I spent my summer of 2020 as an intern at Cloudflare working with the incredible research team. I had recently started my time as a PhD student at the University of Washington’s Paul G Allen School of Computer Science and Engineering working on decentralizing and securing cellular network infrastructure, and measuring the adoption of HTTPS by government websites worldwide. Here’s the story of how I ended up on Cloudflare TV talking about my award-winning research on a project I wasn’t even aware of when the pandemic hit.
Prior to the Internship
It all started before the pandemic, when I came across a job posting over LinkedIn for an internship with the research team at Cloudflare. I had been a happy user of Cloudflare’s products and services and this seemed like a very exciting opportunity to really work with them towards their mission to help build a better Internet. While working on research at UW, I came across a lot of prior research work published by the researchers at Cloudflare, and was excited to possibly be a part of the research team and interact with them. Without second thoughts, I submitted an application through LinkedIn and waited to hear back from the team.
I received a first call from a recruiter a few months later, asking me if I was still interested in the internship position, and informing me that the internships would be remote due to the pandemic. I was told that the research team was interested in interviewing me for the internship and during the call also informed about the process, which included a programming task to work with an existing open source Cloudflare project, a pair programming interview task with a member of the team, followed by phone calls with some research leads. I was extremely excited and said “Yes! I’d love to try out the interview process”.
Adding Certificate Transparency Log Scans to Scan families
Within the next few hours I received a task from Nick Sullivan with a clear problem statement to add support for producing a certificate transparency report in CFSSL, an open source project from Cloudflare which contained cfssl-scan, a tool that scanned hostnames for connectivity, TLS information, TLS session support, and PKI information (certificates). I was tasked with adding a new family of scanners to look into Certificate Transparency logs (CT Logs) and integrate the information from the CT logs into the output. After a few back and forth emails with Nick and other researchers CC’d on the email thread, I set out to work and submitted a draft detailing my design rationale, supported features and examples of how different error conditions were handled by the changes to the code.
The task was very exciting because it allowed me to gain more familiarity with Go, a language I would use even more at Cloudflare during my internship. With the task complete, I was invited for a pair programming task with Watson Ladd. We discussed my current research work at the university, the areas of research which interested me and learnt about new cool projects that Cloudflare was working on and problems they were interested in solving to help make the Internet better. We then started working on a pair programming problem and discussed the design rationale for solving the problem, extensibility, code-reuse and writing test coverage.
Soon after, I had a bunch of similar calls talking about my current research work, understanding potential research problems that Cloudflare was interested in solving before finally receiving an internship offer for the summer. Yay!
The Internship
My summer internship with Cloudflare was like none other. It all started with a seamless onboarding process with clear documentation and training. The access control for the account worked flawlessly from the first day, and I had all the tools, documentation and internal resources available to get started. However, this is where the first challenge started: there are too many interesting research problems to try and tackle! It felt like a kid at a carnival. I liked everything and wanted to try everything, but I knew, given the short duration of the internship, I had to pick one research problem which interested me. After a week of deliberation, long conversations with different researchers on the team and reading highly relevant prior research relevant in the different areas, I decided to explore and work on Oblivious DNS over HTTPS (ODoH).
Initially, I was worried about not being able to make a decision regarding which project to pursue, because the interactions with other people in Cloudflare were remote, with no in-person conversations like I’d had at other companies. I also worried this setup made me overlook something that might have been easier to discuss in person. But the team was super supportive through it and ensured that I had all the relevant information before making my decision.
Oblivious DNS over HTTPS (ODoH) is a protocol proposed at the IETF with the goal of providing privacy to the clients making DNS requests using DNS over HTTPS (DoH). Cloudflare operates a popular public recursive DNS resolver to which clients can make DNS queries. However, DNS over HTTPS (DoH) requests made by clients to the resolver leak client IP addresses despite providing a secure encrypted communication channel. While DoH enhances the security of the DNS queries and responses when used instead of the default insecure UDP based DNS requests, the leakage of client IP information could be problematic. Cloudflare maintains users’ privacy through a rigorous privacy policy, audits, and purging client information.
Along with my advisors, I spent time building interoperable versions of ODoH services, and the necessary components in Go and Rust which were experimentally deployed on cloud services for performing measurements of the protocol. Through frequent conversations, we identified interesting research questions, performed the necessary measurements, found both security and performance issues, improved our design and drove towards conclusions iteratively. Then, we worked with the help of the brilliant engineering and reliability engineering teams at Cloudflare to move the support for the protocol into production, to convince the community about the advantages and practicality of the ODoH protocol.
The interoperable implementations of the protocol were made open source. They served as a reference implementation presented during the standardization process and various presentations we made at IETF and OARC, through which we obtained valuable feedback. With all the experiments in place, we submitted our work to the proceedings of Privacy Enhancing Technologies Symposium (PETS 2021) where it was accepted and awarded the Andreas Pfitzmann best student paper.
Cloudflare strongly believes in transparency. The effects of this are visible within the company, from open and inclusive discussions about social and technological issues, to the way people across the company can collaborate and share information with the public. I was fortunate to present and share some work on ODoH on Cloudflare TV. I was definitely nervous about presenting the work on live Internet TV, but it became possible with the support and encouragement of the TV team and members of the research team.
Outside work
While the work that I did during my time as an intern at Cloudflare was exciting, it was not the only thing that kept me occupied. It was very easy to interact with engineers, designers, sales and marketing teams within the company, learn about their work, their experiences and gain an understanding of all the amazing work happening throughout the company. The internship also provided me an opportunity to engage in random engineer chats — a program which randomly matched me with other engineers, and researchers, allowing me to learn more about their work. The research team at Cloudflare operated very similarly to an academic research lab and frequently discussed papers during scheduled reading group meetings. The weekly intern hangouts allowed me to build friendships with the other interns in the team. However, not everything was rosy: it was hard to make it to all the intern hangouts, and time zone differences did add to the challenges for scheduling time to get to know the other interns.
Takeaways
Cloudflare is an incredibly transparent company built for scale, and a brilliant place to work with a lot of interesting research and engineering work that could move from prototype to production. The transparent collaboration between different teams, academia, and the shared mission to help build a better Internet make it possible to leverage the strengths of various teams, and highly motivated people to contribute to a project. In retrospect, I strongly believe that I got lucky working on a problem which interested me, and had value for Cloudflare’s mission. And while I get to write this blog post about my experience, this experience and the work I was able to do during my time at Cloudflare wouldn’t have been possible without the hundreds of motivated and brilliant people in various teams (media, content, design, legal etc.) with whom I interacted, along with the direct involvement of the research, engineering and reliability teams. The internship experience was truly humbling!
If this sort of experience interests you, and you would love to join an innovative and collaborative environment, Cloudflare Research is currently accepting applications for 2022 internships!
As part of Cloudflare’s effort to build collaborations with academia, we host research focused internships all year long. Interns collaborate cross-functionally in research projects and are encouraged to ship code and write a blog post and a peer-reviewed publication at the end of their internship. Post-internship, many of our interns have joined Cloudflare to continue their work and often connect back with their alma mater strengthening idea sharing and collaborative initiatives.
Last year, we extended the intern experience by hosting Thomas Ristenpart, Associate Professor at Cornell Tech. Thomas collaborated for half a year on a project related to password breach alerting. Based on the success of this experience we are taking a further step in creating a structured Visiting Researcher program, to broaden our capabilities and invest further on a shared motivation with academics.
Foster engagement and closer partnerships
Our current research focuses on applied cryptography, privacy, network protocols and architecture, measurement and performance evaluation, and, increasingly, distributed systems. With the Visiting Researcher program, Cloudflare aims to foster a shared motivation with academia and engage together in seeking innovative solutions to help build a better Internet in the mentioned domains.
We expect to support the operationalization of ideas that emerge in academia and put them to the test in deployable services that will be used worldwide, hence giving the opportunity to develop collaborative projects with real world applicability and also push industry forward.
About the Visiting Researcher Program
The Visiting Researcher Program is available to both postdocs and full-time faculty members who aim to collaborate primarily with Cloudflare Research for periods of three to 12 months. There are a few eligibility criteria to meet before expressing interest in the program:
Have a PhD and a well-established research track record demonstrated by peer-reviewed journal publications and conference papers.
Relevant research experience and interest in one of the research areas.
Ability to design and execute on a research agenda.
We know we will receive excellent proposals but we expect selected expressions of interest to have the potential to have a significant impact on one of the mentioned domains and reinforce the contribution to the Internet community at large. Proposals should aim at wide dissemination and have the potential to deliver value to both technical and academic communities.
You can explore more about the program on the Cloudflare Research website and learn more about Thomas Ristenpart’s experience in the next section .
The Visiting Researcher experience so far
There are a lot of potential reasons for a short-term visit in industry. For senior researchers it’s an opportunity to refresh one’s perspectives on problems observed in practice, and potentially transfer research ideas from “the lab” to products. Compared to some companies, Cloudflare’s research organization is smaller, has clear connections with product teams, and has an outsized portfolio of exciting, high-impact research projects.
As mentioned above, I joined Cloudflare in the summer of 2020, during my academic sabbatical. I worked three days a week — remotely given the COVID-19 pandemic — and spent the rest of the work week advising my academic group at Cornell. A lot of my academic research over the past few years has focused on how to improve security for password-based authentication, including developing some of the first protocols for privacy-preserving password breach alerting. I knew Cloudflare well due to its ongoing engagement with the applied cryptography community, and it made sense to visit: Cloudflare’s focus on security, privacy, and its position as a first-line of defense for millions of websites made it a unique opportunity for working on improving authentication security.
I worked directly with research engineers in the team to implement a new type of password breach alerting service, that we called Might I Get Pwned (MIGP). While it built off prior work done in academia, we encountered a number of fascinating challenges in architecting and implementing the system. We also found new opportunities for impact, realizing that the Web Application Firewall (WAF) team was simultaneously interested in breach alerting and could utilize the infrastructure we were building. Ultimately, my work contributed directly to the WAF’s breach alerting feature that launched in Spring 2021.
At the same time, being embedded at Cloudflare surfaced fascinating new research questions. At one point, the CEO asked the team about how we could handle the potential threat of hoarding attacks against Privacy Pass, a deployed cryptographic protocol that Cloudflare customers rely on to help prevent bots from mounting attacks. This led to a foundational cryptographic protocol question: can we build partially oblivious pseudorandom function protocols that match the efficiency of standard oblivious pseudorandom functions? I won’t unpack that jargon here, but for those who are curious you can check out the preprint. We ended up tackling this question as a collaboration between my academic research group, the University of Washington, and Cloudflare, culminating in a new protocol that is sure to get deployed quite widely in the years to come.
Overall, this was a hugely successful visit. I’m excited to see the Cloudflare visiting scholar program expand and develop, and would definitely recommend it to interested academics.
Express your interest
We’re very excited to have this program going forward and diversifying our collaborations with academia! You can read more about the Visiting Researcher program and send us your expression of interest through Cloudflare Research website. We are expecting to host you in early 2022!
Great technology companies build innovative products and bring them into the world; iconic technology companies change the nature of the world itself.
Cloudflare’s mission reflects our ambitions: to help build a better Internet. Fulfilling this mission requires a multifaceted approach that includes ongoing product innovation, strategic decision-making, and the audacity to challenge existing assumptions about the structure and potential of the Internet. Two years ago, Cloudflare Research was founded to explore opportunities that leverage fundamental and applied computer science research to help change the playing field.
We’re excited to share five operating principles that guide Cloudflare’s approach to applying research to help build a better Internet and five case studies that exemplify these principles. Cloudflare Research will be all over the blog for the next several days, so subscribe and follow along!
Innovation comes from all places
Innovative companies don’t become innovative by having one group of people within the company dedicated to the future; they become that way by having a culture where new ideas are free-flowing and can come from anyone. Research is most effective when it is permitted to grow beyond or outside isolated lab environments, is deeply integrated into all facets of a company’s work, and connected with the world at large. We think of our research team as a support organization dedicated to identifying and nurturing ideas that are between three and five years away.
Cloudflare Research prioritizes strong collaboration to stay on top of big questions from our product, ETI, engineering teams and industry. Within Cloudflare, we learn about problems by embedding ourselves within other teams. Externally, we invite visiting researchers and academia, sit on boards and committees, contribute to open standards design and development, attend dozens of tech conferences a year, and publish papers in conferences.
Research engineering is truly full-stack. We incubate ideas from conception to prototype through to production code. Our team employs specialists from academic and industry backgrounds and generalists that help connect ideas across disciplines. We work closely with the product and engineering organizations on graduation plans where code ownership is critical. We also hire many research interns who help evaluate and de-risk new ideas before we help build them into production systems and eventually hand them off to other teams at the company.
Research questions can come from all parts of the company and even from customers. Our collaborative approach has led to many positive outcomes for Cloudflare and the Internet at large.
Case Study #1: Password security
Several years ago, a service called Have I Been Pwned, which lets people check if their password has been compromised in a breach, started using Cloudflare to keep the site up and running under load. However, the setup also highlighted a privacy issue: Have I Been Pwned would inevitably have access to every password submitted to the service, making it a juicy target for attackers. This insight raised the question: can such a service be offered in a privacy-preserving way?
Like much of the research team’s work, the kernel of a solution came from somewhere else at the company. The first work on the problem came from members of the support engineering organization, who developed a clever solution that mostly solved the problem. However, this initial investigation outlined a deep and complex problem space that could have applications far beyond passwords. At this point, the research team got involved and reached out to experts, including Thomas Ristenpart at Cornell Tech, to help study it more deeply.
This collaboration led us down a path to devise a new protocol and publish a paper entitled Protocols for Checking Compromised Credentials at ACM CCS 2019. The paper pointed us in a direction, but a desire to take this research and make it applicable to people led us to host our first visiting researcher to help build a prototype. We found even more inspiration and support internally when we learned that another team at Cloudflare was interested in adding capabilities to the Cloudflare Web Application Firewall to detect breached passwords for customers. This team ended up helping us build the prototype and integrate it into Cloudflare’s service.
This combination of customer insight, internal alignment, and external collaboration not only resulted in a powerful and unique customer feature, but it also helped advance the state of the art in privacy-preserving technology for an essential aspect of our online lives: Authentication. We’ll be making an exciting announcement around this technology on Thursday, so stay tuned.
A question-oriented approach leads to better products
To support Cloudflare’s fast-paced roadmap, the Research team takes a question-first approach. Focusing on questions is the essence of research itself, but it’s important to recognize what that means for an industry-leading company. We never stop asking big questions about the problems our products are already solving. Changes like the move from desktop to mobile computing or the transition from on-premise security solutions to the cloud happened within a decade, so it’s important to ask questions like:
How will social and geopolitical forces changes impact the products we’re building today?
What assumptions may be present in existing systems based on the homogenous experiences of their creators?
What changes are happening in the industry that will affect the way the Internet works?
What opportunities do we see to leverage new and lower-cost hardware?
How can we scale to meet growing needs?
Are there new computing paradigms that need to be understood?
How are user expectations shifting?
Is there something we can build to help move the Internet in the right direction?
Which security or privacy risks are likely to be exacerbated in the coming years?
By focusing on broader questions and being open to answers that don’t fit within the boundaries of existing solutions, we have the opportunity to see around corners. This type of foresight helps solve more than business problems; it can help improve products and the Internet at large. These types of questions are asked across the R&D functions of the company, but research focuses on the questions that aren’t easily answered in the short-term.
Case Study #2: SSL/TLS Recommender
When Cloudflare made SSL certificates free and automatic for all customers, it was a big step towards securing the web. One of the early criticisms of Cloudflare’s SSL offerings was the so-called “mullet” critique. Cloudflare offers a mode called “Flexible SSL,” which enables encryption between the browser and Cloudflare but keeps the connection between Cloudflare and the origin site unencrypted for backward compatibility. It’s called the mullet criticism because Flexible SSL provides encryption on the front half of the connection but none on the back half.
Most security risks for online communication occur between the user and Cloudflare (at the ISP or in the coffee shop, for example), not between Cloudflare and the origin server. The customers who couldn’t enable encryption on their servers had a much better security posture with Cloudflare.
In a few isolated instances, however, a customer did not take advantage of the most secure configuration possible, which resulted in unexpected and impactful security problems. Given the non-zero risk and acknowledging this valid product critique, we asked: what could we do to improve the security posture of millions of websites?
With the help of research interns with Internet scanning and measurement expertise, we built an advanced scanning/crawling tool to see how much things could be improved. It turned out we could do a lot, so we worked with various teams across the company to connect our scanning infrastructure to Cloudflare’s product. We now offer a service to all customers called the SSL/TLS recommender that has helped thousands of customers secure their sites and trim their mullets. The underlying reason that websites don’t use encryption for parts of their backends is complex, and what makes this project a good example of asking questions in a pragmatic way is that it not only gives Cloudflare an improved product, but it gives researcher set of tools to further explore the fundamental problem.
Build the tools today to deal with the issues of tomorrow
Another critical objective of research in the Cloudflare context is to help us prepare for the unknown. We identify and solve “what-if” scenarios based on how society is changing or may change. Thousands of companies rely on our infrastructure to serve their users and meet their business needs. We are continually improving their experience by future-proofing the technology that supports them during the best of times and the potential worst of times.
To prepare, we:
Identify areas of future risk.
Explore the fundamentals of the problem.
Build expertise and validate that expertise in peer-reviewed venues.
Build operating experience with prototypes and large-scale experiments.
Build networks of relationships with those who can help in a crisis.
We would like to emulate the strategic thinking and planning required of the often unseen groups that support society — like the forestry service or a public health department. When the fire hits or the next virus arrives, we have the best chance to not only get through it but to innovate and flourish because of the mitigations put in place and the relationships built while thinking through impending challenges.
Case Study #3: IP Address Agility
One area of impending risk for the Internet is the exhaustion of IPv4 addresses. There are only around four billion potential IPv4 addresses, which is fewer than the number of humans globally, let alone the number of Internet-connected devices. We decided to examine this problem more deeply in the context of Cloudflare’s unique approach to networking.
Cloudflare’s architecture challenges several assumptions about how different aspects of the Internet relate to each other. Historically, a server IP address corresponds to a specific machine. Cloudflare’s anycast architecture and server design allow any server to serve any customer site. This architecture has allowed the service to scale in incredible ways with very little work.
This insight led us to question other fundamental assumptions about how the Internet could potentially work. If an IP address doesn’t need to correspond with a specific server, what else could we decouple from it? Could we decouple hostnames from IPs? Maybe we could! We could also frame the question negatively: what do we lose if we don’t take advantage of this decoupling? It was worth an experiment, at least.
We decided to validate this assumption empirically. We ran an experiment serving all free customers from the same IP in an entire region in a cross-organizational effort that involved the DNS team, the IP addressing team, and the edge load balancing team. The experiment proved that using a single IP for millions of services was feasible, but it also highlighted some risks. The result was a paper published in ACM SIGCOMM 2021 and a project to re-architect our authoritative DNS system to be infinitely more flexible.
Going further together
The Internet is not simply a loose federation of companies and billions of dollars of deployed hardware; it’s a network of interconnected relationships with a global societal impact. These relationships and the technical standards that govern them are the connective tissue that allows us to build important aspects of modern society on the Internet.
Millions of Internet properties use Cloudflare’s network, which serves tens of millions of requests per second. The decisions we make, and the products we release, have significant implications on the industry and billions of people. For the majority of cases, we only control one side of the Internet connection. To serve billions of users and Internet-connected devices, we are governed by and need to support protocols such as DNS, BGP, TLS, and QUIC, defined by technical standards organizations like the Internet Engineering Task Force (IETF).
Protocols evolve, and new protocols are constantly changing to serve the evolving needs of the Internet. An important part of our mission to help build a more secure, more private, more performant, and more available Internet involves taking a leadership role in shaping these protocols, deploying them at scale, and building the open-source software that implements them.
Case Study #4: Oblivious DNS
When Cloudflare launched the 1.1.1.1 recursive DNS service in 2019, privacy was again at the forefront. We offered 1.1.1.1 with a new encryption standard called DNS-over-HTTPS (DoH) to keep queries private as they travel over the Internet. However, even with DoH, a DNS query is associated with the IP address of the user who sent it. Cloudflare wrote a privacy policy and created technical measures to ensure that user IP data is only kept for a short amount of time and even engaged a top auditing firm to confirm this. But still, the question remained, could we offer the service without needing to have this privacy-sensitive information in the first place? We created the Onion Resolver to let users access the service over the Tor anonymity network, but it was extremely slow to use. Could we offer cryptographically private DNS with acceptable performance? It was an open problem.
The breakthrough came through a combination of sources. We learned about new results out of academia describing a novel proxying technique called Oblivious DNS. We also found other folks in the industry from Apple and Fastly who were working on the same problem. The resulting proposal combined Oblivious DNS and DoH into an elegant protocol called Oblivious DoH (or ODoH). ODoH was published and discussed extensively at the IETF. DNS is an especially standards-dependent protocol since different parties operate so many components of the system. ODoH adds another participant to the equation, making careful interoperability standards even more critical.
The research team took an early draft of ODoH and, with the help of an intern (whose experience on the team you’ll hear from tomorrow), we built a prototype on Cloudflare Workers. With it, we measured the performance and confirmed the viability of a large-scale ODoH deployment, leading to this paper, published at PoPETS 2021.
The results of our experimentation gave us the confidence to build a production-quality implementation. Our research engineers worked with the engineers on the resolver team to implement and launch ODoH for 1.1.1.1. We also open-sourced ODoH-related code in Go, Rust, and a Cloudflare Workers-compatible implementation. We also worked with the open source community to land the protocol in widely available tools, like dnscrypt, to help further ODoH adoption. ODoH is just one example of cross-industry work to develop standards that you’ll learn more about in an upcoming post.
From theory to practice at a global scale
There are thousands of papers published at dozens of venues every year on Internet technology. The ideas in academic research can change our fundamental understanding of the world scientifically but often haven’t impacted users yet. Innovation comes from all places, and it’s important to adopt ideas from the wider/outside community since we’re in a fortunate position to do so.
As an academic, you are rewarded for the breakthrough, not the follow-through. We value the ability to pursue, even drive, the follow-through because of the tangible improvements challenges offer to the Internet. We find that we can often learn much more about an idea by building and deploying it than by only thinking it up and writing it down. The smallest wrinkle in a lab environment or theoretical paper can become a large issue at Internet scale, and seemingly minor insights can unlock enormous potential.
We are grateful at Cloudflare to be in a rare position to leverage the diversity of the Internet to further existing research and study its real-world impact. We can bring the insights and solutions described in papers to reality because we have the insight into user behavior required to do it: right now, nearly every user on the Internet uses Cloudflare directly or indirectly.
We also have enough scale that problems that could have been solved conventionally must now use new tools. For example, cryptographic tools like identity-based encryption and zero-knowledge proofs have been around on paper for decades. They have only recently been deployed in a few live systems but are now emerging as valuable tools in the conventional Internet and have real-life impact.
Case Study #5: Cryptographic Attestation of Personhood
In Case Study #4, we explored a deep and fundamental networking question. As fun as exploring the plumbing can be, it’s also important to explore user experience questions because clients and customers can immediately feel them. A big part of Cloudflare’s value is protecting customers from bots, and one of the tools we use is the CAPTCHA. People hate CAPTCHAs. Few aspects of the web experience inspire more seething anger in the user experience than being stopped and asked to identify street signs and trucks in low-res images when trying to go to a site. Furthermore, the most common CAPTCHAs are inaccessible to many communities, including the blind and the visually impaired. The Bots team at Cloudflare has made great strides to reduce the number of CAPTCHAs shown on the server-side using machine learning (a challenging problem in itself). We decided to complement their work by asking if we could leverage accessibility on the client-side to provide equivalent protection to a CAPTCHA?
This question led us down the path to developing a new technique we call the Cryptographic Attestation of Personhood (CAP). Instead of users proving to Cloudflare that they are human by performing a human task, we could ask them to prove that they have trusted physical hardware. We identified the widely deployed WebAuthn standard to do this so that millions of users could leverage their hard security keys or the hardware biometric system built into their phones and laptops.
This project raised several exciting and profound privacy and user experience questions. With the help of a research intern experienced in anonymous authentication, we published a paper at SAC 2021 that leveraged and improved upon zero-knowledge cryptography systems to add additional privacy features to our solution. Cloudflare’s ubiquity allows us to expose millions of users to this new idea and understand how it’s understood: for example, do users think sites can collect biometrics from their users this way? We have an upcoming paper submission (with the user research team) about these user experience questions.
Some answers to these research-shaped questions are surprising, some weren’t, but in all cases, the outcome of taking a questions-oriented approach was tools for solving problems.
What to expect from the blog
As mentioned above, Cloudflare Research will be all over the Cloudflare blog in the next several days to make several announcements and share technical explainers, including:
A new landing page where you can read our research and find additional resources.
Technical deep dives into research papers and standards, including the projects referenced above (and MANY more).
Insights into our process and ways to collaborate with us.
The Raspberry Pi Foundation’s mission is to make computing and digital making accessible to all. To support young people at risk of educational disadvantage because they don’t have access to computing devices outside of school, we’ve set up the Learn at Home campaign. But access is only one part of the story. To learn more about what support these young people need across organisations and countries, we set up a panel discussion at the Tapia Celebration of Diversity in Computing conference.
The three panelists provided a stimulating discussion of some key issues in supporting young people in low-income areas in the UK, USA, and Guyana to engage with computing, and we hope their insights are of use to educators, youth workers, and organisations around the world.
The panellists and their perspectives
Our panellists represent three different countries, and all have experience of teaching in schools and/or working with young people outside of the formal education system. Because of the differences between countries in terms of access to computing, having this spread of expertise and contexts allowed the panelists to compare lessons learned in different sectors and locations.
Panelist Lenandlar Singh is a Senior Lecturer in the Department of Computer Science at the University of Guyana. In Guyana, there is a range of computing-related courses for high school students, and access to optional qualifications in computer science at A level (age 17–18).
Panelist Yolanda Payne is a Research Associate at the Constellations Center at Georgia Tech, USA. In the US, computing curricula differ across states, although there is some national leadership through associations, centres, and corporations.
Christina Watson is Assistant Director of Design at UK Youth*, UK. The UK has a mandatory computing curriculum for learners aged 5–18, although curricula vary across the four home nations (England, Scotland, Wales, Northern Ireland).
As the moderator, I posed the following three questions, which the panelists answered from their own perspectives and experiences:
What are the key challenges for young people to engage with computing in or out of school, and what have you done to overcome these challenges?
What do you see as the role of formal and non-formal learning opportunities in computing for these young people?
What have you learned that could help other people working with these young people and their communities in the future?
Similarities across contexts
One of the aspects of the discussion that really stood out was the number of similarities across the panellists’ different contexts.
The first of these similarities was the lack of access to computing amongst young people from low-income families, particularly in more rural areas, across all three countries. These access issues concerned devices and digital infrastructure, but also the types of opportunities in and out of school that young people were able to engage with.
Christina (UK) shared results from a survey conducted with Aik Saath, a youth organisation in the UK Youth network (see graphs below). The results highlighted that very few young people in low-income areas had access to their own device for online learning, and mostly their access was to a smartphone or tablet rather than a computer. She pointed out that youth organisations can struggle to provide access to computing not only due to lack of funding, but also because they don’t have secure spaces in which to store equipment.
Lenandlar (Guyana) and Christina (UK) also discussed the need to improve the digital skills and confidence of teachers and youth workers so they can support young people with their computing education. While Lenandlar spoke about recruitment and training of qualified computing teachers in Guyana, Christina suggested that it was less important for youth workers in the UK to become experts in the field and more important for them to feel empowered and confident in supporting young people to explore computing and understand different career paths. UK Youth found that partnering with organisations that provided technical expertise (such as us at the Raspberry Pi Foundation) allowed youth workers to focus on the broader support that the young people needed.
Both Yolanda (US) and Lenandlar (Guyana) discussed the restrictive nature of the computing curriculum in schools, agreeing with Christina (UK) that outside of the classroom, there was more freedom for young people to explore different aspects of computing. All three agreed that introducing more fun and relevant activities into the curriculum made young people excited about computing and reduced stereotypes and misconceptions about the discipline and career. Yolanda explained that using modern, real-life examples and role models was a key part of connecting with young people and engaging them in computing.
What can teachers do to support young people and their families?
Yolanda (US) advocated strongly for listening to students and their communities to help understand what is meaningful and relevant to them. One example of this approach is to help young people and their families understand the economics of technology, and how computing can be used to support, develop, and sustain businesses and employment in their community. As society has become more reliant on computing and technology, this can translate into real economic impact.
The panellists also discussed the importance of partnering with other education settings, with tech companies, and with non-profit organisations to provide access to equipment and opportunities for students in schools that have limited budgets and capacity for computing. These links can also highlight key role models and help to build strong relationships in the community between businesses and schools.
What is the role of non-formal settings in low-income areas?
All of the panellists agreed that non-formal settings provided opportunities for further exploration and skill development outside of a strict curriculum. Christina (UK) particularly highlighted that these settings helped support young people and families who feel left behind by the education system, allowing them to develop practical skills and knowledge that can help their whole family. She emphasised the strong relationships that can be developed in these settings and how these can provide relatable role models for young people in low-income areas.
Tips and suggestions
After the presentation, the panelists responded to the audience’s questions with some practical tips and suggestions for engaging young people in low-income communities with computing:
How do you engage young people who are non-native English speakers with mainly English computing materials?
For curriculum materials, it’s possible to use Google Translate to allow students to access them. The software is not always totally accurate but goes some way to supporting these students. You can also try to use videos that have captioning and options for non-English subtitles.
We offer translated versions of our free online projects, thanks to a community of dedicated volunteer translators from around the world. Learners can choose from up to 30 languages (as shown in the picture below).
Young people can learn about computing in their first language by using the menu on our projects site.
How do you set up partnerships with other organisations?
Follow companies on social media and share how you are using their products or tools, and how you are aligned with their goals. This can form the basis of future partnerships.
When you are actively applying for partnerships, consider the following points:
What evidence do you have that you need support from the potential partner?
What support are you asking for? This may differ across potential partners, so make sure your pitch is relevant and tailored to a specific partner.
What evidence could you use to show the impact you are already having or previous successful projects or partnerships?
Make use of our free training resources and guides
For anyone wishing to learn computing knowledge and skills, and the skills you need to teach young people in and out of school about these topics, we provide a wide range of free online training courses to cover all your needs. Educators in England can also access the free CPD that we and our consortium partners offer through the National Centre for Computing Education.
To help you support your learners in and out of school to engage with computing in ways that are meaningful and relevant for them, we recently published a guide on culturally relevant teaching.
We also support a worldwide network of volunteers to run CoderDojos, which are coding clubs for young people in local community spaces. Head over to the CoderDojo website to discover more about the free materials and help we’ve got for you.
We would like to thank our panellists Lenandlar Singh, Yolanda Payne, and Christina Watson for sharing their time and expertise, and the Tapia conference organisers for providing a great platform to discuss issues of diversity, equality, and inclusion in computing.
*UK Youth is a leading charity working across the UK with an open network of over 8000 youth organisations. The charity has influence as a sector-supporting infrastructure body, a direct delivery partner, and a campaigner for social change.
If you’ve been keeping tabs on the state of vulnerabilities, you’ve probably noticed that Microsoft Exchange has been in the news more than usual lately. Back in March 2021, Microsoft acknowledged a series of threats exploiting zero-day CVEs in on-premises instances of Exchange Server. Since then, several related exploit chains targeting Exchange have continued to be exploited in the wild.
Microsoft quicklyreleasedpatches to help security teams keep attackers out of their Exchange environments. So, what does the state of patching look like today among organizations running impacted instances of Exchange?
The answer is more mixed — and more troubling — than you’d expect.
What is Exchange, and why should you care?
Exchange is a popular email and messaging service that runs on Windows Server operating systems, providing email and calendaring services to tens of thousands of organizations. It also integrates with unified messaging, video chat, and phone services. That makes Exchange an all-in-one messaging service that can handle virtually all communication streams for an enterprise customer.
An organization’s Exchange infrastructure can contain copious amounts of sensitive business and customer information in the form of emails and a type of shared mailbox called Public Folders. This is one of the reasons why Exchange Server vulnerabilities pose such a significant threat. Once compromised, Exchange’s search mechanisms can make this data easy to find for attackers, and a robust rules engine means attackers can create hard-to-find automation that forwards data out of the organization.
An attacker who manages to get into an organization’s Exchange Server could gain visibility into their Active Directory or even compromise it. They could also steal credentials and impersonate an authentic user, making phishing and other attempts at fraud more likely to land with targeted victims.
Sizing up the threats
The credit for discovering this recent family of Exchange Server vulnerabilities goes primarily to security researcher Orange Tsai, who overviewed them in an August 2021 Black Hat talk. He cited 8 vulnerabilities, which resulted in 3 exploit chains:
ProxyLogon: This vulnerability could allow attackers to use pre-authentication server-side request forgery (SSRF) plus a post-authentication arbitrary file write, resulting in remote code execution (RCE) on the server.
ProxyOracle: With a cookie from an authenticated user (obtained through a reflected XSS link), a Padding Oracle attack could provide an intruder with plain-text credentials for the user.
ProxyShell: Using a pre-authentication access control list (ACL) bypass, a PrivEsc (not going up to become an administrator but down to a user mailbox), and a post-authentication arbitrary file write, this exploit chain could allow attackers to execute an RCE attack.
Given the sensitivity of Exchange Server data and the availability of patches and resources from Microsoft to help defend against these threats, you’d think adoption of these patches would be almost universal. But unfortunately, the picture of patching for this family of vulnerabilities is still woefully incomplete.
A patchwork of patch statuses
In Rapid7’s OCTO team, we keep tabs on the exposure for major vulnerabilities like these, to keep our customers and the security community apprised of where these threats stand and if they might be at risk. To get a good look at the patch status among Exchange Servers for this family of attack chains, we had to develop new techniques for fingerprinting Exchange versions so we could determine which specific hotfixes had been applied.
With a few tweaks, we were able to adjust our measurement approach to get a clear enough view that we can draw some strong conclusions about the patch statuses of Exchange Servers on the public-facing internet. Here’s what we found:
Out of the 306,552 Exchange OWA servers we observed, 222,145 — or 72.4% —were running an impacted version of Exchange (this includes 2013, 2016, and 2019).
Of the impacted servers, 29.08% were still unpatched for the ProxyShell vulnerability, and 2.62% were partially patched. That makes 31.7% of servers that may still be vulnerable.
To put it another, starker way: 6 months after patches have been available for the ProxyLogon family of vulnerabilities, 1 in 3 impacted Exchange Servers are still susceptible to attacks using the ProxyShell method.
When we sort this data by the Exchange Server versions that organizations are using, we see the uncertainty in patch status tends to cluster around specific versions, particularly 2013 Cumulative Update 23.
We also pulled the server header for these instances with the goal of using the version of IIS as a proxy indicator of what OS the servers may be running — and we found an alarmingly large proportion of instances that were running end-of-life servers and/or operating systems, for which Microsoft no longer issues patch updates.
That group includes the two bars on the left of this graph, which represent 2007 and 2010 Exchange Server versions: 75,300 instances of 2010 and 8,648 instances of 2007 are still running out there on the internet, roughly 27% of all instances we observed. Organizations still operating these products can count themselves lucky that ProxyShell and ProxyLogon don’t impact these older versions of Exchange (as far as we know). But that doesn’t mean those companies are out of the woods — if you still haven’t replaced Exchange Server 2010, you’re probably also doing other risky things in your environment.
Looking ahead, the next group of products that will go end-of-life are the Windows Server 2012 and 2012 R2 operating systems, represented in green and yellow, respectively, within the graph. That means 92,641 instances of Exchange — nearly a third of all Exchange Servers on the internet — will be running unsupported operating systems for which Microsoft isn’t obligated to provide security fixes after they go end-of-life in 2023.
What you can do now
It’s a matter of when, not if, we encounter the next family of vulnerabilities that lets attackers have a field day with huge sets of sensitive data like those contained in Exchange Servers. And for companies that haven’t yet patched, ProxyShell and its related attack chains are still a real threat. Here’s what you can do now to proactively mitigate these vulnerabilities.
First things first: If your organization is running one of the 1 in 3 affected instances that are vulnerable due to being unpatched, install the appropriate patch right away.
Stay current with patch updates as a routine priority. It is possible to build Exchange environments with near-100% uptimes, so there isn’t much argument to be made for foregoing critical patches in order to prevent production interruptions.
If you’re running a version of Exchange Server or Windows OS that will soon go end-of-life, start planning for how you’ll update to products that Microsoft will continue to support with patches. This way, you’ll be able to quickly and efficiently mitigate vulnerabilities that arise, before attackers take advantage of them.
If you’re already a Rapid7 customer, there’s good news: InsightVM already has authenticated scans to detect these vulnerabilities, so users of the product should already have a good sense of where their Exchange environments stand. On the offensive side, your red teams and penetration testers can highlight the risk of running vulnerable Exchange instances with modules exercising ProxyLogon and ProxyShell. And as our research team continues to develop techniques for getting this kind of detailed information about exposures, we ensure our products know about those methods so they can more effectively help customers understand their vulnerabilities.
But for all of us, these vulnerabilities are a reminder that security requires a proactive mindset — and failing to cover the basics like upgrading to supported products and installing security updates leaves organizations at risk when a particularly thorny set of attack chains rears its head.
NEVER MISS A BLOG
Get the latest stories, expertise, and news about security today.
It’s cliché to say that the Internet has undergone massive changes in the last five years. New technologies like distributed ledgers, NFTs, and cross-platform metaverses have become all the rage. Unless you happen to hang out with the Web3 community in Hong Kong, San Francisco, and London, these technologies have a high barrier to entry for the average developer. You have to understand how to run distributed nodes, set up esoteric developer environments, and keep up with the latest chains just to get your app to run. That stops today. Today you can sign up for the private beta of our Web3 product suite starting with our Ethereum and IPFS gateway.
Before we go any further, a brief introduction to blockchain (Ethereum in our example) and the InterPlanetary FileSystem (IPFS). In a Web3 setting, you can think of Ethereum as the compute layer, and IPFS as the storage layer. By leveraging decentralised ledger technology, Ethereum provides verifiable decentralised computation. Publicly available binaries, called “smart contracts”, can be instantiated by users to perform operations on an immutable set of records. This set of records is the state of the blockchain. It has to be maintained by every node on the network, so they can verify, and participate in the computation. Performing operations on a lot of data is therefore expensive. A common pattern is to use IPFS as an external storage solution. IPFS is a peer-to-peer network for storing content on a distributed file system. Content is identified by its hash, making it inexpensive to reference from a blockchain context.
Over the last four years, while we have been working to mature the technology required to provide access to Web3 services at a global scale, the idea of the Metaverse has come back into vogue. Popularized by novels like “Snowcrash,” and “Ready Player One,” the idea is a simple one. Imagine an Internet where you can hop into an app and have access to all of your favorite digital goods available for you to use regardless of where you purchased them. You could sell your work on social media without granting them a worldwide license, and the buyer could use it on their online game. The Metaverse is a place where copyright and ownership can be managed through NFTs (Non-Fungible Tokens) stored on IPFS, and accessed trustlessly through Ethereum. It is a place where everyday creators can easily monetize their content, and have it be used by everyone, regardless of platform, since content is not being stored in walled gardens but decentralised ecosystems with open standards.
This shifts the way users and content creators think about the Internet. Questions like: “Do you actually need a Model View Controller system with a server to build an application?” “What is the best way to provide consistent naming of web resources across platforms?” “Do we actually need to keep our data locked behind another company’s systems or can the end-user own their data?”. This builds different trust assumptions. Instead of trusting a single company because they are the only one to have your users’ data, trust is being built leveraging a source verifiable by all participants. This can be people you physically interact with for messaging applications, X.509 certificates logged in a public Certificate Transparency Log for websites, or public keys that interact with blockchains for distributed applications.
It’s an exciting time. Unlike the emergence of the Internet however, there are large established companies that want to control the shape and direction of Web3 and this Metaverse. We believe in a future of a decentralised and private web. An open, standards-based web independent of any one company or centralizing force. We believe that we can be one of the many technical platforms that supports Web3 and the growing Metaverse ecosystem. It’s why we are so excited to be announcing the private beta of our Ethereum and IPFS gateways. Technologies that are at the forefront of Web3 and its emerging Metaverse.
Time and time again over the last year we have been asked by our customers to support their exploration of Web3, and oftentimes their core product offering. At Cloudflare, we are committed to helping build a better Internet for everyone, regardless of their preferred tech stack. We want to be the pickaxes and shovels for everyone. We believe that Web3 and the Metaverse is not just an experiment, but an entirely new networking paradigm where many of the next multi-billion dollar businesses are going to be built. We believe that the first complete metaverse could be built entirely on Cloudflare today using systems like Ethereum, IPFS, RTC, R2 storage, and Workers. Maybe you will be the one to build it…
We are excited to be on this journey with our Web3 community members, and can’t wait to show you what else we have been working on.
Introducing the Cloudflare Web3 Gateways!
A gateway is a computer that sits between clients (such as your browser or mobile device) and a number of other systems and helps translate traffic from one protocol to another, so the systems powering an application required to handle the request can do so properly. But there are different types of gateways that exist today.
You have probably heard mention of an API gateway, which is responsible for accepting API calls inbound to an application and aggregating the appropriate services to fulfill those requests and return a proper response to the end user. You utilize gateways every time you watch Netflix! Their company leverages an API gateway to ensure the hundreds of different devices that access their streaming service can receive a successful and proper response, allowing end users to watch their shows. Gateways are a critical component of how Web3 is being enabled for every end user on the planet.
Remember that Web3 or the distributed web is a set of technologies that enables hosting of content and web applications in a serverless manner by leveraging purely distributed systems and consensus protocols. Gateways let you use these applications in your browser without having to install plugins or run separate pieces of software called nodes. The distributed web community runs into the same problem of needing a stable, reliable, and resilient method to translate HTTP requests into the correct Web3 functions or protocols.
Today, we are introducing the Cloudflare Ethereum and IPFS Gateways to help Web3 developers do what they do best, develop applications, without having to worry about also running the infrastructure required to support Ethereum (Eth) or IPFS nodes.
What’s the problem with existing Eth or IPFS Web Gateways?
Traditional web technologies such as HTTP have had decades to develop standards and best practices that make sites fast, secure, and available. These haven’t been developed on the distributed web side of the Internet, which focuses more on redundancy. We identified an opportunity to bring the optimizations and infrastructure of the web to the distributed web by building a gateway — a service that translates HTTP API calls to IPFS or Ethereum functions, while adding Cloudflare added-value services on the HTTP side. The ability for a customer to operate their entire network control layer with a single pane of glass using Cloudflare is huge. You can manage the DNS, Firewall, Load Balancing, Rate Limiting, Tunnels, and more for your marketing site, your distributed application (Dapp), and corporate security, all from one location.
For many of our customers, the existing solutions for Web3 gateway do not have a large enough network to handle the growing amount of requests within the Ethereum and IPFS networks, but more importantly do not have the degree of resilience and redundancy that businesses expect and require operating at scale. The idea of the distributed web is to do just that… stay distributed, so no single actor can control the overall market. Speed, security, and reliability are at the heart of what we do. We are excited to be part of the growing Web3 infrastructure community so that we can help Dapp developers have more choice, scalability, and reliability from their infrastructure providers.
A clear example of this is when existing gateways have an outage. With too few gateways to handle the traffic, the result of this outage is pre-process transactions falling behind the blockchain they are accessing, thus leading to increased latency for the transaction, potentially leading to it failing. Worse, when decentralised application (Dapp) developers use IPFS to power their front end, it can lead to their entire application falling over. Overall, this leads to massive amounts of frustration from businesses and end users alike — not being able to collect revenue for products or services, thus putting a portion of the business at a halt and breaking trust with end users who depend on the reliability of these services to manage their Web3 assets.
How is Cloudflare solving this problem?
We found that there was a unique opportunity in a segment of the Web3 community that closely mirrored Cloudflare’s traditional customer base: the distributed web. This segment has some major usability issues that Cloudflare could help solve around reliability, performance, and caching. Cloudflare has an advantage that no other company in this space — and very few in the industry — have: a global network. For instance, content fetched through our IPFS Gateway can be cached near users, allowing download latency in the milliseconds. Compare this with up to seconds per asset using native IPFS. This speed enables services based on IPFS to go hybrid. Content can be served over the source decentralised protocols while browsers and tools are maturing to access them, and served to regular web users through a gateway like Cloudflare. We do provide a convenient, fast and secure option to browse this distributed content.
On Ethereum, users can be categorised in two ways. Application developers that operate smart contracts, and users that want to interact with the said contracts. While smart contracts operate autonomously based on their code, users have to fetch data and send transactions. As part of the chain, smart contracts do not have to worry about the network or a user interface to be online. This is why decentralised exchanges have had the ability to operate continuously across multiple interfaces without disruptions. Users on the other hand do need to know the state of the chain, and be able to interact with it. Application developers therefore have to require the users to run an Ethereum node, or can point them to use remote nodes through a standardised JSON RPC API. This is where Cloudflare comes in. Cloudflare Ethereum gateway relies on Ethereum nodes and provides a secure and fast interface to the Ethereum network. It allows application developers to leverage Ethereum in front-facing applications. The gateway can interact with any content part of the Ethereum chain. This includes NFT contracts, DeFi exchanges, or name services like ENS.
How are the gateways doing so far?
Since our alpha release to very early customers as research experiments, we’ve seen a staggering number of customers wanting to leverage the new gateway technology and benefit from the availability, resiliency, and caching benefits of Cloudflare’s network.
Our current alpha includes companies that have raised billions of dollars in venture capital, companies that power the decentralised finance ecosystem on Ethereum, and emerging metaverses that make use of NFT technology.
In fact, we have over 2,000 customers leveraging our IPFS gateway lending to over 275TB of traffic per month. For Ethereum, we have over 200 customers transacting over 13TB, including 1.6 billion requests per month. We’ve seen extremely stable results from these customers and fully expect to see these metrics continue to ramp up as we add more customers to use this new product.
We are now very happy to announce the opening of our private beta for both the Ethereum and IPFS gateways. Sign up to participate in the private beta and our team will reach out shortly to ensure you are set up!
P.S. We are hiring for Web3! If you want to come work on it with us, check out our careers page.
By reading this, you are a participant of the web. It’s amazing that we can write this blog and have it appear to you without operating a server or writing a line of code. In general, the web of today empowers us to participate more than we could at any point in the past.
Last year, we mentioned the next phase of the Internet would be always on, always secure, always private. Today, we dig into a similar trend for the web, referred to as Web3. In this blog we’ll start to explain Web3 in the context of the web’s evolution, and how Cloudflare might help to support it.
Going from Web 1.0 to Web 2.0
When Sir Tim Berners-Lee wrote his seminal 1989 document “Information Management: A Proposal”, he outlined a vision of the “web” as a network of information systems interconnected via hypertext links. It is often assimilated to the Internet, which is the computer network it operates on. Key practical requirements for this web included being able to access the network in a decentralized manner through remote machines and allowing systems to be linked together without requiring any central control or coordination.
The original proposal for what we know as the web, fitting in one diagram – Source: w3
This vision materialized into an initial version of the web that was composed of interconnected static resources delivered via a distributed network of servers and accessed primarily on a read-only basis from the client side — “Web 1.0”. Usage of the web soared with the number of websites growing well over 1,000% in the ~2 years following the introduction of the Mosaic graphical browser in 1993, based on data from the World Wide Web Wanderer.
The early 2000s marked an inflection point in the growth of the web and a key period of its development, as technology companies that survived the dot-com crash evolved to deliver value to customers in new ways amidst heightened skepticism around the web:
Desktop browsers like Netscape became commoditized and paved the way for native web services for discovering content like search engines.
Network effects that were initially driven by hyperlinks in web directories like Yahoo! were hyperscaled by platforms that enabled user engagement and harnessed collective intelligence like review sites.
The massive volume of data generated by Internet activity and the growing realization of its competitive value forced companies to become experts at database management.
O’Reilly Media coined the concept of Web 2.0 in an attempt to capture such shifts in design principles, which were transformative to the usability and interactiveness of the web and continue to be core building blocks for Internet companies nearly two decades later.
However, in the midst of the web 2.0 transformation, the web fell out of touch with one of its initial core tenets — decentralization.
Decentralization: No permission is needed from a central authority to post anything on the web, there is no central controlling node, and so no single point of failure … and no “kill switch”! — History of the web by Web Foundation
A new paradigm for the Internet
This is where Web3 comes in. The last two decades have proven that building a scalable system that decentralizes content is a challenge. While the technology to build such systems exists, no content platform achieves decentralization at scale.
There is one notable exception: Bitcoin. Bitcoin was conceptualized in a 2008 whitepaper by Satoshi Nakamoto as a type of distributed ledger known as a blockchain designed so that a peer-to-peer (P2P) network could transact in a public, consistent, and tamper-proof manner.
That’s a lot said in one sentence. Let’s break it down by term:
A peer-to-peer network is a network architecture. It consists of a set of computers, called nodes, that store and relay information. Each node is equally privileged, preventing one node from becoming a single point of failure. In the Bitcoin case, nodes can send, receive, and process Bitcoin transactions.
A ledger is a collection of accounts in which transactions are recorded. For Bitcoin, the ledger records Bitcoin transactions.
A distributed ledger is a ledger that is shared and synchronized among multiple computers. This happens through a consensus, so each computer holds a similar replica of the ledger. With Bitcoin, the consensus process is performed over a P2P network, the Bitcoin network.
A blockchain is a type of distributed ledger that stores data in “blocks” that are cryptographically linked together into an immutable chain that preserves their chronological order. Bitcoin leverages blockchain technology to establish a shared, single source of truth of transactions and the sequence in which they occurred, thereby mitigating the double-spending problem.
Bitcoin — which currently has over 40,000 nodes in its network and processes over $30B in transactions each day — demonstrates that an application can be run in a distributed manner at scale, without compromising security. It inspired the development of other blockchain projects such as Ethereum which, in addition to transactions, allows participants to deploy code that can verifiably run on each of its nodes.
Today, these programmable blockchains are seen as ideal open and trustless platforms to serve as the infrastructure of a distributed Internet. They are home to a rich and growing ecosystem of nearly 7,000 decentralized applications (“Dapps”) that do not rely on any single entity to be available. This provides them with greater flexibility on how to best serve their users in all jurisdictions.
The web is for the end user
Distributed systems are inherently different from centralized systems. They should not be thought about in the same way. Distributed systems enable the data and its processing to not be held by a single party. This is useful for companies to provide resilience, but it’s also useful for P2P-based networks where data can stay in the hands of the participants.
For instance, if you were to host a blog the old-fashioned way, you would put up a server, expose it to the Internet (via Cloudflare 😀), et voilà. Nowadays, your blog would be hosted on a platform like WordPress, Ghost, Notions, or even Twitter. If these companies were to have an outage, this affects a lot more people. In a distributed fashion, via IPFS for instance, your blog content can be hosted and served from multiple locations operated by different entities.
Web 1.0Web 2.0Web3
Each participant in the network can choose what they host/provide and can be home to different content. Similar to your home network, you are in control of what you share, and you don’t share everything.
This is a core tenet of decentralized identity. The same cryptographic principles underpinning cryptocurrencies like Bitcoin and Ethereum are being leveraged by applications to provide secure, cross-platform identity services. This is fundamentally different from other authentication systems such as OAuth 2.0, where a trusted party has to be reached to assess one’s identity. This materializes in the form of “Login with <Big Cloud provider>” buttons. These cloud providers are the only ones with enough data, resources, and technical expertise.
In a decentralised web, each participant holds a secret key. They can then use it to identify each other. You can learn about this cryptographic system in a previous blog. In a Web3 setting where web participants own their data, they can selectively share these data with applications they interact with. Participants can also leverage this system to prove interactions they had with one another. For example, if a college issues you a Decentralized Identifier (DID), you can later prove you have been registered at this college without reaching out to the college again. Decentralized Identities can also serve as a placeholder for a public profile, where participants agree to use a blockchain as a source of trust. This is what projects such as ENS or Unlock aim to provide: a way to verify your identity online based on your control over a public key.
This trend of proving ownership via a shared source of trust is key to the NFT craze. We have discussed NFTs before on this blog. Blockchain-based NFTs are a medium of conveying ownership. Blockchain enables this information to be publicly verified and updated. If the blockchain states a public key I control is the owner of an NFT, I can refer to it on other platforms to prove ownership of it. For instance, if my profile picture on social media is a cat, I can prove the said cat is associated with my public key. What this means depends on what I want to prove, especially with the proliferation of NFT contracts. If you want to understand how an NFT contract works, you can build your own.
How does Cloudflare fit in Web3?
Decentralization and privacy are challenges we are tackling at Cloudflare as part of our mission to help build a better Internet.
In a previous post, Nick Sullivan described Cloudflare’s contributions to enabling privacy on the web. We launched initiatives to fix information leaks in HTTPS through Encrypted Client Hello (ECH), make DNS even more private by supporting Oblivious DNS-over-HTTPS (ODoH), and develop OPAQUE which makes password breaches less likely to occur. We have also released our data localization suite to help businesses navigate the ever evolving regulatory landscape by giving them control over where their data is stored without compromising performance and security. We’ve even built a privacy-preserving attestation that is based on the same zero-knowledge proof techniques that are core to distributed systems such as ZCash and Filecoin.
It’s exciting to think that there are already ways we can change the web to improve the experience for its users. However, there are some limitations to build on top of the exciting infrastructure. This is why projects such as Ethereum and IPFS build on their own architecture. They are still relying on the Internet but do not operate with the web as we know it. To ease the transition, Cloudflare operates distributed web gateways. These gateways provide an HTTP interface to Web3 protocols: Ethereum and IPFS. Since HTTP is core to the web we know today, distributed content can be accessed securely and easily without requiring the user to operate experimental software.
Where do we go next?
The journey to a different web is long but exciting. The infrastructure built over the last two decades is truly stunning. The Internet and the web are now part of 4.6 billion people’s lives. At the same time, the top 35 websites had more visits than all others (circa 2014). Users have less control over their data and are even more reliant on a few players.
The early Web was static. Then Web 2.0 came to provide interactiveness and service we use daily at the cost of centralisation. Web3 is a trend that tries to challenge this. With distributed networks built on open protocols, users of the web are empowered to participate.
At Cloudflare, we are embracing this distributed future. Applying the knowledge and experience we have gained from running one of the largest edge networks, we are making it easier for users and businesses to benefit from Web3. This includes operating a distributed web product suite, contributing to open standards, and moving privacy forward.
If you would like to help build a better web with us, we are hiring.
Cloudflare’s journey with IPFS started in 2018 when we announced a public gateway for the distributed web. Since then, the number of infrastructure providers for the InterPlanetary FileSystem (IPFS) has grown and matured substantially. This is a huge benefit for users and application developers as they have the ability to choose their infrastructure providers.
Today, we’re excited to announce new secure filtering capabilities in IPFS. The Cloudflare IPFS module is a tool to protect users from threats like phishing and ransomware. We believe that other participants in the network should have the same ability. We are releasing that software as open source, for the benefit of the entire community.
Before we get to understand how IPFS filtering works, we need to dive a little deeper into the operation of an IPFS node.
The InterPlanetary FileSystem (IPFS) is a peer-to-peer network for storing content on a distributed file system. It is composed of a set of computers called nodes that store and relay content using a common addressing system.
Nodes communicate with each other over the Internet using a Peer-to-Peer (P2P) architecture, preventing one node from becoming a single point of failure. This is even more true given that anyone can operate a node with limited resources. This can be light hardware such as a Raspberry Pi, a server at a cloud provider, or even your web browser.
This creates a challenge since not all nodes may support the same protocols, and networks may block some types of connections. For instance, your web browser does not expose a TCP API and your home router likely doesn’t allow inbound connections. This is where libp2p comes to help.
libp2p is a modular system of protocols, specifications, and libraries that enable the development of peer-to-peer network applications – libp2p documentation
That’s exactly what four IPFS nodes need to connect to the IPFS network. From a node point of view, the architecture is the following:
Any node that we maintain a connection with is a peer. A peer that does not have 🐱 content can ask their peers, including you, they WANT🐱. If you do have it, you will provide the 🐱 to them. If you don’t have it, you can give them information about the network to help them find someone who might have it. As each node chooses the resources they store, it means some might be stored on a limited number of nodes.
For instance, everyone likes 🐱, so many nodes will dedicate resources to store it. However, 🐶 is less popular. Therefore, only a few nodes will provide it.
This assumption does not hold for public gateways like Cloudflare. A gateway is an HTTP interface to an IPFS node. On our gateway, we allow a user of the Internet to retrieve arbitrary content from IPFS. If a user asks for 🐱, we provide 🐱. If they ask for 🐶, we’ll find 🐶 for them.
Cloudflare’s IPFS gateway is simply a cache in front of IPFS. Cloudflare does not have the ability to modify or remove content from the IPFS network. However, IPFS is a decentralized and open network, so there is the possibility of users sharing threats like phishing or malware. This is content we do not want to provide to the P2P network or to our HTTP users.
In the next section, we describe how an IPFS node can protect its users from such threats.
If you would like to learn more about the inner workings of libp2p, you can go to ProtoSchool which has a great tutorial about it.
How IPFS filtering works
As we described earlier, an IPFS node provides content in two ways: to its peers through the IPFS P2P network and to its users via an HTTP gateway.
Filtering content of the HTTP interface is no different from the current protection Cloudflare already has in place. If 🐶 is considered malicious and is available at cloudflare-ipfs.com/ipfs/🐶, we can filter these requests, so the end user is kept safe.
The P2P layer is different. We cannot filter URLs because that’s not how the content is requested. IPFS is content-addressed. This means that instead of asking for a specific location such as cloudflare-ipfs.com/ipfs/🐶, peers request the content directly using its Content IDentifiers (CID), 🐶.
More precisely, 🐶 is an abstraction of the content address. A CID looks like QmXnnyufdzAWL5CqZ2RnSNgPbvCc1ALT73s6epPrRnZ1Xy (QmXnnyufdzAWL5CqZ2RnSNgPbvCc1ALT73s6epPrRnZ1Xy happens to be the hash of a .txt file containing the string “I’m trying out IPFS”). CID is a convenient way to refer to content in a cryptographically verifiable manner.
This is great, because it means that when peers ask for malicious 🐶 content, we can prevent our node from serving it. This includes both the P2P layer and the HTTP gateway.
In addition, the working of IPFS makes it, so content can easily be reused. On directories for instance, the address is a CID based on the CID of its files. This way, a file can be shared across multiple directories, and still be referred to by the same CID. It allows IPFS nodes to efficiently store content without duplicating it. This can be used to share docker container layers for example.
In the filtering use case, it means that if 🐶 content is included in other IPFS content, our node can also prevent content linking to malicious 🐶 content from being served. This results in 😿, a mix of valid and malicious content.
By now, you should have an understanding of how an IPFS node retrieves and provides content, as well as how we can protect peers and users from shared nodes accessing threats. Using this knowledge, Cloudflare went on to implement IPFS Safemode, a node protection layer on top of go-ipfs. It is up to every node operator to build their own list of threats to be blocked based on their policy.
Et voilà. You are ready to use your IPFS node, with safemode capabilities.
# alias ipfs command to make it easier to use
alias ipfs=’./cmd/ipfs/ipfs’
# run an ipfs daemon
ipfs daemon &
# understand how to use IPFS safemode
ipfs safemode --help
USAGE
ipfs safemode - Interact with IPFS Safemode to prevent certain CIDs from being provided.
...
Going further
IPFS nodes are running in a diverse set of environments and operated by parties at various scales. The same software has to accommodate configuration in which it is accessed by a single-user, and others where it is shared by thousands of participants.
At Cloudflare, we believe that decentralization is going to be the next major step for content networks, but there is still work to be done to get these technologies in the hands of everyone. Content filtering is part of this story. If the community aims at embedding a P2P node in every computer, there needs to be ways to prevent nodes from serving harmful content. Users need to be able to give consent on the content they are willing to serve, and the one they aren’t.
By providing an IPFS safemode tool, we hope to make this protection more widely available.
Between September 2021 and March 2022, we’re partnering with The Alan Turing Institute to host speakers from the UK, Finland, Germany, and the USA presenting a series of free research seminars about AI and data science education for young people. These rapidly developing technologies have a huge and growing impact on our lives, so it’s important for young people to understand them both from a technical and a societal perspective, and for educators to learn how to best support them to gain this understanding.
In our first seminar we were beyond delighted to hear from Dr Mhairi Aitken, Ethics Fellow at The Alan Turing Institute. Mhairi is a sociologist whose research examines social and ethical dimensions of digital innovation, particularly relating to uses of data and AI. You can catch up on her full presentation and the Q&A with her in the video below.
Why we need AI ethics
The increased use of AI in society and industry is bringing some amazing benefits. In healthcare for example, AI can facilitate early diagnosis of life-threatening conditions and provide more accurate surgery through robotics. AI technology is also already being used in housing, financial services, social services, retail, and marketing. Concerns have been raised about the ethical implications of some aspects of these technologies, and Mhairi gave examples of a number of controversies to introduce us to the topic.
“Ethics considers not what we can do but rather what we should do — and what we should not do.”
Mhairi Aitken
One such controversy in England took place during the coronavirus pandemic, when an AI system was used to make decisions about school grades awarded to students. The system’s algorithm drew on grades awarded in previous years to other students of a school to upgrade or downgrade grades given by teachers; this was seen as deeply unfair and raised public consciousness of the real-life impact that AI decision-making systems can have.
An AI system was used in England last year to make decisions about school grades awarded to students — this was seen as deeply unfair.
Another high-profile controversy was caused by biased machine learning-based facial recognition systems and explored in Shalini Kantayya’s documentary Coded Bias. Such facial recognition systems have been shown to be much better at recognising a white male face than a black female one, demonstrating the inequitable impact of the technology.
What should AI be used for?
There is a clear need to consider both the positive and negative impacts of AI in society. Mhairi stressed that using AI effectively and ethically is not just about mitigating negative impacts but also about maximising benefits. She told us that bringing ethics into the discussion means that we start to move on from what AI applications can do to what they should and should not do. To outline how ethics can be applied to AI, Mhairi first outlined four key ethical principles:
Beneficence (do good)
Nonmaleficence (do no harm)
Autonomy
Justice
Mhairi shared a number of concrete questions that ethics raise about new technologies including AI:
How do we ensure the benefits of new technologies are experienced equitably across society?
Do AI systems lead to discriminatory practices and outcomes?
Do new forms of data collection and monitoring threaten individuals’ privacy?
Do new forms of monitoring lead to a Big Brother society?
To what extent are individuals in control of the ways they interact with AI technologies or how these technologies impact their lives?
How can we protect against unjust outcomes, ensuring AI technologies do not exacerbate existing inequalities or reinforce prejudices?
How do we ensure diverse perspectives and interests are reflected in the design, development, and deployment of AI systems?
Who gets to inform AI systems? The kangaroo metaphor
To mitigate negative impacts and maximise benefits of an AI system in practice, it’s crucial to consider the context in which the system is developed and used. Mhairi illustrated this point using the story of an autonomous vehicle, a self-driving car, developed in Sweden in 2017. It had been thoroughly safety-tested in the country, including tests of its ability to recognise wild animals that may cross its path, for example elk and moose. However, when the car was used in Australia, it was not able to recognise kangaroos that hopped into the road! Because the system had not been tested with kangaroos during its development, it did not know what they were. As a result, the self-driving car’s safety and reliability significantly decreased when it was taken out of the context in which it had been developed, jeopardising people and kangaroos.
Mitigating negative impacts and maximising benefits of AI systems requires actively involving the perspectives of groups that may be affected by the system — ‘kangoroos’ in Mhairi’s metaphor.
Mhairi used the kangaroo example as a metaphor to illustrate ethical issues around AI: the creators of an AI system make certain assumptions about what an AI system needs to know and how it needs to operate; these assumptions always reflect the positions, perspectives, and biases of the people and organisations that develop and train the system. Therefore, AI creators need to include metaphorical ‘kangaroos’ in the design and development of an AI system to ensure that their perspectives inform the system. Mhairi highlighted children as an important group of ‘kangaroos’.
AI in children’s lives
AI may have far-reaching consequences in children’s lives, where it’s being used for decision-making around access to resources and support. Mhairi explained the impact that AI systems are already having on young people’s lives through these systems’ deployment in children’s education, in apps that children use, and in children’s lives as consumers.
AI systems are already having an impact on children’s lives.
Children can be taught not only that AI impacts their lives, but also that it can get things wrong and that it reflects human interests and biases. However, Mhairi was keen to emphasise that we need to find out what children know and want to know before we make assumptions about what they should be taught. Moreover, engaging children in discussions about AI is not only about them learning about AI, it’s also about ethical practice: what can people making decisions about AI learn from children by listening to their views and perspectives?
AI research that listens to children
UNICEF, the United Nations Children’s Fund, has expressed concerns about the impact of new AI technologies used on children and young people. They have developed the UNICEF Requirements for Child-Centred AI.
UNICEF’s requirements for child-centred AI, as presented by Mhairi. Click to enlarge.
Together with UNICEF, Mhairi and her colleagues working on the Ethics Theme in the Public Policy Programme at The Alan Turing Institute are engaged in new research to pilot UNICEF’s Child-Centred Requirements for AI, and to examine how these impact public sector uses of AI. A key aspect of this research is to hear from children themselves and to develop approaches to engage children to inform future ethical practices relating to AI in the public sector. The researchers hope to find out how we can best engage children and ensure that their voices are at the heart of the discussion about AI and ethics.
We all learned a tremendous amount from Mhairi and her work on this important topic. After her presentation, we had a lively discussion where many of the participants relayed the conversations they had had about AI ethics and shared their own concerns and experiences and many links to resources. The Q&A with Mhairi is included in the video recording.
What we love about our research seminars is that everyone attending can share their thoughts, and as a result we learn so much from attendees as well as from our speakers!
It’s impossible to cover more than a tiny fraction of the seminar here, so I do urge you to take the time to watch the seminar recording. You can also catch up on our previous seminars through our blogs and videos.
Join our next seminar
We have six more seminars in our free series on AI, machine learning, and data science education, taking place every first Tuesday of the month. At our next seminar on Tuesday 5 October at 17:00–18:30 BST / 12:00–13:30 EDT / 9:00–10:30 PDT / 18:00–19:30 CEST, we will welcome Professor Carsten Schulte, Yannik Fleischer, and Lukas Höper from the University of Paderborn, Germany, who will be presenting on the topic of teaching AI and machine learning (ML) from a data-centric perspective (find out more here). Their talk will raise the questions of whether and how AI and ML should be taught differently from other themes in the computer science curriculum at school.
Sign up now and we’ll send you the link to join on the day of the seminar — don’t forget to put the date in your diary.
Much ado has been made (by this very author on this very blog!) about the incentives for attackers and defenders around ransomware. There is also a wealth of information on the internet about how to protect yourself from ransomware. One thing we want to avoid losing sight of, however, is just how we go from a machine that is working perfectly fine to one that is completely inoperable due to ransomware. We’ll use MITRE’s ATT&CK as a vague guide, but we don’t follow it exactly.
If you’re running an Exchange server, please stop reading this blog and go patch right away.
When a widely exploitable vulnerability is available, ransomware actors will target it — no matter who you are.
Highly targeted attacks have certainly leveraged ransomware, but for nearly all of these actors, the goal is profit. That means widespread scanning for and exploitation of server-side vulnerabilities that allow for initial access, coupled with tools for privilege escalation and lateral movement. It also means the use of watering hole attacks, exploit kits, and spam campaigns.
That is to say, there are a few ways the initial access to a particular machine can come about, including through:
Server-side vulnerability
Lateral movement
Watering hole or exploit kit
Spam or phishing
The particular method tends to be subject to the availability of widely exploitable vulnerabilities and the preferences of the cybercrime group in question.
Droppers
The overwhelming majority of ransomware operators don’t directly drop the ransomware payload on a victim machine. Instead, the first stage tends to be something like TrickBot, Qbot, Dridex, Ursnif, BazarLoader, or some other dropper. Upon execution, the dropper will often disable detection and response software, extract credentials for lateral movement, and — crucially — download the second-stage payload.
This all happens quietly, and the second-stage payload may not be dropped immediately. In some cases, the dropper will drop a second-stage payload which is not ransomware — something like Cobalt Strike. This tends to happen more frequently in larger organizations, where the potential payoff is much greater. When something that appears to be a home computer is infected, actors will typically quickly encrypt the machine, demand a payment that they expect to be paid, and move on with their day.
Once the attacker has compromised to their heart’s content — one machine, one subnet, or every machine at an organization — they pull the trigger on the ransomware.
How ransomware works
By this point, nearly every security practitioner and many laypeople have a conceptual understanding of the mechanics of ransomware: A program encrypts some or all of your files, displays a message demanding payment, and (usually) sends a decryption key when the ransom is paid. But under the hood, how do these things happen? Once the dropper executes the ransomware, how does it work?
Launching the executable
The dropper will launch the executable. Typically, once it has achieved persistence and escalated privileges, the ransomware will either be injected into a running process or executed as a DLL. After successful injection or execution, the ransomware will build its imports and kill processes that could stop it. Many ransomware families will also delete all shadow copies and possible backups to maximize the damage.
The key
The first step of the encryption process is getting a key to actually encrypt the files with. Older and less advanced ransomware families will first reach out to a command and control server to request a key. Others come with built-in secret keys — these are typically easy to decrypt, with the right decrypter. Others still will use RSA or some other public key encryption so that no key needs to be imported. Many advanced families of ransomware today use both symmetric key encryption for speed and public key encryption to prevent defenders from intercepting the symmetric key.
For these modern families, an RSA public key is embedded in the executable, and an AES key is generated on the victim machine. Then, the files are encrypted using AES, and the key is encrypted using the RSA public key. Therefore, if a victim pays the ransom, they’re paying for the private key to decrypt the key that was used to encrypt all of their files.
Encryption
Once the right key is in place, the ransomware begins encryption of the filesystem. Sometimes, this is file-by-file. In other cases, they encrypt blocks of bytes on the system directly. In both cases, the end result is the same — an encrypted filesystem and a ransom note requesting payment for the decryption key.
Payment and decryption
The typical “business” transaction involves sending a certain amount of bitcoin to a specified wallet and proof of payment. Then, the hackers provide their private key and a decryption utility to the victim. In most cases, the attackers actually do follow through on giving decryption keys, though we have recently seen a rise in double encryption, where two payments need to be made.
Once the ransom is paid and the files are decrypted, the real work begins.
Recovery
Recovering encrypted files is an important part of the ransomware recovery process, and whether you pay for decryption, use an available decrypter, or some other method, there’s a catch to all of it. The attackers can still be in your environment.
As mentioned, in all but the least interesting cases (one machine on one home network), attackers are looking for lateral movement, and they’re looking to establish persistence. That means that even after the files have been decrypted, you will need to scour your entire environment for residual backdoors, cobalt strike deployments, stolen credentials, and so on. A full-scale incident response is warranted.
Even beyond the cost of paying the ransom, this can be an extremely expensive endeavor. Reimaging systems, resetting passwords throughout an organization, and performing threat hunting is a lot of work, but it’s necessary. Ultimately, failing to expunge the attacker from all of your systems means that if they want to double dip on your willingness to pay (especially if you paid them!), they just have to walk through the back door.
Proactive ransomware defense
Ransomware is a popular tactic for cybercrime organizations and shows no signs of slowing down. Unlike intellectual property theft or other forms of cybercrime, ransomware is typically an attack of opportunity and is therefore a threat to organizations of all sizes and industries. By understanding the different parts of the ransomware killchain, we can identify places to plug into the process and mitigate the issue.
Patching vulnerable systems and knowing your attack surface is a good first step in this process. Educating your staff on phishing emails, the threats of enabling macros, and other security knowledge can also help prevent the initial access.
The use of two-factor authentication, disabling of unnecessary or known-insecure services, and other standard hardening measures can help limit the spread of lateral movement. Additionally, having a security program that identifies and responds to threats in your environment is crucial for controlling the movement of attackers.
Having off-site backups is a really important step in this process as well. Between double extortion and the possibility that the group that attacked your organization and encrypted your files just isn’t an honest broker, there are many ways that things could go wrong after you’ve decided to pay the ransom. This can also make the incident response process easier, since the backup images themselves can be checked for signs of intrusion.
NEVER MISS A BLOG
Get the latest stories, expertise, and news about security today.
Our own wvu along with Jang added a module that exploits an OGNL injection (CVE-2021-26804)in Atlassian Confluence’s WebWork component to execute commands as the Tomcat user. CVE-2021-26804 is a critical remote code execution vulnerability in Confluence Server and Confluence Data Center and is actively being exploited in the wild. Initial discovery of this exploit was by Benny Jacob (SnowyOwl).
More Enhancements
In addition to the module, we would like to highlight some of the enhancements that have been added for this release. Contributor e2002e added the OUTFILE and DATABASE options to the zoomeye_search module allowing users to save results to a local file or local database along with improving the output of the module to provide better information about the target. Our own dwelch-r7 has added support for fully interactive shells against Linux environments with shell -it. In order to use this functionality, users will have to enable the feature flag with features set fully_interactive_shells true. Contributor pingport80 has added powershell support for write_file method that is binary safe and has also replaced explicit cat calls with file reads from the file library to provide broader support.
#15278 from e2002e – The zoomeye_search module has been enhanced to add the OUTFILE and DATABASE options, which allow users to save results to a local file or to the local database respectively. Additionally the output saved has been improved to provide better information about the target and additional error handling has been added to better handle potential edge cases.
#15522 from dwelch-r7 – Adds support for fully interactive shells against Linux environments with shell -it. This functionality is behind a feature flag and can be enabled with features set fully_interactive_shells true
#15560 from pingport80 – This PR add powershell support for write_file method that is binary safe.
#15627 from pingport80 – This PR removes explicit cat calls and replaces them with file reads from the file library so that they have broader support.
Bugs fixed
#15634 from maikthulhu – This PR fixes an issue in exploit/multi/misc/erlang_cookie_rce where a missing bitwise flag caused the exploit to fail in some circumstances.
#15636 from adfoster-r7 – Fixes a regression in datastore serialization that caused some event processing to fail.
#15637 from adfoster-r7 – Fixes a regression issue were Metasploit incorrectly marked ipv6 address as having an ‘invalid protocol’
#15639 from gwillcox-r7 – This fixes a bug in the rename_files method that would occur when run on a non-Windows shell session.
#15640 from adfoster-r7 – Updates modules/auxiliary/gather/office365userenum.py to require python3
#15652 from jmartin-r7 – A missing dependency, py3-pip, was preventing certain external modules such as auxiliary/gather/office365userenum from working due to requests requiring py3-pip to run properly. This has been fixed by updating the Docker container to install the missing py3-pip dependency.
#15654 from space-r7 – A bug has been fixed in lib/msf/core/payload/windows/encrypted_reverse_tcp.rb whereby a call to recv() was not being passed the proper arguments to receive the full payload before returning. This could result in cases where only part of the payload was received before continuing, which would have resulted in a crash. This has been fixed by adding a flag to the recv() function call to ensure it receives the entire payload before returning.
#15655 from adfoster-r7 – This cleans up the MySQL client-side options that are used within the library code.
Get it
As always, you can update to the latest Metasploit Framework with msfupdate
and you can get more details on the changes since the last blog post from
GitHub:
If you are a git user, you can clone the Metasploit Framework repo (master branch) for the latest.
To install fresh without using git, you can use the open-source-only Nightly Installers or the binary installers (which also include the commercial edition).
Our collective use of and dependence on technology has come quite a long way since 1989. That year, the first documented ransomware attack — the AIDS Trojan — was spread via physical media (5 1⁄4″ floppy disks) delivered by the postal service to individuals subscribed to a mailing list. The malware encrypted filenames (not the contents) and demanded payment ($189 USD) to be sent to a post office box to gain access to codes that would unscramble the directory entries.
That initial ransomware attack — started by an emotionally disturbed AIDS researcher — gave rise to a business model that has evolved since then to become one of the most lucrative and increasingly disruptive cybercriminal enterprises in modern history.
In this post, we’ll:
Examine what has enabled this growth
See how tactics and targets have morphed over the years
Take a hard look at the societal impacts of more recent campaigns
Paint an unfortunately bleak picture of where these attacks may be headed if we cannot work together to curtail them
Building the infrastructure of our own demise: Ransomware’s growth enablers
As PCs entered homes and businesses, individuals and organizations increasingly relied on technology for everything from storing albums of family pictures to handling legitimate business processes of all shapes and sizes. They were also becoming progressively more connected to the internet — a domain formerly dominated by academics and researchers. Electronic mail (now email) morphed from a quirky, niche tool to a ubiquitous medium, connecting folks across the globe. The World Wide Web shifted from being a medium solely used for information exchange to the digital home of corporations and a cadre of storefronts.
The capacity and capabilities of cyberspace grew at a frenetic pace and fueled great innovation. The cloud was born, cheaply putting vast compute resources into the hands of anyone with a credit card and reducing the complexity of building internet-enabled services. Today, sitting on the beach in an island resort, we can speak to the digital assistant on our smartphones and issue commands to our home automatons thousands of miles away.
Despite appearances, this evolution and expansion was — for the most part — unplanned and emerged with little thought towards safety and resilience, creating (unseen by most) fragile interconnections and interdependencies.
The concept and exchange mechanisms of currency also changed during this time. Checks in the mail and wire transfers over copper lines have been replaced with digital credit and debit transactions and fiat-less digital currency ledger updates.
So, we now have blazing fast network access from even the most remote locations, globally distributed, cheap, massive compute resources, and baked-in dependence on connected technology in virtually every area of modern life, coupled with instantaneous (and increasingly anonymous) capital exchange. Most of this infrastructure — and nearly all the processes and exchanges that run on it — are unprotected or woefully under protected, making it the perfect target for bold, brazen, and clever criminal enterprises.
From pictures to pipelines: Ransomware’s evolving targets and tactics
At their core, financially motivated cybercriminals are entrepreneurs who understand that their business models must be diverse and need to evolve with the changing digital landscape. Ransomware is only one of many business models, and it’s taken a somewhat twisty path to where we are today.
Attacks in the very early 2000s were highly regional (mostly Eastern Europe) and used existing virus/trojan distribution mechanisms that randomly targeted businesses via attachments spread by broad stroke spam campaigns. Unlike their traditional virus counterparts, these ransomware pioneers sought small, direct payouts in e-gold, one of the first widely accessible digital currency exchanges.
By the mid-2000s, e-gold was embroiled in legal disputes and was, for the most part, defunct. Instead of assuaging attackers, even more groups tried their hands at the ransomware scheme, since it had a solid track record of ensuring at least some percentage of payouts.
Many groups shifted attacks towards individuals, encrypting anything from pictures of grandkids to term papers. Instead of currency, these criminals forced victims to procure medications from online pharmacies and hand over account credentials so the attackers could route delivery to their drop boxes.
Others took advantage of the fear of exposure and locked up the computer itself (rather than encrypt files or drives), displaying explicit images that could be dismissed after texting or calling a “premium-rate” number for a code.
However, there were those who still sought the refuge of other fledgling digital currency markets, such as Liberty Reserve, and migrated the payout portion of encryption-based campaigns to those exchanges.
By the early 2010s — due, in part, to the mainstreaming of Bitcoin and other digital currencies/exchanges, combined with the absolute reliance of virtually all business processes on technology — these initial, experimental business models coalesced into a form we should all recognize today:
Gain initial access to a potential victim business. This can be via phishing, but it’s increasingly performed via compromising internet-facing gateways or using legitimate credentials to log onto VPNs — like the attack on Colonial Pipeline — and other remote access portals. The attacks shifted focus to businesses for higher payouts and also a higher likelihood of receiving a payout.
Encrypt critical files on multiple critical systems. Attackers developed highly capable, customized utilities for performing encryption quickly across a wide array of file types. They also had a library of successful, battle-tested techniques for moving laterally throughout an organization. Criminals also know the backup and recovery processes at most organizations are lacking.
Demanding digital currency payout in a given timeframe. Introducing a temporal component places added pressure on the organization to pay or potentially lose files forever.
The technology and business processes to support this new model became sophisticated and commonplace enough to cause an entire new ransomware as a service criminal industry to emerge, enabling almost anyone with a computer to become an aspiring ransomware mogul.
On the cusp of 2020 a visible trend started to emerge where victim organizations declined to pay ransom demands. Not wanting to lose a very profitable revenue source, attackers added some new techniques into the mix:
Identify and exfiltrate high-value files and data before encrypting them. Frankly, it’s odd more attackers did not do this before the payment downturn (though, some likely did). By spending a bit more time identifying this prized data, attackers could then use it as part of their overall scheme.
Threaten to leak the data publicly or to the individuals/organizations identified in the data. It should come as no surprise that most ransomware attacks go unreported to the authorities and unseen by the media. No organization wants the reputation hit associated with an attack of this type, and adding exposure to the mix helped return payouts to near previous levels.
The high-stakes gambit of disruptive attacks: Risky business with significant collateral damage
Not all ransomware attacks go unseen, but even the ones that gained some attention rarely make it to mainstream national news. In the U.S. alone, hundreds of schools and municipalities have experienced disruptive and costly ransomware attacks each year going back as far as 2016.
Municipal ransomware attacks
When a town or city is taken down by a ransomware attack, critical safety services such as police and first responders can be taken offline for days. Businesses and citizens cannot make payments on time-critical bills. Workers, many of whom exist paycheck-to-paycheck, cannot be paid. Even when a city like Atlanta refuses to reward criminals with a payment, it can still cost taxpayers millions of dollars and many, many months to have systems recovered to their previous working state.
School-district ransomware attacks
Similarly, when a school district is impacted, schools — which increasingly rely on technology and internet access in the classroom — may not be able to function, forcing parents to scramble for child care or lose time from work. As schools were forced online during the pandemic, disruptive ransomware attacks also made remote, online classes inaccessible, exacerbating an already stressful learning environment.
Hobbled learning is not the only potential outcome as well. Recently, one of the larger districts in the U.S. fell victim to a $547,000 USD ransom attack, which was ultimately paid to stop sensitive student and personnel data from becoming public. The downstream identity theft and other impacts of such a leak are almost impossible to calculate.
Healthcare ransomware attacks
Hundreds of healthcare organizations across the U.S. have also suffered annual ransomware attacks over the same period. When the systems, networks, and data in a hospital are frozen, personnel must revert to back up “pen-and-paper” processes, which are far less efficient than their digital counterparts. Healthcare emergency communications are also increasing digital, and a technology blackout can force critical care facilities into “divert” mode, meaning that incoming ambulances with crisis care patients will have to go miles out of their way to other facilities and increase the chances of severe negative outcomes for those patients — especially when coupled with pandemic-related outbreak surges.
The U.K. National Health Service was severely impacted by the WannaCry ransom-“worm” gone awry back in 2017. In total, “1% of NHS activity was directly affected by the WannaCry attack. 80 out of 236 hospital trusts across England [had] services impacted even if the organisation was not infected by the virus (for instance, they took their email offline to reduce the risk of infection); [and,] 595 out of 7,4545 GP practices (8%) and eight other NHS and related organisations were infected,” according to the NHS’s report.
An attack on Scripps Health in the U.S. in 2021 disrupted operations across the entire network for over a month and has — to date — cost the organization over $100M USD, plus impacted emergency and elective care for thousands of individuals.
An even more deliberate massive attack against Ireland’s healthcare network is expected to ultimately cost taxpayers over $600M USD, with recovery efforts still underway months after the attack, despite attackers providing the decryption keys free of charge.
Transportation ransomware attacks
San Francisco, Massachusetts, Colorado, Montreal, the UK, and scores of other public and commercial transportation systems across the globe have been targets of ransomware attacks. In many instances, systems are locked up sufficiently to prevent passengers from getting to destinations such as work, school, or medical care. Locking up freight transportation means critical goods cannot be delivered on time.
Critical infrastructure ransomware attacks
U.S. citizens came face-to-face with the impacts of large-scale ransomware attacks in 2021 as attackers disrupted access to fuel and impacted the food supply chain, causing shortages, panic buying, and severe price spikes in each industry.
Water systems and other utilities across the U.S. have also fallen victim to ransomware attacks in recent years, exposing deficiencies in the cyber defenses in these sectors.
Service provider ransomware attacks
Finally, one of the most high-profile ransomware attacks of all time has been the Kaseya attack. Ultimately, over 1,500 organizations — everything from regional retail and grocery chains to schools, governments, and businesses — were taken offline for over a week due to attackers compromising a software component used by hundreds of managed service providers. Revenue was lost, parents scrambled for last-minute care, and other processes were slowed or completely stopped. If the attackers had been just a tad more methodical, patient, and competent, this mass ransomware attack could have been even more far-reaching and even more devastating than it already was.
The road ahead: Ransomware will get worse until we get better
The first section of this post showed how we created the infrastructure of our own ransomware demise. Technology has advanced and been adopted faster than our ability to ensure the safety and resilience of the processes that sit on top of it. When one of the largest distributors of our commercial fuel supply still supports simple credential access for remote access, it is clear we have all not done enough — up to now — to inform, educate, and support critical infrastructure security, let alone those of schools, hospitals, municipalities, and businesses in general.
As ransomware attacks continue to escalate and become broader in reach and scope, we will also continue to see increasing societal collateral damage.
Now is the time for action. Thankfully, we have a framework for just such action! Rapid7 was part of a multi-stakeholder task force charged with coming up with a framework to combat ransomware. As we work toward supporting each of the efforts detailed in the report, we encourage all other organizations and especially all governments to dedicate time and resources towards doing the same. We must work together to stem the tide, change the attacker economics, and reduce the impacts of ransomware on society as a whole.
NEVER MISS A BLOG
Get the latest stories, expertise, and news about security today.
Researchers from the University of Trento have developed a Raspberry Pi-powered device that automatically detects pests in fruit orchards so they can get sorted out before they ruin a huge amount of crop. There’s no need for farmer intervention either, saving their time as well as their harvest.
One of the prototypes used during indoor testing
The researchers devised an embedded system that uses machine learning to process images captured inside pheromone traps. The pheromones lure the potential pests in to have their picture taken.
Hardware
Each trap is built on a custom hardware platform that comprises:
Sony IMX219 image sensor to collect images (chosen because it’s small and low-power)
Intel Neural Compute module for machine learning optimisation
Long-range radio chip for communication
Solar energy-harvesting power system
Here’s a diagram showing how all the hardware works together
The research paper mentions that Raspberry Pi 3 was chosen because it offered the best trade-off between computing capability, energy demand, and cost. However, we don’t know which Raspberry Pi 3 they used. But we’re chuffed nonetheless.
How does it work?
The Raspberry Pi computer manages the sensor, processing the captured images and transmitting them for classification.
Then the Intel Neural Compute Stick is activated to perform the machine learning task. It provides a boost to the project by reducing the inference time, so we can tell more quickly whether a potentially disruptive bug has been caught, or just a friendly bug.
The image on the far left is a photo taken inside a pheromone based trap by the smart camera. The images in the middle and on the right are examples of extracted regions of interest with a single insect
In this case, it’s codling moths we want to watch out for. They are major pests to agricultural crops, mainly fruits, and they’re the reason you end up with apples that look like they’ve been feasted on by hundreds of maggots.
Red boxes = bad codling moths Blue boxes = friendly bugs
When this task is done manually, farmers typically check codling moth traps twice a week. But this automated system checks the pheromone traps twice every day, making it much more likely to detect an infestation before it gets out of hand.
A lot changed in 2020, and the way businesses use the cloud was no exception. According to one study, 90% of organizations plan to increase their use of cloud infrastructure following the COVID-19 pandemic, and 61% are planning to optimize the way they currently use the cloud. The move to the cloud has increased organizations’ ability to innovate, but it’s also significantly impacted security risks.
Cloud misconfigurations have been among the leading sources of attacks and data breaches in recent years. One report found the top causes of cloud misconfigurations were lack of awareness of cloud security and policies, lack of adequate controls and oversight, and the presence of too many APIs and interfaces. As employees started working from home, the problem only got worse. IBM’s 2021 Cost of a Data Breach report found the difference in cost of a data breach involving remote work was 24.2% higher than those involving non-remote work.
What’s causing misconfigurations?
Rapid7 researchers found and studied 121 publicly reported cases of data exposures in 2020 that were directly caused by a misconfiguration in the organization’s cloud environment. The good news is that 62% of these cases were discovered by independent researchers and not hackers. The bad news? There are likely many more data exposures that hackers have found but the impacted organizations still don’t know about.
Here are some of our key findings:
A lot of misconfigurations happen because an organization wants to make access to a resource easier
The top three industries impacted by data exposure incidents were information, entertainment, and healthcare.
AWS S3 and ElasticSearch databases accounted for 45% of the incidents.
On average, there were 10 reported incidents a month across 15 industries.
The median data exposure was 10 million records.
Traditionally, security has been at the end of the cycle, allowing for vulnerabilities to get missed — but we’re here to help. InsightCloudSec is a cloud-native security platform meant to help you shift your cloud security programs left to allow security to become an earlier part of the cycle along with increasing workflow automation and reducing noise in your cloud environment.
Check out our full report that goes deeper into how and why these data breaches are occurring.
Over the course of routine security research, Rapid7 researchers Jonathan Peterson, Cale Black, William Vu, and Adam Cammack discovered that the Akkadian Console (often referred to as “ACO”) version 4.7, a call manager solution, is affected by two vulnerabilities. The first, CVE-2021-35468, allows root system command execution with a single authenticated POST request, and CVE-2021-35467 allows for the decryption of data encrypted by the application, which results in the arbitrary creation of sessions and the uncovering of any other sensitive data stored within the application. Combined, an unauthenticated attacker could gain remote, root privileges to a vulnerable instance of Akkadian Console Server.
CWE-78: Improper Neutralization of Special Elements used in an OS Command (‘OS Command Injection’)
Fixed in Version 4.9
Product Description
Akkadian Console (ACO) is a call management system allowing users to handle incoming calls with a centralized management web portal. More information is available at the vendor site for ACO.
Credit
These issues were discovered by Jonathan Peterson (@deadjakk), Cale Black, William Vu, and Adam Cammack, all of Rapid7, and it is being disclosed in accordance with Rapid7’s vulnerability disclosure policy.
Exploitation
The following were observed and tested on the Linux build of the Akkadian Console Server, version 4.7.0 (build 1f7ad4b) (date of creation: Feb 2 2021 per naming convention).
CVE-2021-35467: Akkadian Console Server Hard-Coded Encryption Key
Using DnSpy to decompile the bytecode of ‘acoserver.dll’ on the Akkadian Console virtual appliance, Rapid7 researchers identified that the Akkadian Console was using a static encryption key, “0c8584b9-020b-4db4-9247-22dd329d53d7”, for encryption and decryption of sensitive data. Specifically, researchers observed at least the following data encrypted using this hardcoded string:
User sessions (the most critical of the set, as outlined below)
FTP Passwords
LDAP credentials
SMTP credentials
Miscellaneous service credentials
The string constant that is used to encrypt/decrypt this data is hard-coded into the ‘primary’ C# library. So anyone that knows the string, or can learn the string by interrogating a shipping version of ‘acoserver.dll’ of the server, is able to decrypt and recover these values.
In addition to being able to recover the saved credentials of various services, Rapid7 researchers were able to write encrypted user sessions for the Akkadian Console management portal with arbitrary data, granting access to administrative functionality of the application.
The hardcoded key as shown in the decompiled code of the ACO server
The TokenService of acoserver.dll uses a hardcoded string to encrypt and decrypt user session information, as well as other data in the application that uses the ‘Encrypt’ method.
As shown in the function below, the application makes use of an ECB cipher, as well as PKCS7 padding to decrypt (and encrypt) this sensitive data.
Decrypt function present in acoserver.dll viewed with DnSpy
The image below shows an encrypted and decrypted version of an ‘Authorization’ header displaying possible variables available for manipulation. Using a short python script, one is able to create a session token with arbitrary values and then use it to connect to the Akkadian web console as an authenticated user.
Successfully decrypted a session generated by the application
Using the decrypted values of a session token, a ‘custom’ token can be created, substituting whatever values we want with a recent timestamp to successfully authenticate to the web portal.
The figure below shows this technique being used to issue a request to a restricted web endpoint that responds with the encrypted passwords of the user account. Since the same password is used to encrypt most things in the application (sessions, saved passwords for FTP, backups, LDAP, etc.), we can decrypt the encrypted passwords sent back in the response by certain portions of the application:
Using the same private key to decrypt the encrypted admin password returned by the application
This vulnerability can be used with the next vulnerability, CVE-2021-35468, to achieve remote command execution.
CVE-2021-35468: Akkadian Console Server OS Command Injection
The Akkadian Console application provides SSL certificate generation. See the corresponding web form in the screenshot below:
The web functionality associated with the vulnerable endpoint
The way the application generates these certificates is by issuing a system command using ‘/bin/bash’ to run an unsanitized ‘openssl’ command constructed from the parameters of the user’s request.
The screenshot below shows this portion of the code as it exists within the decompiled ‘acoserver.dll’.
Vulnerable method as seen from DnSpy
Side Note: In newer versions (likely 4.7+), this “Authorization” header is actually validated. In older versions of the Akkadian Console, this API endpoint does not appear to actually enforce authorization and instead only checks for the presence of the “Authorization” header. Therefore in these older, affected versions, this endpoint and the related vulnerability could be accessed directly without the crafting of the header using CVE-2021-35467. Exact affected versions have not been researched.
The below curl command will cause the Akkadian Console server to itself run its own curl command (in the Organization field) and pipe the results to bash.
Once this is received by ACO, the named curl payload is executed, and a shell is spawned, but any operating system command can be executed.
Impact
CVE-2021-35467, by itself, can be exploited to allow an unauthenticated user administrative access to the application. Given that this device supports LDAP-related functionality, an attacker could then leverage this access to pivot to other assets in the organization via Active Directory via stored LDAP accounts.
CVE-2021-35468 could allow any authenticated user to execute operating system level commands with root privileges.
By combining CVE-2021-35467 and CVE-2021-35468, an unauthenticated user can first establish themselves as an authenticated user by crafting an arbitrary session, then execute commands on ACO’s host operating system as root. From there, the attacker can install any malicious software of their choice on the affected device.
Remediation
Users of Akkadian Console should update to 4.9, which has addressed these issues. In the absence of an upgrade, users of Akkadian Console version 4.7 or older should only expose the web interface to trusted networks — notably, not the internet.
Disclosure Timeline
April, 2021: Discovery by Jonathan Peterson and friends at Rapid7
Wed, Jun 16, 2021: Initial disclosure to the vendor
Wed, Jun 23, 2021: Updated details disclosed to the vendor
Tue, Jul 13, 2021: Vendor indicated that version 4.9 fixed the issues
Rapid7 researcher Arvind Vishwakarma discovered multiple vulnerabilities in the Fortress S03 WiFi Home Security System. These vulnerabilities could result in unauthorized access to control or modify system behavior, and access to unencrypted information in storage or in transit. CVE-2021-39276 describes an instance of CWE-287; specifically, it describes an insecure cloud API deployment which allows unauthenticated users to trivially learn a secret that can then be used to alter the system’s functionality remotely. It has an initial CVSS score of 5.3 (medium). CVE-2021-39277 describes an instance of CWE-294, a vulnerability where anyone within Radio Frequency (RF) signal range could capture and replay RF signals to alter systems behavior, and has an initial CVSS score of 5.7.
Product Description
The Fortress S03 WiFi Home Security System is a do it yourself (DIY) consumer grade home security system which leverages WiFi and RF communication to monitor doors, windows, and motion detection to spot possible intruders. Fortress can also electronically monitor the system for you, for a monthly fee. More information about the product can be found at the vendor’s website.
What follows are details regarding the two disclosed vulnerabilities. Generally speaking, these issues are trivially easy to exploit by motivated attackers who already have some knowledge of the target.
CVE-2021-39276: Unauthenticated API Access
If a malicious actor knows a user’s email address, they can use it to query the cloud-based API to return an International Mobile Equipment Identity (IMEI) number, which appears to also serve as the device’s serial number. The following post request structure is used to make this unauthenticated query and return the IMEI:
With a device IMEI number and the user’s email address, it is then possible for a malicious actor to make changes to the system, including disarming its alarm. To disarm the system, the following unauthenticated POST can be sent to the API:
CVE-2021-39277: Vulnerable to RF Signal Replay Attack
The system under test was discovered to be vulnerable to an RF replay attack. When a radio-controlled device has not properly implemented encryption or rotating key protections, this can allow an attacker to capture command-and-control signals over the air and then replay those radio signals in order to perform a function on an associated device.
As a test example, the RF signals used to communicate between the Key Fobs, Door/Window Contact Sensors, and the Fortress Console were identified in the 433 MHz band. Using a software defined radio (SDR) device, the researcher was able to capture normal operations of the device “arm” and “disarm” commands. Then, replaying the captured RF signal communication command would arm and disarm the system without further user interaction.
Impact
For CVE-2021-39276, an attacker can use a Fortress S03 user’s email address to easily disarm the installed home alarm without the user’s knowledge. While this is not usually much of a concern for random, opportunistic home invaders, this is particularly concerning when the attacker already knows the victim well, such as an ex-spouse or other estranged relationship partner.
CVE-2021-39277 presents similar problems but requires less prior knowledge of the victim, as the attacker can simply stake out the property and wait for the victim to use the RF-controlled devices within radio range. The attacker can then replay the “disarm” command later, without the victim’s knowledge.
Mitigations
In the absence of a patch or update, to work around the IMEI number exposure described in CVE-2021-39276, users could configure their alarm systems with a unique, one-time email address. Many email systems allow for “plus tagging” an email address. For example, a user could register “[email protected]” and treat that plus-tagged email address as a stand-in for a password.
For CVE-2021-39277, there seems to be very little a user can do to mitigate the effects of the RF replay issues, absent a firmware update to enforce cryptographic controls on RF signals. Users concerned about this exposure should avoid using key fobs and other RF devices linked to their home security systems.
Earlier this year we announced that we are committed to making online human verification easier for more users, all around the globe. We want to end the endless loops of selecting buses, traffic lights, and convoluted word diagrams. Not just because humanity wastes 500 years per day on solving other people’s machine learning problems, but because we are dedicated to making an Internet that is fast, transparent, and private for everyone. CAPTCHAs are not very human-friendly, being hard to solve for even the most dedicated Internet users. They are extremely difficult to solve for people who don’t speak certain languages, and people who are on mobile devices (which is most users!).
Today, we are taking another step in helping to reduce the Internet’s reliance on CAPTCHAs to prove that you are not a robot. We are expanding the reach of our Cryptographic Attestation of Personhood experiment by adding support for a much wider range of devices. This includes biometric authenticators — like Apple’s Face ID, Microsoft Hello, and Android Biometric Authentication. This will let you solve challenges in under five seconds with just a touch of your finger or a view of your face — without sending this private biometric data to anyone.
In addition to support for hardware biometric authenticators, we are also announcing support for many more hardware tokens today in the Cryptographic Attestation of Personhood experiment. We support all USB and NFC keys that are both certified by the FIDO alliance and have no known security issues according to the FIDO Alliance Metadata service (MDS 3.0).
Privacy First
Privacy is at the center of Cryptographic Attestation of Personhood. Information about your biometric data is never shared with, transmitted to, or processed by Cloudflare. We simply never see it, at all. All of your sensitive biometric data is processed on your device. While each operating system manufacturer has a slightly different process, they all rely on the idea of a Trusted Execution Environment (TEE) or Trusted Platform Module (TPM). TEEs and TPMs allow only your device to store and use your encrypted biometric information. Any apps or software running on the device never have access to your data, and can’t transmit it back to their systems. If you are interested in digging deeper into how each major operating system implements their biometric security, read the articles we have linked below:
Our commitment to privacy doesn’t just end at the device. The WebAuthn API also prevents the transmission of biometric information. If a user interacts with a biometric key (like Apple TouchID or Windows Hello), no third party — such as Cloudflare — can receive any of that biometric data: it remains on your device and is never transmitted by your browser. To get an even deeper understanding of how the Cryptographic Attestation of Personhood protects your private information, we encourage you to read our initial announcement blog post.
Making a Great Privacy Story Even Better
While building out this technology, we have always been committed to providing the best possible privacy guarantees. The existing assurances are already quite strong: as described in our previous post, when using CAP, you may disclose a small amount of information about your authentication hardware — at most, its make and model. By design, this information is not unique to you: the underlying standard requires that this be indistinguishable from thousands of others, which hides you in a crowd of identical hardware.
Even though this is a great start, we wanted to see if we could push things even farther. Could we learn just the one fact that we need — that you have a valid security key — without learning anything else?
We are excited to announce that we have made great strides on answering that question by using a form of the next generation of cryptography called Zero Knowledge Proofs (ZKP). ZKP prevents us from discovering anything from you, other than the fact that you have a device that can generate an approved certificate that proves that you are human.
If you are interested in learning more about Zero Knowledge Proofs, we highly recommend reading about it here.
Driven by Speed, Ease of Use, and Bot Defense
At the start of this project we set out three goals:
How can we dramatically improve the user experience of proving that you are a human?
How can we make sure that any solution that we develop centers around ease of use, and increases global accessibility on the Internet?
How do we make a solution that does not harm our existing bot management system?
Before we deployed this new evolution of our CAPTCHA solution, we did a proof of concept test with some real users, to confirm whether this approach was worth pursuing (just because something sounds great in theory doesn’t mean it will work out in practice!). Our testing group tried our Cryptographic Attestation of Personhood solution using Face ID and told us what they thought. We learned that solving times with Face ID and Touch ID were significantly faster than selecting pictures, with almost no errors. People vastly preferred this alternative, and provided suggestions for improvements in the user experience that we incorporated into our deployment.
This was even more evident in our production usage data. While we did not enable attestation with biometrics providers during our first phase of the CAP roll out, we did record when people attempted to use a biometric authentication service. The highest recorded attempt solve rate besides YubiKeys was Face ID on iOS, and Android Biometric Authentication. We are excited to offer those mobile users their first choice of challenge for proving their humanity.
One of the things we heard about in testing was — not surprisingly — concerns around privacy. As we explained in our initial launch, the WebAuthn technology underpinning our solution provides a high level of privacy protection. Cloudflare is able to view an identifier shared by thousands of similar devices, which provides general make and model information. This cannot be used to uniquely identify or track you — and that’s exactly how we like it.
Now that we have opened up our solution to more device types, you’re able to use biometric readers as well. Rest assured that the same privacy protections apply — we never see your biometric data: that remains on your device. Once your device confirms a match, it sends only a basic attestation message, just as it would for any security key. In effect, your device sends a message proving that “yes, someone correctly entered a fingerprint on this trustworthy device”, and never sends the fingerprint itself.
We have also been reviewing feedback from people who have been testing out CAP on either our demo site or through routine browsing. We appreciate the helpful comments you’ve been sending, and we’d love to hear more, so we can continue to make improvements. We’ve set up a survey at our demo site. Your input is key to ensuring that we get usability right, so please let us know what you think.
This week was more quiet than normal with Black Hat USA and DEF CON, but that didn’t stop the team from delivering some small enhancements and bug fixes! We are also excited to see two new modules #15519 and #15520 from researcher Jacob Baines’ DEF CON talk Bring Your Own Print Driver Vulnerability already appear in the PR queue. Keep an eye out for those modules in the near future!
Our very own Simon Janusz enhanced the CommandDispatcher and SessionManager to support using a negative ID with both the jobs and sessions commands. Quickly access the last job or session by passing -1 to the command. The change allows users to upgrade the most recently opened session to meterpreter using the command sessions -u -1, thus removing the need to run the post/multi/manage/shell_to_meterpreter module.
In addition, our very own Alan David Foster updated the PostgreSQL scanner/postgres/postgres_schemadump module so that it does not ignore the default postgres database. That default database might contain valuable information after all! The enhancements also introduce a new datastore option, IGNORED_DATABASES, to configure a list of databases ignored during the schema dump.
Enhancements and features
#15492 from sjanusz-r7 – Adds support for negative session and job ids.
#15498 from adfoster-r7 – Updates the PostgreSQL schema_dump module to no longer ignore the default postgres database which may contain useful information, and adds a new datastore option to configure ignored databases.
Bugs fixed
#15500 from agalway-r7 – Fixes a regression issue for gitlab_file_read_rce and cacti_filter_sqli_rce where the modules failed to run
#15503 from jheysel-r7 – A bug has been fixed in the Cisco Hyperflex file upload RCE module that prevented it from properly deleting the uploaded payload files. Uploaded payload files should now be properly deleted.
Get it
As always, you can update to the latest Metasploit Framework with msfupdate
and you can get more details on the changes since the last blog post from
GitHub:
If you are a git user, you can clone the Metasploit Framework repo (master branch) for the latest.
To install fresh without using git, you can use the open-source-only Nightly Installers or the binary installers (which also include the commercial edition).
Here we are again, back for another day of Rapid7 expert debriefings and analysis for some of the most talked-about Black Hat sessions of this year. So without further delay, let’s take it away!
Get more DEF CON 2021 insights from our Research team on Tuesday, August 10
How do human behaviors — learned or learning — factor into incident response? Depending on the volume of stakeholders, your team may be under varying extremes of action bias. As in, are speedy actions being prioritized on vulnerabilities that don’t present a high risk profile? Is speed even possible if mitigating actions must suddenly be learned? Vendors have caught on, practicing “Security Theater”— peddling solutions to problems that might not present real risks.
Tangential to the previous topic, a question arises when exploring the weaponization of C2 channels: Due to the unlikelihood of an attack via, say, LDAP attributes when establishing C2, does it make sense to roll out an entirely new detection-and-response plan? Many different conditions must be met for an attacker to gain access in the wild, but teams might already have similar responses in place, on the off chance it happens.
Zooming out to a topic with broader public appeal, let’s consider how companies use — and abuse — our personal data. An 18-month test run by a professor and a group of students at Virginia Tech revealed how unlikely it is we’ll be able to predict which companies will abuse personal information after someone, say, creates login credentials for a TikTok account and the company launches cookie tracking for that person.
Vulnerability Risk Management
Key takeaways
Are Microsoft Exchange Servers creating an entirely new attack surface via Client Access Services (CAS)? Exchange architecture is incredibly complex, so it contains multitudes when it comes to vulnerabilities. CAS ties front-end and back-end services together, receiving the front-end request through a variety of protocols, including some extremely geriatric ones like POP3 and IMAP4. These legacy protocols are contributing to expanded attack surfaces.
Vulnerability Exploitability eXchange (VEX) helps teams rethink security advisories and what it means to be vulnerable. Essentially, it enables software providers to communicate they’re not affected by a vulnerability. Two advantages of VEX are 1) that creation and management of vulnerabilities are automated, and 2) that its results are machine-readable.
Open-source software (OSS) is incredible… and incredibly vulnerable. There are so many risks with OSS that a vendor might even put off patching a vulnerability — for whatever business reason — if alerted to it. There’s currently no mechanism to secure so many classes of vulnerabilities in OSS, but maybe there should be. Researchers should work together to create those class-eliminating mechanisms, ultimately reducing the lift when it comes to risk management.
Research and Policy
Key takeaways
What is Electromagnetic Fault Injection (EMFI)? It’s when hardware attackers use electromagnetism to hack hardware chips. When it comes to something like a car’s modern combustion engine, EMFI can be leveraged to change a vehicle’s performance, slithering past manufacturer-imposed security protocols. Some owners are beginning to “tune” chips with EMFI in order to push the limits of their vehicles.
There’s cause for concern that AI security products are simply repeating back to us the tables on which they were trained. If this is the case, can someone create more nefarious tables to sway AI security entities away from actual security? Attackers can now train explainable AI models on private data, turning them into the latest tool in their arsenals. Consider your attack surface expanded.
When companies export their technology beyond their own borders, it isn’t as easy as it sounds in a press release. Whereas policy constantly lagged behind technology, it’s starting to catch up as companies realize the cost of doing business with both digital authoritarians and digital democracies. Is proprietary tech compromised when entering a new country where it must adhere to each and every law imposed on it by local regulators?
Thanks for joining the Rapid7 team at another round of Black Hat debriefings. We hope to see you live and in person in Vegas next year. Until then, stay secure and stay safe!
The casino floor at Bally’s is a thrilling place, one that loads of hackers are familiar with from our time at DEF CON. One feature of these casinos is the unmistakable song of slots being played. Imagine a slot machine that costs a dollar to play, and pays out $75 if you win — what probability of winning would it take for you to play?
Naively, I’d guess most people’s answers are around “1 in 75” or maybe “1 in 74” if they want to turn a profit. One in 74 is a payout probability of about 1.37%. Now, at 1.37%, you turn a profit, on average, of $1 for 74 games — so how many times do you play? Probably not that many. You’re basically playing for free — but you’re not pulling much off $1 profit per 74 pulls. At least on average.
But what if that slot machine paid out about half the time, giving you $75 every other time you played? How many times would you play?
This is the game that ransomware operators are playing.
Playing Against the Profiteers
Between Wannacry, the Colonial Pipeline hack, and the recent Kaseya incident, everyone is now familiar with supply chain attacks — particularly those that use ransomware. As a result, ransomware has entered the public consciousness, and a natural question is: why ransomware? From an attacker’s perspective, the answer is simple: why not?
For the uninitiated, ransomware is a family of malware that encrypts files on a system and demands a payment to decrypt the files. Proof-of-concept ransomware has existed since at least 1996, but the attack vector really hit its stride with CryptoLocker’s innovative use of Bitcoin as a payment method. This allowed ransomware operators to perpetuate increasingly sophisticated attacks, including the 2017 WannaCry attack — the effects of which, according to the ransomware payment tracker Ransomwhere, are still being felt today.
Between the watering hole attacks and exploit kits of the Angler EK era and the recent spate of ransomware attacks targeting high-profile companies, the devastation of ransomware is being felt even by those outside of infosec. The topic of whether or not to pay ransoms — and whether or not to ban them — has sparked heated debate and commentary from folks like Tarah Wheeler and Ciaran Martin at the Brookings Institute, the FBI, and others in both industrial and academic circles. One noteworthy academic paper by Cartwright, Castro, and Cartwright uses game theory to ask the question of whether or not to pay.
Ransomware operators aren’t typically strategic actors with a long-term plan; rather, they’re profiteers who seek targets of opportunity. No target is too big or too small for these groups. Although these analyses differ in the details, they get the message right — if the ransomware operators don’t get paid, they won’t want to play the game anymore.
Warning: Math Ahead
According to Kaspersky, 56% of ransomware victims pay the ransom. Most other analyses put it around 50%, so we’ll use Kaspersky’s. In truth, it’s unlikely we have an accurate number for this, as many organizations specifically choose to pay the ransom in order to avoid public exposure of the incident.
If a ransomware attack costs some amount of money to launch and is successful some percentage of the time, the amount of money made from each attack is:
We call this the expected value of an attack.
It’s hard to know how many attacks are launched — and how many of those launched attacks actually land. Attackers use phishing, RDP exploits, and all kinds of other methods to gain initial access. For the moment, let’s ignore that problem and assume that every attack that gets launched lands. Ransomware that lands on a machine is successful about 54% of the time, and the probability of payment is 56%. Together, this means that the expected value of an attack is:
Given the average ransom payment is up to $312,493 as of 2020 — or using Sophos’s more conservative estimate, $170,404 — that means ransomware authors are turning a profit as long as the cost of an attack is less than $127,747.14 (or the more conservative $51,530.17). Based on some of the research that’s been done on the cost of attacks, where high-end estimates put it at around $4,200, we can start to see how a payout of almost 75 times the cost to play becomes an incentive.
In fact, because expected values are linear and the expected value is only for one play, we can see pretty quickly that in general, two attacks will give us double the value of one, and three will triple it. This means that if we let our payout be a random variable X, a ransomware operator’s expected value over an infinite number of attacks is… infinite.
Obviously, an infinite number of ransomware attacks is not reasonable, and there is a limit to the amount that any individual or business can pay over time before they just give up. But from an ideal market standpoint, the message is clear: While ransoms are being paid at these rates and sizes, the problem is only going to grow. Just like you’d happily play a slot machine that paid out almost half the time, attackers are happy to play a game that gets them paid more than 40% of the time, especially because the profits are so large.
Removing Incentives
So why would ransomware operators ever stop if, in an idealized model, there’s potentially infinite incentive to keep playing? A few reasons:
The value of payments is lower
The cost becomes prohibitive
The attacks don’t work
Nobody is paying
Out of the gate, we can more or less dismiss the notion that payment values will get lower. The only way to lower the value of the payment is to lower the value of Bitcoin to nearly zero. We’ve seen attempts to ban and regulate cryptocurrencies, but none of those have been successful.
In terms of the monetary cost, this is also pretty much a dead end for us. Even if we could remove all of the efficiencies and resilience of darknet markets, that would only remove the lowest-skill attackers from the equation. Other groups would still be capable of developing their own exploits and ransomware.
Ultimately, what our first two options have in common is that they deal, in a pretty direct way, with adversary capabilities. They leave room for adversaries to adapt and respond, ultimately trying to affect things that are in the control of attackers. This makes them much less desirable avenues for response.
So let’s look at the things that victims have control over: defenses and payments.
Defending Against Ransomware
Defending against ransomware is quite similar to defending against other attack types. In general, ransomware is not the first-stage payload delivered by an exploit; instead, it’s dropped by a loader. So the name of the game is to prevent code execution on endpoints. As security professionals, this is something we know quite well.
For ransomware, the majority of attacks come via a handful of vectors, which will be familiar to most security practitioners:
Phishing
Vulnerable services
Weak passwords, especially on Remote Desktop Protocol
Exploit kits
Many of these initial access vectors are things that can be kept in check with user training, vulnerability scans, and sound patching practices. Once initial access is established, many of these ransomware operators use software like WMI, PSExec, Powershell, and Cobalt Strike, in addition to commodity malware like Trickbot, to move laterally before hitting the entire network with ransomware.
Looking for these indicators of compromise is one way to limit the potential impact of ransomware. But of course, these techniques are hard to detect, and no organization is able to catch 100% of the bad things that are coming at them. So what do victims do when the worst happens?
Choosing Not to Pay
When ransomware attacks are successful, victims have two primary choices: pay or don’t. There are many follow-on decisions from each of these decisions, but the first and most critical decision (for the attacker) is whether or not to pay the ransom.
When people pay the ransom, they’re likely — though not guaranteed — to get their files back. However, because of the significant amounts of first stage implants and lateral movement associated with ransomware attacks, there’s still a lot of incident response work to be done beyond the return of the files. For many organizations, if they don’t have a suitable off-site backup in place, this may feel like an inevitable impact of this type of attack. As Tarah Wheeler pointed out, this is often something that can simply be written off as a business expense. Consequently, hackers get paid, companies get to write off the loss, and nobody learns a lesson.
As we discussed above, when you pay a ransom, you’re paying for the next attack, and according to reports from the UK’s NCSC, you may also be paying for human trafficking. None of us wants to be funding these attackers, but we want to protect our data. So how do we get away from paying?
As we mentioned before, preventing the attacks in the first place is the optimal outcome for us as defenders, but security solutions are never 100% effective. The easiest way not to pay is to have an off-site backup. That will let you invoke your normal incident response process but have your data intact. In many cases, this isn’t any more expensive than paying, and you’re guaranteed to get your data back.
In some cases, a decrypter is available for the ransomware. The decrypters can be used by victims to restore their files without paying the ransom. Organizations like No More Ransomware make decrypters available for free, saving organizations significant amounts of money paying for decryption keys.
Having a network configuration that makes lateral movement difficult will also reduce the “blast radius” of the attack and can help mitigate the spread. In these cases, you may be able to get away with reimaging a handful of employee laptops and accepting the loss. Ultimately, letting people write off their backups instead of their ransom payments encourages the switch to having sensible backup policies and discouraging these ransomware operators.
Why the Wheel Keeps Spinning
Ransomware remains a significant problem, and I hope we’ve demonstrated why: the incentives for everyone, including victims, are there to increase the number of ransomware attacks. Attackers who do more attacks will see more profits, which fund subsequent attacks. While victims can write off their payments, there’s no incentive to take steps to mitigate the impact of ransomware, so the problem will continue.
Crucially, ransomware attackers aren’t picky about their victims. They’re not nation-state actors who seek to target only the largest companies with the most intellectual property. Rather, they’re attackers of opportunity — their victim is anyone who lets their lever be pulled, and as long as the victims keep paying out often enough, attackers are happy to play.
NEVER MISS A BLOG
Get the latest stories, expertise, and news about security today.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.




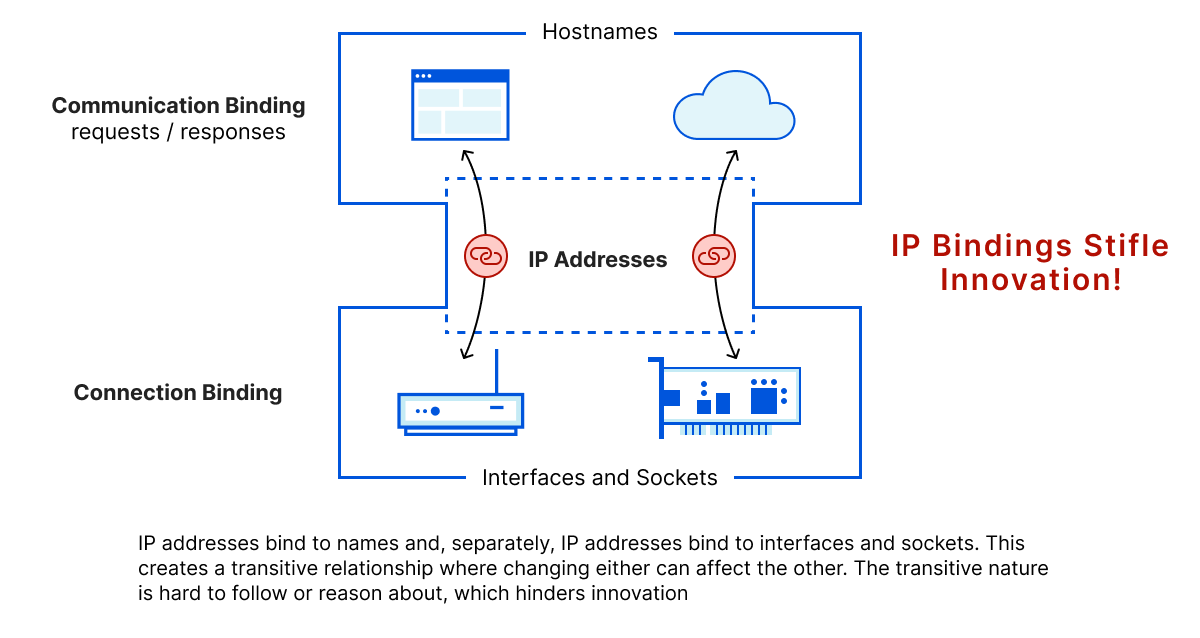
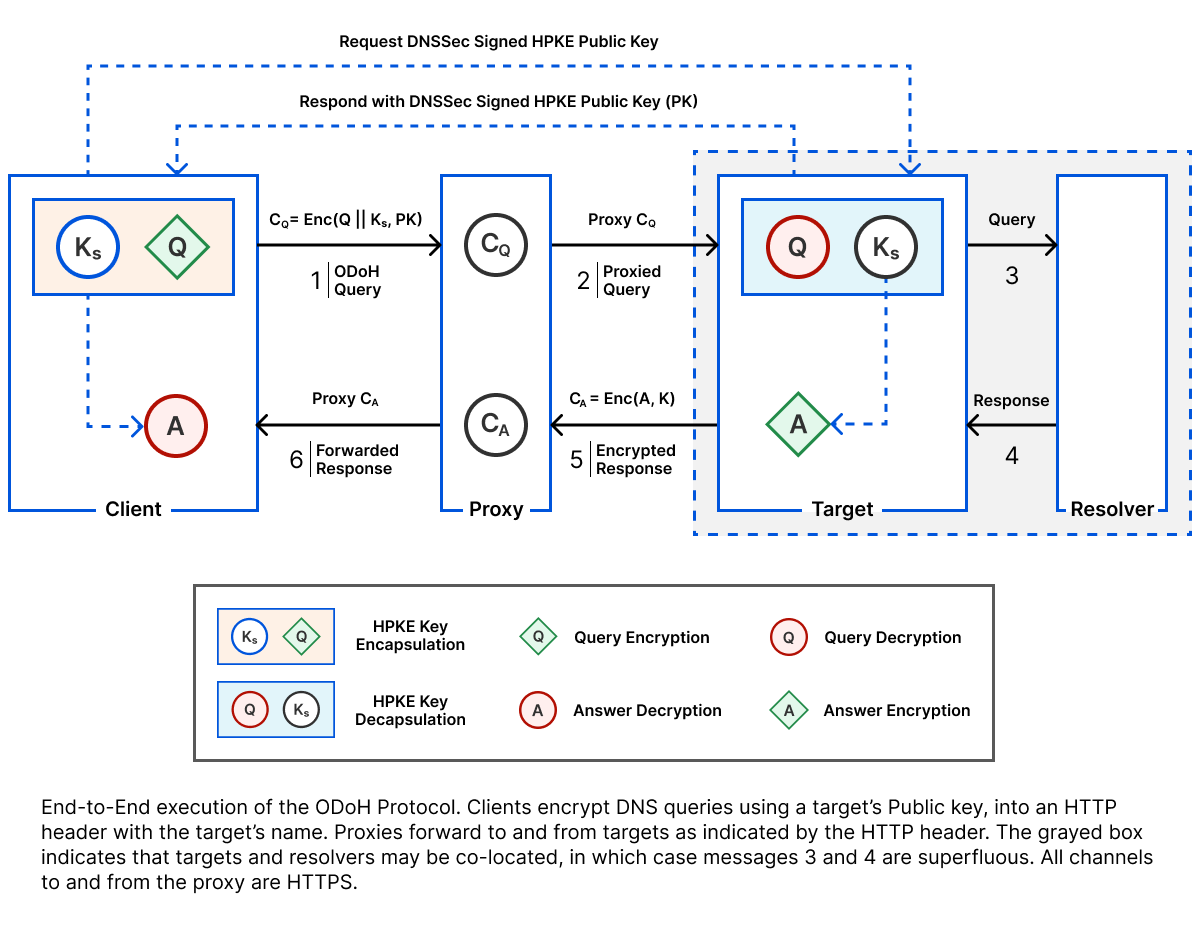
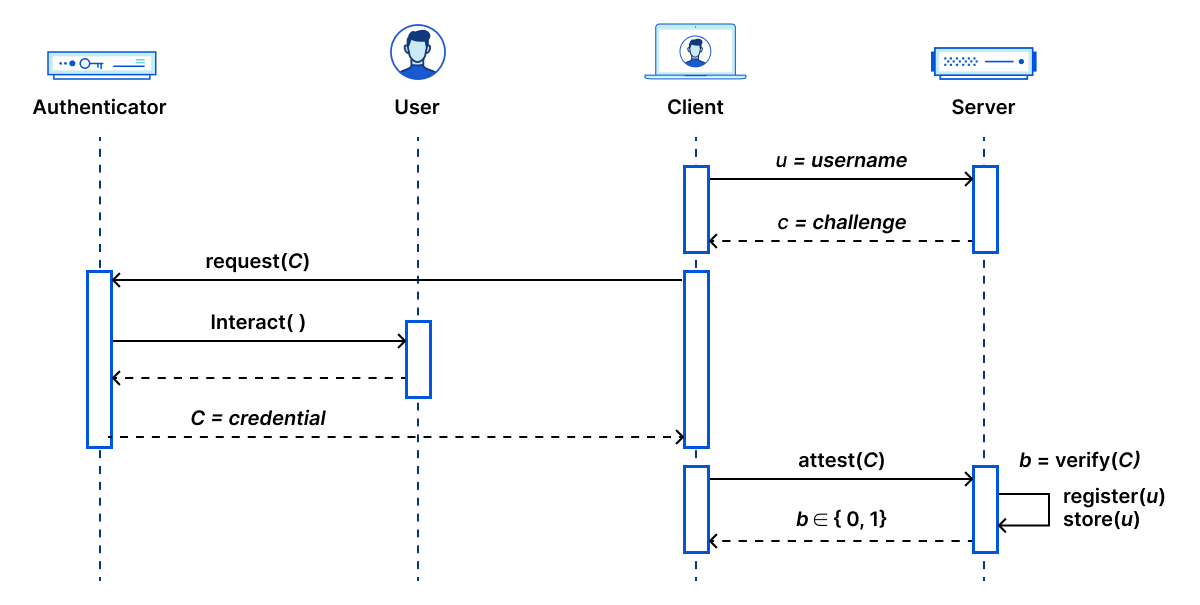





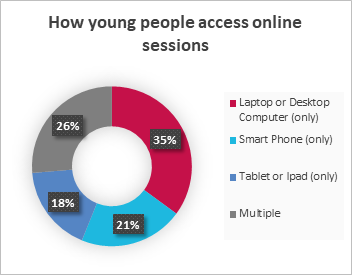




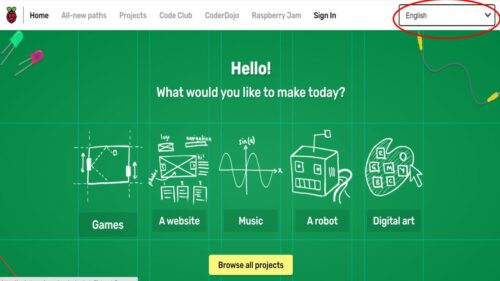

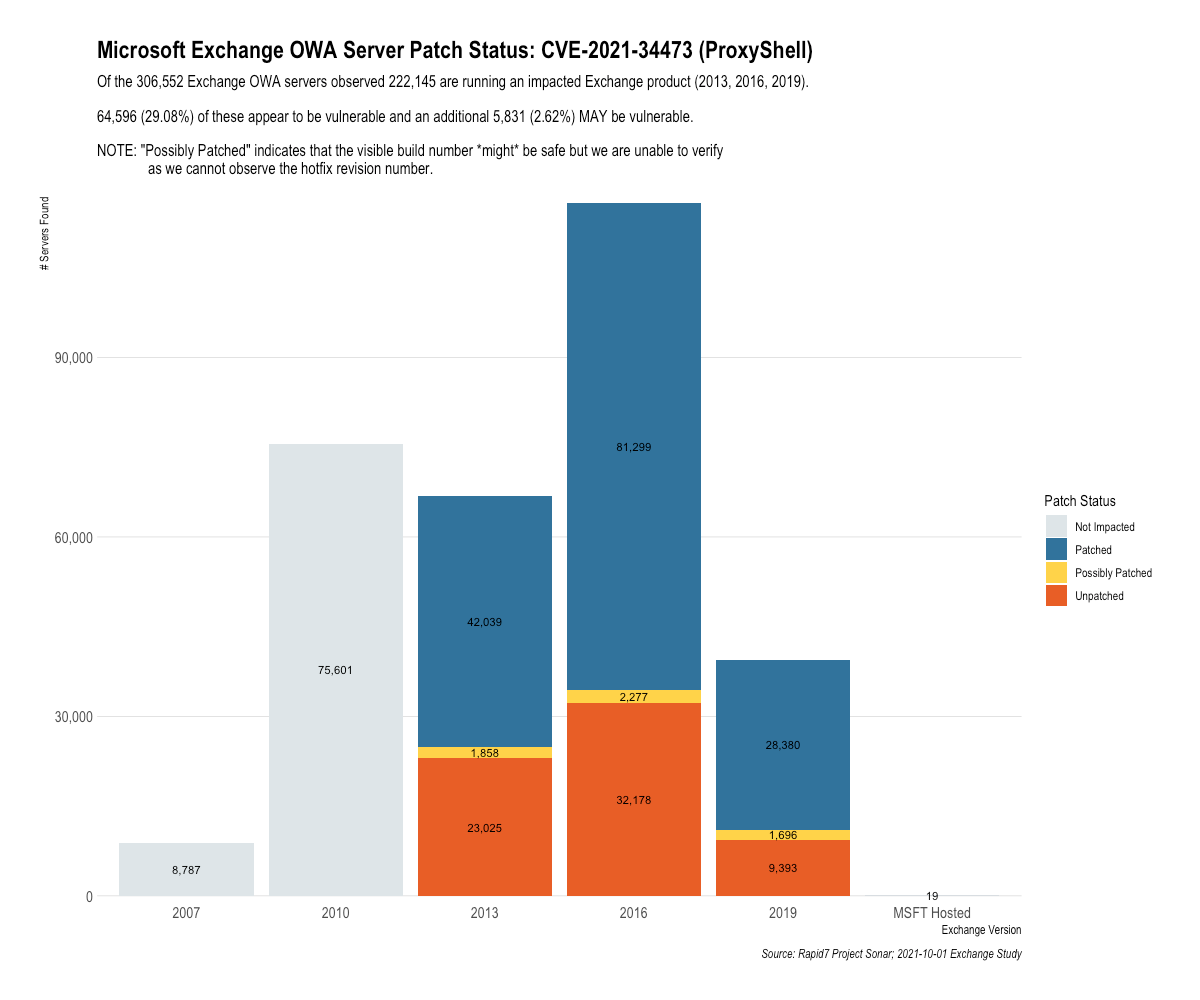
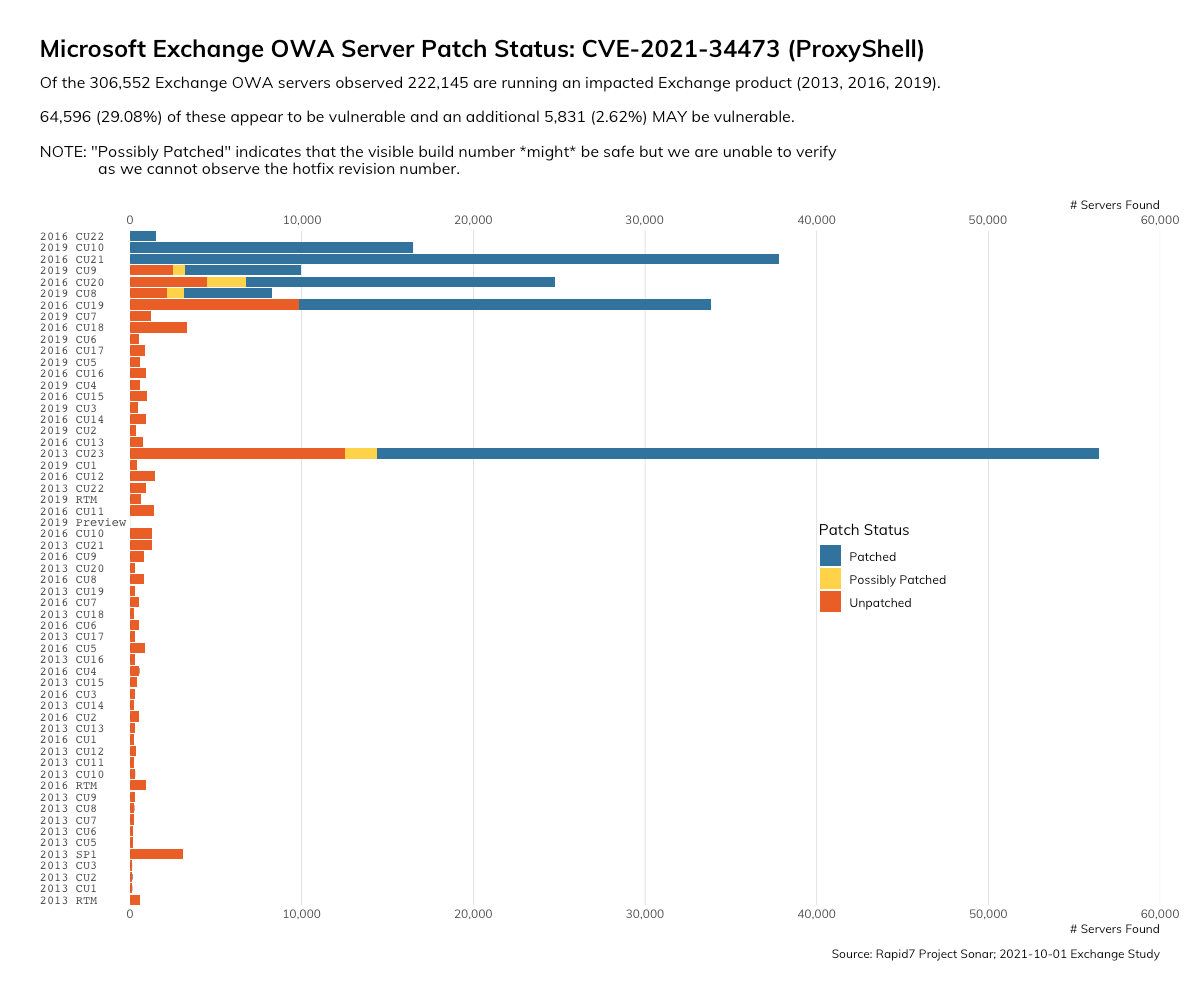
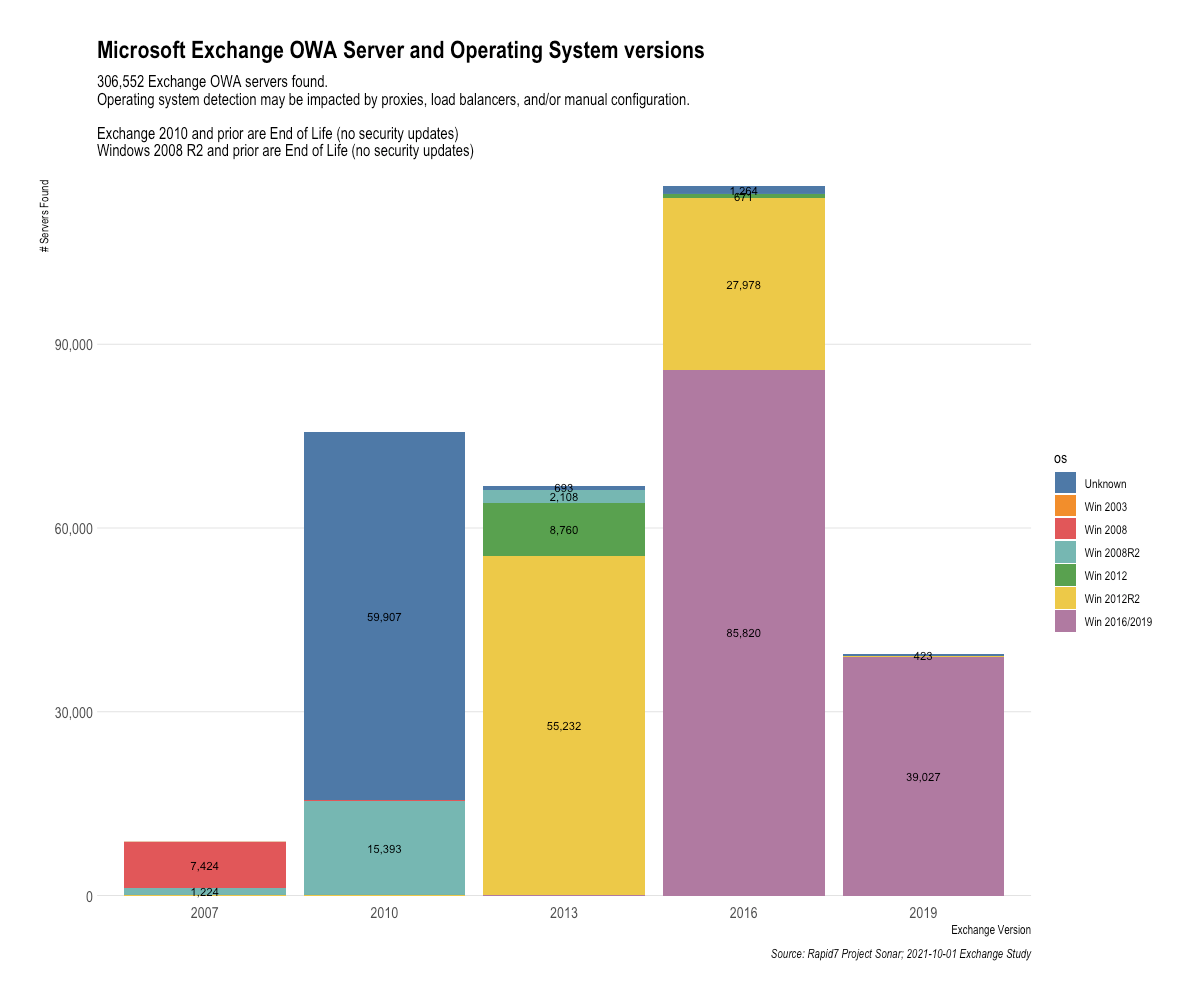




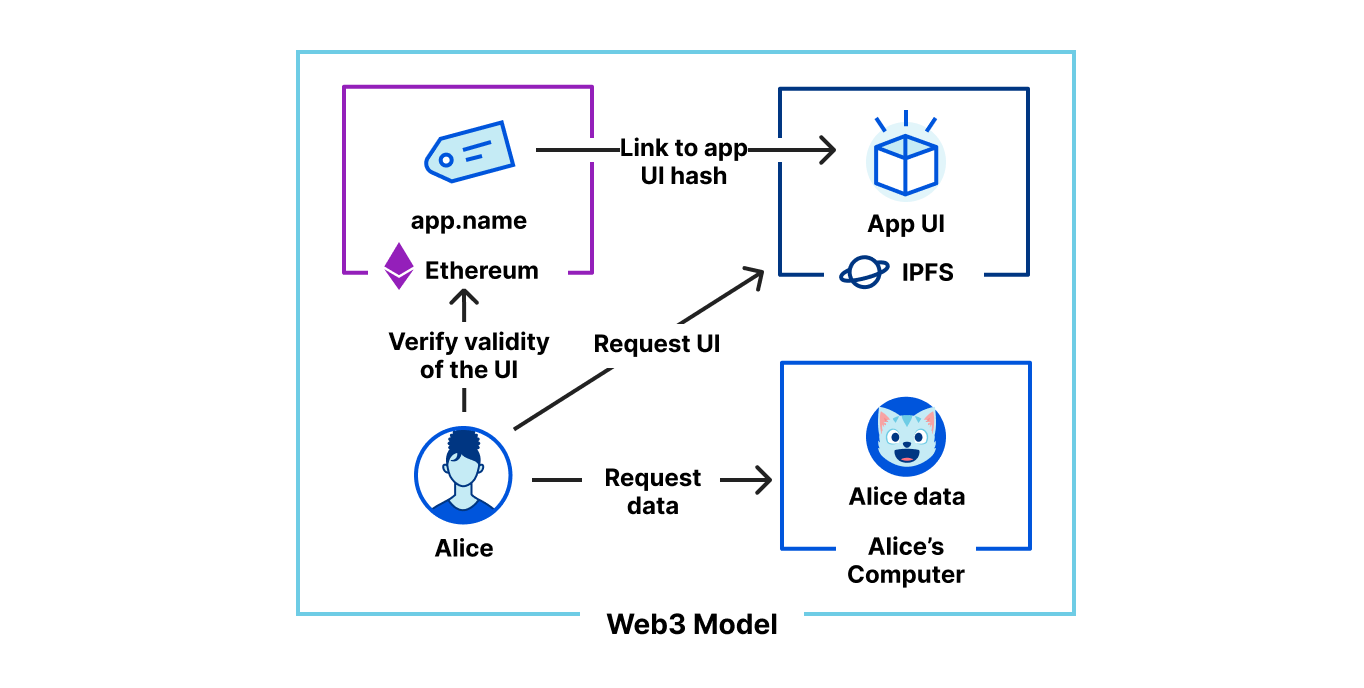
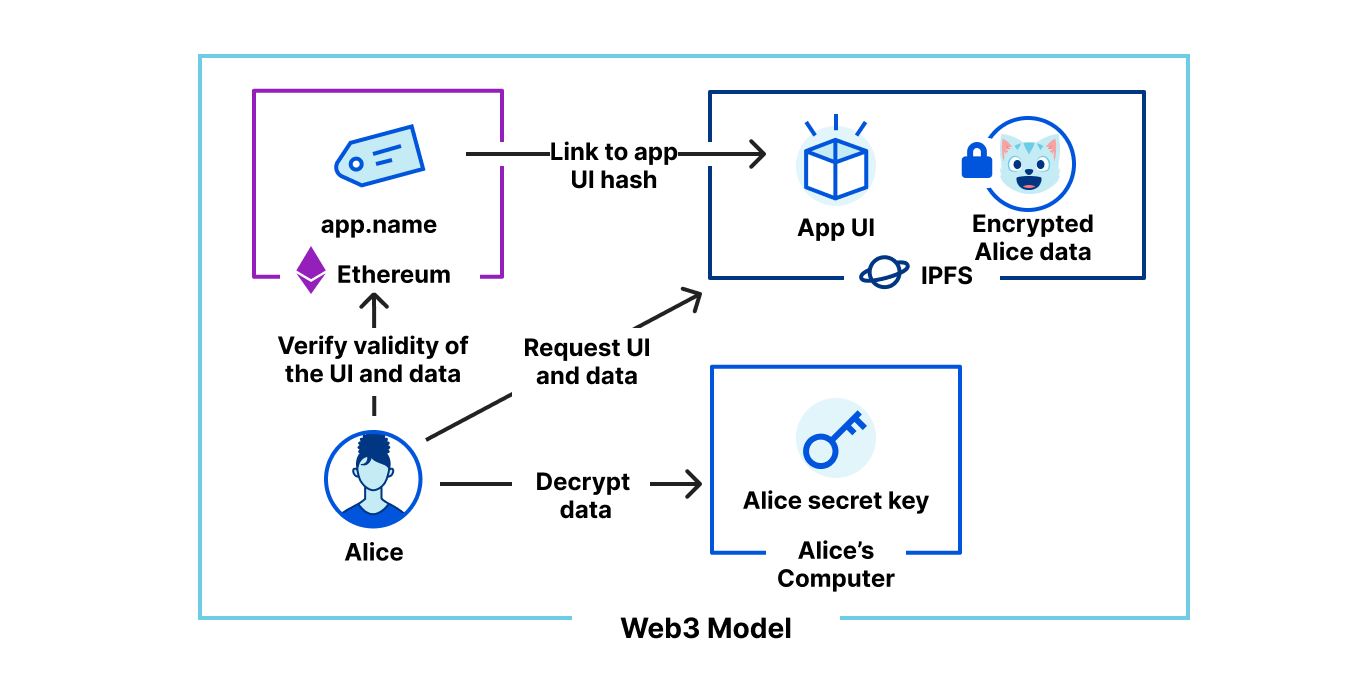






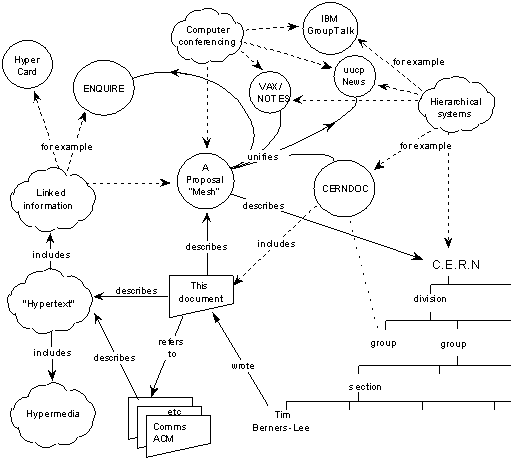
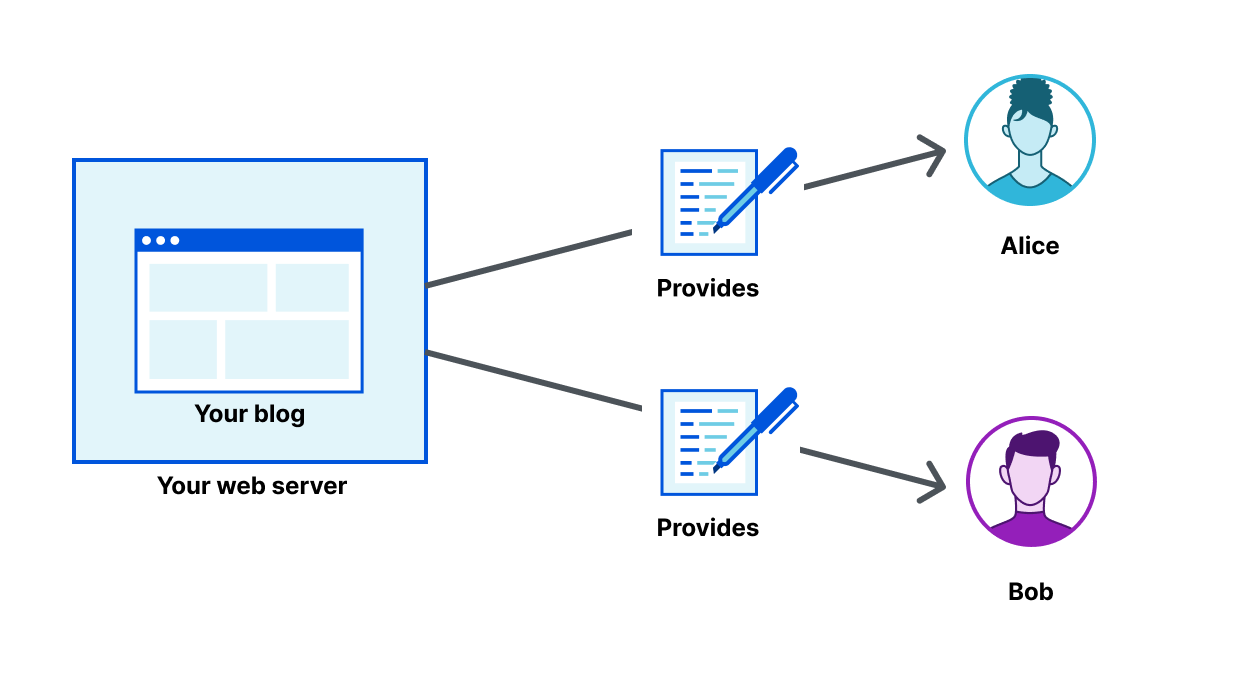
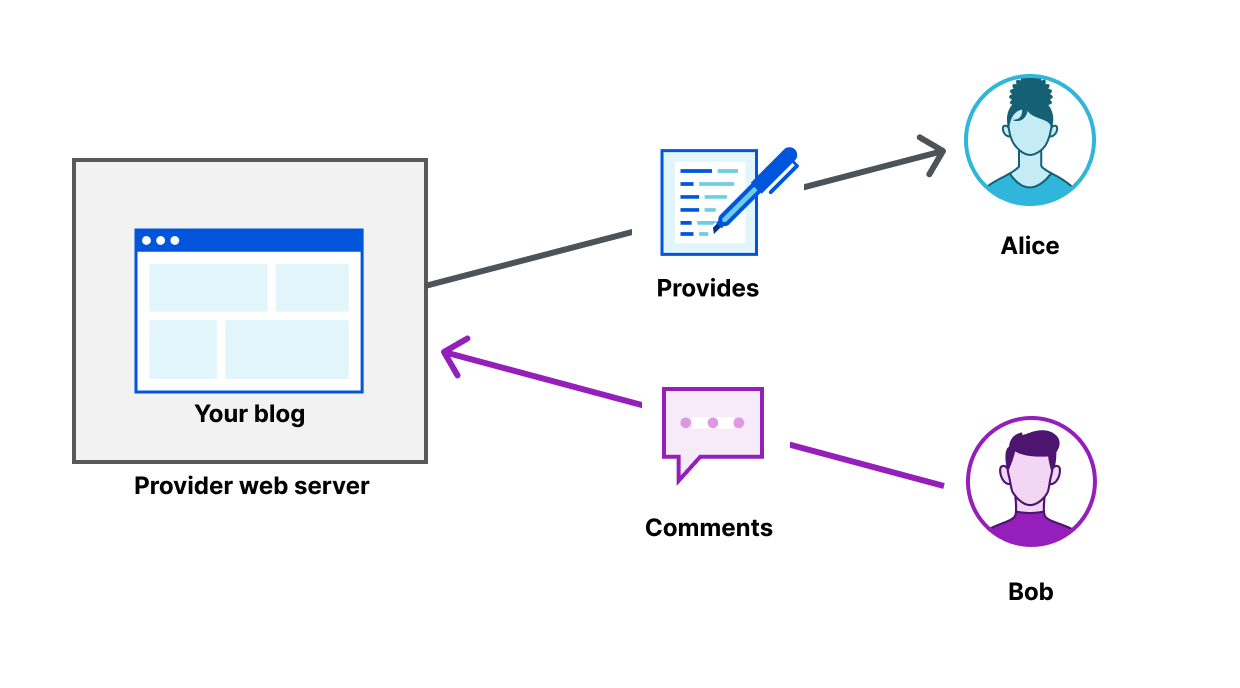
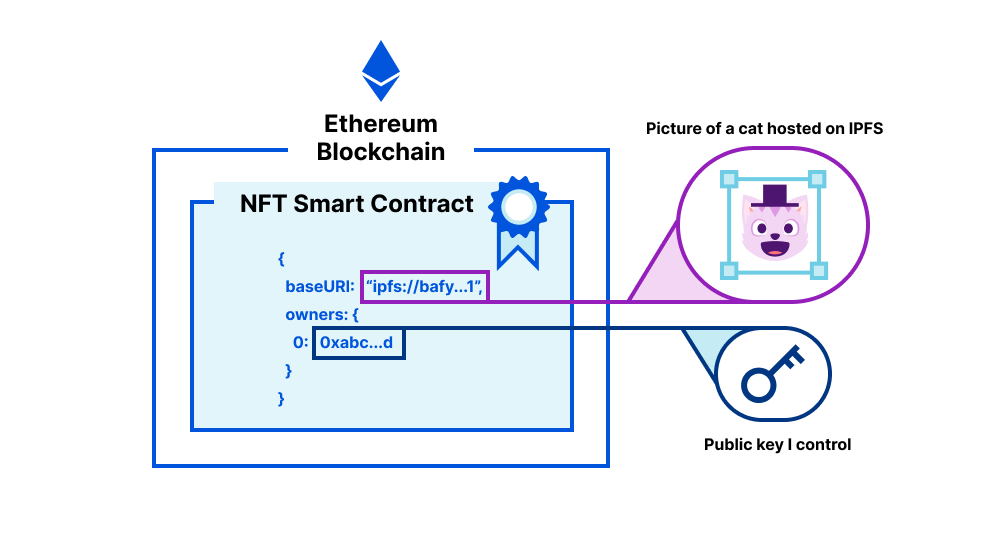


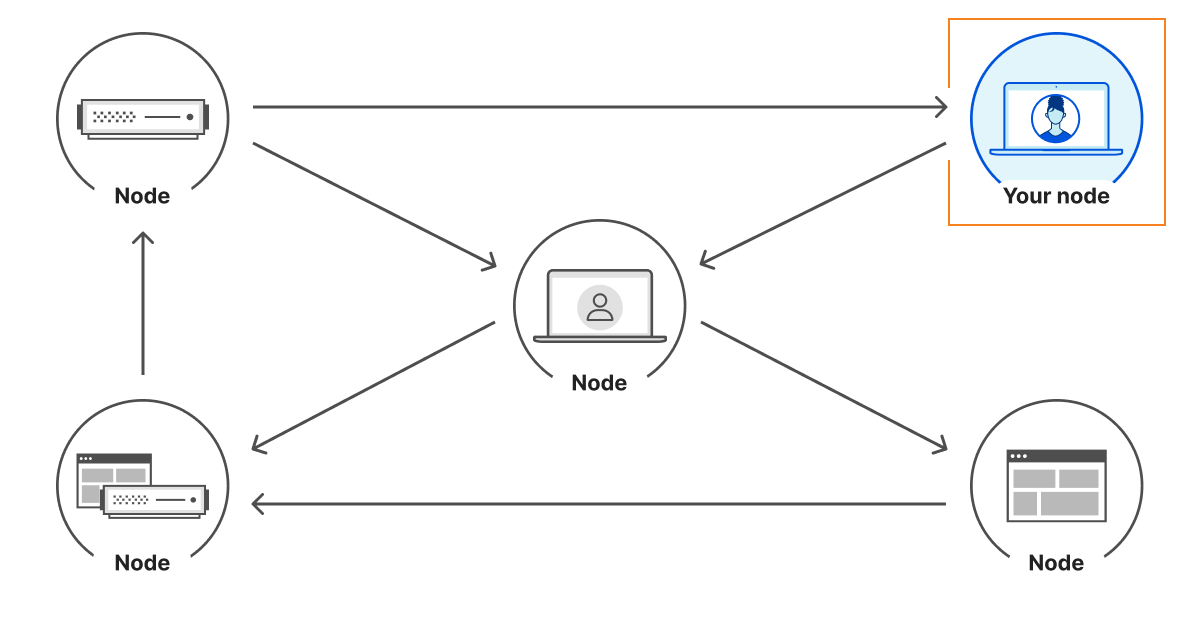
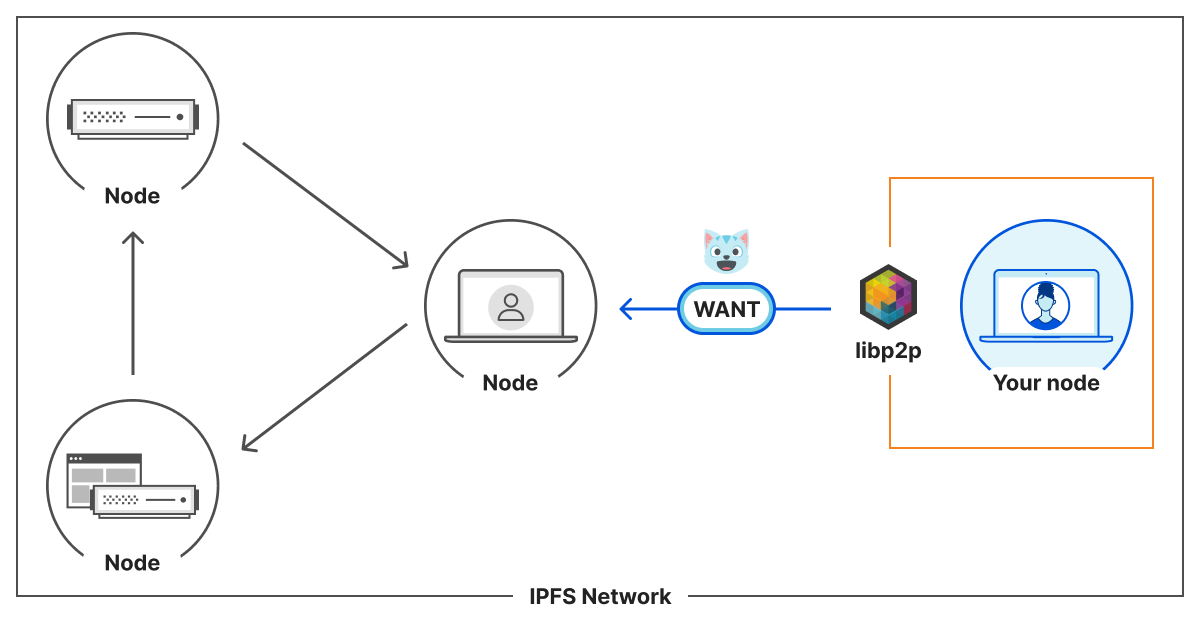
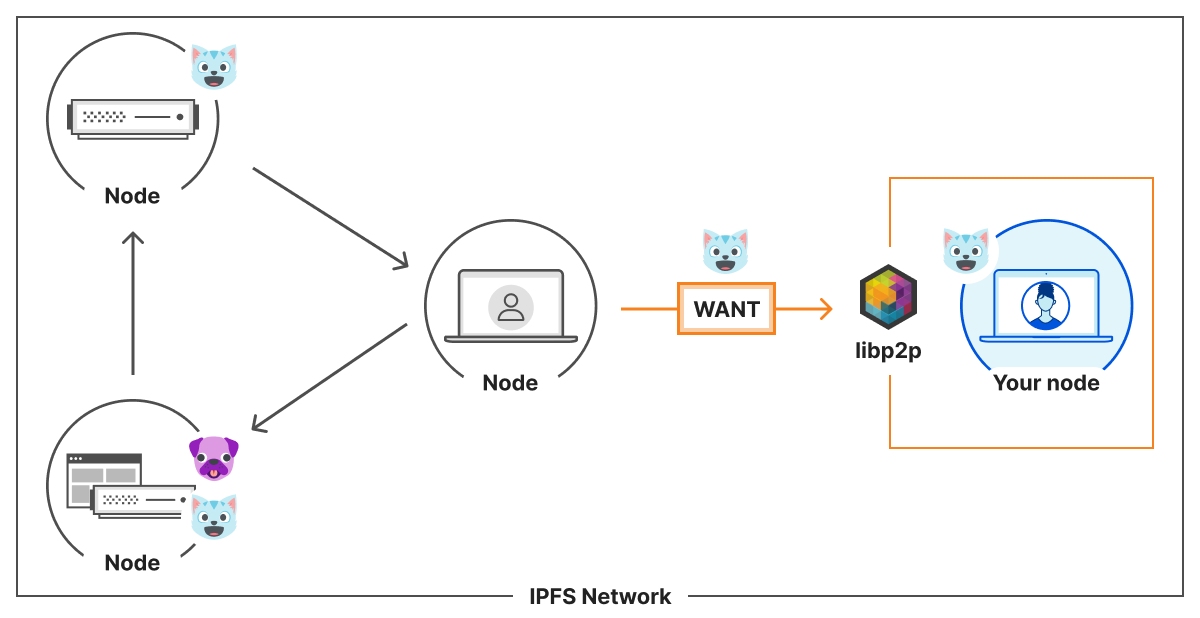
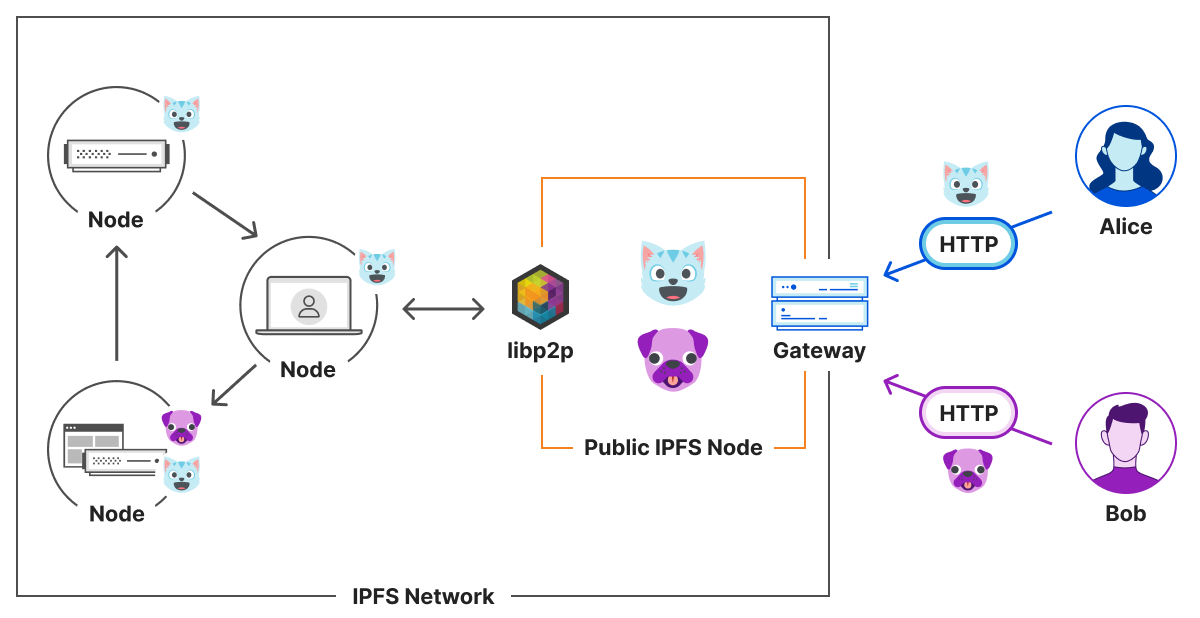
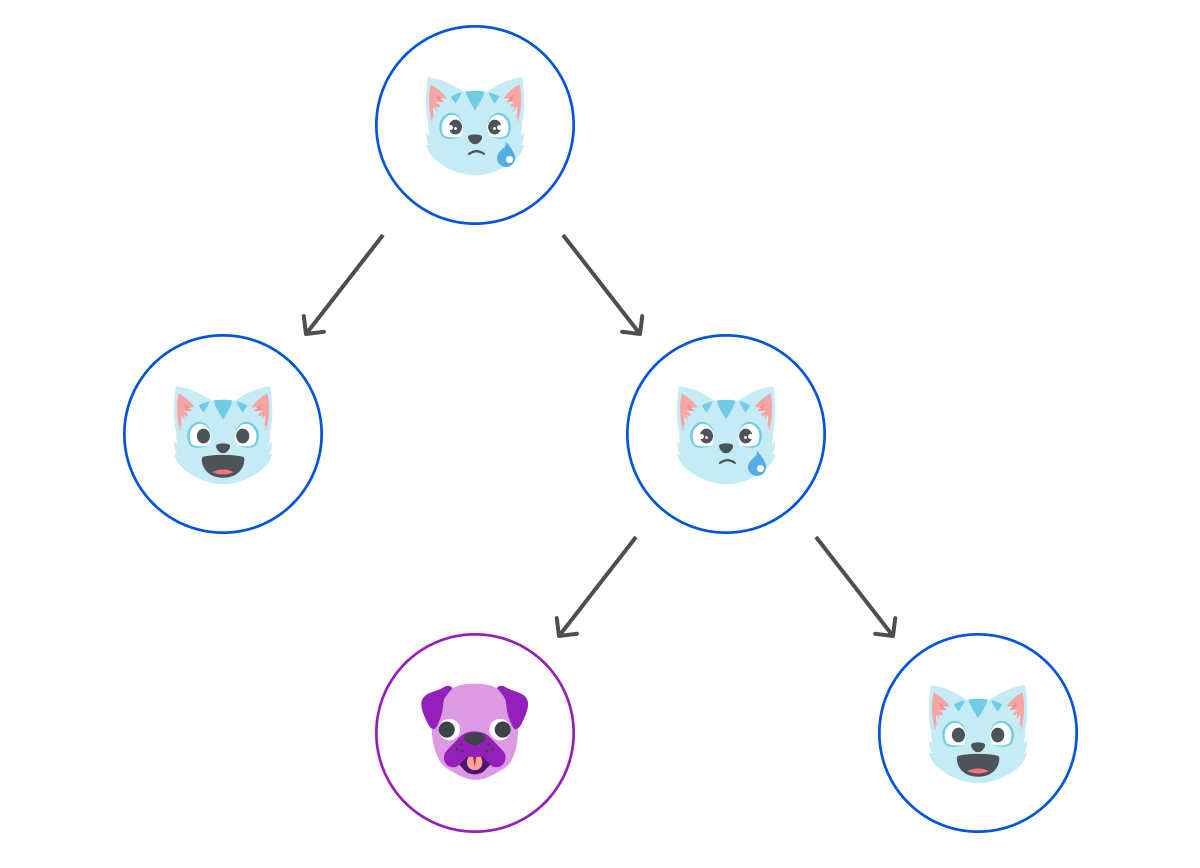




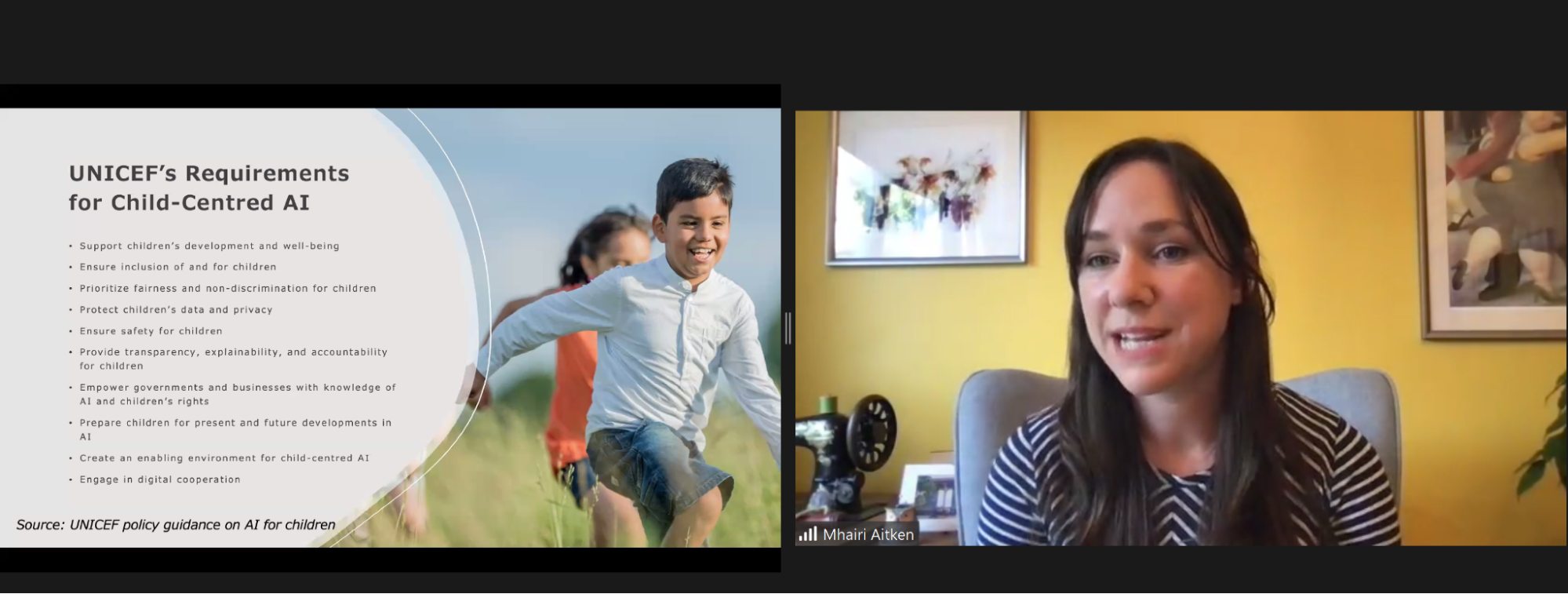









![CVE-2021-3546[78]: Akkadian Console Server Vulnerabilities (FIXED)](https://blog.rapid7.com/content/images/2021/09/akkadian-vuln.jpg)
![CVE-2021-3546[78]: Akkadian Console Server Vulnerabilities (FIXED)](https://blog.rapid7.com/content/images/2021/09/image5.jpg)
![CVE-2021-3546[78]: Akkadian Console Server Vulnerabilities (FIXED)](https://blog.rapid7.com/content/images/2021/09/image3-1.png)
![CVE-2021-3546[78]: Akkadian Console Server Vulnerabilities (FIXED)](https://blog.rapid7.com/content/images/2021/09/image4-1.png)
![CVE-2021-3546[78]: Akkadian Console Server Vulnerabilities (FIXED)](https://blog.rapid7.com/content/images/2021/09/image2-1.png)
![CVE-2021-3546[78]: Akkadian Console Server Vulnerabilities (FIXED)](https://blog.rapid7.com/content/images/2021/09/image6.png)
![CVE-2021-3546[78]: Akkadian Console Server Vulnerabilities (FIXED)](https://blog.rapid7.com/content/images/2021/09/image1-2.png)
![CVE-2021-3927[67]: Fortress S03 WiFi Home Security System Vulnerabilities](https://blog.rapid7.com/content/images/2021/08/fortress-vuln.jpg)
![CVE-2021-3927[67]: Fortress S03 WiFi Home Security System Vulnerabilities](https://blog.rapid7.com/content/images/2021/08/image1.png)
![CVE-2021-3927[67]: Fortress S03 WiFi Home Security System Vulnerabilities](https://blog.rapid7.com/content/images/2021/08/image2-1.png)
![CVE-2021-3927[67]: Fortress S03 WiFi Home Security System Vulnerabilities](https://blog.rapid7.com/content/images/2021/08/image3.png)










