Post Syndicated from Andrea Courtright original https://aws.amazon.com/blogs/architecture/top-architecture-blog-posts-of-2023/
2023 was a rollercoaster year in tech, and we at the AWS Architecture Blog feel so fortunate to have shared in the excitement. As we move into 2024 and all of the new technologies we could see, we want to take a moment to highlight the brightest stars from 2023.
As always, thanks to our readers and to the many talented and hardworking Solutions Architects and other contributors to our blog.
I give you our 2023 cream of the crop!
#10: Build a serverless retail solution for endless aisle on AWS
In this post, Sandeep and Shashank help retailers and their customers alike in this guided approach to finding inventory that doesn’t live on shelves.

Figure 1. Building endless aisle architecture for order processing
#9: Optimizing data with automated intelligent document processing solutions
Who else dreads wading through large amounts of data in multiple formats? Just me? I didn’t think so. Using Amazon AI/ML and content-reading services, Deependra, Anirudha, Bhajandeep, and Senaka have created a solution that is scalable and cost-effective to help you extract the data you need and store it in a format that works for you.

Figure 2: AI-based intelligent document processing engine
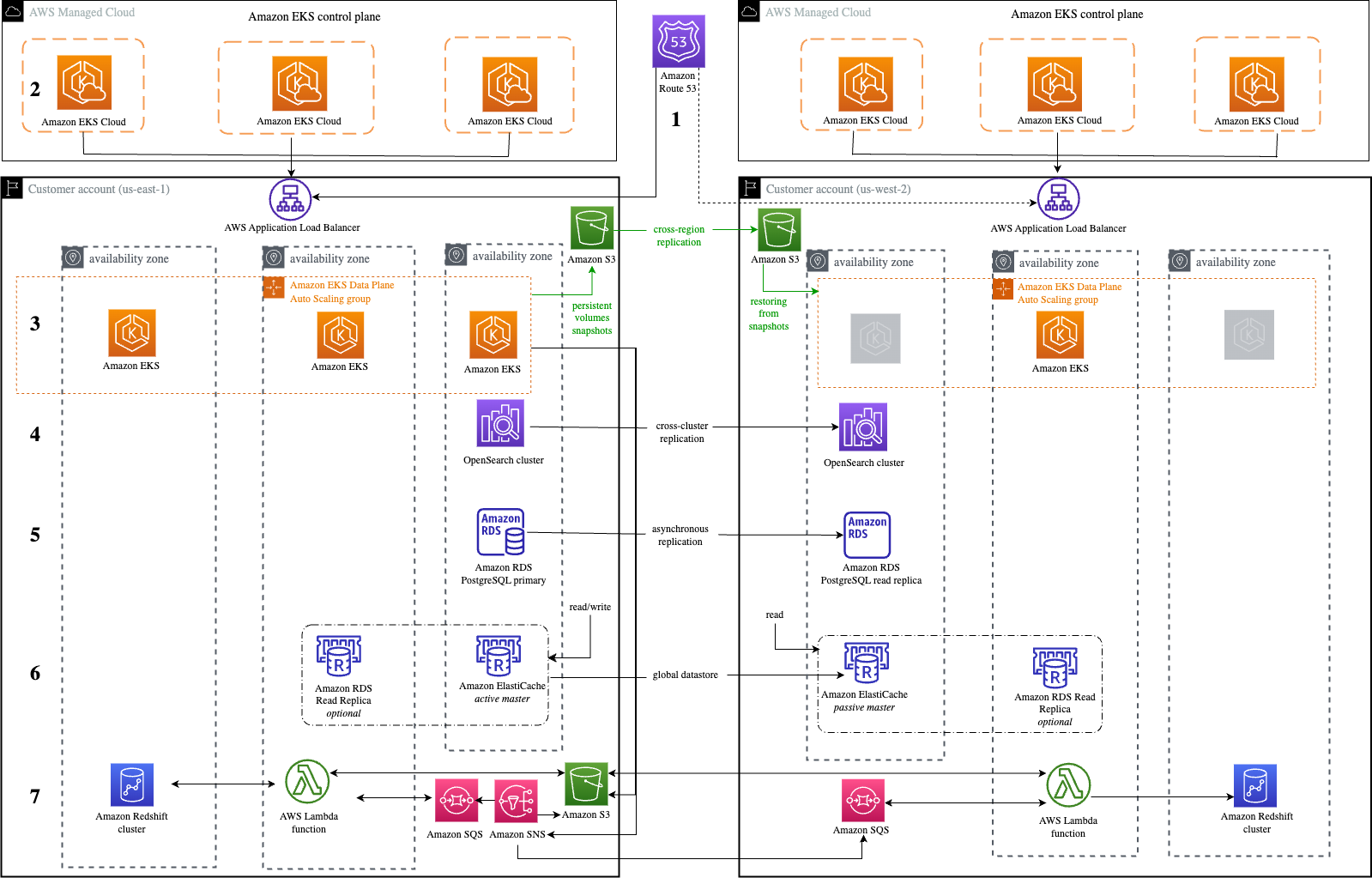
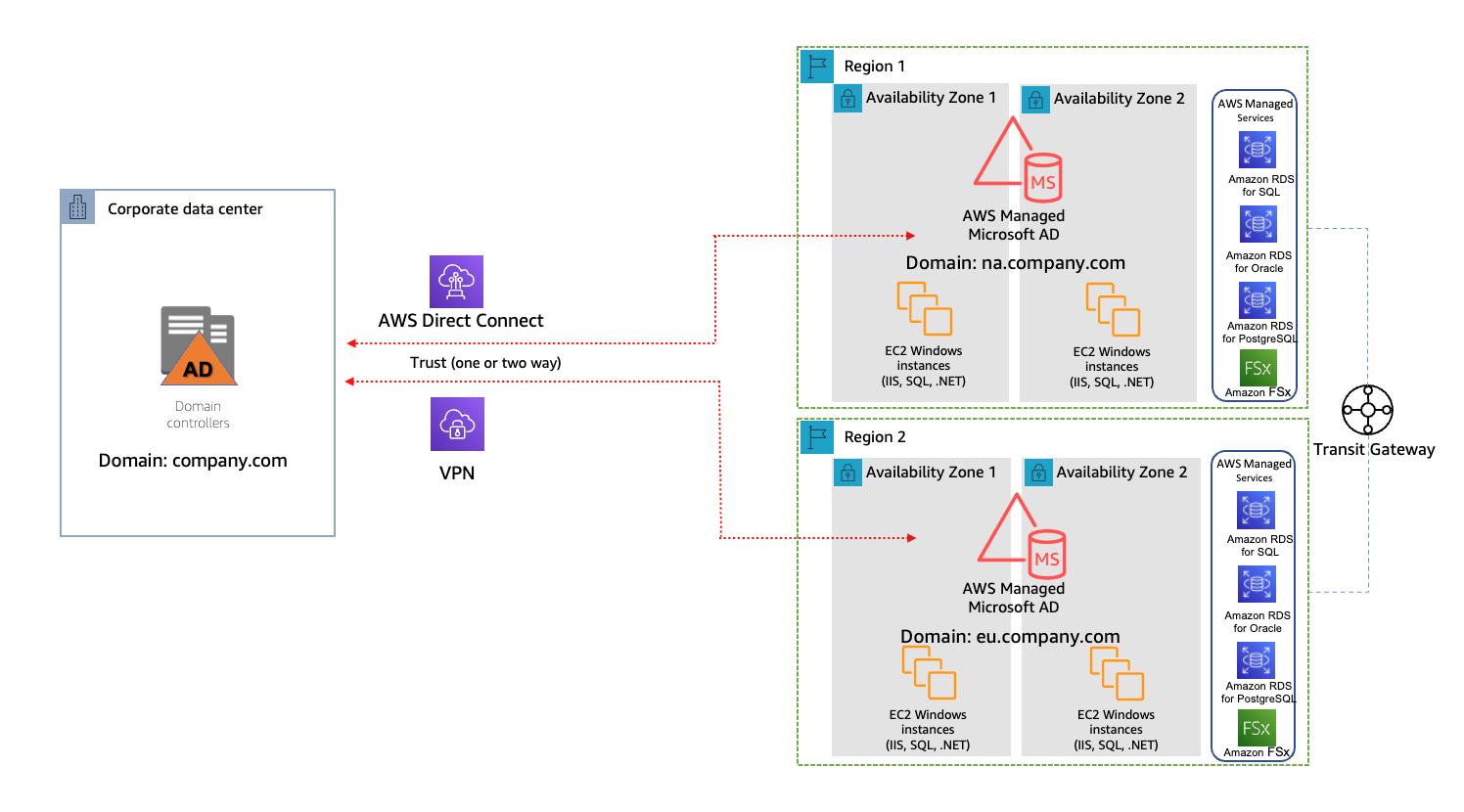
#8: Disaster Recovery Solutions with AWS managed services, Part 3: Multi-Site Active/Passive
Disaster recovery posts are always popular, and this post by Brent and Dhruv is no exception. Their creative approach in part 3 of this series is most helpful for customers who have business-critical workloads with higher availability requirements.

Figure 3. Warm standby with managed services
#7: Simulating Kubernetes-workload AZ failures with AWS Fault Injection Simulator
Continuing with the theme of “when bad things happen,” we have Siva, Elamaran, and Re’s post about preparing for workload failures. If resiliency is a concern (and it really should be), the secret is test, test, TEST.

Figure 4. Architecture flow for Microservices to simulate a realistic failure scenario
#6: Let’s Architect! Designing event-driven architectures
Luca, Laura, Vittorio, and Zamira weren’t content with their four top-10 spots last year – they’re back with some things you definitely need to know about event-driven architectures.

Figure 5. Let’s Architect artwork
#5: Use a reusable ETL framework in your AWS lake house architecture
As your lake house increases in size and complexity, you could find yourself facing maintenance challenges, and Ashutosh and Prantik have a solution: frameworks! The reusable ETL template with AWS Glue templates might just save you a headache or three.

Figure 6. Reusable ETL framework architecture
#4: Invoking asynchronous external APIs with AWS Step Functions
It’s possible that AWS’ menagerie of services doesn’t have everything you need to run your organization. (Possible, but not likely; we have a lot of amazing services.) If you are using third-party APIs, then Jorge, Hossam, and Shirisha’s architecture can help you maintain a secure, reliable, and cost-effective relationship among all involved.

Figure 7. Invoking Asynchronous External APIs architecture
#3: Announcing updates to the AWS Well-Architected Framework
The Well-Architected Framework continues to help AWS customers evaluate their architectures against its six pillars. They are constantly striving for improvement, and Haleh’s diligence in keeping us up to date has not gone unnoticed. Thank you, Haleh!
Figure 8. Well-Architected logo
#2: Let’s Architect! Designing architectures for multi-tenancy
The practically award-winning Let’s Architect! series strikes again! This time, Luca, Laura, Vittorio, and Zamira were joined by Federica to discuss multi-tenancy and why that concept is so crucial for SaaS providers.
Figure 9. Let’s Architect
And finally…
#1: Understand resiliency patterns and trade-offs to architect efficiently in the cloud
Haresh, Lewis, and Bonnie revamped this 2022 post into a masterpiece that completely stole our readers’ hearts and is among the top posts we’ve ever made!

Figure 10. Resilience patterns and trade-offs
Bonus! Three older special mentions
These three posts were published before 2023, but we think they deserve another round of applause because you, our readers, keep coming back to them.
- Overview of Data Transfer Costs for Common Architectures – Our most popular post of all time! Special shout-out to Birender, Sebastian, and Dennis for creating this winner.
- Disaster Recovery (DR) Architecture on AWS, Part I: Strategies for Recovery in the Cloud – Seth has a whole series of amazing DR posts that you just can’t miss!
- Exponential Backoff And Jitter – After eight years, Marc’s post remains timeless and helpful. Well done!
Thanks again to everyone for their contributions during a wild year. We hope you’re looking forward to the rest of 2024 as much as we are!


 Prabhat Chaturvedi
Prabhat Chaturvedi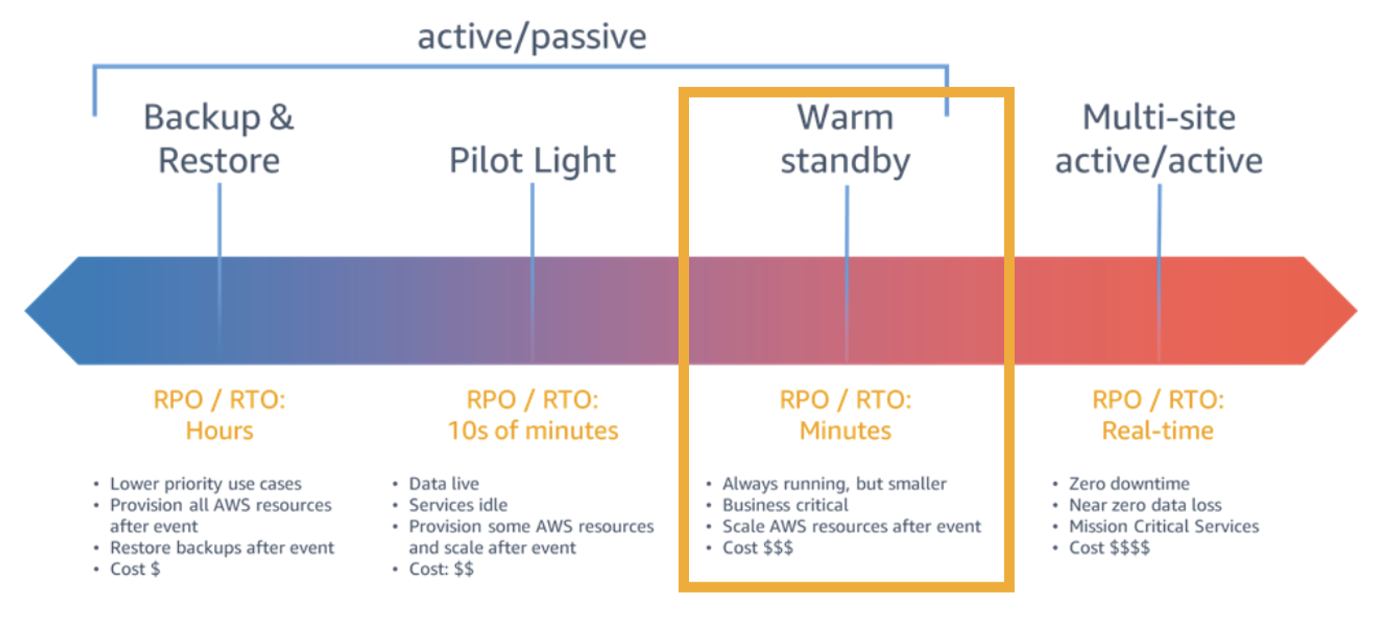




 study
study