Post Syndicated from Alex Krivit original https://blog.cloudflare.com/the-rum-diaries-enabling-web-analytics-by-default/
Measuring and improving performance on the Internet can be a daunting task because it spans multiple layers: from the user’s device and browser, to DNS lookups and the network routes, to edge configurations and origin server location. Each layer introduces its own variability such as last-mile bandwidth constraints, third-party scripts, or limited CPU resources, that are often invisible unless you have robust observability tooling in place. Even if you gather data from most of these Internet hops, performance engineers still need to correlate different metrics like front-end events, network processing times, and server-side logs in order to pinpoint where and why elusive “latency” occurs to understand how to fix it.
We want to solve this problem by providing a powerful, in-depth monitoring solution that helps you debug and optimize applications, so you can understand and trace performance issues across the Internet, end to end.
That’s why we’re excited to announce the start of a major upgrade to Cloudflare’s performance analytics suite: Web Analytics as part of our real user monitoring (RUM) tools will soon be combined with network-level insights to help you pinpoint performance issues anywhere on a packet’s journey — from a visitor’s browser, through Cloudflare’s network, to your origin.
Some popular web performance monitoring tools have also sacrificed user privacy in order to achieve depth of visibility. We’re also going to remove that tradeoff. By correlating client-side metrics (like Core Web Vitals) with detailed network and origin data, developers can see where slowdowns occur — and why — all while preserving end user privacy (by dropping client-specific information and aggregating data by visits as explained in greater detail below).
Over the next several months we’ll share:
-
How Web Analytics work
-
Real-world debugging examples from across the Internet
-
Tips to get the most value from Cloudflare’s analytics tools
The journey starts on October 15, 2025, when Cloudflare will enable Web Analytics for all free domains by default — helping you see how your site actually performs for visitors around the world in real time, without ever collecting any personal data (not applicable to traffic originating from the EU or UK, see below). By the middle of 2026, we’ll deliver something nobody has ever had before: a comprehensive, privacy-first platform for performance monitoring and debugging. Unlike many other tools, this platform won’t just show you where latency lives, it will help you fix it, all in one place. From untangling the trickiest bottlenecks, to getting a crystal-clear view of global performance, this new tool will change how you see your web application and experiment with new performance features. And we’re not building it behind closed doors, we want to bring you along as we launch it in public. Follow along in this series, The RUM Diaries, as we share the journey.
Performance monitoring is only as good as the detail you can see — and the trust your users have that while you’re watching traffic performance, you aren’t watching them. As we explain below, by combining real user metrics with deep, in-network instrumentation, we’ll give developers the visibility to debug any layer of the stack while maintaining Cloudflare’s zero-compromise stance on privacy.
Many performance monitoring solutions provide only a narrow slice of the performance layer cake, focusing on either the client or the origin while lumping everything in between under a vague “processing time” due to lack of visibility. But as web applications get more complex and user expectations continue to rise, traditional analytics alone don’t cut it. Knowing what happened is just the tip of the iceberg; modern teams need to understand why a bottleneck occurred and how network conditions, code changes, or even a single external script can degrade load times. Moreover, often the tools available can only observe performance rather than helping to optimize it, which leaves teams unable to understand what to try to move the needle on latency.
We want to pull back the curtain so you can understand performance implications of the services you use on our platform and how you can make sure you’re getting the best performance possible.
Consider Shannon in Detroit, Michigan. She operates an e-commerce site selling hard-to-find watches to horology enthusiasts around the globe. Shannon knows that her customers are impatient (she pictures them frequently checking their wrists). If her site loads slowly, she loses sales, her SEO drops, and her customers go to a different store where they have a better online shopping experience.
As a result, Shannon continually monitors her site performance, but she frequently runs into problems trying to understand how her site is experienced by customers in different parts of the world. After updating her site, she frequently spot checks its performance using her browser on her office wifi in Detroit, but she continually hears complaints about slow load from her customers in Germany. So Shannon shops around for a solution that monitors performance around the globe.
This off-the-shelf performance monitoring solution offers her the ability to run similar tests from virtual machines situated around the world across various desktops, mobile devices, and even ISPs, close to her customers. Shannon receives data from these tests, ranging from how fast these synthetic clients’ DNS resolved, how quickly they connected to a particular server, and even when a response was on its way back to a client. Thankfully for Shannon, the off-the-shelf performance monitoring solution identified “server processing time” as the latency culprit in Germany. However, she can’t help but wonder, is it my server that is slow or the transit connection of my users in Germany? Can I make my site faster by adding another server in Germany, or updating my CDN configuration? It’s a three option head-scratcher: is it a networking problem, a server problem, or something else?
Cloudflare can help Shannon (and others!) because we sit in a unique place to provide richer performance analytics. As a reverse proxy positioned between the client and the origin, we are often the first web server a user connects to when requesting content. In addition to moving what’s important closer to your customers, our product suite can generate responses at our edge (e.g. Workers), steer traffic through our dedicated backbone (e.g. cloudflared and more), and route around Internet traffic jams (e.g. Argo). By tailoring a solution that brings together:
-
client performance data,
-
real-time network metrics,
-
customer configuration settings, and
-
origin performance measurements
we can provide more insightful information about what’s happening in the vague “processing time.” This will allow developers like Shannon to understand what they should tweak to make their site more performant, build her business and her customers happier.
Turning back to what’s happening on October 15, 2025: We’re enabling Web Analytics so teams can track down performance bottlenecks. Web Analytics works by adding a lightweight JavaScript snippet to your website, which helps monitor performance metrics from visitors to your site. In the Web Analytics dashboard you can see aggregate performance data related to: how a browser has painted the page (via LCP, INP, and CLS), general load time metrics associated with server processing, as well as aggregate counts of visitors.
If you’ve ever popped open DevTools in your browser and stared at the waterfall chart of a slow-loading page, you’ve had a taste of what Web Analytics is doing, except instead of measuring your load times from your laptop, it’s measuring it directly from the browsers of real visitors.
Here’s the high-level architecture:
A lightweight beacon in the browser
Every page that you track with Cloudflare’s Web Analytics includes a tiny JavaScript snippet, optimized to load asynchronously so it won’t block rendering.
-
This snippet hooks into modern browser APIs like the Performance API, Resource Timing, etc
-
This is how Cloudflare collects Core Web Vital metrics like Largest Contentful Paint and Interaction to Next Paint, plus data about resource load times, TLS handshake duration from the perspective of the client.
Aggregation at the edge
When the browser sends performance data, it goes to the nearest Cloudflare data center. Instead of pushing raw events straight to a database, we pre-process at the edge. This reduces storage needs, minimizes latency, and removes personal information like IP addresses. After this pre-processing, it is sent to a core datacenter to be processed and queried by users.

Web Analytics sits under the Analytics & Logs section of the dashboard (at both the account and domain level of the dashboard). Starting on October 15, 2025, free domains will begin to see Web Analytics enabled by default and will be able to view the performance of their visitors in their dashboard. Pro, Biz and ENT accounts can enable Web Analytics by selecting the hostname of the website to add the snippet to and selecting Automatic Setup. Alternatively, you can manually paste the JavaScript beacon before the closing </body> tag on any HTML page you’d like to track from your origin. Just select “manage site” from the Web Analytics tab in the dashboard.

Once enabled, the JS snippet works with visitors’ browsers to measure how the user experienced page load times and reports on critical client-side metrics. Below these metrics are resource attribution tables that help users understand which assets are taking the most time per metrics to load so that users can better optimize their site performance.

From the beginning, our Web Analytics tools have centered on providing insights without compromising privacy. Being privacy-first means we don’t track individual users for analytics. We don’t use any client-side state (like cookies or localStorage) for analytics purposes, and we don’t track users over time by IP address, User Agent, or any other fingerprinting technique.
Moreover, when enabling Web Analytics, you can choose to drop requests from European and UK visitors if you so desire (listed here specifically), meaning we will not collect any RUM metrics from traffic that passes through our European and UK data centers. The version of Web Analytics that will be enabled by default excludes data from EU visitors (this can be changed in the dashboard if you want).
The concept of a visit is key to our privacy approach. Rather than count unique IP addresses (requiring storing state about each visitor), we simply count page views that originate from a distinct referral or navigation event, avoiding the need to store information that might be considered personal data. We believe this same concept that we’ve used for years in providing our privacy-first Web Analytics can be logically extended to network and origin metrics. This will allow customers to gain the insights they need to debug and solve performance issues while ensuring they are not collecting unneeded data on visitors.

We built our Web Analytics service to give you the insights you need to run your website, all while maintaining a privacy-first approach. However, if you do want to opt-out, here are the steps to do so.
If you have a free domain and do not want Web Analytics automatically enabled for your zone you should do the following before October 15, 2025:
-
Navigate to the zone in the Cloudflare dashboard
-
In the list on the left of the screen, navigate to Web Analytics

-
On the next page, select either `Enable Globally` or `Exclude EU` to activate the feature
-
Once Web Analytics has been activated, navigate to `Manage RUM Settings` in the Web Analytics dashboard
-
Then, on the next page, select `Disable` to disable Web Analytics for the zone
-
OR, to remove Web Analytics from the zone entirely, delete the configs by clicking
Advanced Optionsand thenDelete
Once you have disabled the product once, we will not re-enable it again. You can choose to enable it whenever you want, however.





-
Create a Web Analytics configuration with the following API call:
curl https://api.cloudflare.com/client/v4/accounts/$ACCOUNT_ID/rum/site_info \ -H 'Content-Type: application/json' \ -H "X-Auth-Email: $CLOUDFLARE_EMAIL" \ -H "X-Auth-Key: $CLOUDFLARE_API_KEY" \ -d '{ "auto_install": false, "host": "example.com", "zone_tag": "023e105f4ecef8ad9ca31a8372d0c353" }'Note: This will not cause your zone to collect RUM data because auto_install is set to `false`
-
Collect the
site_tagandzone_tagfields from the response to this call-
site_tagin this response will correspond to$SITE_IDin the following calls
-
-
EITHER Disable the Web Analytics configuration with the following API call:
curl https://api.cloudflare.com/client/v4/accounts/$ACCOUNT_ID/rum/site_info/$SITE_ID \ -X PUT \ -H 'Content-Type: application/json' \ -H "X-Auth-Email: $CLOUDFLARE_EMAIL" \ -H "X-Auth-Key: $CLOUDFLARE_API_KEY" \ -d '{ "auto_install": true, "enabled": false, "host": "example.com", "zone_tag": "023e105f4ecef8ad9ca31a8372d0c353" }' -
OR Delete the Web Analytics configuration with the following API call:
curl https://api.cloudflare.com/client/v4/accounts/$ACCOUNT_ID/rum/site_info/$SITE_ID \ -X DELETE \ -H "X-Auth-Email: $CLOUDFLARE_EMAIL" \ -H "X-Auth-Key: $CLOUDFLARE_API_KEY"
Today, Web Analytics gives you visibility into how people experience your site in the browser. Next, we’re expanding that lens to show what’s happening across the entire request path, from the click in a user’s browser, through Cloudflare’s global network, to your origin servers, and back.
Here’s what’s coming:
-
Correlating Across Layers
We’ll match RUM data from the client with network timing, Cloudflare edge processing, and origin response latency, allowing you to pinpoint whether a spike in TTFB comes from a slow script, a cache miss, or an origin bottleneck. -
Proactive Alerting
Configurable alerts will tell you when performance regresses in specific geographies, when a data center underperforms, or when origin latency spikes. -
Actionable Insights
We’ll go beyond “processing time” as a single number, breaking it into the real-world steps that make up the journey: proxy routing, security checks, cache lookups, origin fetches, and more. -
Unified View
All of this will live in one place (your Cloudflare dashboard) alongside your analytics, logs, firewall events, and configuration settings, so you can see cause and effect in one workflow.
Stay tuned as we work alongside you, in public, to build the most comprehensive, privacy-focused performance analytics platform. Together, we will illuminate every corner of the request journey so you can optimize, innovate, and deliver the best experiences to your users, every time.
The next chapters of this journey will unlock proactive alerts, cross-layer correlation, and actionable insights you can’t get anywhere else. Follow along as the RUM Diaries are just getting started.
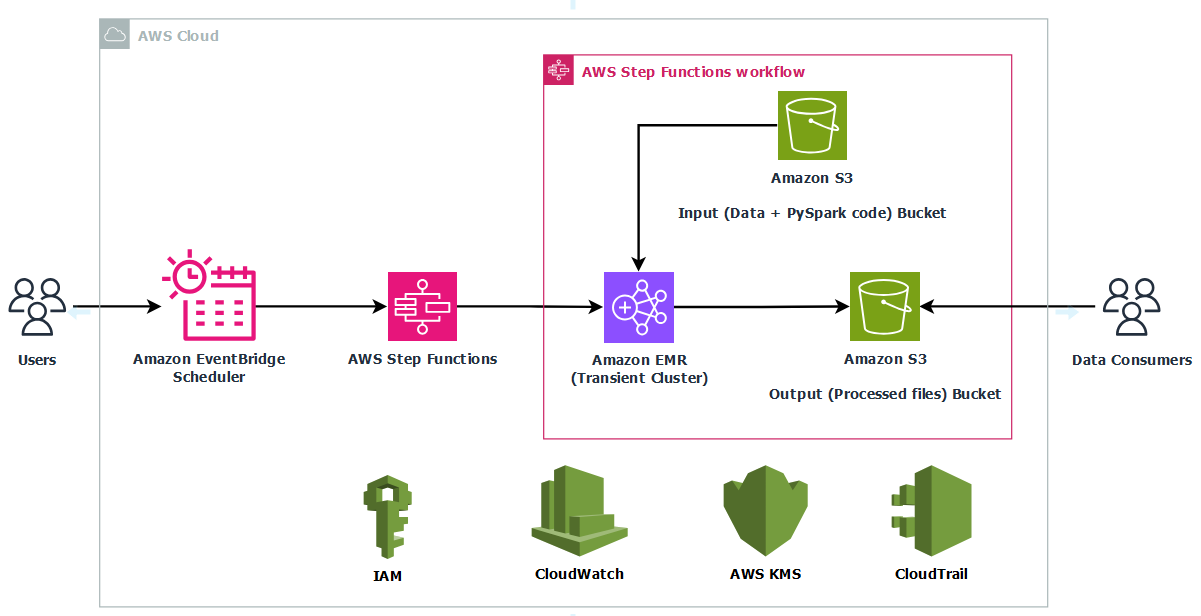
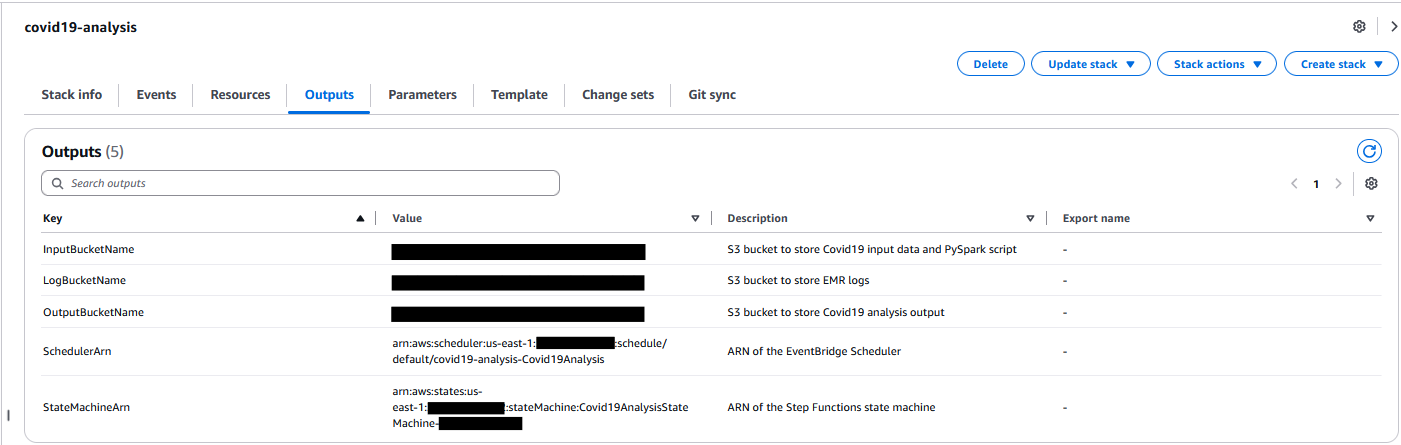
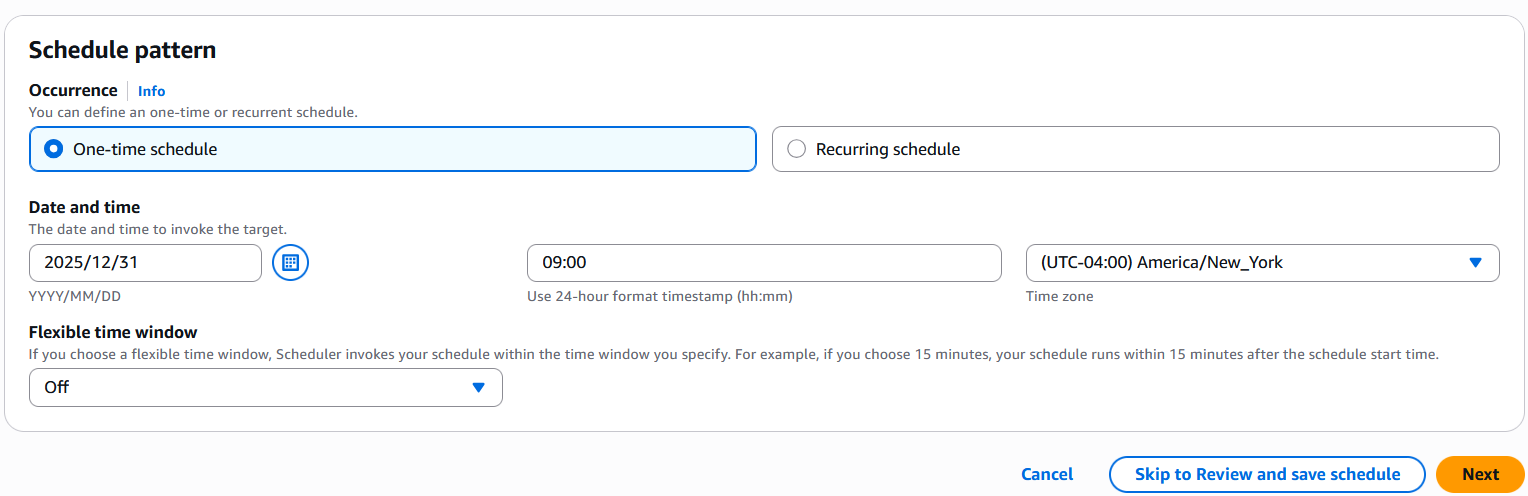
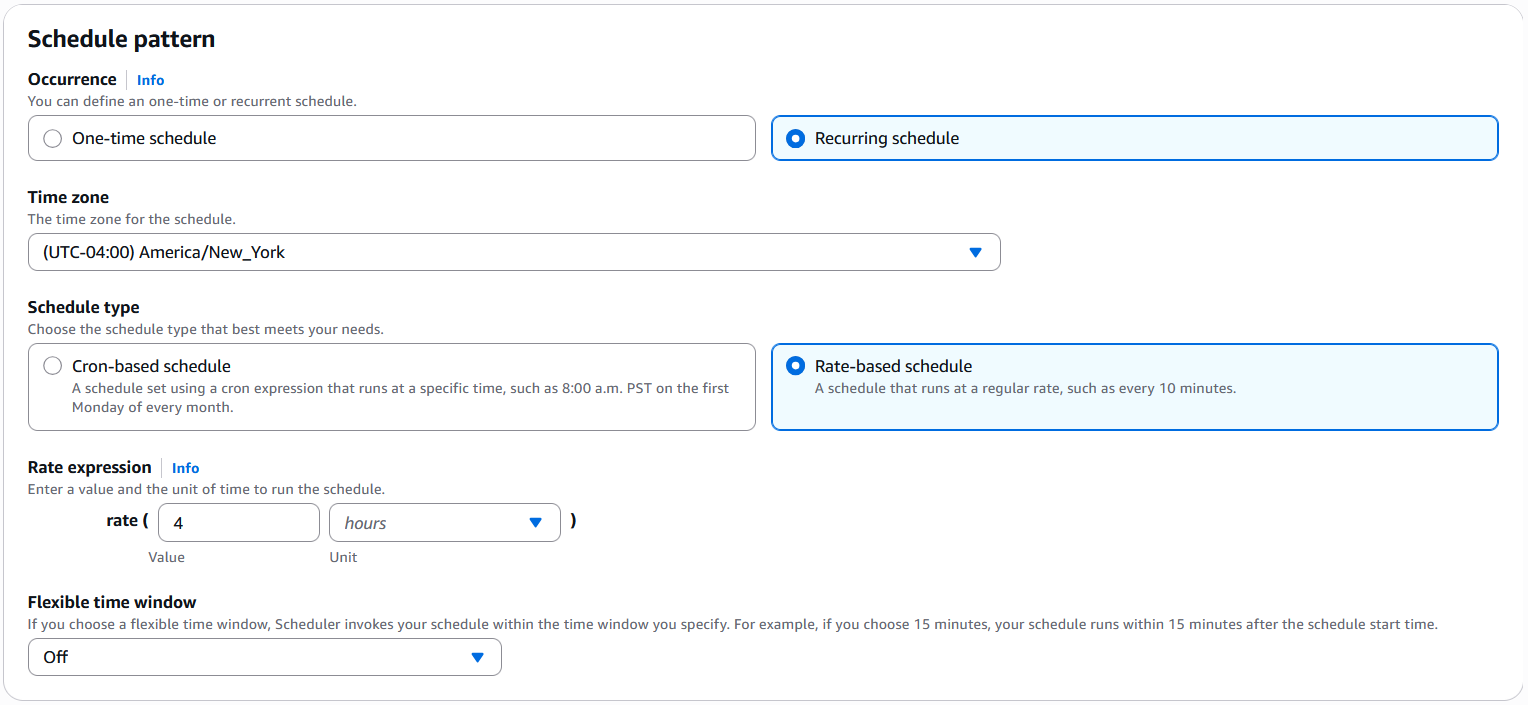

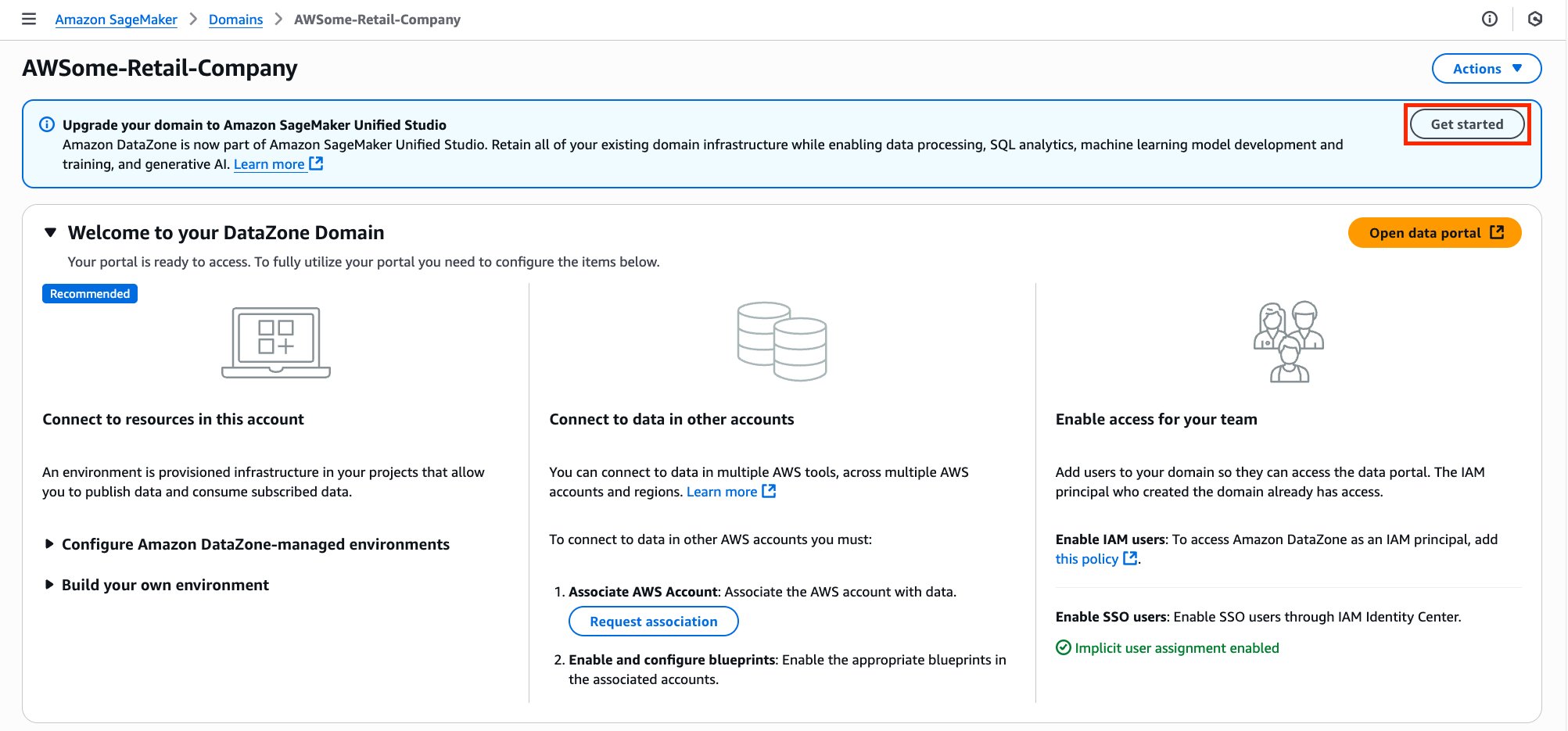
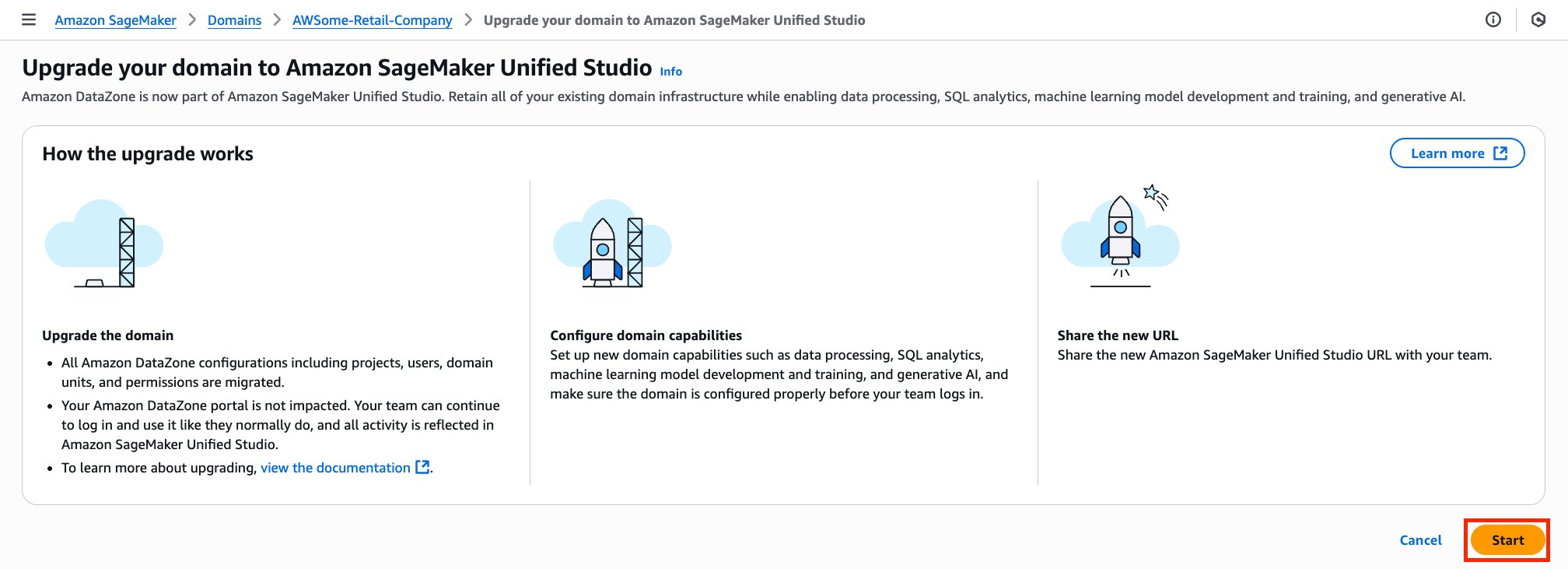
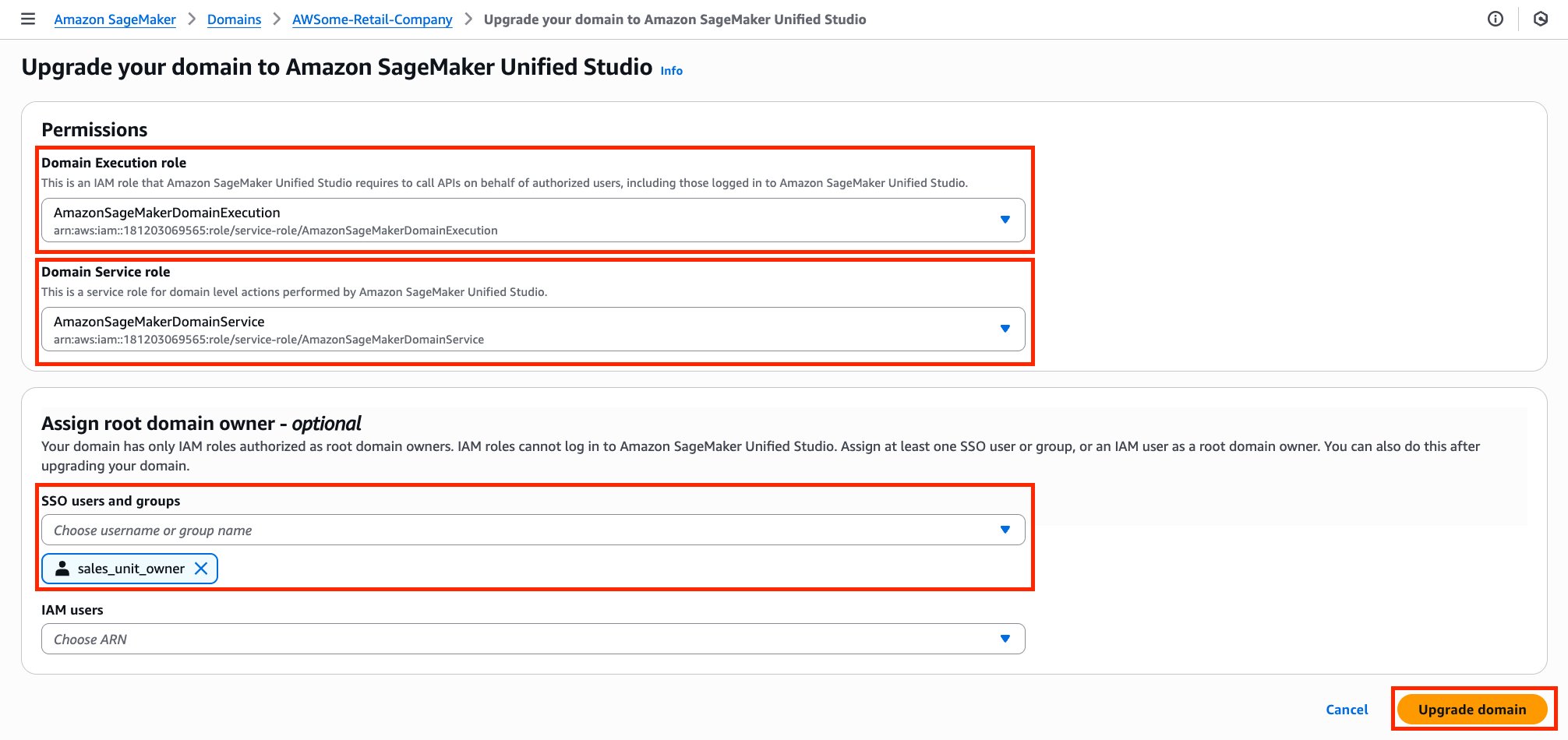
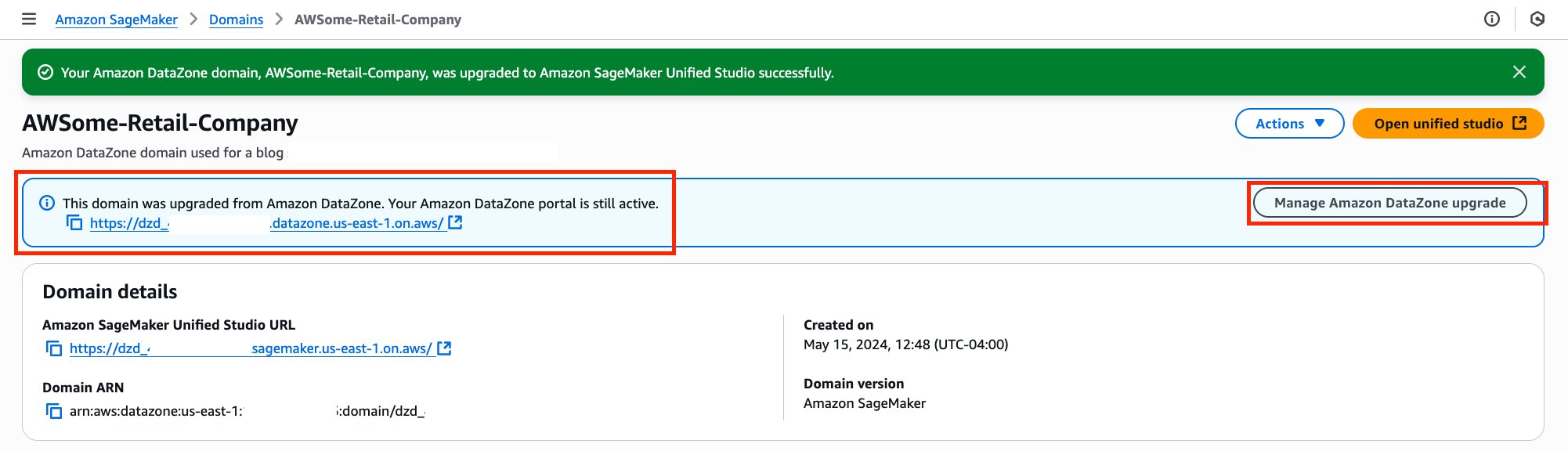
 David Victoria is a Senior Technical Product Manager with Amazon SageMaker at AWS. He focuses on improving administration and governance capabilities needed for customers to support their analytics systems. He is passionate about helping customers realize the most value from their data in a secure, governed manner.
David Victoria is a Senior Technical Product Manager with Amazon SageMaker at AWS. He focuses on improving administration and governance capabilities needed for customers to support their analytics systems. He is passionate about helping customers realize the most value from their data in a secure, governed manner. Leonardo David Gomez Virahonda is a Principal Analytics Specialist Solutions Architect at AWS, with a strong focus on data governance. He helps organizations across industries implement effective governance strategies using AWS services like Amazon DataZone, AWS Glue, Lake Formation, and SageMaker Catalog. Leonardo’s work spans metadata management, data lineage, access control, and compliance—empowering customers to make their data secure, discoverable, and ready for analytics and AI. He regularly shares best practices through technical blogs, enablement content, and sessions at AWS events like re:Invent and regional Summits.
Leonardo David Gomez Virahonda is a Principal Analytics Specialist Solutions Architect at AWS, with a strong focus on data governance. He helps organizations across industries implement effective governance strategies using AWS services like Amazon DataZone, AWS Glue, Lake Formation, and SageMaker Catalog. Leonardo’s work spans metadata management, data lineage, access control, and compliance—empowering customers to make their data secure, discoverable, and ready for analytics and AI. He regularly shares best practices through technical blogs, enablement content, and sessions at AWS events like re:Invent and regional Summits.
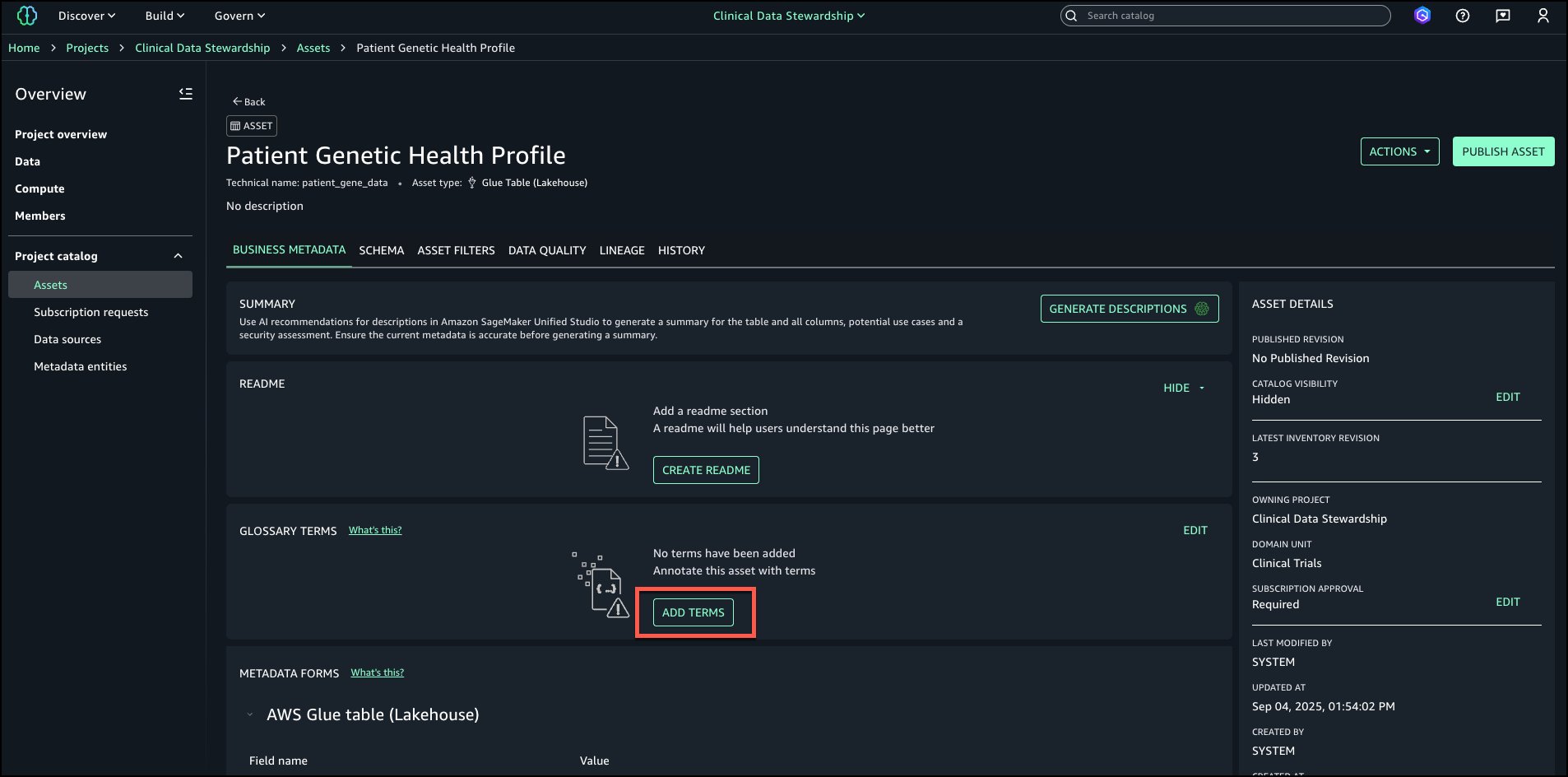
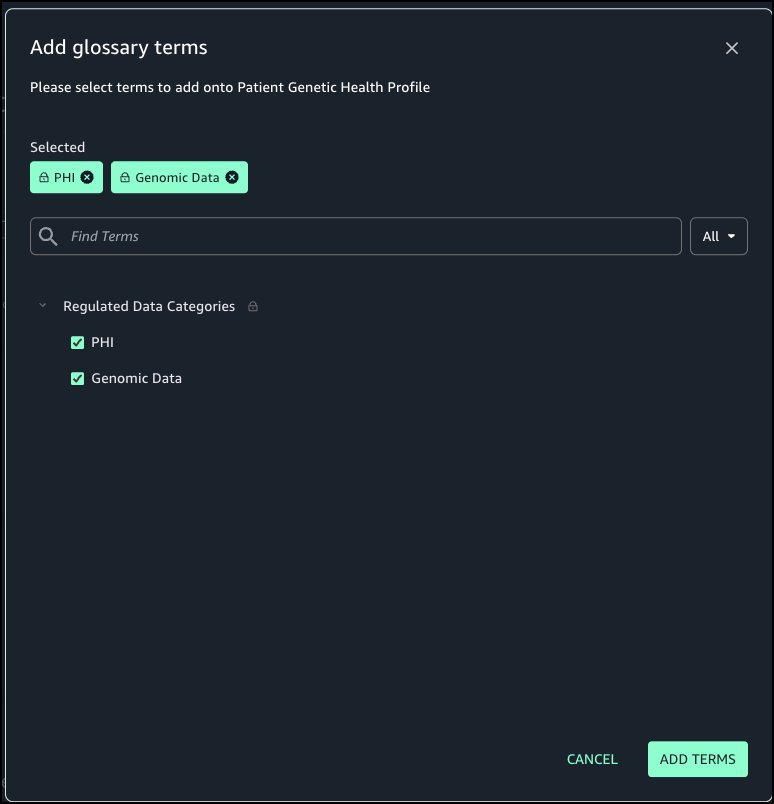
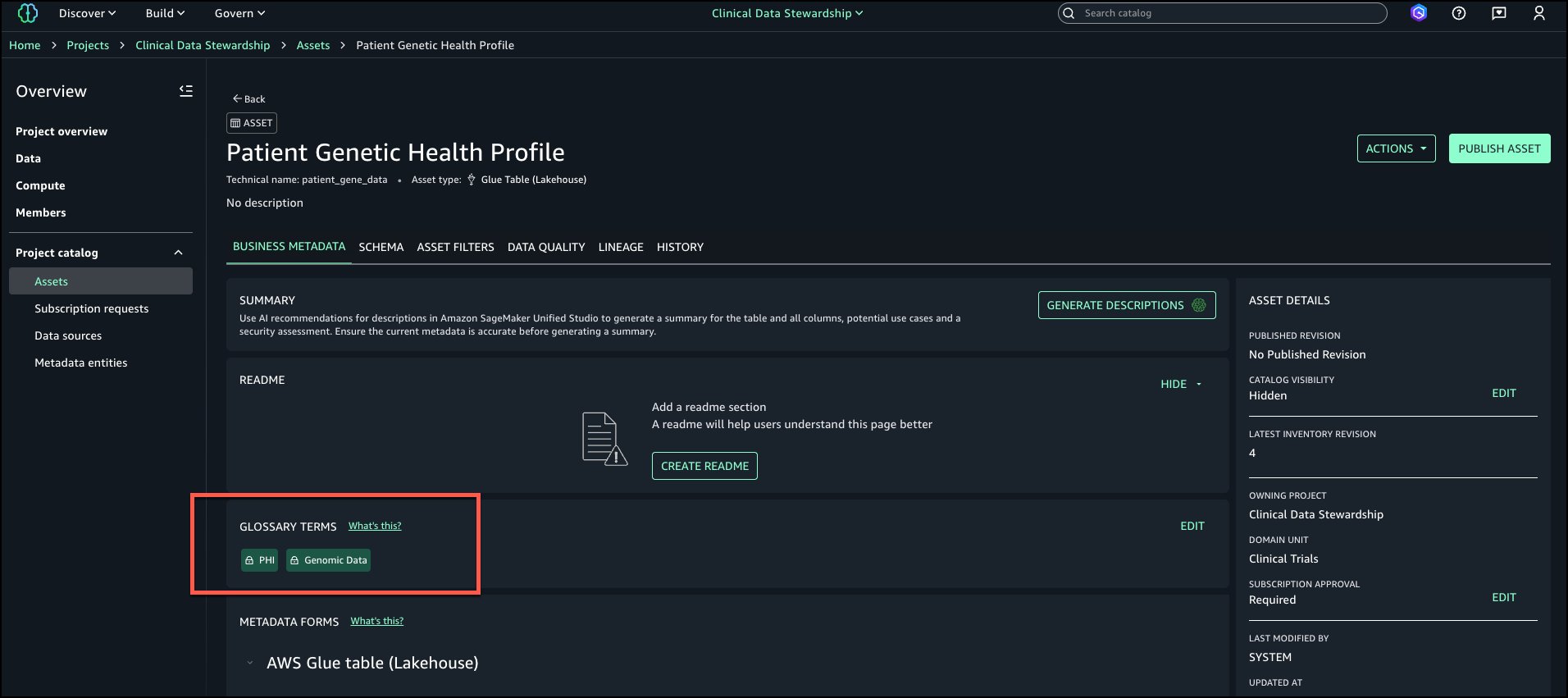

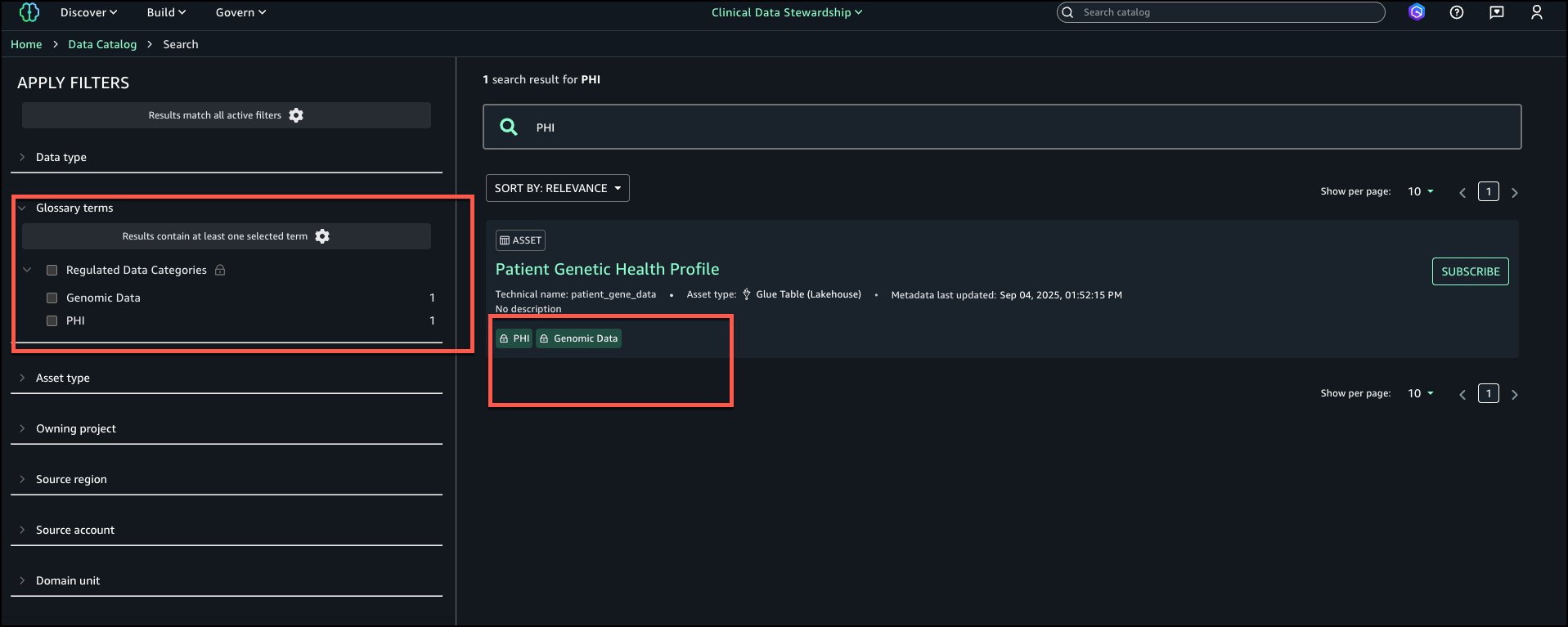


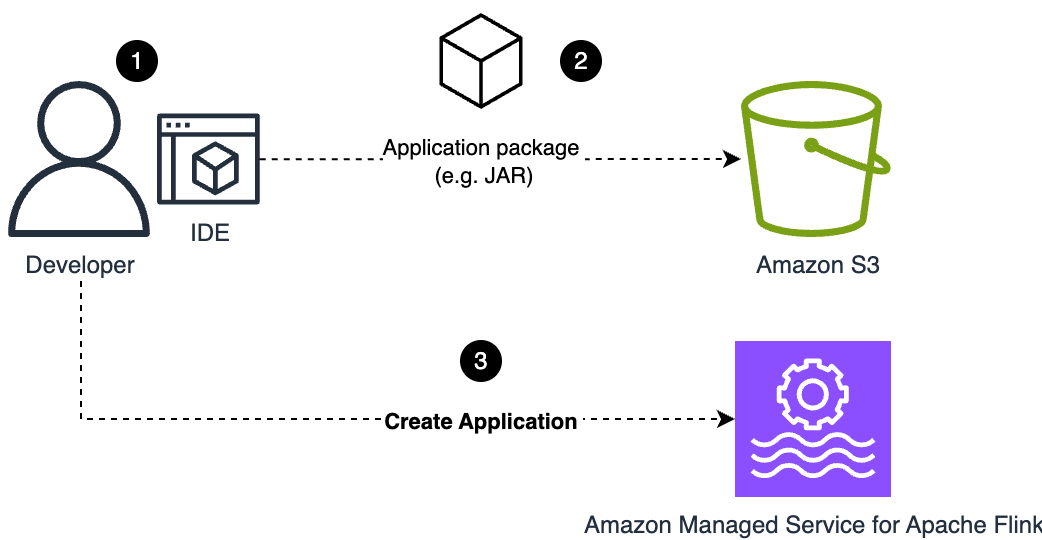
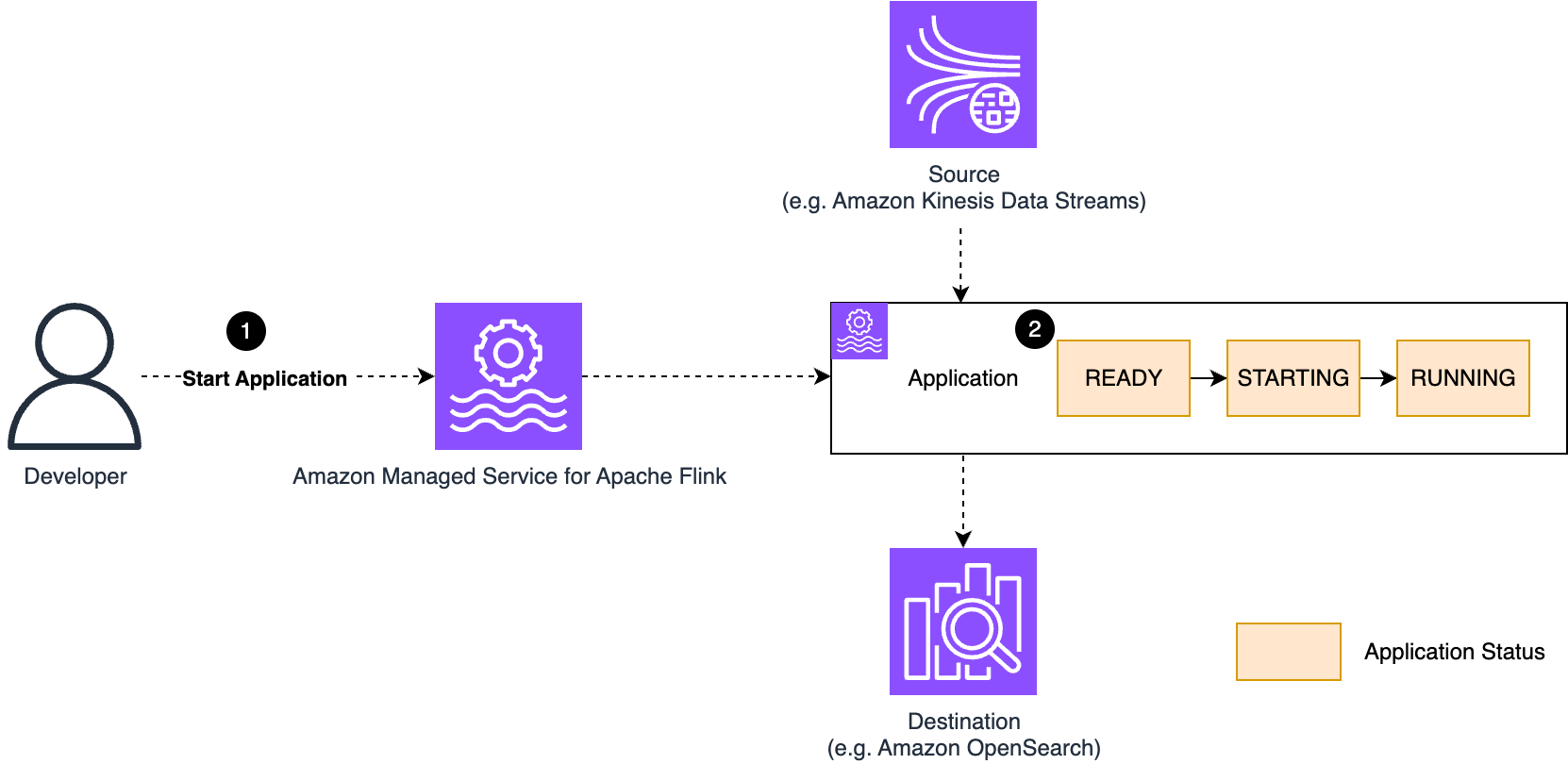
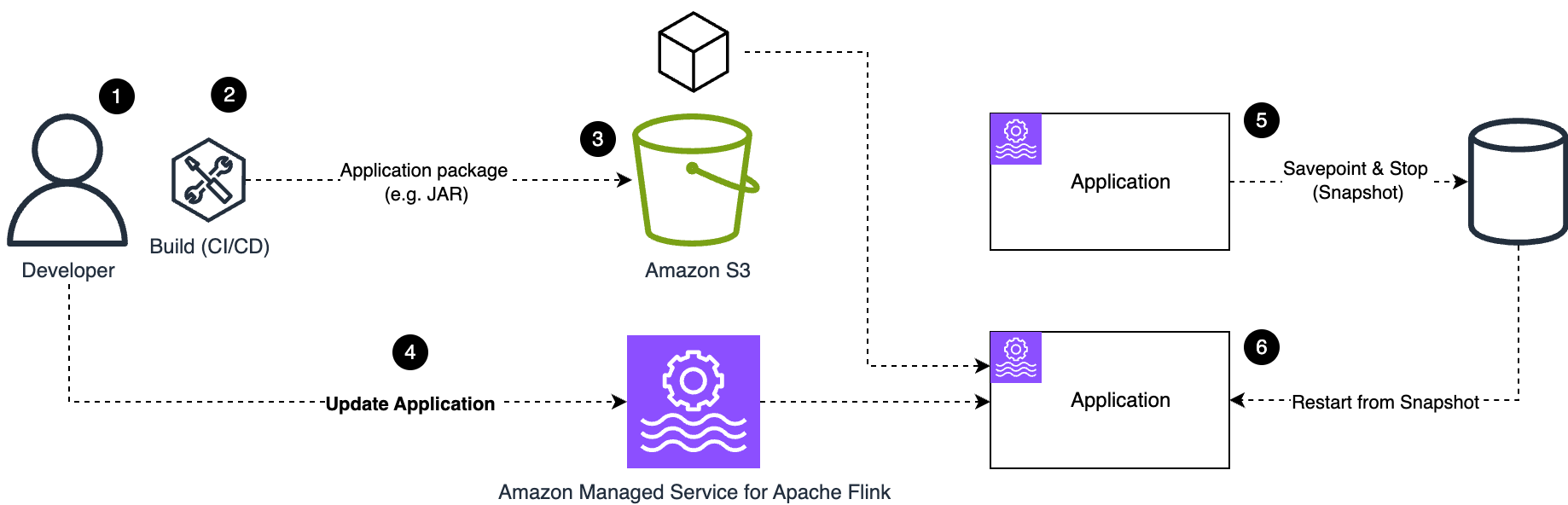
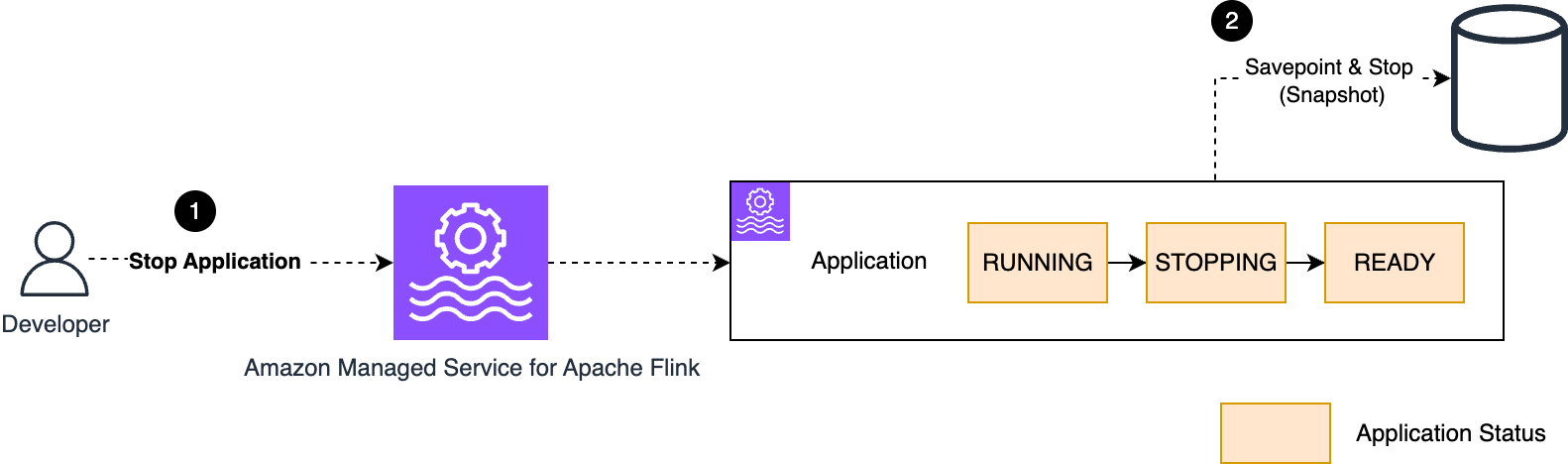
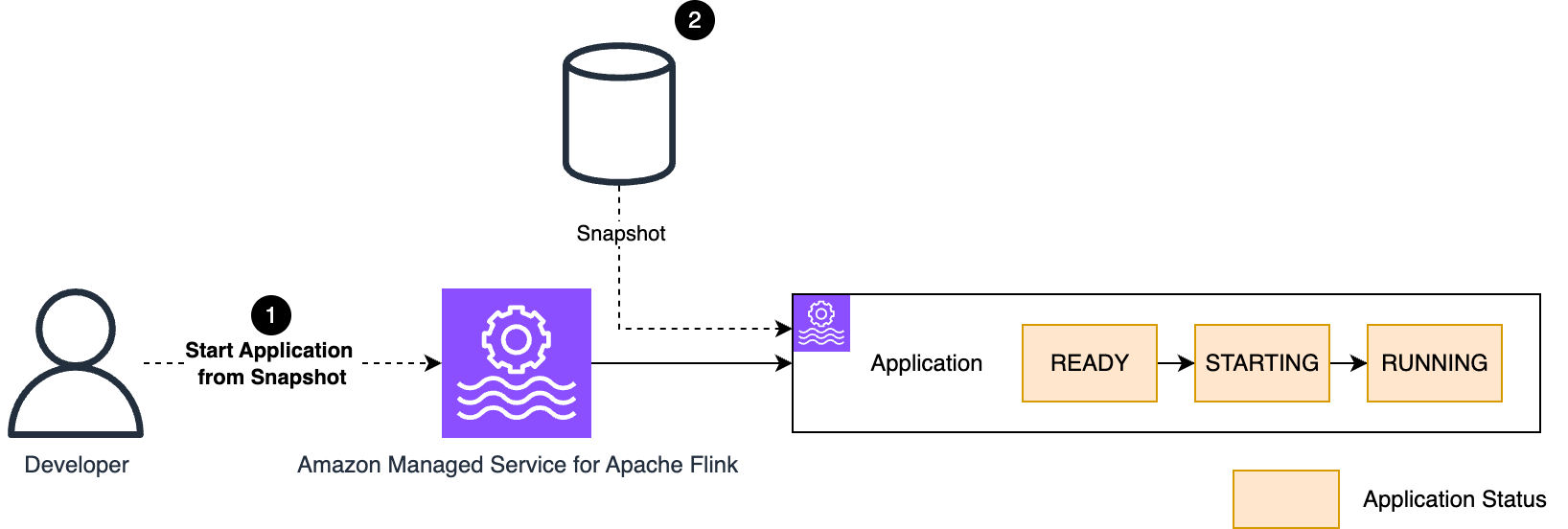
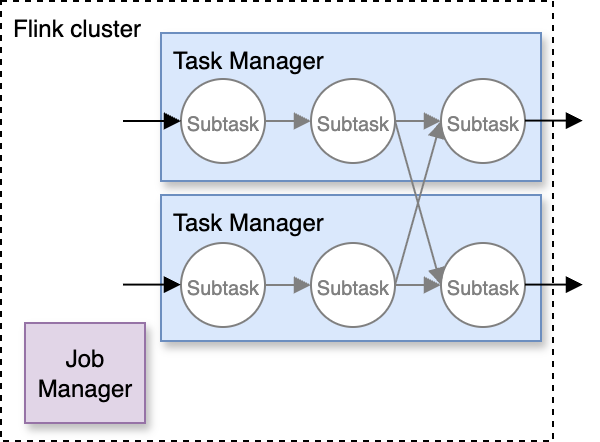
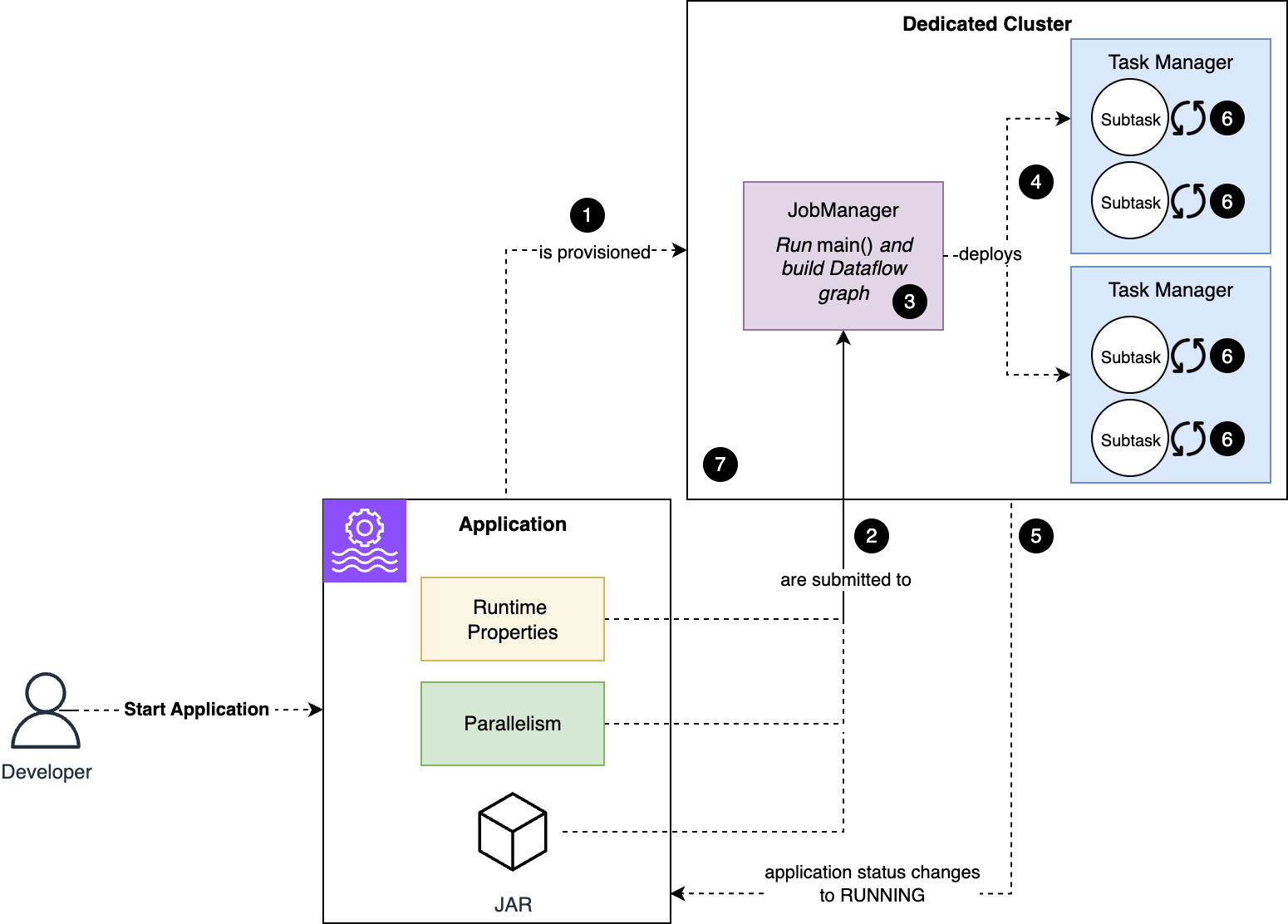
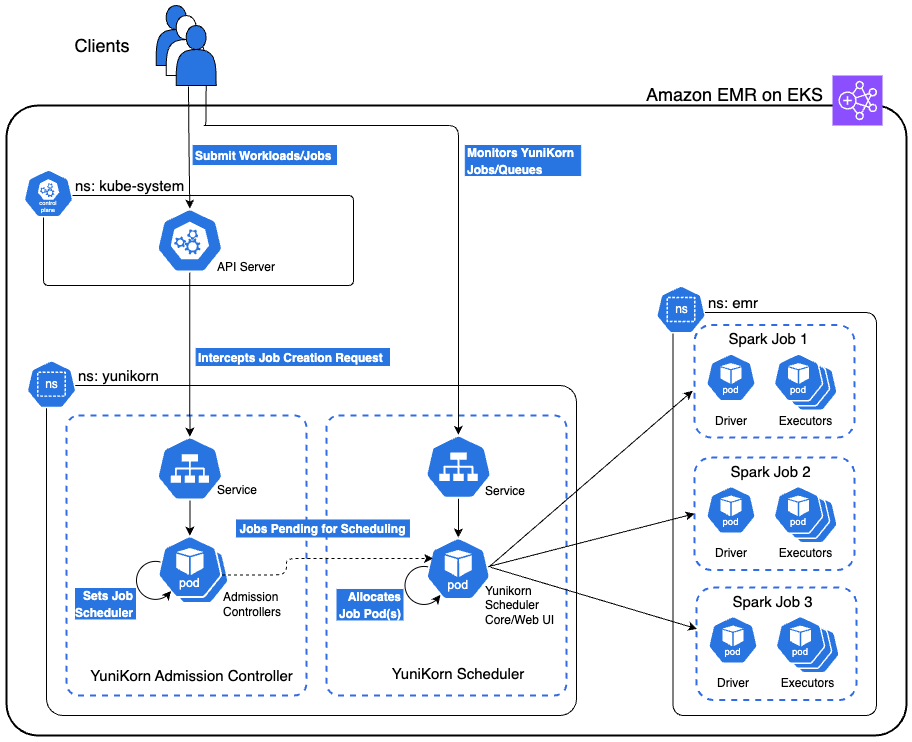
 Suvojit Dasgupta is a Principal Data Architect at Amazon Web Services. He leads a team of skilled engineers in designing and building scalable data solutions for diverse customers. He specializes in developing and implementing innovative data architectures to address complex business challenges.
Suvojit Dasgupta is a Principal Data Architect at Amazon Web Services. He leads a team of skilled engineers in designing and building scalable data solutions for diverse customers. He specializes in developing and implementing innovative data architectures to address complex business challenges. Peter Manastyrny is a Senior Product Manager at AWS Analytics. He leads Amazon EMR on EKS, a product that makes it straightforward and efficient to run open-source data analytics frameworks such as Spark on Amazon EKS.
Peter Manastyrny is a Senior Product Manager at AWS Analytics. He leads Amazon EMR on EKS, a product that makes it straightforward and efficient to run open-source data analytics frameworks such as Spark on Amazon EKS. Matt Poland is a Senior Cloud Infrastructure Architect at Amazon Web Services. He is passionate about solving complex problems and delivering well-structured solutions for diverse customers. His expertise spans across a range of cloud technologies, providing scalable and reliable infrastructure tailored to each project’s unique challenges.
Matt Poland is a Senior Cloud Infrastructure Architect at Amazon Web Services. He is passionate about solving complex problems and delivering well-structured solutions for diverse customers. His expertise spans across a range of cloud technologies, providing scalable and reliable infrastructure tailored to each project’s unique challenges. Gregory Fina is a Principal Startup Solutions Architect for Generative AI at Amazon Web Services, where he empowers startups to accelerate innovation through cloud adoption. He specializes in application modernization, with a strong focus on serverless architectures, containers, and scalable data storage solutions. He is passionate about using generative AI tools to orchestrate and optimize large-scale Kubernetes deployments, as well as advancing GitOps and DevOps practices for high-velocity teams. Outside of his customer-facing role, Greg actively contributes to open source projects, especially those related to Backstage.
Gregory Fina is a Principal Startup Solutions Architect for Generative AI at Amazon Web Services, where he empowers startups to accelerate innovation through cloud adoption. He specializes in application modernization, with a strong focus on serverless architectures, containers, and scalable data storage solutions. He is passionate about using generative AI tools to orchestrate and optimize large-scale Kubernetes deployments, as well as advancing GitOps and DevOps practices for high-velocity teams. Outside of his customer-facing role, Greg actively contributes to open source projects, especially those related to Backstage.
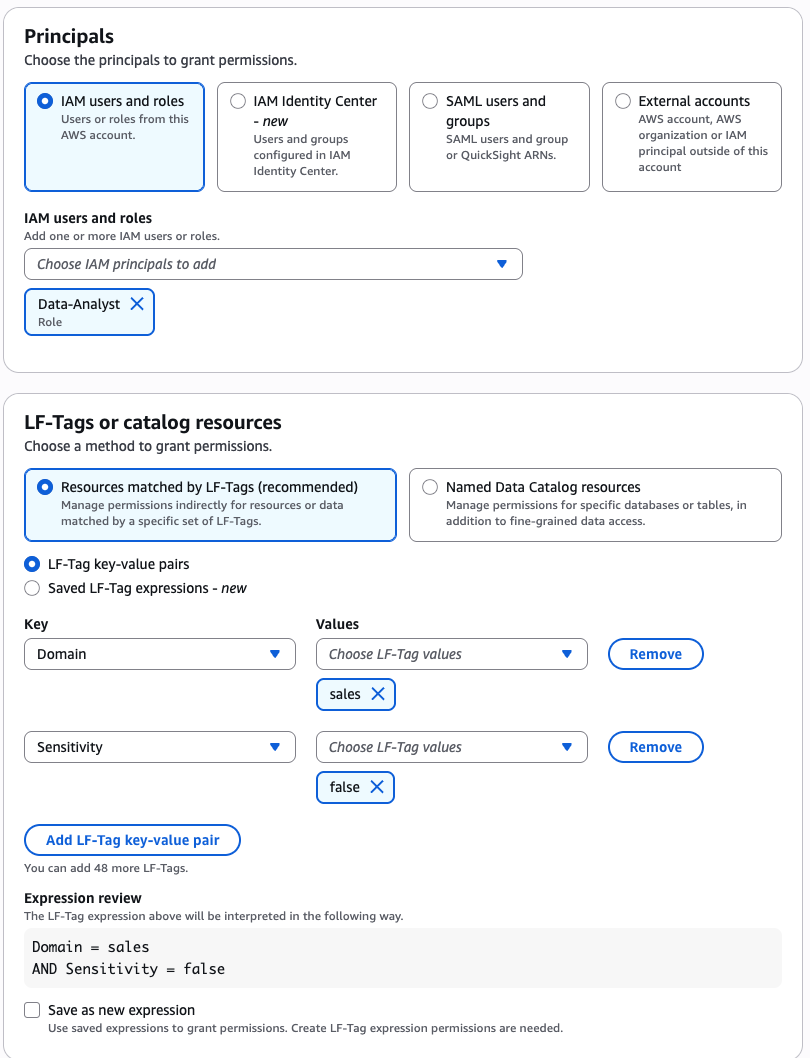
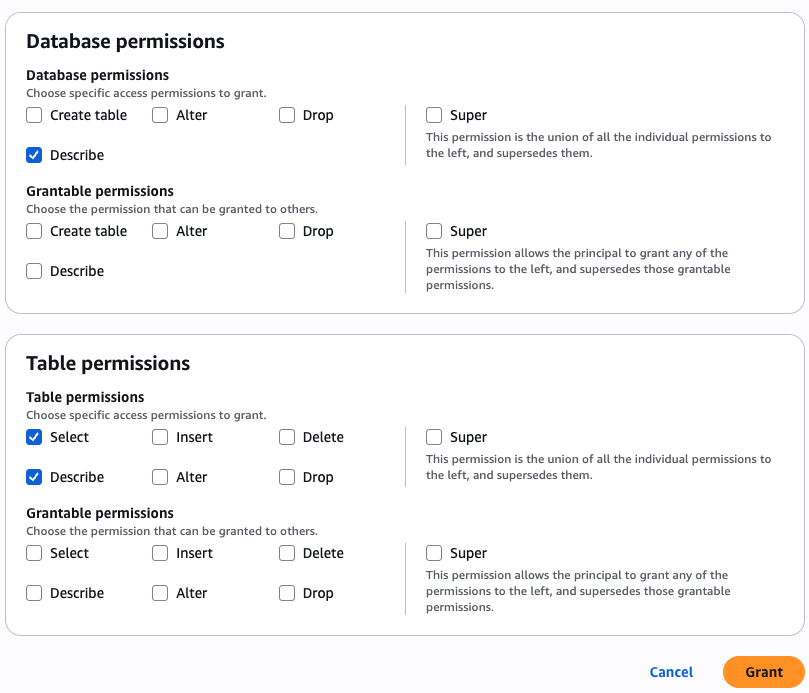
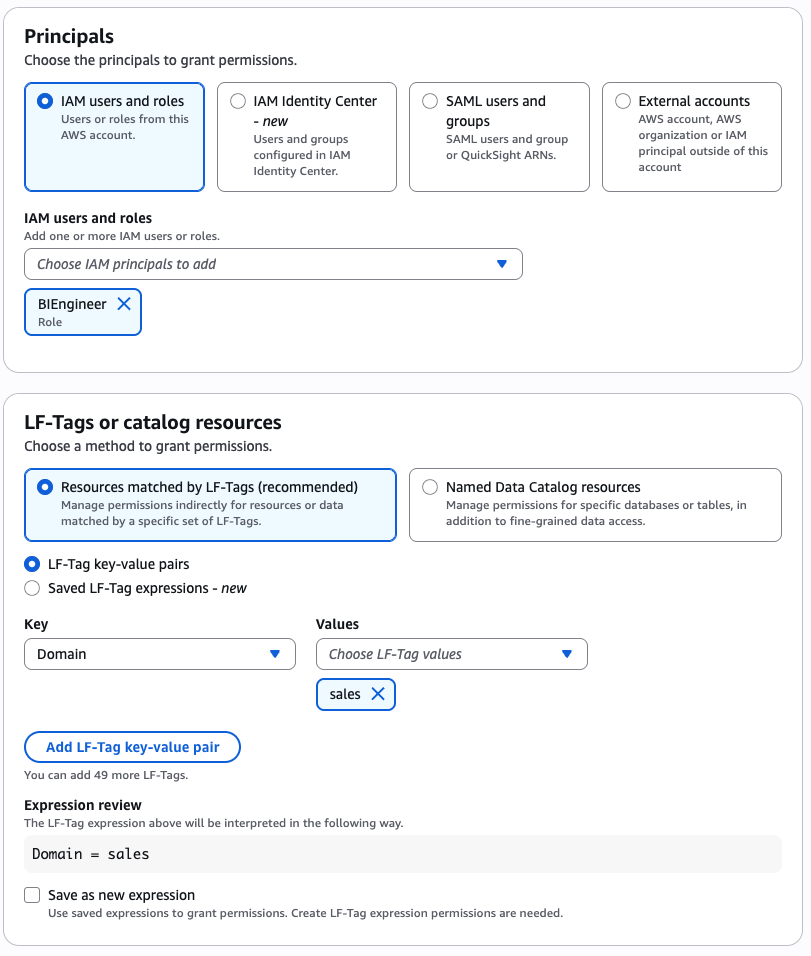
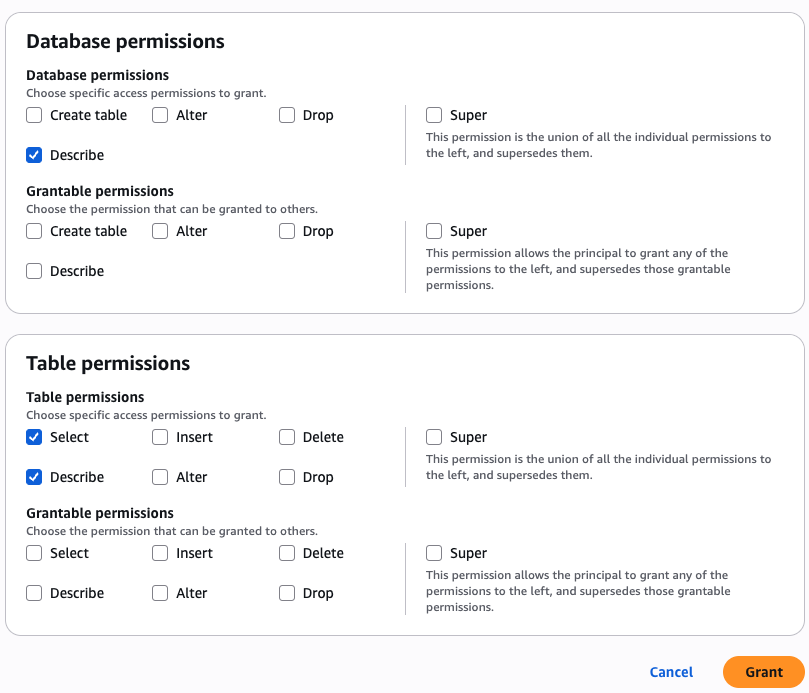
 Sandeep Adwankar is a Senior Product Manager with Amazon SageMaker Lakehouse . Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that help customers improve how they manage, secure, and access data.
Sandeep Adwankar is a Senior Product Manager with Amazon SageMaker Lakehouse . Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that help customers improve how they manage, secure, and access data. Srividya Parthasarathy is a Senior Big Data Architect with Amazon SageMaker Lakehouse. She works with the product team and customers to build robust features and solutions for their analytical data platform. She enjoys building data mesh solutions and sharing them with the community.
Srividya Parthasarathy is a Senior Big Data Architect with Amazon SageMaker Lakehouse. She works with the product team and customers to build robust features and solutions for their analytical data platform. She enjoys building data mesh solutions and sharing them with the community. Aarthi Srinivasan is a Senior Big Data Architect with Amazon SageMaker Lakehouse. She works with AWS customers and partners to architect lakehouse solutions, enhance product features, and establish best practices for data governance.
Aarthi Srinivasan is a Senior Big Data Architect with Amazon SageMaker Lakehouse. She works with AWS customers and partners to architect lakehouse solutions, enhance product features, and establish best practices for data governance.






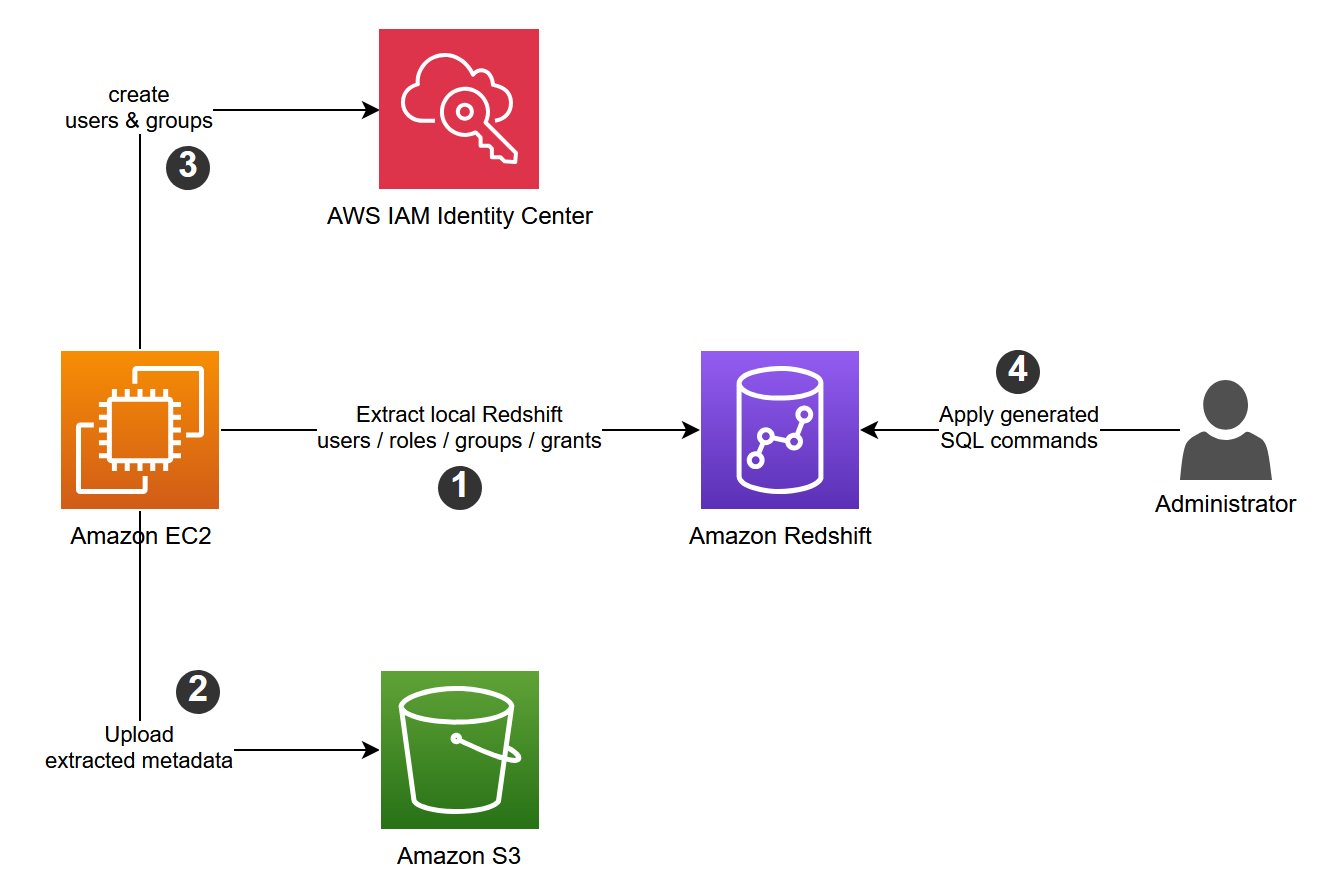
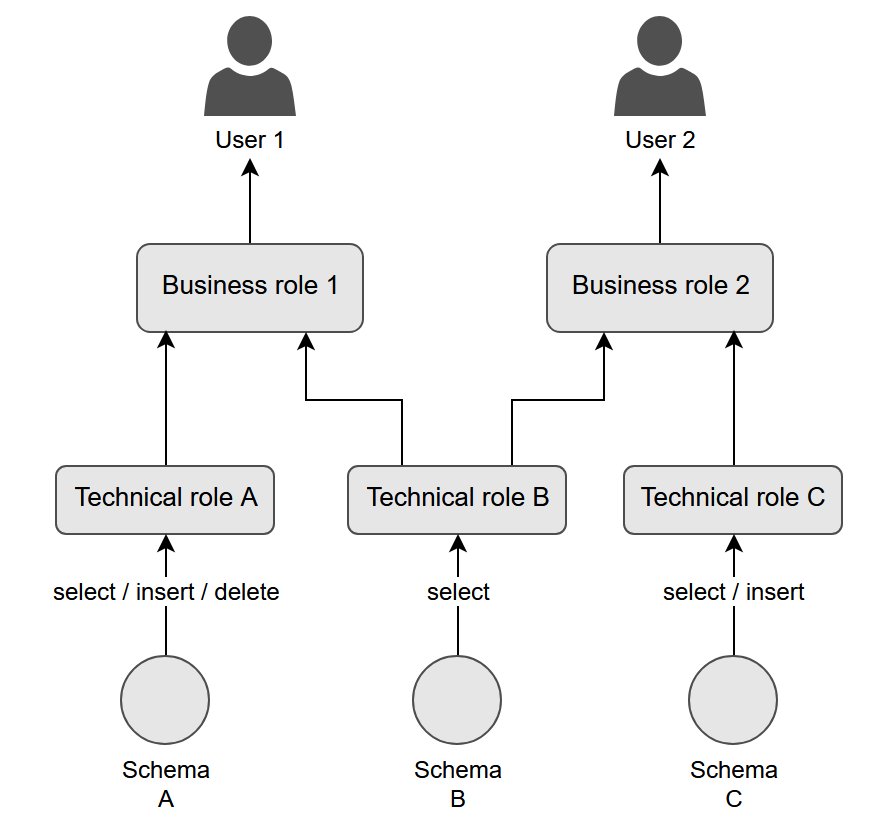
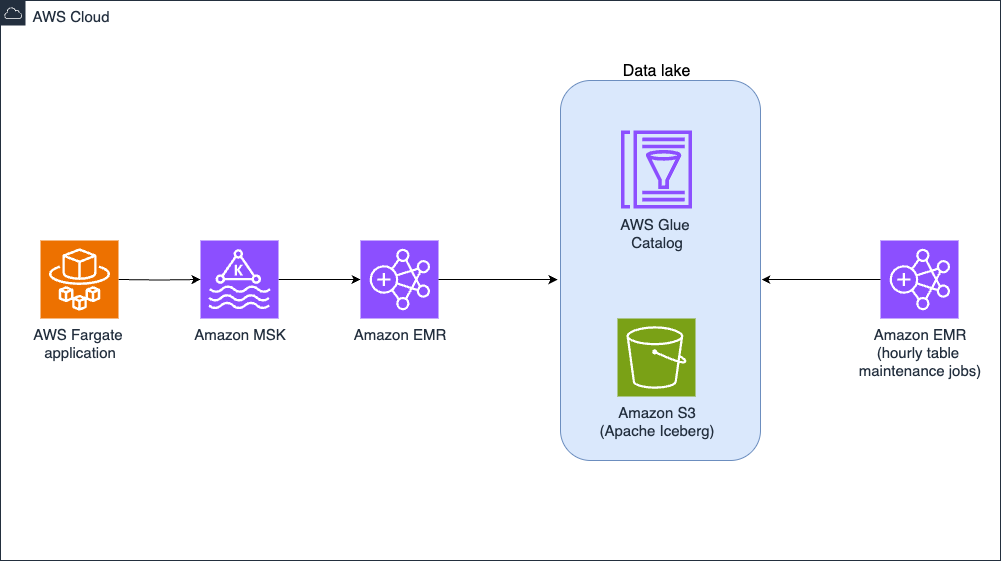
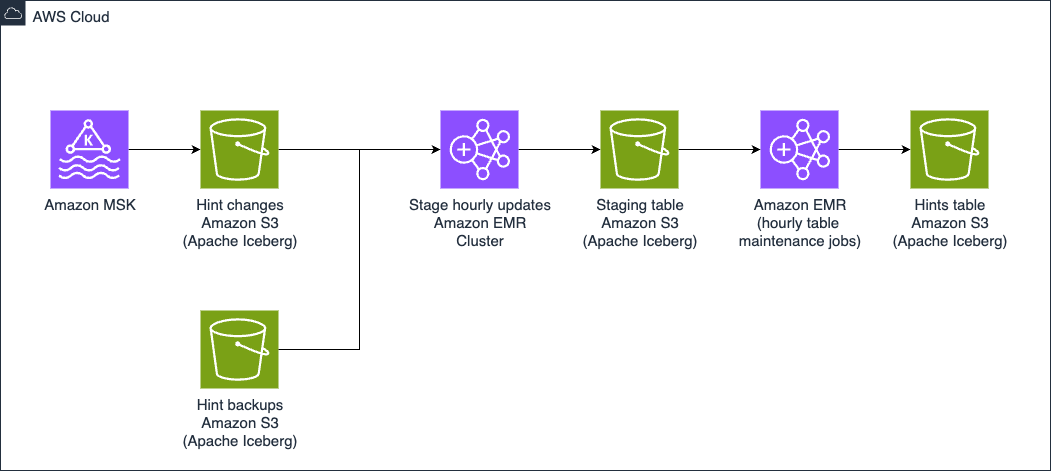
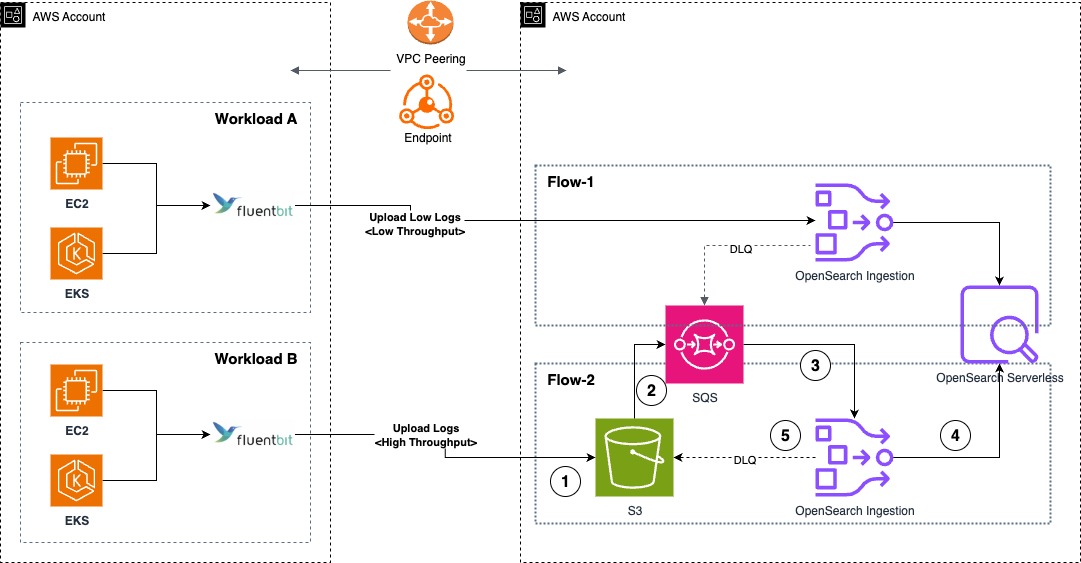

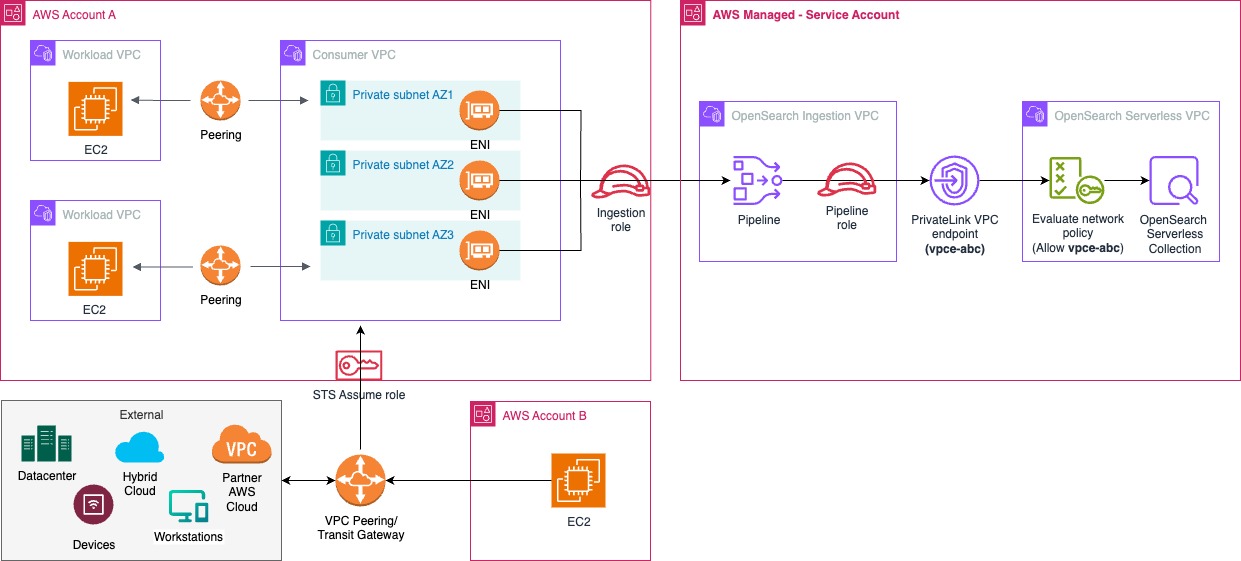
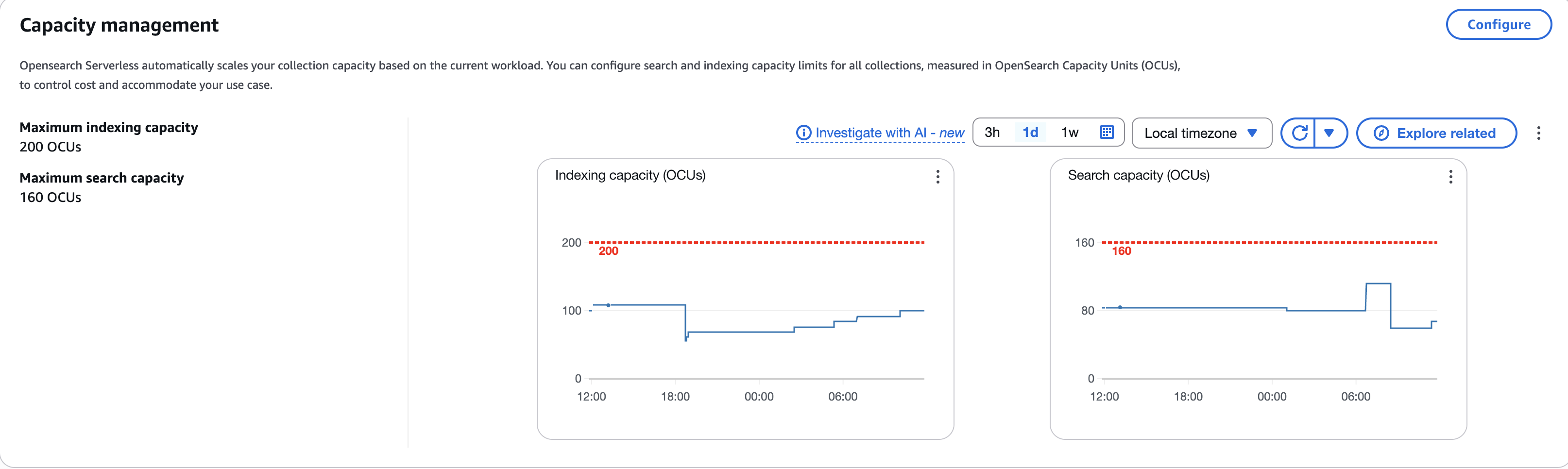
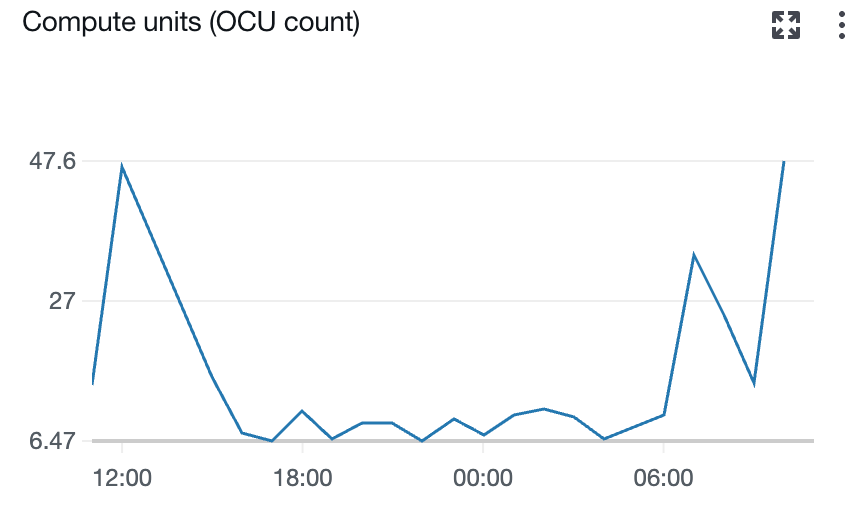
 Prashanth Dudipala is a DevOps Architect at AppZen, where he helps build scalable, secure, and automated cloud platforms on AWS. He’s passionate about simplifying complex systems, enabling teams to move faster, and sharing practical insights with the cloud community.
Prashanth Dudipala is a DevOps Architect at AppZen, where he helps build scalable, secure, and automated cloud platforms on AWS. He’s passionate about simplifying complex systems, enabling teams to move faster, and sharing practical insights with the cloud community. Madhuri Andhale is a DevOps Engineer at AppZen, focused on building and optimizing cloud-native infrastructure. She is passionate about managing efficient CI/CD pipelines, streamlining infrastructure and deployments, modernizing systems, and enabling development teams to deliver faster and more reliably. Outside of work, Madhuri enjoys exploring emerging technologies, traveling to new places, experimenting with new recipes, and finding creative ways to solve everyday challenges.
Madhuri Andhale is a DevOps Engineer at AppZen, focused on building and optimizing cloud-native infrastructure. She is passionate about managing efficient CI/CD pipelines, streamlining infrastructure and deployments, modernizing systems, and enabling development teams to deliver faster and more reliably. Outside of work, Madhuri enjoys exploring emerging technologies, traveling to new places, experimenting with new recipes, and finding creative ways to solve everyday challenges. Manoj Gupta is a Senior Solutions Architect at AWS, based in San Francisco. With over 4 years of experience at AWS, he works closely with customers like AppZen to build optimized cloud architectures. His primary focus areas are Data, AI/ML, and Security, helping organizations modernize their technology stacks. Outside of work, he enjoys outdoor activities and traveling with family.
Manoj Gupta is a Senior Solutions Architect at AWS, based in San Francisco. With over 4 years of experience at AWS, he works closely with customers like AppZen to build optimized cloud architectures. His primary focus areas are Data, AI/ML, and Security, helping organizations modernize their technology stacks. Outside of work, he enjoys outdoor activities and traveling with family. Prashant Agrawal is a Sr. Search Specialist Solutions Architect with Amazon OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat.
Prashant Agrawal is a Sr. Search Specialist Solutions Architect with Amazon OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat.
 Nikki Rouda works in product marketing at AWS. He has many years experience across a wide range of IT infrastructure, storage, networking, security, IoT, analytics, and modern applications.
Nikki Rouda works in product marketing at AWS. He has many years experience across a wide range of IT infrastructure, storage, networking, security, IoT, analytics, and modern applications.











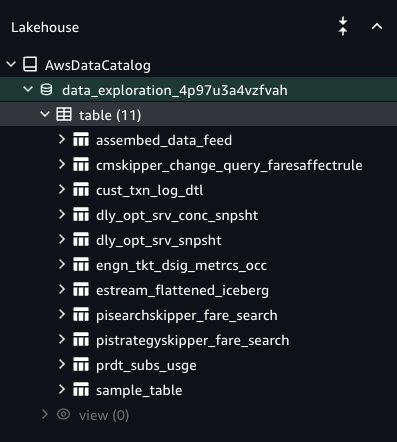
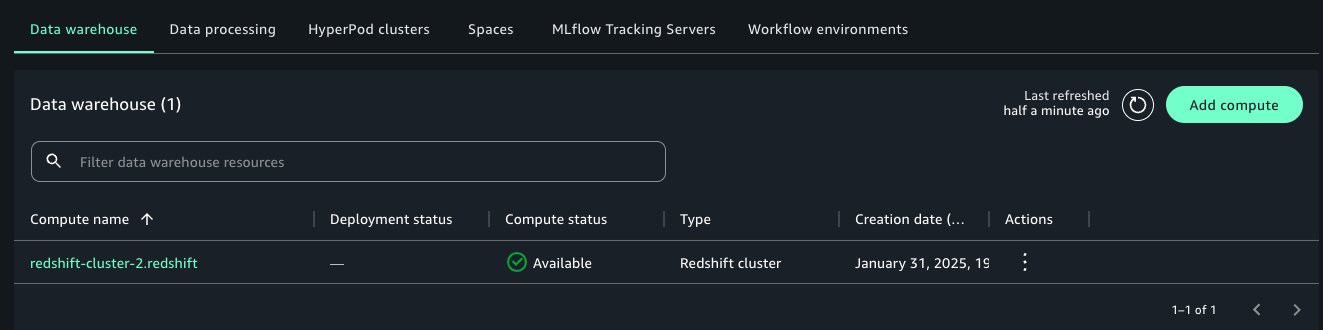
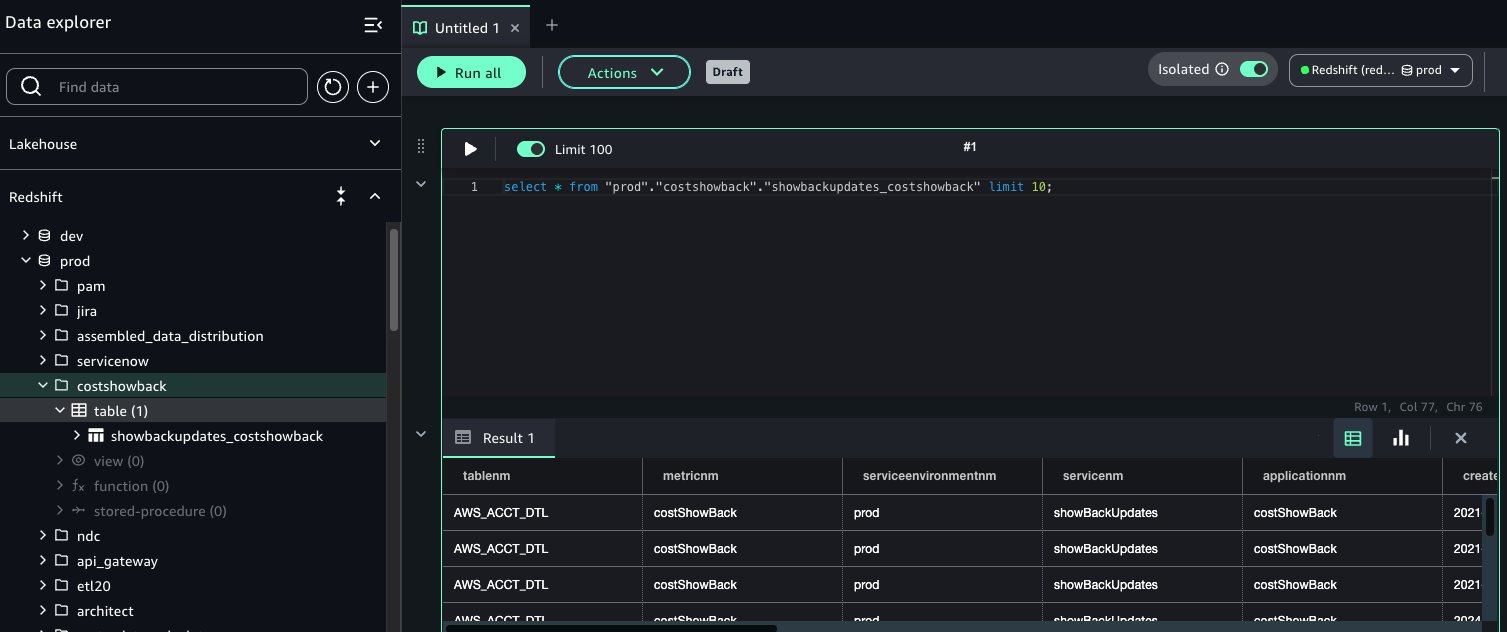
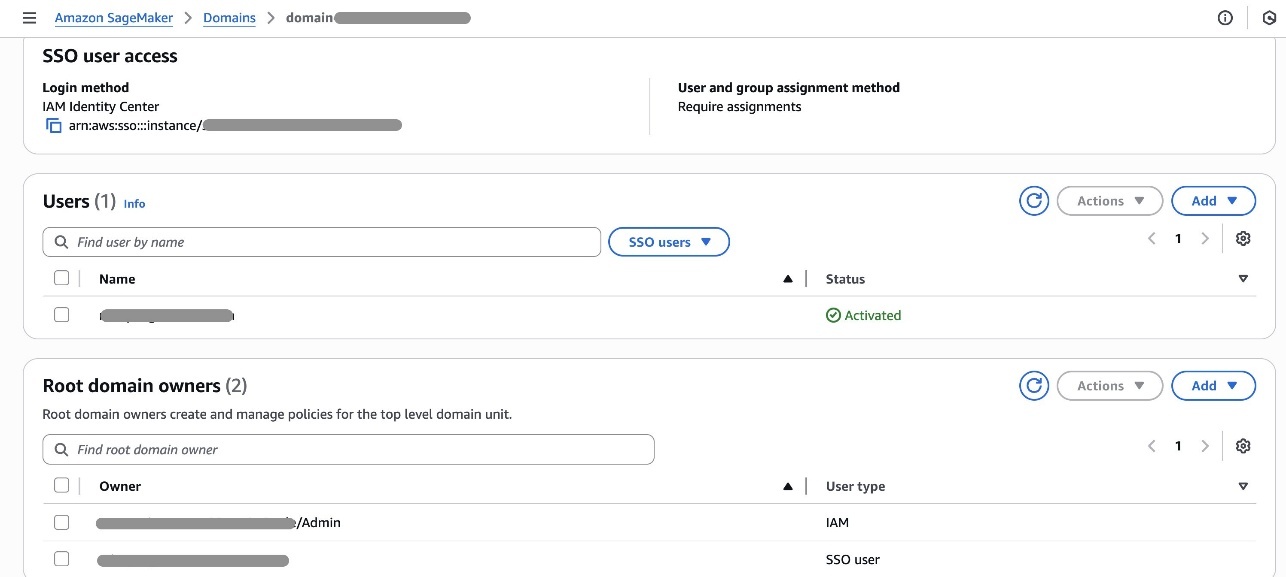

 Mitesh Patel is a Principal Solutions Architect at AWS. His passion is helping customers harness the power of Analytics, Machine Learning, AI & GenAI to drive business growth. He engages with customers to create innovative solutions on AWS.
Mitesh Patel is a Principal Solutions Architect at AWS. His passion is helping customers harness the power of Analytics, Machine Learning, AI & GenAI to drive business growth. He engages with customers to create innovative solutions on AWS. Raj Samineni is the Director of Data Engineering at ATPCO, leading the creation of advanced cloud-based data platforms. His work ensures robust, scalable solutions that support the airline industry’s strategic transformational objectives. By leveraging machine learning and AI, Raj drives innovation and data culture, positioning ATPCO at the forefront of technological advancement.
Raj Samineni is the Director of Data Engineering at ATPCO, leading the creation of advanced cloud-based data platforms. His work ensures robust, scalable solutions that support the airline industry’s strategic transformational objectives. By leveraging machine learning and AI, Raj drives innovation and data culture, positioning ATPCO at the forefront of technological advancement. Saurabh Rawat is a Solution Architect at AWS with 13 years of experience working with enterprise data systems. He has designed and delivered large-scale, cloud-native solutions for customers across industries, with a focus on data engineering, analytics, and well-architected architectures. Over his career, he has helped organizations modernize their data platforms, optimize for performance, and cost, and adopt best practices for scalability and security. Outside of work, he is a passionate musician and enjoys playing with his band.
Saurabh Rawat is a Solution Architect at AWS with 13 years of experience working with enterprise data systems. He has designed and delivered large-scale, cloud-native solutions for customers across industries, with a focus on data engineering, analytics, and well-architected architectures. Over his career, he has helped organizations modernize their data platforms, optimize for performance, and cost, and adopt best practices for scalability and security. Outside of work, he is a passionate musician and enjoys playing with his band.