Post Syndicated from Sakti Mishra original https://aws.amazon.com/blogs/big-data/enforce-fine-grained-access-control-on-data-lake-tables-using-aws-glue-5-0-integrated-with-aws-lake-formation/
AWS Glue 5.0 supports fine-grained access control (FGAC) based on your policies defined in AWS Lake Formation. FGAC enables you to granularly control access to your data lake resources at the table, column, and row levels. This level of control is essential for organizations that need to comply with data governance and security regulations, or those that deal with sensitive data.
Lake Formation makes it straightforward to build, secure, and manage data lakes. It allows you to define fine-grained access controls through grant and revoke statements, similar to those used with relational database management systems (RDBMS), and automatically enforce those policies using compatible engines like Amazon Athena, Apache Spark on Amazon EMR, and Amazon Redshift Spectrum. With AWS Glue 5.0, the same Lake Formation rules that you set up for use with other services like Athena now apply to your AWS Glue Spark jobs and Interactive Sessions through built-in Spark SQL and Spark DataFrames. This simplifies security and governance of your data lakes.
This post demonstrates how to enforce FGAC on AWS Glue 5.0 through Lake Formation permissions.
How FGAC works on AWS Glue 5.0
Using AWS Glue 5.0 with Lake Formation lets you enforce a layer of permissions on each Spark job to apply Lake Formation permissions control when AWS Glue runs jobs. AWS Glue uses Spark resource profiles to create two profiles to effectively run jobs. The user profile runs user-supplied code, and the system profile enforces Lake Formation policies. For more information, see the AWS Lake Formation Developer Guide.
The following diagram demonstrates a high-level overview of how AWS Glue 5.0 gets access to data protected by Lake Formation permissions.

The workflow consists of the following steps:
- A user calls the
StartJobRunAPI on a Lake Formation enabled AWS Glue job. - AWS Glue sends the job to a user driver and runs the job in the user profile. The user driver runs a lean version of Spark that has no ability to launch tasks, request executors, or access Amazon Simple Storage Service (Amazon S3) or the AWS Glue Data Catalog. It builds a job plan.
- AWS Glue sets up a second driver called the system driver and runs it in the system profile (with a privileged identity). AWS Glue sets up an encrypted TLS channel between the two drivers for communication. The user driver uses the channel to send the job plans to the system driver. The system driver doesn’t run user-submitted code. It runs full Spark and communicates with Amazon S3 and the Data Catalog for data access. It requests executors and compiles the Job Plan into a sequence of execution stages.
- AWS Glue then runs the stages on executors with the user driver or system driver. The user code in any stage is run exclusively on user profile executors.
- Stages that read data from Data Catalog tables protected by Lake Formation or those that apply security filters are delegated to system executors.
Enable FGAC on AWS Glue 5.0
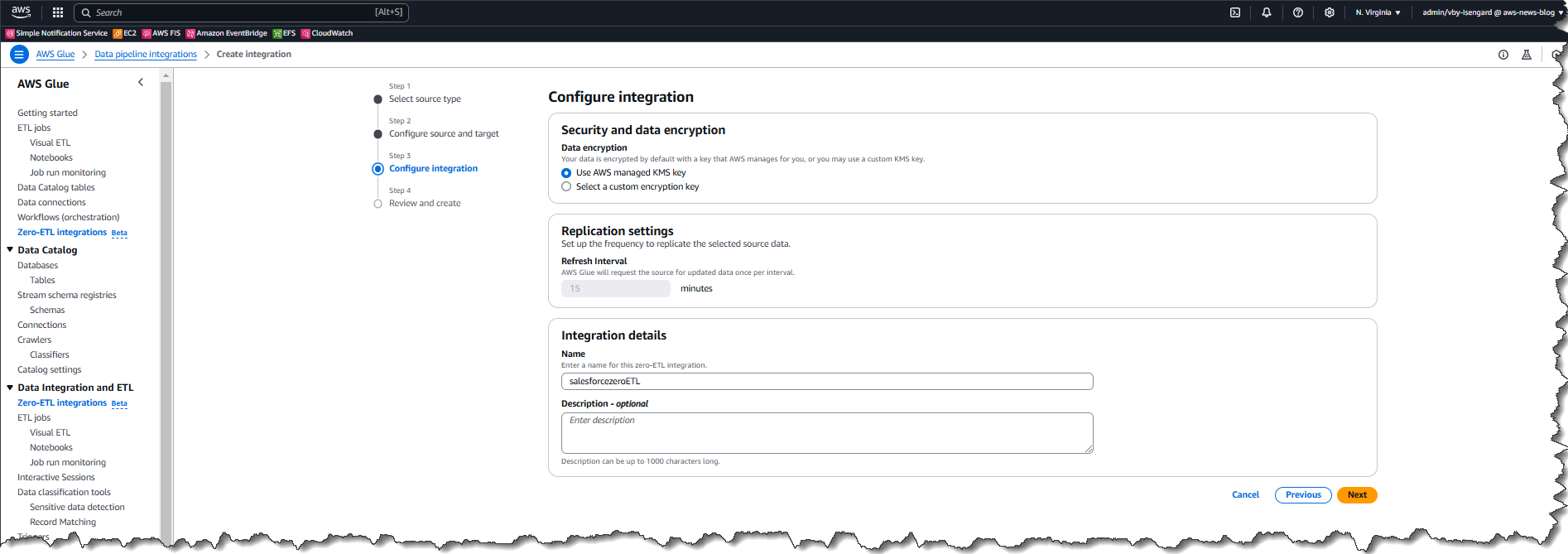
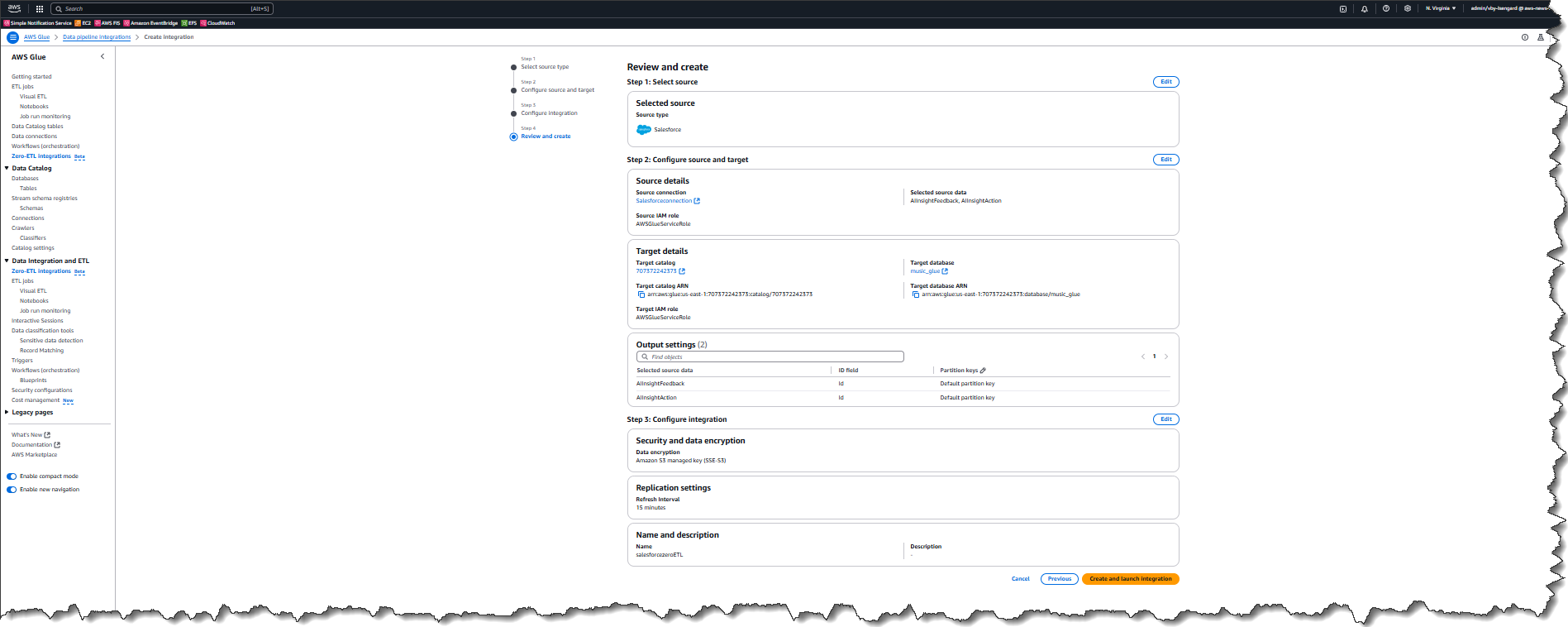
To enable Lake Formation FGAC for your AWS Glue 5.0 jobs on the AWS Glue console, complete the following steps:
- On the AWS Glue console, choose ETL jobs in the navigation pane.
- Choose your job.
- Choose the Job details
- For Glue version, choose Glue 5.0 – Supports spark 3.5, Scala 2, Python 3.
- For Job parameters, add following parameter:
- Key:
--enable-lakeformation-fine-grained-access - Value:
true
- Key:
- Choose Save.
To enable Lake Formation FGAC for your AWS Glue notebooks on the AWS Glue console, use %%configure magic:

Example use case
The following diagram represents the high-level architecture of the use case we demonstrate in this post. The objective of the use case is to showcase how can you enforce Lake Formation FGAC on both CSV and Iceberg tables and configure an AWS Glue PySpark job to read from them.
The implementation consists of the following steps:
- Create an S3 bucket and upload the input CSV dataset.
- Create a standard Data Catalog table and an Iceberg table by reading data from the input CSV table, using an Athena CTAS query.
- Use Lake Formation to enable FGAC on both CSV and Iceberg tables using row- and column-based filters.
- Run two sample AWS Glue jobs to showcase how you can run a sample PySpark script in AWS Glue that respects the Lake Formation FGAC permissions, and then write the output to Amazon S3.
To demonstrate the implementation steps, we use sample product inventory data that has the following attributes:
- op – The operation on the source record. This shows values
Ito represent insert operations,Uto represent updates, andDto represent deletes. - product_id – The primary key column in the source database’s products table.
- category – The product’s category, such as
ElectronicsorCosmetics. - product_name – The name of the product.
- quantity_available – The quantity available in the inventory for a product.
- last_update_time – The time when the product record was updated at the source database.
To implement this workflow, we create AWS resources such as an S3 bucket, define FGAC with Lake Formation, and build AWS Glue jobs to query those tables.
Prerequisites
Before you get started, make sure you have the following prerequisites:
- An AWS account with AWS Identity and Access Management (IAM) roles as needed.
- The required permissions to perform the following actions:
- Read or write to an S3 bucket.
- Create and run AWS Glue crawlers and jobs.
- Manage Data Catalog databases and tables.
- Manage Athena workgroups and run queries.
- Lake Formation already set up in the account and a Lake Formation administrator role or a similar role to follow along with the instructions in this post. To learn more about setting up permissions for a data lake administrator role, see Create a data lake administrator.
For this post, we use the eu-west-1 AWS Region, but you can integrate it in your preferred Region if the AWS services included in the architecture are available in that Region.
Next, let’s dive into the implementation steps.
Create an S3 bucket
To create an S3 bucket for the raw input datasets and Iceberg table, complete the following steps:
- On the Amazon S3 console, choose Buckets in the navigation pane.
- Choose Create bucket.
- Enter the bucket name (for example,
glue5-lf-demo-${AWS_ACCOUNT_ID}-${AWS_REGION_CODE}), and leave the remaining fields as default. - Choose Create bucket.
- On the bucket details page, choose Create folder.
- Create two subfolders:
raw-csv-inputandiceberg-datalake.

- Upload the LOAD00000001.csv file into the
raw-csv-inputfolder of the bucket.

Create tables
To create input and output tables in the Data Catalog, complete the following steps:
- On the Athena console, navigate to the query editor.
- Run the following queries in sequence (provide your S3 bucket name):
- Run the following query to validate the raw CSV input data:
The following screenshot shows the query result.

- Run the following query to validate the Iceberg table data:
The following screenshot shows the query result.

This step used DDL to create table definitions. Alternatively, you can use a Data Catalog API, the AWS Glue console, the Lake Formation console, or an AWS Glue crawler.
Next, let’s configure Lake Formation permissions on the raw_csv_input table and iceberg_datalake table.
Configure Lake Formation permissions
To validate the capability, let’s define FGAC permissions for the two Data Catalog tables we created.
For the raw_csv_input table, we enable permission for specific rows, for example allow read access only for the Furniture category. Similarly, for the iceberg_datalake table, we enable a data filter for the Electronics product category and limit read access to a few columns only.
To configure Lake Formation permissions for the two tables, complete the following steps:
- On the Lake Formation console, choose Data lake locations under Administration in the navigation pane.
- Choose Register location.
- For Amazon S3 path, enter the path of your S3 bucket to register the location.
- For IAM role, choose your Lake Formation data access IAM role, which is not a service linked role.
- For Permission mode, select Lake Formation.

- Choose Register location.

Grant table permissions on the standard table
The next step is to grant table permissions on the raw_csv_input table to the AWS Glue job role.
- On the Lake Formation console, choose Data lake permissions under Permissions in the navigation pane.
- Choose Grant.
- For Principals, choose IAM users and roles.
- For IAM users and roles, choose your IAM role that is going to be used on an AWS Glue job.
- For LF-Tags or catalog resources, choose Named Data Catalog resources.
- For Databases, choose
glue5_lf_demo. - For Tables, choose
raw_csv_input. - For Data filters, choose Create new.
- In the Create data filter dialog, provide the following information:
- For Data filter name, enter
product_furniture. - For Column-level access, select Access to all columns.
- Select Filter rows.
- For Row filter expression, enter
category='Furniture'. - Choose Create filter.

- For Data filter name, enter

- For Data filters, select the filter
product_furnitureyou created.

- For Data filter permissions, choose Select and Describe.
- Choose Grant.



Grant permissions on the Iceberg table
The next step is to grant table permissions on the iceberg_datalake table to the AWS Glue job role.
- On the Lake Formation console, choose Data lake permissions under Permissions in the navigation pane.
- Choose Grant.
- For Principals, choose IAM users and roles.
- For IAM users and roles, choose your IAM role that is going to be used on an AWS Glue job.
- For LF-Tags or catalog resources, choose Named Data Catalog resources.
- For Databases, choose
glue5_lf_demo. - For Tables, choose
iceberg_datalake. - For Data filters, choose Create new.
- In the Create data filter dialog, provide the following information:
- For Data filter name, enter
product_electronics. - For Column-level access, select Include columns.
- For Included columns, choose
category,last_update_time,op,product_name, andquantity_available. - Choose Filter rows.
- For Row filter expression, enter
category='Electronics'. - Choose Create filter.
- For Data filter name, enter
- For Data filters, select the filter
product_electronicsyou created. - For Data filter permissions, choose Select and Describe.
- Choose
Next, let’s create the AWS Glue PySpark job to process the input data.
Query the standard table through an AWS Glue 5.0 job
Complete the following steps to create an AWS Glue job to load data from the raw_csv_input table:
- On the AWS Glue console, choose ETL jobs in the navigation pane.
- For Create job, choose Script Editor.
- For Engine, choose Spark.
- For Options, choose Start fresh.
- Choose Create script.
- For Script, use the following code, providing your S3 output path. This example script writes the output in Parquet format; you can change this according to your use case.
- On the Job details tab, for Name, enter
glue5-lf-demo. - For IAM Role, assign an IAM role that has the required permissions to run an AWS Glue job and read and write to the S3 bucket.

- For Glue version, choose Glue 5.0 – Supports spark 3.5, Scala 2, Python 3.
- For Job parameters, add following parameter:
- Key:
--enable-lakeformation-fine-grained-access - Value:
true

- Key:


- Choose Save and then Run.
- When the job is complete, on the Run details tab at the bottom of job runs, choose Output logs.
You’re redirected to the Amazon CloudWatch console to validate the output.
The printed table is shown in the following screenshot. Only two records were returned because they are Furniture category products.

Query the Iceberg table through an AWS Glue 5.0 job
Next, complete the following steps to create an AWS Glue job to load data from the iceberg_datalake table:
- On the AWS Glue console, choose ETL jobs in the navigation pane.
- For Create job, choose Script Editor.
- For Engine, choose Spark.
- For Options, choose Start fresh.
- Choose Create script.
- For Script, replace the following parameters:
- Replace
aws_regionwith your Region. - Replace
aws_account_idwith your AWS account ID. - Replace
warehouse_pathwith your S3 warehouse path for the Iceberg table. - Replace
<s3_output_path>with your S3 output path.
- Replace
This example script writes the output in Parquet format; you can change it according to your use case.
- On the Job details tab, for Name, enter
glue5-lf-demo-iceberg. - For IAM Role, assign an IAM role that has the required permissions to run an AWS Glue job and read and write to the S3 bucket.
- For Glue version, choose Glue 5.0 – Supports spark 3.5, Scala 2, Python 3.
- For Job parameters, add following parameters:
- Key:
--enable-lakeformation-fine-grained-access - Value:
true - Key:
--datalake-formats - Value:
iceberg
- Key:
- Choose Save and then Run.
- When the job is complete, on the Run details tab, choose Output logs.
You’re redirected to the CloudWatch console to validate the output.
The printed table is shown in the following screenshot. Only two records were returned because they are Electronics category products, and the product_id column is excluded.

You are now able to verify that records of the table raw_csv_input and the table iceberg_datalake are successfully retrieved with configured Lake Formation data cell filters.
Clean up
Complete the following steps to clean up your resources:
- Delete the AWS Glue jobs
glue5-lf-demoandglue5-lf-demo-iceberg. - Delete the Lake Formation permissions.
- Delete the output files written to the S3 bucket.
- Delete the bucket you created for the input datasets, which might have a name similar to
glue5-lf-demo-${AWS_ACCOUNT_ID}-${AWS_REGION_CODE}.
Conclusion
This post explained how you can enable Lake Formation FGAC in AWS Glue jobs and notebooks that will enforce access control defined using Lake Formation grant commands. Previously, you needed to integrate AWS Glue DynamicFrames to enforce FGAC in AWS Glue jobs, but with this release, you can enforce FGAC through Spark DataFrame or Spark SQL. This capability also works not only with standard file formats like CSV, JSON, and Parquet but also with Apache Iceberg.
This feature can save you effort and encourage portability while migrating Spark scripts to different serverless environments such as AWS Glue and Amazon EMR.
About the Authors
 Sakti Mishra is a Principal Solutions Architect at AWS, where he helps customers modernize their data architecture and define end-to end-data strategies, including data security, accessibility, governance, and more. He is also the author of Simplify Big Data Analytics with Amazon EMR and AWS Certified Data Engineer Study Guide. Outside of work, Sakti enjoys learning new technologies, watching movies, and visiting places with family. He can be reached via LinkedIn.
Sakti Mishra is a Principal Solutions Architect at AWS, where he helps customers modernize their data architecture and define end-to end-data strategies, including data security, accessibility, governance, and more. He is also the author of Simplify Big Data Analytics with Amazon EMR and AWS Certified Data Engineer Study Guide. Outside of work, Sakti enjoys learning new technologies, watching movies, and visiting places with family. He can be reached via LinkedIn.
 Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is also the author of the book Serverless ETL and Analytics with AWS Glue. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his road bike.
Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is also the author of the book Serverless ETL and Analytics with AWS Glue. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his road bike.
 Matt Su is a Senior Product Manager on the AWS Glue team. He enjoys helping customers uncover insights and make better decisions using their data with AWS Analytics services. In his spare time, he enjoys skiing and gardening.
Matt Su is a Senior Product Manager on the AWS Glue team. He enjoys helping customers uncover insights and make better decisions using their data with AWS Analytics services. In his spare time, he enjoys skiing and gardening.
 Layth Yassin is a Software Development Engineer on the AWS Glue team. He’s passionate about tackling challenging problems at a large scale, and building products that push the limits of the field. Outside of work, he enjoys playing/watching basketball, and spending time with friends and family.
Layth Yassin is a Software Development Engineer on the AWS Glue team. He’s passionate about tackling challenging problems at a large scale, and building products that push the limits of the field. Outside of work, he enjoys playing/watching basketball, and spending time with friends and family.



 Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his road bike.
Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his road bike. Stuti Deshpande is a Big Data Specialist Solutions Architect at AWS. She works with customers around the globe, providing them strategic and architectural guidance on implementing analytics solutions using AWS. She has extensive experience in big data, ETL, and analytics. In her free time, Stuti likes to travel, learn new dance forms, and enjoy quality time with family and friends.
Stuti Deshpande is a Big Data Specialist Solutions Architect at AWS. She works with customers around the globe, providing them strategic and architectural guidance on implementing analytics solutions using AWS. She has extensive experience in big data, ETL, and analytics. In her free time, Stuti likes to travel, learn new dance forms, and enjoy quality time with family and friends. Martin Ma is a Software Development Engineer on the AWS Glue team. He is passionate about improving the customer experience by applying problem-solving skills to invent new software solutions, as well as constantly searching for ways to simplify existing ones. In his spare time, he enjoys singing and playing the guitar.
Martin Ma is a Software Development Engineer on the AWS Glue team. He is passionate about improving the customer experience by applying problem-solving skills to invent new software solutions, as well as constantly searching for ways to simplify existing ones. In his spare time, he enjoys singing and playing the guitar. Anshul Sharma is a Software Development Engineer in AWS Glue Team.
Anshul Sharma is a Software Development Engineer in AWS Glue Team. Rajendra Gujja is a Software Development Engineer on the AWS Glue team. He is passionate about distributed computing and everything and anything about data.
Rajendra Gujja is a Software Development Engineer on the AWS Glue team. He is passionate about distributed computing and everything and anything about data. Maheedhar Reddy Chappidi is a Sr. Software Development Engineer on the AWS Glue team. He is passionate about building fault tolerant and reliable distributed systems at scale. Outside of his work, Maheedhar is passionate about listening to podcasts and playing with his two-year-old kid.
Maheedhar Reddy Chappidi is a Sr. Software Development Engineer on the AWS Glue team. He is passionate about building fault tolerant and reliable distributed systems at scale. Outside of his work, Maheedhar is passionate about listening to podcasts and playing with his two-year-old kid. Savio Dsouza is a Software Development Manager on the AWS Glue team. His team works on generative AI applications for the Data Integration domain and distributed systems for efficiently managing data lakes on AWS and optimizing Apache Spark for performance and reliability.
Savio Dsouza is a Software Development Manager on the AWS Glue team. His team works on generative AI applications for the Data Integration domain and distributed systems for efficiently managing data lakes on AWS and optimizing Apache Spark for performance and reliability. Kartik Panjabi is a Software Development Manager on the AWS Glue team. His team builds generative AI features for the Data Integration and distributed system for data integration.
Kartik Panjabi is a Software Development Manager on the AWS Glue team. His team builds generative AI features for the Data Integration and distributed system for data integration. Mohit Saxena is a Senior Software Development Manager on the AWS Glue and Amazon EMR team. His team focuses on building distributed systems to enable customers with simple-to-use interfaces and AI-driven capabilities to efficiently transform petabytes of data across data lakes on Amazon S3, and databases and data warehouses on the cloud.
Mohit Saxena is a Senior Software Development Manager on the AWS Glue and Amazon EMR team. His team focuses on building distributed systems to enable customers with simple-to-use interfaces and AI-driven capabilities to efficiently transform petabytes of data across data lakes on Amazon S3, and databases and data warehouses on the cloud.






 Raj Ramasubbu is a Sr. Analytics Specialist Solutions Architect focused on big data and analytics and AI/ML with Amazon Web Services. He helps customers architect and build highly scalable, performant, and secure cloud-based solutions on AWS. Raj provided technical expertise and leadership in building data engineering, big data analytics, business intelligence, and data science solutions for over 20 years prior to joining AWS. He helped customers in various industry verticals like healthcare, medical devices, life science, retail, asset management, car insurance, residential REIT, agriculture, title insurance, supply chain, document management, and real estate.
Raj Ramasubbu is a Sr. Analytics Specialist Solutions Architect focused on big data and analytics and AI/ML with Amazon Web Services. He helps customers architect and build highly scalable, performant, and secure cloud-based solutions on AWS. Raj provided technical expertise and leadership in building data engineering, big data analytics, business intelligence, and data science solutions for over 20 years prior to joining AWS. He helped customers in various industry verticals like healthcare, medical devices, life science, retail, asset management, car insurance, residential REIT, agriculture, title insurance, supply chain, document management, and real estate. Srividya Parthasarathy is a Senior Big Data Architect on the AWS Lake Formation team. She works with product team and customer to build robust features and solutions for their analytical data platform. She enjoys building data mesh solutions and sharing them with the community.
Srividya Parthasarathy is a Senior Big Data Architect on the AWS Lake Formation team. She works with product team and customer to build robust features and solutions for their analytical data platform. She enjoys building data mesh solutions and sharing them with the community. Pratik Das is a Senior Product Manager with AWS Lake Formation. He is passionate about all things data and works with customers to understand their requirements and build delightful experiences. He has a background in building data-driven solutions and machine learning systems in production.
Pratik Das is a Senior Product Manager with AWS Lake Formation. He is passionate about all things data and works with customers to understand their requirements and build delightful experiences. He has a background in building data-driven solutions and machine learning systems in production.























 Praveen Kumar is an Analytics Solutions Architect at AWS with expertise in designing, building, and implementing modern data and analytics platforms using cloud-based services. His areas of interest are serverless technology, data governance, and data-driven AI applications.
Praveen Kumar is an Analytics Solutions Architect at AWS with expertise in designing, building, and implementing modern data and analytics platforms using cloud-based services. His areas of interest are serverless technology, data governance, and data-driven AI applications. Alexandra Tello is a Senior Front End Engineer with the AWS Analytics services in New York City. She is a passionate advocate for usability and accessibility. In her free time, she’s an espresso enthusiast and enjoys building mechanical keyboards.
Alexandra Tello is a Senior Front End Engineer with the AWS Analytics services in New York City. She is a passionate advocate for usability and accessibility. In her free time, she’s an espresso enthusiast and enjoys building mechanical keyboards. Ranu Shah is a Software Development Manager with AWS Analytics services. She loves building data analytics features for customers. Outside work, she enjoys reading books or listening to music.
Ranu Shah is a Software Development Manager with AWS Analytics services. She loves building data analytics features for customers. Outside work, she enjoys reading books or listening to music. Gal Heyne is a Technical Product Manager for AWS Analytics services with a strong focus on AI/ML and data engineering. She is passionate about developing a deep understanding of customers’ business needs and collaborating with engineers to design simple-to-use data products.
Gal Heyne is a Technical Product Manager for AWS Analytics services with a strong focus on AI/ML and data engineering. She is passionate about developing a deep understanding of customers’ business needs and collaborating with engineers to design simple-to-use data products.



















 Shovan Kanjilal is a Senior Analytics and Machine Learning Architect with Amazon Web Services. He is passionate about helping customers build scalable, secure and high-performance data solutions in the cloud.
Shovan Kanjilal is a Senior Analytics and Machine Learning Architect with Amazon Web Services. He is passionate about helping customers build scalable, secure and high-performance data solutions in the cloud. Vivek Pinyani is a Data Architect at AWS Professional Services with expertise in Big Data technologies. He focuses on helping customers build robust and performant Data Analytics solutions and Data Lake migrations. In his free time, he loves to spend time with his family and enjoys playing cricket and running.
Vivek Pinyani is a Data Architect at AWS Professional Services with expertise in Big Data technologies. He focuses on helping customers build robust and performant Data Analytics solutions and Data Lake migrations. In his free time, he loves to spend time with his family and enjoys playing cricket and running. Kartikay Khator is a Solutions Architect within Global Life Sciences at AWS, where he dedicates his efforts to developing innovative and scalable solutions that cater to the evolving needs of customers. His expertise lies in harnessing the capabilities of AWS analytics services. Extending beyond his professional pursuits, he finds joy and fulfillment in the world of running and hiking. Having already completed multiple marathons, he is currently preparing for his next marathon challenge.
Kartikay Khator is a Solutions Architect within Global Life Sciences at AWS, where he dedicates his efforts to developing innovative and scalable solutions that cater to the evolving needs of customers. His expertise lies in harnessing the capabilities of AWS analytics services. Extending beyond his professional pursuits, he finds joy and fulfillment in the world of running and hiking. Having already completed multiple marathons, he is currently preparing for his next marathon challenge. Caio Sgaraboto Montovani is a Sr. Specialist Solutions Architect, Data Lake and AI/ML within AWS Professional Services, developing scalable solutions according customer needs. His vast experience has helped customers in different industries such as life sciences and healthcare, retail, banking, and aviation build solutions in data analytics, machine learning, and generative AI. He is passionate about rock and roll and cooking and loves to spend time with his family.
Caio Sgaraboto Montovani is a Sr. Specialist Solutions Architect, Data Lake and AI/ML within AWS Professional Services, developing scalable solutions according customer needs. His vast experience has helped customers in different industries such as life sciences and healthcare, retail, banking, and aviation build solutions in data analytics, machine learning, and generative AI. He is passionate about rock and roll and cooking and loves to spend time with his family. Kamen Sharlandjiev is a Sr. Big Data and ETL Solutions Architect, Amazon MWAA and AWS Glue ETL expert. He’s on a mission to make life easier for customers who are facing complex data integration and orchestration challenges. His secret weapon? Fully managed AWS services that can get the job done with minimal effort. Follow Kamen on LinkedIn to keep up to date with the latest Amazon MWAA and AWS Glue features and news!
Kamen Sharlandjiev is a Sr. Big Data and ETL Solutions Architect, Amazon MWAA and AWS Glue ETL expert. He’s on a mission to make life easier for customers who are facing complex data integration and orchestration challenges. His secret weapon? Fully managed AWS services that can get the job done with minimal effort. Follow Kamen on LinkedIn to keep up to date with the latest Amazon MWAA and AWS Glue features and news!
















 Sandeep Adwankar is a Senior Product Manager at AWS. Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that enable customers to improve how they manage, secure, and access data.
Sandeep Adwankar is a Senior Product Manager at AWS. Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that enable customers to improve how they manage, secure, and access data. Scott Rigney is a Senior Technical Product Manager with AWS and has expertise in analytics, data science, and machine learning. He is passionate about building software products that enable enterprises to make data-driven decisions and drive innovation.
Scott Rigney is a Senior Technical Product Manager with AWS and has expertise in analytics, data science, and machine learning. He is passionate about building software products that enable enterprises to make data-driven decisions and drive innovation.
 G2 Krishnamoorthy is VP of Analytics, leading AWS data lake services, data integration, Amazon OpenSearch Service, and Amazon QuickSight. Prior to his current role, G2 built and ran the Analytics and ML Platform at Facebook/Meta, and built various parts of the SQL Server database, Azure Analytics, and Azure ML at Microsoft.
G2 Krishnamoorthy is VP of Analytics, leading AWS data lake services, data integration, Amazon OpenSearch Service, and Amazon QuickSight. Prior to his current role, G2 built and ran the Analytics and ML Platform at Facebook/Meta, and built various parts of the SQL Server database, Azure Analytics, and Azure ML at Microsoft. Rahul Pathak is VP of Relational Database Engines, leading Amazon Aurora, Amazon Redshift, and Amazon QLDB. Prior to his current role, he was VP of Analytics at AWS, where he worked across the entire AWS database portfolio. He has co-founded two companies, one focused on digital media analytics and the other on IP-geolocation.
Rahul Pathak is VP of Relational Database Engines, leading Amazon Aurora, Amazon Redshift, and Amazon QLDB. Prior to his current role, he was VP of Analytics at AWS, where he worked across the entire AWS database portfolio. He has co-founded two companies, one focused on digital media analytics and the other on IP-geolocation.



 Leo Ramsamy is a Platform Architect specializing in data and analytics for ANZ’s Institutional division. He focuses on modern data practices, including Data Mesh architecture, data governance, quality management, and observability. His work aligns data strategies with business goals, improving accessibility and enabling better decision-making across ANZ.
Leo Ramsamy is a Platform Architect specializing in data and analytics for ANZ’s Institutional division. He focuses on modern data practices, including Data Mesh architecture, data governance, quality management, and observability. His work aligns data strategies with business goals, improving accessibility and enabling better decision-making across ANZ. Srinivasan Kuppusamy is a Senior Cloud Architect – Data at AWS ProServe, where he helps customers solve their business problems using the power of AWS Cloud technology. His areas of interests are data and analytics, data governance, and AI/ML.
Srinivasan Kuppusamy is a Senior Cloud Architect – Data at AWS ProServe, where he helps customers solve their business problems using the power of AWS Cloud technology. His areas of interests are data and analytics, data governance, and AI/ML. Rada Stanic is a Chief Technologist at Amazon Web Services, where she helps ANZ customers across different segments solve their business problems using AWS Cloud technologies. Her special areas of interest are data analytics, machine learning/AI, and application modernization.
Rada Stanic is a Chief Technologist at Amazon Web Services, where she helps ANZ customers across different segments solve their business problems using AWS Cloud technologies. Her special areas of interest are data analytics, machine learning/AI, and application modernization.



















 Sotaro Hikita is an Analytics Solutions Architect. He supports customers across a wide range of industries in building and operating analytics platforms more effectively. He is particularly passionate about big data technologies and open source software.
Sotaro Hikita is an Analytics Solutions Architect. He supports customers across a wide range of industries in building and operating analytics platforms more effectively. He is particularly passionate about big data technologies and open source software. Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He works based in Tokyo, Japan. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his road bike.
Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He works based in Tokyo, Japan. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his road bike. Kyle Duong is a Senior Software Development Engineer on the AWS Glue and AWS Lake Formation team. He is passionate about building big data technologies and distributed systems.
Kyle Duong is a Senior Software Development Engineer on the AWS Glue and AWS Lake Formation team. He is passionate about building big data technologies and distributed systems. Sandeep Adwankar is a Senior Product Manager at AWS. Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that enable customers to improve how they manage, secure, and access data.
Sandeep Adwankar is a Senior Product Manager at AWS. Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that enable customers to improve how they manage, secure, and access data.




































































































 Allison Quinn is a Sr. ANZ Analytics Specialist Solutions Architect for Data and AI based in Melbourne, Australia working closely with Financial Service customers in the region. Allison worked over 15 years with SAP products before concentrating her Analytics technical specialty on AWS native services. She’s very passionate about all things data, and democratizing so that customers of all types can drive business benefit.
Allison Quinn is a Sr. ANZ Analytics Specialist Solutions Architect for Data and AI based in Melbourne, Australia working closely with Financial Service customers in the region. Allison worked over 15 years with SAP products before concentrating her Analytics technical specialty on AWS native services. She’s very passionate about all things data, and democratizing so that customers of all types can drive business benefit. Pavol is an Innovation Solution Architect at AWS, specializing in SAP cloud adoption across EMEA. With over 20 years of experience, he helps global customers migrate and optimize SAP systems on AWS. Pavol develops tailored strategies to transition SAP environments to the cloud, leveraging AWS’s agility, resiliency, and performance. He assists clients in modernizing their SAP landscapes using AWS’s AI/ML, data analytics, and application services to enhance intelligence, automation, and performance.
Pavol is an Innovation Solution Architect at AWS, specializing in SAP cloud adoption across EMEA. With over 20 years of experience, he helps global customers migrate and optimize SAP systems on AWS. Pavol develops tailored strategies to transition SAP environments to the cloud, leveraging AWS’s agility, resiliency, and performance. He assists clients in modernizing their SAP landscapes using AWS’s AI/ML, data analytics, and application services to enhance intelligence, automation, and performance. Partha Pratim Sanyal is a Software Development Engineer with AWS Glue in Vancouver, Canada, specializing in Data Integration, Analytics, and Connectivity. With extensive backend development expertise, he is dedicated to crafting impactful, customer-centric solutions. His work focuses on building features that empower users to effortlessly analyze and understand their data. Partha’s commitment to addressing complex user needs drives him to create intuitive and value-driven experiences that elevate data accessibility and insights for customers.
Partha Pratim Sanyal is a Software Development Engineer with AWS Glue in Vancouver, Canada, specializing in Data Integration, Analytics, and Connectivity. With extensive backend development expertise, he is dedicated to crafting impactful, customer-centric solutions. His work focuses on building features that empower users to effortlessly analyze and understand their data. Partha’s commitment to addressing complex user needs drives him to create intuitive and value-driven experiences that elevate data accessibility and insights for customers. Diego is an experienced Enterprise Solutions Architect with over 20 years’ experience across SAP technologies, specializing in SAP innovation and data and analytics. He has worked both as partner and as a customer, giving him a complete perspective on what it takes to sell, implement, and run systems and organizations. He is passionate about technology and innovation, focusing on customer outcomes and delivering business value.
Diego is an experienced Enterprise Solutions Architect with over 20 years’ experience across SAP technologies, specializing in SAP innovation and data and analytics. He has worked both as partner and as a customer, giving him a complete perspective on what it takes to sell, implement, and run systems and organizations. He is passionate about technology and innovation, focusing on customer outcomes and delivering business value. Luis Alberto Herrera Gomez is a Software Development Engineer with AWS Glue in Vancouver, specializing in backend engineering, microservices, and cloud computing. With 7-8 years of experience, including roles as a backend and full-stack developer for multiple startups before joining Amazon and AWS; Luis focuses on developing scalable and efficient cloud-based applications. His expertise in AWS technologies enables him to design high-performance systems that handle complex data processing tasks. Luis is passionate about leveraging cloud computing to solving challenging business problems.
Luis Alberto Herrera Gomez is a Software Development Engineer with AWS Glue in Vancouver, specializing in backend engineering, microservices, and cloud computing. With 7-8 years of experience, including roles as a backend and full-stack developer for multiple startups before joining Amazon and AWS; Luis focuses on developing scalable and efficient cloud-based applications. His expertise in AWS technologies enables him to design high-performance systems that handle complex data processing tasks. Luis is passionate about leveraging cloud computing to solving challenging business problems.

 Raks Khare is a Senior Analytics Specialist Solutions Architect at AWS based out of Pennsylvania. He helps customers across varying industries and regions architect data analytics solutions at scale on the AWS platform. Outside of work, he likes exploring new travel and food destinations and spending quality time with his family.
Raks Khare is a Senior Analytics Specialist Solutions Architect at AWS based out of Pennsylvania. He helps customers across varying industries and regions architect data analytics solutions at scale on the AWS platform. Outside of work, he likes exploring new travel and food destinations and spending quality time with his family. Poulomi Dasgupta is a Senior Analytics Solutions Architect with AWS. She is passionate about helping customers build cloud-based analytics solutions to solve their business problems. Outside of work, she likes travelling and spending time with her family.
Poulomi Dasgupta is a Senior Analytics Solutions Architect with AWS. She is passionate about helping customers build cloud-based analytics solutions to solve their business problems. Outside of work, she likes travelling and spending time with her family. Saurav Das is part of the Amazon Redshift Product Management team. He has more than 16 years of experience in working with relational databases technologies and data protection. He has a deep interest in solving customer challenges centered around high availability and disaster recovery.
Saurav Das is part of the Amazon Redshift Product Management team. He has more than 16 years of experience in working with relational databases technologies and data protection. He has a deep interest in solving customer challenges centered around high availability and disaster recovery.