Post Syndicated from original http://www.gatchev.info/blog/?p=2406
Ситуацията в Украйна хич не ми харесва. Нещата, които стигат до мен иззад кулисите – още повече.
Възможно ли е просто да съм уплашен? Или да ме гони параноята? Разбира се. Но е възможно и да съм прав. А кое от двете е реалното – преценете си вие. Или, ако го покажат фактите, си направете изводи.
Малко скучна теория
Описанието почва доста отдалече – нещата в него са важни за разбирането на ситуацията. И е поразводнено – пиша го много набързо, за което поднасям извинения.
Всяка икономическа система си има два етапа на развитие – екстензивен и интензивен. Примерно съвременната индустриално-пазарна икономика отначало заменя мотиките с трактори, прави излишните селяни на работници, разорава целините и т.н. Екстензивен растеж – усвояват се налични крайни, изчерпваеми ресурси… Когато се изчерпят – колкото може селяни са направени на работници, колкото има целини са разорани и т.н. – започва интензивният етап. На който вече за да намериш работници за нов завод трябва да закриеш стар (не-заети с високопроизводителен труд вече няма), за да построиш нова сграда трябва да разрушиш стара (свободно място вече няма), и т.н.
Защо е важно това? Авторитарните и демократичните системи имат различни силни и слаби страни. Много опростено: авторитарните са по-силни на екстензивния етап, заради централизираната си координация. Пуснете на два еднакви девствени острова авторитарна и демократична системи – авторитарната ще усвои изцяло своя остров първа. Но пък демократичните системи са по-силни на интензивния етап, при тях съпротивата срещу замяната на старото с ново във всякакви отношения се преодолява по-лесно.
Къде е важната разлика? Екстензивният етап е фон Нойманов като характеристика на развитие, бързо изчерпва наличните ресурси. Затова и трае десетки пъти по-малко от интензивния. Съответно в началото на икономическата система авторитарните икономики дръпват рязко и изпреварват пазарните. Но стигнат ли до интензивния етап, влизат в стагнация. Съответно демократичните постепенно ги настигат, задминават и надконкурирват до разпад. Примерно през 1930-те СССР расте с двуцифрени темпове, докато западните икономики ги тресат кризи и депресии. Или пък Германия след катастрофата от Първата световна прави невиждана експлозия на развитие след централизирането на икономиката си под Хитлер, за няма десет години задминава победителите си Англия и Франция… Но малко след средата на 1930-те екстензивният етап за западните икономики приключва и започват да се съвземат. А пък през 1950-те етапът приключва и за СССР (и сателитите му), и в тях започва стагнация. Как свършва това надпреварване знаем.
(Ако питате къде е в картинката Хитлер – идеологията му го притисна към военна експанзия преди да успее да го притисне икономическия преход. Ако беше лидер с мирна визия, до още година-две щеше да приключи екстензивния етап на развитие, и до още максимум 2-3 години след това нуждата от военна експанзия пак щеше да е дошла, с брутална сила заради бързия растеж. А и неговият тип икономика е доста авторитарен, близо до китайския модел. В такива тя притиска много по-тежко, отколкото би притиснала примерно САЩ или някоя западноевропейска страна… Така че Втората световна беше въпрос не на „дали“, а на „кога“.)
От теорията – към практиката
В момента Русия и Китай са на етапа на преход от екстензивен към интензивен растеж. При Русия този преход е доста замазан и постепенен. Започна още преди към 15 години, на базата на оставеното от СССР наследство, и вероятно ще продължава поне още 20-30. Съответно спадането на растежа и стагнацията са разточени върху няколко десетилетия – руските управници не са твърде притиснати от ситуацията. Китай обаче тръгва от де факто феодализъм, и западните фирми и технологии и безмилостната експлоатация на китаеца съградиха индустриална икономика в него с темпове почти като на Хитлерова Германия. За трийсет години – от дървените мотики до първа по сравними цени икономика на света. Няма как преходът да не е рязък и брутален, със силна стагнация след него.
Какъв е резултатът? Дойде ли стагнацията, авторитарната система реагира според ситуацията си. Ако стагнацията е мека и постепенна, околният свят е тежко въоръжен с атомно оръжие и лидерите са хора без много мечти и амбиции извън техния си санджак, ще си кротуват и ще се радват на султанатите си. Ако обаче стагнацията е рязка, околният свят е слаб и разделен, и лидерите са с амбиции да го тъпчат, имат чудесен вариант – военна експанзия. Хем обявяват военни положения и разстрелват и най-дребното несъгласие в страните си, хем прибавят лебенсраум.
Защото са зли психопати ли го правят? Психопатите са със силно еволюционно предимство в авторитарната система, тя винаги издига на върха си такива. Но по-страшното е, че освен психопата на върха тя издига и психопати и под него, които дебнат да заемат мястото му на всяка цена, дори с риск за живота им. Така че този на върха не може да си позволи никаква слабост в управлението на държавата, ще му коства поста, а с него и главата. Ако е мухльо, сложен на върха като компромис, може и да го пратят да председателства някой забутан колхоз, но свален силен лидер не могат да си позволят да го оставят жив, винаги ще е твърде опасен. Това е един от структурните проблеми на авторитарната система – няма механизъм за мирно пенсиониране на силен лидер.
(Жокер: нито Путин, нито Кси са компромисни мухльовци.)
Ето затова мине-не мине, войските на Русия нагазват където е по-беззащитно и късат по някое парче, да поддържат широка опора за Фюрера сред „патриотизираната“ тълпа. Кога в Молдова, кога в Грузия, кога в Украйна… Путин не е кръволок, би бил щастлив да минава без това. Или поне да спазва подписа си под гаранцията, че ще пази териториалната цялост на Украйна, ако тя се откаже от ядреното оръжие. Само че би означавало сам да влезе в ковчега…
Проблемите на Путин са проблеми на Кси на десета степен. Ако има около някой трон по-безмилостни главорези от тези около руския, това е китайският. И Китай вече влиза в интензивния етап с трясък. Все още рапортува официално годишен растеж от 5-6-7%, но и това е доста надолу от обичайните за последните десетилетия 10-15%. А косвените данни показват, че е лъжа и че реалният растеж вече е не повече от 2-3%. И вероятно и ще продължава да спада… Така че Кси вече е изправен пред проблема „военна експанзия или смърт“.
Съотборници или противници?
В момента Путин изглежда големият проблем и страшният агресор, но не е. Русия временно е сравнително стабилизирана, той не е в остра нужда от външна агресия. Кси обаче е. И, за разлика от Хитлер, той е не маниакален идеолог, а наследник на 5000 години традиция на манипулиране на околните да се избиват едни други, за да печели Китай. За него Русия е просто средство, с което да отвлече войските на „врага“ (НАТО и САЩ) по-далеч от Тайван, или където другаде Кси реши да атакува.
Какво прави Кси? Съюз с Русия. Срещу мръсния империализъм, който ги обгражда, въоръжава съседните им страни… и абе изобщо, не ще да се предаде доброволно и да признае превъзходството на арийската раса. Малко учения, съвместни действия, един-два тайни договора. И преди към година и половина – договореност как да действат заедно, по взаимна изгода.
Путин също е играч от класа. Хем е щастлив от тази договореност, хем не много. Затова играе с Китай, но и си прави своите сметки.
Защо е щастлив? Ако около Китай има наистина лакома хапка, това е Русия. Огромна територия, огромни ресурси, слабо защитени срещу такъв като Китай. Русия няма и 150 милиона население – Китай може да мобилизира 300 милиона армия. И има индустрията да я снабдява с оръжия, над 20 пъти руската. Да, Русия има купища атомно оръжие и може за минути да анихилира 200-300 милиона китайци. От което другарят Кси ще си го премести в другия крачол. В Китай има точно един китаец, чийто живот струва за Кси повече от нищо, и това е той самият. Десет години по-късно Китай ще е една трета от земното кълбо, ако не и повече, а Кси – най-великият император в историята му… И Путин разбира този начин на мислене много добре, твърде сходен е с неговия собствен. Така че е много щастлив, че подобно развитие се отлага.
А защо Путин не е много щастлив? Защото знае и че и Кси разбира какво разбира той, и че отлагането няма да е безплатно. Че ще се наложи да участва в някои китайски планове. И че дори да превземат заедно с Кси целия свят, след това Китай пак ще се обърне срещу Русия – и тя няма да може да го спре. Така че се налага да си прави плановете много внимателно – иначе падането на Русия ще е не „дали“, а „кога“.
Генералната репетиция
През януари миналата година планът влезе в действие. Русия се заподготвя за атака срещу Украйна, Китай – срещу Тайван. Сметката беше да ангажират САЩ едновременно в две войни на двата противоположни края на света. Разпокъсани така, САЩ вероятно ще изгубят и двете. А откажат ли се да участват, външнополитическата им катастрофа ще е равностойна на двойно военно поражение. И в двата случая целият свят ще премине на страната на Русия и Китай. На цената, естествено, на безпрекословно подчинение.
Само че Джо Байдън се оказа лисица, която разбира този начин на мислене и знае как да му противостои ефективно. Моментално разбра, че слабото звено в картинката е Путин, и оказа върху него адекватния вид натиск. Обясни му, че няма да прати нито един войник в Украйна, а ще концентрира цялата си армия в Тайван, за да разгроми там китайците – разположи ли я всичката на враждебна за тях територия, ще успее. А Украйна ще зарине с оръжия и пари. И евросъюзниците от НАТО с удоволствие ще помогнат – те са военни джуждета, но не и икономически или индустриални. Бъдат ли така оборудвани, украинците ще поотстъпят, но вероятно ще успеят да задавят руската армия до окопна война, и няма да подписват примирия на тези позиции. А окопната война е война на изтощение, печели я по-силната икономика. С икономиките на САЩ и Русия зад Украйна и разгромен в Тайван Китай, Русия ще изгуби тази война. А Путин – вероятно главата си… И когато към тоягата се прибави и морков – обещание за международна среща, на която Путин да може да блесне – Путин предаде Кси. Спаси си главата.
(Байдън би трябвало да не е загадка за всеки мислещ българин. Ние вече сме имали управник, който изглеждаше идиот, но 35 години седя на власт сред също жадни за власт психопати и нищо не можеше да го помръдне. Чак докато не направи истинската глупост – да се опъне на промени, наредени от Москва… И Байдън винаги е трупал издънка върху издънка – правел е идиотски лапсуси, изглеждал е палячо и като почне да говори, е забравял да спре. Само че вече почти 50 години е непоклатим конгресмен и сенатор в Сената на САЩ. Също място, където недостатъчно акълните не могат и да припарят, камо ли да се задържат. Не е редно мислещ българин да не си зададе въпроса идиот ли е всъщност, или…)
Само че ако Путин беше изкаран от войната с голи обещания, Китай беше изкаран без дори да му се обърне капка видимо внимание. Падна по лице с трясък, без дори да са го погледнали накриво. Дипломатите по света се подрискаха от смях, китайският авторитет олекна осезаемо, вместо да натежи. Познайте дали това хареса на Кси. Да, не беше достатъчно, за да го свали от трона (доколкото знаем – пословично е как си приличат китайците…), но няма и как да го е направило щастлив.
Началото на пиесата
Какво е станало между Русия и Китай през пролетта и началото на лятото на 2021, мога само да се досещам. Май е било по-тайно от повечето дипломатически договорки… Но резултатът започна да се вижда още в началото на лятото. Русия продължи да доставя на ЕС договорените количества газ, но нищо повече. А част от потреблението на руски газ в ЕС винаги е било пряко купуване на борсата… И към началото на зимата всички газохранилища в ЕС, които разчитат на руски газ, се оказаха на практика празни. А ЕС политиците решиха, че руснаците просто ще се опитват да качват цената на газа и да натискат за Северен поток – 2. Къде им беше акълът, та не мислиха за военни развития дори след януарската криза, не знам. Европолитиците често са идиоти в това отношение, историята го доказва.
В тази ситуация наглед Путин е агресивен самодържец, но на практика е притиснат в ъгъла. И Западът е, който може да му осигури накъде да се измъкне. Осигури ли му, той ще се измъкне, не е глупав… Проблемът е, че Западът е глупав. Там руско-китайският начин на мислене е познат и разбираем за буквално единични политици, особено в САЩ…
Сега сме в същата ситуация като през януари, но този път много по-сериозна. От видимото: Русия спря доставките на газ за ЕС през украинските газопроводи. Турция беше изкарана от руската орбита и почна да доставя оръжие на Украйна – не ща да мисля какъв натиск е бил, за да огъне Ердоган. Натовски самолети разтоварват в Украйна оръжие и военни инструктори с бесни темпове и правят разузнавателни полети над Източна Украйна – преди първото беше в много по-скромни обеми, а второто изобщо го нямаше. Украйна обяви резервистки списъци за всички мъже и жени под 60 години – както високата възраст, така и ангажирането на жените е без аналог в историята ѝ. Швеция обяви повишена бойна готовност за армията си, и се готви да обяви готовност за евакуация на градовете и мобилизация на населението… Има и още много неща, и всичките ги нямаше при предишната криза. И говорят за същото – този път войната ще е трудна за избягване.
Новостите от последния момент
Планът за преговори беше за 10 януари за телефонен разговор между Путин и Байдън, а на 12 – за преговори между НАТО и Русия. Но от Белия дом днес изнесоха, че Путин е поискал спешен разговор с Байдън тази вечер, в 22:30 българско време… Кой и с какво може да накара Путин да си промени рязко плановете до степен да се моли на Байдън за спешен разговор? Точно един човек – Кси. И с нищо по-малко от директна заплаха или за война с Русия, или за живота на Путин. Добра демонстрация кой от двамата в каква позиция е в техния съюз.
А също и колко сериозно е ангажиран Китай с идеята за война срещу Запада. Или по-точно за война на Русия срещу Запада, за да срещне по-малко съпротива в Тайван. Колко здраво ще бъде притисната Русия да стигне на всяка цена до война с НАТО, и по възможност директно със САЩ… Аз лично смятам да следя изказванията на Белия дом след разговора много внимателно. (Кремъл не вярвам да даде информация по въпроса.)
Възможно ли е избягването на войната?
Ако Западът е наистина адекватен, ще търси как да даде на Путин изход от ъгъла. Да, в противен случай дори при успешен руски блицкриг в Украйна може буквално да срине руската икономика, със съответните последствия за Путин. Но този път натискът на Китай вероятно е също на живот и смърт. Знаят отлично руския начин на мислене (същия като техния), имат силни икономически връзки с много руски олигарси (главорезите под Путин), вече веднъж са се парили от руска „измяна“ – с гаранция са се погрижили да няма място за мърдане. Така че този път въпросът е дали Кси ще надманеврира Путин, или Путин (с помощта на Запада) ще надманеврира Кси. Колкото и да е парадоксално, техният съюз всъщност е надлъгване между тях двамата. И именно то е централното, от което зависи сега положението в света.
Какво следва?
Путин ще бави нещата колкото може да изтърпи Китай, за да даде на Запада възможност да му даде изход от ъгъла. Но пък Китай ще притиска Путин да бърза колкото се може повече, именно за да не даде на Запада възможност да даде на Путин изход. И очевидно има лостовете да притисне Путин до смърт… Така че нещата нищо чудно да се развият по-бързо, отколкото очакваме. А и да стигнат по-далече – може би много по-далече.
Ако Путин получи изход от ъгъла, Украйна ще се спаси. (Този път. Следващият може да е и много скоро – Китай няма да се откаже от военната експанзия, и успехът му в нея зависи от помощта на Русия. Така че дори този път да се мине с мир…) Ако (май по-скоро когато) не го получи, ще нападне Украйна. Кси ще го подкрепя „прикрито“ икономически (ако се наложи – вероятно и военно) и ще следи развитието. Успее ли Русия да прегази Украйна, Кси ще натисне Путин да продължи и към източноевропейските членки на НАТО, за да ангажира САЩ там, и вероятно ще успее. Путин пък вероятно ще поиска първо Китай да нападне Тайван, за да няма възможност САЩ да анихилират руската армия по бързата процедура, преди военната сила да им е потрябвала извън Европа. Може би също ще успее – руската армия има няколко много боеспособни единици, но масата ѝ е пушечно месо. Бъдат ли унищожени боеспособните единици, Русия може да се окаже неспособна да спре натовските армии. А те вероятно ще са амбицирани да се докажат след потенциална загуба на САЩ в Тайван, и ще се опитат да прегазят останалата без ресурси за съпротива Русия. Стигне ли се дотам, Путин ще си изгуби главата още в хода на войната. Съответно при този вариант той може дори официално да смени страните и да се съюзи със Запада срещу Китай – и Кси знае това. Така че има изгода да му помогне, като се ангажира в Тайван преди или едновременно с нападението на Русия срещу НАТО, и да го подкрепя масивно в Украйна и в Европа.
Как ще протече войната в Украйна? Основният удар ще е срещу източните и южни области, да подсигури на Русия дори при по-нататъшно задавяне до окопна война сухопътна граница с Крим и Приднестровието и да откъсне Украйна от Черно море. Най-вероятно ще бъдат бързо прегазени – украинската армия знае, че няма да може да спре първи удар там, ще съсредоточи основните си сили да отбранява Киев. Успее ли да прегази бързо (за седмица-две) Източна и Южна Украйна, Русия ще продължи и срещу Западна. Дали ще смогне да я превземе, и колко бързо ще е, вече е под въпрос. Зависи например от адекватността на украинската армия и западните инструктори в нея, а това е голямо неизвестно.
Ако Русия успее да превземе сравнително бързо и Западна Украйна, натискът от Китай да продължи срещу Източна Европа ще е още по-силен от сегашния. Путин вероятно няма особено желание да го прави, завземането дори само на Източна и Южна Украйна ще е покрило целите му и нуждите на Русия и занапред, а да нападне НАТО е много сериозен риск. Може да се опита да мотае нещата на този етап, да се прави на задавен в Украйна, но надали номерът ще мине пред китайците за дълго. Те търсят да нападнат Тайван, а това със сигурност ще предизвика намесата там на САЩ. А стигне ли се дотам, ще има потенциал дори за варианта с пълна трета световна с ядрено ангажиране. И с разгръщане на войната из целия тихоокеански театър и цяла Европа. (Оттук и реакцията на шведите. Вероятно не са единствената европейска страна, която го прави, просто при тях е по-публично и се разбира.)
Как сме засегнати конкретно българите?
Ако войната се размине този път – вдигаме наздравица и се молим да е за по-дълго. (Но знаем и че надали ще е за повече от година-две, ако и толкова.) Ако обаче започне, търсим как да спасяваме от Русия и Украйна който може да бъде засегнат. Украинското правителство не е така пълно с руски агенти като българското, няма да предаде Украйна на Русия на тепсия. Които и в двете страни са здрави, ще са в риск да бъдат пратени на фронта. Които не са, ще са в риск заради трудностите и военната истерия.
Превземе ли Русия Украйна, там може да стане истински страшно и за напълно аполитичните. За да контролира превзетите територии с военна сила, Русия трябва да ангажира там значителна част от армията си, а тя ще ѝ трябва за в Европа. Затова ще предпочете да ги контролира както контролираше България след 9.9.1944. Ще събере отрепките на обществото, които за нищо не стават и мразят до смърт успелите и талантливите, ще ги въоръжи до зъби и ще им даде карт бланш да убиват, грабят и изнасилват колкото и когото щат, стига да държат положението под руски контрол. И отрепките ще убиват, грабят и изнасилват – най-вече тези, които притежават нещо, заемат някакви позиции, известни са или просто са ценност и стойност сами по себе си. Тези, които те мразят, откакто ги има. Не само местните Богдан Филовци и принц Кириловци, а и местните Райко Алексиевци и Сашо Сладуровци, може би даже още по-напред. Всеки, който не е готов да лиже задника на довчерашния сводник, джебчия, наемен убиец, мафиот…
И това е само началото. Русия няма да може да се противопостави на натиска на Китай да започне война с НАТО, за да ангажира войските му в Европа, далеч от Тайван. В такива ситуации кой плод късат най-напред? Който виси най-ниско към берача. А кой в Европа виси най-ниско към Русия?
И как тя ще задържи под контрол България, след като я превземе? Китайският натиск няма да спре – армията пак ще ѝ трябва, за срещу Западна Европа…
Колко е шансът да се стигне до най-черните варианти? Много ми се иска да е малък, но може и да не е. Затова и пиша този запис – предупреденият е въоръжен. Ако Русия нападне Украйна реално, е важно ситуацията в Тайван да се държи под око. Намеси ли се Китай там, няма да е чудно на България да ѝ остава до руска атака не повече от седмица-две след допрегазването на Украйна. И да е в опасност не само Черноморието, а цяла България.
Как би изглеждала руската атака? Съмнявам се да е с бомбардировки и десант. Правителството ни в момента е гъчкано с руски агенти. Министърът на отбраната се доказа публично и пред НАТО като такъв. Така че най-много Русия просто да пусне в центъра на София десетина парашутисти, които да арестуват няколко най-важни хора и да сложат на тяхно място своите мекерета. Армията ни най-вероятно ще е под заповед са неоказване на никаква съпротива и безпрекословно подчинение на руската, под страх от смъртно наказание… А може и до това да не се стигне – просто някои „отечественофронтовци“ ще вземат властта, вероятно със също толкова смешно количество сила, и ще обявят излизане от НАТО и официален съюз с Русия.
Какво ще последва – този филм вече сме го гледали преди няма и 80 години. И подозирам, че в епохата на съвременните комуникации ще стане доста по-бързо.
С една важна добавка – този път руснаците вероятно ще искат да осигурят руско етническо мнозинство в България. Което значи, че над половината българи може да получат възможността да обикнат Сибир, чрез опознаването му. Примерно всеки, който е постигнал нещо, успял в нещо, станал известен, или дори просто не е любимец на най-долната категория отрепки тук…
Ще стане ли? Не зная. Колко е вероятността? Надявам се да не е много. Но ако Русия прегази цяла Украйна, и Китай нападне Тайван… чувствайте се предупредени.
Пък ако всичко това се окажат просто параноични страхове, аз ще съм най-щастлив.







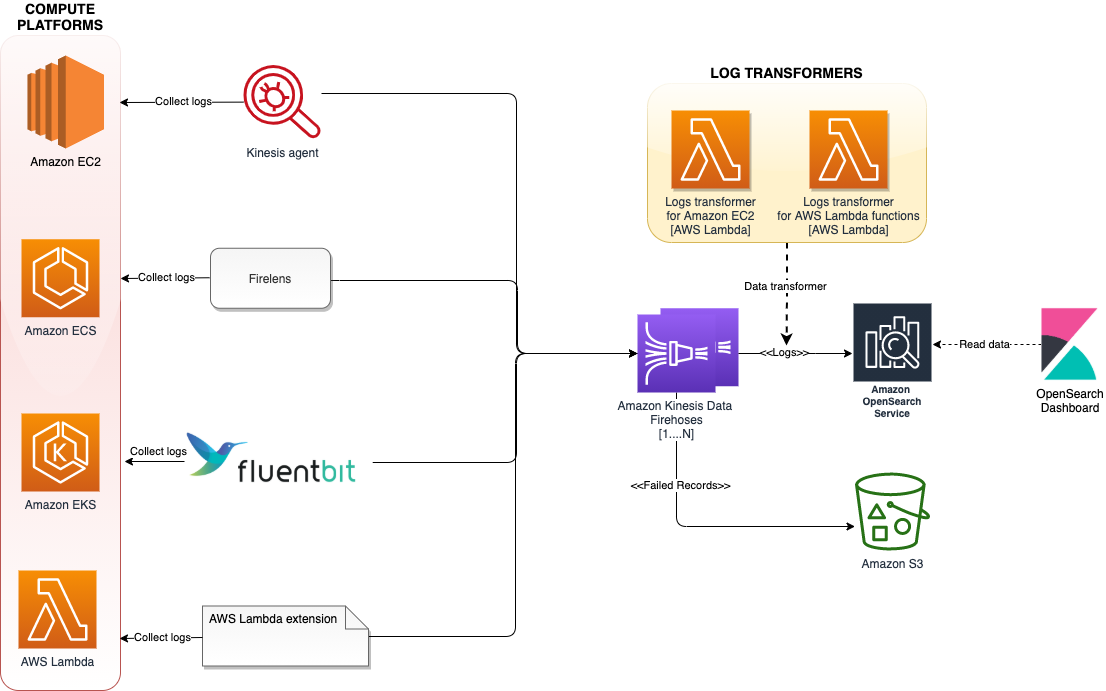




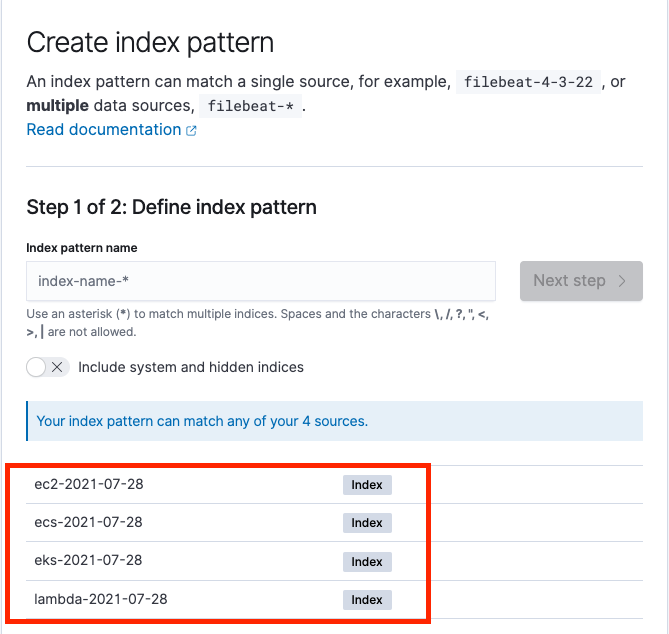
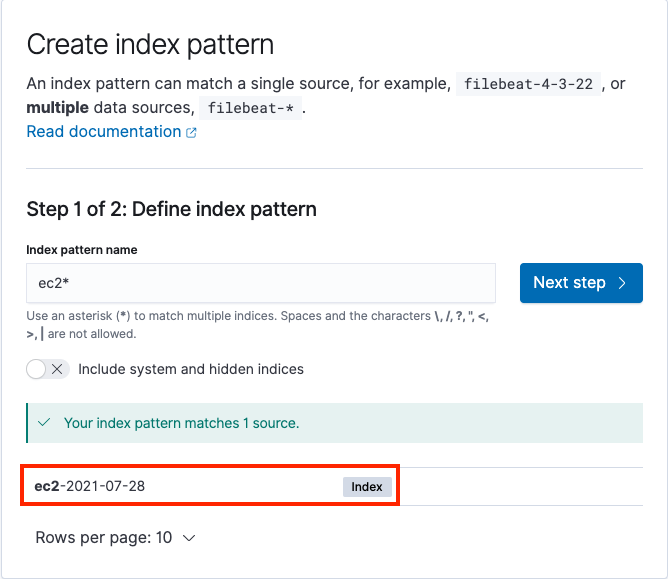

 Hari Ohm Prasath is a Senior Modernization Architect at AWS, helping customers with their modernization journey to become cloud native. Hari loves to code and actively contributes to the open source initiatives. You can find him in Medium, Github & Twitter @hariohmprasath.
Hari Ohm Prasath is a Senior Modernization Architect at AWS, helping customers with their modernization journey to become cloud native. Hari loves to code and actively contributes to the open source initiatives. You can find him in Medium, Github & Twitter @hariohmprasath. Ballu Singh is a Principal Solutions Architect at AWS. He lives in the San Francisco Bay area and helps customers architect and optimize applications on AWS. In his spare time, he enjoys reading and spending time with his family.
Ballu Singh is a Principal Solutions Architect at AWS. He lives in the San Francisco Bay area and helps customers architect and optimize applications on AWS. In his spare time, he enjoys reading and spending time with his family.