Post Syndicated from Channy Yun original https://aws.amazon.com/blogs/aws/new-amazon-ecs-service-connect-enabling-easy-communication-between-microservices/
Microservices architectures are a well-known software development approach to make applications composed of small independent services that communicate over well-defined application programming interfaces (APIs). Customers faced challenges when they started breaking down their monolith applications into microservices, as it required specialized networking knowledge to communicate internally with other microservices.
Amazon Elastic Container Services (Amazon ECS) customers have several solutions for service-to-service, but each one comes with some challenges and complications: 1) Elastic Load Balancing (ELB) needs to carefully plan for configuring infrastructure for high availability and incur additional infrastructure cost. 2) Using Amazon ECS Service Discovery often requires developers to write custom application code for collecting traffic metrics and for making network calls resilient. 3) Service mesh solutions such as AWS App Mesh run outside of Amazon ECS despite having advanced traffic monitoring and routing features between services.
Today, we are announcing the general availability of Amazon ECS Service Connect, a new capability that simplifies building and operating resilient distributed applications. ECS Service Connect provides an easy network setup and seamless service communication deployed across multiple ECS clusters and virtual private clouds (VPCs). You can add a layer of resilience to your ECS service communication and get traffic insights with no changes to your application code.

With ECS Service Connect, you can refer and connect to your services by logical names using a namespace provided by AWS Cloud Map and automatically distribute traffic between ECS tasks without deploying and configuring load balancers. You can set some safe defaults for traffic resilience, such as health checking, automatic retries for 503 errors, and connection draining, for each of your ECS services. Additionally, the Amazon ECS console provides easy-to-use dashboards with real-time network traffic metrics for operational convenience and simplified debugging.
Getting Started with Amazon ECS Service Connect
To get started with the ECS Service Connect, you can specify a namespace as part of creating an ECS cluster or create one in the Cloud Map. A namespace represents a way to structure your services and can span across multiple ECS clusters residing in different VPCs. All ECS services that belong to a specific namespace can communicate with existing services in the namespaces, provided existing network-level connectivity.

You can also see a list of Cloud Map namespaces in Namespaces in the left navigation pane of the Amazon ECS console. When you select a namespace, it shows a list of services with the same namespace from two different ECS clusters with database services (db-mysql, db-redis) and backend services (webui, appserver).

When you create an ECS cluster, you can select one of the namespaces in the Default namespaces of the Networking setting. ECS Service Connect is enabled for all new ECS services running in both AWS Fargate and Amazon EC2 instances. To enable all existing services, you would need to redeploy with either a new version of ECS-optimized Amazon Machine Image (AMI), or with a new Fargate Agent that supports ECS Service Connect.

Or, you can simply create a cluster via AWS Command Line Interface (AWS CLI) with serviceConnect parameter and a default Cloud Map namespace name for service discovery purposes.
$ aws ecs create-cluster
--cluster "svc-cluster-2"
--serviceConnect {
"defaultNamespace": "svc-namespace"
}This command will create an ECS cluster with the namespace on AWS’s behalf. If you would like to use an already existing Cloud Map namespace, you can simply pass the name of the existing namespace here.
Next, let’s create a service with a task definition and expose your web user-interface server using ECS Service Connect.
$ aws ecs create-service
--cluster "svc-cluster-2"
--service-name "webui"
--task-definition "webui-svc-cluster"
--serviceConnect {
"enabled": true,
"namespace": "svc-namespace",
"services":
[
{
"portName": "webui-port",
"discoveryName": "webui-svc",
"clientAliases": [
{
"port": 80, // *Required *//
"dnsName": "webui-svc-domain" // * Optional *//
}
}
]
]
}In this command, portName represents a reference to the container port, and clientAliases assigns the port number and DNS name, overriding the discovery name that is used in the endpoint. Each service has an endpoint URL that contains the protocol, a DNS name, and the port. You can select the protocol and port name in the task definition or the ECS service configuration. For example, an endpoint could be http://webui:80, grpc://appserver:8080, or http://db-redis:8888.
In the ECS console, you can see this configuration of ECS Service Connect for the webui service in the svc-cluster-2 cluster.

As you can see, you can run the same workloads across different clusters with the same clientAlias and namespace name for high availability. ECS Service Connect will intelligently load balance the traffic to the ECS tasks. To connect to services running in different ECS clusters, you need to specify the same namespace name for all your ECS services that need to talk to each other. ECS Service Connect will make your services discoverable to all other services in the same namespace.
Improving Service Resilience with Observability Data
You can collect traffic metrics with ECS Service Connect observability capabilities. By default, for each ECS service, you can see the number of healthy and unhealthy endpoints, along with inbound and outbound traffic volume.
ECS Service Connect supports HTTP/1, HTTP/2, gRPC, and TCP protocols. So, you can collect the number of requests, number of HTTP errors, and average call latency. For gRPC and TCP, you can see the total number of active connections. All of these metrics are pushed to Amazon CloudWatch or other AWS analytics services via custom log routing
In the Advanced menu, you can publish ECS Service Connect Agent logs for help in debugging in case of issues.

These metrics are only visible in the original interface of the CloudWatch console. When you use the CloudWatch console, switch to the original interface to see the additional metric dimensions of “discovery name” and “target discovery name” under the ECS grouping.
The default settings provide you with a starting point for building resilient applications, and you can fine-tune parameters to limit the impact of failures, latency spikes, and network fluctuations on your application behavior using AWS Management Console or dedicated ECS APIs.
Now Available
Amazon ECS Service Connect is available in all commercial Regions, except China, where Amazon ECS is available. ECS Service Connect is fully supported in AWS CloudFormation, AWS CDK, AWS Copilot, and AWS Proton for infrastructure provisioning, code deployments, and monitoring of your services. To learn more, see the Amazon ECS Service Connect Developer Guide.
My colleagues, Hemanth AVS, Senior Container Specialist SA, and Satya Vajrapu, Senior DevOps Consultant, prepared a hands-on workshop to demonstrate an example of the ECS Service Connect. Join CON303 Networking, service mesh, and service discovery with Amazon ECS when you attend AWS re:Invent 2022.
Give it a try, and please send feedback to AWS re:Post for Amazon ECS or through your usual AWS support contacts.
– Channy
 In November 2020, Jeff
In November 2020, Jeff 











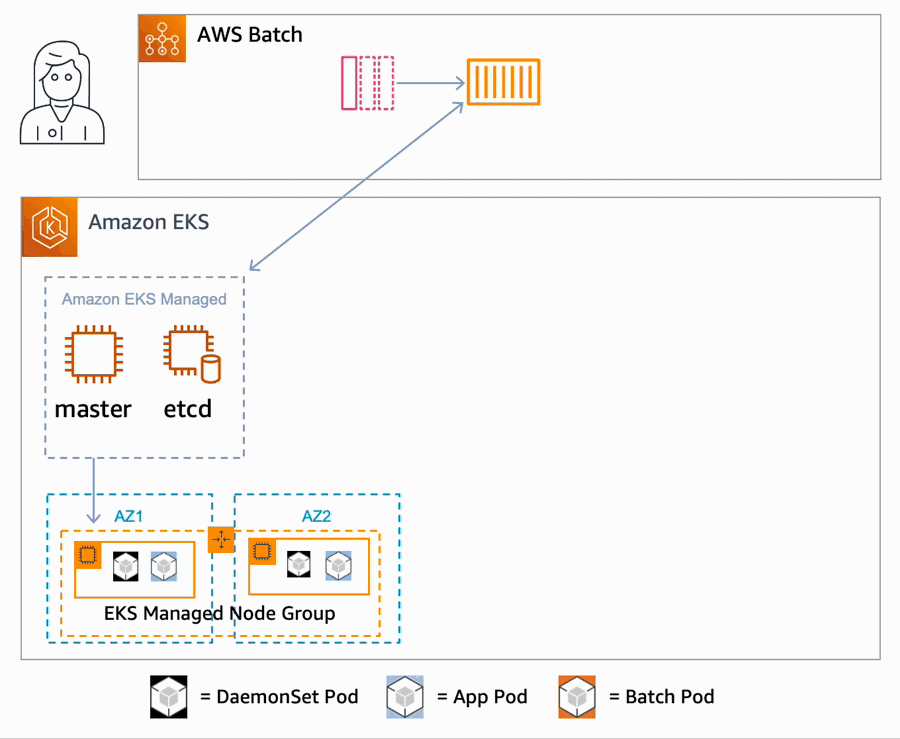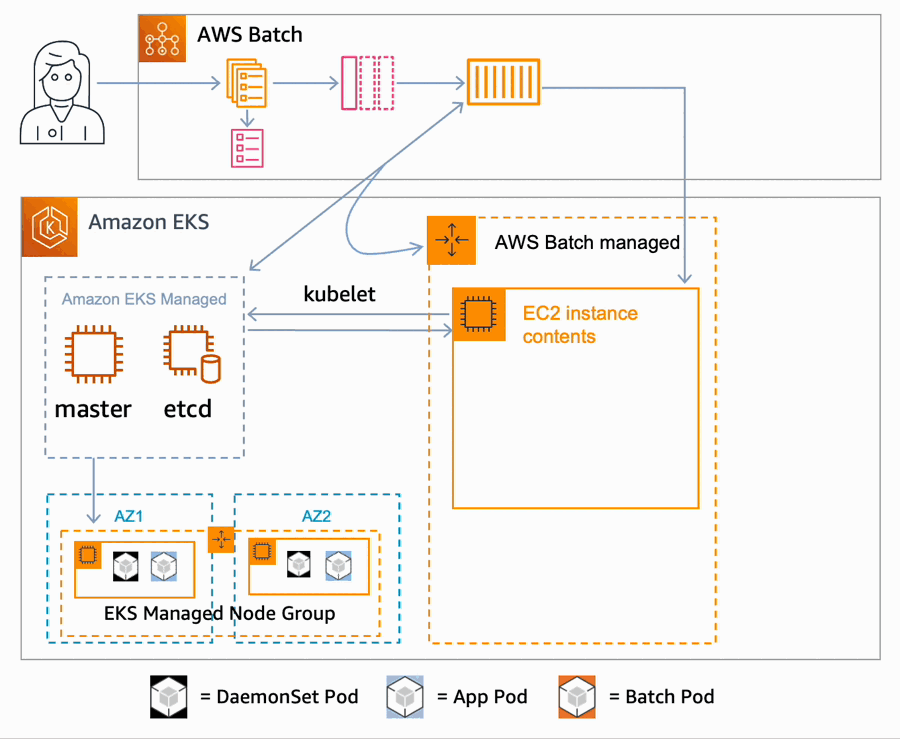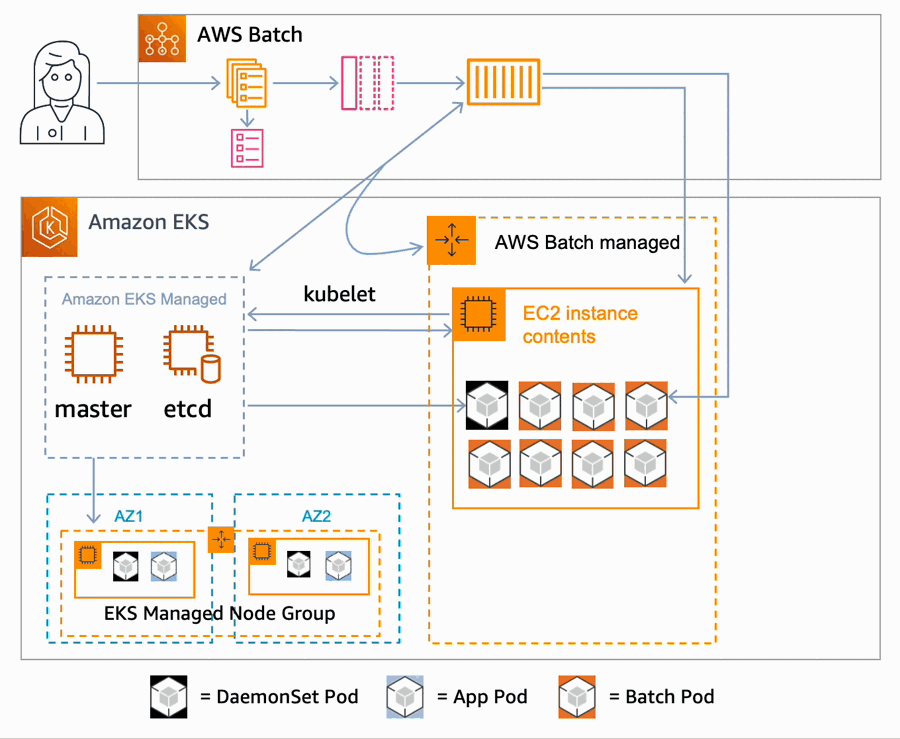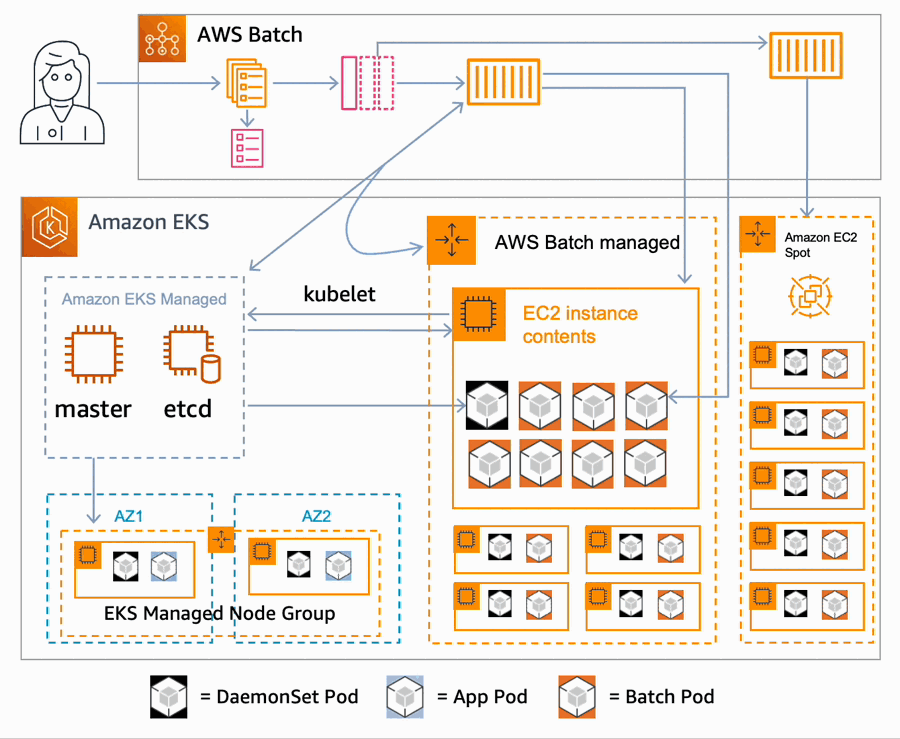
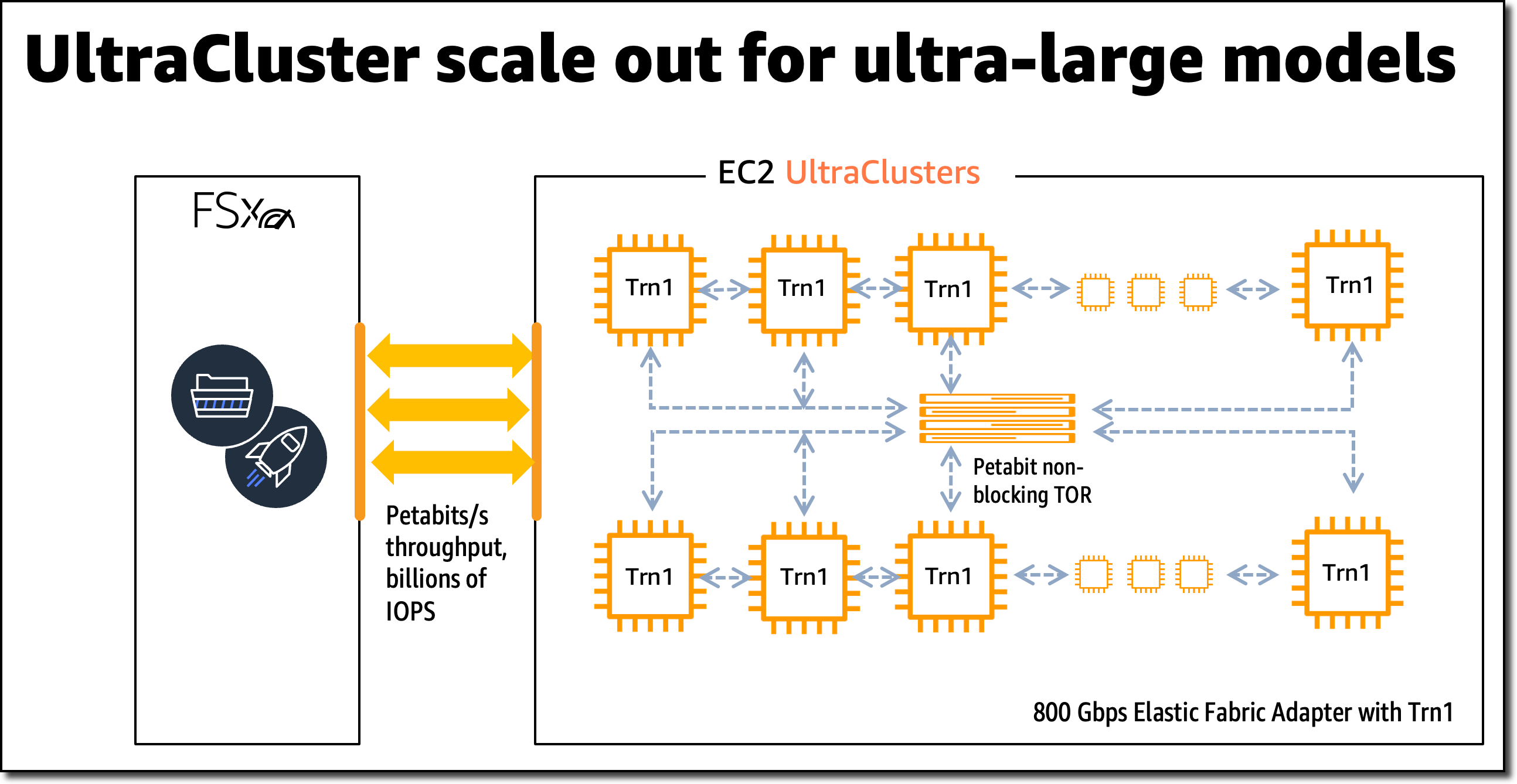




 Available.
Available.