Post Syndicated from Jocelyn Woolbright original https://blog.cloudflare.com/celebrating-12-years-of-project-galileo/
Twelve years ago this month, Cloudflare launched an ambitious project built on a simple idea: people shouldn’t be knocked offline just because someone more powerful disagrees with them. Today, Project Galileo provides free access to cybersecurity services to more than 3,400 websites belonging to journalists, human rights defenders, and other nonprofit organizations in 120 countries. We continue to believe that a better Internet is one where anyone with an idea can reach a global audience.
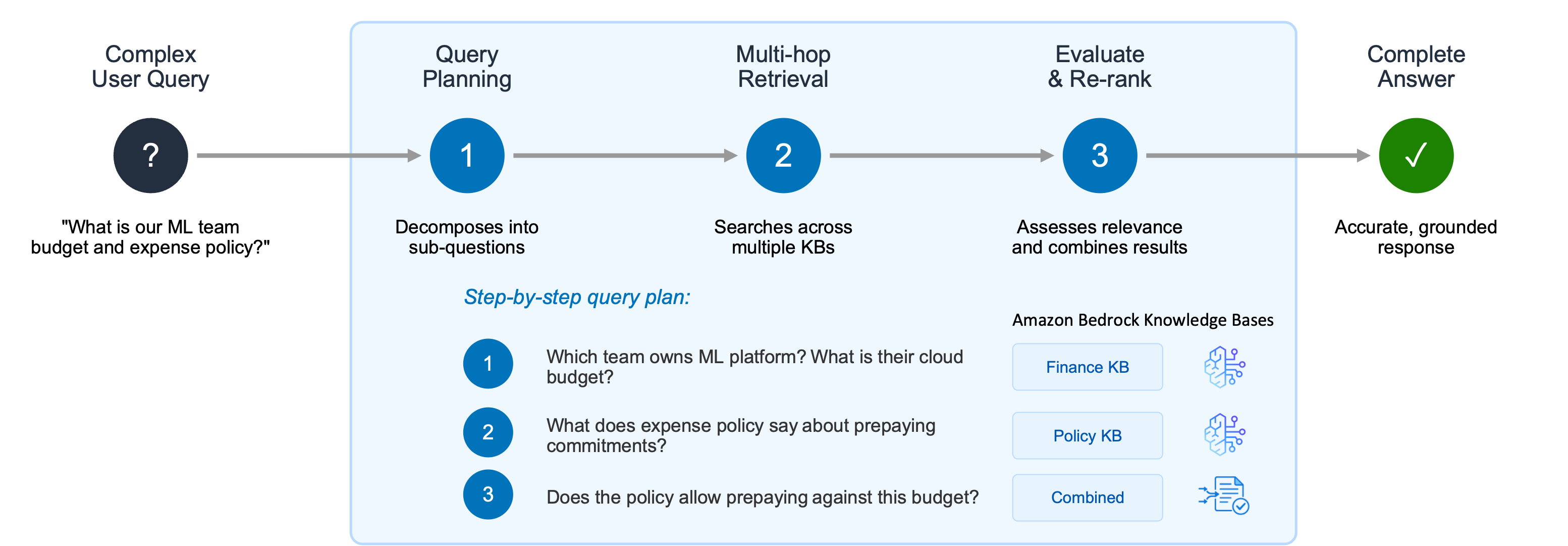
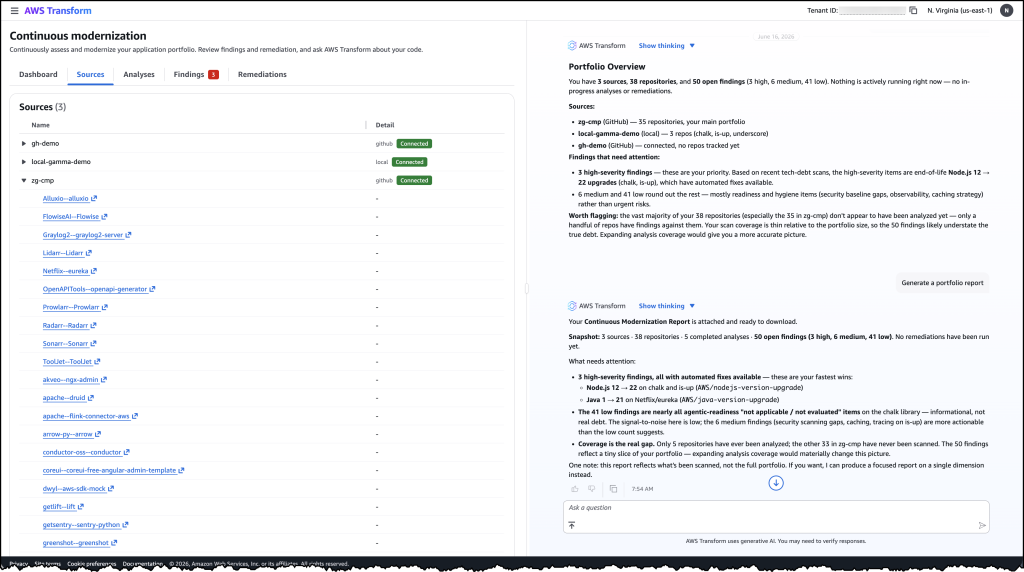
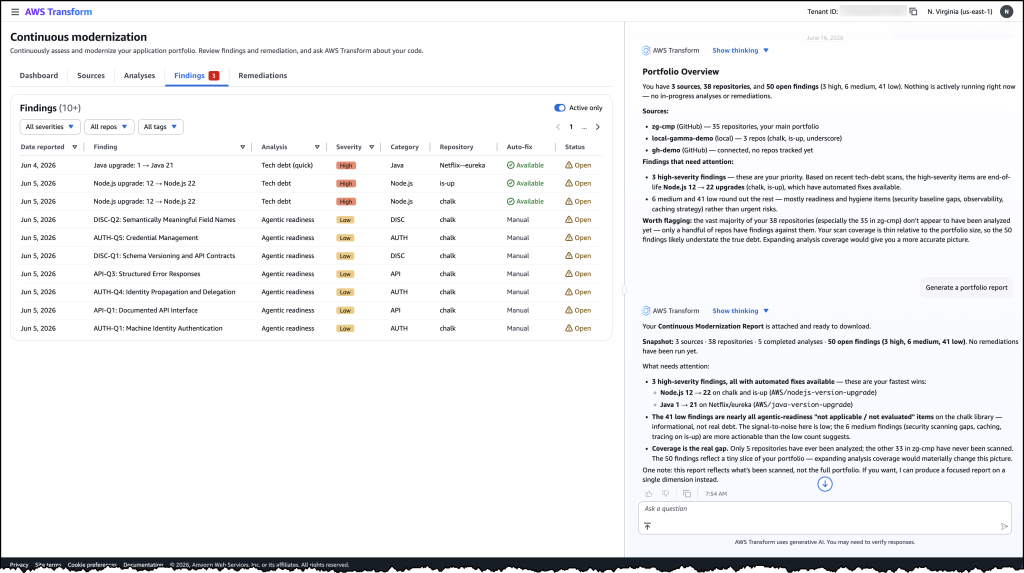
Each year on the anniversary of Project Galileo, we announce new products, programs, and strategic partnerships. To celebrate our 12th anniversary this year, we’re publishing our first comprehensive report on cyberattacks targeting civil society, releasing case studies that explore the security needs of 16 Project Galileo participants, and announcing new project partners.

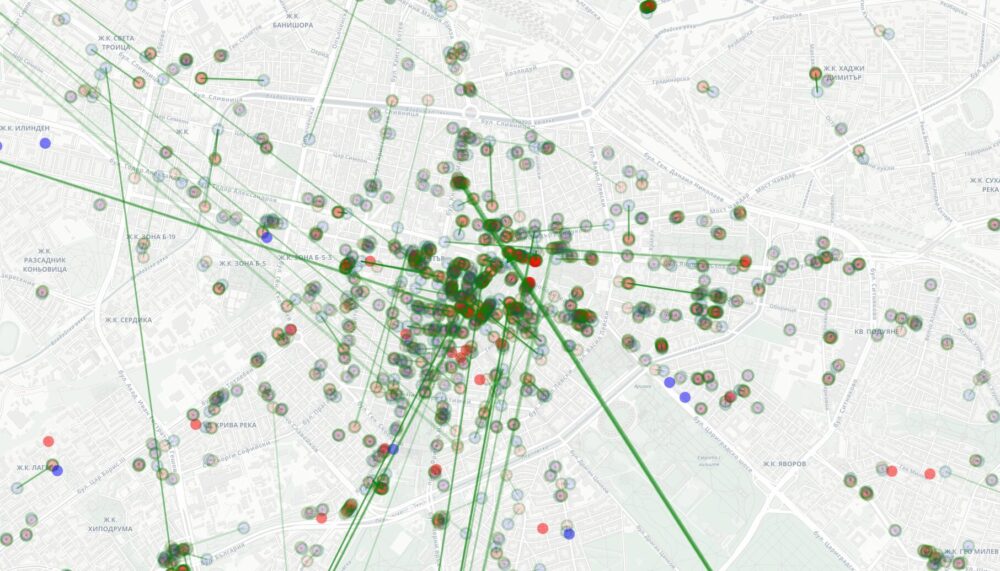
Because Project Galileo now includes 3,400 domains belonging to organizations in over 120 countries, Cloudflare has access to unique data regarding the cyber threats, attacks, and trends targeting civil society — a critical pillar of global democracy. In addition, because the Cloudflare network spans more than 335 cities in 125 countries and more than 20% of the web sits behind it, we were also able to compare attacks targeting civil society with those targeting the Internet more broadly. The full report can be explored here.
This year’s data demonstrates that civil society organizations were targeted more frequently, and often more intensely, than other Internet users. Cyberattacks often coincided with critical moments in civil society’s work, such as publishing investigative reporting or conducting public advocacy. Our key findings include:
-
DDoS attacks were the most common cyber threat against civil society. Their defining feature was duration, with some spanning days and weeks.
-
Civil society groups faced attempts to exploit website vulnerabilities at a rate more than seven times higher than other Cloudflare customers. Media organizations were disproportionately impacted.
-
Journalists operating in exile faced a rate of malicious traffic that was nearly four times higher than journalism organizations overall.
-
Nearly 10% of all emails Cloudflare processed for civil society included potential phishing material.
We conclude our report with a call to action: ensure simple and affordable cybersecurity for all, expand transparency about cyberattacks and Internet shutdowns, and embed AI and post-quantum protections into security tools by default. We hope this report can serve as a resource for civil society, policymakers, and the broader public seeking to understand and respond to cyberattacks. Moving forward, we plan to produce it annually, allowing us to compare cyber threat trends over time.

In addition to the report, Cloudflare released the following qualitative case studies that add context about each organization’s security needs.
|
Organization |
Description |
Country/Region of Operation |
|---|---|---|
|
Nonprofit advocating for privacy, free expression, and other digital rights. |
Serbia |
|
|
Online platform/database for finding lost and found pets, connecting owners with animal shelters. |
Czech Republic |
|
|
Research project tracking Iran’s weapons capabilities and nonproliferation issues, run by the Wisconsin Project on Nuclear Arms Control. |
United States |
|
|
Nonprofit media organization covering nuclear risk, climate change, and disruptive tech. |
United States |
|
|
Society for weather and climate science, supporting meteorology research, education, and professional accreditation. |
United Kingdom |
|
|
An engineering collective that develops tools and research for human rights organizations, lawyers, and activists operating in high-risk environments. |
Global |
|
|
Digital archive documenting and preserving evidence of war crimes and events from the Russia-Ukraine war. |
Ukraine |
|
|
Research and data publication on global issues like poverty, health, and climate. |
United Kingdom |
|
|
Think-and-do tank focused on user-friendly justice systems and resolving justice problems for people worldwide. |
Netherlands |
|
|
Progressive public policy research and advocacy think tank. |
United States |
|
|
Brazilian chapter of Sea Shepherd, marine conservation organization protecting ocean wildlife and ecosystems. |
Brazil |
|
|
Independent digital media outlet covering Cuba, including news, economics, and exchange rate tracking. |
Global |
|
|
Nonprofit ticketing platform donating booking fees to children’s education and health charities. |
Australia |
|
|
Global investigative journalism network exposing organized crime and corruption. |
Netherlands |
|
|
Legal information resource for activists on their rights and legal risks during protest and campaigning. |
Australia |
|
|
Bilingual news website covering censorship, human rights, and politics in China. |
United States |
Project Galileo relies on its 59 civil society partners to be a success. Every single organization that applies to the program is reviewed and approved by one of these partners. These groups volunteer their time and expertise, often reviewing multiple applications per day, to help make sure our services go to deserving organizations.
Over time, these relationships have not only helped grow Project Galileo into the program it is today, but also launched entirely new initiatives, like our email security partnership with Protect.ngo (formerly CyberPeace Institute) or our work supporting Internet measurement at public schools through UNICEF’s Giga project.
For several years, one of our goals for Project Galileo has been to reach more organizations in regions outside North America and Europe. Part of that effort has been attending regional events like RightsCon in Costa Rica (2023) and Taiwan (2025) to speak directly with local digital rights organizations. We have also welcomed new partners who bring their own active networks and communities into the program. For example, last year we announced two new partners in the Asia-Pacific region: EngageMedia and the OpenCulture Foundation.
Because of the new services we recently added to Project Galileo to help local news organizations protect their content from AI crawlers, our partnership focus this year was groups serving journalists. To that end, we are proud to announce three new partners:
|
Organization |
Description |
Country/Region of Operation |
|---|---|---|
|
Nonprofit focused on promoting high-quality independent journalism. Provides training, fellowships, mentorship, and financial support to journalists, specializing in helping reporters leverage digital technologies. |
Based in the United States and supporting journalists in 180+ countries. |
|
|
Innovation hub focused on next-generation media technology. Provides collaborative research spaces, funding opportunities, business incubation, and networking events for 100+ creators and local newsrooms. |
Norway |
|
|
Nonprofit network focused on protecting civil society from cybersecurity threats. Provides threat intelligence, defensive coordination, training, and support to its network of over 1,000 nonprofit organizations. |
United States |
Today’s new report, case studies, and new partners are all aimed at working toward Project Galileo’s fundamental goal: ensuring that cyberattacks do not silence organizations working in vulnerable, essential areas like journalism and human rights.
As we look to the future, we remain committed to finding new ways to expand our protections to at-risk groups worldwide. If your organization is looking for protection under Project Galileo, please visit cloudflare.com/galileo.