Post Syndicated from Derrick Stolee original https://github.blog/2021-11-10-make-your-monorepo-feel-small-with-gits-sparse-index/
One way that Git scales to the largest monorepos is the sparse-checkout feature, which allows you to focus on a subset of the files. This is supposed to make it feel like you are actually in a small repository, even though you are contributing to a large repository.
There’s only one problem: the Git index is still large in a monorepo, and users can feel it. Until now.
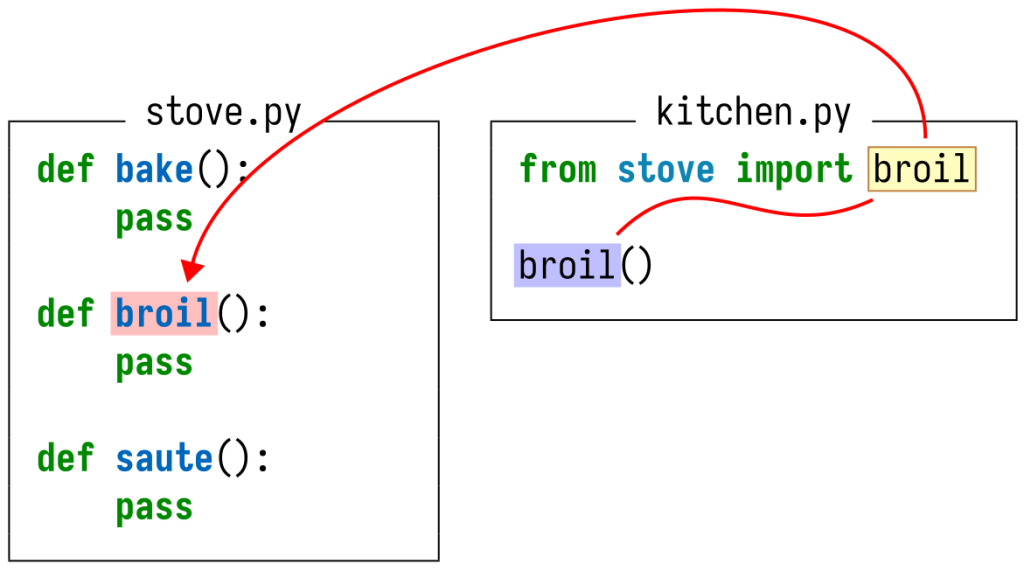
The Git index is a critical data structure in Git. It serves as the “staging area” between the files you have on your filesystem and your commit history. When you run git add, the files from your working directory are hashed and stored as objects in the index, leading them to be “staged changes”. When you run git commit, the staged changes as stored in the index are used to create that new commit. When you run git checkout, Git takes the data from a commit and writes it to the working directory and the index.

In addition to storing your staged changes, the index also stores filesystem information about your working directory. This helps Git report changed files more quickly. One problem is that the index stores this information for every file at HEAD, even if those files are outside of the sparse-checkout definition. This means that the index can be much larger in a monorepo than it would be if your important subset of files was in its own repository.
Throughout the past year, the Git Fundamentals team at GitHub contributed a new feature to Git called the sparse index, which allows the index to focus on the files within the sparse-checkout cone. If you are in a repository that can use sparse-checkout, then you can enable the sparse index using these commands:
git sparse-checkout init --cone --sparse-index
git sparse-checkout set <dir1> <dir2> ... <dirN>
The size of the sparse index will scale with the number of files within your chosen directories, instead of the full size of your repository. When enabled with a number of other performance features, this can have a dramatic performance impact.
As we built the sparse index, we tested its performance against a large monorepo that has over two million files at HEAD, and with a sparse-checkout definition that populated the working directory with about 100,000 of those files. We then compared the performance between having a normal “full” index, a sparse index, and a repository that only contained the files matching the sparse-checkout definition.

The chart above demonstrates the significant performance improvements enabled by the sparse index. The bottom bars for each Git command show the runtime without the sparse index. The middle bars show the runtime of the same commands with the sparse index enabled. The top bars show the runtime of these commands, except in a repository that only contained the files within the sparse-checkout cone, representing the theoretical optimum. Since the sparse index still contains pointers to the rest of the monorepo, there is still some overhead. This overhead is hardly noticeable, since the difference is at most 60 milliseconds, even in the worst case above.
Today, I will go deep into the design and implementation of the sparse index. In particular, I’ll focus on how the Git community made such a significant change to a critical data structure in a safe way. I will include links to the actual changes in the Git codebase as I go.
This post is going to go deep into the guts of Git. If you are unfamiliar with Git’s object model, then learn about commits, trees, and blobs before continuing.
You can also get an overview of the sparse index alongside several other advanced Git features in this presentation I gave with colleague Lessley Dennington at the GitHub Nova event.
First, let’s dig into the Git index to understand its structure and purpose. I’ll use the derrickstolee/trace2-flamechart repository as a concrete example (and to generate some of the figures). If you want to follow along with the Git commands shown, then clone that repository.
The Git index
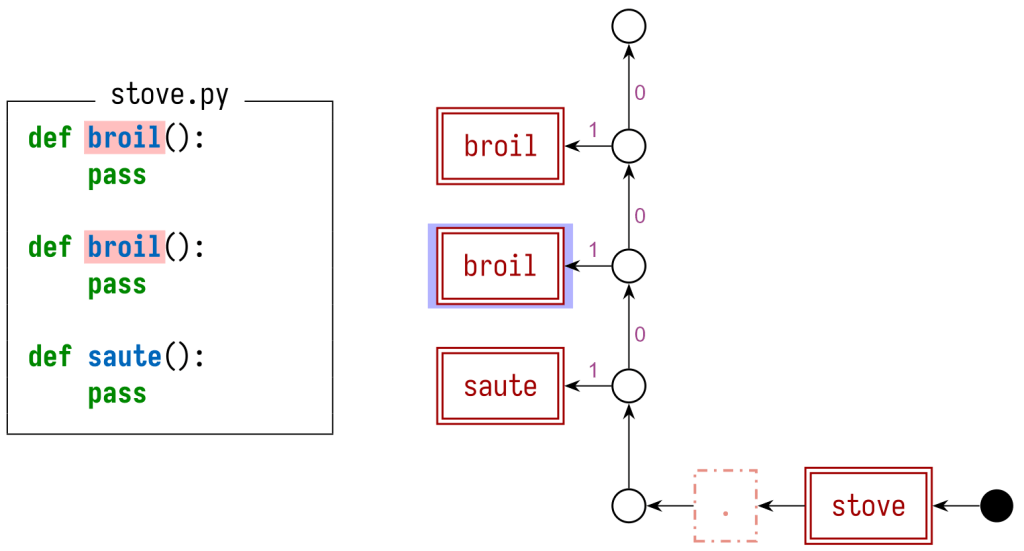
The index file stores a list of every file at HEAD, along with the object ID for its blob and some metadata. This list of files is stored as a flat list and Git parses the index into an array.
You can expose the list of files in the index using the git ls-files command:
$ git ls-files
LICENSE
README.md
bin/index.js
examples/fetch/git-fetch-after.png
examples/fetch/git-fetch-after.svg
examples/fetch/git-fetch-after.txt
examples/fetch/git-fetch-before.png
examples/fetch/git-fetch-before.svg
examples/fetch/git-fetch-before.txt
examples/fetch/git-fetch-combined.png
examples/fetch/git-fetch-combined.svg
examples/maintenance/trace.png
examples/maintenance/trace.svg
examples/maintenance/trace.txt
package.json
In this repository, many of the files live in an examples/ directory, but you don’t actually need them for the functionality of the code, which lives in the bin/ directory. You can focus the repository only on the necessary files using the git sparse-checkout command:
$ ls
LICENSE README.md bin examples package.json
$ git sparse-checkout init --cone --sparse-index
$ git sparse-checkout set bin
$ ls
LICENSE README.md bin package.json
Even though I used the sparse-checkout command to reduce the size of the working directory, my git ls-files command will return the same set of files as before. In fact, I can dig in a little more and expose some more information using git ls-files --debug.
$ git ls-files --debug
LICENSE
ctime: 1634910503:287405820
mtime: 1634910503:287405820
dev: 16777220 ino: 119325319
uid: 501 gid: 20
size: 1098 flags: 0
README.md
ctime: 1634910503:288090279
mtime: 1634910503:288090279
dev: 16777220 ino: 119325320
uid: 501 gid: 20
size: 934 flags: 0
bin/index.js
ctime: 1634910767:828434033
mtime: 1634910767:828434033
dev: 16777220 ino: 119325520
uid: 501 gid: 20
size: 7292 flags: 0
examples/fetch/git-fetch-after.png
ctime: 0:0
mtime: 0:0
dev: 0 ino: 0
uid: 0 gid: 0
size: 0 flags: 40004000
(...)
The above output is truncated, but it shows that each index entry contains additional filesystem information for each path. The last entry listed shows what happens for a file that is outside of the sparse-checkout definition: all of the filesystem information is removed and the flags entry has some bits enabled. These bits include a SKIP_WORKTREE bit that signifies that Git will not write that file to the working directory.
If these files are not written to disk, then why are they listed in the index at all? The reason is that Git still needs to understand the content that would be there if the index was expanded. Further, that information is used to generate a commit with the git commit command.
In the Git codebase, there is a test helper that can show additional information from the index: test-tool read-cache. (You won’t have this command if you just have normal Git installed.) Running it here, you can see that the index also stores the object IDs for every file:
$ test-tool read-cache --table
100644 blob 646521d0d6c070e6f15e0f5828be1127d3b75503 LICENSE
100644 blob b230b3a6e2d81d50dc00177e970a10726b5baf08 README.md
100755 blob 918533d51c7a5f91622311893dcfd40bfd4f43d7 bin/index.js
100644 blob e0f88531b916b92821476760672e8161b9954898 examples/fetch/git-fetch-after.png
100644 blob f4a523cd1acb0a9d2620970ad7a43405d6e305dc examples/fetch/git-fetch-after.svg
100644 blob fc4e30dca5fcb0c3d2031dc82a43d5d644e26b41 examples/fetch/git-fetch-after.txt
100644 blob 15dc889965617df3b5a30cf01e52c491e41c59c1 examples/fetch/git-fetch-before.png
100644 blob 602bd5bcbd815914a035d0d4f0d2a3896f600de2 examples/fetch/git-fetch-before.svg
100644 blob bc40a8e4658d17c35de996f3655e737b85ce7ad9 examples/fetch/git-fetch-before.txt
100644 blob 356cdd36e0d78a62af8b010d25d658054bb6fdc7 examples/fetch/git-fetch-combined.png
100644 blob cc0c23f2c8a822c51a17c46268f38c2268b400ae examples/fetch/git-fetch-combined.svg
100644 blob dfc0893d172d841d971e206461466db935b7c192 examples/maintenance/trace.png
100644 blob a10a876472e46c6ae58e6fc6e2adc64d4dae809b examples/maintenance/trace.svg
100644 blob 8f5e8bfbc44674feb3aa96e0b7bf1bf717495658 examples/maintenance/trace.txt
100644 blob a4599a9e0a01c28a2c0a622457664fc8c55bfdf9 package.json
Notice in particular how every single row lists the object type as blob, meaning a file. Also, the bin/index.js file has executable permissions, so the file permission column shows 100755 instead of 100644 like the others. This is all important metadata to store for each index entry.
To visualize the index, the diagram below displays our blobs as boxes in a line in the order given above, but it represents the trees that connect the root tree to those blobs as triangles. Thus, the root tree has two subtrees for bin/ and examples/, and the examples/ subtree has two subtrees for fetch/ and maintenance/.

This figure represents all of the links between the trees and blobs. However, the core index data structure stores only the list of blobs as a flat list. The nesting tree structure does not exist in the core of the file.
However, there is an extension to the format that includes the information of the nesting directories: the cache-tree extension. Each node of the cache-tree stores a list of sub-nodes and a range of index entries that are covered by the current node. Each node stores the object ID for the tree it represents.
The root node always covers all of the blobs in the index. The contained nodes have ranges contained within that range.
Git commands such as git add update the cache-tree extension in order to make the next git commit command very fast. To create the new commit, Git can use the tree from the root of the cache-tree extension.
Many Git commands use the index in many different ways. Some commands compare the working directory to the index and update one or the other when there is a difference. Others compare the index and a commit. Some compare multiple indexes together. Some use the cache-tree extension to navigate the nested tree structure, but mostly they scan the flat list of files in the form of an array.
The index can be very large in monorepos. I will show Git performance data from an example monorepo that has over two million files at HEAD. Even using the latest compression techniques available, the index file is over 180 MB in this monorepo.
This has a significant effect on normal Git commands. Presented below is an annotated flamechart of a git status command with one of these large indexes. The x-axis represents time since the start of the command, and each rectangle represents a region of Git’s execution that is marked by its trace2 logging library.

Three regions are annotated here:
- The index is read from disk and parsed into memory.
- The working directory is compared to the index. This triggers a lazy initialization of some hash tables that are required for this effort.
- The modified index is written to disk.
Parsing is multi-threaded, but writes are not. This explains some of the differences in how long those actions take.
Clearly, the amount of data in the index is a significant portion of this command. This also affects other commands such as git add and git commit, which are expected to be fast.
This performance concern became abundantly clear when our monorepo customer wanted to group more dependencies within the monorepo. Some teams had isolated Git repositories that were hundreds of times smaller than the monorepo, but these repositories created packages that were consumed by the monorepo, causing complications in tracking dependencies. The hope was that they could merge into the monorepo and rely on sparse-checkout to make it feel like they were still working in a small repository. The user experience was actually much worse, and the root cause was the time it took to read and write the index.
The main culprit is that there are millions of index entries corresponding to files these users do not care about for their daily work. When they push to the server and create a pull request, the build machines can handle the massive scale of building the entire tree and verifying that the small change works within the larger whole of the monorepo. Users should not need to pay that cost.
As members of the Git Fundamentals team, we are very focused on Git performance, and the index has been on our minds for years. For example, the index is a bottleneck for the VFS for Git environment, but that environment has particular needs that prevent improvements in this area.
The biggest thing that has changed recently is the creation of “cone mode” sparse-checkout patterns. These use directory-based pattern matching instead of file-based pattern matching. While cone mode was originally designed to speed up pattern matching in the sparse-checkout feature, it has now unlocked a new way to shrink the index.
The sparse index
The sparse index differs from a normal “full” index in one aspect: it can store directory paths with the object ID for its tree object. This is in addition to the file paths which are paired with blob objects. Since the cone mode sparse-checkout patterns match on a directory level, we can determine that an entire directory is out of the sparse-checkout cone and replace all of its contained file paths with a single directory path.
Back in my example derrickstolee/trace2-flamegraph repository, you can enable the sparse index command and then use the test-tool read-cache tool to show the contents of the index.
$ git sparse-checkout init --cone --sparse-index
$ test-tool read-cache --table
100644 blob 646521d0d6c070e6f15e0f5828be1127d3b75503 LICENSE
100644 blob b230b3a6e2d81d50dc00177e970a10726b5baf08 README.md
100755 blob 918533d51c7a5f91622311893dcfd40bfd4f43d7 bin/index.js
040000 tree b395192a7adbf21793f9489f3623c117802b2043 examples/
100644 blob a4599a9e0a01c28a2c0a622457664fc8c55bfdf9 package.json
Similar to my previous visualizations, you can now see how the index contains a directory entry in addition to the four blobs.

The sparse directory entries correspond to directories that are just outside of the sparse-checkout definition. These directories also have a cache-tree node whose range is only one entry: that sparse directory entry.
I can even display the full details of the --debug output for git ls-files. This currently requires a --sparse flag that I have implemented in my personal fork of Git, but a similar feature will eventually be available in the core Git client.
$ git ls-files --debug --sparse
LICENSE
ctime: 1634910503:287405820
mtime: 1634910503:287405820
dev: 16777220 ino: 119325319
uid: 501 gid: 20
size: 1098 flags: 200000
README.md
ctime: 1634910503:288090279
mtime: 1634910503:288090279
dev: 16777220 ino: 119325320
uid: 501 gid: 20
size: 934 flags: 200000
bin/index.js
ctime: 1634910767:828434033
mtime: 1634910767:828434033
dev: 16777220 ino: 119325520
uid: 501 gid: 20
size: 7292 flags: 200000
examples/
ctime: 0:0
mtime: 0:0
dev: 0 ino: 0
uid: 0 gid: 0
size: 0 flags: 40004000
package.json
ctime: 1634910503:288676330
mtime: 1634910503:288676330
dev: 16777220 ino: 119325321
uid: 501 gid: 20
size: 680 flags: 200000
This output is not truncated as it was before, and you can see that the sparse directory entry for examples/ is the only one with blank filesystem data. It also has the same flags value as the sparse file entries did before.
By removing the number of index entries as well as reducing the average path length, you can shrink the index size significantly. In our example monorepo, most users will reduce their index size from 180 MB to less than 10 MB!
Back to our monorepo, let’s try that git status example again and create a new flamechart. Here, I compare the flamechart for git status with a full index followed by one with a sparse index.

With the sparse index, the git status command drops from 1.3 seconds to under 200 milliseconds! In the flame chart above I highlighted some regions that have similar appearance in each run. These represent the parts of the git status command that are actually walking the working directory and doing work independent of the index size. Everything else is slower in the full index case entirely because of the size of the index!
Building the sparse index safely
Pruning the index at the directory level is a relatively simple idea with a rather complicated result: our flat list of paths now contains two types of Git objects! There are dozens of places in the Git codebase that interact directly with the index in subtly different ways, and all of them are expecting every index entry to point to a blob object.
In order to make such a change to a critical data structure, we needed to first create a compatibility layer. To safely interact with a sparse index, we needed a way to expand a sparse index to an equivalent full index. This way, code paths that have not been integrated and tested with a sparse index can still be used, even if the on-disk format is sparse.
In the Git codebase, we started by creating the ensure_full_index() method, which converts a sparse index into a full one. This method inspects the list for directory entries and replaces them with its contained file entries. Since the directory is outside of the sparse-checkout cone, we could ignore all of the filesystem metadata information and populate the list by traversing the tree objects under that directory. Before anything else happens, the ensure_full_index() method is called immediately after parsing the index so no interactions with the index happen until the sparse directories are removed.

When Git expands a sparse index to a full one, it scans the entries in lexicographic order. If the entry is a file, then Git copies it to the new list. If the entry is a directory, then the tree at that location is passed to the read_tree_at() method to iterate over all contained blobs. For each contained blob, Git generates an index entry for the corresponding file. Finally, the index entry list is copied back into the index and the index is no longer sparse.
Once that protection was in place, we extended Git to write the sparse index format. When writing the index, a full index is converted to a sparse one in-memory using the convert_to_sparse() method.

To convert from a full index to a sparse one, Git uses the cache-tree extension to find the object ID for our new sparse directory entries. The existing file entries are copied, and Git inserts the directory entries as needed.
Once these steps were built, we could verify that the index size was shrinking to the scale we expected. Both of these steps were included in a single series that introduced the format and implemented the conversions.
While it is nice that the index size has shrunk, we couldn’t stop there. The index is a very compact data structure, so it is more efficient to read it from disk than to recreate it by parsing trees. The ensure_full_index() method takes noticeably longer to expand a sparse index to a full one than it would take to read a full one from disk. In order to gain the performance benefits of a sparse index, we needed to teach Git what to do when encountering sparse directory entries.
Before embarking on these integrations, we first set up more guardrails. A new setting, command_requires_full_index, was created which is enabled by default. This setting is used to trigger ensure_full_index() upon parsing a sparse index unless the Git command being run has explicitly disabled the setting. This allowed us to integrate with Git commands one-by-one without disrupting the behavior of other Git commands. In addition to these settings, we inserted calls to ensure_full_index() before most index interactions. to make sure that we were operating on a full index in any code path that might iterate over the index entries. This allowed us to find which code paths needed integration: we could debug a Git command with a breakpoint on ensure_full_index() and see the call stack that led to that expansion.
The first command to integrate with the sparse index was git status. In hindsight, this was a challenging command to use as a starting point, because it performs multiple index operations that are common to other commands. This became clear when integrating with git checkout and git commit because most of the work was already done in the git status integration.
Let’s explore some of the smaller interactions that needed special care with directory entries.
Example implementation detail: git diff
The git diff command can show what is different between different representations of a working directory. There are two interesting cases that involve the index: comparing the working directory to the index, and comparing the index to a commit.
With no other arguments, git diff shows the differences in the working directory compared to what is staged in the index. This algorithm is mostly simple to integrate with the sparse index: while walking the working directory, Git drills into a directory only if it exists. If the sparse directory entries in the sparse index do not appear as directories in the working directory, then it never tries to drill into the sparse directory entries. If Git finds that a sparse directory entry does exist in the filesystem as a real directory, then the ensure_full_index() method expands the index and Git continues as normal. This is not desired, so we did everything possible to make sure that these directories do not exist, including updating the sparse-checkout feature to delete ignored files outside the cone.
The git diff --cached command compares the files staged in the index with the commit at HEAD. Here, it is easier to have differences outside the sparse-checkout cone, such as when using git reset --soft to change the HEAD commit without changing the working directory or index. In this case, the git diff --cached command wants to compare the root tree for the HEAD commit to the files in the index. This can proceed normally for the files that exist in the sparse index, but when we reach a sparse directory entry, we see the tree object staged in the index as well as a tree object from the tree walk. At this point, we shift from a tree-vs-index comparison to a tree-vs-tree comparison of those subtrees. When that diff is complete, we can continue with the larger comparison.
One major benefit to the tree-vs-tree comparison is that it is easier to compare the same type of objects. The recursive comparison can also prune the walk when it finds two subtrees with the same object ID, as all of their content is the same at that point.
This change allows us to report on these differences not only in the git diff command, but also such diffs as are written during git status, git checkout, and git commit.
Implementation detail: ORT merge strategy
When beginning the sparse index work, there was a huge question that we did not know how to tackle: three-way merges. The default merge strategy, recursive, uses the index as a data structure during its computation. It was going to be difficult to reconcile that algorithm to work within the confines of a sparse index. In fact, many merges that a monorepo user runs would need to resolve merges outside of the sparse-checkout cone.
Luckily, another contributor, Elijah Newren, announced that he was creating a new merge strategy, named the ORT strategy, that did not use the index. We prioritized reviewing and testing that strategy so that we could take advantage of it. It turns out that it is also a better algorithm in general, so it will become the new default strategy with Git 2.34.
The critical feature of the ORT strategy was its replacement of the index with a recursive tree-like structure. That structure is built from the root tree and only creates subtrees for paths that have changed since the merge base. At the end, the ORT strategy creates an index to match its representation of the resulting merge commit.
Because of the ORT merge strategy, integrating the sparse index into git merge, git rebase, git cherry-pick, and git revert was very simple. We just needed to make sure the index that was created at the end of the merge was sparse from its original creation.

As we reported earlier, the ORT strategy improves over the recursive strategy in the typical case, but also the recursive strategy has significant outliers as shown in the box plot above. Enabling the sparse index on top of the ORT strategy provides even more improvements.
Without the ORT merge strategy, the sparse index work could have easily doubled in scope. For a detailed look at the ORT strategy and its many optimizations, take a look at Elijah’s six-part blog series:
Testing the sparse index
The sparse index was touching critical code and doing so in interesting ways. We needed a way to carefully test that these changes were as correct as possible. The Git test suite is substantial and has excellent coverage of most index operations. However, almost all of those tests do not use sparse-checkout, so we couldn’t immediately gain value in checking the sparse index by enabling it globally.
We created a test script that focused on testing the sparse index in a new way. The test starts by creating a repository with some interesting data shapes in it. Then, each test case starts by copying that repository into three new repositories. Those three repositories have different configurations:
- The repository as-is, without sparse-checkout.
- The repository with cone mode sparse-checkout enabled.
- The repository with cone mode sparse-checkout and sparse index enabled.
Then, each test case runs a number of Git commands against all three repositories, expecting the same output and results in the working directory. This allowed us to be confident that the changes we were making to enable the sparse index would have identical behavior with the other two cases.
Along the way, we found some interesting differences between sparse-checkout and full repositories. Several of these bugs have been fixed since. Sometimes, it was unclear whether the sparse-checkout feature should do the same thing as a normal repository, specifically when interacting with files outside of the sparse-checkout cone. This led to changing how some commands interact with sparse entries. In Git 2.34, some commands will need a --sparse flag in order to modify paths outside of the sparse-checkout cone.
In addition to these test scripts, we routinely ran the Scalar functional tests against our development branches, since many of those tests focus on special circumstances around the sparse-checkout feature. If a Scalar test would fail when the Git tests did not, then we would create a similar test in Git to prevent such a bug in the future.
Once we had integrated with a core set of Git commands, we also created an experimental release that contained early versions of these integrations. We provided this version to a subset of monorepo users to evaluate the performance. We found some interesting data from some of the users, but overall the results confirmed that the sparse index was going to significantly improve the user experience in the monorepo. The most important thing we discovered is that the sparse-checkout feature should remove ignored files outside of the cone, as those files cause the sparse index to expand to a full one, negating the performance benefits. There is an additional benefit in that the working directory shrinks even more by deleting these files.
The current state of the sparse index
Not all Git commands understand the sparse index. Those that have not been integrated trigger a compatibility check that converts a sparse index into a full one during the first index read. The integrated commands are ones that have been carefully tested with the sparse index. They likely received some code updates in order to properly handle a sparse index. These integrations were dispersed across the last few Git versions, and some only exist in the microsoft/git fork until we can complete contributing them to the core Git project.

In June, Git 2.32.0 was released with an understanding of the sparse index format. In August, Git 2.33.0 included integrations with git status, git commit, and git checkout. Git 2.34.0 is slated for a November release with integrations for git add, git merge, git rebase, git cherry-pick, and git reset. In order to serve our monorepo users, we fast-tracked some integrations into a pre-release in our fork including integrations with git diff, git blame, git clean, git sparse-checkout, and git stash.
Based on our understanding of how users interact with a monorepo, the commands that are listed here are sufficient to cover almost all users’ needs. We expect that users who adopt the sparse index with these integrations will have a significantly improved experience from before. This all depends on the size of their monorepo and on the size of their sparse-checkout cone.
We will release this feature widely to our monorepo users with the sparse index on by default in the 2.34 release of our Git fork. The core Git project will keep the sparse index off by default until it has all of these features and the implementation has been stable for a few versions.
Looking to the future
At this point, we have covered all of the integrations we need to have a successful monorepo experience. There is more work to be done. In particular, we need to finish contributing the final integrations in our list. Upstream progress takes time and we are grateful for all of the feedback we have received from the community so far. There are more commands that could use integrations, as well.
For now, we are focused on ensuring that monorepo users transition to the sparse index without incident. If you are interested in the sparse index, then we believe it is in an excellent state to start using it. If you have any issues with its performance or stability, then please do not hesitate to create an issue or start a discussion. We will be there to help!
Through the sparse index, we broke through a significant barrier to monorepo scale. We continue to seek the next innovation that will help Git scale to the largest repos out there.








 Before the end of the current LTS period, you will be able to use your AWS account to complete the FreeRTOS EMP registration on the FreeRTOS console, review and agree to the associated terms and conditions, select the LTS version, and buy an annual subscription. You will then gain access to the private repository where you’ll receive .zip files containing a git repo with chosen libraries, patches, and related notifications.
Before the end of the current LTS period, you will be able to use your AWS account to complete the FreeRTOS EMP registration on the FreeRTOS console, review and agree to the associated terms and conditions, select the LTS version, and buy an annual subscription. You will then gain access to the private repository where you’ll receive .zip files containing a git repo with chosen libraries, patches, and related notifications.