Post Syndicated from xkcd.com original https://xkcd.com/3143/

Post Syndicated from xkcd.com original https://xkcd.com/3143/
Post Syndicated from Crosstalk Solutions original https://www.youtube.com/shorts/17Gd_ZczFqg
Post Syndicated from Harsh Bansal original https://aws.amazon.com/blogs/big-data/get-started-with-amazon-opensearch-service-t-shirt-size-your-domain-for-log-analytics/
When you’re spinning up your Amazon OpenSearch Service domain, you need to figure out the storage, instance types, and instance count; decide the sharding strategies and whether to use a cluster manager; and enable zone awareness. Generally, we consider storage as a guideline for determining instance count, but not other parameters. In this post, we offer some recommendations based on T-shirt sizing for log analytics workloads.
When you use OpenSearch Service for your streaming workloads, you send data from one or more sources into OpenSearch Service. OpenSearch Service indexes your data in an index that you define.
Log data naturally follows a time series pattern, and therefore a time-based indexing strategy (daily or weekly indexes) is recommended. For efficient management of log data, you must implement time-based index patterns and set retention periods. You further define time slicing and a retention period for the data to manage its lifecycle in your domain.
For illustration, consider that you have a data source producing a continuous stream of log data, and you’ve configured a daily rolling index and set a retention period of 3 days. As the logs arrive, OpenSearch Service creates an index per day with names like stream1_2025.05.21, stream1_2025.05.22, and so on. The prefix stream1_* is what we call an index pattern, a naming convention that helps group-related indexes.
The following diagram shows three primary shards for each daily index. These shards are deployed across three OpenSearch Service data instances, with one replica for each primary shard. (For simplicity, the diagram doesn’t show that primary and replica shards are always placed on different instances for fault tolerance.)
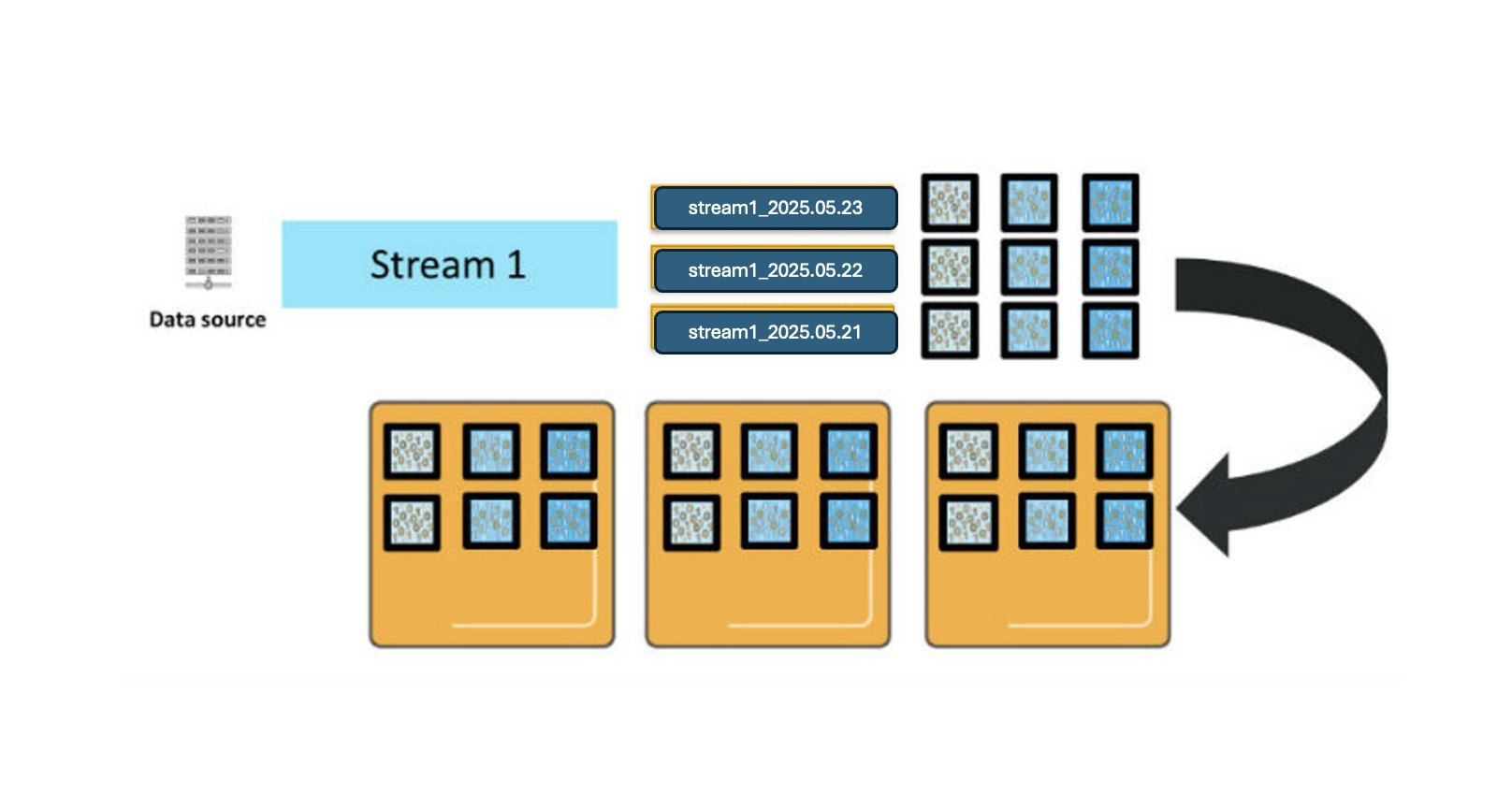
When OpenSearch Service processes new log entries, they are sent to all relevant primary shards and their replicas in the active index, which in this example is only today’s index due to the daily index configuration.
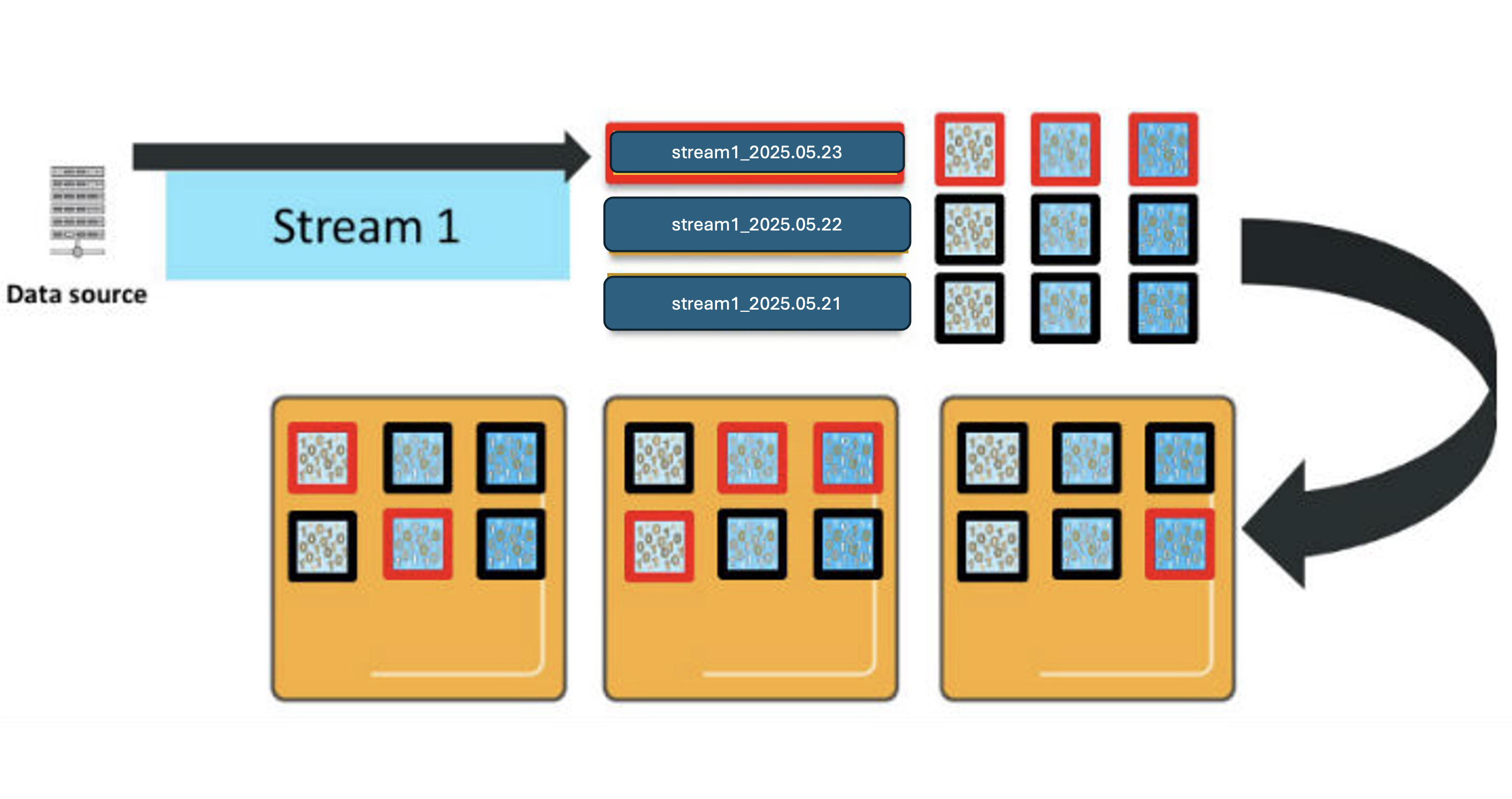
There are several important characteristics of how OpenSearch Service processes your new entries:
_bulk request.Similarly, OpenSearch Service distributes queries across the shards for the indexes involved. If you query this index pattern across all 3 days, you will engage 9 shards, and need 9 vCPUs to process the request.
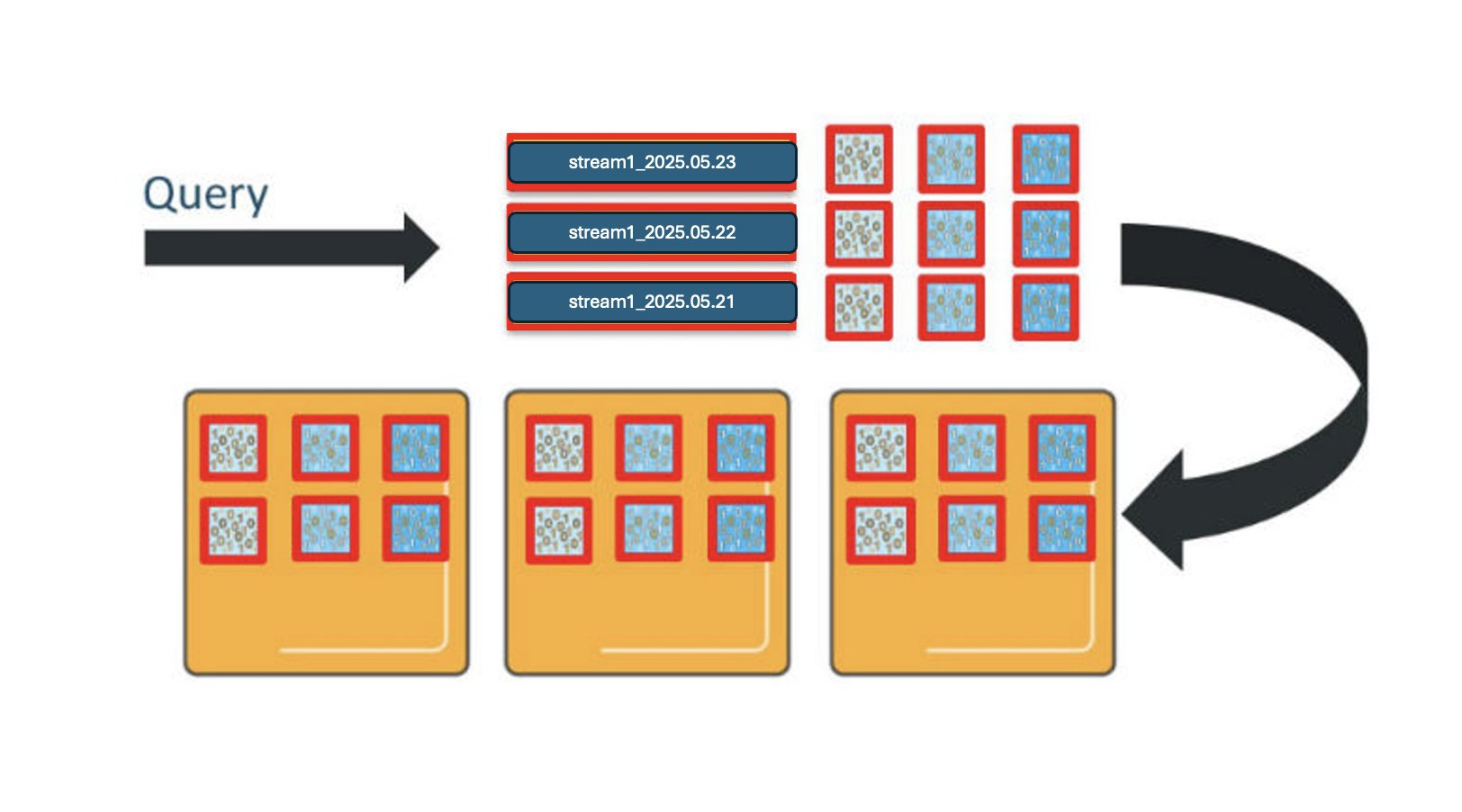
This will get even more complicated when you add in more data streams and index patterns. For each additional data stream or index pattern, you deploy shards for each of the daily indexes and use vCPUs to process requests in proportion to the shards deployed, as shown in the preceding diagram. When you make concurrent requests to more than one index, each shard for all the indexes involved must process those requests.
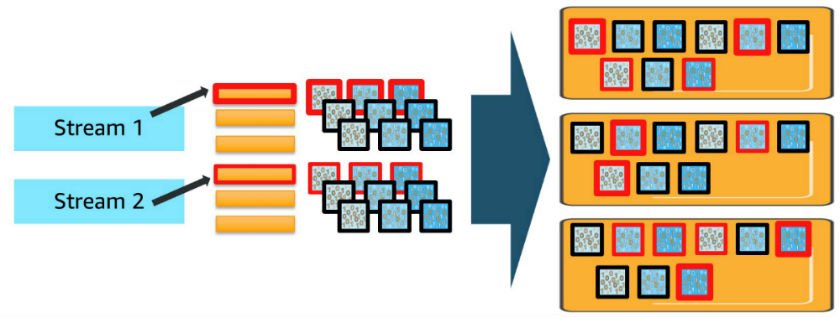
As the number of index patterns and concurrent requests increases, you can quickly overwhelm the cluster’s resources. OpenSearch Service includes internal queues that buffer requests and mitigate this concurrency demand. You can monitor these queues using the _cat/thread_pool API, which shows queue depths and helps you understand when your cluster is approaching capacity limits.
Another complicating dimension is that the time to process your updates and queries depends on the contents of the updates and queries. As requests come in, the queues are filling at the rate you are sending them. They are draining at a rate that is governed by the available vCPUs, the time they take on each request, and the processing time for that request. You can interleave more requests if those requests clear in a millisecond than if they clear in a second. You can use the _nodes/stats OpenSearch API to monitor average load on your CPUs. For more information about the query phases, refer to A query, or There and Back Again on the OpenSearch blog.
If you see the queue depths increasing, you are moving into a “warning” area, where the cluster is handling load. But if you continue, you can start to exceed the available queues and must scale to add more CPUs. If you start to see load increasing, which is correlated with queue depth increasing, you are also in a “warning” area and should consider scaling.
For sizing a domain, consider the following steps:
Let’s look at an example for domain sizing. The initial requirements are as follows:

We make the following instance calculation.
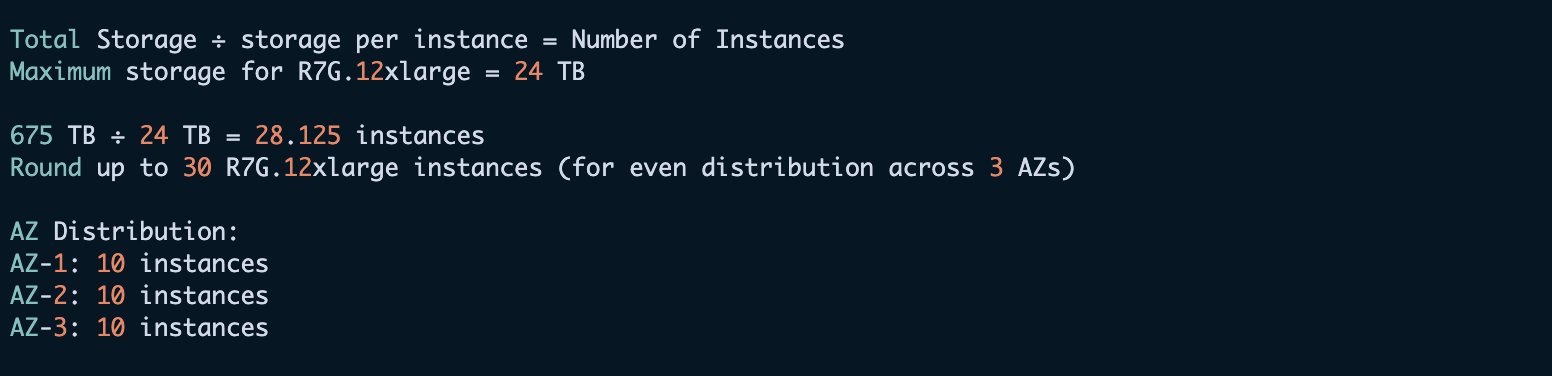
The following table recommends instances, amount of source data, storage needed for 7 days of retention, and active shards based on the preceding guidelines.
| T-Shirt Size | Data (Per Day) | Storage Needed (with 7 days Retention) | Active Shards | Data Nodes | Primary Nodes |
| XSmall | 10 GB | 175 GB | 2 @ 50 GB | 3 * r7g.large. search | 3 * m7g.large. search |
| Small | 100 GB | 1.75 TB | 6 @ 50 GB | 3 * r7g.xlarge. search | 3 * m7g.large. search |
| Medium | 500 GB | 8.75 TB | 30 @ 50 GB | 6 * r7g.2xlarge.search | 3 * m7g.large. search |
| Large | 1 TB | 17.5 TB | 60 @ 50 GB | 6 * r7g.4xlarge.search | 3 * m7g.large. search |
| XLarge | 10 TB | 175 TB | 600 @ 50 GB | 30 * i4g.8xlarge | 3 * m7g.2xlarge.search |
| XXL | 80 TB | 1.4 PB | 2400 @ 50 GB | 87 * I4g.16xlarge | 3 * m7g.4xlarge.search |
As with all sizing recommendations, these guidelines represent a starting point and are based on assumptions. Your workload will differ, and so your actual needs will differ from these recommendations. Make sure to deploy, monitor, and adjust your configuration as needed.
For T-shirt sizing the workloads, an extra-small use case encompasses 10 GB or less of data per day from a single data stream to a single index pattern. A small use case falls between 10–100 GB per day of data, a medium use case between 100–500 GB of data, and so on. Default instance count per domain is 80 for most of the instance family. Refer to the “Amazon OpenSearch Service quotas “ for details.
Additionally, consider the following best practices:
This post provided comprehensive guidelines for sizing your OpenSearch Service domain for log analytic workloads, covering several critical aspects. These recommendations serve as a solid starting point, but each workload has unique characteristics. For optimal performance, consider implementing additional optimizations like data tiering and storage tiers. Evaluate cost-saving options such as reserved instances, and scale your deployment based on actual performance metrics and queue depths.By following these guidelines and actively monitoring your deployment, you can build a well-performing OpenSearch Service domain that meets your log analytics needs while maintaining efficiency and cost-effectiveness.
Post Syndicated from Hari Ramesh original https://aws.amazon.com/blogs/big-data/amazon-sagemaker-introduces-amazon-s3-based-shared-storage-for-enhanced-project-collaboration/
AWS recently announced that Amazon SageMaker now offers Amazon Simple Storage Service (Amazon S3) based shared storage as the default project file storage option for new Amazon SageMaker Unified Studio projects. This feature addresses the deprecation of AWS CodeCommit while providing teams with a straightforward and consistent way to collaborate on project files across the integrated development tools in SageMaker.
This new Amazon S3 storage option provides the following benefits:
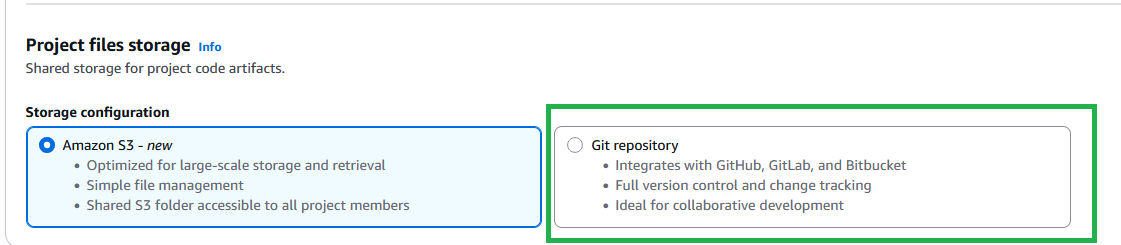
Although Amazon S3 is the default option for file storage, you can also use Git version control for more robust source control capabilities.
In this post, we discuss this new feature and how to get started using Amazon S3 shared storage in SageMaker Unified Studio.
When you create a new SageMaker Unified Studio domain, the service automatically configures Amazon S3 storage as your default project storage option. Each project receives a dedicated shared location in Amazon S3, accessible to project members, following the structure [bucket]./[domain-id]/[project-id]/shared/
SageMaker tools JupyterLab and Code Editor provide the following to users:
shared folder containing the project’s Amazon S3 shared storageThe shared storage is accessible across SageMaker integrated development tools:
Files saved to the shared location are immediately visible and available to project members. Users can continue working with personal files in their EBS volumes in tools like JupyterLab and Code Editor and explicitly move files to shared storage when ready to collaborate.If you want to use Git for collaboration, you can continue to do so by integrating projects with your GitHub version control, GitLab version control, or managed Bitbucket repositories.
For teams currently using Amazon CodeCommit, existing projects will remain fully functional. New projects will default to Amazon S3 storage. If you want to have version control for Amazon S3 based projects, you can enable versioning in Amazon S3 directly.
You will need to complete the following prerequisites before you can follow the instructions in the next section:
To begin using Amazon S3 shared storage, complete the following steps:

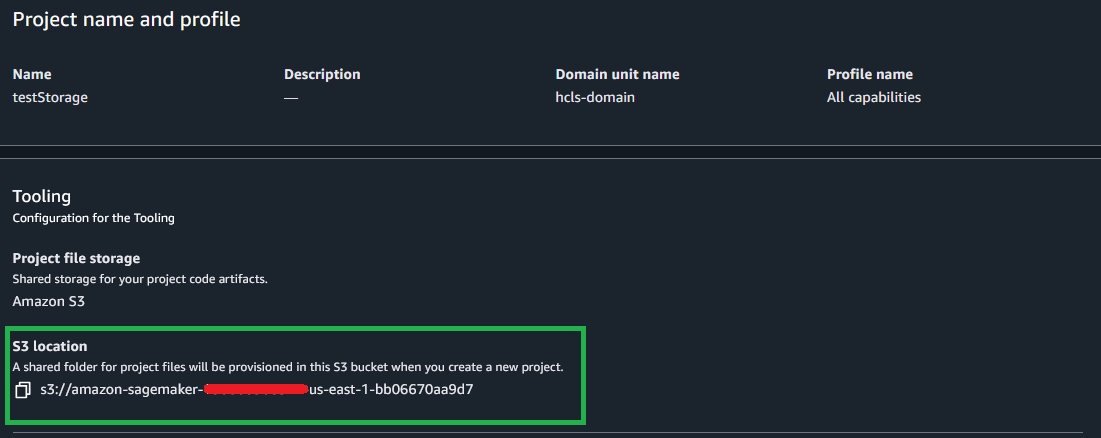

After the project is saved, project users can view the saved notebook in the Project files section under the S3 path [bucket]./[domain-id]/[project-id]/shared/
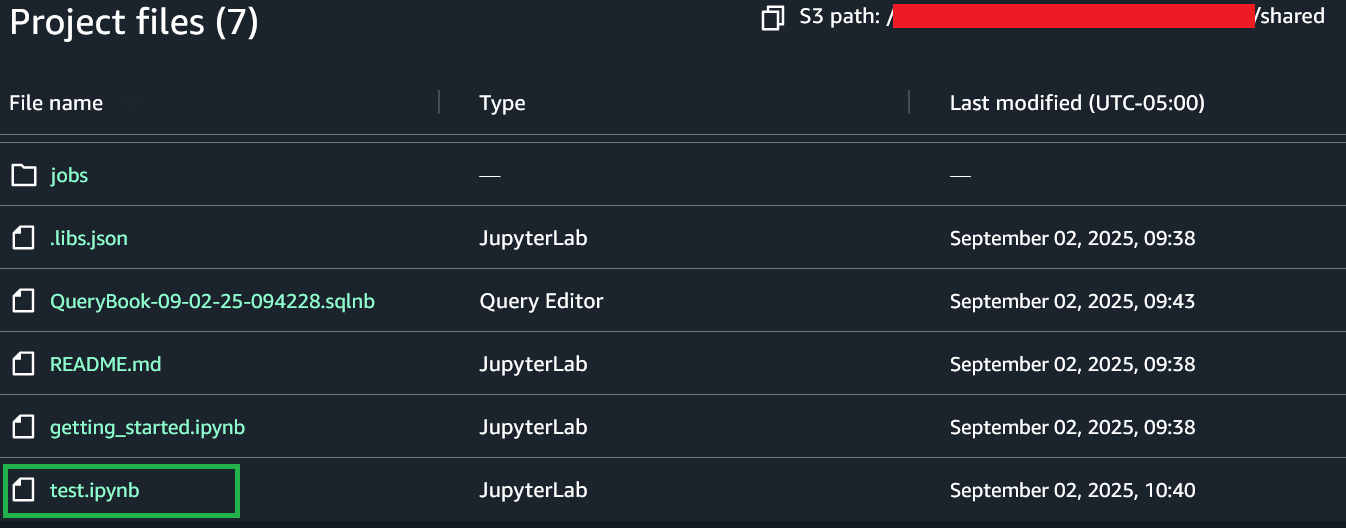
To enable version control using Git, complete the following steps:
To use the shared storage feature in Query Editor, complete the following steps:
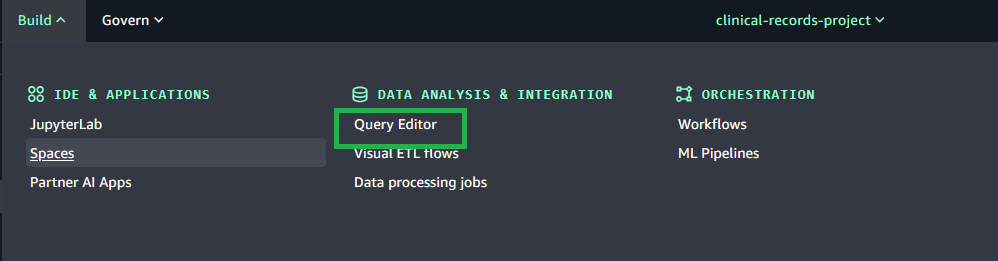
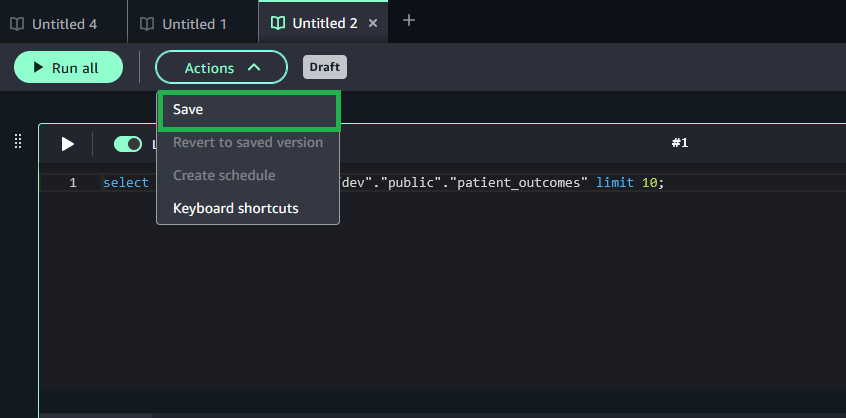
[bucket]/[domain-id]/[project-id]/shared/.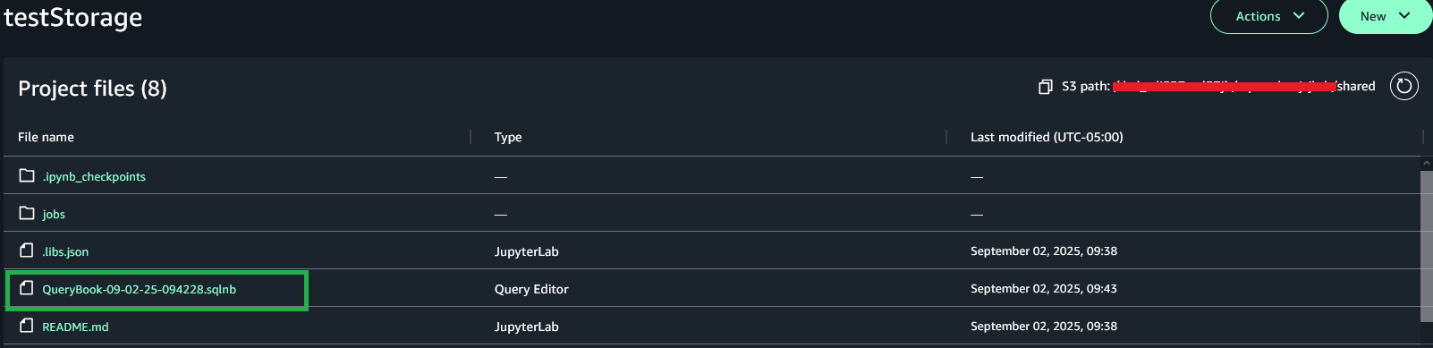
To use the shared storage feature in Visual ETL flows, complete the following steps:


/[domain-id]/[project-id]/shared/jobs/uploads/<ETL name>.
Make sure you remove the SageMaker Unified Studio resources to mitigate any unexpected costs. This involves a few steps:
amazon-datazone-AWSACCOUNTID-AWSREGION-DOMAINIDThe launch of Amazon S3 shared storage in SageMaker represents another step in simplifying the analytics and machine learning (ML) development experience for our customers. By reducing the complexity of Git operations while maintaining robust collaboration capabilities, teams can now focus on building and deploying analytics and ML solutions faster. The feature is now available in Regions where SageMaker is available.
For detailed information about this feature, including setup instructions and best practices, refer to Unified storage in Amazon SageMaker Unified Studio. Share your feedback on this feature in the comments section.
Post Syndicated from Ruy Cavalcanti original https://aws.amazon.com/blogs/security/multi-region-keys-a-new-approach-to-key-replication-in-aws-payment-cryptography/
In our previous blog post (Part 1 of our key replication series), Automatically replicate your card payment keys across AWS Regions, we explored an event-driven, serverless architecture using AWS PrivateLink to securely replicate card payment keys across AWS Regions. That solution demonstrated how to build a custom replication framework for payment cryptography keys.
Based on customer feedback requesting a more automated, no-code approach, we’re excited to announce an additional option to this capability with Multi-Region keys for AWS Payment Cryptography in Part 2 of our series.
By using this new feature, you can automatically synchronize payment cryptography keys from a primary Region to other Regions that you select, improving resilience and availability of payment applications. You can also choose between account-level replication or key-level replication, giving more flexibility in how to manage payment keys across Regions.
The new Multi-Region key replication feature for AWS Payment Cryptography offers you flexible control over your key replication strategy through the following primary capabilities:
Multi-Region keys help deliver several benefits for global payment operations, including:
Payment Cryptography provides two distinct methods for configuring Multi-Region key replication, giving flexibility to implement a strategy that best fits your organization’s needs. You can choose between a broad, account-level approach or a more granular, key-level method.
With account-level configuration, AWS automatically replicates exportable symmetric keys created in your Payment Cryptography account from your designated primary Region to other Regions you specify. This simplifies key management in multi-Region deployments, provides consistent key availability in the Regions that you specify, and reduces the operational overhead of key management.
To configure account-level replication using the AWS Command Line Interface (AWS CLI), use the new enable-default-key-replication-regions API to set the Regions where AWS will replicate your keys. To remove Regions from your default replication list, use the disable-default-key-replication-regions API.
Note: Only symmetric keys created after the account-level replication is enabled will be replicated.
By using key-level replication, you can achieve more granular control by:
Note: Within each Region, Payment Cryptography maintains redundancy of your keys across multiple Availability Zones for high availability. Multi-Region key replication extends across geographic boundaries, giving you additional resilience against Regional outages while maintaining control over where your keys are stored.
You can specify replication Regions during key creation using the --replication-regions parameter, using the AWS CLI, with the create-key or import-key APIs. For existing keys, you can use the new add-key-replication-regions and remove-key-replication-regions APIs to manage which regions receive your replicated keys.
Important: When you specify replication Regions during key creation, these settings take precedence over default replication Regions configured at the account level.
Figure 1 shows the process when you replicate a key in Payment Cryptography.
MultiRegionKeyType: PRIMARYMultiRegionKeyType: REPLICA and include a reference to the primary Region

Figure 1: Representation of key replication from us-east-1 to us-west-2
The following is an example of creating a card verification key (CVK) in the primary Region (us-east-1) with replication to us-west-2:
The response shows the key being created with replication in progress:
After replication completes, the status updates to SYNCHRONIZED:
You can then access the key in the replica Region (us-west-2) using the same key ID and changing only the Region name:
The response shows the replica key with a reference to the primary Region:
When using multi-Region keys, several important aspects should be considered. Multi-Region key replication supports only symmetric keys with the exportable attribute enabled, and asymmetric keys are not supported. For billing purposes, AWS bills per key per Region, which means replicating to three Regions incurs costs for the primary key plus costs for each key in the replica Regions.
Key aliases and tags require separate management in each Region because they are not part of the replication process. While primary keys support modifications and updates, replica keys are read-only copies that support only cryptographic operations. Modifications must be made to the key in the primary Region, and Payment Cryptography automatically propagates these changes to the replica Regions. Monitor the replication status to confirm successful synchronization of these changes.
The deletion process for multi-Region keys follows specific behavior patterns that are important to understand. When a primary key is scheduled for deletion, associated replica keys are deleted immediately. The primary key enters a pending deletion state with a minimum 3-day waiting period, during which the deletion can be canceled. However, if you restore the primary key by canceling its deletion, you will need to re-enable replication to recreate the replica keys in your desired Regions. After the 3-day waiting period expires, the primary key is permanently deleted and becomes unrecoverable. Note that deleting a replica key affects only that specific Region and does not impact the primary key or other replica keys.
Multi-Region key replication operates with eventual consistency. When creating new keys or making changes to existing keys, these updates might not appear immediately across all Regions. Applications should be designed to handle this eventual consistency model and not assume immediate availability of keys or key changes in replica Regions. If your application requires strong consistency, implement polling mechanisms using the GetKey API to verify that changes have been synchronized before proceeding with key operations.
Payment Cryptography logs API activity through AWS CloudTrail, which now includes new events and attributes specific to Multi-Region key replication.
The service logs a new event type called SynchronizeMultiRegionKey, which appears in primary and replica Regions.
Primary Region events:
Two SynchronizeMultiRegionKey events are logged in the primary Region for each replication Region defined:
One event related to a key export process.
One event related to a key import process.
Replica Region events:
One SynchronizeMultiRegionKey event is logged as an import key process in each replicated Region.
New attributes were included in the service key management APIs. The following are examples of the CreateKey API highlighting the new attributes.
One CreateKey event in the primary Region:
One CreateKey event in a replica Region:
To start using Multi-Region key replication in Payment Cryptography:
The new Multi-Region key replication feature in Payment Cryptography enhances our automatic key replication capabilities, providing improved resilience and simplified management for global payment applications. This feature helps make sure your payment cryptography keys are available when and where you need them, with the flexibility to choose between account-level or key-level replication strategies.
For more information about AWS Payment Cryptography, visit https://aws.amazon.com/payment-cryptography/.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Post Syndicated from Kari Rivas original https://www.backblaze.com/blog/the-truth-about-cloud-security-costs-why-high-costs-dont-always-mean-better-protection/

When evaluating cloud providers, cost is often the most visible factor—but in enterprise IT, information security (InfoSec), and compliance, security is always the first (and likely most important) concern. As a technology leader, you know that determining “acceptable” risk is a moving target, but you’re likely also regularly squeezed by budget pressures and a mandate to contribute to the company’s bottom line.
Taking a chance on providers with lower price tags might feel like too big of a risk—lower-cost providers must be sacrificing something, and all too often, that something is security. Right?
It’s a fair question, but the answer might surprise you. Today, we’re talking about how specialized cloud providers provide surprising value—and even provide security benefits—when compared with traditional, hyperscaler architectures. Let’s talk about what you need to know to evaluate a cloud provider’s security posture.
Join our upcoming session to hear from Backblaze experts Troy Liljedahl, Sr. Director, Solutions Engineering, and Pat Patterson, Chief Technical Evangelist, about the knowledge and features you need to stay ahead of modern threats.
Join us to learn:

In theory, cloud architecture encourages redundancy. But in practice, many companies—even those using multi-cloud strategies—tend to consolidate key services like authentication and orchestration with a single vendor. When that vendor’s services go down, it doesn’t matter that your data is replicated across three availability zones in the same data center. If you can’t log in to access it, your redundancy becomes purely theoretical. This year alone, there have been major outages that had widespread consequences from the likes of Google, IBM cloud, and others.
Specialized cloud providers and multi-cloud strategies provide inherent benefits here.
This means that organizations don’t have to choose between cost efficiency and security—they can and should get both.
Choosing the right cloud provider isn’t just about price, features, or performance—it’s about knowing they can safeguard your data and prove it. Here are key areas to assess:
By using this evaluation framework, IT leaders can look past marketing promises and price tags, focusing on verifiable controls and independent certifications.
Many enterprises assume that higher cloud storage costs from hyperscalers like AWS, Azure, or Google Cloud translate directly into better security. In reality, much of that premium is a “hyperscaler tax” driven by complex business models, bundled services, and legacy infrastructure—not inherently superior protection. Specialized cloud providers can often deliver the same enterprise-grade security controls—encryption, compliance certifications, access management—without the inflated price tag, proving that security and affordability are not mutually exclusive.
From the beginning, Backblaze has architected its storage solution to be both performant and cost-effective. And, by specializing in storage (as opposed to the myriad of solutions offered by, say, Amazon Web Services and other hyperscalers), Backblaze is able to optimize for the economics of storage and storage alone.
To help you get past the price tag and into the technical details, let’s break down the pillars of Backblaze B2 security and compliance.
Want a quick glance on how Backblaze compares to other cloud storage providers on key security and compliance elements? Check out our comparison matrices.
Our security starts with our physical infrastructure. Our data centers are designed for 11 nines of data durability and are staffed 24/7/365. They feature:
This physical and architectural security is the bedrock of our service, and it’s backed by industry-standard certifications like SOC 2 Type 2 certification.
Data security is a core tenet of our platform. From the moment your data leaves your system until it is stored on our pods, it is protected by multiple layers of encryption.
Controlling who can access your data is paramount. We provide granular, enterprise-grade access management controls that give you full command over your storage:
Security is not just a feature; it’s a commitment that’s verified by independent third parties. Backblaze has achieved a number of security and compliance attestations, including:
While some competitors may also offer these certifications, Backblaze’s pricing model is built to ensure you don’t have to pay a premium for them. Our efficiencies mean that we can pass the savings directly to you without compromising on the security and compliance that your business demands.
In the end, our goal is to free you from the false choice between security and affordability. The reality is that the high cost of some cloud providers is a result of their complex, multi-tiered business models—not a reflection of superior security. Backblaze’s commitment to building a focused, innovative, and transparent cloud storage solution allows us to deliver on our promise: enterprise-grade security and compliance, at a fraction of the cost.
The post The Truth About Cloud Security Costs: Why High Costs Don’t Always Mean Better Protection appeared first on Backblaze Blog | Cloud Storage & Cloud Backup
Post Syndicated from daroc original https://lwn.net/Articles/1036912/
Safe, ergonomic interoperability between Rust and C/C++ was a popular topic at
RustConf 2025 in Seattle, Washington. Chandler Carruth gave a presentation
about the different approaches to interoperability in Rust and
Carbon, the
experimental “(C++)++” language.
His ultimate conclusion was that
while Rust’s ability to interface with other languages is expanding over time,
it wouldn’t offer a complete solution to C++ interoperability anytime soon — and so there is room for
Carbon to take a different approach to incrementally upgrading existing C++ projects.
His
slides are available for readers wishing to study his example code in more
detail.
Post Syndicated from BeardedTinker original https://www.youtube.com/shorts/2M9bYP57OiQ
Post Syndicated from corbet original https://lwn.net/Articles/1038345/
Version
143.0 of the Firefox browser has been released. Changes include the
ability to pin tabs by dragging them to the edge, previews in the camera
permissions dialog, improved fingerprinting protection, and (optional)
automatic deletion of files downloaded in private browsing mode.
Post Syndicated from Joseph Goh original https://aws.amazon.com/blogs/security/ospar-2025-report-now-available-with-170-services-in-scope-based-on-the-newly-enhanced-ospar-v2-0-guidelines/
We’re pleased to announce the completion of our annual AWS Outsourced Service Provider’s Audit Report (OSPAR) audit cycle on August 7, 2025, based on the newly enhanced version 2.0 guidelines (OSPAR v2.0). AWS is the first global cloud service provider in Singapore to obtain the report using the new OSPAR v2.0 guidelines.
The Association of Banks in Singapore (ABS) established the Guidelines on Control Objectives and Procedures for Outsourced Service Providers (ABS Guidelines) to provide baseline controls criteria that outsourced service providers (OSPs) operating in Singapore should have in place. ABS enhanced the ABS Guidelines to version 2.0, which OSPs—such as AWS—need to comply with for the audit period commencing on or after January 1, 2025. The enhanced ABS Guidelines integrate key elements from the Monetary Authority of Singapore (MAS) regulatory updates on cyber hygiene, technology risk management, and business continuity management, and include new control domains such as data security, cryptography, software application development and management, and business continuity management.
The 2025 OSPAR certification cycle includes the addition of seven new services in scope, bringing the total number of services in scope to 170 in the AWS Asia Pacific (Singapore) Region. Newly added services in scope include the following:
Successfully completing the OSPAR assessment demonstrates that AWS continues to maintain a robust system of controls to meet these guidelines. This underscores our commitment to fulfill the security expectations for cloud service providers set by the financial services industry in Singapore.Customers can use OSPAR to streamline their due diligence processes, thereby reducing the effort and costs associated with compliance. OSPAR remains a core assurance program for our financial services customers because it is closely aligned with local regulatory requirements from MAS.
You can download the latest OSPAR report from AWS Artifact, a self-service portal for on-demand access to AWS compliance reports. Sign in to AWS Artifact in the AWS Management Console, or learn more at Getting Started with AWS Artifact. The list of services in scope for OSPAR is available in the report, and is also available on the AWS Services in Scope by Compliance Program webpage.
As always, we’re committed to bringing new services into the scope of our OSPAR program based on your architectural and regulatory needs. If you have questions about the OSPAR report, contact your AWS account team.
If you have feedback about this post, submit comments in the Comments section below.
Post Syndicated from Andrew Csizmadia original https://www.raspberrypi.org/blog/join-the-uk-bebras-challenge-2025/

The UK Bebras Challenge, the nation’s largest computing competition, is back! Schools can enter now for this year’s Challenge, which runs from 10 to 21 November.
Last year, more than 467,000 students from across the UK took part, tackling fun and thought-provoking puzzles that introduce key ideas in computational thinking with no extra preparation needed.
Read on to learn how your school can get involved.
The UK Bebras Challenge is a free-to-enter annual challenge that is designed to spark interest in both computational thinking and computer science among students aged 6 to 19. The 45-minute challenge is accessible to everyone, offering age-appropriate but challenging interactive tasks for students at different levels, including a tailored version for students with severe sight impairments.
The tasks are designed to give every student the opportunity to showcase their potential and all participating students receive a certificate. There are also certificates based on performance within school and gold certificates based on national boundaries. With self-marking tasks and no text-based programming required, it’s easy to have your school participate in the UK Bebras Challenge.
This year, each task’s background section is linked to the Ada Computer Science platform. Teachers and students can now explore detailed explanations of the computing concepts behind the Bebras tasks, along with the computational thinking skills students may use to solve them.
“Bebras provides us with incredibly useful insights and conversations about our students who might otherwise have struggled with accessing traditional CS materials. It’s also a great resource for baseline tests where students may not have studied the curriculum the way we present it.” – Teacher in the UK
“I think the problems are a really great way to promote critical thinking, computational thinking, and logic in general. I have only seen a couple but I am very impressed and excited to share with some of my students. Thanks for what you are doing.” – Teacher in the UK
The tasks are inspired by classic computing problems and presented in a fun, age-appropriate way. For example, younger students aged 6 to 8 might solve the mystery of a dancing doll, while older students aged 16 to 19 could take on the challenge of an art theft. Both of these tasks involve the use of data structures.
Here’s a question we ran in 2021 for the Juniors group (ages 10 to 12). Can you solve it?
Farmer Mert grows wheat in the fields, which contain a ![]() symbol in the map below.
symbol in the map below.
He also has stony fields where nothing grows, shown by the ![]() symbol.
symbol.
To save water, Mert only wants to water the wheat fields. He can block the water channels coming from the lake at the spots marked with the letters A to J.
The water will only flow downwards towards the fields and will never flow back towards the lake.
Select the letters to block the water from flowing to the empty fields while still letting it flow to the wheat fields.
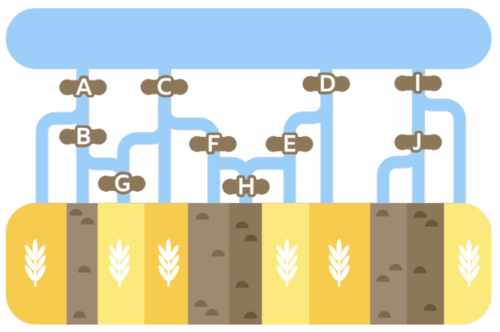
The correct answer is that spots labelled B, F, H, and J must be closed, as shown in the following figure:
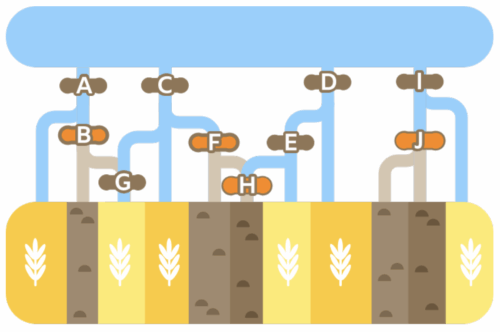
If none of the gates are closed, the water will reach the stony fields. If more gates than shown above are closed, then some wheat fields will get no water. If we review all spots:
This Bebras task was developed by the Bebras team in Turkey and refined by members of the international Bebras community.
Did you get it right?
If you are either a UK school or teach a UK-based curriculum, then visit the UK Bebras website for more information and to register your school.
Once you’ve registered, you’ll get access to the entire UK Bebras back catalogue of questions, allowing you to create custom quizzes for your students to tackle at any time throughout the year. These quizzes are self-marking, and you can download your students’ results to keep track of their progress. The questions are perfect for enrichment activities, end-of-term quizzes, lesson starters, and even full lessons to develop computational thinking skills and promote computing concepts.
Join for free at bebras.uk/admin.
The post Join the UK Bebras Challenge 2025 appeared first on Raspberry Pi Foundation.
Post Syndicated from Crosstalk Solutions original https://www.youtube.com/watch?v=5WbtzyvNKw0
Post Syndicated from corbet original https://lwn.net/Articles/1038326/
The Socket.dev blog describes
this week’s attack on JavaScript packages in the npm repository.
A malicious update to @ctrl/tinycolor (2.2M weekly
downloads) was detected on npm as part of a broader supply chain
attack that impacted more than 40 packages spanning multiple
maintainers.The compromised versions include a function
(NpmModule.updatePackage) that downloads a package
tarball, modifies package.json, injects a local script
(bundle.js), repacks the archive, and republishes it,
enabling automatic trojanization of downstream packages.
Post Syndicated from Боян Юруков original https://yurukov.net/blog/2025/itn-zakonoproekt2/
Миналата седмица писах за законопроект на ИТН, който цели да вдигне възможната височина на строителство в София на места на 125 метра. Законопроектът е едно изречение и въвежда много странно изключение (на изключението) за имоти по Цариградско шосе. Всъщност, става дума за доста конкретни имоти и така формулирано предложението ме накара да се зачудя кои са те. Именно тях показах в предишната си статия. Както обещах, разгледах и останалите из София, макар там височината да се вдига „само“ с 25%.
За подробно описание какво предлага предложението на тримата депутати ще намерите в предишната ми статия. Най-общо обаче текстът, който искат да променят сега позволява 100 метра височина в Смф зоните (в сиво) на 400 метра от метростанции (в зелено) изключвайки централната част и четири района (в червено). Тук съм добавил бъдещите метростанции и съм махнал тези изцяло в изключените райони. Те вдигат 100 на 125 и добавят няколко имота в Младост по Цариградско. Ако ви изглежда крайно специфично, това е защото е. Практическата липса на аргументация, това че тримата депутати нямат нищо общо със София и как е формулиран законопроектът ме накара да се разровя.
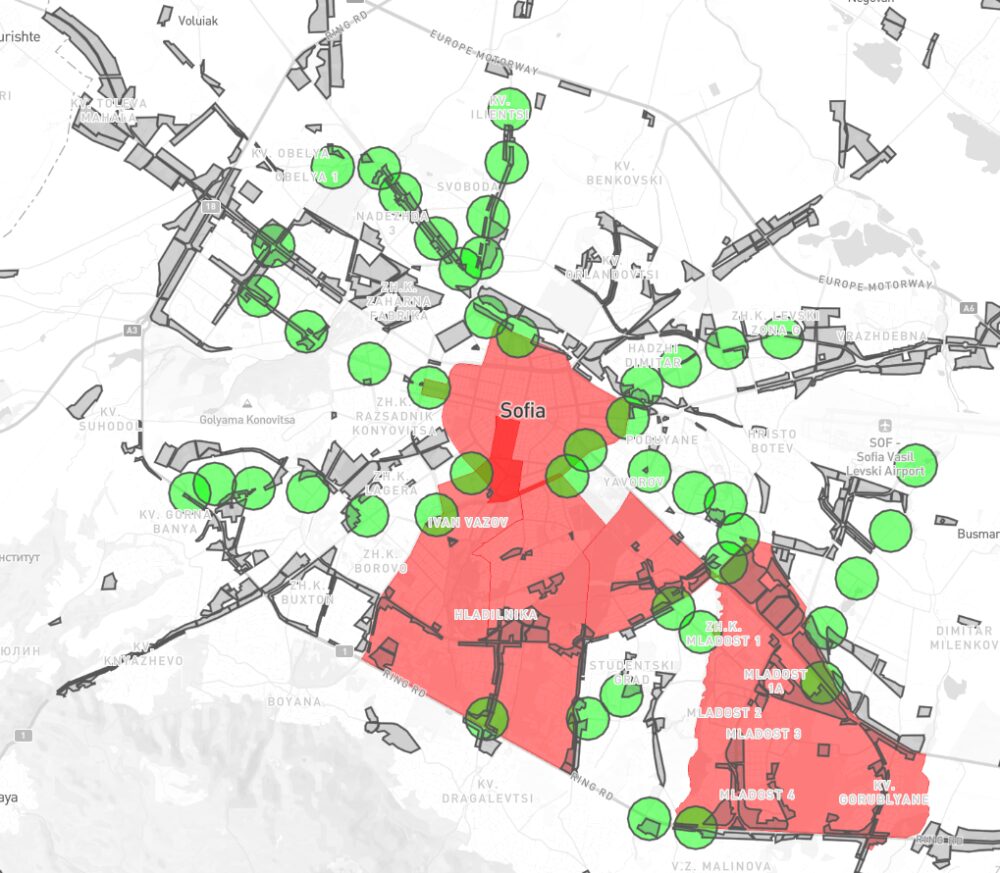
Първо, ще добавя двете карти, които направих. Те са по подобие на другите ми за държавните имоти за продажба от списъка на Желязков и 3D картата на застрояването на София. Те показват имотите отговарящи на горните критерии, които открих. Изключих общинските и държавните имоти, въпреки че, както се разбра, може да бъдат продадени без много шум. Изключих най-малките под 500 кв. макар би могло да се обединят с други по-големи, за да се застоят високо. Махнах метростанциите, около които няма Смф или не намерих имоти. Остават тези на картата. Възможно е да съм пропуснал някои предвид, че данните за собствеността в КАИС и iSofMap не са непременно актуални все още. Ако натиснете върху парцелите ще намерите последните данни за вид и предназначение според КАИС.
Тази карта показва същите данни, но само с парцелите в обемен вид. В някои от откритите парцели вече има построени сгради и повечето надали ще бъдат съборени, за да се възползва някой от новата височина. Тук виждате състоянието на застрояването до преди две години, тъй като тогава последно е 3D заснемането, което използва. Повече за това тук.
Отделно, размерът на имота и съседните има значение, защото има редица други изисквания като отстояние и разгърната площ. Те могат да се преценят при предложен проект, какъвто сега няма или нямам достъп за всеки от тези имоти. Затова маркирам само онези, които са засегнати по този един параметър обсъждан във внесеното предложение.
Може да отворите двете карти на цял екран тук и тук.
Първо, в близост до горната част на Цариградско виждаме голям участък, който попада в хипотезата на този законопроект. Тези имоти се намират точно на границата на район Младост. Този най-вляво промени проекта си поне веднъж, а преди месец беше на комисия в НАГ с други предложения. Вдясно виждаме доста отделни сгради и към настоящия момент някои от празните парцели вече са запълнени. Получих дост сигнали за озеленяването там и колко е бутафорно.

Друг интересен парцел е този до районната община в Слатина. Той също попада в описаните критерии и е още на виза за проектиране. Има проект до 75 метра. Над това, както и при другите такива, трябва гласуване в СОС. Спорно е обаче колко има желание да се спират такива проекти, както и дали няма гласуване за подобни сгради да бъде из търгувано за подкрепа за други проекти, в парламента или просто за асансьори. Виждали сме и от трите. Не бих могъл да твърдя такова нещо за конкретния парцел. Давам просто пример за такава възможност след промените. Докато за 8 етажа повече може би не биха се занимавали, за 16 или 50 метра отгоре – биха.
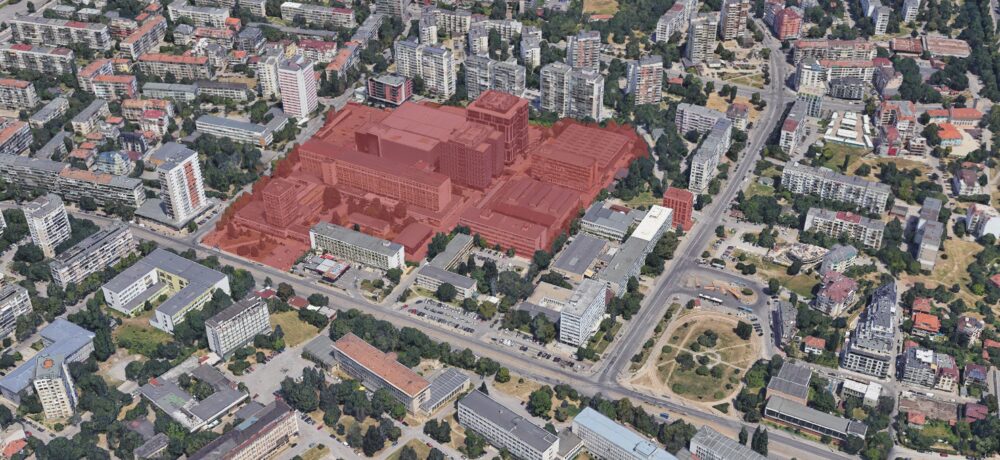
Следващите имоти са малки, но показателни. Един от тях се вижда вече застроен – NV Tower. При нея имаше един интересен казус преди години – осветяваше целия квартал като дискотека нощем. После се оказа, че според отговор на ДНСК артистичното осветление беше незаконно и спряха. Съседният парцел е изцяло жилищна сграда в Смф (уж смесен) имот. Питайте Здравков защо. До тях се виждат няколко частни имота, които са отредени към този момент за многоетажен гараж. Попадат в хипотезата за 125 метра небостъргачи и предвид местоположението изглежда отстоянията им ще достатъчни.
На това кръстовище се вижда метростанцията Г.М. Димитров и това показва ключов проблем с този законопроект. Интересен факт тук е, че сградата отсреща на обсъжданите парцели е построена от инвеститорска компания с едноименна поправка предшестваща и наподобяваща обсъждания законопроект. Живущи в сградата на горни етажи се оплакват отдавна от неприятни вибрации и клатене когато минава метрото. При това говорим са само 50 метрова сграда. Този ефект ще е значително по-голям при по-високо строителство. От това следва, че би трябвало да се намалява етажността, а не да се уличава. Имало е, разбира се, ограничения за т.н. „вибрационна зона“ около метрото, както и изисквания за луфтове и конкретни елементи. За съжаление, според архитекти, доста от тези са отпаднали незнайно как в голяма част от града. Резултатът е видим, както казваше един партиен лозунг.

Продължаваме на юг с незастроени парцели до Студентски парк и Симеоновско шосе. Отново – на границата на районите с ограничения. Някои от тях са застроени, а други се подготвят за това и нямат започната процедура. Тук е полезно да се отбележи скандалната кула, която ще бъде забучена по очертанията на парцела на автокъщата в Студентски парк. Изискванията по ЗУТ и ЗУЗСО са специфично направени, за да са възможни такива опасни неща. А са опасни, защото тази отсечка от пътя е навярно най-опасната в Студентски град. Затова ще бъде отрязано още от парка, за да се направи нов булевард – специално за тази 60 метрова сграда. Очакваме същото за други подобни засегнати от този законопроект, независимо, че вносителите настояват, че промените им не пречат и не засягат никого и няма да има допълнителна тежест или разходи за общината.
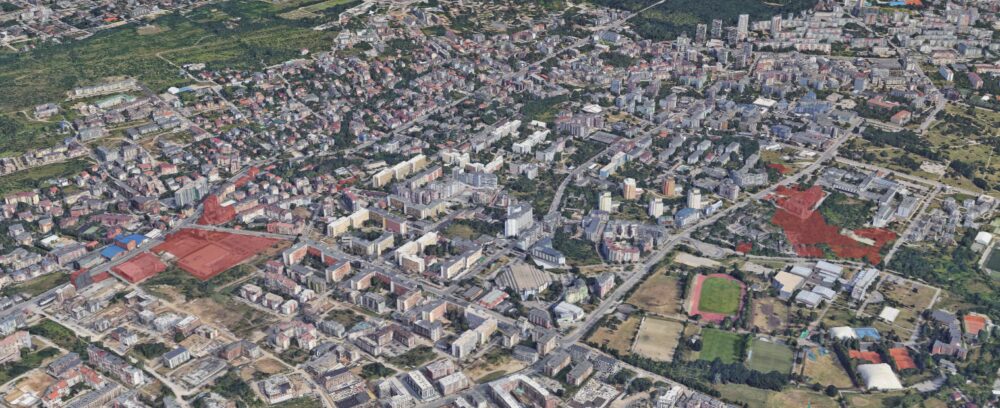
Доколкото Черни връх е изключен от списъка, там има други проблеми, включително 215 метровата кула и стената от сгради по горната част от булеварда, някои от които според главния архитект незаконно са настроили етажи, но това е било прието от Здравков и ДНСК. Има обаче няколко парцела от другата страна, където сега има складове и един магазин Фантастико. Някой ден някой може да реши да инвестира там и тази промяна ги засяга.

На запад из Овча купел има няколко парцела, но ще обърна внимание на тези по булевард Цар Борис. Някои са застроени, а други – не. Това ще стане възможно с планираните спирки на метрото стигащи Южната дъга.
В северната част на София има доста имоти, особено до Надежда в индустриалните части. Правят впечатление обаче имотите до и зад гарата. Особени тези от северната част на линията. Там вече има застроени масивни комплекси, но ще има още много. Отстоянията няма да са им проблем и отново ще могат да стигнат 125 метра с малко машинации в СОС.

Новото метро донася този проблем този проблем и в квартал Левски. Някои от отбелязаните парцели са вече застроени, други не са и дори нямат виза за проектиране.
Утре, 17-ти септември ще има обсъждане на законопроектът в комисия в парламента. Един от вносителите в заместник председател на ИТН в тази комисия. С липсата на аргументи на този проект не виждам как може да мине. В сегашната политическа среда и изтъргуване на лобистки поправки срещу подкрепа за други гласувания – като вето на недоверие – не изключвам да мине през гласуването доста бързо и необезпокоявано.
Ще следим какво ще се случи на комисията утре. Би трябвало да се излъчва на живо и ще разберем дали ще бъдат изнесени някакви аргументи и обяснена липсата на такива към законопроекта или ще бъде задушена всякаква дискусия и критика по темата.
The post Кого конкретно обслужва законопроектът на ИТН в останалата част на София? first appeared on Блогът на Юруков.
Post Syndicated from digiblur DIY original https://www.youtube.com/shorts/i0KKG9Fc1mw
Post Syndicated from corbet original https://lwn.net/Articles/1038325/
Security updates have been issued by AlmaLinux (kernel and kernel-rt), Debian (node-sha.js and python-django), Fedora (chromium, cups, exiv2, perl-Catalyst-Authentication-Credential-HTTP, perl-Catalyst-Plugin-Session, perl-Plack-Middleware-Session, and qemu), Red Hat (container-tools:rhel8, podman, and udisks2), SUSE (cargo-audit, cargo-c, cargo-packaging, and kernel-devel), and Ubuntu (libcpanel-json-xs-perl, libjson-xs-perl, rubygems, sqlite3, and vim).
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=nC6lU_OJeBY
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2025/09/microsoft-still-uses-rc4.html
Senator Ron Wyden has asked the Federal Trade Commission to investigate Microsoft over its continued use of the RC4 encryption algorithm. The letter talks about a hacker technique called Kerberoasting, that exploits the Kerberos authentication system.
Post Syndicated from Patrik Uytterhoeven original https://blog.zabbix.com/building-ha-zabbix-with-postgresql-and-patroni/30960/

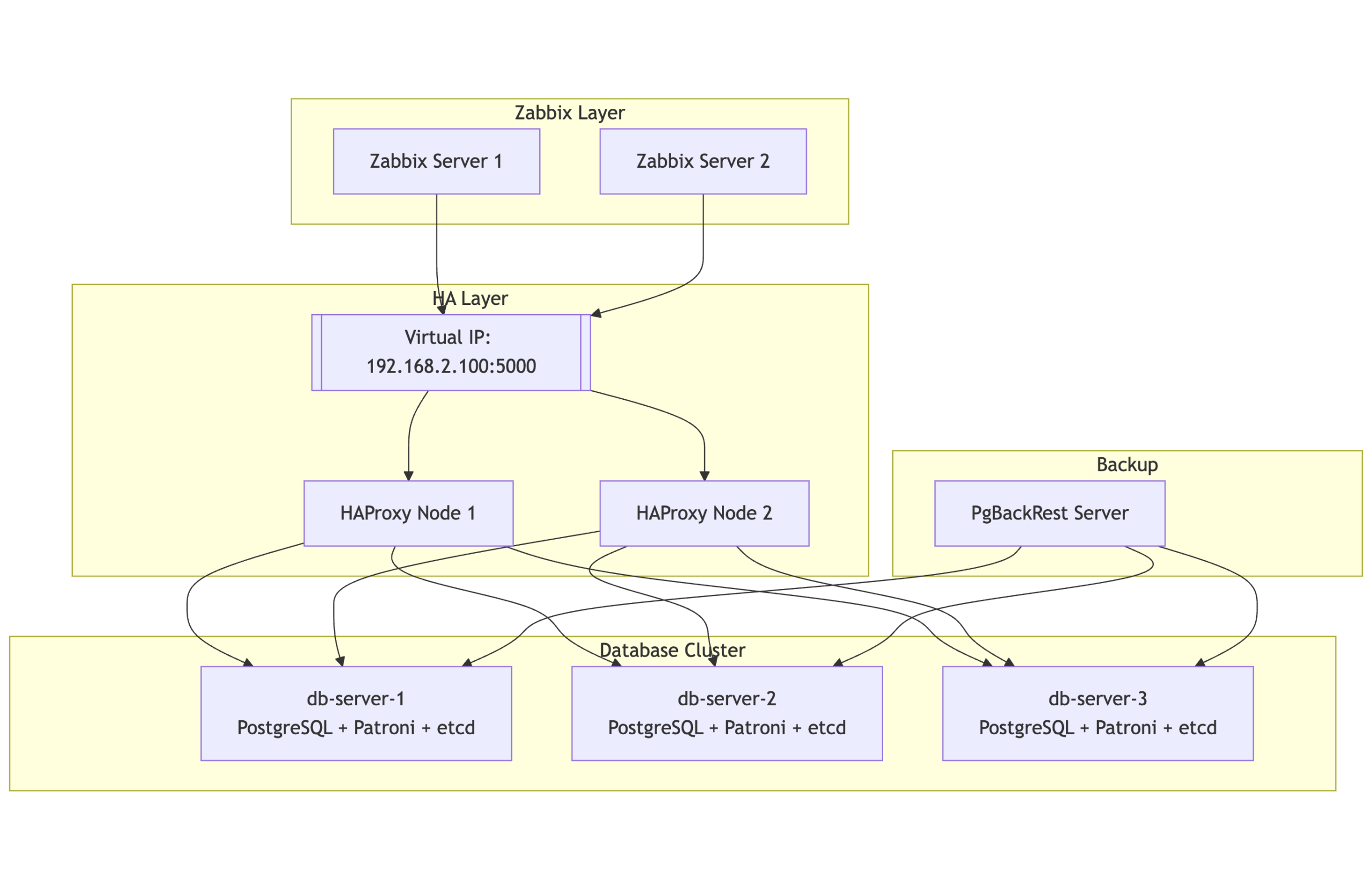
Running a monitoring platform like Zabbix in a production environment demands reliability and resilience. When your monitoring solution is down, you’re flying blind – and for many organizations, that simply isn’t acceptable. This post introduces a robust high-availability (HA) architecture for Zabbix, using PostgreSQL, Patroni, etcd, HAProxy, keepalived and PgBackRest. Built on RHEL 9 or derrivates, this solution combines modern open-source tools to provide automatic failover, load balancing, and seamless monitoring, all while maintaining consistency and performance.
The HA design consists of multiple layers working in tandem to maintain continuity even during node or service failures:
Database Cluster Layer
2 or more nodes form the PostgreSQL cluster, managed by Patroni and coordinated using etcd. At any given time, one node is the primary (read/write), and the others are hot standbys ready to take over automatically.
etcd runs on the same nodes and acts as the distributed configuration store and coordination layer for Patroni. It ensures a consistent cluster state and enables safe failover decisions.
Two HAProxy nodes provide a single point of entry for all clients (including Zabbix), routing requests to the current PostgreSQL primary. These nodes are monitored and coordinated via Keepalived to maintain a floating Virtual IP (VIP), ensuring seamless failover at the connection layer.
A separate backup server is responsible for running PgBackRest, which handles full and incremental backups, WAL archiving, and Point-In-Time Recovery (PITR). This server communicates securely with all database nodes over SSH.
Two Zabbix servers, running in active-passive mode, continuously monitor all layers of this stack including the HAProxy health, Patroni cluster role, and etcd status by accessing the PostgreSQL VIP for backend connectivity.
This multi-tiered setup ensures that no single failure be it a database, load balancer, or monitoring server brings down the monitoring platform.
Zabbix depends heavily on its PostgreSQL database backend. Every metric, trigger, event, and alert is stored there. If PostgreSQL becomes unavailable, even briefly, data loss or monitoring blind spots can occur. That’s why introducing HA at the database layer is a crucial step when scaling Zabbix for enterprise environments.
While Zabbix itself supports HA at the application level, this architecture ensures that the database backend is also fully fault-tolerant, using modern consensus-based clustering with automatic failover.
To achieve HA, we bring together several specialized components, each fulfilling a critical role in the system:
The relational database engine used by Zabbix. In this example setup, it runs on three nodes, forming a cluster managed by Patroni.
Patroni is the orchestrator for the PostgreSQL cluster. It monitors node health, manages replication, promotes standbys when needed, and ensures only one writable leader exists at any time. Patroni leverages a distributed consensus store in this case, etcd but other DCS’s are possible to coordinate decisions across the cluster.
etcd is a lightweight and highly available key-value store used by Patroni to maintain the cluster’s state. It stores leader election data, health statuses, and locks. We deploy it as a three-node cluster, co-located with the PostgreSQL nodes for convenience, though this setup can be scaled independently if needed as etcd is very latency prone.
To simplify application connectivity, HAProxy acts as a load balancer in front of the database cluster. It monitors the role of each node using Patroni’s REST API and routes connections to the active primary server. If the leader fails, HAProxy automatically reroutes traffic to the new primary.

Keepalived provides a floating virtual IP address (VIP) across the HAProxy nodes. This VIP allows client systems, such as the Zabbix frontend, to connect to a single stable IP even if one HAProxy node fails.
To protect the data itself, we use PgBackRest for full and incremental backups, as well as Point-In-Time Recovery (PITR). A dedicated backup server is included to pull and store archive logs and backups securely via SSH.
Finally, we run two Zabbix servers in active-passive mode. Both are configured to connect to the PostgreSQL cluster through the VIP exposed by HAProxy. The Zabbix frontend is deployed on both nodes as well, ensuring continued accessibility through the load-balanced setup.
Here’s a simplified view of the architecture:
All systems are tied together with consistent hostname mappings, time synchronization (Chrony), and service monitoring.
Notes:
Design rationale
This setup prioritizes resilience and self-healing. If any single component fails a database node, a load balancer, or even a monitoring server the system continues to function.
Using Patroni with etcd ensures that failovers are handled automatically, without human intervention. HAProxy ensures client traffic is always routed to the current primary, while Keepalived ensures that this routing layer itself is highly available.
We opted for PgBackRest over simple scripts or base backups because it provides not just efficient incremental backups, but also full WAL archiving and point-in-time recovery, which are invaluable for both disaster recovery and debugging.
Lastly, we chose to integrate Zabbix itself into this HA design, treating it not just as a application but as a fully resilient service able to monitor itself, so to speak.
Conclusion
This architecture provides a solid foundation for running Zabbix in a fault-tolerant, production-ready environment. It not only ensures high availability for the database layer but also offers flexibility, observability, and operational safety.
Whether you’re running internal infrastructure monitoring or offering Zabbix as a managed service, adopting this type of HA setup removes single points of failure and gives you peace of mind — all using open-source technologies that are battle-tested and widely supported.
If you need assistance with the migration or want to ensure best practices for scaling and optimizing Zabbix, don’t hesitate to reach out to OICTS. We are a Zabbix Premium Partner operating globally, with offices in the USA, UK, Netherlands, and Belgium, and we’re ready to help you every step of the way.
The post Building HA Zabbix with PostgreSQL and Patroni appeared first on Zabbix Blog.
Post Syndicated from Grab Tech original https://engineering.grab.com/taming-monorepo-beast
At Grab, our engineering teams rely on a massive Go monorepo that serves as the backbone for a large portion of our backend services. This repository has been our development foundation for over a decade, but age brought complexity, and size brought sluggishness. What was once a source of unified code became a bottleneck that was slowing down our developers and straining our infrastructure.
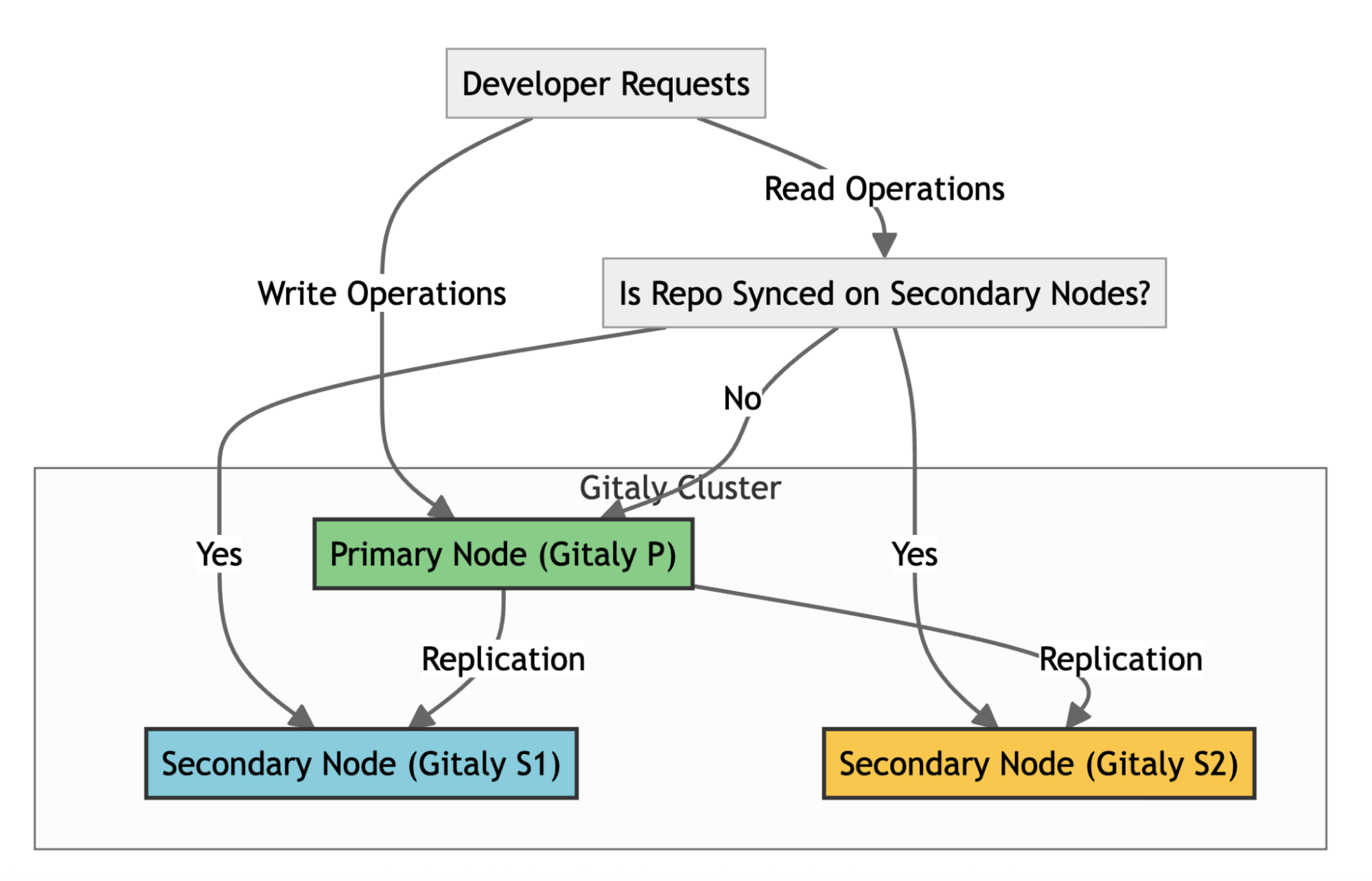
To understand our core problem, it’s helpful to know how GitLab handles repositories at scale. GitLab uses Gitaly, its Git RPC service, to manage all Git operations. In a high-availability setup like ours, we use a Gitaly Cluster with multiple nodes.
Here’s how it works:
Our Go monorepo started as a simple repository 11 years ago but ballooned as Grab grew. A Git analysis using the git-sizer utility in early 2025 revealed the shocking scale:
This massive size wasn’t just a number—it was crippling our daily operations.
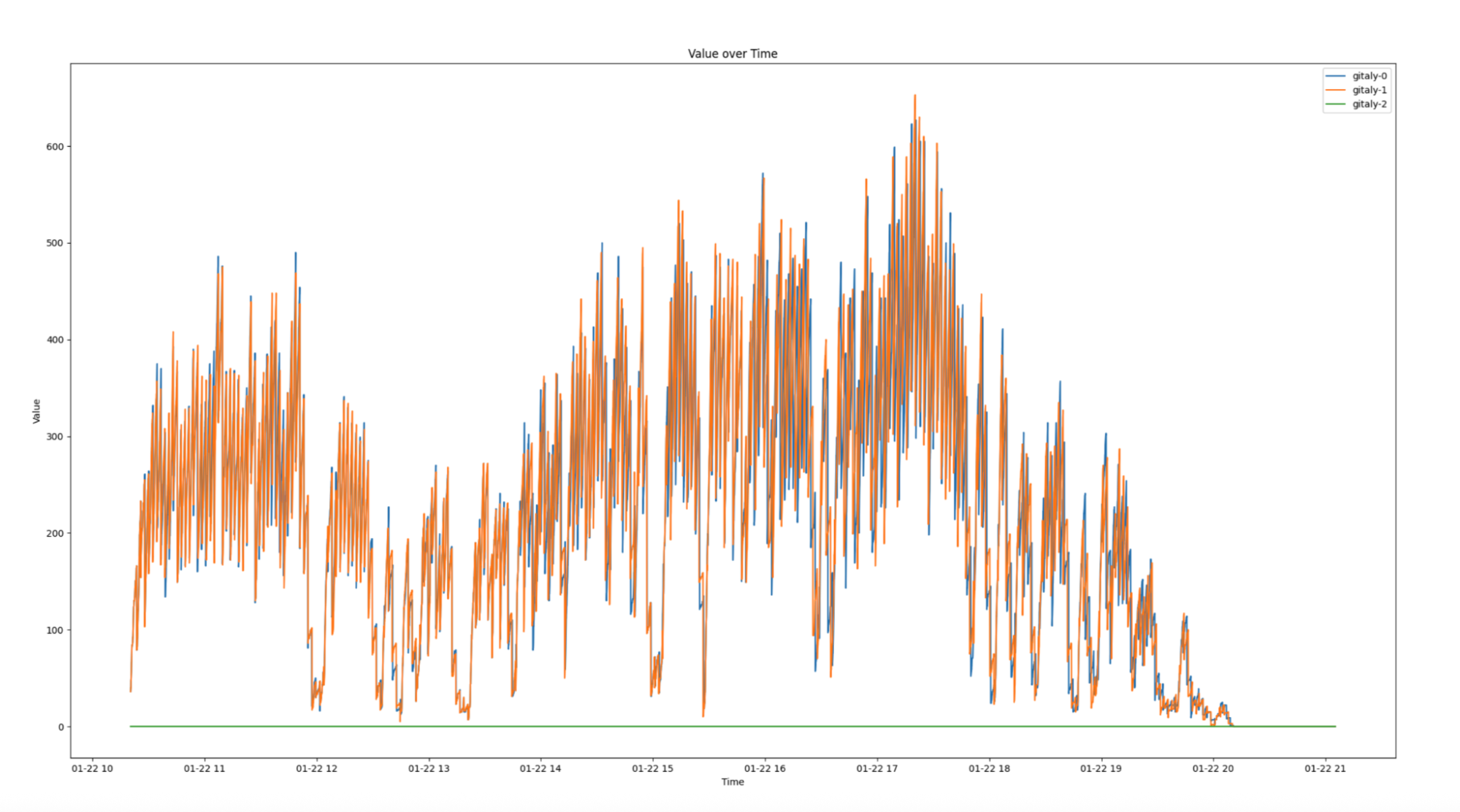
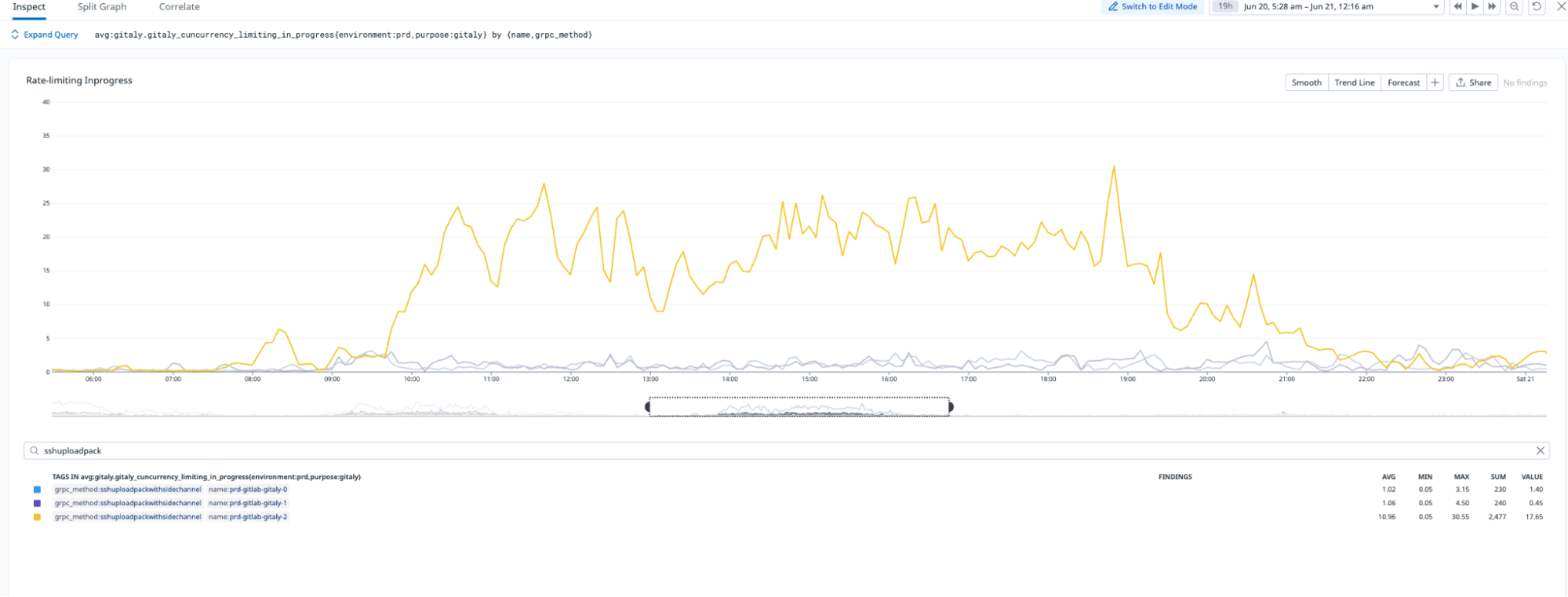
In high-availability setups, replication is critical for distributing workloads and ensuring system reliability. However, when replication delays occur, they can severely impact infrastructure performance and create bottlenecks. Figure 2 illustrates replication delays of up to four minutes which caused both secondary nodes, Gitaly S1 (orange) and Gitaly S2 (blue), to lag behind the primary node, Gitaly P (green). As a result, all requests were routed exclusively to the primary node, creating significant performance challenges.
The key issues here are:
The growing size of the monorepo directly impacted developer workflows:
The repository’s scale introduced significant operational hurdles:
All these factors were dragging down developer productivity. It was clear that continuing to let the monorepo grow unchecked wasn’t sustainable. We needed to make the repository leaner and faster, without losing the important history that teams relied on.
Before making any changes, we needed to answer a critical question: “Would trimming repository history solve our replication issues?” Without proof, committing to such a major change felt risky. So we set out to test the idea.
The test setup:
We designed a simple experiment. In our staging environment, we created two repositories:
Both repositories contained the same number of files and directories. We then simulated production-like load on both of the repositories.
The results:
This was nearly a 100x improvement in replication performance.
This proof of concept gave us confidence that history trimming was the right approach and provided baseline performance expectations.
Initially, we wanted to keep commits from the last 1-2 years and archive everything else, as this seemed like a reasonable balance between recent history and size reduction. However, when we developed our custom migration script, we discovered it could only process 100 commits per hour, approximately 2,400 commits per day. With millions of commits in the original repository, even keeping 1-2 years of history would take months.
git gc, git reflog expire) to prevent local disk and memory exhaustion.The bottleneck wasn’t just the number of commits, it was the 10-minute cleanup process.
Additional constraints discovered:
As we dug deeper, we discovered more obstacles.
Given the processing speed constraint of 100 commits per hour, we needed to drastically reduce the number of commits while preserving essential functionality. After careful evaluation, we settled on a tag-based approach combined with recent history.
What we decided to keep:
Why this approach worked:
The trade-off:
We sacrificed deep historical browsing of 1 to 2 years for practical migration feasibility, while ensuring no critical functionality was lost.
The approach: Use Git’s filter-repo tool with git replace --graft to remove commits older than a specified criteria.
Why it failed:
git replace --graft commands to account for various branches and dependencies, significantly complicating the workflow.The approach: Use git rebase --onto to preserve selected commits while pruning unwanted history.
Why it failed:
The approach: Create and apply patches for each commit individually to preserve repository history.
Why it failed:
The breakthrough: A sophisticated custom script that could handle our specific requirements and processing constraints. Unlike traditional Git history rewriting tools, our script implements a two-phase chronological processing approach that efficiently handles large-scale repositories.
Phase 1: Bulk migration
In this phase, the script focuses on reconstructing history based on critical tags.
Then, push the processed batch of 20 commits to the destination repository, with LFS tolerance.
Phase 2: Delta migration
This phase integrates recent commits after the cutoff date.
Then, push the processed batch of commits to the destination repository, with LFS tolerance.
LFS handling
The script incorporates robust mechanisms to handle Git LFS efficiently.
Key features:
With our strategy defined (tags + last month), we executed the migration using our custom script. This process involved careful planning, smart processing techniques, and overcoming technical challenges.
Our custom script employed several key strategies to ensure efficient and reliable migration:
The migration addressed several critical technical hurdles.
The migration was executed in two carefully planned phases.
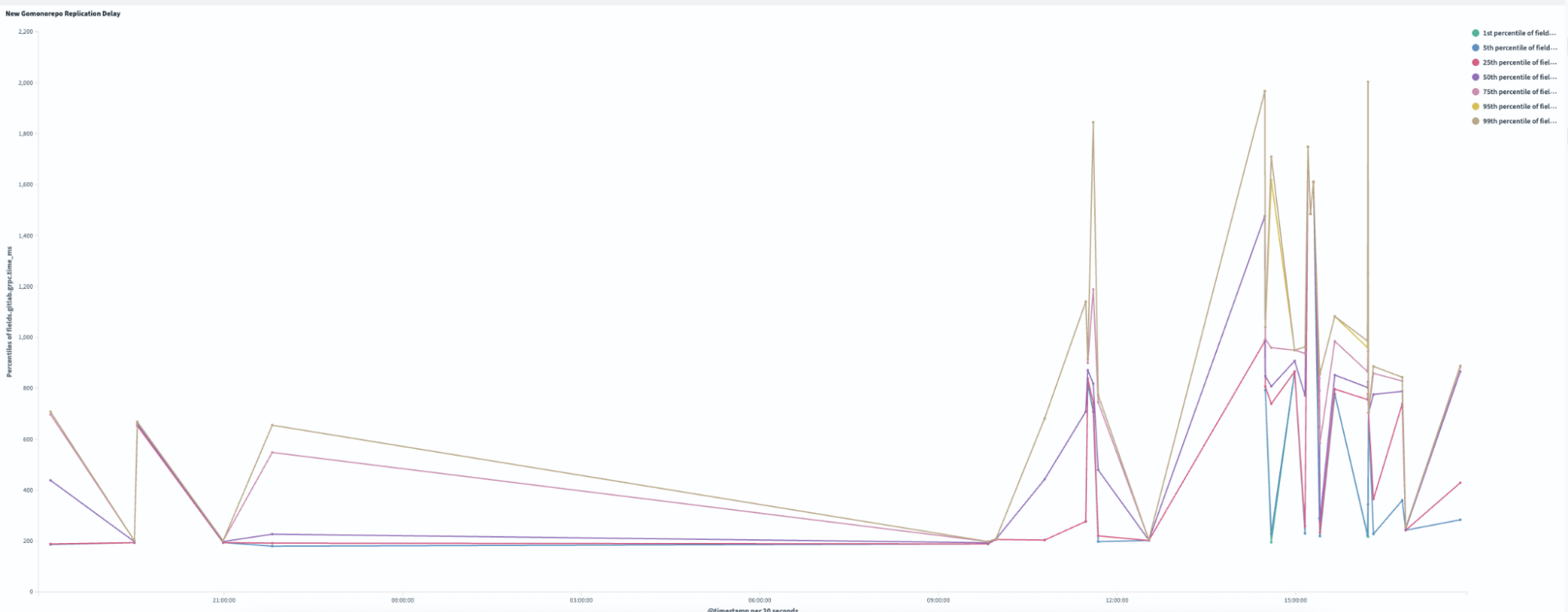
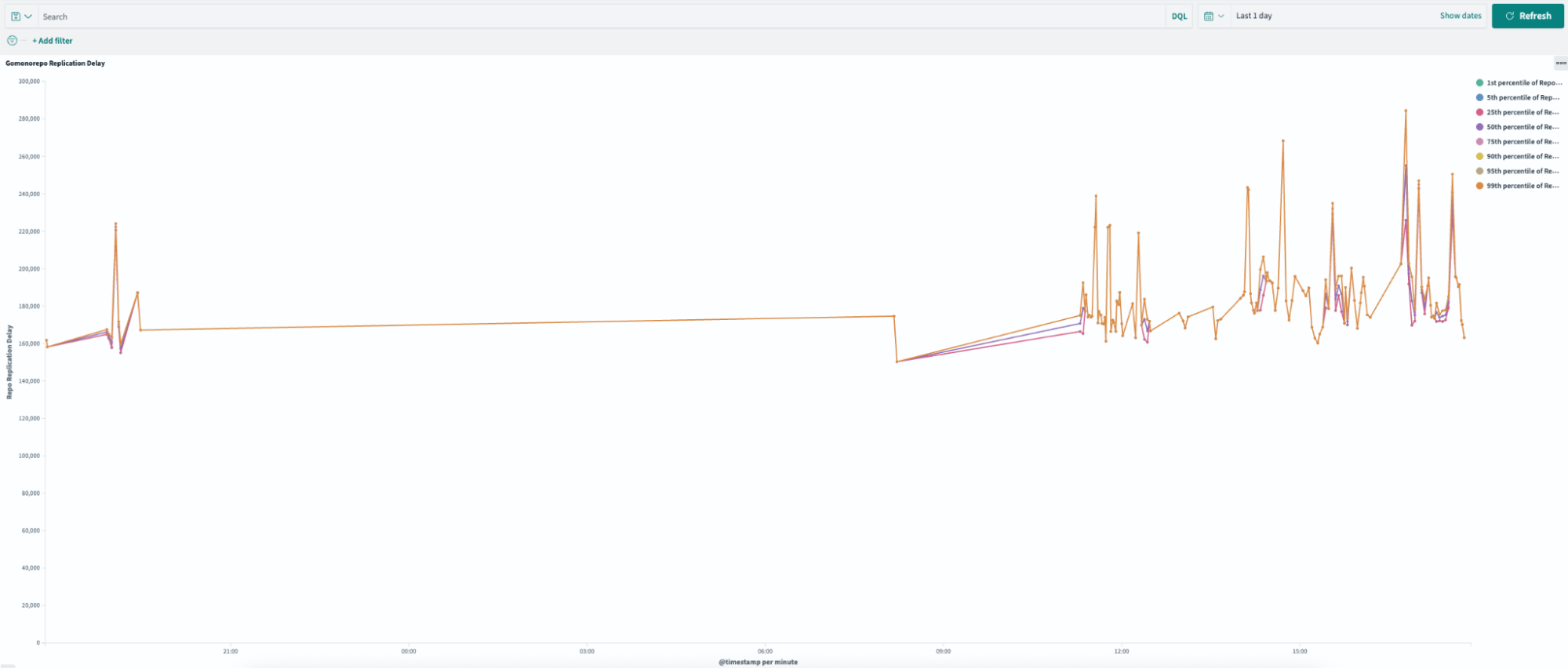
Replication delay, or the time required to sync across all Gitaly nodes, improved by 99.4% following the pruning process. As illustrated in Figures 3 and 4, the new pruned monorepo achieves replication in under ~1.5 seconds on average, compared to ~240 seconds for the old repository. This transformation eliminated the previous single-node bottleneck, enabling read requests to be distributed evenly across all three storage nodes, significantly enhancing system reliability and performance.
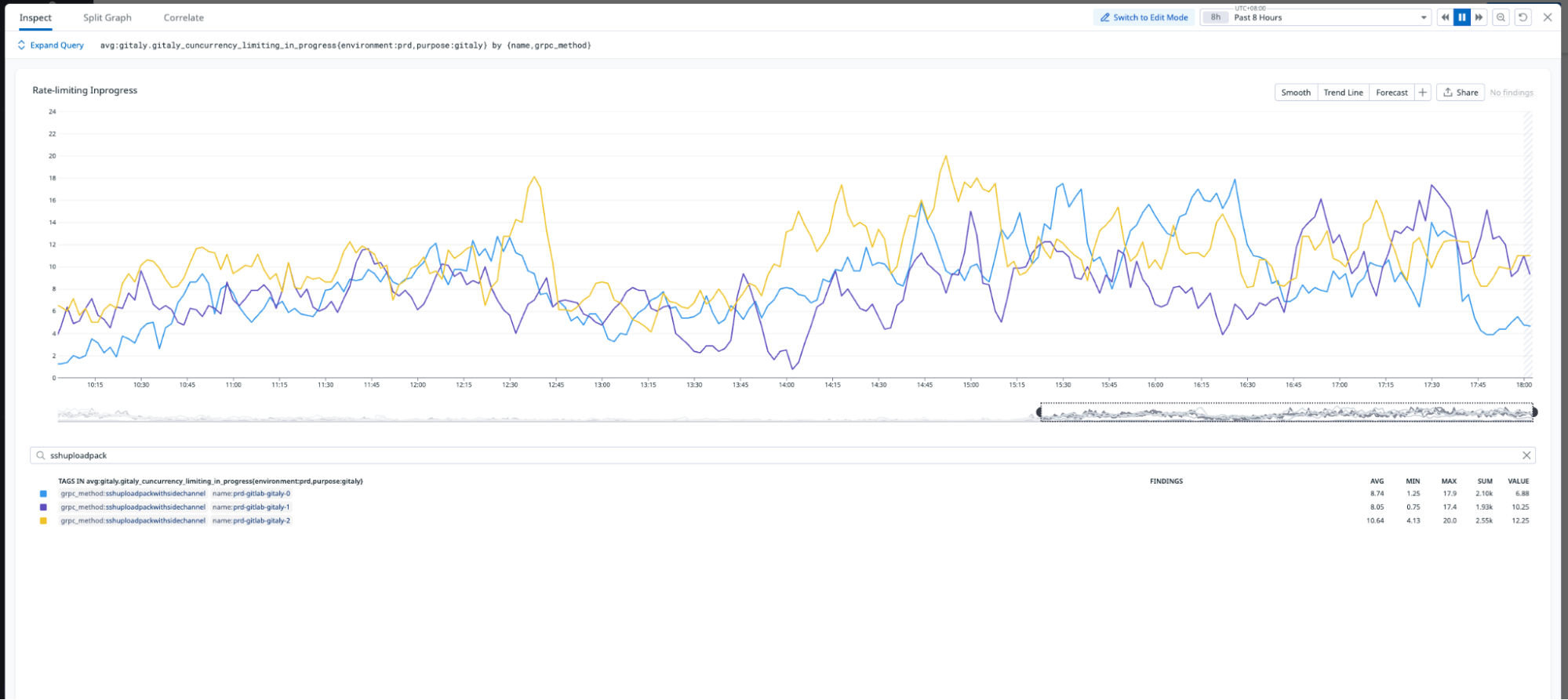
The migration significantly improved load distribution across Gitaly nodes. As shown in Figure 5, the new monorepo leverages all three Gitaly nodes to serve requests, effectively tripling read capacity. Additionally, the migration eliminated the single point of failure that existed in the old monorepo, ensuring greater reliability and scalability.
The migration resulted in significant improvements across multiple areas.
The migration also transformed the developer experience.
The following table summarizes the key repository metrics, comparing the state of the repository before and after the migration:
| Metric | Old Monorepo | New Monorepo | Reduction |
|---|---|---|---|
| Commits | ~13,000,000 | ~15,800 | −99.9% (histories squashed) |
| Git trees | ~23,600,000 | ~2,080,000 | −91% (pruned) |
| Git references | ~12,200,000 | 9,860 | −99.9% (cleaned) |
| Blob storage | 214 GiB | 86.8 GiB | −59% (smaller packs) |
| Files in checkout | ~444,000 | ~444,000 | ~0% (no change) |
| Latest code size | ~9.9 GiB | ~8.4 GiB | ~−15% (slightly leaner) |
Such a large-scale migration wasn’t without its hiccups and lessons. Here are some challenges we faced and what we learned:
Initially, GitLab rejected some commits due to missing LFS objects, even old commits that we weren’t keeping. This happened because GitLab’s push hook expected the content of LFS pointers, even if the files weren’t required. To fix this, we had to allow incomplete pushes and skip LFS download errors. We also wrote logic to selectively fetch LFS objects for commits we were keeping. This ensured that any binary assets needed by tagged commits were present in the new repo. The takeaway is that LFS adds complexity to history rewrites – plan for it by adjusting Git LFS settings (e.g., lfs.allowincompletepush) and verifying important large files are carried over.
Right after the cutover, some CI pipelines failed to access resources. We discovered a GitLab CI/CD pipeline token issue – our new repo’s ID wasn’t in the allowed list for certain secure token scopes. We quickly updated the settings to include the new project, resolving the authorization error. If your CI jobs interact with other projects or use project-scoped tokens, remember to update those references when you migrate repositories.
One of our internal tools was using commit SHA-1 hashes to track deployed versions. Since rewriting history means changing all commit hashes, the tool couldn’t find the expected commits. The solution was to map old hashes to new ones for the tagged releases, or better, to modify the tool to use tag names instead of raw hashes going forward. We learned to communicate early with teams that have any dependency on Git commit IDs or history assumptions. In our case, providing a mapping of old tag→new tag (which were mostly 1-to-1 except for the commit SHA) helped them adjust. In hindsight, using stable identifiers like semantic version tags, is much more robust than relying on commit hashes, which are ephemeral in a rewritten history.
A few engineers were concerned when they noticed that the git log in the new repo only showed two years of history. From their perspective, useful historical context seemed gone. We addressed this by pointing them to the archived full-history repo. In fact, we kept the old repository read-only in our GitLab, so anyone can still search the old history if needed (just not in the main repo). Additionally, we received suggestions on making the archive easily accessible or even automate a way to query old commits on demand. From this we learned, if you prune history, ensure there’s a plan to access legacy information for those rare times it’s needed – whether that’s an archive repo, a Git bundle, or a read-only mirror.
Interestingly, after the migration, a few developers in certain offices didn’t feel a huge speed improvement in clones. It turned out their corporate network/VPN was the limiting factor – cloning 8 GiB vs 10 GiB over a slow link is not a night and day difference. This highlighted that we should continue to work with the IT team on improving network performance. The repo is faster, but the environment matters too. We’re using this as an opportunity to improve our office VPN throughput so that the 36% clone improvement is realized by everyone, not just CI machines.
We had a lot of automation around the monorepo (scripts, webhooks, integrations). Most of these referenced the project by name, which remained the same, so they were fine. However, a few used the project’s numeric ID in the GitLab API, which changed when we created a new repo. Those broke. We had to scan and update some configs to use the new project ID. Our learning here is to audit all external references such as CI configs, deploy scripts, and monitor jobs when migrating repositories. Ideally, use identifiable names instead of IDs, or ensure you’re prepared to update them during the cutover.
Some teams had to adjust their workflows after the prune. For instance, one team was in the habit of digging into 3 to 5 year old commit logs to debug issues. Post-migration, git log doesn’t go back that far in the main repo; they have to consult the archive for that. It’s a cultural shift to not have all history at your fingertips. We held a short information session to explain how to access the archived repo and emphasized the benefits (faster operations) that come with the lean history. After a while, teams embraced the new normal, appreciating the speed and rarely needing the older commits anyway.
In the end, we had zero data loss – all actual code and tags were preserved – and only some minor inconveniences that were resolved within a day or two. The challenges reinforced the importance of thorough testing (our staging dry-runs caught many issues) and cross-team communication when making such a change.
This migration transformed our development infrastructure from a bottleneck into a performance enabler. We eliminated the single point of failure, restored confidence in our Git operations, and created a foundation that can support our growing engineering team.
As the next step, we plan to generalize our pruning script to apply the same optimization techniques to other repositories, ensuring consistency and scalability across our infrastructure. Additionally, we will implement continuous performance monitoring to track repository health and proactively address any emerging issues. To prevent future repository bloat, we aim to establish clear best practices and guidelines, empowering teams to maintain efficiency while supporting the growth of our engineering operations.
What started as a performance crisis became one of our most successful infrastructure projects. By focusing on the right problems—infrastructure reliability and performance rather than just size—we achieved dramatic improvements that benefit every developer daily.
The key takeaway is that sometimes the biggest technical challenges require custom solutions, careful planning, and willingness to iterate until you find what works. Our 99% improvement in replication performance is just the beginning of what’s possible when you tackle infrastructure problems systematically.
This migration was completed by Grab Tech Infra DevTools team, involving months of analysis, custom tooling development, and careful production migration of critical infrastructure serving thousands of developers across multiple time zones.
Grab is a leading superapp in Southeast Asia, operating across the deliveries, mobility and digital financial services sectors. Serving over 800 cities in eight Southeast Asian countries, Grab enables millions of people everyday to order food or groceries, send packages, hail a ride or taxi, pay for online purchases or access services such as lending and insurance, all through a single app. Grab was founded in 2012 with the mission to drive Southeast Asia forward by creating economic empowerment for everyone. Grab strives to serve a triple bottom line – we aim to simultaneously deliver financial performance for our shareholders and have a positive social impact, which includes economic empowerment for millions of people in the region, while mitigating our environmental footprint.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!