Post Syndicated from Jeff Barr original https://aws.amazon.com/blogs/aws/new-general-purpose-compute-optimized-and-memory-optimized-amazon-ec2-instances-with-higher-packet-processing-performance/
Today I would like to tell you about the next generation of Intel-powered general purpose, compute-optimized, and memory-optimized instances. All three of these instance families are powered by 3rd generation Intel Xeon Scalable processors (Ice Lake) running at 3.5 GHz, and are designed to support your data-intensive workloads with up to 200 Gbps of network bandwidth, the highest EBS performance in EC2 (up to 80 Gbps of bandwidth and up to 350,000 IOPS), and the ability to handle up to twice as many packets per second (PPS) as earlier instances.
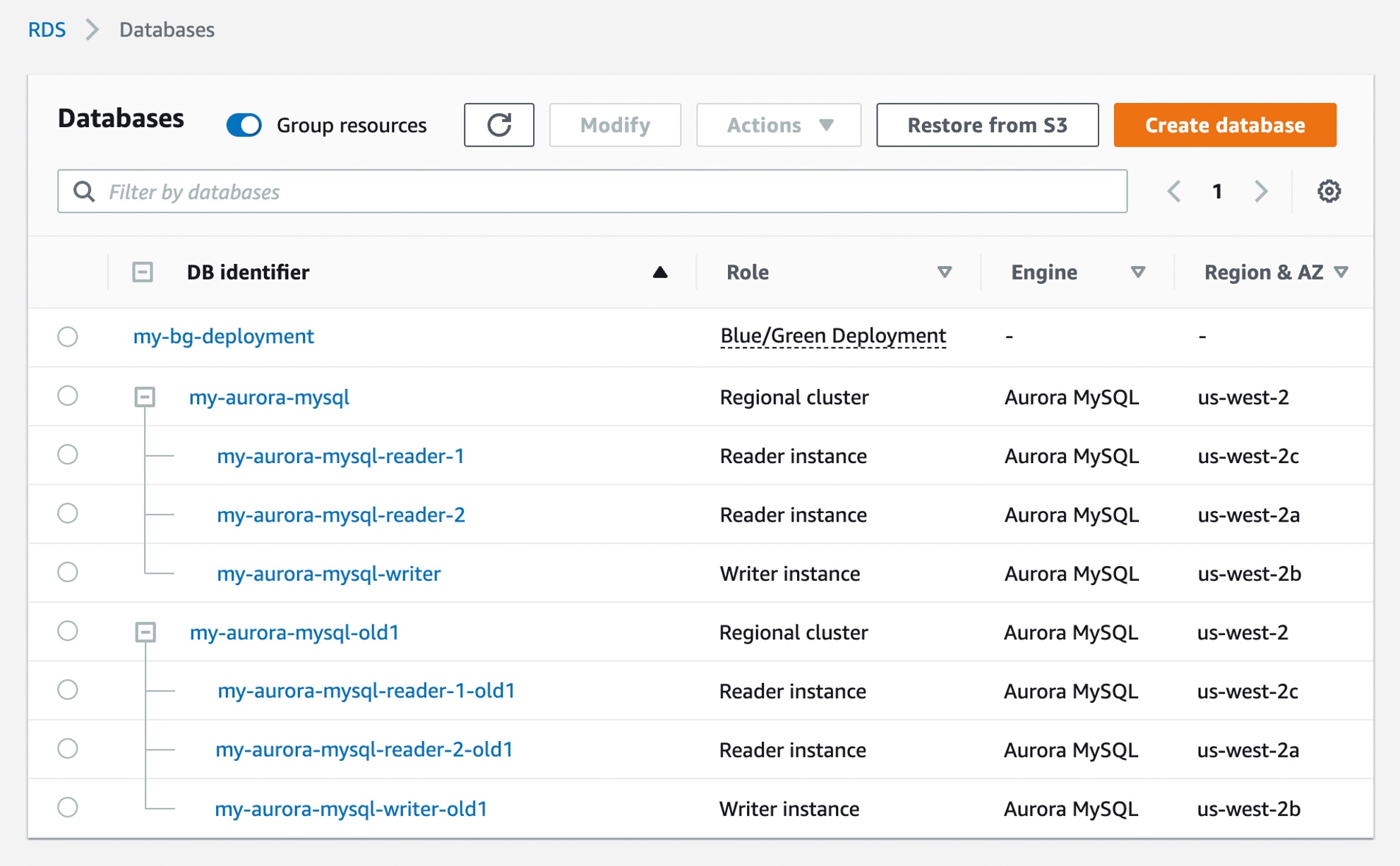
New General Purpose (M6in/M6idn) Instances
The original general purpose EC2 instance (m1.small) was launched in 2006 and was the one and only instance type for a little over a year, until we launched the m1.large and m1.xlarge in late 2007. After that, we added the m3 in 2012, m4 in 2015, and the first in a very long line of m5 instances starting in 2017. The family tree branched in 2018 with the addition of the m5d instances with local NVMe storage.
And that brings us to today, and to the new m6in and m6idn instances, both available in 9 sizes:
| Name | vCPUs | Memory | Local Storage (m6idn only) |
Network Bandwidth | EBS Bandwidth | EBS IOPS |
| m6in.large m6idn.large |
2 | 8 GiB | 118 GB | Up to 25 Gbps | Up to 20 Gbps | Up to 87,500 |
| m6in.xlarge m6idn.xlarge |
4 | 16 GiB | 237 GB | Up to 30 Gbps | Up to 20 Gbps | Up to 87,500 |
| m6in.2xlarge m6idn.2xlarge |
8 | 32 GiB | 474 GB | Up to 40 Gbps | Up to 20 Gbps | Up to 87,500 |
| m6in.4xlarge m6idn.4xlarge |
16 | 64 GiB | 950 GB | Up to 50 Gbps | Up to 20 Gbps | Up to 87,500 |
| m6in.8xlarge m6idn.8xlarge |
32 | 128 GiB | 1900 GB | 50 Gbps | 20 Gbps | 87,500 |
| m6in.12xlarge m6idn.12xlarge |
48 | 192 GiB | 2950 GB (2 x 1425) |
75 Gbps | 30 Gbps | 131,250 |
| m6in.16xlarge m6idn.16xlarge |
64 | 256 GiB | 3800 GB (2 x 1900) |
100 Gbps | 40 Gbps | 175,000 |
| m6in.24xlarge m6idn.24xlarge |
96 | 384 GiB | 5700 GB (4 x 1425) |
150 Gbps | 60 Gbps | 262,500 |
| m6in.32xlarge m6idn.32xlarge |
128 | 512 GiB | 7600 GB (4 x 1900) |
200 Gbps | 80 Gbps | 350,000 |
The m6in and m6idn instances are available in the US East (Ohio, N. Virginia) and Europe (Ireland) regions in On-Demand and Spot form. Savings Plans and Reserved Instances are available.
New C6in Instances
Back in 2008 we launched the first in what would prove to be a very long line of Amazon Elastic Compute Cloud (Amazon EC2) instances designed to give you high compute performance and a higher ratio of CPU power to memory than the general purpose instances. Starting with those initial c1 instances, we went on to launch cluster computing instances in 2010 (cc1) and 2011 (cc2), and then (once we got our naming figured out), multiple generations of compute-optimized instances powered by Intel processors: c3 (2013), c4 (2015), and c5 (2016). As our customers put these instances to use in environments where networking performance was starting to become a limiting factor, we introduced c5n instances with 100 Gbps networking in 2018. We also broadened the c5 instance lineup by adding additional sizes (including bare metal), and instances with blazing-fast local NVMe storage.
Today I am happy to announce the latest in our lineup of Intel-powered compute-optimized instances, the c6in, available in 9 sizes:
| Name | vCPUs | Memory |
Network Bandwidth | EBS Bandwidth |
EBS IOPS |
| c6in.large | 2 | 4 GiB | Up to 25 Gbps | Up to 20 Gbps | Up to 87,500 |
| c6in.xlarge | 4 | 8 GiB | Up to 30 Gbps | Up to 20 Gbps | Up to 87,500 |
| c6in.2xlarge | 8 | 16 GiB | Up to 40 Gbps | Up to 20 Gbps | Up to 87,500 |
| c6in.4xlarge | 16 | 32 GiB | Up to 50 Gbps | Up to 20 Gbps | Up to 87,500 |
| c6in.8xlarge | 32 | 64 GiB | 50 Gbps | 20 Gbps | 87,500 |
| c6in.12xlarge | 48 | 96 GiB | 75 Gbps | 30 Gbps | 131,250 |
| c6in.16xlarge | 64 | 128 GiB | 100 Gbps | 40 Gbps | 175,000 |
| c6in.24xlarge | 96 | 192 GiB | 150 Gbps | 60 Gbps | 262,500 |
| c6in.32xlarge | 128 | 256 GiB | 200 Gbps | 80 Gbps | 350,000 |
The c6in instances are available in the US East (Ohio, N. Virginia), US West (Oregon), and Europe (Ireland) Regions.
As I noted earlier, these instances are designed to be able to handle up to twice as many packets per second (PPS) as their predecessors. This allows them to deliver increased performance in situations where they need to handle a large number of small-ish network packets, which will accelerate many applications and use cases includes network virtual appliances (firewalls, virtual routers, load balancers, and appliances that detect and protect against DDoS attacks), telecommunications (Voice over IP (VoIP) and 5G communication), build servers, caches, in-memory databases, and gaming hosts. With more network bandwidth and PPS on tap, heavy-duty analytics applications that retrieve and store massive amounts of data and objects from Amazon Amazon Simple Storage Service (Amazon S3) or data lakes will benefit. For workloads that benefit from low latency local storage, the disk versions of the new instances offer twice as much instance storage versus previous generation.
New Memory-Optimized (R6in/R6idn) Instances
The first memory-optimized instance was the m2, launched in 2009 with the now-quaint Double Extra Large and Quadruple Extra Large names, and a higher ration of memory to CPU power than the earlier m1 instances. We had yet to learn our naming lesson and launched the High Memory Cluster Eight Extra Large (aka cr1.8xlarge) in 2013, before settling on the r prefix and launching r3 instances in 2013, followed by r4 instances in 2014, and r5 instances in 2018.
And again that brings us to today, and to the new r6in and r6idn instances, also available in 9 sizes:
| Name | vCPUs | Memory | Local Storage (r6idn only) |
Network Bandwidth | EBS Bandwidth | EBS IOPS |
| r6in.large r6idn.large |
2 | 16 GiB | 118 GB | Up to 25 Gbps | Up to 20 Gbps | Up to 87,500 |
| r6in.xlarge r6idn.xlarge |
4 | 32 GiB | 237 GB | Up to 30 Gbps | Up to 20 Gbps | Up to 87,500 |
| r6in.2xlarge r6idn.2xlarge |
8 | 64 GiB | 474 GB | Up to 40 Gbps | Up to 20 Gbps | Up to 87,500 |
| r6in.4xlarge r6idn.4xlarge |
16 | 128 GiB | 950 GB | Up to 50 Gbps | Up to 20 Gbps | Up to 87,500 |
| r6in.8xlarge r6idn.8xlarge |
32 | 256 GiB | 1900 GB | 50 Gbps | 20 Gbps | 87,500 |
| r6in.12xlarge r6idn.12xlarge |
48 | 384 GiB | 2950 GB (2 x 1425) |
75 Gbps | 30 Gbps | 131,250 |
| r6in.16xlarge r6idn.16xlarge |
64 | 512 GiB | 3800 GB (2 x 1900) |
100 Gbps | 40 Gbps | 175,000 |
| r6in.24xlarge r6idn.24xlarge |
96 | 768 GiB | 5700 GB (4 x 1425) |
150 Gbps | 60 Gbps | 262,500 |
| r6in.32xlarge r6idn.32xlarge |
128 | 1024 GiB | 7600 GB (4 x 1900) |
200 Gbps | 80 Gbps | 350,000 |
The r6in and r6idn instances are available in the US East (Ohio, N. Virginia), US West (Oregon), and Europe (Ireland) regions in On-Demand and Spot form. Savings Plans and Reserved Instances are available.
Inside the Instances
As you can probably guess from these specs and from the blog post that I wrote to launch the c6in instances, all of these new instance types have a lot in common. I’ll do a rare cut-and-paste from that post in order to reiterate all of the other cool features that are available to you:
Ice Lake Processors – The 3rd generation Intel Xeon Scalable processors run at 3.5 GHz, and (according to Intel) offer a 1.46x average performance gain over the prior generation. All-core Intel Turbo Boost mode is enabled on all instance sizes up to and including the 12xlarge. On the larger sizes, you can control the C-states. Intel Total Memory Encryption (TME) is enabled, protecting instance memory with a single, transient 128-bit key generated at boot time within the processor.
NUMA – Short for Non-Uniform Memory Access, this important architectural feature gives you the power to optimize for workloads where the majority of requests for a particular block of memory come from one of the processors, and that block is “closer” (architecturally speaking) to one of the processors. You can control processor affinity (and take advantage of NUMA) on the 24xlarge and 32xlarge instances.
Networking – Elastic Network Adapter (ENA) is available on all sizes of m6in, m6idn, c6in, r6in, and r6idn instances, and Elastic Fabric Adapter (EFA) is available on the 32xlarge instances. In order to make use of these adapters, you will need to make sure that your AMI includes the latest NVMe and ENA drivers. You can also make use of Cluster Placement Groups.
io2 Block Express – You can use all types of EBS volumes with these instances, including the io2 Block Express volumes that we launched earlier this year. As Channy shared in his post (Amazon EBS io2 Block Express Volumes with Amazon EC2 R5b Instances Are Now Generally Available), these volumes can be as large as 64 TiB, and can deliver up to 256,000 IOPS. As you can see from the tables above, you can use a 24xlarge or 32xlarge instance to achieve this level of performance.
Choosing the Right Instance
Prior to today’s launch, you could choose a c5n, m5n, or r5n instance to get the highest network bandwidth on an EC2 instance, or an r5b instance to have access to the highest EBS IOPS performance and high EBS bandwidth. Now, customers who need high networking or EBS performance can choose from a full portfolio of instances with different memory to vCPU ratio and instance storage options available, by selecting one of c6in, m6in, m6idn, r6in, or r6idn instances.
The higher performance of the c6in instances will allow you to scale your network intensive workloads that need a low memory to vCPU, such as network virtual appliances, caching servers, and gaming hosts.
The higher performance of m6in instances will allow you to scale your network and/or EBS intensive workloads such as data analytics, and telco applications including 5G User Plane Functions (UPF). You have the option to use the m6idn instance for workloads that benefit from low-latency local storage, such as high-performance file systems, or distributed web-scale in-memory caches.
Similarly, the higher network and EBS performance of the r6in instances will allow you to scale your network-intensive SQL, NoSQL, and in-memory database workloads, with the option to use the r6idn when you need low-latency local storage.
— Jeff;
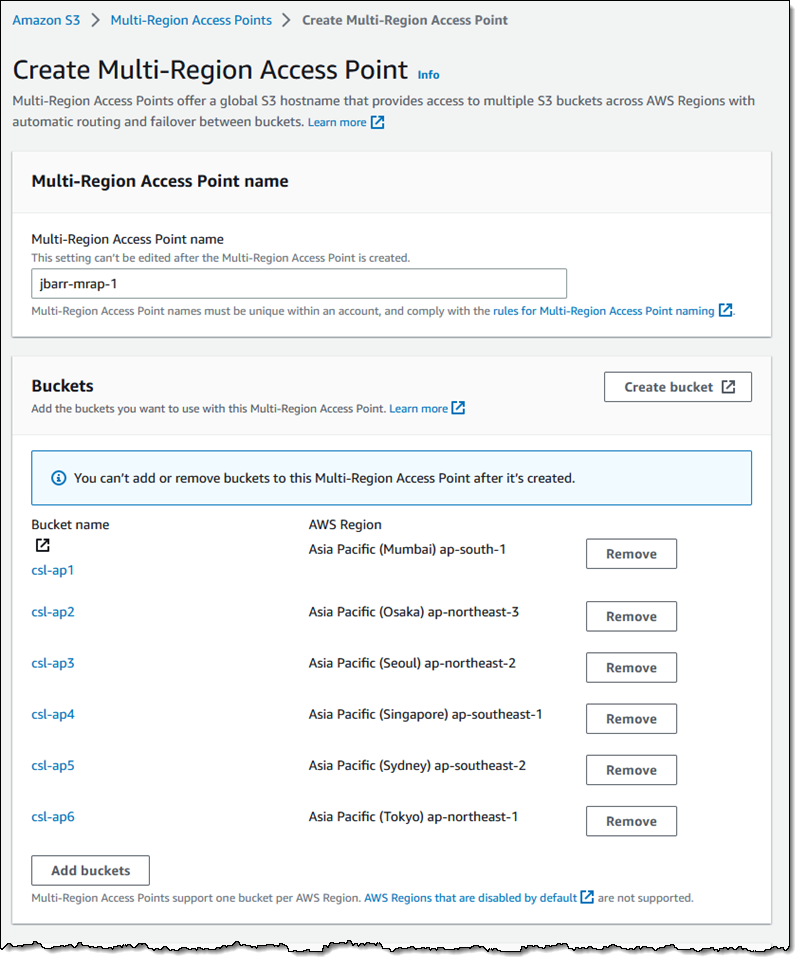



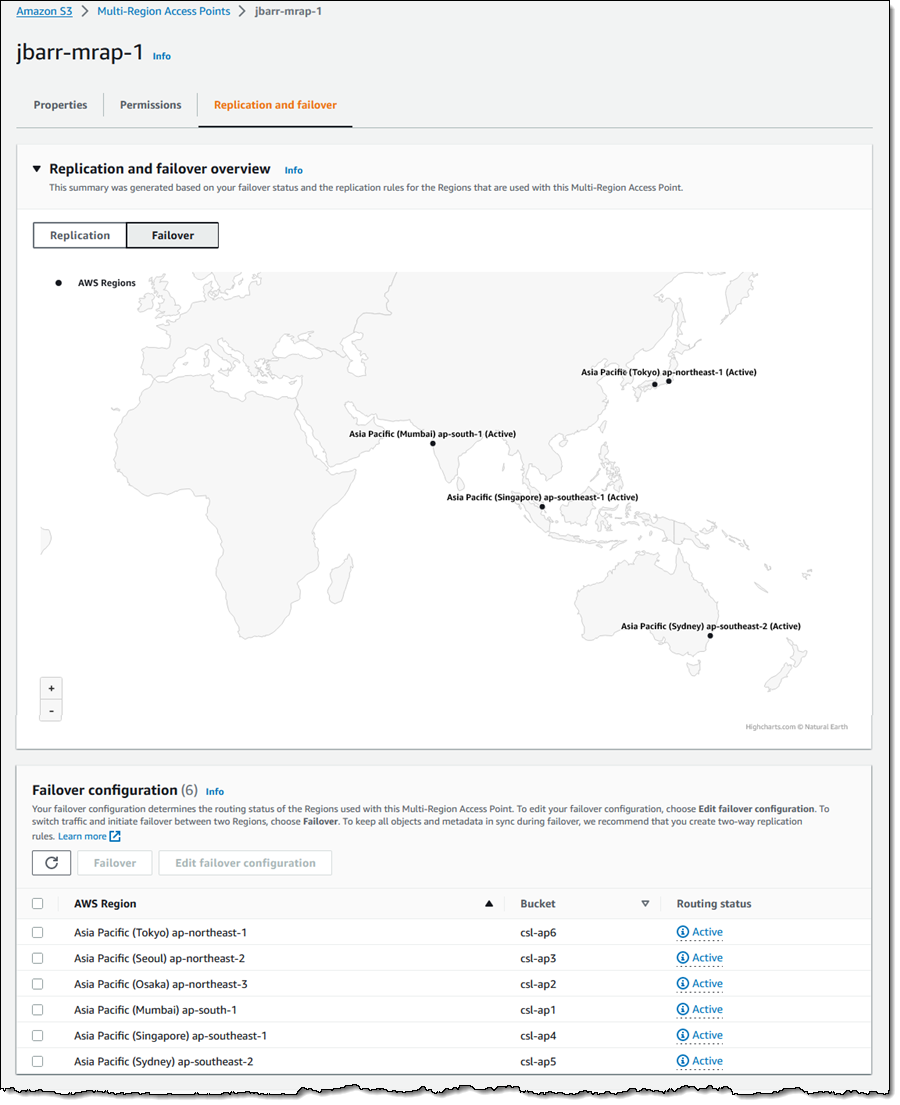




















 Choose Create instance profile and specify your default VPC or a new VPC,
Choose Create instance profile and specify your default VPC or a new VPC,