Post Syndicated from Explosm.net original https://explosm.net/comics/ice-sculpture
New Cyanide and Happiness Comic
Post Syndicated from Explosm.net original https://explosm.net/comics/ice-sculpture
New Cyanide and Happiness Comic
Post Syndicated from original https://lwn.net/Articles/924358/
Security updates have been issued by Debian (binwalk, chromium, curl, emacs, frr, git, libgit2, and tiff), Fedora (qt5-qtbase), SUSE (c-ares, kernel, openssl-1_1-livepatches, pesign, poppler, rubygem-activerecord-5_1, and webkit2gtk3), and Ubuntu (linux-aws).
Post Syndicated from digiblurDIY original https://www.youtube.com/watch?v=NAWR19q5JrU
Post Syndicated from Sam Howson original https://blog.cloudflare.com/rust-nginx-module/


At Cloudflare, engineers spend a great deal of time refactoring or rewriting existing functionality. When your company doubles the amount of traffic it handles every year, what was once an elegant solution to a problem can quickly become outdated as the engineering constraints change. Not only that, but when you’re averaging 40 million requests a second, issues that might affect 0.001% of requests flowing through our network are big incidents which may impact millions of users, and one-in-a-trillion events happen several times a day.
Recently, we’ve been working on a replacement to one of our oldest and least-well-known components called cf-html, which lives inside the core reverse web proxy of Cloudflare known as FL (Front Line). Cf-html is the framework in charge of parsing and rewriting HTML as it streams back through from the website origin to the website visitor. Since the early days of Cloudflare, we’ve offered features which will rewrite the response body of web requests for you on the fly. The first ever feature we wrote in this way was to replace email addresses with chunks of JavaScript, which would then load the email address when viewed in a web browser. Since bots are often unable to evaluate JavaScript, this helps to prevent scraping of email addresses from websites. You can see this in action if you view the source of this page and look for this email address: [email protected].
FL is where most of the application infrastructure logic for Cloudflare runs, and largely consists of code written in the Lua scripting language, which runs on top of NGINX as part of OpenResty. In order to interface with NGINX directly, some parts (like cf-html) are written in lower-level languages like C and C++. In the past, there were many such OpenResty services at Cloudflare, but these days FL is one of the few left, as we move other components to Workers or Rust-based proxies. The platform that once was the best possible blend of developer ease and speed has more than started to show its age for us.
When discussing what happens to an HTTP request passing through our network and in particular FL, nearly all the attention is given to what happens up until the request reaches the customer’s origin. That’s understandable as this is where most of the business logic happens: firewall rules, Workers, and routing decisions all happen on the request. But it’s not the end of the story. From an engineering perspective, much of the more interesting work happens on the response, as we stream the HTML response back from the origin to the site visitor.
The logic to handle this is contained in a static NGINX module, and runs in the Response Body Filters phase in NGINX, as chunks of the HTTP response body are streamed through. Over time, more features were added, and the system became known as cf-html. cf-html uses a streaming HTML parser to match on specific HTML tags and content, called Lazy HTML or lhtml, with much of the logic for both it and the cf-html features written using the Ragel state machine engine.
All the cf-html logic was written in C, and therefore was susceptible to memory corruption issues that plague many large C codebases. In 2017 this led to a security bug as the team was trying to replace part of cf-html. FL was reading arbitrary data from memory and appending it to response bodies. This could potentially include data from other requests passing through FL at the same time. This security event became known widely as Cloudbleed.
Since this episode, Cloudflare implemented a number of policies and safeguards to ensure something like that never happened again. While work has been carried out on cf-html over the years, there have been few new features implemented on the framework, and we’re now hyper-sensitive to crashes happening in FL (and, indeed, any other process running on our network), especially in parts that can reflect data back with a response.
Fast-forward to 2022 into 2023, and the FL Platform team have been getting more and more requests for a system they can easily use to look at and rewrite response body data. At the same time, another team has been working on a new response body parsing and rewriting framework for Workers called lol-html or Low Output Latency HTML. Not only is lol-html faster and more efficient than Lazy HTML, but it’s also currently in full production use as part of the Worker interface, and written in Rust, which is much safer than C in terms of its handling of memory. It’s ideal, therefore, as a replacement for the ancient and creaking HTML parser we’ve been using in FL up until now.
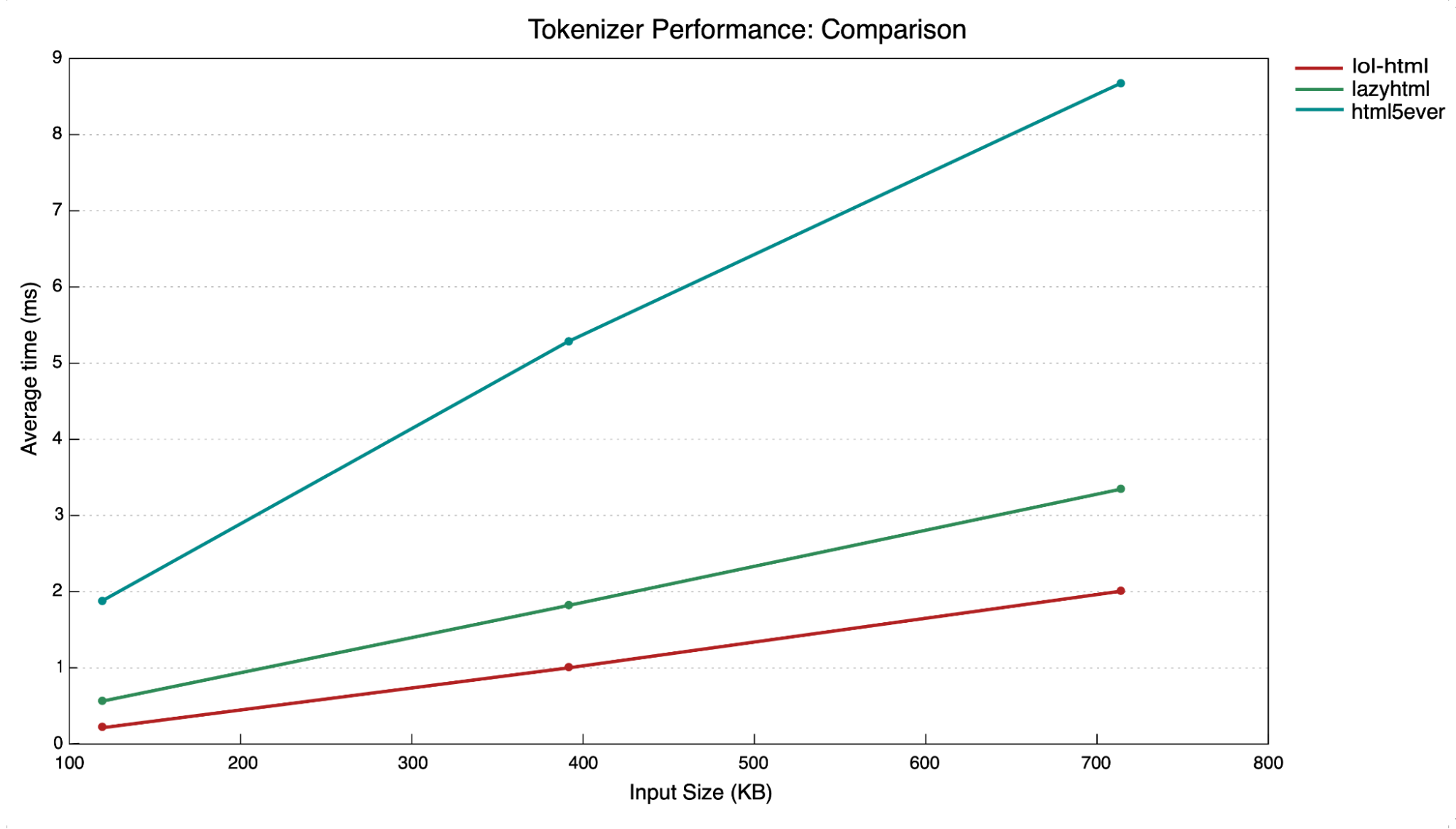
So we started working on a new framework, written in Rust, that would incorporate lol-html and allow other teams to write response body parsing features without the threat of causing massive security issues. The new system is called ROFL or Response Overseer for FL, and it’s a brand-new NGINX module written completely in Rust. As of now, ROFL is running in production on millions of responses a second, with comparable performance to cf-html. In building ROFL, we’ve been able to deprecate one of the scariest bits of code in Cloudflare’s entire codebase, while providing teams at Cloudflare with a robust system they can use to write features which need to parse and rewrite response body data.
While writing the new module, we learned a lot about how NGINX works, and how we can get it to talk to Rust. NGINX doesn’t provide much documentation on writing modules written in languages other than C, and so there was some work which needed to be done to figure out how to write an NGINX module in our language of choice. When starting out, we made heavy use of parts of the code from the nginx-rs project, particularly around the handling of buffers and memory pools. While writing a full NGINX module in Rust is a long process and beyond the scope of this blog post, there are a few key bits that make the whole thing possible, and that are worth talking about.
The first one of these is generating the Rust bindings so that NGINX can communicate with it. To do that, we used Rust’s library Bindgen to build the FFI bindings for us, based on the symbol definitions in NGINX’s header files. To add this to an existing Rust project, the first thing is to pull down a copy of NGINX and configure it. Ideally this would be done in a simple script or Makefile, but when done by hand it would look something like this:
$ git clone --depth=1 https://github.com/nginx/nginx.git
$ cd nginx
$ ./auto/configure --without-http_rewrite_module --without-http_gzip_module
With NGINX in the right state, we need to create a build.rs file in our Rust project to auto-generate the bindings at build-time of the module. We’ll now add the necessary arguments to the build, and use Bindgen to generate us the bindings.rs file. For the arguments, we just need to include all the directories that may contain header files for clang to do its thing. We can then feed them into Bindgen, along with some allowlist arguments, so it knows for what things it should generate the bindings, and which things it can ignore. Adding a little boilerplate code to the top, the whole file should look something like this:
use std::env;
use std::path::PathBuf;
fn main() {
println!("cargo:rerun-if-changed=build.rs");
let clang_args = [
"-Inginx/objs/",
"-Inginx/src/core/",
"-Inginx/src/event/",
"-Inginx/src/event/modules/",
"-Inginx/src/os/unix/",
"-Inginx/src/http/",
"-Inginx/src/http/modules/"
];
let bindings = bindgen::Builder::default()
.header("wrapper.h")
.layout_tests(false)
.allowlist_type("ngx_.*")
.allowlist_function("ngx_.*")
.allowlist_var("NGX_.*|ngx_.*|nginx_.*")
.parse_callbacks(Box::new(bindgen::CargoCallbacks))
.clang_args(clang_args)
.generate()
.expect("Unable to generate bindings");
let out_path = PathBuf::from(env::var("OUT_DIR").unwrap());
bindings.write_to_file(out_path.join("bindings.rs"))
.expect("Unable to write bindings.");
}
Hopefully this is all fairly self-explanatory. Bindgen traverses the NGINX source and generates equivalent constructs in Rust in a file called bindings.rs, which we can import into our project. There’s just one more thing to add- Bindgen has trouble with a couple of symbols in NGINX, which we’ll need to fix in a file called wrapper.h. It should have the following contents:
#include <ngx_http.h>
const char* NGX_RS_MODULE_SIGNATURE = NGX_MODULE_SIGNATURE;
const size_t NGX_RS_HTTP_LOC_CONF_OFFSET = NGX_HTTP_LOC_CONF_OFFSET;
With this in place and Bindgen set in the [build-dependencies] section of the Cargo.toml file, we should be ready to build.
$ cargo build
Compiling rust-nginx-module v0.1.0 (/Users/sam/cf-repos/rust-nginx-module)
Finished dev [unoptimized + debuginfo] target(s) in 4.70s
With any luck, we should see a file called bindings.rs in the target/debug/build directory, which contains Rust definitions of all the NGINX symbols.
$ find target -name 'bindings.rs'
target/debug/build/rust-nginx-module-c5504dc14560ecc1/out/bindings.rs
$ head target/debug/build/rust-nginx-module-c5504dc14560ecc1/out/bindings.rs
/* automatically generated by rust-bindgen 0.61.0 */
[...]
To be able to use them in the project, we can include them in a new file under the src directory which we’ll call bindings.rs.
$ cat > src/bindings.rs
include!(concat!(env!("OUT_DIR"), "/bindings.rs"));
With that set, we just need to add the usual imports to the top of the lib.rs file, and we can access NGINX constructs from Rust. Not only does this make bugs in the interface between NGINX and our Rust module much less likely than if these values were hand-coded, but it’s also a fantastic reference we can use to check the structure of things in NGINX when building modules in Rust, and it takes a lot of the leg-work out of setting everything up. It’s really a testament to the quality of a lot of Rust libraries such as Bindgen that something like this can be done with so little effort, in a robust way.
Once the Rust library has been built, the next step is to hook it into NGINX. Most NGINX modules are compiled statically. That is, the module is compiled as part of the compilation of NGINX as a whole. However, since NGINX 1.9.11, it has supported dynamic modules, which are compiled separately and then loaded using the load_module directive in the nginx.conf file. This is what we needed to use to build ROFL, so that the library could be compiled separately and loaded-in at the time NGINX starts up. Finding the right format so that the necessary symbols could be found from the documentation was tricky, though, and although it is possible to use a separate config file to set some of this metadata, it’s better if we can load it as part of the module, to keep things neat. Luckily, it doesn’t take much spelunking through the NGINX codebase to find where dlopen is called.
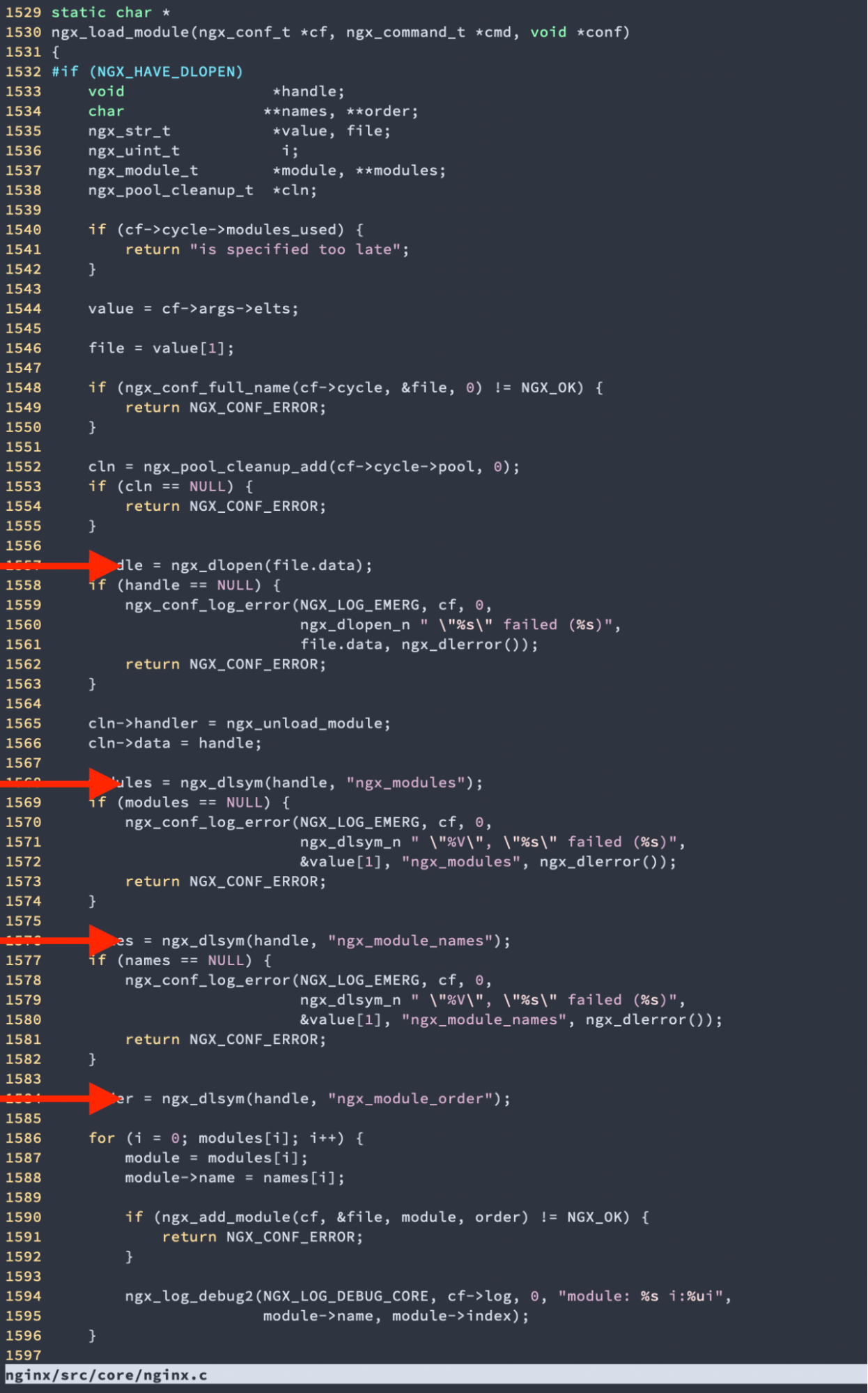
So after that it’s just a case of making sure the relevant symbols exist.
use std::os::raw::c_char;
use std::ptr;
#[no_mangle]
pub static mut ngx_modules: [*const ngx_module_t; 2] = [
unsafe { rust_nginx_module as *const ngx_module_t },
ptr::null()
];
#[no_mangle]
pub static mut ngx_module_type: [*const c_char; 2] = [
"HTTP_FILTER\0".as_ptr() as *const c_char,
ptr::null()
];
#[no_mangle]
pub static mut ngx_module_names: [*const c_char; 2] = [
"rust_nginx_module\0".as_ptr() as *const c_char,
ptr::null()
];
When writing an NGINX module, it’s crucial to get its order relative to the other modules correct. Dynamic modules get loaded as NGINX starts, which means they are (perhaps counterintuitively) the first to run on a response. Ensuring your module runs after gzip decompression by specifying its order relative to the gunzip module is essential, otherwise you can spend lots of time staring at streams of unprintable characters, wondering why you aren’t seeing the response you expected. Not fun. Fortunately this is also something that can be solved by looking at the NGINX source, and making sure the relevant entities exist in your module. Here’s an example of what you might set-
pub static mut ngx_module_order: [*const c_char; 3] = [
"rust_nginx_module\0".as_ptr() as *const c_char,
"ngx_http_headers_more_filter_module\0".as_ptr() as *const c_char,
ptr::null()
];
We’re essentially saying we want our module rust_nginx_module to run just before the ngx_http_headers_more_filter_module module, which should allow it to run in the place we expect.
One of the quirks of NGINX and OpenResty is how it is really hostile to making calls to external services at the point that you’re dealing with the HTTP response. It’s something that isn’t provided as part of the OpenResty Lua framework, even though it would make working with the response phase of a request much easier. While we could do this anyway, that would mean having to fork NGINX and OpenResty, which would bring its own challenges. As a result, we’ve spent a lot of time over the years thinking about ways to pass state from the time when NGINX’s dealing with an HTTP request, over to the time when it’s streaming through the response, and much of our logic is built around this style of work.
For ROFL, that means in order to determine if we need to apply a certain feature for a response, we need to figure that out on the request, then pass that information over to the response so that we know which features to activate. To do that, we need to use one of the utilities that NGINX provides you with. With the help of the bindings.rs file generated earlier, we can take a look at the definition of the ngx_http_request_s struct, which contains all the state associated with a given request:
#[repr(C)]
#[derive(Debug, Copy, Clone)]
pub struct ngx_http_request_s {
pub signature: u32,
pub connection: *mut ngx_connection_t,
pub ctx: *mut *mut ::std::os::raw::c_void,
pub main_conf: *mut *mut ::std::os::raw::c_void,
pub srv_conf: *mut *mut ::std::os::raw::c_void,
pub loc_conf: *mut *mut ::std::os::raw::c_void,
pub read_event_handler: ngx_http_event_handler_pt,
pub write_event_handler: ngx_http_event_handler_pt,
pub cache: *mut ngx_http_cache_t,
pub upstream: *mut ngx_http_upstream_t,
pub upstream_states: *mut ngx_array_t,
pub pool: *mut ngx_pool_t,
pub header_in: *mut ngx_buf_t,
pub headers_in: ngx_http_headers_in_t,
pub headers_out: ngx_http_headers_out_t,
pub request_body: *mut ngx_http_request_body_t,
[...]
}
As we can see, there’s a member called ctx. As the NGINX Development Guide mentions, it’s a place where you’re able to store any value associated with a request, which should live for as long as the request does. In OpenResty this is used heavily for the storing of state to do with a request over its lifetime in a Lua context. We can do the same thing for our module, so that settings initialised during the request phase are there when our HTML parsing and rewriting is run in the response phase. Here’s an example function which can be used to get the request ctx:
pub fn get_ctx(request: &ngx_http_request_t) -> Option<&mut Ctx> {
unsafe {
match *request.ctx.add(ngx_http_rofl_module.ctx_index) {
p if p.is_null() => None,
p => Some(&mut *(p as *mut Ctx)),
}
}
}
Notice that ctx is at the offset of the ctx_index member of ngx_http_rofl_module – this is the structure of type ngx_module_t that’s part of the module definition needed to make an NGINX module. Once we have this, we can point it to a structure containing any setting we want. For example, here’s the actual function we use to enable the Email Obfuscation feature from Lua, via FFI to the Rust module using LuaJIT’s FFI tools:
#[no_mangle]
pub extern "C" fn rofl_module_email_obfuscation_new(
request: &mut ngx_http_request_t,
dry_run: bool,
decode_script_url: *const u8,
decode_script_url_len: usize,
) {
let ctx = context::get_or_init_ctx(request);
let decode_script_url = unsafe {
std::str::from_utf8(std::slice::from_raw_parts(decode_script_url, decode_script_url_len))
.expect("invalid utf-8 string for decode script")
};
ctx.register_module(EmailObfuscation::new(decode_script_url.to_owned()), dry_run);
}
The function is called get_or_init_ctx here- it performs the same job as get_ctx, but also initialises the structure if it doesn’t exist yet. Once we’ve set whatever data we need in ctx during the request, we can then check what features need to be run in the response, without having to make any calls to external databases, which might slow us down.
One of the nice things about storing state on ctx in this way, and working with NGINX in general, is that it relies heavily on memory pools to store request content. This largely removes any need for the programmer to have to think about freeing memory after use- the pool is automatically allocated at the start of a request, and is automatically freed when the request is done. All that’s needed is to allocate the memory using NGINX’s built-in functions for allocating memory to the pool and then registering a callback that will be called to free everything. In Rust, that would look something like the following:
pub struct Pool<'a>(&'a mut ngx_pool_t);
impl<'a> Pool<'a> {
/// Register a cleanup handler that will get called at the end of the request.
fn add_cleanup<T>(&mut self, value: *mut T) -> Result<(), ()> {
unsafe {
let cln = ngx_pool_cleanup_add(self.0, 0);
if cln.is_null() {
return Err(());
}
(*cln).handler = Some(cleanup_handler::<T>);
(*cln).data = value as *mut c_void;
Ok(())
}
}
/// Allocate memory for a given value.
pub fn alloc<T>(&mut self, value: T) -> Option<&'a mut T> {
unsafe {
let p = ngx_palloc(self.0, mem::size_of::<T>()) as *mut _ as *mut T;
ptr::write(p, value);
if let Err(_) = self.add_cleanup(p) {
ptr::drop_in_place(p);
return None;
};
Some(&mut *p)
}
}
}
unsafe extern "C" fn cleanup_handler<T>(data: *mut c_void) {
ptr::drop_in_place(data as *mut T);
}
This should allow us to allocate memory for whatever we want, safe in the knowledge that NGINX will handle it for us.
It is regrettable that we have to write a lot of unsafe blocks when dealing with NGINX’s interface in Rust. Although we’ve done a lot of work to minimise them where possible, unfortunately this is often the case with writing Rust code which has to manipulate C constructs through FFI. We have plans to do more work on this in the future, and remove as many lines as possible from unsafe.
The NGINX module system allows for a massive amount of flexibility in terms of the way the module itself works, which makes it very accommodating to specific use-cases, but that flexibility can also lead to problems. One that we ran into had to do with the way the response data is handled between Rust and FL. In NGINX, response bodies are chunked, and these chunks are then linked together into a list. Additionally, there may be more than one of these linked lists per response, if the response is large.
Efficiently handling these chunks means processing them and passing them on as quickly as possible. When writing a Rust module for manipulating responses, it’s tempting to implement a Rust-based view into these linked lists. However, if you do that, you must be sure to update both the Rust-based view and the underlying NGINX data structures when mutating them, otherwise this can lead to serious bugs where Rust becomes out of sync with NGINX. Here’s a small function from an early version of ROFL that caused headaches:
fn handle_chunk(&mut self, chunk: &[u8]) {
let mut free_chain = self.chains.free.borrow_mut();
let mut out_chain = self.chains.out.borrow_mut();
let mut data = chunk;
self.metrics.borrow_mut().bytes_out += data.len() as u64;
while !data.is_empty() {
let free_link = self
.pool
.get_free_chain_link(free_chain.head, self.tag, &mut self.metrics.borrow_mut())
.expect("Could not get a free chain link.");
let mut link_buf = unsafe { TemporaryBuffer::from_ngx_buf(&mut *(*free_link).buf) };
data = link_buf.write_data(data).unwrap_or(b"");
out_chain.append(free_link);
}
}
What this code was supposed to do is take the output of lol-html’s HTMLRewriter, and write it to the output chain of buffers. Importantly, the output can be larger than a single buffer, so you need to take new buffers off the chain in a loop until you’ve written all the output to buffers. Within this logic, NGINX is supposed to take care of popping the buffer off the free chain and appending the new chunk to the output chain, which it does. However, if you’re only thinking in terms of the way NGINX handles its view of the linked list, you may not notice that Rust never changes which buffer its free_chain.head points to, causing the logic to loop forever and the NGINX worker process to lock-up completely. This sort of issue can take a long time to track down, especially since we couldn’t reproduce it on our personal machines until we understood it was related to the response body size.
Getting a coredump to perform some analysis with gdb was also hard because once we noticed it happening, it was already too late and the process memory had grown to the point the server was in danger of falling over, and the memory consumed was too large to be written to disk. Fortunately, this code never made it to production. As ever, while Rust’s compiler can help you to catch a lot of common mistakes, it can’t help as much if the data is being shared via FFI from another environment, even without much direct use of unsafe, so extra care must be taken in these cases, especially when NGINX allows the kind of flexibility that might lead to a whole machine being taken out of service.
Another major challenge we faced had to do with backpressure from incoming response body chunks. In essence, if ROFL increased the size of the response due to having to inject some large amount of code into the stream (such as replacing an email address with a large chunk of JavaScript), NGINX can feed the output from ROFL to the other downstream modules faster than they could push it along, potentially leading to data being dropped and HTTP response bodies being truncated if the EAGAIN error from the next module is left unhandled. This was another case where the issue was really hard to test, because most of the time the response would be flushed fast enough for backpressure never to be a problem. To handle this, we had to create a special chain to store these chunks called saved_in, which required a special method for appending to it.
#[derive(Debug)]
pub struct Chains {
/// This saves buffers from the `in` chain that were not processed for any reason (most likely
/// backpressure for the next nginx module).
saved_in: RefCell<Chain>,
pub free: RefCell<Chain>,
pub busy: RefCell<Chain>,
pub out: RefCell<Chain>,
[...]
}
Effectively we’re ‘queueing’ the data for a short period of time so that we don’t overwhelm the other modules by feeding them data faster than they can handle it. The NGINX Developer Guide has a lot of great information, but many of its examples are trivial to the point where issues like this don’t come up. Things such as this are the result of working in a complex NGINX-based environment, and need to be discovered independently.
The obvious question a lot of people might ask is: why are we still using NGINX? As already mentioned, Cloudflare is well on its way to replacing components that either used to run NGINX/OpenResty proxies, or would have done without heavy investment in home-grown platforms. That said, some components are easier to replace than others and FL, being where most of the logic for Cloudflare’s application services runs, is definitely on the more challenging end of the spectrum.
Another motivating reason for doing this work is that whichever platform we eventually migrate to, we’ll need to run the features that make up cf-html, and in order to do that we’ll want to have a system that is less heavily integrated and dependent on NGINX. ROFL has been specifically designed with the intention of running it in multiple places, so it will be easy to move it to another Rust-based web proxy (or indeed our Workers platform) without too much trouble. That said it’s hard to imagine we’d be in the same place without a language like Rust, which offers speed at the same time as a high degree of safety, not to mention high-quality libraries like Bindgen and Serde. More broadly, the FL team are working to migrate other aspects of the platform over to Rust, and while cf-html and the features of which make it up are a key part of our infrastructure that needed work, there are many others.
Safety in programming languages is often seen as beneficial in terms of preventing bugs, but as a company we’ve found that it also allows you to do things which would be considered very hard, or otherwise impossible to do safely. Whether it be providing a Wireshark-like filter language for writing firewall rules, allowing millions of users to write arbitrary JavaScript code and run it directly on our platform or rewriting HTML responses on the fly, having strict boundaries in place allows us to provide services we wouldn’t be able to otherwise, all while safe in the knowledge that the kind of memory-safety issues that used to plague the industry are increasingly a thing of the past.
If you enjoy rewriting code in Rust, solving challenging application infrastructure problems and want to help maintain the busiest web server in the world, we’re hiring!
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=X80b8oOsNk8
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2023/02/putting-undetectable-backdoors-in-machine-learning-models.html
This is really interesting research from a few months ago:
Abstract: Given the computational cost and technical expertise required to train machine learning models, users may delegate the task of learning to a service provider. Delegation of learning has clear benefits, and at the same time raises serious concerns of trust. This work studies possible abuses of power by untrusted learners.We show how a malicious learner can plant an undetectable backdoor into a classifier. On the surface, such a backdoored classifier behaves normally, but in reality, the learner maintains a mechanism for changing the classification of any input, with only a slight perturbation. Importantly, without the appropriate “backdoor key,” the mechanism is hidden and cannot be detected by any computationally-bounded observer. We demonstrate two frameworks for planting undetectable backdoors, with incomparable guarantees.
First, we show how to plant a backdoor in any model, using digital signature schemes. The construction guarantees that given query access to the original model and the backdoored version, it is computationally infeasible to find even a single input where they differ. This property implies that the backdoored model has generalization error comparable with the original model. Moreover, even if the distinguisher can request backdoored inputs of its choice, they cannot backdoor a new inputa property we call non-replicability.
Second, we demonstrate how to insert undetectable backdoors in models trained using the Random Fourier Features (RFF) learning paradigm (Rahimi, Recht; NeurIPS 2007). In this construction, undetectability holds against powerful white-box distinguishers: given a complete description of the network and the training data, no efficient distinguisher can guess whether the model is “clean” or contains a backdoor. The backdooring algorithm executes the RFF algorithm faithfully on the given training data, tampering only with its random coins. We prove this strong guarantee under the hardness of the Continuous Learning With Errors problem (Bruna, Regev, Song, Tang; STOC 2021). We show a similar white-box undetectable backdoor for random ReLU networks based on the hardness of Sparse PCA (Berthet, Rigollet; COLT 2013).
Our construction of undetectable backdoors also sheds light on the related issue of robustness to adversarial examples. In particular, by constructing undetectable backdoor for an “adversarially-robust” learning algorithm, we can produce a classifier that is indistinguishable from a robust classifier, but where every input has an adversarial example! In this way, the existence of undetectable backdoors represent a significant theoretical roadblock to certifying adversarial robustness.
Turns out that securing ML systems is really hard.
Post Syndicated from Емилия Милчева original https://www.toest.bg/kak-radev-postavi-bulgaria-na-kartata/

Президентът Румен Радев постави България на международната сцена – и тази заслуга трябва да му бъде призната. Постави я така, че всички я забелязаха – с поредица от изявления, че войната в Украйна трябва да се реши с дипломатически средства. Подразбира се, че Русия ще запази завоюваните окупирани територии, а на военната подкрепа за Киев е най-добре да се сложи край, що се отнася до България.
Този човек не предлага мир, не предлага войната да се прекрати, защото не предлага основното – Русия да напусне нашата територия. Той ни предлага да застанем на колене и да продължаваме да позволяваме нашите деца да бъдат убивани,
коментира в „120 минути“ по bTV Михайло Подоляк, съветник на украинския държавен глава Володимир Зеленски.
Българският президент, както и останалите на планетата, живее в свят, в който ядрена сила, член на Съвета за сигурност на ООН, напада независима европейска държава, за да откъсне територии от нея. Това е на първи план. На втори, битката е епична – сражават се демократичният свят и контролираната демокрация, либералните ценности срещу конституционната диктатура. „Заедно сме, за да защитим Европа“, както каза в Европейския парламент украинският президент. Когато войната на Русия срещу Украйна приключи, единственото, което ще се помни, е изборът – кой на чия страна е застанал.
Благодарение на българския държавен глава демократичният свят разбра, че един от партньорите му е на позиция, различна от тази, споделяна от общността, към която принадлежи по силата на международни договори. Позицията е не просто различна, тя е диаметрално противоположна. Ако можеше да се изпее, щеше да звучи като „ний не сме веке рая покорна“ в съпровод на руски военен хор, също и „Възраждане“, и БСП, и други хористи. Лайтмотивът е как България трябва да следва своите национални интереси (които да не са в противоречие с руските).
В условията на разпуснат парламент и назначено от него служебно правителство президентът се явява на всички Европейски съвети и той – и само той – е България. Парламентарната демокрация на практика е суспендирана. Радев зачерква парламентарни решения за военна подкрепа на Украйна и се гневи на „част от партиите“:
Недопустимо е немалка част от политическите партии да гледат на българската армия не като гарант за сигурността на страната, а като донор на въоръжените сили на Украйна.
С тези позиции България губи уважението на съюзниците си, а на Русия никога не го е имала. Москва винаги е унижавала България, третирайки я като васал и лакей, но никога – като партньор.
Дори Швейцария, на която Европа е разрешила да бъде неутрална от 1815 г. насам, която не е продала нито един патрон на воюващите в Първата и Втората световна война, възнамерява да преосмисли позицията си и да позволи реекспорт на швейцарски боеприпаси и военно оборудване от други европейски страни. Независимо че неутралитетът ѝ, залегнал в Хагската конвенция, го забранява, Комитетът по политиката на сигурността към Федералния съвет вече предложи законодателни промени в тази посока.
Но Румен Радев, бивш военен, натовски генерал, настоява, че България е приключила с военната подкрепа за Украйна, изпращайки боеприпаси и дреболии за 20 млн. лв., и че който иска това да продължи, не мисли за националната сигурност и боеспособността на българската армия.
Когато президентът втори мандат не вижда по-далеч от кокардата на фуражката си, държавата има системен проблем.
Обвързването на военната помощ за Украйна с боеспособността на българската армия е добър пропаганден прийом. Кой, ако не генерал като президента, ги разбира най-добре тия работи. Но същият този генералпрезидент беше опроверган на два пъти – от Словакия и от Вашингтон – заради твърденията му, че нито една държава, която е дала оръжие на Украйна, не е получила нищо в замяна от страните от НАТО, както и че компенсациите отнемат твърде много време и не трябва да се реализират.
Съединените щати предоставиха 200 млн. долара на Чехия, за да модернизира армията си и да попълни своите запаси след помощта за Украйна. А десетина дни след като Братислава изпрати десетки бронирани машини на Киев, започна да получава танкове от Германия.
Словения праща 28 модернизирани танка M-55S на Киев, а в замяна Берлин дава 35 камиона и пет автомобилни цистерни. Гърция и Германия също се договориха за суапова сделка, при която гръцката страна отпуска 40 бойни машини БМП-1 на пехотата и ще получи германски Marders.
Великобритания, Германия и САЩ се съгласиха да доставят танкове на Украйна, но засега искането на Киев за бойни самолети не е изпълнено поради опасения, че конфликтът може да излезе извън украинските граници. В интервю за Sky News украинският външен министър Дмитро Кулеба увери, че няма да използват изтребителите от Запада за поразяване на цели в Русия.
Примерите за тройни сделки са много, но България отсъства. Така нареченият кръгов обмен започна миналата есен, а сега вече западните държави все повече даряват и доставят директно на Украйна. Въпреки че с решение от 3 ноември м.г. 48-мият парламент задължи служебното правителство, освен да подпомогне Украйна, в срок от един месец „да проведе преговори с правителствата на съюзниците в НАТО и партньорите в Европейския съюз за придобиване, предоставяне или разполагане на заместващи способности или усилващ отбранителните ни способности капацитет, което да позволи ускореното освобождаване от остарялото съветско въоръжение и техника“.
Резултатите показват, че това не е направено. Преди дни министърът на отбраната и бивш съветник на президента Димитър Стоянов потвърди по bTV („Лице в лице“), че „към момента не можем да си позволим предоставяне на въоръжение на Украйна“. Ако има възможност за „триъгълна сделка“, тя отново трябва да мине през парламента, няма как правителството да вземе такова решение, каза Стоянов.
Военният министър даде на заден и за искането за предоставяне на боеприпаси за Украйна, отправено от върховния представител на ЕС по външната политика и сигурността Жозеп Борел до всички страни членки. България не разполага със 155-милиметрови гаубици, а предоставяне на зенитноракетни комплекси означава да загубим въздушен суверенитет, публично заяви Стоянов.
Всички системи, с които разполагат българските противовъздушни сили, са съветско въоръжение, като най-новите – С-300, са от 90-те години на миналия век. Докато съседна Румъния вече е приела първите две от поръчаните общо четири противовъздушни системи Patriot, а тестването и приемането на третата и четвъртата ще приключи през април т.г.
България остава със старото съветско въоръжение, което така или иначе ще трябва да се бракува, защото в противен случай изисква средства за поддръжка и резервни части. Отговорността за това е на президента – същия Радев, който доста успешно забави обновяването на военната авиация, и на неговите подчинени министри.
Навременна помощ за Украйна гарантира и българския национален интерес, обявиха от „Демократична България“ в позиция, предизвикана от изявления на президента. Победата на Киев означава и освобождение на България от мечешката „прегръдка“ на Русия.
Заради европейските санкции България се освободи от почти стопроцентовата си газова подчиненост на Русия. На път е да бъде прекратена и петролната зависимост, когато през 2024 г. изтече срокът на дерогацията за България за вноса на руски суров петрол по море. Въпреки заплахите за вето на Унгария и България върху санкции за руската ядрена индустрия руският монопол при доставките на гориво за АЕЦ вече се разрушава. Няколко европейски държави от бившия източен блок, сред които и България, допуснаха нови касети – „Уестингхаус“ и „Фраматом“ ще зареждат V и VI блок на АЕЦ „Козлодуй“.
Руската пропаганда и действията на Радев и служебния кабинет влияят на общественото мнение. „Евробарометър“ измери, че България е страната в ЕС, в която най-малко хора подкрепят финансирането и военната помощ за Украйна – 33%. Само в три страни членки мнозинството от анкетираните не подкрепят тази помощ – Гърция с 59% против (36% за, 5% не могат да вземат решение), България с 57 на сто (10%, които не знаят) и 56% в Словакия (38% за, 6% не знаят). 65 на сто от гражданите на ЕС одобряват тези мерки.
Липсата на действащ парламент оставя в ръцете на Радев и служебния му кабинет ключови за България решения, чиито измерения надхвърлят конкретния исторически момент. След няколко години обаче Радев ще отлети от Президентството. Срамът ще остане.
Post Syndicated from Зорница Христова original https://www.toest.bg/po-bukvite-ivanov-borges-nikolova/

съставителство Яна Букова, София: изд. „Аквариус“, 2022

Отлична е идеята на Даря Хараланова за поредицата „Поет за поета“. Не само защото създава поетически антологии с концептуалната сила на конкретно замислената книга (вместо на случайна сглобка от съществуващи неща), а защото онагледява потенциалните приемствености и структурни връзки в най-новата ни литературна история, която все още стои аморфна и разпиляна в публичното въображение. Ролята на разпоредител в литературноисторическия салон обичайно се заема от идеологията, така че е прекрасно поне в този случай самите поети да решават кой до кого ще седи.
Съставителството на Яна Букова осуетява възможността поезията на Биньо Иванов да бъде четена наивно и сантиментално – нещо, което изобщо не би било изключено, ако се подберат повече от ранните му стихотворения с тяхната ефектна, динамична космология. Особено пък тези, в които локалното е особено осезаемо – като наноси в езика (фолклорно-възрожденската употреба на числителните например), изобилието от природни образи, вкл. установени репери, като планините и Дунав, проблясването на локални думи дори в изцяло екзистенциални стихотворения („до другата трева на мартеница ахнала“) и пр.
„Вятър иде и аз те обичам“ например би могло – и дори би трябвало – да бъде учено наизуст и рецитирано на Трети март редом с Далчевото „само затова, че си родина моя“. Първо, защото представлява един от редките примери на неопосредствано от националните клишета чувство, и второ, заради езиковото съвършенство на първите две строфи (доколкото може да се говори за строфи в този тип поезия) – бързото, плавно движение подлог–сказуемо, подлог–сказуемо, положени в едно разгръщане на дъха и навързани просто, без обяснения („вятър иде и аз те обичам, / изгрев вдига ръка, залез вехне, / облак съхне и аз те обичам“), а после насечения ритъм на безглаголни фрази, метафори за родината.
Стихотворенията от този период биха могли да бъдат четени удобно с акцент върху тази поетика. Това обаче би представило Биньо Иванов в невярна светлина. Защото в късните си стихотворения, както тази антология доказва, той става рязко неупотребим за какъвто и да било наивен прочит – било национално сантиментален („дишам в тебе, гина в тебе, коренче“ и после „родино моя родна, отечество привидно, / което си мобилизира граници, границите – граничари, / граничарите – кучета“), било дори езиково сантиментален в допускането, че читателят има спокойствието да разчита на плавен и ароматизиран досег със смисъла. Послесловът на Яна Букова говори за сблъсъци вътре в езика; това, което се случва в късните стихотворения на Биньо Иванов, по някакъв начин ми напомня на Дилън Томас или на Къмингс:
сълзите-блясъка изсъхналото-сивото краят началото
цигарата кислорода алкохола водата устните зъбите
целувката отпечатъка храната гладът, проклета мила,
мила
проклета!
Преди чуждестранните препратки обаче има нужда от внятен разказ за българската поезия от последните десетилетия на XX век и мястото на Биньо Иванов в нея – да речем, спрямо Борис Христов и Ани Илков. Настоящото издание сочи в тази посока.
превод и съставителство Рада Панчовска, илюстрации Капка Кънева, София: изд. „Колибри“, 2022

Тази книга също е антология, също обхваща цялото поетично творчество на своя автор; също е съставена от поетеса – както пише на корицата, „сбогуване на Рада Панчовска с творчеството на Борхес“.
Първият ѝ превод на негови стихотворения – „За ада и рая“, излиза успоредно с превода на „Вавилонската библиотека“ у нас – през 1989 г. Нейната „Поетическа антология 1923–1977“ е издадена в собственото ѝ издателство „Проксима-РП“ през 2016 г. В този смисъл „Възхвала на тъмнината“ не е радикално ново издание, но пък безспорно ще стигне до много хора и ще донесе удоволствие на немалобройните почитатели на Борхес у нас.
Изданието е двуезично, което дава на читателя възможност да оцени трудността на преводаческата задача – стихотворенията, макар и не подчертано звънки, нерядко са римувани и изобщо следват определена формална постройка, а ритъмът на езика е бавен като на обрасла с растителност широка река. Стихотворенията не се поддават на заучаване, дори на четене на глас, което не прави формата им лесна за препредаване – смисловата пауза често е по средата на стиха, дребни нюанси в избора на синоним може да бъдат значими в метафоричния контекст на думата. Не е едно и също дали огледалото ще е „уморено“, или „обезсилено“.
Подобна сложност стои и пред самия читател, ако той рече да разплита смисъла до неговата ежедневна разбираемост. Като че ли стихотворенията предразполагат повече да следваш ритъма на образите и тук-там да запаметяваш онзи, към който искаш да се върнеш пак.
За мен човечност е да чувствам, че сме гласовете на една и съща бедност.
Освободен от паметта и от надеждата, абстрактен, неограничаван, утрешен почти, мъртвецът не е просто мъртъв, а самата смърт. […] Ограбваме му всичко, не му оставяме ни багра, нито сричка.
Ако сънят ни (както се говори) бил е покой, почивка на разсъдъка бездейна, защо усещаш, ако те събудят ненадейно, че от безценно щастие са те лишили?
В тази поезия има някакво тематично постоянство, което не е само в завъртането на ключови и за прозата на Борхес образи – лабиринта, библиотеката, огледалото („уморено“!), анонимния персонаж, чиято прочута самоличност ни се разкрива мигновено – само колкото да видим, че е безвъзвратно изгубена.
Ето пример: в разказа „Безсмъртният“ в последния момент ни се разкрива самоличността на оскотелия Омир; в едно от стихотворенията тук гаснещият старец казва, че е бил (тоест вече не е) Уитман. В друго ръцете, търкащи лещите, принадлежат на Спиноза, който обаче е изгнаник, занаятчия, лишен от символната сила на името си. Но не е само до темите. Усеща се по-скоро стилистичното единство на „Рубайят“ – един общ масив от творби, които не си противоречат помежду си. Така, за разлика от антологията на Биньо Иванов, „Възхвала на тъмнината“ като че ли не би се променила значително, ако я четем безразборно или пък отзад напред.
Принципно, критиката е разделена в оценката си на поезията на Борхес. Някои, като Майкъл Ууд, смятат, че тя е тромава като прозодия и лишена от най-важното, което осветява разказите му – сложната игра с читателя, който никога не може да предскаже следващия ход на писателя из лабиринта на прозата. Други, като Пол де Ман, смятат за най-важна тема на Борхес изковаването на самия стил – и тук поезията е напълно намясто. Лично аз съм благодарна на Рада Панчовска за вниманието и вещината, с които я е предала на български.
София: Издателство за поезия „ДА“, 2022

Говорейки за преводите на „Хиляда и една нощ“ – всички един през друг допълвали, изменяли, нагласяли оригинала спрямо своето време, – Борхес казва, че единственият лош сред тях е верният. Разбира се, това твърдение само по себе си е литература, и то точно онази литература, която носи наслада чрез постоянното изместване на смисъла, играта на ума. Неслучайно „Вавилонската библиотека“ беше обикната у нас по същото време, по което най-голямата литературнотеоретична мода беше деконструкцията.
В книгата на Галина Николова обаче разнородните версии на реалността не са игра между автора и читателя, а вид автотерапия. Езикът е ясен като въздуха в северен пейзаж; читателят е по условие невидим двойник, друго „аз“, отстоящо във времето. Не „уморено огледало“, в което образът се губи, като при Борхес, а „саморефлексия“, тоест вглеждане в собственото отражение, ултразвук, рентген. Сравненията не са случайни – в центъра на много от стихотворенията стои точката на кризата, неназованата рязка загуба, срезът. Няма нужда от назоваване – сам слагаш своя момент на криза върху същото място и проверяваш точността на описаното чувство: когато си идентичен с табелката на болничното си легло; когато внезапно си по-малък от детето си, когато в обаждането „за проверка“ на близките тревогата обърне посоката си, и т.н.
Част от терапевтичната сила на стиховете е в истинността на тези репери – ако ги разпознаеш, ще припознаеш и стратегиите за тяхното преодоляване. Въпреки че тези стратегии са литературни по своята същност – или пък тъкмо затова. Защото и собственото ни въображение често може да бъде „недобросъвестен разказвач“, неуморен писател със слабост към катастрофичните сценарии, измисляч на страхове.
Имам една вътрешна стая, пълна с писатели,
наведени денонощно над своите листове
улавят мисъл за пазаруване на хляб,
приготвяне на вечеря, пътуване
или каквото и да е всъщност
и създават апокалипсис
в няколко изречения.
Справянето с прекомерната дарба на съзнанието да измисля плашещи реалности е през ангажирането му с друга задача – да тръгне в обратната посока, да измисля щастливи реалности, да мечтае. Това решение присъства в три отделни стихотворения – вече цитираното стихотворение с писателите, стихотворението, което завършва с шеговит разговор с персонифицираното въображение, и стихотворението, дало заглавието на книгата. В него се разказва за въображаема градина, в чийто край има гора, а в гората – умираща сърна. Освен ако… понеже градината е въображаема и всъщност ние можем да определим какво се случва, в гората има не умираща, а току-що родила сърна, която побутва малкото си с муцуна.
Колкото и да е странно, езикът и литературата ни влияят до такава степен, че променят начина, по който говорим със себе си. Думите, в които обличаме вътрешните си диалози. Книгата на Галина Николова следи този вътрешен език – наблюдава например кога фразите, с които говорим за себе си, заприличват на инструкции на електроуред; или пък кога думите, с които описваме неудържимото уж влечение, съдържат в себе си предупреждението за краха. И ги променя, използва силата на езика, за да ги пренапише. Електроуредът може да бъде изключен от веригата, оставен да си почине. Пръстите, намокрени вече от водовъртежа, просто ще изсъхнат.
Чудесен урок – да следим литературните волности на вътрешния си монолог поне толкова критично, колкото бихме се отнесли към новоизлязла книга. Благодаря.
Активните дарители на „Тоест“ получават постоянна отстъпка в размер на 20% от коричната цена на всички заглавия от каталозите на „Аквариус“ и „Колибри“, както и на няколко други български издателства в рамките на партньорската програма Читателски клуб „Тоест“. За повече информация прочетете на toest.bg/club.
В емблематичната си колонка, започната още през 2008 г. във в-к „Култура“, Марин Бодаков ни представяше нови литературни заглавия и питаше с какво точно тези книги ни променят. Вярваме, че е важно тази рубрика да продължи. От човек до човек, с нова книга в ръка.
Post Syndicated from Тоест original https://www.toest.bg/stihotvorienie-na-mesetsa-tiho-shte-vali/

(Военно време)
Тихо ще вали и ароматна ще бъде земята,
ще кръжат лястовици и ще блещукат крилата;
ще запеят жабоци в среднощния гьол
и дивата слива ще сложи трепетен воал,
червеношийки, облечени в перушина от плам,
ще свирукат по жиците та-там-тири-рам.
И никой не ще помни войната, нито един
не ще го е грижа след последния пушечен дим,
и нито птиците, ни дърветата ще заплачат,
ако човекът напълно изчезне в здрача;
и самата Пролет, щом се събуди в зори,
едва ли и тя ще узнае, че някога сме били.
(1918)
Сара Тисдейл
превод от английски Димитър Кенаров
Сара Тисдейл (1884–1933) е американска поетеса, авторка на осем стихосбирки, сред които Flame and Shadow (1920) и Strange Victory (1933). Носителка на „Пулицър“ за книгата си Love Songs (1917). Самоубива се през 1933 г.
Димитър Кенаров (р. 1981) е поет, преводач и журналист, автор на книгите „Пътуване към кухнята“ (2001) и „Апокрифни животни“ (2010). Преводач на поезията на Елизабет Бишъп („Крузо в Америка“, 2006) и Джак Гилбърт („Да се откажеш от рая“, 2022).
Според Екатерина Йосифова „четящият стихотворение сутрин… добре понася другите часове“ от деня. Убедени, че поезията държи умовете ни будни, а сърцата – отворени, в края на всеки месец ви предлагаме по едно стихотворение. Защото и в най-смутни времена доброто стихотворение е добра новина.
Post Syndicated from original https://www.toest.bg/myastoto-ukrayna-ne-e-zagubena-s01e06/
След толкова много обстрели ставаш като животно, което сякаш надушва кога идва опасността.

На 24 февруари преди точно една година руската армия нахлу в Украйна. Случи се немислимото за ХХI век – война в Европа. През тези 365 дни Русия подложи Украйна на постоянен обстрел с ракети, а украинците „вече познават по звука какъв тип е снарядът и от какво е изстрелян“.
В страната бяха разрушени болници, училища, детски градини, жилищни блокове, цели села и градове, заради което загинаха хиляди невинни деца и възрастни. В много украински градове бяха извършени зверства от руските войници. „Кланета, изнасилвания… Ужас!“ В навечерието на 2023 г. по нареждане на руската държава в Украйна бяха разрушени топлоцентрали и отоплителна инфраструктура.
Хиляди украински бежанци днес са пръснати в европейски градове. Навсякъде държавите, които ги приемат, се опитват да им осигурят достоен живот. България прави изключение – „тя е държавата, която се отнася с безпрецедентна жестокост към бежанците“. Пак България, за разлика от останалия демократичен свят, е държавата, чийто президент не желае да изпраща военна помощ за Украйна. През това време в Русия пропагандата е толкова могъща, че руснаците не знаят какво се случва наистина в Украйна. „В Русия войната е тема табу. Голяма част от народа там е изпаднал във вътрешна емиграция, за да оцелее, други са напълно зомбирани.“
Това са думите, с които героите ни в този епизод пресъздават своите преживявания в Украйна, България и Русия през тези 365 дни на война. Война, която продължава и до днес.
Автор: Николета Атанасова
Участват: Алла, една украинска жена; Маргарита Шурупова, руска журналистка, избягала в България от режима на Владимир Путин; Десислава Олованова от Фондация „Три жени“; Калоян Константинов, главен редактор на „КлинКлин“, посетил Украйна през 2022 г.; доц. Ирина Перянова, преподавателка в УНСС
Превод от руски: Албена Стаменова и Николета Атанасова
Аудиообработка: Николета Атанасова
Звукови ефекти: Бомбардировка и вой на сирени за тревога в Киев
Звукови среди: Николета Атанасова
Музика: Фрагменти от украинската песен „Червона калина“ в изпълнение на Николета Атанасова и Бойко Амаров
Заглавна снимка: Светлана Йорданова, която изработва брошките „Мир“ в подкрепа на пострадалите от конфликта в Украйна
Поредицата е част от документалния подкаст „Мястото“ с Николета Атанасова.
Абониране: RSS | Spotify | Apple Podcasts | Google Podcasts | Overcast | SoundCloud
Post Syndicated from original https://xkcd.com/2742/

Post Syndicated from Sandeep Adwankar original https://aws.amazon.com/blogs/big-data/introducing-aws-glue-crawlers-using-aws-lake-formation-permission-management/
Data lakes provide a centralized repository that consolidates your data at scale and makes it available for different kinds of analytics. AWS Glue crawlers are a popular way to scan data in a data lake, classify it, extract schema information from it, and store the metadata automatically in the AWS Glue Data Catalog. AWS Lake Formation enables you to centrally govern, secure, and share your data, and lets you scale permissions easily.
We are pleased to announce AWS Glue crawler and Lake Formation integration. You can now use Lake Formation permissions for the crawler’s access to your Lake Formation managed data lakes, whether those are in your account or in other accounts. Before this release, you had to set up AWS Glue crawler IAM role with Amazon Simple Storage Service (Amazon S3) permissions to crawl data source on Amazon S3. And also establish Amazon S3 bucket policies on the source bucket for the crawler role to access S3 data source. Now you can use AWS Lake Formation permission defined on data lake for crawling the data and you no longer need to configure dedicated Amazon S3 permissions for crawlers. AWS Lake Formation manages crawler IAM role access to various Amazon S3 buckets and/or its prefix using data locations permissions to simplify security management. Further you can apply the same security model for crawlers in addition to AWS Glue jobs, Amazon Athena for centralized governance.
When you configure an AWS Glue crawler to use Lake Formation, by default, the crawler uses Lake Formation in the same account to obtain data access credentials. However, you can also configure the crawler to use Lake Formation of a different account by providing an account ID during creation. The cross-account capability allows you to perform permissions management from a central governance account. Customers prefer the central governance experience over writing bucket policies separately in each bucket-owning account. To build a data mesh architecture, you can author permissions in a single Lake Formation governance to manage access to data locations and crawlers spanning multiple accounts in your data lake. You can refer to How to configure a crawler to use Lake Formation credentials for more information.
In this post, we walk through a single in-account architecture that shows how to enable Lake Formation permissions on the data lake, configure an AWS Glue crawler with Lake Formation permission to scan and populate schema from an S3 data lake into the AWS Glue Data Catalog, and then use an analytical engine like Amazon Athena to query the data.
The AWS Glue crawler and Lake Formation integration supports in-account crawling as well as cross-account crawling. You can configure a crawler to use Lake Formation permissions to access an S3 data store or a Data Catalog table with an underlying S3 location within the same AWS account or another AWS account. You can configure an existing Data Catalog table as a crawler’s target if the crawler and the Data Catalog table reside in the same account. The following figure shows the in-account crawling architecture.

Complete the following prerequisite steps:

We set up the solution resources using AWS CloudFormation. Complete the following steps:
LFBusinessAnalyst.Databasename, DataLakeBucket, and GlueCrawlerName.LFBusinessAnalystUserCredentials value to navigate to the AWS Secrets Manager console.
LFBusinessAnalyst.In your account, validate the following resources created by template:
DataLakeBucketvalue value noted from the CloudFormation template.GlueCrawlerName value noted from the CloudFormation template.The template registers the S3 bucket with Lake Formation as the data location. On Lake Formation console left navigation choose Data lake locations under Register and ingest.

The template also grants data location permission on the S3 bucket to the crawler role. On Lake Formation console left navigation choose Data locations under Permissions.

Lastly, the template grants database permission to the crawler role. On Lake Formation console left navigation choose Data lake permissions under Permissions.

To configure and run the AWS Glue crawler, complete the following steps:
lfcrawler-<your-account-id> and edit it.
Note that the crawler IAM role uses Lake Formation permission to access the data and doesn’t have any S3 policies.


lfcrawlerdb<your-account-id>, verify that the table is created and the schema matches with what you have in the S3 bucket.
The crawler was able to crawl the S3 data source and successfully populate the schema using Lake Formation permissions.
Now the data lake admin can delegate permissions on the database and table to the LFBusinessAnalyst user via the Lake Formation console.
Grant the LFBusinessAnalyst IAM user access to the database with Describe permissions.
LFBusinessAnalystlfcrawlerdb<your-accountid> for Databases.
Grant the LFBusinessAnalyst IAM user Select and Describe access to the table.
LFBusinessAnalyst.lfcrawlerdb<your-accountid> for Databases and lf_datalake_<your-accountid>_<region> for Tables
To verify the tables using Athena, complete the following steps:
LFBusinessAnalyst using the password noted earlier through the CloudFormation stack.lfconsumer-primary-workgroup as the Athena workgroup.
We have successfully crawled Amazon S3 data store using the crawler with Lake Formation permission and populated the metadata in AWS Glue Data Catalog. We have granted Lake Formation permission on database and table to consumer user and validated user access to the data using Athena.
To avoid unwanted charges to your AWS account, you can delete the AWS resources:
In this post, we showed how to use the new AWS Glue crawler integration with Lake Formation. Data lake admins can now share crawled tables with data analysts using Lake Formation, allowing analysts to use analytical services such as Athena. You can centrally manage all permissions in Lake Formation, making it easier to administer and protect data lakes.
Special thanks to everyone who contributed to this crawler feature launch: Anshuman Sharma, Jessica Cheng, Aditya K, Sandya Krishnanand
If you have questions or suggestions, submit them in the comments section.
 Sandeep Adwankar is a Senior Technical Product Manager at AWS. Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that enable customers to improve how they manage, secure, and access data.
Sandeep Adwankar is a Senior Technical Product Manager at AWS. Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that enable customers to improve how they manage, secure, and access data.
 Srividya Parthasarathy is a Senior Big Data Architect on the AWS Lake Formation team. She enjoys building data mesh solutions and sharing them with the community.
Srividya Parthasarathy is a Senior Big Data Architect on the AWS Lake Formation team. She enjoys building data mesh solutions and sharing them with the community.
Post Syndicated from Curious Droid original https://www.youtube.com/watch?v=q_9I2i5JypI
Post Syndicated from Adeleke Coker original https://aws.amazon.com/blogs/big-data/configure-adfs-identity-federation-with-amazon-quicksight/
Amazon QuickSight Enterprise edition can integrate with your existing Microsoft Active Directory (AD), providing federated access using Security Assertion Markup Language (SAML) to dashboards. Using existing identities from Active Directory eliminates the need to create and manage separate user identities in AWS Identity Access Management (IAM). Federated users assume an IAM role when access is requested through an identity provider (IdP) such as Active Directory Federation Service (AD FS) based on AD group membership. Although, you can connect AD to QuickSight using AWS Directory Service, this blog focuses on federated logon to QuickSight Dashboards.
With identity federation, your users get one-click access to Amazon QuickSight applications using their existing identity credentials. You also have the security benefit of identity authentication by your IdP. You can control which users have access to QuickSight using your existing IdP. Refer to Using identity federation and single sign-on (SSO) with Amazon QuickSight for more information.
In this post, we demonstrate how you can use a corporate email address as an authentication option for signing in to QuickSight. This post assumes you have an existing Microsoft Active Directory Federation Services (ADFS) configured in your environment.
While connecting to QuickSight from an IdP, your users initiate the sign-in process from the IdP portal. After the users are authenticated, they are automatically signed in to QuickSight. After QuickSight checks that they are authorized, your users can access QuickSight.
The following diagram shows an authentication flow between QuickSight and a third-party IdP. In this example, the administrator has set up a sign-in page to access QuickSight. When a user signs in, the sign-in page posts a request to a federation service that complies with SAML 2.0. The end-user initiates authentication from the sign-in page of the IdP. For more information about the authentication flow, see Initiating sign-on from the identity provider (IdP).

The solution consists of the following high-level steps:
The following are the prerequisites to build the solution explained in this post:
To add your IdP, complete the following steps:
QuickSight_Federation).
In this step, you create IAM policies that allow users to access QuickSight only after federating their identities. To provide access to QuickSight and also the ability to create QuickSight admins, authors (standard users), and readers, use the following policy examples.
The following code is the author policy:
The following code is the reader policy:
The following code is the admin policy:
You can configure email addresses for your users to use when provisioning through your IdP to QuickSight. To do this, add the sts:TagSession action to the trust relationship for the IAM role that you use with AssumeRoleWithSAML. Make sure the IAM role names start with ADFS-.

ADFS-ACCOUNTID-QSAdmin.ADFS-ACCOUNTID-QSAuthor and attach the author IAM policy.ADFS-ACCOUNTID-QSReader and attach the reader IAM policy.Now you need to create AD groups that determine the permissions to sign in to AWS. Create an AD security group for each of the three roles you created earlier. Note that the group name should follow same format as your IAM role names.
One approach for creating the AD groups that uniquely identify the IAM role mapping is by selecting a common group naming convention. For example, your AD groups would start with an identifier, for example AWS-, which will distinguish your AWS groups from others within the organization. Next, include the 12-digit AWS account number. Finally, add the matching role name within the AWS account. You should do this for each role and corresponding AWS account you wish to support with federated access. The following screenshot shows an example of the naming convention we use in this post.

Later in this post, we create a rule to pick up AD groups starting with AWS-, the rule will remove AWS-ACCOUNTID- from AD groups name to match the respective IAM role, which is why we use this naming convention here.
Users in Active Directory can subsequently be added to the groups, providing the ability to assume access to the corresponding roles in AWS. You can add AD users to the respective groups based on your business permissions model. Note that each user must have an email address configured in Active Directory.
To add a relying party trust, complete the following steps:

https://signin.aws.amazon.com/static/saml-metadata.xml.


In this section, you create claim rules that identify accounts, set LDAP attributes, get the AD groups, and match them to the roles created earlier. Complete the following steps to create the claim rules for NameId, RoleSessionName, Get AD Groups, Roles, and (optionally) Session Duration:
NameId with the following parameters:

RoleSessionName with the following parameters:
RoleSessionName.https://aws.amazon.com/SAML/Attributes/RoleSessionName.https://aws.amazon.com/SAML/Attributes/PrincipalTag:Email.
Get AD Groups with the following parameters:

Roles with the following parameters:

Optionally, you can create a rule called Session Duration. This configuration determines how long a session is open and active before users are required to reauthenticate. The value is in seconds. For this post, we configure the rule for 8 hours.
Session Duration with the following parameters:
Session Duration.
You should be able to see these five claim rules, as shown in the following screenshot.

With QuickSight Enterprise edition integrated with an IdP, you can restrict new users from using personal email addresses. This means users can only log in to QuickSight with their on-premises configured email addresses. This approach allows users to bypass manually entering an email address. It also ensures that users can’t use an email address that might differ from the email address configured in Active Directory.
QuickSight uses the preconfigured email addresses passed through the IdP when provisioning new users to your account. For example, you can make it so that only corporate-assigned email addresses are used when users are provisioned to your QuickSight account through your IdP. When you configure email syncing for federated users in QuickSight, users who log in to your QuickSight account for the first time have preassigned email addresses. These are used to register their accounts.
To configure E-mail syncing for federated users in QuickSight, complete the following steps:


To configure the relay state URL, complete the following steps (revise the input information as needed to match your environment’s configuration):
https://ADFSServerEndpoint/adfs/ls/idpinitiatedsignon.aspx.urn:amazon:webservices or https://signin.aws.amazon.com/saml.https://quicksight.aws.amazon.com.
You should be presented with a login to your IdP landing page.

Make sure the user logging in has an email address attribute configured in Active Directory. A successful login should redirect you to the QuickSight dashboard after authentication. If you’re not redirected to the QuickSight dashboard page, make sure you ran the commands listed earlier after you configured your claim rules.
In this post, we demonstrated how to configure federated identities to a QuickSight dashboard and ensure that users can only sign in with preconfigured email address in your existing Active Directory.
We’d love to hear from you. Let us know what you think in the comments section.
 Adeleke Coker is a Global Solutions Architect with AWS. He helps customers globally accelerate workload deployments and migrations at scale to AWS. In his spare time, he enjoys learning, reading, gaming and watching sport events.
Adeleke Coker is a Global Solutions Architect with AWS. He helps customers globally accelerate workload deployments and migrations at scale to AWS. In his spare time, he enjoys learning, reading, gaming and watching sport events.
Post Syndicated from Raghu Boppanna original https://aws.amazon.com/blogs/big-data/how-vanguard-made-their-technology-platform-resilient-and-efficient-by-building-cross-region-replication-for-amazon-kinesis-data-streams/
This is a guest post co-written with Raghu Boppanna from Vanguard.
At Vanguard, the Enterprise Advice line of business improves investor outcomes through digital access to superior, personalized, and affordable financial advice. They made it possible, in part, by driving economies of scale across the globe for investors with a highly resilient and efficient technical platform. Vanguard opted for a multi-Region architecture for this workload to help protect against impairments of Regional services. For high availability purposes, there is a need to make the data used by the workload available not just in the primary Region, but also in the secondary Region with minimal replication lag. In the event of a service impairment in the primary Region, the solution should be able to fail over to the secondary Region with as little data loss as possible and the ability to resume data ingestion.
Vanguard Cloud Technology Office and AWS partnered to build an infrastructure solution on AWS that met their resilience requirements. The multi-Region solution enables a robust fail-over mechanism, with built-in observability and recovery. The solution also supports streaming data from multiple sources to different Kinesis data streams. The solution is currently being rolled out to the different lines of business teams to improve the resilience posture of their workloads.
The use case discussed here requires Change Data Capture (CDC) to stream data from a remote data source (mainframe DB2) to Amazon Kinesis Data Streams, because the business capability depends on this data. Kinesis Data Streams is a fully managed, massively scalable, durable, and low-cost streaming service that can continuously capture and stream large amounts of data from multiple sources, and makes the data available for consumption within milliseconds. The service is built to be highly resilient and uses multiple Availability Zones to process and store data.
The solution discussed in this post explains how AWS and Vanguard innovated to build a resilient architecture to meet their high availability goals.
The solution uses AWS Lambda to replicate data from Kinesis data streams in the primary Region to a secondary Region. In the event of any service impairment impacting the CDC pipeline, the failover process promotes the secondary Region to primary for the producers and consumers. We use Amazon DynamoDB global tables for replication checkpoints that allows to resume data streaming from the checkpoint and also maintains a primary Region configuration flag that prevents an infinite replication loop of the same data back and forth.
The solution also provides the flexibility for Kinesis Data Streams consumers to use the primary or any secondary Region within the same AWS account.
The following diagram illustrates the reference architecture.

Let’s look at each component in detail:
example-stream-1 in this example). The following code is a sample payload containing only the primary key of the record that changed and the commit timestamp (for simplicity, the rest of the table row data is not shown below):
{
"eventSource": "aws:kinesis",
"kinesis":
{
"ApproximateArrivalTimestamp": "Mon July 18 20:00:00 UTC 2022",
"SequenceNumber": "49544985256907370027570885864065577703022652638596431874",
"PartitionKey": "12349999",
"KinesisSchemaVersion": "1.0",
"Data": "eyJLZXkiOiAxMjM0OTk5OSwiQ29tbWl0VGltZXN0YW1wIjogIjIwMjItMDctMThUMjA6MDA6MDAifQ=="
},
"eventId": "shardId-000000000000:49629136582982516722891309362785181370337771525377097730",
"invokeIdentityArn": "arn:aws:iam::6243876582:role/kds-crr-LambdaRole-1GZWP67437SD",
"eventName": "aws:kinesis:record",
"eventVersion": "1.0",
"eventSourceARN": "arn:aws:kinesis:us-east-1:6243876582:stream/kds-stream-1/consumer/kds-crr:6243876582",
"awsRegion": "us-east-1"
}The Base64 decoded value of Data is as follows. The actual Kinesis record would contain the entire row data of the table row that changed, in addition to the primary key and the commit timestamp.
{"Key": 12349999,"CommitTimestamp": "2022-07-18T20:00:00"}
The CommitTimestamp in the Data field is used in the replication checkpoint and is critical to accurately track how much of the stream data has been replicated to the secondary Region. The checkpoint can then be used to facilitate a CDC processor (producer) failover and accurately resume producing data from the replication checkpoint timestamp onwards.
The alternative to using a remote data source CommitTimestamp (if unavailable) is to use the ApproximateArrivalTimestamp (which is the timestamp when the record is actually written to the data stream).
kdsReplicationCheckpoint.kdsActiveRegionConfig and put an item with the following data:
{
"stream-name": "example-stream-1",
"active-region" : "us-east-1"
}
example-stream-1 in both the Regions, with the same shard configuration and access policies.Let’s briefly look at how the architecture is exercised using the following sequence diagram.

The sequence consists of the following steps:
us-east-1) reads the CDC data from the remote data source.us-east-1) streams the CDC data to Kinesis Data Streams (in us-east-1).us-east-1). The enhanced fan-out pattern is recommended for dedicated and increased throughput for cross-Region replication.us-east-1) validates its current Region with the active Region configuration for the stream being consumed, with the help of the kdsActiveRegionConfig DynamoDB global tableThe following sample code (in Java) can help illustrate the condition being evaluated:
// Fetch the current AWS Region from the Lambda function’s environment
String currentAWSRegion = System.getenv(“AWS_REGION”);
// Read the stream name from the first Kinesis Record once for the entire batch being processed. This is done because we are reusing the same Lambda function for replicating multiple streams.
String currentStreamNameConsumed = kinesisRecord.getEventSourceARN().split(“:”)[5].split(“/”)[1];
// Build the DynamoDB query condition using the stream name
Map<String, Condition> keyConditions = singletonMap(“streamName”, Condition.builder().comparisonOperator(EQ).attributeValueList(AttributeValue.builder().s(currentStreamNameConsumed).build()).build());
// Query the DynamoDB Global Table
QueryResponse queryResponse = ddbClient.query(QueryRequest.builder().tableName("kdsActiveRegionConfig").keyConditions(keyConditions).attributesToGet(“ActiveRegion”).build());// Evaluate the response
if (queryResponse.hasItems()) {
AttributeValue activeRegionForStream = queryResponse.items().get(0).get(“ActiveRegion”);
return currentAWSRegion.equalsIgnoreCase(activeRegionForStream.s());
}true, the replicator function produces the records to Kinesis Data Streams in us-east-2 in a sequential manner.
false, the replicator function returns without performing any replication. To reduce the cost of the Lambda invocations, you can set the reserved concurrency of the function in the DR Region (us-east-2) to zero. This will prevent the function from being invoked. When you failover, you can update this value to an appropriate number based on the CDC throughput and set the reserved concurrency of the function in us-east-1 to zero to prevent it from executing unnecessarily.us-east-2, the replicator function checkpoints to the kdsReplicationCheckpoint DynamoDB global table (in us-east-1) with the following data:
{ "streamName": "example-stream-1", "lastReplicatedTimestamp": "2022-07-18T20:00:00" }
The performance expectations of the solution should be understood with respect to the following factors:
It’s recommended to track and observe the replication as it happens. You can tailor the Lambda function to publish custom metrics to CloudWatch with the following metrics at the end of every invocation. Publishing these metrics to both the primary and secondary Regions helps protect yourself from impairments affecting observability in the primary Region.
ApproximateArrivalTimestamp of the last record that was replicatedThe following example CloudWatch metric graph shows the average replication lag was 2 seconds with a throughput of 100 records replicated from us-east-1 to us-east-2.

During any impairments impacting the CDC pipeline in the primary Region, business continuity or disaster recovery needs may dictate a pipeline failover to the secondary (standby) Region. This means a couple of things need to be done as part of this failover process:
us-east-1.kdsActiveRegionConfig DynamoDB global table needs to be updated. For instance, for the stream example-stream-1 used in our example, the active Region is changed to us-east-2:{
"stream-name": "example-stream-1",
"active-Region" : "us-east-2"
}kdsReplicationCheckpoint DynamoDB global table (in us-east-2), and the timestamps from each of the checkpoints are used to start the CDC tasks in the producer tool in us-east-2 Region. This minimizes the chances of data loss and accurately resumes streaming the CDC data from the remote data source from the checkpoint timestamp onwards.us-east-1) and to a suitable non-zero value in the secondary Region(us-east-2).Some of the third-party tools that Vanguard uses have a two-step CDC process of streaming data from a remote data source to a destination. Vanguard’s tool of choice for their CDC processor follows this two-step approach:
Let’s look at an example to explain the scenario:
example-stream-1.example-stream-2.The following sequence diagram demonstrates the exact steps to run during a failover to us-east-2 (the standby Region).

The steps are as follows:
us-east-2 in this example) when required. Note that the trigger can be automated using comprehensive health checks of the pipeline in the primary Region.us-east-2 for all the stream names.kdsReplicationCheckpoint DynamoDB global table (in us-east-2).lastReplicatedTimestamp.us-east-2 with the timestamp found in Step 4. It begins reading CDC data from the remote data source from this timestamp onwards and persists them in the staging location on AWS.kdsReplicationCheckpoint table according to the streamName to which the task streams the data.After all the consumer tasks are started, data is produced to the Kinesis data streams in us-east-2. From there on, the process of cross-Region replication is the same as described earlier – the replication Lambda function in us-east-2 starts replicating data to the data stream in us-east-1.
The consumer applications reading data from the streams are expected to be idempotent to be able to handle duplicates. Duplicates can be introduced in the stream due to many reasons, some of which are called out below.
kdsReplicationCheckpoint table data has a replication lag, the failover process may potentially use an older checkpoint timestamp to replay the CDC data.Also, consumer applications should checkpoint the CommitTimestamp of the last record that was consumed. This is to facilitate better monitoring and recovery.
The ideal state is to fully automate the failover process, reducing time to recover and meeting the resilience Service Level Objective (SLO). However, in most organizations, the decision to fail over, fail back, and trigger the failover requires manual intervention in assessing the situation and deciding the outcome. Creating scripted automation to perform the failover that can be run by a human is a good place to start.
Vanguard has automated all of the steps of failover, but still have humans make the decision on when to invoke it. You can customize the solution to meet your needs and depending on the CDC processor tool you use in your environment.
In this post, we described how Vanguard innovated and built a solution for replicating data across Regions in Kinesis Data Streams to make the data highly available. We also demonstrated a robust checkpoint strategy to facilitate a Regional failover of the replication process when needed. The solution also illustrated how to use DynamoDB global tables for tracking the replication checkpoints and configuration. With this architecture, Vanguard was able to deploy workloads depending on the CDC data to multiple Regions to meet business needs of high availability in the face of service impairments impacting CDC pipelines in the primary Region.
If you have any feedback please leave a comment in the Comments section below.
 Raghu Boppanna works as an Enterprise Architect at Vanguard’s Chief Technology Office. Raghu specializes in Data Analytics, Data Migration/Replication including CDC Pipelines, Disaster Recovery and Databases. He has earned several AWS Certifications including AWS Certified Security – Specialty & AWS Certified Data Analytics – Specialty.
Raghu Boppanna works as an Enterprise Architect at Vanguard’s Chief Technology Office. Raghu specializes in Data Analytics, Data Migration/Replication including CDC Pipelines, Disaster Recovery and Databases. He has earned several AWS Certifications including AWS Certified Security – Specialty & AWS Certified Data Analytics – Specialty.
 Parameswaran V Vaidyanathan is a Senior Cloud Resilience Architect with Amazon Web Services. He helps large enterprises achieve the business goals by architecting and building scalable and resilient solutions on the AWS Cloud.
Parameswaran V Vaidyanathan is a Senior Cloud Resilience Architect with Amazon Web Services. He helps large enterprises achieve the business goals by architecting and building scalable and resilient solutions on the AWS Cloud.
 Richa Kaul is a Senior Leader in Customer Solutions serving Financial Services customers. She is based out of New York. She has extensive experience in large scale cloud transformation, employee excellence, and next generation digital solutions. She and her team focus on optimizing value of cloud by building performant, resilient and agile solutions. Richa enjoys multi sports like triathlons, music, and learning about new technologies.
Richa Kaul is a Senior Leader in Customer Solutions serving Financial Services customers. She is based out of New York. She has extensive experience in large scale cloud transformation, employee excellence, and next generation digital solutions. She and her team focus on optimizing value of cloud by building performant, resilient and agile solutions. Richa enjoys multi sports like triathlons, music, and learning about new technologies.
 Mithil Prasad is a Principal Customer Solutions Manager with Amazon Web Services. In his role, Mithil works with Customers to drive cloud value realization, provide thought leadership to help businesses achieve speed, agility, and innovation.
Mithil Prasad is a Principal Customer Solutions Manager with Amazon Web Services. In his role, Mithil works with Customers to drive cloud value realization, provide thought leadership to help businesses achieve speed, agility, and innovation.
Post Syndicated from Patrick Kennedy original https://www.servethehome.com/supermicro-x12sdv-10c-spt4f-review-intel-xeon-d-1749nt-motherboard/
In our Supermicro X12SDV-10C-SPT4F we see how this mITX platform combines a 10 core Intel Xeon D-1749NT, 25GbE, and 10GbE for edge servers
The post Supermicro X12SDV-10C-SPT4F Review Intel Xeon D-1749NT Motherboard appeared first on ServeTheHome.
Post Syndicated from Stefan Appel original https://aws.amazon.com/blogs/big-data/control-access-to-amazon-opensearch-service-dashboards-with-attribute-based-role-mappings/
Federated users of Amazon OpenSearch Service often need access to OpenSearch Dashboards with roles based on their user profiles. OpenSearch Service fine-grained access control maps authenticated users to OpenSearch Search roles and then evaluates permissions to determine how to handle the user’s actions. However, when an enterprise-wide identity provider (IdP) manages the users, the mapping of users to OpenSearch Service roles often needs to happen dynamically based on IdP user attributes. One option to map users is to use OpenSearch Service SAML integration and pass user group information to OpenSearch Service. Another option is Amazon Cognito role-based access control, which supports rule-based or token-based mappings. But neither approach supports arbitrary role mapping logic. For example, when you need to interpret multivalued user attributes to identify a target role.
This post shows how you can implement custom role mappings with an Amazon Cognito pre-token generation AWS Lambda trigger. For our example, we use a multivalued attribute provided over OpenID Connect (OIDC) to Amazon Cognito. We show how you are in full control of the mapping logic and process of such a multivalued attribute for AWS Identity and Access Management (IAM) role lookups. Our approach is generic for OIDC-compatible IdPs. To make this post self-contained, we use the Okta IdP as an example to walk through the setup.
The provided solution intercepts the OICD-based login process to OpenSearch Dashboards with a pre-token generation Lambda function. The login to OpenSearch Dashboards with a third-party IdP and Amazon Cognito as an intermediary consists of several steps:
The following architecture outlines the login flow from a user’s perspective.

On the backend, OpenSearch Dashboards integrates with an Amazon Cognito user pool and an Amazon Cognito identity pool during the authentication flow. The steps are as follows:
The following architecture shows this backend perspective to the authentication process.

In the remainder of this post, we walk through the configurations necessary for an authentication flow in which a Lambda function implements custom role mapping logic. We provide sample Lambda code for the mapping of multivalued OIDC attributes to IAM roles based on a DynamoDB lookup table with the following structure.
| OIDC Attribute Value | IAM Role |
["attribute_a","attribute_b"] |
arn:aws:iam::<aws-account-id>:role/<role-name-01> |
["attribute_a","attribute_x"] |
arn:aws:iam::<aws-account-id>:role/<role-name-02> |
The high-level steps of the solution presented in this post are as follows:
For this walkthrough, you should have the following prerequisites:
attributes_array as this attribute’s name and Okta as an IdP provider. You can create an Okta Developer Edition free account to test the setup.The modification of authentication tokens requires you to configure the OpenSearch Service domain to use Amazon Cognito for authentication. For instructions, refer to Configuring Amazon Cognito authentication for OpenSearch Dashboards.
The Lambda function implements custom role mappings by setting the cognito:preferred_role claim (for more information, refer to Role-based access control). For the correct interpretation of this claim, set the Amazon Cognito identity pool to Choose role from token. The Amazon Cognito identity pool then uses the value of the cognito:preferred_role claim to select the correct IAM role. The following screenshot shows the required settings in the Amazon Cognito identity pool that is created during the configuration of Amazon Cognito authentication for OpenSearch Service.

IAM roles used for mappings to OpenSearch roles require a trust policy so that authenticated users can assume them. The trust policy needs to reference the Amazon Cognito identity pool created during the configuration of Amazon Cognito authentication for OpenSearch Service. Create at least one IAM role with a custom trust policy. For instructions, refer to Creating a role using custom trust policies. The IAM role doesn’t require the attachment of a permission policy. For a sample trust policy, refer to Role-based access control.
In this section, we describe the configuration steps to include a multivalued attribute_array attribute in the token provided by Okta. For more information, refer to Customize tokens returned from Okta with custom claims. We use the Okta UI to perform the configurations. Okta also provides an API that you can use to script and automate the setup.
The first step is adding the attributes_array attribute to the Okta user profile.
attributes_array of type string array.The following screenshot shows the Okta default user profile after the custom attribute has been added.

attributes_array attribute values to users using Okta’s user management interface under Directory, People.The following screenshot shows an example of attributes_array attribute values within a user profile.

The next step is adding the attributes_array attribute to the ID token that is generated during the authentication process.
default authorization server.attributes_array attribute as part of the ID token.openid and as the attribute value, enter user.attributes_array.This references the previously created attribute in a user’s profile.

The last step assigns the Okta application to Okta users.
We are implementing the role mapping based on the information provided in a multivalued OIDC attribute. The authentication token needs to include this attribute. If you followed the previously described Okta configuration, the attribute is automatically added to the ID token of a user. If you used another IdP, you might have to request the attribute explicitly. For this, add the attribute name to the Authorized scopes list of the IdP in Amazon Cognito.
For instructions on how to set up the federation between a third-party IdP and an Amazon Cognito user pool and how to request additional attributes, refer to Adding OIDC identity providers to a user pool. For a detailed walkthrough for Okta, refer to How do I set up Okta as an OpenID Connect identity provider in an Amazon Cognito user pool.
After requesting the token via OIDC, you need to map the attribute to an Amazon Cognito user pool attribute. For instructions, refer to Specifying identity provider attribute mappings for your user pool. The following screenshot shows the resulting configuration on the Amazon Cognito console.
Upon login, OpenSearch Service maps users to an OpenSearch Service role based on the IAM role ARN set in the cognito:preferred_role claim by the pre-token generation Lambda trigger. This requires a role mapping in OpenSearch Service. To add such role mappings to IAM backend roles, refer to Mapping roles to users. The following screenshot shows a role mapping on the OpenSearch Dashboards console.

For this solution, we use DynamoDB to store mappings of users to IAM roles. For instructions, refer to Create a table and define a partition key named Key of type String. You need the table name in the subsequent step to configure the Lambda function.
The next step is writing the mapping information into the table. A mapping entry consists of the following attributes:
For details on how to add data to a DynamoDB table, refer to Write data to a table using the console or AWS CLI.
For example, if the previously configured OIDC attribute attributes_array contains three values, attribute_a, attribute_b, and attribute_c, the entry in the mapping table looks like table line 1 in the following screenshot.

A Lambda function implements the custom role mapping logic. The Lambda function receives an Amazon Cognito event as input and extracts attribute information out of it. It uses the attribute information for a lookup in a DynamoDB table and retrieves the value for cognito:preferred_role. Follow the steps in Getting started with Lambda to create a Node.js Lambda function and insert the following source code:
The Lambda function expects three environment variables. Refer to Using AWS Lambda environment variables for instructions to add the following entries:
custom:attributes_array.The following screenshot shows the final configuration.

The Lambda function needs permissions to access the DynamoDB lookup table. Set permissions as follows: attach the following policy to the Lambda execution role (for instructions, refer to Lambda execution role) and provide the Region, AWS account number, and DynamoDB table name:
The configuration of the Lambda function is now complete.
As final step, add a pre-token generation trigger to the Amazon Cognito user pool and reference the newly created Lambda function. For details, refer to Customizing user pool workflows with Lambda triggers. The following screenshot shows the configuration.

This step completes the setup; Amazon Cognito now maps users to OpenSearch Service roles based on the values provided in an OIDC attribute.
The following diagram shows an exemplary login flow and the corresponding screenshots for an Okta user user1 with a user profile attribute attribute_array and value: ["attribute_a", "attribute_b", "attribute_c"].

To avoid incurring future charges, delete the OpenSearch Service domain, Amazon Cognito user pool and identity pool, Lambda function, and DynamoDB table created as part of this post.
In this post, we demonstrated how to set up a custom mapping to OpenSearch Service roles using values provided via an OIDC attribute. We dynamically set the cognito:preferred_role claim using an Amazon Cognito pre-token generation Lambda trigger and a DynamoDB table for lookup. The solution is capable of handling dynamic multivalued user attributes, but you can extend it with further application logic that goes beyond a simple lookup. The steps in this post are a proof of concept. If you plan to develop this into a productive solution, we recommend implementing Okta and AWS security best practices.
The post highlights just one use case of how you can use Amazon Cognito support for Lambda triggers to implement custom authentication needs. If you’re interested in further details, refer to How to Use Cognito Pre-Token Generation trigger to Customize Claims In ID Tokens.
 Stefan Appel is a Senior Solutions Architect at AWS. For 10+ years, he supports enterprise customers adopt cloud technologies. Before joining AWS, Stefan held positions in software architecture, product management, and IT operations departments. He began his career in research on event-based systems. In his spare time, he enjoys hiking and has walked the length of New Zealand following Te Araroa.
Stefan Appel is a Senior Solutions Architect at AWS. For 10+ years, he supports enterprise customers adopt cloud technologies. Before joining AWS, Stefan held positions in software architecture, product management, and IT operations departments. He began his career in research on event-based systems. In his spare time, he enjoys hiking and has walked the length of New Zealand following Te Araroa.
 Modood Alvi is Senior Solutions Architect at Amazon Web Services (AWS). Modood is passionate about digital transformation and is committed helping large enterprise customers across the globe accelerate their adoption of and migration to the cloud. Modood brings more than a decade of experience in software development, having held various technical roles within companies like SAP and Porsche Digital. Modood earned his Diploma in Computer Science from the University of Stuttgart.
Modood Alvi is Senior Solutions Architect at Amazon Web Services (AWS). Modood is passionate about digital transformation and is committed helping large enterprise customers across the globe accelerate their adoption of and migration to the cloud. Modood brings more than a decade of experience in software development, having held various technical roles within companies like SAP and Porsche Digital. Modood earned his Diploma in Computer Science from the University of Stuttgart.
Post Syndicated from Molly Clancy original https://www.backblaze.com/blog/aws-cloudfront-vs-bunny-net-how-do-the-cdns-compare/

Remember the story about the hare and the tortoise? Well, this is not that story, but we are comparing bunny.net with another global content delivery network (CDN) provider, AWS CloudFront, to see how the two stack up. When you think of rabbits, you automatically think of speed, but a CDN is not just about speed; sometimes, other factors “win the race.”
As a leading specialized cloud storage provider, we provide application storage that folks use with many of the top CDNs. Working with these vendors allows us deep insight into the features of each platform so we can share the information with you. Read on to get our take on these two leading CDNs.
A CDN is a network of servers dispersed around the globe that host content closer to end users to speed up website performance. Let’s say you keep your website content on a server in New York City. If you use a CDN, when a user in Las Vegas calls up your website, the request can pull your content from a server in, say, Phoenix instead of going all the way to New York. This is known as caching. A CDN’s job is to reduce latency and improve the responsiveness of online content.
Tune in to our webinar on Tuesday, February 28, 2022 at 10:00 a.m. PT/1:00 p.m. ET to learn how you can leverage bunny.net’s CDN and Backblaze B2 to accelerate content delivery and scale media workflows with zero-cost egress.

Before we compare these two CDNs, it’s important to understand how they might fit into your overall tech stack. Some common use cases for a CDN include:
Speed tests are a valuable tool that businesses can use to gauge site performance, page load times, and customer experience. You can use dozens of free online speed tests to evaluate time to first byte (TTFB) and the number of requests (how many times the browser has to make the request before the page loads). Some speed tests show other more advanced metrics.
A CDN is one aspect that can affect speed and performance, but there are other factors at play as well. A speed test can help you identify bottlenecks and other issues.
Some of the most popular tools are:
Although bunny.net and AWS CloudFront provide CDN services, their features and technology work differently. You will want all of the details when deciding which CDN is right for your application.
bunny.net is a powerfully simple CDN that delivers content at lightning speeds across the globe. The service is scalable, affordable, and secure. They offer edge storage, optimization services, and DNS resources for small to large companies.
AWS CloudFront is a global CDN designed to work primarily with other AWS services. The service offers robust cloud-based resources for enterprise businesses.
Let’s compare all the features to get a good sense of how each CDN option stacks up. To best understand how the two CDNs compare, we’ll look at different aspects of each one so you can decide which option works best for you, including:
Distribution points are the number of servers within a CDN network. These points are distributed throughout the globe to reach users anywhere. When users request content through a website or app, the CDN connects them to the closest distribution point server to deliver the video, image, script, etc., as quickly as possible.
bunny.net has 114 global distribution points (also called points of presence or PoPs) in 113 cities and 77 countries. For high-bandwidth users, they also offer a separate, cost-optimized network of 10 PoPs. They don’t charge any request fees and offer multiple payment options.
Currently, AWS CloudFront advertises that they have roughly 450 distribution points in 90 cities in 48 countries.
While AWS CloudFront has many points in some major cities, bunny.net has a wider global distribution—AWS CloudFront covers 90 cities, and bunny.net covers 114. And bunny.net ranks first on CDNPerf, a third-party CDN performance analytics and comparison tool.
Caching files allows a CDN to serve up copies of your digital content from distribution points closer to end users, thus improving performance and reliability.
With their Origin Shield feature, when CDN nodes have a cache miss (meaning the content an end user wants isn’t at the node closest to them), the network directs the request to another node versus the origin. They offer Perma-Cache where you can permanently store your files at the edge for a 100% cache hit rate. They also recently introduced request coalescing, where requests by different users for the same file are combined into one request. Request coalescing works well for streaming content or large objects.
AWS CloudFront uses caching to reduce the load of requests to your origin store. When a user visits your website, AWS CloudFront directs them to the closest edge cache so they can view content without any wait. You can configure AWS CloudFront’s cache settings using the backend interface.
Caching is one of bunny.net’s strongest points of differentiation, primarily around static content. They also offer dynamic caching with one-click configuration by query string, cookie, and state cache as well as cache chunking for video delivery. With their Perma-Cache and request coalescing, their capabilities for dynamic caching are improving.
Compressing files makes them smaller, which saves space and makes them load faster. Many CDNs allow compression to maximize your server space and decrease page load times. The two services are on par with each other when it comes to compression.
The bunny.net system automatically optimizes/compresses images and minifies CSS and JavaScript files to improve performance. Images are compressed by roughly 80%, improving load times by up to 90%. bunny.net supports both .gzip and .br (Brotli) compression formats. The bunny.net optimizer can compress images and optimize files on the fly.
AWS CloudFront allows you to compress certain file types automatically and use them as compressed objects. The service supports both .gzip and .br compression formats.
Distributed denial of service (DDoS) attacks can overwhelm a website or app with too much traffic causing it to crash and interrupting actual website traffic. CDNs can help prevent DDoS attacks.
bunny.net stops DDoS attacks via a layered DDoS protection system that stops both network and HTTP layer attacks. Additionally, a number of checks and balances—like download speed limits, connection counts for IP addresses, burst requests, and geoblocking—can be configured. You can hide IP addresses and use edge rules to block requests.
AWS CloudFront uses security technology called AWS Shield designed to prevent DDoS and other types of attacks.
As an independent, specialized CDN service, bunny.net has put most of their focus on being a standout when it comes to core CDN tasks like caching static content. That’s not to say that their security services are lacking, but just that their security capabilities are sufficient to meet most users’ needs. AWS Shield is a specialized DDoS protection software, so it is more robust. However, that robustness comes at an added cost.
Integrations allow you to customize a product or service using add-ons or APIs to extend the original functionality. One popular tool we’ll highlight here is Terraform, a tool that allows you to provision infrastructure as code (IaC).
HashiCorp’s Terraform is a third-party program that allows you to manage your CDN, store source code in repositories like GitHub, track each version, and even roll back to an older version if needed. You can use Terraform to configure bunny.net CDN pull zones only. You can use Terraform with AWS CloudFront by editing configuration files and installing Terraform on your local machine.
Transport Layer Security (TLS), formerly known as secure sockets layer (SSL), are encryption protocols used to protect website data. Whenever you see the lock sign on your internet browser, you are using a website that is protected by an TLS (HTTPS). Both services conform adequately to TLS standards.
bunny.net offers customers free TLS with its CDN service. They make setting it up a breeze (two clicks) in the backend of your account. You also have the option of installing your own SSL. They provide helpful step-by-step instructions on how to install it.
Because AWS CloudFront assigns a unique URL for your CDN content, you can use the default TLS certificate installed on the server or your own TLS. If you use your own, you should consult the explicit instructions for key length and install it correctly. You also have the option of using an Amazon TLS certificate.
Cross-origin resource sharing (CORS) is a service that allows your internet browser to deliver content from different sources seamlessly on a single webpage or app. Default security settings normally reject certain items if they come from a different origin and they may block the content. CORS is a security exception that allows you to host various types of content from other servers and deliver them to your users without any errors.
bunny.net and AWS CloudFront both offer customers CORS support through configurable CORS headers. Using CORS, you can host images, scripts, style sheets, and other content in different locations without any issues.
Signed exchange (SXG) is a service that allows search engines to find and serve cached pages to users in place of the original content. SXG speeds up performance and improves SEO in the process. The service uses cryptography to authenticate the origin of digital assets.
Both bunny.net and AWS CloudFront support SXG. bunny.net supports signed exchange through its token authentication system. The service allows you to enable, configure, and generate tokens and assign them an expiration date to stop working when you want.
AWS CloudFront supports SXG through its security settings. When configuring your settings, you can choose which cipher to use to verify the origin of the content.
bunny.net offers simple, affordable, region-based pricing starting at $0.01/GB in the U.S. For high-bandwidth projects, their volume pricing starts at $0.005/GB for the first 500TB.
AWS CloudFront offers a free plan, including 1TB of data transfer out, 10,000,000 HTTP or HTTPS requests, and 2,000,000 functions invocations each month.
AWS CloudFront’s paid service is tiered based on bandwidth usage. AWS CloudFront’s pricing starts at $0.085 per GB up to 10TB in North America. All told, there are seven pricing tiers from 10TB to >5PB. If you stay within the AWS ecosystem, data transfer is free from Amazon S3, their object storage service, however you’ll be charged to transfer data outside of AWS. Each tier is priced by location/country.
bunny.net is probably one of the most cost effective CDNs on the market. For example, their traffic pricing for 5TB in Europe or North America is $50 compared to $425 with CloudFront. There are no request fees, you only pay for the bandwidth you actually use. All of their features are included without extra charges. And finally, egress is free between bunny.net and Backblaze B2, if you choose to pair the two services.
bunny.net’s key advantages are its simplicity, pricing, and customer support. Many of the above features are configured in one-click, giving you advanced capabilities without the headache of trying to figure out complicated provisioning. Their pricing is straightforward and affordable. And, not for nothing, they also offer one-to-one, round-the-clock customer support. If it’s important to you to be able to speak with an expert when you need to, bunny.net is the better choice.
AWS CloudFront offers more robust features, like advanced security services, but those services come with a price tag and you’re on your own when it comes to setting them up properly. AWS also prefers customers to stay within the AWS ecosystem, so using any third-party services outside of AWS can be costly.
If you’re looking for an agnostic, specialized, affordable CDN, bunny.net would be a great fit. If you need more advanced features and have the time, know-how, and money to make them work for you, AWS CloudFront offers those.
A CDN can boost the speed of your website pages and apps. However, you still need reliable, affordable application storage for the cache to pull from. Pairing robust application storage with a speedy CDN is the perfect solution for improved performance, security, and scalability.
The post AWS CloudFront vs. bunny.net: How Do the CDNs Compare? appeared first on Backblaze Blog | Cloud Storage & Cloud Backup.
Post Syndicated from João Tomé original https://blog.cloudflare.com/one-year-of-war-in-ukraine/


The Internet has become a significant factor in geopolitical conflicts, such as the ongoing war in Ukraine. Tomorrow marks one year since the Russian invasion of that country. This post reports on Internet insights and discusses how Ukraine’s Internet remained resilient in spite of dozens of disruptions in three different stages of the conflict.
Key takeaways:
In Ukraine, human Internet traffic dropped as much as 33% in the weeks following February 24. The following chart shows Cloudflare’s perspective on daily traffic (by number of requests).

Internet traffic levels recovered over the next few months, including strong growth seen in September and October, when many Ukrainian refugees returned to the country. That said, there were also country-wide outages, mostly after October, that are discussed below.
14% of total traffic from Ukraine (including traffic from Crimea and other occupied regions) was mitigated as potential attacks, while 10% of total traffic to Ukraine was mitigated as potential attacks in the last 12 months.
Before February 24, 2022, typical weekday Internet traffic in Ukraine initially peaked after lunch, around 15:00 local time, dropped between 17:00 and 18:00 (consistent with people leaving work), and reached the biggest peak of the day at around 21:00 (possibly after dinner for mobile and streaming use).
After the invasion started, we observed less variation during the day in a clear change in the usual pattern given the reported disruption and “exodus” from the country. During the first few days after the invasion began, peak traffic occurred around 19:00, at a time when nights for many in cities such as Kyiv were spent in improvised underground bunkers. By late March, the 21:00 peak had returned, but the early evening drop in traffic did not return until May.
When looking at Ukraine Internet requests by type of traffic in the chart below (from February 10, 2022, through February 2023), we observe that while traffic from both mobile and desktop devices dropped after the invasion, request volume from mobile devices has remained higher over the past year. Pre-war, mobile devices accounted for around 53% of traffic, and grew to around 60% during the first weeks of the invasion. By late April, it had returned to typical pre-war levels, falling back to around 54% of traffic. There’s also a noticeable December drop/outage that we’ll go over below.
The invasion brought attacks and failing infrastructure across a number of cities, but the target in the early days wasn’t the country’s energy infrastructure, as it was in October 2022. In the first weeks of the war, Internet traffic changes were largely driven by people evacuating conflict zones with their families. Over eight million Ukrainians left the country in the first three months, and many more relocated internally to safer cities, although many returned during the summer of 2022. The Internet played a critical role during this refugee crisis, supporting communications and access to real-time information that could save lives, as well as apps providing services, among others.
There was also an increase in traffic in the western part of Ukraine, in areas such as Lviv (further away from the conflict areas), and a decrease in the east, in areas like Kharkiv, where the Russian military was arriving and attacks were a constant threat. The figure below provides a view of how Internet traffic across Ukraine changed in the week after the war began (a darker pink means a drop in traffic — as much as 60% — while a darker green indicates an increase in Internet traffic — as much as 50%).
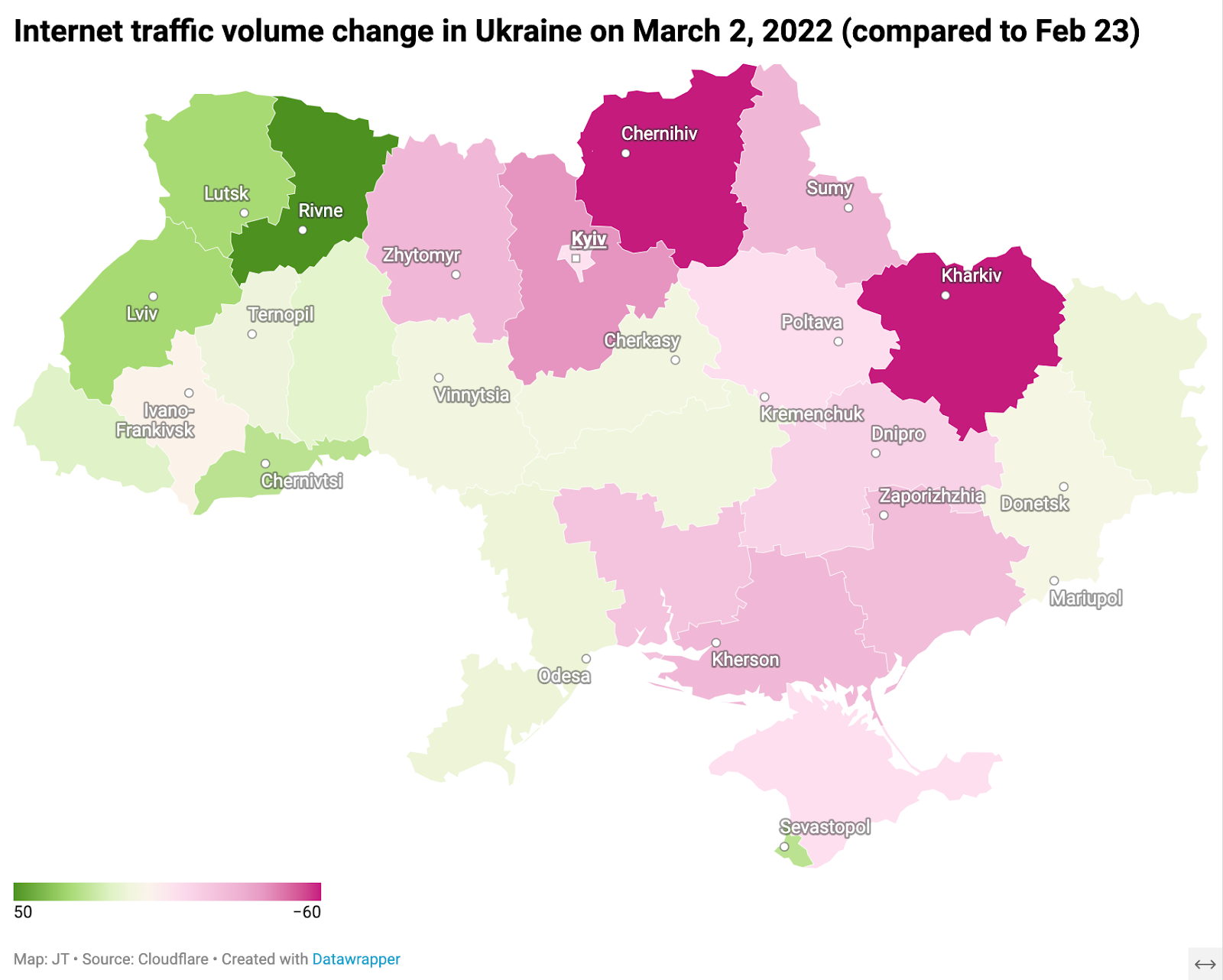
The biggest drops in Internet traffic observed in Ukraine in the first days of the war were in Kharkiv Oblast in the east, and Chernihiv in the north, both with a 60% decrease, followed by Kyiv Oblast, with traffic 40% lower on March 2, 2022, as compared with February 23.
In western Ukraine, traffic surged. The regions with the highest observed traffic growth included Rivne (50%), Volyn (30%), Lviv (28%), Chernivtsi (25%), and Zakarpattia (15%).
At the city level, analysis of Internet traffic in Ukraine gives us some insight into usage of the Internet and availability of Internet access in those first weeks, with noticeable outages in places where direct conflict was going on or that was already occupied by Russian soldiers.
North of Kyiv, the city of Chernihiv had a significant drop in traffic the first week of the war and residual traffic by mid-March, with traffic picking up only after the Russians retreated in early April.
In the capital city of Kyiv, there is a clear disruption in Internet traffic right after the war started, possibly caused by people leaving, attacks and use of underground shelters.
Near Kyiv, we observed a clear outage in early March in Bucha. After April 1, when the Russians withdrew, Internet traffic started to come back a few weeks later.
In Irpin, just outside Kyiv, close to the Hostomel airport and Bucha, a similar outage pattern to Bucha was observed. Traffic only began to come back more clearly in late May.
In the east, in the city of Kharkiv, traffic dropped 50% on March 3, with a similar scenario seen not far away in Sumy. The disruption was related to people leaving and also by power outages affecting some networks.
Other cities in the south of Ukraine, like Berdyansk, had outages. This graph shows Enerhodar, the small city where Europe’s largest nuclear plant, Zaporizhzhya NPP, is located, with residual traffic compared to before.
In the cities located in the south of Ukraine, there were clear Internet disruptions. The Russians laid siege to Mariupol on February 24. Energy infrastructure strikes and shutdowns had an impact on local networks and Internet traffic, which fell to minimal levels by March 1. Estimates indicate that 95% of the buildings in the city were destroyed, and by mid-May, the city was fully under Russian control. While there was some increase in traffic by the end of April, it reached only ~22% of what it was before the war’s start.
When looking at Ukrainian Internet Service Providers (ISPs) or the autonomous systems (ASNs) they use, we observed more localized disruptions in certain regions during the first months of the war, but recovery was almost always swift. AS6849 (Ukrtel) experienced problems with very short-term outages in mid-March. AS13188 (Triolan), which services Kyiv, Chernihiv, and Kharkiv, was another provider experiencing problems (they reported a cyberattack on March 9), as could be observed in the next chart:
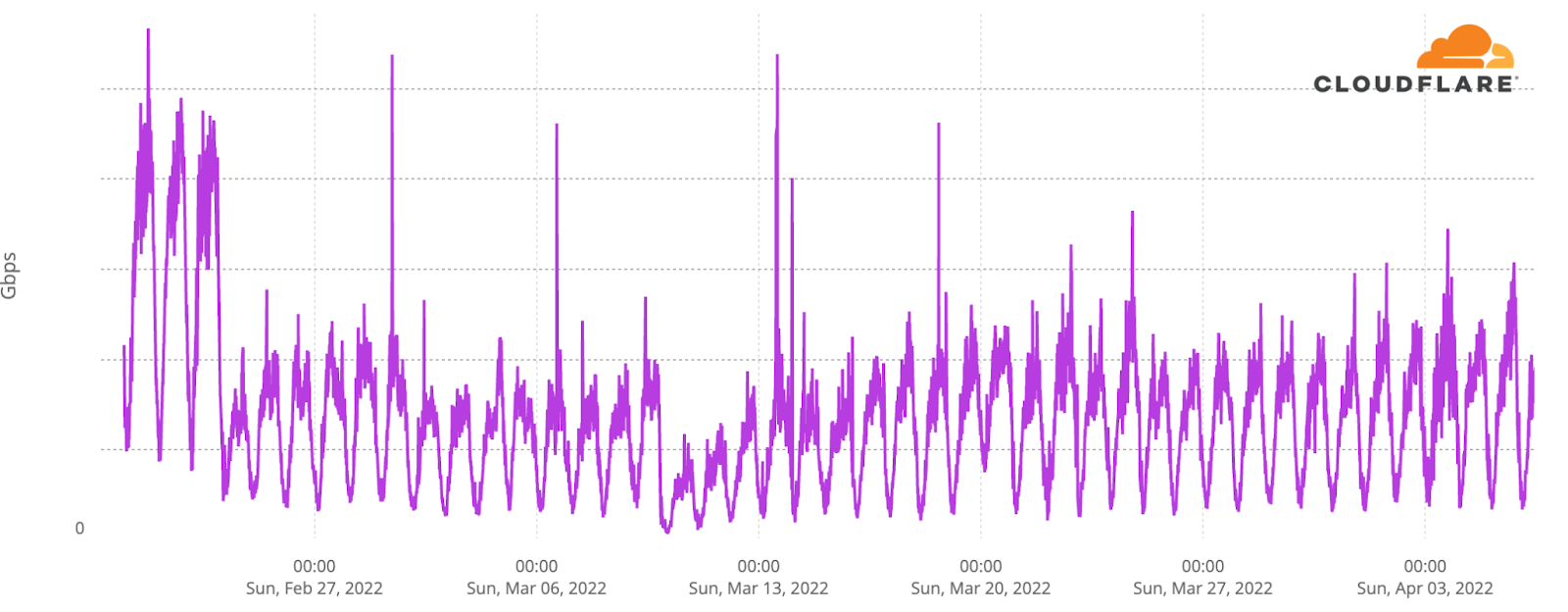
We did not observe a clear national outage in Ukraine’s main ISP, AS15895 (Kyivstar) until the October-November attacks on energy infrastructure, which also shows some early resilience of Ukrainian networks.
As Russian troops retreated from the northern front in Ukraine, they shifted their efforts to gain ground in the east (Battle of Donbas) and south (occupation of the Kherson region) after late April. This resulted in Internet disruptions and traffic shifts, which are discussed in more detail in a section below. However, Internet traffic in the Kherson region was intermittent and included outages after May, given the battle for Internet control. News reports in June revealed that ISP workers damaged their own equipment to thwart Russia’s efforts to control the Ukrainian Internet.
Before the September Ukrainian counteroffensive, another example of the war’s impact on a city’s Internet traffic occurred during the summer, when Russian troops seized Lysychansk in eastern Ukraine in early July after what became known as the Battle of Lysychansk. Internet traffic in Lysychansk clearly decreased after the war started. That slide continues during the intense fighting that took place after April, which led to most of the city’s population leaving. By May, traffic was almost residual (with a mid-May few days short term increase).
In early September the Ukrainian counteroffensive took off in the east, although the media initially reported a south offensive in Kherson Oblast that was a “deception” move. The Kherson offensive only came to fruition in late October and early November. Ukraine was able to retake in September over 500 settlements and 12,000 square kilometers of territory in the Kharkiv region. At that time, there were Internet outages in several of those settlements.
In response to the successful Ukrainian counteroffensive, Russian airstrikes caused power outages and Internet disruptions in the region. That was the case in Kharkiv on September 11, 12, and 13. The figure below shows a 12-hour near-complete outage on September 11, followed by two other periods of drop in traffic.
In the Zaporizhzhia region, there were also outages. On September 1, 2022, the day the International Atomic Energy Agency (IAEA) inspectors arrived at the Russian-controlled Zaporizhzhia nuclear power plant in Enerhodar, there were Internet outages in two local ASNs that service the area: AS199560 (Engrup) and AS197002 (OOO Tenor). Those outages lasted until September 10, as shown in the charts below.


More broadly, the city of Enerhodar, where the nuclear power plant is located, experienced a four-day outage after September 6.
In mid-September, following Ukraine’s counteroffensive, there were questions as to when Crimea might be targeted by Ukrainian forces, with news reports indicating that there was an evacuation of the Russian population from Crimea around September 13. We saw a clear drop in traffic on that Tuesday, compared with the previous day, as seen in the map of Crimea below (red is decrease in traffic, green is increase).

As we have seen, the Russian air strikes targeting critical energy infrastructure began in September as a retaliation to Ukraine’s counteroffensive. The following month, the Crimean Bridge explosion on Saturday, October 8 (when a truck-borne bomb destroyed part of the bridge) led to more air strikes that affected networks and Internet traffic across Ukraine.
On Monday, October 10, Ukraine woke up to air strikes on energy infrastructure and experienced severe electricity and Internet outages. At 07:35 UTC, traffic in the country was 35% below its usual level compared with the previous week and only fully recovered more than 24 hours later. The impact was particularly significant in regions like Kharkiv, where traffic was down by around 80%, and Lviv, where it dropped by about 60%. The graph below shows how new air strikes in Lviv Oblast the following day affected Internet traffic.

There were clear disruptions in Internet connectivity in several regions on October 17, but also on October 20, when the destruction of several power stations in Kyiv resulted in a 25% drop in Internet traffic from Kyiv City as compared to the two previous weeks. It lasted 12 hours, and was followed the next day by a shorter partial outage as seen in the graph below.

In late October, according to Ukrainian officials, 30% of Ukraine’s power stations were destroyed. Self-imposed power limitations because of this destruction resulted in drops in Internet traffic observed in places like Kyiv and the surrounding region.
The start of a multi-week Internet disruption in Kherson Oblast can be seen in the graph below, showing ~70% lower traffic than in previous weeks. The disruption began on Saturday, October 22, when Ukrainians were gaining ground in the Kherson region.

Traffic began to return after Ukrainian forces took Kherson city on November 11, 2022. The graph below shows a week-over-week comparison for Kherson Oblast for the weeks of November 7, November 28, and December 19 for better visualization in the chart while showing the evolution through a seven-week period.

Throughout the rest of the year and into 2023, Ukraine has continued to face intermittent Internet disruptions. On November 23, 2022, the country experienced widespread power outages after Russian strikes, causing a nearly 50% decrease in Internet traffic in Ukraine. This disruption lasted for almost a day and a half, further emphasizing the ongoing impact of the conflict on Ukraine’s infrastructure.
Although there was a recovery after that late November outage, only a few days later traffic seemed closer to normal levels. Below is a chart of the week-over-week evolution of Internet traffic in Ukraine at both a national and local level during that time:
In Kyiv Oblast:

In the Odessa region:

And Kharkiv (where a December 16 outage is also clear — in the green line):
On December 16, there was another country-level Internet disruption caused by air strikes targeting energy infrastructure. Traffic at a national level dropped as much as 13% compared with the previous week, but Ukrainian networks were even more affected. AS13188 (Triolan) had a 70% drop in traffic, and AS15895 (Kyivstar) a 40% drop, both shown in the figures below.
In January 2023, air strikes caused additional Internet disruptions. One such recent event was in Odessa, where traffic dropped as low as 54% compared with the previous week during an 18-hour disruption.
The US government and the FBI issued warnings in March to all citizens, businesses, and organizations in the country, as well as allies and partners, to be aware of the need to “enhance cybersecurity.” The US Cybersecurity and Infrastructure Security Agency (CISA) launched the Shields Up initiative, noting that “Russia’s invasion of Ukraine could impact organizations both within and beyond the region.” The UK and Japan, among others, also issued warnings.
Below, we discuss Web Application Firewall (WAF) mitigations and DDoS attacks. A WAF helps protect web applications by filtering and monitoring HTTP traffic between a web application and the Internet. A WAF is a protocol layer 7 defense (in the OSI model), and is not designed to defend against all types of attacks. Distributed Denial of Service (DDoS) attacks are cyber attacks that aim to take down Internet properties and make them unavailable for users.
The charts below are based on normalized data, and show threats mitigated by our WAF.
Mitigated application-layer threats blocked by our WAF skyrocketed after the war started on February 24. Mitigated requests were 105% higher on Monday, February 28 than in the previous (pre-war) Monday, and peaked on March 8, reaching 1,300% higher than pre-war levels.
Between February 2022 and February 2023, an average of 10% of all traffic to Ukraine was mitigations of potential attacks.
The graph below shows the daily percentage of application layer traffic to Ukraine that Cloudflare mitigated as potential attacks. In early March, 30% of all traffic was mitigated. This fell in April, and remained low for several months, but it picked up in early September around the time of the Ukrainian counteroffensive in east and south Ukraine. The peak was reached on October 29 when DDoS attack traffic constituted 39% of total traffic to Cloudflare’s Ukrainian customer websites.

This trend is more evident when looking at all traffic to sites on the “.ua” top-level domain (from Cloudflare’s perspective). The chart below shows that DDoS attack traffic accounted for over 80% of all traffic by early March 2022. The first clear spikes occurred on February 16 and 19, with around 25% of traffic mitigated. There was no moment of rest after the war started, except towards the end of November and December, but the attacks resumed just before Christmas. An average of 13% of all traffic to “.ua”, between February 2022 and February 2023 was mitigations of potential attacks. The following graph provides a comprehensive view of DDoS application layer attacks on “.ua” sites:

Moving on to types of mitigations of product groups that were used (related to “.ua” sites), as seen in the next chart, around 57% were done by the ruleset which automatically detects and mitigates HTTP DDoS attacks (DDoS Mitigation), 31% were being mitigated by firewall rules put in place (WAF), and 10% were blocking requests based on our IP threat reputation database (IP Reputation).

It’s important to note that WAF rules in the graph above are also associated with custom firewall rules created by customers to provide a more tailored protection. “DDoS Mitigation” (application layer DDoS protection) and “Access Rules” (rate limiting) are specifically used for DDoS protection.
In contrast to the first graph shown in this section, which looked at mitigated attack traffic targeting Ukraine, we can also look at mitigated attack traffic originating in Ukraine. The graph below also shows that the share of mitigated traffic from Ukraine also increased considerably after the invasion started.

The industries sectors that had a higher share of WAF mitigations were government administration, financial services, and the media, representing almost half of all WAF mitigations targeting Ukraine during 2022.
Looking at DDoS attacks, there was a surge in attacks on media and publishing companies during 2022 in Ukraine. Entities targeting Ukrainian companies appeared to be focused on information-related websites. The top five most attacked industries in the Ukraine in the first two quarters of 2022 were all in broadcasting, Internet, online media, and publishing, accounting for almost 80% of all DDoS attacks targeting Ukraine.
In a more focused look at the type of websites Cloudflare has protected throughout the war, the next two graphs provide a view of mitigated application layer attacks by the type of “.ua” sites we helped to protect. In the first days of the war, mitigation spikes were observed at a news service, a TV channel, a government website, and a bank.

In July, spikes in mitigations we observed across other types of “.ua” websites, including food delivery, e-commerce, auto parts, news, and government.

More recently, in February 2023, the spikes in mitigations were somewhat similar to what we saw one year ago, including electronics, e-commerce, IT, and education websites.
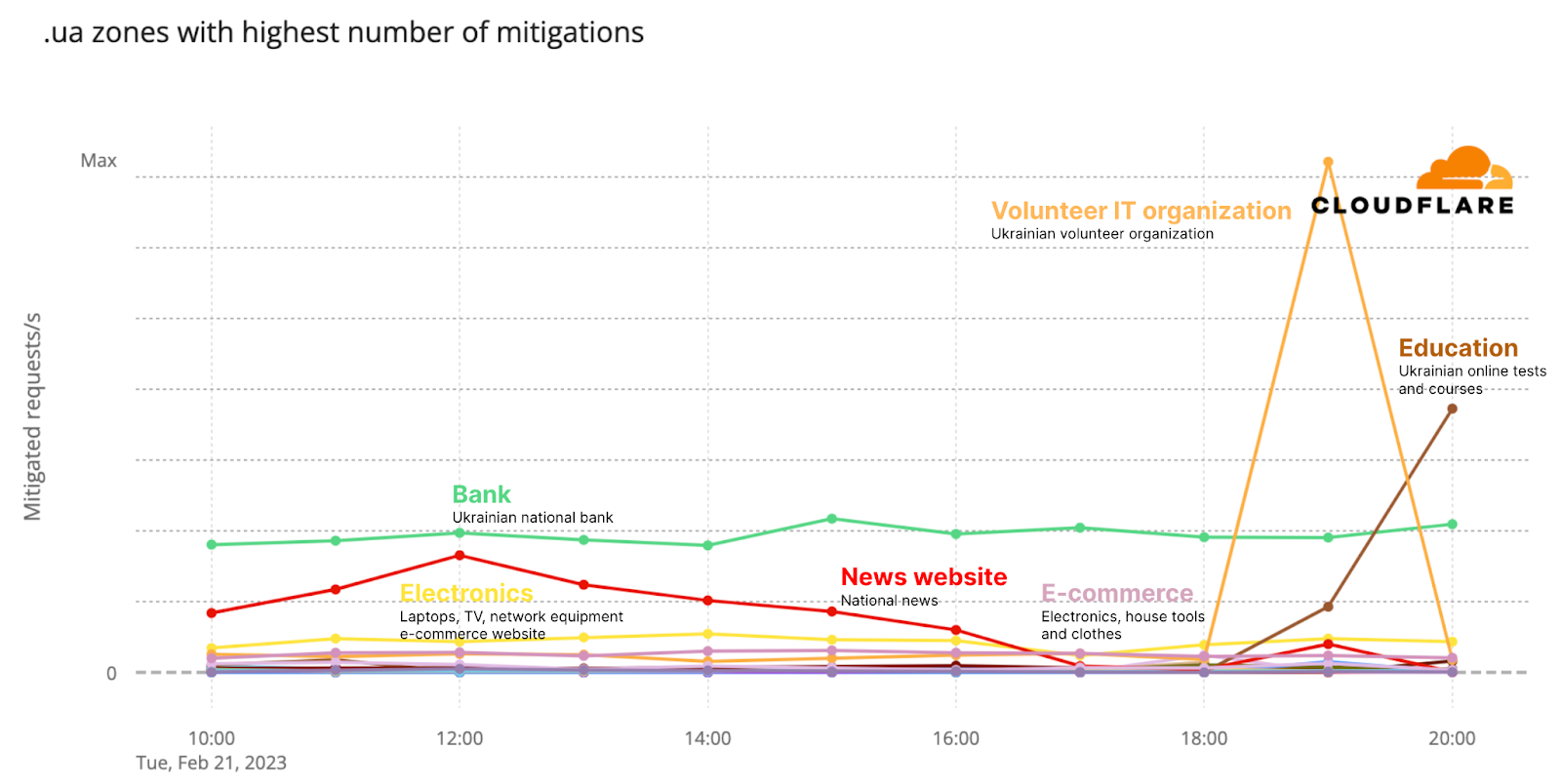
Network-layer (layer 3 and 4) traffic is harder to attribute to a specific domain or target because IP addresses are shared across different customers. Looking at network-level DDoS traffic hitting our Kyiv data center, we saw peaks of DDoS traffic higher than before the war in early March, but they were much higher in June and August.

In our Q1 2022 DDoS report, we also noted that 12.6% of Ukraine’s traffic was DDoS activity, compared with 1% in the previous quarter, a 1,160% quarter-over-quarter increase.
Several of our quarterly DDoS reports from 2022 include attack trends related to the war in Ukraine, with quarter over quarter interactive comparisons.
On February 24, 2022, Russian forces invaded Ukraine’s Kherson Oblast region. The city of Kherson was captured on March 2, as the first major city and only regional capital to be captured by Russian forces during the initial invasion. The Russian occupation of Kherson Oblast continued until Ukrainian forces resumed control on November 11, after launching a counteroffensive at the end of August.
On May 4, 2022, we published Tracking shifts in Internet connectivity in Kherson, Ukraine, a blog post that explored a re-routing event that impacted AS47598 (Khersontelecom), a telecommunications provider in Kherson Oblast. Below, we summarize this event, and explore similar activity across other providers in Kherson that has taken place since then.
On May 1, 2022, we observed a shift in routing for the IPv4 prefix announced by Ukrainian network AS47598 (Khersontelecom). During April, it reached the Internet through several other Ukrainian network providers, including AS12883 (Vega Telecom) and AS3326 (Datagroup). However, after the shift, its routing path now showed a Russian network, AS201776 (Miranda-Media), as the sole upstream provider. With traffic from KhersonTelecom passing through a Russian network, it was subject to the restrictions and limitations imposed on any traffic transiting Russian networks, including content filtering.
The flow of traffic from Khersontelecom before and after May 1, with rerouting through Russian network provider Miranda-Media, is illustrated in the chart below. This particular re-routing event was short-lived, as a routing update for AS47598 on May 4 saw it return to reaching the Internet through other Ukrainian providers.

As a basis for our analysis, we started with a list of 15 Autonomous System Numbers (ASNs) belonging to networks in Kherson Oblast. Using that list, we analyzed routing information collected by route-views2 over the past year, from February 1, 2022, to February 15, 2023. route-views2 is a BGP route collector run by the University of Oregon Route Views Project. Note that with respect to the discussions of ASNs in this and the following section, we are treating them equally, and have not specifically factored estimated user population into these analyses.
The figure below illustrates the result of this analysis, showing that re-routing of Kherson network providers (listed along the y-axis) through Russian upstream networks was fairly widespread, and for some networks, has continued into 2023. During the analysis time frame, there were three primary Russian networks that appeared as upstream providers: AS201776 (Miranda-Media), AS52091 (Level-MSK Ltd.), and AS8492 (OBIT Ltd.).
Within the graph, black bars indicate periods when the ASN effectively disappeared from the Internet; white segments indicate the ASN was dependent on other Ukraine networks as immediate upstreams; and red indicates the presence of Russian networks in the set of upstream providers. The intensity of the red shading corresponds to the percentage of announced prefixes for which a Russian network provider is present in the routing path as observed from networks outside Ukraine. Bright red shading, equivalent to “1” in the legend, indicates the presence of a Russian provider in all routing paths for announced prefixes.

In the blog post linked above, we referenced an outage that began on April 30. This is clearly visible in the figure as a black bar that runs for several days across all the listed ASNs. In this instance, AS47598 (KhersonTelecom) recovered a day later, but was sending traffic through AS201776 (Miranda-Media), a Russian provider, as discussed above.
Another Ukrainian network, AS49168 (Brok-X), recovered from the outage on May 2, and was also sending traffic through Miranda-Media. By May 4, most of the other Kherson networks recovered from the outage, and both AS47598 and AS49168 returned to using Ukrainian networks as immediate upstream providers. Routing remained “normal” until May 30. Then, a more widespread shift to routing traffic through Russian providers began, although it appears that this shift was preceded by a brief outage for a few networks. For the most part, this re-routing lasted through the summer and into October. Some networks saw a brief outage on October 17, but most stopped routing directly through Russia by October 22.
However, this shift away from Russia was followed by periods of extended outages. KhersonTelecom suffered such an outage, and has remained offline since October, except for the first week of November when all of its traffic routed through Russia. Many other networks rejoined the Internet in early December, relying mostly on other Ukrainian providers for Internet connectivity. However, since early December, AS204485 (PE Berislav Cable Television), AS56359 (CHP Melnikov Roman Sergeevich), and AS49465 (Teleradiocompany RubinTelecom Ltd.) have continued to use Miranda-Media as an upstream provider, in addition to experiencing several brief outages. In addition, over the last several months, AS25082 (Viner Telecom) has used both a Ukrainian network and Miranda-Media as upstream providers.
In the context of the Internet, “resilience” refers to the ability of a network to operate continuously in a manner that is highly resistant to disruption. This includes the ability of a network to: (1) operate in a degraded mode if damaged, (2) rapidly recover if failure does occur, and (3) scale to meet rapid or unpredictable demands. Throughout the Russia-Ukraine conflict, media coverage (VICE, Bloomberg, Washington Post) has highlighted the work done in Ukraine to repair damaged fiber-optic cables and mobile network infrastructure to keep the country online. This work has been critically important to maintaining the resilience of Ukrainian Internet infrastructure.
According to PeeringDB, as of February 2023, there are 25 Internet Exchange Points (IXPs) in Ukraine and 50 interconnection facilities. (An IXP may span multiple physical facilities.) Within this set of IXPs, Autonomous Systems (ASes) belonging to international providers are currently present in over half of them. The number of facilities, IXPs, and international ASes present in Ukraine points to a resilient interconnection fabric, with multiple locations for both domestic and international providers to exchange traffic.
To better understand these international interconnections, we first analyze the connectivity of ASes in Ukraine, and we classify the links to domestic networks (links where both ASes are registered in Ukraine) and international networks (links between ASes in Ukraine and ASes outside Ukraine). To determine which ASes are domestic in Ukraine, we can use information from the extended delegation reports from the Réseaux IP Européens Network Coordination Centre (RIPE NCC), the Regional Internet Registry that covers Ukraine. We also parsed collected BGP data to extract the AS-level links between Ukrainian ASes and ASes registered in a different country, and we consider these the international connectivity of the domestic ASes.
A March 2022 article in The Economist noted that “For one thing, Ukraine boasts an unusually large number of internet-service providers—by one reckoning the country has the world’s fourth-least-concentrated Internet market. This means the network has few choke points, so is hard to disable.” As of the writing of this blog post, there are 2,190 ASes registered in Ukraine (UA ASes), and 1,574 of those ASes appear in the BGP routing table as active. These counts support the article’s characterization, and below we discuss several additional observations that reinforce Ukraine’s Internet resilience.

The figure above is a cumulative distribution function showing the fraction of domestic Ukrainian ASes that have direct connections to international networks. In February 2023, approximately 50% had more than one (100) international link, while approximately 10% had more than 10, and approximately 2% had 100 or more. Although these numbers have dropped slightly over the last year, they underscore the lack of centralized choke points in the Ukrainian Internet.
For the networks with international connectivity, we can also look at the distribution of “next-hop” countries – countries with which those international networks are associated. (Note that some networks may have a global footprint, and for these, the associated country is the one recorded in their autonomous system registration.) Comparing the choropleth maps below illustrates how this set of countries, and their fraction of international paths, have changed between February 2022 and February 2023. The data underlying these maps shows that international connectivity from Ukraine is distributed across 18 countries — unsurprisingly, mostly in Europe.

In February 2022, these countries/locations accounted for 77% of Ukraine’s next-hop international paths. The top four all had 7.8% each. However, in February 2023, the top 10 next-hop countries/locations dropped slightly to 76% of international paths. While just a slight change from the previous year, the set of countries/locations and many of their respective fractions saw considerable change.
| February 2022 | February 2023 | |||
|---|---|---|---|---|
| 1 | Germany | 7.85% | Russia | 11.62% |
| 2 | Netherlands | 7.85% | Germany | 11.43% |
| 3 | United Kingdom | 7.83% | Hong Kong | 8.38% |
| 4 | Hong Kong | 7.81% | Poland | 7.93% |
| 5 | Sweden | 7.77% | Italy | 7.75% |
| 6 | Romania | 7.72% | Turkey | 6.86% |
| 7 | Russia | 7.67% | Bulgaria | 6.20% |
| 8 | Italy | 7.64% | Netherlands | 5.31% |
| 9 | Poland | 7.60% | United Kingdom | 5.30% |
| 10 | Hungary | 7.54% | Sweden | 5.26% |
Russia’s share grew by 50% year to 11.6%, giving it the biggest share of next-hop ASes. Germany also grew to account for more than 11% of paths.

Cloudflare observed a rapid growth in Starlink’s ASN (AS14593) traffic to Ukraine during 2022 and into 2023. Between mid-March and mid-May, Starlink’s traffic in the country grew over 530%, and continued to grow from mid-May up until mid-November, increasing nearly 300% over that six-month period — from mid-March to mid-December the growth percentage was over 1600%. After that, traffic stabilized and even dropped a bit during January 2023.

Our data shows that between November and December 2022, Starlink represented between 0.22% and 0.3% of traffic from Ukraine, but that number is now lower than 0.2%.

One year in, the war in Ukraine has taken an unimaginable humanitarian toll. The Internet in Ukraine has also become a battleground, suffering attacks, re-routing, and disruptions. But it has proven to be exceptionally resilient, recovering time and time again from each setback.
We know that the need for a secure and reliable Internet there is more critical than ever. At Cloudflare, we’re committed to continue providing tools that protect Internet services from cyber attack, improve security for those operating in the region, and share information about Internet connectivity and routing inside Ukraine.
Post Syndicated from original https://lwn.net/Articles/923846/
As of this writing, 5,776 non-merge changesets have been pulled into the
mainline kernel for the 6.3 release; that is a bit less than half of the
work that was waiting in linux-next before the merge window opened. This
merge window is thus well underway, but far from complete. Quite a bit of
significant work has been pulled so far; read on to see what entered the
kernel in the first half of the 6.3 merge window.