Post Syndicated from Anubhav Awasthi original https://aws.amazon.com/blogs/big-data/fine-grained-access-control-in-amazon-emr-serverless-with-aws-lake-formation/
In today’s data-driven world , enterprises are increasingly reliant on vast amounts of data to drive decision-making and innovation. With this reliance comes the critical need for robust data security and access control mechanisms. Fine-grained access control restricts access to specific data subsets, protecting sensitive information and maintaining regulatory compliance. It allows organizations to set detailed permissions at various levels, including database, table, column, and row. This precise control mitigates risks of unauthorized access, data leaks, and misuse. In the unfortunate event of a security incident, fine-grained access control helps limit the scope of the breach, minimizing potential damage.
AWS is introducing general availability of fine-grained access control based on AWS Lake Formation for Amazon EMR Serverless on Amazon EMR 7.2. Enterprises can now significantly enhance their data governance and security frameworks. This new integration supports the implementation of modern data lake architectures, such as data mesh, by providing a seamless way to manage and analyze data. You can use EMR Serverless to enforce data access controls using Lake Formation when reading data from Amazon Simple Storage Service (Amazon S3), enabling robust data processing workflows and real-time analytics without the overhead of cluster management.
In this post, we discuss how to implement fine-grained access control in EMR Serverless using Lake Formation. With this integration, organizations can achieve better scalability, flexibility, and cost-efficiency in their data operations, ultimately driving more value from their data assets.
Key use cases for fine-grained access control in analytics
The following are key use cases for fine-grained access control in analytics:
- Customer 360 – You can enable different departments to securely access specific customer data relevant to their functions. For example, the sales team can be granted access only to data such as customer purchase history, preferences, and transaction patterns. Meanwhile, the marketing team is limited to viewing campaign interactions, customer demographics, and engagement metrics.
- Financial reporting – You can enable financial analysts to access the necessary data for reporting and analysis while restricting sensitive financial details to authorized executives.
- Healthcare analytics – You can enable healthcare researchers and data scientists to analyze de-identified patient data for medical advancements and research, while making sure Protected Health Information (PHI) remains confidential and accessible only to authorized healthcare professionals and personnel.
- Supply chain optimization – You can grant logistics teams visibility into inventory and shipment data while limiting access to pricing or supplier information to relevant stakeholders.
Solution overview
In this post, we explore how to implement fine-grained access control on Iceberg tables within an EMR Serverless application, using the capabilities of Lake Formation. If you’re interested in learning how to implement fine-grained access control on open table formats in Amazon EMR running on Amazon Elastic Compute Cloud (Amazon EC2) instances using Lake Formation, refer to Enforce fine-grained access control on Open Table Formats via Amazon EMR integrated with AWS Lake Formation.
With the data access control features available in Lake Formation, you can enforce granular permissions and govern access to specific columns, rows, or cells within your Iceberg tables. This approach makes sure sensitive data remains secure and accessible only to authorized users or applications, aligning with your organization’s data governance policies and regulatory compliance requirements.
A cross-account modern data platform on AWS involves setting up a centralized data lake in a primary AWS account, while allowing controlled access to this data from secondary AWS accounts. This setup helps organizations maintain a single source of truth for their data, provides consistent data governance, and uses the robust security features of AWS across multiple business units or project teams.
To demonstrate how you can use Lake Formation to implement cross account fine-grained access control within an EMR Serverless environment, we use the TPC-DS dataset to create tables in the AWS Glue Data Catalog in the AWS producer account and provision different user personas to reflect various roles and access levels in the AWS consumer account, forming a secure and governed data lake.
The following diagram illustrates the solution architecture.

The producer account contains the following persona:
- Data engineer – Tasks include data preparation, bulk updates, and incremental updates. The data engineer has the following access:
- Table-level access – Full read/write access to all TPC-DS tables.
The consumer account contains the following personas:
- Finance analyst – We run a sample query that performs a sales data analysis to guide marketing, inventory, and promotion strategies based on demographic and geographic performance. The finance analyst has the following access:
- Table-level access – Full access to tables
store_sales,catalog_sales,web_sales,item, andpromotionfor comprehensive financial analysis. - Column-level access – Limited access to cost-related columns in the
salestables to avoid exposure to sensitive pricing strategies. Limited access to sensitive columns likecredit_ratingin thecustomer_demographicstable. - Row-level access – Access only to sales data from the current fiscal year or specific promotional periods.
- Table-level access – Full access to tables
- Product analyst – We run a sample query that does a customer behavior analysis to tailor marketing, promotions, and loyalty programs based on purchase patterns and regional insights. The product analyst has the following access:
- Table-level access – Full access to tables
item,store_sales, andcustomertables to evaluate product and market trends. - Column-level access – Restricted access to personal identifiers in the
customertable, such ascustomer_address,email_address, anddate of birth.
- Table-level access – Full access to tables
Prerequisites
You should have the following prerequisites:
- Access to the producer account and consumer account with adequate permissions to create and deploy AWS CloudFormation stacks, upload files to S3 buckets, accept shared resources in AWS Resource Access Manager (AWS RAM), and other actions taken in this post.
- Access to AWS Identity and Access Management (IAM) roles or users who are a Lake Formation data lake administrator in both the producer and consumer account. For instructions, refer to Create a data lake administrator.
Set up infrastructure in the producer account
We provide a CloudFormation template to deploy the data lake stack with the following resources:
- Two S3 buckets: one for scripts and query results, and one for the data lake storage
- An Amazon Athena workgroup
- An EMR Serverless application
- An AWS Glue database and tables on external public S3 buckets of TPC-DS data
- An AWS Glue database for the data lake
- An IAM role and polices
![]()
Set up Lake Formation for the data engineer in the producer account
Set up Lake Formation cross-account data sharing version settings:
- Open the Lake Formation console with the Lake Formation data lake administrator in the producer account.
- Under Data Catalog settings, pick Version 4 under Cross-account version settings.
To learn more about the differences between data sharing versions, refer to Updating cross-account data sharing version settings. Make sure Default permissions for newly created databases and tables is unchecked.

Register the Amazon S3 location as the data lake location
When you register an Amazon S3 location with Lake Formation, you specify an IAM role with read/write permissions on that location. After registering, when EMR Serverless requests access to this Amazon S3 location, Lake Formation will supply temporary credentials of the provided role to access the data. We already created the role LakeFormationServiceRole using the CloudFormation template. To register the Amazon S3 location as the data lake location, complete the following steps:
- Open the Lake Formation console with the Lake Formation data lake administrator in the producer account.
- In the navigation pane, choose Data lake locations under Administration.
- Choose Register location.
- For Amazon S3 path, enter
s3://<DatalakeBucketName>. (Copy the bucket name from the CloudFormation stack’s Outputs tab.) - For IAM role, enter
LakeFormationServiceRoleDatalake. - For Permission mode, select Lake Formation.
- Choose Register location.

Generate TPC-DS tables in the producer account
In this section, we generate TPC-DS tables in Iceberg format in the producer account.
Grant database permissions to the data engineer
First, let’s grant database permissions to the data engineer IAM role Amazon-EMR-ExecutionRole_DE that we will use with EMR Serverless. Complete the following steps:
- Open the Lake Formation console with the Lake Formation data lake administrator in the producer account.
- Choose Databases and Create database.
- Enter
iceberg_dbfor Name ands3://<DatalakeBucketName>for Location. - Choose Create database.
- In the navigation pane, choose Data lake permissions and choose Grant.

- In the Principles section, select IAM users and roles and choose
Amazon-EMR-ExecutionRole_DE. - In the LF-Tags or catalog resources section, select Named Data Catalog resources and choose
tpc-sourceandiceberg_dbfor Databases.

- Select Super for both Database permissions and Grantable permissions and choose Grant.



Create an EMR Serverless application
Now, let’s log in to EMR Serverless using Amazon EMR Studio and complete the following steps:
- On the Amazon EMR console, choose EMR Serverless.
- Under Manage applications, choose
my-emr-studio. You will be directed to the Create application page on EMR Studio. Let’s create a Lake Formation enabled EMR Serverless application - Under Application settings, provide the following information:
- For Name, enter a name
emr-fgac-application. - For Type, choose Spark.
- For Release version, choose emr-7.2.0.
- For Architecture, choose x86_64.
- For Name, enter a name
- Under Application setup options, select Use custom settings.
- Under Interactive endpoint, select Enable endpoint for EMR studio
- Under Additional configurations, for Metastore configuration, select Use AWS Glue Data Catalog as metastore, then select Use Lake Formation for fine-grained access control.
- Under Network connections, choose
emrs-vpcfor the VPC, enter any two private subnets, and enteremr-serverless-sgfor Security groups.

- Choose Create and start application.

Create a Workspace
Complete the following steps to create an EMR Workspace:
- On the Amazon EMR console, choose Workspaces in the navigation pane and choose Create Workspace.
- Enter the Workspace name
emr-fgac-workspace. - Leave all other settings as default and choose Create Workspace.
- Choose Launch Workspace. Your browser might request to allow pop-up permissions for the first time launching the Workspace.
- After the Workspace is launched, in the navigation pane, choose Compute.
- For Compute type¸ select EMR Serverless application and enter
emr-fgac-applicationfor the application andAmazon-EMR-ExecutionRole_DEas the runtime role. - Make sure the kernel attached to the Workspace is PySpark.

- Navigate to the File browser section and choose Upload files.
- Upload the file Iceberg-ingest-final_v2.ipynb.
- Update the data lake bucket name, AWS account ID, and AWS Region accordingly.
- Choose the double arrow icon to restart the kernel and rerun the notebook.


To verify that the data is generated, you can go to the AWS Glue console. Under Data Catalog, Databases, you should see TPC-DS tables ending with _iceberg for the database iceberg_db.
Share the database and TPC-DS tables to the consumer account
We now grant permissions to the consumer account, including grantable permissions. This allows the Lake Formation data lake administrator in the consumer account to control access to the data within the account.
Grant database permissions to the consumer account
Complete the following steps:
- Open the Lake Formation console with the Lake Formation data lake administrator in the producer account.
- In the navigation pane, choose Databases.
- Select the database
iceberg_db, and on the Actions menu, under Permissions, choose Grant. - In the Principles section, select External accounts and enter the consumer account.
- In the LF-Tags or catalog resources section, select Named Data Catalog resources and choose
iceberg_dbfor Databases. - In the Database permissions section, select Describe for both Database permissions and Grantable permissions.
This allows the data lake administrator in the consumer account to describe the database and grant describe permissions to other principals in the consumer account.

Grant table permissions to the consumer account
Repeat the preceding steps to grant table permissions to the consumer account.

Choose All tables under Tables and provide select and describe permissions for Table permissions and Grantable permissions.

Set up Lake Formation in the consumer account
For the remaining section of the post, we focus on the consumer account. Deploy the following CloudFormation stack to set up resources:
![]()
The template will create the Amazon EMR runtime role for both analyst user personas.
Log in to the AWS consumer account and accept the AWS RAM invitation first:
- Open the AWS RAM console with the IAM identity that has AWS RAM access.
- In the navigation pane, choose Resource shares under Shared with me.
- You should see two pending resource shares from the producer account.
- Accept both invitations.
You should be able to see the iceberg_db database on the Lake Formation console.
Create a resource link for the shared database
To access the database and table resources that were shared by the producer AWS account, you need to create a resource link in the consumer AWS account. A resource link is a Data Catalog object that is a link to a local or shared database or table. After you create a resource link to a database or table, you can use the resource link name wherever you would use the database or table name. In this step, you grant permission on the resource links to the job runtime roles for EMR Serverless. The runtime roles will then access the data in shared databases and underlying tables through the resource link.
To create a resource link, complete the following steps:
- Open the Lake Formation console with the Lake Formation data lake administrator in the consumer account.
- In the navigation pane, choose Databases.
- Select the
iceberg_dbdatabase, verify that the owner account ID is the producer account, and on the Actions menu, choose Create resource links. - For Resource link name, enter the name of the resource link (
iceberg_db_shared). - For Shared database’s region, choose the Region of the iceberg_db database.
- For Shared database, choose the
iceberg_dbdatabase. - For Shared database’s owner ID, enter the account ID of the producer account.
- Choose Create.

Grant permissions on the resource link to the EMR job runtime roles
Grant permissions on the resource link to Amazon-EMR-ExecutionRole_Finance and Amazon-EMR-ExecutionRole_Product using the following steps:
- Open the Lake Formation console with the Lake Formation data lake administrator in the consumer account.
- In the navigation pane, choose Databases.
- Select the resource link (
iceberg_db_shared) and on the Actions menu, choose Grant. - In the Principles section, select IAM users and roles, and choose Amazon-EMR-ExecutionRole_Finance and Amazon-EMR-ExecutionRole_Product.
- In the LF-Tags or catalog resources section, select Named Data Catalog resources and for Databases, choose
iceberg_db_shared. - In the Resource link permissions section, select Describe for Resource link permissions.
This allows the EMR Serverless job runtime roles to describe the resource link. We don’t make any selections for grantable permissions because runtime roles shouldn’t be able to grant permissions to other principles.
Choose Grant.

Grant table permissions for the finance analyst
Complete the following steps:
- Open the Lake Formation console with the Lake Formation data lake administrator in the consumer account.
- In the navigation pane, choose Databases.
- Select the resource link (
iceberg_db_shared) and on the Actions menu, choose Grant on target. - In the Principles section, select IAM users and roles, then choose
Amazon-EMR-ExecutionRole_Finance. - In the LF-Tags or catalog resources section, select Named Data Catalog resources and specify the following:
- For Databases, choose
iceberg_db. - For Tables¸ choose
store_sales_iceberg.

- For Databases, choose
- In the Table permissions section, for Table permissions, select Select.
- In the Data permissions section, select Column-based access.
- Select Exclude columns and choose all cost-related columns (
ss_wholesale_costandss_ext_wholesale_cost). - Choose Grant.

- Similarly, grant access to table
customer_demographics_icebergand exclude the columncd_credit_rating. - Following the same steps, grant All data access for tables
store_iceberganditem_iceberg. - For the table
date_dim_iceberg, we provide selective row-level access. - Similar to the preceding table permissions, select
date_dim_icebergunder Tables and in the Data filters section, choose Create new.

- For Data filter name, enter
FA_Filter_year. - Select Access to all columns under Column-level access.
- Select Filter rows and for Row filter expression, enter
d_year=2002to only provide access to the 2002 year. - Choose Save changes.

- Choose Create filter.
- Make sure
FA_Filter_yearis selected under Data filters and grant select permissions on the filter.




Grant table permissions for the product analyst
You can provide permissions for the next set of tables required for the product analyst role using the Lake Formation console. Alternatively, you can use the AWS Command Line Interface (AWS CLI) to grant permissions. We provide grant on target permissions for the resource link iceberg_db_shared to IAM role Amazon-EMR-ExecutionRole_Product.
- Similar to steps followed in previous sections, for table
store_sales_iceberg,date_dim_iceberg,store_iceberg, andhouse_hold_demographics_iceberg, provide select permissions for All data access. Make sure the role selected isAmazon-EMR-ExecutionRole_Product.
For table customer_iceberg, we limit access to personally identifiable information (PII) columns.
- Under Data permissions, select Column-based access and Exclude columns.
- Choose columns
c_birth_day,c_birth_month,c_birth_year,c_current_addr_sk,c_customer_id,c_email_address, andc_birth_country.
Verify access using interactive notebooks from EMR Studio
Complete the following steps to test role access:
- Log in to the AWS consumer account and open the Amazon EMR console.
- Choose EMR Serverless in the navigation pane and choose an existing EMR Studio.
- If you don’t have EMR Studio configured, choose Get Started and select Create and launch EMR Studio.
- Create a Lake Formation enabled EMR Serverless application as described in previous sections.
- Create an EMR Studio Workspace as described in previous sections.
- Use
emr-studio-service-rolefor Service role anddatalake-resources-<account_id>-<region>for Workspace storage, then launch your Workspace.
Now, let’s verify access for the finance analyst.
- Make sure the compute type inside your Workspace is pointing to the EMR Serverless application created in the prior step and
Amazon-EMR-ExecutionRole_Financeas the interactive runtime role. - Go to File browser in the navigation pane, choose Upload files, and add Notebook_FA.ipynb to your Workspace.
- Run all the cells to verify fine-grained access.


Now let’s test access for the product analyst.
- In the same Workspace, detach and attach the same EMR Serverless application with
Amazon-EMR-ExecutionRole_Productas the interactive runtime role. - Upload Notebook_PA.ipynb under the File browser section.
- Run all the cells to verify fine-grained access for the product analyst.


In a real-world scenario, both analysts will likely have their own Workspace with restricted rights to assume only the authorized interactive runtime role.
Considerations and limitations
EMR Serverless with Lake Formation uses Spark resource profiles to create two profiles and two Spark drivers for access control. Read this white paper to learn about the feature details. The user profile runs the supplied code, and the system profile enforces Lake Formation policies. Therefore, it’s recommended that you have a minimum of two Spark drivers when pre-initialized capacity is used with Lake Formation enabled jobs. No change in executor count is required. Refer to Using EMR Serverless with AWS Lake Formation for fine-grained access control to learn more about the technical implementation of the Lake Formation integration with EMR Serverless.

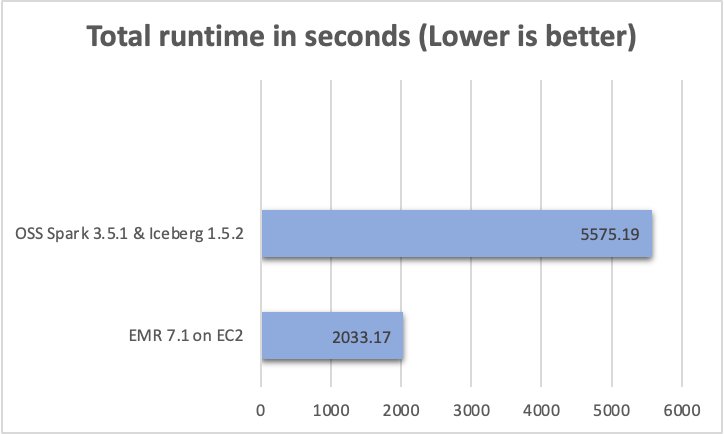
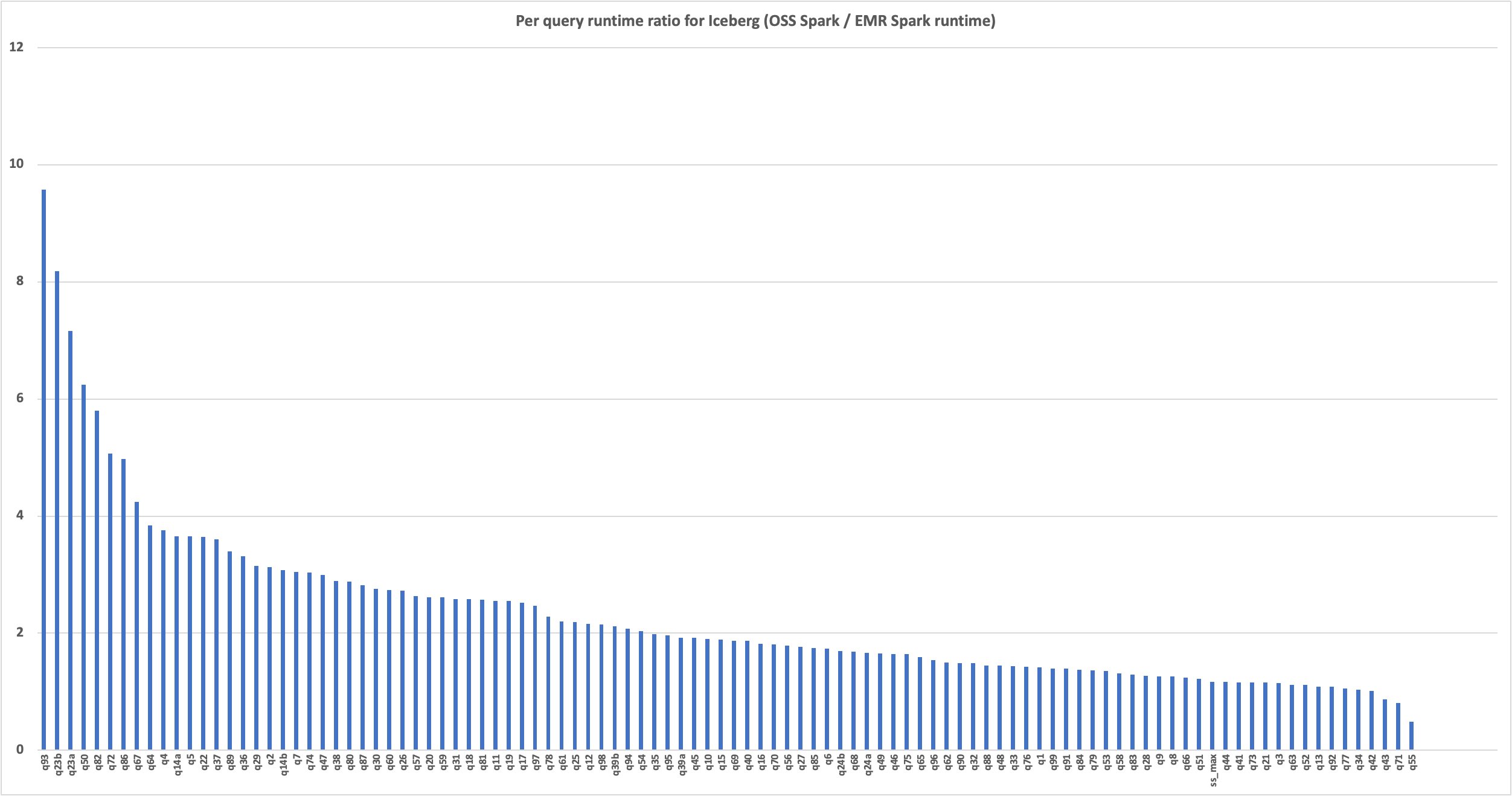
You can expect a performance overhead after enabling Lake Formation. The level of access (table, column, or row) and the amount of data filtered will have significant impact on query performance.
Clean up
To avoid incurring ongoing costs, complete the following steps to clean up your resources:
- In your secondary (consumer) account, log in to the Lake Formation console.
- Drop the resource share table.
- In your primary (producer) account, log in to the Lake Formation console.
- Revoke the access you configured.
- Drop the AWS Glue tables and database.
- Delete the AWS Glue job.
- Delete the S3 buckets and any other resources that you created as part of the prerequisites for this post.
Conclusion
In this post, we showed how to integrate Lake Formation with EMR Serverless to manage access to Iceberg tables. This solution showcases a modern way to enforce fine-grained access control in a multi-account open data lake setup. The approach simplifies data management in the main account while carefully controlling how users access data in other secondary accounts.
Try out the solution for your own use case, and let us know your feedback and questions in the comments section.
About the Authors
 Anubhav Awasthi is a Sr. Big Data Specialist Solutions Architect at AWS. He works with customers to provide architectural guidance for running analytics solutions on Amazon EMR, Amazon Athena, AWS Glue, and AWS Lake Formation.
Anubhav Awasthi is a Sr. Big Data Specialist Solutions Architect at AWS. He works with customers to provide architectural guidance for running analytics solutions on Amazon EMR, Amazon Athena, AWS Glue, and AWS Lake Formation.
 Nishchai JM is an Analytics Specialist Solutions Architect at Amazon Web services. He specializes in building Big-data applications and help customer to modernize their applications on Cloud. He thinks Data is new oil and spends most of his time in deriving insights out of the Data.
Nishchai JM is an Analytics Specialist Solutions Architect at Amazon Web services. He specializes in building Big-data applications and help customer to modernize their applications on Cloud. He thinks Data is new oil and spends most of his time in deriving insights out of the Data.








 Boon Lee Eu is a Senior Technical Account Manager at Amazon Web Services (AWS). He works closely and proactively with Enterprise Support customers to provide advocacy and strategic technical guidance to help plan and achieve operational excellence in AWS environment based on best practices. Based in Singapore, Boon Lee has over 20 years of experience in IT & Telecom industries.
Boon Lee Eu is a Senior Technical Account Manager at Amazon Web Services (AWS). He works closely and proactively with Enterprise Support customers to provide advocacy and strategic technical guidance to help plan and achieve operational excellence in AWS environment based on best practices. Based in Singapore, Boon Lee has over 20 years of experience in IT & Telecom industries. Kyara Labrador is a Sr. Analytics Specialist Solutions Architect at Amazon Web Services (AWS) Philippines, specializing in big data and analytics. She helps customers in designing and implementing scalable, secure, and cost-effective data solutions, as well as migrating and modernizing their big data and analytics workloads to AWS. She is passionate about empowering organizations to unlock the full potential of their data.
Kyara Labrador is a Sr. Analytics Specialist Solutions Architect at Amazon Web Services (AWS) Philippines, specializing in big data and analytics. She helps customers in designing and implementing scalable, secure, and cost-effective data solutions, as well as migrating and modernizing their big data and analytics workloads to AWS. She is passionate about empowering organizations to unlock the full potential of their data. Vikas Omer is the Head of Data & AI Solution Architecture for ASEAN at Amazon Web Services (AWS). With over 15 years of experience in the data and AI space, he is a seasoned leader who leverages his expertise to drive innovation and expansion in the region. Vikas is passionate about helping customers and partners succeed in their digital transformation journeys, focusing on cloud-based solutions and emerging technologies.
Vikas Omer is the Head of Data & AI Solution Architecture for ASEAN at Amazon Web Services (AWS). With over 15 years of experience in the data and AI space, he is a seasoned leader who leverages his expertise to drive innovation and expansion in the region. Vikas is passionate about helping customers and partners succeed in their digital transformation journeys, focusing on cloud-based solutions and emerging technologies.



















 Dalei Xu is a Analytics Specialist Solution Architect at Amazon Web Services, responsible for consulting, designing, and implementing AWS data analytics solutions. With over 20 years of experience in data-related work, proficient in data development, migration to AWS, architecture design, and performance optimization. Hoping to promote AWS data analytics services to more customers, achieving a win-win situation and mutual growth with customers.
Dalei Xu is a Analytics Specialist Solution Architect at Amazon Web Services, responsible for consulting, designing, and implementing AWS data analytics solutions. With over 20 years of experience in data-related work, proficient in data development, migration to AWS, architecture design, and performance optimization. Hoping to promote AWS data analytics services to more customers, achieving a win-win situation and mutual growth with customers. Zhiyong Su is a Migration Specialist Solution Architect at Amazon Web Services, primarily responsible for cloud migration or cross-cloud migration for enterprise-level clients. Has held positions such as R&D Engineer, Solutions Architect, and has years of practical experience in IT professional services and enterprise application architecture.
Zhiyong Su is a Migration Specialist Solution Architect at Amazon Web Services, primarily responsible for cloud migration or cross-cloud migration for enterprise-level clients. Has held positions such as R&D Engineer, Solutions Architect, and has years of practical experience in IT professional services and enterprise application architecture. Shijian Tang is a Analytics Specialist Solution Architect at Amazon Web Services.
Shijian Tang is a Analytics Specialist Solution Architect at Amazon Web Services.




 Miranda Diaz is a Software Development Engineer for EMR at AWS. Miranda works to design and develop technologies that make it easy for customers across the world to automatically scale their computing resources to their needs, helping them achieve the best performance at the optimal cost.
Miranda Diaz is a Software Development Engineer for EMR at AWS. Miranda works to design and develop technologies that make it easy for customers across the world to automatically scale their computing resources to their needs, helping them achieve the best performance at the optimal cost. Sajjan Bhattarai is a Senior Cloud Support Engineer at AWS, and specializes in BigData and Machine Learning workloads. He enjoys helping customers around the world to troubleshoot and optimize their data platforms.
Sajjan Bhattarai is a Senior Cloud Support Engineer at AWS, and specializes in BigData and Machine Learning workloads. He enjoys helping customers around the world to troubleshoot and optimize their data platforms. Bezuayehu Wate is an Associate Big Data Specialist Solutions Architect at AWS. She works with customers to provide strategic and architectural guidance on designing, building, and modernizing their cloud-based analytics solutions using AWS.
Bezuayehu Wate is an Associate Big Data Specialist Solutions Architect at AWS. She works with customers to provide strategic and architectural guidance on designing, building, and modernizing their cloud-based analytics solutions using AWS.















 Kashif Khan is a Sr. Analytics Specialist Solutions Architect at AWS, specializing in big data services like Amazon EMR, AWS Lake Formation, AWS Glue, Amazon Athena, and Amazon DataZone. With over a decade of experience in the big data domain, he possesses extensive expertise in architecting scalable and robust solutions. His role involves providing architectural guidance and collaborating closely with customers to design tailored solutions using AWS analytics services to unlock the full potential of their data.
Kashif Khan is a Sr. Analytics Specialist Solutions Architect at AWS, specializing in big data services like Amazon EMR, AWS Lake Formation, AWS Glue, Amazon Athena, and Amazon DataZone. With over a decade of experience in the big data domain, he possesses extensive expertise in architecting scalable and robust solutions. His role involves providing architectural guidance and collaborating closely with customers to design tailored solutions using AWS analytics services to unlock the full potential of their data. Veena Vasudevan is a Principal Partner Solutions Architect and Data & AI specialist at AWS. She helps customers and partners build highly optimized, scalable, and secure solutions; modernize their architectures; and migrate their big data, analytics, and AI/ML workloads to AWS.
Veena Vasudevan is a Principal Partner Solutions Architect and Data & AI specialist at AWS. She helps customers and partners build highly optimized, scalable, and secure solutions; modernize their architectures; and migrate their big data, analytics, and AI/ML workloads to AWS.





 Umair Nawaz is a Senior DevOps Architect at Amazon Web Services. He works on building secure architectures and advises enterprises on agile software delivery. He is motivated to solve problems strategically by utilizing modern technologies.
Umair Nawaz is a Senior DevOps Architect at Amazon Web Services. He works on building secure architectures and advises enterprises on agile software delivery. He is motivated to solve problems strategically by utilizing modern technologies. Ravikiran Rao is a Data Architect at Amazon Web Services and is passionate about solving complex data challenges for various customers. Outside of work, he is a theater enthusiast and amateur tennis player.
Ravikiran Rao is a Data Architect at Amazon Web Services and is passionate about solving complex data challenges for various customers. Outside of work, he is a theater enthusiast and amateur tennis player. Sri Potluri is a Cloud Infrastructure Architect at Amazon Web Services. He is passionate about solving complex problems and delivering well-structured solutions for diverse customers. His expertise spans across a range of cloud technologies, ensuring scalable and reliable infrastructure tailored to each project’s unique challenges.
Sri Potluri is a Cloud Infrastructure Architect at Amazon Web Services. He is passionate about solving complex problems and delivering well-structured solutions for diverse customers. His expertise spans across a range of cloud technologies, ensuring scalable and reliable infrastructure tailored to each project’s unique challenges. Suvojit Dasgupta is a Principal Data Architect at Amazon Web Services. He leads a team of skilled engineers in designing and building scalable data solutions for AWS customers. He specializes in developing and implementing innovative data architectures to address complex business challenges.
Suvojit Dasgupta is a Principal Data Architect at Amazon Web Services. He leads a team of skilled engineers in designing and building scalable data solutions for AWS customers. He specializes in developing and implementing innovative data architectures to address complex business challenges.


 Julien Lafaye is a director at Capital Fund Management (CFM) where he is leading the implementation of a data platform on AWS. He is also heading a team of data scientists and software engineers in charge of delivering intraday features to feed CFM trading strategies. Before that, he was developing low latency solutions for transforming & disseminating financial market data. He holds a Phd in computer science and graduated from Ecole Polytechnique Paris. During his spare time, he enjoys cycling, running and tinkering with electronic gadgets and computers.
Julien Lafaye is a director at Capital Fund Management (CFM) where he is leading the implementation of a data platform on AWS. He is also heading a team of data scientists and software engineers in charge of delivering intraday features to feed CFM trading strategies. Before that, he was developing low latency solutions for transforming & disseminating financial market data. He holds a Phd in computer science and graduated from Ecole Polytechnique Paris. During his spare time, he enjoys cycling, running and tinkering with electronic gadgets and computers. Matthieu Bonville is a Solutions Architect in AWS France working with Financial Services Industry (FSI) customers. He leverages his technical expertise and knowledge of the FSI domain to help customer architect effective technology solutions that address their business challenges.
Matthieu Bonville is a Solutions Architect in AWS France working with Financial Services Industry (FSI) customers. He leverages his technical expertise and knowledge of the FSI domain to help customer architect effective technology solutions that address their business challenges. Joel Farvault is Principal Specialist SA Analytics for AWS with 25 years’ experience working on enterprise architecture, data governance and analytics, mainly in the financial services industry. Joel has led data transformation projects on fraud analytics, claims automation, and Master Data Management. He leverages his experience to advise customers on their data strategy and technology foundations.
Joel Farvault is Principal Specialist SA Analytics for AWS with 25 years’ experience working on enterprise architecture, data governance and analytics, mainly in the financial services industry. Joel has led data transformation projects on fraud analytics, claims automation, and Master Data Management. He leverages his experience to advise customers on their data strategy and technology foundations.















 This migration approach uses the following tools to perform the migration:
This migration approach uses the following tools to perform the migration:


 Ashok Chintalapati is a software development engineer for Amazon EMR at Amazon Web Services.
Ashok Chintalapati is a software development engineer for Amazon EMR at Amazon Web Services. Steve Koonce is an Engineering Manager for EMR at Amazon Web Services.
Steve Koonce is an Engineering Manager for EMR at Amazon Web Services.




 Yonatan Dolan is a Principal Analytics Specialist at Amazon Web Services. He is located in Israel and helps customers harness AWS analytical services to leverage data, gain insights, and derive value. Yonatan is an Apache Iceberg evangelist.
Yonatan Dolan is a Principal Analytics Specialist at Amazon Web Services. He is located in Israel and helps customers harness AWS analytical services to leverage data, gain insights, and derive value. Yonatan is an Apache Iceberg evangelist. Amit Gilad is a Senior Data Engineer on the Data Infrastructure team at Cloudinar. He is currently leading the strategic transition from traditional data warehouses to a modern data lakehouse architecture, utilizing Apache Iceberg to enhance scalability and flexibility.
Amit Gilad is a Senior Data Engineer on the Data Infrastructure team at Cloudinar. He is currently leading the strategic transition from traditional data warehouses to a modern data lakehouse architecture, utilizing Apache Iceberg to enhance scalability and flexibility. Alex Dickman is a Staff Data Engineer on the Data Infrastructure team at Cloudinary. He focuses on engaging with various internal teams to consolidate the team’s data infrastructure and create new opportunities for data applications, ensuring robust and scalable data solutions for Cloudinary’s diverse requirements.
Alex Dickman is a Staff Data Engineer on the Data Infrastructure team at Cloudinary. He focuses on engaging with various internal teams to consolidate the team’s data infrastructure and create new opportunities for data applications, ensuring robust and scalable data solutions for Cloudinary’s diverse requirements. Itay Takersman is a Senior Data Engineer at Cloudinary data infrastructure team. Focused on building resilient data flows and aggregation pipelines to support Cloudinary’s data requirements.
Itay Takersman is a Senior Data Engineer at Cloudinary data infrastructure team. Focused on building resilient data flows and aggregation pipelines to support Cloudinary’s data requirements.


























 Sudipta Mitra is a Senior Data Architect for AWS, and passionate about helping customers to build modern data analytics applications by making innovative use of latest AWS services and their constantly evolving features. A pragmatic architect who works backwards from customer needs, making them comfortable with the proposed solution, helping achieve tangible business outcomes. His main areas of work are Data Mesh, Data Lake, Knowledge Graph, Data Security and Data Governance.
Sudipta Mitra is a Senior Data Architect for AWS, and passionate about helping customers to build modern data analytics applications by making innovative use of latest AWS services and their constantly evolving features. A pragmatic architect who works backwards from customer needs, making them comfortable with the proposed solution, helping achieve tangible business outcomes. His main areas of work are Data Mesh, Data Lake, Knowledge Graph, Data Security and Data Governance. Deepak Sharma is a Senior Data Architect with the AWS Professional Services team, specializing in big data and analytics solutions. With extensive experience in designing and implementing scalable data architectures, he collaborates closely with enterprise customers to build robust data lakes and advanced analytical applications on the AWS platform.
Deepak Sharma is a Senior Data Architect with the AWS Professional Services team, specializing in big data and analytics solutions. With extensive experience in designing and implementing scalable data architectures, he collaborates closely with enterprise customers to build robust data lakes and advanced analytical applications on the AWS platform. Nanda Chinnappa is a Cloud Infrastructure Architect with AWS Professional Services at Amazon Web Services. Nanda specializes in Infrastructure Automation, Cloud Migration, Disaster Recovery and Databases which includes Amazon RDS and Amazon Aurora. He helps AWS Customer’s adopt AWS Cloud and realize their business outcome by executing cloud computing initiatives.
Nanda Chinnappa is a Cloud Infrastructure Architect with AWS Professional Services at Amazon Web Services. Nanda specializes in Infrastructure Automation, Cloud Migration, Disaster Recovery and Databases which includes Amazon RDS and Amazon Aurora. He helps AWS Customer’s adopt AWS Cloud and realize their business outcome by executing cloud computing initiatives. Kinnar Kumar Sen is a Sr. Solutions Architect at Amazon Web Services (AWS) focusing on Flexible Compute. As a part of the EC2 Flexible Compute team, he works with customers to guide them to the most elastic and efficient compute options that are suitable for their workload running on AWS. Kinnar has more than 15 years of industry experience working in research, consultancy, engineering, and architecture.
Kinnar Kumar Sen is a Sr. Solutions Architect at Amazon Web Services (AWS) focusing on Flexible Compute. As a part of the EC2 Flexible Compute team, he works with customers to guide them to the most elastic and efficient compute options that are suitable for their workload running on AWS. Kinnar has more than 15 years of industry experience working in research, consultancy, engineering, and architecture. Alex Lines is a Principal Containers Specialist at AWS helping customers modernize their Data and ML applications on Amazon EKS.
Alex Lines is a Principal Containers Specialist at AWS helping customers modernize their Data and ML applications on Amazon EKS. Mengfei Wang is a Software Development Engineer specializing in building large-scale, robust software infrastructure to support big data demands on containers and Kubernetes within the EMR on EKS team. Beyond work, Mengfei is an enthusiastic snowboarder and a passionate home cook.
Mengfei Wang is a Software Development Engineer specializing in building large-scale, robust software infrastructure to support big data demands on containers and Kubernetes within the EMR on EKS team. Beyond work, Mengfei is an enthusiastic snowboarder and a passionate home cook. Jerry Zhang is a Software Development Manager in AWS EMR on EKS. His team focuses on helping AWS customers to solve their business problems using cutting-edge data analytics technology on AWS infrastructure.
Jerry Zhang is a Software Development Manager in AWS EMR on EKS. His team focuses on helping AWS customers to solve their business problems using cutting-edge data analytics technology on AWS infrastructure.
 Carlos Rodrigues is a Big Data Specialist Solutions Architect at AWS. He helps customers worldwide build transactional data lakes on AWS using open table formats like Apache Iceberg and Apache Hudi. He can be reached via
Carlos Rodrigues is a Big Data Specialist Solutions Architect at AWS. He helps customers worldwide build transactional data lakes on AWS using open table formats like Apache Iceberg and Apache Hudi. He can be reached via  Imtiaz (Taz) Sayed is the WW Tech Leader for Analytics at AWS. He is an expert on data engineering and enjoys engaging with the community on all things data and analytics. He can be reached via
Imtiaz (Taz) Sayed is the WW Tech Leader for Analytics at AWS. He is an expert on data engineering and enjoys engaging with the community on all things data and analytics. He can be reached via  Shana Schipers is an Analytics Specialist Solutions Architect at AWS, focusing on big data. She supports customers worldwide in building transactional data lakes using open table formats like Apache Hudi, Apache Iceberg, and Delta Lake on AWS.
Shana Schipers is an Analytics Specialist Solutions Architect at AWS, focusing on big data. She supports customers worldwide in building transactional data lakes using open table formats like Apache Hudi, Apache Iceberg, and Delta Lake on AWS.







































 Pradeep Misra is a Principal Analytics Solutions Architect at AWS. He works across Amazon to architect and design modern distributed analytics and AI/ML platform solutions. He is passionate about solving customer challenges using data, analytics, and AI/ML. Outside of work, Pradeep likes exploring new places, trying new cuisines, and playing board games with his family. He also likes doing science experiments with his daughters.
Pradeep Misra is a Principal Analytics Solutions Architect at AWS. He works across Amazon to architect and design modern distributed analytics and AI/ML platform solutions. He is passionate about solving customer challenges using data, analytics, and AI/ML. Outside of work, Pradeep likes exploring new places, trying new cuisines, and playing board games with his family. He also likes doing science experiments with his daughters. Deepmala Agarwal works as an AWS Data Specialist Solutions Architect. She is passionate about helping customers build out scalable, distributed, and data-driven solutions on AWS. When not at work, Deepmala likes spending time with family, walking, listening to music, watching movies, and cooking!
Deepmala Agarwal works as an AWS Data Specialist Solutions Architect. She is passionate about helping customers build out scalable, distributed, and data-driven solutions on AWS. When not at work, Deepmala likes spending time with family, walking, listening to music, watching movies, and cooking! Abhilash Nagilla is a Senior Specialist Solutions Architect at Amazon Web Services (AWS), helping public sector customers on their cloud journey with a focus on AWS analytics services. Outside of work, Abhilash enjoys learning new technologies, watching movies, and visiting new places.
Abhilash Nagilla is a Senior Specialist Solutions Architect at Amazon Web Services (AWS), helping public sector customers on their cloud journey with a focus on AWS analytics services. Outside of work, Abhilash enjoys learning new technologies, watching movies, and visiting new places.










![Job[14]: showString at NativeMethodAccessorImpl.java:0 and Job[15]: showString at NativeMethodAccessorImpl.java:0](https://d2908q01vomqb2.cloudfront.net/b6692ea5df920cad691c20319a6fffd7a4a766b8/2024/04/05/BDB-3979-image025.png)





 Sekar Srinivasan is a Principal Specialist Solutions Architect at AWS focused on Data Analytics and AI. Sekar has over 20 years of experience working with data. He is passionate about helping customers build scalable solutions modernizing their architecture and generating insights from their data. In his spare time he likes to work on non-profit projects, focused on underprivileged Children’s education.
Sekar Srinivasan is a Principal Specialist Solutions Architect at AWS focused on Data Analytics and AI. Sekar has over 20 years of experience working with data. He is passionate about helping customers build scalable solutions modernizing their architecture and generating insights from their data. In his spare time he likes to work on non-profit projects, focused on underprivileged Children’s education. Disha Umarwani is a Sr. Data Architect with Amazon Professional Services within Global Health Care and LifeSciences. She has worked with customers to design, architect and implement Data Strategy at scale. She specializes in architecting Data Mesh architectures for Enterprise platforms.
Disha Umarwani is a Sr. Data Architect with Amazon Professional Services within Global Health Care and LifeSciences. She has worked with customers to design, architect and implement Data Strategy at scale. She specializes in architecting Data Mesh architectures for Enterprise platforms.











