Post Syndicated from original https://lwn.net/Articles/938617/
The
6.4.4 and
6.1.39
stable kernel updates have been released; each contains a large number of
important fixes.
Post Syndicated from original https://lwn.net/Articles/938617/
The
6.4.4 and
6.1.39
stable kernel updates have been released; each contains a large number of
important fixes.
Post Syndicated from Qiushuang Feng original https://aws.amazon.com/blogs/big-data/migrate-data-from-google-cloud-storage-to-amazon-s3-using-aws-glue/
Today, we are pleased to announce a new AWS Glue connector for Google Cloud Storage that allows you to move data bi-directionally between Google Cloud Storage and Amazon Simple Storage Service (Amazon S3).
We’ve seen that there is a demand to design applications that enable data to be portable across cloud environments and give you the ability to derive insights from one or more data sources. One of the data sources you can now quickly integrate with is Google Cloud Storage, a managed service for storing both unstructured data and structured data. With this connector, you can bring the data from Google Cloud Storage to Amazon S3.
In this post, we go over how the new connector works, introduce the connector’s functions, and provide you with key steps to set it up. We provide you with prerequisites, share how to subscribe to this connector in AWS Marketplace, and describe how to create and run AWS Glue for Apache Spark jobs with it.
AWS Glue is a serverless data integration service that makes it simple to discover, prepare, and combine data for analytics, machine learning, and application development. AWS Glue natively integrates with various data stores such as MySQL, PostgreSQL, MongoDB, and Apache Kafka, along with AWS data stores such as Amazon S3, Amazon Redshift, Amazon Relational Database Service (Amazon RDS), Amazon DynamoDB, and Amazon S3. AWS Glue Marketplace connectors allow you to discover and integrate additional data sources, such as software as a service (SaaS) applications and your custom data sources. With just a few clicks, you can search and select connectors from AWS Marketplace and begin your data preparation workflow in minutes.
This connector relies on the Spark DataSource API in AWS Glue and calls Hadoop’s FileSystem interface. The latter has implemented libraries for reading and writing various distributed or traditional storage. This connector also includes the Google Cloud Storage Connector for Hadoop, which lets you run Apache Hadoop or Apache Spark jobs directly on data in Google Cloud Storage. AWS Glue loads the library from the Amazon Elastic Container Registry (Amazon ECR) repository during initialization (as a connector), reads the connection credentials using AWS Secrets Manager, and reads data source configurations from input parameters. When AWS Glue has internet access, the Spark job in AWS Glue can read from and write to Google Cloud Storage.
The following architecture diagram shows how AWS Glue connects to Google Cloud Storage for data ingestion.

In the following sections, we show you how to create a new secret for Google Cloud Storage in Secrets Manager, subscribe to the AWS Glue connector, and move data from Google Cloud Storage to Amazon S3.
You need the following prerequisites:
We assume that you are already familiar with the key concepts of Secrets Manager, IAM, and AWS Glue. Regarding IAM, these roles should be granted the permissions needed to communicate with AWS services and nothing more, according to the principle of least privilege.
Complete the following steps to create a secret in Secrets Manager to store the Google Cloud Storage credentials:
keyS3Uri and the value as your key file in the s3 bucket, for example, s3://keys/project-gcs-connector **.json.
googlecloudstorage_credentials.To subscribe to the connector, complete the following steps:





The console will display the Create marketplace connection page in AWS Glue Studio.
To move your data to Amazon S3, you must configure the custom connection and then set up an AWS Glue job.
An AWS Glue connection stores connection information for a particular data store, including login credentials, URI strings, virtual private cloud (VPC) information, and more. Complete the following steps to create your connection:
GCSConnection).googlecloudstorage_credentials).
The connector and connection information is now visible on the Connectors page.

Complete the following steps:
GCSConnection).

GCSConnection).gs://bucket/covid-csv-data/).fileFormat. For Value, enter csv, because our sample data is this format.

After the job succeeds, we can check the logs in Amazon CloudWatch.

The data is ingested into Amazon S3, as shown in the following screenshot. 
We are now able to import data from Google Cloud Storage to Amazon S3.
In this example, we set the AWS Glue capacity as 10 DPU (Data Processing Units). A DPU is a relative measure of processing power that consists of 4 vCPUs of compute capacity and 16 GB of memory. To scale your AWS Glue job, you can increase the number of DPU, and also take advantage of Auto Scaling. With Auto Scaling enabled, AWS Glue automatically adds and removes workers from the cluster depending on the workload. This removes the need for you to experiment and decide on the number of workers to assign for your AWS Glue ETL jobs. If you choose the maximum number of workers, AWS Glue will adapt the right size of resources for the workload.
To clean up your resources, complete the following steps:
In this post, we showed how to use AWS Glue and the new connector for ingesting data from Google Cloud Storage to Amazon S3. This connector provides access to Google Cloud Storage, facilitating cloud ETL processes for operational reporting, backup and disaster recovery, data governance, and more.
This connector enables your data to be portable across Google Cloud Storage and Amazon S3. We welcome any feedback or questions in the comments section.
 Qiushuang Feng is a Solutions Architect at AWS, responsible for Enterprise customers’ technical architecture design, consulting, and design optimization on AWS Cloud services. Before joining AWS, Qiushuang worked in IT companies such as IBM and Oracle, and accumulated rich practical experience in development and analytics.
Qiushuang Feng is a Solutions Architect at AWS, responsible for Enterprise customers’ technical architecture design, consulting, and design optimization on AWS Cloud services. Before joining AWS, Qiushuang worked in IT companies such as IBM and Oracle, and accumulated rich practical experience in development and analytics.
 Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is passionate about architecting fast-growing data environments, diving deep into distributed big data software like Apache Spark, building reusable software artifacts for data lakes, and sharing knowledge in AWS Big Data blog posts.
Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is passionate about architecting fast-growing data environments, diving deep into distributed big data software like Apache Spark, building reusable software artifacts for data lakes, and sharing knowledge in AWS Big Data blog posts.
 Greg Huang is a Senior Solutions Architect at AWS with expertise in technical architecture design and consulting for the China G1000 team. He is dedicated to deploying and utilizing enterprise-level applications on AWS Cloud services. He possesses nearly 20 years of rich experience in large-scale enterprise application development and implementation, having worked in the cloud computing field for many years. He has extensive experience in helping various types of enterprises migrate to the cloud. Prior to joining AWS, he worked for well-known IT enterprises such as Baidu and Oracle.
Greg Huang is a Senior Solutions Architect at AWS with expertise in technical architecture design and consulting for the China G1000 team. He is dedicated to deploying and utilizing enterprise-level applications on AWS Cloud services. He possesses nearly 20 years of rich experience in large-scale enterprise application development and implementation, having worked in the cloud computing field for many years. He has extensive experience in helping various types of enterprises migrate to the cloud. Prior to joining AWS, he worked for well-known IT enterprises such as Baidu and Oracle.
 Maciej Torbus is a Principal Customer Solutions Manager within Strategic Accounts at Amazon Web Services. With extensive experience in large-scale migrations, he focuses on helping customers move their applications and systems to highly reliable and scalable architectures in AWS. Outside of work, he enjoys sailing, traveling, and restoring vintage mechanical watches.
Maciej Torbus is a Principal Customer Solutions Manager within Strategic Accounts at Amazon Web Services. With extensive experience in large-scale migrations, he focuses on helping customers move their applications and systems to highly reliable and scalable architectures in AWS. Outside of work, he enjoys sailing, traveling, and restoring vintage mechanical watches.
Post Syndicated from Yair Dovrat original http://blog.cloudflare.com/cloudflare-zaraz-steps-up-general-availability-and-new-pricing/

This post is also available in Deutsch, Français.
Cloudflare Zaraz has transitioned out of beta and is now generally available to all customers. It is included under the free, paid, and enterprise plans of the Cloudflare Developer Platform. Visit our docs to learn more on our different plans.

Cloudflare Zaraz is a solution that developers and marketers use to load third-party tools like Google Analytics 4, Facebook CAPI, TikTok, and others. With Zaraz, Cloudflare customers can easily transition to server-side data collection with just a few clicks, without the need to set up and maintain their own cloud environment or make additional changes to their website for installation. Server-side data collection, as facilitated by Zaraz, simplifies analytics reporting from the server rather than loading numerous JavaScript files on the user's browser. It's a rapidly growing trend due to browser limitations on using third-party solutions and cookies. The result is significantly faster websites, plus enhanced security and privacy on the web.
We've had Zaraz in beta mode for a year and a half now. Throughout this time, we've dedicated our efforts to meeting as many customers as we could, gathering feedback, and getting a deep understanding of our users' needs before addressing them. We've been shipping features at a high rate and have now reached a stage where our product is robust, flexible, and competitive. It also offers unique features not found elsewhere, thanks to being built on Cloudflare’s global network, such as Zaraz’s Worker Variables. We have cultivated a strong and vibrant discord community, and we have certified Zaraz developers ready to help anyone with implementation and configuration.
With more than 25,000 websites running Zaraz today – from personal sites to those of some of the world's biggest companies – we feel confident it's time to go out of beta, and introduce our new pricing system. We believe this pricing is not only generous to our customers, but also competitive and sustainable. We view this as the next logical step in our ongoing commitment to our customers, for whom we're building the future.
If you're building a web application, there's a good chance you've spent at least some time implementing third-party tools for analytics, marketing performance, conversion optimization, A/B testing, customer experience and more. Indeed, according to the Web Almanac report, 94% percent of mobile pages used at least one third-party solution in 2022, and third-party requests accounted for 45% of all requests made by websites. It's clear that third-party solutions are everywhere. They have become an integral part of how the web has evolved. Third-party tools are here to stay, and they require effective developer solutions. We are building Zaraz to help developers manage the third-party layer of their website properly.
Starting today, Cloudflare Zaraz is available to everyone for free under their Cloudflare dashboard, and the paid version of Zaraz is included in the Workers Paid plan. The Free plan is designed to meet the needs of most developers who want to use Zaraz for personal use cases. For a price starting at $5/month, customers of the Workers Paid plan can enjoy the extensive list of features that makes Zaraz powerful, deploy Zaraz on their professional projects, and utilize the pay-as-you-go system. This is in addition to everything else included in the Workers Paid plan. The Enterprise plan, on the other hand, addresses the needs of larger businesses looking to leverage our platform to its fullest potential.
Zaraz pricing is based on two components: Zaraz Loads and the set of features. A Zaraz Load is counted each time a web page loads the Zaraz script within it, and/or the Pageview trigger is being activated. For Single Page Applications, each URL navigation is counted as a new Zaraz Load. Under the Zaraz Monitoring dashboard, you can find a report showing how many Zaraz Loads your website has generated during a specific time period. Zaraz Loads and features are factored into our billing as follows:
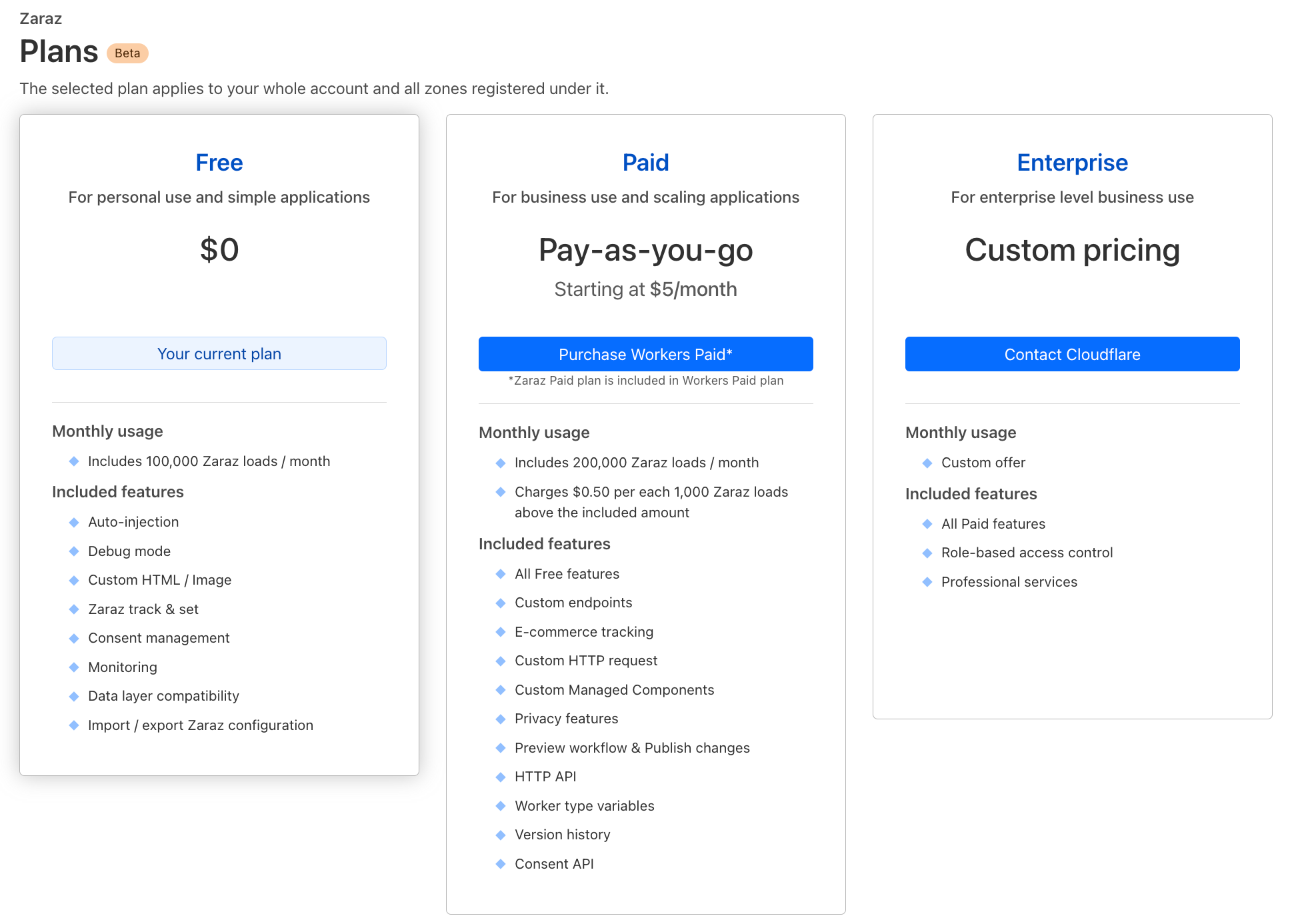
The Free Plan has a limit of 100,000 Zaraz Loads per month per account. This should allow almost everyone wanting to use Zaraz for personal use cases, like personal websites or side projects, to do so for free. After 100,000 Zaraz Loads, Zaraz will simply stop functioning.
Following the same logic, the free plan includes everything you need in order to use Zaraz for personal use cases. That includes Auto-injection, Zaraz Debugger, Zaraz Track and Zaraz Set from our Web API, Consent Management Platform (CMP), Data Layer compatibility mode, and many more.
If your websites generate more than 100,000 Zaraz loads combined, you will need to upgrade to the Workers Paid plan to avoid service interruption. If you desire some of the more advanced features, you can upgrade to Workers Paid and get access for only $5/month.
The Workers Paid Plan includes the first 200,000 Zaraz Loads per month per account, free of charge.
If you exceed the free Zaraz Loads allocations, you'll be charged $0.50 for every additional 1,000 Zaraz Loads, but the service will continue to function. (You can set notifications to get notified when you exceed a certain threshold of Zaraz Loads, to keep track of your usage.)
Workers Paid customers can enjoy most of Zaraz robust and existing features, amongst other things, this includes: Zaraz E-commerce from our Web API, Custom Endpoints, Workers Variables, Preview/Publish Workflow, Privacy Features, and more.
If your websites generate Zaraz Loads in the millions, you might want to consider the Workers Enterprise plan. Beyond the free 200,000 Zaraz Loads per month for your account, it offers additional volume discounts based on your Zaraz Loads usage as well as Cloudflare’s professional services.
The Workers Enterprise Plan includes the first 200,000 Zaraz Loads per month per account free of charge. Based on your usage volume, Cloudflare’s sales representatives can offer compelling discounts. Get in touch with us here. Workers Enterprise customers enjoy all paid enterprise features.
If you were using Zaraz under the free beta, you have a period of two months to adjust and decide how you want to go about this change. Nothing will change until September 20, 2023. In the meantime we advise you to:
* Please note, as of now, free plan users won't have access to any paid features. However, if you're already using a paid feature without a Workers Paid subscription, you can continue to use it risk-free until September 20. After this date, you'll need to upgrade to keep using any paid features.
As we make this important transition, we want to extend our sincere gratitude to all our beta users who have provided invaluable feedback and have helped us shape Zaraz into what it is today. We are excited to see Zaraz move beyond its beta stage and look forward to continuing to serve your needs and helping you build better, faster, and more secure web experiences. We know this change comes with adjustments, and we are committed to making the transition as smooth as possible. In the next couple of days, you can expect an email from us, with clear next steps and a way to get advice in case of need. You can always get in touch directly with the Cloudflare Zaraz team on Discord, or the community forum.
Thank you for joining us on this journey and for your ongoing support and trust in Cloudflare Zaraz. Let's continue to build the future of the web together!
Post Syndicated from Zack Koppert original https://github.blog/2023-07-19-metrics-for-issues-pull-requests-and-discussions/
At GitHub, we believe that data-driven insights are the keys to success for any software development project. Understanding the health and progress of your issues, pull requests, and discussions is crucial for effective collaboration, maintainership, and project management.
That is why we’re excited to announce the release of the Issue Metrics GitHub Action, a powerful tool that empowers developers and teams to measure key metrics and gain valuable insights into their projects.
With the new Issue Metrics GitHub Action, you can now easily track and monitor important metrics related to issues, pull requests, and discussions, such as time to first response, time to close, and more for any given time period.
Whether you’re an individual developer, a small team, or a large organization, these metrics will help you gauge the overall health, progress, and engagement of your projects.

As a maintainer, it is essential to give reasonable attention to the issues and pull requests in the repositories you maintain. With the Issue Metrics GitHub Action, you can track metrics, such as the number of open issues, closed issues, open pull requests, and merged pull requests.
These metrics can provide you with a clear overview of the workload for a project over a given week, month, or even year. The action can also allow you to consider how you or your team prioritize time and attention effectively while also highlighting potentially overlooked requests in need of attention.
As a first responder in a repository, it’s part of the job description to ensure that users receive contact in a reasonable amount of time. By utilizing the Issue Metrics GitHub Action, you can keep track of metrics like the number of discussions awaiting replies, unresolved issues, or pull requests waiting for reviews. These metrics enable you to maintain a high level of responsiveness, fostering a positive user experience and timely problem resolution. These can be used to build a to-do list or retrospectively to reflect on how long users had to wait for a response during a given time period.
An important part of what OSPOs do is making the open source release process easy and efficient while adhering to company policy. This process usually involves employees opening an issue, pull request, or discussion. With the Issue Metrics GitHub Action, OSPOs can gain valuable insights into the number of requests, the ratio of open to closed requests, and metrics related to the time it takes to navigate the open-source process to completion.
These metrics empower you to streamline your workflows, optimize response times, and ensure a smooth open-source collaboration experience. Optimizing the open source release process encourages employees to continue to produce open source projects on the organization’s behalf.
Product development teams rely heavily on the code review process to collaborate and build high-quality software. By leveraging the Issue Metrics GitHub Action, teams can measure metrics such as the time it takes to get pull request reviews. These insights allow you to reflect on the data during retrospectives, identify areas for improvement, and optimize the review process to enhance team collaboration and accelerate development cycles.
Certain aspects of efficiency and flow may be hard to measure but often it is possible to spot and remove inefficiencies in the value stream.
Setting up the Issue Metrics GitHub Action takes a few minutes, compared to the few hours it takes to calculate these metrics manually. You also only need to set up the action once, and it will run on a regular basis of your own choosing. It integrates into your existing GitHub Actions workflow or you can create a new workflow specifically for metrics tracking.
The action provides a wide range of customizable options, allowing you to tailor the issues, pull requests, and discussions measured by utilizing GitHub’s powerful search filtering. Ready to use configurations have been tested and used internally at GitHub and are now available for you to try out as well.
Here is one such example that runs monthly to report on metrics for issues created last month:
name: Monthly issue metrics
on:
workflow_dispatch:
schedule:
- cron: '3 2 1 * *'
jobs:
build:
name: issue metrics
runs-on: ubuntu-latest
steps:
- name: Get dates for last month
shell: bash
run: |
# Get the current date
current_date=$(date +'%Y-%m-%d')
# Calculate the previous month
previous_date=$(date -d "$current_date -1 month" +'%Y-%m-%d')
# Extract the year and month from the previous date
previous_year=$(date -d "$previous_date" +'%Y')
previous_month=$(date -d "$previous_date" +'%m')
# Calculate the first day of the previous month
first_day=$(date -d "$previous_year-$previous_month-01" +'%Y-%m-%d')
# Calculate the last day of the previous month
last_day=$(date -d "$first_day +1 month -1 day" +'%Y-%m-%d')
echo "$first_day..$last_day"
echo "last_month=$first_day..$last_day" >> "$GITHUB_ENV"
- name: Run issue-metrics tool
uses: github/issue-metrics@v2
env:
GH_TOKEN: ${{ secrets.GH_TOKEN }}
SEARCH_QUERY: 'repo:owner/repo is:issue created:${{ env.last_month }} -reason:"not planned"'
- name: Create issue
uses: peter-evans/create-issue-from-file@v4
with:
title: Monthly issue metrics report
content-filepath: ./issue_metrics.md
assignees: <YOUR_GITHUB_HANDLE_HERE>
Head over to the Issue Metrics GitHub Action repository to explore the documentation, installation instructions, and examples. The repository provides a comprehensive README file that guides you through the setup process and showcases the wide range of metrics you can measure. If you need additional help, feel free to open an issue in the repository.
GitHub is committed to providing developers with the best tools to enhance collaboration and productivity. The Issue Metrics GitHub Action is a significant step towards empowering teams to measure key metrics related to issues, pull requests, and discussions. By gaining valuable insights into the pulse of your projects, you can drive continuous improvement and deliver exceptional software. We are using this in several places internally across GitHub to help us continually improve and hope this action can help you as well. Happy coding!
Post Syndicated from Danilo Poccia original https://aws.amazon.com/blogs/aws/reimagine-software-development-with-codewhisperer-as-your-ai-coding-companion/
In the few months since Amazon CodeWhisperer became generally available, many customers have used it to simplify and streamline the way they develop software. CodeWhisperer uses generative AI powered by a foundational model to understand the semantics and context of your code and provide relevant and useful suggestions. It can help build applications faster and more securely, and it can help at different levels, from small suggestions to writing full functions and unit tests that help decompose a complex problem into simpler tasks.
Imagine you want to improve your code test coverage or implement a fine-grained authorization model for your application. As you begin writing your code, CodeWhisperer is there, working alongside you. It understands your comments and existing code, providing real-time suggestions that can range from snippets to entire functions or classes. This immediate assistance adapts to your flow, reducing the need for context-switching to search for solutions or syntax tips. Using a code companion can enhance focus and productivity during the development process.
When you encounter an unfamiliar API, CodeWhisperer accelerates your work by offering relevant code suggestions. In addition, CodeWhisperer offers a comprehensive code scanning feature that can detect elusive vulnerabilities and provide suggestions to rectify them. This aligns with best practices such as those outlined by the Open Worldwide Application Security Project (OWASP). This makes coding not just more efficient, but also more secure and with an increased assurance in the quality of your work.
CodeWhisperer can also flag code suggestions that resemble open-source training data, and flag and remove problematic code that might be considered biased or unfair. It provides you with the associated open-source project’s repository URL and license, making it easier for you to review them and add attribution where necessary.
Here are a few examples of CodeWhisperer in action that span different areas of software development, from prototyping and onboarding to data analytics and permissions management.
CodeWhisperer Speeds Up Prototyping and Onboarding
One customer using CodeWhisperer in an interesting way is BUILDSTR, a consultancy that provides cloud engineering services focused on platform development and modernization. They use Node.js and Python in the backend and mainly React in the frontend.
I talked with Kyle Hines, co-founder of BUILDSTR, who said, “leveraging CodeWhisperer across different types of development projects for different customers, we’ve seen a huge impact in prototyping. For example, we are impressed by how quickly we are able to create templates for AWS Lambda functions interacting with other AWS services such as Amazon DynamoDB.” Kyle said their prototyping now takes 40% less time, and they noticed a reduction of more than 50% in the number of vulnerabilities present in customer environments.

Kyle added, “Because hiring and developing new talent is a perpetual process for consultancies, we leveraged CodeWhisperer for onboarding new developers and it helps BUILDSTR Academy reduce the time and complexity for onboarding by more than 20%.”
CodeWhisperer for Exploratory Data Analysis
Wendy Wong is a business performance analyst building data pipelines at Service NSW and agile projects in AI. For her contributions to the community, she’s also an AWS Data Hero. She says Amazon CodeWhisperer has significantly accelerated her exploratory data analysis process, when she is analyzing a dataset to get a summary of its main characteristics using statistics and visualization tools.
She finds CodeWhisperer to be a swift, user-friendly, and dependable coding companion that accurately infers her intent with each line of code she crafts, and ultimately aids in the enhancement of her code quality through its best practice suggestions.
“Using CodeWhisperer, building code feels so much easier when I don’t have to remember every detail as it will accurately autocomplete my code and comments,” she shared. “Earlier, it would take me 15 minutes to set up data preparation pre-processing tasks, but now I’m ready to go in 5 minutes.”

Wendy says she has gained efficiency by delegating these repetitive tasks to CodeWhisperer, and she wrote a series of articles to explain how to use it to simplify exploratory data analysis.
Another tool used to explore data sets is SQL. Wendy is looking into how CodeWhisperer can help data engineers who are not SQL experts. For instance, she noticed they can just ask to “write multiple joins” or “write a subquery” to quickly get the correct syntax to use.

CodeWhisperer Accelerates Testing and Other Daily Tasks
I had the opportunity to spend some time with software engineers in the AWS Developer Relations Platform team. That’s the team that, among other things, builds and operates the community.aws website.

Nikitha Tejpal’s work primarily revolves around TypeScript, and CodeWhisperer aids her coding process by offering effective autocomplete suggestions that come up as she types. She said she specifically likes the way CodeWhisperer helps with unit tests.
“I can now focus on writing the positive tests, and then use a comment to have CodeWhisperer suggest negative tests for the same code,” she says. “In this way, I can write unit tests in 40% less time.”
Her colleague, Carlos Aller Estévez, relies on CodeWhisperer’s autocomplete feature to provide him with suggestions for a line or two to supplement his existing code, which he accepts or ignores based on his own discretion. Other times, he proactively leverages the predictive abilities of CodeWhisperer to write code for him. “If I want explicitly to get CodeWhisperer to code for me, I write a method signature with a comment describing what I want, and I wait for the autocomplete,” he explained.
For instance, when Carlos’s objective was to check if a user had permissions on a given path or any of its parent paths, CodeWhisperer provided a neat solution for part of the problem based on Carlos’s method signature and comment. The generated code checks the parent directories of a given resource, then creates a list of all possible parent paths. Carlos then implemented a simple permission check over each path to complete the implementation.
“CodeWhisperer helps with algorithms and implementation details so that I have more time to think about the big picture, such as business requirements, and create better solutions,” he added.

CodeWhisperer is a Multilingual Team Player
CodeWhisperer is polyglot, supporting code generation for 15 programming languages: Python, Java, JavaScript, TypeScript, C#, Go, Rust, PHP, Ruby, Kotlin, C, C++, Shell scripting, SQL, and Scala.
CodeWhisperer is also a team player. In addition to Visual Studio (VS) Code and the JetBrains family of IDEs (including IntelliJ, PyCharm, GoLand, CLion, PhpStorm, RubyMine, Rider, WebStorm, and DataGrip), CodeWhisperer is also available for JupyterLab, in AWS Cloud9, in the AWS Lambda console, and in Amazon SageMaker Studio.
At AWS, we are committed to helping our customers transform responsible AI from theory into practice by investing to build new services to meet the needs of our customers and make it easier for them to identify and mitigate bias, improve explainability, and help keep data private and secure.
You can use Amazon CodeWhisperer for free in the Individual Tier. See CodeWhisperer pricing for more information. To get started, follow these steps.
— Danilo
Post Syndicated from Leo da Silva original https://aws.amazon.com/blogs/security/how_amazon_codeguru_security_helps_effectively_balance_security_and_velocity/
Software development is a well-established process—developers write code, review it, build artifacts, and deploy the application. They then monitor the application using data to improve the code. This process is often repeated many times over. As Amazon Web Services (AWS) customers embrace modern software development practices, they sometimes face challenges with the use of third-party code security tools, such as an overwhelming number of findings, high rates of false positives among those findings, and the logistics of tracking open issues across code versions.
Customers tell us they need help to identify the top risks in their application code as it is being built and to receive actionable recommendations to mitigate these risks. In this blog post, we demonstrate how the new Amazon CodeGuru Security service and its fully managed, machine learning (ML)-powered code security analysis capabilities provide intelligent recommendations to improve code security and quality. Amazon CodeGuru Security enhances the overall security posture of applications that are deployed in your environment while reducing the time to deploy in production.
Amazon CodeGuru Security is a managed static application security tool (SAST) service that is also available through Amazon CodeGuru Reviewer, Amazon CodeWhisperer security scanning, the Amazon SageMaker Studio CodeGuru extension, and Amazon Inspector code scanning.
In this blog post, we introduce you to the features and capabilities of Amazon CodeGuru Security. Amazon CodeGuru Security helps you focus on security risks that are relevant to your environment, along with contextually relevant remediation suggestions (provided as code diffs). Integration, centralization, and scalability of the service are facilitated by using an API-based design, plus bug tracking to automatically detect code fixes and close findings without user intervention. Amazon CodeGuru Security currently supports applications that are written in Python, Java, and JavaScript, along with associated artifacts like scripts, configuration, and documentation files.
Created to improve the security posture of applications that were built for the cloud, Amazon CodeGuru Security rules are developed in partnership with Amazon application security teams, applying learnings and adhering to best practices that govern the development of Amazon internal systems and services.
Amazon CodeGuru Security offers multiple integration points:
In Figure 1, you can see one of the proposed architecture patterns that supports the integration of Amazon CodeGuru Security into your existing application deployment pipeline. In this scenario, developers write application code and get it committed into Amazon CodeCommit. This event causes AWS CodeBuild to start building the application and the static security code analysis of the application code, using a pre-build hook. The code and build artifacts are copied to a local Amazon S3 bucket within your account, and Amazon CodeGuru Security scans the application assets.

Figure 1: Example of CodeGuru Security integration with deployment pipeline
At the core of the CodeGuru detector design is the idea of user action in response to findings. Detectors flag security risks or quality issues with a high degree of precision, such that action can be taken directly to remediate the finding. With this goal in mind, we have designed the Guru Query Language (GQL) toolkit. GQL enables precise expression of scenario-centric micro-analyzers that check specific properties (for example, misuse of a particular Java cryptography library or API) through a wide range of analysis constructs (more than 200 at the time of publication).
Among these constructs are capabilities such as type inference (determining the precise types of variables and fields), inter-procedural analysis (analyzing across function boundaries), and advanced taint tracking capabilities, where untrusted data (from taint sources) is tracked through the application to determine whether it reaches security-sensitive operations (known as taint sinks) without being sanitized.
By using GQL, the rule author can combine constructs as building blocks to precisely match the vulnerable patterns that are being targeted. As an example, you can specify taint sources and sinks in a contextual way so that only data read from remote (as opposed to local) files is considered untrusted.
We benchmark detectors against ever-growing datasets, and improve them based on feedback from our partner security teams and customers, as well as metrics that we collect. Detectors are subjected to a rigorous quality control process. Starting from the detector specification, we work closely with subject matter experts (SMEs) to make sure that the suggestions cover the most important application surfaces and are not overly defensive in the warnings they raise. Moving from specification to implementation, detections are reviewed and sampled from shadow runs on live codebases with the same SMEs as well as internal CodeGuru users. If detectors meet an internal performance bar, they are launched internally at AWS. After they are launched, the detectors are monitored by using weekly metrics. A detector graduates into the commercial CodeGuru service only if it meets a high quality bar for several weeks.
Amazon CodeGuru Security uses a detection engine to find security issues in the application code that is scanned. The engine uses a Detector Library, which is a resource that contains detailed information about the CodeGuru security and code quality detectors, to help you build secure and efficient applications. Each detection page within the Detector Library contains descriptions, compliant and non-compliant example code snippets, severities, and additional information that helps you mitigate risks (such as Common Weakness Enumeration (CWE) numbers). The materials presented in the Amazon CodeGuru Detector Library are intended to be a high-level summary of the service’s capabilities, but might not be inclusive of all detectors or their functionality.
With user action as the ultimate goal, an important metric to us is whether code fixes are made in response to our recommendations. As such, AWS has designed a novel Bug Fix Tracking (BFT) algorithm, whose key functionality is to relate CodeGuru findings across revisions of a given codebase or application. If, for example, CodeGuru reports misuse of a cryptographic API on version V1 of codebase C, then BFT detects whether that misuse issue is still present when version V2 of C is scanned.
Tracking bugs and bug fixes are nontrivial. Code can be refactored into different locations within a file, and sometimes also into different files. In addition, syntax may be adjusted in ways that are orthogonal to fixing an issue (for example, if variables are renamed). The CodeGuru BFT algorithm constructs a bi-partite graph to relate a pair of findings across revisions, or otherwise declare a finding as either closed (no match in V2) or new (no match in V1).
Figure 2 shows the process that is used by BFT in tracking application bugs. After the application version being scanned is identified and the bug detection verification starts, BFT updates the database with its findings, validating the existing issues with findings uncovered in version N-1.

Figure 2: Overview of the Bug Fix Tracking algorithm
The algorithm is staged, starting from the simple case of 1:1 correspondence between findings, through cases where findings might have drifted to a new location but are otherwise the same. For the final, most complex scenario of fuzzy matching, we use advanced hashing techniques to establish the mapping.
BFT provides a metric that guides our own rule development and tuning process on an ongoing basis. Data about BFT findings is available to our customers through the CodeGuru Security API. With gathered data about fixes, security engineers and leaders can measure exposure to security risks, quantify the lifetime of high and critical security issues, monitor burn rate for security issues, and form other insights from the raw data.
To align with our goal of encouraging user action in response to our recommendations, we’ve added a feature powered by automated reasoning for including concrete remediation advice as part of CodeGuru recommendations. This comes in the form of a code diff, which you can apply mechanically by using standard utilities like patch.
The screenshot in Figure 3 shows how this functionality creates an important bridge between security engineers and software engineers—the former have the necessary security expertise, while the latter are often responsible for carrying out the code fix. Recommendations that are accompanied by concrete fix suggestions can cut through multiple correspondences, alignment issues, and validation cycles, which can help accelerate remediation.

Figure 3: Example of recommendation showing difference between compliant and non-compliant code
To enable the reasoning illustrated in Figure 3, where the data reaching the addObject call goes through sanitization in the form of an HtmlUtils::htmlEscape call, the underlying algorithm performs several steps. First, a formal representation of the code, known as its Abstract Syntax Tree (AST), is constructed. The AST is then visited by one or more transformation “recipes,” whose goal is to manipulate the program such that the vulnerability is mitigated.
Code transformation is done in a contextual manner, so that syntax (for example, variable names) and formatting (for example, indentation levels) are preserved. To verify that the transformation is valid, the algorithm further runs post-processing checks on the resulting code structure and syntax.
An important refinement of the remediation capability is that Amazon CodeGuru Security performs pre-analysis ahead of running the security scan to classify code artifacts into application- versus library-dependencies. It’s more feasible to take action on a recommendation for code owned by you, compared to code in a third-party library. The classification algorithm has been trained on hundreds of thousands of open-source libraries to disassemble code artifacts, including bundling application and library content in the same file, and focus downstream analysis on the most pertinent scanning surfaces.
Critical security issues have been shown to sometimes take hundreds of days to address (as discussed in this study). Internal studies that look at use of CodeGuru have seen a steep drop in time to fix issues thanks to concrete fix suggestions, which is value that the service excited to share with you.
Amazon CodeGuru Security is a static application security testing (SAST) tool that combines ML and automated reasoning to identify security issues in your code. Amazon CodeGuru detection capabilities that use GQL (Guru Query Language), Bug Fix Tracking (BFT), and efficacy mechanisms and AppSec expertise can help you precisely identify code security issues with a low rate of false positives. High signal-to-noise ratio is a key enabler in integrating SAST into the daily work of security engineers and software developers.
In addition, Amazon CodeGuru Security provides thorough fix recommendations, which your development teams can use to improve the overall time to remediate application security issues. At the same time, the recommendations can help you to implement security best practices based on an ML model that was trained on millions of lines of code and vulnerability assessments performed within Amazon. Get started with Amazon CodeGuru Security.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
Post Syndicated from sakoppes original https://aws.amazon.com/blogs/messaging-and-targeting/amazon-simple-email-service-adds-email-delivery-analysis-features-to-revised-free-tier/
On August 1st, 2023, Amazon Simple Email Service (SES) will launch a revised, more flexible free tier that allows AWS customers to try more SES features without commitment or cost. SES customers will be able to send or receive up to 3,000 messages each month for a year after they begin using SES, free of charge[1]. Customers can now try advanced SES capabilities, like deliverability analytics and optimization through Virtual Deliverability Manager (VDM), in the free tier. With access to these new features, customers can use the free tier to build full proof-of-concept workloads to experiment with SES’ powerful tools.
Previously, the SES free tier only covered outbound messages sent from AWS compute services such as EC2 instances. Customers using other types of computing services for sending outbound messages had no SES free tier available. Customers could also receive up to 1,000 inbound email messages free each month. Customers evaluating SES had to pay to explore more advanced features like Virtual Deliverability Manager, a suite of tools customers use to improve delivery rates for outbound emails. This made it difficult to avoid charges when exploring advanced SES use cases, such as when building prototype email sending workloads to explore ways to monitor and optimize email delivery success and engagement rates.
The revised SES free tier offers a more flexible model, introducing a shared limit which applies to pay-as-you-go message charges including inbound email messages, outbound email messages sent from any source, and email charges for Virtual Deliverability Manager. This model makes it easier to choose the right combination of features to fit your use cases when exploring SES features end-to-end without commitment. The revised free tier includes up to 3,000 messages each month for 12 months after you start using SES, which are shared across the features included in the revised SES free tier (note that Virtual Deliverability Manager counts separately from outbound messages). Here some examples to illustrate the revised free tier (all numbers are messages per month), note the 3,000 message free tier is applied first to more expensive charges (e.g. outbound messages) in situations where multiple products are in use (inbound, outbound, Virtual Deliverability Manager):

The revised SES free tier makes it easier to build proof-of-concept workflows to demonstrate SES’ advanced deliverability optimization capabilities without commitment. For example, you could set up a pilot workload to show how SES can help you interpret the results of A/B testing using configuration sets. Imagine creating a few versions of a marketing email, then sending each version to a sample set of recipients to test response rates. You could track each version of the email separately in Virtual Deliverability Manager using configuration sets (essentially a campaign), then use VDM to analyze the differences in deliverability metrics for each campaign. You can look at the bounce rates, open, and click rates of each campaign to determine which version performed best before sending to all your target customers. This helps you see what SES can do, before deciding whether you want to build production workloads on SES.
The revised SES free tier will be active on August 1st, 2023 for all SES customers; no action is required. Customers who are using SES today will benefit from the revised free tier for one year (until August 2024). Customers who start using SES after August 1st, 2023, will benefit from the revised free tier for one year from the month they start using SES. The revised free tier replaces the current free tier, and we are not able to offer an opportunity to continue using current free tier. To start using the SES free tier, just create and verify an email address to send outbound email messages, and/or set up a receipt rule for receiving inbound email messages. To see advanced analytics with deliverability recommendations and traffic shaping through Virtual Deliverability Manager, just click on “Virtual Deliverability Manager” in the SES console navigation and follow the steps to enable it.
Get started with SES free tier at https://aws.amazon.com/ses/.
Post Syndicated from Patrick Kennedy original https://www.servethehome.com/amd-epyc-bergamo-epyc-9754-cloud-native-sp5/
The AMD EPYC 9754 128 core and 256 thread part is a fantastically fresh take on cloud native compute that beat our high expectations
The post AMD EPYC Bergamo is a Fantastically Fresh Take on Cloud Native Compute appeared first on ServeTheHome.
Post Syndicated from digiblurDIY original https://www.youtube.com/watch?v=Wb-n2IZAX2s
Post Syndicated from original https://lwn.net/Articles/938596/
Security updates have been issued by Debian (bind9, libapache2-mod-auth-openidc, and python-django), Fedora (nodejs18 and redis), Red Hat (python3.9 and webkit2gtk3), Scientific Linux (bind and kernel), SUSE (cni, cni-plugins, cups-filters, curl, dbus-1, ImageMagick, kernel, libheif, and python-requests), and Ubuntu (bind9, connman, curl, libwebp, and yajl).
Post Syndicated from Luca Mezzalira original https://aws.amazon.com/blogs/architecture/lets-architect-devops-best-practices-on-aws/
DevOps has revolutionized software development and operations by fostering collaboration, automation, and continuous improvement. By bringing together development and operations teams, organizations can accelerate software delivery, enhance reliability, and achieve faster time-to-market.
In this blog post, we will explore the best practices and architectural considerations for implementing DevOps with Amazon Web Services (AWS), enabling you to build efficient and scalable systems that align with DevOps principles. The Let’s Architect! team wants to share useful resources that help you to optimize your software development and operations.
Distributed systems are adopted from enterprises more frequently now. When an organization wants to leverage distributed systems’ characteristics, it requires a mindset and approach shift, akin to a new model for software development lifecycle.
In this re:Invent 2021 video, Emily Freeman, now Head of Community Engagement at AWS, shares with us the insights gained in the trenches when adapting a new software development lifecycle that will help your organization thrive using distributed systems.
Take me to this re:Invent 2021 video!

Operationalizing the DevOps revolution
Designing effective DevOps workflows is necessary for achieving seamless collaboration between development and operations teams. The Amazon Builders’ Library offers a wealth of guidance on designing DevOps workflows that promote efficiency, scalability, and reliability. From continuous integration and deployment strategies to configuration management and observability, this resource covers various aspects of DevOps workflow design. By following the best practices outlined in the Builders’ Library, you can create robust and scalable DevOps workflows that facilitate rapid software delivery and smooth operations.

A pipeline coordinates multiple inflight releases and promotes them through three stages
Cloud fitness functions provide a powerful mechanism for driving evolutionary architecture within your DevOps practices. By defining and measuring architectural fitness goals, you can continuously improve and evolve your systems over time.
This AWS Architecture Blog post delves into how AWS services, like AWS Lambda, AWS Step Functions, and Amazon CloudWatch can be leveraged to implement cloud fitness functions effectively. By integrating these services into your DevOps workflows, you can establish an architecture that evolves in alignment with changing business needs: improving system resilience, scalability, and maintainability.
Take me to this AWS Architecture Blog post!

Fitness functions provide feedback to engineers via metrics
Achieving consistent deployments across multiple regions is a common challenge. This AWS DevOps Blog post demonstrates how to use Terraform, AWS CodePipeline, and infrastructure-as-code principles to automate Multi-Region deployments effectively. By adopting this approach, you can demonstrate the consistent infrastructure and application deployments, improving the scalability, reliability, and availability of your DevOps practices.
The post also provides practical examples and step-by-step instructions for implementing Multi-Region deployments with Terraform and AWS services, enabling you to leverage the power of infrastructure-as-code to streamline DevOps workflows.
Take me to this AWS DevOps Blog post!

Multi-Region AWS deployment with IaC and CI/CD pipelines
Thanks for joining our discussion on DevOps best practices! Next time we’ll talk about how to create resilient workloads on AWS.
To find all the blogs from this series, check out the Let’s Architect! list of content on the AWS Architecture Blog. See you soon!
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=75Jew239QeI
Post Syndicated from Светла Енчева original https://www.toest.bg/homofobiya-kazaha-go/

Игнориране, посочване, назоваване. Това са стадиите на отношението към хомофобията, през които премина коалицията между „Продължаваме промяната“ и „Демократична България“ за половин година – от създаването си с предизборно споразумение на 10 февруари до 17 юли 2023 г. Това е и първият път, когато коалиция, участваща в управлението на България, говори за хомофобия в своя официална позиция.
Позицията на ПП–ДБ е озаглавена „Остро осъждаме разпространението на език на омразата, призиви за насилие и хомофобия“. До нея се стигна след ескалираща поредица от прояви на омраза от страна на партия „Възраждане“ или свързани по един или друг начин с нея.
За последната (засега) проява от еврейската организация „Шалом“ сигнализираха прокуратурата, която образува проверка. Става дума за колаж, публикуван в канал на „Възраждане“ в приложението Telegram. На снимка на евреин в затворническа униформа, дърпан от нацистки войници, е сложено лицето на Соломон Паси. На нея пише (оригиналният правопис е запазен): „Щом не искаш от руския газ ела да ти пуснем от нашия.“
Соломон Паси е основател на Атлантическия клуб в България, бивш външен министър и депутат, предложил България да стане член на НАТО. Освен това е от еврейски произход, а надписът на колажа е пряка препратка към убийствата на евреи в газови камери в нацистките концлагери.
От „Възраждане“ заплашиха да съдят председателя на „Шалом“ Александър Оскар за набеждаване. В позицията на партията на Костадин Костадинов се твърди, че групата на „Възраждане“ в Telegram не е официален комуникационен канал на партията и че тя не носи отговорност за публикациите на потребителите.
На официалната страница на „Възраждане“ във Facebook впоследствие са публикувани думи на Кеворк Кеворкян срещу Соломон Паси, в които последният е наричан „главният Осквернител на Българското“ и се твърди, че „народът никога няма да му прости“. Под публикацията има антисемитски коментари, които не са изтрити.
Въпреки че конкретният повод за позицията на ПП–ДБ е колажът със Соломон Паси, в заглавието ѝ присъства думата „хомофобия“. От текста не се разбира какво търси тази дума там. Контекстът става отчасти ясен от предишна позиция на коалицията, публикувана на Facebook страниците на ПП и ДБ, в която обаче думата не присъства. Става въпрос за акциите на политици и активисти от „Възраждане“ против белгийския филм „Близо“, набеден от тях за „педофилски“. Пред безучастния поглед на полицията те не допуснаха филмът да се прожектира в столичното кино „Одеон“.
След позицията на ПП–ДБ, от която не ставаше ясно защо „възрожденци“ не искат хората да идат на кино, по аналогичен начин беше провалена и прожекцията на „Близо“ във Варна. С надпис „педофи ли“ (оригиналният правопис е запазен) на 11 юли беше вандализирана фасадата на „Гьоте-институт“ в София, който също беше организирал прожекция на „Близо“. От института квалифицираха посланието на надписа като хомофобско и подчертаха важността на изповядването на демократични принципи.
Прожекцията в „Гьоте-институт“ се проведе при засилен интерес, но междувременно последствията от хомофобската кампания срещу филма, инспирирана от „Възраждане“, придоби международни измерения. „Гьоте-институт“ е държавният културен институт на Германия. Немското посолство сподели на страницата си във Facebook позицията му, като добави свой коментар срещу речта на омразата, вандализма и взаимното оклеветяване.
В началото на коалиционното си съ-съществуване ПП и ДБ се отнасяха към проявите на хомофобия също както преди това поотделно – с малки изключения ги игнорираха и правеха всичко възможно да не ги назовават. Те постъпваха така, от една страна, заради различните позиции към правата на ЛГБТИ+ хората в собствените си редици (което важи в голяма степен за ДБ). От друга страна, защото на защитата на човешки права, и особено на правата на дискриминирани малцинства, в България се гледа като на стратегия, която не е политически печеливша.
Така в политиката темата за ЛГБТИ+ хората беше монополизирана от хомофобското и трансфобското (свързаното с омраза към трансхората) говорене. Защото, докато мразещите говореха, нямаше кой да им се противопостави. Александър Урумов, Ангел Джамбазки, Корнелия Нинова, а по-късно и Костадин Костадинов години наред безпрепятствено промиваха мозъците на гражданите с нелепи пропагандни твърдения. Затова и кампанията срещу Истанбулската конвенция успя да стигне толкова далеч – до две решения в трансфобски и хомофобски дух на Конституционния съд и едно на Касационния.
Политиката обаче има не само вътрешни измерения, особено в контекста на войната на Русия срещу Украйна и противопоставянето на проруския президент Румен Радев на прозападното правителство и парламентарно мнозинство. Оцеляването на правителството на ПП–ДБ и ГЕРБ–СДС е в немалка степен свързано с неговата външнополитическа легитимност. При правителствата на Бойко Борисов тази легитимност оставаше на декларативно равнище. В настоящата изострена ситуация обаче всеки жест е важен.
Ето защо забелязването на човешките права, за чието системно нарушение България е била многократно санкционирана, най-сетне е на дневен ред. Защото вече е очевидно, че „неутралитетът“ по отношение на омразата и насилието не е неутралитет, а е толериране на насилника. И че бездействието също е заемане на страна.
Ала назоваването на хомофобията е само първата стъпка. Жестът на ПП и ДБ ще си остане само на декларативно равнище, ако коалицията не направи всичко по силите си за промени в законодателството, с които хомофобията и трансфобията да бъдат поставени там, където им е мястото. Става въпрос за включването на омразата към ЛГБТИ+ хората в чл. 162 от Наказателния кодекс. В него за престъпления от омраза се признават само тези на основата на раса, народност и етническа принадлежност, а ако са свързани и с насилие – и на религия и политически убеждения. Затова в съда хомофобските и трансфобските подбуди се интерпретират като „хулигански“ – няма друг параграф, по който могат да минат. А хулиганството се наказва като нещо по-безобидно от престъпленията от омраза.
Едно от основните постижения на хомофобската и трансфобската пропаганда в България е липсата на равни права. Затова е логично назоваването на хомофобията да бъде последвано и от някакви стъпки за преодоляването на тази липса. Днес в България това звучи утопично, но кой знае – кризисните времена изискват решителни действия.
Post Syndicated from original https://www.toest.bg/kak-si-komunikirat-mozukut-i-imunnata-sistema/

Нервната и имунната система са еднакво значими за оцеляването на организма. Традиционно се е смятало, че са независими една от друга, а взаимодействията помежду им са свързани главно с проявата на мозъчни заболявания. Пример е множествената склероза, при която имунната система атакува мозъчната тъкан. Въпреки това увеличаващите се научни доказателства и дори нашите собствени преживявания подсказват, че между тези две системи има активен диалог.
Напредъкът в молекулярната биология значително обогатява знанията ни за човешката физиология. Молекулярната биология е в центъра на прогресивното развитие на генетиката и омикстехнологиите (анализ на ДНК, РНК, белтъци и метаболити). Преди няколко десетилетия изследването на експресията и функциите на дадена молекула в различни физиологични системи (освен в тази, в която е установена) е било рядкост. В днешно време сигналните пътища в клетките често се изследват при различни физиологични системи с използването на едни и същи лабораторни техники. Размиването на границите между дисциплините е основният резултат от този научен подход. Въпреки това той е сравнително нов. Доказателство и пример е развитието на научните изследвания при невроимунитета.
Изследването на невронно-имунните взаимодействия започва с психосоматичния подход: психологическите фактори и емоциите влияят на проявата и развитието на болестни състояния като алергии, язва на стомаха, рак, автоимунни заболявания, инфекции. Вторият подход е „биоповеденчески“: експериментални стресови фактори влияят на имунната система. При този подход се смята, че имунната система може да бъде модулирана и от условни стимули. Третият подход е основан на междуклетъчната комуникация: клетките на имунната система експресират невротрансмитерни рецептори и хипофизни пептиди. Той е последван от невроанатомичния подход: инервирането на далака и другите лимфоидни органи се осъществява посредством автономна нервна система. Последният подход разглежда ефектите на имунните фактори върху невроендокринната система.
Изследванията на физиологичните стресови фактори при човека, водещи до предразположеност към тежки инфекции – бактериални, алергични, автоимунни и ракови заболявания – или до трудно възстановяване след тях, включват промени в механизмите на имунологичната защита. Смъртта на близък човек от семейството например е смятана за силен стресов момент в живота, който се свързва с депресия и повишен риск от заболеваемост и смъртност.
Голяма част от тези заболявания са с имунологичен характер. Промените във функциите на имунната система се дължат, от една страна, на връзката между психологическите фактори и от друга – на промяна в податливостта на развитие на дадено заболяване или влошаването му. Промяната в имунната реактивност – например пониженото ниво на лимфопролиферативния отговор към стимулиране с митогени (малки протеини или пептиди, които предизвикват клетъчно делене) или нарушената активност на клетките „натурални убийци“ (NK клетки) – е установена при хора, преминали през тежка загуба на близък. Други изследвания сочат, че понижаването на имунитета е свързано също с раздяла или развод.
Въпреки че гореспоменатите житейски събития, логично, са стресиращи, промяна във функциите на имунната система може да настъпи и при хора, преминаващи през по-леки стресови ситуации, които обикновено са неизбежна част от живота. Например промени в имунитета са установени при студенти по медицина, на които им предстоят изпити, и при футболисти преди важен мач. Нивото на безпокойство по време на сесия при студентите е значително по-високо в сравнение с другите периоди от учебната година.
Установено е, че при студентите по медицина, които са в сесия, нивото на активността на NK клетките и процентът на хелперните Т-лимфоцити намаляват. При студенти, серопозитивни за Епщайн-Бар вирус (EBV), e повишен титърът на анти-EBV антителата, което означава, че вирусът се размножава в по-големи количества. Това се обяснява с понижен клетъчен отговор на латентния вирус по време на изпитните периоди. На участвалите в изследването студенти са направени и личностни тестове, чрез които е изяснено, че други събития в личния им живот не са имали подобно влияние.
Въпреки че знанията за влиянието на имунитета върху невронната активност са се увеличили значително през последното десетилетие, разбирането на учените за обратния процес – как мозъкът влияе върху периферната имунна активност – е много по-ограничено.
Част от молекулите, които играят роля и при нервната, и при имунната система, са ключови за мониторинга и отговора на промените във вътрешната и външната среда. HLA гените от клас I са основни участници в представянето на антигени. Тяхната експресия е установена в невроните, в областта на аксоните, дендритите и синапсите и в глиалните клетки, особено в началните постнатални стадии на развитието. Накратко, те участват в усъвършенстването на пластичността на зрителната система и двигателното обучение в малкия мозък.
Все още предстои да се изясни дали HLA молекулите от клас I имат специфични функции и дали голямото им разнообразие (полиморфизъм) е свързано с развитието на централната нервна система (ЦНС) и когнитивните функции при определени заболявания, като аутизъм и шизофрения. Друг неизяснен въпрос е дали HLA молекулите от клас I наистина представят антигени в ЦНС и ако е така, какъв тип антигени са представени и дали са съществени за образуването на специфични невронни мрежи.
Стареенето е свързано с промени от имунен характер, които водят до клинични прояви. Например когато един човек остарява, се увеличава податливостта на определени инфекции и активността на много ваксини се понижава. Тези клинични характеристики на стареенето са придружени от общо понижаване на защитните имунни отговори, известни като „имунно стареене“. Стареенето е свързано и с ниска степен на постоянно възпаление, което съществува без явна инфекция. Имунното стареене и описаното възпаление са взаимнозависими процеси и настъпват с напредване на възрастта поради редица фактори, включително латентни инфекции, метаболитни промени и др.
Болестта на Алцхаймер е често срещано невродегенеративно заболяване, като най-големият рисков фактор за проявата му е стареенето. Невродегенеративните маркери включват два патологични белтъка, които се натрупват в мозъка: амилоид бета и тау. Смята се, че освен тях има и други маркери, които могат да регулират развитието на заболяването и проявата на клиничните симптоми. Един от тях е аполпопротеин Е (ApoE). Той има имуномодулаторна активност. Смята се, че изоформата ApoE4 има роля при развитието на заболяването, като лимитира пречистването на бета-амилоидните плаки от мозъка.
В продължение на няколко десетилетия нервната и имунната система са изследвани независимо една от друга, но сега се знае, че те комуникират и че тази комуникация служи за физиологичното адаптиране и в здраво състояние, и при развитие на дадено заболяване. Въпреки това все още има сериозни празнини в изясняването на сложната комуникация. Голяма част от техниките, необходими за разплитането на тези въпроси (например РНК секвениране), и анализът на огромните бази данни започват да стават по-достъпни. Така учените имат уникална възможност да изяснят какъв е терапевтичният капацитет на мозъка.
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=2WYP-1B4IQE
Post Syndicated from Explosm.net original https://explosm.net/comics/papa-bear
New Cyanide and Happiness Comic
Post Syndicated from original https://xkcd.com/2804/

Post Syndicated from Patrick Kennedy original https://www.servethehome.com/asus-and-intel-agree-on-deal-for-a-nuc-future/
Intel and ASUS announced a term sheet that will see a new ASUS NUC BU stood up and 10th to 13th gen NUC manufacturing to be done by ASUS
The post ASUS and Intel Agree on Deal for a NUC Future appeared first on ServeTheHome.
Post Syndicated from original https://lwn.net/Articles/938536/
Version
3.0 of Cython (described
as “a programming language that makes writing C
“) has been
extensions for the Python language as easy as Python itself
released. Changes include support for Python through 3.11 (but 2.6 support
was dropped), the implementation of a number of PEPs, initial support for
the CPython limited API, better exception handling, and more.
Post Syndicated from original https://lwn.net/Articles/938524/
The 2023 sambaXP conference was held May 10 and 11 in Goettingen, Germany.
Videos
of the talks held there have now been posted on YouTube; topics covered
include an io_uring update, fuzzing, passwordless services, GPL compliance,
and much more.