Acronis Cyber Protect/Backup machine info disclosure
Authors: Sandro Tolksdorf of usd AG. and h00die-gr3y [email protected]
Type: Auxiliary
Pull request: #19582 contributed by h00die-gr3y
Path: gather/acronis_cyber_protect_machine_info_disclosure
AttackerKB reference: CVE-2022-3405
Description: Adds an auxiliary module which exploits Sensitive information disclosure due to an improper authentication vulnerability in Acronis Cyber Protect 15 before build 29486 and Acronis Cyber Backup 12.5 before build 16545.
Strapi CMS Unauthenticated Password Reset
Authors: WackyH4cker and h00die
Type: Auxiliary
Pull request: #19654 contributed by h00die
Path: scanner/http/strapi_3_password_reset
AttackerKB reference: CVE-2019-18818
Description: Adds a module that lets you leverage the mishandling of a password reset request for Strapi CMS version 3.0.0-beta.17.4, which results in the ability to change the password of the admin user.
Authors: Florent Sicchio, Hugo Clout, and ostrichgolf
Type: Exploit
Pull request: #19531 contributed by ostrichgolf
Path: linux/http/projectsend_unauth_rce
Description: Adds a new exploit module targeting ProjectSend versions r1335 through r1605. The module exploits an improper authorization vulnerability, allowing unauthenticated RCE by manipulating the application’s configuration settings.
CUPS IPP Attributes LAN Remote Code Execution
Authors: David Batley, RageLtMan rageltman@sempervictus, Rick de Jager, Ryan Emmons, Simone Margaritelli, and Spencer McIntyre
Type: Exploit
Pull request: #19630 contributed by remmons-r7
Path: multi/misc/cups_ipp_remote_code_execution
AttackerKB reference: CVE-2024-47176
Description: This adds an exploit for CUPS, where a remote attacker can advertise a malicious printing service that when used will execute a command on the printing client.
Enhancements and features (2)
#19651 from smashery – This updates the smb_version module to detect the host OS version when SMB 1 is disabled.
#19678 from smashery – This adds a new LDAP query to enumerate computer accounts that were created with the "pre-Windows 2000 computer" option which might mean they weak passwords.
Bugs fixed (0)
None
Documentation
You can find the latest Metasploit documentation on our docsite at docs.metasploit.com.
Get it
As always, you can update to the latest Metasploit Framework with msfupdate
and you can get more details on the changes since the last blog post from
GitHub:
Around the world, organizations are evaluating and embracing artificial intelligence (AI) and machine learning (ML) to drive innovation and efficiency. From accelerating research and enhancing customer experiences to optimizing business processes, improving patient outcomes, and enriching public services, the transformative potential of AI is being realized across sectors. Although using emerging technologies helps drive positive outcomes, leaders worldwide must balance these benefits with the need to maintain security, compliance, and resilience. Many organizations, including those in the public sector and regulated industries, are investing in generative AI applications powered by large language models (LLMs) and other foundation models (FMs) because these applications can transform and scale their work and provide better experiences for customers. Beyond computing power, unlocking this AI potential resides in the AI applications that organizations can create based on a variety of AI/ML development services, models, and data sources. Organizations must navigate the complexity of building AI applications in light of existing and emerging regulatory regimes while verifying that their AI applications and related data are secure, protected, and resilient to risks and threats.
AWS offers a wide range of AI/ML services and capabilities, built on our sovereign-by-design foundation, that are making it simpler for our customers to meet their digital sovereignty needs while getting the security, control, compliance, and resilience that they need. For example, Amazon Bedrock is a fully managed service that offers a choice of high-performing FMs from leading AI companies such as AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, and Stability AI through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI. Amazon SageMaker provides tools and infrastructure to build, train, and deploy ML models at scale while supporting responsible AI with governance controls and access to pretrained models.
Innovating securely across the AI lifecycle
Security is and always has been our top priority at AWS. AWS customers benefit from our ongoing investment in data centers, networks, custom hardware, and secure software services, built to satisfy the requirements of the most security-sensitive organizations, including the government, healthcare, and financial services. We have always believed that it is essential that customers have control over their data and its location. That’s why we architected the AWS Cloud to be secure and sovereign-by-design from day one. We remain committed to giving our customers more control and choice so that they can use the full power of AWS while meeting their unique digital sovereignty needs.
As organizations develop and implement generative AI, they want to make sure that their data and applications are secured across the AI lifecycle, including data preparation, training, and inferencing. To help ensure the confidentiality and integrity of customer data, all of our Nitro-based Amazon Elastic Compute Cloud (Amazon EC2) instances that run ML accelerators such as AWS Inferentia and AWS Trainium, and graphics processing units (GPUs) such as P4, P5, G5, and G6, are backed by the industry-leading security capabilities of the AWS Nitro System. By design, there is no mechanism for anyone at AWS to access Nitro EC2 instances that customers use to run their workloads. The NCC Group, an independent cybersecurity firm, has validated the design of the Nitro System.
We take a secure approach to generative AI and make it practical for our customers to secure their generative AI workloads across the generative AI stack so that they can focus on building and scaling. All AWS services—including generative AI services—support encryption, and we continue to innovate and invest in controls and encryption features that allow our customers to encrypt everything everywhere.
For example, Amazon Bedrock uses encryption to protect data in transit and at rest, and data remains in the AWS Region where Amazon Bedrock is being used. Customer data, such as prompts, completions, custom models, and data used for fine-tuning or continued pre-training, is not used for Amazon Bedrock service improvement and is never shared with third-party model providers. When customers fine-tune a model in Amazon Bedrock, the data is never exposed to the public internet, never leaves the AWS network, is securely transferred through a customer’s virtual private cloud (VPN), and is encrypted in transit and at rest.
SageMaker protects ML model artifacts and other system artifacts by encrypting data in transit and at rest. Amazon Bedrock and SageMaker integrate with AWS Key Management Service (AWS KMS) so that customers can securely manage cryptographic keys. AWS KMS is designed so that no one—not even AWS employees—can retrieve plaintext keys from the service.
Developing responsibly
The responsible development and use of AI is a priority for AWS. We believe that AI should take a people-centric approach that makes AI safe, fair, secure, and robust. We are committed to supporting customers with responsible AI and helping them build fairer and more transparent AI applications to foster trust, meet regulatory requirements, and use AI to benefit their business and stakeholders. AWS is the first major cloud service provider to announce ISO/IEC 42001 accredited certification for AI services, covering Amazon Bedrock, Amazon Q Business, Amazon Textract, and Amazon Transcribe. ISO/IEC 42001 is an international management system standard that outlines requirements and controls for organizations to promote the responsible development and use of AI systems.
We take responsible AI from theory into practice by providing the necessary tools, guidance, and resources, including Amazon Bedrock Guardrails to help implement safeguards tailored to customer generative AI applications and aligned with their responsible AI policies, or Model Evaluation on Amazon Bedrock to evaluate, compare, and select the best FMs for specific use cases based on custom metrics, such as accuracy, robustness, and toxicity. Additionally, Amazon SageMaker Model Monitor automatically detects and alerts customers of inaccurate predictions from deployed models. We continue to publish AI Service Cards to enhance transparency by providing a single place to find information on the intended use cases and limitations, responsible AI design choices, and performance optimization best practices for our AI services and models.
Building resilience
Resilience plays a pivotal role in the development of any workload, and AI/ML workloads are no different. Customers need to know that their workloads in the cloud will continue to operate in the face of natural disasters, network disruptions, or disruptions due to geopolitical crises. AWS delivers the highest network availability of any cloud provider and is the only cloud provider to offer three or more Availability Zones (AZs) in all Regions, providing more redundancy. Understanding and prioritizing resilience is crucial for generative AI workloads to meet organizational availability and business continuity requirements. We have published guidance on designing generative AI workloads for resilience. To enable higher throughput and enhanced resilience during periods of peak demands in Amazon Bedrock, customers can use cross-region inference to distribute traffic across multiple Regions. For customers with specific European Union data sovereignty requirements, we are launching the AWS European Sovereign Cloud in 2025 to offer an additional layer of control and resilience.
Supporting choice and flexibility
It’s important that customers have access to diverse AI technologies, while having the freedom to choose the right solutions to meet their needs. AWS provides more diversity, choice, and flexibility so that customers can select the AI solution that best aligns with their specific requirements, whether that’s using open-source models, proprietary solutions, or their own custom AI models. For example, we understand the importance of open-source AI in fostering transparency, collaboration, and rapid innovation. Open-source models enable scrutiny of vulnerabilities, drive security improvements, and support research on AI safety. Amazon SageMaker JumpStart provides pretrained, open-source models for a wide range of common use cases. To provide practitioners and developers with the guidance and tools that they need to create secure-by-design AI systems, we are a founding member of the open-source initiative Coalition for Secure AI (CoSAI).
Also, our commitment to portability and interoperability helps ensure that customers can move easily between environments. For customers changing IT providers, we’ve taken concrete steps to lower costs, and AWS is actively engaged in efforts to facilitate switching between cloud providers, including through our support of the Cloud Infrastructure Service Providers in Europe (CISPE)Cloud Switching Framework, which lays out guidance to assist providers and customers in the switching process. This gives organizations the flexibility to adapt their cloud and AI strategies as their needs evolve.
We remain committed to providing customers with a choice of diverse AI technologies, along with secure and compliant ways to build their AI applications throughout the development lifecycle. Through this approach, customers can enhance the security, compliance, and resilience of their systems.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
От време разделно в 51-вия парламент печели президентът Румен Радев, формално – БСП. Осмото гласуване за председател на 51-вото Народно събрание също не излъчи председател, макар ГЕРБ–СДС да обяви, че ще подкрепи експертката по конституционно право доц. Наталия Киселова, представителка на гражданската квота в парламентарната група на БСП – Обединена левица. Резултатът е, че Киселова, приближена до президентския кръг, работила в президентската администрация при Росен Плевнелиев и Радев, за първи път излезе на балотаж с номинацията на доц. Силви Кирилов от „Има такъв народ“ (ИТН). А това в момента е политическата сила, която е най-близка до президента.
Партията на Бойко Борисов оттегли кандидатурата на Рая Назарян с предварителното условие номинацията на доц. Киселова да събере гласове извън „Възраждане“ и ДПС – Ново начало на санкционирания за корупция олигарх Делян Пеевски. Компромисът на Борисов даде известна тактическа преднина на ГЕРБ, макар да показа, че с първата политическа сила не може да има избран председател на парламента.
„Пакетиране“
А ситуационно ПП–ДБ бяха „пакетирани“ с проруската и евроскептична „Възраждане“, тъй като депутатите на ПП заедно с ИТН и МЕЧ подкрепиха при досегашните гласувания кандидата на „Има такъв народ“ доц. Силви Кирилов. Укори ги Борисов, а в синхрон с него Пеевски ги определи като „коалиция Москва“. Аргументът, заявен от ПП–ДБ, бе заради „обективен критерий като най-възрастния депутат“. Два гласа не позволиха на 28 ноември урологът, помагал на партията на Христо Ковачки ЛИДЕР и бивш съдружник на Любен Беров – „сламения човек“ на „Мултигруп“ и ДПС, да оглави парламента. Гласуването на депутатите от ПП–ДБ Явор Божанков и Даниел Лорер предизвика силно напрежение, а „Продължаваме промяната“ светкавично обяви, че изключва Лорер от партията, и поиска двамата да напуснат парламента.
Тази ad hoc реакция показа високите очаквания, с които е бил натоварен изборът на Кирилов, далеч извън твърденията, че се избира председател на 51-вото НС и се отпушва работата му. Но отзвукът беше още по-голям. След обвиненията в парламента, отправени от „Възраждане“ и ИТН към ПП–ДБ, последваха реакции в социалните мрежи от симпатизанти и активисти на коалицията – някои подкрепиха Лорер и Божанков, други ги обвиниха във връзки с Борисов и Пеевски. Но най-сериозната критика бе отправена от евродепутата Радан Кънев.
Днешното [вчерашното – б.а.] гласуване на ПП–ДБ е политически безпринципно. Никакви аргументи от типа „да спрем Сарафов“ не оправдават съюзяване с антиевропейска, путинска, антидемократична и антипазарна политическа формация. Не и в днешния геополитически момент, а според мен – никога.
Позициите на Лорер и Божанков, че няма да гласуват с „Възраждане“, защото е путинистка и фашистка партия, са последователни. Гласуването извади публично разлома между ПП и ДБ. Първоначално ДБ отказа да подкрепи Кирилов заради ценностна несъвместимост с „Възраждане“, но лека-полека твърдостта им се сломи. Те дори склониха на „еднократна подкрепа“ за Кирилов – трудна за комуникация позиция, тъй като на осмото гласуване отново не го подкрепиха с обяснението, че партиите, гласуващи за депутата на ИТН, не са подписали декларацията за санитарния кордон на Пеевски. Междувременно ДБ защити двамата си колеги от групата и Ивайло Мирчев от ДБ обяви по БНТ, че Лорер и Божанков остават в парламентарната група.
Това, че са имали различно мнение, включително и за толкова критично важно гласуване, не означава, че те не трябва да бъдат част от нашата група.
Заешката дупка
Когато политиците се спънат още на входа на парламента в невъзможността да изберат председател, всеки здравомислещ българин би се досетил, че зад този спор се крият дълбоки интереси. Перманентната политическа нестабилност направи силна и перманентната власт – служебните правителства, които действат съвсем като редовните, при това в „комфорта“ на известна безконтролност. След като председателят на Народното събрание влезе по Конституция в „домовата книга“, от която президентът може да избира служебен премиер, този пост неизменно е плод на сериозни преговори и определяне на политическа цена за сделката.
В случай че на Радев бъде осигурена възможност да избира и друг освен Димитър Главчев за служебен премиер, ще го направи. Спря се на Горица Кожарева от Сметната палата, но го възпря нейният повторен избор вътрешен министър да е Калин Стоянов. Това е доказателство колко важен е постът министър на вътрешните работи за изборните резултати. Настоящият вътрешен министър Атанас Илков се представи така, както би се справил и предишният – Калин Стоянов, вече депутат от ДПС – Ново начало на Пеевски.
Политическата криза прехвърли към Конституционния съд част от решенията, които са и задължения, и отговорност на политиците – например провеждането на честни и демократични избори. Сега КС ще е арбитърът по внесените пет иска за частично касиране, но не и за честността и извършването на престъпления. Записите от видеонаблюдението, където се видяха най-големите злоупотреби, не са обект на проверка от експертите към КС. Юристи, математици и ИТ специалисти ще работят по ключовата експертиза, която ще изследва резултатите от вота в общо 2219 секции. До 10 януари те ще трябва да преброят повторно гласовете в 1777 секции и протоколите за недействителните бюлетини в 442.
Наред с това КС ще се произнесе по искане на президента, който не се отказва да си върне правомощията за назначаване на служебно правителство, и ще разтълкува какво може и какво не може да прави ВСС с изтекъл мандат – например да избира главен прокурор.
В условията на отслабени партии Румен Радев подсилва влиянието си и няма нужда да се явява като бога от машината. Партиите са толкова изчерпани откъм обществено доверие, че всеки на „Дондуков“ 2 би изглеждал титан. Радев често е питан в разгара на втория си и последен мандат дали ще създаде политическа сила, за да стане новият партиен титан и така да капитализира акумулираните в последните седем години висок рейтинг и влияние.
Накъде отива републиката
С каквото и да бъде сравнена днешна България – дали с Ваймарската република, или със залеза на Римската република, – означава едно и също: политическа нестабилност и загуба на републикански традиции. Също като Рим в I век пр.Хр., и България – 21 столетия по-късно – страда от липса на ефективно лидерство, а общественото доверие в институциите е силно подкопано. Но има и тежка загуба на граждански добродетели (последното е в основата на разпадането на Рим според Едуард Гибсън в „Залез и упадък на Римската империя“).
Големият въпрос е към какво ни води политическата криза? Дали към диктатури като на Сула и Цезар – заради конфликтите между оптимати и популари, или към разпад на политическата система заради неспособност за стабилни коалиции, довел до възхода на радикални движения и до най-голямото зло за XX век – нацизма.
Радикализацията е видима, диктатурите остават политически блян за някои лидери. Доверието в институциите не може да бъде възстановено, освен ако бъдещо стабилно управление не започне процес по оздравяването им и съзнателен избор на почтени професионалисти, които да ги ръководят.
Но засега партиите виждат не по-далеко от „хоризонта“ на едно служебно правителство.
These are two attacks against the system components surrounding LLMs:
We propose that LLM Flowbreaking, following jailbreaking and prompt injection, joins as the third on the growing list of LLM attack types. Flowbreaking is less about whether prompt or response guardrails can be bypassed, and more about whether user inputs and generated model outputs can adversely affect these other components in the broader implemented system.
[…]
When confronted with a sensitive topic, Microsoft 365 Copilot and ChatGPT answer questions that their first-line guardrails are supposed to stop. After a few lines of text they halt—seemingly having “second thoughts”—before retracting the original answer (also known as Clawback), and replacing it with a new one without the offensive content, or a simple error message. We call this attack “Second Thoughts.”
[…]
After asking the LLM a question, if the user clicks the Stop button while the answer is still streaming, the LLM will not engage its second-line guardrails. As a result, the LLM will provide the user with the answer generated thus far, even though it violates system policies.
In other words, pressing the Stop button halts not only the answer generation but also the guardrails sequence. If the stop button isn’t pressed, then ‘Second Thoughts’ is triggered.
What’s interesting here is that the model itself isn’t being exploited. It’s the code around the model:
By attacking the application architecture components surrounding the model, and specifically the guardrails, we manipulate or disrupt the logical chain of the system, taking these components out of sync with the intended data flow, or otherwise exploiting them, or, in turn, manipulating the interaction between these components in the logical chain of the application implementation.
In modern LLM systems, there is a lot of code between what you type and what the LLM receives, and between what the LLM produces and what you see. All of that code is exploitable, and I expect many more vulnerabilities to be discovered in the coming year.
Оплакването от „пластмасовите домати“ е често срещано и добре познато на учените, които се занимават със селекция на любимия на мнозина плод. Истината, която стои зад популярността на този тип сортове, е възможността да бъдат транспортирани и съхранявани за дълги периоди, без търговският им вид да пострада значително. Вкусните меки домати се нараняват лесно и се развалят бързо, което носи значителни щети на производителите и търговците.
Създаването на нов сорт е фин процес, при който се балансират много фактори – вкусови качества, добив, размер на плодовете, транспортабилност, устойчивост на различни заболявания. Тъй като те са свързани в сложна мрежа от биохимични взаимодействия, обикновено промяната в един от тях води до други промени, които могат да бъдат и нежелани. Пример за това са гените за устойчивост на патогени, които често влияят негативно на вкуса.
Отрицателен ефект има и подборът на растения с по-големи плодове – те съдържат значително по-малко захари, поради което повечето чери сортове са по-сладки. Учените могат да насочат селекционния процес към повишаване на захарността, но тогава пък спада добивът. Растенията имат ограничено количество енергия и могат да го насочат към различни процеси, определени от молекулярни механизми, които са се развивали в продължение на милиони години. Но с малка намеса в генома им това не може да се промени.
В основата на синтеза на захари стои магията на фотосинтезата. При този процес, най-общо, от въглеродния диоксид във въздуха, от водата и от слънчевата енергия се получава глюкоза, която може да бъде модифицирана до фруктоза, а при свързването на двете се получава захарта, позната ни от белите кубчета – захарозата. Растенията я използват за транспорт и съхранение на енергия (например захарното цвекло я концентрира в кореноплода си) и с помощта на специални ензими я превръщат обратно в по-прости захари, които мога да използват за метаболизма си.
С промяна на тези процеси китайски учени успешно са създали по-сладки домати. Те са открили два протеина, които се експресират основно в плодовете на доматите и унищожават един от ензимите, който може да разгради захарозата до глюкоза и фруктоза. С помощта на CRISPR/Cas9 гените за синтеза им са инактивирани, което води до значително увеличение на количеството захари в плодовете. В едно от растенията нивата на глюкоза са се повишили с 35%, а на фруктозата – с 30%. Най-впечатляващото е, че размерът на плодовете не се е повлиял от редакциите. Негативно е било отражението върху броя и масата на семената, но не и върху способността им за покълване, което може дори да се хареса на потребителите и не създава пречка за селекционерите. По-високото съдържание на захари ще бъде полезно и за сортове, които се използват за преработка, тъй като намалява необходимостта от добавяне на захар в сосове и други продукти.
Хипотезата на учените е, че двата манипулирани гена отговарят за преразпределението на енергия между плода и семената по време на узряване. Това откритие може да се окаже важно, тъй като е много вероятно подобен механизъм да присъства и в други плодове. Експериментът показва как понякога с минимална намеса може да се получат впечатляващи резултати.
Да спасим бананите
Бананът е интересна култура, която има голямо икономическо значение. Поради наличието на семена в дивите видове, сравнително рано в селекционния процес са подбрани сортове, които са триплоидни – те носят три копия на генома, за разлика от по-традиционните две. Полиплоидността е често срещана при растенията и обикновено е търсено качество за културните растения. Но когато броят на копията е нечетен, растенията са стерилни и или не произвеждат семена, или семената са изключително малки.
Принципно липсата на семена не е проблем, тъй като повечето овощни култури се размножават вегетативно, като по този начин се гарантира, че характеристиките на плода ще се запазят. Но тъй като всички растения на практика са едни и същи (клонинги), те са много по-чувствителни към заболявания. Обикновено в процеса на половото размножаване характеристиките на майчиното и бащиното растение се разпределят в потомството и така то е хетерогенно: някои от растенията са по-чувствителни, а други – по-устойчиви и в еволюционния процес видът е по-устойчив на неприятели и патогени.
Именно това налага драстична промяна в производството на банани през 50-те години на миналия век, когато гъбата Fusarium oxysporumf.sp. cubense, причинител на панамската болест (фузарийно увяхване) завзема големите плантации по света. Масовият тогава сорт „Гро Мишел“ (Gros Michel) е изключително чувствителен към заболяването, което прави мащабната му култивация невъзможна. Поради тежките последствия от заболяването и премахването на „Гро Мишел“ от плантациите, за него понякога се говори като за „изчезнал сорт“, но всъщност той все още може да се открие в редица тропически страни.
Решението е въвеждането на нов сорт – „Кавендиш“(Cavendish), който поради устойчивостта си на патогена бързо се налага като основен и покрива над 90% от бананите, отглеждани за износ. Освен необходимостта от подмяна на насажденията, преходът има и други негативи – общоприетото мнение е, че вкусът на новия сорт не е толкова добър, колкото на „Гро Мишел“.
50 години по-късно ситуацията се повтаря – нов щам на патогена (tropical race 4, Foc TR4) успява да преодолее защитите на „Кавендиш“ и застрашава масовото производство. За проблема се говори от доста време и за съжаление, към момента няма окончателно решение за справяне със заболяването. Въпреки това не бива да гледаме прекалено драматично на случващото се, тъй като учените работят усилено върху различни подходи за контрол на заболяването.
Благодарение на скорошно изследванезнаем повече за произхода и метода на действие на патогена. След сравнителен анализ на генома на 36 щама се оказва, че той не е произлязъл от поразилия „Гро Мишел“, а има собствена еволюционна история. Установено е също, че има специфични гени, които служат както за синтез, така и за детоксификация на азотен оксид. Изследователите не са сигурни каква функция има този механизъм, но е ясно, че е отговорен за високата патогенност на щама, тъй като при премахването на въпросните гени патогенността значително намалява.
Работи се и по създаването на нови сортове. Вече има няколко генетично модифицирани сорта, които показват добра устойчивост. Първото полско изпитване на един от тях е направено още през 2017 г., като за създаването му са използвани два различни гена за устойчивост. Единият от тях (RGA2) е открит в див банан, устойчив на патогена, а другият (Ced9) е трансген, изолиран от нематоди.
Въпреки трудностите при подхода на класическата селекция, немски учени в сътрудничество с компанията „Чикита“ и други партньори са успели да създадат нов сорт –Yelloway One, който освен на фузарийното увяхване е устойчив и на черната сигатока – друго икономически важно заболяване. За улесняване на процеса са използвани и модерните геномни технологии за секвениране и молекулярни маркери. Сортът все още е прототип и се отглежда само в оранжерии, но се планират пилотни изпитвания във Филипините и Индонезия – региони, силно засегнати от заболяванията. Интригуващото е, че той е част от по-мащабен план (т.нар. инициатива Yelloway) за създаване на множество нови сортове, които не отстъпват на „Кавендиш“, но са устойчиви и по-важното – внасят генетично разнообразие в сортовия състав. Така рискът отново да се озовем в сегашната ситуация ще намалее значително.
Интересно решение идва и от Антарктика. Събирайки проби от мъхове и лишеи от студения континент, изследователи са успели да изолират значителен брой актиномицети. Това са бактерии, чиито колонии образуват нишки, подобно на гъбите. Те се срещат повсеместно, дори и в човешкия микробиом, и са важна част от почвената микрофлора, отговорна за разграждането на органични вещества. Част от изолатите проявяват антигъбна активност, като в девет от тях тя е особено висока. При изпитвания върху различни гъбни патогени те се оказват много подходящи за контрол на Foc TR4. Когато патогенът се третира с екстракт от актиномицетите, растежът му се потиска и впоследствие клетките му загиват. Методът показва висока ефективност и се приема за екологосъобразен, което го прави много добро допълнение в арсенала срещу заболяването.
След появата на Foc TR4 бяха публикувани множество сензационни материали как едва ли не бананите ще изчезнат като продукт. Въпреки трудностите, които заболяването поставя пред фермерите, това е малко вероятно, тъй като много учени работят по проблема. С напредъка на науката и появата на нови технологии, сега има доста по-разнообразни методи, които могат да се приложат, някои дори с потенциал за намиране на трайно решение.
Първата CRISPR генна терапия в действие
Casgevy – генната терапия срещу сърповидноклетъчна анемия и бета-таласемия, за която сме разказвали, вече се прилага на пациенти извън клинични проучвания. В съобщение за инвеститорите Verex – компанията, разработила продукта, е обявила приходи от 2 млн. долара от един пациент, който е получил терапията в третото тримесечие на годината.
Към момента има 45 одобрени клиники в обширен географски периметър (САЩ, Канада, Обединеното кралство, Европа, Близкия изток), които могат да извършват процедурата. Освен споменатия пациент още 40 са в началото на процеса – от тях са събрани стволови клетки, които ще бъдат редактирани. Очаквано, процедурата не е бърза, нито лесна и ще отнеме време, преди да бъдат получени данни от терапията. След извършване на редакцията пациентите минават курс на химиотерапия, при който се премахват стволовите клетки в костния им мозък. Тогава редактираните стволови клетки се връщат в пациента и започват да произвеждат хемоглобин F, който намалява симптомите на заболяването.
Според компанията терапията се приема много добре от пациентите и лекарите и се очаква тепърва броят на клиентите да расте, като са предоставени данни, че в САЩ и Европа има около 35 000 пациенти, които могат да бъдат третирани с Casgevy, и допълнителни 25 000 в Саудитска Арабия и Бахрейн. Предстои да разберем дали очакванията ще бъдат оправдани, защото лечението не е евтино и лесно – процесът на извличане на стволовите клетки не е приятен, а химиотерапията крие редица рискове. Въпреки това новината е радостна, защото показва, че този вид генни терапии не са научна самоцел, а имат пряк ефект върху живота на хората.
Пречистване от „вечни химикали“
Пер- и полифлуороалкилираните вещества (PFAS) са широко разпространени химикали, които се използват в множество продукти – незалепващи съдове (тефлонът е най-популярният от тях), най-различни водоустойчиви тъкани, кабелни изолации и дори в козметични продукти (очна линия, червило, спирала). Тъй като съдържат въглерод-флуорни връзки, които са едни от най-силните, те се разграждат изключително трудно, поради което често биват наричани вечни химикали. Някои от тях вече са забранени в ЕС, а забраната на други е обект на дискусия в момента. След като попаднат в човешкото тяло, те имат способността да причинят редица здравословни проблеми, като ракови заболявания, засягащи различни органи, проблеми с хормоналния баланс, понижен фертилитет, проблеми в когнитивното развитие и др. Това ги прави изключително опасен замърсител на околната среда.
Пречистването на вода от PFAS не е лесно и изборът на подход зависи от дължината на веригата на химикалите. Със забраната на молекулите с по-дълга верига, основните замърсители в момента са късите и ултракъсите PFAS. Нова разработка показва обещаващи резултати за премахването им и разкрива потенциал за широкомащабно приложение за третиране на отпадни води. Екипът вече има разработка за пречистване с помощта на метод, наречен електросорбция, при който адсорбцията се стимулира чрез подаване на електричество, но той не е ефективен за ултракъсите PFAS.
За справяне с този проблем в процеса се добавя стъпка на редокс електродиализа – метод, който се използва в обезсоляването на вода. Пробивът настъпва, след като учените установяват, че молекулите с много къси вериги се държат сходно на солевите йони във воден разтвор. Допълнителна иновация е използването на мембрани за нанофилтрация. Те са по-евтини от класическите йонообменни мембрани и за разлика от тях могат да бъдат почиствани чрез пропускането на електричество през тях. След подбиране на методите за пречистване остава екипът да се справи с предизвикателството как в едно устройство да се извършат електросорбцията, електродиализата и електрохимичната оксидация, която унищожава вечните химикали.
Създаденият прототип показва висока ефективност – постигнато е премахване на замърсяването между 76 и 100% в зависимост от типа и дължината на молекулите. Наред с премахването на PFAS, устройството е показало и добра ефективност при обезсоляване на водата, което значи, че може да се използва за едновременно третиране и на води с по-сложна смес от замърсители.
Сега пред учените стои въпросът как могат да увеличат мащаба на устройството, така че да може да се използва извън лабораторията. Това би било от изключителна полза за новите фабрики за производство на полупроводници, които ще работят в САЩ като следствие от указа на американския президент Джо Байдън за създаване на нови мощности в страната с цел намаляване на зависимостта от фабриките в Тайван. Това е стратегически проект за САЩ и първите индикации са добри – преди месец в завода на TMSC в Аризона бяха получени добиви, които са с около 4% по-високи от тези в Тайван.
Новите технологии и молекули обикновено решават много проблеми, но от време на време се оказва че създават нови, които понякога са по-големи. PFAS са изключително полезни, тефлонът е един от „магическите“ материали на XX век, но колкото повече научаваме за тях, толкова повече разбираме, че употребата им трябва да бъде одобрена само след качествена преценка на риска.
Have you heard of ChatGPT, Gemini, or Claude, but haven’t tried any of them yourself? Navigating the world of large language models (LLMs) might feel a bit daunting. However, with the right approach, these tools can really enhance your teaching and make classroom admin and planning easier and quicker.
That’s where the OCEAN prompting process comes in: it’s a straightforward framework designed to work with any LLM, helping you reliably get the results you want.
The great thing about the OCEAN process is that it takes the guesswork out of using LLMs. It helps you move past that ‘blank page syndrome’ — that moment when you can ask the model anything but aren’t sure where to start. By focusing on clear objectives and guiding the model with the right context, you can generate content that is spot on for your needs, every single time.
5 ways to make LLMs work for you using the OCEAN prompting process
OCEAN’s name is an acronym: objective, context, examples, assess, negotiate — so let’s begin at the top.
1. Define your objective
Think of this as setting a clear goal for your interaction with the LLM. A well-defined objective ensures that the responses you get are focused and relevant.
Maybe you need to:
Draft an email to parents about an upcoming school event
Create a beginner’s guide for a new Scratch project
Come up with engaging quiz questions for your next science lesson
By knowing exactly what you want, you can give the LLM clear directions to follow, turning a broad idea into a focused task.
2. Provide some context
This is where you give the LLM the background information it needs to deliver the right kind of response. Think of it as setting the scene and providing some of the important information about why, and for whom, you are making the document.
You might include:
The length of the document you need
Who your audience is — their age, profession, or interests
The tone and style you’re after, whether that’s formal, informal, or somewhere in between
All of this helps the LLM include the bigger picture in its analysis and tailor its responses to suit your needs.
By showing the LLM what you’re aiming for, you make it easier for the model to deliver the kind of output you want. This is called one-shot, few-shot, or many-shot prompting, depending on how many examples you provide.
You can:
Include URL links
Upload documents and images (some LLMs don’t have this feature)
Copy and paste other text examples into your prompt
Without any examples at all (zero-shot prompting), you’ll still get a response, but it might not be exactly what you had in mind. Providing examples is like giving a recipe to follow that includes pictures of the desired result, rather than just vague instructions — it helps to ensure the final product comes out the way you want it.
4. Assess the LLM’s response
This is where you check whether what you’ve got aligns with your original goal and meets your standards.
Keep an eye out for:
Hallucinations: incorrect information that’s presented as fact
Misunderstandings: did the LLM interpret your request correctly?
Bias: make sure the output is fair and aligned with diversity and inclusion principles
A good assessment ensures that the LLM’s response is accurate and useful. Remember, LLMs don’t make decisions — they just follow instructions, so it’s up to you to guide them. This brings us neatly to the next step: negotiate the results.
5. Negotiate the results
If the first response isn’t quite right, don’t worry — that’s where negotiation comes in. You should give the LLM frank and clear feedback and tweak the output until it’s just right. (Don’t worry, it doesn’t have any feelings to be hurt!)
When you negotiate, tell the LLM if it made any mistakes, and what you did and didn’t like in the output. Tell it to ‘Add a bit at the end about …’ or ‘Stop using the word “delve” all the time!’
Another excellent tip is to use descriptors for the desired tone of the document in your negotiations with the LLM, such as, ‘Make that output slightly more casual.’
In this way, you can guide the LLM to be:
Approachable: the language will be warm and friendly, making the content welcoming and easy to understand
Casual: expect laid-back, informal language that feels more like a chat than a formal document
Concise: the response will be brief and straight to the point, cutting out any fluff and focusing on the essentials
Conversational: the tone will be natural and relaxed, as if you’re having a friendly conversation
Educational: the language will be clear and instructive, with step-by-step explanations and helpful details
Formal: the response will be polished and professional, using structured language and avoiding slang
Professional: the tone will be business-like and precise, with industry-specific terms and a focus on clarity
Remember: LLMs have no idea what their output says or means; they are literally just very powerful autocomplete tools, just like those in text messaging apps. It’s up to you, the human, to make sure they are on the right track.
Don’t forget the human edit
Even after you’ve refined the LLM’s response, it’s important to do a final human edit. This is your chance to make sure everything’s perfect, checking for accuracy, clarity, and anything the LLM might have missed. LLMs are great tools, but they don’t catch everything, so your final touch ensures the content is just right.
At a certain point it’s also simpler and less time-consuming for you to alter individual words in the output, or use your unique expertise to massage the language for just the right tone and clarity, than going back to the LLM for a further iteration.
Now it’s time to put the OCEAN process into action! Log in to your preferred LLM platform, take a simple prompt you’ve used before, and see how the process improves the output. Then share your findings with your colleagues. This hands-on approach will help you see the difference the OCEAN method can make!
Sign up for a free account at one of these platforms:
ChatGPT (chat.openai.com)
Gemini (gemini.google.com)
By embracing the OCEAN prompting process, you can quickly and easily make LLMs a valuable part of your teaching toolkit. The process helps you get the most out of these powerful tools, while keeping things ethical, fair, and effective.
If you’re excited about using AI in your classroom preparation, and want to build more confidence in integrating it responsibly, we’ve got great news for you. You can sign up for our totally free online course on edX called ‘Teach Teens Computing: Understanding AI for Educators’ (helloworld.cc/ai-for-educators). In this course, you’ll learn all about the OCEAN process and how to better integrate generative AI into your teaching practice. It’s a fantastic way to ensure you’re using these technologies responsibly and ethically while making the most of what they have to offer. Join us and take your AI skills to the next level!
A version of this article also appears in Hello World issue 25.
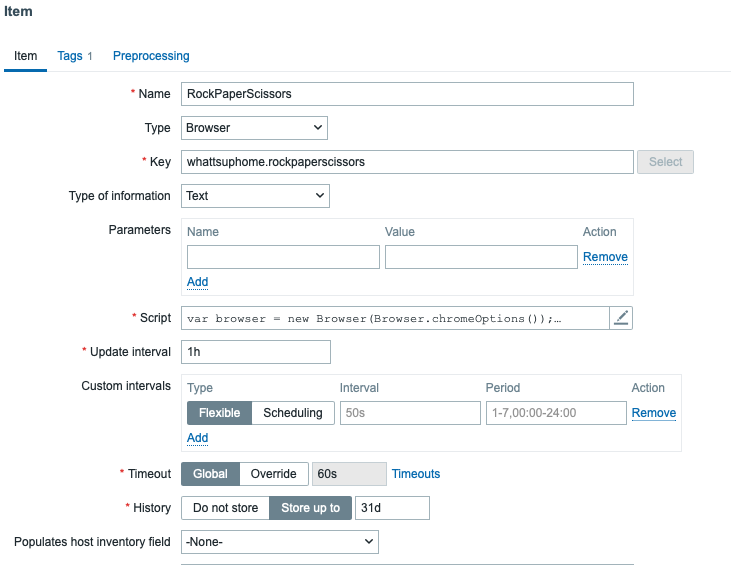
Zabbix 7.0 is so fast that in a small environment such as What’s up, home? it gets bored. Very bored.
What does Zabbix do when it gets bored? It uses its new Selenium-based Browser item type and plays some Rock-Paper-Scissors against this blog site.
But how does that work?
The idea is simple. My website hosts a very simple PHP script which returns back a random value of “Rock”, “Paper” or “Scissors”. Likewise, my Zabbix Selenium test picks up a random word out of those. Then, the Selenium test checks both answers and gets back the result.
So, in all seriousness, this blog post demonstrates you how the new Browser item type can react to different responses.
Nothing to call home about in that script: array with three choices, pick a random choice, print the result, done.
Zabbix side
I created a new Browser type item like this:
… and here’s the script part I just hammered in, so there might or might not be bugs. I really did not test this very thoroughly.
var browser = new Browser(Browser.chromeOptions());
const moves = ["Rock", "Scissors", "Paper"];
const zabbixMove = moves[Math.floor(Math.random() * moves.length)];
try {
browser.navigate("https://whatsuphome.fi/rps.php");
var opponentMove = browser.findElement("xpath", "//p").getText();
if (zabbixMove === opponentMove) {
var winner = "Draw";
}
else if (
(zabbixMove === "Rock" && opponentMove === "Scissors") ||
(zabbixMove === "Scissors" && opponentMove === "Paper") ||
(zabbixMove === "Paper" && opponentMove === "Rock")
) {
var winner="Zabbix";
}
else {
var winner="Opponent";
}
}
finally {
return ("Winner is " + winner + ". Zabbix move was " + zabbixMove + " and opponent move was " + opponentMove);
}
That’s it! From now on my Zabbix will play the game once per hour, although for this blog post I did manually click the Execute now button a few times. Again, here’s the same screenshot that was also in the beginning of this blog post.
В началото на седмицата председателката на Комитета по правата на детето на ООН Ан Скелтън беше в България. Тя се включи в поредица събития, с които професионалистите в сфeрата на правата на децата отбелязаха 35-тата годишнина от подписването на Конвенцията за правата на детето от Общото събрание на ООН. Професор Скелтън е юрист, международен експерт по правата на детето, преподавател в Лайденския университет, Нидерландия, и Университета в Претория, ЮАР.
Специално за читателите на „Тоест“ с проф. Скелтън разговаря Надежда Цекулова. Разговорът е част от поредицата „Разговори за образованието на специалните деца“, осъществена с подкрепата на „Лидл България“.
Вие заемате най-високия международен пост, свързван със защитата на правата на децата, но в България се знае малко за Вас. Какъв е обхватът на работата Ви?
Аз съм южноафриканка и съм посветила целия си живот на работата за правата на децата. Като млад адвокат в Южна Африка започнах работа по време на епохата на апартейда. След това дойдоха политическите промени и се озовах в много благоприятна позиция – можех да помогна на новото правителство да създаде много закони, политики и стратегии за насърчаване на правата на децата.
В един момент обаче осъзнах, че все още има огромна разлика между това, което правителството обещава, и това, което всъщност става. Тогава преминах към съдебни дела, свързани с правата на децата в Южна Африка. Започнах да завеждам дела заради пропуски между това, което трябва да бъде осигурено на децата, и това, което на практика липсва, или когато имаше очевидни нарушения на правата.
През 2017 г. станах член на Комитета за правата на детето на ООН, а през последните две години съм негова председателка. Това ми даде и възможността да видя правата на децата от глобална перспектива.
Вие сте председателка на Комитета в изключително трудни години за правата на човека и правата на децата в частност. Как изглеждат правата на децата по света в този тревожен контекст?
Виждам регрес – два различни типа регрес. Единия бих нарекла „връщане назад“ – това е свързано с глобалните въпроси, които много трудно се управляват от държавите, като война, климатични промени, бедност, миграция, разселване на хора. Всички тези проблеми са актуални едновременно, което създава изключително трудна среда. УНИЦЕФ го нарича „поликриза“ – множество кризисни фактори, които са паралелни.
Някои от тези неща са извън контрола на държавите, но други са в техните възможности и там попада типът регрес, който бих нарекла „целенасочено отстъпление“. Това е умишлено отдръпване от дневния ред за правата на човека, включително правата на децата. Има държави, които казват: „Не, вече не сме съгласни с това.“
Мисля, че всички можем да се сетим за примери, но бих искала да споделите и Вашите.
Например Конвенцията на ООН за правата на детето е най-ратифицираният договор в света. Държавите бяха много ентусиазирани да я подпишат. Миналата седмица отбелязахме 35-тата годишнина от този акт. Но е тревожно, че проблеми, които смятахме за окончателно решени и разбрани – като това, че децата са човешки същества и следователно имат права също като всички други хора, – отново се поставят под въпрос.
През март 2024 г. Комитетът публикува последните си препоръки за България, но те не получиха широк обществен отзвук, затова ще Ви помоля да поговорим за тях.
В заключителните наблюдения Комитетът винаги призовава държавите да ги разпространяват и да ги правят публични. Ако това не става, има проблем. Означава, че има някакво „връщане назад“ – нежелание да се поставят тези въпроси в публичното пространство.
Тревожни ли са тези препоръки?
Когато разглеждам заключителните наблюдения за България, виждам, че дискриминацията е сериозен проблем. Комитетът отбелязва, че съществува нова постоянна работна група в Комисията за защита от дискриминация, но изразява дълбока загриженост относно продължаващата дискриминация срещу ромските деца, децата бежанци, децата с увреждания, ЛГБТИ децата и други групи деца в неравностойно положение.
Също така обърнахме внимание на проблемите с речта на омразата и расизма и подчертахме, че това са области, в които е нужна още много работа.
В светлината на тази препоръка не съм сигурна дали сте запозната с последните събития, но ще се опитам да обясня. През август 2024 г. беше приета поправка в Закона за предучилищното и училищното образование, която забранява обсъждането на ЛГБТИ теми в училищата. Тази поправка беше гласувана на две четения в един ден, без време за обществена реакция. Сега това вече е закон, а една политическа сила направи списък с учители, критикуващи този закон, и го даде на прокуратурата. Как изглеждат тези събития през призмата на опита Ви на правозащитничка?
Това е сериозен проблем.В заключителните наблюдения изрично беше посочено: „Да се адресират дискриминационните стереотипи срещу бежански и мигрантски деца, деца с увреждания и ЛГБТИ деца.“
Един от проблемите с мандата на Комитета е, че имаме възможност да се намесваме веднъж на няколко години, когато разглеждаме държавата. Нямаме мандат да извършваме разследвания на място, освен ако няма конкретна жалба.
Но заключителните наблюдения на Комитета са вече налични. Хората, които защитават правата на децата, могат да използват международните рамки и факта, че тези наблюдения идват от международен орган, за да подчертаят значението им в своята страна.
Независимо дали става въпрос за парламента, съда, публичния дискурс, или публикуването на статии, целта е да поддържаме тези идеи живи и да припомним, че това всъщност е регрес спрямо предишното състояние на правителството или на държавата по тези въпроси.
В България имаме антидискриминационно законодателство, но проблемът е в неговото прилагане. Същото е и при приобщаващото образование. Законодателството е модерно и прогресивно, но на практика невинаги работи.
Тази тема е засегната в заключителните препоръки. Има цял списък за приобщаващо образование. Например да се предприемат целенасочени мерки, включително участие на децата, за да се елиминират насилието в училище, тормозът и кибертормозът. Тези мерки трябва да обхващат превенция, механизми за ранно откриване, овластяване на децата, задължително обучение за учители, протоколи за интервенция, психосоциална подкрепа за жертвите, системно записване и мониторинг на поведението, свързано с тормоз, както и повишаване на осведомеността за вредните ефекти на тормоза.
Това е много подробна препоръка и ако Министерството на образованието и науката е готово да я използва, тя може да подпомогне по-ефективните действия за приобщаващо образование.
Можете ли да посочите положителен пример за държава, която е постигнала напредък?
Винаги ми е трудно да откроя такъв пример без допълнително проучване. Но наскоро например бях в Шотландия и бях много впечатлена от как работят там. Имат специализиран трибунал, който се занимава със случаи, когато дете с увреждания кандидатства за място в основно училище, но е отхвърлено или възникне проблем.
Начинът, по който т.нар. съдии (това са специално обучени хора, някои от тях не са с юридическо образование) работят с децата и изслушват техните нужди, е изключително впечатляващ. Те се фокусират върху това как да създадат среда, която максимално да подкрепя децата. Това е положителен пример за страна, която не само заявява своята политика, но реално търси решения за трудностите.
Представям си, че за да се създаде подобна политика, първо трябва да се приеме идеята, че детето е равнопоставена личност, включително детето с увреждания. Мисля, че все още ни предстои работа в тази посока.
Да, това е нещо, което се подразбира. Може би причината Шотландия да се откроява като пример е, че цялата Конвенция за правата на детето наскоро беше включена в законодателството на държавата. Там има обществен консенсус около това, приемат правата на децата изключително сериозно и искат да направят Шотландия държава, която поставя децата на първо място. Това показва колко голяма разлика може да направи едно правителство, ако реши правата на децата да станат истински приоритет.
У нас все още се случва деца, които имат особености в развитието и нужда от специализирана подкрепа, вместо това да бъдат подлагани на възпитателни мерки. Освен към ефективността на мерките по приобщаващо образование, това ни отвежда и към друг въпрос, който препоръките към страната ни засягат – детското правосъдие. В тази сфера в България все още се прилага един закон от средата на миналия век.
Това е липса на прогрес в прилагането на предишните препоръки [от 2016 г. – б.а.].Член 40 и 37 от Конвенцията включват много подробни разпоредби. В допълнение Комитетът издаде общ коментар №24, който ясно показва как трябва да изглежда модерната система за детско правосъдие.
Това, което се критикува в България, е съществуването на закон за борба с противообществените прояви на малолетни и непълнолетни. Идеята зад този закон е, че „не ги третираме като престъпници“, но въпреки това ги задържаме. Тоест децата не получават същите права, които биха имали като възрастни нарушители. Например ако един възрастен не е извършил престъпление, той би бил обявен за невинен. Но в сивата зона на „противообществените прояви“ децата могат да бъдат задържани или наказвани, без да има представени доказателства срещу тях. Именно това Комитетът изрично критикува.
Това е и „допирателната“ с децата с особености в развитието. Тяхното поведение невинаги попада в рамките на социалната норма.
Има два основни проблема. Единият е възприемането на поведението на детето като нещо, което заслужава наказание, вместо като сигнал за нужда от подкрепа и услуги. Вторият проблем е, че децата попадат в системи, които ги лишават от свобода, но не им предоставят същите гаранции, които една правилна система за детско правосъдие би предложила.
Какви стъпки може да предприеме Комитетът, за да насърчи държавите да се представят по-добре?
На първо място, Комитетът издава заключителни наблюдения. Също така в доклада си до Общото събрание на ООН ние изразяваме обща загриженост относно тези тенденции. Това не е само за България; има много държави в сходно положение.
В сегашните времена, когато наблюдаваме отстъпление от правата на детето навсякъде по света, изглежда, че това не е достатъчно. Задавам Ви този въпрос не само като председателка на Комитета, но и като дългогодишна активистка: какво може да се направи? Как могат обществата, неправителствените организации, гражданите и активистите за правата на децата да се справят по-добре?
Да, съгласна съм, че не е достатъчно. Но мандатът на Комитета е ограничен. Той прави каквото може. Затова обикновено насочвам отговорността към хората, които работят на място. Аз например съм южноафриканска адвокатка за правата на децата. На национално ниво бих се заела с работа. Бих използвала заключителните наблюдения и бих се опитала да държа хората отговорни на това ниво. Но разбира се, има държави, където това е по-лесно да се осъществи, и други, където е по-трудно.
Гражданското общество трябва да се обедини и да обмисли какво може да направи в политическата и правната сфера. Трябва да се намерят начини за застъпничество и държане на отговорните лица под контрол.
Но проблемът не е само в политическата воля, а и в самото общество. Забелязваме, че през последните 4–5 години обществените нагласи се променят много бързо и в негативна посока.
Съгласна съм. Имаме сериозен проблем с дезинформацията. Едно от нещата, за които говорихме по-рано, е поликризата – множеството кризи, които се случват едновременно в света. Друг голям проблем е поляризацията, която наблюдаваме навсякъде. Това води до трудности при обсъждането на права, включително правата на децата.
Не знам как да завърша този разговор след такова заключение. Има ли оптимистичен сценарий?
Бих казала, че има сценарий на устойчивост. С други думи, трябва да продължим напред. Да, международното право може да изглежда нефункциониращо, но ако го изоставим и не го използваме, ще бъдем в по-лоша позиция.
Трябва да продължаваме да използваме това, което имаме. От моите студенти чувам същите въпроси, придружени със същата фрустрация, която усещам у Вас. Те често питат: „Какъв е смисълът?“ Но аз винаги отговарям: смисълът е, че трябва да продължим да използваме инструментите, с които разполагаме. Политиката върви в цикли. Възможно е в бъдеще да се появят по-добри лидери или нови сценарии.
Ако обаче се откажем от проекта за човешки и детски права, защото го смятаме за неефективен, тогава ние сме тези, които се предават. Не можем да си позволим това. Трябва да бъдем устойчиви пред лицето на натиска.
Трябва да покажем, че държим линията. Да признаем, че невинаги постигаме незабавна промяна, но ако всички ние – които вярваме в идеята за човешки и детски права – работим заедно, използваме общ език и документи, поне можем да кажем, че играем по правилата. И ще бъдем тук, когато здравият разум се завърне.
Интервюто е част от поредица разговори за достъпа до образование на децата от уязвими групи. Проектът се осъществява благодарение на най-голямата социално отговорна инициатива на „Лидл България“ – „Ти и Lidl за нашето утре“, в партньорство с Фондация „Работилница за граждански инициативи“, Българския дарителски форум и Асоциацията на европейските журналисти.
At Grab, we are committed to leveraging the power of technology to deliver the best services to our users and partners. As part of this commitment, we have developed the LLM-Kit, a comprehensive framework designed to supercharge the setup of production-ready Generative AI applications. This blog post will delve into the features of the LLM-Kit, the problems it solves, and the value it brings to our organisation.
Challenges
The introduction of the LLM-Kit has significantly addressed the challenges encountered in LLM application development. The involvement of sensitive data in AI applications necessitates that security remains a top priority, ensuring data safety is not compromised during AI application development.
Concerns such as scalability, integration, monitoring, and standardisation are common issues that any organisation will face in their LLM and AI development efforts.
The LLM-Kit has empowered Grab to pursue LLM application development and the rollout of Generative AI efficiently and effectively in the long term.
Introducing the LLM-Kit
The LLM-Kit is our solution to these challenges. Since the introduction of the LLM Kit, it has helped onboard hundreds of GenAI applications at Grab and has become the de facto choice for developers. It is a comprehensive framework designed to supercharge the setup of production-ready LLM applications. The LLM-Kit provides:
Pre-configured structure: The LLM-Kit comes with a pre-configured structure containing an API server, configuration management, a sample LLM Agent, and tests.
Integrated tech stack: The LLM-Kit integrates with Poetry, Gunicorn, FastAPI, LangChain, LangSmith, Hashicorp Vault, Amazon EKS, and Gitlab CI pipelines to provide a robust and end-to-end tech stack for LLM application development.
Observability: The LLM-Kit features built-in observability with Datadog integration and LangSmith, enabling real-time monitoring of LLM applications.
Config & secret management: The LLM-Kit utilises Python’s configparser and Vault for efficient configuration and secret management.
Authentication: The LLM-Kit provides built-in OpenID Connect (OIDC) auth helpers for authentication to Grab’s internal services.
API documentation: The LLM-Kit features comprehensive API documentation using Swagger and Redoc.
Redis & vector databases integration: The LLM-Kit integrates with Redis and Vector databases for efficient data storage and retrieval.
Deployment pipeline: The LLM-Kit provides a deployment pipeline for staging and production environments.
Evaluations: The LLM-Kit seamlessly integrates with LangSmith, utilising its robust evaluations framework to ensure the quality and performance of the LLM applications.
In addition to these features, the team has also included a cookbook with many commonly used examples within the organisation providing a valuable resource for developers. Our cookbook includes a diverse range of examples, such as persistent memory agents, Slackbot LLM agents, image analysers and full-stack chatbots with user interfaces, showcasing the versatility of the LLM-Kit.
The value of the LLM-Kit
The LLM-Kit brings significant value to our teams at Grab:
Increased development velocity: By providing a pre-configured structure and integrated tech stack, the LLM-Kit accelerates the development of LLM applications.
Improved observability: With built-in LangSmith and Datadog integration, teams can monitor their LLM applications in real-time, enabling faster issue detection and resolution.
Enhanced security: The LLM-Kit’s built-in OIDC auth helpers and secret management using Vault ensure the secure development and deployment of LLM applications.
Efficient data management: The integration with Vector databases facilitates efficient data storage and retrieval, crucial for the performance of LLM applications.
Standardisation: The LLM-Kit provides a paved-road framework for building LLM applications, promoting best practices and standardisation across teams.
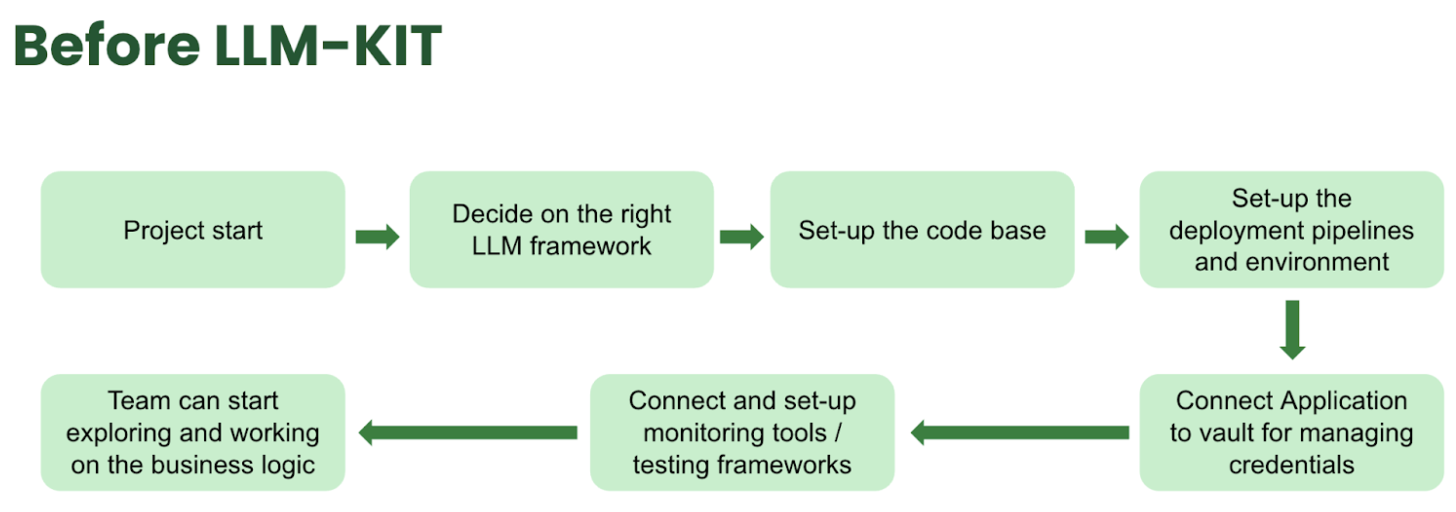
Through the LLM-Kit, we can save an estimate of 1.5 weeks before teams start working on their first feature.
Figure 1. Project development process before LLM-Kit
Figure 2. Project development process after LLM-Kit
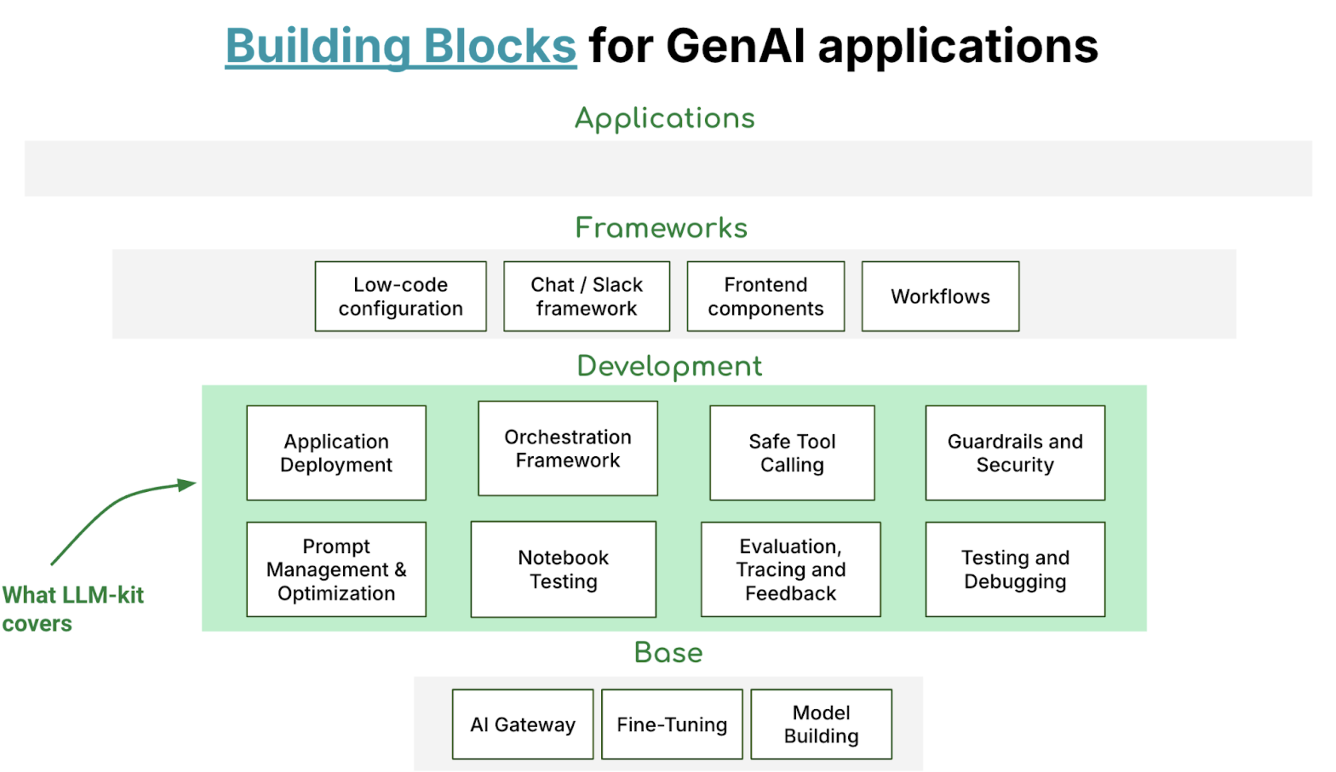
Architecture design and technical implementation
The LLM-Kit is designed with a modular architecture that promotes scalability, flexibility, and ease of use.
Figure 3. LLM-Kit modules
Automated steps
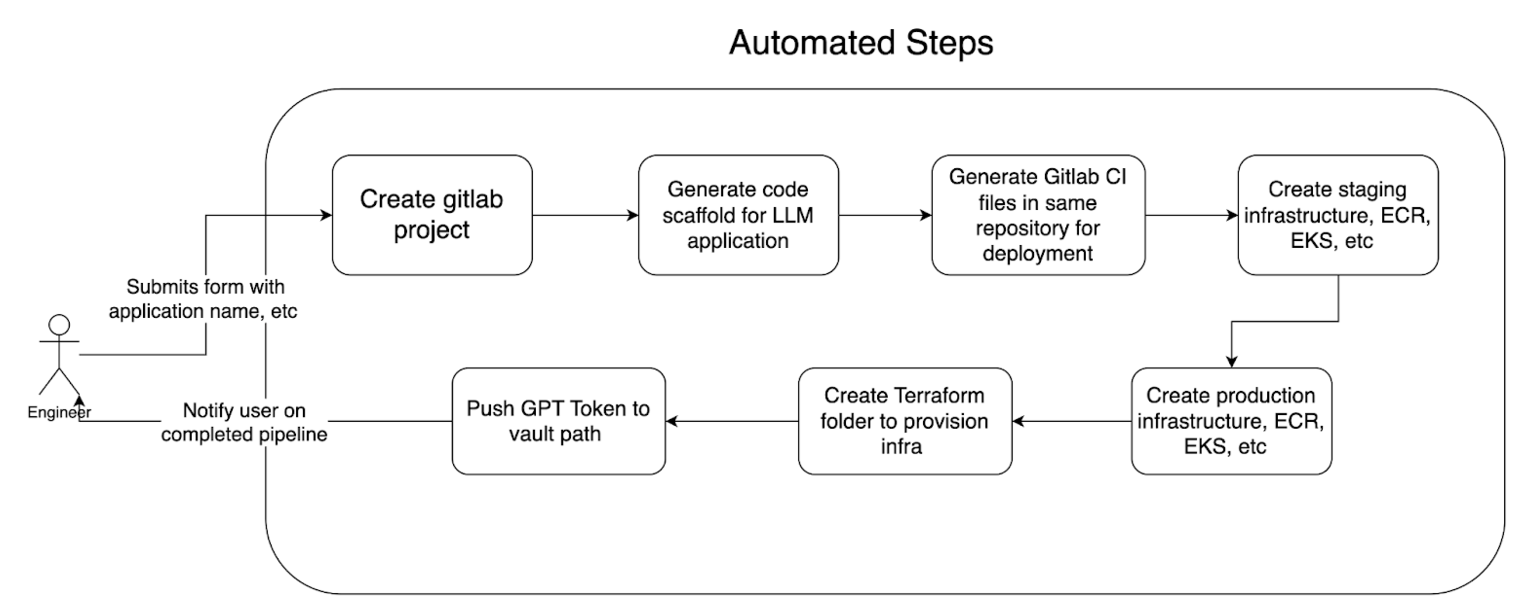
To better illustrate the technical implementation of the LLM-Kit, let’s take a look at figure 4 which outlines the step-by-step process of how an LLM application is generated with the LLM-Kit:
Figure 4. Process of generating LLM apps using LLM-Kit
The process begins when an engineer submits a form with the application name and other relevant details. This triggers the creation of a GitLab project, followed by the generation of a code scaffold specifically designed for the LLM application. GitLab CI files are then generated within the same repository to handle continuous integration and deployment tasks. The process continues with the creation of staging infrastructure, including components like Elastic Container Registry (ECR) and Elastic Kubernetes Service (EKS). Additionally, a Terraform folder is created to provision the necessary infrastructure, eventually leading to the deployment of production infrastructure. At the end of the pipeline, a GPT token is pushed to a secure Vault path, and the engineer is notified upon the successful completion of the pipeline.
Scaffold code structure
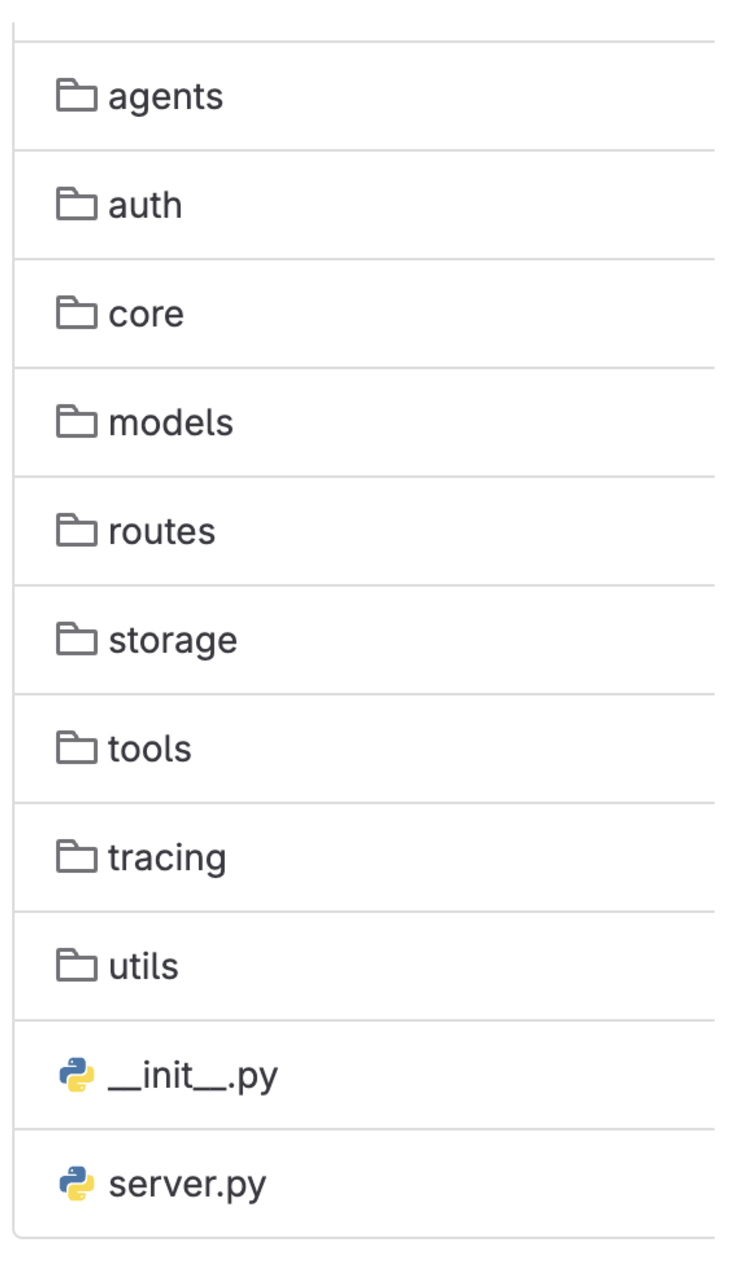
The scaffolded code is broken down into multiple folders:
Agents: Contains the code to initialise an agent. We have gone ahead with LangChain as the agent framework; essentially the entry point for the endpoint defined in the Routes folder.
Auth: Authentication and authorisation module for executing some of the APIs within Grab.
Core: Includes extracting all configurations (i.e. GPT token) and secret decryption for running the LLM application.
Models: Used to define the structure for the core LLM APIs within Grab.
Routes: REST API endpoint definitions for the LLM Applications. It comes with health check, authentication, authorisation, and a simple agent by default.
Storage: Includes connectivity with PGVector, our managed vector database within Grab and database schemas.
Tools: Functions which are used as tools for the LLM Agent.
Tracing: Integration with our tracing and monitoring tools to monitor various metrics for a production application.
Utils: Default folder for utility functions.
Figure 5. Scaffold code structure
Infrastructure provisioning and deployment
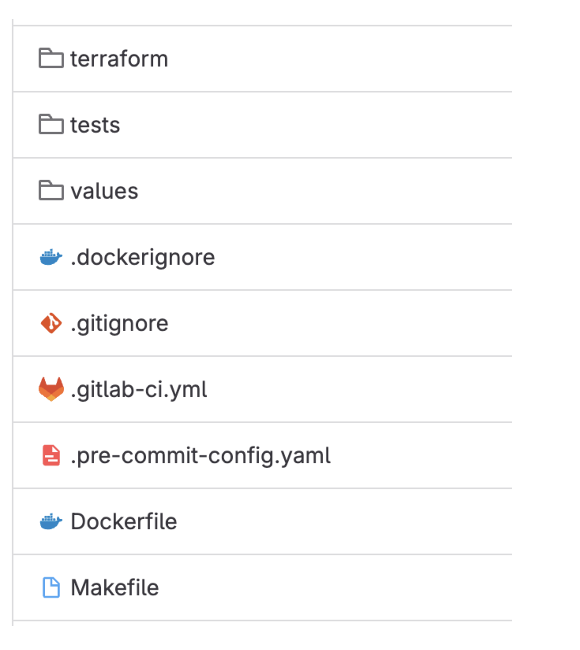
Within the same codebase, we have integrated a comprehensive pipeline that automatically scaffolds the necessary code for infrastructure provisioning, deployment, and build processes. Using Terraform, the pipeline provisions the required infrastructure seamlessly. The deployment pipelines are defined in the .gitlab-ci.yml file, ensuring smooth and automated deployments. Additionally, the build process is specified in the Dockerfile, allowing for consistent builds. This automated scaffolding streamlines the development workflow, enabling developers to focus on writing business logic without worrying about the underlying infrastructure and deployment complexities.
Figure 6. Pipeline infrastructure
RAG scaffolding
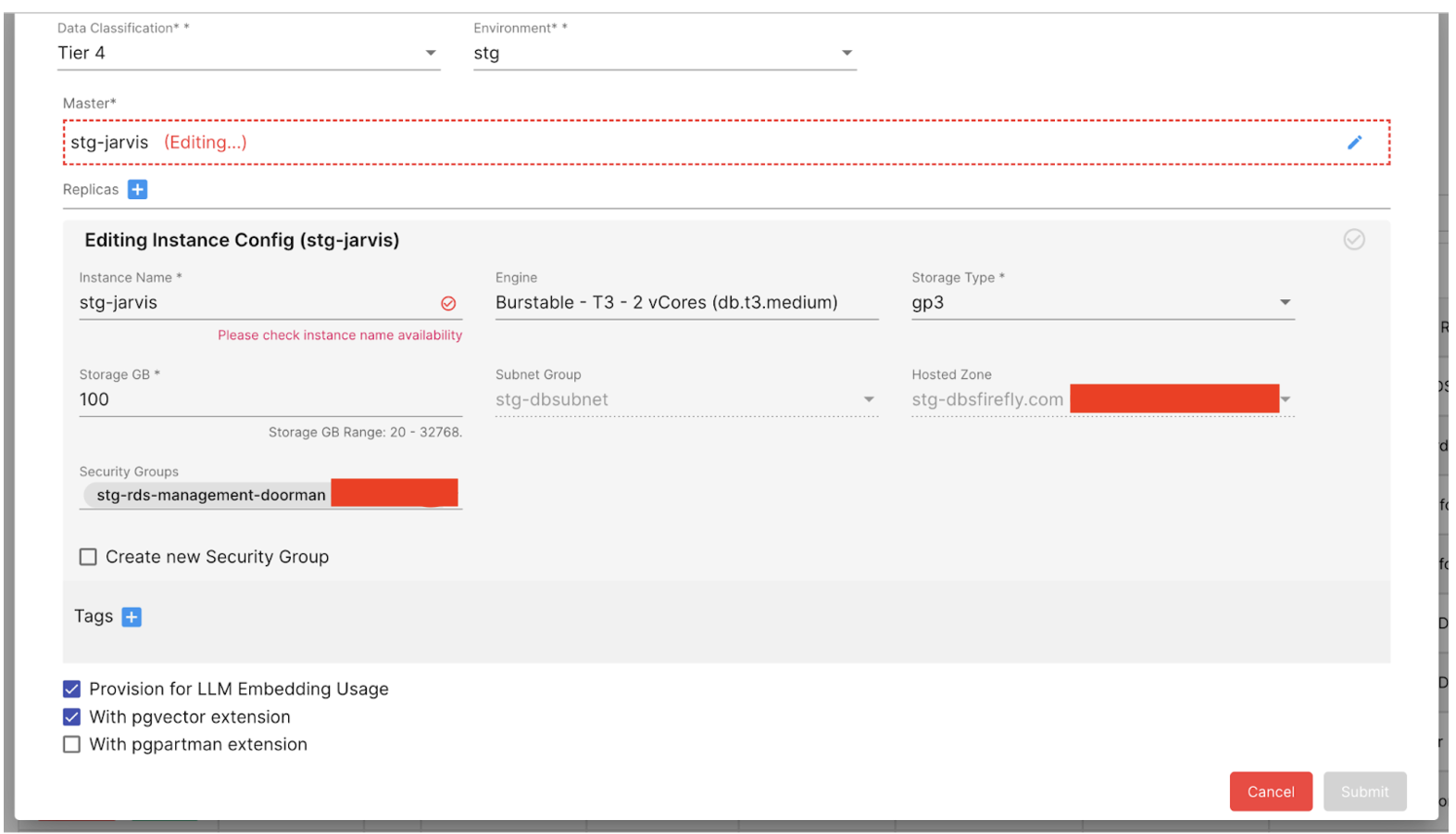
At Grab, we’ve established a streamlined process for setting up a vector database (PGVector) and whitelisting the service using the LLM-Kit. Once the form (figure 7) is submitted, you can access the credentials and database host path. The secrets will be automatically added to the Vault path. Engineers will then only need to include the DB host path in the configuration file of the scaffolded LLM-Kit application.
Figure 7. Form submitted to access credentials and database host path
Conclusion
The LLM-Kit is a testament to Grab’s commitment to fostering innovation and growth in AI and ML. By addressing the challenges faced by our teams and providing a comprehensive, scalable, and flexible framework for LLM application development, the LLM-Kit is paving the way for the next generation of AI applications at Grab.
Growth and future plans
Looking ahead, the LLM-Kit team aims to significantly enhance the web server’s concurrency and scalability while providing reliable and easy-to-use SDKs. The team plans to offer reusable and composable LLM SDKs, including evaluation and guardrails frameworks, to enable service owners to build feature-rich Generative AI programs with ease. Key initiatives also include the development of a CLI for version updates and dev tooling, as well as a polling-based agent serving function. These advancements are designed to drive innovation and efficiency within the organisation, ultimately providing a more seamless and efficient development experience for engineers.
We would like to acknowledge and thank Pak Zan Tan, Han Su, and Jonathan Ku from the Yoshi team and Chen Fei Lee from the MEKS team for their contribution to this project under the leadership of Padarn George Wilson.
Join us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 700 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
Earlier today, one of our subscribers, anselm, posted the one millionth item in our database during a discussion in the comments about the GPL. One million articles and comments is a big milestone — one representing twenty two years of work by both the editors of LWN and the community. I think reaching this milestone on Thanksgiving is a lovely coincidental reminder of how far LWN has come, and how that wouldn’t have been possible without your support. So thank you for reading.
The long-awaited release of the GNU Image
Manipulation Program (GIMP) 3.0 is on the way, marking the first
major update since version 2.10 was
released in April 2018. It now features a GTK 3 user interface and GIMP 3.0
introduces significant changes to the core platform and plugins. This
release also brings performance and usability improvements, as well as more
compatibility with Wayland and complex input sources.
Security updates have been issued by Debian (firefox-esr, netatalk, and thunderbird), Fedora (firefox, libsoup3, mingw-glib2, mingw-libsoup, mingw-python-waitress, mingw-python3, nss, perl-Module-ScanDeps, php, and python-aiohttp), Mageia (dcmtk, golang, iptraf-ng, libsndfile, microcode, php, postgresql15 & postgresql13, rapidjson, tomcat, wget, and zbar), Red Hat (openssl and openssl-fips-provider, toolbox, and webkit2gtk3), SUSE (firefox, frr, glib2, hplip, kernel, neomutt-20241114, ovmf, python-aiohttp, python-virtualenv, python310-tornado6, qemu, webkit2gtk3, and xen), and Ubuntu (mpg123 and vim).
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.