Post Syndicated from Sébastien Stormacq original https://aws.amazon.com/blogs/aws/amazon-chime-sdk-call-analytics-real-time-voice-tone-analysis-and-speaker-search/
Today, I am pleased to announce the availability of Amazon Chime SDK call analytics, a new set of capabilities that helps make it easier and cost effective to record and generate insights on real-time audio calls: transcription, voice tone analysis, and speaker search. We’ve also improved the Amazon Chime SDK section of the AWS Management Console to let you integrate machine learning (ML)-based services, such as these new call analytics capabilities or Amazon Transcribe into your audio applications in just a few steps.
Voice Analytics: Voice Tone Analysis and Speaker Search
Voice analytics delivers real-time insights into audio conversations. It helps detect and classify participants expressing a positive, neutral, or negative tone. Typically, enterprises working in regulated industries have obligations to record or want to analyze conversations between employees and their business partners, customers, or suppliers.
Voice tone analysis uses ML to extract sentiment from a speech signal based on a joint analysis of lexical and linguistic information as well as acoustic and tonal information. Voice tone analysis for live calls are delivered in the data lake of your choice, on top of which you can create your own dashboards to visualize the data.
Let’s take an example from the finance industry. Trading room supervisors are sometimes required to record all the trading conversations occurring on the floor. Voice tone analysis helps them meet their regulatory requirements. They can also deliver these insights to the traders to help to improve their productivity. But finance is not the only industry that needs to record and analyze calls. We have received similar requests from customers in Business Process Outsourcing (BPO), public sector, healthcare, telecom, and insurance industries.
Alongside with voice tone analysis, your applications can now benefit from speaker search to help match speakers to an existing database. It only requires a short sample to recognize a speaker based on their voice stored in a database of known voices. Speaker search helps your applications expedite caller lookup and enrich call records and transcripts with identity attribution. Speaker search delivers a suggested unique internal identifier for the speaker and a confidence score. The decision to match current the speaker with a known speaker from your organization is up to your application. Some of our customers plan to use speaker search for real-time speaker labeling on communication happening over trading turrets, which are shared devices.
Integration with AI Services in the AWS Management Console
We want to make it easier for developers to add these capabilities into existing telephony applications without requiring expertise in telephony, cloud infrastructure, or AI.
This is why we added a easier-to-use graphical configuration in the Amazon Chime SDK section of the console. On the console, you can choose the AWS AI service you want to use to analyze real-time audio data: voice analytics, Amazon Transcribe, or Amazon Transcribe Call Analytics. Whether you choose to use voice analytics or Amazon Transcribe to generate insights, you don’t have to write any integration code. We manage the integrations with AWS AI services and your voice-based or telephony applications. The console helps you define where you want to send the analytics data: an Amazon Kinesis stream or an Amazon Simple Storage Service (Amazon S3) bucket. Voice analytics can send real-time notifications to a function deployed on AWS Lambda, or an SQS queue or Amazon Simple Notification Service (Amazon SNS) topic.
To visualize insights, call analytics also delivers analyses to a data lake of your choice. You can then use Amazon QuickSight or Tableau to build dashboards and get insights from real-time media. These dashboards can be embedded in apps, wikis, and portals. Of course, we don’t leave you alone with your data. You can download prebuilt dashboards as AWS CloudFormation templates to deploy into your own AWS account. The link to download these templates is available on the console.
Finally, call analytics can generate real-time alerts by posting events to Amazon EventBridge. You can route these events to any destination of your choice, on your AWS account or supported third-party applications.
When using call analytics, you can reduce the initial project time to generate insights from real-time audio from months to days.
How It Works
I’d like to show you how it works.
On the Amazon Chime SDK section of the console, I open Configuration under Call Analytics on the left-side menu. Then, I select Create configuration.
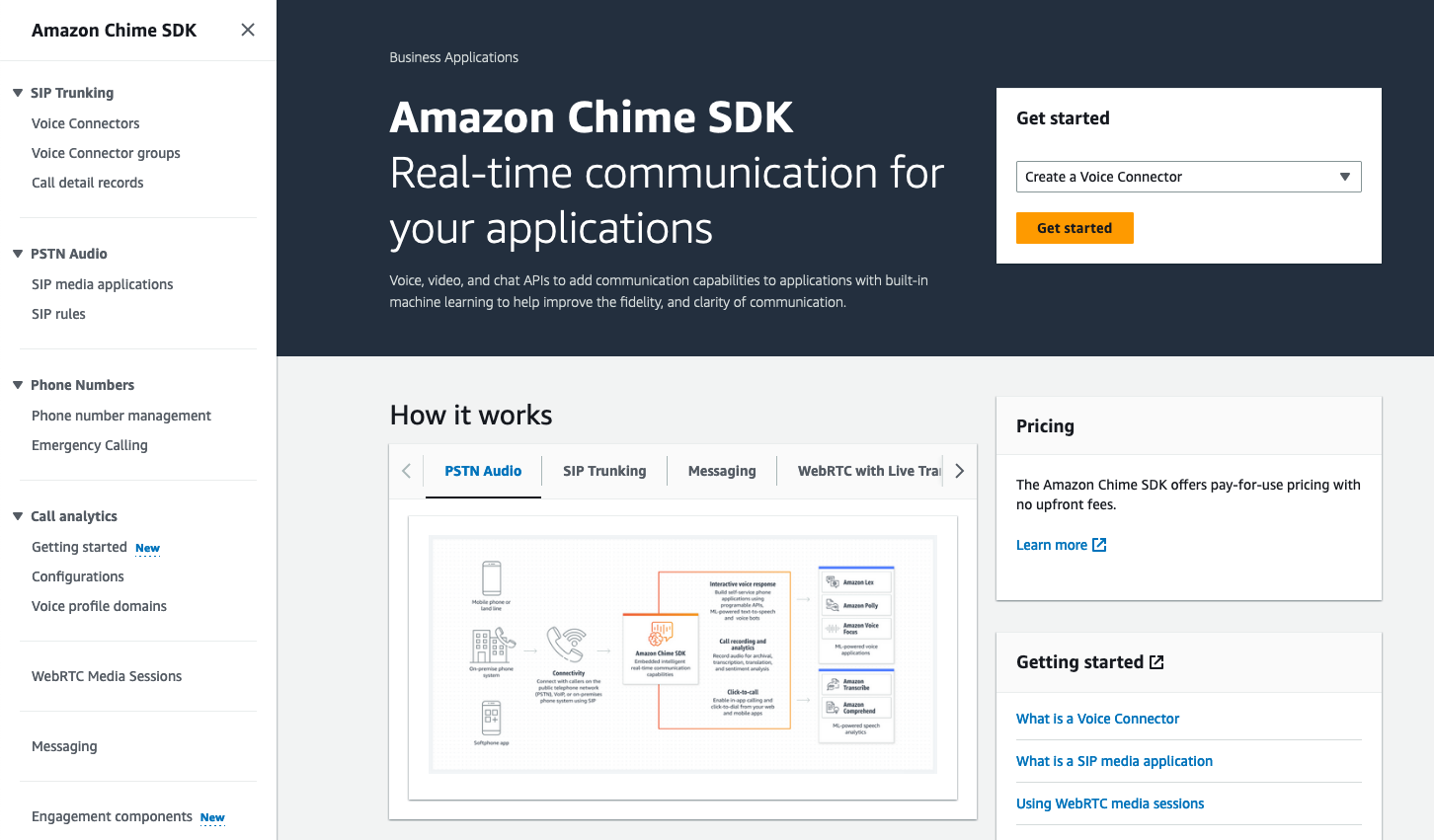
I give a name to my configuration. Optionally, I may also associate tags.

Under Configure analytics service, I can choose between Amazon Chime SDK voice analytics or Amazon Transcribe services to analyse calls. For this demo, I select Voice analytics.
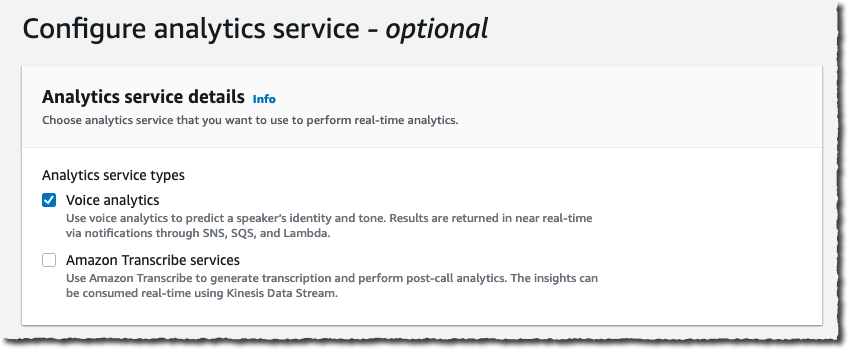
I configure where to send the analysis. Voice analytics results are always sent to Kinesis. I specify a Kinesis data stream I created previously. When I want to use a business intelligence tool such as Quicksight to create a dashboard with analytics results, I also specify an S3 bucket to receive the analysis.
The console also gives me the link to the CloudFormation templates I can use to create the voice analytics dashboards.
Finally, I choose a Lambda function, SQS queue, or SNS topic that will receive notifications of events such as when the analytics are available, a new voice enrollment occurs, or the result of a voice verification. In the later case, the payload looks as follow:
{
...common to all events...
"detail-type": "SpeakerSearchStatus",
"detail": {
"taskId": "uuid",
"detailStatus": "IdentificationSuccessful",
"speakerSearchDetails" : {
"results": [
{
"voiceProfileId": "guid",
"confidenceScore": "0.94",
},
{
"voiceProfileId": "guid",
"confidenceScore": "0.92",
},
{
"voiceProfileId": "guid",
"confidenceScore": "0.91",
},
... (up to 10)
]
},
"isCaller": false,
"voiceConnectorId": "guid",
"transactionId": "guid"
...details from Voice connector
}
}For this demo, I choose an existing SQS queue.
Under Consent acknowledgment, I select all the boxes and select Next.

The next step is only available when I didn’t specify any analytics service in the previous step. It allows us to configure voice recordings. Recordings are available when no analytics are selected.
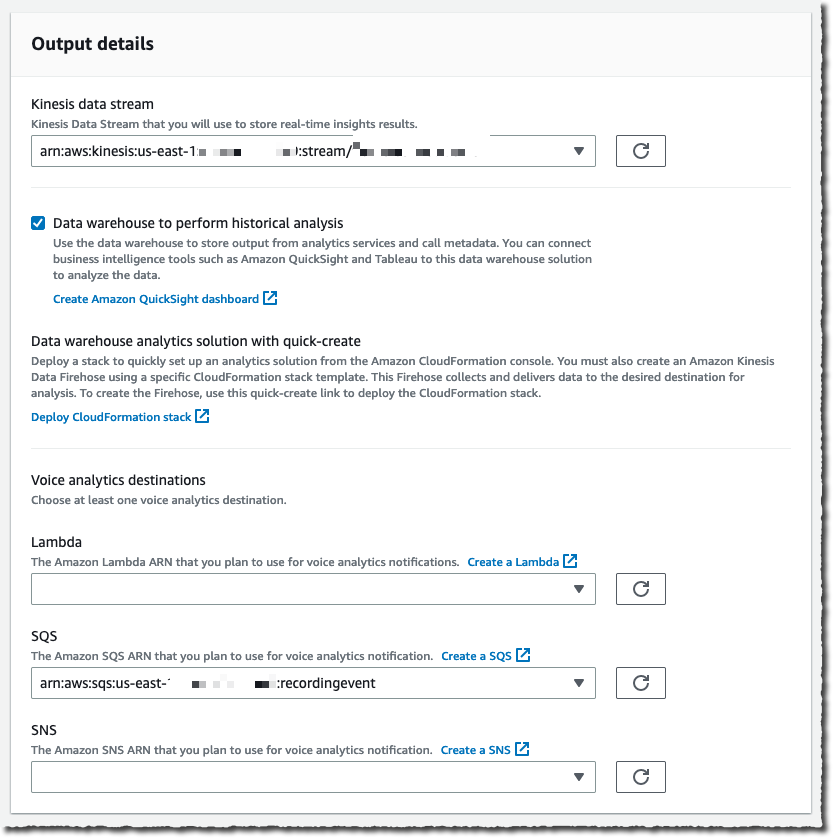
Under Configure access permissions, I choose a previously created AWS Identity and Access Management (IAM) role allowing the Amazon Chime SDK to access the other AWS services I configured: the Kinesis data stream, S3 bucket, and Lambda function, SQS queue, or SNS topic. The console may create an IAM role for me if I don’t have one already.
The next step is available if I selected Amazon Transcribe service under Configure analytics service. It allows me to configure real-time alerts through EventBridge. I may configure rules to send messages based on keyword match, sentiment detected, or issue detection.
The final step is Review and Create my configuration. I review the configuration details and then, I select Create configuration.
Finally, I link this configuration to a voice connector under the Voice Connector section, on the Streaming tab.
That’s it! As I mentioned earlier, no glue between AWS services or AI knowledge is required.
After the data arrives on Kinesis or your S3 bucket, you can point your preferred business reporting solution at it. When you use the QuickSight template we provide, you can get started in minutes with a high-level overview and a deep-dive view, as shown on the following screenshot.
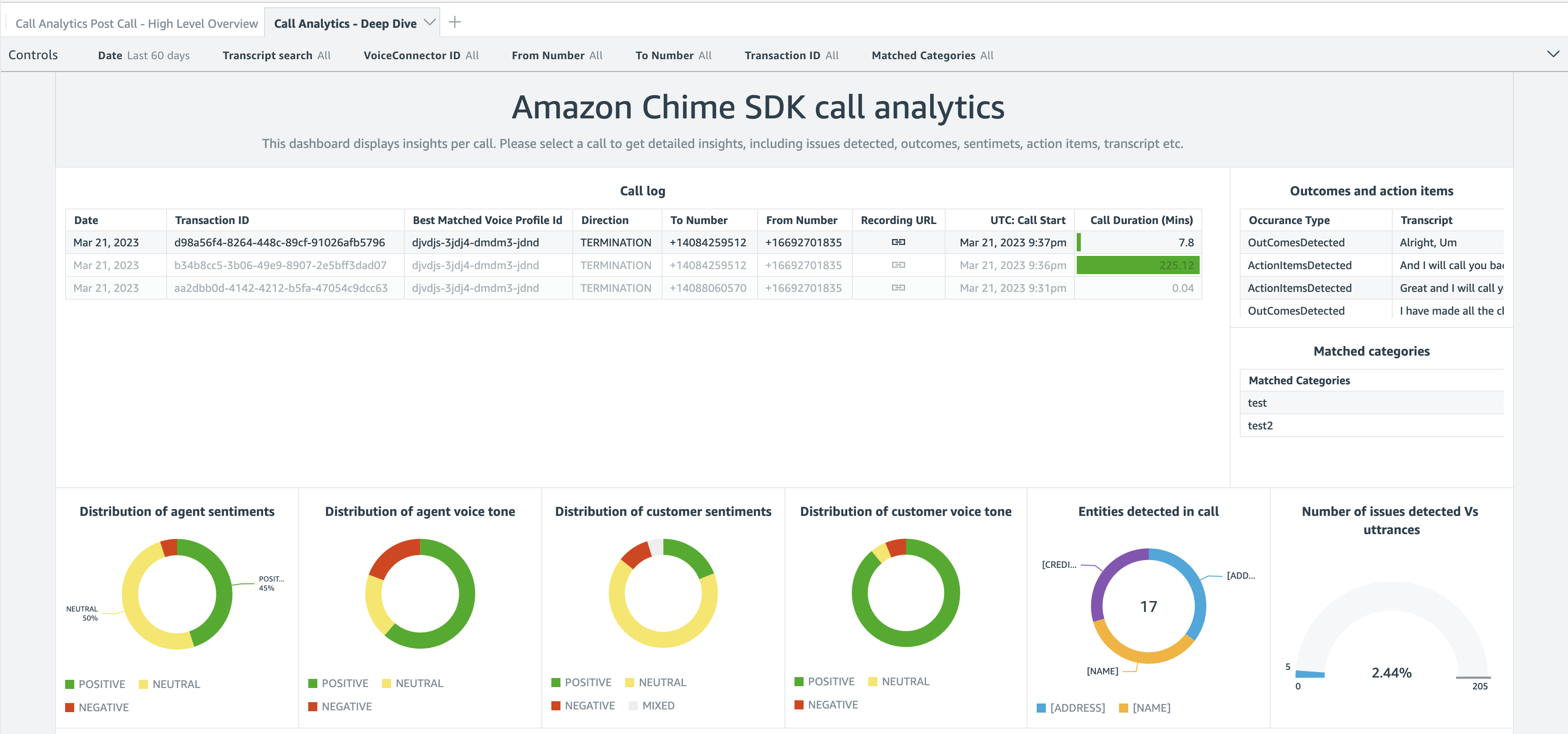

The deep-dive dashboard gives you graphical representations about the distribution of agent and customer sentiments and emotions. You also get a detailed analysis and transcript of the conversation.
Pricing and Availability
Adopting these capabilities in your audio applications requires no up-front infrastructure investment; you will be charged based only on your usage. Pricing is per minute of audio data analyzed. Visit Amazon Chime SDK pricing for details.
Call analytics is available in the following AWS Regions: US East (Ohio, N. Virginia), Asia Pacific (Singapore), and Europe (Frankfurt).
In this post, I discussed Amazon Chime SDK call analytics, a new set of capabilities that makes it easier and cost-effective to record and generate insights on real-time audio calls. With their focus on ease of use, these new capabilities are particularly well adapted to customers with minimal knowledge of cloud infrastructure, telephony, and ML.
Start today and configure your first dashboard!