Post Syndicated from Marshall Jones original https://aws.amazon.com/blogs/security/best-practices-for-cross-region-aggregation-of-security-findings/
AWS Security Hub enables customers to have a centralized view into the security posture across their AWS environment by aggregating your security alerts from various AWS services and partner products in a standardized format so that you can more easily take action on them. To facilitate that central view, Security Hub allows you to designate an aggregation Region, which links some or all Regions to a single aggregated Region in a delegated administrator AWS account. All your findings across all of your accounts and all of your linked Regions will be processed by Security Hub in this one Region. With this feature, you can take advantage of many configurations when ingesting findings into Security Hub, that will benefit you operationally and provide cost savings.
This blog post provides you with a set of best practices when using Security Hub across multiple Regions. After implementing the recommendations in this blog post, you’ll have an optimized and centralized view of Security Hub findings from all integrated AWS services and partner products across all Regions in a single AWS account and Region.
Enable cross-Region aggregation
To enable cross-Region aggregation in Security Hub, you must first enable finding aggregation in Security Hub from the Region that will become the aggregation Region. You cannot use a Region that is disabled by default as your aggregation Region. For a list of Regions that are disabled by default, see Enabling a Region in the AWS General Reference.
You can enable AWS Security Hub finding aggregation using either the console or CLI. You must enable finding aggregation from the Region that will be the aggregation Region.
To enable Security Hub finding aggregation from the console
To enable AWS Security Hub finding aggregation using the AWS console:
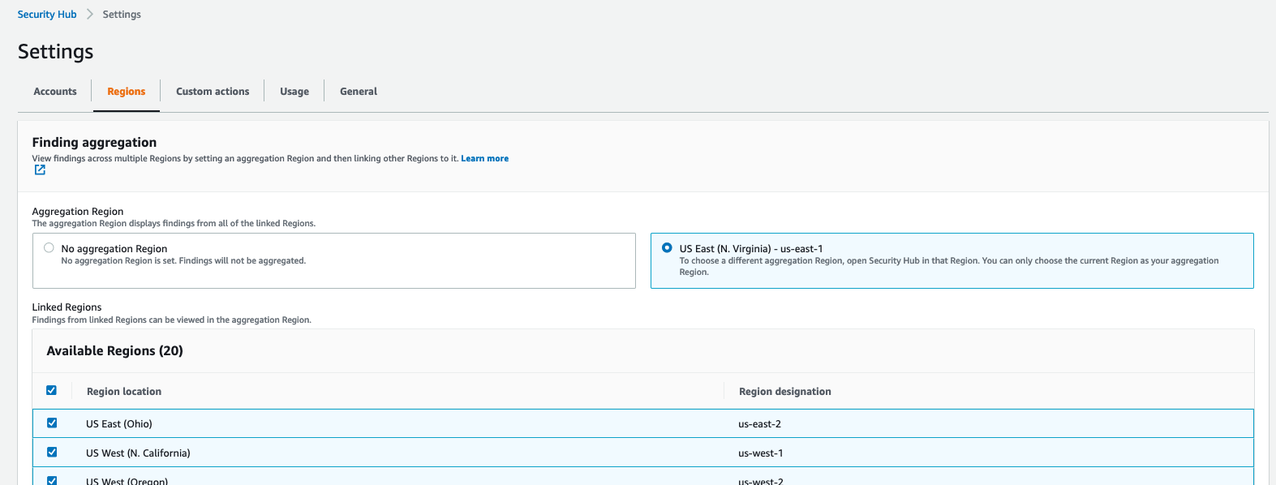
- Start by navigating to the AWS Security Hub console and select Settings on the left side of the screen. Once on the settings page, choose the Regions tab.

Figure 1. Enabling finding aggregation
- Check the checkbox to Link future Regions. As AWS releases new Regions, their results will automatically be aggregated into your designated Region. If this checkbox is not checked, any new Region that is released will not aggregate Security Hub findings to the aggregation Region.
To enable Security Hub finding aggregation using the CLI
Alternatively, you can enable AWS Security Hub finding aggregation using the CLI by using the following command:
aws securityhub create-finding-aggregator –region <aggregation Region> –region-linking-mode ALL_REGIONS | ALL_REGIONS_EXCEPT_SPECIFIED | SPECIFIED_REGIONS –regions <Region list>
Here’s a sample CLI command to enable AWS Security Hub finding aggregation:
aws securityhub create-finding-aggregator –region us-east-1 –region-linking-mode SPECIFIED_REGIONS –regions us-west-1,us-west-2
For more details around AWS Security Hub cross-region aggregation, see Aggregating findings across regions.
Consolidating downstream SIEM and ticketing integrations
Security Hub findings for all AWS accounts in your environment should be integrated into a Security Information and Event Management (SIEM) solution, such as Amazon OpenSearch Service or an APN partner SIEM, or a standardized ticketing system such as JIRA or ServiceNow.
You should send all Security Hub findings to a SIEM or ticketing solution from a single aggregation point to simplify operational overhead. Although integration architectures vary, as an example, this might mean configuring an Amazon EventBridge rule to parse and send findings to AWS Lambda or Amazon Kinesis for a custom integration point with the SIEM or ticketing solution.
You should to configure this integration point in a single delegated administrator account across all member AWS accounts and aggregated Regions. You should avoid having multiple integration points between each Security Hub Region and your SIEM or ticketing solution to avoid unnecessary operational overhead and costs of managing multiple integration points and resources required to stream findings to your SIEM.
Collecting Security Hub findings in a SIEM or ticketing solution can help you correlate findings across many other logs sources. For example, you might use a SIEM solution to analyze operating system logs from an Amazon Elastic Compute Cloud (Amazon EC2) instance to correlate with GuardDuty findings collected by Security Hub to investigate suspicious activity. You could also use ServiceNow or JIRA to create an automated, bidirectional integration between these ticketing solutions that keeps your Security Hub findings and issues in sync.
Auto-archive GuardDuty findings associated with global resources
Amazon GuardDuty creates findings associated with AWS IAM resources. IAM resources are global resources, which means that they are not Region-specific. If GuardDuty generates a finding for an IAM API call that is not Region-specific, such as ListGroups (for example, PenTest:IAMUser/KaliLinux) that finding is created in all GuardDuty Regions and ingested into Security Hub in every Region. You want to implement suppression rules in GuardDuty so that you don’t have multiple copies of this finding in your Security Hub delegated administrator account finding aggregation Region.
To implement AWS GuardDuty suppression rules (Console)
To reduce the duplication of findings in Security Hub, suppress global GuardDuty findings in all Regions except the Security Hub aggregation Region. For example, if you are aggregating Security Hub findings in us-east-1 and your environment uses all commercial AWS Regions in the United States, you would add a suppression rule in GuardDuty in us-east-2, us-west-1, and us-west-2.
To create AWS GuardDuty suppression rules using the AWS console:
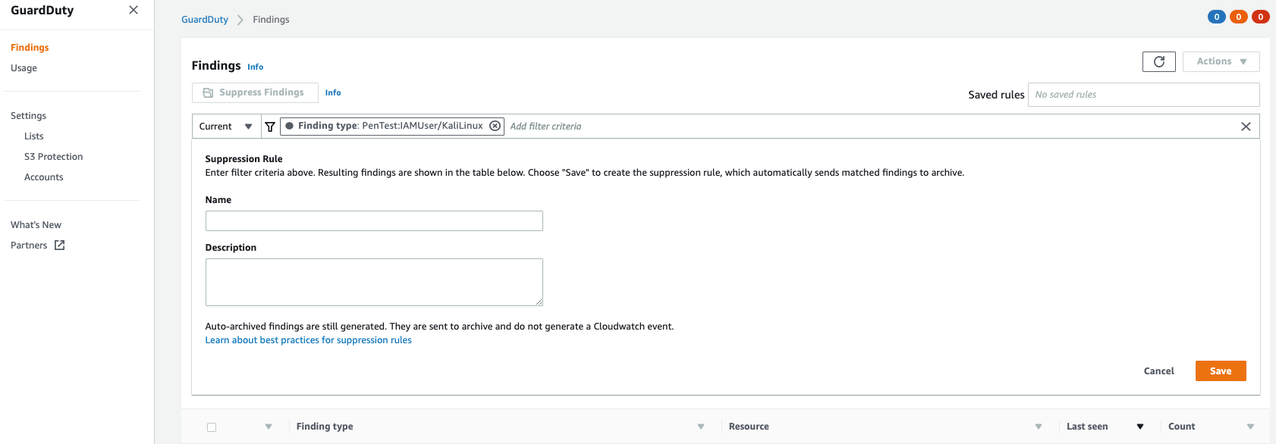
- Navigate to the GuardDuty console and select the Findings link on the left side of the screen.

Figure 2. Creating GuardDuty suppression rules
- Filter to search for the findings you want to suppress, and click Save / edit in the search bar.
- Enter a name and description for the suppression rule and save it.
To implement AWS GuardDuty suppression rules (CLI)
Alternatively, you can create AWS GuardDuty suppression rules using the CreateFilter API via CLI.
- Create a JSON file with your desired suppression filter criteria for the suppression rule.
- The following CLI command will test your filter criteria for AWS GuardDuty findings that will be suppressed:
aws guardduty list-findings –detector-id 12abc34d567e8fa901bc2d34e56789f0 –finding-criteria file://criteria.json
- The following CLI command will create a filter for AWS GuardDuty findings that will be suppressed:
aws guardduty create-filter –action ARCHIVE –detector-id 12abc34d567e8fa901bc2d34e56789f0 –name yourfiltername –finding-criteria file://criteria.json
For more details for creating AWS GuardDuty suppression rules, see Creating AWS GuardDuty suppression rules.
Reduce AWS Config cost by recording global resources in one Region
Like GuardDuty, AWS Config also records supported types of global resources, which are not tied to a specific Region and can be used in all Regions. The global resource types that AWS Config supports are IAM users, groups, roles, and customer managed policies. The configuration details for a specific global resource are the same in all Regions. If you have AWS Security Hub AWS Foundational Best Practices enabled, the feature has certain checks for global resources in AWS Config that you need to disable in all Regions except the aggregated Region.
Customize AWS Config for global resources
If you customize AWS Config in multiple Regions to record global resources, AWS Config creates multiple configuration items each time a global resource changes, one configuration item for each Region. Costs for each configuration item can be found on AWS Config pricing. These configuration items will contain identical data. To prevent duplicate configuration items, consider customizing AWS Config in only one Region to record global resources, unless you want those configuration items to be available in multiple Regions. See this blog post for a comprehensive list of additional AWS Config best practices.
To customize AWS Config for global resources (Console)
Follow the steps below to change the AWS Config global resource configuration in the AWS Console.
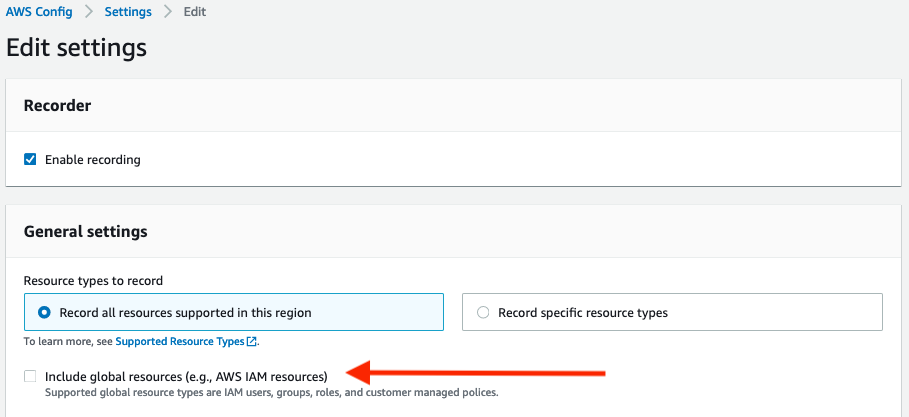
- Navigate to the AWS Config console and select Settings on the left side of the screen
- Click Edit in the top right corner
- Uncheck the Include global resources checkbox.
- Repeat these steps for each Region AWS Config is enabled, except the Region where you would like to track global resources.

Figure 3. AWS Config global resource setting
To customize AWS Config for global resources (CLI)
Alternatively, you can disable the global resource tracking in AWS Config using the CLI.
aws configservice put-configuration-recorder –configuration-recorder name=default,roleARN=arn:aws:iam::123456789012:role/config-role –recording-group allSupported=true,includeGlobalResourceTypes=false
If you have deployed AWS Config using these CloudFormation templates, you would set the IncludeGlobalResourceTypes to False under the AWS::Config::ConfigurationRecorder for the Regions you do not want to track global resources, and set the value to True in the aggregated Region where you would like to use to track global resources. You can use the CloudFormation StackSets multiple AWS Region deployment feature to deploy the CloudFormation template in all AWS Regions where AWS Config is enabled.
For more details for AWS Config global resources, see Selecting AWS Config resources to record.
Disable AWS Security Hub AWS Foundational Best Practices periodic controls associated with global resources
AWS Security Hub AWS Foundational Best Practices perform checks against the resources in your AWS environment utilizing AWS Config rules. After you have disabled the AWS Config global resources in all Regions except for the Region that runs global recording, disable the Security Hub controls that deal with global resources as shown in Figure 5 below.
You can disable AWS Security Hub controls relating to global resources using the console or CLI.
To disable AWS Security Hub controls (Console)
Follow the steps below to disable Security Hub controls that deal with global resources in the AWS Console.
- Navigate to the Security Hub console and select Security Standards on the left side of the screen.
- Click on the AWS Foundation Security Best Practices v.1.0.0 security standard.
- Then use the filter box to search for IAM. Now you should be able to see security controls IAM.1-IAM.7, which are Security Hub global controls.

Figure 4. Security Hub global controls
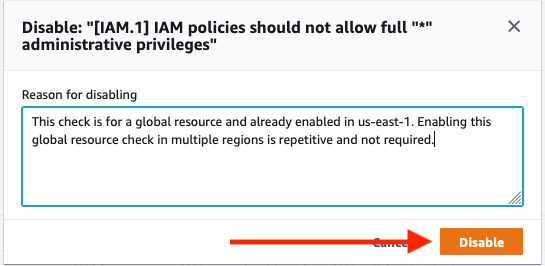
- Click on each control and select Disable in the top right corner
- After you have disabled resources, add a reason for disabling and choose Disable.

Figure 5. Disabling Security Hub control
To disable AWS Security Hub controls (CLI)
Alternatively, you can disable Security Hub controls that deal with global resources using the CLI.
aws securityhub update-standards-control –standards-control-arn <control ARN> –control-status “DISABLED” –disabled-reason <description of reason to disable>
This sample CLI command disables Security Hub controls that deal with global resources:
aws securityhub update-standards-control –standards-control-arn “arn:aws:securityhub:us-east-1:123456789012:control/aws-foundational-security-best-practices/v/1.0.0/ACM.1” –control-status “DISABLED” –disabled-reason “Not applicable for my service”
You can also follow instructions to implement a solution to disable specific Security Hub controls for multiple AWS accounts.
Be sure to only disable the Security Hub controls in the Regions where global recording is also disabled. Verify the Security Hub controls associated with global resources are enabled in the same Region where AWS Config global resources are enabled.
After you have completed disabling these controls and recording of global resources, proceed to disable the [Config.1] AWS Config should be enabled control. This specific control requires recording of global resources in order to pass, which is not required to have enabled in multiple Regions.
For more details for AWS Security Hub controls, see Disabling and enabling individual AWS Security Hub controls .
Implement automatic remediation from a central Region
Once findings are consolidated and ingested into Security Hub across all your organization’s AWS accounts, you should implement auto-remediation where possible, including everything from resource misconfigurations to automated quarantine of infected EC2 instances. Security Hub provides multiple ways to achieve this through end-to-end automation with EventBridge or through human-triggered automation with Security Hub Custom Actions. You can deploy automatic remediation solutions in a single Region to perform cross-Region remediation. This helps you deploy fewer resources, saving money and operational overhead. For more information on how to enable the solution for Security Hub Automated Response and Remediation, see this blog post.
If you have automation currently in place, it’s important to understand how findings from multiple Regions triggering your automation might be affected. For example, you might have a Lambda function that remediates problems with S3 buckets, where it assumes it is being invoked in the same Region as the S3 bucket it needs to remediate. With cross-Region aggregation, your Lambda might need to make a cross-Region AWS SDK call. The Lambda function will run in the Region where the aggregation occurs, but the bucket could be in another Region, so you might have to adjust your function to handle that situation. Also, the role associated with the Lambda function could have its privileges limited to a single Region. If you intend the same function to work in all Regions, you might need change the IAM policy for the IAM role used by the Lambda. Make sure to check Service Control Policies in AWS Organizations, if you use them, because they can also deny actions in one Region while allowing them in another Region.
When enabling cross-Region finding aggregation, you’ll need to understand how any automatic remediation that might be in place today could be affected. Be sure to test your remediation functions on resources in various Regions, to be sure remediation works in all Regions you monitor.
Conclusion
This blog post highlights configurations you can take advantage of to reduce operational overhead and provide cost savings by using cross-Region finding aggregation in Security Hub. The examples given apply to the majority of AWS environments, and are meant to be action items you can use to improve the overall security and operational effectiveness of your AWS environment.
If you have feedback about this post, submit comments in the Comments section below. If you have any questions about this post, start a thread on the re:Post forum.
Want more AWS Security news? Follow us on Twitter.















 Raghu Boppanna works as an Enterprise Architect at Vanguard’s Chief Technology Office. Raghu specializes in Data Analytics, Data Migration/Replication including CDC Pipelines, Disaster Recovery and Databases. He has earned several AWS Certifications including AWS Certified Security – Specialty & AWS Certified Data Analytics – Specialty.
Raghu Boppanna works as an Enterprise Architect at Vanguard’s Chief Technology Office. Raghu specializes in Data Analytics, Data Migration/Replication including CDC Pipelines, Disaster Recovery and Databases. He has earned several AWS Certifications including AWS Certified Security – Specialty & AWS Certified Data Analytics – Specialty. Parameswaran V Vaidyanathan is a Senior Cloud Resilience Architect with Amazon Web Services. He helps large enterprises achieve the business goals by architecting and building scalable and resilient solutions on the AWS Cloud.
Parameswaran V Vaidyanathan is a Senior Cloud Resilience Architect with Amazon Web Services. He helps large enterprises achieve the business goals by architecting and building scalable and resilient solutions on the AWS Cloud.
 Mithil Prasad is a Principal Customer Solutions Manager with Amazon Web Services. In his role, Mithil works with Customers to drive cloud value realization, provide thought leadership to help businesses achieve speed, agility, and innovation.
Mithil Prasad is a Principal Customer Solutions Manager with Amazon Web Services. In his role, Mithil works with Customers to drive cloud value realization, provide thought leadership to help businesses achieve speed, agility, and innovation.






 Fig 5. Terraform state file buckets and state lock tables per environment in the central tooling account.
Fig 5. Terraform state file buckets and state lock tables per environment in the central tooling account.
 Fig 6. Terraform state files per account and Region for each environment in the central tooling account
Fig 6. Terraform state files per account and Region for each environment in the central tooling account
 Fig 7. Git tags and the respective Terraform state files.
Fig 7. Git tags and the respective Terraform state files.
 Fig 8. Multi-Region CI/CD with Terraform state resources stored in the same Region as the workload account resources for the respective Region
Fig 8. Multi-Region CI/CD with Terraform state resources stored in the same Region as the workload account resources for the respective Region