Post Syndicated from Mangesh Budkule original https://aws.amazon.com/blogs/devops/accessing-amazon-q-developer-using-microsoft-entra-id-and-vs-code-to-accelerate-development/
Overview
In this blog post, I’ll explain how to use a Microsoft Entra ID and Visual Studio Code editor to access Amazon Q developer service and speed up your development. Additionally, I’ll explain how to minimize the time spent on repetitive tasks and quickly integrate users from external identity sources so they can immediately use and explore Amazon Web Services (AWS).Generative AI on AWS holds great ability for businesses seeking to unlock new opportunities and drive innovation. AWS offers a robust suite of tools and capabilities that can revolutionize software development, generate valuable insights, and deliver enhanced customer value. AWS is committed to simplifying generative AI for businesses through services like Amazon Q, Amazon Bedrock, Amazon SageMaker, Data foundation & AI infrastructure.
Amazon Q Developer is a generative AI-powered assistant that helps developers and IT professionals with all of their tasks across the software development lifecycle. Amazon Q Developer assists with coding, testing, and upgrading to troubleshooting, performing security scanning and fixes, optimizing AWS resources, and creating data engineering pipelines.
A common request from Amazon Q Developer customers is to allow developer sign-ins using established identity providers (IdP) such as Entra ID. Amazon Q Developer offers authentication support through AWS Builder ID or AWS IAM Identity Center. AWS Builder ID is a personal profile for builders. IAM Identity Center is ideal for an enterprise developer working with Amazon Q and employed by organizations with an AWS account. When using the Amazon Q Developer Pro tier, the developer should authenticate with the IAM Identity Center. See the documentation, Understanding tiers of service for Amazon Q Developer for more information.
How it works
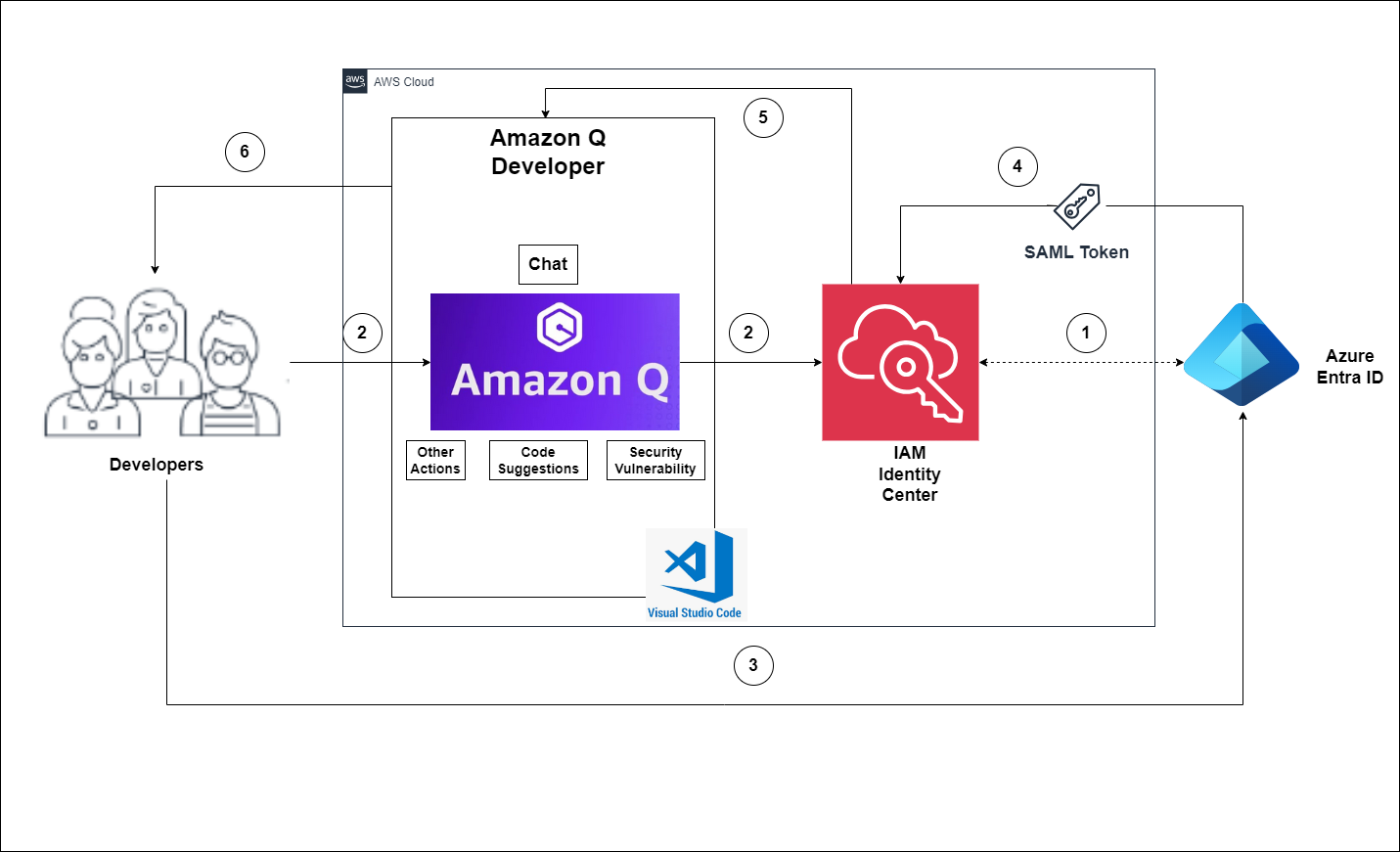
The flow for accessing Amazon Q Developer through the IAM Identity Center involves the authentication of Entra ID users using Security Assertion Markup Language (SAML) 2.0 authentication (Figure 1).

Figure 1 – Solution Overview
The flow for accessing Amazon Q Developer through the IAM Identity Center involves the authentication of Entra ID users using SAML 2.0 authentication. (Figure 1).
- IAM Identity Center synchronizes users and groups information from Entra ID into IAM Identity Center using the System for Cross-domain Identity Management (SCIM) v2.0 protocol.
- Developers with an Entra ID account connect to Amazon Q Developer through IAM Identity Center using the VS Code IDE.
- If a developer isn’t already authenticated, they will be redirected to the Entra ID account login. The developer will sign in using their Entra ID credentials.
- If the sign-in is successful, Entra ID processes the request and sends a SAML response containing the developer identity and authentication status to IAM Identity Center.
- If the SAML response is valid and the developer is authenticated, IAM Identity Center grants access to Amazon Q Developer.
- The developer can now securely access and use Amazon Q Developer.
Prerequisites
In order to perform the following procedure, make sure the following are in place.
Walkthrough
Configure Entra ID and AWS IAM Identity Center integration
In this section, I will show how you can create a SAML base connection between Entra ID and AWS Identity Center so you can access AWS generative AI services using your Entra ID.
Note: You need to switch the console between Entra ID portal and AWS IAM Identity center. I recommend to open new browser tabs for each console.
Step 1 – Prepare your Microsoft tenant
Perform the below steps in the Entra identity provider section.
Entra ID configuration.
- Sign in to the Microsoft Entra admin center with a minimum permission set of a Cloud Application Administrator.
- Navigate to Identity > Applications > Enterprise applications, and then choose New application.
- On the Browse Microsoft Entra Gallery page, enter AWS IAM Identity Center in the search box.
- Select AWS IAM Identity Center from the results area.
- Choose Create.
Now you have created AWS IAM Identity Center application, set up single sign-on to enable users to sign into their applications using their Entra ID credentials. Select the Single sign-on tab from the left navigation plane and select Setup single sign on.
Step 2 – Collect required service provider metadata from IAM Identity Center
In this step, you will launch the Change identity source wizard from within the IAM Identity Center console and retrieve the metadata file and the AWS specific sign-in URL. You will need this to enter when configuring the connection with Entra ID in the next step.
IAM Identity Center.
You need to enable this in order to configure SSO.
- Navigate to Services –> Security, Identity, & Compliance –> AWS IAM Identity Center.
- Choose Enable (Figure 2).

Figure 2 – Get started with AWS IAM Identity Center
- In the left navigation pane, choose Settings.
- On the Settings page, find Identity source, select Actions pull-down menu, and select Change identity source.
- On the Change identity source page, choose External identity provider (Figure 3).

Figure 3 – Select External identity provider
- On the Configure external identity provider page, under Service provider metadata, select Download metadata file (XML file).
- In the same section, locate the AWS access portal sign-in URL value and copy it. You will need to enter this value when prompted in the next step (Figure 4).

Figure 4 – Copy provider metadata URLs
Leave this page open, and move to the next step to configure the AWS IAM Identity Center enterprise application in Entra ID. Later, you will return to this page to complete the process.
Step 3 – Configure the AWS IAM Identity Center enterprise application in Entra ID
This procedure establishes one-half of the SAML connection on the Microsoft side using the values from the metadata file and Sign-On URL you obtained in the previous step.
- In the Microsoft Entra admin center console, navigate to Identity > Applications > Enterprise applications and then choose AWS IAM Identity Center.
- On the left, choose Single sign-on.
- On the Set up Single sign on with SAML page, choose Upload metadata file, choose the folder icon, select the service provider metadata file that you downloaded in the previous step 2.6, and then choose Add.
- On the Basic SAML Configuration page, verify that both the Identifier and Reply URL values now point to endpoints in AWS that start with https://<REGION>.signin.aws.amazon.com/platform/saml/.
- Under Sign on URL (Optional), paste in the AWS access portal sign-in URL value you copied in the previous step (Step 2.7), choose Save, and then choose X to close the window.
- If prompted to test single sign-on with AWS IAM Identity Center, choose No I’ll test later. You will do this verification in a later step.
- On the Set up Single Sign-On with SAML page, in the SAML Certificates section, next to Federation Metadata XML, choose Download to save the metadata file to your system. You will need to upload this file when prompted in the next step.
Step 4 – Configure the Entra ID external IdP in AWS IAM Identity Center
Next you will return to the Change identity source wizard in the IAM Identity Center console to complete the second-half of the SAML connection in AWS.
- Return to the browser session you left open in the IAM Identity Center console.
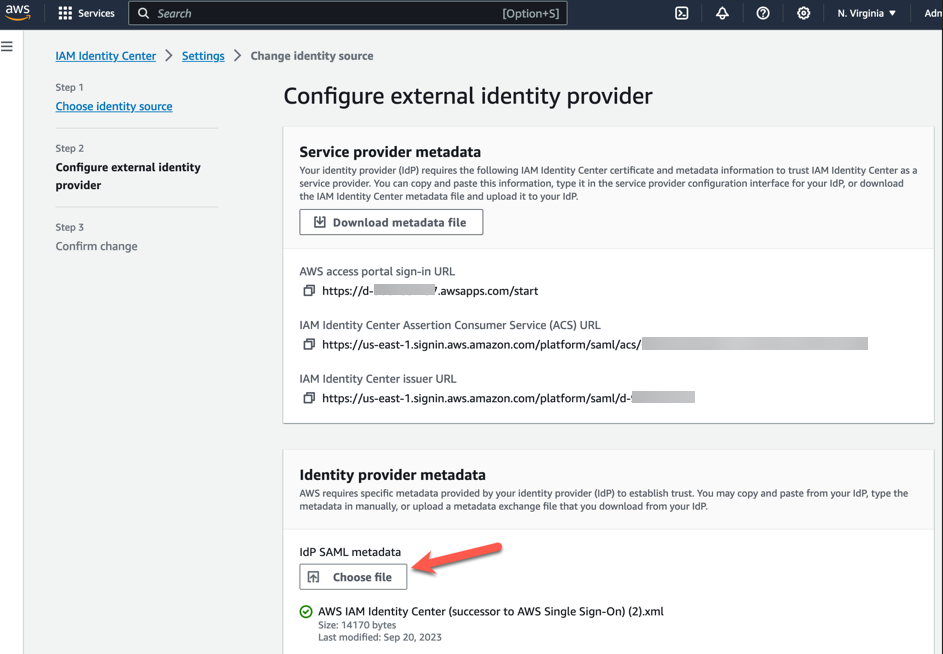
- On the Configure external identity provider page, in the Identity provider metadata section, under IdP SAML metadata, choose the Choose file button, and select the identity provider metadata file that you downloaded from Microsoft Entra ID in the previous step, and then choose Open (Figure 5).

Figure 5 – AWS IAM Identity center metadata
- Choose Next
- After you read the disclaimer and are ready to proceed, enter ACCEPT
- Choose Change identity source to apply your changes (Figure 6).

Figure 6 – AWS IAM Identity center metadata
- Confirm the changes (Figure 7).

Figure 7 – AWS IAM Identity center metadata configuration changes progress console.
Step 5 – Configure and test your SCIM synchronization
In this step, you will set up automatic provisioning (synchronization) of user and group information from Microsoft Entra ID into IAM Identity Center using the SCIM v2.0 protocol. You configure this connection in Microsoft Entra ID using your SCIM endpoint for AWS IAM Identity Center and a bearer token that is created automatically by AWS IAM Identity Center.
To enable automatic provisioning of Entra ID users to IAM Identity Center, follow these steps using the IAM Identity Center application in Entra ID. For testing purposes, you can create a new user (TestUser) in Entra ID with details like First Name, Last Name, Email ID, Department, and more. Once you’ve configured SCIM synchronization, you can verify that this user and their relevant attributes were successfully synced to AWS IAM Identity Center.
In this procedure, you will use the IAM Identity Center console to enable automatic provisioning of users and groups coming from Entra ID into IAM Identity Center.
- Open the IAM Identity Center console and Choose Setting in the left navigation pane.
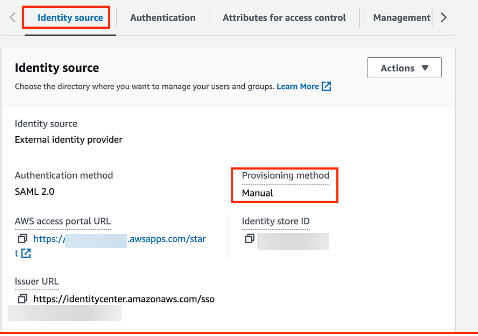
- On the Settings page, under the Identity source tab, notice that Provisioning method is set to Manual (Figure 8).

Figure 8 – AWS IAM Identity center console with provisioning method configuration details
- Locate the Automatic provisioning information box, and then choose Enable. This immediately enables automatic provisioning in IAM Identity Center and displays the necessary SCIM endpoint and access token information.
- In the Inbound automatic provisioning dialog box, copy each of the values for the following options. You will need to paste these in the next step when you configure provisioning in Entra ID.
- SCIM endpoint – For example, https://scim.us-east-2.amazonaws.com/11111111111-2222-3333-4444-555555555555/scim/v2/
- Access token – Choose Show token to copy the value (Figure 9).

Figure 9 – AWS IAM Identity center automatic provisioning info
- Choose Close.
- Under the Identity source tab, notice that Provisioning method is now set to SCIM.
Step 6 – Configure automatic provisioning in Entra ID
Now that you have your test user in place and have enabled SCIM in IAM Identity Center, you can proceed with configuring the SCIM synchronization settings in Entra ID.
- In the Microsoft Entra admin center console, navigate to Identity > Applications > Enterprise applications and then choose AWS IAM Identity Center.
- Choose Provisioning, under Manage, choose Provisioning
- In Provisioning Mode select
- For Admin Credentials, in Tenant URL paste in the SCIM endpoint URL value you copied earlier. In Secret Token, paste in the Access token value (Figure 10).

Figure 10 – Azure Enterprise AWS IAM Identity center application provisioning configuration tab
- Choose Test Connection. You should see a message indicating that the tested credentials were successfully authorized to enable provisioning (Figure 11).

Figure 11 – Azure Enterprise AWS IAM Identity center application provisioning testing status
- Choose Save.
- Under Manage, choose Users and groups, and then choose Add user/group.
- On the Add Assignment page, under Users, choose None Selected.
- Select TestUser, and then choose Select.
- On the Add Assignment page, choose
- Choose Overview, and then choose Start provisioning (Figure 12).

Figure 12 – AWS IAM Identity center application Start provisioning tab
Note : The default provisioning interval is set to 40 minutes. Our users (Figure 13) are successfully provisioned and are now available in the AWS IAM Identity Center console.
In this section, you will verify that TestUser user was successfully provisioned and that all attributes are displayed in IAM Identity Center (Figure 13).

Figure 13 – AWS IAM Identity center application user console example
Preview (opens in a new tab)
In the Identity source in IDC section, enable Identity-aware console sessions (Figure 14). This enables AWS IAM Identity Center user and session IDs to be included in users’ AWS console sessions when they sign in. For example, Amazon Q Developer Pro uses identity-aware console sessions to personalize the service experience.

Figure 14 – Enable Identity aware console sessions
I have completed Entra ID and AWS Identity Center configuration. You can see Entra ID identity synced successfully with AWS IAM identity center.
Step 7 – Set up AWS Toolkit with IAM Identity Center
To use Amazon Q Developer, you will now set up the AWS Toolkit within integrated development environments (IDE) to establish authentication with the IAM Identity Center.
AWS Toolkit for Visual Studio Code is an open-source plug-in for VS Code that makes it easier for developers by providing an integrated experience to create, debug, and deploy applications on AWS. Getting started with Amazon Q Developer in VS Code is simple.
- Open the AWS Toolkit for Visual Studio Code extension in your VS Code IDE. Install AWS Toolkit for VS Code, which is available as a download from the VS Code Marketplace.
- From the AWS Toolkit for Visual Studio Code extension in the VS Code Marketplace, choose Install to begin the installation process.
- When prompted, choose to restart VS Code to complete the installation process.
Step 8 – Setup Amazon Q Developer service with VS Code using AWS IAM identity center.
After installing the Amazon Q extension or plugin, authenticate through IAM Identity Center or AWS Builder ID.
After your identity has been subscribed to Amazon Q Developer Pro, complete the following steps to authenticate.
- Install the Amazon Q IDE extension or plugin in your Visual Studio Code.
- Choose the Amazon Q icon from the sidebar in your IDE
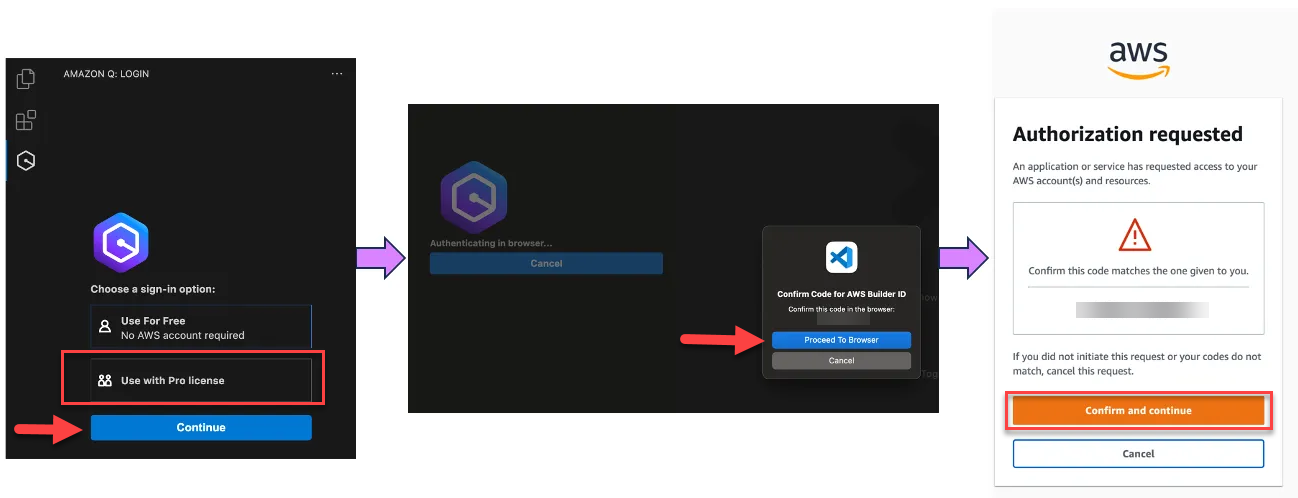
- Choose Use with Pro license and select Continue (Figure 15).

Figure 15 – Visual Studio code Amazon Q Developer extension
- Enter the IAM Identity Center URL you previously copied into the Start URL
- Set the appropriate region, example us-east-1, and select Continue
- Click Copy Code and Proceed to copy the code from the resulting pop-up.
- When prompted by the Do you want Code to open the external website? pop-up, select Open
- Paste the code copied in Step 6 and select Next
- Enter your Entra ID credentials and select Sign in
- Select Allow Access to AWS IDE Extensions for VSCode to access Amazon Q Developer (Figure 16).

Figure 16 – Allow VS Code to access Amazon Q Developer
- When the connection is complete, a notification indicates that it is safe to close your browser. Close the browser tab and return to your IDE.
- You are now all set to use Amazon Q Developer from within IDE, authenticated with your Entra ID credentials.
Step 9 – Test configuration examples
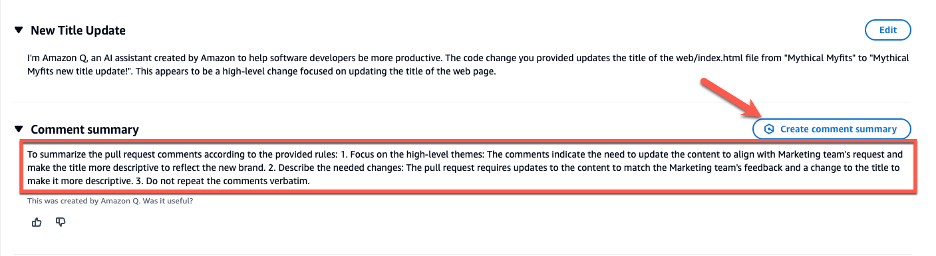
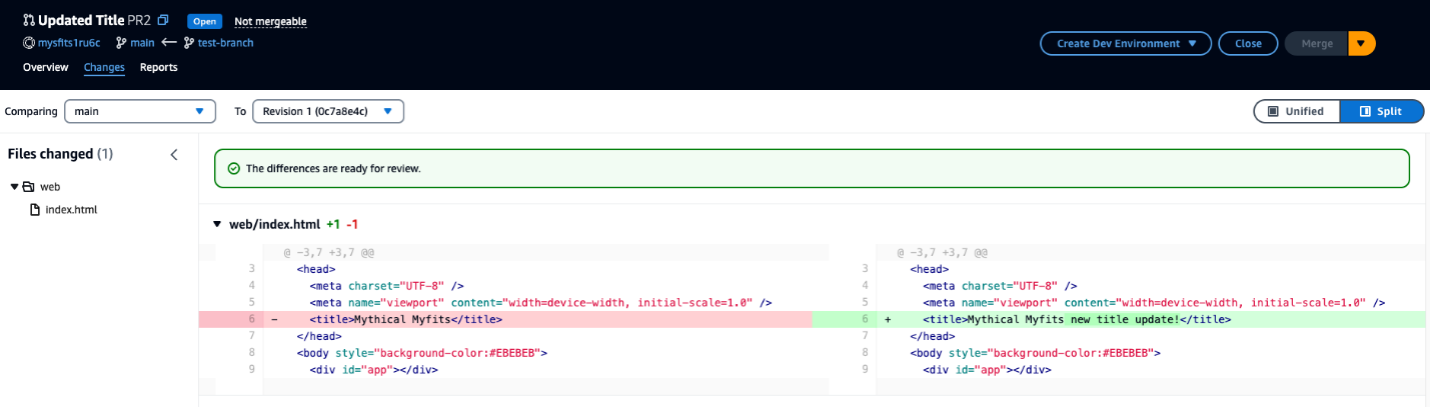
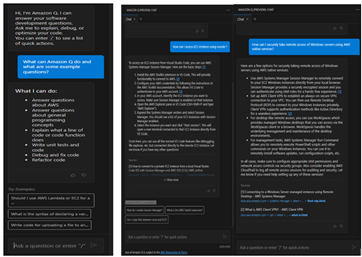
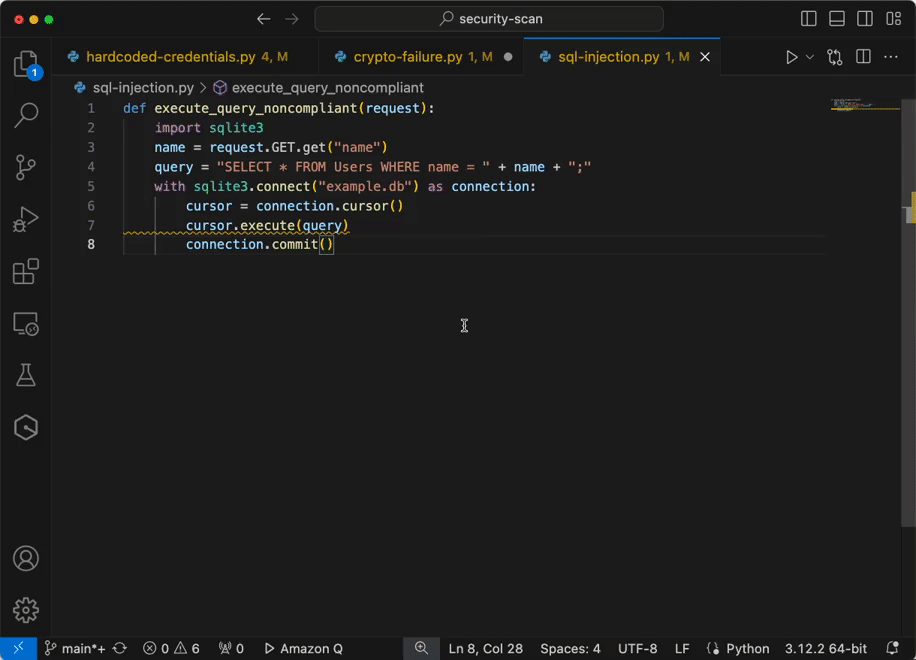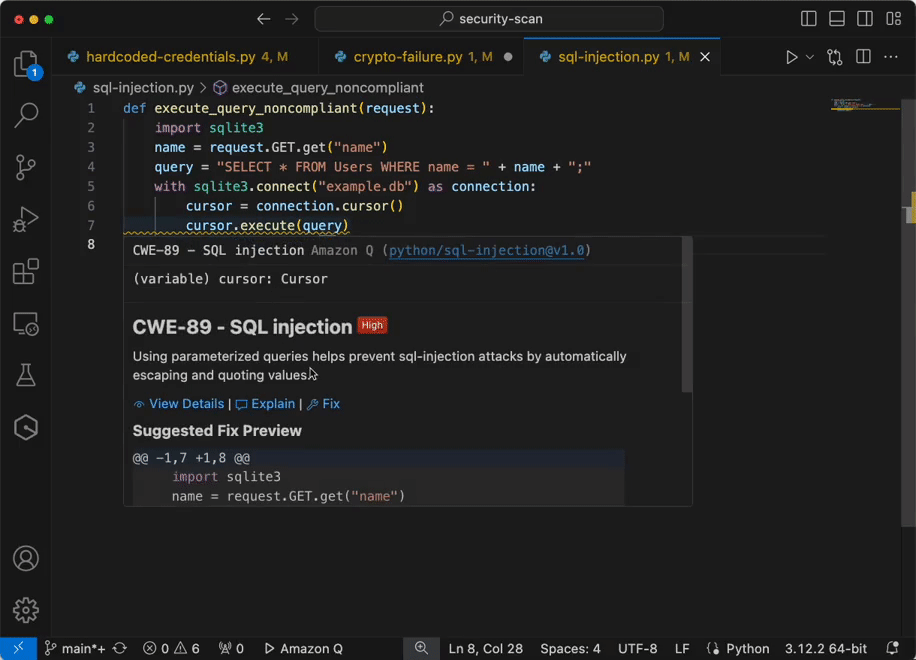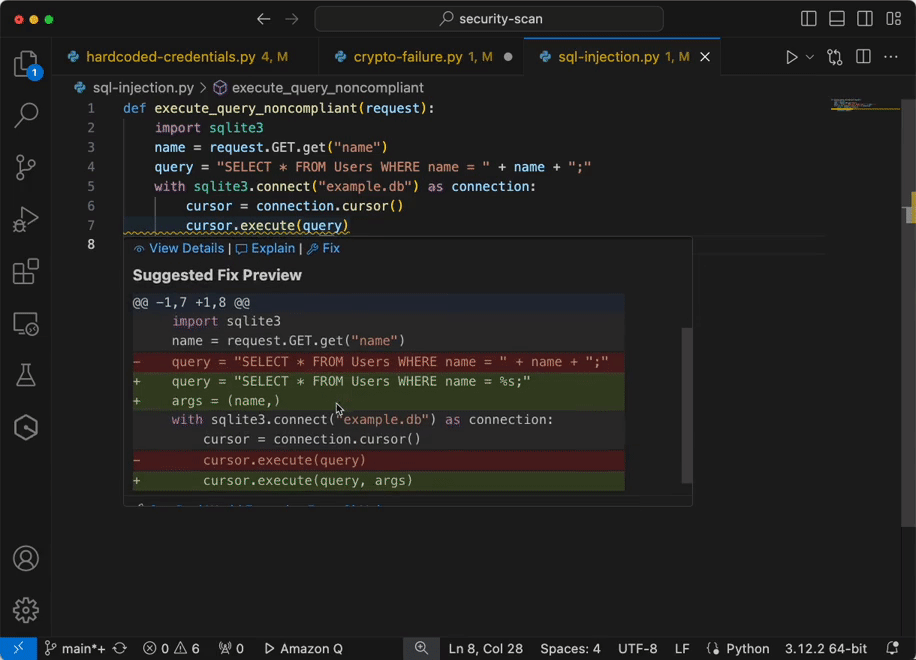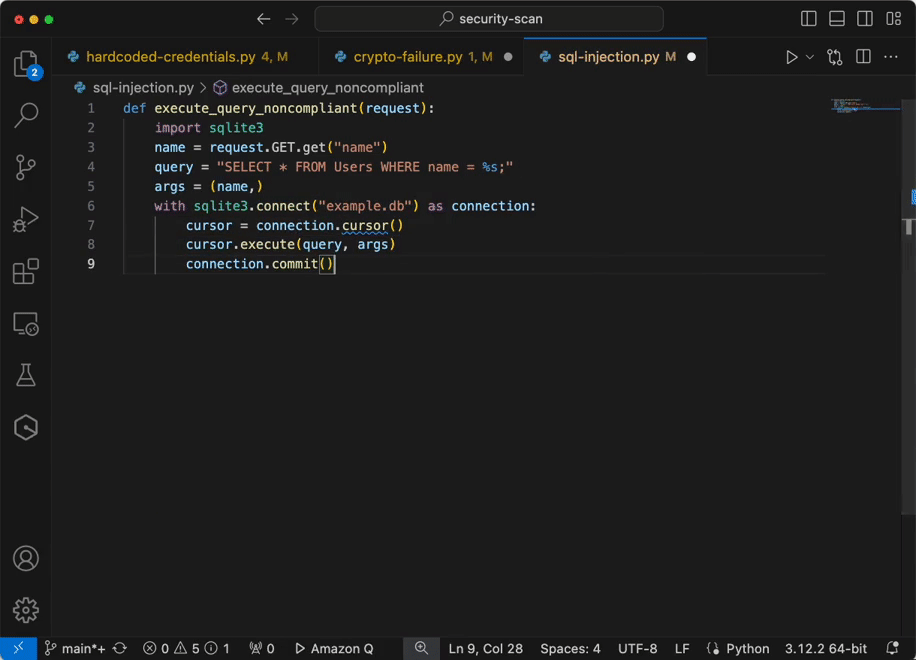
Now you have configured IAM identity Center access with VS code now you can chat, get inline code suggestions, check for security vulnerabilities with Amazon Q Developer to learn about, build, and operate AWS applications. I have mentioned a few examples of Amazon Q Suggestions, Code suggestions, Security Vulnerabilities during development for your reference (Figures 17 ,18 ,19 ,20).

Figure 17 – Amazon Q suggestion examples
Example of developers get the recommendations using Amazon Q developer.

Figure 18 – Amazon Q Developer example

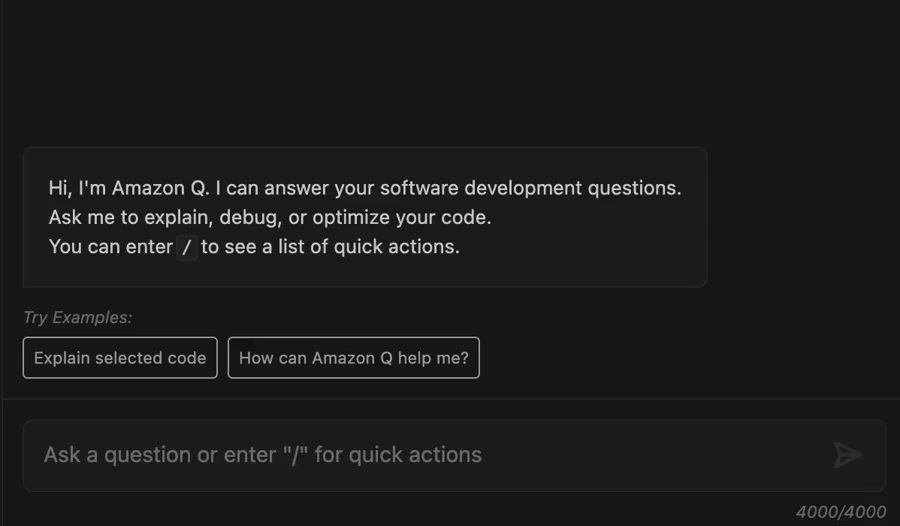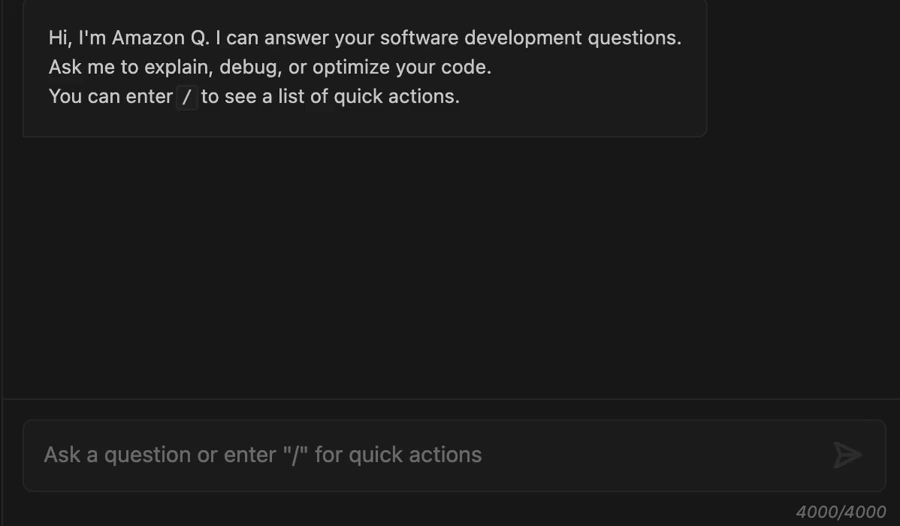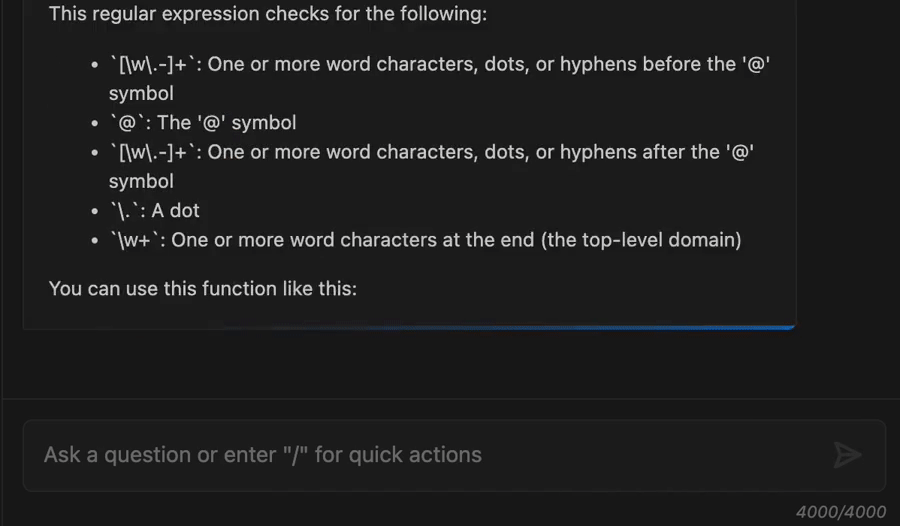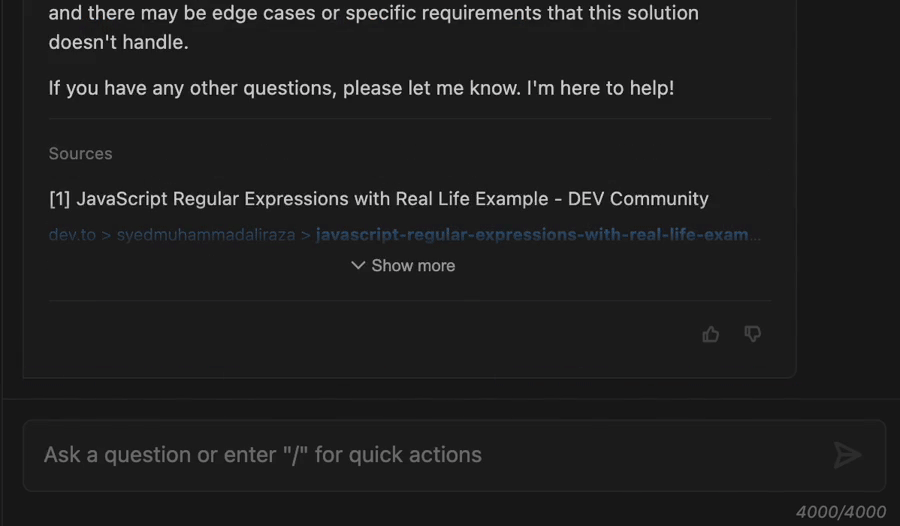
Figure 19 – Generate code, explain code, and get answers to questions about software development.
Example of integrating secure coding practices early in the software development lifecycle using Amazon Q developer.

Figure 20 – Analyze and fix security vulnerabilities in your project example
Cleanup
Configuring AWS and Azure services from this blog will provision resources which incur cost. It is a best practice to delete configurations and resources that you are no longer using so that you do not incur unintended charges.
Conclusion
In this blog post, you learned how to integrate AWS IAM Identity Center and Entra ID IdP for accessing Amazon Q Developer service using VS Code IDE, which speeds up development. Next, you set up the AWS Toolkit to establish a secure connection to AWS using Entra ID credentials, granting you access to the Amazon Q Developer Professional Tier. Using SCIM automatic provisioning for user provisioning and access assignment saves time and speeds up onboarding, allowing for immediate use of AWS services using you own identity. Using Amazon Q, developers get the recommendations and information within their working environment in the IDE, enabling them to integrate secure coding practices early in the software development lifecycle. Developers can proactively scan their existing code using Amazon Q and remediate the security vulnerabilities found in the code.
To learn more about the AWS services
AWS Toolkit for Visual Studio Code
What is IAM Identity Center?
Configure SAML and SCIM with Microsoft Entra ID and IAM Identity Center
How to use Amazon CodeWhisperer using Okta as an external IdP






















 Hemant Aggarwal is a senior Data Engineer at Kaplan India Pvt Ltd, helping in developing and managing ETL pipelines leveraging AWS and process/strategy development for the team.
Hemant Aggarwal is a senior Data Engineer at Kaplan India Pvt Ltd, helping in developing and managing ETL pipelines leveraging AWS and process/strategy development for the team. Naveen Kambhoji is a Senior Manager at Kaplan Inc. He works with Data Engineers at Kaplan for building data lakes using AWS Services. He is the facilitator for the entire migration process. His passion is building scalable distributed systems for efficiently managing data on cloud.Outside work, he enjoys travelling with his family and exploring new places.
Naveen Kambhoji is a Senior Manager at Kaplan Inc. He works with Data Engineers at Kaplan for building data lakes using AWS Services. He is the facilitator for the entire migration process. His passion is building scalable distributed systems for efficiently managing data on cloud.Outside work, he enjoys travelling with his family and exploring new places. Jimy Matthews is an AWS Solutions Architect, with expertise in AI/ML tech. Jimy is based out of Boston and works with enterprise customers as they transform their business by adopting the cloud and helps them build efficient and sustainable solutions. He is passionate about his family, cars and Mixed martial arts.
Jimy Matthews is an AWS Solutions Architect, with expertise in AI/ML tech. Jimy is based out of Boston and works with enterprise customers as they transform their business by adopting the cloud and helps them build efficient and sustainable solutions. He is passionate about his family, cars and Mixed martial arts.





