Post Syndicated from original https://www.toest.bg/spiderman-sreshtu-chalghata-ili-za-neobhodimostta-ot-populyarna-masova-kultura/

Навремето, докато още следвах магистратура в Софийския университет, изтръпнах, когато в една от лекциите покойният професор Петър-Емил Митев цитира мисъл на Мао Дзъдун, според която празните съзнания са най-хубави, тъй като са бели листове и върху тях можеш да напишеш всичко. Много може да се каже за откровения цинизъм на диктатора, известен с това, че по време на Културната революция използва необразовани младежи, за да тероризира хората на изкуството и науката. Трябва обаче да признаем, че той доста вярно е осъзнал възможността с помощта на пропагандата да програмира още бедни на житейски опит хора в една или друга посока.
В демократичните общества подобна работа в смекчен вариант върши масовата култура – тази, която се потребява от хората и особено от младите в ежедневието им. Точно тук ми се струва, че като общество България има проблем, тъй като се опираме на изключително богатата си традиция от времената преди, около и след Освобождението, но изпускаме съвремието.
Можем ли да сме фенове на собствената си култура?
Факт е, че възходът на българската култура, започнал по време на Възраждането и продължил до налагането на комунистическата диктатура на 9 септември 1944 г., буди възхищение. Още от времената на Пенчо Славейков е популярно да се търсят кусури на Иван Вазов, но истината е, че делото му е внушително. Той сам-самичък създава корпус от текстове, достатъчно голям, за да положи основите на бъдещото развитие на литературата у нас, а една сериозна част от тях са наистина на много високо ниво. Повечето съвременни читатели познават Вазов най-вече с „Под игото“ и с някои от стихотворенията му, но той има голям набор от текстове – от хумористични до приключенски.
В по-късен етап от развитието на книжнината ни силно впечатление прави творчеството на Йордан Йовков и Елин Пелин, като в „Гераците“ според мен виждаме най-точното диагностициране на архетиповете в българската народопсихология, въплътени в образите на тримата братя. Още преди тях нещо подобно обаче прави и Алеко Константинов – не само с широко цитирания „Бай Ганьо“, но и с незаслужено подценявания разказ „Пази боже сляпо да прогледа“. Каквото и да кажем за поезията ни пък, ще е малко. Имената на Ботев, Яворов, Дебелянов, Смирненски и Вапцаров заслужено са записани със златни букви в историята ни и е напълно нормално да се преподават в училище и в университета, макар да не съм убеден, че един тийнейджър може напълно да осмисли всичките им текстове, особено пречупени през обобщенията в христоматиите.
В същото време трябва да сме честни: всички тези автори са далеч от съзнанието и вълненията на повечето юноши. Една от причините за това е начинът, по който ги преподаваме – като свещени писания, пред които можем само да се прекланяме, но като че ли не можем да почувстваме като – ще ме извините за съвременния термин – фенове. Друга причина обаче е самото естество на юношеството, когато се формираме като личности, застанали на границата между детството и зрелостта. Ако трябва да бъдем откровени, едва ли и американските тийнейджъри прекарват петък вечер зачетени в томовете на Стайнбек и Хемингуей, при цялото ми уважение към онези от тях, които го правят. Съмнявам се и голяма част от руските юноши да издържат на класиците Достоевски и Толстой.
Какво искат младите хора и къде го намират?
Младите копнеят за истории, близки до тях, до емоциите им, до мястото, на което са самите те в живота – между невинността и съзряването. Докато голямата и сериозна литература сякаш предполага известен житейски опит, за да я оцениш истински и по достойнство.
Затова и тийнейджърите, за голямо раздразнение на родители и още повече на учители, често посягат към остросюжетните жанрове, като фентъзи и ужаси, понякога към комикси, често филмирани от Холивуд или пък нарисувани от японската анимация. И колкото и невероятно да звучи, преживяват много с тях, учат се на емпатия от героите им, попиват някои общочовешки ценности, получават простички, но важни дефиниции за доброто и злото и дори да не направят следващата крачка към класиката, водят някакъв духовен живот. За целта обаче трябва да имат тази възможност.
Ясно е, че американчетата в това отношение са най-облагодетелствани. Философията на САЩ, че всеки човек, ако е добър, може да успее, и кредото, че дори и да се провалиш, важното е да си опитал, вместо да живуркаш на сигурно, са направили така, че много хора са си създали кариера с умението да разказват истории, които да стигат до младите. Може да започнем с цялата плеяда автори на комикси от началото на миналия век – Джери Сийгъл и Джо Шустър, Боб Кейн и Бил Фингър, Стан Лий и Стив Дитко, създали супергероите Батман, Супермен и Спайдър-Мен, да минем през писатели като Франк Хърбърт, Стивън Кинг и Джордж Р.Р. Мартин и да стигнем до холивудските магьосници Лукас и Спилбърг. Ще видим, че тези хора са отговорни за голяма част от епосите на нашето време, истории, които в някаква степен играят ролята, изпълнявана в древността от Омировите поеми, а през средните векове – от рицарските романи, с тази разлика, че не са запазени за висшата класа, а са достъпни за всеки. И макар много от техните произведения да са отричани от сериозната критика като комерсиални, те формират определени ценности и базова етика.
Йода, докато шава с големите си уши, учи, че макар и по-лесен, пътят на гнева и омразата води до гибел; Батман, при все страховития си външен вид, отказва да убива дори най-големите престъпници; а Спайдър-Мен, освен че се катери по небостъргачи в прилепнал костюм, казва, че с голямата сила идва и голямата отговорност. Все още помня как гледах сцените във филмите на Сам Рейми за Човека паяк, в които обикновени хора се опитваха да му се притекат на помощ. Голяма част от публиката в киносалона у нас започна да се подхилква и още тогава на инстинктивно ниво разбрах, че има някакъв проблем, макар още да не осъзнавах точно какъв. Проблемът е, че при нас самата концепция за солидарност – да се подложиш на опасност заради някой друг – буди присмех.
Британците, независимо че разчитат на вековна литературна традиция с автори като Шекспир и Дикенс, никак не отстъпват и плениха света с „Властелинът на пръстените“ от Джон Р.Р. Толкин в средата на ХХ век, а после и с „Хари Потър“ в началото на XXI, като има статистики, че поредицата на Дж. К. Роулинг не само запалва цяло едно ново поколение за четенето, но и увеличава умението му да съчувства. Японците, които винаги са умеели да съчетават високото и популярното изкуство, накараха целия свят да гледа аниме, а истории като „Железният алхимик“ на Хирому Аракава отправиха посланието, че трябва повече да се стремиш да даваш, отколкото да вземаш.
Къде обаче сме ние?
Българската култура действително е в подем в последните години, като наградата „Букър“ за „Времеубежище“ от Георги Господинов е доказателство за развитието на литературата ни, маркирано и от успехи като получилия филмова адаптация „Възвишение“ от Милен Русков и романите на Захари Карабашлиев. Това обаче сякаш са произведения все за зрели хора, да не кажа за хуманитаристи, а в произведенията за подрастващи никакви ни няма. Белите листове на младите умове останаха празни, а върху тях чалгата написа онази пуста думичка от три букви, която редовно виждаме надраскана със спрей къде ли не.
Не искам да бъда разбиран погрешно. Всеки има право да слуша каквото си иска. Но когато изборът е беден, чалгата дава храна, която е изключително оскъдна откъм витамини за душата. Тук мерило за успеха са парите, мечтата е момчето да стане богаташ с беемве, а момичето – плеймейтка и бъдеща негова половинка със силиконов бюст. Учудва ли ни тогава това, че голяма част от младите хора са хиперпрагматични, лишени от съчувствие и от мечти (извън успеха на битово ниво).
Не по-малък проблем има и с част от масовите заглавия, които все пак бележат успех. Книгата „Стопанката на Господ“ от Розмари де Мео е сръчно написана и в нея има симпатични хрумки, но наред с това проповядва мислене за България като обсадена крепост – че светът наоколо е враждебен и ние трябва да сме настръхнали срещу него. Лично аз се отказах от тази книга, когато прочетох в нея, че дори с италианците не можем да осъществим контакт. В „Бабо, разкажи ми спомен“ между уюта и вкусните рецепти има вмъкната хомофобска нишка. Знайни и незнайни автори тракат произведения на струната на крайния национализъм с твърдения от типа на това, че крал Артур е българин или че гърците са ни откраднали историята. Нашето е добро, чуждото е лошо – светоглед, завещан от литературата на късния социализъм, която от своя страна е наследница на нискокачествените партизански романи от ранния. След подобни четива няма да е учудващо, ако в един момент се окаже, че младите, които изобщо си направят труда да гласуват, ще пускат бюлетини в подкрепа на популистки партии.
Въпросът е дали има изход от това
Опитът на България показва, че би трябвало. Най-ярък пример е успехът на „Гунди“, показал, че все още можем да разказваме истории, които да развълнуват голям брой хора у нас. Трябва да имаме предвид, че сме изправени пред много трудна ситуация, в която умението ни да се съсредоточаваме е ерозирано от платформи като TikTok и Instagram, целенасочено направени така, че вниманието да не се захваща за нищо, а постоянно да се търсят нови и нови неща. В резултат вече дори гледането на пълнометражен филм се превръща в трудна задача, да не говорим за прочитането на цяла книга.
Не съм съгласен и не приветствам тезата, че западната култура ще надделее над националната, за да формира ценностите на по-голямата част от младите хора. За мен не е добра стратегия да се разчита на това – по няколко причини. Първо, тя не е правена за нас и не е съвсем сигурно, че може да достигне до потребителите тук със същия успех, с който го прави сред основната си аудитория – хората от държавите, в които е създадена. Преведено на прост език, ние, българите, изпускаме много неща от „Хари Потър“, които англичаните улавят. Преди време в разговор с актьора Станислав Яневски (изиграл една от епизодичните роли във филмите от поредицата) научих, че „Хогуортс“, като изключим магиите, е почти реалистично училище, а разделянето на домове и състезанията си ги има и в британските пансиони.
Второ, западната култура не е лишена от недостатъци, особено във варианта си от последните десет години. Най-малкото, окрупняването на развлекателните компании и в киното, и в литературата направи културата свръхкорпоративна и доведе до пресушаване на новите идеи – не е случайно, че на екран излизат само продължения и епизоди от поредици, а на хартия най-вървежни остават основно все едни и същи автори, изгрели в края на миналия или началото на този век.
На трето място, ако се върнем към България, през десетилетията сме доказвали, че можем да създаваме качествени автори със силни произведения. Така бихме били ценни и за новото глобално село, в което, макар и мъчително, се превръща светът – не само като пасивна страна, която потребява, но и като активна, умееща да създава. Това трудно ще стане с патриотична литература колко сме велики и как другите са лоши, а няма и нужда.
По-паметливите фенове на фантастиката си спомнят и приключенските романи на Петър Бобев, като „Каменното яйце“ (1989), разказващ за избягали в Африка тиранозаври години преди „Джурасик парк“, макар твърденията, че Крайтън е вдъхновен от нашия автор, да са малко пресилени (за любопитните – подобен сюжет се появява години по-рано, през 1984 г., в романа Carnosaur на Хари Адам Найт).
За съжаление, вече са забравени книжки като „Педра Пинтада“ на Ангел Сарафов, но за сметка на това мнозина все още са запалени по книгите игри, превърнали се във феномен на родния пазар през 90-те години. Макар и творящи под западни псевдоними, автори като Любомир Николов – Нарви, Георги Миндизов и Богдан Русев създаваха завладяващи приключения, които не само пленяваха въображението на читателите, но и съумяваха да им създадат представи за добро и зло.
Особено изкусен в това отношение беше отишлият си по-рано през тази година Нарви, винаги възнаграждаващ в интерактивните си сюжети моралния избор. Думите ми не стигат да изразя колко ценен беше той лично за мен в един момент, когато за много младежи от моето поколение в идоли се превръщаха героите от криминалната хроника с лъскавите си германски лимузини, тежки мобифони и леки жени, подпяващи попфолк около тях.
В наши дни има сполучливи опити в популярната литература и затова се зарадвах да науча, че романът „Мамник“ от Васил Попов ще бъде адаптиран като филмов сериал. Потенциал показа и поредицата „Софийски магьосници“ на Мартин Колев, започнаха наново да излизат книги игри. Проблемът обаче е, че поне засега тези произведения остават в сравнително по-затворен кръг, най-често на градската интелигенция, която малко или много вече води активен културен живот. Хубаво е, че тя не е оставена да разчита само на преводни творби, но за съжаление, не е достатъчно. Трябва да се измисли начин да се стигне до широк кръг зрители и читатели, особено млади хора, така че те да получат някакви ориентири за добро и зло и в същото време да не става дума за крайния национализъм, делящ всичко на наше и чуждо.
Въпросът как да стане това, е, както се казва, за един милион долара, а часовникът отдавна тиктака. Може би обаче е ясно как няма да стане. Ако заклеймяваме младите хора и нещата, които обичат – аниме, комикси и видеоигри, – със сигурност няма да успеем да направим нищо, освен да ги отчуждим тотално от опитите ни да осъществим контакт с тях. Преди години писателят Рик Риърдън, по онова време учител по литература, беше споделил, че се е чудил защо учениците му четат само „Хари Потър“, и когато разбрал, че имат потребност от книги с подобен емоционален заряд, създал поредицата „Пърси Джаксън“, на свой ред превърнала се в хит. Може би хората, занимаващи се с култура, имаме нужда от подобен подход – първо да чуем младите. И чак след това да опитаме да ги заговорим.
, and the worst case is that someone checks why.")
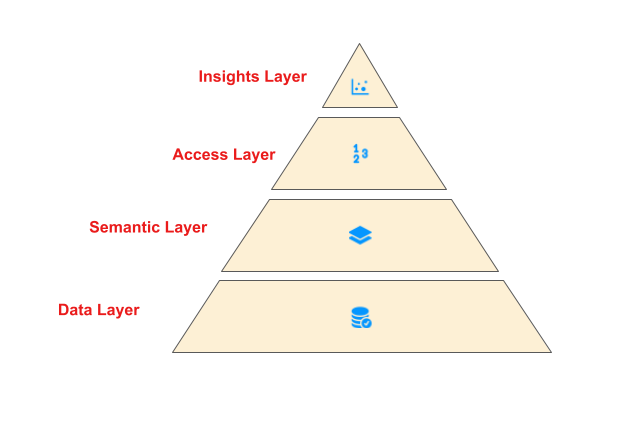









 Neeraja Rentachintala is Director, Product Management with AWS Analytics, leading Amazon Redshift and Amazon SageMaker Lakehouse. Neeraja is a seasoned technology leader, bringing over 25 years of experience in product vision, strategy, and leadership roles in data products and platforms. She has delivered products in analytics, databases, data integration, application integration, AI/ML, and large-scale distributed systems across on-premises and the cloud, serving Fortune 500 companies as part of ventures including MapR (acquired by HPE), Microsoft SQL Server, Oracle, Informatica, and Expedia.com
Neeraja Rentachintala is Director, Product Management with AWS Analytics, leading Amazon Redshift and Amazon SageMaker Lakehouse. Neeraja is a seasoned technology leader, bringing over 25 years of experience in product vision, strategy, and leadership roles in data products and platforms. She has delivered products in analytics, databases, data integration, application integration, AI/ML, and large-scale distributed systems across on-premises and the cloud, serving Fortune 500 companies as part of ventures including MapR (acquired by HPE), Microsoft SQL Server, Oracle, Informatica, and Expedia.com

 Momota Sasaki is an Engineering Manager at DeSC Healthcare, a subsidiary of DeNA. He joined DeNA in 2021 and was seconded to DeSC Healthcare. Since then, he has been consistently involved in the healthcare business, leading and promoting the development and operation of the data platform.
Momota Sasaki is an Engineering Manager at DeSC Healthcare, a subsidiary of DeNA. He joined DeNA in 2021 and was seconded to DeSC Healthcare. Since then, he has been consistently involved in the healthcare business, leading and promoting the development and operation of the data platform. Kaito Tawara is a Data Engineer at DeSC Healthcare, a subsidiary of DeNA, focusing on improving healthcare data platforms. After gaining experience in backend development for web systems and data science, he transitioned to data engineering. He joined DeNA in 2023 and was seconded to DeSC Healthcare. Currently, he works remotely from Nagoya-city, contributing to the enhancement of healthcare data platforms.
Kaito Tawara is a Data Engineer at DeSC Healthcare, a subsidiary of DeNA, focusing on improving healthcare data platforms. After gaining experience in backend development for web systems and data science, he transitioned to data engineering. He joined DeNA in 2023 and was seconded to DeSC Healthcare. Currently, he works remotely from Nagoya-city, contributing to the enhancement of healthcare data platforms. Shota Sato is an Analytics Specialist Solution Architect at AWS Japan, focusing on data analytics solutions powered by AWS for digital native business customers.
Shota Sato is an Analytics Specialist Solution Architect at AWS Japan, focusing on data analytics solutions powered by AWS for digital native business customers.
 Sai Maddali is a Senior Manager Product Management at AWS who leads the product team for Amazon MSK. He is passionate about understanding customer needs, and using technology to deliver services that empowers customers to build innovative applications. Besides work, he enjoys traveling, cooking, and running.
Sai Maddali is a Senior Manager Product Management at AWS who leads the product team for Amazon MSK. He is passionate about understanding customer needs, and using technology to deliver services that empowers customers to build innovative applications. Besides work, he enjoys traveling, cooking, and running. Bill Crew is a Senior Product Marketing Manager. He is the lead marketer for Streaming and Messaging Services at AWS. Including Amazon Managed Streaming for Apache Kafka (Amazon MSK), Amazon Managed Service for Apache Flink, Amazon Data Firehose, Amazon Kinesis Data Streams, Amazon Message Broker (Amazon MQ), Amazon Simple Queue Service (Amazon SQS), and Amazon Simple Notification Services (Amazon SNS). Besides work, he enjoys collecting vintage vinyl records.
Bill Crew is a Senior Product Marketing Manager. He is the lead marketer for Streaming and Messaging Services at AWS. Including Amazon Managed Streaming for Apache Kafka (Amazon MSK), Amazon Managed Service for Apache Flink, Amazon Data Firehose, Amazon Kinesis Data Streams, Amazon Message Broker (Amazon MQ), Amazon Simple Queue Service (Amazon SQS), and Amazon Simple Notification Services (Amazon SNS). Besides work, he enjoys collecting vintage vinyl records.