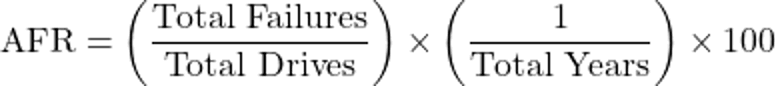Post Syndicated from Pat Patterson original https://www.backblaze.com/blog/experimenting-with-deepseek-backblaze-b2-and-drive-stats/

As we explained in our recent blog post, AI Reasoning Models: OpenAI o3-mini, o1-mini, and DeepSeek R1, Chinese startup DeepSeek caused a stir when it released its R1 reasoning model in January of this year. Interestingly, DeepSeek R1 has an OpenAI-compatible API, so applications written for OpenAI should work with DeepSeek R1 with just a configuration change. Since I had a suitable sample app all ready to go, I decided to put their claim to the test.
Why, and why not, use DeepSeek?
A major difference between DeepSeek and OpenAI is cost. At the time of writing, DeepSeek charges $0.55 per million input tokens and $2.19 per million output tokens for its R1 model. That’s about 3.6% of OpenAI’s $15.00 per million input tokens and $60.00 per million output tokens for its flagship o1 reasoning model, and about half of o3-mini’s $1.10 per million input tokens and $4.40 per million output tokens.
Set against this is the fact that, in using the DeepSeek platform’s API, you are sending your data to a startup located in China that has been accused by OpenAI of “inappropriately” basing its work on the output of OpenAI’s models. It’s up to you, and your organizations’ data governance policy, whether the trade-off is worthwhile.
Another consideration is the ability to run DeepSeek’s models locally, on your own infrastructure, or, more likely, your chosen provider’s infrastructure, rather than sending requests to the DeepSeek platform. Spinning up my own DeepSeek instance was out of scope for this blog post, but I’ll likely return to it in a future blog post.
Swapping OpenAI for DeepSeek
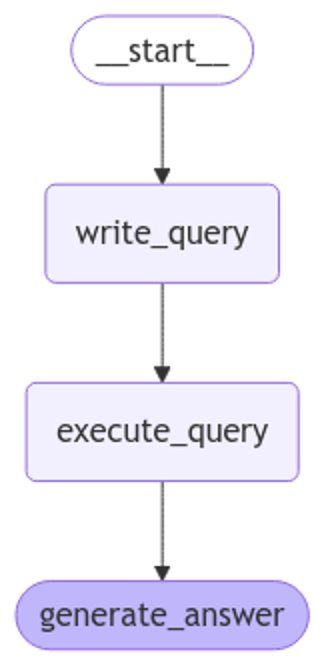
Last month, I explained how you can build an AI agent with Backblaze B2, LangChain, and Drive Stats, walking you through a simple chatbot that can answer questions based on our Drive Stats data set—11 years of metrics gathered from the Backblaze B2 Cloud Storage platform’s fleet of hard drives. In that example, the chatbot accepted a natural language question, used OpenAI’s GPT‑4o mini large language model (LLM) to generate a SQL query that might help provide an answer, executed the query against the Drive Stats data set via the Trino SQL engine, and then used OpenAI again to interpret the result set and either repeat the query-interpret cycle, or generate a natural language answer.
I copied the Jupyter notebook from that example and used it as the basis for investigating the feasibility of swapping out OpenAI for DeepSeek. The DeepSeek version of the notebook contains the full source code of my experiments; I’ll include relevant extracts here, edited for clarity.
Since I used the LangChain AI framework, which provides a layer above a range of AI models, the only place that OpenAI surfaced in my code was in creating an instance of LangChain’s ChatOpenAI wrapper:
# OPENAI_API_KEY must be defined in the .env file
load_dotenv()
llm = ChatOpenAI(model="gpt-4o-mini")
The ChatOpenAI class contains all the code required to communicate with OpenAI via its API.
According to the DeepSeek documentation, all you should need to do is:
- Provide your DeepSeek API key in the same
OPENAI_API_KEYenvironment variable. - Set the API base URL to
https://api.deepseek.com. - Provide a DeepSeek model name in place of the OpenAI one.
If this reminds you of the steps for using Backblaze B2’s S3-compatible API, you’re not alone. The OpenAI API has become a de facto standard for integrating with LLMs in much the same way as Amazon’s S3 API allows an ecosystem of apps and tools to interoperate with object storage systems from a variety of vendors.
Looking at the DeepSeek documentation, you can use one of two models, deepseek-reasoner (aka DeepSeek R1) or deepseek-chat. Let’s see what the much-talked-about DeepSeek R1 came up with.
Using DeepSeek R1 in the AI agent
To make it easy to use both the OpenAI and DeepSeek notebooks, I created a second entry in the .env file for the DeepSeek API key, and copied it to the OpenAI environment variable in the notebook code:
# The .env file needs at least DEEPSEEK_API_KEY, and may also contain
# OPENAI_API_KEY. Move the DeepSeek API key to the OpenAI environment
# variable
load_dotenv()
os.environ["OPENAI_API_KEY"] = os.environ.pop("DEEPSEEK_API_KEY")
llm = ChatOpenAI(model="deepseek-reasoner", base_url='https://api.deepseek.com')
As I set about repeating the steps from the Jupyter notebook that supported my previous blog post, I was disappointed to see DeepSeek fall at the very first hurdle: generating a SQL query for a simple natural language question. Here is the code:
question = {"question": "How many drives are there?"}
write_query(question)
Looking back at the original notebook, OpenAI’s response was valid SQL, although it didn’t have enough information to construct the correct query:
{'query': 'SELECT COUNT(*) AS drive_count FROM drivestats'}
DeepSeek, on the other hand, responded with a Python stack trace and this error:
openai.UnprocessableEntityError: Failed to deserialize the JSON body into the target type: response_format: response_format.type `json_schema` is unavailable now at line 1 column 13827
What went wrong? Searching for the error turns up a comment from a LangChain engineer explaining that we should use BaseChatOpenAI rather than ChatOpenAI since it “[…] accommodates many APIs that are similar to OpenAI. It uses tool calling for structured output by default.”
So, we can redefine llm accordingly, and try generating a query again:
llm = BaseChatOpenAI(model="deepseek-reasoner", base_url='https://api.deepseek.com')
write_query(question)
Unfortunately, DeepSeek returns another error:
BadRequestError: Error code: 400 - {'error': {'message': 'The last message of deepseek-reasoner must be a user message, or an assistant message with prefix mode on (refer to https://api-docs.deepseek.com/guides/chat_prefix_completion).', 'type': 'invalid_request_error', 'param': None, 'code': 'invalid_request_error'}}
Looking back at the AI agent code, we can see that we used an off-the-shelf prompt from the LangChain Prompt Hub that provides the model with a single, system, message:
================================ System Message ================================
Given an input question, create a syntactically correct {dialect} query to run to help find the answer. Unless the user specifies in his question a specific number of examples they wish to obtain, always limit your query to at most {top_k} results. You can order the results by a relevant column to return the most interesting examples in the database.
Never query for all the columns from a specific table, only ask for a few relevant columns given the question.
Pay attention to use only the column names that you can see in the schema description. Be careful to not query for columns that do not exist. Also, pay attention to which column is in which table.
Only use the following tables:
{table_info}
Question: {input}
Does this mean that DeepSeek is not, in fact, API-compatible with OpenAI? I would argue that it does not. DeepSeek implements the same API request/response syntax as OpenAI, but it is a different platform. Some variation in semantics is to be expected. We see similar variations between Backblaze B2 and Amazon S3; for example, the S3 PutObjectAcl operation sets the access control list (ACL) for an object in a bucket. Amazon S3’s access management model allows you to manipulate an object’s ACL independently of its bucket—for example, you can put a private object in a public bucket, and vice versa.
This flexibility comes with a cost: It becomes difficult to reason about the visibility of data. In fact, AWS now recommends “that you keep ACLs disabled, except in unusual circumstances where you need to control access for each object individually.”
Backblaze B2’s model is much simpler: You control access at the bucket level, and all objects have the same ACL as their bucket. Backblaze B2 implements the PutObjectAcl operation, but, if you try to set an object’s ACL to any other value than its bucket’s ACL, the service responds with an error.
Returning to the AI agent code, we can replace the single-system-message prompt with one that combines a system message with a user message:
import textwrap
from langchain_core.prompts import ChatPromptTemplate
query_prompt_template = ChatPromptTemplate([
("system", textwrap.dedent("""Given an input question, create a
syntactically correct {dialect} query to run to help find the answer.
Unless the user specifies in his question a specific number of examples
they wish to obtain, always limit your query to at most {top_k} results.
You can order the results by a relevant column to return the most
interesting examples in the database.
Never query for all the columns from a specific table, only ask for a the
few relevant columns given the question.
Pay attention to use only the column names that you can see in the schema
description. Be careful to not query for columns that do not exist. Also,
pay attention to which column is in which table.
Only use the following tables:
{table_info}""")),
("human", "Question: {input}"),
])
Trying the write_query() call for a third time, this is the response:
BadRequestError: Error code: 400 - {'error': {'message': 'deepseek-reasoner does not support Function Calling', 'type': 'invalid_request_error', 'param': None, 'code': 'invalid_request_error'}}
A third error! What is this “function calling” that deepseek-reasoner does not support? A helpful article on the topic at the Hugging Face AI community explains:
Function calling is a powerful capability that enables Large Language Models (LLMs) to interact with your code and external systems in a structured way. Instead of just generating text responses, LLMs can understand when to call specific functions and provide the necessary parameters to execute real-world actions.
Unfortunately, that is exactly our use case. It’s becoming clear that DeepSeek R1 is not the correct tool for implementing an AI agent—we’ve been trying to use a chisel as a screwdriver!
DeepSeek-V3: A better fit
As its name suggests, the deepseek-chat model is more appropriate for this application. The DeepSeek documentation tells us that it is based on DeepSeek-V3, released in December 2024. DeepSeek-V3 is priced at $0.27 per million input tokens and $1.10 per million output tokens; this is actually more expensive than the GPT-4o mini model I used for the OpenAI agent example ($0.15 per million input tokens, $0.600 per million output tokens), but how does it compare? Let’s take a look.
First, we need to edit the LLM creation code again to set the model name:
llm = BaseChatOpenAI(model="deepseek-chat", base_url='https://api.deepseek.com')
Now we can run write_query() again. It’s immediately clear that it’s a better fit than its “big brother:”
{'query': 'SELECT COUNT(*) AS total_drives FROM drivestats LIMIT 10'}
As with the OpenAI agent, this query is well-formed SQL, but it’s not answering the question we set—it’s giving us the total number of rows in the dataset, rather than the number of drives. Also, it’s a little odd to have a LIMIT clause in a SELECT COUNT(*) query, but it’s legal SQL, and the agent is following its instructions very literally: always limit your query to at most {top_k} results, where we set top_k to 10.
question = {"question": "Each drive has its own serial number. How many drives are there?"}
query = write_query(question)
{'query': 'SELECT COUNT(DISTINCT serial_number) AS total_drives FROM drivestats'}
So far, so good!
I’ll skip some intermediate steps here—they are all in the Jupyter notebook if you want to review them, or run them for yourself—and look at how a simple LangChain graph, built on the DeepSeek LLM, answered the question: “Each drive has its own serial number. How many drives did each data center have on 9/1/2024?”
The OpenAI version generated an invalid query, comparing the date column with the string ’2024-09-01’ without using the required DATE type identifier, but DeepSeek generates a correct SQL query and provides a useful natural language response:
/SELECT datacenter, COUNT(DISTINCT serial_number) AS drive_count FROM drivestats WHERE date = DATE ‘2024-09-01’ GROUP BY datacenter ORDER BY drive_count DESC LIMIT 10
[(‘phx1’, 89477), (‘sac0’, 78444), (‘sac2’, 60775), (”, 24080), (‘iad1’, 22800), (‘ams5’, 16139)]
On September 1, 2024, the data centers had the following number of drives:
- phx1: 89,477 drives
- sac0: 78,444 drives
- sac2: 60,775 drives
- (empty datacenter): 24,080 drives
- iad1: 22,800 drives
- ams5: 16,139 drives
These are the top data centers with the highest drive counts on that date.
DeepSeek scores a point!
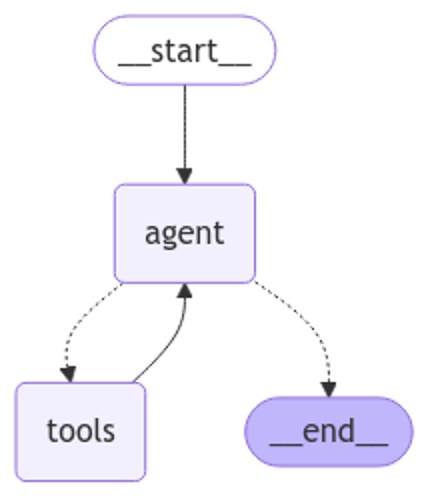
Moving on to the ReAct AI Agent, which allows the LLM to perform multiple SQL queries in generating an answer to a question, DeepSeek performs similarly to OpenAI. Given the question, “Each drive has its own serial number. What is the annualized failure rate of the ST4000DM000 drive model?”, the DeepSeek agent provides the overall failure rate rather than the annualized failure rate (AFR).
When we provide explicit instructions for calculating AFR in its prompt, the DeepSeek agent provides the correct result, identical, in fact, to the OpenAI agent’s response:
The annual failure rate (AFR) for the ST4000DM000 drive model is approximately 2.63%.
However, when given the question, “What was the annual failure rate of the ST8000NM000A drive model in Q3 2024?”, the DeepSeek agent gives us:
[(1.6100573445081607,)]
While OpenAI responds:
The annual failure rate (AFR) of the ST8000NM000A drive model in Q3 2024 is approximately 1.61%.
Wrapping up the investigation, the final question from the OpenAI notebook is more complex:
Considering only drive models which had at least 100 drives in service at the end of the quarter and which accumulated 10,000 or more drive days during the quarter, which drive had the most failures in Q3 2024, and what was its failure rate?
Impressively, the OpenAI agent constructed a well-formed SQL query and provided the correct response:
The drive model with the most failures in Q3 2024 is the TOSHIBA MG08ACA16TA, which had 181 failures. Its failure rate during this period was approximately 1.84%.
BadRequestError: Error code: 400 - {'error': {'message': "An assistant message with 'tool_calls' must be followed by tool messages responding to each 'tool_call_id'. (insufficient tool messages following tool_calls message)", 'type': 'invalid_request_error', 'param': None, 'code': 'invalid_request_error'}}
During task with name 'agent' and id '0aa26ba6-a3ee-ced1-de4d-b60ed7fbca99'
The phrase “insufficient tool messages” suggested that the DeepSeek LLM might need to be reconfigured to allow more tokens. According to the documentation on models and pricing, the deepseek-chat model supports a maximum of 8K output tokens, but defaults to 4K if max_tokens is not specified.
Recreating the DeepSeek wrapper object and agent accordingly, I gave it the last question again:
llm = BaseChatOpenAI(model="deepseek-chat", base_url='https://api.deepseek.com', max_tokens=8192, **extra_kwargs)
agent_executor = create_react_agent(llm, tools, state_modifier=system_message)
response = agent_executor.invoke(
{"messages": [{"role": "user", "content": "Considering only drive models which had at least 100 drives in service at the end of the quarter and which accumulated 10,000 or more drive days during the quarter, which drive had the most failures in Q3 2024, and what was its failure rate?"}]}
)
# Show the SQL query sent to the database
print(response['messages'][-3].tool_calls[0]['args']['query'])
# Show the final response message
display_markdown(response['messages'][-1].content, raw=True)
This time, DeepSeek was able to generate a similar SQL query to OpenAI:
WITH drive_counts AS (
SELECT model, COUNT(DISTINCT serial_number) AS drive_count
FROM drivestats
WHERE date >= DATE '2024-07-01' AND date <= DATE '2024-09-30'
GROUP BY model
HAVING COUNT(DISTINCT serial_number) >= 100
), drive_days AS (
SELECT model, COUNT(*) AS total_drive_days
FROM drivestats
WHERE date >= DATE '2024-07-01' AND date <= DATE '2024-09-30'
GROUP BY model
HAVING COUNT(*) >= 10000
), failures AS (
SELECT model, COUNT(*) AS failure_count
FROM drivestats
WHERE date >= DATE '2024-07-01' AND date <= DATE '2024-09-30' AND failure = 1
GROUP BY model
)
SELECT d.model,
f.failure_count,
100 * (CAST(f.failure_count AS DOUBLE) / (CAST(d.total_drive_days AS DOUBLE) / 365)) AS annual_failure_rate
FROM drive_days d
JOIN failures f ON d.model = f.model
JOIN drive_counts dc ON d.model = dc.model
ORDER BY f.failure_count DESC
LIMIT 1
With a correct response:
To answer the question:
The drive model with the most failures in Q3 2024 is TOSHIBA MG08ACA16TA, which had 181 failures. The annualized failure rate (AFR) for this model during that quarter was 1.84%.
Success! But, unfortunately, this isn’t the whole story.
DeepSeek Reliability

I originally set out to write this blog post at the end of January, but the DeepSeek platform website had gone offline by January 30, so I couldn’t even start until I was able to sign up for an API key on February 5.
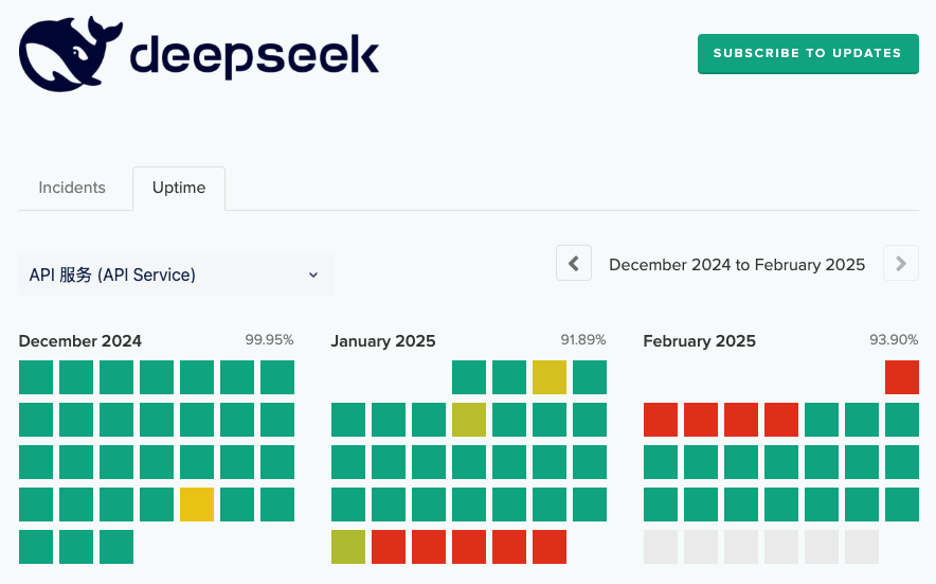
Given my shiny new API key, and DeepSeek’s claims of OpenAI API compatibility, I naïvely expected to be able to work through my earlier OpenAI notebook and write up the results in a couple of days. The reality was more like two weeks.
In this blog post I’ve detailed some of the error messages I encountered along the way, but I saw many more that pointed to the DeepSeek API simply being overwhelmed with traffic. For example, for over a day, when the status page reported no issues, most API requests to DeepSeek terminated after a minute with the error message:
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
A time-consuming investigation revealed that this was caused by the DeepSeek API returning the 200 status code and headers as if the request was successful, then hanging for a minute before terminating the connection without returning any actual data. The calling code saw the 200 as success and tried to decode the non-existent API response body, resulting in the error.
I saw several more instances of intermittent errors that all seemed to point in the same direction: DeepSeek needs to add capacity to its API platform. Notably, the platform seemed faster and more stable on a Saturday morning, U.S. Pacific time, the early hours of Sunday morning in China.
Final thoughts
At present, I would have to classify the DeepSeek-V3 API as “promising, but somewhat flaky.” An agent invocation that succeeds one minute could fail the next with any of a range of error messages. That’s a shame, since when it does work, for instance, in creating the SQL query for the final question above, it tends to work very well.
One final caveat: This is a dynamic field; frameworks and services are literally being updated on a daily basis. For example, since yesterday, as I write this, four of the notebook’s module dependencies have been updated. I encourage you to experiment for yourself as your mileage will almost certainly vary, hopefully in a positive direction.
The post Experimenting with DeepSeek, Backblaze B2, and Drive Stats appeared first on Backblaze Blog | Cloud Storage & Cloud Backup