Debian’s proposed tag2upload
service would be worthy of an article
even if it wasn’t so contentious; tag2upload promises a
streamlined way for Debian developers using Git to upload packages to
the Debian
Archive. But tag2upload has been in limbo for
years due to disagreement and a communication breakdown between the team
behind tag2upload and the ftpmasters team. It took the
threat of a General
Resolution (GR), weeks of discussion, and more than
1,000 emails to finally move forward.
You may think the answer to “What do fireworks and the cloud have in common?” is nothing. But, you would be wrong.Both are carefully designed, highly-researched systems that contain a chain reaction of events that lead to a desired outcome. In the case of data centers (DCs), that’s storing and using data. In the case of fireworks, that’s a delightful explosion.
More importantly for our purposes today, both data centers and fireworks are loud. Not upstairs-neighbor loud; rather, they are hearing-loss-and-noise-pollution loud. But, which thing is louder, the cloud or fireworks? What are their sonic qualities, and which is more dangerous?
So, in honor of America’s Independence Day, let’s quantify that with data.
Let’s talk about how we measure sound
We talked briefly about how loud the cloud is in a previous article. All that noise comes from a combination of factors, largely cooling systems—either those that affect large areas of the DC, or those that are part of the hardware of each server rack. Back in 2017, we measured our DCs at approximately 78dB, and other sources report that DCs can reach up to 96dB.
And, it’s unfair to paint a data center with a broad brush, sonically speaking. There are different zones in a data center, and they can vary widely in the amount of decibels produced based on a variety of factors. Here’s a handy list:
Lower range (40-55 dBs): This quieter zone might be experienced in administrative areas or server rooms with less densely packed equipment. It’s comparable to quiet conversation or background noise in a library.
Mid range (55-70 dBs): This is a more common range within data centers, representing the noise level near operating servers. It’s similar to normal conversation or background noise in a restaurant.
Higher range (70-85 dBs): This zone can be found near high-powered equipment or cooling systems. It’s comparable to a vacuum cleaner or busy traffic. Prolonged exposure at these levels can begin to cause hearing damage.
Very high range (85-96 dBs or above): This is the loudest zone and is typically only encountered near generators or during maintenance activities. It’s similar to a power lawnmower or motorcycle and can cause hearing damage with prolonged exposure.
This can all seem relatively esoteric, but it has real world effects. Noise pollution has been shown to cause all sorts of environmental impacts in humans and other animals, and it’s a hot topic of conversation amongst people who live nearby and amongst those responsible for designing and building DCs.
And, how loud are fireworks?
As we all know, there are many types of fireworks, ranging from the humble sparkler to the professionals-only aerial explosives. In theory, consumer-level explosives are supposed to have a noise limit of 120 dBs when fired from 15 meters (about 50 ft.) away. Just to get us all on the same page (for science), here’s a table that outlines some dB ranges for major types of fireworks:
Type of Firework
Noise Level
Decibel Range
Description
Sparklers
Soft Crackling
80-90 dB
Hand-held sticks that emit showers of sparks.
Glow Worms
Soft Crackling/Hissing
85-100 dB
Ground-based fireworks that glow and crackle slightly.
Snakes
Crackling/Popping
90-110 dB
Long, snake-like fireworks that unfurl with a crackling or popping sound.
Poppers
Moderate Pops
100-115 dB
Small, paper-wrapped fireworks that make a popping sound when lit.
Fountains
Crackling/Hissing
95-120 dB
Ground-based fireworks that spray sparks and make a crackling or hissing noise.
Roman Candles
Moderate Pops/Booms
110-130 dB
Hand-held tubes that shoot out stars with loud pops or small booms.
Bottle Rockets
Loud Whistle/Boom
120-140 dB
Fireworks that launch into the air with a whistle and explode with a loud boom.
Aerial Shells (Small)
Moderate-Loud Booms
130-150 dB
Launched into the air, these explode with moderate to loud booms and create colorful visual effects.
Aerial Shells (Large)
Very Loud Booms
150-175 dB
Large shells launched high into the air, exploding with very loud booms and spectacular visuals.
Salute Batteries
Extremely Loud Booms
150-180 dB+
Rapid-fire bursts of loud explosions, often used in professional displays.
Curveball: A direct comparison of dBs isn’t our only metric for “dangerous”
Here’s the funny thing about sound and human hearing, and it ties back to our discussion of decibels: Different types of sound register differently with us, and “loud” isn’t the only risk factor for potential hearing loss. Think of when you’re listening to singers—in general, humans find deeper ranges to be “quieter” while they find higher-pitched ranges to be “louder.” In theory, they could be putting out the same loudness of sound, but we perceive it differently.
A second factor is that a short, percussive sound (like a firework), and a quieter sound that you’re exposed to for longer periods of time (like in a data center) can cause different types of damage. Any loud noise can cause hearing loss—a rapid change in pressure can easily damage the delicate anatomy of the inner ear.
When you’re talking about prolonged exposure, the safe zone is generally 70dB and below. And, while 85dB is considered safe over a period of eight hours, that safe period gets cut in half for every 3dB increase. So, at 88dBs, safe exposure time is 4 hours. At that 96dBs we cited above, you’re at risk for hearing loss in less than an hour.
Of course, there are several ways to mitigate hearing loss in instances where you know you’ll be exposed to potentially dangerous levels of sound, like if you’re attending a fireworks show or going to visit a data center. Over-ear hearing protection and earplugs—which range from your common wax/silicone variety to specially designed models that let in more or less noise—are your two main options (as it relates to your body). And, data centers and fireworks each have methods of reducing sound.
A warning from our robot friend, and declaring a winner
In doing my very thorough research, I did wonder what would happen if you stack these noises… that is, what happens if you set off a firecracker in a data center? Would the noises stack (80dB + 120dB = 200dB)? Would they equalize, then have an additive increment (80dB + the 40dB between baseline and firecracker spike)?
So, I asked my favorite large language model robot friend, who I seem to have distressed. It answered:
Setting off a firecracker in a server room would be a very bad idea for several reasons, and the combined noise level wouldn’t be the biggest concern.
Turns out, while the noise levels would be significant, the combined effect might not be as dramatic as one might imagine. First, unlike open spaces, server rooms often have soundproofing measures to dampen noise. This would limit the amplification of the firecracker’s sound as it does the existing server noise. And second, the firecracker’s sudden, high-intensity sound would likely be the dominant noise even within the server’s noise range. The combined effect wouldn’t be a simple addition of decibel levels. The firecracker’s very loud, short burst would likely overpower the server’s constant hum within the room.
LLMconclusion:
Setting off a firecracker in a server room is extremely dangerous and has far worse consequences than just a loud noise. It’s crucial to prioritize safety and avoid such actions in these critical environments.
Obviously (or I hope it’s obvious), this is not something we’d test in our real-world environment, and we don’t ever recommend that you do either. However, it’s safe to say that in the battle of cloud vs. fireworks, it’s a tad unfair to do a direct comparison of their loudness. Fireworks are (on average) louder, as they’re designed to be. Data centers are still very loud, and the quality of the sound therein is also likely to cause hearing damage over a period of time, and all that is still true even when we’re making active efforts to reduce and dampen the noise in DCs.
Safety first, friends. Remember that ear protection around both servers and fireworks is advisable, and use fireworks and data centers responsibly. We’ll see you on the other side.
The vulnerability, which is a signal handler race condition in OpenSSH’s server (sshd), allows unauthenticated remote code execution (RCE) as root on glibc-based Linux systems; that presents a significant security risk. This race condition affects sshd in its default configuration.
[…]
This vulnerability, if exploited, could lead to full system compromise where an attacker can execute arbitrary code with the highest privileges, resulting in a complete system takeover, installation of malware, data manipulation, and the creation of backdoors for persistent access. It could facilitate network propagation, allowing attackers to use a compromised system as a foothold to traverse and exploit other vulnerable systems within the organization.
Moreover, gaining root access would enable attackers to bypass critical security mechanisms such as firewalls, intrusion detection systems, and logging mechanisms, further obscuring their activities. This could also result in significant data breaches and leakage, giving attackers access to all data stored on the system, including sensitive or proprietary information that could be stolen or publicly disclosed.
This vulnerability is challenging to exploit due to its remote race condition nature, requiring multiple attempts for a successful attack. This can cause memory corruption and necessitate overcoming Address Space Layout Randomization (ASLR). Advancements in deep learning may significantly increase the exploitation rate, potentially providing attackers with a substantial advantage in leveraging such security flaws.
The Universal Blue
project, which produces operating system images based on Fedora’s Atomic Desktops,
has issued an announcement
that manual steps are required to continue receiving updates. Jorge
Castro wrote:
If you use Bazzite, Bluefin, Aurora, or any other Universal Blue
image (including our toolboxes) then you need to follow the
instructions in this announcement in order to ensure that your device
is getting updates. We were rotating our cosign keypairs this morning,
which is the method that we use to sign our images.
During this process I made a critical error which has resulted in
forcing you to take manual steps to migrate to our newly signed
images.
This applies to all Universal Blue images released before July 2,
2024. See the full announcement for instructions. LWN covered Bluefin in
December, 2023.
In 2016, Oliver Smith reached a point of frustration with the short
lifespan of updates for his Android phone. Taking matters into his own
hands, he began developing postmarketOS, a Linux distribution for
mobile phones. Eight years later, the core team and
trusted contributors have grown to twenty individuals, while the latest
release, v24.06,
now shows support for over 250 devices. Although postmarketOS isn’t
usable as a day-to-day phone operating system on all of them, it can also enable repurposing devices into compact servers or kiosk machines.
Version 4.10.0 of GNU findutils has been released. Notable changes
include allowing find -name / as a valid
pattern, and accepting larger UIDs/GIDs for find -user and find -group. It is also once again possible to build
findutils on systems with musl-libc.
David Rosenthal looks
back at 40 years of the X Window System:
A major reason for Sun’s early success was that they in effect
open-sourced the Network File System. X11 was open source under the
MIT license. I, and some of the other Sun engineers, understood
that NeWS could not displace X11 as the Unix standard window system
without being equally open source. But Sun’s management looked at
NeWS and saw superior technology, an extension of the PostScript
that Adobe was selling, and couldn’t bring themselves to give it
away.
Между табелите Exit и Luggage на летище „Бен Гурион“ има опънат голям транспарант, на който пише: BRING THEM HOME. NOW (Върнете ги у дома. Сега).
Последната дума е написана в червено. И това червено е като крясък, като клетва. Като кръв.
Тeзи четири думи диктуват системното кръвообращение на цялата страна.
Има ги навсякъде: по огради, по фасади, по площади. Там са и снимките на отвлечените заложници: стоят закачени върху колони, върху пътни знаци и билбордове, по пейки и витрини. Усмихнатите физиономии те съпровождат денем и нощем. Блокират собствената ти система за самосъхранение, която не иска да си представяш къде в момента са тези хора, живи ли са, кой ги наблюдава, пият ли си хапчетата, как се къпят, къде спят, до кого се събуждат. Говорят ли, шепнат ли, плачат ли. На какъв език мълчат.
Те са приятели, сестри, съседи. Майки, братя, колеги. Те са деца.
Най-малкото сред тях е червенокосото бебе с беззъба усмивка, което се превърна в символ на бруталността на „Хамас“.
Кфир Бибас. Снимката е от личния архив на семейството, предоставена за целите на движението Bring Them Home
Кфир Бибас е роден на 18 януари 2023 г. Когато го отвличат, е на 9 месеца.
Между 9 и 12 месеца бебетата се научават да стоят, поникват им първите зъбки, правят първите си стъпки, произнасят първата си дума.
Ако Кфир е жив, сега е на 18 месеца.
Между 12 и 18 месеца бебето започва да променя отношението си към хората. То не само се опитва да играе с тях, но и да им подражава.
Ако Кфир е жив, може би започва да подражава на своите похитители.
Ако Кфир е жив, ще е живял по-дълго като заложник, отколкото като свободно човешко същество. Този най-малък от всички отвлечени от терористите човек е живял на свобода само 262 дни.
Вземането на цивилни за заложници е военно престъпление според Женевските конвенции. „Но деца почти никога не се вземат за заложници“, пише в своята студия, публикувана онлайн от Cambridge University Press, изследователката Даниел Гилбърт от Северозападния университет в Чикаго. „Мотивите са брутални: децата не стават за разменна монета, защото трудно оцеляват след изпитанието“, обяснява тя.
2
След 7 октомври животът в Държавата Израел е като имитация на живот в Държавата Израел. Тече застинал, забавен, задръстен, замислен.
Привидно град Тел Авив функционира нормално. Шуми, излъчва, бърза, диша, расте. Расте нависоко със стъписващи темпове.
Снимка: Еми Барух
Долу кафенетата продължават да завземат улиците, климатиците разпръскват лъжлив комфорт, тапите в час пик са епични.
Над плажовете се стеле мараня. По улиците се разминават хора, тротинетки, кучета, велосипеди. Навалица…
Гневни графити гарнират стените в синхрон с една вибрираща енергия на сподавено очакване за промяна. Усеща се, ако поговориш с някого. Ако поспреш. Хората не спират. Блъскат се. Бързат. Поддържат онзи ритъм, който не ти оставя много време за споделяне.
Надписът под изображението на Нетаняху гласи: „Опасност“. Снимка: Еми Барух
3
Ние бяхме два пъти изоставени от нашето правителство. Веднъж на 7 октомври и сега, когато децата ни са още пленници.
Това са думи на един баща, един от хилядите, които всяка седмица участват в протести с призиви за преговори за освобождаване на заложниците, за оставка на правителството на Нетаняху, за край на окупацията, за избори, за мир между араби и евреи, за изход от мъртвата хватка, в която крайнодесните държат страната.
Събота вечер е. Ден за протести.
С моите приятели си проправяме път между групи, носещи израелски знамена. Мнозина са облекли тениски, всяка с лицето на един от сто двайсет и четиримата заложници, които все още се държат от „Хамас“ в Газа.
Снимка: Еми Барух
Това, което ни обединява, е знамето и неистовото желание Нетаняху да си тръгне.
Те са тук всяка седмица от две години. Изтощени са. Но не могат да се откажат. Нямат друг избор.
Когато приятелите ми ме посрещнаха на летището, дори не ги попитах „Как сте? Добре ли сте?“, защото знам: никой не е добре.
Напредваме към кръстовището между „Бегин“ и улица „Каплан“, което от миналата година Общината е преименувала на „Площад на демокрацията“ в чест на нестихващите протести срещу съдебната реформа на правителството. „Демокрацията не е даденост – е написал тогава кметът на Тел Авив в Х, за да обоснове смяната на името. – Трябва да я защитаваме всеки ден“.
Минаваме покрай импозантната сграда на Военния щаб, срещу която екран отброява дните, часовете, минутите и секундите от 7 октомври. Емоционалният часовник на хората обаче е спрял. Всяка сутрин те отново се събуждат на 7 октомври. Медиатизирането на погрома не помага. Новините се прекъсват от профила на поредния загинал войник.
Предната вечер сме говорили дълго колко взаимносвързани са жителите на тази страна, колко всъщност е малка тя. Как всеки е в контакт с всеки. Как всеки или е загубил някого, или познава някого, който е загубил някого на 7 октомври.
Докато израелските заложници и цивилното население на Газа са държани като живи щитове, раната стои отворена. Рационалното мислене е в плен на националната травма.
Доближаваме сцена с огромни екрани, около която се сгъстява гневът на протестиращите. Думата, която всички повтарят в транс, е עכשיו – „сега“. „Освободете ги СЕГА!“
Снимка: Еми Барух
Отчаянието е по-силно от гнева.
4
„Аз съм част от всичко това“, казва Етгар Керет, този най-любим съвременен бард на израелската литература. И продължава:
„Но когато крещя: „Освободете ги сега!“, на кого го крещя? На Синуар ли го крещя? Ако извикам достатъчно силно, дали той ще каже:
– Мохамед, млъкни за момент. – Какво? – Освободете ги сега!… – Добре. Мохамед, пусни ги. Има хора, които ме молят да ги освободя сега.“
Мисля ли, че ще проработи? Или скандирам „Освободете ги сега!“, така че Байдън да разбере, че трябва да направи нещо по въпроса?
Или може би крещя това на Нетаняху? И той ще каже: „О, боже мой, да, трябва да ги освободим сега. Не бях мислил за това…“
Какво точно постигам? Когато крещя СЕГА, не е ли равносилно на молитва? Не е ли това инфантилен сблъсък с реалността?“
Молитва. Заклинание. Клетва. Отсъства „публичната употреба на разума“ (по Имануел Кант).
5
Множеството от улица „Каплан“ е нарицателно за онази колективна енергия, в която е концентриран ураган от непоносимост към религиозната мегаломания на фанатичните екстремисти в коалицията на премиера Нетаняху. Две имена предизвикват яростно освиркване – Бен-Гвир и Смотрич. Известни със своята агресивна и расистка реторика, и двамата са ревностни поддръжници на идеята за завръщане на еврейските заселници в Газа и за разселване на палестинското население. Първият е министър на националната сигурност, вторият е министър на финансите.
Речи, освирквания, скандирания.
Един след друг на сцената се качват артисти, родители на отвлечени деца, политици, дипломати, музиканти. Сцените са няколко. Драматургията на протеста следва емоцията на множеството.
Стигаме до Kikar HaChatufim. „Площадът на заложниците“ се намира пред Музея на изкуствата в Тел Авив. „Директна линия между публиката и изкуството“, написа един от кураторите на музея. Изкуството е излязло на площада. Той е отрупан с инсталации, интерактивни експонати, постери, картини, книги, предмети.
Хората преминават ритуално покрай топоси на травмата.
Около площада има палатки на най-тежко пострадалите кибуци. Разпънати са шатри, където се събират семействата на заложниците; на специални постаменти са подредени фигурки, играчки, писма; има сергии, откъдето може да се снабдиш с жълта панделка, с жълта птица, с жълто пинче, с жълта гривна, на която пише: „Върнете ги. СЕГА.“ Жълтото е символ на солидарност със семействата на отвлечените, призив за тяхното освобождаване. Жълтото (тук и сега) е отправна точка на идентичността.
Снимки: Еми Барух
В средата на площада е поставена дълга маса с празни чинии и празни чаши пред празни столове, подредени за всеки от изчезналите заложници.
Срещу нея е построен тунел – бутафорна реплика в реален размер на тунелите, прокопани под ивицата Газа.
Проходът е висок над човешки ръст. По дъговидните стени има текстове, рисунки, молитви, снимки, имена, карикатури, надписи на различни езици. Високоговорителите възпроизвеждат звук от далечни изстрели. Симулацията в слабоосветеното пространство е клаустрофобична. Минаваме през тунела. До изхода са само 25 метра…
Отвън са инструментите, които чакат собствениците им да се върнат.
Снимка: Еми Барух
6
В един от репортажите, написани по времето, когато аз бях там, на въпрос дали хората са простили на армията провала на 7 октомври, анкетираните отговарят, че няма време за това.
Няма време да се занимаваме с миналото, да го съдим, да го преоценяваме. Ние сме в капана на едно настояще, което продължава от 7 октомври и оставя място само за една дума: СЕГА. Тази дума е обединителен вик, политическо искане и изразява много повече: трябва да се сложи край на безвремието, в което живее страната.
Снимка: Еми Барух
Два дни по-късно присъствам на среща в Кнесета с членове на парламента. Говорят за противоречията, компромисите, контекстите, нюансите.
„Това е най-дългата война, която някога сме водили“, обръща се към присъстващите Мерав Коен, депутатка от центристката либерална партия „Йеш Атид“.
„Няма победа, без заложниците да бъдат върнати. А това не е приоритет за Нетаняху. Той е циничен политик. Не го интересува човешкият живот. Спешно ни трябват избори. Нетаняху разбира, че това ще е неговият край, и точно затова протака войната…“
В капана на едно безкрайно настояще човек се пита: как да останеш цял в този счупен свят?
7
P.S.
Погледната отвън, израелската държава се възприема като монолитно единство на хора, обединени от обща библейска история. За евреите от диаспората тя е някаква неясна амалгама от предания, идеи и спомени, от обичаи и чувства.
Но тази идилична картина е далече от действителността.
Все по-агресивният диктат на ултраортодоксалните евреи отдавна се е превърнал в заплаха за демокрацията в страната. Именно техните партии удържат коалицията на Нетаняху. И ако на тях не им се угоди, правителството може и да падне.
Точно това е политическото земетресение, което започна съвсем скоро с едно решение на Върховния съд на Израел. То сложи край на привилегированата позиция на ултрасите, които изучават Светите писания, и това ги освобождава от армията. И нека да е ясно: несъгласието с отбиването на задължителна военна служба не е поради пацифистки възгледи. По-голямата част от войниците в израелската армия (IDF) не са в бойни части, а изпълняват административни задачи, работят в офиси. А еврейските студенти, които изучават Талмуда и Тората, не работят и се издържат от данъчни постъпления. За огромната част от данъкоплатците те са нещо като търтеи в кошера.
Съдиите от Върховния съд на Израел постановиха с единодушие, че военната служба става задължителна и за ултраортодоксалните евреи. Че те също трябва да участват в националния проект Израел с всички произтичащи от това права и задължения.
Един от ултрарелигиозните евреи заяви по този повод, че решението може да доведе до „две държави“, разделени не между израелци и палестинци, а между религиозни и нерелигиозни евреи.
Стар виц гласи, че Израел е страна, в която една трета от населението отива в армията, една трета работи и една трета плаща данъци. Проблемът е, гласи шегата, че става дума за една и съща една трета.
Израел е държава, която 75 години след създаването си все още няма писмена конституция, държава, която все още се ръководи от еврейските религиозни закони.
Израел е държава на изгнаници. За някои това е избор. За други е съдба.
France is currently electing a new government through early legislative elections that began on Sunday, June 30, 2024, with a second round scheduled for July 7. In this blog, we show how Cloudflare blocked DDoS attacks targeting three different French political parties.
2024 has been dubbed “the year of elections,” with elections taking place in over 60 countries, as we have mentioned before (1, 2, 3). If you regularly follow the Cloudflare blog, you’re aware that we consistently cover election-related trends, including in South Africa, India, Iceland, Mexico, the European Union and the 2024 US presidential debate. We also continuously update our election report on Cloudflare Radar.
Recently in France, as in the early stages of the war in Ukraine and during EU elections in the Netherlands, political events have precipitated cyberattacks. In France, several DDoS (Distributed Denial of Service attack) attacks targeted political parties involved in the elections over the past few days, with two parties hit just before the first round and another on election day itself.
The first political party, shown in yellow in the previous chart, experienced a DDoS attack on June 23, 2024, peaking at 68,000 requests per second (rps); it also endured a second DDoS attack on June 29, the day before the election, peaking at 20,000 rps. Although these rates are small on Cloudflare’s scale, they can be devastating for unprotected websites unaccustomed to such levels of traffic.
The second party, represented by the blue line, was targeted on June 24, June 27, and June 29, 2024, with the most severe attack occurring on June 27, reaching 118,000 rps during a day marked by frequent DDoS spikes that had in total 610 million daily requests.
The third party was attacked on the evening of June 29 in France, with several attempts blocked by Cloudflare on election day, June 30, between 10:00 and 23:00 UTC (12:00 and 01:00 local time). The peak activity targeting this party hit nearly 40,000 rps at 19:00 UTC (21:00 local time), with a total of 620 million daily DDoS requests on election day.
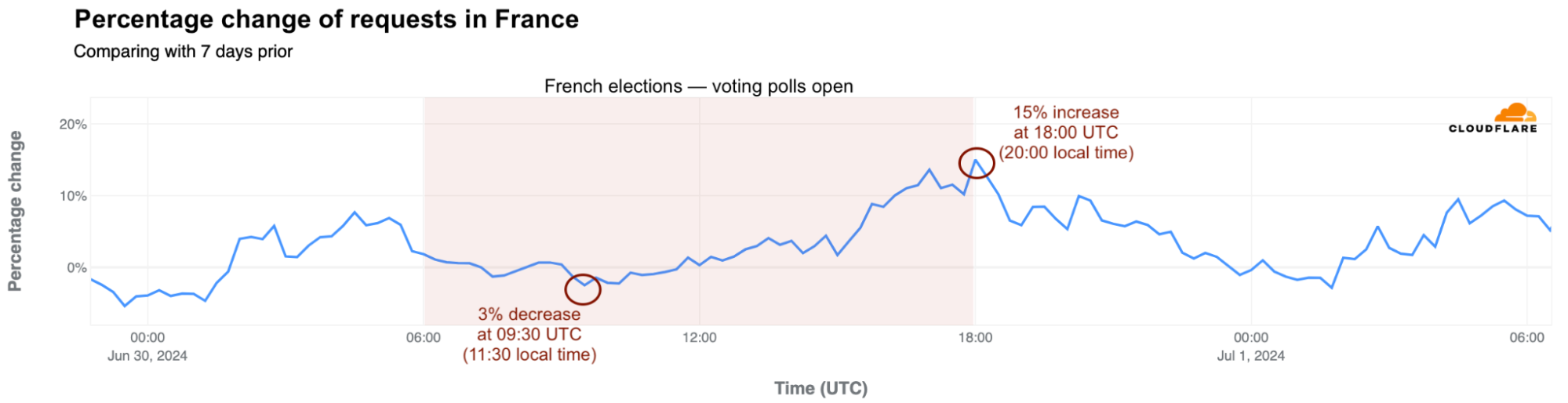
Modest drops and clear traffic increases after voting ends
During the first round of the election this past Sunday, June 30, 2024, Internet traffic was initially higher than the previous week but dropped by as much as 3% at 11:30 local time (09:30 UTC) after the polls opened. Traffic began to increase again after 17:45 local time (15:45 UTC) and peaked at 20:00 local time (18:00 UTC) when the polls closed and the first projections were announced.
We will provide a trends update on the French election after the runoff scheduled for July 7, 2024.
If you want to follow more trends and insights about the Internet and elections in particular, you can check Cloudflare Radar, and more specifically our new 2024 Elections Insights report, which will be updated as elections take place throughout the year.
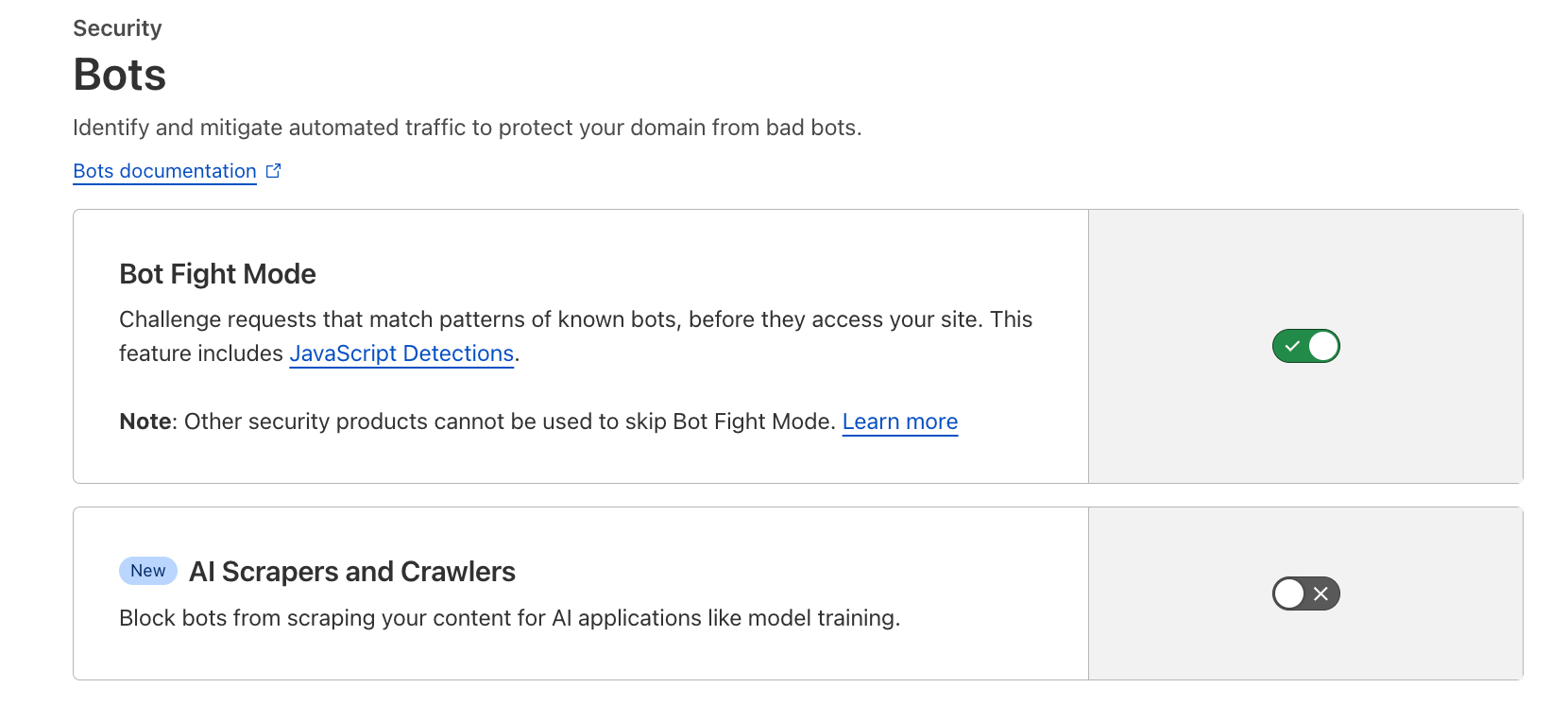
To help preserve a safe Internet for content creators, we’ve just launched a brand new “easy button” to block all AI bots. It’s available for all customers, including those on our free tier.
The popularity of generative AI has made the demand for content used to train models or run inference on skyrocket, and, although some AI companies clearly identify their web scraping bots, not all AI companies are being transparent. Google reportedly paid $60 million a year to license Reddit’s user generated content, Scarlett Johansson alleged OpenAI used her voice for their new personal assistant without her consent, and most recently, Perplexity has been accused of impersonating legitimate visitors in order to scrape content from websites. The value of original content in bulk has never been higher. Last year, Cloudflare announced the ability for customers to easily block AI bots that behave well. These bots follow robots.txt, and don’t use unlicensed content to train their models or run inference for RAG applications using website data. Even though these AI bots follow the rules, Cloudflare customers overwhelmingly opt to block them.
We hear clearly that customers don’t want AI bots visiting their websites, and especially those that do so dishonestly. To help, we’ve added a brand new one-click to block all AI bots. It’s available for all customers, including those on the free tier. To enable it, simply navigate to the Security > Bots section of the Cloudflare dashboard, and click the toggle labeled AI Scrapers and Crawlers.
This feature will automatically be updated over time as we see new fingerprints of offending bots we identify as widely scraping the web for model training. To ensure we have a comprehensive understanding of all AI crawler activity, we surveyed traffic across our network.
AI bot activity today
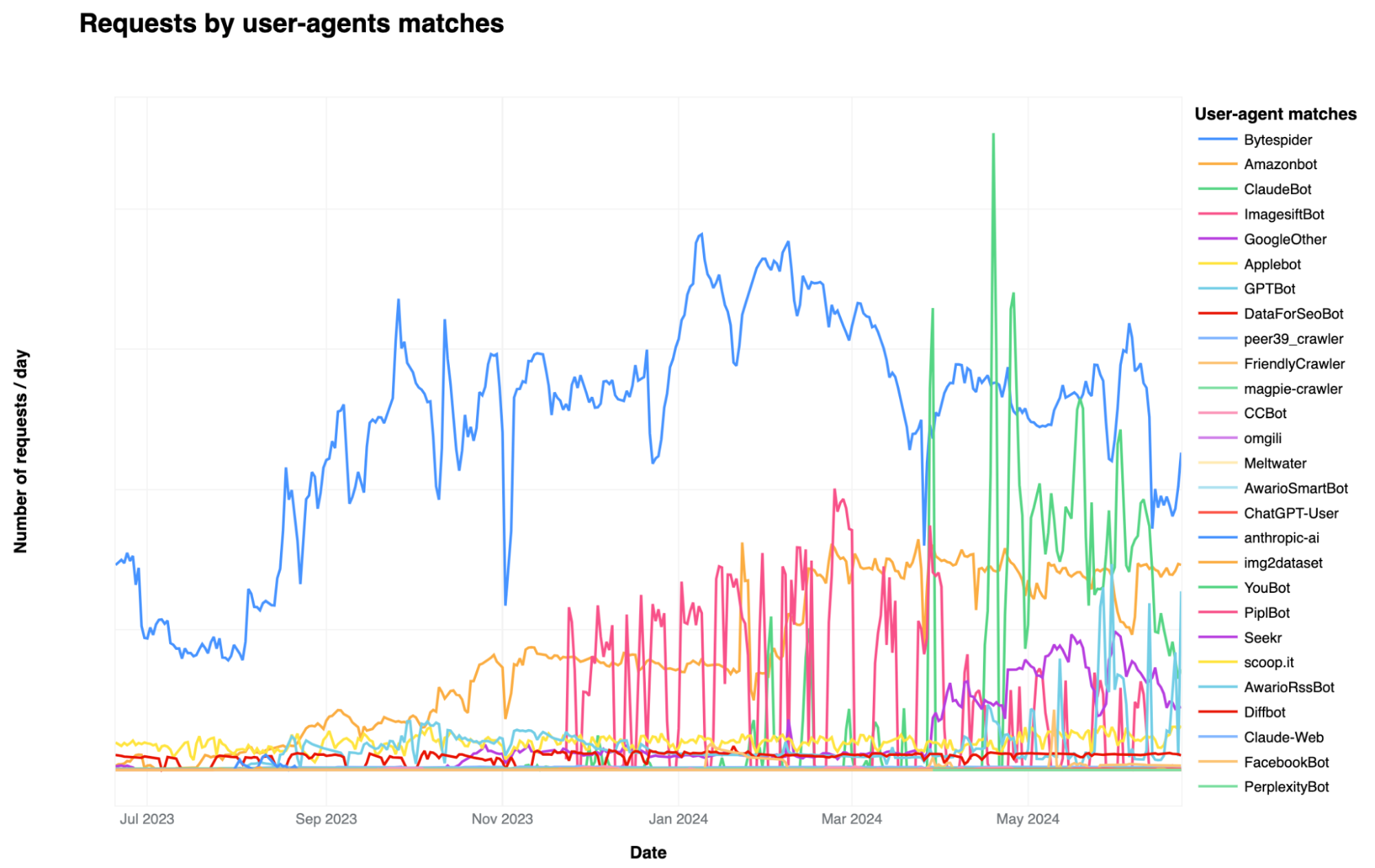
The graph below illustrates the most popular AI bots seen on Cloudflare’s network in terms of their request volume. We looked at common AI crawler user agents and aggregated the number of requests on our platform from these AI user agents over the last year:
When looking at the number of requests made to Cloudflare sites, we see that Bytespider, Amazonbot, ClaudeBot, and GPTBot are the top four AI crawlers. Operated by ByteDance, the Chinese company that owns TikTok, Bytespider is reportedly used to gather training data for its large language models (LLMs), including those that support its ChatGPT rival, Doubao. Amazonbot and ClaudeBot follow Bytespider in request volume. Amazonbot, reportedly used to index content for Alexa’s question-answering, sent the second-most number of requests and ClaudeBot, used to train the Claude chat bot, has recently increased in request volume.
Among the top AI bots that we see, Bytespider not only leads in terms of number of requests but also in both the extent of its Internet property crawling and the frequency with which it is blocked. Following closely is GPTBot, which ranks second in both crawling and being blocked. GPTBot, managed by OpenAI, collects training data for its LLMs, which underpin AI-driven products such as ChatGPT. In the table below, “Share of websites accessed” refers to the proportion of websites protected by Cloudflare that were accessed by the named AI bot.
AI Bot
Share of Websites Accessed
Bytespider
40.40%
GPTBot
35.46%
ClaudeBot
11.17%
ImagesiftBot
8.75%
CCBot
2.14%
ChatGPT-User
1.84%
omgili
0.10%
Diffbot
0.08%
Claude-Web
0.04%
PerplexityBot
0.01%
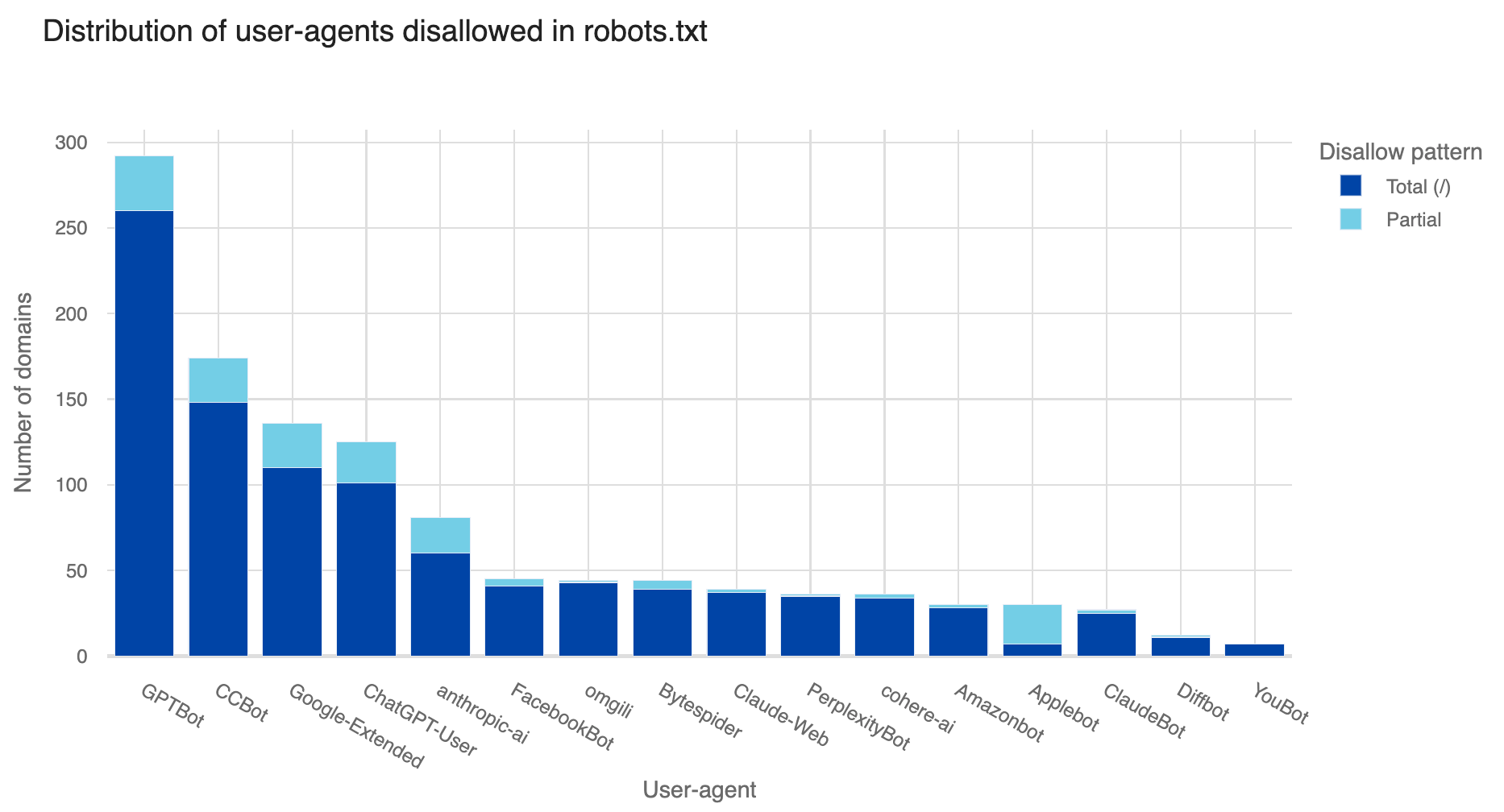
While our analysis identified the most popular crawlers in terms of request volume and number of Internet properties accessed, many customers are likely not aware of the more popular AI crawlers actively crawling their sites. Our Radar team performed an analysis of the top robots.txt entries across the top 10,000 Internet domains to identify the most commonly actioned AI bots, then looked at how frequently we saw these bots on sites protected by Cloudflare.
In the graph below, which looks at disallowed crawlers for these sites, we see that customers most often reference GPTBot, CCBot, and Google in robots.txt, but do not specifically disallow popular AI crawlers like Bytespider and ClaudeBot.
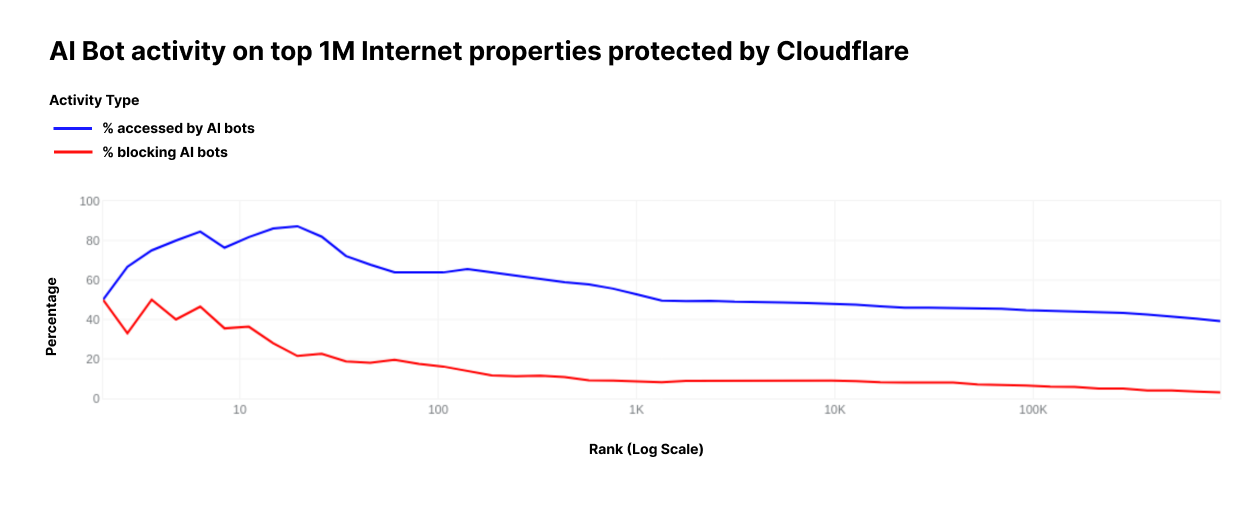
With the Internet now flooded with these AI bots, we were curious to see how website operators have already responded. In June, AI bots accessed around 39% of the top one million Internet properties using Cloudflare, but only 2.98% of these properties took measures to block or challenge those requests. Moreover, the higher-ranked (more popular) an Internet property is, the more likely it is to be targeted by AI bots, and correspondingly, the more likely it is to block such requests.
Top N Internet properties by number of visitors seen by Cloudflare
% accessed by AI bots
% blocking AI bots
10
80.0%
40.0%
100
63.0%
16.0%
1,000
53.2%
8.8%
10,000
47.99%
8.92%
100,000
44.53%
6.36%
1,000,000
38.73%
2.98%
We see website operators completely block access to these AI crawlers using robots.txt. However, these blocks are reliant on the bot operator respecting robots.txt and adhering to RFC9309 (ensuring variations on user against all match the product token) to honestly identify who they are when they visit an Internet property, but user agents are trivial for bot operators to change.
How we find AI bots pretending to be real web browsers
Sadly, we’ve observed bot operators attempt to appear as though they are a real browser by using a spoofed user agent. We’ve monitored this activity over time, and we’re proud to say that our global machine learning model has always recognized this activity as a bot, even when operators lie about their user agent.
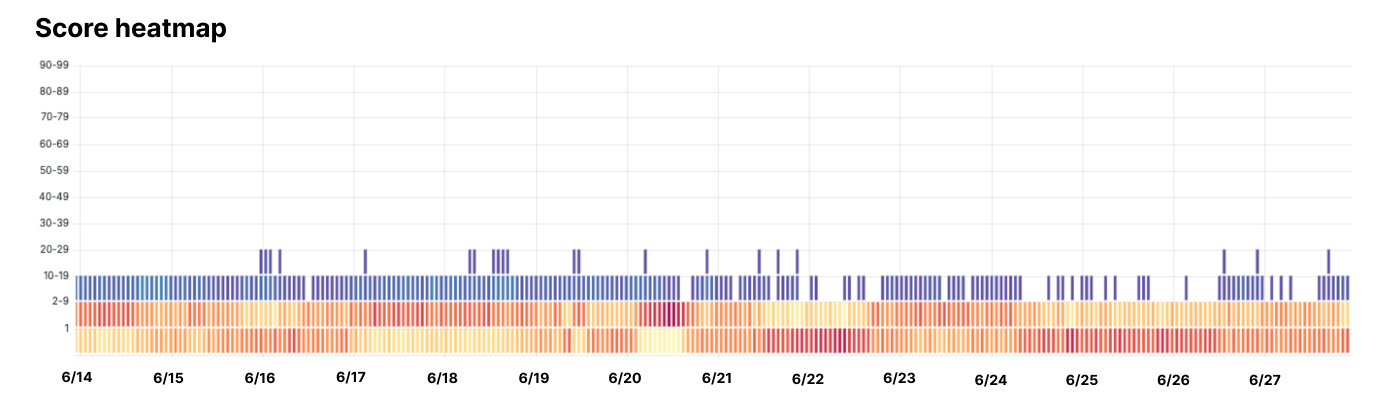
Take one example of a specific bot that others observed to be hiding their activity. We ran an analysis to see how our machine learning models scored traffic from this bot. In the diagram below, you can see that all bot scores are firmly below 30, indicating that our scoring thinks this activity is likely to be coming from a bot.
The diagram reflects scoring of the requests using our newest model, where “hotter” colors indicate more requests falling in that band, and “cooler” colors meaning fewer requests did. We can see the vast majority of requests fell into the bottom two bands, showing that Cloudflare’s model gave the offending bot a score of 9 or less. The user agent changes have no effect on the score, because this is the very first thing we expect bot operators to do.
Any customer with an existing WAF rule set to challenge visitors with a bot score below 30 (our recommendation) automatically blocked all of this AI bot traffic with no new action on their part. The same will be true for future AI bots that use similar techniques to hide their activity.
We leverage Cloudflare global signals to calculate our Bot Score, which for AI bots like the one above, reflects that we correctly identify and score them as a “likely bot.”
When bad actors attempt to crawl websites at scale, they generally use tools and frameworks that we are able to fingerprint. For every fingerprint we see, we use Cloudflare’s network, which sees over 57 million requests per second on average, to understand how much we should trust this fingerprint. To power our models, we compute global aggregates across many signals. Based on these signals, our models were able to appropriately flag traffic from evasive AI bots, like the example mentioned above, as bots.
The upshot of this globally aggregated data is that we can immediately detect new scraping tools and their behavior without needing to manually fingerprint the bot, ensuring that customers stay protected from the newest waves of bot activity.
If you have a tip on an AI bot that’s not behaving, we’d love to investigate. There are two options you can use to report misbehaving AI crawlers:
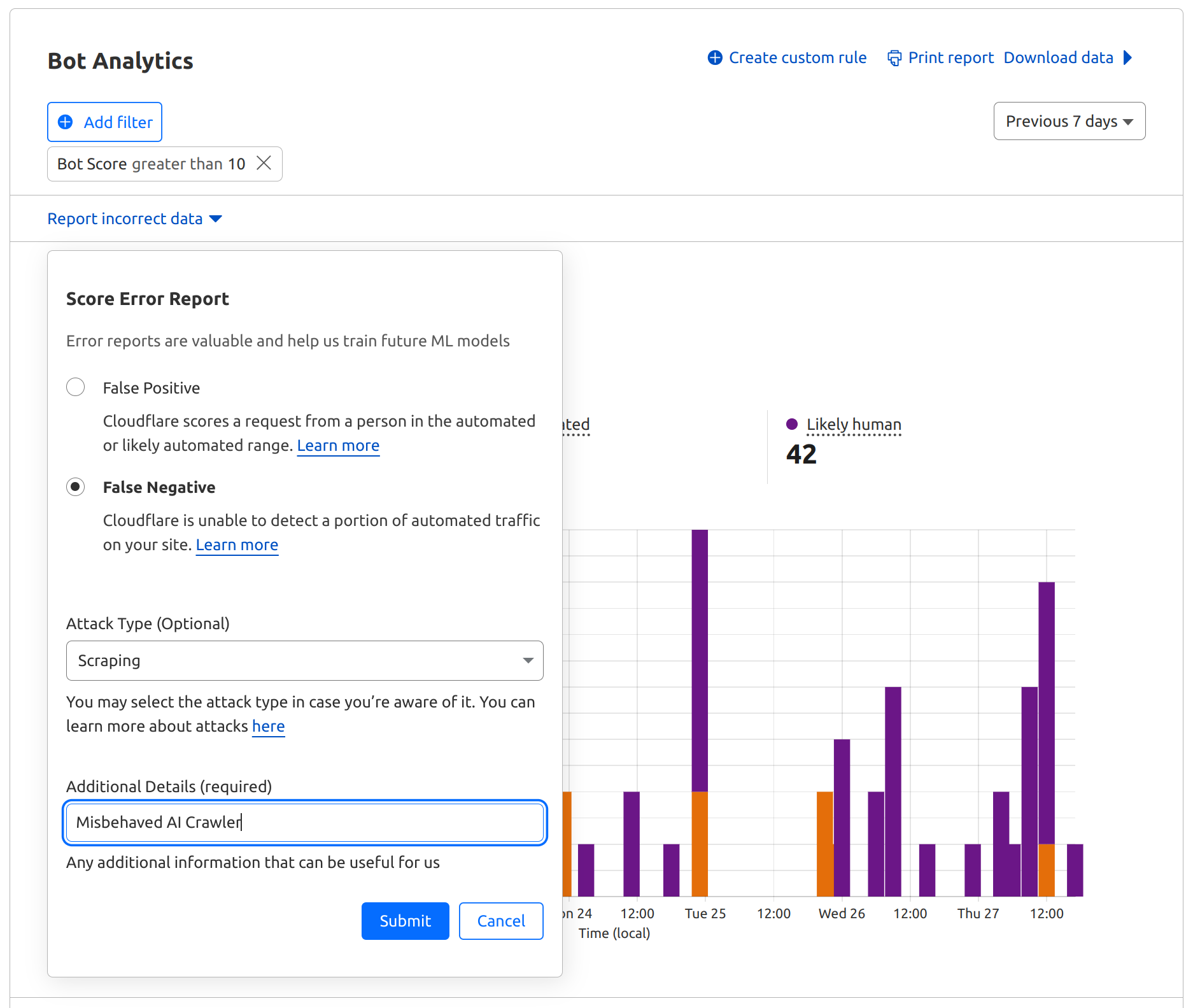
1. Enterprise Bot Management customers can submit a False Negative Feedback Loop report via Bot Analytics by simply selecting the segment of traffic where they noticed misbehavior:
2. We’ve also set up a reporting tool where any Cloudflare customer can submit reports of an AI bot scraping your website without permission.
We fear that some AI companies intent on circumventing rules to access content will persistently adapt to evade bot detection. We will continue to keep watch and add more bot blocks to our AI Scrapers and Crawlers rule and evolve our machine learning models to help keep the Internet a place where content creators can thrive and keep full control over which models their content is used to train or run inference on.
превод от украински Павлина Мартинова, изд. „Ерго“, 2023
Първото нещо, за което ме подсети заглавието на този сборник с разкази, е „За какво мислите“ – подканата на Facebook, когато още не си започнал да пишеш публикация. Украинският писател Васил Габор обаче е възможно най-далеч от света на социалните мрежи, от суетнята, суматохата и поредните скандали на деня. Писането му е лаконично и прозрачно, лишено от големи думи и обобщения, взряно в детайли, дреболии и чудеса. Писането му напомня на Радичковото, защото не се наблюдава умора от чудото, напротив, удоволствието от очарованието на света е невинно и сърцато.
Габор казва:
… всеки писател си има своя карма: едни пишат много, други – малко. Аз пиша много малко. Първата си оригинална „Книга на екзотичните сънища и реалните събития“ писах двайсет години и изписах в нея всички думи, които знаех, а ето към тази, втората, вървях почти петнайсет години, събирайки за нея нови думи, образи и впечатления. Но не бързах да пиша. Защото не ми се искаше да прилича на първата, а и впоследствие ми стана безинтересно да пиша разкази или новели, като спазвам строго изискванията на жанра и измислям нови герои.
Нямам усещането, че тази проява на скромност, за разлика от толкова много други, прикрива раздуто его и безмерни амбиции. Постепенно Габор стига до решението книгата му да бъде в японския жанр „дзуйхицу“, който се характеризира със свободно и асоциативно, фрагментарно и есеистично писане. Родоначалничката на жанра е легендарната и добре позната в България придворна дама Сей Шонагон със своите неподражаеми и красиви „Записки под възглавката“, създадени преди хилядолетие. Парадоксално, писането на Шонагон е изключително съвременно и днес заради списъците си, кратките истории и анекдоти, описанието на всекидневни случки и пейзажи. Някои от тях са точно като разговори с близък от днес или вчера, в чат или на живо.
Габор по спокоен, заземяващ и медитативен начин разкрива личния си и непосредствен свят. Той изрежда за какво мисли човек, докато отива на работа – за улицата, за тъжните неща, за света на детството, за това кое носи удоволствие и радва. Но мисли и за неща, за които не му се иска. Натрапчивите мисли могат да пробият всяка защита. Друг автор, с който спонтанно откривам близост, е Кенет Уайт, също заслужено популярен в България. Неговата особена смесица между източна уединена естетика и западна ирония и отказ от конформизъм също са в родословното дърво на поетиката на Габор.
На пръв поглед изглежда лесно или ненужно фокусът върху очевидното да е толкова интензивен акт, но в това няма нищо самоцелно. Популярни и болезнено актуални са думите на Оруел, че
вече сме потънали до дълбочина, в която потвърждаването на очевидното е първото задължение на интелигентните хора. Ако свободата изобщо означава нещо, то е правото да казваш на хората това, което не искат да чуят. Във времена на всеобща измама да казваш истината ще бъде революционен акт.
Когато Габор пише тази книга, в Лвов и в Украйна все още няма война, но тя от години е на прага. Неговият писателски и човешки опит е да реабилитира очевидното и простото, да създава противоотрова по един безхитростен и честен начин, да свидетелства за това, което е и каквото е, а не за това какво може да бъде. Далечни са му абстракцията и плакатната идеология. В писането на украинския автор има воля да види и разбере тайните неща, трагедията на птичетата, които са паднали от гнездото, да чуе човека в ъгъла, да види сградата на живота му, да види ангела в спящото дете. И не, това не са сантиментални и трогателни по кичозен начин разкази.
Споменах, че се родее с Радичков и с неговия поглед, взрян в неопетненото чудо. Габор също е от страната на светлата и добронамерена наивност. В нея има призраци и върколаци, магия и блаженство, съдба и случайност.
Това е проза, която е старовремска, класическа и ретро по възможно най-добрия начин. В нея го има палавия смях на джаза, но го има и оправдания плач и скръб по един свят, който вече е друг.
Във време на виртуална реалност да пишеш за това, което наистина живееш и виждаш, е важно. Важно е, защото светът не се превръща и няма да се превърне в метареалност, която има някакво отношение към интелектуални, културни или материални натрупвания. Светът няма да се побере в телефон или приложение. Не може да бъде опростен до черно и бяло. И това трябва да се припомня, защото самото нещо постепенно е измествано от символа, територията е замествана от картата и това отдалечаване от естеството на всекидневието започва още от детството.
Книгата на Габор е като гръмоотвод, който отвежда електричеството на тревогата и стреса под земята, обезопасява ги, за да не се превърнат фантазмите в реални болки и причини за крах.
Крахът е обратим. Сборникът няма такъв залог и амбиция, но създава пространство на силни емоции и екзистенциални размисли. Те резонират с масово вроденото днес безпокойство, но прочитът на тази книга е трансформиращо преживяване. Освежава и вълнува.
Няма да се въздържа да споделя част от биографията и възгледите на Габор, защото във времена на носталгици и популисти трябва да се припомнят и очевидни неща. Той е писател, литературовед и издател. Роден в Закарпатието през 1959 г. Завършва Факултета по журналистика в Лвовския университет през 1986 г. и работи в редакционните екипи на местни вестници и списания. От 1993 г. е в академичната библиотека в града. Там се съсредоточава върху изучаването на украинската периодика от XIX и XX век.
В независима Украйна аз, просто момче от планинско село, постигнах това, което някога изглеждаше невъзможно. Получих докторска степен и публикувах няколко научни книги, романи, есета, разкази. Освен това в продължение на две десетилетия ръководех издателската си инициатива „Частна колекция“. В рамките на този проект на бял свят се появиха над 200 книги и антологии на съвременни украински автори.
Габор е допринесъл и за възраждането на интереса към творчеството на забравени и забранени писатели и учени.
По времето на тоталитаризма подобни начинания биха били немислими. Ето защо за мен свободата е най-ценното понятие както в Украйна, така и в световен мащаб. За новите поколения, родени в независима Украйна, свободата е толкова естествена, колкото и въздухът, който дишат, и това е правилно. И все пак днес сме изправени пред сериозна заплаха от страна на Путинова Русия. Тя има за цел да ни лиши от най-ценните ни активи – нашата земя и нашата свобода. Твърдо вярвам, че творческото изразяване на всеки украински писател сега служи като оръжие в тази борба.
Сърцето на книгата, поне за мен, е в разказа за помориеца Стефан Кърнов и за черния пясък на плажа. От него раните зараствали, но не всички. Това обаче не отменя болезнено красивата нужда да се говори за тях.
Активните дарители на „Тоест“ получават постоянна отстъпка в размер на 20% от коричната цена на всички заглавия от каталога на издателство „Ерго“, както и на няколко други български издателства в рамките на партньорската програма Читателски клуб „Тоест“. За повече информация прочетете на toest.bg/club.
Никой от нас не чете единствено най-новите книги. Тогава защо само за тях се пише? „На второ четене“ е рубрика, в която отваряме списъците с книги, публикувани преди поне година, четем ги и препоръчваме любимите си от тях. Рубриката е част от партньорската програма Читателски клуб „Тоест“. Изборът на заглавия обаче е единствено на авторите – Стефан Иванов и Антония Апостолова, които биха ви препоръчали тези книги и ако имаше как веднъж на две седмици да се разходите с тях в книжарницата.
Tuesday 11 June 2024 will be remembered as one of the most important days in the history of Raspberry Pi.
At the London Stock Exchange on 11 June 2024.
The successful introduction of the Raspberry Pi Foundation’s commercial subsidiary on the London Stock Exchange is a genuinely remarkable achievement. I want to put on record my huge congratulations and thanks to Eben Upton, Martin Hellawell, and the whole team at Raspberry Pi Holdings plc for everything they have done to make this possible.
The purpose of the IPO was to secure the next stage of growth and impact for both the Foundation and the company. We have huge ambitions and the IPO has provided both organisations with the capital we need to pursue those ambitions at pace and scale. Our Chief Executive Philip Colligan has already explained what it means for the Raspberry Pi Foundation and our mission to empower young people all over the world.
In this post, I wanted to take a moment to acknowledge the significant contribution that others have made over the years, particularly all of the Trustees who have been so generous with their time, energy, and expertise.
Founding Trustees
The Raspberry Pi Foundation was established in 2008 by six founding Trustees: Alan Mycroft, David Braben, Eben Upton, Jack Lang, Pete Lomas, and Rob Mullins. All of them deserve credit and thanks for setting us off on this incredible journey.
Alan, Eben, Jack, and Rob were all involved with the Computer Lab at the University of Cambridge. They were dealing with a decline in applications to study the computer science undergraduate course, which was a symptom of the much wider challenge that far too many young people weren’t getting access to opportunities to learn computer science, or getting hands-on with programming and electronics.
David Braben brought an industry perspective, drawing on the challenges he was experiencing with recruiting engineers and programmers at the world-leading games company that he had founded, Frontier Developments.
Back in 2012 at the Sony factory that produces Raspberry Pi computers in Pencoed, Wales.
For Pete Lomas, he was paying forward the support and inspiration that he received from a college technician who gave him the opportunity and encouragement to experiment with programming a DEC PDP-8. That experience ultimately led Pete to establish Norcott Technologies, an electronics design and manufacturing business that he still runs today.
The founding Trustees’ original idea was to create a low-cost programmable computer — available for the price of a textbook — that would remove price as a barrier to owning a computer and inspire young people to take their first steps with computing. It took four years for the first Raspberry Pi computer to be launched, an achievement for which Eben and Pete were rightly honoured, along with other members of the team, as recipients of the prestigious MacRobert Prize for engineering.
Combining social impact and commercial success
What none of our founding Trustees could have predicted was the enormous commercial success of Raspberry Pi computers. In realising their vision of a low-cost programmable computer for education, the team created a new category of single-board computers that found a home with enthusiasts and industry, enabling the team to evolve — through hard work and creativity — into a business that is now entering a new phase as a listed company.
They also delivered on the original mission, with computer science at the University of Cambridge now being one of the most oversubscribed undergraduate courses in the country and many applicants citing Raspberry Pi computers as part of their introduction to programming.
The commercial success of Raspberry Pi has enabled the Foundation to expand its educational programmes to the point where it is now established as one of the world’s leading nonprofits focused on democratising access to computing education, and is benefiting the lives of tens of millions of young people already.
It takes a village
While no-one really knows the origin of the proverb ‘It takes a village to raise a child’, we can all recognise the truth in that simple statement. It applies just as much for endeavours like Raspberry Pi.
Over the years, Raspberry Pi has been a genuine team game. Employees in the Foundation and our commercial subsidiary, advisers, partner organisations and supporters, volunteers and community members have all played a crucial role in the success of both the company and the Foundation.
At a Raspberry Pi birthday celebration circa 2017.
Over the years there have been 21 Trustees of the Foundation, bringing an incredible range of skills and experience that has elevated our ambitions and supported the teams in both the Foundation and the company.
All of our Trustees have provided their time and expertise for free, never receiving any financial benefit for their contribution as Trustees.
Serving as a Trustee of a charity is a serious business, with significant responsibility and accountability. While many charities have commercial operations, there is no doubt that the scale and complexity of Raspberry Pi’s commercial business has placed significant additional responsibilities on all of our Trustees.
I especially want to pay tribute to my predecessors as chair of the Board of Trustees: Jack Lang, one of our founding Trustees, who sadly passed away this year; and David Cleevely, who continues to support our work as a Member of the Foundation. Both Jack and David played a particularly important part in the success of Raspberry Pi.
Welcoming our new Trustees
As we enter this new phase for the Foundation’s relationship with Raspberry Pi Holdings Ltd, we are delighted to welcome three new Trustees to the Board:
Andrew Sliwinski is a VP at Lego Education, formerly co-director of Scratch @ MIT, ex-Mozilla, and founder of DIY.org. Andrew is a technologist and maker with a deep understanding of education systems globally.
Laura Turkington leads global partnerships and programmes at EY, and was previously at Vodafone Foundation. Laura has extensive global experience (including Ireland and India), including supporting large-scale initiatives on digital skills, computing education, and AI literacy.
Stephen Greene is the founder and CEO of Rockcorps and the former chair of the National Citizen Service. Stephen brings huge experience of building global volunteer movements, social enterprise, marketing (especially to young people), government relations, and education of disadvantaged youth.
Many organizations have critical legacy Java applications that are increasingly difficult to maintain. Modernizing these applications is a necessary, daunting, and risky task that takes the focus off of creating new value or features. This includes undocumented code, outdated frameworks and libraries, security vulnerabilities, a lack of logging and error handling, and a lack of input validation. Amazon Q Developer simplifies and accelerates the modernization of existing Java applications. It can analyze code to highlight areas for potential improvements, assist with resolving technical debt, suggest code optimizations, and facilitate the transition to current frameworks and libraries.
This blog post explores how to modernize legacy Java applications using Amazon Q Developer. We will take an example of Unicorn Store API, a Java application with Java 8 running on Amazon Elastic Compute Cloud (Amazon EC2). First, we will upgrade the underlying runtime from Java 8 to Java 17 and other common dependencies, including Spring. Then, we will reduce technical debt within the code by improving modularity and logging. Finally, we will redeploy this application in a container image using a modern computing option, AWS Fargate.
The Unicorn Store API provides CRUD operations to manage Unicorn records in a database. It is built with Maven.
You will follow the below steps to modernize this application and bring it to Fargate using Amazon Q Developer.
Upgrade the application to Java 17 to leverage the latest features.
Reduce existing technical debt in the codebase.
Make the application cloud native and deploy it to AWS.
Outdated applications require increased effort to maintain security and stability. As a developer, you must continually relearn framework changes and optimizations that others have discovered in previous upgrades. The effort required to maintain the application makes it difficult to balance necessary updates with adding new features.
With Amazon Q Developer agent for code transformation, you can keep applications updated and supported in just a few steps. This removes vulnerabilities from unsupported versions, improves performance, and frees up time to focus on adding new features. Amazon Q Developer agent for code transformation accelerates application maintenance, upgrades, and migration in minutes. It enables developers to remove much of the undifferentiated work out of the tedious task of maintaining, upgrading and migrating existing application workloads, saving up to days’ or months’ worth of the undifferentiated work involved in moving from older language versions.
Let’s upgrade our Unicorn Store API from Java 8 to Java 17 using Amazon Q Developer agent for code transformation to leverage the latest features and optimization. In IntelliJ IDE, you enter /transform in the Amazon Q chat panel and provide the necessary details for Amazon Q Developer to start upgrading the project.
Amazon Q Developer agent for code transformation automatically analyzes the existing code, generates a transformation plan, and completes the transformation tasks suggested by the plan. While doing so, it upgrades popular libraries and frameworks to a version compatible with Java 17, including Spring, Spring Boot, JUnit, JakartaEE, Mockito, Hibernate, and Log4j to their latest available major versions. It also updates deprecated code components according to Java 17 recommendations. To start with the Amazon Q Developer agent for code transformation capability, you can read and follow the steps at Upgrade language versions with Amazon Q Developer agent for Code Transformation.
Once complete, you can review the transformed code, complete with build and test results, before accepting the changes.
Reduce technical debt in the codebase
Technical debt accumulates in any codebase over time. Some technical debt may be unavoidable to meet deadlines, but must be tracked and prioritized to pay back later. If left unmanaged, compounding technical debt will make development slower and expensive. Reducing technical debt should be an ongoing team effort, but often falls behind other priorities. Amazon Q Developer streamlines modernizing legacy Java code by identifying and remediating technical debt. Amazon Q Developer reduces the time and resources it takes to analyze the code by providing a list of issues that contribute to technical debt in a codebase. This makes it easy for software development teams to prioritize technical debt items and make informed decisions about which technical debt to address first.
Let’s find the list of technical debt in our Unicorn Store API. In IntelliJ IDE, use Send to Prompt option to send the highlighted code to the Amazon Q chat panel and prompt to provide a list of all technical debt. Amazon Q Developer lists all technical debt in detail.
Once you identify the technical debt, the next step is to gradually remediate them. Amazon Q Developer reduces the time it takes to implement the code to remediate the technical debt. As a developer, you can interact with Amazon Q Developer agent for software development within your IDE to get help with code suggestions for a specific task that you are trying to accomplish. It uses the code in whole project as context and provides an implementation plan that includes code updates it plans to make across all the files in the project. You can review the plan, and once you are satisfied with the plan, you can ask Amazon Q Developer to generate the code based on the proposed plan. This saves developers’ effort compared to manual updates.
For the technical debt identified for Unicorn Store API in the above step, let’s use Amazon Q Developer to address the missing logging technical debt. In IntelliJ IDE, enter /dev in the Amazon Q chat panel with the details on the logging technical debt. Amazon Q Developer generates an implementation plan and code to add logging based on the full project context. To get started with Amazon Q Developer agent for software development, you can refer to the steps at Develop software with the Amazon Q Developer agent for software development.
Modernizing legacy Java code requires continuous refactoring to incrementally enhance quality and avoid accumulating technical debt over time. Amazon Q Developer simplifies this iterative process through its Refactor capability. Amazon Q Developer provides a refactored version of the selected code, alongside explanations of each change and its coding benefit. It helps you to understand the changes by explaining each change and the benefit of making the change in the existing code. You can read further about this capability at Explain and update code with Amazon Q Developer.
Let’s leverage this feature to refine methods in the UnicornController class in our Unicorn Store API project. Amazon Q Developer furnishes the updated code with better code readability or efficiency, among other improvements, for you to review.
Make the application cloud native and deploy to AWS
The final step in the modernization journey is to make the application cloud-native and deploy to AWS. Cloud native is the software approach of building, deploying, and managing modern applications in cloud computing environments. These cloud native technologies support fast and frequent changes to applications without impacting service delivery, providing adopters with an innovative, competitive advantage. Let’s see how Amazon Q Developer can assist in making our Unicorn Store API project cloud native.
In IntelliJ IDE, open the Amazon Q Chat, and prompt Amazon Q Developer to provide a recommended approach to make the project cloud native and deploy to AWS.
Let’s ask Amazon Q Developer to implement the steps outlined in the previous chat conversation. First, ask Amazon Q Developer to create a docker file to containerize the application. The containerization process streamlines application development by decoupling the software from the underlying hardware and other dependencies. This approach enhances speed, efficiency, and security by isolating different components within the containerized environment.
Having successfully developed a container-based application, let’s leverage Amazon Q Developer’s capabilities to generate an AWS CloudFormation template. This template will enable us to deploy the required resources to AWS using Infrastructure as Code (IaC). IaC allows us to programmatically provision and manage our computing infrastructure, eliminating the need for manual processes and configurations. Manual infrastructure management can be time-consuming and error-prone, especially when dealing with large-scale applications.
To facilitate the creation of the CloudFormation template, let’s revisit the suggestions from our previous conversation and compile a list of the resources that need to be provisioned in AWS. Once you have this list, you can ask Amazon Q Developer to generate the CloudFormation template based on these resource requirements.
Amazon Q Developer can generate the CloudFormation template with all the required resources as outlined in the steps to deploy the container in AWS in a secure, reliable, and scalable manner.
Now that we have the CloudFormation template, once CloudFormation is deployed, let’s push the local docker image of our Unicorn Store API to Amazon ECR and start the Fargate tasks required to run the application in AWS.
In this way, you can use Amazon Q Developer to make your application cloud native by designing the steps to deploy to the cloud, helping migrate your application to container-based solution and even writes Infrastructure as code scripts to deploy your application to AWS.
Conclusion
Amazon Q Developer empowers developers to simplify and accelerate the modernization of legacy Java applications. By leveraging Amazon Q Developer, developers can bring outdated applications up to current frameworks and deploy them to AWS in a cloud-native architecture. This streamlines the process, reducing the effort, risk, and maintenance required. Developers save significant time and resources, which can now be used to focus on building new features and enhancing modernized applications rather than managing technical debt.
To learn more about Amazon Q Developer, see the following resources:
Fine-grained access control is a crucial aspect of data security for modern data lakes and data warehouses. As organizations handle vast amounts of data across multiple data sources, the need to manage sensitive information has become increasingly important. Making sure the right people have access to the right data, without exposing sensitive information to unauthorized individuals, is essential for maintaining data privacy, compliance, and security.
Today, Amazon DataZone has introduced fine-grained access control, providing you granular control over your data assets in the Amazon DataZone business data catalog across data lakes and data warehouses. With the new capability, data owners can now restrict access to specific records of data at row and column levels, instead of granting access to the entire data asset. For example, if your data contains columns with sensitive information such as personally identifiable information (PII), you can restrict access to only the necessary columns, making sure sensitive information is protected while still allowing access to non-sensitive data. Similarly, you can control access at the row level, allowing users to see only the records that are relevant to their role or task.
In this post, we discuss how to implement fine-grained access control with row and column asset filters using this new feature in Amazon DataZone.
Row and column filters
Row filters enable you to restrict access to specific rows based on criteria you define. For instance, if your table contains data for two regions (America and Europe) and you want to make sure that employees in Europe only access data relevant to their region, you can create a row filter that excludes rows where the region is not Europe (for example, region != 'Europe'). This way, employees in America won’t have access to Europe’s data.
Column filters allow you to limit access to specific columns within your data assets. For example, if your table includes sensitive information such as PII, you can create a column filter to exclude PII columns. This makes sure subscribers can only access non-sensitive data.
The row and column asset filters in Amazon DataZone enable you to control who can access what using a consistent, business user-friendly mechanism for all of your data across AWS data lakes and data warehouses. To use fine-grained access control in Amazon DataZone, you can create row and column filters on top of your data assets in the Amazon DataZone business data catalog. When a user requests a subscription to your data asset, you can approve the subscription by applying the appropriate row and column filters. Amazon DataZone enforces these filters using AWS Lake Formation and Amazon Redshift, making sure the subscriber can only access the rows and columns that they are authorized to use.
Solution overview
To demonstrate the new capability, we consider a sample customer use case where an electronics ecommerce platform is looking to implement fine-grained access controls using Amazon DataZone. The customer has multiple product categories, each operated by different divisions of the company. The platform governance team wants to make sure each division has visibility only to data belonging to their own categories. Additionally, the platform governance team needs to adhere to the finance team requirements that pricing information should be visible only to the finance team.
The sales team, acting as the data producer, has published an AWS Glue table called Product sales that contains data for both Laptops and Servers categories to the Amazon DataZone business data catalog using the project Product-Sales. The analytic teams in both the laptop and server divisions need to access this data for their respective analytics projects. The data owner’s objective is to grant data access to consumers based on the division they belong to. This means giving access to only rows of data with laptop sales to the laptops sales analytics team, and rows with servers sales to the server sales analytics team. Additionally, the data owner wants to restrict both teams from accessing the pricing data. This post demonstrates the implementation steps to achieve this use case in Amazon DataZone.
The steps to configure this solution are as follows:
The publisher creates asset filters for limiting access:
We create two row filters: a Laptop Only row filter that limits access to only the rows of data with laptop sales, and a Server Only row filter that limits access to the rows of data with server sales.
We also create a column filter called exclude-price-columns that excludes the price-related columns from the Product Sales
Consumers discover and request subscriptions:
The analyst from the laptops division requests a subscription to the Product Sales data asset.
The analyst from the servers division also request a subscription to the Product Sales data asset.
Both subscription requests are sent to the publisher for approval.
The publisher approves the subscriptions and applies the appropriate filters:
The publisher approves the request from the analysts in the laptops division, applying the Laptop Only row filter and the exclude-price-columns columns filter.
The publisher approves the request from the consumer in the servers division, applying the Server Only row filter and the exclude-price-columns columns filter.
Consumers access the authorized data in Amazon Athena:
After the subscription is approved, we query the data in Athena to make sure that the analyst from the laptops division can now access only the product sales data for the Laptop
Similarly, the analyst from the servers division can access only the product sales data for the Server
Both consumers can see all columns except the price-related columns, as per the applied column filter.
The following diagram illustrates the solution architecture and process flow.
Prerequisites
To follow along with this post, the publisher of the product sales data asset must have published a sales dataset in Amazon DataZone.
Publisher creates asset filters for limiting access
In this section, we detail the steps the publisher takes to create asset filers.
Create row filters
This dataset contains the product categories Laptops and Servers. We want to restrict access to the dataset that is authorized based on the product category. We use the row filter feature in Amazon DataZone to achieve this.
Amazon DataZone allows you to create row filters that can be used when approving subscriptions to make sure that the subscriber can only access rows of data as defined in the row filters. To create a row filter, complete the following steps:
On the Amazon DataZone console, navigate to the product-sales project (the project to which the asset belongs).
Navigate to the Data tab for the project.
Choose Inventory data in the navigation pane, then the asset Product Sales, where you want to create the row filter.
You can add row filters for assets of type AWS Glue tables or Redshift tables.
On the asset detail page, on the Asset filters tab, choose Add asset filter.
We create two row filters, one each for the Laptops and Servers categories.
Complete the following steps to create a laptop only asset row filter:
Enter a name for this filter (Laptop Only).
Enter a description of the filter (Allow rows with product category as Laptop Only).
For the filter type, select Row filter.
For the row filter expression, enter one or more expressions:
Choose the column Product Category from the column dropdown menu.
Choose the operator = from the operator dropdown menu.
Enter the value Laptops in the Value field.
If you need to add another condition to the filter expression, choose Add condition. For this post, we create a filter with one condition.
When using multiple conditions in the row filter expression, choose And or Or to link the conditions.
You can also define the subscriber visibility. For this post, we kept the default value (No, show values to subscriber).
Choose Create asset filter.
Repeat the same steps to create a row filter called Server Only, except this time enter the value Servers in the Value field.
Create column filters
Next, we create column filters to restrict access to columns with price-related data. Complete the following steps:
In the same asset, add another asset filter of type column filter.
On the Asset filters tab, choose Add asset filter.
For Name, enter a name for the filter (for this post, exclude-price-columns).
For Description, enter a description of the filters (for this post, exclude price data columns).
For the filter type, select Column to create the column filter. This will display all the available columns in the data asset’s schema.
Select all columns except the price-related ones.
Choose Create asset filter.
Consumers discover and request subscriptions
In this section, we switch to the role of an analyst from the laptop division who is working within the project Sales Analytics - Laptop. As the data consumer, we search the catalog to find the Product Sales data asset and request access by subscribing to it.
Log in to your project as a consumer and search for the Product Sales data asset.
On the Product Sales data asset details page, choose Subscribe.
For Project, choose Sales Analytics – Laptops.
For Reason for request, enter the reason for the subscription request.
Choose Subscribe to submit the subscription request.
Publisher approves subscriptions with filters
After the subscription request is submitted, the publisher will receive the request, and they can approve it by following these steps:
As the publisher, open the project Product-Sales.
On the Data tab, choose Incoming requests in the left navigation pane.
Locate the request and choose View request. You can filter by Pending to see only requests that are still open.
This opens the details of the request, where you can see details like who requested the access, for what project, and the reason for the request.
To approve the request, there are two options:
Full access – If you choose to approve the subscription with full access option, the subscriber will get access to all the rows and columns in our data asset.
Approve with row and column filters – To limit access to specific rows and columns of data, you can choose the option to approve with row and column filters. For this post, we use both filters that we created earlier.
Select Choose filter, then on the dropdown menu, choose the Laptops Only and pii-col-filter
Choose Approve to approve the request.
After access is granted and fulfilled, the subscription looks as shown in the following screenshot.
Now let’s log in as a consumer from the server division.
Repeat the same steps, but this time, while approving the subscription, the publisher of sales data approves with the Server only The other steps remain the same.
Consumers access authorized data in Athena
Now that we have successfully published an asset to the Amazon DataZone catalog and subscribed to it, we can analyze it. Let’s log in as a consumer from the laptop division.
In the Amazon DataZone data portal, choose the consumer project Sales Analytics - Laptops.
On the Schema tab, we can view the subscribed assets.
Choose the project Sales Analytics - Laptops and choose the Overview
In the right pane, open the Athena environment.
We can now run queries on the subscribed table.
Choose the table under Tables and views, then choose Preview to view the SELECT statement in the query editor.
Run a query as the consumer of Sales Analytics - Laptops, in which we can view data only with product category Laptops.
Under Tables and views, you can expand the table product_sales. The price-related columns are not visible in the Athena environment for querying.
Next, you can switch to the role of analyst from the server division and analyze the dataset in similar way.
We run the same query and see that under product_category, the analyst can see Servers only.
Conclusion
Amazon DataZone offers a straightforward way to implement fine-grained access controls on top of your data assets. This feature allows you to define column-level and row-level filters to enforce data privacy before the data is available to data consumers. Amazon DataZone fine-grained access control is generally available in all AWS Regions that support Amazon DataZone.
Try out the fine-grained access control feature in your own use case, and let us know your feedback in the comments section.
About the Authors
Deepmala Agarwal works as an AWS Data Specialist Solutions Architect. She is passionate about helping customers build out scalable, distributed, and data-driven solutions on AWS. When not at work, Deepmala likes spending time with family, walking, listening to music, watching movies, and cooking!
Leonardo Gomez is a Principal Analytics Specialist Solutions Architect at AWS. He has over a decade of experience in data management, helping customers around the globe address their business and technical needs. Connect with him on LinkedIn.
Utkarsh Mittal is a Senior Technical Product Manager for Amazon DataZone at AWS. He is passionate about building innovative products that simplify customers’ end-to-end analytics journeys. Outside of the tech world, Utkarsh loves to play music, with drums being his latest endeavor.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.


















































 Deepmala Agarwal works as an AWS Data Specialist Solutions Architect. She is passionate about helping customers build out scalable, distributed, and data-driven solutions on AWS. When not at work, Deepmala likes spending time with family, walking, listening to music, watching movies, and cooking!
Deepmala Agarwal works as an AWS Data Specialist Solutions Architect. She is passionate about helping customers build out scalable, distributed, and data-driven solutions on AWS. When not at work, Deepmala likes spending time with family, walking, listening to music, watching movies, and cooking! Leonardo Gomez is a Principal Analytics Specialist Solutions Architect at AWS. He has over a decade of experience in data management, helping customers around the globe address their business and technical needs. Connect with him on
Leonardo Gomez is a Principal Analytics Specialist Solutions Architect at AWS. He has over a decade of experience in data management, helping customers around the globe address their business and technical needs. Connect with him on  Utkarsh Mittal is a Senior Technical Product Manager for Amazon DataZone at AWS. He is passionate about building innovative products that simplify customers’ end-to-end analytics journeys. Outside of the tech world, Utkarsh loves to play music, with drums being his latest endeavor.
Utkarsh Mittal is a Senior Technical Product Manager for Amazon DataZone at AWS. He is passionate about building innovative products that simplify customers’ end-to-end analytics journeys. Outside of the tech world, Utkarsh loves to play music, with drums being his latest endeavor.