Post Syndicated from Channy Yun original https://aws.amazon.com/blogs/aws/preview-use-amazon-sagemaker-to-build-train-and-deploy-ml-models-using-geospatial-data/
 You use map apps every day to find your favorite restaurant or travel the fastest route using geospatial data. There are two types of geospatial data: vector data that uses two-dimensional geometries such as a building location (points), roads (lines), or land boundary (polygons), and raster data such as satellite and aerial images.
You use map apps every day to find your favorite restaurant or travel the fastest route using geospatial data. There are two types of geospatial data: vector data that uses two-dimensional geometries such as a building location (points), roads (lines), or land boundary (polygons), and raster data such as satellite and aerial images.
Last year, we introduced Amazon Location Service, which makes it easy for developers to add location functionality to their applications. With Amazon Location Service, you can visualize a map, search points of interest, optimize delivery routes, track assets, and use geofencing to detect entry and exit events in your defined geographical boundary.
However, if you want to make predictions from geospatial data using machine learning (ML), there are lots of challenges. When I studied geographic information systems (GIS) in graduate school, I was limited to a small data set that covered only a narrow area and had to contend with limited storage and only the computing power of my laptop at the time.
These challenges include 1) acquiring and accessing high-quality geospatial datasets is complex as it requires working with multiple data sources and vendors, 2) preparing massive geospatial data for training and inference can be time-consuming and expensive, and 3) specialized tools are needed to visualize geospatial data and integrate with ML operation infrastructure
Today I’m excited to announce the preview release of Amazon SageMaker‘s new geospatial capabilities that make it easy to build, train, and deploy ML models using geospatial data. This collection of features offers pre-trained deep neural network (DNN) models and geospatial operators that make it easy to access and prepare large geospatial datasets. All generated predictions can be visualized and explored on the map.
Also, you can use the new geospatial image to transform and visualize data inside geospatial notebooks using open-source libraries such as NumPy, GDAL, GeoPandas, and Rasterio, as well as SageMaker-specific libraries.
With a few clicks in the SageMaker Studio console, a fully integrated development environment (IDE) for ML, you can run an Earth Observation job, such as a land cover segmentation or launch notebooks. You can bring various geospatial data, for example, your own Planet Labs satellite data from Amazon S3, or US Geological Survey LANDSAT and Sentinel-2 images from Open Data on AWS, Amazon Location Service, or bring your own data, such as location data generated from GPS devices, connected vehicles or internet of things (IoT) sensors, retail store foot traffic, geo-marketing and census data.
The Amazon SageMaker geospatial capabilities support use cases across any industry. For example, insurance companies can use satellite images to analyze the damage impact from natural disasters on local economies, and agriculture companies can track the health of crops, predict harvest yield, and forecast regional demand for agricultural produce. Retailers can combine location and map data with competitive intelligence to optimize new store locations worldwide. These are just a few of the example use cases. You can turn your own ideas into reality!
Introducing Amazon SageMaker Geospatial Capabilities
In the preview, you can use SageMaker Studio initialized in the US West (Oregon) Region. Make sure to set the default Jupyter Lab 3 as the version when you create a new user in the Studio. To learn more about setting up SageMaker Studio, see Onboard to Amazon SageMaker Domain Using Quick setup in the AWS documentation.
Now you can find the Geospatial section by navigating to the homepage and scrolling down in SageMaker Studio’s new Launcher tab.

Here is an overview of three key Amazon SageMaker geospatial capabilities:
- Earth Observation jobs – Acquire, transform, and visualize satellite imagery data to make predictions and get useful insights.
- Vector Enrichment jobs – Enrich your data with operations, such as converting geographical coordinates to readable addresses from CSV files.
- Map Visualization – Visualize satellite images or map data uploaded from a CSV, JSON, or GeoJSON file.
Let’s dive deep into each component!
Get Started with an Earth Observation Job
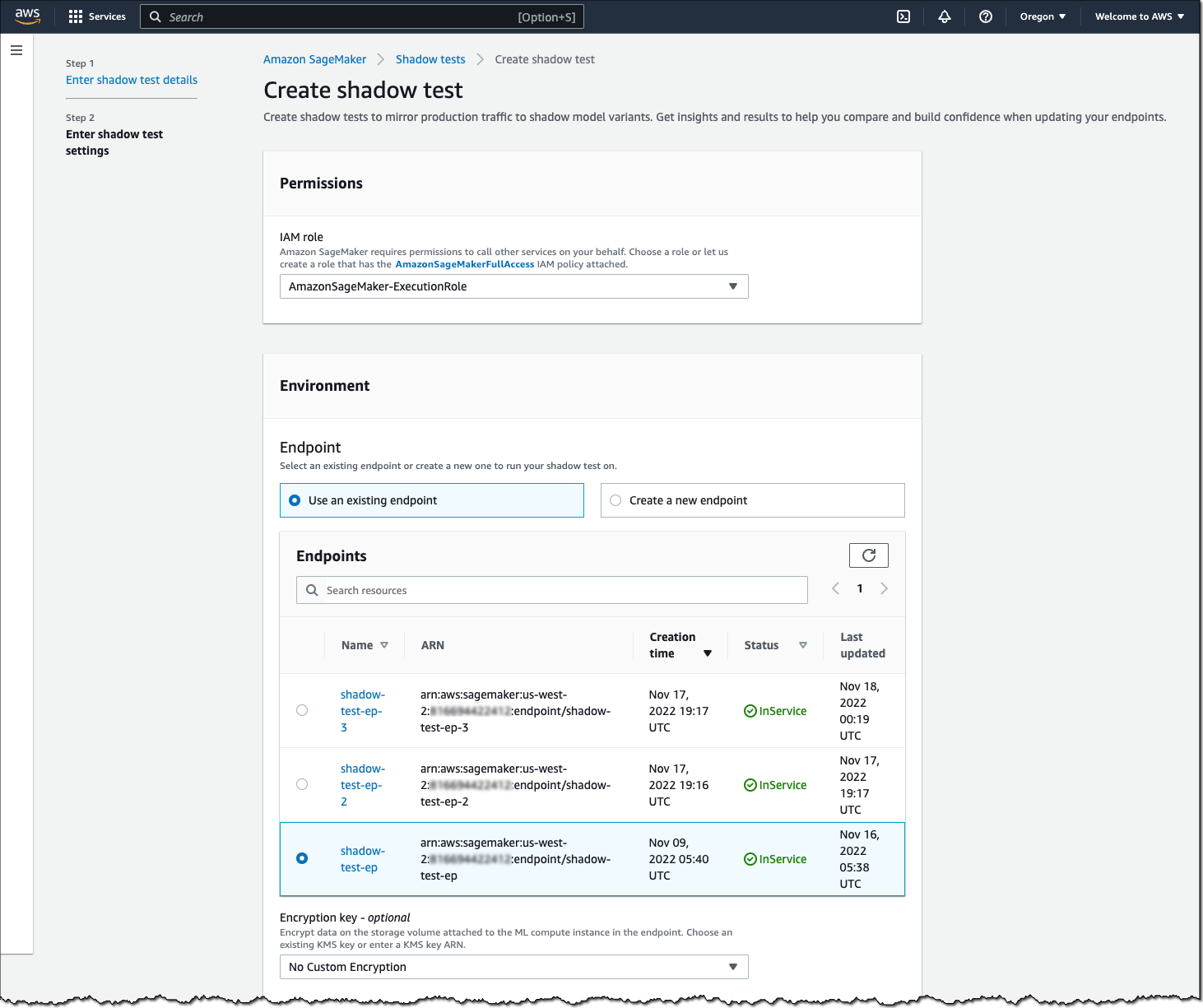
To get started with Earth Observation jobs, select Create Earth Observation job on the front page.

You can select one of the geospatial operations or ML models based on your use case.
- Spectral Index – Obtain a combination of spectral bands that indicate the abundance of features of interest.
- Cloud Masking – Identify cloud and cloud-free pixels to get clear and accurate satellite imagery.
- Land Cover Segmentation – Identify land cover types such as vegetation and water in satellite imagery.
The SageMaker provides a combination of geospatial functionalities that include built-in operations for data transformations along with pretrained ML models. You can use these models to understand the impact of environmental changes and human activities over time, identify cloud and cloud-free pixels, and perform semantic segmentation.
Define a Job name, choose a model to be used, and click the bottom-right Next button to move to the second configuration step.
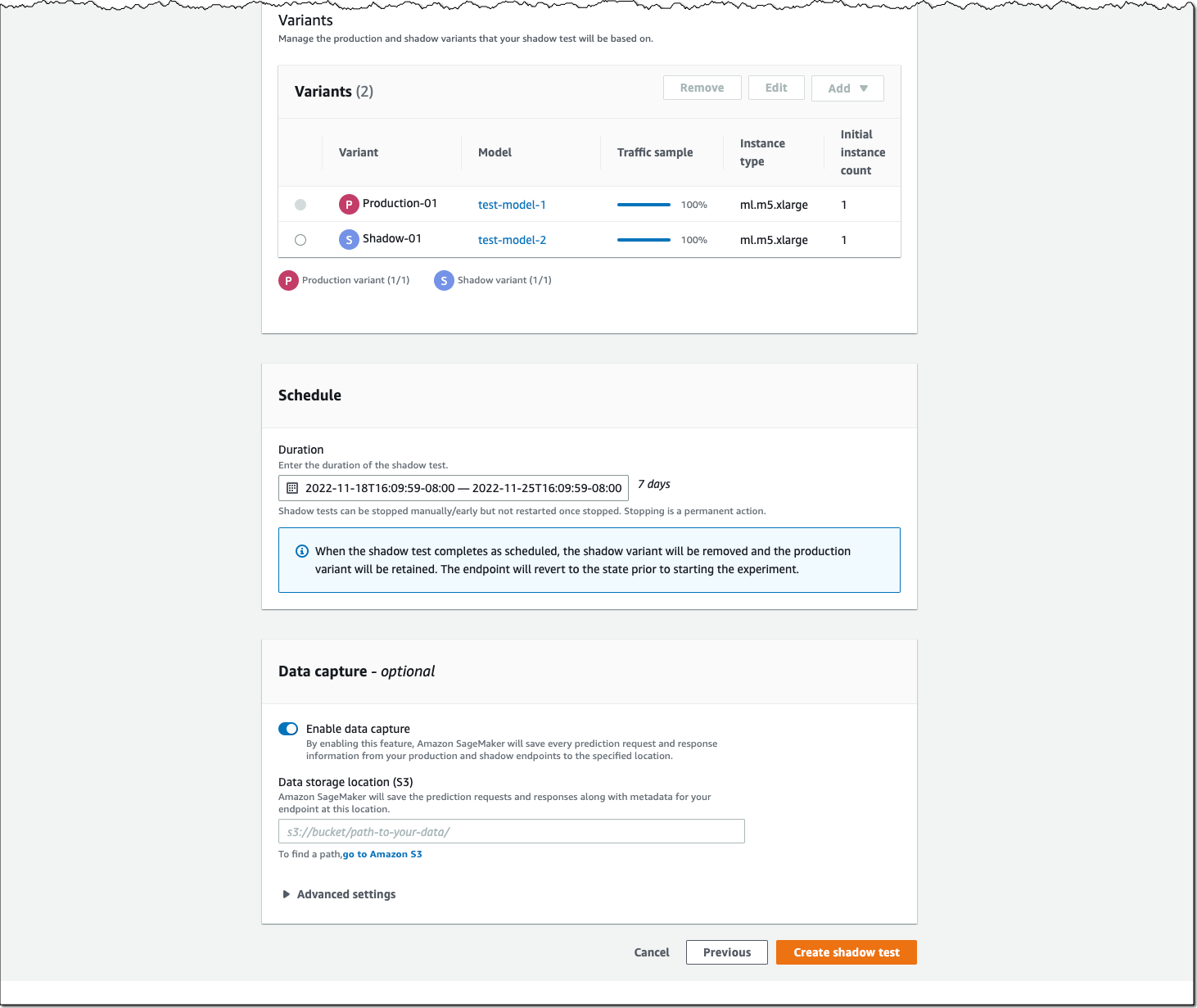
Next, you can define an area of interest (AOI), the satellite image data set you want to use, and filters for your job. The left screen shows the Area of Interest map to visualize for your Earth Observation Job selection, and the right screen contains satellite images and filter options for your AOI.

You can choose the satellite image collection, either USGS LANDSAT or Sentinel-2 images, the date span for your Earth Observation job, and filters on properties of your images in the filter section.
I uploaded GeoJSON format to define my AOI as the Mountain Halla area in Jeju island, South Korea. I select all job properties and options and choose Create.
Once the Earth Observation job is successfully created, a flashbar will appear where I can view my job details by pressing the View job details button.

Once the job is finished, I can Visualize job output.

This image is a job output on rendering process to detect land usage from input satellite images. You can see either input images, output images, or the AOI from data layers in the left pane.
It shows automatic mapping results of land cover for natural resource management. For example, the yellow area is the sea, green is cloud, dark orange is forest, and orange is land.

You can also execute the same job with SageMaker notebook using the geospatial image with geospatial SDKs.
From the File and New, choose Notebook and select the Image dropdown menu in the Setup notebook environment and choose Geospatial 1.0. Let the other settings be set to the default values.

Let’s look at Python sample code! First, set up SageMaker geospatial libraries.
import boto3
import botocore
import sagemaker
import sagemaker_geospatial_map
region = boto3.Session().region_name
session = botocore.session.get_session()
execution_role = sagemaker.get_execution_role()
sg_client= session.create_client(
service_name='sagemaker-geospatial',
region_name=region
)
Start an Earth Observation Job to identify the land cover types in the area of Jeju island.
# Perform land cover segmentation on images returned from the sentinel dataset.
eoj_input_config = {
"RasterDataCollectionQuery": {
"RasterDataCollectionArn": <ArnDataCollection,
"AreaOfInterest": {
"AreaOfInterestGeometry": {
"PolygonGeometry": {
"Coordinates": [
[[126.647226, 33.47014], [126.406116, 33.47014], [126.406116, 33.307529], [126.647226, 33.307529], [126.647226, 33.47014]]
]
}
}
},
"TimeRangeFilter": {
"StartTime": "2022-11-01T00:00:00Z",
"EndTime": "2022-11-22T23:59:59Z"
},
"PropertyFilters": {
"Properties": [
{
"Property": {
"EoCloudCover": {
"LowerBound": 0,
"UpperBound": 20
}
}
}
],
"LogicalOperator": "AND"
}
}
}
eoj_config = {"LandCoverSegmentationConfig": {}}
response = sg_client.start_earth_observation_job(
Name = "jeju-island-landcover",
InputConfig = eoj_input_config,
JobConfig = eoj_config,
ExecutionRoleArn = execution_role
)
# Monitor the EOJ status
sg_client.get_earth_observation_job(Arn = response['Arn'])
After your EOJ is created, the Arn is returned to you. You use the Arn to identify a job and perform further operations. After finishing the job, visualize Earth Observation inputs and outputs in the visualization tool.
# Creates an instance of the map to add EOJ input/ouput layer
map = sagemaker_geospatial_map.create_map({
'is_raster': True
})
map.set_sagemaker_geospatial_client(sg_client)
# render the map
map.render()
# Visualize input, you can see EOJ is not be completed.
time_range_filter={
"start_date": "2022-11-01T00:00:00Z",
"end_date": "2022-11-22T23:59:59Z"
}
arn_to_visualize = response['Arn']
config = {
'label': 'Jeju island'
}
input_layer=map.visualize_eoj_input(Arn=arn_to_visualize, config=config , time_range_filter=time_range_filter)
# Visualize output, EOJ needs to be in completed status
time_range_filter={
"start_date": "2022-11-01T00:00:00Z",
"snd_date": "2022-11-22T23:59:59Z"
}
config = {
'preset': 'singleBand',
'band_name': 'mask'
}
output_layer = map.visualize_eoj_output(Arn=arn_to_visualize, config=config, time_range_filter=time_range_filter)
You can also execute the StartEarthObservationJob API using the AWS Command Line Interface (AWS CLI).
When you create an Earth Observation Job in notebooks, you can use additional geospatial functionalities. Here is a list of some of the other geospatial operations that are supported by Amazon SageMaker:
- Band Stacking – Combine multiple spectral properties to create a single image.
- Cloud Removal – Remove pixels containing parts of a cloud from satellite imagery.
- Geomosaic – Combine multiple images for greater fidelity.
- Resampling – Scale images to different resolutions.
- Temporal Statistics – Calculate statistics through time for multiple GeoTIFFs in the same area.
- Zonal Statistics – Calculate statistics on user-defined regions.
To learn more, see Amazon SageMaker geospatial notebook SDK and Amazon SageMaker geospatial capability Service APIs in the AWS documentation and geospatial sample codes in the GitHub repository.
Perform a Vector Enrichment Job and Map Visualization
A Vector Enrichment Job (VEJ) performs operations on your vector data, such as reverse geocoding or map matching.
- Reverse Geocoding – Convert map coordinates to human-readable addresses powered by Amazon Location Service.
- Map Matching – Match GPS coordinates to road segments.
While you need to use an Amazon SageMaker Studio notebook to execute a VEJ, you can view all the jobs you create.

With the StartVectorEnrichmentJob API, you can create a VEJ for the supplied two job types.
{
"Name":"vej-reverse",
"InputConfig":{
"DocumentType":"csv", //
"DataSourceConfig":{
"S3Data":{
"S3Uri":"s3://channy-geospatial/sample/vej.csv",
}
}
},
"JobConfig": {
"MapMatchingConfig": {
"YAttributeName":"string", // Latitude
"XAttributeName":"string", // Longitude
"TimestampAttributeName":"string",
"IdAttributeName":"string"
}
},
"ExecutionRoleArn":"string"
}
You can visualize the output of VEJ in the notebook or use the Map Visualization feature after you export VEJ jobs output to your S3 bucket. With the map visualization feature, you can easily show your geospatial data on the map.

This sample visualization includes Seattle City Council districts and public-school locations in GeoJSON format. Select Add data to upload data files or select S3 bucket.
{
"type": "FeatureCollection",
"crs": { "type": "name", "properties": {
"name": "urn:ogc:def:crs:OGC:1.3:CRS84" } },
"features": [
{ "type": "Feature", "id": 1, "properties": { "PROPERTY_L": "Jane Addams", "Status": "MS" }, "geometry": { "type": "Point", "coordinates": [ -122.293009024934037, 47.709944862769468 ] } },
{ "type": "Feature", "id": 2, "properties": { "PROPERTY_L": "Rainier View", "Status": "ELEM" }, "geometry": { "type": "Point", "coordinates": [ -122.263172064204767, 47.498863322205558 ] } },
{ "type": "Feature", "id": 3, "properties": { "PROPERTY_L": "Emerson", "Status": "ELEM" }, "geometry": { "type": "Point", "coordinates": [ -122.258636146463658, 47.514820466363943 ] } }
]
}
That’s all! For more information about each component, see Amazon SageMaker geospatial Developer Guide.
Join the Preview
The preview release of Amazon SageMaker geospatial capability is now available in the US West (Oregon) Region.
We want to hear more feedback during the preview. Give it a try, and please send feedback to AWS re:Post for Amazon SageMaker or through your usual AWS support contacts.
– Channy






 Swami Sivasubramanian is the Vice President of AWS Data and Machine Learning.
Swami Sivasubramanian is the Vice President of AWS Data and Machine Learning.


























 You use map apps every day to find your favorite restaurant or travel the fastest route using geospatial data. There are two types of geospatial data: vector data that uses two-dimensional geometries such as a building location (points), roads (lines), or land boundary (polygons), and raster data such as satellite and aerial images.
You use map apps every day to find your favorite restaurant or travel the fastest route using geospatial data. There are two types of geospatial data: vector data that uses two-dimensional geometries such as a building location (points), roads (lines), or land boundary (polygons), and raster data such as satellite and aerial images.