Post Syndicated from Lorenzo Nicora original https://aws.amazon.com/blogs/big-data/introducing-the-new-amazon-kinesis-source-connector-for-apache-flink/
On November 11, 2024, the Apache Flink community released a new version of AWS services connectors, an AWS open source contribution. This new release, version 5.0.0, introduces a new source connector to read data from Amazon Kinesis Data Streams. In this post, we explain how the new features of this connector can improve performance and reliability of your Apache Flink application.
Apache Flink has both a source and sink connector, to read from and write to Kinesis Data Streams. In this post, we focus on the new source connector, because version 5.0.0 does not introduce new functionality for the sink.
Apache Flink is a framework and distributed stream processing engine designed to perform computation at in-memory speed and at any scale. Amazon Managed Service for Apache Flink offers a fully managed, serverless experience to run your Flink applications, implemented in Java, Python or SQL, and using all the APIs available in Flink: SQL, Table, DataStream, and ProcessFunction API.
Apache Flink connectors
Flink supports reading and writing data to external systems, through connectors, which are components that allow your application to interact with stream-storage message brokers, databases, or object stores. Kinesis Data Streams is a popular source and destination for streaming applications. Flink provides both source and sink connectors for Kinesis Data Streams.
The following diagram illustrates a sample architecture.

Before proceeding further, it’s important to clarify three terms often used interchangeably in data streaming and in the Apache Flink documentation:
- Kinesis Data Streams refers to the Amazon service
- Kinesis source and Kinesis consumer refer to the Apache Flink components, in particular the source connectors, that allows reading data from Kinesis Data Streams
- In this post, we use the term stream referring to a single Kinesis data stream
Introducing the new Flink Kinesis source connector
The launch of the version 5.0.0 of AWS connectors introduces a new connector for reading events from Kinesis Data Streams. The new connector is called Kinesis Streams Source and supersedes the Kinesis Consumer as the source connector for Kinesis Data Streams.
The new connector introduces several new features and adheres to the new Flink Source interface, and is compatible with Flink 2.x, the first major version release by the Flink community. Flink 2.x introduces a number of breaking changes, including removing the SourceFunction interface used by legacy connectors. The legacy Kinesis Consumer will no longer work with Flink 2.x.
Setting up the connector is slightly different than with the legacy Kinesis connector. Let’s start with the DataStream API.
How to use the new connector with the DataStream API
To add the new connector to your application, you need to update the connector dependency. For the DataStream API, the dependency has changed its name to flink-connector-aws-kinesis-streams.
At the time of writing, the latest connector version is 5.0.0 and it supports the most recent stable Flink versions, 1.19 and 1.20. The connector is also compatible with Flink 2.0, but no connector has been officially released for Flink 2.x yet. Assuming you are using Flink 1.20, the new dependency is the following:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-aws-kinesis streams</artifactId>
<version>5.0.0-1.20</version>
</dependency>
The connector uses the new Flink Source interface. This interface implements the new FLIP-27 standard, and replaces the legacy SourceFunction interface that has been deprecated. SourceFunction will be completely removed in Flink 2.x.
In your application, you can now use a fluent and expressive builder interface to instantiate and configure the source. The minimal setup only requires the stream Amazon Resource Name (ARN) and the deserialization schema:
KinesisStreamsSource<String> kdsSource = KinesisStreamsSource.<String>builder()
.setStreamArn("arn:aws:kinesis:us-east-1:123456789012:stream/test-stream")
.setDeserializationSchema(new SimpleStringSchema())
.build();
The new source class is called KinesisStreamSource. Not to be confused with the legacy source, FlinkKinesisConsumer.
You can then add the source to the execution environment using the new fromSource() method. This method requires explicitly specifying the watermark strategy, along with a name for the source:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// ...
DataStream<String> kinesisRecordsWithEventTimeWatermarks = env.fromSource(
kdsSource,
WatermarkStrategy.<String>forMonotonousTimestamps()
.withIdleness(Duration.ofSeconds(1)),
"Kinesis source");
These few lines of code introduce some of the main changes in the interface of the connector, which we discuss in the following sections.
Stream ARN
You can now define the Kinesis data stream ARN, as opposed to the stream name. This makes it simpler to consume from streams cross-Region and cross-account.
When running in Amazon Managed Service for Apache Flink, you only need to add to the application AWS Identity and Access Management (IAM) role permissions to access the stream. The ARN allows pointing to a stream located in a different AWS Region or account, without assuming roles or passing any external credentials.
Explicit watermark
One of the most important characteristics of the new Source interface is that you have to explicitly define a watermark strategy when you attach the source to the execution environment. If your application only implements processing-time semantics, you can specify WatermarkStrategy.noWatermarks().
This is an improvement in terms of code readability. Looking at the source, you know immediately which type of watermark you have, or if you don’t have any. Previously, many connectors were providing some type of default watermarks that the user could override. However, the default watermark of each connector was slightly different and confusing for the user.
With the new connector, you can achieve the same behavior as the legacy FlinkKinesisConsumer default watermarks, using WatermarkStrategy.forMonotonousTimestamps(), as shown in the previous example. This strategy generates watermarks based on the approximateArrivalTimestamp returned by Kinesis Data Streams. This timestamp corresponds to the time when the record was published to Kinesis Data Streams.
Idleness and watermark alignment
With the watermark strategy, you can additionally define an idleness, which allows the watermark to progress even when some shards of the stream are idle and receiving no records. Refer to Dealing With Idle Sources for more details about idleness and watermark generators.
A feature introduced by the new Source interface, and fully supported by the new Kinesis source, is watermark alignment. Watermark alignment works in the opposite direction of idleness. It slows down consuming from a shard that is progressing faster than others. This is particularly useful when replaying data from a stream, to reduce the volume of data buffered in the application state. Refer to Watermark alignment for more details.
Set up the connector with the Table API and SQL
Assuming you are using Flink 1.20, the dependency containing both Kinesis source and sink for the Table API and SQL is the following (both Flink 1.19 and 1.20 are supported, adjust the version accordingly):
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kinesis</artifactId>
<version>5.0.0-1.20</version>
</dependency>
This dependency contains both the new source and the legacy source. Refer to Versioning in case you are planning to use both in the same application.
When defining the source in SQL or the Table API, you use the connector name kinesis, as it was with the legacy source. However, many parameters have changed with the new source:
CREATE TABLE KinesisTable (
`user_id` BIGINT,
`item_id` BIGINT,
`category_id` BIGINT,
`behavior` STRING,
`ts` TIMESTAMP(3)
)
PARTITIONED BY (user_id, item_id)
WITH (
'connector' = 'kinesis',
'stream.arn' = 'arn:aws:kinesis:us-east-1:012345678901:stream/my-stream-name',
'aws.region' = 'us-east-1',
'source.init.position' = 'LATEST',
'format' = 'csv'
);
A couple of notable connector options changed from the legacy source are:
stream.arn specifies the stream ARN, as opposed to the stream name used in the legacy source.init.initpos defines the starting position. This option works similarly to the legacy source, but the option name is different. It was previously scan.stream.initpos.
For the full list of connector options refer to Connector Options.
New features and improvements
In this section, we discuss the most important features introduced by the new connector. These features are available in the DataStream API, and also the Table API and SQL.
Ordering guarantees
The most important improvement introduced by the new connector is about ordering guarantees.
With Kinesis Data Streams, the order of the message is retained per partitionId. This is achieved by putting all records with the same partitionId in the same shard. However, when the stream scales, splitting or merging shards, records with the same partitionId end up in a new shard. Kinesis keeps track of the parent-child lineage when resharding happens.

One known limitation of the legacy Kinesis source is that it was unable to follow the parent-child shard lineage. As a consequence, ordering could not be guaranteed when resharding happens. The problem was particularly relevant when the application replayed old messages from a stream that had been resharded because ordering would be lost. This also made watermark generation and event-time processing non-deterministic.
With the new connector, ordering is retained also when resharding happens. This is achieved following the parent-child shard lineage, and consuming all records from a parent shard before proceeding with the child shard.

A better default shard assigner
Each Kinesis data stream is comprised of many shards. Also, the Flink source operator runs in multiple parallel subtasks. The shard assigner is the component that decides how to assign the shards of the stream across the source subtasks. The shard assigner’s job is non-trivial, because shard split or merge operations (resharding) might happen when the stream scales up or down.
The new connector comes with a new default assigner, UniformShardAssigner. This assigner maintains uniform distribution of the stream partitionId across parallel subtasks, also when resharding happens. This is achieved by looking at the range of partition keys (HashKeyRange) of each shard.
This shard assigner was already available in the previous connector version, but for backward compatibility, it was not the default and you had to set it up explicitly. This is no longer the case with the new source. The old default shard assigner, the legacy FlinkKinesisConsumer, was evenly distributing shards (not partitionId) across subtasks. In this case, the actual data distribution might become uneven in the case of resharding, because of the combination of open and closed shards in the stream. Refer to Shard Assignment Strategy for more details.
Reduced JAR size
The size of the JAR file has been reduced by 99%, from about 60 MB down to 200 KB. This substantially reduces the size of the fat-JAR of your application using the connector. A smaller JAR can speed up many operations that require redeploying the application.
AWS SDK for Java 2.x
The new connector is based on the newer AWS SDK for Java 2.x, which adds several features and improves support for non-blocking I/O. This makes the connector future-proof because the AWS SDK v1 will reach end-of-support by end of 2025.
AWS SDK built-in retry strategy
The new connector relies on the AWS SDK built-in retry strategy, as opposed to a custom strategy implemented by the legacy connector. Relying on the AWS SDK improves the classification of some errors as retriable or non-retriable.
Removed dependency on the Kinesis Client Library and Kinesis Producer Library
The new connector package no longer includes the Kinesis Client Library (KCL) and Kinesis Producer Library (KPL), contributing to the substantial reduction of the JAR size that we have mentioned.
An implication of this change is that the new connector no longer supports de-aggregation out of the box. Unless you are publishing records to the stream using the KPL and you enabled aggregation, this will not make any difference for you. If your producers use KPL aggregation, you might consider implementing a custom DeserializationSchema to de-aggregate the records in the source.
Migrating from the legacy connector
Flink sources typically save the position in the checkpoint and savepoints, called snapshots in Amazon Managed Service for Apache Flink. When you stop and restart the application, or when you update the application to deploy a change, the default behavior is saving the source position in the snapshot just before stopping the application, and restoring the position when the application restarts. This allows Flink to provide exactly-once guarantees on the source.
However, due to the major changes introduced by the new KinesisSource, the saved state is no longer compatible with the legacy FlinkKinesisConsumer. This means that when you upgrade the source of an existing application, you can’t directly restore the source position from the snapshot.
For this reason, migrating your application to the new source requires some attention. The exact migration process depends on your use case. There are two general scenarios:
- Your application uses the DataStream API and you are following Flink best practices defining a UID on each operator
- Your application uses the Table API or SQL, or your application used the DataStream API and you are not defining a UID on each operator
Let’s cover each of these scenarios.
Your application uses the DataStream API and you are defining a UID on each operator
In this case, you might consider selectively resetting the state of the source operator, retaining any other application state. The general approach is as follows:
- Update your application dependencies and code, replacing the
FlinkKinesisConsumer with the new KinesisSource.
- Change the UID of the source operator (use a different string). Leave all other operators’ UIDs This will selectively reset the state of the source while retaining the state of all other operators.
- Configure the source starting position using
AT_TIMESTAMP and set the timestamp to just before the moment you will deploy the change. See Configuring Starting Position to learn how to set the starting position. We recommend passing the timestamp as a runtime property to make this more flexible. The configured source starting position is used only when the application can’t restore the state from a savepoint (or snapshot). In this case, we are deliberately forcing this, changing the UID of the source operator.
- Update the Amazon Managed Service for Apache Flink application, selecting the new JAR containing the modified application. Restart from the latest snapshot (default behavior) and select
allowNonRestoredState = true. Without this flag, Flink would prevent restarting the application, not being able to restore the state of the old source that was saved in the snapshot. See Savepointing for more details about allowNonRestoredState.
This approach will cause the reprocessing of some records from the source, and internal state exactly-once consistency can be broken. Carefully evaluate the impact of reprocessing on your application, and the impact of duplicates on the downstream systems.
Your application uses the Table API or SQL, or your application used the DataStream API and you are not defining a UID on each operator
In this case, you can’t selectively reset the state of the source operator.
Why does this happen? When using the Table API or SQL, or the DataStream API without defining the operator’s UID explicitly, Flink automatically generates identifiers for all operators based on the structure of the job graph of your application. These identifiers are used to identify the state of each operator when saved in the snapshots, and to restore it to the correct operator when you restart the application.
Changes to the application might cause changes in the underlying data flow. This changes the auto-generated identifier. If you are using the DataStream API and you are specifying the UID, Flink uses your identifiers instead of the auto-generated identifies, and is able to map back the state to the operator, even when you make changes to the application. This is an intrinsic limitation of Flink, explained in Set UUIDs For All Operators. Enabling allowNonRestoredState does not solve this problem, because Flink is not able to map the state saved in the snapshot with the actual operators, after the changes.
In our migration scenario, the only option is resetting the state of your application. You can achieve this in Amazon Managed Service for Apache Flink by selecting Skip restore from snapshot (SKIP_RESTORE_FROM_SNAPSHOT) when you deploy the change that replaces the source connector.
After the application using the new source is up and running, you can switch back to the default behavior of when restarting the application, using the latest snapshots (RESTORE_FROM_LATEST_SNAPSHOT). This way, no data loss happens when the application is restarted.
Choosing the right connector package and version
The dependency version you need to pick is normally <connector-version>-<flink-version>. For example, the latest Kinesis connector version is 5.0.0. If you are using a Flink runtime version 1.20.x, your dependency for the DataStream API is 5.0.0-1.20.
For the most up-to-date connector versions, see Use Apache Flink connectors with Managed Service for Apache Flink.
Connector artifact
In previous versions of the connector (4.x and before), there were separate packages for the source and sink. This additional level of complexity has been removed with version 5.x.
For your Java application, or Python applications where you package JAR dependencies using Maven, as shown in the Amazon Managed Service for Apache Flink examples GitHub repository, the following dependency contains the new version of both source and sink connectors:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-aws-kinesis-streams</artifactId>
<version>5.0.0-1.20</version>
</dependency>
Make sure you’re using the latest available version. At the time of writing, this is 5.0.0. You can verify the available artifact versions in Maven Central. Also, use the correct version depending on your Flink runtime version. The previous example is for Flink 1.20.0.
Connector artifacts for Python application
If you use Python, we recommend packaging JAR dependencies using Maven, as shown in the Amazon Managed Service for Apache Flink examples GitHub repository. However, if you’re passing directly a single JAR to your Amazon Managed Service for Apache Flink application, you need to use the artifact that includes all transitive dependencies. In the case of the new Kinesis source and sink, this is called flink-sql-connector-aws-kinesis-streams. This artifact includes only the new source. Refer to Amazon Kinesis Data Streams SQL Connector for the right package, in case you want to use both the new and the legacy source.
Conclusion
The new Flink Kinesis source connector introduces many new features that improve stability and performance, and prepares your application for Flink 2.x. Support for watermark idleness and alignment is a particularly important feature if your application uses event-time semantics. The ability to retain record ordering improves data consistency, in particular when stream resharding happens, and when you replay old data from a stream that has been reshared.
You should carefully plan the change if you’re migrating your application from the legacy Kinesis source connector, and make sure you follow Flink’s best practices like specifying a UID on all DataStream operators.
You can find a working example of Java DataStream API application using the new connector, in the Amazon Managed Service for Apache Flink samples GitHub repository.
To learn more about the new Flink Kinesis source connector, refer to Amazon Kinesis Data Streams Connector and Amazon Kinesis Data Streams SQL Connector.
About the Author
 Lorenzo Nicora works as a Senior Streaming Solutions Architect at AWS, helping customers across EMEA. He has been building cloud-centered, data-intensive systems for over 25 years, working across industries both through consultancies and product companies. He has used open source technologies extensively and contributed to several projects, including Apache Flink.
Lorenzo Nicora works as a Senior Streaming Solutions Architect at AWS, helping customers across EMEA. He has been building cloud-centered, data-intensive systems for over 25 years, working across industries both through consultancies and product companies. He has used open source technologies extensively and contributed to several projects, including Apache Flink.

 Ishan Gupta is the Co-Founder and CTO of Juicebox, an AI-powered recruiting software startup backed by top Silicon Valley investors including Y Combinator, Nat Friedman, and Daniel Gross. He has built search products used by thousands of customers to recruit talent for their teams.
Ishan Gupta is the Co-Founder and CTO of Juicebox, an AI-powered recruiting software startup backed by top Silicon Valley investors including Y Combinator, Nat Friedman, and Daniel Gross. He has built search products used by thousands of customers to recruit talent for their teams. Jon Handler is the Director of Solutions Architecture for Search Services at Amazon Web Services, based in Palo Alto, CA. Jon works closely with OpenSearch and Amazon OpenSearch Service, providing help and guidance to a broad range of customers who have search and log analytics workloads for OpenSearch. Prior to joining AWS, Jon’s career as a software developer included four years of coding a large-scale, eCommerce search engine. Jon holds a Bachelor of the Arts from the University of Pennsylvania, and a Master of Science and a Ph. D. in Computer Science and Artificial Intelligence from Northwestern University.
Jon Handler is the Director of Solutions Architecture for Search Services at Amazon Web Services, based in Palo Alto, CA. Jon works closely with OpenSearch and Amazon OpenSearch Service, providing help and guidance to a broad range of customers who have search and log analytics workloads for OpenSearch. Prior to joining AWS, Jon’s career as a software developer included four years of coding a large-scale, eCommerce search engine. Jon holds a Bachelor of the Arts from the University of Pennsylvania, and a Master of Science and a Ph. D. in Computer Science and Artificial Intelligence from Northwestern University.




 Kalyan Janaki is Senior Big Data & Analytics Specialist with Amazon Web Services. He helps customers architect and build highly scalable, performant, and secure cloud-based solutions on AWS.
Kalyan Janaki is Senior Big Data & Analytics Specialist with Amazon Web Services. He helps customers architect and build highly scalable, performant, and secure cloud-based solutions on AWS. Venu Nemallikanti is the Enterprise Architect and Lead for Event Streaming at Fitch Group, a globally recognized financial information services provider operating in over 30 countries. His primary responsibilities include overseeing the architecture and implementation of event streaming solutions, ensuring the seamless integration and performance of systems that deliver credit ratings, research, data, and analytics to a worldwide clientele.
Venu Nemallikanti is the Enterprise Architect and Lead for Event Streaming at Fitch Group, a globally recognized financial information services provider operating in over 30 countries. His primary responsibilities include overseeing the architecture and implementation of event streaming solutions, ensuring the seamless integration and performance of systems that deliver credit ratings, research, data, and analytics to a worldwide clientele. Chaitanya Shah is a Principal Technical Account Manager with AWS, based out of New York. He loves to code and actively contributes to the AWS solutions labs to help customers solve complex problems. He provides guidance to AWS customers on best practices for their Cloud migrations. He is also specialized in AWS data transfer and the data and analytics domain.
Chaitanya Shah is a Principal Technical Account Manager with AWS, based out of New York. He loves to code and actively contributes to the AWS solutions labs to help customers solve complex problems. He provides guidance to AWS customers on best practices for their Cloud migrations. He is also specialized in AWS data transfer and the data and analytics domain. Oleg Chugaev is a Principal Solutions Architect and Serverless evangelist with 20+ years in IT, holding multiple AWS certifications. At AWS, he drives customers through their cloud transformation journeys by converting complex challenges into actionable roadmaps for both technical and business audiences.
Oleg Chugaev is a Principal Solutions Architect and Serverless evangelist with 20+ years in IT, holding multiple AWS certifications. At AWS, he drives customers through their cloud transformation journeys by converting complex challenges into actionable roadmaps for both technical and business audiences.













 Bo Li is a Senior Software Development Engineer on the AWS Glue team. He is devoted to designing and building end-to-end solutions to address customers’ data analytic and processing needs with cloud-based, data-intensive technologies.
Bo Li is a Senior Software Development Engineer on the AWS Glue team. He is devoted to designing and building end-to-end solutions to address customers’ data analytic and processing needs with cloud-based, data-intensive technologies. Stuti Deshpande is a Big Data Specialist Solutions Architect at AWS. She works with customers around the globe, providing them strategic and architectural guidance on implementing analytics solutions using AWS. She has extensive experience in big data, ETL, and analytics. In her free time, Stuti likes to travel, learn new dance forms, and enjoy quality time with family and friends.
Stuti Deshpande is a Big Data Specialist Solutions Architect at AWS. She works with customers around the globe, providing them strategic and architectural guidance on implementing analytics solutions using AWS. She has extensive experience in big data, ETL, and analytics. In her free time, Stuti likes to travel, learn new dance forms, and enjoy quality time with family and friends. Kartik Panjabi is a Software Development Manager on the AWS Glue team. His team builds generative AI features for the Data Integration and distributed system for data integration.
Kartik Panjabi is a Software Development Manager on the AWS Glue team. His team builds generative AI features for the Data Integration and distributed system for data integration. Shubham Mehta is a Senior Product Manager at AWS Analytics. He leads generative AI feature development across services such as AWS Glue, Amazon EMR, and Amazon MWAA, using AI/ML to simplify and enhance the experience of data practitioners building data applications on AWS.
Shubham Mehta is a Senior Product Manager at AWS Analytics. He leads generative AI feature development across services such as AWS Glue, Amazon EMR, and Amazon MWAA, using AI/ML to simplify and enhance the experience of data practitioners building data applications on AWS.




 Luis Campos is the Data & AI Governance GTM Lead for the EMEA market at AWS where he helps customers with their data strategies starting with strong data governance and uses his expertise in end-to-end data & analytics management. Luis is also a public speaking coach, based in the Netherlands, and has two boys with 18 years apart, which has taught him to see problems from both ends of a spectrum.
Luis Campos is the Data & AI Governance GTM Lead for the EMEA market at AWS where he helps customers with their data strategies starting with strong data governance and uses his expertise in end-to-end data & analytics management. Luis is also a public speaking coach, based in the Netherlands, and has two boys with 18 years apart, which has taught him to see problems from both ends of a spectrum.
 Tommaso is the Head of Data & Cloud Platforms at HEMA. He joined the business with the goal of modernising the Data Organization by building cloud-based Data Platform – hosted in AWS – which would power a Data Mesh architecture. With a strong passion for both technical and organizational challenges, Tommaso leads the Solution Architecture efforts as well as all core Data Management and Data Governance initiatives, for which he is also a passionate public speaker. Outside the office, Tommaso is a full-time dad with a passion for traveling and sports.
Tommaso is the Head of Data & Cloud Platforms at HEMA. He joined the business with the goal of modernising the Data Organization by building cloud-based Data Platform – hosted in AWS – which would power a Data Mesh architecture. With a strong passion for both technical and organizational challenges, Tommaso leads the Solution Architecture efforts as well as all core Data Management and Data Governance initiatives, for which he is also a passionate public speaker. Outside the office, Tommaso is a full-time dad with a passion for traveling and sports. Oghosa Omorisiagbon is a Senior Data Engineer at HEMA. He focuses on leveraging AWS-native tools to optimise data pipelines, modernise HEMA’s data infrastructure and introduce reliable and scalable end-to-end data architecture solutions. Outside of work, he enjoys traveling, playing video games and outdoor activities.
Oghosa Omorisiagbon is a Senior Data Engineer at HEMA. He focuses on leveraging AWS-native tools to optimise data pipelines, modernise HEMA’s data infrastructure and introduce reliable and scalable end-to-end data architecture solutions. Outside of work, he enjoys traveling, playing video games and outdoor activities.


 Navnit Shukla serves as an AWS Specialist Solutions Architect with a focus on Analytics. He possesses a strong enthusiasm for assisting clients in discovering valuable insights from their data. Through his expertise, he constructs innovative solutions that empower businesses to arrive at informed, data-driven choices. Notably, Navnit Shukla is the accomplished author of the book titled Data Wrangling on AWS. He can be reached through
Navnit Shukla serves as an AWS Specialist Solutions Architect with a focus on Analytics. He possesses a strong enthusiasm for assisting clients in discovering valuable insights from their data. Through his expertise, he constructs innovative solutions that empower businesses to arrive at informed, data-driven choices. Notably, Navnit Shukla is the accomplished author of the book titled Data Wrangling on AWS. He can be reached through  Angel Conde Manjon is a Sr. PSA Specialist on Data & AI, based in Madrid, and focuses on EMEA South and Israel. He has previously worked on research related to data analytics and artificial intelligence in diverse European research projects. In his current role, Angel helps partners develop businesses centered on data and AI.
Angel Conde Manjon is a Sr. PSA Specialist on Data & AI, based in Madrid, and focuses on EMEA South and Israel. He has previously worked on research related to data analytics and artificial intelligence in diverse European research projects. In his current role, Angel helps partners develop businesses centered on data and AI. Amit Singh currently serves as a Senior Solutions Architect at AWS, specializing in analytics and IoT technologies. With extensive expertise in designing and implementing large-scale distributed systems, Amit is passionate about empowering clients to drive innovation and achieve business transformation through AWS solutions.
Amit Singh currently serves as a Senior Solutions Architect at AWS, specializing in analytics and IoT technologies. With extensive expertise in designing and implementing large-scale distributed systems, Amit is passionate about empowering clients to drive innovation and achieve business transformation through AWS solutions. Sandeep Adwankar is a Senior Technical Product Manager at AWS. Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that enable customers to improve how they manage, secure, and access data.
Sandeep Adwankar is a Senior Technical Product Manager at AWS. Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that enable customers to improve how they manage, secure, and access data.


 Lorenzo Nicora works as a Senior Streaming Solutions Architect at AWS, helping customers across EMEA. He has been building cloud-centered, data-intensive systems for over 25 years, working across industries both through consultancies and product companies. He has used open source technologies extensively and contributed to several projects, including Apache Flink.
Lorenzo Nicora works as a Senior Streaming Solutions Architect at AWS, helping customers across EMEA. He has been building cloud-centered, data-intensive systems for over 25 years, working across industries both through consultancies and product companies. He has used open source technologies extensively and contributed to several projects, including Apache Flink.

 Neeraja Rentachintala is Director, Product Management with AWS Analytics, leading Amazon Redshift and Amazon SageMaker Lakehouse. Neeraja is a seasoned technology leader, bringing over 25 years of experience in product vision, strategy, and leadership roles in data products and platforms. She has delivered products in analytics, databases, data integration, application integration, AI/ML, and large-scale distributed systems across on-premises and the cloud, serving Fortune 500 companies as part of ventures including MapR (acquired by HPE), Microsoft SQL Server, Oracle, Informatica, and Expedia.com
Neeraja Rentachintala is Director, Product Management with AWS Analytics, leading Amazon Redshift and Amazon SageMaker Lakehouse. Neeraja is a seasoned technology leader, bringing over 25 years of experience in product vision, strategy, and leadership roles in data products and platforms. She has delivered products in analytics, databases, data integration, application integration, AI/ML, and large-scale distributed systems across on-premises and the cloud, serving Fortune 500 companies as part of ventures including MapR (acquired by HPE), Microsoft SQL Server, Oracle, Informatica, and Expedia.com

 Momota Sasaki is an Engineering Manager at DeSC Healthcare, a subsidiary of DeNA. He joined DeNA in 2021 and was seconded to DeSC Healthcare. Since then, he has been consistently involved in the healthcare business, leading and promoting the development and operation of the data platform.
Momota Sasaki is an Engineering Manager at DeSC Healthcare, a subsidiary of DeNA. He joined DeNA in 2021 and was seconded to DeSC Healthcare. Since then, he has been consistently involved in the healthcare business, leading and promoting the development and operation of the data platform. Kaito Tawara is a Data Engineer at DeSC Healthcare, a subsidiary of DeNA, focusing on improving healthcare data platforms. After gaining experience in backend development for web systems and data science, he transitioned to data engineering. He joined DeNA in 2023 and was seconded to DeSC Healthcare. Currently, he works remotely from Nagoya-city, contributing to the enhancement of healthcare data platforms.
Kaito Tawara is a Data Engineer at DeSC Healthcare, a subsidiary of DeNA, focusing on improving healthcare data platforms. After gaining experience in backend development for web systems and data science, he transitioned to data engineering. He joined DeNA in 2023 and was seconded to DeSC Healthcare. Currently, he works remotely from Nagoya-city, contributing to the enhancement of healthcare data platforms. Shota Sato is an Analytics Specialist Solution Architect at AWS Japan, focusing on data analytics solutions powered by AWS for digital native business customers.
Shota Sato is an Analytics Specialist Solution Architect at AWS Japan, focusing on data analytics solutions powered by AWS for digital native business customers.
 Sai Maddali is a Senior Manager Product Management at AWS who leads the product team for Amazon MSK. He is passionate about understanding customer needs, and using technology to deliver services that empowers customers to build innovative applications. Besides work, he enjoys traveling, cooking, and running.
Sai Maddali is a Senior Manager Product Management at AWS who leads the product team for Amazon MSK. He is passionate about understanding customer needs, and using technology to deliver services that empowers customers to build innovative applications. Besides work, he enjoys traveling, cooking, and running. Bill Crew is a Senior Product Marketing Manager. He is the lead marketer for Streaming and Messaging Services at AWS. Including Amazon Managed Streaming for Apache Kafka (Amazon MSK), Amazon Managed Service for Apache Flink, Amazon Data Firehose, Amazon Kinesis Data Streams, Amazon Message Broker (Amazon MQ), Amazon Simple Queue Service (Amazon SQS), and Amazon Simple Notification Services (Amazon SNS). Besides work, he enjoys collecting vintage vinyl records.
Bill Crew is a Senior Product Marketing Manager. He is the lead marketer for Streaming and Messaging Services at AWS. Including Amazon Managed Streaming for Apache Kafka (Amazon MSK), Amazon Managed Service for Apache Flink, Amazon Data Firehose, Amazon Kinesis Data Streams, Amazon Message Broker (Amazon MQ), Amazon Simple Queue Service (Amazon SQS), and Amazon Simple Notification Services (Amazon SNS). Besides work, he enjoys collecting vintage vinyl records.










 Chiho Sugimoto is a Cloud Support Engineer on the AWS Big Data Support team. She is passionate about helping customers build data lakes using ETL workloads. She loves planetary science and enjoys studying the asteroid Ryugu on weekends.
Chiho Sugimoto is a Cloud Support Engineer on the AWS Big Data Support team. She is passionate about helping customers build data lakes using ETL workloads. She loves planetary science and enjoys studying the asteroid Ryugu on weekends. Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his new road bike.
Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his new road bike. Shubham Agrawal is a Software Development Engineer on the AWS Glue team. He has expertise in designing scalable, high-performance systems for handling large-scale, real-time data processing. Driven by a passion for solving complex engineering problems, he focuses on building seamless integration solutions that enable organizations to maximize the value of their data.
Shubham Agrawal is a Software Development Engineer on the AWS Glue team. He has expertise in designing scalable, high-performance systems for handling large-scale, real-time data processing. Driven by a passion for solving complex engineering problems, he focuses on building seamless integration solutions that enable organizations to maximize the value of their data. Joju Eruppanal is a Software Development Manager on the AWS Glue team. He strives to delight customers by helping his team build software. He loves exploring different cultures and cuisines.
Joju Eruppanal is a Software Development Manager on the AWS Glue team. He strives to delight customers by helping his team build software. He loves exploring different cultures and cuisines. Julie Zhao is a Senior Product Manager at AWS Glue. She joined AWS in 2021 and brings three years of startup experience leading products in IoT data platforms. Prior to startups, she spent over 10 years in networking with Cisco and Juniper across engineering and product. She is passionate about building products to solve customer problems.
Julie Zhao is a Senior Product Manager at AWS Glue. She joined AWS in 2021 and brings three years of startup experience leading products in IoT data platforms. Prior to startups, she spent over 10 years in networking with Cisco and Juniper across engineering and product. She is passionate about building products to solve customer problems.














 Xu Feng is a Senior Industry Solution Architect at AWS, responsible for designing, building, and promoting industry solutions for the Media & Entertainment and Advertising sectors, such as intelligent customer service and business intelligence. With 20 years of software industry experience, currently focused on researching and implementing generative AI and AI-powered data solutions.
Xu Feng is a Senior Industry Solution Architect at AWS, responsible for designing, building, and promoting industry solutions for the Media & Entertainment and Advertising sectors, such as intelligent customer service and business intelligence. With 20 years of software industry experience, currently focused on researching and implementing generative AI and AI-powered data solutions. Xu Da is a Amazon Web Services (AWS) Partner Solutions Architect based out of Shanghai, China. He has more than 25 years of experience in IT industry, software development and solution architecture. He is passionate about collaborative learning, knowledge sharing, and guiding community in their cloud technologies journey.
Xu Da is a Amazon Web Services (AWS) Partner Solutions Architect based out of Shanghai, China. He has more than 25 years of experience in IT industry, software development and solution architecture. He is passionate about collaborative learning, knowledge sharing, and guiding community in their cloud technologies journey.





















 Rohit Vashishtha is a Senior Analytics Specialist Solutions Architect at AWS based in Dallas, Texas. He has over 17 years of experience architecting, building, leading, and maintaining big data platforms. Rohit helps customers modernize their analytic workloads using the breadth of AWS services and ensures that customers get the best price/performance with utmost security and data governance.
Rohit Vashishtha is a Senior Analytics Specialist Solutions Architect at AWS based in Dallas, Texas. He has over 17 years of experience architecting, building, leading, and maintaining big data platforms. Rohit helps customers modernize their analytic workloads using the breadth of AWS services and ensures that customers get the best price/performance with utmost security and data governance. Jagadish Kumar (Jag) is a Senior Specialist Solutions Architect at AWS focused on Amazon OpenSearch Service. He is deeply passionate about Data Architecture and helps customers build analytics solutions at scale on AWS.
Jagadish Kumar (Jag) is a Senior Specialist Solutions Architect at AWS focused on Amazon OpenSearch Service. He is deeply passionate about Data Architecture and helps customers build analytics solutions at scale on AWS. Adam Gaulding is a Solution Architect at Satori. At Satori, Adam is helping customers implement data security controls on databases, data lakes and data warehouses. Adam has been in and around the data space throughout his 20+ year career. He’s worked with companies large and small and prides himself in building creative solutions for technical problems.
Adam Gaulding is a Solution Architect at Satori. At Satori, Adam is helping customers implement data security controls on databases, data lakes and data warehouses. Adam has been in and around the data space throughout his 20+ year career. He’s worked with companies large and small and prides himself in building creative solutions for technical problems.





















 Chiho Sugimoto is a Cloud Support Engineer on the AWS Big Data Support team. She is passionate about helping customers build data lakes using ETL workloads. She loves planetary science and enjoys studying the asteroid Ryugu on weekends.
Chiho Sugimoto is a Cloud Support Engineer on the AWS Big Data Support team. She is passionate about helping customers build data lakes using ETL workloads. She loves planetary science and enjoys studying the asteroid Ryugu on weekends. Zach Mitchell is a Sr. Big Data Architect. He works within the product team to enhance understanding between product engineers and their customers while guiding customers through their journey to develop data lakes and other data solutions on AWS analytics services.
Zach Mitchell is a Sr. Big Data Architect. He works within the product team to enhance understanding between product engineers and their customers while guiding customers through their journey to develop data lakes and other data solutions on AWS analytics services. Chanu Damarla is a Principal Product Manager on the Amazon SageMaker Unified Studio team. He works with customers around the globe to translate business and technical requirements into products that delight customers and enable them to be more productive with their data, analytics, and AI.
Chanu Damarla is a Principal Product Manager on the Amazon SageMaker Unified Studio team. He works with customers around the globe to translate business and technical requirements into products that delight customers and enable them to be more productive with their data, analytics, and AI.






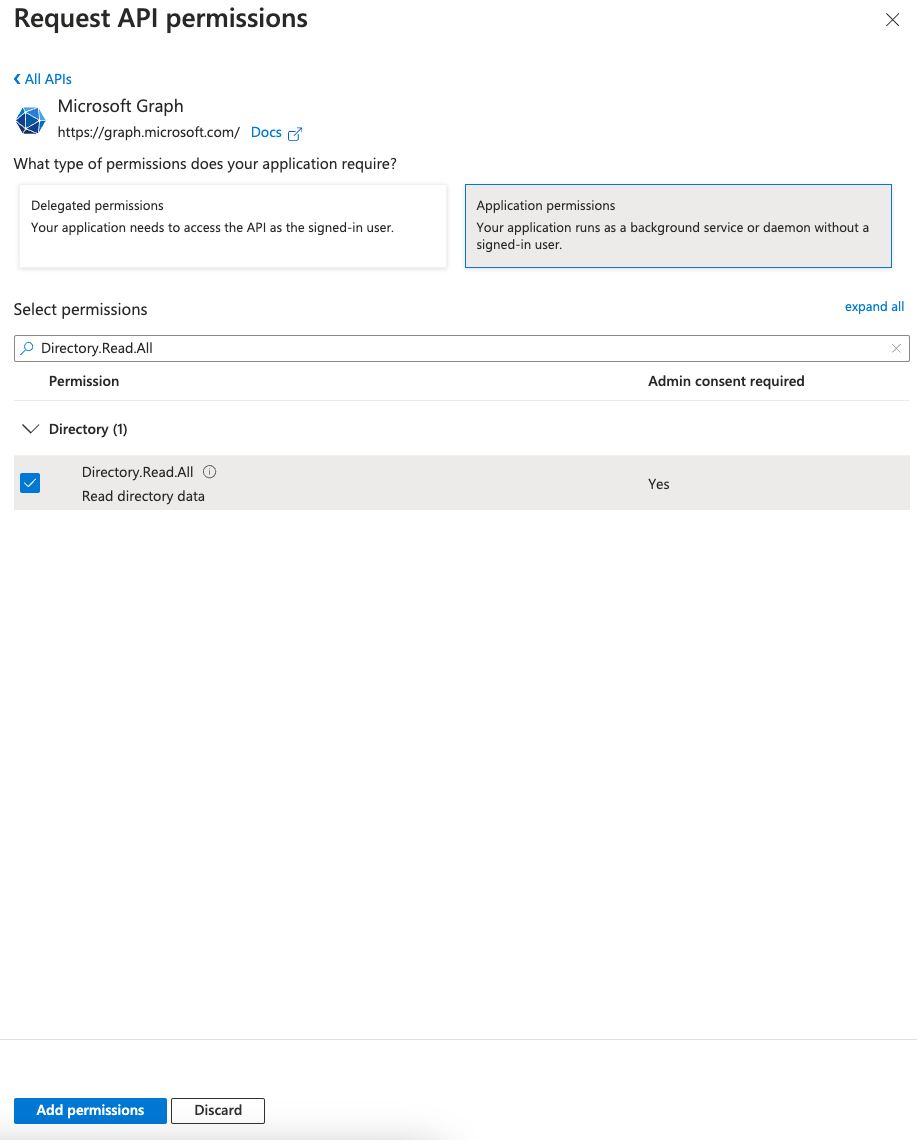
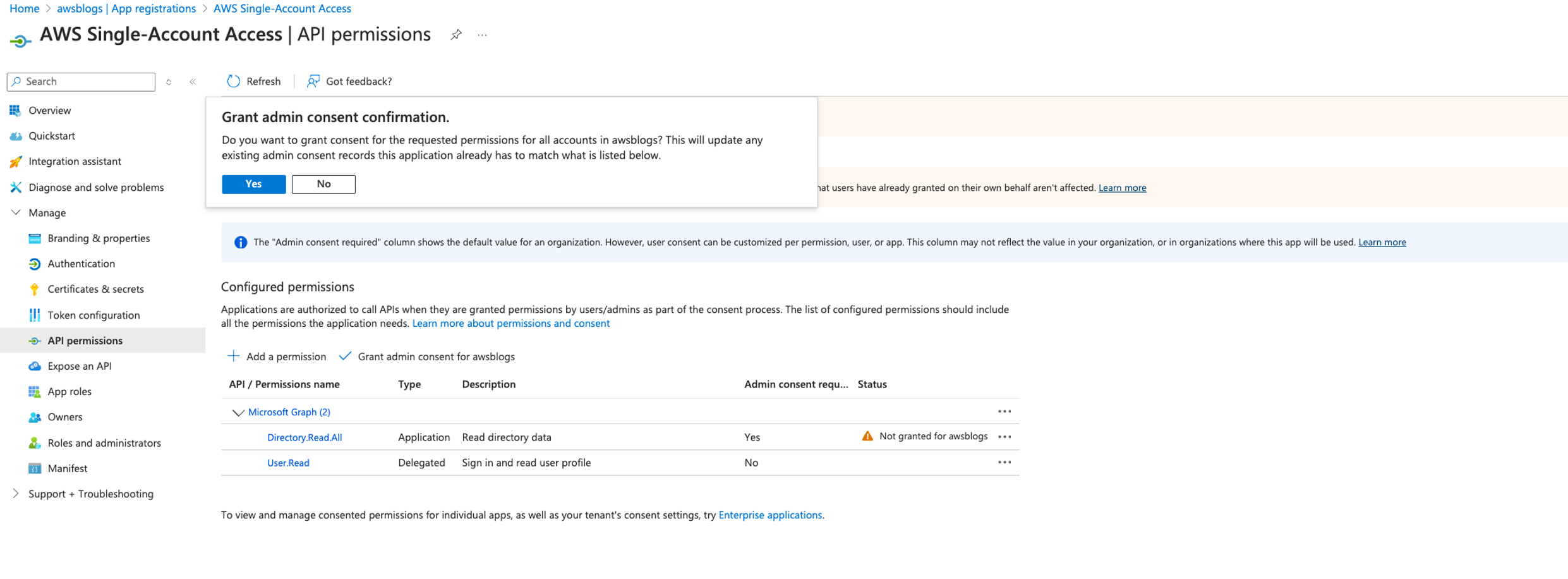
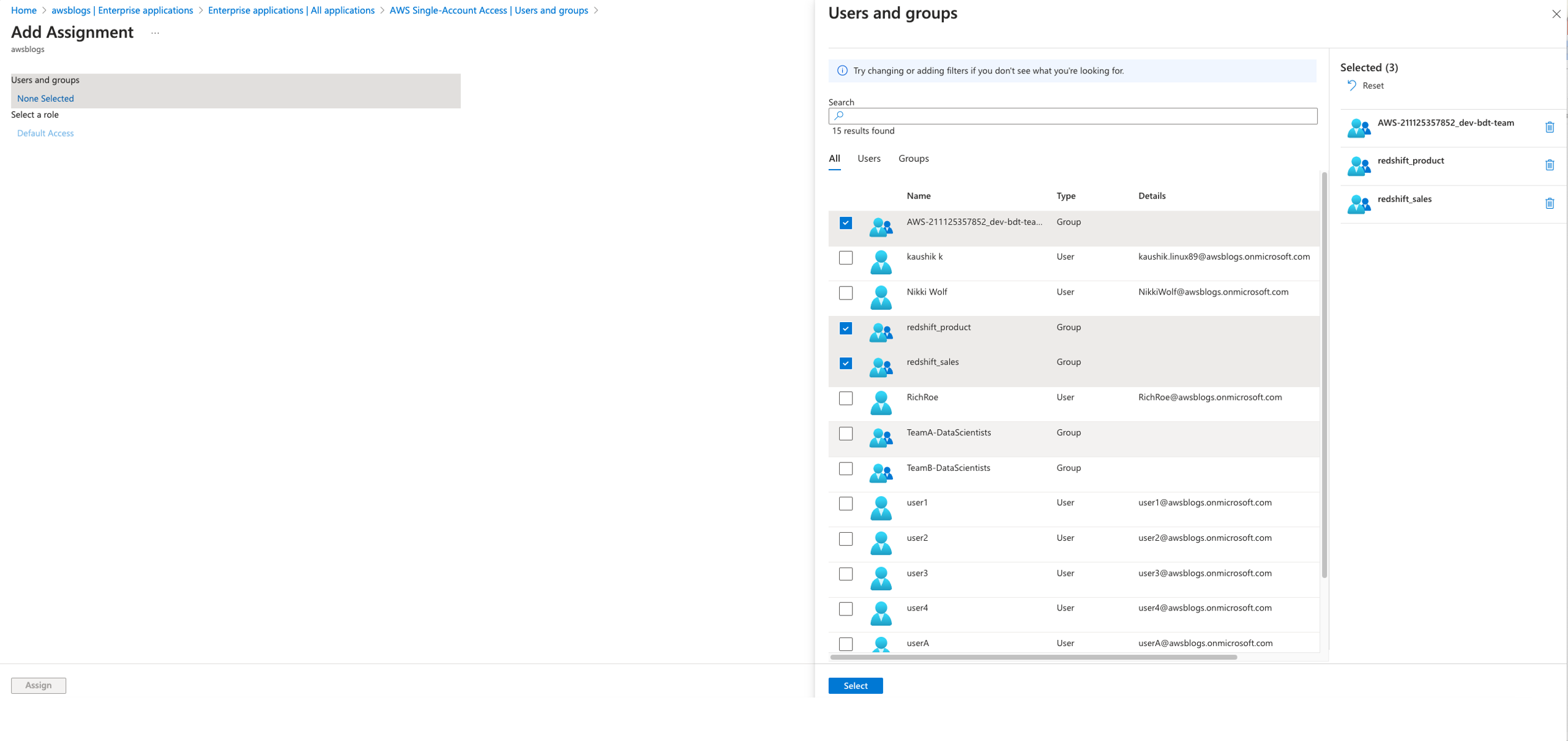
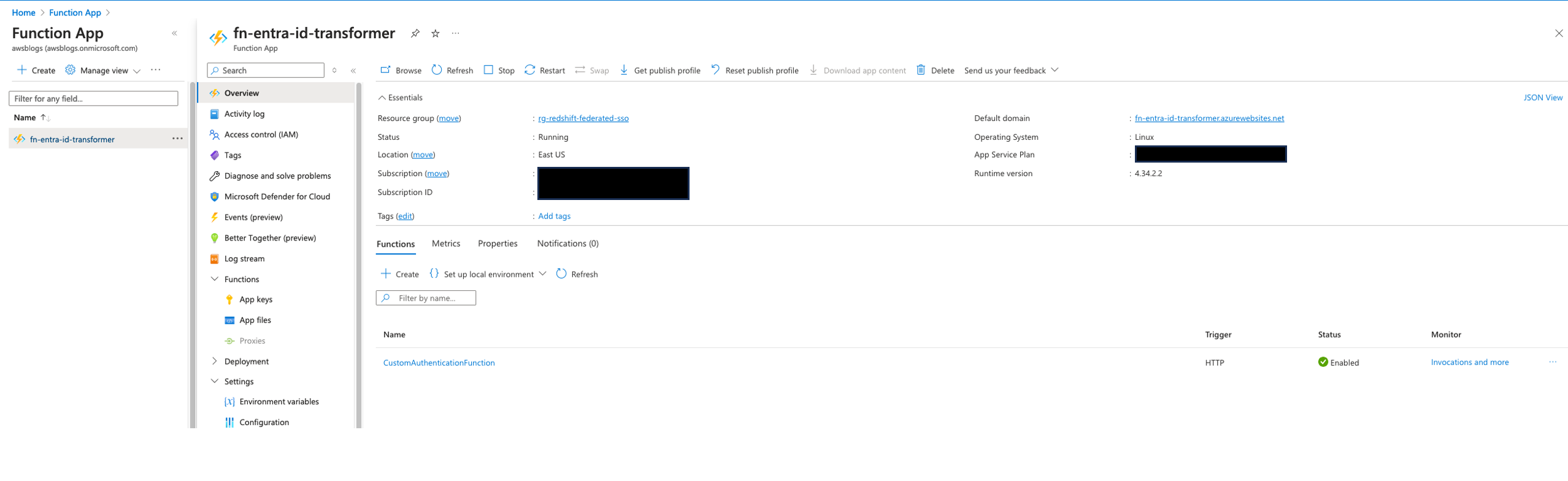


 Koushik Konjeti is a Senior Solutions Architect at Amazon Web Services. He has a passion for aligning architectural guidance with customer goals, ensuring solutions are tailored to their unique requirements. Outside of work, he enjoys playing cricket and tennis.
Koushik Konjeti is a Senior Solutions Architect at Amazon Web Services. He has a passion for aligning architectural guidance with customer goals, ensuring solutions are tailored to their unique requirements. Outside of work, he enjoys playing cricket and tennis.












 Tomohiro Tanaka is a Senior Cloud Support Engineer at Amazon Web Services. He’s passionate about helping customers use Apache Iceberg for their data lakes on AWS. In his free time, he enjoys a coffee break with his colleagues and making coffee at home.
Tomohiro Tanaka is a Senior Cloud Support Engineer at Amazon Web Services. He’s passionate about helping customers use Apache Iceberg for their data lakes on AWS. In his free time, he enjoys a coffee break with his colleagues and making coffee at home. Sotaro Hikita is a Solutions Architect. He supports customers in a wide range of industries, especially the financial industry, to build better solutions. He is particularly passionate about big data technologies and open source software.
Sotaro Hikita is a Solutions Architect. He supports customers in a wide range of industries, especially the financial industry, to build better solutions. He is particularly passionate about big data technologies and open source software.


















 Srividya Parthasarathy is a Senior Big Data Architect on the AWS Lake Formation team. She works with product team and customer to build robust features and solutions for their analytical data platform. She enjoys building data mesh solutions and sharing them with the community.
Srividya Parthasarathy is a Senior Big Data Architect on the AWS Lake Formation team. She works with product team and customer to build robust features and solutions for their analytical data platform. She enjoys building data mesh solutions and sharing them with the community. Harshida Patel is a Analytics Specialist Principal Solutions Architect, with AWS.
Harshida Patel is a Analytics Specialist Principal Solutions Architect, with AWS.