Post Syndicated from Sean Zou original https://aws.amazon.com/blogs/big-data/how-mulesoft-achieved-cloud-excellence-through-an-event-driven-amazon-redshift-lakehouse-architecture/
This post is cowritten with Sean Zou, Terry Quan and Audrey Yuan from MuleSoft.
In our previous thought leadership blog post Why a Cloud Operating Model we defined a COE Framework and showed why MuleSoft implemented it and the benefits they received from it. In this post, we’ll dive into the technical implementation describing how MuleSoft used Amazon EventBridge, Amazon Redshift, Amazon Redshift Spectrum, Amazon S3, & AWS Glue to implement it.
Solution overview
MuleSoft’s solution was to build a lakehouse built on top of AWS services, illustrated in the following diagram, supporting a portal. To provide near real-time analytics we used an event-driven strategy that which would trigger AWS Glue jobs an refresh materialized views. We also implemented a layered approach that included collection, preparation, and enrichment making it straightforward to identify areas that affect data accuracy.

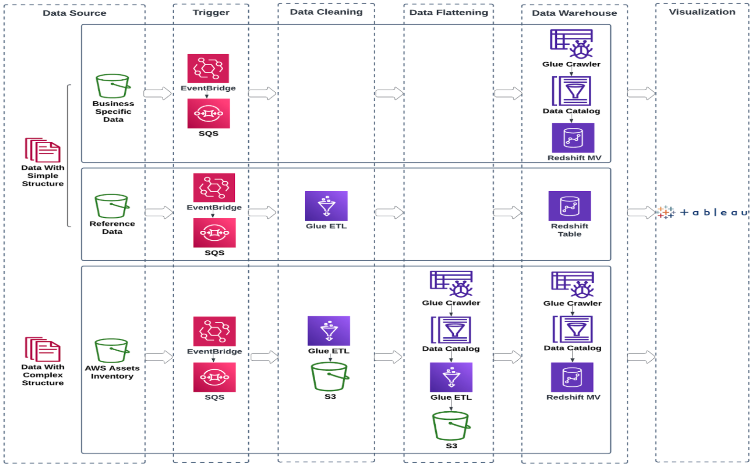
For MuleSoft’s lakehouse end-to-end solution, the following phases are key:
- Preparation phase
- Enrichment phase
- Action phase
In the following sections, we discuss these phases in more detail.
Preparation phase
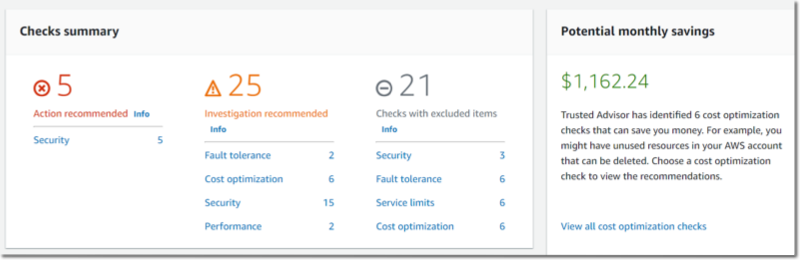
Using the COE Framework, we engaged with the stakeholders in the preparation phase to determine the business goals and identify the data sources to ingest. Examples of data sources were cloud assets inventory, AWS Cost and Usage Reports, and AWS Trusted Advisor data. The ingested data is processed in the lakehouse to implement the Well-Architected pillars, utilization, security, and compliance status checks and measures.
How you configure the CUR data and the Trusted Advisor data to land into S3?
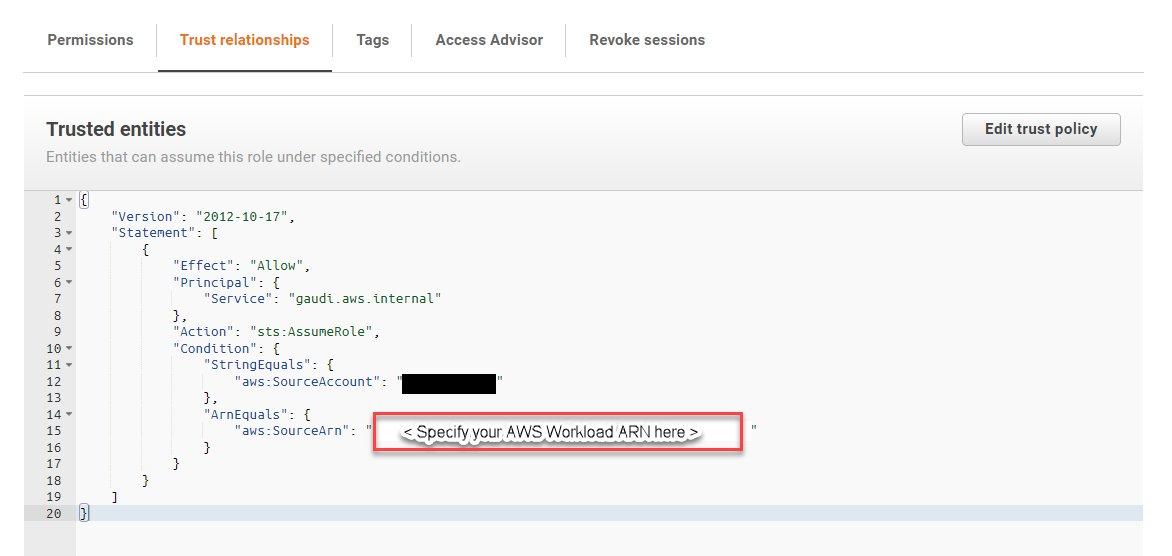
The configuration process involves multiple components for both CUR and Trusted Advisor data storage. For CUR setup, customers need to configure an S3 bucket where the CUR report will be delivered, either by selecting an existing bucket or creating a new one. The S3 bucket requires a policy to be applied and customers must specify an S3 path prefix which creates a subfolder for CUR file delivery .
Trusted Advisor data is configured to use Kinesis Firehose to deliver customer summary data to the Support Data lake S3 bucket .The data ingestion process uses firehose buffer parameters (1MB buffer size and 60-second buffer time) to manage data flow to the S3 bucket .
The Trusted Advisor data is stored in JSON and GZIP format, following a specific folder structure with hourly partitions using the “YYYY-MM-DD-HH” format .
The S3 partition structure for Trusted Advisor customer summary data includes separate paths for success and error data, and the data is encrypted using a KMS key specific to Trusted Advisor data .
MuleSoft used AWS managed services and data ingestion tools to pull from multiple data sources and that can support customizations. Cloudquery is used tool to gather cloud infrastructure information, which can connect many infrastructure data sources out of the box and land it into an Amazon S3 bucket. The MuleSoft Anypoint Platform provides an integration layer to integrate infrastructure tools, accommodating many data sources like on-premise, SaaS, and commercial off-the-shelf (COTS) software. Cloud Custodian was used for its capability of managing cloud resources and auto-remediation with customizations.
Enrichment phase
The enrichment phase includes ingesting raw data aligning with our business goals into the lakehouse through our pipelines, and consolidating the data to create a single pane of glass.
The pipelines adopt the event-driven architecture consisting of EventBridge, Amazon Simple Queue Service (Amazon SQS), and Amazon S3 Event Notifications to provide near real-time data for analysis. When new data arrives in the source bucket, new object creation is captured by the EventBridge rule, which invokes the AWS Glue workflow, consisting of an AWS Glue crawler and AWS Glue extract, transform, and load (ETL) jobs. We also configured S3 Event Notifications to send messages to the SQS queue to make sure the pipeline will only process the new data.
The AWS Glue ETL job cleanses and standardizes the data, so that it’s ready to be analyzed using Amazon Redshift. To tackle data with complex structures, additional processing is performed to flatten the nested data formats into a relational model. The flattening step also extracts the tags of AWS assets out of the nested JSON objects and pivots them into individual columns, enabling tagging enforcement controls and ownership attribution. The ownership attribution of the infrastructure data provides accountability and holds teams responsible for the costs, utilization, security, compliance, and remediation of their cloud assets. One important tag is asset ownership which is from the tags extracted from the flattening step, this data can be attributed to the corresponding owners by SQL scripts.
When the workflow is complete, the raw data from different sources and with various structures is now centralized in the data warehouse. From there, disjointed data with different purposes is ready to be consolidated and translated into actionable intelligence in the Well-Architected Pillars by coding out the business logic.
Solutions for the enrichment phase
In the enrichment phase, we faced a number of storage, efficiency, and scalability challenges given the sheer volume of data. We used three techniques (file partitioning, Redshift Spectrum, and materialized views) to address these issues and scale without compromising performance.
File partitioning
MuleSoft’s infrastructure data is stored in folder structure: year, month, day, hour, account, and Region in an S3 bucket, so AWS Glue crawlers are able to automatically identify and add partitions to the tables in the AWS Glue Data Catalog. Partitioning helps improve query performance significantly because it optimizes parallel processing for queries. The amount of data scanned by each query is restricted based on the partition keys, helping reduce overall data transfers, processing time, and computation costs. Although partitioning is an optimization technique that helps improve query efficiency, it’s important to keep in mind two key points while using this technique:
- The Data Catalog has a maximum cap of 10 million partitions per table
- Query performance gets compromised as partitions grow rapidly
Therefore, balancing the number of partitions in the Data Catalog tables and query efficiency is essential. We decided on a data retention policy of 3 months and configured a lifecycle rule to expire any data older than that.
Our event-driven architecture–AWS Eventbridge event is invoked when objects are put into or removed from an S3 bucket, event messages are published to the SQS queue using S3 Event Notifications, which invokes an AWS Glue crawler to either add new partitions or removes old partitions from the Data Catalog based on the messages handling the partition cleanup.
Amazon Redshift and concurrency scaling
MuleSoft uses Amazon Redshift to query the data in S3 because it provides large scale compute and minimized data redundancy. MuleSoft also used Amazon Redshift concurrency scaling to run concurrent queries with consistently fast query performance. Amazon Redshift automatically added query processing power in seconds to process a high number of concurrent queries without any delays.
Materialized views
Another technique we used is Amazon Redshift materialized views. Materialized views store preset query results that future similar queries can use, so many computation steps can be skipped. Therefore, relevant data can be accessed efficiently, which leads to query optimization. Additionally, materialized views can be automatically and incrementally refreshed. Therefore, we can achieve a single pane of glass in our cloud infrastructure with the most up-to-date projections, trends, and actionable insights to our organization with improved query performance.
Amazon Redshift Materialized Views (MVs) are used extensively for reporting in MuleSoft’s Cloud Central portal, but if users needed to drill down into a granular view they could reference external tables.
Mulesoft is currently manually refreshing the materialized views through the event-driven architecture, but is evaluating a switch to automatic refresh.
Action phase
Using materialized views in Amazon Redshift, we developed a self-serve Cloud Central portal in Tableau to provide a display portal for each team, engineer, and manager offering guidance and recommendations to help them operate in a way that aligns with the organization’s requirements, standards, and budget. Managers are empowered with monitoring and decision-making information for their teams. Engineers are able to identify and tag assets with missing mandatory tagging information, as well as remediate non-compliant resources. A key feature of the portal is personalization, meaning that the portal is enabled to populate visualizations and analysis based on the relevant data associated with a manager’s or engineer’s login information.
Cloud Central also helps engineering teams improve their cloud maturity in the six Well-Architecture pillars: operational excellence, security, reliability, performance efficiency, cost optimization, and sustainability. The team proved out the “art of possible” by poc’ing Amazon Q to assist with 100 and 200 Well-Architected pillar inquiries and how to’s. The following screenshot illustrates the MuleSoft implementation of the portal, Cloud Central. Other companies will design portals that are more bespoke to their own use cases and requirements.

Conclusion
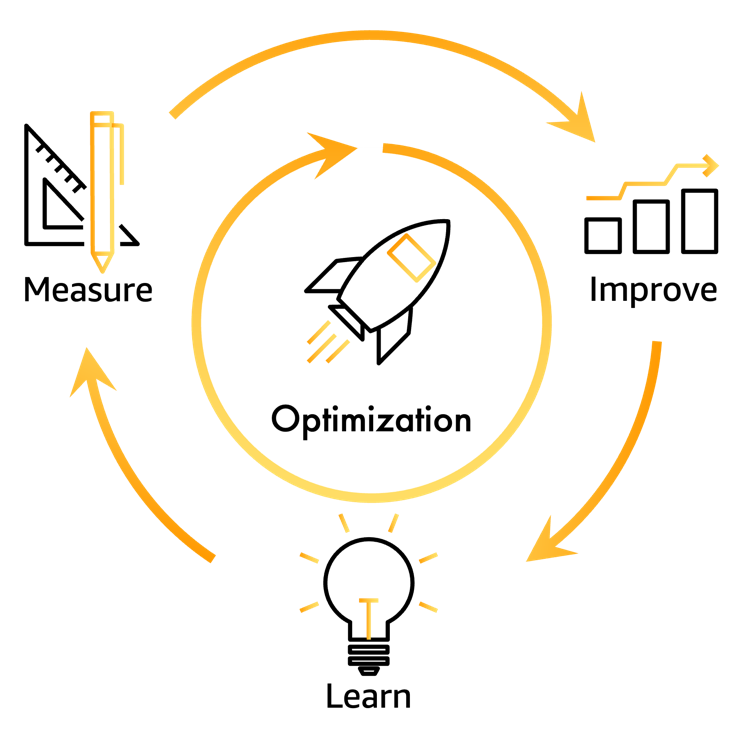
The technical and business impact of MuleSoft’s COE Framework enables an optimization strategy and a cloud usage show back approach which helps MuleSoft continue to grow with a scalable and sustainable cloud infrastructure. The framework also drives continual maturity and benefits in cloud infrastructure centered around the six Well-Architecture pillars shown in the following figure.

The framework helps organizations with expanded public cloud infrastructure achieve their business goals guided by the Well-Architected benefits powered by an event-driven architecture.
The event-driven Amazon Redshift lakehouse architecture solution offers near real-time actionable insights on decision-making, control, and accountability. The event-driven architecutre can be distilled into modules which can be added or deleted depending on your technical/business goals.
The team is exploring new ways to lower the total cost of ownership. They are evaluating Amazon Redshift Serverless for transient database workloads as well as exploring Amazon DataZone to aggregate and correlate data sources into a data catalog to share among teams, applications, and lines of businesses in a democratized way. We can increase visibility, productivity, and scalability with a well-thought-out lakehouse solution.
We invite organizations and enterprises to take a holistic approach to understand their cloud resources, infrastructure, and applications. You can enable and educate your teams through a single pane of glass, while running on a data modernization lakehouse applying Well-Architected concepts, best practices, and cloud-centric principles. This solution can ultimately enable near real-time streaming, leveling up a COE Framework well into the future.
About the Authors
 Sean Zou is a Cloud Operations leader with MuleSoft at Salesforce. Sean has been involved in many aspects of MuleSoft’s Cloud Operations, and helped drive MuleSoft’s cloud infrastructure to scale more than tenfold in 7 years. He built the Oversight Engineering function at MuleSoft from scratch.
Sean Zou is a Cloud Operations leader with MuleSoft at Salesforce. Sean has been involved in many aspects of MuleSoft’s Cloud Operations, and helped drive MuleSoft’s cloud infrastructure to scale more than tenfold in 7 years. He built the Oversight Engineering function at MuleSoft from scratch.
 Terry Quan focuses on FinOps issues. He works on MuleSoft Engineering on cloud computing budgets and forecasting, cost reduction efforts, costs-to-serve, and coordinates with Salesforce Finance. Terry is a FinOps Practitioner and Professional Certified.
Terry Quan focuses on FinOps issues. He works on MuleSoft Engineering on cloud computing budgets and forecasting, cost reduction efforts, costs-to-serve, and coordinates with Salesforce Finance. Terry is a FinOps Practitioner and Professional Certified.
 Audrey Yuan is a Software Engineer with MuleSoft at Salesforce. Audrey works on data lakehouse solutions to help drive cloud maturity across the six pillars of the Well-Architected Framework.
Audrey Yuan is a Software Engineer with MuleSoft at Salesforce. Audrey works on data lakehouse solutions to help drive cloud maturity across the six pillars of the Well-Architected Framework.
 Rueben Jimenez is a Senior Solutions Architect at AWS, designing and implementing complex data analytics, AI/ML, and cloud infrastructure solutions.
Rueben Jimenez is a Senior Solutions Architect at AWS, designing and implementing complex data analytics, AI/ML, and cloud infrastructure solutions.
 Avijit Goswami is a Principal Solutions Architect at AWS specialized in data and analytics. He supports AWS strategic customers in building high-performing, secure, and scalable data lake solutions on AWS using AWS managed services and open source solutions. Outside of his work, Avijit likes to travel, hike, watch sports, and listen to music.
Avijit Goswami is a Principal Solutions Architect at AWS specialized in data and analytics. He supports AWS strategic customers in building high-performing, secure, and scalable data lake solutions on AWS using AWS managed services and open source solutions. Outside of his work, Avijit likes to travel, hike, watch sports, and listen to music.