Post Syndicated from Benjamin Smith original https://aws.amazon.com/blogs/compute/implementing-a-uml-state-machine-using-aws-step-functions/
This post is written by Michael Havey, Senior Specialist Solutions Architect, AWS
This post shows how to model a Unified Modeling Language (UML) state machine as an AWS Step Functions workflow. A UML state machine models the behavior of an object, naming each of its possible resting states and specifying how it moves from one state to another. A Step Functions state machine implements the object behavior. This post shows how the UML diagram guides the state machine implementation and traces back to it.
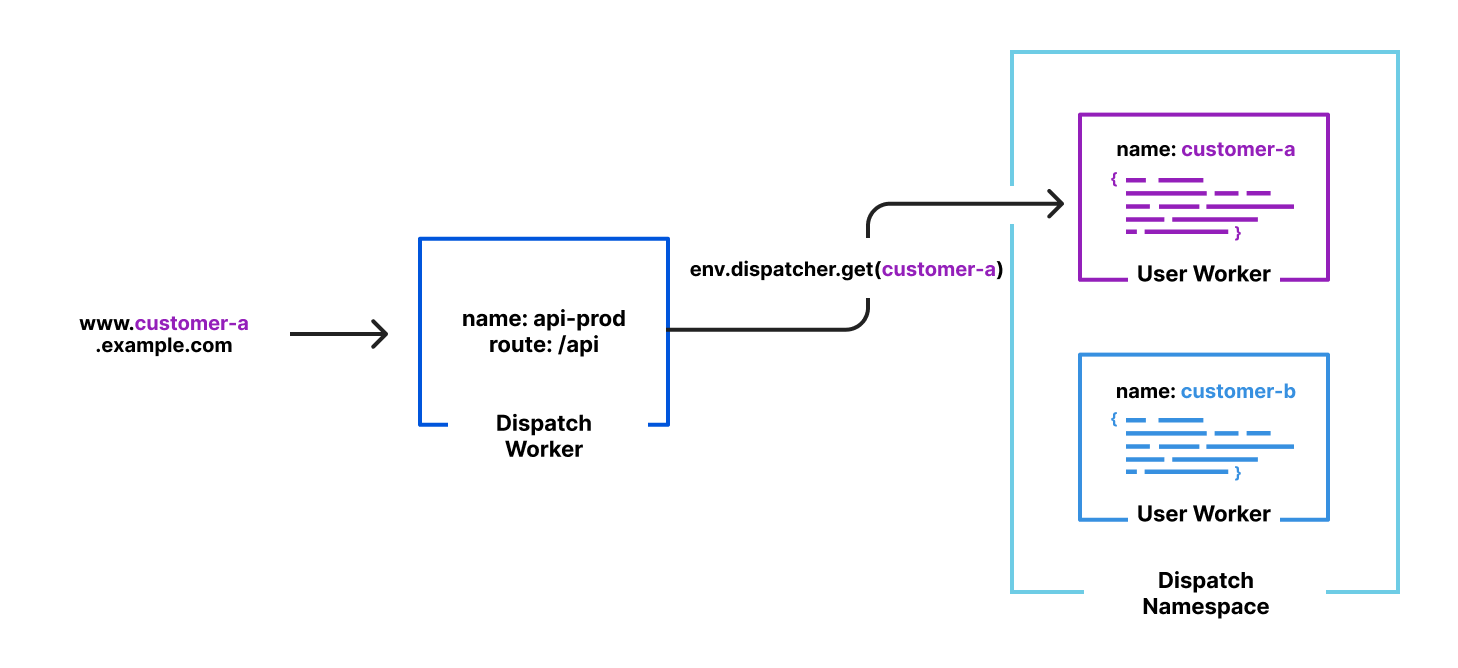
State machines are often used to model real-time systems and devices. This post uses a stock order as an example. What drives a business object from one state to another is its interaction with applications through services. When the object enters a new state, it typically responds by calling the application through a service. It is typically an event arising from that application that transitions the business object to the next state. The UML model declares each state and the service interactions. Step Functions, which is designed for service orchestration, implements the behavior.
Overview
This is the approach discussed in this post:

- A developer implements a Step Functions state machine guided by a UML state machine designed in a third-party UML modeling tool. The implementation explicitly traces back to the UML model by logging execution of state machine activities.
- To invoke the target application, the Step Functions state machine invokes an AWS Lambda handler function. This invocation implements a UML state machine activity.
- The handler function, in turn, invokes the application. The implementation of the call is application-specific.
- If a callback from the application is expected, the application sends an event to a Lambda event dispatcher function. The implementation of this message exchange is application-specific.
- If a callback is expected, the Lambda event dispatcher function calls back the Step Functions state machine with the application event. This enables the Step Functions state machine to implement a UML state transition to the next state.
Traceability is the best way to link the Step Functions implementation to the UML model. This is because it ensures that the implementation is doing what the model intends.
An alternative is to generate Step Functions code based on the UML model using a standard XML format known as XML Metadata Interchange (XMI). A code generator tool can introspect the XMI to generate code from it. While technically feasible, UML state machines are highly expressive with many patterns and idioms. A generator often can’t produce code as lean and readable as that of a developer.
Walkthrough
This example shows a UML state machine in MagicDraw, a UML design tool. This diagram is the basis for the Step Functions implementation. This Git repository includes the XMI file for the UML diagram and the code to set up the Step Functions implementation.
The walkthrough has the following steps:
- Deploy Step Functions and AWS Lambda resources.
- Run the Step Functions state machine. Check the execution results to see how they trace back to the UML state machine.
- Clean up AWS resources.
Provision resources
To run this example, you need an AWS account with permission to use Step Functions and Lambda. On your machine, install the AWS Command Line Interface (CLI) and the AWS Serverless Application Model (AWS SAM) CLI.
Complete the following steps on your machine:
- Clone the Git repository.
- In a command shell, navigate to the
samfolder of the clone. - Run
sam buildto build the application. - Run
sam deploy –-guidedto deploy the application to your AWS account. - In the output, find names of Step Functions state machines and Lambda functions created.
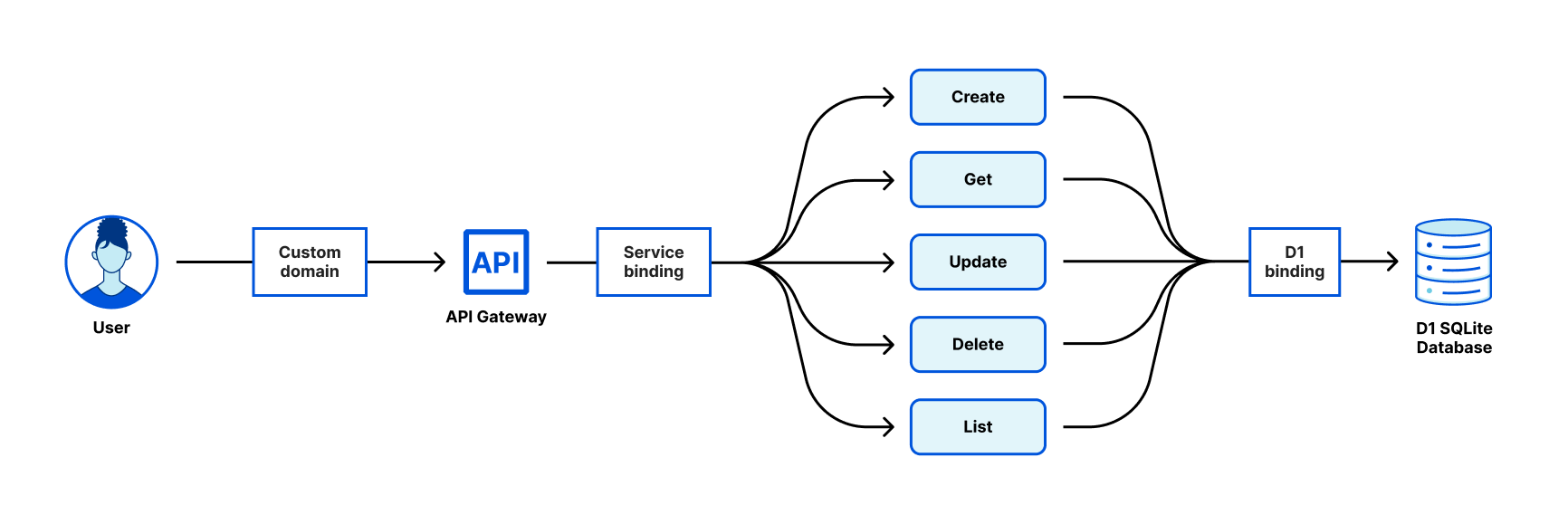
The application creates several state machines, but in this post we consider the simplest: Test Buy Sell. The example models the behavior of a buy/sell stock order, which is based on an example from the Step Functions documentation: https://docs.aws.amazon.com/step-functions/latest/dg/sample-lambda-orchestration.html.
Explore UML model for Test BuySell
Begin with the following UML model (also available in the GitHub repository).

In the model:
- The black dot on the upper left is the initial state. It has an arrow (a transition) to
CheckingStockPrice(a state). CheckingStockPricehas an activity, calledcheckStockPrice, of type do. When that state is visited, the activity is automatically run. When the activity finishes, the machine transitions automatically (a completion transition) to the next state.- That state,
GeneratingBuySellRecommendation, has its own do activitygenerateBuySellRecommendation. Completion of that activity moves to the next state. - The next state is
Approving, whose activityrouteForApprovalis of type entry. That activity is run when the state is entered. It waits for an event to move the machine forward. There are three transitions fromApproving. Each has a trigger, indicating the type of event expected, calledapprovalComplete. Each has a guard that distinguishes the outcome of the approval. - If the guard is
sell, transition to the stateSellingStock. - If it’s
buy, transition to the stateBuyingStock. - If it’s
reject, transition to the terminate state (denoted by an X) and run a transition activity calledlogReject. BuyingStockandSellingStockeach have a do activity –buyStockandsellStock– and transition on completion to the stateReportingResult. That state has do activityreportResult.- Transition to the final state (the black dot enclosed in a circle).
Explore Step Functions implementation
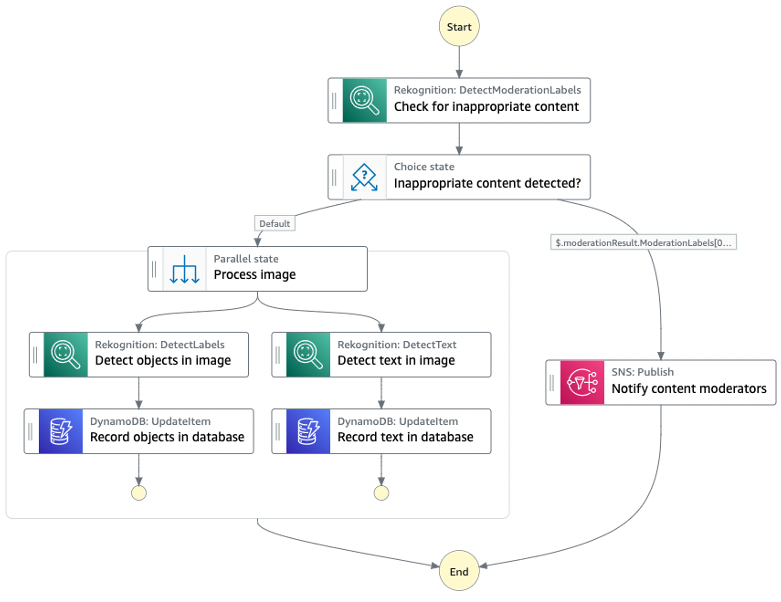
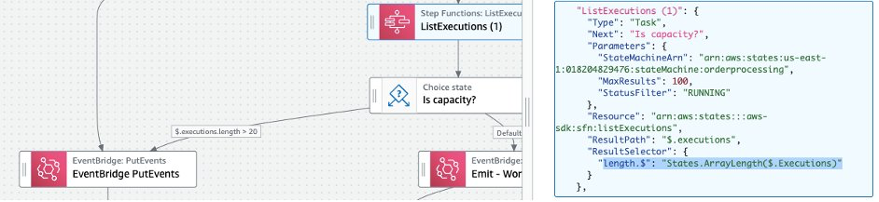
Find the Step Functions implementation in the AWS Console. Under the list of State Machines, select the function with a name starting with BlogBuySell. Choose Edit to view the design of the machine. From there, open it in Workflow Studio to show the state machine workflow visualization:

The Step Function state machine implements all the activities from the UML state machine. There are Lambda tasks to implement the major state do activities: Check Stock Price, Generate Buy/Sell Recommendation, Buy Stock, Sell Stock, Report Result. There is also a Lambda function for the transition activity: Log Reject. Each Lambda function traces back to the UML state machine and uses the following format to log trace records:
{
"sourceState": S,
"activityType": stateEntry|stateExit|stateDo|transition,
"activityName": N
"trigger" T, // if transition activity
"guard": G // if transition activity and has a guard
}The control flow in the Step Functions state machine intuitively matches the UML state machine. The UML model has mostly completion transitions, so the Step Functions state machine largely flows from one Lambda task to another. However, I must consider the Approving state, where the machine waits for an event and then transitions in one of three directions from the choice state Buy or Sell. For this, use the Step Functions callback capability. Route For Approval is a Lambda task with the Wait For Callback option enabled. The Lambda task has three responsibilities:
- Executes the UML state entry activity
routeForApprovalby calling the application. - Logs a tracing record that it has executed that activity.
- Passes the task token provided by the Step Functions state machine to the application.
When the application has an approval decision, it sends an event through messaging. A separate Lambda event dispatcher function receives the message and, using the Step Functions API, calls back the Step Functions state machine with key details from the message: task token, trigger, guard.
Finally, notice the fail step after Log Reject. This implements the terminate state in the UML model.
Execute the Step Functions state machine
Execute the state machine by choosing Start Execution for the BlogBuySell state machine in the Step Functions console. Use this input:
{"appData": "Insert your JSON here"}The console shows a graph view of the progress of the state machine. It should pause at the Route For Approval task.

Confirm traceability
Check the event view to confirm the tracing back to the UML model. The Task Scheduled event for Check Stock Price shows:
"sourceState": "CheckingStockPrice",
"activityType": "stateDo",
"activityName": "checkStockPrice",
The Task Scheduled event for Generate buy/sell Recommendation shows:
"sourceState": "GeneratingBuySellRecommendation",
"activityType": "stateDo",
"activityName": "generateBuySellRecommendation",
The Task Scheduled event for Route For Approval shows output resembling the following. Your taskToken will be different.
"sourceState": "Approving",
"activityType": "stateEntry",
"activityName": "routeForApproval",
"taskToken": "AAAAK . . . 99es="
Approve for buy
The state machine is waiting at Route For Approval. Simulate an application event to continue it forward. First, copy the task token value from above, excluding the quotes.
In a separate browser tab, open the Lambda console and find the function whose name contains BlogDummyUMLEventDispatcher. In the Test tab, create a new event:
{ "taskToken": "<paste the task token here>", "trigger": "approvalComplete", "guard": "buy", "appData": {"x": "y"} }

Choose Test to call the Lambda function with this input, which calls back the state machine.
Confirm execution of approval
In the Step Functions console, confirm that the flow is completed and taken the Buy stock path.

More examples and patterns
The AWS SAM application deploys two additional examples, which show important patterns:
- Hierarchical or composite states.
- Parallel or orthogonal states
- Cancellation events
- Internal transitions
- Transition to history
- Using an event loop for complex flow
You can find a discussion of these examples in the Git repo.
Comparing UML and Step Functions state machines
Step Functions transitions tasks in sequence with the ability to conditionally branch, loop, or parallelize tasks. These tasks aren’t quite the same as states in a UML model. In this approach, tasks map to UML states or transition activities.
A UML state machine spends most of its time waiting in its current state for the next event to happen. A standard workflow in Step Functions can wait too. It can run for up to one year because some activities can pause until they are called back by an external trigger. I used that capability to implement a pattern to trigger the next transition by calling back the Step Functions state machine.
Cleaning up
To avoid incurring future charges, navigate to the directory where you deployed the application and run sam delete to undeploy it.
Conclusion
This post shows code recipes for implementing UML state machines using Step Functions. If your organization already uses modeling tools, this discussion helps you understand the Step Functions implementation path. If you are a Step Functions designer, this discussion shows UML’s expressive power as the model for your implementation.
Learn more about Step Functions implementations on the Sample projects for Step Functions page.