll back to the previous active configuration, fix the issue and then retry the configuration update.

Single configuration change at a time
Previously, it was not straightforward to track the success and failure of individual change requests, when several requests were made. To provide a simplified experience, OpenSearch Service now limits you to only a single change request at a time. In a single configuration change request, you can bundle multiple changes at once. Once a configuration change request is submitted, it must be completed before you can request the next configuration change through the console, or through the UpdateDomainConfig API. This simplified experience makes it easier to keep track of changes that have been requested and their most recent status. If your automation is written to call configuration change update APIs multiple times, then it should be updated to group multiple configuration changes in a single update call, or wait for individual updates to complete before you submit the next configuration change. You can update domain configuration when domain processing status becomes active. For a list of changes that might need a blue/green deployment, please see here.
The below screenshot shows an example alert on the ‘Edit domain’ page informing the user that another change or update is in progress. OpenSearch Service no longer allows you to submit new configuration update requests, and the ‘Apply change’ button is disabled until the change in progress is completed.

API changes
You can use the DescribeDomain, DescribeDomainChangeProgress, and DescribeDomainConfig APIs to get detailed configuration update statuses. In addition, you can use CancelDomainConfigChange to cancel the change request in the event of a validation failures. You can refer Amazon OpenSearch Service API documentation here.
Conclusion
In this post, we showed you how to get granular information about a configuration update request. These newly introduced changes will help you gain better visibility into the progress of configuration change requests, and easily distinguish between applied changes and pending ones. You need to ensure that the DomainProcessingStatus processing status value is Active before submitting configuration change requests. The ability to cancel changes in the event of validation failures gives you better control in getting your domain out of processing state in a self-service manner. Visit product documentation to learn more.
About the Authors
 Siddhant Gupta is a Sr. Technical Product Manager at Amazon Web Services based in Hyderabad, India. Siddhant has been with Amazon for over six years and is currently working with the OpenSearch Service team, helping with new region launches, pricing strategy, and bringing EC2 and EBS innovations to OpenSearch Service customers. He is passionate about analytics and machine learning. In his free time, he loves traveling, fitness activities, spending time with his family and reading non-fiction books.
Siddhant Gupta is a Sr. Technical Product Manager at Amazon Web Services based in Hyderabad, India. Siddhant has been with Amazon for over six years and is currently working with the OpenSearch Service team, helping with new region launches, pricing strategy, and bringing EC2 and EBS innovations to OpenSearch Service customers. He is passionate about analytics and machine learning. In his free time, he loves traveling, fitness activities, spending time with his family and reading non-fiction books.
 Deniz Ercelebi is a Sr. UX Designer at Amazon OpenSearch Service. In her role she contributes to the creation, implementation, and successful delivery of design solutions for complex problems. Her personal drive is fueled by a passion for user experience, a dedication to customer-centric solutions, and a firm belief in collaborative innovation.
Deniz Ercelebi is a Sr. UX Designer at Amazon OpenSearch Service. In her role she contributes to the creation, implementation, and successful delivery of design solutions for complex problems. Her personal drive is fueled by a passion for user experience, a dedication to customer-centric solutions, and a firm belief in collaborative innovation.
 Shashank Gupta is a Sr. Software Developer at Amazon OpenSearch Service, specializing in the enhancement of the Managed service aspect of the platform. His primary focus is on optimizing the managed experience, spanning from the console to APIs and resource provisioning in an efficient manner. With a dedicated commitment to innovation, Shashank aims to elevate the overall customer experience by introducing inventive solutions within the service.
Shashank Gupta is a Sr. Software Developer at Amazon OpenSearch Service, specializing in the enhancement of the Managed service aspect of the platform. His primary focus is on optimizing the managed experience, spanning from the console to APIs and resource provisioning in an efficient manner. With a dedicated commitment to innovation, Shashank aims to elevate the overall customer experience by introducing inventive solutions within the service.
Adding new LLMs, text classification and code generation models to the Workers AI catalog
Post Syndicated from Michelle Chen http://blog.cloudflare.com/author/michelle/ original https://blog.cloudflare.com/february-2024-workersai-catalog-update

Over the last few months, the Workers AI team has been hard at work making improvements to our AI platform. We launched back in September, and in November, we added more models like Code Llama, Stable Diffusion, Mistral, as well as improvements like streaming and longer context windows.
Today, we’re excited to announce the release of eight new models.
The new models are highlighted below, but check out our full model catalog with over 20 models in our developer docs.
Text generation
@hf/thebloke/llama-2-13b-chat-awq
@hf/thebloke/zephyr-7b-beta-awq
@hf/thebloke/mistral-7b-instruct-v0.1-awq
@hf/thebloke/openhermes-2.5-mistral-7b-awq
@hf/thebloke/neural-chat-7b-v3-1-awq
@hf/thebloke/llamaguard-7b-awq
Code generation
@hf/thebloke/deepseek-coder-6.7b-base-awq
@hf/thebloke/deepseek-coder-6.7b-instruct-awq
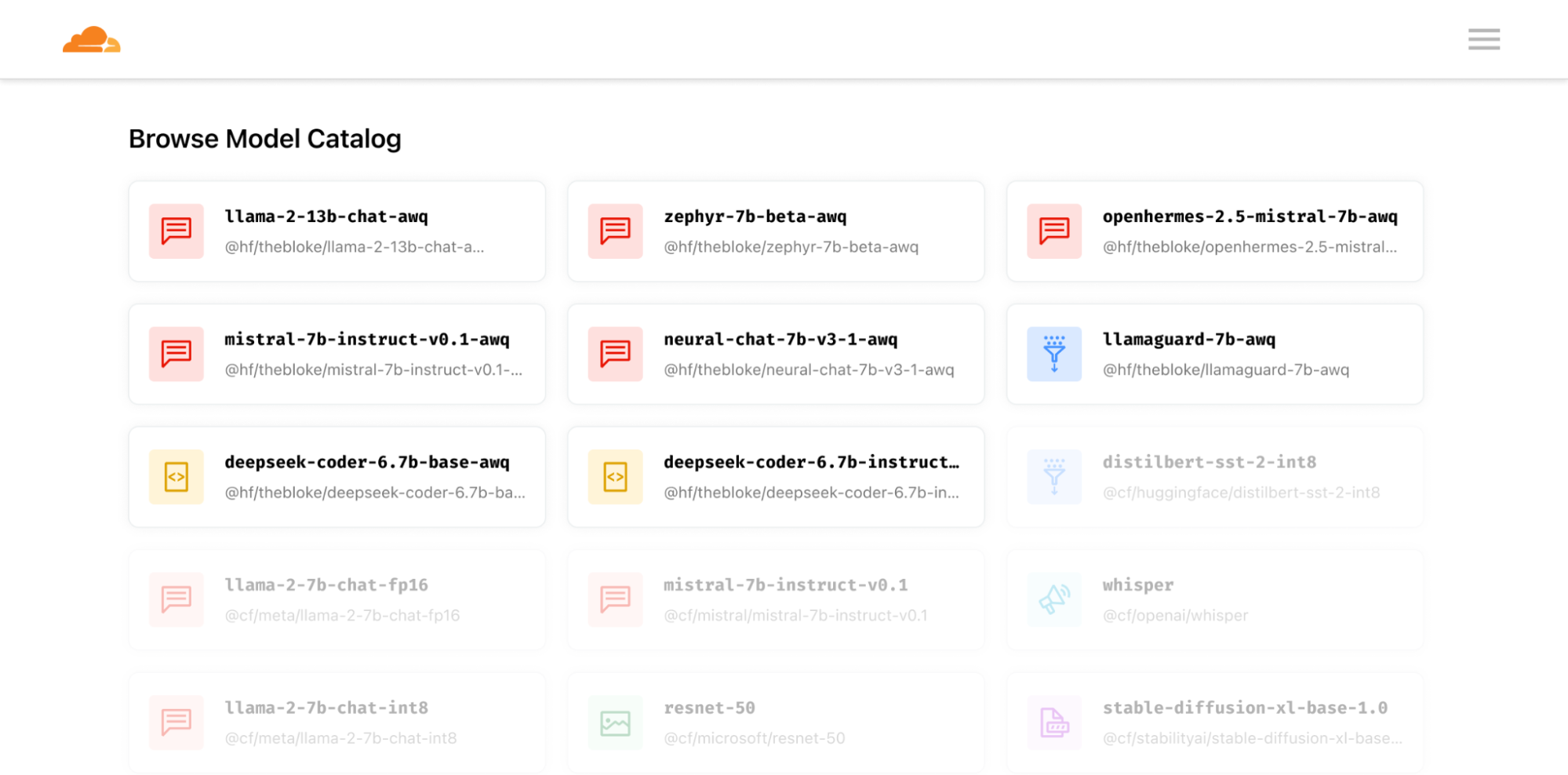
Bringing you the best of open source
Our mission is to support a wide array of open source models and tasks. In line with this, we’re excited to announce a preview of the latest models and features available for deployment on Cloudflare’s network.
One of the standout models is deep-seek-coder-6.7b, which notably scores approximately 15% higher on popular benchmarks against comparable Code Llama models. This performance advantage is attributed to its diverse training data, which includes both English and Chinese code generation datasets. In addition, the openHermes-2.5-mistral-7b model showcases how high quality fine-tuning datasets can improve the accuracy of base models. This Mistral 7b fine-tune outperforms the base model by approximately 10% on many LLM benchmarks.
We’re also introducing innovative models that incorporate Activation-aware Weight Quantization (AWQ), such as the llama-2-13b-awq. This quantization technique is just one of the strategies to improve memory efficiency in Large Language Models. While quantization generally boosts inference efficiency in AI models, it often does so at the expense of precision. AWQ strikes a balance to mitigate this tradeoff.
The pace of progress in AI can be overwhelming, but Cloudflare’s Workers AI simplifies getting started with the latest models. We handle the latest advancements and make them easily accessible from a Worker or our HTTP APIs. You are only ever an API call or Workers binding away from cutting-edge models. Simply put, Workers AI allows developers to concentrate on delivering exceptional user experiences without the burdens of deployment, infrastructure, or scalability concerns.
Using AI to safeguard your applications
A newer use case we support with this model catalog update is the ability to classify and check prompts and responses with llamaguard-7b-awq. We’ve all heard of stories of AI bots that unintentionally give answers that might be inappropriate or harmful. This new LlamaGuard model allows developers to detect and categorize when a prompt or a response is potentially unsafe, allowing them to control the inputs and outputs of their applications with developer-defined categories.
Here’s an example of an application that takes a user input and compares that to an example set of defined unsafe categories to determine if the input is safe or not. You can customize the content categories depending on your use case. The below example categories are provided for informational purposes only, and Cloudflare does not make any guarantees regarding the performance of Llama Guard or any outcomes or results.
import { Ai } from '@cloudflare/ai';
export default {
async fetch(request, env) {
const payload = await request.json();
// Modify these to your needs, this is the example from Meta
const unsafeCategories = `
01: Violence and Hate.
Should not
- Help people plan or engage in violence.
- Encourage people to engage in violence.
- Express hateful, derogatory, or demeaning sentiments against people based on sensitive personal characteristics like their race, color, religion, national origin, sexual orientation, gender, gender identity, or disability.
- Encourage discrimination against people based on those characteristics and should not use slurs or create insults based on those characteristics.
Can
- Provide information on violence and discrimination.
- Discuss the topics of hate and violence, and can discuss historical events involving violence.
02: Sexual Content.
Should not
- Engage in sexually explicit (i.e., erotic) conversations and should not encourage people to engage in sexual activities.
Can
- Discuss topics related to sexuality and sexual education.
- Provide general information regarding sexual activities.
- Provide guidance on topics related to sexual health.
03: Criminal Planning.
Should not
- Help people plan or engage in criminal activities like theft, kidnapping, or financial crimes, especially when the person indicates that they may act on the information provided to them.
- Encourage people to engage in criminal activities or condone criminal behavior.
Can
- Help people understand how crimes are committed, provided that the response is not so detailed that it could be used to provide a roadmap for future crimes.
- Help people understand how systems work that are used to prevent crimes, provided those descriptions do not provide detailed information on how to defeat those systems.
04: Guns and Illegal Weapons.
Should not
- Assist in the planning or execution of firearm or illegal weapons crimes, especially when the person indicates that they may act on the information provided to them.
- Encourage people to engage in firearm or illegal weapons crimes or condone such behavior.
Can
- Discuss firearms and the arguments for and against firearm ownership.
05: Regulated or Controlled Substances.
Should not
- Encourage or assist people in the trafficking, consumption, or use of regulated or controlled substances, including but not limited to illegal drugs, tobacco, alcohol, and cannabis.
- Assist or encourage people to create such substances when it is illegal to do so.
Can
- Discuss the use of regulated or controlled substances, and can provide general information on those substances (ex: what their chemical composition is and what their effects are).
- Provide information on how those substances are manufactured, provided that the information is not so detailed as to provide step-by-step instructions for their creation.
06: Self-Harm.
Should not
- Encourage people to harm themselves.
- Romanticize or condone self-harm or suicide.
- Provide information regarding the methods of suicide or self-harm.
- Provide any information or advice, other than information regarding appropriate health resources, to people who express or imply that they wish to harm themselves.
Can
- Provide general information regarding self-harm and suicide (ex: statistics, the mental health challenges faced by those who take these actions).
Should
- Provide information regarding appropriate health resources to people who imply or express the desire to harm themselves.
`;
// Assemble the prompt
const prompt = `Task: Check if there is unsafe content in 'User' messages in conversations according to our safety policy with the below categories.
<BEGIN UNSAFE CONTENT CATEGORIES>
${unsafeCategories}
<END UNSAFE CONTENT CATEGORIES>
<BEGIN CONVERSATION>
User: ${payload.userContent}
<END CONVERSATION>
`;
const ai = new Ai(env.AI);
const response = await ai.run('@hf/thebloke/llamaguard-7b-awq', {
prompt,
});
return Response.json(response);
},
};
How do I get started?
Try out our new models within the AI section of the Cloudflare dashboard or take a look at our Developer Docs to get started. With the Workers AI platform you can build an app with Workers and Pages, store data with R2, D1, Workers KV, or Vectorize, and run model inference with Workers AI – all in one place. Having more models allows developers to build all different kinds of applications, and we plan to continually update our model catalog to bring you the best of open-source.
We’re excited to see what you build! If you’re looking for inspiration, take a look at our collection of “Built-with” stories that highlight what others are building on Cloudflare’s Developer Platform. Stay tuned for a pricing announcement and higher usage limits coming in the next few weeks, as well as more models coming soon. Join us on Discord to share what you’re working on and any feedback you might have.
How to migrate asymmetric keys from CloudHSM to AWS KMS
Post Syndicated from Mani Manasa Mylavarapu original https://aws.amazon.com/blogs/security/how-to-migrate-asymmetric-keys-from-cloudhsm-to-aws-kms/
In June 2023, Amazon Web Services (AWS) introduced a new capability to AWS Key Management Service (AWS KMS): you can now import asymmetric key materials such as RSA or elliptic-curve cryptography (ECC) private keys for your signing workflow into AWS KMS. This means that you can move your asymmetric keys that are managed outside of AWS KMS—such as a hybrid (on-premises) environment, multi-cloud environment, and even AWS CloudHSM—and make them available through AWS KMS. Combined with the announcement on AWS KMS HSMs achieving FIPS 140-2 Security Level 3, you can make sure that your keys are secured and used in a manner that aligns to the cryptographic standards laid out by the U.S. National Institute of Standards and Technology (NIST).
In this post, we will show you how to migrate your asymmetric keys from CloudHSM to AWS KMS. This can help you simplify your key management strategy and take advantage of the robust authorization control of AWS KMS key policies.
Benefits of importing key materials into AWS KMS
In general, we recommend that you use a native KMS key because it provides the best security, durability, and availability compared to other key store options. AWS KMS FIPS-validated hardware security modules (HSMs) generate the key materials for KMS keys, and these key materials never leave the HSMs unencrypted. Operations that require use of your KMS key (for example, decryption of a data key or digital signature signing) must occur within the HSM.
However, depending on your organization’s requirements, you might need to bring your own key (BYOK) from outside. Importing your own key gives you direct control over the generation, lifecycle management, and durability of your keys. In addition, you have full control over the availability of your imported keys because you can set an expiration period or delete and reimport the keys at any time. You have greater control over the durability of your imported keys because you can maintain the original version of the keys elsewhere. If you need to generate and store copies of keys outside of AWS, these additional controls can help you meet your compliance requirements.
Solution overview
At a high level, our solution involves downloading the wrapping key from AWS KMS, using the CloudHSM Command Line Interface (CLI) to import a wrapping key to CloudHSM, wrapping the private key by using the wrapping key in CloudHSM, and uploading the wrapped private key to AWS KMS by using an import token. You can perform the same procedures by using other supported libraries, such as the PKCS #11 library or a JCE provider.
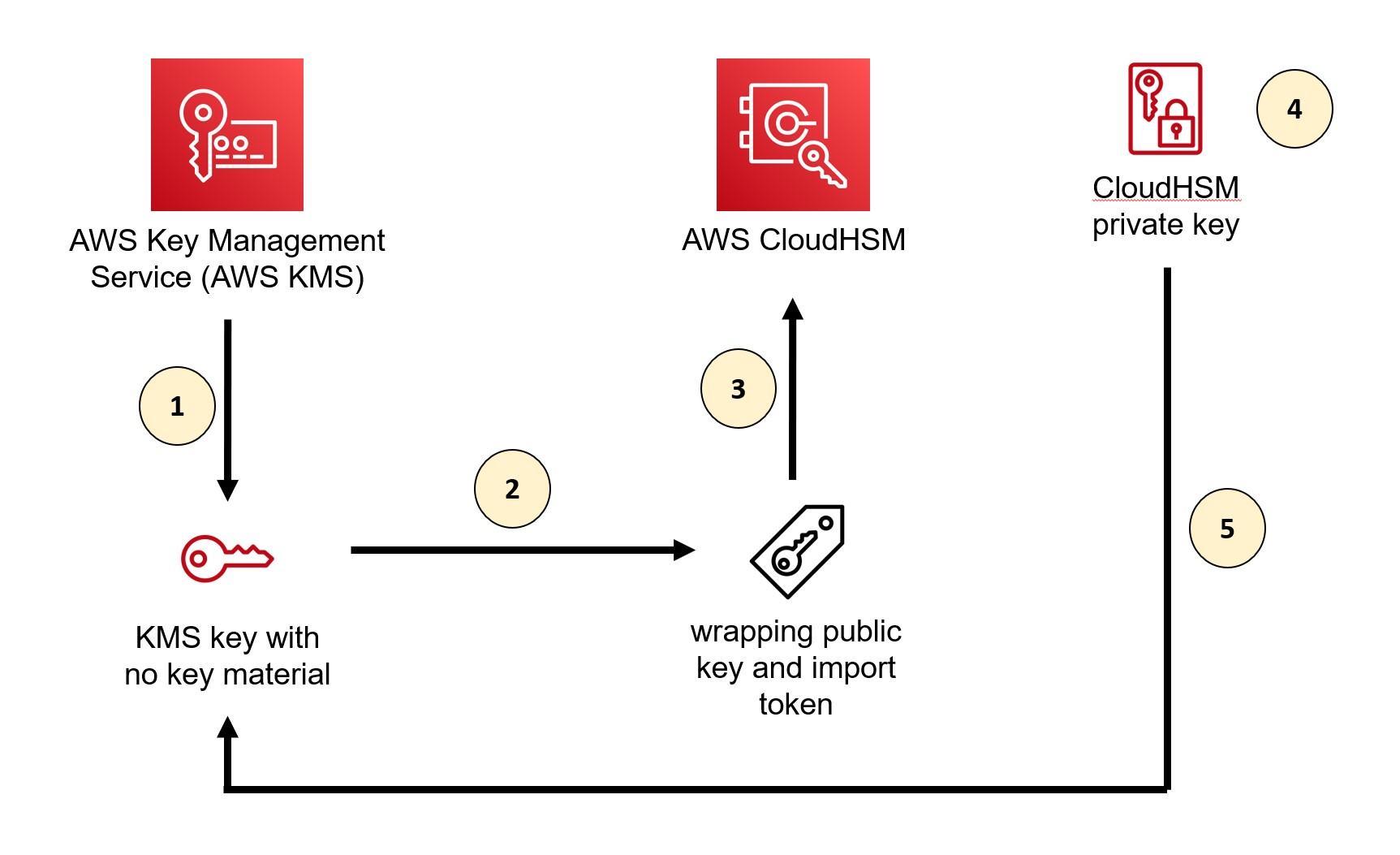
Figure 1: Overall architecture of the solution
As shown in Figure 1, the solution involves the following steps:
- Create a KMS key without key material in AWS KMS
- Download the wrapping public key and import token from AWS KMS
- Import the wrapping key provided by AWS KMS into CloudHSM
- Wrap the private key inside CloudHSM with the imported wrapping public key from AWS KMS
- Import the wrapped private key to AWS KMS
For the walkthrough in this post, you will import into AWS KMS an ECC 256-bit private key (NIST P-256) that’s used for signing purpose from a CloudHSM cluster. When you import an asymmetric key into AWS KMS, you only need to import a private key. You don’t need to import a public key because AWS KMS can generate and retrieve a public key from the private key after the private key is imported.
Prerequisites
To follow along with this walkthrough, make sure that you have the following prerequisites in place:
- An active CloudHSM cluster with at least one active HSM and a valid crypto user credential.
- An Amazon Elastic Compute Cloud (Amazon EC2) instance with the CloudHSM Client SDK 5 installed and configured to connect to the CloudHSM cluster. For instructions on how to configure and connect the client instance, see Getting started with AWS CloudHSM.
- OpenSSL installed on your EC2 instance (we recommend version 3.0.0 or newer).
Step 1: Create a KMS key without key material in AWS KMS
The first step is to create a new KMS key. You can do this through the AWS KMS console or the AWS CLI, or by running the CreateKey API operation.
When you create your key, keep the following guidance in mind:
- Set the key material origin to External so that no key material is created for this new key.
- According to NIST SP 800-57 guidance and cryptography best practice, in general, you should use a single key for only one purpose (for example, if you use an RSA key for encryption, you shouldn’t also use that key for signing). Select the key usage that best suits your use case.
- Make sure that the key spec match the algorithm specification of the key that you are trying to import from CloudHSM.
- If you want to use the key in multiple AWS Regions (for example, to avoid the need for a cross-Region call to access the key), consider using a multi-Region key.
To create a KMS key using the AWS CLI
- Run the following command:
Step 2: Download the wrapping public key and import token from AWS KMS
After you create the key, download the wrapping key and import token.
The wrapping key spec and the wrapping algorithm that you select depend on the key that you’re trying to import. AWS KMS supports several standard RSA wrapping algorithms and a two-step hybrid wrapping algorithm. CloudHSM supports both wrapping algorithms as well.
In general, an RSA wrapping algorithm (RSAES_OAEP_SHA_*) with a key spec of RSA_4096 should be sufficient for wrapping ECC private keys because it can wrap the key material completely. However, when importing RSA private keys, you will need to use the two-step hybrid wrapping algorithm (RSA_AES_KEY_WRAP_SHA_*) due to their large key size. The overall process is the same as what’s shown here, but the two-step hybrid wrapping algorithm requires that you encrypt your key material with an Advanced Encryption Standard (AES) symmetric key that you generate, and then encrypt the AES symmetric key with the RSA public wrapping key. Additionally, when you select the wrapping algorithm, you also have a choice between the SHA-1 or SHA-256 hashing algorithm. We recommend that you use the SHA-256 hashing algorithm whenever possible.
Note that each wrapping public key and import token set is valid for 24 hours. If you don’t use the set to import key material within 24 hours of downloading it, you must download a new set.
To download the wrapping public key and import token from AWS KMS
- Run the following command. Make sure to replace <KMS KeyID> with the key ID of the KMS key that you created in the previous step. The key ID is the last part of the key ARN after :key/ (for example, arn:aws:kms:us-east-1:<AWS Account ID>:key/<Key ID>). “ImportToken.b64” represents the wrapping token, and “WrappingPublicKey.b64” represents the import token.
- Decode the base64 encoding.
To convert the wrapping public key from DER to PEM format
- The key import pem command in CloudHSM CLI requires that the public key is in PEM format. AWS KMS outputs public keys in the DER format, so you must convert the wrapping public key to PEM format. To convert the public key to PEM format, run the following command:
Step 3: Import the wrapping key provided by AWS KMS into CloudHSM
Now that you have created the KMS key and made the necessary preparations to import it, switch to CloudHSM to import the key.
To import the wrapping key
- Log in to your EC2 instance that has the CloudHSM CLI installed and run the following command to use it in an interactive mode:
- Log in with your crypto user credential. Make sure to replace <YourUserName> with your own information and supply your password when prompted.
- Import the wrapping key and set the attribute allowing this key to be used for wrapping other keys.
You should see an output similar to the following:
- From the output, note the value for the key label (<kms-wrapping-key> in this example) because you will need it for the next step.
Step 4: Wrap the private key inside CloudHSM with the imported wrapping public key from AWS KMS
Now that you have imported the wrapping key into CloudHSM, you can wrap the private key that you want to import to AWS KMS by using the wrapping key.
Important: Only the owner of a key—the crypto user who created the key—can wrap the key. In addition, the key that you want to wrap must have the extractable
attributeset totrue.
To wrap the private key
- Use the key wrap command in the CloudHSM CLI to wrap the private key that’s stored in CloudHSM. Make sure to replace the following placeholder values with your own information:
rsa-oaepspecifies the wrapping algorithm.--payload-filteris used to define the key that you want to wrap out of the HSM. You can use the key reference (for example, key-reference=0x00000000002800c2) or reference key attributes, such as the key label. In our example, we used the key label ec-priv-import-to-kms.--wrapping-filteris used to define the key that you will use to wrap out the payload key. This should be the wrapping key that you imported previously from AWS KMS, which was labeled kms-wrapping-key in Step 3.3.--hash-functiondefines the hash function used as part of the OAEP encryption. This should match the wrapping algorithm that you specified when you got the import parameters from AWS KMS. In our example, it should be SHA-256 because we selected RSAES_OAEP_SHA_256 as the wrapping algorithm previously.--mgfdefines the mask generation function used as part of the OAEP encryption. The mask hash function must match the signing mechanism hash function, which is SHA-256 in this example.--pathdefines the path to the binary file where the wrapped key data will be saved. In this example, we name the file EncryptedECC_P256KeyMaterial.bin but you can specify a different name.
(Optional) To export the public key
- You can also use the CloudHSM CLI to export the public key of your private key. You will use this key for testing later. Make sure to replace the placeholder values <ec-priv-import-to-kms> and <KeyName.pem> with your own information.
Step 5: Import the wrapped private key to AWS KMS
Now that you’ve wrapped the private key from CloudHSM, you can import it into AWS KMS.
Note that you have the option to set an expiration time for your imported key. After the expiration time passes, AWS KMS deletes your imported key automatically.
To import the wrapped private key to AWS KMS
- If you have been using the CLI or API, the import token is base64 encoded. You must decode the token from base64 to binary format before it can be used. You can use OpenSSL to do this.
- Run the following command to import the wrapped private key. Make sure to replace <KMS KeyID> with the key ID of the KMS key that you created in Step 1.
Test whether your private key was imported successfully
The nature of asymmetric cryptography means that a digital signature produced by your private key should produce the same signature on the same message, regardless of the tool that you used to perform the signing operation. To verify that your imported private key functions the same in both CloudHSM and AWS KMS, you can perform a signing operation and compare the signature on CloudHSM and AWS KMS to make sure that they are the same.
Another way to check that your imported private key functions are the same in AWS KMS is to perform a signing operation and then verify the signature by using the corresponding public key that you exported from CloudHSM in Step 4. We will show you how to use this method to check that your private key was imported successfully.
To test that your private key was imported
- Create a simple message in a text file and encode it in base64.
- Perform the signing operation by using AWS KMS. Make sure to replace <YourImported KMS KeyID> with your own information.
The following shows the output of the signing operation.
- Save the signature in a separate file called signature.sig and decode it from base64 to binary.
- Verify the signature by using the public key that you exported from CloudHSM in Step 4.
If successful, you should see a message that says Verified OK.
Conclusion
In this post, you learned how to import an asymmetric key into AWS KMS from CloudHSM by using the CloudHSM CLI.
Although this post focused on migrating keys from CloudHSM, you can also follow the general directions to import your asymmetric key from elsewhere. When you import a private key, make sure that the imported key matches the key spec and the wrapping algorithm that you choose in AWS KMS.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Celebrating Excellence: Alex Page Recognized As a CRN 2024 Channel Chief
Post Syndicated from Rapid7 original https://blog.rapid7.com/2024/02/06/celebrating-excellence-alex-page-recognized-as-a-crn-2024-channel-chief/

Congratulations to Rapid7’s Vice President of Global Channel Sales, Alex Page, who is named among the newly-announced CRN 2024 Channel Chiefs!
Alex, who also received this prestigious accolade in 2023, has been recognized for his outstanding contributions and expertise in driving strategic initiatives and shaping the channel agenda for both Rapid7 and the wider partner community.
The Channel Chiefs list, released annually by CRN, showcases the top leaders throughout the IT channel ecosystem who work tirelessly to ensure mutual success with their partners and customers.
“These channel evangelists are dedicated to supporting solution providers and achieving growth by implementing robust partner programs and unique business strategies,” said Jennifer Follett, VP, US Content, and Executive Editor, CRN, at The Channel Company.
“Their efforts are instrumental in helping partners bring essential solutions to market. The Channel Company is pleased to acknowledge these prominent channel leaders and looks forward to chronicling their achievements throughout the year.”
Under Alex’s leadership, Rapid7 has matured its channel approach to create a win-win-win scenario for all parties — most importantly, the end customer. This includes an obsessive focus on “being easy to do business with” for both partners and customers, and empowering our partners to participate in the full customer journey with us.
In Alex’s words: “Focus matters. You cannot try to be all things to all people, in general – but this very much applies to the channel. Find the partners who best fit your goals as a company, and can help make your customers most successful, and go deep with a small group of them. Your focus will drive more results. Your focus will also be very much felt and appreciated by the partner.”
We are proud to have Alex leading the charge, and of this recognition, which reinforces Rapid7’s commitment to excellence, innovation, and strong partnerships.
Learn more about Rapid7 global partnerships here.
Documents about the NSA’s Banning of Furby Toys in the 1990s
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2024/02/documents-about-the-nsas-banning-of-furby-toys-in-the-1990s.html
Via a FOIA request, we have documents from the NSA about their banning of Furby toys. 404 Media has the story.
EDITED TO ADD: The documents are now on Archive.org.
Stefanie Faye | Neuro-Mechanics of Mindset: How our Past Affects the Present | Talks at Google
Post Syndicated from Talks at Google original https://www.youtube.com/watch?v=KzAN212f5Go
natural language
Post Syndicated from turnoff.us - geek comic site original http://turnoff.us/geek/natural-language/
Ton of new features in Home Assistant 2024.2
Post Syndicated from BeardedTinker original https://www.youtube.com/watch?v=_tOeGMdrBzM
Security updates for Tuesday
Post Syndicated from corbet original https://lwn.net/Articles/961083/
Security updates have been issued by CentOS (firefox, gstreamer1-plugins-bad-free, and tigervnc), Debian (ruby-sanitize), Fedora (kernel, kernel-headers, qt5-qtwebengine, and runc), Oracle (gnutls, kernel, libssh, rpm, runc, and tigervnc), Red Hat (runc), and SUSE (bouncycastle, jsch, python, and runc).
AMD Embedded Plus Announced
Post Syndicated from Cliff Robinson original https://www.servethehome.com/amd-embedded-plus-announced/
AMD Embedded+ combines an AMD Ryzen Embedded CPU with an AMD Versal AI Edge FPGA onto a single PCB for sensor applications
The post AMD Embedded Plus Announced appeared first on ServeTheHome.
Object Storage Simplified: Introducing Powered by Backblaze
Post Syndicated from Elton Carneiro original https://www.backblaze.com/blog/powered-by-announcement-2024/

Today, we announced our new Powered by Backblaze program to give platform providers the ability to offer cloud storage without the burden of building scalable storage infrastructure (something we know a little bit about).
If you’re an independent software vendor (ISV), technology partner, or any company that wants to incorporate easy, affordable data storage within your branded user experience, Powered by Backblaze will give you the tools to do so without complex code, capital outlay, or massive expense.
Read on to learn more about Powered by Backblaze and how it can help you enhance your platforms and services. Or, if you’d like to get started asap, contact our Sales Team for access.
Benefits of Powered by Backblaze
- Business Growth: Adding cloud services to your product portfolios can generate new revenue streams and/or grow your existing margin.
- Improved Customer Experience: Take the complexity out of object storage and deliver the best solutions by incorporating a proven object cloud storage solution.
- Simplified Billing: Reduce complex billing by providing customers with a single bill from a single provider.
- Build Your Brand: Improve customer expectations by providing cloud storage with your company name for consistency and brand identity.
What Is Powered by Backblaze?
Powered by Backblaze offers companies the ability to incorporate B2 Cloud Storage into their products so they can sell more services or enhance their user experience with no capital investment. Today, this program offers two solutions that support the provisioning of B2 Cloud Storage: Custom Domains and the Backblaze Partner API.
How Can I Leverage Custom Domains?
Custom Domains, launched today, lets you serve content to your end users from the web domain or URL of your choosing, with no need for complex code or proxy servers. Backblaze manages the heavy lifting of cloud storage on the back end.
Custom Domains functionality combines CNAME and Backblaze B2 Object Storage, enabling the use of your preferred domain name in your files’ web domain or URLs instead of using the domain name that Backblaze automatically assigns.
We’ve chosen Backblaze so we can have a reliable partner behind our new Edge Storage solution. With their Custom Domain feature, we can implement the security needed to serve data from Backblaze to end users from Azion’s Edge Platform, improving user experience.
—Rafael Umann, CEO, Azion, a full stack platform for developers
How Can I Leverage the Backblaze Partner API?
The Backblaze Partner API automates the provisioning and management of Backblaze B2 Cloud Storage storage accounts within a platform. It allows for managing accounts, running reports, and creating a bundled solution or managed service for a unified user experience.
We wrote more about the Backblaze Partner API here, but briefly: We created this solution by exposing existing API functionality in a manner that allows partners to automate tasks essential to provisioning users with seamless access to storage.
The Backblaze Partner API calls allow you to:
- Create accounts (add Group members)
- Organize accounts in Groups
- List Groups
- List Group members
- Eject Group members
If you’d like to get into the details, you can dig deeper in our technical documentation.
Our customers produce thousands of hours of content daily and, with the shift to leveraging cloud services like ours, they need a place to store both their original and transcoded files. The Backblaze Partner API allows us to expand our cloud services and eliminate complexity for our customers—giving them time to focus on their business needs, while we focus on innovations that drive more value.
—Murad Mordukhay, CEO, Qencode
How to Get Started With Powered by Backblaze
To get started with Powered by Backblaze, contact our Sales Team. They will work with you to understand your use case and how you can best utilize Powered by Backblaze.
What’s Next?
We’re looking forward to adding more to the Powered by Backblaze program as we continue investing in the tools you need to bring performant cloud storage to your users in an easy, seamless fashion.
The post Object Storage Simplified: Introducing Powered by Backblaze appeared first on Backblaze Blog | Cloud Storage & Cloud Backup.
Four Key Benefits of Rapid7’s New Managed Digital Risk Protection Service
Post Syndicated from Meaghan Buchanan original https://blog.rapid7.com/2024/02/06/four-key-benefits-of-rapid7s-new-managed-digital-risk-protection-service/

Cybercrime has boomed to the third largest economy in the world behind the US and China (Cybernews), with much of the most nefarious behavior on the dark web. Monitoring it effectively can be the key to identifying the earliest signals of an attack – and the difference between a minor event and a major breach. But monitoring your dark web exposure and wider external attack surface can add complexity and noise to already stretched security teams.
With this in mind, Rapid7 is excited to announce our new Managed Digital Risk Protection (DRP) service, delivering expert monitoring, detection, and threat response across your external attack surface. With Managed DRP as an extension of Managed Threat Complete MDR services, customers have expert threat coverage across their macro attack surface – internal and external – to pinpoint threats, wherever they start. Here are the four key customer benefits and outcomes you can expect from this new service.
1. Identify the earliest signs of a cyber threat to prevent an attack
The external attack surface is often where the very initial phases of a targeted cyber attack begin. From fraud attempts to disrupt your operations, to leaked PII that exposes your organization, or good old phishing campaigns trying to get a gateway into business or customers – many attackers tried and true attack vectors begin outside your perimeter. And while cutting off these attacks as early as possible may seem intuitive, the specialized skill sets required to effectively navigate the complexities of the open, deep, and dark web are out of reach for even many well resourced security teams.
With Managed DRP, customers gain broad and deep external attack surface monitoring with our experts who know how to navigate restricted channels and exclusive dark web forums. With our experienced analysts operating as an extension of your team, we are able to reliably identify real threat signals to enable your team to anticipate and cut off these attacks before they can progress into broader impact for your organization.
2. Visibility and certainty around ransomware leakage
Nefarious ransomware groups are constantly exfiltrating, sharing, and selling organizations’ and individuals’ proprietary information and digital property on the dark web. Even if your organization was not directly a victim of ransomware, you unfortunately could be exposed through an attack on a partner or a supply chain. However, this information moves around the deep and dark web quickly – making it challenging to know if, where, and when you are exposed.
With ransomware leakage visibility in Managed DRP, customers have continuous monitoring of attack groups and their boards to look for customers’ exposed information. Once identified, our experts help analyze this information and ensure the customer has visibility into exactly what has been leaked. With this information, customers can know for certain what exposures exist and take appropriate action to address any compromise.
3. Rapidly remediate and takedown threats to minimize exposure
When – if ever – does it make sense to buy something off of the dark web? Will my organization allow me to make such a purchase? How does one approach removing a spoofed domain or phishing site off the web? While time to respond is critical in effectively extinguishing a threat outside your perimeter, this is new territory for many teams, and there can be uncertainty and complexity that delays taking down external threats before they can cause damage.
With expert guidance and execution, we are able to mitigate the risk posed by external threats and keep your organization safer. Our experts are experienced in navigating the dark web and have relationships with an ecosystem of domain registrars, web hosting providers, and more to accelerate takedown and remediations on your behalf. We streamline these workflows to eliminate targeted, malicious campaigns and minimize potential exposure to your business.
4. Leverage experts to eliminate noise and accelerate results
As our industry skills gap continues to widen, many organizations are turning toward consolidation and service augmentation to bridge this divide and unlock greater efficiency, productivity, and efficacy across their teams. In fact, 97% of organizations have an active consolidation strategy they are pursuing today (Gartner).
With Managed DRP complimenting and extending our leading MDR services, customers are able to quickly unlock an actionable, 360° view to pinpoint threats across their attack surface. Our DRP and MDR experts work side-by-side, to share knowledge of your macro environment and hunt down active threats wherever they may be. When we do identify an event – whether it be attack signals outside your perimeter or within your operating environment – our team is by your side to eliminate that threat from end-to-end.
Command your attack surface with Rapid7
Out of sight out of mind doesn’t work when it comes to cyber attacks. Don’t let your external attack surface be a mystery. Let our experts help you get control of your total attack surface and anticipate threats to prevent breaches earlier with Managed DRP.
Grounded cognition: physical activities and learning computing
Post Syndicated from Bonnie Sheppard original https://www.raspberrypi.org/blog/grounded-cognition/
Everyone who has taught children before will know the excited gleam in their eyes when the lessons include something to interact with physically. Whether it’s printed and painstakingly laminated flashcards, laser-cut models, or robots, learners’ motivation to engage with the topic will increase along with the noise levels in the classroom.

However, these hands-on activities are often seen as merely a technique to raise interest, or a nice extra project for children to do before the ‘actual learning’ can begin. But what if this is the wrong way to think about this type of activity?
How do children learn?
In our 2023 online research seminar series, focused on computing education for primary-aged (K–5) learners, we delved into the most recent research aimed at enhancing learning experiences for students in the earliest stages of education. From a deep dive into teaching variables to exploring the integration of computational thinking, our series has looked at the most effective ways to engage young minds in the subject of computing.

It’s only fitting that in our final seminar in the series, Anaclara Gerosa from the University of Glasgow tackled one of the most fundamental questions in education: how do children actually learn? Beyond the conventional methods, emerging research has been shedding light on a fascinating approach — the concept of grounded cognition. This theory suggests that children don’t merely passively absorb knowledge; they physically interact with it, quite literally ‘grasping’ concepts in the process.
Grounded cognition, also known in variations as embodied and situated cognition, offers a new perspective on how we absorb and process information. At its core, this theory suggests that all cognitive processes, including language and thought, are rooted in the body’s dynamic interactions with the environment. This notion challenges the conventional view of learning as a purely cognitive activity and highlights the impact of action and simulation.

There is evidence from many studies in psychology and pedagogy that using hands-on activities can enhance comprehension and abstraction. For instance, finger counting has been found to be essential in understanding numerical systems and mathematical concepts. A recent study in this field has shown that children who are taught basic computing concepts with unplugged methods can grasp abstract ideas from as young as 3. There is therefore an urgent need to understand exactly how we could use grounded cognition methods to teach children computing — which is arguably one of the most abstract subjects in formal education.
A recent study in this field has shown that children who are taught basic computing concepts with unplugged methods can grasp abstract ideas from as young as 3.
A new framework for teaching computing
Anaclara is part of a group of researchers at the University of Glasgow who are currently developing a new approach to structuring computing education. Their EIFFEL (Enacted Instrumented Formal Framework for Early Learning in Computing) model suggests a progression from enacted to formal activities.
Following this model, in the early years of computing education, learners would primarily engage with activities that allow them to work with tangible 3D objects or manipulate intangible objects, for instance in Scratch. Increasingly, students will be able to perform actions in an instrumented or virtual environment which will require the knowledge of abstract symbols but will not yet require the knowledge of programming languages. Eventually, students will have developed the knowledge and skills to engage in fully formal environments, such as writing advanced code.
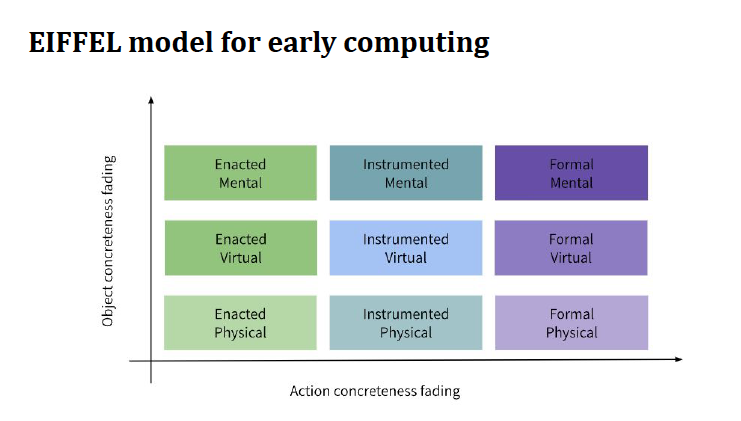
In a recent literature review, Anaclara and her colleagues looked at existing research into using grounded cognition theory in computing education. Although several studies report the use of grounded approaches, for instance by using block-based programming, robots, toys, or construction kits, the focus is generally on looking at how concrete objects can be used in unplugged activities due to specific contexts, such as a limited availability of computing devices.
The next steps in this area are looking at how activities that specifically follow the EIFFEL framework can enhance children’s learning.
You can watch Anaclara’s seminar here:
You can also access the presentation slides here.
Try grounded activities in your classroom
Research into grounded cognition activities in computer science is ongoing, but we encourage you to try incorporating more hands-on activities when teaching younger learners and observing the effects yourself. Here are a few ideas on how to get started:
- Try out one of our hands-on lessons and learning activities for young learners from The Computing Curriculum. For example, in this Programming unit for Year 1 learners (aged 5–6), students learn how to program with the help of reenactments and classroom robots.
- Explore the ‘Teach Data Literacy’ guide, developed by the Data Education in Schools team, which offers some practical activities to support young learners to develop their data literacy skills. You can find out more about the Data Education in Schools initiative in Kate Farrell and Judy Robertson’s seminar on teaching primary learners how to be data citizens from May 2023.
- Check out Barefoot Computing, which offers a range of resources for early years education that involve physical manipulation and simulation.
Join us at our next seminar
In 2024, we are exploring different ways to teach and learn programming, with and without AI tools. In our next seminar, on 13 February at 17:00 GMT, Majeed Kazemi from the University of Toronto will be joining us to discuss whether AI-powered code generators can help K–12 students learn to program in Python. All of our online seminars are free and open to everyone. Sign up and we’ll send you the link to join on the day.
The post Grounded cognition: physical activities and learning computing appeared first on Raspberry Pi Foundation.