Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=RDZybvrgt70
Yearly Archives: 2024
Supermicro AOC-A100-m2CM NVIDIA ConnectX-6 Dx OCP NIC 3.0 Review
Post Syndicated from Rohit Kumar original https://www.servethehome.com/supermicro-aoc-a100-m2cm-nvidia-connectx-6-dx-ocp-nic-3-0-review/
In our Supermicro AOC-A100-m2CM mini-review we see what this NVIDIA ConnectX-6 Dx dual 100GBE offers and how it performs
The post Supermicro AOC-A100-m2CM NVIDIA ConnectX-6 Dx OCP NIC 3.0 Review appeared first on ServeTheHome.
Мила ваканция… Къде си, когато най ми трябваш?
Post Syndicated from original https://www.toest.bg/mila-vakantsia-kude-si-kogato-nay-mi-tryabvash/

Ежедневието ни като възрастни най-често ни идва късо. Не остава време за почивка, освен за неизбежния сън, нямаме достатъчно време за семейството си и за нещата, които ни занимават извън служебните и ежедневните задължения. Да не говорим за време за себе си.
За децата не е много по-различно: надпреварите в училище са безкрайни, а натоварването през учебната година – неимоверно. Часове, домашни, курсове и уроци, тренировки, състезания – от септември до юни. За някои ученици и след това.
Къде е времето за приятелства, за хармония, за семеен живот с най-важното общо между нас – емоционалното, което ни свързва отвъд роднинството? Кога и как в тази въртележка можем да създаваме общи спомени, които да искаме един ден да предадем и нататък?
В България имаме дълга, дори прекалено дълга лятна ваканция, с която добиваме известна популярност. Тазгодишният доклад, който сравнява продължителността на ваканциите в страните от Европейския съюз, онагледява точно това – България е една от малкото страни, в които учебната година започва толкова късно, но за сметка на това пък е в групата на страните с най-непропорционално разпределение на ваканциите през учебната година.
От години вече се говори усилено за реформа на образователната система. Уви, конкретни стъпки се предприемат на парче и без дългосрочен план. Вместо да откриваме топлата вода с опипване, бихме могли да почерпим идеи от положителния опит на други държави при разделяне на учебното време, разпределяне на материала за изучаване, въвеждане на микроетапи в учебната година. Това би я направило много по-компактна и регламентирана както за децата, така и за учителите.
Колко е важно да има ваканция?
Ежедневно по 6, 7, дори 8 учебни часа. Писане на купища домашни – за училище, за курсовете, за уроците. В събота и неделя може би по час-два повече сън, но и подготовка за поредната контролна работа. Всичко това води до стрес и претоварване. Ваканция не е просто весела дума от детска песничка и представа за морски вълни, тя е задължителното време за рестарт, от което се нуждаем всички. Особено децата.
Тялото ни не е създадено да издържа на постоянен висок стрес. Продължителното физическо и психическо натоварване води до физически и психосоматични оплаквания, най-честите от които са нарушения на съня, раздразнимост, стомашни неразположения, болки в гърба.
Почивката е грижа. Тя ни кара да се чувстваме по-добре и е изключително важна за здравето ни. Също така важно е колко често почиваме, защото колкото по-уморени сме, толкова по-невъзможно става да си отпочинем.
Едно от най-куриозните изследвания на тема почивки е на проф. Джонатан Ливав от Колумбийския университет. Заедно с колегите си той проучва каква е вероятността искането за пускане под гаранция да бъде одобрено от съдията. И стига до заключението, че ако сте сред първите трима, които биват обсъждани в началото на работния ден или след обедната почивка, то имате два до шест пъти по-голям шанс да бъдете пуснати под гаранция.
Как почиват другите?
Германия
Член 25 от Споразумението между провинциите относно общата структура на училищното дело и отговорността на провинциите по образователните въпроси регулира продължителността на всички ваканции през учебната година. Ваканцията трябва да е 75 работни дни, с уточнението, че в Германия за работен ден се брои и събота, но тя не е учебен ден, затова тези 75 дни отговарят на 12,5 седмици. Поради големината на държавата и поради това, че с образованието се разпореждат провинциите, лятната ваканция може да се мести. Но не произволно, а стриктно по календар, какъвто има разписан до 2030 г. за всички провинции.
Шестседмичната лятна ваканция е задължителна. В много училища за първите две и последните две от тези шест седмици има възможност срещу изключително достъпно заплащане децата в началния курс, чиито родители не могат да си позволят толкова дълга ваканция, да посещават лятно училище. Всяка година учениците имат и две седмици есенна ваканция, две седмици коледна ваканция, във все повече провинции има една седмица ски ваканция и една до две седмици великденска ваканция. Общо: около 13 седмици ваканция.
От Полша ни пише Николай Б., чиято дъщеря тази година е в VI клас:
Учебната година в Полша започва на 1 септември и трае до предпоследната седмица на юни. Това, което определено е различно от България, е междусрочната ваканция, т.нар. Ferie. Тази ваканция, която е скоро след зимната и е всъщност по-дълга, трае винаги две седмици и има четири различни начални дати в зависимост от областите в държавата. Иначе казано, между 15 януари и 25 февруари в няколко области учениците (и студентите) имат двуседмична ваканция. Предполагам, че това разделение е по чисто практически причини, защото сигурно ще си е главоболие, ако всички ученици и студенти в страната останат без занимание за две седмици. Особено за родителите на по-малките. Затова всичко е организирано по области и датите са зададени за години напред – има готов календар за тази ваканция до 2030 г.
Иначе има няколко църковни празника, които са почивни: 6 януари – Тримата влъхви, 19 юни – Божието тяло. Светските почивни дни са: 11 ноември – Денят на независимостта, 1 май – Денят на труда, 3 май – Денят на конституцията. Често ако 1 и 3 май попаднат в една работна седмица, цялата седмица става почивна за децата.
Така в Полша лятната ваканция е 10 седмици, следвана от зимната, която е две седмици, след която идва междусрочната от две седмици, после великденска от една седмица. Общо приблизително: 14 седмици ваканция.
Приближаваме се още повече до България и сме в Румъния.
Корина има дъщеря в гимназиална възраст и ми изпраща календара за предстоящата учебна година. Тя започва през втората седмица на септември и продължава до предпоследната седмица на юни. Разделена е на 5 модула както ги нарича, всеки от които завършва с едноседмична ваканция. Зимната ваканция е изключение – тя е двуседмична. Тази цикличност, която дава голяма сигурност и обозримост на учебния процес, включва и разделение на учебния материал на тези части. Сигурно е страхотно да развиеш още като ученик умението да планираш и да боравиш с времето си и с работата, определена за това време.
Започваме да броим:
- 11 седмици лятна ваканция
- 5 седмици междумодулни ваканции
Общо: 16 седмици ваканция!
И се оказва, че дори не е трябвало да обикалям толкова далече, защото в България имаме може би най-чудесния и практичен (да не говорим за полезен) пример. Той е на Френския лицей в София, от чийто календар е видна следната учебна година:

На всеки 8 учебни седмици има две седмици ваканция. Лятната ваканция е два месеца (9 седмици). Общо: 17 седмици ваканция!
Говорих с родител, чиито деца посещават Френския лицей, и не можех да скрия завистта си. Регулиран учебен процес, целодневен режим, но обозрим и ясен. С начало и край. Разбит на смилаеми времеви периоди, които завършват със заслужена почивка за цялото семейство. Защото каквото и да си говорим, учебното време е натоварващо не само за учениците, но и за всички покрай тях.
Как е тук?
При всички добри примери и научни доказателства колко е важно да редуваме натоварване и разтоварване, е истинска загадка защо в Министерството на образованието все още не са чували за това. И защо за поредна година календарът на ученическите ваканции изглежда, меко казано, нечовешки. Нека за финал разгледаме и него.
В края на юли тази година в МОН все още не бяха готови с календара за предстоящата учебна година – 2024/2025. Изключително демократично отвориха обществено обсъждане, което не доведе до много по-логично решение от първоначалното.
Така крайният вариант е:
- начало на учебната година: 16 септември (след 11-,13- или 15-седмична лятна ваканция в зависимост от етапа на обучение);
- есенна „ваканция“ от два учебни дни – 31 октомври и 1 ноември;
- коледна ваканция от почти две седмици (но не цели, защото в онзи висящ първи петък на 2025 г. ще бъдат постигнати чудеса).
- междусрочна „ваканция“ в сряда;
- едноседмична пролетна ваканция в началото на април.
За учещите до 30 юни това са: 11 + 2 + 1 = 14 седмици ваканция
За учещите до 15 юни това са: 13 + 2 + 1 = 16 седмици ваканция
За учещите до 1 юни това са: 15 + 2 + 1 = 18 седмици ваканция
В цялото си проучване не намерих държава, която описва почивните събота и неделя като част от учебния календар. Говори се за работни/учебни/празнични/ваканционни дни. Министерството на образованието говори винаги за „ваканция“, пък била тя и само в сряда. Затова и спорадичните ден или два без учебен процес не съм ги преброила в горната извадка.
От изключителна важност за участниците в образователния процес се оказаха тези 36 (пример за горен курс) учебни седмици, от които се състои учебната година. Във всяка от тях има разпределен материал. Не дай боже да отпадне някой ден (или седмица!) – започва се едно препускане, наваксване, неусвояване. На гърба на учители и ученици. Защото цялата ваканция е натъпкана в лятото и не е оставена и минимална резерва.
Даже няма да започваме разговора как учениците са просто изложени на образователен процес, без да бъдат истинска страна в него. Без умения за планиране, без дори бегло усещане за преминаване от етап в етап. Защото ако във вторник сме получили срочната си оценка, в петък просто минаваме нататък.
А основната цел на образователния процес е продуктивността. Това е усещането, че сме свършили нещо – овладели сме ново умение, приложили сме ново знание. Когато обаче се движим напрегнато в постоянна въртележка от седмици без никакъв друг стимул освен заветната оценка, тогава не говорим за продуктивност.
Fake work е термин от работния свят и означава дейност, която изглежда и се усеща като работа, но не води до напредък или постигане на цел. Да, може цял ден да четете и да пишете имейли, да стоите в срещи, да четете рапорти и документация, но всичко това да не води до реален резултат.
Нещо такова е усещането и за учебната година в България. Бързане, струпване на много материал в малко време, натоварване от сутрин до вечер, често и през нощта, когато не можеш да спиш. Без усещане за завършеност и за преодоляване на препятствие. Защото всъщност се въртиш в колело като хамстер и просто ти се вие свят. И нямаш друг изход, освен да чакаш лятната ваканция.
Светът се променя с бясна скорост. Професиите, в които ще се развиват поколенията, започващи днес образователния си път, все още не са измислени. Подготвена ли е нашата образователна система, за да отговори на тези предизвикателства? Какво може и трябва да се промени? А как?
Веднъж месечно в рубриката „Възможното образование“ ще говорим за промяната – такава, каквато искаме да я видим, за добрите примери и за посоките, в които може би е добре да обърне поглед българската образователна система.
[$] The 6.12 merge window begins
Post Syndicated from corbet original https://lwn.net/Articles/990750/
As of this writing, 6,778 non-merge changesets have been pulled into the
mainline kernel for the 6.12 release — over half of the work that had been
staged in linux-next prior to the opening of the merge window. There has
been a lot of refactoring and cleanup work this time around, but also some
significant changes. Read on for a summary of the first half of the 6.12
merge window.
Removing uncertainty through “what-if” capacity planning
Post Syndicated from Curt Robords original https://blog.cloudflare.com/scenario-planner
Infrastructure planning for a network serving more than 81 million requests at peak and which is globally distributed across more than 330 cities in 120+ countries is complex. The capacity planning team at Cloudflare ensures there is enough capacity in place all over the world so that our customers have one less thing to worry about – our infrastructure, which should just work. Through our processes, the team puts careful consideration into “what-ifs”. What if something unexpected happens and one of our data centers fails? What if one of our largest customers triples, or quadruples their request count? Across a gamut of scenarios like these, the team works to understand where traffic will be served from and how the Cloudflare customer experience may change.
This blog post gives a look behind the curtain of how these scenarios are modeled at Cloudflare, and why it’s so critical for our customers.
Scenario planning and our customers
Cloudflare customers rely on the data centers that Cloudflare has deployed all over the world, placing us within 50 ms of approximately 95% of the Internet-connected population globally. But round-trip time to our end users means little if those data centers don’t have the capacity to serve requests. Cloudflare has invested deeply into systems that are working around the clock to optimize the requests flowing through our network because we know that failures happen all the time: the Internet can be a volatile place. See our blog post from August 2024 on how we handle this volatility in real time on our backbone, and our blog post from late 2023 about how another system, Traffic Manager, actively works in and between data centers, moving traffic to optimize the customer experience around constraints in our data centers. Both of these systems do a fantastic job in real time, but there is still a gap — what about over the long term?
Most of the volatility that the above systems are built to manage is resolved within shorter time scales than which we build plans for. (There are, of course, some failures that are exceptions.) Most scenarios we model still need to take into account the state of our data centers in the future, as well as what actions systems like Traffic Manager will take during those periods. But before getting into those constraints, it’s important to note how capacity planning measures things: in units of CPU Time, defined as the time that each request takes in the CPU. This is done for the same reasons that Traffic Manager uses CPU Time, in that it enables the team to 1) use a common unit across different types of customer workloads and 2) speak a common language with other teams and systems (like Traffic Manager). The same reasoning the Traffic Manager team cited in their own blog post is equally applicable for capacity planning:
…using requests per second as a metric isn’t accurate enough when actually moving traffic. The reason for this is that different customers have different resource costs to our service; a website served mainly from cache with the WAF deactivated is much cheaper CPU wise than a site with all WAF rules enabled and caching disabled. So we record the time that each request takes in the CPU. We can then aggregate the CPU time across each plan to find the CPU time usage per plan. We record the CPU time in ms, and take a per second value, resulting in a unit of milliseconds per second.
This is important for customers for the same reason that the Traffic Manager team cited in their blog post as well: we can correlate CPU time to performance, specifically latency.
Now that we know our unit of measurement is CPU time, we need to set up our models with the new constraints associated with the change that we’re trying to model. Specifically, there are a subset of constraints that we are particularly interested in because we know that they have the ability to impact our customers by impacting the availability of CPU in a data center. These are split into two main inputs in our models: Supply and Demand. We can think of these as “what-if” questions, such as the following examples:
Demand what-ifs
-
What if a new customer onboards to Cloudflare with a significant volume of requests and/or bytes?
-
What if an existing customer increased its volume of requests and/or bytes by some multiplier (i.e. 2x, 3x, nx), at peak, for the next three months?
-
What if the growth rate, in number of requests and bytes, of all of our data centers worldwide increased from X to Y two months from now, indefinitely?
-
What if the growth rate, in number of requests and bytes, of data center facility A increased from X to Y one month from now?
-
What if traffic egressing from Cloudflare to a last-mile network shifted from one location (such as Boston) to another (such as New York City) next week?
Supply what-ifs
-
What if data center facility A lost some or all of its available servers two months from now?
-
What if we added X servers to data center facility A today?
-
What if some or all of our connectivity to other ASNs (12,500 Networks/nearly 300 Tbps) failed now?
Output
For any one of these, or a combination of them, in our model’s output, we aim to provide answers to the following:
-
What will the overall capacity picture look like over time?
-
Where will the traffic go?
-
How will this impact our costs?
-
Will we need to deploy additional servers to handle the increased load?
Given these sets of questions and outputs, manually creating a model to answer each of these questions, or a combination of these questions, quickly becomes an operational burden for any team. This is what led us to launch “Scenario Planner”.
Scenario Planner
In August 2024, the infrastructure team finished building “Scenario Planner”, a system that enables anyone at Cloudflare to simulate “what-ifs”. This provides our team the opportunity to quickly model hypothetical changes to our demand and supply metrics across time and in any of Cloudflare’s data centers. The core functionality of the system has to do with the same questions we need to answer in the manual models discussed above. After we enter the changes we want to model, Scenario Planner converts from units that are commonly associated with each question to our common unit of measurement: CPU Time. These inputs are then used to model the updated capacity across all of our data centers, including how demand may be distributed in cases where capacity constraints may start impacting performance in a particular location. As we know, if that happens then it triggers Traffic Manager to serve some portion of those requests from a nearby location to minimize impact on customers and user experience.
Updated demand questions with inputs
-
Question: What if a new customer onboards to Cloudflare with a significant volume of requests?
-
Input: The new customer’s expected volume, geographic distribution, and timeframe of requests, converted to a count of virtual CPUs
-
Calculation(s): Scenario Planner converts from server count to CPU Time, and distributes the new demand across the regions selected according to the aggregate distribution of all customer usage.
-
Question: What if an existing customer increased its volume of requests and/or bytes by some multiplier (i.e. 2x, 3x, nx), at peak, for the next three months?
-
Input: Select the customer name, the multiplier, and the timeframe
-
Calculation(s): Scenario Planner already has how the selected customer’s traffic is distributed across all data centers globally, so this involves simply multiplying that value by the multiplier selected by the user
-
Question: What if the growth rate, in number of requests and bytes, of all of our data centers worldwide increased from X to Y two months from now, indefinitely?
-
Input: Enter a new global growth rate and timeframe
-
Calculation(s): Scenario Planner distributes this growth across all data centers globally according to their current growth rate. In other words, the global growth is an aggregation of all individual data center’s growth rates, and to apply a new “Global” growth rate, the system scales up each of the individual data center’s growth rates commensurate with the current distribution of growth.
-
Question: What if the growth rate, in number of requests and bytes, of data center facility A increased from X to Y one month from now?
-
Input: Select a data center facility, enter a new growth rate for that data center and the timeframe to apply that change across.
-
Calculation(s): Scenario Planner passes the new growth rate for the data center to the backend simulator, across the timeline specified by the user
Updated supply questions with inputs
-
Question: What if data center facility A lost some or all of its available servers two months from now?
-
Input: Select a data center, and enter the number of servers to remove, or select to remove all servers in that location, as well as the timeframe for when those servers will not be available
-
Calculation(s): Scenario Planner converts the server count entered (including all servers in a given location) to CPU Time before passing to the backend
-
Question: What if we added X servers to data center facility A today?
-
Input: Select a data center, and enter the number of servers to add, as well as the timeline for when those servers will first go live
-
Calculation(s): Scenario Planner converts the server count entered (including all servers in a given location) to CPU Time before passing to the backend
We made it simple for internal users to understand the impact of those changes because Scenario Planner outputs the same views that everyone who has seen our heatmaps and visual representations of our capacity status is familiar with. There are two main outputs the system provides: a heatmap and an “Expected Failovers” view. Below, we explore what these are, with some examples.
Heatmap
Capacity planning evaluates its success on its ability to predict demand: we generally produce a weekly, monthly, and quarterly forecast of 12 months to three years worth of demand, and nearly all of our infrastructure decisions are based on the output of this forecast. Scenario Planner provides a view of the results of those forecasts that are implemented via a heatmap: it shows our current state, as well as future planned server additions that are scheduled based on the forecast.
Here is an example of our heatmap, showing some of our largest data centers in Eastern North America (ENAM). Ashburn is showing as yellow, briefly, because our capacity planning threshold for adding more server capacity to our data centers is 65% utilization (based on CPU time supply and demand): this gives the Cloudflare teams time to procure additional servers, ship them, install them, and bring them live before customers will be impacted and systems like Traffic Manager would begin triggering. The little cloud icons indicate planned upgrades of varying sizes to get ahead of forecasted future demand well ahead of time to avoid customer performance degradation.
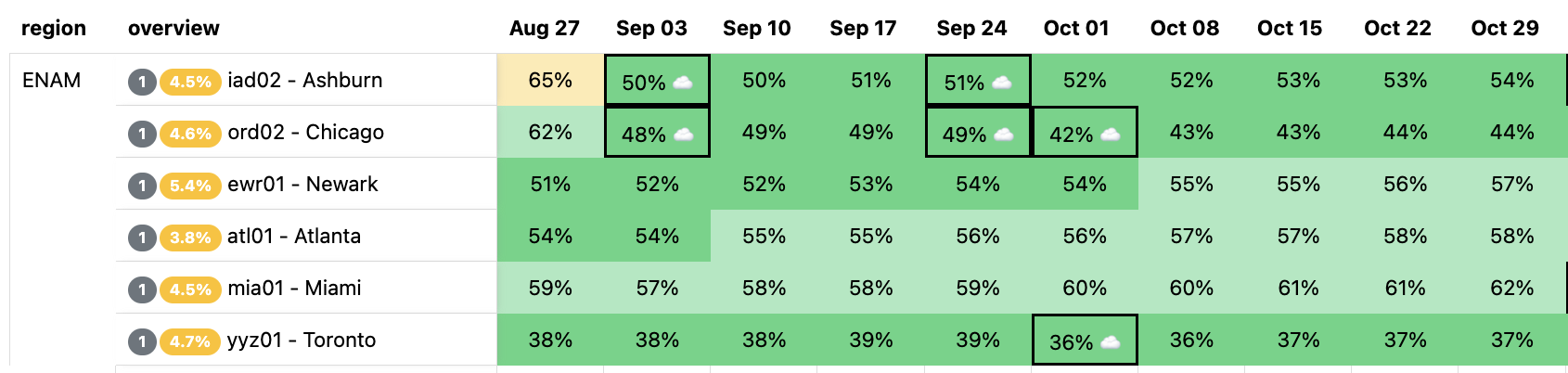
The question Scenario Planner answers then is how this view changes with a hypothetical scenario: What if our Ashburn, Miami, and Atlanta facilities shut down completely? This is unlikely to happen, but we would expect to see enormous impact on the remaining largest facilities in ENAM. We’ll simulate all three of these failing at the same time, taking them offline indefinitely:
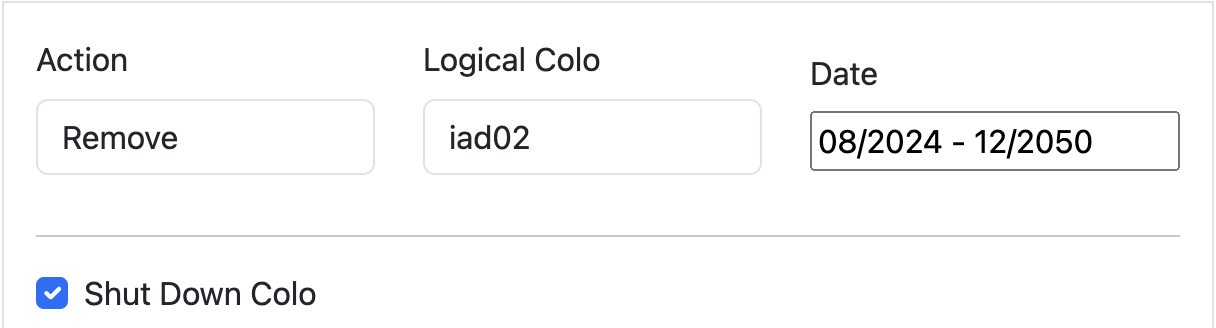
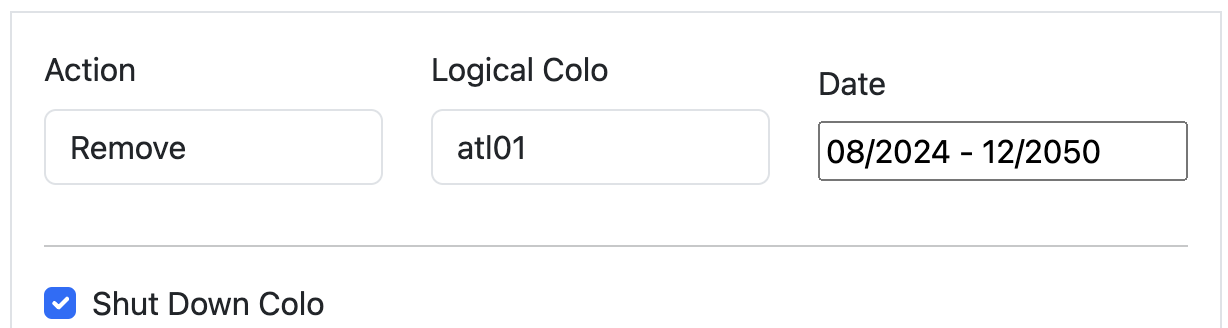
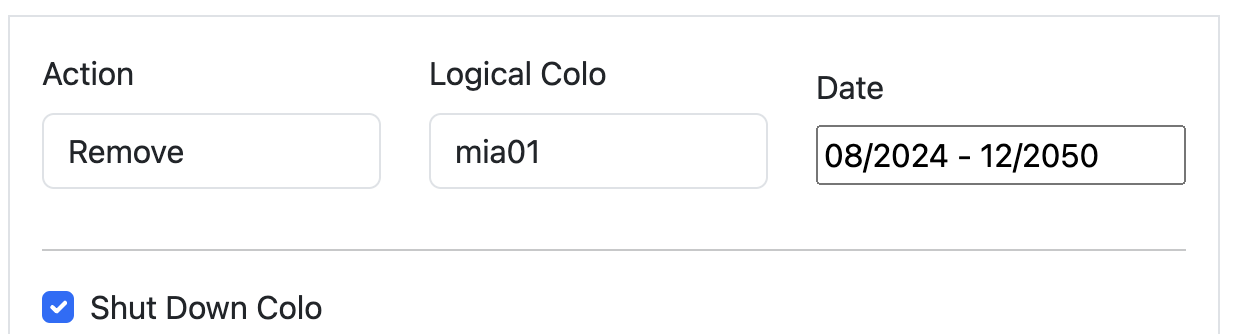
This results in a view of our capacity through the rest of the year in the remaining large data centers in ENAM — capacity is clearly constrained: Traffic Manager will be working hard to mitigate any impact to customer performance if this were to happen. Our capacity view in the heatmap is capped at 75%: this is because Traffic Manager typically engages around this level of CPU utilization. Beyond 75%, Cloudflare customers may begin to experience increased latency, though this is dependent on the product and workload, and is in reality much more dynamic.

This outcome in the heatmap is not unexpected. But now we typically get a follow-up question: clearly this traffic won’t fit in just Newark, Chicago, and Toronto, so where do all these requests get served from? Enter the failover simulator: Capacity Planning has been simulating how Traffic Manager may work in the long term for quite a while, and for Scenario Planner, it was simple to extend this functionality to answer exactly this question.
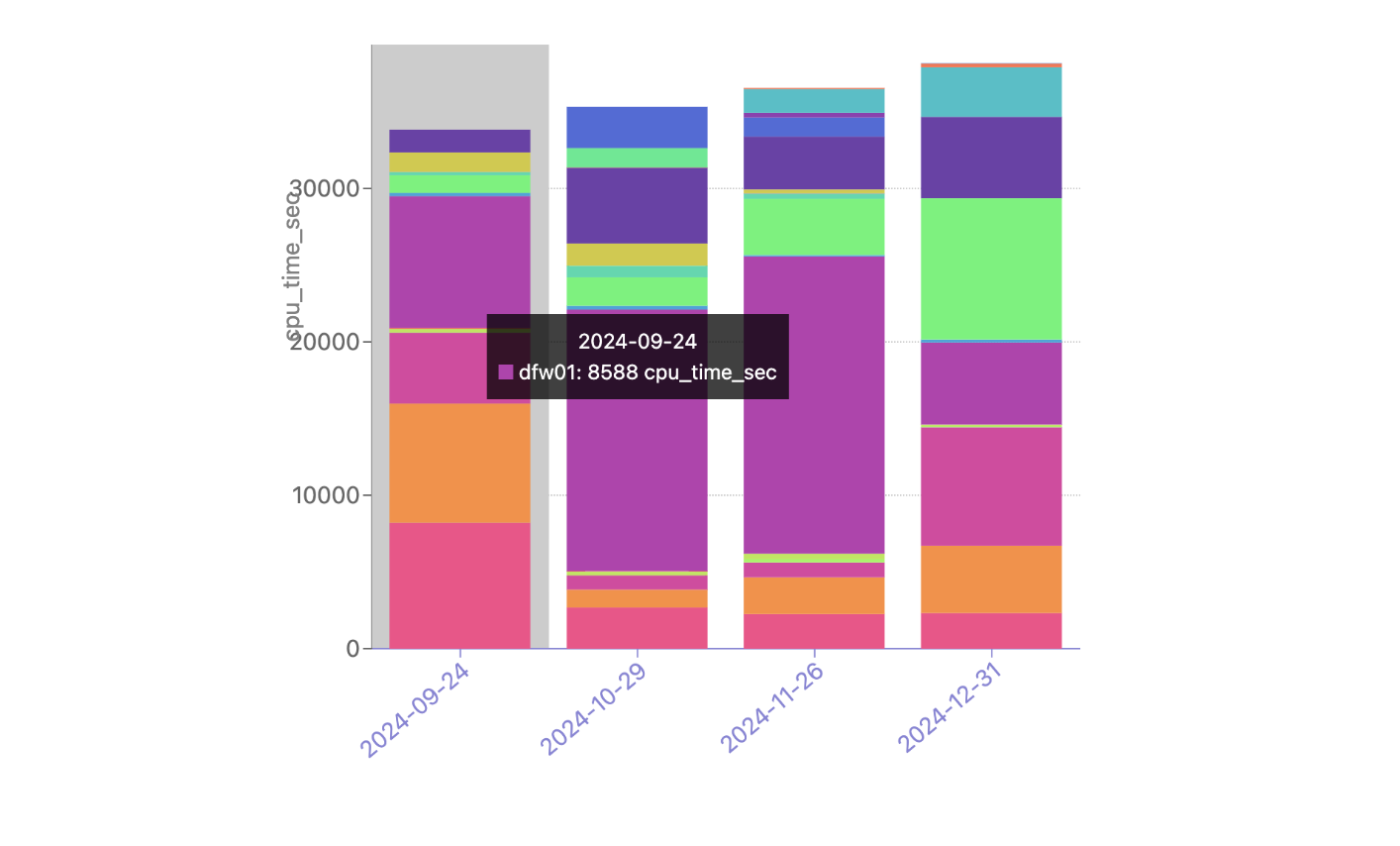
There is currently no traffic being moved by Traffic Manager from these data centers, but our simulation shows a significant portion of the Atlanta CPU time being served from our DFW/Dallas data center as well as Newark (bottom pink), and Chicago (orange) through the rest of the year, during this hypothetical failure. With Scenario Planner, Capacity Planning can take this information and simulate multiple failures all over the world to understand the impact to customers, taking action to ensure that customers trusting Cloudflare with their web properties can expect high performance even in instances of major data center failures.
Planning with uncertainty
Capacity planning a large global network comes with plenty of uncertainties. Scenario Planner is one example of the work the Capacity Planning team is doing to ensure that the millions of web properties our customers entrust to Cloudflare can expect consistent, top tier performance all over the world.
The Capacity Planning team is hiring — check out the Cloudflare careers page and search for open roles on the Capacity Planning team.
Cloudflare incident on September 17, 2024
Post Syndicated from Joe Abley original https://blog.cloudflare.com/cloudflare-incident-on-september-17-2024
On September 17, 2024, during routine maintenance, Cloudflare inadvertently stopped announcing fifteen IPv4 prefixes, affecting some Business plan websites for approximately one hour. During this time, IPv4 traffic for these customers would not have reached Cloudflare, and users attempting to connect to websites assigned addresses within those prefixes would have received errors.
We’re very sorry for this outage.
This outage was the result of an internal software error and not the result of an attack. In this blog post, we’re going to talk about what the failure was, why it occurred, and what we’re doing to make sure this doesn’t happen again.
Background
Cloudflare assembled a dedicated Addressing team in 2019 to simplify the ways that IP addresses are used across Cloudflare products and services. The team builds and maintains systems that help Cloudflare conserve and manage its own network resources. The Addressing team also manages periodic changes to the assignment of IP addresses across infrastructure and services at Cloudflare. In this case, our goal was to reduce the number of IPv4 addresses used for customer websites, allowing us to free up addresses for other purposes, like deploying infrastructure in new locations. Since IPv4 addresses are a finite resource and are becoming more scarce over time, we carry out these kinds of “renumbering” exercises quite regularly.
Renumbering in Cloudflare is carried out using internal processes that move websites between sets of IP addresses. A set of IP addresses that no longer has websites associated with it is no longer needed, and can be retired. Once that has happened, the associated addresses are free to be used elsewhere.
Back in July 2024, a batch of Business plan websites were moved from their original set of IPv4 addresses to a new, smaller set, appropriate to the forecast requirements of that particular plan. On September 17, after confirming that all of the websites using those addresses had been successfully renumbered, the next step was to be carried out: detach the IPv4 prefixes associated with those addresses from Cloudflare’s network and to withdraw them from service. That last part was to be achieved by removing those IPv4 prefixes from the Internet’s global routing table using the Border Gateway Protocol (BGP), so that traffic to those addresses is no longer routed towards Cloudflare. The prefixes concerned would then be ready to be deployed for other purposes.
What was released and how did it break?
When we migrated customer websites out of their existing assigned address space in July, we used a one time migration template that cycles through all the websites associated with the old IP addresses and moves them to new ones. This calls a function that updates the IP assignment mechanism to synchronize the IP address-to-website mapping.
A couple of months prior to the July migration, the relevant function code was updated as part of a separate project related to legacy SSL configurations. That update contained a fix that replaced legacy code to synchronize two address pools with a call to an existing synchronization function. The update was reviewed, approved, merged, and released.
Unfortunately, the fix had consequences for the subsequent renumbering work. Upon closer inspection (we’ve done some very close post-incident inspection), a side effect of the change was to suppress updates in cases where there was no linked reference to a legacy SSL certificate. Since not all websites use legacy certificates, the effect was that not all websites were renumbered — 1,661 customer websites remained linked to old addresses in the address pools that were intended to be withdrawn. This was not noticed during the renumbering work in July, which had concluded with the assumption that every website linked to the old addresses had been renumbered, and that assumption was not checked.
At 2024-09-17 17:51 UTC, fifteen IPv4 prefixes corresponding to the addresses that were thought to be safely unused were withdrawn using BGP. Cloudflare operates a global network with hundreds of data centers, and there was some variation in the precise time when the prefixes were withdrawn from particular parts of the world. In the following ten minutes, we observed an aggregate 10 Gbps drop in traffic to the 1,661 affected websites network-wide.
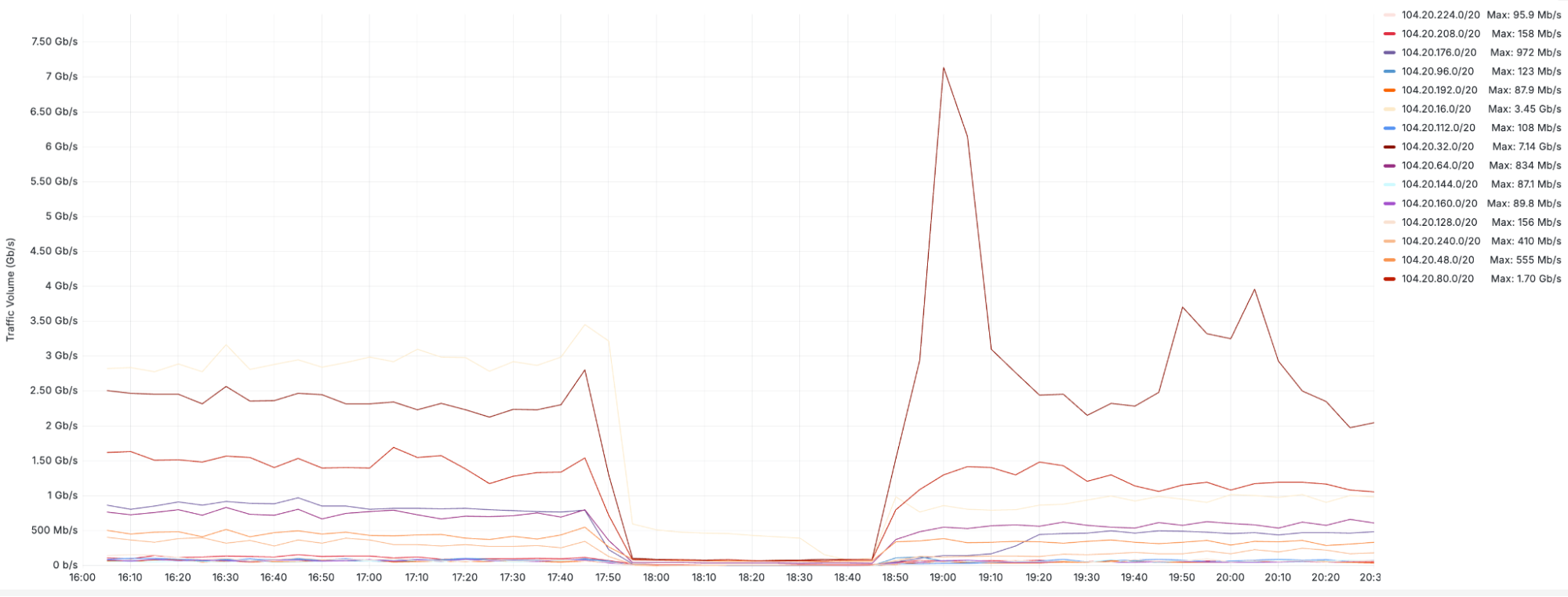
The graph above shows traffic volume (in bits per second) for each individual prefix that was affected by the incident.
Incident timeline and impact
All timestamps are UTC on 2024-09-17.
At 17:41, the Addressing engineering team initiated the release that disabled prefixes in production.
At 17:51, BGP announcements began to be withdrawn and traffic to Cloudflare on the impacted prefixes started to drop.
At 17:57, the SRE team noticed alerts triggered by an increase in unreachable IP address space and began investigating. The investigation ended shortly afterwards, since it is generally expected that IP addresses will become unreachable when they are being removed from service, and consequently the alerts did not seem to indicate an abnormal situation.
At 18:36, Cloudflare received escalations from two customers, and an incident was declared. A limited deployment window was quickly implemented once the severity of the incident was assessed.
At 18:46, Addressing team engineers confirmed that the change introduced in the renumbering release triggered the incident and began preparing the rollback procedure to revert changes.
At 18:50, the release was rolled back, prefixes were re-announced in BGP to the Internet, and traffic began flowing back through Cloudflare.
At 18:50:27, the affected routes were restored and prefixes began receiving traffic again.
There was no impact to IPv6 traffic. 1,661 customer websites that were associated with addresses in the withdrawn IPv4 prefixes were affected. There was no impact to other customers or services.
How did we fix it?
The immediate fix to the problem was to roll back the release that was determined to be the proximal cause. Since all approved changes have tested roll back procedures, this is often a pragmatic first step to fix whatever has just been found to be broken. In this case, as in many, it was an effective way to resolve the immediate impact and return things to normal.
Identifying the root cause took more effort. The code mentioned above that had been modified earlier this year is quite old, and part of a legacy system that the Addressing team has been working on moving away from since the team’s inception. Much of the engineering effort during that time has been on building the modern replacement, rather than line-level dives into the legacy code.
We have since fixed the specific bug that triggered this incident. However, to address the more general problem of relying on old code that is not as well understood as the code in modern systems, we will do more. Sometimes software has bugs, and sometimes software is old, and these are not useful excuses; they are just the way things are. It’s our job to maintain the agility and confidence in our release processes while living in this reality, maintaining the level of safety and stability that our customers and their customers rely on.
What are we doing to prevent this from happening again?
We take incidents like this seriously, and we recognise the impact that this incident had. Though this specific bug has been resolved, we have identified several steps we can take to mitigate the risk of a similar problem occurring in the future. We are implementing the following plan as a result of this incident:
Test: The Addressing Team is adding tests that check for the existence of outstanding assignments of websites to IP addresses as part of future renumbering exercises. These tests will verify that there are no remaining websites that inadvertently depend on the old addresses being in service. The changes that prompted this incident made incorrect assumptions that all websites had been renumbered. In the future, we will avoid making assumptions like those, and instead do explicit checks to make sure.
Process: The Addressing team is improving the processes associated with the withdrawal of Cloudflare-owned prefixes, regardless of whether the withdrawal is associated with a renumbering event, to include automated and manual verification of traffic levels associated with the addresses that are intended to be withdrawn. Where traffic is attached to a service that provides more detailed logging, service-specific request logs will be checked for signs that the addresses thought to be unused are not associated with active traffic.
Implementation: The Addressing Team is reviewing every use of stored procedures and functions associated with legacy systems. Where there is doubt, functionality will be re-implemented with present-day standards of documentation and test coverage.
We are sorry for the disruption this incident caused for our customers. We are actively making these improvements to ensure improved stability moving forward and to prevent this problem from happening again.
Comic for 2024.09.20 – Dr Bizkit, Speech Therapist
Post Syndicated from Explosm.net original https://explosm.net/comics/dr-bizkit-speech-therapist
New Cyanide and Happiness Comic
OpenSSH 9.9 released
Post Syndicated from daroc original https://lwn.net/Articles/991028/
The OpenSSH project has released version 9.9. This version includes support for the
new post-quantum cryptography standard from NIST.
The release also includes
the next step in the deprecation of DSA keys — they are now disabled by default at compile time,
and are expected to be removed entirely in early 2025. The release also contains the normal mixture of bug fixes and small usability improvements.
[$] Considering kernel pass-through interfaces
Post Syndicated from corbet original https://lwn.net/Articles/990802/
The kernel normally sits firmly between user space and the system’s
peripheral devices, and provides a standard interface to those devices. At
times, though, a more direct interface to a device is desired — but such
interfaces can be controversial. At the 2024 Maintainers Summit, the
assembled developers considered a specific case — the proposed fwctl subsystem — as well as the role of such
drivers in general.
Security updates for Friday
Post Syndicated from daroc original https://lwn.net/Articles/991027/
Security updates have been issued by Debian (chromium), Fedora (bluez, chromium, frr, iwd, libell, python3.11, python3.8, python3.9, and ruby), Mageia (kernel, kmod-xtables-addons, and kmod-virtualbox and kernel-linus), Red Hat (kernel), SUSE (kernel, kubernetes1.23, kubernetes1.24, kubernetes1.25, libmfx, and python-azure-identity), and Ubuntu (emacs, emacs24, emacs25, libreoffice, postgresql-9.5, python2.7, python3.5, and tgt).
Collision: RMS Olympic and HMS Hawke
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=Nf2MEeo7brU
The realtime preemption pull request
Post Syndicated from corbet original https://lwn.net/Articles/990985/
![[pull request]](https://lwn.net/images/conf/2024/ms/rt-pull-sm.png)
On September 19, Thomas Gleixner delivered the pull request for the
realtime preemption enablement patches to Linus Torvalds — in printed form,
wrapped in gold, with a ribbon, as Torvalds had requested. It was a
significant milestone, marking the completion of a project that required
20 years of effort. Congratulations are due to everybody involved.
Torvalds acted on
the pull request the following morning.
Мудният асансьор на властта в България
Post Syndicated from Емилия Милчева original https://www.toest.bg/mudniyat-asansyor-na-vlastta-v-bulgaria/

Много имена в кандидатдепутатските листи за изборите на 27 октомври ще предизвикат у избирателите досада, отвращение и апатия. И за това си има основателна причина (освен втръсналата честота на изборите): асансьорът на властта в България е заседнал между 1989 г. и началото на XXI век. Тогава се формираха зависимостите, чадърите, обръчите – и първите милиони, преразпределяха се държавните активи. Макар тези процеси да са приключили, а геополитическата ориентация на България да е променена, политиците, които са ги покровителствали, не бързат да напуснат сцената. Някои го направиха, но партийни апаратчици все така блокират асансьора на последния етаж.
Социалната мобилност и ротацията, благодарение на които една политическа сила се обновява, отсъстват в системните български партии. Отсъства и вътрешнопартийната демокрация. Антисистемните също заимстват тези практики. Трудно е нови хора с идеи да се изкачат на върха, а от него да слязат други, ако тези механизми са блокирани. Затова и обновлението е толкова мъчително и ако се случи, то е с шут от върха – както наблюдаваме в БСП и в ДПС, но също и в ГЕРБ. По-рядко е с подаване на оставка, както направи съпредседателят на „Демократична България“ Христо Иванов заради слабите изборни резултати на ПП–ДБ. Сега на партията му „Да, България“ предстои избор на нов лидер.
Още по-рано обаче, през май 2013 г., когато коалицията между „Демократи за силна България“ и „Български демократичен форум“ не мина 4-процентната бариера на изборите, лидерът на ДСБ Иван Костов подаде оставка заедно с националното ръководство на партията и се оттегли от активната политика. Тогава Петър Москов каза:
С оттеглянето на Костов последният голям лидер напуска политиката.
И президентът Георги Първанов се оттегли в края на 2016 г. от лидерския пост в АБВ – партията, която създаде, след като Националният съвет на БСП го изключи заедно с още няколко функционери през 2014 г. „Правим крачка назад, за да дадем път на младите“, каза той тогава. АБВ обаче не се подмлади особено.
Причините за съпротивата у политическата върхушка в България да освободи позиции могат да се обобщят така: концентрация на власт и влияние, преплитане на неформални мрежи и зависимости, липса на вътрешнопартийна демокрация, спад на общественото доверие и апатия. Към това се прибавят неразвитата демократична култура и наследството на политическата инерция от тоталитаризма, когато лидерите заедно с велможите си оставаха на власт десетилетия.
Старите елити сключват и пакт за ненападение помежду си, един по-комплициран вариант на „гарван гарвану око не вади“. Разбира се, примирието се крепи не на джентълменско споразумение, а на държани „на трупчета“ дела от прокуратурата – застраховка срещу „борбата с корупцията“.
Концентрация на власт и неформални мрежи
В старите политически елити са концентрирани власт, влияние и ресурси. Вижте БСП и ДПС. Тази власт включва не само политически постове, но и икономически връзки, медийна подкрепа и обществени контакти. Така те успяват да съхранят позициите си и да попречат на влизането на нови и несвързани с тях лица, които биха могли да се противопоставят на установения модел. Ако подобни хора все пак биват допуснати, те са лични номинации на лидера, поради което на практика промяна няма как да се осъществи. Например кариерата си в БСП Иван Ченчев, Калоян Методиев и Крум Дончев дължат на личното покровителство на Нинова, както и впрочем някои от организаторите на вътрешния преврат, като Ангел Зафиров, временно и.ф. председател. Той и доскорошната ѝ партийна свита постъпиха с Нинова така, както тя с опозиционерите си.
Но и социалистите си позволяват волности. Софийската организация на БСП например е номинирала за кандидат-депутати от гражданската квота доцентката по конституционно право Наталия Киселова и известния с прозвището „Лорд“ Евгени Минчев – пиар, светска персона и защитник на поправката в Закона за предучилищното и училищното образование, забраняваща ЛГБТ пропагандата в училище.
Липсата на реална вътрешнопартийна демокрация скъсява кадровата скамейка на партиите. Там седят любимците на лидера, макар и изхабени от употреба, като Йорданка Фандъкова от ГЕРБ например, най-дълго управлявалият кмет на София – от есента на 2009-та до октомври 2023-та. Или завърналата се като депутат в 50-тия парламент Цвета Караянчева, шест пъти избирана с листата на ГЕРБ за народна представителка.
Вървят спекулации, че този път лидерът Борисов ще остави на заден план бившите министри и хора като Любен Дилов, чиято добавена стойност е в смешките от трибуната. Водачи на листи ще са успешни кметове на ГЕРБ, като Живко Тодоров (Стара Загора) и Димитър Николов (Бургас), които се харесват много повече от партийните бюрократи. Дали после ще се върнат на кметските си постове, или ще останат в парламента, ще реши отново Бойко Борисов. Целта, която той обяви, е минимум 70, максимум 80 депутати в 51-вия парламент. В настоящия коалираната със СДС партия има 68.
Петнайсета година Борисов управлява ГЕРБ, концентрирайки в ръцете си огромно влияние и ресурси и въпреки че ГЕРБ са машина за избори и рядко са губили първото място, зависимостите на лидера вече тежат на партията. Обвързаностите му с олигарха Делян Пеевски, чието име е нарицателно за задкулисие, са сред причините ПП–ДБ да се въздържат от коалиция с ГЕРБ, освен ако тези връзки не бъдат прекратени.
Политиката в България е силно свързана с неформални мрежи от бизнесмени, обществени фигури и дори престъпни групировки. В системата от зависимости, която те с общи усилия създават, е много трудно да се утвърдят нови и независими кандидати, защото не могат да разчитат на същите връзки и подкрепа, а още не са изградили свои.
Силно привързани към властта
Ние, ДСБ, не сме публика. Не приемаме политиката за сцена. ДСБ предлагаме на обществото силни идеи и принципи, ясни цели и критерий, по който да оценява своето управление.
Тези думи са от реч на Иван Костов година преди да се оттегли от реалната политика.
Затова пък на настоящия председател на ДСБ и съпредседател на „Демократична България“ Атанас Атанасов и през ум не му минава да си тръгне. Заявката, че няма да подаде оставка след изборите на 9 юни, когато ПП–ДБ изгубиха половината си избиратели, а спадът започна от по-рано, той мотивира със запазения брой депутати на ДСБ. Тази бройка обаче се дължи на ловкост и договорки с ПП при подреждането на листите, а не на активността и енергията на „Демократи за силна България“.
В БСП пък разбират асансьора на властта като рециклиране на стари другари на челни места в листите. Мая Манолова от „Изправи се, БГ“ и Румен Петков от АБВ декларираха отказ, но не и Костадин Паскалев, Татяна Дончева, Кирил Добрев, също и бившият председател на БСП Сергей Станишев, който при всяка медийна изява – а те зачестиха напоследък, напомня, че не би отказал да оглави листа. (Решението за водачите ще вземе Националният съвет на БСП до дни.)
Станишев приключи с лидерството на Партията на европейските социалисти, също и с Европарламента, и се бори да се завърне в политиката (в България), което може да му осигури депутатско място в 51-вото НС. За осми пореден път там по всяка вероятност ще бъде и бизнесменът Петър Кънев, отново от листата в Бургас, заедно с друга червена номенклатура като Кристиян Вигенин, Зафиров, Борислав Гуцанов…
Всички те се ослушват дали няма да ги огрее възможността отново да се включат във властта, след като Борисов посочи БСП и „Има такъв народ“ като възможни партньори за коалиционно управление, наред с известните от сглобката ПП–ДБ и ДПС (без да поясни кое ДПС). Зависимостите на Станишев от Пеевски не са тайна не само заради „Ако не изберем Пеевски, правителството пада“ – възходът на Пеевски започна именно при кабинета на Тройната коалиция, оглавяван от Станишев. С ГЕРБ, но и с Пеевски прекрасно си колаборира и друга бивша номенклатура на „Позитано“ 20 – Кирил Добрев.
Скоро всички листи ще са готови за изборите на 27 октомври.
Дали тези хора знаят накъде да поведат България…
How Cloudflare is helping domain owners with the upcoming Entrust CA distrust by Chrome and Mozilla
Post Syndicated from Dina Kozlov original https://blog.cloudflare.com/how-cloudflare-is-helping-domain-owners-with-the-upcoming-entrust-ca
Chrome and Mozilla announced that they will stop trusting Entrust’s public TLS certificates issued after November 12, 2024 and December 1, 2024, respectively. This decision stems from concerns related to Entrust’s ability to meet the CA/Browser Forum’s requirements for a publicly trusted certificate authority (CA). To prevent Entrust customers from being impacted by this change, Entrust has announced that they are partnering with SSL.com, a publicly trusted CA, and will be issuing certs from SSL.com’s roots to ensure that they can continue to provide their customers with certificates that are trusted by Chrome and Mozilla.
We’re excited to announce that we’re going to be adding SSL.com as a certificate authority that Cloudflare customers can use. This means that Cloudflare customers that are currently relying on Entrust as a CA and uploading their certificate manually to Cloudflare will now be able to rely on Cloudflare’s certificate management pipeline for automatic issuance and renewal of SSL.com certificates.
CA distrust: responsibilities, repercussions, and responses
With great power comes great responsibility
Every publicly trusted certificate authority (CA) is responsible for maintaining a high standard of security and compliance to ensure that the certificates they issue are trustworthy. The security of millions of websites and applications relies on a CA’s commitment to these standards, which are set by the CA/Browser Forum, the governing body that defines the baseline requirements for certificate authorities. These standards include rules regarding certificate issuance, validation, and revocation, all designed to secure the data transferred over the Internet.
However, as with all complex software systems, it’s inevitable that bugs or issues may arise, leading to the mis-issuance of certificates. Improperly issued certificates pose a significant risk to Internet security, as they can be exploited by malicious actors to impersonate legitimate websites and intercept sensitive data.
To mitigate such risk, publicly trusted CAs are required to communicate issues as soon as they are discovered, so that domain owners can replace the compromised certificates immediately. Once the issue is communicated, CAs must revoke the mis-issued certificates within 5 days to signal to browsers and clients that the compromised certificate should no longer be trusted. This level of transparency and urgency around the revocation process is essential for minimizing the risk posed by compromised certificates.
Why Chrome and Mozilla are distrusting Entrust
The decision made by Chrome and Mozilla to distrust Entrust’s public TLS certificates stems from concerns regarding Entrust’s incident response and remediation process. In several instances, Entrust failed to report critical issues and did not revoke certificates in a timely manner. The pattern of delayed action has eroded the browsers’ confidence in Entrust’s ability to act quickly and transparently, which is crucial for maintaining trust as a CA.
Google and Mozilla cited the ongoing lack of transparency and urgency in addressing mis-issuances as the primary reason for their distrust decision. Google specifically pointed out that over the past 6 years, Entrust has shown a “pattern of compliance failures” and failed to make the “tangible, measurable progress” necessary to restore trust. Mozilla echoed these concerns, emphasizing the importance of holding Entrust accountable to ensure the integrity and security of the public Internet.
Entrust’s response to the distrust announcement
In response to the distrust announcement from Chrome and Mozilla, Entrust has taken proactive steps to ensure continuity for their customers. To prevent service disruption, Entrust has announced that they are partnering with SSL.com, a CA that’s trusted by all major browsers, including Chrome and Mozilla, to issue certificates for their customers. By issuing certificates from SSL.com’s roots, Entrust aims to provide a seamless transition for their customers, ensuring that they can continue to obtain certificates that are recognized and trusted by the browsers their users rely on.
In addition to their partnership with SSL.com, Entrust stated that they are working on a number of improvements, including changes to their organizational structure, revisions to their incident response process and policies, and a push towards automation to ensure compliant certificate issuances.
How Cloudflare can help Entrust customers
Now available: SSL.com as a certificate authority for Advanced Certificate Manager and SSL for SaaS certificates
We’re excited to announce that customers using Advanced Certificate Manager will now be able to select SSL.com as a certificate authority for Advanced certificates and Total TLS certificates. Once the certificate is issued, Cloudflare will handle all future renewals on your behalf.
By default, Cloudflare will issue SSL.com certificates with a 90 day validity period. However, customers using Advanced Certificate Manager will have the option to set a custom validity period (14, 30, or 90 days) for their SSL.com certificates. In addition, Enterprise customers will have the option to obtain 1-year SSL.com certificates. Every SSL.com certificate order will include 1 RSA and 1 ECDSA certificate.
Note: We are gradually rolling this out and customers should see the CA become available to them through the end of September and into October.
If you’re using Cloudflare as your DNS provider, there are no additional steps for you to take to get the certificate issued. Cloudflare will validate the ownership of the domain on your behalf to get your SSL.com certificate issued and renewed.
If you’re using an external DNS provider and have wildcard hostnames on your certificates, DNS based validation will need to be used, which means that you’ll need to add TXT DCV tokens at your DNS provider in order to get the certificate issued. With SSL.com, two tokens are returned for every hostname on the certificate. This is because SSL.com uses different tokens for the RSA and ECDSA certificates. To reduce the overhead around certificate management, we recommend setting up DCV Delegation to allow Cloudflare to place domain control validation (DCV) tokens on your behalf. Once DCV Delegation is set up, Cloudflare will automatically issue, renew, and deploy all future certificates for you.
Advanced Certificates: selecting SSL.com as a CA through the UI or API
Customers can select SSL.com as a CA through the UI or through the Advanced Certificate API endpoint by specifying “ssl_com” in the certificate_authority parameter.
If you’d like to use SSL.com as a CA for an advanced certificate, you can select “SSL.com” as your CA when creating a new Advanced certificate order.
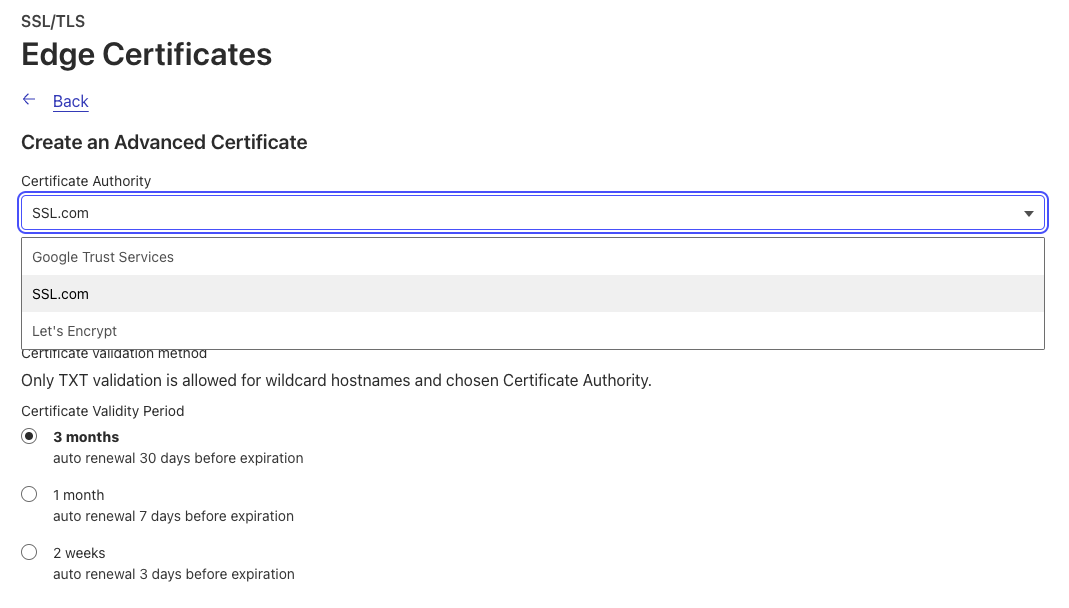
If you’d like to use SSL.com as a CA for all of your certificates, we recommend setting your Total TLS CA to SSL.com. This will issue an individual certificate for each of your proxied hostname from the CA.
Note: Total TLS is a feature that’s only available to customers that are using Cloudflare as their DNS provider.
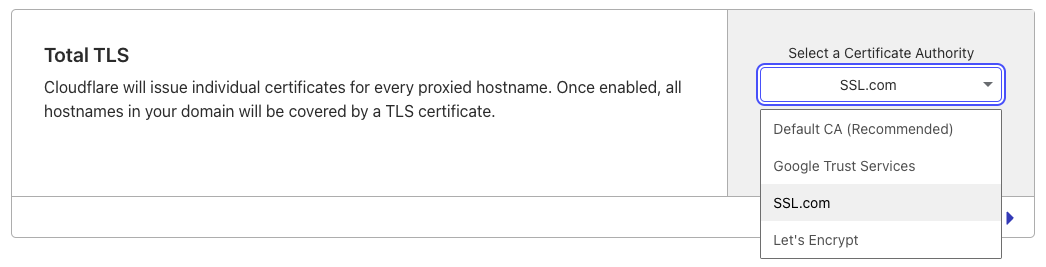
SSL for SaaS: selecting SSL.com as a CA through the UI or API
Enterprise customers can select SSL.com as a CA through the custom hostname creation UI or through the Custom Hostnames API endpoint by specifying “ssl_com” in the certificate_authority parameter.
All custom hostname certificates issued from SSL.com will have a 90 day validity period. If you have wildcard support enabled for custom hostnames, we recommend using DCV Delegation to ensure that all certificate issuances and renewals are automatic.
Our recommendation if you’re using Entrust as a certificate authority
Cloudflare customers that use Entrust as their CA are required to manually handle all certificate issuances and renewals. Since Cloudflare does not directly integrate with Entrust, customers have to get their certificates issued directly from the CA and upload them to Cloudflare as custom certificates. Once these certificates come up for renewal, customers have to repeat this manual process and upload the renewed certificates to Cloudflare before the expiration date.
Manually managing your certificate’s lifecycle is a time-consuming and error prone process. With certificate lifetimes decreasing from 1 year to 90 days, this cycle needs to be repeated more frequently by the domain owner.
As Entrust transitions to issuing certificates from SSL.com roots, this manual management process will remain unless customers switch to Cloudflare’s managed certificate pipeline. By making this switch, you can continue to receive SSL.com certificates without the hassle of manual management — Cloudflare will handle all issuances and renewals for you!
In early October, we will be reaching out to customers who have uploaded Entrust certificates to Cloudflare to recommend migrating to our managed pipeline for SSL.com certificate issuances, simplifying your certificate management process.
If you’re ready to make the transition today, simply go to the SSL/TLS tab in your Cloudflare dashboard, click “Order Advanced Certificate”, and select “SSL.com” as your certificate authority. Once your new SSL.com certificate is issued, you can either remove your Entrust certificate or simply let it expire. Cloudflare will seamlessly transition to serving the managed SSL.com certificate before the Entrust certificate expires, ensuring zero downtime during the switch.
Вместо подкрепа – преследване. Защо България се проваля в борбата с употребата на наркотици
Post Syndicated from Надежда Цекулова original https://www.toest.bg/zashto-bulgaria-se-provalya-v-borbata-s-upotrebata-na-narkotitsi/

Неотдавна млада певица, рекламираща енергийни прахчета за шмъркане, предизвика взрив от публично недоволство. Рекламата беше свалена, певицата обяви, че „се самоканселира“, и темата потъна със скоростта, с която беше грабнала вниманието на публиката. Истински, задълбочен и отговорен разговор за употребата на наркотици и за предотвратяването на тази употреба отново не се проведе.
В следващите редове ще маркираме какви биха били основните спирки на един такъв разговор, без претенцията да го обхванем напълно, но с надеждата поне да посеем началото му. Юлия Георгиева е председател на Фондация „Център за хуманни политики“. Организацията се занимава с дейности за намаляване на вредите от употребата на наркотици и управлява единствения в страната нископрагов център за работа с хора, зависими от наркотици и алкохол – Розовата къща. С нея разговаря Надежда Цекулова.
Вие бяхте човекът, който неотдавна обърна внимание на реклама на енергийни прахчета за шмъркане, и това предизвика грандиозен публичен скандал. Но тази реклама не беше нито нова, нито единствена и вероятно хиляди хора са я видели преди Вашата реакция. И не са се впечатлили силно. Други пък и след скандала недоумяваха какъв е проблемът – нали прахчетата са безвредни. Нека започнем с тази тема с все още отекващо ехо и с обяснението защо рекламирането на прахчета за шмъркане носи рискове.
Проблемът с наркотиците никога не е веществото, а е защо хората искат да вземат наркотици. Какво им дават тези вещества. Популярните лица помагат за създаването на магия около употребата на дадено нещо. В конкретния случай – пред шмъркането по принцип има психологическа бариера, тъй като в нашата култура обичайно нищо не се приема по този начин, за нас то е неестествено. Прескачането на тази граница, на този естествен страх, който е една от бариерите пред един млад човек да започне да взема наркотици, е проблемно. Нормализирането и създаването на магия около употребата драстично повишава риска да се премине от едно вещество към друго.
И пак казвам, веществото няма значение. Значение има всичко останало. Значение има например това, че дамата, чието име беше забъркано в скандала, така и не разбра какво предизвика острата реакция срещу рекламата. А тя не го разбра, защото такъв е нейният свят. Около нея очевидно така се прави, то е нормализирано. Това е страшното в цялата история.
Свалянето на тази реклама за кратко повдигна темата за превенцията на употребата на наркотици, но много бързо тази вълна отмина. А като че ли въпросът какво е работеща превенция и има ли тя почва у нас се нуждае от по-сериозен дебат…
Идеята на превенцията е децата да се чувстват достатъчно спокойни да говорят по темата и ако им се появят мераци да опитат някое вещество, да могат да ги обсъдят и да се спрат навреме. У нас често „превенция“ се прави от МВР – полицай влиза с куче в класната стая и това е най-страшното нещо на света, защото той ей сега ще пусне кучето и то ще разбере кой има у себе си трева. Това не е превенция. Това е сплашване и е най-сигурният начин детето никога да не потърси помощ.
Идеята на превенцията е също да има истинна информация. Тук чуваме: „Ако пушиш трева, ще умреш“, но те вече са пушили трева и не са умрели, и в момента, в който излезеш с такова послание, младежите престават да ти вярват и ставаш за смях, а това води и до неглижиране на проблема.
А как изглежда качествената превенция?
Трябва да се обхващат различните групи спрямо техния риск. Ако отдалечим фокуса, борбата с наркотиците, както се нарича в България, се дели на две основни групи: борба с търсенето и борба с предлагането. Четирите основни стълба за борба с наркотиците са: превенция; терапия и рехабилитация; намаляване на вредите; преследване на трафика и разпространението. Те трябва да бъдат равни и като тежест, и като финансиране. В България за шест години имаше отделени 500 млн. лева за преследване и 50 млн. лева за всичко останало. И всъщност тук вече се вижда как нещата се изкривяват, защото, когато има търсене, винаги ще има и предлагане. Хората трябва да имат по-малко причини да употребяват наркотици, защото това се случва в отговор на определени нужди. Никой не започва с идеята „Аз защо пък да не стана зависим?“.
Има ли някакви доминиращи причини за употреба на наркотици?
Могат да бъдат много различни. Например крайна бедност – неслучайно сегрегираните райони са много силно засегнати, това е начин да оцелееш психически. А може да е и за забавление. Може да е нужда да бъдеш част от някаква среда. И е важно да се работи с тези причини. Така стигаме до добрата превенция. Ние от години искаме да се въведе такава програма в България. Тя работи с конкретни психични нужди сред младите хора и се спира на четири основни неща, които са маркери за риск: импулсивно поведение, тревожност, депресивност и търсене на силни усещания. Тези рискови фактори се установяват чрез въпросник и последващата работа се насочва към децата, които реално са рискови.
Има ли данни колко са те?
Средно 20–30%, въпреки че за България излязоха повече – около 50%. Има високи показатели и в други страни, където децата по-трудно намират мястото си в обществото. У нас го отдавам на това, че ние не сме много подкрепящи хора, ние от българския етнос. Сблъсквала съм се със стотици случаи, в които единият родител знае, че детето има проблем с наркотици, другият не знае, а всички живеят заедно. Докато в ромската общност например става съвсем обратното – ако човек, който употребява наркотици, се прибере вкъщи и каже: „Аз искам да спра“, там веднага се вдига телефонът, събират се 30 човека, обграждат го отвсякъде и се грижат за него. Изключително различно е и е много впечатляваща разликата, защото живеем на една и съща територия.
Но да се върна на въпроса. Да кажем, че до 30% от хлапетата са рискови. С тях се работи в групи, в които всъщност не се говори за наркотици. Говори се за чувства, говори се за това какво и как точно ти пречи – ако например си импулсивен и си се опитал да удариш учителката, това по какъв начин ти влияе и защо не е хубаво да го правиш. И когато се чувстваш така, какво би могъл да направиш, за да се справиш. Тези казуси се обсъждат в групата от млади хора с помощта на фасилитатор, но те сами си търсят решенията, не им ги дава някой назидателен възрастен. В страните, в които тази програма работи, има доста висок процент на успеваемост.
При отсъствието на ефективна превенция очевидно много деца и младежи опитват разнообразни вещества. Какво се случва след това?
След това се обособяват две групи. В едната са младежите, които са опитали някакво вещество еднократно – в това, общо взето, няма проблем, стига да знаят какво точно пробват. В другата са тези, които са започнали да употребяват редовно, и тук историята става зловеща. Те имат нужда от терапия, рехабилитация и нашата цел е, докато са деца и млади хора, да спрат употребата.
В България обаче има само една терапевтична общност, в която приемат младежи под 18 г., и тя е платена. В това няма нищо лошо и доколкото знам, работят добре. Просто е много скъпо за семействата и съответно за най-рисковите деца е абсолютно недостъпно. Ние в момента имаме едно дете, което е в болница в изключително тежко състояние. По принцип не работим с деца, но се обръщат към нас, тъй като няма към кой друг, и аз се чувствам ужасно безпомощна и гневна, защото няма какво да направя за тези деца, няма къде да ги насоча, няма система, която да ги поеме и да гарантира грижа за тях.
Какво се случва с такива деца?
Имаше една история преди повече от десет години за едни хлапета от „Орландовци“, които бяха заразени с ХИВ. Това беше общност от деца на по 12–13 години, които си инжектираха хероин и бяха успели помежду си да се заразят с ХИВ. Стана голям скандал, имаше множество медийни публикации. Много хора от администрацията се ангажираха и положиха усилия да направят нещо за тези деца, но това така и не сработи. Всички починаха впоследствие, едно по едно. От употреба на наркотици, от ХИВ, от липса на грижа. Мисля, че в това отношение не сме мръднали през тези над десет години, независимо от изключително тежкия урок.
По отношение на т.нар. възрастни, които са всъщност млади хора, но над 18 г., положението не е много по-добро. Има ограничен брой места, едното е в „Суходол“, в Държавната психиатрична болница за лечение на наркомании и алкохолизъм. Няма да коментирам думичката „наркомания“ – руски термин, който много отдавна трябваше да изхвърлим. Другата безплатна възможност са психиатриите – с всички ужасяващи неща, които знаем за условията и качеството на грижите в тях.
Съществуват също няколко терапевтични религиозни комуни. В тях проблемът е, че сравнително често хората отново започват да употребяват, след като напуснат комуната. Има един немалък брой терапевтични общности. Някои не са лицензирани и не подлежат на никакъв контрол. Има и такива, които работят превъзходно, но за нуждаещите се невинаги е лесно да се ориентират коя каква е. Освен това тези общности по правило също нямат финансиране и пациентът плаща между 2000 и 3000 лв. на месец, като лечението – за да има шанс за някакъв успех – продължава най-малко десет месеца.
Има ли данни колко души са обхванати от тези възможности за терапия и рехабилитация, с всичките им условности, и колко общо се нуждаят от терапия?
Би трябвало да има някакви данни в годишния доклад на Националния фокусен център. Те отчитат някакво намаляване, но за мен не отразяват реалната ситуация. Терминологията не е осъвременена, проследяването на начина, по който се събират данните, и може би ресурсът, който се отделя за това, не са достатъчни. Като резултат аз смятам, че всъщност не знаем отговора на този въпрос.
Вие всъщност се занимавате с намаляване на вредите от употребата на наркотици. В България преди години дейностите в това направление се развиваха и финансираха от Глобалния фонд за борба срещу СПИН, туберкулоза и малария. Откакто Фондът се оттегли от страната ни обаче, тази дейност, вместо да бъде поета от българските институции, сякаш напълно изчезна. Доколко е вярно това повърхностно впечатление?
Във висока степен. Здравното министерство разпознава само тестване за ХИВ и за кръвнопреносими инфекции и раздаване на материали за превенцията им. Ние спечелихме една обществена поръчка за тази дейност, но парите са крайно недостатъчни. Правим го, защото имаме допълнително финансиране от Elton John AIDS Foundation и можем да си покрием разходите. Но например колегите в Пловдив трябва да работят една година с четири рискови групи за общата сума от 37 000 лв., като с тези пари трябва да наемат трима души, да купят консумативи, да платят гориво и т.н. Парите са смешни.
Говорите за мобилната си услуга. Най-разпознаваемата ви дейност обаче е Розовата къща, където оказвате доста по-широкоспектърна подкрепа. Разкажете в резюме какво предлага екипът ви там.
Винаги ще има хора, които употребяват наркотици. Ние сме там за тях, за да можем да покрием нуждите, които те имат, докато употребяват, и да ги подкрепим, ако решат да се опитат да спрат. Всъщност това е целта на нашата работа – намалявайки вредата за конкретния човек, ние намаляваме вредата за близкото му обкръжение и за обществото.
В Розовата къща специално работим с хората, които са в най-ниската възможна социална позиция. Много често те не са поддържали контакт с никакви близки хора с години, да не кажа с десетилетия. Това също е част от нашата работа. Ако този човек дойде и каже: „Аз много искам да видя майка си“, често се случва ние да се обадим на майка му и да проведем този първи разговор. И много често успяваме, защото на родителите това им тежи и искат да са полезни.
Така колелото се завърта – ако човекът се е прибрал да живее вкъщи, много по-сигурно е, че си взема лекарствата за ХИВ или за хепатит, или за каквото и да е, започва да употребява по-малко наркотици или влиза в някаква програма, започва работа. Така този човек не просто не е на улицата, а вкарва пари в бюджета и допринася за обществото. И не е задължително това да е придружено с пълно спиране на употребата.
Според мен немалко хора вярват, че или вземаш наркотици, или си социално приемлив – двете заедно са несъвместими.
Да, тук отношението е черно-бяло. Чувала съм неведнъж: „Или да спира, или да мре.“ Но аз малко ще обърна нещата. Огромна част от хората, които упражняват висококвалифицирани професии, употребяват наркотици. Огромна част от хората, на които се възхищавате, употребяват наркотици. Така приемливо и съвместимо ли звучи? В момента може би най-популярните вещества са стимулантите – вещества, които ти дават възможност да работиш повече, да бъдеш по-ефективен за по-дълъг период и една част от видимия свят на много успешни хора се крепи на тези вещества. Проблемът е, че при дълга употреба се стига до срив.
Разказвам това, за да стане ясно, че употребата може и да не нарушава функционирането на един човек. Всеки от нас познава такива хора дори без да знае. Те имат семейства, имат социална среда, успешни са в работата си. Хората, с които Розовата къща работи обаче, са точно обратното – те са тези, които са изтеглили късата клечка, нямат нищо и никога досега не са получавали грижа и помощ.
Защото няма друга услуга като Розовата къща?
Да. Имам тъжно-смешна история във връзка с това. Когато за първи път разбрахме, че има шанс да получим финансиране като социална услуга, и отидохме на среща в Социалното министерство, за мен беше шокиращо, когато хората от Министерството казаха: „Ние търсим подобна организация от десет години.“ Същевременно ние от десет години се занимаваме със Здравното министерство и се опитваме да обясним колко е важна работата ни, но никой не ни обръща внимание. Просто липсва всякаква координация.
Какво е положението ви в момента? Розовата къща изгуби къщата си преди няколко месеца и въпреки огромната дарителска съпричастност, опитите на Общината да ви намери ново място засега не са дали резултат. Как ще посрещнете есента?
Столичната община успя да ни намери едно малко помещение. То категорично не може да покрие нуждите ни – няма тоалетна, няма баня, няма пералня, няма базови неща. Не можем да правим превръзки. Практически само осигуряваме храна в момента. Иначе по отношение на самото построяване на Розовата къща – най-после имаме скица от районната община и чакаме виза от главния архитект на София. Процесът върви, но за съжаление, много бавно. Идва зима и това на мен ми е най-големият кошмар. През лятото за четири месеца загубихме шест човека. Какво ще стане през зимата, не искам да мисля…
От разговора ни дотук излиза, че нито превенцията, нито лечението, нито намаляването на вредите са ефективни у нас. Дори разпознаването на крайно рискови реклами става едва след като някой като Вас го обясни достъпно и с картинки. Каква е причината?
Щях да кажа „неглижиране“, но не е това точната дума. Точните думи са „безхаберие“ и „некадърност“. От години се опитвам да не ползвам такива силни думи, защото в системата има хора, на които им пука и които правят всичко по силите си – те не заслужават подобни обобщения. Навсякъде се намира по някой свестен и съвестен човек и благодарение на това ние не сме се сринали напълно. Но не може цялата система да се държи на мускулите на десет човека, които на местно ниво се опитват да направят нещичко за малката си общност.
Извън тези отчайващо малко на брой хора честното обяснение е това – безхаберие и некадърност.
Enabling conversational data discovery with LLMs at Grab
Post Syndicated from Grab Tech original https://engineering.grab.com/hubble-data-discovery
Imagine a world where finding the right data is like searching for a needle in a haystack. In today’s data-driven landscape, companies are drowning in a sea of information, struggling to navigate through countless datasets to uncover valuable insights. At Grab, we faced a similar challenge. With over 200,000 tables in our data lake, along with numerous Kafka streams, production databases, and ML features, locating the most suitable dataset for our Grabber’s use cases promptly has historically been a significant hurdle.
Problem Space
Our internal data discovery tool, Hubble, built on top of the popular open-source platform Datahub, was primarily used as a reference tool. While it excelled at providing metadata for known datasets, it struggled with true data discovery due to its reliance on Elasticsearch, which performs well for keyword searches but cannot accept and use user-provided context (i.e., it can’t perform semantic search, at least in its vanilla form). The Elasticsearch parameters provided by Datahub out of the box also had limitations: our monthly average click-through rate was only 82%, meaning that in 18% of sessions, users abandoned their searches without clicking on any dataset. This suggested that the search results were not meeting their needs.
Another indispensable requirement for efficient data discovery that was missing at Grab was documentation. Documentation coverage for our data lake tables was low, with only 20% of the most frequently queried tables (colloquially referred to as P80 tables) having existing documentation. This made it difficult for users to understand the purpose and contents of different tables, even when browsing through them on the Hubble UI.
Consequently, data consumers heavily relied on tribal knowledge, often turning to their colleagues via Slack to find the datasets they needed. A survey conducted last year revealed that 51% of data consumers at Grab took multiple days to find the dataset they required, highlighting the inefficiencies in our data discovery process.
To address these challenges and align with Grab’s ongoing journey towards a data mesh architecture, the Hubble team recognised the importance of improving data discovery. We embarked on a journey to revolutionise the way our employees find and access the data they need, leveraging the power of AI and Large Language Models (LLMs).
Vision
Given the historical context, our vision was clear: to remove humans in the data discovery loop by automating the entire process using LLM-powered products. We aimed to reduce the time taken for data discovery from multiple days to mere seconds, eliminating the need for anyone to ask their colleagues data discovery questions ever again.

Goals
To achieve our vision, we set the following goals for ourselves for the first half of 2024:
- Build HubbleIQ: An LLM-based chatbot that could serve as the equivalent of a Lead Data Analyst for data discovery. Just as a lead is an expert in their domain and can guide data consumers to the right dataset, we wanted HubbleIQ to do the same across all domains at Grab. We also wanted HubbleIQ to be accessible where data consumers hang out the most: Slack.
- Improve documentation coverage: A new Lead Analyst joining the team would require extensive documentation coverage of very high quality. Without this, they wouldn’t know what data exists and where. Thus, it was important for us to improve documentation coverage.
- Enhance Elasticsearch: We aimed to tune our Elasticsearch implementation to better meet the requirements of Grab’s data consumers.
A Systematic Path to Success
Step 1: Enhance Elasticsearch
Through clickstream analysis and user interviews, the Hubble team identified four categories of data search queries that were seen either on the Hubble UI or in Slack channels:
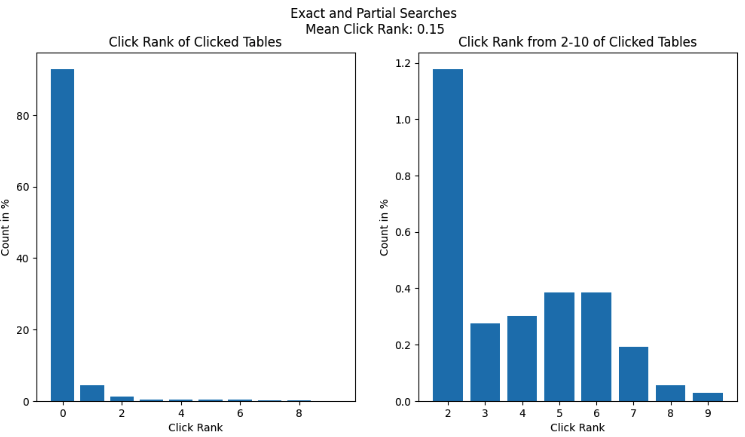
- Exact search: Queries belonging to this category were a substring of an existing dataset’s name at Grab, with the query length being at least 40% of the dataset’s name.
- Partial search: The Levenshtein distance between a query in this category and any existing dataset’s name was greater than 80. This category usually comprised queries that closely resembled an existing dataset name but likely contained spelling mistakes or were shorter than the actual name.
Exact and partial searches accounted for 75% of searches on Hubble (and were non-existent on Slack: as a human, receiving a message that just had the name of a dataset would feel rather odd). Given the effectiveness of vanilla Elasticsearch for these categories, the click rank was close to 0.
- Inexact search: This category comprised queries that were usually colloquial keywords or phrases that may be semantically related to a given table, column, or piece of documentation (e.g., “city” or “taxi type”). Inexact searches accounted for the remaining 25% of searches on Hubble. Vanilla Elasticsearch did not perform well in this category since it relied on pure keyword matching and did not consider any additional context.
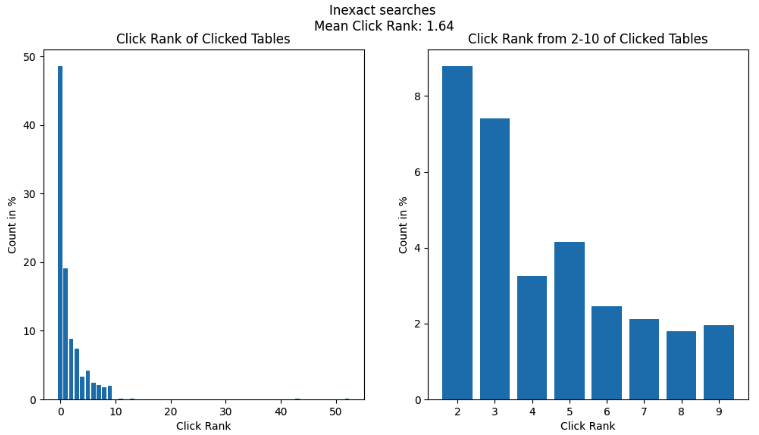
- Semantic search: These were free text queries with abundant contextual information supplied by the user. Hubble did not see any such queries as users rightly expected that Hubble would not be able to fulfil their search needs. Instead, these queries were sent by data consumers to data producers via Slack. Such queries were numerous, but usually resulted in data hunting journeys that spanned multiple days – the root of frustration amongst data consumers.
The first two search types can be seen as “reference” queries, where the data consumer already knows what they are looking for. Inexact and contextual searches are considered “discovery” queries. The Hubble team noticed drop-offs in inexact searches because users learned that Hubble could not fulfil their discovery needs, forcing them to search for alternatives.
Through user interviews, the team discovered how Elasticsearch should be tuned to better fit the Grab context. They implemented the following optimisations:
- Tagging and boosting P80 tables
- Boosting the most relevant schemas
- Hiding irrelevant datasets like PowerBI dataset tables
- Deboosting deprecated tables
- Improving the search UI by simplifying and reducing clutter
- Adding relevant tags
- Boosting certified tables
As a result of these enhancements, the click-through rate rose steadily over the course of the half to 94%, a 12 percentage point increase.
While this helped us make significant improvements to the first three search categories, we knew we had to build HubbleIQ to truly automate the last category – semantic search.
Step 2: Build a Context Store for HubbleIQ
To support HubbleIQ, we built a documentation generation engine that used GPT-4 to generate documentation based on table schemas and sample data. We refined the prompt through multiple iterations of feedback from data producers.
We added a “generate” button on the Hubble UI, allowing data producers to easily generate documentation for their tables. This feature also supported the ongoing Grab-wide initiative to certify tables.
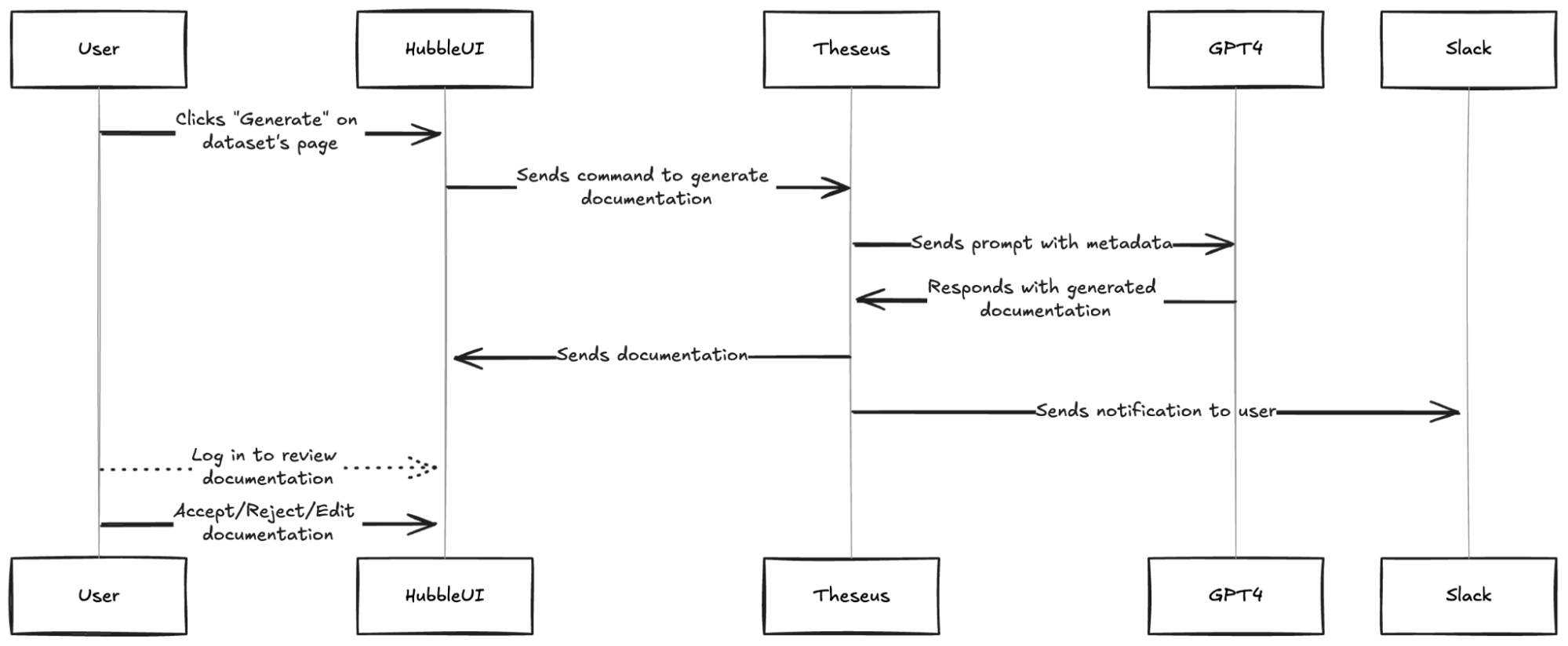
In conjunction, we took the initiative to pre-populate docs for the most critical tables, while notifying data producers to review the generated documentation. Such docs were visible to data consumers with an “AI-generated” tag as a precaution. When data producers accepted or edited the documentation, the tag was removed.
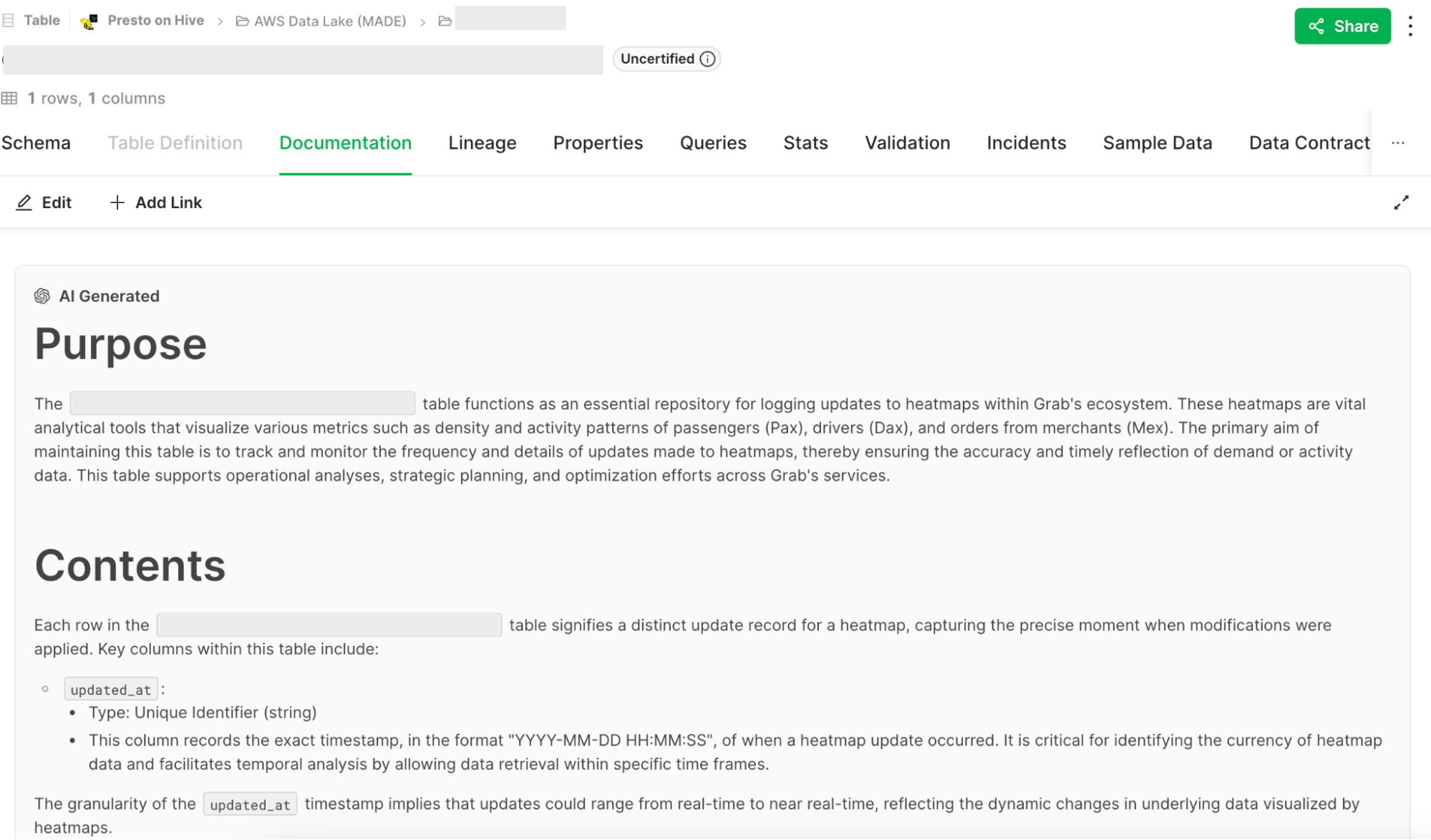
As a result, documentation coverage for P80 tables increased by 70 percentage points to ~90%. User feedback showed that ~95% of users found the generated docs useful.
Step 3: Build and Launch HubbleIQ
With high documentation coverage in place, we were ready to harness the power of LLMs for data discovery. To speed up go-to-market, we decided to leverage Glean, an enterprise search tool used by Grab.
First, we integrated Hubble with Glean, making all data lake tables with documentation available on the Glean platform. Next, we used Glean Apps to create the HubbleIQ bot, which was essentially an LLM with a custom system prompt that could access all Hubble datasets that were catalogued on Glean. Finally, we integrated this bot into Hubble search, such that for any search that is likely to be a semantic search, HubbleIQ results are shown on top, followed by regular search results.
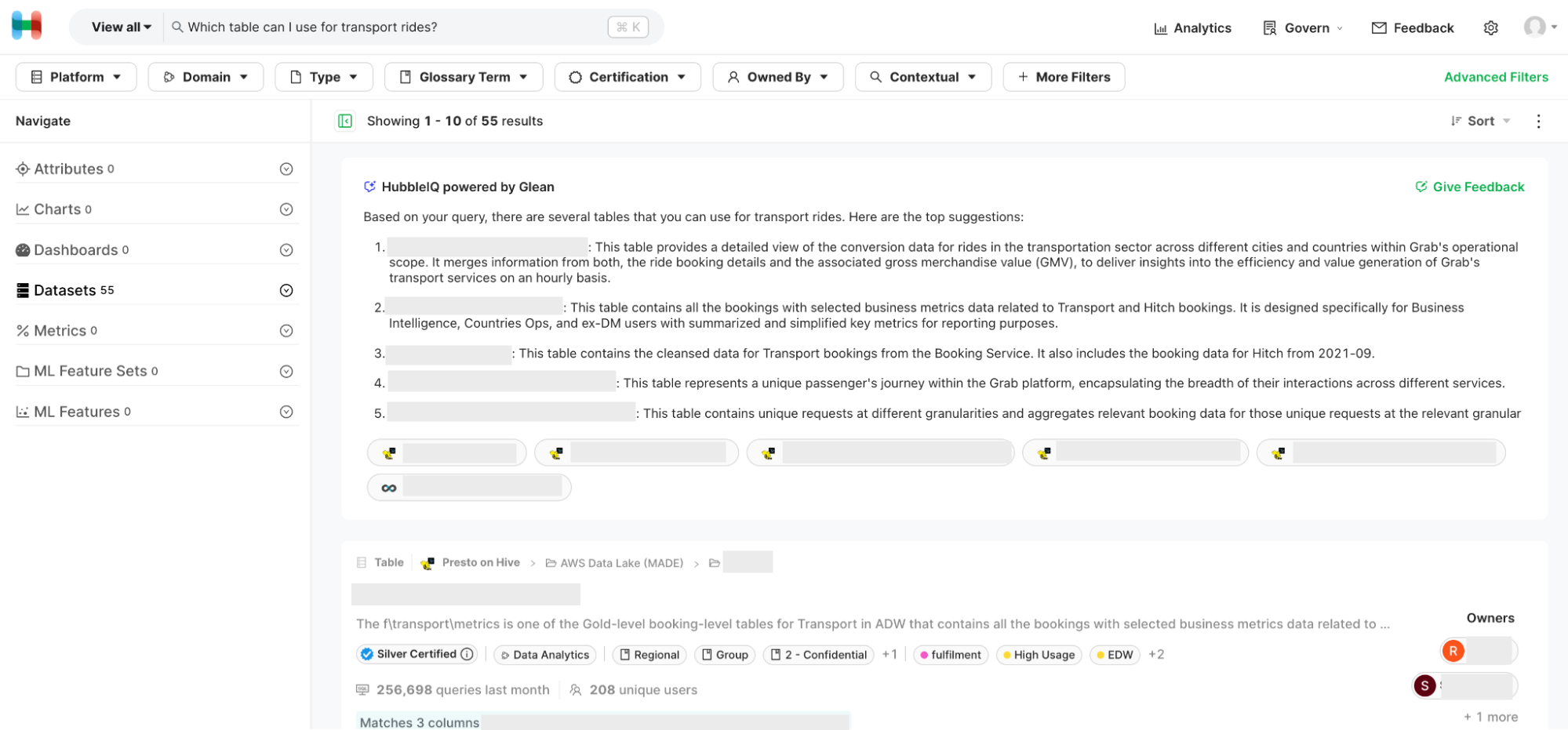
Recently, we integrated HubbleIQ with Slack, allowing data consumers to discover datasets without breaking their flow. Currently, we are working with analytics teams to add the bot to their “ask” channels (where data consumers come to ask contextual search queries for their domains). After integration, HubbleIQ will act as the first line of defence for answering questions in these channels, reducing the need for human intervention.
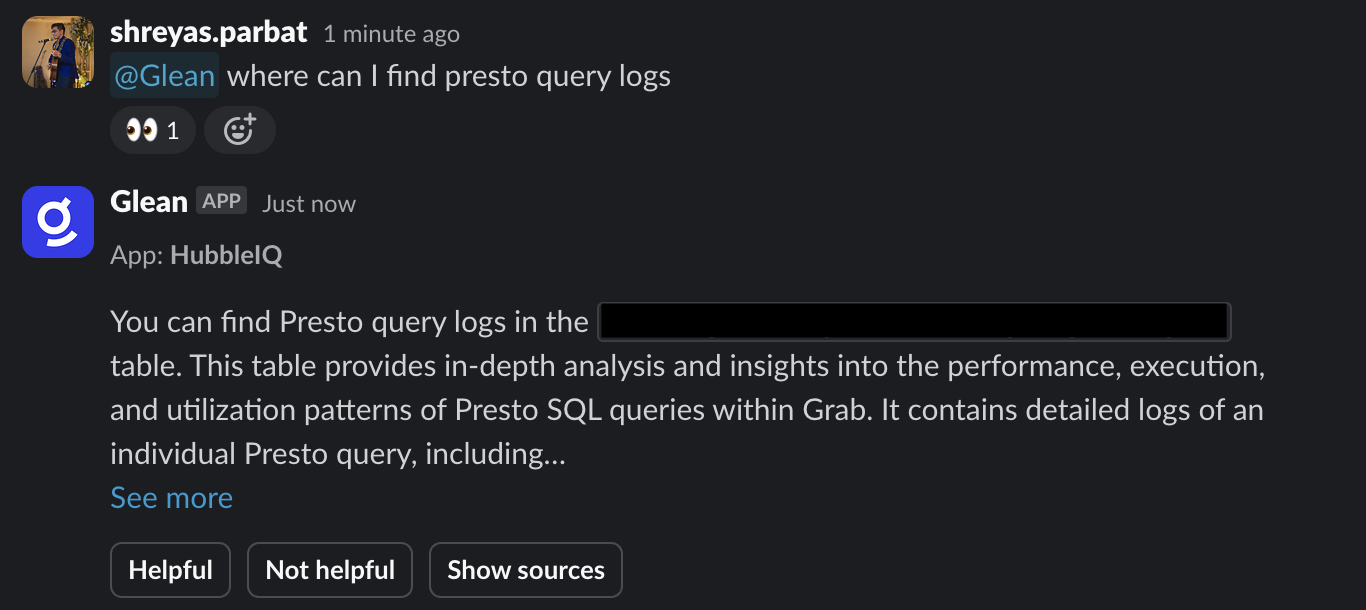
The impact of these improvements was significant. A follow-up survey revealed that 73% of respondents found it easy to discover datasets, marking a substantial 17 percentage point increase from the previous survey. Moreover, Hubble reached an all-time high in monthly active users, demonstrating the effectiveness of the enhancements made to the platform.
Next Steps
We’ve made significant progress towards our vision, but there’s still work to be done. Looking ahead, we have several exciting initiatives planned to further enhance data discovery at Grab.
On the documentation generation front, we aim to enrich the generator with more context, enabling it to produce even more accurate and relevant documentation. We also plan to streamline the process by allowing analysts to auto-update data docs based on Slack threads directly from Slack. To ensure the highest quality of documentation, we will develop an evaluator model that leverages LLMs to assess the quality of both human and AI-written docs. Additionally, we will implement Reflexion, an agentic workflow that utilises the outputs from the doc evaluator to iteratively regenerate docs until a quality benchmark is met or a maximum try-limit is reached.
As for HubbleIQ, our focus will be on continuous improvement. We’ve already added support for metric datasets and are actively working on incorporating other types of datasets as well. To provide a more seamless user experience, we will enable users to ask follow-up questions to HubbleIQ directly on the HubbleUI, with the system intelligently pulling additional metadata when a user mentions a specific dataset.
Conclusion
By harnessing the power of AI and LLMs, the Hubble team has made significant strides in improving documentation coverage, enhancing search capabilities, and drastically reducing the time taken for data discovery. While our efforts so far have been successful, there are still steps to be taken before we fully achieve our vision of completely replacing the reliance on data producers for data discovery. Nonetheless, with our upcoming initiatives and the groundwork we have laid, we are confident that we will continue to make substantial progress in the right direction over the next few production cycles.
As we forge ahead, we remain dedicated to refining and expanding our AI-powered data discovery tools, ensuring that Grabbers have every dataset they need to drive Grab’s success at their fingertips. The future of data discovery at Grab is brimming with possibilities, and the Hubble team is thrilled to be at the forefront of this exciting journey.
To our readers, we hope that our journey has inspired you to explore how you can leverage the power of AI to transform data discovery within your own organisations. The challenges you face may be unique, but the principles and strategies we have shared can serve as a foundation for your own data discovery revolution. By embracing innovation, focusing on user needs, and harnessing the potential of cutting-edge technologies, you too can unlock the full potential of your data and propel your organisation to new heights. The future of data-driven innovation is here, and we invite you to join us on this exhilarating journey.
Join us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 700 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
Sept 19: Talk Like a Pirate Day.
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=ZQJydlY3yYg
Maslow’s Pyramid
Post Syndicated from xkcd.com original https://xkcd.com/2988/

Destruction of the Pirate City
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=Zfu7gtloxmQ
High-risk vulnerabilities in common enterprise technologies
Post Syndicated from Rapid7 original https://blog.rapid7.com/2024/09/19/etr-high-risk-vulnerabilities-in-common-enterprise-technologies/

Rapid7 is warning customers about several high-risk vulnerabilities in common enterprise technologies that are attractive potential attack targets for both state-sponsored and financially motivated adversaries. We are advising customers to prioritize remediation for these issues on an expedited basis wherever possible:
- CVE-2024-41874: Critical remote code execution vulnerability in Adobe ColdFusion
- CVE-2024-38812, CVE-2024-38813: Remote code execution and privilege escalation vulnerabilities (respectively) in Broadcom VMware vCenter Server and Cloud Foundation
- CVE-2024-29847: Critical remote code execution (via deserialization) vulnerability in Ivanti Endpoint Manager (EPM)
Adobe ColdFusion CVE-2024-41874
On September 10, 2024, Adobe published a critical advisory for CVE-2024-41874, an unauthenticated remote code execution issue that occurs as a result of unsafe Web Distributed Data eXchange (“Wddx”) packet deserialization. Rapid7 MDR has previously observed exploitation that targets Wddx for remote code execution; we have also previously observed exploitation of multiple other ColdFusion CVEs.
Affected products and mitigation: Adobe ColdFusion 2023 (update 9 and earlier) and Adobe ColdFusion 2021 (update 15 and earlier) are vulnerable to CVE-2024-41874. The vulnerability is resolved in versions 10 and 16, respectively. For more information, see the vendor advisory.
Broadcom VMware vCenter Server CVEs
On September 17, 2024, Broadcom published an advisory on CVE-2024-38812, a critical heap overflow vulnerability affecting VMware vCenter Server. Successful exploitation of CVE-2024-38812 allows an attacker with network access to the vulnerable server to execute code remotely on the target system. CVE-2024-38813, a local privilege escalation vulnerability, was also reported by the same researchers, making this a full-chain exploit. We are not aware of exploitation in the wild as of September 19, 2024, but vCenter Server is a high-value attack target for ransomware and extortion groups.
Affected products and mitigation: Broadcom VMware vCenter Server 7.0 and 8.0 are vulnerable to CVE-2024-38812 and CVE-2024-38813. Fixes are available as indicated in the vendor advisory. Broadcom also has an FAQ available.
Ivanti Endpoint Manager CVE-2024-29847
On September 10, 2024, Ivanti published a security advisory on CVE-2024-29847, an unsafe deserialization vulnerability in Ivanti Endpoint Manager (EPM) solution. Successful exploitation allows unauthenticated attackers to execute code remotely on target systems. Vulnerability details and proof-of-concept exploit code are available.
Affected products and mitigation: Ivanti Endpoint Manager (EPM) 2022 SU5 (and earlier) and EPM 2024 are vulnerable to CVE-2024-29847. Customers using EPM 2022 can remediate this and other recent vulnerabilities by updating to 2022 SU 6. Per Ivanti’s security advisory, EPM 2024 customers can apply an available security patch while waiting for 2024 SU1, which is yet to be released. See Ivanti’s advisory for the latest information.
Rapid7 customers
InsightVM and Nexpose customers can assess their exposure to Adobe ColdFusion CVE-2024-41874 and Broadcom VMware vCenter Server CVE-2024-28812 and CVE-2024-38813 with vulnerability checks released previously. A vulnerability check for Ivanti EPM CVE-2024-29847 is in development and is expected to be available in tomorrow’s (Friday, September 20) content release.