Post Syndicated from Jeeshan Khetrapal original https://aws.amazon.com/blogs/big-data/how-amazon-optimized-its-high-volume-financial-reconciliation-process-with-amazon-emr-for-higher-scalability-and-performance/
Account reconciliation is an important step to ensure the completeness and accuracy of financial statements. Specifically, companies must reconcile balance sheet accounts that could contain significant or material misstatements. Accountants go through each account in the general ledger of accounts and verify that the balance listed is complete and accurate. When discrepancies are found, accountants investigate and take appropriate corrective action.
As part of Amazon’s FinTech organization, we offer a software platform that empowers the internal accounting teams at Amazon to conduct account reconciliations. To optimize the reconciliation process, these users require high performance transformation with the ability to scale on demand, as well as the ability to process variable file sizes ranging from as low as a few MBs to more than 100 GB. It’s not always possible to fit data onto a single machine or process it with one single program in a reasonable time frame. This computation has to be done fast enough to provide practical services where programming logic and underlying details (data distribution, fault tolerance, and scheduling) can be separated.
We can achieve these simultaneous computations on multiple machines or threads of the same function across groups of elements of a dataset by using distributed data processing solutions. This encouraged us to reinvent our reconciliation service powered by AWS services, including Amazon EMR and the Apache Spark distributed processing framework, which uses PySpark. This service enables users to process files over 100 GB containing up to 100 million transactions in less than 30 minutes. The reconciliation service has become a powerhouse for data processing, and now users can seamlessly perform a variety of operations, such as Pivot, JOIN (like an Excel VLOOKUP operation), arithmetic operations, and more, providing a versatile and efficient solution for reconciling vast datasets. This enhancement is a testament to the scalability and speed achieved through the adoption of distributed data processing solutions.
In this post, we explain how we integrated Amazon EMR to build a highly available and scalable system that enabled us to run a high-volume financial reconciliation process.
Architecture before migration
The following diagram illustrates our previous architecture.

Our legacy service was built with Amazon Elastic Container Service (Amazon ECS) on AWS Fargate. We processed the data sequentially using Python. However, due to its lack of parallel processing capability, we frequently had to increase the cluster size vertically to support larger datasets. For context, 5 GB of data with 50 operations took around 3 hours to process. This service was configured to scale horizontally to five ECS instances that polled messages from Amazon Simple Queue Service (Amazon SQS), which fed the transformation requests. Each instance was configured with 4 vCPUs and 30 GB of memory to allow horizontal scaling. However, we couldn’t expand its capacity on performance because the process happened sequentially, picking chunks of data from Amazon Simple Storage Service (Amazon S3) for processing. For example, a VLOOKUP operation where two files are to be joined required both files to be read in memory chunk by chunk to obtain the output. This became an obstacle for users because they had to wait for long periods of time to process their datasets.
As part of our re-architecture and modernization, we wanted to achieve the following:
- High availability – The data processing clusters should be highly available, providing three 9s of availability (99.9%)
- Throughput – The service should handle 1,500 runs per day
- Latency – It should be able to process 100 GB of data within 30 minutes
- Heterogeneity – The cluster should be able to support a wide variety of workloads, with files ranging from a few MBs to hundreds of GBs
- Query concurrency – The implementation demands the ability to support a minimum of 10 degrees of concurrency
- Reliability of jobs and data consistency – Jobs need to run reliably and consistently to avoid breaking Service Level Agreements (SLAs)
- Cost-effective and scalable – It must be scalable based on the workload, making it cost-effective
- Security and compliance – Given the sensitivity of data, it must support fine-grained access control and appropriate security implementations
- Monitoring – The solution must offer end-to-end monitoring of the clusters and jobs
Why Amazon EMR
Amazon EMR is the industry-leading cloud big data solution for petabyte-scale data processing, interactive analytics, and machine learning (ML) using open source frameworks such as Apache Spark, Apache Hive, and Presto. With these frameworks and related open-source projects, you can process data for analytics purposes and BI workloads. Amazon EMR lets you transform and move large amounts of data in and out of other AWS data stores and databases, such as Amazon S3 and Amazon DynamoDB.
A notable advantage of Amazon EMR lies in its effective use of parallel processing with PySpark, marking a significant improvement over traditional sequential Python code. This innovative approach streamlines the deployment and scaling of Apache Spark clusters, allowing for efficient parallelization on large datasets. The distributed computing infrastructure not only enhances performance, but also enables the processing of vast amounts of data at unprecedented speeds. Equipped with libraries, PySpark facilitates Excel-like operations on DataFrames, and the higher-level abstraction of DataFrames simplifies intricate data manipulations, reducing code complexity. Combined with automatic cluster provisioning, dynamic resource allocation, and integration with other AWS services, Amazon EMR proves to be a versatile solution suitable for diverse workloads, ranging from batch processing to ML. The inherent fault tolerance in PySpark and Amazon EMR promotes robustness, even in the event of node failures, making it a scalable, cost-effective, and high-performance choice for parallel data processing on AWS.
Amazon EMR extends its capabilities beyond the basics, offering a variety of deployment options to cater to diverse needs. Whether it’s Amazon EMR on EC2, Amazon EMR on EKS, Amazon EMR Serverless, or Amazon EMR on AWS Outposts, you can tailor your approach to specific requirements. For those seeking a serverless environment for Spark jobs, integrating AWS Glue is also a viable option. In addition to supporting various open-source frameworks, including Spark, Amazon EMR provides flexibility in choosing deployment modes, Amazon Elastic Compute Cloud (Amazon EC2) instance types, scaling mechanisms, and numerous cost-saving optimization techniques.
Amazon EMR stands as a dynamic force in the cloud, delivering unmatched capabilities for organizations seeking robust big data solutions. Its seamless integration, powerful features, and adaptability make it an indispensable tool for navigating the complexities of data analytics and ML on AWS.
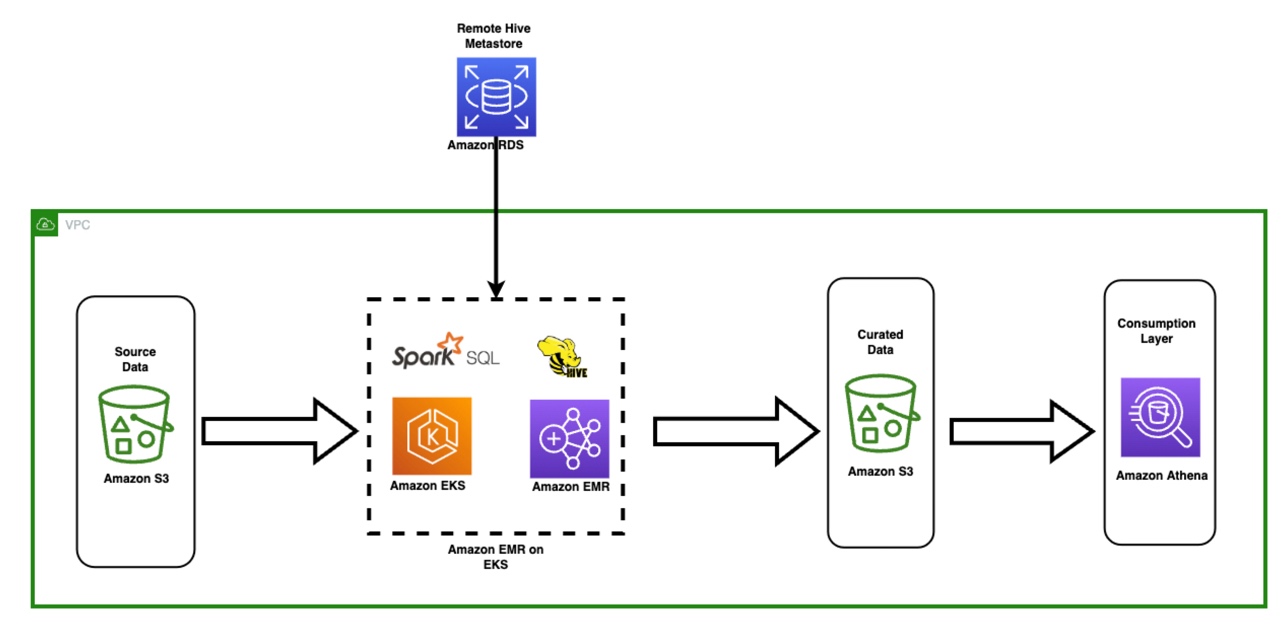
Redesigned architecture
The following diagram illustrates our redesigned architecture.

The solution operates under an API contract, where clients can submit transformation configurations, defining the set of operations alongside the S3 dataset location for processing. The request is queued through Amazon SQS, then directed to Amazon EMR via a Lambda function. This process initiates the creation of an Amazon EMR step for Spark framework implementation on a dedicated EMR cluster. Although Amazon EMR accommodates an unlimited number of steps over a long-running cluster’s lifetime, only 256 steps can be running or pending simultaneously. For optimal parallelization, the step concurrency is set at 10, allowing 10 steps to run concurrently. In case of request failures, the Amazon SQS dead-letter queue (DLQ) retains the event. Spark processes the request, translating Excel-like operations into PySpark code for an efficient query plan. Resilient DataFrames store input, output, and intermediate data in-memory, optimizing processing speed, reducing disk I/O cost, enhancing workload performance, and delivering the final output to the specified Amazon S3 location.
We define our SLA in two dimensions: latency and throughput. Latency is defined as the amount of time taken to perform one job against a deterministic dataset size and the number of operations performed on the dataset. Throughput is defined as the maximum number of simultaneous jobs the service can perform without breaching the latency SLA of one job. The overall scalability SLA of the service depends on the balance of horizontal scaling of elastic compute resources and vertical scaling of individual servers.
Because we had to run 1,500 processes per day with minimal latency and high performance, we choose to integrate Amazon EMR on EC2 deployment mode with managed scaling enabled to support processing variable file sizes.
The EMR cluster configuration provides many different selections:
- EMR node types – Primary, core, or task nodes
- Instance purchasing options – On-Demand Instances, Reserved Instances, or Spot Instances
- Configuration options – EMR instance fleet or uniform instance group
- Scaling options – Auto Scaling or Amazon EMR managed scaling
Based on our variable workload, we configured an EMR instance fleet (for best practices, see Reliability). We also decided to use Amazon EMR managed scaling to scale the core and task nodes (for scaling scenarios, refer to Node allocation scenarios). Lastly, we chose memory-optimized AWS Graviton instances, which provide up to 30% lower cost and up to 15% improved performance for Spark workloads.
The following code provides a snapshot of our cluster configuration:
Performance
With our migration to Amazon EMR, we were able to achieve a system performance capable of handling a variety of datasets, ranging from as low as 273 B to as high as 88.5 GB with a p99 of 491 seconds (approximately 8 minutes).
The following figure illustrates the variety of file sizes processed.

The following figure shows our latency.

To compare against sequential processing, we took two datasets containing 53 million records and ran a VLOOKUP operation against each other, along with 49 other Excel-like operations. This took 26 minutes to process in the new service, compared to 5 days to process in the legacy service. This improvement is almost 300 times greater over the previous architecture in terms of performance.

Considerations
Keep in mind the following when considering this solution:
- Right-sizing clusters – Although Amazon EMR is resizable, it’s important to right-size the clusters. Right-sizing mitigates a slow cluster, if undersized, or higher costs, if the cluster is oversized. To anticipate these issues, you can calculate the number and type of nodes that will be needed for the workloads.
- Parallel steps – Running steps in parallel allows you to run more advanced workloads, increase cluster resource utilization, and reduce the amount of time taken to complete your workload. The number of steps allowed to run at one time is configurable and can be set when a cluster is launched and any time after the cluster has started. You need to consider and optimize the CPU/memory usage per job when multiple jobs are running in a single shared cluster.
- Job-based transient EMR clusters – If applicable, it is recommended to use a job-based transient EMR cluster, which delivers superior isolation, verifying that each task operates within its dedicated environment. This approach optimizes resource utilization, helps prevent interference between jobs, and enhances overall performance and reliability. The transient nature enables efficient scaling, providing a robust and isolated solution for diverse data processing needs.
- EMR Serverless – EMR Serverless is the ideal choice if you prefer not to handle the management and operation of clusters. It allows you to effortlessly run applications using open-source frameworks available within EMR Serverless, offering a straightforward and hassle-free experience.
- Amazon EMR on EKS – Amazon EMR on EKS offers distinct advantages, such as faster startup times and improved scalability resolving compute capacity challenges—which is particularly beneficial for Graviton and Spot Instance users. The inclusion of a broader range of compute types enhances cost-efficiency, allowing tailored resource allocation. Furthermore, Multi-AZ support provides increased availability. These compelling features provide a robust solution for managing big data workloads with improved performance, cost optimization, and reliability across various computing scenarios.
Conclusion
In this post, we explained how Amazon optimized its high-volume financial reconciliation process with Amazon EMR for higher scalability and performance. If you have a monolithic application that’s dependent on vertical scaling to process additional requests or datasets, then migrating it to a distributed processing framework such as Apache Spark and choosing a managed service such as Amazon EMR for compute may help reduce the runtime to lower your delivery SLA, and also may help reduce the Total Cost of Ownership (TCO).
As we embrace Amazon EMR for this particular use case, we encourage you to explore further possibilities in your data innovation journey. Consider evaluating AWS Glue, along with other dynamic Amazon EMR deployment options such as EMR Serverless or Amazon EMR on EKS, to discover the best AWS service tailored to your unique use case. The future of the data innovation journey holds exciting possibilities and advancements to be explored further.
About the Authors
 Jeeshan Khetrapal is a Sr. Software Development Engineer at Amazon, where he develops fintech products based on cloud computing serverless architectures that are responsible for companies’ IT general controls, financial reporting, and controllership for governance, risk, and compliance.
Jeeshan Khetrapal is a Sr. Software Development Engineer at Amazon, where he develops fintech products based on cloud computing serverless architectures that are responsible for companies’ IT general controls, financial reporting, and controllership for governance, risk, and compliance.
 Sakti Mishra is a Principal Solutions Architect at AWS, where he helps customers modernize their data architecture and define their end-to-end data strategy, including data security, accessibility, governance, and more. He is also the author of the book Simplify Big Data Analytics with Amazon EMR. Outside of work, Sakti enjoys learning new technologies, watching movies, and visiting places with family.
Sakti Mishra is a Principal Solutions Architect at AWS, where he helps customers modernize their data architecture and define their end-to-end data strategy, including data security, accessibility, governance, and more. He is also the author of the book Simplify Big Data Analytics with Amazon EMR. Outside of work, Sakti enjoys learning new technologies, watching movies, and visiting places with family.















 Brandon Abear is a Principal Data Engineer in the Data & Analytics (DnA) organization at GoDaddy. He enjoys all things big data. In his spare time, he enjoys traveling, watching movies, and playing rhythm games.
Brandon Abear is a Principal Data Engineer in the Data & Analytics (DnA) organization at GoDaddy. He enjoys all things big data. In his spare time, he enjoys traveling, watching movies, and playing rhythm games. Dinesh Sharma is a Principal Data Engineer in the Data & Analytics (DnA) organization at GoDaddy. He is passionate about user experience and developer productivity, always looking for ways to optimize engineering processes and saving cost. In his spare time, he loves reading and is an avid manga fan.
Dinesh Sharma is a Principal Data Engineer in the Data & Analytics (DnA) organization at GoDaddy. He is passionate about user experience and developer productivity, always looking for ways to optimize engineering processes and saving cost. In his spare time, he loves reading and is an avid manga fan. John Bush is a Principal Software Engineer in the Data & Analytics (DnA) organization at GoDaddy. He is passionate about making it easier for organizations to manage data and use it to drive their businesses forward. In his spare time, he loves hiking, camping, and riding his ebike.
John Bush is a Principal Software Engineer in the Data & Analytics (DnA) organization at GoDaddy. He is passionate about making it easier for organizations to manage data and use it to drive their businesses forward. In his spare time, he loves hiking, camping, and riding his ebike. Ozcan Ilikhan is the Director of Engineering for the Data and ML Platform at GoDaddy. He has over two decades of multidisciplinary leadership experience, spanning startups to global enterprises. He has a passion for leveraging data and AI in creating solutions that delight customers, empower them to achieve more, and boost operational efficiency. Outside of his professional life, he enjoys reading, hiking, gardening, volunteering, and embarking on DIY projects.
Ozcan Ilikhan is the Director of Engineering for the Data and ML Platform at GoDaddy. He has over two decades of multidisciplinary leadership experience, spanning startups to global enterprises. He has a passion for leveraging data and AI in creating solutions that delight customers, empower them to achieve more, and boost operational efficiency. Outside of his professional life, he enjoys reading, hiking, gardening, volunteering, and embarking on DIY projects. Harsh Vardhan is an AWS Solutions Architect, specializing in big data and analytics. He has over 8 years of experience working in the field of big data and data science. He is passionate about helping customers adopt best practices and discover insights from their data.
Harsh Vardhan is an AWS Solutions Architect, specializing in big data and analytics. He has over 8 years of experience working in the field of big data and data science. He is passionate about helping customers adopt best practices and discover insights from their data.



















 Edvin Hallvaxhiu is a Senior Global Security Architect with AWS Professional Services and is passionate about cybersecurity and automation. He helps customers build secure and compliant solutions in the cloud. Outside work, he likes traveling and sports.
Edvin Hallvaxhiu is a Senior Global Security Architect with AWS Professional Services and is passionate about cybersecurity and automation. He helps customers build secure and compliant solutions in the cloud. Outside work, he likes traveling and sports. Rahul Shaurya is a Principal Big Data Architect with AWS Professional Services. He helps and works closely with customers building data platforms and analytical applications on AWS. Outside of work, Rahul loves taking long walks with his dog Barney.
Rahul Shaurya is a Principal Big Data Architect with AWS Professional Services. He helps and works closely with customers building data platforms and analytical applications on AWS. Outside of work, Rahul loves taking long walks with his dog Barney. Andrea Montanari is a Senior Big Data Architect with AWS Professional Services. He actively supports customers and partners in building analytics solutions at scale on AWS.
Andrea Montanari is a Senior Big Data Architect with AWS Professional Services. He actively supports customers and partners in building analytics solutions at scale on AWS. María Guerra is a Big Data Architect with AWS Professional Services. Maria has a background in data analytics and mechanical engineering. She helps customers architecting and developing data related workloads in the cloud.
María Guerra is a Big Data Architect with AWS Professional Services. Maria has a background in data analytics and mechanical engineering. She helps customers architecting and developing data related workloads in the cloud. Pushpraj Singh is a Senior Data Architect with AWS Professional Services. He is passionate about Data and DevOps engineering. He helps customers build data driven applications at scale.
Pushpraj Singh is a Senior Data Architect with AWS Professional Services. He is passionate about Data and DevOps engineering. He helps customers build data driven applications at scale.


















 Manjit Chakraborty is a Senior Solutions Architect at AWS. He is a Seasoned & Result driven professional with extensive experience in Financial domain having worked with customers on advising, designing, leading, and implementing core-business enterprise solutions across the globe. In his spare time, Manjit enjoys fishing, practicing martial arts and playing with his daughter.
Manjit Chakraborty is a Senior Solutions Architect at AWS. He is a Seasoned & Result driven professional with extensive experience in Financial domain having worked with customers on advising, designing, leading, and implementing core-business enterprise solutions across the globe. In his spare time, Manjit enjoys fishing, practicing martial arts and playing with his daughter. Neeraj Roy is a Principal Solutions Architect at AWS based out of London. He works with Global Financial Services customers to accelerate their AWS journey. In his spare time, he enjoys reading and spending time with his family.
Neeraj Roy is a Principal Solutions Architect at AWS based out of London. He works with Global Financial Services customers to accelerate their AWS journey. In his spare time, he enjoys reading and spending time with his family.




















 Stefano Sandona is a Senior Big Data Solution Architect at AWS. He loves data, distributed systems and security. He helps customers around the world architecting secure, scalable and reliable big data platforms.
Stefano Sandona is a Senior Big Data Solution Architect at AWS. He loves data, distributed systems and security. He helps customers around the world architecting secure, scalable and reliable big data platforms. Adnan Hemani is a Software Development Engineer at AWS working with the EMR team. He focuses on the security posture of applications running on EMR clusters. He is interested in modern Big Data applications and how customers interact with them.
Adnan Hemani is a Software Development Engineer at AWS working with the EMR team. He focuses on the security posture of applications running on EMR clusters. He is interested in modern Big Data applications and how customers interact with them.


 Shijian Tang is a Analytics Specialist Solution Architect at Amazon Web Services.
Shijian Tang is a Analytics Specialist Solution Architect at Amazon Web Services. Matthew Liem is a Senior Solution Architecture Manager at Amazon Web Services.
Matthew Liem is a Senior Solution Architecture Manager at Amazon Web Services. Dalei Xu is a Analytics Specialist Solution Architect at Amazon Web Services.
Dalei Xu is a Analytics Specialist Solution Architect at Amazon Web Services. Yuanjun Xiao is a Senior Solution Architect at Amazon Web Services.
Yuanjun Xiao is a Senior Solution Architect at Amazon Web Services.



























 Raymond Lai is a Senior Solutions Architect who specializes in catering to the needs of large enterprise customers. His expertise lies in assisting customers with migrating intricate enterprise systems and databases to AWS, constructing enterprise data warehousing and data lake platforms. Raymond excels in identifying and designing solutions for AI/ML use cases, and he has a particular focus on AWS Serverless solutions and Event Driven Architecture design.
Raymond Lai is a Senior Solutions Architect who specializes in catering to the needs of large enterprise customers. His expertise lies in assisting customers with migrating intricate enterprise systems and databases to AWS, constructing enterprise data warehousing and data lake platforms. Raymond excels in identifying and designing solutions for AI/ML use cases, and he has a particular focus on AWS Serverless solutions and Event Driven Architecture design. Bin Wang, PhD, is a Senior Analytic Specialist Solutions Architect at AWS, boasting over 12 years of experience in the ML industry, with a particular focus on advertising. He possesses expertise in natural language processing (NLP), recommender systems, diverse ML algorithms, and ML operations. He is deeply passionate about applying ML/DL and big data techniques to solve real-world problems.
Bin Wang, PhD, is a Senior Analytic Specialist Solutions Architect at AWS, boasting over 12 years of experience in the ML industry, with a particular focus on advertising. He possesses expertise in natural language processing (NLP), recommender systems, diverse ML algorithms, and ML operations. He is deeply passionate about applying ML/DL and big data techniques to solve real-world problems. Aditya Shah is a Software Development Engineer at AWS. He is interested in Databases and Data warehouse engines and has worked on performance optimisations, security compliance and ACID compliance for engines like Apache Hive and Apache Spark.
Aditya Shah is a Software Development Engineer at AWS. He is interested in Databases and Data warehouse engines and has worked on performance optimisations, security compliance and ACID compliance for engines like Apache Hive and Apache Spark. Melody Yang is a Senior Big Data Solution Architect for Amazon EMR at AWS. She is an experienced analytics leader working with AWS customers to provide best practice guidance and technical advice in order to assist their success in data transformation. Her areas of interests are open-source frameworks and automation, data engineering and DataOps.
Melody Yang is a Senior Big Data Solution Architect for Amazon EMR at AWS. She is an experienced analytics leader working with AWS customers to provide best practice guidance and technical advice in order to assist their success in data transformation. Her areas of interests are open-source frameworks and automation, data engineering and DataOps.






















 Rahul Sonawane is a Principal Analytics Solutions Architect at AWS with AI/ML and Analytics as his area of specialty.
Rahul Sonawane is a Principal Analytics Solutions Architect at AWS with AI/ML and Analytics as his area of specialty. Gaurav Parekh is a Solutions Architect helping AWS customers build large scale modern architecture. He specializes in data analytics and networking. Outside of work, Gaurav enjoys playing cricket, soccer and volleyball.
Gaurav Parekh is a Solutions Architect helping AWS customers build large scale modern architecture. He specializes in data analytics and networking. Outside of work, Gaurav enjoys playing cricket, soccer and volleyball.




 Damon Cortesi is a Principal Developer Advocate with Amazon Web Services. He builds tools and content to help make the lives of data engineers easier. When not hard at work, he still builds data pipelines and splits logs in his spare time.
Damon Cortesi is a Principal Developer Advocate with Amazon Web Services. He builds tools and content to help make the lives of data engineers easier. When not hard at work, he still builds data pipelines and splits logs in his spare time.






 Saurabh Bhutyani is a Principal Analytics Specialist Solutions Architect at AWS. He is passionate about new technologies. He joined AWS in 2019 and works with customers to provide architectural guidance for running generative AI use cases, scalable analytics solutions and data mesh architectures using AWS services like Amazon Bedrock, Amazon SageMaker, Amazon EMR, Amazon Athena, AWS Glue, AWS Lake Formation, and Amazon DataZone.
Saurabh Bhutyani is a Principal Analytics Specialist Solutions Architect at AWS. He is passionate about new technologies. He joined AWS in 2019 and works with customers to provide architectural guidance for running generative AI use cases, scalable analytics solutions and data mesh architectures using AWS services like Amazon Bedrock, Amazon SageMaker, Amazon EMR, Amazon Athena, AWS Glue, AWS Lake Formation, and Amazon DataZone. Harsh Vardhan is an AWS Senior Solutions Architect, specializing in analytics. He has over 8 years of experience working in the field of big data and data science. He is passionate about helping customers adopt best practices and discover insights from their data.
Harsh Vardhan is an AWS Senior Solutions Architect, specializing in analytics. He has over 8 years of experience working in the field of big data and data science. He is passionate about helping customers adopt best practices and discover insights from their data.























 Rahul Sarda is a Senior Analytics & ML Specialist at AWS. He is a seasoned leader with over 20 years of experience, who is passionate about helping customers build scalable data and analytics solutions to gain timely insights and make critical business decisions. In his spare time, he enjoys spending time with his family, stay healthy, running and road cycling.
Rahul Sarda is a Senior Analytics & ML Specialist at AWS. He is a seasoned leader with over 20 years of experience, who is passionate about helping customers build scalable data and analytics solutions to gain timely insights and make critical business decisions. In his spare time, he enjoys spending time with his family, stay healthy, running and road cycling. Varun Rao Bhamidimarri is a Sr Manager, AWS Analytics Specialist Solutions Architect team. His focus is helping customers with adoption of cloud-enabled analytics solutions to meet their business requirements. Outside of work, he loves spending time with his wife and two kids, stay healthy, mediate and recently picked up gardening during the lockdown.
Varun Rao Bhamidimarri is a Sr Manager, AWS Analytics Specialist Solutions Architect team. His focus is helping customers with adoption of cloud-enabled analytics solutions to meet their business requirements. Outside of work, he loves spending time with his wife and two kids, stay healthy, mediate and recently picked up gardening during the lockdown.














 Ashley Zhou is a Software Development Engineer at AWS. She is interested in data analytics and distributed systems.
Ashley Zhou is a Software Development Engineer at AWS. She is interested in data analytics and distributed systems. Srividya Parthasarathy is a Senior Big Data Architect on the AWS Lake Formation team. She enjoys building analytics and data mesh solutions on AWS and sharing them with the community.
Srividya Parthasarathy is a Senior Big Data Architect on the AWS Lake Formation team. She enjoys building analytics and data mesh solutions on AWS and sharing them with the community.
 Mukul Sharma is a Software Development Engineer on Data & Analytics (DnA) organization at GoDaddy. He is a polyglot programmer with experience in a wide array of technologies to rapidly deliver scalable solutions. He enjoys singing karaoke, playing various board games, and working on personal programming projects in his spare time.
Mukul Sharma is a Software Development Engineer on Data & Analytics (DnA) organization at GoDaddy. He is a polyglot programmer with experience in a wide array of technologies to rapidly deliver scalable solutions. He enjoys singing karaoke, playing various board games, and working on personal programming projects in his spare time. Ozcan Ilikhan is a Director of Engineering on Data & Analytics (DnA) organization at GoDaddy. He is passionate about solving customer problems and increasing efficiency using data and ML/AI. In his spare time, he loves reading, hiking, gardening, and working on DIY projects.
Ozcan Ilikhan is a Director of Engineering on Data & Analytics (DnA) organization at GoDaddy. He is passionate about solving customer problems and increasing efficiency using data and ML/AI. In his spare time, he loves reading, hiking, gardening, and working on DIY projects. Ramesh Kumar Venkatraman is a Senior Solutions Architect at AWS who is passionate about containers and databases. He works with AWS customers to design, deploy, and manage their AWS workloads and architectures. In his spare time, he loves to play with his two kids and follows cricket.
Ramesh Kumar Venkatraman is a Senior Solutions Architect at AWS who is passionate about containers and databases. He works with AWS customers to design, deploy, and manage their AWS workloads and architectures. In his spare time, he loves to play with his two kids and follows cricket.







 Amit Maindola is a Senior Data Architect focused on big data and analytics at Amazon Web Services. He helps customers in their digital transformation journey and enables them to build highly scalable, robust, and secure cloud-based analytical solutions on AWS to gain timely insights and make critical business decisions.
Amit Maindola is a Senior Data Architect focused on big data and analytics at Amazon Web Services. He helps customers in their digital transformation journey and enables them to build highly scalable, robust, and secure cloud-based analytical solutions on AWS to gain timely insights and make critical business decisions.

















 Naveen Balaraman is a Sr Cloud Application Architect at Amazon Web Services. He is passionate about Containers, Serverless, Architecting Microservices and helping customers leverage the power of AWS cloud.
Naveen Balaraman is a Sr Cloud Application Architect at Amazon Web Services. He is passionate about Containers, Serverless, Architecting Microservices and helping customers leverage the power of AWS cloud. Karthik Prabhakar is a Senior Big Data Solutions Architect for Amazon EMR at AWS. He is an experienced analytics engineer working with AWS customers to provide best practices and technical advice in order to assist their success in their data journey.
Karthik Prabhakar is a Senior Big Data Solutions Architect for Amazon EMR at AWS. He is an experienced analytics engineer working with AWS customers to provide best practices and technical advice in order to assist their success in their data journey. Parul Saxena is a Big Data Specialist Solutions Architect at Amazon Web Services, focused on Amazon EMR, Amazon Athena, AWS Glue and AWS Lake Formation, where she provides architectural guidance to customers for running complex big data workloads over AWS platform. In her spare time, she enjoys traveling and spending time with her family and friends.
Parul Saxena is a Big Data Specialist Solutions Architect at Amazon Web Services, focused on Amazon EMR, Amazon Athena, AWS Glue and AWS Lake Formation, where she provides architectural guidance to customers for running complex big data workloads over AWS platform. In her spare time, she enjoys traveling and spending time with her family and friends.
 Gaurav Sharma is a Specialist Solutions Architect(Analytics) at Amazon Web Services (AWS), supporting US public sector customers on their cloud journey. Outside of work, Gaurav enjoys spending time with his family and reading books.
Gaurav Sharma is a Specialist Solutions Architect(Analytics) at Amazon Web Services (AWS), supporting US public sector customers on their cloud journey. Outside of work, Gaurav enjoys spending time with his family and reading books.
























 Ashwini Kumar is a Senior Specialist Solutions Architect at AWS based in Delhi, India. Ashwini has more than 18 years of industry experience in systems integration, architecture, and software design, with more recent experience in cloud architecture, DevOps, containers, and big data engineering. He helps customers optimize their cloud spend, minimize compute waste, and improve performance at scale on AWS. He focuses on architectural best practices for various workloads with services including EC2 Spot, AWS Graviton, EC2 Auto Scaling, Amazon EKS, Amazon ECS, and AWS Fargate.
Ashwini Kumar is a Senior Specialist Solutions Architect at AWS based in Delhi, India. Ashwini has more than 18 years of industry experience in systems integration, architecture, and software design, with more recent experience in cloud architecture, DevOps, containers, and big data engineering. He helps customers optimize their cloud spend, minimize compute waste, and improve performance at scale on AWS. He focuses on architectural best practices for various workloads with services including EC2 Spot, AWS Graviton, EC2 Auto Scaling, Amazon EKS, Amazon ECS, and AWS Fargate. Dipayan Sarkar is a Specialist Solutions Architect for Analytics at AWS, where he helps customers modernize their data platform using AWS Analytics services. He works with customers to design and build analytics solutions, enabling businesses to make data-driven decisions.
Dipayan Sarkar is a Specialist Solutions Architect for Analytics at AWS, where he helps customers modernize their data platform using AWS Analytics services. He works with customers to design and build analytics solutions, enabling businesses to make data-driven decisions.