Post Syndicated from Радио „Свобода“ original https://www.toest.bg/maria-stepanova-vlakut-na-istoriyata-otnovo-navliza-v-tumen-tunel/

„Безусловността, с която настоява за поетично възприемане на света“ – така определя приноса на Мария Степанова журито на Лайпцигската литературна награда за европейско взаиморазбирателство. Връчването на наградата се състоя през април тази година. Журито отбелязва също умението на Степанова, „като се вглежда в своите произведения в самото дъно, да дарява надежда“. Какво може да направи днес поетът – в ситуация, когато думите нищо не могат да променят и от друга страна, имаш чувството, че думи вече не са останали? Да пазим речта свободна, освободена от контрол и диктат. „Ние“ – хората, които се опитваме да останем субекти, а не обекти на историята – се заклещихме в нещо като историческа фуния, смята Степанова. И именно затова Манделщам и Хармс ни изглеждат така актуални. Макар че това е не толкова повод за възхищение, колкото знак, че бъдещето с нас „не е настъпило“.
Мария Степанова отговаря на въпросите на Радио „Свобода“.
– През предходните 30 години обществото в Русия – е, да речем, не всички, едно малцинство, макар и на скокове, на зигзази, неуверено – се движеше напред и това чувство за „движение по пътя на прогреса“ все пак беше опора на нашата жизнена мотивация. След началото на агресията ние се оказахме отхвърлени към изходната точка, в една условна 1984-та – ако не и направо в 1937 година. Какъв урок е това за всички нас – поредното прекатурване в „кръга на историята“?
– В края на 80-те – в началото на 90-те наистина изглеждаше, че излизаме, че сме излезли от предишния катастрофален коридор – ех, какъв живот започва! И не щеш ли – „Внимание, вратите се затварят“ и влакът на историята отново навлиза в тъмен тунел – веднага след осветената гара. Вратите отново са залостени; всички усилия, всички надежди и огромното количество частни избори, които е правил всеки от нас – те нямат никакво значение. Ние всички преминаваме към мрака – и после, един ден, ако някой има късмет, ще излезе на светло и ще благодари на съдбата за късмета си. Но самото това състояние на безсубектност (избора правим не ние, а нещо, наречено История, вселенски хаос, мироздание) и това движение по спирала, в кръг или насам-натам подир махалото всъщност е крайно унизително за човешкото същество. Излиза, че ние нищо не решаваме. Но как така, нали се мислехме за самостоятелни единици? Просто основа на всички наши решения беше необходимостта от мир, съпротивата на самата идея за война с когото и да било – и ни се струваше, че този въпрос вече е решен безвъзвратно от предишните поколения, за това поне можем да не се тревожим, never again, нали така?
Днес тази увереност ни изглежда наивна. Веднъж когато Надежда Яковлевна се оплаквала колко е нещастна, Манделщам ѝ казал: „А някой обещавал ли ти е да бъдеш щастлива?“
Кой ни е обещавал да живеем щастливо и мирно –
сякаш зло не съществува, сякаш на света няма нещастие? През цялото това време са се случвали нещастия и катастрофи – но с други. Ирак, Сирия, Афганистан, Руанда… Но някой е имал чувството, че ако замижи и си седи у дома, нещастието ще го заобиколи. Не ни заобиколи.
– Влакът, вагонът представляват затворено пространство, от което не можеш да изскочиш в движение. Със съзнанието, че спирки вече няма да има. „Влакът ни пътува за Освиенцим, днес и ежедневно“ – спомням си един ред от Галич.
– В Берлин, на две крачки от мястото, където разговаряме, се намира Grunewald Gleis 17 – мемориал на пункта, откъдето са изпращани композициите към лагерите за унищожение, предимно с евреи. Хубав мемориал е – не се опитва да стане предмет на изкуството. Една чиста, безпримесна територия на паметта. На перона са изписани датите: кога именно са тръгвали ешелоните, накъде, колко души месечно са откарвали тези влакове. Те са поемали на път буквално до април 1945 г., когато според нашите представи всичко вече е било ясно. И бройката вече не е била хиляди, нито стотици – само петнайсетина души, че нали до края на войната е имало само няколко седмици, върху Берлин се сипят бомби, друга работа нямали ли са, та ще снабдяват концлагерите. Тях обаче са ги натоварили във вагоните и са ги пратили на смърт – въпреки всичко. В този момент ти разбираш, че тези влакове са били управлявани, контролирани от хора. Безспорно сега на всички щеше да ни е по-леко да смятаме въпросните влакове за някаква имперсонална, безсубектна сила. За съжаление, не е така. И тогава, и сега всичко това се прави от хора.
– През тези предходни 30 години ни се струваше също, че „историята е свършила“ – всичко най-лошо в историята на човечеството вече се е случило и ние живеем в постистория. Всъщнност вашата книга „В памет на Паметта“ беше потвърждение и дори символ на това усещане. Погрешна ли беше тази проекция?
– Наистина, ние (какво е това „ние“, хайде да смятаме, че онези, които са се занимавали с история или са се интересували от нея, от миналото, от културата на паметта, представляват широк кръг от хора) изхождахме от увереността, че съществуваме донякъде в бъдещето, в посткатастрофална ситуация. И че единствената задача, към която трябва да бъдат насочени всички интелектуални сили на човечеството, е да се опитаме да направим равносметка на миналото, на историята с нейните катастрофи, да запазим, да си спомним, да не забравим, да меморизираме всичко, което е останало. Всичко трябва да бъде подредено, обяснено, каталогизирано: с изградени паметници, с премислени ритуали, които са нужни, за да се простим с историята по правилния начин. Е, и разбира се, всички пишехме книгите си за миналото – за какво друго. Никога няма да забравя как веднъж бях в журито на една литературна награда – и в задълженията ми влизаше да прочета около 80 книги проза. От тях близо 70 бяха за миналото. Много добре разбирам авторите, и аз съм такава.
Само дето се получава, че сме хвърлили всичките си сили за любов към миналото и сме изгубили доверието си в бъдещето.
Впрочем това е така не само в Русия. Случва ми се да преподавам в Европа или в Америка. И понякога питам студентите – това е нещо като игра – да назоват сравнително нов филм, някой блокбастър, който ни предлага добър вариант за бъдещето. Не задължително лъчезарно-утопичен, но приемлив, неплашещ, поносим. И на това място моите студенти се умълчават, нямат какво да кажат. Най-сетне – и това се случва много рядко – някой вдига ръка и предлага безпогрешното „Назад към бъдещето“. „Назад към бъдещето“! Филм, заснет през 1985 г. Това означава, че цели 30 години всички машини на човешкото въображение, цялата супериндустрия на киното не е могла или не е пожелала да ни предложи позитивна версия на бъдещето. За сметка на това всяка година по екраните излиза пълен асортимент антиутопии – политически, икономически, социални, екологични. Тоест децата, още неизлюпили се от яйцето, вече добре знаят, че бъдещето е нещо страшно, докато виж, миналото може и да е плашещо, но поне знаем какво е било. И им се струва, че то е по-безопасно от бъдещето, че могат да научат правилата, за да не ги сгази поредният влак на историята. И се получава, че ние с безумна скорост препускаме в обратна посока, опитваме да се върнем в тази „история“ – естествено, фикционална, измислена, друга нямаме на разположение. Каква ще бъде тя, зависи изключително от източниците, от които черпим.
– И при всяко положение е подобрена версия на миналото.
– Подправена. Така или иначе, лично обагрена. При всяко положение имаме работа с фантазия за миналото, индивидуална или колективна. И ето, днес виждаме как фантазията по мотиви от миналото – произведена, бих казала, все пак от един човек и неговото обкръжение и тиражирана „в мащабите на цялата страна“ – се реализира. Февруарското нахлуване в Украйна от самото начало имаше, как да се изразя, персоналистични черти. Това е фантазията на Путин, която той има сили, средства, възможности да осъществи не в компютърна игра, не в някакъв безумен предутринен сън – а на територията на Европа с цената на хиляди човешки съдби.
– „Настоява за поетично възприемане на света“ е формулировката, с която Ви връчиха Лайпцигската литературна награда за европейско взаиморазбирателство през 2023 г. Като се върнем още веднъж към вашата метафора за влака: на поета – индивида в концентриран вид – по-лесно ли е да се изтръгне от желязното менгеме на историята с помощта на езика? Да се издигне подобно на балон над препускащия влак?
– Известно е, че стиховете са своеобразно убежище и в някои ситуации могат да спасяват. Прочитате едно стихотворение – и то се заселва у вас. Или е обратното – вие се заселвате у него? Ако знаеш наизуст достатъчно много стихове, можеш да се скриеш в тях. И да изчакаш, да си отдъхнеш, да си поемеш въздух. Можеш и да си поделиш стихотворението – като палатка или хранителна дажба – с другиго. Всичко това е истина, макар да звучи красиво и възвишено. Но за съжаление, ние знаем също, че стиховете изобщо не спасяват хората, които ги пишат. Тъкмо за това си мислех, когато пишех речта си за Лайпцигската награда, и си спомних Хармс:
Стиховете трябва да се пишат така, че ако ги запокитиш по прозорец, той да се счупи.
Това е чиста истина. Хармс го е написал през 1940 г., а в началото на 1942-ра е умрял от глад в затворническа болница…
– А Валтер Бенямин приблизително по същото време гълта отрова.
– А Цветаева се обесва в Елабуга. И ние можем да продължим тази поредица. Както е казал Одън:
Poetry makes nothing happen.
Стиховете не карат нещата да се случват. Те нищо не променят. Това е разговор със себе си вътре в затворено пространство. Ето защо, когато мисля за стиховете, аз постоянно мисля и за това – до каква степен те не са достатъчни сега. Ала има и друга страна на този въпрос. Главната функция на стиховете, освен чудното чуруликане в рими и без рими, е да формират езика. Стиховете говорят на езика на близкото или далечното бъдеще. Стиховете на Манделщам, които той е написал по време на заточението си във Воронеж, са изглеждали на неговите съвременници толкова неясни, че им е било нужно усилие, за да разберат какво иска да каже той. А той е отговарял:
Аз мисля с пропуснати брънки.
В крайна сметка 80 години по-късно днешният ученик от горните класове чете Манделщам – и разбира всичко или почти всичко. За 80 години текстът не е престанал да бъде съвременен – но освен това изведнъж става и разбираем: през това време езикът, на който са изговорени текстовете, е успял да стане всеобщ. По отношение на езика стиховете изпълняват хигиенизираща функция. Хигиената далеч не се свежда само до запазване на езиковата норма, спусната от началник някъде отгоре – „кафето да се нарича еди-как си“ – и в гледане отвисоко на онези, които пият това кафе в неправилна форма. Хигиената е обратното – когато стиховете раздрусват езика, освобождавайки допълнителни коридори. Допълнителни опции. И в този смисъл
днешните стихове работят против Путин, против днешната власт в Русия.
Против вцепенението и помъртвяването, които те привнасят в езика. Стиховете – докато се пишат – посочват възможност за друго: различно, не като сегашното.
– Спомням си и думите на Ахматова – „но ние ще те запазим, руска реч“. Да се запази свободната, безцензурна руска реч днес е напълно достойна задача за интелектуалеца.
– Да, но аз бих отбелязала също: това е задача не само за интелектуалеца с руски паспорт в джоба. Защото пред всички нас днес се очертава печално прочулата се „отмяна на руската култура“. Отмяна, разбира се, не буквална, с която обичат да ни плашат пропутинските средства за масова информация, това им е любима тема; а ментална, която ще се случва незабелязано и обективно чрез помъртвяването и корозията на езика. Единственото, което можем да противопоставим на това, е да отделим руския език, руската култура от днешния режим, от държавата. Днес благодарение на новата порция напуснали Русия езикът вече се отделя от определена територия, превръща се в език на диаспора – и този „напуснал“ руски би трябвало да се сдобие с нови черти. Това е добре: никой не може да му натрапи отвън някакви норми, правила на поведение, да го консервира, да го изложи в кристален ковчег в мавзолей. Струва ми се, че „запазването на руската реч“ може да се свежда само до нейното разкрепостяване, най-сетне. Нека нашата реч живее където иска, нека се смесва с други наречия. Нека свири, чурулика, произвежда неологизми – нека се англифицира, германизира, арабизира. Това е, което се случва с езиците, които искат да остават живи. И това ще бъде не обичайното натрапване, няма да е експанзия, нашествие – това ще бъде… скитащ руски. Тръгнал на разходка из света. Един от многото световни езици.
… Веднъж бях в компания на швейцарци; те се забавляваха, като произнасяха една и съща фраза всеки на своя диалект. Невъзможно е да си представи човек, че това се случва вътре в един език. Такова богатство, такава разлика – и такава прекрасна способност на хората да не превръщат това в проблем, big deal. Това е смехотворно, прекрасно – и то съществува. Способност за разнообразие, за различаване – тя просто е дадена на хората от люлката. Така е и в Италия, да речем. В Германия съществута берлински диалект, съществува кьолнски, има баварски, има вестници, които излизат на тези диалекти, има пиеси, които се пишат на диалекти. И това ни най-малко не пречи на съществуването на така наречения висок немски. Защо с нас такова нещо не се е случило?
Защо в Русия, на тази огромна територия, практически не съществуват диалекти?
У нас е била императивно установена единствена езикова норма (по образеца на френската езикова реформа в края на ХVIII век), а после руската империя, а после съветската гледат на въпросния единен език като на свой приоритет. И ние сме наследили този норматив – и заедно с него потребността между развиването на езика и неговата консервация да избираме второто. Хомогенния, неизменяемия, невариативния руски – който не признава различия между областите, народите, градовете. „Така трябва.“ Струва ми се, че нашата печално прочута несвобода има своите корени и тук например. И това води до съкрушителни последствия.
– Упреците по повод имперскостта на руската култура са в известен смисъл справедливи. Тя наистина до голяма степен е създадена от хора с колониален опит. Но ако потърсим съвършено неопетнена фигура, изведнъж изниква пак Хармс. Трябва да кажем, че сега – колкото и да е странно – Хармс звучи още по-често, отколкото преди войната. Сякаш всички са се вкопчили в него като в последно спасение/оправдание. Пък и целият вледеняващ абсурд на случващото се е най-лесно да се изрази пак с помощта на Хармс. Показателно е: днес именно Хармс от една страна, а от друга – Бекет и Кафка – само те помагат да не полудееш.
– Добре казано. Аз мисля за това в малко по-различен аспект: може би работата е там, че Хармс и Введенски в много по-голяма степен са наши съвременници от тяхната по-възрастна съвременничка Ахматова. Или отколкото техния дори по-млад съвременник Бродски. Става дума не за сравнителни достойнства. А по-скоро за ситуацията, в която изведнъж се озовахме. Манделщам има една статия – „Краят на романа“, в която пише, че измислицата вече няма тежест, смисъл, интерес за читателя. Защото ние много добре разбрахме във времена на катастрофи и масова смърт, че човекът вече не определя своята биография. Биографията става типова и както се изразявахме през 90-те, „изчезва в заоблянията“. Частната биография вече не съществува. А щом тя не съществува, значи няма и сюжетостроене. Няма автор, който стои зад решението дали мадам Бовари да умре, или не. Няма автор, който се разпорежда с бъдещето на Наташа Ростова. И затова – по Манделщам – важен се оказва жанрът, който днес наричаме нонфикшън. Литературата на реалния живот, където е важен не сюжетът, а нещо друго. Важно е, че това някога с някого наистина се е случвало. Това е един от начините да си имаме работа с водовъртежа на историята.
Вторият начин е онова, което правят Бекет и Кафка (и Хармс, да). Ние се намираме в ситуация, където всички връзки между предметите са случайни или произволни. Можем да предположим, че зад тях стои някаква външна воля. Но не сме в състояние да дешифрираме нейната логика. И в този смисъл световната литература, като се започне от Първата световна, се занимава приблизително с едно и също. Да, ето, избухва взрив (сега тази дума звучи съвсем различно – сега тя не е метафора, а нещо от реално по-реално); случва се някакво движение, изместване на историческата ос. Всичко замира, увисва във въздуха. И единственото, с което може да се работи сега, са фрагментите. С елементите на предишната система, които са повредени, разпилени, разединени. Ние знаем, че някога те са били част от цяло – и това цяло вече никога няма да бъде предишното. Но от късчетата на цялото може да се премонтира друга система, в която старите елементи ще присъстват при други условия и в други връзки. В руската литература вероятно най-точно по това са работили Хармс и Введенски – в поезията, а в прозата – Добичин, и по съвсем друг начин Платонов.
Лошото обаче е там, че всичко написано от тези автори упорито не престава да бъде актуално. Прието е да се възхищаваме от това, но ето какво се получава: излиза, че оттогава насам с нас не се е случило нищо ново. Хайде да сравним това с англоезичната литуратура от ХХ век. Да речем, с Елиът, Йейтс, Къмингс. Велики хора, прекрасни, гениални стихове – но ние добре разбираме, че това са стихове, написани не сега, между тях и нас има дистанция. И това е правилно чувство. А с руските стихове се получава
усещането, че се намираме във все същия културен аквариум, онзи отпреди 100 години.
Където на чаша чай и разговори за съдбините изведнъж се сещаме за стих от Манделщам – и всички имат чувството, че той е написан вчера и няма какво да се добави. Защото нищо не се е променило. И ето това непреодоляно, неизминато минало е нещо доста плашещо и тъжно.
– Критикът Игор Гулин пише: „Мария Степанова говори не от свое име, а от името на чужди гласове“; критиците датират този поетичен обрат, случил се с вас, приблизително в 2014 г. Но сега ми се струва, че сме се озовали в ситуация, когато ще се наложи отново да преминем в друг регистър – скръбно мълчание. Да говорим от името на самата немота, немотата на срама. Възможно ли е това в поезията?
– Не съм сигурна, че е възможно. Поне за мен. Струва ми се, че мислещите хора, хората, които пишат на руски, така или иначе са свързани с Русия – сега те усещат едно: изгубили сме възможността да представяме единствено себе си. Да говорим от свое име и само от свое име. Тъй като ти, аз, вие, ние сега сме на първо място руснаци – без значение какво е гражданството ни, етническият ни произход, езикът; дори „ние“ да сме се преселили в Германия или в Щатите още през 1978 г. Това нищо не променя. Отсега нататък всички ние сме част от множеството хора, които извършиха, сториха това.
Аз например съм родена през 1972 г. Заварих пионерските сборове, речите, политатестациите и приемането в Комсомола – целия този комичен балет. И от ранна възраст ми беше много близка, дори прекалено, логиката на неприсъединяването.
Никъде не влизам, не съм член на никаква партия. И не съм представител на никакво нищо – нито на болшинство, нито на малцинство. Говоря само от свое име.
Много точно сумира това Бродски в своята Нобелова реч, която започва с думите:
За любител на усамотението, за човек, който цял живот го е предпочитал пред всяка обществена роля…
Е, и така нататък.
… Ако изкуството учи на нещо, то е тъкмо частността на човешкото съществуване.
Това винаги е било много разбираемо за мен. И това по-скоро е моя психосоматика, отколкото политическо самоопределение. Но резултатът беше именно такъв: никога не съм имала предвид да представлявам нито руската литература, нито, пази боже, руската държавност, нито някакво въображаемо съдружие. Отстоявала съм възможността да говоря от свое име. От свое и за своето. И в продължение на някакъв брой години съм успявала. Сега вече нямам такава възможност и мисля, че никога повече няма да имам. Каквото и да пиша сега – може да пиша за пеперуди, за вятърни мелници, за какво ли не, – то така или иначе ще се възприема като текст, създаден на езика на хората, които извършиха това. И с това трябва някак да се живее. Тоест бих могла с лекота да посоча с пръст – ето там са нашите „лоши хора“, на мен обаче браво, аз мислех и постъпвах правилно, така че сега съм част от друго, просветено съдружие и мога свободно, без никакви утежнения да осъждам тези хора като други, странични. Не, за съжаление не е така. Значи ще трябва да поема част от общата вина – и някак да живея и да работя с нея. Ако съумея. И да се опитвам да намеря нови принципи на съществуване в езика.
Как ли?… Не знам, сега не пиша стихове. Не знам дали това е немота. Немота е Паул Целан например. Немотата е начин да минеш през неизговоримото. И да направиш така, че мълчанието да бъде определящо в текста, който пишеш. Но ние не можем да се сравняваме с Целан, нали така? С Целан може да се сравнява поет или поетеса от Украйна.
А ние се оказахме част от множеството, чийто език се превърна в оръдие на насилието.
И това е съвсем друга немота. И друг ужас. И какво да правим с това? Поет от Русия не може да описва Буча. Защото това би било апроприация, използване на чуждо страдание, за да – какво – за да напишеш текст? Ние можем най-много да споменем Буча, пък и не си представям добре как именно може да се направи това. Миналото лято написах някакви стихове, но не съм напълно сигурна, че това са стихове. Може би те имат някакъв смисъл като свидетелство, като надпис на стена. Но проблемът, с който се сблъсках тогава, когато ги пишех, бе проблематичността на тяхната агентност. На точката, от която всъщност произлиза речта – отговорът на въпроса какво е това „аз“, което говори. Имам едно стихотворение, което започва с
докато спяхме, ние бомбардирахме Харков.
Ето го разединеното, биполярно „ние“, което едновременно се срамува и убива, иска да потъне вдън земя и яде шишчета на слънчице край вилата си. И всичко това се случва едновременно. Ситуация, с която не е ясно как да си имаш работа. Засега на мен не ми е ясно.
– При това в нета, просто във въздуха се появи огромно количество талантливи и безпощадни украински стихове. Как ги оценявате вие? Като хронология на болката?
– Струва ми се, че това е невероятно важно и аз ги следя, защото украинските поети сега имат нещо, което ние нямаме. И не можем да имаме. Намираме се в състояние на абсолютна неувереност, в състояние на самоотмяна. Не е нужно дори специално да ни канцелират (от думата cancel), ние сами сме си канцелария. Пак Манделщам е смятал – и за това е интересно да се поразмишлява, – че „поезията е съзнание за собствената правота“. Дали е така, или не е, но сега никой от нас няма това съзнание за правота. Имаме съзнание само за собствената си неправота. И какво може да се направи от това чувство, и може ли изобщо да се направи нещо – това е открит въпрос. Поезията в Украйна винаги е заемала особено място. А сега пък съвсем се намира на онази точка, където всеки написан ред, текст придобиват силата на окончателно свидетелство. Но работата не се ограничава с това. Сега на украински се пишат велики стихове. Ето в момента чета текстовете на Мариана Кияновска, които тя е написала през последните няколко месеца. Поразителни стихове са – те ще се четат след сто, след двеста години, този език е за векове. Но това е възможно, защото тези стихове имат слушател, имат чуваемост. Поезията в Украйна изначално е заемала по-важно място. Не говоря за огромни културни фигури като Сергей Жадан например, който събира стадиони. В Русия аудиторията на една поетична вечер е 25 души, при повече късмет – 50. Тоест това е съвършено несъпоставим резонанс. И докато ние предполагаме, че стихотворението, след като е чуто, прочетено, ще образува в съзнанието на читателя някакви пространства на бъдещето, Украйна реализира това свое бъдеще още сега.
Колкото до мен, сега аз не пиша стихове, както вече казах; бавно довършвам романа, който започнах да пиша в началото на пандемията и на няколко пъти го зарязвах, защото историческото колело толкова рязко завиваше настрани, че аз трябваше наново да сглобявам някакви основи, някакъв фундамент, върху който се опитвах да поставя тази конструкция. Мисля, че този текст по някакъв начин ми помага да се крепя. Това е удивителна способност на прозата. Защото със стиховете ти така или иначе си принуден да чакаш в главата ти да се образува някаква невидима въздушна форма, която трябва – като пъзел – да запълниш с думи, да проявиш като фотолента. А в прозата все пак е важен елементът воля. Ти знаеш, че това нещо трябва и може да бъде написано. И влизаш в него като в друга стая, и в тази стая времето така или иначе спира. Това време е насаме с текста, езика – и с някаква чужда история, която много относително засяга твоята собствена. Тази възможност е голям подарък, трябва да кажа. Цял живот съм смятала, че ще пиша изключително стихове. Но се оказва, че прозата работи по други закони – и за човек, чието съществуване от време на време му причинява остра болка, прозата се превръща в прозорче, което може да открехне.
– Накрая въпрос за онлайн изданието Colta: възнамерявате ли да го възобновите на друга платформа? Да го презаредите, да го реанимирате?
– Да съществуваме в режима, в който работехме до февруари 2022 г., е невъзможно поради очевидни етични причини. Не можем да работим така, сякаш нищо не се е случило. Colta и нейният предшественик OpenSpace бяха замислени като ежедневни издания за култура, които се занимават с текущия културен процес. Книги, изложби – година след година следяхме това. Сега, когато Русия продължава агресията, би било пределно странно да описваме московски или петербургски концерти или изложба „Нонфикшън“. Да не говорим за финансовата част: ние много дълго съществувахме с читателски дарения и по партньорски програми. Сега и едното, и другото по различни причини са затруднени. Опитваме се да работим в полудоброволчески режим – разработваме едни кратки спецпроекти, известен брой материали, обединени от обща тема. Неотдавна публикувахме цикъл материали за бъдещето, там разни умни хора (в диапазона от Елена Фанайлова до Оксана Тимофеева) размишляват дали Русия има що-годе поносимо бъдеще – и какво би могло да бъде то? Самата мен ме владеят доста мрачни мисли по този повод, така че се надявах на тази анкета – ами ако някой предложи версия, която ще ме въодушеви?
Никакви позитивни прогнози.
Интересно е, че единственият автор, чийто текст може да се нарече донякъде оптимистичен, е Кирил Медведев, който сега се намира в Москва и е въвлечен в различни форми на активизъм.
Е, и освен това аз много бих искала нашият сайт да успее да се удържи и да работи, прекосявайки границите, въпреки вече набелязалата се тенденция на разделение между емигранти и останали. Не ми се ще да възпроизвеждаме схизмата, логиката на разкола между съветската и емигрантската литература. Той е продължил толкова години – и в крайна сметка за нищо не е помогнал. За разлика от онази ситуация, ние имаме поне инструментариум, с който диалогът да продължава, така че едни и същи текстове да могат да се четат както в Русия, така и извън нея. И ми се струва, че да се работи за продължаването на разговора е необходимо.
Превод от руски на интервюто за Радио „Свобода“: Здравка Петрова
Мария Степанова (р. 1972, Москва) е руска поетеса, писателка и есеистка, главна редакторка на онлайн изданието за изкуство и култура Colta.ru. Философският ѝ роман-есе „В памет на Паметта“ (прев. Здравка Петрова, изд. „Жанет 45“, 2019) е отличен с най-престижните руски литературни награди – „Ясна поляна“ (2018), „Большая книга“ 2018 (най-високото руско литературно отличие) и „НоС“ („Новая Словестность“, 2019).
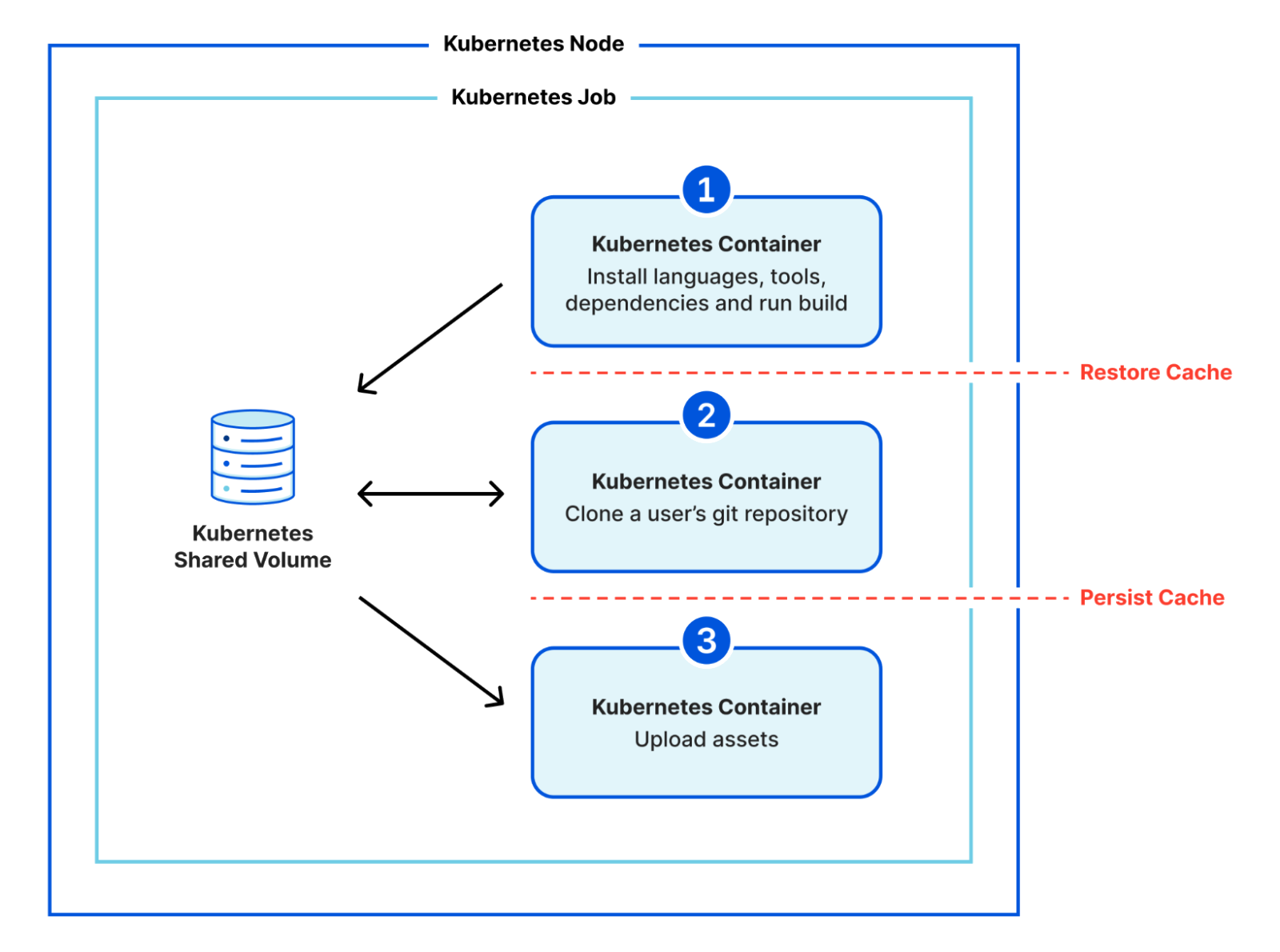



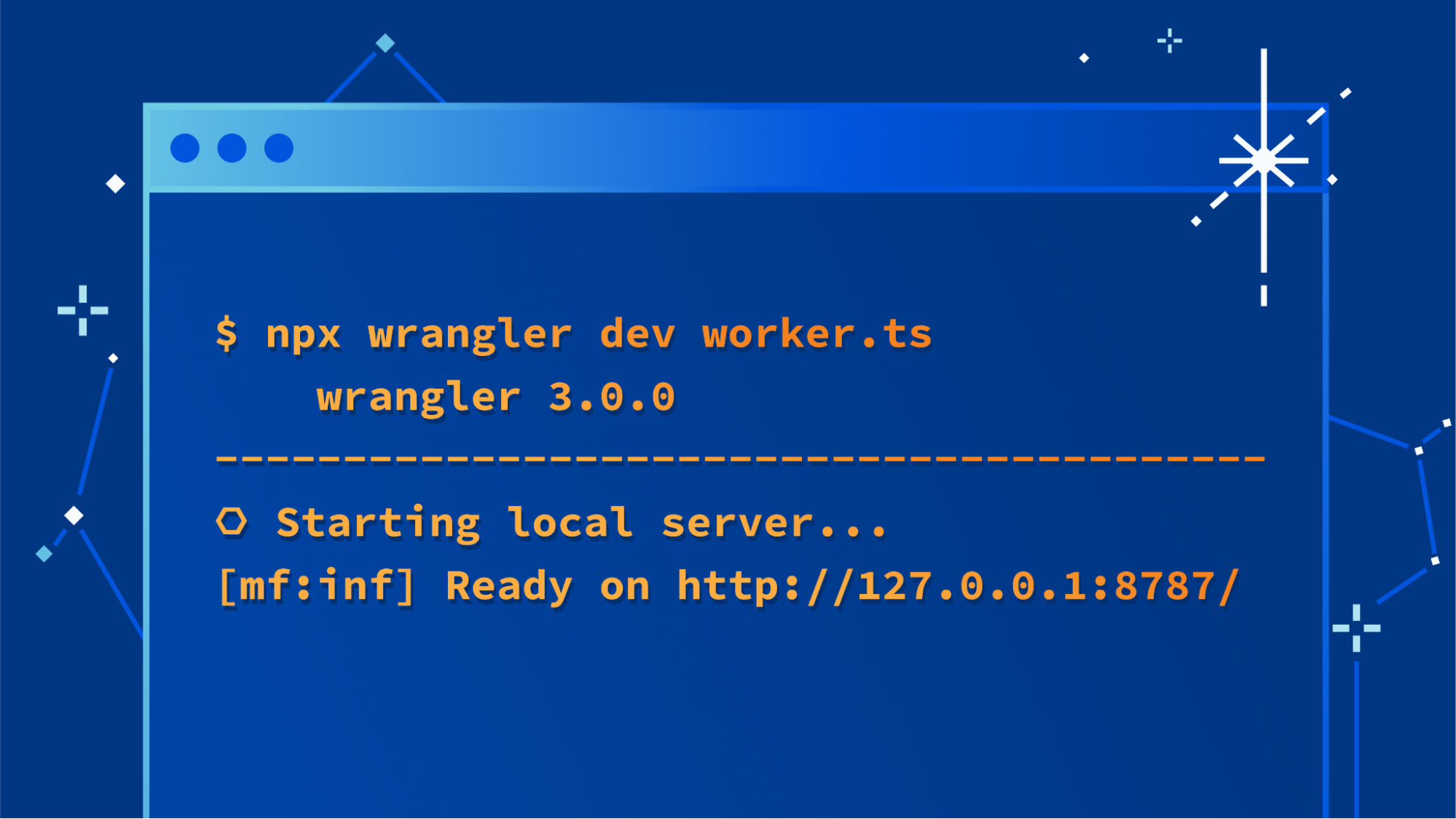
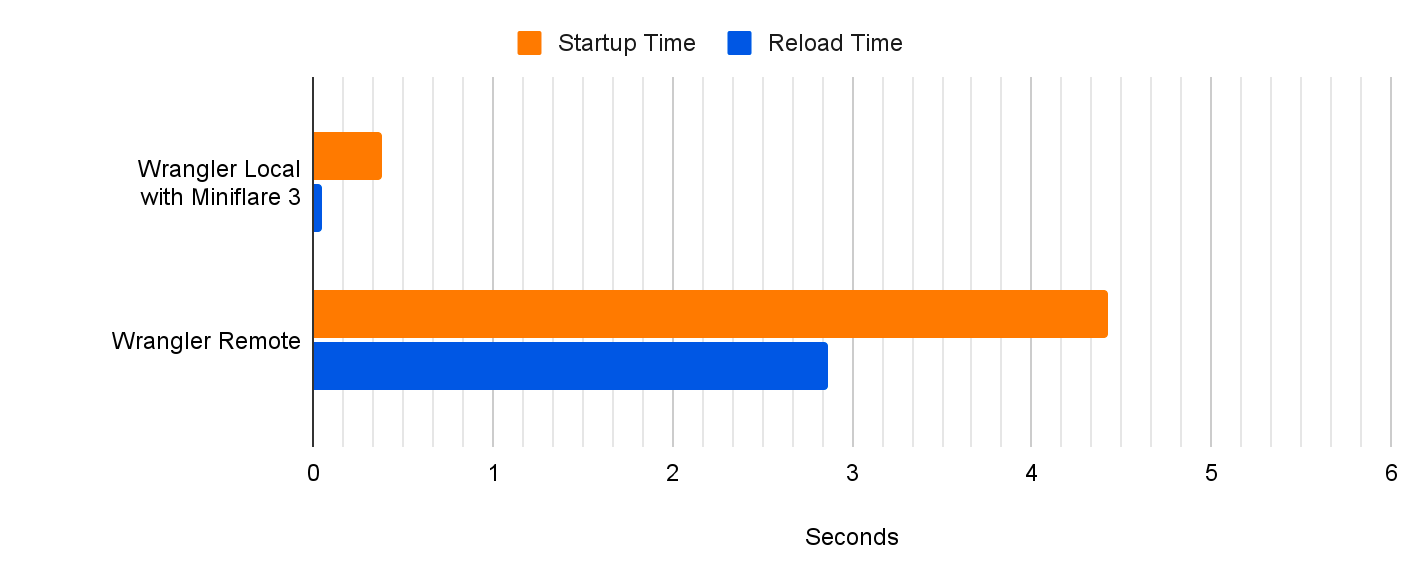
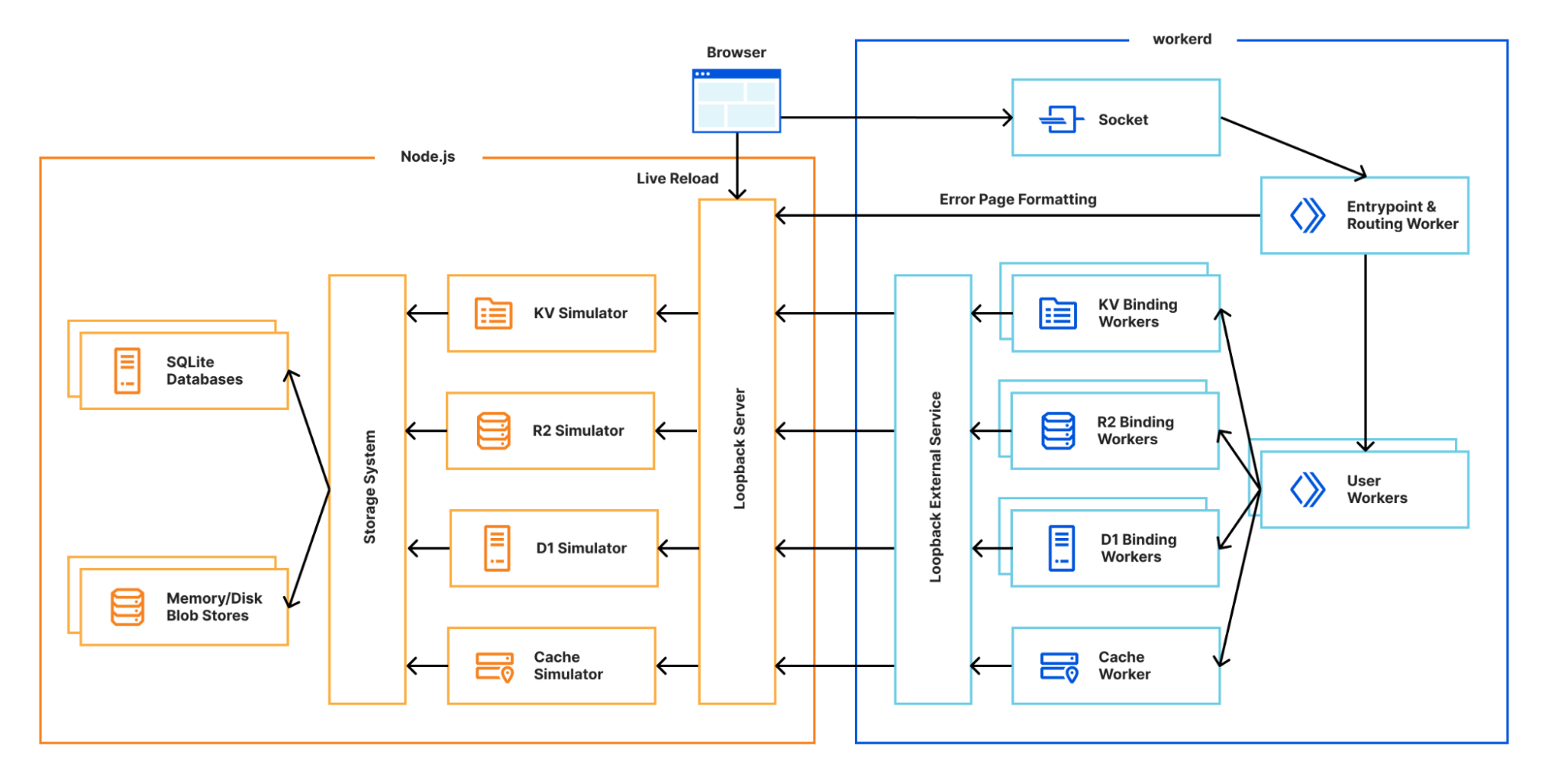
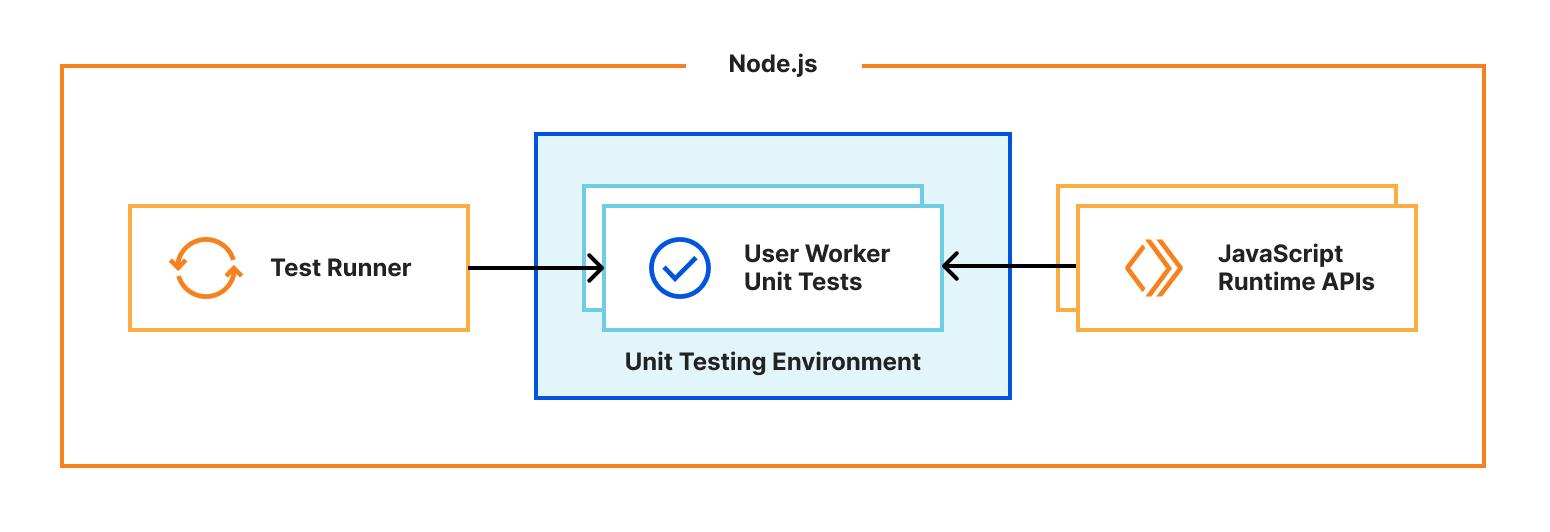
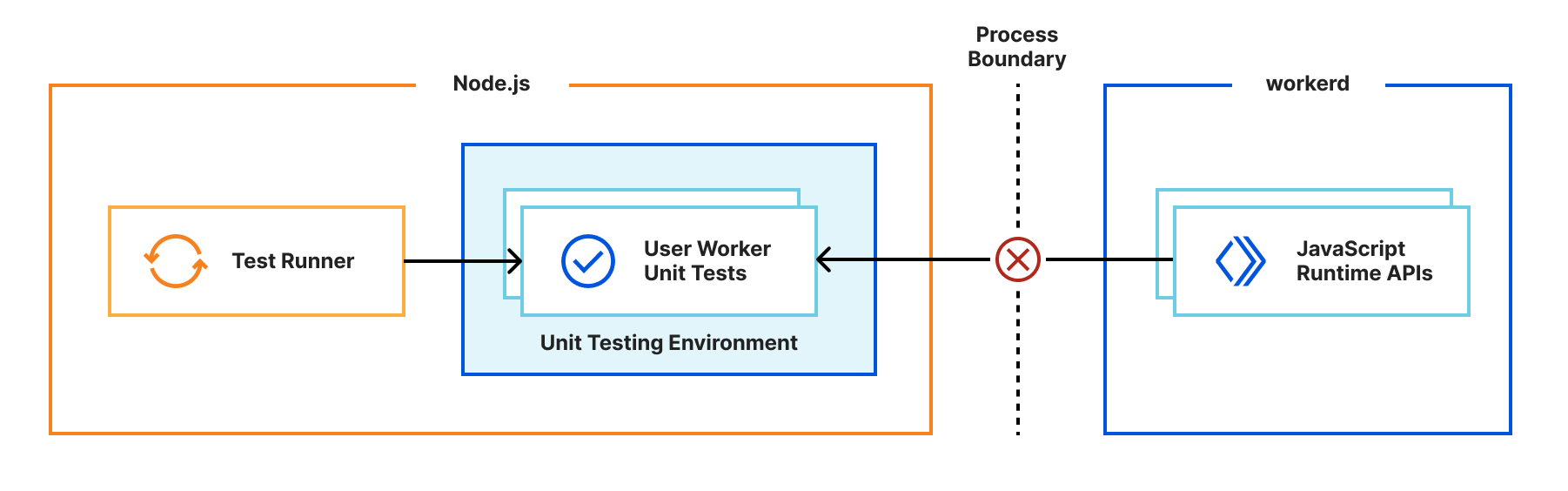
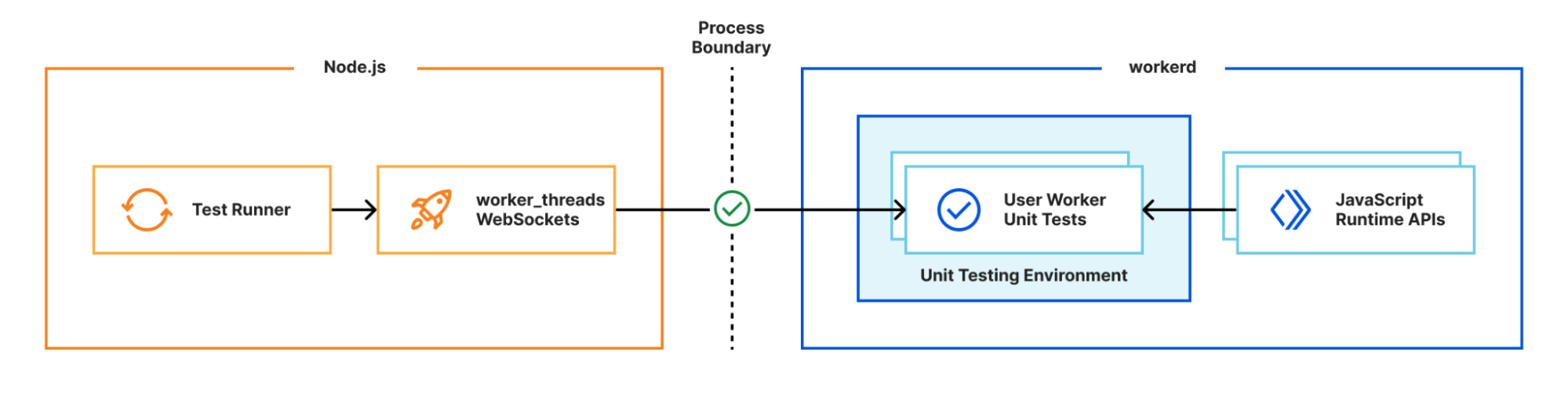
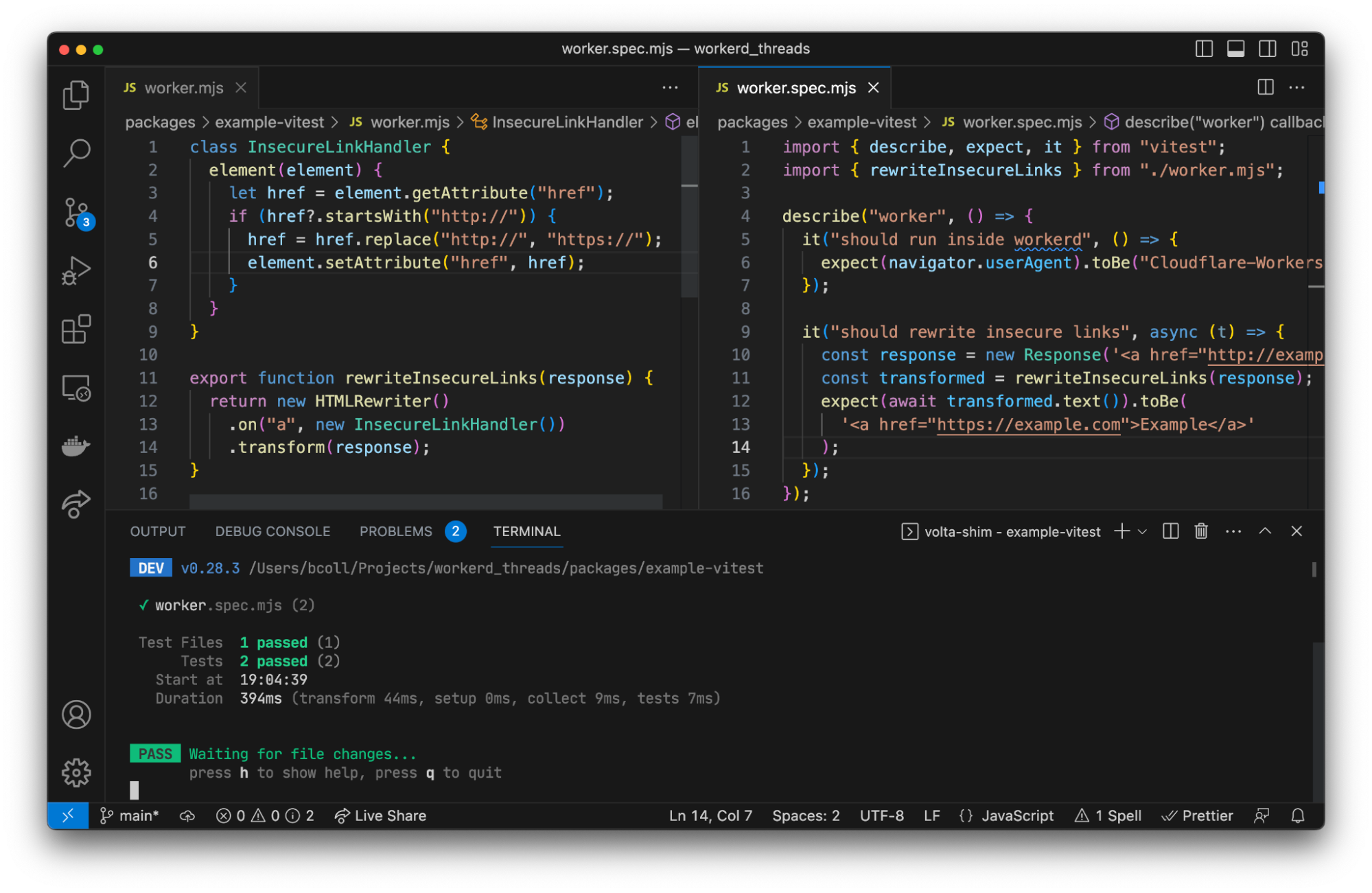




 Sekar Srinivasan is a Sr. Specialist Solutions Architect at AWS focused on Big Data and Analytics. Sekar has over 20 years of experience working with data. He is passionate about helping customers build scalable solutions modernizing their architecture and generating insights from their data. In his spare time he likes to work on non-profit projects focused on underprivileged Children’s education.
Sekar Srinivasan is a Sr. Specialist Solutions Architect at AWS focused on Big Data and Analytics. Sekar has over 20 years of experience working with data. He is passionate about helping customers build scalable solutions modernizing their architecture and generating insights from their data. In his spare time he likes to work on non-profit projects focused on underprivileged Children’s education. Chandra Dhandapani is a Senior Solutions Architect at AWS, where he specializes in creating solutions for customers in Analytics, AI/ML, and Databases. He has a lot of experience in building and scaling applications across different industries including Healthcare and Fintech. Outside of work, he is an avid traveler and enjoys sports, reading, and entertainment.
Chandra Dhandapani is a Senior Solutions Architect at AWS, where he specializes in creating solutions for customers in Analytics, AI/ML, and Databases. He has a lot of experience in building and scaling applications across different industries including Healthcare and Fintech. Outside of work, he is an avid traveler and enjoys sports, reading, and entertainment. Amit Kumar Agrawal is a Senior Solutions Architect at AWS, based out of San Francisco Bay Area. He works with large strategic ISV customers to architect cloud solutions that address their business challenges. During his free time he enjoys exploring the outdoors with his family.
Amit Kumar Agrawal is a Senior Solutions Architect at AWS, based out of San Francisco Bay Area. He works with large strategic ISV customers to architect cloud solutions that address their business challenges. During his free time he enjoys exploring the outdoors with his family. Viral Shah is a Analytics Sales Specialist working with AWS for 5 years helping customers to be successful in their data journey. He has over 20+ years of experience working with enterprise customers and startups, primarily in the data and database space. He loves to travel and spend quality time with his family.
Viral Shah is a Analytics Sales Specialist working with AWS for 5 years helping customers to be successful in their data journey. He has over 20+ years of experience working with enterprise customers and startups, primarily in the data and database space. He loves to travel and spend quality time with his family.


 Bin Qiu is a Global Partner Solutions Architect focusing on ER&I at AWS. He has more than 20 years’ experience in the energy and power industries, designing, leading, and building different smart grid projects, such as distributed energy resources, microgrid, AI/ML implementation for resource optimization, IoT smart sensor application for equipment predictive maintenance, EV car and grid integration, and more. Bin is passionate about helping utilities achieve digital and sustainability transformations.
Bin Qiu is a Global Partner Solutions Architect focusing on ER&I at AWS. He has more than 20 years’ experience in the energy and power industries, designing, leading, and building different smart grid projects, such as distributed energy resources, microgrid, AI/ML implementation for resource optimization, IoT smart sensor application for equipment predictive maintenance, EV car and grid integration, and more. Bin is passionate about helping utilities achieve digital and sustainability transformations. Steve Alexander is a Senior Manager, IT Products at PG&E. He leads product teams building wildfire prevention and risk mitigation data products. Recent work has been focused on integrating data from various sources including weather, asset data, sensors, and dynamic protective devices to improve situational awareness and decision-making. Steve has over 20 years of experience with data systems and cutting-edge IT research and development, and is passionate about applying creative thinking in technical domains.
Steve Alexander is a Senior Manager, IT Products at PG&E. He leads product teams building wildfire prevention and risk mitigation data products. Recent work has been focused on integrating data from various sources including weather, asset data, sensors, and dynamic protective devices to improve situational awareness and decision-making. Steve has over 20 years of experience with data systems and cutting-edge IT research and development, and is passionate about applying creative thinking in technical domains. Karthik Tharmarajan is a Senior Specialist Solutions Architect for Amazon QuickSight. Karthik has over 15 years of experience implementing enterprise business intelligence (BI) solutions and specializes in integration of BI solutions with business applications and enabling data-driven decisions.
Karthik Tharmarajan is a Senior Specialist Solutions Architect for Amazon QuickSight. Karthik has over 15 years of experience implementing enterprise business intelligence (BI) solutions and specializes in integration of BI solutions with business applications and enabling data-driven decisions. Ranjan Banerji is a Principal Partner Solutions Architect at AWS focused on the power and utilities vertical. Ranjan has been at AWS for 5 years, first on the department of defense (DoD) team helping the branches of the DoD migrate and/or build new systems on AWS ensuring security and compliance requirements and now supporting the power and utilities team. Ranjan’s expertise ranges from server less architecture to security and compliance for regulated industries. Ranjan has over 25 years of experience building and designing systems for the DoD, federal agencies, energy, and financial industry.
Ranjan Banerji is a Principal Partner Solutions Architect at AWS focused on the power and utilities vertical. Ranjan has been at AWS for 5 years, first on the department of defense (DoD) team helping the branches of the DoD migrate and/or build new systems on AWS ensuring security and compliance requirements and now supporting the power and utilities team. Ranjan’s expertise ranges from server less architecture to security and compliance for regulated industries. Ranjan has over 25 years of experience building and designing systems for the DoD, federal agencies, energy, and financial industry.