Post Syndicated from Tanushree Sharma original https://blog.cloudflare.com/browser-rendering-api-ga-rolling-out-cloudflare-snippets-swr-and-bringing-workers-for-platforms-to-our-paygo-plans
Browser Rendering API is now available to all paid Workers customers with improved session management
In May 2023, we announced the open beta program for the Browser Rendering API. Browser Rendering allows developers to programmatically control and interact with a headless browser instance and create automation flows for their applications and products.
At the same time, we launched a version of the Puppeteer library that works with Browser Rendering. With that, developers can use a familiar API on top of Cloudflare Workers to create all sorts of workflows, such as taking screenshots of pages or automatic software testing.
Today, we take Browser Rendering one step further, taking it out of beta and making it available to all paid Workers’ plans. Furthermore, we are enhancing our API and introducing a new feature that we’ve been discussing for a long time in the open beta community: session management.
Session Management
Session management allows developers to reuse previously opened browsers across Worker’s scripts. Reusing browser sessions has the advantage that you don’t need to instantiate a new browser for every request and every task, drastically increasing performance and lowering costs.
Before, to keep a browser instance alive and reuse it, you’d have to implement complex code using Durable Objects. Now, we’ve simplified that for you by keeping your browsers running in the background and extending the Puppeteer API with new session management methods that give you access to all of your running sessions, activity history, and active limits.
Here’s how you can list your active sessions:
const sessions = await puppeteer.sessions(env.RENDERING);
console.log(sessions);
[
{
"connectionId": "2a2246fa-e234-4dc1-8433-87e6cee80145",
"connectionStartTime": 1711621704607,
"sessionId": "478f4d7d-e943-40f6-a414-837d3736a1dc",
"startTime": 1711621703708
},
{
"sessionId": "565e05fb-4d2a-402b-869b-5b65b1381db7",
"startTime": 1711621703808
}
]
We have added a Worker script example on how to use session management to the Developer Documentation.
Analytics and logs
Observability is an essential part of any Cloudflare product. You can find detailed analytics and logs of your Browser Rendering usage in the dashboard under your account’s Worker & Pages section.
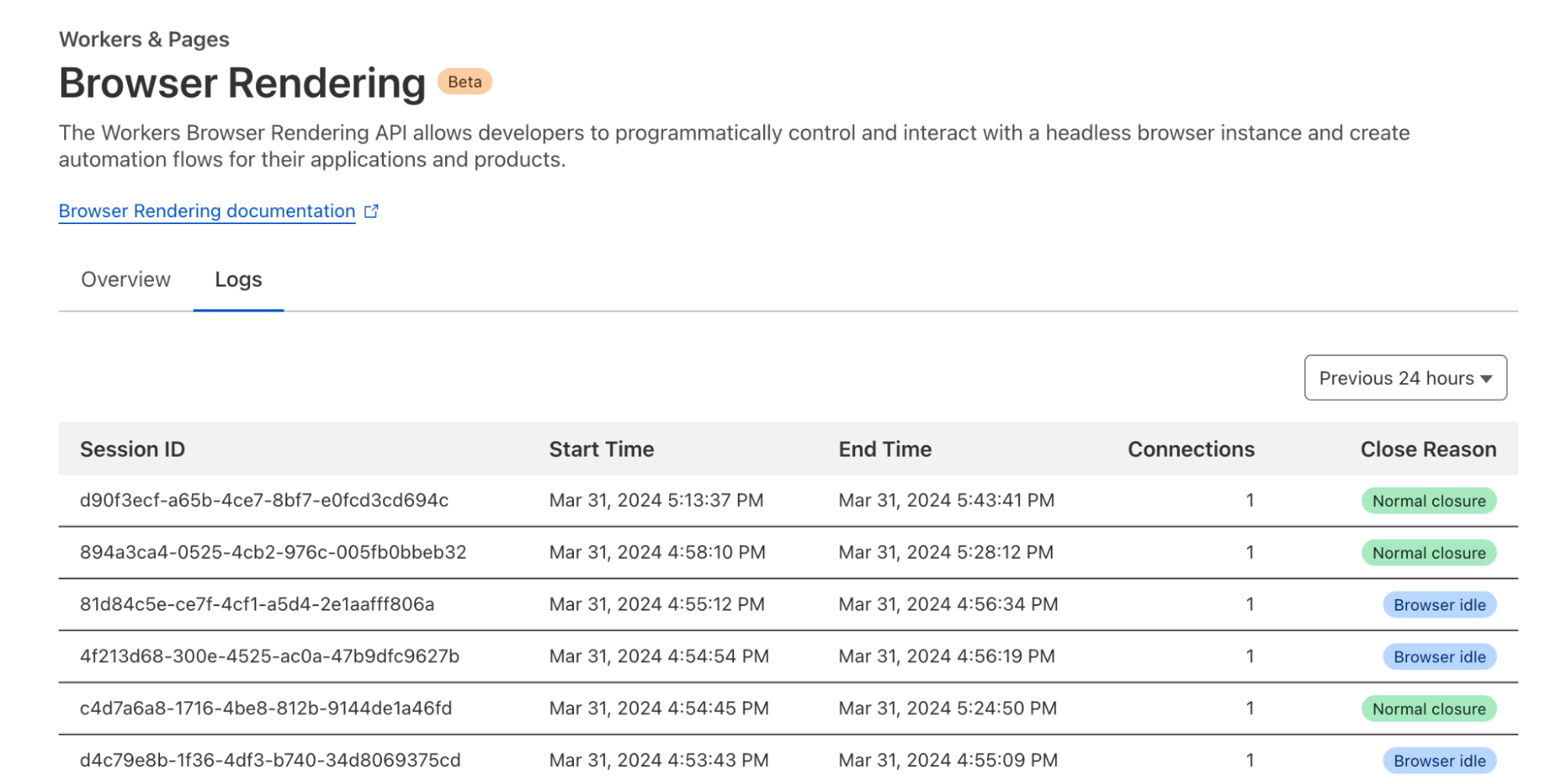
Browser Rendering is now available to all customers with a paid Workers plan. Each account is limited to running two new browsers per minute and two concurrent browsers at no cost during this period. Check our developers page to get started.
We are rolling out access to Cloudflare Snippets
Powerful, programmable, and free of charge, Snippets are the best way to perform complex HTTP request and response modifications on Cloudflare. What was once too advanced to achieve using Rules products is now possible with Snippets. Since the initial announcement during Developer Week 2022, the promise of extending out-of-the-box Rules functionality by writing simple JavaScript code is keeping the Cloudflare community excited.
During the first 3 months of 2024 alone, the amount of traffic going through Snippets increased over 7x, from an average of 2,200 requests per second in early January to more than 17,000 in March.
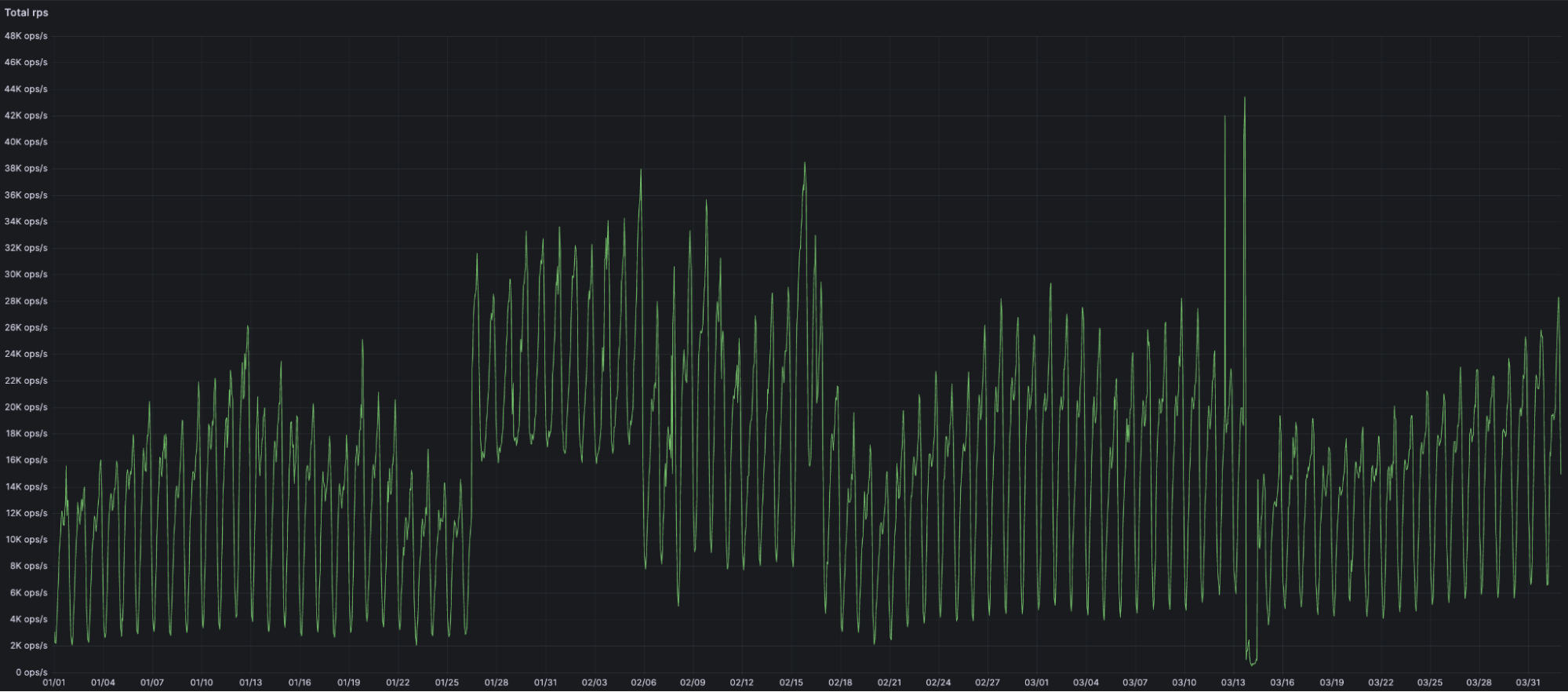
However, instead of opening the floodgates and letting millions of Cloudflare users in to test (and potentially break) Snippets in the most unexpected ways, we are going to pace ourselves and opt for a phased rollout, much like the newly released Gradual Rollouts for Workers.
In the next few weeks, 5% of Cloudflare users will start seeing “Snippets” under the Rules tab of the zone-level menu in their dashboard. If you happen to be part of the first 5%, snip into action and try out how fast and powerful Snippets are even for advanced use cases like dynamically changing the date in headers or A / B testing leveraging the `math.random` function. Whatever you use Snippets for, just keep one thing in mind: this is still an alpha, so please do not use Snippets for production traffic just yet.
Until then, keep your eyes out for the new Snippets tab in the Cloudflare dashboard and learn more how powerful and flexible Snippets are at the developer documentation in the meantime.
Coming soon: asynchronous revalidation with stale-while-revalidate
One of the features most requested by our customers is the asynchronous revalidation with stale-while-revalidate (SWR) cache directive, and we will be bringing this to you in the second half of 2024. This functionality will be available by design as part of our new CDN architecture that is being built using Rust with performance and memory safety at top of mind.
Currently, when a client requests a resource, such as a web page or an image, Cloudflare checks to see if the asset is in cache and provides a cached copy if available. If the file is not in the cache or has expired and become stale, Cloudflare connects to the origin server to check for a fresh version of the file and forwards this fresh version to the end user. This wait time adds latency to these requests and impacts performance.
Stale-while-revalidate is a cache directive that allows the expired or stale version of the asset to be served to the end user while simultaneously allowing Cloudflare to check the origin to see if there’s a fresher version of the resource available. If an updated version exists, the origin forwards it to Cloudflare, updating the cache in the process. This mechanism allows the client to receive a response quickly from the cache while ensuring that it always has access to the most up-to-date content. Stale-while-revalidate strikes a balance between serving content efficiently and ensuring its freshness, resulting in improved performance and a smoother user experience.
Customers who want to be part of our beta testers and “cache” in on the fun can register here, and we will let you know when the feature is ready for testing!
Coming on April 16, 2024: Workers for Platforms for our pay-as-you-go plan
Today, we’re excited to share that on April 16th, Workers for Platforms will be available to all developers through our new $25 pay-as-you-go plan!
Workers for Platforms is changing the way we build software – it gives you the ability to embed personalization and customization directly into your product. With Workers for Platforms, you can deploy custom code on behalf of your users or let your users directly deploy their own code to your platform, without you or your users having to manage any infrastructure. You can use Workers for Platforms with all the exciting announcements that have come out this Developer Week – it supports all the bindings that come with Workers (including Workers AI, D1 and Durable Objects) as well as Python Workers.
Here’s what some of our customers – ranging from enterprises to startups – are building on Workers for Platforms:
- Shopify Oxygen is a hosting platform for their Remix-based eCommerce framework Hydrogen, and it’s built on Workers for Platforms! The Hydrogen/Oxygen combination gives Shopify merchants control over their buyer experience without the restrictions of generic storefront templates.
- Grafbase is a data platform for developers to create a serverless GraphQL API that unifies data sources across a business under one endpoint. They use Workers for Platforms to give their developers the control and flexibility to deploy their own code written in JavaScript/TypeScript or WASM.
- Triplit is an open-source database that syncs data between server and browser in real-time. It allows users to build low latency, real-time applications with features like relational querying, schema management and server-side storage built in. Their query and sync engine is built on top of Durable Objects, and they’re using Workers for Platforms to allow their customers to package custom Javascript alongside their Triplit DB instance.
Tools for observability and platform level controls
Workers for Platforms doesn’t just allow you to deploy Workers to your platform – we also know how important it is to have observability and control over your users’ Workers. We have a few solutions that help with this:
- Custom Limits: Set CPU time or subrequest caps on your users’ Workers. Can be used to set limits in order to control your costs on Cloudflare and/or shape your own pricing and packaging model. For example, if you run a freemium model on your platform, you can lower the CPU time limit for customers on your free tier.
- Tail Workers: Tail Worker events contain metadata about the Worker, console.log() messages, and capture any unhandled exceptions. They can be used to provide your developers with live logging in order to monitor for errors and troubleshoot in real time.
- Outbound Workers: Get visibility into all outgoing requests from your users’ Workers. Outbound Workers sit between user Workers and the fetch() requests they make, so you get full visibility over the request before it’s sent out to the Internet.
Pricing
We wanted to make sure that Workers for Platforms was affordable for hobbyists, solo developers, and indie developers. Workers for Platforms is part of a new $25 pay-as-you-go plan, and it includes the following:
| Included Amounts | |
|---|---|
| Requests | 20 million requests/month +$0.30 per additional million |
| CPU time | 60 million CPU milliseconds/month +$0.02 per additional million CPU milliseconds |
| Scripts | 1000 scripts +0.02 per additional script/month |
Workers for Platforms will be available to purchase on April 16, 2024!
The Workers for Platforms will be available to purchase under the Workers for Platforms tab on the Cloudflare Dashboard on April 16, 2024.
In the meantime, to learn more about Workers for Platforms, check out our starter project and developer documentation.











 Amir Souchami, Chief Architect of Aura from Unity, focusing on creating resilient and performant cloud systems and mobile apps at major scale.
Amir Souchami, Chief Architect of Aura from Unity, focusing on creating resilient and performant cloud systems and mobile apps at major scale. Fabian Szenkier is the ML and Big Data Architect at Aura by Unity, works on building modern AI/ML solutions and state of the art data engineering pipelines at scale.
Fabian Szenkier is the ML and Big Data Architect at Aura by Unity, works on building modern AI/ML solutions and state of the art data engineering pipelines at scale. Liat Tzur is a Senior Technical Account Manager at Amazon Web Services. She serves as the customer’s advocate and assists her customers in achieving cloud operational excellence in alignment with their business goals.
Liat Tzur is a Senior Technical Account Manager at Amazon Web Services. She serves as the customer’s advocate and assists her customers in achieving cloud operational excellence in alignment with their business goals. Adi Jabkowski is a Sr. Redshift Specialist in EMEA, part of the Worldwide Specialist Organization (WWSO) at AWS.
Adi Jabkowski is a Sr. Redshift Specialist in EMEA, part of the Worldwide Specialist Organization (WWSO) at AWS. Yonatan Dolan is a Principal Analytics Specialist at Amazon Web Services. He is located in Israel and helps customers harness AWS analytical services to leverage data, gain insights, and derive value.
Yonatan Dolan is a Principal Analytics Specialist at Amazon Web Services. He is located in Israel and helps customers harness AWS analytical services to leverage data, gain insights, and derive value.











