Post Syndicated from Dhrubajyoti Mukherjee original https://aws.amazon.com/blogs/big-data/how-volkswagen-autoeuropa-built-a-data-mesh-to-accelerate-digital-transformation-using-amazon-datazone/
This is a joint blog post co-authored with Martin Mikoleizig from Volkswagen Autoeuropa.
Volkswagen Autoeuropa is a Volkswagen Group plant that produces the T-Roc. The plant is located near Lisbon, Portugal and produces about 934 cars per day. In 2023, Volkswagen Autoeuropa represented 1.3% of the national GDP of Portugal and 4% in national export of goods impact with a sales volume of 3.3511 billion Euros. Volkswagen Autoeuropa aims to become a data-driven factory and has been using cutting-edge technologies to enhance digitalization efforts.
In this post, we discuss how Volkswagen Autoeuropa used Amazon DataZone to build a data marketplace based on data mesh architecture to accelerate their digital transformation. The data mesh, built on Amazon DataZone, simplified data access, improved data quality, and established governance at scale to power analytics, reporting, AI, and machine learning (ML) use cases. As a result, the data solution offers benefits such as faster access to data, expeditious decision making, accelerated time to value for use cases, and enhanced data governance.
Understanding Volkswagen Autoeuropa’s challenges
At the time of writing this post, Volkswagen Autoeuropa has already implemented more than 15 successful digital use cases in the context of real-time visualization, business intelligence, industrial computer vision, and AI.
Before the AWS partnership, Volkswagen Autoeuropa faced the following challenges.
- Long lead time to access data – The digital use cases launched by Volkswagen Autoeuropa spent most of their project time getting access to the data that was relevant to their use cases. After the right data for the use case was found, the IT team provided access to the data through manual configuration. The lead time to access data was often from several days to weeks.
- Insufficient data governance and auditing – Data was shared directly to use cases by copying it. Therefore, the IT team connected the data manually from their sources to the desired destinations multiple times. This process wasn’t centrally tracked to discover any information on the data sharing process. For example, if the data was copied in the past, how many use cases have access to the data, when access was granted, and who granted the access.
- Redundant effort to process the same information – Because the IT team copied the data sources based on the exact use case requirements, they shared specific columns of the tables from the data. As additional use cases requested access to the same data with different column requirements, even more copies of the data were created.
- Repeated process to establish security and governance guardrails – Each time the IT and the security team provided a connection to a new data source, they had to set up the security and governance guardrails. This required repeated manual effort.
- Data quality issues – Because the data was processed redundantly and shared multiple times, there was no guarantee of or control over the quality of the data. This led to reduced trust in the data.
- Absence of data catalog and metadata management – Data didn’t have any metadata associated with it, and so use cases couldn’t consume the data without further explanation from the data source owners and specialists. Furthermore, no process to discover new data existed. Similar to the consumption process, use cases would consult specialists to understand the context of the data and if it could provide value.
Envisioning a data solution for Volkswagen Autoeuropa
To address these challenges, Volkswagen Autoeuropa embarked on a bold vision. They envisioned a seamless data consumption process, similar to an online shopping experience. They envisioned a data marketplace where data users could browse and access high-quality, secure data with clear specifications, business context, and relevant attributes. This vision materialized into a project aimed at transforming data accessibility and governance as the foundation for the digital ecosystem. The vision to be realized: Data as seamless as online shopping.
In collaboration with Amazon Web Services (AWS), Volkswagen Autoeuropa joined the Enhanced Plant Onboarding Program of the Global Volkswagen Group’s Digital Production Platform (DPP EPO) strategy. Through this partnership, AWS and Volkswagen Autoeuropa created a data marketplace that significantly improved data availability.
In the discovery phase of the project, Volkswagen Autoeuropa and AWS evaluated several options to build the data solution. In the end, Volkswagen Autoeuropa chose a solution based on data mesh architecture using Amazon DataZone. Being a managed service, Amazon DataZone provided the necessary speed and agility to build the solution. At the same time, it led to higher operational efficiencies and lower operational overhead. The team adopted a data mesh architecture because the principles of the data mesh aligned with Volkswagen Autoeuropa’s vision of being a data driven factory.
Solution overview
This section describes the key features and architecture of the Volkswagen Autoeuropa data solution. The solution is based on a data mesh architecture.
Data solution features
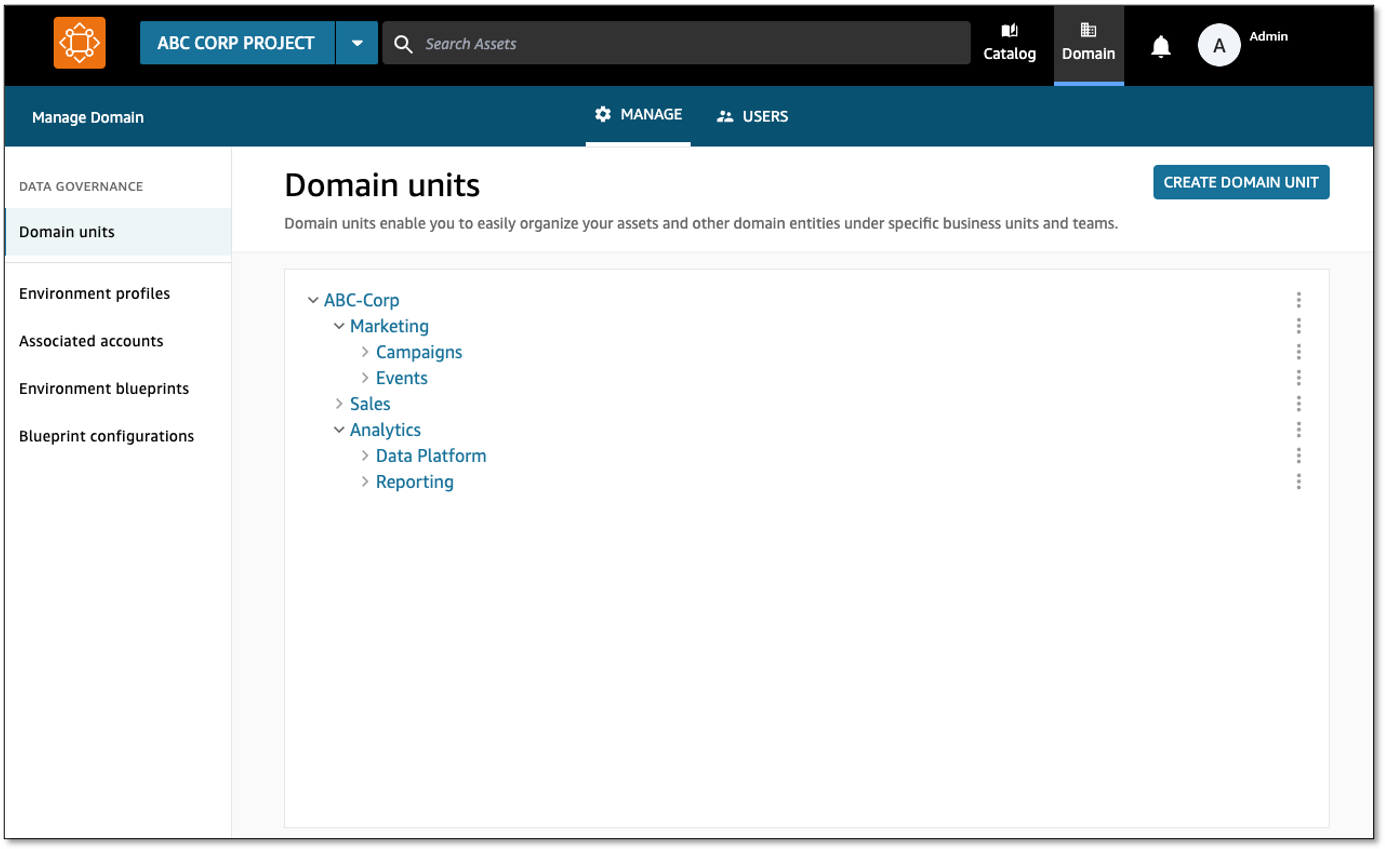
The following figure shows the key capabilities of the Volkswagen Autoeuropa data solution.

The key capabilities of the solution are:
- Data quality – In the solution, we’ve built a data quality framework to streamline the process of data quality checks and publishing quality scores. It uses AWS Glue Data Quality to generate recommendation rulesets, run orchestrated jobs, store results, and send notifications to users. This framework can be seamlessly integrated into AWS Glue jobs, providing a quality score for data pipeline jobs. In addition, the quality score is published in the Amazon DataZone data portal, allowing consumers to subscribe to the data based on its quality score.Assigning a quality score to the data helps build trust in the data, and shifts the responsibility of maintaining data quality to the data owner. As a result, the quality of the results delivered by these use cases improves.
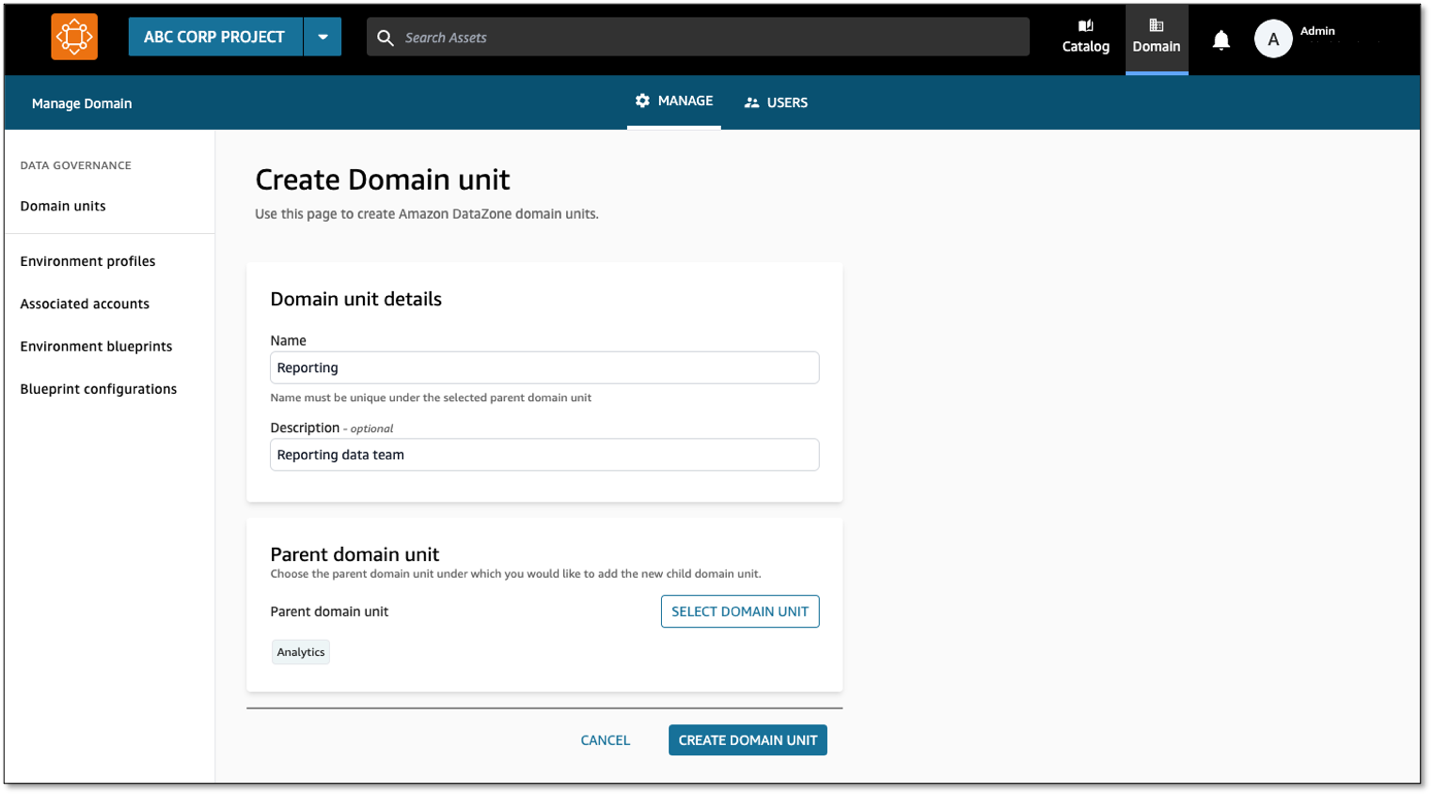
- Data registration – The producers sign in to the Amazon DataZone data portal using their AWS Identity and Access Management (IAM) credentials or single sign-on with integration through AWS IAM Identity Center. They register their data assets, which are stored in Amazon Simple Storage Service (Amazon S3), in the Amazon DataZone data catalog. The metadata of the data assets is stored in an AWS Glue catalog and made available in the business data catalog of Amazon DataZone and in the Amazon DataZone data source. The producers add business context such as business unit name, data owner contact information, and data refresh frequency using Amazon DataZone glossaries and metadata forms. In addition, they use generative AI capabilities to generate business metadata. After the business metadata is generated, they review the changes and modify the metadata if needed.Because all data products in Volkswagen Autoeuropa are now registered in the same location, the likelihood of data duplication is significantly reduced. Moreover, the data producers are improving the quality of the data by adding business context to it.
- Data discovery – The consumers sign in to the Amazon DataZone data portal using their IAM credentials or single sign-on with integration through IAM Identity Center and search the data using keywords in the search bar. After the results are returned, they can further filter the results using glossary terms and project names. Finally, they review the business metadata of the data assets to evaluate if the data is relevant to their business use cases. They can check the quality score of the data assets and the refresh schedule for their use cases.With a data discovery capability in place, consumers can gain information about the data without the need to consult the source system owners or specialists.
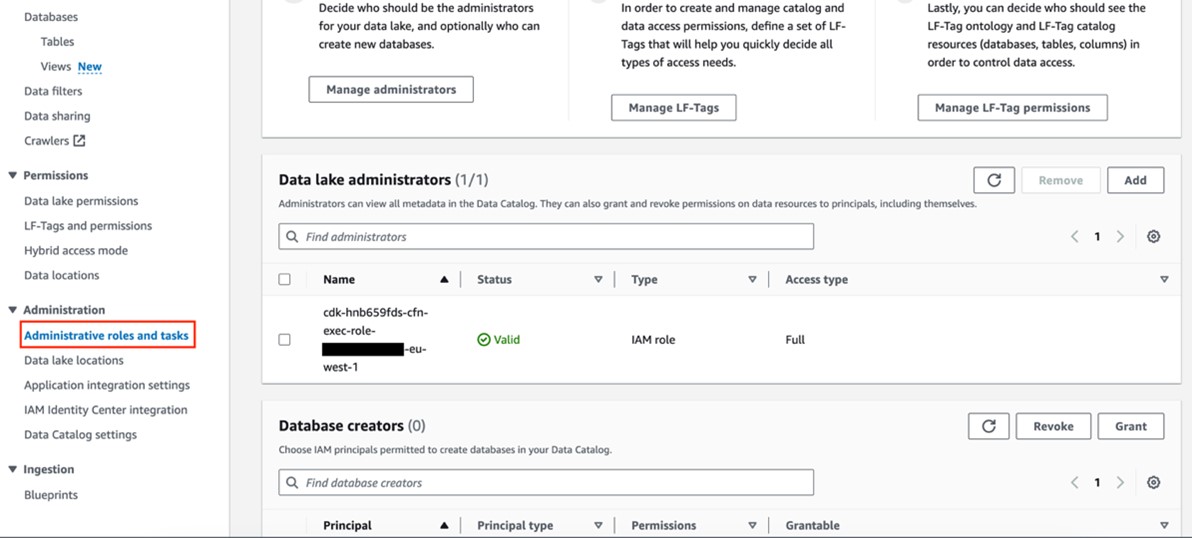
- Data access management – When the consumers find a data asset that’s relevant to their use case, they request access to it using the subscription feature of Amazon DataZone. Data is classified as public, internal, and confidential. For public and internal data assets, the access request is automatically approved. For confidential data assets, the data producer team reviews the access request and either accepts or rejects the subscription request.With a central place to manage data access, data owners can view which use cases have access to their data and when the access request was granted. The fine-grained access control feature of Amazon DataZone gives data owners granular control of their data at the row and column levels.
- Data consumption – Upon approval of the subscription request, Amazon DataZone provisions the backend infrastructure to make the data accessible to the corresponding consumers. After this process is complete, the consumers can access the data through Amazon Athena using the deep link feature of Amazon DataZone. The data consumption pattern in Volkswagen Autoeuropa supports two use cases:
- Cloud-to-cloud consumption – Both data assets and consumer teams or applications are hosted in the cloud.
- Cloud-to-on-premises consumption – Data assets are hosted in the cloud and consumer use cases or applications are hosted on-premises.
Requirements specific to a use case requires access to the relevant data assets; sharing data to use cases using Amazon DataZone doesn’t require creating multiple copies. As a result, duplication and processing of data. Furthermore, by reducing the number of copies of the data, the overall quality of the data products improves. In addition, the backend automation of Amazon DataZone to make data available to use cases reduces the manual effort and improves the lead time to access data.
- Single collaborative environment – The Amazon DataZone data portal provides a single collaborative environment to the users in Volkswagen Autoeuropa. Data consumers such as use case owners, data engineers, data scientists, and ML engineers can browse and request access to data assets. At the same time, data producers, such as use case owners and source system owners, can publish and curate their data in the Amazon DataZone data portal. This collaborative experience promotes teamwork and accelerates the realization of business value. Furthermore, the security and governance guardrails scales across the organization as the number of use cases increases.
Data solution architecture
The following figure displays the reference architecture of the data solution at Volkswagen Autoeuropa. In the next part of the post, we discuss how we arrived at the solution.

The architecture includes:
- The data from SAP applications, manufacturing execution systems (MES), and supervisory control and data acquisition (SCADA) systems is ingested into the producer accounts of Volkswagen Autoeuropa.
- In the producer account, raw data is transformed using AWS Glue. The technical metadata of the data is stored in AWS Glue catalog. The data quality is measured using the data quality framework. The data stored in Amazon Simple Storage Service (Amazon S3) is registered as an asset in the Amazon DataZone data catalog hosted in the central governance account.
- The central governance account hosts the Amazon DataZone domain and the related Amazon DataZone data portal. The AWS accounts of the data producers and consumers are associated with the Amazon DataZone domain. Amazon DataZone projects belonging to the data producers and consumers are created under the related Amazon DataZone domain units.
- Consumers of the data products sign in to the Amazon DataZone data portal hosted in the central governance account using their IAM credentials or single sign-on with integration through IAM Identity Center. They search, filter, and view asset information (for example, data quality, business, and technical metadata).
- After the consumer finds the asset they need, they request access to the asset using the subscription feature of Amazon DataZone. Based on the validity of the request, the asset owner approves or rejects the request.
- After the subscription request is granted and fulfilled, the asset is accessed in the consumer account for a one-time query using Athena and Microsoft Power BI applications hosted on premises. This consumption pattern can be extended for AI and machine learning (AI/ML) model development using Amazon SageMaker and reporting purposes using Amazon QuickSight.
User journey
After discussing the desired system with the use case teams and stakeholders and analyzing the current workflow, Volkswagen Autoeuropa grouped the user personas of the data solution into three main categories: data producer, data consumer, and data solution administrator. This sets the foundation for the desired user experience and what’s needed to achieve the solution goals.
Data producer
Data producers create the data products in the data solution. There are two types of data producers.
- Data source owners – Data source owners publish the raw data in the Amazon DataZone data portal. These data products are attributed as source-based data.
- Use case owners – Use case owners publish data that’s fit for consumption by other use cases. These data products are called consumer-based data.
The following figure shows the user journey of a data producer:

A data producer’s journey includes:
- Identify data of interest –
- Identify data (Volkswagen Autoeuropa network).
- Perform data quality checks (Volkswagen Autoeuropa network).
- Connect data to the data solution –
- Ingest data into the data solution (Amazon DataZone portal).
- Start process to connect data using AWS Glue.
- Locate the data source in the data solution –
- Register data (Amazon DataZone portal).
- Add data to the inventory in Amazon DataZone.
- Add or edit metadata –
- Add or edit metadata (Amazon DataZone portal).
- Publish data assets (Amazon DataZone portal).
- Approve or reject subscription request –
- Review subscription requests.
- Maintain data assets –
- Manage data assets (Amazon DataZone portal).
Data consumer
Data consumers use data for business analytics, machine learning, AI, and business reporting. Data consumers are data engineers, data scientists, ML engineers, and business users. The following diagram shows the journey of a data consumer.

A data consumer’s journey includes:
- Access Amazon DataZone portal –
- Amazon DataZone portal – Access is granted based on the user’s assigned domain and projects.
- Search for data assets –
- Data assets in Amazon DataZone portal – Search for data and brows the results by glossary terms or the project name. Use additional filters to refine the results.
- View business metadata –
- Select a data asset to see additional information – Review the description, data quality score and metadata.
- Request access to data (subscribe) –
- Subscribe to request access.
- After the subscription request is approved, review the data products that you have access to.
- Query the data to view and consume the data.
- Retrieve additional data –
- Repeat the steps as needed to access and retrieve additional data.
Data solution administrator
Data solution administrators are responsible for performing administrative tasks on the data solution. The following figure shows the common tasks performed by the data solution administrator.

A data administrator’s journey includes:
- Manage projects –
- Manage Amazon DataZone domain.
- Manage Amazon DataZone projects within the domain.
- Manage environment –
- Set up the environment to manage the infrastructure.
- Manage business metadata glossary –
- Manage and enable Amazon DataZone glossaries and metadata forms.
- Manage data assets –
- Manage assets.
- Query the data to view and consume the data.
- Manage access to data solution –
- Monitor and revoke access when appropriate.
Conclusion
In this post, you learned how Volkswagen Autoeuropa embarked on a bold vision to become a data driven factory. It shows how this vision was put into action by building a data solution based on data mesh architecture using Amazon DataZone. It highlights the key features and architecture of the data solutions and presents the user journey. As of writing this post, Volkswagen Autoeuropa reduced the data discovery time from days to minutes using the data solution. The time to access data took several weeks before the Volkswagen Autoeuropa and AWS collaboration. Now, with the help of the data solution, the data access time has been reduced to several minutes.
In May 2024, the team achieved a major milestone by successfully offering data on the data solution and transporting it instantly to Power BI, a process that previously took several weeks.
“After one year of work, we did the full roundtrip from offering data on our new data marketplace built using Amazon DataZone to transporting it instantly to third-party tools, a process that previously took several weeks. This was a big achievement for our team.”
– Jorge Paulino, Product owner of the data solution. Volkswagen Autoeuropa.
The next post of the two-part series details discusses how we built the solution, its technical details, and the business value created.
If you want to harness the agility and scalability of a data mesh architecture and Amazon DataZone to accelerate innovation and drive business value for your organization, we have the resources to get you started. Be sure to check out the AWS Prescriptive Guidance: Strategies for building a data mesh-based enterprise solution on AWS. This comprehensive guide covers the key considerations and best practices for establishing a robust, well-governed data mesh on AWS. From aligning your data mesh with overall business strategy to scaling the data mesh across your organization, this Prescriptive Guidance provides a clear roadmap to help you succeed.
If you’re curious to get hands-on, see the GitHub repository: Building an enterprise Data Mesh with Amazon DataZone, Amazon DataZone, AWS CDK, and AWS CloudFormation. This open source project delivers a step-by-step guide to build a data mesh architecture using Amazon DataZone, AWS Cloud Development Kit (AWS CDK), and AWS CloudFormation.
About the Authors
 Dhrubajyoti Mukherjee is a Cloud Infrastructure Architect with a strong focus on data strategy, data analytics, and data governance at Amazon Web Services (AWS). He uses his deep expertise to provide guidance to global enterprise customers across industries, helping them build scalable and secure AWS solutions that drive meaningful business outcomes. Dhrubajyoti is passionate about creating innovative, customer-centric solutions that enable digital transformation, business agility, and performance improvement. An active contributor to the AWS community, Dhrubajyoti authors AWS Prescriptive Guidance publications, blog posts, and open-source artifacts, sharing his insights and best practices with the broader community. Outside of work, Dhrubajyoti enjoys spending quality time with his family and exploring nature through his love of hiking mountains.
Dhrubajyoti Mukherjee is a Cloud Infrastructure Architect with a strong focus on data strategy, data analytics, and data governance at Amazon Web Services (AWS). He uses his deep expertise to provide guidance to global enterprise customers across industries, helping them build scalable and secure AWS solutions that drive meaningful business outcomes. Dhrubajyoti is passionate about creating innovative, customer-centric solutions that enable digital transformation, business agility, and performance improvement. An active contributor to the AWS community, Dhrubajyoti authors AWS Prescriptive Guidance publications, blog posts, and open-source artifacts, sharing his insights and best practices with the broader community. Outside of work, Dhrubajyoti enjoys spending quality time with his family and exploring nature through his love of hiking mountains.
 Ravi Kumar is a Data Architect and Analytics expert at Amazon Web Services; he finds immense fulfillment in working with data. His days are dedicated to designing and analyzing complex data systems, uncovering valuable insights that drive business decisions. Outside of work, he unwinds by listening to music and watching movies, activities that allow him to recharge after a long day of data wrangling.
Ravi Kumar is a Data Architect and Analytics expert at Amazon Web Services; he finds immense fulfillment in working with data. His days are dedicated to designing and analyzing complex data systems, uncovering valuable insights that drive business decisions. Outside of work, he unwinds by listening to music and watching movies, activities that allow him to recharge after a long day of data wrangling.
 Martin Mikoleizig studied mechanical engineering and production technology at the RWTH Aachen University before starting to work in Dr. h.c. Ing. F. Porsche AG 2015 as a production planner for the engine assembly. In several years as a Project Manager on Testing Technology for new engine models he also introduced several innovations like human-machine-collaborations and intelligent assistance systems. From 2017, he was responsible for the Shopfloor IT team of the module lines in Zuffenhausen before he became responsible for the Planning of the E-Drive assembly at Porsche. Beside this he was responsible for the Digitalisation Strategy of the Production Ressort at Porsche. Since October 2022, he has been assigned to Volkswagen Autoeuropa in Portugal in the role of a Digital Transformation Manager for the plant driving the Digital Transformation towards a Data Driven Factory.
Martin Mikoleizig studied mechanical engineering and production technology at the RWTH Aachen University before starting to work in Dr. h.c. Ing. F. Porsche AG 2015 as a production planner for the engine assembly. In several years as a Project Manager on Testing Technology for new engine models he also introduced several innovations like human-machine-collaborations and intelligent assistance systems. From 2017, he was responsible for the Shopfloor IT team of the module lines in Zuffenhausen before he became responsible for the Planning of the E-Drive assembly at Porsche. Beside this he was responsible for the Digitalisation Strategy of the Production Ressort at Porsche. Since October 2022, he has been assigned to Volkswagen Autoeuropa in Portugal in the role of a Digital Transformation Manager for the plant driving the Digital Transformation towards a Data Driven Factory.
 Weizhou Sun is a Lead Architect at Amazon Web Services, specializing in digital manufacturing solutions and IoT. With extensive experience in Europe, she has enhanced operational efficiencies, reducing latency and increasing throughput. Weizhou’s expertise includes Industrial Computer Vision, predictive maintenance, and predictive quality, consistently delivering top performance and client satisfaction. A recognized thought leader in IoT and remote driving, she has contributed to business growth through innovations and open-source work. Committed to knowledge sharing, Weizhou mentors colleagues and contributes to practice development. Known for her problem-solving skills and customer focus, she delivers solutions that exceed expectations. In her free time, Weizhou explores new technologies and fosters a collaborative culture.
Weizhou Sun is a Lead Architect at Amazon Web Services, specializing in digital manufacturing solutions and IoT. With extensive experience in Europe, she has enhanced operational efficiencies, reducing latency and increasing throughput. Weizhou’s expertise includes Industrial Computer Vision, predictive maintenance, and predictive quality, consistently delivering top performance and client satisfaction. A recognized thought leader in IoT and remote driving, she has contributed to business growth through innovations and open-source work. Committed to knowledge sharing, Weizhou mentors colleagues and contributes to practice development. Known for her problem-solving skills and customer focus, she delivers solutions that exceed expectations. In her free time, Weizhou explores new technologies and fosters a collaborative culture.
 Shameka Almond is an Advisory Consultant at Amazon Web Services. She works closely with enterprise customers to help them better understand the business impact and value of implementing data solutions, including data governance best practices. Shameka has over a decade of wide-ranging IT experience in the manufacturing and aerospace industries, and the nonprofit sector. She has supported several data governance initiatives, helping both public and private organizations identify opportunities for improvement and increased efficiency. Outside of the office she enjoys hosting large family gatherings, and supporting community outreach events dedicated to introducing students in K-12 to STEM.
Shameka Almond is an Advisory Consultant at Amazon Web Services. She works closely with enterprise customers to help them better understand the business impact and value of implementing data solutions, including data governance best practices. Shameka has over a decade of wide-ranging IT experience in the manufacturing and aerospace industries, and the nonprofit sector. She has supported several data governance initiatives, helping both public and private organizations identify opportunities for improvement and increased efficiency. Outside of the office she enjoys hosting large family gatherings, and supporting community outreach events dedicated to introducing students in K-12 to STEM.
 Adjoa Taylor has over 20 years of experience in industrial manufacturing, providing industry and technology consulting services, digital transformation, and solution delivery. Currently Adjoa leads Product Centric Digital Transformation, enabling customers to solve complex manufacturing problems by leveraging Smart Factory and Industry leading transformation mechanisms. Most recently driving value with AI/ML and generative AI use-cases for the plant floor. Adjoa is an experienced leader spending over 20 years of her career delivering projects in countries throughout North America, Latin America, Europe, and Asia. Through prior roles, Adjoa brings deep experience across multiple business segments with a focus on business outcome driven solutions. Adjoa is passionate about helping customers solve problems while realizing the art of the possible via the right impacting value-based solution.
Adjoa Taylor has over 20 years of experience in industrial manufacturing, providing industry and technology consulting services, digital transformation, and solution delivery. Currently Adjoa leads Product Centric Digital Transformation, enabling customers to solve complex manufacturing problems by leveraging Smart Factory and Industry leading transformation mechanisms. Most recently driving value with AI/ML and generative AI use-cases for the plant floor. Adjoa is an experienced leader spending over 20 years of her career delivering projects in countries throughout North America, Latin America, Europe, and Asia. Through prior roles, Adjoa brings deep experience across multiple business segments with a focus on business outcome driven solutions. Adjoa is passionate about helping customers solve problems while realizing the art of the possible via the right impacting value-based solution.










 Ramesh H Singh is a Senior Product Manager Technical (External Services) at AWS in Seattle, Washington, currently with the Amazon DataZone team. He is passionate about building high-performance ML/AI and analytics products that enable enterprise customers to achieve their critical goals using cutting-edge technology. Connect with him on
Ramesh H Singh is a Senior Product Manager Technical (External Services) at AWS in Seattle, Washington, currently with the Amazon DataZone team. He is passionate about building high-performance ML/AI and analytics products that enable enterprise customers to achieve their critical goals using cutting-edge technology. Connect with him on  Adiascar Cisneros is a Tableau Senior Product Manager based in Atlanta, GA. He focuses on the integration of the Tableau Platform with AWS services to amplify the value users get from our products and accelerate their journey to valuable, actionable insights. His background includes analytics, infrastructure, network security, and migrations. Follow him on
Adiascar Cisneros is a Tableau Senior Product Manager based in Atlanta, GA. He focuses on the integration of the Tableau Platform with AWS services to amplify the value users get from our products and accelerate their journey to valuable, actionable insights. His background includes analytics, infrastructure, network security, and migrations. Follow him on  Joel Farvault is Principal Specialist SA Analytics for AWS with 25 years’ experience working on enterprise architecture, data governance and analytics, mainly in the financial services industry. Joel has led data transformation projects on fraud analytics, claims automation, and Master Data Management. He leverages his experience to advise customers on their data strategy and technology foundations.
Joel Farvault is Principal Specialist SA Analytics for AWS with 25 years’ experience working on enterprise architecture, data governance and analytics, mainly in the financial services industry. Joel has led data transformation projects on fraud analytics, claims automation, and Master Data Management. He leverages his experience to advise customers on their data strategy and technology foundations. Yogesh Dhimate is a Sr. Partner Solutions Architect at AWS, leading technology partnership with Tableau. Prior to joining AWS, Yogesh worked with leading companies including Salesforce driving their industry solution initiatives. With over 20 years of experience in product management and solutions architecture Yogesh brings unique perspective in cloud computing and artificial intelligence.
Yogesh Dhimate is a Sr. Partner Solutions Architect at AWS, leading technology partnership with Tableau. Prior to joining AWS, Yogesh worked with leading companies including Salesforce driving their industry solution initiatives. With over 20 years of experience in product management and solutions architecture Yogesh brings unique perspective in cloud computing and artificial intelligence. Ariana Rahgozar is a Sr. Senior Solutions Architect at AWS, leading customers design and implement technical solutions as part of their cloud journey.
Ariana Rahgozar is a Sr. Senior Solutions Architect at AWS, leading customers design and implement technical solutions as part of their cloud journey.




















 Eric Fleishman is a software engineer at AWS in Seattle. He loves diving into cloud technology and solving complex problems to build impactful solutions. Outside of work, he is all about staying active—whether its snowboarding down the slopes or working out. He enjoys pushing his limits and embracing new challenges.
Eric Fleishman is a software engineer at AWS in Seattle. He loves diving into cloud technology and solving complex problems to build impactful solutions. Outside of work, he is all about staying active—whether its snowboarding down the slopes or working out. He enjoys pushing his limits and embracing new challenges. Theo Tolv is a Senior Analytics Architect based in Stockholm, Sweden. He’s worked with small and big data for most of his career, and has built applications running on AWS since 2008. In his spare time he likes to tinker with electronics and read space opera.
Theo Tolv is a Senior Analytics Architect based in Stockholm, Sweden. He’s worked with small and big data for most of his career, and has built applications running on AWS since 2008. In his spare time he likes to tinker with electronics and read space opera. Lakshmi Nair is a Senior Analytics Specialist Solutions Architect at AWS. She specializes in designing advanced analytics systems across industries. She focuses on crafting cloud-based data platforms, enabling real-time streaming, big data processing, and robust data governance.
Lakshmi Nair is a Senior Analytics Specialist Solutions Architect at AWS. She specializes in designing advanced analytics systems across industries. She focuses on crafting cloud-based data platforms, enabling real-time streaming, big data processing, and robust data governance. Fabricio Hamada is a Senior Data Strategy Solutions Architect at AWS.
Fabricio Hamada is a Senior Data Strategy Solutions Architect at AWS. Lionel Pulickal is Sr. Solutions Architect at AWS
Lionel Pulickal is Sr. Solutions Architect at AWS




 Debaprasun Chakraborty is an AWS Solutions Architect, specializing in the analytics domain. He has around 20 years of software development and architecture experience. He is passionate about helping customers in cloud adoption, migration and strategy.
Debaprasun Chakraborty is an AWS Solutions Architect, specializing in the analytics domain. He has around 20 years of software development and architecture experience. He is passionate about helping customers in cloud adoption, migration and strategy.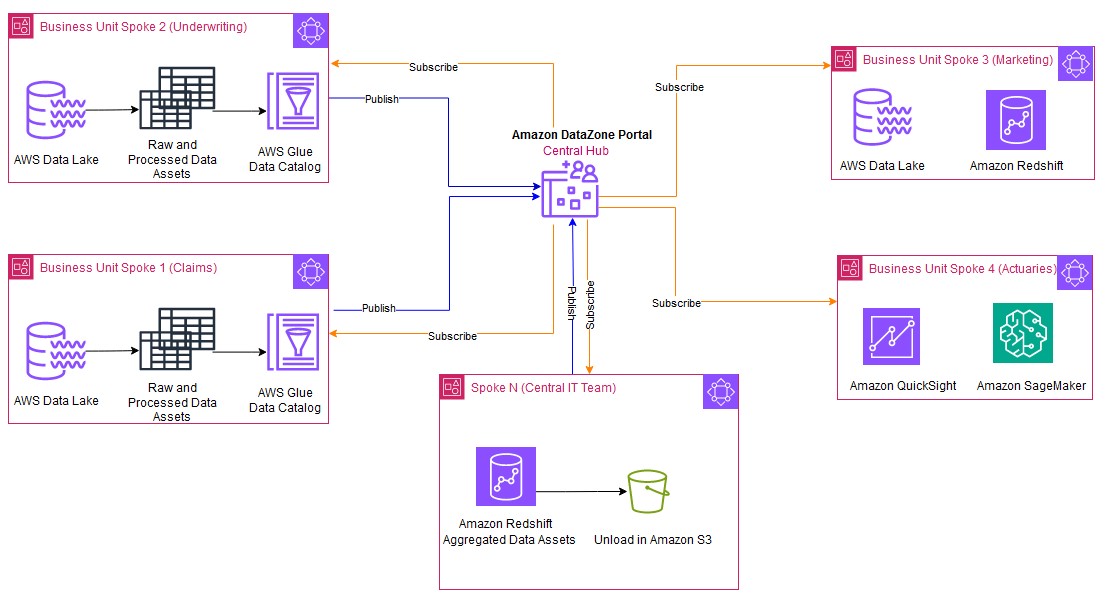





 Srividya Parthasarathy is a Senior Big Data Architect on the AWS Lake Formation team. She enjoys building analytics and data mesh solutions on AWS and sharing them with the community.
Srividya Parthasarathy is a Senior Big Data Architect on the AWS Lake Formation team. She enjoys building analytics and data mesh solutions on AWS and sharing them with the community.









 Fabrizio Napolitano is a Principal Specialist Solutions Architect for DB and Analytics. He has worked in the analytics space for the last 20 years, and has recently and quite by surprise become a Hockey Dad after moving to Canada.
Fabrizio Napolitano is a Principal Specialist Solutions Architect for DB and Analytics. He has worked in the analytics space for the last 20 years, and has recently and quite by surprise become a Hockey Dad after moving to Canada. Varsha Velagapudi is a Senior Technical Product Manager with Amazon DataZone at AWS. She focuses on improving data discovery and curation required for data analytics. She is passionate about simplifying customers’ AI/ML and analytics journey to help them succeed in their day-to-day tasks. Outside of work, she enjoys nature and outdoor activities, reading, and traveling.
Varsha Velagapudi is a Senior Technical Product Manager with Amazon DataZone at AWS. She focuses on improving data discovery and curation required for data analytics. She is passionate about simplifying customers’ AI/ML and analytics journey to help them succeed in their day-to-day tasks. Outside of work, she enjoys nature and outdoor activities, reading, and traveling.
 David Victoria is a Senior Technical Product Manager with Amazon DataZone at AWS. He focuses on improving administration and governance capabilities needed for customers to support their analytics systems. He is passionate about helping customers realize the most value from their data in a secure, governed manner. Outside of work, he enjoys hiking, traveling, and making his newborn baby laugh.
David Victoria is a Senior Technical Product Manager with Amazon DataZone at AWS. He focuses on improving administration and governance capabilities needed for customers to support their analytics systems. He is passionate about helping customers realize the most value from their data in a secure, governed manner. Outside of work, he enjoys hiking, traveling, and making his newborn baby laugh. Nora O Sullivan is a Senior Solutions Architect at AWS. She focuses on helping HCLS customers choose the right AWS services for their data and analytics needs so they can derive value from their data. Outside of work, she enjoys golfing and discovering new wines and authors.
Nora O Sullivan is a Senior Solutions Architect at AWS. She focuses on helping HCLS customers choose the right AWS services for their data and analytics needs so they can derive value from their data. Outside of work, she enjoys golfing and discovering new wines and authors. Navneet Srivastava, a Principal Specialist and Analytics Strategy Leader, develops strategic plans for building an end-to-end analytical strategy for large biopharma, healthcare, and life sciences organizations. Navneet is responsible for helping life sciences organizations and healthcare companies deploy data governance and analytical applications, electronic medical records, devices, and AI/ML-based applications while educating customers about how to build secure, scalable, and cost-effective AWS solutions. His expertise spans across data analytics, data governance, AI, ML, big data, and healthcare-related technologies.
Navneet Srivastava, a Principal Specialist and Analytics Strategy Leader, develops strategic plans for building an end-to-end analytical strategy for large biopharma, healthcare, and life sciences organizations. Navneet is responsible for helping life sciences organizations and healthcare companies deploy data governance and analytical applications, electronic medical records, devices, and AI/ML-based applications while educating customers about how to build secure, scalable, and cost-effective AWS solutions. His expertise spans across data analytics, data governance, AI, ML, big data, and healthcare-related technologies.
 For example, for customer-obsessed security, we build and use Mithra, a powerful neural network model to detect and respond to cyber threats. It analyzes up to 200 trillion internet domain requests daily from the AWS global network, identifying an average of 182,000 new malicious domains with remarkable accuracy. Mithra is just one example of how AWS uses global scale, advanced artificial intelligence and machine learning (AI/ML) technology, and constant innovation to lead the way in cloud security, making the internet safer for everyone. To learn more, visit the blog post of Chief Information Security Officer at Amazon CJ Moses,
For example, for customer-obsessed security, we build and use Mithra, a powerful neural network model to detect and respond to cyber threats. It analyzes up to 200 trillion internet domain requests daily from the AWS global network, identifying an average of 182,000 new malicious domains with remarkable accuracy. Mithra is just one example of how AWS uses global scale, advanced artificial intelligence and machine learning (AI/ML) technology, and constant innovation to lead the way in cloud security, making the internet safer for everyone. To learn more, visit the blog post of Chief Information Security Officer at Amazon CJ Moses, 



















 Jason Hines is a Senior Solutions Architect, at AWS, specializing in serving global customers in the Healthcare and Life Sciences industries. With over 25 years of experience, he has worked with numerous Fortune 100 companies across multiple verticals, bringing a wealth of knowledge and expertise to his role. Outside of work, Jason has a passion for an active lifestyle. He enjoys various outdoor activities such as hiking, scuba diving, and exploring nature. Maintaining a healthy work-life balance is essential to him.
Jason Hines is a Senior Solutions Architect, at AWS, specializing in serving global customers in the Healthcare and Life Sciences industries. With over 25 years of experience, he has worked with numerous Fortune 100 companies across multiple verticals, bringing a wealth of knowledge and expertise to his role. Outside of work, Jason has a passion for an active lifestyle. He enjoys various outdoor activities such as hiking, scuba diving, and exploring nature. Maintaining a healthy work-life balance is essential to him. Leonardo Gomez is a Principal Analytics Specialist Solutions Architect at AWS. He has over a decade of experience in data management, helping customers around the globe address their business and technical needs. Connect with him on
Leonardo Gomez is a Principal Analytics Specialist Solutions Architect at AWS. He has over a decade of experience in data management, helping customers around the globe address their business and technical needs. Connect with him on 





































 Carlos Gallegos is a Senior Analytics Specialist Solutions Architect at AWS. Based in Austin, TX, US. He’s an experienced and motivated professional with a proven track record of delivering results worldwide. He specializes in architecture, design, migrations, and modernization strategies for complex data and analytics solutions, both on-premises and on the AWS Cloud. Carlos helps customers accelerate their data journey by providing expertise in these areas. Connect with him on
Carlos Gallegos is a Senior Analytics Specialist Solutions Architect at AWS. Based in Austin, TX, US. He’s an experienced and motivated professional with a proven track record of delivering results worldwide. He specializes in architecture, design, migrations, and modernization strategies for complex data and analytics solutions, both on-premises and on the AWS Cloud. Carlos helps customers accelerate their data journey by providing expertise in these areas. Connect with him on  Jose Romero is a Senior Solutions Architect for Startups at AWS. Based in Austin, TX, US. He’s passionate about helping customers architect modern platforms at scale for data, AI, and ML. As a former senior architect in AWS Professional Services, he enjoys building and sharing solutions for common complex problems so that customers can accelerate their cloud journey and adopt best practices. Connect with him on
Jose Romero is a Senior Solutions Architect for Startups at AWS. Based in Austin, TX, US. He’s passionate about helping customers architect modern platforms at scale for data, AI, and ML. As a former senior architect in AWS Professional Services, he enjoys building and sharing solutions for common complex problems so that customers can accelerate their cloud journey and adopt best practices. Connect with him on  Arun Pradeep Selvaraj is a Senior Solutions Architect at AWS. Arun is passionate about working with his customers and stakeholders on digital transformations and innovation in the cloud while continuing to learn, build, and reinvent. He is creative, fast-paced, deeply customer-obsessed and uses the working backwards process to build modern architectures to help customers solve their unique challenges. Connect with him on
Arun Pradeep Selvaraj is a Senior Solutions Architect at AWS. Arun is passionate about working with his customers and stakeholders on digital transformations and innovation in the cloud while continuing to learn, build, and reinvent. He is creative, fast-paced, deeply customer-obsessed and uses the working backwards process to build modern architectures to help customers solve their unique challenges. Connect with him on 










 Under Authorized projects, you can pick the authorized projects allowed to use this environment profile to create an environment. By default, this is set to All projects.
Under Authorized projects, you can pick the authorized projects allowed to use this environment profile to create an environment. By default, this is set to All projects.










 As a consumer, you’re now able to explore data and create reports, or you can aggregate data and create new assets to publish in Amazon DataZone, becoming a producer of a new data product to share with other users and departments.
As a consumer, you’re now able to explore data and create reports, or you can aggregate data and create new assets to publish in Amazon DataZone, becoming a producer of a new data product to share with other users and departments. Carmen is a Solutions Architect at AWS, based in Milan (Italy). She is a Data Lover that enjoys helping companies in the adoption of Cloud technologies, especially with Data Analytics and Data Governance. Outside of work, she is a creative people who loves being in contact with nature and sometimes practicing adrenaline activities.
Carmen is a Solutions Architect at AWS, based in Milan (Italy). She is a Data Lover that enjoys helping companies in the adoption of Cloud technologies, especially with Data Analytics and Data Governance. Outside of work, she is a creative people who loves being in contact with nature and sometimes practicing adrenaline activities.












 Raj Samineni is the Director of Data Engineering at ATPCO, leading the creation of advanced cloud-based data platforms. His work ensures robust, scalable solutions that support the airline industry’s strategic transformational objectives. By leveraging machine learning and AI, Raj drives innovation and data culture, positioning ATPCO at the forefront of technological advancement.
Raj Samineni is the Director of Data Engineering at ATPCO, leading the creation of advanced cloud-based data platforms. His work ensures robust, scalable solutions that support the airline industry’s strategic transformational objectives. By leveraging machine learning and AI, Raj drives innovation and data culture, positioning ATPCO at the forefront of technological advancement. Sonal Panda is a Senior Solutions Architect at AWS with over 20 years of experience in architecting and developing intricate systems, primarily in the financial industry. Her expertise lies in Generative AI, application modernization leveraging microservices and serverless architectures to drive innovation and efficiency.
Sonal Panda is a Senior Solutions Architect at AWS with over 20 years of experience in architecting and developing intricate systems, primarily in the financial industry. Her expertise lies in Generative AI, application modernization leveraging microservices and serverless architectures to drive innovation and efficiency.





 Bandana Das is a Senior Data Architect at Amazon Web Services and specializes in data and analytics. She builds event-driven data architectures to support customers in data management and data-driven decision-making. She is also passionate about enabling customers on their data management journey to the cloud.
Bandana Das is a Senior Data Architect at Amazon Web Services and specializes in data and analytics. She builds event-driven data architectures to support customers in data management and data-driven decision-making. She is also passionate about enabling customers on their data management journey to the cloud. Gezim Musliaj is a Senior DevOps Consultant with AWS Professional Services. He is interested in various things CI/CD, data, and their application in the field of IoT, massive data ingestion, and recently MLOps and GenAI.
Gezim Musliaj is a Senior DevOps Consultant with AWS Professional Services. He is interested in various things CI/CD, data, and their application in the field of IoT, massive data ingestion, and recently MLOps and GenAI. Sameer Ranjha is a Software Development Engineer on the Amazon DataZone team. He works in the domain of modern data architectures and software engineering, developing scalable and efficient solutions.
Sameer Ranjha is a Software Development Engineer on the Amazon DataZone team. He works in the domain of modern data architectures and software engineering, developing scalable and efficient solutions. Sindi Cali is an Associate Consultant with AWS Professional Services. She supports customers in building data-driven applications in AWS.
Sindi Cali is an Associate Consultant with AWS Professional Services. She supports customers in building data-driven applications in AWS. Bhaskar Singh is a Software Development Engineer on the Amazon DataZone team. He has contributed to implementing AWS CloudFormation support for Amazon DataZone. He is passionate about distributed systems and dedicated to solving customers’ problems.
Bhaskar Singh is a Software Development Engineer on the Amazon DataZone team. He has contributed to implementing AWS CloudFormation support for Amazon DataZone. He is passionate about distributed systems and dedicated to solving customers’ problems.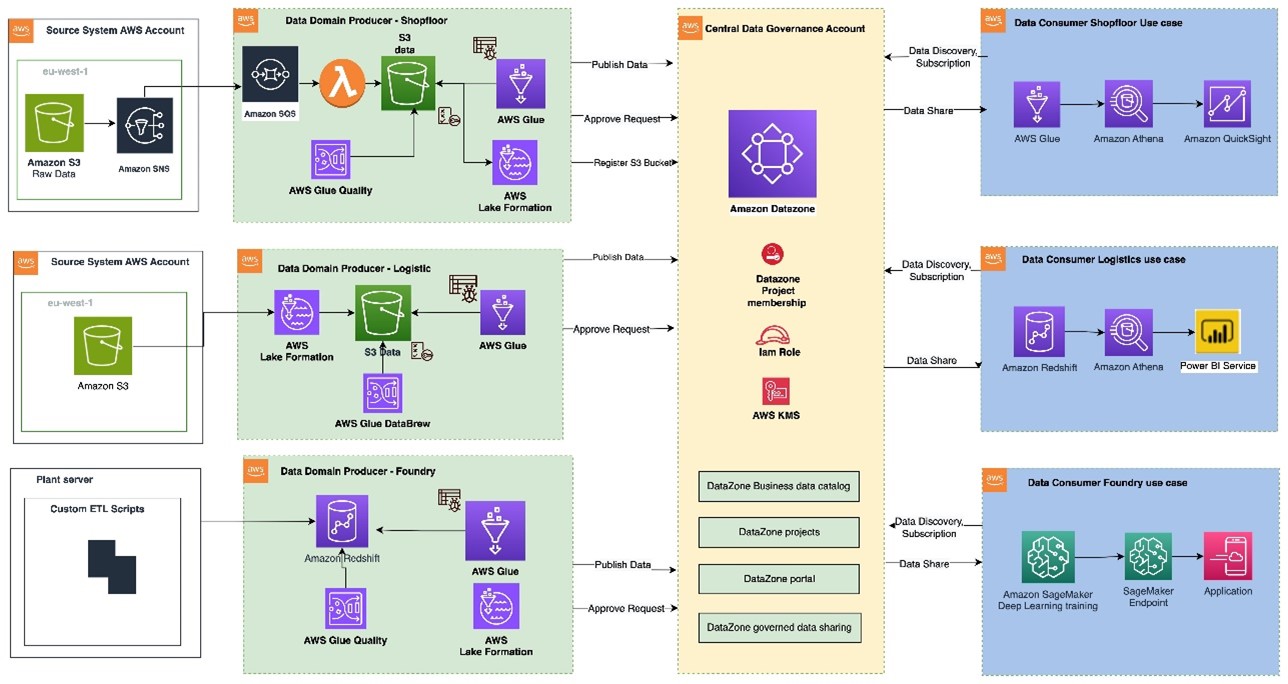






 Anirban Saha is a DevOps Architect at AWS, specializing in architecting and implementation of solutions for customer challenges in the automotive domain. He is passionate about well-architected infrastructures, automation, data-driven solutions and helping make the customer’s cloud journey as seamless as possible. Personally, he likes to keep himself engaged with reading, painting, language learning and traveling.
Anirban Saha is a DevOps Architect at AWS, specializing in architecting and implementation of solutions for customer challenges in the automotive domain. He is passionate about well-architected infrastructures, automation, data-driven solutions and helping make the customer’s cloud journey as seamless as possible. Personally, he likes to keep himself engaged with reading, painting, language learning and traveling. Chandana Keswarkar is a Senior Solutions Architect at AWS, who specializes in guiding automotive customers through their digital transformation journeys by using cloud technology. She helps organizations develop and refine their platform and product architectures and make well-informed design decisions. In her free time, she enjoys traveling, reading, and practicing yoga.
Chandana Keswarkar is a Senior Solutions Architect at AWS, who specializes in guiding automotive customers through their digital transformation journeys by using cloud technology. She helps organizations develop and refine their platform and product architectures and make well-informed design decisions. In her free time, she enjoys traveling, reading, and practicing yoga.











































 Leonardo Gomez is a Principal Analytics Specialist at AWS, with over a decade of experience in data management. Specializing in data governance, he assists customers worldwide in maximizing their data’s potential while promoting data democratization. Connect with him on
Leonardo Gomez is a Principal Analytics Specialist at AWS, with over a decade of experience in data management. Specializing in data governance, he assists customers worldwide in maximizing their data’s potential while promoting data democratization. Connect with him on  Priya Tiruthani is a Senior Technical Product Manager with Amazon DataZone at AWS. She focuses on improving data discovery and curation required for data analytics. She is passionate about building innovative products to simplify customers’ end-to-end data journey, especially around data governance and analytics. Outside of work, she enjoys being outdoors to hike, capture nature’s beauty, and recently play pickleball.
Priya Tiruthani is a Senior Technical Product Manager with Amazon DataZone at AWS. She focuses on improving data discovery and curation required for data analytics. She is passionate about building innovative products to simplify customers’ end-to-end data journey, especially around data governance and analytics. Outside of work, she enjoys being outdoors to hike, capture nature’s beauty, and recently play pickleball. Ron Kyker is a Principal Engineer with Amazon DataZone at AWS, where he helps drive innovation, solve complex problems, and set the bar for engineering excellence for his team. Outside of work, he enjoys board gaming with friends and family, movies, and wine tasting.
Ron Kyker is a Principal Engineer with Amazon DataZone at AWS, where he helps drive innovation, solve complex problems, and set the bar for engineering excellence for his team. Outside of work, he enjoys board gaming with friends and family, movies, and wine tasting. Srinivasan Kuppusamy is a Senior Cloud Architect – Data at AWS ProServe, where he helps customers solve their business problems using the power of AWS Cloud technology. His areas of interests are data and analytics, data governance, and AI/ML.
Srinivasan Kuppusamy is a Senior Cloud Architect – Data at AWS ProServe, where he helps customers solve their business problems using the power of AWS Cloud technology. His areas of interests are data and analytics, data governance, and AI/ML.



















 Deepmala Agarwal works as an AWS Data Specialist Solutions Architect. She is passionate about helping customers build out scalable, distributed, and data-driven solutions on AWS. When not at work, Deepmala likes spending time with family, walking, listening to music, watching movies, and cooking!
Deepmala Agarwal works as an AWS Data Specialist Solutions Architect. She is passionate about helping customers build out scalable, distributed, and data-driven solutions on AWS. When not at work, Deepmala likes spending time with family, walking, listening to music, watching movies, and cooking! Utkarsh Mittal is a Senior Technical Product Manager for Amazon DataZone at AWS. He is passionate about building innovative products that simplify customers’ end-to-end analytics journeys. Outside of the tech world, Utkarsh loves to play music, with drums being his latest endeavor.
Utkarsh Mittal is a Senior Technical Product Manager for Amazon DataZone at AWS. He is passionate about building innovative products that simplify customers’ end-to-end analytics journeys. Outside of the tech world, Utkarsh loves to play music, with drums being his latest endeavor.







 Chaitanya Vejendla is a Senior Solutions Architect specialized in DataLake & Analytics primarily working for Healthcare and Life Sciences industry division at AWS. Chaitanya is responsible for helping life sciences organizations and healthcare companies in developing modern data strategies, deploy data governance and analytical applications, electronic medical records, devices, and AI/ML-based applications, while educating customers about how to build secure, scalable, and cost-effective AWS solutions. His expertise spans across data analytics, data governance, AI, ML, big data, and healthcare-related technologies.
Chaitanya Vejendla is a Senior Solutions Architect specialized in DataLake & Analytics primarily working for Healthcare and Life Sciences industry division at AWS. Chaitanya is responsible for helping life sciences organizations and healthcare companies in developing modern data strategies, deploy data governance and analytical applications, electronic medical records, devices, and AI/ML-based applications, while educating customers about how to build secure, scalable, and cost-effective AWS solutions. His expertise spans across data analytics, data governance, AI, ML, big data, and healthcare-related technologies. Rishabh Asthana is a Front-end Engineer at AWS, working with the Amazon DataZone team based in New York City, USA.
Rishabh Asthana is a Front-end Engineer at AWS, working with the Amazon DataZone team based in New York City, USA. Somdeb Bhattacharjee is an Enterprise Solutions Architect based out of New York, USA focused on helping customers on their cloud journey. He has interest in Databases, Big Data and Analytics.
Somdeb Bhattacharjee is an Enterprise Solutions Architect based out of New York, USA focused on helping customers on their cloud journey. He has interest in Databases, Big Data and Analytics.





