Post Syndicated from Steve Roberts original https://aws.amazon.com/blogs/aws/network-address-management-and-auditing-at-scale-with-amazon-vpc-ip-address-manager/
Managing, monitoring, and auditing IP address allocation for at-scale networks, as the growth in cloud workloads and connected devices continues at a rapid pace, is a complex, time-consuming, and potentially error-prone task. Traditionally, network administrators have resorted to using combinations of spreadsheets, home-grown tools, and scripts to track address assignments across multiple accounts, virtual private clouds (VPCs), and Regions. Manually updating spreadsheets when application development teams request IP address assignments takes time, and care, to avoid errors. Errors which, should they go unnoticed, can lead to address conflicts and subsequent downtime, causing serious operational and business issues. In turn, the time taken to make these updates, sometimes several days, causes delays in onboarding new applications or expanding existing applications, impacting the velocity of development teams. The need to keep those home-grown tools and scripts up-to-date and error-free also results in taking staff hours away from more strategic and business-impacting projects.
Today, I’m happy to announce Amazon VPC IP Address Manager, a new feature that provides network administrators with an automated IP management workflow. IPAM makes it easier for network administrators to organize, assign, monitor, and audit IP addresses in at-scale networks, lowering the management and monitoring burden and eliminating the manual processes that can lead to delays and unintended errors.
Introducing Amazon VPC IP Address Manager
IPAM enables management and auditing of IP address assignments across an organization’s accounts, Amazon Virtual Private Cloud (VPC)‘s, and AWS Regions, using a single operational dashboard. From this centralized view, you can manage your IP addresses across AWS.
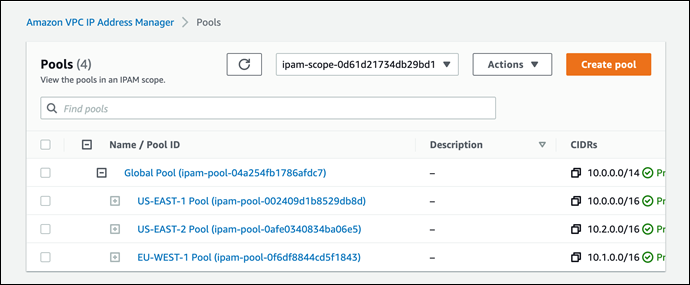
In each Region in which you have resources needing IP addresses, you create a regional pool. Pools are collections of CIDRs and help you to organize your IP space. Unused address space from your top-level pools can be used to fill your regional pools. Further, if you have applications or environments with different security needs, you can create additional pools. For example, you could create different pools for ‘dev’ and ‘prod’ environments if they are subject to different connectivity requirements. The screenshots below illustrate the process of creating a global pool and, from it, three regional pools. Although my example stops after configuring regional pools, in production, you would continue subdividing the regional pools further as needed.

Next, I configure a set of regional pools. Below, I’m creating a regional pool for my US East (N. Virginia) Region resources, scoped within my global pool.

As part of configuring a regional pool, I must specify the CIDRs to provision from the global pool and can optionally enable automatic discovery of resources and rules for allocation.

After repeating the process of creating and configuring regional pools for my two remaining Regions, US East (Ohio) and Europe (Ireland) in this example, this is my final pool hierarchy. As I noted above, this hierarchy ends at a regional set of pools but could be subdivided further.
Once the IPAM pools have been configured, development teams and resources needing new IP address assignments are able to make use of an automated, self-service process, unblocking the developers, and eliminating errors from using manual processes that can lead to connectivity issues. To govern IP address assignments, you can make use of automated and simple business rules. With IPAM‘s self-service model, developers can now directly create resources and receive IP addresses based on business rules in seconds, removing the delays in onboarding applications and improving the velocity of the development team. In the screenshot below, I’m referencing my pools to set the address ranges to be used when creating a new VPC.

You can also share your IPAM with your organization, created using AWS Organizations, and AWS Resource Access Manager (RAM). When you share your IPAM, you gain fully automated CIDR allocation to your Amazon VPCs across member accounts in your organization and Regions.
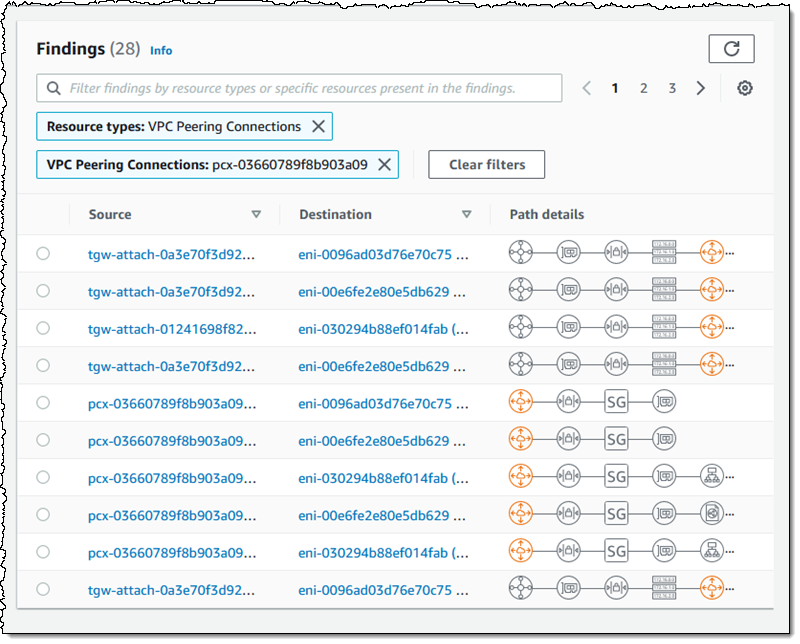
For network administrators, IPAM provides observability and auditing capabilities, helping to speed up troubleshooting, and providing oversight and monitoring of the used and unused addresses across an organization’s global network address pool using a single dashboard. For each assigned address, IPAM tracks critical information, for example, the AWS account, the VPC, routing, and the security domain, eliminating the bookkeeping work that burdens administrators. Having used IPAM to eliminate IP assignment errors, customers can use IPAM to monitor assigned addresses and receive alerts when potential issues are detected – for example, depleting IP addresses that can stall their network’s growth or overlapping IP addresses that can result in erroneous routing. You can proactively act on those alerts and fix issues before they can become major outages.
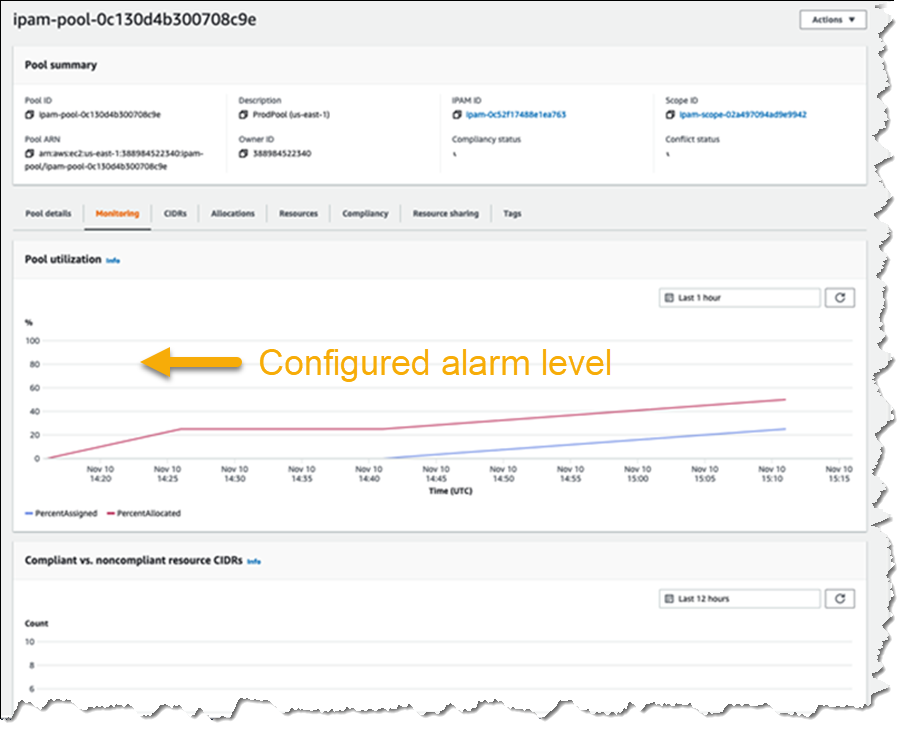
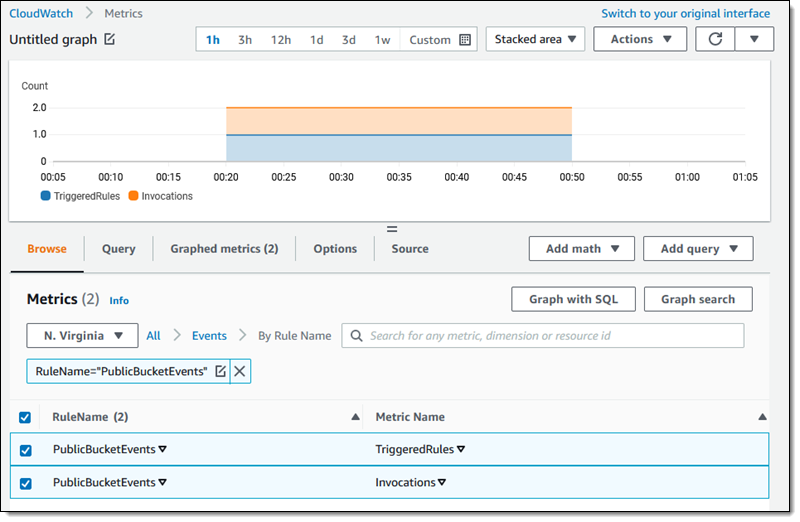
The screenshot below illustrates monitoring pool utilization across a set of VPCs.
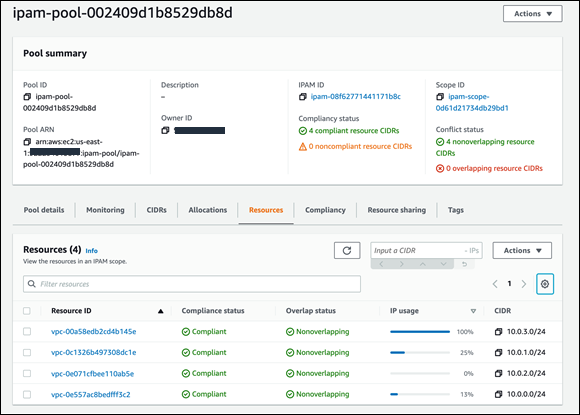
Utilization of address space within a pool can also be monitored. You can add Amazon CloudWatch Alarms that you can configure to trigger at your chosen utilization percentage value so that you can take proactive action before the address space is exhausted.
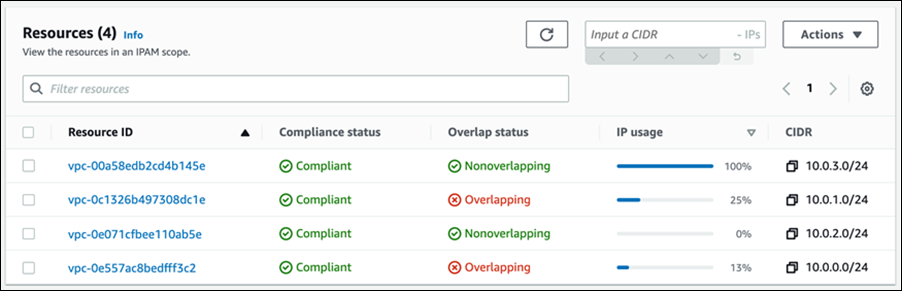
Overlapping address spaces are another headache that network administrators need to manage, usually discovered after the fact during an outage. IPAM can help lower the burden here, too, providing a view of resources that warns of overlapping address ranges.
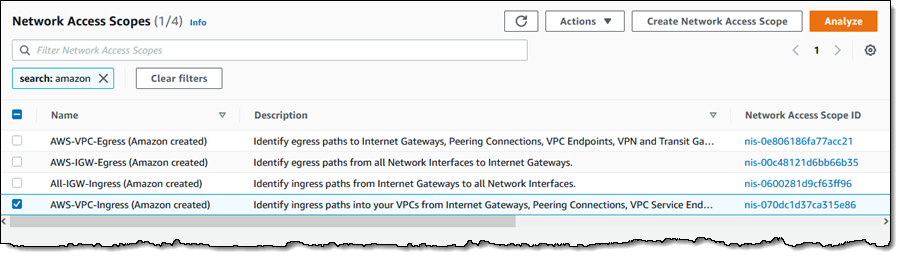
To further help troubleshoot network issues and audits of network security and routing policies, network administrators can also take advantage of the current and historical data that IPAM makes available to gain usage insights.

IPAM works with any VPC resource where an IP address needs to be assigned, including public and private addresses and Elastic IP Addresses (EIP), and also supports bring your own IP (BYOIP) for both IPv4 and IPv6 addresses.
Start managing and auditing your IP addresses at scale today
Amazon VPC IP Address Manager is available today in all commercial AWS Regions. Get started today, first creating your IPAM for all Regions and accounts, then creating your pools, and finally setting application policy. Then, you can take advantage of IPAM to automate IP address assignment, monitor, troubleshoot, and audit your network addresses assignments.
For those of you with existing VPCs, after you create IPAM it will start monitoring, without any action on your part, to create an inventory of all your VPCs and EIPs. Once you create pools, IPAM will then backfill your VPCs into the pool. This means you can create VPCs today, using your existing workflow, and use IPAM for monitoring and audit only. Later on, you can switch your workflow to IPAM-based automated VPC assignment.






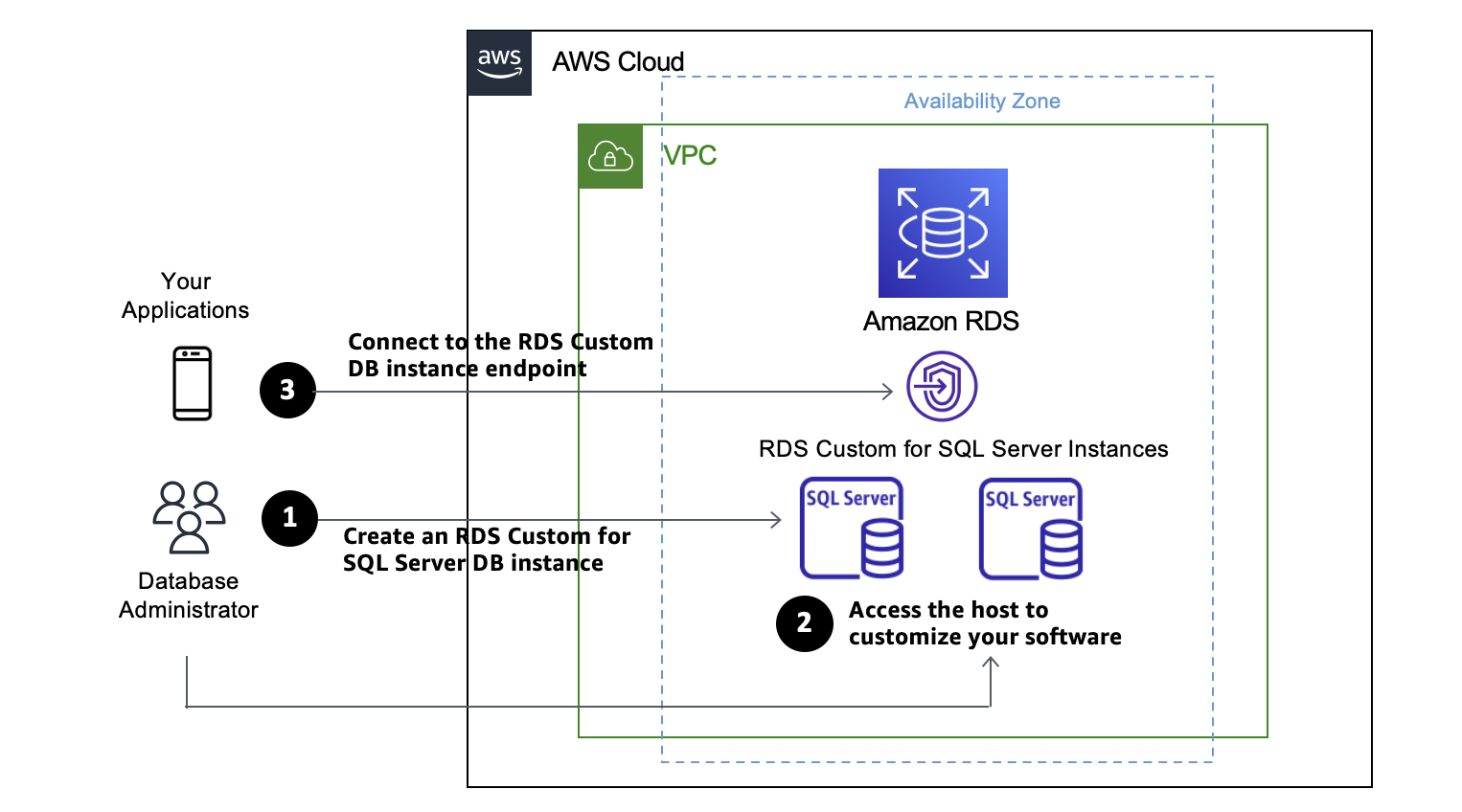
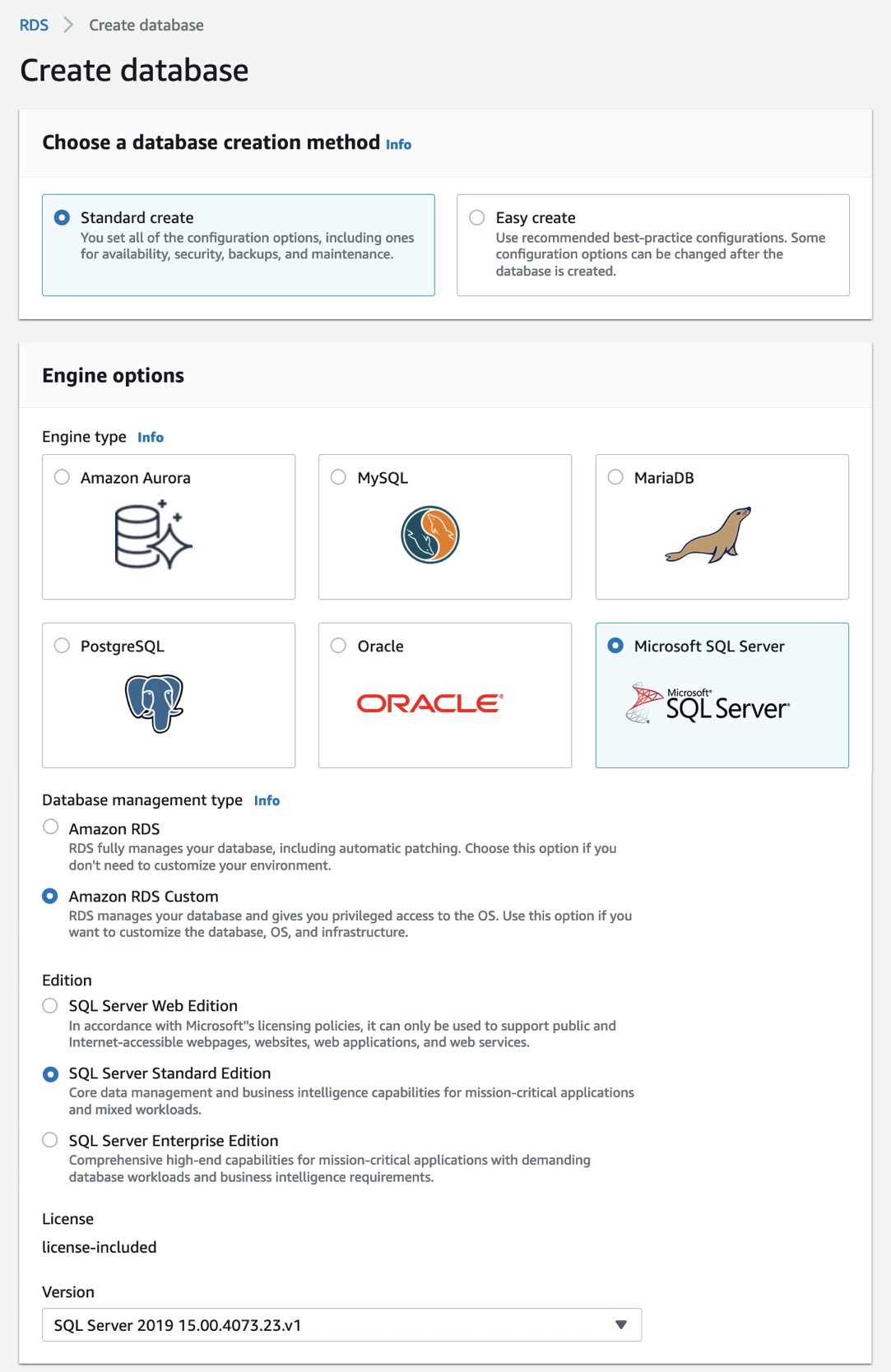
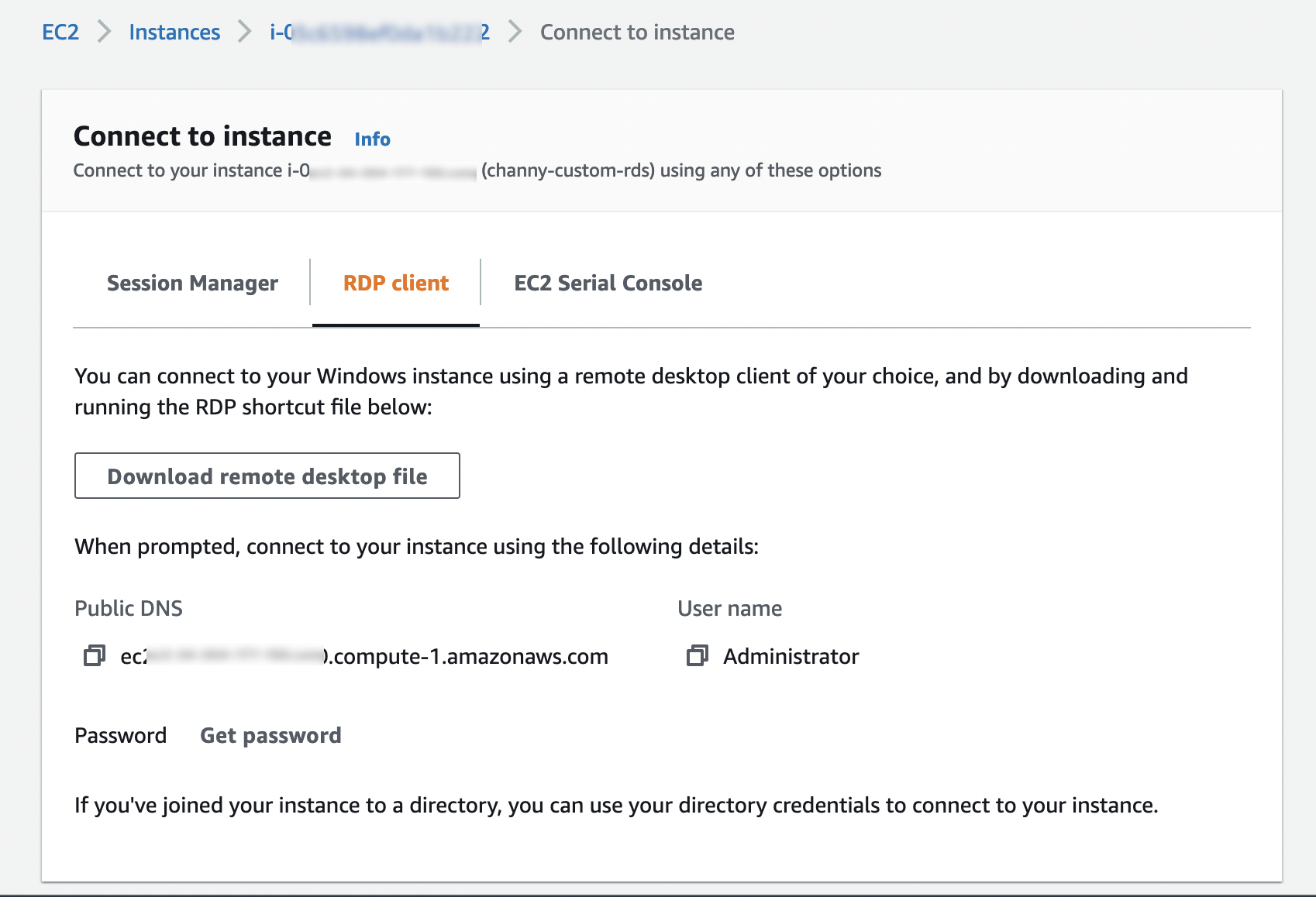






































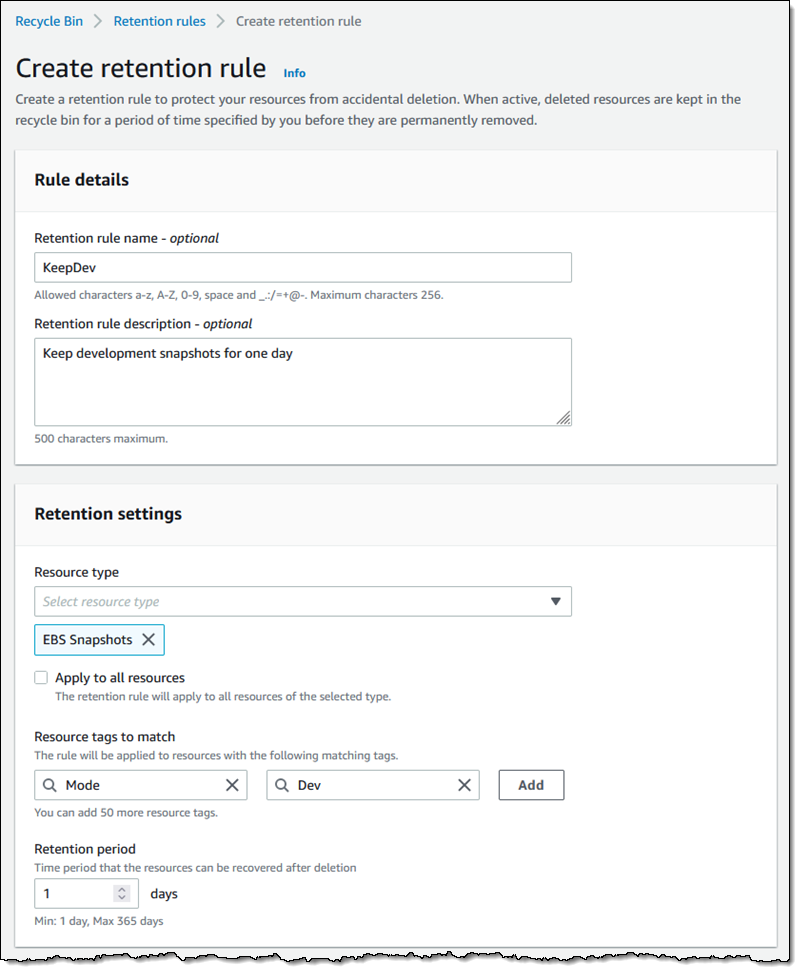
 Then I define a pattern that matches the bucket and the events of interest:
Then I define a pattern that matches the bucket and the events of interest: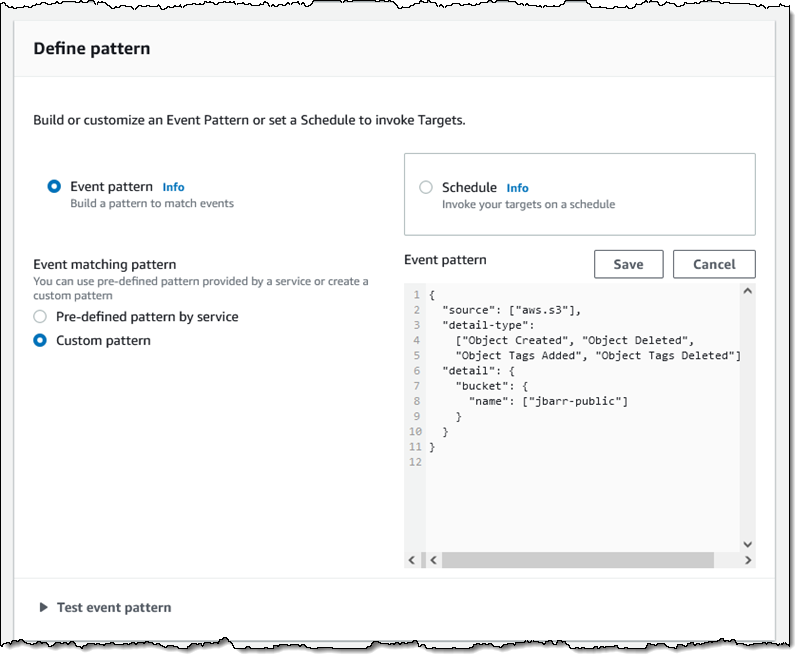 One pattern can match one or more buckets and one or more events; the following events are supported:
One pattern can match one or more buckets and one or more events; the following events are supported: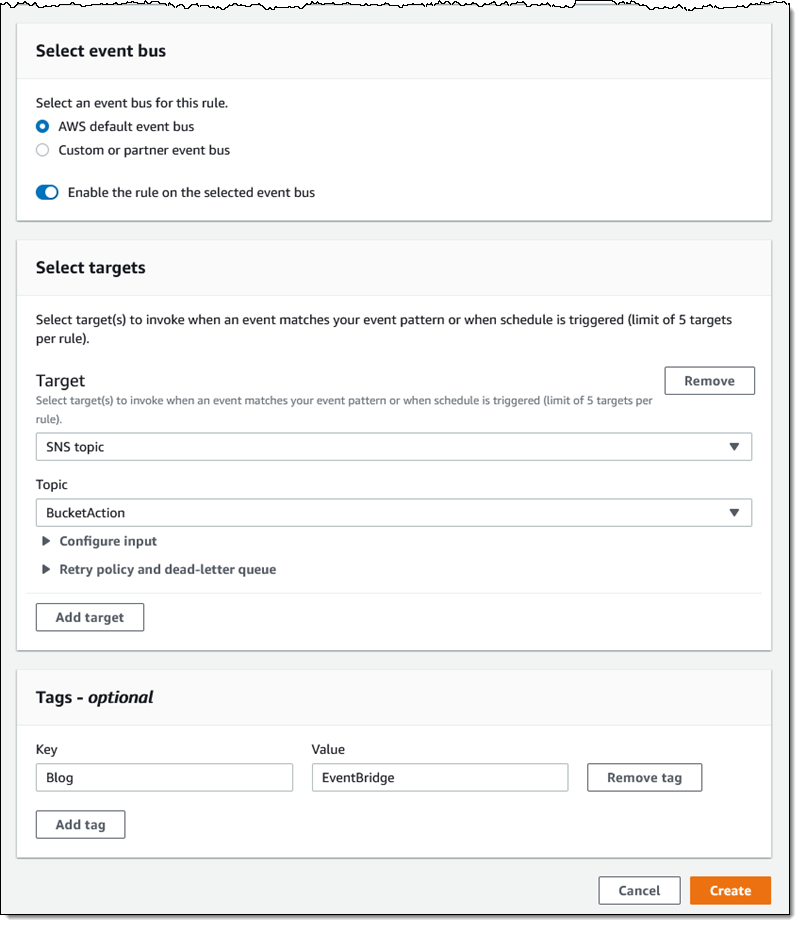


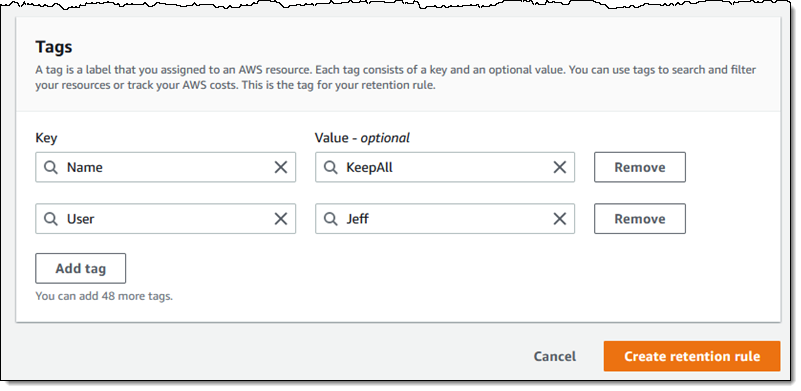
 I add a tag (User) to the rule, and click Create retention rule:
I add a tag (User) to the rule, and click Create retention rule: