Amazon Web Services (AWS) is pleased to announce the successful renewal of the United Kingdom Cyber Essentials Plus certification. The Cyber Essentials Plus certificate is valid for one year until March 22, 2025.
Cyber Essentials Plus is a UK Government–backed, industry-supported certification scheme intended to help organizations demonstrate controls against common cyber security threats. An independent third-party auditor certified by Information Assurance for Small and Medium Enterprises (IASME) completed the audit. The scope of our Cyber Essentials Plus certificate covers the AWS corporate network for the United Kingdom, Ireland, and Germany.
As always, we value your feedback and questions. Reach out to the AWS Compliance team through the Contact Us page. If you have feedback about this post, submit a comment in the Comments section below. To learn more about our other compliance and security programs, see AWS Compliance Programs.
RSA Conference 2024 drew 650 speakers, 600 exhibitors, and thousands of security practitioners from across the globe to the Moscone Center in San Francisco, California from May 6 through 9.
The keynote lineup was diverse, with 33 presentations featuring speakers ranging from WarGames actor Matthew Broderick, to public and private-sector luminaries such as Cybersecurity and Infrastructure Security Agency (CISA) Director Jen Easterly, U.S. Secretary of State Antony Blinken, security technologist Bruce Schneier, and cryptography experts Tal Rabin, Whitfield Diffie, and Adi Shamir.
Topics aligned with this year’s conference theme, “The art of possible,” and focused on actions we can take to revolutionize technology through innovation, while fortifying our defenses against an evolving threat landscape.
This post highlights three themes that caught our attention: artificial intelligence (AI) security, the Secure by Design approach to building products and services, and Chief Information Security Officer (CISO) collaboration.
AI security
Organizations in all industries have started building generative AI applications using large language models (LLMs) and other foundation models (FMs) to enhance customer experiences, transform operations, improve employee productivity, and create new revenue channels. So it’s not surprising that AI dominated conversations. Over 100 sessions touched on the topic, and the desire of attendees to understand AI technology and learn how to balance its risks and opportunities was clear.
“Discussions of artificial intelligence often swirl with mysticism regarding how an AI system functions. The reality is far more simple: AI is a type of software system.” — CISA
FMs and the applications built around them are often used with highly sensitive business data such as personal data, compliance data, operational data, and financial information to optimize the model’s output. As we explore the advantages of generative AI, protecting highly sensitive data and investments is a top priority. However, many organizations aren’t paying enough attention to security.
A joint generative AI security report released by Amazon Web Services (AWS) and the IBM Institute for Business Value during the conference found that 82% of business leaders view secure and trustworthy AI as essential for their operations, but only 24% are actively securing generative AI models and embedding security processes in AI development. In fact, nearly 70% say innovation takes precedence over security, despite concerns over threats and vulnerabilities (detailed in Figure 1).
Figure 1: Generative AI adoption concerns, Source: IBM Security
Because data and model weights—the numerical values models learn and adjust as they train—are incredibly valuable, organizations need them to stay protected, secure, and private, whether that means restricting access from an organization’s own administrators, customers, or cloud service provider, or protecting data from vulnerabilities in software running in the organization’s own environment.
There is no silver AI-security bullet, but as the report points out, there are proactive steps you can take to start protecting your organization and leveraging AI technology to improve your security posture:
Establish a governance, risk, and compliance (GRC) foundation. Trust in gen AI starts with new security governance models (Figure 2) that integrate and embed GRC capabilities into your AI initiatives, and include policies, processes, and controls that are aligned with your business objectives.
Figure 2: Updating governance, risk, and compliance models, Source: IBM Security
Strengthen your security culture. When we think of securing AI, it’s natural to focus on technical measures that can help protect the business. But organizations are made up of people—not technology. Educating employees at all levels of the organization can help avoid preventable harms such as prompt-based risks and unapproved tool use, and foster a resilient culture of cybersecurity that supports effective risk mitigation, incident detection and response, and continuous collaboration.
“You’ve got to understand early on that security can’t be effective if you’re running it like a project or a program. You really have to run it as an operational imperative—a core function of the business. That’s when magic can happen.” — Hart Rossman, Global Services Security Vice President at AWS
Engage with partners. Developing and securing AI solutions requires resources and skills that many organizations lack. Partners can provide you with comprehensive security support—whether that’s informing and advising you about generative AI, or augmenting your delivery and support capabilities. This can help make your engineers and your security controls more effective.
While many organizations purchase security products or solutions with embedded generative AI capabilities, nearly two-thirds, as detailed in Figure 3, report that their generative AI security capabilities come through some type of partner.
Figure 3: Most security gen AI capabilities are coming from third-party products or partners, Source: IBM Security
Tens of thousands of customers are using AWS, for example, to experiment and move transformative generative AI applications into production. AWS provides AI-powered tools and services, a Generative AI Innovation Center program, and an extensive network of AWS partners that have demonstrated expertise delivering machine learning (ML) and generative AI solutions. These resources can support your teams with hands-on help developing solutions mapped to your requirements, and a broader collection of knowledge they can use to help you make the nuanced decisions required for effective security.
Building secure software was a popular and related focus at the conference. Insecure design is ranked as the number four critical web application security concern on the Open Web Application Security Project (OWASP) Top 10.
The concept known as Secure by Design is gaining importance in the effort to mitigate vulnerabilities early, minimize risks, and recognize security as a core business requirement. Secure by Design builds off of security models such as Zero Trust, and aims to reduce the burden of cybersecurity and break the cycle of constantly creating and applying updates by developing products that are foundationally secure.
More than 60 technology companies—including AWS—signed CISA’s Secure by Design Pledge during RSA Conference as part of a collaborative push to put security first when designing products and services.
The pledge demonstrates a commitment to making measurable progress towards seven goals within a year:
Broaden the use of multi-factor authentication (MFA)
Reduce default passwords
Enable a significant reduction in the prevalence of one or more vulnerability classes
Increase the installation of security patches by customers
Publish a vulnerability disclosure policy (VDP)
Demonstrate transparency in vulnerability reporting
Strengthen the ability of customers to gather evidence of cybersecurity intrusions affecting products
“From day one, we have pioneered secure by design and secure by default practices in the cloud, so AWS is designed to be the most secure place for customers to run their workloads. We are committed to continuing to help organizations around the world elevate their security posture, and we look forward to collaborating with CISA and other stakeholders to further grow and promote security by design and default practices.” — Chris Betz, CISO at AWS
The need for security by design applies to AI like any other software system. To protect users and data, we need to build security into ML and AI with a Secure by Design approach that considers these technologies to be part of a larger software system, and weaves security into the AI pipeline.
Since models tend to have very high privileges and access to data, integrating an AI bill of materials (AI/ML BOM) and Cryptography Bill of Materials (CBOM) into BOM processes can help you catalog security-relevant information, and gain visibility into model components and data sources. Additionally, frameworks and standards such as the AI RMF 1.0, the HITRUST AI Assurance Program, and ISO/IEC 42001 can facilitate the incorporation of trustworthiness considerations into the design, development, and use of AI systems.
CISO collaboration
In the RSA Conference keynote session CISO Confidential: What Separates The Best From The Rest, Trellix CEO Bryan Palma and CISO Harold Rivas noted that there are approximately 32,000 global CISOs today—4 times more than 10 years ago. The challenges they face include staffing shortages, liability concerns, and a rapidly evolving threat landscape. According to research conducted by the Information Systems Security Association (ISSA), nearly half of organizations (46%) report that their cybersecurity team is understaffed, and more than 80% of CISOs recently surveyed by Trellix have experienced an increase in cybersecurity threats over the past six months. When asked what would most improve their organizations’ abilities to defend against these threats, their top answer was industry peers sharing insights and best practices.
Building trusted relationships with peers and technology partners can help you gain the knowledge you need to effectively communicate the story of risk to your board of directors, keep up with technology, and build success as a CISO.
AWS CISO Circles provide a forum for cybersecurity executives from organizations of all sizes and industries to share their challenges, insights, and best practices. CISOs come together in locations around the world to discuss the biggest security topics of the moment. With NDAs in place and the Chatham House Rule in effect, security leaders can feel free to speak their minds, ask questions, and get feedback from peers through candid conversations facilitated by AWS Security leaders.
“When it comes to security, community unlocks possibilities. CISO Circles give us an opportunity to deeply lean into CISOs’ concerns, and the topics that resonate with them. Chatham House Rule gives security leaders the confidence they need to speak openly and honestly with each other, and build a global community of knowledge-sharing and support.” — Clarke Rodgers, Director of Enterprise Strategy at AWS
At RSA Conference, CISO Circle attendees discussed the challenges of adopting generative AI. When asked whether CISOs or the business own generative AI risk for the organization, the consensus was that security can help with policies and recommendations, but the business should own the risk and decisions about how and when to use the technology. Some attendees noted that they took initial responsibility for generative AI risk, before transitioning ownership to an advisory board or committee comprised of leaders from their HR, legal, IT, finance, privacy, and compliance and ethics teams over time. Several CISOs expressed the belief that quickly taking ownership of generative AI risk before shepherding it to the right owner gave them a valuable opportunity to earn trust with their boards and executive peers, and to demonstrate business leadership during a time of uncertainty.
Embrace the art of possible
There are many more RSA Conference highlights on a wide range of additional topics, including post-quantum cryptography developments, identity and access management, data perimeters, threat modeling, cybersecurity budgets, and cyber insurance trends. If there’s one key takeaway, it’s that we should never underestimate what is possible from threat actors or defenders. By harnessing AI’s potential while addressing its risks, building foundationally secure products and services, and developing meaningful collaboration, we can collectively strengthen security and establish cyber resilience.
Join us to learn more about cloud security in the age of generative AI at AWS re:Inforce 2024 June 10–12 in Pennsylvania. Register today with the code SECBLOfnakb to receive a limited time $150 USD discount, while supplies last.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
A full conference pass is $1,099. Register today with the code flashsale150 to receive a limited time $150 discount, while supplies last.
We’re counting down to AWS re:Inforce, our annual cloud security event! We are thrilled to invite security enthusiasts and builders to join us in Philadelphia, PA, from June 10–12 for an immersive two-and-a-half-day journey into cloud security learning. This year, we’ve expanded the event by half a day to give you more opportunities to delve into the latest security trends and technologies. At AWS re:Inforce, you’ll have the chance to explore the breadth of the Amazon Web Services (AWS) security landscape, learn how to operationalize security services, and enhance your skills and confidence in cloud security to improve your organization’s security posture. As an attendee, you will have access to over 250 sessions across multiple topic tracks, including data protection; identity and access management; threat detection and incident response; network and infrastructure security; generative AI; governance, risk, and compliance; and application security. Plus, get ready to be inspired by our lineup of customer speakers, who will share their firsthand experiences of innovating securely on AWS.
In this post, we’ll provide an overview of the key sessions that include lecture-style presentations featuring real-world use cases from our customers, as well as the interactive small-group sessions led by AWS experts that guide you through practical problems and solutions.
The threat detection and incident response track is designed to demonstrate how to detect and respond to security risks to help protect workloads at scale. AWS experts and customers will present key topics such as threat detection, vulnerability management, cloud security posture management, threat intelligence, operationalization of AWS security services, container security, effective security investigation, incident response best practices, and strengthening security through the use of generative AI and securing generative AI workloads.
Breakout sessions, chalk talks, and lightning talks
TDR201 | Breakout session | How NatWest uses AWS services to manage vulnerabilities at scale As organizations move to the cloud, rapid change is the new normal. Safeguarding against potential security threats demands continuous monitoring of cloud resources and code that are constantly evolving. In this session, NatWest shares best practices for monitoring their AWS environment for software and configuration vulnerabilities at scale using AWS security services like Amazon Inspector and AWS Security Hub. Learn how security teams can automate the identification and prioritization of critical security insights to manage alert fatigue and swiftly collaborate with application teams for remediation.
TDR301 | Breakout session | Developing an autonomous framework with Security Lake & Torc Robotics Security teams are increasingly seeking autonomy in their security operations. Amazon Security Lake is a powerful solution that allows organizations to centralize their security data across AWS accounts and Regions. In this session, learn how Security Lake simplifies centralizing and operationalizing security data. Then, hear from Torc Robotics, a leading autonomous trucking company, as they share their experience and best practices for using Security Lake to establish an autonomous security framework.
TDR302 | Breakout session | Detecting and responding to threats in generative AI workloads While generative AI is an emerging technology, many of the same services and concepts can be used for threat detection and incident response. In this session, learn how you can build out threat detection and incident response capabilities for a generative AI workload that uses Amazon Bedrock. Find out how to effectively monitor this workload using Amazon Bedrock, Amazon GuardDuty, and AWS Security Hub. The session also covers best practices for responding to and remediating security issues that may come up.
TDR303 | Breakout session | Innovations in AWS detection and response services In this session, learn about the latest advancements and recent AWS launches in the field of detection and response. This session focuses on use cases like threat detection, workload protection, automated and continual vulnerability management, centralized monitoring, continuous cloud security posture management, unified security data management, and discovery and protection of workloads and data. Through these use cases, gain a deeper understanding of how you can seamlessly integrate AWS detection and response services to help protect your workloads at scale, enhance your security posture, and streamline security operations across your entire AWS environment.
TDR304 | Breakout session | Explore cloud workload protection with GuardDuty, feat. Booking.com Monitoring your workloads at runtime allows you to detect unexpected activity sooner—before it escalates to broader business-impacting security issues. Amazon GuardDuty Runtime Monitoring offers fully managed threat detection that gives you end-to-end visibility across your AWS environment. GuardDuty’s unique detection capabilities are guided by AWS’s visibility into the cloud threat landscape. In this session, learn why AWS built the Runtime Monitoring feature and how it works. Also discover how Booking.com used GuardDuty for runtime protection, supporting their mission to make it easier for everyone to experience the world.
TDR305 | Breakout session | Cyber threat intelligence sharing on AWS Real-time, contextual, and comprehensive visibility into security issues is essential for resilience in any organization. In this session, join the Australian Cyber Security Centre (ACSC) as they present their Cyber Threat Intelligence Sharing (CTIS) program, built on AWS. With the aim to improve the cyber resilience of the Australian community and help make Australia the most secure place to connect online, the ACSC protects Australia from thousands of threats every day. Learn the technical fundamentals that can help you apply best practices for real-time, bidirectional sharing of threat intelligence across all sectors.
TDR331 | Chalk talk | Unlock OCSF: Turn raw logs into insights with generative AI So, you have security data stored using the Open Cybersecurity Schema Framework (OCSF)—now what? In this chalk talk, learn how to use AWS analytics tools to mine data stored using the OCSF and leverage generative AI to consume insights. Discover how services such as Amazon Athena, Amazon Q in QuickSight, and Amazon Bedrock can extract, process, and visualize security insights from OCSF data. Gain practical skills to identify trends, detect anomalies, and transform your OCSF data into actionable security intelligence that can help your organization respond more effectively to cybersecurity threats.
TDR332 | Chalk talk | Anatomy of a ransomware event targeting data within AWS Ransomware events can interrupt operations and cost governments, nonprofits, and businesses billions of dollars. Early detection and automated responses are important mechanisms that can help mitigate your organization’s exposure. In this chalk talk, learn about the anatomy of a ransomware event targeting data within AWS including detection, response, and recovery. Explore the AWS services and features that you can use to protect against ransomware events in your environment, and learn how you can investigate possible ransomware events if they occur.
TDR333 | Chalk talk | Implementing AWS security best practices: Insights and strategies Have you ever wondered if you are using AWS security services such as Amazon GuardDuty, AWS Security Hub, AWS WAF, and others to the best of their ability? Do you want to dive deep into common use cases to better operationalize AWS security services through insights developed via thousands of deployments? In this chalk talk, learn tips and tricks from AWS experts who have spent years talking to users and documenting guidance outlining AWS security services best practices.
TDR334 | Chalk talk | Unlock your security superpowers with generative AI Generative AI can accelerate and streamline the process of security analysis and response, enhancing the impact of your security operations team. Its unique ability to combine natural language processing with large existing knowledge bases and agent-based architectures that can interact with your data and systems makes it an ideal tool for augmenting security teams during and after an event. In this chalk talk, explore how generative AI will shape the future of the SOC and lead to new capabilities in incident response and cloud security posture management.
TDR431 | Chalk talk | Harnessing generative AI for investigation and remediation To help businesses move faster and deliver security outcomes, modern security teams need to identify opportunities to automate and simplify their workflows. One way of doing so is through generative AI. Join this chalk talk to learn how to identify use cases where generative AI can help with investigating, prioritizing, and remediating findings from Amazon GuardDuty, Amazon Inspector, and AWS Security Hub. Then find out how you can develop architectures from these use cases, implement them, and evaluate their effectiveness. The talk offers tenets for generative AI and security that can help you safely use generative AI to reduce cognitive load and increase focus on novel, high-value opportunities.
TDR432 | Chalk talk | New tactics and techniques for proactive threat detection This insightful chalk talk is led by the AWS Customer Incident Response Team (CIRT), the team responsible for swiftly responding to security events on the customer side of the AWS Shared Responsibility Model. Discover the latest trends in threat tactics and techniques observed by the CIRT, along with effective detection and mitigation strategies. Gain valuable insights into emerging threats and learn how to safeguard your organization’s AWS environment against evolving security risks.
TDR433 | Chalk talk | Incident response for multi-account and federated environments In this chalk talk, AWS security experts guide you through the lifecycle of a compromise involving federation and third-party identity providers. Learn how AWS detects unauthorized access and which approaches can help you respond to complex situations involving organizations with multiple accounts. Discover insights into how you can contain and recover from security events and discuss strong IAM policies, appropriately restrictive service control policies, and resource termination for security event containment. Also, learn how to build resiliency in an environment with IAM permission refinement, organizational strategy, detective controls, chain of custody, and IR break-glass models.
TDR227 | Lightning talk | How Razorpay scales threat detection using AWS Discover how Razorpay, a leading payment aggregator solution provider authorized by the Reserve Bank of India, efficiently manages millions of business transactions per minute through automated security operations using AWS security services. Join this lightning talk to explore how Razorpay’s security operations team uses AWS Security Hub, Amazon GuardDuty, and Amazon Inspector to monitor their critical workloads on AWS. Learn how they orchestrate complex workflows, automating responses to security events, and reduce the time from detection to remediation.
TDR321 | Lightning talk | Scaling incident response with AWS developer tools In incident response, speed matters. Responding to incidents at scale can be challenging as the number of resources in your AWS accounts increases. In this lightning talk, learn how to use SDKs and the AWS Command Line Interface (AWS CLI) to rapidly run commands across your estate so you can quickly retrieve data, identify issues, and resolve security-related problems.
TDR322 | Lightning talk | How Snap Inc. secures its services with Amazon GuardDuty In this lightning talk, discover how Snap Inc. established a secure multi-tenant compute platform on AWS and mitigated security challenges within shared Kubernetes clusters. Snap uses Amazon GuardDuty and the OSS tool Falco for runtime protection across build time, deployment time, and runtime phases. Explore Snap’s techniques for facilitating one-time cluster access through AWS IAM Identity Center. Find out how Snap has implemented isolation strategies between internal tenants using the Pod Security Standards (PSS) and network policies enforced by the Amazon VPC Container Network Interface (CNI) plugin.
TDR326 | Lightning talk | Streamlining security auditing with generative AI For identifying and responding to security-related events, collecting and analyzing logs is only the first step. Beyond this initial phase, you need to utilize tools and services to parse through logs, understand baseline behaviors, identify anomalies, and create automated responses based on the type of event. In this lightning talk, learn how to effectively parse security logs, identify anomalies, and receive response runbooks that you can implement within your environment.
Interactive sessions (builders’ sessions, code talks, and workshops)
TDR351 | Builders’ session | Accelerating incident remediation with IR playbooks & Amazon Detective In this builders’ session, learn how to investigate incidents more effectively and discover root cause with Amazon Detective. Amazon Detective provides finding-group summaries by using generative AI to automatically analyze finding groups. Insights in natural language then help you accelerate security investigations. Find out how you can create your own incident response playbooks and test them by handling multi-event security issues.
TDR352 | Builders’ session | How to automate containment and forensics for Amazon EC2 Automated Forensics Orchestrator for Amazon EC2 deploys a mechanism that uses AWS services to orchestrate and automate key digital forensics processes and activities for Amazon EC2 instances in the event of a potential security issue being detected. In this builders’ session, learn how to deploy and scale this self-service AWS solution. Explore the prerequisites, learn how to customize it for your environment, and experience forensic analysis on live artifacts to identify what potential unauthorized users could do in your environment.
TDR353 | Builders’ session | Preventing top misconfigurations associated with security events Have you ever wondered how you can prevent top misconfigurations that could lead to a security event? Join this builders’ session, where the AWS Customer Incident Response Team (CIRT) reviews some of the most commonly observed misconfigurations that can lead to security events. Then learn how to build mechanisms using AWS Security Hub and other AWS services that can help detect and prevent these issues.
TDR354 | Builders’ session | Insights in your inbox: Build email reporting with AWS Security Hub AWS Security Hub provides you with a comprehensive view of the security state of your AWS resources by collecting security data from across AWS accounts, AWS Regions, and AWS services. In this builders’ session, learn how to set up a customizable and automated summary email that distills security posture information, insights, and critical findings from Security Hub. Get hands-on with the Security Hub console and discover easy-to-implement code examples that you can use in your own organization to drive security improvements.
TDR355 | Builders’ session | Detecting ransomware and suspicious activity in Amazon RDS In this builders’ session, acquire skills that can help you detect and respond to threats targeting AWS databases. Using services such as AWS Cloud9 and AWS CloudFormation, simulate real-world intrusions on Amazon RDS and Amazon Aurora and use Amazon Athena to detect unauthorized activities. The session also covers strategies from the AWS Customer Incident Response Team (CIRT) for rapid incident response and configuring essential security settings to enhance your database defenses. The session provides practical experience in configuring audit logging and enabling termination protection to ensure robust database security measures.
TDR451 | Builders’ session | Create a generative AI runbook to resolve security findings Generative AI has the potential to accelerate and streamline security analysis, response, and recovery, enhancing the effectiveness of human engagement. In this builders’ session, learn how to use Amazon SageMaker notebooks and Amazon Bedrock to quickly resolve security findings in your AWS account. You rely on runbooks for the day-to-day operations, maintenance, and troubleshooting of AWS services. With generative AI, you can gain deeper insights into security findings and take the necessary actions to streamline security analysis and response.
TDR441 | Code talk | How to use generative AI to gain insights in Amazon Security Lake In this code talk, explore how you can use generative AI to gather enhanced security insights within Amazon Security Lake by integrating Amazon SageMaker Studio and Amazon Bedrock. Learn how AI-powered analytics can help rapidly identify and respond to security threats. By using large language models (LLMs) within Amazon Bedrock to process natural language queries and auto-generate SQL queries, you can expedite security investigations, focusing on relevant data sources within Security Lake. The talk includes a threat analysis exercise to demonstrate the effectiveness of LLMs in addressing various security queries. Learn how you can streamline security operations and gain actionable insights to strengthen your security posture and mitigate risks effectively within AWS environments.
TDR442 | Code talk | Security testing, the practical way Join this code talk for a practical demonstration of how to test security capabilities within AWS. The talk can help you evaluate and quantify your detection and response effectiveness against key metrics like mean time to detect and mean time to resolution. Explore testing techniques that use open source tools alongside AWS services such as Amazon GuardDuty and AWS WAF. Gain insights into testing your security configurations in your environment and uncover best practices tailored to your testing scenarios. This talk equips you with actionable strategies to enhance your security posture and establish robust defense mechanisms within your AWS environment.
TDR443 | Code talk | How to conduct incident response in your Amazon EKS environment Join this code talk to gain insights from both adversaries’ and defenders’ perspectives as AWS experts simulate a live security incident within an application across multiple Amazon EKS clusters, invoking an alert in Amazon GuardDuty. Witness the incident response process as experts demonstrate detection, containment, and recovery procedures in near real time. Through this immersive experience, learn how you can effectively respond to and recover from Amazon EKS–specific incidents, and gain valuable insights into incident handling within cloud environments. Don’t miss this opportunity to enhance your incident response capabilities and learn how to more effectively safeguard your AWS infrastructure.
TDR444 | Code talk | Identity forensics in the realm of short-term credentials AWS Security Token Service (AWS STS) is a common way for users to access AWS services and allows you to utilize role chaining for navigating AWS accounts. When investigating security incidents, understanding the history and potential impact is crucial. Examining a single session is often insufficient because the initial abused credential may be different than the one that precipitated the investigation, and other tokens might be generated. Also, a single session investigation may not encompass all permissions that the adversary controls, due to trust relationships between the roles. In this code talk, learn how you can construct identity forensics capabilities using Amazon Detective and create a custom graph database using Amazon Neptune.
TDR371-R | Workshop | Threat detection and response on AWS Join AWS experts for an immersive threat detection and response workshop using Amazon GuardDuty, Amazon Inspector, AWS Security Hub, and Amazon Detective. This workshop simulates security events for different types of resources and behaviors and illustrates both manual and automated responses with AWS Lambda. Dive in and learn how to improve your security posture by operationalizing threat detection and response on AWS.
TDR372-R | Workshop | Container threat detection and response with AWS security services Join AWS experts for an immersive container security workshop using AWS threat detection and response services. This workshop simulates scenarios and security events that may arise while using Amazon ECS and Amazon EKS. The workshop also demonstrates how to use different AWS security services to detect and respond to potential security threats, as well as suggesting how you can improve your security practices. Dive in and learn how to improve your security posture when running workloads on AWS container orchestration services.
TDR373-R | Workshop | Vulnerability management with Amazon Inspector and Jenkins Join AWS experts for an immersive vulnerability management workshop using Amazon Inspector and Jenkins for continuous integration and continuous delivery (CI/CD). This workshop takes you through approaches to vulnerability management with Amazon Inspector for EC2 instances, container images residing in Amazon ECR and within CI/CD tools, and AWS Lambda functions. Explore the integration of Amazon Inspector with Jenkins, and learn how to operationalize vulnerability management on AWS.
Browse the full re:Inforce catalog to learn more about sessions in other tracks, plus gamified learning, innovation sessions, partner sessions, and labs.
Our comprehensive track content is designed to help arm you with the knowledge and skills needed to securely manage your workloads and applications on AWS. Don’t miss out on the opportunity to stay updated with the latest best practices in threat detection and incident response. Join us in Philadelphia for re:Inforce 2024 by registering today. We can’t wait to welcome you!
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
We continue to expand the scope of our assurance programs at Amazon Web Services (AWS) and are pleased to announce that the Spring 2024 System and Organization Controls (SOC) 1, 2, and 3 reports are now available. The reports cover the 12-month period from April 1, 2023 to March 31, 2024, so that customers have a full year of assurance from each report. These reports demonstrate our continuous commitment to adhere to the heightened expectations for cloud service providers.
The Spring 2024 SOC reports include an additional six services in scope, for a total of 177 services in scope. For up-to-date information, including when additional services are added, visit the AWS Services in Scope by Compliance Program webpage and choose SOC.
The six additional services in scope for the Spring 2024 SOC reports are:
AWS strives to continuously bring services into scope of its compliance programs to help you meet your architectural and regulatory needs. Please reach out to your AWS account team if you have questions or feedback about SOC compliance.
To learn more about our compliance and security programs, see AWS Compliance Programs. As always, we value your feedback and questions; reach out to the AWS Compliance team through the Contact Us page.
If you have feedback about this post, submit comments in the Comments section below.
During this special onboarding, we added two additional AWS Regions (Israel (Tel Aviv)) and Canada West (Calgary)) and three additional AWS services to the scope since the last certification issued on Nov 22, 2023. The following are the three additional services:
For a full list of AWS services that are certified under ISO and CSA Star, see the AWS ISO and CSA STAR Certified page. Customers can also access the certifications in the AWS Management Console through AWS Artifact.
If you have feedback about this post, submit comments in the Comments section below.
Want more AWS Security how-to content, news, and feature announcements? Follow us on X.
Join us in Philadelphia, Pennsylvania on June 10–12, 2024 for AWS re:Inforce, a security learning conference where you can gain skills and confidence in cloud security, compliance, identity, and privacy. As an attendee, you have access to hundreds of technical and non-technical sessions, an Expo featuring Amazon Web Services (AWS) experts and AWS Security Competency Partners, and keynote and leadership sessions featuring Security leadership.
AWS re:Inforce features content in the following six areas:
Data Protection
Governance, Risk, and Compliance
Identity and Access Management
Network and Infrastructure Security
Threat Detection and Incident Response
Application Security
This post will highlight some of the Data Protection sessions that you can add to your agenda. The data protection content showcases best practices for data in transit, at rest, and in use. Learn how AWS, customers, and AWS Partners work together to protect data across industries like financial services, healthcare, and the public sector. You will learn from AWS leaders about how customers innovate in the cloud, use the latest generative AI tools, and raise the bar on data security, resilience, and privacy.
Breakout sessions, chalk talks, and lightning talks
DAP221: Secure your healthcare generative AI workloads on Amazon EKS Many healthcare organizations have been modernizing their applications using containers on Amazon EKS. Today, they are increasingly adopting generative AI models to innovate in areas like patient care, drug discovery, and medical imaging analysis. In addition, these organizations must comply with healthcare security and privacy regulations. In this lightning talk, learn how you can work backwards from expected healthcare data protection outcomes. This talk offers guidance on extending healthcare organizations’ standardization of containerized applications on Amazon EKS to build more secure and resilient generative AI workloads.
DAP232: Innovate responsibly: Deep dive into data protection for generative AI AWS solutions such as Amazon Bedrock and Amazon Q are helping organizations across industries boost productivity and create new ways of operating. Despite all of the excitement, organizations often pause to ask, “How do these new services handle and manage our data?” AWS has designed these services with data privacy in mind and many security controls enabled by default, such as encryption of data at rest and in transit. In this chalk talk, dive into the data flows of these new generative AI services to learn how AWS prioritizes security and privacy for your sensitive data requirements.
DAP301: Building resilient event-driven architectures, feat. United Airlines United Airlines plans to accept a delivery of 700 new planes by 2032. With this growing fleet comes more destinations, passengers, employees, and baggage—and a big increase in data, the lifeblood of airline operations. United Airlines is using event-driven architecture (EDA) to build a system that scales with their operations and evolves with their hybrid cloud throughout this journey. In this session, learn how United Airlines built a hybrid operations management system by modernizing from mainframes to AWS. Using Amazon MSK, Amazon DynamoDB, AWS KMS, and event mesh AWS ISV Partner Solace, they were able to design a well-crafted EDA to address their needs.
DAP302: Capital One’s approach for secure and resilient applications Join this session to learn about Capital One’s strategic AWS Secrets Manager implementation that has helped ensure unified security across environments. Discover the key principles that can guide consistent use, with real-world examples to showcase the benefits and challenges faced. Gain insights into achieving reliability and resilience in financial services applications on AWS, including methods for maintaining system functionality amidst failures and scaling operations safely. Find out how you can implement chaos engineering and site reliability engineering using multi-Region services such as Amazon Route 53, AWS Auto Scaling, and Amazon DynamoDB.
DAP321: Securing workloads using data protection services, feat. Fannie Mae Join this lightning talk to discover how Fannie Mae employs a comprehensive suite of AWS data protection services to securely manage their own keys, certificates, and application secrets. Fannie Mae demonstrates how they utilized services such as AWS Secrets Manager, AWS KMS, and AWS Private Certificate Authority to empower application teams to build securely and align with their organizational and compliance expectations.
DAP331: Encrypt everything: How different AWS services help you protect data Encryption is supported by every AWS service that stores data. However, not every service implements encryption and key management identically. In this chalk talk, learn in detail how different AWS services such as Amazon S3 or Amazon Bedrock use encryption and manage keys. These insights can help you model threats to your applications and be better prepared to respond to questions about adherence to security standards and compliance requirements. Also, find out about some of the methodologies AWS uses when designing for encryption and key management at scale in a diverse set of services.
Hands-on sessions (builders’ sessions, code talks, and workshops)
DAP251: Build a privacy-enhancing healthcare data collaboration solution In this builders’ session, learn how to build a privacy-enhanced environment to analyze datasets from multiple sources using AWS Clean Rooms. Build a solution for a fictional life sciences company that is researching a new drug and needs to perform analyses with a hospital system. Find out how you can help protect sensitive data using SQL query controls to limit how the data can be queried, Cryptographic Computing for Clean Rooms (C3R) to keep the data encrypted at all times, and differential privacy to quantifiably safeguard patients’ personal information in the datasets. You must bring your laptop to participate.
DAP341: Data protection controls for your generative AI applications on AWS Generative AI is one of the most disruptive technologies of our generation and has the potential to revolutionize all industries. Cloud security data protection strategies need to evolve to meet the changing needs of businesses as they adopt generative AI. In this code talk, learn how you can implement various data protection security controls for your generative AI applications using Amazon Bedrock and AWS data protection services. Discover best practices and reference architectures that can help you enforce fine-grained data protection controls to scale your generative AI applications on AWS.
DAP342: Leveraging developer platforms to improve secrets management at scale In this code talk, learn how you can leverage AWS Secrets Manager and Backstage.io to give developers the freedom to deploy secrets close to their applications while maintaining organizational standards. Explore how using a developer portal can remove the undifferentiated heavy lifting of creating secrets that have consistent naming, tagging, access controls, and encryption. This talk touches on cross-Region replication, cross-account IAM permissions and policies, and access controls and integration with AWS KMS. Also find out about secrets rotation as well as new AWS Secrets Manager features such as BatchGetSecretValue and managed rotation.
DAP371: Encryption in transit Encryption in transit is a fundamental aspect of data protection. In this workshop, walk through multiple ways to accomplish encryption in transit on AWS. Find out how to enable HTTPS connections between microservices on Amazon ECS and AWS Lambda via Amazon VPC Lattice, enforce end-to-end encryption in Amazon EKS, and use AWS Private Certificate Authority to issue TLS certificates for private applications. You must bring your laptop to participate.
If these sessions look interesting to you, join us in Philadelphia by registering for re:Inforce 2024. We look forward to seeing you there!
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Amazon Web Services (AWS) continues to believe it’s essential that our customers have control over their data and choices for how they secure and manage that data in the cloud. AWS gives customers the flexibility to choose how and where they want to run their workloads, including a proven track record of innovation to support specialized workloads around the world. While many customers are able to meet their stringent security, sovereignty, and privacy requirements using our existing sovereign-by-design AWS Regions, we know there’s not a one-size-fits-all solution. AWS continues to innovate based on the criteria we know are most important to our customers to give them more choice and more control. Last year we announced the AWS European Sovereign Cloud, a new independent cloud for Europe, designed to give public sector organizations and customers in highly regulated industries further choice to meet their unique sovereignty needs. Today, we’re excited to share more details about the AWS European Sovereign Cloud roadmap so that customers and partners can start planning. The AWS European Sovereign Cloud is planning to launch its first AWS Region in the State of Brandenburg, Germany by the end of 2025. Available to all AWS customers, this effort is backed by a €7.8B investment in infrastructure, jobs creation, and skills development.
The AWS European Sovereign Cloud will utilize the full power of AWS with the same familiar architecture, expansive service portfolio, and APIs that customers use today. This means that customers using the AWS European Sovereign Cloud will get the benefits of AWS infrastructure including industry-leading security, availability, performance, and resilience. We offer a broad set of services, including a full suite of databases, compute, storage, analytics, machine learning and AI, networking, mobile, developer tools, IoT, security, and enterprise applications. Today, customers can start building applications in any existing Region and simply move them to the AWS European Sovereign Cloud when the first Region launches in 2025. Partners in the AWS Partner Network, which features more than 130,000 partners, already provide a range of offerings in our existing AWS Regions to help customers meet requirements and will now be able to seamlessly deploy applications on the AWS European Sovereign Cloud.
More control, more choice
Like our existing Regions, the AWS European Sovereign Cloud will be powered by the AWS Nitro System. The Nitro System is an unparalleled computing backbone for AWS, with security and performance at its core. Its specialized hardware and associated firmware are designed to enforce restrictions so that nobody, including anyone in AWS, can access customer workloads or data running on Amazon Elastic Compute Cloud (Amazon EC2) Nitro based instances. The design of the Nitro System has been validated by the NCC Group, an independent cybersecurity firm. The controls that help prevent operator access are so fundamental to the Nitro System that we’ve added them in our AWS Service Terms to provide an additional contractual assurance to all of our customers.
To date, we have launched 33 Regions around the globe with our secure and sovereign-by-design approach. Customers come to AWS because they want to migrate to and build on a secure cloud foundation. Customers who need to comply with European data residency requirements have the choice to deploy their data to any of our eight existing Regions in Europe (Ireland, Frankfurt, London, Paris, Stockholm, Milan, Zurich, and Spain) to keep their data securely in Europe.
For customers who need to meet additional stringent operational autonomy and data residency requirements within the European Union (EU), the AWS European Sovereign Cloud will be available as another option, with infrastructure wholly located within the EU and operated independently from existing Regions. The AWS European Sovereign Cloud will allow customers to keep all customer data and the metadata they create (such as the roles, permissions, resource labels, and configurations they use to run AWS) in the EU. Customers who need options to address stringent isolation and in-country data residency needs will be able to use AWS Dedicated Local Zones or AWS Outposts to deploy AWS European Sovereign Cloud infrastructure in locations they select. We continue to work with our customers and partners to shape the AWS European Sovereign Cloud, applying learnings from our engagements with European regulators and national cybersecurity authorities.
Continued investment in Europe
Over the last 25 years, we’ve driven economic development through our investment in infrastructure, jobs, and skills in communities and countries across Europe. Since 2010, Amazon has invested more than €150 billion in the EU, and we’re proud to employ more than 150,000 people in permanent roles across the European Single Market.
AWS now plans to invest €7.8 billion in the AWS European Sovereign Cloud by 2040, building on our long-term commitment to Europe and ongoing support of the region’s sovereignty needs. This long-term investment is expected to lead to a ripple effect in the local cloud community through accelerating productivity gains, empowering the digital transformation of businesses, empowering the AWS Partner Network (APN), upskilling the cloud and digital workforce, developing renewable energy projects, and creating a positive impact in the communities where AWS operates. In total, the AWS planned investment is estimated to contribute €17.2 billion to Germany’s total Gross Domestic Product (GDP) through 2040, and support an average 2,800 full-time equivalent jobs in local German businesses each year. These positions, including construction, facility maintenance, engineering, telecommunications, and other jobs within the broader local economy, are part of the AWS data center supply chain.
In addition, AWS is also creating new highly skilled permanent roles to build and operate the AWS European Sovereign Cloud. These jobs will include software engineers, systems developers, and solutions architects. This is part of our commitment that all day-to-day operations of the AWS European Sovereign Cloud will be controlled exclusively by personnel located in the EU, including access to data centers, technical support, and customer service.
In Germany, we also collaborate with local communities on long-term, innovative programs that will have a lasting impact in the areas where our infrastructure is located. This includes developing cloud workforce and education initiatives for learners of all ages, helping to solve for the skills gap and prepare for the tech jobs of the future. For example, last year AWS partnered with Siemens AG to design the first apprenticeship program for AWS data centers in Germany, launched the first national cloud computing certification with the German Chamber of Commerce (DIHK), and established the AWS Skills to Jobs Tech Alliance in Germany. We will work closely with local partners to roll out these skills programs and make sure they are tailored to regional needs.
“High performing, reliable, and secure infrastructure is the most important prerequisite for an increasingly digitalized economy and society. Brandenburg is making progress here. In recent years, we have set on a course to invest in modern and sustainable data center infrastructure in our state, strengthening Brandenburg as a business location. State-of-the-art data centers for secure cloud computing are the basis for a strong digital economy. I am pleased Amazon Web Services (AWS) has chosen Brandenburg for a long-term investment in its cloud computing infrastructure for the AWS European Sovereign Cloud.”
— Brandenburg’s Minister of Economic Affairs, Prof. Dr. Jörg Steinbach
Build confidently with AWS
For customers that are early in their cloud adoption journey and are considering the AWS European Sovereign Cloud, we provide a wide range of resources to help adopt the cloud effectively. From lifting and shifting workloads to migrating entire data centers, customers get the organizational, operational, and technical capabilities needed for a successful migration to AWS. For example, we offer the AWS Cloud Adoption Framework (AWS CAF) to provide best practices for organizations to develop an efficient and effective plan for cloud adoption, and AWS Migration Hub to help assess migration needs, define migration and modernization strategy, and leverage automation. We frequently host AWS events, webinars, and workshops focused on cloud adoption and migration strategies, where customers can learn from AWS experts and connect with other customers and partners.
We’re committed to giving customers more control and more choice to help meet their unique digital sovereignty needs, without compromising on the full power of AWS. The AWS European Sovereign Cloud is a testament to this. To help customers and partners continue to plan and build, we will share additional updates as we drive towards launch. You can discover more about the AWS European Sovereign Cloud on our European Digital Sovereignty website.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
AWS European Sovereign Cloud bis Ende 2025: AWS plant Investitionen in Höhe von 7,8 Milliarden Euro
Amazon Web Services (AWS) ist davon überzeugt, dass es für Kunden von essentieller Bedeutung ist, die Kontrolle über ihre Daten und Auswahlmöglichkeiten zu haben, wie sie diese Daten in der Cloud sichern und verwalten. Daher können Kunden flexibel wählen, wie und wo sie ihre Workloads ausführen. Dazu gehört auch eine langjährige Erfolgsbilanz von Innovationen zur Unterstützung spezialisierter Workloads auf der ganzen Welt. Viele Kunden können bereits ihre strengen Sicherheits-, Souveränitäts- und Datenschutzanforderungen mit unseren AWS-Regionen unter dem „sovereign-by-design“-Ansatz erfüllen. Aber wir wissen ebenso: Es gibt keine Einheitslösung für alle. Daher arbeitet AWS kontinuierlich an Innovationen, die auf jenen Kriterien basieren, die für unsere Kunden am wichtigsten sind und ihnen mehr Auswahl sowie Kontrolle bieten. Vor diesem Hintergrund haben wir letztes Jahr die AWS European Sovereign Cloud angekündigt. Mit ihr entsteht eine neue, unabhängige Cloud für Europa. Sie soll Organisationen des öffentlichen Sektors und Kunden in stark regulierten Branchen dabei helfen, die sich wandelnden Anforderungen an die digitale Souveränität zu erfüllen.
Heute freuen wir uns, dass wir weitere Details über die Roadmap der AWS European Sovereign Cloud bekanntgeben können. So können unsere Kunden und Partner mit ihren weiteren Planungen beginnen. Der Start der ersten Region der AWS European Sovereign Cloud ist in Brandenburg bis zum Jahresende 2025 geplant. Dieses Angebot steht allen AWS-Kunden zur Verfügung und wird von einer Investition in Höhe von 7,8 Milliarden Euro in die Infrastruktur, Arbeitsplatzschaffung und Kompetenzentwicklung unterstützt.
Die AWS European Cloud in Brandenburg bietet die volle Leistungsfähigkeit, mit der bekannten Architektur, dem umfangreichen Angebot an Services und denselben APIs, die Millionen von Kunden bereits kennen. Das bedeutet: Kunden der AWS European Sovereign Cloud profitieren somit bei voller Unabhängigkeit von den bekannten Vorteilen der AWS-Infrastruktur, einschließlich der branchenführenden Sicherheit, Verfügbarkeit, Leistung und Resilienz.
AWS-Kunden haben Zugriff auf ein breites Spektrum an Services – darunter ein umfangreiches Angebot bestehend aus Datenbanken, Datenverarbeitung, Datenspeicherung, Analytics, maschinellem Lernen (ML) und künstlicher Intelligenz (KI), Netzwerken, mobilen Applikationen, Entwickler-Tools, Internet of Things (IoT), Sicherheit und Unternehmensanwendungen. Bereits heute können Kunden Anwendungen in jeder bestehenden Region entwickeln und diese einfach in die AWS European Sovereign Cloud auslagern, sobald die erste AWS-Region 2025 startet. Die Partner im AWS-Partnernetzwerks (APN), das mehr als 130.000 Partner umfasst, bietet bereits eine Reihe von Angeboten in den bestehenden AWS-Regionen an. Dadurch unterstützen sie Kunden dabei, ihre Anforderungen zu erfüllen und Anwendungen einfach in der AWS European Sovereign Cloud bereitzustellen.
Mehr Kontrolle, größere Auswahl
Die AWS European Sovereign Cloud nutzt wie auch unsere bestehenden Regionen das AWS Nitro System. Dabei handelt es sich um einen Computing-Backbone für AWS, bei dem Sicherheit und Leistung im Mittelpunkt stehen. Die spezialisierte Hardware und zugehörige Firmware sind so konzipiert, dass strikte Beschränkungen gelten und niemand, auch nicht AWS selbst, auf die Workloads oder Daten von Kunden zugreifen kann, die auf Amazon Elastic Compute Cloud (Amazon EC2) Nitro-basierten Instanzen laufen. Dieses Design wurde von der NCC Group validiert, einem unabhängigen Unternehmen für Cybersicherheit. Die Kontrollen, die den Zugriff durch Betreiber verhindern, sind grundlegend für das Nitro System. Daher haben wir sie in unsere AWS Service Terms aufgenommen, um allen unseren Kunden diese zusätzliche vertragliche Zusicherung zu geben.
Bis heute haben wir 33 Regionen rund um den Globus mit unserem sicheren und „sovereign-by-design“-Ansatz gestartet. Unsere Kunden nutzen AWS, weil sie auf einer sicheren Cloud-Umgebung migrieren und aufbauen möchten. Für Kunden, die europäische Anforderungen an den Ort der Datenverarbeitung erfüllen müssen, bietet AWS die Möglichkeit, ihre Daten in einer unserer acht bestehenden Regionen in Europa zu verarbeiten: Irland, Frankfurt, London, Paris, Stockholm, Mailand, Zürich und Spanien. So können sie ihre Daten sicher innerhalb Europas halten.
Müssen Kunden zusätzliche Anforderungen an die betriebliche Autonomie und den Ort der Datenverarbeitung innerhalb der Europäischen Union erfüllen, steht die AWS European Sovereign Cloud als weitere Option zur Verfügung. Die Infrastruktur hierfür ist vollständig in der EU angesiedelt und wird unabhängig von den bestehenden Regionen betrieben. Sie ermöglicht es AWS-Kunden, ihre Kundeninhalte und von ihnen erstellten Metadaten in der EU zu behalten – etwa Rollen, Berechtigungen, Ressourcenbezeichnungen und Konfigurationen für den Betrieb von AWS.
Sollten Kunden weitere Optionen benötigen, um eine Isolierung zu ermöglichen und strenge Anforderungen an den Ort der Datenverarbeitung in einem bestimmten Land zu erfüllen, können sie auf AWS Dedicated Local Zones oder AWS Outposts zurückgreifen. Auf diese Weise können sie die Infrastruktur der AWS European Sovereign Cloud am Ort ihrer Wahl einsetzen. Wir arbeiten mit unseren Kunden und Partnern kontinuierlich daran, die AWS European Sovereign Cloud so zu gestalten, dass sie den benötigten Anforderungen entspricht. Dabei nutzen wir auch Feedback aus unseren Gesprächen mit europäischen Regulierungsbehörden und nationalen Cybersicherheitsbehörden.
„Eine funktionierende, verlässliche und sichere Infrastruktur ist die wichtigste Vorrausetzung für eine zunehmend digitalisierte Wirtschaft und Gesellschaft. Brandenburg schreitet hier voran. Wir haben in den vergangenen Jahren entscheidende Weichen gestellt, um Investitionen in eine moderne und nachhaltige Rechenzentruminfrastruktur in unserem Land auszubauen und so den Wirtschaftsstandort Brandenburg zu stärken. Hochmoderne Rechenzentren für sicheres Cloud-Computing sind die Basis für eine digitale Wirtschaft. Für unsere digitale Souveränität ist es wichtig, dass Rechenleistungen vor Ort in Deutschland erbracht werden. Ich freue mich, dass Amazon Web Services Brandenburg für ein langfristiges Investment in ihre Cloud-Computing-Infrastruktur für die AWS European Sovereign Cloud ausgewählt hat.“
— sagt Brandenburgs WirtschaftsministerProf. Dr.-Ing. Jörg Steinbach
Kontinuierliche Investitionen in Europa
Im Laufe der vergangenen 25 Jahre haben wir die wirtschaftliche Entwicklung in europäischen Ländern und Gemeinden vorangetrieben und in Infrastruktur, Arbeitsplätze sowie den Ausbau von Kompetenzen investiert. Seit 2010 hat Amazon über 150 Milliarden Euro in der Europäischen Union investiert und wir sind stolz darauf, im gesamten europäischen Binnenmarkt mehr als 150.000 Menschen in Festanstellung zu beschäftigen.
AWS plant bis zum Jahr 2040 7,8 Milliarden Euro in die AWS European Sovereign Cloud zu investieren. Diese Investition ist Teil der langfristigen Bestrebungen von AWS, das europäische Bedürfnis nach digitaler Souveränität zu unterstützen. Mit dieser langfristigen Investition löst AWS einen Multiplikatoreffekt für Cloud-Computing in Europa aus. Sie wird die digitale Transformation der Verwaltung und von Unternehmen vorantreiben, das AWS Partner Network (APN) stärken, die Zahl der Cloud- und Digitalfachkräfte erhöhen, erneuerbare Energieprojekte vorantreiben und eine positive Wirkung in den Gemeinden erzielen, in denen AWS präsent ist. Insgesamt wird die geplante AWS-Investition bis 2040 voraussichtlich 17,2 Milliarden Euro zum deutschen Bruttoinlandsprodukt und zur Schaffung von 2.800 Vollzeitstellen bei regionalen Unternehmen beitragen. Diese Arbeitsplätze in den Bereichen Bau, Instandhaltung, Ingenieurwesen, Telekommunikation und der breiteren regionalen Wirtschaft sind Teil der Lieferkette für AWS-Rechenzentren.
Darüber hinaus wird AWS neue Stellen für hochqualifizierte festangestellte Fachkräfte wie Softwareentwickler, Systemingenieure und Lösungsarchitekten schaffen, um die AWS European Sovereign Cloud aufzubauen und zu betreiben. Die Investition in zusätzliches Personal unterstreicht unser Commitment, dass der gesamte Betrieb dieser souveränen Cloud-Umgebung – angefangen bei der Zugangskontrolle zu den Rechenzentren über den technischen Support bis hin zum Kundendienst – ausnahmslos durch Fachkräfte innerhalb der Europäischen Union kontrolliert und gesteuert wird.
In Deutschland arbeitet AWS mit den Beteiligten vor Ort auch an langfristigen und innovativen Programmen zusammen. Diese sollen einen nachhaltigen positiven Einfluss auf die Gemeinden haben, in denen sich die Infrastruktur des Unternehmens befindet. AWS konzentriert sich auf die Entwicklung von Cloud-Fachkräften und Schulungsinitiativen für Lernende aller Altersgruppen. Diese Maßnahmen tragen dazu bei, den Fachkräftemangel zu beheben und sich auf die technischen Berufe der Zukunft vorzubereiten. Im vergangenen Jahr hat AWS beispielsweise gemeinsam mit der Siemens AG das erste Ausbildungsprogramm für AWS-Rechenzentren in Deutschland entwickelt. Ebenso hat das Unternehmen in Kooperation mit dem Deutschen Industrie und Handelstag (DIHK) den bundeseinheitlichen Zertifikatslehrgang zum „Cloud Business Expert“ entwickelt sowie die AWS Skills to Jobs Tech Alliance in Deutschland ins Leben gerufen. AWS wird gemeinsam mit lokalen Partnern daran arbeiten, Ausbildungsprogramme und Fortbildungen anzubieten, die auf die Bedürfnisse vor Ort zugeschnitten sind.
Vertrauensvoll bauen mit AWS
Für Kunden, die sich noch am Anfang ihrer Cloud-Reise befinden und die AWS European Sovereign Cloud in Betracht ziehen, bieten wir eine Vielzahl von Ressourcen an, um den Wechsel in die Cloud effektiv zu gestalten. Egal ob einzelne Workloads verlagert oder ganze Rechenzentren migriert werden sollen – Kunden erhalten von uns die nötigen organisatorischen, operativen und technischen Fähigkeiten für eine erfolgreiche Migration zu AWS. Beispielsweise bieten wir das AWS Cloud Adoption Framework (AWS CAF) an, das Unternehmen bei der Entwicklung eines effizienten und effektiven Cloud-Adoptionsplans mit Best Practices unterstützt. Auch der AWS Migration Hub hilft bei der Bewertung des Migrationsbedarfs, der Definition der Migrations- und Modernisierungsstrategie und der Nutzung von Automatisierung. Darüber hinaus veranstalten wir regelmäßig AWS-Events, Webinare und Workshops rund um die Themen Cloud-Adoption und Migrationsstrategie. Dabei können Kunden von AWS-Experten lernen und sich mit anderen Kunden und Partnern vernetzen.
Wir sind bestrebt, unseren Kunden mehr Kontrolle und weitere Optionen anzubieten, damit diese ihre ganz individuellen Anforderungen an die digitale Souveränität erfüllen können, ohne dabei auf die volle Leistungsfähigkeit von AWS verzichten zu müssen.
Um Kunden und Partnern bei der weiteren Planung und Entwicklung zu unterstützen, werden wir laufend zusätzliche Updates bereitstellen, während wir auf den Start der AWS European Sovereign Cloud hinarbeiten. Mehr über die AWS European Sovereign Cloud erfahren Sie auf unserer Website zur European Digital Sovereignty.
AWS IAM Identity Center is the preferred way to provide workforce access to Amazon Web Services (AWS) accounts, and enables you to provide workforce access to many AWS managed applications, such as Amazon Q Developer (Formerly known as Code Whisperer).
As we continue to release more AWS managed applications, customers have told us they want to onboard to IAM Identity Center to use AWS managed applications, but some aren’t ready to migrate their existing IAM federation for AWS account management to Identity Center.
In this blog post, I’ll show you how you can enable Identity Center and use AWS managed applications—such as Amazon Q Developer—without migrating existing IAM federation flows to Identity Center.
A recap on AWS managed applications and trusted identity propagation
Just before re:Invent 2023, AWS launched trusted identity propagation, a technology that allows you to use a user’s identity and groups when accessing AWS services. This allows you to assign permissions directly to users or groups, rather than model entitlements in AWS Identity and Access Management (IAM). This makes permissions management simpler for users. For example, with trusted identity propagation, you can grant users and groups access to specific Amazon Redshift clusters without modeling all possible unique combinations of permissions in IAM. Trusted identity propagation is available today for Redshift and Amazon Simple Storage Service (Amazon S3), with more services and features coming over time.
In 2023, we released Amazon Q Developer, which is integrated with IAM Identity Center, generally available as an AWS managed application. When you’re using Amazon Q Developer outside of AWS in integrated development environments (IDEs) such as Microsoft Visual Studio Code, Identity Center is used to sign in to Amazon Q Developer.
Amazon Q Developer is one of many AWS managed applications that are integrated with the OAuth 2.0 functionality of IAM Identity Center, and it doesn’t use IAM credentials to access the Q Developer service from within your IDEs. AWS managed applications and trusted identity propagation don’t require you to use the permission sets feature of Identity Center and instead use OpenID Connect to grant your workforce access to AWS applications and features.
IAM Identity Center for AWS application access only
In the following section, we use IAM Identity Center to sign in to Amazon Q Developer as an example of an AWS managed application.
Prerequisites
The steps in this post require that you have administrative level access to an organization in AWS Organizations.
Step 1: Enable an organization instance of IAM Identity Center
To begin, you must enable an organization instance of IAM Identity Center. While it’s possible to use IAM Identity Center without an AWS Organizations organization, we generally recommend that customers operate with such an organization.
The IAM Identity Center documentation provides the steps to enable an organizational instance of IAM Identity Center, as well as prerequisites and considerations. One consideration I would emphasize here is the identity source. We recommend, wherever possible, that you integrate with an external identity provider (IdP), because this provides the most flexibility and allows you to take advantage of the advanced security features of modern identity platforms.
IAM Identity Center is available at no additional cost.
Note: In late 2023, AWS launched account instances for IAM Identity Center. Account instances allow you to create additional Identity Center instances within member accounts of your organization. Wherever possible, we recommend that customers use an organization instance of IAM Identity Center to give them a centralized place to manage their identities and permissions. AWS recommends account instances when you want to perform a proof of concept using Identity Center, when there isn’t a central IdP or directory that contains all the identities you want to use on AWS and you want to use AWS managed applications with distinct directories, or when your AWS account is a member of an organization in AWS Organizations that is managed by another party and you don’t have access to set up an organization instance.
Step 2: Set up your IdP and synchronize identities and groups
After you’ve enabled your IAM Identity Center instance, you need to set up your instance to work with your chosen IdP and synchronize your identities and groups. The IAM Identity Center documentation includes examples of how to do this with many popular IdPs.
After your identity source is connected, IAM Identity Center can act as the single source of identity and authentication for AWS managed applications, bridging your external identity source and AWS managed applications. You don’t have to create a bespoke relationship between each AWS application and your IdP, and you have a single place to manage user permissions.
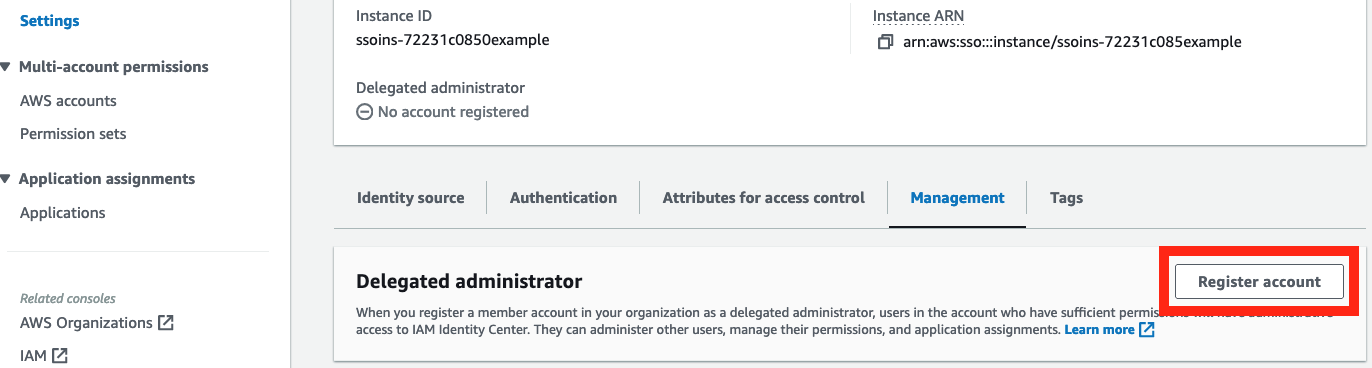
Step 3: Set up delegated administration for IAM Identity Center
As a best practice, we recommend that you only access the management account of your AWS Organizations organization when absolutely necessary. IAM Identity Center supports delegated administration, which allows you to manage Identity Center from a member account of your organization.
To set up delegated administration
Go to the AWS Management Console and navigate to IAM Identity Center.
In the left navigation pane, select Settings. Then select the Management tab and choose Register account.
From the menu that follows, select the AWS account that will be used for delegated administration for IAM Identity Center. Ideally, this member account is dedicated solely to the purpose of administrating IAM Identity Center and is only accessible to users who are responsible for maintaining IAM Identity Center.
Figure 1: Set up delegated administration
Step 4: Configure Amazon Q Developer
You now have IAM Identity Center set up with the users and groups from your directory, and you’re ready to configure AWS managed applications with IAM Identity Center. From a member account within your organization, you can now enable Amazon Q Developer. This can be any member account in your organization and should not be the one where you set up delegated administration of IAM Identity Center, or the management account.
Note: If you’re doing this step immediately after configuring IAM Identity Center with an external IdP with SCIM synchronization, be aware that the users and groups from your external IdP might not yet be synchronized to Identity Center by your external IdP. Identity Center updates user information and group membership as soon as the data is received from your external IdP. How long it takes to finish synchronizing after the data is received depends on the number of users and groups being synchronized to Identity Center.
To enable Amazon Q Developer
Open the Amazon Q Developer console. This will take you to the setup for Amazon Q Developer.
Figure 2: Open the Amazon Q Developer console
Choose Subscribe to Amazon Q.
Figure 3: The Amazon Q developer console
You’ll be taken to the Amazon Q console. Choose Subscribe to subscribe to Amazon Q Developer Pro.
Figure 4: Subscribe to Amazon Q Developer Pro
After choosing Subscribe, you will be prompted to select users and groups you want to enroll for Amazon Q Developer. Select the users and groups you want and then choose Assign.
Figure 5: Assign user and group access to Amazon Q Developer
After you perform these steps, the setup of Amazon Q Developer as an AWS managed application is complete, and you can now use Amazon Q Developer. No additional configuration is required within your external IdP or on-premises Microsoft Active Directory, and no additional user profiles have to be created or synchronized to Amazon Q Developer.
Note: There are charges associated with using the Amazon Q Developer service.
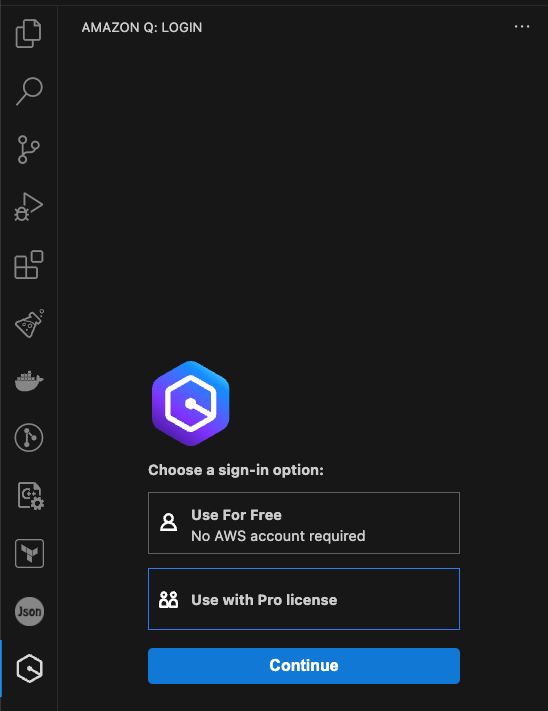
In their IDE, a user can sign in to Amazon Q Developer by entering the start URL and AWS Region and choosing Sign in. Figure 6 shows what this looks like in Visual Studio Code. The Amazon Q extension for Visual Studio Code is available to download within Visual Studio Code.
Figure 6: Signing in to the Amazon Q Developer extension in Visual Studio Code
After choosing Use with Pro license, and entering their Identity Center’s start URL and Region, the user will be directed to authenticate with IAM Identity Center and grant the Amazon Q Developer application access to use the Amazon Q Developer service.
When this is successful, the user will have the Amazon Q Developer functionality available in their IDE. This was achieved without migrating existing federation or AWS account access patterns to IAM Identity Center.
Clean up
If you don’t wish to continue using IAM Identity Center or Amazon Q Developer, you can delete the Amazon Q Developer Profile and Identity Center instance within their respective consoles, within the AWS account they are deployed into. Deleting your Identity Center instance won’t make changes to existing federation or AWS account access that is not done through IAM Identity Center.
Conclusion
In this post, we talked about some recent significant launches of AWS managed applications and features that integrate with IAM Identity Center and discussed how you can use these features without migrating your AWS account management to permission sets. We also showed how you can set up Amazon Q Developer with IAM Identity Center. While the example in this post uses Amazon Q Developer, the same approach and guidance applies to Amazon Q Business and other AWS managed applications integrated with Identity Center.
In this post, we explore how Amazon Web Services (AWS) customers can use Amazon Security Lake to efficiently collect, query, and centralize logs on AWS. We also discuss new use cases for Security Lake, such as applying generative AI to Security Lake data for threat hunting and incident response, and we share the latest service enhancements and developments from our growing landscape. Security Lake centralizes security data from AWS environments, software as a service (SaaS) providers, and on-premises and cloud sources into a purpose-built data lake that is stored in your AWS account. Using Open Cybersecurity Schema Framework (OCSF) support, Security Lake normalizes and combines security data from AWS and a broad range of third-party data sources. This helps provide your security team with the ability to investigate and respond to security events and analyze possible threats within your environment, which can facilitate timely responses and help to improve your security across multicloud and hybrid environments.
One year ago, AWS embarked on a mission driven by the growing customer need to revolutionize how security professionals centralize, optimize, normalize, and analyze their security data. As we celebrate the one-year general availability milestone of Amazon Security Lake, we’re excited to reflect on the journey and showcase how customers are using the service, yielding both productivity and cost benefits, while maintaining ownership of their data.
In this section, we highlight how some of our customers have found the most value with Security Lake and how you can use Security Lake in your organization.
Simplify the centralization of security data management across hybrid environments to enhance security analytics
Many customers use Security Lake to gather and analyze security data from various sources, including AWS, multicloud, and on-premises systems. By centralizing this data in a single location, organizations can streamline data collection and analysis, help eliminate data silos, and improve cross-environment analysis. This enhanced visibility and efficiency allows security teams to respond more effectively to security events. With Security Lake, customers simplify data gathering and reduce the burden of data retention and extract, transform, and load (ETL) processes with key AWS data sources.
For example, Interpublic Group (IPG), an advertising company, uses Security Lake to gain a comprehensive, organization-wide grasp of their security posture across hybrid environments. Watch this video from re:Inforce 2023 to understand how IPG streamlined their security operations.
Before adopting Security Lake, the IPG team had to work through the challenge of managing diverse log data sources. This involved translating and transforming the data, as well as reconciling complex elements like IP addresses. However, with the implementation of Security Lake, IPG was able to access previously unavailable log sources. This enabled them to consolidate and effectively analyze security-related data. The use of Security Lake has empowered IPG to gain comprehensive insight into their security landscape, resulting in a significant improvement in their overall security posture.
“We can achieve a more complete, organization-wide understanding of our security posture across hybrid environments. We could quickly create a security data lake that centralized security-related data from AWS and third-party sources,” — Troy Wilkinson, Global CISO at Interpublic Group
Streamline incident investigation and reduce mean time to respond
As organizations expand their cloud presence, they need to gather information from diverse sources. Security Lake automates the centralization of security data from AWS environments and third-party logging sources, including firewall logs, storage security, and threat intelligence signals. This removes the need for custom, one-off security consolidation pipelines. The centralized data in Security Lake streamlines security investigations, making security management and investigations simpler. Whether you’re in operations or a security analyst, dealing with multiple applications and scattered data can be tough. Security Lake makes it simpler by centralizing the data, reducing the need for scattered systems. Plus, with data stored in your Amazon Simple Storage Service (Amazon S3) account, Security Lake lets you store a lot of historical data, which helps when looking back for patterns or anomalies indicative of security issues.
For example, SEEK, an Australian online employment marketplace, uses Security Lake to streamline incident investigations and reduce mean time to respond (MTTR). Watch this video from re:Invent 2023 to understand how SEEK improved its incident response. Prior to using Security Lake, SEEK had to rely on a legacy VPC Flow Logs system to identify possible indicators of compromise, which took a long time. With Security Lake, the company was able to more quickly identify a host in one of their accounts that was communicating with a malicious IP. Now, Security Lake has provided SEEK with swift access to comprehensive data across diverse environments, facilitating forensic investigations and enabling them scale their security operations better.
Optimize your log retention strategy
Security Lake simplifies data management for customers who need to store large volumes of security logs to meet compliance requirements. It provides customizable retention settings and automated storage tiering to optimize storage costs and security analytics. It automatically partitions and converts incoming security data into a storage and query-efficient Apache Parquet format. Security Lake uses the Apache Iceberg open table format to enhance query performance for your security analytics. Customers can now choose which logs to keep for compliance reasons, which logs to send to their analytics solutions for further analysis, and which logs to query in place for incident investigation use cases. Security Lake helps customers to retain logs that were previously unfeasible to store and to extend storage beyond their typical retention policy, within their security information and event management (SIEM) system.
Figure 2 shows a section of the Security Lake activation page, which presents users with options to set rollup AWS Regions and storage classes.
Figure 2: Security Lake activation page with options to select a roll-up Region and set storage classes
For example, Carrier, an intelligent climate and energy solutions company, relies on Security Lake to strengthen its security and governance practices. By using Security Lake, Carrier can adhere to compliance with industry standards and regulations, safeguarding its operations and optimizing its log retention.
“Amazon Security Lake simplifies the process of ingesting and analyzing all our security-related log and findings data into a single data lake, strengthening our enterprise-level security and governance practices. This streamlined approach has enhanced our ability to identify and address potential issues within our environment more effectively, enabling us to proactively implement mitigations based on insights derived from the service,” — Justin McDowell, Associate Director for Enterprise Cloud Services at Carrier
Proactive threat and vulnerability detection
Security Lake helps customers identify potential threats and vulnerabilities earlier in the development process by facilitating the correlation of security events across different data sources, allowing security analysts to identify complex attack patterns more effectively. This proactive approach shifts the responsibility for maintaining secure coding and infrastructure to earlier phases, enhancing overall security posture. Security Lake can also optimize security operations by automating safeguard protocols and involving engineering teams in decision-making, validation, and remediation processes. Also, by seamlessly integrating with security orchestration tools, Security Lake can help expedite responses to security incidents and preemptively help mitigate vulnerabilities before exploitation occurs.
For example, SPH Media, a Singapore media company, uses Security Lake to get better visibility into security activity across their organization, enabling proactive identification of potential threats and vulnerabilities.
Security Lake and generative AI for threat hunting and incident response practices
Centralizing security-related data allows organizations to efficiently analyze behaviors from systems and users across their environments, providing deeper insight into potential risks. With Security Lake, customers can centralize their security logs and have them stored in a standardized format using OCSF. OCSF implements a well-documented schema maintained at schema.ocsf.io, which generative AI can use to contextualize the structured data within Security Lake tables. Security personnel can then ask questions of the data using familiar security investigation terminology rather than needing data analytics skills to translate an otherwise simple question into complex SQL (Structured Query Language) queries. Building upon the previous processes, Amazon Bedrock then takes an organization’s natural language incident response playbooks and converts them into a sequence of queries capable of automating what would otherwise be manual investigation tasks.
“Organizations can benefit from using Amazon Security Lake to centralize and manage security data with the OCSF and Apache Parquet format. It simplifies the integration of disparate security log sources and findings, reducing complexity and cost. By applying generative AI to Security Lake data, SecOps can streamline security investigations, facilitate timely responses, and enhance their overall security,” — Phil Bues, Research Manager, Cloud Security at IDC
Enhance incident response workflow with contextual alerts
Incident responders commonly deal with a high volume of automatically generated alerts from their IT environment. Initially, the response team members sift through numerous log sources to uncover relevant details about affected resources and the causes of alerts, which adds time to the remediation process. This manual process also consumes valuable analyst time, particularly if the alert turns out to be a false positive.
To reduce this burden on incident responders, customers can use generative AI to perform initial investigations and generate human-readable context from alerts. Amazon QuickSight Q is a generative AI–powered assistant that can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in your enterprise systems. Incident responders can now combine these capabilities with data in Amazon Security Lake to begin their investigation and build detailed dashboards in minutes. This allows them to visually identify resources and activities that could potentially trigger alerts, giving incident responders a head start in their response efforts. The approach can also be used to validate alert information against alternative sources, enabling faster identification of false positives and allowing responders to focus on genuine security incidents.
As natural language processing (NLP) models evolve they can also interpret incident response playbooks, often written in a human-readable, step-by-step format. Amazon Q Apps will enable the incident responder to use natural language to quickly and securely build their own generative AI playbooks to automate their tasks. This automation can streamline incident response tasks such as creating tickets in the relevant ticketing system, logging bugs in the version control system that hosts application code, and tagging resources as non-compliant if they fail to adhere to the organization’s IT security policy.
Incident investigation with automatic dashboard generation
By using Amazon QuickSight Q and data in Security Lake, incident responders can now generate customized visuals based on the specific characteristics and context of the incident they are investigating. The incident response team can start with a generic investigative question and automatically produce dashboards without writing SQL queries or learning the complexities of how to build a dashboard.
After building a topic in Amazon QuickSight Q. The investigator can either ask their own question or utilize the AI generated questions that Q has provided. In the example shown in Figure 3, the incident responder suspects a potential security incident and is seeking more information about Create or Update API calls in their environment, by asking ” I’m looking for what accounts ran an update or create api call in the last week, can you display the API Operation?
Figure 3: AI Generated visual to begin the investigation
This automatically generated dashboard can be saved for later and from this dashboard the investigator can just focus on one account with a simple right click and get more information about the API calls performed by a single account. as shown in Figure 4.
Figure 4: Investigating API calls for a single account
Using the centralized security data in Amazon Security Lake and Amazon QuickSight Q, incident responders can jump-start investigations and rapidly validate potential threats without having to write complex queries or manually construct dashboards.
Updates since GA launch
Security Lake makes it simpler to analyze security data, gain a more comprehensive understanding of security across your entire organization, and improve the protection of your workloads, applications, and data. Since the general availability release in 2023, we have made various updates to the service. It’s now available in 17 AWS Regions globally. To assist you in evaluating your current and future Security Lake usage and cost estimates, we’ve introduced a new usage page. If you’re currently in a 15-day free trial, your trial usage can serve as a reference for estimating post-trial costs. Accessing Security Lake usage and projected costs is as simple as logging into the Security Lake console.
We have released an integration with Amazon Detective that enables querying and retrieving logs stored in Security Lake. Detective begins pulling raw logs from Security Lake related to AWS CloudTrail management events and Amazon VPC Flow Logs. Security Lake enhances analytics performance with support for OCSF 1.1.0 and Apache Iceberg. Also, Security Lake has integrated several OCSF mapping enhancements, including OCSF Observables, and has adopted the latest version of the OCSF datetime profile for improved usability. Security Lake seamlessly centralizes and normalizes Amazon Elastic Kubernetes Service (Amazon EKS) audit logs, simplifying monitoring and investigation of potential suspicious activities in your Amazon EKS clusters, without requiring additional setup or affecting existing configurations.
The global team of experts in the AWS Professional Services organization can help customers realize their desired business outcomes with AWS. Our teams of data architects and security engineers collaborate with customer security, IT, and business leaders to develop enterprise solutions.
The AWS ProServe Amazon Security Lake Assessment offering is a complimentary workshop for customers. It entails a two-week interactive assessment, delving deep into customer use cases and creating a program roadmap to implement Security Lake alongside a suite of analytics solutions. Through a series of technical and strategic discussions, the AWS ProServe team analyzes use cases for data storage, security, search, visualization, analytics, AI/ML, and generative AI. The team then recommends a target future state architecture to achieve the customer’s security operations goals. At the end of the workshop, customers receive a draft architecture and implementation plan, along with infrastructure cost estimates, training, and other technical recommendations.
Summary
In this post, we showcased how customers use Security Lake to collect, query, and centralize logs on AWS. We discussed new applications for Security Lake and generative AI for threat hunting and incident response. We invite you to discover the benefits of using Security Lake through our 15-day free trial and share your feedback. To help you in getting started and building your first security data lake, we offer a range of resources including an infographic, eBook, demo videos, and webinars. There are many different use cases for Security Lake that can be tailored to suit your AWS environment. Join us at AWS re:Inforce 2024, our annual cloud security event, for more insights and firsthand experiences of how Security Lake can help you centralize, normalize, and optimize your security data.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Amazon Web Services (AWS) has recently renewed the Esquema Nacional de Seguridad (ENS) High certification, upgrading to the latest version regulated under Royal Decree 311/2022. The ENS establishes security standards that apply to government agencies and public organizations in Spain and service providers on which Spanish public services depend.
This security framework has gone through significant updates since the Royal Decree 3/2010 to the latest Royal Decree 311/2022 to adapt to evolving cybersecurity threats and technologies. The current scheme defines basic requirements and lists additional security reinforcements to meet the bar of the different security levels (Low, Medium, High).
Achieving the ENS High certification for its 311/2022 version underscores AWS commitment to maintaining robust cybersecurity controls and highlights our proactive approach to cybersecurity.
We are happy to announce the addition of 14 services to the scope of our ENS certification, for a new total of 172 services in scope. The certification now covers 31 Regions. Some of the additional services in scope for ENS High include the following:
Amazon Bedrock – This fully managed service offers a choice of high-performing foundation models (FMs) from leading artificial intelligence (AI) companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI.
Amazon EventBridge – Use this service to easily build loosely coupled, event-driven architectures. It creates point-to-point integrations between event producers and consumers without needing to write custom code or manage and provision servers.
AWS HealthOmics – This service helps healthcare and life science organizations and their software partners store, query, and analyze genomic, transcriptomic, and other omics data and then uses that data to generate insights to improve health.
AWS Signer – This is a fully managed code-signing service to ensure the trust and integrity of your code. AWS Signer manages the code-signing certificate’s public and private keys and enables central management of the code-signing lifecycle.
AWS Wickr – This service encrypts messages, calls, and files with a 256-bit end-to-end encryption protocol. Only the intended recipients and the customer organization can decrypt these communications, reducing the risk of adversary-in-the-middle attacks.
AWS achievement of the ENS High certification is verified by BDO Auditores S.L.P., which conducted an independent audit and confirmed that AWS continues to adhere to the confidentiality, integrity, and availability standards at its highest level as described in Royal Decree 311/2022.
As always, we are committed to bringing new services into the scope of our ENS High program based on your architectural and regulatory needs. If you have questions about the ENS program, reach out to your AWS account team or contact AWS Compliance.
If you have feedback about this post, submit comments in the Comments section below.
Want more AWS Security how-to content, news, and feature announcements? Follow us onTwitter.
We’re pleased to announce that Amazon Web Services (AWS) demonstrated continuous compliance with the Baseline Informatiebeveiliging Overheid (BIO) Thema-uitwerking Clouddiensten while increasing the AWS services and AWS Regions in scope. This alignment with the BIO Thema-uitwerking Clouddiensten requirements demonstrates our commitment to adhere to the heightened expectations for cloud service providers.
AWS customers across the Dutch public sector can use AWS certified services with confidence, knowing that the AWS services listed in the certificate adhere to the strict requirements imposed on the consumption of cloud-based services.
Baseline Informatiebeveiliging Overheid (BIO)
The BIO framework is an information security framework that the four layers of the Dutch public sector are required to adhere to. This means that it’s mandatory for the Dutch central government, all provinces, municipalities, and regional water authorities to be compliant with the BIO framework.
To support AWS customers in demonstrating their compliance with the BIO framework, AWS developed a Landing Zone for the BIO framework. This Landing Zone for the BIO framework is a pre-configured AWS environment that includes a subset of the technical requirements of the BIO framework. It’s a helpful tool that provides a starting point from which customers can further build their own AWS environment.
In addition to the BIO framework, there’s another information security framework designed specifically for the use of cloud services, called BIO Thema-uitwerking Clouddiensten. The BIO Thema-uitwerking Clouddiensten is a guidance document for Dutch cloud service consumers to help them formulate controls and objectives when using cloud services. Consumers can consider it to be an additional control framework on top of the BIO framework.
AWS strives to continuously bring services into scope of its compliance programs to help you meet your architectural and regulatory needs.
To learn more about our compliance and security programs, see AWS Compliance Programs. As always, we value your feedback and questions; reach out to the AWS Compliance team through the Contact Us page.
If you have feedback about this post, submit comments in the Comments section below.
Amazon Web Services (AWS) is pleased to announce that a translated version of our 2023 ISO 27001 and 2023 ISO 22301 certifications are now available:
The 2023 ISO 27001 certificate is available in Spanish and French.
The 2023 ISO 22301 certificate is available in Spanish.
Translated certificates are available to customers through AWS Artifact.
These translated certificates will help drive greater engagement and alignment with customer and regulatory requirements across France, Latin America, and Spain.
We continue to listen to our customers, regulators, and stakeholders to understand their needs regarding audit, assurance, certification, and attestation programs at AWS. If you have questions or feedback about ISO compliance, reach out to your AWS account team.
French version
La certification ISO 27001 2023 est désormais disponible en espagnol et en français et le certification ISO 22301 est désormais disponible en espagnol
Nous restons à l’écoute de nos clients, des autorités de régulation et des parties prenantes pour mieux comprendre leurs besoins en matière de programmes d’audit, d’assurance, de certification et d’attestation au sein d’Amazon Web Services (AWS). La certification ISO 27001 2023 est désormais disponible en espagnol et en français. La certification ISO 22301 2023 est également désormais disponible en espagnol. Ces certifications traduites contribueront à renforcer notre engagement et notre conformité aux exigences des clients et de la réglementation en France, en Amérique latine et en Espagne.
Les certifications traduites sont mises à la disposition des clients via AWS Artifact.
Si vous avez des commentaires sur cet article, soumettez-les dans la section Commentaires ci-dessous.
Vous souhaitez davantage de contenu, d’actualités et d’annonces sur les fonctionnalités AWS Security ? Suivez-nous sur Twitter.
Spanish version
El certificado ISO 27001 2023 ahora está disponible en Español y Francés y el certificado ISO 22301 ahora está disponible en Español
Seguimos escuchando a nuestros clientes, reguladores y partes interesadas para comprender sus necesidades en relación con los programas de auditoría, garantía, certificación y atestación en Amazon Web Services (AWS). El certificado ISO 27001 2023 ya está disponible en español y francés. Además, el certificado ISO 22301 de 2023 ahora está disponible en español. Estos certificados traducidos ayudarán a impulsar un mayor compromiso y alineación con los requisitos normativos y de los clientes en Francia, América Latina y España.
Los certificados traducidos están disponibles para los clientes en AWS Artifact.
Si tienes comentarios sobre esta publicación, envíalos en la sección Comentarios a continuación.
¿Desea obtener más noticias sobre seguridad de AWS? Síguenos en Twitter.
Our customers depend on Amazon Web Services (AWS) for their mission-critical applications and most sensitive data. Every day, the world’s fastest-growing startups, largest enterprises, and most trusted governmental organizations are choosing AWS as the place to run their technology infrastructure. They choose us because security has been our top priority from day one. We designed AWS from its foundation to be the most secure way for our customers to run their workloads, and we’ve built our internal culture around security as a business imperative.
While technical security measures are important, organizations are made up of people. A recent report from the Cyber Safety Review Board (CSRB) makes it clear that a deficient security culture can be a root cause for avoidable errors that allow intrusions to succeed and remain undetected.
Security is our top priority
Our security culture starts at the top, and it extends through every part of our organization. Over eight years ago, we made the decision for our security team to report directly to our CEO. This structural design redefined how we build security into the culture of AWS and informs everyone at the company that security is our top priority by providing direct visibility to senior leadership. We empower our service teams to fully own the security of their services and scale security best practices and programs so our customers have the confidence to innovate on AWS.
We believe that there are four key principles to building a strong culture of security:
Security is built into our organizational structure
At AWS, we view security as a core function of our business, deeply connected to our mission objectives. This goes beyond good intentions—it’s embedded directly into our organizational structure. At Amazon, we make an intentional choice for all our security teams to report directly to the CEO while also being deeply embedded in our respective business units. The goal is to build security into the structural fabric of how we make decisions. Every week, the AWS leadership team, led by our CEO, meets with my team to discuss security and ensure we’re making the right choices on tactical and strategic security issues and course-correcting when needed. We report internally on operational metrics that tie our security culture to the impact that it has on our customers, connecting data to business outcomes and providing an opportunity for leadership to engage and ask questions. This support for security from the top levels of executive leadership helps us reinforce the idea that security is accelerating our business outcomes and improving our customers’ experiences rather than acting as a roadblock.
Security is everyone’s job
AWS operates with a strong ownership model built around our culture of security. Ownership is one of our key Leadership Principles at Amazon. Employees in every role receive regular training and reinforcement of the message that security is everyone’s job. Every service and product team is fully responsible for the security of the service or capability that they deliver. Security is built into every product roadmap, engineering plan, and weekly stand-up meeting, just as much as capabilities, performance, cost, and other core responsibilities of the builder team. The best security is not something that can be “bolted on” at the end of a process or on the outside of a system; rather, security is integral and foundational.
AWS business leaders prioritize building products and services that are designed to be secure. At the same time, they strive to create an environment that encourages employees to identify and escalate potential security concerns even when uncertain about whether there is an actual issue. Escalation is a normal part of how we work in AWS, and our practice of escalation provides a “security reporting safe space” to everyone. Our teams and individuals are encouraged to report and escalate any possible security issues or concerns with a high-priority ticket to the security team. We would much rather hear about a possible security concern and investigate it, regardless of whether it is unlikely or not. Our employees know that we welcome reports even for things that turn out to be nonissues.
Distributing security expertise and ownership across AWS
Our central AWS Security team provides a number of critical capabilities and services that support and enable our engineering and service teams to fulfill their security responsibilities effectively. Our central team provides training, consultation, threat-modeling tools, automated code-scanning frameworks and tools, design reviews, penetration testing, automated API test frameworks, and—in the end—a final security review of each new service or new feature. The security reviewer is empowered to make a go or no-go decision with respect to each and every release. If a service or feature does not pass the security review process in the first review, we dive deep to understand why so we can improve processes and catch issues earlier in development. But, releasing something that’s not ready would be an even bigger failure, so we err on the side of maintaining our high security bar and always trying to deliver to the high standards that our customers expect and rely on.
One important mechanism to distribute security ownership that we’ve developed over the years is the Security Guardians program. The Security Guardians program trains, develops, and empowers service team developers in each two-pizza team to be security ambassadors, or Guardians, within the product teams. At a high level, Guardians are the “security conscience” of each team. They make sure that security considerations for a product are made earlier and more often, helping their peers build and ship their product faster, while working closely with the central security team to help ensure the security bar remains high at AWS. Security Guardians feel empowered by being part of a cross-organizational community while also playing a critical role for the team and for AWS as a whole.
Scaling security through innovation
Another way we scale security across our culture at AWS is through innovation. We innovate to build tools and processes to help all of our people be as effective as possible and maintain focus. We use artificial intelligence (AI) to accelerate our secure software development process, as well as new generative AI–powered features in Amazon Inspector, Amazon Detective, AWS Config, and Amazon CodeWhisperer that complement the human skillset by helping people make better security decisions, using a broader collection of knowledge. This pattern of combining sophisticated tooling with skilled engineers is highly effective because it positions people to make the nuanced decisions required for effective security.
For large organizations, it can take years to assess every scenario and prove systems are secure. Even then, their systems are constantly changing. Our automated reasoning tools use mathematical logic to answer critical questions about infrastructure to detect misconfigurations that could potentially expose data. This provable security provides higher assurance in the security of the cloud and in the cloud. We apply automated reasoning in key service areas such as storage, networking, virtualization, identity, and cryptography. Amazon scientists and engineers also use automated reasoning to prove the correctness of critical internal systems. We process over a billion mathematical queries per day that power AWS Identity and Access Management Access Analyzer, Amazon Simple Storage Service (Amazon S3) Block Public Access, and other security offerings. AWS is the first and only cloud provider to use automated reasoning at this scale.
Advancing the future of cloud security
At AWS, we care deeply about our culture of security. We’re consistently working backwards from our customers and investing in raising the bar on our security tools and capabilities. For example, AWS enables encryption of everything. AWS Key Management Service (AWS KMS) is the first and only highly scalable, cloud-native key management system that is also FIPS 140-2 Level 3 certified. No one can retrieve customer plaintext keys, not even the most privileged admins within AWS. With the AWS Nitro System, which is the foundation of the AWS compute service Amazon Elastic Compute Cloud (Amazon EC2), we designed and delivered first-of-a-kind and still unique in the industry innovation to maximize the security of customers’ workloads. The Nitro System provides industry-leading privacy and isolation for all their compute needs, including GPU-based computing for the latest generative AI systems. No one, not even the most privileged admins within AWS, can access a customer’s workloads or data in Nitro-based EC2 instances.
We continue to innovate on behalf of our customers so they can move quickly, securely, and with confidence to enable their businesses, and our track record in the area of cloud security is second to none. That said, cybersecurity challenges continue to evolve, and while we’re proud of our achievements to date, we’re committed to constant improvement as we innovate and advance our technologies and our culture of security.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
We continue to listen to our customers, regulators, and stakeholders to understand their needs regarding audit, assurance, certification, and attestation programs at Amazon Web Services (AWS). We are pleased to announce that for the first time an AWS System and Organization Controls (SOC) 1 report is now available in Japanese and Korean, along with Spanish. This translated report will help drive greater engagement and alignment with customer and regulatory requirements across Japan, Korea, Latin America, and Spain.
The Japanese, Korean, and Spanish language versions of the report do not contain the independent opinion issued by the auditors, but you can find this information in the English language version. Stakeholders should use the English version as a complement to the Japanese, Korean, or Spanish versions.
Going forward, the following reports in each quarter will be translated. Because the SOC 1 controls are included in the Spring and Fall SOC 2 reports, this schedule provides year-round coverage in all translated languages when paired with the English language versions.
The Winter 2023 SOC 1 report includes a total of 171 services in scope. For up-to-date information, including when additional services are added, visit the AWS Services in Scope by Compliance Program webpage and choose SOC.
AWS strives to continuously bring services into scope of its compliance programs to help you meet your architectural and regulatory needs. Please reach out to your AWS account team if you have questions or feedback about SOC compliance.
To learn more about our compliance and security programs, see AWS Compliance Programs. As always, we value your feedback and questions; reach out to the AWS Compliance team through the Contact Us page.
If you have feedback about this post, submit comments in the Comments section below.
Want more AWS Security how-to content, news, and feature announcements? Follow us onX.
Japanese version
冬季 2023 SOC 1 レポートの日本語、韓国語、スペイン語版の提供を開始
当社はお客様、規制当局、利害関係者の声に継続的に耳を傾け、Amazon Web Services (AWS) における監査、保証、認定、認証プログラムに関するそれぞれのニーズを理解するよう努めています。この度、AWS System and Organization Controls (SOC) 1 レポートが今回初めて、日本語、韓国語、スペイン語で利用可能になりました。この翻訳版のレポートは、日本、韓国、ラテンアメリカ、スペインのお客様および規制要件との連携と協力体制を強化するためのものです。
Amazon은 고객, 규제 기관 및 이해 관계자의 의견을 지속적으로 경청하여 Amazon Web Services (AWS)의 감사, 보증, 인증 및 증명 프로그램과 관련된 요구 사항을 파악하고 있습니다. 이제 처음으로 스페인어와 함께 한국어와 일본어로도 AWS System and Organization Controls(SOC) 1 보고서를 이용할 수 있게 되었음을 알려드립니다. 이 번역된 보고서는 일본, 한국, 중남미, 스페인의 고객 및 규제 요건을 준수하고 참여도를 높이는 데 도움이 될 것입니다.
보고서의 일본어, 한국어, 스페인어 버전에는 감사인의 독립적인 의견이 포함되어 있지 않지만, 영어 버전에서는 해당 정보를 확인할 수 있습니다. 이해관계자는 일본어, 한국어 또는 스페인어 버전을 보완하기 위해 영어 버전을 사용해야 합니다.
앞으로 매 분기마다 다음 보고서가 번역본으로 제공됩니다. SOC 1 통제 조치는 춘계 및 추계 SOC 2 보고서에 포함되어 있으므로, 이 일정은 영어 버전과 함께 모든 번역된 언어로 연중 내내 제공됩니다.
AWS는 고객이 아키텍처 및 규제 요구 사항을 충족할 수 있도록 지속적으로 서비스를 규정 준수 프로그램의 범위에 포함시키기 위해 노력하고 있습니다. SOC 규정 준수에 대한 질문이나 피드백이 있는 경우 AWS 계정 팀에 문의하시기 바랍니다.
규정 준수 및 보안 프로그램에 대한 자세한 내용은 AWS 규정 준수 프로그램을 참조하세요. 언제나 그렇듯이 AWS는 여러분의 피드백과 질문을 소중히 여깁니다. 문의하기 페이지를 통해 AWS 규정 준수 팀에 문의하시기 바랍니다.
이 게시물에 대한 피드백이 있는 경우, 아래의 의견 섹션에 의견을 제출해 주세요.
더 많은 AWS 보안 방법 콘텐츠, 뉴스 및 기능 발표를 원하시나요? X 에서 팔로우하세요.
Spanish version
El informe SOC 1 invierno 2023 se encuentra disponible actualmente en japonés, coreano y español
Seguimos escuchando a nuestros clientes, reguladores y partes interesadas para comprender sus necesidades en relación con los programas de auditoría, garantía, certificación y acreditación en Amazon Web Services (AWS). Nos enorgullece anunciar que, por primera vez, un informe de controles de sistema y organización (SOC) 1 de AWS se encuentra disponible en japonés y coreano, junto con la versión en español. Estos informes traducidos ayudarán a impulsar un mayor compromiso y alineación con los requisitos normativos y de los clientes en Japón, Corea, Latinoamérica y España.
Estas versiones del informe en japonés, coreano y español no contienen la opinión independiente emitida por los auditores, pero se puede acceder a esta información en la versión en inglés del documento. Las partes interesadas deben usar la versión en inglés como complemento de las versiones en japonés, coreano y español.
De aquí en adelante, los siguientes informes trimestrales estarán traducidos. Dado que los controles SOC 1 se incluyen en los informes de primavera y otoño de SOC 2, esta programación brinda una cobertura anual para todos los idiomas traducidos cuando se la combina con las versiones en inglés.
SOC 1 invierno (del 1/1 al 31/12)
SOC 2 primavera (del 1/4 al 31/3)
SOC 1 verano (del 1/7 al 30/6)
SOC 2 otoño (del 1/10 al 30/9)
Los clientes pueden descargar los informes SOC 1 invierno 2023 traducidos al japonés, coreano y español a través de AWS Artifact, un portal de autoservicio para el acceso bajo demanda a los informes de conformidad de AWS. Inicie sesión en AWS Artifact mediante la Consola de administración de AWS u obtenga más información en Introducción a AWS Artifact.
El informe SOC 1 invierno 2023 incluye un total de 171 servicios que se encuentran dentro del alcance. Para acceder a información actualizada, que incluye novedades sobre cuándo se agregan nuevos servicios, consulte los Servicios de AWS en el ámbito del programa de conformidad y seleccione SOC.
AWS se esfuerza de manera continua por añadir servicios dentro del alcance de sus programas de conformidad para ayudarlo a cumplir con sus necesidades de arquitectura y regulación. Si tiene alguna pregunta o sugerencia sobre la conformidad de los SOC, no dude en comunicarse con su equipo de cuenta de AWS.
Para obtener más información sobre los programas de conformidad y seguridad, consulte los Programas de conformidad de AWS. Como siempre, valoramos sus comentarios y preguntas; de modo que no dude en comunicarse con el equipo de conformidad de AWS a través de la página Contacte con nosotros.
Si tiene comentarios sobre esta publicación, envíelos a través de la sección de comentarios que se encuentra a continuación.
¿Quiere acceder a más contenido instructivo, novedades y anuncios de características de seguridad de AWS? Síganos en X.
As the Chief Information Security Officer (CISO) at AWS, I’m personally committed to helping security teams of all skill levels and sizes navigate security for generative artificial intelligence (AI). As a former AWS customer, I know the value of hands-on security learning and talking in-person to the people who build and run AWS security. That’s why I’m excited for you to join me at AWS re:Inforce 2024, our annual cloud security event, where you can collaborate with experts, partners, and the builders who are driving the future of security in the generative AI era.
Whether you want to build deep technical expertise, understand how to prioritize your security investments, or learn how to apply foundational security best practices, re:Inforce is a great opportunity to dive deep into the convergence of security and AI. AI and machine learning (ML) have been a focus for Amazon for more than 25 years. It’s inspiring to take advantage of and adapt to the impact generative AI is having on the world.
AWS re:Inforce isn’t just a conference—it’s a catalyst for innovation and collaboration in the realm of cloud security. This year, we’re coming together June 10–12 in Pennsylvania for 2.5 days of immersive cloud security learning designed to help drive your business initiatives. At AWS, we’ve always believed that security is a business enabler. Security reduces risk, reinforces resilience, and empowers confident innovation. Security helps organizations use new technologies such as generative AI quickly and safely, creating better experiences for customers, partners, and employees.
Here’s a bit of what you can expect:
How we secure AWS today and my vision for the future AWS re:Inforce 2024 will begin with my keynote on Tuesday, June 11, 2024 at 9:00 AM EST. By the time re:Inforce comes around, I will have been the CISO of AWS for nearly a year. It’s incredible to think about all the innovations that have happened within AWS Security during that time. You’ll hear about these innovations, what we learned from them, and how we use them to secure AWS. I’ll also share my vision for the future of AWS Security. Steve Schmidt, CSO of Amazon, will take the stage to share his thoughts on how a strong culture of security supports the safe use of generative AI.
Navigate security for generative AI and other emerging trends Now is the time for security teams to empower their builders to confidently innovate with generative AI. Be the first to hear about the latest AWS security advances around generative AI and have access to interactive sessions where you can learn how to implement AI workloads securely, explore use cases from other customers, and see demos from AWS and our partners of AI-driven security in action. Be sure to check out our Innovation Talks, where AWS security experts will give in-depth talks on essential topics including cryptography, generative AI, and building a culture of security.
This year, we’ve extended the event by half a day to give you more learning opportunities. At re:Inforce, you can personalize your agenda by choosing from more than 250 different sessions spanning data protection; identity and access management; threat detection and incident response; network and infrastructure security; governance, risk, and compliance; and application security. And we have an inspiring line-up of customer speakers this year who will share their firsthand experience innovating securely on AWS. More than 90 of our trusted security partners will also be there to help you simplify and integrate your security portfolio, and those of you looking to deepen security expertise will find more than 70 percent of re:Inforce sessions are advanced or expert level.
Take advantage of the latest innovations in AWS security You’ll hear about our latest announcements and product launches and learn how to operationalize these security innovations in over 100 interactive-format sessions. In response to customer feedback, we’ve added more interactive session formats, including chalk talks, code talks, workshops, and builders’ sessions. Don’t miss this chance to connect directly with AWS experts to learn how you can get more out of the security tools you already have.
Connect with AWS experts, partners, and your peers The opportunity to come together with other members of the security community is something that really energizes me. Coming together in person gives us all the opportunity to connect with peers, find mentors, and learn from each other. You can advance your career development goals with attendee-matchmaking tools, explore the Expo to connect with trusted partners, and join lounges and activities designed for specific interest groups in the security community.
Meet up with AWS Security Heroes, security professionals, IT leaders, educators, and developers with a shared mission to foster excellence in the practice and profession of cybersecurity and digital identity. Or, connect with members of the AWS Community Builders program, AWS technical enthusiasts and emerging thought leaders who are passionate about sharing knowledge and connecting with the security community. There’s no better opportunity to make new connections with the diverse AWS security community.
Register today with the code SECBLOfnakb to receive a limited time $150 USD discount, while supplies last.
If you’re in the first five years of your cloud security career, you might qualify for the All Builders Welcome Grant. This grant removes the financial barrier to attend AWS re:Inforce for underrepresented technologists as part of our commitment to creating a cybersecurity community that is inclusive, diverse, and equitable.
As we’ve innovated and expanded the Amazon Web Services (AWS) Cloud, we continue to prioritize making sure customers are in control and able to meet regulatory requirements anywhere they operate. With the AWS Digital Sovereignty Pledge, which is our commitment to offering all AWS customers the most advanced set of sovereignty controls and features available in the cloud, we are investing in an ambitious roadmap of capabilities for data residency, granular access restriction, encryption, and resilience. Today, I’ll focus on the resilience pillar of our pledge and share how customers are able to improve their resilience posture while meeting their digital sovereignty and resilience goals with AWS.
Resilience is the ability for any organization or government agency to respond to and recover from crises, disasters, or other disruptive events while maintaining its core functions and services. Resilience is a core component of sovereignty and it’s not possible to achieve digital sovereignty without it. Customers need to know that their workloads in the cloud will continue to operate in the face of natural disasters, network disruptions, and disruptions due to geopolitical crises. Public sector organizations and customers in highly regulated industries rely on AWS to provide the highest level of resilience and security to help meet their needs. AWS protects millions of active customers worldwide across diverse industries and use cases, including large enterprises, startups, schools, and government agencies. For example, the Swiss public transport organization BERNMOBIL improved its ability to protect data against ransomware attacks by using AWS.
Building resilience into everything we do
AWS has made significant investments in building and running the world’s most resilient cloud by building safeguards into our service design and deployment mechanisms and instilling resilience into our operational culture. We build to guard against outages and incidents, and account for them in the design of AWS services—so when disruptions do occur, their impact on customers and the continuity of services is as minimal as possible. To avoid single points of failure, we minimize interconnectedness within our global infrastructure. The AWS global infrastructure is geographically dispersed, spanning 105 Availability Zones (AZs) within 33 AWS Regions around the world. Each Region is comprised of multiple Availability Zones, and each AZ includes one or more discrete data centers with independent and redundant power infrastructure, networking, and connectivity. Availability Zones in a Region are meaningfully distant from each other, up to 60 miles (approximately 100 km) to help prevent correlated failures, but close enough to use synchronous replication with single-digit millisecond latency. AWS is the only cloud provider to offer three or more Availability Zones within each of its Regions, providing more redundancy and better isolation to contain issues. Common points of failure, such as generators and cooling equipment, aren’t shared across Availability Zones and are designed to be supplied by independent power substations. To better isolate issues and achieve high availability, customers can partition applications across multiple Availability Zones in the same Region. Learn more about how AWS maintains operational resilience and continuity of service.
Resilience is deeply ingrained in how we design services. At AWS, the services we build must meet extremely high availability targets. We think carefully about the dependencies that our systems take. Our systems are designed to stay resilient even when those dependencies are impaired; we use what is called static stability to achieve this level of resilience. This means that systems operate in a static state and continue to operate as normal without needing to make changes during a failure or when dependencies are unavailable. For example, in Amazon Elastic Compute Cloud (Amazon EC2), after an instance is launched, it’s just as available as a physical server in a data center. The same property holds for other AWS resources such as virtual private clouds (VPCs), Amazon Simple Storage Service (Amazon S3) buckets and objects, and Amazon Elastic Block Store (Amazon EBS) volumes. Learn more in our Fault Isolation Boundaries whitepaper.
Information Services Group (ISG) cited strengthened resilience when naming AWS a Leader in their recent report, Provider Lens for Multi Public Cloud Services – Sovereign Cloud Infrastructure Services (EU), “AWS delivers its services through multiple Availability Zones (AZs). Clients can partition applications across multiple AZs in the same AWS region to enhance the range of sovereign and resilient options. AWS enables its customers to seamlessly transport their encrypted data between regions. This ensures data sovereignty even during geopolitical instabilities.”
AWS empowers governments of all sizes to safeguard digital assets in the face of disruptions. We proudly worked with the Ukrainian government to securely migrate data and workloads to the cloud immediately following Russia’s invasion, preserving vital government services that will be critical as the country rebuilds. We supported the migration of over 10 petabytes of data. For context, that means we migrated data from 42 Ukraine government authorities, 24 Ukrainian universities, a remote learning K–12 school serving hundreds of thousands of displaced children, and dozens of other private sector companies.
For customers who are running workloads on-premises or for remote use cases, we offer solutions such as AWS Local Zones,AWS Dedicated Local Zones, and AWS Outposts. Customers deploy these solutions to help meet their needs in highly regulated industries. For example, to help meet the rigorous performance, resilience, and regulatory demands for the capital markets, Nasdaq used AWS Outposts to provide market operators and participants with added agility to rapidly adjust operational systems and strategies to keep pace with evolving industry dynamics.
Enabling you to build resilience into everything you do
Millions of customers trust that AWS is the right place to build and run their business-critical and mission-critical applications. We provide a comprehensive set of purpose-built resilience services, strategies, and architectural best practices that you can use to improve your resilience posture and meet your sovereignty goals. These services, strategies, and best practices are outlined in the AWS Resilience Lifecycle Framework across five stages—Set Objectives, Design and Implement, Evaluate and Test, Operate, and Respond and Learn. The Resilience Lifecycle Framework is modeled after a standard software development lifecycle, so you can easily incorporate resilience into your existing processes.
For example, you can use the AWS Resilience Hub to set your resilience objectives, evaluate your resilience posture against those objectives, and implement recommendations for improvement based on the AWS Well-Architected Framework and AWS Trusted Advisor. Within Resilience Hub, you can create and run AWS Fault Injection Service experiments, which allow you to test how your application will respond to certain types of disruptions. Recently, Pearson, a global provider of educational content, assessment, and digital services to learners and enterprises, used Resilience Hub to improve their application resilience.
Other AWS resilience services such as AWS Backup, AWS Elastic Disaster Recovery (AWS DRS), and Amazon Route53 Application Recovery Controller (Route 53 ARC) can help you quickly respond and recover from disruptions. When Thomson Reuters, an international media company that provides solutions for tax, law, media, and government to clients in over 100 countries, wanted to improve data protection and application recovery for one of its business units, they adopted AWS DRS. AWS DRS provides Thomson Reuters continuous replication, so changes they made in the source environment were updated in the disaster recovery site within seconds.
Achieve your resilience goals with AWS and our AWS Partners
AWS offers multiple ways for you to achieve your resilience goals, including assistance from AWS Partners and AWS Professional Services. AWS Resilience Competency Partners specialize in improving customers’ critical workloads’ availability and resilience in the cloud. AWS Professional Services offers Resilience Architecture Readiness Assessments, which assess customer capabilities in eight critical domains—change management, disaster recovery, durability, observability, operations, redundancy, scalability, and testing—to identify gaps and areas for improvement.
We remain committed to continuing to enhance our range of sovereign and resilient options, allowing customers to sustain operations through disruption or disconnection. AWS will continue to innovate based on customer needs to help you build and run resilient applications in the cloud to keep up with the changing world.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
This alignment with DESC requirements demonstrates our continuous commitment to adhere to the heightened expectations for CSPs. Government customers of AWS can run their applications in AWS Cloud-certified Regions with confidence.
The independent third-party auditor BSI evaluated AWS on behalf of DESC on January 23, 2024. The Certificate of Compliance that illustrates the compliance status of AWS is available through AWS Artifact. AWS Artifact is a self-service portal for on-demand access to AWS compliance reports. Sign in to AWS Artifact in the AWS Management Console, or learn more at Getting Started with AWS Artifact.
The certification includes 25 additional services in scope, for a total of 87 services. This is a 40% increase in the number of services in the Middle East (UAE) Region that are in scope of the DESC CSP certification. For up-to-date information, including when additional services are added, see the AWS Services in Scope by Compliance Program webpage and choose DESC CSP.
AWS strives to continuously bring services into the scope of its compliance programs to help you meet your architectural and regulatory needs. If you have questions or feedback about DESC compliance, reach out to your AWS account team.
To learn more about our compliance and security programs, see AWS Compliance Programs. As always, we value your feedback and questions; reach out to the AWS Compliance team through the Contact Us page.
If you have feedback about this post, submit comments in the Comments section below.
The IAR provides management and technical information security controls to help establish, implement, maintain, and continuously improve information assurance. AWS alignment with IAR requirements demonstrates our ongoing commitment to adhere to the heightened expectations for cloud service providers. As such, IAR-regulated customers can continue to use AWS services with confidence.
Independent third-party auditors from BDO evaluated AWS for the period of November 1, 2022, to October 31, 2023. The assessment report that illustrates the status of AWS compliance is available through AWS Artifact. AWS Artifact is a self-service portal for on-demand access to AWS compliance reports. Sign in to AWS Artifact in the AWS Management Console, or learn more at Getting Started with AWS Artifact.
AWS strives to continuously bring services into the scope of its compliance programs to help you meet your architectural and regulatory needs. If you have questions or feedback about IAR compliance, reach out to your AWS account team.
To learn more about our compliance and security programs, see AWS Compliance Programs. As always, we value your feedback and questions; reach out to the AWS Compliance team through the Contact Us page.
If you have feedback about this post, submit comments in the Comments section below.
Amazon Web Services (AWS) is excited to announce that AWS Wickr has achieved Federal Risk and Authorization Management Program (FedRAMP) authorization at the High impact level from the FedRAMP Joint Authorization Board (JAB).
FedRAMP is a U.S. government–wide program that promotes the adoption of secure cloud services by providing a standardized approach to security and risk assessment for cloud technologies and federal agencies.
Customers find security and control in Wickr
Wickr is an end-to-end encrypted messaging and collaboration service with features designed to help keep your communications secure, private, and compliant. Wickr protects one-to-one and group messaging, voice and video calling, file sharing, screen sharing, and location sharing with 256-bit encryption, and provides data retention capabilities.
You can create Wickr networks through the AWS Management Console. Administrative controls allow your Wickr administrators to add, remove, and invite users, and organize them into security groups to manage messaging, calling, security, and federation settings. You maintain full control over data, which includes addressing information governance polices, configuring ephemeral messaging options, and deleting credentials for lost or stolen devices.
You can log internal and external communications—including conversations with guest users, contractors, and other partner networks—in a private data store that you manage. This allows you to retain messages and files that are sent to and from your organization, to help meet requirements such as those that fall under the Federal Records Act (FRA) and the National Archives and Records Administration (NARA).
The FedRAMP milestone
In obtaining a FedRAMP High authorization, Wickr has been measured against a rigorous set of security controls, procedures, and policies established by the U.S. Federal Government, based on National Institute of Standards and Technology (NIST) standards.
“For many federal agencies and organizations, having the ability to securely communicate and share information—whether in an office or out in the field—is key to helping achieve their critical missions. AWS Wickr helps our government customers collaborate securely through messaging, calling, file and screen sharing with end-to-end encryption. The FedRAMP High authorization for Wickr demonstrates our commitment to delivering solutions that give government customers the control and confidence they need to support their sensitive and regulated workloads.” — Christian Hoff, Director, US Federal Civilian & Health at AWS
FedRAMP on AWS
AWS is continually expanding the scope of our compliance programs to help you use authorized services for sensitive and regulated workloads. We now offer 150 services that are authorized in the AWS US East/West Regions under FedRAMP Moderate authorization, and 132 services authorized in the AWS GovCloud (US) Regions under FedRAMP High authorization.
The FedRAMP High authorization of Wickr further validates our commitment at AWS to public-sector customers. With Wickr, you can combine the security of end-to-end encryption with the administrative flexibility you need to secure mission-critical communications, and keep up with recordkeeping requirements. Wickr is available under FedRAMP High in the AWS GovCloud (US-West) Region.
This whitepaper summarizes OSFI’s expectations with respect to Technology and Cyber Risk Management (OSFI Guideline B-13). It also gives OSFI-regulated institutions information that they can use to commence their due diligence and assess how to implement the appropriate programs for their use of AWS Cloud services. In subsequent versions of the whitepaper, we will provide considerations for other OSFI guidelines as applicable.
In addition to this whitepaper, AWS provides updates on the evolving Canadian regulatory landscape on the AWS Security Blog and the AWS Compliance page. Customers looking for more information on cloud-related regulatory compliance in different countries around the world can refer to the AWS Compliance Center. For additional resources or support, reach out to your AWS account manager or contact us here.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.