Post Syndicated from Talks at Google original https://www.youtube.com/watch?v=tyc65lMasiQ
Asustor Flashstor 12 Pro FS6712X Review 12x M.2 SSD and 10Gbase-T NAS
Post Syndicated from Eric Smith original https://www.servethehome.com/asustor-flashstor-12-pro-fs6712x-review-12x-m-2-ssd-and-10gbase-t-nas/
We review the Asustor Flashstor 12 Pro FS6712X getting into the topology, performance, power, and noise of this 12x M.2 SSD and 10Gbase-T NAS
The post Asustor Flashstor 12 Pro FS6712X Review 12x M.2 SSD and 10Gbase-T NAS appeared first on ServeTheHome.
Amazon SageMaker Geospatial Capabilities Now Generally Available with Security Updates and More Use Case Samples
Post Syndicated from Channy Yun original https://aws.amazon.com/blogs/aws/amazon-sagemaker-geospatial-capabilities-now-generally-available-with-security-updates-and-more-use-case-samples/
At AWS re:Invent 2022, we previewed Amazon SageMaker geospatial capabilities, allowing data scientists and machine learning (ML) engineers to build, train, and deploy ML models using geospatial data. Geospatial ML with Amazon SageMaker supports access to readily available geospatial data, purpose-built processing operations and open source libraries, pre-trained ML models, and built-in visualization tools with Amazon SageMaker’s geospatial capabilities.
 During the preview, we had lots of interest and great feedback from customers. Today, Amazon SageMaker geospatial capabilities are generally available with new security updates and additional sample use cases.
During the preview, we had lots of interest and great feedback from customers. Today, Amazon SageMaker geospatial capabilities are generally available with new security updates and additional sample use cases.
Introducing Geospatial ML features with SageMaker Studio
To get started, use the quick setup to launch Amazon SageMaker Studio in the US West (Oregon) Region. Make sure to use the default Jupyter Lab 3 version when you create a new user in the Studio. Now you can navigate to the homepage in SageMaker Studio. Then select the Data menu and click on Geospatial.
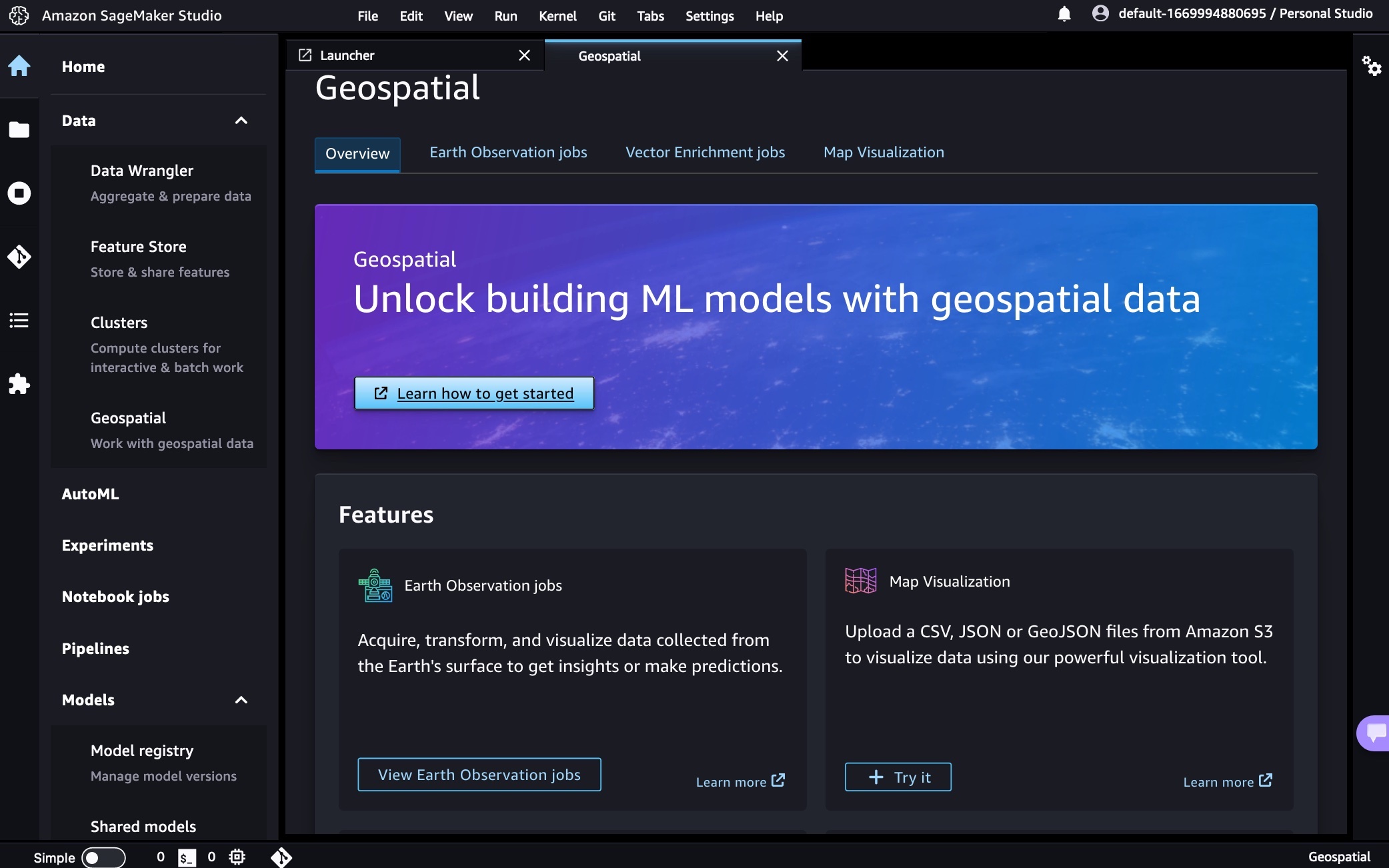
Here is an overview of three key Amazon SageMaker geospatial capabilities:
- Earth Observation jobs – Acquire, transform, and visualize satellite imagery data using purpose-built geospatial operations or pre-trained ML models to make predictions and get useful insights.
- Vector Enrichment jobs – Enrich your data with operations, such as converting geographical coordinates to readable addresses.
- Map Visualization – Visualize satellite images or map data uploaded from a CSV, JSON, or GeoJSON file.
You can create all Earth Observation Jobs (EOJ) in the SageMaker Studio notebook to process satellite data using purpose-built geospatial operations. Here is a list of purpose-built geospatial operations that are supported by the SageMaker Studio notebook:
- Band Stacking – Combine multiple spectral properties to create a single image.
- Cloud Masking – Identify cloud and cloud-free pixels to get improved and accurate satellite imagery.
- Cloud Removal – Remove pixels containing parts of a cloud from satellite imagery.
- Geomosaic – Combine multiple images for greater fidelity.
- Land Cover Segmentation – Identify land cover types such as vegetation and water in satellite imagery.
- Resampling – Scale images to different resolutions.
- Spectral Index – Obtain a combination of spectral bands that indicate the abundance of features of interest.
- Temporal Statistics – Calculate statistics through time for multiple GeoTIFFs in the same area.
- Zonal Statistics – Calculate statistics on user-defined regions.
A Vector Enrichment Job (VEJ) enriches your location data through purpose-built operations for reverse geocoding and map matching. While you need to use a SageMaker Studio notebook to execute a VEJ, you can view all the jobs you create using the user interface. To use the visualization in the notebook, you first need to export your output to your Amazon S3 bucket.
- Reverse Geocoding – Convert coordinates (latitude and longitude) to human-readable addresses.
- Map Matching – Snap inaccurate GPS coordinates to road segments.
Using the Map Visualization, you can visualize geospatial data, the inputs to your EOJ or VEJ jobs as well as the outputs exported from your Amazon Simple Storage Service (Amazon S3) bucket.
Security Updates
At GA, we have two major security updates—AWS Key Management Service (AWS KMS) for customer managed AWS KMS key support and Amazon Virtual Private Cloud (Amazon VPC) for geospatial operations in the customer Amazon VPC environment.
AWS KMS customer managed keys offer increased flexibility and control by enabling customers to use their own keys to encrypt geospatial workloads.
You can use KmsKeyId to specify your own key in StartEarthObservationJob and StartVectorEnrichmentJob as an optional parameter. If the customer doesn’t provide KmsKeyId, a service owned key will be used to encrypt the customer content. To learn more, see SageMaker geospatial capabilities AWS KMS Support in the AWS documentation.
Using Amazon VPC, you have full control over your network environment and can more securely connect to your geospatial workloads on AWS. You can use SageMaker Studio or Notebook in your Amazon VPC environment for SageMaker geospatial operations and execute SageMaker geospatial API operations through an interface VPC endpoint in SageMaker geospatial operations.
To get started with Amazon VPC support, configure Amazon VPC on SageMaker Studio Domain and create a SageMaker geospatial VPC endpoint in your VPC in the Amazon VPC console. Choose the service name as com.amazonaws.us-west-2.sagemaker-geospatial and select the VPC in which to create the VPC endpoint.
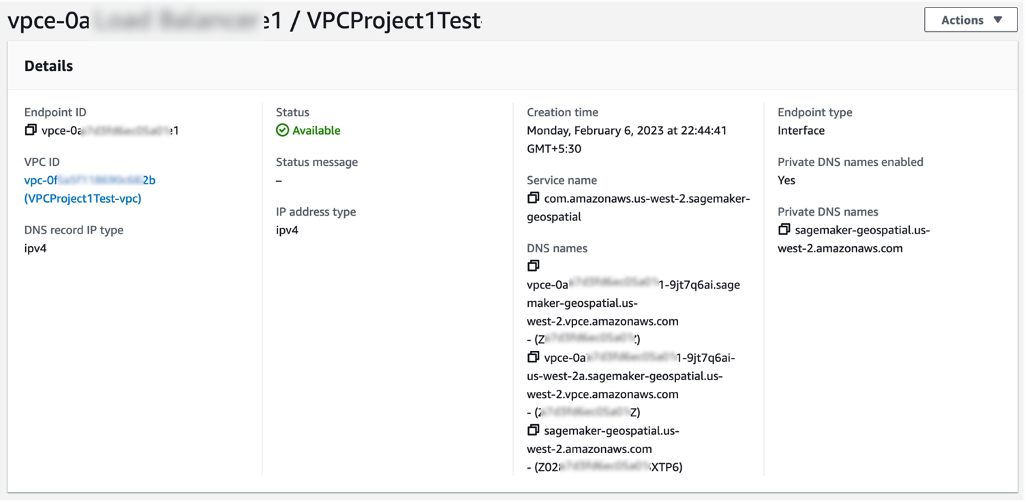
All Amazon S3 resources that are used for input or output in EOJ and VEJ operations should have internet access enabled. If you have no direct access to those Amazon S3 resources via the internet, you can grant SageMaker geospatial VPC endpoint ID access to it by changing the corresponding S3 bucket policy. To learn more, see SageMaker geospatial capabilities Amazon VPC Support in the AWS documentation.
Example Use Case for Geospatial ML
Customers across various industries use Amazon SageMaker geospatial capabilities for real-world applications.
Maximize Harvest Yield and Food Security
Digital farming consists of applying digital solutions to help farmers optimize crop production in agriculture through the use of advanced analytics and machine learning. Digital farming applications require working with geospatial data, including satellite imagery of the areas where farmers have their fields located.

You can use SageMaker to identify farm field boundaries in satellite imagery through pre-trained models for land cover classification. Learn about How Xarvio accelerated pipelines of spatial data for digital farming with Amazon SageMaker Geospatial in the AWS Machine Learning Blog. You can find an end-to-end digital farming example notebook via the GitHub repository.
Damage Assessment
As the frequency and severity of natural disasters increase, it’s important that we equip decision-makers and first responders with fast and accurate damage assessment. You can use geospatial imagery to predict natural disaster damage and geospatial data in the immediate aftermath of a natural disaster to rapidly identify damage to buildings, roads, or other critical infrastructure.
From an example notebook, you can train, deploy, and predict natural disaster damage from the floods in Rochester, Australia, in mid-October 2022. We use images from before and after the disaster as input to its trained ML model. The results of the segmentation mask for the Rochester floods are shown in the following images. Here we can see that the model has identified locations within the flooded region as likely damaged.

You can train and deploy a geospatial segmentation model to assess wildfire damages using multi-temporal Sentinel-2 satellite data via GitHub repository. The area of interest for this example is located in Northern California, from a region that was affected by the Dixie Wildfire in 2021.
Monitor Climate Change
Earth’s climate change increases the risk of drought due to global warming. You can see how to acquire data, perform analysis, and visualize the changes with SageMaker geospatial capabilities to monitor shrinking shoreline caused by climate change in the Lake Mead example, the largest reservoir in the US.
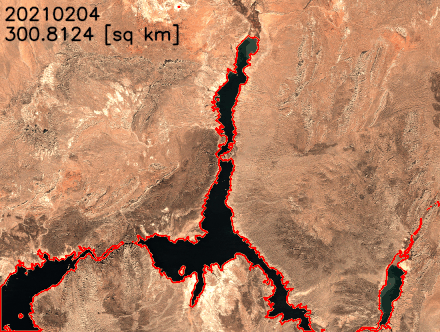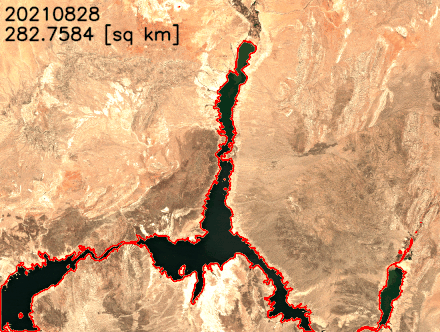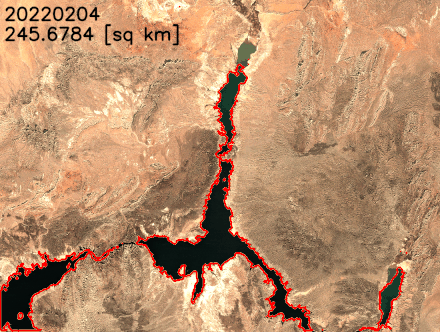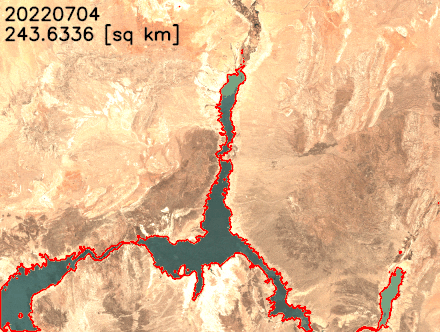
You can find the notebook code for this example in the GitHub repository.
Predict Retail Demand
The new notebook example demonstrates how to use SageMaker geospatial capabilities to perform a vector-based map-matching operation and visualize the results. Map matching allows you to snap noisy GPS coordinates to road segments. With Amazon SageMaker geospatial capabilities, it is possible to perform a VEJ for map matching. This type of job takes a CSV file with route information (such as longitude, latitude, and timestamps of GPS measurements) as input and produces a GeoJSON file that contains the predicted route.
Support Sustainable Urban Development
Arup, one of our customers, uses digital technologies like machine learning to explore the impact of heat on urban areas and the factors that influence local temperatures to deliver better design and support sustainable outcomes. Urban Heat Islands and the associated risks and discomforts are one of the biggest challenges cities are facing today.
Using Amazon SageMaker geospatial capabilities, Arup identifies and measures urban heat factors with earth observation data, which significantly accelerated their ability to counsel clients. It enabled its engineering teams to carry out analytics that weren’t possible previously by providing access to increased volumes, types, and analysis of larger datasets. To learn more, see Facilitating Sustainable City Design Using Amazon SageMaker with Arup in AWS customer stories.
Now Available
Amazon SageMaker geospatial capabilities are now generally available in the US West (Oregon) Region. As part of the AWS Free Tier, you can get started with SageMaker geospatial capabilities for free. The Free Tier lasts 30 days and includes 10 free ml.geospatial.interactive compute hours, up to 10 GB of free storage, and no $150 monthly user fee.
After the 30-day free trial period is complete, or if you exceed the Free Tier limits defined above, you pay for the components outlined on the pricing page.
To learn more, see Amazon SageMaker geospatial capabilities and the Developer Guide. Give it a try and send feedback to AWS re:Post for Amazon SageMaker or through your usual AWS support contacts.
– Channy
How Cirrusgo enabled rapid resolution with Amazon DevOps Guru
Post Syndicated from Harish Bannai original https://aws.amazon.com/blogs/devops/how-cirrusgo-enabled-rapid-resolution-with-devops-guru/
![]()
In this blog, we will walk through how Cirrusgo used Amazon DevOps Guru for RDS to quickly identify and resolve their operational issue related to database performance and reduce the impact on their business. This capability is offered by Amazon DevOps Guru for RDS which uses machine learning algorithms to help organizations identify and resolve operational issues in their applications and infrastructure.
Challenge:
Knowlegebeam, one of Cirrusgo’s managed service customers, has an e-learning web application that serves as a mission-critical tool for nearly 90,000 teachers. The application tracks daily activities, including teaching and evaluating homework and quizzes submitted by students. Any interruption of the availability of this application causes significant inconvenience to teachers and students, as well as damage to the company’s reputation. Ensuring the continuous and reliable performance of customer workloads is of utmost importance to Cirrusgo.
Identification of Operational issues with Amazon DevOps Guru:
To streamline the troubleshooting process and avoid time-consuming manual analysis of logs, Cirrusgo leveraged the power of Amazon DevOps Guru to monitor Knowledge Beam’s stack. With just a few clicks in the AWS console, Cirrusgo seamlessly enabled DevOps Guru that uses advanced machine learning techniques to analyze Amazon CloudWatch metrics, AWS CloudTrail, and Amazon Relational Database Service (Amazon RDS) Performance Insights. This enables it to quickly identify behaviors that deviate from standard operating patterns and pinpoint the root cause of operational issues.
When users reported difficulty submitting assignments via the e-learning portal, Cirrusgo’s team launched an investigation. The team discovered 4xx and 5xx Amazon Elastic Load Balancing errors in the CloudWatch metrics. There was no additional information available. While examining the load balancer and application logs, the engineers received Amazon DevOps Guru notifications regarding Amazon RDS) replica lag. The team promptly investigated and confirmed the existence of the Amazon RDS replica lag. The team ran commands to stop traffic to the replica instance and shift all traffic to the Amazon RDS primary node. Thanks to DevOps Guru’s insightful recommendations, the team identified and resolved the issue. The team was able to use the root cause of the issue and take additional steps to prevent its recurrence. This included creating an Amazon RDS Read Replica and upgrading the instance type based on the current workload.
Cirrusgo quickly identified and addressed critical operational issues in Knowledge Beam’s application. This enabled them to minimize the immediate impact and enhance their customer’s applications’ future reliability and performance.
“Amazon DevOps Guru was very beneficial that helped us identify incidents in Amazon RDS. It provided useful insights we previously didn’t have, and it helped reduce our mitigation time. We implemented it to some accounts we are managing and are taking advantage”, says Mohammed Douglas Otaibi, Technical Co-Founder of Cirrusgo
Conclusion:
This post highlights how Cirrusgo leveraged Amazon DevOps Guru to identify and quickly address anomalous behavior.
Are you looking for a way to improve the monitoring of your Amazon RDS databases? Look no further than Amazon DevOps Guru. With DevOps Guru’s RDS monitoring capabilities, you can gain deep insights into the performance and health of your databases. This includes automatic anomaly detection, proactive recommendations, and alerts for issues that require your attention.
About the authors:
[$] FUSE and io_uring
Post Syndicated from original https://lwn.net/Articles/932079/
Bernd Schubert led a session at the 2023 Linux Storage, Filesystem,
Memory-Management and BPF Summit on the intersection
of FUSE
and io_uring. He
works for DDN Storage, which is using FUSE for two network-storage
products; he has found FUSE to be a bottleneck for those filesystems. That
could perhaps be
improved by using io_uring, which is something he has been working on and
wanted to discuss.
Exploring a PC Built by Bond, J. Bond – The 99¢ 386
Post Syndicated from LGR original https://www.youtube.com/watch?v=v2vc4ww1aVU
[$] Phyr: a potential scatterlist replacement
Post Syndicated from original https://lwn.net/Articles/931943/
The “scatterlist” is a core-kernel data structure used to describe DMA I/O
operations from the point of view of both the CPU and the peripheral
device. Over the years, the shortcomings of scatterlists have become more
apparent, but there has not been a viable replacement on the horizon.
During a memory-management session at the 2023 Linux Storage, Filesystem, Memory-Management
and BPF Summit, Jason Gunthorpe described a possible alternative, known
alternatively as “phyr”, “physr”, or “rlist”, that might improve on
scatterlists for at least some use cases.
[$] Memory passthrough for virtual machines
Post Syndicated from original https://lwn.net/Articles/931933/
Memory management is tricky enough on it own, but virtualization adds
another twist: now there are two kernels (host and guest) managing the same
memory. This duplicated effort can be wasteful if not implemented
carefully, so it is not surprising that a lot of effort, from both hardware
and software developers, has gone into this problem. As Pasha Tatashin
pointed out during a memory-management-track session at the 2023 Linux Storage, Filesystem, Memory-Management
and BPF Summit, though, there are still ways in which these systems run
less efficiently than they could. He has put some effort into improving
that situation.
Security updates for Friday
Post Syndicated from original https://lwn.net/Articles/932464/
Security updates have been issued by Fedora (cups-filters, kitty, mingw-LibRaw, nispor, rust-ybaas, and rust-yubibomb), Mageia (kernel-linus), Red Hat (jenkins and jenkins-2-plugins), SUSE (openvswitch and ucode-intel), and Ubuntu (linux-azure, linux-azure-4.15, linux-gcp, linux-gcp-5.15, linux-gke, linux-gke-5.15, linux-gkeop,
linux-oracle-5.15, linux-ibm, linux-oracle, and linux-oem-6.0).
More Node.js APIs in Cloudflare Workers — Streams, Path, StringDecoder
Post Syndicated from James M Snell original http://blog.cloudflare.com/workers-node-js-apis-stream-path/
Today we are announcing support for three additional APIs from Node.js in Cloudflare Workers. This increases compatibility with the existing ecosystem of open source npm packages, allowing you to use your preferred libraries in Workers, even if they depend on APIs from Node.js.
We recently added support for AsyncLocalStorage, EventEmitter, Buffer, assert and parts of util. Today, we are adding support for:
- Node.js Streams
- Path
- StringDecoder
We are also sharing a preview of a new module type, available in the open-source Workers runtime, that mirrors a Node.js environment more closely by making some APIs available as globals, and allowing imports without the node: specifier prefix.
You can start using these APIs today, in the open-source runtime that powers Cloudflare Workers, in local development, and when you deploy your Worker. Get started by enabling the nodejs_compat compatibility flag for your Worker.
Stream
The Node.js streams API is the original API for working with streaming data in JavaScript that predates the WHATWG ReadableStream standard. Now, a full implementation of Node.js streams (based directly on the official implementation provided by the Node.js project) is available within the Workers runtime.
Let's start with a quick example:
import {
Readable,
Transform,
} from 'node:stream';
import {
text,
} from 'node:stream/consumers';
import {
pipeline,
} from 'node:stream/promises';
// A Node.js-style Transform that converts data to uppercase
// and appends a newline to the end of the output.
class MyTransform extends Transform {
constructor() {
super({ encoding: 'utf8' });
}
_transform(chunk, _, cb) {
this.push(chunk.toString().toUpperCase());
cb();
}
_flush(cb) {
this.push('\n');
cb();
}
}
export default {
async fetch() {
const chunks = [
"hello ",
"from ",
"the ",
"wonderful ",
"world ",
"of ",
"node.js ",
"streams!"
];
function nextChunk(readable) {
readable.push(chunks.shift());
if (chunks.length === 0) readable.push(null);
else queueMicrotask(() => nextChunk(readable));
}
// A Node.js-style Readable that emits chunks from the
// array...
const readable = new Readable({
encoding: 'utf8',
read() { nextChunk(readable); }
});
const transform = new MyTransform();
await pipeline(readable, transform);
return new Response(await text(transform));
}
};
In this example we create two Node.js stream objects: one stream.Readable and one stream.Transform. The stream.Readable simply emits a sequence of individual strings, piped through the stream.Transform which converts those to uppercase and appends a new-line as a final chunk.
The example is straightforward and illustrates the basic operation of the Node.js API. For anyone already familiar with using standard WHATWG streams in Workers the pattern here should be recognizable.
The Node.js streams API is used by countless numbers of modules published on npm. Now that the Node.js streams API is available in Workers, many packages that depend on it can be used in your Workers. For example, the split2 module is a simple utility that can break a stream of data up and reassemble it so that every line is a distinct chunk. While simple, the module is downloaded over 13 million times each week and has over a thousand direct dependents on npm (and many more indirect dependents). Previously it was not possible to use split2 within Workers without also pulling in a large and complicated polyfill implementation of streams along with it. Now split2 can be used directly within Workers with no modifications and no additional polyfills. This reduces the size and complexity of your Worker by thousands of lines.
import {
PassThrough,
} from 'node:stream';
import { default as split2 } from 'split2';
const enc = new TextEncoder();
export default {
async fetch() {
const pt = new PassThrough();
const readable = pt.pipe(split2());
pt.end('hello\nfrom\nthe\nwonderful\nworld\nof\nnode.js\nstreams!');
for await (const chunk of readable) {
console.log(chunk);
}
return new Response("ok");
}
};
Path
The Node.js Path API provides utilities for working with file and directory paths. For example:
import path from "node:path"
path.join('/foo', 'bar', 'baz/asdf', 'quux', '..');
// Returns: '/foo/bar/baz/asdf'
Note that in the Workers implementation of path, the path.win32 variants of the path API are not implemented, and will throw an exception.
StringDecoder
The Node.js StringDecoder API is a simple legacy utility that predates the WHATWG standard TextEncoder/TextDecoder API and serves roughly the same purpose. It is used by Node.js' stream API implementation as well as a number of popular npm modules for the purpose of decoding UTF-8, UTF-16, Latin1, Base64, and Hex encoded data.
import { StringDecoder } from 'node:string_decoder';
const decoder = new StringDecoder('utf8');
const cent = Buffer.from([0xC2, 0xA2]);
console.log(decoder.write(cent));
const euro = Buffer.from([0xE2, 0x82, 0xAC]);
console.log(decoder.write(euro));
In the vast majority of cases, your Worker should just keep on using the standard TextEncoder/TextDecoder APIs, but the StringDecoder is available directly for workers to use now without relying on polyfills.
Node.js Compat Modules
One Worker can already be a bundle of multiple assets. This allows a single Worker to be made up of multiple individual ESM modules, CommonJS modules, JSON, text, and binary data files.
Soon there will be a new type of module that can be included in a Worker bundles: the NodeJsCompatModule.
A NodeJsCompatModule is designed to emulate the Node.js environment as much as possible. Within these modules, common Node.js global variables such as process, Buffer, and even __filename will be available. More importantly, it is possible to require() our Node.js core API implementations without using the node: specifier prefix. This maximizes compatibility with existing NPM packages that depend on globals from Node.js being present, or don’t import Node.js APIs using the node: specifier prefix.
Support for this new module type has landed in the open source workerd runtime, with deeper integration with Wrangler coming soon.
What’s next
We’re adding support for more Node.js APIs each month, and as we introduce new APIs, they will be added under the nodejs_compat compatibility flag — no need to take any action or update your compatibility date.
Have an NPM package that you wish worked on Workers, or an API you’d like to be able to use? Join the Cloudflare Developers Discord and tell us what you’re building, and what you’d like to see next.
Cloudflare Queues: messages at your speed with consumer concurrency and explicit acknowledgement
Post Syndicated from Charles Burnett original http://blog.cloudflare.com/messages-at-your-speed-with-concurrency-and-explicit-acknowledgement/
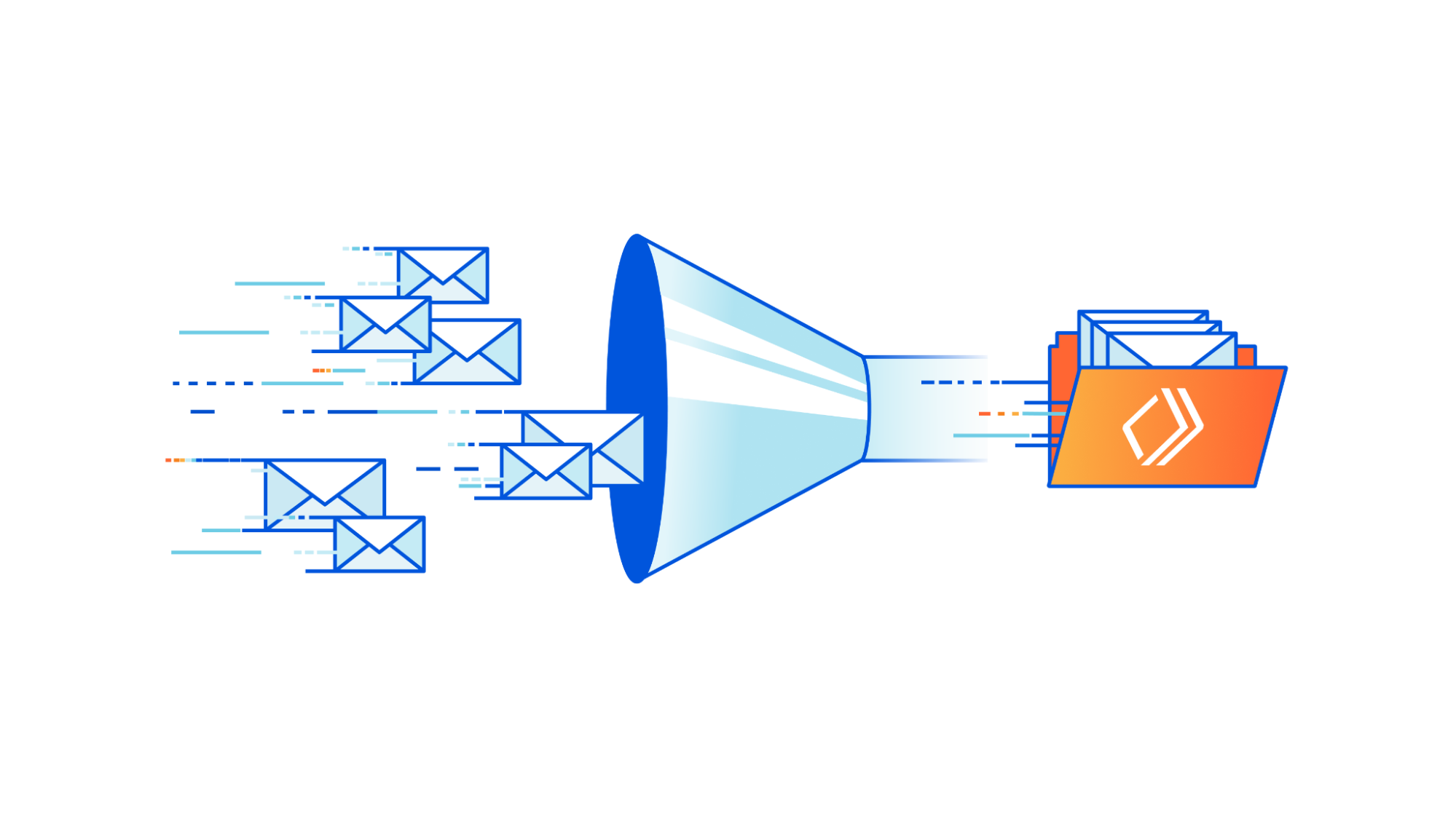
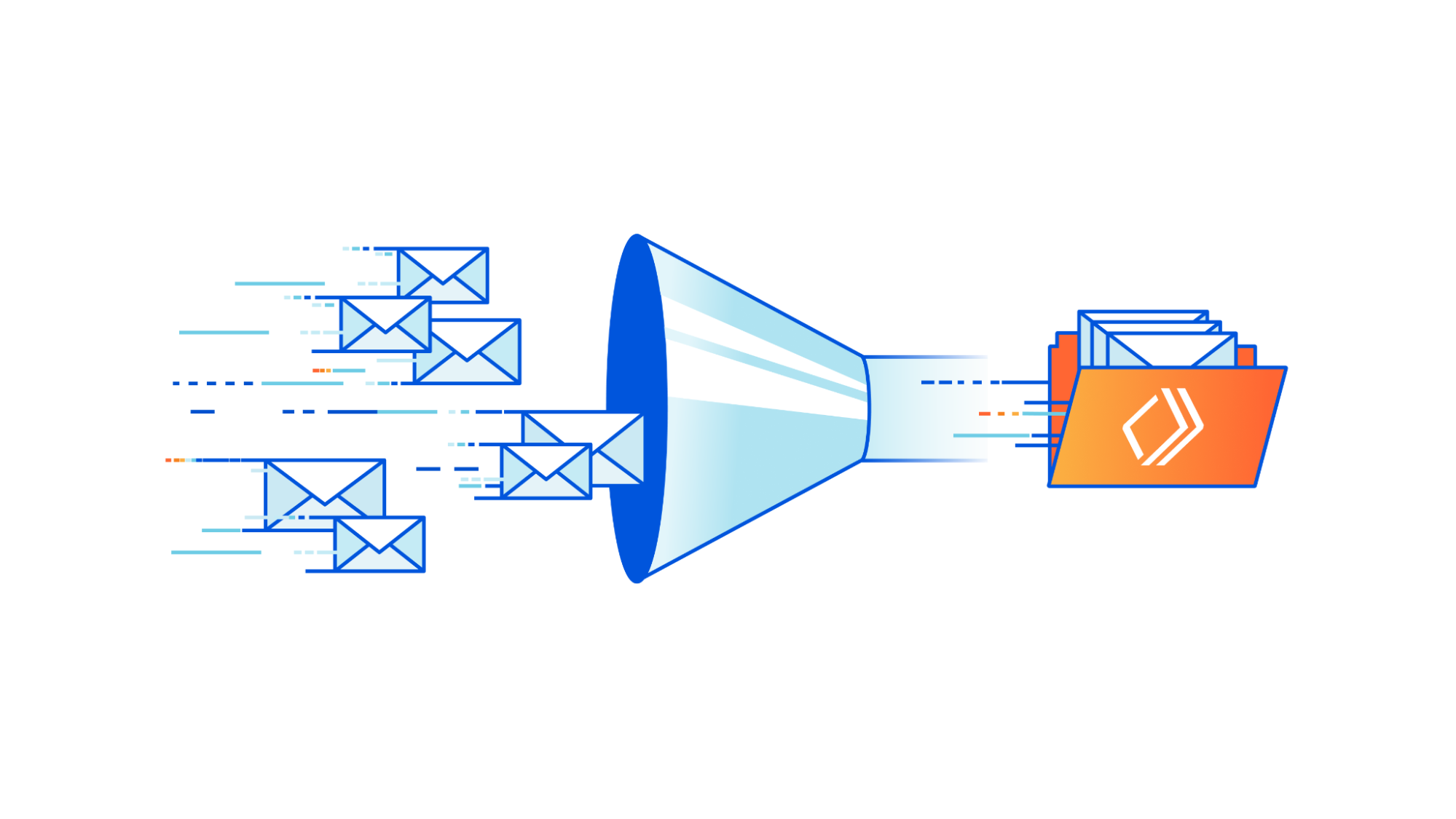
Communicating between systems can be a balancing act that has a major impact on your business. APIs have limits, billing frequently depends on usage, and end-users are always looking for more speed in the services they use. With so many conflicting considerations, it can feel like a challenge to get it just right. Cloudflare Queues is a tool to make this balancing act simple. With our latest features like consumer concurrency and explicit acknowledgment, it’s easier than ever for developers to focus on writing great code, rather than worrying about the fees and rate limits of the systems they work with.
Queues is a messaging service, enabling developers to send and receive messages across systems asynchronously with guaranteed delivery. It integrates directly with Cloudflare Workers, making for easy message production and consumption working with the many products and services we offer.
What’s new in Queues?
Consumer concurrency
Oftentimes, the systems we pull data from can produce information faster than other systems can consume them. This can occur when consumption involves processing information, storing it, or sending and receiving information to a third party system. The result of which is that sometimes, a queue can fall behind where it should be. At Cloudflare, a queue shouldn't be a quagmire. That’s why we’ve introduced Consumer Concurrency.
With Concurrency, we automatically scale up the amount of consumers needed to match the speed of information coming into any given queue. In this way, customers no longer have to worry about an ever-growing backlog of information bogging down their system.
How it works
When setting up a queue, developers can set a Cloudflare Workers script as a target to send messages to. With concurrency enabled, Cloudflare will invoke multiple instances of the selected Worker script to keep the messages in the queue moving effectively. This feature is enabled by default for every queue and set to automatically scale.
Autoscaling considers the following factors when spinning up consumers: the number of messages in a queue, the rate of new messages, and successful vs. unsuccessful consumption attempts.
If a queue has enough messages in it, concurrency will increase each time a message batch is successfully processed. Concurrency is decreased when message batches encounter errors. Customers can set a max_concurrency value in the Dashboard or via Wrangler, which caps out how many consumers can be automatically created to perform processing for a given queue.
Setting the max_concurrency value manually can be helpful in the following situations where producer data is provided in bursts, the datasource API is rate limited, and datasource API has higher costs with more usage.
Setting a max concurrency value manually allows customers to optimize their workflows for other factors beyond speed.
// in your wrangler.toml file
[[queues.consumers]]
queue = "my-queue"
//max concurrency can be set to a number between 1 and 10
//this defines the total amount of consumers running simultaneously
max_concurrency = 7
To learn more about concurrency you can check out our developer documentation here.
Concurrency in practice
It’s baseball season in the US, and for many of us that means fantasy baseball is back! This year is the year we finally write a program that uses data and statistics to pick a winning team, as opposed to picking players based on “feelings” and “vibes”. We’re engineers after all, and baseball is a game of rules. If the Oakland A’s can do it, so can we!
So how do we put this together? We’ll need a few things:
- A list of potential players
- An API to pull historical game statistics from
- A queue to send this data to its consumer
- A Worker script to crunch the numbers and generate a score
A developer can pull from a baseball reference API into a Workers script, and from that worker pass this information to a queue. Historical data is… historical, so we can pull data into our queue as fast as the baseball API will allow us. For our list of potential players, we pull statistics for each game they’ve played. This includes everything from batting averages, to balls caught, to game day weather. Score!
//get data from a third party API and pass it along to a queue
const response = await fetch("http://example.com/baseball-stats.json");
const gamesPlayedJSON = await response.json();
for (game in gamesPlayedJSON){
//send JSON to your queue defined in your workers environment
env.baseballqueue.send(jsonData)
}
Our producer Workers script then passes these statistics onto the queue. As each game contains quite a bit of data, this results in hundreds of thousands of “game data” messages waiting to be processed in our queue. Without concurrency, we would have to wait for each batch of messages to be processed one at a time, taking minutes if not longer. But, with Consumer Concurrency enabled, we watch as multiple instances of our worker script invoked to process this information in no time!
Our Worker script would then take these statistics, apply a heuristic, and store the player name and a corresponding quality score into a database like a Workers KV store for easy access by your application presenting the data.
Explicit Acknowledgment
In Queues previously, a failure of a single message in a batch would result in the whole batch being resent to the consumer to be reprocessed. This resulted in extra cycles being spent on messages that were processed successfully, in addition to the failed message attempt. This hurts both customers and developers, slowing processing time, increasing complexity, and increasing costs.
With Explicit Acknowledgment, we give developers the precision and flexibility to handle each message individually in their consumer, negating the need to reprocess entire batches of messages. Developers can now tell their queue whether their consumer has properly processed each message, or alternatively if a specific message has failed and needs to be retried.
An acknowledgment of a message means that that message will not be retried if the batch fails. Only messages that were not acknowledged will be retried. Inversely, a message that is explicitly retried, will be sent again from the queue to be reprocessed without impacting the processing of the rest of the messages currently being processed.
How it works
In your consumer, there are 4 new methods you can call to explicitly acknowledge a given message: .ack(), .retry(), .ackAll(), .retryAll().
Both ack() and retry() can be called on individual messages. ack() tells a queue that the message has been processed successfully and that it can be deleted from the queue, whereas retry() tells the queue that this message should be put back on the queue and delivered in another batch.
async queue(batch, env, ctx) {
for (const msg of batch.messages) {
try {
//send our data to a 3rd party for processing
await fetch('https://thirdpartyAPI.example.com/stats', {
method: 'POST',
body: msg,
headers: {
'Content-type': 'application/json'
}
});
//acknowledge if successful
msg.ack();
// We don't have to re-process this if subsequent messages fail!
}
catch (error) {
//send message back to queue for a retry if there's an error
msg.retry();
console.log("Error processing", msg, error);
}
}
}
ackAll() and retryAll() work similarly, but act on the entire batch of messages instead of individual messages.
For more details check out our developer documentation here.
Explicit Acknowledgment in practice
In the course of making our Fantasy Baseball team picker, we notice that data isn’t always sent correctly from the baseball reference API. This results in data not being correctly parsed and rejected from our player heuristics.
Without Explicit Acknowledgment, the entire batch of baseball statistics would need to be retried. Thankfully, we can use Explicit Acknowledgment to avoid that, and tell our queue which messages were parsed successfully and which were not.
import heuristic from "baseball-heuristic";
export default {
async queue(batch: MessageBatch, env: Env, ctx: ExecutionContext) {
for (const msg of batch.messages) {
try {
// Calculate the score based on the game stats
heuristic.generateScore(msg)
// Explicitly acknowledge results
msg.ack()
} catch (err) {
console.log(err)
// Retry just this message
msg.retry()
}
}
},
};
Higher throughput
Under the hood, we’ve been working on improvements to further increase the amount of messages per second each queue can handle. In the last few months, that number has quadrupled, improving from 100 to over 400 messages per second.
Scalability can be an essential factor when deciding which services to use to power your application. You want a service that can grow with your business. We are always aiming to improve our message throughput and hope to see this number quadruple again over the next year. We want to grow with you.
What’s next?
As our service grows, we want to provide our customers with more ways to interact with our service beyond the traditional Cloudflare Workers workflow. We know our customers’ infrastructure is often complex, spanning across multiple services. With that in mind, our focus will be on enabling easy connection to services both within the Cloudflare ecosystem and beyond.
R2 as a consumer
Today, the only type of consumer you can configure for a queue is a Workers script. While Workers are incredibly powerful, we want to take it a step further and give customers a chance to write directly to other services, starting with R2. Coming soon, customers will be able to select an R2 bucket in the Cloudflare Dashboard for a Queue to write to directly, no code required. This will save valuable developer time by avoiding the initial setup in a Workers script, and any maintenance that is required as services evolve. With R2 as a first party consumer in Queues, customers can simply select their bucket, and let Cloudflare handle the rest.
HTTP pull
We're also working to allow you to consume messages from existing infrastructure you might have outside of Cloudflare. Cloudflare Queues will provide an HTTP API for each queue from which any consumer can pull batches of messages for processing. Customers simply make a request to the API endpoint for their queue, receive data they requested, then send an acknowledgment that they have received the data, so the queue can continue working on the next batch.
Always working to be faster
For the Queues team, speed is always our focus, as we understand our customers don't want bottlenecks in the performance of their applications. With this in mind the team will be continuing to look for ways to increase the velocity through which developers can build best in class applications on our developer platform. Whether it's reducing message processing time, the amount of code you need to manage, or giving developers control over their application pipeline, we will continue to implement solutions to allow you to focus on just the important things, while we handle the rest.
Cloudflare Queues is currently in Open Beta and ready to power your most complex applications.
Check out our getting started guide and build your service with us today!
Workers Browser Rendering API enters open beta
Post Syndicated from Celso Martinho original http://blog.cloudflare.com/browser-rendering-open-beta/

The Workers Browser Rendering API allows developers to programmatically control and interact with a headless browser instance and create automation flows for their applications and products.
Since the private beta announcement, based on the feedback we've been receiving and our own roadmap, the team has been working on the developer experience and improving the platform architecture for the best possible performance and reliability. Today we enter the open beta and will start onboarding the customers on the wait list.
Developer experience
Starting today, Wrangler, our command-line tool for configuring, building, and deploying applications with Cloudflare developer products, has support for the Browser Rendering API bindings.
You can install Wrangler Beta using npm:
npm install wrangler --save-dev
Bindings allow your Workers to interact with resources on the Cloudflare developer platform. In this case, they will provide your Worker script with an authenticated endpoint to interact with a dedicated Chromium browser instance.
This is all you need in your wrangler.toml once this service is enabled for your account:
browser = { binding = "MYBROWSER", type = "browser" }
Now you can deploy any Worker script that requires Browser Rendering capabilities. You can spawn Chromium instances and interact with them programmatically in any way you typically do manually behind your browser.
Under the hood, the Browser Rendering API gives you access to a WebSocket endpoint that speaks the DevTools Protocol. DevTools is what allows us to instrument a Chromium instance running in our global network, and it's the same protocol that Chrome uses on your computer when you inspect a page.
With enough dedication, you can, in fact, implement your own DevTools client and talk the protocol directly. But that'd be crazy; almost no one does that.
So…
Puppeteer
Puppeteer is one of the most popular libraries that abstract the lower-level DevTools protocol from developers and provides a high-level API that you can use to easily instrument Chrome/Chromium and automate browsing sessions. It's widely used for things like creating screenshots, crawling pages, and testing web applications.
Puppeteer typically connects to a local Chrome or Chromium browser using the DevTools port.
We forked a version of Puppeteer and patched it to connect to the Workers Browser Rendering API instead. The changes are minimal; after connecting the developers can then use the full Puppeteer API as they would on a standard setup.
Our version is open sourced here, and the npm can be installed from npmjs as @cloudflare/puppeteer. Using it from a Worker is as easy as:
import puppeteer from "@cloudflare/puppeteer";
And then all it takes to launch a browser from your script is:
const browser = await puppeteer.launch(env.MYBROWSER);
In the long term, we will update Puppeteer to keep matching the version of our Chromium instances infrastructure running in our network.
Developer documentation
Following the tradition with other Developer products, we created a dedicated section for the Browser Rendering APIs in our Developer's Documentation site.
You can access this page to learn more about how the service works, Wrangler support, APIs, and limits, and find examples of starter templates for common applications.

An example application: taking screenshots
Taking screenshots from web pages is one of the typical cases for browser automation.
Let's create a Worker that uses the Browser Rendering API to do just that. This is a perfect example of how to set up everything and get an application running in minutes, it will give you a good overview of the steps involved and the basics of the Puppeteer API, and then you can move from here to other more sophisticated use-cases.
Step one, start a project, install Wrangler and Cloudflare’s fork of Puppeteer:
npm init -f
npm install wrangler -save-dev
npm install @cloudflare/puppeteer -save-dev
Step two, let’s create the simplest possible wrangler.toml configuration file with the Browser Rendering API binding:
name = "browser-worker"
main = "src/index.ts"
compatibility_date = "2023-03-14"
node_compat = true
workers_dev = true
browser = { binding = "MYBROWSER", type = "browser" }
Step three, create src/index.ts with your Worker code:
import puppeteer from "@cloudflare/puppeteer";
export default {
async fetch(request: Request, env: Env): Promise<Response> {
const { searchParams } = new URL(request.url);
let url = searchParams.get("url");
let img: Buffer;
if (url) {
const browser = await puppeteer.launch(env.MYBROWSER);
const page = await browser.newPage();
await page.goto(url);
img = (await page.screenshot()) as Buffer;
await browser.close();
return new Response(img, {
headers: {
"content-type": "image/jpeg",
},
});
} else {
return new Response(
"Please add the ?url=https://example.com/ parameter"
);
}
},
};
That's it, no more steps. This Worker instantiates a browser using Puppeteer, opens a new page, navigates to whatever you put in the "url" parameter, takes a screenshot of the page, closes the browser, and responds with the JPEG image of the screenshot. It can't get any easier to get started with the Browser Rendering API.
Run npx wrangler dev –remote to test it and npx wrangler publish when you’re done.
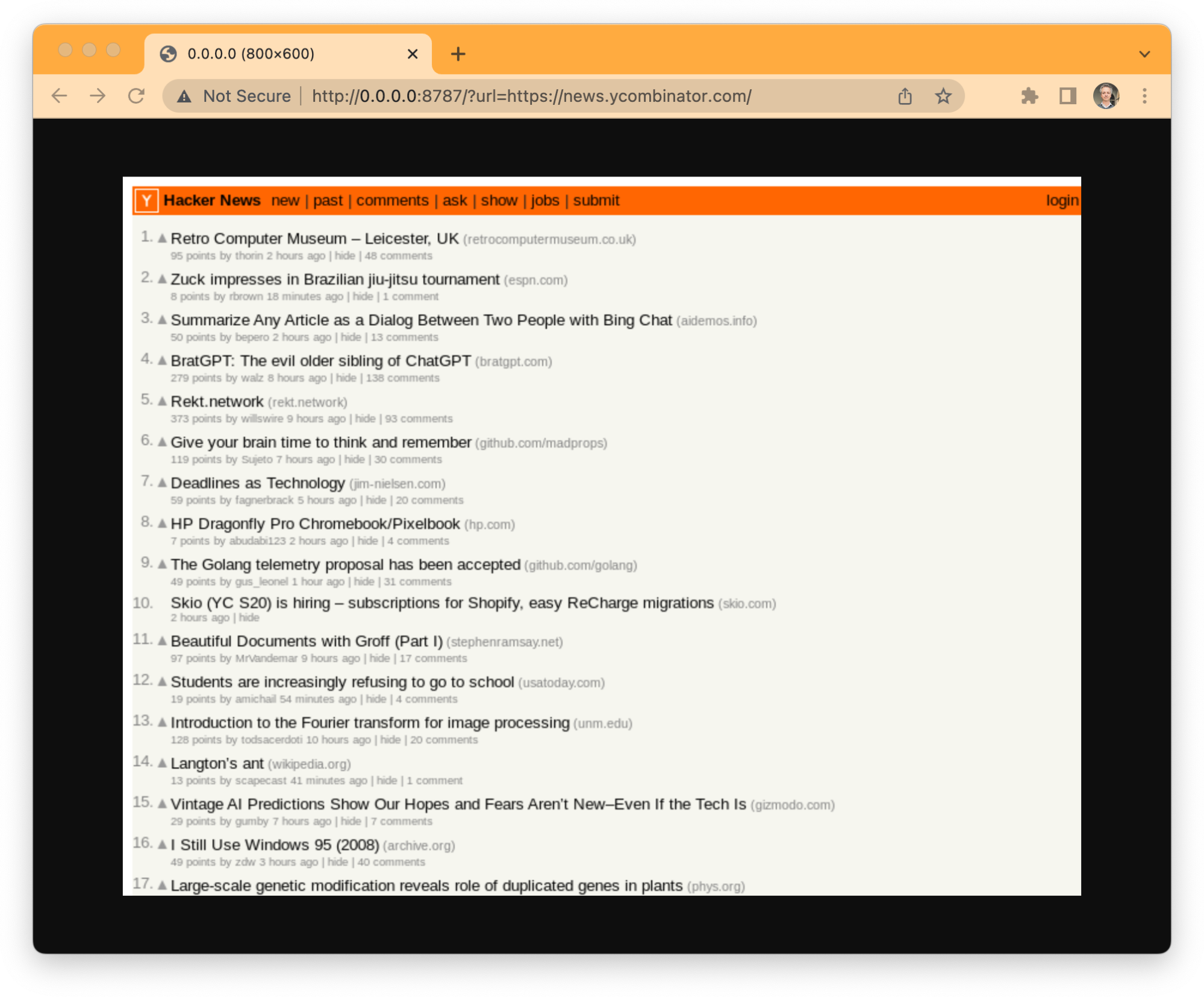
You can explore the entire Puppeteer API and implement other functionality and logic from here. And, because it's Workers, you can add other developer products to your code. You might need a relational database, or a KV store to cache your screenshots, or an R2 bucket to archive your crawled pages and assets, or maybe use a Durable Object to keep your browser instance alive and share it with multiple requests, or queues to handle your jobs asynchronous, we have all of this and more.
You can also find this and other examples of how to use Browser Rendering in the Developer Documentation.
How do we use Browser Rendering
Dogfooding our products is one of the best ways to test and improve them, and in some cases, our internal needs dictate or influence our roadmap. Workers Browser Rendering is a good example of that; it was born out of our necessities before we realized it could be a product. We've been using it extensively for things like taking screenshots of pages for social sharing or dashboards, testing web software in CI, or gathering page load performance metrics of our applications.
But there's one product we've been using to stress test and push the limits of the Browser Rendering API and drive the engineering sprints that brought us to open the beta to our customers today: The Cloudflare Radar URL Scanner.
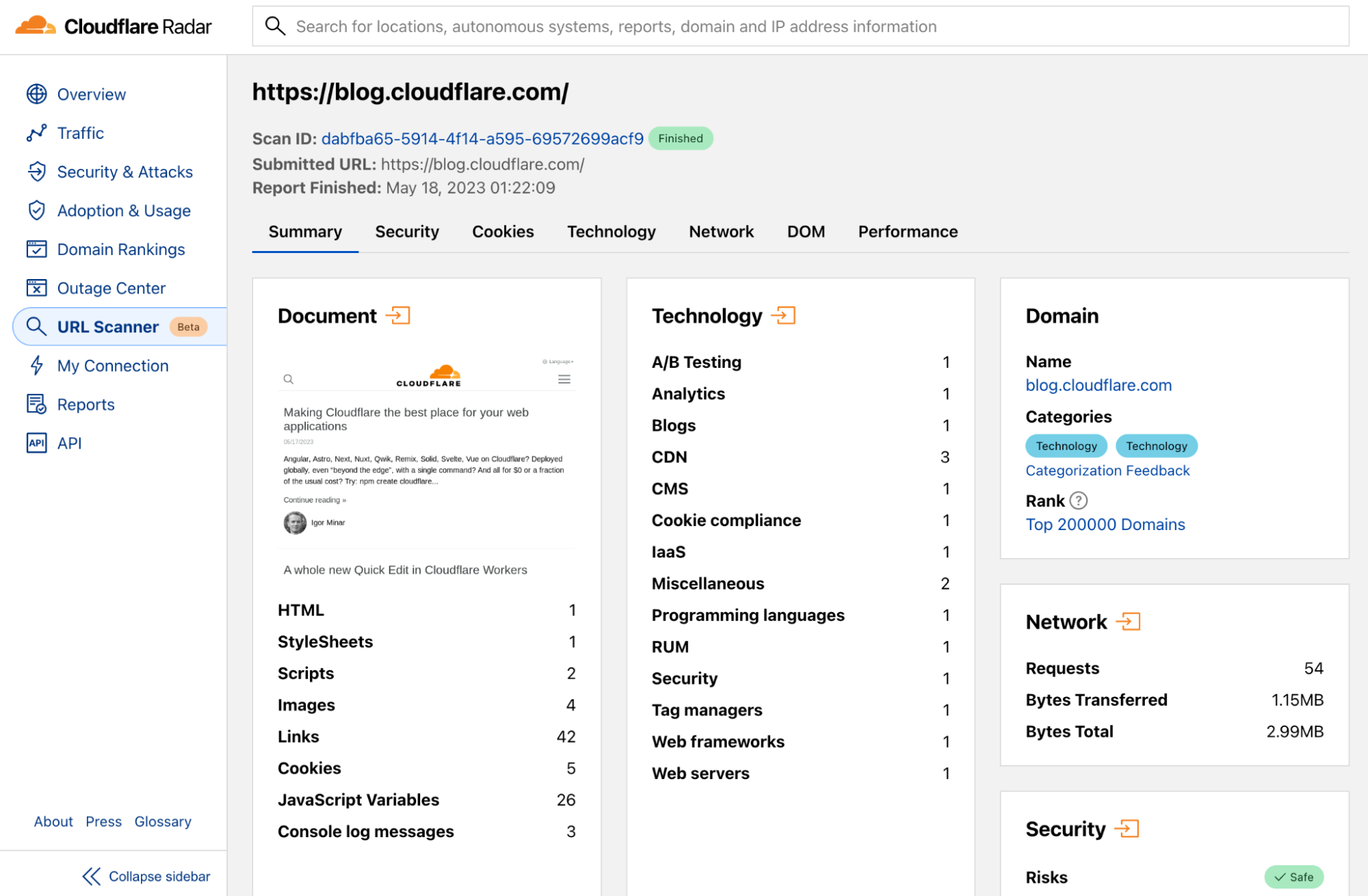
The URL Scanner scans any URL and compiles a full report containing technical, performance, privacy, and security details about that page. It's processing thousands of scans per day currently. It was built on top of Workers and uses a combination of the Browser Rendering APIs with Puppeteer to create enriched HAR archives and page screenshots, Durable Objects to reuse browser instances, Queues to handle customers' load and execute jobs asynchronously, and R2 to store the final reports.
This tool will soon have its own "how we built it" blog. Still, we wanted to let you know about it now because it is a good example of how you can build sophisticated applications using Browser Rendering APIs at scale starting today.
Future plans
The team will keep improving the Browser Rendering API, but a few things are worth mentioning today.
First, we are looking into upstreaming the changes in our Puppeteer fork to the main project so that using the official library with the Cloudflare Workers Browser Rendering API becomes as easy as a configuration option.
Second, one of the reasons why we decided to expose the DevTools protocol bare naked in the Worker binding is so that it can support other browser instrumentalization libraries in the future. Playwright is a good example of another popular library that developers want to use.
And last, we are also keeping an eye on and testing WebDriver BiDi, a "new standard browser automation protocol that bridges the gap between the WebDriver Classic and CDP (DevTools) protocols." Click here to know more about the status of WebDriver BiDi.
Final words
The Workers Browser Rendering API enters open beta today. We will gradually be enabling the customers in the wait list in batches and sending them emails. We look forward to seeing what you will be building with it and want to hear from you.
As usual, you can talk to us on our Developers Discord or the Community forum; the team will be listening.
Developer Week Performance Update: Spotlight on R2
Post Syndicated from David Tuber original http://blog.cloudflare.com/r2-is-faster-than-s3/


For developers, performance is everything. If your app is slow, it will get outclassed and no one will use it. In order for your application to be fast, every underlying component and system needs to be as performant as possible. In the past, we’ve shown how our network helps make your apps faster, even in remote places. We’ve focused on how Workers provides the fastest compute, even in regions that are really far away from traditional cloud datacenters.
For Developer Week 2023, we’re going to be looking at one of the newest Cloudflare developer offerings and how it compares to an alternative when retrieving assets from buckets: R2 versus Amazon Simple Storage Service (S3). Spoiler alert: we’re faster than S3 when serving media content via public access. Our test showed that on average, Cloudflare R2 was 20-40% faster than Amazon S3. For this test, we used 95th percentile Response tests, which measures the time it takes for a user to make a request to the bucket, and get the entirety of the response. This test was designed with the goal of measuring end-user performance when accessing content in public buckets.
In this blog we’re going to talk about why your object store needs to be fast, how much faster R2 is, why that is, and how we measured it.
Storage performance is user-facing
Storage performance is critical to a snappy user experience. Storage services are used for many scenarios that directly impact the end-user experience, particularly in the case where the data stored doesn’t end up in a cache (uncacheable or dynamic content). Compute and database services can rely on storage services, so if they’re not fast, the services using them won’t be either. Even the basic content fetching scenarios that use a CDN require storage services to be fast if the asset is either uncacheable or was not cached on the request: if the storage service is slow or far away, users will be impacted by that performance. And as every developer knows, nobody remembers the nine fast API calls if the last call was slow. Users don’t care about API calls, they care about overall experience. One slow API call, one slow image, one slow anything can muck up the works and provide users with a bad experience.
Because there are lots of different ways to use storage services, we’re going to focus on a relatively simple scenario: fetching static images from these services. Let’s talk about R2 and how it compares to one of the alternatives in this scenario: Amazon S3.
Benchmarking storage performance
When looking at uncached raw file delivery for users in North America retrieving content from a bucket in Ashburn, Virginia (US-East) and examining 95th percentile Response, R2 is 38% faster than S3:
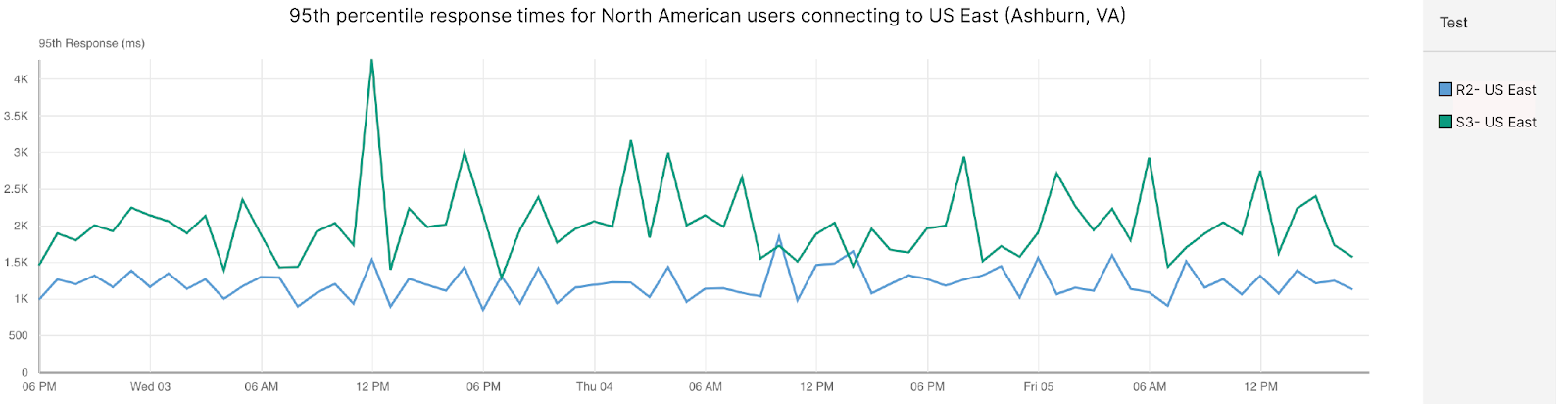
| Storage Performance: Response in North America (US-East) | |
|---|---|
| 95th percentile (ms) | |
| Cloudflare R2 | 1,262 |
| Amazon S3 | 2,055 |
For content hosted in US-East (Ashburn, VA) and only looking at North America-based eyeballs, R2 beats S3 by 30% in response time. When we look at why this is the case, the answer lies in our closeness to users and highly optimized HTTP stacks. Let’s take a look at the TCP connect and SSL times for these tests, which are the times it takes to reach the storage bucket (TCP connect) and the time to complete TLS handshake (SSL time):
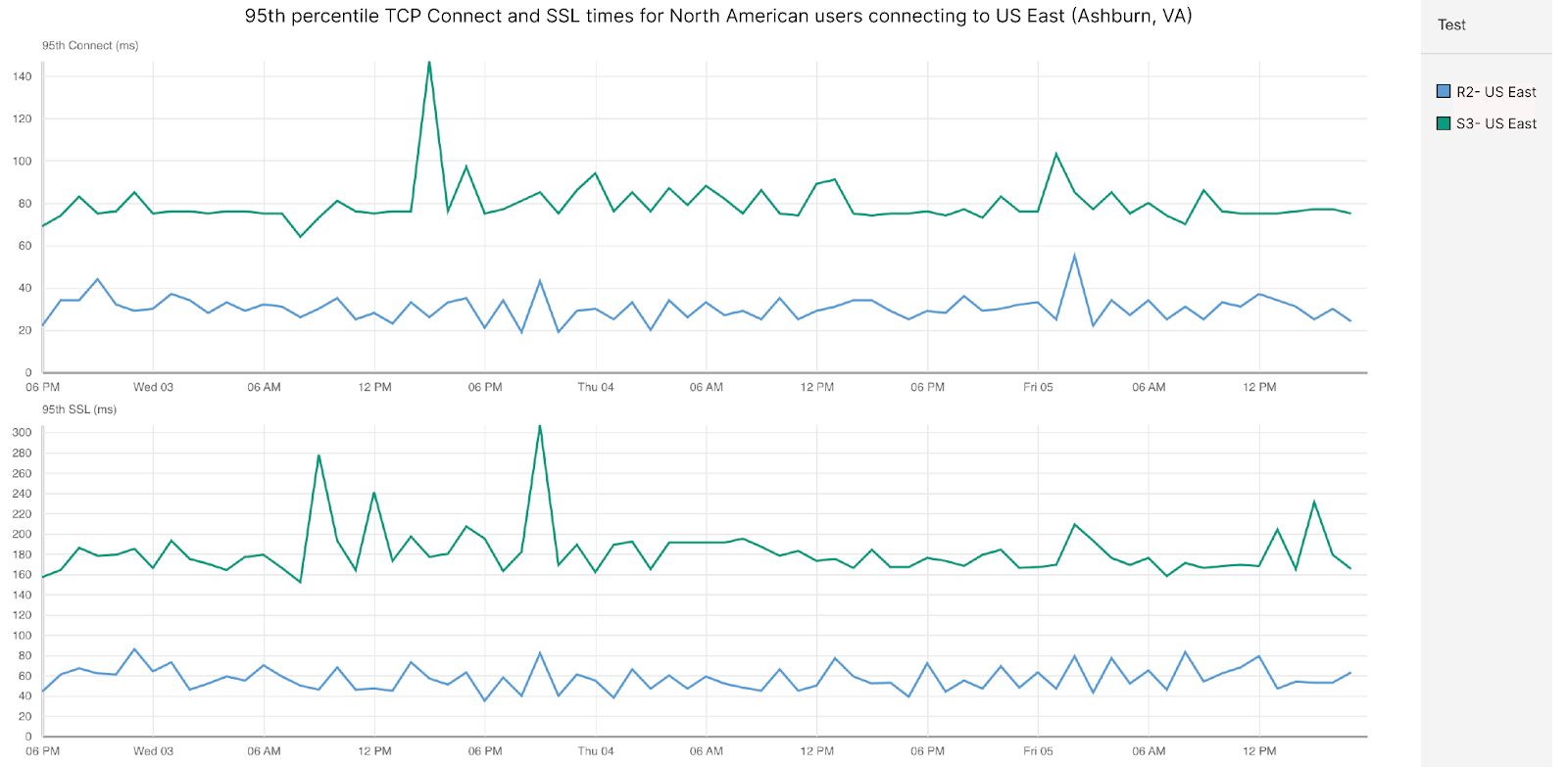
| Storage Performance: Connect and SSL in North America (US-East) | ||
|---|---|---|
| 95th percentile connect (ms) | 95th percentile SSL (ms) | |
| Cloudflare R2 | 32 | 59 |
| Amazon S3 | 78 | 180 |
Cloudflare’s cumulative connect + SSL time is almost 1/2 of Amazon’s SSL time alone. Being able to be fast on connection establishment gives us an edge right off the bat, especially in North America where cloud and storage providers tend to optimize for performance, and connect times tend to be low because ISPs have good peering with cloud and storage providers. But this isn’t just true in North America. Let’s take a look at Europe (EMEA) and Asia (APAC), where Cloudflare also beats out AWS in 95th percentile response time when we look at eyeballs in region for both regions:
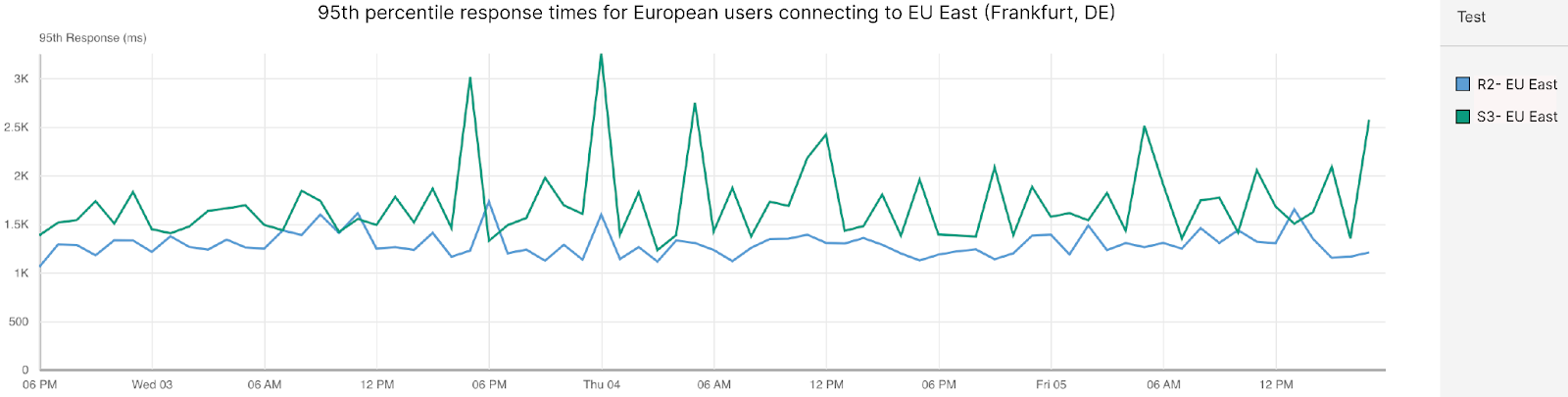
| Storage Performance: Response in EMEA (EU-East) | |
|---|---|
| 95th percentile (ms) | |
| Cloudflare R2 | 1,303 |
| Amazon S3 | 1,729 |
Cloudflare beats Amazon by 20% in EMEA. And when you look at the SSL times, you’ll see the same trends that were present in North America: faster Connect and SSL times:
| Storage Performance: Connect and SSL in EMEA (EU-East) | ||
|---|---|---|
| 95th percentile connect (ms) | 95th percentile SSL (ms) | |
| Cloudflare R2 | 57 | 94 |
| Amazon S3 | 80 | 178 |
Again, the separator is how optimized Cloudflare is at setting up connections to deliver content. This is also true in APAC, where objects stored in Tokyo are served about 1.5 times faster on Cloudflare than for AWS:
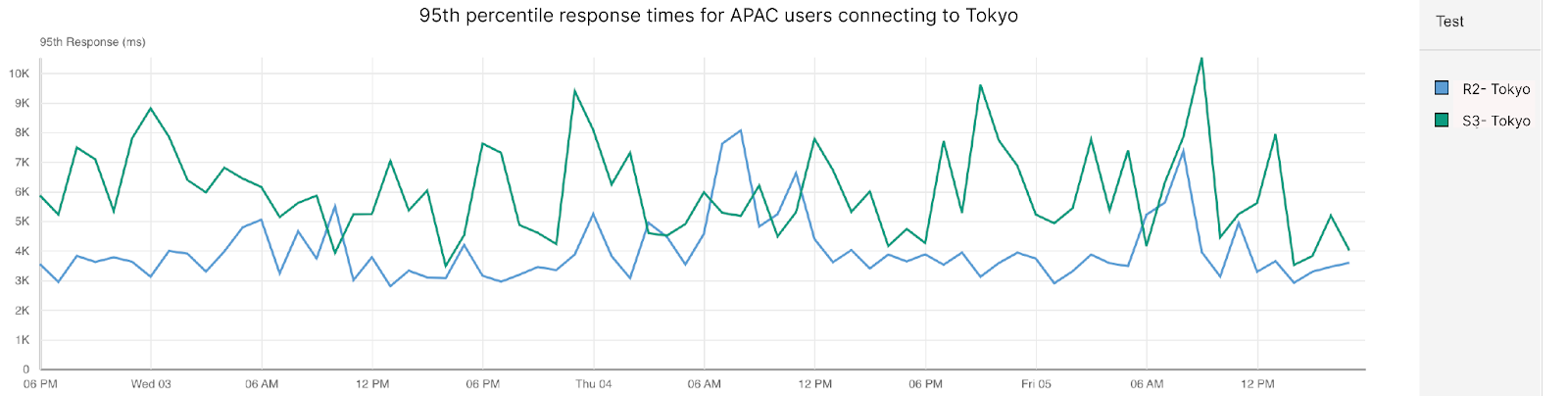
| Storage Performance: Response in APAC (Tokyo) | |
|---|---|
| 95th percentile (ms) | |
| Cloudflare R2 | 4,057 |
| Amazon S3 | 6,850 |
Focus on cross-region
Up until this point, we’ve been looking at scenarios where users are accessing data that is stored in the same region as they are. But what if that isn’t the case? What if a user in Germany is accessing content in Ashburn? In those cases, Cloudflare also pulls ahead. This is a chart showing 95th percentile response times for cases where users outside the United States are accessing content hosted in Ashburn, VA, or US-East:
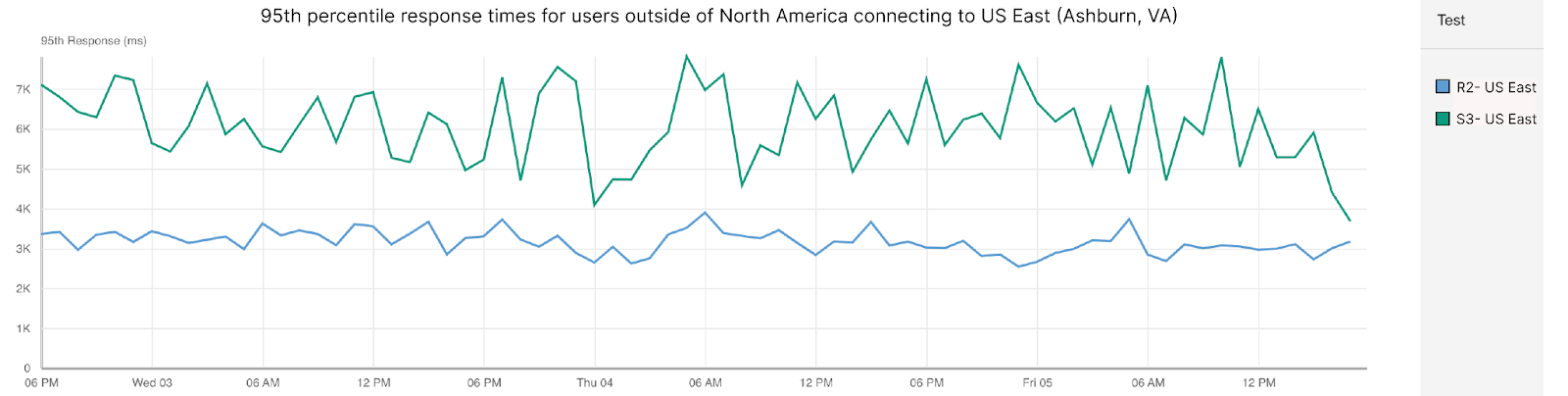
| Storage Performance: Response for users outside of US connecting to US-East | |
|---|---|
| 95th percentile (ms) | |
| Cloudflare R2 | 3,224 |
| Amazon S3 | 6,387 |
Cloudflare wins again, at almost 2x faster than S3 at P95. This data shows that not only do our in-region calls win out, but we win across the world. Even if you don’t have the money to buy storage everywhere in the world, R2 can still give you world-class performance because not only is R2 faster cross-region, R2’s default no-region setup ensures your data will be close to your users as often as possible.
Testing methodology
To measure these tests, we set up over 400 Catchpoint backbone nodes embedded in last mile ISPs around the world to retrieve a 1 MB file from R2 and S3 in specific locations: Ashburn, Tokyo, and Frankfurt. We recognize that many users will store larger files than the one we tested with, and we plan to test with larger files next showing that we’re faster delivering larger files as well.
We had these 400 nodes retrieve the file uncached from each storage service every 30 minutes for four days. We configured R2 to disable caching. This allows us to make sure that we aren’t reaping any benefits from our CDN pipeline and are only retrieving uncached files from the storage services.
Finally, we had to fix where the public buckets were stored in R2 to get an equivalent test compared to S3. You may notice that when configuring R2, you aren’t able to select specific datacenter locations like you can in AWS. Instead, you can provide a location hint to a general region. Cloudflare will store data anywhere in that region.
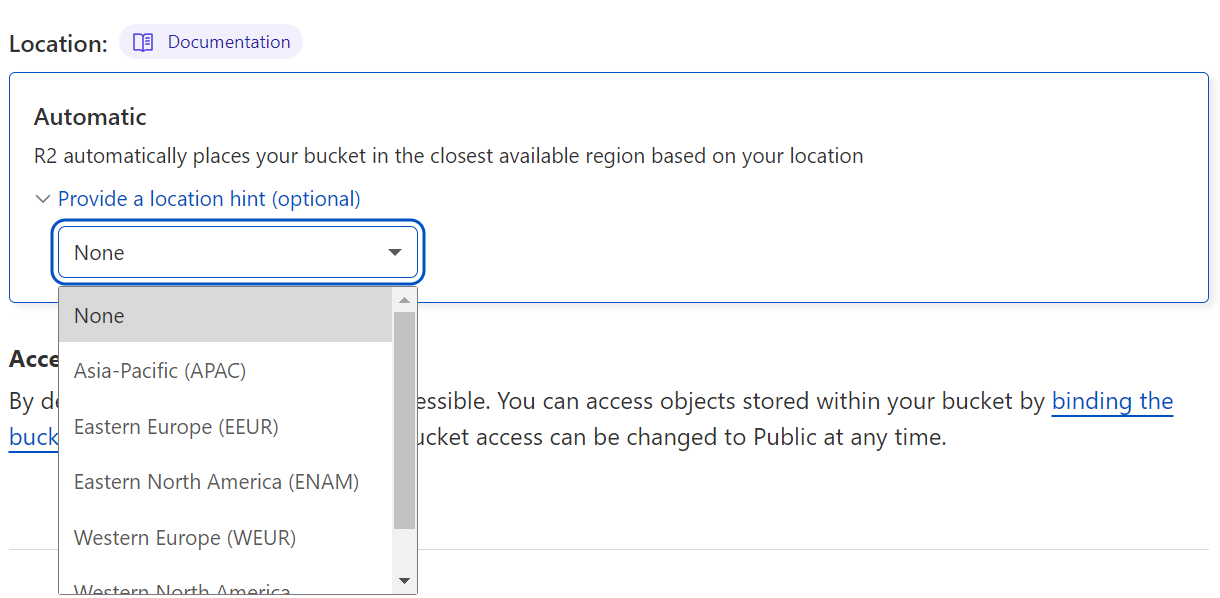
This feature is designed to make it easier for developers to deploy storage that benefits larger ranges of users as opposed to needing to know where specific datacenters are. However, that makes performance comparisons difficult, so for this test we configured R2 to store data in those specific locations (consistent with the S3 placement) on the backend as opposed to in any location in that region to ensure we would get better apples-to-apples results.
Putting the pieces together
Storage services like R2 are only part of the equation. Developers will often use storage services in conjunction with other compute services for a complete end-to-end application experience. Previously, we performed comparisons of Workers and other compute products such as Fastly’s Compute@Edge and AWS’s Lambda@Edge. We’ve rerun the numbers, and for compute times, Workers is still the fastest compute around, beating AWS Lambda@Edge and Fastly’s Compute@Edge for end-to-end performance for Rust hard tests:
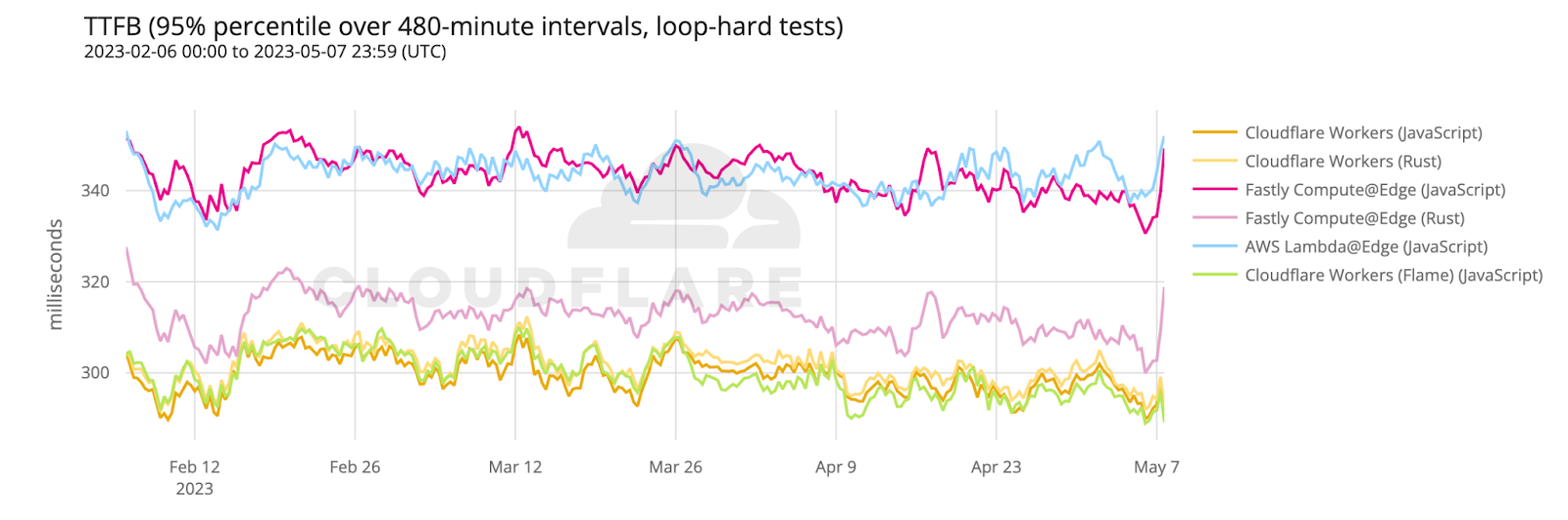
Cloudflare is faster than Fastly for both JavaScript and Rust tests, while also being faster than AWS at JavaScript, which is the only test Lambda@Edge supports
To run these tests, we perform two tests against each provider: a complex JavaScript function, and a complex Rust function. These tests run as part of our network benchmarking tests that run from real user browsers around the world. For a more in-depth look at how we collect this data for Workers scenarios, check our previous Developer Week posts.
Here are the functions for both complex functions in JavaScript and Rust:
JavaScript complex function:
function testHardBusyLoop() {
let value = 0;
let offset = Date.now();
for (let n = 0; n < 15000; n++) {
value += Math.floor(Math.abs(Math.sin(offset + n)) * 10);
}
return value;
}
Rust complex function:
fn test_hard_busy_loop() -> i32 {
let mut value = 0;
let offset = Date::now().as_millis();
for n in 0..15000 {
value += (((offset + n) as f64).sin().abs() * 10.0) as i32;
}
value
}
By combining Workers and R2, you get a much simpler developer experience and a much faster user experience than you would get with any of the competition.
Storage, sped up and simplified
R2 is a unique storage service that doesn’t require the knowledge of specific locations, has a more global footprint, and integrates easily with existing Cloudflare Developer Platform products for a simple, performant experience for both users and developers. However, because it’s built on top of Cloudflare, it comes with performance baked in, and that’s evidenced by R2 being faster than its primary alternatives.
At Cloudflare, we believe that developers shouldn’t have to think about performance, you have so many other things to think about. By choosing Cloudflare, you should be able to rest easy knowing that your application will be faster because it’s built on Cloudflare, not because you’re manipulating Cloudflare to be faster for you. And by using R2 and the rest of our developer platform, we’re happy to say that we’re delivering on our vision to make performance easy for you.
D1: We turned it up to 11
Post Syndicated from Matt Silverlock original http://blog.cloudflare.com/d1-turning-it-up-to-11/
This post is also available in 简体中文, 日本語, Español.
We’re not going to bury the lede: we’re excited to launch a major update to our D1 database, with dramatic improvements to performance and scalability. Alpha users (which includes any Workers user) can create new databases using the new storage backend right now with the following command:
$ wrangler d1 create your-database --experimental-backend
In the coming weeks, it’ll be the default experience for everyone, but we want to invite developers to start experimenting with the new version of D1 immediately. We’ll also be sharing more about how we built D1’s new storage subsystem, and how it benefits from Cloudflare’s distributed network, very soon.
Remind me: What’s D1?
D1 is Cloudflare’s native serverless database, which we launched into alpha in November last year. Developers have been building complex applications with Workers, KV, Durable Objects, and more recently, Queues & R2, but they’ve also been consistently asking us for one thing: a database they can query.
We also heard consistent feedback that it should be SQL-based, scale-to-zero, and (just like Workers itself), take a Region: Earth approach to replication. And so we took that feedback and set out to build D1, with SQLite giving us a familiar SQL dialect, robust query engine and one of the most battle tested code-bases to build on.
We shipped the first version of D1 as a “real” alpha: a way for us to develop in the open, gather feedback directly from developers, and better prioritize what matters. And living up to the alpha moniker, there were bugs, performance issues and a fairly narrow “happy path”.
Despite that, we’ve seen developers spin up thousands of databases, make billions of queries, popular ORMs like Drizzle and Kysely add support for D1 (already!), and Remix and Nuxt templates build directly around it, as well.
Turning it up to 11
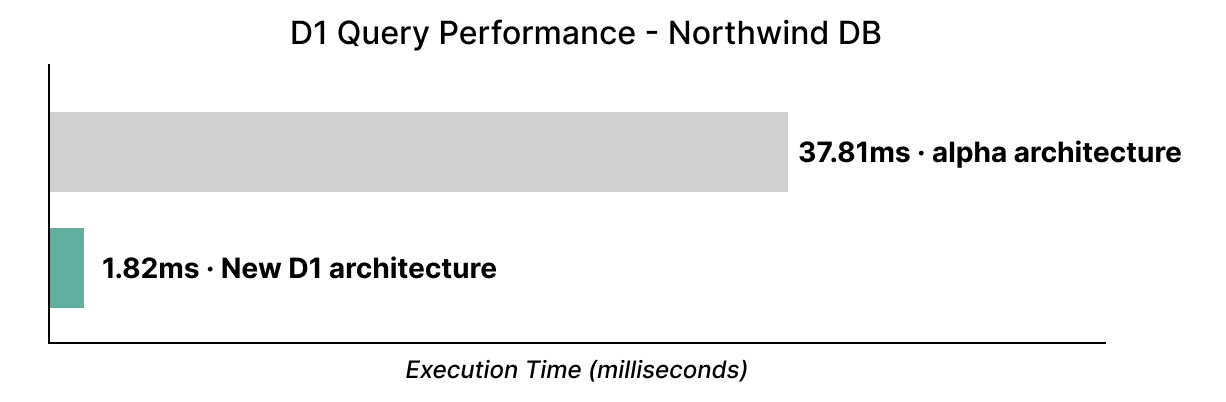
If you’ve used D1 in its alpha state to date: forget everything you know. D1 is now substantially faster: up to 20x faster on the well-known Northwind Traders Demo, which we’ve just migrated to use our new storage backend:
Our new architecture also increases write performance: a simple benchmark inserting 1,000 rows (each row about 200 bytes wide) is approximately 6.8x faster than the previous version of D1.
Larger batches (10,000 rows at ~200 bytes wide) see an even larger improvement: between 10-11x, with the new storage backend’s latency also being significantly more consistent. We’ve also not yet started to optimize our overall write throughput, and so expect D1 to only get faster here.
With our new storage backend, we also want to make clear that D1 is not a toy, and we’re constantly benchmarking our performance against other serverless databases. A query against a 500,000 row key-value table (recognizing that benchmarks are inherently synthetic) sees D1 perform about 3.2x faster than a popular serverless Postgres provider:
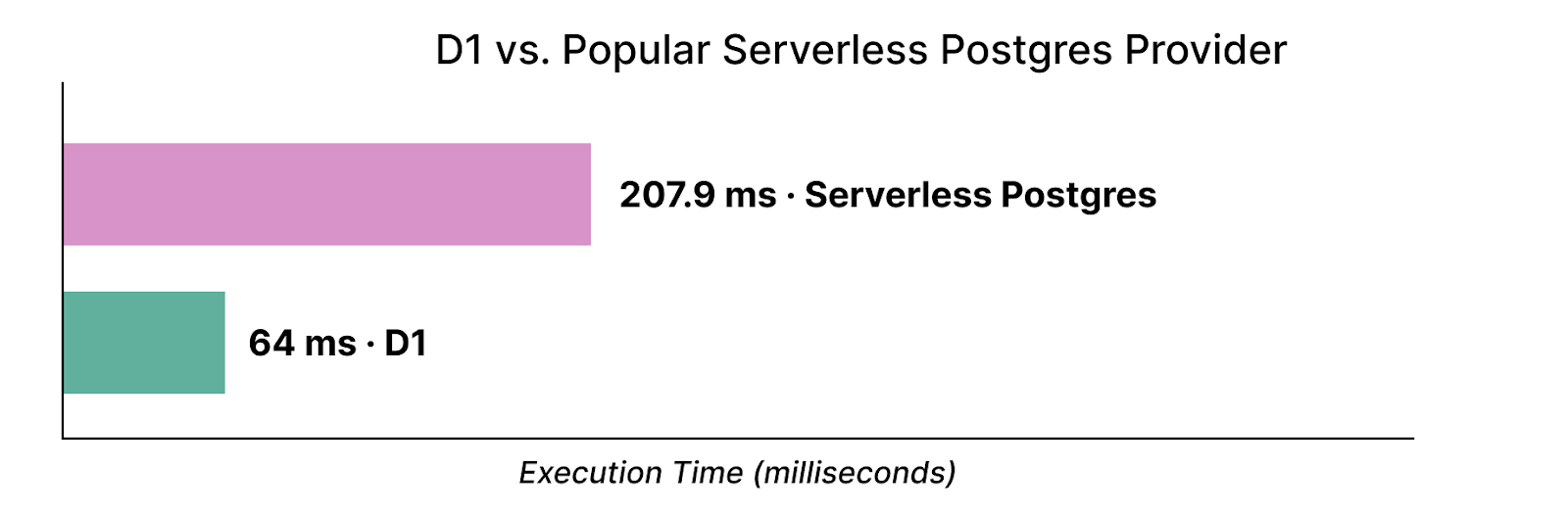
We ran the Postgres queries several times to prime the page cache and then took the median query time, as measured by the server. We’ll continue to sharpen our performance edge as we go forward.
Developers with existing databases can import data into a new database backed by the storage engine by following the steps to export their database and then import it in our docs.
What did I miss?
We’ve also been working on a number of improvements to D1’s developer experience:
- A new console interface that allows you to issue queries directly from the dashboard, making it easier to get started and/or issue one-shot queries.
- Formal support for JSON functions that query over JSON directly in your database.
- Location Hints, allowing you to influence where your leader (which is responsible for writes) is located globally.
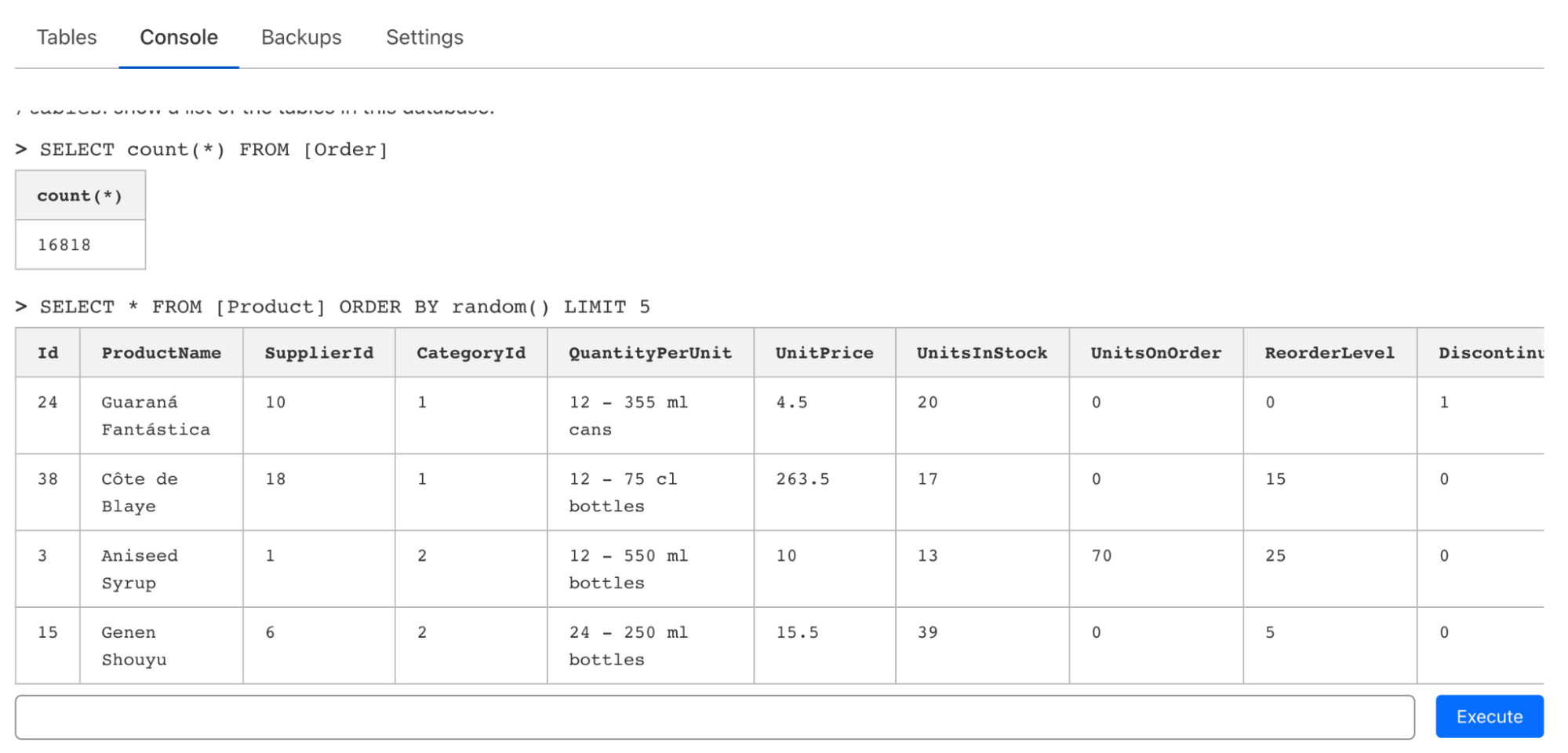
Although D1 is designed to work natively within Cloudflare Workers, we realize that there’s often a need to quickly issue one-shot queries via CLI or a web editor when prototyping or just exploring a database. On top of the support in wrangler for executing queries (and files), we’ve also introduced a console editor that allows you to issue queries, inspect tables, and even edit data on the fly:
JSON functions allow you to query JSON stored in TEXT columns in D1: allowing you to be flexible about what data is associated strictly with your relational database schema and what isn’t, whilst still being able to query all of it via SQL (before it reaches your app).
For example, suppose you store the last login timestamps as a JSON array in a login_history TEXT column: I can query (and extract) sub-objects or array items directly by providing a path to their key:
SELECT user_id, json_extract(login_history, '$.[0]') as latest_login FROM users
D1’s support for JSON functions is extremely flexible, and leverages the SQLite core that D1 builds on.
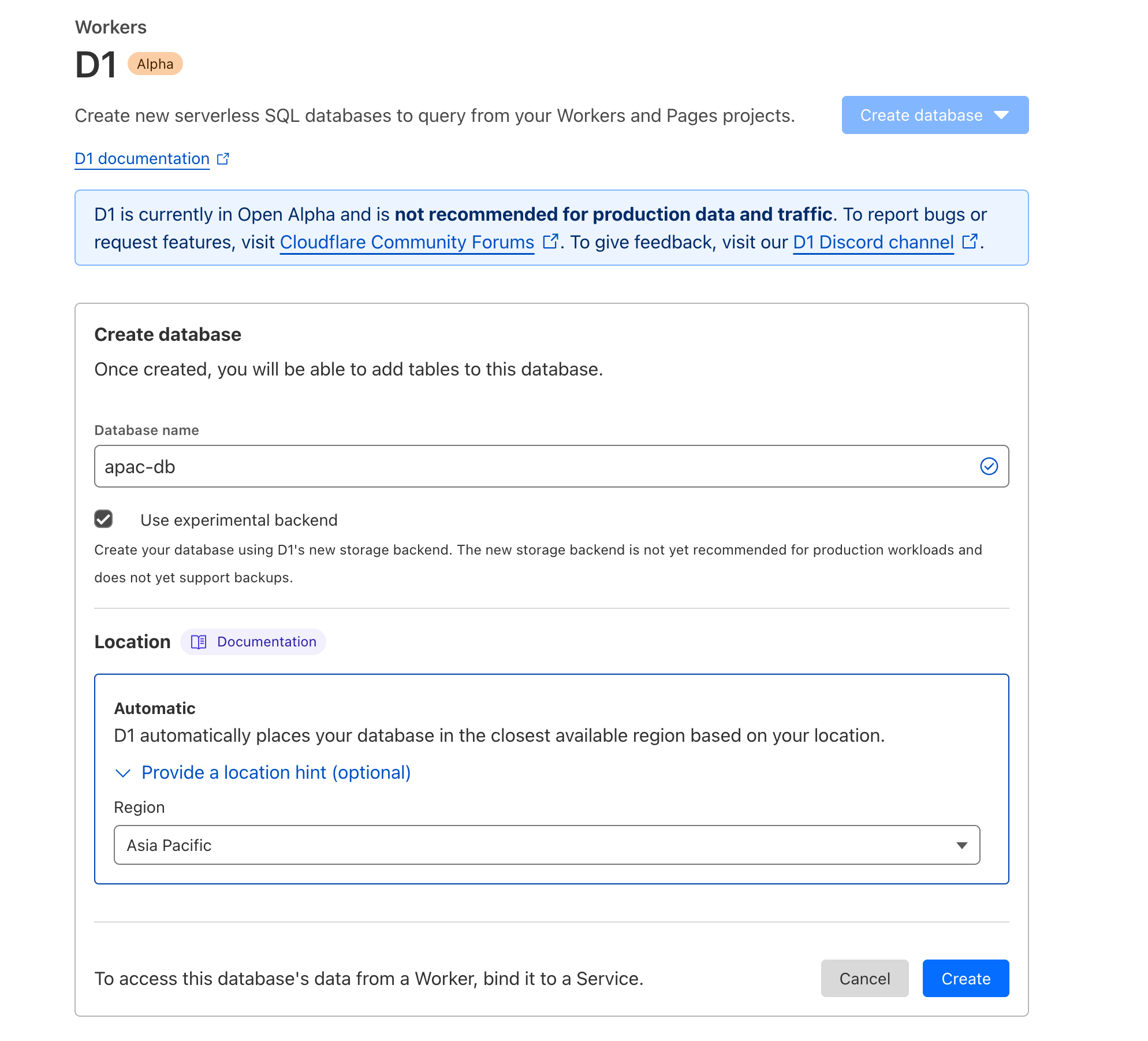
When you create a database for the first time with D1, we automatically infer the location based on where you’re currently connecting from. There are some cases, however, where you might want to influence that — maybe you’re traveling, or you have a distributed team that’s distinct from the region you expect the majority of your writes to come from.
D1’s support for Location Hints makes that easy:
# Automatically inferred based your location
$ wrangler d1 create user-prod-db --experimental-backend
# Indicate a preferred location to create your database
$ wrangler d1 create eu-users-db --location=weur --experimental-backend
Location Hints are also now available in the Cloudflare dashboard:
We’ve also published more documentation to help developers not only get started, but make use of D1’s advanced features. Expect D1’s documentation to continue to grow substantially over the coming months.
Not going to burn a hole in your wallet
We’ve had many, many developers ask us about how we’ll be pricing D1 since we announced the alpha, and we’re ready to share what it’s going to look like. We know it’s important to understand what something might cost before you start building on it, so you’re not surprised six months later.
In a nutshell:
- We’re announcing pricing so that you can start to model how much D1 will cost for your use-case ahead of time. Final pricing may be subject to change, although we expect changes to be relatively minor.
- We won’t be enabling billing until later this year, and we’ll notify existing D1 users via email ahead of that change. Until then, D1 will remain free to use.
- D1 will include an always-free tier, included usage as part of our $5/mo Workers subscription, and charge based on reads, writes and storage.
If you’re already subscribed to Workers, then you don’t have to lift a finger: your existing subscription will have D1 usage included when we enable billing in the future.
Here’s a summary (we’re keeping it intentionally simple):

Importantly, when we enable global read replication, you won’t have to pay extra for it, nor will replication multiply your storage consumption. We think built-in, automatic replication is important, and we don’t think developers should have to pay multiplicative costs (replicas x storage fees) in order to make their database fast everywhere.
Beyond that, we wanted to ensure D1 took the best parts of serverless pricing — scale-to-zero and pay-for-what-you-use — so that you’re not trying to figure out how many CPUs and/or how much memory you need for your workload or writing scripts to scale down your infrastructure during quieter hours.
D1’s read pricing is based on the familiar concept of a read unit (per 4KB read), and a write unit (per 1KB written). A query that reads (scans) ~10,000 rows of 64 bytes each would consume 160 read units. Write a big 3KB row in a “blog_posts” table that has a lot of Markdown, and that’s three write units. And if you create indexes for your most popular queries to improve performance and reduce how much data those queries need to scan, you’ll also reduce how much we bill you. We think making the fast path more cost-efficient by default is the right approach.
Importantly: we’ll continue to take feedback on our pricing before we flip the switch.
Time Travel
We’re also introducing new backup functionality: point-in-time-recovery, and we’re calling this Time Travel, because it feels just like it. Time Travel allows you to restore your D1 database to any minute within the last 30 days, and will be built into D1 databases using our new storage system. We expect to turn on Time Travel for new D1 databases in the very near future.
What makes Time Travel really powerful is that you no longer need to panic and wonder “oh wait, did I take a backup before I made this major change?!” — because we do it for you. We retain a stream of all changes to your database (the Write-Ahead Log), allowing us to restore your database to a point in time by replaying those changes in sequence up until that point.
Here’s an example (subject to some minor API changes):
# Using a precise Unix timestamp (in UTC):
$ wrangler d1 time-travel my-database --before-timestamp=1683570504
# Alternatively, restore prior to a specific transaction ID:
$ wrangler d1 time-travel my-database --before-tx-id=01H0FM2XHKACETEFQK2P5T6BWD
And although the idea of point-in-time recovery is not new, it’s often a paid add-on, if it is even available at all. Realizing you should have had it turned on after you’ve deleted or otherwise made a mistake means it’s often too late.
For example, imagine if I made the classic mistake of forgetting a WHERE on an UPDATE statement:
-- Don't do this at home
UPDATE users SET email = '[email protected]' -- missing: WHERE id = "abc123"
Without Time Travel, I’d have to hope that either a scheduled backup ran recently, or that I remembered to make a manual backup just prior. With Time Travel, I can restore to a point a minute or so before that mistake (and hopefully learn a lesson for next time).
We’re also exploring features that can surface larger changes to your database state, including making it easier to identify schema changes, the number of tables, large deltas in data stored and even specific queries (via transaction IDs) — to help you better understand exactly what point in time to restore your database to.
On the roadmap
So what’s next for D1?
- Open beta: we’re ensuring we’ve observed our new storage subsystem under load (and real-world usage) prior to making it the default for all `d1 create` commands. We hold a high bar for durability and availability, even for a “beta”, and we also recognize that access to backups (Time Travel) is important for folks to trust a new database. Keep an eye on the Cloudflare blog in the coming weeks for more news here!
- Bigger databases: we know this is a big ask from many, and we’re extremely close. Developers on the Workers Paid plan will get access to 1GB databases in the very near future, and we’ll be continuing to ramp up the maximum per-database size over time.
- Metrics & observability: you’ll be able to inspect overall query volume by database, failing queries, storage consumed and read/write units via both the D1 dashboard and our GraphQL API, so that it’s easier to debug issues and track spend.
- Automatic read replication: our new storage subsystem is built with replication in mind, and we’re working on ensuring our replication layer is both fast & reliable before we roll it out to developers. Read replication is not only designed to improve query latency by storing copies — replicas — of your data in multiple locations, close to your users, but will also allow us to scale out D1 databases horizontally for those with larger workloads.
In the meantime, you can start prototyping and experimenting with D1 right now, explore our D1 + Drizzle + Remix example project, or join the #d1 channel on the Cloudflare Developers Discord server to engage directly with the D1 team and others building on D1.
ABAC on SpiceDB: Enabling Netflix’s Complex Identity Types
Post Syndicated from Netflix Technology Blog original https://netflixtechblog.com/abac-on-spicedb-enabling-netflixs-complex-identity-types-c118f374fa89
By Chris Wolfe, Joey Schorr, and Victor Roldán Betancort
Introduction
The authorization team at Netflix recently sponsored work to add Attribute Based Access Control (ABAC) support to AuthZed’s open source Google Zanzibar inspired authorization system, SpiceDB. Netflix required attribute support in SpiceDB to support core Netflix application identity constructs. This post discusses why Netflix wanted ABAC support in SpiceDB, how Netflix collaborated with AuthZed, the end result–SpiceDB Caveats, and how Netflix may leverage this new feature.
Netflix is always looking for security, ergonomic, or efficiency improvements, and this extends to authorization tools. Google Zanzibar is exciting to Netflix as it makes it easier to produce authorization decision objects and reverse indexes for resources a principal can access.
Last year, while experimenting with Zanzibar approaches to authorization, Netflix found SpiceDB, the open source Google Zanzibar inspired permission system, and built a prototype to experiment with modeling. The prototype uncovered trade-offs required to implement Attribute Based Access Control in SpiceDB, which made it poorly suited to Netflix’s core requirements for application identities.
Why did Netflix Want Caveated Relationships?
Netflix application identities are fundamentally attribute based: e.g. an instance of the Data Processor runs in eu-west-1 in the test environment with a public shard.
Authorizing these identities is done not only by application name, but by specifying specific attributes on which to match. An application owner might want to craft a policy like “Application members of the EU data processors group can access a PI decryption key”. This is one normal relationship in SpiceDB. But, they might also want to specify a policy for compliance reasons that only allows access to the PI key from data processor instances running in the EU within a sensitive shard. Put another way, an identity should only be considered to have the “is member of the EU-data-processors group” if certain identity attributes (like region==eu) match in addition to the application name. This is a Caveated SpiceDB relationship.
Netflix Modeling Challenges Before Caveats
SpiceDB, being a Relationship Based Access Control (ReBAC) system, expected authorization checks to be performed against the existence of a specific relationship between objects. Users fit this model — they have a single user ID to describe who they are. As described above, Netflix applications do not fit this model. Their attributes are used to scope permissions to varying degrees.
Netflix ran into significant difficulties in trying to fit their existing policy model into relations. To do so Netflix’s design required:
- An event based mechanism that could ingest information about application autoscaling groups. An autoscaling group isn’t the lowest level of granularity, but it’s relatively close to the lowest level where we’d typically see authorization policy applied.
- Ingest the attributes describing the autoscaling group and write them as separate relations. That is for the data-processor, Netflix would need to write relations describing the region, environment, account, application name, etc.
- At authZ check time, provide the attributes for the identity to check, e.g. “can app bar in us-west-2 access this document.” SpiceDB is then responsible for figuring out which relations map back to the autoscaling group, e.g. name, environment, region, etc.
- A cleanup process to prune stale relationships from the database.
What was problematic about this design? Aside from being complicated, there were a few specific things that made Netflix uncomfortable. The most salient being that it wasn’t resilient to an absence of relationship data, e.g. if a new autoscaling group started and reporting its presence to SpiceDB had not yet happened, the autoscaling group members would be missing necessary permissions to run. All this meant that Netflix would have to write and prune the relationship state with significant freshness requirements. This would be a significant departure from its existing policy based system.
While working through this, Netflix hopped into the SpiceDB Discord to chat about possible solutions and found an open community issue: the caveated relationships proposal.
The Beginning of SpiceDB Caveats
The SpiceDB community had already explored integrating SpiceDB with Open Policy Agent (OPA) and concluded it strayed too far from Zanzibar’s core promise of global horizontal scalability with strong consistency. With Netflix’s support, the AuthZed team pondered a Zanzibar-native approach to Attribute-Based Access Control.
The requirements were captured and published as the caveated relationships proposal on GitHub for feedback from the SpiceDB community. The community’s excitement and interest became apparent through comments, reactions, and conversations on the SpiceDB Discord server. Clearly, Netflix wasn’t the only one facing challenges when reconciling SpiceDB with policy-based approaches, so Netflix decided to help! By sponsoring the project, Netflix was able to help AuthZed prioritize engineering effort and accelerate adding Caveats to SpiceDB.
Building SpiceDB Caveats
Quick Intro to SpiceDB
The SpiceDB Schema Language lays the rules for how to build, traverse, and interpret SpiceDB’s Relationship Graph to make authorization decisions. SpiceDB Relationships, e.g., document:readme writer user:emilia, are stored as relationships that represent a graph within a datastore like CockroachDB or PostgreSQL. SpiceDB walks the graph and decomposes it into subproblems. These subproblems are assigned through consistent hashing and dispatched to a node in a cluster running SpiceDB. Over time, each node caches a subset of subproblems to support a distributed cache, reduce the datastore load, and achieve SpiceDB’s horizontal scalability.
SpiceDB Caveats Design
The fundamental challenge with policies is that their input arguments can change the authorization result as understood by a centralized relationships datastore. If SpiceDB were to cache subproblems that have been “tainted” with policy variables, the likelihood those are reused for other requests would decrease and thus severely affect the cache hit rate. As you’d suspect, this would jeopardize one of the pillars of the system: its ability to scale.
Once you accept that adding input arguments to the distributed cache isn’t efficient, you naturally gravitate toward the first question: what if you keep those inputs out of the cached subproblems? They are only known at request-time, so let’s add them as a variable in the subproblem! The cost of propagating those variables, assembling them, and executing the logic pales compared to fetching relationships from the datastore.
The next question was: how do you integrate the policy decisions into the relationships graph? The SpiceDB Schema Languages’ core concepts are Relations and Permissions; these are how a developer defines the shape of their relationships and how to traverse them. Naturally, being a graph, it’s fitting to add policy logic at the edges or the nodes. That leaves at least two obvious options: policy at the Relation level, or policy at the Permission level.
After iterating on both options to get a feel for the ergonomics and expressiveness the choice was policy at the relation level. After all, SpiceDB is a Relationship Based Access Control (ReBAC) system. Policy at the relation level allows you to parameterize each relationship, which brought about the saying “this relationship exists, but with a Caveat!.” With this approach, SpiceDB could do request-time relationship vetoing like so:
definition human {}
caveat the_answer(received int) {
received == 42
}
definition the_answer_to_life_the_universe_and_everything {
relation humans: human with the_answer
permission enlightenment = humans
Netflix and AuthZed discussed the concept of static versus dynamic Caveats as well. A developer would define static Caveat expressions in the SpiceDB Schema, while dynamic Caveats would have expressions defined at run time. The discussion centered around typed versus dynamic programming languages, but given SpiceDB’s Schema Language was designed for type safety, it seemed coherent with the overall design to continue with static Caveats. To support runtime-provided policies, the choice was to introduce expressions as arguments to a Caveat. Keeping the SpiceDB Schema easy to understand was a key driver for this decision.
For defining Caveats, the main requirement was to provide an expression language with first-class support for partially-evaluated expressions. Google’s CEL seemed like the obvious choice: a protobuf-native expression language that evaluates in linear time, with first-class support for partial results that can be run at the edge, and is not turing complete. CEL expressions are type-safe, so they wouldn’t cause as many errors at runtime and can be stored in the datastore as a compiled protobuf. Given the near-perfect requirement match, it does make you wonder what Google’s Zanzibar has been up to since the white paper!
To execute the logic, SpiceDB would have to return a third response CAVEATED, in addition to ALLOW and DENY, to signal that a result of a CheckPermission request depends on computing an unresolved chain of CEL expressions.
SpiceDB Caveats needed to allow static input variables to be stored before evaluation to represent the multi-dimensional nature of Netflix application identities. Today, this is called “Caveat context,” defined by the values written in a SpiceDB Schema alongside a Relation and those provided by the client. Think of build time variables as an expansion of a templated CEL expression, and those take precedence over request-time arguments. Here is an example:
caveat the_answer(received int, expected int) {
received == expected
}
Lastly, to deal with scenarios where there are multiple Caveated subproblems, the decision was to collect up a final CEL expression tree before evaluating it. The result of the final evaluation can be ALLOW, DENY, or CAVEATED. Things get trickier with wildcards and SpiceDB APIs, but let’s save that for another post! If the response is CAVEATED, the client receives a list of missing variables needed to properly evaluate the expression.
To sum up! The primary design decisions were:
- Caveats defined at the Relation-level, not the Permission-level
- Keep Caveats in line with SpiceDB Schema’s type-safe nature
- Support well-typed values provided by the caller
- Use Google’s CEL to define Caveat expressions
- Introduce a new result type: CAVEATED
How do SpiceDB Caveats Change Authorizing Netflix Identities?
SpiceDB Caveats simplify this approach by allowing Netflix to specify authorization policy as they have in the past for applications. Instead of needing to have the entire state of the authorization world persisted as relations, the system can have relations and attributes of the identity used at authorization check time.
Now Netflix can write a Caveat similar to match_fine , described below, that takes lists of expected attributes, e.g. region, account, etc. This Caveat would allow the specific application named by the relation as long as the context of the authorization check had an observed account, stack, detail, region, and extended attribute values that matched the values in their expected counterparts. This playground has a live version of the schema, relations, etc. with which to experiment.
definition app {}
caveat match_fine(
expected_accounts list<string>,
expected_regions list<string>,
expected_stacks list<string>,
expected_details list<string>,
expected_ext_attrs map<any>,
observed_account string,
observed_region string,
observed_stack string,
observed_detail string,
observed_ext_attrs map<any>
) {
observed_account in expected_accounts &&
observed_region in expected_regions &&
observed_stack in expected_stacks &&
observed_detail in expected_details &&
expected_ext_attrs.isSubtreeOf(observed_ext_attrs)
}
definition movie {
relation replicator: app with match_fine
permission replicate = replicator
}
Using this SpiceDB Schema we can write a relation to restrict access to the replicator application. It should only be allowed to run when
- It is in the highrisk or birdie accounts
- AND in either us-west-1 or us-east-1
- AND it has stack bg
- AND it has detail casser
- AND its extended attributes contain the key-value pair ‘foo: bar’
movie:newspecial#replicator@app:mover[match_fine:{"expected_accounts":["highrisk","birdie"],"expected_regions":["us-west-1","us-east-1"],"expected_stacks":["bg"],"expected_details":["casser"],"expected_ext_attrs":{"foo":"bar"}}]
With the playground we can also make assertions that can mirror the behavior we’d see from the CheckPermission API. These assertions make it clear that our caveats work as expected.
assertTrue:
- 'movie:newspecial#replicate@app:mover with {"observed_account": "highrisk", "observed_region": "us-west-1", "observed_stack": "bg", "observed_detail": "casser", "observed_ext_attrs": {"foo": "bar"}}'
assertFalse:
- 'movie:newspecial#replicate@app:mover with {"observed_account": "lowrisk", "observed_region": "us-west-1", "observed_stack": "bg", "observed_detail": "casser", "observed_ext_attrs": {"foo": "bar"}}'
- 'movie:newspecial#replicate@app:purger with {"observed_account": "highrisk", "observed_region": "us-west-1", "observed_stack": "bg", "observed_detail": "casser", "observed_ext_attrs": {"foo": "bar"}}'
Closing
Netflix and AuthZed are both excited about the collaboration’s outcome. Netflix has another authorization tool it can employ and SpiceDB users have another option with which to perform rich authorization checks. Bridging the gap between policy based authorization and ReBAC is a powerful paradigm that is already benefiting companies looking to Zanzibar based implementations for modernizing their authorization stack.
Acknowledgments
Additional Reading
- What is Google Zanzibar
- Annotated Google Zanzibar Paper
- SpiceDB, an Open Source, Google Zanzibar Inspired Authorization System
- Google’s CEL
- SpiceDB Glossary
- Top-3 Most Used SpiceDB Caveat Patterns (authzed.com)
- How Permissions are Answered in SpiceDB
- Netflix Complex Identities Example Schema
![]()
ABAC on SpiceDB: Enabling Netflix’s Complex Identity Types was originally published in Netflix TechBlog on Medium, where people are continuing the conversation by highlighting and responding to this story.
New England’s "Dark Day." May 19, 1780
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=EPQz9FpdOrw
По буквите: Варсано, Радева, Буш
Post Syndicated from Зорница Христова original https://www.toest.bg/po-bukvite-varsano-radeva-bush/
„Крадецът на самота“ от Раймондо Варсано

илюстрации Кирил Златков, София: изд. „Сиела“, 2023
Разказите на Раймондо Варсано първоначално създават усещането, че са отрязък от някакъв по-голям текст – може би роман или новела. Темпото им сякаш е пригодено за по-дълъг преход и преди да го усетиш, като че ли търсиш продължение, развой. Действието в тях е на пръв поглед оскъдно спрямо количеството детайли, които разказвачът внимателно регистрира и поднася под светлината. Виенското колело, което потъва в зеленината. Неудобната, килната на една страна поза на човека на пейката. Студеното кафе, по което човек може да разбере, че жена му си е тръгнала. И така нататък. Освен това фабулите почти не съдържат физически случки – ако някой тръгне да ги заснема, актьорите ще стоят неподвижно на екрана.
Защото случващото се в тези разкази се случва в езика, в диалозите между героите.
Дори да са половин изтърсено изречение. Или не изтърсено, а по-скоро премисляно, сдържано и в някакъв момент недосдържано. Няколко думи, които могат да отворят зев в земята, да разпорят тъканта на привидното разбирателство. Героите са премълчавали в името на това да бъдат заедно. В един кратък момент спират да го правят.

Детето на цирковия артист, сънуващо успеха на баща си и наблюдаващо неговия пореден провал, го пита кога циркът ще си тръгне от града (с подразбирането, че не иска баща му да остане). Мъжът и жената, които ходят поред при разведените си приятели, за да се уверяват в здравината на връзката си след загуба на дете, внезапно започват да си крещят – чайки ли се чуват, или гарги. Смелият, който след години е събрал кураж да помоли приятеля си да го свърже с момиче, различно от напълнялата с годините съпруга, започва да избягва същия този приятел – за да не обяснява защо не се е явил на срещата. Или възрастният майстор изведнъж признава защо винаги е намръщен, и читателят рязко обръща думите му към себе си, към целия си живот.
В по-силните разкази от сборника се случва именно това – преместват се някакви атоми от думи и това променя всичко. Точно
тази плашеща сила на езика държи вниманието на читателя обострено, сякаш във въздуха край него са полетели саби и всеки момент ще се забият на сцената.
Има и една друга линия от разкази импресии без човешки персонажи (за кораба ресторант, за върха и облака и пр.), но те стоят по-скоро декоративно, за задаване на ритъм на цялото. Същото бих казала за разказа с листата и камиона, въпреки че той пък е повод за разкошна илюстрация, най-хубавата в сборника.
Впрочем особената унесеност на персонажите в илюстрациите на Кирил Златков улавя едно друго важно свойство на разказите – те са видени през пелената на времето, положени в едно минало, леко маркирано като 80-те и 90-те (камиона с „другарките“, уличните телефони, страшничкото шествие със знамената). Минало, което разказвачът помни смътно, но въпреки това се връща към него – сякаш за да види къде всичко се е объркало.
„Едно възможно начало“ от Тодора Радева
дизайн Албена Лимони, София: ICU, 2023
Ако героите на Раймондо се интересуват от думата обрат, то героините на Тодора Радева от „Едно възможно начало“ имат нужда да изприказват, да споделят своята версия, своята история.
Още в първата новела ме впечатли една фантазия, която ми се видя огледална на еротичните описания на жените в класическата литература – ако се доверим на версиите, че те утоляват преди всичко вътрешното око на мъжа читател. В тази новела е изфантазиран
копнежът на двама мъже по една жена отвъд физическото отдаване –
изфантазирана е нуждата им да я познават изцяло, да познават нейната история, да вникнат в нея.
Единият дори каталогизира болките ѝ, има в тефтера си графа „болките на Рая“ – фразата неволно ми припомня началото на „Черна книга“ на Орхан Памук („когато Рюя е тъжна, натъжи се и ти“). И когато най-сетне излиза от ролята си на приятел/довереник, прави това само за да премине към изследване на физическото местоположение на тези болки – къде точно в тялото се намира сърцето.

Това, разбира се, не е само женски копнеж – потребността да бъдем видени и чути в нашата цялост е присъща на всички полове.
От една страна, става дума за основен механизъм на терапията, чуждият поглед функционира като зряла версия на огледалото, в което се формира Азът. Героините на Тодора Радева мечтаят за този поглед, за това придаващо им цялостност изслушване – и в същото време му се съпротивляват, поставят пречки пред него. Историята им се разкрива за читателя, но остава скрита за другите герои в книгата.
Причината понякога е определена обществена конвенция – дали тази на недостъпната тайнственост (като инструмент за съблазън), или представата за приличие (класическата фигура на битата жена, която след смъртта на съпруга си алкохолик влиза в стандартния наратив на скръбната вдовица). Или разбира се, поради естествената несводимост на човешкия опит до логичен разказ, поради естественото пренареждане на акцентите – вътрешните каденци на разказа изваждат на показ едно и скриват друго, та в самото си говорене човек се проваля, остава недоизказан, скрит зад лъжата на току-що споделената истина. Нали в мига на споделянето е престанала да бъде такава!
Толкова много пропускам да споделя, всъщност почти всичко, което е важно за мен. Но може би това е нормално.
(Неволно се връщам към „Крадецът на самота“ на Раймондо и се опитвам да си спомня дали любовните завръзки в част от разказите включват такова влечение към тайните на жените. Комай не.)
Копнеещи да се разкрият, никога недоразкриващи се, героините на Тодора Радева пишат писма, разкопчават ризите си, говорят – и все пак не казват важното. Затова след целия порив към споделяне последната глава се нарича „Какво всъщност се случи“ и дава уж обективен, страничен отчет на конкретно смилащо физическо преживяване. Привидно истината е най-сетне споделена. Де факто обаче веднага е погълната от своя метафоричен двойник. Ако болестта е метафора, какво да кажем за раждането, за аборта? Езикът бърза да скрие това, което най-сетне е казал.
„Макс и Мориц“, текст и илюстрации Вилхелм Буш
превод Любомир Илиев, София: изд. „Лист“, 2023
Следващите редове са рецензия не толкова на една книга, колкото на нейния прочит – на историята на нейните тукашни прочити. „Макс и Мориц“ е световна класика за деца, дошла у нас на вълната на своята изключителна популярност.
Първият свободен превод, разбирайте преразказ, излиза още през 1911 г. – под формата обаче на разкази. През 1928 г. е издаден свободен поетичен превод от Елин Пелин с подзаглавие „Лудориите на две деца в стихове и картинки“. Същата година, забележете, Ран Босилек публикува свое дописване на същата история – „Сестрите на Макс и Мориц“, очевидно като полъх от новите времена, в които двата пола имат право на равен достъп до пакости.
Впрочем неговите „Патиланци“ също заемат нещичко от немската класика – римувани, звънки разкази за бели, които не остават ненаказани по-скоро заради хатъра на местните поукотърсачи, отколкото защото авторът действително смята белите за нещо осъдително. Че би ли ги измислял тогава? Е, разбира се, патиланците винаги правят своите пакости неволно, също като Емил от Льонеберя, но тяхната невинност като че ли само усилва комичния елемент. Ами да, съдбата също прави пакости! Между другото, охлювите, полазили баба Цоцолана, изглеждат не толкова далечен отзвук от бръмбарите, които Макс и Мориц пъхат в леглото на своя чичо.
„Сестрите на Макс и Мориц“ впрочем са преиздавани неколкократно – през 1937-ма, през 1943-та и последно през 2019 г. Самите „Макс и Мориц“ излизат през 1929 г. като „Комедия в 7 сцени, за детски театър нагласена от Ернст Зиверт“. През 1937 г. (и 1943-та) ги срещаме в превод на Христо Радевски, през 1976 г. (и 1983-та) в превод на Димитър Стоевски. Неговите преводи на Буш, допълнени с тези на Севдалина Малинова, са издадени от „Труд“ през 2000 г. През 1991 г. пък е публикуван преводът на Марко Ганчев. През 2016 г. излиза отново преводът на Елин Пелин (дали причината не е в това, че за разлика от останалите, той е с изтекли поради давност авторски права?).
Макс и Мориц са навлезли дори в езика ни (само мога да предполагам какво са направили с ежедневния немски).
Вържеш ли кърпата си по определен начин, огледалото задължително те посреща с „Ооо, тетка Грета!“. С други думи, Вилхелм Буш вече повече от сто години се радва на извънредно радушен прием у нас – и е логично големият преводач на немска литература Любомир Илиев да се обърне към него.
Любопитна в случая е по-скоро промяната във времената. Ако погледнете какъв е приемът на Макс и Мориц
в българското интернет пространство, ще попаднете на куп сърдити коментари –
било че белите им са жестоки, било че краят им е несправедлив – ама как така са смлени и изядени от патките! А преди това един пекар се опитва да ги опече! Садистична приказка ли е това?
За да си отговорим, нека изгледаме един епизод на „Том и Джери“ – или която и да е анимация с преследване, с погаждане на номера, с герои, които се сплескват при сблъсък със стените, стават като звездички от хваналия ги ток, биват прегазени, разпъвани, усукани и какво ли не още – и секунди след това са си живи и здрави.

Буш се смята за един от бащите на комикса –
немалко анимационни животни (Бъгс Бъни например) изглеждат преки потомци на Плиш и Плюм (превеждани от Марко Ганчев като „Цоп и Цап“. А въпреки че никога не е рисувал в ленти и не е слагал балончета с „Бам!“ и „Прас!“, неговите истории са пълни със звуци – и с въображаемия джангър на счупена посуда, строшен мост, вайкащи се лели, гърмящи лули и какво ли не още, и с фонетичната въртележка на самите стихове.
Всичко е в движение и нищо не е на сериозно и завинаги;
„опечените“ Макс и Мориц се измъкват от хрупкавата коричка и продължават с белите, сякаш нищо не се е случило. А „поучителният“ им край всъщност е толкова невероятен, че едно продължение никак не е изключено – щом може деца да се смелят в мелница и да се превърнат в зрънца за домашни птици, затваряйки кръга с кокошките на леля Грета, защо да не може впоследствие да намерят чудодеен начин да се съберат отново? (Няма да даваме идеи, да не разстроим някой благоприличен читател).
Между другото, това безвредно за детската физика „изпичане“ на двамата вагабонти е буквално цитирано от Морис Сендак във „В нощната кухня“ (превод Стефан Русинов), където то вече присъства не като наказание, а като фантазия – да бъдеш превърнат в нещо меко, тестено, хрупкаво и уханно.
Впрочем Макс и Мориц също не се раждат от нищото – малко преди тях излиза Struwweipeter, 12 истории за деца, които правят каквото не трябва и биват сполетени от различни преувеличени наказания. На пръв поглед това са поучителни истории, които ни предупреждават да си изяждаме супата, да си режем ноктите, да не си смучем палците и изобщо да бъдем примерни дечица. На практика обаче
непослушанието е просто извинение да разкажем малко страхотии –
така както Роалд Дал признава, че първо измисля достатъчно ужасен персонаж, за да има извинение да струпа върху него комични нещастия.
Знаем ли защо такива истории привличат? Те преобръщат правилата, правят страшното смешно, превръщат смъртта в комичен персонаж, увличат ни в дързостта си, в кикота. Е, може да не се харесваме особено, когато изпитваме Schadenfreude, но какво да се прави! И Вилхелм Буш искал да се прочуе с живописните си платна и така и не изпитал особено задоволство от колосалния успех на своите „разкази в картинки“, но…
Впрочем по отношение на трогателната ни, уязвима душевност по-красноречив е фактът, че в супермаркетите се продава пастет „Макс и Мориц“.
Security Risks of New .zip and .mov Domains
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2023/05/security-risks-of-new-zip-and-mov-domains.html
Researchers are worried about Google’s .zip and .mov domains, because they are confusing. Mistaking a URL for a filename could be a security vulnerability.
Борисов vs. Гешев. Cui bono?
Post Syndicated from Емилия Милчева original https://www.toest.bg/borisov-vs-geshev-cui-bono/

Кой има полза от войната между лидера на ГЕРБ Бойко Борисов и главния прокурор Иван Гешев?
Римският политик и народен трибун Луций Касий Лонгин Равила препоръчвал на съдиите винаги да търсят кой се възползва от дадено престъпление, тъй като виновен е облагодетелстваният от деянието. Така се появил изразът „Кой има полза?“ (Cui bono, cui prodest – За кого е удобно, кой се облагодетелства).
Правилото на Равила помага да се проясни зацапаната картина в България, която европейското издание Politico определи като конкуренция на сериалите по Netflix с публикация под заглавие „Каскета срещу Тиквата. Българската мафиотска държава достигна повратна точка“. Трудно е да се прогледне през толкова много пластове мръсотия в не-правовата държава: взривната вълна по маршрута на главния прокурор; последвалото искане за освобождаването му от най-голямата политическа сила, известна като негов подемен кран и крепостна стена; забития в гърба нож от заместника, който се е клел във вярност и дружба на Началника, но сега иска охрана, защото го било страх да не го убие, и задвижва процедури за отстраняването му от поста.
Президент, „Възраждане“, Русия
Ако политическата нестабилност продължи и се върви към шести парламентарни избори за по-малко от три години, във вътрешнополитически план това би било изгодно за президента Радев и за проруската „Възраждане“. Държавният глава ще продължи да управлява чрез правителствата си и назначените от него шефове на спецслужби, да формира външнополитическите позиции на България – и чрез министъра на външните работи, и чрез своя представител в НАТО (изпратения наскоро бивш дипломат №1 Николай Милков).
Президентските възгледи доминират в българската позиция за Северна Македония още от редовното правителство на Кирил Петков, когато за министър на външните работи бе назначена Теодора Генчовска, бивша служителка на „Дондуков“ 2 (формално от квотата на ИТН). Въпреки че в последните си дни кабинетът все пак успя да вкара и парламентът да приеме т.нар. френско предложение за Северна Македония. На фона на заетите със себе си партии обаче за Румен Радев е лесно да изпъкне като единствения български политик, ангажиран с националните интереси – например българите да бъдат вписани в македонската Конституция (според същото това френско предложение).
„Възраждане“ неотклонно зове за избори, очевидно решена да превърне в свой актив гроздовете на гнева, които зреят в обществото заради политическата криза, и да атакува по-предни места след третото си на вота на 2 април. Няма друга политическа сила, отбелязала такъв подем за толкова кратко време. На изборите през ноември 2021 г., когато за първи път прескочи бариерата за парламента, „Възраждане“ спечели 127 549 гласа, на следващите през октомври 2022 г. почти ги удвои, а априлският вот ѝ донесе още 100 000 гласа, или близо 40%.
Продължаващо управление на президента и неспирен възход на „Възраждане“ са в синхрон с руските интереси. Това би осигурило още едно отличие за посланичката на Русия у нас Елеонора Митрофанова, наградена през май от президента Путин с орден „Александър Невски“ – за голeмия ѝ принос „в осъществяването на външнополитическия курс на Руската федерация“.
Една дестабилизирана България отслабва източния фланг на НАТО точно когато се очаква контраофанзива на Украйна, а преломът във войната на Москва срещу Киев не е настъпил. Регионът е в сферата на геополитическо влияние на Москва – облъчван с неотслабваща сила от 2014-та насам с ударни дози руска пропаганда с цел алиенация от ЕС и НАТО. Част от този наратив е прозападни политически сили и елити да бъдат определяни като „лакеи на Брюксел и Вашингтон“ и на „евроатлантическите господари“.
Съдебната система, Конституцията, статуквото
Войната в прокуратурата – институцията, превзета най-напред от политици и задкулисие, за да си гарантират недосегаемост, неминуемо засегна преговорите за правителство. В значително по-малка степен обаче ще бъде засегната съдебната система. Шансовете да бъде преобразена от дълбока конституционна реформа не изглеждат особено големи, независимо от заявката на ПП–ДБ „да тестват наличието на конституционно мнозинство, съгласие между всички политически сили около няколко едри идеи“. („Конституционното мнозинство“ лансира преди изборите съпредседателят на „Демократична България“ Христо Иванов. Макар да не тестваха такова съгласие по време на 7-месечното си управление.)
Готови сме на разговори за конституционна реформа, заяви в кулоарите Борисов, показал усърдна диалогичност в 49-тото НС. Поредното доказателство за такова прилежание на политик, известен като автократ, е спазване на джентълменското споразумение с ПП–ДБ да им отстъпят председателското място в Правната комисия, след като ГЕРБ–СДС получи стола на „пръв сред равни“ – председател на парламента.
Няма обаче големи шансове да бъдат събрани необходимите за промени в Конституцията 160 гласа, които да одобрят „едрите идеи“, като преструктуриране на ВСС и окончателно разделяне на съдийската от прокурорската квота, силно ограничаване на правомощията на главния прокурор, преосмисляне на института на служебното правителство, което да се занимава само с избори и процесите между тях, за да не възниква „квазипрезидентски режим“. Последното разгневи президента. „Няма проблем, стига редовното правителство да си върши работата и да не завещава тежки кризи на служебното“, коментира той, изброявайки постиженията на овластените от него.
Ако изобщо се състави правителство в рамките на 49-тия парламент, то ще е с твърде ограничен срок на действие и едва ли ще изтрае повече от година – недостатъчна за обсъждане и приемане на дълбока реформа на Конституцията в частта за съдебната система. В рамките на възможното обаче е парламентът да приеме онова, което се изисква от него по Плана за възстановяване и устойчивост – механизъм за разследване на главния прокурор.
В четвъртък, 18 май, Правната комисия одобри на първо четене законопроекта на служебното правителство за промени в НПК и Закона за съдебната власт и амбициите са скоростно да бъде гласуван в пленарната зала. Основната идея е назначен ad hoc наказателен съдия от Върховния касационен съд да образува проверка и да води разследвания срещу главния прокурор или негов заместник, когато има достатъчно данни за извършено престъпление. Промените намаляват на 13 изискваните сега 17 гласа за избор и освобождаване на главния прокурор, или ⅔ от ВСС, и може да се окаже, че Иван Гешев ще е първият засегнат от тях.
Колкото и да трака саби и щитове, той изглежда като счупен човек. Осъзнава, че подкрепата за него се оттегля, ГЕРБ и ДПС го жертват в името на европейското си ребрандиране и отпушване на Плана за възстановяване и устойчивост и няма особен смисъл да се бие, освен ако не смята да напуска България. Разполага с твърде много информация. Министърът на вътрешните работи Иван Демерджиев съобщи, че близо 100 производства по обществено значими казуси са поставени „на трупчета“ от прокуратурата поради две основни причини – политическо влияние върху съдебното производство или влияние на лица от криминалния контингент. Никой от засегнатите не би искал този човек да остане на поста си.
Борисов, Нинова, вторият мандат
Едва измъкнала се от изолация, партия ГЕРБ има всички шансове да влезе отново в нея заради заплаха от съдебно разголване на лидера си след знаците от главния прокурор за „къщата в Барселона“. Затова и на Борисов му е нужно пакетиране в съвместно управление с ПП–ДБ.
БСП се отдръпна от преговорите за първия мандат – така предопределя провала му и отваря път за следващия. ДПС и ИТН са съгласни и заедно с ГЕРБ–СДС биха осигурили подкрепа от 116 депутатски гласа. За мнозинство от 121 не им достигат петима, а изходът от гласуването в пленарната зала за кабинета на Мария Габриел ще предопределят 37-те от „Възраждане“ – или пък отсъствието на депутати от различни политически сили, за да не бие на очи.
Корнелия Нинова смени посоката толкова рязко, че дори не си направи труда да пита членовете на БСП (както обеща преди време) или Националния съвет (както обеща наскоро). На 14 май Нинова заяви, че социалистите биха подкрепили „национален експертен кабинет“ и ако вътрешното допитване каже „да“, ще участват с експерти. На 15 май лидерката на БСП седна на една маса в парламента заедно с кандидата за премиер на ГЕРБ Мария Габриел и Бойко Борисов, за да каже, че крайното решение ще вземе пленумът, и даже постави разделителната линия:
Ако партиите подкрепим общо правителство, надпартийно, и то реши да изнася оръжия за Украйна, смятайте, че на секундата се оттегляме.
Буквално броени часове след тази среща дойде заявката ѝ, че излиза от преговорите. Но пък БСП е готова да преговаря с ПП–ДБ, ако я поканят за разговори за втория мандат – при същите червени линии за Украйна. Ще ги приемат ли? Гешев е в задънена улица, Борисов – притиснат до стената, Радев – единственият печеливш. Дори да се състави редовно правителство, стабилността няма да е присъща на българската политика в близките години. А мандатът на президента изтича през 2026 г. Дотогава и двамата, които бяха негови политически противници през 2020 г., ще бъдат елиминирани. А Радев ще управлява.
Пластмасов живот. Микропластмасата в нашите тела
Post Syndicated from original https://www.toest.bg/plastmasov-zhivot-mikroplastmasata-v-nashite-tela/

Пластмасата представлява верига от молекули (полимер), която се получава при свързването на малки молекули (мономери), извлечени от петрол или газ. Макропластмасата са големи (над 20 мм) пластмасови отпадъци (например пластмасовите бутилки). Мезопластмасата представлява големи пластмасови частици, които се получават от пелети от необработена пластмаса (без съдържание на рециклирани материали) и обикновено са с размер между 5 и 10 мм.
Микропластмасата са малки частици (под 5 мм), получени при разграждането на макропластмасата. Микроперлите, които също са вид микропластмаса, са малки гранули, част от състава на продуктите за лична хигиена, като паста за зъби и гелове за почистване (ексфолианти/скраб). От прането също се получава микропластмаса, когато синтетичните дрехи отделят малки нишки (микровлакна). Нанопластмасата представлява малки частици от микропластмаса с размер от 0,2 до 2 мм.
Какво точно е микропластмаса?
Микропластмасата е смятана за замърсител на околната среда, защото пластмасата се разгражда между 20 и 500 години в зависимост от състава си и се открива в огромни количества в морската среда. Пластмасовите частици се категоризират като първична и вторична микропластмаса. Първичната се произвежда в сурова форма за целите на пластмасовата индустрия. Тя е под формата на пелети или се преработва, за да се добави към фармацевтични и козметични продукти (микроперли). Първичната микропластмаса се използва и като абразивен компонент за почистване на промишлени машини с въздух под налягане.
Вторичната микропластмаса е резултат от разграждането на по-големи продукти. Отпадъците на плажа допринасят за получаването на микропластмасата, тъй като по-големи пластмасови части се разграждат под влиянието на слънцето и морските вълни. Микровлакната от дрехите попадат в отпадъчната вода и достигат до океана, ако не успеят да се филтрират.
Типовете микропластмаса са: полипропилен (PP), полиетилен (PE), полиетилентерефталат (PET), поливинилхлорид (PVC), полиметилметакрилат (PMMA), полиетилен с висока плътност (HDPE), полиетилен с ниска плътност (LDPE), поливинилацетат (PVA).
Микропластмасата е навсякъде?!
Още преди 20 години учените започват да разсъждават какви са потенциалните рискове, които микропластмасата крие. Първоначално фокусът на изследванията е насочен предимно към рисковете за морския живот. Оттогава е установено, че микропластмаса се открива не само в дълбокия океан, но и в aрктическия сняг и aнтарктическия лед, в миди, трапезна сол, във водата за пиене и бирата. Микропластмасата циркулира и във въздуха или пада заедно с дъжда над планините и градовете. През 2015 г. океанографите установяват, че микропластмасовите частици на повърхността на водните източници по целия свят са между 15 и 51 трилиона.
През 2017 г. австралийски учени съобщават, че зоопланктон, който е изложен на замърсяване с микровлакна, произвежда наполовина по-малко ларви, а възрастните са значително по-малки по размер. Микровлакната не са били погълнати от зоопланктона, но учените са установили, че те възпрепятстват плуването му и водят до деформации. В друго изследване от 2019 г. става ясно, че възрастни индивиди от тихоокеански вид раци (Emerita analoga), които са изложени на замърсяване с микровлакна, живеят по-кратко.
Един от най-сериозните проблеми за океанския свят е натрупаната в седимента микропластмаса, която няма как да се почисти, тъй като не изплува на повърхността. Тези места са известни като „горещи точки“, където нивата на замърсяване са по-сериозни и крият рискове за здравето на рибите и останалите морски обитатели.
Опасности за човешкото здраве
Доказателство, че сме изложени на замърсяване с микропластмаса, откриваме в изследване, установило наличието на микропластмаса в човешки проби от фецес. Микропластмаса се открива и в проби от слюнка на пациенти с различни белодробни заболявания. Тя е установена и в белите дробове на хора, които работят в текстилната индустрия, като съществува връзка с редица респираторни и белодробни заболявания.
Поради етични ограничения, стриктните правила за работа с човешки проби и ограничения брой лабораторни техники изследванията върху влиянието на микро- и нанопластмасата върху човешкото здраве са трудноизпълними. Поради тази причина учените работят с in vitro модели – клетъчни линии с човешки произход. Посредством такива изследвания е установено, че нанопластмасата може да бъде погълната от нашите клетки чрез различни механизми в зависимост от вида на клетката, големината и химичната структура на частиците.
Най-силно изложен на микро- и нанопластмаса е гастроинтестиналният тракт. In vitro изследване с използването на клетки от чревен епител сочи, че в рамките на 4 часа при част от клетките настъпва т.нар. апоптоза (програмирана клетъчна смърт). В in vitro изследване на Ву и сътрудници от 2020 г. е установено че микропластмасата възпрепятства размножаването на клетките от клетъчната линия Caco-2, съставена от клетки от чревния епител. Но доста фактори не могат да се вземат предвид – pH в червата, наличието на йони, органични вещества и ензими. Освен това изследваният полистирен e модифициран и не е известно да има същите ефекти в немодифицирано състояние.
Редица in vitro изследвания са насочени и към влиянието на микро- и нанопластмасата върху белодробните клетки, клетките на имунната система, нервните клетки, червените кръвни клетки. Въпреки установените клетъчни отговори към пластмасовите частици и цитотоксичността, която предизвикват, тези проучвания са противоречиви, тъй като не могат напълно да пресъздадат всички условия на реалната среда, а именно човешкото тяло.
Други фактори, от които зависят резултатите от тези изследвания, са концентрацията, големината и химичната структура на повърхността на пластмасовите частици. В in vitro условия токсичността на микро- и нанопластмасата се изразява в нарушение на структурата на клетъчната мембрана, предизвикване на оксидативен стрес (излагане на увеличено количество свободни радикали), индуциране на възпалителни процеси, генотоксичност (повреда на ДНК), апоптоза и автофагия (поглъщане на увредени органели, грешно нагънати белтъци и други клетъчни структури, наречени автофагозоми), нарушения в енергийната хомеостаза и метаболитни нарушения на клетките.
Въпреки всички известни до момента данни непосредствен риск за човешкото здраве не е установен, но това не значи, че такъв липсва. В световен мащаб хроничните заболявания са отговорни за 71% от смъртността. Хроничното възпаление е предпоставка за развитието на хронични болести, като диабет, сърдечносъдови и респираторни заболявания, а оказва се, микропластмасата във въздуха („пластмасов прах“) може да доведе до възпаление.
Замърсяването с микропластмаса и как се справяме с него
Засега не се справяме особено. Но ограничаването на производството на пластмаса е първата предприета стъпка. Научните изследвания върху влиянието на пластмасата при голям брой живи организми продължават. Кампаниите за рециклиране и правилно изхвърляне на битовите отпадъци не спират.
Интегрираната система за управление на отпадъците, известна като „четирите R“ (reduce, reuse, recycle, recover – намаляване, повторно използване, рециклиране и възстановяване), предлага списък с 10 препоръки към страните, които биха искали да намалят замърсяването с пластмаса:
(1) регулиране на производството и потреблението на пластмаса;
(2) екодизайн;
(3) увеличаване на търсенето на рециклирана пластмаса;
(4) намаляване на употребата на пластмаси;
(5) използване на възобновяема енергия за рециклиране;
(6) увеличена отговорност на производителя по отношение на отпадъците;
(7) подобрения в системите за събиране на отпадъци;
(8) приоритизиране на рециклирането;
(9) използване на биоразградими пластмаси;
(10) подобряване на рециклируемостта на отпадъците от електроника.
Какво лично всеки от нас може да предприеме, за да намали всекидневното излагане на микропластмасово замърсяване? На първо място, се препоръчва да проветряваме редовно помещенията, в които се намираме. Заедно с това е необходимо да почистваме редовно с прахосмукачка и да пречистваме въздуха. По този начин се отстранява прахта, която често съдържа микропластмаса. Добре е да избягваме козметични продукти, съдържащи микроперли, както и дрехи от синтетични материали (акрил и полиестер). Загряването на пластмасови кутии за храна в микровълнова фурна също не е препоръчително, както и излагането на пластмасови бутилки с вода на слънчевите лъчи.
Най-трудната стъпка за разрешаване на този проблем е човечеството да започне да разчита по-малко на пластмасата и по възможност да я замени с алтернативни и по-здравословни продукти.