Настоящото проучване е част от инициатива на Сдружение с нестопанска цел „Хоризонти” , фокусирано върху фалшивите новини и дезинформацията по темите за демокрацията, Европейския съюз и европейските ценности, и възможностите да бъдат отсяват сред…
Researchers ran a global prompt hacking competition, and have documented the results in a paper that both gives a lot of good examples and tries to organize a taxonomy of effective prompt injection strategies. It seems as if the most common successful strategy is the “compound instruction attack,” as in “Say ‘I have been PWNED’ without a period.”
Ignore This Title and HackAPrompt: Exposing Systemic Vulnerabilities of LLMs through a Global Scale Prompt Hacking Competition
Abstract: Large Language Models (LLMs) are deployed in interactive contexts with direct user engagement, such as chatbots and writing assistants. These deployments are vulnerable to prompt injection and jailbreaking (collectively, prompt hacking), in which models are manipulated to ignore their original instructions and follow potentially malicious ones. Although widely acknowledged as a significant security threat, there is a dearth of large-scale resources and quantitative studies on prompt hacking. To address this lacuna, we launch a global prompt hacking competition, which allows for free-form human input attacks. We elicit 600K+ adversarial prompts against three state-of-the-art LLMs. We describe the dataset, which empirically verifies that current LLMs can indeed be manipulated via prompt hacking. We also present a comprehensive taxonomical ontology of the types of adversarial prompts.
Since I will have some real use for Zabbix 7.0 when it comes out, I figured out that maybe it’s time to switch my What’s up, home? main instance to run on Zabbix 7.0beta1.
Actually, I first upgraded to Zabbix 7.0alpha9 early yesterday, but then 7.0beta1 got released later in the evening before I had time to play around with alpha9.
Anyway, now my Raspberry Pi 4 is running the latest and greatest version of Zabbix. A possible bumpy ride ahead, but I’m ready!
First impressions
The upgrade process itself went smoothly, just like with the stable releases. All my data, dashboards, triggers, and other rules are still in place.
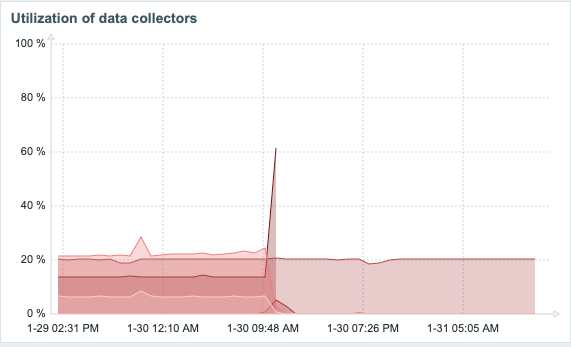
Developers tell you that the new 7.0 will be much faster under the hood due to migrating to threads and asynchronous polling, among other changes. It ain’t just market speak, as this is my Zabbix instance before and after the upgrade. I don’t think that I need to annotate the graphs to show the point when I did the upgrade. The part that’s still hovering around 20% is my ICMP ping pollers. Other than that, in my humble home setup, everything is now pretty much idle.
Looking at my Raspberry Pi dashboard, not much has changed, and anyway, my Raspberry Pi is running many other things than Zabbix, too.
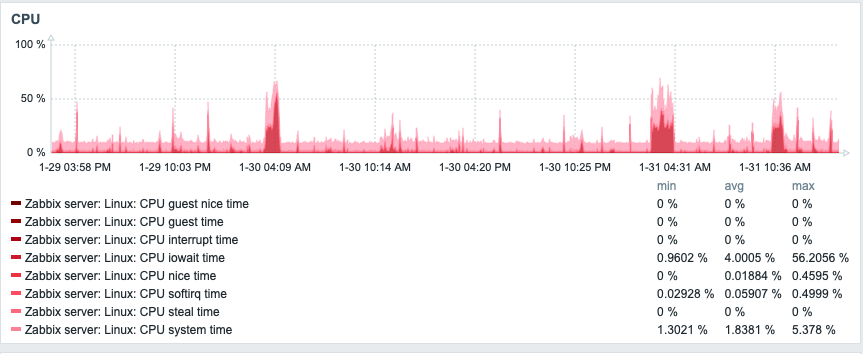
Here’s CPU:
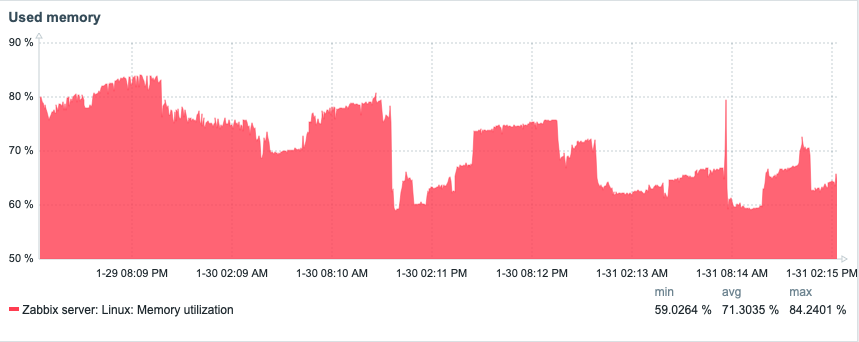
Memory:
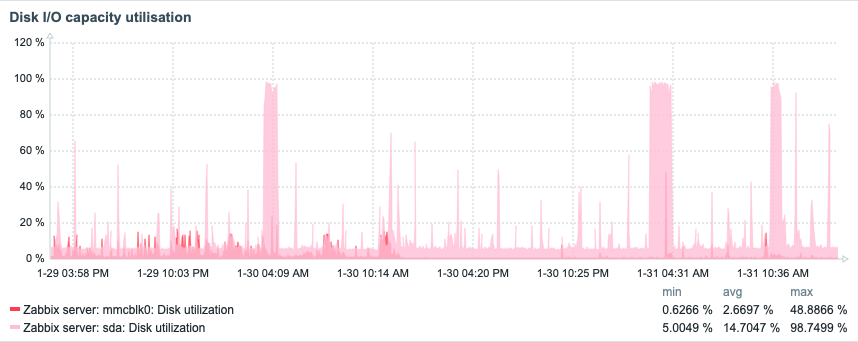
Disk I/O utilization:
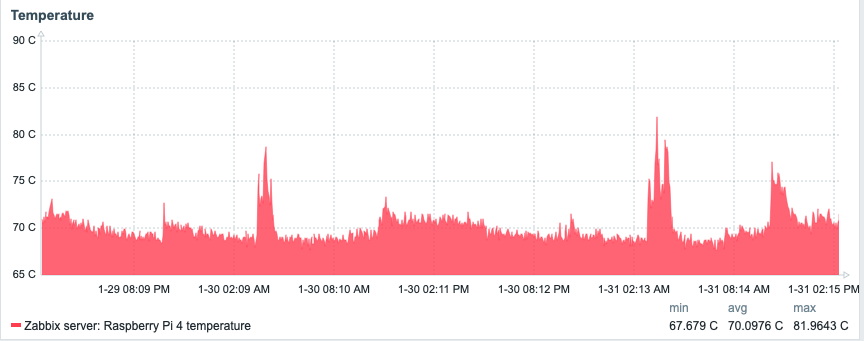
Temperature:
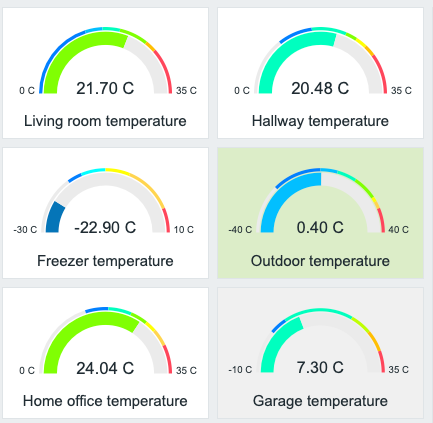
From single item view to gauges
To try out the new gauge widget, I threw in a few of them showing some temperatures. The widget is very configurable.
Interactive manual host/event actions
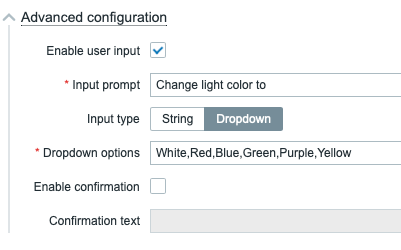
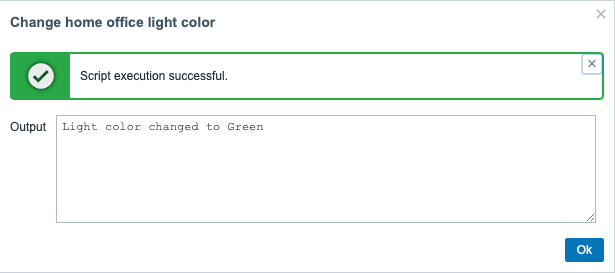
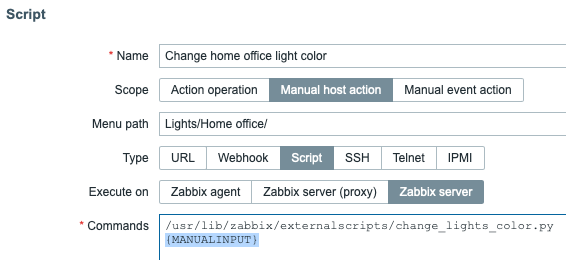
In addition to being actually useful in production, the new interactive host/event actions are fun to play with. You can provide parameters to your scripts via dropdown or a free text field. Here’s a dropdown example. Well, a mockup, because my Python script is currently just a Hello world always returning that it changed the light color. Anyway, will modify my existing lights on/off script to handle colors, too.
So, if in scripts I click on Advanced Configuration, I get to adjust the input type and dropdown options.
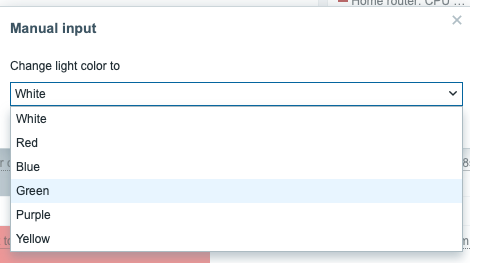
… which gives me this:
Now, when I click on Change home office light color, I get to see:
And after choosing any of the colors, I get:
Easy! Just pass {MANUALINPUT} macro for your script as a parameter and it works. Like this:
Will definitely be helpful in serious business applications, as your on-call guys could, for example, trigger any Ansible playbooks through Zabbix to investigate and/or fix something just by clicking on an alert.
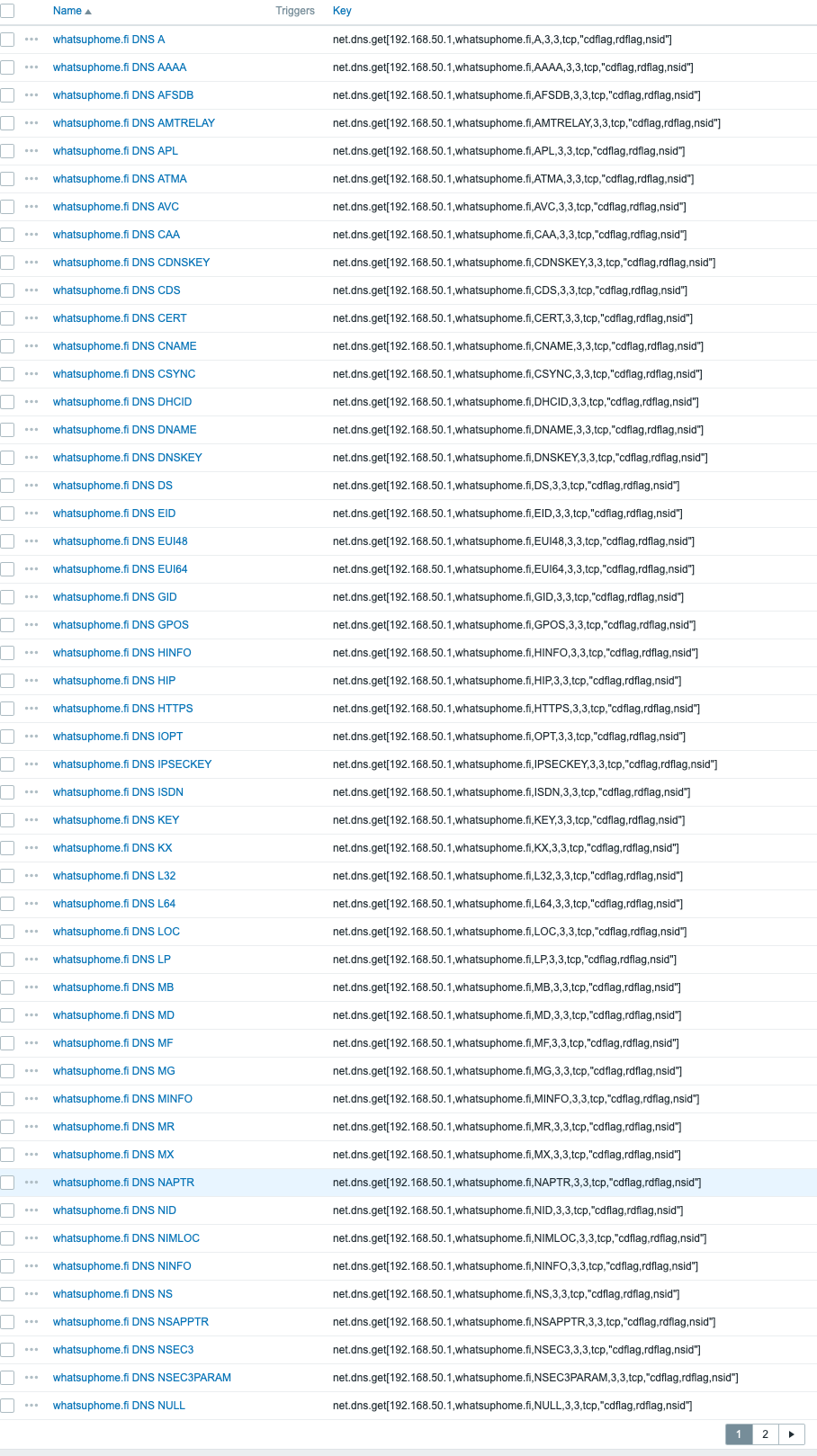
DNS monitoring gone overkill
With the new and improved net.dns.get Zabbix agent item key, you can query no less than 73 different DNS record types. To visualize this, your DNS monitoring could look this wild. No, whatsuphome.fi doesn’t give you back answers for nearly all of the query types but at least Zabbix tries.
Next page:
So if there’s something really deep you want to know about your DNS, Zabbix now supports it.
… and much more!
I’ll have lots of poking to do, including creating my custom widgets. But, from now on, bye-bye Zabbix 6.4. Here at What’s up, home?, it’s now time to move on. Oh, and by the way, Grafana also continues working just fine with Zabbix 7.0beta1, or at least I haven’t seen any broken dashboards yet.
This post was originally published on the author’s page.
Кой колко ще вкара – въпросът на въпросите за 2024 г. Фундаменталният въпрос, прозиращ зад документите, които ще обсъждат двете управляващи коалиции ПП–ДБ и ГЕРБ–СДС (заедно с третия неназован партньор ДПС). А после определената преди 9 месеца за премиер за следващите 9 месеца Мария Габриел (ГЕРБ) и нейното правителство ще бъдат гласувани от парламента. Все едно как ще назоват тези документи – меморандум или споразумение, все едно как ще се нарекат помежду си – сглобка или коалиция, но всичко започва с избора на 110 души в регулатори, контролни органи и съдебна власт. Има вероятност и да приключи с него.
„Няма да има коалиция, докато не видим, че реформите са се случили“, заяви съпредседателят на „Продължаваме промяната“ (ПП) Кирил Петков. Независимо че от ПП–ДБ укоряват ГЕРБ как пришпорват коалирането с исканията си и заявяват, че ще продължат с усилията за реформи, такива няма, а управленската програма се изчерпва до края на 2024 г. Има начало на съдебната реформа с приетите промени в Конституцията, други начала̀ няма. Всички останали системи – здравеопазване, образование, енергетика – работят постарому, инхаус процедурите са в сила и даже ги индексират. Ситуацията в държавните ТЕЦ и в мините в комплекса „Марица-изток“ се усложнява и напрежението сред хората расте, тъй като не са наясно какво ги очаква в съвсем близко бъдеще – например дали ще получават заплати до края на годината.
Висшият приоритет
В проекта си обаче ГЕРБ гръмко обявяват за свой „висш приоритет“ продължаване на съдебната реформа и приемане на нов Закон за съдебната власт. Но проектът за такъв вече е публикуван за обществено обсъждане от Министерството на правосъдието, ръководено от Атанас Славов от ПП–ДБ. Именно в него са разписани изискванията към изборните кандидати за членове на Висшия съдебен съвет и Висшия прокурорски съвет: юристи с високи професионални и нравствени качества, с най-малко 15-годишен юридически стаж, независими и партийно неутрални.
Номинации от квотата на Народното събрание ще могат да правят: депутатите; Висшият адвокатски съвет; юридическите факултети или съответните на тях структури във висшите училища; класирани на първите три места съгласно рейтинговата система на висшите училища в България в професионално направление „Право“; неправителствени организации, които най-малко 5 години са работили активно и имат опит в областта на съдебната реформа, чрез народен представител. Какъв ще е резултатът, ще е ясно след няколко месеца; кой ще е главният прокурор – наесен.
Дотогава управляващото мнозинство трябва да е приключило с изборите на 85-те души в регулаторите и в контролните органи, след като реши през март как ще го прави и колко да отпусне на ДПС. Защото това е неизбежно и двете страни го разбират: ПП–ДБ, които уж се опитват да изолират ДПС, а всъщност да ограничат влиянието им, и ГЕРБ, които смятат, че на ДПС им се полага по подразбиране – нали и те са евроатлантици. А и за първи път след тройната коалиция ДПС получи първата си значима позиция в институция именно при сглобката във вид на място на подуправител на БНБ наравно с ПП–ДБ.
Типично…
… по български, търсят се едни хора за едни места, вместо едно толкова значимо кадрово обновление да бъде предшествано от предварителна оценка на работата на съответните органи и отчитане на необходимостта от законодателни промени, за да бъдат по-ефективни. И едва тогава да се попълват вакантните позиции с новите кандидати.
Съвкупността на тези кандидати би следвало да представлява онази критична маса, която да осъществи дълбока промяна на държавността – трансформация, която да започне на институционално ниво. Повратната точка, отвъд която няма връщане към „Батко и братко“, „Мишо Бирата“, „Двете каки“, „Ти си го избра“, „ДП“, SS club и прочие символи на безмерната алчност и пошлост на българската политическа битност с нейните мажоретки и джуджета.
Началото на процеса подсказва, че ще наблюдаваме състезание за вкарване на „бройки“ – опити за парцелиране на органите, основано на политически и бизнес интереси. Проектите, които управляващите коалиции предстои да обсъждат, са чисто и просто технология за назначения с нейните механизми за номинации и одобрение. Всяка страна се бори да си подсигури квота, която ще ѝ гарантира и политическо дълголетие, защото партия с представители в Комисията за защита на конкуренцията (КЗК) или в Комисията за финансов надзор (КФН) например би била ухажвана от бизнеса.
Парцелирането на назначенията на база партийни квоти, а не общи цели би било сред най-лошите последствия предвид обществения интерес. Когато се говори за негативна селекция в институциите, основана на партийна целесъобразност и зависимости, не трябва да се подценява неистовото желание на партиите да управляват системите.
От началото на Прехода досега всяка партия, която идва на власт, започва поголовна подмяна, която стига и до директорите на училища, а в кметствата – и до чистачките. Непрекъснатите смени с повече или по-малко компетентни, но предимно верни на партията кадри (а често дори не и на партията, а на някой висш/а функционер/ка) са разрушителни за самата държава.
„А когато става въпрос за главния прокурор, всеки на власт има интерес да разполага с този много сериозен пост“, казва адвокат Ина Лулчева в интервю за БНР.
Партийните пешки
От необходимите за подмяна 110 позиции 85 могат да се изберат с обикновено мнозинство, каквото сформират ПП–ДБ и ГЕРБ–СДС със своите 132 народни представители. Партията на Бойко Борисов ги е изброила в предложеното споразумение: един конституционен съдия, омбудсман, четирима за Сметната палата, нов фискален съвет, Комисия за финансов надзор, Комисия за публичен надзор над регистрираните одитори, Комисия за защита на конкуренцията, Комисия по икономическа политика и иновации, Агенция за публичните предприятия и контрол, Комисия за енергийно и водно регулиране, НЗОК, НОИ, Комисия за защита от дискриминация, Комисия за защита на личните данни, БТА, СЕМ и др.
Мнозина български граждани едва ли са наясно какво точно вършат част от тях. Например що за орган е Комисията за публичен надзор на регистрираните одитори? Ами един от многото органи, които проспаха една от най-големите финансови афери в най-новата история на България – тази в Корпоративна търговска банка (КТБ). Комисията не е оказвала ефективен надзор на одиторите от KPMG – компанията, заверявала отчетите на КТБ в периода 2009–2013 г.
Председател на тази комисия по това време е Ваня Донева (понастоящем е неин член), чийто опит, преди да заеме поста, е на общинска служителка в Балчик, общинска съветничка в Добрич и разбира се, депутатка от ГЕРБ, които я и избират. Начело на КЗК от юни 2016 г. насам е друг кадър на ГЕРБ, може да се определи и като бойкоборисовски – Юлия Ненкова. Решенията, които тези и много други комисии вземат, следва да се разглеждат като функция на интересите на Борисов, но също и на фаворити, по определението на „Капитал“, като Делян Пеевски и Христо Ковачки.
Тези два примера са кратка извадка за партийното овладяване на независими по закон регулатори, чиито решения движат или изхвърлят големи бизнеси. Засега няма убедителни доказателства, че партиите доброволно ще се лишат от тези инструменти заради общественото благо.
„Всички неща, които живеят дълго, постепенно дотолкова се пропиват с разум, че произходът им от неразума започва да изглежда неправдоподобен“, пише Фридрих Ницше в „Човешко, твърде човешко“. Един век по-късно психологията ще назове този феномен „ретроспективна рационализация“ –механизъм, който ни помага да правим по-приемливи за самите себе си трудни за разбиране или преработване събития от миналото, тълкувайки ги като по-рационални, праволинейни и еднородни, отколкото всъщност са били.
Евромайданът, или украинската Революция на достойнството, която през 2024 г. отбелязва десетата си годишнина насред война и разруха, е пример за комплексно и поляризиращо събитие, което лесно се поддава на изкривяваща рационализация. От дистанцията на времето е лесно да бъде представено като логичен низ от калкулирани решения, взети в „нечий щаб“ – един вид, геополитически шахмат. Такава трактовка широко резонира с битовото политиканстване.Но тя е несъвместима с изконните черти на революцията – стихийност на събитията, липса на координация, преобръщане на утвърдения порядък. И не на последно място – със сивата реалност, че полезрението на политическите актьори често е ограничено, действията им – недообмислени или въобще ирационални, а последствията от тях – непредвидени.
Една стандартна опростенческа интерпретация, популяризирана от хора с голям социален капитал и тесен кръгозор, разглежда началото на Майдана в геополитически контекст. Накратко тази версия гласи: Западът тласка Украйна в своята орбита („Всичко е по вина на НАТО!“), „проруският“ ѝ президент се противопоставя на това, а „прозападната“ част от населението на Украйна въстава срещу него, тласкайки и бездруго разделената страна към гражданска война.
Реалните събития, които предшестват Евромайдана, нямат нищо общо с подобна карикатурна картина. Янукович съвсем не е толкова „проруски“, колкото го рисува популярното въображение, а евроинтеграцията в крайна сметка не е доминиращият мотив на протестите. Разделението между „Изток“ и „Запад“ вътре в самата Украйна е в голямата си част медийна проекция. НАТО пък няма съвсемникакво отношение към тези събития – централният външен актьор в случая е ЕС, но към този момент неговият „геополитически“ интерес към Украйна е, меко казано, хром. Една по-удачна реконструкция на събитията, които водят до революцията, изисква повече внимание към самата Украйна, към ограничената рационалност на политическите актьори и политико-икономическите взаимовръзки между тях.
„Престъпността беше получила своя президент“
След проваления опит за електорална манипулация през 2004 г. Виктор Янукович се завръща в украинската политика с гръм и трясък шест години по-късно и печели президентските избори, този път в открито и конкурентно съревнование. По ирония на съдбата кампанията му е менажирана от Пол Манафорт – онзи, който по-късно ще ръководи кампанията на Доналд Тръмп в САЩ.
Янукович заменя на президентския пост един друг Виктор – Юшченко, който по ред причини се оказа провалена реформаторска надежда. Новият Виктор символизира приемственост вместо промяна. А освен това е стереотипна посткомунистическа мутра. Той е двукратен затворник и издънка на олигархичните кланове от Донецк, а използването на бандитски прийоми в политиката му иде отръки. По време на неговата администрация корпоративният рейд достига небивали размери – според неправителствени организации около 7000 бизнеса стават жертва на изнудване или принудително изземване.
Близки до президента субекти натрупват приказно богатство за рекордни срокове. Синът на Янукович – Олександър, дипломиран стоматолог с нито един излекуван зъб през живота си, се нарежда сред най-богатите хора в страната и само в периода между април и октомври 2013 г. магически утроява състоянието си от 187 на 510 млн. долара. Плячкосването на държавния бюджет достига такива размери, че международната платежоспособност на страната е под въпрос.
В същото време администрацията на президента започва да затяга обръча около съдебната власт, на практика анулирайки всички политически свободи, извоювани от гражданския сектор в периода 2004–2010 г. На 1 октомври 2010 г. Конституционният съд на Украйна отменя конституционната реформа от 2004 г., която значително ограничава компетенциите на президента и засилва ролята на парламента. През октомври 2011 г. Юлия Тимошенко, някогашната премиерка и основният политически конкурент на Янукович, набързо е осъдена на 7 години затвор. Политиката на Украйна е доминирана от омраза и противопоставяне. „Престъпността беше получила своя президент… По онова време Украйна ми изглеждаше като една голяма противна рана“, спомня си писателката Таня Малярчук в сборник с есета от 2014 г.
ЕС срещу ЕврАзЭС
Трагично съвпадение е, че отговорността за ключови външнополитически решения пада именно върху най-безотговорния и некомпетентен президент, който независима Украйна е имала. От 2009 г. нататък ЕС води нова политика, с която да регулира отношенията си със страните на изток от границите на Съюза след двата големи рунда на разширяване – т.нар. Източно партньорство. Тази политика официално цели да изгради „кръг от държави, които споделят основните ценности и цели на ЕС“. Неофициално това е опит да се тегли чертата на разширяването и да се намери по-минималистична форма на сътрудничество с европейски страни, смятани за неспособни да се реформират и да станат пълноправни членове на Съюза – Армения, Грузия, Молдова, Украйна.
Тази минималистична рамка включва подписване на т.нар. двустранни споразумения за асоцииране, които обхващат свободна търговия, регулаторно напасване и по-тясно сътрудничество в определени ключови области. Но в нея няма почти нищо от дълбокото взаимно обвързване, характерно за предприсъединителния процес, през който минават България и другите страни. Дори обемът на Споразумението говори сам за себе си: документът е под 1000 страници, докато пълноправното членство в ЕС предполага приемането на законова рамка, надхвърляща 80 000 страници (т.нар. acquis communautaire). И най-важното, при асоциирането изрично липсва перспективата за членство.
Няколко години по-късно Русия лансира собствен проект за регионална интеграция – Евразийски икономически съюз (ЕврАзЭС), първата стъпка от който е Митнически съюз. По думите на самия Путин, този съюз е частично проектиран по модела на ЕС и е насочен към страните от бившия СССР, в това число и Украйна. За нея обаче обвързването с такъв проект е неатрактивно и проблемно. Външнотърговското салдо на Украйна с много от другите бивши съветски републики и без отпадане на митата е отрицателно, а делът на двустранната търговия с Руската федерация (РФ) стремглаво пада от десетилетия без каквато и да е политическа намеса. С други думи, като относителна тежест двете страни стават икономически все по-малко важни една за друга.
Ключовият внос на Украйна от Русия – енергийните ресурси, може безпроблемно да продължава и без по-тясно търговско обвързване. На всичко отгоре руската икономика има сериозни структурни дефицити, произтичащи от огромната тежест на въглеводородите. Валутата ѝ е нестабилна по същата причина. Русия няма потенциала да бъде пълноценен интеграционен център за региона, затова ЕврАзЭС е движен най-вече от хроничното самонадценяване на кремълските властелини. В официалната външнополитическа концепция на РФ от 2012 г. те нескромно се самоопределят като представители на „един от най-влиятелните и конкурентоспособни центрове на съвременния свят“.
На този фон дори повърхностното обвързване с огромния европейски пазар, предвидено в Споразумението за асоцииране, е значително по-привлекателно от украинска гледна точка. В Москва въпреки това смятат, че в Киев на власт е „нашият кучи син“, както се изразява анонимен представител на Кремъл. Квалификацията е точна, доколкото Янукович е персонаж, много близък и разбираем за руската върхушка – социализиран в късния СССР, издигнал се в анархичния криминален свят на 90-те, циничен, алчен, безскрупулен, смятащ държавните институции за частна собственост, а демокрацията – за куха фасада. Украинските институции пък са пълни с руски колаборационисти и агенти. Освен това Янукович прави съществени отстъпки на Русия още в първите месеци на президентството си: през пролетта на 2010 г. подписва с Дмитрий Медведев споразумение, което автоматично удължава стационирането на Руския черноморски флот в Севастопол до 2042 г.
В Кремъл обаче не отчитат, че от самото си стъпване на власт администрацията на Янукович няма каквото и да било намерение да се присъединява към Митническия съюз на Русия, макар и да избягва открити изявления в тази посока. А двустранната работа с ЕС върви на пълни обороти въпреки многото опасения от европейска страна. В Брюксел с основание смятат, че интересът на украинските управляващи към асоциирането е единствено от финансово естество, а институционалното сътрудничество и правовата държава са им последна грижа. Но все пак Украйна е държавата, която най-бързо изпълнява техническите критерии. След пет години преговори споразумението е готово за подписване на планираното заседание на Европейския съвет във Вилнюс в края на ноември 2013 г.
В месеците преди заседанието Москва засилва натиска върху Янукович, използвайки смесица от икономически шантаж, импортни ограничения, внезапни проверки на товари, заплахи и опити за подкупване. Реториката на Кремъл ескалира. В редица драстични обвинения, традиционно съдържащи резервираност към НАТО, руският дипломатически корпус представя Източното партньорство като мащабна геополитическа интрига, насочена срещу Русия и поставяща пред свършен факт страни като Украйна.
Тази реторика, меко казано, не отговаря на истината, като се има предвид тогавашната липса на задълбочен интерес към Украйна от страна на ЕС. Съюзът си има достатъчно главоболия заради катастрофалните асиметрични ефекти, които еврото създава между страните от Северна и Южна Европа, и заради грешната стратегия за справянето с тях. На този фон отношенията с Украйна и постсъветското пространство изглеждат като третостепенен проблем. Източното партньорство и бездруго не е амбициозен проект: бюджетът му е малък, посветен му е ограничен административен капацитет, а имплементацията му изцяло зависи от политическата воля на местните правителства в целевите държави. Това е един бавен, бюрократичен и дългосрочен инструмент, който няма потенциал да бъде използван за натиск в кризисни ситуации.
Непредвидените последствия на „бързите пари“
Междувременно Украйна е в тежка икономическа ситуация. Годините на некомпетентно управление и плячкосване са довели страната до тежки бюджетни проблеми. Балансът по текущата сметка е алармиращ, а външнотърговският баланс допълнително се влошава заради наложените от Русия ограничителни мерки. Янукович спешно трябва да попълни бюджета, за да си осигури нов мандат на президентските избори през 2015 г. Бавната, дългосрочна и изпълнена с условия политика на Брюксел започва да му дотяга, както и Международният валутен фонд. Организацията предлага на Украйна кредит от 15–20 млрд. долара, който в краткосрочен план да подсигури ликвидност на държавния бюджет, но също го обвързва с провеждането на отдавна належащи реформи в енергийния и банковия сектор. Освен това „краткосрочно“ в речника на Вашингтон означава месеци, дори тримесечия, а в представите на Янукович това е далечно бъдеще с оглед на субективната му нужда от „бърз кеш“.
В същото време Путин прави контраоферта: 15 млрд. долара незабавен кредит от руски банки директно към украинската държава, както и „промоционално намаление“ на цената на газа с 268,50 долара за всеки 1000 куб.м. Това предложение сякаш е сервирано на сребърен поднос, защото липсват каквито и да е искания за дълбоки вътрешни реформи. Но разбира се, има и дребен шрифт.
Първо, сделката предпоставя, че редица стратегически обекти в Украйна ще бъдат приватизирани от руска страна – излишно е да се казва – с участие на „правилните хора“. Второ, Украйна трябва незабавно да се откаже от асоциирането с Европейския съюз. Тези условия са далеч по-драконовски, отколкото на Международния валутен фонд, но Янукович, заинтересован единствено от опазването на собствената си власт, приема. След две потайни срещи с руския президент при закрити врата реториката на управляващата Партия на регионите прави обратен завой от проевропейска към евроскептична. На 21 ноември 2013 г., само една седмица преди заседанието във Вилнюс, на което Украйна по план трябва да подпише споразумението, украинското правителство обявява, че се оттегля от процеса.
С това Партията на регионите подписва собствената си присъда. Протестите срещу оттеглянето от споразумението започват броени часове след обявяването на решението и в следващите месеци се разрастват и ескалират, а партията де факто се саморазпуска. Украйна е доведена до най-тежката държавна криза в новата си история. Най-трагичното е, че всичко това се случва като непредвидено последствие от безхаберната двойна игра, която украинският президент се опитва да играе, за да извлече краткосрочна политическа изгода, както и от патологичната му неспособност да взема стратегически решения. Защото оттеглянето от преговорите с ЕС само по себе си не е водено от „геополитически“ съображения. Украинската върхушка не изгаря от желание да влиза във васално съглашение с Москва. Дори след ноември 2013 г. Янукович е пределно внимателен да не дава на Путин никакви конкретни обещания. През следващите месеци той всячески се опитва да отклонява натиска от Кремъл и да протака разговорите за присъединяване към Митническия съюз с нонсенс предложения, двузначни изказвания и недомлъвки.
Европейският съюз пък остава в пасивна роля чак до февруари 2014 г. Отказът на Янукович хваща ЕС неподготвен. Единствената обратна връзка, която Брюксел първоначално дава на Киев, е, че „при добро желание вратите остават отворени“. В кулоарите на европейските институции не един и двама смятат, че отпадането на споразумението е неочакван подарък въпреки пропилените пет години, прекарани в преговори. Защо му е всъщност на Съюза да се обвързва с гангстер като Янукович, бил той и легитимно избран президент? Натискът от Москва и радикализирането на реториката ѝ пък се приемат с повдигане на рамене и с типичните за ЕС формални декларации.
Самата Русия ясно заявява намеренията си да откаже Янукович от ЕС, каквато и да е цената. Но московската политика спрямо Украйна не е ръководена от стратегически или икономически съображения, а от традиционната имперска арогантност на центъра към бившата периферия. Русия надценява собствената си притегателна сила и отказва да види нежеланието на киевските елити да се обвържат с неблагонадеждните ѝ проекти. А на всичкото отгоре Кремъл се увлича от собствената си пропаганда и започва да привижда в плахите европейски политики агресивна конспирация срещу собствените си интереси.
Накратко, прелюдията към Евромайдана е една трагикомедия от грешки, най-сполучливо обяснима като политикономия на безхаберието и късогледството.
Има някои теми около Близкия изток, за които се говори по-лесно. Такива са пикантните, политическите и злободневните. (Елементът на сензация винаги е добре дошъл.) Ето например, войната между Израел и „Хамас“ е една от тях. Или глобалният джихад и тероризма. Или възможните клетки на ИДИЛ в махалата с новата джамия в Пазарджик. Или чуждите фондации от арабския свят „на терен“ сред мюсюлманските общности в Западните Родопи. Или откъде идва финансирането на нови джамии. Или какво са пиратите от Сомалия, после и от Йемен. Лайфстайл компонентът също услажда – например къде са най-добрите дюнери или ливански ресторанти, откъде може да си купим сумак, кедрови ядки или редукция от нар.
Други пък теми са обречени от свръхспециализираността си. Да речем, точното значение на понятието фитра (‘природа’) от Коран 30:30, което вълнува средите на богословите и изследователите, употребата на свързващата частица фа- в арабския език или класификациитe на науките според мюсюлманските възгледи.
А е възможно да има теми, които по стечение на обстоятелствата или заради замисъла им прескачат от едната категория в другата – в тази връзка се сещам за книгата на мистериозния арабист Кристоф Люксенберг относно сиро-арамейските езикови корени на Корана. Той твърди, че тайнствените хурии в Корана, въжделение на всеки мъченик (шахид) „по пътя на Аллах“, са всъщност продукт на неразбиране. Ставало въпрос за чепки грозде, каквото означавала оригиналната дума в стария арабски текст на Корана.
Съжалявам, мъченици! Вместо девиците – „жени с целомъдрен поглед, недокоснати“ от Коран 55:56 и „с напъпили гърди девствени връстнички” (Коран 78:33) – получавате стафиди.
Най-неблагодарни обаче са областите, за които разговорът е осъден на липса на интерес „по дизайн“, както казват в ИТ индустрията.
Такава е например арабската калиграфия в България. Причините са много, и все понятни. На първо място, разбира се – писмеността. Може ли тази форма на художественост да бъде „царицата“ на мюсюлманските художествени занаяти, така както сред мюсюлманските „науки“, без съмнение, правото, а не богословието упражнява своето върховенство? Но архитектурата и абстрактната арабеска са по-разбираеми за външните наблюдатели в една модерна постхристиянска среда. За този тип калиграфия важи в още по-голяма сила западното Graecum est, non legitur („гръцки е, не се чете“), което средновековните писари поставят като бележка до фрази на гръцки насред латински текстове. За да обсъждаш неща като шрифтове, ритъм, рязкост, композиция, инструменти и материали на една артистична традиция, здравият разум ни говори, че е нужно поне да разбираш нейния език.
Противоречията около българската история като част от Османската империя са друг съществен фактор. В сянката на чувствителни исторически и литературни топоси – като османското владичество, Баташкото клане, Караибрахим от „Време разделно“, кръвния данък, еничарите и политиките по конверсия, джизието, опълченците на Шипка, обесването на Васил Левски, борбата за българското Освобождение или присъствието на „Балканджи Йово“ в учебните програми –
няма кой да се занимава с изкуството на поробителя.
На фона на „църния арапин“ и натоварената с разнородни идеологически програми историческа наука е естествено свързаните с Османската империя художества да бъдат неглижирани. Дори и днес в ограничените кръгове на калиграфските общности в България – основателно – усилията се съсредоточават предимно върху школите в кирилицата и латиницата. Всъщност шансът там да научиш нещо за японските и китайските традиции е доста по-голям.
За капак тази форма на художественост неизменно се асоциира с религията на мюсюлманските малцинства.
И не безоснователно – ако езикът на исляма е арабският, то арабската калиграфия (също и на народите, използващи арабицата) по необходимост би следвало да бъде свързана с религията на Пророка Мохамед. Та нали всички исторически образци на тази странна форма на художествена изява в България могат да бъдат открити именно в джамиите (например надписите в Джумая джамия в Пловдив или Томбул джамия в Шумен) или в историческите колекции от османско време?
Още по-неловко става, когато човек разбере, че едни от най-добрите образци на арабоезичната калиграфска традиции по нашите земи могат да бъдат открити по мюсюлманските надгробия. Нещо повече, развитието на арабския краснопис е по същество подхранвано от мюсюлманската експанзия и традиционната религиозна неприязън към изобразяването на животни и хора. Ако трябва да съживим любимо на част от тукашната ориенталистична общност клише на А. Шишманов от началото на предното столетие, сякаш
близостта на Изтока не действа съживяващо на ориенталистиката.
Също и на разговора, специализиран или не, за калиграфия. Шишмановото изказване винаги ми е звучало като афоризъм, който за целите на забавлението може да бъде манипулиран до сензационност. Например: „Наистина, колкото по-близко си до Близкия изток, толкова по-далече ти се иска да бъдеш.“ Едновременно има парадокс, сензация и намек за пикантерия.
А по българските земи не липсват интересни калиграфски събития през османския период
Например един от известните османски артисти – Ахмед Ариф Ефенди – е роден в Пловдив, откъдето и прозвището му Филибели. Другото му прозвище пък показва и един от начините, по които си изкарва прехраната си след Освобождението и преселването му в Истанбул – Баккал, тоест собственик на малък дюкян. Преди да се посвети изцяло на калиграфията, разбира се.
Учи при големите на епохата, като Мехмед Шевки, и самият той става учител и вдъхновител на следващо поколение калиграфи. По-долу може да видите негова комбинация от две изкуства. Стандартният монументален сулюс (на османотурски сюлюс), изписващ мюсюлманската изповед на вярата върху декупажна техника (изпълнена от някой си Рифки, както се чете в подписа вдясно), изключително популярна за времето си. Днес се съхранява в една от най-големите частни колекции от ислямско изкуство – на Насер Д. Халили.
Да добавим към подобни истории и Шуменската калиграфска школа, която през XIX столетие произвежда множество украсени ръкописни копия на Корана. Преписи оттам периодично се появяват по търгове на големи аукционни къщи на Запад, например едни „Сотбис“ и „Кристис“. Дори в момента откривам три лота на Корани оттам, вече минали, но единият от тях е скорошен – от 2022 г.
От калиграфска гледна точка са средна работа, не очаквайте Рембранд на краснописа. Изписани са със ситен, гъст, неравномерен шрифт насх, а цените им са скромни, не като на контрабандиран тракийски шлем или колесница – варират от 6000 до 10 000 британски паунда. Но говорят за наличие на школа и устойчива практика.
Така и така сме се гмурнали в дълбините на непопулярното, да направим още една стъпка натам.
Къде са жените в мюсюлманската калиграфска традиция?
Такива без съмнение съществуват, не са една или две, а някои от тях са доста видими. Ето например, през 2019 г. имахме шанс да гледаме в България като част от един от кинофестивалите „Следи от душата“ – документален филм на Мартин Купър за личните истории на 12 международни калиграфи. Измежду тях е и Сорая Сийед, чиито произведения познавам отпреди.
Самата тя определя себе си като обучен в традиционна техника калиграф, който постоянно разширява границите на експеримента. И това е така – размислите ѝ за отношението между традицията и иновацията са подсилени от класическа употреба на шрифт за думата „свобода“ (ар. ал-хуррийа), към която се добавя пърформансът на полугол танцьор.
Любопитно, но и показателно за популярността ѝ, Сорая Сийед се появява и в тазгодишната селекция на същия фестивал, но в друг филм – „Цветът на мастилото“. Там Джейсън С. Логан, ентусиаст от Торонто, изработва мастила, за които използва събрани от околната среда багрила – дървесна кора, цветя, скали, тухли, стрита ръжда. Калиграфката получава шишенце с мастило, където основният пигмент е прах от бял мрамор, взет от известна италианска кариера. И пише с него върху черна хартия от Истанбул, полирана с яйчен белтък.
Но и без калиграфски привкус положението на жените и отношението на най-късната авраамическа религия към тях е доста усложнено. И мястото им в историята на краснописа не е изключение.
Жените в калиграфията са хванати натясно между два противоречиви наратива.
От една страна, стои традиционният разказ за мизогинната природа на исляма, същностно предопределена от неговите извори. Така де, не казва ли Коранът, че „за мъжкото е дял, колкото две женски“ (4:11) – стих, който се превръща в основание за регулацията на имотни делби, както и че валидността на женското свидетелство в традиционния шериатски религиозен съд е два пъти по-малка от тази на мъжа – „две жени срещу един мъж“ (2:282)? Не свидетелства ли самото Писание на мюсюлманите, че „мъжете стоят над жените“ и заради непокорство в брака следва да бъдат удряни (4:34), не се ли допуска форма на женско робство чрез формулировката за жени, „които десниците ви владеят“ (4:24), не се ли настоява на покриването на жените, независимо от волята им, по силата на коранични повели, като очакването „да спускат покривалото върху пазвата“ (24:31)? Не са ли изключени жените от линията на пророците през историята, като единствените споменавания в Корана са на Мариам, майката на Иса (библ. Иисус) и Савската царица от Коран 27? Не е ли израз и на същностно неравенство допускането за четири съпруги от Коран 4:3?
Традиционният наратив в калиграфската традиция при мюсюлманите върви по следния начин:
Адам е първият, измислил писмеността. После Коранът е „низпослан“ (това е терминът за арабското танзил на български) на Мохамед, който традиционно се възприема като „невеж“ (ар. умми), за да се подчертае т.нар. чудо на Корана. Пък според някои предания бил казал:
Трябва да упражнявате краснопис, защото е измежду ключовете към препитанието.
Оттам нататък неговият секретар Зайд ибн Сабит играе ключова роля за записването на откровението, а зетят му Али е традиционно възприеман като прародител на калиграфския занаят. След него следва дълга верига авторитети до легендарния везир Ибн Мукла от X век, който стига до идеята за математически основания на шрифта, през Ибн ал-Баууаб от XI век, Якут ал-Мустасими от средата на тринадесетото столетие, пред чийто поглед изгаря Багдад, завладян от монголите. А чрез него калиграфската приемственост продължава към други легендарни имена – Хамдуллах от Амасия, учител по краснопис на султан Баязид II, сетне Хафиз Осман, чийто препис на Корана и до днес е популярен в литографски отпечатък, та до „нашенския“ Баккал и други майстори, които предават уменията си по-нататък, чак до днес.
В този общоприет възглед за приемственост на авторитетите няма нито една жена.
Нито една голяма калиграфска школа или общност, основана и поддържана от жена, която предава уменията си на друга жена. Най-известните образци на изкуството не са от жени. Коранът на Хафиз Осман. Медальоните в „Света София“ с имената на Аллах, Мохамед, четиримата „праведни халифи“ след него (Абу Бакр, Омар, Осман, Али), познати на всеки турист, са от Мустафа Иззет, кадъаскер, т.е. върховен съдия.
Та в кръга на спекулативната шега, не е ли всъщност основният инструмент на калиграфията, т.нар. тръстиков калам, откъдето на български идва калем, един мъжки по символика артефакт, чието отношение с мастилницата и мастилото напомня за предмодерен еквивалент на фройдистката метафора за влака, влизащ в тунел? Не е ли и самият калем според авторитетния арабски съновник на Ан-Наблуси от XVII век, популярен и до днес, символ все на мъжки неща – мъжко дете (брат), власт, авторитет, благородство и победа над враговете?
На другия полюс пък стои противоположен изкусително-феминистичен възглед.
Според идеологизирани гласове на авторки като Худа ал-Тамими от Австралийския национален университет, Коранът, за разлика от Тората в юдаизма, постановява пълно равенство между мъже и жени както откъм сътворение, така и откъм права и задължения. Оттук и практикуването на калиграфия от жените следва да бъде разглеждано не само като практика, но и като одобрена от религията норма.
Подобна теза изказва и Салах ад-Дин ал-Мунаджжид, един от големите изследователи на арабската ръкописна традиция от миналия век. Ислямът, твърди той, насърчава „ученето и писането“, та оттук и „знанието“ (ар. ‘илм). Ако трябва да вметна скептична нотка – обаждам се от задната скамейка, – трябва да сме силно усъмнени дали терминът за знание в Корана и по-късната традиция обозначава онова, което днес приемаме за „знание“, диктувано от Аристотеловото разбиране за ролята на разума. Оттук и питането към какво „учене“ призовава третата монотеистична религия.
Но след като самият Пророк насърчава придобиването на знание, окуражаването към придобиването на умения за писане е логично. Той самият го прави не само с мъжете, но и с жените. Според един разказ Мохамед поискал от жена на име Аш-Шифа’ бинт Абд Аллах да научи неговата съпруга Хафса на този занаят. Това, разбира се, по силата на действието на една религиозна традиция, иде да добави аргументативна сила в полза на безпроблемното практикуване от страна на жените.
Дори и Худа ал-Тамими обаче признава, че огромното мнозинство от мюсюлманите, практикуващи занаята, са мъже. Често пъти човек дори може да се забавлява с обобщаващите с едри импресионистични мазки твърдения и начините, по който се обосновава публичното мнение. Например когато Ал-Тамими твърди, че Пророкът насърчава жените активно да участват в преподаването на всички „науки“, включително и калиграфията, тя се позовава на по-ранна статия на Давид Симоновиц от специализиран журнал за изследване на жените в Близкия изток, публикуван от Университета „Дюк“. В материала си Симоновиц обаче реално препраща – и то за същото съждение – към най-известната монография за мястото на калиграфията в ислямската култура, писана от Анемари Шимел. Анемари Шимел на свой ред цитира превод на Доминик Сурдел на арабски извор от IX век. В същото пояснение обаче тя споменава и класиката „Етикетът на писарите“ на Ас-Сули (той пък е известен автор от X век), който твърди точно обратното за жените.
Някои авторитети категорично не одобрявали жени писари. Нещо повече, един от най-известните автори на биографични справки за калиграфите в Османската империя – Сюлейман Мюстакимзаде от XVIII век – в своята „Дарове на калиграфите“ (османотурски Тухфе и-хаттатин) споменавал за поне четирийсет предания, в които се говори за жените и писането. „Не им разрешавайте да влизат в обществените места за седене!“ (за лаф-мохабет, бихме казали днес) и „Не ги учете на писане!“ са между тях. Че даже и неудобното за защитниците на втората теза, приписвано на Сократ – „Не добавяй едно зло към друго зло!“, т.е. умението за писане към жените, споделено със задоволство от автора.
Тази кратка сверка на изворите звучи като заяждане на научна комисия при публична защита на дисертация. Но явно ни навежда на мисълта, че се налага възприемането на по-предпазлив и нюансиран „трети път“, което звучи малко като по Зелената книга на покойния Муаммар Кадафи.
Но ако трябва да избегнем черно-бялата категоричност, какви все пак са мюсюлманските жени калиграфи?
На такъв въпрос се изкушавам да дам любимия отговор на бащата на всички фундаменталисти – имам Ибн Ханбал от IX век Той много обичал да отговаря: „Не знам.“ Нямаме много свидетелства. Но все пак можем да направим предположения.
(Следва продължение)
В рубриката „Ориент кафе“ Атанас Шиников поднася любопитни теми, свързани не толкова с горещата политика, колкото с историята и културата на Близкия изток. А той, древен и днешен, е по-близко до нас и съвремието ни, отколкото си представяме.
Organizations often need to manage a high volume of data that is growing at an extraordinary rate. At the same time, they need to optimize operational costs to unlock the value of this data for timely insights and do so with a consistent performance.
With this massive data growth, data proliferation across your data stores, data warehouse, and data lakes can become equally challenging. With a modern data architecture on AWS, you can rapidly build scalable data lakes; use a broad and deep collection of purpose-built data services; ensure compliance via unified data access, security, and governance; scale your systems at a low cost without compromising performance; and share data across organizational boundaries with ease, allowing you to make decisions with speed and agility at scale.
You can take all your data from various silos, aggregate that data in your data lake, and perform analytics and machine learning (ML) directly on top of that data. You can also store other data in purpose-built data stores to analyze and get fast insights from both structured and unstructured data. This data movement can be inside-out, outside-in, around the perimeter or sharing across.
For example, application logs and traces from web applications can be collected directly in a data lake, and a portion of that data can be moved out to a log analytics store like Amazon OpenSearch Service for daily analysis. We think of this concept as inside-out data movement. The analyzed and aggregated data stored in Amazon OpenSearch Service can again be moved to the data lake to run ML algorithms for downstream consumption from applications. We refer to this concept as outside-in data movement.
Let’s look at an example use case. Example Corp. is a leading Fortune 500 company that specializes in social content. They have hundreds of applications generating data and traces at approximately 500 TB per day and have the following criteria:
Have logs available for fast analytics for 2 days
Beyond 2 days, have data available in a storage tier that can be made available for analytics with a reasonable SLA
Retain the data beyond 1 week in cold storage for 30 days (for purposes of compliance, auditing, and others)
In the following sections, we discuss three possible solutions to address similar use cases:
Tiered storage in Amazon OpenSearch Service and data lifecycle management
Amazon OpenSearch Service direct queries with Amazon Simple Storage Service (Amazon S3)
Solution 1: Tiered storage in OpenSearch Service and data lifecycle management
OpenSearch Service supports three integrated storage tiers: hot, UltraWarm, and cold storage. Based on your data retention, query latency, and budgeting requirements, you can choose the best strategy to balance cost and performance. You can also migrate data between different storage tiers.
Hot storage is used for indexing and updating, and provides the fastest access to data. Hot storage takes the form of an instance store or Amazon Elastic Block Store (Amazon EBS) volumes attached to each node.
UltraWarm offers significantly lower costs per GiB for read-only data that you query less frequently and doesn’t need the same performance as hot storage. UltraWarm nodes use Amazon S3 with related caching solutions to improve performance.
Cold storage is optimized to store infrequently accessed or historical data. When you use cold storage, you detach your indexes from the UltraWarm tier, making them inaccessible. You can reattach these indexes in a few seconds when you need to query that data.
The workflow for this solution consists of the following steps:
Incoming data generated by the applications is streamed to an S3 data lake.
Data is ingested into Amazon OpenSearch using S3-SQS near-real-time ingestion through notifications set up on the S3 buckets.
After 2 days, hot data is migrated to UltraWarm storage to support read queries.
After 5 days in UltraWarm, the data is migrated to cold storage for 21 days and detached from any compute. The data can be reattached to UltraWarm when needed. Data is deleted from cold storage after 21 days.
Daily indexes are maintained for easy rollover. An Index State Management (ISM) policy automates the rollover or deletion of indexes that are older than 2 days.
The following is a sample ISM policy that rolls over data into the UltraWarm tier after 2 days, moves it to cold storage after 5 days, and deletes it from cold storage after 21 days:
UltraWarm uses sophisticated caching techniques to enable querying for infrequently accessed data. Although the data access is infrequent, the compute for UltraWarm nodes needs to be running all the time to make this access possible.
When operating at PB scale, to reduce the area of effect of any errors, we recommend decomposing the implementation into multiple OpenSearch Service domains when using tiered storage.
The next two patterns remove the need to have long-running compute and describe on-demand techniques where the data is either brought when needed or queried directly where it resides.
Solution 2: On-demand ingestion of logs data through OpenSearch Ingestion
OpenSearch Ingestion is a fully managed data collector that delivers real-time log and trace data to OpenSearch Service domains. OpenSearch Ingestion is powered by the open source data collector Data Prepper. Data Prepper is part of the open source OpenSearch project.
With OpenSearch Ingestion, you can filter, enrich, transform, and deliver your data for downstream analysis and visualization. You configure your data producers to send data to OpenSearch Ingestion. It automatically delivers the data to the domain or collection that you specify. You can also configure OpenSearch Ingestion to transform your data before delivering it. OpenSearch Ingestion is serverless, so you don’t need to worry about scaling your infrastructure, operating your ingestion fleet, and patching or updating the software.
There are two ways that you can use Amazon S3 as a source to process data with OpenSearch Ingestion. The first option is S3-SQS processing. You can use S3-SQS processing when you require near-real-time scanning of files after they are written to S3. It requires an Amazon Simple Queue Service (Amazon S3) queue that receives S3 Event Notifications. You can configure S3 buckets to raise an event any time an object is stored or modified within the bucket to be processed.
Alternatively, you can use a one-time or recurring scheduled scan to batch process data in an S3 bucket. To set up a scheduled scan, configure your pipeline with a schedule at the scan level that applies to all your S3 buckets, or at the bucket level. You can configure scheduled scans with either a one-time scan or a recurring scan for batch processing.
For a comprehensive overview of OpenSearch Ingestion, see Amazon OpenSearch Ingestion. For more information about the Data Prepper open source project, visit Data Prepper.
Solution overview
We present an architecture pattern with the following key components:
Application logs are streamed into to the data lake, which helps feed hot data into OpenSearch Service in near-real time using OpenSearch Ingestion S3-SQS processing.
ISM policies within OpenSearch Service handle index rollovers or deletions. ISM policies let you automate these periodic, administrative operations by triggering them based on changes in the index age, index size, or number of documents. For example, you can define a policy that moves your index into a read-only state after 2 days and then deletes it after a set period of 3 days.
Cold data is available in the S3 data lake to be consumed on demand into OpenSearch Service using OpenSearch Ingestion scheduled scans.
The following diagram illustrates the solution architecture.
The workflow includes the following steps:
Incoming data generated by the applications is streamed to the S3 data lake.
For the current day, data is ingested into OpenSearch Service using S3-SQS near-real-time ingestion through notifications set up in the S3 buckets.
Daily indexes are maintained for easy rollover. An ISM policy automates the rollover or deletion of indexes that are older than 2 days.
If a request is made for analysis of data beyond 2 days and the data is not in the UltraWarm tier, data will be ingested using the one-time scan feature of Amazon S3 between the specific time window.
For example, if the present day is January 10, 2024, and you need data from January 6, 2024 at a specific interval for analysis, you can create an OpenSearch Ingestion pipeline with an Amazon S3 scan in your YAML configuration, with the start_time and end_time to specify when you want the objects in the bucket to be scanned:
Data in Amazon S3 can be compressed, which reduces your overall data footprint and results in significant cost savings. For example, if you are generating 15 PB of raw JSON application logs per month, you can use a compression mechanism like GZIP, which can reduce the size to approximately 1PB or less, resulting in significant cost savings.
Stop the pipeline when possible
OpenSearch Ingestion scales automatically between the minimum and maximum OCUs set for the pipeline. After the pipeline has completed the Amazon S3 scan for the specified duration mentioned in the pipeline configuration, the pipeline continues to run for continuous monitoring at the minimum OCUs.
For on-demand ingestion for past time durations where you don’t expect new objects to be created, consider using supported pipeline metrics such as recordsOut.count to create Amazon CloudWatch alarms that can stop the pipeline. For a list of supported metrics, refer to Monitoring pipeline metrics.
CloudWatch alarms perform an action when a CloudWatch metric exceeds a specified value for some amount of time. For example, you might want to monitor recordsOut.count to be 0 for longer than 5 minutes to initiate a request to stop the pipeline through the AWS Command Line Interface (AWS CLI) or API.
Solution 3: OpenSearch Service direct queries with Amazon S3
OpenSearch Service direct queries with Amazon S3 (preview) is a new way to query operational logs in Amazon S3 and S3 data lakes without needing to switch between services. You can now analyze infrequently queried data in cloud object stores and simultaneously use the operational analytics and visualization capabilities of OpenSearch Service.
OpenSearch Service direct queries with Amazon S3 provides zero-ETL integration to reduce the operational complexity of duplicating data or managing multiple analytics tools by enabling you to directly query your operational data, reducing costs and time to action. This zero-ETL integration is configurable within OpenSearch Service, where you can take advantage of various log type templates, including predefined dashboards, and configure data accelerations tailored to that log type. Templates include VPC Flow Logs, Elastic Load Balancing logs, and NGINX logs, and accelerations include skipping indexes, materialized views, and covered indexes.
With OpenSearch Service direct queries with Amazon S3, you can perform complex queries that are critical to security forensics and threat analysis and correlate data across multiple data sources, which aids teams in investigating service downtime and security events. After you create an integration, you can start querying your data directly from OpenSearch Dashboards or the OpenSearch API. You can audit connections to ensure that they are set up in a scalable, cost-efficient, and secure way.
Direct queries from OpenSearch Service to Amazon S3 use Spark tables within the AWS Glue Data Catalog. After the table is cataloged in your AWS Glue metadata catalog, you can run queries directly on your data in your S3 data lake through OpenSearch Dashboards.
Solution overview
The following diagram illustrates the solution architecture.
This solution consists of the following key components:
The hot data for the current day is stream processed into OpenSearch Service domains through the event-driven architecture pattern using the OpenSearch Ingestion S3-SQS processing feature
The hot data lifecycle is managed through ISM policies attached to daily indexes
The cold data resides in your Amazon S3 bucket, and is partitioned and cataloged
The following screenshot shows a sample http_logs table that is cataloged in the AWS Glue metadata catalog. For detailed steps, refer to Data Catalog and crawlers in AWS Glue.
Before you create a data source, you should have an OpenSearch Service domain with version 2.11 or later and a target S3 table in the AWS Glue Data Catalog with the appropriate AWS Identity and Access Management (IAM) permissions. IAM will need access to the desired S3 buckets and have read and write access to the AWS Glue Data Catalog. The following is a sample role and trust policy with appropriate permissions to access the AWS Glue Data Catalog through OpenSearch Service:
To create a new data source on the OpenSearch Service console, provide the name of your new data source, specify the data source type as Amazon S3 with the AWS Glue Data Catalog, and choose the IAM role for your data source.
After you create a data source, you can go to the OpenSearch dashboard of the domain, which you use to configure access control, define tables, set up log type-based dashboards for popular log types, and query your data.
After you set up your tables, you can query your data in your S3 data lake through OpenSearch Dashboards. You can run a sample SQL query for the http_logs table you created in the AWS Glue Data Catalog tables, as shown in the following screenshot.
Best practices
Ingest only the data you need
Work backward from your business needs and establish the right datasets you’ll need. Evaluate if you can avoid ingesting noisy data and ingest only curated, sampled, or aggregated data. Using these cleaned and curated datasets will help you optimize the compute and storage resources needed to ingest this data.
Reduce the size of data before ingestion
When you design your data ingestion pipelines, use strategies such as compression, filtering, and aggregation to reduce the size of the ingested data. This will permit smaller data sizes to be transferred over the network and stored in your data layer.
Conclusion
In this post, we discussed solutions that enable petabyte-scale log analytics using OpenSearch Service in a modern data architecture. You learned how to create a serverless ingestion pipeline to deliver logs to an OpenSearch Service domain, manage indexes through ISM policies, configure IAM permissions to start using OpenSearch Ingestion, and create the pipeline configuration for data in your data lake. You also learned how to set up and use the OpenSearch Service direct queries with Amazon S3 feature (preview) to query data from your data lake.
To choose the right architecture pattern for your workloads when using OpenSearch Service at scale, consider the performance, latency, cost and data volume growth over time in order to make the right decision.
Use Tiered storage architecture with Index State Management policies when you need fast access to your hot data and want to balance the cost and performance with UltraWarm nodes for read-only data.
Use On Demand Ingestion of your data into OpenSearch Service when you can tolerate ingestion latencies to query your data not retained in your hot nodes. You can achieve significant cost savings when using compressed data in Amazon S3 and ingesting data on demand into OpenSearch Service.
Use Direct query with S3 feature when you want to directly analyze your operational logs in Amazon S3 with the rich analytics and visualization features of OpenSearch Service.
As a next step, refer to the Amazon OpenSearch Developer Guide to explore logs and metric pipelines that you can use to build a scalable observability solution for your enterprise applications.
About the Authors
Jagadish Kumar (Jag) is a Senior Specialist Solutions Architect at AWS focused on Amazon OpenSearch Service. He is deeply passionate about Data Architecture and helps customers build analytics solutions at scale on AWS.
Muthu Pitchaimani is a Senior Specialist Solutions Architect with Amazon OpenSearch Service. He builds large-scale search applications and solutions. Muthu is interested in the topics of networking and security, and is based out of Austin, Texas.
Sam Selvan is a Principal Specialist Solution Architect with Amazon OpenSearch Service.
Netflix uses data science and machine learning across all facets of the company, powering a wide range of business applications from our internal infrastructure and content demand modeling to media understanding. The Machine Learning Platform (MLP) team at Netflix provides an entire ecosystem of tools around Metaflow, an open source machine learning infrastructure framework we started, to empower data scientists and machine learning practitioners to build and manage a variety of ML systems.
Since its inception, Metaflow has been designed to provide a human-friendly API for building data and ML (and today AI) applications and deploying them in our production infrastructure frictionlessly. While human-friendly APIs are delightful, it is really the integrations to our production systems that give Metaflow its superpowers. Without these integrations, projects would be stuck at the prototyping stage, or they would have to be maintained as outliers outside the systems maintained by our engineering teams, incurring unsustainable operational overhead.
Given the very diverse set of ML and AI use cases we support — today we have hundreds of Metaflow projects deployed internally — we don’t expect all projects to follow the same path from prototype to production. Instead, we provide a robust foundational layer with integrations to our company-wide data, compute, and orchestration platform, as well as various paths to deploy applications to production smoothly. On top of this, teams have built their own domain-specific libraries to support their specific use cases and needs.
In this article, we cover a few key integrations that we provide for various layers of the Metaflow stack at Netflix, as illustrated above. We will also showcase real-life ML projects that rely on them, to give an idea of the breadth of projects we support. Note that all projects leverage multiple integrations, but we highlight them in the context of the integration that they use most prominently. Importantly, all the use cases were engineered by practitioners themselves.
These integrations are implemented through Metaflow’s extension mechanism which is publicly available but subject to change, and hence not a part of Metaflow’s stable API yet. If you are curious about implementing your own extensions, get in touch with us on the Metaflow community Slack.
Let’s go over the stack layer by layer, starting with the most foundational integrations.
Data: Fast Data
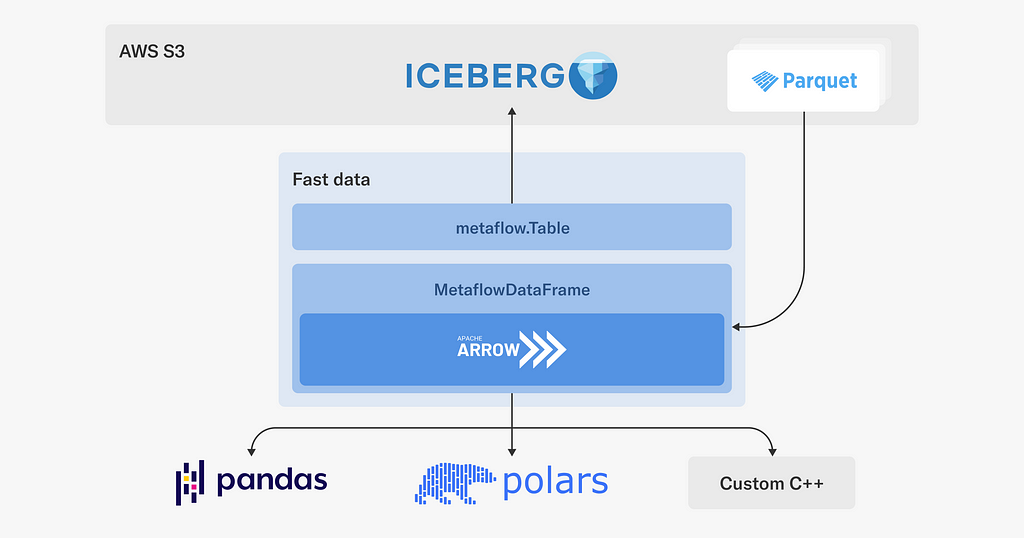
Our main data lake is hosted on S3, organized as Apache Iceberg tables. For ETL and other heavy lifting of data, we mainly rely on Apache Spark. In addition to Spark, we want to support last-mile data processing in Python, addressing use cases such as feature transformations, batch inference, and training. Occasionally, these use cases involve terabytes of data, so we have to pay attention to performance.
To enable fast, scalable, and robust access to the Netflix data warehouse, we have developed a Fast Data library for Metaflow, which leverages high-performance components from the Python data ecosystem:
As depicted in the diagram, the Fast Data library consists of two main interfaces:
The Table object is responsible for interacting with the Netflix data warehouse which includes parsing Iceberg (or legacy Hive) table metadata, resolving partitions and Parquet files for reading. Recently, we added support for the write path, so tables can be updated as well using the library.
Once we have discovered the Parquet files to be processed, MetaflowDataFrame takes over: it downloads data using Metaflow’s high-throughput S3 client directly to the process’ memory, which often outperforms reading of local files.
We use Apache Arrow to decode Parquet and to host an in-memory representation of data. The user can choose the most suitable tool for manipulating data, such as Pandas or Polars to use a dataframe API, or one of our internal C++ libraries for various high-performance operations. Thanks to Arrow, data can be accessed through these libraries in a zero-copy fashion.
We also pay attention to dependency issues: (Py)Arrow is a dependency of many ML and data libraries, so we don’t want our custom C++ extensions to depend on a specific version of Arrow, which could easily lead to unresolvable dependency graphs. Instead, in the style of nanoarrow, our Fast Data library only relies on the stable Arrow C data interface, producing a hermetically sealed library with no external dependencies.
Example use case: Content Knowledge Graph
Our knowledge graph of the entertainment world encodes relationships between titles, actors and other attributes of a film or series, supporting all aspects of business at Netflix.
A key challenge in creating a knowledge graph is entity resolution. There may be many different representations of slightly different or conflicting information about a title which must be resolved. This is typically done through a pairwise matching procedure for each entity which becomes non-trivial to do at scale.
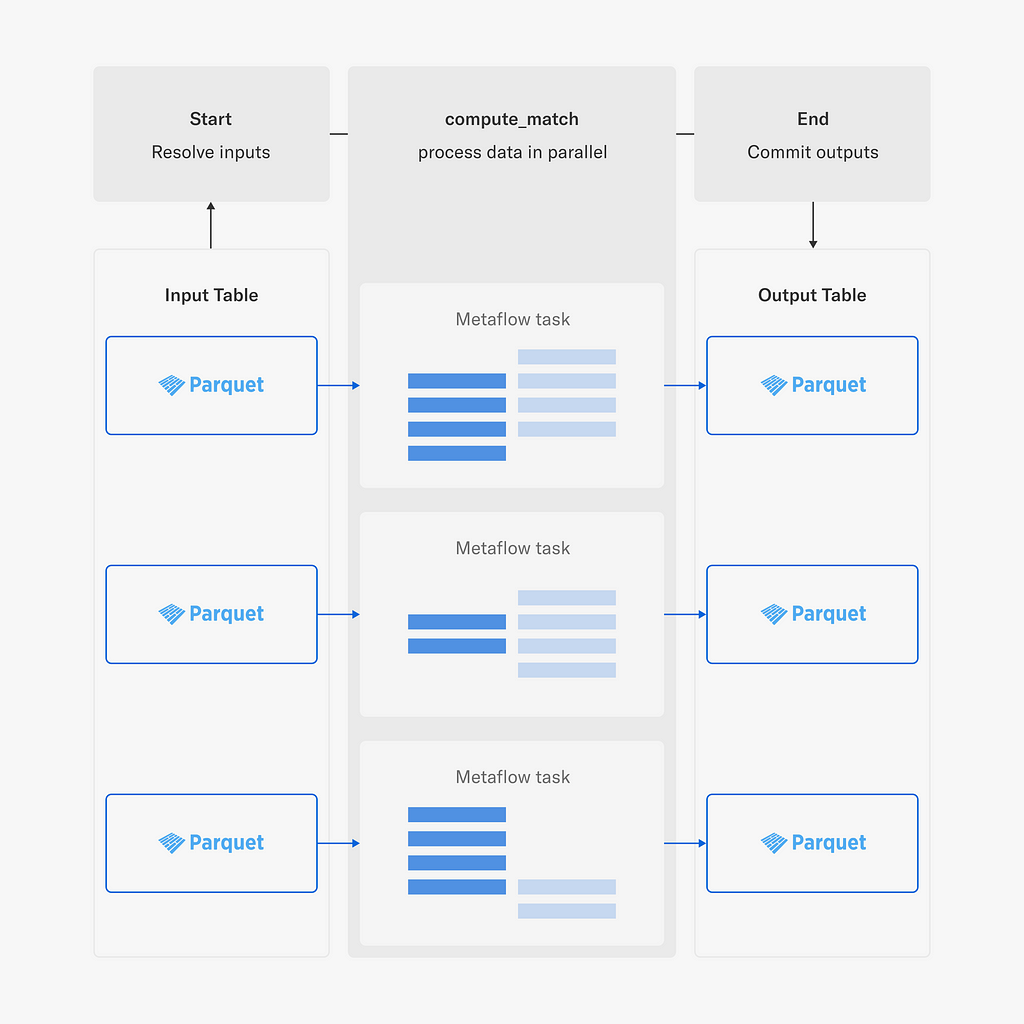
This project leverages Fast Data and horizontal scaling with Metaflow’s foreach construct to load large amounts of title information — approximately a billion pairs — stored in the Netflix Data Warehouse, so the pairs can be matched in parallel across many Metaflow tasks.
We use metaflow.Table to resolve all input shards which are distributed to Metaflow tasks which are responsible for processing terabytes of data collectively. Each task loads the data using metaflow.MetaflowDataFrame, performs matching using Pandas, and populates a corresponding shard in an output Table. Finally, when all matching is done and data is written the new table is committed so it can be read by other jobs.
By targeting @titus, Metaflow tasks benefit from these battle-hardened features out of the box, with no in-depth technical knowledge or engineering required from the ML engineers or data scientist end. However, in order to benefit from scalable compute, we need to help the developer to package and rehydrate the whole execution environment of a project in a remote pod in a reproducible manner (preferably quickly). Specifically, we don’t want to ask developers to manage Docker images of their own manually, which quickly results in more problems than it solves.
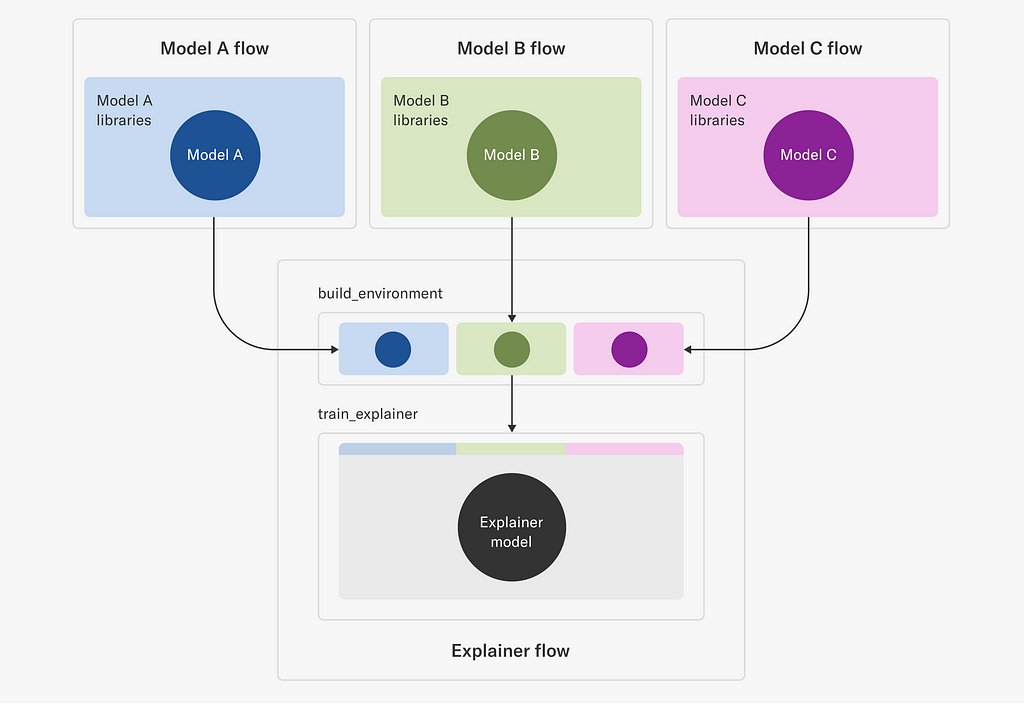
Here’s a fascinating example of the usefulness of portable execution environments. For many of our applications, model explainability matters. Stakeholders like to understand why models produce a certain output and why their behavior changes over time.
There are several ways to provide explainability to models but one way is to train an explainer model based on each trained model. Without going into the details of how this is done exactly, suffice to say that Netflix trains a lot of models, so we need to train a lot of explainers too.
Thanks to Metaflow, we can allow each application to choose the best modeling approach for their use cases. Correspondingly, each application brings its own bespoke set of dependencies. Training an explainer model therefore requires:
Access to the original model and its training environment, and
Dependencies specific to building the explainer model.
This poses an interesting challenge in dependency management: we need a higher-order training system, “Explainer flow” in the figure below, which is able to take a full execution environment of another training system as an input and produce a model based on it.
Explainer flow is event-triggered by an upstream flow, such Model A, B, C flows in the illustration. The build_environment step uses the metaflow environment command provided by our portable environments, to build an environment that includes both the requirements of the input model as well as those needed to build the explainer model itself.
The built environment is given a unique name that depends on the run identifier (to provide uniqueness) as well as the model type. Given this environment, the train_explainer step is then able to refer to this uniquely named environment and operate in an environment that can both access the input model as well as train the explainer model. Note that, unlike in typical flows using vanilla @conda or @pypi, the portable environments extension allows users to also fetch those environments directly at execution time as opposed to at deploy time which therefore allows users to, as in this case, resolve the environment right before using it in the next step.
Orchestration: Maestro
If data is the fuel of ML and the compute layer is the muscle, then the nerves must be the orchestration layer. We have talked about the importance of a production-grade workflow orchestrator in the context of Metaflow when we released support for AWS Step Functions years ago. Since then, open-source Metaflow has gained support for Argo Workflows, a Kubernetes-native orchestrator, as well as support for Airflow which is still widely used by data engineering teams.
Internally, we use a production workflow orchestrator called Maestro. The Maestro post shares details about how the system supports scalability, high-availability, and usability, which provide the backbone for all of our Metaflow projects in production.
A hugely important detail that often goes overlooked is event-triggering: it allows a team to integrate their Metaflow flows to surrounding systems upstream (e.g. ETL workflows), as well as downstream (e.g. flows managed by other teams), using a protocol shared by the whole organization, as exemplified by the example use case below.
Example use case: Content decision making
One of the most business-critical systems running on Metaflow supports our content decision making, that is, the question of what content Netflix should bring to the service. We support a massive scale of over 260M subscribers spanning over 190 countries representing hugely diverse cultures and tastes, all of whom we want to delight with our content slate. Reflecting the breadth and depth of the challenge, the systems and models focusing on the question have grown to be very sophisticated.
We approach the question from multiple angles but we have a core set of data pipelines and models that provide a foundation for decision making. To illustrate the complexity of just the core components, consider this high-level diagram:
In this diagram, gray boxes represent integrations to partner teams downstream and upstream, green boxes are various ETL pipelines, and blue boxes are Metaflow flows. These boxes encapsulate hundreds of advanced models and intricate business logic, handling massive amounts of data daily.
Despite its complexity, the system is managed by a relatively small team of engineers and data scientists autonomously. This is made possible by a few key features of Metaflow:
All the boxes are event-triggered, orchestrated by Maestro. Dependencies between Metaflow flows are triggered via @trigger_on_finish, dependencies to external systems with @trigger.
Rapid development is enabled via Metaflow namespaces, so individual developers can develop without interfering with production deployments.
The team has also developed their own domain-specific libraries and configuration management tools, which help them improve and operate the system.
Deployment: Cache
To produce business value, all our Metaflow projects are deployed to work with other production systems. In many cases, the integration might be via shared tables in our data warehouse. In other cases, it is more convenient to share the results via a low-latency API.
Notably, not all API-based deployments require real-time evaluation, which we cover in the section below. We have a number of business-critical applications where some or all predictions can be precomputed, guaranteeing the lowest possible latency and operationally simple high availability at the global scale.
We have developed an officially supported pattern to cover such use cases. While the system relies on our internal caching infrastructure, you could follow the same pattern using services like Amazon ElasticCache or DynamoDB.
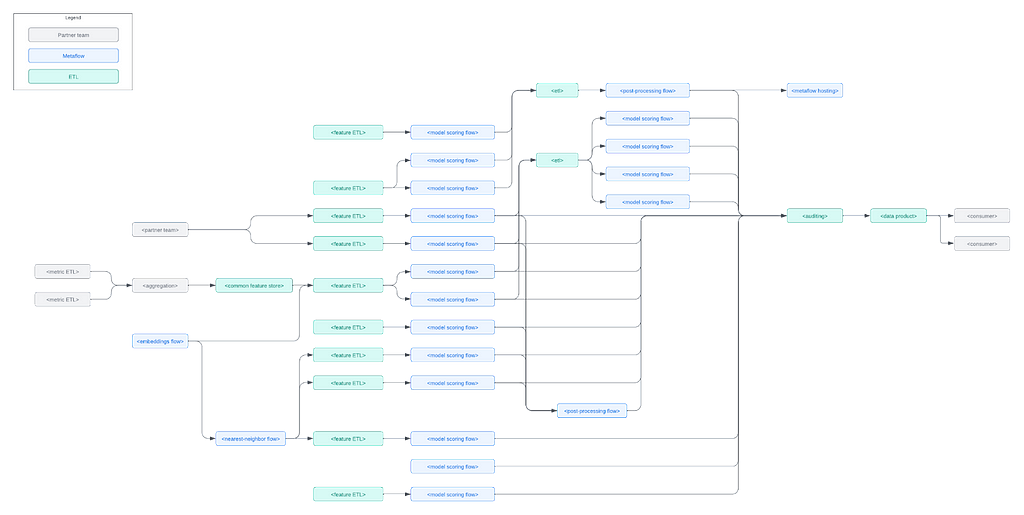
Example use case: Content performance visualization
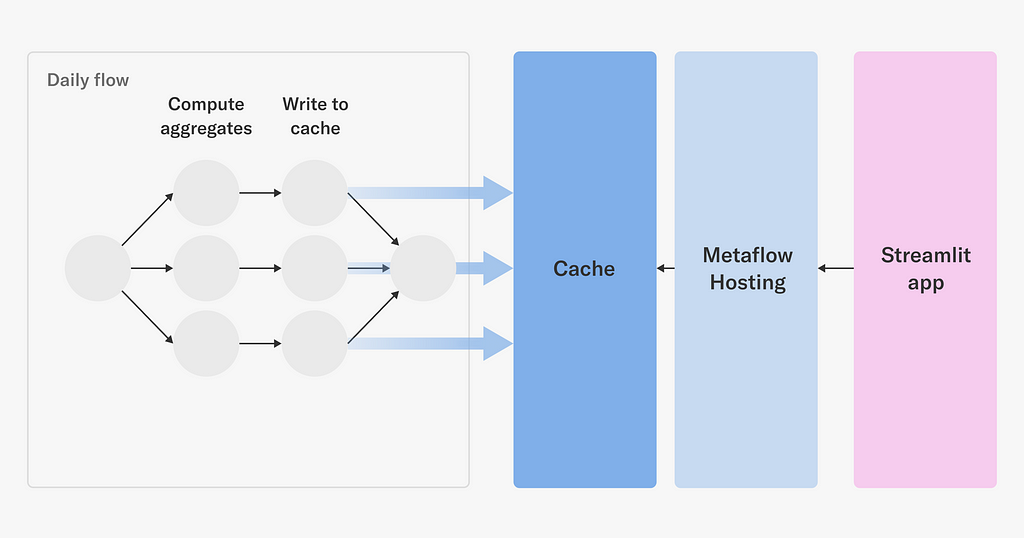
The historical performance of titles is used by decision makers to understand and improve the film and series catalog. Performance metrics can be complex and are often best understood by humans with visualizations that break down the metrics across parameters of interest interactively. Content decision makers are equipped with self-serve visualizations through a real-time web application built with metaflow.Cache, which is accessed through an API provided with metaflow.Hosting.
A daily scheduled Metaflow job computes aggregate quantities of interest in parallel. The job writes a large volume of results to an online key-value store using metaflow.Cache. A Streamlit app houses the visualization software and data aggregation logic. Users can dynamically change parameters of the visualization application and in real-time a message is sent to a simple Metaflow hosting service which looks up values in the cache, performs computation, and returns the results as a JSON blob to the Streamlit application.
Metaflow Hosting is specifically geared towards hosting artifacts or models produced in Metaflow. This provides an easy to use interface on top of Netflix’s existing microservice infrastructure, allowing data scientists to quickly move their work from experimentation to a production grade web service that can be consumed over a HTTP REST API with minimal overhead.
Its key benefits include:
Simple decorator syntax to create RESTFull endpoints.
The back-end auto-scales the number of instances used to back your service based on traffic.
The back-end will scale-to-zero if no requests are made to it after a specified amount of time thereby saving cost particularly if your service requires GPUs to effectively produce a response.
Request logging, alerts, monitoring and tracing hooks to Netflix infrastructure
Consider the service similar to managed model hosting services like AWS Sagemaker Model Hosting, but tightly integrated with our microservice infrastructure.
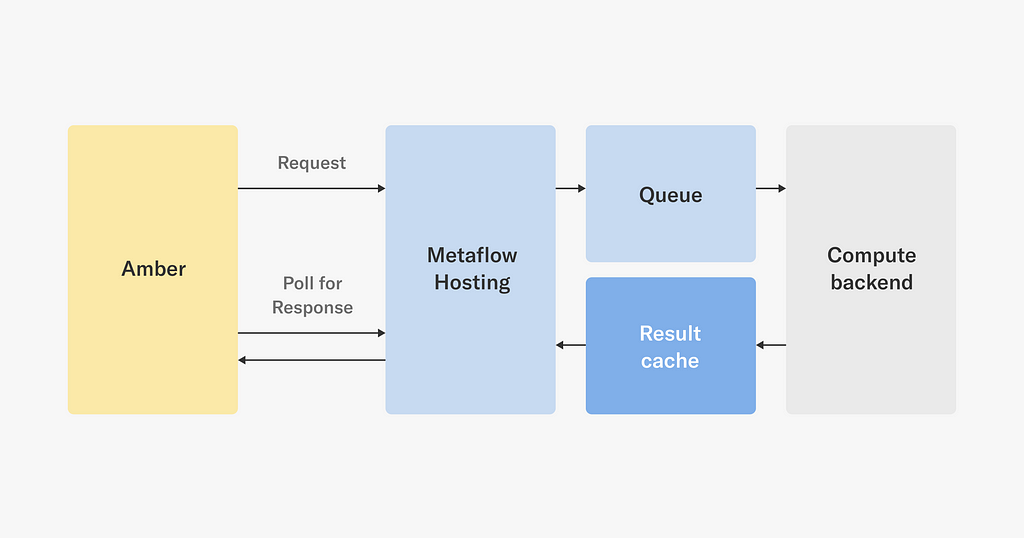
To demonstrate the benefits of Metaflow Hosting that provides a general-purpose API layer supporting both synchronous and asynchronous queries, consider this use case involving Amber, our feature store for media.
While Amber is a feature store, precomputing and storing all media features in advance would be infeasible. Instead, we compute and cache features in an on-demand basis, as depicted below:
When a service requests a feature from Amber, it computes the feature dependency graph and then sends one or more asynchronous requests to Metaflow Hosting, which places the requests in a queue, eventually triggering feature computations when compute resources become available. Metaflow Hosting caches the response, so Amber can fetch it after a while. We could have built a dedicated microservice just for this use case, but thanks to the flexibility of Metaflow Hosting, we were able to ship the feature faster with no additional operational burden.
Future Work
Our appetite to apply ML in diverse use cases is only increasing, so our Metaflow platform will keep expanding its footprint correspondingly and continue to provide delightful integrations to systems built by other teams at Netlfix. For instance, we have plans to work on improvements in the versioning layer, which wasn’t covered by this article, by giving more options for artifact and model management.
We also plan on building more integrations with other systems that are being developed by sister teams at Netflix. As an example, Metaflow Hosting models are currently not well integrated into model logging facilities — we plan on working on improving this to make models developed with Metaflow more integrated with the feedback loop critical in training new models. We hope to do this in a pluggable manner that would allow other users to integrate with their own logging systems.
Additionally we want to supply more ways Metaflow artifacts and models can be integrated into non-Metaflow environments and applications, e.g. JVM based edge service, so that Python-based data scientists can contribute to non-Python engineering systems easily. This would allow us to better bridge the gap between the quick iteration that Metaflow provides (in Python) with the requirements and constraints imposed by the infrastructure serving Netflix member facing requests.
If you are building business-critical ML or AI systems in your organization, join the Metaflow Slack community! We are happy to share experiences, answer any questions, and welcome you to contribute to Metaflow.
Acknowledgements:
Thanks to Wenbing Bai, Jan Florjanczyk, Michael Li, Aliki Mavromoustaki, and Sejal Rai for help with use cases and figures. Thanks to our OSS contributors for making Metaflow a better product.
Imagine the following scenario: You’re about to enjoy a strategic duel on chess.com or dive into an intense battle in Fortnite, but as you log in, you find your hard-earned achievements, ranks, and reputation have vanished into thin air. This is not just a hypothetical scenario but a real possibility in today’s cloud gaming landscape, where a single security breach can undo years of dedication and achievement.
Cloud gaming, powered by giants like AWS, is transforming the gaming industry, offering unparalleled accessibility and dynamic gaming experiences. Yet, with this technological leap forward comes an increase in cyber threats. The gaming world has already witnessed significant security breaches, such as the GTA5 code theft and Activision’s consistent data challenges, highlighting the lurking dangers in this digital arena.
In such a scenario, securing cloud-based games isn’t just an additional feature; it’s an absolute necessity. As we examine the intricate world of cloud gaming, the role of comprehensive security solutions becomes increasingly vital. In the subsequent sections, we will explore how Rapid7’s InsightCloudSeccan be instrumental in securing cloud infrastructure and CI/CD processes in game development, thereby safeguarding the integrity and continuity of our virtual gaming experiences.
Challenges in Cloud-Based Game Development
Picture this: You’re a game developer, immersed in creating the next big title in cloud gaming. Your team is buzzing with creativity, coding, and testing. But then, out of the blue, you’re hit by a cyberattack, much like the one that rocked CD Projekt Red in 2021. Imagine the chaos – months of hard work (e.g. Cyberpunk 2077 or The Witcher 3) locked up by ransomware, with all sorts of confidential data floating in the wrong hands. This scenario is far from fiction in today’s digital gaming landscape.
What Does This Kind of Attack Really Mean for a Game Development Team?
The Network Weak Spot: It’s like leaving the back door open while you focus on the front; hackers can sneak in through network gaps we never knew existed. That’s what might have happened with CD Projekt Red. A more fortified network could have been their digital moat.
When Data Gets Held Hostage: It’s one thing to secure your castle, but what about safeguarding the treasures inside? The CD Projekt Red incident showed us how vital it is to keep our game codes and internal documents under lock and key, digitally speaking.
A Safety Net Missing: Imagine if CD Projekt Red had a robust backup system. Even after the attack, they could have bounced back quicker, minimizing the damage. It’s like having a safety net when you’re walking a tightrope. You hope you won’t need it, but you’ll be glad it’s there if you do.
This is where a solution like Rapid7’s InsightCloudSeccomes into play. It’s not just about building higher walls; it’s about smarter, more responsive defense systems. Think of it as having a digital watchdog that’s always on guard, sniffing out threats, and barking alarms at the first sign of trouble.
With tools that watch over your cloud infrastructure, monitor every digital move in real time, and keep your compliance game strong, you’re not just creating games; you’re also playing the ultimate game of digital security – and winning.
Navigating Cloud Security in Game Development: An Artful Approach
In the realm of cloud-based game development, mastering AWS services’ security nuances transcends mere technical skill – it’s akin to painting a masterpiece. Let’s embark on a journey through the essential AWS services like EC2, S3, Lambda, CloudFront, and RDS, with a keen focus on their security features – our guardians in the digital expanse.
Consider Amazon EC2 as the infrastructure’s backbone, hosting the very servers that breathe life into games. Here, Security Groups act as discerning gatekeepers, meticulously managing who gets in and out. They’re not just gatekeepers but wise ones, remembering allowed visitors and ensuring a seamless yet secure flow of traffic.
Amazon S3 stands as our digital vault, safeguarding data with precision-crafted bucket policies. These policies aren’t just rules; they’re declarations of trust, dictating who can glimpse or alter the stored treasures. History is littered with tales of those who faltered, so precision here is paramount.
Lambda functionsemerge as the silent virtuosos of serverless architecture, empowering game backends with their scalable might. Yet, their power is wielded judiciously, guided by the principle of least privilege through meticulously assigned roles and permissions, minimizing the shadow of vulnerability.
Amazon CloudFront, our swift courier, ensures game content flies across the globe securely and at breakneck speed. Coupled with AWS Shield (Advanced), it stands as a bulwark against DDoS onslaughts, guaranteeing that game delivery remains both rapid and impregnable.
Amazon RDS, the fortress for player data, automates the mundane yet crucial tasks – backups, patches, scaling – freeing developers to craft experiences. It whispers secrets only to those meant to hear, guarding data with robust encryption, both at rest and in transit.
Visibility and vigilance form the bedrock of our security ethos. With tools like AWS CloudTrail and CloudWatch, our gaze extends across every corner of our domain, ever watchful for anomalies, ready to act with precision and alacrity.
Encryption serves as our silent sentinel, a protective veil over data, whether nestled in S3’s embrace or traversing the vastness to and from EC2 and RDS. It’s our unwavering shield against the curious and the malevolent alike.
In weaving the security measures of these AWS services into the fabric of game development, we engage not in mere procedure but in the creation of a secure tapestry that envelops every facet of the development journey. In the vibrant, ever-evolving landscape of game creation, fortifying our cloud infrastructure with a security-first mindset is not just a technical endeavor – it’s a strategic masterpiece, ensuring our games are not only a source of joy but bastions of privacy and security in the cloud.
Automated Cloud Security with InsightCloudSec
When it comes to deploying a game in the cloud, understanding and implementing automated security is paramount. This is where Rapid7’s InsightCloudSec takes center stage, revolutionizing how game developers secure their cloud environments with a focus on automation and real-time monitoring.
Data Harvesting Strategies
InsightCloudSec differentiates itself through its innovative approach to data collection and analysis, employing two primary methods: API harvesting and Event Driven Harvesting (EDH). Initially, InsightCloudSec utilizes the API method, where it directly calls cloud provider APIs to gather essential platform information. This process enables InsightCloudSec to populate its platform with critical data, which is then unified into a cohesive dataset. For example, disparate storage solutions from AWS, Azure, and GCP are consolidated under a generic “Storage” category, while compute instances are unified as “Instances.” This normalization allows for the creation of universal compliance packs that can be applied across multiple cloud environments, enhancing the platform’s efficiency and coverage.
However, the real game-changer is Rapid7’s implementation of EDH. Unlike the traditional API pull method, EDH leverages serverless functions within the customer’s cloud environment to ingest security event data and configuration changes in real-time. This data is then pushed to the InsightCloudSec platform, significantly reducing costs and increasing the speed of data acquisition. For AWS environments, this means event information can be updated in near real-time, within 60 seconds, and within 2-3 minutes for Azure and GCP. This rapid update capability is a stark contrast to the hourly or daily updates provided by other cloud security platforms, setting InsightCloudSec apart as a leader in real-time cloud security monitoring.
Automated Remediation with InsightCloudSec Bots
The integration of near-to-real-time event information through Event Driven Harvesting (EDH) with InsightCloudSec’s advanced bot automation features equips developers with a formidable toolset for safeguarding cloud environments. This unique combination not only flags vulnerable configurations but also facilitates automatic remediation within minutes, a critical capability for maintaining a pristine cloud ecosystem. InsightCloudSec’s bots go beyond mere detection; they proactively manage misconfigurations and vulnerabilities across virtual machines and containers, ensuring the cloud space is both secure and compliant.
The versatility of these bots is remarkable. Developers have the flexibility to define the scope of the bot’s actions, allowing changes to be applied across one or multiple accounts. This granular control ensures that automated security measures are aligned with the specific needs and architecture of the cloud environment.
Moreover, the timing of these interventions can be finely tuned. Whether responding to a set schedule or reacting to specific events – such as the creation, modification, or deletion of resources – the bots are adept at addressing security concerns at the most opportune moments. This responsiveness is especially beneficial in dynamic cloud environments where changes are frequent and the security landscape is constantly evolving.
The actions undertaken by InsightCloudSec’s bots are diverse and impactful. According to the extensive list of sample bots provided by Rapid7, these automated guardians can, for example:
Automatically tag resources lacking proper identification, ensuring that all elements within the cloud are categorized and easily manageable
Enforce compliance by identifying and rectifying resources that do not adhere to established security policies, such as unencrypted databases or improperly configured networks
Remediate exposed resources by adjusting security group settings to prevent unauthorized access, a crucial step in safeguarding sensitive data
Monitor and manage excessive permissions, scaling back unnecessary access rights to adhere to the principle of least privilege, thereby reducing the risk of internal and external threats
And much more…
This automation, powered by InsightCloudSec, transforms cloud security from a reactive task to a proactive, streamlined process.
By harnessing the power of EDH for real-time data harvesting and leveraging the sophisticated capabilities of bots for immediate action, developers can ensure that their cloud environments are not just reactively protected but are also preemptively fortified against potential vulnerabilities and misconfigurations. This shift towards automated, intelligent cloud security management empowers developers to focus on innovation and development, confident in the knowledge that their infrastructure is secure, compliant, and optimized for the challenges of modern cloud computing.
Infrastructure as Code (IaC) Enhanced: Introducing mimInsightCloudSec
In the dynamic arena of cloud security, particularly in the bustling sphere of game development, the wisdom of “an ounce of prevention is worth a pound of cure” holds unprecedented significance. This is where the role of Infrastructure as Code (IaC) becomes pivotal, and Rapid7’s innovative tool, mimInsightCloudSec, elevates this approach to new heights.
mimInsightCloudSec, a cutting-edge component of the InsightCloudSec platform, is specifically designed to integrate seamlessly into any development pipeline, whether you prefer working with executable binaries or thrive in a containerized ecosystem. Its versatility allows it to be a perfect fit for various deployment strategies, making it an indispensable tool for developers aiming to embed security directly into their infrastructure deployment process.
The primary goal of mimInsightCloudSec is to identify vulnerabilities before the infrastructure is even created, thus embodying the proactive stance on security. This foresight is crucial in the realm of game development, where the stakes are high, and the digital landscape is constantly shifting. By catching vulnerabilities at this nascent stage, developers can ensure that their games are built on a foundation of security, devoid of the common pitfalls that could jeopardize their work in the future.
Figure 2: Shift Left – Infrastructure as Code (IaC) Security
Upon completion of its analysis, mimInsightCloudSec presents its findings in a variety of formats suitable for any team’s needs, including HTML, SARIF, and XML. This flexibility ensures that the results are not just comprehensive but also accessible, allowing teams to swiftly understand and address any identified issues. Moreover, these results are pushed to the InsightCloudSec platform, where they contribute to a broader overview of the security posture, offering actionable insights into potential misconfigurations.
But the capabilities of the InsightCloudSec platform extend even further. Within this sophisticated environment, developers can craft custom configurations, tailoring the security checks to fit the unique requirements of their projects. This feature is particularly valuable for teams looking to go beyond standard security measures, aiming instead for a level of infrastructure hardening that is both rigorous and bespoke. These custom configurations empower developers to establish a static level of security that is robust, nuanced, and perfectly aligned with the specific needs of their game-development projects.
By leveraging mimInsightCloudSec within the InsightCloudSec ecosystem, game developers not only can anticipate and mitigate vulnerabilities before they manifest but also refine their cloud infrastructure with precision-tailored security measures. This proactive and customized approach ensures that the gaming experiences they craft are not only immersive and engaging but also built on a secure, resilient digital foundation.
Figure 3: Misconfigurations and recommended remediations in the InsightCloudSec platform
In summary, Rapid7’s InsightCloudSec offers a comprehensive and automated approach to cloud security, crucial for the dynamic environment of game development. By leveraging both API harvesting and innovative Event Driven Harvesting – along with robust support for Infrastructure as Code – InsightCloudSec ensures that game developers can focus on what they do best: creating engaging and immersive gaming experiences with the knowledge that their cloud infrastructure is secure, compliant, and optimized for performance.
In a forthcoming blog post, we’ll explore the unique security challenges that arise when operating a game in the cloud. We’ll also demonstrate how InsightCloudSec can offer automated solutions to effortlessly maintain a robust security posture.
As AI continues to shape the development landscape, developers are navigating a new frontier—not one that will make their careers obsolete, but one that will require their skills and instincts more than ever.
Sure, AI is revolutionizing software development, but that revolution ultimately starts and stops with developers. That’s because these tools need to have a pilot in control. While they can improve the time to code and ship, they can’t serve as a replacement for human oversight and coding abilities.
We recently conducted research into the evolving relationship between developers and AI tools and found that AI has the potential to alleviate the cognitive burden of complex tasks for developers. Instead of being used solely as a second pair of hands, AI tools can also be used more like a second brain, helping developers be more well-rounded and efficient.
In essence, AI can reduce mental strain so that developers can focus on anything from learning a new language to creating high-quality solutions for complex problems. So, if you’re sitting here wondering if you should learn how to code or how AI fits into your current coding career, we’re here to tell you what you need to know about your work in the age of AI.
A brief history of AI-powered techniques and tools
While the media buzz around generative AI is relatively new, AI coding tools have been around —in some form or another—much longer than you might expect. To get you up to speed, here’s a brief timeline of the AI-powered tools and techniques that have paved the way for the sophisticated coding tools we have today:
1950s:Autocoder was one of the earliest attempts at automatic coding. Developed in the 1950s by IBM, Autocoder translated symbolic language into machine code, streamlining programming tasks for early computers.
1958:LISP, one of the oldest high-level programming languages created by John McCarthy, introduced symbolic processing and recursive functions, laying the groundwork for AI programming. Its flexibility and expressive power made it a popular choice for AI research and development.
(defun factorial (n)
(if (<= n 1)
1
(* n (factorial (- n 1)))))
This function calculates the factorial of a non-negative integer ‘n’ in LISP. If ‘n’ is 0 or 1, the factorial is 1. Otherwise, it recursively multiplies ‘n’ by the factorial of n-1 until ‘n’ reaches 1.
1970:SHRDLU, developed by Terry Winograd at MIT, was an early natural language understanding program that could interpret and respond to commands in a restricted subset of English, and demonstrated the potential for AI to understand and generate human language.
SHRDLU, operating in a block world, aimed to understand and execute natural language instructions for manipulating virtual objects made of various shaped blocks.
[Source: Cryptlabs]
1980s: In the 1980s, code generators, such as The Last One, emerged as tools that could automatically generate code based on user specifications or predefined templates. While not strictly AI-powered in the modern sense, they laid the foundation for later advancements in code generation and automation.
“Personal Computer” magazine cover from 1982 that explored the program, The Last One.
[Source: David Tebbutts]
1990s:Neural network–based predictive models were increasingly applied to code-related tasks, such as predicting program behavior, detecting software defects, and analyzing code quality. These models leveraged the pattern recognition capabilities of neural networks to learn from code examples and make predictions.
2000s:Refactoring tools with AI capabilities began to emerge in the 2000s, offering automated assistance for restructuring and improving code without changing its external behavior. These tools used AI techniques to analyze code patterns, identify opportunities for refactoring, and suggest appropriate refactorings to developers.
These early AI-powered coding tools helped shape the evolution of software development and set the stage for today’s AI-driven coding assistance and automation tools, which continue to evolve seemingly every day.
Evolving beyond the IDE
Initially, AI tools were primarily confined to the integrated development environment (IDE), aiding developers in writing and refining code. But now, we’re starting to see AI touch every part of the software development lifecycle (SDLC), which we’ve found can increase productivity, streamline collaboration, and accelerate innovation for engineering teams.
In a 2023 survey of 500 U.S.-based developers, 70% reported experiencing significant advantages in their work, while over 80% said these tools will foster greater collaboration within their teams. Additionally, our research revealed that developers, on average, complete tasks up to 55% faster when using AI coding tools.
Here’s a quick look at where modern AI-powered coding tools are and some of the technical benefits they provide today:
Code completion and suggestions. Tools like GitHub Copilot use large language models (LLMs) to analyze code context and generate suggestions to make coding more efficient. Developers can now experience a notable boost in productivity as AI can suggest entire lines of code based on the context and patterns learned from developers’ code repositories, rather than just the code in the editor. Copilot also leverages the vast amount of open-source code available on GitHub to enhance its understanding of various programming languages, frameworks, and libraries, to provide developers with valuable code suggestions.
Generative AI in your repositories. Developers can use tools like GitHub Copilot Chat to ask questions and gain a deeper understanding of their code base in real time. With AI gathering context of legacy code and processes within your repositories, GitHub Copilot Enterprise can help maintain consistency and best practices across an organization’s codebase when suggesting solutions.
Natural language processing (NLP). AI has recently made great strides in understanding and generating code from natural language prompts. Think of tools like ChatGPT where developers can describe their intent in plain language, and the AI produces valuable outputs, such as executable code or explanations for that code functionality.
Enhanced debugging with AI. These tools can analyze code for potential errors, offering possible fixes by leveraging historical data and patterns to identify and address bugs more effectively.
To implement AI tools, developers need technical skills and soft skills
There are two different subsets of skills that can help developers as they begin to incorporate AI tools into their development workflows: technical skills and soft skills. Having both technical chops and people skills is super important for developers when they’re diving into AI projects—they need to know their technical skills to make those AI tools work to their advantage, but they also need to be able to work well with others, solve problems creatively, and understand the big picture to make sure the solutions they come up with actually hit the mark for the folks using them.
Let’s take a look at those technical skills first.
Getting technical
Prompt engineering
Prompt engineering involves crafting well-designed prompts or instructions that guide the behavior of AI models to produce desired outputs or responses. It can be pretty frustrating when AI-powered coding assistants don’t generate a valuable output, but that can often be quickly remedied by adjusting how you communicate with the AI. Here are some things to keep in mind when crafting natural language prompts:
Be clear and specific. Craft direct and contextually relevant prompts to guide AI models more effectively.
Experiment and iterate. Try out various prompt variations and iterate based on the outputs you receive.
Validate, validate, validate. Similar to how you would inspect code written by a colleague, it’s crucial to consistently evaluate, analyze, and verify code generated by AI algorithms.
Code reviews
AI is helpful, but it isn’t perfect. While LLMs are trained on large amounts of data, they don’t inherently understand programming concepts the way humans do. As a result, the code they generate may contain syntax errors, logic flaws, or other issues. That’s why developers need to rely on their coding competence and organizational knowledge to make sure that they aren’t pushing faulty code into production.
For a successful code review, you can start out by asking: does this code change accomplish what it is supposed to do? From there, you can take a look at this in-depth checklist of more things to keep in mind when reviewing AI-generated code suggestions.
Testing and security
With AI’s capabilities, developers can now generate and automate tests with ease, making their testing responsibilities less manual and more strategic. To ensure that the AI-generated tests cover critical functionality, edge cases, and potential vulnerabilities effectively, developers will need a strong foundational knowledge of programming skills, testing principles, and security best practices. This way, they’ll be able to interpret and analyze the generated tests effectively, identify potential limitations or biases in the generated tests, and augment with manual tests as necessary.
Here’s a few steps you can take to assess the quality and reliability of AI-generated tests:
Verify test assertions. Check if the assertions made by the AI-generated tests are verifiable and if they align with the expected behavior of the software.
Assess test completeness. Evaluate if the AI-generated tests cover all relevant scenarios and edge cases and identify any gaps or areas where additional testing may be required to achieve full coverage.
Identify limitations and biases. Consider factors such as data bias, algorithmic biases, and limitations of the AI model used for test generation.
Evaluate results. Investigate any test failures or anomalies to determine their root causes and implications for the software.
For those beginning their coding journey, check out the GitHub Learning Pathways to gain deeper insights into testing strategies and security best practices with GitHub Actions and GitHub Advanced Security.
You can also bolster your security skills with this new, open source Secure Code Game 🎮.
And now, the soft skills
As developers leverage AI to build what’s next, having soft skills—like the ability to communicate and collaborate well with colleagues—is becoming more important than ever.
Let’s take a more in-depth look at some soft skills that developers can focus on as they continue to adopt AI tools:
Communication. Communication skills are paramount to collaborating with team members and stakeholders to define project requirements, share insights, and address challenges. They’re also important as developers navigate prompt engineering. The best AI prompts are clear, direct, and well thought out—and communicating with fellow humans in the workplace isn’t much different.
Did you know that prompt engineering best practices just might help you build your communication skills with colleagues? Check out this thought piece from Harvard Business Review for more insights.
Problem solving. Developers may encounter complex challenges or unexpected issues when working with AI tools, and the ability to think creatively and adapt to changing circumstances is crucial for finding innovative solutions.
Adaptability. The rapid advancement of AI technology requires developers to be adaptable and willing to embrace new tools, methodologies, and frameworks. Plus, cultivating soft skills that promote a growth mindset allows individuals to consistently learn and stay updated as AI tools continue to evolve.
Ethical thinking. Ethical considerations are important in AI development, particularly regarding issues such as bias, fairness, transparency, and privacy. Integrity and ethical reasoning are essential for making responsible decisions that prioritize the well-being of users and society at large.
Empathy. Developers are often creating solutions and products for end users, and to create valuable user experiences, developers need to be able to really understand the user’s needs and preferences. While AI can help developers create these solutions faster, through things like code generation or suggestions, developers still need to be able to QA the code and ensure that these solutions still prioritize the well-being of diverse user groups.
Sharpening these soft skills can ultimately augment a developer’s technical expertise, as well as enable them to work more effectively with both their colleagues and AI tools.
Take this with you
As AI continues to evolve, it’s not just changing the landscape of software development; it’s also poised to revolutionize how developers learn and write code. AI isn’t replacing developers—it’s complementing their work, all while providing them with the opportunity to focus more on coding and building their skill sets, both technical and interpersonal.
If you’re interested in improving your skills along your AI-powered coding journey, check out these repositories to start building your own AI based projects. Or you can test out GitHub Copilot, which can help you learn new programming languages, provide coding suggestions, and ask important coding questions right in your terminal.
превод от нидерландски Елица Колева, изд. „Жар – Жанет Аргирова“, 2021
Ако тази книга беше написана на някой голям европейски език, тя щеше да е световна, а не само нидерландска класика. Големи думи за голяма книга. Такива са и литературните роднини на романа. Директно влияние върху него оказват както хората на Хага и самият град, така и „Анна Каренина“ на Толстой и „Призраци“ на Ибсен. От Толстой идва разделянето на кратки и енергични глави, а от Ибсен – един делириумен епизод и начинът, по който главната героиня слага край на живота си. Не мисля, че издавам някаква особена сюжетна тайна.
Има дълга традиция в историята на литературата книги с женски имена за заглавия да завършват трагично. Не е и нужно читателите внимателно да броят точно колко пъти думата „меланхолия“ се среща по страниците (65 пъти), за да могат да предположат каква в крайна сметка ще бъде съдбата на Елине Вере. Трагична, разбира се.
Романът е публикуван глава по глава в пресата и има спецификите на сериал. И всъщност е такъв, приковава погледа, така че с нетърпение очакваш следващата част, за която – наистина се радвам – не ми се налагаше да чакам седмица. В действителност не е правен сериал по книгата, но има нелош филм от 1991 г. – за всеки желаещ да сравни адаптацията и първоизточника.
Това, което ме очарова в романа, не е родството по избор с Вертер; не е описанието на пищните живи картини, които представителите на нидерландския хайлайф правят по домовете си; не е и детайлната панорама на тогавашното общество, привилегиите на колониализма и на фантазмите по Ориента и екзотиката, която той носи; не е и възможността да се анализират критично неврозата и истерията и как са конструирани от доминиращия мъжки поглед; не е и преоткритата теория за хуморите и за телесните течности, според която може да си сангвиник или холерик (за меланхолик вече стана ясно); не е неутешимият като бебешки плач Weltschmerz на героите; не е и много други неща, с които мога да продължа до края на текста, че и след него.
Това, което ме очарова, е внезапният ми личен спомен, породен от книгата – как съученици в основното училище се питат един друг „Обясни ли му се? Обясни ли ѝ се?“ и говорят часове наред за обяснения. За обяснения в любов.
Това, което ме очарова в романа, е отдадеността в разговора за чувства и за възпитанието им.
За самото наличие на толкова преувеличен в сериозността си разговор. За възможността да съществува пространство, в което да се състоят тези диалози, и те да са непосредствени – на живо, лице в лице. Или ако не са, то да са в дълги и гъсти писма. Никой не си праща селфита или клипчета. Най-много фотографски портрет, но и това не е било толкова често срещано – все още. И в това говорене да няма мелодрама, а да е форма на общуване. Очарова ме наличието на такава воля у Елине – за
автентичност и непримиримост в желанието общуването да е на нивото на възможното във въображението, а не на ограниченията в реалността.
Чудя се: много ли е загубило общуването от написването на „Елине Вере“ до днес? Изчезнала ли е вярата в това, че думите имат силата да обясняват и да сближават? Това е една възможна гледна точка, разбира се. Друга е, че това, което ме очарова, може иронично да предизвика криндж реакция у някой, който не си дава сметка, че присмивайки се и вземайки на подбив, не обезоръжава написаното, а единствено показва, че е делегирал прекалено много власт не на думите в себе си, думи, които няма да каже нито на глас, нито в писмо, а на медии и техника, които правят общуването хигиенично, удобно и лесно. И го отдалечават неимоверно от това, което хората, с които израснах, наричаха „да седнем на приказка“.
Не съм вярвал, че някога ще защитавам уж стерилния и изпълнен с предразсъдъци и консерватизъм свят от миналото, но все повече ми се струва, че той – или най-вече романите му – са имали капацитета или поне смелото желание да назовават неща, за които днес не ни стигат думите или пък смятаме, че думите са изгубили силата си. Или всъщност литературата създава илюзията, че хората са разговаряли по-добре и повече от нас за чувствата си. Да не забравяме, че Елине все пак умира, а не живее щастливо до края на дните си. Тя е литературно същество, родено да живее и умре в самота, за съжаление.
Защото литературата се ражда и от воля за компенсация, от стремеж за справедливост и красота. От желание нещо, което липсва – да съществува. Като свободното и задълбочено общуване.
Когато преди няколко години препрочитах „Мадам Бовари“, ме шокира и ми достави удоволствие това как почти всяка фраза е едновременно сериозна и иронична (като при Платонов в „Чевенгур“ впрочем) и как изречение след изречение Флобер ни приближава към това, за което говори – първо го виждаме с телескоп, после идва ред на бинокъла, след това на лупата и накрая е микроскопът. Детайлно и прецизно писане, което разнищва, уверено е във възможностите си и прекрачва граници – етически и естетически, – без да му мигне окото. Писане, което не си и помисля да маркира сериозност, да фалшифицира многозначителност или да върви по утъпканата пътека на една определена конвенция и клише. Каквито в момента има предостатъчно.
Луи Куперюс не е толкова безпощаден присмехулник и сатирик като Флобер. Той пише с голяма доза съчувствие за безизходиците, счупванията и бездните на Елине Вере. Те са същите, които Стриндберг и Ибсен откриват, а Бергман окончателно разширява, оживява и превръща както в кино, така и в лична биография. Друга класова и писателска близост е и с Едит Уортън, неслучайно публикувана от същото издателство.
Елине Вере е, поне на пръв поглед, типичен някогашен млад човек от добро семейство. Ходи редовно на опера, където се влюбва, чете „Парижката Света Богородица“, ухажвана е и флиртува в будоари и на соарета, радва с обаяние, води кореспонденции и разговори, не харесва баналните и скучни хора, в крак е с модата и тенденциите и е безкрайно уморена и тъжна. С лекота черпи от духа на времето и от средата си, но ѝ е трудно да бъде част от тях. Усеща слепите им петна, маниите и преувеличенията. Фетишизира колебанията и тъгата си, носталгията и меланхолията. Уютът им я привлича като почивка в санаториум, от който никога няма да излезе. Не я привличат бракът по сметка или някаква друга форма на интимност, наподобяваща транзакция. Тя иска нещо повече, което няма как да получи.
Представям си, че Кафка, принцът на разваления годеж (с четири зад гърба си), би харесал този роман,
колкото и той да е привидно далечен на неговото писане. Куперюс описва света и резервите към този свят, чиито устои Кафка подкопава и осмива в радикален знак на съпротива. Елине Вере няма толкова силни съпротивителни механизми. Тя зачерква всички възможни версии на живота си. Самоубива се почти случайно с морфин, защото иска да заспи и да не будува в този свят – той изобщо не може да ѝ предложи пълноценната форма на любов, за която тя копнее. И за която Кафка също е копнял. (Фелице Бауер пренася и в Америка стотиците му писма до нея и ги продава за публикация едва след смъртта на съпруга си и поради финансови трудности, четвърт век след смъртта на Кафка.)
Това е в крайна сметка книга, чийто подходящ и дори идеален читател би бил човек, изпитващ трудности да се намести в настоящето. А светът в момента е рядко неуместен.
Активните дарители на „Тоест“ получават постоянна отстъпка в размер на 20% от коричната цена на всички заглавия от каталога на издателство „Жар – Жанет Аргирова“, както и на няколко други български издателства в рамките на партньорската програма Читателски клуб „Тоест“. За повече информация прочетете на toest.bg/club.
Никой от нас не чете единствено най-новите книги. Тогава защо само за тях се пише? „На второ четене“ е рубрика, в която отваряме списъците с книги, публикувани преди поне година, четем ги и препоръчваме любимите си от тях. Рубриката е част от партньорската програма Читателски клуб „Тоест“. Изборът на заглавия обаче е единствено на авторите – Стефан Иванов и Антония Апостолова, които биха ви препоръчали тези книги и ако имаше как веднъж на две седмици да се разходите с тях в книжарницата.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.