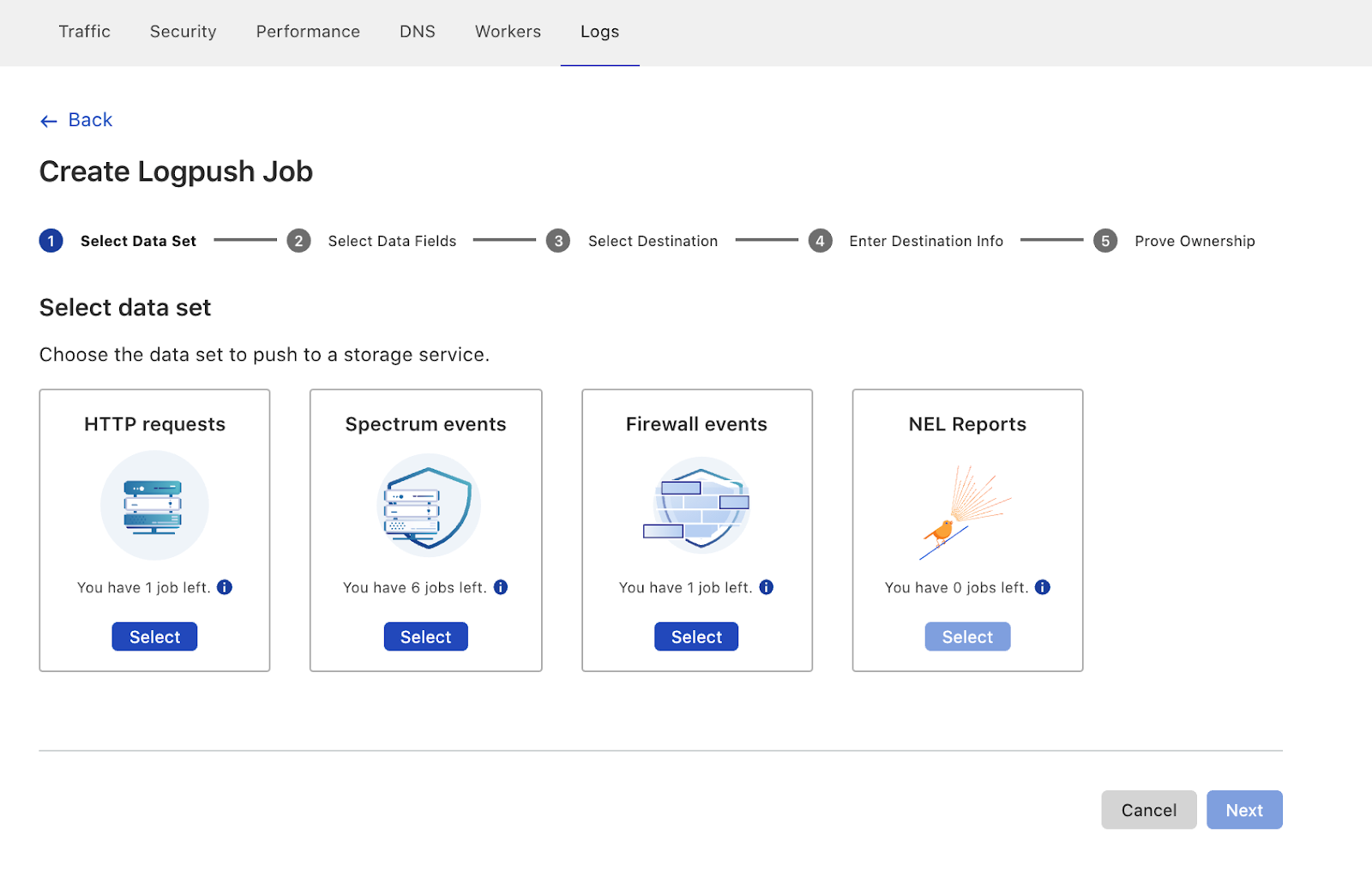
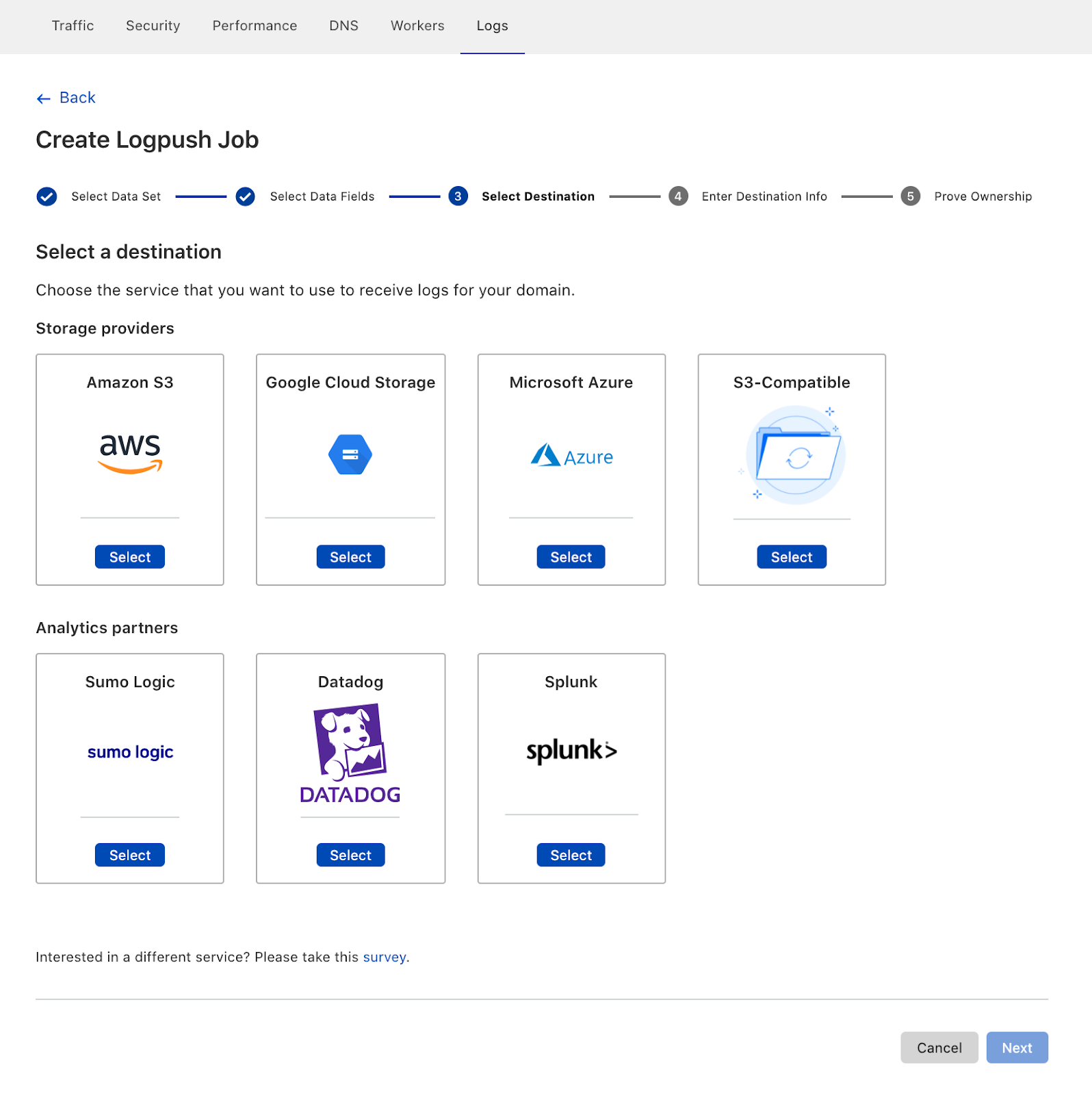
Today, we are excited to share that Cloudflare and Accenture Federal Services (AFS) have been selected by the Department of Homeland Security (DHS) to develop a joint solution to help the federal government defend itself against cyberattacks. The solution consists of Cloudflare’s protective DNS resolver which will filter DNS queries from offices and locations of the federal government and stream events directly to Accenture’s analysis platform.
Located within DHS, the Cybersecurity and Infrastructure Security Agency (CISA) operates as “the nation’s risk advisor.”1 CISA works with partners across the public and private sector to improve the security and reliability of critical infrastructure; a mission that spans across the federal government, State, Local, Tribal, and Territorial partnerships and the private sector to provide solutions to emerging and ever-changing threats.
Over the last few years, CISA has repeatedly flagged the cyber risk posed by malicious hostnames, phishing emails with malicious links, and untrustworthy upstream Domain Name System (DNS) resolvers.2 Attackers can compromise devices or accounts, and ultimately data, by tricking a user or system into sending a DNS query for a specific hostname. Once that query is resolved, those devices establish connections that can lead to malware downloads, phishing websites, or data exfiltration.
In May 2021, CISA and the National Security Agency (NSA) proposed that teams deploy protective DNS resolvers to prevent those attacks from becoming incidents. Unlike standard DNS resolvers, protective DNS resolvers check the hostname being resolved to determine if the destination is malicious. If that is the case, or even if the destination is just suspicious, the resolver can stop answering the DNS query and block the connection.
Earlier this year, CISA announced they are not only recommending a protective DNS resolver — they have launched a program to offer a solution to their partners. After a thorough review process, CISA has announced that they have selected Cloudflare and AFS to deliver a joint solution that can be used by departments and agencies of any size within the Federal Civilian Executive Branch.
Helping keep governments safer
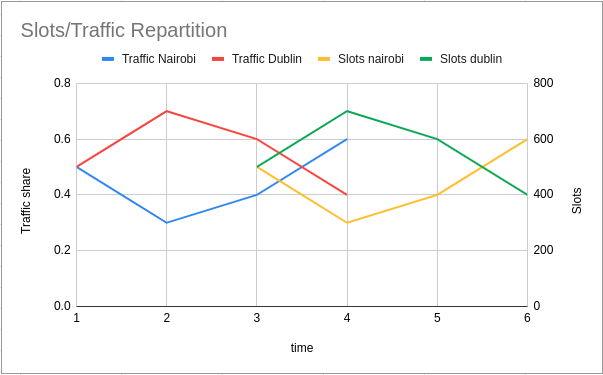
Attacks against the critical infrastructure in the United States are continuing to increase. Cloudflare Radar, where we publish insights from our global network, consistently sees the U.S. as one of the most targeted countries for DDoS attacks. Attacks like phishing campaigns compromise credentials to sensitive systems. Ransomware bypasses traditional network perimeters and shuts down target systems.
The sophistication of those attacks also continues to increase. Last year’s SolarWinds Orion compromise represents a new type of supply chain attack where trusted software becomes the backdoor for data breaches. Cloudflare’s analysis of the SolarWinds incident observed compromise patterns that were active over eight months, during which the destinations used grew to nearly 5,000 unique subdomains.
The increase in volume and sophistication has driven a demand for the information and tools to defend against these types of threats at all levels of the US government. Last year, CISA advised over 6,000 state and local officials, as well as federal partners, on mechanisms to protect their critical infrastructure.
At Cloudflare, we have observed a similar pattern. In 2017, Cloudflare launched the Athenian Project to provide state, county, or municipal governments with security for websites that administer elections or report results. In 2020, 229 state and local governments, in 28 states, trusted Cloudflare to help defend their election websites. State and local government websites served by Cloudflare’s Athenian Project increased by 48% last year.
As these attacks continue to evolve, one thing many have in common is their use of a DNS query to a malicious hostname. From SolarWinds to last month’s spearphishing attack against the U.S. Agency for International Development, attackers continue to rely on one of the most basic technologies used when connecting to the Internet.
Delivering a protective DNS resolver
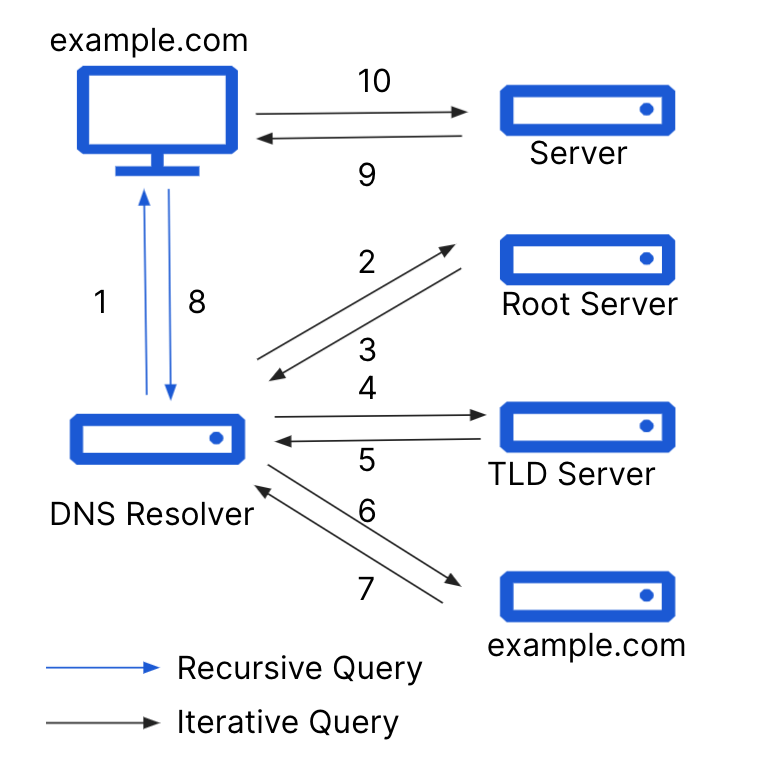
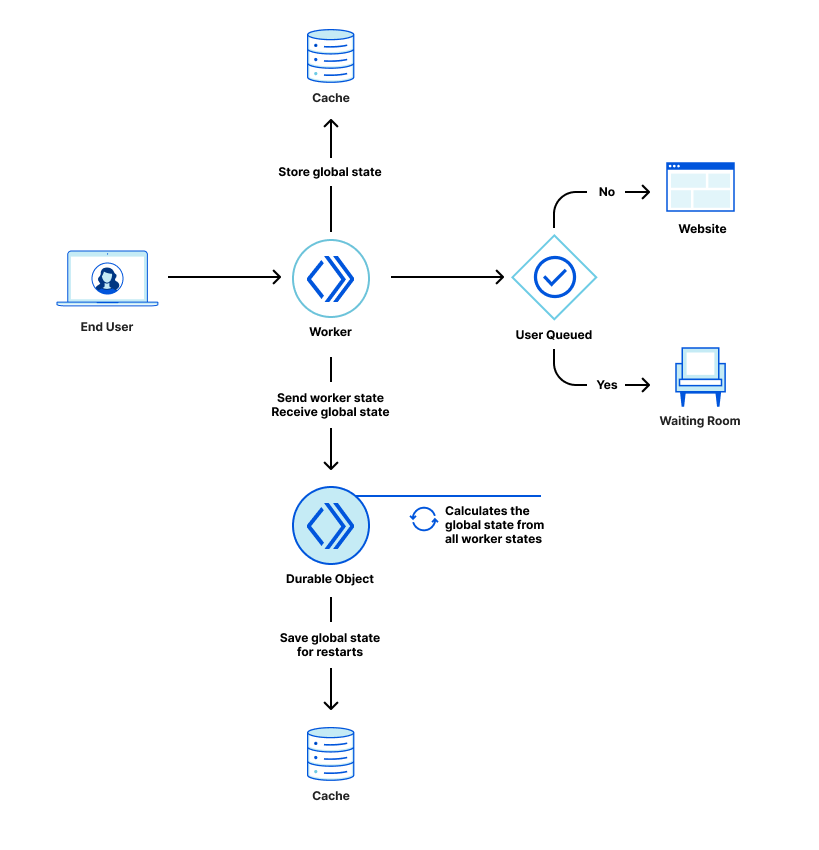
User activity on the Internet typically starts with a DNS query to a DNS resolver. When users visit a website in their browser, open a link in an email, or use a mobile application, their device first sends a DNS query to convert the domain name of the website or server into the Internet Protocol (IP) address of the host serving that site. Once their device has the IP address, they can establish a connection.
Figure 1. Complete DNS lookup and web page query
Attacks on the Internet can also start the same way. Devices that download malware begin making DNS queries to establish connections and leak information. Users that visit an imposter website input their credentials and become part of a phishing attack.
These attacks are successful because DNS resolvers, by default, trust all destinations. If a user sends a DNS query for any hostname, the resolver returns the IP address without determining if that destination is suspicious.
Some hostnames are known to security researchers, including hostnames used in previous attacks or ones that use typos of popular hostnames. Other attacks start from unknown or new threats. Detecting those requires monitoring DNS query behavior, detecting patterns to new hostnames, or blocking newly seen and registered domains altogether.
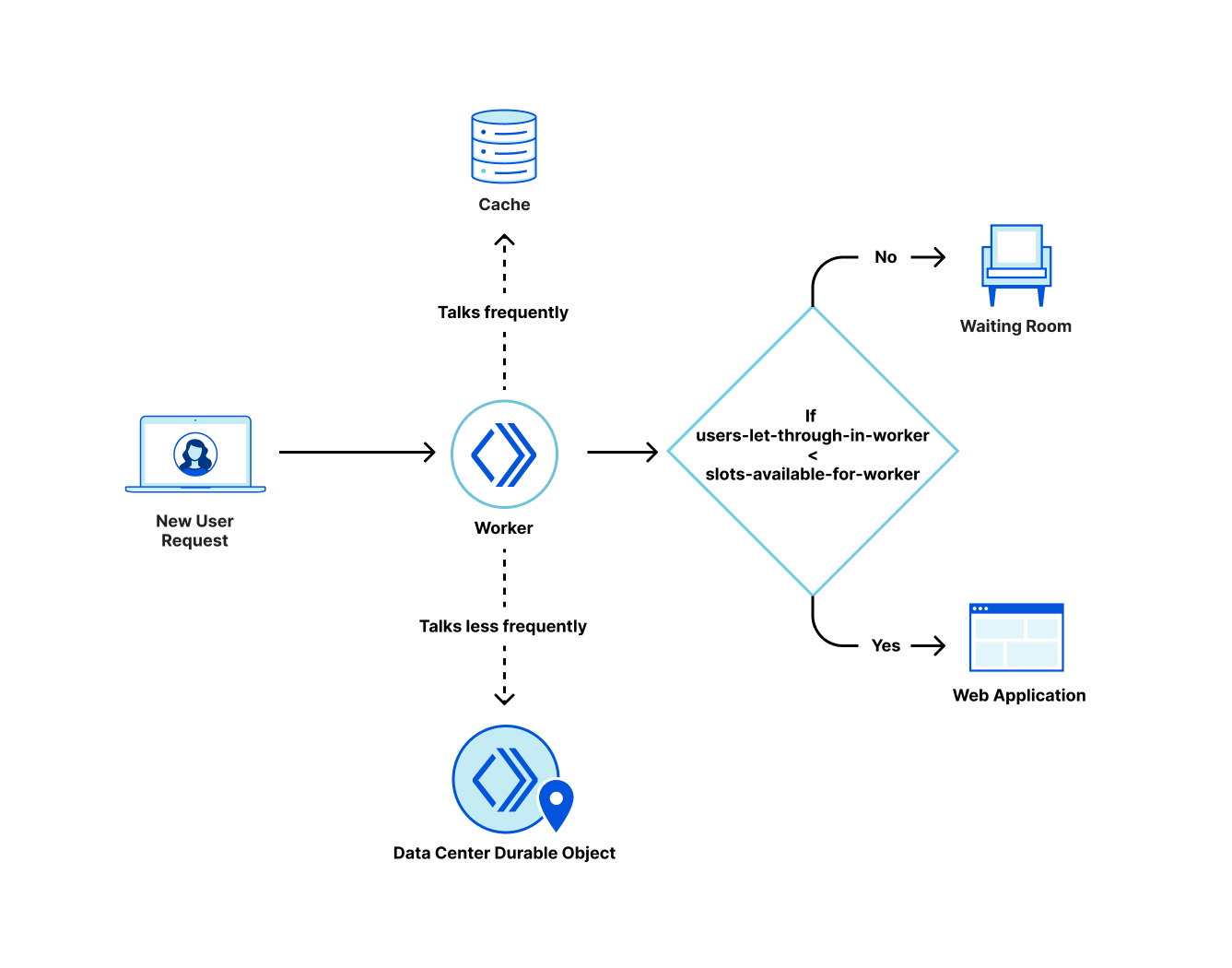
Protective DNS resolvers apply a Zero Trust model to DNS queries. Instead of trusting any destination, protective resolvers check the hostname of every query and IP address of every response against a list of known malicious destinations. If the hostname or IP address is in that list, the resolver will not return the result to the user and the connection will fail.
Building a solution with Accenture Federal Services
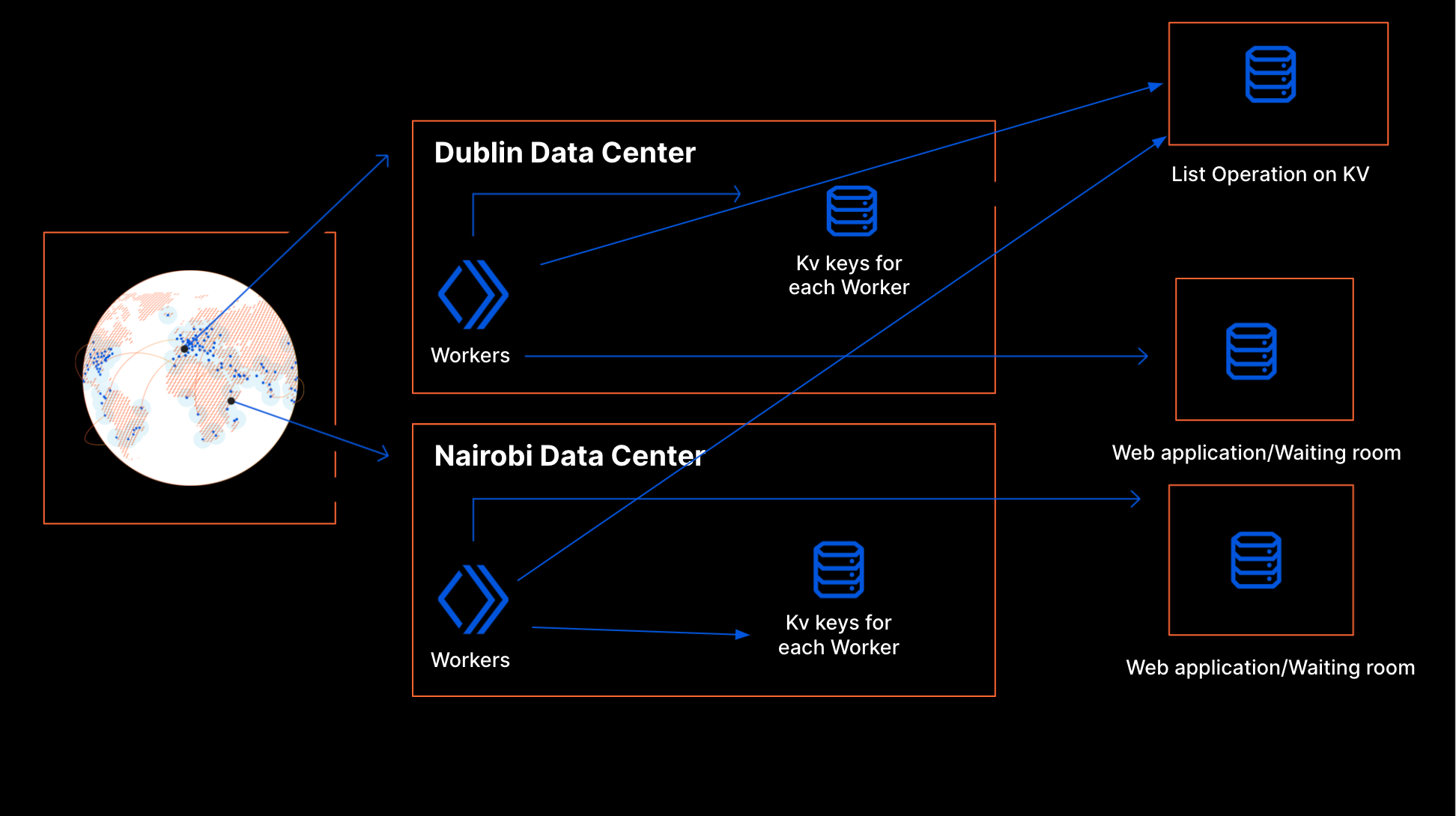
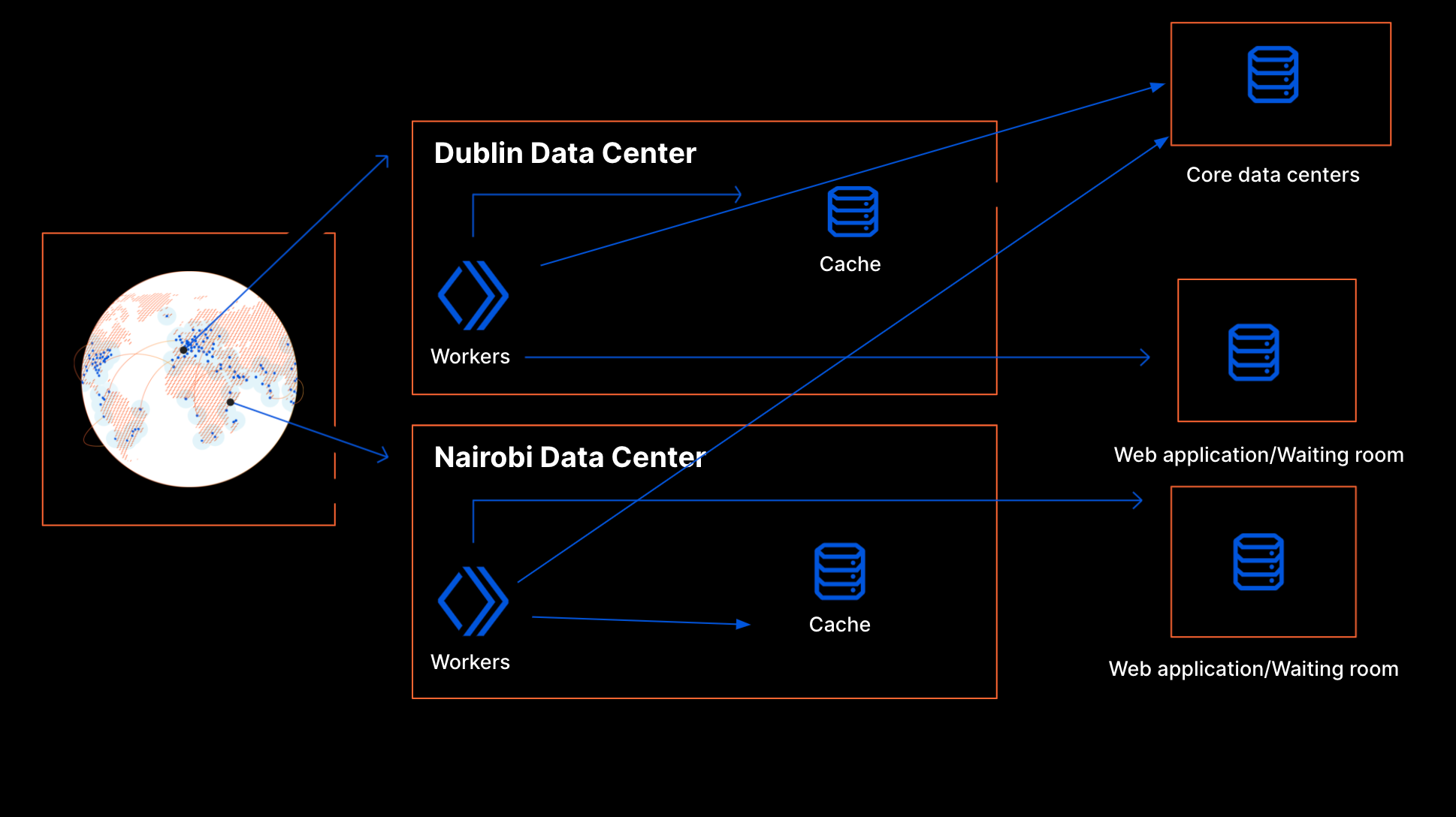
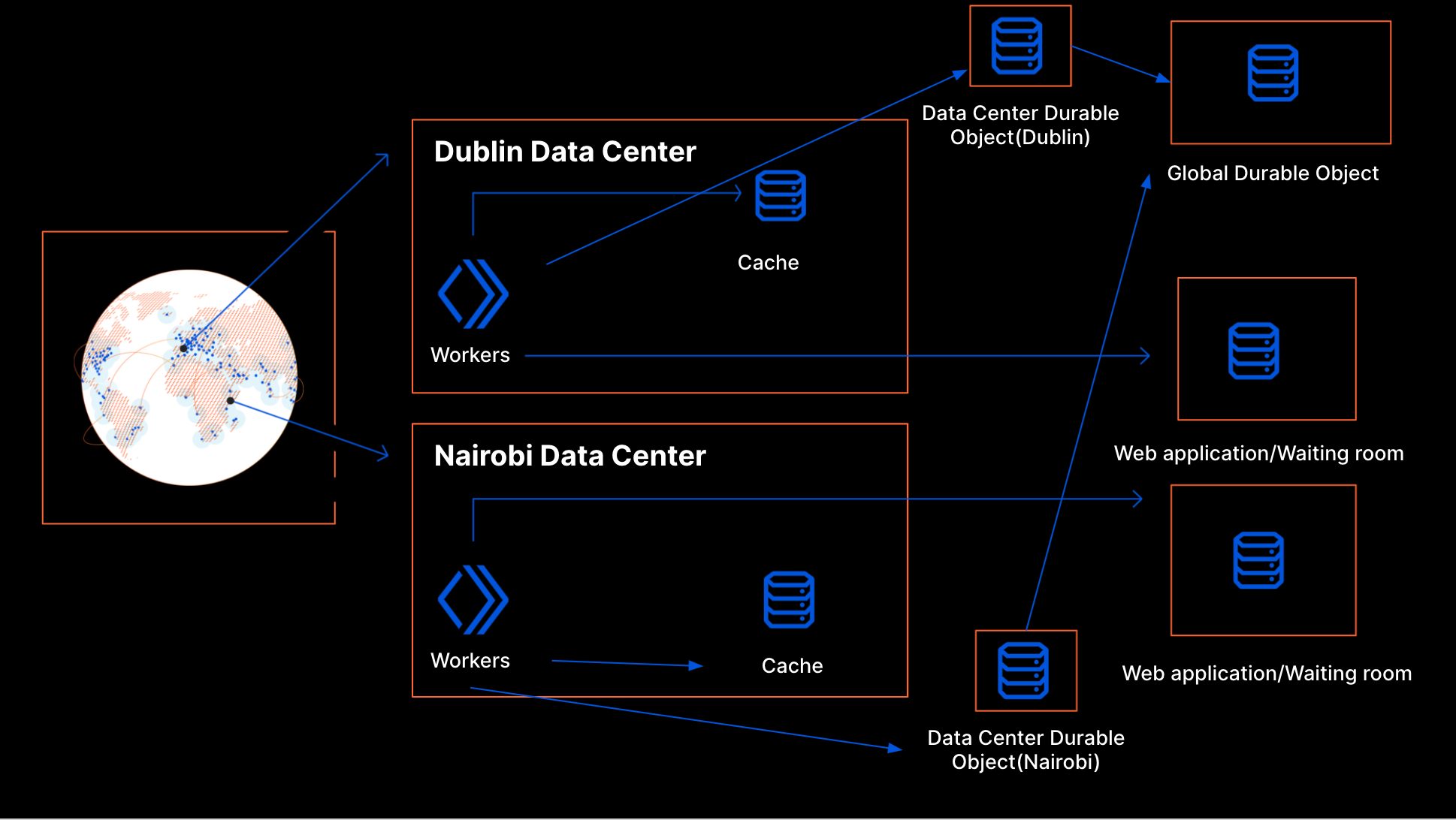
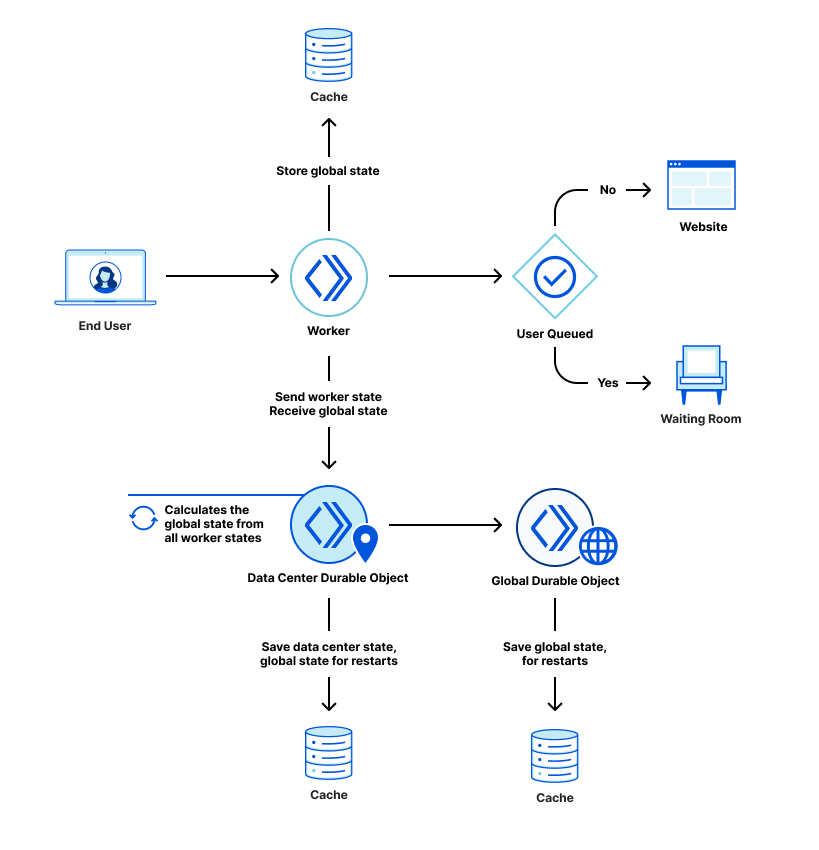
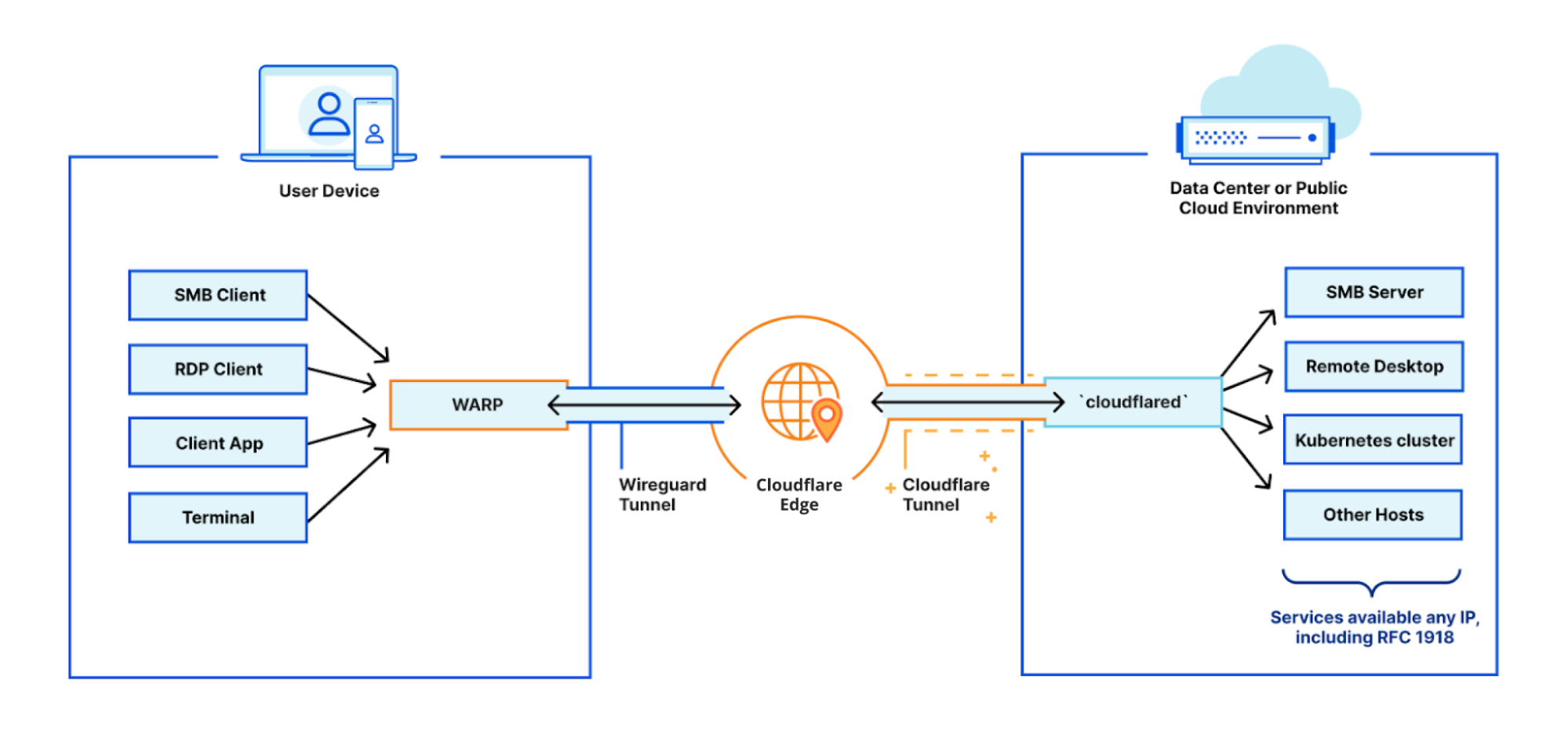
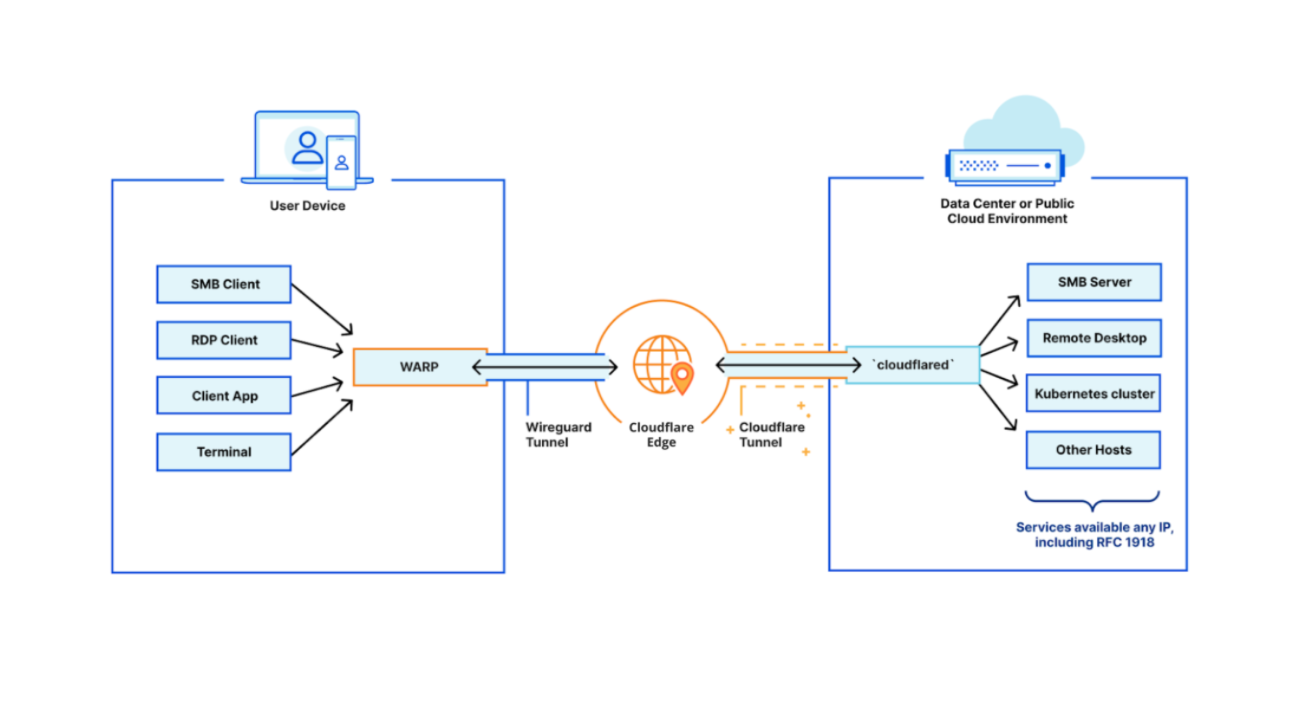
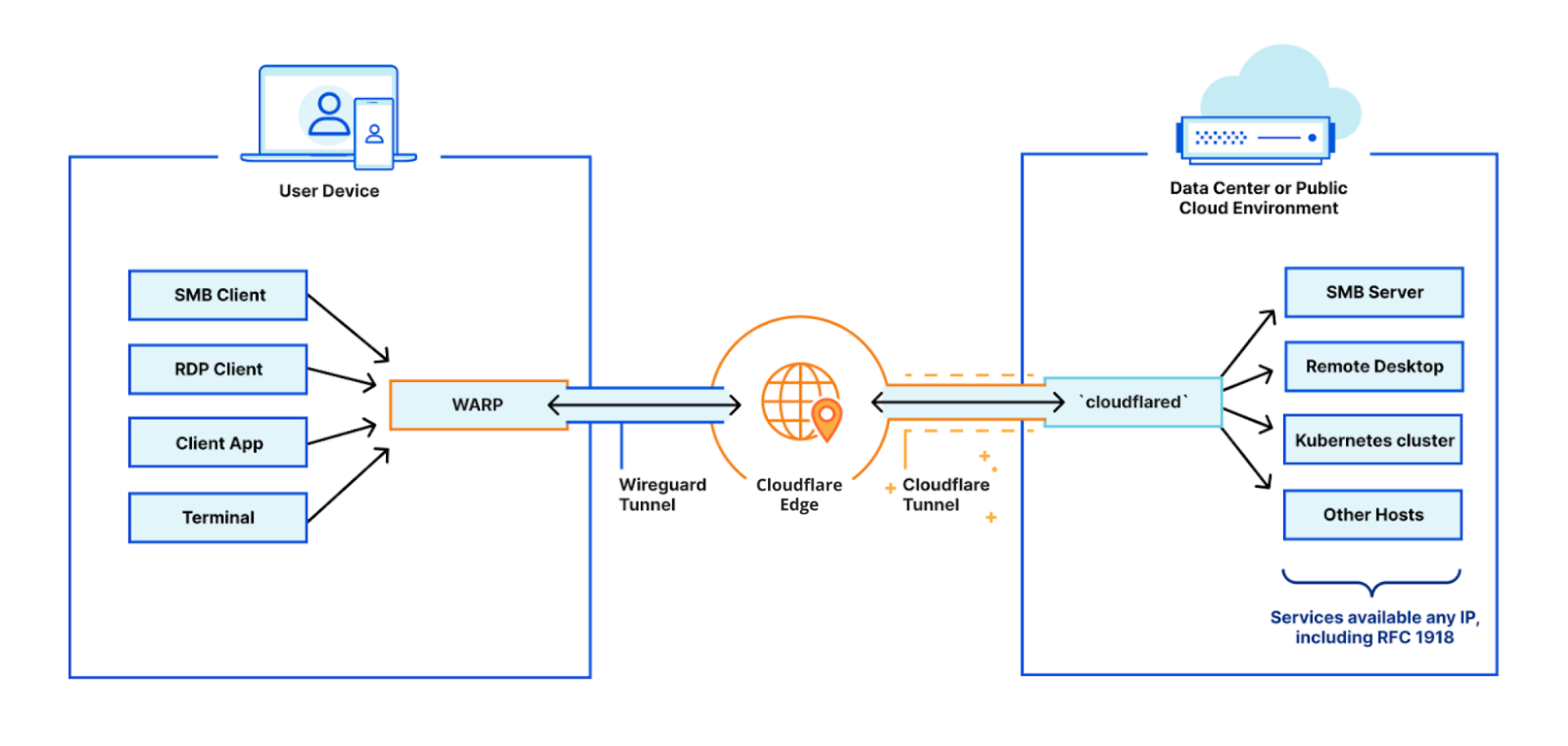
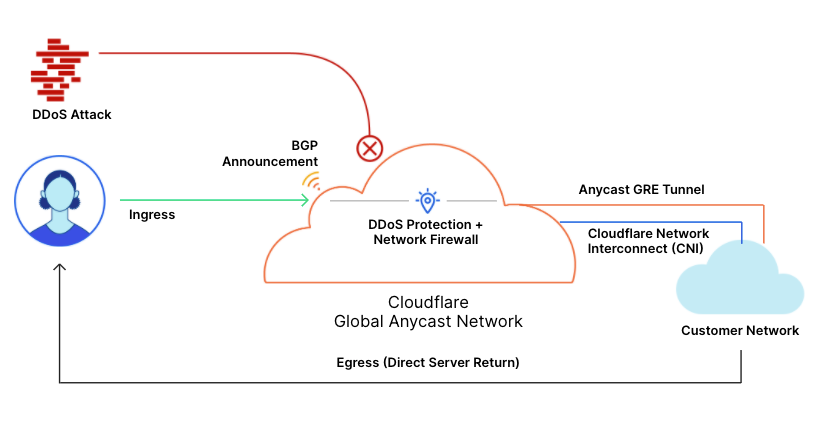
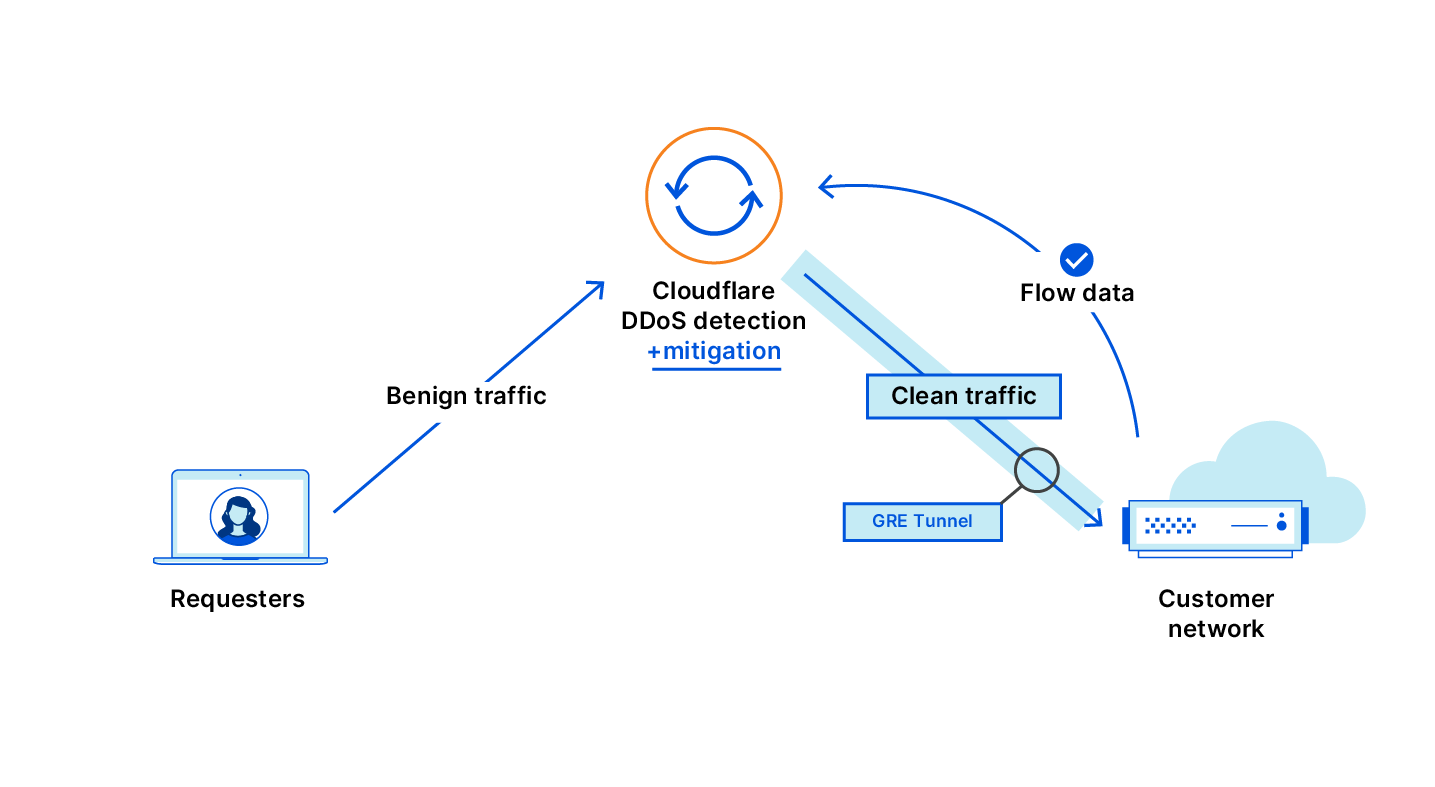
The solution being delivered to CISA, Cloudflare Gateway, builds on Cloudflare’s network to deliver a protective DNS resolver that does not compromise performance. It starts by sending all DNS queries from enrolled devices and offices to Cloudflare’s network. While more of the HTTP Internet continues to be encrypted, the default protocol for sending DNS queries on most devices is still unencrypted. Cloudflare Gateway’s protective DNS resolver supports encrypted options like DNS over HTTPS (DoH) and DNS over TLS (DoT).
Next, blocking DNS queries to malicious hostnames starts with knowing what hostnames are potentially malicious. Cloudflare’s network provides our protective DNS resolver with unique visibility into threats on the Internet. Every day, Cloudflare’s network handles over 800 billion DNS queries. Our infrastructure responds to 25 million HTTP requests per second. We deploy that network in more than 200 cities in over 100 countries around the world, giving our team the ability to see attack patterns around the world.
We convert that data into the insights that power our security products. For example, we analyze the billions of DNS queries we handle to detect anomalous behavior that would indicate a hostname is being used to leak data through a DNS tunneling attack. For the CISA solution, Cloudflare’s datasets are further enriched by applying additional cybersecurity research along with Accenture’s Cyber Threat Intelligence (ACTI) feed to provide signals to detect new and changing threats on the internet. This dataset is further analyzed by data scientists using advanced business intelligence tools powered by artificial intelligence and machine learning.
Working towards a FedRAMP future
Our Public Sector team is focused on partnering with Federal, State and Local Governments to provide a safe and secure digital experience. We are excited to help CISA deliver an innovative, modern, and cost-efficient solution to the entire civilian federal government.
We will continue this path following our recent announcement that we are currently “In Process” in the Federal Risk and Authorization Management Program (FedRAMP) Marketplace. The government’s rigorous security assessment will allow other federal agencies to adopt Cloudflare’s Zero Trust Security solutions in the future.
What’s next?
We are looking forward to working with Accenture Federal Services to deliver this protective DNS resolver solution to CISA. This contract award demonstrates CISA’s belief in the importance of having protective DNS capabilities as part of a layered defense. We applaud CISA for taking this step and allowing us to partner with the US Government to deliver this solution.
Like CISA, we believe that teams large and small should have the tools they need to protect their critical systems. Your team can also get started using Cloudflare to secure your organization today. Cloudflare Gateway, part of Cloudflare for Teams, is available to organizations of any size.
Early in the life of most startups, there is a time of incredible hustle, creative problem solving, and making the impossible possible through out-of-the-box thinking and elbow grease. Grizzled veterans, who have lived through those days of running on coffee and shoestring budgets, look back on that time and fascinate the newcomers with war stories of back in the day, of adventures and first wins, when they kept the lights on by sheer force of will.
To help early stage startups get going, Cloudflare is giving away one year of the Startup Enterprise plan to all early stage startups in participating accelerator programs. That early stage time is special for product development, and entrepreneurs unlock worlds of possibilities when they have advanced tools on their hands, such as the power of the Cloudflare network.
What’s included in the Startup Enterprise plan?
In addition to the core offerings in the Pro and Business plans (e.g., CDN, DNS, WAF, custom SSL cert, 50 page rules), when founders sign up for the Startup Enterprise plan they’ll get special access to:
An affordable, scalable, on-demand video platform with simple, comprehensive APIs.
Additionally, when there are new Cloudflare products that are still in early access, participants on the Startup Enterprise plan can tell us about their use case for the product managers’ consideration for early access.
What startups are eligible for the Startup Enterprise plan?
To be eligible for the Startup Enterprise plan, a startup must be currently enrolled in a participating accelerator program or be a recent graduate. Additional eligibility criteria will be listed on the vendor perk info page of the accelerator program.
Get started
If you are a founder in a participating accelerator program, find the Cloudflare perk from your program’s vendor perk page and follow the instructions there.
If you are a founder in a program that is not yet a partner, drop us a line at [email protected], or ask the folks who run the vendor perk program at your accelerator program to drop us a line at [email protected].If you run or work for an accelerator program, or are friends with folks who do, do drop us a line at [email protected]. We’d love to make our tools available to your portfolio companies.
Over the past few years, we’ve seen an increasing use of Internet shutdowns and cyberattacks that restrict the availability of information in communities around the world. In 2020, Access Now’s #KeepItOn coalition documented at least 155 Internet shutdowns in 29 countries. During the same period, Cloudflare witnessed a five-fold increase in cyberattacks against the human rights, journalism, and non-profit websites that benefit from the protection of Project Galileo.
These disruptive measures, which put up barriers to those looking to use the Internet to express themselves, earn a livelihood, gather and disseminate information, and participate in public life, affect the lives of millions of people around the world.
As described by the UN Human Rights Council (UNHRC), the Internet is not only a key means by which individuals exercise their rights to freedom of opinion and expression, it “facilitates the realization of a range of other human rights” including “economic, social and cultural rights, such as the right to education and the right to take part in cultural life and to enjoy the benefits of scientific progress and its applications, as well as civil and political rights, such as the rights to freedom of association and assembly.” The effect of Internet disruptions are particularly profound during elections, as they disrupt the dissemination and sharing of information about electoral contests and undermine the integrity of the democratic process.
At Cloudflare, we’ve spent time talking to human rights defenders who push back on governments that shut down the Internet to stifle dissent, and on those who help encourage fair, democratic elections around the world. Although we’ve long protected those defenders from cyberattacks with programs like Project Galileo, we thought we could do more. That is why today, we are announcing new programs to help our civil society partners track and document Internet shutdowns and protect democratic elections around the world from cyberattacks.
Radar Alerts
Internet shutdowns intended to prevent or disrupt access to or dissemination of information online are widely condemned, and have been described as “measures that can never be justified under human rights law.” Nonetheless, the UN Special Rapporteur on the rights to freedom of peaceful assembly and of association recently reported that Internet shutdowns have increased in length, scale, and sophistication, and have become increasingly challenging to detect. From January 2019 through May 2021, the #KeepItOn coalition documented at least 79 incidents of protest-related shutdowns, including in the context of elections.
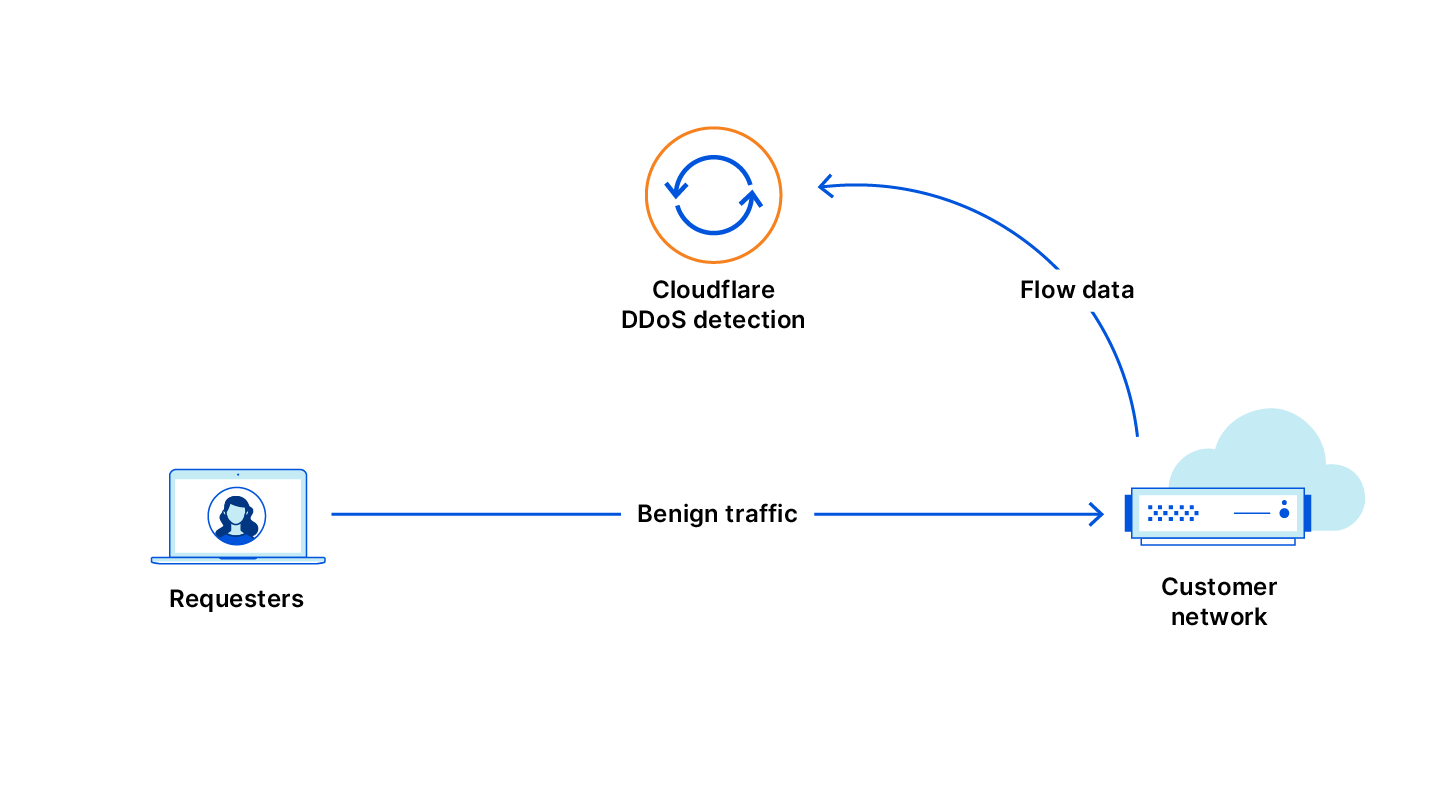
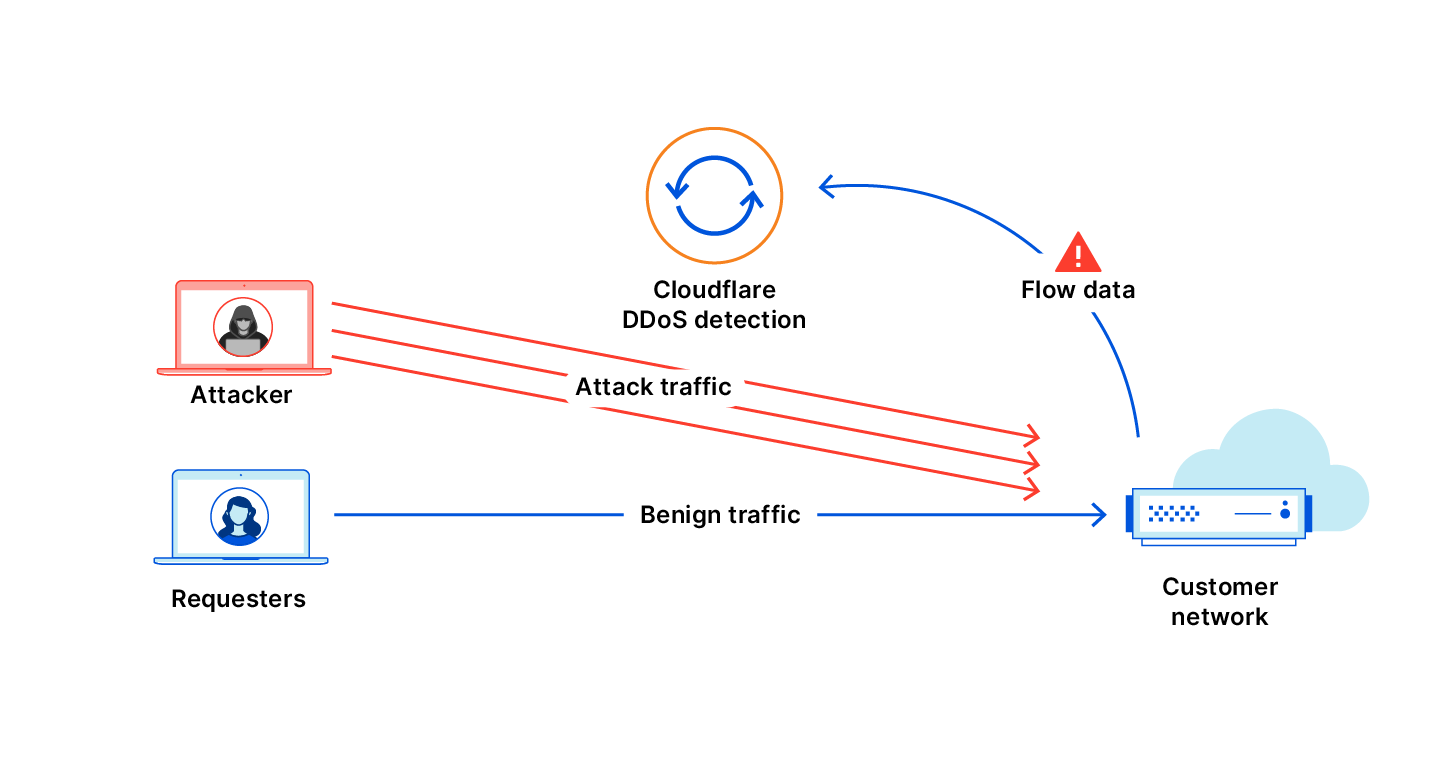
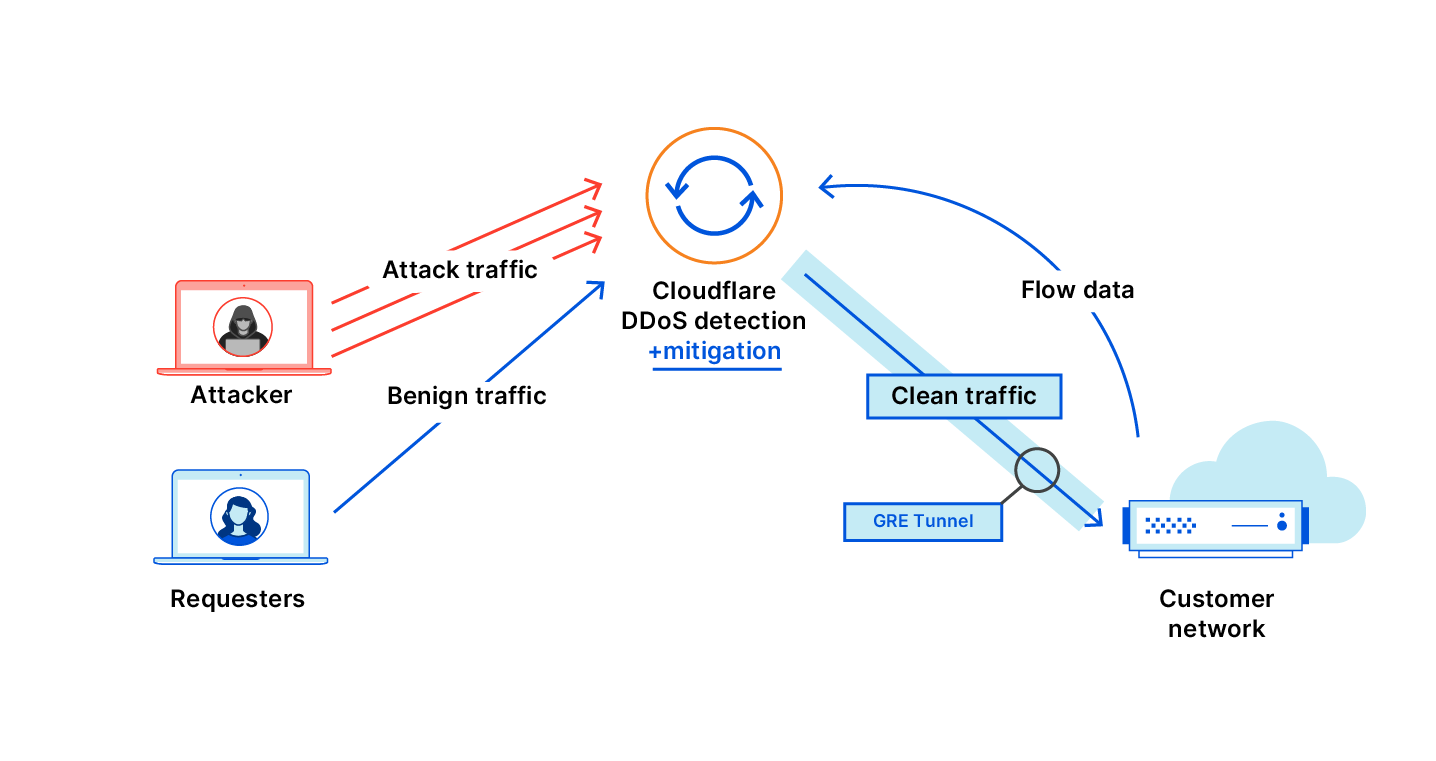
Cloudflare runs one of the world’s largest networks, with data centers in more than 100 countries worldwide and one billion unique IP addresses connecting to Cloudflare’s network. That global network gives us exceptional visibility into Internet traffic patterns, including the variations in traffic that signal network anomalies. To help provide insight to these Internet trends, Cloudflare launched Radar in 2020, a platform that helps anyone see how the Internet is being used around the globe. In Radar one can visually identify significant drops in traffic, typically associated with an Internet shutdown, but these trend graphs are most helpful when one is already looking for something specific.
Radar chart for Internet Traffic in Uganda, showing a significant change for January 13-15
Internally Cloudflare has had an alert system for potential Internet disruptions, that we use as an early warning to shifts in network patterns and incidents. This internal system allows us to see these disruptions in real-time, and after many conversations with civil society groups that track and report these shutdowns, such as The Carter Center, the International Foundation for Electoral Systems, Internet Society, Internews, The National Democratic Institute and Access Now, it was clear that they would benefit from such a system, fine-tuned to report Internet traffic drops quickly and reliably. We then built an additional validation layer and a notification system that sends notifications through various channels, including e-mail and social media.
“In the fight to end internet shutdowns, our community needs accurate reports on internet disruptions at a global scale. When leading companies like Cloudflare share their data and insights, we can make more timely interventions. Together with civil society, Cloudflare will help #KeepItOn.” — Peter Micek, General Counsel, Access Now
“Internet shutdowns undermine election integrity by restricting the right of access to information and freedom of expression. When shutdowns are enacted, reports of their occurrence are often anecdotal, piecemeal, and difficult to substantiate. Radar Alerts provide The Carter Center with real-time information about the occurrence, breadth, and impact of shutdowns on an election process. This information enables The Carter Center to issue evidence-backed statements to substantiate harms to election integrity and demand the restoration of fundamental human rights.” — Michael Baldassaro, Senior Advisor, Digital Threats to Democracy at The Carter Center.
“Internet censorship, throttling and shutdowns are threats to an open Internet and to the ability of people to access and produce trustworthy information. Internews is excited to see Cloudflare share its data to help raise the visibility of shutdowns around the world.” — Jon Camfield, Director of Global Technological Strategy, Internews
Now, as we detect these drops in traffic, we may still not have the expertise, backstory or sense of what is happening on the ground when this occurs — at least not in as much detail as our partners. We are excited to be working with these organizations to provide alerts on when Cloudflare has detected significant drops in traffic with the hope that the information is used to document, track and hold institutions accountable for these human rights violations.
Cloudflare is known for innovation, for needle-moving projects that help make the Internet better. For Impact Week, we wanted to take this approach to innovation and apply it to the environmental impact of the Internet. When it comes to tech and the environment, it’s often assumed that the only avenue tech has open to it is harm mitigation: for example, climate credits, carbon offsets, and the like. These are undoubtedly important steps, but we wanted to take it further — to get into harm reduction. So we asked — how can the Internet at large use less energy and be more thoughtful about how we expend computing resources in the first place?
Cloudflare has a global view into the traffic of the Internet. More than 1 in 6 websites use our network, and we observe the traffic flowing to and from them continuously. While most people think of surfing the Internet as a very human activity, nearly half of all traffic on the global network is generated by automated systems.
We’ve analyzed this automated traffic, from so-called “bots,” in order to understand the environmental impact. Most of the bot traffic is malicious. Cloudflare protects our clients from this malicious traffic and, in doing so, mitigates their environmental impact. If these bots were not stopped by Cloudflare, they would generate database requests and force dynamic page generation on services far less efficient than Cloudflare’s network.
We even went a step further, committing to plant trees to offset the carbon cost of our bot mitigation services. While we’d love to be able to tell the bad actors to think of the environment and stop running their bots, we don’t think they’d listen. So, instead, we aim to mitigate them as efficiently as possible.
But there’s another type of bot that we don’t want to go away: good bots that index the web for useful reasons. These good bots represent more than 5% of global Internet traffic. The majority of this good bot traffic comes from what are known as search engine crawlers, and they are critical to making the web navigable.
Large-Scale Problems, Large-Scale Opportunities
Online search remains magical. Enter a query into a box on a search engine like Google, Bing, Yandex, or Baidu and, in a fraction of a second, get a list of web resources with information on whatever you’re looking for. To make this magic happen, search engines need to scour the web and, simplistically, make a copy of its contents that are stored and sorted on their own systems to be quickly retrieved whenever needed.
Companies that run search engines have worked hard to make the process as efficient as possible, pushing the state-of-the-art in terms of server and data center efficiency. But there remains one clear area of waste: excessive crawl.
At Cloudflare, we see traffic from all the major search crawlers. We’ve spent the last year studying how often these good bots revisit a page that hasn’t changed since they last saw it. Every one of these visits is a waste. And, unfortunately, our observation suggests that 53% of this good bot traffic is wasted.
The Boston Consulting Group estimates that running the Internet generated 2% of all carbon output, or about 1 billion metric tonnes per year. If 5% of all Internet traffic is good bots, and 53% of that traffic is wasted by excessive crawl, then finding a solution to reduce excessive crawl could help save as much as 26 million tonnes of carbon cost per year. According to the U.S. Environmental Protection Agency, that’s the equivalent of planting 31 million acres of forest, shutting down 6 coal-fired power plants forever, or taking 5.5 million passenger vehicles off the road.
Obviously, it’s not quite that simple. But suffice it to say there’s a big opportunity to make a meaningful impact on the environmental cost of the Internet if we are able to ensure that any search engine only crawls once or whenever it changes.
Recognizing this problem, we’ve been talking with the largest operators of good bots for the last several years to see if, together, we could address the issue.
Crawler Hints
Today, we’re excited to announce Crawler Hints. Crawler Hints provide high quality data to search engine crawlers on when content has been changed on sites using Cloudflare, allowing them to precisely time their crawling, avoid wasteful crawls, and generally reduce resource consumption of customer origins, crawler infrastructure, and Cloudflare infrastructure in the process. The cherry on top: because search engine crawlers now receive signals on when content is fresh, the search experiences powered by these “good bots” will improve, delighting Internet users at large with more relevant and useful content. Crawler Hints is a win for the Internet and a win for the Internet’s energy footprint.
With Crawler Hints, we expect to make crawling a bit more tractable by providing an additional heuristic to bot developers that will allow them to know when content has been changed or added to a site instead of relying on preferences or previous changes that might not reflect the true change cadence for a site.
How will this work?
At its simplest we want a way to proactively tell a search engine when a page has changed, rather than having to wait for the search engine to discover a change has happened. Search engines actually typically have a few ways to tell them about when an individual page or group of pages changes.
If you wanted to efficiently tell Google about changes you’d have to keep track of when Google last crawled the page and tell them to recrawl when a change happens. You wouldn’t want to tell Google every time a page changes as there’s a time delay between requesting a recrawl and the spider coming to visit. You could be telling Google to come back during the gap between the request and the spider coming to call.
And there isn’t just one search engine and new search crawlers get created. Trying to keep search engines up to date as your site changes, efficiently, would be messy and very difficult. This is, in part, because this model does not contain explicit information about when something changed.
This model just doesn’t work well. And that’s partly why search engine crawlers inevitably waste energy recrawling sites over and over again regardless of whether there is something new to find.
However, there is an existing mechanism used by search engines to discover the structure of websites that’s perfect: the sitemap. The sitemap is a well-defined, open protocol for telling a crawler about the pages on a site, when they last changed and how often they are likely to change.
Sitemaps have some limitations (on number of URLs and bytes) but do have a mechanism for large sites with millions of URLs. But building sitemaps can be complex and require special software. Getting a consistent, up to date sitemap for a website (especially one that uses different technologies) can be very hard.
That’s where Cloudflare comes in. We see what pages our customers are serving, we know which ones have changed (either by hash value or timestamp) and so can automatically build a complete record of when and which pages have changed.
And we can keep track of when a search crawler visited a particular page and only serve up exactly what changed since last time. Since we can keep track of this on a per-search engine basis it can be very efficient. Each search engine gets its own automagically updated list of URLs or sitemap of just what’s changed since their last visit.
And it adds absolutely no load to the origin website. Cloudflare can tell a search engine in almost real-time about a page’s modifications and provide a view of what changed since their last visit.
The sitemaps protocol also contains a priority for a page. Since we know how often a page is visited we can also hint to a search engine that a page is seen frequently by visitors and thus may be more important to add to the index than another page.
There are a few details to work out, such as how a search engine should identify itself to get its personalized list of URLs, but the protocol is open and in no way depends on Cloudflare. In fact, we hope that every host and Cloudflare-like service will consider implementing the protocol. We plan to continue to work with the search and hosting communities to refine the protocol in order to make it more efficient. Our goal is to ensure that search engines can have the freshest index, content creators will have their new content optimally indexed, and a big chunk of unnecessary Internet traffic, and the corresponding carbon cost, will disappear.
Conclusion
Crawler Hints doesn’t just benefit search engines. For our customers and origin owners, Crawler Hints will ensure that search engines and other bot-powered experiences will always have the freshest version of your content, translating into happier users and ultimately influencing search rankings. Crawler Hints will also mean less traffic hitting your origin, improving resource consumption and limiting carbon impact. Moreover, your site performance will be improved as well: your human customers will not be competing with bots!
And for Internet users? When you interact with bot-fed experiences — which we all do every day, whether we realize it or not, like search engines or pricing tools — these will now deliver more useful results from crawled data, because Cloudflare has signaled to the owners of the bots the moment they need to update their results.
Finally, and perhaps the one we’re most excited about, for the Internet more generally: it’s going to be greener. Energy usage across the web will be greatly reduced.
Win win win. The types of outcomes that bring us to work every day, and what we think of in helping to build a better Internet.
This is an exciting problem to solve, and we look forward to working with others that want to help the Internet be more efficient and performant while reducing needless energy consumption. We plan on having more news to share on this front soon. If you operate a bot that relies on content freshness and are interested in working with us on this project, please email [email protected].
Yandex prioritizes long-term sustainability over short-lived success, and joins the global community in its pursuit of climate change mitigation. As a part of its commitment to quality service and user experience, Yandex focuses on ensuring relevance and usability of search results. We believe that a Cloudflare’s solution will strengthen search performance by improving the accuracy of returned results, and look forward to partnering with Cloudflare on boosting the efficiency of valuable bots across the Internet.
“DuckDuckGo is supportive of anything that makes search more environmentally friendly and better for end users without harming privacy. We’re looking forward to working with Cloudflare on this proposal.” – Gabriel Weinberg, CEO and Founder, DuckDuckGo.
Nearly a year ago (the Internet Archive’s Wayback Machine partnered with Cloudflare) to help power their “Always Online” service and, in turn, to have the Internet Archive learn about high-quality Web URLs to archive. That win-win partnership has been a huge success for the Wayback Machine and, in turn, our partners, as it has helped ensure we better fulfill our mission to help make the Web more useful and reliable by backing up, and making available for future generations, much of the public Web. Building on that ongoing relationship with Cloudflare, the Internet Archive is thrilled to start using this new “Crawler Hints” service. With it, we expect to be able to do more with less. To be able to focus our server and bandwidth resources on more of the Web pages that have changed, and less on those that have not. We expect this will have a material impact on our work. The fact the service also promises to reduce the carbon impact of the Web overall makes it especially worthwhile and, as such, we are proud to be part of the effort. –– Mark Graham, Director, the Wayback Machine at the Internet Archive
Today we’re excited to announce Smart Edge Revalidation. It was designed to ensure that compute resources are synchronized efficiently between our edge and a browser. Right now, as many as 30% of objects cached on Cloudflare’s edge do not have the HTTP response headers required for revalidation. This can result in unnecessary origin calls. Smart Edge Revalidation fixes this: it does the work to ensure that these headers are present, even when an origin doesn’t send them to us. The advantage of this? There’s less wasted bandwidth and compute for objects that do not need to be redownloaded. And there are faster browser page loads for users.
So What Is Revalidation?
Revalidation is one part of a longer story about efficiently serving objects that live on an origin server from an intermediary cache. Visitors to a website want it to be fast. One foundational way to make sure that a website is fast for visitors is to serve objects from cache. In this way, requests and responses do not need to transit unnecessary parts of the Internet back to an origin and, instead, can be served from a data center that is closer to the visitor. As such, website operators generally only want to serve content from an origin when content has changed. So how do objects stay in cache for as long as necessary?
One way to do that is with HTTP response headers.
When Cloudflare gets a response from an origin, included in that response are a number of headers. You can see these headers by opening any webpage, inspecting the page, going to the network tab, and clicking any file. In the response headers section there will generally be a header known as “Cache-Control.” This header is a way for origins to answer caching intermediaries’ questions like: is this object eligible for cache? How long should this object be in cache? And what should the caching intermediary do after that time expires?
How long something should be in cache can be specified through the max-age or s-maxage directives. These directives specify a TTL or time-to-live for the object in seconds. Once the object has been in cache for the requisite TTL, the clock hits 0 (zero) and it is marked as expired. Cache can no longer safely serve expired content to requests without figuring out if the object has changed on the origin or if it is the same.
If it has changed, it must be redownloaded from the origin. If it hasn’t changed, then it can be marked as fresh and continue to be served. This check, again, is known as revalidation.
We’re excited that Smart Edge Revalidation extends the efficiency of revalidation to everyone, regardless of an origin sending the necessary response headers
How is Revalidation Accomplished?
Two additional headers, Last-Modified and ETag, are set by an origin in order to distinguish different versions of the same URL/object across modifications. After the object expires and the revalidation check occurs, if the ETag value hasn’t changed or a more recent Last-Modified timestamp isn’t present, the object is marked “revalidated” and the expired object can continue to be served from cache. If there has been a change as indicated by the ETag value or Last-Modified timestamp, then the new object is downloaded and the old object is removed from cache.
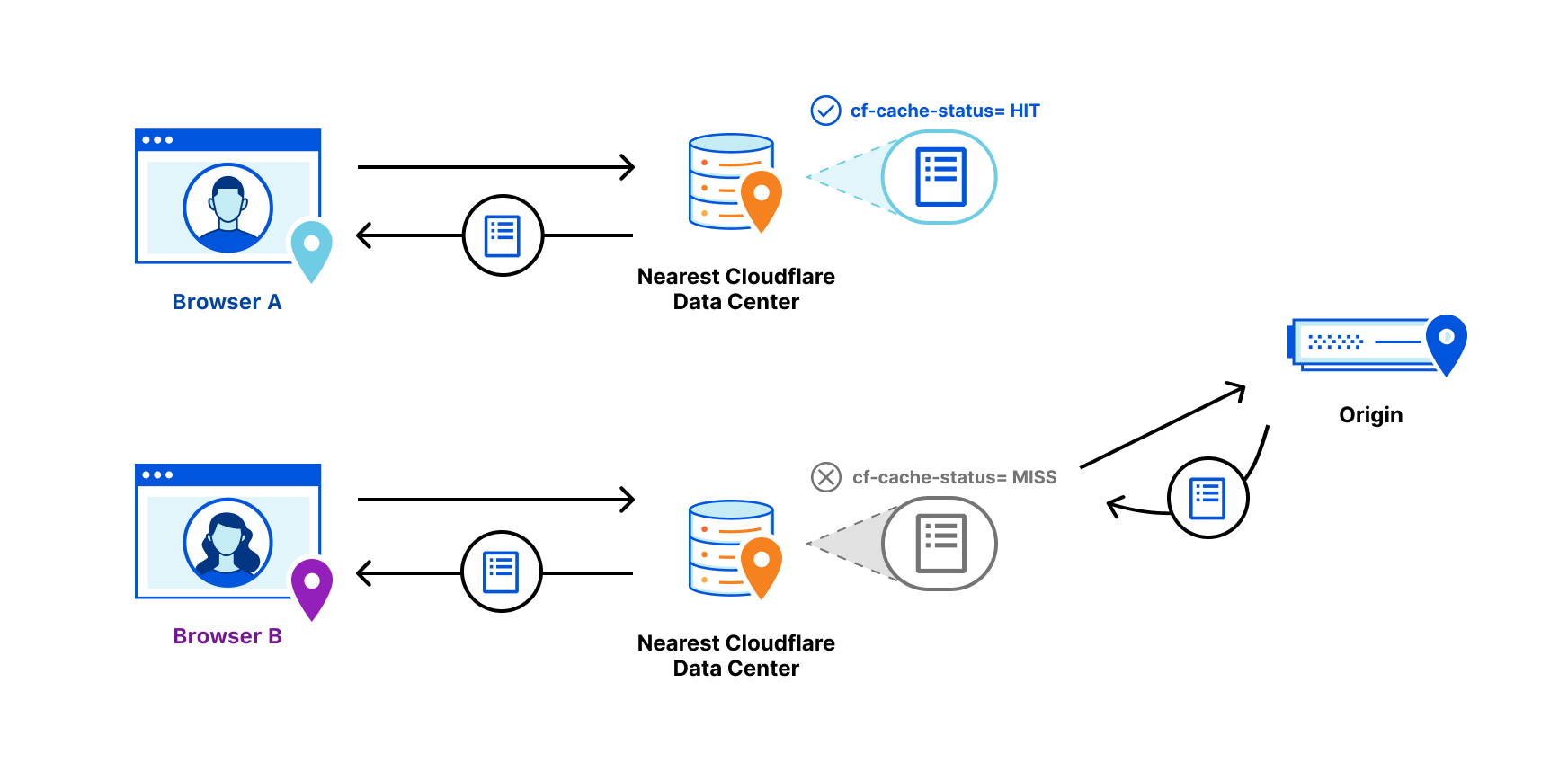
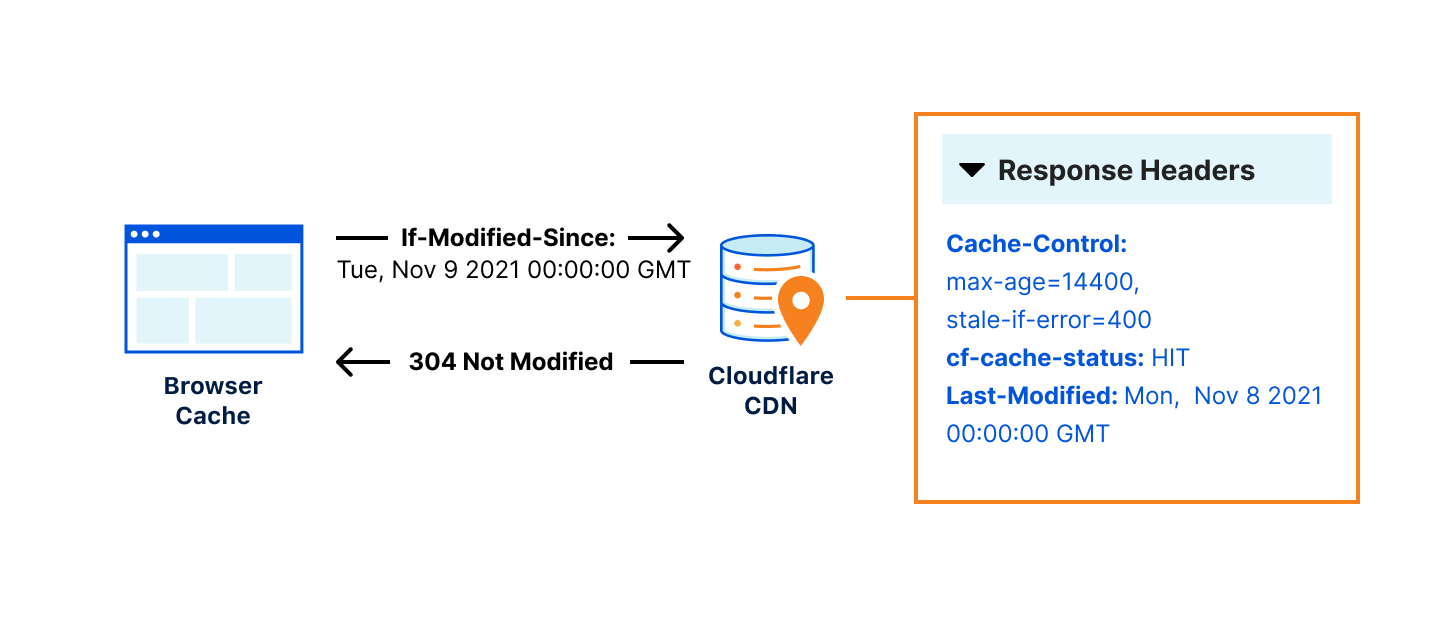
Revalidation checks occur when a browser sends a request to a cache server using If-Modified-Since or If-None-Match headers. These request headers are questions sent from the browser cache about when an object has last changed that can be answered via the ETag or Last-Modifiedresponse headers on the cache server. For example, if the browser sends a request to a cache server with If-Modified-Since: Tue, 8 Nov 2021 07:28:00 GMT the cache server must look at the object being asked about and if it has not changed since November 8 at 7:28 AM, it will respond with a 304 status code indicating it’s unchanged. If the object has changed, the cache server will respond with the new object.
Sending a 304 status code that indicates an object can be reused is much more efficient than sending the entire object. It’s like if you ran a news website that updated every 24 hours. Once the content is updated for the day, you wouldn’t want to keep redownloading the same unchanged content from the origin and instead, you would prefer to make sure that the day’s content was just reused by sending a lightweight signal to that effect, until the site changes the next day.
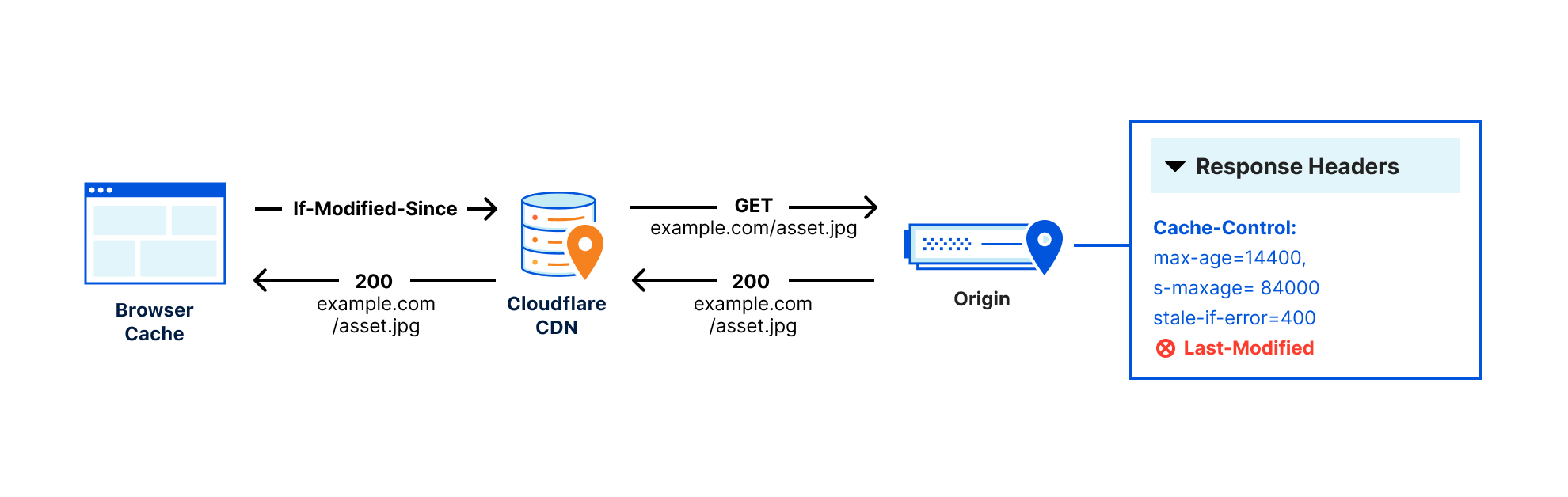
The problem with this system of browser questions and revalidation responses is that sometimes origins don’t set ETag or Last-Modified headers, or they aren’t configured by the website’s admin, making revalidation impossible. This means that every time an object expires, it must be redownloaded regardless of if there has been a change or not, because we have to assume that the asset has been updated, or else risk serving stale content.
This is an incredible waste of resources which costs hundreds of GB/sec of needless bandwidth between the edge and the visitor. Meaning browsers are downloading hundreds of GB/sec of content they may already have. If our baseline of revalidation is around 10% of all traffic and in initial tests, Smart Edge Revalidation increased revalidation just under 50%, this means that without a user needing to configure anything, we can increase total revalidations by around 5%!
Such a large reduction in bandwidth use also comes with potential environmental benefits. Based on Cloudflare’s carbon emissions per byte, the needless bandwidth being used could amount to 2000+ metric tons CO2e/year, the equivalent of the CO2 emissions from more than 400 cars in a year.
Revalidation also comes with a performance improvement because it usually means a browser is downloading less than 1KB of data to check if the asset has changed or not, while pulling the full asset can be 100sKB. This can improve performance and reduce the bandwidth between the visitor and our edge.
How Smart Edge Revalidation Works
When both Last-Modified and Etag headers are absent from the origin server response, Smart Edge Revalidation will use the time the object was cached on Cloudflare’s edge as the Last-Modified header value. When a browser sends a revalidation request to Cloudflare using If-Modified-Since or If-None-Match, our edge can answer those revalidation questions using the Last-Modified header generated from Smart Edge Revalidation. In this way, our edge can ensure efficient revalidation even if the headers are not sent from the origin.
Smart Edge Revalidation will be enabled automatically for all Cloudflare customers over the coming weeks. If this behavior is undesired, you can always ensure that Smart Edge Revalidation is not activated by confirming your origin is sending ETag or Last-Modified headers when you want to indicate changed content. Additionally, you could have your origin direct your desired revalidation behavior by making sure it sets appropriate cache-control headers.
Smart Edge Revalidation is a win for everyone: visitors will get more content faster from cache, website owners can serve and revalidate additional content from Cloudflare efficiently, and the Internet will get a bit greener and more efficient.
At Cloudflare, we are continuing to expand our sustainability initiatives to build a greener Internet in more than one way. We are seeing a shift in attitudes towards eco-consciousness and have noticed that with all things considered equal, if an option to reduce environmental impact is available, that’s the one widely preferred by our customers. With Pages now Generally Available, we believe we have the power to help our customers reach their sustainability goals. That is why we are excited to partner with the Green Web Foundation as we commit to making sure our Pages infrastructure is powered by 100% renewable energy.
The Green Web Foundation
As part of Cloudflare’s Impact Week, Cloudflare is proud to announce its collaboration with the Green Web Foundation (GWF), a not-for-profit organization with the mission of creating an Internet that one day will run on entirely renewable energy. GWF maintains an extensive and globally categorized Green Hosting Directory with over 320 certified hosts in 26 countries! In addition to this directory, the GWF also develops free online tools, APIs and open datasets readily available for companies looking to contribute to its mission.
What does it mean to be a Green Web Foundation partner?
All websites certified as operating on 100 percent renewable energy by GWF must provide evidence of their energy usage and renewable energy purchases. Cloudflare Pages have already taken care of that step for you, including by sharing our public Carbon Emissions Inventory report. As a result, all Cloudflare Pages are automatically listed on GWF’s public global directory as official green hosts.
After these claims were approved by the team at GWF, what do I have to do to get certified?
If you’re hosting your site on Cloudflare Pages, absolutely nothing.
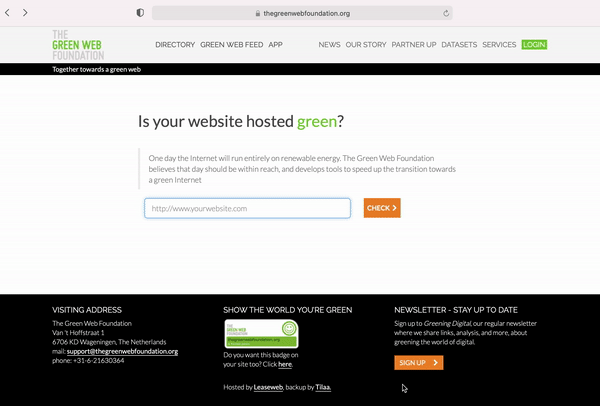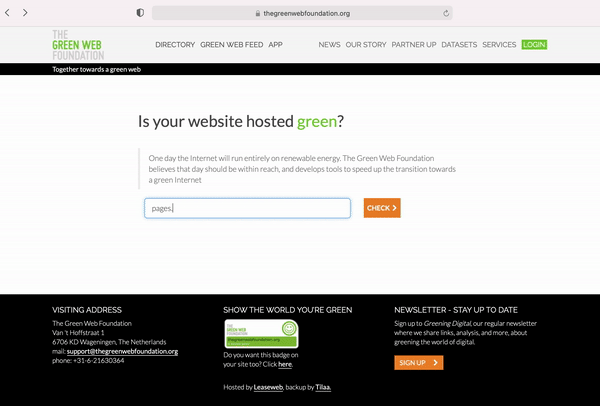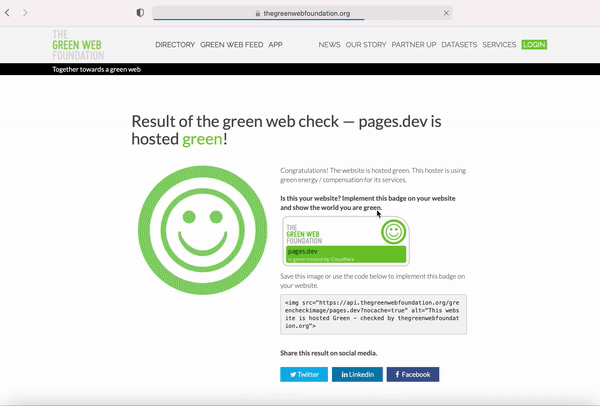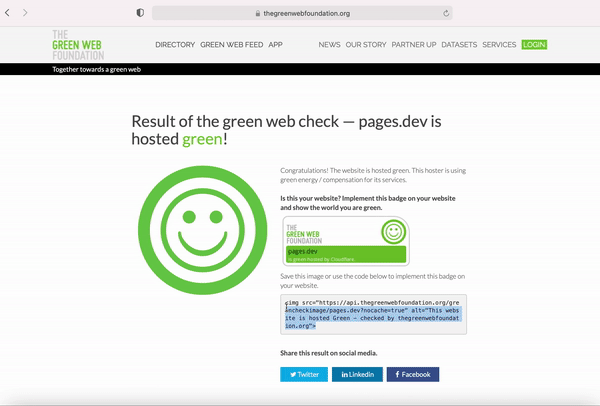
All existing and new sites created on Pages are automatically certified as “green” too! But don’t just take our word for it. With our partnership with GWF and as a Pages user, you can enter your own pages.dev or custom domain into the Green Web Check to verify your site’s green hosting status. Once the domain is shown as verified, you can display the Green Web Foundation badge on your webpage to showcase your contributions to a more sustainable Internet as a green-hosted site. You can obtain this badge by one of two ways:
Saving the badge image directly.
Adding the provided snippet of HTML to your existing code.
Helping to Build a Greener Internet
Cloudflare is committed to helping our customers achieve their sustainability goals through the use of our products. In addition to our initiative with the Green Web Foundation for this year’s Impact Week, we are thrilled to announce the other ways we are building a greener Internet, such as our Carbon Impact Report and Green Compute on Cloudflare Workers.
We can all play a small part in reducing our carbon footprint. Start today by setting up your site with Cloudflare Pages!
“Cloudflare’s recent climate disclosures and commitments are encouraging, especially given how much traffic flows through their network. Every provider should be at least this transparent when it comes to accounting for the environmental impact of their services. We see a growing number of users relying on CDNs to host their sites, and they are often confused when their sites no longer show as green, because they’re not using a green CDN. It’s good to see another more sustainable option available to users, and one that is independently verified.” – Chris Adams, Co-director of The Green Web Foundation
Half of the world’s population has no access to the Internet, with many more limited to poor, expensive, and unreliable connectivity. This problem persists despite large levels of public investment, private infrastructure, and effort by local organizers.
Today, Cloudflare is excited to announce Project Pangea: a piece of the puzzle to help solve this problem. We’re launching a program that provides secure, performant, reliable access to the Internet for community networks that support underserved communities, and we’re doing it for free1 because we want to help build an Internet for everyone.
What is Cloudflare doing to help?
Project Pangea is Cloudflare’s project to help bring underserved communities secure connectivity to the Internet through Cloudflare’s global and interconnected network.
Cloudflare is offering our suite of network services — Cloudflare Network Interconnect, Magic Transit, and Magic Firewall — for free to nonprofit community networks, local networks, or other networks primarily focused on providing Internet access to local underserved or developing areas. This service would dramatically reduce the cost for communities to connect to the Internet, with industry leading security and performance functions built-in:
Cloudflare Network Interconnect provides access to Cloudflare’s edge in 200+ cities across the globe through physical and virtual connectivity options.
Magic Transit acts as a conduit to and from the broader Internet and protects community networks by mitigating DDoS attacks within seconds at the edge.
Magic Firewall gives community networks access to a network-layer firewall as a service, providing further protection from malicious traffic.
We’ve learned from working with customers that pure connectivity is not enough to keep a network sustainably connected to the Internet. Malicious traffic, such as DDoS attacks, can target a network and saturate Internet service links, which can lead to providers aggressively rate limiting or even entirely shutting down incoming traffic until the attack subsides. This is why we’re including our security services in addition to connectivity as part of Project Pangea: no attacker should be able to keep communities closed off from accessing the Internet.
What is a community network?
Community networks have existed almost as long as commercial subscribership to the Internet that began with dial-up service. The Internet Society, or ISOC, describes community networks as happening “when people come together to build and maintain the necessary infrastructure for Internet connection.”
Most often, community networks emerge from need, and in response to the lack or absence of available Internet connectivity. They consistently demonstrate success where public and private-sector initiatives have either failed or under-deliver. We’re not talking about stop-gap solutions here, either — community networks around the world have been providing reliable, sustainable, high-quality connections for years.
Many will operate only within their communities, but many others can grow, and have grown, to regional or national scale. The most common models of governance and operation are as not-for-profits or cooperatives, models that ensure reinvestment within the communities being served. For example, we see networks that reinvest their proceeds to replace Wi-Fi infrastructure with fibre-to-the-home.
Cloudflare celebrates these networks’ successes, and also the diversity of the communities that these networks represent. In that spirit, we’d like to dispel myths that we encountered during the launch of this program — many of which we wrongly assumed or believed to be true — because the myths turn out to be barriers that communities so often are forced to overcome. Community networks are built on knowledge sharing, and so we’re sharing some of that knowledge, so others can help accelerate community projects and policies, rather than rely on the assumptions that impede progress.
Myth #1: Only very rural or remote regions are underserved and in need. It’s true that remote regions are underserved. It is also true that underserved regions exist within 10 km (about six miles) of large city centers, and even within the largest cities themselves, as evidenced by the existence of some of our launch partners.
Myth #2: Remote, rural, or underserved is also low-income. This might just be the biggest myth of all. Rural and remote populations are often thriving communities that can afford service, but have no access. In contrast, the need for urban community networks are often egalitarian, and emerge because the access that is available is unaffordable to many.
Myth #3: Service is necessarily more expensive. This myth is sometimes expressed by statements such as, “if large service providers can’t offer affordable access, then no one can.” More than a myth, this is a lie. Community networks (including our launch partners) use novel governance and cost models to ensure that subscribers pay rates similar to the wider market.
Myth #4: Technical expertise is a hard requirement and is unavailable. There is a rich body of evidence and examples showing that, with small amounts of training and support, communities can build their own local networks cheaply and reliably with commodity hardware and non-specialist equipment.
These myths aside, there is one truth: the path to sustainability is hard. The start and initial growth of community networks often consists of volunteer time or grant funding, which are difficult to sustain in the long-term. Eventually the starting models need to transition to models of “willing to charge and willing to pay” — Project Pangea is designed to help fill this gap.
What is the problem?
Communities around the world can and have put up Wi-Fi antennas and laid their own fibre. Even so, and however well-connected the community is to itself, Internet services are prohibitively expensive — if they can be found at all.
Two elements are required to connect to the Internet, and each incurs its own cost:
Backhaul connections to an interconnection point — the connection point may be anything from a local cabinet to a large Internet exchange point (IXP).
Internet Services are provided by a network that interfaces with the wider Internet, and agrees to route traffic to and from on behalf of the community network.
These are distinct elements. Backhaul service carries data packets along a physical link (a fibre cable or wireless medium). Internet service is separate and may be provided over that link, or at its endpoint.
The cost of Internet service for networks is both dominant and variable (with usage), so in most cases it is cheaper to purchase both as a bundle from service providers that also own or operate their own physical network. Telecommunications and energy companies are prime examples.
However, the operating costs and complexity of long-distance backhaul is significantly lower than the costs of Internet service. If reliable, high capacity service were affordable, then community networks could extend their knowledge and governance models sustainably to also provide their own backhaul.
For all that community networks can build, establish, and operate, the one element entirely outside their control is the cost of Internet service — a problem that Project Pangea helps to solve.
Why does the problem persist?
On this subject, I — Marwan — can only share insights drawn from prior experience as a computer science professor, and a co-founder of HUBS c.i.c., launched with talented professors and a network engineer. HUBS is a not-for-profit backhaul and Internet provider in Scotland. It is a cooperative of more than a dozen community networks — some that serve communities with no roads in or out — across thousands of square kilometers along Scotland’s West Coast and Borders regions. As is true of many community networks, not least some of Pangea’s launch partners, HUBS’ is award-winning, and engages in advocacy and policy.
During that time my co-founders and I engaged with research funders, economic development agencies, three levels of government, and so many communities that I lost track. After all that, the answer to the question is still far from clear. There are, however, noteworthy observations and experiences that stood out, and often came from surprising places:
Cables on the ground get chewed by animals that, small or large, might never be seen.
Burying power and Ethernet cables, even 15 centimeters below soil, makes no difference because (we think) animals are drawn by the electrical current.
Property owners sometimes need to be convinced that 8 to 10 square meters to build a small tower in exchange for free Internet and community benefit is a good thing.
The raising of small towers, even that no one will see, is sometimes blocked by legislation or regulation that assumes private non-residential structures can only be a shed, or never taller than a shed.
Private fibre backbone installations installed with public funds are often inaccessible, or are charged by distance even though the cost to light 100 meters of fibre is identical to the cost of lighting 1 km of fibre.
Civil service agencies may be enthusiastic, but are also cautious, even in the face of evidence. Be patient, suffer frustration, be more patient, and repeat. Success is possible.
If and where possible, it’s best to avoid attempts to deliver service where national telecommunications companies have plans to do so.
Never underestimate tidal fading — twice a day, wireless signals over water will be amazing, and will completely disappear. We should have known!
All anecdotes aside, the best policies and practices are non-trivial — but because of so many prior community efforts, and organizations such as ISOC, the APC, the A4AI, and more, the challenges and solutions are better understood than ever before.
How does a community network reach the Internet?
First, we’d like to honor the many organisations we’ve learned from who might say that there are no technical barriers to success. Connections within the community networks may be shaped by geographical features or regional regulations. For example, wireless lines of sight between antenna towers on personal property are guided by hills or restricted by regulations. Similarly, Ethernet cables and fibre deployments are guided by property ownership, digging rights, and the presence or migration of grazing animals that dig into soil and gnaw at cables — yes, they do, even small rabbits.
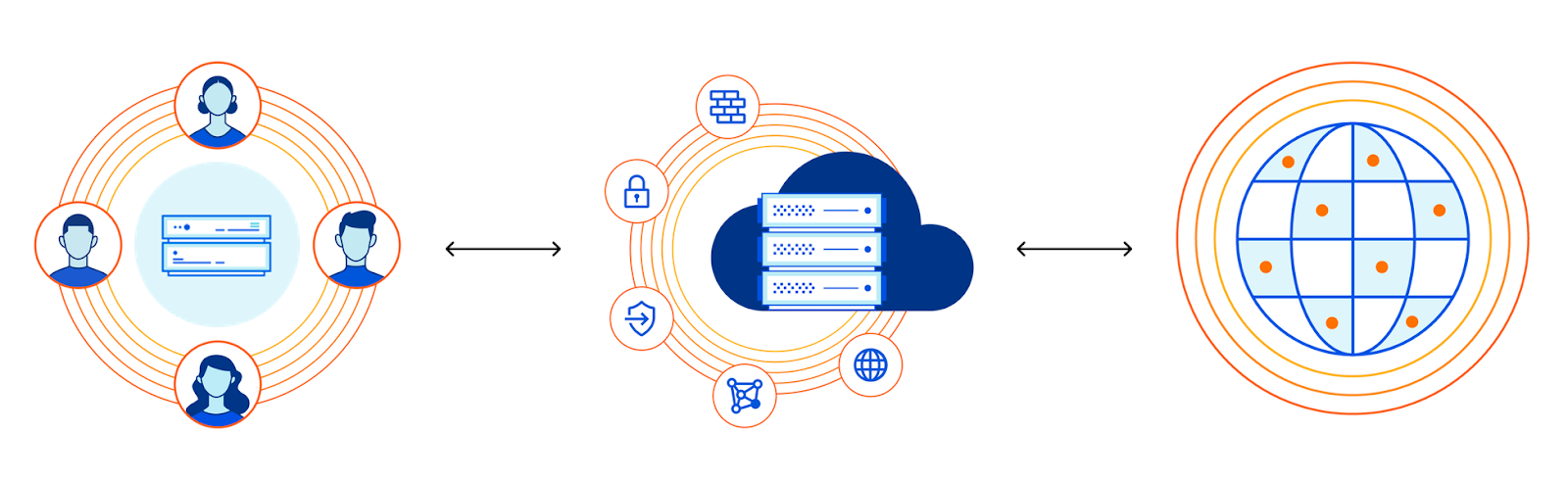
Once the community establishes its own area network, the connections to meet Internet services are more conventional, more familiar. In part, the choice is influenced or determined by proximity to Internet exchanges, PoPs, or regional fibre cabinet installations. The connections with community networks fall into three broad categories.
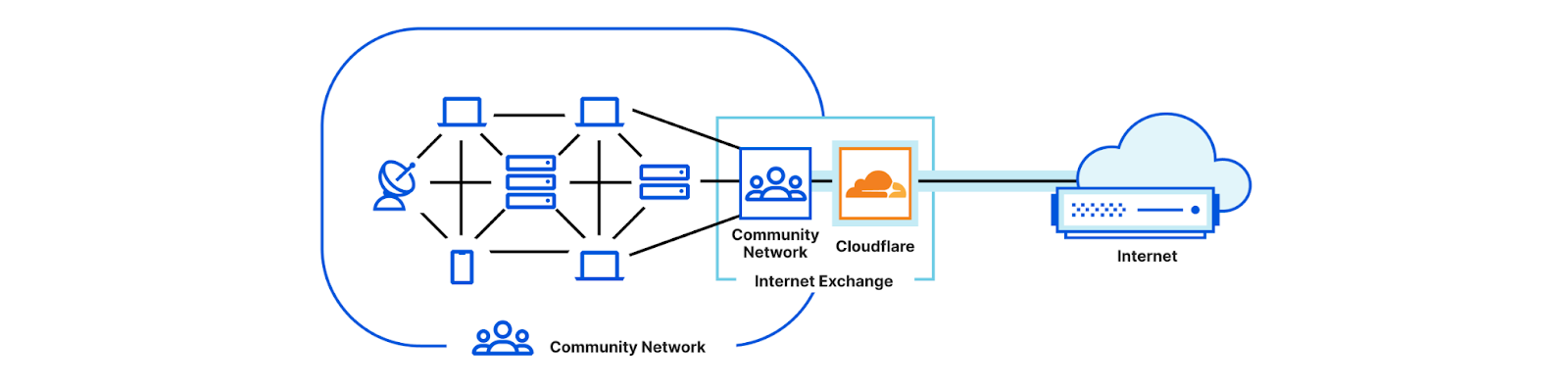
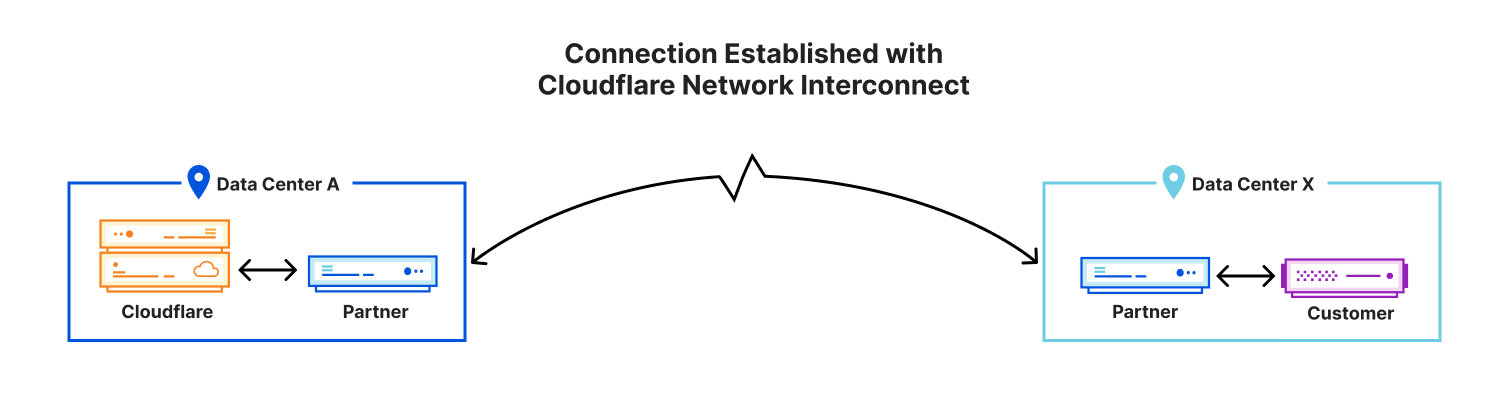
Colocation. A community network may be fortunate enough to have service coverage that overlaps with, or is near to, an Internet eXchange Point (IXP), as shown in the figure below. In this case a natural choice is to colocate a router within the exchange, near to the Internet service provider’s router (labeled as Cloudflare in the figure). Our launch partner NYC Mesh connects in this manner. Unfortunately, being that exchanges are most often located in urban settings, colocation is unavailable to many, if not most, community networks.
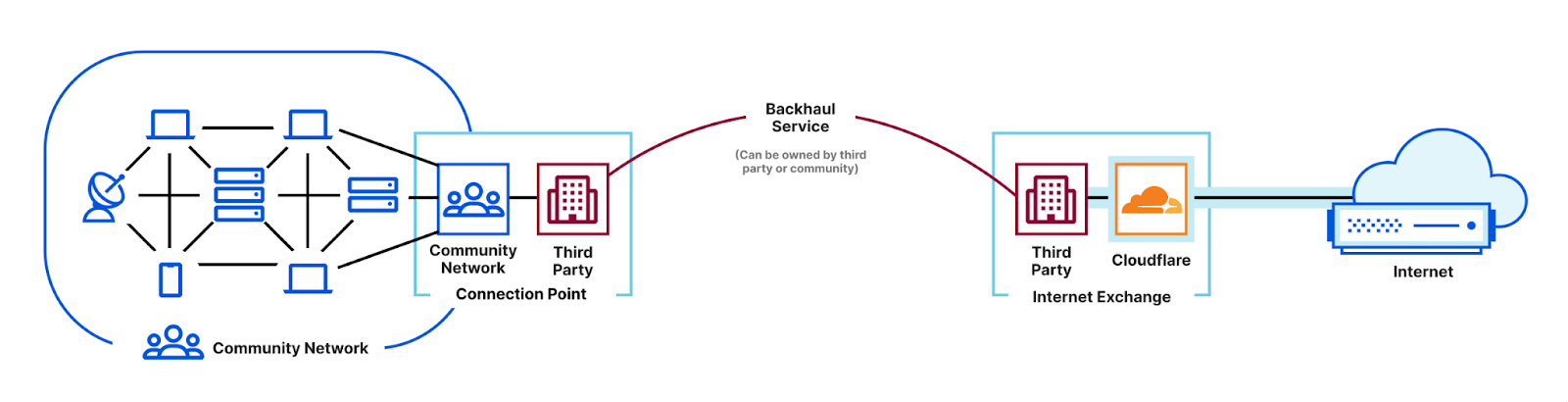
Conventional point-to-point backhaul. Community networks that are remote must establish a point-to-point backhaul connection to the Internet exchange. This connection method is shown in the figure below in which the community network in the previous figure has moved to the left, and is joined by a physical long-distance link to the Internet service router that remains in the exchange on the right.
Point-to-point backhaul is familiar. If the infrastructure is available — and this is a big ‘if’ — then backhaul is most often available from a utility company, such as a telecommunications or energy provider, that may also bundle Internet service as a way to reduce total costs. Even bundled, the total cost is variable and unaffordable to individual community networks, and is exacerbated by distance. Some community networks have succeeded in acquiring backhaul through university, research and education, or publicly-funded networks that are compelled or convinced to offer the service in the public interest. On the west coast of Scotland, for example, Tegola launched with service from the University of Highlands and Islands and the University of Edinburgh.
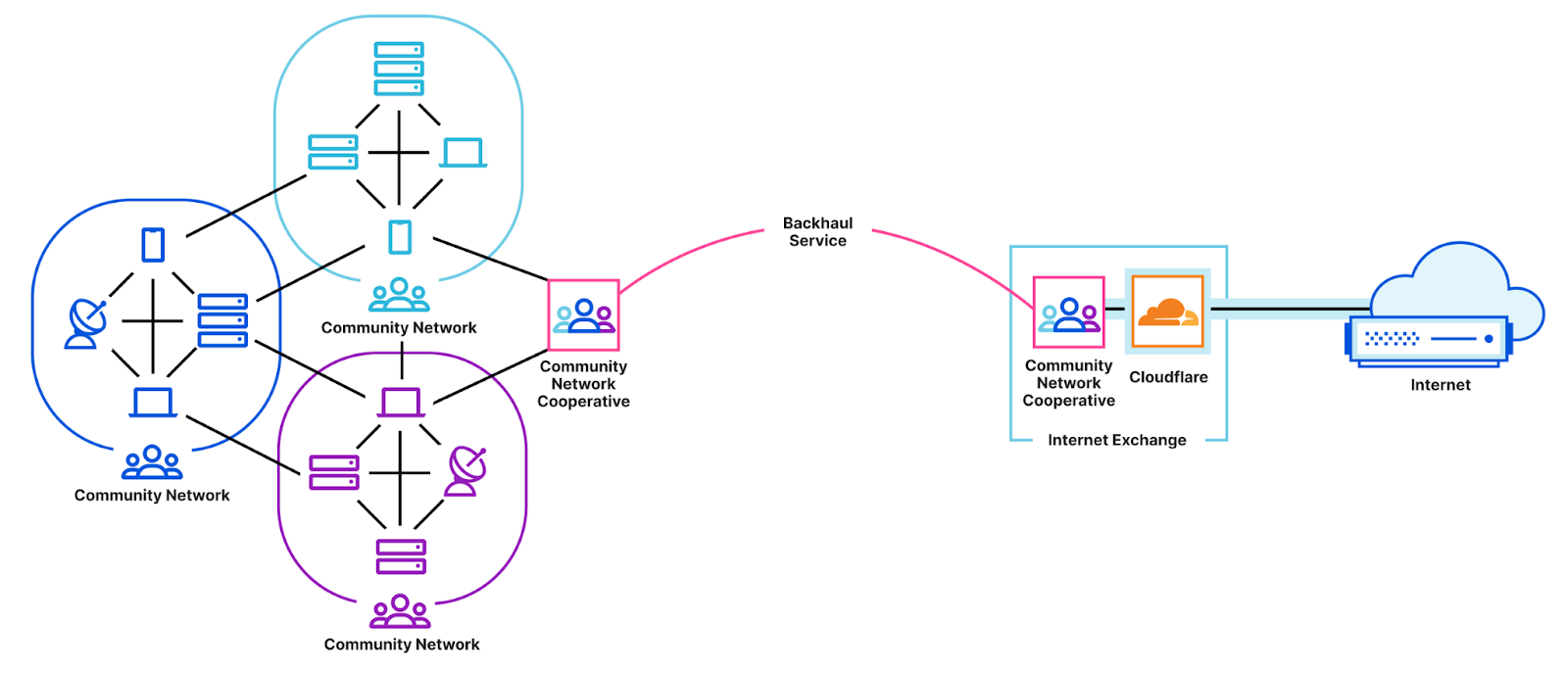
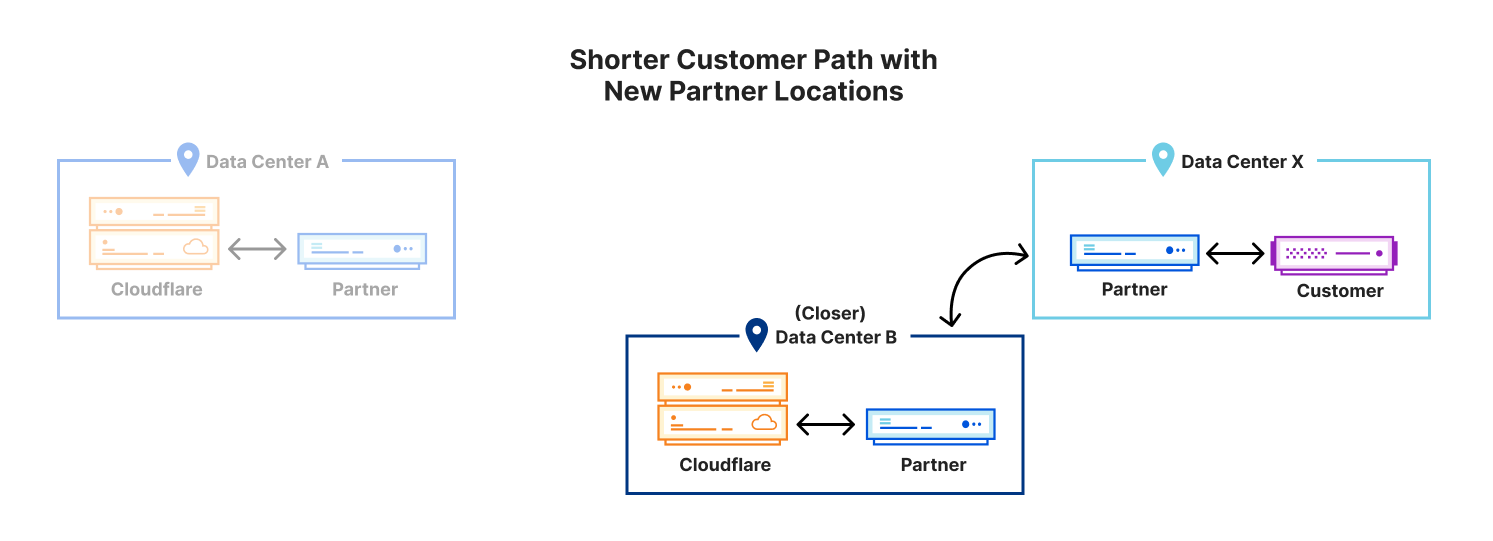
Start a backhaul cooperative for point-to-point and colocation. The last connection option we see among our launch partners overcomes the prohibitive costs by forming a cooperative network in which the individual subscriber community networks are also members. The cooperative model can be seen in the figure below. The exchange remains on the right. On the left the community network in the previous figure is now replaced by a collection of community networks that may optionally connect with each other (for example, to establish reliable routing if any link fails). Either directly or indirectly via other community networks, each of these community networks has a connection to a remote router at the near-end of the point-to-point connection. Crucially, the point-to-point backhaul service — as well as the co-located end-points — are owned and operated by the cooperative. In this manner, an otherwise expensive backhaul service is made affordable by being a shared cost.
Two of our launch partners, Guifi.net and HUBS c.i.c., are organised this way and their 10+ years in operation demonstrate both success and sustainability. Since the backhaul provider is a cooperative, the community network members have a say in the ways that revenue is saved, spent, and — best of all — reinvested back into the service and infrastructure.
Why is Cloudflare doing this?
Cloudflare’s mission is to help build a better Internet, for everyone, not just those with privileged access based on their geographical location. Project Pangea aligns with this mission by extending the Internet we’re helping to build — a faster, more reliable, more secure Internet — to otherwise underserved communities.
How can my community network get involved?
Check out our landing page to learn more and apply for Project Pangea today.
The ‘community’ in Cloudflare
Lastly, in a blog post about community networks, we feel it is appropriate to acknowledge the ‘community’ at Cloudflare: Project Pangea is the culmination of multiple projects, and multiple peoples’ hours, effort, dedication, and community spirit. Many, many thanks to all. ______
1For eligible networks, free up to 5Gbps at p95 levels.
If I’m completely honest, Cloudflare didn’t start out as a mission-driven company. When Lee, Michelle, and I first started thinking about starting a company in 2009 we saw an opportunity as the world was shifting from on-premise hardware and software to services in the cloud. It seemed inevitable to us that the same shift would come to security, performance, and reliability services. And, getting ahead of that trend, we could build a great business.
Matthew Prince, Michelle Zatlyn, and Lee Holloway, Cloudflare’s cofounders, in 2009.
One problem we had was that we knew in order to have a great business we needed to win large organizations with big IT budgets as customers. And, in order to do that, we needed to have the data to build a service that would keep them safe. But we only could get data on security threats once we had customers. So we had a chicken and egg problem.
Our solution was to provide a basic version of Cloudflare’s services for free. We reasoned that individual developers and small businesses would sign up for the free service. We’d learn a lot about security threats and performance and reliability opportunities based on their traffic data. And, from that, we would build a service we could sell to large businesses.
And, generally, Cloudflare’s business model made sense. We found that, for the most part, small companies got a low volume of cyber attacks, and so we could charge them a relatively small amount. Large businesses faced more attacks, so we could charge them more.
But what surprised us, and we only discovered because we were providing a free version of our service, was that there was a certain set of small organizations with very limited resources that received very large attacks. Servicing them was what made Cloudflare the mission-driven company we are today.
The Committee to Protect Journalists
If you ever want to be depressed, sign up for the newsletter of the Committee to Protect Journalists (CPJ). They’re the organization that, when a journalist is kidnapped or killed anywhere in the world, negotiates their release or, far too often, recovers their body.
I’d met the director of the organization at an event in early 2012. Not long after, he called me and asked if I wanted to meet three Cloudflare customers who were in town. I didn’t, I have to confess, but Michelle pushed me to take the meeting.
On a rainy San Francisco afternoon the director of CPJ brought three African journalists to our office. All three of them hugged me. One was from Ethiopia, another was from Angola, and the third they wouldn’t tell us his name or where he was from because he was “currently being hunted by death squads.”
For the next 90 minutes, I listened to stories of how the journalists were covering corruption in their home countries, how their work put them constantly in harm’s way, how powerful forces worked to silence them, how cyberattacks had been a constant struggle, and how, today, they depended on Cloudflare’s free service to keep their work online. That last bit hit me like a ton of bricks.
After our meeting finished, and we saw the journalists out, with Cloudflare T-shirts and other swag in hand, I turned to Michelle and said, “Whoa. What have we gotten ourselves into?”
Becoming Mission Driven
I’ve thought about that meeting often since. It was the moment I realized that Cloudflare had a mission beyond just being a good business. The Internet was a critically important resource for those three journalists and many others like them. At the same time, forces that sought to limit their work would use cyberattacks to shut them down. While we hadn’t set out to ensure everyone had world-class cybersecurity, regardless of their ability to pay, now it seemed critically important.
With that realization, Cloudflare’s mission came naturally: we aim to help build a better Internet. One where you don’t need to be a giant company to be fast and reliable. And where even a journalist, working on their own against daunting odds, can be secure online.
This is why we’ve prioritized projects that give back to the Internet. We launched Project Galileo, which provides our enterprise-grade services to organizations performing politically or artistically important work. We launched the Athenian Project to help protect elections against cyber attacks. We launched Project Fair Shot to make sure the organizations distributing the COVID-19 vaccine had the technical resources they needed to do so equitably.
And, even on the technical side, we work hard to make the Internet better even when there’s no clear economic benefit to us, or even when it’s against our economic benefit. We don’t monetize user data because it seems clear to us that a better Internet is a more private Internet. We enabled encryption for everyone even though, when we did it, it was the biggest differentiator between our free and paid plans and the number one reason people upgraded. But clearly a better Internet was an encrypted Internet, and it seemed silly that someone should have to pay extra for a little bit of math.
Our First Impact Week
This week we kick off Cloudflare’s first Impact Week. We originally conceived the idea of the week as a way to highlight some of the things we were doing as a company around our environmental, social, and governance (ESG) initiatives. But, as is the nature of innovation weeks at Cloudflare, as soon as we announced it internally our team started proposing new products and features to take some of our existing initiatives even further.
So, over the course of the week, in addition to talking about how we’ve built our network to consume less power we’ll also be demonstrating how we’re increasingly using hyper power-efficient Arm-based servers to achieve even higher levels of efficiency in order to lessen the environmental impact of running the Internet. We’ll launch a new Workers option for developers who want to be more environmentally conscious. And we’ll announce an initiative in partnership with other leading Internet companies that we hope, if broadly adopted, could cut down as much as 25% of global web traffic and the corresponding energy wasted to serve it.
We’ll also focus on how we can bring the Internet to more people. While broadband has been a revolution where it’s available, rural and underserved-urban communities around the world still suffer from slow Internet speeds and limited ISP choice. We can’t completely solve that problem (yet) but we’ll be announcing an initiative that will help with some critical aspects.
Finally, as Cloudflare becomes a larger part of the Internet, we’ll be announcing programs both to monitor the network’s health, affirm our commitments to human rights, and extend our protections of critical societal functions like protecting elections.
When I first was trying to convince Michelle that we should start a business together, I pitched her a bunch of ideas. Most of them involved finding a clever way to extract rents from some group or another, often for not much benefit to society at large. Sitting in an Ethiopian restaurant in Central Square, I remember so clearly her saying to me, “Matthew, those are all great business ideas. But they’re not for me. I want to do something where I can be proud of the work we’re doing and the positive impact we’ve made.”
That sentence made me go back to the drawing board. The next business idea I pitched to her turned out to be Cloudflare. Today, Cloudflare’s mission remains helping build a better Internet. And, as we kick off Impact Week, we are proud to continue to live that mission in everything we do.
So you’ve built an application on the Workers platform. The first thing you might be wondering after pushing your code out into the world is “what does my production traffic look like?” How many requests is my Worker handling? How long are those requests taking? And as your production traffic evolves overtime it can be a lot to keep up with. The last thing you want is to be surprised by the traffic your serverless application is handling. But, you have a million things to do in your day job, and having to log in to the Workers dashboard every day to check usage statistics is one extra thing you shouldn’t need to worry about.
Today we’re excited to launch Workers usage notifications that proactively send relevant usage information directly to your inbox. Usage notifications come in two flavors. The first is a weekly summary of your Workers usage with a breakdown of your most popular Workers. The second flavor is an on-demand usage notification, triggered when a worker’s CPU usage is 25% above its average CPU usage over the previous seven days. This on-demand notification helps you proactively catch large changes in Workers usage as soon as those changes occur whether from a huge spike in traffic or a change in your code.
As of today, if you create a new free account with Workers, we’ll enable both the weekly summary and the CPU usage notification by default. All other account types will not have Workers usage notifications turned on by default, but the notifications can be enabled as needed. Once we collect substantial user feedback, our goal is to turn these notifications on by default for all accounts.
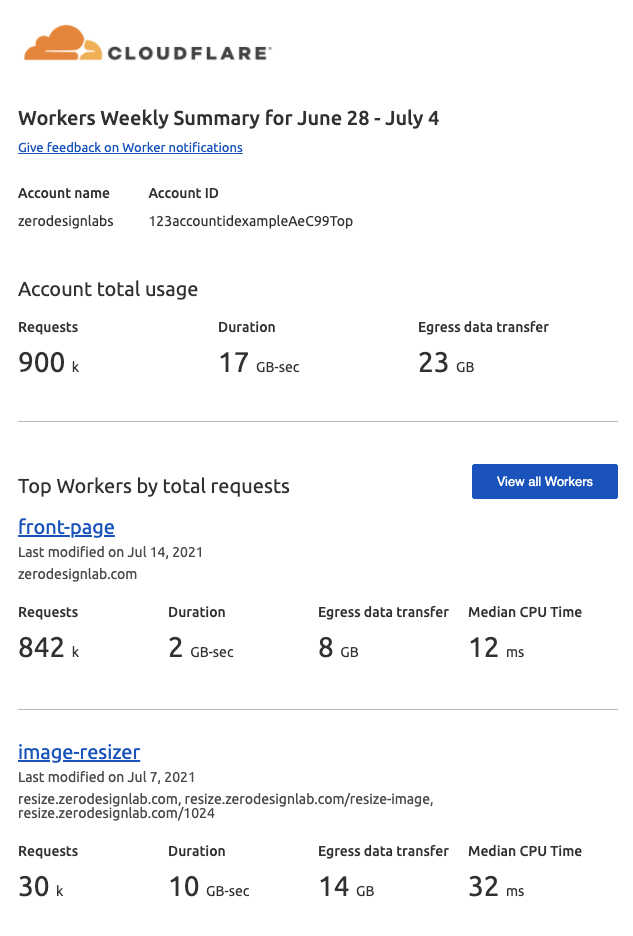
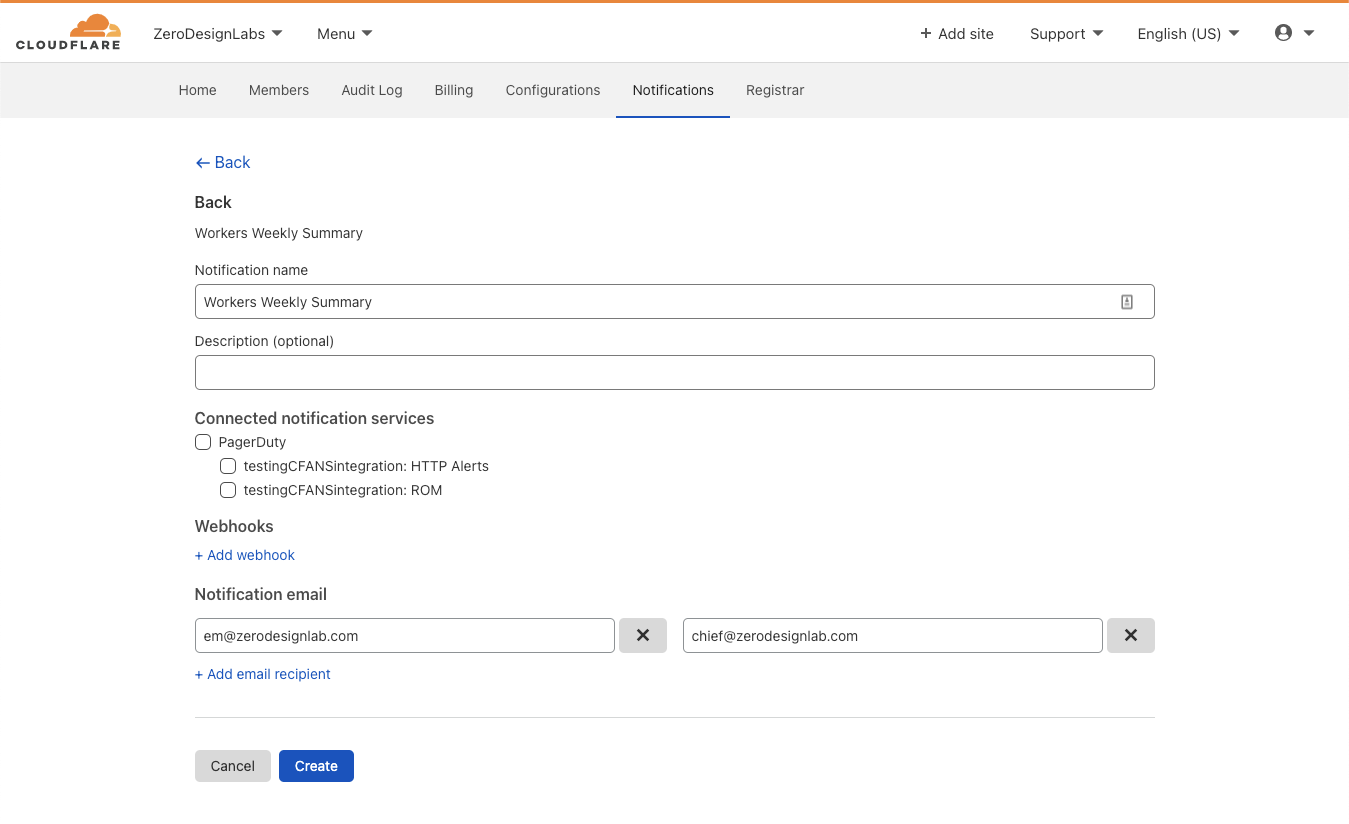
The Worker Weekly Summary
The mission of the Worker Weekly Summary is to give you a high-level view of your Workers usage automatically, in your inbox, without needing to sign in to the Worker’s dashboard. The summary includes valuable information such as total request counts, duration and egress data transfer, aggregated across your account, with breakouts for your most popular Workers that include median CPU time. Where duration accounts for the entire time your Worker spends responding to a request, CPU time is the time a script spends in computational work on the Cloudflare edge, discounting any time spent waiting on network requests, including requests to third-party APIs.
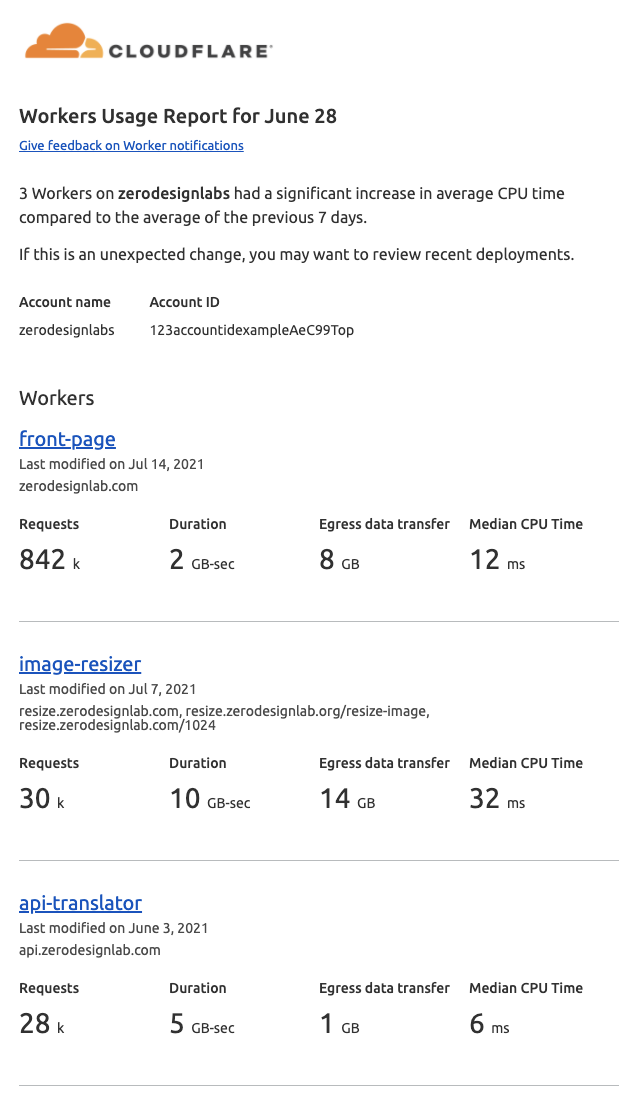
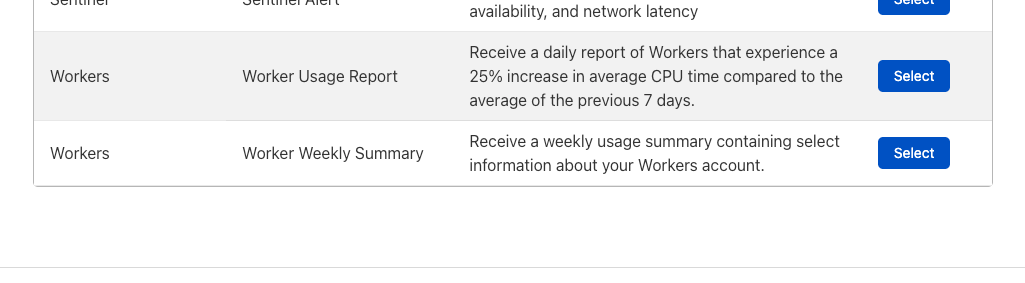
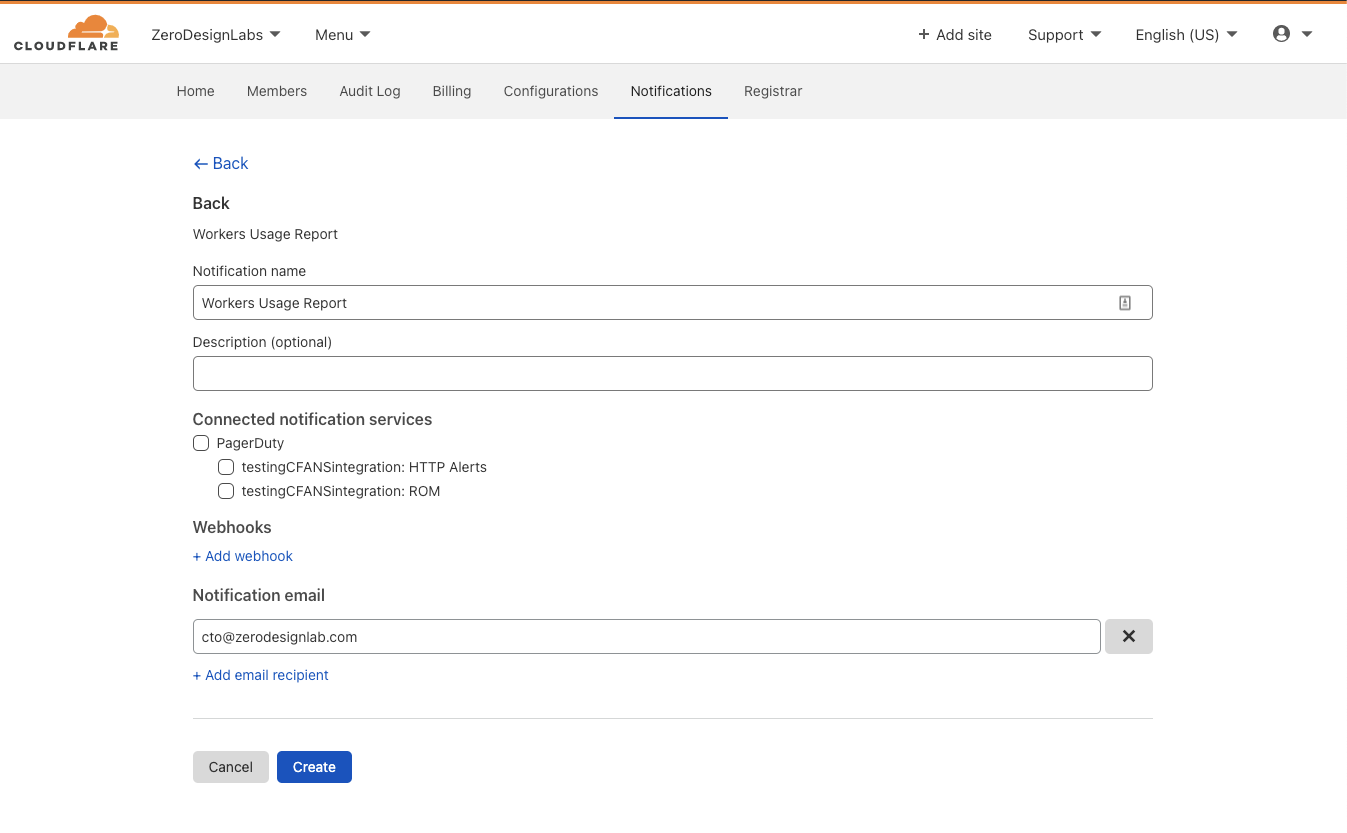
Workers Usage Report
Where the Workers Weekly Summary provides a high-level view of your account usage statistics, the Workers Usage Report is targeted, event-driven and potentially actionable. It identifies those Workers with greater than a 25% increase in CPU time compared to the average of the previous 7 days (i.e., those Workers taking significantly more CPU resources now than in the recent past).
While sometimes these increases may be no surprise, perhaps because you’ve recently pushed a new deployment that you expected to do more CPU heavy work, at other times they may indicate a bug or reveal that a script is unintentionally expensive. The Workers Usage Report gives us an opportunity to let you know when a noticeable change in your compute footprint occurs, so that you can remedy any potential problems right away.
Enabling Notifications
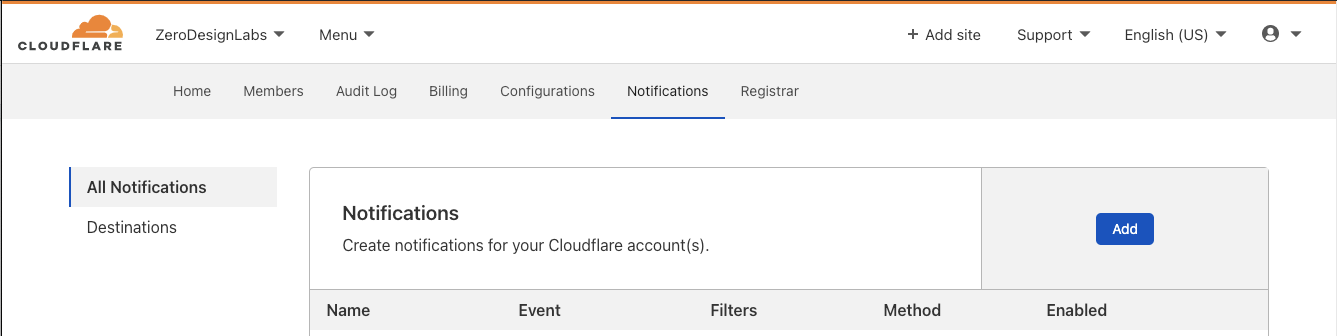
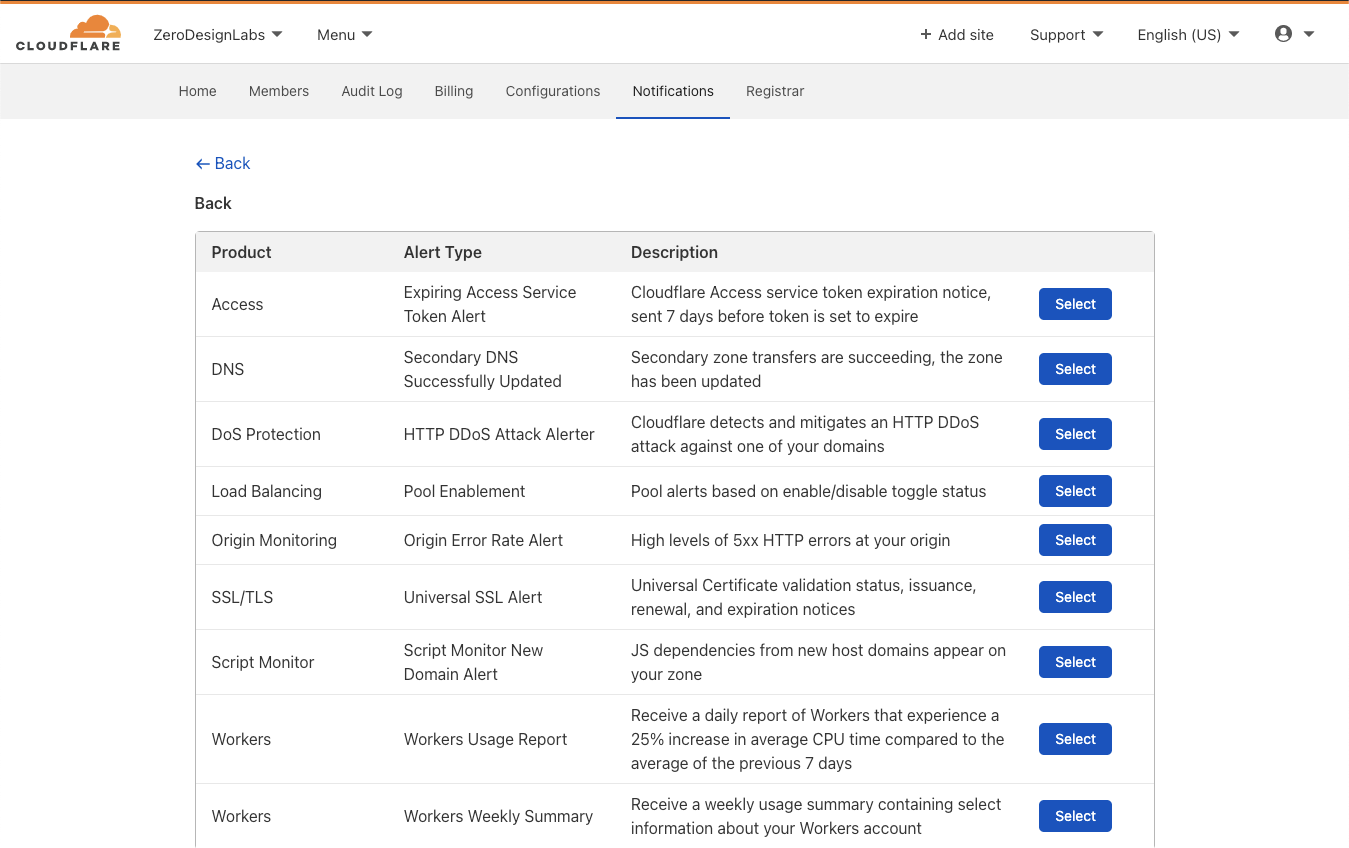
If you’d like to explicitly opt in to notifications, you can start off by clicking Add in the Notifications section of the Cloudflare zone dashboard.
After clicking Add, note the two new entries below “Create Notifications” under the “Workers” Product:
Click on the Select box in line with “ Weekly Summary” for the weekly roll-up, which will then allow you to configure email recipients, webhooks or connect the notification to PagerDuty.
Clicking Select next to “Usage Report” for CPU threshold notifications will send you to a similar configuration experience where you can customize email recipients and other integrations.
What’s next?
As mentioned above, we’re enabling notifications by default for all new free plans on Workers. Before rolling out these notifications by default to all our users, we want to hear from you. Let us know your experience with our Workers usage notifications by joining our Developer Community discord or by sending feedback via the survey in the email notifications.
Our Workers Weekly Summary and on-demand CPU usage notification are just the beginning of our journey to support a wide range of useful, relevant notifications that help you get visibility into your deployments. We want to surface the right usage information, exactly when you need it.
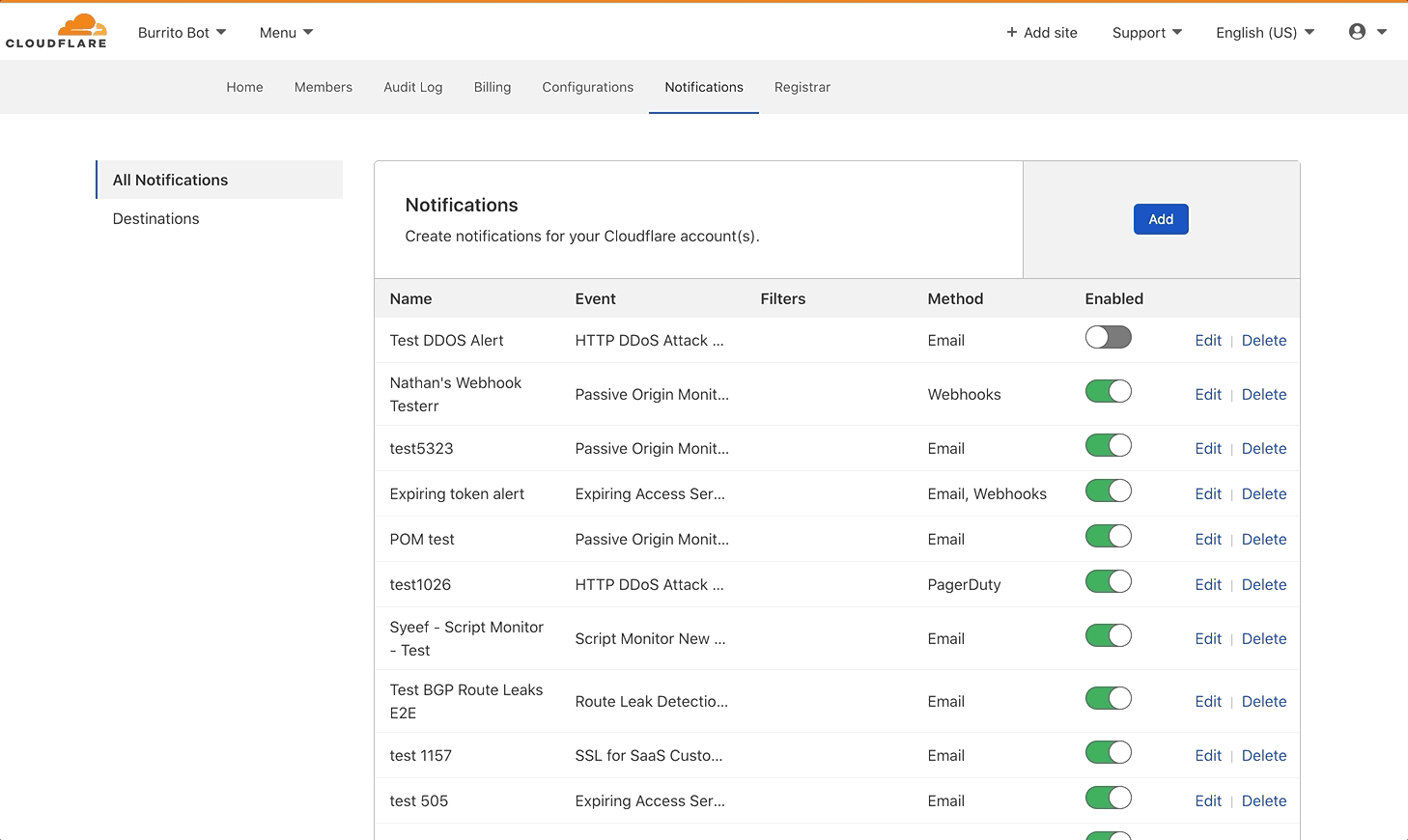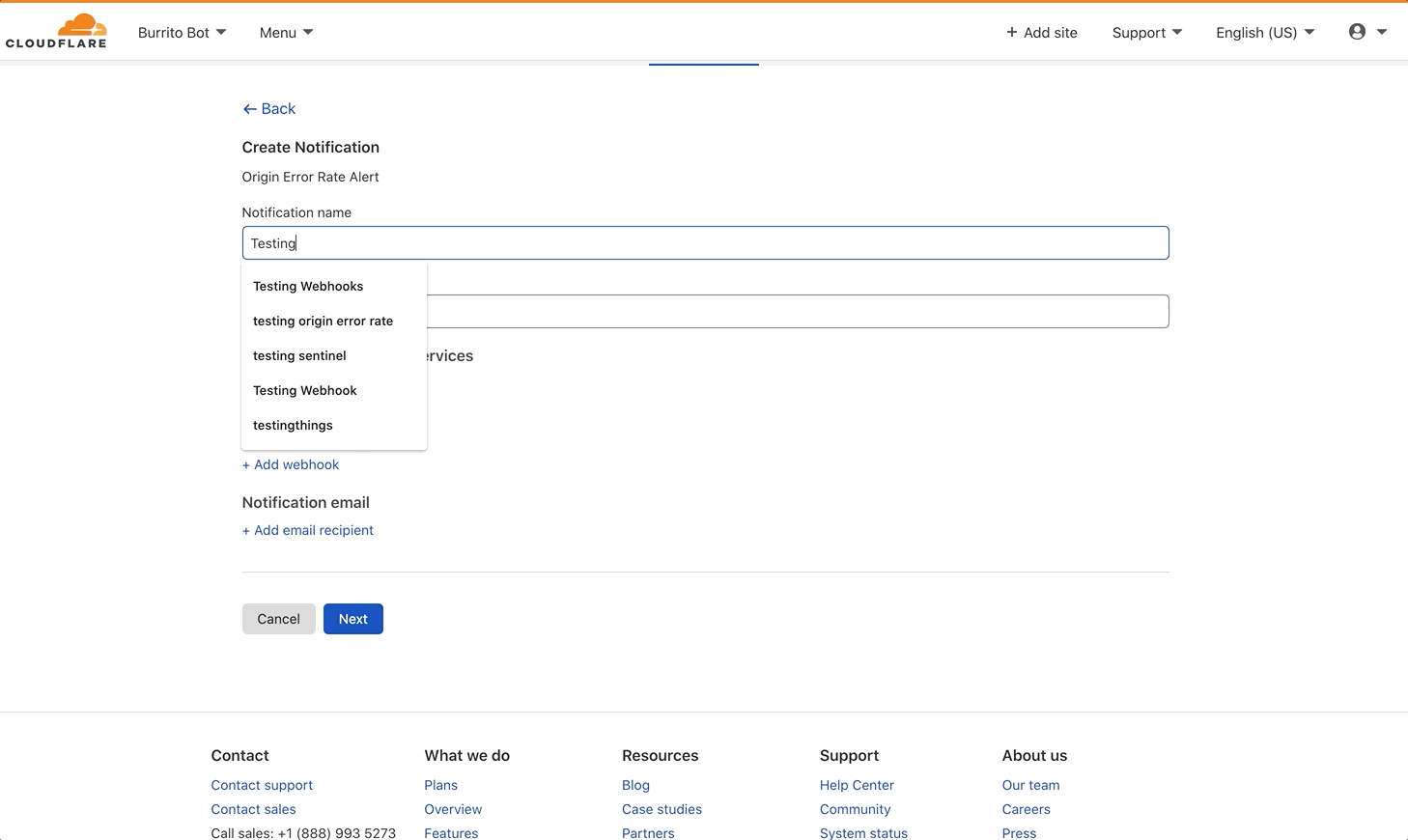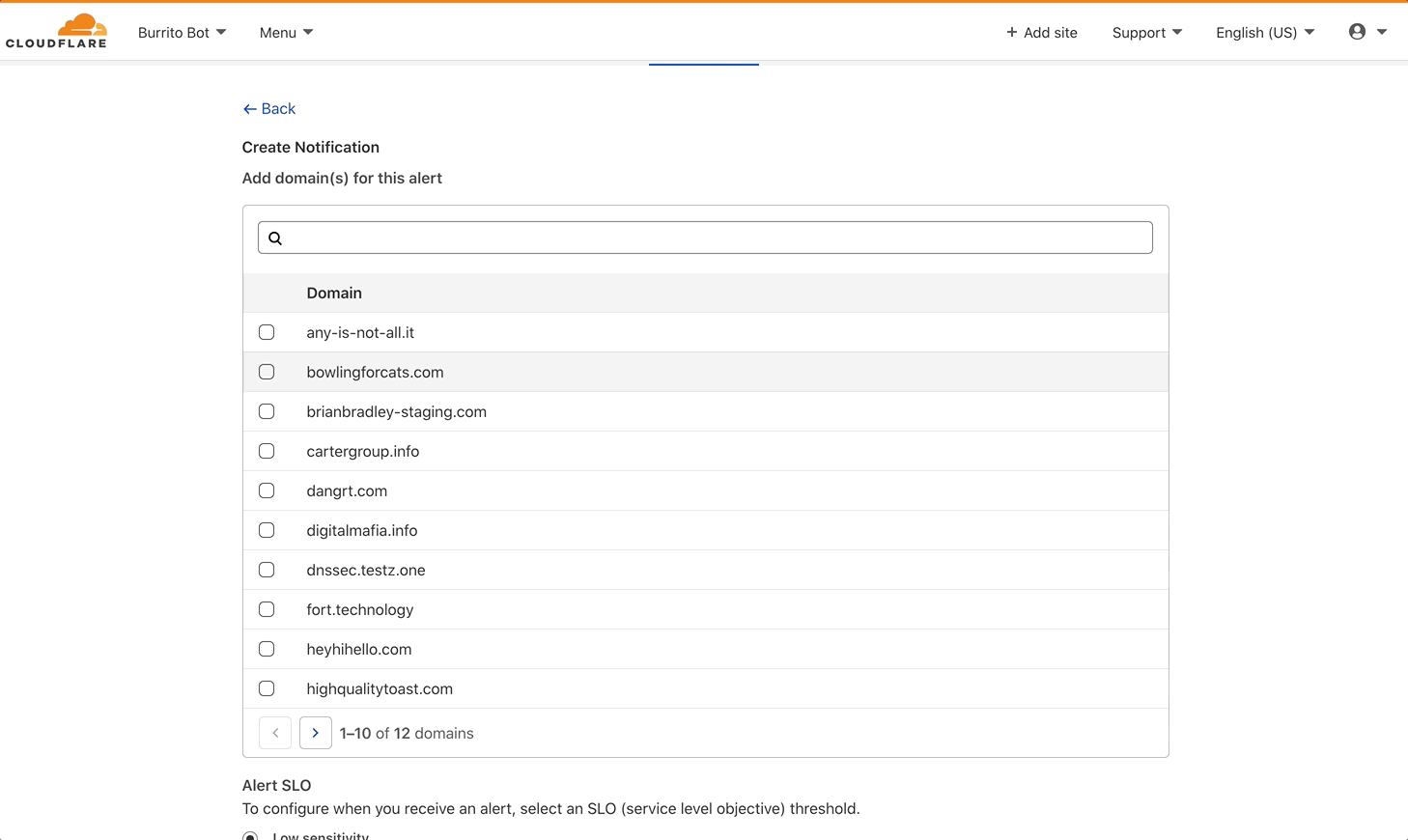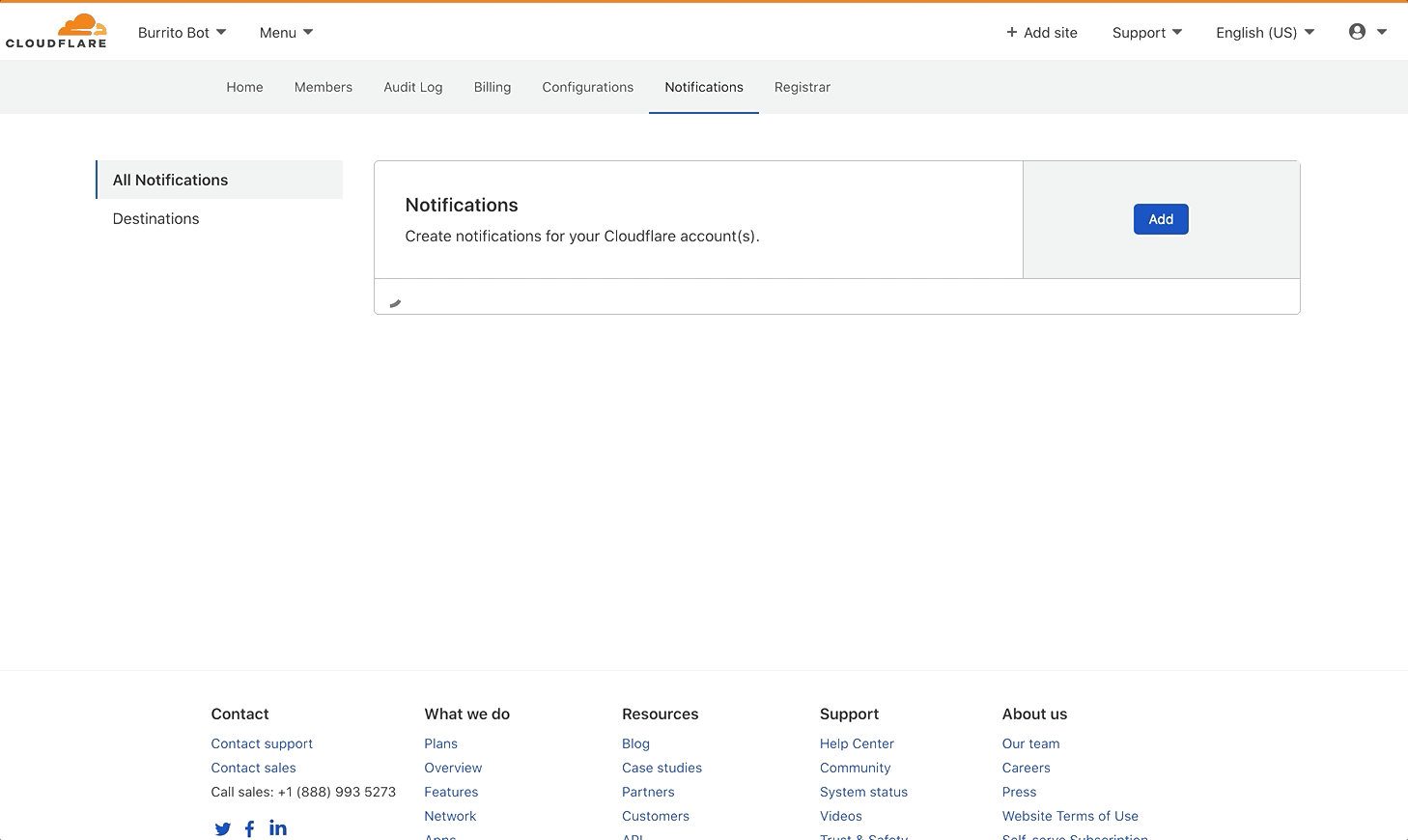
Today we’re excited to announce Origin Error Rate notifications: a new, sophisticated way to detect and notify you when Cloudflare sees elevated levels of 5xx errors from your origin.
In 2019, we announced Passive Origin Monitoring alerts to notify you when your origin goes down. Passive Origin Monitoring is great — it tells you if every request to your origin is returning a 521 error (web server down) for a full five minutes. But sometimes that’s not enough. You don’t want to wait for all of your users to have issues; you want to be notified when more users than normal are having issues before it becomes a big problem.
Calculating Anomalies
No service is perfect — we know that a very small percentage of your origin responses are likely to be 5xx errors. Most of the time, these issues are one-offs and nothing actually needs to be done. However, for Internet properties with very high traffic, even a very small percentage could potentially be a large number. If we alerted you for every one of these errors, you would never stop getting useless notifications. When it comes to notifying, the question isn’t whether there are any errors, but how many errors need to exist before it’s a problem.
So how do we actually tell if something is a problem? As humans, it’s relatively easy for us to look at a graph, identify a spike, and think “hmm, that’s not supposed to be there.” For a computer it gets a little more complicated. Unlike humans, who have intuition and can exercise judgement in grey areas, a computer needs an exact set of criteria to tell whether something is out of the ordinary.
The simplest way to detect abnormalities in a time series dataset is to set a single threshold — for example, “notify me whenever more than 5% of the requests to my Internet properties result in errors.” Unfortunately, it’s really hard to pick an effective threshold. Too high and you never actually get notified; too low, and you’re drowning in notifications:
Even when we find that happy medium, we can still miss issues that burn “low and slow”. This is where there’s no obvious, dramatic spike, but something has been going a little wrong for a long time:
We can try layering on multiple thresholds. For example: notify you if the error rate is ever over 10%, or if it’s over 5% for more than five minutes, or if it’s over 2% for more than 10 minutes. Not only does this quickly become complicated, but it also doesn’t account for periodic issues, such as kubernetes pods restarting or deployments going out at a regular interval. What if the error rate is over 5% for only four minutes, but it happens every five minutes? We know that a lot of your end users are being affected, but even the long set of rules listed above wouldn’t catch it.
So thresholds probably aren’t sophisticated enough to detect origin issues. Instead, we turn to the Google SRE Handbook for alerting based on Service Level Objectives (SLOs). An SLO is a part of an agreement between a customer and a service provider. It’s a defined metric and value that both parties agree on. One of the most common types of SLOs is availability, or “the service will be available for a certain percentage of the time”. In this case, the service is your origin and the agreement is between you and your end users. Your end users expect your origin to be available a certain percent of the time.
If we revisit our original concept, we know that you’re comfortable with your origin returning a certain number of errors. We define that number as your SLO. An SLO of 99.9 means that you’re OK with 0.01% of all of your requests over a month being errors. Therefore, 0.01% of all the requests that reach your origin is your total error budget — you can have this many errors in a month and never be notified, because you’ve defined that as acceptable.
What you really want to know is when you’re burning through that error budget too quickly — this probably means that something is actually going wrong (instead of a one-time occurrence). We can measure a burn rate to gauge how quickly you’re burning through your error budget, given the rate of errors that we’re currently seeing. A burn rate of one means that the entirety of the error budget will be used up exactly within the set time period — an ideal scenario. A burn rate of zero is even better since we’re not seeing any errors at all, but ultimately is pretty unrealistic. A burn rate of 10 is most likely a problem — if that rate keeps up for the full month, you’ll have had 10x the number of errors than you originally said was acceptable.
Even when using burn rates instead of thresholds, we still want to have multiple criteria. We want to measure a short time period with a high burn rate (a short indicator). This covers your need to “alert me quickly when something dramatic is happening.” But we also want to have a longer time period with a lower burn rate (a long indicator), in order to cover your need to “don’t alert me on issues that are over quickly.” This way we can ensure that we alert quickly without sending too many false positives.
Let’s take a look at the life of an incident using this methodology. In our first measurement, the short indicator tells us it looks like something is starting to go wrong. However, the long indicator is still within reasonable bounds. We’re not going to sound the alarm yet.
When we measure next, we see that the problem is worse. Now we’re at the point where there are enough errors that not only is the short indicator telling us there’s something wrong, but the long indicator has been impacted too. We feel confident that there’s a problem, and it’s time to notify you.
A couple cycles later, the incident is over. The long indicator is still telling us that something is wrong, because the incident is still within the long time period. However, the short indicator shows that nothing is currently concerning. Since we don’t have both indicators telling us that something is wrong, we won’t notify you. This keeps us from sending notifications for incidents that are already over.
This methodology is cool because of how well it responds to different incidents. If the original spike had been more dramatic, it would have triggered both the long and short indicators immediately. The more errors we’re seeing, the more confident we are that there’s an issue and the sooner we can notify you.
Even with this methodology, we know that different services behave differently. So for this notification, you can choose the Service Level Objective (SLO) you want to use to monitor your Internet property: 99.9% (high sensitivity), 99.8% (medium sensitivity), or 99.7% (low sensitivity). You can also choose which Internet properties you want to monitor — no need to be notified for test properties or lower priority domains.
Getting started today
HTTP Origin Error Rate notifications can be configured in the Notifications tab of the dashboard. Select Origin Error Rate Alert as your alert type. As with all Cloudflare notifications, you’re able to name and describe your notification, and choose how you want to be notified. From there, you can select which domains you want to monitor, and at what SLO.
This notification is available to all Enterprise customers. If you’re interested in monitoring your origin, we encourage you to give it a try.
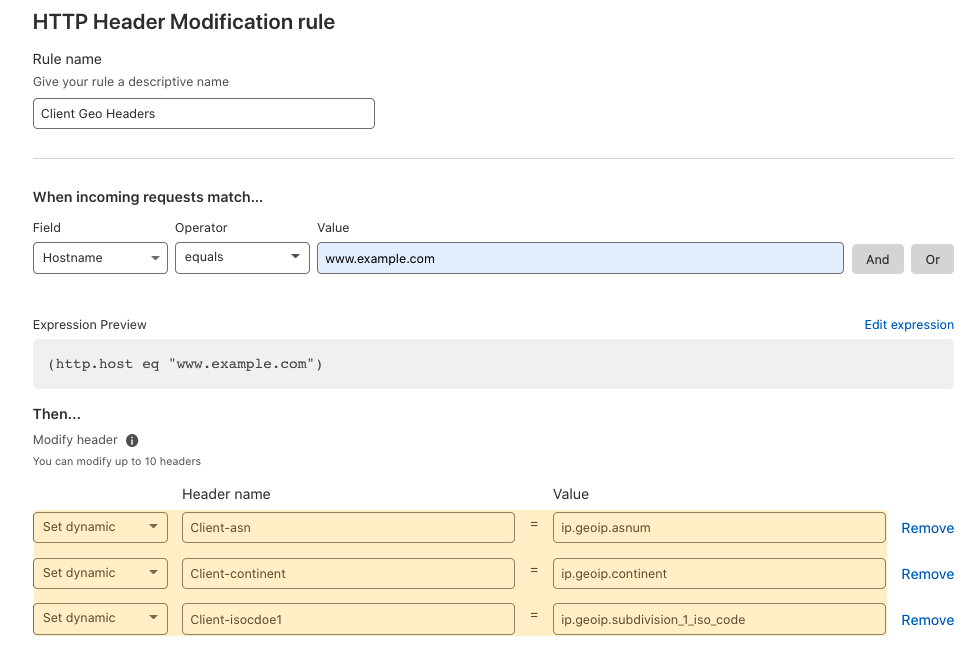
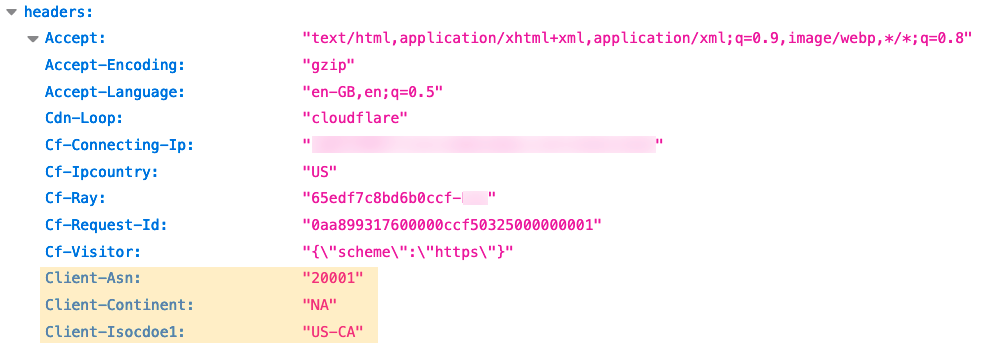
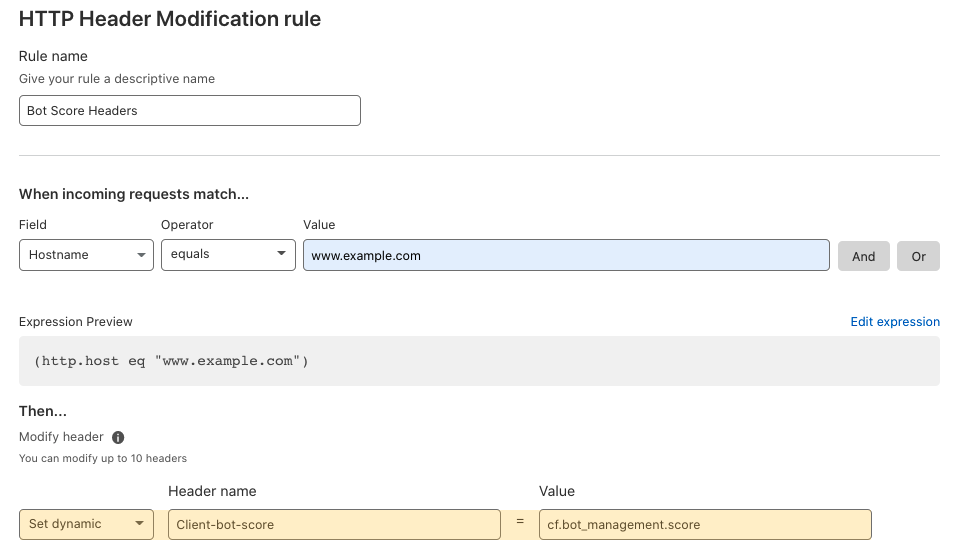
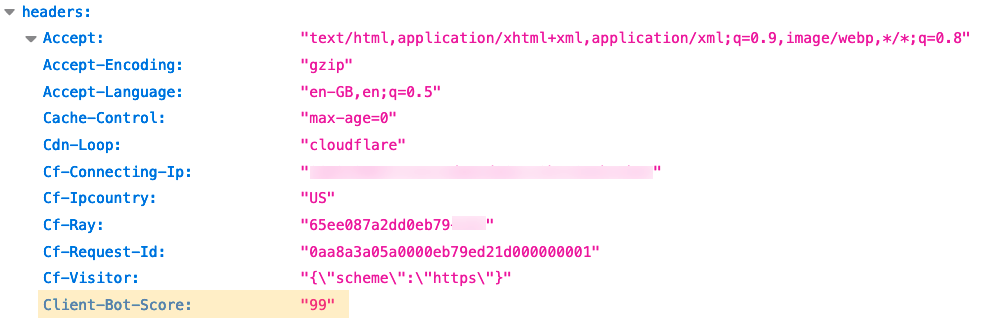
Applications expect specific inputs in order to perform optimally. Techniques used to shape inputs to meet an application’s requirements might include normalizing the URLs to conform to a consistent formatting standard, rewriting the URL’s path and query based on different conditions and logic, and/or modifying headers to indicate an application’s specific information. These are expensive to run and complex to manage. Cloudflare can help you to offload the heavy lifting of modifying requests for your servers with Transform Rules. In this blog we will cover the nuts and bolts of the functionality.
Origin server🤒 : Thank you so much for offloading that for me, Cloudflare
Cloudflare edge servers😎 : No problem, buddy, I have taken care of that for you
Why do people need Transform Rules?
When it comes to modifying an HTTP/HTTPS request with normalization, rewriting the URLs, and/or modifying headers, Cloudflare users often use Cloudflare Workers, code they craft that runs on Cloudflare’s edge.
Cloudflare Workers open the door to many possibilities regarding the amount of work that can be done for your applications, close to where your end users are located. It provides a serverless execution environment that allows you to create application functionality without configuring or maintaining infrastructure. However, using a Worker to modify the request is kind of like wearing a diving suit in a kiddie pool. Therefore, a simple tool to modify requests without Workers has long been wanted.
It’s in this context that we looked at the most common request modifications that customers were making, and built out Transform Rules to cover them. Once Transform Rules were announced we anticipated they’d become the favourite tool in our customers’ tool box.
What do Transform Rules do?
URL Normalization: normalizes HTTP requests to a standard format which then allows you to predictably write security rule filters.
URL Rewrite: static and dynamic rewrites of the URL’s path and/or query string based on various attributes of the request.
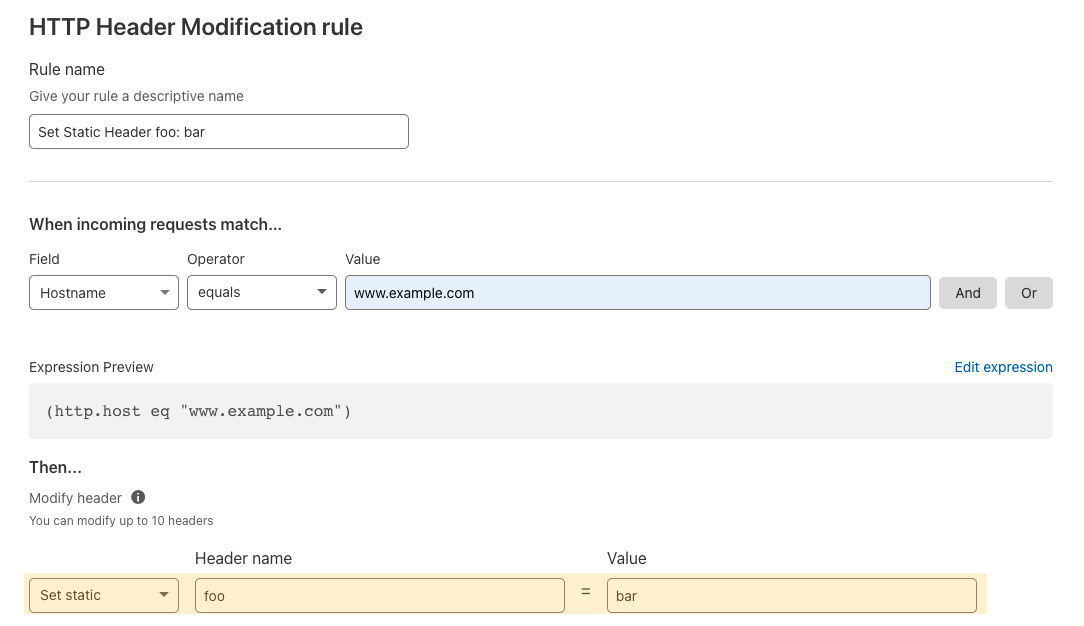
Header Modify: add or remove static or dynamic headers (based on Cloudflare specific attributes) to requests based on different various attributes of the request.
URL Normalization
Bad actors on the Internet often encode your URLs to attack your applications because encoded URLs can bypass some security rules. URL Normalization transforms the request URL from encoded to unencoded before Cloudflare’s security features, so no one can bypass the firewall rules you configure.
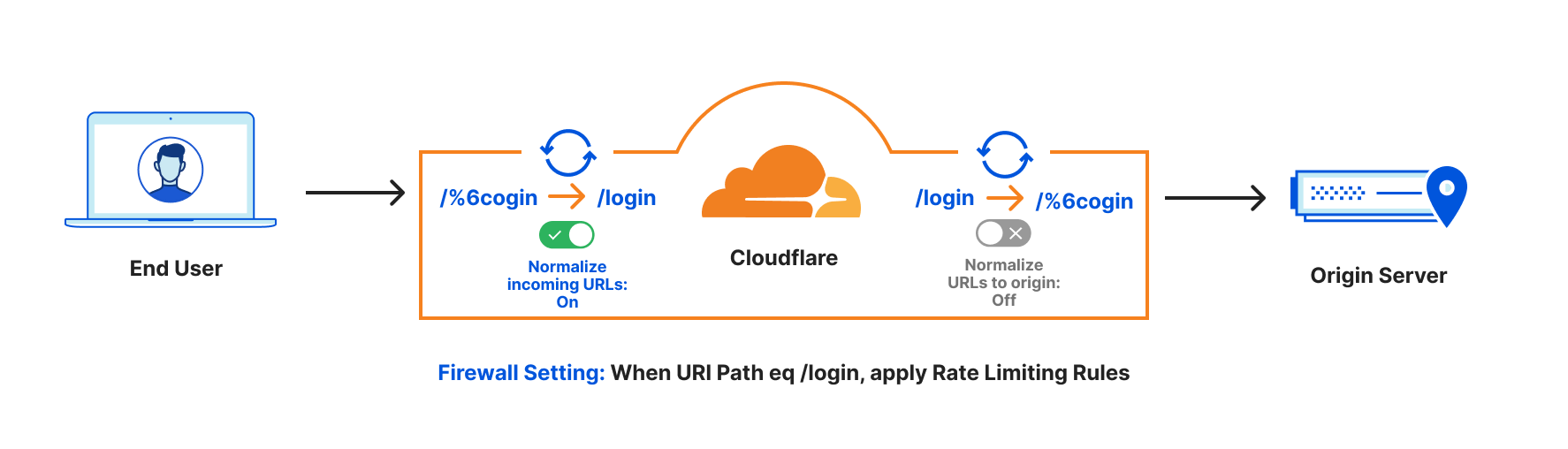
For example, say you had a rate limiting rule for the path “/login” but someone sent the request as “/%6cogin”. Illustrated below:
You😤: Rate Limiting for https://www.example.com/login to avoid brute force attacks.
Attacker😈: You think you can stop me? I will issue massive requests to https://www.example.com/%6cogin to bypass your rate limiting rule.
Without URL Normalization, the request would bypass the rate limiting rule, but with URL Normalization the request is converted from the URL path /%6cogin to /login before the rule is applied.
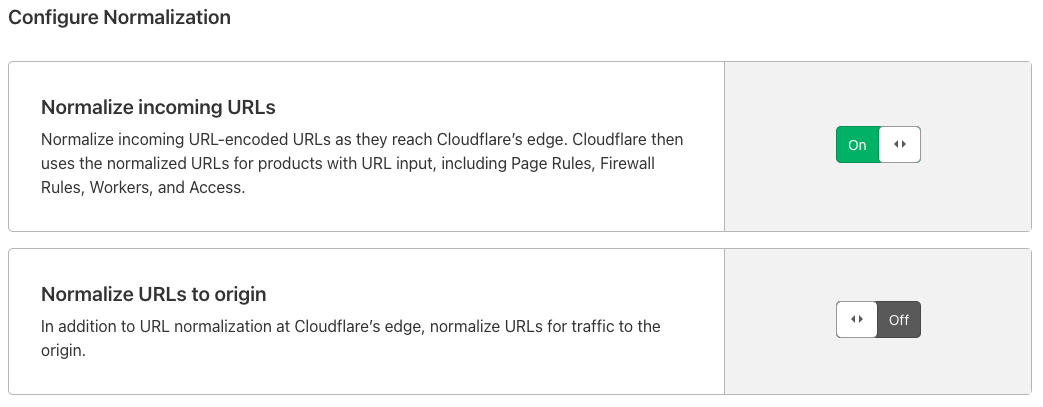
By default, URL Normalization is enabled for all the zones on Cloudflare at Cloudflare’s edge, and disabled when going to origins. This means incoming URLs will be decoded to standard format before any Cloudflare security execution. When going back to the origins, we will use the original URL. In this way, no encoded URL can bypass security features and the origin also can see the original URL.
The default settings are flexible to adjust if you need. This FAQ page has more information about URL Normalization.
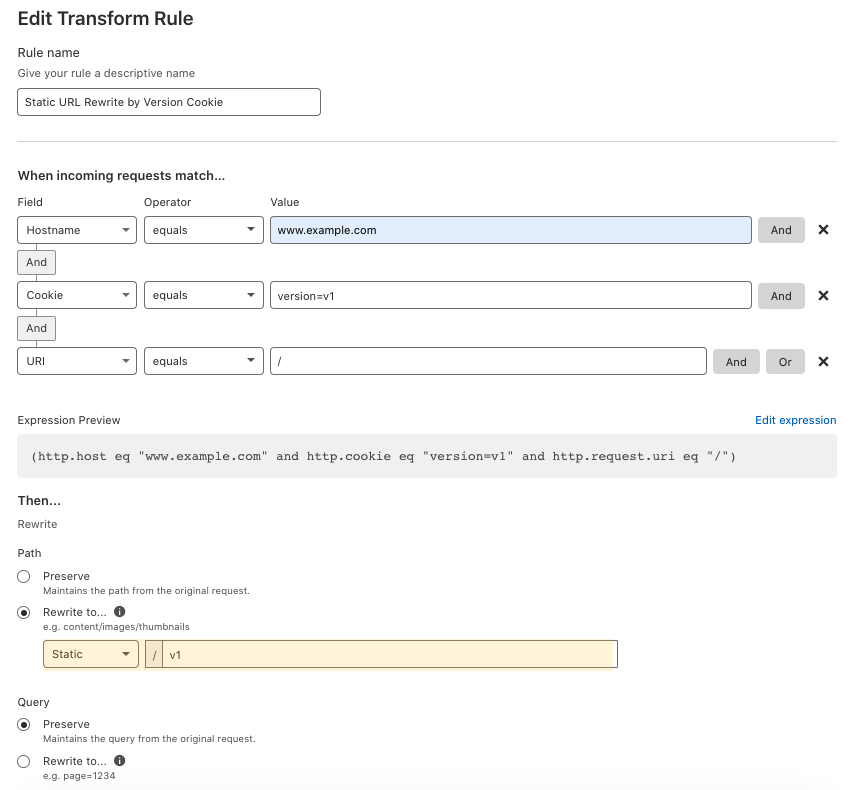
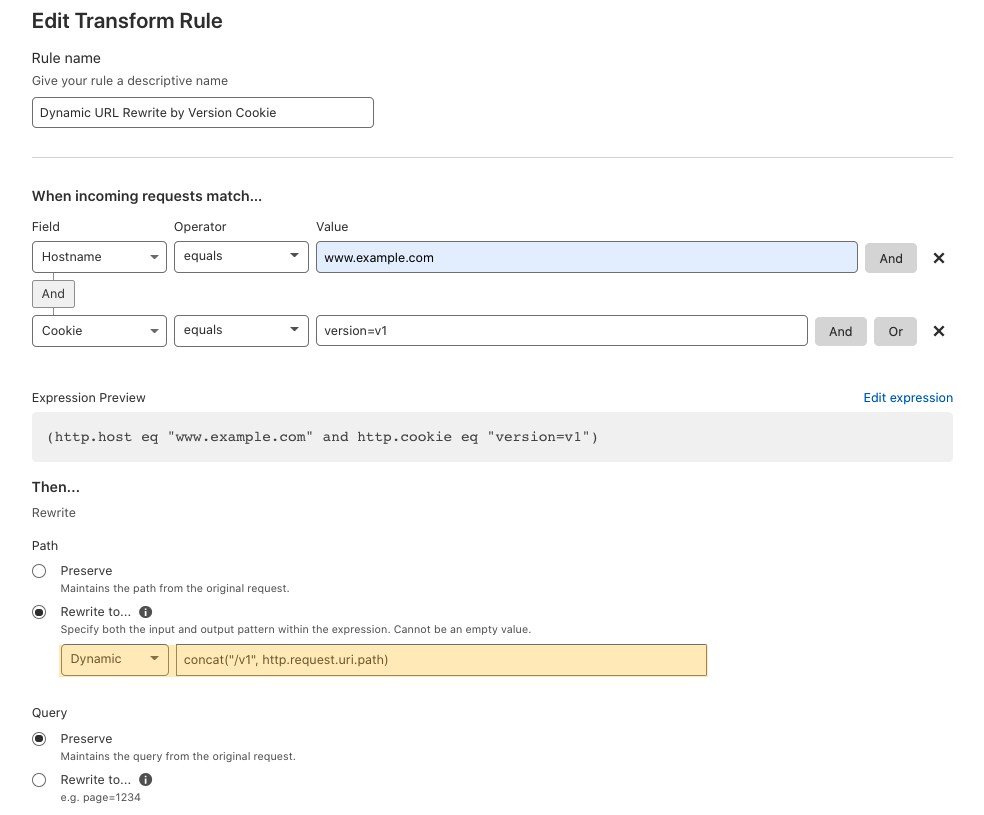
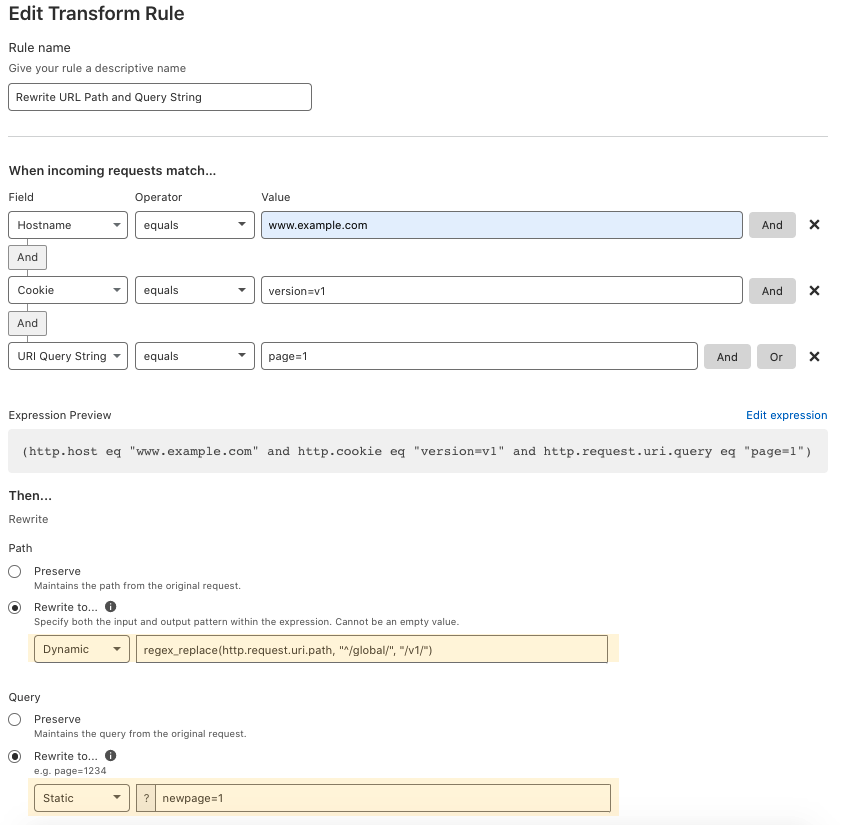
URL Rewrite
When talking about URL Rewrites, we always want to distinguish them from URL Redirects. They are like twins. Rewrites is a server-side modification of the URL before it is fully processed by the web server. This will not change what is seen in the user’s browser. Redirects forward URLs to other locations via a 301 or 302 HTTP status code. This will change what is seen in the user’s browser. You can do a URL Redirect with “Forwarding URL” in Cloudflare Pages Rules. Page Rules trigger actions whenever a request matches one of the URL patterns you define.
Transform Rules come into play when we need to use URL Rewrite. This allows you to rewrite a URL’s path and/or query string based on the logic of your applications. The rewrite can be a fixed string (which we call ‘static’) or a computed string (called ‘dynamic’) based on various attributes of a request, like the country it came from, the referrer, or parts of the path. These rewrites come before products such as Firewall Rules, Page Rules, and Cloudflare Workers.
Static URL Rewrite Example
When visitingwww.example.com with a cookie of version=v1, you want to rewrite the URL to www.example.com/v1when going to the origin server. In this case, the end-user facing URL will not change, but the content will be the /v1’s content. This is a static URL rewrite. It only does rewrites when end users visit the URL www.example.com with cookie version=v1. It can help you to do A/B testing when rolling out new content.
Dynamic URL Rewrite Example
When visiting any URL of www.example.com with a cookie of version=v1, you want to rewrite the request by adding /v1/ to the beginning of the URL for v1 content, when going to the origin server.
In this use case, when end users visit www.example.com/Literaturelibrary/book1314with cookie version=v1,Cloudflare will rewrite the URL towww.example.com/v1/Literaturelibrary/book1314.
When end users visit www.example.com/fictionlibrary/book52/line43/universewith cookie version=v1,Cloudflare will rewrite the URL towww.example.com/v1/fictionlibrary/book52/line43/universe.
In this case, the URL visible in the client’s browser will not change, but the content returned will be from the /v1 location. This is a dynamic URL rewrite, so it applies the rewrite to all URLs when end users visit with the cookie.
Another Dynamic URL Rewrite Example
When visiting any URL of www.example.com with a cookie of version=v1 and query string of page=1 that has /globalin the beginning of the URL, this rule rewrites the request by replacing /globalin the beginning for the URL with /v1 and updates the query string to newpage=1, when going to the origin server.
When end users visit www.example.com/global/Literaturelibarary/book1013?page=1with cookie of version=v1, Cloudflare will rewrite the URL towww.example.com/v1/Literaturelibarary/book1013?newpage=1.
And when end users visit www.example.com/global/fictionlibarary/book52/line43/universe?page=1with cookie of version=v1, Cloudflare will rewrite the URL towww.example.com/v1/fictionlibarary/book52/line43/universe?newpage=1.
In this case, the end-user facing URLs will not change, but the content will be v1’s content. This is a dynamic URL rewrite, so it applies the rewrite to all URLs when end users visit with the cookie of version=v1 and a query string of page=1.
Header Modify
Adding/removing request headers of the requests when going to origin servers. This is one of the most requested features of customers using Cloudflare Workers, especially those sending the Bot Score as a request header to origin. You can use this feature to add/remove strings and non-strings, and static or dynamic request header values.
Set Static header: Adds a static header and value to the request and sends it to the origin.
For example, add a request header such as foo: bar only when the requests have the hostname of www.example.com.
With the above setting, Cloudflare appends a static header Foo: bar to your origin when this rule triggers. Here is what the origin should see.
Set Dynamic header : Adds a dynamic header value from the computed field, like the end user’s geolocation.
The dynamic request headers are added.
Set Dynamic Bot Management headers: Cloudflare Bot Management protects applications from bad bot traffic by scoring each request with a “bot score” from 1 to 99. With Bot Management enabled, we can send the bot score to the origin server as a request header via Transform Rules.
The bot score header is added.
It has never been easier
With Transform Rules, you can modify the request with URL Normalization, URL Rewrites, and HTTP Header Modification with easy settings to power your application. There’s no script required for Cloudflare to offload those duties from your origin servers. Just like Optimus Prime says “Autobots, transform and roll out!”, Cloudflare says “Requests, transform and roll out!”.
A couple of months ago, we announced the general availability of Cloudflare Pages: the easiest way to host and collaboratively develop websites on Cloudflare’s global network. It’s been amazing to see over 20,000 incredible sites built by users and hear your feedback. Since then, we’ve released user-requested features like URL redirects, web analytics, and Access integration.
We’ve been listening to your feedback and today we announce two new features: rollbacks and the Pages API. Deployment rollbacks allow you to host production-level code on Pages without needing to stress about broken builds resulting in website downtime. The API empowers you to create custom functionality and better integrate Pages with your development workflows. Now, it’s even easier to use Pages for production hosting.
Rollbacks
You can now rollback your production website to a previous working deployment with just a click of a button. This is especially useful when you want to quickly undo a new deployment for troubleshooting. Before, developers would have to push another deployment and then wait for the build to finish updating production. Now, you can restore a working version within a few moments by rolling back to a previous working build.
To rollback to a previous build, just click the “Rollback to this deployment” button on either the deployments list menu or on a specific deployment page.
API Access
The Pages API exposes endpoints for you to easily create automations and to integrate Pages within your development workflow. Refer to the API documentation for a full breakdown of the object types and endpoints. To get started, navigate to the Cloudflare API Tokens page and copy your “Global API Key”. Now, you can authenticate and make requests to the API using your email and auth key in the request headers.
For example, here is an API request to get all projects on an account.
Try out an API request with one of your projects by replacing {account_id}, {deployment_id},{email}, and {auth_key}. You can find your account_id in the URL address bar by navigating to the Cloudflare Dashboard. (Ex: 41643ed677c7c7gba4x463c4zdb9563c).
Refer to the API documentation for a full breakdown of the object types and endpoints.
Using the Pages API on Workers
The Pages API is even more powerful and simple to use with workers.new. If you haven’t used Workers before, feel free to go through the getting started guide to learn more. However, you’ll need to have set up a Pages project to follow along. Next, you can copy and paste this template for the new worker. Then, customize the values such as {account_id}, {project_name}, {auth_key}, and {your_email}.
const endpoint = "https://api.cloudflare.com/client/v4/accounts/{account_id}/pages/projects/{project_name}/deployments";
const email = "{your_email}";
addEventListener("scheduled", (event) => {
event.waitUntil(handleScheduled(event.scheduledTime));
});
async function handleScheduled(request) {
const init = {
method: "POST",
headers: {
"content-type": "application/json;charset=UTF-8",
"X-Auth-Email": email,
"X-Auth-Key": API_KEY,
//We recommend you store API keys as secrets using the Workers dashboard or using Wrangler as documented here https://developers.cloudflare.com/workers/cli-wrangler/commands#secret
},
};
const response = await fetch(endpoint, init);
return new Response(200);
}
To finish configuring the script, click the back arrow near the top left of the window and click on the settings tab. Then, set an environment variable “API_KEY” with the value of your Cloudflare Global key and click “Encrypt” and then “Save”.
The script just makes a POST request to the deployments’ endpoint to trigger a new build. Click “Quick edit” to go back to the code editor to finish testing the script. You can test out your configuration and make a request by clicking on the “Trigger scheduled event” button in the “Schedule” tab near the tabs saying “HTTP” and “Preview”. You should see a new queued build on your Project through the Pages dashboard. Now, you can click “Save and Deploy” to publish your work. Finally, back to the worker settings page by clicking the back arrow near the top left of the window.
All that’s left to do is set a cron trigger to periodically run this Worker on the “Triggers tab”. Click on “Add Cron Trigger”.
Next, we can input “0 * * * *” to trigger the build every hour.
Finally, click save and your automation using the Pages API will trigger a new build every hour.
2. Deleting old deployments after a week: Pages hosts and serves all project deployments on preview links. Suppose you want to keep your project relatively private and prevent access to old deployments. You can use the API to delete deployments after a month so that they are no longer public online. This is easy to do on Workers using Cron Triggers.
3. Sharing project information: Imagine you are working on a development team using Pages to build our websites. You probably want an easy way to share deployment preview links and build status without having to share Cloudflare accounts. Using the API, you can easily share project information, including deployment status and preview links, and serve this content as HTML from a Cloudflare Worker.
Find the code snippets for all three examples here.
Conclusion
We will continue making the API more powerful with features such as supporting prebuilt deployments in the future. We are excited to see what you build with the API and hope you enjoy using rollbacks. At Cloudflare, we are committed to building the best developer experience on Pages, and we always appreciate hearing your feedback. Come chat with us and share more feedback on the Workers Discord (We have a dedicated #pages-help channel!).
We are excited to announce a new look and new capabilities for Cloudflare Logs! Customers on our Enterprise plan can now configure Logpush for Firewall Events and Network Error Logs Reports directly from the dashboard. Additionally, it’s easier to send Logs directly to our analytics partners Microsoft Azure Sentinel, Splunk, Sumo Logic, and Datadog. This blog post discusses how customers use Cloudflare Logs, how we’ve made it easier to consume logs, and tours the new user interface.
New data sets for insight into more products
Cloudflare Logs are almost as old as Cloudflare itself, but we have a few big improvements: new datasets and new destinations.
Cloudflare has a large number of products, and nearly all of them can generate Logs in different data sets. We have “HTTP Request” Logs, or one log line for every L7 HTTP request that we handle (whether cached or not). We also provide connection Logs for Spectrum, our proxy for any TCP or UDP based application. Gateway, part of our Cloudflare for Teams suite, can provide Logs for HTTP and DNS traffic.
Today, we are introducing two new data sets:
Firewall Events gives insight into malicious traffic handled by Cloudflare. It provides detailed information about everything our WAF does. For example, Firewall Events shows whether a request was blocked outright or whether we issued a CAPTCHA challenge. About a year ago we introduced the ability to send Firewall Events directly to your SIEM; starting today, I’m thrilled to share that you can enable this directly from the dashboard!
Network Error Logging(NEL) Reports provides information about clients that can’t reach our network. To enable NEL Reports for your zone and start seeing where clients are having issues reaching our network, reach out to your account manager.
Take your Logs anywhere with an S3-compatible API
To start using logs, you need to store them first. Cloudflare has long supported AWS, Azure, and Google Cloud as storage destinations. But we know that customers use a huge variety of storage infrastructure, which could be hosted on-premise or with one of our Bandwidth Alliance partners.
Starting today, we support any storage destination with an S3-compatible API. This includes:
And best of all, it’s super easy to get data into these locations using our new UI!
“As always, we love that our partnership with Cloudflare allows us to seamlessly offer customers our easy, plug and play storage solution, Backblaze B2 Cloud Storage. Even better is that, as founding members of the Bandwidth Alliance, we can do it all with free egress.” — Nilay Patel, Co-founder and VP of Solutions Engineering and Sales, Backblaze.
Push Cloudflare Logs directly to our analytics partners
While many customers like to store Logs themselves, we’ve also heard that many customers want to get Logs into their analytics provider directly — without going through another layer. Getting high volume log data out of object storage and into an analytics provider can require building and maintaining a costly, time-consuming, and fragile integration.
Because of this, we now provide direct integrations with four analytics platforms: Microsoft Azure Sentinel, Sumo Logic, Splunk, and Datadog. And starting today, you can push Logs directly into Sumo Logic, Splunk and Datadog from the UI! Customers can add Cloudflare to Azure Sentinel using the Azure Marketplace.
“Organizations are in a state of digital transformation on a journey to the cloud. Most of our customers deploy services in multiple clouds and have legacy systems on premise. Splunk provides visibility across all of this, and more importantly, with SOAR we can automate remediation. We are excited about the Cloudflare partnership, and adding their data into Splunk drives the outcomes customers need to modernize their security operations.” — Jane Wong, Vice President, Product Management, Security at Splunk
“Securing enterprise IT environments can be challenging – from devices, to users, to apps, to data centers on-premises or in the cloud. In today’s environment of increasingly sophisticated cyber-attacks, our mutual customers rely on Microsoft Azure Sentinel for a comprehensive view of their enterprise. Azure Sentinel enables SecOps teams to collect data at cloud scale and empowers them with AI and ML to find the real threats in those signals, reducing alert fatigue by as much as 90%. By integrating directly with Cloudflare Logs we are making it easier and faster for customers to get complete visibility across their entire stack.” — Sarah Fender, Partner Group Program Manager, Azure Sentinel at Microsoft
“As a long time Cloudflare partner we’ve worked together to help joint customers analyze events and trends from their websites and applications to provide end-to-end visibility to improve digital experiences. We’re excited to expand our partnership as part of the Cloudflare Analytics Ecosystem to provide comprehensive real-time insights for both observability and the security of mission-critical applications and services with our Cloud SIEM solution.” — John Coyle, Vice President of Business Development for Sumo Logic
“Knowing that applications perform as well in the real world as they do in the datacenter is critical to ensuring great digital experiences. Combining Cloudflare Logs with Datadog telemetry about application performance in a single pane of glass ensures teams will have a holistic view of their application delivery.” — Michael Gerstenhaber, Sr. Director of Product, Datadog
Why Cloudflare Logs?
Cloudflare’s mission is to help build a better Internet. We do that by providing a massive global network that protects and accelerates our customers’ infrastructure. Because traffic flows across our network before reaching our customers, it means we have a unique vantage point into that traffic. In many cases, we have visibility that our customers don’t have — whether we’re telling them about the performance of our cache, the malicious HTTP requests we drop at our edge, a spike in L3 data flows, the performance of their origin, or the CPU used by their serverless applications.
To provide this ability, we have analytics throughout our dashboard to help customers understand their network traffic, firewall, cache, load balancer, and much more. We also provide alerts that can tell customers when they see an increase in errors or spike in DDoS activity.
But some customers want more than what we currently provide with our analytics products. Many of our enterprise customers use SIEMs like Splunk and Sumo Logic or cloud monitoring tools like Datadog. These products can extend the capabilities of Cloudflare by showcasing Cloudflare data in the context of customers’ other infrastructure and providing advanced functionality on this data.
To understand how this works, consider a typical L7 DDoS attack against one of our customers. Very commonly, an attack like this might originate from a small number of IP addresses and a customer might choose to block the source IPs completely. After blocking the IP addresses, customers may want to:
Search through their Logs to see all the past instances of activity from those IP addresses.
Search through Logs from all their other applications and infrastructure to see all activity from those IP addresses
Understand exactlywhat that attacker was trying to do by looking at the request payload blocked in our WAF (securely encrypted thanks to HPKE!)
Set an alert for similar activity, to be notified if something similar happens again
All these are made possible using SIEMs and infrastructure monitoring tools. For example, our customer NOV uses Splunk to “monitor our network and applications by alerting us to various anomalies and high-fidelity incidents”.
“One of the most valuable sources of data is Cloudflare,” said John McLeod, Chief Information Security Officer at NOV. “It provides visibility into network and application attacks. With this integration, it will be easier to get Cloudflare Logs into Splunk, saving my team time and money.”
A new UI for our growing product base
With so many new data sets and new destinations, we realized that our existing user interface was not good enough. We went back to the drawing board to design a more intuitive user experience to help you quickly and easily set up Logpush.
You can still set up Logpush in the same place in the dashboard, in the Analytics > Logs tab:
The new UI first prompts users to select the data set to push. Here you’ll also notice that we’ve added support for Firewall Events and NEL Reports!
After configuring details like which fields to push, customers can then select where the Logs are going. Here you can see our three new destinations, S3-compatible storage, Sumo Logic, Datadog and Splunk:
Coming soon
Of course, we’re not done yet! We have more Cloudflare products in the pipeline and more destinations planned where customers can send their Logs. Additionally, we’re working on adding more flexibility to our logging pipeline so that customers can configure to send Logs for the entire account, plus filter Logs to just send error codes, for example.
Ultimately, we want to make working with Cloudflare Logs as useful as possible — on Cloudflare itself! We’re working to help customers solve their performance and security challenges with data at massive scale. If that sounds interesting, please join us! We’re hiring Systems Engineers for the Data team.
Last October we released WARP for Desktop, bringing a safer and faster way to use the Internet to billions of devices for free. At the same time, we gave our enterprise customers the ability to use WARP with Cloudflare for Teams. By routing all an enterprise’s traffic from devices anywhere on the planet through WARP, we’ve been able to seamlessly power advanced capabilities such as Secure Web Gateway and Browser Isolation and, in the future, our Data Loss Prevention platforms.
Today, we are excited to announce Cloudflare WARP for Linux and, across all desktop platforms, the ability to use WARP with single applications instead of your entire device.
What is WARP?
WARP was built on the philosophy that even people who don’t know what “VPN” stands for should be able to still easily get the protection a VPN offers. It was also built for those of us who are unfortunately all too familiar with traditional corporate VPNs, and need an innovative, seamless solution to meet the challenges of an always-connected world.
Enter our own WireGuard implementation called BoringTun.
The WARP application uses BoringTun to encrypt traffic from your device and send it directly to Cloudflare’s edge, ensuring that no one in between is snooping on what you’re doing. If the site you are visiting is already a Cloudflare customer, the content is immediately sent down to your device. With WARP+, we use Argo Smart Routing to use the shortest path through our global network of data centers to reach whomever you are connecting to.
Combined with the power of 1.1.1.1 (the world’s fastest public DNS resolver), WARP keeps your traffic secure, private and fast. Since nearly everything you do on the Internet starts with a DNS request, choosing the fastest DNS server across all your devices will accelerate almost everything you do online.
Bringing WARP to Linux
When we built out the foundations of our desktop client last year, we knew a Linux client was something we would deliver. If you have ever shipped software at this scale, you’ll know that maintaining a client across all major operating systems is a daunting (and error-prone) task. To avoid these pitfalls, we wrote the core of the product in Rust, which allows for 95% of the code to be shared across platforms.
Internally we refer to this common code as the shared Daemon (or Service, for Windows folks), and it allows our engineers to spend less time duplicating code across multiple platforms while ensuring most quality improvements hit everyone at the same time. The really cool thing about this is that millions of existing WARP users have already helped us solidify the code base for Linux!
The other 5% of code is split into two main buckets: UI and quirks of the operating system. For now, we are forgoing a UI on Linux and instead working to support three distributions:
Ubuntu
Red Hat Enterprise Linux
CentOS
We want to add more distribution support in the future, so if your favorite distro isn’t there, don’t despair — the client may in fact already work with other Debian and Redhat based distributions, so please give it a try. If we missed your favorite distribution, we’d love to hear from you in our Community Forums.
So without a UI — what’s the mechanism for controlling WARP? The command line, of course! Keen observers may have noticed an executable that already ships with each client called the warp-cli. This platform-agnostic interface is already the preferred mechanism of interacting with the daemon by some of our engineers and is the main way you’ll interact with WARP on Linux.
Installing Cloudflare WARP for Linux
Seasoned Linux developers can jump straight to https://pkg.cloudflareclient.com/install. After linking our repository, get started with either sudo apt install cloudflare-warp or sudo yum install cloudflare-warp, depending on your distribution.
Once you’ve installed WARP, you can begin using the CLI with a single command:
warp-cli --help
The CLI will display the output below.
~$ warp-cli --help
WARP 0.2.0
Cloudflare
CLI to the WARP service daemon
USAGE:
warp-cli [FLAGS] [SUBCOMMAND]
FLAGS:
--accept-tos Accept the Terms of Service agreement
-h, --help Prints help information
-l Stay connected to the daemon and listen for status changes and DNS logs (if enabled)
-V, --version Prints version information
SUBCOMMANDS:
register Registers with the WARP API, will replace any existing registration (must be run
before first connection)
teams-enroll Enroll with Cloudflare for Teams
delete Deletes current registration
rotate-keys Generates a new key-pair, keeping the current registration
status Asks the daemon to send the current status
warp-stats Retrieves the stats for the current WARP connection
settings Retrieves the current application settings
connect Asks the daemon to start a connection, connection progress should be monitored with
-l
disconnect Asks the daemon to stop a connection
enable-always-on Enables always on mode for the daemon (i.e. reconnect automatically whenever
possible)
disable-always-on Disables always on mode
disable-wifi Pauses service on WiFi networks
enable-wifi Re-enables service on WiFi networks
disable-ethernet Pauses service on ethernet networks
enable-ethernet Re-enables service on ethernet networks
add-trusted-ssid Adds a trusted WiFi network, for which the daemon will be disabled
del-trusted-ssid Removes a trusted WiFi network
allow-private-ips Exclude private IP ranges from tunnel
enable-dns-log Enables DNS logging, use with the -l option
disable-dns-log Disables DNS logging
account Retrieves the account associated with the current registration
devices Retrieves the list of devices associated with the current registration
network Retrieves the current network information as collected by the daemon
set-mode
set-families-mode
set-license Attaches the current registration to a different account using a license key
set-gateway Forces the app to use the specified Gateway ID for DNS queries
clear-gateway Clear the Gateway ID
set-custom-endpoint Forces the client to connect to the specified IP:PORT endpoint
clear-custom-endpoint Remove the custom endpoint setting
add-excluded-route Adds an excluded IP
remove-excluded-route Removes an excluded IP
get-excluded-routes Get the list of excluded routes
add-fallback-domain Adds a fallback domain
remove-fallback-domain Removes a fallback domain
get-fallback-domains Get the list of fallback domains
restore-fallback-domains Restore the fallback domains
get-device-posture Get the current device posture
override Temporarily override MDM policies that require the client to stay enabled
set-proxy-port Set the listening port for WARP proxy (127.0.0.1:{port})
help Prints this message or the help of the given subcommand(s)
You can begin connecting to Cloudflare’s network with just two commands. The first command, register, will prompt you to authenticate. The second command, connect, will enable the client, creating a WireGuard tunnel from your device to Cloudflare’s network.
Once you’ve connected the client, the best way to verify it is working is to run our trace command:
~$ curl https://www.cloudflare.com/cdn-cgi/trace/
And look for the following output:
warp=on
Want to switch from encrypting all traffic in WARP to just using our 1.1.1.1 DNS resolver? Use the warp-cli set-mode command:
~$ warp-cli help set-mode
warp-cli-set-mode
USAGE:
warp-cli set-mode [mode]
FLAGS:
-h, --help Prints help information
-V, --version Prints version information
ARGS:
<mode> [possible values: warp, doh, warp+doh, dot, warp+dot, proxy]
~$ warp-cli set-mode doh
Success
Protecting yourself against malware with 1.1.1.1 for Families is just as easy, and it can be used with either WARP enabled or in straight DNS mode:
~$ warp-cli set-families-mode --help
warp-cli-set-families-mode
USAGE:
warp-cli set-families-mode [mode]
FLAGS:
-h, --help Prints help information
-V, --version Prints version information
ARGS:
<mode> [possible values: off, malware, full]
~$ warp-cli set-families-mode malware
Success
A note on Cloudflare for Teams support
Cloudflare for Teams support is on the way, and just like our other clients, it will ship in the same package. Stay tuned for an in-app update or reach out to your Account Executive to be notified when a beta is available.
We need feedback
If you encounter an error, send us feedback with the sudo warp-diag feedback command:
When WARP launched in 2019, one of our primary goals was ease of use. You turn WARP on and all traffic from your device is encrypted to our edge. Through all releases of the client, we’ve kept that as a focus. One big switch to turn on and you are protected.
However, as we’ve grown, so have the requirements for our client. Earlier this year we released split tunnel and local domain fallback as a way for our Cloudflare for Teams customers to exclude certain routes from WARP. Our consumer customers may have noticed this stealthily added in the last release as well. We’ve heard from customers who want to deploy WARP in one additional mode: Single Applications. Today we are also announcing the ability for our customers to run WARP in a local proxy mode in all desktop clients.
When WARP is configured as a local proxy, only the applications that you configure to use the proxy (HTTPS or SOCKS5) will have their traffic sent through WARP. This allows you to pick and choose which traffic is encrypted (for instance, your web browser or a specific app), and everything else will be left open over the Internet.
Because this feature restricts WARP to just applications configured to use the local proxy, leaving all other traffic unencrypted over the Internet by default, we’ve hidden it in the advanced menu. To turn it on:
1. Navigate to Preferences -> Advanced and click the Configure Proxy button.
2. On the dialog that opens, check the box and configure the port you want to listen on.
3. This will enable a new mode you can select from:
To configure your application to use the proxy, you want to specify 127.0.0.1 for the address and the value you specified for a port (40000 by default). For example, if you are using Firefox, the configuration would look like this:
Download today
You can start using these capabilities right now by visiting https://one.one.one.one. We’re super excited to hear your feedback.
In January, we announced the Cloudflare Waiting Room, which has been available to select customers through Project Fair Shot to help COVID-19 vaccination web applications handle demand. Back then, we mentioned that our system was built on top of Cloudflare Workers and the then brand new Durable Objects. In the coming days, we are making Waiting Room available to customers on our Business and Enterprise plans. As we are expanding availability, we are taking this opportunity to share how we came up with this design.
What does the Waiting Room do?
You may have seen lines of people queueing in front of stores or other buildings during sales for a new sneaker or phone. That is because stores have restrictions on how many people can be inside at the same time. Every store has its own limit based on the size of the building and other factors. If more people want to get inside than the store can hold, there will be too many people in the store.
The same situation applies to web applications. When you build a web application, you have to budget for the infrastructure to run it. You make that decision according to how many users you think the site will have. But sometimes, the site can see surges of users above what was initially planned. This is where the Waiting Room can help: it stands between users and the web application and automatically creates an orderly queue during traffic spikes.
The main job of the Waiting Room is to protect a customer’s application while providing a good user experience. To do that, it must make sure that the number of users of the application around the world does not exceed limits set by the customer. Using this product should not degrade performance for end users, so it should not add significant latency and should admit them automatically. In short, this product has three main requirements: respect the customer’s limits for users on the web application, keep latency low, and provide a seamless end user experience.
When there are more users trying to access the web application than the limits the customer has configured, new users are given a cookie and greeted with a waiting room page. This page displays their estimated wait time and automatically refreshes until the user is automatically admitted to the web application.
Configuring Waiting Rooms
The important configurations that define how the waiting room operates are:
Total Active Users – the total number of active users that can be using the application at any given time
New Users Per Minute – how many new users per minute are allowed into the application, and
Session Duration – how long a user session lasts. Note: the session is renewed as long as the user is active. We terminate it after Session Duration minutes of inactivity.
How does the waiting room work?
If a web application is behind Cloudflare, every request from an end user to the web application will go to a Cloudflare data center close to them. If the web application enables the waiting room, Cloudflare issues a ticket to this user in the form of an encrypted cookie.
Waiting Room Overview
At any given moment, every waiting room has a limit on the number of users that can go to the web application. This limit is based on the customer configuration and the number of users currently on the web application. We refer to the number of users that can go into the web application at any given time as the number of user slots. The total number of users slots is equal to the limit configured by the customer minus the total number of users that have been let through.
When a traffic surge happens on the web application the number of user slots available on the web application keeps decreasing. Current user sessions need to end before new users go in. So user slots keep decreasing until there are no more slots. At this point the waiting room starts queueing.
The chart above is a customer’s traffic to a web application between 09:40 and 11:30. The configuration for total active users is set to 250 users (yellow line). As time progresses there are more and more users on the application. The number of user slots available (orange line) in the application keeps decreasing as more users get into the application (green line). When there are more users on the application, the number of slots available decreases and eventually users start queueing (blue line). Queueing users ensures that the total number of active users stays around the configured limit.
To effectively calculate the user slots available, every service at the edge data centers should let its peers know how many users it lets through to the web application.
Coordination within a data center is faster and more reliable than coordination between many different data centers. So we decided to divide the user slots available on the web application to individual limits for each data center. The advantage of doing this is that only the data center limits will get exceeded if there is a delay in traffic information getting propagated. This ensures we don’t overshoot by much even if there is a delay in getting the latest information.
The next step was to figure out how to divide this information between data centers. For this we decided to use the historical traffic data on the web application. More specifically, we track how many different users tried to access the application across every data center in the preceding few minutes. The great thing about historical traffic data is that it’s historical and cannot change anymore. So even with a delay in propagation, historical traffic data will be accurate even when the current traffic data is not.
Let’s see an actual example: the current time is Thu, 27 May 2021 16:33:20 GMT. For the minute Thu, 27 May 2021 16:31:00 GMT there were 50 users in Nairobi and 50 in Dublin. For the minute Thu, 27 May 2021 16:32:00 GMT there were 45 users in Nairobi and 55 in Dublin. This was the only traffic on the application during that time.
Every data center looks at what the share of traffic to each data center was two minutes in the past. For Thu, 27 May 2021 16:33:20 GMT that value is Thu, 27 May 2021 16:31:00 GMT.
For the minute Thu, 27 May 2021 16:33:00 GMT, the number of user slots available will be divided equally between Nairobi and Dublin as the traffic ratio for Thu, 27 May 2021 16:31:00 GMT is 0.5 and 0.5. So, if there are 1000 slots available, Nairobi will be able to send 500 and Dublin can send 500.
For the minute Thu, 27 May 2021 16:34:00 GMT, the number of user slots available will be divided using the ratio 0.45 (Nairobi) to 0.55 (Dublin). So if there are 1000 slots available, Nairobi will be able to send 450 and Dublin can send 550.
The service at the edge data centers counts the number of users it let into the web application. It will start queueing when the data center limit is approached. The presence of limits for the data center that change based on historical traffic helps us to have a system that doesn’t need to communicate often between data centers.
Clustering
In order to let people access the application fairly we need a way to keep track of their position in the queue. A bucket has an identifier (bucketId) calculated based on the time the user tried to visit the waiting room for the first time. All the users who visited the waiting room between 19:51:00 and 19:51:59 are assigned to the bucketId 19:51:00. It’s not practical to track every end user in the waiting room individually. When end users visit the application around the same time, they are given the same bucketId. So we cluster users who came around the same time as one time bucket.
What is in the cookie returned to an end user?
We mentioned an encrypted cookie that is assigned to the user when they first visit the waiting room. Every time the user comes back, they bring this cookie with them. The cookie is a ticket for the user to get into the web application. The content below is the typical information the cookie contains when visiting the web application. This user first visited around Wed, 26 May 2021 19:51:00 GMT, waited for around 10 minutes and got accepted on Wed, 26 May 2021 20:01:13 GMT.
{
"bucketId": "Wed, 26 May 2021 19:51:00 GMT",
"lastCheckInTime": "Wed, 26 May 2021 20:01:13 GMT",
"acceptedAt": "Wed, 26 May 2021 20:01:13 GMT",
}
Here
bucketId – the bucketId is the cluster the ticket is assigned to. This tracks the position in the queue.
acceptedAt – the time when the user got accepted to the web application for the first time.
lastCheckInTime – the time when the user was last seen in the waiting room or the web application.
Once a user has been let through to the web application, we have to check how long they are eligible to spend there. Our customers can customize how long a user spends on the web application using Session Duration. Whenever we see an accepted user we set the cookie to expireSession Duration minutes from when we last saw them.
Waiting Room State
Previously we talked about the concept of user slots and how we can function even when there is a delay in communication between data centers. The waiting room state helps to accomplish this. It is formed by historical data of events happening in different data centers. So when a waiting room is first created, there is no waiting room state as there is no recorded traffic. The only information available is the customer’s configured limits. Based on that we start letting users in. In the background the service (introduced later in this post as Data Center Durable Object) running in the data center periodically reports about the tickets it has issued to a co-ordinating service and periodically gets a response back about things happening around the world.
As time progresses more and more users with different bucketIds show up in different parts of the globe. Aggregating this information from the different data centers gives the waiting room state.
Let’s look at an example: there are two data centers, one in Nairobi and the other in Dublin. When there are no user slots available for a data center, users start getting queued. Different users who were assigned different bucketIds get queued. The data center state from Dublin looks like this:
This information from data centers are reported in the background and aggregated to form a data structure similar to the one below:
activeUsers: 201, // 151(Nairobi) + 50(Dublin)
buckets:
[
{
key: "Thu, 27 May 2021 15:54:00 GMT",
data:
{
waiting: 2, // 2 users from (Nairobi)
},
}
{
key: "Thu, 27 May 2021 15:55:00 GMT",
data:
{
waiting: 50, // 20 from Nairobi and 30 from Dublin
}
},
{
key: "Thu, 27 May 2021 15:56:00 GMT",
data:
{
waiting: 60, // 20 from Nairobi and 40 from Dublin
}
}
]
The data structure above is a sorted list of all the bucketIds in the waiting room. The waiting field has information about how many people are waiting with a particular bucketId. The activeUsers field has information about the number of users who are active on the web application.
Imagine for this customer, the limits they have set in the dashboard are
Total Active Users – 200 New Users Per Minute – 200
As per their configuration only 200 customers can be at the web application at any time. So users slots available for the waiting room state above are 200 – 201(activeUsers) = -1. So no one can go in and users get queued.
Now imagine that some users have finished their session and activeUsers is now 148.
Now userSlotsAvailable = 200 – 148 = 52 users. We should let 52 of the users who have been waiting the longest into the application. We achieve this by giving the eligible slots to the oldest buckets in the queue. In the example below 2 users are waiting from bucket Thu, 27 May 2021 15:54:00 GMT and 50 users are waiting from bucket Thu, 27 May 2021 15:55:00 GMT. These are the oldest buckets in the queue who get the eligible slots.
If there are eligible slots available for all the users in their bucket, then they can be sent to the web application from any data center. This ensures the fairness of the waiting room.
There is another case that can happen where we do not have enough eligible slots for a whole bucket. When this happens things get a little more complicated as we cannot send everyone from that bucket to the web application. Instead, we allocate a share of eligible slots to each data center.
As we did before, we use the ratio of past traffic from each data center to decide how many users it can let through. So if the current time is Thu, 27 May 2021 16:34:10 GMT both data centers look at the traffic ratio in the past at Thu, 27 May 2021 16:32:00 GMT and send a subset of users from those data centers to the web application.
When a request comes from a user we look at their bucketId. Based on the bucketId it is possible to know how many people are in front of the user’s bucketId from the sorted list. Similar to how we track the activeUsers we also calculate the average number of users going to the web application per minute. Dividing the number of people who are in front of the user by the average number of users going to the web application gives us the estimated time. This is what is shown to the user who visits the waiting room.
In the case above for a user with bucketId Thu, 27 May 2021 15:56:00 GMT, there are 60 users ahead of them. With 30 activeUsersToWebApplication per minute, the estimated time to get into the web application is 60/30 which is 2 minutes.
Implementation with Workers and Durable Objects
Now that we have talked about the user experience and the algorithm, let’s focus on the implementation. Our product is specifically built for customers who experience high volumes of traffic, so we needed to run code at the edge in a highly scalable manner. Cloudflare has a great culture of building upon its own products, so we naturally thought of Workers. The Workers platform uses Isolates to scale up and can scale horizontally as there are more requests.
The Workers product has an ecosystem of tools like wrangler which help us to iterate and debug things quickly.
Workers also reduce long-term operational work.
For these reasons, the decision to build on Workers was easy. The more complex choice in our design was for the coordination. As we have discussed before, our workers need a way to share the waiting room state. We need every worker to be aware of changes in traffic patterns quickly in order to respond to sudden traffic spikes. We use the proportion of traffic from two minutes before to allocate user slots among data centers, so we need a solution to aggregate this data and make it globally available within this timeframe. Our design also relies on having fast coordination within a data center to react quickly to changes. We considered a few different solutions before settling on Cache and Durable Objects.
Idea #1: Workers KV
We started to work on the project around March 2020. At that point, Workers offered two options for storage: the Cache API and KV. Cache is shared only at the data center level, so for global coordination we had to use KV. Each worker writes its own key to KV that describes the requests it received and how it processed them. Each key is set to expire after a few minutes if the worker stopped writing. To create a workerState, the worker periodically does a list operation on the KV namespace to get the state around the world.
Design using KV
This design has some flaws because KV wasn’t built for a use case like this. The state of a waiting room changes all the time to match traffic patterns. Our use case is write intensive and KV is intended for read-intensive workflows. As a consequence, our proof of concept implementation turned out to be more expensive than expected. Moreover, KV is eventually consistent: it takes time for information written to KV to be available in all of our data centers. This is a problem for Waiting Room because we need fine-grained control to be able to react quickly to traffic spikes that may be happening simultaneously in several locations across the globe.
Idea #2: Centralized Database
Another alternative was to run our own databases in our core data centers. The Cache API in Workers lets us use the cache directly within a data center. If there is frequent communication with the core data centers to get the state of the world, the cached data in the data center should let us respond with minimal latency on the request hot path. There would be fine-grained control on when the data propagation happens and this time can be kept low.
Design using Core Data centers
As noted before, this application is very write-heavy and the data is rather short-lived. For these reasons, a standard relational database would not be a good fit. This meant we could not leverage the existing database clusters maintained by our in-house specialists. Rather, we would need to use an in-memory data store such as Redis, and we would have to set it up and maintain it ourselves. We would have to install a data store cluster in each of our core locations, fine tune our configuration, and make sure data is replicated between them. We would also have to create a proxy service running in our core data centers to gate access to that database and validate data before writing to it.
We could likely have made it work, at the cost of substantial operational overhead. While that is not insurmountable, this design would introduce a strong dependency on the availability of core data centers. If there were issues in the core data centers, it would affect the product globally whereas an edge-based solution would be more resilient. If an edge data center goes offline Anycast takes care of routing the traffic to the nearby data centers. This will ensure a web application will not be affected.
The Scalable Solution: Durable Objects
Around that time, we learned about Durable Objects. The product was in closed beta back then, but we decided to embrace Cloudflare’s thriving dogfooding culture and did not let that deter us. With Durable Objects, we could create one global Durable Object instance per waiting room instead of maintaining a single database. This object can exist anywhere in the world and handle redundancy and availability. So Durable Objects give us sharding for free. Durable Objects gave us fine-grained control as well as better availability as they run in our edge data centers. Additionally, each waiting room is isolated from the others: adverse events affecting one customer are less likely to spill over to other customers.
Implementation with Durable Objects Based on these advantages, we decided to build our product on Durable Objects.
As mentioned above, we use a worker to decide whether to send users to the Waiting Room or the web application. That worker periodically sends a request to a Durable Object saying how many users it sent to the Waiting Room and how many it sent to the web application. A Durable Object instance is created on the first request and remains active as long as it is receiving requests. The Durable Object aggregates the counters sent by every worker to create a count of users sent to the Waiting Room and a count of users on the web application.
A Durable Object instance is only active as long as it is receiving requests and can be restarted during maintenance. When a Durable Object instance is restarted, its in-memory state is cleared. To preserve the in-memory data on Durable Object restarts, we back up the data using the Cache API. This offers weaker guarantees than using the Durable Object persistent storage as data may be evicted from cache, or the Durable Object can be moved to a different data center. If that happens, the Durable Object will have to start without cached data. On the other hand, persistent storage at the edge still has limited capacity. Since we can rebuild state very quickly from worker updates, we decided that cache is enough for our use case.
Scaling up When traffic spikes happen around the world, new workers are created. Every worker needs to communicate how many users have been queued and how many have been let through to the web application. However, while workers automatically scale horizontally when traffic increases, Durable Objects do not. By design, there is only one instance of any Durable Object. This instance runs on a single thread so if it receives requests more quickly than it can respond, it can become overloaded. To avoid that, we cannot let every worker send its data directly to the same Durable Object. The way we achieve scalability is by sharding: we create per data center Durable Object instances that report up to one global instance.
Durable Objects implementation
The aggregation is done in two stages: at the data-center level and at the global level.
Data Center Durable Object When a request comes to a particular location, we can see the corresponding data center by looking at the cf.colo field on the request. The Data Center Durable Object keeps track of the number of workers in the data center. It aggregates the state from all those workers. It also responds to workers with important information within a data center like the number of users making requests to a waiting room or number of workers. Frequently, it updates the Global Durable Object and receives information about other data centers as the response.
Worker User Slots
Above we talked about how a data center gets user slots allocated to it based on the past traffic patterns. If every worker in the data center talks to the Data Center Durable Object on every request, the Durable Object could get overwhelmed. Worker User Slots help us to overcome this problem.
Every worker keeps track of the number of users it has let through to the web application and the number of users that it has queued. The worker user slots are the number of users a worker can send to the web application at any point in time. This is calculated from the user slots available for the data center and the worker count in the data center. We divide the total number of user slots available for the data center by the number of workers in the data center to get the user slots available for each worker. If there are two workers and 10 users that can be sent to the web application from the data center, then we allocate five as the budget for each worker. This division is needed because every worker makes its own decisions on whether to send the user to the web application or the waiting room without talking to anyone else.
Waiting room inside a data center
When the traffic changes, new workers can spin up or old workers can die. The worker count in a data center is dynamic as the traffic to the data center changes. Here we make a trade off similar to the one for inter data center coordination: there is a risk of overshooting the limit if many more workers are created between calls to the Data Center Durable Object. But too many calls to the Data Center Durable Object would make it hard to scale. In this case though, we can use Cache for faster synchronization within the data center.
Cache
On every interaction to the Data Center Durable Object, the worker saves a copy of the data it receives to the cache. Every worker frequently talks to the cache to update the state it has in memory with the state in cache. We also adaptively adjust the rate of writes from the workers to the Data Center Durable Object based on the number of workers in the data center. This helps to ensure that we do not take down the Data Center Durable Object when traffic changes.
Global Durable Object
The Global Durable Object is designed to be simple and stores the information it receives from any data center in memory. It responds with the information it has about all data centers. It periodically saves its in-memory state to cache using the Workers Cache API so that it can withstand restarts as mentioned above.
Components of waiting room
Recap
This is how the waiting room works right now. Every request with the enabled waiting room goes to a worker at a Cloudflare edge data center. When this happens, the worker looks for the state of the waiting room in the Cache first. We use cache here instead of Data Center Durable Object so that we do not overwhelm the Durable Object instance when there is a spike in traffic. Plus, reading data from cache is faster. The workers periodically make a request to the Data Center Durable Object to get the waiting room state which they then write to the cache. The idea here is that the cache should have a recent copy of the waiting room state.
Workers can examine the request to know which data center they are in. Every worker periodically makes a request to the corresponding Data Center Durable Object. This interaction updates the worker state in the Data Center Durable Object. In return, the workers get the waiting room state from the Data Center Durable Object. The Data Center Durable Object sends the data center state to the Global Durable Object periodically. In the response, the Data Center Durable Object receives all data center states globally. It then calculates the waiting room state and returns that state to a worker in its response.
The advantage of this design is that it’s possible to adjust the rate of writes from workers to the Data Center Durable Object and from the Data Center Durable Object to the Global Durable Object based on the traffic received in the waiting room. This helps us respond to requests during high traffic without overloading the individual Durable Object instances.
Conclusion
By using Workers and Durable Objects, Waiting Room was able to scale up to keep web application servers online for many of our early customers during large spikes of traffic. It helped keep vaccination sign-ups online for companies and governments around the world for free through Project Fair Shot: Verto Health was able to serve over 4 million customers in Canada; Ticket Tailor reduced their peak resource utilization from 70% down to 10%; the County of San Luis Obispo was able to stay online during traffic surges of up to 23,000 users; and the country of Latvia was able to stay online during surges of thousands of requests per second. These are just a few of the customers we served and will continue to serve until Project Fair Shot ends.
In the coming days, we are rolling out the Waiting Room to customers on our business plan. Sign up today to prevent spikes of traffic to your web application. If you are interested in access to Durable Objects, it’s currently available to try out in Open Beta.
Customers choose Cloudflare for our network performance, privacy and security. Cloudflare Network Interconnect is the best on-ramp for our customers to utilize our diverse product suite. In the past, we’ve talked about Cloudflare’s physical footprint in over 200+ data centers, and how Cloudflare Network Interconnect enabled companies in those data centers to connect securely to Cloudflare’s network. Today, Cloudflare is excited to announce expanded partnerships that allows customers to connect to Cloudflare from their own Layer 2 service fabric. There are now over 1,600 locations where enterprise security and network professionals have the option to connect to Cloudflare securely and privately from their existing fabric.
Interconnect Anywhere is a journey
Since we launched Cloudflare Network Interconnect (CNI) in August 2020, we’ve been focused on extending the availability of Cloudflare’s network to as many places as possible. The initial launch opened up 150 physical locations alongside 25 global partner locations. During Security Week this year, we grew that availability by adding data center partners to our CNI Partner Program. Today, we are adding even more connectivity options by expanding Cloudflare availability to all of our partners’ locations, as well as welcoming CoreSite Open Cloud Exchange (OCX) and Infiny by Epsilon into our CNI Partner Program. This totals 1,638 locations where our customers can now connect securely to the Cloudflare network. As we continue to expand, customers are able to connect the fabric of their choice to Cloudflare from a growing list of data centers.
Fabric Partner
Enabled Locations
PacketFabric
180+
Megaport
700+
Equinix Fabric
46+
Console Connect
440+
CoreSite Open Cloud Exchange
22+
Infiny by Epsilon
250+
“We are excited to expand our partnership with Cloudflare to ensure that our mutual customers can benefit from our carrier-class Software Defined Network (SDN) and Cloudflare’s network security in all Packetfabric locations. Now customers can easily connect from wherever they are located to access best of breed security services alongside Packetfabric’s Cloud Connectivity options.” – Alex Henthorn-Iwane, PacketFabric’s Chief Marketing Officer
“With the significant rise in DDoS attacks over the past year, it’s becoming ever more crucial for IT and Operations teams to prevent and mitigate network security threats. We’re thrilled to enable Cloudflare Interconnect everywhere on Megaport’s global Software Defined Network, which is available in over 700 enabled locations in 24 countries worldwide. Our partnership will give organizations the ability to reduce their exposure to network attacks, improve customer experiences, and simplify their connectivity across our private on-demand network in a matter of a few mouse clicks.” – Misha Cetrone, Megaport VP of Strategic Partnerships
“Expanding the connectivity options to Cloudflare ensures that customers can provision hybrid architectures faster and more easily, leveraging enterprise-class network services and automation on the Open Cloud Exchange. Simplifying the process of establishing modern networks helps achieve critical business objectives, including reducing total cost of ownership, and improving business agility as well as interoperability.” – Brian Eichman, CoreSite Senior Director of Product Development
“Partner accessibility is key in our cloud enablement and interconnection strategy. We are continuously evolving to offer our customers and partners simple and secure connectivity no matter where their network resides in the world. Infiny enables access to Cloudflare from across a global footprint while delivering high-quality cloud connectivity solutions at scale. Customers and partners gain an innovative Network-as-a-Service SDN platform that supports them with programmable and automated connectivity for their cloud and networking needs.” – Mark Daley, Epsilon Director of Digital Strategy
Uncompromising security and increased reliability from your choice of network fabric
Now, companies can connect to Cloudflare’s suite of network and security products without traversing shared public networks by taking advantage of software-defined networking providers. No matter where a customer is connected to one of our fabric partners, Cloudflare’s 200+ data centers ensure that world-class network security is close by and readily available via a secure, low latency, and cost-effective connection. An increased number of locations further allows customers to have multiple secure connections to the Cloudflare network, increasing redundancy and reliability. As we further expand our global network and increase the number of data centers where Cloudflare and our partners are connected, latency becomes shorter and customers will reap the benefits.
Let’s talk about how a customer can use Cloudflare Network Interconnect to improve their security posture through a fabric provider.
Plug and Play Fabric connectivity
Acme Corp is an example company that wants to deliver highly performant digital services to their customers and ensure employees can securely connect to their business apps from anywhere. They’ve purchased Magic Transit and Cloudflare Access and are evaluating Magic WAN to secure their network while getting the performance Cloudflare provides. They want to avoid potential network traffic congestion and latency delays, so they have designed a network architecture with their software-defined network fabric and Cloudflare using Cloudflare Network Interconnect.
With Cloudflare Network Interconnect, provisioning this connection is simple. Acme goes to their partner portal, and requests a virtual layer 2 connection to Cloudflare with the bandwidth of their choice. Cloudflare accepts the connection, provides the BGP session establishment information and organizes a turn up call if required. Easy!
Let’s talk about how Cloudflare and our partners have worked together to simplify the interconnectivity experience for the customer.
With Cloudflare Network interconnect, availability only gets better
Connection Established with Cloudflare Network Interconnect
When a customer uses CNI to establish a connection between a fabric partner and Cloudflare, that connection runs over layer 2, configured via the partner user interface. Our new partnership model allows customers to connect privately and securely to Cloudflare’s network even when the customer is not located in the same data center as Cloudflare.
Shorter Customer Path with New Partner Locations
The diagram above shows a shorter customer path thanks to an incremental partner-enabled location. Every time Cloudflare brings a new data center online and connects with a partner fabric, all customers in that region immediately benefit from the closer proximity and reduced latency.
Network fabrics in action
For those who want to self-serve, we’ve published documentation that details the steps in provisioning these connections. You can find the steps for each partner below:
As we expand our network, it’s critical we provide more ways to allow our customers to connect easily. We will continue to shorten the time it takes to set up a new interconnection, drive down costs, strengthen security and improve customer experience with all of our Network On-Ramp partners.
If you are using one of our software-defined networking partners and would like to connect to Cloudflare via their fabric, contact your fabric partner account team or reach out to us using the Cloudflare Network Interconnect page. If you are not using a fabric today, but would like to take advantage of software-defined networking to connect to Cloudflare, reach out to your account team.
Starting today, you can build identity-aware, Zero Trust network policies using Cloudflare for Teams. You can apply these rules to connections bound for the public Internet or for traffic inside a private network running on Cloudflare. These rules are enforced in Cloudflare’s network of data centers in over 200 cities around the world, giving your team comprehensive network filtering and logging, wherever your users work, without slowing them down.
Last week, my teammate Pete’s blog post described the release of network-based policies in Cloudflare for Teams. Your team can now keep users safe from threats by limiting the ports and IPs that devices in your fleet can reach. With that release, security teams can now replace even more security appliances with Cloudflare’s network.
We’re excited to help your team replace that hardware, but we also know that those legacy network firewalls were used to keep private data and applications safe in a castle-and-moat model. You can now use Cloudflare for Teams to upgrade to a Zero Trust networking model instead, with a private network running on Cloudflare and rules based on identity, not IP address.
To learn how, keep reading or watch the demo below.
Deprecating the castle-and-moat model
Private networks provided security by assuming that the network should trust you by virtue of you being in a place where you could physically connect. If you could enter an office and connect to the network, the network assumed that you should be trusted and allowed to reach any other destination on that network. When work happened inside the closed walls of offices, with security based on the physical door to the building, that model at least offered some basic protections.
That model fell apart when users left the offices. Even before the pandemic sent employees home, roaming users or branch offices relied on virtual private networks (VPNs) to punch holes back into the private network. Users had to authenticate to the VPN but, once connected, still had the freedom to reach almost any resource. With more holes in the firewall, and full lateral movement, this model became a risk to any security organization.
However, the alternative was painful or unavailable to most teams. Building network segmentation rules required complex configuration and still relied on source IPs instead of identity. Even with that level of investment in network segmentation, organizations still had to trust the IP of the user rather than the user’s identity.
These types of IP-based rules served as band-aids while the rest of the use cases in an organization moved into the future. Resources like web applications migrated to models that used identity, multi-factor authentication, and continuous enforcement while networking security went unchanged.
But private networks can be great!
There are still great reasons to use private networks for applications and resources. It can be easier and faster to create and share something on a private network instead of waiting to create a public DNS and IP record.
Also, IPs are more easily discarded and reused across internal networks. You do not need to give every team member permission to edit public DNS records. And in some cases, regulatory and security requirements flat out prohibit tools being exposed publicly on the Internet.
Private networks should not disappear, but the usability and security compromises they require should stay in the past. Two months ago, we announced the ability to build a private network on Cloudflare. This feature allows your team to replace VPN appliances and clients with a network that has a point of presence in over 200 cities around the world.
Zero Trust rules are enforced on the Cloudflare edge
While that release helped us address the usability compromises of a traditional VPN, today’s announcement handles the security compromises. You can now build identity-based, Zero Trust policies inside that private network. This means that you can lock down specific CIDR ranges or IP addresses based on a user’s identity, group, device or network. You can also control and log every connection without additional hardware or services.
How it works
Cloudflare’s daemon, cloudflared, is used to create a secure TCP tunnel from your network to Cloudflare’s edge. This tunnel is private and can only be accessed by connections that you authorize. On their side, users can deploy Cloudflare WARP on their machines to forward their network traffic to Cloudflare’s edge — this allows them to hit specific private IP addresses. Since Cloudflare has 200+ data centers across the globe, all of this occurs without any traffic backhauls or performance penalties.
With today’s release, we now enforce in-line network firewall policies as well. All traffic arriving to Cloudflare’s edge will be evaluated by the Layer 4 firewall. So while you can choose to enable or disable the Layer 7 firewall or bypass HTTP inspection for a given domain, all TCP traffic arriving to Cloudflare will traverse the Layer 4 firewall. Network-level policies will allow you to match traffic that arrives from (or is destined to) data centers, branch offices, and remote users based on the following traffic criteria:
Source IP address or CIDR in the header
Destination IP address or CIDR in the header
Source port or port range in the header
Destination port or port range in the header
With these criteria in place, you can enforce identity-aware policies down to a specific port across your entire network plane.
Get started with Zero Trust networking
There are a few things you’ll want to have configured before building your Zero Trust private network policies (we cover these in detail in our previous private networking post):
Install cloudflared on your private network
Route your private IP addresses to Cloudflare’s edge
Deploy the WARP client to your users’ machines
Once the initial setup is complete, this is how you can configure your Zero Trust network policies on the Teams Dashboard:
1. Create a new network policy in Gateway.
2. Specify the IP and Port combination you want to allow access to. In this example, we are exposing an RDP port on a specific private IP address.
3. Add any desired identity policies to your network policy. In this example, we have limited access to users in a “Developers” group specified in the identity provider.
Once this policy is configured, only users in the specific identity group running the WARP client will be able to access applications on the specified IP and port combination.
And that’s it. Without any additional software or configuration, we have created an identity-aware network policy for all of my users that will work on any machine or network across the world while maintaining Zero Trust. Existing infrastructure can be securely exposed in minutes not hours or days.
What’s Next
We want to make this even easier to use and more secure. In the coming months, we are planning to add support for Private DNS resolution, Private IP conflict management and granular session control for private network policies. Additionally, for now this flow only works for client-to-server (WARP to cloudflared) connections. Coming soon, we’ll introduce support for east-west connections that will allow teams to connect cloudflared and other parts of Cloudflare One routing.
Over the past year, Cloudflare Gateway has grown from a DNS filtering solution to a Secure Web Gateway. That growth has allowed customers to protect their organizations with fine-grained identity-based HTTP policies and malware protection wherever their users are. But what about other Internet-bound, non-HTTP traffic that users generate every day — like SSH?
Today we’re excited to announce the ability for administrators to configure network-based policies in Cloudflare Gateway. Like DNS and HTTP policy enforcement, organizations can use network selectors like IP address and port to control access to any network origin.
Because Cloudflare for Teams integrates with your identity provider, it also gives you the ability to create identity-based network policies. This means you can now control access to non-HTTP resources on a per-user basis regardless of where they are or what device they’re accessing that resource from.
A major goal for Cloudflare One is to expand the number of on-ramps to Cloudflare — just send your traffic to our edge however you wish and we’ll make sure it gets to the destination as quickly and securely as possible. We released Magic WAN and Magic Firewall to let administrators replace MPLS connections, define routing decisions, and apply packet-based filtering rules on network traffic from entire sites. When coupled with Magic WAN, Gateway allows customers to define network-based rules that apply to traffic between whole sites, data centers, and that which is Internet-bound.
Solving Zero Trust networking problems
Until today, administrators could only create policies that filtered traffic at the DNS and HTTP layers. However, we know that organizations need to control the network-level traffic leaving their endpoints. We kept hearing two categories of problems from our users and we’re excited that today’s announcement addresses both.
First, organizations want to replace their legacy network firewall appliances. Those appliances are complex to manage, expensive to maintain, and force users to backhaul traffic. Security teams deploy those appliances in part to control the ports and IPs devices can use to send traffic. That level of security helps prevent devices from sending traffic over non-standard ports or to known malicious IPs, but customers had to deal with the downsides of on-premise security boxes.
Second, moving to a Zero Trust model for named resources is not enough. Cloudflare Access provides your team with Zero Trust controls over specific applications, including non-HTTP applications, but we know that customers who are migrating to this model want to bring that level of Zero Trust control to all of their network traffic.
How it works
Cloudflare Gateway, part of Cloudflare One, helps organizations replace legacy firewalls and upgrade to Zero Trust networking by starting with the endpoint itself. Wherever your users do their work, they can connect to a private network running on Cloudflare or the public Internet without backhauling traffic.
First, administrators deploy the Cloudflare WARP agent on user devices, whether those devices are MacOS, Windows, iOS, Android and (soon) Linux. The WARP agent can operate in two modes:
DNS filtering: WARP becomes a DNS-over-HTTPS (DoH) client and sends all DNS queries to a nearby Cloudflare data center where Cloudflare Gateway can filter those queries for threats like websites that host malware or phishing campaigns.
Proxy mode: WARP creates a WireGuard tunnel from the device to Cloudflare’s edge and sends all network traffic through the tunnel. Cloudflare Gateway can then inspect HTTP traffic and apply policies like URL-based rules and virus scanning.
Today’s announcement relies on the second mode. The WARP agent will send all TCP traffic leaving the device to Cloudflare, along with the identity of the user on the device and the organization in which the device is enrolled. The Cloudflare Gateway service will take the identity and then review the TCP traffic against four criteria:
Source IP or network
Source Port
Destination IP or network
Destination Port
Before allowing the packets to proceed to their destination, Cloudflare Gateway checks the organization’s rules to determine if they should be blocked. Rules can apply to all of an organization’s traffic or just specific users and directory groups. If the traffic is allowed, Cloudflare Gateway still logs the identity and criteria above.
Cloudflare Gateway accomplishes this without slowing down your team. The Gateway service runs in every Cloudflare data center in over 200 cities around the world, giving your team members an on-ramp to the Internet that does not backhaul or hairpin traffic. We enforce rules using Cloudflare’s Rust-based Wirefilter execution engine, taking what we’ve learned from applying IP-based rules in our reverse proxy firewall at scale and giving your team the performance benefits.
Building a Zero Trust networking rule
SSH is a versatile protocol that allows users to connect to remote machines and even tunnel traffic from a local machine to a remote machine before reaching the intended destination. That’s great but it also leaves organizations with a gaping hole in their security posture. At first, an administrator could configure a rule that blocks all outbound SSH traffic across the organization.
As soon as you save that policy, the phone rings and it’s an engineer asking why they can’t use a lot of their development tools. Right, engineers use SSH a lot so we should use the engineering IdP group to allow just our engineers to use SSH.
You take advantage of rule precedence and place that rule above the existing rule that affects all users to allow engineers to SSH outbound but not any other users in the organization.
It doesn’t matter which corporate device engineers are using or where they are located, they will be allowed to use SSH and all other users will be blocked.
One more thing
Last month, we announced the ability for customers to create private networks on Cloudflare. Using Cloudflare Tunnel, organizations can connect environments they control using private IP space and route traffic between sites; better, WARP users can connect to those private networks wherever they’re located. No need for centralized VPN concentrators and complicated configurations–connect your environment to Cloudflare and configure routing.
Today’s announcement gives administrators the ability to configure network access policies to control traffic within those private networks. What if the engineer above wasn’t trying to SSH to an Internet-accessible resource but to something an organization deliberately wants to keep within an internal private network (e.g., a development server)? Again, not everyone in the organization should have access to that either. Now administrators can configure identity-based rules that apply to private networks built on Cloudflare.
What’s next?
We’re laser-focused on our Cloudflare One goal to secure organizations regardless of how their traffic gets to Cloudflare. Applying network policies to both WARP users and routing between private networks is part of that vision.
We’re excited to release these building blocks to Zero Trust Network Access policies to protect an organization’s users and data. We can’t wait to dig deeper into helping organizations secure applications that use private hostnames and IPs like they can today with their publicly facing applications.
We’re just getting started–follow this link so you can too.
Network-layer DDoS attacks are on the rise, prompting security teams to rethink their L3 DDoS mitigation strategies to prevent business impact. Magic Transit protects customers’ entire networks from DDoS attacks by placing our network in front of theirs, either always on or on demand. Today, we’re announcing new functionality to improve the experience for on-demand Magic Transit customers: flow-based monitoring. Flow-based monitoring allows us to detect threats and notify customers when they’re under attack so they can activate Magic Transit for protection.
Magic Transit is Cloudflare’s solution to secure and accelerate your network at the IP layer. With Magic Transit, you get DDoS protection, traffic acceleration, and other network functions delivered as a service from every Cloudflare data center. With Cloudflare’s global network (59 Tbps capacity across 200+ cities) and <3sec time to mitigate at the edge, you’re covered from even the largest and most sophisticated attacks without compromising performance. Learn more about Magic Transit here.
Using Magic Transit on demand
With Magic Transit, Cloudflare advertises customers’ IP prefixes to the Internet with BGP in order to attract traffic to our network for DDoS protection. Customers can choose to use Magic Transit always on or on demand. With always on, we advertise their IPs and mitigate attacks all the time; for on demand, customers activate advertisement only when their networks are under active attack. But there’s a problem with on demand: if your traffic isn’t routed through Cloudflare’s network, by the time you notice you’re being targeted by an attack and activate Magic Transit to mitigate it, the attack may have already caused impact to your business.
On demand with flow-based monitoring
Flow-based monitoring solves the problem with on-demand by enabling Cloudflare to detect and notify you about attacks based on traffic flows from your data centers. You can configure your routers to continuously send NetFlow or sFlow (coming soon) to Cloudflare. We’ll ingest your flow data and analyze it for volumetric DDoS attacks.
Send flow data from your network to Cloudflare for analysis
When an attack is detected, we’ll notify you automatically (by email, webhook, and/or PagerDuty) with information about the attack.
Cloudflare detects attacks based on your flow data
You can choose whether you’d like to activate IP advertisement with Magic Transit manually – we support activation via the Cloudflare dashboard or API – or automatically, to minimize the time to mitigation. Once Magic Transit is activated and your traffic is flowing through Cloudflare, you’ll receive only the clean traffic back to your network over your GRE tunnels.
Activate Magic Transit for DDoS protection
Using flow-based monitoring with Magic Transit on demand will provide your team peace of mind. Rather than acting in response to an attack after it impacts your business, you can complete a simple one-time setup and rest assured that Cloudflare will notify you (and/or start protecting your network automatically) when you’re under attack. And once Magic Transit is activated, Cloudflare’s global network and industry-leading DDoS mitigation has you covered: your users can continue business as usual with no impact to performance.
Example flow-based monitoring workflow: faster time to mitigate for Acme Corp
Let’s walk through an example customer deployment and workflow with Magic Transit on demand and flow-based monitoring. Acme Corp’s network was hit by a large ransom DDoS attack recently, which caused downtime for both external-facing and internal applications. To make sure they’re not impacted again, the Acme network team chose to set up on-demand Magic Transit. They authorize Cloudflare to advertise their IP space to the Internet in case of an attack, and set up Anycast GRE tunnels to receive clean traffic from Cloudflare back to their network. Finally, they configure their routers at each data center to send NetFlow data to a Cloudflare Anycast IP.
Cloudflare receives Acme’s NetFlow data at a location close to the data center sending it (thanks, Anycast!) and analyzes it for DDoS attacks. When traffic exceeds attack thresholds, Cloudflare triggers an automatic PagerDuty incident for Acme’s NOC team and starts advertising Acme’s IP prefixes to the Internet with BGP. Acme’s traffic, including the attack, starts flowing through Cloudflare within minutes, and the attack is blocked at the edge. Clean traffic is routed back to Acme through their GRE tunnels, causing no disruption to end users – they’ll never even know Acme was attacked. When the attack has subsided, Acme’s team can withdraw their prefixes from Cloudflare with one click, returning their traffic to its normal path.
When the attack subsides, withdraw your prefixes from Cloudflare to return to normal
Get started
To learn more about Magic Transit and flow-based monitoring, contact us today.
Around the world government and medical organizations are struggling with one of the most difficult logistics challenges in history: equitably and efficiently distributing the COVID-19 vaccine. There are challenges around communicating who is eligible to be vaccinated, registering those who are eligible for appointments, ensuring they show up for their appointments, transporting the vaccine under the required handling conditions, ensuring that there are trained personnel to administer the vaccine, and then doing it all over again as most of the vaccines require two doses.
Cloudflare can’t help with most of that problem, but there is one key part that we realized we could help facilitate: ensuring that registration websites don’t crash under load when they first begin scheduling vaccine appointments. Project Fair Shot provides Cloudflare’s new Waiting Room service for free for any government, municipality, hospital, pharmacy, or other organization responsible for distributing COVID-19 vaccines. It is open to eligible organizations around the world and will remain free until at least July 1, 2021 or longer if there is still more demand for appointments for the vaccine than there is supply.
Crashing Registration Websites
The problem of vaccine scheduling registration websites crashing under load isn’t theoretical: it is happening over and over as organizations attempt to schedule the administration of the vaccine. This hit home at Cloudflare last weekend. The wife of one of our senior team members was trying to register her parents to receive the vaccine. They met all the criteria and the municipality where they lived was scheduled to open appointments at noon.
When the time came for the site to open, it immediately crashed. The cause wasn’t hackers or malicious activity. It was merely that so many people were trying to access the site at once. “Why doesn’t Cloudflare build a service that organizes a queue into an orderly fashion so these sites don’t get overwhelmed?” she asked her husband.
A Virtual Waiting Room
Turns out, we were already working on such a feature, but not for this use case. The problem of fairly distributing something where there is more demand than supply comes up with several of our clients. Whether selling tickets to a hot concert, the latest new sneaker, or access to popular national park hikes it is a difficult challenge to ensure that everyone eligible has a fair chance.
The solution is to open registration to acquire the scarce item ahead of the actual sale. Anyone who visits the site ahead of time can be put into a queue. The moment before the sale opens, the order of the queue can be randomly (and fairly) shuffled. People can then be let in in order of their new, random position in the queue — allowing only so many at any time as the backend of the site can handle.
At Cloudflare, we were building this functionality for our customers as a feature called Waiting Room. (You can learn more about the technical details of Waiting Room in this post by Brian Batraski who helped build it.) The technology is powerful because it can be used in front of any existing web registration site without needing any code changes or hardware installation. Simply deploy Cloudflare through a simple DNS change and then configure Waiting Room to ensure any transactional site, no matter how meagerly resourced, can keep up with demand.
Recognizing a Critical Need; Moving Up the Launch
We planned to release it in February. Then, when we saw vaccine sites crashing under load and frustration of people eligible for the vaccine building, we realized we needed to move the launch up and offer the service for free to organizations struggling to fairly distribute the vaccine. With that, Project Fair Shot was born.
Government, municipal, hospital, pharmacy, clinic, and any other organizations charged with scheduling appointments to distribute the vaccine can apply to participate in Project Fair Shot by visiting: projectfairshot.org
Giving Front Line Organizations the Technical Resources They Need
The service will be free for qualified organizations at least until July 1, 2021 or longer if there is still more demand for appointments for the vaccine than there is supply. We are not experts in medical cold storage and I get squeamish at the sight of needles, so we can’t help with many of the logistical challenges of distributing the vaccine. But, seeing how we could support this aspect, our team knew we needed to do all we could to help.
The superheroes of this crisis are the medical professionals who are taking care of the sick and the scientists who so quickly invented these miraculous vaccines. We’re proud of the supporting role Cloudflare has played helping ensure the Internet has continued to function well when the world needed it most. Project Fair Shot is one more way we are living up to our mission of helping build a better Internet.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.