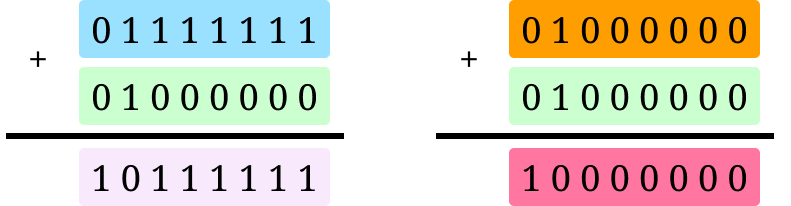In the AWS Security Profile series, we interview Amazon Web Services (AWS) thought leaders who help keep our customers safe and secure. This interview features Matt Campagna, Senior Principal, Security Engineering, AWS Cryptography, and re:Inforce 2023 session speaker, who shares thoughts on data protection, cloud security, post-quantum cryptography, and more. Matthew was first profiled on the AWS Security Blog in 2019. This is part 1 of 3 in a series of interviews with our AWS Cryptography team.
What do you do in your current role and how long have you been at AWS?
I started at Amazon in 2013 as the first cryptographer at AWS. Today, my focus is on the cryptographic security of our customers’ data. I work across AWS to make sure that our cryptographic engineering meets our most sensitive customer needs. I lead our migration to quantum-resistant cryptography, and help make privacy-preserving cryptography techniques part of our security model.
How did you get started in the data protection and cryptography space? What about it piqued your interest?
I first learned about public-key cryptography (for example, RSA) during a math lesson about group theory. I found the mathematics intriguing and the idea of sending secret messages using only a public value astounding. My undergraduate and graduate education focused on group theory, and I started my career at the National Security Agency (NSA) designing and analyzing cryptologics. But what interests me most about cryptography is its ability to enable business by reducing risks. I look at cryptography as a financial instrument that affords new business cases, like e-commerce, digital currency, and secure collaboration. What enables Amazon to deliver for our customers is rooted in cryptography; our business exists because cryptography enables trust and confidentiality across the internet. I find this the most intriguing aspect of cryptography.
AWS has invested in the migration to post-quantum cryptography by contributing to post-quantum key agreement and post-quantum signature schemes to protect the confidentiality, integrity, and authenticity of customer data. What should customers do to prepare for post-quantum cryptography?
Our focus at AWS is to help ensure that customers can migrate to post-quantum cryptography as fast as prudently possible. This work started with inventorying our dependencies on algorithms that aren’t known to be quantum-resistant, like integer-factorization-based cryptography, and discrete-log-based cryptography, like ECC. Customers can rely on AWS to assist with transitioning to post-quantum cryptography for their cloud computing needs.
We recommend customers begin inventorying their dependencies on algorithms that aren’t quantum-resistant, and consider developing a migration plan, to understand if they can migrate directly to new post-quantum algorithms or if they should re-architect them. For the systems that are provided by a technology provider, customers should ask what their strategy is for post-quantum cryptography migration.
AWS offers post-quantum TLS endpoints in some security services. Can you tell us about these endpoints and how customers can use them?
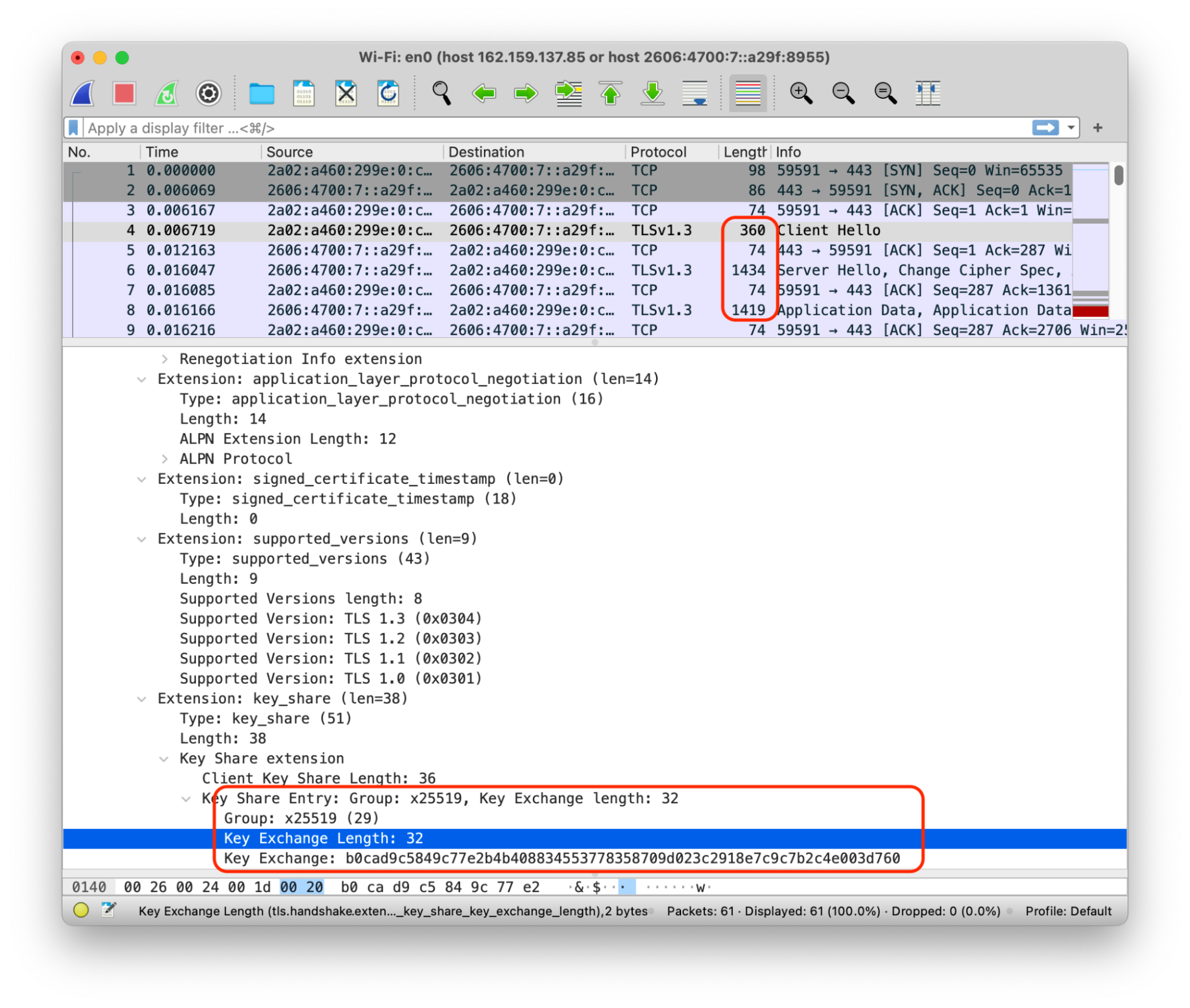
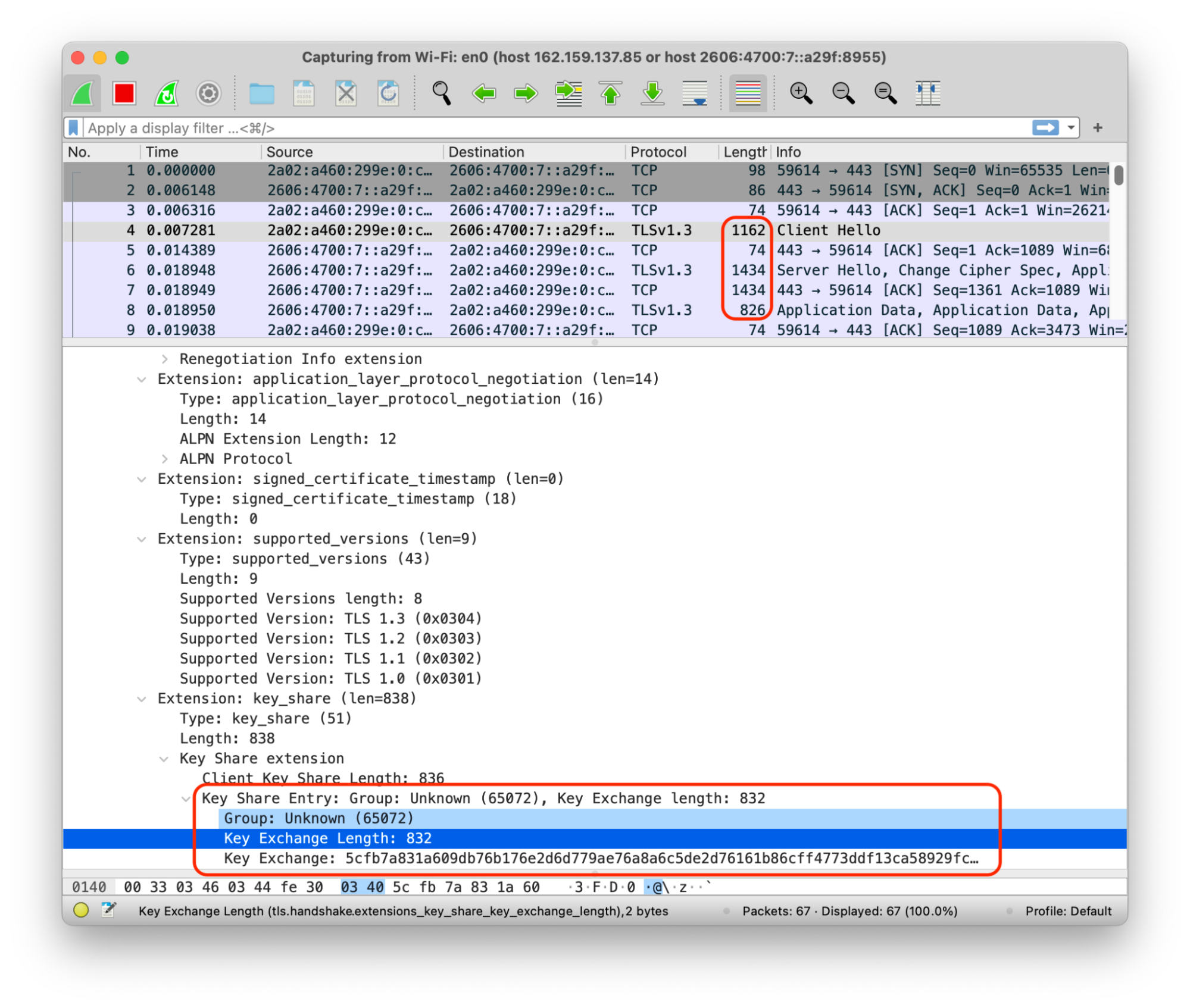
Our open source TLS implementation, s2n-TLS, includes post-quantum hybrid key exchange (PQHKEX) in its mainline. It’s deployed everywhere that s2n is deployed. AWS Key Management Service, AWS Secrets Manager, and AWS Certificate Manager have enabled PQHKEX cipher suites in our commercial AWS Regions. Today customers can use the AWS SDK for Java 2.0 to enable PQHKEX on their connection to AWS, and on the services that also have it enabled, they will negotiate a post-quantum key exchange method. As we enable these cipher suites on additional services, customers will also be able to connect to these services using PQHKEX.
You are a frequent contributor to the Amazon Science Blog. What were some of your recent posts about?
In 2022, we published a post on preparing for post-quantum cryptography, which provides general information on the broader industry development and deployment of post-quantum cryptography. The post links to a number of additional resources to help customers understand post-quantum cryptography. The AWS Post-Quantum Cryptography page and the Science Blog are great places to start learning about post-quantum cryptography.
We also published a post highlighting the security of post-quantum hybrid key exchange. Amazon believes in evidencing the cryptographic security of the solutions that we vend. We are actively participating in cryptographic research to validate the security that we provide in our services and tools.
What’s been the most dramatic change you’ve seen in the data protection and post-quantum cryptography landscape since we talked to you in 2019?
Since 2019, there have been two significant advances in the development of post-quantum cryptography.
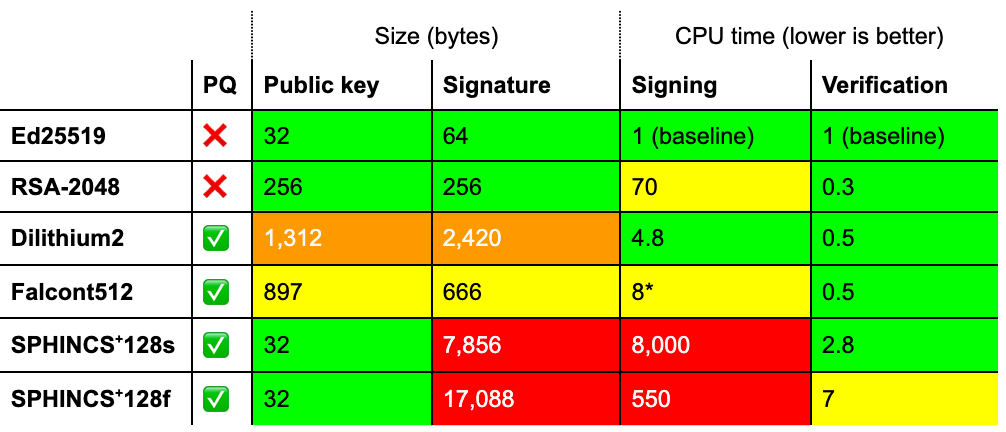
First, the National Institute of Standards and Technology (NIST) announced their selection of PQC algorithms for standardization. NIST expects to finish the standardization of a post-quantum key encapsulation mechanism (Kyber) and digital signature scheme (Dilithium) by 2024 as part of the Federal Information Processing Standard (FIPS). NIST will also work on standardization of two additional signature standards (FALCON and SPHINCS+), and continue to consider future standardization of the key encapsulation mechanisms BIKE, HQC, and Classical McEliece.
Second, the NSA announced their Commercial National Security Algorithm (CNSA) Suite 2.0, which includes their timelines for National Security Systems (NSS) to migrate to post-quantum algorithms. The NSA will begin preferring post-quantum solutions in 2025 and expect that systems will have completed migration by 2033. Although this timeline might seem far away, it’s an aggressive strategy. Experience shows that it can take 20 years to develop and deploy new high-assurance cryptographic algorithms. If technology providers are not already planning to migrate their systems and services, they will be challenged to meet this timeline.
What makes cryptography exciting to you?
Cryptography is a dynamic area of research. In addition to the business applications, I enjoy the mathematics of cryptography. The state-of-the-art is constantly progressing in terms of new capabilities that cryptography can enable, and the potential risks to existing cryptographic primitives. This plays out in the public sphere of cryptographic research across the globe. These advancements are made public and are accessible for companies like AWS to innovate on behalf of our customers, and protect our systems in advance of the development of new challenges to our existing crypto algorithms. This is happening now as we monitor the advancements of quantum computing against our ability to define and deploy new high-assurance quantum-resistant algorithms. For me, it doesn’t get more exciting than this.
Where do you see the cryptography and post-quantum cryptography space heading to in the future?
While NIST transitions from their selection process to standardization, the broader cryptographic community will be more focused on validating the cryptographic assurances of these proposed schemes for standardization. This is a critical part of the process. I’m optimistic that we will enter 2025 with new cryptographic standards to deploy.
There is a lot of additional cryptographic research and engineering ahead of us. Applying these new primitives to the cryptographic applications that use classical asymmetric schemes still needs to be done. Some of this work is happening in parallel, like in the IETF TLS working group, and in the ETSI Quantum-Safe Cryptography Technical Committee. The next five years should see the adoption of PQHKEX in protocols like TLS, SSH, and IKEv2 and certification of new FIPS hardware security modules (HSMs) for establishing new post-quantum, long-lived roots of trust for code-signing and entity authentication.
I expect that the selected primitives for standardization will also be used to develop novel uses in fields like secure multi-party communication, privacy preserving machine learning, and cryptographic computing.
With AWS re:Inforce 2023 around the corner, what will your session focus on? What do you hope attendees will take away from your session?
Session DAP302 – “Post-quantum cryptography migration strategy for cloud services” is about the challenge quantum computers pose to currently used public-key cryptographic algorithms and how the industry is responding. Post-quantum cryptography (PQC) offers a solution to this challenge, providing security to help protect against quantum computer cybersecurity events. We outline current efforts in PQC standardization and migration strategies. We want our customers to leave with a better understanding of the importance of PQC and the steps required to migrate to it in a cloud environment.
Is there something you wish customers would ask you about more often?
The question I am most interested in hearing from our customers is, “when will you have a solution to my problem?” If customers have a need for a novel cryptographic solution, I’m eager to try to solve that with them.
How about outside of work, any hobbies?
My main hobbies outside of work are biking and running. I wish I was as consistent attending to my hobbies as I am to my work desk. I am happier being able to run every day for a constant speed and distance as opposed to running faster or further tomorrow or next week. Last year I was fortunate enough to do the Cycle Oregon ride. I had registered for it twice before without being able to find the time to do it.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
In the AWS Security Profile series, we interview Amazon Web Services (AWS) experts who help keep our customers safe and secure. This interview features Valerie Lambert, Senior Software Development Engineer, Crypto Tools, and upcoming AWS re:Inforce 2023 speaker, who shares thoughts on data protection, cloud security, cryptography tools, and more.
What do you do in your current role and how long have you been at AWS? I’m a Senior Software Development Engineer on the AWS Crypto Tools team in AWS Cryptography. My team focuses on building open source, client-side encryption solutions, such as the AWS Encryption SDK. I’ve been working in this space for the past four years.
How did you get started in cryptography? What about it piqued your interest? When I started on this team back in 2019, I knew very little about the specifics of cryptography. I only knew its importance for securing our customers’ data and that security was our top priority at AWS. As a developer, I’ve always taken security and data protection very seriously, so when I learned about this particular team from one of my colleagues, I was immediately interested and wanted to learn more. It also helped that I’m a very math-oriented person. I find this domain endlessly interesting, and love that I have the opportunity to work with some truly amazing cryptography experts.
Why do cryptography tools matter today? Customers need their data to be secured, and builders need to have tools they can rely on to help provide that security. It’s well known that no one should cobble together their own encryption scheme. However, even if you use well-vetted, industry-standard cryptographic primitives, there are still many considerations when applying those primitives correctly. By using tools that are simple to use and hard to misuse, builders can be confident in protecting their customers’ most sensitive data, without cryptographic expertise required.
What’s been the most dramatic change you’ve seen in the data protection and cryptography space? In the past few years, I’ve seen more and more formal verification used to help prove various properties about complex systems, as well as build confidence in the correctness of our libraries. In particular, the AWS Crypto Tools team is using Dafny, a formal verification-aware programming language, to implement the business logic for some of our libraries. Given the high bar for correctness of cryptographic libraries, having formal verification as an additional tool in the toolbox has been invaluable. I look forward to how these tools mature in the next couple years.
You are speaking in Anaheim June 13-14 at AWS re:Inforce 2023 — what will your session focus on? Our team has put together a workshop (DAP373) that will focus on strategies to use client-side encryption with Amazon DynamoDB, specifically focusing on solutions for effectively searching on data that has been encrypted on the client side. I hope that attendees will see that, with a bit of forethought put into their data access patterns, they can still protect their data on the client side.
Where do you see the cryptography tools space heading in the future? More and more customers have been coming to us with use cases that involve client-side encryption with different database technologies. Although my team currently vends an out-of-the-box solution for DynamoDB, customers working with other database technologies have to build their own solutions to help keep their data safe. There are many, many considerations that come with encrypting data on the client side for use in a database, and it’s very expensive for customers to design, build, and maintain these solutions. The AWS Crypto Tools team is actively investigating this space—both how we can expand the usability of client-side encrypted data in DynamoDB, and how to bring our tools to more database technologies.
Is there something you wish customers would ask you about more often? Customers shouldn’t need to understand the cryptographic details that underpin the security properties that our tools provide to protect their end users’ data. However, I love when our customers are curious and ask questions and are themselves interested in the nitty-gritty details of our solutions.
How about outside of work, any hobbies? A couple years ago, I picked up aerial circus arts as a hobby. I’m still not very good, but it’s a lot of fun to play around on silks and trapeze. And it’s great exercise!
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
AWS is excited to announce a new eBook, 5 Keys to Secure Enterprise Messaging. The new eBook includes best practices for addressing the security and compliance risks associated with messaging apps.
An estimated 3.09 billion mobile phone users access messaging apps to communicate, and this figure is projected to grow to 3.51 billion users in 2025.
Legal and regulatory requirements for data protection, privacy, and data retention have made protecting business communications a priority for organizations across the globe. Although consumer messaging apps are convenient and support real-time communication with colleagues, customers, and partners, they often lack the robust security and administrative controls many businesses require.
The eBook details five keys to secure enterprise messaging that balance people, process, and technology.
We encourage you to read the eBook, and learn about:
Establishing messaging policies and guidelines that are effective for your workforce
Training employees to use messaging apps in a way that doesn’t increase organizational risk
Building a security-first culture
Using true end-to-end encryption (E2EE) to secure communications
Retaining data to help meet requirements, without exposing it to outside parties
In this post, we’d like to introduce you to the cryptographic computing feature of AWS Clean Rooms. With AWS Clean Rooms, customers can run collaborative data-query sessions on sensitive data sets that live in different AWS accounts, and can do so without having to share, aggregate, or replicate the data. When customers also use the cryptographic computing feature, their data remains cryptographically protected even while it is being processed by an AWS Clean Rooms collaboration.
Where would AWS Clean Rooms be useful? Consider a scenario where two different insurance companies want to identify duplicate claims so they can identify potential fraud. This would be simple if they could compare their claims with each other, but they might not be able to do so due to privacy constraints.
Alternately, consider an advertising network and a client that want to measure the effectiveness of an advertising campaign. To that end, they would like to know how many of the people who saw the campaign (exposures) went on to make a purchase from the client (purchasers). However, confidentiality concerns might prevent the advertising network from sharing their list of exposures with the client or prevent the client from sharing their list of purchasers with the advertising network.
As these examples show, there can be many situations in which different organizations want to collaborate on a joint analysis of their pooled data, but cannot share their individual datasets directly. One solution to this problem is a data clean room, which is a service trusted by a collaboration’s participants to do the following:
Hold the data of individual parties
Enforce access-control rules that collaborators specify regarding their data
Perform analyses over the pooled data
To serve customers with these needs, AWS recently launched a new data clean-room service called AWS Clean Rooms. This service provides AWS customers with a way to collaboratively analyze data (stored in other AWS services as SQL tables) without having to replicate the data, move the data outside of the AWS Cloud, or allow their collaborators to see the data itself.
Additionally, AWS Clean Rooms provides a feature that gives customers even more control over their data: cryptographic computing. This feature allows AWS Clean Rooms to operate over data that customers encrypt themselves and that the service cannot actually read. Specifically, customers can use this feature to select which portions of their data should be encrypted and to encrypt that data themselves. Collaborators can continue to analyze that data as if it were in the clear, however, even though the data in question remains encrypted while it is being processed in AWS Clean Rooms collaborations. In this way, customers can use AWS Clean Rooms to securely collaborate on data they may not have been able to share due to internal policies or regulations.
Cryptographic computing
Using the cryptographic computing feature of AWS Clean Rooms involves these steps:
Users create AWS Clean Rooms collaborations and set collaboration-wide encryption settings. They then invite collaborators to support the analysis process.
Outside of AWS Clean Rooms, those collaborators agree on a shared secret: a common, secret, cryptographic key.
Collaborators individually encrypt their tables outside of the AWS Cloud (typically on their own premises) using the shared secret, the collaboration ID of the intended collaboration, and the Cryptographic Computing for Clean Rooms (C3R) encryption client (which AWS provides as an open-source package). Collaborators then provide the encrypted tables to AWS Clean Rooms, just as they would have provided plaintext tables.
Collaborators continue to use AWS Clean Rooms for their data analysis. They impose access-control rules on their tables, submit SQL queries over the tables in the collaboration, and retrieve results.
These results might contain encrypted columns, and so collaborators decrypt the results by using the shared secret and the C3R encryption client.
As a result, data that enters AWS Clean Rooms in encrypted format will remain encrypted from input tables to intermediate values to result sets. AWS Clean Rooms will be unable to decrypt or read the data even while performing the queries.
Note: For those interested in the academic aspects of this process, the cryptographic computing feature of AWS Clean Rooms is based on server-aided private set intersection (PSI). Server-aided PSI allows two or more participants to submit sets of values to a server and learn which elements are found in all sets, but without (1) allowing the participants to learn anything about the other (non-shared) elements, or (2) allowing the server to learn anything about the underlying data (aside from the degrees to which the sets overlap). PSI is just one example of the field of cryptographic computing, which provides a variety of new methods by which encrypted data can be processed for various purposes and without decryption. These techniques allow our customers to use the scale and power of AWS systems on data that AWS will not be able to read. See our Cryptographic Computing webpage for more about our work in this area.
Let’s dive deeper into each new step in the process for using cryptographic computing in AWS Clean Rooms.
Key agreement. Each collaboration needs its own shared secret: a secure cryptographic secret (of at least 256 bits). Customers sometimes have a regulatory need to maintain ownership of their encryption keys. Therefore, the cryptographic computing feature supports the case where customers generate, distribute, and store their collaboration’s secret themselves. In this way, customers’ encryption keys are never stored on an AWS system.
Encryption. AWS Clean Rooms allows table owners to control how tables are encrypted on a column-by-column basis. In particular, each column in an encrypted table will be one of three types: cleartext, sealed, or fingerprint. These types map directly to both how columns are used in queries and how they are protected with cryptography, described as follows:
Cleartext columns are not cryptographically processed at all. They are copied to encrypted tables verbatim, and can be used anywhere in a SQL query.
Sealed columns are encrypted. The encryption scheme used (AES-GCM) is randomized, meaning that encrypting the same value multiple times yields different ciphertexts each time. This helps prevent the statistical analysis of these columns, but also means that these columns cannot be used in JOIN clauses. They can be used in SELECT clauses, however, which allows them to appear in query results.
Fingerprint columns are hashed using the Hash-based Message Authentication Code (HMAC) algorithm. There is no way to decrypt these values, and therefore no reason for them to appear in the SELECT clause of a query. They can, however, be used in JOIN clauses: HMAC will map a given value to the same fingerprint every time, meaning that JOINs will be able to unify common values across different fingerprint columns.
Encryption settings. This last point—that fingerprint values will always map a given plaintext value to the same fingerprint—might give pause to some readers. If this is true, won’t the encrypted table be vulnerable to statistical analysis? That is absolutely correct: it will. For this reason, users might wish to set collaboration-wide encryption settings to control these forms of analysis.
To see how statistical analysis might be a concern, imagine a table where one fingerprint column is named US_State. In this case, a simple frequency analysis will reverse-engineer the plaintext values relatively quickly: the most common fingerprint is almost certain to be “California”, followed by “Texas”, “Florida”, and so on. Also, imagine that the same table has another fingerprint column called US_City, and that a given fingerprint appears in both columns. In that case, the fingerprint in question is almost certain to be “New York”. If a row has a fingerprint in the US_City column but a NULL in the US_State column, furthermore, it’s very likely that the fingerprint is for “District of Columbia”. And finally, imagine that the table has a cleartext column called Time_Zone. In this case, values of “HST” (Hawaii standard time) or “AKST” (Alaska standard time) reveal the value in the US_State column regardless of the cryptography.
Not all datasets will be vulnerable to these kinds of statistical analysis, but some will. Only customers can determine which types of analysis may reveal their data and which may not. Because of this, the cryptographic computing feature allows the customer to decide which protections will be needed. At the time of collaboration creation, that is, the creator of the AWS Clean Rooms collaboration can configure the following collaboration-wide encryption settings:
Whether or not fingerprint columns can contain duplicate plaintext values (addressing the “California” example)
Whether or not fingerprint columns with different names should fingerprint values in the same way (addressing the “New York” example)
Whether or not NULL values in the plaintext table should be left as NULL in the encrypted table (addressing the “District of Columbia” example)
Whether or not encrypted tables should be allowed to have cleartext columns at all (addressing the time zone example)
Security is maximized when all of these options are set to “no,” but each “no” will limit the queries that C3R will be able to support. For example, the choice of whether or not encrypted tables should be allowed to have cleartext columns will determine which WHERE clauses will be supported: If cleartext columns are not supported, then the Time_Zone column must be cryptographically processed — meaning that the clause WHERE Time_Zone=”EST” will not act as intended. There might be reasons to set these options to “yes” in order to enable a wider variety of queries, which we discuss in the Query behavior section later in this post.
Decryption. AWS Clean Rooms will write query results to an Amazon Simple Storage Service (Amazon S3) bucket. The recipient copies these results from the bucket to some on-premises storage and then runs the C3R encryption client. The client will find encrypted elements of the output and decrypt them. Note that the client can only decrypt elements from sealed columns. If the output contains elements from a fingerprint column, the client will warn you, but will also leave these elements untouched, as cryptographic fingerprints can’t be decrypted.
Having finished our overview, let’s return to the discussion regarding how encryption can affect the behavior of queries.
Query behavior
Implicit in the discussion so far is something worth calling out explicitly: AWS Clean Rooms runs queries over the data that is provided to it. If the data given to AWS Clean Rooms is encrypted, therefore, queries will be run on the ciphertexts and not the plaintexts. This will not affect the results returned, so long as the columns are used for their intended purposes:
Fingerprint columns are used in JOIN clauses
Sealed columns are used in SELECT clauses
(Cleartext columns can be used anywhere.) Queries might produce unexpected results, however, if the columns are used outside of their intended purposes:
Sometimes queries will fail when they would have succeeded on the plaintext. For example, ciphertexts and fingerprints will be string values, even if the original plaintext values were another type. Therefore, SUM() or AVG() calls on fingerprint or sealed columns will yield errors even if the corresponding plaintext columns were numeric.
Sometimes queries will omit results that would have been found by querying the plaintext. For example, attempting to JOIN on sealed columns will yield empty result sets: no two ciphertexts will be the same, even if they encrypt the same plaintext value. (Also, performing a JOIN on fingerprint columns with different names will exhibit the same behavior, if the collaboration-wide encryption settings specified that fingerprint columns of different names should fingerprint values differently.)
Sometimes results will include rows that would not be found by querying the plaintext. As mentioned, ciphertexts and fingerprints will be string values—base64 encodings of random-looking bytes, specifically. This means that a clause such as WHERE ‘US_State’ CONTAINS ‘CA’ will match some ciphertexts or fingerprints even when they would not match the plaintext.
To avoid these issues, fingerprint and sealed columns should only be used for their intended purposes (JOIN and SELECT clauses, respectively).
Conclusion
In this blog post, you have learned how AWS Clean Rooms can help you harness the power of AWS services to query and analyze your most-sensitive data. By using cryptographic computing, you can work with collaborators to perform joint analyses over pooled data without sharing your “raw” data with each other—or with AWS. If you believe that you can benefit from cryptographic computing (in AWS Clean Rooms or elsewhere), we’d like to hear from you. Please contact us with any questions or feedback. Also, we invite you to learn more about AWS Clean Rooms (including its use of cryptographic computing). Finally, the C3R client is open source, and can be downloaded from its GitHub page.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
In the AWS Security Profile — Cryptography Edition series, we interview Amazon Web Services (AWS) thought leaders who help keep our customers safe and secure. This interview features Panos Kampanakis, Principal Security Engineer, AWS Cryptography. Panos shares thoughts on data protection, cloud security, post-quantum cryptography, and more.
What do you do in your current role and how long have you been at AWS?
I have been with AWS for two years. I started as a Technical Program Manager in AWS Cryptography, where I led some AWS Cryptography projects related to cryptographic libraries and FIPS, but I’m currently working as a Principal Security Engineer on a team that focuses on applied cryptography, research, and cryptographic software. I also participate in standardization efforts in the security space, especially in cryptographic applications. It’s a very active space that can consume as much time as you have to offer.
How did you get started in the data protection/ cryptography space? What about it piqued your interest?
I always found cybersecurity fascinating. The idea of proactively focusing on security and enabling engineers to protect their assets against malicious activity was exciting. After working in organizations that deal with network security, application security, vulnerability management, and security information sharing, I found myself going back to what I did in graduate school: applied cryptography.
Cryptography is a constantly evolving, fundamental area of security that requires breadth of technical knowledge and understanding of mathematics. It provides a challenging environment for those that like to constantly learn. Cryptography is so critical to the security and privacy of data and assets that it is top of mind for the private and public sector worldwide.
How do you explain your job to your non-tech friends?
I usually tell them that my work focuses on protecting digital assets, information, and the internet from malicious actors. With cybersecurity incidents constantly in the news, it’s an easy picture to paint. Some of my non-technical friends still joke that I work as a security guard!
What makes cryptography exciting to you?
Cryptography is fundamental to security. It’s critical for the protection of data and many other secure information use cases. It combines deep mathematical topics, data information, practical performance challenges that threaten deployments at scale, compliance with various requirements, and subtle potential security issues. It’s certainly a challenging space that keeps evolving. Post-quantum or privacy preserving cryptography are examples of areas that have gained a lot of attention recently and have been consistently growing.
Given the consistent evolution of security in general, this is an important and impactful space where you can work on challenging topics. Additionally, working in cryptography, you are surrounded by intelligent people who you can learn from.
AWS has invested in the migration to post-quantum cryptography by contributing to post-quantum key agreement and post-quantum signature schemes to protect the confidentiality, integrity, and authenticity of customer data. What should customers do to prepare for post-quantum cryptography?
There are a few things that customers can do while waiting for the ratification of the new quantum-safe algorithms and their deployment. For example, you can inventory the use of asymmetric cryptography in your applications and software. Admittedly, this is not a simple task, but with proper subject matter expertise and instrumentation where necessary, you can identify where you’re using quantum-vulnerable algorithms in order to prioritize the uses. AWS is doing this exercise to have a prioritized plan for the upcoming migration.
You can also study and experiment with the potential impact of these new algorithms in critical use cases. There have been many studies on transport protocols like TLS, virtual private networks (VPNs), Secure Shell (SSH), and QUIC, but organizations might have unique uses that haven’t been accounted for yet. For example, a firm that specializes in document signing might require efficient signature methods with small size constraints, so deploying Dilithium, NIST’s preferred quantum-safe signature, could come at a cost. Evaluating its impact and performance implications would be important. If you write your own crypto software, you can also strive for algorithm agility, which would allow you to swap in new algorithms when they become available.
More importantly, you should push your vendors, your hardware suppliers, the software and open-source community, and cloud providers to adjust and enable their solutions to become quantum-safe in the near future.
What’s been the most dramatic change you’ve seen in the data protection and post-quantum cryptography landscape?
The transition from typical cryptographic algorithms to ones that can operate on encrypted data is an important shift in the last decade. This is a field that’s still seeing great development. It’s interesting how the power of data has brought forward a whole new area of being able to operate on encrypted information so that we can benefit from the analytics. For more information on the work that AWS is doing in this space, see Cryptographic Computing.
In terms of post-quantum cryptography, it’s exciting to see how an important potential risk brought a community from academia, industry, and research together to collaborate and bring new schemes to life. It’s also interesting how existing cryptography has reached optimal efficiency levels that the new cryptographic primitives sometimes cannot meet, which pushes the industry to reconsider some of our uses. Sometimes the industry might overestimate the potential impact of quantum computing to technology, but I don’t believe we should disregard the effect of heavier algorithms on performance, our carbon footprint, energy consumption, and cost. We ought to aim for efficient solutions that don’t undermine security.
Where do you see post-quantum cryptography heading in the future?
Post-quantum cryptography has received a lot of attention, and a transition is about to start ramping up after we have ratified algorithms. Although it’s sometimes considered a Herculian effort, some use cases can transition smoothly.
AWS and other industry peers and researchers have already evaluated some post-quantum migration strategies. With proper prioritization and focus, we can address some of the most important applications and gradually transition the rest. There might be some applications that will have no clear path to a post-quantum future, but most will. At AWS, we are committed to making the transitions necessary to protect our customer data against future threats.
What are you currently working on that you look forward to sharing with customers’?
I’m currently focused on bringing post-quantum algorithms to our customers’ cryptographic use cases. I’m looking into the challenges that this upcoming migration will bring and participating in standards and industry collaborations that will hopefully enable a simpler transition for everyone.
I also engage on various topics with our cryptographic libraries teams (for example, AWS-LC and s2n-tls). We build these libraries with security and performance in mind, and they are used in software across AWS.
Additionally, I work with some AWS service teams to help enable compliance with various cryptographic requirements and regulations.
Is there something you wish customers would ask you about more often?
I wish customers asked more often about provable security and how to integrate such solutions in their software. This is a fascinating field that can prevent serious issues where cryptography can go wrong. It’s a complicated topic. I would like for customers to become more aware of the importance of provable security especially in open-source software before adopting it in their solutions. Using provably secure software that is designed for performance and compliance with crypto requirements is beneficial to everyone.
I also wish customers asked more about why AWS made certain choices when deploying new mechanisms. In areas of active research, it’s often simpler to experimentally build a proof-of-concept of a new mechanism and test and prove its performance in a controlled benchmark scenario. On the other hand, it’s usually not trivial to deploy new solutions at scale (especially given the size and technological breadth of AWS), to help ensure backwards compatibility, commit to supporting these solutions in the long run, and make sure they’re suitable for various uses. I wish I had more opportunities to go over with customers the effort that goes into vetting and deploying new mechanisms at scale.
You have frequently contributed to cybersecurity publications, what is your favorite recent article and why?
I used to play basketball when I was younger, but I no longer have time. I spend most of my time with my family and little toddlers who have infinite amounts of energy. When I find an opportunity, I like reading books and short stories or watching quality films.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
News coverage of a recent paper caused a bit of a stir with this headline: “AI Helps Crack NIST-Recommended Post-Quantum Encryption Algorithm”. The news article claimed that Kyber, the encryption algorithm in question, which we have deployed world-wide, had been “broken.” Even more dramatically, the news article claimed that “the revolutionary aspect of the research was to apply deep learning analysis to side-channel differential analysis”, which seems aimed to scare the reader into wondering what will Artificial Intelligence (AI) break next?
Reporting on the paper has been wildly inaccurate: Kyber is not broken and AI has been used for more than a decade now to aid side-channel attacks. To be crystal clear: our concern is with the news reporting around the paper, not the quality of the paper itself. In this blog post, we will explain how AI is actually helpful in cryptanalysis and dive into the paper by Dubrova, Ngo, and Gärtner (DNG), that has been misrepresented by the news coverage. We’re honored to have Prof. Dr. Lejla Batina and Dr. Stjepan Picek, world-renowned experts in the field of applying AI to side-channel attacks, join us on this blog.
We start with some background, first on side-channel attacks and then on Kyber, before we dive into the paper.
Breaking cryptography
When one thinks of breaking cryptography, one imagines a room full of mathematicians puzzling over minute patterns in intercepted messages, aided by giant computers, until they figure out the key. Famously in World War II, the Nazis’ Enigma cipher machine code was completely broken in this way, allowing the Allied forces to read along with their communications.
It’s exceedingly rare for modern established cryptography to get broken head-on in this way. The last catastrophically broken cipher was RC4, designed in 1987, while AES, designed in 1998, stands proud with barely a scratch. The last big break of a cryptographic hash was on SHA-1, designed in 1995, while SHA-2, published in 2001, remains untouched in practice.
So what to do if you can’t break the cryptography head-on? Well, you get clever.
Side-channel attacks
Can you guess the pin code for this gate?
You can clearly see that some of the keys are more worn than the others, suggesting heavy use. This observation gives us some insight into the correct pin, namely the digits. But the correct order is not immediately clear. It might be 1580, 8510, or even 115085, but it’s a lot easier than trying every possible pin code. This is an example of a side-channel attack. Using the security feature (entering the PIN) had some unintended consequences (abrading the paint), which leaks information.
There are many different types of side channels, and which one you should worry about depends on the context. For instance, the sounds your keyboard makes as you type leaks what you write, but you should not worry about that if no one is listening in.
Remote timing side channel
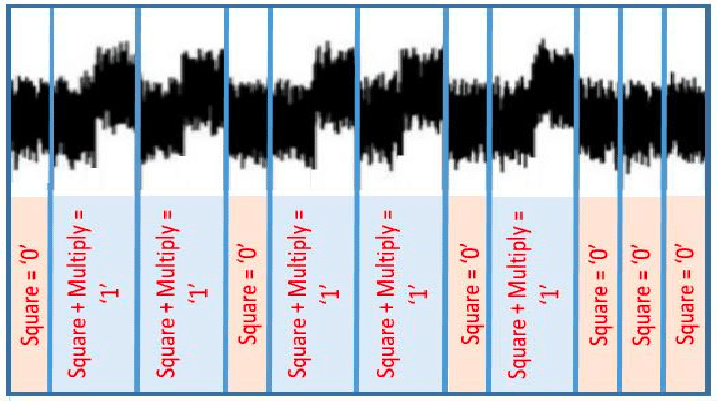
When writing cryptography in software, one of the best known side channels is the time it takes for an algorithm to run. For example, let’s take the classic example of creating an RSA signature. Grossly simplified, to sign a message m with private key d, we compute the signature s as md (mod n). Computing the exponent of a big number is hard, but luckily, because we’re doing modular arithmetic, there is the square-and-multiply trick. Here is a naive implementation in pseudocode:
The algorithm loops over the bits of the secret key, and does a multiply step if the current bit is a 1. Clearly, the runtime depends on the secret key. Not great, but if the attacker can only time the full run, then they only learn the number of 1s in the secret key. The typical catastrophic timing attack against RSA instead is hidden behind the “mod n”. In a naive implementation this modular reduction is slower if the number being reduced is larger or equal n. This allows an attacker to send specially crafted messages to tease out the secret key bit-by-bit and similar attacks are surprisingly practical.
Because of this, the mantra is: cryptography should run in “constant time”. This means that the runtime does not depend on any secret information. In our example, to remove the first timing issue, one would replace the if-statement with something equivalent to:
s = ((s * powerOfM) mod n) * bit(s, i) + s * (1 - bit(s, i))
This ensures that the multiplication is always done. Similar countermeasures prevent practically all remote timing attacks.
Power side-channel
The story is quite different for power side-channel attacks. Again, the classic example is RSA signatures. If we hook up an oscilloscope to a smartcard that uses the naive algorithm from before, and measure the power usage while it signs, we can read off the private key by eye:
Even if we use a constant-time implementation, there are still minute changes in power usage that can be detected. The underlying issue is that hardware gates that switch use more power than those that don’t. For instance, computing 127 + 64 takes more energy than 64 + 64.
127+64 and 64+64 in binary. There are more switched bits in the first.
Masking A common countermeasure against power side-channel leakage is masking. This means that before using the secret information, it is split randomly into shares. Then, the brunt of the computation is done on the shares, which are finally recombined.
In the case of RSA, before creating a new signature, one can generate a random r and compute md+r (mod n) and mr (mod n) separately. From these, the final signature md (mod n) can be computed with some extra care.
Masking is not a perfect defense. The parts where shares are created or recombined into the final value are especially vulnerable. It does make it harder for the attacker: they will need to collect more power traces to cut through the noise. In our example we used two shares, but we could bump that up even higher. There is a trade-off between power side-channel resistance and implementation cost.
One of the challenging parts in the field is to estimate how much secret information is actually leaked through the traces, and how to extract it. Here machine learning enters the picture.
Machine learning: extracting the key from the traces
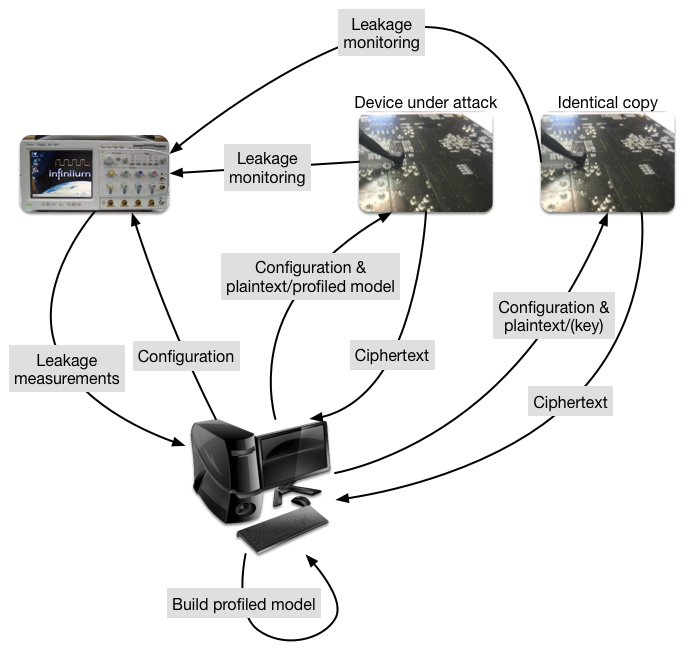
Machine learning, of which deep learning is a part, represents the capability of a system to acquire its knowledge by extracting patterns from data — in this case, the secrets from the power traces. Machine learning algorithms can be divided into several categories based on their learning style. The most popular machine learning algorithms in side-channel attacks follow the supervised learning approach. In supervised learning, there are two phases: 1) training, where a machine learning model is trained based on known labeled examples (e.g., side-channel measurements where we know the key) and 2) testing, where, based on the trained model and additional side-channel measurements (now, with an unknown key), the attacker guesses the secret key. A common depiction of such attacks is given in the figure below.
While the threat model may sound counterintuitive, it is actually not difficult to imagine that the attacker will have access (and control) of a device similar to the one being attacked.
In side-channel analysis, the attacks following those two phases (training and testing) are called profiling attacks.
Profiling attacks are not new. The first such attack, called the template attack, appeared in 2002. Diverse machine learning techniques have been used since around 2010, all reporting good results and the ability to break various targets. The big breakthrough came in 2016, when the side-channel community started using deep learning. It greatly increased the effectiveness of power side-channel attacks both against symmetric-key and public-key cryptography, even if the targets were protected with, for instance, masking or some other countermeasures. To be clear: it doesn’t magically figure out the key, but it gets much better at extracting the leaked bits from a smaller number of power traces.
While machine learning-based side-channel attacks are powerful, they have limitations. Carefully implemented countermeasures make the attacks more difficult to conduct. Finding a good machine learning model that can break a target can be far from trivial: this phase, commonly called tuning, can last weeks on powerful clusters.
What will the future bring for machine learning/AI in side-channel analysis? Counter intuitively, we would like to see more powerful and easy to use attacks. You’d think that would make us worse off, but to the contrary it will allow us to better estimate how much actual information is leaked by a device. We also hope that we will be able to better understand why certain attacks work (or not), so that more cost-effective countermeasures can be developed. As such, the future for AI in side-channel analysis is bright especially for security evaluators, but we are still far from being able to break most of the targets in real-world applications.
Kyber
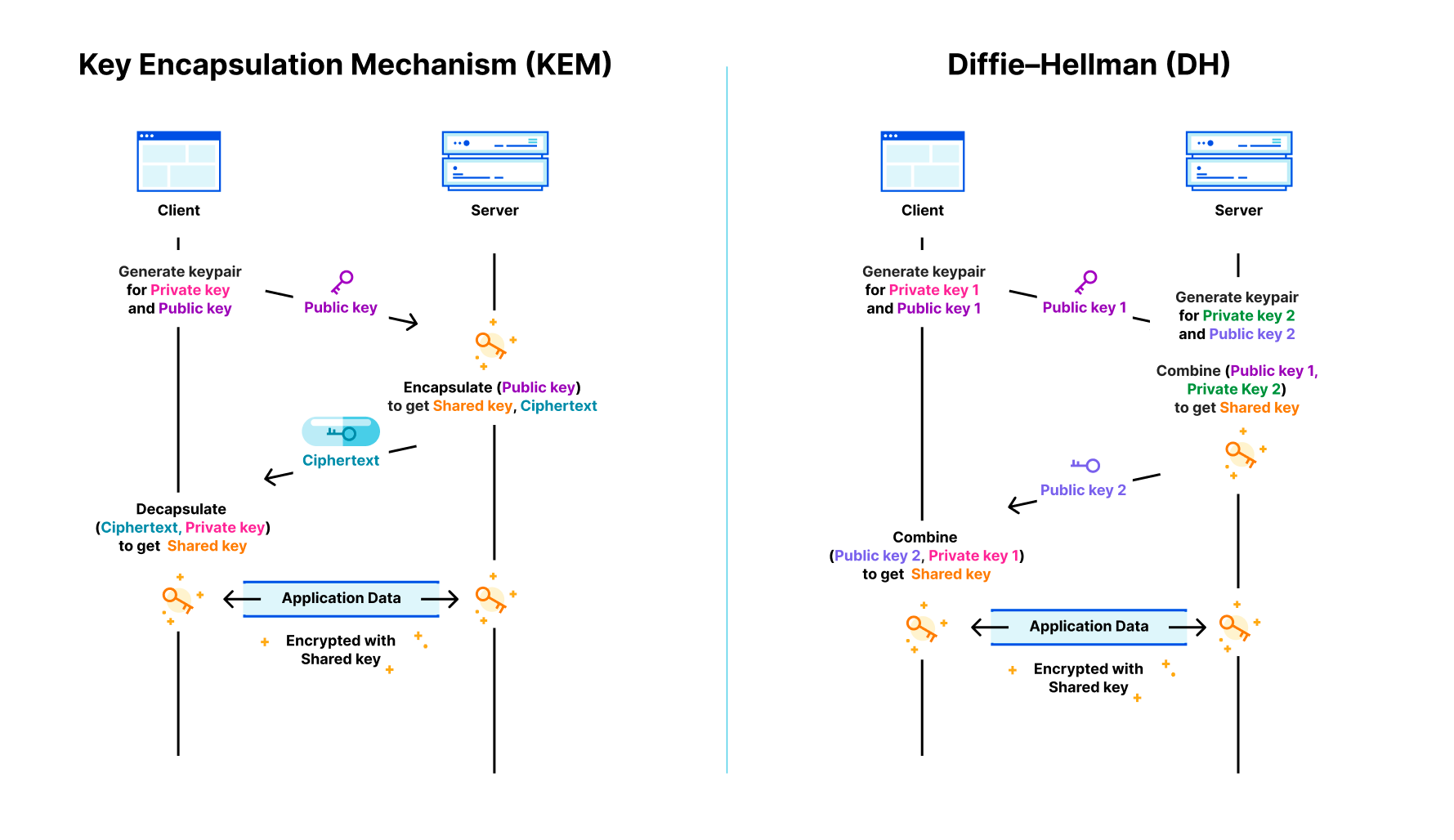
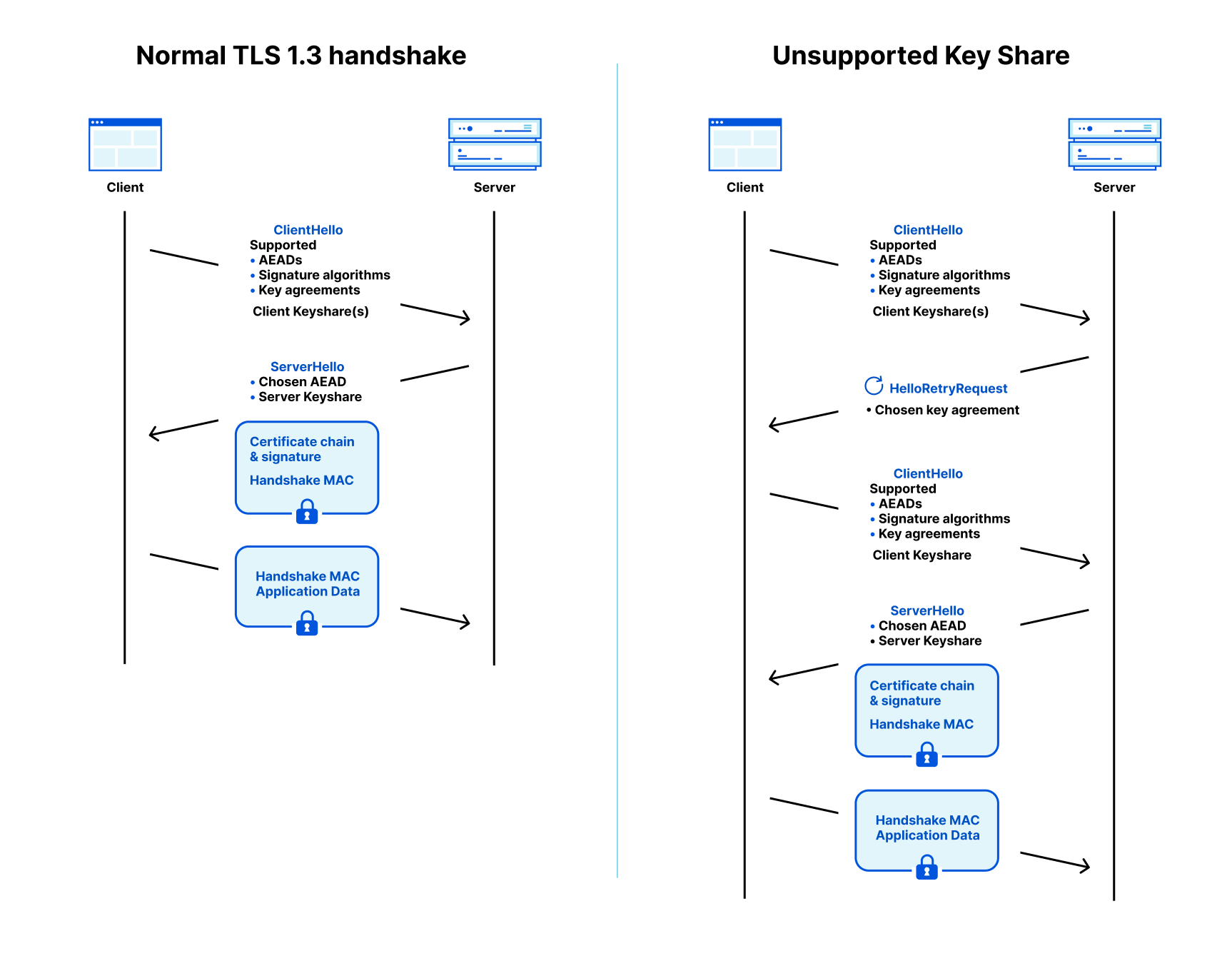
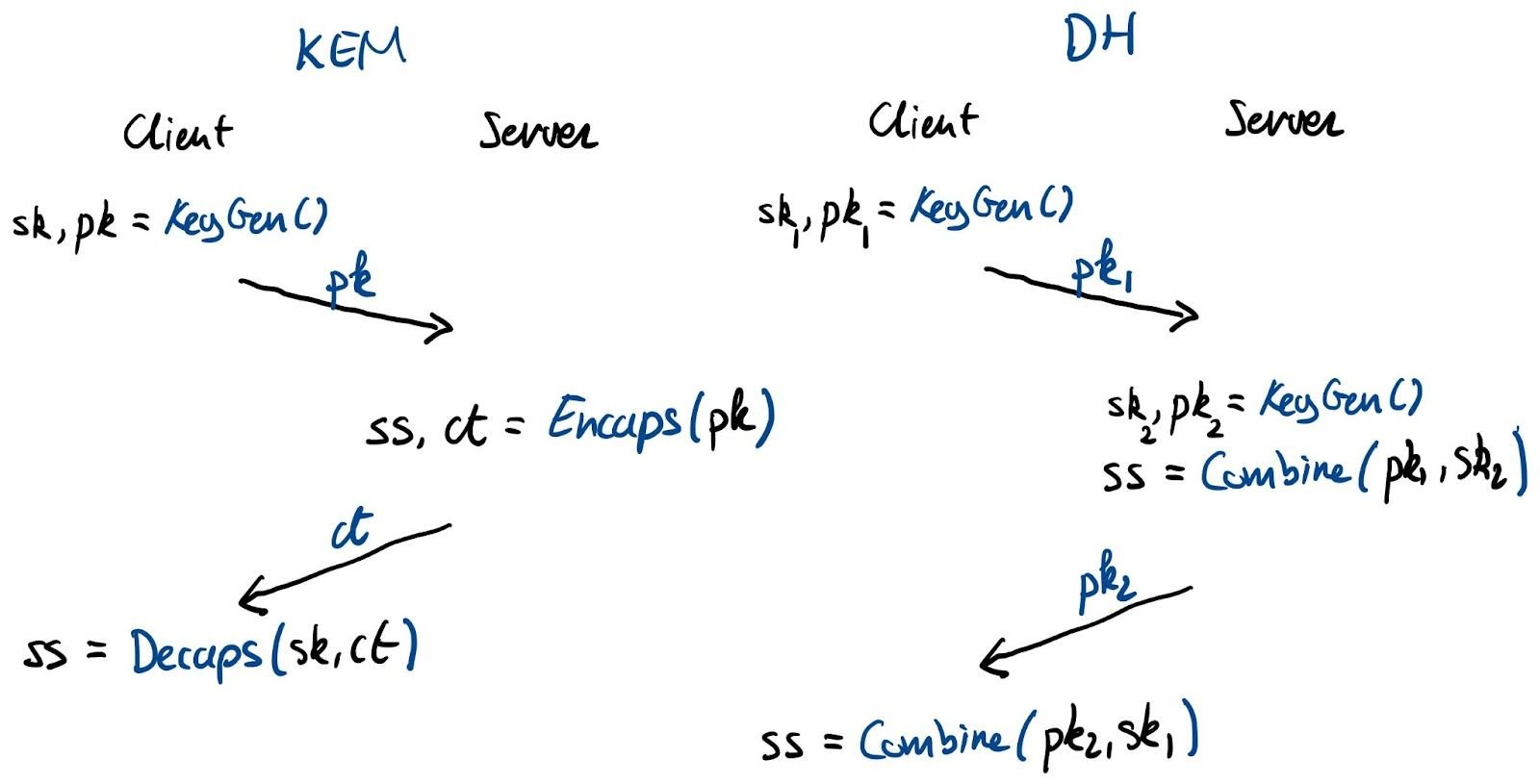
Kyber is a post-quantum (PQ) key encapsulation method (KEM). After a six-year worldwide competition, the National Institute of Standards and Technology (NIST) selected Kyber as the post-quantum key agreement they will standardize. The goal of a key agreement is for two parties that haven’t talked to each other before to agree securely on a shared key they can use for symmetric encryption (such as Chacha20Poly1305). As a KEM, it works slightly different with different terminology than a traditional Diffie–Hellman key agreement (such as X25519):
When connecting to a website the client first generates a new ephemeral keypair that consists of a private and public key. It sends the public key to the server. The server then encapsulates a shared key withthat public key, which gives it a random shared key, which it keeps, and a ciphertext (in which the shared key is hidden), which the server returns to the client. The client can then use its private key to decapsulate the shared key from the ciphertext. Now the server and client can communicate with each other using the shared key.
Key agreement is particularly important to make secure against attacks of quantum computers. The reason is that an attacker can store traffic today, and crack the key agreement in the future, revealing the shared key and all communication encrypted with it afterwards. That is why we have already deployed support for Kyber across our network.
The DNG paper
With all the background under our belt, we’re ready to take a look at the DNG paper. The authors perform a power side-channel attack on their own masked implementation of Kyber with six shares.
Point of attack
They attack the decapsulation step. In the decapsulation step, after the shared key is extracted, it’s encapsulated again, and compared against the original ciphertext to detect tampering. For this re-encryption step, the precursor of the shared key—let’s call it the secret—is encoded bit-by-bit into a polynomial. To be precise, the 256-bit secret needs to be converted to a polynomial with 256 coefficients modulo q=3329, where the ith coefficient is (q+1)/2 if the ith bth is 1 and zero otherwise.
This function sounds simple enough, but creating a masked version is tricky. The rub is that the natural way to create shares of the secret is to have shares that xor together to be the secret, and that the natural way to share polynomials is to have shares that add together to get to the intended polynomial.
This is the two-shares implementation of the conversion that the DNG paper attacks:
The code loops over the bits of the two shares. For each bit, it creates a mask, that’s 0xffff if the bit was 1 and 0 otherwise. Then this mask is used to add (q+1)/2 to the polynomial share if appropriate. Processing a 1 will use a bit more power. It doesn’t take an AI to figure out that this will be a leaky function. In fact, this pattern was pointed out to be weak back in 2016, and explicitly mentioned to be a risk for masked Kyber in 2020. Apropos, one way to mitigate this, is to process multiple bits at once — for the state of the art, tune into April 2023’s NIST PQC seminar. For the moment, let’s allow the paper its weak target.
The authors do not claim any fundamentally new attack here. Instead, they improve the effectiveness of the attack in two ways: the way they train the neural network, and how to use multiple traces more effectively by changing the ciphertext sent. So, what did they achieve?
Effectiveness
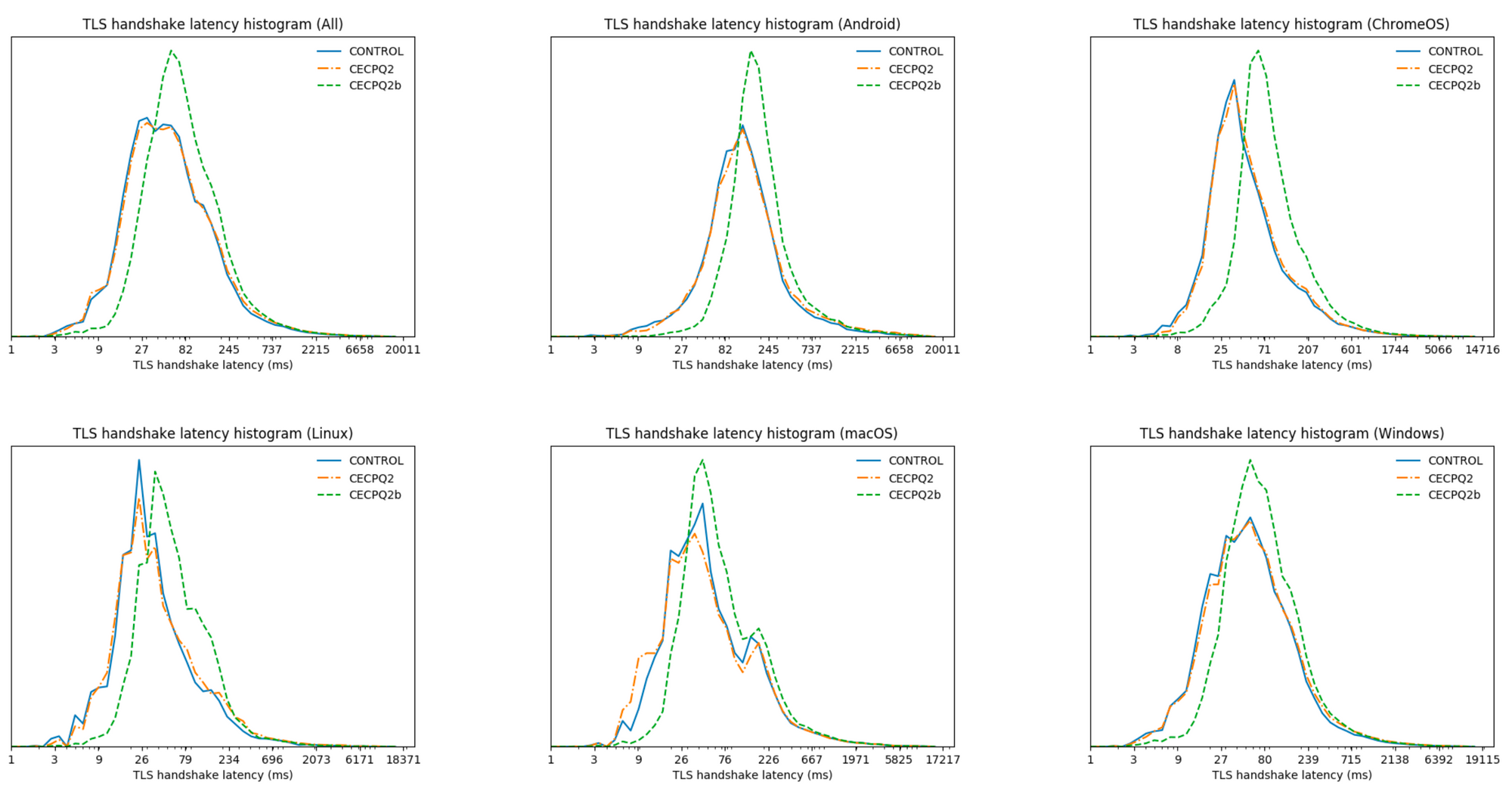
To test the attack, they use a Chipwhisperer-lite board, which has a Cortex M4 CPU, which they downclock to 24Mhz. Power usage is sampled at 24Mhz, with high 10-bit precision.
To train the neural networks, 150,000 power traces are collected for decapsulation of different ciphertexts (with known shared key) for the same KEM keypair. This is already a somewhat unusual situation for a real-world attack: for key agreement KEM keypairs are ephemeral; generated and used only once. Still, there are certainly legitimate use cases for long-term KEM keypairs, such as for authentication, HPKE, and in particular ECH.
The training is a key step: different devices even from the same manufacturer can have wildly different power traces running the same code. Even if two devices are of the same model, their power traces might still differ significantly.
The main contribution highlighted by the authors is that they train their neural networks to attack an implementation with 6 shares, by starting with a neural network trained to attack an implementation with 5 shares. That one can be trained from a model to attack 4 shares, and so on. Thus to apply their method, of these 150,000 power traces, one-fifth must be from an implementation with 6 shares, another one-fifth from one with 5 shares, et cetera. It seems unlikely that anyone will deploy a device where an attacker can switch between the number of shares used in the masking on demand.
Given these affordances, the attack proper can commence. The authors report that, from a single power trace of a two-share decapsulation, they could recover the shared key under these ideal circumstances with probability… 0.12%. They do not report the numbers for single trace attacks on more than two shares.
When we’re allowed multiple traces of the same decapsulation, side-channel attacks become much more effective. The second trick is a clever twist on this: instead of creating a trace of decapsulation of exactly the same message, the authors rotate the ciphertext to move bits of the shared key in more favorable positions. With 4 traces that are rotations of the same message, the success probability against the two-shares implementation goes up to 78%. The six-share implementation stands firm at 0.5%. When allowing 20 traces from the six-share implementation, the shared key can be recovered with an 87% chance.
In practice
The hardware used in the demonstration might be somewhat comparable to a smart card, but it is very different from high-end devices such as smartphones, desktop computers and servers. Simple power analysis side-channel attacks on even just embedded 1GHz processors are much more challenging, requiring tens of thousands of traces using a high-end oscilloscope connected close to the processor. There are much better avenues for attack with this kind of physical access to a server: just connect the oscilloscope to the memory bus.
Except for especially vulnerable applications, such as smart cards and HSMs, power-side channel attacks are widely considered infeasible. Although sometimes, when the planets align, an especially potent power side-channel attack can be turned into a remote timing attack due to throttling, as demonstrated by Hertzbleed. To be clear: the present attack does not even come close.
And even for these vulnerable applications, such as smart cards, this attack is not particularly potent or surprising. In the field, it is not a question of whether a masked implementation leaks its secrets, because it always does. It’s a question of how hard it is to actually pull off. Papers such as the DNG paper contribute by helping manufacturers estimate how many countermeasures to put in place, to make attacks too costly. It is not the first paper studying power side-channel attacks on Kyber and it will not be the last.
Wrapping up
AI did not completely undermine a new wave of cryptography, but instead is a helpful tool to deal with noisy data and discover the vulnerabilities within it. There is a big difference between a direct break of cryptography and a power side-channel attack. Kyber is not broken, and the presented power side-channel attack is not cause for alarm.
Researchers have just published a side-channel attack—using power consumption—against an implementation of the algorithm that was supposed to be resistant against that sort of attack.
The algorithm is not “broken” or “cracked”—despite headlines to the contrary—this is just a side-channel attack. What makes this work really interesting is that the researchers used a machine-learning model to train the system to exploit the side channel.
Amazon RDS now offers integration with Secrets Manager to manage master database credentials. You no longer have to manage master database credentials, such as creating a secret in Secrets Manager or setting up rotation, because Amazon RDS does it for you.
In this blog post, you will learn how to set up an Amazon RDS database instance and use the Secrets Manager integration to manage master database credentials. You will also learn how to set up alternating users rotation for application credentials.
Benefits of the integration
Managing Amazon RDS master database credentials with Secrets Manager provides the following benefits:
Amazon RDS automatically generates and helps secure master database credentials, so that you don’t have to do the heavy lifting of securely managing credentials.
Amazon RDS automatically stores and manages database credentials in Secrets Manager.
Amazon RDS rotates database credentials regularly without requiring application changes.
Secrets Manager helps to secure database credentials from human access and plaintext view.
Secrets Manager allows retrieval of database credentials using its API or the console.
In this blog post, we’ll show you how to use the console to do the following:
Manage master database credentials for new Amazon RDS instances in Secrets Manager. We will use the MySQL engine, but you can also use this process for other Amazon RDS database engines.
Use the managed master database secret to set up alternating users rotation for a new database user.
Manage Amazon RDS master database credentials in Secrets Manager
In this section, you will create a database instance with Secrets Manager integration.
To manage Amazon RDS master database credentials in Secrets Manager:
For Choose a database creation method, choose Standard create.
In Engine options, for Engine type, choose MySQL.
In Settings, under Credentials Settings, select Manage master credentials in AWS Secrets Manager.
Figure 1: Select Secrets Manager integration
You will have the option to encrypt the managed master database credentials. In this example, we will use the default KMS key.
Figure 2: Choose KMS key
(Optional) Choose other settings to meet your requirements. For more information, see Settings for DB instances.
Choose Create Database, and wait a few minutes for the database to be created.
After the database is created, from the Instances dashboard in the Amazon RDS console, navigate to your new Amazon RDS instance.
Choose the Configuration tab, and under Master Credentials ARN, you will find the secret that contains your master database credentials.
Create a new database user by using the master database credentials
In this section you will learn how to create and secure a credential that could be used in your application to connect to the database. You will learn how to access the master database credentials and use the master database credentials to create and set up rotation on child (application) credentials.
To create a new database user by using the master database credentials
Retrieve the master database credentials from Secrets Manager as follows:
Choose the Configuration tab of your RDS instance dashboard, and under Master Credentials ARN, choose Manage in Secrets Manager to open your managed master database secret in Secrets Manager.
Figure 3: View DB configuration
You can see that Amazon RDS has added some system tags to the secret and that rotation is turned on by default.
Figure 4: View secret details
To see the password, in the Secret value section, choose Retrieve secret value.
For the master database, create a new database user with the permissions that you want by running the following SQL command. Make sure to replace <password> with your own information, and make sure to use a strong password.
For Secret type, select Credentials for Amazon RDS database.
In the Credentials section, enter the username and password of the new database user.
In the Database section, select your Amazon RDS instance, and then choose Next, as shown in Figure 5.
Figure 5: Select the RDS instance
On the Configure secret page, give the secret a name and description. No other configuration is needed.
On the Configure rotation – optional page, turn on Automatic rotation.
Figure 6: Select automatic rotation
In the Rotation schedule section, configure the rotation schedule according to your needs.
In the Rotation function section, do the following:
Enter a descriptive name for the Lambda function that will be created.
For Use separate credentials to rotate this secret, select Yes.
For Secrets, choose the master database secret that was created by Amazon RDS.
Note: To find the name of your master database secret, in the Amazon RDS console, on your Amazon RDS instance details page, choose the Configuration tab and then see the Master Credentials ARN.
Figure 7: Select separate credentials for rotation
Choose Next, and then on the Review page, choose Store.
It will take a few minutes for the Secrets Manager workflow to set up the rotation Lambda function before the new database user secret is ready to be rotated.
To check that rotation is enabled
In the Secrets Manager console, navigate to the new database user secret.
Figure 8: View the child secret
In the Rotation configuration section, verify that Rotation status is Enabled.
In the Rotation configuration section, choose the Lambda rotation function.
Figure 12: View the rotation function
In the Lambda console, under Application, select the application.
Figure 13: Open application
On the Deployments tab, choose CloudFormation stack.
Choose Delete and then follow the Delete menu steps. You might need to navigate to the root stack and choose Delete again. You might also need to disable termination protection for the stack. The console will guide you through that.
Figure 14: Choose delete
Now that you have cleaned up rotation for the new database user secret, you need to delete the child secret. Navigate to the Secrets Manager console and select the secret that you want to delete.
In the Actions dropdown, select Delete secret to delete the secret.
Figure 15: Delete child secret
Summary
Amazon RDS integration with Secrets Manager helps you better secure and manage master DB credentials. This integration helps you store the credentials when the DB instances are created and eliminates the effort for you to set up credential rotation.
In this blog post, you learned how to do the following:
Set up an Amazon RDS instance that uses Secrets Manager to store the master database credentials
View the credentials in Secrets Manager and confirm that rotation is set up
Use the master database credentials to create database user credentials
Set up alternating users rotation on database user credentials
Additional resources
For instructions on how to create database users for other Amazon RDS engine types, see the following resources:
The team of computer scientist George Lasry, pianist Norbert Biermann and astrophysicist Satoshi Tomokiyo—all keen cryptographers—initially thought the batch of encoded documents related to Italy, because that was how they were filed at the Bibliothèque Nationale de France.
However, they quickly realised the letters were in French. Many verb and adjectival forms being feminine, regular mention of captivity, and recurring names—such as Walsingham—all put them on the trail of Mary. Sir Francis Walsingham was Queen Elizabeth’s spymaster.
The code was a simple replacement system in which symbols stand either for letters, or for common words and names. But it would still have taken centuries to crunch all the possibilities, so the team used an algorithm that homed in on likely solutions.
The field of machine learning (ML) security—and corresponding adversarial ML—is rapidly advancing as researchers develop sophisticated techniques to perturb, disrupt, or steal the ML model or data. It’s a heady time; because we know so little about the security of these systems, there are many opportunities for new researchers to publish in this field. In many ways, this circumstance reminds me of the cryptanalysis field in the 1990. And there is a lesson in that similarity: the complex mathematical attacks make for good academic papers, but we mustn’t lose sight of the fact that insecure software will be the likely attack vector for most ML systems.
We are amazed by real-world demonstrations of adversarial attacks on ML systems, such as a 3D-printed object that looks like a turtle but is recognized (from any orientation) by the ML system as a gun. Or adding a few stickers that look like smudges to a stop sign so that it is recognized by a state-of-the-art system as a 45 mi/h speed limit sign. But what if, instead, somebody hacked into the system and just switched the labels for “gun” and “turtle” or swapped “stop” and “45 mi/h”? Systems can only match images with human-provided labels, so the software would never notice the switch. That is far easier and will remain a problem even if systems are developed that are robust to those adversarial attacks.
At their core, modern ML systems have complex mathematical models that use training data to become competent at a task. And while there are new risks inherent in the ML model, all of that complexity still runs in software. Training data are still stored in memory somewhere. And all of that is on a computer, on a network, and attached to the Internet. Like everything else, these systems will be hacked through vulnerabilities in those more conventional parts of the system.
This shouldn’t come as a surprise to anyone who has been working with Internet security. Cryptography has similar vulnerabilities. There is a robust field of cryptanalysis: the mathematics of code breaking. Over the last few decades, we in the academic world have developed a variety of cryptanalytic techniques. We have broken ciphers we previously thought secure. This research has, in turn, informed the design of cryptographic algorithms. The classified world of the NSA and its foreign counterparts have been doing the same thing for far longer. But aside from some special cases and unique circumstances, that’s not how encryption systems are exploited in practice. Outside of academic papers, cryptosystems are largely bypassed because everything around the cryptography is much less secure.
The problem is that encryption is just a bunch of math, and math has no agency. To turn that encryption math into something that can actually provide some security for you, it has to be written in computer code. And that code needs to run on a computer: one with hardware, an operating system, and other software. And that computer needs to be operated by a person and be on a network. All of those things will invariably introduce vulnerabilities that undermine the perfection of the mathematics…
This remains true even for pretty weak cryptography. It is much easier to find an exploitable software vulnerability than it is to find a cryptographic weakness. Even cryptographic algorithms that we in the academic community regard as “broken”—meaning there are attacks that are more efficient than brute force—are usable in the real world because the difficulty of breaking the mathematics repeatedly and at scale is much greater than the difficulty of breaking the computer system that the math is running on.
ML systems are similar. Systems that are vulnerable to model stealing through the careful construction of queries are more vulnerable to model stealing by hacking into the computers they’re stored in. Systems that are vulnerable to model inversion—this is where attackers recover the training data through carefully constructed queries—are much more vulnerable to attacks that take advantage of unpatched vulnerabilities.
But while security is only as strong as the weakest link, this doesn’t mean we can ignore either cryptography or ML security. Here, our experience with cryptography can serve as a guide. Cryptographic attacks have different characteristics than software and network attacks, something largely shared with ML attacks. Cryptographic attacks can be passive. That is, attackers who can recover the plaintext from nothing other than the ciphertext can eavesdrop on the communications channel, collect all of the encrypted traffic, and decrypt it on their own systems at their own pace, perhaps in a giant server farm in Utah. This is bulk surveillance and can easily operate on this massive scale.
On the other hand, computer hacking has to be conducted one target computer at a time. Sure, you can develop tools that can be used again and again. But you still need the time and expertise to deploy those tools against your targets, and you have to do so individually. This means that any attacker has to prioritize. So while the NSA has the expertise necessary to hack into everyone’s computer, it doesn’t have the budget to do so. Most of us are simply too low on its priorities list to ever get hacked. And that’s the real point of strong cryptography: it forces attackers like the NSA to prioritize.
This analogy only goes so far. ML is not anywhere near as mathematically sound as cryptography. Right now, it is a sloppy misunderstood mess: hack after hack, kludge after kludge, built on top of each other with some data dependency thrown in. Directly attacking an ML system with a model inversion attack or a perturbation attack isn’t as passive as eavesdropping on an encrypted communications channel, but it’s using the ML system as intended, albeit for unintended purposes. It’s much safer than actively hacking the network and the computer that the ML system is running on. And while it doesn’t scale as well as cryptanalytic attacks can—and there likely will be a far greater variety of ML systems than encryption algorithms—it has the potential to scale better than one-at-a-time computer hacking does. So here again, good ML security denies attackers all of those attack vectors.
We’re still in the early days of studying ML security, and we don’t yet know the contours of ML security techniques. There are really smart people working on this and making impressive progress, and it’ll be years before we fully understand it. Attacks come easy, and defensive techniques are regularly broken soon after they’re made public. It was the same with cryptography in the 1990s, but eventually the science settled down as people better understood the interplay between attack and defense. So while Google, Amazon, Microsoft, and Tesla have all faced adversarial ML attacks on their production systems in the last three years, that’s not going to be the norm going forward.
All of this also means that our security for ML systems depends largely on the same conventional computer security techniques we’ve been using for decades. This includes writing vulnerability-free software, designing user interfaces that help resist social engineering, and building computer networks that aren’t full of holes. It’s the same risk-mitigation techniques that we’ve been living with for decades. That we’re still mediocre at it is cause for concern, with regard to both ML systems and computing in general.
I love cryptography and cryptanalysis. I love the elegance of the mathematics and the thrill of discovering a flaw—or even of reading and understanding a flaw that someone else discovered—in the mathematics. It feels like security in its purest form. Similarly, I am starting to love adversarial ML and ML security, and its tricks and techniques, for the same reasons.
I am not advocating that we stop developing new adversarial ML attacks. It teaches us about the systems being attacked and how they actually work. They are, in a sense, mechanisms for algorithmic understandability. Building secure ML systems is important research and something we in the security community should continue to do.
There is no such thing as a pure ML system. Every ML system is a hybrid of ML software and traditional software. And while ML systems bring new risks that we haven’t previously encountered, we need to recognize that the majority of attacks against these systems aren’t going to target the ML part. Security is only as strong as the weakest link. As bad as ML security is right now, it will improve as the science improves. And from then on, as in cryptography, the weakest link will be in the software surrounding the ML system.
This essay originally appeared in the May 2020 issue of IEEE Computer. I forgot to reprint it here.
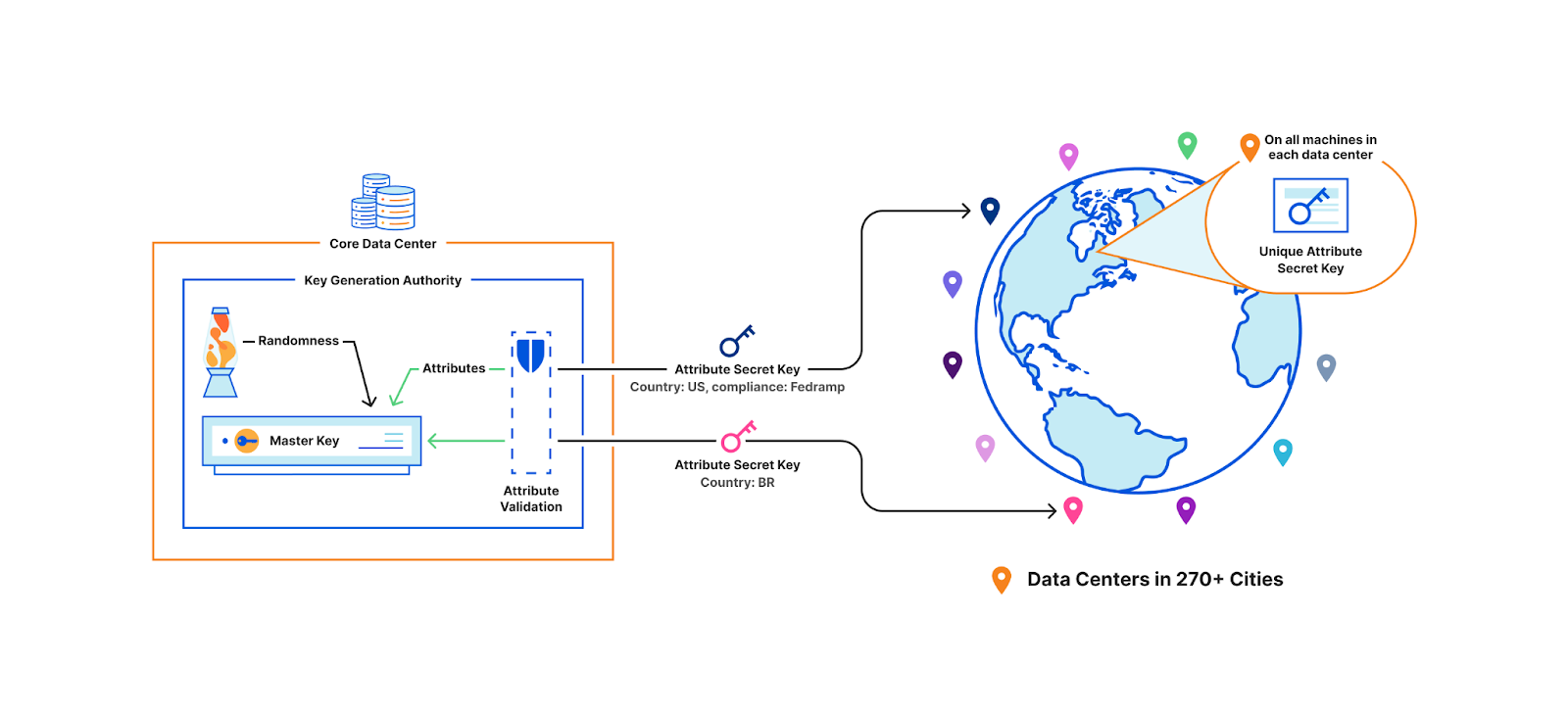
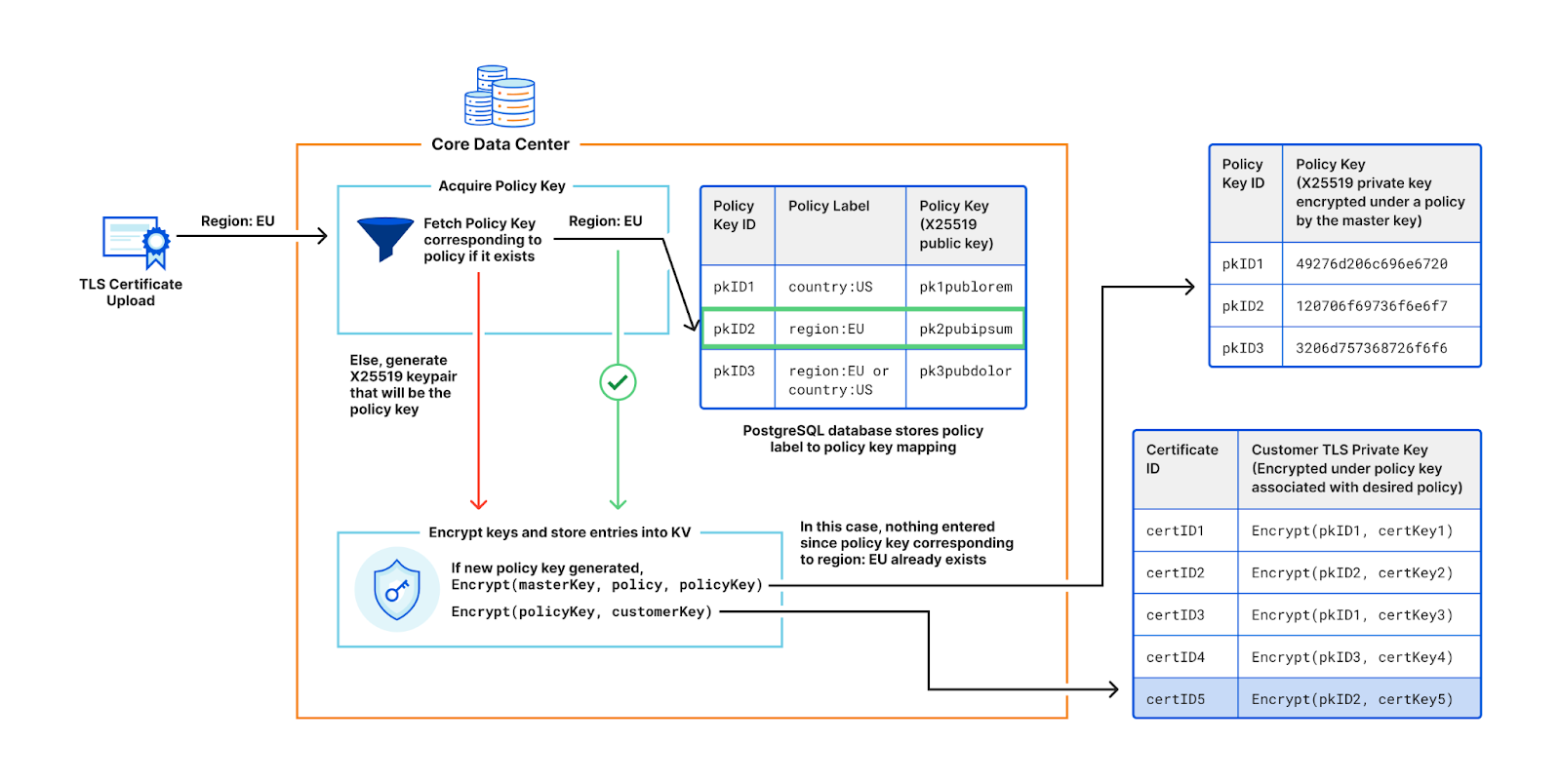
In December 2022 we announced the closed beta of the new version of Geo Key Manager. Geo Key Manager v2 (GeoV2) is the next step in our journey to provide customers with a secure and flexible way to control the distribution of their private keys by geographic location. Our original system, Geo Key Manager v1, was launched as a research project in 2017, but as customer needs evolved and our scale increased, we realized that we needed to make significant improvements to provide a better user experience.
One of the principal challenges we faced with Geo Key Manager v1 (GeoV1) was the inflexibility of our access control policies. Customers required richer data localization, often spurred by regulatory concerns. Internally, events such as the conflict in Ukraine reinforced the need to be able to quickly restrict access to sensitive key material. Geo Key Manager v1’s underlying cryptography was a combination of identity-based broadcast encryption and identity-based revocation that simulated a subset of the functionality offered by Attribute-Based Encryption (ABE). Replacing this with an established ABE scheme addressed the inflexibility of our access control policies and provided a more secure foundation for our system.
Unlike our previous scheme, which limited future flexibility by freezing the set of participating data centers and policies at the outset, using ABE made the system easily adaptable for future needs. It allowed us to take advantage of performance gains from additional data centers added after instantiation and drastically simplified the process for handling changes to attributes and policies. Furthermore, GeoV1 struggled with some perplexing performance issues that contributed to high tail latency and a painfully manual key rotation process. GeoV2 is our answer to these challenges and limitations of GeoV1.
While this blog focuses on our solution for geographical key management, the lessons here can also be applied to other access control needs. Access control solutions are traditionally implemented using a highly-available central authority to police access to resources. As we will see, ABE allows us to avoid this single point of failure. As there are no large scale ABE-based access control systems we are aware of, we hope our discussion can help engineers consider using ABE as an alternative to access control with minimal reliance on a centralized authority. To facilitate this, we’ve included our implementation of ABE in CIRCL, our open source cryptographic library.
Unsatisfactory attempts at a solution
Before coming back to GeoV2, let’s take a little detour and examine the problem we’re trying to solve.
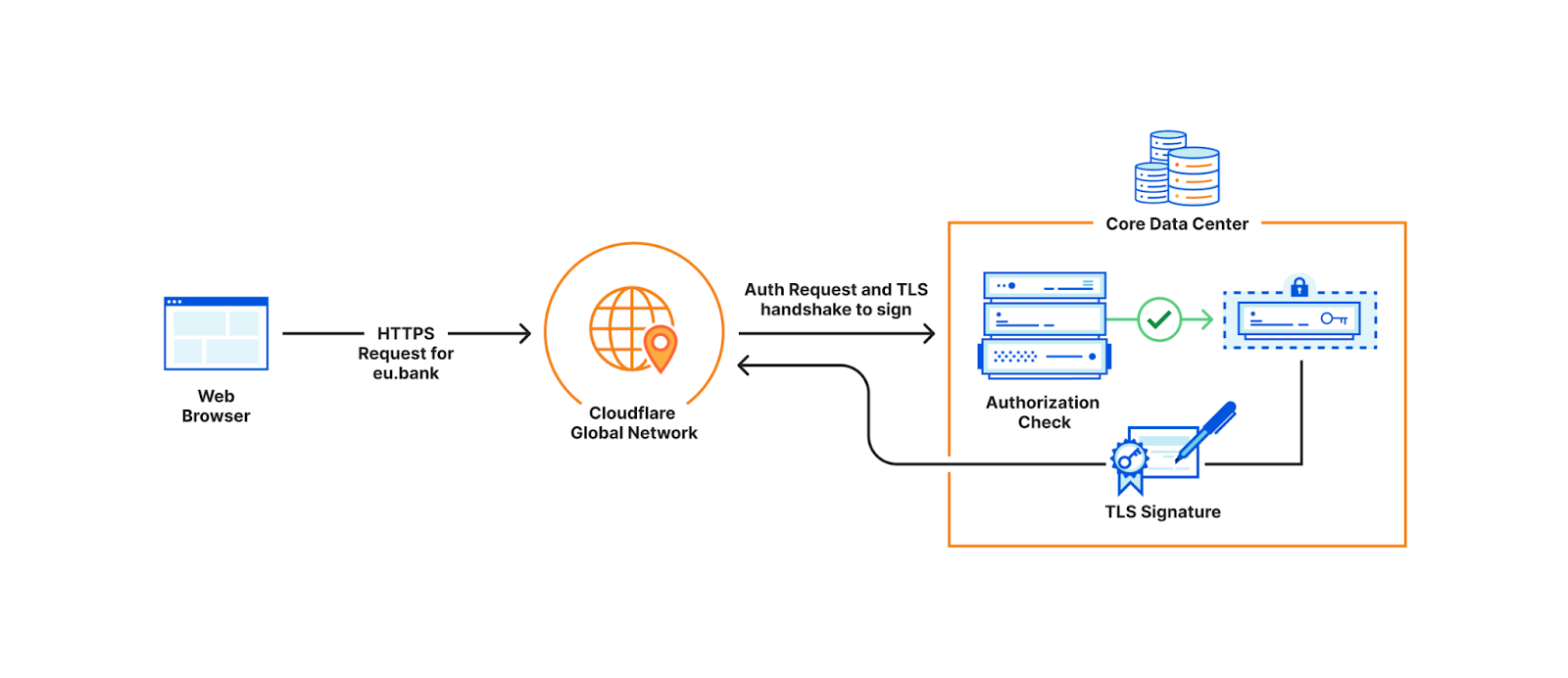
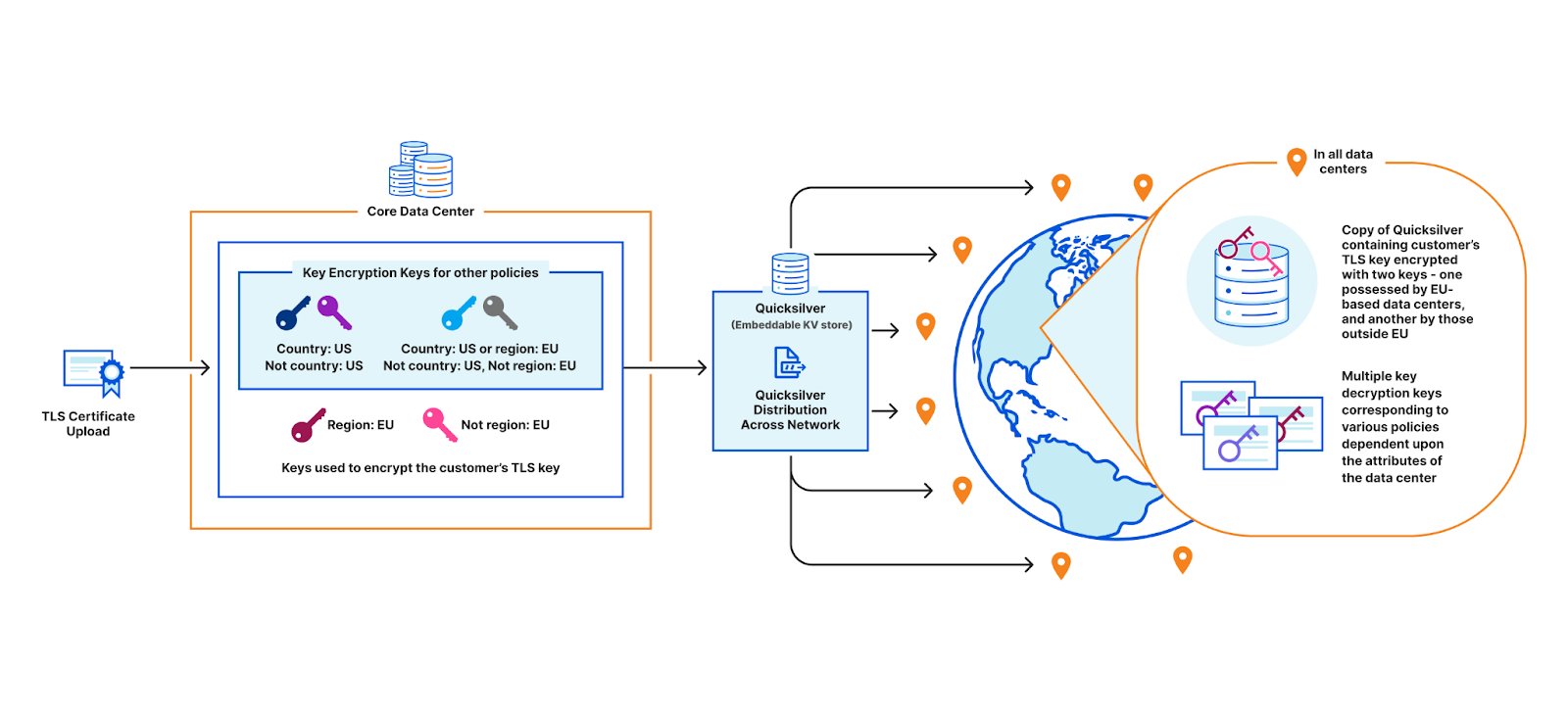
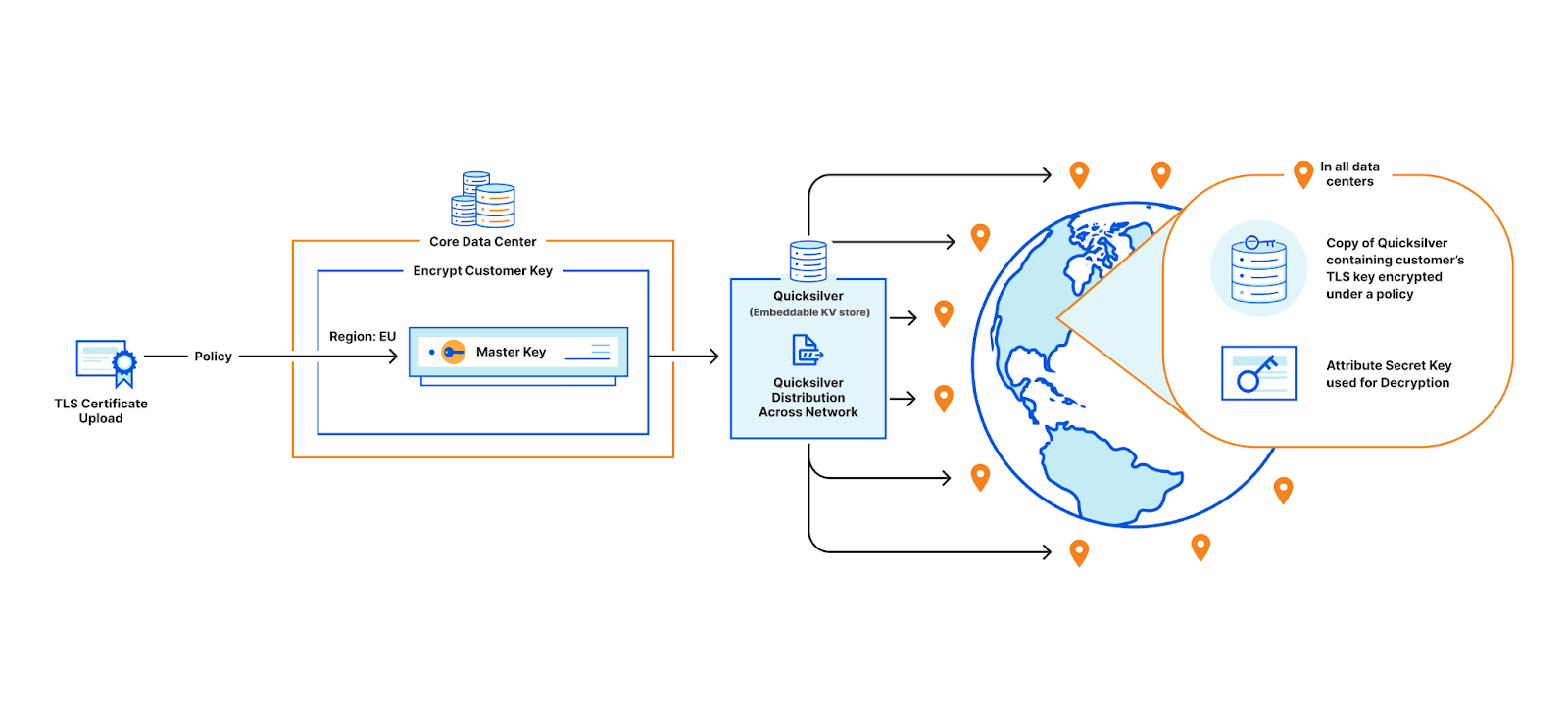
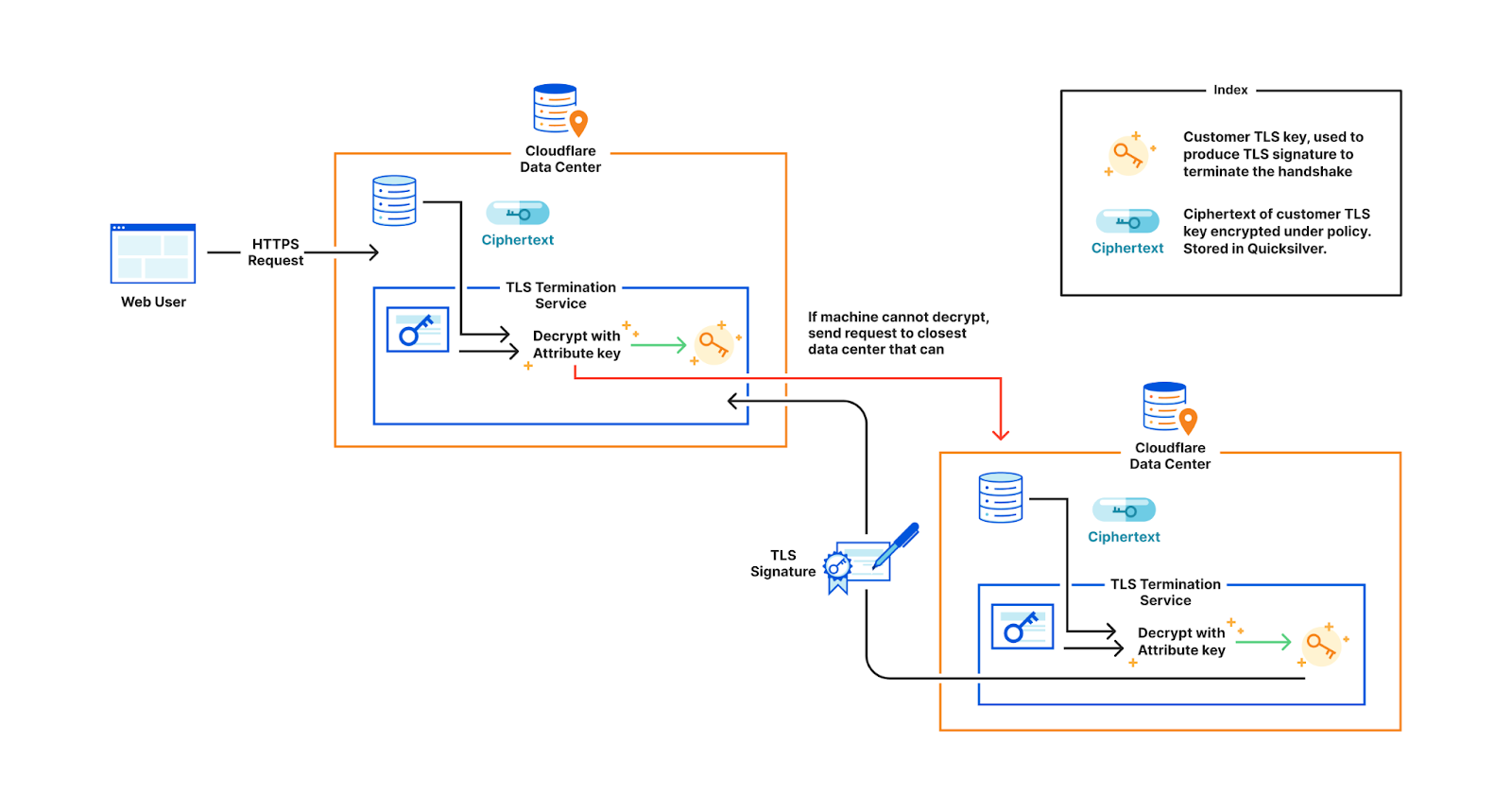
Consider this example: a large European bank wants to store their TLS private keys only within the EU. This bank is a customer of Cloudflare, which means we perform TLS handshakes on their behalf. The reason we need to terminate TLS for them is so that we can provide the best protection against DDoS attacks, improve performance by caching, support web application firewalls, etc.
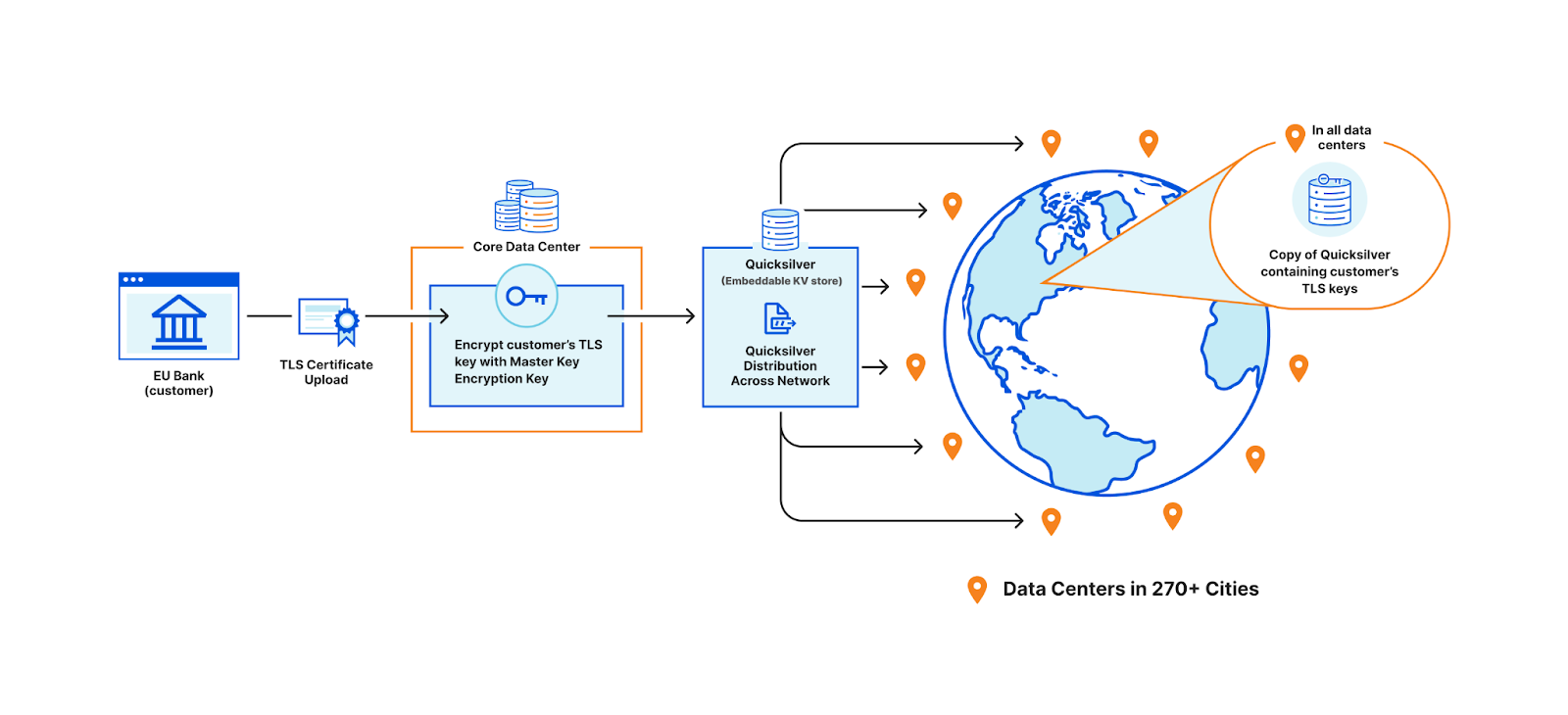
In order to terminate TLS, we need to have access to their TLS private keys1. The control plane, which handles API traffic, encrypts the customer’s uploaded private key with a master public key shared amongst all machines globally. It then puts the key into a globally distributed KV store, Quicksilver. This means every machine in every data center around the world has a local copy of this customer’s TLS private key. Consequently, every machine in each data center has a copy of every customer’s private key.
Customer uploading their TLS certificate and private key to be stored in all data centers
This bank however, wants its key to be stored only in EU data centers. In order to allow this to happen, we have three options.
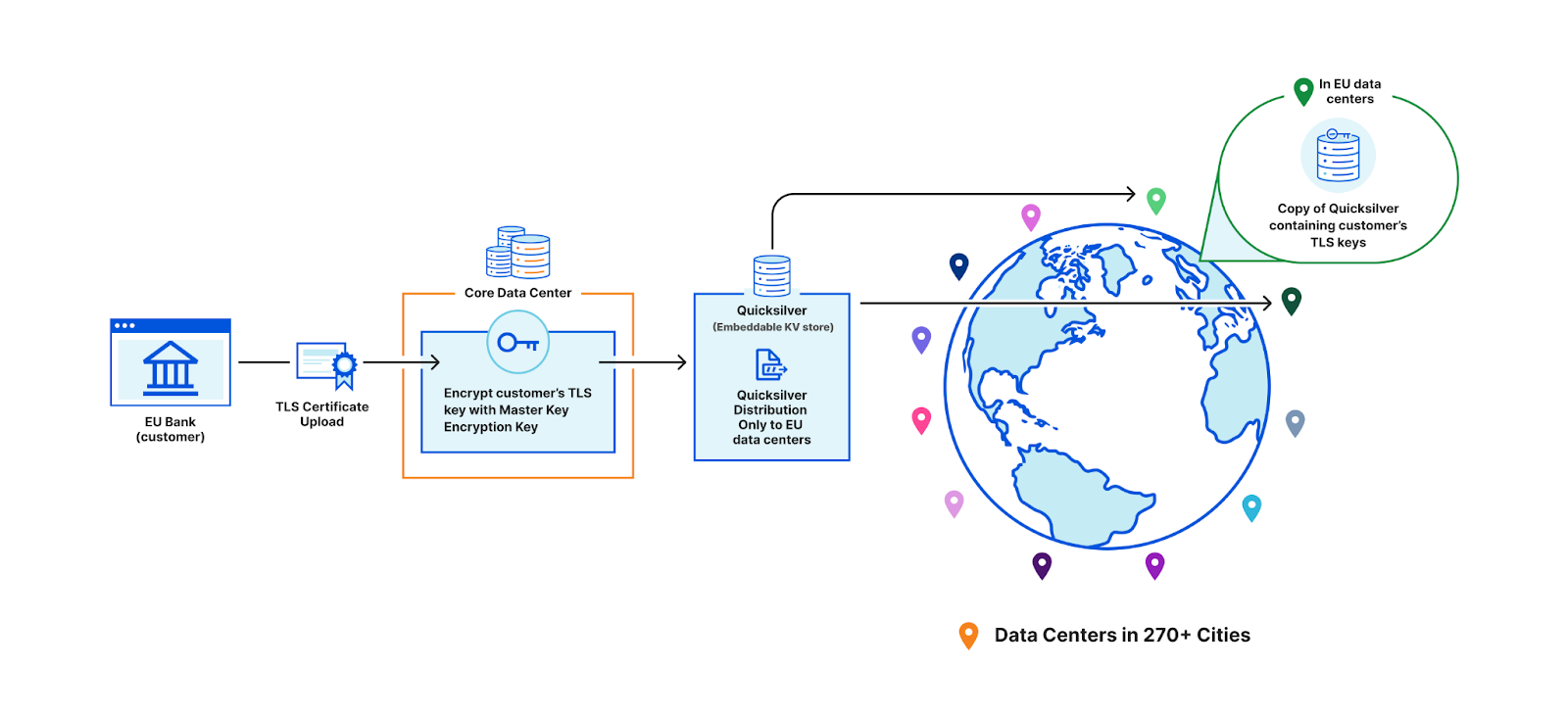
The first option is to ensure that only EU data centers can receive this key and terminate the handshake. All other machines proxy TLS requests to an EU server for processing. This would require giving each machine only a subset of the entire keyset stored in Quicksilver, which challenges core design decisions Cloudflare has made over the years that assume the entire dataset is replicated on every machine.
Restricting customer keys to EU data centers
Another option is to store the keys in the core data center instead of Quicksilver. This would allow us to enforce the proper access control policy every time, ensuring that only certain machines can access certain keys. However, this would defeat the purpose of having a global network in the first place: to reduce latency and avoid a single point of failure at the core.
Storing keys in core data center where complicated business logic runs to enforce policies
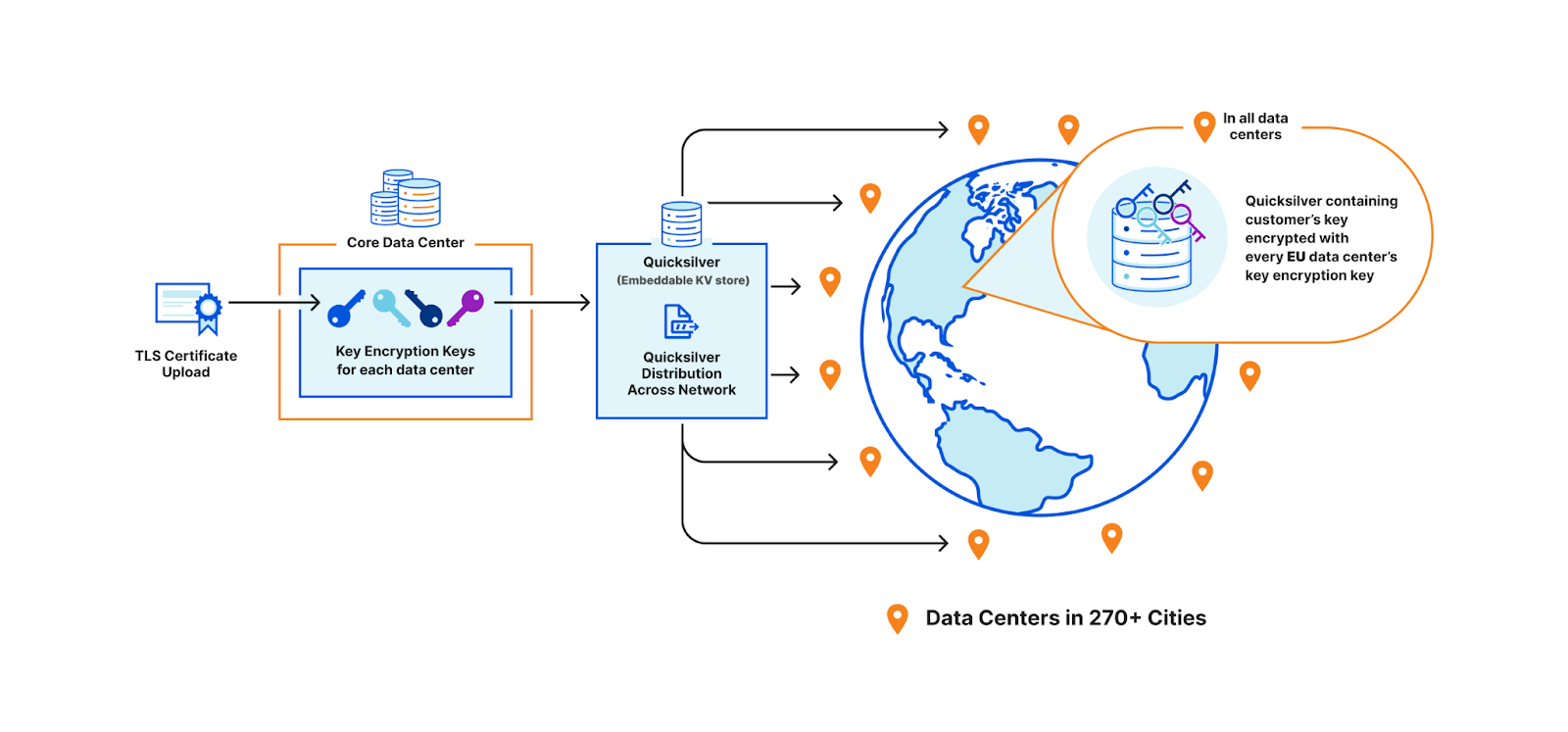
A third option is to use public key cryptography. Instead of having a master key pair, every data center is issued its own key pair. The core encrypts the customer’s private key with the keys of every data center allowed to use it. Only machines in the EU will be able to access the key in this example. Let’s assume there are 500 data centers, with 50 machines each. Of these 500 data centers, let’s say 200 are in the EU. Where 100 keys of 1kB consumed a total of 100 x 500 x 50 x 1 kB (globally), now they will consume 200 times that, and in the worst case, up to 500 times. This increases the space it takes to store the keys on each machine by a whole new factor – before, the storage space was purely a function of how many customer keys are registered; now, the storage space is still a function of the number of customer keys, but also multiplied by the number of data centers.
Assigning unique keys to each data center and wrapping customer key with EU data center keys
Unfortunately, all three of these options are undesirable in their own ways. They would either require changing fundamental assumptions we made about the architecture of Cloudflare, abandoning the advantages of using a highly distributed network, or quadratically increasing the storage this feature uses.
A deeper look at the third option reveals – why not create two key pairs instead of a unique one for each data center? One pair would be common among all EU data centers, and one for all non-EU data centers. This way, the core only needs to encrypt the customer’s key twice instead of for each EU data center. This is a good solution for the EU bank, but it doesn’t scale once we start adding additional policies. Consider the example: a data center in New York City could have a key for the policy “country: US”, another one for “country: US or region: EU”, another one for “not country: RU”, and so on… You can already see this getting rather unwieldy. And every time a new data center is provisioned, all policies must be re-evaluated and the appropriate keys assigned.
A key for each policy and its negation
Geo Key Manager v1: identity-based encryption and broadcast encryption
The invention of RSA in 1978 kicked off the era of modern public key cryptography, but anyone who has used GPG or is involved with certificate authorities can attest to the difficulty of managing public key infrastructure that connects keys to user identities. In 1984, Shamir asked if it was possible to create a public-key encryption system where the public key could be any string. His motivation for this question was to simplify email management. Instead of encrypting an email to Bob using Bob’s public key, Alice could encrypt it to Bob’s identity [email protected]. Finally, in 2001, Boneh and Franklin figured out how to make it work.
Broadcast encryption was first proposed in 1993 by Fiat and Naor. It lets you send the same encrypted message to everyone, but only people with the right key can decrypt it. Looking back to our third option, instead of wrapping the customer’s key with the key of every EU data center, we could use broadcast encryption to create a singular encryption of the customer’s key that only EU-based data centers could decrypt. This would solve the storage problem.
Geo Key Manager v1 used a combination of identity-based broadcast encryption and identity-based revocation to implement access control. Briefly, a set of identities is designated for each region and each data center location. Then, each machine is issued an identity-based private key for its region and location. With this in place, access to the customer’s key can be controlled using three sets: the set of regions to encrypt to, the set of locations inside the region to exclude, and the set of locations outside the region to include. For example, the customer’s key could be encrypted so that it is available in all regions except for a few specific locations, and also available in a few locations outside those regions. This blog post has all the nitty-gritty details of this approach.
Unfortunately this scheme was insufficiently responsive to customer needs; the parameters used during initial cryptographic setup, such as the list of regions, data centers, and their attributes, were baked into the system and could not be easily changed. Tough luck excluding the UK from the EU region post Brexit, or supporting a new region based on a recent compliance standard that customers need. Using a predetermined static list of locations also made it difficult to quickly revoke machine access. Additionally, decryption keys could not be assigned to new data centers provisioned after setup, preventing them from speeding up requests. These limitations provided the impetus for integrating Attribute-Based Encryption (ABE) into Geo Key Manager.
Attribute-Based Encryption
In 2004, Amit Sahai and Brent Waters proposed a new cryptosystem based on access policies, known as attribute-based encryption (ABE). Essentially, a message is encrypted under an access policy rather than an identity. Users are issued a private key based on their attributes, and they can only decrypt the message if their attributes satisfy the policy. This allows for more flexible and fine-grained access control than traditional methods of encryption.
Brief timeline of Public Key Encryption
The policy can be attached either to the key or to the ciphertext, leading to two variants of ABE: key-policy attribute-based encryption (KP-ABE) and ciphertext-policy attribute-based encryption (CP-ABE). There exist trade-offs between them, but they are functionally equivalent as they are duals of each other. Let’s focus on CP-ABE it aligns more closely with real-world access control. Imagine a hospital where a doctor has the attributes “role: doctor” and “region: US”, while a nurse has the attributes “role: nurse” and “region: EU”. A document encrypted under the policy “role: doctor or region: EU” can be decrypted by both the doctor and nurse. In other words, ABE is like a magical lock that only opens for people who have the right attributes.
Policy
Semantics
country: US or region: EU
Decryption is possible either in the US or in the European Union
not (country: RU or country: US)
Decryption is not possible in Russia and US
country: US and security: high
Decryption is possible only in data centers within the US that have a high level of security (for some security definition established previously)
There are many different ABE schemes out there, with varying properties. The scheme we choose must satisfy a few requirements:
Negation We want to be able to support boolean formulas consisting of AND, OR and NOT, aka non-monotonic boolean formulas. While practically every scheme handles AND and OR, NOT is rarer to find. Negation makes blocklisting certain countries or machines easier.
Repeated Attributes Consider the policy “organization: executive or (organization: weapons and clearance: top-secret)”. The attribute “organization” has been repeated twice in the policy. Schemes with support for repetition add significant expressibility and flexibility when composing policies.
Security against Chosen Ciphertext Attacks Most schemes are presented in a form that is only secure if the attacker doesn’t choose the messages to decrypt (CPA). There are standard ways to convert such a scheme into one that is secure even if the attacker manipulates ciphertexts (CCA), but it isn’t automatic. We apply the well-known Boneh-Katz transform to our chosen scheme to make it secure against this class of attacks. We will present a proof of security for the end to end scheme in our forthcoming paper.
Negation in particular deserves further comment. For an attribute to be satisfied when negated, the name must stay the same, but the value must differ. It’s like the data center is saying, “I have a country, but it’s definitely not Japan”, instead of “I don’t have a country”. This might seem counterintuitive, but it enables decryption without needing to examine every attribute value. It also makes it safe to roll out attributes incrementally. Based on these criteria, we ended up choosing the scheme by Tomida et al (2021).
Implementing a complex cryptographic scheme such as this can be quite challenging. The discrete log assumption that underlies traditional public key cryptography is not sufficient to meet the security requirements of ABE. ABE schemes must secure both ciphertexts and the attribute-based secret keys, whereas traditional public key cryptography only imposes security constraints on the ciphertexts, while the secret key is merely an integer. To achieve this, most ABE schemes are constructed using a mathematical operation known as bilinear pairings.
The speed at which we can perform pairing operations determines the baseline performance of our implementation. Their efficiency is particularly desirable during decryption, where they are used to combine the attribute-based secret key with the ciphertext in order to recover the plaintext. To this end, we rely on our highly optimized pairing implementations in our open source library of cryptographic suites, CIRCL, which we discuss at length in a previous blog. Additionally, the various keys, attributes and the ciphertext that embeds the access structure are expressed as matrices and vectors. We wrote linear algebra routines to handle matrix operations such as multiplication, transpose, inverse that are necessary to manipulate the structures as needed. We also added serialization, extensive testing and benchmarking. Finally, we implemented our conversion to a CCA2 secure scheme.
In addition to the core cryptography, we had to decide how to express and represent policies. Ultimately we decided on using strings for our API. While perhaps less convenient for programs than structures would be, users of our scheme would have to implement a parser anyway. Having us do it for them seemed like a way to have a more stable interface. This means the frontend of our policy language was composed of boolean expressions as strings, such as “country: JP or (not region: EU)”, while the backend is a monotonic boolean circuit consisting of wires and gates. Monotonic boolean circuits only include AND and OR gates. In order to handle NOT gates, we assigned positive or negative values to the wires. Every NOT gate can be placed directly on a wire because of De Morgan’s Law, which allows the conversion of a formula like “not (X and Y)” into “not X or not Y”, and similarly for disjunction.
The following is a demonstration of the API. The central authority runs Setup to generate the master public key and master secret key. The master public key can be used by anyone to encrypt a message over an access policy. The master secret key, held by the central authority, is used to generate secret keys for users based on their attributes. Attributes themselves can be supplied out-of-band. In our case, we rely on the machine provisioning database to provide and validate attributes. These attribute-based secret keys are securely distributed to users, such as over TLS, and are used to decrypt ciphertexts. The API also includes helper functions to check decryption capabilities and extract policies from ciphertexts for improved usability.
We now come back to our original example. This time, the central authority holds the master secret key. Each machine in every data center presents its set of attributes to the central authority, which, after some validation, generates a unique attribute-based secret key for that particular machine. Key issuance happens when a machine is first brought up, if keys must be rotated, or if an attribute has changed, but never in the critical path of a TLS handshake. This solution is also collusion resistant, which means two machines without the appropriate attributes cannot combine their keys to decrypt a secret that they individually could not decrypt. For example, a machine with the attribute “country: US” and another with “security: high”. These machines cannot collude together to decrypt a resource with the policy “country: US and security: high”.
Crucially, this solution can seamlessly scale and respond to changes to machines. If a new machine is added, the central authority can simply issue it a secret key since the participants of the scheme don’t have to be predetermined at setup, unlike our previous identity-broadcast scheme.
Key Distribution
When a customer uploads their TLS certificate, they can specify a policy, and the central authority will encrypt their private key with the master public key under the specified policy. The encrypted customer key then gets written to Quicksilver, to be distributed to all data centers. In practice, there is a layer of indirection here that we will discuss in a later section.
Encryption using Master Public Key
When a user visits the customer’s website, the TLS termination service at the data center that first receives the request, fetches the customer’s encrypted private key from Quicksilver. If the service’s attributes do not satisfy the policy, decryption fails and the request is proxied to the closest data center that satisfies the policy. Whichever data center can successfully decrypt the key performs the signature to complete the TLS handshake.
Decryption using Attribute-based Secret Key (Simplified)
The following table summarizes the pros and cons of the various solutions we discussed:
Solution
Flexible policies
Fault Tolerant
Efficient Space
Low Latency
Collusion-resistant
Changes to machines
Different copies of Quicksilver in data centers
✅
✅
✅
✅
✅
Complicated Business Logic in Core
✅
✅
✅
✅
Encrypt customer keys with each data center’s unique keypair
✅
✅
✅
✅
Encrypt customer keys with a policy-based keypair, where each data center has multiple policy-based keypairs
We characterize our scheme’s performance on measures inspired by ECRYPT. We set the attribute size to 50, which is significantly higher than necessary for most applications, but serves as a worst case scenario for benchmarking purposes. We conduct our measurements on a laptop with Intel Core i7-10610U CPU @ 1.80GHz and compare the results against RSA with 2048-bit security, X25519 and our previous scheme.
Scheme
Secret key(bytes)
Public key(bytes)
Overhead of encrypting 23 bytes (ciphertext length – message length)
Overhead of encrypting 10k bytes (ciphertext length – message length)
RSA-2048
1190 (PKCS#1)
256
233
3568
X25519
32
32
48
48
GeoV1 scheme
4838
4742
169
169
GeoV2 ABE scheme
33416
3282
19419
19419
Different attribute based encryption schemes optimize for different performance profiles. Some may have fast key generation, while others may prioritize fast decryption. In our case, we only care about fast decryption because it is the only part of the process that lies in the critical path of a request. Everything else happens out-of-band where the extra overhead is acceptable.
Scheme
Generating keypair
Encrypting 23 bytes
Decrypting 23 bytes
RSA-2048
117 ms
0.043 ms
1.26 ms
X25519
0.045 ms
0.093 ms
0.046 ms
GeoV1 scheme
75 ms
10.7 ms
13.9 ms
GeoV2 ABE scheme
1796 ms
704 ms
62.4 ms
A Brief Note on Attribute-Based Access Control (ABAC)
ABAC is an extension of the more familiar Role-Based Access Control (RBAC). To understand why ABAC is relevant, let’s briefly discuss its origins. In 1970, the United States Department of Defense introduced Discretionary Access Control (DAC). DAC is how Unix file systems are implemented. But DAC isn’t enough if you want to restrict resharing, because the owner of the resource can grant other users permission to access it in ways that the central administrator does not agree with. To address this, the Department of Defense introduced Mandatory Access Control (MAC). DRM is a good example of MAC. Even though you have the file, you don’t have a right to share it to others.
RBAC is an implementation of certain aspects of MAC. ABAC is an extension of RBAC that was defined by NIST in 2017 to address the increasing characteristics of users that are not restricted to their roles, such as time of day, user agent, and so on.
However, RBAC/ABAC is simply a specification. While they are traditionally implemented using a central authority to police access to some resource, it doesn’t have to be so. Attribute-based encryption is an excellent mechanism to implement ABAC in distributed systems.
Key rotation
While it may be tempting to attribute all failures to DNS, changing keys is another strong contender in this race. Suffering through the rather manual and error-prone key rotation process of Geo Key Manager v1 taught us to make robust and simple key rotation without impact on availability, an explicit design goal for Geo Key Manager v2.
To facilitate key rotation and improve performance, we introduce a layer of indirection to the customer key wrapping (encryption) process. When a customer uploads their TLS private key, instead of encrypting with the Master Public Key, we generate a X25519 keypair, called the policy key. The central authority then adds the public part of this newly minted policy keypair and its associated policy label to a database. It then encrypts the private half of the policy keypair with the Master Public Key, over the associated access policy. The customer’s private key is encrypted with the public policy key, and saved into Quicksilver.
When a user accesses the customer’s website, the TLS termination service at the data center that receives the request fetches the encrypted policy key associated with the customer’s access policy. If the machine’s attributes don’t satisfy the policy, decryption fails and the request is forwarded to the closest satisfying data center. If decryption succeeds, the policy key is used to decrypt the customer’s private key and complete the handshake.
Key
Purpose
CA in core
Core
Network
Master Public Key
Encrypts private policy keys over an access policy
Generate
Read
Master Secret Key
Generates secret keys for machines based on their attributes
Generate,Read
Machine Secret Key / Attribute-Based Secret Key
Decrypts private policy keys stored in global KV store, Quicksilver
Generate
Read
Customer TLS Private Key
Performs digital signature necessary to complete TLS handshake to the customer’s website
Read (transiently on upload)
Read
Public Policy Key
Encrypts customers’ TLS private keys
Generate, Read
Private Policy Key
Decrypts customer’s TLS private keys
Read (transiently during key rotation)
Generate
Read
However, policy keys are not generated for every customer’s certificate upload. As shown in the figure below, if a customer requests a policy that already exists in the system and thus has an associated policy key, the policy key will get re-used. Since most customers use the same few policies, such as restricting to one country, or restricting to the EU, the number of policy keys is orders of magnitude smaller compared to the number of customer keys.
Policy Keys
This sharing of policy keys is tremendously useful for key rotation. When master keys are rotated (and consequently the machine secret keys), only the handful of policy keys used to control access to the customers’ keys need to be re-encrypted, rather than every customer’s key encryption. This reduces compute and bandwidth requirements. Additionally, caching policy keys at the TLS termination service improves performance by reducing the need for frequent decryptions in the critical path.
This is similar to hybrid encryption, where public key cryptography is used to establish a shared symmetric key, which then gets used to encrypt data. The difference here is that the policy keys are not symmetric, but rather X25519 keypairs, which is an asymmetric scheme based on elliptic curves. While not as fast as symmetric schemes like AES, traditional elliptic curve cryptography is significantly faster than attribute-based encryption. The advantage here is that the central service doesn’t need access to secret key material to encrypt customer keys.
The other component of robust key rotation involves maintaining multiple key versions.The latest key generation is used for encryption, but the latest and previous versions can be used for decryption. We use a system of states to manage key transitions and safe deletion of older keys. We also have extensive monitoring in place to alert us if any machines are not using the appropriate key generations.
The Tail At Scale
Geo Key Manager suffered from high tail latency, which occasionally impacted availability. Jeff Dean’s paper, The Tail at Scale, is an enlightening read on how even elevated p99 latency at Cloudflare scale can be damaging. Despite revamping the server and client components of our service, the p99 latency didn’t budge. These revamps, such as switching from worker pools to one goroutine per request, did simplify the service, as they removed thousands of lines of code. Distributed tracing was able to pin down the delays: they took place between the client sending a request and the server receiving it. But we could not dig in further. We even wrote a blog last year describing our debugging endeavors, but without a concrete solution.
Finally, we realized that there is a level of indirection between the client and the server. Our data centers around the world are very different sizes. To avoid swamping smaller data centers with connections, larger data centers would task individual, intermediary machines with proxying requests to other data centers using the Go net/rpc library.
Once we included the forwarding function on the intermediary server in the trace, the problem became clear. There was a long delay between issuing the request and processing it. Yet the code was merely a call to a built-in library function. Why was it delaying the request?
Ultimately we found that there was a lock held while the request was serialized. The net/rpc package does not support streams, but our packet-oriented custom application protocol, which we wrote before the advent of gRPC, does support streaming. To bridge this gap, we executed a request and waited for the response in the serialization function. While an expedient way to get the code written, it created a performance bottleneck as only one request could be forwarded at a time.
Our solution was to use channels for coordination, letting multiple requests execute while we waited for the responses to arrive. When we rolled it out we saw dramatic decreases in tail latency.
The results of fixing RPC failures in remote colo in Australia
Unfortunately we cannot make the speed of light any faster (yet). Customers who want their keys kept only in the US while their website users are in the land down under will have to endure some delays as we make the trans-pacific voyage. But thanks to session tickets, those delays only affect new connections.
Uptime was also significantly improved. Data centers provisioned after cryptographic initiation could now participate in the system, which also implies that data centers that did not satisfy a certain policy had a broader range of satisfying neighbors to which they could forward the signing request to. This increased redundancy in the system, and particularly benefited data centers in regions without the best internet connectivity. The graph below represents successful probes spanning every machine globally over a two-day period. For GeoV1, we see websites with policies for US and EU regions falling to under 98% at one point, while for GeoV2, uptime rarely drops below 4 9s of availability.
Uptime by Key Profile across US and EU for GeoV1 and GeoV2, and IN for GeoV2
Conclusion
Congratulations dear reader for making it this far. Just like you, applied cryptography has come a long way, but only limited slivers manage to penetrate the barrier between research and real-world adoption. Bridging this gap can help enable novel capabilities for protecting sensitive data. Attribute-based encryption itself has become much more efficient and featureful over the past few years. We hope that this post encourages you to consider ABE for your own access control needs, particularly if you deal with distributed systems and don’t want to depend on a highly available central authority. We have open-sourced our implementation of CP-ABE in CIRCL, and plan on publishing a paper with additional details.
We look forward to the numerous product improvements to Geo Key Manager made possible by this new cryptographic foundation. We plan to use this ABE-based mechanism for storing not just private keys, but also other types of data. We are working on making it more user-friendly and generalizable for internal services to use.
Acknowledgements
We’d like to thank Watson Ladd for his contributions to this project during his tenure at Cloudflare.
…… 1While true for most customers, we do offer Keyless SSL that allows customers who can run their own keyservers, the ability to store their private keys on-prem
A group of Chinese researchers have just published a paper claiming that they can—although they have not yet done so—break 2048-bit RSA. This is something to take seriously. It might not be correct, but it’s not obviously wrong.
We have long known from Shor’s algorithm that factoring with a quantum computer is easy. But it takes a big quantum computer, on the orders of millions of qbits, to factor anything resembling the key sizes we use today. What the researchers have done is combine classical lattice reduction factoring techniques with a quantum approximate optimization algorithm. This means that they only need a quantum computer with 372 qbits, which is well within what’s possible today. (The IBM Osprey is a 433-qbit quantum computer, for example. Others are on their way as well.)
The Chinese group didn’t have that large a quantum computer to work with. They were able to factor 48-bit numbers using a 10-qbit quantum computer. And while there are always potential problems when scaling something like this up by a factor of 50, there are no obvious barriers.
Honestly, most of the paper is over my head—both the lattice-reduction math and the quantum physics. And there’s the nagging question of why the Chinese government didn’t classify this research. But…wow…maybe…and yikes! Or not.
Abstract: Shor’s algorithm has seriously challenged information security based on public key cryptosystems. However, to break the widely used RSA-2048 scheme, one needs millions of physical qubits, which is far beyond current technical capabilities. Here, we report a universal quantum algorithm for integer factorization by combining the classical lattice reduction with a quantum approximate optimization algorithm (QAOA). The number of qubits required is O(logN/loglogN ), which is sublinear in the bit length of the integer N , making it the most qubit-saving factorization algorithm to date. We demonstrate the algorithm experimentally by factoring integers up to 48 bits with 10 superconducting qubits, the largest integer factored on a quantum device. We estimate that a quantum circuit with 372 physical qubits and a depth of thousands is necessary to challenge RSA-2048 using our algorithm. Our study shows great promise in expediting the application of current noisy quantum computers, and paves the way to factor large integers of realistic cryptographic significance.
In email, Roger Grimes told me: “Apparently what happened is another guy who had previously announced he was able to break traditional asymmetric encryption using classical computers…but reviewers found a flaw in his algorithm and that guy had to retract his paper. But this Chinese team realized that the step that killed the whole thing could be solved by small quantum computers. So they tested and it worked.”
EDITED TO ADD: One of the issues with the algorithm is that it relies on a recent factoring paper by Claus Schnorr. It’s a controversial paper; and despite the “this destroys the RSA cryptosystem” claim in the abstract, it does nothing of the sort. Schnorr’s algorithm works well with smaller moduli—around the same order as ones the Chinese group has tested—but falls apart at larger sizes. At this point, nobody understands why. The Chinese paper claims that their quantum techniques get around this limitation (I think that’s what’s behind Grimes’s comment) but don’t give any details—and they haven’t tested it with larger moduli. So if it’s true that the Chinese paper depends on this Schnorr technique that doesn’t scale, the techniques in this Chinese paper won’t scale, either. (On the other hand, if it does scale then I think it also breaks a bunch of lattice-based public-key cryptosystems.)
I am much less worried that this technique will work now. But this is something the IBM quantum computing people can test right now.
EDITED TO ADD (1/4): A reporter just asked me my gut feel about this. I replied that I don’t think this will break RSA. Several times a year the cryptography community received “breakthroughs” from people outside the community. That’s why we created the RSA Factoring Challenge: to force people to provide proofs of their claims. In general, the smart bet is on the new techniques not working. But someday, that bet will be wrong. Is it today? Probably not. But it could be. We’re in the worst possible position right now: we don’t have the facts to know. Someone needs to implement the quantum algorithm and see.
EDITED TO ADD (1/5): Scott Aaronson’s take is a “no”:
In the new paper, the authors spend page after page saying-without-saying that it might soon become possible to break RSA-2048, using a NISQ (i.e., non-fault-tolerant) quantum computer. They do so via two time-tested strategems:
the detailed exploration of irrelevancies (mostly, optimization of the number of qubits, while ignoring the number of gates), and
complete silence about the one crucial point.
Then, finally, they come clean about the one crucial point in a single sentence of the Conclusion section:
It should be pointed out that the quantum speedup of the algorithm is unclear due to the ambiguous convergence of QAOA.
“Unclear” is an understatement here. It seems to me that a miracle would be required for the approach here to yield any benefit at all, compared to just running the classical Schnorr’s algorithm on your laptop. And if the latter were able to break RSA, it would’ve already done so.
All told, this is one of the most actively misleading quantum computing papers I’ve seen in 25 years, and I’ve seen … many.
EDITED TO ADD (1/7): More commentary. Again: no need to panic.
AWS Certificate Manager (ACM) is a managed service that enables you to provision, manage, and deploy public and private SSL/TLS certificates that you can use to securely encrypt network traffic. You can now use ACM to request Elliptic Curve Digital Signature Algorithm (ECDSA) certificates and associate the certificates with AWS services like Application Load Balancer (ALB) or Amazon CloudFront. As a result, you get the benefit of managed renewal, where ACM can automatically renew ECDSA certificates before they expire. Previously, you could only request certificates with an RSA 2048 key algorithm from ACM. ECDSA certificates could be imported to ACM, but imported certificates cannot use managed renewal.
You can request both ECDSA P-256 and P-384 certificates from ACM. If you do not request an ECDSA certificate, ACM will issue an RSA 2048 certificate by default.
In this blog post, we will briefly examine the differences between RSA and ECDSA certificates, discuss some important considerations when evaluating which certificate type to use, and walk through how you can request an ECDSA certificate and associate it with an application load balancer in AWS.
Cryptographic certificates overview
TLS certificates are used to secure network communications and establish the identity of websites over the internet, as well as the identity of resources on private networks. Public certificates that you request through ACM are obtained from Amazon Trust Services, which is an Amazon managed public certificate authority (CA).
Both public and private certificates can help customers identify resources on networks and secure communication between these resources. Public certificates identify resources on the public internet, whereas private certificates do the same for private networks. One key difference is that applications and browsers trust public certificates by default, but an administrator must explicitly configure applications and devices to trust private certificates.
RSA and ECDSA primer
RSA and ECDSA are two widely used public-key cryptographic algorithms—algorithms that use two different keys to encrypt and decrypt data. In the case of TLS, a public key is used to encrypt data, and a private key is used to decrypt data. Public key (or asymmetric key) algorithms are not as computationally efficient as symmetric key algorithms like AES. For this reason, public key algorithms like RSA and ECDSA are primarily used to exchange secrets between two parties initiating a TLS connection. These secrets are then used by both parties to decipher the same symmetric key that actually encrypts the data in transit.
RSA stands for Rivest, Shamir, and Adleman: the researchers who first publicly described this algorithm in 1977. The basic functionality of RSA relies on the idea that large prime numbers are very difficult to efficiently factor. ECDSA, or Elliptic Curve Digital Signature Algorithm, is based on certain unique mathematical properties of elliptic curves that make them very useful for cryptographic operations. The cryptographic utility of ECDSA comes from a concept called the discrete logarithm problem.
Considerations when choosing between RSA and ECDSA
What are the important differences between RSA and ECDSA certificates? When should you choose ECDSA certificates to encrypt network traffic? In this section, we’ll examine the security and performance considerations that help to determine whether ECDSA or RSA certificates are the best choice for your workload.
Security
In cryptography, security is measured as the computational work it takes to exhaust all possible values of a symmetric key in an ideal cipher. An ideal cipher is a theoretical algorithm that has no weaknesses, so you must try every possible key to discover which is the correct key. This is similar to the idea of “brute forcing” a password: trying every possible character combination to find the correct password.
Let’s imagine you have a 112-bit key ideal cipher, which means it would take 2112 tries to exhaust the key space—we would say this cipher has a 112-bit security strength. However, it is important to realize that security strength and key length are not always equal—meaning that an encryption key with a length of 112 bits will not always have a 112-bit security strength.
ECDSA provides higher security strength for lower computational cost. ECDSA P-256, for example, provides 128-bit security strength and is equivalent to an RSA 3072 key. Meanwhile, ECDSA P-384 provides 192-bit security strength, equivalent to the key associated with an RSA 7680 certificate. In other words, an ECDSA P-384 key would require 2192 tries to exhaust the key space.
The following table provides an in-depth comparison of the different security strengths for RSA key lengths and ECDSA curve types. Note that only RSA 2048 and ECDSA P-256 and P-384 are currently issued by ACM. However, ACM does support the import and usage of the other certificate types listed in the table. For more information, see Importing certificates into AWS Certificate Manager.
Security strength
RSA key length
ECDSA curve type
80-bit
1024
160
112-bit
2048
224
128-bit
3072
256
192-bit
7680
384
256-bit
15360
512
Performance
ECDSA provides a higher security strength (for a given key length) than RSA but does not add performance overhead. For example, ECDSA P-256 is as performant as RSA 2048 while providing security strength that is comparable to RSA 3072.
ECDSA certificates also have up to a 50% smaller certificate size when compared to RSA certificates, and are therefore more suitable to protect data-in-transit over low bandwidth or for applications with limited memory and storage, such as Internet of Things (IoT) devices.
Take a look at the following certificate examples; you can see the size difference between RSA and ECDSA certificates.
Consider a small IoT sensor device that tracks temperature in an office building. This device typically has very low storage capacity and compute power, so the smaller ECDSA certificate will be easier to process and store. In the case of an IoT device, you might not be able to store the entire RSA certificate chain on the device due to memory limitations and the larger size of RSA certificates. This can make it more difficult to validate the chain of trust for that certificate.
Using ECDSA, customers can take advantage of the smaller size of the certificates (and the certificate trust chain) and store the entire chain of trust on the IoT device itself, enabling the IoT device to more easily validate the certificate.
When should I use ECDSA certificates from ACM?
In general, you should consider using ECDSA certificates wherever possible, because they provide stronger security (for a given key length) compared to RSA, without impacting performance. You can also choose to issue ECDSA certificates from ACM to implement 128-bit or 192-bit TLS security, where previously you could request up to 112-bit security from ACM by using RSA 2048 certificates.
ECDSA certificates are strongly recommended for applications that need to securely send data over low-bandwidth connections, or when you are using IoT devices that might not have much memory or computational power to store and process the larger certificate sizes that RSA offers.
If your application is not ECDSA compatible, you will need to continue using RSA certificates. RSA 2048 remains the default certificate type issued by ACM, in order to prevent compatibility issues with legacy applications or with applications that do not support ECDSA certificate types. We will provide links to check if your application is compatible with ECDSA certificate types in the next section of this blog.
Getting started with ECDSA certificates
Modern browsers and operating systems are ECDSA compatible. That said, some custom applications might not be ECDSA compatible. You can check whether your calling application is ECDSA compatible by accessing the following links from your application:
When you access one of these links, you should see a message stating “Expected Status: good”. This indicates that the application is ECDSA compatible. See Figure 1 for an example of a successful result.
Figure 1: ECDSA application compatibility example
When you terminate your TLS traffic with ALB, you can work around compatibility concerns by binding both ECDSA and RSA certificates for a given domain. ALB will prioritize and present the ECDSA certificate when the calling application is ECDSA compatible and will use the RSA certificate if the calling application is not ECDSA compatible. We’ll walk through this configuration in the demonstration portion of this post.
How to request an ECDSA certificate from ACM
You can use the ACM console, APIs, or AWS Command Line Interface (AWS CLI) to issue public or private ECDSA P-256 and P-384 TLS certificates. When you request certificates by using the API or AWS CLI, you can use the request-certificate API action with either EC_prime256v1 or EC_secp384r1 as the key-algorithm parameter to request a P-256 or P-384 ECDSA certificate, respectively.
Certificates have a defined validity period, and ACM will attempt to renew certificates that were issued by ACM and that are in use before they expire. ACM will also attempt to automatically bind the renewed certificates with an integrated service. ACM issued private ECDSA certificates can also be exported and used on other workloads to terminate TLS traffic.
Associate an ECDSA certificate with an Application Load Balancer for TLS
To demonstrate how to request and use ECDSA certificates from ACM, let’s examine a common use case: requesting a public certificate from ACM and associating it with an ALB. This walkthrough will also include requesting an RSA 2048 certificate and associating it with the same ALB, to facilitate TLS connections for applications that do not support ECDSA. ALB will prioritize and present the ECDSA certificate when the calling application is ECDSA compatible, and will use the RSA certificate if the calling application is not ECDSA compatible.
Navigate to the ACM console and choose Request a certificate.
Choose Request a public certificate, and then choose Next.
For Fully qualified domain name, enter your domain name.
Choose DNS validation. DNS validation is recommended wherever possible, because it enables automatic renewal of ACM issued certificates with no action required by the domain owner. If you use Amazon Route 53, you can use ACM to directly update your DNS records. DNS-validated certificates will be renewed by ACM as long as the certificate is in use and the DNS record is in place.
Figure 2: Requesting a public ECDSA certificate
In the Key algorithm options section, select your preferred algorithm based on your security requirements:
ECDSA P-256 — Equivalent in security strength to RSA 3072
ECDSA P-384 — Equivalent in security strength to RSA 7680
Figure 3: Key algorithms
(Optional) Add tags to help you identify and manage your certificate. You can find more information on using tags in Tagging AWS resources in the AWS General Reference.
Choose Request to request the public certificate.
The certificate will now be in the Pending Validation state until the domain can be validated, either through DNS or email validation, depending on your selection in the previous steps. For information on how to validate ownership of the domain name or names, see Validating domain ownership in the AWS Certificate Manager User Guide.
Take note of the certificate ARN; you will need this later to identify the certificate.
To request an RSA 2048 certificate from ACM
To request a public RSA 2048 certificate, use the same steps noted in the preceding section, but select RSA 2048 in the Key algorithm options section.
Make sure that both certificates you request have the same fully qualified domain name.
For this post, we will use an Application Load Balancer. You can view more details on each type of Load Balancer, and see a feature-to-feature breakdown, on the Elastic Load Balancing features page.
For the Application Load Balancer type, choose Create.
Enter a name for your load balancer.
Select the scheme and IP address type of the application load balancer. For this post, we will choose Internet-facing for the scheme and use the IPv4 address type.
Under Default SSL/TLS certificate, verify thatFrom ACM is selected, and then in the drop-down list, select the RSA certificate you requested earlier.
Note: We are using the RSA certificate as the default so that the ALB will use this certificate if the connecting client does not support ECDSA or the Server Name Indication (SNI) protocol. This is to maximize availability and compatibility with legacy applications.
Figure 6: Secure listener settings
(Optional) Add tags to the Application Load Balancer.
Review your selections, and then choose Create load balancer.
Figure 7: Review and create load balancer
To associate the ECDSA certificate with the Application Load Balancer
In the EC2 console, select the new ALB you just created, and choose the Listeners tab.
In the SSL Certificate column, you should see the default certificate you added when you created the ALB. Choose View/edit certificates to see the full list of certificates associated with this ALB.
Figure 8: ALB listeners
Under Listener certificates for SNI, choose Add certificate.
Figure 9: Listener certificates for SNI
Under ACM and IAM certificates, select the ECDSA certificate you requested earlier.
Note: You can use the certificate ARN to identify the appropriate certificate.
Choose Include as pending below to add the ECDSA certificate to the listener.
Figure 10: Adding the ECDSA certificate to the load balancer listener
Under Listener certificates for SNI, confirm that the ECDSA certificate is listed as pending, and choose Add pending certificates.
Figure 11: Confirm addition of pending certificates
Great! We’ve used ACM to request a public ECDSA certificate and a public RSA 2048 certificate. Next, we associated both of these certificates with an Application Load Balancer to facilitate TLS communications between the load balancer and client devices.
If clients support the SNI protocol, the ALB uses a smart certificate selection algorithm. The load balancer will select the best certificate that the client can support from the certificate list. Certificate selection is based on the following criteria, in the following order:
Public key algorithm (prefer ECDSA over RSA)
Hashing algorithm (prefer SHA over MD5)
Key length (prefer the longest key)
Validity period
In the earlier example, this means if clients support SNI and ECDSA, the ECDSA certificate will be prioritized and presented to the client. If the client does not support SNI or ECDSA, the RSA certificate will be used to maximize compatibility with legacy applications.
Conclusion
In this blog post, we discussed the basic differences between RSA and ECDSA certificates, when you might choose ECDSA over RSA, and how you can use AWS Certificate Manager to request public or private ECDSA certificates. We also covered how to request a public ECDSA certificate from ACM and associate it with an Application Load Balancer. Finally, we showed you how to request an RSA 2048 certificate and associate it with the same load balancer to facilitate TLS for applications that do not support ECDSA certificates.
There is an expiration date on the cryptography we use every day. It’s not easy to read, but somewhere between 15 or 40 years, a sufficiently powerful quantum computer is expected to be built that will be able to decrypt essentially any encrypted data on the Internet today.
Luckily, there is a solution: post-quantum (PQ) cryptography has been designed to be secure against the threat of quantum computers. Just three months ago, in July 2022, after a six-year worldwide competition, the US National Institute of Standards and Technology (NIST), known for AES and SHA2, announced which post-quantum cryptography they will standardize. NIST plans to publish the final standards in 2024, but we want to help drive early adoption of post-quantum cryptography.
Starting today, as a beta service, all websites and APIs served through Cloudflare support post-quantum hybrid key agreement. This is on by default1; no need for an opt-in. This means that if your browser/app supports it, the connection to our network is also secure against any future quantum computer.
We offer this post-quantum cryptography free of charge: we believe that post-quantum security should be the new baseline for the Internet.
Deploying post-quantum cryptography seems like a no-brainer with quantum computers on the horizon, but it’s not without risks. To start, this is new cryptography: even with years of scrutiny, it is not inconceivable that a catastrophic attack might still be discovered. That is why we are deploying hybrids: a combination of a tried and tested key agreement together with a new one that adds post-quantum security.
We are primarily worried about what might seem mere practicalities. Even though the protocols used to secure the Internet are designed to allow smooth transitions like this, in reality there is a lot of buggy code out there: trying to create a post-quantum secure connection might fail for many reasons — for example a middlebox being confused about the larger post-quantum keys and other reasons we have yet to observe because these post-quantum key agreements are brand new. It’s because of these issues that we feel it is important to deploy post-quantum cryptography early, so that together with browsers and other clients we can find and work around these issues.
In this blog post we will explain how TLS, the protocol used to secure the Internet, is designed to allow a smooth and secure migration of the cryptography it uses. Then we will discuss the technical details of the post-quantum cryptography we have deployed, and how, in practice, this migration might not be that smooth at all. We finish this blog post by explaining how you can build a better, post-quantum secure, Internet by helping us test this new generation of cryptography.
TLS: Transport Layer Security
When you’re browsing a website using a secure connection, whether that’s using HTTP/1.1 or QUIC, you are using the Transport Layer Security (TLS) protocol under the hood. There are two major versions of TLS in common use today: the new TLS 1.3 (~90%) and the older TLS 1.2 (~10%), which is on the decline.
TLS 1.3 is a huge improvement over TLS 1.2: it’s faster, more secure, simpler and more flexible in just the right places. This makes it easier to add post-quantum security to TLS 1.3 compared to 1.2. For the moment, we will leave it at that: we’ve only added post-quantum support to TLS 1.3.
So, what is TLS all about? The goal is to set up a connection between a browser and website such that
Confidentiality and integrity, no one can read along or tamper with the data undetected.
Authenticity you know you’re connected to the right website; not an imposter.
Building blocks: AEAD, key agreement and signatures
Three different types of cryptography are used in TLS to reach this goal.
Symmetric encryption, or more precisely Authenticated Encryption With Associated Data (AEAD), is the workhorse of cryptography: it’s used to ensure confidentiality and integrity. This is a straight-forward kind of encryption: there is a single key that is used to encrypt and decrypt the data. Without the right key you cannot decrypt the data and any tampering with the encrypted data results in an error while decrypting.
In TLS 1.3, ChaCha20-Poly1305 and AES128-GCM are in common use today. What about quantum attacks? At first glance, it looks like we need to switch to 256-bit symmetric keys to defend against Grover’s algorithm. In practice, however, Grover’s algorithm doesn’t parallelize well, so the currently deployed AEADs will serve just fine.
So if we can agree on a shared key to use with symmetric encryption, we’re golden. But how to get to a shared key? You can’t just pick a key and send it to the server: anyone listening in would know the key as well. One might think it’s an impossible task, but this is where the magic of asymmetric cryptography helps out:
A key agreement, also called key exchange or key distribution, is a cryptographic protocol with which two parties can agree on a shared key without an eavesdropper being able to learn anything. Today the X25519 Elliptic Curve Diffie–Hellman protocol (ECDH) is the de facto standard key agreement used in TLS 1.3. The security of X25519 is based on the discrete logarithm problem for elliptic curves, which is vulnerable to quantum attacks, as it is easily solved by a cryptographically relevant quantum computer using Shor’s algorithm. The solution is to use a post-quantum key agreement, such as Kyber.
A key agreement only protects against a passive attacker. An active attacker, that can intercept and modify messages (MitM), can establish separate shared keys with both the server and the browser, re-encrypting all data passing through. To solve this problem, we need the final piece of cryptography.
With a digitalsignature algorithm, such as RSA or ECDSA, there are two keys: a public and a private key. Only with the private key, one can create a signature for a message. Anyone with the corresponding public key can check whether a signature is indeed valid for a given message. These digital signatures are at the heart of TLS certificates that are used to authenticate websites. Both RSA and ECDSA are vulnerable to quantum attacks. We haven’t replaced those with post-quantum signatures, yet. The reason is that authentication is less urgent: we only need to have them replaced by the time a sufficiently large quantum computer is built, whereas any data secured by a vulnerable key agreement today can be stored and decrypted in the future. Even though we have more time, deploying post-quantum authentication will be quite challenging.
So, how do these building blocks come together to create TLS?
High-level overview of TLS 1.3
A TLS connection starts with a handshake which is used to authenticate the server and derive a shared key. The browser (client) starts by sending a ClientHello message that contains a list of the AEADs, signature algorithms, and key agreement methods it supports. To remove a roundtrip, the client is allowed to make a guess of what the server supports and start the key agreement by sending one or more client keyshares. That guess might be correct (on the left in the diagram below) or the client has to retry (on the right).
Protocol flow for server-authenticated TLS 1.3 with a supported client keyshare on the left and a HelloRetryRequest on the right.
Key agreement
Before we explain the rest of this interaction, let’s dig into the key agreement: what is a keyshare? The way the key agreement for Kyber and X25519 work is different: the first is a Key Encapsulation Mechanism (KEM), while the latter is a Diffie–Hellman (DH) style agreement. The latter is more flexible, but for TLS it doesn’t make a difference.
The shape of a KEM and Diffie–Hellman key agreement in TLS-compatible handshake is the same.
In both cases the client sends a client keyshare to the server. From this client keyshare the server generates the shared key. The server then returns a server keyshare with which the client can also compute the shared key.
Going back to the TLS 1.3 flow: when the server receives the ClientHello message it picks an AEAD (cipher), signature algorithm and client keyshare that it supports. It replies with a ServerHello message that contains the chosen AEAD and the server keyshare for the selected key agreement. With the AEAD and shared key locked in, the server starts encrypting data (shown with blue boxes).
Authentication
Together with the AEAD and server keyshare, the server sends a signature, the handshake signature, on the transcript of the communication so far together with a certificate (chain) for the public key that it used to create the signature. This allows the client to authenticate the server: it checks whether it trusts the certificate authority (e.g. Let’s Encrypt) that certified the public key and whether the signature verifies for the messages it sent and received so far. This not only authenticates the server, but it also protects against downgrade attacks.
Downgrade protection
We cannot upgrade all clients and servers to post-quantum cryptography at once. Instead, there will be a transition period where only some clients and some servers support post-quantum cryptography. The key agreement negotiation in TLS 1.3 allows this: during the transition servers and clients will still support non post-quantum key agreements, and can fall back to it if necessary.
This flexibility is great, but also scary: if both client and server support post-quantum key agreement, we want to be sure that they also negotiate the post-quantum key agreement. This is the case in TLS 1.3, but it is not obvious: the keyshares, the chosen keyshare and the list of supported key agreements are all sent in plain text. Isn’t it possible for an attacker in the middle to remove the post-quantum key agreements? This is called a downgrade attack.
This is where the transcript comes in: the handshake signature is taken over all messages received and sent by the server so far. This includes the supported key agreements and the key agreement that was picked. If an attacker changes the list of supported key agreements that the client sends, then the server will not notice. However, the client checks the server’s handshake signature against the list of supported key agreements it has actually sent and thus will detect the mischief.
The downgrade attack problems are muchmorecomplicated for TLS 1.2, which is one of the reasons we’re hesitant to retrofit post-quantum security in TLS 1.2.
Wrapping up the handshake
The last part of the server’s response is “server finished”, a message authentication code (MAC) on the whole transcript so far. Most of the work has been done by the handshake signature, but in other operating modes of TLS without handshake signature, such as session resumption, it’s important.
With the chosen AEAD and server keyshare, the client can compute the shared key and decrypt and verify the certificate chain, handshake signature and handshake MAC. We did not mention it before, but the shared key is not used directly for encryption. Instead, for good measure, it’s mixed together with communication transcripts, to derive several specific keys for use during the handshake and the main connection afterwards.
To wrap up the handshake, the client sends its own handshake MAC, and can then proceed to send application-specific data encrypted with the keys derived during the handshake.
Hello! Retry Request?
What we just sketched is the desirable flow where the client sends a keyshare that is supported by the server. That might not be the case. If the server doesn’t accept any key agreements advertised by the client, then it will tell the client and abort the connection.
If there is a key agreement that both support, but for which the client did not send a keyshare, then the server will respond with a HelloRetryRequest (HRR) message requesting a keyshare of a specific key agreement that the client supports as shown on the diagram on the right. In turn, the client responds with a new ClientHello with the selected keyshare.
If there is a key agreement that both support, but for which the client did not send a keyshare, then the server will respond with a HelloRetryRequest (HRR) message requesting a keyshare of a specific key agreement that the client supports as shown on the diagram on the right. In turn, the client responds with a new ClientHello with the selected keyshare.
This is not the whole story: a server is also allowed to send a HelloRetryRequest to request a different key agreement that it prefers over those for which the client sent shares. For instance, a server can send a HelloRetryRequest to a post-quantum key agreement if the client supports it, but didn’t send a keyshare for it.
HelloRetryRequests are rare today. Almost every server supports the X25519 key-agreement and almost every client (98% today) sends a X25519 keyshare. Earlier P-256 was the de facto standard and for a long time many browsers would send both a P-256 and X25519 keyshare to prevent a HelloRetryRequest. As we will discuss later, we might not have the luxury to send two post-quantum keyshares.
That’s the theory
TLS 1.3 is designed to be flexible in the cryptography it uses without sacrificing security or performance, which is convenient for our migration to post-quantum cryptography. That is the theory, but there are some serious issues in practice — we’ll go into detail later on. But first, let’s check out the post-quantum key agreements we’ve deployed.
What we deployed
Today we have enabled support for the X25519Kyber512Draft00 and X25519Kyber768Draft00 key agreements using TLS identifiers 0xfe30 and 0xfe31 respectively. These are exactly the same key agreements we enabled on a limited number of zones this July.
These two key agreements are a combination, a hybrid, of the classical X25519 and the new post-quantum Kyber512 and Kyber768 respectively and in that order. That means that even if Kyber turns out to be insecure, the connection remains as secure as X25519.
Kyber, for now, is the only key agreement that NIST has selected for standardization. Kyber is very light on the CPU: it is faster than X25519 which is already known for its speed. On the other hand, its keyshares are much bigger:
Size keyshares(in bytes)
Ops/sec (higher is better)
Algorithm
PQ
Client
Server
Client
Server
Kyber512
✅
800
768
50,000
100,000
Kyber768
✅
1,184
1,088
31,000
70,000
X25519
❌
32
32
17,000
17,000
Size and CPU performance compared between X25519 and Kyber. Performance varies considerably by hardware platform and implementation constraints and should be taken as a rough indication only.
Kyber is expected to change in minor, but backwards incompatible ways, before final standardization by NIST in 2024. Also, the integration with TLS, including the choice and details of the hybrid key agreement, are not yet finalized by the TLS working group. Once they are, we will adopt them promptly.
Because of this, we will not support the preliminary key agreements announced today for the long term; they’re provided as a beta service. We will post updates on our deployment on pq.cloudflareresearch.com and announce it on the IETF PQC mailing list.
Now that we know how TLS negotiation works in theory, and which key agreements we’re adding, how could it fail?
Where things might break in practice
Protocol ossification
Protocols are often designed with flexibility in mind, but if that flexibility is not exercised in practice, it’s often lost. This is called protocol ossification. The roll-out of TLS 1.3 was difficult because of several instances of ossification. One poignant example is TLS’ version negotiation: there is a version field in the ClientHello message that indicates the latest version supported by the client. A new version was assigned to TLS 1.3, but in testing it turned out that many servers would not fallback properly to TLS 1.2, but crash the connection instead. How do we deal with ossification?
Workaround
Today, TLS 1.3 masquerades itself as TLS 1.2 down to including many legacy fields in the ClientHello. The actual version negotiation is moved into a new extension to the message. A TLS 1.2 server will ignore the new extension and ignorantly continue with TLS 1.2, while a TLS 1.3 server picks up on the extension and continues with TLS 1.3 proper.
Protocol grease
How do we prevent ossification? Having learnt from this experience, browsers will regularly advertise dummy versions in this new version field, so that misbehaving servers are caught early on. This is not only done for the new version field, but in many other places in the TLS handshake, and presciently also for the key agreement identifiers. Today, 40% of browsers send two client keyshares: one X25519 and another a bogus 1-byte keyshare to keep key agreement flexibility.
This behavior is standardized in RFC 8701: Generate Random Extensions And Sustain Extensibility (GREASE) and we call it protocol greasing, as in “greasing the joints” from Adam Langley’s metaphor of protocols having rusty joints in need of oil.
This keyshare grease helps, but it is not perfect, because it is the size of the keyshare that in this case causes the most concern.
Fragmented ClientHello
Post-quantum keyshares are big. The two Kyber hybrids are 832 and 1,216 bytes. Compared to that, X25519 is tiny with only 32 bytes. It is not unlikely that some implementations will fail when seeing such large keyshares.
Our biggest concern is with the larger Kyber768 based keyshare. A ClientHello with the smaller 832 byte Kyber512-based keyshare will just barely fit in a typical network packet. On the other hand, the larger 1,216 byte Kyber768-keyshare will typically fragment the ClientHello into two packets.
Assembling packets together isn’t free: it requires you to keep track of the partial messages around. Usually this is done transparently by the operating system’s TCP stack, but optimized middleboxes and load balancers that look at each packet separately, have to (and might not) keep track of the connections themselves.
QUIC The situation for HTTP/3, which is built on QUIC, is particularly interesting. Instead of a simple port number chosen by the client (as in TCP), a QUIC packet from the client contains a connection ID that is chosen by the server. Think of it as “your reference” and “our reference” in snailmail. This allows a QUIC load-balancer to encode the particular machine handling the connection into the connection ID.
When opening a connection, the QUIC client doesn’t know which connection ID the server would like and sends a random one instead. If the client needs multiple initial packets, such as with a big ClientHello, then the client will use the same random connection ID. Even though multiple initial packets are allowed by the QUIC standard, a QUIC load balancer might not expect this, and won’t be able to refer to an underlying TCP connection.
Performance
Aside from these hard failures, soft failures, such as performance degradation are also of concern: if it’s too slow to load, a website might as well have been broken to begin with.
Back in 2019 in a joint experiment with Google, we deployed two post-quantum key agreements: CECPQ2, based on NTRU-HRSS, and CECPQ2b, based on SIKE. NTRU-HRSS is very similar to Kyber: it’s a bit larger and slower. Results from 2019 are very promising: X25519+NTRU-HRSS (orange line) is hard to distinguish from X25519 on its own (blue line).
We will continue to keep a close eye on performance, especially on the tail performance: we want a smooth transition for everyone, from the fastest to the slowest clients on the Internet.
How to help out
The Internet is a very heterogeneous system. To find all issues, we need sufficient numbers of diverse testers. We are working with browsers to add support for these key agreements, but there may not be one of these browsers in every network.
So, to help the Internet out, try and switch a small part of your traffic to Cloudflare domains to use these new key agreement methods. We have open-sourced forks for BoringSSL, Go and quic-go. For BoringSSL and Go, check out the sample code here. If you have any issues, please let us know at [email protected]. We will be discussing any issues and workarounds at the IETF TLS working group.
Outlook
The transition to a post-quantum secure Internet is urgent, but not without challenges. Today we have deployed a preliminary post-quantum key agreement on all our servers — a sizable portion of the Internet — so that we can all start testing the big migration today. We hope that come 2024, when NIST puts a bow on Kyber, we will all have laid the groundwork for a smooth transition to a Post-Quantum Internet.
….. 1We only support these post-quantum key agreements in protocols based on TLS 1.3 including HTTP/3. There is one exception: for the moment we disable these hybrid key exchanges for websites in FIPS-mode.
Undoubtedly, one of the big themes in IT for the next decade will be the migration to post-quantum cryptography. From tech giants to small businesses: we will all have to make sure our hardware and software is updated so that our data is protected against the arrival of quantum computers. It seems far away, but it’s not a problem for later: any encrypted data captured today (not protected by post-quantum cryptography) can be broken by a sufficiently powerful quantum computer in the future.
Luckily we’re almost there: after a tremendous worldwide effort by the cryptographic community, we know what will be the gold standard of post-quantum cryptography for the next decades. Release date: somewhere in 2024. Hopefully, for most, the transition will be a simple software update then, but it will not be that simple for everyone: not all software is maintained, and it could well be that hardware needs an upgrade as well. Taking a step back, many companies don’t even have a full list of all software running on their network.
For Cloudflare Tunnel customers, this migration will be much simpler: introducing Post-QuantumCloudflare Tunnel. In this blog post, first we give an overview of how Cloudflare Tunnel works and explain how it can help you with your post-quantum migration. Then we’ll explain how to get started and finish with the nitty-gritty technical details.
Cloudflare Tunnel
With Cloudflare Tunnel you can securely expose a server sitting within an internal network to the Internet by running the cloudflared service next to it. For instance, after having installed cloudflared on your internal network, you can expose your on-prem webapp on the Internet under, say example.com, so that remote workers can access it from anywhere,
Life of a Cloudflare Tunnel request.
How does it work? cloudflared creates long-running connections to two nearby Cloudflare data centers, for instance San Francisco (connection 3) and one other. When your employee visits your domain, they connect (1) to a Cloudflare server close to them, say in Frankfurt. That server knows that this is a Cloudflare Tunnel and that your cloudflared has a connection to a server in San Francisco, and thus it relays (2) the request to it. In turn, via the reverse connection, the request ends up at cloudflared, which passes it (4) to the webapp via your internal network.
In essence, Cloudflare Tunnel is a simple but convenient tool, but the magic is in what you can do on top with it: you get Cloudflare’s DDoS protection for free; fine-grained access control with Cloudflare Access (even if the application didn’t support it) and request logs just to name a few. And let’s not forget the matter at hand:
Post-quantum tunnels
Our goal is to make it easy for everyone to have a fully post-quantum secure connection from users to origin. For this, Post-Quantum Cloudflare Tunnel is a powerful tool, because with it, your users can benefit from a post-quantum secure connection without upgrading your application (connection 4 in the diagram).
Today, we make two important steps towards this goal: cloudflared2022.9.1 adds the --post-quantum flag, that when given, makes the connection from cloudflared to our network (connection 3) post-quantum secure.
Also today, we have announced support for post-quantum browser connections (connection 1).
We aren’t there yet: browsers (and other HTTP clients) do not support the post-quantum security offered by our network, yet, and we still have to make the connections between our data centers (connection 2) post-quantum secure.
An attacker only needs to have access to one vulnerable connection, but attackers don’t have access everywhere: with every connection we make post-quantum secure, we remove one opportunity for compromise.
We are eager to make post-quantum tunnels the default, but for now it is a beta feature. The reason is that the cryptography used and its integration into the network protocol are not yet final. Making post-quantum the default now, would require users to update cloudflared more often than we can reasonably expect them to.
Getting started
Are frequent updates to cloudflared not a problem for you? Then please do give post-quantum Cloudflare Tunnel a try. Make sure you’re on at least 2022.9.1 and simply run cloudflared with the --post-quantum flag:
$ cloudflared tunnel run --post-quantum tunnel-name
2022-09-23T11:44:42Z INF Starting tunnel tunnelID=[...]
2022-09-23T11:44:42Z INF Version 2022.9.1
2022-09-23T11:44:42Z INF GOOS: darwin, GOVersion: go1.19.1, GoArch: amd64
2022-09-23T11:44:42Z INF Settings: map[post-quantum:true pq:true]
2022-09-23T11:44:42Z INF Generated Connector ID: [...]
2022-09-23T11:44:42Z INF cloudflared will not automatically update if installed by a package manager.
2022-09-23T11:44:42Z INF Initial protocol quic
2022-09-23T11:44:42Z INF Using experimental hybrid post-quantum key agreement X25519Kyber768Draft00
2022-09-23T11:44:42Z INF Starting metrics server on 127.0.0.1:53533/metrics
2022-09-23T11:44:42Z INF Connection [...] registered connIndex=0 ip=[...] location=AMS
2022-09-23T11:44:43Z INF Connection [...] registered connIndex=1 ip=[...] location=AMS
2022-09-23T11:44:44Z INF Connection [...] registered connIndex=2 ip=[...] location=AMS
2022-09-23T11:44:45Z INF Connection [...] registered connIndex=3 ip=[...] location=AMS
If you run cloudflaredas a service, you can turn on post-quantum by adding post-quantum: true to the tunnel configuration file. Conveniently, the cloudflared service will automatically update itself if not installed by a package manager.
If, for some reason, creating a post-quantum tunnel fails, you’ll see an error message like
2022-09-22T17:30:39Z INF Starting tunnel tunnelID=[...]
2022-09-22T17:30:39Z INF Version 2022.9.1
2022-09-22T17:30:39Z INF GOOS: darwin, GOVersion: go1.19.1, GoArch: amd64
2022-09-22T17:30:39Z INF Settings: map[post-quantum:true pq:true]
2022-09-22T17:30:39Z INF Generated Connector ID: [...]
2022-09-22T17:30:39Z INF cloudflared will not automatically update if installed by a package manager.
2022-09-22T17:30:39Z INF Initial protocol quic
2022-09-22T17:30:39Z INF Using experimental hybrid post-quantum key agreement X25519Kyber512Draft00
2022-09-22T17:30:39Z INF Starting metrics server on 127.0.0.1:55889/metrics
2022-09-22T17:30:39Z INF
===================================================================================
You are hitting an error while using the experimental post-quantum tunnels feature.
Please check:
https://pqtunnels.cloudflareresearch.com
for known problems.
===================================================================================
2022-09-22T17:30:39Z ERR Failed to create new quic connection error="failed to dial to edge with quic: CRYPTO_ERROR (0x128): tls: handshake failure" connIndex=0 ip=[...]
When the post-quantum flag is given, cloudflared will not fall back to a non post-quantum connection.
What to look for
The setup phase is the crucial part: once established, the tunnel is the same as a normal tunnel. That means that performance and reliability should be identical once the tunnel is established.
The post-quantum cryptography we use is very fast, but requires roughly a kilobyte of extra data to be exchanged during the handshake. The difference will be hard to notice in practice.
Our biggest concern is that some network equipment/middleboxes might be confused by the bigger handshake. If the post-quantum Cloudflare Tunnel isn’t working for you, we’d love to hear about it. Contact us at [email protected] and tell us which middleboxes or ISP you’re using.
Under the hood
When the --post-quantum flag is given, cloudflared restricts itself to the QUIC transport for the tunnel connection to our network and will only allow the post-quantum hybrid key exchanges X25519Kyber512Draft00 and X25519Kyber768Draft00 with TLS identifiers 0xfe30 and 0xfe31 respectively. These are hybrid key exchanges between the classical X25519 and the post-quantum secure Kyber. Thus, on the off-chance that Kyber turns out to be insecure, we can still rely on the non-post quantum security of X25519. These are the same key exchanges supported on our network.
cloudflared randomly picks one of these two key exchanges. The reason is that the latter usually requires two initial packets for the TLS ClientHello whereas the former only requires one. That allows us to test whether a fragmented ClientHello causes trouble.
When cloudflared fails to set up the post-quantum connection, it will report the attempted key exchange, cloudflared version and error to pqtunnels.cloudflareresearch.com so that we have visibility into network issues. Have a look at that page for updates on our post-quantum tunnel deployment.
The control connection and authentication of the tunnel between cloudflared and our network are not post-quantum secure yet. This is less urgent than the store-now-decrypt-later issue of the data on the tunnel itself.
We have open-sourced support for these post-quantum QUIC key exchanges in Go.
Outlook
In the coming decade the industry will roll out post-quantum data protection. Some cases will be as simple as a software update and others will be much more difficult. Post-Quantum Cloudflare Tunnel will secure the connection between Cloudflare’s network and your origin in a simple and user-friendly way — an important step towards the Post-Quantum Internet, so that everyone may continue to enjoy a private and secure Internet.
My personal definition of a brilliant idea is one that is immediately obvious once it’s explained, but no one has thought of it before. I can’t believe that no one has described this taxonomy of access control before Ittay Eyal laid it out in this paper. The paper is about cryptocurrency wallet design, but the ideas are more general. Ittay points out that a key—or an account, or anything similar—can be in one of four states:
safe Only the user has access, loss No one has access, leak Both the user and the adversary have access, or theft Only the adversary has access.
Once you know these states, you can assign probabilities of transitioning from one state to another (someone hacks your account and locks you out, you forgot your own password, etc.) and then build optimal security and reliability to deal with it. It’s a truly elegant way of conceptualizing the problem.
Quantum computing is a completely new paradigm for computers. A quantum computer uses quantum properties such as superposition, which allows a qubit (a quantum bit) to be neither 0 nor 1, but something much more complicated. In theory, such a computer can solve problems too complex for conventional computers.
Current quantum computers are still toy prototypes, and the engineering advances required to build a functionally useful quantum computer are somewhere between a few years away and impossible. Even so, we already know that that such a computer could potentially factor large numbers and compute discrete logs, and break the RSA and Diffie-Hellman public-key algorithms in all of the useful key sizes.
Cryptographers hate being rushed into things, which is why NIST began a competition to create a post-quantum cryptographic standard in 2016. The idea is to standardize on both a public-key encryption and digital signature algorithm that is resistant to quantum computing, well before anyone builds a useful quantum computer.
NIST is an old hand at this competitive process, having previously done this with symmetric algorithms (AES in 2001) and hash functions (SHA-3 in 2015). I participated in both of those competitions, and have likened them to demolition derbies. The idea is that participants put their algorithms into the ring, and then we all spend a few years beating on each other’s submissions. Then, with input from the cryptographic community, NIST crowns a winner. It’s a good process, mostly because NIST is both trusted and trustworthy.
In 2017, NIST received eighty-two post-quantum algorithm submissions from all over the world. Sixty-nine were considered complete enough to be Round 1 candidates. Twenty-six advanced to Round 2 in 2019, and seven (plus another eight alternates) were announced as Round 3 finalists in 2020. NIST was poised to make final algorithm selections in 2022, with a plan to have a draft standard available for public comment in 2023.
Cryptanalysis over the competition was brutal. Twenty-five of the Round 1 algorithms were attacked badly enough to remove them from the competition. Another eight were similarly attacked in Round 2. But here’s the real surprise: there were newly published cryptanalysis results against at least four of the Round 3 finalists just months ago—moments before NIST was to make its final decision.
One of the most popular algorithms, Rainbow, was found to be completely broken. Not that it could theoretically be broken with a quantum computer, but that it can be broken today—with an off-the-shelf laptop in just over two days. Three other finalists, Kyber, Saber, and Dilithium, were weakened with new techniques that will probably work against some of the other algorithms as well. (Fun fact: Those three algorithms were broken by the Center of Encryption and Information Security, part of the Israeli Defense Force. This represents the first time a national intelligence organization has published a cryptanalysis result in the open literature. And they had a lot of trouble publishing, as the authors wanted to remain anonymous.)
That was a close call, but it demonstrated that the process is working properly. Remember, this is a demolition derby. The goal is to surface these cryptanalytic results before standardization, which is exactly what happened. At this writing, NIST has chosen a single algorithm for general encryption and three digital-signature algorithms. It has not chosen a public-key encryption algorithm, and there are still four finalists. Check NIST’s webpage on the project for the latest information.
Ian Cassels, British mathematician and World War II cryptanalyst, once said that “cryptography is a mixture of mathematics and muddle, and without the muddle the mathematics can be used against you.” This mixture is particularly difficult to achieve with public-key algorithms, which rely on the mathematics for their security in a way that symmetric algorithms do not. We got lucky with RSA and related algorithms: their mathematics hinge on the problem of factoring, which turned out to be robustly difficult. Post-quantum algorithms rely on other mathematical disciplines and problems—code-based cryptography, hash-based cryptography, lattice-based cryptography, multivariate cryptography, and so on—whose mathematics are both more complicated and less well-understood. We’re seeing these breaks because those core mathematical problems aren’t nearly as well-studied as factoring is.
The moral is the need for cryptographic agility. It’s not enough to implement a single standard; it’s vital that our systems be able to easily swap in new algorithms when required. We’ve learned the hard way how algorithms can get so entrenched in systems that it can take many years to update them: in the transition from DES to AES, and the transition from MD4 and MD5 to SHA, SHA-1, and then SHA-3.
We need to do better. In the coming years we’ll be facing a double uncertainty. The first is quantum computing. When and if quantum computing becomes a practical reality, we will learn a lot about its strengths and limitations. It took a couple of decades to fully understand von Neumann computer architecture; expect the same learning curve with quantum computing. Our current understanding of quantum computing architecture will change, and that could easily result in new cryptanalytic techniques.
The second uncertainly is in the algorithms themselves. As the new cryptanalytic results demonstrate, we’re still learning a lot about how to turn hard mathematical problems into public-key cryptosystems. We have too much math and an inability to add more muddle, and that results in algorithms that are vulnerable to advances in mathematics. More cryptanalytic results are coming, and more algorithms are going to be broken.
We can’t stop the development of quantum computing. Maybe the engineering challenges will turn out to be impossible, but it’s not the way to bet. In the face of all that uncertainty, agility is the only way to maintain security.
This essay originally appeared in IEEE Security & Privacy.
EDITED TO ADD: One of the four public-key encryption algorithms selected for further research, SIKE, was just broken.
Practically all data sent over the Internet today is at risk in the future if a sufficiently large and stable quantum computer is created. Anyone who captures data now could decrypt it.
Luckily, there is a solution: we can switch to so-called post-quantum (PQ) cryptography, which is designed to be secure against attacks of quantum computers. After a six-year worldwide selection process, in July 2022, NIST announced they will standardize Kyber, a post-quantum key agreement scheme. The standard will be ready in 2024, but we want to help drive the adoption of post-quantum cryptography.
Today we have added support for the X25519Kyber512Draft00 and X25519Kyber768Draft00 hybrid post-quantum key agreements to a number of test domains, including pq.cloudflareresearch.com.
Do you want to experiment with post-quantum on your test website for free? Mail [email protected] to enroll your test website, but read the fine-print below.
What does it mean to enable post-quantum on your website?
If you enroll your website to the post-quantum beta, we will add support for these two extra key agreements alongside the existing classical encryption schemes such as X25519. If your browser doesn’t support these post-quantum key agreements (and none at the time of writing do), then your browser will continue working with a classically secure, but not quantum-resistant, connection.
Then how to test it?
We have open-sourced a fork of BoringSSL and Go that has support for these post-quantum key agreements. With those and an enrolled test domain, you can check how your application performs with post-quantum key exchanges. We are working on support for more libraries and languages.
What to look for?
Kyber and classical key agreements such as X25519 have different performance characteristics: Kyber requires less computation, but has bigger keys and requires a bit more RAM to compute. It could very well make the connection faster if used on its own.
We are not using Kyber on its own though, but are using hybrids. That means we are doing both an X25519 and Kyber key agreement such that the connection is still classically secure if either is broken. That also means that connections will be a bit slower. In our experiments, the difference is verysmall, but it’s best to check for yourself.
The fine-print
Cloudflare’s post-quantum cryptography support is a beta service for experimental use only. Enabling post-quantum on your website will subject the website to Cloudflare’s Beta Services terms and will impact other Cloudflare services on the website as described below.
No stability or support guarantees
Over the coming months, both Kyber and the way it’s integrated into TLS will change for several reasons, including:
Kyber will see small, but backward-incompatible changes in the coming months.
We want to be compatible with other early adopters and will change our integration accordingly.
As, together with the cryptography community, we find issues, we will add workarounds in our integration.
We will update our forks accordingly, but cannot guarantee any long-term stability or continued support. PQ support may become unavailable at any moment. We will post updates on pq.cloudflareresearch.com.
Features in enrolled domains
For the moment, we are running enrolled zones on a slightly different infrastructure for which not all features, notably QUIC, are available.
With that out of the way, it’s…
Demo time!
BoringSSL
With the following commands build our fork of BoringSSL and create a TLS connection with pq.cloudflareresearch.com using the compiled bssl tool. Note that we do not enable the post-quantum key agreements by default, so you have to pass the -curves flag.
$ git clone https://github.com/cloudflare/boringssl-pq
[snip]
$ cd boringssl-pq && mkdir build && cd build && cmake .. -Gninja && ninja
[snip]
$ ./tool/bssl client -connect pq.cloudflareresearch.com -server-name pq.cloudflareresearch.com -curves Xyber512D00
Connecting to [2606:4700:7::a29f:8a55]:443
Connected.
Version: TLSv1.3
Resumed session: no
Cipher: TLS_AES_128_GCM_SHA256
ECDHE curve: X25519Kyber512Draft00
Signature algorithm: ecdsa_secp256r1_sha256
Secure renegotiation: yes
Extended master secret: yes
Next protocol negotiated:
ALPN protocol:
OCSP staple: no
SCT list: no
Early data: no
Encrypted ClientHello: no
Cert subject: CN = *.pq.cloudflareresearch.com
Cert issuer: C = US, O = Let's Encrypt, CN = E1
Go
Our Go fork doesn’t enable the post-quantum key agreement by default. The following simple Go program enables PQ by default for the http package and GETs pq.cloudflareresearch.com.
package main
import (
"crypto/tls"
"fmt"
"net/http"
)
func main() {
http.DefaultTransport.(*http.Transport).TLSClientConfig = &tls.Config{
CurvePreferences: []tls.CurveID{tls.X25519Kyber512Draft00, tls.X25519},
CFEventHandler: func(ev tls.CFEvent) {
switch e := ev.(type) {
case tls.CFEventTLS13HRR:
fmt.Printf("HelloRetryRequest\n")
case tls.CFEventTLS13NegotiatedKEX:
switch e.KEX {
case tls.X25519Kyber512Draft00:
fmt.Printf("Used X25519Kyber512Draft00\n")
default:
fmt.Printf("Used %d\n", e.KEX)
}
}
},
}
if _, err := http.Get("https://pq.cloudflareresearch.com"); err != nil {
fmt.Println(err)
}
}
$ git clone https://github.com/cloudflare/go
[snip]
$ cd go/src && ./all.bash
[snip]
$ ../bin/go run path/to/example.go
Used X25519Kyber512Draft00
On the wire
So what does this look like on the wire? With Wireshark we can capture the packet flow. First a non-post quantum HTTP/2 connection with X25519:
This is a normal TLS 1.3 handshake: the client sends a ClientHello with an X25519 keyshare, which fits in a single packet. In return, the server sends its own 32 byte X25519 keyshare. It also sends various other messages, such as the certificate chain, which requires two packets in total.
Let’s check out Kyber:
As you can see the ClientHello is a bit bigger, but still fits within a single packet. The response takes three packets now, instead of two, because of the larger server keyshare.
Under the hood
Want to add client support yourself? We are using a hybrid of X25519 and Kyber version 3.02. We are writing out the details of the latter in version 00 of this CRFG IETF draft, hence the name. We are using TLS group identifiers0xfe30 and 0xfe31 for X25519Kyber512Draft00 and X25519Kyber768Draft00 respectively.
There are some differences between our Go and BoringSSL forks that are interesting to compare.
Our Go fork only sends one keyshare. If the server doesn’t support it, it will respond with a HelloRetryRequest message and the client will fallback to one the server does support. This adds a roundtrip. Our BoringSSL fork, on the other hand, will send two keyshares: the post-quantum hybrid and a classical one (if a classical key agreement is still enabled). If the server doesn’t recognize the first, it will be able to use the second. In this way we avoid a roundtrip if the server does not support the post-quantum key agreement.
Looking ahead
The quantum future is here. In the coming years the Internet will move to post-quantum cryptography. Today we are offering our customers the tools to get a headstart and test post-quantum key agreements. We love to hear your feedback: e-mail it to [email protected].
This is just a small, but important first step. We will continue our efforts to move towards a secure and private quantum-secure Internet. Much more to come — watch this space.
We present an efficient key recovery attack on the Supersingular Isogeny Diffie-Hellman protocol (SIDH), based on a “glue-and-split” theorem due to Kani. Our attack exploits the existence of a small non-scalar endomorphism on the starting curve, and it also relies on the auxiliary torsion point information that Alice and Bob share during the protocol. Our Magma implementation breaks the instantiation SIKEp434, which aims at security level 1 of the Post-Quantum Cryptography standardization process currently ran by NIST, in about one hour on a single core.
On Tuesday, the US National Institute of Standards and Technology (NIST) announced which post-quantum cryptography they will standardize. We were already drafting this post with an educated guess on the choice NIST would make. We almost got it right, except for a single choice we didn’t expect—and which changes everything.
At Cloudflare, post-quantum cryptography is a topic close to our heart, as the future of a secure and private Internet is on the line. We have been working towards this day for many years, by implementing post-quantum cryptography, contributing tostandards, and testing post-quantum cryptographyinpractice, and we are excited to share our perspective.
In this long blog post, we explain how we got here, what NIST chose to standardize, what it will mean for the Internet, and what you need to know to get started with your own post-quantum preparations.
How we got here
Shor’s algorithm
Our story starts in 1994, when mathematician Peter Shor discovered a marvelous algorithm that efficiently factors numbers and computes discrete logarithms. With it, you can break nearly all public-key cryptography deployed today, including RSA and elliptic curve cryptography. Luckily, Shor’s algorithm doesn’t run on just any computer: it needs a quantum computer. Back in 1994, quantum computers existed only on paper.
But in the years since, physicists started building actual quantum computers. Initially, these machines were (and still are) too small and too error-prone to be threatening to the integrity of public-key cryptography, but there is a clear and impending danger: it only seems a matter of time now before a quantum computer is built that has the capability to break public-key cryptography. So what can we do?
Encryption, key agreement and signatures
To understand the risk, we need to distinguish between the three cryptographic primitives that are used to protect your connection when browsing on the Internet:
Symmetric encryption. With a symmetric cipher there is one key to encrypt and decrypt a message. They’re the workhorse of cryptography: they’re fast, well understood and luckily, as far as known, secure against quantum attacks. (We’ll touch on this later when we get to security levels.) Examples are AES and ChaCha20.
Symmetric encryption alone is not enough: which key do we use when visiting a website for the first time? We can’t just pick a random key and send it along in the clear, as then anyone surveilling that session would know that key as well. You’d think it’s impossible to communicate securely without ever having met, but there is some clever math to solve this.
Key agreement, also called a key exchange, allows two parties that never met to agree on a shared key. Even if someone is snooping, they are not able to figure out the agreed key. Examples include Diffie–Hellman over elliptic curves, such as X25519.
The key agreement prevents a passive observer from reading the contents of a session, but it doesn’t help defend against an attacker who sits in the middle and does two separate key agreements: one with you and one with the website you want to visit. To solve this, we need the final piece of cryptography:
Shor’s algorithm breaks all widely deployed key agreement and digital signature schemes, which are both critical to the security of the Internet. However, the urgency and mitigation challenges between them are quite different.
Impact
Most signatures on the Internet have a relatively short lifespan. If we replace them before quantum computers can crack them, we’re golden. We shouldn’t be too complacent here: signatures aren’t that easy to replace as we will see later on.
More urgently, though, an attacker can store traffic today and decrypt later by breaking the key agreement using a quantum computer. Everything that’s sent on the Internet today (personal information, credit card numbers, keys, messages) is at risk.
NIST Competition
Luckily cryptographers took note of Shor’s work early on and started working on post-quantum cryptography: cryptography not broken by quantum algorithms. In 2016, NIST, known for standardizing AES and SHA, opened a public competition to select which post-quantum algorithms they will standardize. Cryptographers from all over the world submitted algorithms and publicly scrutinized each other’s submissions. To focus attention, the list of potential candidates were whittled down over three rounds. From the original 82 submissions, eight made it into the final third round. From those eight, NIST chose one key agreement scheme and three signature schemes. Let’s have a look at the key agreement first.
What NIST announced
Key agreement
For key agreement, NIST picked only Kyber, which is a Key Encapsulation Mechanism (KEM). Let’s compare it side-by-side to an RSA-based KEM and the X25519 Diffie–Hellman key agreement:
Performance characteristics of Kyber and RSA. We compare instances of security level 1, see below. Timings vary considerably by platform and implementation constraints and should be taken as a rough indication only.Performance characteristics of the X25519 Diffie–Hellman key agreement commonly used in TLS 1.3.
KEM versus Diffie–Hellman
To properly compare these numbers, we have to explain how KEM and Diffie–Hellman key agreements are different.
Protocol flow of KEM and Diffie-Hellman key agreement.
Let’s start with the KEM. A KEM is essentially a Public-Key Encryption (PKE) scheme tailored to encrypt shared secrets. To agree on a key, the initiator, typically the client, generates a fresh keypair and sends the public key over. The receiver, typically the server, generates a shared secret and encrypts (“encapsulates”) it for the initiator’s public key. It returns the ciphertext to the initiator, who finally decrypts (“decapsulates”) the shared secret with its private key.
With Diffie–Hellman, both parties generate a keypair. Because of the magic of Diffie–Hellman, there is a unique shared secret between every combination of a public and private key. Again, the initiator sends its public key. The receiver combines the received public key with its own private key to create the shared secret and returns its public key with which the initiator can also compute the shared secret.
Interactive versus non-interactive key agreement
As an aside, in this simple key agreement (such as in TLS), there is not a big difference between using a KEM or Diffie–Hellman: the number of round-trips is exactly the same. In fact, we’re using Diffie–Hellman essentially as a KEM. This, however, is not the case for all protocols: for instance, the 3XDH handshake of Signal can’t be done with plain KEMs and requires the full flexibility of Diffie–Hellman.
Now that we know how to compare KEMs and Diffie–Hellman, how does Kyber measure up?
Kyber
Kyber is a balanced post-quantum KEM. It is very fast: much faster than X25519, which is already known for its speed. Its main drawback, common to many post-quantum KEMs, is that Kyber has relatively large ciphertext and key sizes: compared to X25519 it adds 1,504 bytes. Is this problematic?
We have some indirect data. Back in 2019 together with Google we tested two post-quantum KEMs, NTRU-HRSS and SIKE in Chrome. SIKE has very small keys, but is computationally very expensive. NTRU-HRSS, on the other hand, has similar performance characteristics to Kyber, but is slightly bigger and slower. This is what we found:
Handshake times for TLS with X25519 (control), NTRU-HRSS (CECPQ2) and SIKE (CECPQ2b). Both post-quantum KEMs were combined with a X25519 key agreement.
In this experiment we used a combination (a hybrid) of the post-quantum KEM and X25519. Thus NTRU-HRSS couldn’t benefit from its speed compared to X25519. Even with this disadvantage, the difference in performance is very small. Thus we expect that switching to a hybrid of Kyber and X25519 will have little performance impact.
So can we switch to post-quantum TLS today? We would love to. However, we have to be a bit careful: some TLS implementations are brittle and crash on the larger KeyShare message that contains the bigger post-quantum keys. We will work hard to find ways to mitigate these issues, as was done to deploy TLS 1.3. Stay tuned!
The other finalists
It’s interesting to have a look at the KEMs that didn’t make the cut. NIST intends to standardize some of these in a fourth round. One reason is to increase the diversity in security assumptions in case there is a breakthrough in attacks on structured lattices on which Kyber is based. Another reason is that some of these schemes have specialized, but very useful applications. Finally, some of these schemes might be standardized outside of NIST.
The finalists and candidates of the third round of the competition. The ones marked with 4️⃣ are proceeding to a fourth round and might yet be standardized.
The structured lattice generalists
Just like Kyber, the KEMs SABER, NTRU and NTRU Prime are all structured lattice schemes that are very similar in performance to Kyber. There are some finer differences, but any one of these KEMs would’ve been a great pick. And they still are: OpenSSH 9.0 chose to implement NTRU Prime.
The backup generalists
BIKE, HQC and FrodoKEM are also balanced KEMs, but they’re based on three different underlying hard problems. Unfortunately they’re noticeably less efficient, both in key sizes and computation. A breakthrough in the cryptanalysis of structured lattices is possible, though, and in that case it’s nice to have backups. Thus NIST is advancing BIKE and HQC to a fourth round.
While NIST chose not to advance FrodoKEM, which is based on unstructured lattices, Germany’s BSI prefers it.
The specialists
The last group of post-quantum cryptographic algorithms under NIST’s consideration are the specialists. We’re happy that both are advancing to the fourth round as they can be of great value in just the right application.
First up is Classic McEliece: it has rather unbalanced performance characteristics with its large public key (261kB) and small ciphertexts (128 bytes). This makes McEliece unsuitable for the ephemeral key exchange of TLS, where we need to transmit the public key. On the other hand, McEliece is ideal when the public key is distributed out-of-band anyway, as is often the case in applications and mobile apps that pin certificates. To use McEliece in this way, we need to change TLS a bit. Normally the server authenticates itself by sending a signature on the handshake. Instead, the client can encrypt a challenge to the KEM public key of the server. Being able to decrypt it is an implicit authentication. This variation of TLS is known as KEMTLS and also works great with Kyber when the public key isn’t known beforehand.
Finally, there is SIKE, which is based on supersingular isogenies. It has very small key and ciphertext sizes. Unfortunately, it is computationally more expensive than the other contenders.
Digital signatures
As we just saw, the situation for post-quantum key agreement isn’t too bad: Kyber, the chosen scheme is somewhat larger, but it offers computational efficiency in return. The situation for post-quantum signatures is worse: none of the schemes fit the bill on their own for different reasons. We discussed these issues at length for ten of them in a deep-dive last year. Let’s restrict ourselves for the moment to the schemes that were most likely to be standardized and compare them against Ed25519 and RSA-2048, the schemes that are in common use today.
Performance characteristics of NIST’s chosen signature schemes compared to Ed25519 and RSA-2048. We compare instances of security level 1, see below. Timings vary considerably by platform and implementation constraints and should be taken as a rough indication only. SPHINCS+ was timed with simple haraka as the underlying hash function. (*) Falcon requires a suitable double-precision floating-point unit for fast signing.
Floating points: Falcon’s achilles
All of these schemes have much larger signatures than those commonly used today. Looking at just these numbers, Falcon is the best of the worst. It, however, has a weakness that this table doesn’t show: it requires fast constant-time double-precision floating-point arithmetic to have acceptable signing performance.
Let’s break that down. Constant time means that the time the operation takes does not depend on the data processed. If the time to create a signature depends on the private key, then the private key can often be recovered by measuring how long it takes to create a signature. Writing constant-time code is hard, but over the years cryptographers have got it figured out for integer arithmetic.
Falcon, crucially, is the first big cryptographic algorithm to use double-precision floating-point arithmetic. Initially it wasn’t clear at all whether Falcon could be implemented in constant-time, but impressively, Falcon was implemented in constant-time for several different CPUs, which required several clever workarounds for certain CPU instructions.
Despite this achievement, Falcon’s constant-timeness is built on shaky grounds. The next generation of Intel CPUs might add an optimization that breaks Falcon’s constant-timeness. Also, many CPUs today do not even have fast constant-time double-precision operations. And then still, there might be an obscure bug that has been overlooked.
In time it might be figured out how to do constant-time arithmetic on the FPU robustly, but we feel it’s too early to deploy Falcon where the timing of signature minting can be measured. Notwithstanding, Falcon is a great choice for offline signatures such as those in certificates.
Dilithium’s size
This brings us to Dilithium. Compared to Falcon it’s easy to implement safely and has better signing performance to boot. Its signatures and public keys are much larger though, which is problematic. For example, to each browser visiting this very page, we sent six signatures and two public keys. If we’d replace them all with Dilithium2 we would be looking at 17kB of additional data. Last year, we ran an experiment to see the impact of additional data in the TLS handshake:
Impact of larger signatures on TLS handshake time. For the details, see this blog.
There are some caveats to point out: first, we used a big 30-segment initial congestion window (icwnd). With a normal icwnd, the bump at 40KB moves to 10KB. Secondly, the height of this bump is the round-trip time (RTT), which due to our broadly distributed network, is very low for us. Thus, switching to Dilithium alone might well double your TLS handshake times. More disturbingly, we saw that some connections stopped working when we added too much data:
Amount of failed TLS handshakes by size of added signatures. For the details, see this blog.
We expect this was caused by misbehaving middleboxes. Taken together, we concluded that early adoption of post-quantum signatures on the Internet would likely be more successful if those six signatures and two public keys would fit in 9KB. This can be achieved by using Dilithium for the handshake signature and Falcon for the other (offline) signatures.
At most one of Dilithium or Falcon
Unfortunately, NIST stated on severaloccasions that it would choose only two signature schemes, but not both Falcon and Dilithium:
Slides of NIST’s status update after the conclusion of round 2
The reason given is that both Dilithium and Falcon are based on structured lattices and thus do not add more security diversity. Because of the difficulty of implementing Falcon correctly, we expected NIST to standardize Dilithium and as a backup SPHINCS+. With that guess, we saw a big challenge ahead: to keep the Internet fast we would need some difficult and rigorous changes to the protocols.
The twist
However, to everyone’s surprise, NIST picked both! NIST chose to standardize Dilithium, Falcon and SPHINCS+. This is a very pleasant surprise for the Internet: it means that post-quantum authentication will be much simpler to adopt.
SPHINCS+, the conservative choice
In the excitement of the fight between Dilithium and Falcon, we could almost forget about SPHINCS+, a stateless hash-based signature. Its big advantage is that its security is based on the second-preimage resistance of the underlying hash-function, which is well understood. It is not a stretch to say that SPHINCS+ is the most conservative choice for a signature scheme, post-quantum or otherwise. But even as a co-submitter of SPHINCS+, I have to admit that its performance isn’t that great.
There is a lot of flexibility in the parameter choices for SPHINCS+: there are tradeoffs between signature size, signing time, verification time and the maximum number of signatures that can be minted. Of the current parameter sets, the “s” are optimized for size and “f” for signing speed; both chosen to allow 264 signatures. NIST has hinted at reducing the signature limit, which would improve performance. A custom choice of parameters for a particular application would improve it even more, but would still trail Dilithium.
Having discussed NIST choices, let’s have a look at those that were left out.
The other finalists
There were three other finalists: GeMSS, Picnic and Rainbow. None of these are progressing to a fourth round.
Picnic is a conservative choice similar to SPHINCS+. Its construction is interesting: it is based on the secure multiparty computation of a block cipher. To be efficient, a non-standard block cipher is chosen. This makes Picnic’s assumptions a bit less conservative, which is why NIST preferred SPHINCS+.
GeMSS and Rainbow are specialists: they have large public key sizes (hundreds of kilobytes), but very small signatures (33–66 bytes). They would be great for applications where the public key can be distributed out of band, such as for the Signed Certificate Timestamps included in certificates for Certificate Transparency. Unfortunately, both turned out to bebroken.
Signature schemes on the horizon
Although we expect Falcon and Dilithium to be practical for the Internet, there is ample room for improvement. Many new signature schemes have been proposed after the start of the competition, which could help out a lot. NIST recognizes this and is opening a new competition for post-quantum signature schemes.
A few schemes that have caught our eye already are UOV, which has similar performance trade-offs to those for GeMSS and Rainbow; SQISign, which has small signatures, but is computationally expensive; and MAYO, which looks like it might be a great general-purpose signature scheme.
Stateful hash-based signatures
Finally, we’d be remiss not to mention the post-quantum signature scheme that already has been standardized by NIST: the stateful hash-based signature schemes LMS and XMSS. They share the same conservative security as their sibling SPHINCS+, but have much better performance. The rub is that for each keypair there are a finite number of signature slots and each signature slot can only be used once. If it’s used twice, it is insecure. This is why they are called stateful; as the signer must remember the state of all slots that have been used in the past, and any mistake is fatal. Keeping the state perfectly can be very challenging.
What else
What’s next?
NIST will draft standards for the selected schemes and request public feedback on them. There might be changes to the algorithms, but we do not expect anything major. The standards are expected to be finalized in 2024.
In the coming months, many languages, libraries and protocols will already add preliminary support for the current version of Kyber and the other post-quantum algorithms. We’re helping out to make post-quantum available to the Internet as soon as possible: we’re working within the IETF to add Kyber to TLS and will contribute upstream support to popular open-source libraries.
Start experimenting with Kyber today
Now is a good time for you to try out Kyber in your software stacks. We were lucky to correctly guess Kyber would be picked and have experience running it internally. Our tests so far show it performs great. Your requirements might differ, so try it out yourself.
The reference implementation in C is excellent. The Open Quantum Safe project integrates it with various TLS libraries, but beware: the algorithm identifiers and scheme might still change, so be ready to migrate.
Our CIRCL library has a fast independent implementation of Kyber in Go. We implemented Kyber ourselves so that we could help tease out any implementation bugs or subtle underspecification.
Experimenting with post-quantum signatures
Post-quantum signatures are not as urgent, but might require more engineering to get right. First off, which signature scheme to pick?
Are large signatures and slow operations acceptable? Go for SPHINCS+.
Do you need more performance?
Can your signature generation be timed, for instance when generated on-the-fly? Then go for (a hybrid, see below, with) Dilithium.
For offline signatures, go for (a hybrid with) Falcon.
If you can keep a state perfectly, check out XMSS/LMS.
Open Quantum Safe can be used to test these out. Our CIRCL library also has a fast independent implementation of Dilithium in Go. We’ll add Falcon and SPHINCS+ soon.
Hybrids
A hybrid is a combination of a classical and a post-quantum scheme. For instance, we can combine Kyber512 with X25519 to create a single Kyber512X key agreement. The advantage of a hybrid is that the data remains secure against non-quantum attackers even if Kyber512 turns out broken. It is important to note that it’s not just about the algorithm, but also the implementation: Kyber512 might be perfectly secure, but an implementation might leak via side-channels. The downside is that two key-exchanges are performed, which takes more CPU cycles and bytes on the wire. For the moment, we prefer sticking with hybrids, but we will revisit this soon.
Post-quantum security levels
Each algorithm has different parameters targeting various post-quantum security levels. Up till now we’ve only discussed the performance characteristics of security level 1 (or 2 in case of Dilithium, which doesn’t have level 1 parameters.) The definition of the security levels is rather interesting: they’re defined as being as hard to crack by a classical or quantum attacker as specific instances of AES and SHA:
Level
Definition, as least as hard to break as …
1
To recover the key of AES-128 by exhaustive search
2
To find a collision in SHA256 by exhaustive search
3
To recover the key of AES-192 by exhaustive search
4
To find a collision in SHA384 by exhaustive search
5
To recover the key of AES-256 by exhaustive search
So which security level should we pick? Is level 1 good enough? We’d need to understand how hard it is for a quantum computer to crack AES-128.
Grover’s algorithm
In 1996, two years after Shor’s paper, Lov Grover published his quantum search algorithm. With it, you can find the AES-128 key (given known plain and ciphertext) with only 264 executions of the cipher in superposition. That sounds much faster than the 2127 tries on average for a classical brute-force attempt. In fact, it sounds like security level 1 isn’t that secure at all. Don’t be alarmed: level 1 is much more secure than it sounds, but it requires some context.
To start, a classical brute-force attempt can be parallelized — millions of machines can participate, sharing the work. Grover’s algorithm, on the other hand, doesn’t parallelize well because the quadratic speedup disappears over that portion. To wit, a billion quantum computers would still have to do 249 iterations each to crack AES-128.
Then each iteration requires many gates. It’s estimated that these 249 operations take roughly 264 noiseless quantum gates. If each of our billion quantum computers could execute a billion noiseless quantum gates per second, then it’d still take 500 years.
That already sounds more secure, but we’re not done. Quantum computers do not execute noiseless quantum gates: they’re analogue machines. Every operation has a little bit of noise. Does this mean that quantum computing is hopeless? Not at all! There are clever algorithms to turn, say, a million noisy qubits into one less noisy qubit. It doesn’t just add qubits, but also extra gates. How much depends very much on the exact details of the quantum computer.
It is not inconceivable that in the future there will be quantum computers that effectively execute far more than a billion noiseless gates per second, but it will likely be decades after Shor’s algorithm is practical. This all is a long-winded way of saying that security level 1 seems solid for the foreseeable future.
Hedging against attacks
A different reason to pick a higher security level is to hedge against better attacks on the algorithm. This makes a lot of sense, but it is important to note that this isn’t a foolproof strategy:
Not all attacks are small improvements. It’s possible that improvements in cryptanalysis break all security levels at once.
Higher security levels do not protect against implementation flaws, such as (new) timing vulnerabilities.
A different aspect, that’s arguably more important than picking a high number, is crypto agility: being able to switch to a new algorithm/implementation in case of a break of trouble. Let’s hope that we will not need it, but now we’re going to switch, it’s nice to make it easier in the future.
CIRCL is Post-Quantum Enabled
We already mentioned CIRCL a few times, it’s our optimized crypto-library for Go whose development we started in 2019. CIRCL already contains support for several post-quantum algorithms such as the KEMs Kyber and SIKE and signature schemes Dilithium and Frodo. The code is up to date and compliant with test vectors from the third round. CIRCL is readily usable in Go programs either as a library or natively as part of Go using this fork.
One goal of CIRCL is to enable experimentation with post-quantum algorithms in TLS. For instance, we ran a measurement study to evaluate the feasibility of the KEMTLS protocol for which we’ve adapted the TLS package of the Go library.
As an example, this code uses CIRCL to sign a message with eddilithium2, a hybrid signature scheme pairing Ed25519 with Dilithium mode 2.
Message: Signed with CIRCL using Ed25519-Dilithium2
Signature (2484 bytes): 84d6882a...
Signature Valid: true
Errors: <nil>
As can be seen the application programming interface is the same as the crypto.Signer interface from the standard library. Try it out, and we’re happy to hear your feedback.
Conclusion
This is a big moment for the Internet. From a set of excellent options for post-quantum key agreement, NIST chose Kyber. With it, we can secure the data on the Internet today against quantum adversaries of the future, without compromising on performance.
On the authentication side, NIST pleasantly surprised us by choosing both Falcon and Dilithium against their earlier statements. This was a great choice, as it will make post-quantum authentication more practical than we expected it would be.
Together with the cryptography community, we have our work cut out for us: we aim to make the Internet post-quantum secure as fast as possible.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.