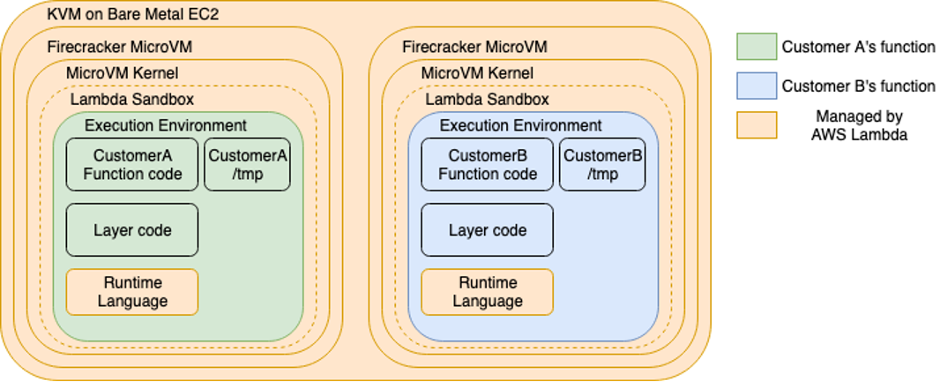
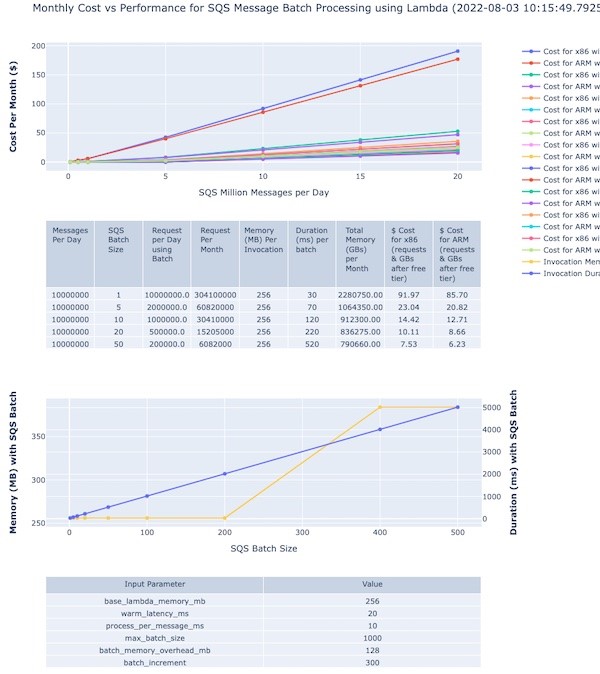
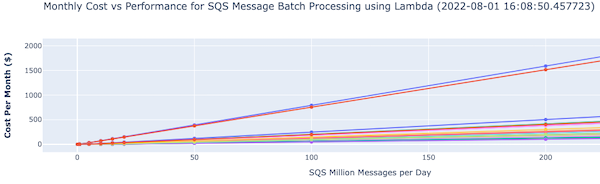
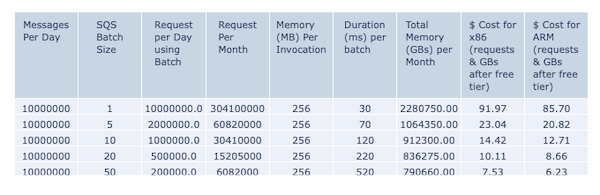
Post Syndicated from James Beswick original https://aws.amazon.com/blogs/compute/deploying-aws-lambda-functions-using-aws-controllers-for-kubernetes-ack/
This post is written by Rajdeep Saha, Sr. SSA, Containers/Serverless.
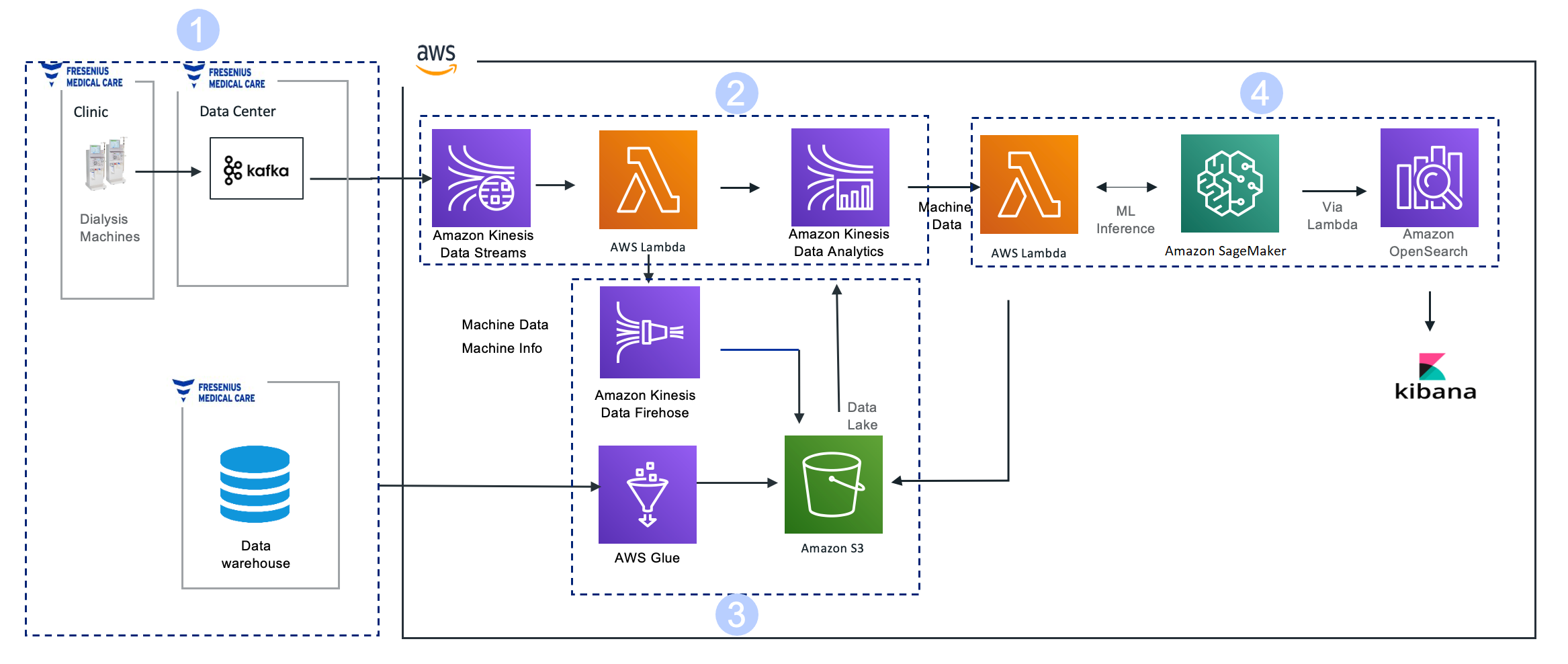
AWS Controllers for Kubernetes (ACK) allows you to manage AWS services directly from Kubernetes. With the ACK service controller for AWS Lambda, you can provision and manage Lambda functions with kubectl and custom resources. With ACK, you can have a single consolidated approach to managing container workloads and other AWS services, such as Lambda, directly from Kubernetes without needing additional infrastructure automation tools.
This post walks you through deploying a sample Lambda function from a Kubernetes cluster provided by Amazon EKS.
Use cases
Some of the use cases for provisioning Lambda functions from ACK include:
- Your organization already has a DevOps process to deploy resources into the Amazon EKS cluster using Kubernetes declarative YAMLs (known as manifest files). With ACK for AWS Lambda, you can now use manifest files to provision Lambda functions without creating separate infrastructure as a code template.
- Your project has implemented GitOps with Kubernetes. With GitOps, git becomes the single source of truth, and all the changes are done via git repo. In this model, Kubernetes continuously reconciles the git repo (desired state) with the resources running inside the cluster (current state). If any differences are found, the GitOps process automatically implements changes to the cluster from the git repo. Using ACK for AWS Lambda, since you are creating the Lambda function using Kubernetes custom resource, the GitOps model is applied for Lambda.
- Your organization has established permissions boundaries for different users and groups using role-based access control (RBAC) and IAM roles for service accounts (IRSA). You can reuse this security model for Lambda without having to create new users and policies.
How ACK for AWS Lambda works
- The ‘Ops’ team deploys the ACK service controller for Lambda. This controller runs as a pod within the Amazon EKS cluster.
- The controller pod needs permission to read the Lambda function code and create the Lambda function. The Lambda function code is stored as a zip file in an S3 bucket for this example. The permissions are granted to the pod using IRSA.
- Each AWS service has separate ACK service controllers. This specific controller for AWS Lambda can act on the custom resource type ‘Function’.
- The ‘Dev’ team deploys Kubernetes manifest file with custom resource type ‘Function’. This manifest file defines the necessary fields required to create the function, such as S3 bucket name, zip file name, Lambda function IAM role, etc.
- The ACK service controller creates the Lambda function using the values from the manifest file.
Prerequisites
You need a few tools before deploying the sample application. Ensure that you have each of the following in your working environment:
- kubectl
- eksctl
- AWS Command Line Interface (AWS CLI)
- Helm
This post uses shell variables to make it easier to substitute the actual names for your deployment. When you see placeholders like NAME=<your xyz name>, substitute in the name for your environment.
Setting up the Amazon EKS cluster
- Run the following to create an Amazon EKS cluster. The following single command creates a two-node Amazon EKS cluster with a unique name.
eksctl create cluster - It may take 15–30 minutes to provision the Amazon EKS cluster. When the cluster is ready, run:
kubectl get nodes - The output shows the following:

- To get the Amazon EKS cluster name to use throughout the walkthrough, run:
eksctl get cluster export EKS_CLUSTER_NAME=<provide the name from the previous command>

Setting up the ACK Controller for Lambda
To set up the ACK Controller for Lambda:
- Install an ACK Controller with Helm by following these instructions:
– Change ‘export SERVICE=s3’ to ‘export SERVICE=lambda’.
– Change ‘export AWS_REGION=us-west-2’ to reflect your Region appropriately. - To configure IAM permissions for the pod running the Lambda ACK Controller to permit it to create Lambda functions, follow these instructions.
– Replace ‘SERVICE=”s3”’ with ‘SERVICE=”lambda”’. - Validate that the ACK Lambda controller is running:
kubectl get pods -n ack-system - The output shows the running ACK Lambda controller pod:


Provisioning a Lambda function from the Kubernetes cluster
In this section, you write a sample “Hello world” Lambda function. You zip up the code and upload the zip file to an S3 bucket. Finally, you deploy that zip file to a Lambda function using the ACK Controller from the EKS cluster you created earlier. For this example, use Python3.9 as your language runtime.
To provision the Lambda function:
- Run the following to create the sample “Hello world” Lambda function code, and then zip it up:
mkdir my-helloworld-function cd my-helloworld-function cat << EOF > lambda_function.py import json def lambda_handler(event, context): # TODO implement return { 'statusCode': 200, 'body': json.dumps('Hello from Lambda!') } EOF zip my-deployment-package.zip lambda_function.py - Create an S3 bucket following the instructions here. Alternatively, you can use an existing S3 bucket in the same Region of the Amazon EKS cluster.
- Run the following to upload the zip file into the S3 bucket from the previous step:
export BUCKET_NAME=<provide the bucket name from step 2> aws s3 cp my-deployment-package.zip s3://${BUCKET_NAME} - The output shows:
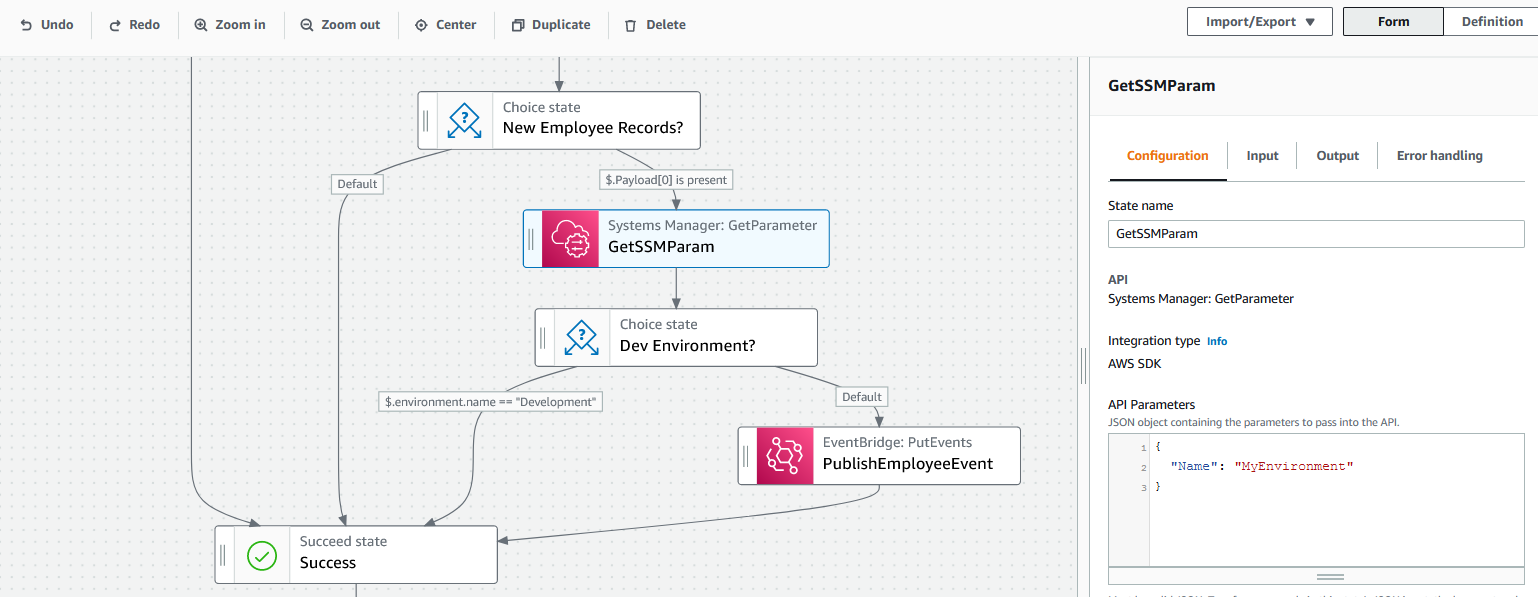
upload: ./my-deployment-package.zip to s3://<BUCKET_NAME>/my-deployment-package.zip - Create your Lambda function using the ACK Controller. The full spec with all the available fields is listed here. First, provide a name for the function:
export FUNCTION_NAME=hello-world-s3-ack - Create and deploy the Kubernetes manifest file. The command at the end,
kubectl create -f function.yamlsubmits the manifest file, with kind as ‘Function’. The ACK Controller for Lambda identifies this custom ‘Function’ object and deploys the Lambda function based on the manifest file.export AWS_ACCOUNT_ID=$(aws sts get-caller-identity --query "Account" --output text) export LAMBDA_ROLE="arn:aws:iam::${AWS_ACCOUNT_ID}:role/lambda_basic_execution" cat << EOF > lambdamanifest.yaml apiVersion: lambda.services.k8s.aws/v1alpha1 kind: Function metadata: name: $FUNCTION_NAME annotations: services.k8s.aws/region: $AWS_REGION spec: name: $FUNCTION_NAME code: s3Bucket: $BUCKET_NAME s3Key: my-deployment-package.zip role: $LAMBDA_ROLE runtime: python3.9 handler: lambda_function.lambda_handler description: function created by ACK lambda-controller e2e tests EOF kubectl create -f lambdamanifest.yaml - The output shows:
function.lambda.services.k8s.aws/< FUNCTION_NAME> created
- To retrieve the details of the function using a Kubernetes command, run:
kubectl describe function/$FUNCTION_NAME - This Lambda function returns a “Hello world” message. To invoke the function, run:
aws lambda invoke --function-name $FUNCTION_NAME response.json cat response.json - The Lambda function returns the following output:
{"statusCode": 200, "body": "\"Hello from Lambda!\""}
Congratulations! You created a Lambda function from your Kubernetes cluster.
To learn how to provision the Lambda function using the ACK controller from an OCI container image instead of a zip file in an S3 bucket, follow these instructions.
Cleaning up
This section cleans up all the resources that you have created. To clean up:
- Delete the Lambda function:
kubectl delete function $FUNCTION_NAME - If you have created a new S3 bucket, delete it by running:
aws s3 rm s3://${BUCKET_NAME} --recursive aws s3api delete-bucket --bucket ${BUCKET_NAME} - Delete the EKS cluster:
eksctl delete cluster --name $EKS_CLUSTER_NAME - Delete the IAM role created for the ACK Controller. Get the IAM role name by running the following command, then delete the role from the IAM console:
echo $ACK_CONTROLLER_IAM_ROLE
Conclusion
This blog post shows how AWS Controllers for Kubernetes enables you to deploy a Lambda function directly from your Amazon EKS environment. AWS Controllers for Kubernetes provides a convenient way to connect your Kubernetes applications to AWS services directly from Kubernetes.
ACK is open source: you can request new features and report issues on the ACK community GitHub repository.
For more serverless learning resources, visit Serverless Land.




































 Edvin Hallvaxhiu is a Senior Global Security Architect with AWS Professional Services and is passionate about cybersecurity and automation. He helps customers build secure and compliant solutions in the cloud. Outside work, he likes traveling and sports.
Edvin Hallvaxhiu is a Senior Global Security Architect with AWS Professional Services and is passionate about cybersecurity and automation. He helps customers build secure and compliant solutions in the cloud. Outside work, he likes traveling and sports. Rahul Shaurya is a Senior Big Data Architect with AWS Professional Services. He helps and works closely with customers building data platforms and analytical applications on AWS. Outside of work, Rahul loves taking long walks with his dog Barney.
Rahul Shaurya is a Senior Big Data Architect with AWS Professional Services. He helps and works closely with customers building data platforms and analytical applications on AWS. Outside of work, Rahul loves taking long walks with his dog Barney. Andrea Montanari is a Big Data Architect with AWS Professional Services. He actively supports customers and partners in building analytics solutions at scale on AWS.
Andrea Montanari is a Big Data Architect with AWS Professional Services. He actively supports customers and partners in building analytics solutions at scale on AWS. María Guerra is a Big Data Architect with AWS Professional Services. Maria has a background in data analytics and mechanical engineering. She helps customers architecting and developing data related workloads in the cloud.
María Guerra is a Big Data Architect with AWS Professional Services. Maria has a background in data analytics and mechanical engineering. She helps customers architecting and developing data related workloads in the cloud. Pushpraj is a Data Architect with AWS Professional Services. He is passionate about Data and DevOps engineering. He helps customers build data driven applications at scale.
Pushpraj is a Data Architect with AWS Professional Services. He is passionate about Data and DevOps engineering. He helps customers build data driven applications at scale.








 Dylan Qu is a Specialist Solutions Architect focused on big data and analytics with Amazon Web Services. He helps customers architect and build highly scalable, performant, and secure cloud-based solutions on AWS.
Dylan Qu is a Specialist Solutions Architect focused on big data and analytics with Amazon Web Services. He helps customers architect and build highly scalable, performant, and secure cloud-based solutions on AWS.