Post Syndicated from Donnie Prakoso original https://aws.amazon.com/blogs/aws/amazon-q-brings-generative-ai-powered-assistance-to-it-pros-and-developers-preview/
Today, we are announcing the preview of Amazon Q, a new type of generative artificial intelligence (AI) powered assistant that is specifically for work and can be tailored to a customer’s business.
Amazon Q brings a set of capabilities to support developers and IT professionals. Now you can use Amazon Q to get started building applications on AWS, research best practices, resolve errors, and get assistance in coding new features for your applications. For example, Amazon Q Code Transformation can perform Java application upgrades now, from version 8 and 11 to version 17.
Amazon Q is available in multiple areas of AWS to provide quick access to answers and ideas wherever you work. Here’s a quick look at Amazon Q, including in integrated development environment (IDE):

Building applications together with Amazon Q
Application development is a journey. It involves a continuous cycle of researching, developing, deploying, optimizing, and maintaining. At each stage, there are many questions—from figuring out the right AWS services to use, to troubleshooting issues in the application code.
Trained on 17 years of AWS knowledge and best practices, Amazon Q is designed to help you at each stage of development with a new experience for building applications on AWS. With Amazon Q, you minimize the time and effort you need to gain the knowledge required to answer AWS questions, explore new AWS capabilities, learn unfamiliar technologies, and architect solutions that fuel innovation.
Let us show you some capabilities of Amazon Q.
1. Conversational Q&A capability
You can interact with the Amazon Q conversational Q&A capability to get started, learn new things, research best practices, and iterate on how to build applications on AWS without needing to shift focus away from the AWS console.
To start using this feature, you can select the Amazon Q icon on the right-hand side of the AWS Management Console.
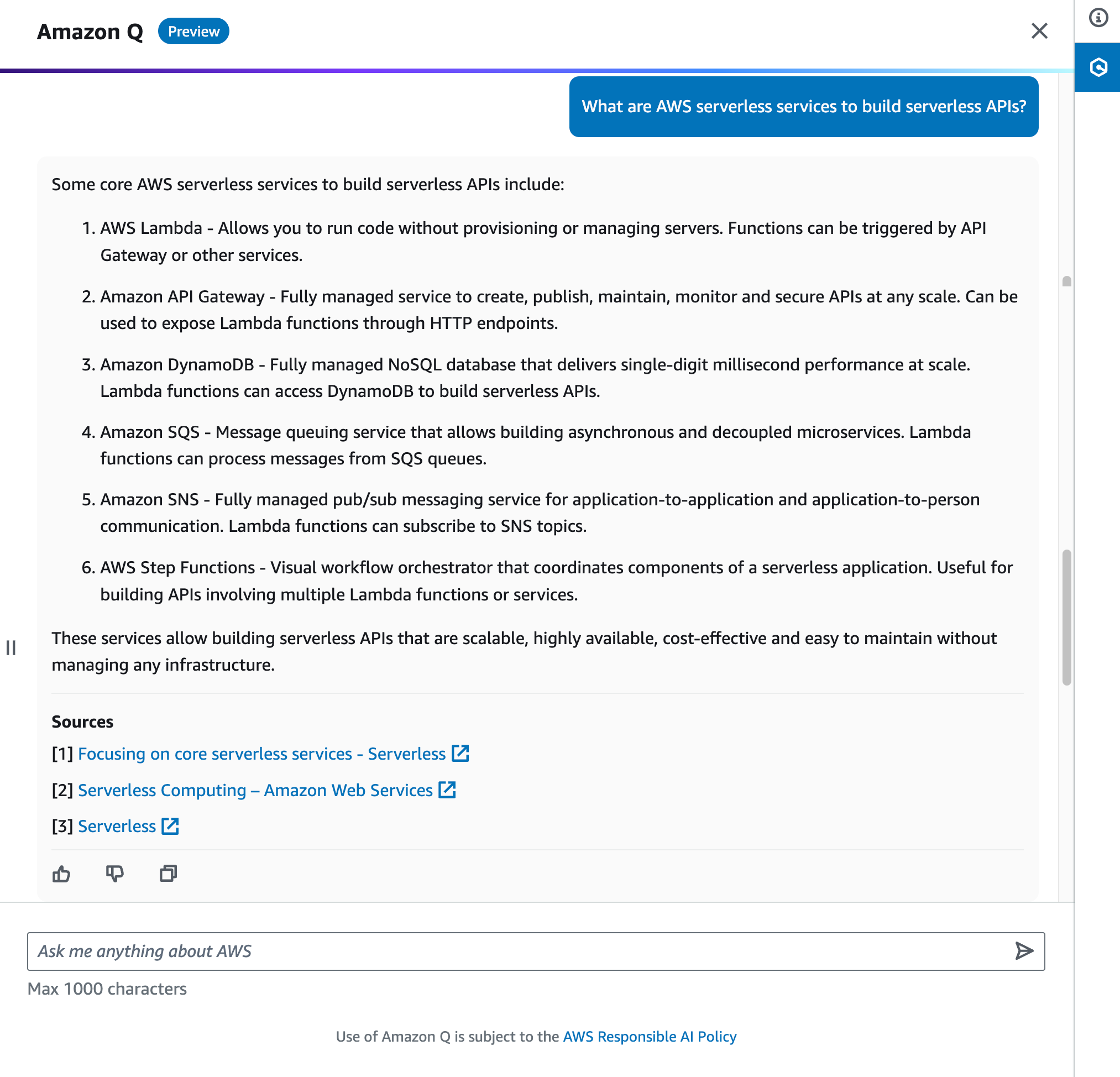
For example, you can ask, “What are AWS serverless services to build serverless APIs?” Amazon Q provides concise explanations along with references you can use to follow up on your questions and validate the guidance. You can also use Amazon Q to follow up on and iterate your questions. Amazon Q will show more deep-dive answers for you with references.
There are times when we have questions for a use case with fairly specific requirements. With Amazon Q, you can elaborate on your use cases in more detail to provide context.
For example, you can ask Amazon Q, “I’m planning to create serverless APIs with 100k requests/day. Each request needs to lookup into the database. What are the best services for this workload?” Amazon Q responds with a list of AWS services you can use and tries to limit the answer results to those that are accurately referenceable and verified with best practices.
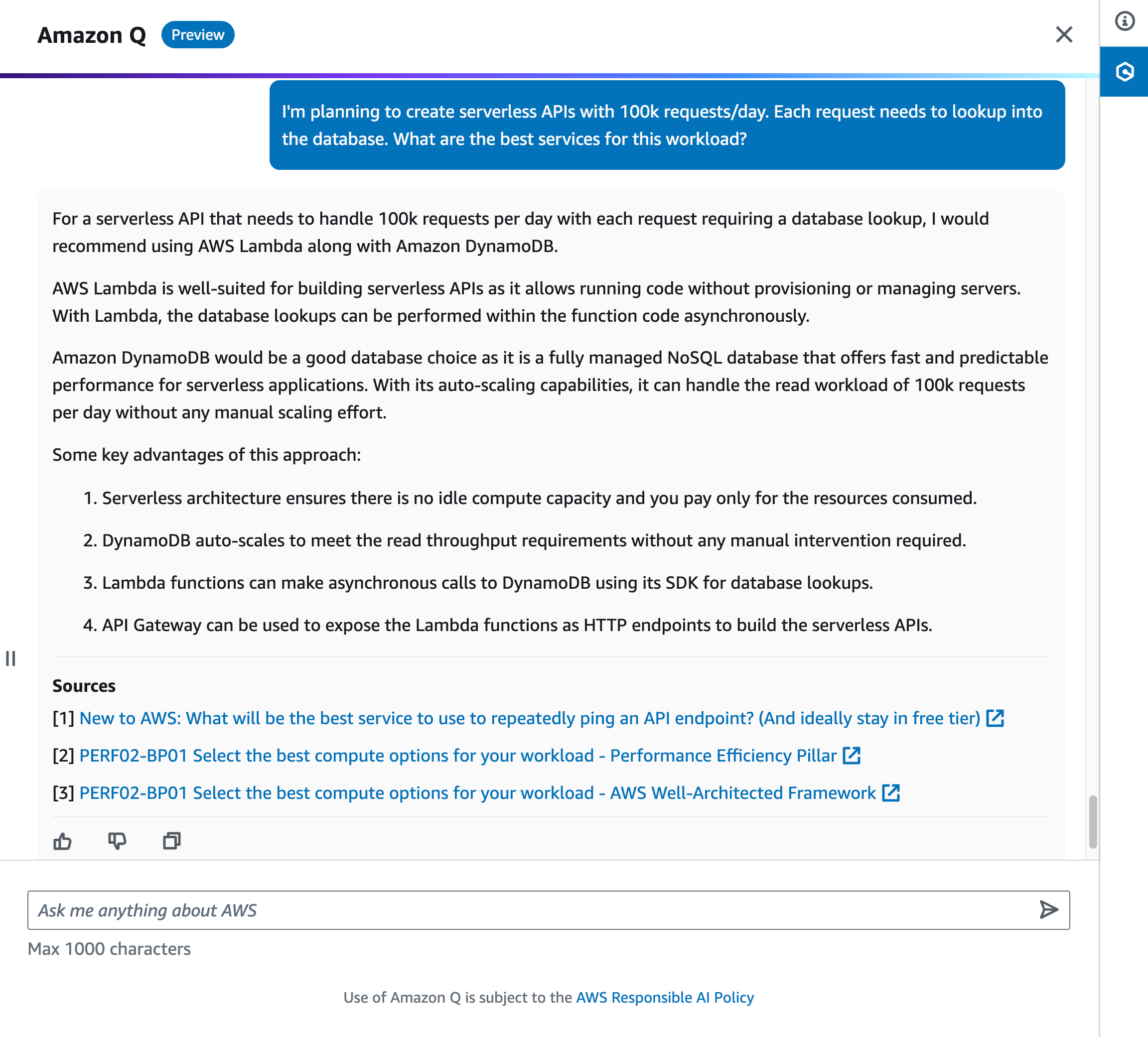
Here is some additional information that you might want to note:
- Amazon Q conversational Q&A capability is currently in preview in all commercial AWS Regions.
- This capability is integrated into the AWS Management Console, AWS Console Mobile Application, AWS Documentation, AWS websites, and Slack and Teams through AWS Chatbot, making it more convenient and easier to find what you need.
2. Optimize Amazon EC2 instance selection
Choosing the right Amazon Elastic Compute Cloud (Amazon EC2) instance type for your workload can be challenging with all the options available. Amazon Q aims to make this easier by providing personalized recommendations.
To use this feature, you can ask Amazon Q, “Which instance families should I use to deploy a Web App Server for hosting an application?” This feature is also available when you choose to launch an instance in the Amazon EC2 console. In Instance type, you can select Get advice on instance type selection. This will show a dialog to define your requirements.
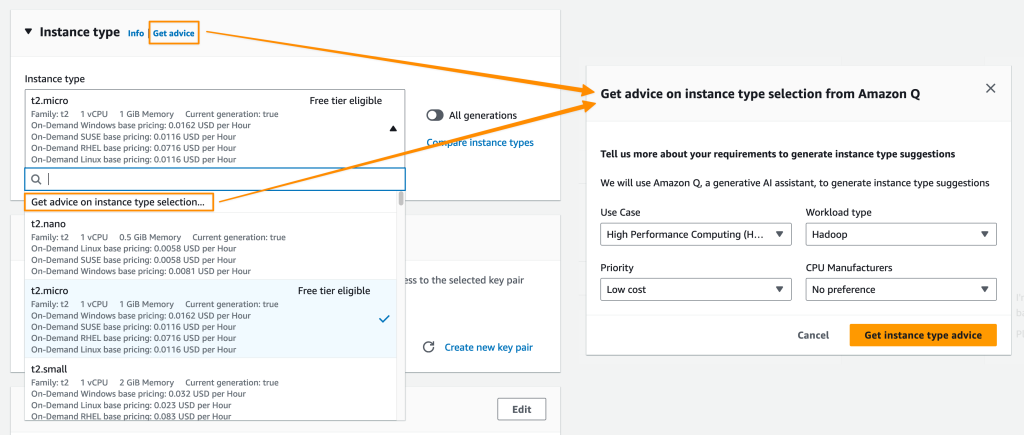
Your requirements are automatically translated into a prompt on the Amazon Q chat panel. Amazon Q returns with a list of suggestions of EC2 instances that are suitable for your use cases. This capability helps you pick the right instance type and settings so your workloads will run smoothly and more cost-efficiently.

This capability to provide EC2 instance type recommendations based on your use case is available in preview in all commercial AWS Regions.
3. Troubleshoot and solve errors directly in the console
Amazon Q can also help you to solve errors for various AWS services directly in the console. With Amazon Q proposed solutions, you can avoid slow manual log checks or research.
Let’s say that you have an AWS Lambda function that tries to interact with an Amazon DynamoDB table. But, for an unknown reason (yet), it fails to run. Now, with Amazon Q, you can troubleshoot and resolve this issue faster by selecting Troubleshoot with Amazon Q.

Amazon Q provides concise analysis of the error which helps you to understand the root cause of the problem and the proposed resolution. With this information, you can follow the steps described by Amazon Q to fix the issue.

In just a few minutes, you will have the solution to solve your issues, saving significant time without disrupting your development workflow. The Amazon Q capability to help you troubleshoot errors in the console is available in preview in the US West (Oregon) for Amazon Elastic Compute Cloud (Amazon EC2), Amazon Simple Storage Service (Amazon S3), Amazon ECS, and AWS Lambda.
4. Network troubleshooting assistance
You can also ask Amazon Q to assist you in troubleshooting network connectivity issues caused by network misconfiguration in your current AWS account. For this capability, Amazon Q works with Amazon VPC Reachability Analyzer to check your connections and inspect your network configuration to identify potential issues.
This makes it easy to diagnose and resolve AWS networking problems, such as “Why can’t I SSH to my EC2 instance?” or “Why can’t I reach my web server from the Internet?” which you can ask Amazon Q.

Then, on the response text, you can select preview experience here, which will provide explanations to help you to troubleshoot network connectivity-related issues.
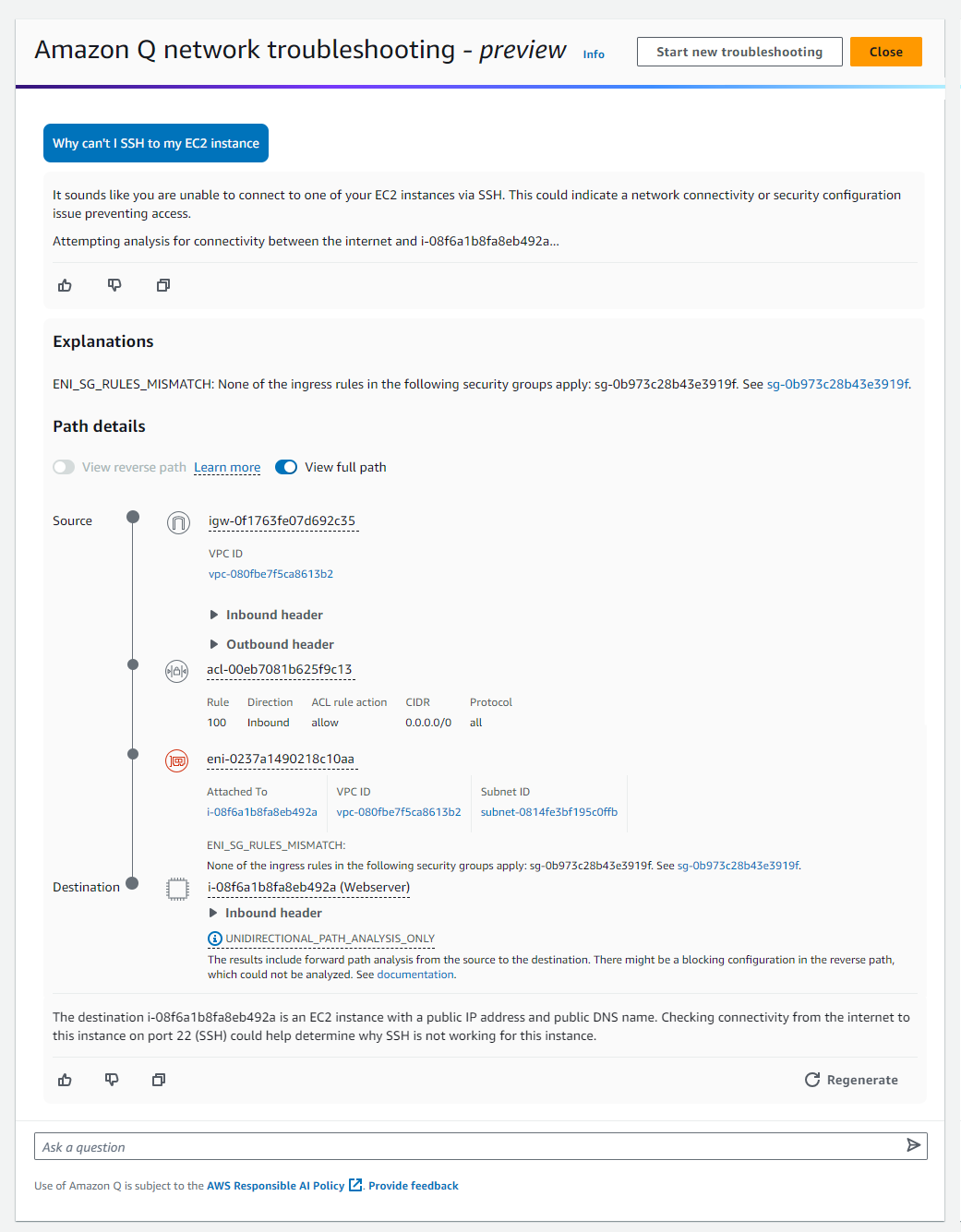
Here are a few things you need to know:
- This capability is currently available in preview in the US East (N. Virginia).
- To learn more about the feature and sample questions, see Getting started with Amazon Q network troubleshooting in the AWS Documentation.
5. Integration and conversational capabilities within your IDEs
As we mentioned, Amazon Q is also available in supported IDEs. This allows you to ask questions and get help within your IDE by chatting with Amazon Q or invoking actions by typing / in the chat box.
To get started, you need to install or update the latest AWS Toolkit and sign in to Amazon CodeWhisperer. Once you’re signed in to Amazon CodeWhisperer, it will automatically activate the Amazon Q conversational capability in the IDE. With Amazon Q enabled, you can now start chatting to get coding assistance.
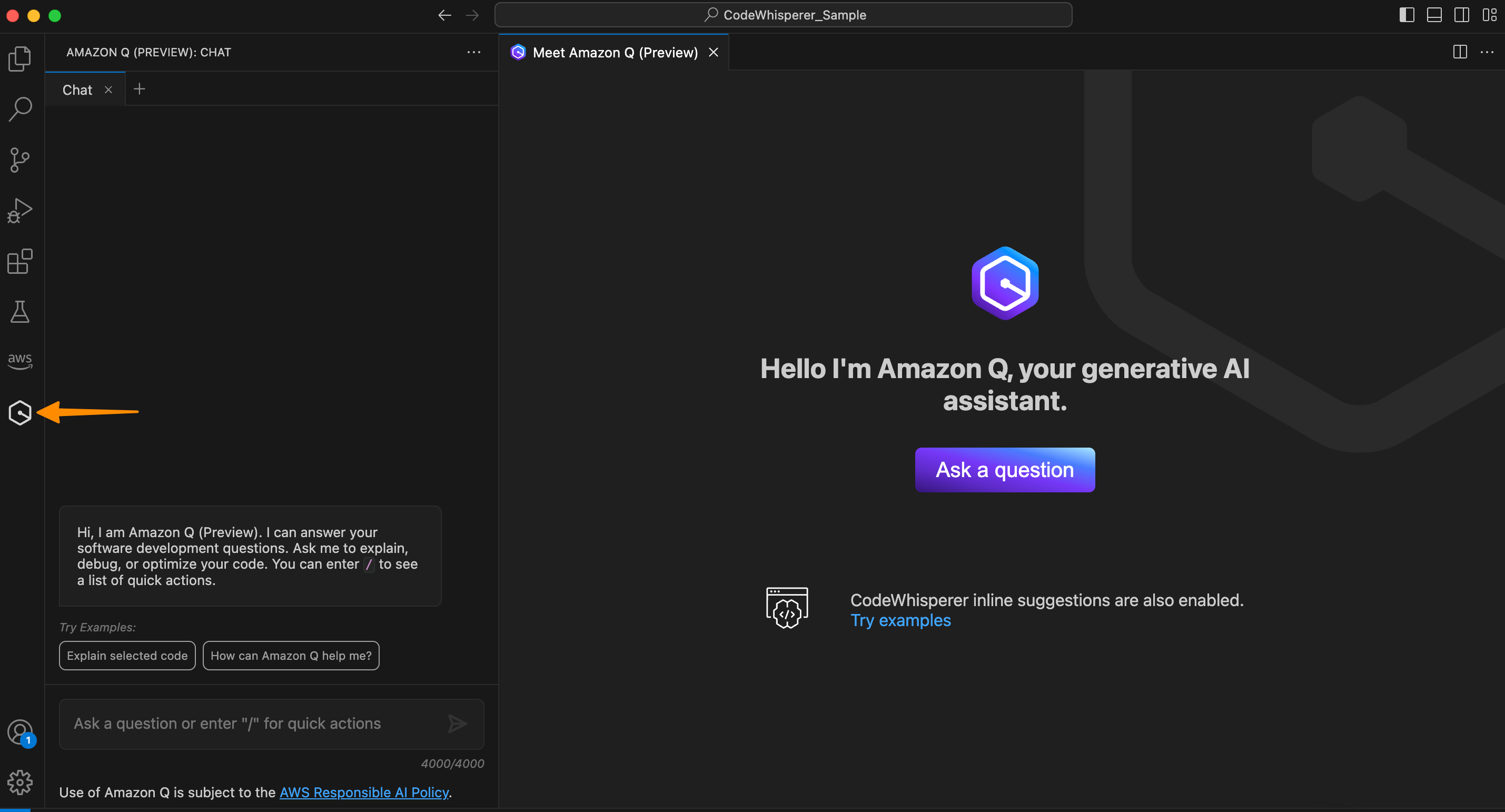
You can ask Amazon Q to describe your source code file.

From here, you can improve your application, for example, by integrating it with Amazon DynamoDB. You can ask Amazon Q, “Generate code to save data into DynamoDB table called save_data() accepting data parameter and return boolean status if the operation successfully runs.”
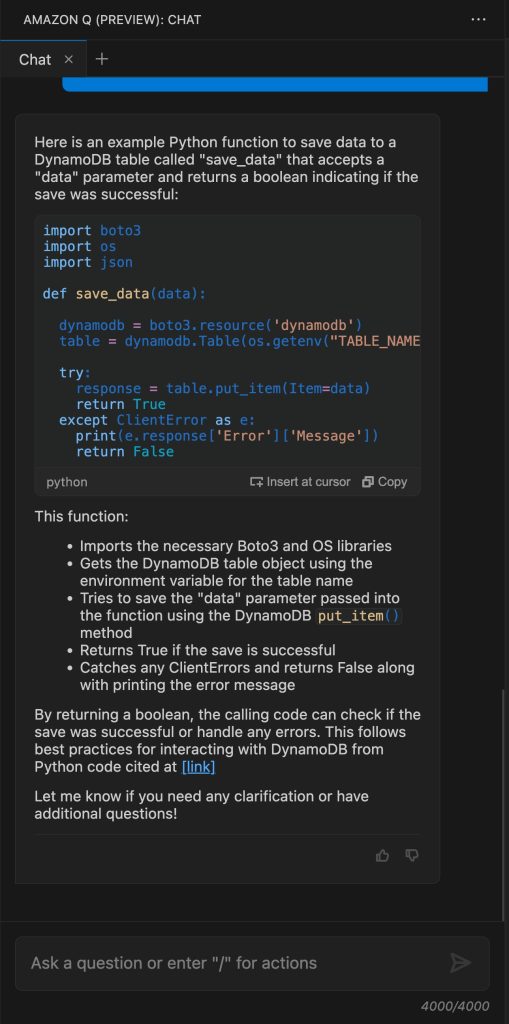
Once you’ve reviewed the generated code, you can do a manual copy and paste into the editor. You can also select Insert at cursor to place the generated code into the source code directly.
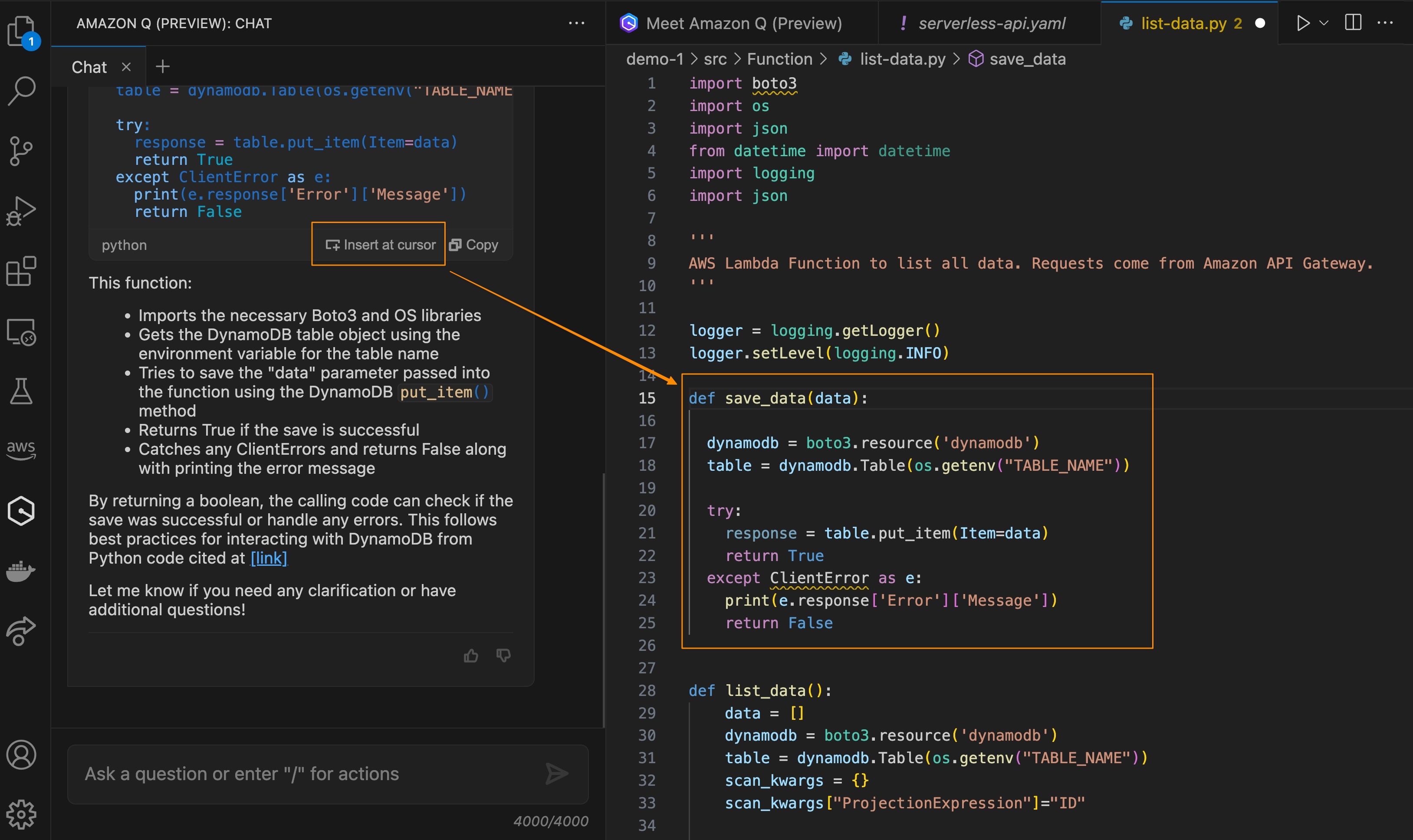
This feature makes it really easy to help you focus on building applications because you don’t have to leave your IDE to get answers and context-specific coding guidance. You can try the preview of this feature in Visual Studio Code and JetBrains IDEs.
6. Feature development capability
Another exciting feature that Amazon Q provides is guiding you interactively from idea to building new features within your IDE and Amazon CodeCatalyst. You can go from a natural language prompt to application features in minutes, with interactive step-by-step instructions and best practices, right from your IDE. With a prompt, Amazon Q will attempt to understand your application structure and break down your prompt into logical, atomic implementation steps.
To use this capability, you can start by invoking an action command /dev in Amazon Q and describe the task you need Amazon Q to process.
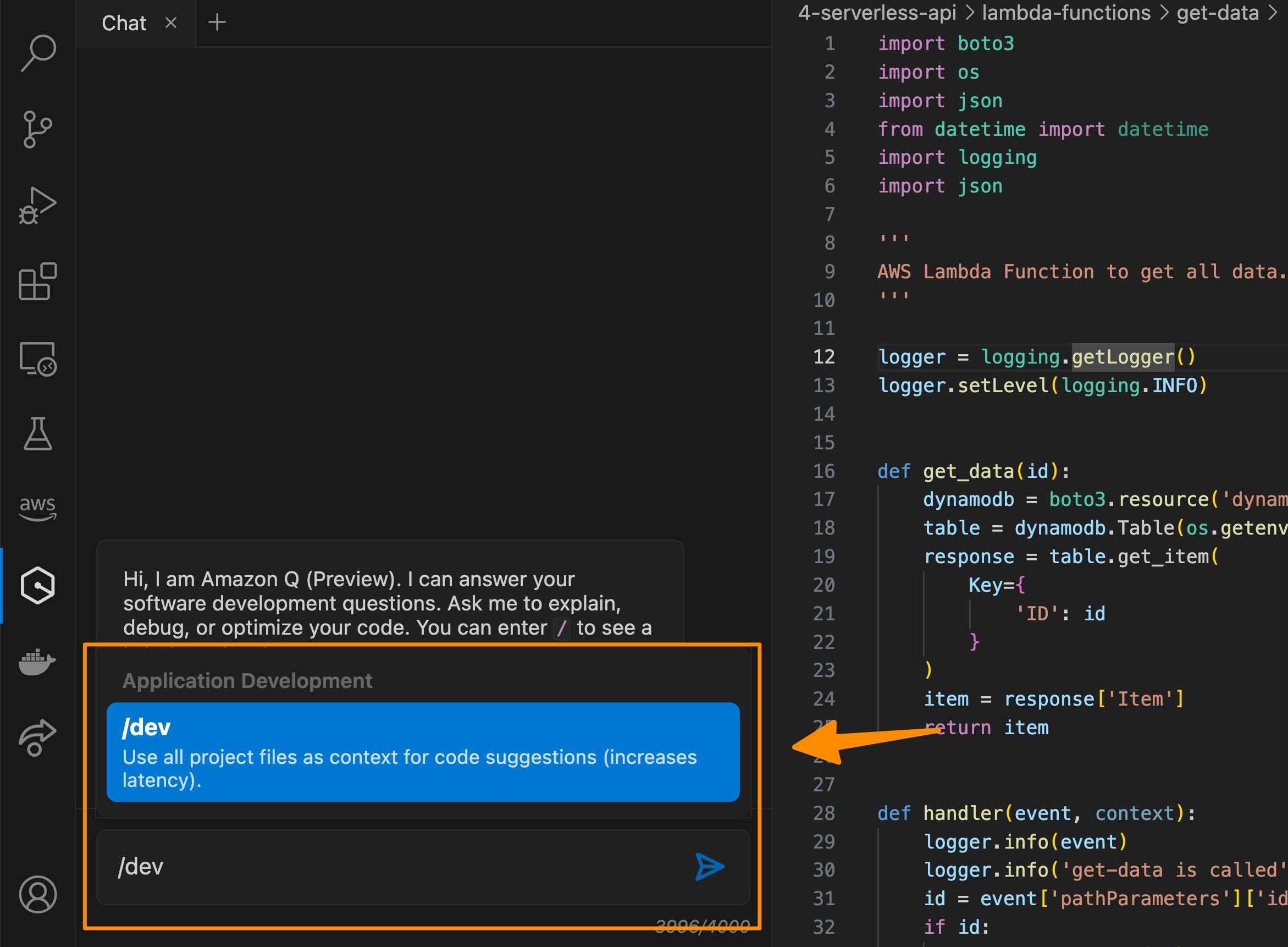
Then, from here, you can review, collaborate and guide Amazon Q in the chat for specific areas that need to be implemented.
Additional capabilities to help you ship features faster with complete pull requests are available if you’re using Amazon CodeCatalyst. In Amazon CodeCatalyst, you can assign a new or an existing issue to Amazon Q, and it will process an end-to-end development workflow for you. Amazon Q will review the existing code, propose a solution approach, seek feedback from you on the approach, generate merge-ready code, and publish a pull request for review. All you need to do after is to review the proposed solutions from Amazon Q.
The following screenshots show a pull request created by Amazon Q in Amazon CodeCatalyst.
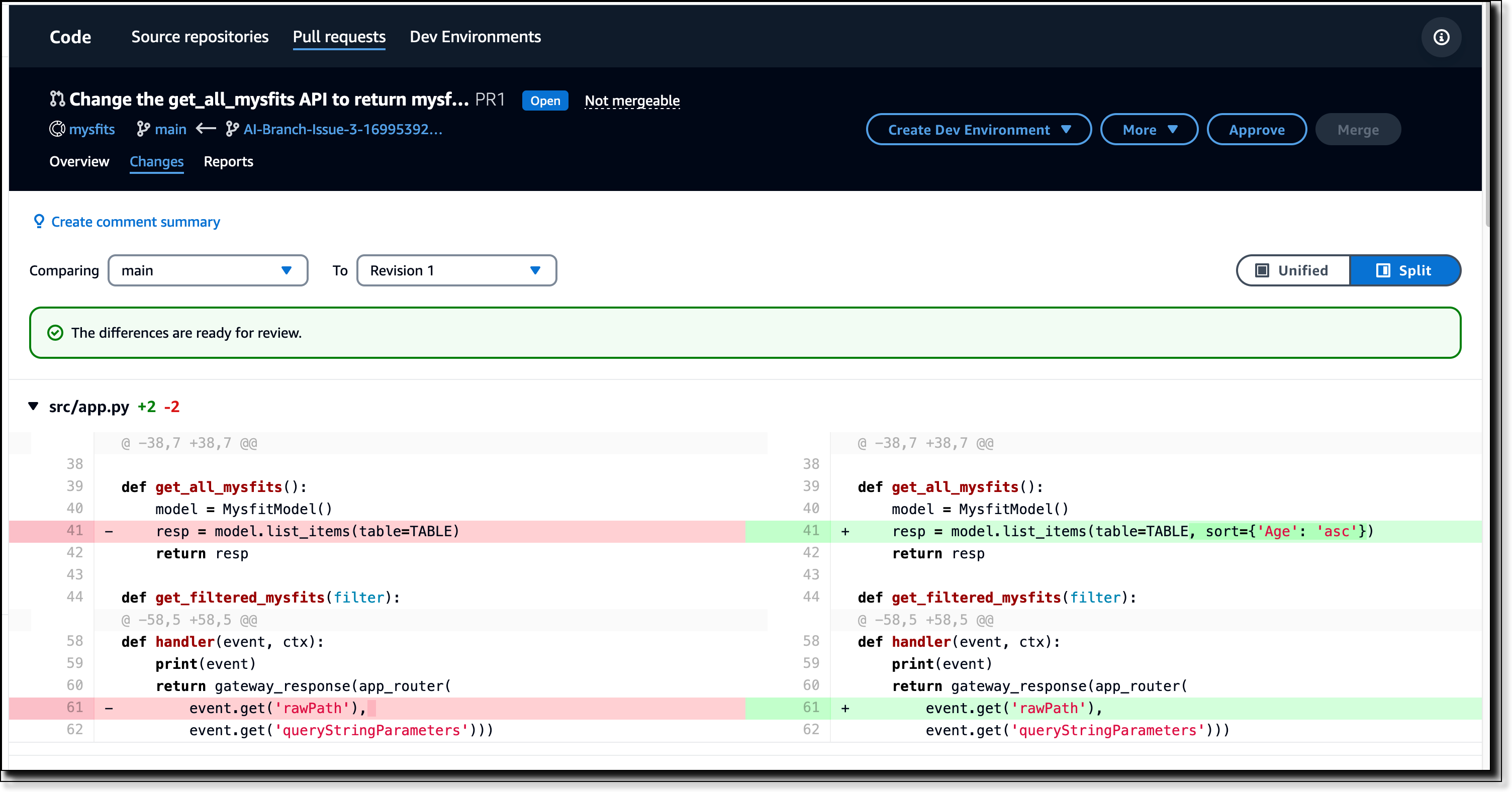
Here are a couple of things that you should know:
- Amazon Q feature development capability is currently in preview in Visual Studio Code and Amazon CodeCatalyst
- To use this capability in IDE, you need to have the Amazon CodeWhisperer Professional tier. Learn more on the Amazon CodeWhisperer pricing page.
7. Upgrade applications with Amazon Q Code Transformation
With Amazon Q, you can now upgrade an entire application within a few hours by starting a guided code transformation. This capability, called Amazon Q Code Transformation, simplifies maintaining, migrating, and upgrading your existing applications.
To start, navigate to the CodeWhisperer section and then select Transform. Amazon Q Code Transformation automatically analyzes your existing codebase, generates a transformation plan, and completes the key transformation tasks suggested by the plan.
![]()
Some additional information about this feature:
- Amazon Q Code Transformation is available in preview today in the AWS Toolkit for IntelliJ IDEA and the AWS Toolkit for Visual Studio Code.
- To use this capability, you need to have the Amazon CodeWhisperer Professional tier during the preview.
- During preview, you can can upgrade Java 8 and 11 applications to version 17, a Java Long-Term Support (LTS) release.
Get started with Amazon Q today
With Amazon Q, you have an AI expert by your side to answer questions, write code faster, troubleshoot issues, optimize workloads, and even help you code new features. These capabilities simplify every phase of building applications on AWS.
Amazon Q lets you engage with AWS Support agents directly from the Q interface if additional assistance is required, eliminating any dead ends in the customer’s self-service experience. The integration with AWS Support is available in the console and will honor the entitlements of your AWS Support plan.
Learn more
















 I’m happy to be able to tell you about the latest in our series of innovative
I’m happy to be able to tell you about the latest in our series of innovative





 3. Access to cutting-edge capabilities
3. Access to cutting-edge capabilities