Post Syndicated from Maddie Bacon original https://aws.amazon.com/blogs/security/aws-security-profiles-jenny-brinkley-director-aws-security/

In the week leading up to AWS re:Invent 2021, we’ll share conversations we’ve had with people at AWS who will be presenting, and get a sneak peek at their work.
How long have you been at AWS, and what do you do in your current role?
I’ve been at AWS for 5½ years. I get to focus on the future of security and compliance. It gives me a lot of space to experiment and try new things, which is how I like to operate.
How did you get started in AWS Security?
I joined AWS through a startup acquisition, and I actually didn’t think I was going to go with the acquisition. I thought AWS would be way too big and move way too slow. I love being in environments where I get to move fast and be entrepreneurial. I started on the product side. I was able to learn what it takes to build and ship products at the scale of AWS – which is on another level and mind-blowing.
Then, like others at AWS, I was able to reinvent myself, find different passions, and experiment with new things. One of those areas for me was compliance. I started to get perspective on how that space was being defined by regulatory activity for the cloud, and it started opening my mind in different ways.
I started thinking, how do you make compliance easier for customers? How do you work with regulated entities to understand how to audit, and to understand the function of how the cloud operates? From there, my career has been about changing how to think about product, about how to make security easier. Layering in this compliance aspect, too, means I get to play in all these different worlds, work with internal and external customers, and work to simplify security, while also understanding where and how compliance fits in, without slowing down innovation.
How do you explain your job to non-tech friends?
I explain my work as removing the fear around security. You go see images of people in hoodies, with darkened faces, and binary code running behind them, and my job is to break that perception and walk in the light – yes, that’s my nod to Olivia Pope in Scandal. I love the idea of that gladiator mentality. You’re going in and solving the big problems, but you’re also creating more visibility and transparency around how security operates. And you’re doing this without making anyone afraid that they’re being watched or monitored, and without holding back innovation. My job is to provide that transparency and clarity, and give people prescriptive guidance on how to operate securely on AWS.
What are you currently working on that you’re excited about?
So much! That’s what I really love about my job – I get to play in a lot of spaces, and the context switching is something that really fuels me. One of the top projects I’m working on is something we just released in response to an ask from the White House, which I feel really privileged to work on. We released a new Cybersecurity Awareness training which is now available to everyone in the world. You can access this training right now, and you can share it with your grandparents or implement it in your corporation or small business. We were able to take a training product we built for all Amazon employees–and then externalize it. The size and the scope is something I’m really excited about. Making security easier for everybody is a big mission for us.
Another big area is up-skilling. You hear a lot about security jobs being the future, so we’re building everything from apprenticeships to new learning paths for anyone interested in security. We’re thinking about how we can build quick learning modules for people to listen to on the go. That’s something I get really excited about in this job – creating opportunities for people to understand that security jobs and opportunities are vast. If you’re curious and want to learn new things, AWS is endless.
You’re presenting at re:Invent this year – can you give readers a sneak peek at what you’re covering?
I am partnering with Eric Brandwine, AWS VP/Distinguished Engineer for a session called Introverts and extroverts collide: Build an inclusive workforce (SEC204). Eric and I are night and day in terms of how we work. In our talk we’ll touch on some of the challenges we had when we first started working together, but how we found value in our different approaches.
We’ll be discussing how he solves problems with technology and how I solve problems regarding people, and thinking about how that empathetic layer resonates between the two perspectives. Not every problem needs technology, and not every problem needs a people-focused solution. But, humans are behind any of those aspects of impact.
We’ll give prescriptive guidance to customers on how they should think about their security culture as it relates to people and as it relates to technology. We’ll talk about how those two worlds can blend together in a way that empowers an entire organization to prioritize security, and that they shouldn’t be afraid of it. We want to help bridge the gaps between the technologists and the empathetic individuals who think about how the technology lands in use cases across a business.
From your perspective, what’s the most important thing leaders can do to create an inclusive work environment?
Listening. Sitting back, getting the feedback, being vulnerable, asking the questions. So much of what we need to do now is practice that listening skill, really understand the motivations of our teams, and then try to create these safe working environments where people feel comfortable sharing their perspectives. It’s not that you’re going to act on everything everyone’s talking about, but at least you get diverse perspectives and points of view to help create an inclusive work environment that makes everyone want to show up, support each other, and do the best work possible.
What’s your favorite Leadership Principle at Amazon and why?
I have two. One is Learn and Be Curious because that is how I like to operate. I think, “what if…” or “why can’t we…”. Then Think Big pairs with “why can’t we…” The culture within AWS really supports that. On a daily basis, we can flip the script on how we think about our jobs and how we position the business.
If you’re entrepreneurial and like to create, this place is like a magic playground. Some people look at my job and they’re so confused with all the different things I get to do – but it goes back to that context switching. I believe that Learn and Be Curious and Think Big fit in that realm for me–I feel like I can be anything, I can do anything. I also had parents who told me as a kid that I could do anything and be anything, so I think that’s just who I am. Those two leadership principles help me to produce and do my best work.
What’s the thing you’re most proud of in your career?
That’s hard. It’s a couple of things. I’ve had a lot of incredible opportunities. One of which was being involved in a startup. We raised the money quickly, we worked with incredible customers, we solved really challenging business issues. The fact that I was able to bring that here to AWS, in a way that now hundreds of thousands of people get to see the kind of work we’re able to produce, is pretty cool.
But honestly, working with some of our new hires who are just getting into the workforce–especially with our diverse candidates–I’m at a place in my career where I want to create opportunities for others. I’m working to create safe spaces for people to operate and do their best work and really break down barriers for people who might not otherwise get those opportunities. That’s what I’m most excited about for the future, and also the most proud about–giving people opportunities to work in careers they never thought were available to them. I love that, and I get to do it daily.
If you had to pick any other job, what would you want to do?
Sports agent. I think I’d be so good at it. I would love to go work with young athletes, especially with the new NCAA ruling that college athletes can get paid for the use of their likeness. I would love to help them develop really interesting business plans.
If you have feedback about this post, submit comments in the Comments section below.
Want more AWS Security news? Follow us on Twitter.














 processors in 2018 such as
processors in 2018 such as 
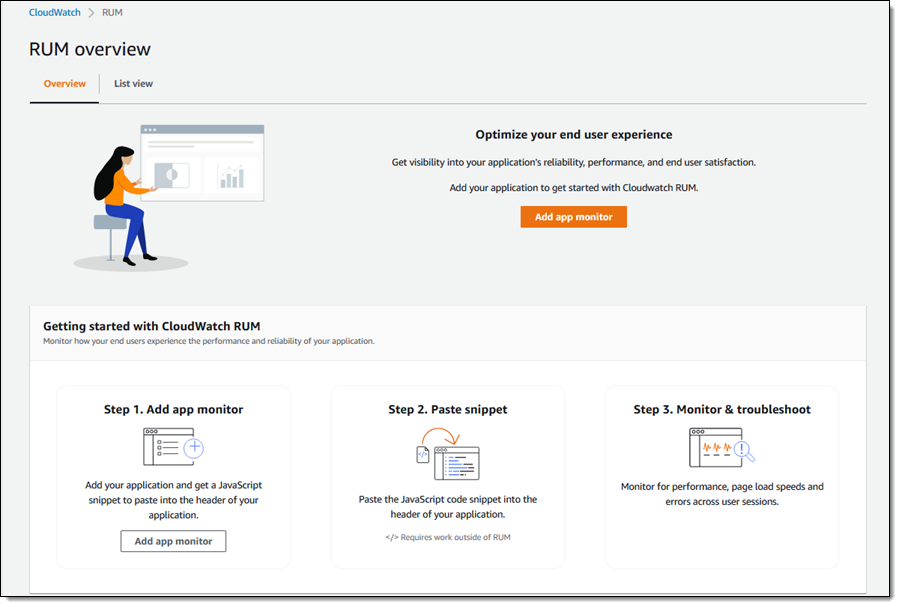


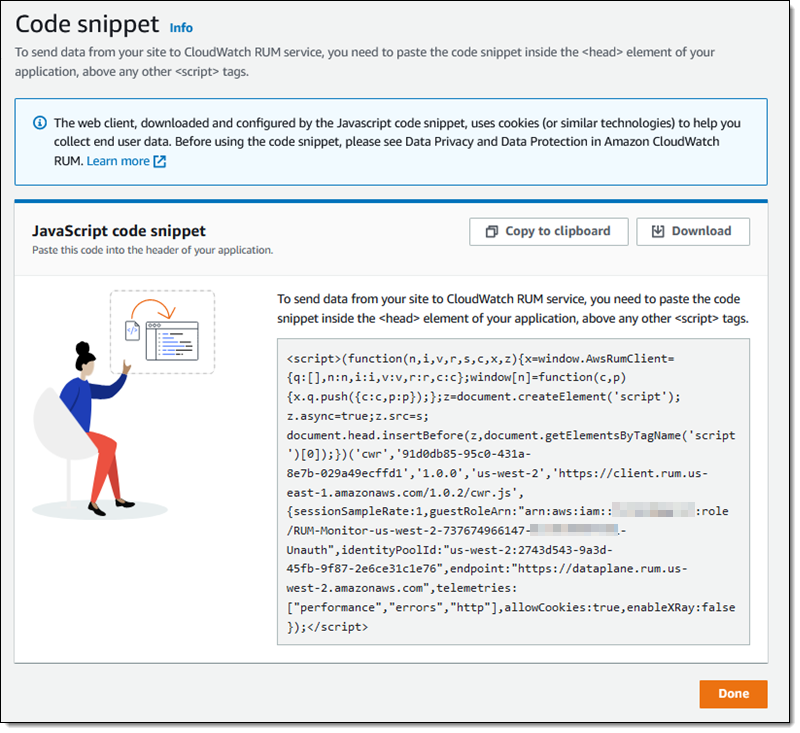


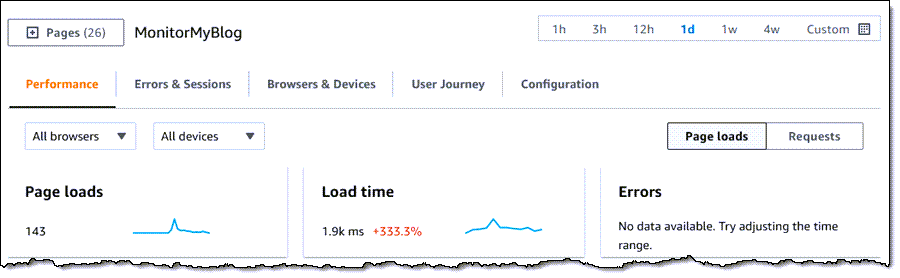




















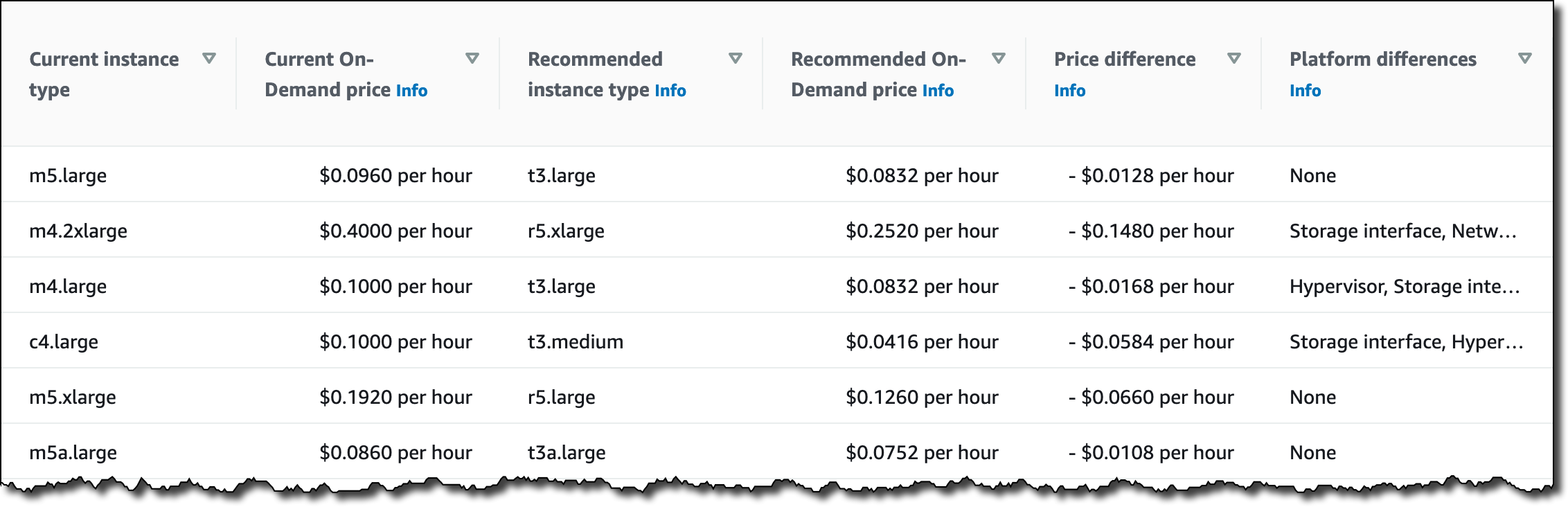

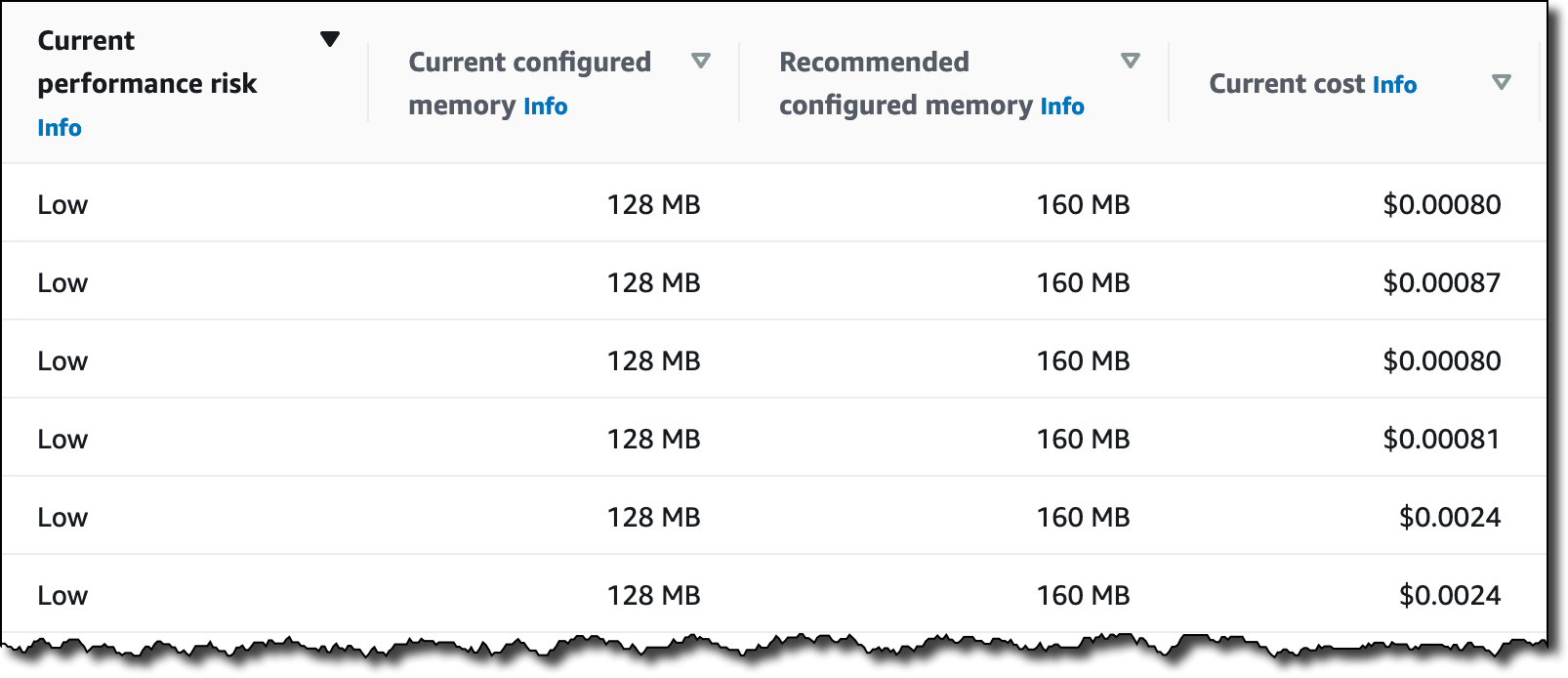


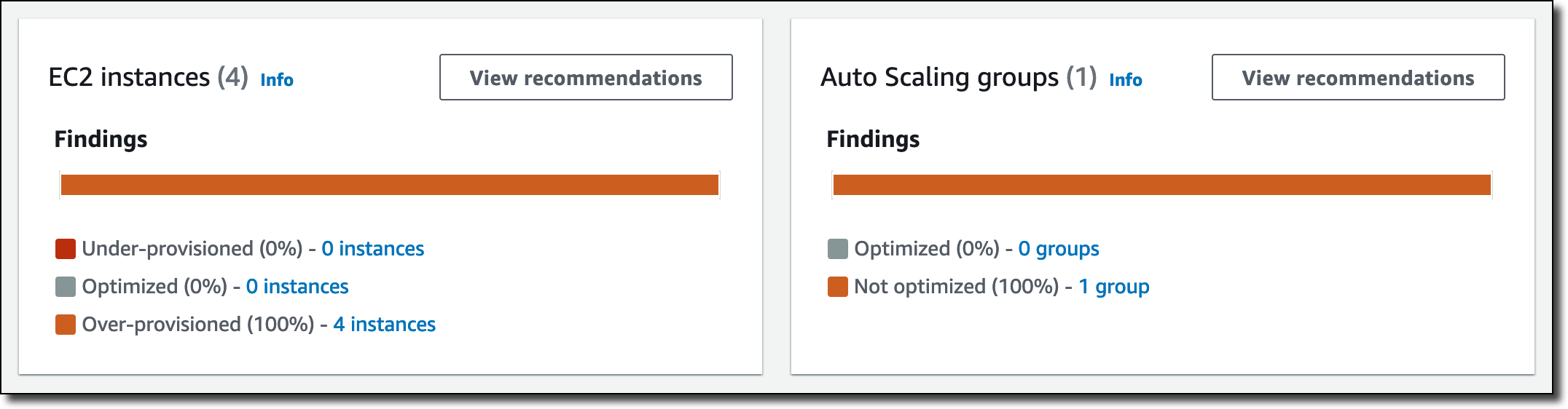








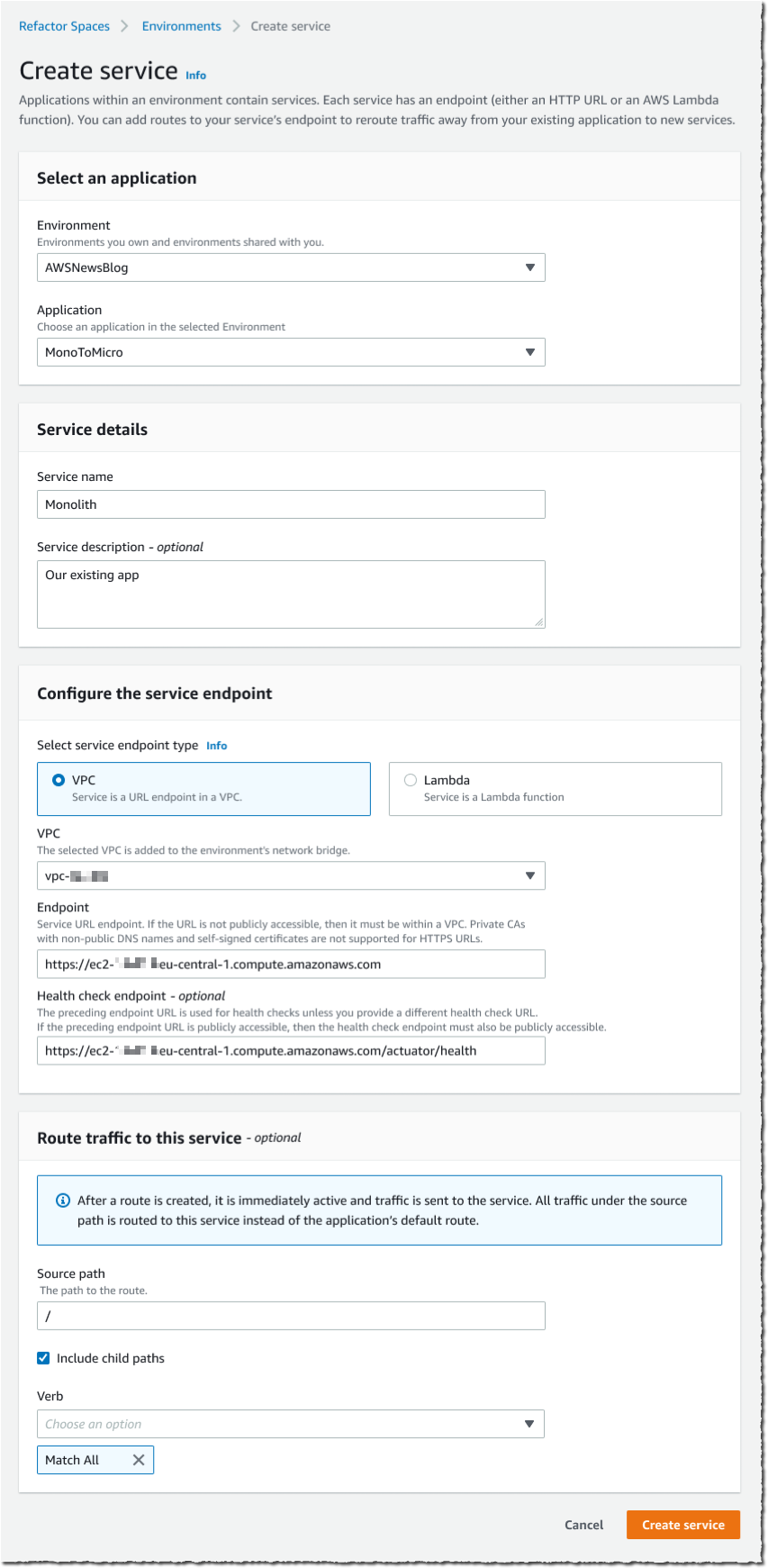


 Scaling is a really interesting problem, with challenges around performance, storage, availability, cost, and effectiveness. In addition to handling hundreds of millions of ad requests per second (trillions of ads per day) within a latency budget of 120 ms, the ad server must be able to:
Scaling is a really interesting problem, with challenges around performance, storage, availability, cost, and effectiveness. In addition to handling hundreds of millions of ad requests per second (trillions of ads per day) within a latency budget of 120 ms, the ad server must be able to: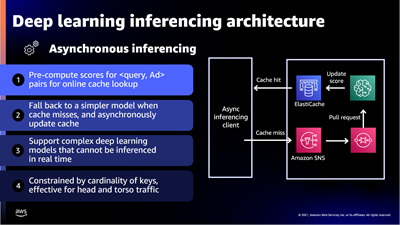 The presentation wraps up by discussing some of the ways that they were able to apply machine learning at scale. For example, to select the right ad for each request, Amazon Ads uses deep learning models to predict relevant ads to show shoppers, predict whether a shopper will click or purchase, and allocate and price an ad. In order to do this, they needed to be able to score thousands of ads per request within a 20 ms window at over 100K transactions per second, all across hundreds of models that each required different hardware and software optimizations.
The presentation wraps up by discussing some of the ways that they were able to apply machine learning at scale. For example, to select the right ad for each request, Amazon Ads uses deep learning models to predict relevant ads to show shoppers, predict whether a shopper will click or purchase, and allocate and price an ad. In order to do this, they needed to be able to score thousands of ads per request within a 20 ms window at over 100K transactions per second, all across hundreds of models that each required different hardware and software optimizations.