Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=gIcgh8Jwx1Q
Fostering creativity through open-ended projects with Code Editor for Education
Post Syndicated from Philippa Hanman original https://www.raspberrypi.org/blog/fostering-creativity-through-open-ended-projects-with-code-editor-for-education/
Tom Mason is Head of Mathematics and Head of ICT at St Joseph’s College, an all-boys secondary school in South East London. He is passionate about teaching and learning, and has a keen interest in digital education practices.
Mr Mason recently set his Year 10 students a creative coding challenge, which they completed using our Code Editor for Education. The challenge not only boosted student engagement, but also showcased the effectiveness of open-ended, student-led learning in computer science education.

Challenges in the classroom
Teaching coding in a classroom setting presents a unique set of challenges, with one of the most significant being the rise of artificial intelligence (AI). Instead of engaging deeply with concepts like loops, conditions, and sorting algorithms, students now increasingly rely on AI tools to generate entire blocks of code for them, without understanding their functions.
Meanwhile, traditional teacher-led instruction methods that focus on isolated coding concepts like inputs and outputs often leave students disconnected from the practical and creative aspects of programming.
Against this backdrop, Mr Mason wanted to give his students the opportunity to:
- Apply their Python knowledge in meaningful ways
- Collaborate and problem-solve independently
- Explore unfamiliar programming concepts in a guided but open-ended fashion
The project
Mr Mason set a simple but powerful brief:
“Over three lessons, build a quiz that asks 10 questions about what you’ve learnt on the course.”
With this simple instruction, Mr Mason gave students a clear idea about what to do, while giving them the freedom to design their quiz however they liked. Students were also told that:
- Their 10 quiz questions had to relate to Python
- After creating their quiz, their classmates would give feedback based on key criteria (how well the code worked, the level of creativity, the user experience, etc.)
To complete the project, students used the Code Editor for Education. Created in collaboration with educators and built purposefully for the classroom, the Code Editor supports a range of teaching styles and learning abilities. Its simple interface encourages students to engage with the logic behind their code — they can’t rely on autocomplete.
Results
The open-ended structure led to an explosion of creativity and problem-solving.
Without step-by-step instructions, students had to independently explore solutions to questions like:
- “How do I randomise questions?”
- “How can I hide quiz answers in a separate file?”
Some students created multi-file Python projects, separating the logic controlling how the quiz worked from the content, or static information. For example, some students created one file to store the player’s answers and another file to manage the quiz interface and score logic. Students also created other advanced features:
- Score tracking based on speed of response
- Use of external Python libraries
- Custom input and output formatting
- Algorithms to randomly order quiz questions
All students met the base requirements, but the open-ended nature of the project allowed more advanced students to push the boundaries, without the need for additional scaffolding.
Educator reflection
“They couldn’t just Google the answer; they had to think critically and test ideas. That’s what made it powerful.”
Mr Mason noted that the project’s success was due in large part to the flexibility and responsiveness of the Code Editor. Students could iterate quickly, test their ideas, and collaborate, all within a platform built for classroom coding.
“It was the most successful thing I’ve done. I’ll definitely be doing it again every year.”
Key takeaways
- Project-based learning fosters deeper engagement and knowledge, and creative application of programming concepts.
- Open-ended prompts empower students to explore and develop their own solutions.
- Code Editor for Education encourages thoughtful questions and experimentation rather than reliance on autocomplete solutions. With built-in class management and project tools, it offers a safe, browser-based environment ideal for coding in the classroom.
Join St Joseph’s College and the 1300+ other schools helping their students build a strong foundation in text-based programming with the Code Editor for Education.
The post Fostering creativity through open-ended projects with Code Editor for Education appeared first on Raspberry Pi Foundation.
Калипсо
Post Syndicated from Тоест original https://www.toest.bg/kalipso/

Във всяка къща имам тайници, места за желания,
а вътре – подводни костюми в куфари, пуловери
от чиста вълна, книжа и нерешени кръстословици.
Оставям ги, излизам от вкъщи усмихната – не издържам
на грижата за тях, да ги пазя и крия от себе си, нека
те сами се кътат, да си намерят нови провинции.
*
Отруден и изгорял от слънцето, смрачен,
той не спира със своите сънища в края на света,
където островът не е остров, завръщането не е завръщане.
Огигия или Скопелос – да решат картографите –
със зокумите, сусамените симидчета, със скуката,
казвам му: ти не си толкова беден на способи,
неутешим, проснат, нищо и никой. Тръгвай.
Не чува или се прави, че не чува, смъртната треска
нахлува и заразява бъдещето ни. Забрави за нас.
Върни се и избий женихите. Вече аз съм тайната.
Камелия Спасова
Камелия Спасова е доцент по антична и западноевропейска литература и ръководител на катедра „Теория на литературата“ в СУ „Св. Климент Охридски“. Автор е на две теоретични („Събитие и пример у Платон и Аристотел“ и „Модерният мимесис“) и на две поетични книги („Парцел N17“ и „Кеносис, книга на празнотата“). Редактор в „Литературен вестник“.
Според Екатерина Йосифова „четящият стихотворение сутрин… добре понася другите часове“ от деня. Убедени, че поезията държи умовете ни будни, а сърцата – отворени, в края на всеки месец ви предлагаме по едно стихотворение. Защото и в най-смутни времена доброто стихотворение е добра новина.
How Cloudflare uses the world’s greatest collection of performance data to make the world’s fastest global network even faster
Post Syndicated from Steve Goldsmith original https://blog.cloudflare.com/how-cloudflare-uses-the-worlds-greatest-collection-of-performance-data/
Cloudflare operates the fastest network on the planet. We’ve shared an update today about how we are overhauling the software technology that accelerates every server in our fleet, improving speed globally.
That is not where the work stops, though. To improve speed even further, we have to also make sure that our network swiftly handles the Internet-scale congestion that hits it every day, routing traffic to our now-faster servers.
We have invested in congestion control for years. Today, we are excited to share how we are applying a superpower of our network, our massive Free Plan user base, to optimize performance and find the best way to route traffic across our network for all our customers globally.
Early results have seen performance increases that average 10% faster than the prior baseline. We achieved this by applying different algorithmic methods to improve performance based on the data we observe about the Internet each day. We are excited to begin rolling out these improvements to all customers.
The Internet is a massive collection of interconnected networks, each composed of many machines (“nodes”). Data is transmitted by breaking it up into small packets, and passing them from one machine to another (over a “link”). Each one of these machines is linked to many others, and each link has limited capacity.

When we send a packet over the Internet, it will travel in a series of “hops” over the links from A to B. At any given time, there will be one link (one “hop”) with the least available capacity for that path. It doesn’t matter where in the connection this hop is — it will be the bottleneck.
But there’s a challenge — when you’re sending data over the Internet, you don’t know what route it’s going to take. In fact, each node decides for itself which route to send the traffic through, and different packets going from A to B can take entirely different routes. The dynamic and decentralized nature of the system is what makes the Internet so effective, but it also makes it very hard to work out how much data can be sent. So — how can a sender know where the bottleneck is, and how fast to send data?
Between Cloudflare nodes, our Argo Smart Routing product takes advantage of our visibility into the global network to speed up communication. Similarly, when we initiate connections to customer origins, we can leverage Argo and other insights to optimize them. However, the speed of a connection from your phone or laptop (the Client below) to the nearest Cloudflare datacenter will depend on the capacity of the bottleneck hop in the chain from you to Cloudflare, which happens outside our network.

If too much data arrives at any one node in a network in the path of a request being processed, the requestor will experience delays due to congestion. The data will either be queued for a while (risking bufferbloat), or some of it will simply get dropped. Protocols like TCP and QUIC respond to packets being dropped by retransmitting the data, but this introduces a delay, and can even make the problem worse by further overloading the limited capacity.
If cloud infrastructure providers like Cloudflare don’t manage congestion carefully, we risk overloading the system, slowing down the rate of data getting through. This actually happened in the early days of the Internet. To avoid this, the Internet infrastructure community has developed systems for controlling congestion, which give everyone a turn to send their data, without overloading the network. This is an evolving challenge, as the network grows ever more complicated, and the best method to implement congestion control is a constant pursuit. Many different algorithms have been developed, which take different sources of information and signals, optimize in a particular method, and respond to congestion in different ways.
Congestion control algorithms use a number of signals to estimate the right rate to send traffic, without knowing how the network is set up. One important signal has been loss. When a packet is received, the receiver sends an “ACK,” telling the sender the packet got through. If it’s dropped somewhere along the way, the sender never gets the receipt, and after a timeout will treat the packet as having been lost.
More recent algorithms have used additional data. For example, a popular algorithm called BBR (Bottleneck Bandwidth and Round-trip propagation time), which we have been using for much of our traffic, attempts to build a model during each connection of the maximum amount of data that can be transmitted in a given time period, using estimates of the round trip time as well as loss information.
The best algorithm to use often depends on the workload. For example, for interactive traffic like a video call, an algorithm that biases towards sending too much traffic can cause queues to build up, leading to high latency and poor video experience. If one were to optimize solely for that use case though, and avoid that by sending less traffic, the network will not make the best use of the connection for clients doing bulk downloads. The performance optimization outcome varies, depending on a lot of different factors. But – we have visibility into many of them!
BBR was an exciting development in congestion control approach, moving from reactive loss-based approaches to proactive model-based optimization, resulting in significantly better performance for modern networks. Our data gives us an opportunity to go further, applying different algorithmic methods to improve performance.
All the existing algorithms are constrained to use only information gathered during the lifetime of the current connection. Thankfully, we know far more about the Internet at any given moment than this! With Cloudflare’s perspective on traffic, we see much more than any one customer or ISP might see at any given time.
Every day, we see traffic from essentially every major network on the planet. When a request comes into our system, we know what client device we’re talking to, what type of network is enabling the connection, and whether we’re talking to consumer ISPs or cloud infrastructure providers.
We know about the patterns of load across the global Internet, and the locations where we believe systems are overloaded, within our network, or externally. We know about the networks that have stable properties, which have high packet loss due to cellular data connections, and the ones that traverse low earth orbit satellite links and radically change their routes every 15 seconds.
We have been in the process of migrating our network technology stack to use a new platform, powered by Rust, that provides more flexibility to experiment with varying the parameters in the algorithms used to handle congestion control. Then we needed data.
The data powering these experiments needs to reflect the measure we’re trying to optimize, which is the user experience. It’s not just enough that we’re sending data to nearly all the networks on the planet; we have to be able to see what is the experience that customers have. So how do we do that, at our scale?
First, we have detailed “passive” logs of the rate at which data is able to be sent from our network, and how long it takes for the destination to acknowledge receipt. This covers all our traffic, and gives us an idea of how quickly the data was received by the client, but doesn’t guarantee to tell us about the user experience.
Next, we have a system for gathering Real User Measurement (RUM) data, which records information in supported web browsers about metrics such as Page Load Time (PLT). Any Cloudflare customer can enable this and will receive detailed insights in their dashboard. In addition, we use this metadata in aggregate across all our customers and networks to understand what customers are really experiencing.
However, RUM data is only going to be present for a small proportion of connections across our network. So, we’ve been working to find a way to predict the RUM measures by extrapolating from the data we see only in passive logs. For example, here are the results of an experiment we performed comparing two different algorithms against the cubic baseline.

Now, here’s the same timescale, observed through the prediction based on our passive logs. The curves are very similar – but even more importantly, the ratio between the curves is very similar. This is huge! We can use a relatively small amount of RUM data to validate our findings, but optimize our network in a much more fine-grained way by using the full firehose of our passive logs.

Extrapolating too far becomes unreliable, so we’re also working with some of our largest customers to improve our visibility of the behaviour of the network from their clients’ point of view, which allows us to extend this predictive model even further. In return, we’ll be able to give our customers insights into the true experience of their clients, in a way that no other platform can offer.
We’re currently running our experiments and improved algorithms for congestion control on all of our free tier QUIC traffic. As we learn more, verify on more complex customers, and expand to TCP traffic, we’ll gradually roll this out to all our customers, for all traffic, over 2026 and beyond. The results have led to as much as a 10% improvement as compared to the baseline!
We’re working with a select group of enterprises to test this in an early access program. If you’re interested in learning more, contact us!
Comic for 2025.09.26 – My Wife’s Clothes…
Post Syndicated from Explosm.net original https://explosm.net/comics/my-wifes-clothes
New Cyanide and Happiness Comic
User foundation models for Grab
Post Syndicated from Grab Tech original https://engineering.grab.com/user-foundation-models-for-grab
Introduction
Artificial intelligence (AI) is central to Grab’s mission of delivering valuable, personalised experiences to millions of users across Southeast Asia. Achieving this requires a deep understanding of individual preferences, such as their favorite foods, relevant advertisements, spending habits, and more. This personalisation is driven by recommender models, which depend heavily on high-quality representations of the user.
Traditionally, these models have relied on hundreds to thousands of manually engineered features. Examples include the types of food ordered in the past week, the frequency of rides taken, or the average spending per transaction. However, these features were often highly specific to individual tasks, siloed within teams, and required substantial manual effort to create. Furthermore, they struggled to effectively capture time-series data, such as the sequence of user interactions with the app.
With advancements in learning from tabular and sequential data, Grab has developed a foundation model that addresses these limitations. By simultaneously learning from user interactions (clickstream data) and tabular data (e.g. transaction data), the model generates user embeddings that capture app behavior in a more holistic and generalised manner. These embeddings, represented as numerical values, serve as input features for downstream recommender models, enabling higher levels of personalisation and improved performance. Unlike manually engineered features, they generalise effectively across a wide range of tasks, including advertisement optimisation, dual app prediction, fraud detection, and churn probability, among others.
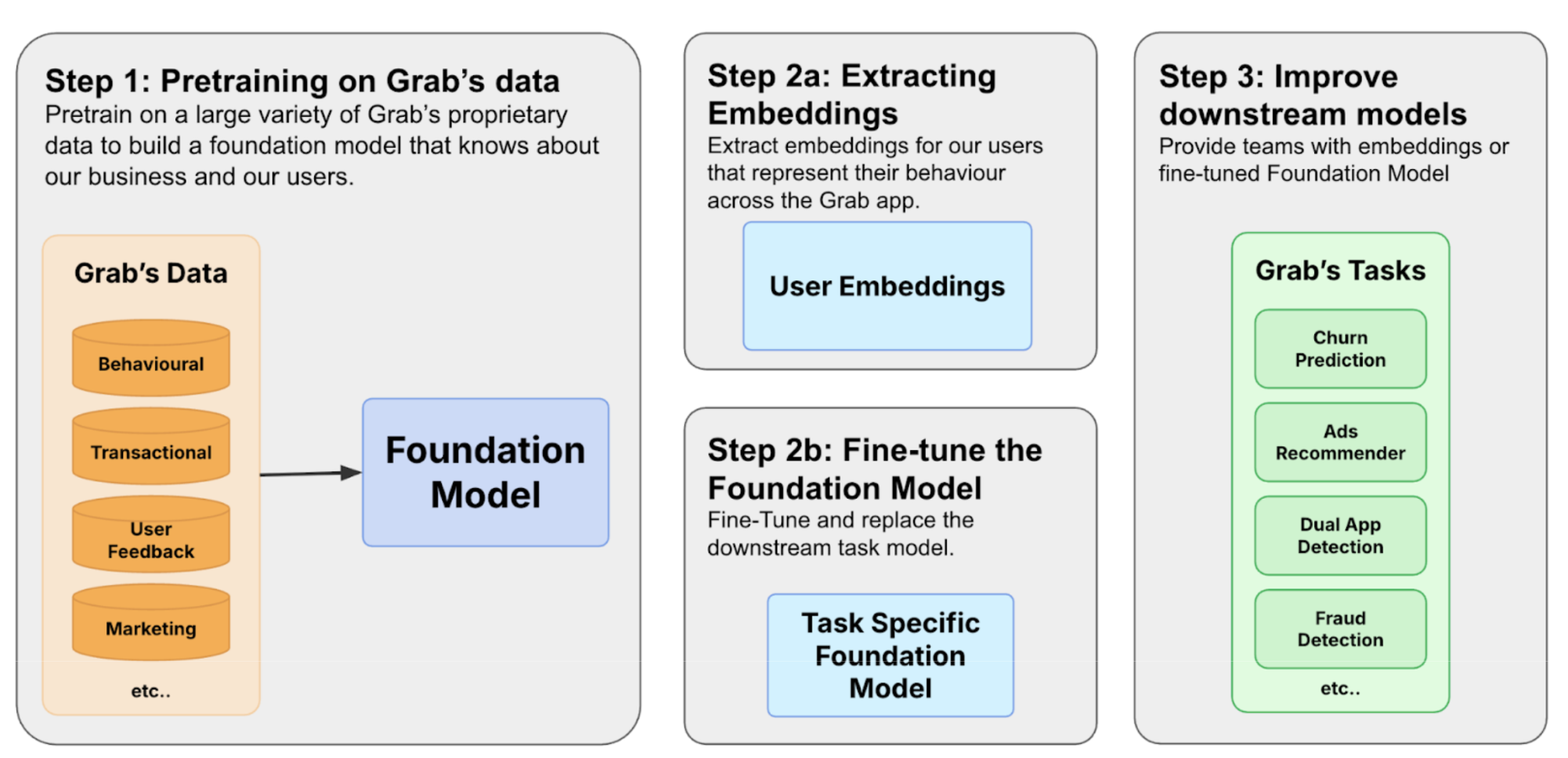
We build foundation models by first constructing a diverse training corpus encompassing user, merchant, and driver interactions. The pre-trained model can then be used in two ways. Based on Figure 1, in 2a we extract user embeddings from the model to serve downstream tasks to improve user understanding. The other path is 2b, where we fine-tune the model to make predictions directly.
Crafting a foundation model for Grab’s users
Grab’s journey towards building its own foundation model began with a clear recognition: existing models are not well-suited to our data. A general-purpose Large Language Model (LLM), for example, lacks the contextual understanding required to interpret why a specific geohash represents a bustling mall rather than a quiet residential area. Yet, this level of insight is precisely what we need for effective personalisation. This challenge extends beyond IDs, encompassing our entire ecosystem of text, numerical values, locations, and transactions.
Moreover, this rich data exists in two distinct forms: tabular data that captures a user’s long-term profile, and sequential time-series data that reflects their immediate intent. To truly understand our users, we needed a model capable of mastering both forms simultaneously. It became evident that off-the-shelf solutions would not suffice, prompting us to develop a custom foundation model tailored specifically to our users and their unique data.
The importance of data
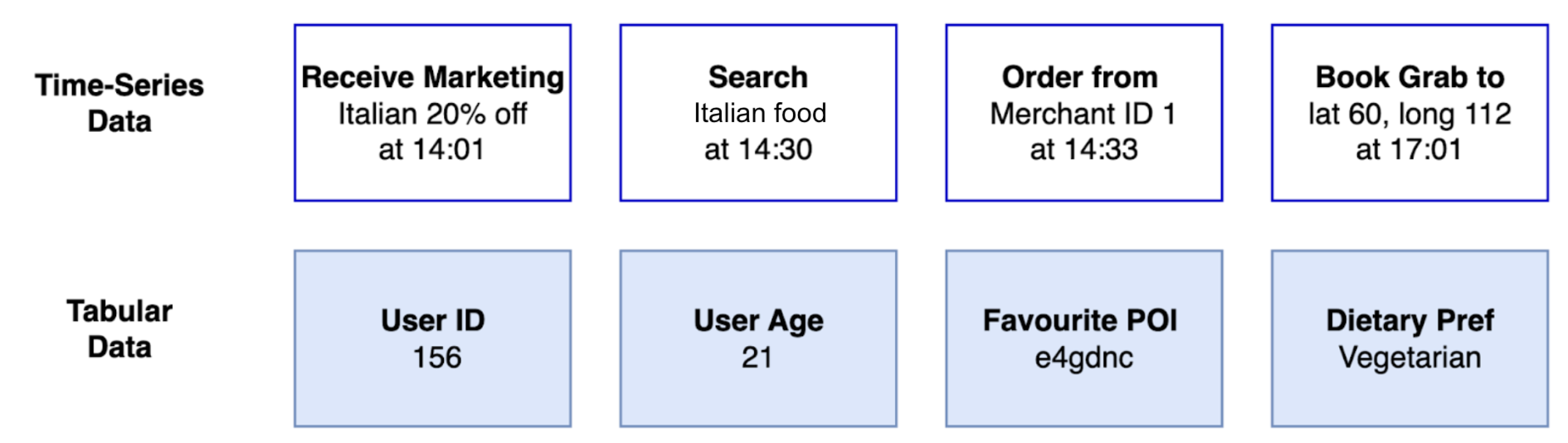
The success of foundation models hinges on the quality and diversity of the datasets used for training. Grab identified two essential sources of data for building user embeddings as shown in Figure 2. Tabular data provides general attributes and long-term behavior. Time-series data reflects how the user uses the app and captures the evolution of user preferences.
-
Tabular data: This classic data source provides general user attributes and insights into long-term behavior. For example, this includes attributes like a user’s age and saved locations, along with aggregated behavioral data such as their average monthly spending or most frequently used service.
-
Time-series clickstream data: Sequential data captures the dynamic nature of user decision-making and trends. Grab tracks every interaction on its app, including what users view, click, consider, and ultimately transact. Additionally, metrics like the duration between events reveal insights into user decisiveness. Time-series data provides a valuable perspective on evolving user preferences.
A successful user foundation model must be capable of integrating both tabular and time-series data. Adding to the complexity is the diversity of data modalities, including categorical/text, numerical, user IDs, images, and location data. Each modality carries unique information, often specific to Grab’s business, underscoring the need for a bespoke architecture.
This inherent diversity in data modalities distinguishes Grab from many other platforms. For example, a video recommendation platform primarily deals with a single modality: videos, supplemented by user interaction data such as watch history and ratings. Similarly, social media platforms are largely centred around posts, images, and videos. In contrast, Grab’s identity as a “superapp” generates a far broader spectrum of user actions and data types. As users navigate between ordering food, booking taxis, utilising courier services, and more, their interactions produce a rich and varied data trail that a successful model must be able to comprehend. Moreover, an effective foundation model for Grab must not only create embeddings for our users but also for our merchant-partners and driver-partners, each of whom brings their own distinctive sets of data modalities.
Examples of data modalities at Grab
To illustrate the breadth of data, consider these examples across different modalities:
-
Text: This includes user-provided information such as search queries within GrabFood or GrabMart (“chicken rice,” “fresh milk”) and reviews or ratings for drivers and restaurants. For merchants, this could encompass the restaurant’s name, menu descriptions, and promotional texts.
-
Numerical: This modality is rich with data points such as the price of a food order, the fare for a ride, the distance of a delivery, the waiting time for a driver, and the commission earned by a driver-partner. User behavior can also be quantified through numerical data, such as the frequency of app usage or average spending over a month.
-
Merchant/User/Driver ID: These categorical identifiers are central to the platform. A
user_idtracks an individual’s activity across all of Grab’s services. Amerchant_idrepresents a specific restaurant or store, linking to its menu, location, and order history. Adriver_idcorresponds to a driver-partner, associated with their vehicle type, service area, and performance metrics. -
Location data: Geographic information is fundamental to Grab’s operations. This includes airport locations, malls, pickup and drop-off points for a ride (
(lat_A, lon_A)to(lat_B, lon_B)), the delivery address for a food order, and the real-time location of drivers. This data helps in understanding user routines (e.g., commuting patterns) and logistical flows.
The challenges and opportunities of diverse modalities
The sheer variety of these data modalities presents several significant challenges and opportunities for building a unified user foundation model:
-
Data heterogeneity: The different data types—text, numbers, geographical coordinates, and categorical IDs do not naturally lend themselves to being combined. Each modality has its own unique structure and requires specialised processing techniques before it can be integrated into a single model.
-
Complex interactions as an opportunity: The relationships between different modalities are often intricate, revealing a user’s context and intent. A model that only sees one data type at a time will miss the full picture.
For example, consider a single user’s evening out. The journey begins when they book a ride (involving their user_id and a driver_id) to a specific drop-off point, such as a popular shopping mall (location data). Two hours later, from that same mall location, they open the app again and perform a search for “Japanese food” (text data). They then browse several restaurant profiles (merchant_ids) before placing an order, which includes a price (numerical data).
A traditional, siloed model would treat the ride and the food search as two independent events. However, the real opportunity lies in capturing the interactions within a single user’s journey. This is precisely what our unified foundation model is designed to achieve: to identify the connections and recognise that the drop-off location of a ride provides valuable context for a subsequent text search. A model that understands a location is not merely a coordinate, but a place that influences a user’s next action, can develop a far deeper understanding of user context. Unlocking this capability is the key to achieving superior performance in downstream tasks, such as personalisation.
Model architecture
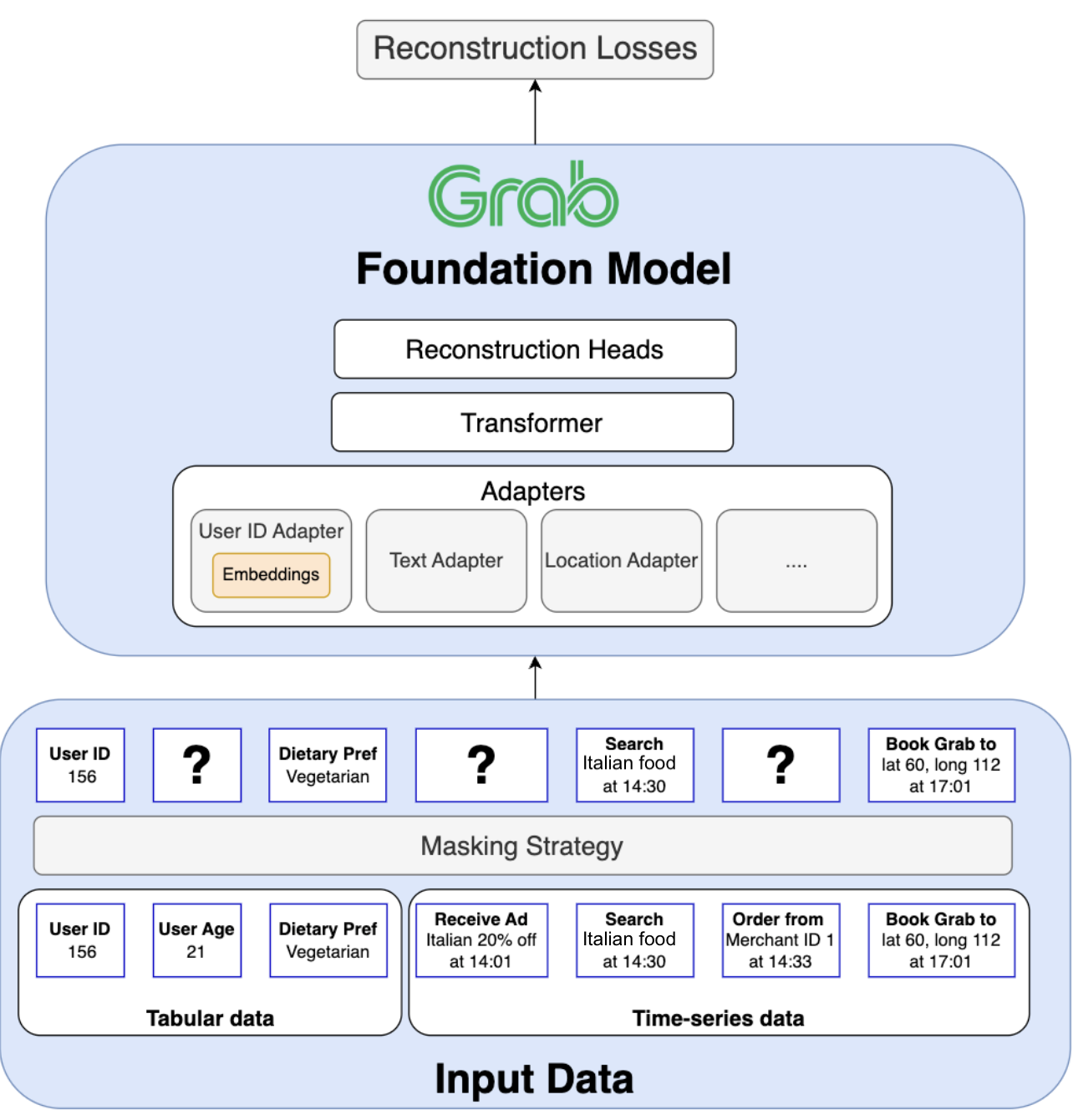
Figure 3 displays Grab’s transformer architecture, enabling joint pre-training on tabular and time-series data with different modalities. Grab’s foundation model is built on a transformer architecture specifically designed to tackle four fundamental challenges inherent to Grab’s superapp ecosystem:
-
Jointly training on tabular and time-series data: A core requirement is to unify column order invariant tabular data (e.g. user attributes) with order-dependent time-series data (e.g. a sequence of user actions) within a single, coherent model.
-
Handling a wide variety of data modalities: The model must process and integrate diverse data types, including text, numerical values, categorical IDs, and geographic locations, each requiring its own specialised encoding techniques.
-
Generalising beyond a single task: The model must learn a universal representation from the entire ecosystem to power a wide array of downstream applications (e.g., recommendations, churn prediction, logistics) across all of Grab’s verticals.
-
Scaling to massive entity vocabularies: The architecture must efficiently handle predictions across vocabularies containing hundreds of millions of unique entities (users, merchants, drivers), a scale that makes standard classification techniques computationally prohibitive.
In the following section, we highlight how we tackled each challenge.
1. Unifying tabular and time-series data
A key architectural challenge lies in jointly training on both tabular and time-series data. Tabular data, which contains user attributes, is inherently order-agnostic — the sequence of columns does not matter. In contrast, time-series data is order-dependent, as the sequence of user actions is critical for understanding intent and behavior.
Traditional approaches often process these data types separately or attempt to force tabular data into a sequential format. However, this can result in suboptimal representations, as the model may incorrectly infer meaning from the arbitrary order of columns.
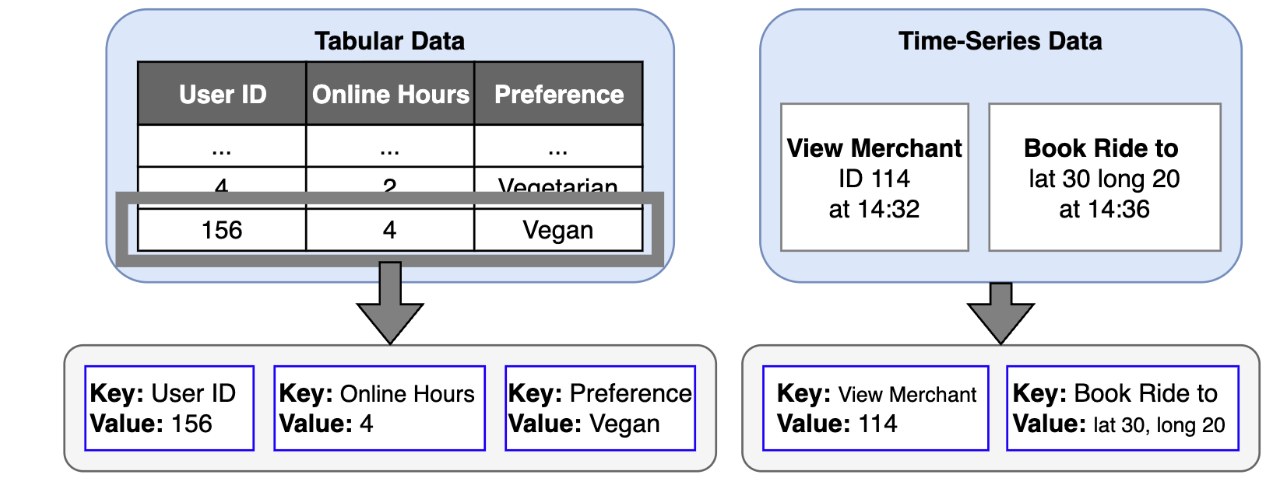
Our solution begins with a novel tokenisation strategy. We define a universal token structure as a key:value pair.
-
For tabular data, the
keyis the column name (e.g.online_hours) and thevalueis the user’s attribute (e.g.4). -
For time-series data, the
keyis the event type (e.g.view_merchant) and thevalueis the specific entity involved (e.g.merchant_id_114).
This key:value format creates a common language for all input data. To preserve the distinct nature of each data source, we employ custom positional embeddings and attention masks. These components instruct the model to treat key:value pairs from tabular data as an unordered set while treating tokens from time-series data as an ordered sequence. This allows the model to benefit from both data structures simultaneously within a single, coherent framework.
2. Handling diverse modalities with an adapter-based design
The second major challenge is the sheer variety of data modalities: user IDs, text, numerical values, locations, and more. To manage this diversity, our model uses a flexible adapter-based design. Each adapter acts as a specialised “expert” encoder for a specific modality, transforming its unique data format into a unified, high-dimensional vector space.
-
For modalities like text, adapters can be initialised with powerful pre-trained language models to leverage their existing knowledge.
-
For ID data like user/merchant/driver IDs, we initialise dedicated embedding layers.
-
For complex and specialised data like location coordinates or not-so-well-modeled modalities like numbers in existing LLMs, we design custom adapters.
After each token passes through its corresponding modality adapter, an additional alignment layer ensures that all the resulting vectors are projected into the same representation space. This step is critical for allowing the model to compare and combine insights from different data types, for example, to understand the relationship between a text search query (“chicken rice”) and a location pin (a specific hawker center). Finally, we feed the aligned vectors into the main transformer model.
This modular adapter approach is highly scalable and future-proof, enabling us to easily incorporate new modalities like images or audio and upgrade individual components as more advanced architectures become available.
3. Unsupervised pre-training for a complex ecosystem
A powerful model architecture is only half the story; the learning strategy determines the quality and generality of the knowledge captured in the final embeddings.
In the industry, recommender models are often trained using a semi-supervised approach. A model is trained on a specific, supervised objective, such as predicting the next movie a user will watch or whether they will click on an ad. After this training, the internal embeddings, which now carry information fine-tuned for that one task, can be extracted and used for related applications. This method is highly effective for platforms with a relatively homogeneous primary task, like video recommendation or social media platforms.
However, this single-task approach is fundamentally misaligned with the needs of a superapp. At Grab, we need to power a vast and diverse set of downstream use cases, including food recommendations, ad targeting, transport optimisation, fraud detection, and churn prediction. Training a model solely on one of these objectives would create biased embeddings, limiting their utility for all other tasks. Furthermore, focusing on a single vertical like Food would mean ignoring the rich signals from a user’s activity in Transport, GrabMart, and Financial Services, preventing the model from forming a truly holistic understanding.
Our goal is to capture the complex and diverse interactions between our users, merchants, and drivers across all verticals. To achieve this, we concluded that unsupervised pre-training is the most effective path forward. This approach allows us to leverage the full breadth of data available, learning a universal representation of the entire Grab ecosystem without being constrained to a single predictive task.
To pre-train our model on tabular and time-series data, we combine masked language modeling (reconstructing randomly masked tokens) with next action prediction. On a superapp like Grab, a user’s journey is inherently unpredictable. A user might finish a ride and immediately search for a place to eat, or transition from browsing groceries on GrabMart to sending a package with GrabExpress. The next action could belong to any of our diverse services like mobility, deliveries, or financial services.
This ambiguity means the model faces a complex challenge: it’s not enough to predict which item a user might choose; it must first predict the type of interaction they will even initiate. Therefore, to capture the full complexity of user intent, our model performs a dual prediction that directly mirrors our key:value token structure:
-
It predicts the type of the next action, such as
click_restaurant,book_ride, orsearch_mart. -
It predicts the value associated with that action, like the specific restaurant ID, the destination coordinates, or the text of the search query.
This dual-prediction task forces the model to learn the intricate patterns of user behavior, creating a powerful foundation that can be extended across our entire platform. To handle these predictions, where the output could be of any modality (an ID, a location, text, etc.), we employ modality-specific reconstruction heads. Each head is designed for a particular data type and uses a tailored loss function (e.g. cross-entropy for categorical IDs, mean squared error for numerical values) to accurately evaluate the model’s predictions.
4. The ID reconstruction challenge
A significant challenge is the sheer scale of our categorical ID vocabularies. The total number of unique merchants, users, and drivers on the Grab platform runs into the hundreds of millions. A standard cross-entropy loss function would require a final prediction layer with a massive output dimension. For instance, a vocabulary of 100 million IDs with a 768-dimension embedding would result in a prediction head of nearly 80 billion parameters, blowing up model parameter count.
To overcome this, we employ hierarchical classification. Instead of predicting from a single flat list of millions of IDs, we first classify IDs into smaller, meaningful groups based on their attributes (e.g. by city, cuisine type, etc). This is followed by a second-stage prediction within that much smaller subgroup. This technique dramatically reduces the computational complexity, making it feasible to learn meaningful representations for an enormous vocabulary of entities.
Extracting value from our foundation model
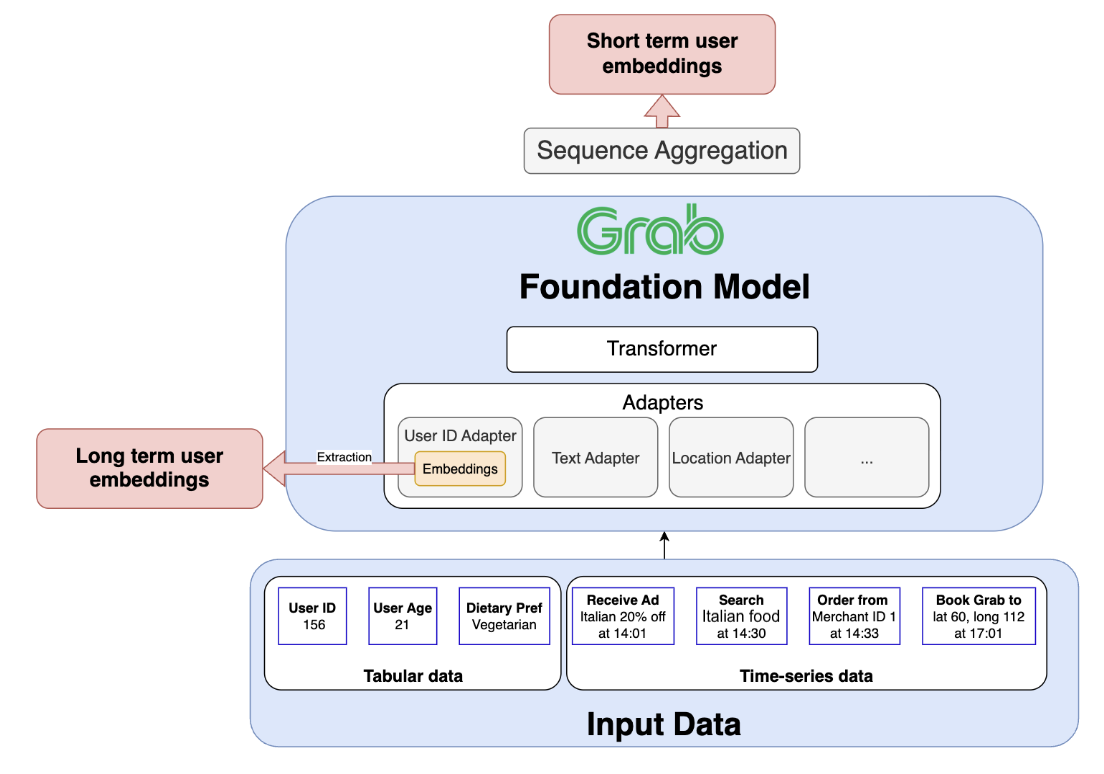
Once our foundation model is pre-trained on the vast and diverse data within the Grab ecosystem, it becomes a powerful engine for driving business value. There are two primary pathways to harness its capabilities: fine-tuning and embedding extraction.
The first pathway involves fine-tuning the entire model on a labeled dataset for a specific downstream task, such as churn probability or fraud detection, to create a highly specialised and performant predictor.
The second, more flexible pathway is to use the model to generate powerful pre-trained embeddings. These embeddings serve as rich, general-purpose features that can support a wide range of separate downstream models. The remainder of this section will focus on this second pathway, exploring the types of embeddings we extract and how they empower our applications.
The dual-embedding strategy: Long-term and short-term memory
Our architecture is deliberately designed to produce two distinct but complementary types of user embeddings, providing a holistic view by capturing both the user’s stable, long-term identity and their dynamic, short-term intent.
The long-term representation: A stable identity profile
The long-term embedding captures a user’s persistent habits, established preferences, and overall persona. This representation is the learned vector for a given user_id, which is stored within the specialised User ID adapter. As the model trains on countless sequences from a user’s history, the adapter learns to distill their consistent behaviors into this single, stable vector. After training, we can directly extract this embedding, which effectively serves as the user’s “long-term memory” on the platform.
The short-term representation: A snapshot of recent intent
The short-term embedding is designed to capture a user’s immediate context and current mission. To generate this, a sequence of the user’s most recent interactions is processed through the model’s adapters and main transformer block. A Sequence Aggregation Module then condenses the transformer’s output into a single vector. This creates a snapshot of recent user intent, reflecting their most up-to-date activities and providing a fresh understanding of what they are trying to accomplish.
Scaling the foundation: From terabytes of data to millions of daily embeddings
Building a foundation model of this magnitude introduces monumental engineering challenges that extend beyond the model architecture itself. The practical success of our system hinges on our ability to solve two distinct scalability problems:
-
Massive-scale training: Pre-training our model involves processing terabytes of diverse, multimodal data. This requires a distributed computing framework that is not only powerful but also flexible enough to handle our unique data processing needs efficiently.
-
High-throughput inference: To keep our user understanding current, we must regenerate embeddings for millions of active users daily. This demands a highly efficient, scalable, and reliable batch processing system.
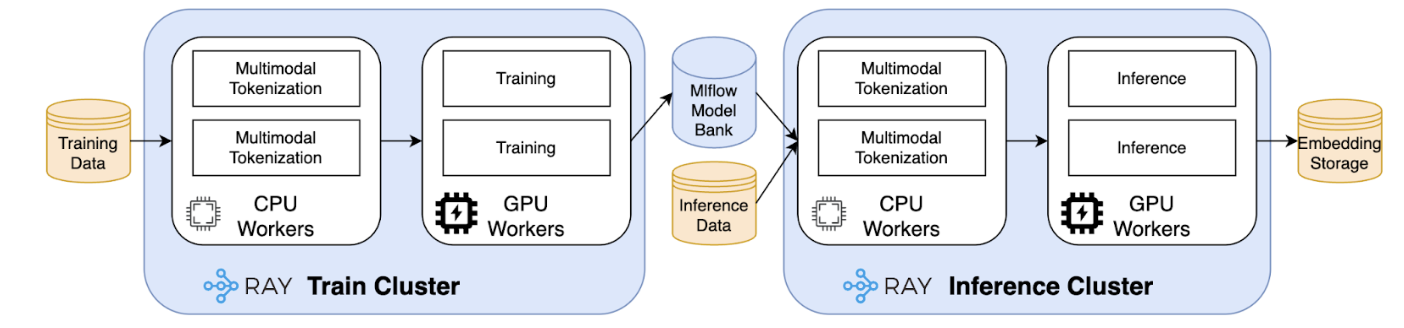
To meet these challenges, we built upon the Ray framework, an open-source standard for scalable computing. This choice allows us to manage both training and inference within a unified ecosystem, tailored to our specific needs.
Core principle: A unified architecture for heterogeneous workloads
As illustrated by the Ray framework, both our training and inference pipelines share a fundamental workflow: they begin with a complex Central Processing Unit (CPU) intensive data preprocessing stage (tokenisation), which is followed by a Graphics Processing Unit (GPU) intensive neural network computation.
A naive approach would bundle these tasks together, forcing expensive GPU resources to sit idle while the CPU handles data preparation. Our core architectural principle is to decouple these workloads. Using Ray’s native ability to manage heterogeneous hardware, we create distinct, independently scalable pools of CPU and GPU workers.
This allows for a highly efficient, assembly-line-style process. Data is first ingested by the CPU workers for parallelised tokenisation. The resulting tensors are then streamed directly to the GPU workers for model computation. This separation is the key to achieving near-optimal GPU utilisation, which dramatically reduces costs and accelerates processing times for both training and inference.
Distributed training
Applying this core principle, our training pipeline efficiently processes terabytes of raw data. The CPU workers handle the complex key:value tokenisation at scale, ensuring the GPU workers are consistently fed with training batches. This robust setup significantly reduces the end-to-end training time, enabling faster experimentation and iteration. We will go into more detail on our training framework in a future blog post.
Efficient and scalable daily inference
This same efficient architecture is mirrored for our daily inference task. To generate fresh embeddings for millions of users, we leverage Ray Data—an open-source library used for data processing in AI and Machine Learning (ML) workload, to execute a distributed batch inference pipeline. The process seamlessly orchestrates our CPU workers for tokenisation and our GPU workers for model application.
This batch-oriented approach is the key to our efficiency, allowing us to process thousands of users’ data simultaneously and maximise throughput. This robust and scalable inference setup ensures that our dozens of downstream systems are always equipped with fresh, high-quality embeddings, enabling the timely and personalised experiences our users expect.
Conclusion: A general foundation for intelligence across Grab
The development of our user foundation model marks a pivotal shift in how Grab leverages AI. It moves us beyond incremental improvements on task-specific models toward a general, unified intelligence layer designed to understand our entire ecosystem. While previous efforts at Grab have combined different data modalities, this model is the first to do so at a foundational level, creating a truly holistic and reusable understanding of our users, merchants, and drivers.
The generality of this model is its core strength. By pre-training on diverse and distinct data sources from across our platform—ranging from deep, vertical-specific interactions to broader behavioral signals—it is designed to capture rich, interconnected signals that task-specific models invariably miss. The potential of this approach is immense: a user’s choice of transport can become a powerful signal to inform food recommendations, and a merchant’s location can help predict ride demand.
This foundational approach fundamentally accelerates AI development across the organisation. Instead of starting from scratch, teams can now build new models on top of our high-quality, pre-trained embeddings, significantly reducing development time and improving performance. Existing models can be enhanced by incorporating these rich features, leading to better predictions and more personalised user experiences. Key areas such as ad optimisation, dual app prediction, fraud detection, and churn probability already heavily benefit from our foundation model, but this is just the beginning.
Our vision for the future
Our work on this foundation model is just the beginning. The ultimate goal is to deliver “embeddings as a product”. A stable, reliable, and powerful basis for any AI-driven application at Grab. While our initial embeddings for users, driver-partners, and merchant-partners have already proven their value, our vision extends to becoming the central provider for all fundamental entities within our ecosystem, including Locations, Bookings, Marketplace items, and more.
To realise this vision, we are focused on a path of continuous improvement across several key areas:
-
Unifying and enriching our datasets: Our current success comes from leveraging distinct, powerful data sources that capture different facets of the user journey. The next frontier is to unify these streams into a single, cohesive training corpus that holistically represents user activity across all of Grab’s services. This effort will create a comprehensive, low-noise view of user behavior, unlocking an even deeper level of insight.
-
Evolving the model architecture: We will continue to evolve the model itself, focusing on research to enhance its learning capabilities and predictive power to make the most of our increasingly rich data.
-
Improving scale and efficiency: As Grab grows, so must our systems. We are dedicated to further scaling our training and inference infrastructure to handle more data and complexity at an even greater efficiency.
By providing a continuously improving, general-purpose understanding of these core components, we are not just building a better model; we are building a more intelligent future for Grab. This enables us to innovate faster and deliver exceptional value to the millions who rely on our platform every day.
Join us
Grab is a leading superapp in Southeast Asia, operating across the deliveries, mobility and digital financial services sectors. Serving over 800 cities in eight Southeast Asian countries, Grab enables millions of people everyday to order food or groceries, send packages, hail a ride or taxi, pay for online purchases or access services such as lending and insurance, all through a single app. Grab was founded in 2012 with the mission to drive Southeast Asia forward by creating economic empowerment for everyone. Grab strives to serve a triple bottom line – we aim to simultaneously deliver financial performance for our shareholders and have a positive social impact, which includes economic empowerment for millions of people in the region, while mitigating our environmental footprint.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
Hiking
Post Syndicated from xkcd.com original https://xkcd.com/3147/

Richard Ayoade and David Letterman on Their Approach to Comedy Full | The Atlantic Festival 2025
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=RAvm9Wa7wEw
Controlling AWS API Calls from Amazon Q Developer: Enterprise Governance with Built-in User Agent Markers
Post Syndicated from Kirankumar Chandrashekar original https://aws.amazon.com/blogs/devops/controlling-aws-api-calls-from-amazon-q-developer-enterprise-governance-with-built-in-user-agent-markers/
As organizations increasingly adopt AI-powered development tools, a critical challenge emerges: how do you maintain security governance when AI assistants execute AWS operations on behalf of users? Organizations want to leverage AI assistance for development and read operations while maintaining strict controls over write operations that impact production systems and auditing calls made via AI assistants. Consider this scenario: A developer asks Amazon Q Developer “List my S3 buckets”, Q Developer suggests aws s3 ls, the developer approves, and Q Developer executes the command via AWS CLI. From an AWS perspective, this looks identical to the developer manually running the aws s3 ls command on the terminal outside of Amazon Q Developer. But what if your organization needs to distinguish between AI-assisted operations and manual commands for governance or compliance?
Amazon Q Developer, the most capable generative AI–powered assistant for software development, generates AWS CLI commands in response to user requests and executes them using its use_aws and execute_bash built-in tools. The challenge of distinguishing AI-assisted operations from manual commands is a key consideration for Amazon Q Developer adoption in enterprise environments. To address this governance challenge, Amazon Q Developer includes a built-in solution: user-agent markers that automatically identify AWS CLI calls made through Q Developer in CloudTrail logs, enabling precise IAM policy controls.
This blog post explores how Amazon Q Developer’s built-in user agent markers set for AWS CLI calls enable precise IAM policy controls, allowing organizations to distinguish and govern AI-assisted AWS operations while maintaining the productivity benefits of AI-powered development. The following sections demonstrate how these user agent markers work, how to implement IAM policies that leverage them, and how to monitor their effectiveness in your environment.
Understanding Amazon Q Developer User Agent Markers
Prerequisites
This section builds on your knowledge of these concepts and assumes you have the necessary setup in place. These foundational elements are essential for understanding how user agent markers work and for implementing the governance controls discussed later in this post. If you need guidance on any of these topics, please refer to the linked documentation:
- AWS CLI v2.x installation and configuration with credential setup – Required to execute AWS commands and observe user agent behavior
- Amazon Q Developer setup for CLI and/or IDE extensions – Needed to generate the user agent markers this post examines
- AWS CloudTrail concepts and API logging – Essential for monitoring and verifying user agent markers in practice
- IAM policies and permissions management – Critical for implementing the governance controls that leverage these markers
Amazon Q Developer automatically includes identifiable markers in the user agent string of all AWS API calls it makes via AWS CLI. These markers appear in two primary contexts: CLI tool operations and IDE integration operations.
Q Developer CLI Tool
When using Amazon Q Developer CLI (both use_aws and execute_bash tools), all AWS CLI calls include:
exec-env/AmazonQ-For-CLI-Version-<QCLI-VersionNo>
How It Works: Amazon Q Developer CLI automatically sets:
AWS_EXECUTION_ENV=AmazonQ-For-CLI-Version-<QCLI-VersionNo>
This means all AWS CLI commands executed through Q Developer CLI – whether via the use_aws tool or execute_bash commands – automatically include this marker.
Q Developer IDE Integration
When using Amazon Q Developer from IDE integrations, AWS CLI calls include:
exec-env/AmazonQ-For-IDE-Version-<QIDE-Plugin-VersionNo>
How It Works: Amazon Q Developer IDE plugin automatically sets:
AWS_EXECUTION_ENV=AmazonQ-For-IDE-Version-<QIDE-Plugin-VersionNo>
This applies when Q Developer makes AWS API calls through IDE integrations, such as when analyzing your codebase or suggesting AWS resource configurations. The IDE marker enables you to distinguish between CLI-based and IDE-based Q Developer operations.
Complete User Agent Example
Here’s how a complete user agent string appears in CloudTrail:
From Q Developer CLI:
"userAgent": "aws-cli/2.27.17 md/awscrt#0.26.1 ua/2.1 os/macos#24.6.0 md/arch#x86_64 lang/python#3.13.3 md/pyimpl#CPython exec-env/AmazonQ-For-CLI-Version-1.15.0
cfg/retry-mode#standard md/installer#exe md/prompt#off md/command#sts.get-caller-identity"
From Q Developer IDE Integration:
"user-agent": "aws-cli/2.27.17 md/awscrt#0.26.1 ua/2.1 os/macos#24.6.0 md/arch#x86_64 lang/python#3.13.3 md/pyimpl#CPython exec-env/AmazonQ-For-IDE-Version-1.93.0
cfgretry-mode#standard md/installer#exe md/prompt#off md/command#sts.get-caller-identity"
The key identifiers are exec-env/AmazonQ-For-CLI-Version-* and exec-env/AmazonQ-For-IDE-Version-*, which clearly distinguish Amazon Q Developer operations from regular AWS CLI/SDK usage executed outside of Q Developer.
Architecture Diagram
┌─────────────────────────────────────────────────────────────────────────────┐
│ Amazon Q Developer Flow │
└─────────────────────────────────────────────────────────────────────────────┘
┌──────────────────┐ ┌──────────────────┐ ┌──────────────────┐
│ Developer │ │ Amazon Q │ │ AWS APIs │
│ │ │ Developer │ │ │
│ ┌──────────────┐ │ │ │ │ │
│ │ Q CLI │ │ │ ┌──────────────┐ │ │ ┌──────────────┐ │
│ │ use_aws tool │ │────┼─│ Adds marker: │ │────┼─│ CloudTrail │ │
│ └──────────────┘ │ │ │ exec-env/ │ │ │ │ Event with │ │
│ │ │ │ AmazonQ-For- │ │ │ │ User Agent │ │
│ ┌──────────────┐ │ │ │ CLI-Version │ │ │ │ Marker │ │
│ │ IDE │ │ │ └──────────────┘ │ │ └──────────────┘ │
│ │ Integration │ │────┼─│ Adds marker: │ │ │ │
│ └──────────────┘ │ │ │ exec-env/ │ │ │ │
│ │ │ │ AmazonQ-For- │ │ │ │
│ ┌──────────────┐ │ │ │ IDE-Version │ │ │ │
│ │ execute_bash │ │────┼─└──────────────┘ │ │ │
│ │ commands │ │ │ │ │ │
│ └──────────────┘ │ │ │ │ │
└──────────────────┘ └──────────────────┘ └──────────────────┘
│ │ │
│ │ │
▼ ▼ ▼
┌──────────────────────────────────────────────────────────────────────────────┐
│ IAM Policy Engine │
│ │
│ ┌─────────────────────────────────────────────────────────────────────────┐ │
│ │ Condition: StringLike │ │
│ │ "aws:userAgent": "*exec-env/AmazonQ-For-*" │ │
│ │ │ │
│ │ ┌─────────────────┐ ┌─────────────────┐ │ │
│ │ │ Q Developer │ │ Regular AWS │ │ │
│ │ │ Operations │ │ CLI Operations │ │ │
│ │ │ │ │ │ │ │
│ │ │ • Block writes │ │ • Allow writes │ │ │
│ │ │ • Allow reads │ │ • Allow reads │ │ │
│ │ └─────────────────┘ └─────────────────┘ │ │
│ └─────────────────────────────────────────────────────────────────────────┘ │
└──────────────────────────────────────────────────────────────────────────────┘
IAM Policy Implementation
Use the aws:userAgent condition in IAM policies to control Amazon Q Developer operations through two approaches:
IAM Policies: Deploy in each AWS account where developers have access for deploying workloads or performing AWS operations. Q Developer operates using the developer’s existing AWS credentials and permissions – it doesn’t have additional access beyond what the user already possesses. Attach these policies to the same IAM users, groups, or roles that developers use for their regular AWS work.
Service Control Policies (SCPs): Deploy once at the AWS Organizations level for organization-wide governance. SCPs apply to all member accounts automatically and cannot be overridden by account-level policies.
The following policy allows read operations from Q Developer, blocks write operations from Q Developer, and allows write operations from regular AWS CLI executed outside Q Developer:
Note: This IAM policy example is for illustration purposes only. Follow least privilege principles in production environments. For more details refer prepare for least previlege permissions.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowReadOperationsFromQDeveloper",
"Effect": "Allow",
"Action": [
"s3:GetObject*",
"s3:ListBucket*",
"ec2:Describe*"
],
"Resource": "*",
"Condition": {
"StringLike": {
"aws:userAgent": "*exec-env/AmazonQ-For-*"
}
}
},
{
"Sid": "BlockWriteOperationsFromQDeveloper",
"Effect": "Deny",
"Action": [
"s3:DeleteObject*",
"ec2:TerminateInstances",
"iam:DeleteUser"
],
"Resource": "*",
"Condition": {
"StringLike": {
"aws:userAgent": "*exec-env/AmazonQ-For-*"
}
}
},
{
"Sid": "AllowWriteOperationsFromRegularCLI",
"Effect": "Allow",
"Action": [
"s3:DeleteObject*",
"ec2:TerminateInstances",
"iam:DeleteUser"
],
"Resource": "*",
"Condition": {
"StringNotLike": {
"aws:userAgent": "*exec-env/AmazonQ-For-*"
}
}
}
]
}
Note on User Agent Reliability: While AWS warns that user agents can be “spoofed,” this concern is reduced for Q Developer governance use cases. The user agent is automatically set by Q Developer’s tools, not manually controlled by users. Any spoofing would require deliberate effort and would be detectable through usage pattern analysis. This approach is designed for operational governance and policy differentiation, not as a sole security control.
Additional Control Layer: Custom Agent Configuration
For an additional layer of control, you can create a custom agent configuration that restricts which AWS services Amazon Q Developer can access using allowedServices and deniedServices parameters for the use_aws tool:
{
"toolsSettings": {
"use_aws": {
"allowedServices": ["s3", "lambda", "ec2"],
"deniedServices": ["eks", "rds"]
}
}
}
This custom agent configuration works in conjunction with IAM policies to provide defense-in-depth governance of AI-assisted AWS operations. For more details, refer to the agent configuration documentation.
Verification and Monitoring
CloudTrail Event Analysis
To verify that your policies are working correctly, examine CloudTrail events. Here’s what to look for:
Amazon Q Developer Event
{
"eventTime": "2025-01-15T10:30:00Z",
"eventName": "GetCallerIdentity",
"userAgent": "aws-cli/2.27.17 md/awscrt#0.26.1 ua/2.1 os/macos#24.6.0 md/arch#x86_64 lang/python#3.13.3 md/pyimpl#CPython exec-env/AmazonQ-For-CLI-Version-1.15.0 cfg/retry-mode#standard md/installer#exe md/prompt#off md/command#sts.get-caller-identity",
"sourceIPAddress": "203.0.113.12",
"userIdentity": {
"type": "IAMUser",
"principalId": "AIDACKCEVSQ6C2EXAMPLE",
"arn": "arn:aws:iam::123456789012:user/developer"
}
}
Regular AWS CLI Event
{
"eventTime": "2025-01-15T10:35:00Z",
"eventName": "GetCallerIdentity",
"userAgent": "aws-cli/2.27.17 md/awscrt#0.26.1 ua/2.1 os/macos#24.6.0 md/arch#x86_64 lang/python#3.13.3 md/pyimpl#CPython cfg/retry-mode#standard md/installer#exe md/prompt#off md/command#sts.get-caller-identity",
"sourceIPAddress": "203.0.113.12",
"userIdentity": {
"type": "IAMUser",
"principalId": "AIDACKCEVSQ6C2EXAMPLE",
"arn": "arn:aws:iam::123456789012:user/developer"
}
}
Monitoring Script Example
Create a simple monitoring script to track Amazon Q Developer usage:
#!/bin/bash
# Monitor Amazon Q Developer AWS API usage
# Get events from last 24 hours and filter for Q Developer user agents
aws cloudtrail lookup-events \
--start-time $(date -u -v-24H '+%Y-%m-%dT%H:%M:%SZ') \
--lookup-attributes AttributeKey=EventName,AttributeValue=GetCallerIdentity \
--query 'Events[?contains(CloudTrailEvent, `AmazonQ-For-CLI`)].[EventTime,EventName,UserIdentity.userName]' \
--output table
Conclusion
Amazon Q Developer’s built-in user agent markers provide a powerful foundation for implementing enterprise-grade security controls around AI-assisted AWS operations. By leveraging these markers in IAM policies, organizations can:
- Distinguish between AI-assisted and manual AWS operations
- Implement differentiated security policies based on operation source
- Maintain detailed audit trails for compliance requirements
- Enable secure Amazon Q Developer adoption in enterprise environments while maintaining strict controls over write operations that could impact production systems
For organizations currently evaluating Amazon Q Developer adoption, implementing user agent marker-based controls is a key component of your deployment strategy. This approach enables you to realize the productivity benefits of AI-assisted development while maintaining the governance and security controls your organization requires.
Experience the power of Amazon Q Developer as your AI-powered coding assistant, and implement the governance controls outlined in this post to ensure secure adoption in your enterprise environment. These built-in user agent markers enable you to maintain enterprise-grade security while unlocking the productivity benefits of AI-assisted development.
To learn more about Amazon Q Developer’s features and capabilities, visit the Amazon Q Developer product page.
About the Author

Kirankumar Chandrashekar is a Generative AI Specialist Solutions Architect at AWS, focusing on Amazon Q Developer/Kiro and developer productivity. Bringing deep expertise in AWS cloud services, DevOps, modernization, and infrastructure as code, he helps customers accelerate their development cycles and elevate developer productivity through innovative AI-powered solutions. By leveraging Amazon Q Developer and Kiro, he enables teams to build applications faster, automate routine tasks, and streamline development workflows. Kirankumar is dedicated to enhancing developer efficiency while solving complex customer challenges, and enjoys music, cooking, and traveling.
Multi Agent Collaboration with Strands
Post Syndicated from Aaron Sempf original https://aws.amazon.com/blogs/devops/multi-agent-collaboration-with-strands/
In the evolving landscape of autonomous systems, multi-agent collaboration is becoming not only feasible but necessary. As agents gain more capabilities, like advanced reasoning, adaptation, and tool use, the challenge shifts from individual performance to effective coordination. The question is no longer “can an agent solve a task?” but “how do we organize execution across many intelligent agents?”
A foundational step toward answering this came with the Supervisor pattern, introduced in our article on creating asynchronous AI agents with Amazon Bedrock. The Supervisor addresses the first generation of coordination challenges by acting as a centralized orchestrator, monitoring and delegating tasks across agents in a structured, serverless workflow. It provides asynchronous orchestration, fallback handling, and state tracking across loosely coupled agents, giving organizations a reliable way to move from single-agent prototypes to multi-agent systems.
Yet as agentic systems scale and become more dynamic, the limitations of static supervision become clear. The Supervisor model assumes a relatively stable set of agents and predictable workflows; but modern systems face constantly shifting tasks, emergent capabilities, and the need for adaptive coordination. This is where the Arbiter pattern emerges as the natural evolution: a next-generation supervisory model that extends the Supervisor with dynamic agent generation, semantic task routing, and blackboard-model-based coordination. By addressing the unpredictability and fluidity of large, evolving agent ecosystems, the Arbiter pattern enables systems not only to manage complexity but to thrive in it.
The Arbiter pattern builds directly on this by adding three key capabilities:
- Semantic Capability Matching: Instead of only assigning known tasks to known agents, the Arbiter reasons about what kind of agent should exist for a task—even if that agent doesn’t exist yet.
- Delegated Agent Creation: If no suitable agent is found, the Arbiter escalates the request to a Fabricator agent that dynamically generates a task-specific agent on demand. This moves beyond delegation to true adaptive generation.
- Task Planning + Contextual Memory: Building on the Supervisors task coordination capability, Arbiter decomposes complex inputs into structured task plans, and uses contextual memory to track execution, retry logic, and agent performance.
In short, the Arbiter transforms static orchestration into adaptive coordination.
The Blackboard Model Revisited
To enable loose, extensible collaboration across agents, the Arbiter Pattern incorporates principles from the blackboard model – a classic architecture from distributed AI. In this model, agents contribute opportunistically to a shared data space (the “blackboard”), reacting to changes and collectively solving problems.
Reference: See “The Blackboard Model of Control” (Hayes-Roth et al.), and early applications like Hearsay-II for foundational research.
In our extended Arbiter Pattern, the blackboard becomes a semantic event substrate. Agents, including the Arbiter, publish and consume task-relevant state, enabling loosely coupled, event-driven collaboration.
How It Works
When an event enters the system, the Arbiter takes on the supervisory role but extends it with greater dynamism and adaptability. Like the Supervisor pattern, it begins by interpreting the event and identifying the required objectives and sub-tasks. It then performs a capability assessment, using a local index or peer-published manifests, much like the Supervisor querying an Agents config table.
- Interpretation: The Arbiter uses LLM-based reasoning to extract task objectives and sub-tasks.
- Capability Assessment: It evaluates which agents can handle each sub-task using a local index or peer capability manifests.
- Delegation or Generation:
- If a suitable agent exists, the task is routed accordingly.
- If not, the Arbiter sends a generation request to the fabricator agent.
- Blackboard Coordination: All agents involved read/write to a shared semantic blackboard, contributing as needed based on observed task state.
- Reflection and Adaptation: Performance data is logged and used to inform future agent creation, adaptation, or deprecation.
Arbiter Pattern Architecture
Unlike the Supervisor, which maintains orchestration through a static config list, the Arbiter introduces a shared semantic blackboard that allows all participating agents to read, write, and coordinate based on evolving task state. This blackboard serves as a dynamic collaboration space, enabling mid-task adaptation and richer multi-agent coordination.
The following Diagram 1: Agentic AI Arbiter pattern implemented as a code example can be downloaded here
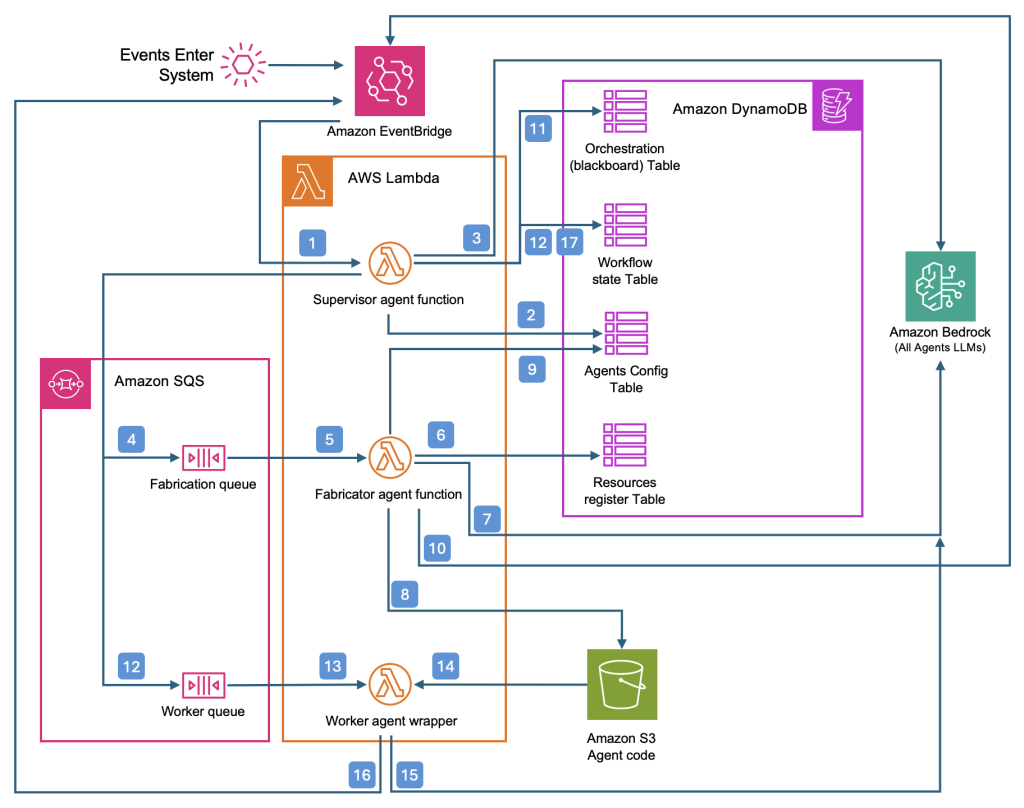
Diagram 1: Agentic AI Arbiter pattern
The following sequence describes the Arbiter pattern, according to the numbered steps in the diagram 1: Agentic AI Arbiter pattern
- Events entering the system trigger the Supervisor function
- Supervisor queries Agents Config table for agent capabilities
- Supervisor uses Agents config list as context to plan orchestration of tasks
Option: New Agent:
If no capable agent is found, the Arbiter goes further than the basic supervisor pattern: it issues a generation request to a fabricator agent, which synthesizes new worker code, stores it for runtime access, and updates the capability registry so the agentic system can immediately benefit from the new skill.
- Task cannot be completed, request create new capability
- Request to fabricate triggers Fabrication agent instance
- Fabrication agent queries resources register for available tools (capabilities)
- Fabricator generates worker agent code
- Worker agent code stored in bucket for runtime access
- New worker added to Agents config list with agent capabilities description
- Result of fabrication posted to message bus
Repeat steps 1, 2 & 3
Option: Orchestrate workflow:
If a suitable agent exists, the Arbiter orchestrates the workflow by invoking the appropriate worker agents, tracking progress and state as in the Supervisor model.
- Orchestration of tasks is stored for tracking end-to-end process
- Request to invoke worker agent, by name/id. Add workflow state for agent invocation.
- Request to invoke worker agent triggers worker agent wrapper instance
- Worker agent wrapper loads agent code
- Worker agent reasons and takes action
- Worker agent sends response to message bus
- Supervisor agent updates workflow state and tracks against orchestration
The Arbiter incorporates a reflection and adaptation loop: performance data from task execution is logged, analyzed, and fed back into the fabricator and coordination logic. This ensures that not only are tasks completed in the moment, but the system continuously adapts, retires underperforming agents, and evolves toward greater efficiency.
The Arbiter Agent: Event Orchestration Engine
The Supervisor Agent (Arbiter Agent) serves as the central coordinator component, managing complex event-driven workflows through intelligent task delegation.
Event Processing Workflow:
The Arbiter pattern follows a structured approach to handle incoming events
- Configuration Loading: Loads available agent configurations from Amazon DynamoDB via load_config_from_dynamodb()
- LLM Invocation: Invokes Amazon Bedrock LLM with event context and available tool specifications
- Decision Analysis: LLM analyzes the event and returns tool invocation decisions with parameters
- Task Dispatch: For each specified tool call:
- Extracts tool name, input parameters, and tool use ID
- Dispatches message to corresponding Amazon Simple Queue Service (SQS) queue via process_tool_call()
- Maintains tool invocation list for workflow tracking
Workflow State Management:
The system maintains comprehensive state tracking throughout execution
- Creates workflow tracking record in DynamoDB with create_workflow_tracking_record()
- Initializes all invoked agents as incomplete
- Associates unique request ID with orchestration instance
- Persists orchestration state including conversation history and request mapping
Completion Coordination:
The Arbiter coordinates task completion through a systematic process
- Event Reception: Receives agent completion events via Amazon EventBridge
- Status Updates: Updates workflow tracking with update_workflow_tracking()
- Completion Check: Performs completion check across all tracked agents
- Result Aggregation: When all agents complete:
- Aggregates results from DynamoDB data field
- Appends tool results to conversation as user messages
- Re-invokes orchestration with updated context
- Continuation: Continues until LLM provides final response without tool calls
The Fabricator Agent: Dynamic Capability Generation
The Fabricator Agent implements just-in-time agent development using the Strands agents framework, creating new capabilities when required functionality doesn’t exist in the system.
Agent Development Architecture:
The Fabricator operates as a specialized Strands Agent with specific characteristics
- Implemented as a Strands Agent with specialized system prompt for code generation
- Triggered by “New worker agent” events from the Arbiter
- Receives capability requirements through prompt augmentation with agent directive
- System prompt includes:
- Strands Agent implementation examples
- Complete catalog of available Strands Tools
- Code generation patterns and conventions
- Standardized handler() function requirements
Code Generation Process:
The agent follows a structured development workflow
- Requirement Analysis: LLM analyzes capability requirements and generates Python implementation
- Tool Selection: Prioritizes use of existing Strands Tools over custom @tool implementations
- Code Structure: Creates agents following standardized patterns:
- Bedrock model initialization with models.BedrockModel()
- Agent instantiation with appropriate tool selection
- Standardized handler() function interface
- Event-driven completion signaling
- File Creation: Writes generated code to /tmp/ directory for immediate availability
Capability Registration Pipeline:
New capabilities are registered through a multi-step process
- File Storage: File upload to Amazon Simple Storage Service (S3) via upload_file_to_s3() tool
- Metadata Registration: Registration in DynamoDB via store_agent_config_dynamo():
- toolId: Unique capability identifier
- filename: S3 object reference
- schema: OpenAPI specification for LLM tool calling
- description: Human-readable capability documentation
- action: SQS queue routing configuration for Generic Wrapper
- Completion Notification: Completion event publication to Arbiter via complete_task() tool
Testing Considerations:
The original implementation revealed important insights about testing approaches
- Previous Approach: Agent testing within the Fabricator resulted in:
- Unstructured testing leading to false negatives
- Overzealous optimization of generated agents
- Recommendation: Separate testing agent with standardized harness for validation feedback
The Generic Wrapper: Dynamic Execution Runtime
The Generic Wrapper implements a hot-loading pattern that enables unlimited agent creation without infrastructure scaling, providing a universal execution environment for Fabricator-generated agents.
This hot-loading approach is critical because it decouples capability growth from infrastructure scaling. Instead of provisioning and maintaining new infrastructure components for every new agent, which could be dozens or even hundreds of agents, the system reuses a single execution wrapper that can dynamically load and execute arbitrary agent code.
This not only makes agent creation effectively limitless but also ensures infrastructure efficiency, cost optimization, and simplified operations, allowing the Arbiter and Fabricator to evolve system capabilities without operational bottlenecks.
In the AWS Samples code, found here, the Hot-loading handler is implemented as am AWS Lambda function, represented in the following code snippet:
def process_event(event, context):
orchestration_id = event["orchestration_id"]
tool_use_id = event["tool_use_id"]
request = event["tool_input"]
tool_name = event['node']
# Based on the tool from the event, load the details from DDB
tool = load_config_from_dynamodb(tool_name)
config = tool['config']
if isinstance(config, str):
config = json.loads(config)
file_name = config['filename']
load_file_from_s3_into_tmp(os.environ["AGENT_BUCKET_NAME"], file_name)
# Hot load the module from the tmp directory
spec = importlib.util.spec_from_file_location("module.name", "/tmp/loaded_module.py")
loaded_module = importlib.util.module_from_spec(spec)
sys.modules["module.name"] = loaded_module
spec.loader.exec_module(loaded_module)
# Invoke the generic handler with whatever args were passed in by the Arbiter
try:
print("attempting to use module")
response = loaded_module.handler(**request)
print(f"response: {response}")
except Exception as e:
print(f"error running module: {e}")
response = "The task could not be completed, this agent has issues, please ignore for now."
# Finally. report back to the Arbiter. Handled by the wrapper. To avoid the Frabricator from attempting to code this part itself
post_task_complete(response, tool_use_id, tool_name, orchestration_id)
Although this example is demonstrated through a lambda function, the Hot-Loading code can be executed in Amazon Bedrock AgentCore Runtime, or AWS native container services, such as Amazon Elastic Container Service (ECS) or Amazon Elastic Kubernetes Service (EKS)
Hot-Loading Architecture:
The wrapper implements several key architectural principles
- Single infrastructure component handles execution of all dynamically created agents
- Eliminates need for separate infrastructure provisioning per agent
- Implements runtime code loading from S3 storage
- Accepts latency trade-off for infrastructure efficiency in non-ultra-low-latency environment
Dynamic Loading Process:
The system follows a precise loading sequence
- Message Processing: Extracts agent identifier from incoming SQS message
- Configuration Retrieval: Queries DynamoDB for agent configuration via load_config_from_dynamodb()
- Code Download: Downloads agent implementation from S3 to /tmp/ directory
- Runtime Loading: Module loading using importlib.util:
- spec_from_file_location() creates module specification
- module_from_spec() instantiates module object
- exec_module() performs actual code loading and execution
Execution Management:
The wrapper provides comprehensive execution oversight
- Invokes standardized handler() function with provided parameters
- Captures execution results and handles error conditions gracefully
- Maintains execution isolation between different agent invocations
- Implements resource cleanup after agent execution completion
Standardized Communication Protocol:
Communication follows strict standardization to ensure system reliability, which is critical in multi-agent environments where dozens or even hundreds of dynamically generated agents may interact. Without consistent message formats, routing rules, and completion signals, orchestration would become brittle, errors would propagate unpredictably, and debugging would be nearly impossible. Standardization guarantees that every agent, no matter when it was created, can interoperate seamlessly, enabling the Arbiter to maintain end-to-end visibility, traceability, and fault-tolerance across the entire system.
Event Handling Principles:
- Event posting handled exclusively by Generic Wrapper, not individual agents
- Ensures consistent event-driven communication patterns across all agents
Completion Event Structure:
- orchestration_id: Workflow context linkage
- tool_use_id: LLM tool invocation mapping
- node: Agent identifier for tracking
- data: Execution results or error information
Reliability Measures:
- Publishes completion events to EventBridge for Arbiter processing
- Guarantees workflow tracking receives completion signals regardless of execution outcome
Scalability Characteristics:
The hot-loading approach provides significant scalability benefits
- Enables agent scaling creation without minimal infrastructure impact
- S3 download latency acceptable within overall system performance profile
- Single wrapper instance can execute multiple agent types
- Memory and resource management handled at container level
Conclusion
The Arbiter Pattern represents a significant evolution beyond the Supervisor architecture, delivering the flexibility required for truly autonomous agentic systems. By introducing semantically rich, context-aware orchestration, it enables dynamic scalability, where agent capabilities grow in step with task demands. The architecture is resilient, redistributing or regenerating tasks when agents fail, and it achieves loose coupling by having agents interact through semantically meaningful events rather than rigid APIs. Most importantly, it embeds continuous adaptation through Arbiter-guided feedback loops, allowing systems to learn and evolve over time. This marks a shift from pre-programmed logic to generative, blackboard-model-based coordination, paving the way for decentralized, intelligent systems that can learn, adapt, and collaborate effectively at scale.
The system delivers several critical capabilities
- Asynchronous Processing: SQS-based message passing for scalable execution
- Persistent State Management (Short-term memory): DynamoDB-based workflow tracking
- Scalability: Hot-loading architecture for unlimited agent creation
- Intelligent Orchestration: LLM-driven task decomposition and sequencing
- Self-Expanding Capabilities: Strands-based agent creation on demand
- Standardized Communication: Reliable event-driven protocols
This architecture enables processing of arbitrary event types by dynamically creating necessary processing capabilities and coordinating their execution through LLM-driven workflow orchestration, while maintaining infrastructure efficiency through hot-loading patterns.
About the Authors
 Aaron Sempf is Next Gen Tech Lead for the AWS Partner Organization in Asia-Pacific and Japan. With over 20 years in distributed system engineering design and development, he focuses on solving for large scale complex integration and event driven systems. In his spare time, he can be found coding prototypes for autonomous robots, IoT devices, distributed solutions, and designing agentic architecture patterns for generative AI assisted business automation.
Aaron Sempf is Next Gen Tech Lead for the AWS Partner Organization in Asia-Pacific and Japan. With over 20 years in distributed system engineering design and development, he focuses on solving for large scale complex integration and event driven systems. In his spare time, he can be found coding prototypes for autonomous robots, IoT devices, distributed solutions, and designing agentic architecture patterns for generative AI assisted business automation.
 Joshua Toth is a Senior Prototyping Engineer with over a decade of experience in software engineering and distributed systems. He specializes in solving complex business challenges through technical prototypes, demonstrating the art of the possible. With deep expertise in proof of concept development, he focuses on bridging the gap between emerging technologies and practical business applications. In his spare time, he can be found developing next-generation interactive demonstrations and exploring cutting-edge technological innovations.
Joshua Toth is a Senior Prototyping Engineer with over a decade of experience in software engineering and distributed systems. He specializes in solving complex business challenges through technical prototypes, demonstrating the art of the possible. With deep expertise in proof of concept development, he focuses on bridging the gap between emerging technologies and practical business applications. In his spare time, he can be found developing next-generation interactive demonstrations and exploring cutting-edge technological innovations.
Cuni: Tracing JITs in the real world @ CPython Core Dev Sprint
Post Syndicated from jake original https://lwn.net/Articles/1039612/
Longtime PyPy developer Antonio Cuni has a
lengthy
blog post that describes his talk at the recently completed
2025
CPython
Core Dev Sprint, held at Arm in Cambridge, UK. The talk, entitled
“Tracing JIT and real world Python — aka: what we can learn from PyPy” was
meant to try to pass on some of his experiences “optimizing existing
” to the
code for PyPy at a high-frequency trading firm
developers working on the CPython JIT compiler. His goal was
to raise awareness of some of the problems he encountered:
Until now CPython’s performance has been particularly predictable, there are well established “performance tricks” to make code faster, and generally speaking you can mostly reason about the speed of a given piece of code “locally”.
Adding a JIT completely changes how we reason about performance of a given program, for two reasons:
- JITted code can be very fast if your code conforms to the heuristics applied by the JIT compiler, but unexpectedly slow(-ish) otherwise;
- the speed of a given piece of code might depend heavily on what
happens elsewhere in the program, making it much harder to reason about
performance locally.The end result is that modifying a line of code can significantly impact seemingly unrelated code. This effect becomes more pronounced as the JIT becomes more sophisticated.
Cuni also gave a talk on Python performance, which LWN covered, at
EuroPython 2025 in July.
Nexstar & Brendan Carr #lastweektonight
Post Syndicated from LastWeekTonight original https://www.youtube.com/shorts/IhmjgncyBiI
Enabling AI adoption at scale through enterprise risk management framework – Part 2
Post Syndicated from Milind Dabhole original https://aws.amazon.com/blogs/security/enabling-ai-adoption-at-scale-through-enterprise-risk-management-framework-part-2/
In Part 1 of this series, we explored the fundamental risks and governance considerations. In this part, we examine practical strategies for adapting your enterprise risk management framework (ERMF) to harness generative AI’s power while maintaining robust controls.
This part covers:
- Adapting your ERMF for the cloud
- Adapting your ERMF for generative AI
- Sustainable Risk Management
By the end of this post, you’ll have a roadmap for scaling generative AI adoption securely and responsibly.
Adapting your ERMF for the cloud
Before diving into generative AI-specific controls, it’s crucial to understand the fundamental infrastructure that enables these technologies. Cloud computing is the foundational infrastructure that has made generative AI possible and accessible at scale. The development and deployment of large language models and other generative AI systems require massive computational resources, vast amounts of data storage, and sophisticated distributed processing capabilities that cloud systems can efficiently provide.
Cloud technology differs from on-premises IT solutions, and the relationship between financial institutions and cloud service providers is also different from the relationship with a traditional outsourcing provider.
These differences change the nature of many risks that financial institutions face and how they manage them. However, if cloud technology is implemented in the right way, it can reduce risk and provide tools to help Chief Risk Officers (CROs) to manage risk too.
You can read more about how your ERMF needs to change for large scale cloud adoption in Is your Enterprise Risk Management Framework ready for the Cloud?
Adapting your ERMF for generative AI
Organizations adopting generative AI can use their enterprise risk management framework to realize business value while maintaining appropriate controls. This approach allows you to build on existing risk management practices while addressing generative AI’s unique characteristics.
For a structured approach to cloud-enabled AI transformation, the AWS Cloud Adoption Framework for AI, ML, and generative AI (AWS CAF for AI) provides detailed implementation guidance aligned with enterprise risk management principles. For a detailed user guide, see AWS User Guide to Governance, Risk and Compliance for Responsible AI Adoption within Financial Services Industries, available in AWS Artifact using your AWS sign in. AWS Artifact provides AWS security and compliance reports, helping organizations maintain compliance through best practices.
When it comes to model management and the AI system lifecycle, customers can consult ISO42001 AI Management, Section A6. This section encompasses capturing the objective and processes for the responsible design and development of AI systems, including criteria and requirements for each stage of the AI system life cycle. This guidance can help organizations verify that their model management practices align with industry standards for responsible AI development.
From a business leader’s perspective, incorporating generative AI considerations into your ERMF helps establish documented good practices, implement effective controls, and maintain transparency about usage across the enterprise. This enables both responsible innovation and prudent risk management. Here’s how organizations are approaching this:
Generative AI policy and governance foundations in ERMF
In the field of generative AI, organizations establish both guardrails for innovation and clear accountability for risk management. The three lines of defense model provides the structure for implementing these foundational elements:
- Acceptable use framework for your organization: Clear direction on appropriate generative AI use helps organizations manage risks while enabling innovation. The range of use cases for generative AI is large and likely to expand over the years, making it essential to have clear guidance on what applications are permitted and under what conditions. As organizations explore these opportunities, their framework can evolve with their experience and maturity.
- Risk accountability: The generative AI lifecycle—from use case selection through implementation and ongoing monitoring—requires clear ownership across business and control functions. While organizations can establish specific generative AI oversight mechanisms, these should integrate with existing governance structures. Risk reporting and accountability for generative AI initiatives should flow through established enterprise risk committees and governance boards, helping to facilitate consistent risk management across the organization rather than creating isolated pockets of oversight.
Implementation approach for generative AI: Putting principles into practice
Building on the three lines of defense model discussed earlier, organizations can adapt their risk management practices to address the unique characteristics of generative AI while using industry best practices and frameworks. This often involves evolving existing controls and introducing new ones specific to generative AI. AWS services have built-in capabilities that support these enhanced governance, risk management, and compliance requirements, helping organizations to implement controlled and responsible generative AI solutions. This includes, for example, Amazon Bedrock Guardrails, among many others.
Building on the risk areas we outlined earlier, we now explore how organizations can implement controls for each of these areas. For each, we describe the principle and the practical implementation considerations. While organizations might prioritize these areas differently based on their use cases and risk appetite, together they provide a framework for responsible generative AI adoption through ERMF.
While we explore high-level control principles that follow, technical teams can review the AWS Well-Architected Framework – Generative AI Lens for detailed architectural guidance that supports these governance objectives.
Fairness
Generative AI systems can deliver equitable outcomes across different stakeholder groups, helping organizations build trust and meet expectations. Organizations can support this by setting up clear fairness metrics for specific use cases, regularly assessing training data for bias, and closely monitoring performance across different groups. For high-stakes applications, additional checks can help facilitate fair treatment across diverse populations.
Amazon Bedrock Guardrails provides configurable safeguards to help maintain fair and unbiased outputs, with customizable thresholds to match different use case requirements. Amazon Bedrock provides comprehensive model evaluation tools including model cards with detailed bias metrics, to assess bias across demographic groups. Amazon Bedrock includes built-in prompt datasets like the Bias in Open-ended Language Generation Dataset (BOLD), which automatically evaluates fairness across key areas such as profession, gender, race, and various ideologies. These capabilities integrate with Amazon SageMaker Clarify for comprehensive bias detection and mitigation, supported by built-in bias metrics and reporting.
Explainability
Generative AI systems can provide understanding of their decision-making processes, supporting accountability and effective oversight. Explainability is essential for all generative AI systems—whether using custom-built or pre-built models, particularly for complex models like transformer networks.
Organizations can implement practical controls by establishing clear explainability thresholds based on use case risk levels. This remains an active industry challenge, with ongoing research and evolving approaches. For critical business applications, tailoring explanations to different stakeholders while maintaining accuracy can improve understanding and trust.
Amazon Bedrock provides tools that help identify which factors influenced the generative AI’s decisions, while maintaining detailed records of system inputs and outputs. For complex workflows, Chain-of-Thought (CoT) reasoning traces are available through Amazon Bedrock Agents, showing the step-by-step logic behind each decision. Organizations can monitor how responses are generated in real time. For Retrieval-Augmented Generation (RAG) applications, which optimize AI outputs by referencing specific knowledge bases, Amazon Bedrock Knowledge Bases automatically includes references and links to source materials used in generating responses.
Privacy and security
Generative AI systems benefit from strong privacy and security measures to protect sensitive information and help prevent unauthorized access or data exposure. These systems can potentially generate content or unintentionally reveal confidential data, which organizations can proactively manage.
Organizations can set up multi-layered protection strategies, including access controls, content filtering, and data privacy safeguards. This can involve creating company-wide standards for prompt engineering to help prevent harmful outputs, using techniques like RAG to control information sources, and using automated systems to detect and protect personal information. Regular testing and validation, especially to comply with regulations like GDPR, can be part of the development and deployment process.
Amazon Bedrock implements multiple security layers including private endpoints with Amazon Virtual Private Cloud (Amazon VPC) support, fine-grained AWS Identity and Access Management (IAM) access control, and end-to-end encryption. Importantly, it maintains no persistent storage of prompt or completion data and helps preserve model provider isolation.
Amazon Bedrock Guardrails provides sensitive information filters that can detect and protect personally identifiable information (PII) through automated input rejection, response redaction, and configurable regex patterns, supporting various use cases while maintaining data privacy. Organizations like Genesys demonstrate these capabilities at scale, maintaining GDPR compliance while processing 1.5 billion monthly customer interactions through Amazon Bedrock.
For detailed security considerations, see Generative AI Security Scoping Matrix, which provides a comprehensive framework for assessing and addressing generative AI security risks.
Safety
Generative AI systems can be designed and operated with safeguards to avoid harm to individuals, and communities. This includes addressing risks of generating dangerous, illegal, or abusive content, and helping to prevent system misuse.
Organizations can implement specific safety measures through predeployment content filtering, real-time safety boundaries with prompt constraints, and output classification systems to detect and block dangerous content. Context-aware content moderation considers the specific application domain, while automated detection can identify potential safety violations before content generation. Ongoing monitoring and updating of these controls help address evolving capabilities and potential risks of generative AI systems.
Amazon Bedrock Guardrails delivers industry-leading safety protections across text and images, blocking up to 85 percent more harmful content on top of native protections provided by foundation models (FMs). Additional safety controls include token limits to avoid excessive responses, rate limiting against misuse, and moderation endpoints for content screening.
For full practical implementation guidance on building safety controls, see Build safe and responsible generative AI applications with guardrails.
Controllability
Organizations can maintain appropriate control over generative AI systems to make sure that they work as intended and can be adjusted or stopped if issues arise. This helps manage risks and maintain system reliability.
A multi-layered approach to control includes implementing technical safeguards and operational processes. Organizations can control model behaviour by adjusting parameters such as temperature (controlling output randomness), and sampling methods like top-k or top-p (managing output diversity). Clear operational boundaries define the system’s scope of action, while human-in-the-loop validation provides oversight for critical applications.
For effective control, organizations can establish parameter thresholds tailored to different use cases, implement rapid adjustment mechanisms, and create clear escalation procedures. Amazon Bedrock enhances control through customizable agent prompts and reasoning techniques, and the ability to break complex tasks into smaller, manageable components. Organizations can choose between structured workflows or flexible agent-based approaches. Regular comparison of outputs against established benchmarks helps maintain system reliability.
This balanced approach supports creative AI outputs while helping to facilitate consistent performance within defined quality limits. This helps prevent service degradation and business disruption while minimizing inefficiencies.
Control capabilities are further enhanced through Amazon CloudWatch monitoring integration and robust knowledge base version control. The capabilities of Amazon Bedrock, including LLM-as-a-judge features, help organizations assess and optimize their generative AI applications efficiently.
Veracity and robustness
Generative AI systems can produce reliable and accurate outputs, even when faced with unexpected or challenging inputs. This helps maintain trust and helps maintain the system’s usefulness across various applications.
Organizations can implement a combination of technical and procedural controls to enhance both system robustness and output reliability. This includes establishing clear parameter thresholds for different use cases, implementing human-in-the-loop validation for critical applications, and regularly comparing outputs against established ground truths. The framework specifies when and how these controls are applied based on the use case criticality and required level of accuracy.
Amazon Bedrock Guardrails improves veracity by helping to prevent factual errors through automated reasoning checks that deliver up to 99 percent accuracy in detecting correct responses from models, using mathematical logic and formal verification techniques. This capability supports processing of large documents up to 80,000 tokens and includes automated scenario generation for comprehensive testing.
Amazon Bedrock also includes sophisticated input sanitization features and supports adversarial testing through AWS testing tools integration.
Governance
Effective governance of generative AI systems helps manage risks, maintain accountability, and align AI use with organizational values and regulations. This covers the entire AI lifecycle, from development to deployment and ongoing operation.
Organizations can create clear governance structures, including defined roles for AI oversight, regular risk assessments, and ways to engage with stakeholders. This involves integrating AI governance into existing risk management practices and making sure of compliance with relevant laws and standards. Because AI technology is evolving rapidly, regular reviews and updates to governance practices are essential to address new capabilities, emerging risks, and changing regulatory requirements. This includes providing appropriate training and skill development for system users.
AWS has achieved of ISO/IEC 42001 certification, demonstrating our commitment to systematic governance approaches in AI implementation. Governance features in Amazon Bedrock include comprehensive model provenance tracking, detailed AWS CloudTrail audit logging, and streamlined model deployment approval workflows integrated with AWS Organizations. AWS Audit Manager provides pre-built frameworks to assess generative AI implementation against best practices.
Transparency
Generative AI systems can operate transparently, helping stakeholders understand system capabilities, limitations, and the context of AI-generated outputs. This builds trust and enables informed decision-making by users and affected parties.
Organizations can implement specific transparency measures including comprehensive model documentation detailing intended use cases, known limitations, and performance boundaries. Clear AI disclosure practices should describe when and how AI is being used and what data is being processed. Regular performance reporting can include accuracy rates, error patterns, and bias assessments.
For customer-facing applications, transparency includes providing clear indicators of AI-generated content, documenting how decisions are made, and establishing processes for users to question or challenge outputs. Maintaining detailed version histories of model updates and changes in system behavior helps track the evolution of AI capabilities and their impacts over time.
From the AWS side of the Shared Responsibility Model, transparency is supported through AWS AI Service Cards and detailed documentation of model characteristics. Amazon Bedrock enhances this with comprehensive logging and monitoring capabilities to track model behavior and performance metrics.
Unified risk management
These eight areas are interconnected and mutually reinforcing within the enterprise risk management framework. While organizations might prioritize them differently based on their use cases and risk appetite, together they provide a comprehensive approach to responsible generative AI adoption. For detailed technical guidance, standards, and compliance requirements, see the AWS guidance documents in Resources for technical implementation, at the end of this blog post, that support implementation across these areas.
AI risk management in practice: Building organizational capability
Successful implementation of generative AI systems involves integrating risk management practices across the organization. This includes establishing processes for measuring outcomes and risks and preparing the organization to adapt as technology evolves. Effective risk management depends on building appropriate knowledge and skills at all levels of the organization.
Organizations can create clear pathways from proof of concept to production by aligning with the three lines of defense model. The ERMF provides broad parameters for reliability, safety, and privacy, which business units can adapt for their specific use cases.
To build and maintain lasting capability for both current and future generative AI adoption, organizations can focus on:
- Developing incident response plans for AI-specific scenarios
- Building expertise through training and certification programs
- Regular review and updates of risk management practices
These elements, when woven into the organization’s operating fabric, create sustainable practices that evolve with advancing technology and emerging risks.
Sustainable risk management: Making your ERMF generative AI-ready
Governance, risk, and compliance (GRC) leaders, Chief Risk Officers (CROs), and Chief Internal Auditors (CIAs) can provide sustained executive sponsorship for generative AI adoption. Long-term capability building extends beyond technology and innovation hubs to encompass business and control functions. Clear direction from leadership helps organizations balance generative AI opportunities with appropriate risk management.
Organizations benefit from viewing generative AI as a transformative capability that touches many functions rather than as isolated initiatives. This approach supports sustainable integration of enterprise-wide governance approaches for generative AI, avoiding the limitations of short-term projects with restricted scope and impact.
Organizations can successfully implement generative AI while maintaining their risk management obligations through controlled, well-defined use cases. TP ICAP’s Parameta division demonstrates this approach in their regulatory compliance implementation. By focusing initially on a highly regulated area, maintaining clear governance controls, and making sure there was human oversight in the compliance review process, they established a framework for responsible AI adoption. This led to creating dedicated oversight roles for AI initiatives, strengthening their governance structure for future AI implementations.
Similarly, Rocket Mortgage’s implementation of AWS services for their AI tool Rocket Logic – Synopsis demonstrates how organizations can use Amazon Bedrock for responsible AI integration at scale. This approach enabled them to maintain stringent data security and compliance measures while saving 40,000 team hours annually through automated processes.
Action checklist for sustainable generative AI implementation:
- ERMF foundations: Assess and enhance your risk framework’s readiness for generative AI, including acceptable use guidelines and clear accountabilities
- Technical controls: Begin with core controls such as Amazon Bedrock Guardrails and expand based on specific use cases and risk profiles
- Organizational capability: Develop broad expertise through training and oversight mechanisms across business and control functions
- Monitoring and measurement: Create dashboards for key risk indicators and maintain regular reviews
- Integration strategy: Align generative AI controls with existing processes and organizational strategy
Conclusion
This two-part series has explored the critical importance of integrating generative AI governance into enterprise risk management frameworks. In Part 1, we introduced the unique risks and governance considerations associated with generative AI adoption. Part 2 has provided a comprehensive guide for adapting your ERMF to address these challenges effectively.
We’ve outlined practical strategies for scaling generative AI adoption securely and responsibly, covering key areas such as fairness, explainability, privacy and security, safety, controllability, veracity and robustness, governance, and transparency. By implementing these strategies and following the action checklist provided, organizations can build sustainable practices that evolve with advancing technology and emerging risks.
Organizations that integrate generative AI governance into their ERMF as described in this post are better positioned to accelerate innovation and operational efficiency while protecting against key risks such as data exposure, model hallucinations, and regulatory non-compliance. This balanced approach enables organizations to capture the transformative potential of generative AI while maintaining the robust controls essential for financial services institutions.
For foundational concepts and risk considerations, see Part 1.
Customer success stories
- Genesys: Successfully integrated Amazon Bedrock while maintaining GDPR compliance
- TP ICAP/Parameta: Transformed regulatory compliance processes with controlled generative AI implementation
- Rocket Mortgage’s implementation of Amazon Bedrock for responsible AI integration at scale
Resources for technical implementation
- AWS Responsible Use of AI Guide
- AWS Cloud Adoption Framework for Artificial Intelligence, Machine Learning and generative AI
- AWS Well-Architected Framework – Generative AI Lens
- AWS Machine Learning Blog: Build safe and responsible generative AI applications with guardrails
- Generative AI Security Scoping Matrix
- Minimize AI hallucinations and deliver up to 99% verification accuracy with Automated Reasoning checks
- Amazon Bedrock Guardrails supports multimodal toxicity detection with image support
- New RAG evaluation and LLM-as-a-judge capabilities in Amazon Bedrock
- Navigating the security landscape of generative AI (whitepaper)
- The AWS User Guide to Governance, Risk and Compliance for Responsible AI Adoption within Financial Services Industries (available in AWS Artifact using your AWS sign in)
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Enabling AI adoption at scale through enterprise risk management framework – Part 1
Post Syndicated from Milind Dabhole original https://aws.amazon.com/blogs/security/enabling-ai-adoption-at-scale-through-enterprise-risk-management-framework-part-1/
According to BCG research, 84% of executives view responsible AI as a top management responsibility, yet only 25% of them have programs that fully address it. Responsible AI can be achieved through effective governance, and with the rapid adoption of generative AI, this governance has become a business imperative, not just an IT concern. By implementing systematic governance approaches at the enterprise level, organizations can balance innovation with control, effectively managing the risks while harnessing the transformative potential of generative AI.
While generative AI technologies offer compelling capabilities, they also introduce new types of risks that need business oversight and management. Financial institutions face real challenges—AI-driven financial analysis tools could make investment recommendations based on biased data, leading to significant losses, while generative AI-powered customer service systems might inadvertently expose confidential customer information. The unprecedented scale and speed at which generative AI operates makes robust business controls essential. However, with the right governance approach and strategic oversight, these risks are manageable.
Part 1 of this two-part blog post guides business leaders, Chief Risk Officers (CROs), and Chief Internal Auditors (CIAs) through three critical questions:
- What specific or unique risks does generative AI introduce and how can they be managed?
- How should your enterprise risk management framework (ERMF) evolve to support generative AI adoption?
- How can you build sustainable generative AI governance in an ever-changing world—what should be on your checklist?
To address these questions, organizations can use established frameworks and standards including:
- AWS Cloud Adoption Framework for AI, ML and generative AI (AWS CAF for AI) – offering detailed implementation guidance aligned with enterprise risk management principles.
- ISO/IEC 42001 AI Management System standard – outlining best practices and controls for responsible development, deployment, and operation of AI systems. AWS is the first major cloud provider to achieve accredited certification for this standard.
- NIST AI Risk Management Framework and its generative AI Profile – providing guidance on identifying and managing risks unique to or exacerbated by generative AI.
These frameworks provide valuable guidance for organizations looking to implement responsible and governed AI practices.
Role of GRC leaders, CROs, and CIAs
Governance, risk and control (GRC) functions led by business leaders, CROs and CIAs are well-positioned to advance generative AI innovation in financial services institutions. These functions have successfully managed complex risks in banks for years, and their existing expertise, proven approaches, and established risk frameworks provide a strong foundation for guiding generative AI adoption. They collaborate across the three lines of defense: business leaders making implementation decisions and managing associated risks (first line), risk and compliance functions providing frameworks and oversight (second line), and internal audit providing independent assurance (third line).
If generative AI risks, both perceived and real, are managed through enterprise-wide governance practices rather than isolated project-by-project approaches, organizations can use the advantages offered by generative AI over the long term. This requires integration with the ERMF, with some practices fitting into existing structures while others need deliberate adjustments to ERMF itself to address generative AI’s unique characteristics.
New frontiers in generative AI risk management
The traditional risk landscape at the enterprise level was based on a paradigm in which risks are predicted from past exposures. Preventive controls help stop unwanted things from happening, detective controls discover when bad things slip through the preventive controls, and corrective controls take remediation actions.
Much of this paradigm is still valid in the world of generative AI. For example, access to generative AI applications needs to be managed carefully to avoid unauthorized use. All three types of the preceding controls should help prevent unauthorized use, identify potential breaches, and remedy unauthorized access when detected.
However, additional focus and attention are required in the following areas when implementing generative AI solutions:
- Non-deterministic outputs – The non-deterministic nature of generative AI outputs poses a specific challenge. While the probabilistic nature of these systems is often useful, the risk of inaccurate output from the black box can have serious business implications, and organizations need to take conscious actions to address these risks. Organizations can address this through Amazon Bedrock Guardrails Automated Reasoning checks, which use mathematically sound verification to help prevent factual errors and hallucinations.
- Deepfake threat – Generative AI’s ability to create authentic-looking images and documents extends beyond traditional fraudulent activities. It elevates the threat to an entirely new level, creating eerily realistic content with unprecedented ease—hence the term deepfake. This poses significant challenges for organizations in verifying document authenticity, particularly in processes like Know Your Customer (KYC).
- Layered opacity – While enterprises are learning about generative AI, they must address risks from multi-layered AI systems where each layer generates content and makes decisions based on potentially unexplainable models, hampering traceability. For example, consider generative AI outputs from a third-party system serving as inputs to internal AI systems, creating a chain of interdependent decisions. This lack of transparency in critical decisions affecting organizational performance and customer treatment could have profound implications for enterprise trustworthiness, brand reputation, and regulatory compliance.
The following table outlines key generative AI risk areas and their potential business impacts. In Part 2, we explain how organizations can address these risks through their ERMF. Effectively managing these risks through enterprise-wide governance not only protects the organization but also forms the foundation for responsible AI adoption. Robust risk management and governance are essential prerequisites for achieving responsible AI outcomes.
For a comprehensive foundation in responsible AI implementation, see the AWS Responsible Use of AI Guide, which aligns with the governance principles that we discuss throughout this article.
| Risk area | Description | Potential risk impact |
| Fairness | Are the underlying data and algorithms fair and unbiased? Are the outputs leading to fair outcomes for different groups of stakeholders? |
|
| Explainability | Can stakeholders understand the black box behavior and evaluate system outputs? |
|
| Privacy and security | Are the systems aligned with privacy regulations and security requirements? |
|
| Safety | Are there controls to help prevent harmful system output and misuse? |
|
| Controllability | Are there mechanisms to monitor and steer AI system behaviour, including detection of model and data drifts? |
|
| Veracity and robustness | Can the system maintain correct outputs even with unexpected or adversarial inputs? |
|
| Governance | Are there documented accountabilities across the AI supply chain including model providers and deployers? Are users adequately trained to use systems? |
|
| Transparency | Can stakeholders make informed choices about their engagement with the AI system? |
|
Remitly’s implementation of Amazon Bedrock Guardrails to protect customer personally identifiable information (PII) data and reduce hallucinations demonstrates how financial institutions can effectively manage privacy and veracity risks in generative AI applications, addressing several of the risk areas outlined above.
Conclusion
In this post, we introduced the critical importance of responsible AI governance for enterprises adopting generative AI at scale. We explored the unique risks that generative AI presents, including non-deterministic outputs, deepfake threats, and layered opacity. We outlined key risk areas such as fairness, explainability, privacy and security, safety, controllability, veracity and robustness, governance, and transparency. These risks underscore the need for a robust enterprise risk management framework tailored to the challenges of generative AI.
We emphasized the crucial role of GRC leaders, CROs, and CIAs in advancing generative AI innovation while managing associated risks. By using established frameworks like the AWS Cloud Adoption Framework for AI, ISO/IEC 42001, and the NIST AI Risk Management Framework, organizations can implement responsible and governed AI practices.
In Part 2 of this series, we explore how organizations can adapt their enterprise risk management framework to address these risks effectively, including specific considerations for cloud and generative AI implementation. We’ll provide detailed guidance on making your ERMF generative AI-ready and outline practical steps for sustainable risk management.
Additional reading
- AWS Responsible Use of AI Guide
- Generative AI Security Scoping Matrix
- AWS Cloud Adoption Framework for Artificial Intelligence, Machine Learning, and Generative AI (AWS CAF for AI
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Equinix Analyst Day 2025 and the Braggawatts
Post Syndicated from Patrick Kennedy original https://www.servethehome.com/equinix-analyst-day-2025-braggawatts/
We are at Equinix Analyst Day 2025, where the mega data center company is giving an update on its business
The post Equinix Analyst Day 2025 and the Braggawatts appeared first on ServeTheHome.
Mount Vernon: George Washington’s Home
Post Syndicated from Geographics original https://www.youtube.com/watch?v=Uha93aoFzGM
[$] The phaseout of the mmap() file operation
Post Syndicated from corbet original https://lwn.net/Articles/1038715/
The file_operations
structure in the kernel is a set of function pointers implementing, as the
name would suggest, operations on files. A subsystem that manages objects
which can be represented by a file descriptor will provide a
file_operations structure providing implementations of the various
operations that a user of the file descriptor may want to carry out. The
mmap() method, in particular, is invoked when user space calls the
mmap()
system call to map the object behind a file descriptor into its address
space. That method, though, is currently on its way out in a multi-release
process that started in 6.17.
Fedora considers an AI-tool policy
Post Syndicated from corbet original https://lwn.net/Articles/1039603/
The Fedora project has posted a
proposal for a policy regarding the use of AI tools when developing for
the distribution.
You are responsible for your contributions. AI-generated
content must be treated as a suggestion, not as final code or
text. It is your responsibility to review, test, and understand
everything you submit. Submitting unverified or low-quality
machine-generated content (sometimes called “AI slop”) creates an
unfair review burden on the community and is not an acceptable
contribution.
Why Cloud-Native Developers Need a Specialized Storage Layer
Post Syndicated from David Johnson original https://www.backblaze.com/blog/why-cloud-native-developers-need-a-specialized-storage-layer/

Cloud-native developers move fast. Continuous integration and continuous development/deployment (CI/CD) pipelines, containerized environments, and growing performance demands leave little room for delays. Even small bottlenecks can slow momentum, and a common source of slowdown is storage.
Most cloud-native teams default to storage from major cloud providers because it’s convenient and deeply integrated with other services, such as compute, networking, and machine learning (ML). But that convenience isn’t always optimized for development velocity. These platforms prioritize flexibility for a wide range of use cases, not the consistency and speed that fast-moving dev teams need.
Here’s the good news: Adding a specialized, always-hot storage layer can reduce friction and unlock faster, smoother development—without changing the tools you already use.
This post kicks off a three-part series on how specialized cloud storage benefits every member of a cloud-native team: developers, DevOps engineers, and SREs.
First up: the developer.
Free ebook: Why object storage is essential for AI workloads
How do you balance scalability with performance while staying on budget? This ebook explores how object storage enhances every stage of the pipeline from collection to training to deployment, and provides real-world use cases.

When storage slows you down and how to fix it
When storage underperforms, it disrupts your development loop. Cold-tier delays, unpredictable time to first byte (TTFB), and inconsistent throughput take time away from building and shipping applications, or from supporting AI/ML workloads that depend on fast, consistent data access.
In the sections below, we look at how these issues show up in practice and how specialized cloud storage can help remove the roadblocks to faster development.
Build-test loops without the bottleneck
Fast feedback loops are the heartbeat of cloud-native development. Every delay in retrieving files, artifacts, or dependencies drags out build-test cycles and can also slow AI/ML workloads that rely on quick, repeated access to large datasets.
Delays often come from the way cloud providers structure tiered storage. Data is divided into hot, cool, and cold tiers. While cooler tiers cost less, they’re built for retention, not speed. When builds depend on files stored in these tiers, retrieving them adds latency.
Lifecycle policies compound this by automatically moving files into cooler tiers if they haven’t been accessed for a set period. When developers need those files again, they first have to retrieve them from a slower tier, adding latency and sometimes fees.
A specialized, always-hot storage layer eliminates these delays by removing tiers and retrieval hurdles altogether. All data stays instantly accessible, so artifacts and dependencies are always ready the moment they’re needed. Builds run without waiting for restores, tests execute without interruption, and feedback loops stay tight.
Consistent throughput, no tuning required
With general-purpose storage from major cloud providers, consistent performance doesn’t come out of the box. Developers are left to manage it themselves, often through manual tweaks such as file-size tuning or other trial-and-error adjustments.
But tuning only goes so far. Even if developers adjust file sizes or request patterns, those tweaks can’t overcome the built-in delays of tiered storage systems. To compensate, many teams add caching layers or complex configurations. Those workarounds may patch performance gaps in the short term, but they create their own set of burdens:
- Extra rules and scripts: Moving data between tiers or maintaining caches often requires custom automation.
- Added complexity: Each workaround becomes another system to monitor and maintain, increasing the risk of errors.
- Slower workflows: Rather than focusing on development, teams burn time managing storage mechanics.
Specialized storage eliminates the need for tuning or caching altogether. With high-throughput performance available from the start, developers don’t have to waste time building or maintaining workarounds. No scripts, no caches, and no trial-and-error.
Predictable performance under real workloads
General-purpose cloud storage can stumble when workloads scale. Because storage is tightly coupled with compute, networking, and access controls in big cloud providers’ environments, conflicts between these layers can slow requests or, in some cases, cause downtime.
These mismatches happen for several reasons:
- Competing goals: Major cloud providers build storage to handle many use cases at once, but that broad design isn’t optimized for any one workload. Compute jobs, in particular, demand consistent speed. The result is a mismatch: infrastructure built for broad efficiency can struggle to deliver reliable performance when applications scale in production, or when AI pipelines push storage and compute simultaneously.
- Complex rules: In big cloud provider environments, storage doesn’t operate in isolation. Access controls, security policies, and service dependencies pile up across layers, and they don’t always work in sync. A permission, routing choice, or automation can create unexpected bottlenecks when combined with other rules.
- Network constraints: High egress and cross-region transfer fees discourage data from moving freely between services or locations. Teams may delay or limit transfers to avoid unexpected costs, but that hesitation creates bottlenecks when workloads need to pull data across clouds or regions.
Together, these issues create hidden instability. Performance that seems fine in testing can falter in production as heavier workloads expose bottlenecks and small delays ripple through applications.
Specialized storage removes this uncertainty by eliminating the hidden conflicts that come from tightly coupled, general-purpose systems. With reliable, low-latency access that stays steady even under production load, teams don’t have to scramble to fix surprises mid-release.
It’s time to rethink the storage layer
You don’t need to rip and replace your entire cloud strategy to get better performance. You just need to be strategic about which layers serve which purposes.
For cloud-native developers, that means choosing storage that keeps pace with your workflows, so you can move fast, stay in flow, and focus on code instead of configuration.
Backblaze B2 was built with developers in mind:
- Always-hot access to every object.
- S3-compatible APIs that work with your existing tools.
- Enterprise-grade reliability with the best price to performance in the industry.
Because it plugs directly into the tools you already use, you can add Backblaze B2 to your stack without rewriting workflows or retraining teams. Instead of working around storage, you finally get storage that works with you.
Tired of babysitting your storage or coding around its quirks? There’s a better way. Explore how Backblaze B2 fits into your cloud-native stack, and how much faster things can move when builds run without bottlenecks, performance stays consistent, and new features ship without delay.
The post Why Cloud-Native Developers Need a Specialized Storage Layer appeared first on Backblaze Blog | Cloud Storage & Cloud Backup