Post Syndicated from LastWeekTonight original https://www.youtube.com/watch?v=phieTCxQRLA
Kernel prepatch 5.18-rc1
Post Syndicated from original https://lwn.net/Articles/890119/
Linus has released 5.18-rc1 and closed the
merge window for the 5.18 release. “In fact, at least in pure
commits, this has been a bigger merge window than we’ve had in some
time. But let’s hope it’s all smooth sailing this release.” In the
end, 13,207 non-merge changesets were merged during this merge window.
Wyze Cam Outdoor V2 Review and Failures
Post Syndicated from digiblurDIY original https://www.youtube.com/watch?v=SvYnU8iYhBU
What Cloudflare is Doing to Keep the Open Internet Flowing into Russia and Keep Attacks from Getting Out
Post Syndicated from Matthew Prince original https://blog.cloudflare.com/what-cloudflare-is-doing-to-keep-the-open-internet-flowing-into-russia-and-keep-attacks-from-getting-out/


Following Russia’s unjustified and tragic invasion of Ukraine in late February, the world has watched closely as Russian troops attempted to advance across Ukraine, only to be resisted and repelled by the Ukrainian people. Similarly, we’ve seen a significant amount of cyber attack activity in the region. We continue to work to protect an increasing number of Ukrainian government, media, financial, and nonprofit websites, and we protected the Ukrainian top level domain (.ua) to help keep Ukraine’s presence on the Internet operational.
At the same time, we’ve closely watched significant and unprecedented activity on the Internet in Russia. The Russian government has taken steps to tighten its control over both the technical components and the content of the Russian Internet. For their part, the people in Russia are doing something very different. They have been adopting tools to maintain access to the global Internet, and they have been seeking out non-Russian media sources. This blog post outlines what we’ve observed.
The Russian Government asserts control over the Internet
Over the last five years, the Russian government has taken steps to tighten its control of a sovereign Internet within Russia’s borders, including laws requiring Russian ISPs to install equipment allowing the government to monitor and block Internet activity, and requiring the establishment of an exclusively Russian DNS (outside ICANN). And it created mechanisms for the Russian government to control how Russia was connected to the global Internet, so they could pull the plug if they wanted.
Since the Russian invasion of Ukraine, the Russian government has made a series of announcements related to implementation of its sovereign Internet laws. Russian government agencies were instructed to switch to Russian DNS servers, move public resources to Russian hosting services, and take a number of other steps designed to reduce reliance on non-Russian providers. Although some took these initiatives as an announcement that Russia intended to disconnect from the global Internet, so far Russia does not appear to have leveraged the tools it has to disconnect itself entirely from the global Internet. We continue to see connections processing successfully in Russia through non-Russia infrastructure.
In the meantime, authorities in Russia have implemented a series of targeted blocking actions against websites and operators that they find objectionable. Initially, officials targeted popular social media sites like Facebook, Instagram, Twitter, and YouTube, as well as Russian language outlets based outside of the country.
We can see the effect of some of those blocks on traffic from Russian users to different news websites in Russia and Ukraine before and after blocks were implemented.
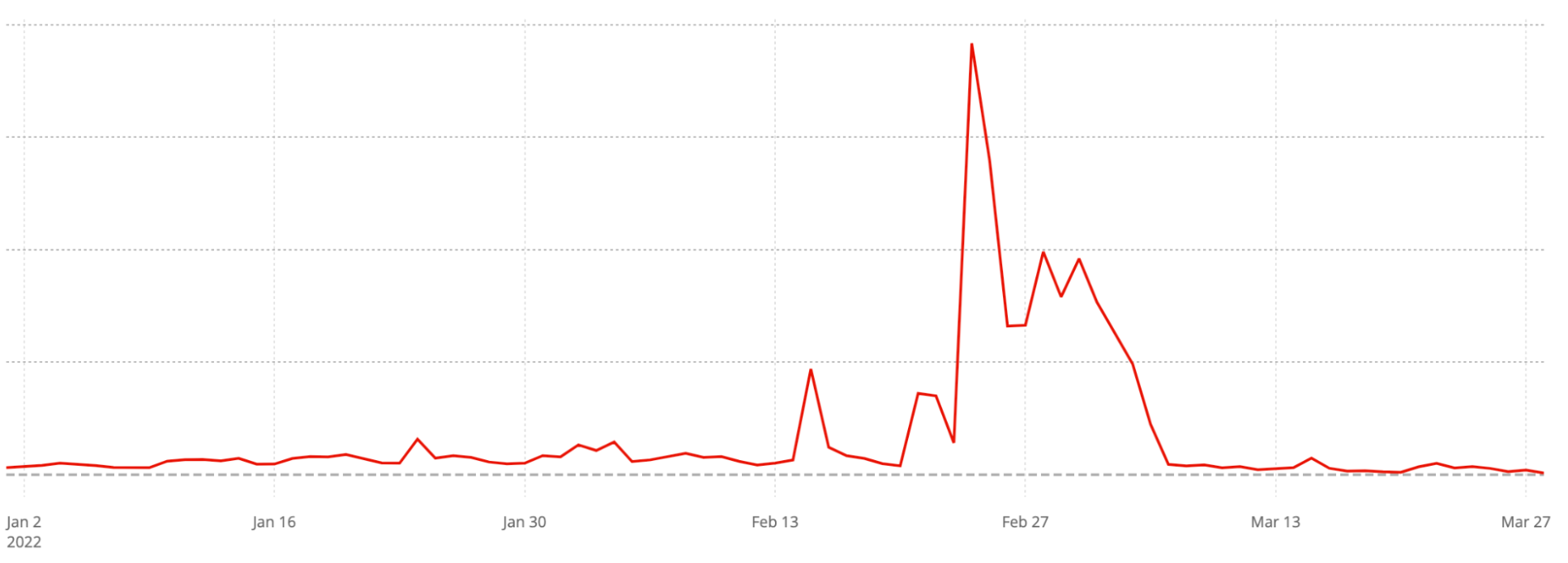
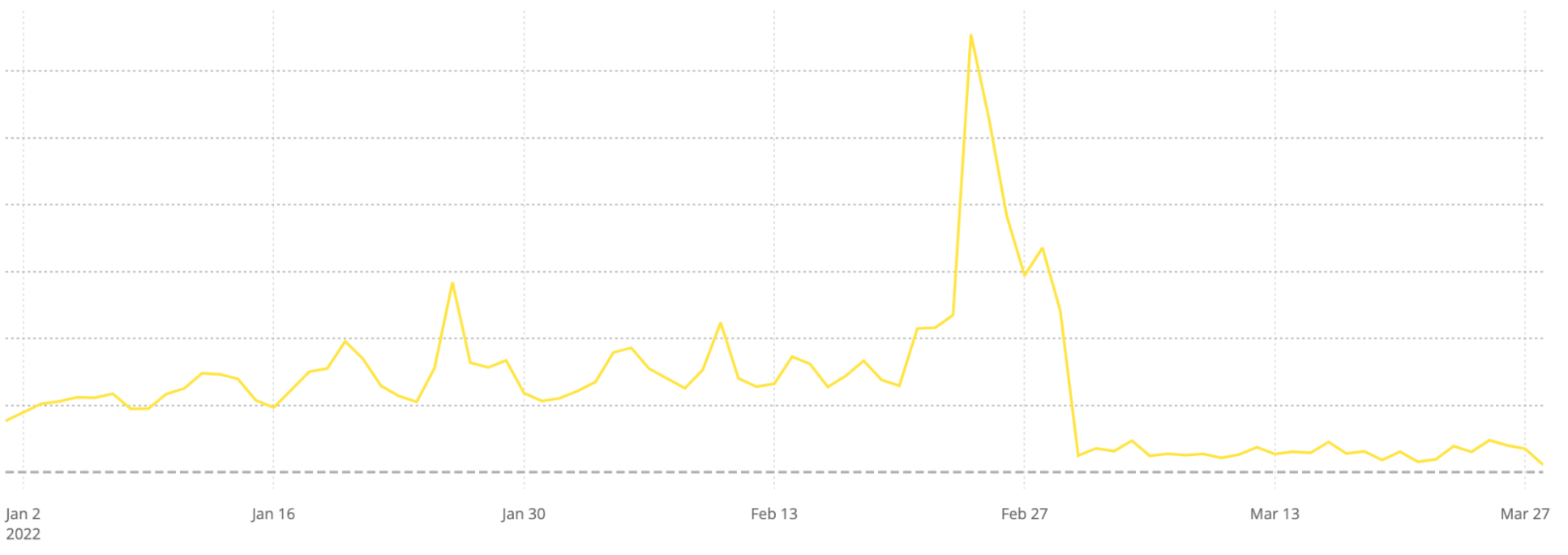
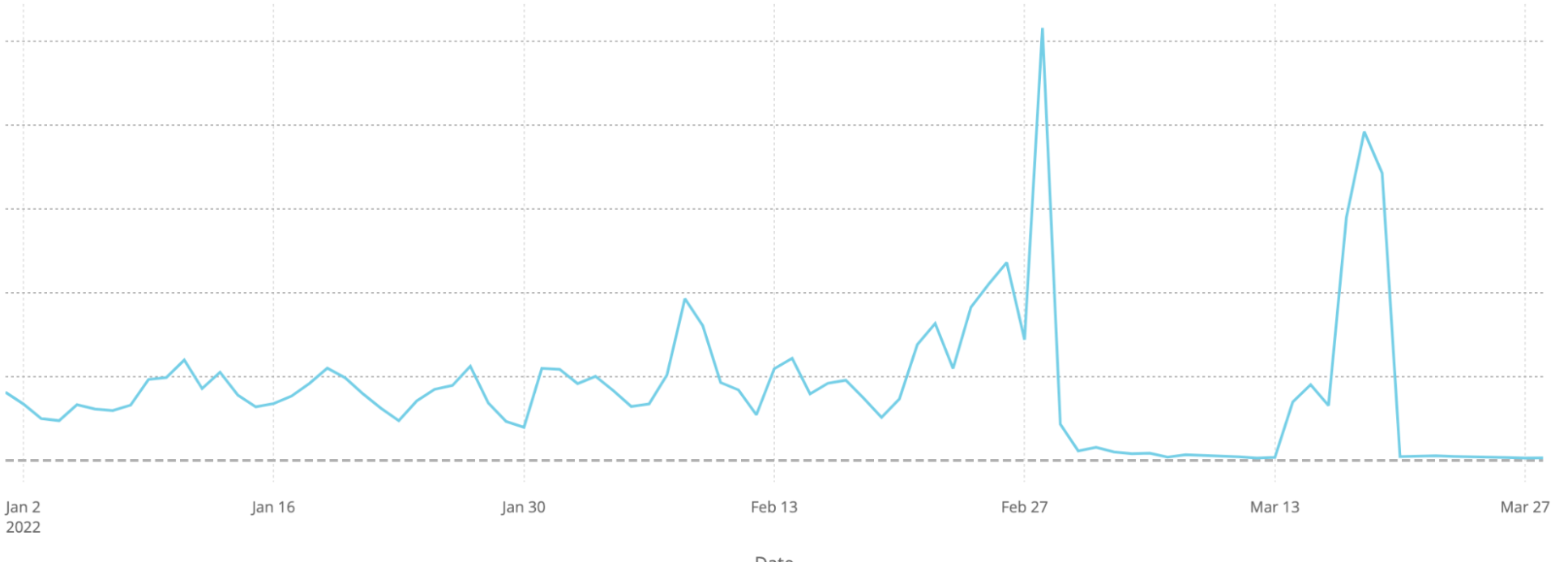
In each case, these news sites saw exponential growth in their traffic in the days around the February 24th invasion of Ukraine. But that increase was met within a matter of days by actions to block traffic to those sites. The blocks had varying degrees of success over the first few weeks, though each of them seem to have been eventually successful in denying access to those sources of news through traditional Internet channels.
But that is only half the story. As the Russian government took steps to control traditional channels for Internet access, there were shifts in the ways many Russians used the Internet.
Russian citizens turning to tools to gain access to the open Internet
Russians have been adopting applications and tools that allow them to engage with the Internet privately and avoid some of the mechanisms that the Russian government is using to control and monitor access to the Internet. Whereas the most popular applications in the Apple App Store in most of the world in March continue to relate to social media and games, the leaderboard in Russia looked very different:

All of the top apps in Russia in March were for private and secure Internet access or encrypted messaging apps, including the most downloaded app – Cloudflare’s own WARP / 1.1.1.1 (a privacy-based recursive DNS resolver). This list of popular apps is a stunning contrast with every other country in the world.
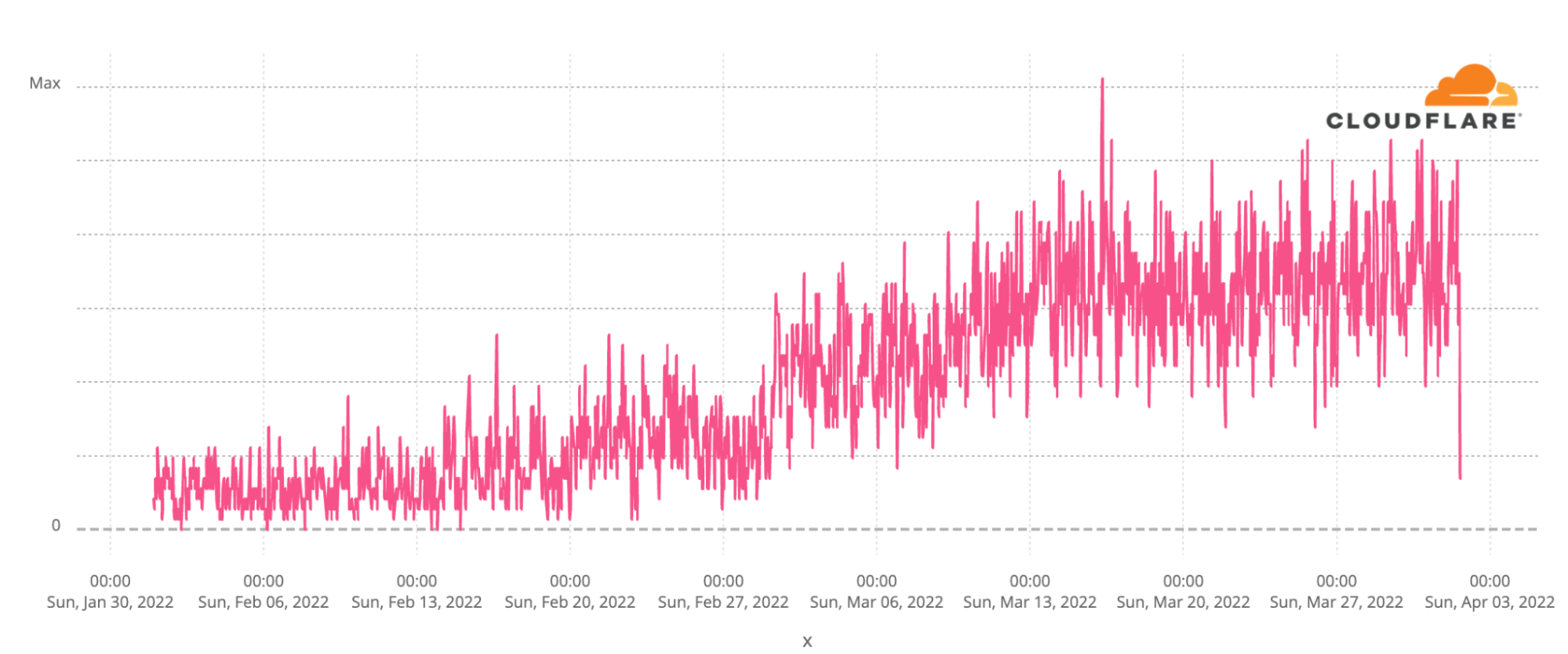
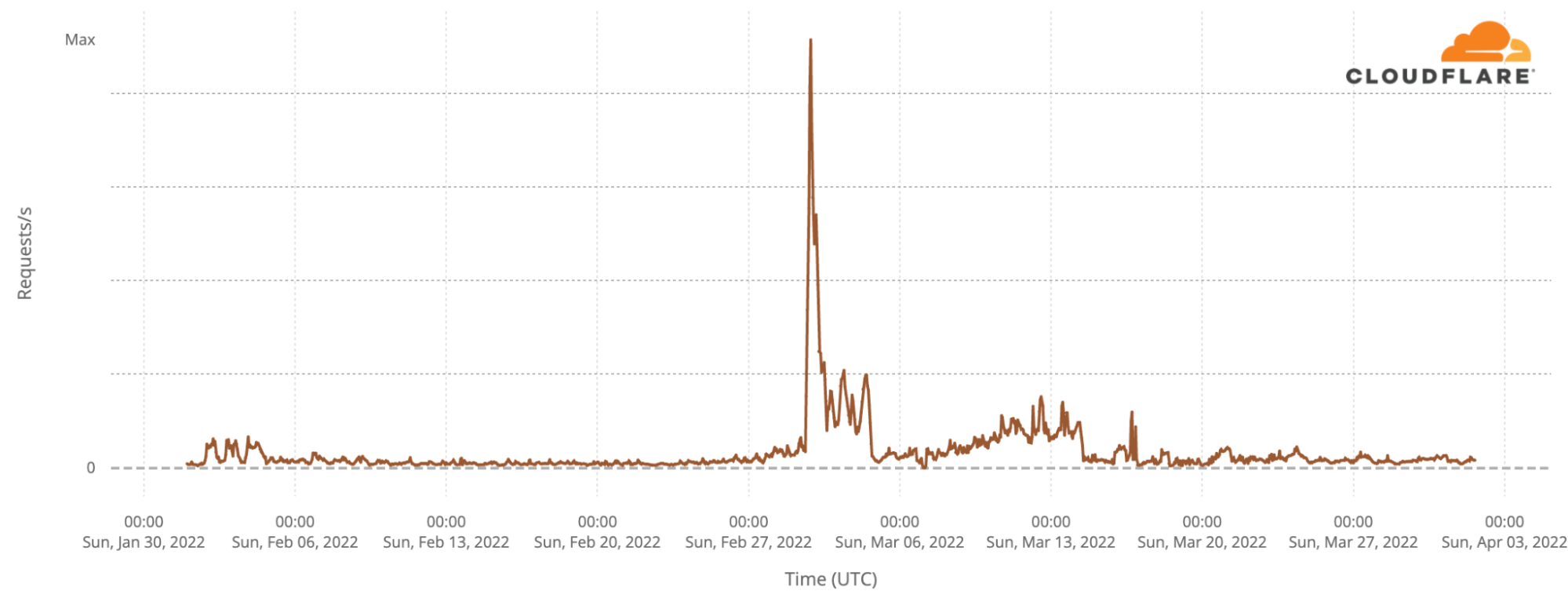
Because of the significant and important popularity of WARP (1.1.1.1), we’ve had some detailed insight into exactly how this has played out. If we look back to the beginning of February we see that Cloudflare’s WARP tool was little used in Russia. Its use took off from the first weekend of the war, and peaked two weeks ago. Later, after this virtual migration to such secure tools became apparent, we saw attempts to block access to the tools used to access the Internet securely.
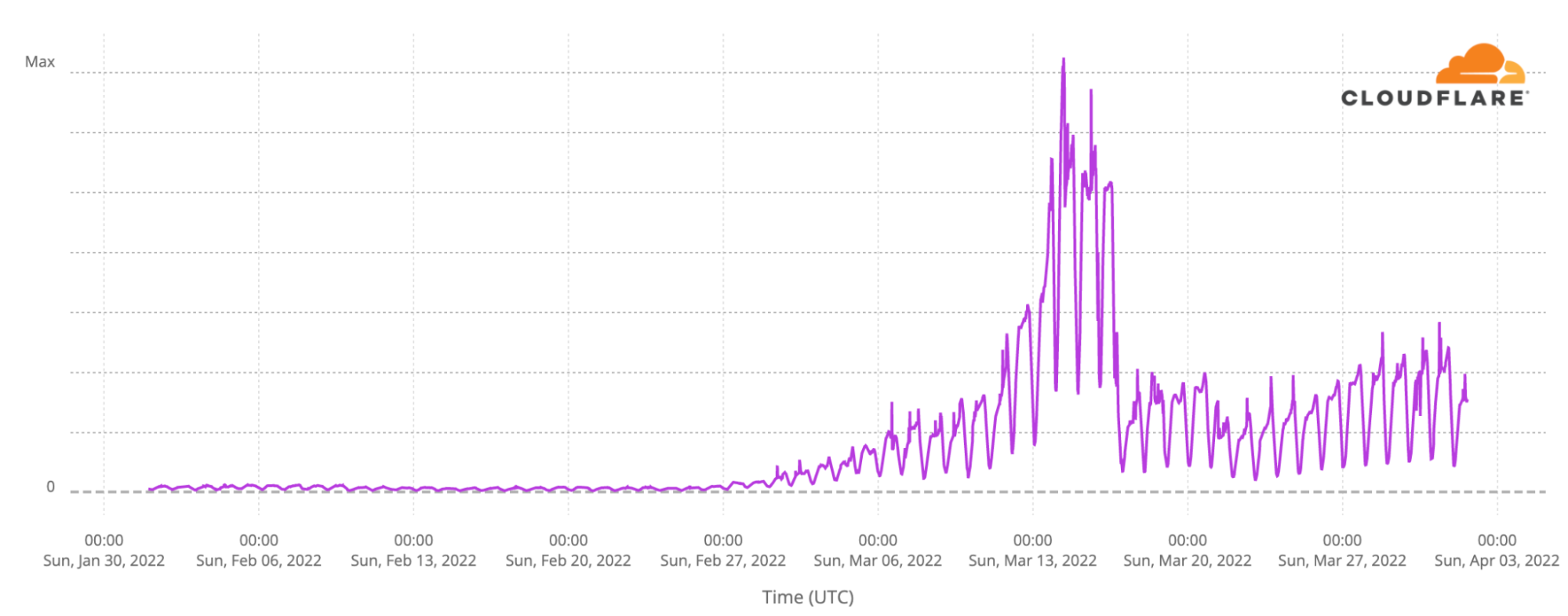
While levels have receded from their peak, a large number of Russians continue to use Cloudflare WARP in Russia at massively higher levels than pre-war.
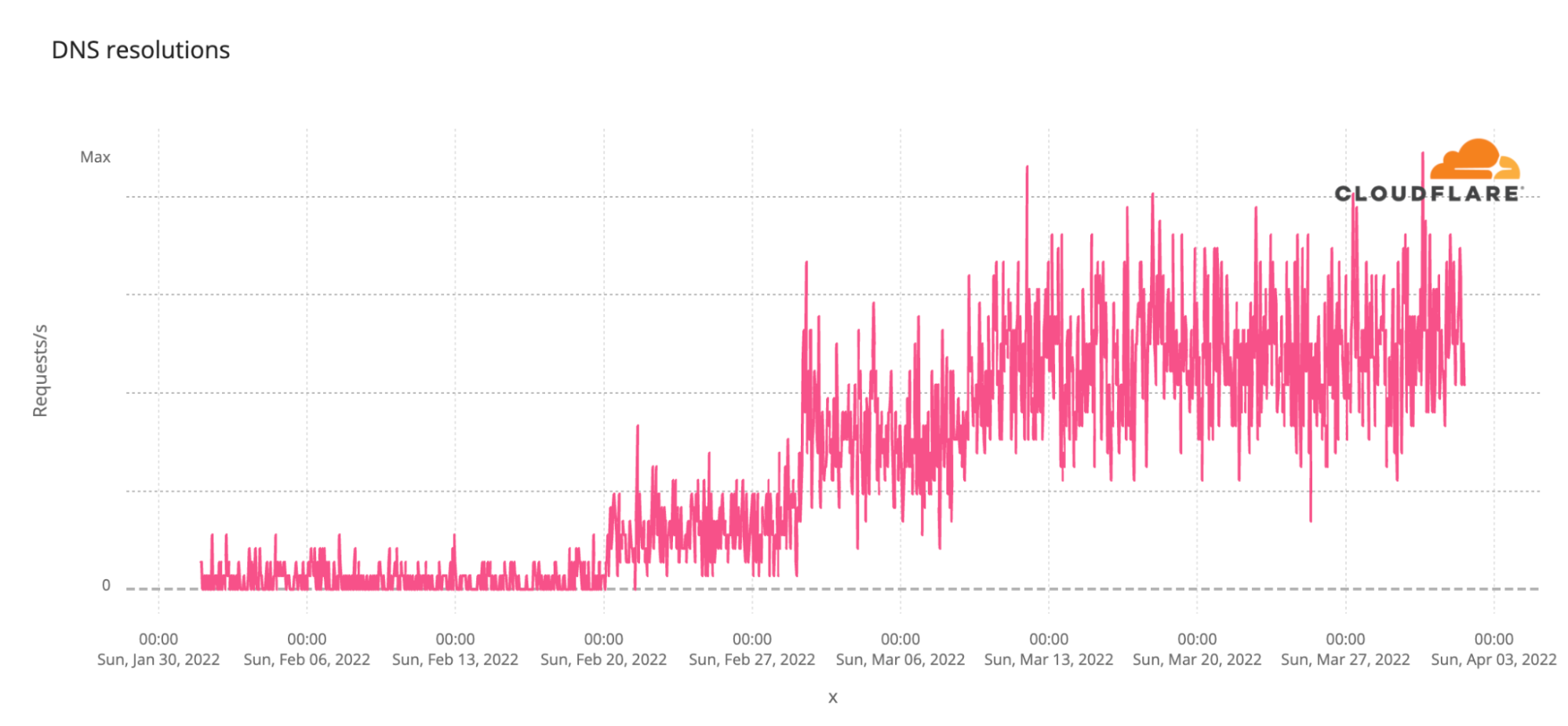
In addition to the ways Russians are using the Internet increasingly relying on private and encrypted communications, we’ve also seen a shift in what they are trying to access. Here’s a chart of DNS requests from Russian users for a well known US newspaper. Recent DNS traffic for the site has quintupled compared to pre-war levels, indicating Russians are trying to access that news source.
And here’s DNS traffic for a large French news source. Again, DNS lookups have grown enormously as Russians try to access it.
And here’s a British newspaper.
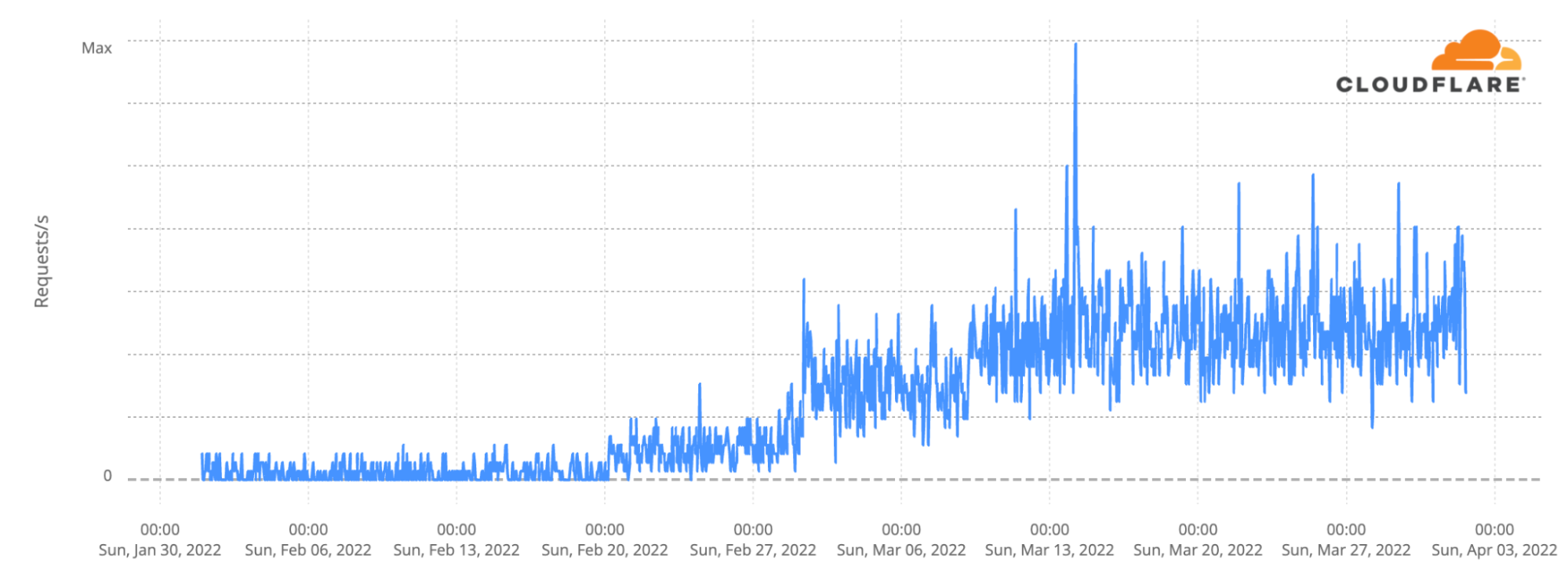
The picture is clear from these three charts. Russians want access to non-Russian news sources and based on the popularity of private Internet access tools and VPNs, they are willing to work to get it.
A front line against cyberattack
In addition to the services we’ve been able to provide average citizens in Russia, our servers at the edge of the Internet in-country have also permitted us to detect and block attacks originating there. When attacks are mitigated inside Russia, they never travel outside Russian borders. That’s always been part of the proposition of Cloudflare’s distributed network – to identify and block cyber attacks (especially DDoS attacks) locally and before they can ever get off the ground.
Here’s what DDoS activity originating inside Russia and blocked there by Cloudflare has looked like since the beginning of February. Normal DDoS activity originating from Russian networks and blocked by Cloudflare’s servers there is relatively low throughout February but then grows massively in the middle of March.
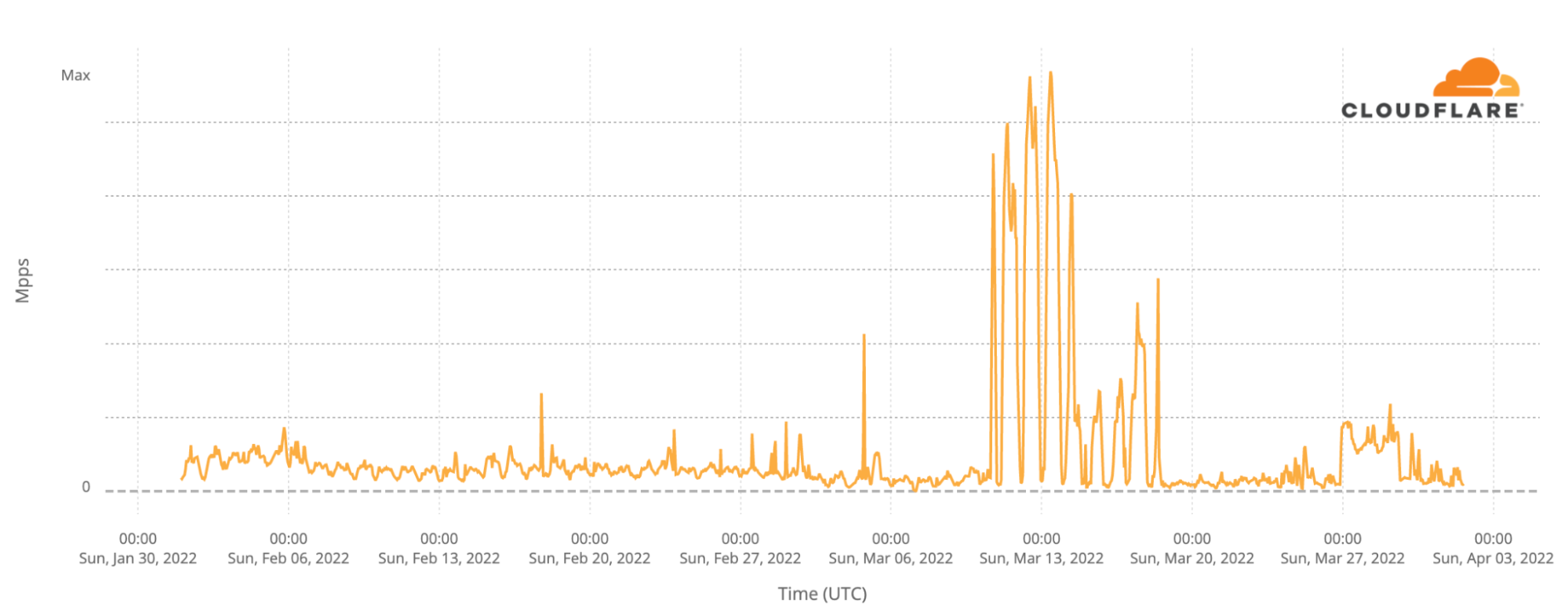
To be clear, being able to identify where cyber attack traffic originates is not the same as being able to attribute where the attacker is located. Attributing cyber attacks is difficult, and now is a time to be particularly careful with attribution. It is relatively common for cyber attackers to launch attacks from remote locations around the world. This often happens when they are able to hijack devices in other countries through things like IoT (Internet of Things) corruptions.
But even with such subterfuge, we’ve still seen a significant increase in the number of blocked attacks that are hitting our servers inside Russia.
A few weeks ago, as the invasion of Ukraine was in its early stages, I noted that “Russia needs more Internet, not less.” At a time of unprecedented economic sanctions by the United States and Europe, there have been calls for all foreign companies to go further and exit Russia completely, including calls for Internet providers to disconnect Russia. To be clear, Cloudflare has minimal sales and commercial activity in Russia – we’ve never had a corporate entity, an office, or employees there – and we’ve taken steps to ensure that we’re not paying taxes or fees to the Russian government. But given the significant impact of our services on the availability and security of the Internet, we believe removing our services from Russia altogether would do more harm than good.
While we deeply appreciate the motivation of the calls for companies to exit Russia, this withdrawal by Internet companies can have the unintended effect of advancing and entrenching the interests of the Russian government to control the Internet in Russia. Efforts to have Russia cut off from the global Internet through ICANN and RIPE will only cut off the Russian people from information about the war in Ukraine that the Russian government doesn’t want them to access. After a number of U.S.-based certificate authorities stopped issuing SSL certificates for Russian websites, Russia responded in early March by encouraging Russian citizens to download a Russian Root Certificate Authority instead. As observed by EFF, “the Russian state’s stopgap measure to keep its services running also enables spying on Russians, now and in the future.”
This is why there has been near universal agreement by experts that it is imperative the Russian Internet stay as open as possible for the Russian people. Dozens of civil society groups have urged governments to work to counteract authoritarian actions “and ensure that sanctions and other steps meant to repudiate the Russian government’s illegal actions do not backfire, by reinforcing Putin’s efforts to assert information control.” Russian digital rights activists have pleaded with service providers to offer Russians free VPN access so they are not left isolated from global news sources. Even the U.S. State Department has made clear, “It is critical to maintain the flow of information to the people of Russia to the fullest extent possible.”
Supporting our mission to help build a better Internet, it’s been a busy six weeks for our team monitoring these developments and working around the clock to make sure Ukrainian web properties are defended and that ordinary Russians can access the global Internet. We remain in awe of the brave Ukrainians standing up in defense of their homeland, and continue to hope that peace will prevail.
How Kafka Connect helps move data seamlessly
Post Syndicated from Grab Tech original https://engineering.grab.com/kafka-connect
Grab’s real-time data platform team a.k.a. Coban has written about Plumbing at scale, Optimally scaling Kakfa consumer applications, and Exposing Kafka via VPCE. In this article, we will cover the importance of being able to easily move data in and out of Kafka in a low-code way and how we achieved this with Kafka Connect.
To build a NoOps managed streaming platform in Grab, the Coban team has:
- Engineered an ecosystem on top of Apache Kafka.
- Successfully adopted it to production for both transactional and analytical use cases.
- Made it a battle-tested industrial-standard platform.
In 2021, the Coban team embarked on a new journey (Kafka Connect) that enables and empowers Grabbers to move data in and out of Apache Kafka seamlessly and conveniently.
Kafka Connect stack in Grab
This is what Coban’s Kafka Connect stack looks like today. Multiple data sources and data sinks, such as MySQL, S3 and Azure Data Explorer, have already been supported and productionised.
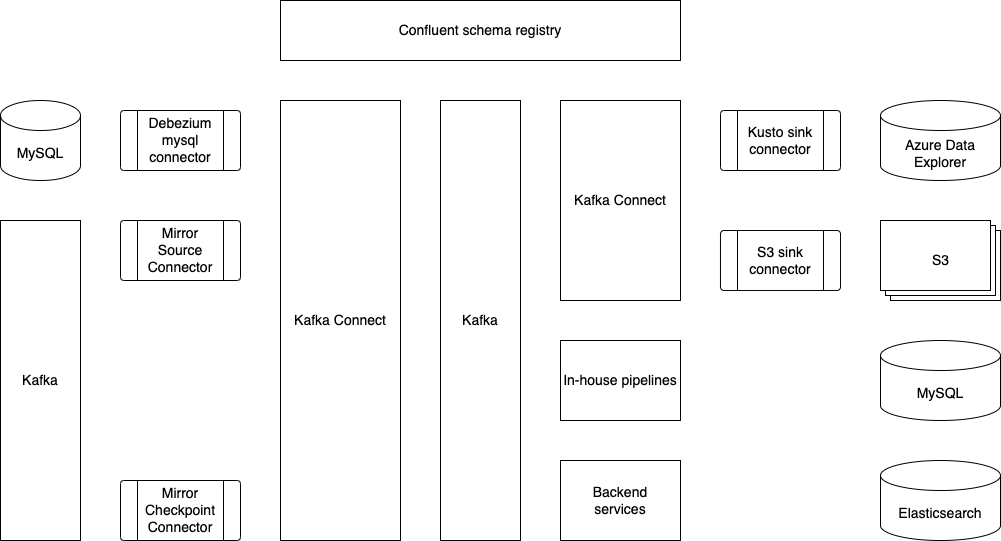
The Coban team has been using Protobuf as the serialisation-deserialisation (SerDes) format in Kafka. Therefore, the role of Confluent schema registry (shown at the top of the figure) is crucial to the Kafka Connect ecosystem, as it serves as the building block for conversions such as Protobuf-to-Avro, Protobuf-to-JSON and Protobuf-to-Parquet.
What problems are we trying to solve?
Problem 1: Change Data Capture (CDC)
In a big organisation like Grab, we handle large volumes of data and changes across many services on a daily basis, so it is important for these changes to be reflected in real time.
In addition, there are other technical challenges to be addressed:
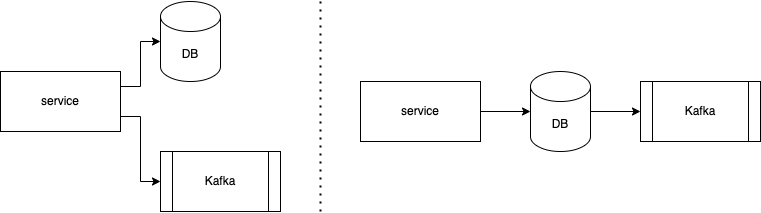
- As shown in the figure below, data is written twice in the code base – once into the database (DB) and once as a message into Kafka. In order for the data in the DB and Kafka to be consistent, the two writes have to be atomic in a two-phase commit protocol (or other atomic commitment protocols), which is non-trivial and impacts availability.
- Some use cases require data both before and after a change.
Problem 2: Message mirroring for disaster recovery
The Coban team has done some research on Kafka MirrorMaker, an open-source solution. While it can ensure better data consistency, it takes significant effort to adopt it onto existing Kubernetes infrastructure hosted by the Coban team and achieve high availability.
Another major challenge that the Coban team faces is offset mirroring and translation, which is a known challenge in Kafka communities. In order for Kafka consumers to seamlessly resume their work with a backup Kafka after a disaster, we need to cater for offset translation.
Data ingestion into Azure Event Hubs
Azure Event Hubs has a Kafka-compatible interface and natively supports JSON and Avro schema. The Coban team uses Protobuf as the SerDes framework, which is not supported by Azure Event Hubs. It means that conversions have to be done for message ingestion into Azure Event Hubs.
Solution
To tackle these problems, the Coban team has picked Kafka Connect because:
- It is an open-source framework with a relatively big community that we can consult if we run into issues.
- It has the ability to plug in transformations and custom conversion logic.
Let us see how Kafka Connect can be used to resolve the previously mentioned problems.
Kafka Connect with Debezium connectors
Debezium is a framework built for capturing data changes on top of Apache Kafka and the Kafka Connect framework. It provides a series of connectors for various databases, such as MySQL, MongoDB and Cassandra.
Here are the benefits of MySQL binlog streams:
- They not only provide changes on data, but also give snapshots of data before and after a specific change.
- Some producers no longer have to push a message to Kafka after writing a row to a MySQL database. With Debezium connectors, services can choose not to deal with Kafka and only handle MySQL data stores.
Architecture
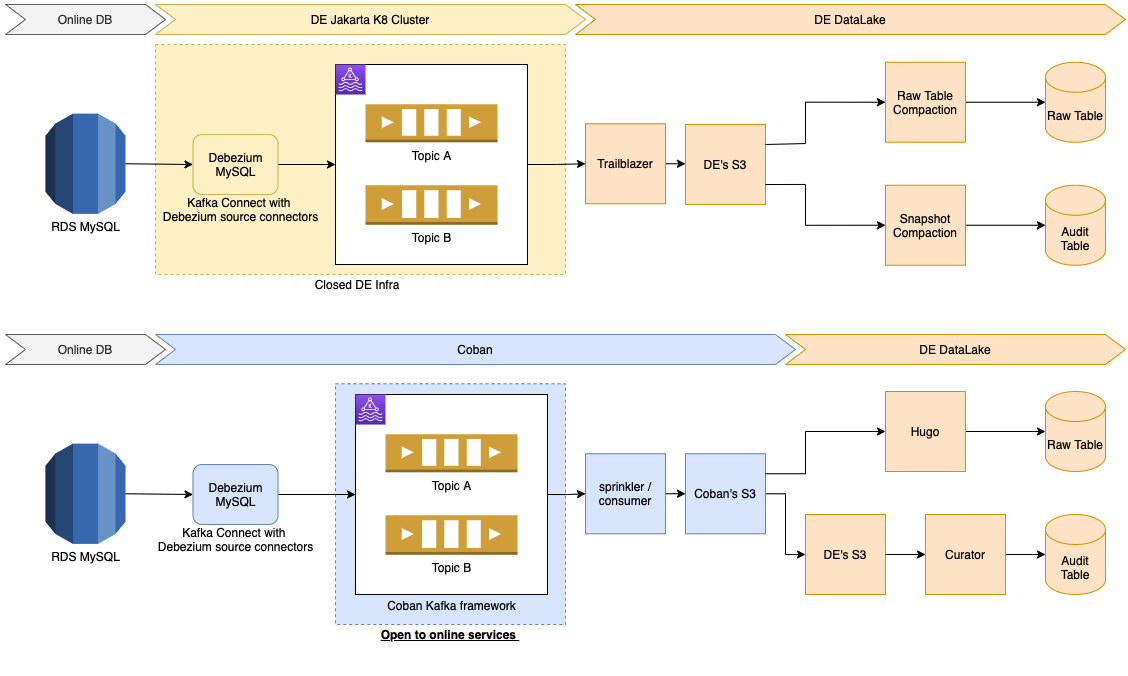
In case of DB upgrades and outages
DB Data Definition Language (DDL) changes, migrations, splits and outages are common in database operations, and each operation type has a systematic resolution.
The Debezium connector has built-in features to handle DDL changes made by DB migration tools, such as pt-online-schema-change, which is used by the Grab DB Ops team.
To deal with MySQL instance changes and database splits, the Coban team leverages on the Kafka Connect framework’s ability to change the offsets of connectors. By changing the offsets, Debezium connectors can properly function after DB migrations and resume binlog synchronisation from any position in any binlog file on a MySQL instance.
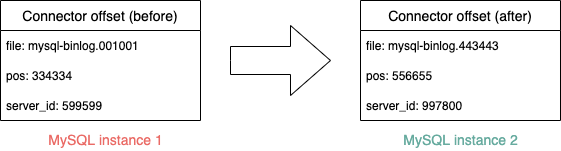
Refer to the Debezium documentation for more details.
Success stories
The CDC project on MySQL via Debezium connectors has been greatly successful in Grab. One of the biggest examples is its adoption in the Elasticsearch optimisation carried out by GrabFood, which has been published in another blog.
MirrorMaker2 with offset translation
Kafka MirrorMaker2 (MM2), developed in and shipped together with the Apache Kafka project, is a utility to mirror messages and consumer offsets. However, in the Coban team, the MM2 stack is deployed on the Kafka Connect framework per connector because:
- A few Kafka Connect clusters have already been provisioned.
- Compared to launching three connectors bundled in MM2, Coban can have finer controls on
MirrorSourceConnectorandMirrorCheckpointConnector, and manage both of them in an infrastructure-as-code way via Hashicorp Terraform.
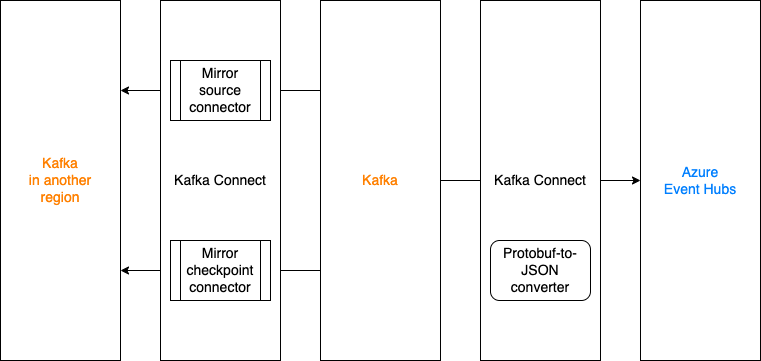
Success stories
Ensuring business continuity is a key priority for Grab and this includes the ability to recover from incidents quickly. In 2021H2, there was a campaign that ran across many teams to examine the readiness and robustness of various services and middlewares. Coban’s Kafka is one of these services that proved to be robust after rounds of chaos engineering. With MM2 on Kafka Connect to mirror both messages and consumer offsets, critical services and pipelines could safely be replicated and launched across AWS regions if outages occur.
Because the Coban team has proven itself as the battle-tested Kafka service provider in Grab, other teams have also requested to migrate streams from self-managed Kafka clusters to ones managed by Coban. MM2 has been used in such migrations and brought zero downtime to the streams’ producers and consumers.
Mirror to Azure Event Hubs with an in-house converter
The Analytics team runs some real time ingestion and analytics projects on Azure. To support this cross-cloud use case, the Coban team has adopted MM2 for message mirroring to Azure Event Hubs.
Typically, Event Hubs only accept JSON and Avro bytes, which is incompatible with the existing SerDes framework. The Coban team has developed a custom converter that converts bytes serialised in Protobuf to JSON bytes at runtime.
These steps explain how the converter works:
- Deserialise bytes in Kafka to a Protobuf
DynamicMessageaccording to a schema retrieved from the Confluent™ schema registry. - Perform a recursive post-order depth-first-search on each field descriptor in the
DynamicMessage. - Convert every Protobuf field descriptor to a JSON node.
- Serialise the root JSON node to bytes.
The converter has not been open sourced yet.
Deployment

Docker containers are the Coban team’s preferred infrastructure, especially since some production Kafka clusters are already deployed on Kubernetes. The long-term goal is to provide Kafka in a software-as-a-service (SaaS) model, which is why Kubernetes was picked. The diagram below illustrates how Kafka Connect clusters are built and deployed.
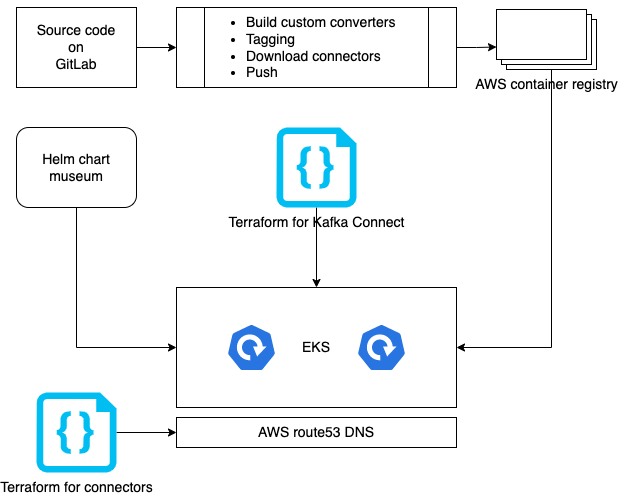
What’s next?
The Coban team is iterating on a unified control plane to manage resources like Kafka topics, clusters and Kafka Connect. In the foreseeable future, internal users should be able to provision Kafka Connect connectors via RESTful APIs and a graphical user interface (GUI).
At the same time, the Coban team is closely working with the Data Engineering team to make Kafka Connect the preferred tool in Grab for moving data in and out of external storages (S3 and Apache Hudi).
Coban is hiring!
The Coban (Real-time Data Platform) team at Grab in Singapore is hiring software and site reliability engineers at all levels as we double down on growing our platform capabilities.
Join us in building state-of-the-art, mission critical, TB/hour scale data platforms that enable thousands of engineers, data scientists, and analysts to serve millions of consumers, businesses, and partners across Southeast Asia!
Join us
Grab is a leading superapp in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across over 400 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
woe
Post Syndicated from Oglaf! -- Comics. Often dirty. original https://www.oglaf.com/woe/


The 4.14.275 stable kernel is out
Post Syndicated from original https://lwn.net/Articles/890067/
The 4.14.275 stable kernel update has been
released; it seems to consist mostly of backports of a set of arm64 Spectre
mitigations.
REVIEW : tonies® – The character-activated audio player for kids
Post Syndicated from Techmoan original https://www.youtube.com/watch?v=P9RbMMJRxzw
Данните на Call.Sofia в разбираем и удобен вид
Post Syndicated from original https://yurukov.net/blog/2022/call-sofia-opendata/
Община София има портал за сигнали и жалби, в който всеки жител или гост на града може да съобщи за проблем – call.sofia.bg. Използвам го активно още преди да се преместя от Франкфурт в София и като замисъл го намирам за добра идея. Самият сайт не е особено добър от гледна точка на използваемост, но по-важното е, че практически всички сигнали се разпределят на районните кметове, които често нямат ресурс или дори право да ги решат.
Подбуден от типично българския ни цинизъм, исках да видя, дали сигнали от сайта изчезват. Повод за това беше наблюдението, че на началната страница се виждат само последните 5000. Затова както с документите на Направление архитектура и градоустройство, написах скрипт, който през час да тегли най-новите сигнали. Тъй като исках да видя къде е имало исторически най-много проблеми, изтеглих всичко назад във времето заедно с обновленията и геометриите. Почти всички сигнали имат посочено местоположение като точка, но някои хора си правят труда да отбелязват пътища и цял регион.
Така се оказа, че имам всичките им данни и мога най-малкото да вадя статистика. Като например брой сигнали със статус приключен – 13%. Повечето сигнали – 77% – получават едно или повече уведомления без да са отбелязани като приключени. Историята на статусите пък ми позволи да видя за колко време отнема от подаването до последното обновление по сигнал. 11% отнемат повече от месец. Също така през работните дни се подават два пъти повече сигнали отколкото през почивните, а в петък – с 10% по-малко от предходните четири дни. Най-много сигнали има за пътна инфраструктура – 28%. На второ място с над два пъти по-малко сигнали е паркирането с 12%. Едва тогава следва замърсяването с 10%, сметоизвозването и осветлението с по 9%.
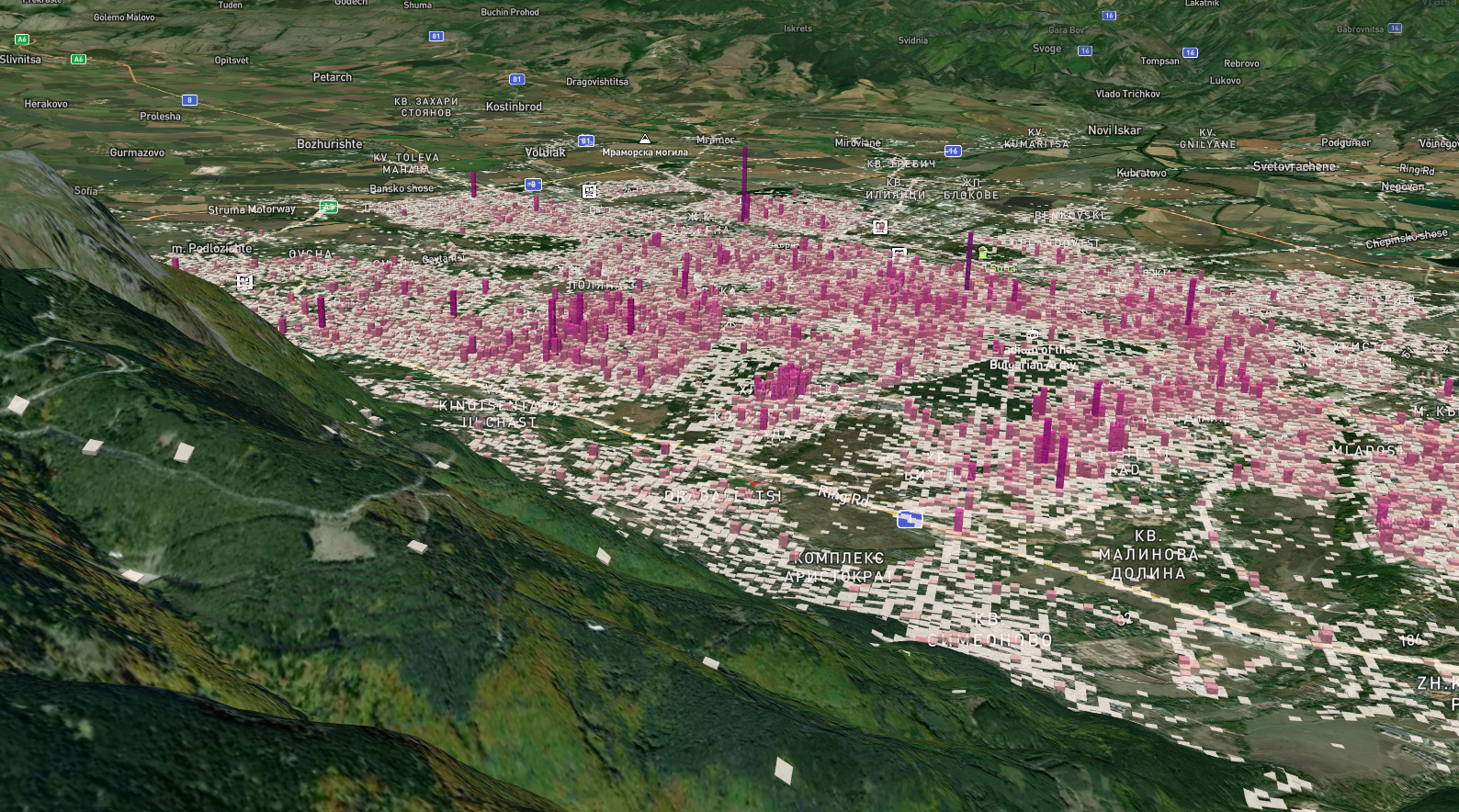
За да осмисля обаче данните географски и да мога да ги прехвърлям в реално време, имах нужда от инструмент. Затова малко по-малко създадох интерактивна карта, която да показва като колони броя на случаите. Колоните са с основа 50 на 50 метра, а всеки случай добавя около 2 метра над височината им. Има филтри, с които да се избират конкретни данни по години или друг период, категории и прочие. Натискайки на дадена колона ще видите списък с всички сигнали на това място с линове към оригиналния сигнал. Списъкът със сигналите на даденото място, както и панелът с филтрите може да се скриват. Вдясно под бутоните за увеличение на картата има бутон за показване отново на филтрите. Бутонът под него е за промяна на прозрачността на триизмерната визуализация върху картата. Полезно е, ако искате да се ориентирате по-добре за улиците под въпросните колони.
След обратна връзка от Linkedin и кмета на Слатина Георги Илиев добавих няколко неща, включително филтър по райони, за да може да се сравни активността и случаите разпределени там. Може също да се превключва показване на абсолютен брой сигнали, както и спрямо населението на региона. Границите и оценката за населението на последните взех от отворените данни на практически закритата вече Софияплан.
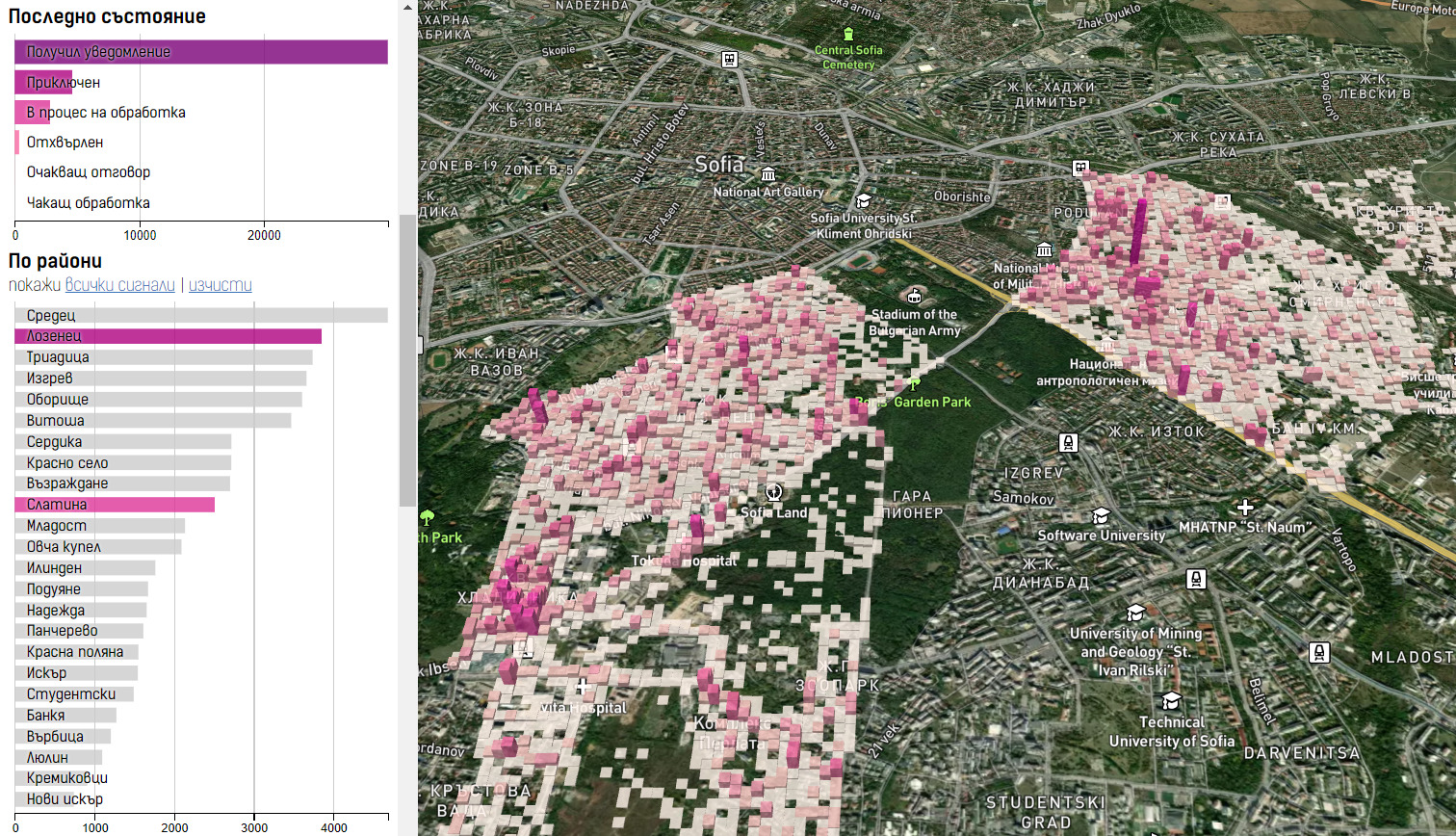
Преди обаче да погледнем самите данни, както винаги следва да поговорим за условностите им. Както при Фонда за лечение на деца поет в последствие от НЗОК, тук също показват единствено това, което се поддържа като масив от данни от СО. Има сигнали с автоматично добавен маркер на мястото на Софийска община. Тях съм ги скрил от картата, например. Има и такива добавени с други общини и области. Има сигнали със сбъркана година в датите, както и понякога с десетки пъти изпратен един и същ сигнал за едно и също нещо. Има също много тестови сигнали използвани видимо за проверка на нови категории и функции.
Активността по сигналите идват най-вече от районните кметства, почти винаги под формата на сканирани и прикачени писма. Рядко се случва да добавят изрични коментари – най-вече при отхвърляне на сигнал. Тук е важно да се разбере, че получен отговор или дори „приключен“ сигнал не означава, че даденият проблем е решен. Това може да се декларира дори в приложените документи, но дори тогава няма някаква форма на проверка или потвърждение. Системата не позволява последващи коментари или обновления или дори съгласие с изпратения статус или информация. Връзката е еднопосочна.
По подадените сигнали може да съдим най-вече за активността по теми, райони и конкретни места. Именно тук визуалното представяне на информацията помага най-много. Докато самата карта на call.sofia да показва някаква форма на групиране по клъстъри, то не позволява откриване на „горещи точки“. Всъщност, използват точно същото групиране в картите си преди единадесет години. Основният проблем обаче е, че показват само активните сигнали, т.е. тези, на които не е отговорено, а се очаква разглеждане. Освен, ако един по един не разглеждаме десетките хиляди преди това познавайки поредните им уникални номера, няма да знаем къде е имало голям интерес към даден проблем. Именно това направих.
Единственото, което може да ни покажат тези данни обаче е точно това – активност, интерес и някаква форма на доверие, че нещо може да се случи по дадената тема, та дори това да е само публичност. Повечето сигнали не означават непременно повече проблем, а наболял такъв, активна група граждани на това място или голям трафик от хора. В централната част на града минават най-много хора и очаквано има повече активност.
Това, което не се забелязва е значимо увеличение на активността през годините. След очаквано ниската активност през 2020-та, има едва леко покачване през 2021-ва, също както предходните две. Излизат между 54 и 60 хиляди сигнала на година, което изглежда много докато не сметнем, че става въпрос за 164 сигнала дневно в град с два милиона жители и ужасна инфраструктура.
Видимо липсва, е двустранна комуникация, прозрачност какво се случва и какво се планира, както и оценка на свършеното от подалите сигнала и живеещите в региона. Това неизменно се обвързва с липсата на самостоятелност при голяма част от решенията и бюджетите на районните кметства, както и абсурдното управление на градското планиране във всичките му аспекти.
Независимо, подаването на сигнали има голямо значение, защото постигат публичност на конкретни проблеми. Отваряйки данните на този портал постигаме и донякъде прозрачност на историята на тези проблеми и натрупването им. Картата, която направих, е пример как следва гражданите да използват отворените данни на администрацията, а защо не и частни организации. За разлика от първата ми визуализация за българчетата родени в чужбина или тази на активните българи зад граница, тази за сигналите в София може да се използва за реално изследване на данните.
Разбира се, както с НАГ и доста други ведомства, обсъжданите данни въобще не са изначално отворени, така че се наложи да ги отворим през публичните им API-та. Това не прави инструмента call.sofia по-малко полезен, а просто морално остарял и създаден по-скоро за комфорт на кмета на София, отколкото на жителите на града.
Интерактивната карта ще намерите тук. Използвал съм d3.js и dc/crossfilter, както при повечето ми графики. Този път вместо leaflet използвах директно api-a на mapbox за триизмерна визуализация и векторните им tile-ове предвид количеството информация, което се показва и обработва в реално време. Oтворените данни са готови за сваляне тук в CSV и GeoJSON формат. Последните съдържат пълен списък със сигнали, статусите и геометрията към тях, както и справките, които използвам за картата. Първите се обновяват на всеки час докато справките за картата – всеки петък вечер.
The post Данните на Call.Sofia в разбираем и удобен вид first appeared on Блогът на Юруков.
Securing Your Applications Against Spring4Shell (CVE-2022-22965)
Post Syndicated from Bria Grangard original https://blog.rapid7.com/2022/04/01/securing-your-applications-against-spring4shell-cve-2022-22965/

The warm weather is starting to roll in, the birds are chirping, and Spring… well, Spring4Shell is making a timely entrance. If you’re still recovering from Log4Shell, we’re here to tell you you’re not alone. While discovery and research of CVE-2022-22965 is evolving, Rapid7 is committed to providing our customers updates and guidance. In this blog, we wanted to share some recent product enhancements across our application security portfolio to help our customers with easy ways to test and secure their apps against Spring4Shell.
What is Spring4Shell?
Before we jump into how we can help you with our products, let’s give a quick overview of Spring4Shell. CVE-2022-22965 affects Spring MVC and Spring WebFlux applications running JDK versions 9 and later. A new feature was introduced in JDK version 9 that allows access to the ClassLoader from a Class. This vulnerability can be exploited for remote code execution (RCE). If you’re looking for more detailed information on Spring4Shell, check out our overview blog here.
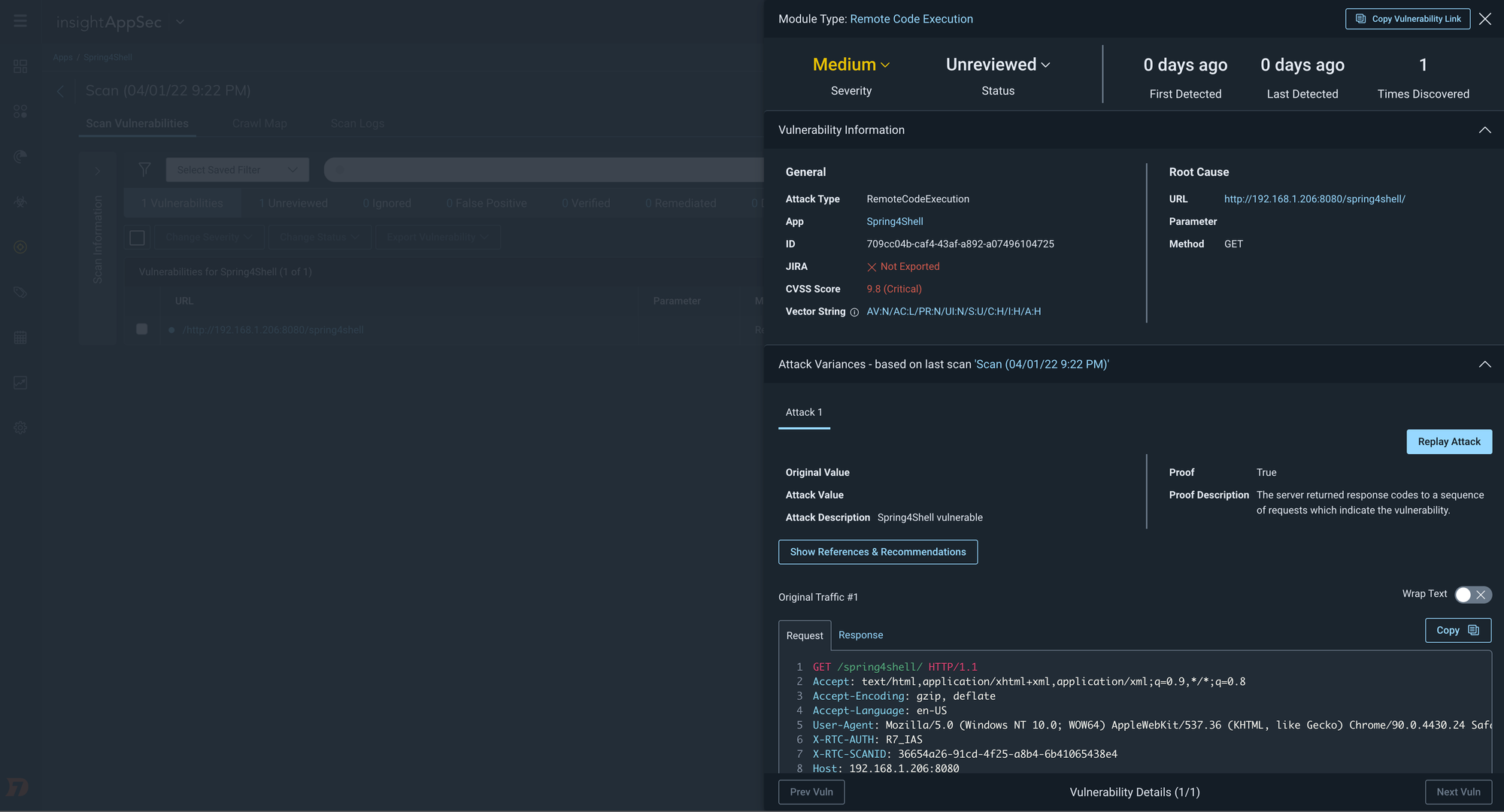
Updated: RCE Attack Module for Spring4Shell
Customers leveraging InsightAppSec, our dynamic application security testing (DAST) tool, can regularly assess the risk of their applications. InsightAppSec allows you to configure 100+ types of web attacks to simulate real-world exploitation attempts. While it may be April 1st, we’re not foolin’ around when it comes to our excitement in sharing this update to our RCE Attack Module that we’ve included in the default All Modules Attack Template – specifically testing for Spring4Shell.
Cloud customers who already have the All Modules Attack Template enabled will automatically benefit from this new RCE attack as part of their regular scan cadence. Please note that these updates are only available for InsightAppSec cloud engines. However, we expect updates for on-premises engines to follow shortly. For those customers with on-premises engines, make sure to have auto-upgrade turned on for your on-prem engines to have the latest and greatest version of the engine.
NEW: Block against Spring4Shell attacks
In addition to assessing your applications for attacks with InsightAppSec, we’ve also got you covered when it comes to protecting your in-production applications. With tCell, customers can both detect and block anomalous activity, such as Spring4Shell exploit attempts. Check out the GIF below on how to enable the recently added Spring RCE block rule in tCell.
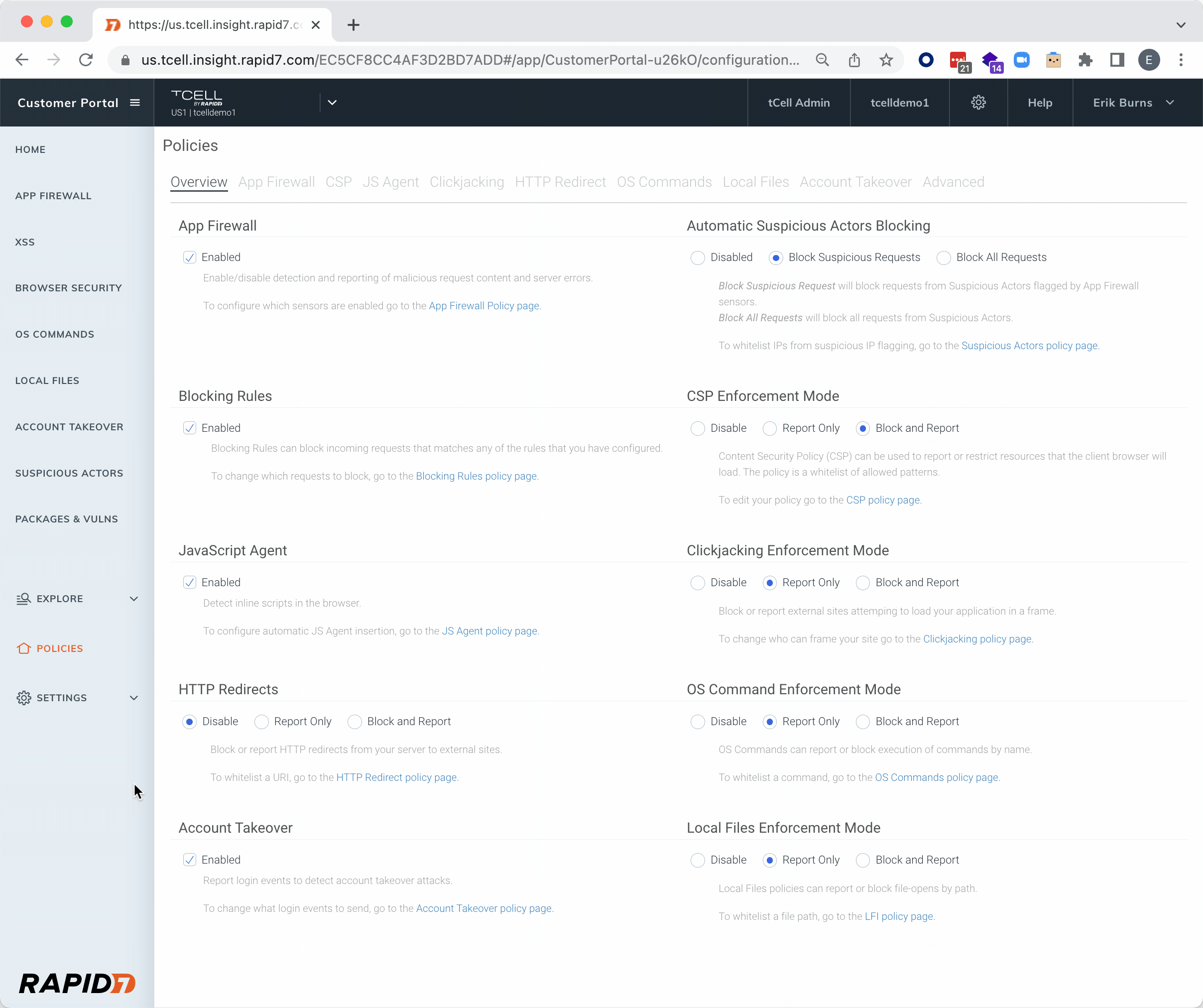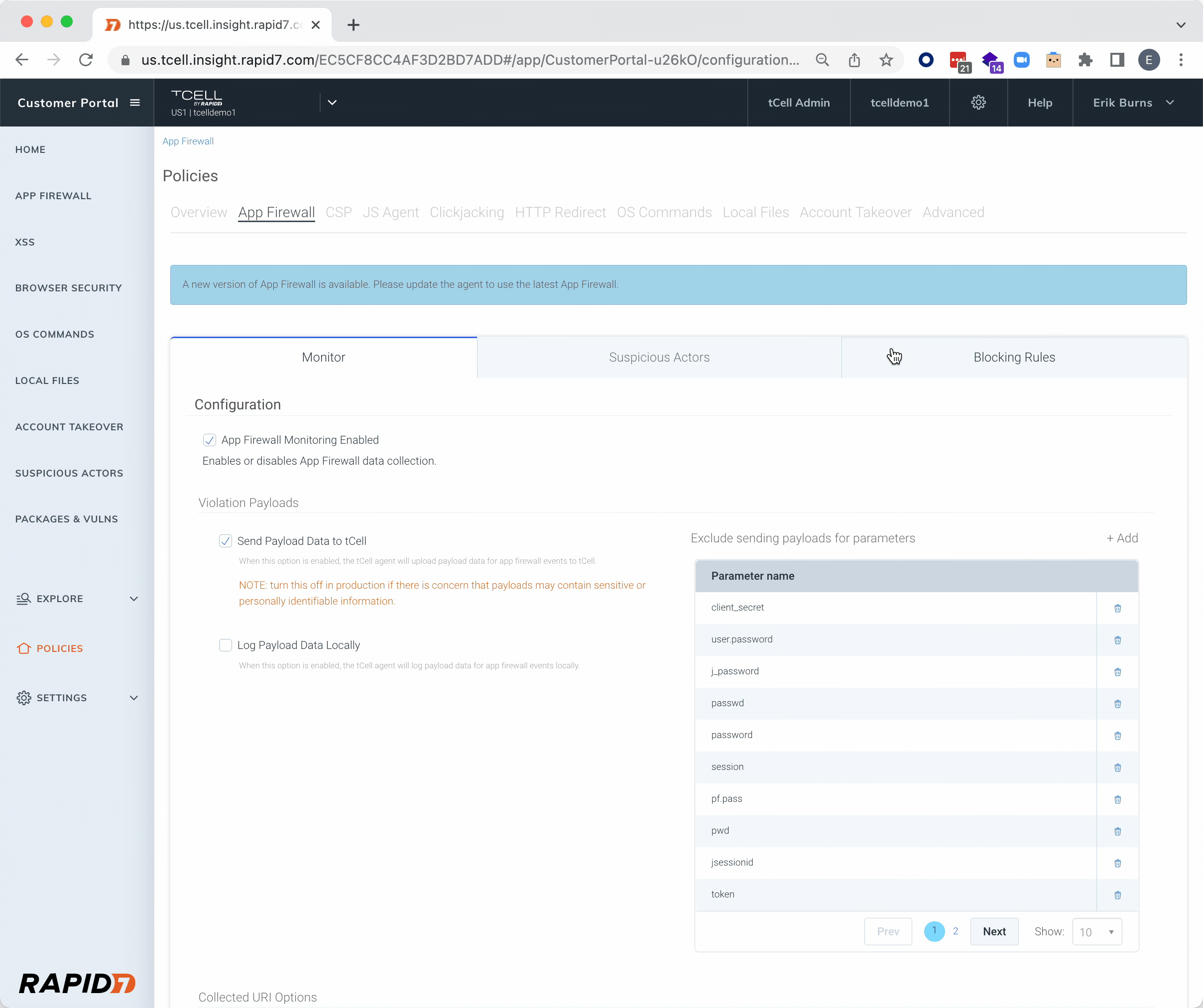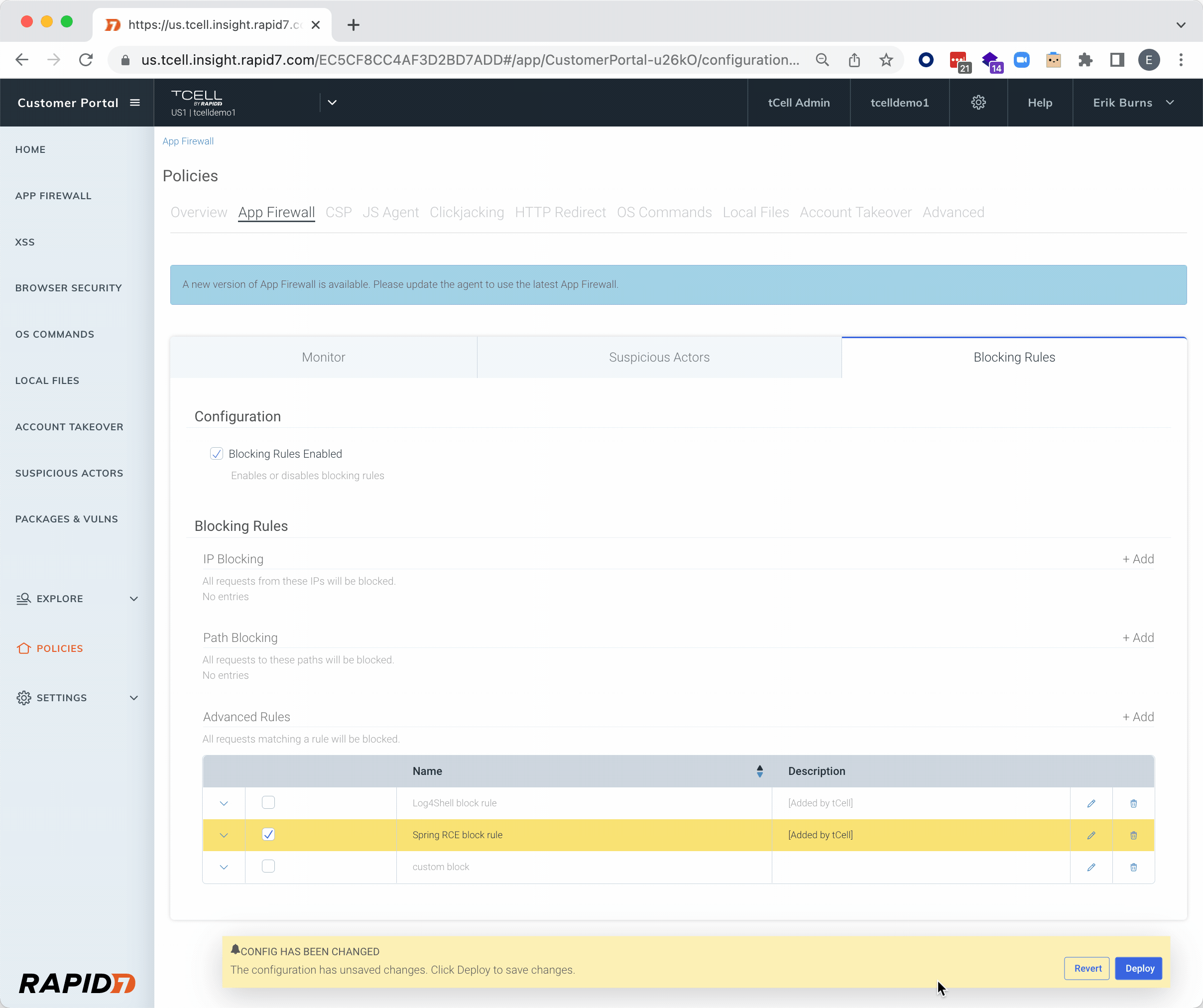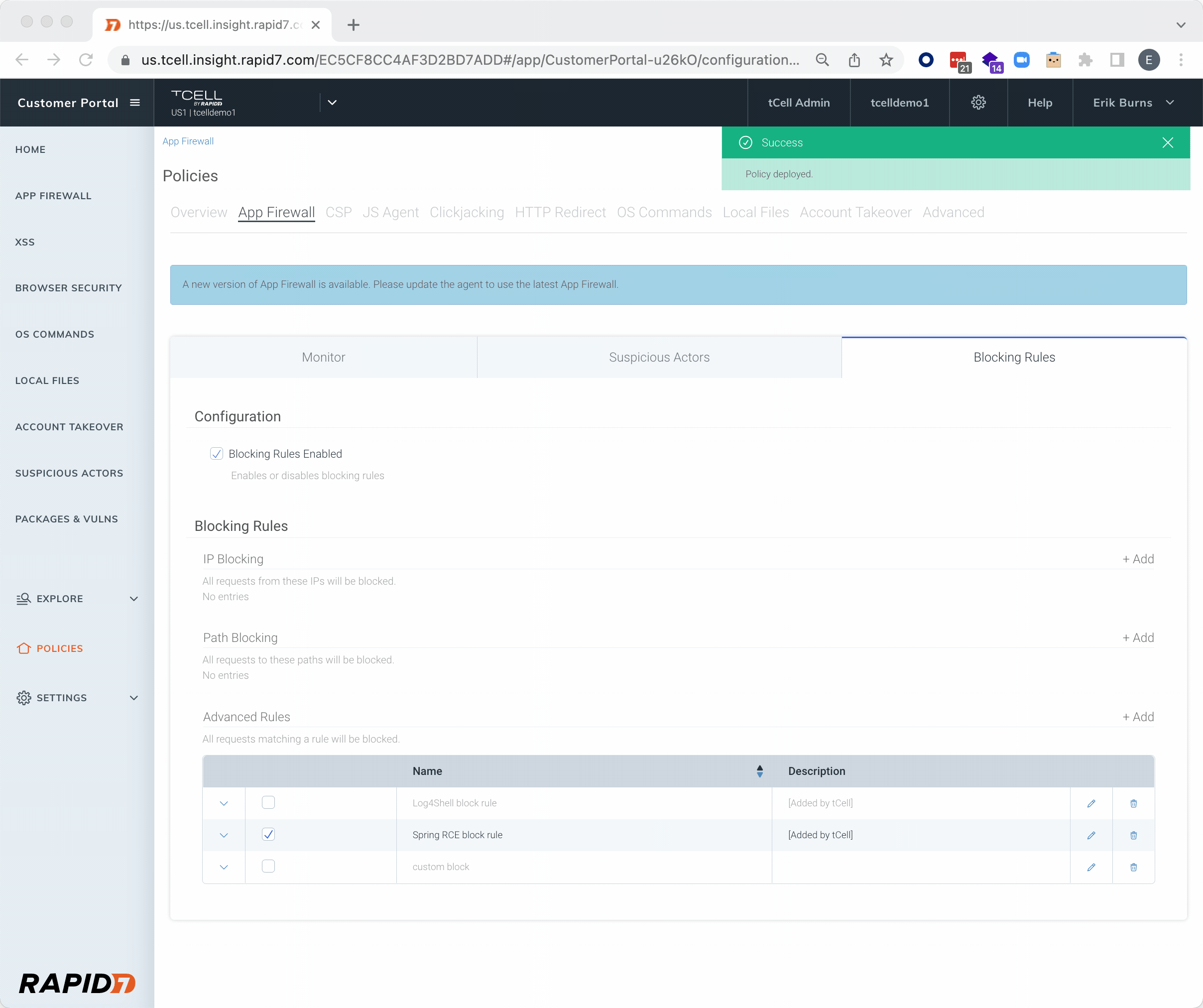
NEW: Identify vulnerable packages (such as CVE-2022-22965)
A key component of Spring4Shell is detecting whether or not you have any vulnerable packages. tCell customers leveraging the Java agent can determine if they have any vulnerable packages, including CVE-2022-22965, in their runtime environment.
Simply navigate to tCell on the Insight Platform, select your application, and navigate to the Packages and Vulns tab. Here you can view any vulnerable packages that were detected at runtime, and follow the specified remediation guidance.
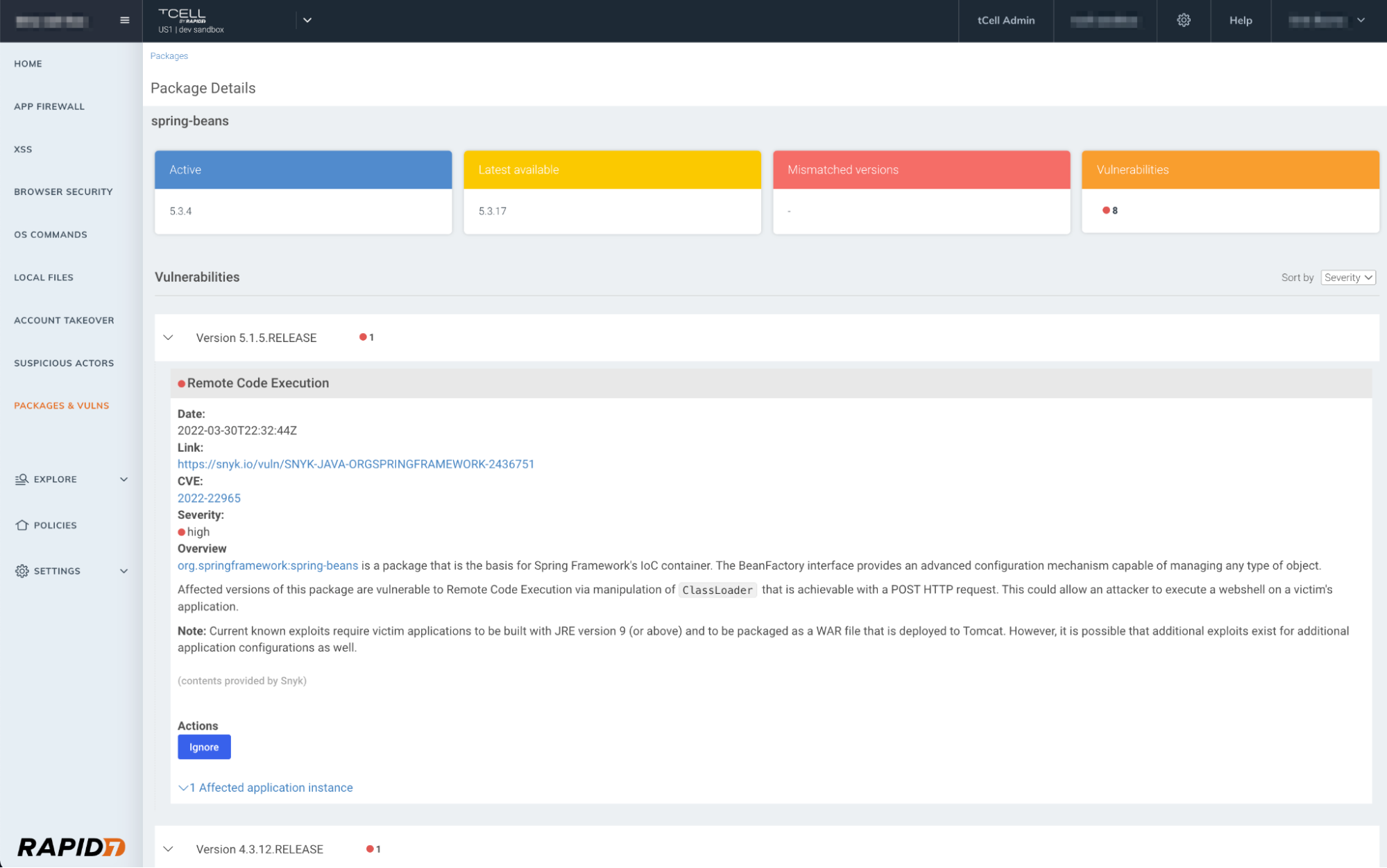
Currently, the recommended mitigation guidance is for Spring Framework users to update to the fixed versions. Further information on the vulnerability and ongoing guidance are being provided in Spring’s blog here.
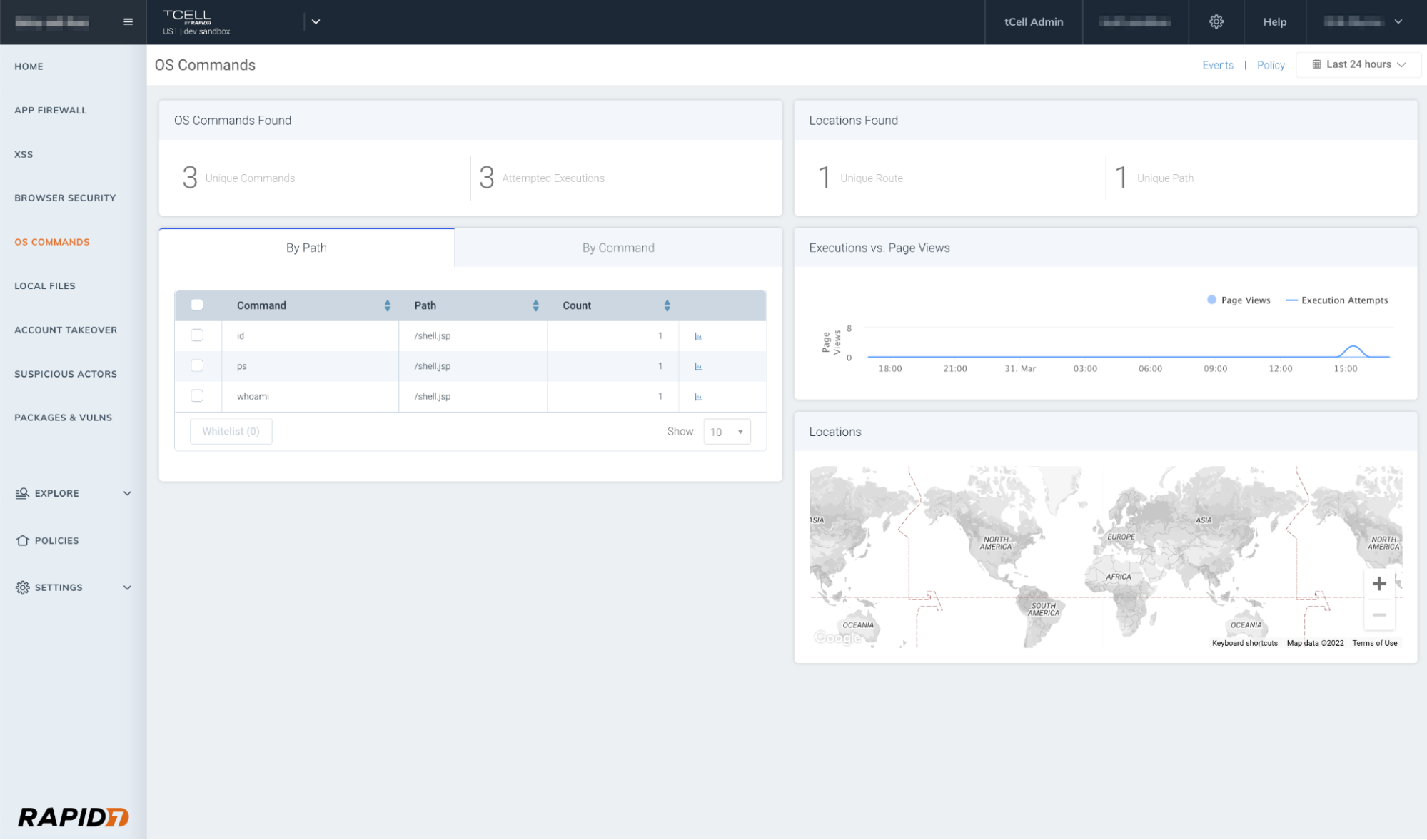
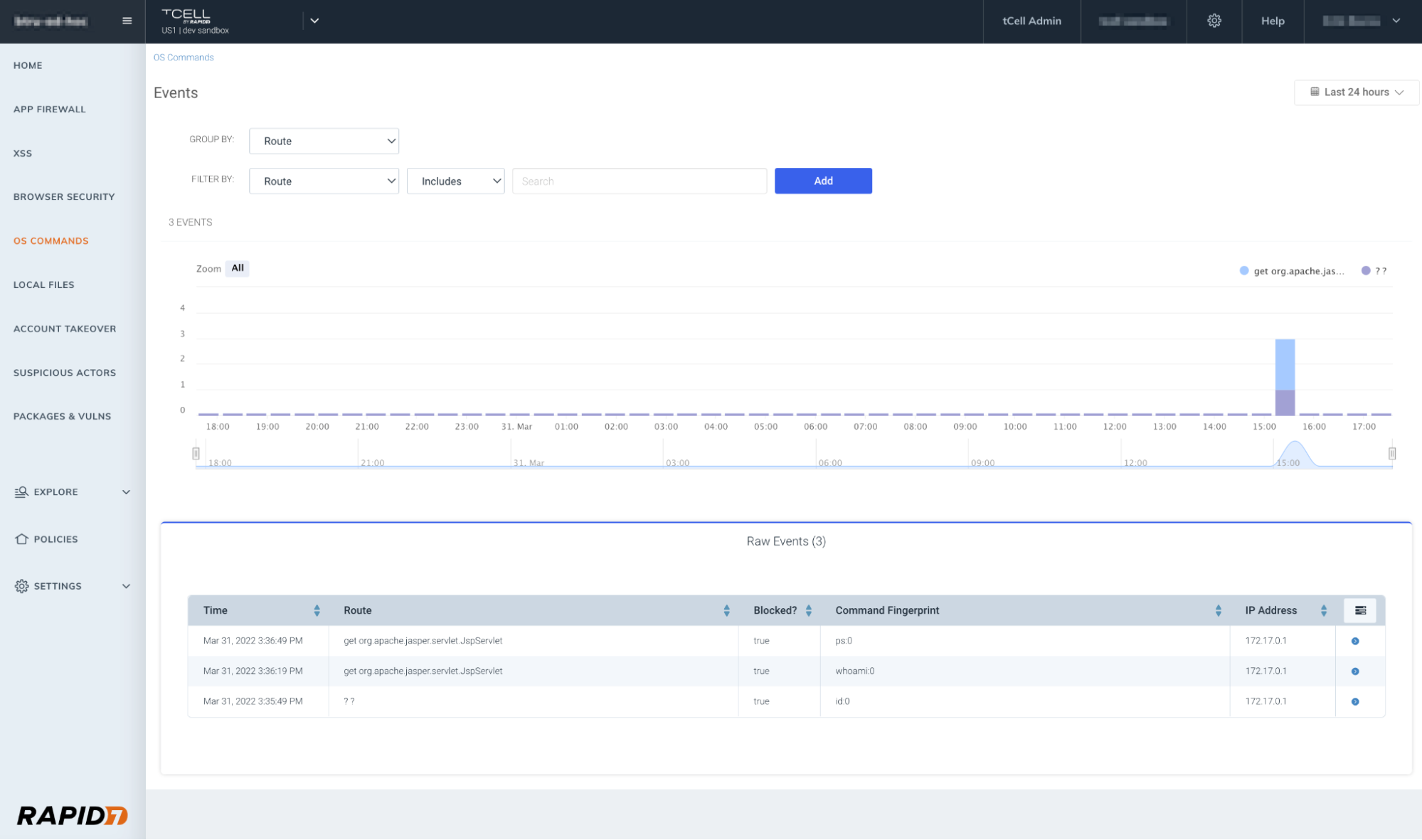
Utilize OS commands
One of the benefits of using tCell’s app server agents is the fact that you can enable blocking (after confirming you’re not blocking any legitimate commands) for OS commands. This will prevent a wide range of exploits including Shell commands. Below you will see an example of our OS Commands dashboard highlighting the execution attempts, and in the second graphic, you’ll see the successfully blocked OS command events.
What’s next?
We recommend following Spring’s latest guidance on remediation to reduce risk in your applications. If you’re looking for more information at any time, we will continue to update both this blog, and our initial response blog to Spring4Shell. Additionally, you can always reach out to your customer success manager, support resources, or anyone on your Rapid7 account team. Happy April – and here’s to hoping the only shells you deal with in the future are those found on the beach!
Friday Squid Blogging: Squid Migration and Climate Change
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2022/04/friday-squid-blogging-squid-migration-and-climate-change.html
New research on the changing migration of the Doryteuthis opalescens as a result of climate change.
News article:
Stanford researchers have solved a mystery about why a species of squid native to California has been found thriving in the Gulf of Alaska about 1,800 miles north of its expected range: climate change.
As usual, you can also use this squid post to talk about the security stories in the news that I haven’t covered.
Read my blog posting guidelines here.
Седмицата (28 март – 2 април)
Post Syndicated from Йовко Ламбрев original https://toest.bg/editorial-28-march-2-april-2022/
Войната продължава. За съжаление, това кратко изречение от две думи е напълно достатъчно да запълни със себе си цялата седмица. Както и предходната, и цялото време от 24 февруари досега. А и още неясно колко седмици напред.
Не ми казвайте, че руските войски не виждат, че стрелят по цивилни домове и убиват мирни хора! Напротив, много добре знаят и разбират какво вършат.

Това споделя Алла от Киев, потърсила в България спасение от войната в собствената ѝ родина, пред микрофона на Николета Атанасова във втория епизод на подкаст поредицата „Украйна не е загубена“. В него участват и Христофор Караджов, преподавател по журналистика в Калифорнийския университет, и журналистката Тетяна Иванска, която изпраща гласови съобщения от атакувания Киев. Публикувахме епизода още в понеделник, а вие, ако искате да бъдете известени веднага за всеки нов епизод, се абонирайте за емисията на „Мястото“ с Николета Атанасова чрез любимото си подкаст приложение.

Правителството уж подписа меморандум за сътрудничество в енергетиката с британско-американски консорциум, но новината мирише на нечистоплътни капитали и токсични връзки в други посоки. В четвъртък Емилия Милчева обобщи известното досега по темата и обърна внимание на рисковете от инвестиции, които може да са опасни за националната сигурност. Особено на фона на активни военни действия в Европа, основателни съмнения в адекватността на службите и институциите у нас и факта, че държавата ни е на прага на енергийната си трансформация, за която е отделена огромна част от средствата в Плана за възстановяване и устойчивост. От това колко целесъобразно ще бъдат инвестирани тези средства, зависи бъдещето на поколения българи.

Друга актуална тема от родния контекст продължава да бъде реформата в прокуратурата и Висшия съдебен съвет. По този повод Венелина Попова разговаря с Калин Калпакчиев, съдия от Софийския апелативен съд и бивш председател на Съюза на съдиите в България, за проблемите с ефективността на разследването, за предложенията на ССБ за промяна на съществуващия модел на съдебната власт, както и за оценката му за закриването на органите на специализираното правосъдие. „Фактите за зависимост на главния прокурор от политическата власт са пред очите на цялото общество, остава и ВСС да прогледне за тях“, казва съдия Калпакчиев.

В рубриката ни „На второ четене“ Севда Семер е избрала този път една много различна детска книга, която наглед е помагало за учене на таблицата за умножение, но е много повече от това. Севда е достатъчно откровена да сподели, че има дискалкулия, ще рече – затруднения със смятането, и че възприема себе си като „човек, който има силна тревога за всичко, свързано с математиката“. В този смисъл си струва да се отбележи, че Севда се е забавлявала с тази книжка и с начина, по който тя отваря вратите към една иначе толкова скучна за много деца (и възрастни) тема. „Умножение без уморение“ е дело на нашата Зорница Христова в тандем с илюстраторката Миглена Папазова.

Ето че вече може да се радваме на нов-новеничък текст в рубриката „Говори с Нева“. „Будь ласка“ е не само заглавието на най-новото есе на Нева Мичева в отговор на читателско писмо, но са и първите думи, които тя научава на украински. Какво означават – ще прочетете сами, а междувременно ще разбере защо според Нева светлата част на живота е „упорството, с което добрите хора правят добри дела“.
И накрая – една препоръка от мен за този уикенд. „Гардиън“ са подбрали три съвременни украински документални филма и с по един откъс от всеки от тях правят кинематографичен портрет триптих на съвременната история на Украйна и нейните хора. С това те ни припомнят за ролята на документалистиката във времена на обществени турбуленции.
Приятно четене, слушане и гледане!
Калин Калпакчиев: „Зависимостта на Гешев е факт, време е и ВСС да прогледне“
Post Syndicated from Венелина Попова original https://toest.bg/kalin-kalpachiev-interview-sudebna-reforma/
Венелина Попова разговаря с Калин Калпакчиев, съдия от Софийския апелативен съд и бивш председател на Съюза на съдиите в България, за проблемите в разследването, за реформата в прокуратурата и за необходимостта от нова структура и състав на колегиите във Висшия съдебен съвет.
Случаят с арестите на Бойко Борисов, Владислав Горанов и Севделина Арнаудова предизвика институционални спорове и политически реакции, включително и в Европейския парламент. По-важният въпрос е освети ли този случай проблеми или дефицити в сферата на разследването?
Събитията от последните няколко седмици извадиха наяве съществуващи от години проблеми с ефективността на разследването. Става въпрос не толкова за нормативни дефицити в наказателния процес, а за невъзможността на държавното обвинение практически да осъществява пълноценно ръководството и надзора върху разследването, каквито правомощия прокурорът има по силата на процесуалния закон. Той разполага с всички инструменти да контролира непрекъснато движението на досъдебното производство, включително да участва лично и сам да извършва действия по разследването, да дава указания на разследващите полицаи и да обсъжда с тях необходимите действия за събиране на доказателства.
Оправданията и оплакванията, които чуваме от главния прокурор, че органите на МВР не разкривали престъпления, съответно не събирали материали за установяването им, с което възпрепятствали работата на прокуратурата, показват непознаване на закона или нежелание за прилагане на точния му разум. По голяма част от досъдебните производства разследващи органи са съответните полицейски служители. За да бъдат техните действия ефективни, които да водят до бързото и качествено приключване на разследванията, те трябва тясно и непрекъснато да си взаимодействат с т.нар. наблюдаващи прокурори.
Преди повече от десет години, когато кандидатът за главен прокурор Сотир Цацаров защитаваше пред Висшия съдебен съвет своята концепция, основна негова теза беше за наблюдаващия прокурор като „прокурор на първа линия“, както и за преодоляване на нареченото от него „кабинетно разследване“. Нищо от това не се реализира на практика. Преди време главният прокурор Филчев не особено ласкаво сравняваше прокурорите с деловодители, доколкото тяхната работа била свързана с разнасяне на документи. В много държави офисите на прокурорите се намират в полицейските управления, което улеснява съвместната им работа по разкриване и доказване на престъпленията. Това е повече от естествено, защото прокуратурата и полицията имат обща цел – да се разкрие извършеното престъпление и да се повдигне обвинение срещу извършителя пред съд.
Причина за невъзможността на прокуратурата да осъществява ефективен контрол върху разследването се крие в неизяснената законодателна концепция на прокурорския статус – в това отношение Конституцията от 1991 г. погрешно приравнява статуса на съдиите и прокурорите. По този начин се създаде невярната представа на прокурорите, че тяхната работа е идентична с тази на съдиите, а и попречи да се формира специфичната прокурорска идентичност, която да отговаря на ролята на държавното обвинение в наказателното разследване. За да осъществяват функцията по повдигане и поддържане на обвинението за извършени престъпления, прокурорите трябва да поддържат добри взаимоотношения с изпълнителната власт – органите на МВР и службите, което по дефиниция е недопустимо за съдиите.
Прокурорите трябва да са независими при решаване на възложените им преписки, но тази независимост е различна от съдийската. Прокуратурата е йерархически структурирана и това е необходимо, за да се гарантира ефективност на разследването, но същевременно прокурорите трябва да не зависят кариерно и дисциплинарно от ръководството на прокуратурата. Тези въпроси трябва да бъдат възложени на прокурорски съвет, където мнозинство трябва да имат представители на обществената квота, което да изключи доминацията на главния прокурор. Това е така, защото при действащото законодателство главният прокурор има възможност да влияе върху досъдебните производства – лично или чрез друг подчинен му прокурор той може да контролира актовете на разследващия орган и/или на наблюдаващия прокурор.
Поради това трябва да се намери баланс между необходимата йерархичност в структурата на прокуратурата, която да е в интерес на функционалните компетентности в сферата на наказателното производство и независимостта на прокурора по отношение на неговия статус.
През обсъждания тези дни случай се вижда и друг проблем – при положение че прокуратурата откаже да образува наказателно производство при наличие на данни за извършено престъпление, не съществува механизъм за преодоляване на тази аномалия. Една от целите на полицейските действия при разглеждания казус е да предизвикат образуване на досъдебно производство при очевидното нежелание на прокуратурата да предприеме действия. Някои юристи предлагат въвеждането на съдебно обжалване на отказите като противодействие на бездействието на прокуратурата. Според мен това не е решение на проблема, защото съществува реална опасност съдебният контрол да се профанизира и практически да превърне съда във втори прокурор. Реформа на статуса на прокурорите и на начина на администриране и функциониране на цялата прокуратура е пътят за постигане на ефективност на разследването, а не заместването на нереформираната прокуратура с въвеждане на повсеместен съдебен контрол.
Реформата на прокуратурата трябва да включва и освобождаването ѝ от несвойствените правомощия извън сферата на наказателното преследване, които са остатък от съществуващия до 1989 г. общ надзор, осъществяван от прокуратурата в социалистическата държава.
Как Съюзът на съдиите в България оценява съдебната реформа, предложена от управляващата коалиция? И по-точно: кои са необходимите промени в структурния и функционален модел на съдебната власт – тема, по която през март имаше дискусия, организирана от ССБ и от Юридическия факултет на СУ?
Предложенията за промяна на съществуващия модел на съдебната власт, които ССБ предлага за обсъждане, са такива, които могат да бъдат извършени от обикновено Народно събрание, съобразявайки ограничителното тълкуване на Решение по к.д. № 3/2003 г., но и отчитайки значението на Решение № 8/2005 г. на Конституционния съд, в което се приема, че всякакви организационни и структурни промени в съдебната власт са възможни, щом не засягат принципа на разделение на властите. В Решение № 8/2005 г. Конституционният съд отхвърля искане за обявяване за противоконституционен на текста, който дава възможност на министъра на правосъдието да прави кадрови предложения.
Съюзът на съдиите в България участва активно в дискусиите за конституционна реформа на модела на съдебната власт, като организираната от нас съвместно с Юридическия факултет на СУ „Св. Климент Охридски“ конференция имаше за цел активизиране на обществените дебати по темата. Предлагаме промяна в структурата на ВСС – премахване на Пленума на ВСС или съществено ограничаване на правомощията му да избира председателите на върховните съдилища и да има решаваща роля по бюджетни и обучителни въпроси за съдиите.
Предлагаме също изцяло нова структура и състав на колегиите – при актуалната структура на прокурорската колегия влиянието на главния прокурор в дейността на кадровия орган е гарантирано, доколкото практиката сочи, че от парламентарната квота се излъчват действащи прокурори, които след приключване на мандата им се връщат отново в прокуратурата. За да може да се гарантира, че съставът на колегията ще даде възможност за осъществяване на реален външен контрол и отчетност на прокуратурата, е необходимо членовете, които не са бивши и/или бъдещи прокурори, да са малцинство. Затова предлагаме един от членовете на прокурорската колегия да се избира от прокурорите в страната; един следовател – от следователите; седем от членовете на колегията – от Народното събрание, като изискването за тях е да бъдат излъчени от други юридически професии; един от членовете да се избира от общото събрание на съдиите в страната; главният прокурор да е член по право, но председателстването на колегията да се осъществява от изборен член, излъчен с решение на мнозинството от останалите членове.
Участието на съдия в прокурорската колегия се налага като противотежест на съществуващото правно положение повдигането на обвинението от прокуратурата да е нейно суверенно правомощие, което не подлежи на съдебен контрол, включително при започване на съдебната фаза на наказателния процес след внасяне на обвинителния акт. Подобна организация на обвинителната функция изисква в правната уредба да бъдат предвидени разумни механизми за оценка на качеството на обвинението, които да го превръщат в значимо обстоятелство за кариерата на прокурорите и следователите. Предвиждането на такива адекватни кариерни механизми ще действа дисциплиниращо и ще способства за утвърждаване на ясна ценностна професионална йерархия.
Новият състав и структура на прокурорската колегия ще дадат възможност да се предвидят и нов състав и структура на съдийската колегия, така че да се създаде мнозинство на съдиите, избрани от съдии. Това е основна гаранция за независимостта на съда, позната в демократичните държави, които са възприели модела за администриране на съдебната власт от съдебни съвети, и е повтаряща се препоръка от органите на Съвета на Европа от повече от десет години. Предлагаме в съдийската колегия, която се състои от 14 членове, 8 от тях да се избират от общото събрание на всички съдии в страната, 4 – от Народното събрание, с условие да не са действащи съдии към момента.
Без специализирано правосъдие съществува ли риск дела срещу организирани престъпни групи да завършат с благоприятен изход за тях, както твърдят и главният прокурор, и други негови колеги?
Специализираното наказателно правосъдие беше създадено без обективна необходимост. Препоръката на Европейската комисия, а и преобладаващата практика в другите европейски държави са за специализация на разследващите органи в областта на организираната престъпност и на корупцията. Специализацията на прокуратурата в различни области на престъпността е условие за постигане на бързина и ефективност на разследването, което се налага от непрекъснато усложняващите се обществени и икономически отношения в съвременните общества.
Специализацията на съда обаче, особено в наказателното правосъдие, е нетипична и по правило е изключение, което е отговор на специфични обстоятелства – каквито са мафията в Италия и терористичните действия в Испания. В България такива условия не съществуват. За всички е известно, че специализираните наказателни съдилища бяха създадени вследствие на недоволството на властта от работата на общите съдилища, които отказваха да „съдействат“ на полицейските акции на Вътрешното министерство. Невъзможността на управляващите да опитомят независимия съд наложи да преодолеят това чрез възлагане на важните за властта наказателни дела на новосъздадения Специализиран съд.
Обсъжданият законопроект за изменение на Закона за съдебната власт предвижда гаранции започнатите наказателни дела да бъдат приключени и да не започват отначало. Няма пречка и за в бъдеще прокуратурата да запази под друга организационна форма специализацията си в разследване на организираната престъпност и на корупцията.
Съдебните кадровици гласуваха процедурни правила, при които трябва да протече обсъждането за освобождаване на главния прокурор, а на 4 април Пленумът на ВСС ще се събере, за да се произнесе дали искането на правосъдната министърка Надежда Йорданова за отстраняването на Иван Гешев е допустимо. Според Вас при тези правила и в този състав на ВСС ще се стигне ли до предсрочното прекратяване на пълномощията на главния прокурор?
Правилата, приети от Пленума на ВСС, с които се ограничава възможността да се разгледа по същество предложението на министъра на правосъдието за предсрочно прекратяване на мандата на главния прокурор, са в противоречие със Закона за съдебната власт. Вероятността да се постигне положителен резултат по предложението на министър Йорданова е слаба, доколкото този състав на ВСС не е показал възможността да действа като независим орган. Това не бива да ни обезкуражава, защото използването на законните средства винаги има значение – спомага за развитието на правовата държава, води до натрупване на демократичен опит, а това дава резултат, макар и след време.
Възможно ли е в конкретния случай политическите съображения за отстраняването на главния прокурор да бъдат отделени от юридическите? И доказал ли е Иван Гешев със свои действия зависимостта си от бившите управляващи и от други нелегитимни властови кръгове в държавата?
Юридическите аргументи за предсрочно прекратяване на мандата на главния прокурор са сериозни и изискват задълбоченото им обсъждане по същество. В тази дискусия ясно ще се покаже дали ВСС има обоснован отговор, или се опитва да избяга от него с процедурни похвати. Още през септември 2020 г. от ССБ отправихме мотивирано искане до всички членове на ВСС за започване на процедура за предсрочно прекратяване на мандата на главния прокурор. Фактите за зависимост на главния прокурор от политическата власт са пред очите на цялото общество, остава и ВСС да прогледне за тях. И рано или късно това ще се случи.
Що се отнася до въпроса за избора на главния прокурор, е добре да не забравяме казаното от Сотир Цацаров – той сподели на заседание на ВСС, че тези избори се решават не в сградата на ВСС, а „в две други сгради“. Независимо че тогава призовахме ВСС да проучи това признание за зависимост, нищо не последва.
Възможно ли е, ако не да бъде пресечено, то поне да бъде ограничено задкулисното кадруване в съдебната система? Практиката показва, че дори в държави с много по-ниски нива на корупция, отколкото в България, има случаи на корумпирани прокурори и магистрати. У нас непрекъснато се говори, че държавата е превзета от мафията, но само с промяна на законите и на начина, по който функционира съдебната ни система, можем ли да върнем върховенството на закона и еднаквото му прилагане за всички?
Премахването на задкулисните назначения, особено за висшите съдийски и прокурорски длъжности, е част от борбата за независимост на съдебната власт. Възможно е да се постигне чрез предприемане на комплексни мерки – законодателни, образователни и административни. Промяната в състава и структурата на ВСС е важна част от законодателните усилия. Същевременно чрез промяна в Закона за съдебната власт трябва да се осъществи деконцентрация на властта на ВСС, което е добра мярка в посттоталитарни общества с крехки демократични традиции. За ВСС трябва да се запазят основно кадровите правомощия, каквото е конституционното изискване. Общите събрания на съдиите и овластените с тяхното доверие председатели на съдилища трябва да имат значително по-голяма роля в администрирането на съдебната власт, защото така ще се противодейства на бюрократизирането на ВСС и превръщането му в център на задкулисно влияние.
Предстоящият избор на нов състав на ВСС е особено важен. Възможно е Народното събрание да не успее в срок да излъчи с 2/3 мнозинство своите 11 представители. И на всяка цена не бива да се позволи безпринципно договаряне между политическите партии и разпределение на квотен принцип. Новите членове на ВСС трябва да са безспорни професионалисти с призната компетентност, авторитет и интегритет, които обаче да не са действащи съдии, прокурори или следователи. Дори това да забави процеса, този риск трябва да се поеме, за да се избегне клониране на досегашните зависимости.
Същевременно трябва ясно да се подчертае, че след изтичане на мандата на ВСС той не може да продължи да осъществява дейността си. Това е така, защото конституционно установените мандати не може да бъдат удължавани по никакъв начин. От друга страна, неизпълнението на задължението на Народното събрание да попълва конституционно създадени органи, освен че е проява на правен нихилизъм, недопустим за висшия законодателен орган, показва отрицателна устойчивост – последен пример е отказът на НС да избере нов състав на Инспектората при ВСС повече от две години.
Доколкото в правовата държава не може да съществува властови вакуум, отказът на държавен орган да изпълни правомощията си трябва да бъде преодолян с предвиден в закона компенсаторен механизъм. Конституционният принцип за взаимно възпиране и баланс на властите изисква да бъде създаден такъв ред, така че да се препятства блокиране на функционирането на една власт от друга – в случая на съдебната от законодателната. Добър пример за такъв механизъм е параграф 7а от Закона за Федералния конституционен съд на Германия. В този текст е предвиден защитен механизъм за номиниране на член на Конституционния съд, в случай че парламентът не изпълни в срок своето задължение за това. Смятам, че подобен ред трябва да бъде създаден и у нас, особено на фона на рецидивиращия отказ на Народното събрание да избира в срок съставите на конституционно установени органи.
Заглавна снимка: Стопкадър от интервю със съдия Калпакчиев в предаването „Денят с Веселин Дремджиев“ от 20 декември 2021 г.
Будь ласка
Post Syndicated from Нева Мичева original https://toest.bg/bud-laska/
Здравей, Нева,
Аз съм щастлив човек, който често си казва: „Абе как не те е срам, хората имат истински проблеми, а на теб всичко ти е наред и пак не си доволна и си намираш за какво да се притесняваш!“ Което обаче не ми помага особено да спра да си чопля моите тревоги, страхове и съмнения. Имам семейство – ние сме трима и ни е добре заедно. Виждам родителите си често, прекарвам с приятелите си колкото време мога да отделя. Разбирам се с всички близки на сърцето ми хора. Е, имаме си и дрязги, но те са в рамките на нормалното. Пътешествам често (и по моите разбирания – задълго) заедно с хлапето и любимия ми човек.
Радвам се много на тези пътувания, но в последната година започнах да имам нещо като угризения на съвестта. Ето, ние пътуваме, вместо да прекарваме време с родителите си. Да, те са здрави, добре са, но времето няма да се върне. Ако не пътувам толкова, мога да прекарвам и повече време с приятелите си вероятно. Да не пропускам важни за тях моменти. Подчертавам, че никой никога не ми е обелвал и думичка по темата. Знам, че времето върви за всички и моят живот също няма да се повтори, и че всеки си има път, трябва да прави каквото му харесва, и т.н. (Ама на мен ми харесва и да пътувам, и да си седя при мама, и да си виждам приятелите често-често.) Случвало ли ти се е да имаш такива мисли и угризения? Как се справяш с тях?
И. М.
„Който го е страх от тъмното – каза пилотът, преди светлините да угаснат за снижаването, – да хване съседа си за ръката, докато кацнем“. И всички се засмяха. Преди полета седнах с мама и я помолих да се сети за подходяща раница. Не непременно да я зарежда отсега с храна, бельо и документи (както са направили родителите на литовската ми приятелка Л.), обаче добре да си помисли кое къде е и да може да реагира, ако се наложи с татко да бягат. „Но къде да бягаме?“, попита мама. Това не знам, още го мисля заедно с всевъзможните причини за бягство. След полета седнах с моите чужбински приятели и си разправихме какво ново-вехто. На витрината в кафенето висеше самоделно хартиено флагче в жълто и синьо с надпис: Viva Slava Ukraini. Обясних им значението на „недо-“ в „недофюрер“ и „недосвастика“. По-късно същата вечер четох за разликите между крадци и мародери – първите се оглеждат за домове, където няма никой, за да ги оберат на спокойствие; вторите се оглеждат за такива, където има някой, за да са сигурни, че ще намерят плячка. Затова, за да не се налага да се сблъскате с мародери лице в лице, дори да ви е страх от тъмното, най-добре е да гасите светлините.
Мила И., получих хубавото ти писмо преди войната. И ми се вижда чудовищно, че когато го получих, „преди войната“ по подразбиране значеше „отдавна“ и „през миналия век“, а сега значи друго. Вижда ми се чудовищно „истинските проблеми“, споменати от теб, изведнъж да са от порядъка на гигантската загуба на живот, здраве, близки, дом, спомени, душевен баланс и доверие в света, която в момента преживява Украйна (а и всички, които ѝ съчувстваме). Вижда ми се чудовищно, че няколко седмици са достатъчни да вкарат в делника ни разговори за видове турникети, спешно запознаване с географията на Украйна, вървящо с ритъма на нейното разкъсване, и неспирно слушане на анализи на жестоко потиснати умни хора. Съжалявам, че ти пиша сега, когато „сега“ е толкова срамно и черно.
Да не говориш по определени въпроси е същото, като да лъжеш. Затова започнах от войната, за която твоето писмо не знае, но моето не може да прескочи. Обаче ето откъде всъщност исках да започна в средата на февруари. Мила И., четох те с удоволствие и малко преди инициалите ти вече знаех коя си. Когато ги видях и си потвърдих догадката, се засмях, но и леко ми домъчня. Понеже сред многото ми приятели съвсем немного биха могли да кажат нещо подобно. А то е нещото, което бих пожелала на всички. Наличието на близки и разбирателството с тях, свободата да се придвижваме в пространството съгласно разбиранията и нуждите си, зрелостта да осъзнаваме богатствата си, ведрото усещане да се събуждаме в собствената си кожа – какво повече да си пожелаем? Може би екзистенциален смисъл, отлепяне от битовото, неограничена свобода? Но как да поискаме каквото и да било отгоре, без да имаме стабилната основа именно на щастието, което описваш и което бих искала да наричам „нормалност“?
Хубавото се заварва, получава се назаем или в замяна на нещо ценно, прави се собственоръчно или в сговорна дружина. Но при всички положения трябва да се поддържа. Няма ситуация, в която в дългосрочен план хубавото да оцелее, ако за него не се полагат съзнателни грижи. Важи за любовта, заложбите, здравето, мира, градската среда, природата, правото да се наричаш „човек“ и каквото още се сетиш. Част от въпросното поддържане става чрез работа в собствената градина и чрез превръщането ѝ в удоволствие за максимален брой хора, но и в отправна точка за тях. Щом щастливият човек е възможен веднъж, значи е възможен милион пъти. Щом един намира начини, значи и друг ще намери. Щом ти си спокойна и удовлетворена, значи няма нужда да те мислят с тревога. Щом твоите усилия дадат плод, ще можеш да нахраниш гладните. И така нататък, и така нататък.
Ако трябва да ти отговоря за себе си: аз също често съм щастлива и имам безчет причини да съм благодарна (естествено, при идентични обстоятелства други хора биха били и далеч повече, и далеч по-малко щастливи и благодарни – обективното и субективното тук са в строго индивидуално съотношение). И да, угризенията, че трябва и повече, и по-иначе, не ме напускат и понякога ме оглозгват почти до петите. Някои от тях са оправдани и ме тласкат към необходима промяна; някои са чиста фантазия. Притеснението за дреболии или нерешими проблеми, вината за това, че ни е добре, докато на други не им е, или че ни е зле, докато на други им е несравнимо по-зле, са неизбежни бъгове на човешката ни натура. А може и да не са бъгове, а залог за постоянното ни заземяване, за правилното ни функциониране и оптималната ни трезвост. Така де, щом сме мислещи тръстики, явно ще сме и неспокойни тръстики. Дори не знам дали има смисъл да се борим срещу моментите си на гузност насред щастието – навярно е много по-редно да се борим за щастието.
Имам един приятел, Я., който навръх пандемията ме посвети в „Масяня“ и рязко повдигна потъналото ми настроение. Масяня е главната героиня на един шантав анимационен сериал, който от две десетилетия върви онлайн и се финансира изцяло от своите почитатели. Прави го от А до Я – тоест от нарочно схематичните рисунки, през хумористичните, често остро политически сюжети и пиперливите реплики, до озвучаването на всички роли – многостранният талант Олег Куваев. Масяня (галено от Мария) и гаджето ѝ Хрюндел (прякор на Александър) живеят в Петербург, минават през най-разнообразни перипетии и постоянно се смеят заедно. Неотдавна излезе новият епизод, за първи път страшен, тъмен. В него Масяня прониква в бункера на диктатора Путин и му носи меч за сепуку.
– Кажи бе, убиецо – пита го тя, – защо започна война?
– Ами те какво така свободно живеят и не слушат мен, великия император? – мънка оня в отговор. – Моите васали ще вземат да се нагледат и също да си поискат нещо хубаво…
Точно такива са враговете на нормалността. Те не се притесняват да са добре, на тях им е нужно наоколо да е ад, за да има къде да се разгърнат.
Имам една приятелка, В., която е толкова свестен и щедър човек, че винаги се чудя откъде черпи сили. Познавам я покрай Уикипедия, петнайсет и кусур години вече – тя е един от най-дейните добротворци там: неспирно създава, разтребва, помага, образова. През 2015 г. В. измисли една игра за международната общност на уикипедианците: 100 уикидни. Ако ти стиска, се ангажираш пред себе си и пред света и всеки божи ден пишеш нова статия по различна тема, докато не стигнеш до 100. Войната я завари към средата на нейната шеста непрекъсната стотица. И знаеш ли какво прави В. сега? Вдига събореното. Пише статии за места, разрушени от руските нашественици: Донецкия областен драматичен театър в Мариупол, музея IT 8-bit, църквата „Рождество Богородично“ във Вязивка, музея „Куинджи“…
Ето я светлата част на „сега“. Упорството, с което добрите хора правят добри дела. Епичният мравуняк на хилядите щедрости, самоотвержености и битки за справедливост, в който през последните седмици се разрази неистова активност и в който няма „малко“ добро – всяко е от „голямо“ нагоре. Всичките приятели, познати и непознати, които приютиха пострадали от войната, дариха пари, сортираха дрехи, превозваха, издирваха, набавяха, превеждаха, утешаваха, бдяха и продължават да не са безучастни по хиляди начини. Когато започнах да посещавам най-многолюдната и ефикасна онлайн група за подкрепа за украинските бежанци в България, първото познато име, което видях сред модераторите, беше твоето. Отново никак не се изненадах. Засмях се и се зарадвах.
Будь ласка са първите ми думи на украински – значат „моля“, „няма защо“, „ако обичаш“. Сигурна съм, че ти като човек на словото също цениш красотата и странността им за българското ухо. Сякаш някой казва: „бъди ласкав“. Или дори „бъди самата ласка“. И правилно казва! Е, скъпа И., будь ласка, добрувай, искай най-хубавото за себе си и за другите, напук на нуждата от ад на диктаторите, трупай радост от живота, за да продължаваш да я споделяш – тя ни е толкова нужна.
Заглавно изображение: „Елбрус“ на мариуполския пейзажист Архип Куинджи (1841–1910)
{kind=link}
На второ четене: „Умножение без уморение“ от Зорница Христова
Post Syndicated from Севда Семер original https://toest.bg/na-vtoro-chetene-umnozhenie-bez-umorenie/
Никой от нас не чете единствено най-новите книги. Тогава защо само за тях се пише? „На второ четене“ е рубрика, в която отваряме списъците с книги, публикувани преди поне година, четем ги и препоръчваме любимите си от тях. Рубриката е част от партньорската програма Читателски клуб „Тоест“. Изборът на заглавия обаче е единствено на авторите – Стефан Иванов и Севда Семер, които биха ви препоръчали тези книги и ако имаше как веднъж на две седмици да се разходите с тях в книжарницата.
„Умножение без уморение“ от Зорница Христова
илюстрации Миглена Папазова, изд. „Точица“, 2018
 Пиша професионално вече към 15 години. Едва ли съществува един-единствен отговор на въпроса защо го правя – с времето са се трупали различни причини. Сред ранните обаче е таблицата за умножение. Тя заема интересно място в живота ми, и то по начин, който ще разберат напълно между 5 и 10% от населението, доколкото видях последно. А именно хората с дискалкулия като мен. За нея ще разкажа малко по-късно, но може би тя е причината да поискам да пиша за „Умножение без уморение“. Тази книжка учи малките деца на различни принципи, които правят по-лесно усвояването на „таблицата за мъчение“, както я наричахме ние. По-важното е, че със стихчета и рима учи малките, че математическите принципи не са нито сухи, нито скучни, нито страшни.
Пиша професионално вече към 15 години. Едва ли съществува един-единствен отговор на въпроса защо го правя – с времето са се трупали различни причини. Сред ранните обаче е таблицата за умножение. Тя заема интересно място в живота ми, и то по начин, който ще разберат напълно между 5 и 10% от населението, доколкото видях последно. А именно хората с дискалкулия като мен. За нея ще разкажа малко по-късно, но може би тя е причината да поискам да пиша за „Умножение без уморение“. Тази книжка учи малките деца на различни принципи, които правят по-лесно усвояването на „таблицата за мъчение“, както я наричахме ние. По-важното е, че със стихчета и рима учи малките, че математическите принципи не са нито сухи, нито скучни, нито страшни.
Всяко от числата до десет, с които умножаваме, има своя кратка част в книгата. Първо весели илюстрации и стихче показват умен принцип за умножение и лесен съвет как да се запомни. Новото се приближава до нещо познато. Наскоро запомних как се казва новият съсед, като си представих сина на близка приятелка със същото име (сега всеки път в главата си ги виждам и двамата, което също е приятно). И тук историите в стихчетата често правят връзки, които са близо до децата и живота им. Така например умножаването по три разказва историята, в която двамата родители имат „две салфетки, две паници“, докато в един момент семейството започва да расте:
Но когато ме видял,
моят татко изкрещял
силно три пъти „Ура“!
Оттогава досега
3 да царства е наред –
три фунийки сладолед…
И така нататък, докато историята стига до своя принцип за умножение по три:
По три значи: удвояваш
и пак същото прибавяш.
Други от историите пък са толкова специфични и с такива находчиви рими, че няма как да не ги запомниш. Като тази, която разказва за „злобен, шкембест и тиран“ цар Осман и неговата дъщеря – Осмица, „ненагледна хубавица“. Героят в стихчето иска да спечели принцесата, но първо трябва да мине през предизвикателството, поставено от баща ѝ. Вместо например да се бие с триглав змей, героят трябва да умножи – наистина страховито! – следното по осем:
… шест камили с дълъг косъм,
седем любопитни лоса,
девет мрачни албатроса.
Умницата Осмица се включва и подсказва:
Осем ли? Не се коси!
Три пъти го удвои!
Лесносмилаемо е по много причини, не само защото някои от числата са изписани от тесто за сладки. След историите следват и задачи: две страници с упражнения, също пълни със смешки и хубави илюстрации. Има и места, на които детето може да пише, но някак не се усеща като учебник или тетрадка – игривата форма се запазва.
Харесва ми, че всичко е обяснено със семантика и език. За мен математиката е неразбираема. В училище се справях толкова зле, че започнах да се притеснявам, че съм глупава. Сякаш това ме мотивира повече да чета и ме приближи към езика, после – и към писането.
До ден днешен не знам таблицата за умножение – факт, който се е превърнал в семейна шега през годините. Също като това колко е лошо пространственото ми мислене и колко лесно се губя. Голямо облекчение беше да имам много висок близък приятел, защото тогава 4, 6 или 10 метра станаха най-сетне разбираеми величини: представях си го легнал на земята два, три или пет пъти и що-годе схващах. Ужасно трудно ми е да помня конкретни данни, дати, години, телефонни номера и много други работи. Всеки път внимавам, когато пиша 6 или 9, 3 или 8 – защото ги бъркам. На клавиатурата сега беше лесно, виждам веднага отляво надясно кое е по-малкото.
Криво-ляво се научих да живея с тези специфики и да избягвам математиката колкото мога. На 19 в университета трябваше да направя задължителен тест за дислексия. Мисля, че беше заради това колко често се случва учениците дори да не знаят, че я имат. Излезе, че имам дискалкулия. Един немного точен, но пък удобен начин да бъде обяснена е, че е като дислексия, но свързана с числа. Най-сетне си отдъхнах, че не съм глупава!
В този смисъл аз чета „Умножение без уморение“ като човек, който до огромна степен няма формирано математическо мислене. С което не искам да кажа, че я чета като дете (ех, за жалост, това е невъзможно), нито пък че тя ще промени начина, по който работи мозъкът ми. Имам все пак един малък бонус поне за това ревю – влизам в темата абсолютно боса.
Помогна ли ми книгата? Донякъде – някои видове сметки са ми по-лесни и съм забелязала, че ако разполагам с трик, като подсказания от Осмица например, нещата са по-възможни. За мен обаче по-важното беше друго – беше ми забавно да чета книгата и да следя задачите. А съм човек, който има силна тревога за всичко, свързано с математика.
В училище не съм имала усещането, че да се учи е забавно, освен доста полезно. А пък тук това е принцип на цялата книга. Не само заради находчивите игри с думи, а и заради илюстрациите. Харесвам много рисунките на Миглена Папазова. Богати, без да има нищо пластмасово в тях, и чудновати по весел начин. Акула си играе с тарантули, мечка носи раничка калинка… Дълго може да се гледат тези рисунки – за разлика от повечето учебни помагала, от които бързо-бързо искаш да избягаш към нещо по-забавно.
А дали книгата подобри разбирането ми за таблицата за умножение? Е, за мен това би било по-трудно. Направи нещо друго обаче – забавлявах се в компанията на таблицата за умножение, а не ми се беше случвало преди. Затова я препоръчвам и за вашето дете. Пък и с принципите си тя, освен че е забавна, е и доста полезна.
Заглавна илюстрация: © Елена и Лина Кривошиеви
Активните дарители на „Тоест“ получават постоянна отстъпка в размер на 20% от коричната цена на всички заглавия от каталога на „Точица“, както и на няколко други български издателства в рамките на партньорската програма Читателски клуб „Тоест“. За повече информация прочетете на toest.bg/club.
Let’s work on ESPHome project together
Post Syndicated from BeardedTinker original https://www.youtube.com/watch?v=OXfTYl3dKaw
Metasploit Weekly Wrap-Up
Post Syndicated from Alan David Foster original https://blog.rapid7.com/2022/04/01/metasploit-weekly-wrap-up-155/
CVE-2022-22963 – Spring Cloud Function SpEL RCE

A new exploit/multi/http/spring_cloud_function_spel_injection module has been developed by our very own Spencer McIntyre which targets Spring Cloud Function versions Prior to 3.1.7 and 3.2.3. This module is unrelated to Spring4Shell CVE-2022-22965, which is a separate vulnerability in the WebDataBinder component of Spring Framework.
This exploit works by crafting an unauthenticated HTTP request to the target application. When the spring.cloud.function.routing-expression HTTP header is received by the server it will evaluate the user provided SpEL (Spring Expression Language) query, leading to remote code execution. This can be seen within the CVE-2022-22963 Metasploit module:
res = send_request_cgi(
'method' => 'POST',
'uri' => normalize_uri(datastore['TARGETURI']),
'headers' => {
'spring.cloud.function.routing-expression' => "T(java.lang.Runtime).getRuntime().exec(new String[]{'/bin/sh','-c','#{cmd.gsub("'", "''")}'})"
}
)
Both patched and unpatched servers will respond with a 500 server error and a JSON encoded message
New module content (1)
- Spring Cloud Function SpEL Injection by Spencer McIntyre, hktalent, and m09u3r, which exploits CVE-2022-22963 – This achieves unauthenticated remote code execution by executing SpEL (Spring Expression Language) queries against Spring Cloud Function versions prior to
3.1.7and3.2.3.
Bugs fixed (2)
- #16364 from zeroSteiner – This adds a fix for a crash in
auxiliary/spoof/dns/native_spooferand adds documentation for the module. - #16386 from adfoster-r7 – Fixes a crash when running the
exploit/multi/misc/java_rmi_servermodule against at target server, such as Metasploitable2
Get it
As always, you can update to the latest Metasploit Framework with msfupdate
and you can get more details on the changes since the last blog post from
GitHub:
If you are a git user, you can clone the Metasploit Framework repo (master branch) for the latest.
To install fresh without using git, you can use the open-source-only Nightly Installers or the
binary installers (which also include the commercial edition).
Build data lineage for data lakes using AWS Glue, Amazon Neptune, and Spline
Post Syndicated from Khoa Nguyen original https://aws.amazon.com/blogs/big-data/build-data-lineage-for-data-lakes-using-aws-glue-amazon-neptune-and-spline/
Data lineage is one of the most critical components of a data governance strategy for data lakes. Data lineage helps ensure that accurate, complete and trustworthy data is being used to drive business decisions. While a data catalog provides metadata management features and search capabilities, data lineage shows the full context of your data by capturing in greater detail the true relationships between data sources, where the data originated from and how it gets transformed and converged. Different personas in the data lake benefit from data lineage:
- For data scientists, the ability to view and track data flow as it moves from source to destination helps you easily understand the quality and origin of a particular metric or dataset
- Data platform engineers can get more insights into the data pipelines and the interdependencies between datasets
- Changes in data pipelines are easier to apply and validate because engineers can identify a job’s upstream dependencies and downstream usage to properly evaluate service impacts
As the complexity of data landscape grows, customers are facing significant manageability challenges in capturing lineage in a cost-effective and consistent manner. In this post, we walk you through three steps in building an end-to-end automated data lineage solution for data lakes: lineage capturing, modeling and storage and finally visualization.
In this solution, we capture both coarse-grained and fine-grained data lineage. Coarse-grained data lineage, which often targets business users, focuses on capturing the high-level business processes and overall data workflows. Typically, it captures and visualizes the relationships between datasets and how they’re propagated across storage tiers, including extract, transform and load (ETL) jobs and operational information. Fine-grained data lineage gives access to column-level lineage and the data transformation steps in the processing and analytical pipelines.
Solution overview
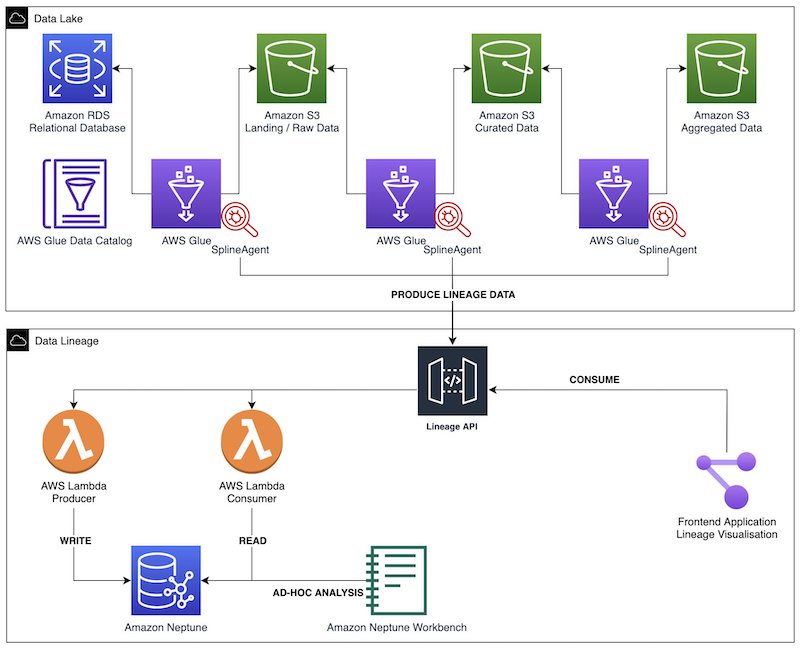
Apache Spark is one of the most popular engines for large-scale data processing in data lakes. Our solution uses the Spline agent to capture runtime lineage information from Spark jobs, powered by AWS Glue. We use Amazon Neptune, a purpose-built graph database optimized for storing and querying highly connected datasets, to model lineage data for analysis and visualization.
The following diagram illustrates the solution architecture. We use AWS Glue Spark ETL jobs to perform data ingestion, transformation, and load. The Spline agent is configured in each AWS Glue job to capture lineage and run metrics, and sends such data to a lineage REST API. This backend consists of producer and consumer endpoints, powered by Amazon API Gateway and AWS Lambda functions. The producer endpoints process the incoming lineage objects before storing them in the Neptune database. We use consumer endpoints to extract specific lineage graphs for different visualizations in the frontend application. We perform ad hoc interactive analysis on the graph through Neptune notebooks.
We provide sample code and Terraform deployment scripts on GitHub to quickly deploy this solution to the AWS Cloud.
Data lineage capturing
The Spline agent is an open-source project that can harvest data lineage automatically from Spark jobs at runtime, without the need to modify the existing ETL code. It listens to Spark’s query run events, extracts lineage objects from the job run plans and sends them to a preconfigured backend (such as HTTP endpoints). The agent also automatically collects job run metrics such as the number of output rows. As of this writing, the Spline agent works only with Spark SQL (DataSet/DataFrame APIs) and not with RDDs/DynamicFrames.
The following screenshot shows how to integrate the Spline agent with AWS Glue Spark jobs. The Spline agent is an uber JAR that needs to be added to the Java classpath. The following configurations are required to set up the Spline agent:
spark.sql.queryExecutionListenersconfiguration is used to register a Spline listener during its initialization.spark.spline.producer.urlspecifies the address of the HTTP server that the Spline agent should send lineage data to.
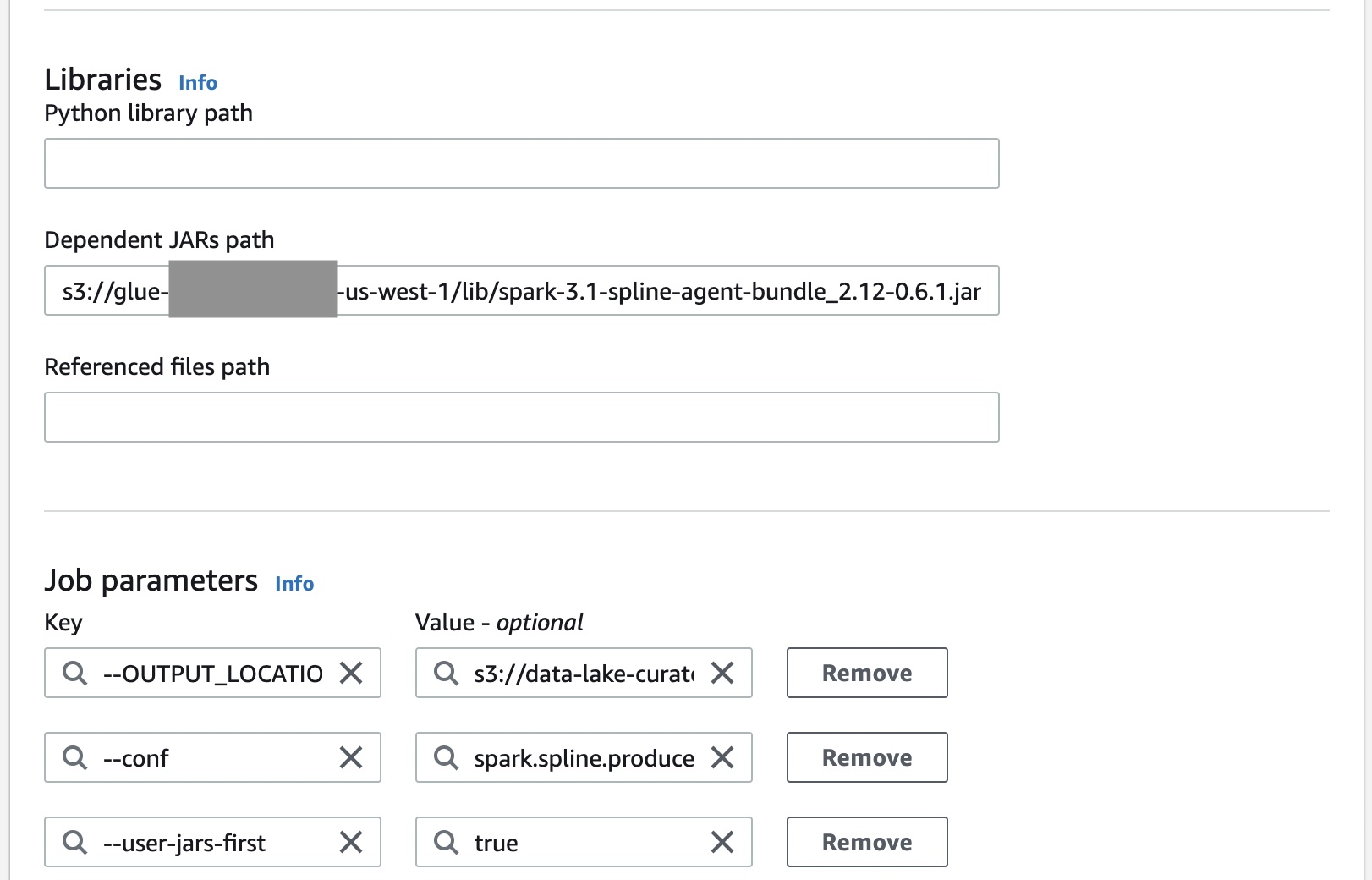
We build a data lineage API that is compatible with the Spline agent. This API facilitates the insertion of lineage data to Neptune database and graph extraction for visualization. The Spline agent requires three HTTP endpoints:
- /status – For health checks
- /execution-plans – For sending the captured Spark execution plans after the jobs are submitted to run
- /execution-events – For sending the job’s run metrics when the job is complete
We also create additional endpoints to manage various metadata of the data lake, such as the names of the storage layers and dataset classification.
When a Spark SQL statement is run or a DataFrame action is called, Spark’s optimization engine, namely Catalyst, generates different query plans: a logical plan, optimized logical plan and physical plan, which can be inspected using the EXPLAIN statement. In a job run, the Spline agent parses the analyzed logical plan to construct a JSON lineage object. The object consists of the following:
- A unique job run ID
- A reference schema (attribute names and data types)
- A list of operations
- Other system metadata such as Spark version and Spline agent version
A run plan specifies the steps the Spark job performs, from reading data sources, applying different transformations, to finally persisting the job’s output into a storage location.
To sum up, the Spline agent captures not only the metadata of the job (such as job name and run date and time), the input and output tables (such as data format, physical location and schema) but also detailed information about the business logic (SQL-like operations that the job performs, such as join, filter, project and aggregate).
Data modeling and storage
Data modeling starts with the business requirements and use cases and maps those needs into a structure for storing and organizing our data. In data lineage for data lakes, the relationships between data assets (jobs, tables and columns) are as important as the metadata of those. As a result, graph databases are suitable to model such highly connected entities, making it efficient to understand the complex and deep network of relationships within the data.
Neptune is a fast, reliable, fully managed graph database service that makes it easy to build and run applications with highly connected datasets. You can use Neptune to create sophisticated, interactive graph applications that can query billions of relationships in milliseconds. Neptune supports three popular graph query languages: Apache TinkerPop Gremlin and openCypher for property graphs and SPARQL for W3C’s RDF data model. In this solution, we use the property graph’s primitives (including vertices, edges, labels and properties) to model the objects and use the gremlinpython library to interact with the graphs.
The objective of our data model is to provide an abstraction for data assets and their relationships within the data lake. In the producer Lambda functions, we first parse the JSON lineage objects to form logical entities such as jobs, tables and operations before constructing the final graph in Neptune.

The following diagram shows a sample data model used in this solution.

This data model allows us to easily traverse the graph to extract coarse-grained and fine-grained data lineage, as mentioned earlier.
Data lineage visualization
You can extract specific views of the lineage graph from Neptune using the consumer endpoints backed by Lambda functions. Hierarchical views of lineage at different levels make it easy for the end-user to analyze the information.
The following screenshot shows a data lineage view across all jobs and tables.
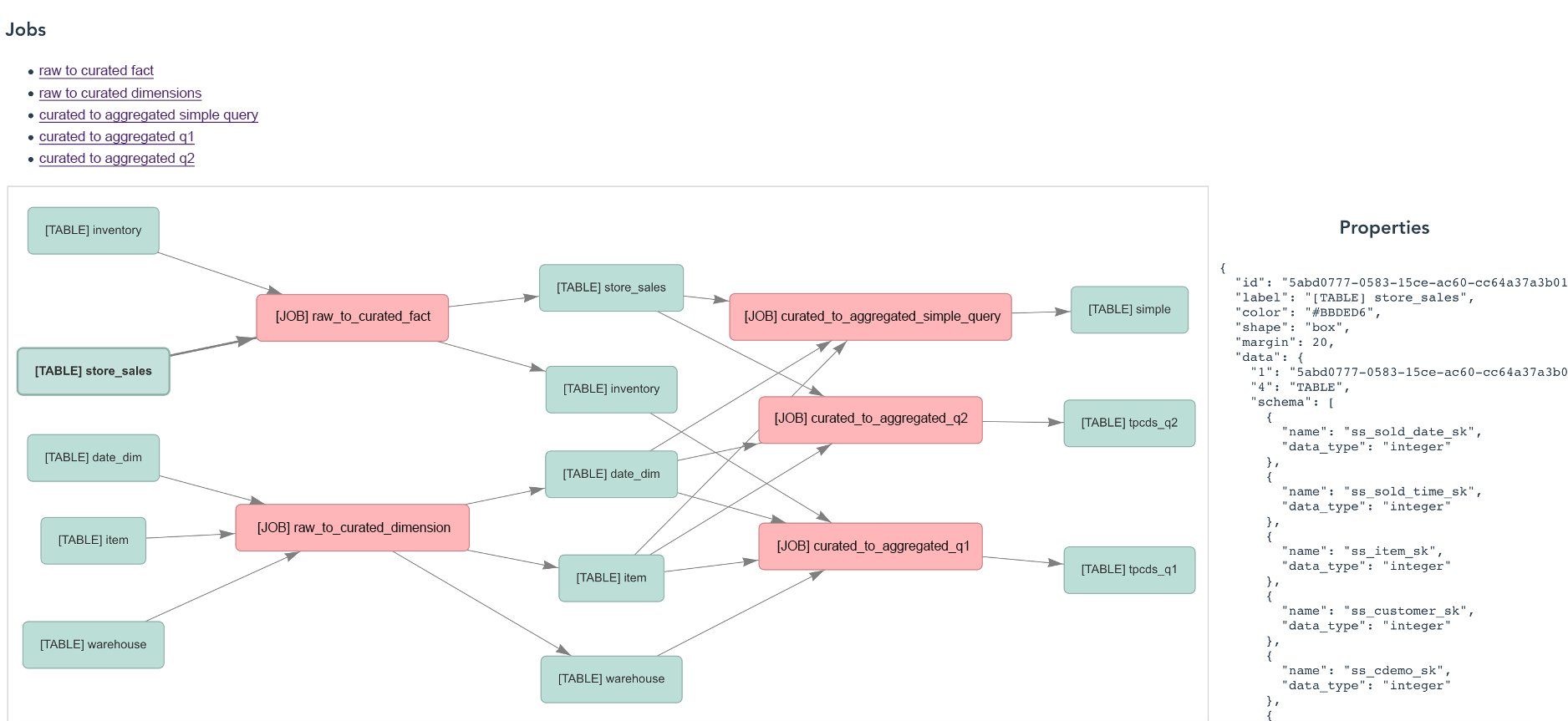
The following screenshot shows a view of a specific job plan.

The following screenshot shows a detailed look into the operations taken by the job.
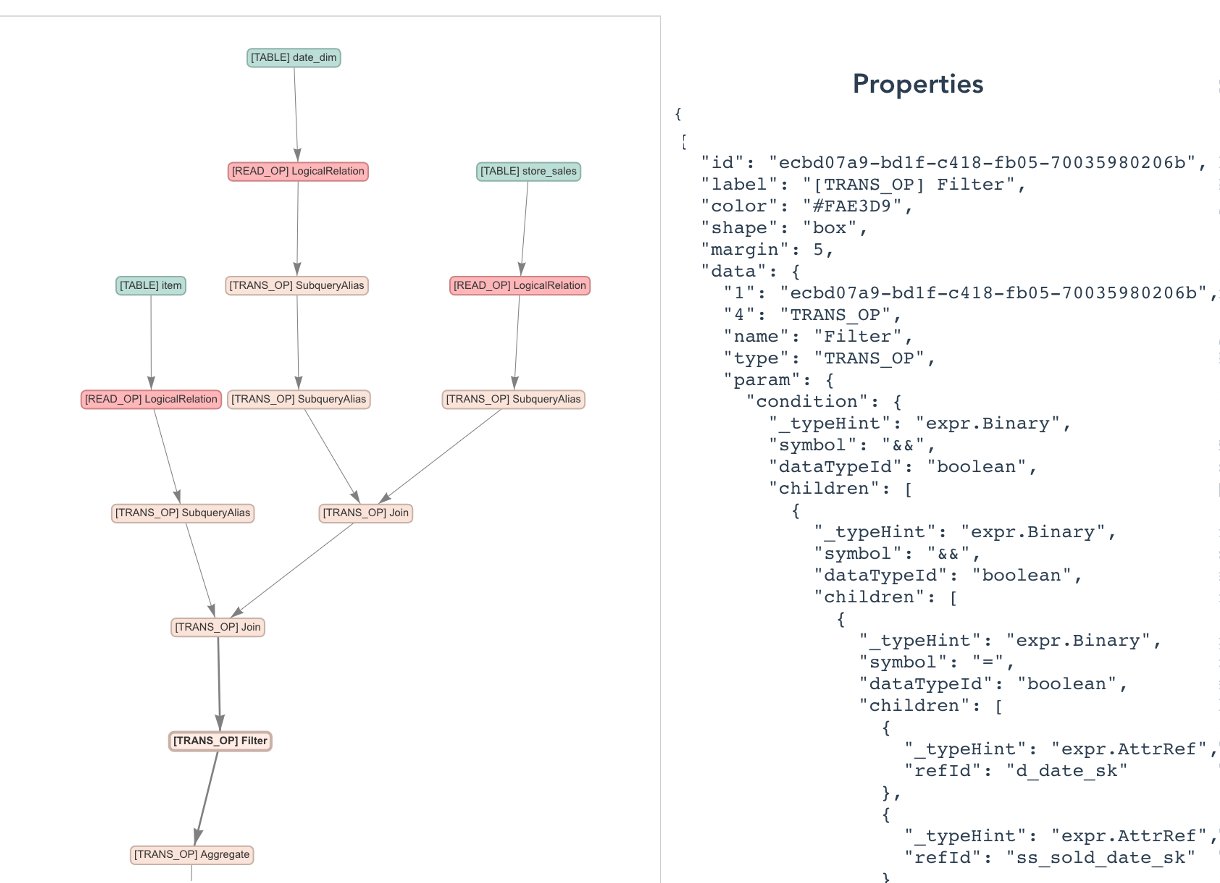
The graphs are visualized using the vis.js network open-source project. You can interact with the graph elements to learn more about the entity’s properties, such as data schema.
Conclusion
In this post, we showed you architectural design options to automatically collect end-to-end data lineage for AWS Glue Spark ETL jobs across a data lake in a multi-account AWS environment using Neptune and the Spline agent. This approach enables searchable metadata, helps to draw insights and achieve an improved organization-wide data lineage posture. The proposed solution uses AWS managed and serverless services, which are scalable and configurable for high availability and performance.
For more information about this solution, see Github. You may modify the code to extend the data model and APIs.
About the Authors
 Khoa Nguyen is a Senior Big Data Architect at Amazon Web Services. He works with large enterprise customers and AWS partners to accelerate customers’ business outcomes by providing expertise in Big Data and AWS services.
Khoa Nguyen is a Senior Big Data Architect at Amazon Web Services. He works with large enterprise customers and AWS partners to accelerate customers’ business outcomes by providing expertise in Big Data and AWS services.
 Krithivasan Balasubramaniyan is a Principal Consultant at Amazon Web Services. He enables global enterprise customers in their digital transformation journey and helps architect cloud native solutions.
Krithivasan Balasubramaniyan is a Principal Consultant at Amazon Web Services. He enables global enterprise customers in their digital transformation journey and helps architect cloud native solutions.
 Rahul Shaurya is a Senior Big Data Architect at Amazon Web Services. He helps and works closely with customers building data platforms and analytical applications on AWS.
Rahul Shaurya is a Senior Big Data Architect at Amazon Web Services. He helps and works closely with customers building data platforms and analytical applications on AWS.
Best practices: Securing your Amazon Location Service resources
Post Syndicated from Dave Bailey original https://aws.amazon.com/blogs/security/best-practices-securing-your-amazon-location-service-resources/
Location data is subjected to heavy scrutiny by security experts. Knowing the current position of a person, vehicle, or asset can provide industries with many benefits, whether to understand where a current delivery is, how many people are inside a venue, or to optimize routing for a fleet of vehicles. This blog post explains how Amazon Web Services (AWS) helps keep location data secured in transit and at rest, and how you can leverage additional security features to help keep information safe and compliant.
The General Data Protection Regulation (GDPR) defines personal data as “any information relating to an identified or identifiable natural person (…) such as a name, an identification number, location data, an online identifier or to one or more factors specific to the physical, physiological, genetic, mental, economic, cultural or social identity of that natural person.” Also, many companies wish to improve transparency to users, making it explicit when a particular application wants to not only track their position and data, but also to share that information with other apps and websites. Your organization needs to adapt to these changes quickly to maintain a secure stance in a competitive environment.
On June 1, 2021, AWS made Amazon Location Service generally available to customers. With Amazon Location, you can build applications that provide maps and points of interest, convert street addresses into geographic coordinates, calculate routes, track resources, and invoke actions based on location. The service enables you to access location data with developer tools and to move your applications to production faster with monitoring and management capabilities.
In this blog post, we will show you the features that Amazon Location provides out of the box to keep your data safe, along with best practices that you can follow to reach the level of security that your organization strives to accomplish.
Data control and data rights
Amazon Location relies on global trusted providers Esri and HERE Technologies to provide high-quality location data to customers. Features like maps, places, and routes are provided by these AWS Partners so solutions can have data that is not only accurate but constantly updated.
AWS anonymizes and encrypts location data at rest and during its transmission to partner systems. In parallel, third parties cannot sell your data or use it for advertising purposes, following our service terms. This helps you shield sensitive information, protect user privacy, and reduce organizational compliance risks. To learn more, see the Amazon Location Data Security and Control documentation.
Integrations
Operationalizing location-based solutions can be daunting. It’s not just necessary to build the solution, but also to integrate it with the rest of your applications that are built in AWS. Amazon Location facilitates this process from a security perspective by integrating with services that expedite the development process, enhancing the security aspects of the solution.
Encryption
Amazon Location uses AWS owned keys by default to automatically encrypt personally identifiable data. AWS owned keys are a collection of AWS Key Management Service (AWS KMS) keys that an AWS service owns and manages for use in multiple AWS accounts. Although AWS owned keys are not in your AWS account, Amazon Location can use the associated AWS owned keys to protect the resources in your account.
If customers choose to use their own keys, they can benefit from AWS KMS to store their own encryption keys and use them to add a second layer of encryption to geofencing and tracking data.
Authentication and authorization
Amazon Location also integrates with AWS Identity and Access Management (IAM), so that you can use its identity-based policies to specify allowed or denied actions and resources, as well as the conditions under which actions are allowed or denied on Amazon Location. Also, for actions that require unauthenticated access, you can use unauthenticated IAM roles.
As an extension to IAM, Amazon Cognito can be an option if you need to integrate your solution with a front-end client that authenticates users with its own process. In this case, you can use Cognito to handle the authentication, authorization, and user management for you. You can use Cognito unauthenticated identity pools with Amazon Location as a way for applications to retrieve temporary, scoped-down AWS credentials. To learn more about setting up Cognito with Amazon Location, see the blog post Add a map to your webpage with Amazon Location Service.
Limit the scope of your unauthenticated roles to a domain
When you are building an application that allows users to perform actions such as retrieving map tiles, searching for points of interest, updating device positions, and calculating routes without needing them to be authenticated, you can make use of unauthenticated roles.
When using unauthenticated roles to access Amazon Location resources, you can add an extra condition to limit resource access to an HTTP referer that you specify in the policy. The aws:referer request context value is provided by the caller in an HTTP header, and it is included in a web browser request.
The following is an example of a policy that allows access to a Map resource by using the aws:referer condition, but only if the request comes from the domain example.com.
To learn more about aws:referer and other global conditions, see AWS global condition context keys.
Encrypt tracker and geofence information using customer managed keys with AWS KMS
When you create your tracker and geofence collection resources, you have the option to use a symmetric customer managed key to add a second layer of encryption to geofencing and tracking data. Because you have full control of this key, you can establish and maintain your own IAM policies, manage key rotation, and schedule keys for deletion.
After you create your resources with customer managed keys, the geometry of your geofences and all positions associated to a tracked device will have two layers of encryption. In the next sections, you will see how to create a key and use it to encrypt your own data.
Create an AWS KMS symmetric key
First, you need to create a key policy that will limit the AWS KMS key to allow access to principals authorized to use Amazon Location and to principals authorized to manage the key. For more information about specifying permissions in a policy, see the AWS KMS Developer Guide.
To create the key policy
Create a JSON policy file by using the following policy as a reference. This key policy allows Amazon Location to grant access to your KMS key only when it is called from your AWS account. This works by combining the kms:ViaService and kms:CallerAccount conditions. In the following policy, replace us-west-2 with your AWS Region of choice, and the kms:CallerAccount value with your AWS account ID. Adjust the KMS Key Administrators statement to reflect your actual key administrators’ principals, including yourself. For details on how to use the Principal element, see the AWS JSON policy elements documentation.
For the next steps, you will use the AWS Command Line Interface (AWS CLI). Make sure to have the latest version installed by following the AWS CLI documentation.
Tip: AWS CLI will consider the Region you defined as the default during the configuration steps, but you can override this configuration by adding –region <your region> at the end of each command line in the following command. Also, make sure that your user has the appropriate permissions to perform those actions.
To create the symmetric key
Now, create a symmetric key on AWS KMS by running the create-key command and passing the policy file that you created in the previous step.
aws kms create-key –policy file://<your JSON policy file>
Alternatively, you can create the symmetric key using the AWS KMS console with the preceding key policy.
After running the command, you should see the following output. Take note of the KeyId value.
Create an Amazon Location tracker and geofence collection resources
To create an Amazon Location tracker resource that uses AWS KMS for a second layer of encryption, run the following command, passing the key ID from the previous step.
Here is the output from this command.
Similarly, to create a geofence collection by using your own KMS symmetric keys, run the following command, also modifying the key ID.
Here is the output from this command.
By following these steps, you have added a second layer of encryption to your geofence collection and tracker.
Data retention best practices
Trackers and geofence collections are stored and never leave your AWS account without your permission, but they have different lifecycles on Amazon Location.
Trackers store the positions of devices and assets that are tracked in a longitude/latitude format. These positions are stored for 30 days by the service before being automatically deleted. If needed for historical purposes, you can transfer this data to another data storage layer and apply the proper security measures based on the shared responsibility model.
Geofence collections store the geometries you provide until you explicitly choose to delete them, so you can use encryption with AWS managed keys or your own keys to keep them for as long as needed.
Asset tracking and location storage best practices
After a tracker is created, you can start sending location updates by using the Amazon Location front-end SDKs or by calling the BatchUpdateDevicePosition API. In both cases, at a minimum, you need to provide the latitude and longitude, the time when the device was in that position, and a device-unique identifier that represents the asset being tracked.
Protecting device IDs
This device ID can be any string of your choice, so you should apply measures to prevent certain IDs from being used. Some examples of what to avoid include:
- First and last names
- Facility names
- Documents, such as driver’s licenses or social security numbers
- Emails
- Addresses
- Telephone numbers
Latitude and longitude precision
Latitude and longitude coordinates convey precision in degrees, presented as decimals, with each decimal place representing a different measure of distance (when measured at the equator).
Amazon Location supports up to six decimal places of precision (0.000001), which is equal to approximately 11 cm or 4.4 inches at the equator. You can limit the number of decimal places in the latitude and longitude pair that is sent to the tracker based on the precision required, increasing the location range and providing extra privacy to users.
Figure 1 shows a latitude and longitude pair, with the level of detail associated to decimals places.

Figure 1: Geolocation decimal precision details
Position filtering
Amazon Location introduced position filtering as an option to trackers that enables cost reduction and reduces jitter from inaccurate device location updates.
- DistanceBased filtering ignores location updates wherein devices have moved less than 30 meters (98.4 ft).
- TimeBased filtering evaluates every location update against linked geofence collections, but not every location update is stored. If your update frequency is more often than 30 seconds, then only one update per 30 seconds is stored for each unique device ID.
- AccuracyBased filtering ignores location updates if the distance moved was less than the measured accuracy provided by the device.
By using filtering options, you can reduce the number of location updates that are sent and stored, thus reducing the level of location detail provided and increasing the level of privacy.
Logging and monitoring
Amazon Location integrates with AWS services that provide the observability needed to help you comply with your organization’s security standards.
To record all actions that were taken by users, roles, or AWS services that access Amazon Location, consider using AWS CloudTrail. CloudTrail provides information on who is accessing your resources, detailing the account ID, principal ID, source IP address, timestamp, and more. Moreover, Amazon CloudWatch helps you collect and analyze metrics related to your Amazon Location resources. CloudWatch also allows you to create alarms based on pre-defined thresholds of call counts. These alarms can create notifications through Amazon Simple Notification Service (Amazon SNS) to automatically alert teams responsible for investigating abnormalities.
Conclusion
At AWS, security is our top priority. Here, security and compliance is a shared responsibility between AWS and the customer, where AWS is responsible for protecting the infrastructure that runs all of the services offered in the AWS Cloud. The customer assumes the responsibility to perform all of the necessary security configurations to the solutions they are building on top of our infrastructure.
In this blog post, you’ve learned the controls and guardrails that Amazon Location provides out of the box to help provide data privacy and data protection to our customers. You also learned about the other mechanisms you can use to enhance your security posture.
Start building your own secure geolocation solutions by following the Amazon Location Developer Guide and learn more about how the service handles security by reading the security topics in the guide.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this blog post, start a new thread on Amazon Location Service forum or contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
Improve workload sustainability with services and features from re:Invent 2021
Post Syndicated from Ernesto Bethencourt Plaz original https://aws.amazon.com/blogs/architecture/improve-workload-sustainability-with-services-and-features-from-reinvent-2021/
At our recent annual AWS re:Invent 2021 conference, we had important announcements regarding sustainability, including the new Sustainability Pillar for AWS Well-Architected Framework and the AWS Customer Carbon Footprint Tool.
In this blog post, I highlight services and features from these announcements to help you design and optimize your AWS workloads from a sustainability perspective.
Architecting for sustainability basics
Environmental sustainability is a shared responsibility between customers and AWS. We maintain sustainability of the cloud by delivering efficient, shared infrastructure. As a customer, you maintain sustainability in the cloud. This means you optimize your workload to efficiently use resources.

Figure 1. Shared responsibility model for sustainability
The Sustainability Pillar of the Well-Architected Framework provides the following design principles that you can use to optimize your workload for sustainability in the cloud:
- Understand your impact.
- Establish sustainability goals.
- Maximize utilization.
- Anticipate and adopt new, more efficient hardware and software offerings.
- Use managed services.
- Reduce the downstream impact of your cloud workloads.
In the next sections, I share new services and service features that were announced at re:Invent 2021 that are related to these design principles and provide recommendations on how they can help you design and operate your workloads more sustainably.
Understand your impact
Measure the environmental impact of your workloads and propose optimizations to meet your sustainability goals:
- Understand your workload’s environmental impact with new AWS Compute Optimizer resource efficiency metrics and enhanced metrics.
- Optimize scaling decisions and reduce idle resources associated with domain controllers with AWS Directory Service for Microsoft Active Directory and information in Amazon CloudWatch.
- Use the SQL-based metrics query engine to simplify gathering metrics to find optimization opportunities with CloudWatch.
Maximize utilization
Reduce the total energy required to power your workloads by right-sizing your workloads to ensure high utilization and eliminating or minimizing idle resources.
Optimize your storage
- Use new storage tiers in Amazon Elastic Block Store (Amazon EBS) snapshots, Amazon Timestream, AWS IoT SiteWise, Amazon DynamoDB, and Amazon ElastiCache for Redis to move data to “colder” tiers.
- Support new storage access patterns with the new Amazon Simple Storage Service (Amazon S3) Glacier Instant Retrieval and Amazon S3 Intelligent-Tiering Archive Instant Access
- Delete data that you don’t need by using lifecycle policies with fine-grained controls that use new actions and filters.
- Use storage optimization for AWS Lake Formation to reduce and optimize your storage with its garbage collection and data compaction features.
Optimize data movement
Moving data across networks can contribute to energy consumption and your overall costs. Optimizing networks and data movement can save energy and costs. Optimize the way you access and move data across networks by:
- Use AWS Direct Connect SiteLink to connect an on-premises network directly through the AWS global network. This helps your data travel more efficiently (across the shortest path) rather than using public network.
- Migrate tape backups to the cloud with AWS Snow Family offline tape data migration. This helps you eliminate physical tapes and store your virtual tapes in the cloud with cold storage.
- Automakers that build connected cars generate loads of data. Use AWS IoT FleetWise to reduce the amount of unnecessary data transferred to the cloud.
Optimize your processing
Minimize the resources you use and increase the utilization of resources you use to run your workloads:
- Optimize the resources you use for your machine learning (ML) models with Amazon SageMaker Inference Recommender.
- Reduce AWS Lambda function executions with the new event filtering for Amazon Simple Queue Service (Amazon SQS), DynamoDB, and Amazon Kinesis.
- Minimize the amount of data that needs to be accessed by consumer clusters and provision flexible compute resources in Amazon Redshift with new performance enhancements.
- Use the open-source Kubernetes cluster auto scaling project, AWS Karpenter, to automatically adjust cluster capacity and meet actual demand.
Anticipate and adopt new, more efficient hardware and software offerings
Rapid adoption of new, more efficient technologies helps you reduce the impact of your workloads.
Adopt more efficient instances
- Deploy your workloads on newer, price-performant hardware with the latest Amazon Elastic Compute Cloud (Amazon EC2) instance families from partner-based chips like the Intel-based R6i, AMD EPYC-based M6a, and Mac-based M1
- Use new AWS-built chip instances based in AWS Graviton2 like G5g, Im4gn and Is4gen for more energy-efficient instances.
- Deploy the latest generation of custom-designed AWS Graviton3-based instances: C7g. These instances offer the same performance and use 60% less energy than comparable EC2 instances.
- Gain efficiency with the AWS Trainium ML chip Trn1.
- Use managed services with AWS Graviton2-based chips like AWS Fargate for Amazon Elastic Container Service (Amazon ECS), Amazon Neptune, ElastiCache, and AWS Elastic Beanstalk, which are more energy efficient than comparable EC2 instances.
- Right-size the on-premises AWS workloads that you run with smaller AWS Outposts form factors.
- For workloads that need bare metal instances, use more efficient hardware with the new Amazon EC2 bare metal instances.
Use more efficient software offerings
- Use the next generation of Amazon FSx for Lustre to reduce storage space consumption and make use of more energy-efficient underlying hardware.
- Minimize data movement with pull-through cache repositories in Amazon Elastic Container Registry (Amazon ECR).
- Accelerate deep learning model training by using GPU instances more efficiently with Amazon SageMaker Training Compiler.
- Improve query performance in Amazon Redshift with Automated Materialized Views.
- Reduce self-managed resources with intra-Region peering for AWS Transit Gateway.
- Build event-driven applications based on changes to the data you store in Amazon S3 to be optimized, flexible, and scalable with AWS serverless offerings and use advanced filtering and routing capabilities to send events to 18 targets by integrating Amazon S3 Event Notifications and Amazon EventBridge.
- Use new Amazon S3 Event Notifications to build event-driven applications and optimize resource efficiency of your workloads.
- Simplify operations and retire infrastructure you use to provide remote access to Windows instances with one-click login with AWS Single Sign-On or AWS System Manager Fleet Manager console-based access.
- Decrease SMS-related usage when you test your campaigns in Amazon Pinpoint with the SMS simulator.
Use managed services
We launched several managed services that shift the responsibility of sustainability optimization to AWS:
- Analytics: Amazon RedShift Serverless, Amazon Managed Streaming for Apache Kafka (Amazon MSK) Serverless, Amazon EMR Serverless, and Kinesis Data Streams On-Demand. AWS managed services are scalable, have high average utilization of resources, and are optimized for sustainability.
- ML: Amazon SageMaker Serverless Inference is ideal for applications with intermittent or unpredictable traffic.
- Storage: Amazon FSx for OpenZFS is a fully managed file system that replaces ZFS and other on-premises Linux-based file servers.
- End-user compute: Amazon Workspaces Web and Amazon Appstream2 Elastic (serverless) fleets help reduce idle resources.
- Managed backup options: AWS Backup for Amazon S3 and DynamoDB automate backup retention and deletion.
- Build and manage your wide area network (WAN) with AWS Cloud WAN.
- Migrate and modernize your workload with AWS Mainframe Modernization, which helps move on-premises mainframe workloads to a managed and highly available runtime environment on AWS.
- Create digital twins of real-world systems with AWS IoT TwinMaker.
- Publish and subscribe to third-party APIs using a managed service with AWS Data Exchange for APIs.
Reduce the downstream impact of your cloud workloads
- Use the AWS Rust SDK for the native energy efficiency gains of the Rust programming language.
- Use Amazon CloudWatch RUM to understand the performance of your application and use that information to make it more efficient.
- Review your carbon emissions with the new AWS Customer Carbon Footprint Tool. This helps you define your sustainability key performance indicators (KPIs), optimize your workloads for sustainability, and improve your KPIs.
Conclusion
Having a well-architected, sustainable workload is a continuous process. This blog post brings you AWS announcements from the sustainability perspective. I encourage you to review your workload and find out which of these announcements can be adopted in your workload.
Ready to get started? I encourage you to check out on our What’s New blog for announcements and check them under a sustainability point of view, to identify if they help you improve and meet your sustainability goals.
Looking for more architecture content? AWS Architecture Center provides reference architecture diagrams, vetted architecture solutions, Well-Architected best practices, patterns, icons, and more!
Related information
- Watch the AWS re:Invent 2021 Breakout Sessions – Sustainability
- Other blog posts on architecting for sustainability
- AWS Architecture Monthly magazine, Sustainability issue, August 2021