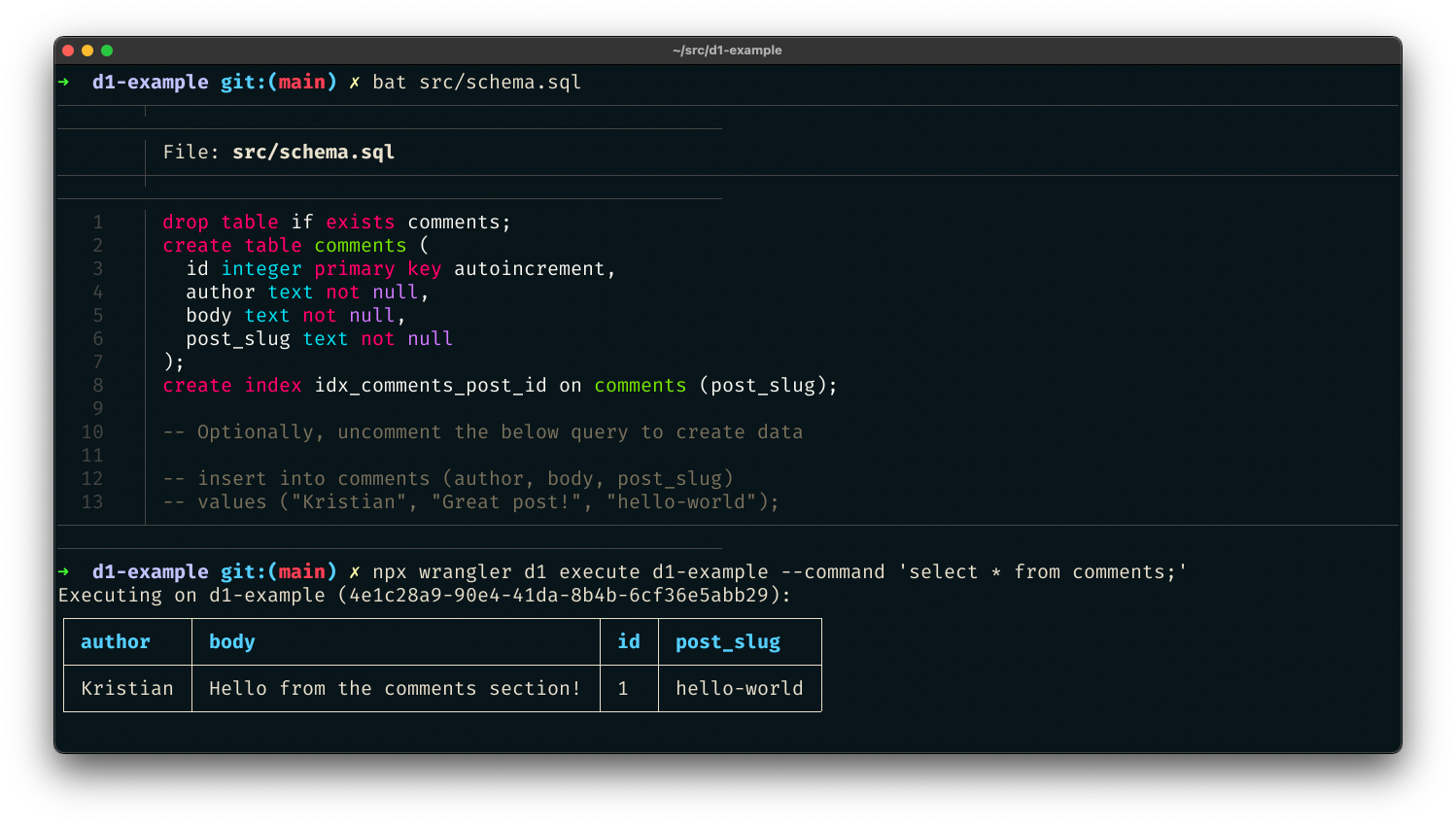
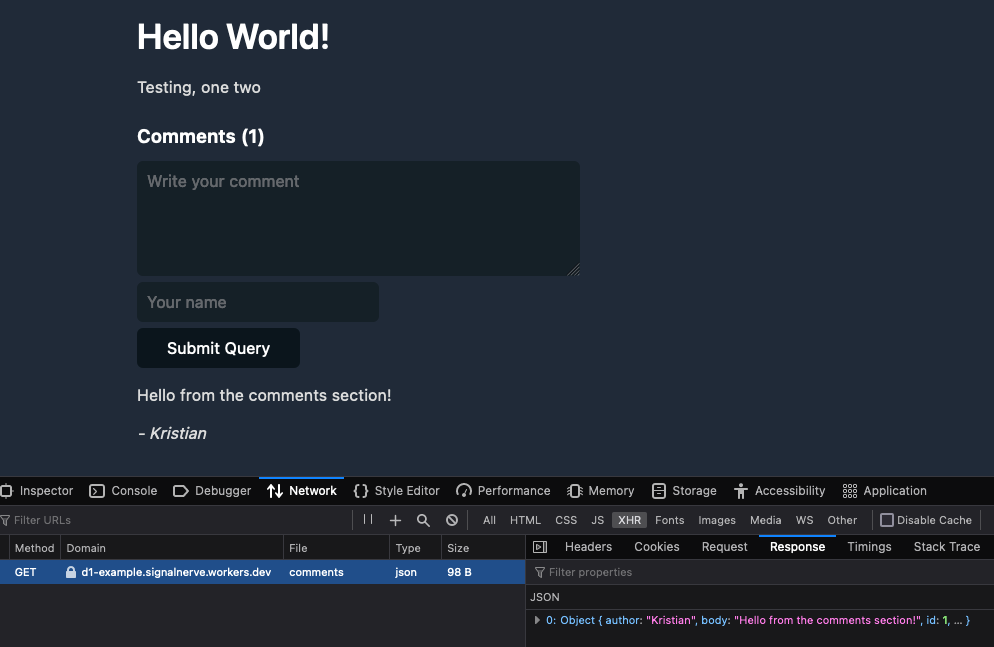
In November, 2022, we introduced deployments for Workers. Deployments are created as you make changes to a Worker. Each one is unique. These let you track changes to your Workers over time, seeing who made the changes, and where they came from.
When we made the announcement, we also said our intention was to build more functionality on top of deployments.
Today, we’re proud to release rollbacks for deployments.
Rollbacks
As nice as it would be to know that every deployment is perfect, it’s not always possible – for various reasons. Rollbacks provide a quick way to deploy past versions of a Worker – providing another layer of confidence when developing and deploying with Workers.
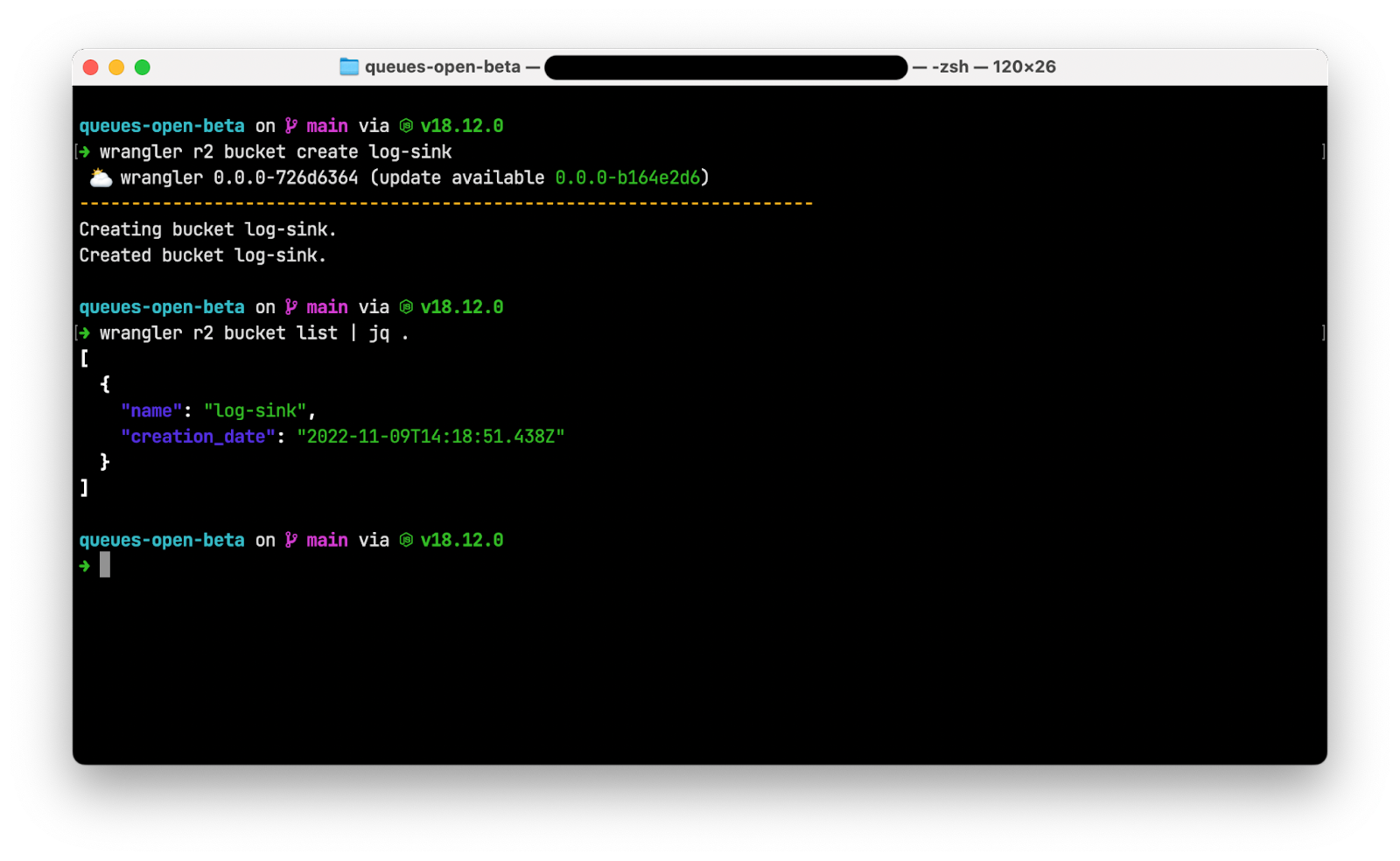
Via the dashboard
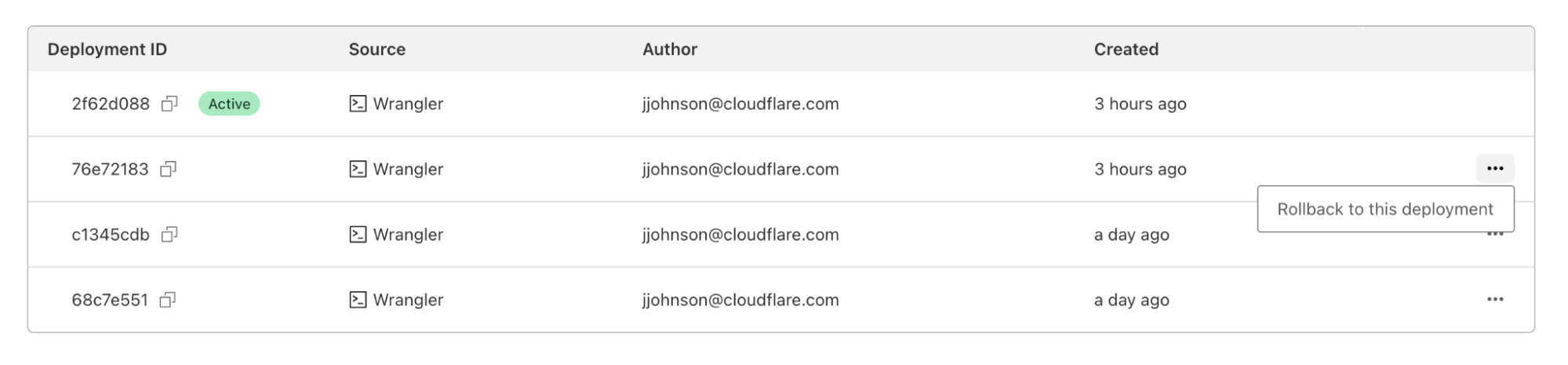
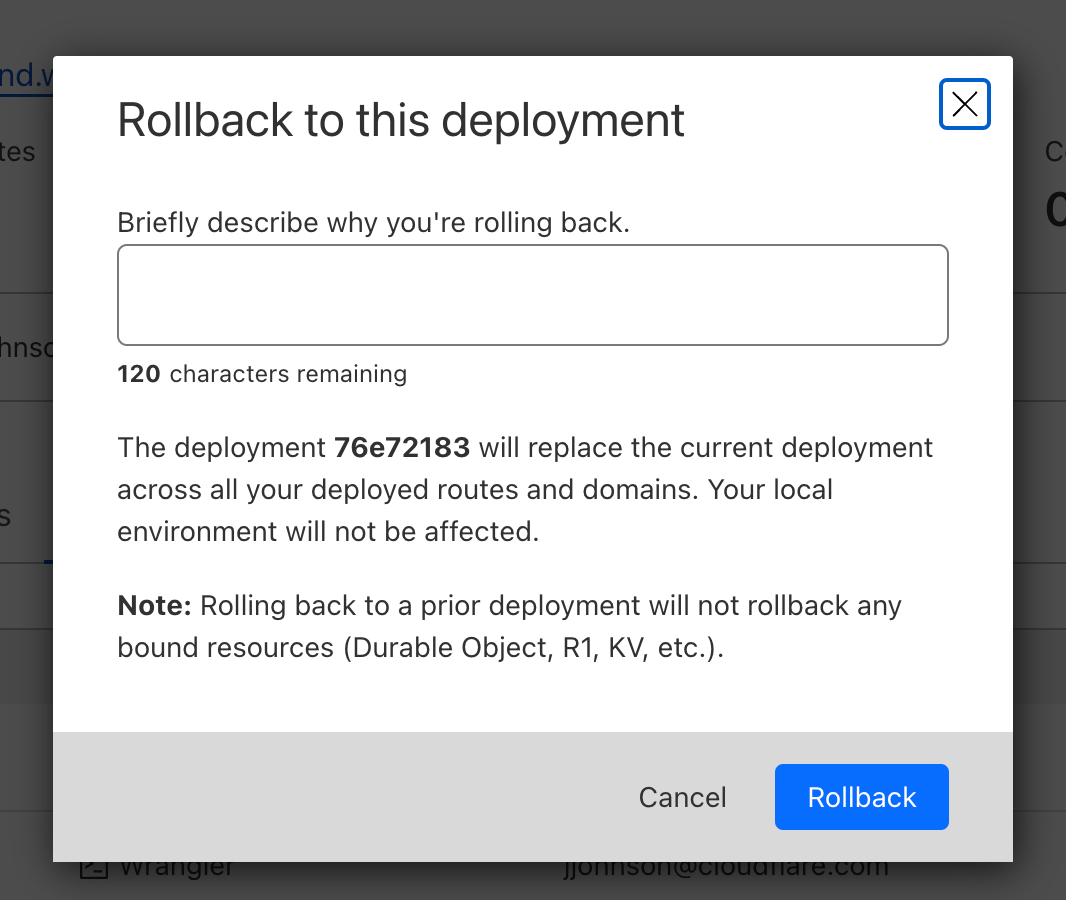
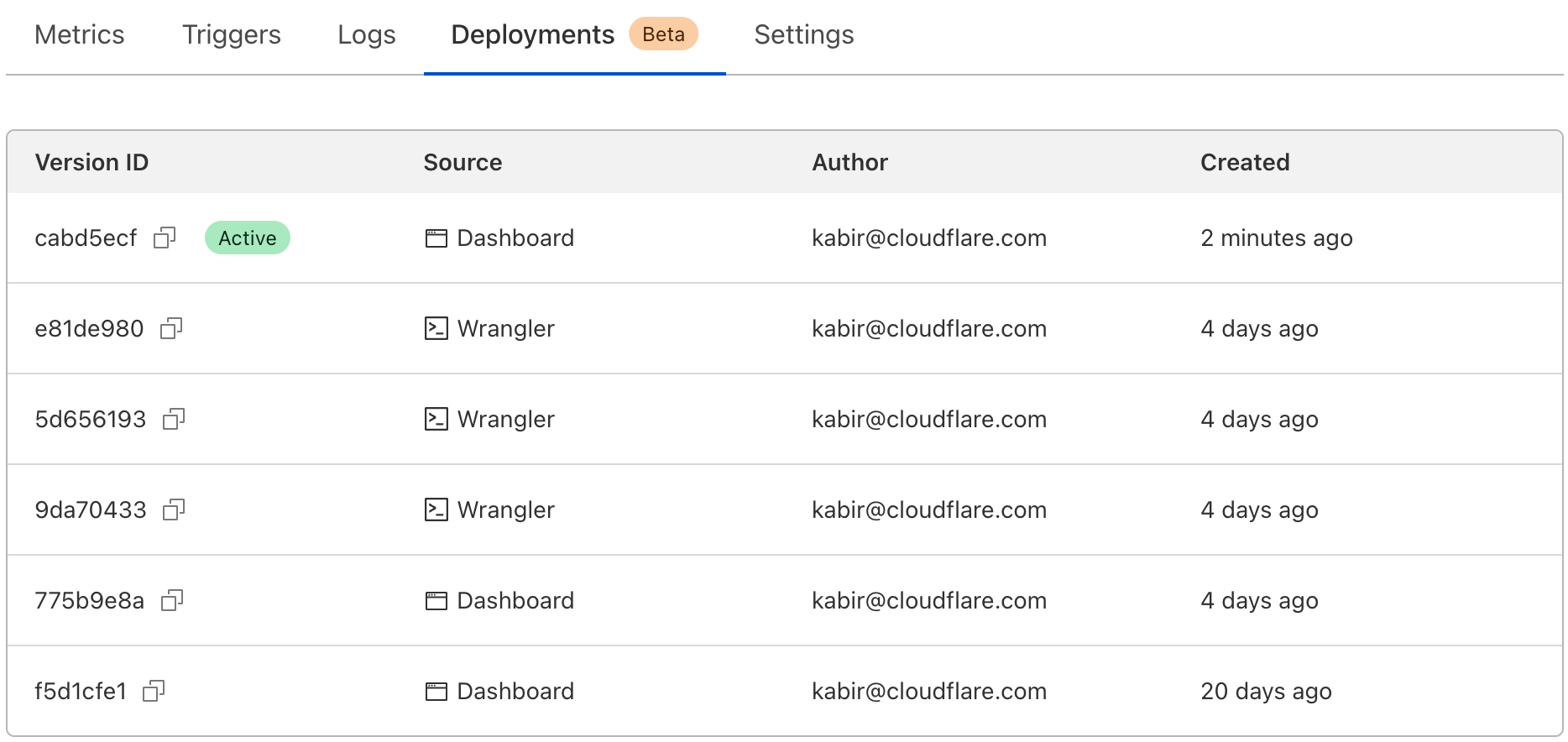
In the dashboard, you can navigate to the Deployments tab. For each deployment that’s not the most recent, you should see a new icon on the far right of the deployment. Hovering over that icon will display the option to rollback to the specified deployment.
Clicking on that will bring up a confirmation dialog, where you can enter a reason for rollback. This provides another mechanism of record-keeping and helps give more context for why the rollback was necessary.
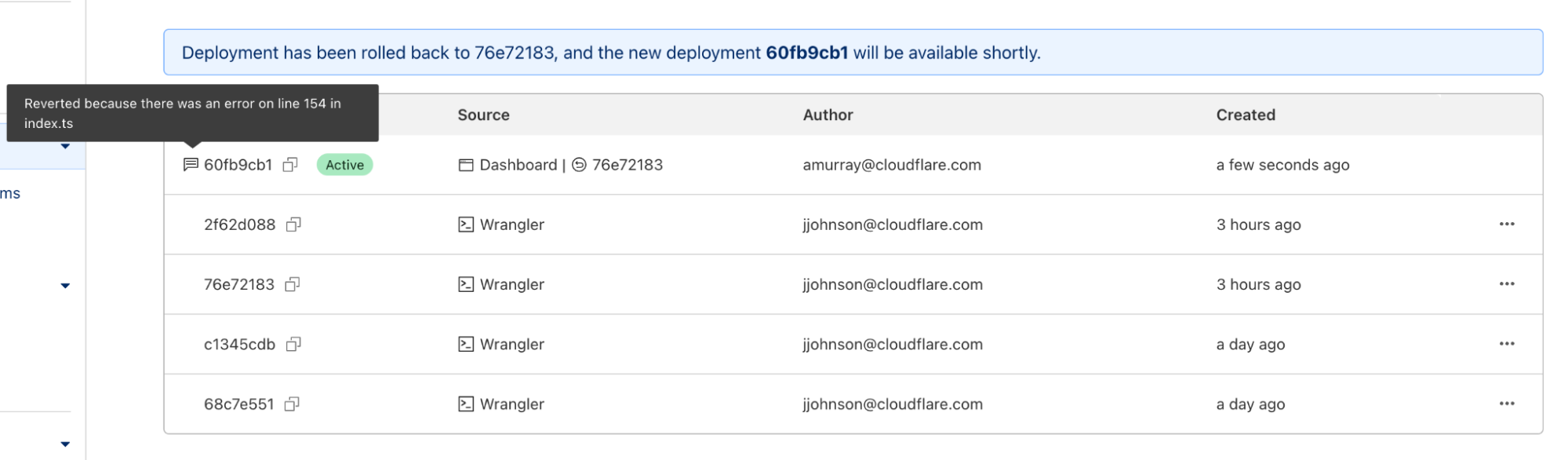
Once you enter a reason and confirm, a new rollback deployment will be created. This deployment has its own ID, but is a duplicate of the one you rolled back to. A message appears with the new deployment ID, as well as an icon showing the rollback message you entered above.
Via Wrangler
With Wrangler version 2.13, rolling back deployments via Wrangler can be done via a new command – wrangler rollback. This command takes an optional ID to rollback to a specific deployment, but can also be run without an ID to rollback to the previous deployment. This provides an even faster way to rollback in a situation where you know that the previous deployment is the one that you want.
Just like the dashboard, when you initiate a rollback you will be prompted to add a rollback reason and to confirm the action.
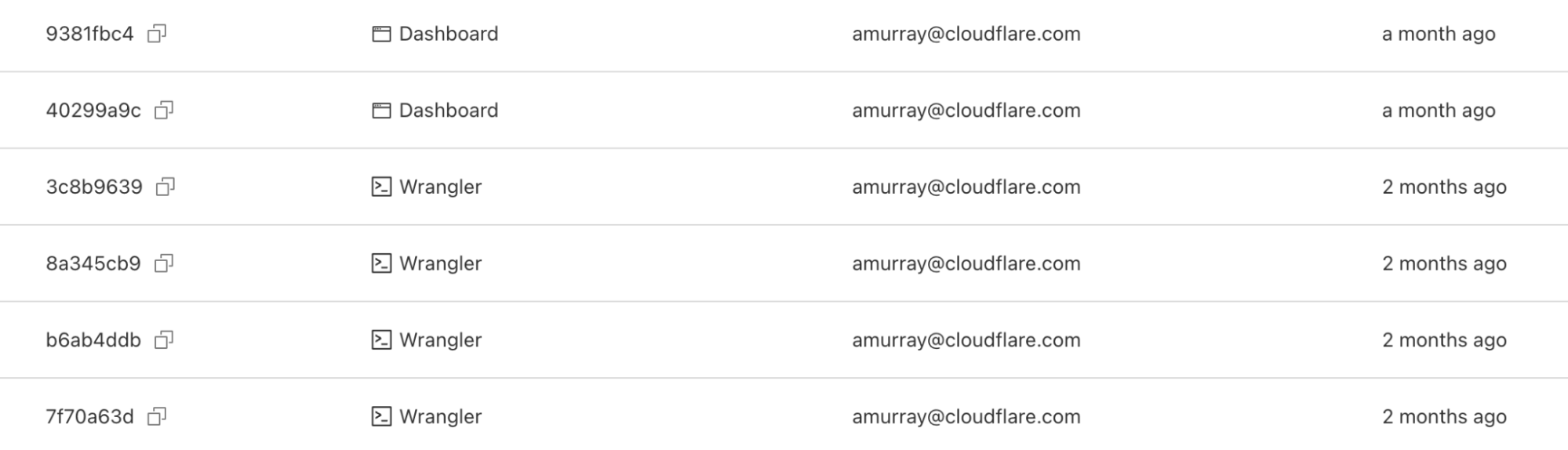
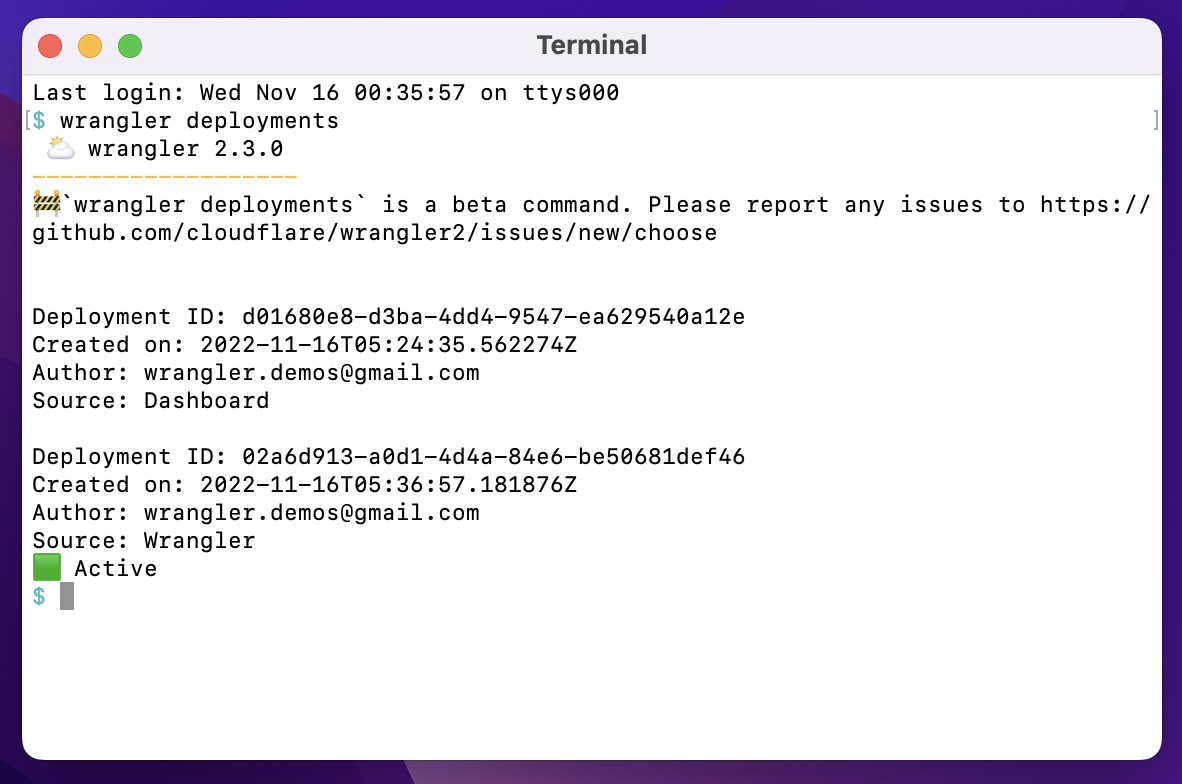
In addition to wrangler rollback we’ve done some refactoring to the wrangler deployments command. Now you can run wrangler deployments list to view up to the last 10 deployments.
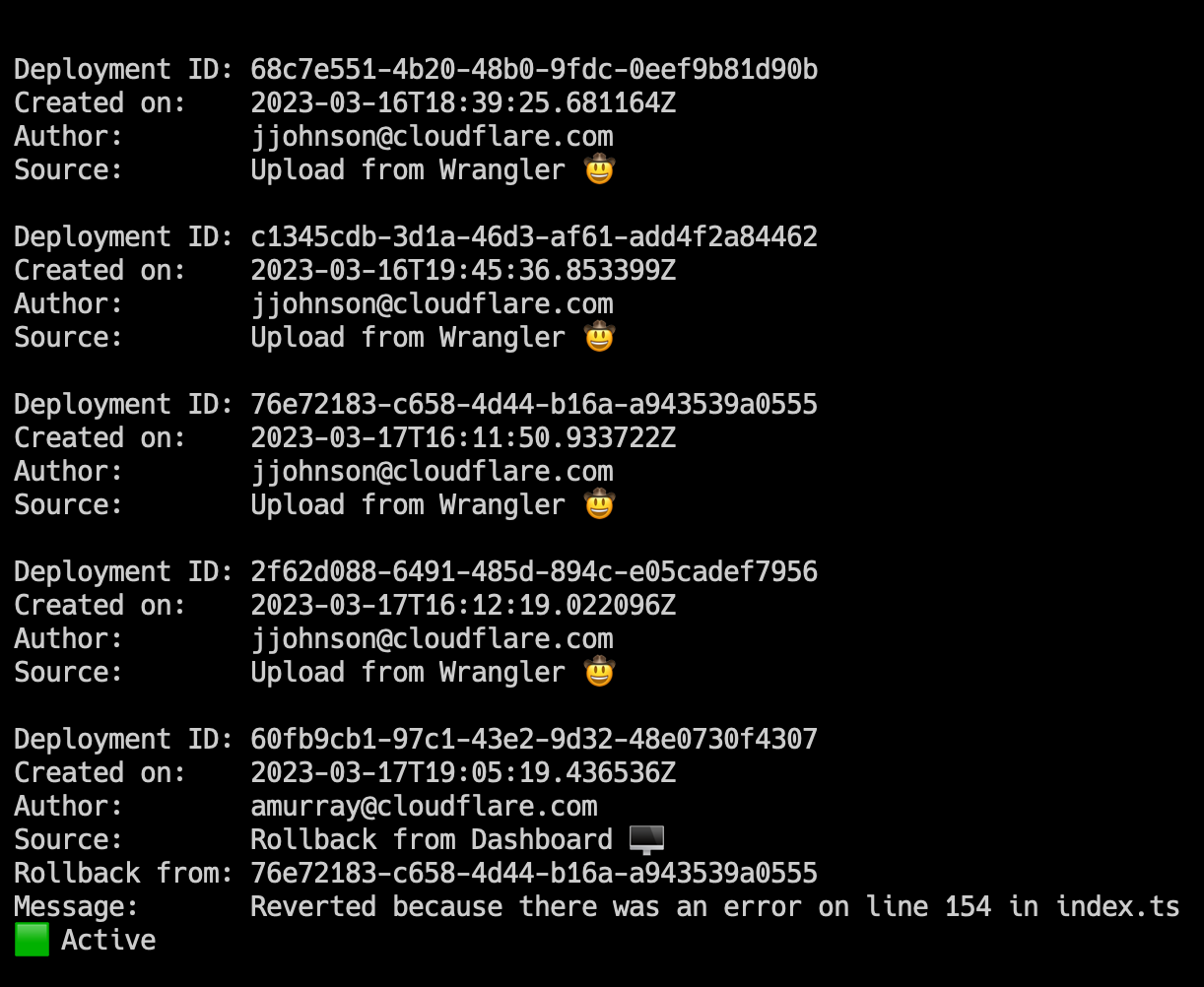
Here, you can see two new annotations: rollback from and message. These match the dashboard experience, and provide more visibility into your deployment history.
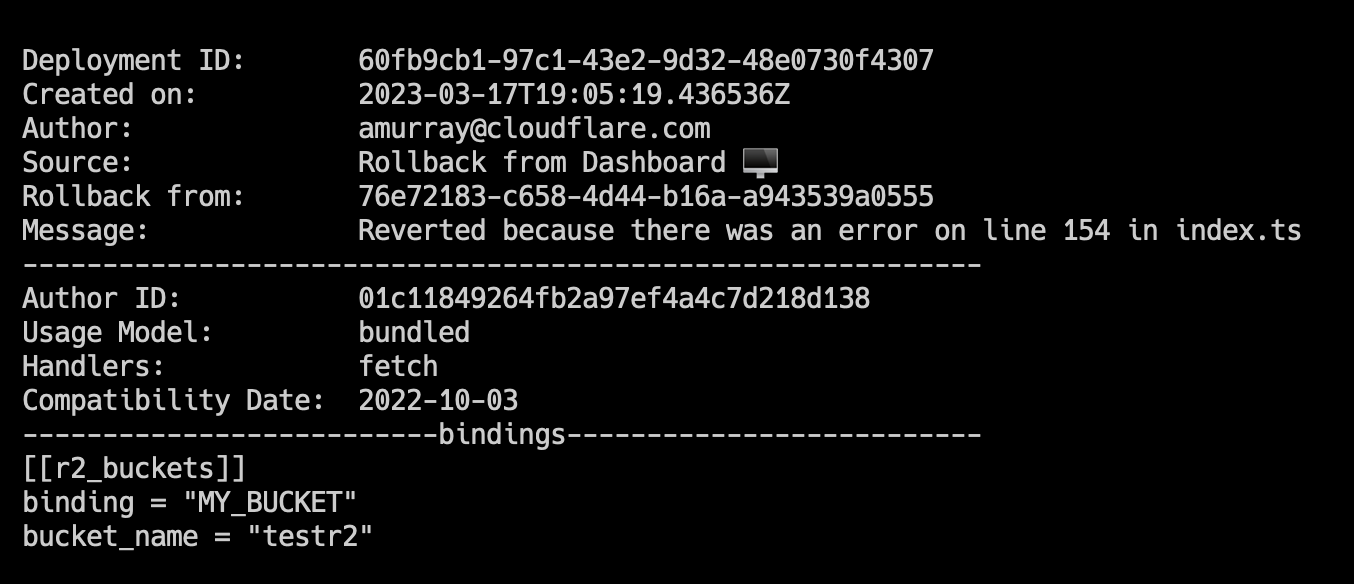
To view an individual deployment, you can run wrangler deployments view. This will display the last deployment made, which is the active deployment. If you would like to see a specific deployment, you can run wrangler deployments view [ID].
We’ve updated this command to display more data like: compatibility date, usage model, and bindings. This additional data will help you to quickly visualize changes to Worker or to see more about a specific Worker deployment without having to open your editor and go through source code.
Keep deploying!
We hope this feature provides even more confidence in deploying Workers, and encourages you to try it out! If you leverage the Cloudflare dashboard to manage deployments, you should have access immediately. Wrangler users will need to update to version 2.13 to see the new functionality.
Make sure to check out our updated deployments docs for more information, as well as information on limitations to rollbacks. If you have any feedback, please let us know via this form.
Building applications on Cloudflare Workers has always been fun. Workers applications have low latency response times by default, and easy developer ergonomics thanks to Wrangler. It’s no surprise that for years now, developers have been going from idea to production with Workers in just a few minutes.
Internally, we’re no different. When a member of our team has a project idea, we often reach for Workers first, and not just for the MVP stage, but in production, too. Workers have been a secret ingredient to Cloudflare’s innovation for some time now, allowing us to build products like Access, Stream and Workers KV. Even better, when we have new ideas and we can use new Cloudflare products to build them, it’s a great way to give feedback on those products.
We’ve discussed this in the past on the Cloudflare blog – in May last year, I wrote how we rebuilt Cloudflare’s developer documentation using many of the tools that had recently been released in the Workers ecosystem: Cloudflare Pages for hosting, and Bulk Redirects for the redirect rules. In November, we released a new version of our API documentation, which again used Pages for hosting, and Pages functions for intelligent caching and transformation of our API schema.
In this blog post, I’m excited to show off some of the new tools in Cloudflare’s developer arsenal, D1 and Queues, to prototype and ship an internal tool for our SEO experts at Cloudflare. We’ve made this project, which we’re calling Prospector, open-source too – check it out in our cloudflare/templates repo on GitHub. Whether you’re a developer looking to understand how to use multiple parts of Cloudflare’s developer stack together, or an SEO specialist who may want to deploy the tool in production, we’ve made it incredibly easy to get up and running.
What we’re building
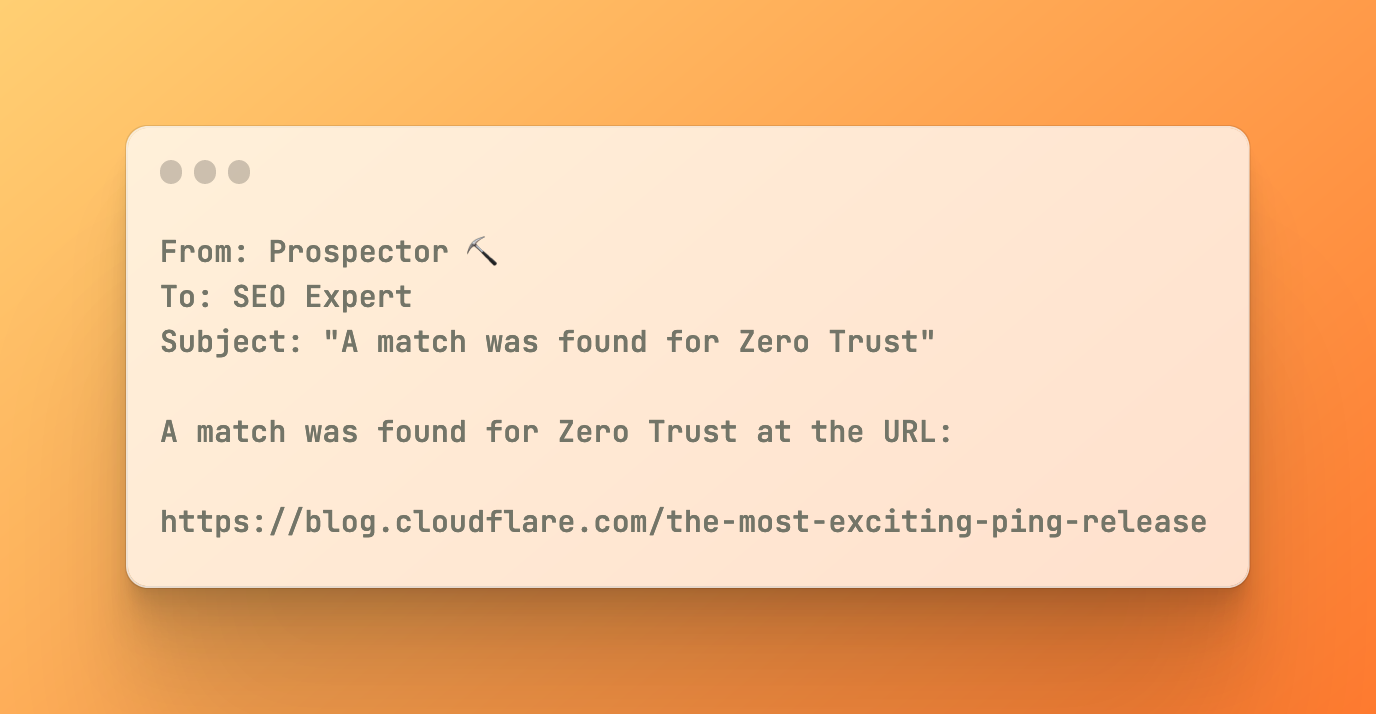
Prospector is a tool that allows Cloudflare’s SEO experts to monitor our blog and marketing site for specific keywords. When a keyword is matched on a page, Prospector will notify an email address. This allows our SEO experts to stay informed of any changes to our website, and take action accordingly.
Using MailChannels’ integration with Workers, we can quickly and easily send emails from our application using a single API call. This allows us to focus on the core functionality of the application, and not worry about the details of sending emails.
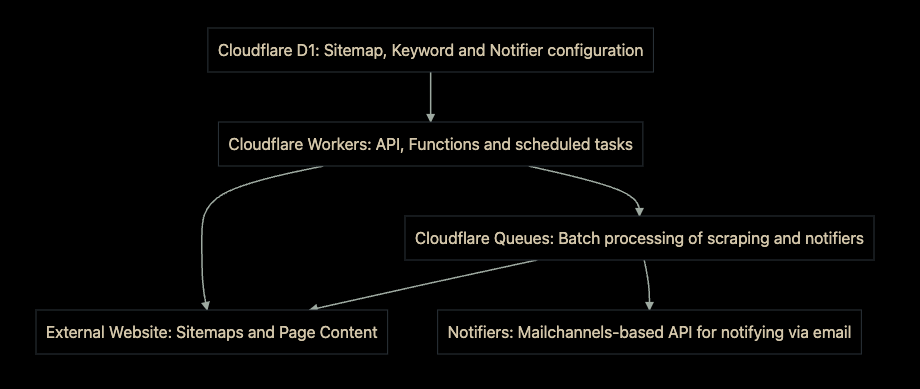
Prospector uses Cloudflare Workers as the user-facing API for the application. It uses D1 to store and retrieve data in real-time, and Queues to handle the fetching of all URLs and the notification process. We’ve also included an intuitive user interface for the application, which is built with HTML, CSS, and JavaScript.
Why we built it
It is widely known in SEO that both internal and external links help Google and other search engines understand what a website is about, which impacts keyword rankings. Not only do these links guide readers to additional helpful information, they also allow web crawlers for search engines to discover and index content on the site.
Acquiring external links is often a time-consuming process and at the discretion of third parties, whereas website owners typically have much more control over internal links. As a result, internal linking is one of the most useful levers available in SEO.
In an ideal world, every piece of content would be fully formed upon publication, replete with helpful internal links throughout the piece. However, this is often not the case. Many times, content is edited after the fact or additional pieces of relevant content come along after initial publication. These situations result in missed opportunities for internal linking.
Like other large organizations, Cloudflare has published thousands of blogs and web pages over the years. We share new content every time a product/technology is introduced and improved. Ultimately, that also means it’s become more challenging to identify opportunities for internal linking in a timely, automated fashion. We needed a tool that would allow us to identify internal linking opportunities as they appear, and speed up the time it takes to identify new internal linking opportunities.
Although we tested several tools that might solve this problem, we found that they were limited in several ways. First, some tools only scanned the first 2,000 characters of a web page. Any opportunities found beyond that limit would not be detected. Next, some tools did not allow us to limit searches to certain areas of the site and resulted in many false positives. Finally, other potential solutions required manual operation, leaving the process at the mercy of human memory.
To solve our problem (and ultimately, improve our SEO), we needed an automated tool that could discover and notify us of new instances of targeted phrases on a specified range of pages.
How it works
Data model
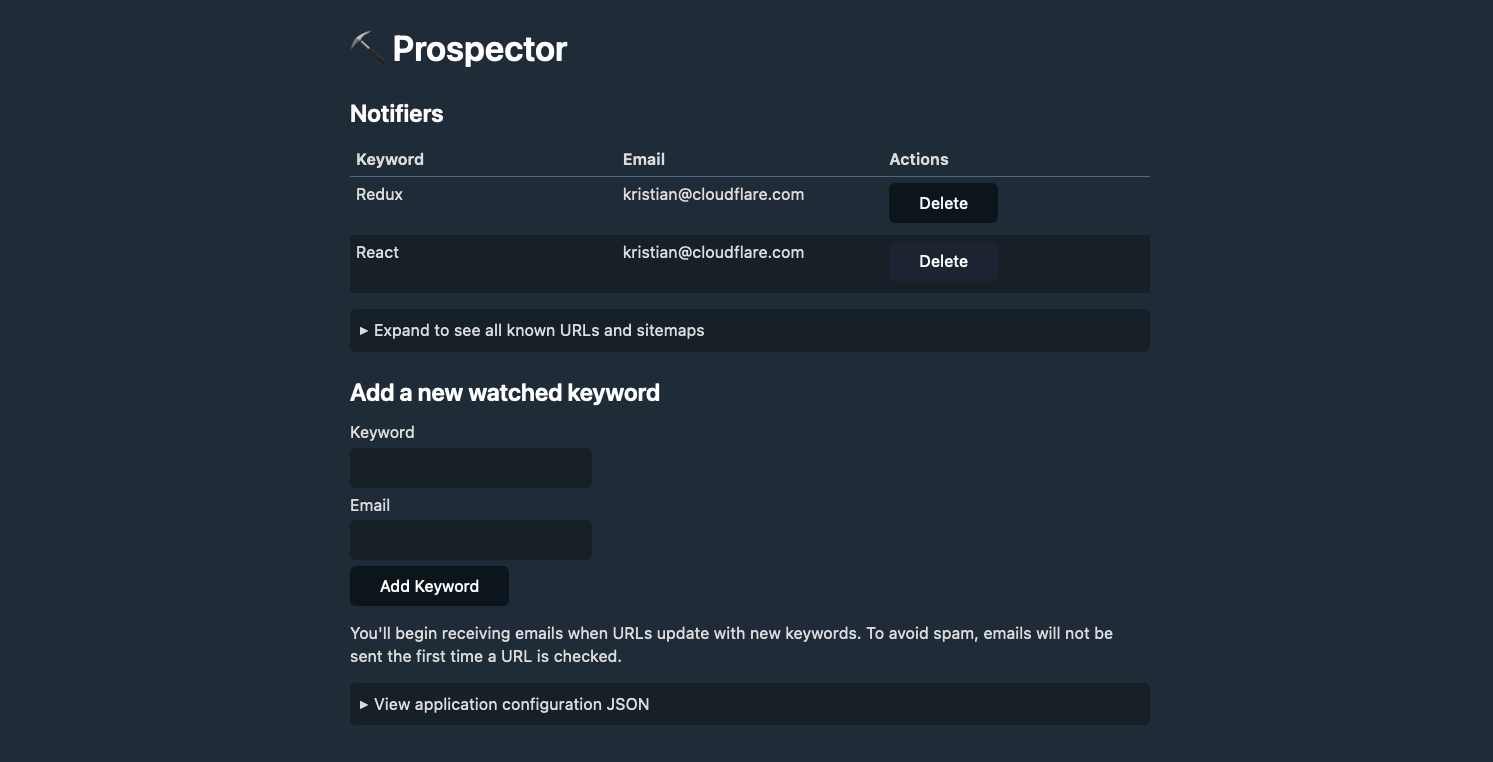
First, let’s explore the data model for Prospector. We have two main tables: notifiers and urls. The notifiers table stores the email address and keyword that we want to monitor. The urls table stores the URL and sitemap that we want to scrape. The notifiers table has a one-to-many relationship with the urls table, meaning that each notifier can have many URLs associated with it.
In addition, we have a sitemaps table that stores the sitemap URLs that we’ve scraped. Many larger websites don’t just have a single sitemap: the Cloudflare blog, for instance, has a primary sitemap that contains four sub-sitemaps. When the application is deployed, a primary sitemap is provided as configuration, and Prospector will parse it to find all of the sub-sitemaps.
Finally, notifier_matches is a table that stores the matches between a notifier and a URL. This allows us to keep track of which URLs have already been matched, and which ones still need to be processed. When a match has been found, the notifier_matches table is updated to reflect that, and “matches” for a keyword are no longer processed. This saves our SEO experts from a crowded inbox, and allows them to focus and act on new matches.
Connecting the pieces with Cloudflare Queues Cloudflare Queues acts as the work queue for Prospector. When a new notifier is added, a new job is created for it and added to the queue. Behind the scenes, Queues will distribute the work across multiple Workers, allowing us to scale the application as needed. When a job is processed, Prospector will scrape the URL and check for matches. If a match is found, Prospector will send an email to the notifier’s email address.
Using the Cron Triggers functionality in Workers, we can schedule the scraping process to run at a regular interval – by default, once a day. This allows us to keep our data up-to-date, and ensures that we’re always notified of any changes to our website. It also allows the end-user to configure when they receive emails in case they want to receive them more or less frequently, or at the beginning of their workday.
The Module Workers syntax for Workers makes accessing the application bindings – the constants available in the application for querying D1, Queues, and other services – incredibly easy. src/index.ts, the entrypoint for the application, looks like this:
With this syntax, we can see where the various events incoming to the application – the fetch event, the queue event, and the scheduled event – are handled. The fetch event is the main entrypoint for the application, and is where we handle all of the API routes. The queue event is where we handle the work that’s been added to the queue, and the scheduled event is where we handle the scheduled scraping process.
Central to the application, of course, is Workers – acting as the API gateway and coordinator. We’ve elected to use the popular open-source framework Hono, an Express-style API for Workers, in Prospector. With Hono, we can quickly map out a REST API in just a few lines of code. Here’s an example of a few API routes and how they’re defined with Hono:
With these bindings, we can define the types for our environment variables, and use them in our application. Here’s an example of the Env type, which defines the environment variables that we use in the application:
Notice the types of the DB and QUEUE bindings – D1Database and Queue, respectively. These types are automatically generated, complete with type signatures for each method inside of the D1 and Queue APIs. This means that we can be sure that we’re using the correct methods, and that we’re passing the correct arguments to them, directly from our text editor – without having to refer to the documentation.
How to use it
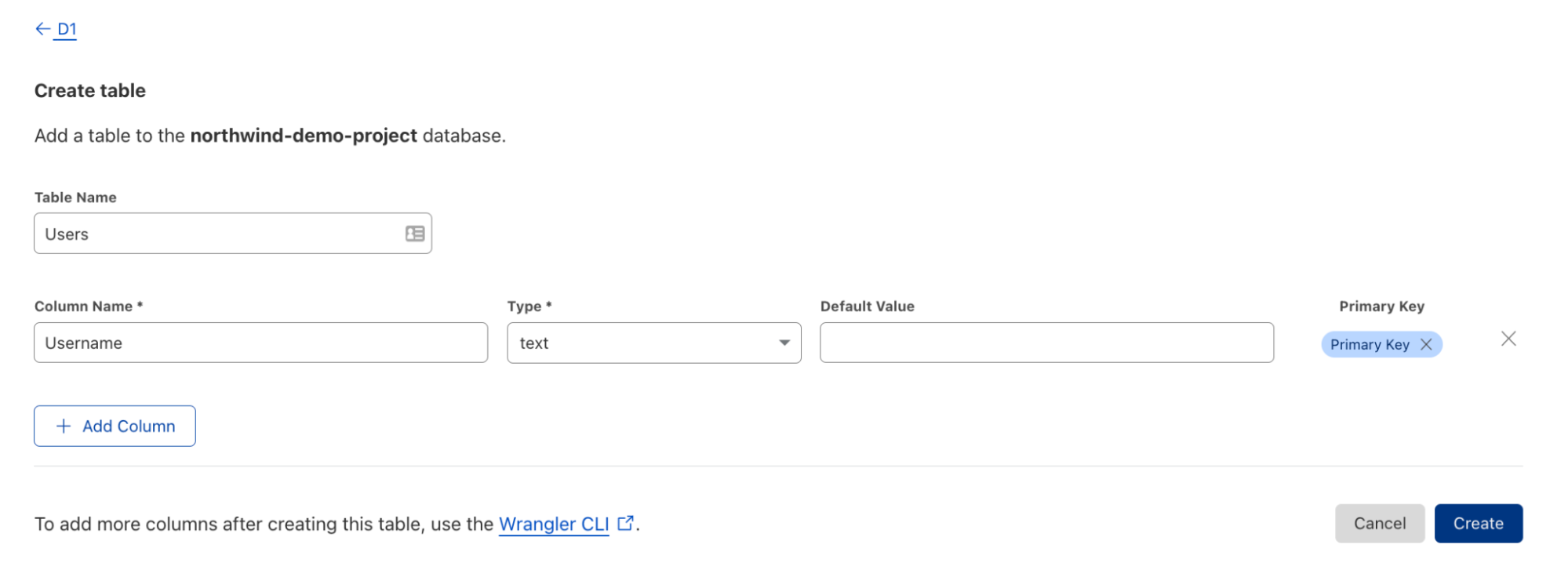
One of my favorite things about Workers is that deploying applications is quick and easy. Using `wrangler.toml` and some simple build scripts, we can deploy a fully-functional application in just a few minutes. Prospector is no different. With just a few commands, we can create the necessary D1 database and Queues instance, and deploy the application to our account.
First, you’ll need to clone the repository from our cloudflare/templates repository:
git clone $URL
If you haven’t installed wrangler yet, you can do so by running:
npm install @cloudflare/wrangler -g
With Wrangler installed, you can login to your account by running:
wrangler login
After you’ve done that, you’ll need to create a new D1 database, as well as a Queues instance. You can do this by running the following commands:
Next, you can run the bin/migrate script to create the tables in your database:
bin/migrate
This will create all the needed tables in your database, both in development (locally) and in production. Note that you’ll even see the creation of a honest-to-goodness .sqlite3 file in your project directory – this is the local development database, which you can connect to directly using the same SQLite CLI that you’re used to:
Finally, you can deploy the application to your account:
npm run deploy
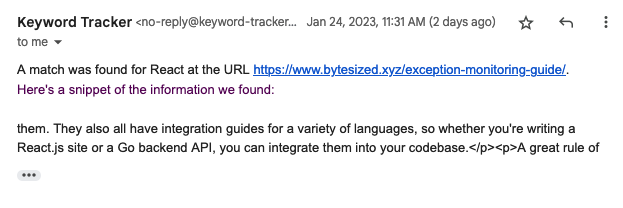
With a deployed application, you can visit your Workers URL to see the user interface. From there, you can add new notifiers and URLs, and see the results of your scraping process. When a new keyword match is found, you’ll receive an email with the details of the match instantly:
Conclusion
For some time, there have been a great deal of applications that were hard to build on Workers without relational data or background task tooling. Now, with D1 and Queues, we can build applications that seamlessly integrate between real-time user interfaces, geographically distributed data, background processing, and more, all using the same developer ergonomics and low latency that Workers is known for.
D1 has been crucial for building this application. On larger sites, the number of URLs that need to be scraped can be quite large. If we were to use Workers KV, our key-value store, for storing this data, we would quickly struggle with how to model, retrieve, and update the data needed for this use-case. With D1, we can build relational data models and quickly query just the data we need for each queued processing task.
Using these tools, developers can build internal tools and applications for their companies that are more powerful and more scalable than ever before. With the integration of Cloudflare’s Zero Trust suite, developers can make these applications secure by default, and deploy them to Cloudflare’s global network. This allows developers to build applications that are fast, secure, and reliable, all without having to worry about the underlying infrastructure.
Prospector is a great example of how easy it is to build applications on Cloudflare Workers. With the recent addition of D1 and Queues, we’ve been able to build fully-functional applications that require real-time data and background processing in just a few hours. We’re excited to share the open-source code for Prospector, and we’d love to hear your feedback on the project.
If you have any questions, feel free to reach out to us on Twitter at @cloudflaredev, or join us in the Cloudflare Workers Discord community, which recently hit 20k members and is a great place to ask questions and get help from other developers.
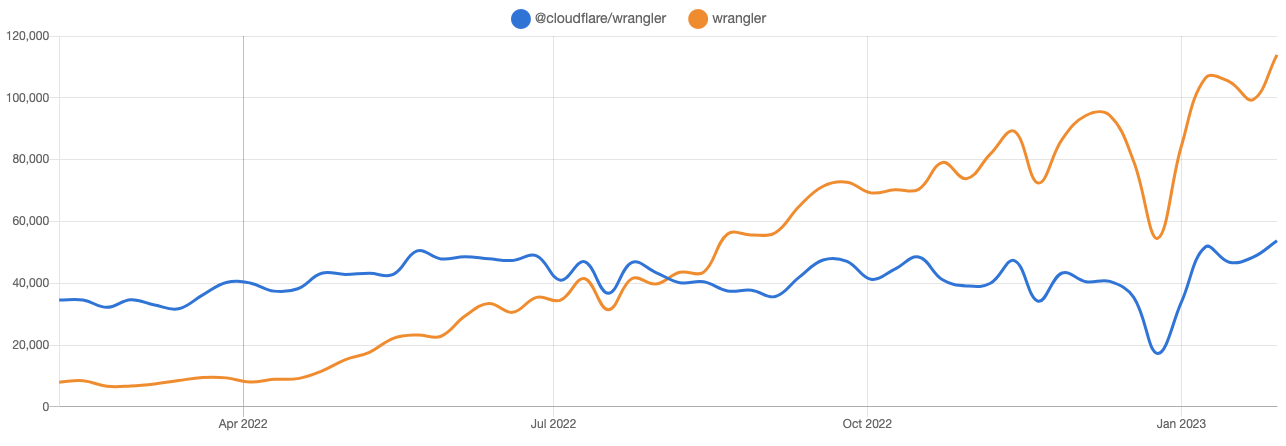
Version 1 of Wrangler (@cloudflare/wrangler on npm) is now deprecated, which means no new features or bug fixes will be published unless they’re critical. Beginning August 2023, no further updates will be provided and the Wrangler v1 GitHub repo will be archived. We strongly recommend you upgrade to version 2 (wrangler on npm) to receive continued support. We have a migration guide to make this process easy!
With that in mind, last year we set out to align our product with our goals. Wrangler was the primary way developers interacted with our platform, but the codebase was difficult to maintain and had spiraled in complexity. Weighing our options, we found that the best way forward was a total rewrite of Wrangler, culminating in the 2.0 release.
For most of our users, deprecation of version 1 will be invisible – they’re already on version 2! If you’re still on version 1, please upgrade – we have a migration guide that details everything you need to do to update to the latest and greatest version. If you encounter any bugs, unexpected behavior, or anything blocking you from upgrading, file an issue! If you’re not using Wrangler, give it a shot! We’re really proud of what we’ve built, and we want your feedback on how we can continue to make it even better.
Developer Week 2022 has come to a close. Over the last week we’ve shared with you 31 posts on what you can build on Cloudflare and our vision and roadmap on where we’re headed. We shared product announcements, customer and partner stories, and provided technical deep dives. In case you missed any of the posts here’s a handy recap.
Our vision of the cloud — a model of cloud computing that promises to make developers highly productive at scaling from one to Internet-scale in the most flexible, efficient, and economical way.
We’ve revamped our API reference documentation to standardize our API content and improve the overall developer experience when using the Cloudflare APIs.
The Segment Edge SDK, built on Workers, helps applications collect and track events from the client, and get access to realtime user state to personalize experiences.
Next
And that’s it for Developer Week 2022. But you can keep the conversation going by joining our Discord Community.
TypeScript makes it easy for developers to write code that doesn’t crash, by catching type errors before your program runs. We want developers to take advantage of this tooling, which is why one year ago, we built a system to automatically generate TypeScript types for the Cloudflare Workers runtime. This enabled developers to see code completions in their IDEs for Workers APIs, and to type check code before deploying. Each week, a new version of the types would be published, reflecting the most recent changes.
Over the past year, we’ve received lots of feedback from customers and internal teams on how we could improve our types. With the switch to the Bazel build system in preparation for open-sourcing the runtime, we saw an opportunity to rebuild our types to be more accurate, easier to use, and simpler to generate. Today, we’re excited to announce the next major release of @cloudflare/workers-types with a bunch of new features, and the open-sourcing of the fully-rewritten automatic generation scripts.
How to use TypeScript with Workers
Setting up TypeScript in Workers is easy! If you’re just getting started with Workers, install Node.js, then run npx wrangler init in your terminal to generate a new project. If you have an existing Workers project and want to take advantage of our improved typings, install the latest versions of TypeScript and @cloudflare/workers-types with npm install --save-dev typescript @cloudflare/workers-types@latest, then create a tsconfig.json file with the following contents:
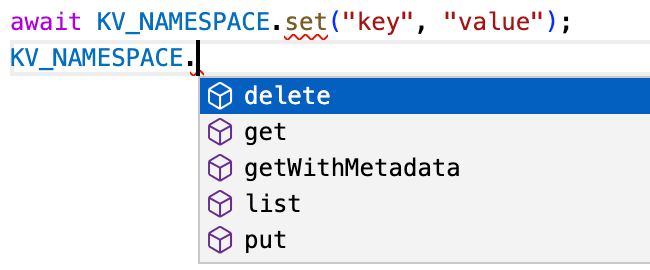
Your editor will now highlight issues and give you code completions as you type, leading to a less error-prone and more enjoyable developer experience.
Editor highlighting incorrect use of set instead of put, and providing code completions
Improved interoperability with standard types
Cloudflare Workers implement many of the same runtime APIs as browsers, and we’re working to improve our standards compliance even more with the WinterCG. However, there will always be fundamental differences between what browsers and Workers can do. For example, browsers can play audio files, whereas Workers have direct access to Cloudflare’s network for storing globally-distributed data. This mismatch means that the runtime APIs and types provided by each platform are different, which in turn makes it difficult to use Workers types with frameworks, like Remix, that run the same files on the Cloudflare network and in the browser. These files need to be type-checked against lib.dom.d.ts, which is incompatible with our types.
To solve this problem, we now generate a separate version of our types that can be selectively imported, without having to include @cloudflare/workers-types in your tsconfig.json’s types field. Here’s an example of what this looks like:
import type { KVNamespace } from "@cloudflare/workers-types";
declare const USERS_NAMESPACE: KVNamespace;
In addition, we automatically generate a diff of our types against TypeScript’s lib.webworker.d.ts. Going forward, we’ll use this to identify areas where we can further improve our spec-compliance.
Improved compatibility with compatibility dates
Cloudflare maintains strong backwards compatibility promises for all the APIs we provide. We use compatibility flags and dates to make breaking changes in a backwards-compatible way. Sometimes these compatibility flags change the types. For example, the global_navigator flag adds a new navigator global, and the url_standard flag changes the URLSearchParams constructor signature.
We now allow you to select the version of the types that matches your compatibility date, so you can be sure you’re not using features that won’t be supported at runtime.
In addition to compatibility dates, your Worker environment configuration also impacts the runtime and type API surface. If you have bindings such as KV namespaces or R2 buckets configured in your wrangler.toml, these need to be reflected in TypeScript types. Similarly, custom text, data and WebAssembly module rules need to be declared so TypeScript knows the types of exports. Previously, it was up to you to create a separate ambient TypeScript file containing these declarations.
To keep wrangler.toml as the single source of truth, you can now run npx wrangler types to generate this file automatically.
For example, the following wrangler.toml…
kv_namespaces = [{ binding = "MY_NAMESPACE", id = "..." }]
rules = [{ type = "Text", globs = ["**/*.txt"] }]
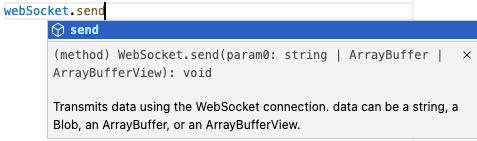
Code completions provide a great way for developers new to the Workers platform to explore the API surface. We now include the documentation for standard APIs from TypeScript’s official types in our types. We’re also starting the process of bringing docs for Cloudflare specific APIs into them too.
For developers already using the Workers platform, it can be difficult to see how types are changing with each release of @cloudflare/workers-types. To avoid type errors and highlight new features, we now generate a detailed changelog with each release that splits out new, changed and removed definitions.
How does type generation work under the hood?
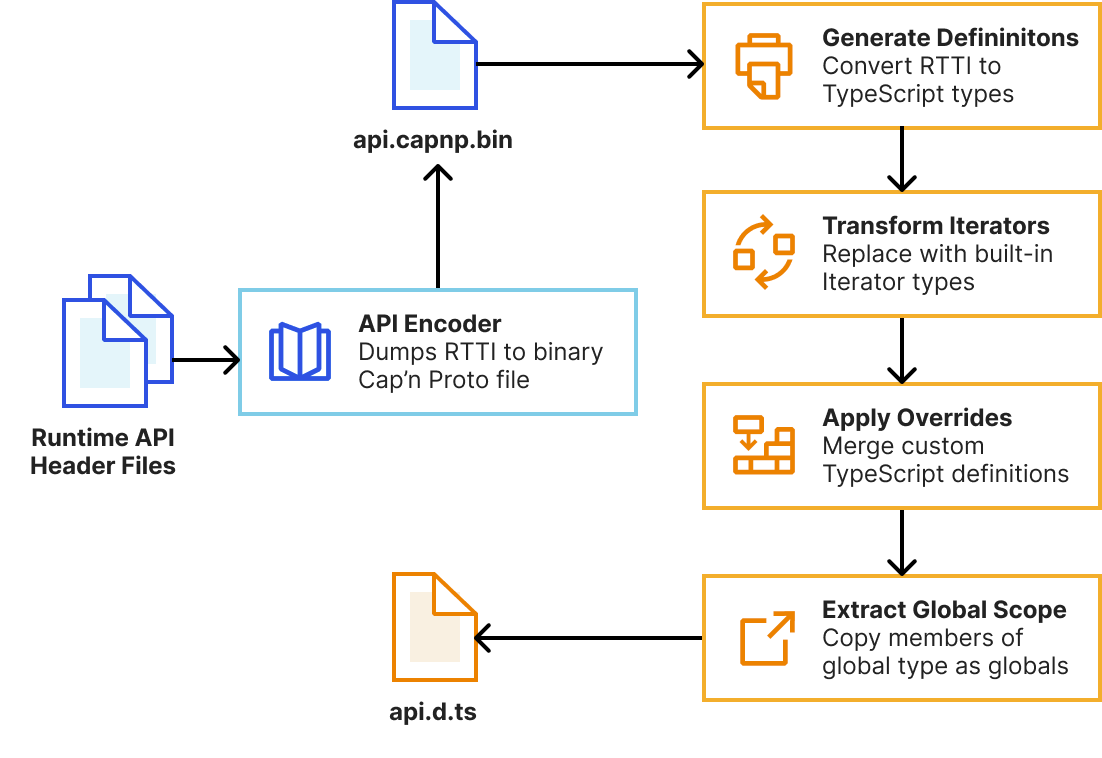
As mentioned earlier, we’ve completely rebuilt the automatic type generation scripts to be more reliable, extensible and maintainable. This means developers will get improved types as soon as new versions of the runtime are published. Our system now uses workerd’s new runtime-type-information (RTTI) system to query types of Workers runtime APIs, rather than attempting to extract this information from parsed C++ ASTs.
// Encode the KV namespace type without any compatibility flags enabled
CompatibilityFlags::Reader flags = {};
auto builder = rtti::Builder(flags);
auto type = builder.structure<KvNamespace>();
capnp::TextCodec codec;
auto encoded = codec.encode(type);
KJ_DBG(encoded); // (name = "KvNamespace", members = [ ... ], ...)
We then pass this RTTI to a TypeScript program that uses the TypeScript Compiler API to generate declarations and perform AST transformations to tidy them up. This is built into workerd’s Bazel build system, meaning generating types is now a single bazel build //types:types command. We leverage Bazel’s cache to rebuild as little as possible during generation.
Whilst the auto-generated types correctly describe the JavaScript interface of Workers runtime APIs, TypeScript provides additional features we can use to provide higher-fidelity types and improve developer ergonomics. Our system allows us to handwrite partial TypeScript “overrides” that get merged with the auto-generated types. This enables us to…
Add type parameters (generics) to types such as ReadableStream and avoid any typed values.
Specify the correspondence between input and output types with method overloads. For example, KVNamespace#get() should return a string when the type argument is text, but ArrayBuffer when it’s arrayBuffer.
Rename types to match TypeScript standards and reduce verbosity.
Fully-replace a type for more accurate declarations. For example, we replace WebSocketPair with a const declaration for better types with Object.values().
Provide types for values that are internally untyped such as the Request#cf object.
Hide internal types that aren’t usable in your workers.
Previously, these overrides were defined in separate TypeScript files to the C++ declarations they were overriding. This meant they often fell out-of-sync with the original declarations. In the new system, overrides are defined alongside the originals with C++ macros, meaning they can be reviewed alongside runtime implementation changes. See the README for workerd’s JavaScript glue code for many more details and examples.
Try typing with workers-types today!
We encourage you to upgrade to the latest version of @cloudflare/workers-types with npm install --save-dev @cloudflare/workers-types@latest, and try out the new wrangler types command. We’ll be publishing a new version of the types with each workerd release. Let us know what you think on the Cloudflare Developers Discord, and please open a GitHub issue if you find any types that could be improved.
The Cloudflare team was so excited to hear how Twilio Segment solved problems they encountered with tracking first-party data and personalization using Cloudflare Workers. We are happy to have guest bloggers Pooya Jaferian and Tasha Alfano from Twilio Segment to share their story.
Introduction
Twilio Segment is a customer data platform that collects, transforms, and activates first-party customer data. Segment helps developers collect user interactions within an application, form a unified customer record, and sync it to hundreds of different marketing, product, analytics, and data warehouse integrations.
There are two “unsolved” problem with app instrumentation today:
Problem #1: Many important events that you want to track happen on the “wild-west” of the client, but collecting those events via the client can lead to low data quality, as events are dropped due to user configurations, browser limitations, and network connectivity issues.
Problem #2: Applications need access to real-time (<50ms) user state to personalize the application experience based on advanced computations and segmentation logic that must be executed on the cloud.
The Segment Edge SDK – built on Cloudflare Workers – solves for both. With Segment Edge SDK, developers can collect high-quality first-party data. Developers can also use Segment Edge SDK to access real-time user profiles and state, to deliver personalized app experiences without managing a ton of infrastructure.
This post goes deep on how and why we built the Segment Edge SDK. We chose the Cloudflare Workers platform as the runtime for our SDK for a few reasons. First, we needed a scalable platform to collect billions of events per day. Workers running with no cold-start made them the right choice. Second, our SDK needed a fast storage solution, and Workers KV fitted our needs perfectly. Third, we wanted our SDK to be easy to use and deploy, and Workers’ ease and speed of deployment was a great fit.
It is important to note that the Segment Edge SDK is in early development stages, and any features mentioned are subject to change.
Serving a JavaScript library 700M+ times per day
analytics.js is our core JavaScript UI SDK that allows web developers to send data to any tool without having to learn, test, or use a new API every time.
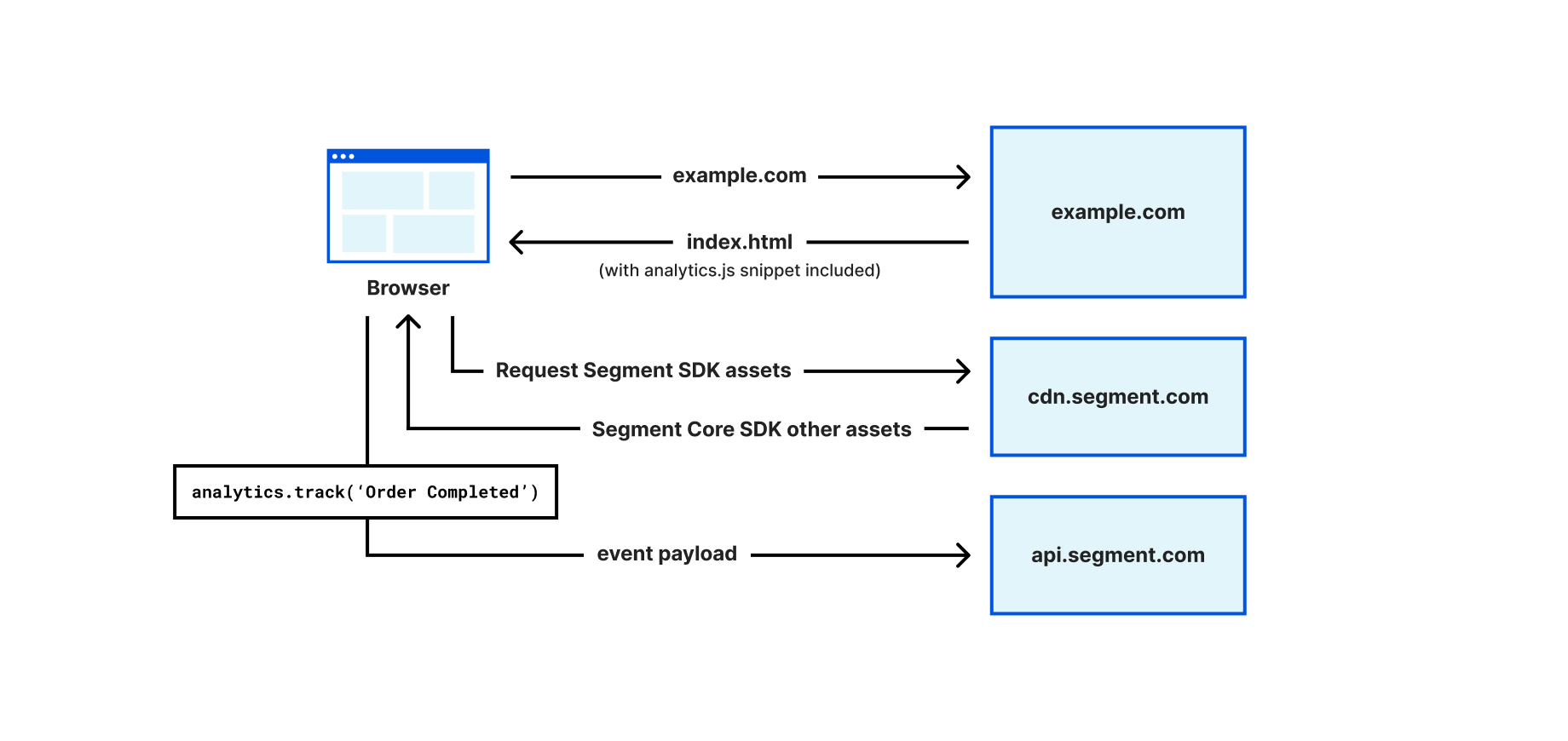
Figure 1 illustrates how Segment can be used to collect data on a web application. Developers add Segment’s web SDK, analytics.js, to their websites by including a JavaScript snippet to the HEAD of their web pages. The snippet can immediately collect and buffer events while it also loads the full library asynchronously from the Segment CDN. Developers can then use analytics.js to identify the visitors, e.g., analytics.identify('john'), and track user behavior, e.g., analytics.track('OrderCompleted'). Calling the `analytics.js methods such as identify or track will send data to Segment’s API (api.segment.io). Segment’s platform can then deliver the events to different tools, as well as create a profile for the user (e.g., build a profile for user “John”, associate “Order Completed”, as well as add all future activities of john to the profile).
Analytics.js also stores state in the browser as first-party cookies (e.g., storing an ajs_user_id cookie with the value of john, with cookie scoped at the example.com domain) so that when the user visits the website again, the user identifier stored in the cookie can be used to recognize the user.
Figure 1- How analytics.js loads on a website and tracks events
While analytics.js only tracks first-party data (i.e., the data is collected and used by the website that the user is visiting), certain browser controls incorrectly identify analytics.js as a third-party tracker, because the SDK is loaded from a third-party domain (cdn.segment.com) and the data is going to a third-party domain (api.segment.com). Furthermore, despite using first-party cookies to store user identity, some browsers such as Safari have limited the TTL for non-HTTPOnly cookies to 7-days, making it challenging to maintain state for long periods of time.
To overcome these limitations, we have built a Segment Edge SDK (currently in early development) that can automatically add Segment’s library to a web application, eliminate the use of third-party domains, and maintain user identity using HTTPOnly cookies. In the process of solving the first-party data problem, we realized that the Edge SDK is best positioned to act as a personalization library, given it has access to the user identity on every request (in the form of cookies), and it can resolve such identity to a full-user profile stored in Segment. The user profile information can be used to deliver personalized content to users directly from the Cloudflare Workers platform.
The remaining portions of this post will cover how we solved the above problems. We first explain how the Edge SDK helps with first-party collection. Then we cover how the Segment profiles database becomes available on the Cloudflare Workers platform, and how to use such data to drive personalization.
Segment Edge SDK and first-party data collection
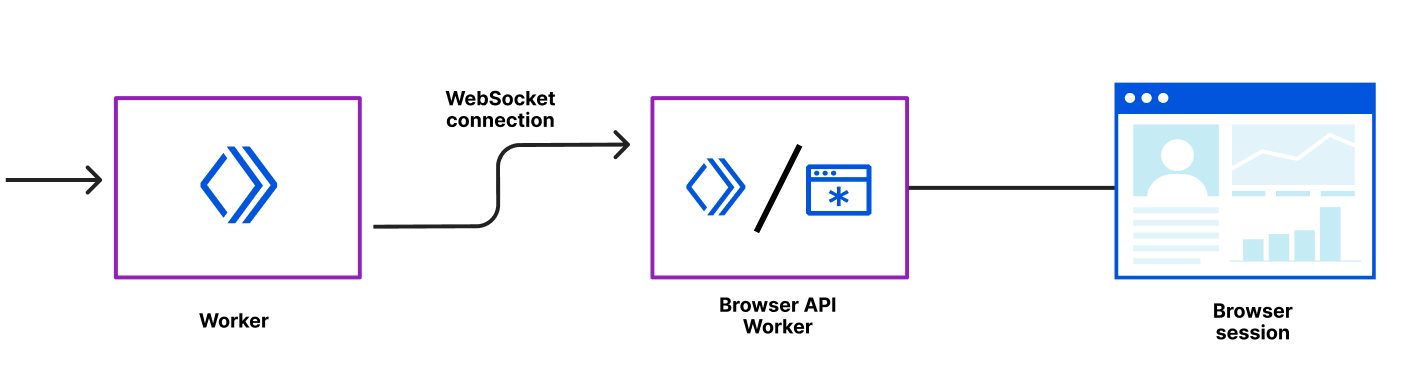
Developers can set up the Edge SDK by creating a Cloudflare Worker sitting in front of their web application (via Routes) and importing the Edge SDK via npm. The Edge SDK will handle requests and automatically injects analytics.js snippets into every webpage. It also configures first-party endpoints to download the SDK assets and send tracking data. The Edge SDK also captures user identity by looking at the Segment events and instructs the browser to store such identity as HTTPOnly cookies.
How the Edge SDK works under the hood to enable first-party data collection
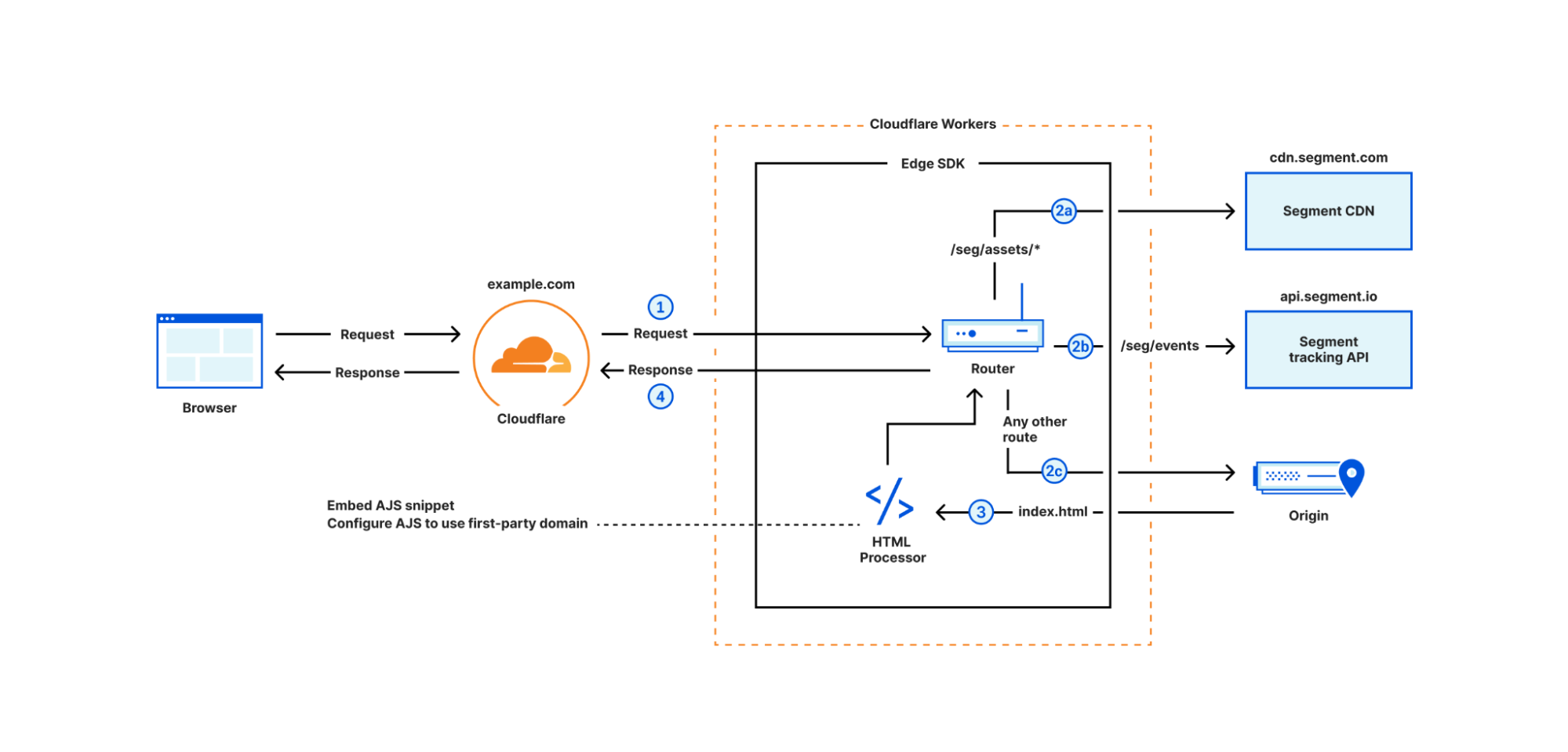
The Edge SDK’s internal router checks the inbound request URL against predefined patterns. If the URL matches a route, the router runs the route’s chain of handlers to process the request, fetch the origin, or modify the response.
Figure 2 demonstrates the routing of incoming requests. The Worker calls segment.handleEvent method with the request object (step 1), then the router matches the request.url and request.method against a set of predefined routes:
GET requests with /seg/assets/* path are proxied to Segment CDN (step 2a)
POST requests with /seg/events/* path are proxied to Segment tracking API (step 2b)
Other requests are proxied to the origin (step 2c) and the HTML responses are enriched with the analytics.js snippet (step 3)
Regardless of the route, the router eventually returns a response to the browser (step 4) containing data from the origin, the response from Segment tracking API, or analytics.js assets. When Edge SDK detects the user identity in an incoming request (more on that later), it sets an HTTPOnly cookie in the response headers to persist the user identity in the browser.
Figure 2- Edge SDK router flow
In the subsequent three sections, we explain how we inject analytics.js, proxy Segment endpoints, and set server-side cookies.
Injecting Segment SDK on requests to origin
For all the incoming requests routed to the origin, the Edge SDK fetches the HTML page and then adds the analytics.js snippet to the <HEAD> tag, embeds the write key, and configures the snippet to download the subsequent javascript bundles from the first-party domain ([first-party host]/seg/assets/*) and sends data to the first-party domain as well ([first-party host]/seg/events/*). This is accomplished using the HTMLRewriter API.
import snippet from "@segment/snippet"; // Existing Segment package that generates snippet
class ElementHandler {
constructor(host: string, writeKey: string)
element(element: Element) {
// generate Segment snippet and configure it with first-party host info
const snip = snippet.min({
host: `${this.host}/seg`,
apiKey: this.writeKey,
})
element.append(`<script>${snip}</script>`, { html: true });
}
}
export const enrichWithAJS: HandlerFunction = async (
request,
response,
context
) => {
const {
settings: { writeKey },
} = context;
const host = request.headers.get("host") || "";
return [
request,
new HTMLRewriter().on("head",
new ElementHandler(host, writeKey))
.transform(response),
context,
];
};
Proxy SDK bundles and Segment API
The Edge SDK proxies the Segment CDN and API under the first-party domain. For example, when the browser loads a page with the injected analytics.js snippet, the snippet loads the full analytics.js bundle from https://example.com/seg/assets/sdk.js, and the Edge SDK will proxy that request to the Segment CDN:
Similarly, analytics.js collects events and sends them via a POST request to https://example.com/seg/events/[method] and the Edge SDK will proxy such requests to the Segment tracking API:
The Edge SDK also re-writes existing client-side analytics.js cookies as HTTPOnly cookies. When Edge SDK intercepts an identify event e.g., analytics.identify('john'), it extracts the user identity (“john”) and then sets a server-side cookie when sending a response back to the user. Therefore, any subsequent request to the Edge SDK can be associated with “john” using request cookies.
Intercepting the ajs_user_id on the Workers, and using the cookie identifier to associate each request to a user, is quite powerful, and it opens the door for delivering personalized content to users. The next section covers how Edge SDK can drive personalization.
Personalization on the Supercloud
The Edge SDK offers a registerVariation method that can customize how a request to a given route should be fetched from the origin. For example, let’s assume we have three versions of a landing page in the origin: /red, /green, and / (default), and we want to deliver one of the three versions based on the visitor traits. We can use Edge SDK as follows:
const segment = new Segment(env.SEGMENT_WRITE_KEY);
segment.registerVariation("/", (profile) => {
if (profile.red_group) {
return "/red"
} else if (profile.green_group)
return "/green"
}
});
const resp = await segment.handleEvent(request, env);
return resp
The registerVariation accepts two inputs: the path that displays the personalized content, and a decision function that should return the origin address for the personalized content. The decision function receives a profile object visitor in Segment. In the example, when users visit example.com/(root path), personalized content is delivered by checking if the visitor has a red_group or green_group trait and subsequently requesting the content from either /red or /green path at the origin.
We already explained that Edge SDK knows the identity of the user via ajs_user_id cookie, but we haven’t covered how the Edge SDK has access to the full profile object. The next section explains how the full profile becomes available on the Cloudflare Workers platform.
How does personalization work under the hood?
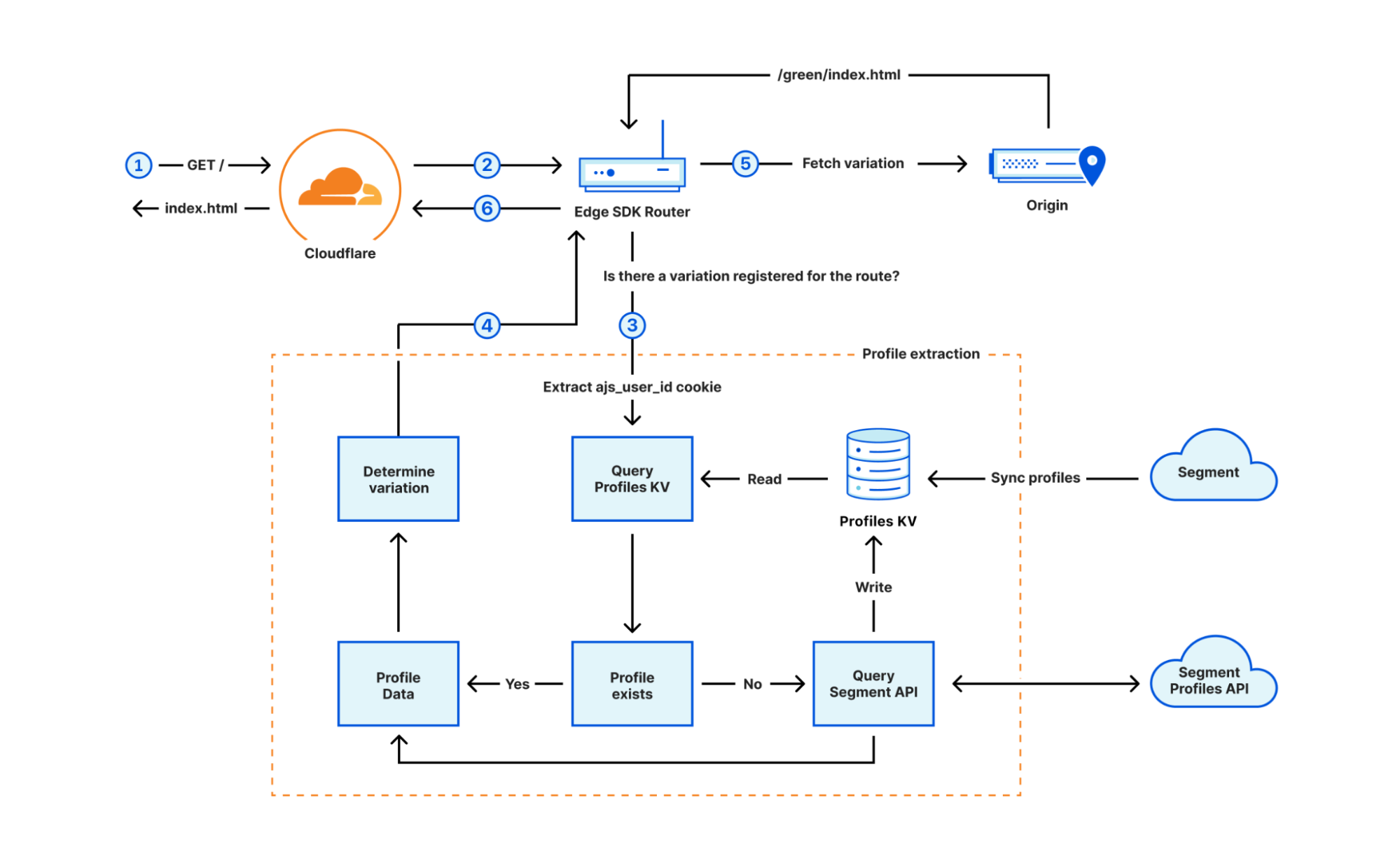
The Personalization feature of the Edge SDK requires storage of profiles on the Cloudflare Workers platform. A Cloudflare KV should be created for the Worker running the Edge SDK and passed to the Edge SDK during initialization. Edge SDK will store profiles in KV, where keys are the ajs_user_id, and values are the serialized profile object. To move Profiles data from Segment to the KV, the SDK uses two methods:
Profiles data push from Segment to the Cloudflare Workers platform: The Segment product can sync user profiles database with different tools, including pushing the data to a webhook. The Edge SDK automatically exposes a webhook endpoint under the first-party domain (e.g., example.com/seg/profiles-webhook) that Segment can call periodically to sync user profiles. The webhook handler receives incoming sync calls from Segment, and writes profiles to the KV.
Pulling data from Segment by the Edge SDK: If the Edge SDK queries the KV for a user id, and doesn’t find the profile (i.e., data hasn’t synced yet), it requests the user profile from the Segment API, and stores it in the KV.
Figure 3 demonstrates how the personalization flow works. In step 1, the user requests content for the root path ( / ), and the Worker sends the request to the Edge SDK (step 2). The Edge SDK router determines that a variation is registered on the route, therefore, extracts the ajs_user_id from the request cookies, and goes through the full profile extraction (step 3). The SDK first checks the KV for a record with the key of ajs_user_id value and if not found, queries Segment API to fetch the profile, and stores the profile in the KV. Eventually, the profile is extracted and passed into the decision function to decide which path should be served to the user (step 4). The router eventually fetches the variation from the origin (step 5) and returns the response under the / path to the browser (step 6).
Figure 3- Personalization flow
Summary
In this post we covered how the Cloudflare Workers platform can help with tracking first-party data and personalization. We also explained how we built a Segment Edge SDK to enable Segment customers to get those benefits out of the box, without having to create their own DIY solution. The Segment Edge SDK is currently in early development, and we are planning to launch a private pilot and open-source it in the near future.
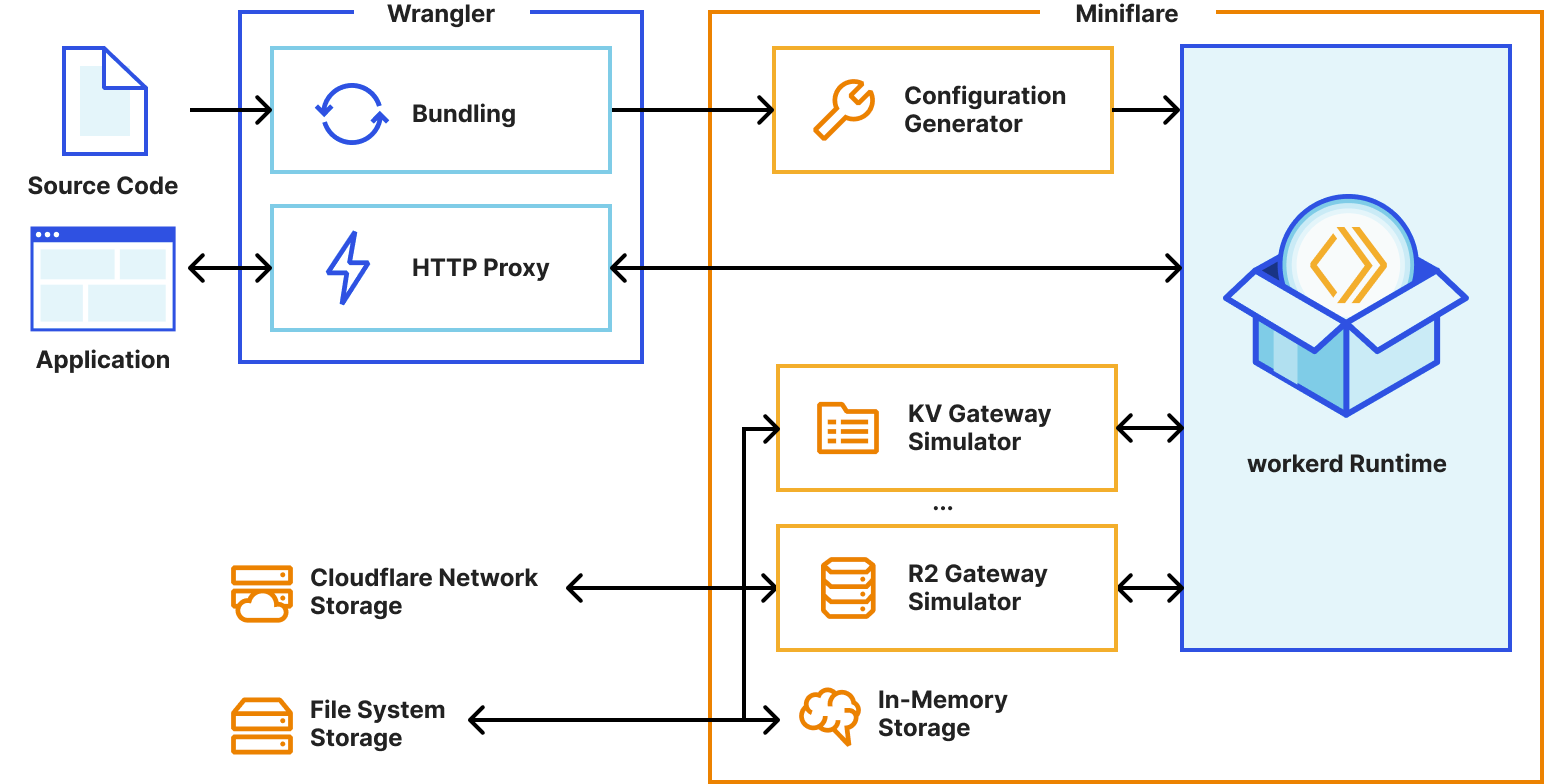
Local development gives you a fully-controllable and easy-to-debug testing environment. At the start of this year, we brought this experience to Workers developers by launching Miniflare 2.0: a local Cloudflare Workers simulator. Miniflare 2 came with features like step-through debugging support, detailed console.logs, pretty source-mapped error pages, live reload and a highly-configurable unit testing environment. Not only that, but we also incorporated Miniflare into Wrangler, our Workers CLI, to enable wrangler dev’s —local mode.
Today, we’re taking local development to the next level! In addition to introducing new support for migrating existing projects to your local development environment, we’re making it easier to work with your remote data—locally! Most importantly, we’re releasing a much more accurate Miniflare 3, powered by the recently open-sourced workerd runtime—the same runtime used by Cloudflare Workers!
Enabling local development with workerd
One of the superpowers of having a local development environment is that you can test changes without affecting users in production. A great local environment offers a level of fidelity on par with production.
The way we originally approached local development was with Miniflare 2, which reimplemented Workers runtime APIs in JavaScript. Unfortunately, there were subtle behavior mismatches between these re-implementations and the real Workers runtime. These types of issues are really difficult for developers to debug, as they don’t appear locally, and step-through debugging of deployed Workers isn’t possible yet. For example, the following Worker returns responses successfully in Miniflare 2, so we might assume it’s safe to publish:
let cachedResponsePromise;
export default {
async fetch(request, env, ctx) {
// Let's imagine this fetch takes a few seconds. To speed up our worker, we
// decide to only fetch on the first request, and reuse the result later.
// This works fine in Miniflare 2, so we must be good right?
cachedResponsePromise ??= fetch("https://example.com");
return (await cachedResponsePromise).clone();
},
};
However, as soon as we send multiple requests to our deployed Worker, it fails with Error: Cannot perform I/O on behalf of a different request. The problem here is that response bodies created in one request’s handler cannot be accessed from a different request’s handler. This limitation allows Cloudflare to improve overall Worker performance, but it was almost impossible for Miniflare 2 to detect these types of issues locally. In this particular case, the best solution is to cache using fetch itself.
Additionally, because the Workers runtime uses a very recent version of V8, it supports some JavaScript features that aren’t available in all versions of Node.js. This meant a few features implemented in Workers, like Array#findLast, weren’t always available in Miniflare 2.
With the Workers runtime now open-sourced, Miniflare 3 can leverage the same implementations that are deployed on Cloudflare’s network, giving bug-for-bug compatibility and practically eliminating behavior mismatches. 🎉
Miniflare 3’s new simplified architecture using worked
This radically simplifies our implementation too. We were able to remove over 50,000 lines of code from Miniflare 2. Of course, we still kept all the Miniflare special-sauce that makes development fun like live reload and detailed logging. 🙂
Local development with real data
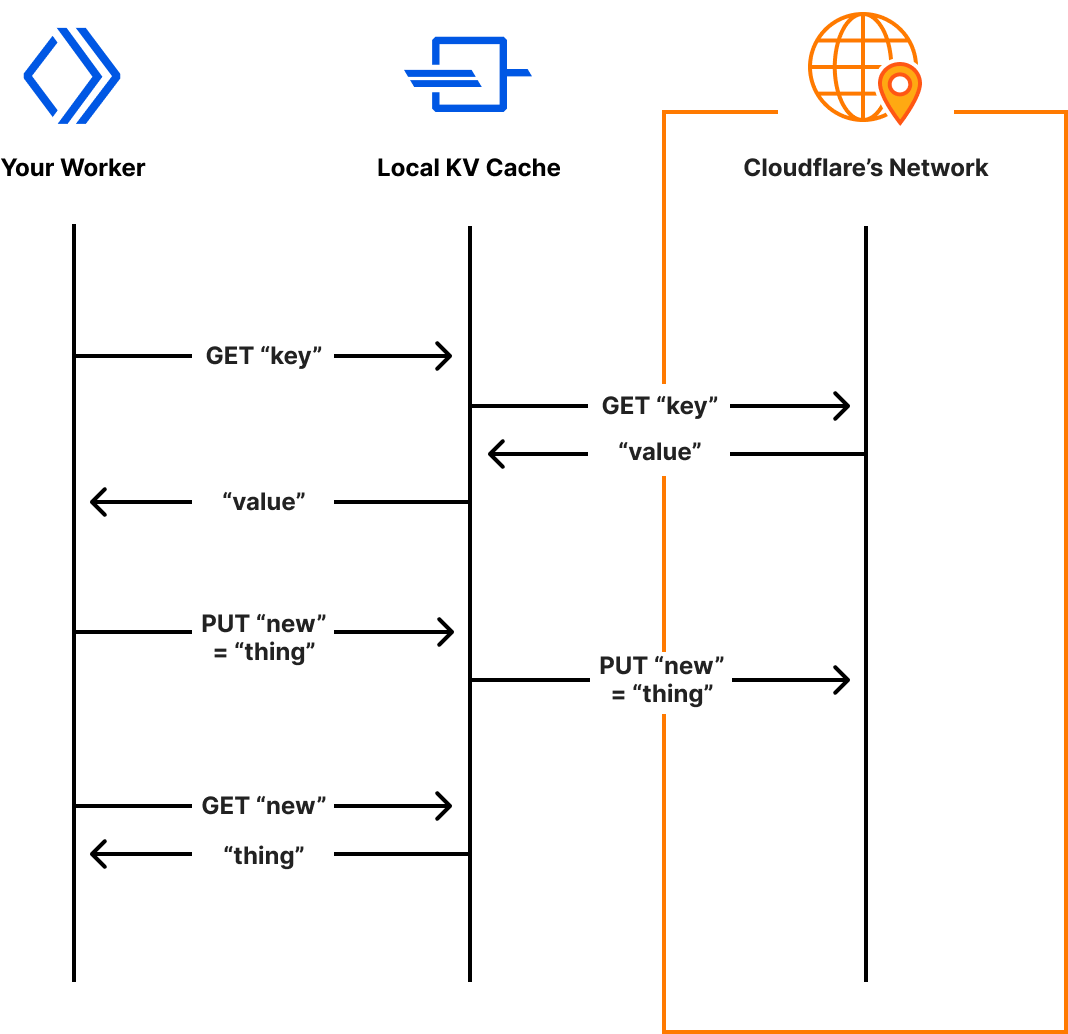
We know that many developers choose to test their Workers remotely on the Cloudflare network as it gives them the ability to test against real data. Testing against fake data in staging and local environments is sometimes difficult, as it never quite matches the real thing.
With Miniflare 3, we’re blurring the lines between local and remote development, by bringing real data to your machine as an experimental opt-in feature. If enabled, Miniflare will read and write data to namespaces on the Cloudflare network, as your Worker would when deployed. This is only supported with Workers KV for now, but we’re exploring similar solutions for R2 and D1.
Miniflare’s system for accessing real KV data, reads and writes are cached locally for future accesses
A new default for Wrangler
With Miniflare 3 now effectively as accurate as the real Workers environment, and the ability to access real data locally, we’re revisiting the decision to make remote development the initial Wrangler experience. In a future update, wrangler dev --local will become the default. --local will no longer be required. Benchmarking suggests this will bring an approximate 10x reduction to startup and a massive 60x reduction to script reload times! Over the next few weeks, we’ll be focusing on further optimizing Wrangler’s performance to bring you the fastest Workers development experience yet!
wrangler init --from-dash
We want all developers to be able to take advantage of the improved local experience, so we’re making it easy to start a local Wrangler project from an existing Worker that’s been developed in the Cloudflare dashboard. With Node.js installed, run npx wrangler init –from-dash <your_worker_name> in your terminal to set up a new project with all your existing code and bindings such as KV namespaces configured. You can now seamlessly continue development of your application locally, taking advantage of all the developer experience improvements Wrangler and Miniflare provide. When you’re ready to deploy your worker, run npx wrangler publish.
Looking to the future
Over the next few months, the Workers team is planning to further improve the local development experience with a specific focus on automated testing. Already, we’ve released a preliminary API for programmatic end-to-end tests with wrangler dev, but we’re also investigating ways of bringing Miniflare 2’s Jest/Vitest environments to workerd. We’re also considering creating extensions for popular IDEs to make developing workers even easier. 👀
Miniflare 3.0 is now included in Wrangler! Try it out by running npx wrangler@latest dev --experimental-local. Let us know what you think in the #wrangler channel on the Cloudflare Developers Discord, and please open a GitHub issue if you hit any unexpected behavior.
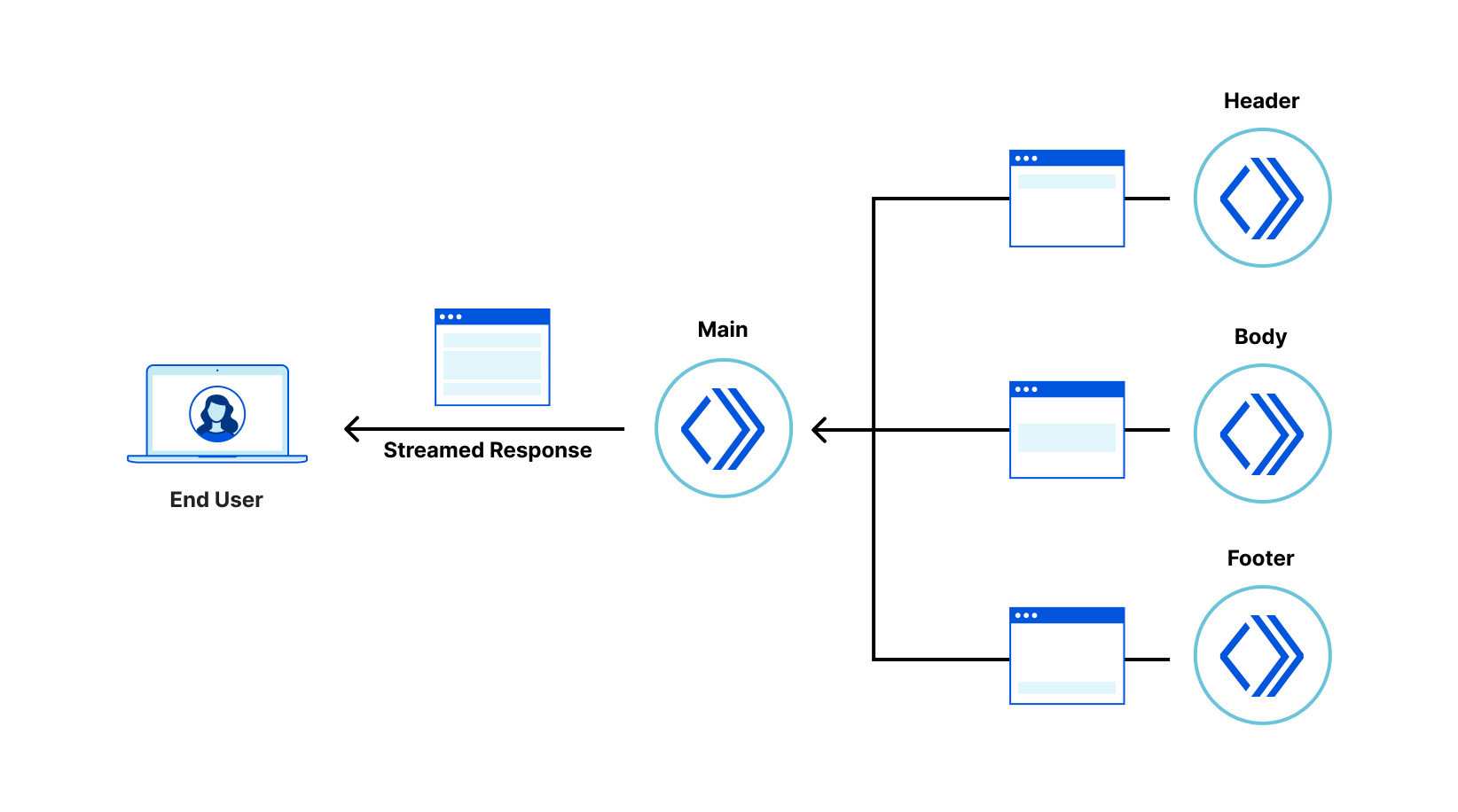
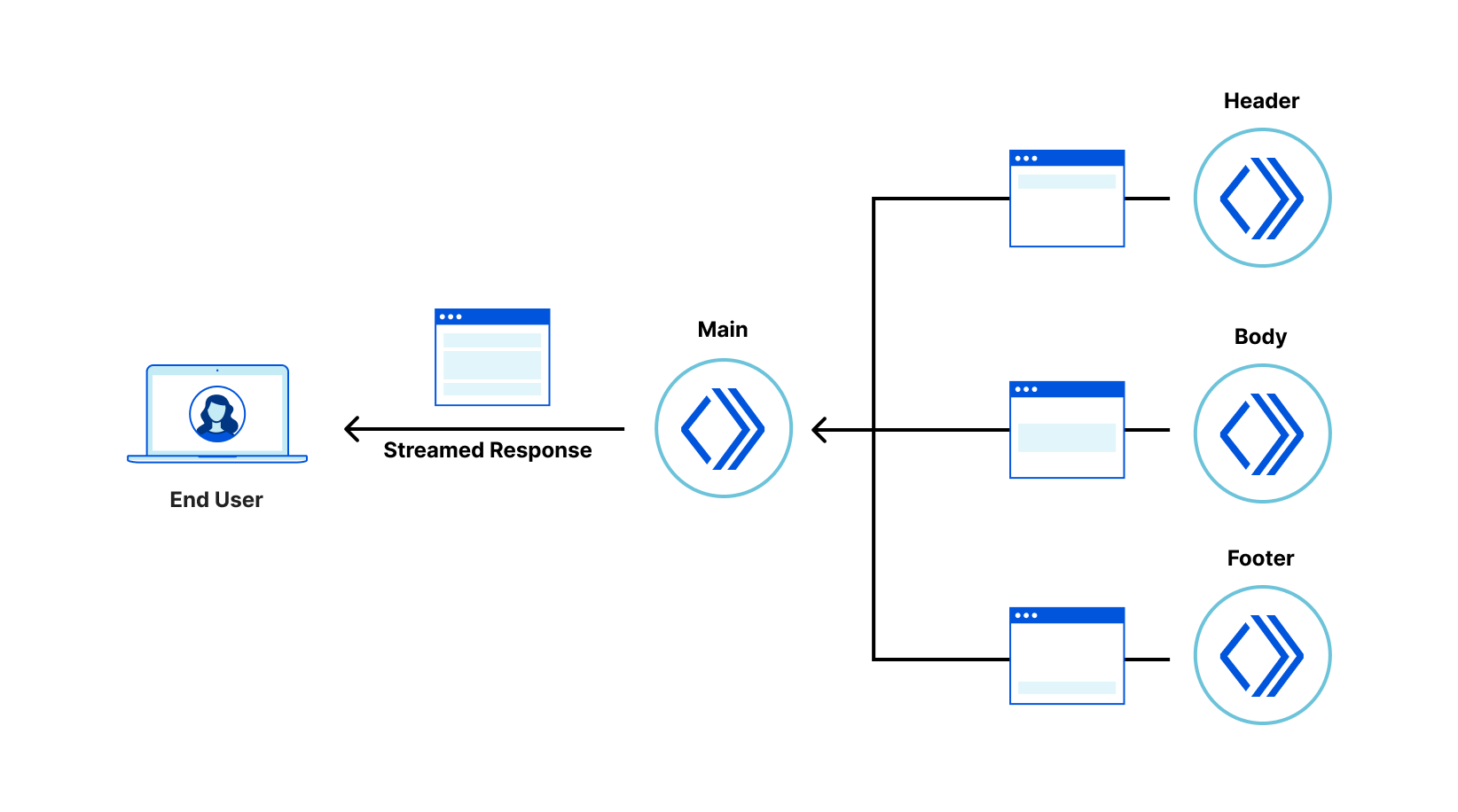
Bring micro-frontend benefits to legacy Web applications
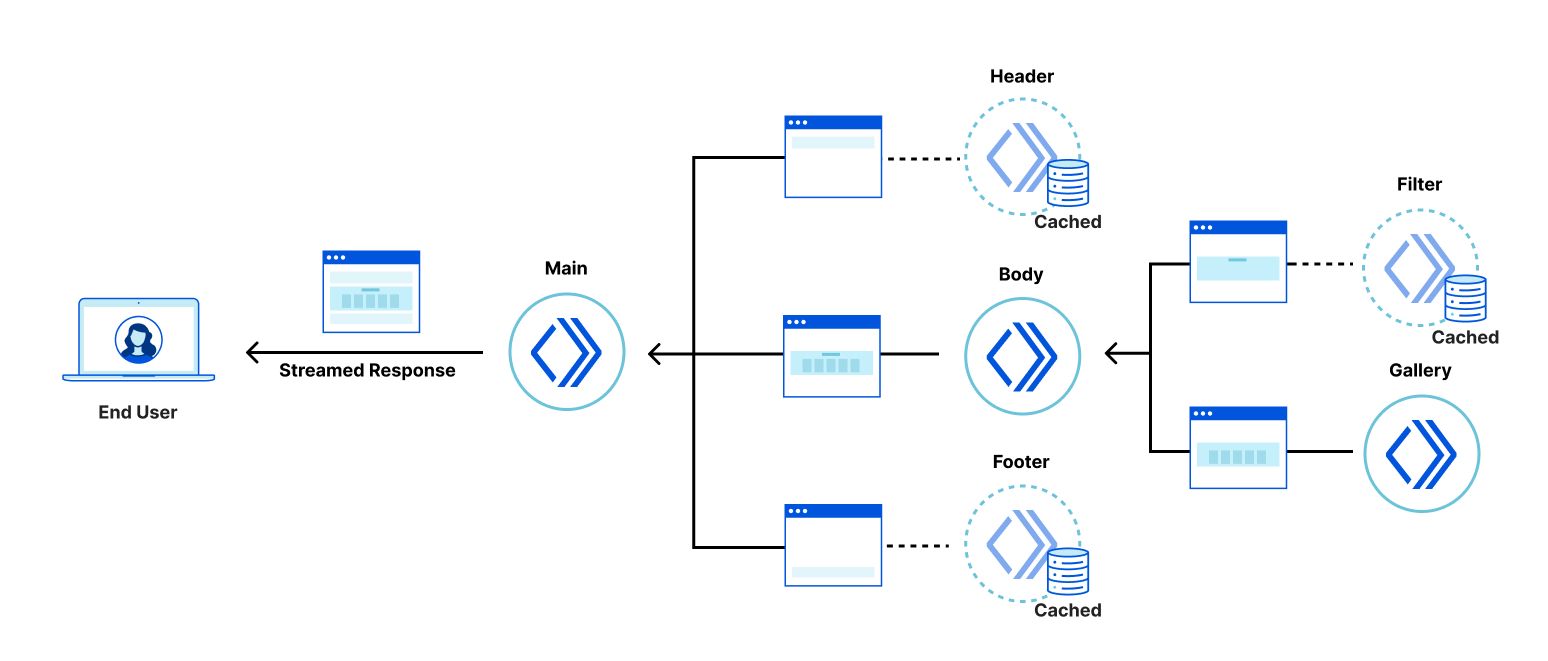
Recently, we wrote about a new fragment architecture for building Web applications that is fast, cost-effective, and scales to the largest projects, while enabling a fast iteration cycle. The approach uses multiple collaborating Cloudflare Workers to render and stream micro-frontends into an application that is interactive faster than traditional client-side approaches, leading to better user experience and SEO scores.
This approach is great if you are starting a new project or have the capacity to rewrite your current application from scratch. But in reality most projects are too large to be rebuilt from scratch and can adopt architectural changes only in an incremental way.
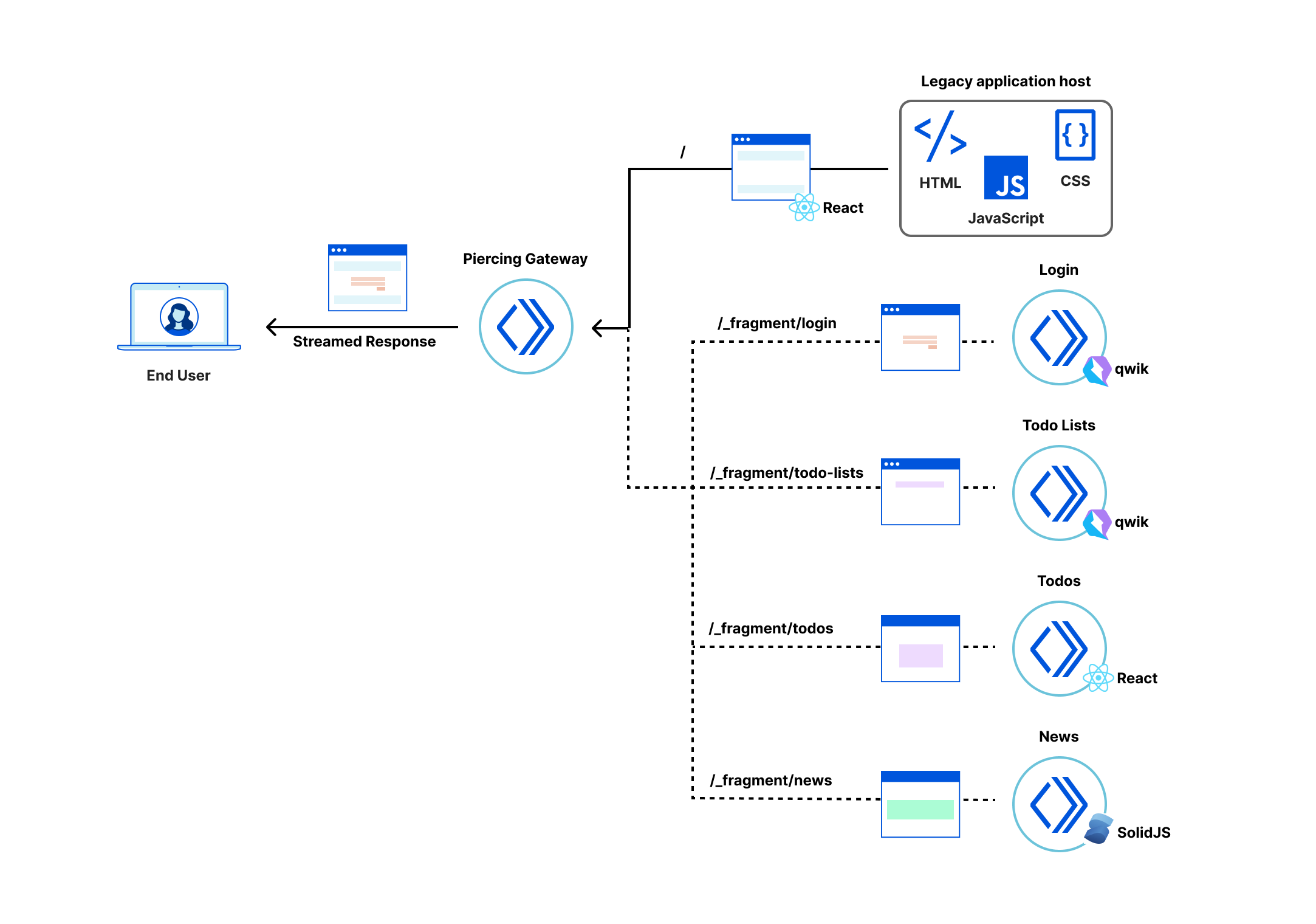
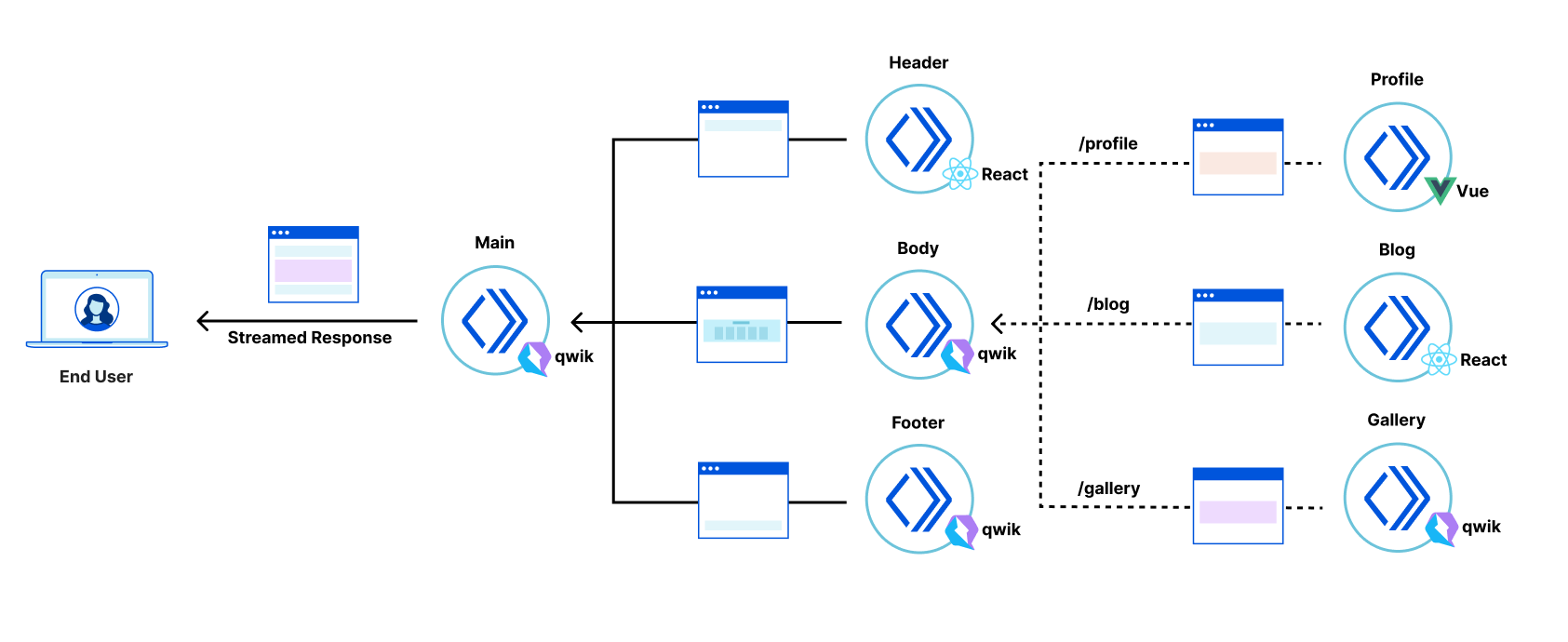
In this post we propose a way to replace only selected parts of a legacy client-side rendered application with server-side rendered fragments. The result is an application where the most important views are interactive sooner, can be developed independently, and receive all the benefits of the micro-frontend approach, while avoiding large rewrites of the legacy codebase. This approach is framework-agnostic; in this post we demonstrate fragments built with React, Qwik, and SolidJS.
The pain of large frontend applications
Many large frontend applications developed today fail to deliver good user experience. This is often caused by architectures that require large amounts of JavaScript to be downloaded, parsed and executed before users can interact with the application. Despite efforts to defer non-critical JavaScript code via lazy loading, and the use of server-side rendering, these large applications still take too long to become interactive and respond to the user’s inputs.
Furthermore, large monolithic applications can be complex to build and deploy. Multiple teams may be collaborating on a single codebase and the effort to coordinate testing and deployment of the project makes it hard to develop, deploy and iterate on individual features.
As outlined in our previous post, micro-frontends powered by Cloudflare Workers can solve these problems but converting an application monolith to a micro-frontend architecture can be difficult and expensive. It can take months, or even years, of engineering time before any benefits are perceived by users or developers.
What we need is an approach where a project can incrementally adopt micro-frontends into the most impactful parts of the application incrementally, without needing to rewrite the whole application in one go.
Fragments to the rescue
The goal of a fragment based architecture is to significantly decrease loading and interaction latency for large web applications (as measured via Core Web Vitals) by breaking the application into micro-frontends that can be quickly rendered (and cached) in Cloudflare Workers. The challenge is how to integrate a micro-frontend fragment into a legacy client-side rendered application with minimal cost to the original project.
The technique we propose allows us to convert the most valuable parts of a legacy application’s UI, in isolation from the rest of the application.
It turns out that, in many applications, the most valuable parts of the UI are often nested within an application “shell” that provides header, footer, and navigational elements. Examples of these include a login form, product details panel in an e-commerce application, the inbox in an email client, etc.
Let’s take a login form as an example. If it takes our application several seconds to display the login form, the users will dread logging in, and we might lose them. We can however convert the login form into a server-side rendered fragment, which is displayed and interactive immediately, while the rest of the legacy application boots up in the background. Since the fragment is interactive early, the user can even submit their credentials before the legacy application has started and rendered the rest of the page.
Animation showing the login form being available before the main application
This approach enables engineering teams to deliver valuable improvements to users in just a fraction of the time and engineering cost compared to traditional approaches, which either sacrifice user experience improvements, or require a lengthy and high-risk rewrite of the entire application. It allows teams with monolithic single-page applications to adopt a micro-frontend architecture incrementally, target the improvements to the most valuable parts of the application, and therefore front-load the return on investment.
An interesting challenge in extracting parts of the UI into server-side rendered fragments is that, once displayed in the browser, we want the legacy application and the fragments to feel like a single application. The fragments should be neatly embedded within the legacy application shell, keeping the application accessible by correctly forming the DOM hierarchy, but we also want the server-side rendered fragments to be displayed and become interactive as quickly as possible — even before the legacy client-side rendered application shell comes into existence. How can we embed UI fragments into an application shell that doesn’t exist yet? We resolved this problem via a technique we devised, which we call “fragment piercing”.
Fragment piercing
Fragment piercing combines HTML/DOM produced by server-side rendered micro-frontend fragments with HTML/DOM produced by a legacy client-side rendered application.
The micro-frontend fragments are rendered directly into the top level of the HTML response, and are designed to become immediately interactive. In the background, the legacy application is client-side rendered as a sibling of these fragments. When it is ready, the fragments are “pierced” into the legacy application – the DOM of each fragment is moved to its appropriate place within the DOM of the legacy application – without causing any visual side effects, or loss of client-side state, such as focus, form data, or text selection. Once “pierced”, a fragment can begin to communicate with the legacy application, effectively becoming an integrated part of it.
Here, you can see a “login” fragment and the empty legacy application “root” element at the top level of the DOM, before piercing.
To keep the fragment from moving and causing a visible layout shift during this transition, we apply CSS styles that position the fragment in the same way before and after piercing.
At any time an application can be displaying any number of pierced fragments, or none at all. This technique is not limited only to the initial load of the legacy application. Fragments can also be added to and removed from an application, at any time. This allows fragments to be rendered in response to user interactions and client-side routing.
With fragment piercing, you can start to incrementally adopt micro-frontends, one fragment at a time. You decide on the granularity of fragments, and which parts of the application to turn into fragments. The fragments don’t all have to use the same Web framework, which can be useful when switching stacks, or during a post-acquisition integration of multiple applications.
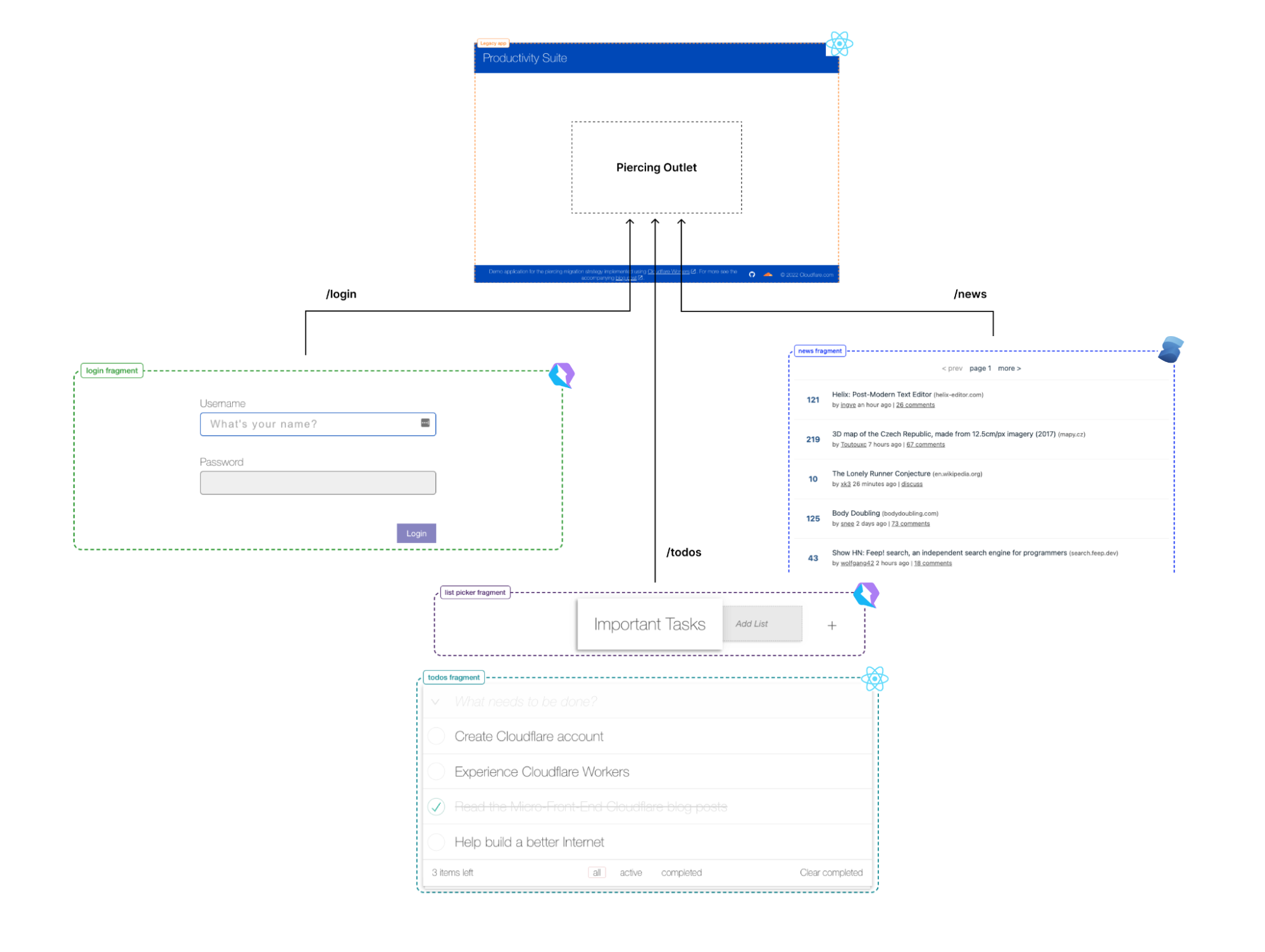
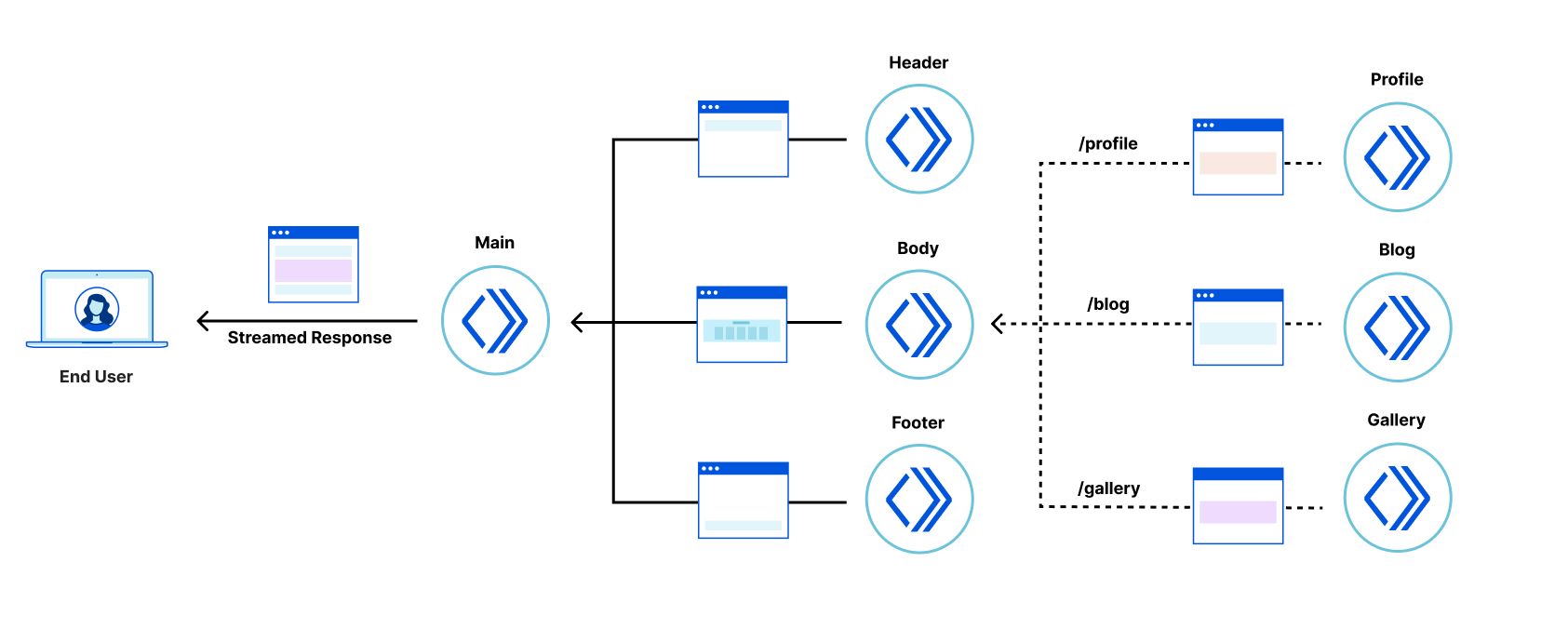
The “Productivity Suite” demo
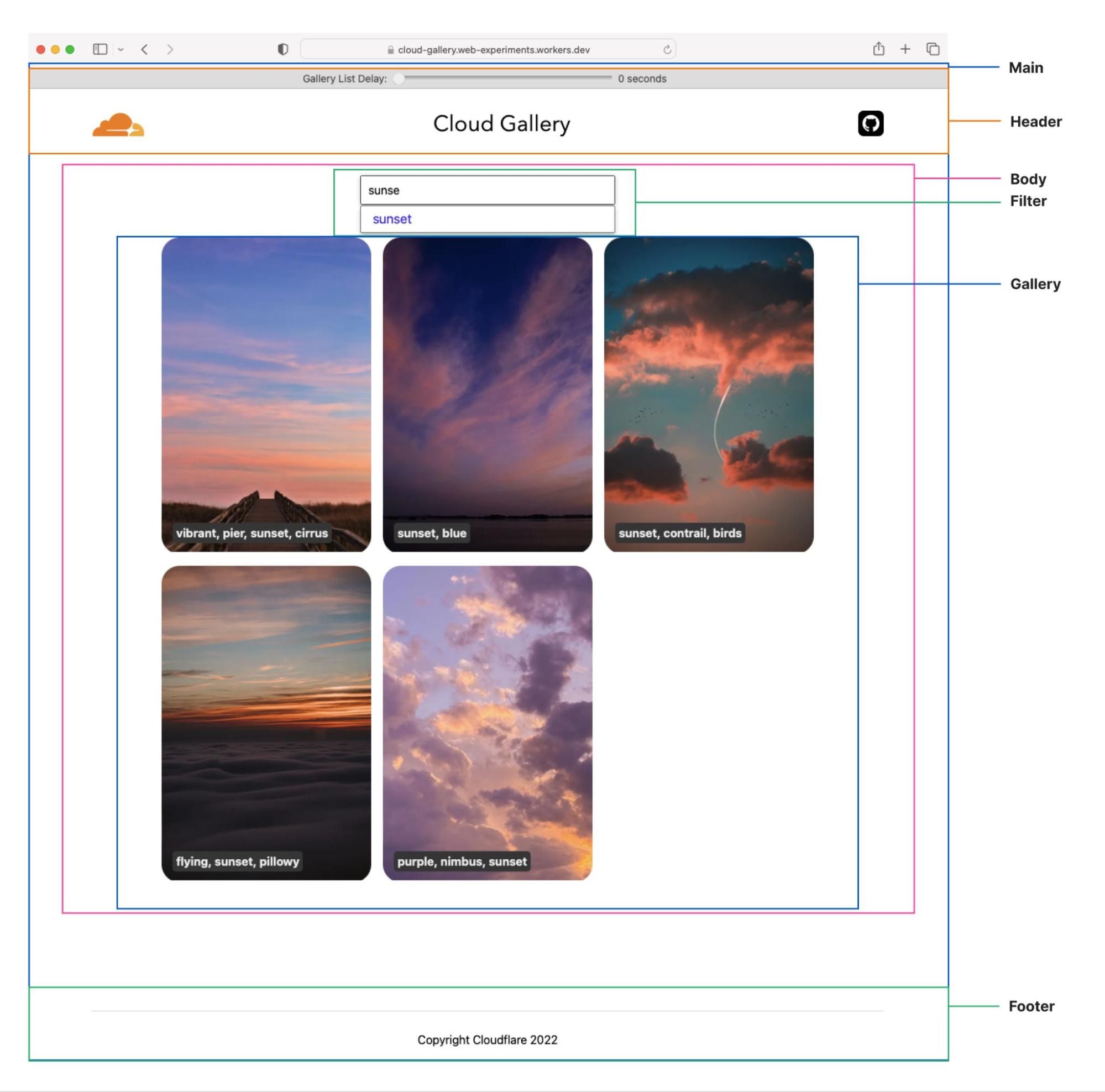
As a demonstration of fragment piercing and incremental adoption we have developed a “productivity suite” demo application that allows users to manage to-do lists, read hacker news, etc. We implemented the shell of this application as a client-side rendered React application — a common tech choice in corporate applications. This is our “legacy application”. There are three routes in the application that have been updated to use micro-frontend fragments:
/login – a simple dummy login form with client-side validation, displayed when users are not authenticated (implemented in Qwik).
/todos – manages one or more todo lists, implemented as two collaborating fragments:
Todo list selector – a component for selecting/creating/deleting Todo lists (implemented in Qwik).
Todo list editor – a clone of the TodoMVC app (implemented in React).
To try it out, you first need to log in – simply use any username you like (no password needed). The user’s data is saved in a cookie, so you can log out and back in using the same username. After you’ve logged in, navigate through the various pages using the navigation bar at the top of the application. In particular, take a look at the “Todo Lists” and “News” pages to see the piercing in action.
At any point, try reloading the page to see that fragments are rendered instantly while the legacy application loads slowly in the background. Try interacting with the fragments even before the legacy application has appeared!
At the very top of the page there are controls to let you see the impact of fragment piercing in action.
Use the “Legacy app bootstrap delay” slider to set the simulated delay before the legacy application starts.
Toggle “Piercing Enabled” to see what the user experience would be if the app did not use fragments.
Toggle “Show Seams” to see where each fragment is on the current page.
How it works
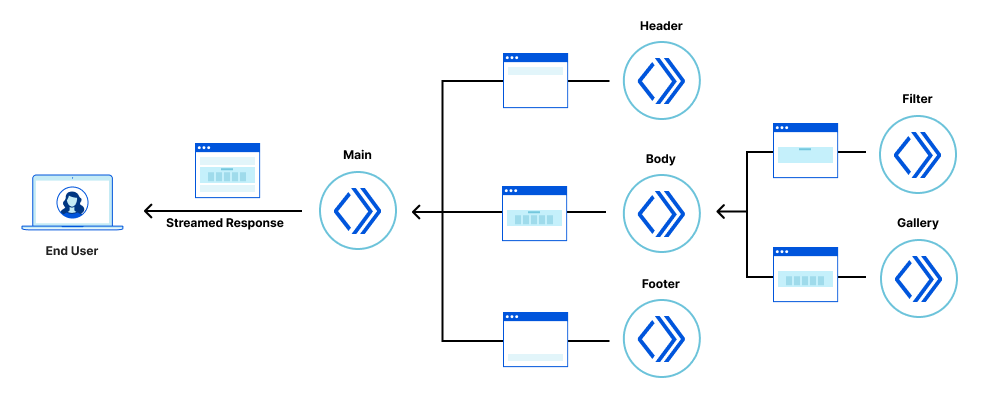
The application is composed of a number of building blocks.
An overview of the collaborating Workers and legacy application host
The Legacy application host in our demoserves the files that define the client-side React application (HTML, JavaScript and stylesheets). Applications built with other tech stacks would work just as well. The Fragment Workers hostthe micro-frontend fragments, as described in our previous fragment architecture post. And the Gateway Worker handles requests from the browser, selecting, fetching and combining response streams from the legacy application and micro-frontend fragments.
Once these pieces are all deployed, they work together to handle each request from the browser. Let’s look at what happens when you go to the `/login` route.
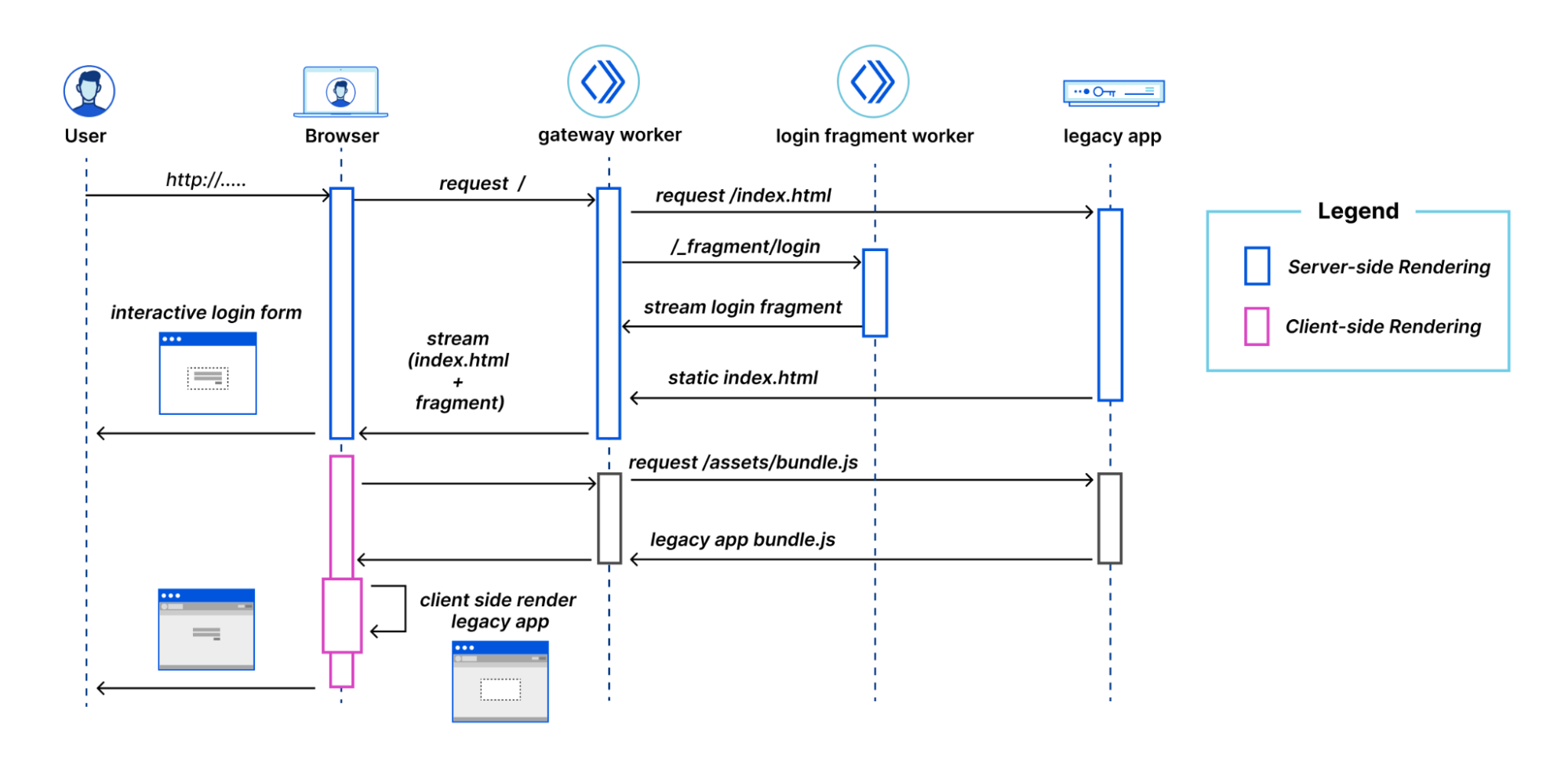
The flow of requests when viewing the login page
The user navigates to the application and the browser makes a request to the Gateway Worker to get the initial HTML. The Gateway Worker identifies that the browser is requesting the login page. It then makes two parallel sub-requests – one to fetch the index.html of the legacy application, and another to request the server-side rendered login fragment. It then combines these two responses into a single response stream containing the HTML that is delivered to the browser.
The browser displays the HTML response containing the empty root element for the legacy application, and the server-side rendered login fragment, which is immediately interactive for the user.
The browser then requests the legacy application’s JavaScript. This request is proxied by the Gateway Worker to the Legacy application host. Similarly, any other assets for the legacy application or fragments get routed through the Gateway Worker to the legacy application host or appropriate Fragment Worker.
Once the legacy application’s JavaScript has been downloaded and executed, rendering the shell of the application in the process, the fragment piercing kicks in, moving the fragment into the appropriate place in the legacy application, while preserving all of its UI state.
While focussed on the login fragment to explain fragment piercing, the same ideas apply to the other fragments implemented in the /todos and /news routes.
The piercing library
Despite being implemented using different Web frameworks, all the fragments are integrated into the legacy application in the same way using helpers from a “Piercing Library”. This library isa collection of server-side and client-side utilities that we developed, for the demo, to handle integrating the legacy application with micro-frontend fragments. The main features of the library are the PiercingGateway class, fragment host and fragment outlet custom elements, and the MessageBus class.
PiercingGateway
The PiercingGateway class can be used to instantiate a Gateway Worker that handles all requests for our application’s HTML, JavaScript and other assets. The `PiercingGateway` routes requests through to the appropriate Fragment Workers or to the host of the Legacy Application. It also combines the HTML response streams from these fragments with the response from the legacy application into a single HTML stream that is returned to the browser.
Implementing a Gateway Worker is straightforward using the Piercing Library. Create a new gateway instance of PiercingGateway, passing it the URL to the legacy application host and a function to determine whether piercing is enabled for the given request. Export the gateway as the default export from the Worker script so that the Workers runtime can wire up its fetch() handler.
const gateway = new PiercingGateway<Env>({
// Configure the origin URL for the legacy application.
getLegacyAppBaseUrl: (env) => env.APP_BASE_URL,
shouldPiercingBeEnabled: (request) => ...,
});
...
export default gateway;
Fragments can be registered by calling the registerFragment() method so that the gateway can automatically route requests for a fragment’s HTML and assets to its Fragment Worker. For example, registering the login fragment would look like:
Routing requests and combining HTML responses in the Gateway Worker is only half of what makes piercing possible. The other half needs to happen in the browser where the fragments need to be pierced into the legacy application using the technique we described earlier.
The Gateway Worker wraps the HTML for each fragment in a fragment host. In the browser, the fragment host manages the life-time of the fragment and is used when moving the fragment’s DOM into position in the legacy application.
In the legacy application, the developer marks where a fragment should appear when it is pierced by adding a fragment outlet. Our demo application’s Login route looks as follows:
When a fragment outlet is added to the DOM, it searches the current document for its associated fragment host. If found, the fragment host and its contents are moved inside the outlet. If the fragment host is not found, the outlet will make a request to the gateway worker to fetch the fragment HTML, which is then streamed directly into the fragment outlet, using the writable-dom library (a small but powerful library developed by the MarkoJS team).
This fallback mechanism enables client-side navigation to routes that contain new fragments. This way fragments can be rendered in the browser via both initial (hard) navigation and client-side (soft) navigation.
Message bus
Unless the fragments in our application are completely presentational or self-contained, they also need to communicate with the legacy application and other fragments. The MessageBus is a simple asynchronous, isomorphic, and framework-agnostic communication bus that the legacy application and each of the fragments can access.
In our demo application the login fragment needs to inform the legacy application when the user has authenticated. This message dispatch is implemented in the Qwik LoginForm component as follows:
We settled on this message bus implementation because we needed a solution that was framework-agnostic, and worked well on both the server as well as client.
Give it a go!
With fragments, fragment piercing, and Cloudflare Workers, you can improve performance as well as the development cycle of legacy client-side rendered applications. These changes can be adopted incrementally, and you can even do so while implementing fragments with a Web framework for your choice.
Feel free to clone the repository. It is easy to run locally and even deploy your own version (for free) to Cloudflare. We tried to make the code as reusable as possible. Most of the core logic is in the piercing library that you could try in your own projects. We’d be thrilled to receive feedback, suggestions, or hear about applications you’d like to use it for. Join our GitHub discussion or also reach us on our discord channel.
We believe that combining Cloudflare Workers with the latest ideas from frameworks will drive the next big steps forward in improved experiences for both users and developers in Web applications. Expect to see more demos, blog posts and collaborations as we continue to push the boundaries of what the Web can offer. And if you’d also like to be directly part of this journey, we are also happy to share that we are hiring!
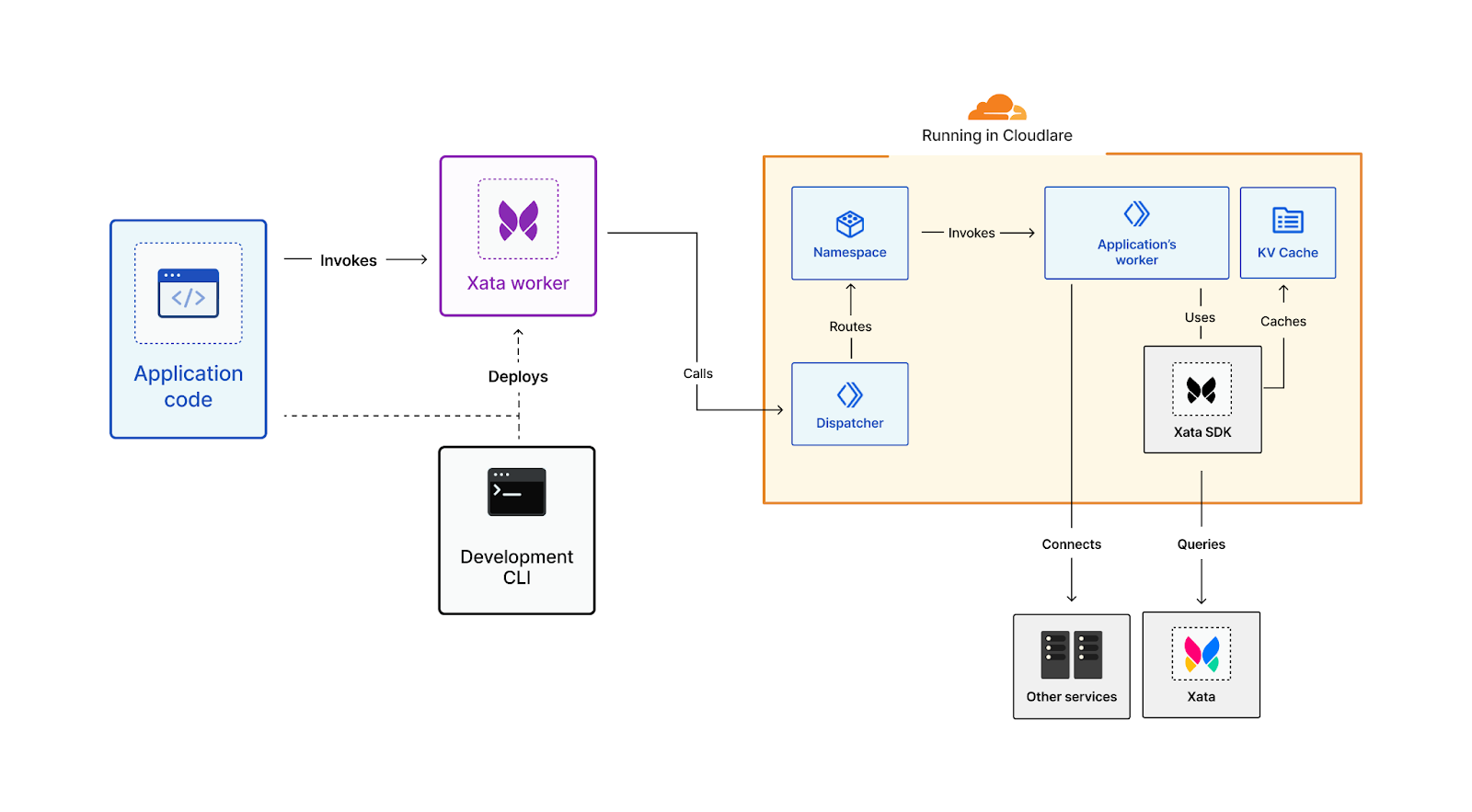
Today we’re happy to introduce Deployments for Workers. Deployments allow developers to keep track of changes to their Worker; not just the code, but the configuration and bindings as well. With deployments, developers now have access to a powerful audit log of changes to their production applications.
And tracking changes is just the beginning! Deployments provide a strong foundation to add: automated deployments, rollbacks, and integration with version control.
Today we’ll dive into the details of deployments, how you can use them, and what we’re thinking about next.
Deployments
Deployments are a powerful new way to track changes to your Workers. With them, you can track who’s making changes to your Workers, where those changes are coming from, and when those changes are being made.
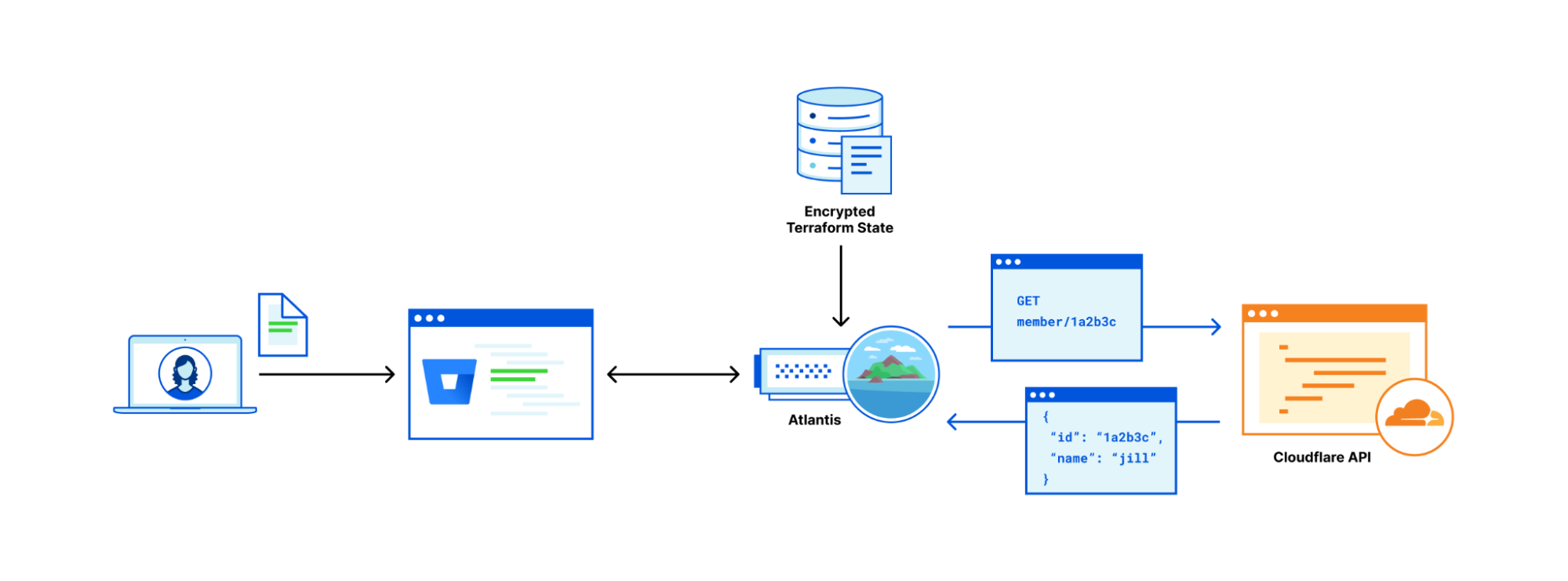
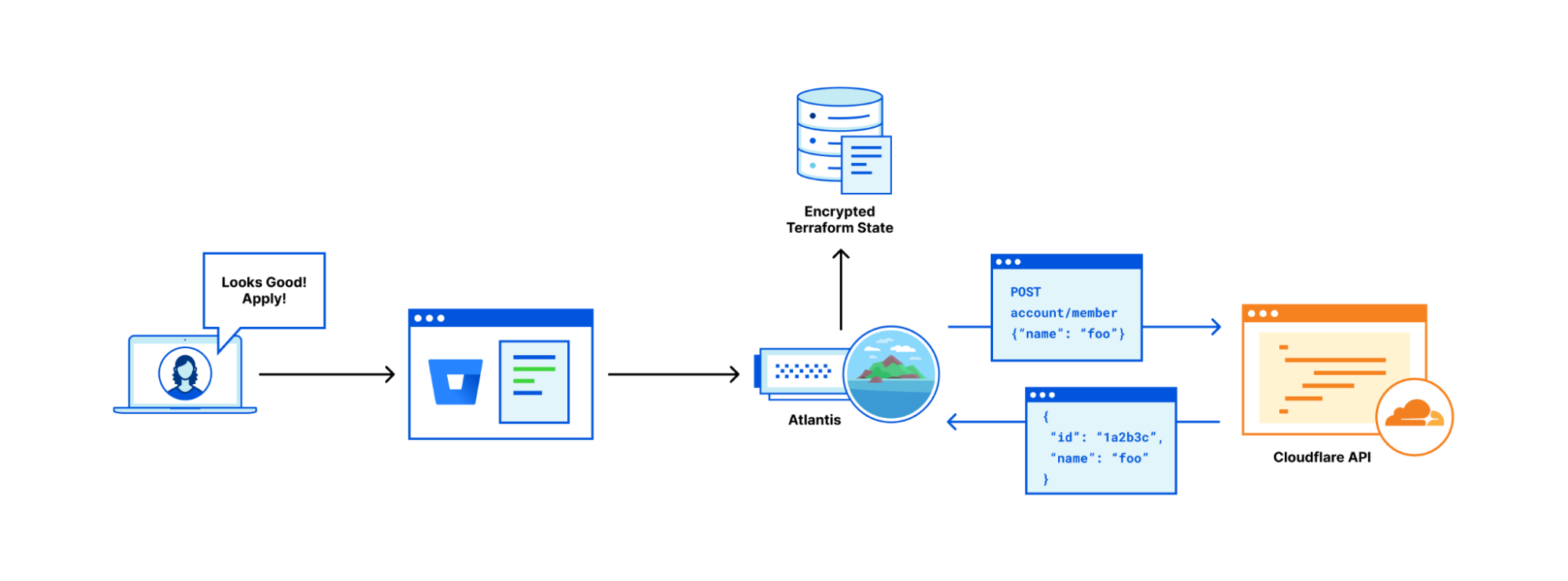
Cloudflare reports on deployments made from wrangler, API, dashboard, or Terraform anytime you make changes to your Worker’s code, edit resource bindings and environment variables, or modify configuration like name or usage model.
We expose the source of your deployments, so you can track where changes are coming from. For example, if you have a CI job that’s responsible for changes, and you see a user made a change through the Cloudflare dashboard, it’s easy to flag that and dig into whether the deployment was a mistake.
Interacting with deployments
Cloudflare tracks the authors, sources, and timestamps of deployments. If you have a set of users responsible for deployment, or an API Token that’s associated with your CI tool, it’s easy to see which made recent deployments. Each deployment also includes a timestamp, so you can track when those changes were made.
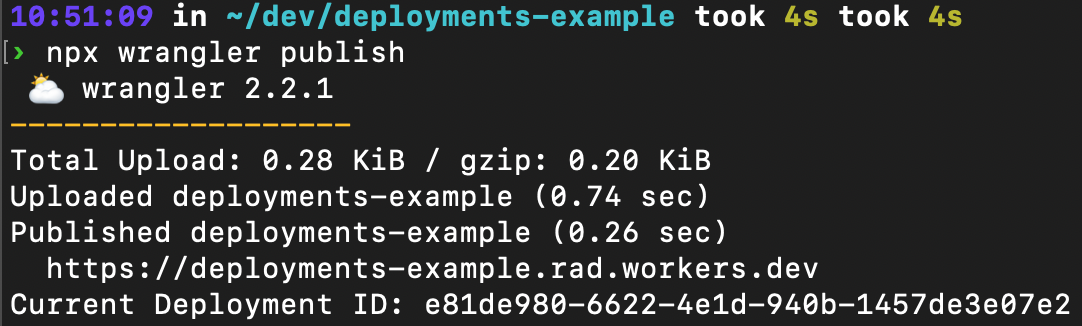
You can access all this deployment information in your Cloudflare dashboard, under your Worker’s Deployments tab. We also report on the active version right at the front of your Worker’s detail page. Wrangler will also report on deployment information. wrangler publish now reports the latest deployed version, and a new `wrangler deployments` command can be used to view a deployment history.
We’re excited to share deployments with our customers, available today in an open beta. As we mentioned up front, we’re just getting started with deployments. We’re also excited for more on-platform tooling like rollbacks, deploy status, deployment rules, and a view-only mode to historical deployments. Beyond that, we want to ensure deployments can be automated from commits to your repository, which means working on version control integrations to services like GitHub, Bitbucket, and Gitlab. We’d love to hear more about how you’re currently using Workers and how we can improve developer experience. If you’re interested, let’s chat.
If you’d like to join the conversation, head over to Cloudflare’s Developer Discord and give us a shout! We love hearing from our customers, and we’re excited to see what you build with Cloudflare.
Configuration management is far from a solved problem. As organizations scale beyond a handful of administrators, having a secure, auditable, and self-service way of updating system settings becomes invaluable. Managing a Cloudflare account is no different. With dozens of products and hundreds of API endpoints, keeping track of current configuration and making bulk updates across multiple zones can be a challenge. While the Cloudflare Dashboard is great for analytics and feature exploration, any changes that could potentially impact users really should get a code review before being applied!
This is where Cloudflare’s Terraform provider can come in handy. Built as a layer on top of the cloudflare-go library, the provider allows users to interface with the Cloudflare API using stateful Terraform resource declarations. Not only do we actively support this provider for customers, we make extensive use of it internally! In this post, we hope to provide some best practices we’ve learned about managing complex Cloudflare configurations in Terraform.
Why Terraform
Unsurprisingly, we find Cloudflare’s products to be pretty useful for securing and enhancing the performance of services we deploy internally. We use DNS, WAF, Zero Trust, Email Security, Workers, and all manner of experimental new features throughout the company. This dog-fooding allows us to battle-harden the services we provide to users and feed our desired features back to the product teams all while running the backend of Cloudflare. But, as Cloudflare grew, so did the complexity and importance of our configuration.
When we were a much smaller company, we only had a handful of accounts with designated administrators making changes on behalf of their colleagues. However, over time this handful of accounts grew into hundreds with each managed by separate teams. Independent accounts are useful in that they allow service-owners to make modifications that can’t impact others, but it comes with overhead.
We faced the challenge of ensuring consistent security policies, up-to-date account memberships, and change visibility. While our accounts were still administered by kind human stewards, we had numerous instances of account members not being removed after they transferred to a different team. While this never became a security incident, it demonstrated the shortcomings of manually provisioning account memberships. In the case of a production service migration, the administrator executing the change would often hop on a video call and ask for others to triple-check an IP address, ruleset, or access policy update. It was an era of looking through the audit logs to see what broke a service.
We wanted to make it easier for developers and users to make the changes they wanted without having to reach out to an administrator. Defining our configuration in code using Terraform has allowed us to keep tabs on the complexity of configuration while improving visibility and change management practices. By dogfooding the Cloudflare Terraform provider, we’ve been able to ensure:
Modifications to accounts are peer reviewed by the team that owns an account.
Each change is tied to a user, commit, and a ticket explaining the rationale for the change.
API Tokens are tied to service accounts rather than individual human users, meaning they survive team changes and offboarding.
Account configuration can be audited by anyone at the company for current state, accuracy, and security without needing to add everyone as a member of every account.
Large changes, such as enforcing hard keys can be done rapidly– even in a single pull request.
Configuration can be easily copied and reused across accounts to promote best practices and speed up development.
We can use and iterate on our awesome provider and provide a better experience to other users (shoutout in particular to Jacob!).
Terraform in CI/CD
Terraform has a fairly mature open source ecosystem, built from years of running-in-production experience. Thus, there are a number of ways to make interacting with the system feel as comfortable to developers as git. One of these tools is Atlantis.
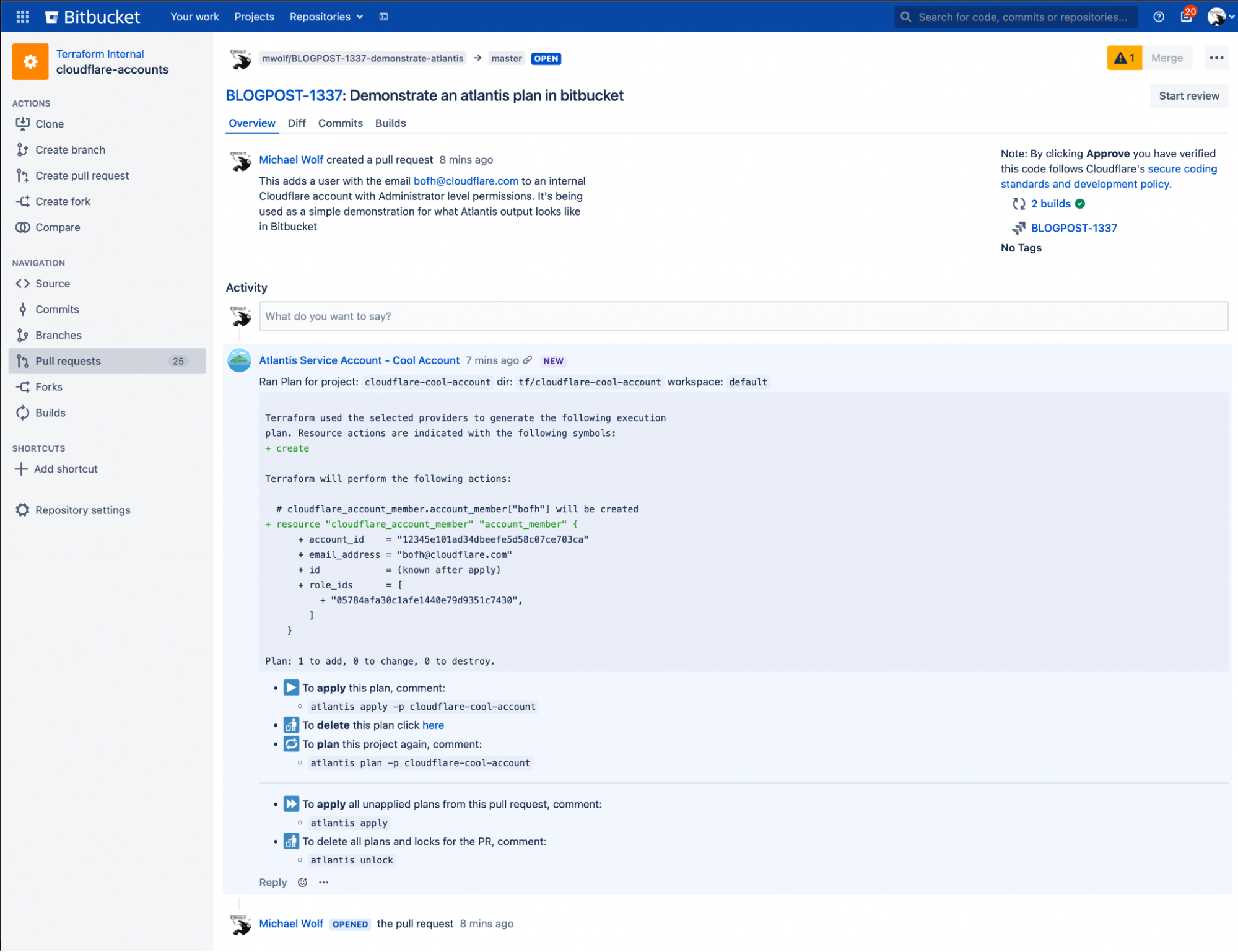
Atlantis acts as continuous integration/continuous delivery (CI/CD) for Terraform; fitting neatly into version control workflows, and giving visibility into the changes being deployed in each code change. We use Atlantis to display Terraform plans (effectively a diff in configuration) within pull requests and apply the changes after the pull request has been approved. Having all the output from the terraform provider in the comments of a pull request means there’s no need to fiddle with the state locally or worry about where a state lock is coming from. Using Terraform CI/CD like this makes configuration management approachable to developers and non-technical folks alike.
In this example pull request, I’m adding a user to the cloudflare-cool-account (see the code in the next section). Once the PR is opened, Bitbucket posts a webhook to Atlantis, telling it to run a `terraform plan` using this branch. The resulting comment is placed in the pull request. Notice that this pull request can’t be applied or merged yet as it doesn’t have an approval! Once the pull request is approved, I would comment “atlantis apply”, wait for Atlantis to post a comment containing the output of the command, and merge the pull request if that output looks correct.
Our Terraforming Cloudflare architecture consists of a monorepo with one directory (and tfstate) for each internally-owned Cloudflare account. This keeps all of our Cloudflare configuration centralized for easier oversight while remaining neatly organized.
It will be possible in a future (as of this writing) release to manage multiple Cloudflare accounts in the same tfstate, but we’ve found that accounts in our use generally map fairly neatly onto teams. Teams can be configured as CODEOWNERS for a given directory and be tagged on any pull requests to that account. With teams owning separate accounts and each account having a separate tfstate, it’s rare for pull requests to get stuck waiting for a lock on the tfstate. Team-account-sized states remain relatively small, meaning that they also build quickly. Later on, we’ll share some of the other optimizations we’ve made to keep the repo user-friendly.
Each of our terraform states, given that they include secrets (including the API key!), is stored encrypted in an internal datastore. When a pull request is opened, Atlantis reaches out to a piece of middleware (that we may open source once it’s cleaned up a bit) that retrieves and decrypts the state for processing. Once the pull request is applied, the state is encrypted and put away again.
We execute a daily Terraform apply across all tfstates to capture any unintended config drift and rotate certificates when they approach expiration. This prevents unrelated changes from popping up in pull request diffs and causing confusion. While we could run more frequent state applies to ensure Terraform remains firmly up to date, once-a-day rectification strikes a balance between code enforcement and avoiding state locks while users are running Terraform plans in pull requests.
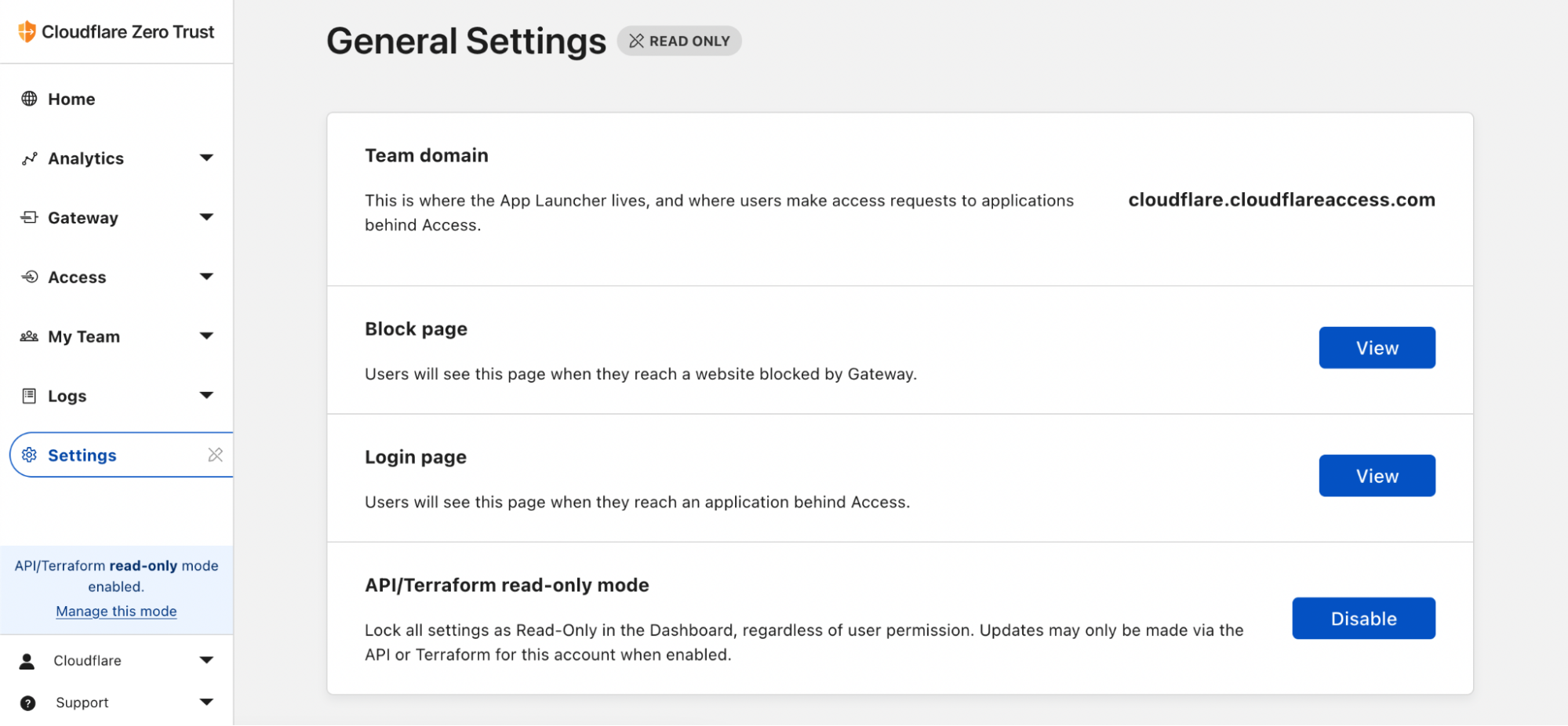
One of the problems that we encountered during our transition to Terraform is that folks were in the habit of making updates to configuration in the Dashboard and were still able to edit settings there. Thus, we didn’t always have a single source of truth for our configuration in code. It also meant the change would get mysteriously (to them) reverted the next day! So that’s why I’m excited to share a new Zero Trust Dashboard toggle that we’ve been turning on for our accounts internally: API/Terraform read-only mode.
Easily one of my favorite new features
With this button, we’re able to politely prevent manual changes to your Cloudflare account’s Zero Trust configuration without removing permissions from the set of users who can fix settings manually in a break-glass emergency scenario. Check out how you can enable this setting in your Zero Trust organization.
Slick Snippets and Terraforming Recommendations
As our Terraform repository has matured, we’ve refined how we define Cloudflare resources in code. By finding a sweet spot between code reuse and readability, we’ve been able to minimize operational overhead and generally let users get their work done. Here’s a couple of useful snippets that have been particularly valuable to us.
Account Membership
This allows for defining a fairly straightforward mapping of user emails to account privileges without code duplication or complex modules. We pull the list of human-friendly names of account roles from the API to show user permission assignments at a glance. Note: status is a new argument that allows for accounts to be added without sending an email to the user; perfect for when an organization is using SSO. (Thanks patrobinson for the feature request and mblackman for the PR!)
The GitHub issue and provider change that enabled automatic Access service token refreshes actually came from a need inside Cloudflare. Here’s how we ended up implementing it. We begin by defining a set of services that need to connect to our hostnames that are protected by Access. Each of these tokens are created and stored in a secret key value store. Next, we reference those access tokens by ID in the target Access policies. Once this has run, the service owner or the service itself can retrieve the credentials from the data store. (Note: we’re using Vault here, but any storage provider could be used in its place).
mTLS (Authenticated Origin Pulls) certificate creation and rotation
To further defense-in-depth objectives, we’ve been rolling out mTLS throughout our internal systems. One of the places where we can take advantage of our Terraform provider is in defining AOP (Authenticated Origin Pulls) certificates to lock down the Cloudflare-edge-to-origin connection. Anyone who has managed certificates of any kind can speak to the headaches they can cause. Having certificate configurations in Terraform takes out the manual work of rotation and expiration.
In this example we’re defining hostname-level AOP as opposed to zone-level AOP. We start by cutting a certificate for each hostname. Once again we’re using Vault for certificate creation, but other backends could be used just as well. This certificate is created with a (not-shown) 30 day expiration, but set to renew automatically. This means once the time-to-expiration is equal to min_seconds_remaining, the resource will be automatically tainted and replaced on the next Terraform run. We like to give this automation plenty of room before expiration to take into account holiday seasons and avoid sending alerts to humans when the alerts hit seven days to expiration. For the rest of this snippet, the certificate is uploaded to Cloudflare and the ID from that upload is then placed in the AOP configuration for the given hostname. The create_before_destroy meta-argument ensures that the replacement certificate is uploaded successfully before we remove the certificate that’s currently in place.
The comfortable automation that we’ve achieved thus far did not come without some hair-pulling. Below are a few of the learnings that have allowed us to maintain the repository as a side project run by two engineers (shoutout David).
Store your state somewhere safe
It feels worth repeating that the tfstate contains secrets including any API keys you’re using with providers and the default location of the tfstate is in the current working directory. It’s very easy to accidentally commit this to source control. By defining a backend, the state can be stored with a cloud storage provider, in a secure location on a filesystem, in a database, or even Cloudflare Workers! Wherever the state is stored, make sure it is encrypted.
Choose simplicity, avoid modules
Modules are intended to reduce code repetition for well-defined chunks of systems such as “I want three clusters of whizz-bangs in locations A, C, and F.” If cloud-computing was like Factorio, this would be amazing. However, financial, technical, and physical constraints mean subtle differences in systems develop over time such as “I want fewer whizz-bangs in C and the whizz-bangs in F should get a different network topology.” In Terraform, implementation logic of these requirements is moved to the module code. HCL is absolutely not the place to write decipherable conditionals. While module versioning prevents having to make every change backwards-compatible, keeping module usage up-to-date becomes another chore for repository maintainers.
An understandable code base is a user-friendly codebase. It’s rare that a deeply cryptic error will return from a misconfigured resource definition. Conversely, modules, especially custom ones, can lead users on a head-scratching adventure. This kind of system can’t scale with confused users.
A few well-designed for_each loops (we’re obviously fans) can achieve similar objectives as modules without the complexity. It’s fine to use plain old resources too! Especially when there are more than a handful of varying arguments, it’s more valuable for the configuration to be clear than to be eloquent. For example: an account_member resource makes sense to be in a for_loop, but a page_rule probably doesn’t.
Keep tfstates small
Maintaining quick pull-request-to-plan turnaround keeps Terraform from feeling like a burden on users’ time. Furthermore, if a plan is taking 30 minutes to run, a rollback in the case of an issue would also take 30 minutes! This post describes our single-account-to-tfstate model.
However, after noticing slow-downs coming from the large number of AOP certificate configurations in a big zone, we moved that code to a separate tfstate. We were able to make this change because AOP configuration is fairly self-contained. To ensure there would be no fighting between the states, we kept the API token permissions for each tfstate mutually exclusive of each other. Our Atlantis Terraform plans typically finish under five minutes. If it feels impossible to keep the size of a tfstate down to a reasonable amount of time, it may be worth considering a different tool for that bit of configuration management.
Know when to use a Different tool
Terraform isn’t a panacea. We generally don’t use Terraform to manage DNS records, for example. We use OctoDNS which integrates more neatly into our infrastructure automation. DNS records can quickly add up to long state-rendering times and are often dynamically generated from systems that Terraform doesn’t know about. To avoid conflicts, there should only ever be one system publishing changes to DNS records.
We also haven’t figured out a maintainable way of managing Workers scripts in Terraform. When a .js script in the Terraform directory changes, Terraform isn’t aware of it. This means a change needs to occur somewhere else in a .tf file before the plan diff is generated. It likely isn’t an unsolvable issue, but doesn’t seem particularly worth cramming into Terraform when there are better options for Worker management like Wrangler.
Looking forward
We’re continuing to invest in the Cloudflare Terraforming experience both for our own use and for the benefit of our users. With the provider, we hope to offer a comfortable and scalable method of interacting with Cloudflare products. Hopefully this post has presented some useful suggestions to anyone interested in adopting Cloudflare-configuration-as-code. Don’t hesitate to reach out on the GitHub project for troubleshooting, bug reports, or feature requests. For more in depth documentation on using Terraform to manage your Cloudflare account, read on here. And if you don’t have a Cloudflare account already, click here to get started.
Today, we’re excited to reveal the first cohort of Launchpad Startups as well as 14 additional VC partners, bringing the Launchpad to $2 billion in potential funding from 40 VC firms in total.
Who are our new VC partners?
We are excited to welcome 14 additional firms to the Workers Launchpad, which you can find included in the image below. They have worked with hundreds of companies that have grown to become leaders in their areas including Asana, Canva, Figma, Netlify, Vercel, Area 1 Security (which Cloudflare acquired in 2022), and many others. Notably, they also represent a diverse group of investors who support startups across North and South America, Europe, and Asia.
Many of these investors have seen the competitive advantages of building on Workers through their own portfolio companies firsthand and are looking forward to providing the capital and resources you need to build and scale your business.
Announcing the Fall 2022 cohort of Launchpad Startups!
We received hundreds of applications for the Fall cohort from startups representing more than 30 countries. We were blown away by the breadth of businesses that folks were building – some are creating tools to simplify developer workflows, while others are helping ecommerce businesses better reach and serve customers around the world. The common thread amongst all the Launchpad companies, however, is their usage of Cloudflare’s developer platform to build more secure, reliable, and feature-rich products faster than they otherwise could.
Introducing the Fall 2022 cohort
Our inaugural cohort of Launchpad startups features 25 diverse businesses. Here’s what they’re building, in their own words:
Nope! We will select Launchpad Startups on a quarterly basis, so if you are building on Workers, interested in pitching VCs, and want to join our next cohort of Workers Founder, apply here! If you’re new to Workers and looking to begin building, check out our Startup Plan for a year of free Cloudflare services, Built with Workers, and join our Cloudflare Developer Discord community.
Cloudflare is not providing any funding or making any funding decisions, and there is no guarantee that any particular company will receive funding through the program. All funding decisions will be made by the venture capital firms that participate in the program. Cloudflare is not a registered broker-dealer, investment adviser, or other similar intermediary.
In May 2022, we announced our quest to simplify databases – building them, maintaining them, integrating them. Our goal is to empower you with the tools to run a database that is powerful, scalable, with world-beating performance without any hassle. And we first set our sights on reimagining the database development experience for every type of user – not just database experts.
Over the past couple of months, we’ve been working to create just that, while learning some very important lessons along the way. As it turns out, building a global relational database product on top of Workers pushes the boundaries of the developer platform to their absolute limit, and often beyond them, but in a way that’s absolutely thrilling to us at Cloudflare. It means that while our progress might seem slow from outside, every improvement, bug fix or stress test helps lay down a path for all of our customers to build the world’s most ambitious serverless application.
However, as we continue down the road to making D1 production ready, it wouldn’t be “the Cloudflare way” unless we stopped for feedback first – even though it’s not quite finished yet. In the spirit of Developer Week, there is no better time to introduce the D1 open alpha!
An “open alpha” is a new concept for us. You’ll likely hear the term “open beta” on various announcements at Cloudflare, and while it makes sense for many products here, it wasn’t quite right for D1. There are still some crucial pieces that are still in active development and testing, so before we release the fully-formed D1 as a public beta for you to start building real-world apps with, we want to make sure everybody can start to get a feel for the product on their hobby apps or side-projects.
What’s included in the alpha?
While a lot is still changing behind the scenes with D1, we’ve put a lot of thought into how you, as a developer, interact with it – even if you’re new to databases.
Using the D1 dashboard
In a few clicks you can get your D1 database up and running right from within your dashboard. In our D1 interface, you can create, maintain and view your database as you please. Changes made in the UI are instantly available to your Worker – no redeploy required!
Use Wrangler
If you’re looking to get your hands a little dirty, you can also work with your database using our Wrangler CLI. Create your database and begin adding your data manually or bootstrap your database with one of two ways:
Migrations are a way to version your database changes. With D1, you can create a migration and then apply it to your database.
To create the migration, execute:
wrangler d1 migrations create <my-database-name> <short description of migration>
This will create an SQL file in a migrations folder where you can then go ahead and add your queries. Then apply the migrations to your database by executing:
wrangler d1 migrations apply <my-database-name>
Access D1 from within your Worker
You can attach your D1 to a Worker by adding the D1 binding to your wrangler.toml configuration file. Then interact with D1 by executing queries inside your Worker like so:
export default {
async fetch(request, env) {
const { pathname } = new URL(request.url);
if (pathname === "/api/beverages") {
const { results } = await env.DB.prepare(
"SELECT * FROM Customers WHERE CompanyName = ?"
)
.bind("Bs Beverages")
.all();
return Response.json(results);
}
return new Response("Call /api/beverages to see Bs Beverages customers");
},
};
Or access D1 from within your Pages Function
In this Alpha launch, D1 also supports integration with Cloudflare Pages! You can add a D1 binding inside the Pages dashboard, and write your queries inside a Pages Function to build a full-stack application! Check out the full documentation to get started with Pages and D1.
Community built tooling
During our private alpha period, the excitement behind D1 led to some valuable contributions to the D1 ecosystem and developer experience by members of the community. Here are some of our favorite projects to date:
d1-orm
An Object Relational Mapping (ORM) is a way for you to query and manipulate data by using JavaScript. Created by a Cloudflare Discord Community Champion, the d1-orm seeks to provide a strictly typed experience while using D1:
const users = new Model(
// table name, primary keys, indexes etc
tableDefinition,
// column types, default values, nullable etc
columnDefinitions
)
// TS helper for typed queries
type User = Infer<type of users>;
// ORM-style query builder
const user = await users.First({
where: {
id: 1,
},
});
This is a zero-dependency query builder that provides a simple standardized interface while keeping the benefits and speed of using raw queries over a traditional ORM. While not intended to provide ORM-like functionality, workers-qb makes it easier to interact with the database from code for direct SQL access:
Instead of running the wrangler d1 execute command in your terminal every time you want to interact with your database, you can interact with D1 from within the d1-console. Created by a Discord Community Champion, this gives the benefit of executing multi-line queries, obtaining command history, and viewing a cleanly formatted table output.
While this is a community project today, we plan to natively support a “D1 Console” in the future. For now, get started by checking out the d1-console package here.
Kysely is a type-safe and autocompletion-friendly typescript SQL query builder. With this adapter you can interact with D1 with the familiar Kysely interface:
// Create Kysely instance with kysely-d1
const db = new Kysely<Database>({
dialect: new D1Dialect({ database: env.DB })
});
// Read row from D1 table
const result = await db
.selectFrom('kv')
.selectAll()
.where('key', '=', key)
.executeTakeFirst();
The biggest pieces that have been disabled for this alpha release are replication and JavaScript transaction support. While we’ll be rolling out these changes gradually, we want to call out some limitations that exist today that we’re actively working on testing:
Database location: Each D1 database only runs a single instance. It’s created close to where you, as the developer, create the database, and does not currently move regions based on access patterns. Workers running elsewhere in the world will see higher latency as a result.
Concurrency limitations: Under high load, read and write queries may be queued rather than triggering new replicas to be created. As a result, the performance & throughput characteristics of the open alpha won’t be representative of the final product.
Availability limitations: Backups will block access to the DB while they’re running. In most cases this should only be a second or two, and any requests that arrive during the backup will be queued.
You can also check out a more detailed, up-to-date list on D1 alpha Limitations.
Request for feedback
While we can make all sorts of guesses and bets on the kind of databases you want to use D1 for, we are not the users – you are! We want developers from all backgrounds to preview the D1 tech at its early stages, and let us know where we need to improve to make it suitable for your production apps.
For general feedback about your experience and to interact with other folks in the alpha, join our #d1-open-alpha channel in the Cloudflare Developers Discord. We plan to make any important announcements and changes in this channel as well as on our monthly community calls.
To file more specific feature requests (no matter how wacky) and report any bugs, create a thread in the Cloudflare Community forum under the D1 category. We will be maintaining this forum as a way to plan for the months ahead!
Get started
Want to get started right away? Check out our D1 documentation to get started today. Build our classic Northwind Traders demo to explore the D1 experience and deploy your first D1 database!
We’re excited to have Xata building their serverless functions product – Xata Workers – on top of Workers for Platforms. Xata Workers act as middleware to simplify database access and allow their developers to deploy functions that sit in front of their databases. Workers for Platforms opens up a whole suite of use cases for Xata developers all while providing the security, scalability and performance of Cloudflare Workers.
Now, handing it over to Alexis, a Senior Software Engineer at Xata to tell us more.
Introduction
In the last few years, there’s been a rise of Jamstack, and new ways of thinking about the cloud that some people call serverless or edge computing. Instead of maintaining dedicated servers to run a single service, these architectures split applications in smaller services or functions.
By simplifying the state and context of our applications, we can benefit from external providers deploying these functions in dozens of servers across the globe. This architecture benefits the developer and user experience alike. Developers don’t have to manage servers, and users don’t have to experience latency. Your application simply scales, even if you receive hundreds of thousands of unexpected visitors.
When it comes to databases though, we still struggle with the complexity of orchestrating replication, failover and high availability. Traditional databases are difficult to scale horizontally and usually require a lot of infrastructure maintenance or learning complex database optimization concepts.
At Xata we are building a modern data platform designed for scalable applications. It allows you to focus on your application logic, instead of having to worry about how the data is stored.
Making databases accessible to everyone
We started Xata with the mission of helping developers build their applications and forget about maintaining the underlying infrastructure.
With that mission in mind, we asked ourselves: how can we make databases accessible to everyone? How can we provide a delightful experience for a frontend engineer or designer using a database?
To begin with, we built an appealing web dashboard, that any developer — no matter their experience — can be comfortable using to work with their data.
Whether they’re defining or refining their schema, viewing or adding records, fine-tuning search results with query boosters, or getting code snippets to speed up development with our SDK. We believe that only the best user experience can provide the best development experience.
We identified a major challenge amongst our user base early on. Many front-end developers want to access their database from client-side code.
Allowing access to a database from client-side code comes with several security risks if not done properly. For example, someone could inspect the code, find the credentials, and if they weren’t scoped to a single operation, potentially query or modify other parts of the database. Unfortunately, this is a common reason for data leaks and security breaches.
It was a hard problem to solve, and after plenty of brainstorming, we agreed on two potential ways forward: implementing row-level access rules or writing API routes that talked to the database from server code.
Row-level access rules are a good way to solve this, but they would have required us to define our own opinionated language. For our users, it would have been hard to migrate away when they outgrow this solution. Instead, we preferred to focus on making serverless functions easier for our users.
Typically, serverless functions require you to either choose a full stack framework or manually write, compile, deploy and use them. This generally adds a lot of cognitive overhead even to choose the right solution. We wanted to simplify accessing the database from the frontend without sacrificing flexibility for developers. This is why we decided to build Xata Workers.
Xata Workers
A Xata Worker is a function that a developer can write in JavaScript or TypeScript as client-side code. Rather than being executed client-side, it will actually be executed on Cloudflare’s global network.
You can think of a Xata Worker as a getServerSideProps function in Next.js or a loader function in Remix. You write your server logic in a function and our tooling takes care of deploying and running it server-side for you (yes, it’s that easy).
The main difference with other alternatives is that Xata Workers are, by design, agnostic to a framework or hosting provider. You can use them to build any kind of application or website, and even upload it as static HTML in a service like GitHub Pages or S3. You don’t need a full stack web framework to use Xata Workers.
With our command line tool, we handle the build and deployment process. When the function is invoked, the Xata Worker actually makes a request to a serverless function over the network.
In the code snippet above, you can see a React component that connects to an e-commerce database with products on sale. Inside the UI component, with a popular client-side data fetching library, data is retrieved from the serverless function and for each product it renders another component in a grid.
As you can see a Xata Worker is a function that wraps any user-defined code and receives an instance of our SDK as a parameter. This instance has access to the database and, given that the code doesn’t run on the browser anymore, your secrets are not exposed for malicious usage.
When using a Xata Worker in TypeScript, our command line tool also generates custom types based on your schema. These types offer type-safety for your queries or mutations, and improve your developer experience by adding extra intellisense to your IDE.
A Xata Worker, like any other function, can receive additional parameters that pass application state, context or user tokens. The code you write in the function can either return an object that will be serialized over the network with a superset of JSON to support dates and other non-primitive data types, or a full response with a custom status code and headers.
Developers can write all their logic, including their own authentication and authorization. Unlike complex row level access control rules, you can easily express your logic without constraints and even unit test it with the rest of your code.
How we use Cloudflare
We are happy to join the Supercloud movement, Cloudflare has an excellent track record, and we are using Cloudflare Workers for Platforms to host our serverless functions. By using the Workers isolated execution contexts we reduce security risks of running untrusted code on our own while being close to our users, resulting in super low latency.
All of it, without having to deploy extra infrastructure to handle our user’s application load or ask them to configure how the serverless functions should be deployed. It really feels like magic! Now, let’s dive into the internals of how we use Cloudflare to run our Xata Workers.
For every workspace in Xata we create a Worker Namespace, a Workers for Platform concept to organize Workers and restrict the routing between them. We used Namespaces to group and encapsulate the different functions coming from all the databases built by a client or team.
When a user deploys a Xata Worker, we create a new Worker Script, and we upload the compiled code to its Namespace. Each script has a unique name with a compilation identifier so that the user can have multiple versions of the same function running at the same time.
During the compilation, we inject the database connection details and the database name. This way, the function can connect to the database without leaking secrets and restricting the scope of access to the database, all of it transparently for the developer.
When the client-side application runs a Xata Worker, it calls a Dispatcher function that processes the request and calls the correct Worker Script. The dispatcher function is also responsible for configuring the CORS headers and the log drain that can be used by the developer to debug their functions.
By using Cloudflare, we are also able to benefit from other products in the Workers ecosystem. For example, we can provide an easy way to cache the results of a query in Cloudflare’s global network. That way, we can serve the results for read-only queries directly from locations closer to the end users, without having to call the database again and again for every Worker invocation. For the developer, it’s only a matter of adding a “cache” parameter to their query with the number of milliseconds they want to cache the results in a KV Namespace.
In development mode, we provide a command to run the functions locally and test them before deploying them to production. This enables rapid development workflows with real-time filesystem change monitoring and hot reloading of the workers code. Internally, we use the latest version of miniflare to emulate the Cloudflare Workers runtime, mimicking the real production environment.
Conclusion
Xata is now out of beta and available for everyone. We offer a generous free tier that allows you to build and deploy your applications and only pay to scale them when you actually need it.
You can sign up for free, create a database in seconds and enjoy features such as branching with zero downtime migrations, search and analytics, transactions, and many others. Check out our website to learn more!
Xata Workers are currently in private beta. If you are interested in trying them out, you can sign up for the waitlist and talk us through your use case. We are looking for developers that are willing to provide feedback and shape this new feature for our serverless data platform.
We are very proud of our collaboration with Cloudflare for this new feature. Processing data closer to where it’s being requested is the future of computing and we are excited to be part of this movement. We look forward to seeing what you build with Xata Workers.
If you’ve ever created a website that shows any kind of analytics, you’ve probably also thought about adding a “Save Image” or “Save as PDF” button to store and share results. This isn’t as easy as it seems (I can attest to this firsthand) and it’s not long before you go down a rabbit hole of trying 10 different libraries, hoping one will work.
This is why we’re excited to announce a private beta of the Workers Browser Rendering API, improving the browser automation experience for developers. With browser automation, you can programmatically do anything that a user can do when interacting with a browser.
The Workers Browser Rendering API, or just Rendering API for short, is our out-of-the-box solution for simplifying developer workflows, including capturing images or screenshots, by running browser automation in Workers.
Browser automation, everywhere
As with many of the best Cloudflare products, Rendering API was born out of an internal need. Many of our teams were setting up or wanted to set up their own tools to perform what sounds like an incredibly simple task: taking automated screenshots.
When gathering use cases, we realized that much of what our internal teams wanted would also be useful for our customers. Some notable ones are:
Taking screenshots for social sharing thumbnails or preview images
Emailed daily screenshots of dashboards (requested specifically by our SVP of Engineering)
Reporting bugs on websites and sending them directly to frontend teams
Not to mention use cases for other browser automation functions like:
Testing UI/UX Flows End-to-end (E2E) testing is used to minimic user behaviour and can identify bugs that unit tests or integration tests have missed. And let’s be honest – no developer wants to manually check the user flow each time they make changes to their application. E2E tests can be especially useful to verify logic on your customer’s critical path like account creation, authentication or checkout.
Performance Tests Application performance metrics, such as page load time, directly impact your user’s experience and your SEO rankings. To avoid performance regressions, you want to test impact on latency in conditions that are as close as possible to your production environment before you merge. By automating performance testing you can measure if your proposed changes will result in a degraded experience for your uses and make improvements accordingly.
Unlocking a new building block
One of the most common browser automation frameworks is Puppeteer. It’s common to run Puppeteer in a containerization tool like Docker or in a serverless environment. Taking automated screenshots should be as easy as writing some code, hitting deploy and having it run when a particular event is triggered or on a regular schedule.
It should be, but it’s not.
Even on a serverless solution like AWS Lambda, running Puppeteer means packaging it, making sure dependencies are covered, uploading packages to S3 and deploying using Layers. Whether using Docker or something like Lambda, it’s clear that this is not easy to set up.
One of the pillars of Cloudflare’s development platform is to provide our developers with tools that are incredibly simple, yet powerful to build on. Rendering API is our out-of-the-box solution for running Puppeteer in Workers.
Screenshotting made simple
To start, the Rendering API will have support for navigating to a webpage and taking a screenshot, with more functions to follow. To use it, all you need to do is add our new browser binding to your project’s wrangler.toml file
wrangler.toml
bindings = [
{ name = "my_browser” type = "browser" }
]
From there, taking a screenshot and saving it to R2 is as simple as:
Down the line, we have plans to add full Puppeteer support, including functions like page.type, page.click, page.evaluate!
What’s happening under the hood?
Remote browser isolation technology is an integral part of our Zero Trust product offering. Remote browser isolation lets users interact with a web browser that instead of running on the client’s device, runs in a remote environment. The Rendering API repurposes this under the hood!
We’ve wrapped the Puppeteer library so that it can be run directly from your own Worker. You can think of your Worker as the client. Each of Cloudflare’s data centers has a pool of warm browsers ready to go and when a Worker requests a browser, the browser is instantly returned and is connected to via a WebSocket. Once the WebSocket connection is established, our internal browser API Worker handles all communication to the browser session via the Chrome Devtools Protocol.
To ensure the security of your Worker, individual remote browsers are run as disposable instances – one instance per request, and never shared. They are secured using gVisor to protect against kernel level exploits. On top of that, the browser is running sandboxed processes with the lowest privilege level using a Linux seccomp profile.
The Rendering API should be used when you’re building and testing your applications. To prevent abuse, Cloudflare Bot Management has baked in signals to indicate that a request is coming from a Worker running Puppeteer. As a Cloudflare Bot Management customer, this will automatically be added to your blocklist, with the option to explicitly opt in and allow it.
How can you get started?
We’re introducing the Workers Browser Rendering API in closed beta. If you’re interested, please tell us a bit about your use case and join the waitlist. We would love to hear what else you want to build using the Workers Browser Rendering API, let us know in the Workers channel on the Cloudflare Developers Discord!
There are many ways to store data in your applications. For example, in Cloudflare Workers applications, we have Workers KV for key-value storage and Durable Objects for real-time, coordinated storage without compromising on consistency. Outside the Cloudflare ecosystem, you can also plug in other tools like NoSQL and graph databases.
But sometimes, you want SQL. Indexes allow us to retrieve data quickly. Joins enable us to describe complex relationships between different tables. SQL declaratively describes how our application’s data is validated, created, and performantly queried.
D1 was released today in open alpha, and to celebrate, I want to share my experience building apps with D1: specifically, how to get started, and why I’m excited about D1 joining the long list of tools you can use to build apps on Cloudflare.
D1 is remarkable because it’s an instant value-add to applications without needing new tools or stepping out of the Cloudflare ecosystem. Using wrangler, we can do local development on our Workers applications, and with the addition of D1 in wrangler, we can now develop proper stateful applications locally as well. Then, when it’s time to deploy the application, wrangler allows us to both access and execute commands to your D1 database, as well as your API itself.
What we’re building
In this blog post, I’ll show you how to use D1 to add comments to a static blog site. To do this, we’ll construct a new D1 database and build a simple JSON API that allows the creation and retrieval of comments.
As I mentioned, separating D1 from the app itself – an API and database that remains separate from the static site – allows us to abstract the static and dynamic pieces of our website from each other. It also makes it easier to deploy our application: we will deploy the frontend to Cloudflare Pages, and the D1-powered API to Cloudflare Workers.
Building a new application
First, we’ll add a basic API in Workers. Create a new directory and in it a new wrangler project inside it:
$ mkdir d1-example && d1-example
$ wrangler init
In this example, we’ll use Hono, an Express.js-style framework, to rapidly build our API. To use Hono in this project, install it using NPM:
$ npm install hono
Then, in src/index.ts, we’ll initialize a new Hono app, and define a few endpoints – GET /API/posts/:slug/comments, and POST /get/api/:slug/comments.
import { Hono } from 'hono'
import { cors } from 'hono/cors'
const app = new Hono()
app.get('/api/posts/:slug/comments', async c => {
// do something
})
app.post('/api/posts/:slug/comments', async c => {
// do something
})
export default app
Now we’ll create a D1 database. In Wrangler 2, there is support for the wrangler d1 subcommand, which allows you to create and query your D1 databases directly from the command line. So, for example, we can create a new database with a single command:
$ wrangler d1 create d1-example
With our created database, we can take the database name ID and associate it with a binding inside of wrangler.toml, wrangler’s configuration file. Bindings allow us to access Cloudflare resources, like D1 databases, KV namespaces, and R2 buckets, using a simple variable name in our code. Below, we’ll create the binding DB and use it to represent our new database:
[[ d1_databases ]]
binding = "DB" # i.e. available in your Worker on env.DB
database_name = "d1-example"
database_id = "4e1c28a9-90e4-41da-8b4b-6cf36e5abb29"
Note that this directive, the [[d1_databases]] field, currently requires a beta version of wrangler. You can install this for your project using the command npm install -D wrangler/beta.
With the database configured in our wrangler.toml, we can start interacting with it from the command line and inside our Workers function.
First, you can issue direct SQL commands using wrangler d1 execute:
$ wrangler d1 execute d1-example --command "SELECT name FROM sqlite_schema WHERE type ='table'"
Executing on d1-example:
┌─────────────────┐
│ name │
├─────────────────┤
│ sqlite_sequence │
└─────────────────┘
You can also pass a SQL file – perfect for initial data seeding in a single command. Create src/schema.sql, which will create a new comments table for our project:
drop table if exists comments;
create table comments (
id integer primary key autoincrement,
author text not null,
body text not null,
post_slug text not null
);
create index idx_comments_post_id on comments (post_slug);
-- Optionally, uncomment the below query to create data
-- insert into comments (author, body, post_slug)
-- values ("Kristian", "Great post!", "hello-world");
With the file created, execute the schema file against the D1 database by passing it with the flag --file:
We’ve created a SQL database with just a few commands and seeded it with initial data. Now we can add a route to our Workers function to retrieve data from that database. Based on our wrangler.toml config, the D1 database is now accessible via the DB binding. In our code, we can use the binding to prepare SQL statements and execute them, for instance, to retrieve comments:
app.get('/api/posts/:slug/comments', async c => {
const { slug } = c.req.param()
const { results } = await c.env.DB.prepare(`
select * from comments where post_slug = ?
`).bind(slug).all()
return c.json(results)
})
In this function, we accept a slug URL query parameter and set up a new SQL statement where we select all comments with a matching post_slug value to our query parameter. We can then return it as a simple JSON response.
So far, we’ve built read-only access to our data. But “inserting” values to SQL is, of course, possible as well. So let’s define another function that allows POST-ing to an endpoint to create a new comment:
app.post('/API/posts/:slug/comments', async c => {
const { slug } = c.req.param()
const { author, body } = await c.req.json<Comment>()
if (!author) return c.text("Missing author value for new comment")
if (!body) return c.text("Missing body value for new comment")
const { success } = await c.env.DB.prepare(`
insert into comments (author, body, post_slug) values (?, ?, ?)
`).bind(author, body, slug).run()
if (success) {
c.status(201)
return c.text("Created")
} else {
c.status(500)
return c.text("Something went wrong")
}
})
In this example, we built a comments API for powering a blog. To see the source for this D1-powered comments API, you can visit cloudflare/templates/worker-d1-api.
Conclusion
One of the things most exciting about D1 is the opportunity to augment existing applications or websites with dynamic, relational data. As a former Ruby on Rails developer, one of the things I miss most about that framework in the world of JavaScript and serverless development tools is the ability to rapidly spin up full data-driven applications without needing to be an expert in managing database infrastructure. With D1 and its easy onramp to SQL-based data, we can build true data-driven applications without compromising on performance or developer experience.
This shift corresponds nicely with the advent of static sites in the last few years, using tools like Hugo or Gatsby. A blog built with a static site generator like Hugo is incredibly performant – it will build in seconds with small asset sizes.
But by trading a tool like WordPress for a static site generator, you lose the opportunity to add dynamic information to your site. Many developers have patched over this problem by adding more complexity to their build processes: fetching and retrieving data and generating pages using that data as part of the build.
This addition of complexity in the build process attempts to fix the lack of dynamism in applications, but it still isn’t genuinely dynamic. Instead of being able to retrieve and display new data as it’s created, the application rebuilds and redeploys whenever data changes so that it appears to be a live, dynamic representation of data. Your application can remain static, and the dynamic data will live geographically close to the users of your site, accessible via a queryable and expressive API.
One of the things we prioritize at Cloudflare is enabling developers to build their applications on our developer platform with ease. We’re excited to share a collection of ready-made templates that’ll help you start building your next application on Workers. We want developers to get started as quickly as possible, so that they can focus on building and innovating and avoid spending so much time configuring and setting up their projects.
Cloudflare Workers enables you to build applications with exceptional performance, reliability, and scale. We are excited to share a collection of templates that helps you get started quickly and give you an idea of what is possible to build on our developer platform.
We have made available a set of starter templates highlighting different use cases of Workers. We understand that you have different ideas you will love to build on top of Workers and you may have questions or wonder if it is possible. These sets of templates go beyond the convention ‘Hello, World’ starter. They’ll help shape your idea of what kind of applications you can build with Workers as well as other products in the Cloudflare Developer Ecosystem.
We are excited to introduce a new collection of starter templates workers.new/templates. This shortcut will serve you a collection of templates that you can immediately start using to build your next application.
Cloudflare Workers Template Collection
How to use Cloudflare Workers templates
We created this collection of templates to support you in getting started with Workers. Some examples listed showcase a use-case with a combination of multiple Cloudflare developer platform products to build applications similar to ones you might use every day. We know that Workers are being used today for different use-cases, we want to showcase some of them to you.
One example to highlight is a template that lets you accept payment for video content. It is powered by Pages Functions, Cloudflare Stream and Stripe Checkout. This app shows how you can use Cloudflare Workers with external payment and authentication systems to create a logged-in experience, without ever having to manage a database or persist any state yourself.
Once a user has paid, Stripe Checkout redirects to a URL that verifies a token from Stripe, and generates a signed URL using Cloudflare Stream to view the video. This signed URL is only valid for a specified amount of time, and access can be restricted by country or IP address.
To use the template, you need to either click the deploy with Workers button or open the template with Stackblitz.
The Deploy with Workers button will redirect you to a page where you can authorize GitHub to deploy a fork of the repository using GitHub actions while opening with StackBlitz creates a new fork of the template for you to start working with.
Deploy to Workers Demo
These templates also comes bundled with additional features I would like to share with you:
We added a deploy button to all templates listed in the templates repository and the collection website, so you can quickly get up to speed with your code. The deploy with Workers button lets you deploy your code in under five minutes, it uses a GitHub action powered with Cloudflare Workers to do this.
GitHub Repository with Deploy to Workers Button
Support for Test Driven Development
As developers, we need to write tests for our code to ensure we’re shipping quality production grade software and also ensure that our code is bug-free. We support writing tests in Workers using the Wrangler unstable_dev API to write integration and end-to-end tests. We want to enable not just the developer experience but also nudge developers to follow best practices and prioritize TDD in development. We configured a number of templates to support integration tests against a local server, this will serve as a template to help you set up tests in your projects.
Here’s an example using Wrangler’s unstable_dev API and Vitest test framework to test the code written in an example ‘Hello worker’ starter template:
We announced StackBlitz’s partnership with Cloudflare Workers during Platform Week early this year. We believe a developer’s experience should be of utmost priority because we want them to build with ease on our developer platform.
StackBlitz is an online development platform for building web applications. It is powered by WebContainers, the first WebAssembly-based operating system which boots Node.js environments in milliseconds, securely within your browser tab.
We made it even easier to get started with Workers with an integrated Open with StackBlitz button for each starter template, making it easier to create a fork of a template and the great thing is you only need a web browser to build your application.
Everything we’ve highlighted in this post, all leads to one thing – How can we create a better experience for developers getting started with Workers. We introduce these ready-made templates to make you more efficient, bring you a wholesome developer experience and help improve your time to deployment. We want you to spend less time getting started with building on the Workers developer platform, so what are you waiting for?
Next Steps
You can start building your own Worker today using the available templates provided in the templates collection to help you get started. If you would like to contribute your own templates to the collection, be sure to send in a pull request we’re more than happy to review and add to the growing collection. Share what you have built with us in the #builtwith channel on our Discord community. Make sure to follow us on Twitter or join our Discord Developers Community server.
It’s no wonder that Postgres is one of the world’s favorite databases. It’s easy to learn, a pleasure to use, and can scale all the way up from your first database in an early-stage startup to the system of record for giant organizations. Postgres has been an integral part of Cloudflare’s journey, so we know this fact well. But when it comes to connecting to Postgres from environments like Cloudflare Workers, there are unfortunately a bunch of challenges, as we mentioned in our Relational Database Connector post.
Neon.tech not only solves these problems; it also has other cool features such as branching databases — being able to branch your database in exactly the same way you branch your code: instant, cheap and completely isolated.
How to use it
It’s easy to get started. Neon’s client library @neondatabase/serverless is a drop-in replacement for node-postgres, the npm pg package with which you may already be familiar. After going through the getting started process to set up your Neon database, you can easily create a Worker to ask Postgres for the current time like so:
Create a new Worker — Run npx wrangler init neon-cf-demo and accept all the defaults. Enter the new folder with cd neon-cf-demo.
Install the Neon package — Run npm install @neondatabase/serverless.
Provide connection details — For deployment, run npx wrangler secret put DATABASE_URL and paste in your connection string when prompted (you’ll find this in your Neon dashboard: something like postgres://user:[email protected]/main). For development, create a new file .dev.vars with the contents DATABASE_URL= plus the same connection string.
Write the code — Lastly, replace src/index.ts with the following code:
import { Client } from '@neondatabase/serverless';
interface Env { DATABASE_URL: string; }
export default {
async fetch(request: Request, env: Env, ctx: ExecutionContext) {
const client = new Client(env.DATABASE_URL);
await client.connect();
const { rows: [{ now }] } = await client.query('select now();');
ctx.waitUntil(client.end()); // this doesn’t hold up the response
return new Response(now);
}
}
To try this locally, type npm start. To deploy it around the globe, type npx wrangler publish.
How does this work? In this case, we take the coordinates supplied to our Worker in request.cf.longitude and request.cf.latitude. We then feed these coordinates to a SQL query that uses the PostGIS distance operator <-> to order our results:
const { longitude, latitude } = request.cf
const { rows } = await client.query(`
select
id_no, name_en, category,
st_makepoint($1, $2) <-> location as distance
from whc_sites_2021
order by distance limit 10`,
[longitude, latitude]
);
Since we created a spatial index on the location column, the query is blazing fast. The result (rows) looks like this:
[{
"id_no": 308,
"name_en": "Yosemite National Park",
"category": "Natural",
"distance": 252970.14782223428
},
{
"id_no": 134,
"name_en": "Redwood National and State Parks",
"category": "Natural",
"distance": 416334.3926827573
},
/* … */
]
For even lower latencies, we could cache these results at a slightly coarser geographical resolution — rounding, say, to one sixtieth of a degree (one arc minute) of longitude and latitude, which is a little under a mile.
Sign up to Neon using the invite code serverless and try the @neondatabase/serverless driver with Cloudflare Workers.
Why we did it
Cloudflare Workers has enormous potential to improve back-end development and deployment. It’s cost-effective, admin-free, and radically scalable.
The use of V8 isolates means Workers are now fast and lightweight enough for nearly any use case. But it has a key drawback: Cloudflare Workers don’t yet support raw TCP communication, which has made database connections a challenge.
Even when Workers eventually support raw TCP communication, we will not have fully solved our problem, because database connections are expensive to set up and also have quite a bit of memory overhead.
This is what the solution looks like:
It consists of three parts:
Connection pooling built into the platform — Given Neon’s serverless compute model, splitting storage and compute operations, it is not recommended to rely on a one-to-one mapping between external clients and Postgres connections. Instead, you can turn on connection pooling simply by flicking a switch (it’s in the Settings area of your Neon dashboard).
WebSocket proxy — We deploy our own WebSocket-to-TCP proxy, written in Go. The proxy simply accepts WebSocket connections from Cloudflare Worker clients, relays message payloads to a requested (Neon-only) host over plain TCP, and relays back the responses.
Client library — Our driver library is based on node-postgres but provides the necessary shims for Node.js features that aren’t present in Cloudflare Workers. Crucially, we replace Node’s net.Socket and tls.connect with code that redirects network reads and writes via the WebSocket connection. To support end-to-end TLS encryption between Workers and the database, we compile WolfSSL to WebAssembly with emscripten. Then we use esbuild to bundle it all together into an easy-to-use npm package.
The @neondatabase/serverless package is currently in public beta. We have plans to improve, extend, and explain it further in the near future on the Neon blog. In line with our commitment to open source, you can configure our serverless driver and/or run our WebSocket proxy to provide access to Postgres databases hosted anywhere — just see the respective repos for details.
Message queues are a fundamental building block of cloud applications—and today the Cloudflare Queues open beta brings queues to every developer building for Region: Earth. Cloudflare Queues follows Cloudflare Workers and Cloudflare R2 in a long line of innovative services built for the Workers Developer Platform, enabling developers to build more complex applications without configuring networks, choosing regions, or estimating capacity. Best of all, like many other Cloudflare services, there are no egregious egress charges!
If you’ve ever purchased something online and seen a message like “you will receive confirmation of your order shortly,” you’ve interacted with a queue. When you completed your order, your shopping cart and information were stored and the order was placed into a queue. At some later point, the order fulfillment service picks and packs your items and hands it off to the shipping service—again, via a queue. Your order may sit for only a minute, or much longer if an item is out of stock or a warehouse is busy, and queues enable all of this functionality.
Message queues are great at decoupling components of applications, like the checkout and order fulfillment services for an ecommerce site. Decoupled services are easier to reason about, deploy, and implement, allowing you to ship features that delight your customers without worrying about synchronizing complex deployments.
Queues also allow you to batch and buffer calls to downstream services and APIs. This post shows you how to enroll in the open beta, walks you through a practical example of using Queues to build a log sink, and tells you how we built Queues using other Cloudflare services. You’ll also learn a bit about the roadmap for the open beta.
Getting started
Enrolling in the open beta
Open the Cloudflare dashboard and navigate to the Workers section. Select Queues from the Workers navigation menu and choose Enable Queues Beta.
Review your order and choose Proceed to Payment Details.
Note: If you are not already subscribed to a Workers Paid Plan, one will be added to your order automatically.
Enter your payment details and choose Complete Purchase. That’s it – you’re enrolled in the open beta! Choose Return to Queues on the confirmation page to return to the Cloudflare Queues home page.
Creating your first queue
After enabling the open beta, open the Queues home page and choose Create Queue. Name your queue `my-first-queue` and choose Create queue. That’s all there is to it!
The dash displays a confirmation message along with a list of all the queues in your account.
Note: As of the writing of this blog post each account is limited to ten queues. We intend to raise this limit as we build towards general availability.
Managing your queues with Wrangler
You can also manage your queues from the command line using Wrangler, the CLI for Cloudflare Workers. In this section, you build a simple but complete application implementing a log aggregator or sink to learn how to integrate Workers, Queues, and R2.
Setting up resources To create this application, you need access to a Cloudflare Workers account with a subscription plan, access to the Queues open beta, and an R2 plan.
Install and authenticate Wrangler then run wrangler queues create log-sink from the command line to create a queue for your application.
Run wrangler queues list and note that Wrangler displays your new queue.
Note: The following screenshots use the jq utility to format the JSON output of wrangler commands. You do not need to install jq to complete this application.
Finally, run wrangler r2 bucket create log-sink to create an R2 bucket to store your aggregated logs. After the bucket is created, run wrangler r2 bucket list to see your new bucket.
Creating your Worker Next, create a Workers application with two handlers: a fetch() handler to receive individual incoming log lines and a queue() handler to aggregate a batch of logs and write the batch to R2.
In an empty directory, run wrangler init to create a new Cloudflare Workers application. When prompted:
Choose “y” to create a new package.json
Choose “y” to use TypeScript
Choose “Fetch handler” to create a new Worker at src/index.ts
Open wrangler.toml and replace the contents with the following:
The [[queues.producers]] section creates a producer binding for the Worker at src/index.ts called BUFFER that refers to the log-sink queue. This Worker can place messages onto the log-sink queue by calling await env.BUFFER.send(log);
The [[queues.consumers]] section creates a consumer binding for the log-sink queue for your Worker. Once the log-sink queue has a batch ready to be processed (or consumed), the Workers runtime will look for the queue() event handler in src/index.ts and invoke it, passing the batch as an argument. The queue() function signature looks as follows:
The final binding in your wrangler.toml creates a binding for the log-sink R2 bucket that makes the bucket available to your Worker via env.LOG_BUCKET.
src/index.ts
Open src/index.ts and replace the contents with the following code:
The export interface Env section exposes the two bindings you defined in wrangler.toml: a queue named BUFFER and an R2 bucket named LOG_BUCKET.
The fetch() handler transforms the request body into JSON, adds the body to the BUFFER queue, then returns an HTTP 200 response with the message Success!
The `queue()` handler receives a batch of messages that each contain log entries, iterates through concatenating each log into a string buffer, then writes that buffer to the LOG_BUCKET R2 bucket using the current timestamp as the filename.
Publishing and running your application To publish your log sink application, run wrangler publish. Wrangler packages your application and its dependencies and deploys it to Cloudflare’s global network.
Note that the output of wrangler publish includes the BUFFER queue binding, indicating that this Worker is a producer and can place messages onto the queue. The final line of output also indicates that this Worker is a consumer for the log-sink queue and can read and remove messages from the queue.
Use your favorite API client, like curl, httpie, or Postman, to send JSON log entries to the published URL for your Worker via HTTP POST requests. Navigate to your log-sink R2 bucket in the Cloudflare dashboard and note that the logs prefix is now populated with aggregated logs from your request.
Download and open one of the logfiles to view the JSON array inside. That’s it – with fewer than 45 lines of code and config, you’ve built a log aggregator to ingest and store data in R2!
Buffering R2 writes with Queues in the real world
In the previous example, you create a simple Workers application that buffers data into batches before writing the batches to R2. This reduces the number of calls to the downstream service, reducing load on the service and saving you money.
UUID.rocks, the fastest UUIDv4-as-a-service, wanted to confirm whether their API truly generates unique IDs on every request. With 80,000 requests per day, it wasn’t trivial to find out. They decided to write every generated UUID to R2 to compare IDs across the entire population. However, writing directly to R2 at the rate UUIDs are generated is inefficient and expensive.
To reduce writes and costs, UUID.rocks introduced Cloudflare Queues into their UUID generation workflow. Each time a UUID is requested, a Worker places the value of the UUID into a queue. Once enough messages have been received, the buffered batch of JSON objects is written to R2. This avoids invoking an R2 write on every API call, saving costs and making the data easier to process later.
Like many of the Cloudflare services you use and love, we built Queues by composing other Cloudflare services like Workers and Durable Objects. This enabled us to rapidly solve two difficult challenges: securely invoking your Worker from our own service and maintaining a strongly consistent state at scale. Several recent Cloudflare innovations helped us overcome these challenges.
Securely invoking your Worker
In the Before Times (early 2022), invoking one Worker from another Worker meant a fresh HTTP call from inside your script. This was a brittle experience, requiring you to know your downstream endpoint at deployment time. Nested invocations ran as HTTP calls, passing all the way through the Cloudflare network a second time and adding latency to your request. It also meant security was on you – if you wanted to control how that second Worker was invoked, you had to create and implement your own authentication and authorization scheme.
Worker to Worker requests During Platform Week in May 2022, Service Worker Bindings entered general availability. With Service Worker Bindings, your Worker code has a binding to another Worker in your account that you invoke directly, avoiding the network penalty of a nested HTTP call. This removes the performance and security barriers discussed previously, but it still requires that you hard-code your nested Worker at compile time. You can think of this setup as “static dispatch,” where your Worker has a static reference to another Worker where it can dispatch events.
Dynamic dispatch As Service Worker Bindings entered general availability, we also launched a closed beta of Workers for Platforms, our tool suite to help make any product programmable. With Workers for Platforms, software as a service (SaaS) and platform providers can allow users to upload their own scripts and run them safely via Cloudflare Workers. User scripts are not known at compile time, but are dynamically dispatched at runtime.
With dynamic dispatch generally available, we now have the ability to discover and invoke Workers at runtime without the performance penalty of HTTP traffic over the network. We use dynamic dispatch to invoke your queue’s consumer Worker whenever a message or batch of messages is ready to be processed.
Consistent stateful data with Durable Objects
Another challenge we faced was storing messages durably without sacrificing performance. We took the design goal of ensuring that all messages were persisted to disk in multiple locations before we confirmed receipt of the message to the user. Again, we turned to an existing Cloudflare product—Durable Objects—which entered general availability nearly one year ago today.
Durable Objects are named instances of JavaScript classes that are guaranteed to be unique across Cloudflare’s entire network. Durable Objects process messages in-order and on a single-thread, allowing for coordination across messages and provide a strongly consistent storage API for key-value pairs. Offloading the hard problem of storing data durably in a distributed environment to Distributed Objects allowed us to reduce the time to build Queues and prepare it for open beta.
Open beta roadmap
Our open beta process empowers you to influence feature prioritization and delivery. We’ve set ambitious goals for ourselves on the path to general availability, most notably supporting unlimited throughput while maintaining 100% durability. We also have many other great features planned, like first-in first-out (FIFO) message processing and API compatibility layers to ease migrations, but we need your feedback to build what you need most, first.
Conclusion
Cloudflare Queues is a global message queue for the Workers developer. Building with Queues makes your applications more performant, resilient, and cost-effective—but we’re not done yet. Join the Open Beta today and share your feedback to help shape the Queues roadmap as we deliver application integration services for the next generation cloud.
While scaling our new Feature Flagging product DevCycle, we’ve encountered an interesting challenge: our Cloudflare Workers-based infrastructure can handle way more instantaneous load than our traditional AWS infrastructure. This led us to rethink how we design our infrastructure to always use Cloudflare Workers for everything.
The origin of DevCycle
For almost 10 years, Taplytics has been a leading provider of no-code A/B testing and feature flagging solutions for product and marketing teams across a wide range of use cases for some of the largest consumer-facing companies in the world. So when we applied ourselves to build a new engineering-focused feature management product, DevCycle, we built upon our experience using Workers which have served over 140 billion requests for Taplytics customers.
The inspiration behind DevCycle is to build a focused feature management tool for engineering teams, empowering them to build their software more efficiently and deploy it faster. Helping engineering teams reach their goals, whether it be continuous deployment, lower change failure rate, or a faster recovery time. DevCycle is the culmination of our vision of how teams should use Feature Management to build high-quality software faster. We’ve used DevCycle to build DevCycle, enabling us to implement continuous deployment successfully.
DevCycle architecture
One of the first things we asked ourselves when ideating DevCycle was how we could get out of the business of managing 1000’s of vCPUs worth of AWS instances and move our core business logic closer to our end-user devices. Based on our experience with Cloudflare Workers at Taplytics we knew we wanted it to be a core part of our future infrastructure for DevCycle.
By using the global computing power of Workers and moving as much logic to the SDKs as possible with our local bucketing server-side SDKs, we were able to massively reduce or eliminate the latency of fetching feature flag configurations for our users. In addition, we used a shared WASM library across our Workers and local bucketing SDKs to dramatically reduce the amount of code we need to maintain per SDK, and increase the consistency of our platform. This architecture has also fundamentally changed our business’s cost structure to easily serve any customer of any scale.
The core architecture of DevCycle revolves around publishing and consuming JSON configuration files per project environment. The publishing side is managed in our AWS services, while Cloudflare manages the consumption of these config files at scale. This split in responsibilities allows for all high-scale requests to be managed by Cloudflare, while keeping our AWS services simple and low-scale.
“Workers are breaking our events pipeline”
One of the primary challenges as a feature management platform is that we don’t have direct control over the load from our customers’ applications using our SDKs; our systems need the ability to scale instantly to match their load. For example, we have a couple of large customers whose mobile traffic is primarily driven by push notifications, which causes massive instantaneous spikes in traffic to our APIs in the range of 10x increases in load. As you can imagine, any traditional auto-scaled API service and the load balancer cannot manage that type of increase in load. Thus, our choices are to dramatically increase the minimum size of our cluster and load balancer to handle these unknown load spikes, accept that some requests will be rate-limited, or move to an architecture that can handle this load.
Given that all our SDK API requests are already served with Workers, they have no problem scaling instantly to 10x+ their base load. Sadly we can’t say the same about the traditional parts of our infrastructure.
For each feature flag configuration request to a Worker, a corresponding events request is sent to our AWS events infrastructure. The events are received by our events API container in Kubernetes, where they are then published to Kafka and eventually ingested by Snowflake. While Cloudflare Workers have no problem handling instantaneous spikes in feature flag requests, the events system can’t keep up. Our cluster and events API containers need to be scaled up faster to prevent the existing instances from being overwhelmed. Even the load balancer has issues accepting the sudden increase. Cloudflare Workers just work too well in comparison to EC2 instances + EKS.
To solve this issue we are moving towards a new events Cloudflare Worker which will be able to handle the instantaneous events load from these requests and make use of the Kinesis Data Firehose to write events to our existing S3 bucket which is ingested by Snowflake. In the future, we look forward to testing out Cloudflare Queues writing to R2 once a Snowflake connector has been created. This architecture should allow us to ingest events at almost any scale and withstand instantaneous traffic spikes with a predictable and efficient cost structure.
Building without a database next to your code
Workers provide many benefits, including fast response times, infinite scalability, serverless architecture, and excellent up-time performance. However, if you want to see all these benefits, you need to architect your Workers to assume that you don’t have direct access to a centralized SQL / NoSQL database (or D1) like you would with a traditional API service. For example, suppose you build your workers to require reaching out to a database to fetch and update user data every time a request is made to your Workers. In that case, your request latency will be tied to the geographic distance between your Worker and the database plus the latency of the database. In addition, your Workers will be able to scale significantly beyond the number of database connections you can support, and your uptime will be tied to the uptime of your external database. Therefore, when architecting your systems to use Workers, we advise relying primarily on data sent as part of the API request and cacheable data on Cloudflare’s global network.
Cloudflare provides multiple products and services to help with data on their global network:
However, the lowest latency way of retrieving data from within a Worker is limited by a minimum 60-second TTL. So you’ll need to be ok with cached data that is 60 seconds stale.
Durable Objects: “provide low-latency coordination and consistent storage for the Workers platform through two features: global uniqueness and a transactional storage API.”
Ability to store user-level information closer to the end user.
Unfamiliar worker interface for accessing data for developers with SQL / NoSQL experience.
Each of these tools that Cloudflare provides has made building APIs far more accessible than when Workers launched initially; however, each service has aspects which need to be accounted for when architecting your systems. Being an open platform, you can also access any publically available database you want from a Worker. For example, we are making use of Macrometa for our EdgeDB product built into our Workers to help customers access their user data.
The predictable cost structure of Workers
One of the greatest advantages of moving most of our workloads towards Cloudflare Workers is the predictable cost structure that can scale 1:1 with our request loads and can be easily mapped to usage-based billing for our customers. In addition, we no longer have to run excess EC2 instances to handle random spikes in load, just in case they happen.
Too many SaaS services have opaque billing based on max usage or other metrics that don’t relate directly to their costs. Moving from our legacy AWS architecture with high fixed costs like databases and caching layers to Workers has resulted in our infrastructure spending is directly tied to using our APIs and SDKs. For DevCycle, this architecture has been over ~5x more cost-efficient to operate.
The future of DevCycle and Cloudflare
With DevCycle we will continue to invest in leveraging serverless computing and moving our core business logic as close to our users as possible, either on Cloudflare’s global network or locally within our SDKs. We’re excited to integrate even more deeply with the Cloudflare developer platform as new services evolve. We already see future use cases for R2, Queues and Durable Objects and look forward to what’s coming next from Cloudflare.
To help developers build better web applications we researched and devised a fragments architecture to build micro-frontends using Cloudflare Workers that is lightning fast, cost-effective to develop and operate, and scales to the needs of the largest enterprise teams without compromising release velocity or user experience.
Here we share a technical overview and a proof of concept of this architecture.
Why micro-frontends?
One of the challenges of modern frontend web development is that applications are getting bigger and more complex. This is especially true for enterprise web applications supporting e-commerce, banking, insurance, travel, and other industries, where a unified user interface provides access to a large amount of functionality. In such projects it is common for many teams to collaborate to build a single web application. These monolithic web applications, usually built with JavaScript technologies like React, Angular, or Vue, span thousands, or even millions of lines of code.
When a monolithic JavaScript architecture is used with applications of this scale, the result is a slow and fragile user experience with low Lighthouse scores. Furthermore, collaborating development teams often struggle to maintain and evolve their parts of the application, as their fates are tied with fates of all the other teams, so the mistakes and tech debt of one team often impacts all.
Drawing on ideas from microservices, the frontend community has started to advocate for micro-frontends to enable teams to develop and deploy their features independently of other teams. Each micro-frontend is a self-contained mini-application, that can be developed and released independently, and is responsible for rendering a “fragment” of the page. The application then combines these fragments together so that from the user’s perspective it feels like a single application.
An application consisting of multiple micro-frontends
Fragments could represent vertical application features, like “account management” or “checkout”, or horizontal features, like “header” or “navigation bar”.
Client-side micro-frontends
A common approach to micro-frontends is to rely upon client-side code to lazy load and stitch fragments together (e.g. via Module Federation). Client-side micro-frontend applications suffer from a number of problems.
Common code must either be duplicated or published as a shared library. Shared libraries are problematic themselves. It is not possible to tree-shake unused library code at build time resulting in more code than necessary being downloaded to the browser and coordinating between teams when shared libraries need to be updated can be complex and awkward.
Also, the top-level container application must bootstrap before the micro-frontends can even be requested, and they also need to boot before they become interactive. If they are nested, then you may end up getting a waterfall of requests to get micro-frontends leading to further runtime delays.
These problems can result in a sluggish application startup experience for the user.
Server-side rendering could be used with client-side micro-frontends to improve how quickly a browser displays the application but implementing this can significantly increase the complexity of development, deployment and operation. Furthermore, most server-side rendering approaches still suffer from a hydration delay before the user can fully interact with the application.
Addressing these challenges was the main motivation for exploring an alternative solution, which relies on the distributed, low latency properties provided by Cloudflare Workers.
Micro-frontends on Cloudflare Workers
Cloudflare Workers is a compute platform that offers a highly scalable, low latency JavaScript execution environment that is available in over 275 locations around the globe. In our exploration we used Cloudflare Workers to host and render micro-frontends from anywhere on our global network.
Fragments architecture
In this architecture the application consists of a tree of “fragments” each deployed to Cloudflare Workers that collaborate to server-side render the overall response. The browser makes a request to a “root fragment”, which will communicate with “child fragments” to generate the final response. Since Cloudflare Workers can communicate with each other with almost no overhead, applications can be server-side rendered quickly by child fragments, all working in parallel to render their own HTML, streaming their results to the parent fragment, which combines them into the final response stream delivered to the browser.
The demo application is a simple filtered gallery of cloud images built using our fragments architecture. Try selecting a tag in the type-ahead to filter the images listed in the gallery. Then change the delay on the stream of cloud images to see how the type-ahead filtering can be interactive before the page finishes loading.
Multiple Cloudflare Workers
The application is composed of a tree of six collaborating but independently deployable Cloudflare Workers, each rendering their own fragment of the screen and providing their own client-side logic, and assets such as CSS stylesheets and images.
Architectural overview of the Cloud Gallery app
The “main” fragment acts as the root of the application. The “header” fragment has a slider to configure an artificial delay to the display of gallery images. The “body” fragment contains the “filter” fragment and “gallery” fragments. Finally, the “footer” fragment just shows some static content.
The full source code of the demo app is available on GitHub.
Benefits and features
This architecture of multiple collaborating server-side rendered fragments, deployed to Cloudflare Workers has some interesting features.
Encapsulation
Fragments are entirely encapsulated, so they can control what they own and what they make available to other fragments.
Fragments can be developed and deployed independently
Updating one of the fragments is as simple as redeploying that fragment. The next request to the main application will use the new fragment. Also, fragments can host their own assets (client-side JavaScript, images, etc.), which are streamed through their parent fragment to the browser.
Server-only code is not sent to the browser
As well as reducing the cost of downloading unnecessary code to the browser, security sensitive code that is only needed for server-side rendering the fragment is never exposed to other fragments and is not downloaded to the browser. Also, features can be safely hidden behind feature flags in a fragment, allowing more flexibility with rolling out new behavior safely.
Composability
Fragments are fully composable – any fragment can contain other fragments. The resulting tree structure gives you more flexibility in how you architect and deploy your application. This helps larger projects to scale their development and deployment. Also, fine-grain control over how fragments are composed, could allow fragments that are expensive to server-side render to be cached individually.
Fantastic Lighthouse scores
Streaming server-rendered HTML results in great user experiences and Lighthouse scores, which in practice means happier users and higher chance of conversions for your business.
Lighthouse scores for the Cloud Gallery app
Each fragment can parallelize requests to its child fragments and pipe the resulting HTML streams into its own single streamed server-side rendered response. Not only can this reduce the time to render the whole page but streaming each fragment through to the browser reduces the time to the first byte of each fragment.
Eager interactivity
One of the powers of a fragments architecture is that fragments can become interactive even while the rest of the application (including other fragments) is still being streamed down to the browser.
In our demo, the “filter” fragment is immediately interactive as soon as it is rendered, even if the image HTML for the “gallery” fragment is still loading.
To make it easier to see this, we added a slider to the top of the “header” that can simulate a network or database delay that slows down the HTML stream which renders the “gallery” images. Even when the “gallery” fragment is still loading, the type-ahead input, in the “filter” fragment, is already fully interactive.
Just think of all the frustration that this eager interactivity could avoid for web application users with unreliable Internet connection.
Under the hood
As discussed already this architecture relies upon deploying this application as many cooperating Cloudflare Workers. Let’s look into some details of how this works in practice.
We experimented with various technologies, and while this approach can be used with many frontend libraries and frameworks, we found the Qwik framework to be a particularly good fit, because of its HTML-first focus and low JavaScript overhead, which avoids any hydration problems.
Implementing a fragment
Each fragment is a server-side rendered Qwik application deployed to its own Cloudflare Worker. This means that you can even browse to these fragments directly. For example, the “header” fragment is deployed to https://cloud-gallery-header.web-experiments.workers.dev/.
A screenshot of the self-hosted “header” fragment
The header fragment is defined as a Header component using Qwik.This component is rendered in a Cloudflare Worker via a fetch() handler:
The renderResponse() function is a helper we wrote that server-side renders the fragment and streams it into the body of a Response that we return from the fetch() handler.
The header fragment serves its own JavaScript and image assets from its Cloudflare Worker. We configure Wrangler to upload these assets to Cloudflare and serve them from our network.
Implementing fragment composition
Fragments that contain child fragments have additional responsibilities:
Request and inject child fragments when rendering their own HTML.
Proxy requests for child fragment assets through to the appropriate fragment.
Injecting child fragments
The position of a child fragment inside its parent can be specified by a FragmentPlaceholder helper component that we have developed. For example, the “body” fragment has the “filter” and “gallery” fragments.
The FragmentPlaceholder component is responsible for making a request for the fragment and piping the fragment stream into the output stream.
Proxying asset requests
As mentioned earlier, fragments can host their own assets, especially client-side JavaScript files. When a request for an asset arrives at the parent fragment, it needs to know which child fragment should receive the request.
In our demo we use a convention that such asset paths will be prefixed with /_fragment/<fragment-name>. For example, the header logo image path is /_fragment/header/cf-logo.png. We developed a tryGetFragmentAsset() helper which can be added to the parent fragment’s fetch() handler to deal with this:
If a fragment hosts its own assets, then we need to ensure that any HTML it renders uses the special _fragment/<fragment-name> path prefix mentioned above when referring to these assets. We have implemented a strategy for this in the helpers we developed.
The FragmentPlaceholder component adds a base searchParam to the fragment request to tell it what this prefix should be. The renderResponse() helper extracts this prefix and provides it to the Qwik server-side renderer. This ensures that any request for client-side JavaScript has the correct prefix. Fragments can apply a hook that we developed called useFragmentRoot(). This allows components to gather the prefix from a FragmentContext context.
For example, since the “header” fragment hosts the Cloudflare and GitHub logos as assets, it must call the useFragmentRoot() hook:
Cloudflare Workers provide a mechanism called service bindings to make requests between Cloudflare Workers efficiently that avoids network requests. In the demo we use this mechanism to make the requests from parent fragments to their child fragments with almost no performance overhead, while still allowing the fragments to be independently deployed.
Comparison to current solutions
This fragments architecture has three properties that distinguish it from other current solutions.
Unlike monoliths, or client-side micro-frontends, fragments are developed and deployed as independent server-side rendered applications that are composed together on the server-side. This significantly improves rendering speed, and lowers interaction latency in the browser.
Unlike server-side rendered micro-frontends with Node.js or cloud functions, Cloudflare Workers is a globally distributed compute platform with a region-less deployment model. It has incredibly low latency, and a near-zero communication overhead between fragments.
Unlike solutions based on module federation, a fragment’s client-side JavaScript is very specific to the fragment it is supporting. This means that it is small enough that we don’t need to have shared library code, eliminating the version skew issues and coordination problems when updating shared libraries.
Future possibilities
This demo is just a proof of concept, so there are still areas to investigate. Here are some of the features we’d like to explore in the future.
Caching
Each micro-frontend fragment can be cached independently of the others based on how static its content is. When requesting the full page, the fragments only need to run server-side rendering for micro-frontends that have changed.
An application where the output of some fragments are cached
With per-fragment caching you can return the HTML response to the browser faster, and avoid incurring compute costs in re-rendering content unnecessarily.
Fragment routing and client-side navigation
Our demo application used micro-frontend fragments to compose a single page. We could however use this approach to implement page routing as well. When server-side rendering, the main fragment could insert the appropriate “page” fragment based on the visited URL. When navigating, client-side, within the app, the main fragment would remain the same while the displayed “page” fragment would change.
An application where each route is delegated to a different fragment
This approach combines the best of server-side and client-side routing with the power of fragments.
Using other frontend frameworks
Although the Cloud Gallery application uses Qwik to implement all fragments, it is possible to use other frameworks as well. If really necessary, it’s even possible to mix and match frameworks.
To achieve good results, the framework of choice should be capable of server-side rendering, and should have a small client-side JavaScript footprint. HTML streaming capabilities, while not required, can significantly improve performance of large applications.
An application using different frontend frameworks
Incremental migration strategies
Adopting a new architecture, compute platform, and deployment model is a lot to take in all at once, and for existing large applications is prohibitively risky and expensive. To make this fragment-based architecture available to legacy projects, an incremental adoption strategy is a key.
Developers could test the waters by migrating just a single piece of the user-interface within their legacy application to a fragment, integrating with minimal changes to the legacy application. Over time, more of the application could then be moved over, one fragment at a time.
Convention over configuration
As you can see in the Cloud Gallery demo application, setting up a fragment-based micro-frontend requires quite a bit of configuration. A lot of this configuration is very mechanical and could be abstracted away via conventions and better tooling. Following productivity-focused precedence found in Ruby on Rails, and filesystem based routing meta-frameworks, we could make a lot of this configuration disappear.
Try it yourself!
There is still so much to dig into! Web applications have come a long way in recent years and their growth is hard to overstate. Traditional implementations of micro-frontends have had only mixed success in helping developers scale development and deployment of large applications. Cloudflare Workers, however, unlock new possibilities which can help us tackle many of the existing challenges and help us build better web applications.
If all of these sounds interesting to you, and you would like to work with us on improving the developer experience for Cloudflare Workers, we are also happy to share that we are hiring!
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.